
Upload 12 files
Browse files- LICENSE +400 -0
- README.md +191 -8
- app (1).py +122 -0
- config.py +59 -0
- dataset.py +224 -0
- gitattributes +5 -0
- index.html +139 -0
- inference_onnx.py +63 -0
- loss.py +145 -0
- main.py +131 -0
- requirements (1).txt +18 -0
- sample.wav +0 -0
LICENSE
ADDED
|
@@ -0,0 +1,400 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Attribution-NonCommercial 4.0 International
|
| 3 |
+
|
| 4 |
+
=======================================================================
|
| 5 |
+
|
| 6 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
| 7 |
+
does not provide legal services or legal advice. Distribution of
|
| 8 |
+
Creative Commons public licenses does not create a lawyer-client or
|
| 9 |
+
other relationship. Creative Commons makes its licenses and related
|
| 10 |
+
information available on an "as-is" basis. Creative Commons gives no
|
| 11 |
+
warranties regarding its licenses, any material licensed under their
|
| 12 |
+
terms and conditions, or any related information. Creative Commons
|
| 13 |
+
disclaims all liability for damages resulting from their use to the
|
| 14 |
+
fullest extent possible.
|
| 15 |
+
|
| 16 |
+
Using Creative Commons Public Licenses
|
| 17 |
+
|
| 18 |
+
Creative Commons public licenses provide a standard set of terms and
|
| 19 |
+
conditions that creators and other rights holders may use to share
|
| 20 |
+
original works of authorship and other material subject to copyright
|
| 21 |
+
and certain other rights specified in the public license below. The
|
| 22 |
+
following considerations are for informational purposes only, are not
|
| 23 |
+
exhaustive, and do not form part of our licenses.
|
| 24 |
+
|
| 25 |
+
Considerations for licensors: Our public licenses are
|
| 26 |
+
intended for use by those authorized to give the public
|
| 27 |
+
permission to use material in ways otherwise restricted by
|
| 28 |
+
copyright and certain other rights. Our licenses are
|
| 29 |
+
irrevocable. Licensors should read and understand the terms
|
| 30 |
+
and conditions of the license they choose before applying it.
|
| 31 |
+
Licensors should also secure all rights necessary before
|
| 32 |
+
applying our licenses so that the public can reuse the
|
| 33 |
+
material as expected. Licensors should clearly mark any
|
| 34 |
+
material not subject to the license. This includes other CC-
|
| 35 |
+
licensed material, or material used under an exception or
|
| 36 |
+
limitation to copyright. More considerations for licensors:
|
| 37 |
+
wiki.creativecommons.org/Considerations_for_licensors
|
| 38 |
+
|
| 39 |
+
Considerations for the public: By using one of our public
|
| 40 |
+
licenses, a licensor grants the public permission to use the
|
| 41 |
+
licensed material under specified terms and conditions. If
|
| 42 |
+
the licensor's permission is not necessary for any reason--for
|
| 43 |
+
example, because of any applicable exception or limitation to
|
| 44 |
+
copyright--then that use is not regulated by the license. Our
|
| 45 |
+
licenses grant only permissions under copyright and certain
|
| 46 |
+
other rights that a licensor has authority to grant. Use of
|
| 47 |
+
the licensed material may still be restricted for other
|
| 48 |
+
reasons, including because others have copyright or other
|
| 49 |
+
rights in the material. A licensor may make special requests,
|
| 50 |
+
such as asking that all changes be marked or described.
|
| 51 |
+
Although not required by our licenses, you are encouraged to
|
| 52 |
+
respect those requests where reasonable. More_considerations
|
| 53 |
+
for the public:
|
| 54 |
+
wiki.creativecommons.org/Considerations_for_licensees
|
| 55 |
+
|
| 56 |
+
=======================================================================
|
| 57 |
+
|
| 58 |
+
Creative Commons Attribution-NonCommercial 4.0 International Public
|
| 59 |
+
License
|
| 60 |
+
|
| 61 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 62 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 63 |
+
Attribution-NonCommercial 4.0 International Public License ("Public
|
| 64 |
+
License"). To the extent this Public License may be interpreted as a
|
| 65 |
+
contract, You are granted the Licensed Rights in consideration of Your
|
| 66 |
+
acceptance of these terms and conditions, and the Licensor grants You
|
| 67 |
+
such rights in consideration of benefits the Licensor receives from
|
| 68 |
+
making the Licensed Material available under these terms and
|
| 69 |
+
conditions.
|
| 70 |
+
|
| 71 |
+
Section 1 -- Definitions.
|
| 72 |
+
|
| 73 |
+
a. Adapted Material means material subject to Copyright and Similar
|
| 74 |
+
Rights that is derived from or based upon the Licensed Material
|
| 75 |
+
and in which the Licensed Material is translated, altered,
|
| 76 |
+
arranged, transformed, or otherwise modified in a manner requiring
|
| 77 |
+
permission under the Copyright and Similar Rights held by the
|
| 78 |
+
Licensor. For purposes of this Public License, where the Licensed
|
| 79 |
+
Material is a musical work, performance, or sound recording,
|
| 80 |
+
Adapted Material is always produced where the Licensed Material is
|
| 81 |
+
synched in timed relation with a moving image.
|
| 82 |
+
|
| 83 |
+
b. Adapter's License means the license You apply to Your Copyright
|
| 84 |
+
and Similar Rights in Your contributions to Adapted Material in
|
| 85 |
+
accordance with the terms and conditions of this Public License.
|
| 86 |
+
|
| 87 |
+
c. Copyright and Similar Rights means copyright and/or similar rights
|
| 88 |
+
closely related to copyright including, without limitation,
|
| 89 |
+
performance, broadcast, sound recording, and Sui Generis Database
|
| 90 |
+
Rights, without regard to how the rights are labeled or
|
| 91 |
+
categorized. For purposes of this Public License, the rights
|
| 92 |
+
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
| 93 |
+
Rights.
|
| 94 |
+
d. Effective Technological Measures means those measures that, in the
|
| 95 |
+
absence of proper authority, may not be circumvented under laws
|
| 96 |
+
fulfilling obligations under Article 11 of the WIPO Copyright
|
| 97 |
+
Treaty adopted on December 20, 1996, and/or similar international
|
| 98 |
+
agreements.
|
| 99 |
+
|
| 100 |
+
e. Exceptions and Limitations means fair use, fair dealing, and/or
|
| 101 |
+
any other exception or limitation to Copyright and Similar Rights
|
| 102 |
+
that applies to Your use of the Licensed Material.
|
| 103 |
+
|
| 104 |
+
f. Licensed Material means the artistic or literary work, database,
|
| 105 |
+
or other material to which the Licensor applied this Public
|
| 106 |
+
License.
|
| 107 |
+
|
| 108 |
+
g. Licensed Rights means the rights granted to You subject to the
|
| 109 |
+
terms and conditions of this Public License, which are limited to
|
| 110 |
+
all Copyright and Similar Rights that apply to Your use of the
|
| 111 |
+
Licensed Material and that the Licensor has authority to license.
|
| 112 |
+
|
| 113 |
+
h. Licensor means the individual(s) or entity(ies) granting rights
|
| 114 |
+
under this Public License.
|
| 115 |
+
|
| 116 |
+
i. NonCommercial means not primarily intended for or directed towards
|
| 117 |
+
commercial advantage or monetary compensation. For purposes of
|
| 118 |
+
this Public License, the exchange of the Licensed Material for
|
| 119 |
+
other material subject to Copyright and Similar Rights by digital
|
| 120 |
+
file-sharing or similar means is NonCommercial provided there is
|
| 121 |
+
no payment of monetary compensation in connection with the
|
| 122 |
+
exchange.
|
| 123 |
+
|
| 124 |
+
j. Share means to provide material to the public by any means or
|
| 125 |
+
process that requires permission under the Licensed Rights, such
|
| 126 |
+
as reproduction, public display, public performance, distribution,
|
| 127 |
+
dissemination, communication, or importation, and to make material
|
| 128 |
+
available to the public including in ways that members of the
|
| 129 |
+
public may access the material from a place and at a time
|
| 130 |
+
individually chosen by them.
|
| 131 |
+
|
| 132 |
+
k. Sui Generis Database Rights means rights other than copyright
|
| 133 |
+
resulting from Directive 96/9/EC of the European Parliament and of
|
| 134 |
+
the Council of 11 March 1996 on the legal protection of databases,
|
| 135 |
+
as amended and/or succeeded, as well as other essentially
|
| 136 |
+
equivalent rights anywhere in the world.
|
| 137 |
+
|
| 138 |
+
l. You means the individual or entity exercising the Licensed Rights
|
| 139 |
+
under this Public License. Your has a corresponding meaning.
|
| 140 |
+
|
| 141 |
+
Section 2 -- Scope.
|
| 142 |
+
|
| 143 |
+
a. License grant.
|
| 144 |
+
|
| 145 |
+
1. Subject to the terms and conditions of this Public License,
|
| 146 |
+
the Licensor hereby grants You a worldwide, royalty-free,
|
| 147 |
+
non-sublicensable, non-exclusive, irrevocable license to
|
| 148 |
+
exercise the Licensed Rights in the Licensed Material to:
|
| 149 |
+
|
| 150 |
+
a. reproduce and Share the Licensed Material, in whole or
|
| 151 |
+
in part, for NonCommercial purposes only; and
|
| 152 |
+
|
| 153 |
+
b. produce, reproduce, and Share Adapted Material for
|
| 154 |
+
NonCommercial purposes only.
|
| 155 |
+
|
| 156 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where
|
| 157 |
+
Exceptions and Limitations apply to Your use, this Public
|
| 158 |
+
License does not apply, and You do not need to comply with
|
| 159 |
+
its terms and conditions.
|
| 160 |
+
|
| 161 |
+
3. Term. The term of this Public License is specified in Section
|
| 162 |
+
6(a).
|
| 163 |
+
|
| 164 |
+
4. Media and formats; technical modifications allowed. The
|
| 165 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 166 |
+
all media and formats whether now known or hereafter created,
|
| 167 |
+
and to make technical modifications necessary to do so. The
|
| 168 |
+
Licensor waives and/or agrees not to assert any right or
|
| 169 |
+
authority to forbid You from making technical modifications
|
| 170 |
+
necessary to exercise the Licensed Rights, including
|
| 171 |
+
technical modifications necessary to circumvent Effective
|
| 172 |
+
Technological Measures. For purposes of this Public License,
|
| 173 |
+
simply making modifications authorized by this Section 2(a)
|
| 174 |
+
(4) never produces Adapted Material.
|
| 175 |
+
|
| 176 |
+
5. Downstream recipients.
|
| 177 |
+
|
| 178 |
+
a. Offer from the Licensor -- Licensed Material. Every
|
| 179 |
+
recipient of the Licensed Material automatically
|
| 180 |
+
receives an offer from the Licensor to exercise the
|
| 181 |
+
Licensed Rights under the terms and conditions of this
|
| 182 |
+
Public License.
|
| 183 |
+
|
| 184 |
+
b. No downstream restrictions. You may not offer or impose
|
| 185 |
+
any additional or different terms or conditions on, or
|
| 186 |
+
apply any Effective Technological Measures to, the
|
| 187 |
+
Licensed Material if doing so restricts exercise of the
|
| 188 |
+
Licensed Rights by any recipient of the Licensed
|
| 189 |
+
Material.
|
| 190 |
+
|
| 191 |
+
6. No endorsement. Nothing in this Public License constitutes or
|
| 192 |
+
may be construed as permission to assert or imply that You
|
| 193 |
+
are, or that Your use of the Licensed Material is, connected
|
| 194 |
+
with, or sponsored, endorsed, or granted official status by,
|
| 195 |
+
the Licensor or others designated to receive attribution as
|
| 196 |
+
provided in Section 3(a)(1)(A)(i).
|
| 197 |
+
|
| 198 |
+
b. Other rights.
|
| 199 |
+
|
| 200 |
+
1. Moral rights, such as the right of integrity, are not
|
| 201 |
+
licensed under this Public License, nor are publicity,
|
| 202 |
+
privacy, and/or other similar personality rights; however, to
|
| 203 |
+
the extent possible, the Licensor waives and/or agrees not to
|
| 204 |
+
assert any such rights held by the Licensor to the limited
|
| 205 |
+
extent necessary to allow You to exercise the Licensed
|
| 206 |
+
Rights, but not otherwise.
|
| 207 |
+
|
| 208 |
+
2. Patent and trademark rights are not licensed under this
|
| 209 |
+
Public License.
|
| 210 |
+
|
| 211 |
+
3. To the extent possible, the Licensor waives any right to
|
| 212 |
+
collect royalties from You for the exercise of the Licensed
|
| 213 |
+
Rights, whether directly or through a collecting society
|
| 214 |
+
under any voluntary or waivable statutory or compulsory
|
| 215 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 216 |
+
reserves any right to collect such royalties, including when
|
| 217 |
+
the Licensed Material is used other than for NonCommercial
|
| 218 |
+
purposes.
|
| 219 |
+
|
| 220 |
+
Section 3 -- License Conditions.
|
| 221 |
+
|
| 222 |
+
Your exercise of the Licensed Rights is expressly made subject to the
|
| 223 |
+
following conditions.
|
| 224 |
+
|
| 225 |
+
a. Attribution.
|
| 226 |
+
|
| 227 |
+
1. If You Share the Licensed Material (including in modified
|
| 228 |
+
form), You must:
|
| 229 |
+
|
| 230 |
+
a. retain the following if it is supplied by the Licensor
|
| 231 |
+
with the Licensed Material:
|
| 232 |
+
|
| 233 |
+
i. identification of the creator(s) of the Licensed
|
| 234 |
+
Material and any others designated to receive
|
| 235 |
+
attribution, in any reasonable manner requested by
|
| 236 |
+
the Licensor (including by pseudonym if
|
| 237 |
+
designated);
|
| 238 |
+
|
| 239 |
+
ii. a copyright notice;
|
| 240 |
+
|
| 241 |
+
iii. a notice that refers to this Public License;
|
| 242 |
+
|
| 243 |
+
iv. a notice that refers to the disclaimer of
|
| 244 |
+
warranties;
|
| 245 |
+
|
| 246 |
+
v. a URI or hyperlink to the Licensed Material to the
|
| 247 |
+
extent reasonably practicable;
|
| 248 |
+
|
| 249 |
+
b. indicate if You modified the Licensed Material and
|
| 250 |
+
retain an indication of any previous modifications; and
|
| 251 |
+
|
| 252 |
+
c. indicate the Licensed Material is licensed under this
|
| 253 |
+
Public License, and include the text of, or the URI or
|
| 254 |
+
hyperlink to, this Public License.
|
| 255 |
+
|
| 256 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 257 |
+
reasonable manner based on the medium, means, and context in
|
| 258 |
+
which You Share the Licensed Material. For example, it may be
|
| 259 |
+
reasonable to satisfy the conditions by providing a URI or
|
| 260 |
+
hyperlink to a resource that includes the required
|
| 261 |
+
information.
|
| 262 |
+
|
| 263 |
+
3. If requested by the Licensor, You must remove any of the
|
| 264 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 265 |
+
reasonably practicable.
|
| 266 |
+
|
| 267 |
+
4. If You Share Adapted Material You produce, the Adapter's
|
| 268 |
+
License You apply must not prevent recipients of the Adapted
|
| 269 |
+
Material from complying with this Public License.
|
| 270 |
+
|
| 271 |
+
Section 4 -- Sui Generis Database Rights.
|
| 272 |
+
|
| 273 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 274 |
+
apply to Your use of the Licensed Material:
|
| 275 |
+
|
| 276 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
| 277 |
+
to extract, reuse, reproduce, and Share all or a substantial
|
| 278 |
+
portion of the contents of the database for NonCommercial purposes
|
| 279 |
+
only;
|
| 280 |
+
|
| 281 |
+
b. if You include all or a substantial portion of the database
|
| 282 |
+
contents in a database in which You have Sui Generis Database
|
| 283 |
+
Rights, then the database in which You have Sui Generis Database
|
| 284 |
+
Rights (but not its individual contents) is Adapted Material; and
|
| 285 |
+
|
| 286 |
+
c. You must comply with the conditions in Section 3(a) if You Share
|
| 287 |
+
all or a substantial portion of the contents of the database.
|
| 288 |
+
|
| 289 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 290 |
+
replace Your obligations under this Public License where the Licensed
|
| 291 |
+
Rights include other Copyright and Similar Rights.
|
| 292 |
+
|
| 293 |
+
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
| 294 |
+
|
| 295 |
+
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
| 296 |
+
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
| 297 |
+
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
| 298 |
+
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
| 299 |
+
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
| 300 |
+
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
| 301 |
+
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
| 302 |
+
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
| 303 |
+
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
| 304 |
+
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
| 305 |
+
|
| 306 |
+
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
| 307 |
+
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
| 308 |
+
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
| 309 |
+
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
| 310 |
+
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
| 311 |
+
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
| 312 |
+
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
| 313 |
+
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
| 314 |
+
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
| 315 |
+
|
| 316 |
+
c. The disclaimer of warranties and limitation of liability provided
|
| 317 |
+
above shall be interpreted in a manner that, to the extent
|
| 318 |
+
possible, most closely approximates an absolute disclaimer and
|
| 319 |
+
waiver of all liability.
|
| 320 |
+
|
| 321 |
+
Section 6 -- Term and Termination.
|
| 322 |
+
|
| 323 |
+
a. This Public License applies for the term of the Copyright and
|
| 324 |
+
Similar Rights licensed here. However, if You fail to comply with
|
| 325 |
+
this Public License, then Your rights under this Public License
|
| 326 |
+
terminate automatically.
|
| 327 |
+
|
| 328 |
+
b. Where Your right to use the Licensed Material has terminated under
|
| 329 |
+
Section 6(a), it reinstates:
|
| 330 |
+
|
| 331 |
+
1. automatically as of the date the violation is cured, provided
|
| 332 |
+
it is cured within 30 days of Your discovery of the
|
| 333 |
+
violation; or
|
| 334 |
+
|
| 335 |
+
2. upon express reinstatement by the Licensor.
|
| 336 |
+
|
| 337 |
+
For the avoidance of doubt, this Section 6(b) does not affect any
|
| 338 |
+
right the Licensor may have to seek remedies for Your violations
|
| 339 |
+
of this Public License.
|
| 340 |
+
|
| 341 |
+
c. For the avoidance of doubt, the Licensor may also offer the
|
| 342 |
+
Licensed Material under separate terms or conditions or stop
|
| 343 |
+
distributing the Licensed Material at any time; however, doing so
|
| 344 |
+
will not terminate this Public License.
|
| 345 |
+
|
| 346 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 347 |
+
License.
|
| 348 |
+
|
| 349 |
+
Section 7 -- Other Terms and Conditions.
|
| 350 |
+
|
| 351 |
+
a. The Licensor shall not be bound by any additional or different
|
| 352 |
+
terms or conditions communicated by You unless expressly agreed.
|
| 353 |
+
|
| 354 |
+
b. Any arrangements, understandings, or agreements regarding the
|
| 355 |
+
Licensed Material not stated herein are separate from and
|
| 356 |
+
independent of the terms and conditions of this Public License.
|
| 357 |
+
|
| 358 |
+
Section 8 -- Interpretation.
|
| 359 |
+
|
| 360 |
+
a. For the avoidance of doubt, this Public License does not, and
|
| 361 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 362 |
+
conditions on any use of the Licensed Material that could lawfully
|
| 363 |
+
be made without permission under this Public License.
|
| 364 |
+
|
| 365 |
+
b. To the extent possible, if any provision of this Public License is
|
| 366 |
+
deemed unenforceable, it shall be automatically reformed to the
|
| 367 |
+
minimum extent necessary to make it enforceable. If the provision
|
| 368 |
+
cannot be reformed, it shall be severed from this Public License
|
| 369 |
+
without affecting the enforceability of the remaining terms and
|
| 370 |
+
conditions.
|
| 371 |
+
|
| 372 |
+
c. No term or condition of this Public License will be waived and no
|
| 373 |
+
failure to comply consented to unless expressly agreed to by the
|
| 374 |
+
Licensor.
|
| 375 |
+
|
| 376 |
+
d. Nothing in this Public License constitutes or may be interpreted
|
| 377 |
+
as a limitation upon, or waiver of, any privileges and immunities
|
| 378 |
+
that apply to the Licensor or You, including from the legal
|
| 379 |
+
processes of any jurisdiction or authority.
|
| 380 |
+
|
| 381 |
+
=======================================================================
|
| 382 |
+
|
| 383 |
+
Creative Commons is not a party to its public
|
| 384 |
+
licenses. Notwithstanding, Creative Commons may elect to apply one of
|
| 385 |
+
its public licenses to material it publishes and in those instances
|
| 386 |
+
will be considered the “Licensor.” The text of the Creative Commons
|
| 387 |
+
public licenses is dedicated to the public domain under the CC0 Public
|
| 388 |
+
Domain Dedication. Except for the limited purpose of indicating that
|
| 389 |
+
material is shared under a Creative Commons public license or as
|
| 390 |
+
otherwise permitted by the Creative Commons policies published at
|
| 391 |
+
creativecommons.org/policies, Creative Commons does not authorize the
|
| 392 |
+
use of the trademark "Creative Commons" or any other trademark or logo
|
| 393 |
+
of Creative Commons without its prior written consent including,
|
| 394 |
+
without limitation, in connection with any unauthorized modifications
|
| 395 |
+
to any of its public licenses or any other arrangements,
|
| 396 |
+
understandings, or agreements concerning use of licensed material. For
|
| 397 |
+
the avoidance of doubt, this paragraph does not form part of the
|
| 398 |
+
public licenses.
|
| 399 |
+
|
| 400 |
+
Creative Commons may be contacted at creativecommons.org.
|
README.md
CHANGED
|
@@ -1,13 +1,196 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: streamlit
|
| 7 |
-
|
| 8 |
app_file: app.py
|
| 9 |
-
|
| 10 |
-
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: FRN
|
| 3 |
+
emoji: 📉
|
| 4 |
+
colorFrom: gray
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: streamlit
|
| 7 |
+
pinned: true
|
| 8 |
app_file: app.py
|
| 9 |
+
sdk_version: 1.10.0
|
| 10 |
+
python_version: 3.8
|
| 11 |
---
|
| 12 |
|
| 13 |
+
# FRN - Full-band Recurrent Network Official Implementation
|
| 14 |
+
|
| 15 |
+
**Improving performance of real-time full-band blind packet-loss concealment with predictive network - ICASSP 2023**
|
| 16 |
+
|
| 17 |
+
[](https://arxiv.org/abs/2211.04071)
|
| 18 |
+
[](https://github.com/Crystalsound/FRN/)
|
| 19 |
+
[](https://github.com/Crystalsound/FRN/commits)
|
| 20 |
+
|
| 21 |
+
## License and citation
|
| 22 |
+
|
| 23 |
+
This repository is released under the CC-BY-NC 4.0. license as found in the LICENSE file.
|
| 24 |
+
|
| 25 |
+
If you use our software, please cite as below.
|
| 26 |
+
For future queries, please contact [anh.nguyen@namitech.io](mailto:anh.nguyen@namitech.io).
|
| 27 |
+
|
| 28 |
+
Copyright © 2022 NAMI TECHNOLOGY JSC, Inc. All rights reserved.
|
| 29 |
+
|
| 30 |
+
```
|
| 31 |
+
@misc{Nguyen2022ImprovingPO,
|
| 32 |
+
title={Improving performance of real-time full-band blind packet-loss concealment with predictive network},
|
| 33 |
+
author={Viet-Anh Nguyen and Anh H. T. Nguyen and Andy W. H. Khong},
|
| 34 |
+
year={2022},
|
| 35 |
+
eprint={2211.04071},
|
| 36 |
+
archivePrefix={arXiv},
|
| 37 |
+
primaryClass={cs.LG}
|
| 38 |
+
}
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
# 1. Results
|
| 42 |
+
|
| 43 |
+
Our model achieved a significant gain over baselines. Here, we include the predicted packet loss concealment
|
| 44 |
+
mean-opinion-score (PLCMOS) using Microsoft's [PLCMOS](https://github.com/microsoft/PLC-Challenge/tree/main/PLCMOS)
|
| 45 |
+
service. Please refer to our paper for more benchmarks.
|
| 46 |
+
|
| 47 |
+
| Model | PLCMOS |
|
| 48 |
+
|---------|-----------|
|
| 49 |
+
| Input | 3.517 |
|
| 50 |
+
| tPLC | 3.463 |
|
| 51 |
+
| TFGAN | 3.645 |
|
| 52 |
+
| **FRN** | **3.655** |
|
| 53 |
+
|
| 54 |
+
We also provide several audio samples in [https://crystalsound.github.io/FRN/](https://crystalsound.github.io/FRN/) for
|
| 55 |
+
comparison.
|
| 56 |
+
|
| 57 |
+
# 2. Installation
|
| 58 |
+
|
| 59 |
+
## Setup
|
| 60 |
+
|
| 61 |
+
### Clone the repo
|
| 62 |
+
|
| 63 |
+
```
|
| 64 |
+
$ git clone https://github.com/Crystalsound/FRN.git
|
| 65 |
+
$ cd FRN
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
### Install dependencies
|
| 69 |
+
|
| 70 |
+
* Our implementation requires the `libsndfile` libraries for the Python packages `soundfile`. On Ubuntu, they can be
|
| 71 |
+
easily installed using `apt-get`:
|
| 72 |
+
```
|
| 73 |
+
$ apt-get update && apt-get install libsndfile-dev
|
| 74 |
+
```
|
| 75 |
+
* Create a Python 3.8 environment. Conda is recommended:
|
| 76 |
+
```
|
| 77 |
+
$ conda create -n frn python=3.8
|
| 78 |
+
$ conda activate frn
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
* Install the requirements:
|
| 82 |
+
```
|
| 83 |
+
$ pip install -r requirements.txt
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
# 3. Data preparation
|
| 87 |
+
|
| 88 |
+
In our paper, we conduct experiments on the [VCTK](https://datashare.ed.ac.uk/handle/10283/3443) dataset.
|
| 89 |
+
|
| 90 |
+
* Download and extract the datasets:
|
| 91 |
+
```
|
| 92 |
+
$ wget http://www.udialogue.org/download/VCTK-Corpus.tar.gz -O data/vctk/VCTK-Corpus.tar.gz
|
| 93 |
+
$ tar -zxvf data/vctk/VCTK-Corpus.tar.gz -C data/vctk/ --strip-components=1
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
After extracting the datasets, your `./data` directory should look like this:
|
| 97 |
+
|
| 98 |
+
```
|
| 99 |
+
.
|
| 100 |
+
|--data
|
| 101 |
+
|--vctk
|
| 102 |
+
|--wav48
|
| 103 |
+
|--p225
|
| 104 |
+
|--p225_001.wav
|
| 105 |
+
...
|
| 106 |
+
|--train.txt
|
| 107 |
+
|--test.txt
|
| 108 |
+
```
|
| 109 |
+
* In order to load the datasets, text files that contain training and testing audio paths are required. We have
|
| 110 |
+
prepared `train.txt` and `test.txt` files in `./data/vctk` directory.
|
| 111 |
+
|
| 112 |
+
# 4. Run the code
|
| 113 |
+
|
| 114 |
+
## Configuration
|
| 115 |
+
|
| 116 |
+
`config.py` is the most important file. Here, you can find all the configurations related to experiment setups,
|
| 117 |
+
datasets, models, training, testing, etc. Although the config file has been explained thoroughly, we recommend reading
|
| 118 |
+
our paper to fully understand each parameter.
|
| 119 |
+
|
| 120 |
+
## Training
|
| 121 |
+
|
| 122 |
+
* Adjust training hyperparameters in `config.py`. We provide the pretrained predictor in `lightning_logs/predictor` as stated in our paper. The FRN model can be trained entirely from scratch and will work as well. In this case, initiate `PLCModel(..., pred_ckpt_path=None)`.
|
| 123 |
+
|
| 124 |
+
* Run `main.py`:
|
| 125 |
+
```
|
| 126 |
+
$ python main.py --mode train
|
| 127 |
+
```
|
| 128 |
+
* Each run will create a version in `./lightning_logs`, where the model checkpoint and hyperparameters are saved. In
|
| 129 |
+
case you want to continue training from one of these versions, just set the argument `--version` of the above command
|
| 130 |
+
to your desired version number. For example:
|
| 131 |
+
```
|
| 132 |
+
# resume from version 0
|
| 133 |
+
$ python main.py --mode train --version 0
|
| 134 |
+
```
|
| 135 |
+
* To monitor the training curves as well as inspect model output visualization, run the tensorboard:
|
| 136 |
+
```
|
| 137 |
+
$ tensorboard --logdir=./lightning_logs --bind_all
|
| 138 |
+
```
|
| 139 |
+
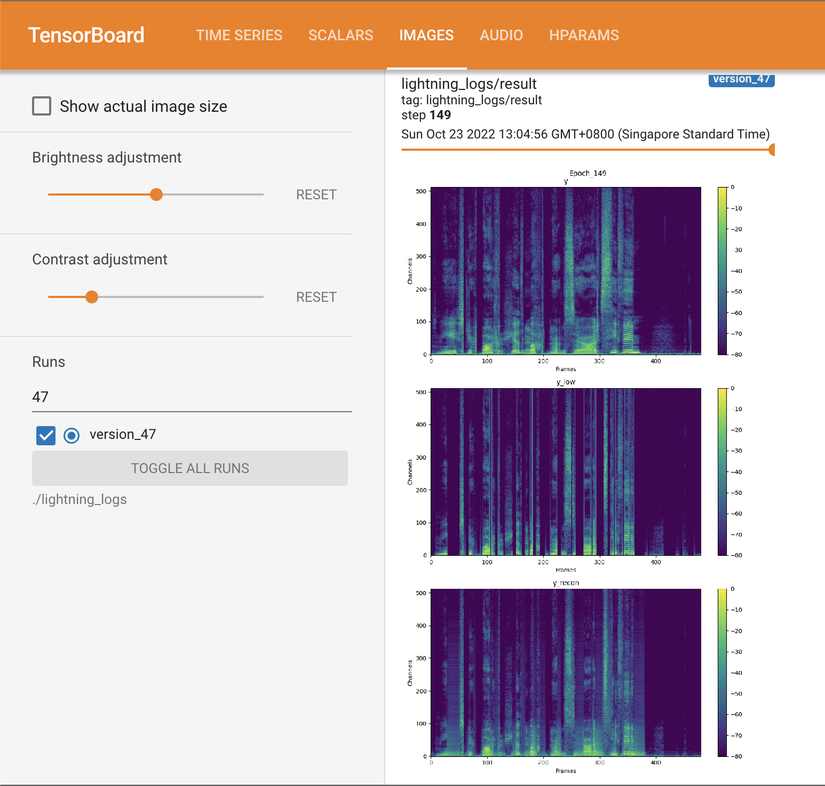
|
| 140 |
+
|
| 141 |
+
## Evaluation
|
| 142 |
+
|
| 143 |
+
In our paper, we evaluated with 2 masking methods: simulation using Markov Chain and employing real traces in PLC
|
| 144 |
+
Challenge.
|
| 145 |
+
|
| 146 |
+
* Get the blind test set with loss traces:
|
| 147 |
+
```
|
| 148 |
+
$ wget http://plcchallenge2022pub.blob.core.windows.net/plcchallengearchive/blind.tar.gz
|
| 149 |
+
$ tar -xvf blind.tar.gz -C test_samples
|
| 150 |
+
```
|
| 151 |
+
* Modify `config.py` to change evaluation setup if necessary.
|
| 152 |
+
* Run `main.py` with a version number to be evaluated:
|
| 153 |
+
```
|
| 154 |
+
$ python main.py --mode eval --version 0
|
| 155 |
+
```
|
| 156 |
+
During the evaluation, several output samples are saved to `CONFIG.LOG.sample_path` for sanity testing.
|
| 157 |
+
|
| 158 |
+
## Configure a new dataset
|
| 159 |
+
|
| 160 |
+
Our implementation currently works with the VCTK dataset but can be easily extensible to a new one.
|
| 161 |
+
|
| 162 |
+
* Firstly, you need to prepare `train.txt` and `test.txt`. See `./data/vctk/train.txt` and `./data/vctk/test.txt` for
|
| 163 |
+
example.
|
| 164 |
+
* Secondly, add a new dictionary to `CONFIG.DATA.data_dir`:
|
| 165 |
+
```
|
| 166 |
+
{
|
| 167 |
+
'root': 'path/to/data/directory',
|
| 168 |
+
'train': 'path/to/train.txt',
|
| 169 |
+
'test': 'path/to/test.txt'
|
| 170 |
+
}
|
| 171 |
+
```
|
| 172 |
+
**Important:** Make sure each line in `train.txt` and `test.txt` joining with `'root'` is a valid path to its
|
| 173 |
+
corresponding audio file.
|
| 174 |
+
|
| 175 |
+
# 5. Audio generation
|
| 176 |
+
|
| 177 |
+
* In order to generate output audios, you need to modify `CONFIG.TEST.in_dir` to your input directory.
|
| 178 |
+
* Run `main.py`:
|
| 179 |
+
```
|
| 180 |
+
python main.py --mode test --version 0
|
| 181 |
+
```
|
| 182 |
+
The generated audios are saved to `CONFIG.TEST.out_dir`.
|
| 183 |
+
|
| 184 |
+
## ONNX inferencing
|
| 185 |
+
We provide ONNX inferencing scripts and the best ONNX model (converted from the best checkpoint)
|
| 186 |
+
at `lightning_logs/best_model.onnx`.
|
| 187 |
+
* Convert a checkpoint to an ONNX model:
|
| 188 |
+
```
|
| 189 |
+
python main.py --mode onnx --version 0
|
| 190 |
+
```
|
| 191 |
+
The converted ONNX model will be saved to `lightning_logs/version_0/checkpoints`.
|
| 192 |
+
* Put test audios in `test_samples` and inference with the converted ONNX model (see `inference_onnx.py` for more
|
| 193 |
+
details):
|
| 194 |
+
```
|
| 195 |
+
python inference_onnx.py --onnx_path lightning_logs/version_0/frn.onnx
|
| 196 |
+
```
|
app (1).py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import librosa
|
| 3 |
+
import soundfile as sf
|
| 4 |
+
import librosa.display
|
| 5 |
+
from config import CONFIG
|
| 6 |
+
import torch
|
| 7 |
+
from dataset import MaskGenerator
|
| 8 |
+
import onnxruntime, onnx
|
| 9 |
+
import matplotlib.pyplot as plt
|
| 10 |
+
import numpy as np
|
| 11 |
+
from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
|
| 12 |
+
|
| 13 |
+
@st.cache
|
| 14 |
+
def load_model():
|
| 15 |
+
path = 'lightning_logs/version_0/checkpoints/frn.onnx'
|
| 16 |
+
onnx_model = onnx.load(path)
|
| 17 |
+
options = onnxruntime.SessionOptions()
|
| 18 |
+
options.intra_op_num_threads = 2
|
| 19 |
+
options.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_ALL
|
| 20 |
+
session = onnxruntime.InferenceSession(path, options)
|
| 21 |
+
input_names = [x.name for x in session.get_inputs()]
|
| 22 |
+
output_names = [x.name for x in session.get_outputs()]
|
| 23 |
+
return session, onnx_model, input_names, output_names
|
| 24 |
+
|
| 25 |
+
def inference(re_im, session, onnx_model, input_names, output_names):
|
| 26 |
+
inputs = {input_names[i]: np.zeros([d.dim_value for d in _input.type.tensor_type.shape.dim],
|
| 27 |
+
dtype=np.float32)
|
| 28 |
+
for i, _input in enumerate(onnx_model.graph.input)
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
output_audio = []
|
| 32 |
+
for t in range(re_im.shape[0]):
|
| 33 |
+
inputs[input_names[0]] = re_im[t]
|
| 34 |
+
out, prev_mag, predictor_state, mlp_state = session.run(output_names, inputs)
|
| 35 |
+
inputs[input_names[1]] = prev_mag
|
| 36 |
+
inputs[input_names[2]] = predictor_state
|
| 37 |
+
inputs[input_names[3]] = mlp_state
|
| 38 |
+
output_audio.append(out)
|
| 39 |
+
|
| 40 |
+
output_audio = torch.tensor(np.concatenate(output_audio, 0))
|
| 41 |
+
output_audio = output_audio.permute(1, 0, 2).contiguous()
|
| 42 |
+
output_audio = torch.view_as_complex(output_audio)
|
| 43 |
+
output_audio = torch.istft(output_audio, window, stride, window=hann)
|
| 44 |
+
return output_audio.numpy()
|
| 45 |
+
|
| 46 |
+
def visualize(hr, lr, recon):
|
| 47 |
+
sr = CONFIG.DATA.sr
|
| 48 |
+
window_size = 1024
|
| 49 |
+
window = np.hanning(window_size)
|
| 50 |
+
|
| 51 |
+
stft_hr = librosa.core.spectrum.stft(hr, n_fft=window_size, hop_length=512, window=window)
|
| 52 |
+
stft_hr = 2 * np.abs(stft_hr) / np.sum(window)
|
| 53 |
+
|
| 54 |
+
stft_lr = librosa.core.spectrum.stft(lr, n_fft=window_size, hop_length=512, window=window)
|
| 55 |
+
stft_lr = 2 * np.abs(stft_lr) / np.sum(window)
|
| 56 |
+
|
| 57 |
+
stft_recon = librosa.core.spectrum.stft(recon, n_fft=window_size, hop_length=512, window=window)
|
| 58 |
+
stft_recon = 2 * np.abs(stft_recon) / np.sum(window)
|
| 59 |
+
|
| 60 |
+
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, sharey=True, sharex=True, figsize=(16, 10))
|
| 61 |
+
ax1.title.set_text('Target signal')
|
| 62 |
+
ax2.title.set_text('Lossy signal')
|
| 63 |
+
ax3.title.set_text('Enhanced signal')
|
| 64 |
+
|
| 65 |
+
canvas = FigureCanvas(fig)
|
| 66 |
+
p = librosa.display.specshow(librosa.amplitude_to_db(stft_hr), ax=ax1, y_axis='linear', x_axis='time', sr=sr)
|
| 67 |
+
p = librosa.display.specshow(librosa.amplitude_to_db(stft_lr), ax=ax2, y_axis='linear', x_axis='time', sr=sr)
|
| 68 |
+
p = librosa.display.specshow(librosa.amplitude_to_db(stft_recon), ax=ax3, y_axis='linear', x_axis='time', sr=sr)
|
| 69 |
+
return fig
|
| 70 |
+
|
| 71 |
+
packet_size = CONFIG.DATA.EVAL.packet_size
|
| 72 |
+
window = CONFIG.DATA.window_size
|
| 73 |
+
stride = CONFIG.DATA.stride
|
| 74 |
+
|
| 75 |
+
title = 'Packet Loss Concealment'
|
| 76 |
+
st.set_page_config(page_title=title, page_icon=":sound:")
|
| 77 |
+
st.title(title)
|
| 78 |
+
|
| 79 |
+
st.subheader('Upload audio')
|
| 80 |
+
uploaded_file = st.file_uploader("Upload your audio file (.wav) at 48 kHz sampling rate")
|
| 81 |
+
|
| 82 |
+
is_file_uploaded = uploaded_file is not None
|
| 83 |
+
if not is_file_uploaded:
|
| 84 |
+
uploaded_file = 'sample.wav'
|
| 85 |
+
|
| 86 |
+
target, sr = librosa.load(uploaded_file, sr=48000)
|
| 87 |
+
target = target[:packet_size * (len(target) // packet_size)]
|
| 88 |
+
|
| 89 |
+
st.text('Audio sample')
|
| 90 |
+
st.audio(uploaded_file)
|
| 91 |
+
|
| 92 |
+
st.subheader('Choose expected packet loss rate')
|
| 93 |
+
slider = [st.slider("Expected loss rate for Markov Chain loss generator", 0, 100, step=1)]
|
| 94 |
+
loss_percent = float(slider[0])/100
|
| 95 |
+
mask_gen = MaskGenerator(is_train=False, probs=[(1 - loss_percent, loss_percent)])
|
| 96 |
+
lossy_input = target.copy().reshape(-1, packet_size)
|
| 97 |
+
mask = mask_gen.gen_mask(len(lossy_input), seed=0)[:, np.newaxis]
|
| 98 |
+
lossy_input *= mask
|
| 99 |
+
lossy_input = lossy_input.reshape(-1)
|
| 100 |
+
hann = torch.sqrt(torch.hann_window(window))
|
| 101 |
+
lossy_input_tensor = torch.tensor(lossy_input)
|
| 102 |
+
re_im = torch.stft(lossy_input_tensor, window, stride, window=hann, return_complex=False).permute(1, 0, 2).unsqueeze(
|
| 103 |
+
1).numpy().astype(np.float32)
|
| 104 |
+
session, onnx_model, input_names, output_names = load_model()
|
| 105 |
+
|
| 106 |
+
if st.button('Conceal lossy audio!'):
|
| 107 |
+
with st.spinner('Please wait for completion'):
|
| 108 |
+
output = inference(re_im, session, onnx_model, input_names, output_names)
|
| 109 |
+
|
| 110 |
+
st.subheader('Visualization')
|
| 111 |
+
fig = visualize(target, lossy_input, output)
|
| 112 |
+
st.pyplot(fig)
|
| 113 |
+
st.success('Done!')
|
| 114 |
+
sf.write('target.wav', target, sr)
|
| 115 |
+
sf.write('lossy.wav', lossy_input, sr)
|
| 116 |
+
sf.write('enhanced.wav', output, sr)
|
| 117 |
+
st.text('Original audio')
|
| 118 |
+
st.audio('target.wav')
|
| 119 |
+
st.text('Lossy audio')
|
| 120 |
+
st.audio('lossy.wav')
|
| 121 |
+
st.text('Enhanced audio')
|
| 122 |
+
st.audio('enhanced.wav')
|
config.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class CONFIG:
|
| 2 |
+
gpus = "0,1" # List of gpu devices
|
| 3 |
+
|
| 4 |
+
class TRAIN:
|
| 5 |
+
batch_size = 90 # number of audio files per batch
|
| 6 |
+
lr = 1e-4 # learning rate
|
| 7 |
+
epochs = 150 # max training epochs
|
| 8 |
+
workers = 12 # number of dataloader workers
|
| 9 |
+
val_split = 0.1 # validation set proportion
|
| 10 |
+
clipping_val = 1.0 # gradient clipping value
|
| 11 |
+
patience = 3 # learning rate scheduler's patience
|
| 12 |
+
factor = 0.5 # learning rate reduction factor
|
| 13 |
+
|
| 14 |
+
# Model config
|
| 15 |
+
class MODEL:
|
| 16 |
+
enc_layers = 4 # number of MLP blocks in the encoder
|
| 17 |
+
enc_in_dim = 384 # dimension of the input projection layer in the encoder
|
| 18 |
+
enc_dim = 768 # dimension of the MLP blocks
|
| 19 |
+
pred_dim = 512 # dimension of the LSTM in the predictor
|
| 20 |
+
pred_layers = 1 # number of LSTM layers in the predictor
|
| 21 |
+
|
| 22 |
+
# Dataset config
|
| 23 |
+
class DATA:
|
| 24 |
+
dataset = 'vctk' # dataset to use
|
| 25 |
+
'''
|
| 26 |
+
Dictionary that specifies paths to root directories and train/test text files of each datasets.
|
| 27 |
+
'root' is the path to the dataset and each line of the train.txt/test.txt files should contains the path to an
|
| 28 |
+
audio file from 'root'.
|
| 29 |
+
'''
|
| 30 |
+
data_dir = {'vctk': {'root': 'data/vctk/wav48',
|
| 31 |
+
'train': "data/vctk/train.txt",
|
| 32 |
+
'test': "data/vctk/test.txt"},
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
assert dataset in data_dir.keys(), 'Unknown dataset.'
|
| 36 |
+
sr = 48000 # audio sampling rate
|
| 37 |
+
audio_chunk_len = 122880 # size of chunk taken in each audio files
|
| 38 |
+
window_size = 960 # window size of the STFT operation, equivalent to packet size
|
| 39 |
+
stride = 480 # stride of the STFT operation
|
| 40 |
+
|
| 41 |
+
class TRAIN:
|
| 42 |
+
packet_sizes = [256, 512, 768, 960, 1024,
|
| 43 |
+
1536] # packet sizes for training. All sizes should be divisible by 'audio_chunk_len'
|
| 44 |
+
transition_probs = ((0.9, 0.1), (0.5, 0.1), (0.5, 0.5)) # list of trainsition probs for Markow Chain
|
| 45 |
+
|
| 46 |
+
class EVAL:
|
| 47 |
+
packet_size = 960 # 20ms
|
| 48 |
+
transition_probs = [(0.9, 0.1)] # (0.9, 0.1) ~ 10%; (0.8, 0.2) ~ 20%; (0.6, 0.4) ~ 40%
|
| 49 |
+
masking = 'gen' # whether using simulation or real traces from Microsoft to generate masks
|
| 50 |
+
assert masking in ['gen', 'real']
|
| 51 |
+
trace_path = 'test_samples/blind/lossy_singals' # must be clarified if masking = 'real'
|
| 52 |
+
|
| 53 |
+
class LOG:
|
| 54 |
+
log_dir = 'lightning_logs' # checkpoint and log directory
|
| 55 |
+
sample_path = 'audio_samples' # path to save generated audio samples in evaluation.
|
| 56 |
+
|
| 57 |
+
class TEST:
|
| 58 |
+
in_dir = 'test_samples/blind/lossy_signals' # path to test audio inputs
|
| 59 |
+
out_dir = 'test_samples/blind/lossy_signals_out' # path to generated outputs
|
dataset.py
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
|
| 5 |
+
import librosa
|
| 6 |
+
import numpy as np
|
| 7 |
+
import soundfile as sf
|
| 8 |
+
import torch
|
| 9 |
+
from numpy.random import default_rng
|
| 10 |
+
from pydtmc import MarkovChain
|
| 11 |
+
from sklearn.model_selection import train_test_split
|
| 12 |
+
from torch.utils.data import Dataset
|
| 13 |
+
|
| 14 |
+
from config import CONFIG
|
| 15 |
+
|
| 16 |
+
np.random.seed(0)
|
| 17 |
+
rng = default_rng()
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def load_audio(
|
| 21 |
+
path,
|
| 22 |
+
sample_rate: int = 16000,
|
| 23 |
+
chunk_len=None,
|
| 24 |
+
):
|
| 25 |
+
with sf.SoundFile(path) as f:
|
| 26 |
+
sr = f.samplerate
|
| 27 |
+
audio_len = f.frames
|
| 28 |
+
|
| 29 |
+
if chunk_len is not None and chunk_len < audio_len:
|
| 30 |
+
start_index = torch.randint(0, audio_len - chunk_len, (1,))[0]
|
| 31 |
+
|
| 32 |
+
frames = f._prepare_read(start_index, start_index + chunk_len, -1)
|
| 33 |
+
audio = f.read(frames, always_2d=True, dtype="float32")
|
| 34 |
+
|
| 35 |
+
else:
|
| 36 |
+
audio = f.read(always_2d=True, dtype="float32")
|
| 37 |
+
|
| 38 |
+
if sr != sample_rate:
|
| 39 |
+
audio = librosa.resample(np.squeeze(audio), sr, sample_rate)[:, np.newaxis]
|
| 40 |
+
|
| 41 |
+
return audio.T
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def pad(sig, length):
|
| 45 |
+
if sig.shape[1] < length:
|
| 46 |
+
pad_len = length - sig.shape[1]
|
| 47 |
+
sig = torch.hstack((sig, torch.zeros((sig.shape[0], pad_len))))
|
| 48 |
+
|
| 49 |
+
else:
|
| 50 |
+
start = random.randint(0, sig.shape[1] - length)
|
| 51 |
+
sig = sig[:, start:start + length]
|
| 52 |
+
return sig
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class MaskGenerator:
|
| 56 |
+
def __init__(self, is_train=True, probs=((0.9, 0.1), (0.5, 0.1), (0.5, 0.5))):
|
| 57 |
+
'''
|
| 58 |
+
is_train: if True, mask generator for training otherwise for evaluation
|
| 59 |
+
probs: a list of transition probability (p_N, p_L) for Markov Chain. Only allow 1 tuple if 'is_train=False'
|
| 60 |
+
'''
|
| 61 |
+
self.is_train = is_train
|
| 62 |
+
self.probs = probs
|
| 63 |
+
self.mcs = []
|
| 64 |
+
if self.is_train:
|
| 65 |
+
for prob in probs:
|
| 66 |
+
self.mcs.append(MarkovChain([[prob[0], 1 - prob[0]], [1 - prob[1], prob[1]]], ['1', '0']))
|
| 67 |
+
else:
|
| 68 |
+
assert len(probs) == 1
|
| 69 |
+
prob = self.probs[0]
|
| 70 |
+
self.mcs.append(MarkovChain([[prob[0], 1 - prob[0]], [1 - prob[1], prob[1]]], ['1', '0']))
|
| 71 |
+
|
| 72 |
+
def gen_mask(self, length, seed=0):
|
| 73 |
+
if self.is_train:
|
| 74 |
+
mc = random.choice(self.mcs)
|
| 75 |
+
else:
|
| 76 |
+
mc = self.mcs[0]
|
| 77 |
+
mask = mc.walk(length - 1, seed=seed)
|
| 78 |
+
mask = np.array(list(map(int, mask)))
|
| 79 |
+
return mask
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class TestLoader(Dataset):
|
| 83 |
+
def __init__(self):
|
| 84 |
+
dataset_name = CONFIG.DATA.dataset
|
| 85 |
+
self.mask = CONFIG.DATA.EVAL.masking
|
| 86 |
+
|
| 87 |
+
self.target_root = CONFIG.DATA.data_dir[dataset_name]['root']
|
| 88 |
+
txt_list = CONFIG.DATA.data_dir[dataset_name]['test']
|
| 89 |
+
self.data_list = self.load_txt(txt_list)
|
| 90 |
+
if self.mask == 'real':
|
| 91 |
+
trace_txt = glob.glob(os.path.join(CONFIG.DATA.EVAL.trace_path, '*.txt'))
|
| 92 |
+
trace_txt.sort()
|
| 93 |
+
self.trace_list = [1 - np.array(list(map(int, open(txt, 'r').read().strip('\n').split('\n')))) for txt in
|
| 94 |
+
trace_txt]
|
| 95 |
+
else:
|
| 96 |
+
self.mask_generator = MaskGenerator(is_train=False, probs=CONFIG.DATA.EVAL.transition_probs)
|
| 97 |
+
|
| 98 |
+
self.sr = CONFIG.DATA.sr
|
| 99 |
+
self.stride = CONFIG.DATA.stride
|
| 100 |
+
self.window_size = CONFIG.DATA.window_size
|
| 101 |
+
self.audio_chunk_len = CONFIG.DATA.audio_chunk_len
|
| 102 |
+
self.p_size = CONFIG.DATA.EVAL.packet_size # 20ms
|
| 103 |
+
self.hann = torch.sqrt(torch.hann_window(self.window_size))
|
| 104 |
+
|
| 105 |
+
def __len__(self):
|
| 106 |
+
return len(self.data_list)
|
| 107 |
+
|
| 108 |
+
def load_txt(self, txt_list):
|
| 109 |
+
target = []
|
| 110 |
+
with open(txt_list) as f:
|
| 111 |
+
for line in f:
|
| 112 |
+
target.append(os.path.join(self.target_root, line.strip('\n')))
|
| 113 |
+
target = list(set(target))
|
| 114 |
+
target.sort()
|
| 115 |
+
return target
|
| 116 |
+
|
| 117 |
+
def __getitem__(self, index):
|
| 118 |
+
target = load_audio(self.data_list[index], sample_rate=self.sr)
|
| 119 |
+
target = target[:, :(target.shape[1] // self.p_size) * self.p_size]
|
| 120 |
+
|
| 121 |
+
sig = np.reshape(target, (-1, self.p_size)).copy()
|
| 122 |
+
if self.mask == 'real':
|
| 123 |
+
mask = self.trace_list[index % len(self.trace_list)]
|
| 124 |
+
mask = np.repeat(mask, np.ceil(len(sig) / len(mask)), 0)[:len(sig)][:, np.newaxis]
|
| 125 |
+
else:
|
| 126 |
+
mask = self.mask_generator.gen_mask(len(sig), seed=index)[:, np.newaxis]
|
| 127 |
+
sig *= mask
|
| 128 |
+
sig = torch.tensor(sig).reshape(-1)
|
| 129 |
+
|
| 130 |
+
target = torch.tensor(target).squeeze(0)
|
| 131 |
+
|
| 132 |
+
sig_wav = sig.clone()
|
| 133 |
+
target_wav = target.clone()
|
| 134 |
+
|
| 135 |
+
target = torch.stft(target, self.window_size, self.stride, window=self.hann,
|
| 136 |
+
return_complex=False).permute(2, 0, 1)
|
| 137 |
+
sig = torch.stft(sig, self.window_size, self.stride, window=self.hann, return_complex=False).permute(2, 0, 1)
|
| 138 |
+
return sig.float(), target.float(), sig_wav, target_wav
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class BlindTestLoader(Dataset):
|
| 142 |
+
def __init__(self, test_dir):
|
| 143 |
+
self.data_list = glob.glob(os.path.join(test_dir, '*.wav'))
|
| 144 |
+
self.sr = CONFIG.DATA.sr
|
| 145 |
+
self.stride = CONFIG.DATA.stride
|
| 146 |
+
self.chunk_len = CONFIG.DATA.window_size
|
| 147 |
+
self.hann = torch.sqrt(torch.hann_window(self.chunk_len))
|
| 148 |
+
|
| 149 |
+
def __len__(self):
|
| 150 |
+
return len(self.data_list)
|
| 151 |
+
|
| 152 |
+
def __getitem__(self, index):
|
| 153 |
+
sig = load_audio(self.data_list[index], sample_rate=self.sr)
|
| 154 |
+
sig = torch.from_numpy(sig).squeeze(0)
|
| 155 |
+
sig = torch.stft(sig, self.chunk_len, self.stride, window=self.hann, return_complex=False).permute(2, 0, 1)
|
| 156 |
+
return sig.float()
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
class TrainDataset(Dataset):
|
| 160 |
+
|
| 161 |
+
def __init__(self, mode='train'):
|
| 162 |
+
dataset_name = CONFIG.DATA.dataset
|
| 163 |
+
self.target_root = CONFIG.DATA.data_dir[dataset_name]['root']
|
| 164 |
+
|
| 165 |
+
txt_list = CONFIG.DATA.data_dir[dataset_name]['train']
|
| 166 |
+
self.data_list = self.load_txt(txt_list)
|
| 167 |
+
|
| 168 |
+
if mode == 'train':
|
| 169 |
+
self.data_list, _ = train_test_split(self.data_list, test_size=CONFIG.TRAIN.val_split, random_state=0)
|
| 170 |
+
|
| 171 |
+
elif mode == 'val':
|
| 172 |
+
_, self.data_list = train_test_split(self.data_list, test_size=CONFIG.TRAIN.val_split, random_state=0)
|
| 173 |
+
|
| 174 |
+
self.p_sizes = CONFIG.DATA.TRAIN.packet_sizes
|
| 175 |
+
self.mode = mode
|
| 176 |
+
self.sr = CONFIG.DATA.sr
|
| 177 |
+
self.window = CONFIG.DATA.audio_chunk_len
|
| 178 |
+
self.stride = CONFIG.DATA.stride
|
| 179 |
+
self.chunk_len = CONFIG.DATA.window_size
|
| 180 |
+
self.hann = torch.sqrt(torch.hann_window(self.chunk_len))
|
| 181 |
+
self.mask_generator = MaskGenerator(is_train=True, probs=CONFIG.DATA.TRAIN.transition_probs)
|
| 182 |
+
|
| 183 |
+
def __len__(self):
|
| 184 |
+
return len(self.data_list)
|
| 185 |
+
|
| 186 |
+
def load_txt(self, txt_list):
|
| 187 |
+
target = []
|
| 188 |
+
with open(txt_list) as f:
|
| 189 |
+
for line in f:
|
| 190 |
+
target.append(os.path.join(self.target_root, line.strip('\n')))
|
| 191 |
+
target = list(set(target))
|
| 192 |
+
target.sort()
|
| 193 |
+
return target
|
| 194 |
+
|
| 195 |
+
def fetch_audio(self, index):
|
| 196 |
+
sig = load_audio(self.data_list[index], sample_rate=self.sr, chunk_len=self.window)
|
| 197 |
+
while sig.shape[1] < self.window:
|
| 198 |
+
idx = torch.randint(0, len(self.data_list), (1,))[0]
|
| 199 |
+
pad_len = self.window - sig.shape[1]
|
| 200 |
+
if pad_len < 0.02 * self.sr:
|
| 201 |
+
padding = np.zeros((1, pad_len), dtype=np.float)
|
| 202 |
+
else:
|
| 203 |
+
padding = load_audio(self.data_list[idx], sample_rate=self.sr, chunk_len=pad_len)
|
| 204 |
+
sig = np.hstack((sig, padding))
|
| 205 |
+
return sig
|
| 206 |
+
|
| 207 |
+
def __getitem__(self, index):
|
| 208 |
+
sig = self.fetch_audio(index)
|
| 209 |
+
|
| 210 |
+
sig = sig.reshape(-1).astype(np.float32)
|
| 211 |
+
|
| 212 |
+
target = torch.tensor(sig.copy())
|
| 213 |
+
p_size = random.choice(self.p_sizes)
|
| 214 |
+
|
| 215 |
+
sig = np.reshape(sig, (-1, p_size))
|
| 216 |
+
mask = self.mask_generator.gen_mask(len(sig), seed=index)[:, np.newaxis]
|
| 217 |
+
sig *= mask
|
| 218 |
+
sig = torch.tensor(sig.copy()).reshape(-1)
|
| 219 |
+
|
| 220 |
+
target = torch.stft(target, self.chunk_len, self.stride, window=self.hann,
|
| 221 |
+
return_complex=False).permute(2, 0, 1).float()
|
| 222 |
+
sig = torch.stft(sig, self.chunk_len, self.stride, window=self.hann, return_complex=False)
|
| 223 |
+
sig = sig.permute(2, 0, 1).float()
|
| 224 |
+
return sig, target
|
gitattributes
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lightning_logs/version_0/checkpoints/frn-epoch=65-val_loss=0.2290.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
lightning_logs/version_0/checkpoints/frn.onnx filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
lightning_logs/predictor/checkpoints/predictor.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
index.html
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html>
|
| 3 |
+
<head>
|
| 4 |
+
<link href="css/styles.css" rel="stylesheet">
|
| 5 |
+
|
| 6 |
+
<title>Full-band Recurrent Network</title>
|
| 7 |
+
</head>
|
| 8 |
+
<body>
|
| 9 |
+
<nav>
|
| 10 |
+
<ul>
|
| 11 |
+
<!-- <li><a href="/">Home</a></li> -->
|
| 12 |
+
<li><a href="https://github.com/Crystalsound/FRN/">Github</a></li>
|
| 13 |
+
<li><a href="https://arxiv.org/abs/2211.04071">Arxiv</a></li>
|
| 14 |
+
<li><a href="https://www.namitech.io/">Website</a></li>
|
| 15 |
+
</ul>
|
| 16 |
+
</nav>
|
| 17 |
+
<div class=”container”>
|
| 18 |
+
<div class=”blurb”>
|
| 19 |
+
<h1>Audio samples</h1>
|
| 20 |
+
<p><b>Improving performance of real-time full-band blind packet-loss concealment with predictive network</b></a>
|
| 21 |
+
</p>
|
| 22 |
+
<p><i>Viet-Anh Nguyen<sup>1</sup>, Anh H. T. Nguyen<sup>1</sup>, and Andy W. H. Khong<sup>2</sup></i>
|
| 23 |
+
<br><sup>1</sup>Crystalsound Team, NamiTech JSC, Ho Chi Minh City, Vietnam
|
| 24 |
+
<br><sup>2</sup>Nanyang Technological University, Singapore
|
| 25 |
+
<br><TT>{vietanh.nguyen, anh.nguyen}@namitech.io, andykhong@ntu.edu.sg
|
| 26 |
+
</div>
|
| 27 |
+
</div>
|
| 28 |
+
<h3> Audio samples of our full-band recurrent network (FRN) versus TFGAN and tPLCNet for blind packet loss concealment
|
| 29 |
+
(PLC)</h3>
|
| 30 |
+
Audio files are at 48 kHz sampling rate with packet size of 20 ms. Our FRN is a causal and blind PLC model while TFGAN
|
| 31 |
+
is non-causal and tPLC is an informed PLC model.
|
| 32 |
+
<br> </br>
|
| 33 |
+
<table>
|
| 34 |
+
<thead>
|
| 35 |
+
<tr>
|
| 36 |
+
<th align="middle">Clean target</th>
|
| 37 |
+
<th align="middle">Lossy input</th>
|
| 38 |
+
<th align="middle">TFGAN</th>
|
| 39 |
+
<th align="middle">tPLCNet</th>
|
| 40 |
+
<th align="middle">FRN (Ours)</th>
|
| 41 |
+
</tr>
|
| 42 |
+
</thead>
|
| 43 |
+
|
| 44 |
+
<tbody>
|
| 45 |
+
<tr>
|
| 46 |
+
<td>
|
| 47 |
+
<audio controls style="width: 250px; height: 50px">
|
| 48 |
+
<source src="audio_samples/sample_1/clean.wav" type="audio/wav">
|
| 49 |
+
</audio>
|
| 50 |
+
</td>
|
| 51 |
+
<td>
|
| 52 |
+
<audio controls style="width: 250px; height: 50px">
|
| 53 |
+
<source src="audio_samples/sample_1/lossy.wav" type="audio/wav">
|
| 54 |
+
</audio>
|
| 55 |
+
</td>
|
| 56 |
+
<td>
|
| 57 |
+
<audio controls style="width: 250px; height: 50px">
|
| 58 |
+
<source src="audio_samples/sample_1/TFGAN_enhanced.wav" type="audio/wav">
|
| 59 |
+
</audio>
|
| 60 |
+
</td>
|
| 61 |
+
<td>
|
| 62 |
+
<audio controls style="width: 250px; height: 50px">
|
| 63 |
+
<source src="audio_samples/sample_1/tPLC_enhanced.wav" type="audio/wav">
|
| 64 |
+
</audio>
|
| 65 |
+
</td>
|
| 66 |
+
<td>
|
| 67 |
+
<audio controls style="width: 250px; height: 50px">
|
| 68 |
+
<source src="audio_samples/sample_1/FRN_enhanced.wav" type="audio/wav">
|
| 69 |
+
</audio>
|
| 70 |
+
</td>
|
| 71 |
+
</tr>
|
| 72 |
+
|
| 73 |
+
<tr>
|
| 74 |
+
<td>
|
| 75 |
+
<audio controls style="width: 250px; height: 50px">
|
| 76 |
+
<source src="audio_samples/sample_2/clean.wav" type="audio/wav">
|
| 77 |
+
</audio>
|
| 78 |
+
</td>
|
| 79 |
+
<td>
|
| 80 |
+
<audio controls style="width: 250px; height: 50px">
|
| 81 |
+
<source src="audio_samples/sample_2/lossy.wav" type="audio/wav">
|
| 82 |
+
</audio>
|
| 83 |
+
</td>
|
| 84 |
+
<td>
|
| 85 |
+
<audio controls style="width: 250px; height: 50px">
|
| 86 |
+
<source src="audio_samples/sample_2/TFGAN_enhanced.wav" type="audio/wav">
|
| 87 |
+
</audio>
|
| 88 |
+
</td>
|
| 89 |
+
<td>
|
| 90 |
+
<audio controls style="width: 250px; height: 50px">
|
| 91 |
+
<source src="audio_samples/sample_2/tPLC_enhanced.wav" type="audio/wav">
|
| 92 |
+
</audio>
|
| 93 |
+
</td>
|
| 94 |
+
<td>
|
| 95 |
+
<audio controls style="width: 250px; height: 50px">
|
| 96 |
+
<source src="audio_samples/sample_2/FRN_enhanced.wav" type="audio/wav">
|
| 97 |
+
</audio>
|
| 98 |
+
</td>
|
| 99 |
+
</tr>
|
| 100 |
+
|
| 101 |
+
<tr>
|
| 102 |
+
<td>
|
| 103 |
+
<audio controls style="width: 250px; height: 50px">
|
| 104 |
+
<source src="audio_samples/sample_3/clean.wav" type="audio/wav">
|
| 105 |
+
</audio>
|
| 106 |
+
</td>
|
| 107 |
+
<td>
|
| 108 |
+
<audio controls style="width: 250px; height: 50px">
|
| 109 |
+
<source src="audio_samples/sample_3/lossy.wav" type="audio/wav">
|
| 110 |
+
</audio>
|
| 111 |
+
</td>
|
| 112 |
+
<td>
|
| 113 |
+
<audio controls style="width: 250px; height: 50px">
|
| 114 |
+
<source src="audio_samples/sample_3/TFGAN_enhanced.wav" type="audio/wav">
|
| 115 |
+
</audio>
|
| 116 |
+
</td>
|
| 117 |
+
<td>
|
| 118 |
+
<audio controls style="width: 250px; height: 50px">
|
| 119 |
+
<source src="audio_samples/sample_3/tPLC_enhanced.wav" type="audio/wav">
|
| 120 |
+
</audio>
|
| 121 |
+
</td>
|
| 122 |
+
<td>
|
| 123 |
+
<audio controls style="width: 250px; height: 50px">
|
| 124 |
+
<source src="audio_samples/sample_3/FRN_enhanced.wav" type="audio/wav">
|
| 125 |
+
</audio>
|
| 126 |
+
</td>
|
| 127 |
+
</tr>
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
</tbody>
|
| 131 |
+
</table>
|
| 132 |
+
<!-- <footer>
|
| 133 |
+
<ul>
|
| 134 |
+
<li><a href=”mailto:YOUREMAIL”>YOUREMAIL</a></li>
|
| 135 |
+
</ul>
|
| 136 |
+
</footer> -->
|
| 137 |
+
|
| 138 |
+
</body>
|
| 139 |
+
</html>
|
inference_onnx.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import librosa
|
| 6 |
+
import numpy as np
|
| 7 |
+
import onnx
|
| 8 |
+
import onnxruntime
|
| 9 |
+
import soundfile as sf
|
| 10 |
+
import torch
|
| 11 |
+
import tqdm
|
| 12 |
+
|
| 13 |
+
from config import CONFIG
|
| 14 |
+
|
| 15 |
+
parser = argparse.ArgumentParser()
|
| 16 |
+
|
| 17 |
+
parser.add_argument('--onnx_path', default=None,
|
| 18 |
+
help='path to onnx')
|
| 19 |
+
args = parser.parse_args()
|
| 20 |
+
|
| 21 |
+
if __name__ == '__main__':
|
| 22 |
+
path = args.onnx_path
|
| 23 |
+
window = CONFIG.DATA.window_size
|
| 24 |
+
stride = CONFIG.DATA.stride
|
| 25 |
+
onnx_model = onnx.load(path)
|
| 26 |
+
options = onnxruntime.SessionOptions()
|
| 27 |
+
options.intra_op_num_threads = 8
|
| 28 |
+
options.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_ALL
|
| 29 |
+
session = onnxruntime.InferenceSession(path, options)
|
| 30 |
+
input_names = [x.name for x in session.get_inputs()]
|
| 31 |
+
output_names = [x.name for x in session.get_outputs()]
|
| 32 |
+
print(input_names)
|
| 33 |
+
print(output_names)
|
| 34 |
+
|
| 35 |
+
audio_files = glob.glob(os.path.join(CONFIG.TEST.in_dir, '*.wav'))
|
| 36 |
+
hann = torch.sqrt(torch.hann_window(window))
|
| 37 |
+
os.makedirs(CONFIG.TEST.out_dir, exist_ok=True)
|
| 38 |
+
for file in tqdm.tqdm(audio_files, total=len(audio_files)):
|
| 39 |
+
sig, _ = librosa.load(file, sr=48000)
|
| 40 |
+
sig = torch.tensor(sig)
|
| 41 |
+
re_im = torch.stft(sig, window, stride, window=hann, return_complex=False).permute(1, 0, 2).unsqueeze(
|
| 42 |
+
1).numpy().astype(np.float32)
|
| 43 |
+
|
| 44 |
+
inputs = {input_names[i]: np.zeros([d.dim_value for d in _input.type.tensor_type.shape.dim],
|
| 45 |
+
dtype=np.float32)
|
| 46 |
+
for i, _input in enumerate(onnx_model.graph.input)
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
output_audio = []
|
| 50 |
+
for t in range(re_im.shape[0]):
|
| 51 |
+
inputs[input_names[0]] = re_im[t]
|
| 52 |
+
out, prev_mag, predictor_state, mlp_state = session.run(output_names, inputs)
|
| 53 |
+
inputs[input_names[1]] = prev_mag
|
| 54 |
+
inputs[input_names[2]] = predictor_state
|
| 55 |
+
inputs[input_names[3]] = mlp_state
|
| 56 |
+
output_audio.append(out)
|
| 57 |
+
|
| 58 |
+
output_audio = torch.tensor(np.concatenate(output_audio, 0))
|
| 59 |
+
output_audio = output_audio.permute(1, 0, 2).contiguous()
|
| 60 |
+
output_audio = torch.view_as_complex(output_audio)
|
| 61 |
+
output_audio = torch.istft(output_audio, window, stride, window=hann)
|
| 62 |
+
sf.write(os.path.join(CONFIG.TEST.out_dir, os.path.basename(file)), output_audio, samplerate=48000,
|
| 63 |
+
subtype='PCM_16')
|
loss.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import librosa
|
| 2 |
+
import pytorch_lightning as pl
|
| 3 |
+
import torch
|
| 4 |
+
from auraloss.freq import STFTLoss, MultiResolutionSTFTLoss, apply_reduction, SpectralConvergenceLoss, STFTMagnitudeLoss
|
| 5 |
+
|
| 6 |
+
from config import CONFIG
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class STFTLossDDP(STFTLoss):
|
| 10 |
+
def __init__(self,
|
| 11 |
+
fft_size=1024,
|
| 12 |
+
hop_size=256,
|
| 13 |
+
win_length=1024,
|
| 14 |
+
window="hann_window",
|
| 15 |
+
w_sc=1.0,
|
| 16 |
+
w_log_mag=1.0,
|
| 17 |
+
w_lin_mag=0.0,
|
| 18 |
+
w_phs=0.0,
|
| 19 |
+
sample_rate=None,
|
| 20 |
+
scale=None,
|
| 21 |
+
n_bins=None,
|
| 22 |
+
scale_invariance=False,
|
| 23 |
+
eps=1e-8,
|
| 24 |
+
output="loss",
|
| 25 |
+
reduction="mean",
|
| 26 |
+
device=None):
|
| 27 |
+
super(STFTLoss, self).__init__()
|
| 28 |
+
self.fft_size = fft_size
|
| 29 |
+
self.hop_size = hop_size
|
| 30 |
+
self.win_length = win_length
|
| 31 |
+
self.window = getattr(torch, window)(win_length)
|
| 32 |
+
self.w_sc = w_sc
|
| 33 |
+
self.w_log_mag = w_log_mag
|
| 34 |
+
self.w_lin_mag = w_lin_mag
|
| 35 |
+
self.w_phs = w_phs
|
| 36 |
+
self.sample_rate = sample_rate
|
| 37 |
+
self.scale = scale
|
| 38 |
+
self.n_bins = n_bins
|
| 39 |
+
self.scale_invariance = scale_invariance
|
| 40 |
+
self.eps = eps
|
| 41 |
+
self.output = output
|
| 42 |
+
self.reduction = reduction
|
| 43 |
+
self.device = device
|
| 44 |
+
|
| 45 |
+
self.spectralconv = SpectralConvergenceLoss()
|
| 46 |
+
self.logstft = STFTMagnitudeLoss(log=True, reduction=reduction)
|
| 47 |
+
self.linstft = STFTMagnitudeLoss(log=False, reduction=reduction)
|
| 48 |
+
|
| 49 |
+
# setup mel filterbank
|
| 50 |
+
if self.scale == "mel":
|
| 51 |
+
assert (sample_rate is not None) # Must set sample rate to use mel scale
|
| 52 |
+
assert (n_bins <= fft_size) # Must be more FFT bins than Mel bins
|
| 53 |
+
fb = librosa.filters.mel(sample_rate, fft_size, n_mels=n_bins)
|
| 54 |
+
self.fb = torch.tensor(fb).unsqueeze(0)
|
| 55 |
+
elif self.scale == "chroma":
|
| 56 |
+
assert (sample_rate is not None) # Must set sample rate to use chroma scale
|
| 57 |
+
assert (n_bins <= fft_size) # Must be more FFT bins than chroma bins
|
| 58 |
+
fb = librosa.filters.chroma(sample_rate, fft_size, n_chroma=n_bins)
|
| 59 |
+
self.fb = torch.tensor(fb).unsqueeze(0)
|
| 60 |
+
|
| 61 |
+
if scale is not None and device is not None:
|
| 62 |
+
self.fb = self.fb.to(self.device) # move filterbank to device
|
| 63 |
+
|
| 64 |
+
def compressed_loss(self, x, y, alpha=None):
|
| 65 |
+
self.window = self.window.to(x.device)
|
| 66 |
+
x_mag, x_phs = self.stft(x.view(-1, x.size(-1)))
|
| 67 |
+
y_mag, y_phs = self.stft(y.view(-1, y.size(-1)))
|
| 68 |
+
|
| 69 |
+
if alpha is not None:
|
| 70 |
+
x_mag = x_mag ** alpha
|
| 71 |
+
y_mag = y_mag ** alpha
|
| 72 |
+
|
| 73 |
+
# apply relevant transforms
|
| 74 |
+
if self.scale is not None:
|
| 75 |
+
x_mag = torch.matmul(self.fb.to(x_mag.device), x_mag)
|
| 76 |
+
y_mag = torch.matmul(self.fb.to(y_mag.device), y_mag)
|
| 77 |
+
|
| 78 |
+
# normalize scales
|
| 79 |
+
if self.scale_invariance:
|
| 80 |
+
alpha = (x_mag * y_mag).sum([-2, -1]) / ((y_mag ** 2).sum([-2, -1]))
|
| 81 |
+
y_mag = y_mag * alpha.unsqueeze(-1)
|
| 82 |
+
|
| 83 |
+
# compute loss terms
|
| 84 |
+
sc_loss = self.spectralconv(x_mag, y_mag) if self.w_sc else 0.0
|
| 85 |
+
mag_loss = self.logstft(x_mag, y_mag) if self.w_log_mag else 0.0
|
| 86 |
+
lin_loss = self.linstft(x_mag, y_mag) if self.w_lin_mag else 0.0
|
| 87 |
+
|
| 88 |
+
# combine loss terms
|
| 89 |
+
loss = (self.w_sc * sc_loss) + (self.w_log_mag * mag_loss) + (self.w_lin_mag * lin_loss)
|
| 90 |
+
loss = apply_reduction(loss, reduction=self.reduction)
|
| 91 |
+
return loss
|
| 92 |
+
|
| 93 |
+
def forward(self, x, y):
|
| 94 |
+
return self.compressed_loss(x, y, 0.3)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class MRSTFTLossDDP(MultiResolutionSTFTLoss):
|
| 98 |
+
def __init__(self,
|
| 99 |
+
fft_sizes=(1024, 2048, 512),
|
| 100 |
+
hop_sizes=(120, 240, 50),
|
| 101 |
+
win_lengths=(600, 1200, 240),
|
| 102 |
+
window="hann_window",
|
| 103 |
+
w_sc=1.0,
|
| 104 |
+
w_log_mag=1.0,
|
| 105 |
+
w_lin_mag=0.0,
|
| 106 |
+
w_phs=0.0,
|
| 107 |
+
sample_rate=None,
|
| 108 |
+
scale=None,
|
| 109 |
+
n_bins=None,
|
| 110 |
+
scale_invariance=False,
|
| 111 |
+
**kwargs):
|
| 112 |
+
super(MultiResolutionSTFTLoss, self).__init__()
|
| 113 |
+
assert len(fft_sizes) == len(hop_sizes) == len(win_lengths) # must define all
|
| 114 |
+
self.stft_losses = torch.nn.ModuleList()
|
| 115 |
+
for fs, ss, wl in zip(fft_sizes, hop_sizes, win_lengths):
|
| 116 |
+
self.stft_losses += [STFTLossDDP(fs,
|
| 117 |
+
ss,
|
| 118 |
+
wl,
|
| 119 |
+
window,
|
| 120 |
+
w_sc,
|
| 121 |
+
w_log_mag,
|
| 122 |
+
w_lin_mag,
|
| 123 |
+
w_phs,
|
| 124 |
+
sample_rate,
|
| 125 |
+
scale,
|
| 126 |
+
n_bins,
|
| 127 |
+
scale_invariance,
|
| 128 |
+
**kwargs)]
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
class Loss(pl.LightningModule):
|
| 132 |
+
def __init__(self):
|
| 133 |
+
super(Loss, self).__init__()
|
| 134 |
+
self.stft_loss = MRSTFTLossDDP(sample_rate=CONFIG.DATA.sr, device="cpu", w_log_mag=0.0, w_lin_mag=1.0)
|
| 135 |
+
self.window = torch.sqrt(torch.hann_window(CONFIG.DATA.window_size))
|
| 136 |
+
|
| 137 |
+
def forward(self, x, y):
|
| 138 |
+
x = x.permute(0, 2, 3, 1)
|
| 139 |
+
y = y.permute(0, 2, 3, 1)
|
| 140 |
+
wave_x = torch.istft(torch.view_as_complex(x.contiguous()), CONFIG.DATA.window_size, CONFIG.DATA.stride,
|
| 141 |
+
window=self.window.to(x.device))
|
| 142 |
+
wave_y = torch.istft(torch.view_as_complex(y.contiguous()), CONFIG.DATA.window_size, CONFIG.DATA.stride,
|
| 143 |
+
window=self.window.to(y.device))
|
| 144 |
+
loss = self.stft_loss(wave_x, wave_y)
|
| 145 |
+
return loss
|
main.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import pytorch_lightning as pl
|
| 5 |
+
import soundfile as sf
|
| 6 |
+
import torch
|
| 7 |
+
from pytorch_lightning.callbacks import ModelCheckpoint
|
| 8 |
+
from pytorch_lightning.utilities.model_summary import summarize
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
|
| 11 |
+
from config import CONFIG
|
| 12 |
+
from dataset import TrainDataset, TestLoader, BlindTestLoader
|
| 13 |
+
from models.frn import PLCModel, OnnxWrapper
|
| 14 |
+
from utils.tblogger import TensorBoardLoggerExpanded
|
| 15 |
+
from utils.utils import mkdir_p
|
| 16 |
+
|
| 17 |
+
parser = argparse.ArgumentParser()
|
| 18 |
+
|
| 19 |
+
parser.add_argument('--version', default=None,
|
| 20 |
+
help='version to resume')
|
| 21 |
+
parser.add_argument('--mode', default='train',
|
| 22 |
+
help='training or testing mode')
|
| 23 |
+
|
| 24 |
+
args = parser.parse_args()
|
| 25 |
+
os.environ["CUDA_VISIBLE_DEVICES"] = str(CONFIG.gpus)
|
| 26 |
+
assert args.mode in ['train', 'eval', 'test', 'onnx'], "--mode should be 'train', 'eval', 'test' or 'onnx'"
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def resume(train_dataset, val_dataset, version):
|
| 30 |
+
print("Version", version)
|
| 31 |
+
model_path = os.path.join(CONFIG.LOG.log_dir, 'version_{}/checkpoints/'.format(str(version)))
|
| 32 |
+
config_path = os.path.join(CONFIG.LOG.log_dir, 'version_{}/'.format(str(version)) + 'hparams.yaml')
|
| 33 |
+
model_name = [x for x in os.listdir(model_path) if x.endswith(".ckpt")][0]
|
| 34 |
+
ckpt_path = model_path + model_name
|
| 35 |
+
checkpoint = PLCModel.load_from_checkpoint(ckpt_path,
|
| 36 |
+
strict=True,
|
| 37 |
+
hparams_file=config_path,
|
| 38 |
+
train_dataset=train_dataset,
|
| 39 |
+
val_dataset=val_dataset,
|
| 40 |
+
window_size=CONFIG.DATA.window_size)
|
| 41 |
+
|
| 42 |
+
return checkpoint
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def train():
|
| 46 |
+
train_dataset = TrainDataset('train')
|
| 47 |
+
val_dataset = TrainDataset('val')
|
| 48 |
+
checkpoint_callback = ModelCheckpoint(monitor='val_loss', mode='min', verbose=True,
|
| 49 |
+
filename='frn-{epoch:02d}-{val_loss:.4f}', save_weights_only=False)
|
| 50 |
+
gpus = CONFIG.gpus.split(',')
|
| 51 |
+
logger = TensorBoardLoggerExpanded(CONFIG.DATA.sr)
|
| 52 |
+
if args.version is not None:
|
| 53 |
+
model = resume(train_dataset, val_dataset, args.version)
|
| 54 |
+
else:
|
| 55 |
+
model = PLCModel(train_dataset,
|
| 56 |
+
val_dataset,
|
| 57 |
+
window_size=CONFIG.DATA.window_size,
|
| 58 |
+
enc_layers=CONFIG.MODEL.enc_layers,
|
| 59 |
+
enc_in_dim=CONFIG.MODEL.enc_in_dim,
|
| 60 |
+
enc_dim=CONFIG.MODEL.enc_dim,
|
| 61 |
+
pred_dim=CONFIG.MODEL.pred_dim,
|
| 62 |
+
pred_layers=CONFIG.MODEL.pred_layers)
|
| 63 |
+
|
| 64 |
+
trainer = pl.Trainer(logger=logger,
|
| 65 |
+
gradient_clip_val=CONFIG.TRAIN.clipping_val,
|
| 66 |
+
gpus=len(gpus),
|
| 67 |
+
max_epochs=CONFIG.TRAIN.epochs,
|
| 68 |
+
accelerator="gpu" if len(gpus) > 1 else None,
|
| 69 |
+
callbacks=[checkpoint_callback]
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
print(model.hparams)
|
| 73 |
+
print(
|
| 74 |
+
'Dataset: {}, Train files: {}, Val files {}'.format(CONFIG.DATA.dataset, len(train_dataset), len(val_dataset)))
|
| 75 |
+
trainer.fit(model)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def to_onnx(model, onnx_path):
|
| 79 |
+
model.eval()
|
| 80 |
+
|
| 81 |
+
model = OnnxWrapper(model)
|
| 82 |
+
|
| 83 |
+
torch.onnx.export(model,
|
| 84 |
+
model.sample,
|
| 85 |
+
onnx_path,
|
| 86 |
+
export_params=True,
|
| 87 |
+
opset_version=12,
|
| 88 |
+
input_names=model.input_names,
|
| 89 |
+
output_names=model.output_names,
|
| 90 |
+
do_constant_folding=True,
|
| 91 |
+
verbose=False)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
if __name__ == '__main__':
|
| 95 |
+
|
| 96 |
+
if args.mode == 'train':
|
| 97 |
+
train()
|
| 98 |
+
else:
|
| 99 |
+
model = resume(None, None, args.version)
|
| 100 |
+
print(model.hparams)
|
| 101 |
+
print(summarize(model))
|
| 102 |
+
|
| 103 |
+
model.eval()
|
| 104 |
+
model.freeze()
|
| 105 |
+
if args.mode == 'eval':
|
| 106 |
+
model.cuda(device=0)
|
| 107 |
+
trainer = pl.Trainer(accelerator='gpu', devices=1, enable_checkpointing=False, logger=False)
|
| 108 |
+
testset = TestLoader()
|
| 109 |
+
test_loader = DataLoader(testset, batch_size=1, num_workers=4)
|
| 110 |
+
trainer.test(model, test_loader)
|
| 111 |
+
print('Version', args.version)
|
| 112 |
+
masking = CONFIG.DATA.EVAL.masking
|
| 113 |
+
prob = CONFIG.DATA.EVAL.transition_probs[0]
|
| 114 |
+
loss_percent = (1 - prob[0]) / (2 - prob[0] - prob[1]) * 100
|
| 115 |
+
print('Evaluate with real trace' if masking == 'real' else
|
| 116 |
+
'Evaluate with generated trace with {:.2f}% packet loss'.format(loss_percent))
|
| 117 |
+
elif args.mode == 'test':
|
| 118 |
+
model.cuda(device=0)
|
| 119 |
+
testset = BlindTestLoader(test_dir=CONFIG.TEST.in_dir)
|
| 120 |
+
test_loader = DataLoader(testset, batch_size=1, num_workers=4)
|
| 121 |
+
trainer = pl.Trainer(accelerator='gpu', devices=1, enable_checkpointing=False, logger=False)
|
| 122 |
+
preds = trainer.predict(model, test_loader, return_predictions=True)
|
| 123 |
+
mkdir_p(CONFIG.TEST.out_dir)
|
| 124 |
+
for idx, path in enumerate(test_loader.dataset.data_list):
|
| 125 |
+
out_path = os.path.join(CONFIG.TEST.out_dir, os.path.basename(path))
|
| 126 |
+
sf.write(out_path, preds[idx], samplerate=CONFIG.DATA.sr, subtype='PCM_16')
|
| 127 |
+
|
| 128 |
+
else:
|
| 129 |
+
onnx_path = 'lightning_logs/version_{}/checkpoints/frn.onnx'.format(str(args.version))
|
| 130 |
+
to_onnx(model, onnx_path)
|
| 131 |
+
print('ONNX model saved to', onnx_path)
|
requirements (1).txt
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
auraloss==0.3.0
|
| 2 |
+
einops==0.6.0
|
| 3 |
+
librosa==0.9.2
|
| 4 |
+
matplotlib==3.5.3
|
| 5 |
+
numpy==1.22.3
|
| 6 |
+
onnxruntime==1.13.1
|
| 7 |
+
pandas==1.5.3
|
| 8 |
+
pydtmc==7.0.0
|
| 9 |
+
pytorch_lightning==1.9.0
|
| 10 |
+
scikit_learn==1.2.1
|
| 11 |
+
soundfile==0.11.0
|
| 12 |
+
torch==1.13.1
|
| 13 |
+
torchmetrics==0.11.0
|
| 14 |
+
tqdm==4.64.0
|
| 15 |
+
pystoi==0.3.3
|
| 16 |
+
pesq==0.0.4
|
| 17 |
+
onnx==1.13.0
|
| 18 |
+
altair<5
|
sample.wav
ADDED
|
Binary file (797 kB). View file
|
|
|