Spaces:
Runtime error

Runtime error
Commit
·
52ca9c9
1
Parent(s):
45bde32
Upload 131 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +7 -0
- CODE_OF_CONDUCT.md +128 -0
- LICENSE.md +14 -0
- LICENSE_Lavis.md +14 -0
- MiniGPT4_Train.md +41 -0
- MiniGPTv2.pdf +3 -0
- README.md +182 -13
- SECURITY.md +21 -0
- dataset/README_1_STAGE.md +96 -0
- dataset/README_2_STAGE.md +19 -0
- dataset/convert_cc_sbu.py +20 -0
- dataset/convert_laion.py +20 -0
- dataset/download_cc_sbu.sh +6 -0
- dataset/download_laion.sh +6 -0
- demo.py +171 -0
- demo_v2.py +662 -0
- environment.yml +33 -0
- eval_configs/minigpt4_eval.yaml +22 -0
- eval_configs/minigpt4_llama2_eval.yaml +22 -0
- eval_configs/minigptv2_eval.yaml +24 -0
- examples/ad_1.png +0 -0
- examples/ad_2.png +0 -0
- examples/cook_1.png +0 -0
- examples/cook_2.png +0 -0
- examples/describe_1.png +0 -0
- examples/describe_2.png +0 -0
- examples/fact_1.png +0 -0
- examples/fact_2.png +0 -0
- examples/fix_1.png +0 -0
- examples/fix_2.png +0 -0
- examples/fun_1.png +0 -0
- examples/fun_2.png +0 -0
- examples/logo_1.png +0 -0
- examples/op_1.png +0 -0
- examples/op_2.png +0 -0
- examples/people_1.png +0 -0
- examples/people_2.png +0 -0
- examples/rhyme_1.png +0 -0
- examples/rhyme_2.png +0 -0
- examples/story_1.png +0 -0
- examples/story_2.png +0 -0
- examples/web_1.png +0 -0
- examples/wop_1.png +0 -0
- examples/wop_2.png +0 -0
- examples_v2/2000x1372_wmkn_0012149409555.jpg +0 -0
- examples_v2/KFC-20-for-20-Nuggets.jpg +0 -0
- examples_v2/cockdial.png +3 -0
- examples_v2/float.png +3 -0
- examples_v2/glip_test.jpg +0 -0
- examples_v2/office.jpg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,10 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
examples_v2/cockdial.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
examples_v2/float.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
figs/demo.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
figs/minigpt2_demo.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
figs/online_demo.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
figs/overview.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
MiniGPTv2.pdf filter=lfs diff=lfs merge=lfs -text
|
CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributor Covenant Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
We as members, contributors, and leaders pledge to make participation in our
|
| 6 |
+
community a harassment-free experience for everyone, regardless of age, body
|
| 7 |
+
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
| 8 |
+
identity and expression, level of experience, education, socio-economic status,
|
| 9 |
+
nationality, personal appearance, race, religion, or sexual identity
|
| 10 |
+
and orientation.
|
| 11 |
+
|
| 12 |
+
We pledge to act and interact in ways that contribute to an open, welcoming,
|
| 13 |
+
diverse, inclusive, and healthy community.
|
| 14 |
+
|
| 15 |
+
## Our Standards
|
| 16 |
+
|
| 17 |
+
Examples of behavior that contributes to a positive environment for our
|
| 18 |
+
community include:
|
| 19 |
+
|
| 20 |
+
* Demonstrating empathy and kindness toward other people
|
| 21 |
+
* Being respectful of differing opinions, viewpoints, and experiences
|
| 22 |
+
* Giving and gracefully accepting constructive feedback
|
| 23 |
+
* Accepting responsibility and apologizing to those affected by our mistakes,
|
| 24 |
+
and learning from the experience
|
| 25 |
+
* Focusing on what is best not just for us as individuals, but for the
|
| 26 |
+
overall community
|
| 27 |
+
|
| 28 |
+
Examples of unacceptable behavior include:
|
| 29 |
+
|
| 30 |
+
* The use of sexualized language or imagery, and sexual attention or
|
| 31 |
+
advances of any kind
|
| 32 |
+
* Trolling, insulting or derogatory comments, and personal or political attacks
|
| 33 |
+
* Public or private harassment
|
| 34 |
+
* Publishing others' private information, such as a physical or email
|
| 35 |
+
address, without their explicit permission
|
| 36 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 37 |
+
professional setting
|
| 38 |
+
|
| 39 |
+
## Enforcement Responsibilities
|
| 40 |
+
|
| 41 |
+
Community leaders are responsible for clarifying and enforcing our standards of
|
| 42 |
+
acceptable behavior and will take appropriate and fair corrective action in
|
| 43 |
+
response to any behavior that they deem inappropriate, threatening, offensive,
|
| 44 |
+
or harmful.
|
| 45 |
+
|
| 46 |
+
Community leaders have the right and responsibility to remove, edit, or reject
|
| 47 |
+
comments, commits, code, wiki edits, issues, and other contributions that are
|
| 48 |
+
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
| 49 |
+
decisions when appropriate.
|
| 50 |
+
|
| 51 |
+
## Scope
|
| 52 |
+
|
| 53 |
+
This Code of Conduct applies within all community spaces, and also applies when
|
| 54 |
+
an individual is officially representing the community in public spaces.
|
| 55 |
+
Examples of representing our community include using an official e-mail address,
|
| 56 |
+
posting via an official social media account, or acting as an appointed
|
| 57 |
+
representative at an online or offline event.
|
| 58 |
+
|
| 59 |
+
## Enforcement
|
| 60 |
+
|
| 61 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 62 |
+
reported to the community leaders responsible for enforcement at
|
| 63 |
+
https://discord.gg/2aNvvYVv.
|
| 64 |
+
All complaints will be reviewed and investigated promptly and fairly.
|
| 65 |
+
|
| 66 |
+
All community leaders are obligated to respect the privacy and security of the
|
| 67 |
+
reporter of any incident.
|
| 68 |
+
|
| 69 |
+
## Enforcement Guidelines
|
| 70 |
+
|
| 71 |
+
Community leaders will follow these Community Impact Guidelines in determining
|
| 72 |
+
the consequences for any action they deem in violation of this Code of Conduct:
|
| 73 |
+
|
| 74 |
+
### 1. Correction
|
| 75 |
+
|
| 76 |
+
**Community Impact**: Use of inappropriate language or other behavior deemed
|
| 77 |
+
unprofessional or unwelcome in the community.
|
| 78 |
+
|
| 79 |
+
**Consequence**: A private, written warning from community leaders, providing
|
| 80 |
+
clarity around the nature of the violation and an explanation of why the
|
| 81 |
+
behavior was inappropriate. A public apology may be requested.
|
| 82 |
+
|
| 83 |
+
### 2. Warning
|
| 84 |
+
|
| 85 |
+
**Community Impact**: A violation through a single incident or series
|
| 86 |
+
of actions.
|
| 87 |
+
|
| 88 |
+
**Consequence**: A warning with consequences for continued behavior. No
|
| 89 |
+
interaction with the people involved, including unsolicited interaction with
|
| 90 |
+
those enforcing the Code of Conduct, for a specified period of time. This
|
| 91 |
+
includes avoiding interactions in community spaces as well as external channels
|
| 92 |
+
like social media. Violating these terms may lead to a temporary or
|
| 93 |
+
permanent ban.
|
| 94 |
+
|
| 95 |
+
### 3. Temporary Ban
|
| 96 |
+
|
| 97 |
+
**Community Impact**: A serious violation of community standards, including
|
| 98 |
+
sustained inappropriate behavior.
|
| 99 |
+
|
| 100 |
+
**Consequence**: A temporary ban from any sort of interaction or public
|
| 101 |
+
communication with the community for a specified period of time. No public or
|
| 102 |
+
private interaction with the people involved, including unsolicited interaction
|
| 103 |
+
with those enforcing the Code of Conduct, is allowed during this period.
|
| 104 |
+
Violating these terms may lead to a permanent ban.
|
| 105 |
+
|
| 106 |
+
### 4. Permanent Ban
|
| 107 |
+
|
| 108 |
+
**Community Impact**: Demonstrating a pattern of violation of community
|
| 109 |
+
standards, including sustained inappropriate behavior, harassment of an
|
| 110 |
+
individual, or aggression toward or disparagement of classes of individuals.
|
| 111 |
+
|
| 112 |
+
**Consequence**: A permanent ban from any sort of public interaction within
|
| 113 |
+
the community.
|
| 114 |
+
|
| 115 |
+
## Attribution
|
| 116 |
+
|
| 117 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
| 118 |
+
version 2.0, available at
|
| 119 |
+
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
| 120 |
+
|
| 121 |
+
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
| 122 |
+
enforcement ladder](https://github.com/mozilla/diversity).
|
| 123 |
+
|
| 124 |
+
[homepage]: https://www.contributor-covenant.org
|
| 125 |
+
|
| 126 |
+
For answers to common questions about this code of conduct, see the FAQ at
|
| 127 |
+
https://www.contributor-covenant.org/faq. Translations are available at
|
| 128 |
+
https://www.contributor-covenant.org/translations.
|
LICENSE.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright 2023 Deyao Zhu
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 9 |
+
|
| 10 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 11 |
+
|
| 12 |
+
3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 13 |
+
|
| 14 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
LICENSE_Lavis.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Salesforce, Inc.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 9 |
+
|
| 10 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 11 |
+
|
| 12 |
+
3. Neither the name of Salesforce.com nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 13 |
+
|
| 14 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
MiniGPT4_Train.md
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Training of MiniGPT-4
|
| 2 |
+
|
| 3 |
+
The training of MiniGPT-4 contains two alignment stages.
|
| 4 |
+
|
| 5 |
+
**1. First pretraining stage**
|
| 6 |
+
|
| 7 |
+
In the first pretrained stage, the model is trained using image-text pairs from Laion and CC datasets
|
| 8 |
+
to align the vision and language model. To download and prepare the datasets, please check
|
| 9 |
+
our [first stage dataset preparation instruction](dataset/README_1_STAGE.md).
|
| 10 |
+
After the first stage, the visual features are mapped and can be understood by the language
|
| 11 |
+
model.
|
| 12 |
+
To launch the first stage training, run the following command. In our experiments, we use 4 A100.
|
| 13 |
+
You can change the save path in the config file
|
| 14 |
+
[train_configs/minigpt4_stage1_pretrain.yaml](train_configs/minigpt4_stage1_pretrain.yaml)
|
| 15 |
+
|
| 16 |
+
```bash
|
| 17 |
+
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage1_pretrain.yaml
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
A MiniGPT-4 checkpoint with only stage one training can be downloaded
|
| 21 |
+
[here (13B)](https://drive.google.com/file/d/1u9FRRBB3VovP1HxCAlpD9Lw4t4P6-Yq8/view?usp=share_link) or [here (7B)](https://drive.google.com/file/d/1HihQtCEXUyBM1i9DQbaK934wW3TZi-h5/view?usp=share_link).
|
| 22 |
+
Compared to the model after stage two, this checkpoint generate incomplete and repeated sentences frequently.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
**2. Second finetuning stage**
|
| 26 |
+
|
| 27 |
+
In the second stage, we use a small high quality image-text pair dataset created by ourselves
|
| 28 |
+
and convert it to a conversation format to further align MiniGPT-4.
|
| 29 |
+
To download and prepare our second stage dataset, please check our
|
| 30 |
+
[second stage dataset preparation instruction](dataset/README_2_STAGE.md).
|
| 31 |
+
To launch the second stage alignment,
|
| 32 |
+
first specify the path to the checkpoint file trained in stage 1 in
|
| 33 |
+
[train_configs/minigpt4_stage1_pretrain.yaml](train_configs/minigpt4_stage2_finetune.yaml).
|
| 34 |
+
You can also specify the output path there.
|
| 35 |
+
Then, run the following command. In our experiments, we use 1 A100.
|
| 36 |
+
|
| 37 |
+
```bash
|
| 38 |
+
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage2_finetune.yaml
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
After the second stage alignment, MiniGPT-4 is able to talk about the image coherently and user-friendly.
|
MiniGPTv2.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:429b0f5e3d70828fd691ef4ffb90c6efa094a8454bf03f8ec00b10fcd443f346
|
| 3 |
+
size 4357853
|
README.md
CHANGED
|
@@ -1,13 +1,182 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MiniGPT-V
|
| 2 |
+
|
| 3 |
+
<font size='5'>**MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-task Learning**</font>
|
| 4 |
+
|
| 5 |
+
Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong☨, Mohamed Elhoseiny☨
|
| 6 |
+
|
| 7 |
+
☨equal last author
|
| 8 |
+
|
| 9 |
+
<a href='https://minigpt-v2.github.io'><img src='https://img.shields.io/badge/Project-Page-Green'></a> <a href='https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPTv2.pdf'><img src='https://img.shields.io/badge/Paper-PDF-red'></a> <a href='https://minigpt-v2.github.io'><img src='https://img.shields.io/badge/Gradio-Demo-blue'></a> [](https://www.youtube.com/watch?v=atFCwV2hSY4)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
<font size='5'>**MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models**</font>
|
| 13 |
+
|
| 14 |
+
Deyao Zhu*, Jun Chen*, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny
|
| 15 |
+
|
| 16 |
+
*equal contribution
|
| 17 |
+
|
| 18 |
+
<a href='https://minigpt-4.github.io'><img src='https://img.shields.io/badge/Project-Page-Green'></a> <a href='https://arxiv.org/abs/2304.10592'><img src='https://img.shields.io/badge/Paper-Arxiv-red'></a> <a href='https://huggingface.co/spaces/Vision-CAIR/minigpt4'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue'></a> <a href='https://huggingface.co/Vision-CAIR/MiniGPT-4'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a> [](https://colab.research.google.com/drive/1OK4kYsZphwt5DXchKkzMBjYF6jnkqh4R?usp=sharing) [](https://www.youtube.com/watch?v=__tftoxpBAw&feature=youtu.be)
|
| 19 |
+
|
| 20 |
+
*King Abdullah University of Science and Technology*
|
| 21 |
+
|
| 22 |
+
## 💡 Get help - [Q&A](https://github.com/Vision-CAIR/MiniGPT-4/discussions/categories/q-a) or [Discord 💬](https://discord.gg/5WdJkjbAeE)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## News
|
| 26 |
+
[Oct.13 2023] Breaking! We release the first major update with our MiniGPT-v2
|
| 27 |
+
|
| 28 |
+
[Aug.28 2023] We now provide a llama 2 version of MiniGPT-4
|
| 29 |
+
|
| 30 |
+
## Online Demo
|
| 31 |
+
|
| 32 |
+
Click the image to chat with MiniGPT-v2 around your images
|
| 33 |
+
[](https://minigpt-v2.github.io/)
|
| 34 |
+
|
| 35 |
+
Click the image to chat with MiniGPT-4 around your images
|
| 36 |
+
[](https://minigpt-4.github.io)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
## MiniGPT-v2 Examples
|
| 40 |
+
|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
## MiniGPT-4 Examples
|
| 46 |
+
| | |
|
| 47 |
+
:-------------------------:|:-------------------------:
|
| 48 |
+
 | 
|
| 49 |
+
 | 
|
| 50 |
+
|
| 51 |
+
More examples can be found in the [project page](https://minigpt-4.github.io).
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
## Getting Started
|
| 56 |
+
### Installation
|
| 57 |
+
|
| 58 |
+
**1. Prepare the code and the environment**
|
| 59 |
+
|
| 60 |
+
Git clone our repository, creating a python environment and activate it via the following command
|
| 61 |
+
|
| 62 |
+
```bash
|
| 63 |
+
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
|
| 64 |
+
cd MiniGPT-4
|
| 65 |
+
conda env create -f environment.yml
|
| 66 |
+
conda activate minigpt4
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
**2. Prepare the pretrained LLM weights**
|
| 71 |
+
|
| 72 |
+
**MiniGPT-v2** is based on Llama2 Chat 7B. For **MiniGPT-4**, we have both Vicuna V0 and Llama 2 version.
|
| 73 |
+
Download the corresponding LLM weights from the following huggingface space via clone the repository using git-lfs.
|
| 74 |
+
|
| 75 |
+
| Llama 2 Chat 7B | Vicuna V0 13B | Vicuna V0 7B |
|
| 76 |
+
:------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:
|
| 77 |
+
[Download](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf/tree/main) | [Downlad](https://huggingface.co/Vision-CAIR/vicuna/tree/main) | [Download](https://huggingface.co/Vision-CAIR/vicuna-7b/tree/main)
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
Then, set the variable *llama_model* in the model config file to the LLM weight path.
|
| 81 |
+
|
| 82 |
+
* For MiniGPT-v2, set the LLM path
|
| 83 |
+
[here](minigpt4/configs/models/minigpt_v2.yaml#L15) at Line 14.
|
| 84 |
+
|
| 85 |
+
* For MiniGPT-4 (Llama2), set the LLM path
|
| 86 |
+
[here](minigpt4/configs/models/minigpt4_llama2.yaml#L15) at Line 15.
|
| 87 |
+
|
| 88 |
+
* For MiniGPT-4 (Vicuna), set the LLM path
|
| 89 |
+
[here](minigpt4/configs/models/minigpt4_vicuna0.yaml#L18) at Line 18
|
| 90 |
+
|
| 91 |
+
**3. Prepare the pretrained model checkpoints**
|
| 92 |
+
|
| 93 |
+
Download the pretrained model checkpoints
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
| MiniGPT-v2 (LLaMA-2 Chat 7B) |
|
| 97 |
+
|------------------------------|
|
| 98 |
+
| [Download](https://drive.google.com/file/d/1aVbfW7nkCSYx99_vCRyP1sOlQiWVSnAl/view?usp=sharing) |
|
| 99 |
+
|
| 100 |
+
For **MiniGPT-v2**, set the path to the pretrained checkpoint in the evaluation config file
|
| 101 |
+
in [eval_configs/minigptv2_eval.yaml](eval_configs/minigptv2_eval.yaml#L10) at Line 8.
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
| MiniGPT-4 (Vicuna 13B) | MiniGPT-4 (Vicuna 7B) | MiniGPT-4 (LLaMA-2 Chat 7B) |
|
| 106 |
+
|----------------------------|---------------------------|---------------------------------|
|
| 107 |
+
| [Download](https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link) | [Download](https://drive.google.com/file/d/1RY9jV0dyqLX-o38LrumkKRh6Jtaop58R/view?usp=sharing) | [Download](https://drive.google.com/file/d/11nAPjEok8eAGGEG1N2vXo3kBLCg0WgUk/view?usp=sharing) |
|
| 108 |
+
|
| 109 |
+
For **MiniGPT-4**, set the path to the pretrained checkpoint in the evaluation config file
|
| 110 |
+
in [eval_configs/minigpt4_eval.yaml](eval_configs/minigpt4_eval.yaml#L10) at Line 8 for Vicuna version or [eval_configs/minigpt4_llama2_eval.yaml](eval_configs/minigpt4_llama2_eval.yaml#L10) for LLama2 version.
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
### Launching Demo Locally
|
| 115 |
+
|
| 116 |
+
For MiniGPT-v2, run
|
| 117 |
+
```
|
| 118 |
+
python demo_v2.py --cfg-path eval_configs/minigpt4v2_eval.yaml --gpu-id 0
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
For MiniGPT-4 (Vicuna version), run
|
| 122 |
+
|
| 123 |
+
```
|
| 124 |
+
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
For MiniGPT-4 (Llama2 version), run
|
| 128 |
+
|
| 129 |
+
```
|
| 130 |
+
python demo.py --cfg-path eval_configs/minigpt4_llama2_eval.yaml --gpu-id 0
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
To save GPU memory, LLMs loads as 8 bit by default, with a beam search width of 1.
|
| 135 |
+
This configuration requires about 23G GPU memory for 13B LLM and 11.5G GPU memory for 7B LLM.
|
| 136 |
+
For more powerful GPUs, you can run the model
|
| 137 |
+
in 16 bit by setting `low_resource` to `False` in the relevant config file:
|
| 138 |
+
|
| 139 |
+
* MiniGPT-v2: [minigptv2_eval.yaml](eval_configs/minigptv2_eval.yaml#6)
|
| 140 |
+
* MiniGPT-4 (Llama2): [minigpt4_llama2_eval.yaml](eval_configs/minigpt4_llama2_eval.yaml#6)
|
| 141 |
+
* MiniGPT-4 (Vicuna): [minigpt4_eval.yaml](eval_configs/minigpt4_eval.yaml#6)
|
| 142 |
+
|
| 143 |
+
Thanks [@WangRongsheng](https://github.com/WangRongsheng), you can also run MiniGPT-4 on [Colab](https://colab.research.google.com/drive/1OK4kYsZphwt5DXchKkzMBjYF6jnkqh4R?usp=sharing)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
### Training
|
| 147 |
+
For training details of MiniGPT-4, check [here](MiniGPT4_Train.md).
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
## Acknowledgement
|
| 153 |
+
|
| 154 |
+
+ [BLIP2](https://huggingface.co/docs/transformers/main/model_doc/blip-2) The model architecture of MiniGPT-4 follows BLIP-2. Don't forget to check this great open-source work if you don't know it before!
|
| 155 |
+
+ [Lavis](https://github.com/salesforce/LAVIS) This repository is built upon Lavis!
|
| 156 |
+
+ [Vicuna](https://github.com/lm-sys/FastChat) The fantastic language ability of Vicuna with only 13B parameters is just amazing. And it is open-source!
|
| 157 |
+
+ [LLaMA](https://github.com/facebookresearch/llama) The strong open-sourced LLaMA 2 language model.
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
If you're using MiniGPT-4/MiniGPT-v2 in your research or applications, please cite using this BibTeX:
|
| 161 |
+
```bibtex
|
| 162 |
+
|
| 163 |
+
@article{Chen2023minigpt,
|
| 164 |
+
title={MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-task Learning},
|
| 165 |
+
author={Chen, Jun and Zhu, Deyao and Shen, Xiaoqian and Li, Xiang and Liu, Zechu and Zhang, Pengchuan and Krishnamoorthi, Raghuraman and Chandra, Vikas and Xiong, Yunyang and Elhoseiny, Mohamed},
|
| 166 |
+
journal={github},
|
| 167 |
+
year={2023}
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
@article{zhu2023minigpt,
|
| 171 |
+
title={MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models},
|
| 172 |
+
author={Zhu, Deyao and Chen, Jun and Shen, Xiaoqian and Li, Xiang and Elhoseiny, Mohamed},
|
| 173 |
+
journal={arXiv preprint arXiv:2304.10592},
|
| 174 |
+
year={2023}
|
| 175 |
+
}
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
## License
|
| 180 |
+
This repository is under [BSD 3-Clause License](LICENSE.md).
|
| 181 |
+
Many codes are based on [Lavis](https://github.com/salesforce/LAVIS) with
|
| 182 |
+
BSD 3-Clause License [here](LICENSE_Lavis.md).
|
SECURITY.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Security Policy
|
| 2 |
+
|
| 3 |
+
## Supported Versions
|
| 4 |
+
|
| 5 |
+
Use this section to tell people about which versions of your project are
|
| 6 |
+
currently being supported with security updates.
|
| 7 |
+
|
| 8 |
+
| Version | Supported |
|
| 9 |
+
| ------- | ------------------ |
|
| 10 |
+
| 5.1.x | :white_check_mark: |
|
| 11 |
+
| 5.0.x | :x: |
|
| 12 |
+
| 4.0.x | :white_check_mark: |
|
| 13 |
+
| < 4.0 | :x: |
|
| 14 |
+
|
| 15 |
+
## Reporting a Vulnerability
|
| 16 |
+
|
| 17 |
+
Use this section to tell people how to report a vulnerability.
|
| 18 |
+
|
| 19 |
+
Tell them where to go, how often they can expect to get an update on a
|
| 20 |
+
reported vulnerability, what to expect if the vulnerability is accepted or
|
| 21 |
+
declined, etc.
|
dataset/README_1_STAGE.md
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Download the filtered Conceptual Captions, SBU, LAION datasets
|
| 2 |
+
|
| 3 |
+
### Pre-training datasets download:
|
| 4 |
+
We use the filtered synthetic captions prepared by BLIP. For more details about the dataset, please refer to [BLIP](https://github.com/salesforce/BLIP).
|
| 5 |
+
|
| 6 |
+
It requires ~2.3T to store LAION and CC3M+CC12M+SBU datasets
|
| 7 |
+
|
| 8 |
+
Image source | Filtered synthetic caption by ViT-L
|
| 9 |
+
--- | :---:
|
| 10 |
+
CC3M+CC12M+SBU | <a href="https://storage.googleapis.com/sfr-vision-language-research/BLIP/datasets/ccs_synthetic_filtered_large.json">Download</a>
|
| 11 |
+
LAION115M | <a href="https://storage.googleapis.com/sfr-vision-language-research/BLIP/datasets/laion_synthetic_filtered_large.json">Download</a>
|
| 12 |
+
|
| 13 |
+
This will download two json files
|
| 14 |
+
```
|
| 15 |
+
ccs_synthetic_filtered_large.json
|
| 16 |
+
laion_synthetic_filtered_large.json
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
## prepare the data step-by-step
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
### setup the dataset folder and move the annotation file to the data storage folder
|
| 23 |
+
```
|
| 24 |
+
export MINIGPT4_DATASET=/YOUR/PATH/FOR/LARGE/DATASET/
|
| 25 |
+
mkdir ${MINIGPT4_DATASET}/cc_sbu
|
| 26 |
+
mkdir ${MINIGPT4_DATASET}/laion
|
| 27 |
+
mv ccs_synthetic_filtered_large.json ${MINIGPT4_DATASET}/cc_sbu
|
| 28 |
+
mv laion_synthetic_filtered_large.json ${MINIGPT4_DATASET}/laion
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
### Convert the scripts to data storate folder
|
| 32 |
+
```
|
| 33 |
+
cp convert_cc_sbu.py ${MINIGPT4_DATASET}/cc_sbu
|
| 34 |
+
cp download_cc_sbu.sh ${MINIGPT4_DATASET}/cc_sbu
|
| 35 |
+
cp convert_laion.py ${MINIGPT4_DATASET}/laion
|
| 36 |
+
cp download_laion.sh ${MINIGPT4_DATASET}/laion
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
### Convert the laion and cc_sbu annotation file format to be img2dataset format
|
| 41 |
+
```
|
| 42 |
+
cd ${MINIGPT4_DATASET}/cc_sbu
|
| 43 |
+
python convert_cc_sbu.py
|
| 44 |
+
|
| 45 |
+
cd ${MINIGPT4_DATASET}/laion
|
| 46 |
+
python convert_laion.py
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
### Download the datasets with img2dataset
|
| 50 |
+
```
|
| 51 |
+
cd ${MINIGPT4_DATASET}/cc_sbu
|
| 52 |
+
sh download_cc_sbu.sh
|
| 53 |
+
cd ${MINIGPT4_DATASET}/laion
|
| 54 |
+
sh download_laion.sh
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
The final dataset structure
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
.
|
| 62 |
+
├── ${MINIGPT4_DATASET}
|
| 63 |
+
│ ├── cc_sbu
|
| 64 |
+
│ ├── convert_cc_sbu.py
|
| 65 |
+
│ ├── download_cc_sbu.sh
|
| 66 |
+
│ ├── ccs_synthetic_filtered_large.json
|
| 67 |
+
│ ├── ccs_synthetic_filtered_large.tsv
|
| 68 |
+
│ └── cc_sbu_dataset
|
| 69 |
+
│ ├── 00000.tar
|
| 70 |
+
│ ├── 00000.parquet
|
| 71 |
+
│ ...
|
| 72 |
+
│ ├── laion
|
| 73 |
+
│ ├── convert_laion.py
|
| 74 |
+
│ ├── download_laion.sh
|
| 75 |
+
│ ├── laion_synthetic_filtered_large.json
|
| 76 |
+
│ ├── laion_synthetic_filtered_large.tsv
|
| 77 |
+
│ └── laion_dataset
|
| 78 |
+
│ ├── 00000.tar
|
| 79 |
+
│ ├── 00000.parquet
|
| 80 |
+
│ ...
|
| 81 |
+
...
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## Set up the dataset configuration files
|
| 86 |
+
|
| 87 |
+
Then, set up the LAION dataset loading path in
|
| 88 |
+
[here](../minigpt4/configs/datasets/laion/defaults.yaml#L5) at Line 5 as
|
| 89 |
+
${MINIGPT4_DATASET}/laion/laion_dataset/{00000..10488}.tar
|
| 90 |
+
|
| 91 |
+
and the Conceptual Captoin and SBU datasets loading path in
|
| 92 |
+
[here](../minigpt4/configs/datasets/cc_sbu/defaults.yaml#L5) at Line 5 as
|
| 93 |
+
${MINIGPT4_DATASET}/cc_sbu/cc_sbu_dataset/{00000..01255}.tar
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
dataset/README_2_STAGE.md
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Second Stage Data Preparation
|
| 2 |
+
|
| 3 |
+
Our second stage dataset can be downloaded from
|
| 4 |
+
[here](https://drive.google.com/file/d/1nJXhoEcy3KTExr17I7BXqY5Y9Lx_-n-9/view?usp=share_link)
|
| 5 |
+
After extraction, you will get a data follder with the following structure:
|
| 6 |
+
|
| 7 |
+
```
|
| 8 |
+
cc_sbu_align
|
| 9 |
+
├── filter_cap.json
|
| 10 |
+
└── image
|
| 11 |
+
├── 2.jpg
|
| 12 |
+
├── 3.jpg
|
| 13 |
+
...
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
Put the folder to any path you want.
|
| 17 |
+
Then, set up the dataset path in the dataset config file
|
| 18 |
+
[here](../minigpt4/configs/datasets/cc_sbu/align.yaml#L5) at Line 5.
|
| 19 |
+
|
dataset/convert_cc_sbu.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import csv
|
| 3 |
+
|
| 4 |
+
# specify input and output file paths
|
| 5 |
+
input_file = 'ccs_synthetic_filtered_large.json'
|
| 6 |
+
output_file = 'ccs_synthetic_filtered_large.tsv'
|
| 7 |
+
|
| 8 |
+
# load JSON data from input file
|
| 9 |
+
with open(input_file, 'r') as f:
|
| 10 |
+
data = json.load(f)
|
| 11 |
+
|
| 12 |
+
# extract header and data from JSON
|
| 13 |
+
header = data[0].keys()
|
| 14 |
+
rows = [x.values() for x in data]
|
| 15 |
+
|
| 16 |
+
# write data to TSV file
|
| 17 |
+
with open(output_file, 'w') as f:
|
| 18 |
+
writer = csv.writer(f, delimiter='\t')
|
| 19 |
+
writer.writerow(header)
|
| 20 |
+
writer.writerows(rows)
|
dataset/convert_laion.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import csv
|
| 3 |
+
|
| 4 |
+
# specify input and output file paths
|
| 5 |
+
input_file = 'laion_synthetic_filtered_large.json'
|
| 6 |
+
output_file = 'laion_synthetic_filtered_large.tsv'
|
| 7 |
+
|
| 8 |
+
# load JSON data from input file
|
| 9 |
+
with open(input_file, 'r') as f:
|
| 10 |
+
data = json.load(f)
|
| 11 |
+
|
| 12 |
+
# extract header and data from JSON
|
| 13 |
+
header = data[0].keys()
|
| 14 |
+
rows = [x.values() for x in data]
|
| 15 |
+
|
| 16 |
+
# write data to TSV file
|
| 17 |
+
with open(output_file, 'w') as f:
|
| 18 |
+
writer = csv.writer(f, delimiter='\t')
|
| 19 |
+
writer.writerow(header)
|
| 20 |
+
writer.writerows(rows)
|
dataset/download_cc_sbu.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
img2dataset --url_list ccs_synthetic_filtered_large.tsv --input_format "tsv"\
|
| 4 |
+
--url_col "url" --caption_col "caption" --output_format webdataset\
|
| 5 |
+
--output_folder cc_sbu_dataset --processes_count 16 --thread_count 128 --image_size 224 \
|
| 6 |
+
--enable_wandb True
|
dataset/download_laion.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
img2dataset --url_list laion_synthetic_filtered_large.tsv --input_format "tsv"\
|
| 4 |
+
--url_col "url" --caption_col "caption" --output_format webdataset\
|
| 5 |
+
--output_folder laion_dataset --processes_count 16 --thread_count 128 --image_size 224 \
|
| 6 |
+
--enable_wandb True
|
demo.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.backends.cudnn as cudnn
|
| 8 |
+
import gradio as gr
|
| 9 |
+
|
| 10 |
+
from transformers import StoppingCriteriaList
|
| 11 |
+
|
| 12 |
+
from minigpt4.common.config import Config
|
| 13 |
+
from minigpt4.common.dist_utils import get_rank
|
| 14 |
+
from minigpt4.common.registry import registry
|
| 15 |
+
from minigpt4.conversation.conversation import Chat, CONV_VISION_Vicuna0, CONV_VISION_LLama2, StoppingCriteriaSub
|
| 16 |
+
|
| 17 |
+
# imports modules for registration
|
| 18 |
+
from minigpt4.datasets.builders import *
|
| 19 |
+
from minigpt4.models import *
|
| 20 |
+
from minigpt4.processors import *
|
| 21 |
+
from minigpt4.runners import *
|
| 22 |
+
from minigpt4.tasks import *
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def parse_args():
|
| 26 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 27 |
+
parser.add_argument("--cfg-path", required=True, help="path to configuration file.")
|
| 28 |
+
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
|
| 29 |
+
parser.add_argument(
|
| 30 |
+
"--options",
|
| 31 |
+
nargs="+",
|
| 32 |
+
help="override some settings in the used config, the key-value pair "
|
| 33 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 34 |
+
"change to --cfg-options instead.",
|
| 35 |
+
)
|
| 36 |
+
args = parser.parse_args()
|
| 37 |
+
return args
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def setup_seeds(config):
|
| 41 |
+
seed = config.run_cfg.seed + get_rank()
|
| 42 |
+
|
| 43 |
+
random.seed(seed)
|
| 44 |
+
np.random.seed(seed)
|
| 45 |
+
torch.manual_seed(seed)
|
| 46 |
+
|
| 47 |
+
cudnn.benchmark = False
|
| 48 |
+
cudnn.deterministic = True
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
# ========================================
|
| 52 |
+
# Model Initialization
|
| 53 |
+
# ========================================
|
| 54 |
+
|
| 55 |
+
conv_dict = {'pretrain_vicuna0': CONV_VISION_Vicuna0,
|
| 56 |
+
'pretrain_llama2': CONV_VISION_LLama2}
|
| 57 |
+
|
| 58 |
+
print('Initializing Chat')
|
| 59 |
+
args = parse_args()
|
| 60 |
+
cfg = Config(args)
|
| 61 |
+
|
| 62 |
+
model_config = cfg.model_cfg
|
| 63 |
+
model_config.device_8bit = args.gpu_id
|
| 64 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 65 |
+
model = model_cls.from_config(model_config).to('cuda:{}'.format(args.gpu_id))
|
| 66 |
+
|
| 67 |
+
CONV_VISION = conv_dict[model_config.model_type]
|
| 68 |
+
|
| 69 |
+
vis_processor_cfg = cfg.datasets_cfg.cc_sbu_align.vis_processor.train
|
| 70 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 71 |
+
|
| 72 |
+
stop_words_ids = [[835], [2277, 29937]]
|
| 73 |
+
stop_words_ids = [torch.tensor(ids).to(device='cuda:{}'.format(args.gpu_id)) for ids in stop_words_ids]
|
| 74 |
+
stopping_criteria = StoppingCriteriaList([StoppingCriteriaSub(stops=stop_words_ids)])
|
| 75 |
+
|
| 76 |
+
chat = Chat(model, vis_processor, device='cuda:{}'.format(args.gpu_id), stopping_criteria=stopping_criteria)
|
| 77 |
+
print('Initialization Finished')
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
# ========================================
|
| 81 |
+
# Gradio Setting
|
| 82 |
+
# ========================================
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def gradio_reset(chat_state, img_list):
|
| 86 |
+
if chat_state is not None:
|
| 87 |
+
chat_state.messages = []
|
| 88 |
+
if img_list is not None:
|
| 89 |
+
img_list = []
|
| 90 |
+
return None, gr.update(value=None, interactive=True), gr.update(placeholder='Please upload your image first', interactive=False),gr.update(value="Upload & Start Chat", interactive=True), chat_state, img_list
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def upload_img(gr_img, text_input, chat_state):
|
| 94 |
+
if gr_img is None:
|
| 95 |
+
return None, None, gr.update(interactive=True), chat_state, None
|
| 96 |
+
chat_state = CONV_VISION.copy()
|
| 97 |
+
img_list = []
|
| 98 |
+
llm_message = chat.upload_img(gr_img, chat_state, img_list)
|
| 99 |
+
chat.encode_img(img_list)
|
| 100 |
+
return gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def gradio_ask(user_message, chatbot, chat_state):
|
| 104 |
+
if len(user_message) == 0:
|
| 105 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 106 |
+
chat.ask(user_message, chat_state)
|
| 107 |
+
chatbot = chatbot + [[user_message, None]]
|
| 108 |
+
return '', chatbot, chat_state
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def gradio_answer(chatbot, chat_state, img_list, num_beams, temperature):
|
| 112 |
+
llm_message = chat.answer(conv=chat_state,
|
| 113 |
+
img_list=img_list,
|
| 114 |
+
num_beams=num_beams,
|
| 115 |
+
temperature=temperature,
|
| 116 |
+
max_new_tokens=300,
|
| 117 |
+
max_length=2000)[0]
|
| 118 |
+
chatbot[-1][1] = llm_message
|
| 119 |
+
return chatbot, chat_state, img_list
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
title = """<h1 align="center">Demo of MiniGPT-4</h1>"""
|
| 123 |
+
description = """<h3>This is the demo of MiniGPT-4. Upload your images and start chatting!</h3>"""
|
| 124 |
+
article = """<p><a href='https://minigpt-4.github.io'><img src='https://img.shields.io/badge/Project-Page-Green'></a></p><p><a href='https://github.com/Vision-CAIR/MiniGPT-4'><img src='https://img.shields.io/badge/Github-Code-blue'></a></p><p><a href='https://raw.githubusercontent.com/Vision-CAIR/MiniGPT-4/main/MiniGPT_4.pdf'><img src='https://img.shields.io/badge/Paper-PDF-red'></a></p>
|
| 125 |
+
"""
|
| 126 |
+
|
| 127 |
+
#TODO show examples below
|
| 128 |
+
|
| 129 |
+
with gr.Blocks() as demo:
|
| 130 |
+
gr.Markdown(title)
|
| 131 |
+
gr.Markdown(description)
|
| 132 |
+
gr.Markdown(article)
|
| 133 |
+
|
| 134 |
+
with gr.Row():
|
| 135 |
+
with gr.Column(scale=1):
|
| 136 |
+
image = gr.Image(type="pil")
|
| 137 |
+
upload_button = gr.Button(value="Upload & Start Chat", interactive=True, variant="primary")
|
| 138 |
+
clear = gr.Button("Restart")
|
| 139 |
+
|
| 140 |
+
num_beams = gr.Slider(
|
| 141 |
+
minimum=1,
|
| 142 |
+
maximum=10,
|
| 143 |
+
value=1,
|
| 144 |
+
step=1,
|
| 145 |
+
interactive=True,
|
| 146 |
+
label="beam search numbers)",
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
temperature = gr.Slider(
|
| 150 |
+
minimum=0.1,
|
| 151 |
+
maximum=2.0,
|
| 152 |
+
value=1.0,
|
| 153 |
+
step=0.1,
|
| 154 |
+
interactive=True,
|
| 155 |
+
label="Temperature",
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
with gr.Column(scale=2):
|
| 159 |
+
chat_state = gr.State()
|
| 160 |
+
img_list = gr.State()
|
| 161 |
+
chatbot = gr.Chatbot(label='MiniGPT-4')
|
| 162 |
+
text_input = gr.Textbox(label='User', placeholder='Please upload your image first', interactive=False)
|
| 163 |
+
|
| 164 |
+
upload_button.click(upload_img, [image, text_input, chat_state], [image, text_input, upload_button, chat_state, img_list])
|
| 165 |
+
|
| 166 |
+
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
|
| 167 |
+
gradio_answer, [chatbot, chat_state, img_list, num_beams, temperature], [chatbot, chat_state, img_list]
|
| 168 |
+
)
|
| 169 |
+
clear.click(gradio_reset, [chat_state, img_list], [chatbot, image, text_input, upload_button, chat_state, img_list], queue=False)
|
| 170 |
+
|
| 171 |
+
demo.launch(share=True, enable_queue=True)
|
demo_v2.py
ADDED
|
@@ -0,0 +1,662 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
from collections import defaultdict
|
| 5 |
+
|
| 6 |
+
import cv2
|
| 7 |
+
import re
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import torch
|
| 12 |
+
import html
|
| 13 |
+
import gradio as gr
|
| 14 |
+
|
| 15 |
+
import torchvision.transforms as T
|
| 16 |
+
import torch.backends.cudnn as cudnn
|
| 17 |
+
|
| 18 |
+
from minigpt4.common.config import Config
|
| 19 |
+
|
| 20 |
+
from minigpt4.common.registry import registry
|
| 21 |
+
from minigpt4.conversation.conversation import Conversation, SeparatorStyle, Chat
|
| 22 |
+
|
| 23 |
+
# imports modules for registration
|
| 24 |
+
from minigpt4.datasets.builders import *
|
| 25 |
+
from minigpt4.models import *
|
| 26 |
+
from minigpt4.processors import *
|
| 27 |
+
from minigpt4.runners import *
|
| 28 |
+
from minigpt4.tasks import *
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def parse_args():
|
| 32 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 33 |
+
parser.add_argument("--cfg-path", default='eval_configs/minigptv2_eval.yaml',
|
| 34 |
+
help="path to configuration file.")
|
| 35 |
+
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
|
| 36 |
+
parser.add_argument(
|
| 37 |
+
"--options",
|
| 38 |
+
nargs="+",
|
| 39 |
+
help="override some settings in the used config, the key-value pair "
|
| 40 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 41 |
+
"change to --cfg-options instead.",
|
| 42 |
+
)
|
| 43 |
+
args = parser.parse_args()
|
| 44 |
+
return args
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
random.seed(42)
|
| 48 |
+
np.random.seed(42)
|
| 49 |
+
torch.manual_seed(42)
|
| 50 |
+
|
| 51 |
+
cudnn.benchmark = False
|
| 52 |
+
cudnn.deterministic = True
|
| 53 |
+
|
| 54 |
+
print('Initializing Chat')
|
| 55 |
+
args = parse_args()
|
| 56 |
+
cfg = Config(args)
|
| 57 |
+
|
| 58 |
+
device = 'cuda:{}'.format(args.gpu_id)
|
| 59 |
+
|
| 60 |
+
model_config = cfg.model_cfg
|
| 61 |
+
model_config.device_8bit = args.gpu_id
|
| 62 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 63 |
+
model = model_cls.from_config(model_config).to(device)
|
| 64 |
+
bounding_box_size = 100
|
| 65 |
+
|
| 66 |
+
vis_processor_cfg = cfg.datasets_cfg.cc_sbu_align.vis_processor.train
|
| 67 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 68 |
+
|
| 69 |
+
model = model.eval()
|
| 70 |
+
|
| 71 |
+
CONV_VISION = Conversation(
|
| 72 |
+
system="",
|
| 73 |
+
roles=(r"<s>[INST] ", r" [/INST]"),
|
| 74 |
+
messages=[],
|
| 75 |
+
offset=2,
|
| 76 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 77 |
+
sep="",
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def extract_substrings(string):
|
| 82 |
+
# first check if there is no-finished bracket
|
| 83 |
+
index = string.rfind('}')
|
| 84 |
+
if index != -1:
|
| 85 |
+
string = string[:index + 1]
|
| 86 |
+
|
| 87 |
+
pattern = r'<p>(.*?)\}(?!<)'
|
| 88 |
+
matches = re.findall(pattern, string)
|
| 89 |
+
substrings = [match for match in matches]
|
| 90 |
+
|
| 91 |
+
return substrings
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def is_overlapping(rect1, rect2):
|
| 95 |
+
x1, y1, x2, y2 = rect1
|
| 96 |
+
x3, y3, x4, y4 = rect2
|
| 97 |
+
return not (x2 < x3 or x1 > x4 or y2 < y3 or y1 > y4)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def computeIoU(bbox1, bbox2):
|
| 101 |
+
x1, y1, x2, y2 = bbox1
|
| 102 |
+
x3, y3, x4, y4 = bbox2
|
| 103 |
+
intersection_x1 = max(x1, x3)
|
| 104 |
+
intersection_y1 = max(y1, y3)
|
| 105 |
+
intersection_x2 = min(x2, x4)
|
| 106 |
+
intersection_y2 = min(y2, y4)
|
| 107 |
+
intersection_area = max(0, intersection_x2 - intersection_x1 + 1) * max(0, intersection_y2 - intersection_y1 + 1)
|
| 108 |
+
bbox1_area = (x2 - x1 + 1) * (y2 - y1 + 1)
|
| 109 |
+
bbox2_area = (x4 - x3 + 1) * (y4 - y3 + 1)
|
| 110 |
+
union_area = bbox1_area + bbox2_area - intersection_area
|
| 111 |
+
iou = intersection_area / union_area
|
| 112 |
+
return iou
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def save_tmp_img(visual_img):
|
| 116 |
+
file_name = "".join([str(random.randint(0, 9)) for _ in range(5)]) + ".jpg"
|
| 117 |
+
file_path = "/tmp/" + file_name
|
| 118 |
+
visual_img.save(file_path)
|
| 119 |
+
return file_path
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def mask2bbox(mask):
|
| 123 |
+
if mask is None:
|
| 124 |
+
return ''
|
| 125 |
+
mask = mask.resize([100, 100], resample=Image.NEAREST)
|
| 126 |
+
mask = np.array(mask)[:, :, 0]
|
| 127 |
+
|
| 128 |
+
rows = np.any(mask, axis=1)
|
| 129 |
+
cols = np.any(mask, axis=0)
|
| 130 |
+
|
| 131 |
+
if rows.sum():
|
| 132 |
+
# Get the top, bottom, left, and right boundaries
|
| 133 |
+
rmin, rmax = np.where(rows)[0][[0, -1]]
|
| 134 |
+
cmin, cmax = np.where(cols)[0][[0, -1]]
|
| 135 |
+
bbox = '{{<{}><{}><{}><{}>}}'.format(cmin, rmin, cmax, rmax)
|
| 136 |
+
else:
|
| 137 |
+
bbox = ''
|
| 138 |
+
|
| 139 |
+
return bbox
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def escape_markdown(text):
|
| 143 |
+
# List of Markdown special characters that need to be escaped
|
| 144 |
+
md_chars = ['<', '>']
|
| 145 |
+
|
| 146 |
+
# Escape each special character
|
| 147 |
+
for char in md_chars:
|
| 148 |
+
text = text.replace(char, '\\' + char)
|
| 149 |
+
|
| 150 |
+
return text
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def reverse_escape(text):
|
| 154 |
+
md_chars = ['\\<', '\\>']
|
| 155 |
+
|
| 156 |
+
for char in md_chars:
|
| 157 |
+
text = text.replace(char, char[1:])
|
| 158 |
+
|
| 159 |
+
return text
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
colors = [
|
| 163 |
+
(255, 0, 0),
|
| 164 |
+
(0, 255, 0),
|
| 165 |
+
(0, 0, 255),
|
| 166 |
+
(210, 210, 0),
|
| 167 |
+
(255, 0, 255),
|
| 168 |
+
(0, 255, 255),
|
| 169 |
+
(114, 128, 250),
|
| 170 |
+
(0, 165, 255),
|
| 171 |
+
(0, 128, 0),
|
| 172 |
+
(144, 238, 144),
|
| 173 |
+
(238, 238, 175),
|
| 174 |
+
(255, 191, 0),
|
| 175 |
+
(0, 128, 0),
|
| 176 |
+
(226, 43, 138),
|
| 177 |
+
(255, 0, 255),
|
| 178 |
+
(0, 215, 255),
|
| 179 |
+
]
|
| 180 |
+
|
| 181 |
+
color_map = {
|
| 182 |
+
f"{color_id}": f"#{hex(color[2])[2:].zfill(2)}{hex(color[1])[2:].zfill(2)}{hex(color[0])[2:].zfill(2)}" for
|
| 183 |
+
color_id, color in enumerate(colors)
|
| 184 |
+
}
|
| 185 |
+
|
| 186 |
+
used_colors = colors
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def visualize_all_bbox_together(image, generation):
|
| 190 |
+
if image is None:
|
| 191 |
+
return None, ''
|
| 192 |
+
|
| 193 |
+
generation = html.unescape(generation)
|
| 194 |
+
print('gen begin', generation)
|
| 195 |
+
|
| 196 |
+
image_width, image_height = image.size
|
| 197 |
+
image = image.resize([500, int(500 / image_width * image_height)])
|
| 198 |
+
image_width, image_height = image.size
|
| 199 |
+
|
| 200 |
+
string_list = extract_substrings(generation)
|
| 201 |
+
if string_list: # it is grounding or detection
|
| 202 |
+
mode = 'all'
|
| 203 |
+
entities = defaultdict(list)
|
| 204 |
+
i = 0
|
| 205 |
+
j = 0
|
| 206 |
+
for string in string_list:
|
| 207 |
+
try:
|
| 208 |
+
obj, string = string.split('</p>')
|
| 209 |
+
except ValueError:
|
| 210 |
+
print('wrong string: ', string)
|
| 211 |
+
continue
|
| 212 |
+
bbox_list = string.split('<delim>')
|
| 213 |
+
flag = False
|
| 214 |
+
for bbox_string in bbox_list:
|
| 215 |
+
integers = re.findall(r'-?\d+', bbox_string)
|
| 216 |
+
if len(integers) == 4:
|
| 217 |
+
x0, y0, x1, y1 = int(integers[0]), int(integers[1]), int(integers[2]), int(integers[3])
|
| 218 |
+
left = x0 / bounding_box_size * image_width
|
| 219 |
+
bottom = y0 / bounding_box_size * image_height
|
| 220 |
+
right = x1 / bounding_box_size * image_width
|
| 221 |
+
top = y1 / bounding_box_size * image_height
|
| 222 |
+
|
| 223 |
+
entities[obj].append([left, bottom, right, top])
|
| 224 |
+
|
| 225 |
+
j += 1
|
| 226 |
+
flag = True
|
| 227 |
+
if flag:
|
| 228 |
+
i += 1
|
| 229 |
+
else:
|
| 230 |
+
integers = re.findall(r'-?\d+', generation)
|
| 231 |
+
|
| 232 |
+
if len(integers) == 4: # it is refer
|
| 233 |
+
mode = 'single'
|
| 234 |
+
|
| 235 |
+
entities = list()
|
| 236 |
+
x0, y0, x1, y1 = int(integers[0]), int(integers[1]), int(integers[2]), int(integers[3])
|
| 237 |
+
left = x0 / bounding_box_size * image_width
|
| 238 |
+
bottom = y0 / bounding_box_size * image_height
|
| 239 |
+
right = x1 / bounding_box_size * image_width
|
| 240 |
+
top = y1 / bounding_box_size * image_height
|
| 241 |
+
entities.append([left, bottom, right, top])
|
| 242 |
+
else:
|
| 243 |
+
# don't detect any valid bbox to visualize
|
| 244 |
+
return None, ''
|
| 245 |
+
|
| 246 |
+
if len(entities) == 0:
|
| 247 |
+
return None, ''
|
| 248 |
+
|
| 249 |
+
if isinstance(image, Image.Image):
|
| 250 |
+
image_h = image.height
|
| 251 |
+
image_w = image.width
|
| 252 |
+
image = np.array(image)
|
| 253 |
+
|
| 254 |
+
elif isinstance(image, str):
|
| 255 |
+
if os.path.exists(image):
|
| 256 |
+
pil_img = Image.open(image).convert("RGB")
|
| 257 |
+
image = np.array(pil_img)[:, :, [2, 1, 0]]
|
| 258 |
+
image_h = pil_img.height
|
| 259 |
+
image_w = pil_img.width
|
| 260 |
+
else:
|
| 261 |
+
raise ValueError(f"invaild image path, {image}")
|
| 262 |
+
elif isinstance(image, torch.Tensor):
|
| 263 |
+
|
| 264 |
+
image_tensor = image.cpu()
|
| 265 |
+
reverse_norm_mean = torch.tensor([0.48145466, 0.4578275, 0.40821073])[:, None, None]
|
| 266 |
+
reverse_norm_std = torch.tensor([0.26862954, 0.26130258, 0.27577711])[:, None, None]
|
| 267 |
+
image_tensor = image_tensor * reverse_norm_std + reverse_norm_mean
|
| 268 |
+
pil_img = T.ToPILImage()(image_tensor)
|
| 269 |
+
image_h = pil_img.height
|
| 270 |
+
image_w = pil_img.width
|
| 271 |
+
image = np.array(pil_img)[:, :, [2, 1, 0]]
|
| 272 |
+
else:
|
| 273 |
+
raise ValueError(f"invaild image format, {type(image)} for {image}")
|
| 274 |
+
|
| 275 |
+
indices = list(range(len(entities)))
|
| 276 |
+
|
| 277 |
+
new_image = image.copy()
|
| 278 |
+
|
| 279 |
+
previous_bboxes = []
|
| 280 |
+
# size of text
|
| 281 |
+
text_size = 0.5
|
| 282 |
+
# thickness of text
|
| 283 |
+
text_line = 1 # int(max(1 * min(image_h, image_w) / 512, 1))
|
| 284 |
+
box_line = 2
|
| 285 |
+
(c_width, text_height), _ = cv2.getTextSize("F", cv2.FONT_HERSHEY_COMPLEX, text_size, text_line)
|
| 286 |
+
base_height = int(text_height * 0.675)
|
| 287 |
+
text_offset_original = text_height - base_height
|
| 288 |
+
text_spaces = 2
|
| 289 |
+
|
| 290 |
+
# num_bboxes = sum(len(x[-1]) for x in entities)
|
| 291 |
+
used_colors = colors # random.sample(colors, k=num_bboxes)
|
| 292 |
+
|
| 293 |
+
color_id = -1
|
| 294 |
+
for entity_idx, entity_name in enumerate(entities):
|
| 295 |
+
if mode == 'single' or mode == 'identify':
|
| 296 |
+
bboxes = entity_name
|
| 297 |
+
bboxes = [bboxes]
|
| 298 |
+
else:
|
| 299 |
+
bboxes = entities[entity_name]
|
| 300 |
+
color_id += 1
|
| 301 |
+
for bbox_id, (x1_norm, y1_norm, x2_norm, y2_norm) in enumerate(bboxes):
|
| 302 |
+
skip_flag = False
|
| 303 |
+
orig_x1, orig_y1, orig_x2, orig_y2 = int(x1_norm), int(y1_norm), int(x2_norm), int(y2_norm)
|
| 304 |
+
|
| 305 |
+
color = used_colors[entity_idx % len(used_colors)] # tuple(np.random.randint(0, 255, size=3).tolist())
|
| 306 |
+
new_image = cv2.rectangle(new_image, (orig_x1, orig_y1), (orig_x2, orig_y2), color, box_line)
|
| 307 |
+
|
| 308 |
+
if mode == 'all':
|
| 309 |
+
l_o, r_o = box_line // 2 + box_line % 2, box_line // 2 + box_line % 2 + 1
|
| 310 |
+
|
| 311 |
+
x1 = orig_x1 - l_o
|
| 312 |
+
y1 = orig_y1 - l_o
|
| 313 |
+
|
| 314 |
+
if y1 < text_height + text_offset_original + 2 * text_spaces:
|
| 315 |
+
y1 = orig_y1 + r_o + text_height + text_offset_original + 2 * text_spaces
|
| 316 |
+
x1 = orig_x1 + r_o
|
| 317 |
+
|
| 318 |
+
# add text background
|
| 319 |
+
(text_width, text_height), _ = cv2.getTextSize(f" {entity_name}", cv2.FONT_HERSHEY_COMPLEX, text_size,
|
| 320 |
+
text_line)
|
| 321 |
+
text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2 = x1, y1 - (
|
| 322 |
+
text_height + text_offset_original + 2 * text_spaces), x1 + text_width, y1
|
| 323 |
+
|
| 324 |
+
for prev_bbox in previous_bboxes:
|
| 325 |
+
if computeIoU((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), prev_bbox['bbox']) > 0.95 and \
|
| 326 |
+
prev_bbox['phrase'] == entity_name:
|
| 327 |
+
skip_flag = True
|
| 328 |
+
break
|
| 329 |
+
while is_overlapping((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), prev_bbox['bbox']):
|
| 330 |
+
text_bg_y1 += (text_height + text_offset_original + 2 * text_spaces)
|
| 331 |
+
text_bg_y2 += (text_height + text_offset_original + 2 * text_spaces)
|
| 332 |
+
y1 += (text_height + text_offset_original + 2 * text_spaces)
|
| 333 |
+
|
| 334 |
+
if text_bg_y2 >= image_h:
|
| 335 |
+
text_bg_y1 = max(0, image_h - (text_height + text_offset_original + 2 * text_spaces))
|
| 336 |
+
text_bg_y2 = image_h
|
| 337 |
+
y1 = image_h
|
| 338 |
+
break
|
| 339 |
+
if not skip_flag:
|
| 340 |
+
alpha = 0.5
|
| 341 |
+
for i in range(text_bg_y1, text_bg_y2):
|
| 342 |
+
for j in range(text_bg_x1, text_bg_x2):
|
| 343 |
+
if i < image_h and j < image_w:
|
| 344 |
+
if j < text_bg_x1 + 1.35 * c_width:
|
| 345 |
+
# original color
|
| 346 |
+
bg_color = color
|
| 347 |
+
else:
|
| 348 |
+
# white
|
| 349 |
+
bg_color = [255, 255, 255]
|
| 350 |
+
new_image[i, j] = (alpha * new_image[i, j] + (1 - alpha) * np.array(bg_color)).astype(
|
| 351 |
+
np.uint8)
|
| 352 |
+
|
| 353 |
+
cv2.putText(
|
| 354 |
+
new_image, f" {entity_name}", (x1, y1 - text_offset_original - 1 * text_spaces),
|
| 355 |
+
cv2.FONT_HERSHEY_COMPLEX, text_size, (0, 0, 0), text_line, cv2.LINE_AA
|
| 356 |
+
)
|
| 357 |
+
|
| 358 |
+
previous_bboxes.append(
|
| 359 |
+
{'bbox': (text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), 'phrase': entity_name})
|
| 360 |
+
|
| 361 |
+
if mode == 'all':
|
| 362 |
+
def color_iterator(colors):
|
| 363 |
+
while True:
|
| 364 |
+
for color in colors:
|
| 365 |
+
yield color
|
| 366 |
+
|
| 367 |
+
color_gen = color_iterator(colors)
|
| 368 |
+
|
| 369 |
+
# Add colors to phrases and remove <p></p>
|
| 370 |
+
def colored_phrases(match):
|
| 371 |
+
phrase = match.group(1)
|
| 372 |
+
color = next(color_gen)
|
| 373 |
+
return f'<span style="color:rgb{color}">{phrase}</span>'
|
| 374 |
+
|
| 375 |
+
print('gen before', generation)
|
| 376 |
+
generation = re.sub(r'{<\d+><\d+><\d+><\d+>}|<delim>', '', generation)
|
| 377 |
+
print('gen after', generation)
|
| 378 |
+
generation_colored = re.sub(r'<p>(.*?)</p>', colored_phrases, generation)
|
| 379 |
+
else:
|
| 380 |
+
generation_colored = ''
|
| 381 |
+
|
| 382 |
+
pil_image = Image.fromarray(new_image)
|
| 383 |
+
return pil_image, generation_colored
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def gradio_reset(chat_state, img_list):
|
| 387 |
+
if chat_state is not None:
|
| 388 |
+
chat_state.messages = []
|
| 389 |
+
if img_list is not None:
|
| 390 |
+
img_list = []
|
| 391 |
+
return None, gr.update(value=None, interactive=True), gr.update(placeholder='Upload your image and chat',
|
| 392 |
+
interactive=True), chat_state, img_list
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
def image_upload_trigger(upload_flag, replace_flag, img_list):
|
| 396 |
+
# set the upload flag to true when receive a new image.
|
| 397 |
+
# if there is an old image (and old conversation), set the replace flag to true to reset the conv later.
|
| 398 |
+
print('flag', upload_flag, replace_flag)
|
| 399 |
+
print("SET UPLOAD FLAG!")
|
| 400 |
+
upload_flag = 1
|
| 401 |
+
if img_list:
|
| 402 |
+
print("SET REPLACE FLAG!")
|
| 403 |
+
replace_flag = 1
|
| 404 |
+
print('flag', upload_flag, replace_flag)
|
| 405 |
+
return upload_flag, replace_flag
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
def example_trigger(text_input, image, upload_flag, replace_flag, img_list):
|
| 409 |
+
# set the upload flag to true when receive a new image.
|
| 410 |
+
# if there is an old image (and old conversation), set the replace flag to true to reset the conv later.
|
| 411 |
+
print('flag', upload_flag, replace_flag)
|
| 412 |
+
print("SET UPLOAD FLAG!")
|
| 413 |
+
upload_flag = 1
|
| 414 |
+
if img_list or replace_flag == 1:
|
| 415 |
+
print("SET REPLACE FLAG!")
|
| 416 |
+
replace_flag = 1
|
| 417 |
+
|
| 418 |
+
print('flag', upload_flag, replace_flag)
|
| 419 |
+
return upload_flag, replace_flag
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
def gradio_ask(user_message, chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag):
|
| 423 |
+
if isinstance(gr_img, dict):
|
| 424 |
+
gr_img, mask = gr_img['image'], gr_img['mask']
|
| 425 |
+
else:
|
| 426 |
+
mask = None
|
| 427 |
+
|
| 428 |
+
if '[identify]' in user_message:
|
| 429 |
+
# check if user provide bbox in the text input
|
| 430 |
+
integers = re.findall(r'-?\d+', user_message)
|
| 431 |
+
if len(integers) != 4: # no bbox in text
|
| 432 |
+
bbox = mask2bbox(mask)
|
| 433 |
+
user_message = user_message + bbox
|
| 434 |
+
|
| 435 |
+
if len(user_message) == 0:
|
| 436 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 437 |
+
|
| 438 |
+
if chat_state is None:
|
| 439 |
+
chat_state = CONV_VISION.copy()
|
| 440 |
+
|
| 441 |
+
print('upload flag: {}'.format(upload_flag))
|
| 442 |
+
if upload_flag:
|
| 443 |
+
if replace_flag:
|
| 444 |
+
print('RESET!!!!!!!')
|
| 445 |
+
chat_state = CONV_VISION.copy() # new image, reset everything
|
| 446 |
+
replace_flag = 0
|
| 447 |
+
chatbot = []
|
| 448 |
+
print('UPLOAD IMAGE!!')
|
| 449 |
+
img_list = []
|
| 450 |
+
llm_message = chat.upload_img(gr_img, chat_state, img_list)
|
| 451 |
+
upload_flag = 0
|
| 452 |
+
|
| 453 |
+
chat.ask(user_message, chat_state)
|
| 454 |
+
|
| 455 |
+
chatbot = chatbot + [[user_message, None]]
|
| 456 |
+
|
| 457 |
+
if '[identify]' in user_message:
|
| 458 |
+
visual_img, _ = visualize_all_bbox_together(gr_img, user_message)
|
| 459 |
+
if visual_img is not None:
|
| 460 |
+
print('Visualizing the input')
|
| 461 |
+
file_path = save_tmp_img(visual_img)
|
| 462 |
+
chatbot = chatbot + [[(file_path,), None]]
|
| 463 |
+
|
| 464 |
+
return '', chatbot, chat_state, img_list, upload_flag, replace_flag
|
| 465 |
+
|
| 466 |
+
|
| 467 |
+
def gradio_answer(chatbot, chat_state, img_list, temperature):
|
| 468 |
+
llm_message = chat.answer(conv=chat_state,
|
| 469 |
+
img_list=img_list,
|
| 470 |
+
temperature=temperature,
|
| 471 |
+
max_new_tokens=500,
|
| 472 |
+
max_length=2000)[0]
|
| 473 |
+
chatbot[-1][1] = llm_message
|
| 474 |
+
return chatbot, chat_state
|
| 475 |
+
|
| 476 |
+
|
| 477 |
+
def gradio_stream_answer(chatbot, chat_state, img_list, temperature):
|
| 478 |
+
print('chat state', chat_state.get_prompt())
|
| 479 |
+
if not isinstance(img_list[0], torch.Tensor):
|
| 480 |
+
chat.encode_img(img_list)
|
| 481 |
+
streamer = chat.stream_answer(conv=chat_state,
|
| 482 |
+
img_list=img_list,
|
| 483 |
+
temperature=temperature,
|
| 484 |
+
max_new_tokens=500,
|
| 485 |
+
max_length=2000)
|
| 486 |
+
output = ''
|
| 487 |
+
for new_output in streamer:
|
| 488 |
+
escapped = escape_markdown(new_output)
|
| 489 |
+
output += escapped
|
| 490 |
+
chatbot[-1][1] = output
|
| 491 |
+
yield chatbot, chat_state
|
| 492 |
+
# print('message: ', chat_state.messages)
|
| 493 |
+
chat_state.messages[-1][1] = '</s>'
|
| 494 |
+
return chatbot, chat_state
|
| 495 |
+
|
| 496 |
+
|
| 497 |
+
def gradio_visualize(chatbot, gr_img):
|
| 498 |
+
if isinstance(gr_img, dict):
|
| 499 |
+
gr_img, mask = gr_img['image'], gr_img['mask']
|
| 500 |
+
|
| 501 |
+
unescaped = reverse_escape(chatbot[-1][1])
|
| 502 |
+
visual_img, generation_color = visualize_all_bbox_together(gr_img, unescaped)
|
| 503 |
+
if visual_img is not None:
|
| 504 |
+
print('Visualizing the output')
|
| 505 |
+
if len(generation_color):
|
| 506 |
+
chatbot[-1][1] = generation_color
|
| 507 |
+
file_path = save_tmp_img(visual_img)
|
| 508 |
+
chatbot = chatbot + [[None, (file_path,)]]
|
| 509 |
+
|
| 510 |
+
return chatbot
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
def gradio_taskselect(idx):
|
| 514 |
+
prompt_list = [
|
| 515 |
+
'',
|
| 516 |
+
'[grounding] describe this image in detail',
|
| 517 |
+
'[refer] ',
|
| 518 |
+
'[detection] ',
|
| 519 |
+
'[identify] what is this ',
|
| 520 |
+
'[vqa] '
|
| 521 |
+
]
|
| 522 |
+
instruct_list = [
|
| 523 |
+
'**Hint:** Type in whatever you want',
|
| 524 |
+
'**Hint:** Send the command to generate a grounded image description',
|
| 525 |
+
'**Hint:** Type in a phrase about an object in the image and send the command',
|
| 526 |
+
'**Hint:** Type in a caption or phrase, and see object locations in the image',
|
| 527 |
+
'**Hint:** Draw a bounding box on the uploaded image then send the command. Click the "clear" botton on the top right of the image before redraw',
|
| 528 |
+
'**Hint:** Send a question to get a short answer',
|
| 529 |
+
]
|
| 530 |
+
return prompt_list[idx], instruct_list[idx]
|
| 531 |
+
|
| 532 |
+
|
| 533 |
+
|
| 534 |
+
|
| 535 |
+
chat = Chat(model, vis_processor, device=device)
|
| 536 |
+
|
| 537 |
+
title = """<h1 align="center">MiniGPT-v2 Demo</h1>"""
|
| 538 |
+
description = 'Welcome to Our MiniGPT-v2 Chatbot Demo!'
|
| 539 |
+
# article = """<p><a href='https://minigpt-v2.github.io'><img src='https://img.shields.io/badge/Project-Page-Green'></a></p><p><a href='https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPTv2.pdf'><img src='https://img.shields.io/badge/Paper-PDF-red'></a></p><p><a href='https://github.com/Vision-CAIR/MiniGPT-4'><img src='https://img.shields.io/badge/GitHub-Repo-blue'></a></p><p><a href='https://www.youtube.com/watch?v=atFCwV2hSY4'><img src='https://img.shields.io/badge/YouTube-Video-red'></a></p>"""
|
| 540 |
+
article = """<p><a href='https://minigpt-v2.github.io'><img src='https://img.shields.io/badge/Project-Page-Green'></a></p>"""
|
| 541 |
+
|
| 542 |
+
introduction = '''
|
| 543 |
+
For Abilities Involving Visual Grounding:
|
| 544 |
+
1. Grounding: CLICK **Send** to generate a grounded image description.
|
| 545 |
+
2. Refer: Input a referring object and CLICK **Send**.
|
| 546 |
+
3. Detection: Write a caption or phrase, and CLICK **Send**.
|
| 547 |
+
4. Identify: Draw the bounding box on the uploaded image window and CLICK **Send** to generate the bounding box. (CLICK "clear" button before re-drawing next time).
|
| 548 |
+
5. VQA: Input a visual question and CLICK **Send**.
|
| 549 |
+
6. No Tag: Input whatever you want and CLICK **Send** without any tagging
|
| 550 |
+
|
| 551 |
+
You can also simply chat in free form!
|
| 552 |
+
'''
|
| 553 |
+
|
| 554 |
+
text_input = gr.Textbox(placeholder='Upload your image and chat', interactive=True, show_label=False, container=False,
|
| 555 |
+
scale=8)
|
| 556 |
+
with gr.Blocks() as demo:
|
| 557 |
+
gr.Markdown(title)
|
| 558 |
+
# gr.Markdown(description)
|
| 559 |
+
gr.Markdown(article)
|
| 560 |
+
|
| 561 |
+
with gr.Row():
|
| 562 |
+
with gr.Column(scale=0.5):
|
| 563 |
+
image = gr.Image(type="pil", tool='sketch', brush_radius=20)
|
| 564 |
+
|
| 565 |
+
temperature = gr.Slider(
|
| 566 |
+
minimum=0.1,
|
| 567 |
+
maximum=2.0,
|
| 568 |
+
value=1.0,
|
| 569 |
+
step=0.1,
|
| 570 |
+
interactive=True,
|
| 571 |
+
label="Temperature",
|
| 572 |
+
)
|
| 573 |
+
|
| 574 |
+
clear = gr.Button("Restart")
|
| 575 |
+
|
| 576 |
+
gr.Markdown(introduction)
|
| 577 |
+
|
| 578 |
+
with gr.Column():
|
| 579 |
+
chat_state = gr.State(value=None)
|
| 580 |
+
img_list = gr.State(value=[])
|
| 581 |
+
chatbot = gr.Chatbot(label='MiniGPT-v2')
|
| 582 |
+
|
| 583 |
+
dataset = gr.Dataset(
|
| 584 |
+
components=[gr.Textbox(visible=False)],
|
| 585 |
+
samples=[['No Tag'], ['Grounding'], ['Refer'], ['Detection'], ['Identify'], ['VQA']],
|
| 586 |
+
type="index",
|
| 587 |
+
label='Task Shortcuts',
|
| 588 |
+
)
|
| 589 |
+
task_inst = gr.Markdown('**Hint:** Upload your image and chat')
|
| 590 |
+
with gr.Row():
|
| 591 |
+
text_input.render()
|
| 592 |
+
send = gr.Button("Send", variant='primary', size='sm', scale=1)
|
| 593 |
+
|
| 594 |
+
upload_flag = gr.State(value=0)
|
| 595 |
+
replace_flag = gr.State(value=0)
|
| 596 |
+
image.upload(image_upload_trigger, [upload_flag, replace_flag, img_list], [upload_flag, replace_flag])
|
| 597 |
+
|
| 598 |
+
with gr.Row():
|
| 599 |
+
with gr.Column():
|
| 600 |
+
gr.Examples(examples=[
|
| 601 |
+
["examples_v2/office.jpg", "[grounding] describe this image in detail", upload_flag, replace_flag,
|
| 602 |
+
img_list],
|
| 603 |
+
["examples_v2/sofa.jpg", "[detection] sofas", upload_flag, replace_flag, img_list],
|
| 604 |
+
["examples_v2/2000x1372_wmkn_0012149409555.jpg", "[refer] the world cup", upload_flag, replace_flag,
|
| 605 |
+
img_list],
|
| 606 |
+
["examples_v2/KFC-20-for-20-Nuggets.jpg", "[identify] what is this {<4><50><30><65>}", upload_flag,
|
| 607 |
+
replace_flag, img_list],
|
| 608 |
+
], inputs=[image, text_input, upload_flag, replace_flag, img_list], fn=example_trigger,
|
| 609 |
+
outputs=[upload_flag, replace_flag])
|
| 610 |
+
with gr.Column():
|
| 611 |
+
gr.Examples(examples=[
|
| 612 |
+
["examples_v2/glip_test.jpg", "[vqa] where should I hide in this room when playing hide and seek",
|
| 613 |
+
upload_flag, replace_flag, img_list],
|
| 614 |
+
["examples_v2/float.png", "Please write a poem about the image", upload_flag, replace_flag, img_list],
|
| 615 |
+
["examples_v2/thief.png", "Is the weapon fateful", upload_flag, replace_flag, img_list],
|
| 616 |
+
["examples_v2/cockdial.png", "What might happen in this image in the next second", upload_flag,
|
| 617 |
+
replace_flag, img_list],
|
| 618 |
+
], inputs=[image, text_input, upload_flag, replace_flag, img_list], fn=example_trigger,
|
| 619 |
+
outputs=[upload_flag, replace_flag])
|
| 620 |
+
|
| 621 |
+
dataset.click(
|
| 622 |
+
gradio_taskselect,
|
| 623 |
+
inputs=[dataset],
|
| 624 |
+
outputs=[text_input, task_inst],
|
| 625 |
+
show_progress="hidden",
|
| 626 |
+
postprocess=False,
|
| 627 |
+
queue=False,
|
| 628 |
+
)
|
| 629 |
+
|
| 630 |
+
text_input.submit(
|
| 631 |
+
gradio_ask,
|
| 632 |
+
[text_input, chatbot, chat_state, image, img_list, upload_flag, replace_flag],
|
| 633 |
+
[text_input, chatbot, chat_state, img_list, upload_flag, replace_flag], queue=False
|
| 634 |
+
).success(
|
| 635 |
+
gradio_stream_answer,
|
| 636 |
+
[chatbot, chat_state, img_list, temperature],
|
| 637 |
+
[chatbot, chat_state]
|
| 638 |
+
).success(
|
| 639 |
+
gradio_visualize,
|
| 640 |
+
[chatbot, image],
|
| 641 |
+
[chatbot],
|
| 642 |
+
queue=False,
|
| 643 |
+
)
|
| 644 |
+
|
| 645 |
+
send.click(
|
| 646 |
+
gradio_ask,
|
| 647 |
+
[text_input, chatbot, chat_state, image, img_list, upload_flag, replace_flag],
|
| 648 |
+
[text_input, chatbot, chat_state, img_list, upload_flag, replace_flag], queue=False
|
| 649 |
+
).success(
|
| 650 |
+
gradio_stream_answer,
|
| 651 |
+
[chatbot, chat_state, img_list, temperature],
|
| 652 |
+
[chatbot, chat_state]
|
| 653 |
+
).success(
|
| 654 |
+
gradio_visualize,
|
| 655 |
+
[chatbot, image],
|
| 656 |
+
[chatbot],
|
| 657 |
+
queue=False,
|
| 658 |
+
)
|
| 659 |
+
|
| 660 |
+
clear.click(gradio_reset, [chat_state, img_list], [chatbot, image, text_input, chat_state, img_list], queue=False)
|
| 661 |
+
|
| 662 |
+
demo.launch(share=True, enable_queue=True)
|
environment.yml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: minigpt4
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- defaults
|
| 5 |
+
- anaconda
|
| 6 |
+
dependencies:
|
| 7 |
+
- python=3.9
|
| 8 |
+
- cudatoolkit
|
| 9 |
+
- pip
|
| 10 |
+
- pip:
|
| 11 |
+
- torch==2.0.0
|
| 12 |
+
- torchaudio
|
| 13 |
+
- torchvision
|
| 14 |
+
- huggingface-hub==0.18.0
|
| 15 |
+
- matplotlib==3.7.0
|
| 16 |
+
- psutil==5.9.4
|
| 17 |
+
- iopath
|
| 18 |
+
- pyyaml==6.0
|
| 19 |
+
- regex==2022.10.31
|
| 20 |
+
- tokenizers==0.13.2
|
| 21 |
+
- tqdm==4.64.1
|
| 22 |
+
- transformers==4.30.0
|
| 23 |
+
- timm==0.6.13
|
| 24 |
+
- webdataset==0.2.48
|
| 25 |
+
- omegaconf==2.3.0
|
| 26 |
+
- opencv-python==4.7.0.72
|
| 27 |
+
- decord==0.6.0
|
| 28 |
+
- peft==0.2.0
|
| 29 |
+
- sentence-transformers
|
| 30 |
+
- gradio==3.47.1
|
| 31 |
+
- accelerate==0.20.3
|
| 32 |
+
- bitsandbytes==0.37.0
|
| 33 |
+
- wandb
|
eval_configs/minigpt4_eval.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: minigpt4
|
| 3 |
+
model_type: pretrain_vicuna0
|
| 4 |
+
max_txt_len: 160
|
| 5 |
+
end_sym: "###"
|
| 6 |
+
low_resource: True
|
| 7 |
+
prompt_template: '###Human: {} ###Assistant: '
|
| 8 |
+
ckpt: 'please set this value to the path of pretrained checkpoint'
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
datasets:
|
| 12 |
+
cc_sbu_align:
|
| 13 |
+
vis_processor:
|
| 14 |
+
train:
|
| 15 |
+
name: "blip2_image_eval"
|
| 16 |
+
image_size: 224
|
| 17 |
+
text_processor:
|
| 18 |
+
train:
|
| 19 |
+
name: "blip_caption"
|
| 20 |
+
|
| 21 |
+
run:
|
| 22 |
+
task: image_text_pretrain
|
eval_configs/minigpt4_llama2_eval.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: minigpt4
|
| 3 |
+
model_type: pretrain_llama2
|
| 4 |
+
max_txt_len: 160
|
| 5 |
+
end_sym: "</s>"
|
| 6 |
+
low_resource: True
|
| 7 |
+
prompt_template: '[INST] {} [/INST] '
|
| 8 |
+
ckpt: 'please set this value to the path of pretrained checkpoint'
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
datasets:
|
| 12 |
+
cc_sbu_align:
|
| 13 |
+
vis_processor:
|
| 14 |
+
train:
|
| 15 |
+
name: "blip2_image_eval"
|
| 16 |
+
image_size: 224
|
| 17 |
+
text_processor:
|
| 18 |
+
train:
|
| 19 |
+
name: "blip_caption"
|
| 20 |
+
|
| 21 |
+
run:
|
| 22 |
+
task: image_text_pretrain
|
eval_configs/minigptv2_eval.yaml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: minigpt_v2
|
| 3 |
+
model_type: pretrain
|
| 4 |
+
max_txt_len: 160
|
| 5 |
+
end_sym: "</s>"
|
| 6 |
+
low_resource: True
|
| 7 |
+
prompt_template: '[INST] {} [/INST]'
|
| 8 |
+
ckpt: 'please set this value to the path of pretrained checkpoint'
|
| 9 |
+
lora_r: 64
|
| 10 |
+
lora_alpha: 16
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
datasets:
|
| 14 |
+
cc_sbu_align:
|
| 15 |
+
vis_processor:
|
| 16 |
+
train:
|
| 17 |
+
name: "blip2_image_eval"
|
| 18 |
+
image_size: 448
|
| 19 |
+
text_processor:
|
| 20 |
+
train:
|
| 21 |
+
name: "blip_caption"
|
| 22 |
+
|
| 23 |
+
run:
|
| 24 |
+
task: image_text_pretrain
|
examples/ad_1.png
ADDED
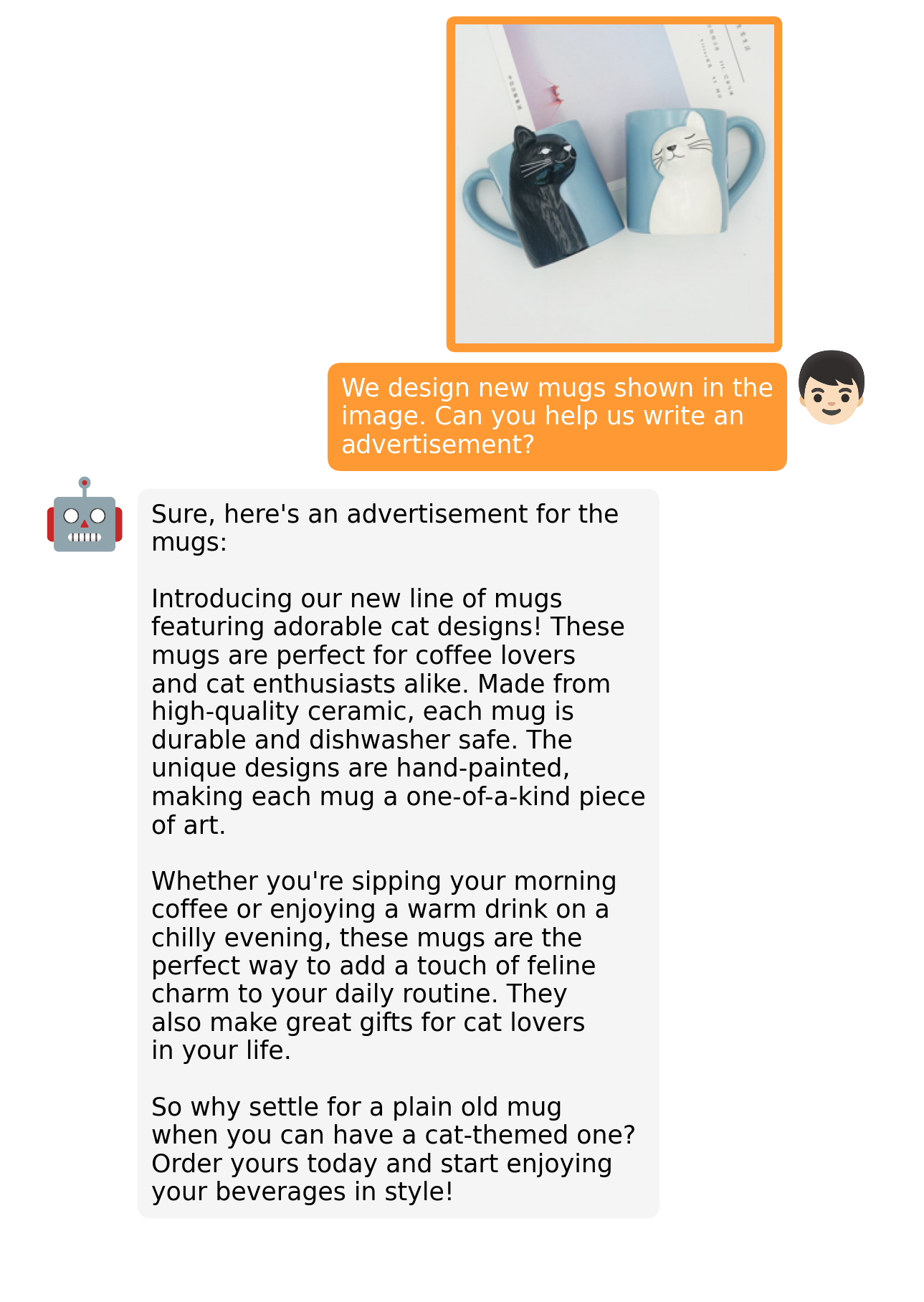
|
examples/ad_2.png
ADDED
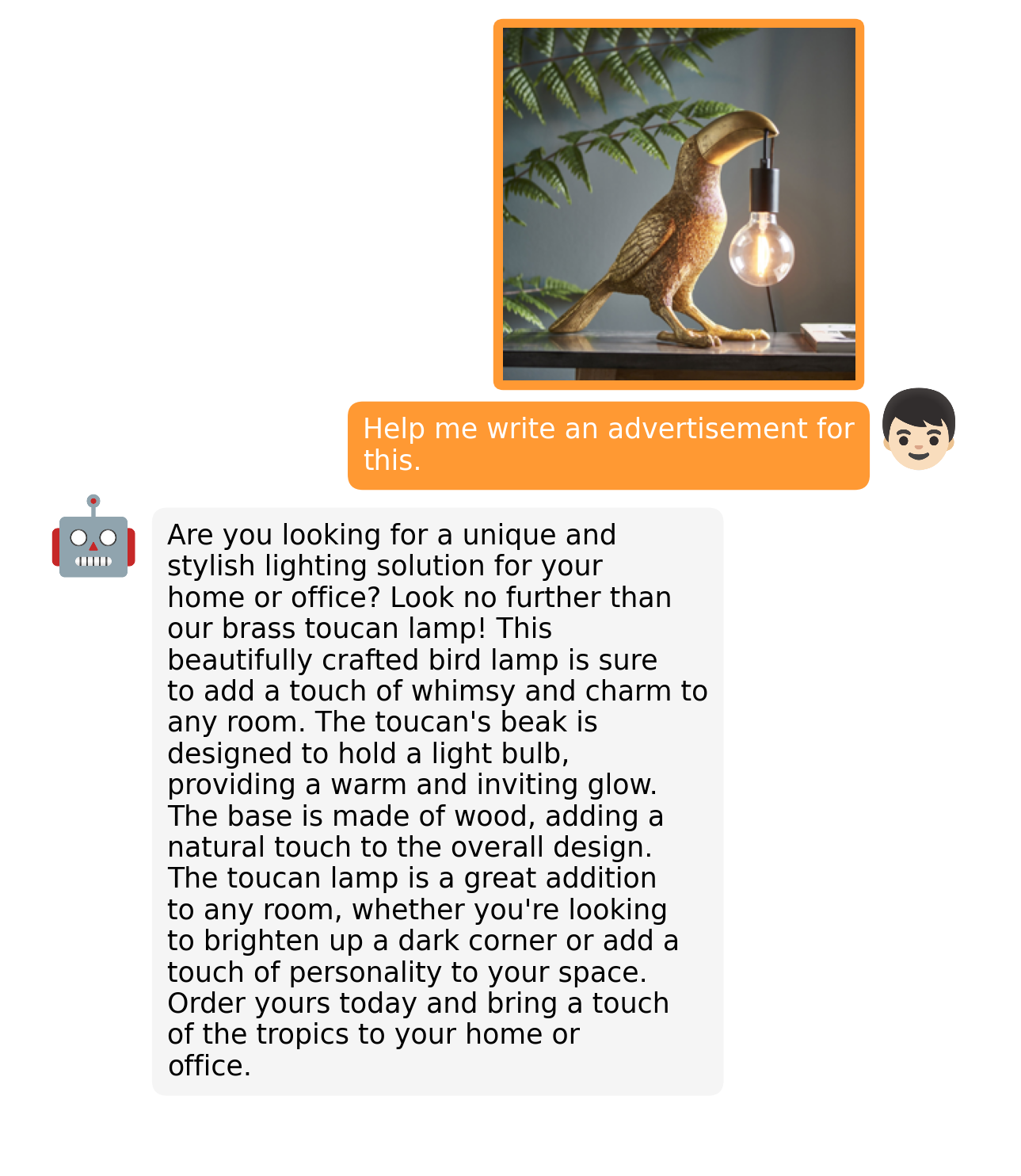
|
examples/cook_1.png
ADDED
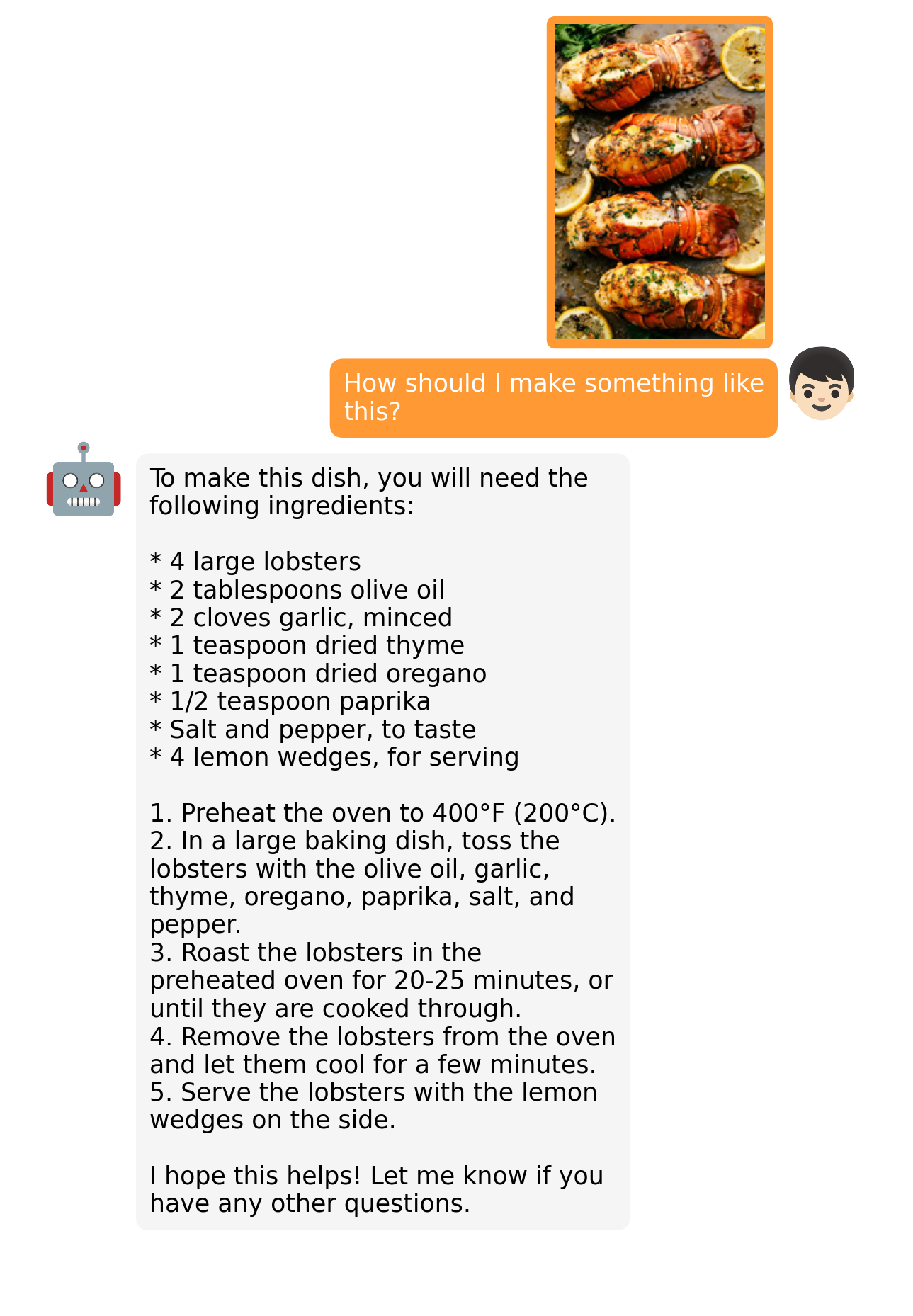
|
examples/cook_2.png
ADDED
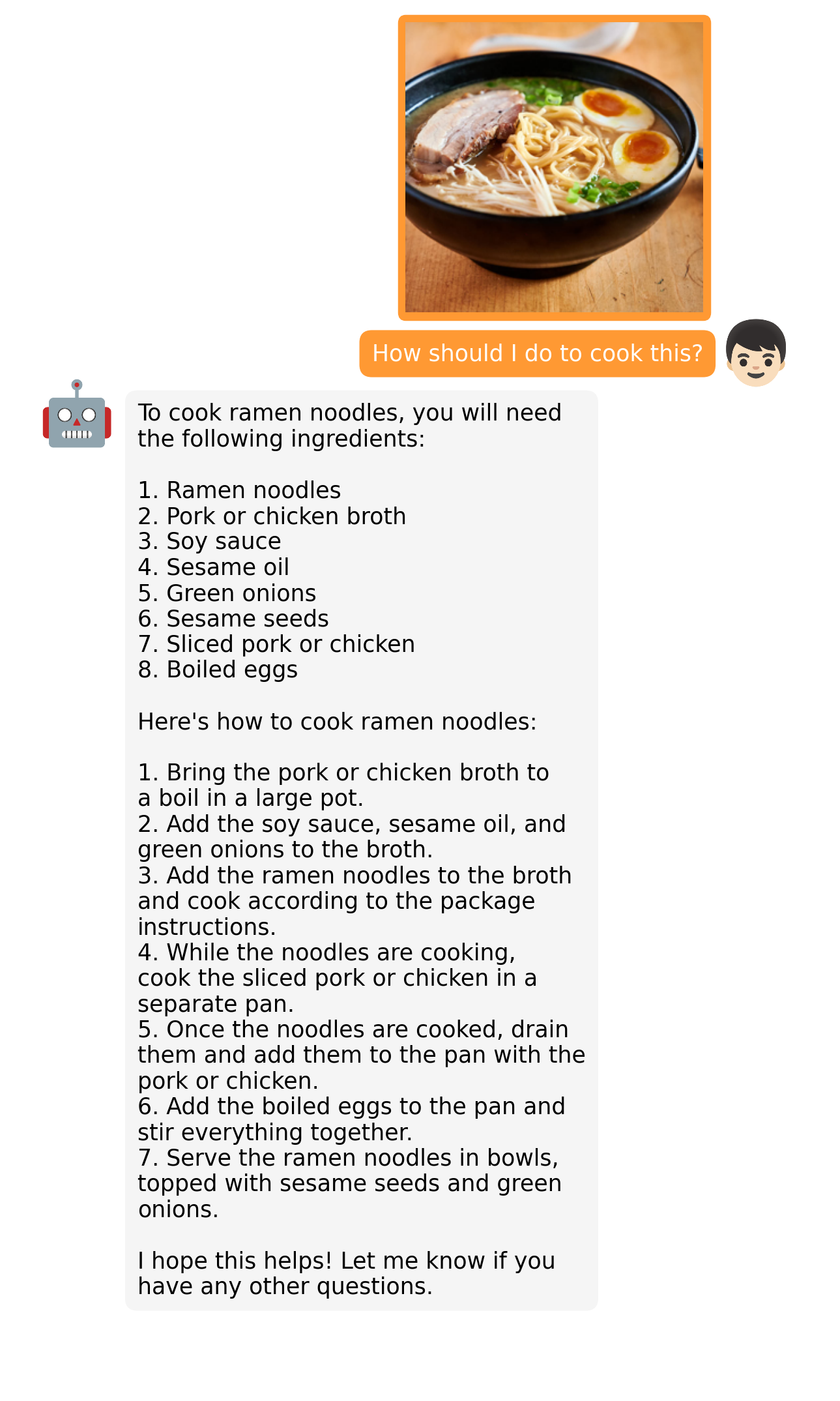
|
examples/describe_1.png
ADDED
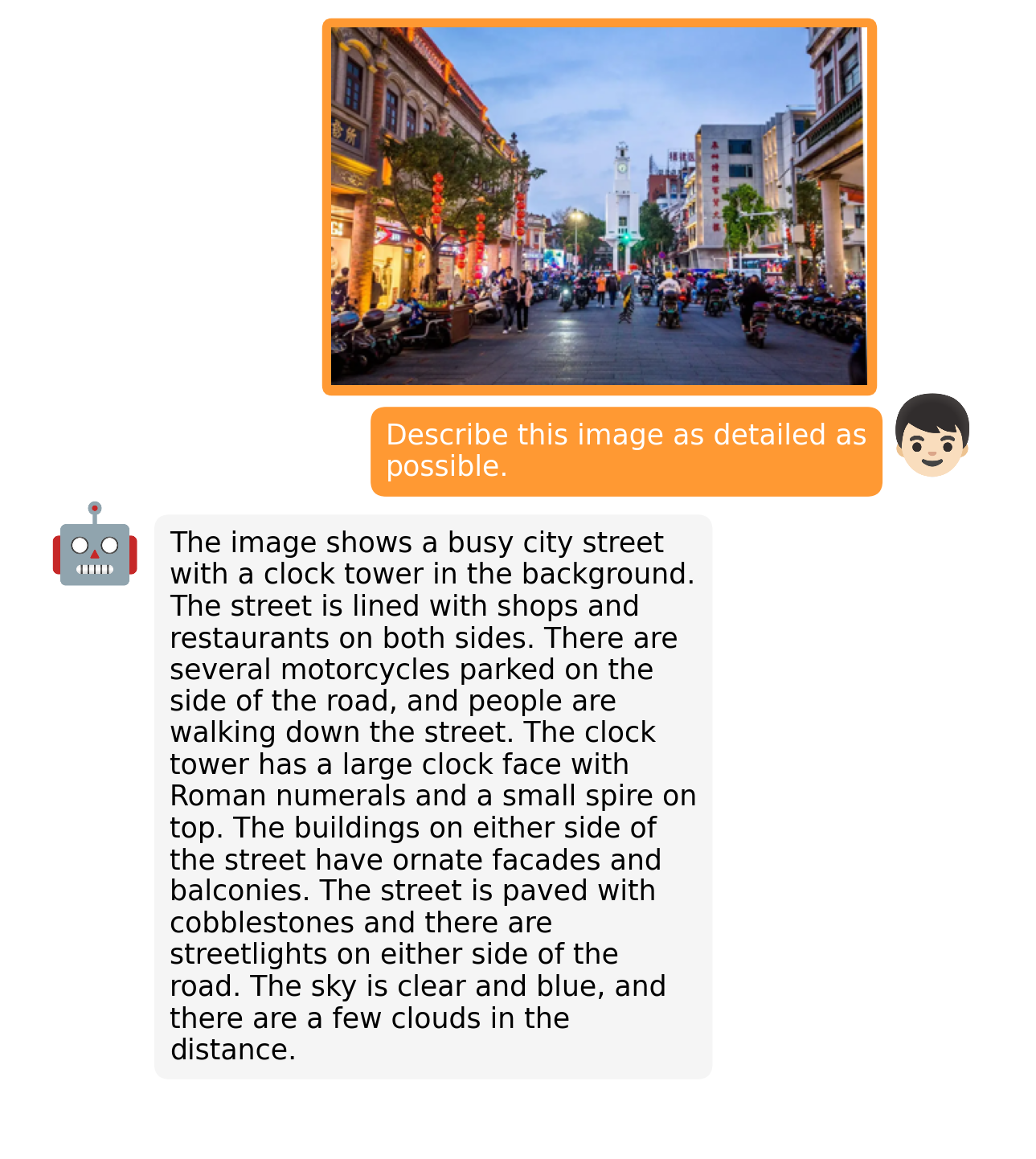
|
examples/describe_2.png
ADDED
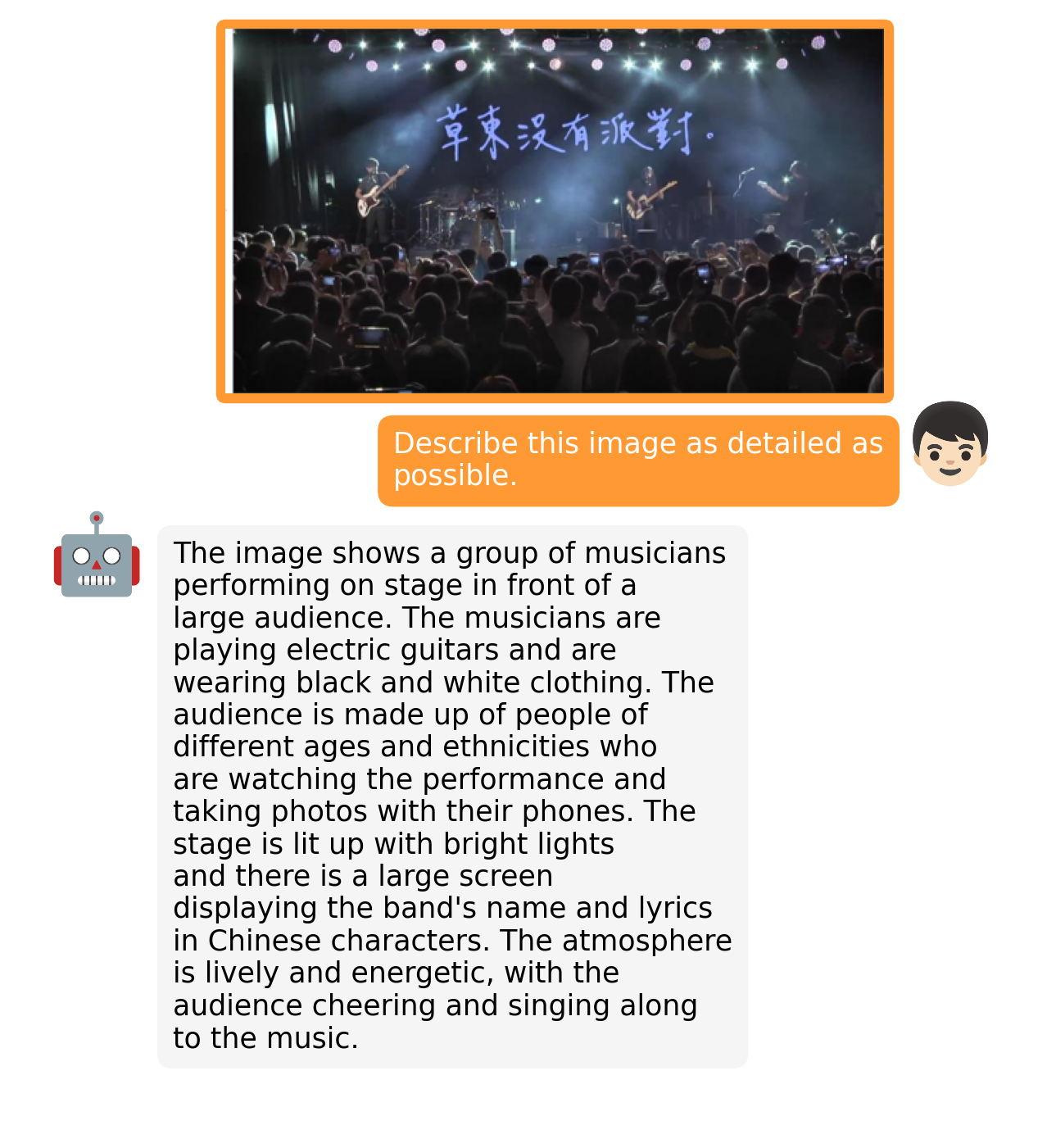
|
examples/fact_1.png
ADDED
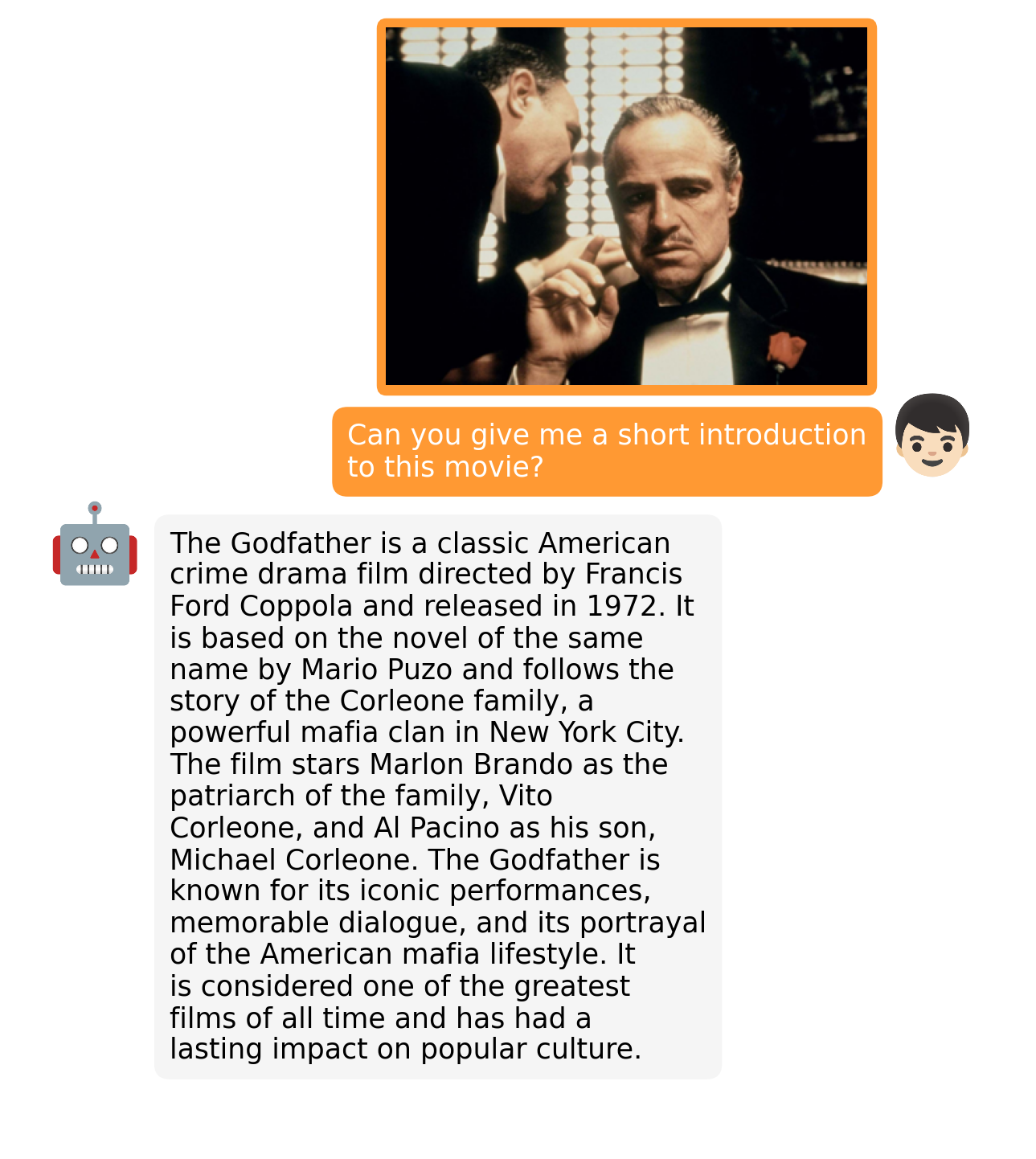
|
examples/fact_2.png
ADDED
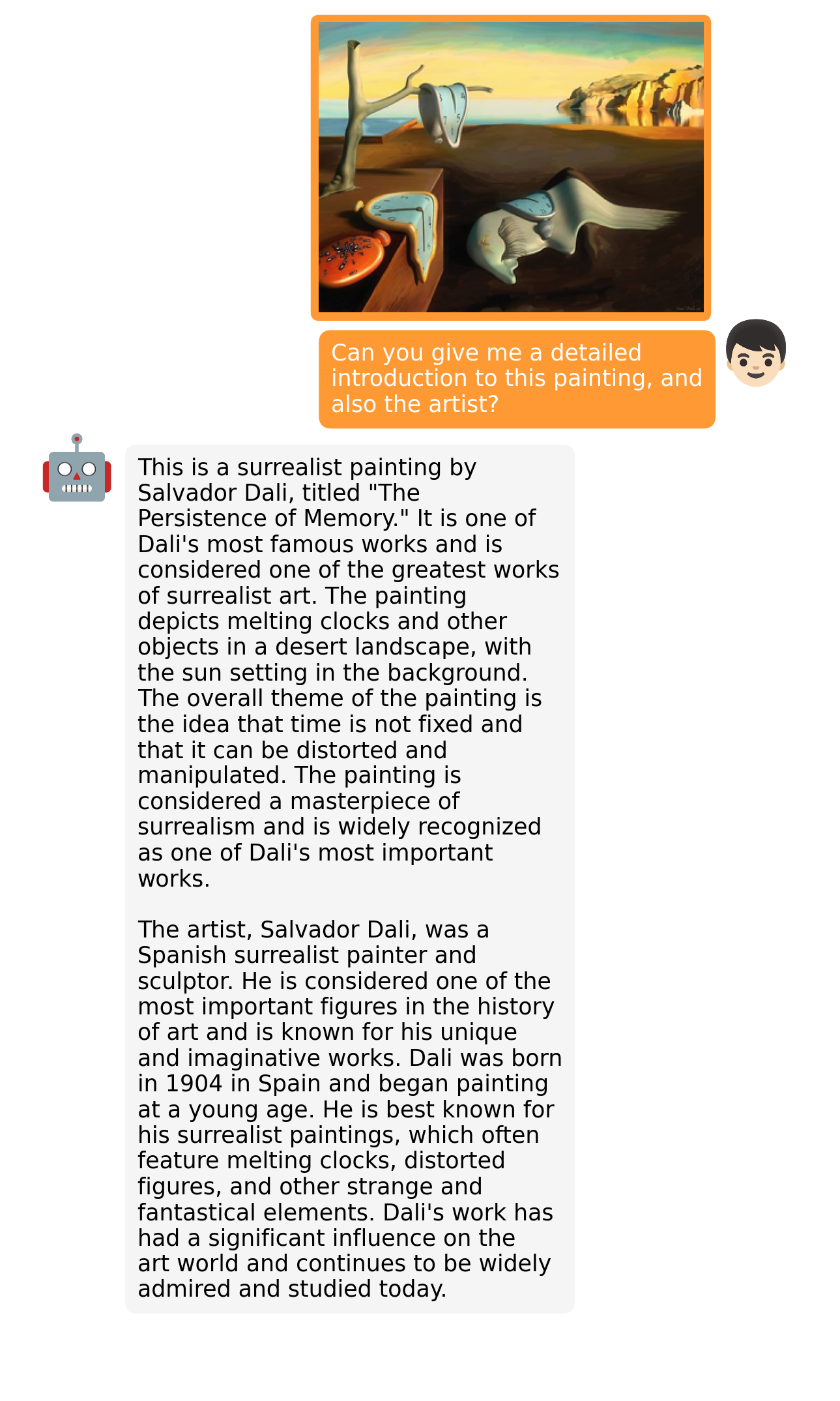
|
examples/fix_1.png
ADDED
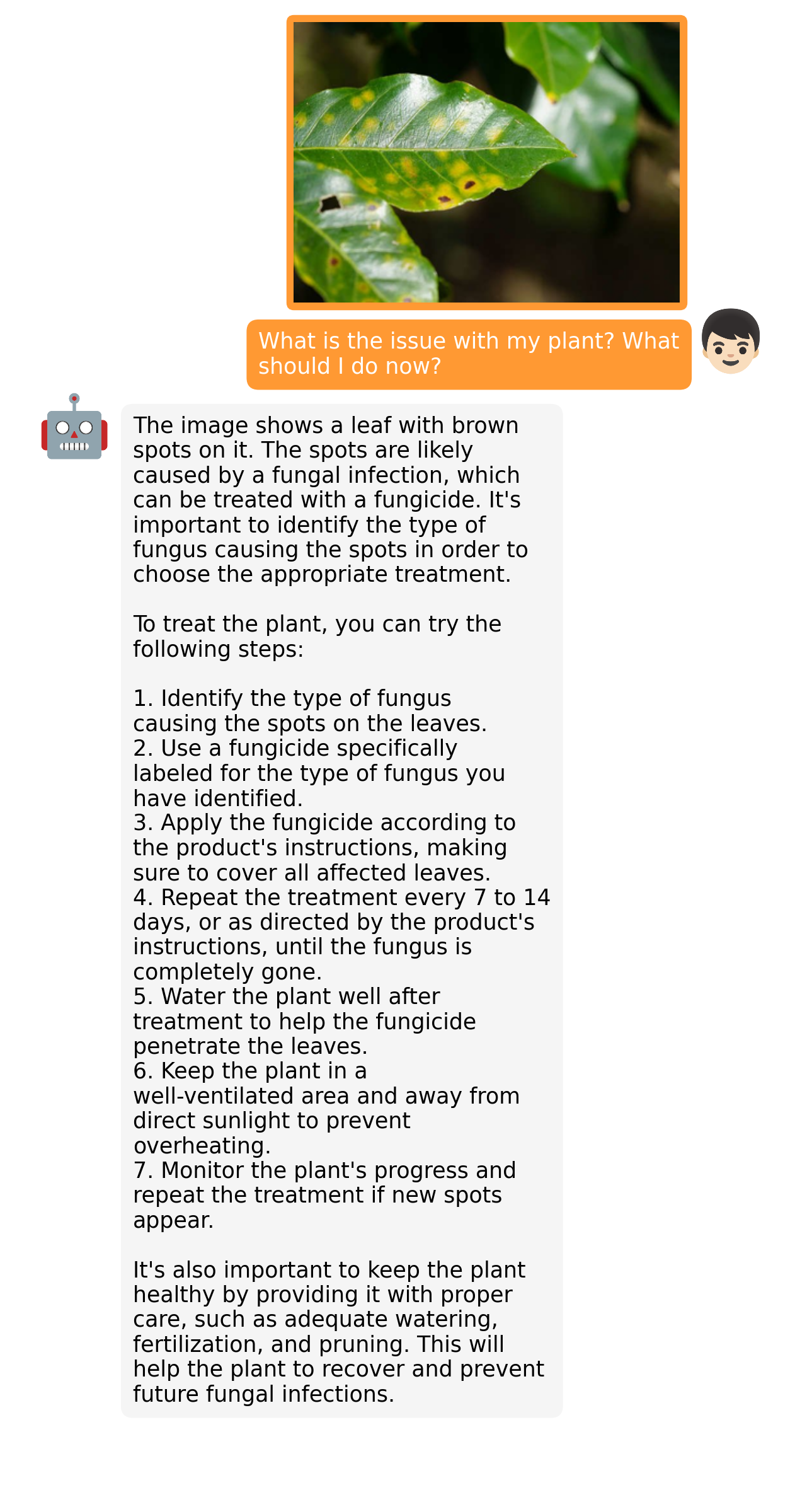
|
examples/fix_2.png
ADDED
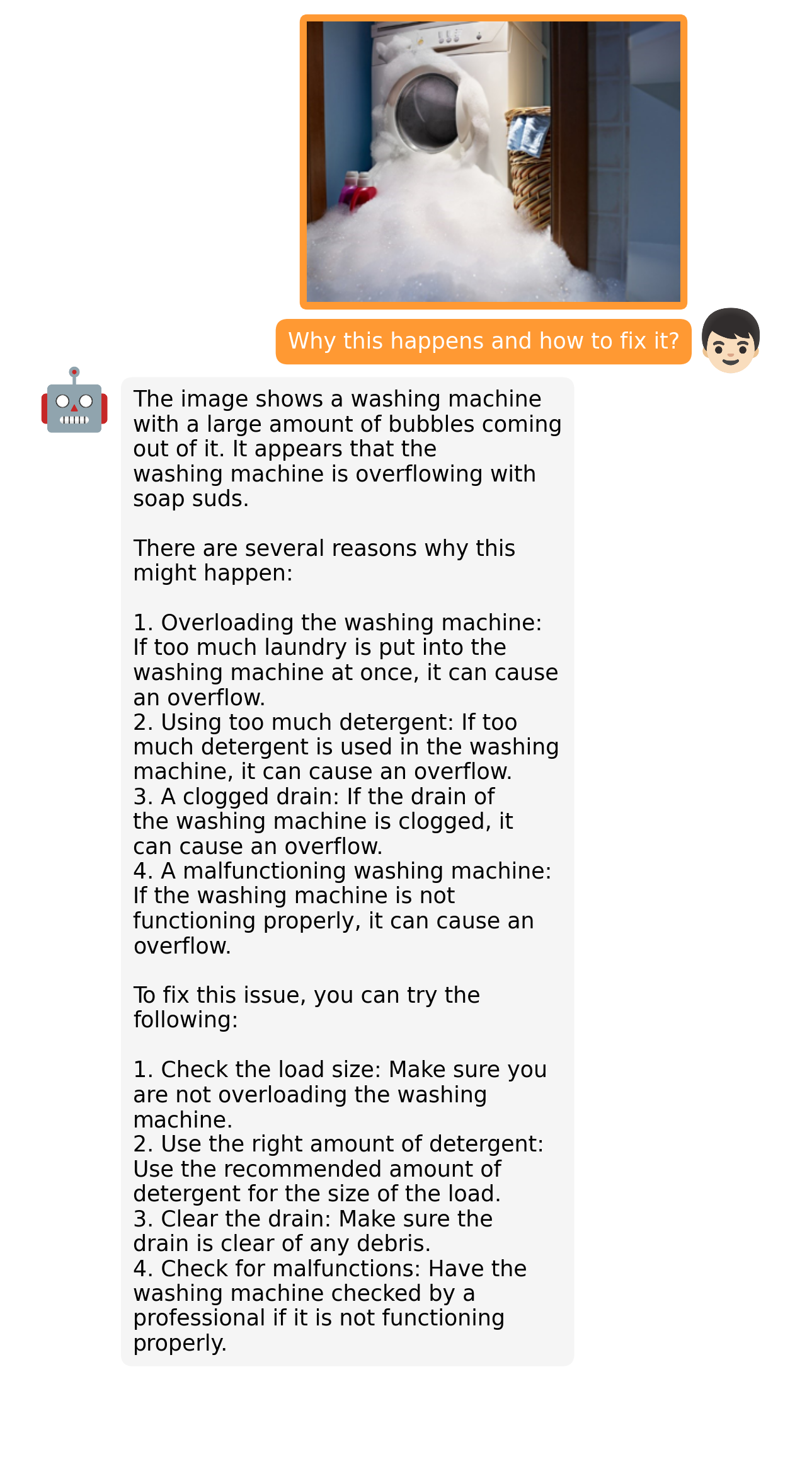
|
examples/fun_1.png
ADDED
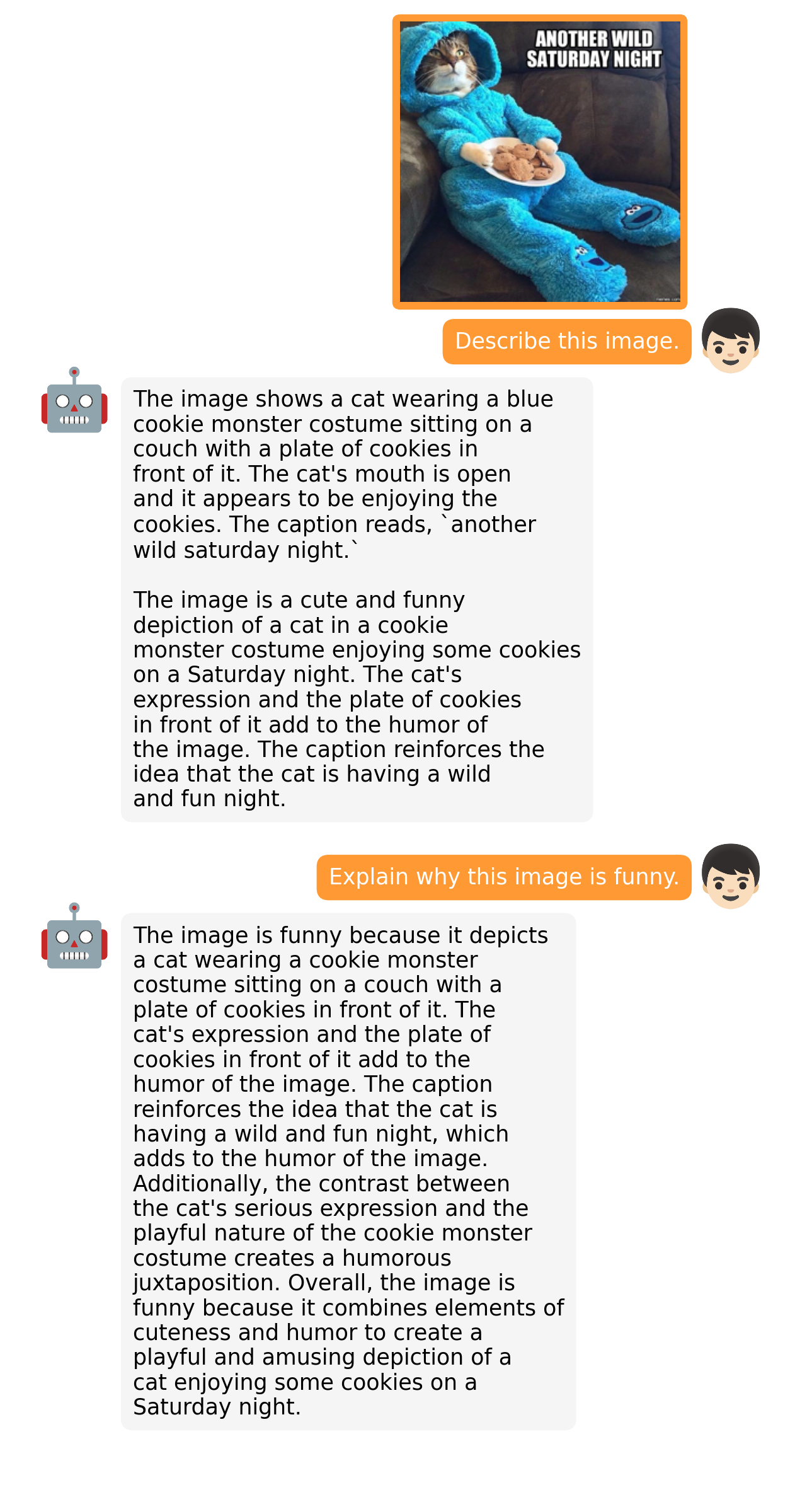
|
examples/fun_2.png
ADDED
|
examples/logo_1.png
ADDED
|
|
examples/op_1.png
ADDED
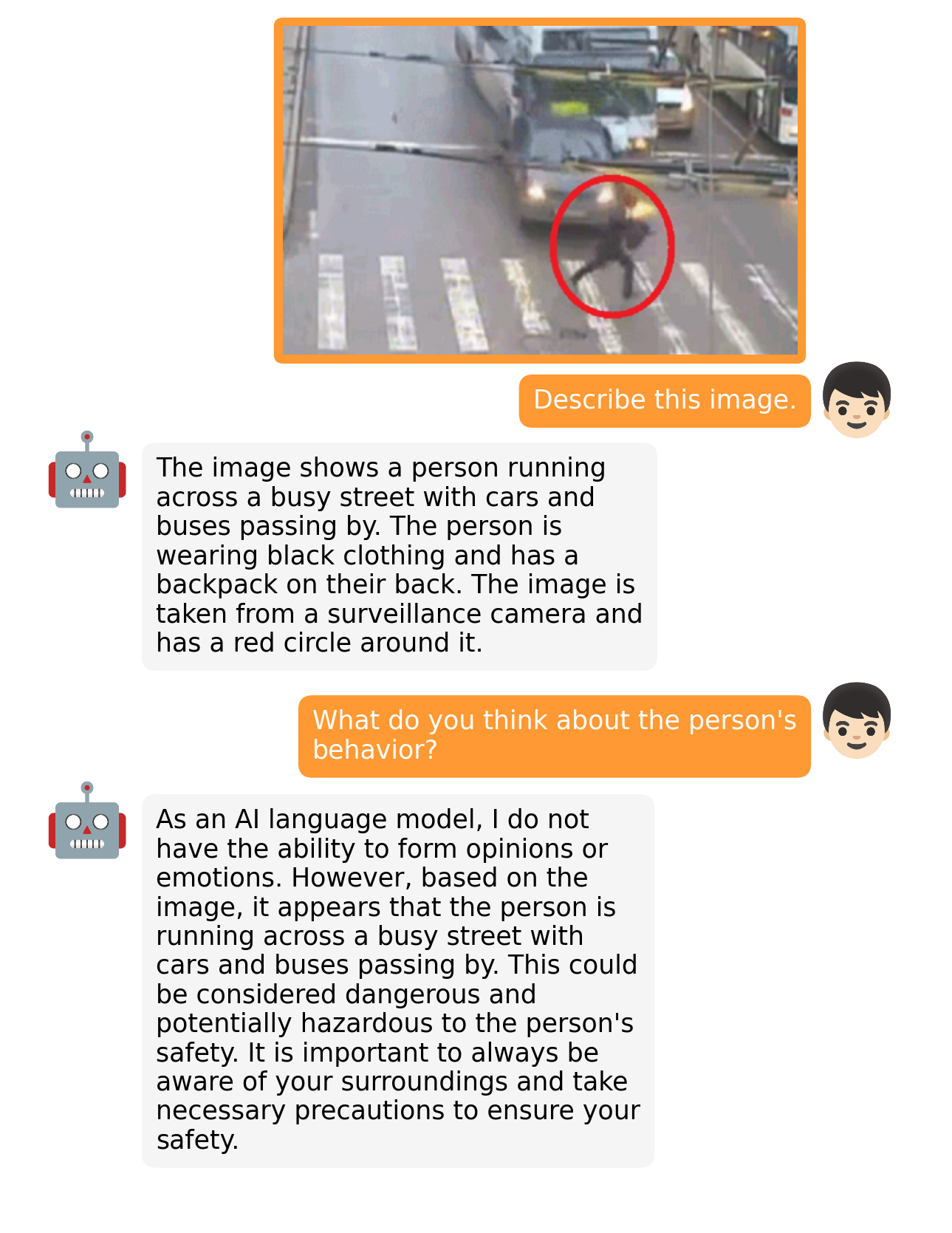
|
examples/op_2.png
ADDED
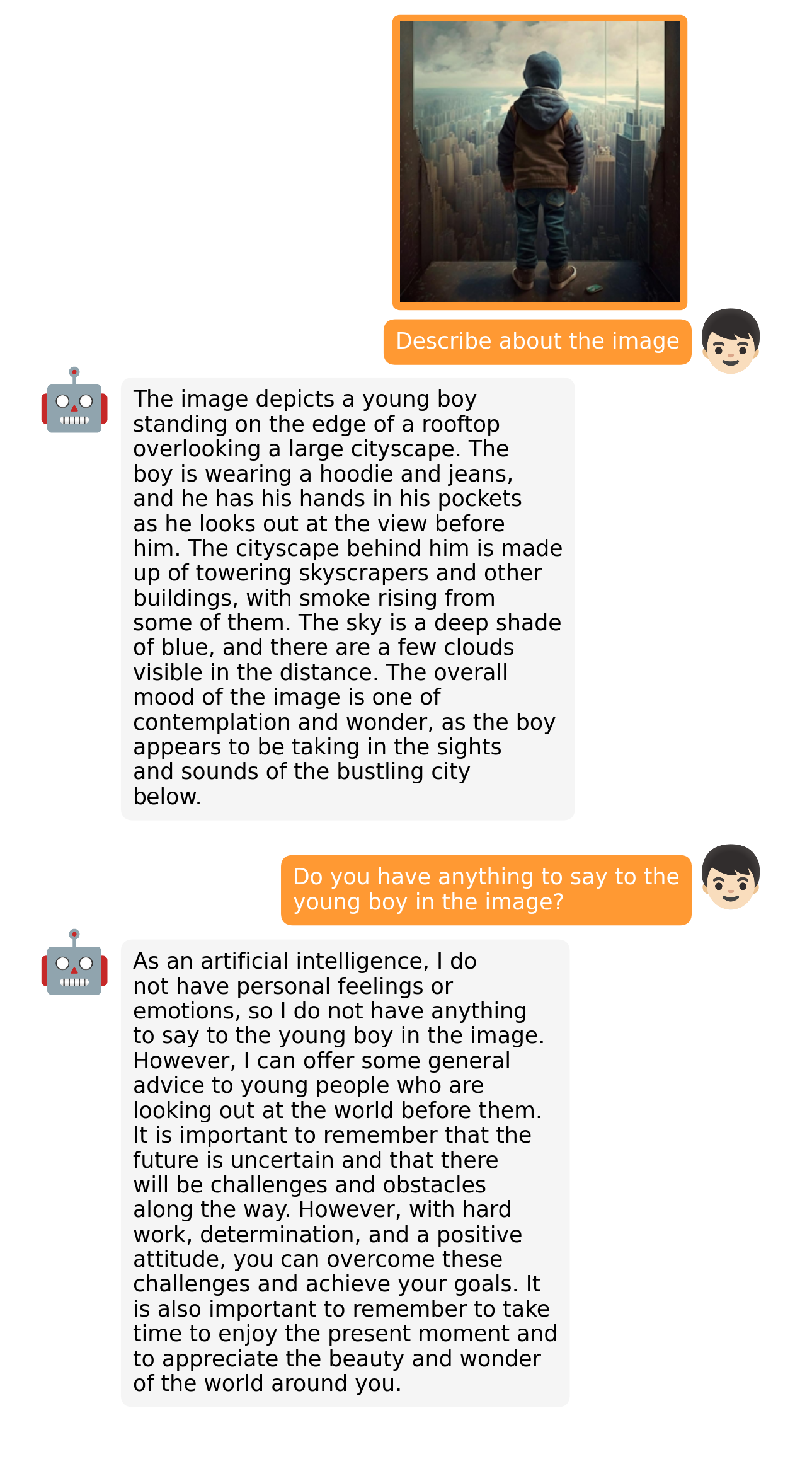
|
examples/people_1.png
ADDED

|
examples/people_2.png
ADDED

|
examples/rhyme_1.png
ADDED
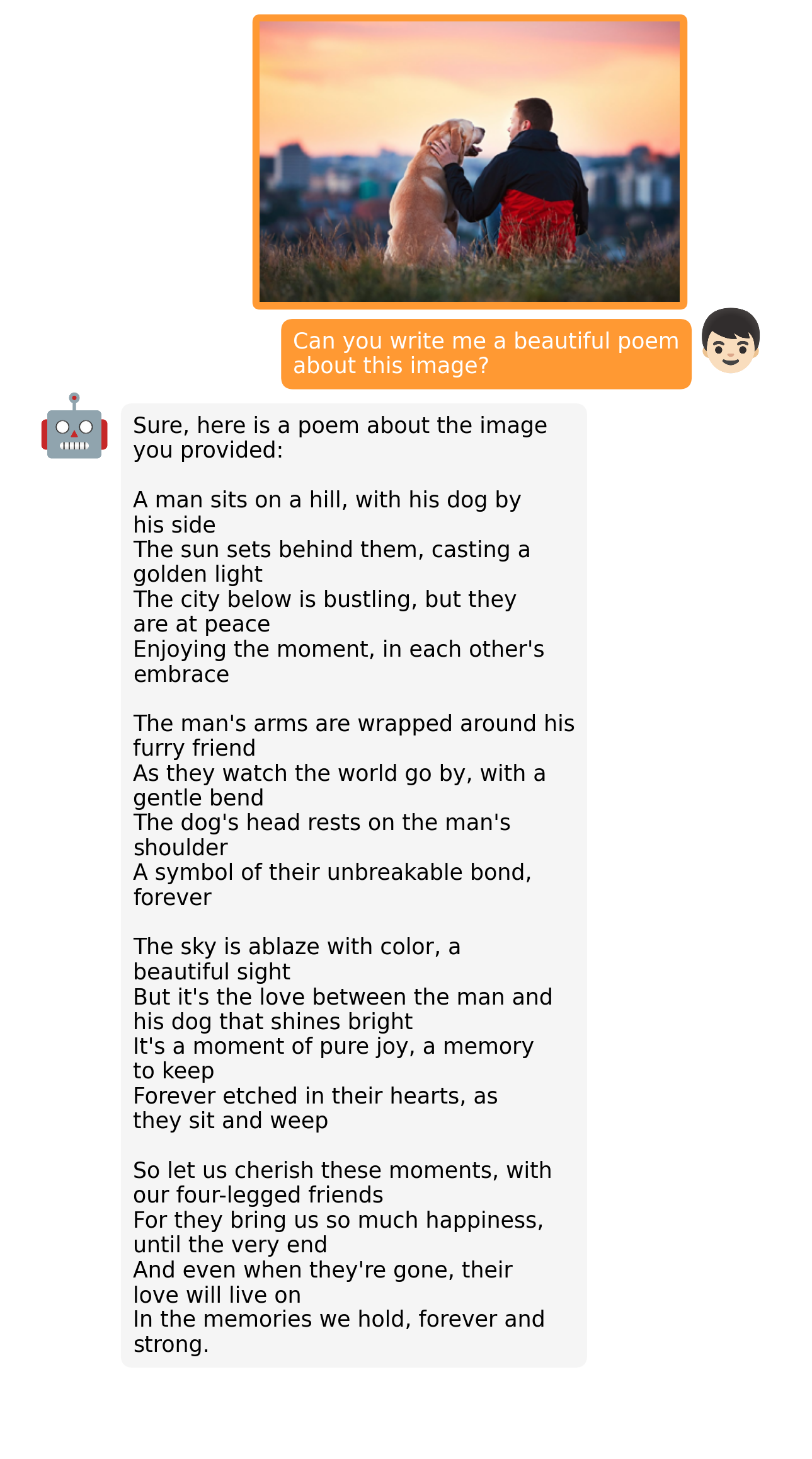
|
examples/rhyme_2.png
ADDED

|
examples/story_1.png
ADDED
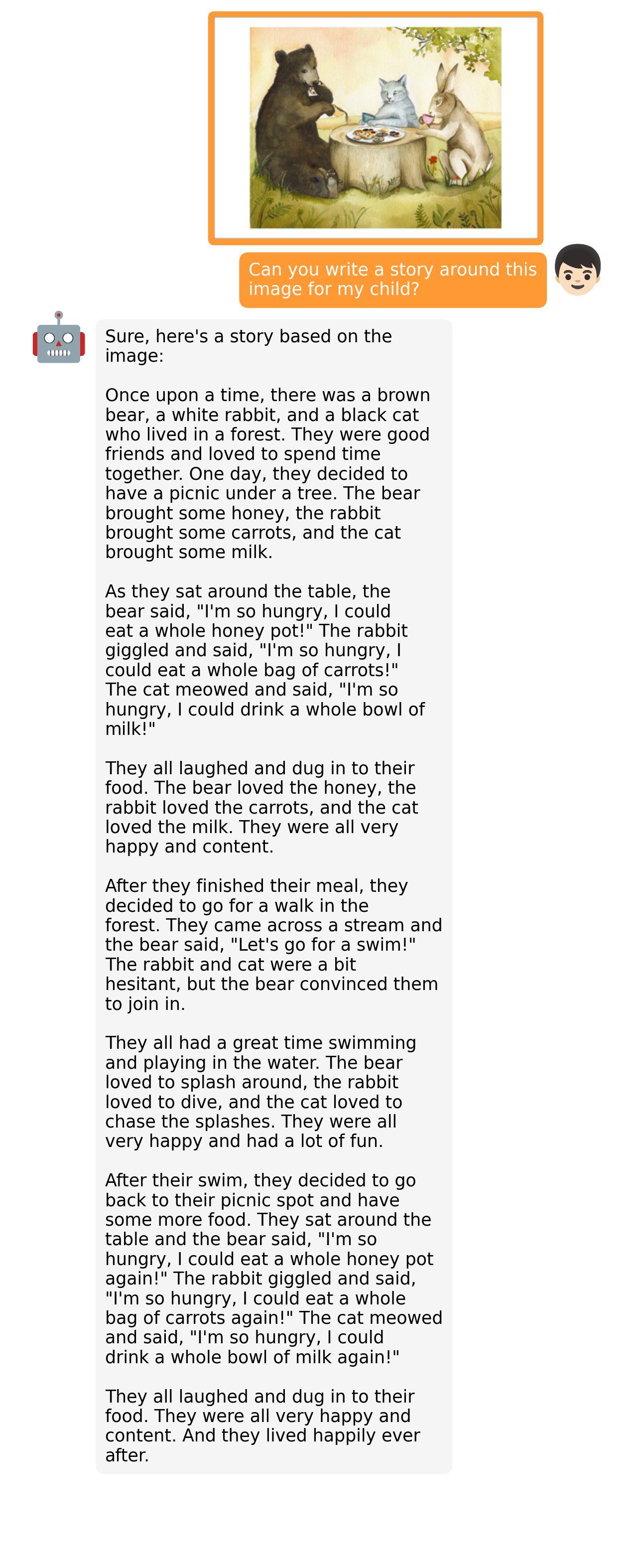
|
examples/story_2.png
ADDED
|
examples/web_1.png
ADDED

|
examples/wop_1.png
ADDED
|
examples/wop_2.png
ADDED
|
examples_v2/2000x1372_wmkn_0012149409555.jpg
ADDED

|
examples_v2/KFC-20-for-20-Nuggets.jpg
ADDED

|
examples_v2/cockdial.png
ADDED

|
Git LFS Details
|
examples_v2/float.png
ADDED

|
Git LFS Details
|
examples_v2/glip_test.jpg
ADDED

|
examples_v2/office.jpg
ADDED

|