Spaces:
Sleeping

Sleeping
Upload 9 files
Browse files- .gitattributes +1 -0
- app.py +27 -0
- eda.py +29 -0
- eda_1.png +0 -0
- eda_2.png +0 -0
- eda_3.png +0 -0
- eda_4.png +0 -0
- model_lstm_3.keras +3 -0
- prediction.py +47 -0
- requirements.txt +6 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
model_lstm_3.keras filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
# import joblib as jb
|
| 4 |
+
import eda
|
| 5 |
+
import prediction
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
#header
|
| 9 |
+
"""
|
| 10 |
+
# Graded Challenge 7
|
| 11 |
+
**Name : Frederick Kurniawan Putra**
|
| 12 |
+
|
| 13 |
+
**Batch : HCK016**
|
| 14 |
+
|
| 15 |
+
This is model deployment of Hate Speech Sentiment Prediction.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
PAGES = {
|
| 21 |
+
"Eda": eda,
|
| 22 |
+
"Prediction": prediction
|
| 23 |
+
}
|
| 24 |
+
st.sidebar.title('Navigation')
|
| 25 |
+
selection = st.sidebar.radio("Go to", list(PAGES.keys()))
|
| 26 |
+
page = PAGES[selection]
|
| 27 |
+
page.app()
|
eda.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
|
| 4 |
+
def app():
|
| 5 |
+
st.title('EDA')
|
| 6 |
+
|
| 7 |
+
# EDA 1
|
| 8 |
+
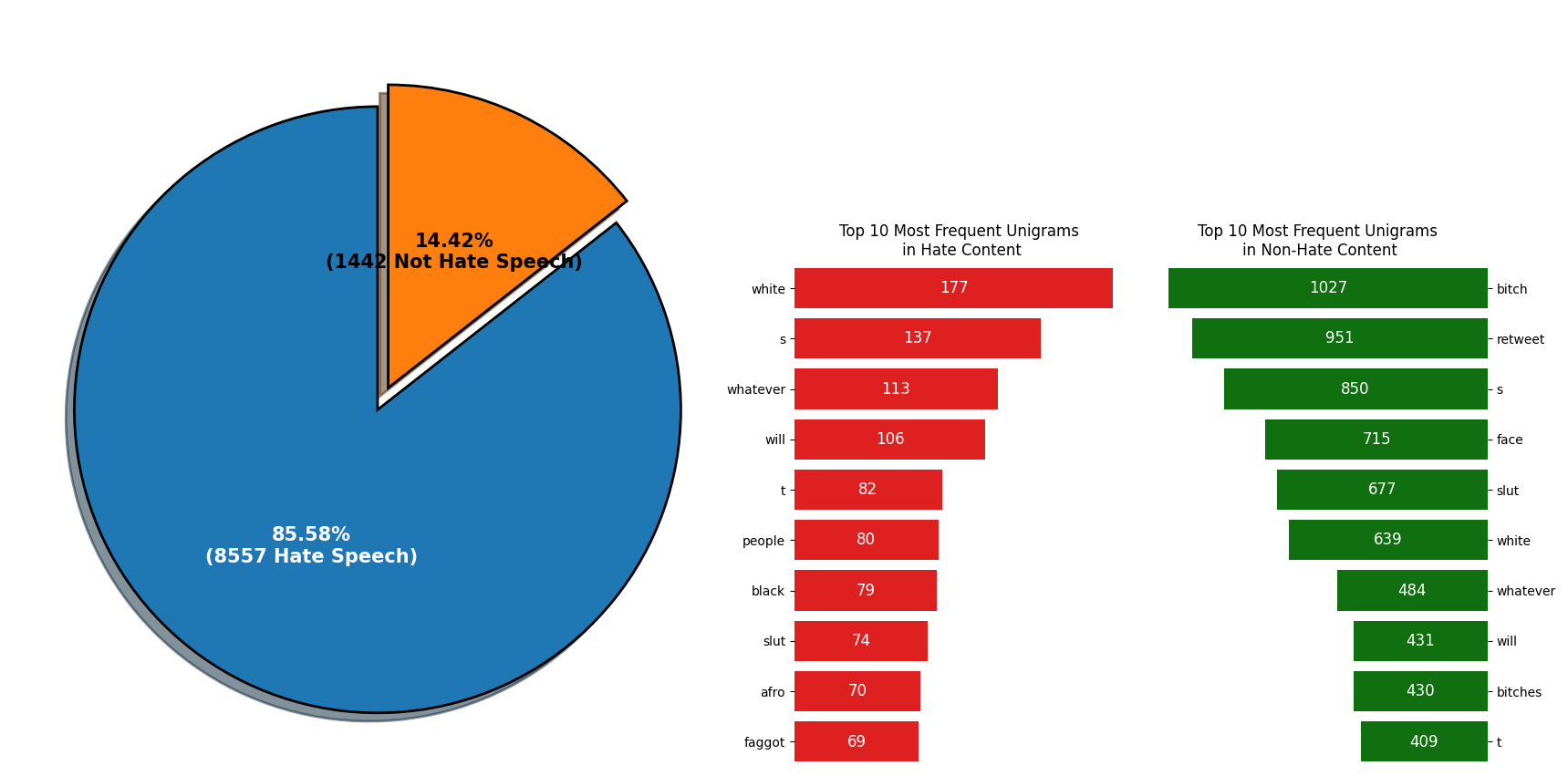
st.write('1. Percentage of Hate Speech and Non Hate Speech')
|
| 9 |
+
image = Image.open('eda_1.png')
|
| 10 |
+
st.image(image)
|
| 11 |
+
st.write('Here we can see that our dataset has 85.58% Non Hate Speech, while hate speech represents 14.42% data. This means that the data is imbalanced.')
|
| 12 |
+
|
| 13 |
+
# EDA 2
|
| 14 |
+
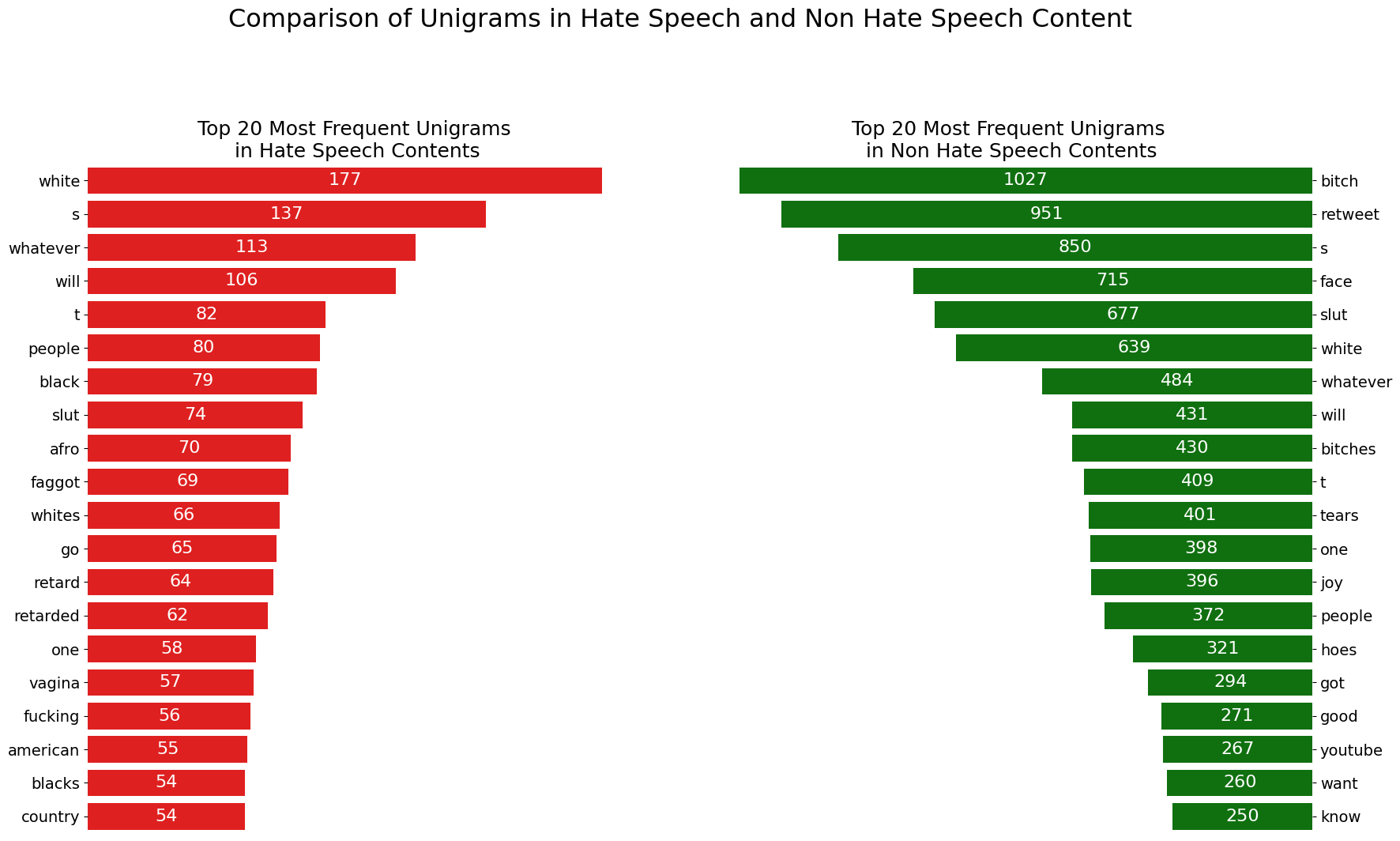
st.write('2. Most Frequent Unigram in dataset')
|
| 15 |
+
image = Image.open('eda_2.png')
|
| 16 |
+
st.image(image)
|
| 17 |
+
st.write("In this data we can see that Most frequent Unigrams that might represent mockery and racism are white, black, slut, afro, faggot. This indicates that racism slur is a indication of hate speech.")
|
| 18 |
+
|
| 19 |
+
# EDA 3
|
| 20 |
+
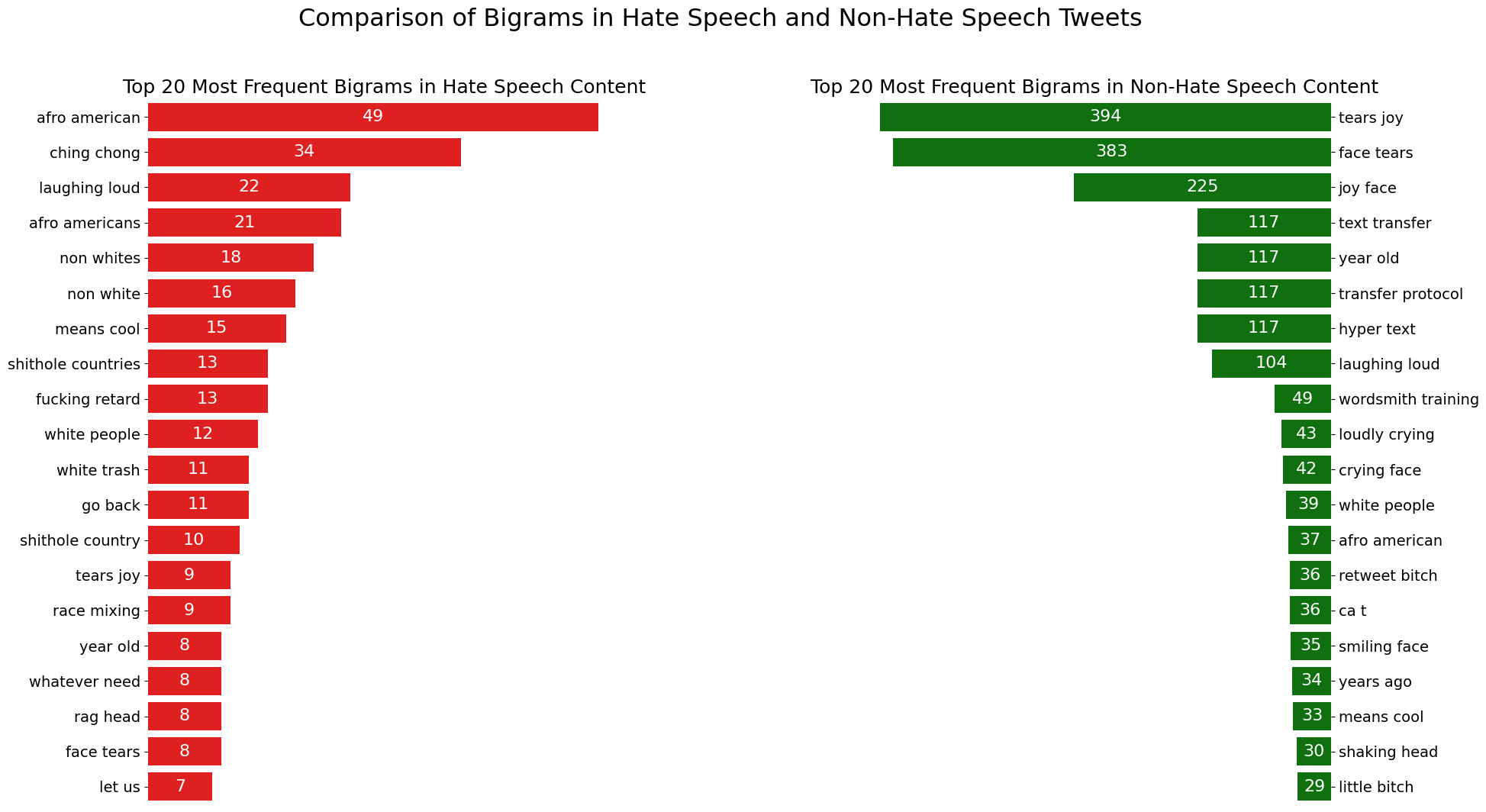
st.write('3. Most Frequent Bigram in dataset')
|
| 21 |
+
image = Image.open('eda_3.png')
|
| 22 |
+
st.image(image)
|
| 23 |
+
st.write("Here we can see that Most Frequent Bigrams in hate speech content also dominated with racial slur such as afro american, ching chong, non whites, while also followed by mockery such as shithole countries and fucking retard.")
|
| 24 |
+
|
| 25 |
+
# EDA 4
|
| 26 |
+
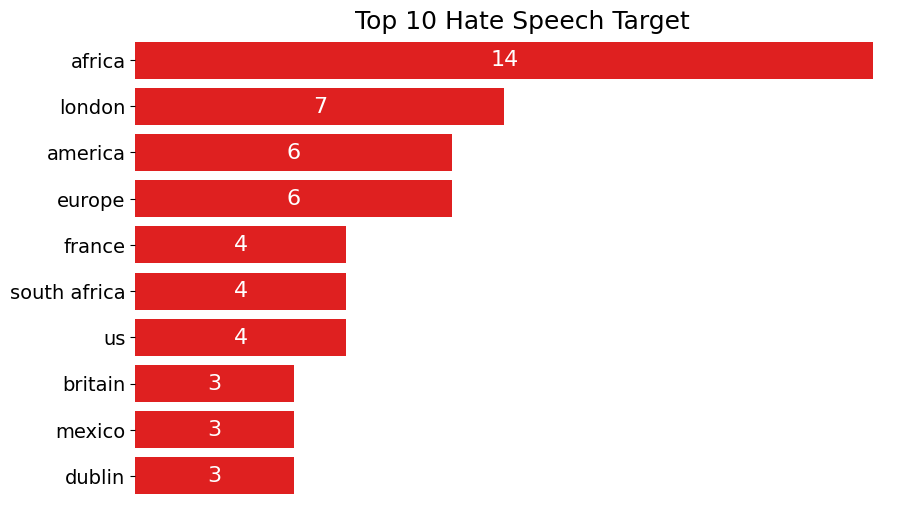
st.write('4. Top County that become topic of target in Content')
|
| 27 |
+
image = Image.open('eda_4.png')
|
| 28 |
+
st.image(image)
|
| 29 |
+
st.write("Here we can see that country that become a topic or target for hate speeech are africa, america, europt or london. We can safely assume based on bigram analysis that the context is refering to african american.")
|
eda_1.png
ADDED
|
eda_2.png
ADDED
|
eda_3.png
ADDED
|
eda_4.png
ADDED
|
model_lstm_3.keras
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1bb97107b62ea08755bafef7adb9f9931eb5a5f121deb9cd9e3c34a4a3a1ebb7
|
| 3 |
+
size 32582869
|
prediction.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import pickle
|
| 4 |
+
import tensorflow as tf
|
| 5 |
+
from tensorflow.keras.layers import Dense, Concatenate, Input, Dropout
|
| 6 |
+
from tensorflow.keras.models import load_model, Sequential, Model
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def user_input():
|
| 10 |
+
|
| 11 |
+
txt = st.text_area('Text to analyze', '''
|
| 12 |
+
It was the best of times, it was the worst of times, it was
|
| 13 |
+
the age of wisdom, it was the age of foolishness, it was
|
| 14 |
+
the epoch of belief, it was the epoch of incredulity, it
|
| 15 |
+
was the season of Light, it was the season of Darkness, it
|
| 16 |
+
was the spring of hope, it was the winter of despair, (
|
| 17 |
+
''')
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
data = {
|
| 21 |
+
'Content': txt
|
| 22 |
+
|
| 23 |
+
}
|
| 24 |
+
features = pd.DataFrame(data, index=[0])
|
| 25 |
+
return features
|
| 26 |
+
|
| 27 |
+
def app():
|
| 28 |
+
st.title('Hate Speech Sentiment Analysis')
|
| 29 |
+
# Getting user input
|
| 30 |
+
input_df = user_input()
|
| 31 |
+
|
| 32 |
+
# load model
|
| 33 |
+
model_1 = load_model('model_lstm_3.keras')
|
| 34 |
+
|
| 35 |
+
# Predict Score
|
| 36 |
+
if st.button('Analyze Now'):
|
| 37 |
+
predict_proba = model_1.predict(input_df)
|
| 38 |
+
predictions = tf.where(predict_proba >= 0.5, 1, 0)
|
| 39 |
+
if predictions == 1:
|
| 40 |
+
st.write("Analysis: Hate Speech")
|
| 41 |
+
else:
|
| 42 |
+
st.write("Analysis: Non-Hate Speech")
|
| 43 |
+
else:
|
| 44 |
+
st.write('Analysis:')
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
app()
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
scikit-learn==1.5.0
|
| 2 |
+
pandas
|
| 3 |
+
matplotlib
|
| 4 |
+
joblib
|
| 5 |
+
streamlit==0.71.0
|
| 6 |
+
tensorflow==2.15.0
|