Spaces:
Sleeping

Sleeping
Upload folder using huggingface_hub
Browse files- .github/workflows/update_space.yml +28 -0
- .gitignore +4 -0
- .gradio/certificate.pem +31 -0
- FuelInFranceData/full_dataset.parquet +3 -0
- README.md +3 -8
- downloadandconvertdataset.py +14 -0
- fuel_price_model.pkl +3 -0
- fuel_price_model_E10.pkl +3 -0
- fuel_price_model_Gazole.pkl +3 -0
- fuel_price_model_SP95.pkl +3 -0
- fuel_price_model_SP98.pkl +3 -0
- full_dataset.parquet +3 -0
- mainscript.py +395 -0
- runningscript.py +273 -0
- scaler.pkl +3 -0
- scaler_E10.pkl +3 -0
- scaler_Gazole.pkl +3 -0
- scaler_SP95.pkl +3 -0
- scaler_SP98.pkl +3 -0
- trainingscript.py +224 -0
- validation_E10.png +0 -0
- validation_Gazole.png +0 -0
- validation_SP95.png +0 -0
- validation_SP98.png +0 -0
.github/workflows/update_space.yml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Run Python script
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- main
|
| 7 |
+
|
| 8 |
+
jobs:
|
| 9 |
+
build:
|
| 10 |
+
runs-on: ubuntu-latest
|
| 11 |
+
|
| 12 |
+
steps:
|
| 13 |
+
- name: Checkout
|
| 14 |
+
uses: actions/checkout@v2
|
| 15 |
+
|
| 16 |
+
- name: Set up Python
|
| 17 |
+
uses: actions/setup-python@v2
|
| 18 |
+
with:
|
| 19 |
+
python-version: '3.9'
|
| 20 |
+
|
| 21 |
+
- name: Install Gradio
|
| 22 |
+
run: python -m pip install gradio
|
| 23 |
+
|
| 24 |
+
- name: Log in to Hugging Face
|
| 25 |
+
run: python -c 'import huggingface_hub; huggingface_hub.login(token="${{ secrets.hf_token }}")'
|
| 26 |
+
|
| 27 |
+
- name: Deploy to Spaces
|
| 28 |
+
run: gradio deploy
|
.gitignore
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#macosfile
|
| 2 |
+
**/.DS_Store
|
| 3 |
+
|
| 4 |
+
venv/
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
FuelInFranceData/full_dataset.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d9c34c7529b8d83ce451fd486b9d23e7775906331c227abf448b1cd123a315ec
|
| 3 |
+
size 1187133604
|
README.md
CHANGED
|
@@ -1,12 +1,7 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: indigo
|
| 5 |
-
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 5.0.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
| 11 |
-
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: fuelprediction
|
| 3 |
+
app_file: runningscript.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.0.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
predict fuel price in france
|
|
|
downloadandconvertdataset.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datasets import load_dataset, concatenate_datasets
|
| 2 |
+
|
| 3 |
+
# Charger le dataset depuis Hugging Face
|
| 4 |
+
dataset_dict = load_dataset("VincentGOURBIN/FuelInFranceData")
|
| 5 |
+
|
| 6 |
+
# Récupérer toutes les partitions du dataset
|
| 7 |
+
datasets = [dataset for dataset in dataset_dict.values()]
|
| 8 |
+
|
| 9 |
+
# Concaténer toutes les partitions en un seul dataset
|
| 10 |
+
full_dataset = concatenate_datasets(datasets)
|
| 11 |
+
|
| 12 |
+
# Sauvegarder le dataset concaténé au format Parquet
|
| 13 |
+
full_dataset.to_parquet("full_dataset.parquet")
|
| 14 |
+
print("Le dataset complet a été sauvegardé en 'full_dataset.parquet'")
|
fuel_price_model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb289ddde1c8f47da78c132c31a7e85886021d6b2f24fb253fc8cff34f195a5e
|
| 3 |
+
size 501316
|
fuel_price_model_E10.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:317842c5746adeda2c4d33a3d771dc6dca0dbc5fa01d9b6cabd884974c0f162b
|
| 3 |
+
size 501177
|
fuel_price_model_Gazole.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e510361c8a8671e89ef42321ef12df7b8ea38178266afe55fd06e7f7fde19074
|
| 3 |
+
size 501587
|
fuel_price_model_SP95.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:756bce1166a7b448d342decc8fbc8cf4eedf96cec30c698d433078c257ab05c3
|
| 3 |
+
size 500839
|
fuel_price_model_SP98.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a2a5fb48757eaf190fa686dc9ed2feb435279c6889f2b3b9ca7e8de95c0e492
|
| 3 |
+
size 501519
|
full_dataset.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d9c34c7529b8d83ce451fd486b9d23e7775906331c227abf448b1cd123a315ec
|
| 3 |
+
size 1187133604
|
mainscript.py
ADDED
|
@@ -0,0 +1,395 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.optim as optim
|
| 4 |
+
import torch.nn.init as init
|
| 5 |
+
from torch.utils.data import Dataset, DataLoader
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import numpy as np
|
| 8 |
+
from sklearn.preprocessing import StandardScaler
|
| 9 |
+
from sklearn.model_selection import train_test_split
|
| 10 |
+
import os
|
| 11 |
+
from datetime import datetime, timedelta
|
| 12 |
+
import argparse
|
| 13 |
+
import json
|
| 14 |
+
import matplotlib.pyplot as plt
|
| 15 |
+
|
| 16 |
+
# Vérifier si MPS est disponible
|
| 17 |
+
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
|
| 18 |
+
print(f"Utilisation de l'appareil: {device}")
|
| 19 |
+
|
| 20 |
+
def load_brent_data(file_path):
|
| 21 |
+
print(f"Chargement des données Brent depuis {file_path}")
|
| 22 |
+
brent_data = pd.read_csv(file_path)
|
| 23 |
+
brent_data['brent_date'] = pd.to_datetime(brent_data['brent_date'])
|
| 24 |
+
|
| 25 |
+
# Filtrer les données à partir de 2024
|
| 26 |
+
brent_data = brent_data[brent_data['brent_date'].dt.year >= 2024]
|
| 27 |
+
|
| 28 |
+
brent_data = brent_data.sort_values('brent_date')
|
| 29 |
+
print(f"Données Brent chargées, triées et filtrées à partir de 2024. Shape: {brent_data.shape}")
|
| 30 |
+
return brent_data
|
| 31 |
+
|
| 32 |
+
def load_fuel_data(folder_path):
|
| 33 |
+
print(f"Chargement des données de carburant depuis {folder_path}")
|
| 34 |
+
all_data = []
|
| 35 |
+
for filename in os.listdir(folder_path):
|
| 36 |
+
if filename.endswith('.csv'):
|
| 37 |
+
file_path = os.path.join(folder_path, filename)
|
| 38 |
+
df = pd.read_csv(file_path)
|
| 39 |
+
df['rate_date'] = pd.to_datetime(df['rate_date'])
|
| 40 |
+
all_data.append(df)
|
| 41 |
+
fuel_data = pd.concat(all_data, ignore_index=True)
|
| 42 |
+
fuel_data = fuel_data[~fuel_data['fuel_name'].isin(['GPLc', 'E85'])]
|
| 43 |
+
|
| 44 |
+
# Filtrer les données à partir de 2024
|
| 45 |
+
fuel_data = fuel_data[fuel_data['rate_date'].dt.year >= 2024]
|
| 46 |
+
|
| 47 |
+
print(f"Données de carburant chargées et filtrées à partir de 2024. Shape: {fuel_data.shape}")
|
| 48 |
+
return fuel_data
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def classify_stations(fuel_data):
|
| 52 |
+
print("Classification des stations par gamme de prix")
|
| 53 |
+
station_classifications = {}
|
| 54 |
+
fuel_types = fuel_data['fuel_name'].unique()
|
| 55 |
+
|
| 56 |
+
for fuel_type in fuel_types:
|
| 57 |
+
fuel_type_data = fuel_data[fuel_data['fuel_name'] == fuel_type]
|
| 58 |
+
station_avg_prices = fuel_type_data.groupby('id')['price'].mean().reset_index()
|
| 59 |
+
|
| 60 |
+
thresholds = np.percentile(station_avg_prices['price'], [33, 66])
|
| 61 |
+
|
| 62 |
+
def classify_price(price):
|
| 63 |
+
if price <= thresholds[0]:
|
| 64 |
+
return 'low-cost'
|
| 65 |
+
elif price <= thresholds[1]:
|
| 66 |
+
return 'normal'
|
| 67 |
+
else:
|
| 68 |
+
return 'premium'
|
| 69 |
+
|
| 70 |
+
station_classifications[fuel_type] = station_avg_prices.set_index('id')['price'].apply(classify_price).to_dict()
|
| 71 |
+
|
| 72 |
+
return station_classifications
|
| 73 |
+
|
| 74 |
+
def save_station_classifications(station_classifications, output_dir):
|
| 75 |
+
classification_df = pd.DataFrame(station_classifications)
|
| 76 |
+
classification_df.index.name = 'station_id'
|
| 77 |
+
classification_df.reset_index(inplace=True)
|
| 78 |
+
|
| 79 |
+
classification_file = os.path.join(output_dir, 'station_classifications.csv')
|
| 80 |
+
classification_df.to_csv(classification_file, index=False)
|
| 81 |
+
print(f"Classifications des stations sauvegardées dans {classification_file}")
|
| 82 |
+
|
| 83 |
+
class FuelPriceDataset(Dataset):
|
| 84 |
+
def __init__(self, data, sequence_length, target_days):
|
| 85 |
+
self.data = data
|
| 86 |
+
self.sequence_length = sequence_length
|
| 87 |
+
self.target_days = target_days
|
| 88 |
+
print(f"Shape of data in FuelPriceDataset: {self.data.shape}")
|
| 89 |
+
|
| 90 |
+
def __len__(self):
|
| 91 |
+
return len(self.data) - self.sequence_length - max(self.target_days)
|
| 92 |
+
|
| 93 |
+
def __getitem__(self, idx):
|
| 94 |
+
x = self.data.iloc[idx:idx+self.sequence_length].values
|
| 95 |
+
y = self.data.iloc[idx+self.sequence_length:idx+self.sequence_length+max(self.target_days)+1]['price'].values
|
| 96 |
+
y = [y[day] for day in self.target_days]
|
| 97 |
+
|
| 98 |
+
if idx == 0: # Print only for the first item
|
| 99 |
+
print(f"Sample input (X) at index 0:")
|
| 100 |
+
print(x)
|
| 101 |
+
print(f"Sample output (y) at index 0:")
|
| 102 |
+
print(y)
|
| 103 |
+
|
| 104 |
+
return torch.FloatTensor(x), torch.FloatTensor(y)
|
| 105 |
+
|
| 106 |
+
class LSTMModel(nn.Module):
|
| 107 |
+
def __init__(self, input_size, hidden_size, num_layers, output_size):
|
| 108 |
+
super(LSTMModel, self).__init__()
|
| 109 |
+
self.hidden_size = hidden_size
|
| 110 |
+
self.num_layers = num_layers
|
| 111 |
+
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
|
| 112 |
+
self.fc = nn.Linear(hidden_size, output_size)
|
| 113 |
+
|
| 114 |
+
# Initialisation des poids
|
| 115 |
+
for name, param in self.lstm.named_parameters():
|
| 116 |
+
if 'weight' in name:
|
| 117 |
+
init.xavier_uniform_(param)
|
| 118 |
+
elif 'bias' in name:
|
| 119 |
+
init.constant_(param, 0.0)
|
| 120 |
+
init.xavier_uniform_(self.fc.weight)
|
| 121 |
+
init.constant_(self.fc.bias, 0.0)
|
| 122 |
+
|
| 123 |
+
def forward(self, x):
|
| 124 |
+
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
|
| 125 |
+
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
|
| 126 |
+
out, _ = self.lstm(x, (h0, c0))
|
| 127 |
+
out = self.fc(out[:, -1, :])
|
| 128 |
+
return out
|
| 129 |
+
|
| 130 |
+
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs, patience, output_dir, fuel_type, price_range, scaler):
|
| 131 |
+
train_losses = []
|
| 132 |
+
val_losses = []
|
| 133 |
+
best_val_loss = float('inf')
|
| 134 |
+
epochs_no_improve = 0
|
| 135 |
+
|
| 136 |
+
for epoch in range(num_epochs):
|
| 137 |
+
model.train()
|
| 138 |
+
train_loss = 0
|
| 139 |
+
for batch_x, batch_y in train_loader:
|
| 140 |
+
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
|
| 141 |
+
optimizer.zero_grad()
|
| 142 |
+
outputs = model(batch_x)
|
| 143 |
+
loss = criterion(outputs, batch_y)
|
| 144 |
+
loss.backward()
|
| 145 |
+
optimizer.step()
|
| 146 |
+
train_loss += loss.item()
|
| 147 |
+
|
| 148 |
+
model.eval()
|
| 149 |
+
val_loss = 0
|
| 150 |
+
with torch.no_grad():
|
| 151 |
+
for batch_x, batch_y in val_loader:
|
| 152 |
+
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
|
| 153 |
+
outputs = model(batch_x)
|
| 154 |
+
loss = criterion(outputs, batch_y)
|
| 155 |
+
val_loss += loss.item()
|
| 156 |
+
|
| 157 |
+
train_loss /= len(train_loader)
|
| 158 |
+
val_loss /= len(val_loader)
|
| 159 |
+
train_losses.append(train_loss)
|
| 160 |
+
val_losses.append(val_loss)
|
| 161 |
+
|
| 162 |
+
print(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.6f}, Val Loss: {val_loss:.6f}")
|
| 163 |
+
|
| 164 |
+
if val_loss < best_val_loss:
|
| 165 |
+
best_val_loss = val_loss
|
| 166 |
+
epochs_no_improve = 0
|
| 167 |
+
# Sauvegarder le meilleur modèle
|
| 168 |
+
torch.save(model.state_dict(), os.path.join(output_dir, f'best_model_{fuel_type}_{price_range}.pth'))
|
| 169 |
+
else:
|
| 170 |
+
epochs_no_improve += 1
|
| 171 |
+
|
| 172 |
+
if epochs_no_improve == patience:
|
| 173 |
+
print(f"Early stopping triggered after {epoch + 1} epochs")
|
| 174 |
+
break
|
| 175 |
+
|
| 176 |
+
# Charger le meilleur modèle avant de faire les prédictions finales
|
| 177 |
+
model.load_state_dict(torch.load(os.path.join(output_dir, f'best_model_{fuel_type}_{price_range}.pth')))
|
| 178 |
+
|
| 179 |
+
# Générer le graphique et calculer les métriques
|
| 180 |
+
mse, mae, r2 = plot_predictions_vs_actual(model, val_loader, scaler, output_dir, fuel_type, price_range)
|
| 181 |
+
|
| 182 |
+
return train_losses, val_losses, mse, mae, r2
|
| 183 |
+
|
| 184 |
+
def plot_learning_curves(train_losses, val_losses, output_dir, fuel_type, price_range):
|
| 185 |
+
plt.figure(figsize=(10, 6))
|
| 186 |
+
plt.plot(train_losses, label='Train Loss')
|
| 187 |
+
plt.plot(val_losses, label='Validation Loss')
|
| 188 |
+
plt.title(f'Learning Curves - {fuel_type} - {price_range}')
|
| 189 |
+
plt.xlabel('Epochs')
|
| 190 |
+
plt.ylabel('Loss')
|
| 191 |
+
plt.legend()
|
| 192 |
+
plt.grid(True)
|
| 193 |
+
plt.tight_layout()
|
| 194 |
+
plt.savefig(os.path.join(output_dir, f'learning_curves_{fuel_type}_{price_range}.png'))
|
| 195 |
+
plt.close()
|
| 196 |
+
|
| 197 |
+
def plot_predictions_vs_actual(model, val_loader, scaler, output_dir, fuel_type, price_range):
|
| 198 |
+
model.eval()
|
| 199 |
+
predictions = []
|
| 200 |
+
actual_values = []
|
| 201 |
+
|
| 202 |
+
with torch.no_grad():
|
| 203 |
+
for batch_x, batch_y in val_loader:
|
| 204 |
+
batch_x = batch_x.to(device)
|
| 205 |
+
outputs = model(batch_x)
|
| 206 |
+
predictions.extend(outputs.cpu().numpy())
|
| 207 |
+
actual_values.extend(batch_y.numpy())
|
| 208 |
+
|
| 209 |
+
predictions = np.array(predictions)
|
| 210 |
+
actual_values = np.array(actual_values)
|
| 211 |
+
|
| 212 |
+
plt.figure(figsize=(12, 6))
|
| 213 |
+
plt.scatter(actual_values[:, 0], predictions[:, 0], alpha=0.5)
|
| 214 |
+
plt.plot([actual_values[:, 0].min(), actual_values[:, 0].max()],
|
| 215 |
+
[actual_values[:, 0].min(), actual_values[:, 0].max()],
|
| 216 |
+
'r--', lw=2)
|
| 217 |
+
plt.xlabel('Valeurs réelles')
|
| 218 |
+
plt.ylabel('Prédictions')
|
| 219 |
+
plt.title(f'Prédictions vs Valeurs réelles - {fuel_type} - {price_range}')
|
| 220 |
+
plt.tight_layout()
|
| 221 |
+
plt.savefig(os.path.join(output_dir, f'predictions_vs_actual_{fuel_type}_{price_range}.png'))
|
| 222 |
+
plt.close()
|
| 223 |
+
|
| 224 |
+
# Calcul des métriques
|
| 225 |
+
mse = np.mean((predictions[:, 0] - actual_values[:, 0])**2)
|
| 226 |
+
mae = np.mean(np.abs(predictions[:, 0] - actual_values[:, 0]))
|
| 227 |
+
r2 = 1 - (np.sum((actual_values[:, 0] - predictions[:, 0])**2) /
|
| 228 |
+
np.sum((actual_values[:, 0] - np.mean(actual_values[:, 0]))**2))
|
| 229 |
+
|
| 230 |
+
print(f"MSE: {mse:.4f}")
|
| 231 |
+
print(f"MAE: {mae:.4f}")
|
| 232 |
+
print(f"R2 Score: {r2:.4f}")
|
| 233 |
+
|
| 234 |
+
return mse, mae, r2
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def prepare_data_for_fuel_type_and_range(merged_data, fuel_type, price_range, station_classifications, sequence_length, target_days):
|
| 238 |
+
print(f"Préparation des données pour {fuel_type} - {price_range}")
|
| 239 |
+
stations_in_range = [station for station, range_ in station_classifications[fuel_type].items() if range_ == price_range]
|
| 240 |
+
fuel_data = merged_data[(merged_data['fuel_name'] == fuel_type) & (merged_data['id'].isin(stations_in_range))].copy()
|
| 241 |
+
|
| 242 |
+
# Traitement des variables temporelles
|
| 243 |
+
fuel_data['day_of_week'] = fuel_data['rate_date'].dt.dayofweek
|
| 244 |
+
fuel_data['month'] = fuel_data['rate_date'].dt.month
|
| 245 |
+
|
| 246 |
+
# Encodage cyclique pour le jour de la semaine et le mois
|
| 247 |
+
fuel_data['day_of_week_sin'] = np.sin(2 * np.pi * fuel_data['day_of_week'] / 7)
|
| 248 |
+
fuel_data['day_of_week_cos'] = np.cos(2 * np.pi * fuel_data['day_of_week'] / 7)
|
| 249 |
+
fuel_data['month_sin'] = np.sin(2 * np.pi * fuel_data['month'] / 12)
|
| 250 |
+
fuel_data['month_cos'] = np.cos(2 * np.pi * fuel_data['month'] / 12)
|
| 251 |
+
|
| 252 |
+
# Standardisation du prix du Brent (au lieu de normaliser)
|
| 253 |
+
scaler = StandardScaler()
|
| 254 |
+
fuel_data['brent_rate_eur_scaled'] = scaler.fit_transform(fuel_data[['brent_rate_eur']])
|
| 255 |
+
|
| 256 |
+
# Sélection des colonnes finales
|
| 257 |
+
columns_to_use = ['price', 'brent_rate_eur_scaled', 'day_of_week_sin', 'day_of_week_cos', 'month_sin', 'month_cos']
|
| 258 |
+
fuel_data_prepared = fuel_data[columns_to_use]
|
| 259 |
+
|
| 260 |
+
print("Statistiques des données préparées:")
|
| 261 |
+
print(fuel_data_prepared.describe())
|
| 262 |
+
|
| 263 |
+
print("\nNombre de valeurs uniques par colonne:")
|
| 264 |
+
print(fuel_data_prepared.nunique())
|
| 265 |
+
|
| 266 |
+
print("\nVérification des valeurs nulles:")
|
| 267 |
+
print(fuel_data_prepared.isnull().sum())
|
| 268 |
+
|
| 269 |
+
dataset = FuelPriceDataset(fuel_data_prepared, sequence_length, target_days)
|
| 270 |
+
|
| 271 |
+
train_size = int(0.8 * len(dataset))
|
| 272 |
+
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, len(dataset) - train_size])
|
| 273 |
+
|
| 274 |
+
return train_dataset, val_dataset, scaler
|
| 275 |
+
|
| 276 |
+
def main(args):
|
| 277 |
+
print("Début du processus principal")
|
| 278 |
+
|
| 279 |
+
brent_data = load_brent_data(args.brent_data)
|
| 280 |
+
fuel_data = load_fuel_data(args.fuel_data)
|
| 281 |
+
|
| 282 |
+
print("Fusion des données Brent et carburant")
|
| 283 |
+
merged_data = pd.merge_asof(fuel_data.sort_values('rate_date'),
|
| 284 |
+
brent_data.reset_index().sort_values('brent_date'),
|
| 285 |
+
left_on='rate_date',
|
| 286 |
+
right_on='brent_date',
|
| 287 |
+
direction='nearest')
|
| 288 |
+
print(f"Données fusionnées. Shape: {merged_data.shape}")
|
| 289 |
+
|
| 290 |
+
station_classifications = classify_stations(fuel_data)
|
| 291 |
+
save_station_classifications(station_classifications, args.output_dir)
|
| 292 |
+
|
| 293 |
+
price_ranges = ['low-cost', 'normal', 'premium']
|
| 294 |
+
fuel_types = merged_data['fuel_name'].unique()
|
| 295 |
+
|
| 296 |
+
for fuel_type in fuel_types:
|
| 297 |
+
for price_range in price_ranges:
|
| 298 |
+
print(f"\nTraitement de {fuel_type} - {price_range}")
|
| 299 |
+
|
| 300 |
+
output_dir = os.path.join(args.output_dir, fuel_type, price_range)
|
| 301 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 302 |
+
|
| 303 |
+
try:
|
| 304 |
+
train_dataset, val_dataset, scaler = prepare_data_for_fuel_type_and_range(
|
| 305 |
+
merged_data, fuel_type, price_range, station_classifications, args.sequence_length, args.target_days
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
if len(train_dataset) < args.min_train_samples:
|
| 309 |
+
print(f"Pas assez de données pour {fuel_type} - {price_range}. Ignoré.")
|
| 310 |
+
continue
|
| 311 |
+
|
| 312 |
+
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
|
| 313 |
+
val_loader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False)
|
| 314 |
+
|
| 315 |
+
print(f"Taille du dataset d'entraînement : {len(train_dataset)}")
|
| 316 |
+
print(f"Taille du dataset de validation : {len(val_dataset)}")
|
| 317 |
+
print(f"Nombre de batchs d'entraînement : {len(train_loader)}")
|
| 318 |
+
print(f"Nombre de batchs de validation : {len(val_loader)}")
|
| 319 |
+
|
| 320 |
+
sample_x, sample_y = next(iter(train_loader))
|
| 321 |
+
input_size = sample_x.shape[2]
|
| 322 |
+
model = LSTMModel(input_size, args.hidden_size, args.num_layers, len(args.target_days)).to(device)
|
| 323 |
+
|
| 324 |
+
criterion = nn.MSELoss()
|
| 325 |
+
optimizer = optim.Adam(model.parameters(), lr=args.learning_rate)
|
| 326 |
+
|
| 327 |
+
train_losses, val_losses, mse, mae, r2 = train_model(
|
| 328 |
+
model, train_loader, val_loader, criterion, optimizer,
|
| 329 |
+
args.num_epochs, args.patience, output_dir, fuel_type, price_range, scaler
|
| 330 |
+
)
|
| 331 |
+
|
| 332 |
+
# Sauvegarder le modèle final
|
| 333 |
+
model_filename = os.path.join(output_dir, f'final_model_{fuel_type}_{price_range}.pth')
|
| 334 |
+
torch.save(model.state_dict(), model_filename)
|
| 335 |
+
|
| 336 |
+
# Sauvegarder le scaler
|
| 337 |
+
scaler_filename = os.path.join(output_dir, f'scaler_{fuel_type}_{price_range}.pkl')
|
| 338 |
+
pd.to_pickle(scaler, scaler_filename)
|
| 339 |
+
|
| 340 |
+
# Sauvegarder les paramètres du modèle
|
| 341 |
+
params = {
|
| 342 |
+
'input_size': input_size,
|
| 343 |
+
'hidden_size': args.hidden_size,
|
| 344 |
+
'num_layers': args.num_layers,
|
| 345 |
+
'output_size': len(args.target_days),
|
| 346 |
+
'sequence_length': args.sequence_length,
|
| 347 |
+
'target_days': args.target_days
|
| 348 |
+
}
|
| 349 |
+
params_filename = os.path.join(output_dir, f'model_params_{fuel_type}_{price_range}.json')
|
| 350 |
+
with open(params_filename, 'w') as f:
|
| 351 |
+
json.dump(params, f)
|
| 352 |
+
|
| 353 |
+
# Sauvegarder les métriques
|
| 354 |
+
metrics = {
|
| 355 |
+
'mse': mse,
|
| 356 |
+
'mae': mae,
|
| 357 |
+
'r2': r2
|
| 358 |
+
}
|
| 359 |
+
metrics_filename = os.path.join(output_dir, f'metrics_{fuel_type}_{price_range}.json')
|
| 360 |
+
with open(metrics_filename, 'w') as f:
|
| 361 |
+
json.dump(metrics, f)
|
| 362 |
+
|
| 363 |
+
# Tracer et sauvegarder les courbes d'apprentissage
|
| 364 |
+
plot_learning_curves(train_losses, val_losses, output_dir, fuel_type, price_range)
|
| 365 |
+
|
| 366 |
+
print(f"Modèle, paramètres, métriques et graphiques pour {fuel_type} - {price_range} sauvegardés dans {output_dir}")
|
| 367 |
+
|
| 368 |
+
except Exception as e:
|
| 369 |
+
print(f"Erreur lors du traitement de {fuel_type} - {price_range}: {str(e)}")
|
| 370 |
+
|
| 371 |
+
print("Processus terminé pour tous les types de carburant et gammes de prix.")
|
| 372 |
+
|
| 373 |
+
if __name__ == "__main__":
|
| 374 |
+
parser = argparse.ArgumentParser(description="Entraînement du modèle de prédiction des prix du carburant")
|
| 375 |
+
parser.add_argument("--brent_data", type=str, required=True, help="Chemin vers le fichier de données Brent")
|
| 376 |
+
parser.add_argument("--fuel_data", type=str, required=True, help="Chemin vers le dossier contenant les données de carburant")
|
| 377 |
+
parser.add_argument("--output_dir", type=str, default="./output", help="Dossier de sortie pour les modèles et les paramètres")
|
| 378 |
+
parser.add_argument("--hidden_size", type=int, default=64, help="Taille de la couche cachée LSTM")
|
| 379 |
+
parser.add_argument("--num_layers", type=int, default=2, help="Nombre de couches LSTM")
|
| 380 |
+
parser.add_argument("--sequence_length", type=int, default=30, help="Longueur de la séquence d'entrée")
|
| 381 |
+
parser.add_argument("--target_days", nargs='+', type=int, default=[3, 7, 15, 30], help="Jours cibles pour la prédiction")
|
| 382 |
+
parser.add_argument("--batch_size", type=int, default=32, help="Taille du batch pour l'entraînement")
|
| 383 |
+
parser.add_argument("--num_epochs", type=int, default=50, help="Nombre d'époques d'entraînement")
|
| 384 |
+
parser.add_argument("--learning_rate", type=float, default=0.001, help="Taux d'apprentissage")
|
| 385 |
+
parser.add_argument("--min_train_samples", type=int, default=50, help="Nombre minimum d'échantillons d'entraînement")
|
| 386 |
+
parser.add_argument("--patience", type=int, default=5, help="Nombre d'époques sans amélioration avant l'arrêt précoce")
|
| 387 |
+
|
| 388 |
+
args = parser.parse_args()
|
| 389 |
+
|
| 390 |
+
print(f"Arguments reçus: {args}")
|
| 391 |
+
|
| 392 |
+
os.makedirs(args.output_dir, exist_ok=True)
|
| 393 |
+
print(f"Dossier de sortie principal créé/vérifié: {args.output_dir}")
|
| 394 |
+
|
| 395 |
+
main(args)
|
runningscript.py
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Importation des bibliothèques nécessaires
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import glob
|
| 5 |
+
import os
|
| 6 |
+
import joblib
|
| 7 |
+
import gradio as gr
|
| 8 |
+
from sklearn.preprocessing import LabelEncoder, StandardScaler
|
| 9 |
+
from xgboost import XGBRegressor
|
| 10 |
+
|
| 11 |
+
# 1. Chargement des données
|
| 12 |
+
print("Chargement des données...")
|
| 13 |
+
parquet_files = glob.glob('FuelInFranceData/*.parquet')
|
| 14 |
+
|
| 15 |
+
if not parquet_files:
|
| 16 |
+
raise FileNotFoundError("Aucun fichier Parquet trouvé dans le répertoire spécifié.")
|
| 17 |
+
|
| 18 |
+
df_list = []
|
| 19 |
+
for f in parquet_files:
|
| 20 |
+
print(f"Chargement du fichier {f}")
|
| 21 |
+
df_list.append(pd.read_parquet(f))
|
| 22 |
+
df = pd.concat(df_list, ignore_index=True)
|
| 23 |
+
del df_list # Libération de la mémoire
|
| 24 |
+
print(f"Nombre total d'enregistrements: {len(df)}")
|
| 25 |
+
|
| 26 |
+
# 2. Prétraitement des données
|
| 27 |
+
print("Prétraitement des données...")
|
| 28 |
+
df['rate_date'] = pd.to_datetime(df['rate_date'])
|
| 29 |
+
df['brent_date'] = pd.to_datetime(df['brent_date'])
|
| 30 |
+
df = df.sort_values('rate_date')
|
| 31 |
+
df = df.dropna()
|
| 32 |
+
|
| 33 |
+
# Exclure les carburants E85 et GPLc
|
| 34 |
+
df = df[~df['fuel_name'].isin(['E85', 'GPLc'])]
|
| 35 |
+
|
| 36 |
+
# Sélection des colonnes pertinentes
|
| 37 |
+
cols_to_use = ['station_id', 'commune', 'marque', 'departement', 'regioncode',
|
| 38 |
+
'coordlatitude', 'coordlongitude', 'fuel_name', 'price',
|
| 39 |
+
'rate_date', 'brent_rate_eur', 'brent_date']
|
| 40 |
+
df = df[cols_to_use]
|
| 41 |
+
|
| 42 |
+
# Encodage des variables catégorielles
|
| 43 |
+
print("Encodage des variables catégorielles...")
|
| 44 |
+
label_encoders = {}
|
| 45 |
+
categorical_cols = ['station_id', 'commune', 'marque', 'departement',
|
| 46 |
+
'regioncode', 'fuel_name']
|
| 47 |
+
|
| 48 |
+
for col in categorical_cols:
|
| 49 |
+
le = LabelEncoder()
|
| 50 |
+
df[col] = le.fit_transform(df[col].astype(str))
|
| 51 |
+
label_encoders[col] = le
|
| 52 |
+
|
| 53 |
+
# Création des mappings pour les communes et les départements
|
| 54 |
+
commune_mapping = pd.DataFrame({
|
| 55 |
+
'commune_encoded': np.arange(len(label_encoders['commune'].classes_)),
|
| 56 |
+
'commune_decoded': label_encoders['commune'].classes_
|
| 57 |
+
})
|
| 58 |
+
|
| 59 |
+
departement_mapping = pd.DataFrame({
|
| 60 |
+
'departement_encoded': np.arange(len(label_encoders['departement'].classes_)),
|
| 61 |
+
'departement_decoded': label_encoders['departement'].classes_
|
| 62 |
+
})
|
| 63 |
+
|
| 64 |
+
# Obtenir les types de carburant uniques
|
| 65 |
+
fuel_types = label_encoders['fuel_name'].classes_.tolist()
|
| 66 |
+
|
| 67 |
+
# Obtenir les départements uniques
|
| 68 |
+
departments = label_encoders['departement'].classes_.tolist()
|
| 69 |
+
|
| 70 |
+
# Fonction pour mettre à jour la liste des stations
|
| 71 |
+
def update_stations(commune_input, departments):
|
| 72 |
+
if commune_input:
|
| 73 |
+
# Recherche insensible à la casse avec correspondance partielle
|
| 74 |
+
matching_communes = commune_mapping[commune_mapping['commune_decoded'].str.contains(commune_input, case=False, na=False)]
|
| 75 |
+
if matching_communes.empty:
|
| 76 |
+
return gr.update(choices=[], value=None)
|
| 77 |
+
commune_encoded_values = matching_communes['commune_encoded'].values
|
| 78 |
+
# Filtrer les stations par les communes correspondantes
|
| 79 |
+
filtered_df = df[df['commune'].isin(commune_encoded_values)]
|
| 80 |
+
elif departments:
|
| 81 |
+
# Vérifier si les départements existent
|
| 82 |
+
valid_departments = [dept for dept in departments if dept in label_encoders['departement'].classes_]
|
| 83 |
+
if not valid_departments:
|
| 84 |
+
return gr.update(choices=[], value=None)
|
| 85 |
+
# Filtrer les stations par départements
|
| 86 |
+
departments_encoded = label_encoders['departement'].transform(valid_departments)
|
| 87 |
+
filtered_df = df[df['departement'].isin(departments_encoded)]
|
| 88 |
+
else:
|
| 89 |
+
# Si aucun filtre, afficher toutes les stations
|
| 90 |
+
filtered_df = df.copy()
|
| 91 |
+
|
| 92 |
+
if filtered_df.empty:
|
| 93 |
+
return gr.update(choices=[], value=None)
|
| 94 |
+
|
| 95 |
+
# Obtenir les informations des stations uniques
|
| 96 |
+
station_info = filtered_df[['station_id', 'commune', 'marque']].drop_duplicates()
|
| 97 |
+
|
| 98 |
+
# Décoder les valeurs encodées
|
| 99 |
+
station_info['station_id_decoded'] = label_encoders['station_id'].inverse_transform(station_info['station_id'])
|
| 100 |
+
station_info['commune_decoded'] = label_encoders['commune'].inverse_transform(station_info['commune'])
|
| 101 |
+
station_info['marque_decoded'] = label_encoders['marque'].inverse_transform(station_info['marque'])
|
| 102 |
+
|
| 103 |
+
# Construire les chaînes d'affichage
|
| 104 |
+
station_info['station_display'] = station_info.apply(
|
| 105 |
+
lambda row: f"{row['commune_decoded']} - {row['marque_decoded']} ({row['station_id_decoded']})",
|
| 106 |
+
axis=1
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
# Construire les choix sous forme de tuples (affichage, valeur)
|
| 110 |
+
station_choices = list(zip(station_info['station_display'], station_info['station_id_decoded']))
|
| 111 |
+
|
| 112 |
+
return gr.update(choices=station_choices, value=None)
|
| 113 |
+
|
| 114 |
+
# Fonction pour effectuer les prévisions
|
| 115 |
+
def forecast_prices(model, last_known_data, scaler, required_columns, brent_price, horizons=[3, 7, 15, 30]):
|
| 116 |
+
forecasts = {}
|
| 117 |
+
for horizon in horizons:
|
| 118 |
+
future_date = last_known_data['rate_date'] + pd.Timedelta(days=horizon)
|
| 119 |
+
input_data = last_known_data.copy()
|
| 120 |
+
input_data['rate_date'] = future_date
|
| 121 |
+
input_data['day_of_week'] = future_date.dayofweek
|
| 122 |
+
input_data['month'] = future_date.month
|
| 123 |
+
input_data['year'] = future_date.year
|
| 124 |
+
|
| 125 |
+
# Mise à jour des variables de décalage du Brent
|
| 126 |
+
for lag in [1, 3, 7, 15, 30]:
|
| 127 |
+
input_data[f'brent_rate_eur_lag_{lag}'] = brent_price
|
| 128 |
+
|
| 129 |
+
# Préparation des features
|
| 130 |
+
input_features = input_data.drop(['price', 'rate_date', 'brent_date'])
|
| 131 |
+
input_features = input_features.to_frame().T
|
| 132 |
+
|
| 133 |
+
# S'assurer que toutes les colonnes sont présentes
|
| 134 |
+
missing_cols = set(required_columns) - set(input_features.columns)
|
| 135 |
+
for col in missing_cols:
|
| 136 |
+
input_features[col] = 0
|
| 137 |
+
|
| 138 |
+
input_features = input_features[required_columns]
|
| 139 |
+
|
| 140 |
+
# Mise à l'échelle des features
|
| 141 |
+
input_features_scaled = scaler.transform(input_features)
|
| 142 |
+
predicted_price = model.predict(input_features_scaled)
|
| 143 |
+
forecasts[horizon] = predicted_price[0]
|
| 144 |
+
return forecasts
|
| 145 |
+
|
| 146 |
+
# Fonction principale pour obtenir les prédictions
|
| 147 |
+
def get_predictions(station_selection, fuel_types_selected, brent_price, commune_input, departments):
|
| 148 |
+
if not station_selection or not fuel_types_selected:
|
| 149 |
+
return "Veuillez sélectionner une station et au moins un type de carburant."
|
| 150 |
+
|
| 151 |
+
results = ""
|
| 152 |
+
|
| 153 |
+
# station_selection est l'ID décodé de la station
|
| 154 |
+
station_id = station_selection
|
| 155 |
+
if station_id not in label_encoders['station_id'].classes_:
|
| 156 |
+
return f"Station ID {station_id} non trouvé dans les données."
|
| 157 |
+
station_id_encoded = label_encoders['station_id'].transform([station_id])[0]
|
| 158 |
+
|
| 159 |
+
for fuel_type in fuel_types_selected:
|
| 160 |
+
# Charger le modèle et le scaler pour le type de carburant
|
| 161 |
+
model_filename = f'fuel_price_model_{fuel_type}.pkl'
|
| 162 |
+
scaler_filename = f'scaler_{fuel_type}.pkl'
|
| 163 |
+
|
| 164 |
+
if not os.path.exists(model_filename) or not os.path.exists(scaler_filename):
|
| 165 |
+
results += f"\nModèle ou scaler pour le carburant {fuel_type} non trouvé."
|
| 166 |
+
continue
|
| 167 |
+
|
| 168 |
+
model = joblib.load(model_filename)
|
| 169 |
+
scaler = joblib.load(scaler_filename)
|
| 170 |
+
|
| 171 |
+
# Obtenir les 5 derniers prix
|
| 172 |
+
fuel_name_encoded = label_encoders['fuel_name'].transform([fuel_type])[0]
|
| 173 |
+
|
| 174 |
+
df_station_fuel = df[(df['station_id'] == station_id_encoded) & (df['fuel_name'] == fuel_name_encoded)]
|
| 175 |
+
df_station_fuel = df_station_fuel.sort_values('rate_date', ascending=False)
|
| 176 |
+
|
| 177 |
+
if df_station_fuel.empty:
|
| 178 |
+
results += f"\nAucune donnée trouvée pour la station {station_id} et le carburant {fuel_type}."
|
| 179 |
+
continue
|
| 180 |
+
|
| 181 |
+
last_5_prices = df_station_fuel.head(5)[['rate_date', 'price']]
|
| 182 |
+
last_5_prices['rate_date'] = last_5_prices['rate_date'].dt.strftime('%Y-%m-%d %H:%M:%S')
|
| 183 |
+
results += f"\n\nType de carburant : {fuel_type}\nLes 5 derniers prix :\n{last_5_prices.to_string(index=False)}"
|
| 184 |
+
|
| 185 |
+
# Préparation des données pour la prédiction
|
| 186 |
+
last_known_data = df_station_fuel.iloc[0].copy()
|
| 187 |
+
last_known_data['brent_rate_eur'] = brent_price
|
| 188 |
+
|
| 189 |
+
# Recréer les features utilisées lors de l'entraînement
|
| 190 |
+
df_fuel = df[df['fuel_name'] == fuel_name_encoded].copy()
|
| 191 |
+
|
| 192 |
+
# Ingénierie des caractéristiques
|
| 193 |
+
df_fuel['day_of_week'] = df_fuel['rate_date'].dt.dayofweek
|
| 194 |
+
df_fuel['month'] = df_fuel['rate_date'].dt.month
|
| 195 |
+
df_fuel['year'] = df_fuel['rate_date'].dt.year
|
| 196 |
+
|
| 197 |
+
for lag in [1, 3, 7, 15, 30]:
|
| 198 |
+
df_fuel[f'brent_rate_eur_lag_{lag}'] = df_fuel['brent_rate_eur'].shift(lag)
|
| 199 |
+
df_fuel = df_fuel.dropna()
|
| 200 |
+
|
| 201 |
+
X = df_fuel.drop(['price', 'rate_date', 'brent_date'], axis=1)
|
| 202 |
+
required_columns = X.columns.tolist()
|
| 203 |
+
|
| 204 |
+
# Prévisions
|
| 205 |
+
forecasts = forecast_prices(model, last_known_data, scaler, required_columns, brent_price)
|
| 206 |
+
|
| 207 |
+
results += "\nPrévisions :\n"
|
| 208 |
+
for horizon, price in forecasts.items():
|
| 209 |
+
results += f"Dans {horizon} jours : {price:.4f} €\n"
|
| 210 |
+
|
| 211 |
+
return results
|
| 212 |
+
|
| 213 |
+
# 7. Construction de l'Interface Gradio
|
| 214 |
+
with gr.Blocks() as demo:
|
| 215 |
+
gr.Markdown("# Prédiction du Prix des Carburants")
|
| 216 |
+
|
| 217 |
+
with gr.Row():
|
| 218 |
+
fuel_type_checkbox = gr.CheckboxGroup(
|
| 219 |
+
choices=fuel_types,
|
| 220 |
+
label="Sélectionnez les types de carburant",
|
| 221 |
+
value=fuel_types # Tous sélectionnés par défaut
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
with gr.Row():
|
| 225 |
+
commune_input = gr.Textbox(
|
| 226 |
+
label="Entrez la commune",
|
| 227 |
+
placeholder="Tapez le nom de la commune..."
|
| 228 |
+
)
|
| 229 |
+
department_dropdown = gr.Dropdown(
|
| 230 |
+
choices=departments,
|
| 231 |
+
label="Sélectionnez le(s) département(s)",
|
| 232 |
+
multiselect=True
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
station_dropdown = gr.Dropdown(
|
| 236 |
+
choices=[],
|
| 237 |
+
label="Sélectionnez la station"
|
| 238 |
+
)
|
| 239 |
+
|
| 240 |
+
# Mettre à jour la liste des stations lorsque la commune ou le département change
|
| 241 |
+
def update_stations_wrapper(commune, departments):
|
| 242 |
+
return update_stations(commune, departments)
|
| 243 |
+
|
| 244 |
+
commune_input.change(
|
| 245 |
+
fn=update_stations_wrapper,
|
| 246 |
+
inputs=[commune_input, department_dropdown],
|
| 247 |
+
outputs=station_dropdown
|
| 248 |
+
)
|
| 249 |
+
department_dropdown.change(
|
| 250 |
+
fn=update_stations_wrapper,
|
| 251 |
+
inputs=[commune_input, department_dropdown],
|
| 252 |
+
outputs=station_dropdown
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
brent_price_input = gr.Number(
|
| 256 |
+
label="Entrez le cours du Brent (€)",
|
| 257 |
+
value=70.0
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
predict_button = gr.Button("Prédire")
|
| 261 |
+
|
| 262 |
+
output = gr.Textbox(label="Résultats")
|
| 263 |
+
|
| 264 |
+
def on_predict_click(station_selection, fuel_types_selected, brent_price, commune_input, departments):
|
| 265 |
+
return get_predictions(station_selection, fuel_types_selected, brent_price, commune_input, departments)
|
| 266 |
+
|
| 267 |
+
predict_button.click(
|
| 268 |
+
fn=on_predict_click,
|
| 269 |
+
inputs=[station_dropdown, fuel_type_checkbox, brent_price_input, commune_input, department_dropdown],
|
| 270 |
+
outputs=output
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
demo.launch(share=True)
|
scaler.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:30e5e37b6791b83db7bc3ec6ce5385ec4b85bd5c1d8545e465c89e4a1caa414a
|
| 3 |
+
size 1959
|
scaler_E10.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:163f18a61e413e08dae4c57a509f14caadf11dab483b94b139abede236e27c64
|
| 3 |
+
size 1631
|
scaler_Gazole.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1947942b4c27af30944d8e4b0e5f9dd3e7837b4a1289d62f635d35e5f99d365a
|
| 3 |
+
size 1631
|
scaler_SP95.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc4af1fa4538632ee67d0cd4e5fab37ae7e60458950b023dc0e0f7273a14afcc
|
| 3 |
+
size 1631
|
scaler_SP98.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e97859428b468552eee47ec5ca923c790ffa0fd50e83d0cb0529e351b10aba9f
|
| 3 |
+
size 1631
|
trainingscript.py
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Importation des bibliothèques nécessaires
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import glob
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
import matplotlib as mpl
|
| 7 |
+
from sklearn.preprocessing import LabelEncoder, StandardScaler
|
| 8 |
+
from sklearn.metrics import mean_absolute_error, mean_squared_error
|
| 9 |
+
from sklearn.model_selection import TimeSeriesSplit
|
| 10 |
+
from xgboost import XGBRegressor
|
| 11 |
+
import joblib
|
| 12 |
+
import os
|
| 13 |
+
|
| 14 |
+
# Ajustement du paramètre agg.path.chunksize pour éviter l'OverflowError
|
| 15 |
+
mpl.rcParams['agg.path.chunksize'] = 10000 # Vous pouvez ajuster la valeur si nécessaire
|
| 16 |
+
|
| 17 |
+
# 1. Chargement des données
|
| 18 |
+
print("Chargement des données...")
|
| 19 |
+
parquet_files = glob.glob('FuelInFranceData/*.parquet')
|
| 20 |
+
|
| 21 |
+
if not parquet_files:
|
| 22 |
+
raise FileNotFoundError("Aucun fichier Parquet trouvé dans le répertoire spécifié.")
|
| 23 |
+
|
| 24 |
+
df_list = []
|
| 25 |
+
for f in parquet_files:
|
| 26 |
+
print(f"Chargement du fichier {f}")
|
| 27 |
+
df_list.append(pd.read_parquet(f))
|
| 28 |
+
df = pd.concat(df_list, ignore_index=True)
|
| 29 |
+
del df_list # Libération de la mémoire
|
| 30 |
+
print(f"Nombre total d'enregistrements: {len(df)}")
|
| 31 |
+
|
| 32 |
+
# 2. Prétraitement des données
|
| 33 |
+
print("Prétraitement des données...")
|
| 34 |
+
df['rate_date'] = pd.to_datetime(df['rate_date'])
|
| 35 |
+
df['brent_date'] = pd.to_datetime(df['brent_date'])
|
| 36 |
+
df = df.sort_values('rate_date')
|
| 37 |
+
df = df.dropna()
|
| 38 |
+
|
| 39 |
+
# Exclure les carburants E85 et GPLc
|
| 40 |
+
df = df[~df['fuel_name'].isin(['E85', 'GPLc'])]
|
| 41 |
+
|
| 42 |
+
# Sélection des colonnes pertinentes (inclure 'brent_date')
|
| 43 |
+
cols_to_use = ['station_id', 'commune', 'marque', 'departement', 'regioncode',
|
| 44 |
+
'coordlatitude', 'coordlongitude', 'fuel_name', 'price',
|
| 45 |
+
'rate_date', 'brent_rate_eur', 'brent_date']
|
| 46 |
+
|
| 47 |
+
df = df[cols_to_use]
|
| 48 |
+
|
| 49 |
+
# Encodage des variables catégorielles
|
| 50 |
+
print("Encodage des variables catégorielles...")
|
| 51 |
+
label_encoders = {}
|
| 52 |
+
categorical_cols = ['station_id', 'commune', 'marque', 'departement',
|
| 53 |
+
'regioncode', 'fuel_name']
|
| 54 |
+
|
| 55 |
+
for col in categorical_cols:
|
| 56 |
+
le = LabelEncoder()
|
| 57 |
+
df[col] = le.fit_transform(df[col].astype(str))
|
| 58 |
+
label_encoders[col] = le
|
| 59 |
+
|
| 60 |
+
# 3. Nettoyage des valeurs aberrantes (outliers)
|
| 61 |
+
print("Nettoyage des valeurs aberrantes...")
|
| 62 |
+
# Suppression des outliers en utilisant l'IQR (Interquartile Range)
|
| 63 |
+
def remove_outliers_iqr(data, column):
|
| 64 |
+
Q1 = data[column].quantile(0.25)
|
| 65 |
+
Q3 = data[column].quantile(0.75)
|
| 66 |
+
IQR = Q3 - Q1
|
| 67 |
+
lower_bound = Q1 - 1.5 * IQR
|
| 68 |
+
upper_bound = Q3 + 1.5 * IQR
|
| 69 |
+
data_clean = data[(data[column] >= lower_bound) & (data[column] <= upper_bound)]
|
| 70 |
+
return data_clean
|
| 71 |
+
|
| 72 |
+
df = remove_outliers_iqr(df, 'price')
|
| 73 |
+
|
| 74 |
+
# 4. Entraînement de modèles séparés pour chaque type de carburant avec validation croisée temporelle
|
| 75 |
+
print("Entraînement de modèles séparés pour chaque type de carburant avec validation croisée temporelle...")
|
| 76 |
+
fuel_types = df['fuel_name'].unique()
|
| 77 |
+
models = {}
|
| 78 |
+
scalers = {}
|
| 79 |
+
results = {}
|
| 80 |
+
|
| 81 |
+
for fuel in fuel_types:
|
| 82 |
+
fuel_name_decoded = label_encoders['fuel_name'].inverse_transform([fuel])[0]
|
| 83 |
+
print(f"\nTraitement du carburant: {fuel_name_decoded}")
|
| 84 |
+
df_fuel = df[df['fuel_name'] == fuel].copy()
|
| 85 |
+
|
| 86 |
+
# Ingénierie des caractéristiques
|
| 87 |
+
df_fuel['day_of_week'] = df_fuel['rate_date'].dt.dayofweek
|
| 88 |
+
df_fuel['month'] = df_fuel['rate_date'].dt.month
|
| 89 |
+
df_fuel['year'] = df_fuel['rate_date'].dt.year
|
| 90 |
+
|
| 91 |
+
# Création des variables de décalage (lags) pour le prix du Brent
|
| 92 |
+
for lag in [1, 3, 7, 15, 30]:
|
| 93 |
+
df_fuel[f'brent_rate_eur_lag_{lag}'] = df_fuel['brent_rate_eur'].shift(lag)
|
| 94 |
+
df_fuel = df_fuel.dropna()
|
| 95 |
+
|
| 96 |
+
# Variables features et target
|
| 97 |
+
X = df_fuel.drop(['price', 'rate_date', 'brent_date'], axis=1)
|
| 98 |
+
y = df_fuel['price']
|
| 99 |
+
dates = df_fuel['rate_date']
|
| 100 |
+
|
| 101 |
+
# Normalisation des données
|
| 102 |
+
scaler = StandardScaler()
|
| 103 |
+
X_scaled = scaler.fit_transform(X)
|
| 104 |
+
|
| 105 |
+
# Validation croisée temporelle
|
| 106 |
+
tscv = TimeSeriesSplit(n_splits=5)
|
| 107 |
+
y_tests = []
|
| 108 |
+
y_preds = []
|
| 109 |
+
dates_list = []
|
| 110 |
+
|
| 111 |
+
for fold, (train_index, test_index) in enumerate(tscv.split(X_scaled)):
|
| 112 |
+
print(f" Fold {fold+1}/{tscv.get_n_splits()}")
|
| 113 |
+
X_train, X_test = X_scaled[train_index], X_scaled[test_index]
|
| 114 |
+
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
|
| 115 |
+
dates_test = dates.iloc[test_index]
|
| 116 |
+
|
| 117 |
+
# Entraînement du modèle
|
| 118 |
+
model = XGBRegressor(objective='reg:squarederror', n_estimators=100, learning_rate=0.1)
|
| 119 |
+
model.fit(X_train, y_train)
|
| 120 |
+
|
| 121 |
+
# Prédiction sur l'ensemble de test
|
| 122 |
+
y_pred = model.predict(X_test)
|
| 123 |
+
|
| 124 |
+
# Stockage des résultats
|
| 125 |
+
y_tests.append(y_test)
|
| 126 |
+
y_preds.append(y_pred)
|
| 127 |
+
dates_list.append(dates_test)
|
| 128 |
+
|
| 129 |
+
# Concaténation des résultats
|
| 130 |
+
y_test_total = pd.concat(y_tests)
|
| 131 |
+
y_pred_total = np.concatenate(y_preds)
|
| 132 |
+
dates_total = pd.concat(dates_list)
|
| 133 |
+
|
| 134 |
+
# Évaluation du modèle
|
| 135 |
+
mae = mean_absolute_error(y_test_total, y_pred_total)
|
| 136 |
+
rmse = mean_squared_error(y_test_total, y_pred_total, squared=False)
|
| 137 |
+
print(f"Erreur Absolue Moyenne (MAE): {mae:.4f}")
|
| 138 |
+
print(f"Racine de l'Erreur Quadratique Moyenne (RMSE): {rmse:.4f}")
|
| 139 |
+
|
| 140 |
+
# Entraînement final sur l'ensemble des données pour la prévision future
|
| 141 |
+
model_final = XGBRegressor(objective='reg:squarederror', n_estimators=100, learning_rate=0.1)
|
| 142 |
+
model_final.fit(X_scaled, y)
|
| 143 |
+
|
| 144 |
+
# Sauvegarde du modèle final et du scaler
|
| 145 |
+
models[fuel] = model_final
|
| 146 |
+
scalers[fuel] = scaler
|
| 147 |
+
|
| 148 |
+
# Stockage des résultats pour l'analyse
|
| 149 |
+
results[fuel] = {
|
| 150 |
+
'y_test': y_test_total,
|
| 151 |
+
'y_pred': y_pred_total,
|
| 152 |
+
'dates': dates_total
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
# Sous-échantillonnage des données pour le tracé
|
| 156 |
+
downsample_rate = max(1, len(dates_total) // 1000) # Limiter à 1000 points
|
| 157 |
+
dates_sampled = dates_total.iloc[::downsample_rate]
|
| 158 |
+
y_test_sampled = y_test_total.iloc[::downsample_rate]
|
| 159 |
+
y_pred_sampled = y_pred_total[::downsample_rate]
|
| 160 |
+
|
| 161 |
+
# Tri des données pour le tracé
|
| 162 |
+
sorted_indices = np.argsort(dates_sampled)
|
| 163 |
+
dates_sampled = dates_sampled.iloc[sorted_indices]
|
| 164 |
+
y_test_sampled = y_test_sampled.iloc[sorted_indices]
|
| 165 |
+
y_pred_sampled = y_pred_sampled[sorted_indices]
|
| 166 |
+
|
| 167 |
+
# Graphique de validation (Prix prédit vs Prix réel)
|
| 168 |
+
plt.figure(figsize=(12, 6))
|
| 169 |
+
plt.plot(dates_sampled, y_test_sampled, label='Prix Réel', marker='o', linestyle='None', markersize=4)
|
| 170 |
+
plt.plot(dates_sampled, y_pred_sampled, label='Prix Prédit', marker='x', linestyle='None', markersize=4)
|
| 171 |
+
plt.xlabel('Date')
|
| 172 |
+
plt.ylabel('Prix (€)')
|
| 173 |
+
plt.title(f"Comparaison du Prix Réel et Prédit pour le Carburant {fuel_name_decoded}")
|
| 174 |
+
plt.legend()
|
| 175 |
+
plt.tight_layout()
|
| 176 |
+
# Enregistrer le graphique
|
| 177 |
+
plt.savefig(f'validation_{fuel_name_decoded}.png')
|
| 178 |
+
plt.close()
|
| 179 |
+
|
| 180 |
+
# 5. Prévision pour les 3, 7, 15 et 30 prochains jours pour chaque carburant
|
| 181 |
+
print("\nPrévision pour les prochains jours pour chaque carburant...")
|
| 182 |
+
for fuel in fuel_types:
|
| 183 |
+
fuel_name_decoded = label_encoders['fuel_name'].inverse_transform([fuel])[0]
|
| 184 |
+
print(f"\nPrévisions pour le carburant: {fuel_name_decoded}")
|
| 185 |
+
df_fuel = df[df['fuel_name'] == fuel]
|
| 186 |
+
last_known_data = df_fuel.iloc[-1]
|
| 187 |
+
model = models[fuel]
|
| 188 |
+
scaler = scalers[fuel]
|
| 189 |
+
|
| 190 |
+
def forecast_prices(model, last_known_data, scaler, horizons=[3, 7, 15, 30]):
|
| 191 |
+
forecasts = {}
|
| 192 |
+
for horizon in horizons:
|
| 193 |
+
future_date = last_known_data['rate_date'] + pd.Timedelta(days=horizon)
|
| 194 |
+
input_data = last_known_data.to_frame().T.copy()
|
| 195 |
+
input_data['rate_date'] = future_date
|
| 196 |
+
input_data['day_of_week'] = future_date.dayofweek
|
| 197 |
+
input_data['month'] = future_date.month
|
| 198 |
+
input_data['year'] = future_date.year
|
| 199 |
+
|
| 200 |
+
# Mise à jour des variables de décalage du Brent
|
| 201 |
+
for lag in [1, 3, 7, 15, 30]:
|
| 202 |
+
input_data[f'brent_rate_eur_lag_{lag}'] = last_known_data['brent_rate_eur']
|
| 203 |
+
input_data = input_data.dropna(axis=1, how='all')
|
| 204 |
+
|
| 205 |
+
# Préparation des données pour la prédiction
|
| 206 |
+
input_features = input_data.drop(['price', 'rate_date', 'brent_date'], axis=1)
|
| 207 |
+
input_features_scaled = scaler.transform(input_features)
|
| 208 |
+
predicted_price = model.predict(input_features_scaled)
|
| 209 |
+
forecasts[horizon] = predicted_price[0]
|
| 210 |
+
return forecasts
|
| 211 |
+
|
| 212 |
+
# Prévision des prix
|
| 213 |
+
forecasts = forecast_prices(model, last_known_data, scaler)
|
| 214 |
+
for horizon, price in forecasts.items():
|
| 215 |
+
print(f"Dans {horizon} jours: {price:.4f} €")
|
| 216 |
+
|
| 217 |
+
# 6. Sauvegarde des modèles et des scalers pour une utilisation future
|
| 218 |
+
print("\nSauvegarde des modèles et des scalers...")
|
| 219 |
+
for fuel in fuel_types:
|
| 220 |
+
fuel_name_decoded = label_encoders['fuel_name'].inverse_transform([fuel])[0]
|
| 221 |
+
joblib.dump(models[fuel], f'fuel_price_model_{fuel_name_decoded}.pkl')
|
| 222 |
+
joblib.dump(scalers[fuel], f'scaler_{fuel_name_decoded}.pkl')
|
| 223 |
+
|
| 224 |
+
print("Script terminé avec succès.")
|
validation_E10.png
ADDED

|
validation_Gazole.png
ADDED
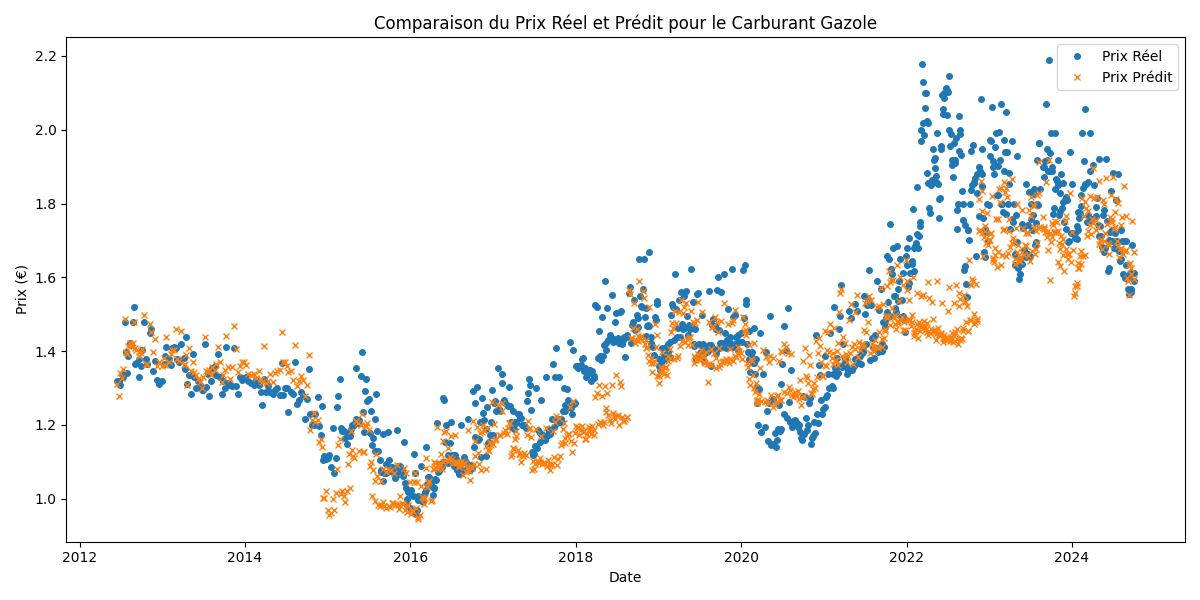
|
validation_SP95.png
ADDED
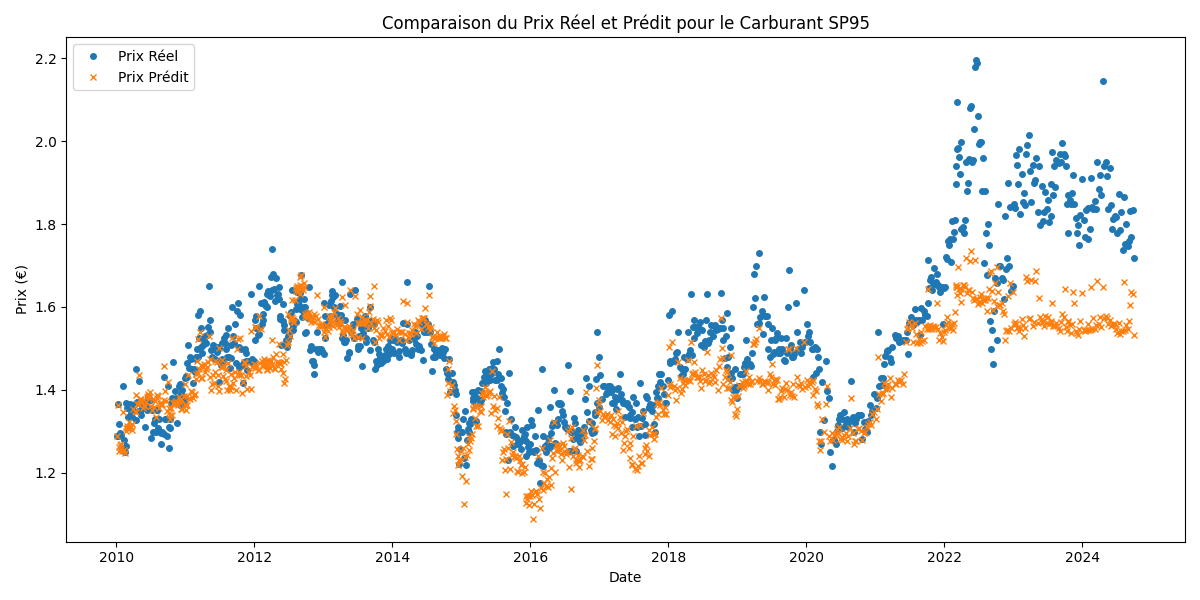
|
validation_SP98.png
ADDED

|