Spaces:
Runtime error

Runtime error
Commit
•
3b12eab
1
Parent(s):
4e5e275
Upload 13 files
Browse files- app.py +231 -0
- config.yaml +3 -0
- image.png +0 -0
- ingest.py +30 -0
- posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/data_level0.bin +3 -0
- posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/header.bin +3 -0
- posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/length.bin +3 -0
- posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/link_lists.bin +3 -0
- posts_db/chroma.sqlite3 +0 -0
- query.py +236 -0
- requirements.txt +10 -0
- tests.py +75 -0
- utils.py +122 -0
app.py
ADDED
|
@@ -0,0 +1,231 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from langchain_google_genai import ChatGoogleGenerativeAI
|
| 3 |
+
from langchain.output_parsers import CommaSeparatedListOutputParser
|
| 4 |
+
from utils import fetch_wordpress_data, extract_text, generate_embeddings
|
| 5 |
+
import chromadb, yaml
|
| 6 |
+
from langchain_chroma import Chroma
|
| 7 |
+
from langchain_community.embeddings.sentence_transformer import (
|
| 8 |
+
SentenceTransformerEmbeddings,
|
| 9 |
+
)
|
| 10 |
+
from langchain_core.prompts import ChatPromptTemplate
|
| 11 |
+
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
|
| 12 |
+
from langchain_core.output_parsers import StrOutputParser
|
| 13 |
+
from dotenv import load_dotenv
|
| 14 |
+
load_dotenv()
|
| 15 |
+
try:
|
| 16 |
+
# Attempt to load configuration data from config.yaml file
|
| 17 |
+
with open("./config.yaml", 'r') as file:
|
| 18 |
+
config_data = yaml.safe_load(file)
|
| 19 |
+
except Exception as e:
|
| 20 |
+
# Raise exception if config.yaml file is not found
|
| 21 |
+
raise Exception(f"Not able to find the file ./config.yaml")
|
| 22 |
+
|
| 23 |
+
# Set Streamlit page layout to wide
|
| 24 |
+
st.set_page_config(layout="wide")
|
| 25 |
+
|
| 26 |
+
# Initialize Chroma database client
|
| 27 |
+
client = chromadb.PersistentClient("./posts_db")
|
| 28 |
+
collection_name = config_data['collection_name']
|
| 29 |
+
collection = client.get_collection(name=collection_name)
|
| 30 |
+
|
| 31 |
+
# Initialize embedding function for sentence transformer
|
| 32 |
+
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
|
| 33 |
+
|
| 34 |
+
# Initialize Langchain Chroma retriever
|
| 35 |
+
langchain_chroma = Chroma(
|
| 36 |
+
client=client,
|
| 37 |
+
collection_name=collection_name,
|
| 38 |
+
embedding_function=embedding_function,
|
| 39 |
+
).as_retriever()
|
| 40 |
+
|
| 41 |
+
# Initialize Chat Google Generative AI model
|
| 42 |
+
model = ChatGoogleGenerativeAI(model="gemini-pro")
|
| 43 |
+
|
| 44 |
+
def update_vector_database(collection, post_id, embeddings, text):
|
| 45 |
+
"""
|
| 46 |
+
Update the vector database with post ID, embeddings, and text.
|
| 47 |
+
|
| 48 |
+
Args:
|
| 49 |
+
collection: The collection in the database.
|
| 50 |
+
post_id (str): The ID of the post.
|
| 51 |
+
embeddings (list): List of embeddings generated from the post text.
|
| 52 |
+
text (str): The text of the post.
|
| 53 |
+
"""
|
| 54 |
+
collection.upsert(ids=[str(post_id)], documents=[text], embeddings=[embeddings])
|
| 55 |
+
|
| 56 |
+
def fetch_existing_posts(collection):
|
| 57 |
+
"""
|
| 58 |
+
Fetch existing posts from the database.
|
| 59 |
+
|
| 60 |
+
Args:
|
| 61 |
+
collection: The collection in the database.
|
| 62 |
+
|
| 63 |
+
Returns:
|
| 64 |
+
list: List of existing posts.
|
| 65 |
+
"""
|
| 66 |
+
# Fetch existing posts from the database or any other storage
|
| 67 |
+
existing_posts = collection.get()
|
| 68 |
+
return existing_posts
|
| 69 |
+
|
| 70 |
+
def update_embeddings_on_new_post(collection):
|
| 71 |
+
"""
|
| 72 |
+
Update embeddings for new posts fetched from WordPress data.
|
| 73 |
+
|
| 74 |
+
Args:
|
| 75 |
+
collection: The collection in the database.
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
# Fetch existing posts from the database or any other storage
|
| 79 |
+
existing_posts = fetch_existing_posts(collection)
|
| 80 |
+
new_posts = fetch_wordpress_data(config_data['site_url'])
|
| 81 |
+
|
| 82 |
+
# Compare old and new posts to find the difference
|
| 83 |
+
existing_post_ids = set(str(post_id) for post_id in existing_posts['ids'])
|
| 84 |
+
new_posts_to_update = [post for post in new_posts if str(post['id']) not in existing_post_ids]
|
| 85 |
+
|
| 86 |
+
# Update embeddings for new posts
|
| 87 |
+
for post in new_posts_to_update:
|
| 88 |
+
# Extract text from post
|
| 89 |
+
text = extract_text(post)
|
| 90 |
+
# Generate embeddings for the post text
|
| 91 |
+
embeddings = generate_embeddings(text)
|
| 92 |
+
# Update vector database with post ID and embeddings
|
| 93 |
+
update_vector_database(collection,post['id'], embeddings, text)
|
| 94 |
+
|
| 95 |
+
def rag_generate_response():
|
| 96 |
+
"""
|
| 97 |
+
Generate a prompt for generating reasoning steps for answering the user query.
|
| 98 |
+
|
| 99 |
+
Returns:
|
| 100 |
+
ChatPromptTemplate: The generated prompt template.
|
| 101 |
+
"""
|
| 102 |
+
template = """You are tasked with designing a prompt for generating reasoning steps for answering to the user_query in a website. Write a Prompt to generate a series of intermediate thoughts or reasoning steps to answer the query. Avoid providing specific solutions or examples, allowing the LLM to explore different approaches independently. Give the output as a list of steps. eg: [1,2,3,...]
|
| 103 |
+
|
| 104 |
+
Question: {user_query}
|
| 105 |
+
Previous_context : {previous_context}
|
| 106 |
+
"""
|
| 107 |
+
prompt = ChatPromptTemplate.from_template(template)
|
| 108 |
+
return prompt
|
| 109 |
+
|
| 110 |
+
def develop_reasoning_steps(user_query, initial_prompt, previous_context):
|
| 111 |
+
"""
|
| 112 |
+
Develop reasoning steps based on the user query, initial prompt, and previous context.
|
| 113 |
+
|
| 114 |
+
Args:
|
| 115 |
+
user_query (str): The query from the user.
|
| 116 |
+
initial_prompt (ChatPromptTemplate): The initial prompt template.
|
| 117 |
+
previous_context (str): The previous context.
|
| 118 |
+
|
| 119 |
+
Returns:
|
| 120 |
+
list: List of thought steps.
|
| 121 |
+
"""
|
| 122 |
+
chain = (
|
| 123 |
+
RunnableParallel({"user_query": RunnablePassthrough(), "previous_context": RunnablePassthrough()})
|
| 124 |
+
| initial_prompt
|
| 125 |
+
| model
|
| 126 |
+
| CommaSeparatedListOutputParser()
|
| 127 |
+
)
|
| 128 |
+
thought_steps = chain.invoke({"user_query" : user_query, "previous_context" : previous_context})
|
| 129 |
+
thought_steps = thought_steps[0].split('\n')
|
| 130 |
+
return thought_steps
|
| 131 |
+
|
| 132 |
+
def refine_response_based_on_thought_steps(user_query, thought_steps):
|
| 133 |
+
"""
|
| 134 |
+
Refine the response based on thought steps.
|
| 135 |
+
|
| 136 |
+
Args:
|
| 137 |
+
user_query (str): The query from the user.
|
| 138 |
+
thought_steps (list): List of thought steps.
|
| 139 |
+
|
| 140 |
+
Returns:
|
| 141 |
+
str: Final refined response.
|
| 142 |
+
"""
|
| 143 |
+
all_retrieved_content = ""
|
| 144 |
+
|
| 145 |
+
for thought_step in thought_steps:
|
| 146 |
+
# print(langchain_chroma.invoke(thought_step))
|
| 147 |
+
retrieved_content = langchain_chroma.invoke(thought_step)
|
| 148 |
+
for i in retrieved_content:
|
| 149 |
+
all_retrieved_content+=i.page_content
|
| 150 |
+
all_retrieved_content+="\n"
|
| 151 |
+
template = """You are a helpful assistant which answers the query from the context. If the context does not provide the answer simply reply I cannot answer this and give a suggestion to refer the website. DO NOT say that 'there is no information in the context' or 'the answer from the context is this.' phrases, instead give directly the solution or answer I cannot answer this and give a suggestion to refer the website or similar kind of text based on the context.:
|
| 152 |
+
|
| 153 |
+
query : {user_query}
|
| 154 |
+
|
| 155 |
+
context : {context}
|
| 156 |
+
"""
|
| 157 |
+
prompt = ChatPromptTemplate.from_template(template)
|
| 158 |
+
reason_chain = (
|
| 159 |
+
RunnableParallel({'user_query': RunnablePassthrough(), 'context': RunnablePassthrough()})
|
| 160 |
+
| prompt
|
| 161 |
+
| model
|
| 162 |
+
| StrOutputParser()
|
| 163 |
+
)
|
| 164 |
+
final_response = reason_chain.invoke({'user_query': user_query ,'context' : all_retrieved_content})
|
| 165 |
+
return final_response
|
| 166 |
+
|
| 167 |
+
def process_query_with_chain_of_thought(user_query, previous_context):
|
| 168 |
+
"""
|
| 169 |
+
Process the user query using the RAG + COT approach.
|
| 170 |
+
|
| 171 |
+
Args:
|
| 172 |
+
user_query (str): The query from the user.
|
| 173 |
+
previous_context (list): List of previous chat contexts.
|
| 174 |
+
|
| 175 |
+
Returns:
|
| 176 |
+
tuple: A tuple containing thought steps and final refined response.
|
| 177 |
+
"""
|
| 178 |
+
initial_response = rag_generate_response(user_query) # initial response is the prompt
|
| 179 |
+
thought_steps = develop_reasoning_steps(user_query, initial_response, previous_context)
|
| 180 |
+
final_response = refine_response_based_on_thought_steps(user_query,thought_steps)
|
| 181 |
+
return thought_steps, final_response
|
| 182 |
+
|
| 183 |
+
def bot():
|
| 184 |
+
"""
|
| 185 |
+
Streamlit application to run the conversational AI bot.
|
| 186 |
+
"""
|
| 187 |
+
def web_bot():
|
| 188 |
+
global persist_directory
|
| 189 |
+
if st.button("New Chat 🤖",key="Start New Chat"):
|
| 190 |
+
st.session_state.clear()
|
| 191 |
+
st.session_state.app = web_bot
|
| 192 |
+
st.rerun()
|
| 193 |
+
|
| 194 |
+
# Initialize chat history
|
| 195 |
+
if "messages" not in st.session_state:
|
| 196 |
+
st.session_state.messages = []
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
# Display chat messages from history and rerun
|
| 200 |
+
for message in st.session_state.messages:
|
| 201 |
+
with st.chat_message(message["role"]):
|
| 202 |
+
st.markdown(message["content"])
|
| 203 |
+
if message["role"]=="assistant":
|
| 204 |
+
for i in message["thought_steps"]:
|
| 205 |
+
st.markdown("- " + i)
|
| 206 |
+
|
| 207 |
+
# Respond to user input after receiving
|
| 208 |
+
if user_query:= st.chat_input("What's up?"):
|
| 209 |
+
# Display user messages in chat message container
|
| 210 |
+
with st.chat_message("User"):
|
| 211 |
+
st.markdown(user_query)
|
| 212 |
+
# Add user message to chat history
|
| 213 |
+
st.session_state.messages.append({"role": "user", "content": user_query})
|
| 214 |
+
|
| 215 |
+
thought_steps, final_response = process_query_with_chain_of_thought(user_query, st.session_state.messages)
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
# Display assistant response in hcat message container
|
| 219 |
+
with st.chat_message("assistant"):
|
| 220 |
+
for i in thought_steps:
|
| 221 |
+
st.markdown("- " + i)
|
| 222 |
+
st.markdown(final_response)
|
| 223 |
+
|
| 224 |
+
st.session_state.messages.append({"role" : "assistant", "content": final_response, "thought_steps": thought_steps})
|
| 225 |
+
|
| 226 |
+
if 'app' not in st.session_state:
|
| 227 |
+
st.session_state.app = web_bot
|
| 228 |
+
|
| 229 |
+
st.session_state.app()
|
| 230 |
+
|
| 231 |
+
bot()
|
config.yaml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
site_url: https://learn.wordpress.org
|
| 2 |
+
collection_name: post_collection
|
| 3 |
+
embedding_model: all-MiniLM-L6-v2
|
image.png
ADDED
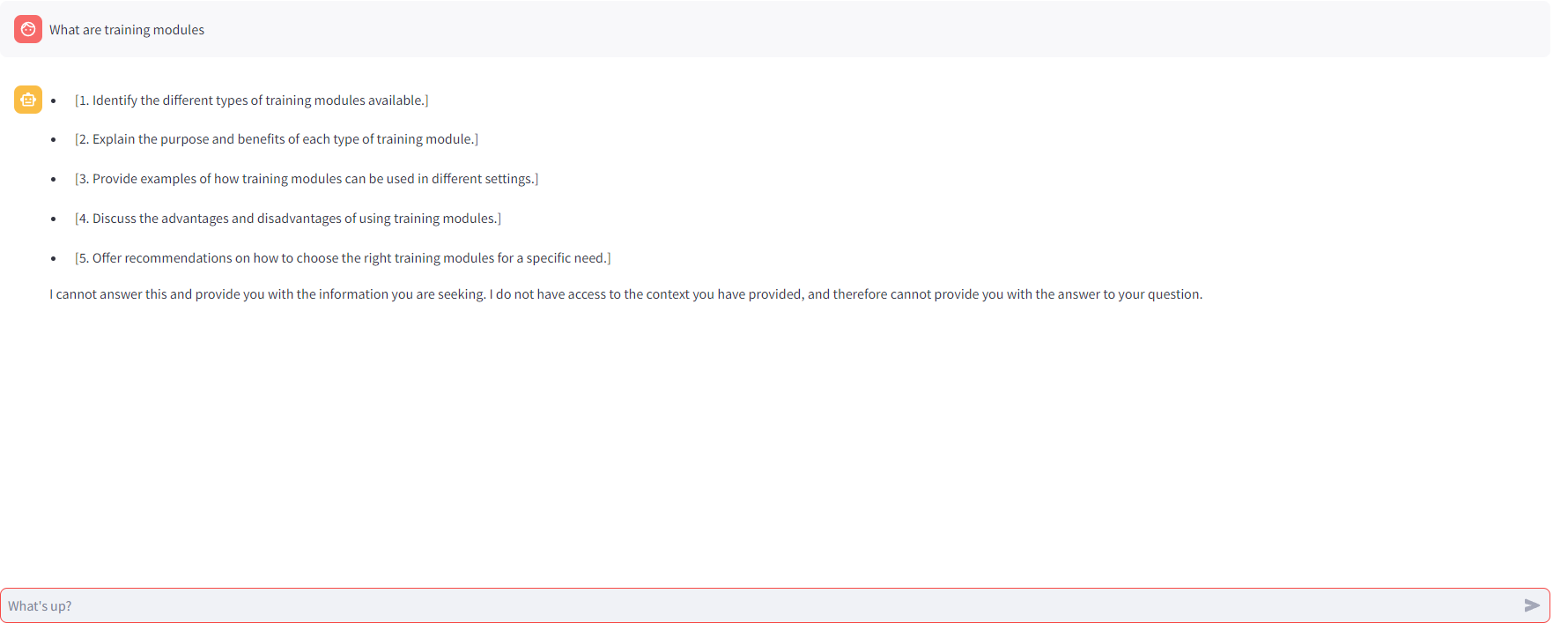
|
ingest.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utils import fetch_wordpress_data,create_vector_store_and_add_posts
|
| 2 |
+
import yaml
|
| 3 |
+
|
| 4 |
+
def main():
|
| 5 |
+
"""
|
| 6 |
+
Main function to fetch WordPress data, create vector store, and add posts to it.
|
| 7 |
+
|
| 8 |
+
This function reads configuration data from a YAML file, fetches WordPress data using the specified site URL,
|
| 9 |
+
and creates a vector store in the database with the fetched posts.
|
| 10 |
+
|
| 11 |
+
Raises:
|
| 12 |
+
Exception: If the config.yaml file is not found or if there are any other errors during execution.
|
| 13 |
+
"""
|
| 14 |
+
try:
|
| 15 |
+
# Attempt to load configuration data from config.yaml file
|
| 16 |
+
with open("./config.yaml", 'r') as file:
|
| 17 |
+
config_data = yaml.safe_load(file)
|
| 18 |
+
print(config_data) # Printing configuration data for debugging purposes
|
| 19 |
+
except Exception as e:
|
| 20 |
+
# Raise exception if config.yaml file is not found
|
| 21 |
+
raise Exception(f"Not able to find the file ./config.yaml")
|
| 22 |
+
|
| 23 |
+
# Fetch WordPress data using the site URL specified in the configuration
|
| 24 |
+
wordpress_data = fetch_wordpress_data(config_data['site_url'])
|
| 25 |
+
|
| 26 |
+
# Create vector store in the database and add WordPress posts to it
|
| 27 |
+
client, collection = create_vector_store_and_add_posts(wordpress_data)
|
| 28 |
+
|
| 29 |
+
if __name__ == "__main__":
|
| 30 |
+
main()
|
posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/data_level0.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d3c9fd302f000d7790aa403c2d0d8fec363fe46f30b07d53020b6e33b22435a9
|
| 3 |
+
size 1676000
|
posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/header.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e87a1dc8bcae6f2c4bea6d5dd5005454d4dace8637dae29bff3c037ea771411e
|
| 3 |
+
size 100
|
posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/length.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:589714b29b763e833a33a2e5da994d6d404335449926d0341a8df001fab545cc
|
| 3 |
+
size 4000
|
posts_db/234f5c2c-1705-4f1b-b309-3779d27238a3/link_lists.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
|
| 3 |
+
size 0
|
posts_db/chroma.sqlite3
ADDED
|
Binary file (381 kB). View file
|
|
|
query.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Importing modules and functions
|
| 2 |
+
from utils import fetch_wordpress_data, extract_text, generate_embeddings
|
| 3 |
+
import chromadb, yaml
|
| 4 |
+
from langchain_chroma import Chroma
|
| 5 |
+
from langchain_community.embeddings.sentence_transformer import (
|
| 6 |
+
SentenceTransformerEmbeddings,
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
from langchain_google_genai import ChatGoogleGenerativeAI
|
| 10 |
+
from langchain_core.prompts import ChatPromptTemplate
|
| 11 |
+
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
|
| 12 |
+
from langchain.output_parsers import CommaSeparatedListOutputParser
|
| 13 |
+
from langchain_core.output_parsers import StrOutputParser
|
| 14 |
+
from dotenv import load_dotenv
|
| 15 |
+
import argparse
|
| 16 |
+
|
| 17 |
+
# Load environment variables from .env file
|
| 18 |
+
load_dotenv()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# Parse command-line arguments
|
| 22 |
+
parser = argparse.ArgumentParser(description='Information retrieval from blog archives')
|
| 23 |
+
parser.add_argument('--query', '-q', default="What are WordPress tutorials", type=str, help='What do you want to know...?', required=False)
|
| 24 |
+
parser.add_argument('--chats', '-c', default=[("Hello", "Hey, How may i help you?")], type=list, help='Chats of the user', required=False)
|
| 25 |
+
|
| 26 |
+
args = parser.parse_args()
|
| 27 |
+
|
| 28 |
+
try:
|
| 29 |
+
# Attempt to load configuration data from config.yaml file
|
| 30 |
+
with open("./config.yaml", 'r') as file:
|
| 31 |
+
config_data = yaml.safe_load(file)
|
| 32 |
+
except Exception as e:
|
| 33 |
+
# Raise exception if config.yaml file is not found
|
| 34 |
+
raise Exception(f"Not able to find the file ./config.yaml")
|
| 35 |
+
|
| 36 |
+
# Initialize Chroma database client
|
| 37 |
+
client = chromadb.PersistentClient("./posts_db")
|
| 38 |
+
collection_name = config_data['collection_name']
|
| 39 |
+
collection = client.get_collection(name=collection_name)
|
| 40 |
+
|
| 41 |
+
# Initialize embedding function for sentence transformer
|
| 42 |
+
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
|
| 43 |
+
|
| 44 |
+
# Initialize Langchain Chroma retriever
|
| 45 |
+
langchain_chroma = Chroma(
|
| 46 |
+
client=client,
|
| 47 |
+
collection_name=collection_name,
|
| 48 |
+
embedding_function=embedding_function,
|
| 49 |
+
).as_retriever(n_results=1)
|
| 50 |
+
|
| 51 |
+
# Initialize Chat Google Generative AI model
|
| 52 |
+
model = ChatGoogleGenerativeAI(model="gemini-pro")
|
| 53 |
+
|
| 54 |
+
def update_vector_database(collection, post_id, embeddings, text):
|
| 55 |
+
"""
|
| 56 |
+
Update the vector database with post ID, embeddings, and text.
|
| 57 |
+
|
| 58 |
+
Args:
|
| 59 |
+
collection: The collection in the database.
|
| 60 |
+
post_id (str): The ID of the post.
|
| 61 |
+
embeddings (list): List of embeddings generated from the post text.
|
| 62 |
+
text (str): The text of the post.
|
| 63 |
+
"""
|
| 64 |
+
collection.upsert(ids=[str(post_id)], documents=[text], embeddings=[embeddings])
|
| 65 |
+
|
| 66 |
+
def fetch_existing_posts(collection):
|
| 67 |
+
"""
|
| 68 |
+
Fetch existing posts from the database.
|
| 69 |
+
|
| 70 |
+
Args:
|
| 71 |
+
collection: The collection in the database.
|
| 72 |
+
|
| 73 |
+
Returns:
|
| 74 |
+
list: List of existing posts.
|
| 75 |
+
"""
|
| 76 |
+
# Fetch existing posts from the database or any other storage
|
| 77 |
+
existing_posts = collection.get()
|
| 78 |
+
return existing_posts
|
| 79 |
+
|
| 80 |
+
def update_embeddings_on_new_post(collection):
|
| 81 |
+
"""
|
| 82 |
+
Update embeddings for new posts fetched from WordPress data.
|
| 83 |
+
|
| 84 |
+
Args:
|
| 85 |
+
collection: The collection in the database.
|
| 86 |
+
"""
|
| 87 |
+
|
| 88 |
+
# Fetch existing posts from the database or any other storage
|
| 89 |
+
existing_posts = fetch_existing_posts(collection)
|
| 90 |
+
new_posts = fetch_wordpress_data(config_data['site_url'])
|
| 91 |
+
|
| 92 |
+
# Compare old and new posts to find the difference
|
| 93 |
+
# new_post_ids = set(str(post['id']) for post in new_posts)
|
| 94 |
+
existing_post_ids = set(str(post_id) for post_id in existing_posts['ids'])
|
| 95 |
+
new_posts_to_update = [post for post in new_posts if str(post['id']) not in existing_post_ids]
|
| 96 |
+
print(new_posts_to_update)
|
| 97 |
+
# Update embeddings for new posts
|
| 98 |
+
for post in new_posts_to_update:
|
| 99 |
+
# Extract text from post
|
| 100 |
+
text = extract_text(post)
|
| 101 |
+
# Generate embeddings for the post text
|
| 102 |
+
embeddings = generate_embeddings(text)
|
| 103 |
+
# Update vector database with post ID and embeddings
|
| 104 |
+
update_vector_database(collection,post['id'], embeddings, text)
|
| 105 |
+
|
| 106 |
+
def rag_generate_response():
|
| 107 |
+
"""
|
| 108 |
+
Generate a prompt for generating reasoning steps for answering the user query.
|
| 109 |
+
|
| 110 |
+
Returns:
|
| 111 |
+
ChatPromptTemplate: The generated prompt template.
|
| 112 |
+
"""
|
| 113 |
+
template = """You are tasked with designing a prompt for generating reasoning steps for answering to the user_query in a website. Write a Prompt to generate a series of intermediate thoughts or reasoning steps to answer the query. Avoid providing specific solutions or examples, allowing the LLM to explore different approaches independently. Give the output as a list of steps. eg: [1,2,3,...]
|
| 114 |
+
|
| 115 |
+
Question: {user_query}
|
| 116 |
+
Previous_context : {previous_context}
|
| 117 |
+
"""
|
| 118 |
+
prompt = ChatPromptTemplate.from_template(template)
|
| 119 |
+
# chain = (
|
| 120 |
+
# RunnableParallel({"user_query": RunnablePassthrough()})
|
| 121 |
+
# | prompt
|
| 122 |
+
# | model
|
| 123 |
+
# | CommaSeparatedListOutputParser()
|
| 124 |
+
# )
|
| 125 |
+
# initial_response = chain.invoke(user_query)
|
| 126 |
+
# print("Initial Response: ", initial_response)
|
| 127 |
+
# return initial_response
|
| 128 |
+
return prompt
|
| 129 |
+
|
| 130 |
+
def develop_reasoning_steps(user_query, initial_prompt, previous_context):
|
| 131 |
+
"""
|
| 132 |
+
Develop reasoning steps based on the user query, initial prompt, and previous context.
|
| 133 |
+
|
| 134 |
+
Args:
|
| 135 |
+
user_query (str): The query from the user.
|
| 136 |
+
initial_prompt (ChatPromptTemplate): The initial prompt template.
|
| 137 |
+
previous_context (str): The previous context.
|
| 138 |
+
|
| 139 |
+
Returns:
|
| 140 |
+
list: List of thought steps.
|
| 141 |
+
"""
|
| 142 |
+
chain = (
|
| 143 |
+
RunnableParallel({"user_query": RunnablePassthrough(), "previous_context": RunnablePassthrough()})
|
| 144 |
+
| initial_prompt
|
| 145 |
+
| model
|
| 146 |
+
| CommaSeparatedListOutputParser()
|
| 147 |
+
)
|
| 148 |
+
thought_steps = chain.invoke({"user_query" : user_query, "previous_context" : previous_context})
|
| 149 |
+
thought_steps = thought_steps[0].split('\n')
|
| 150 |
+
print("thought_steps: ", thought_steps)
|
| 151 |
+
return thought_steps
|
| 152 |
+
|
| 153 |
+
# template = """You are a helpfull assistant which generates the thought steps used for generating a response to a query based on the relevant documents and the previous context. Generate thought steps on how to answer to the user's previous context with the relevant documents. This helps the LLM to answer in the next step accurately. I am giving the initial_response as relevant documents and previous context is the chat history. Now write the thought steps using the relavant documents, and the previous context on how to answer to the query. Thought steps are the sub questions and their answers asked using the query, context and previous context. Thought steps should be in the format Question: , Response: :
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
# Relevant Document : {reasoning_step}
|
| 157 |
+
|
| 158 |
+
# previous context: {previous_context}
|
| 159 |
+
# """
|
| 160 |
+
# prompt = ChatPromptTemplate.from_template(template)
|
| 161 |
+
# reason_chain = (
|
| 162 |
+
# RunnableParallel({"user_query": RunnablePassthrough(),"relevant_doc": RunnablePassthrough(), "previous_context": RunnablePassthrough()})
|
| 163 |
+
# | prompt
|
| 164 |
+
# | model
|
| 165 |
+
# | StrOutputParser()
|
| 166 |
+
# )
|
| 167 |
+
# thought_steps = reason_chain.invoke({'user_query' : user_query, 'relevant_doc' : relevant_doc,'previous_context' : previous_context})
|
| 168 |
+
# return thought_steps
|
| 169 |
+
|
| 170 |
+
def refine_response_based_on_thought_steps(user_query, thought_steps):
|
| 171 |
+
"""
|
| 172 |
+
Refine the response based on thought steps.
|
| 173 |
+
|
| 174 |
+
Args:
|
| 175 |
+
user_query (str): The query from the user.
|
| 176 |
+
thought_steps (list): List of thought steps.
|
| 177 |
+
|
| 178 |
+
Returns:
|
| 179 |
+
str: Final refined response.
|
| 180 |
+
"""
|
| 181 |
+
retrieved_content = []
|
| 182 |
+
all_retrieved_content = ""
|
| 183 |
+
|
| 184 |
+
for thought_step in thought_steps:
|
| 185 |
+
# print(langchain_chroma.invoke(thought_step))
|
| 186 |
+
retrieved_content = langchain_chroma.invoke(thought_step)
|
| 187 |
+
for i in retrieved_content:
|
| 188 |
+
all_retrieved_content+=i.page_content
|
| 189 |
+
all_retrieved_content+="\n"
|
| 190 |
+
|
| 191 |
+
# print("--------------------------------------------------")
|
| 192 |
+
# print("Retrieved: ", retrieved_content[0])
|
| 193 |
+
# print("Len Retrieved: ", len(retrieved_content))
|
| 194 |
+
# print("----------------------------")
|
| 195 |
+
# print("All Retrieved Content: ",all_retrieved_content)
|
| 196 |
+
# print("Len Retrieved: ", len(retrieved_content[0]))
|
| 197 |
+
template = """You are a helpful assistant which answers the query from the context. If the context does not provide the answer simply reply I cannot answer this and give a suggestion to refer the website. DO NOT say that 'there is no information in the context' or 'the answer from the context is this.' phrases, instead give directly the solution or answer I cannot answer this and give a suggestion to refer the website or similar kind of text based on the context.:
|
| 198 |
+
|
| 199 |
+
query : {user_query}
|
| 200 |
+
|
| 201 |
+
context : {context}
|
| 202 |
+
"""
|
| 203 |
+
prompt = ChatPromptTemplate.from_template(template)
|
| 204 |
+
reason_chain = (
|
| 205 |
+
RunnableParallel({'user_query': RunnablePassthrough(), 'context': RunnablePassthrough()})
|
| 206 |
+
| prompt
|
| 207 |
+
| model
|
| 208 |
+
| StrOutputParser()
|
| 209 |
+
)
|
| 210 |
+
final_response = reason_chain.invoke({'user_query': user_query ,'context' : all_retrieved_content})
|
| 211 |
+
return final_response
|
| 212 |
+
|
| 213 |
+
# Function to process the query with RAG + COT
|
| 214 |
+
def process_query_with_chain_of_thought(user_query, previous_context):
|
| 215 |
+
"""
|
| 216 |
+
Process the user query using the RAG + COT approach.
|
| 217 |
+
|
| 218 |
+
Args:
|
| 219 |
+
user_query (str): The query from the user.
|
| 220 |
+
previous_context (list): List of previous chat contexts.
|
| 221 |
+
|
| 222 |
+
Returns:
|
| 223 |
+
tuple: A tuple containing thought steps and final refined response.
|
| 224 |
+
"""
|
| 225 |
+
initial_response = rag_generate_response(user_query) # initial response is the prompt
|
| 226 |
+
thought_steps = develop_reasoning_steps(user_query, initial_response, previous_context)
|
| 227 |
+
final_response = refine_response_based_on_thought_steps(user_query,thought_steps)
|
| 228 |
+
return thought_steps, final_response
|
| 229 |
+
|
| 230 |
+
# Updating the embeddings and post content of the website into the vector store
|
| 231 |
+
update_embeddings_on_new_post(collection)
|
| 232 |
+
|
| 233 |
+
# Precessing the query from the user using the RAG + COT approach
|
| 234 |
+
thought_steps, final_response = process_query_with_chain_of_thought(args.query, args.chats)
|
| 235 |
+
print("Thought_steps : ",thought_steps)
|
| 236 |
+
print("Final_response : ",final_response)
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
chromadb==0.4.24
|
| 2 |
+
sentence-transformers==2.2.2
|
| 3 |
+
langchain==0.1.17
|
| 4 |
+
langchain-chroma==0.1.0
|
| 5 |
+
langchain-community==0.0.37
|
| 6 |
+
langchain-core==0.1.52
|
| 7 |
+
langchain-google-genai==1.0.3
|
| 8 |
+
python-dotenv==1.0.1
|
| 9 |
+
streamlit==1.34.0
|
| 10 |
+
google-generativeai==0.5.3
|
tests.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import unittest
|
| 2 |
+
import chromadb
|
| 3 |
+
import subprocess
|
| 4 |
+
import time
|
| 5 |
+
import yaml
|
| 6 |
+
import psutil
|
| 7 |
+
from langchain_community.embeddings.sentence_transformer import (
|
| 8 |
+
SentenceTransformerEmbeddings,
|
| 9 |
+
)
|
| 10 |
+
from langchain_chroma import Chroma
|
| 11 |
+
from langchain_google_genai import ChatGoogleGenerativeAI
|
| 12 |
+
from dotenv import load_dotenv
|
| 13 |
+
# Load environment variables from .env file
|
| 14 |
+
load_dotenv()
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class TestChromaVectorStore(unittest.TestCase):
|
| 18 |
+
def setUp(self):
|
| 19 |
+
try:
|
| 20 |
+
# Attempt to load configuration data from config.yaml file
|
| 21 |
+
with open("./config.yaml", 'r') as file:
|
| 22 |
+
config_data = yaml.safe_load(file)
|
| 23 |
+
except Exception as e:
|
| 24 |
+
# Raise exception if config.yaml file is not found
|
| 25 |
+
raise Exception(f"Not able to find the file ./config.yaml")
|
| 26 |
+
|
| 27 |
+
self.client = chromadb.PersistentClient("./posts_db")
|
| 28 |
+
collection_name = config_data['collection_name']
|
| 29 |
+
|
| 30 |
+
self.collection = self.client.get_collection(name=collection_name)
|
| 31 |
+
# Initialize embedding function for sentence transformer
|
| 32 |
+
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
|
| 33 |
+
|
| 34 |
+
self.langchain_chroma = Chroma(
|
| 35 |
+
client=self.client,
|
| 36 |
+
collection_name=collection_name,
|
| 37 |
+
embedding_function=embedding_function,
|
| 38 |
+
).as_retriever(n_results=1)
|
| 39 |
+
|
| 40 |
+
def test_retrieve_vector_store(self):
|
| 41 |
+
# Testing whether the Chroma vector store retrieves data
|
| 42 |
+
data = self.langchain_chroma.invoke("Wordpress")
|
| 43 |
+
self.assertIsNotNone(data)
|
| 44 |
+
print("Vector Store is Working Properly!")
|
| 45 |
+
|
| 46 |
+
class TestLLM(unittest.TestCase):
|
| 47 |
+
def setUp(self):
|
| 48 |
+
self.model = ChatGoogleGenerativeAI(model="gemini-pro")
|
| 49 |
+
|
| 50 |
+
def test_response_from_model(self):
|
| 51 |
+
# Testing whether LLM returns responses
|
| 52 |
+
response = self.model.invoke("Hello!")
|
| 53 |
+
self.assertIsNotNone(response)
|
| 54 |
+
print("LLM is generating responses!")
|
| 55 |
+
|
| 56 |
+
class TestStreamlitUI(unittest.TestCase):
|
| 57 |
+
def test_streamlit_ui(self):
|
| 58 |
+
process = subprocess.Popen(["streamlit", "run", "app.py"], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
|
| 59 |
+
|
| 60 |
+
time.sleep(60)
|
| 61 |
+
if process.poll() is None:
|
| 62 |
+
print("Streamlit app is running. Stopping the app...")
|
| 63 |
+
|
| 64 |
+
process_id = process.pid
|
| 65 |
+
parent = psutil.Process(process_id)
|
| 66 |
+
for child in parent.children(recursive=True):
|
| 67 |
+
child.terminate()
|
| 68 |
+
parent.terminate()
|
| 69 |
+
process.wait()
|
| 70 |
+
print("Streamlit is working properly.")
|
| 71 |
+
else:
|
| 72 |
+
print("Streamlit app has already terminated.")
|
| 73 |
+
|
| 74 |
+
if __name__ == '__main__':
|
| 75 |
+
unittest.main()
|
utils.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
import re
|
| 3 |
+
from html import unescape
|
| 4 |
+
from sentence_transformers import SentenceTransformer
|
| 5 |
+
import chromadb
|
| 6 |
+
import yaml
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
try:
|
| 10 |
+
# Attempt to load configuration data from config.yaml file
|
| 11 |
+
with open("./config.yaml", 'r') as file:
|
| 12 |
+
config_data = yaml.safe_load(file)
|
| 13 |
+
except Exception as e:
|
| 14 |
+
# Raise exception if config.yaml file is not found
|
| 15 |
+
raise Exception(f"Not able to find the file ./config.yaml")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# function to fetch data from WordPress site
|
| 19 |
+
def fetch_wordpress_data(site_url):
|
| 20 |
+
"""
|
| 21 |
+
Fetches data from a WordPress site using its REST API.
|
| 22 |
+
|
| 23 |
+
Args:
|
| 24 |
+
site_url (str): The URL of the WordPress site.
|
| 25 |
+
|
| 26 |
+
Returns:
|
| 27 |
+
dict: JSON data retrieved from the WordPress site.
|
| 28 |
+
"""
|
| 29 |
+
api_url = f"{site_url}/wp-json/wp/v2/posts"
|
| 30 |
+
try:
|
| 31 |
+
# Send GET request to WordPress API
|
| 32 |
+
response = requests.get(api_url)
|
| 33 |
+
response.raise_for_status() # Raise exception for unsuccessful responses
|
| 34 |
+
|
| 35 |
+
# Extract and return JSON data from response
|
| 36 |
+
return response.json()
|
| 37 |
+
|
| 38 |
+
except requests.exceptions.RequestException as e:
|
| 39 |
+
# Handle any errors that occur during request
|
| 40 |
+
print("Error fetching WordPress data:", e)
|
| 41 |
+
return None
|
| 42 |
+
|
| 43 |
+
def preprocess_text(text):
|
| 44 |
+
"""
|
| 45 |
+
Preprocesses text by removing HTML tags, decoding special characters, and removing extra whitespaces.
|
| 46 |
+
|
| 47 |
+
Args:
|
| 48 |
+
text (str): The text to be preprocessed.
|
| 49 |
+
|
| 50 |
+
Returns:
|
| 51 |
+
str: The preprocessed text.
|
| 52 |
+
"""
|
| 53 |
+
# Remove HTML tags
|
| 54 |
+
clean_text = re.sub('<.*?>', '', text)
|
| 55 |
+
# Decode special characters
|
| 56 |
+
clean_text = unescape(clean_text)
|
| 57 |
+
# Removing extra newline characters
|
| 58 |
+
clean_text = re.sub('\n+', '\n', clean_text)
|
| 59 |
+
# Remove extra whitespaces and newline characters
|
| 60 |
+
clean_text = clean_text.strip()
|
| 61 |
+
|
| 62 |
+
return clean_text
|
| 63 |
+
|
| 64 |
+
def generate_embeddings(text):
|
| 65 |
+
"""
|
| 66 |
+
Generates sentence embeddings using a pre-trained embedding model.
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
text (str): The input text.
|
| 70 |
+
|
| 71 |
+
Returns:
|
| 72 |
+
list: List of sentence embeddings.
|
| 73 |
+
"""
|
| 74 |
+
# Load pre-trained embedding model
|
| 75 |
+
model = SentenceTransformer(config_data['embedding_model'])
|
| 76 |
+
|
| 77 |
+
# Generate embeddings for input text
|
| 78 |
+
embeddings = model.encode(text)
|
| 79 |
+
return embeddings.tolist()
|
| 80 |
+
|
| 81 |
+
def extract_text(post):
|
| 82 |
+
"""
|
| 83 |
+
Extracts and preprocesses text content from a WordPress post.
|
| 84 |
+
|
| 85 |
+
Args:
|
| 86 |
+
post (dict): The WordPress post data.
|
| 87 |
+
|
| 88 |
+
Returns:
|
| 89 |
+
str: The preprocessed text content of the post.
|
| 90 |
+
"""
|
| 91 |
+
return preprocess_text(post['content']['rendered'])
|
| 92 |
+
|
| 93 |
+
def create_vector_store_and_add_posts(wordpress_data):
|
| 94 |
+
"""
|
| 95 |
+
Creates a vector store in Chroma database and adds WordPress posts to it.
|
| 96 |
+
|
| 97 |
+
Args:
|
| 98 |
+
wordpress_data (list): List of WordPress post data.
|
| 99 |
+
|
| 100 |
+
Returns:
|
| 101 |
+
tuple: A tuple containing the Chroma client and collection objects.
|
| 102 |
+
"""
|
| 103 |
+
client = chromadb.PersistentClient("./posts_db")
|
| 104 |
+
collection = client.get_or_create_collection(name = config_data['collection_name'], metadata={"hnsw:space": "cosine"})
|
| 105 |
+
ids = []
|
| 106 |
+
documents = []
|
| 107 |
+
metadatas = []
|
| 108 |
+
embeddings = []
|
| 109 |
+
for post in wordpress_data:
|
| 110 |
+
ids.append(str(post['id']))
|
| 111 |
+
cleaned_content = extract_text(post)
|
| 112 |
+
embeddings.append(generate_embeddings(cleaned_content))
|
| 113 |
+
documents.append(cleaned_content)
|
| 114 |
+
metadata = {}
|
| 115 |
+
metadata['title'] = post['title']['rendered']
|
| 116 |
+
metadata['date'] = post['date']
|
| 117 |
+
metadata['modified'] = post['modified']
|
| 118 |
+
metadatas.append(metadata)
|
| 119 |
+
collection.upsert(ids=ids, documents=documents, metadatas=metadatas, embeddings=embeddings)
|
| 120 |
+
return client,collection
|
| 121 |
+
|
| 122 |
+
|