Spaces:
Runtime error

Runtime error
tabbed page and highlighted context
Browse files- README.md +1 -1
- diagram.png +0 -0
- pages/⚙️_Settings.py +3 -0
- pages/💁♀️_Info.py +12 -0
- requirements.txt +2 -0
- utils/frontend.py +0 -2
- utils/haystack.py +1 -1
- app.py → 🏡_Home.py +45 -20
README.md
CHANGED
|
@@ -5,6 +5,6 @@ colorFrom: green
|
|
| 5 |
colorTo: yellow
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.2.0
|
| 8 |
-
app_file:
|
| 9 |
pinned: false
|
| 10 |
---
|
|
|
|
| 5 |
colorTo: yellow
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.2.0
|
| 8 |
+
app_file: 🏡_Home.py
|
| 9 |
pinned: false
|
| 10 |
---
|
diagram.png
ADDED
|
pages/⚙️_Settings.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.write("This is the settings page")
|
pages/💁♀️_Info.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.markdown("""
|
| 4 |
+
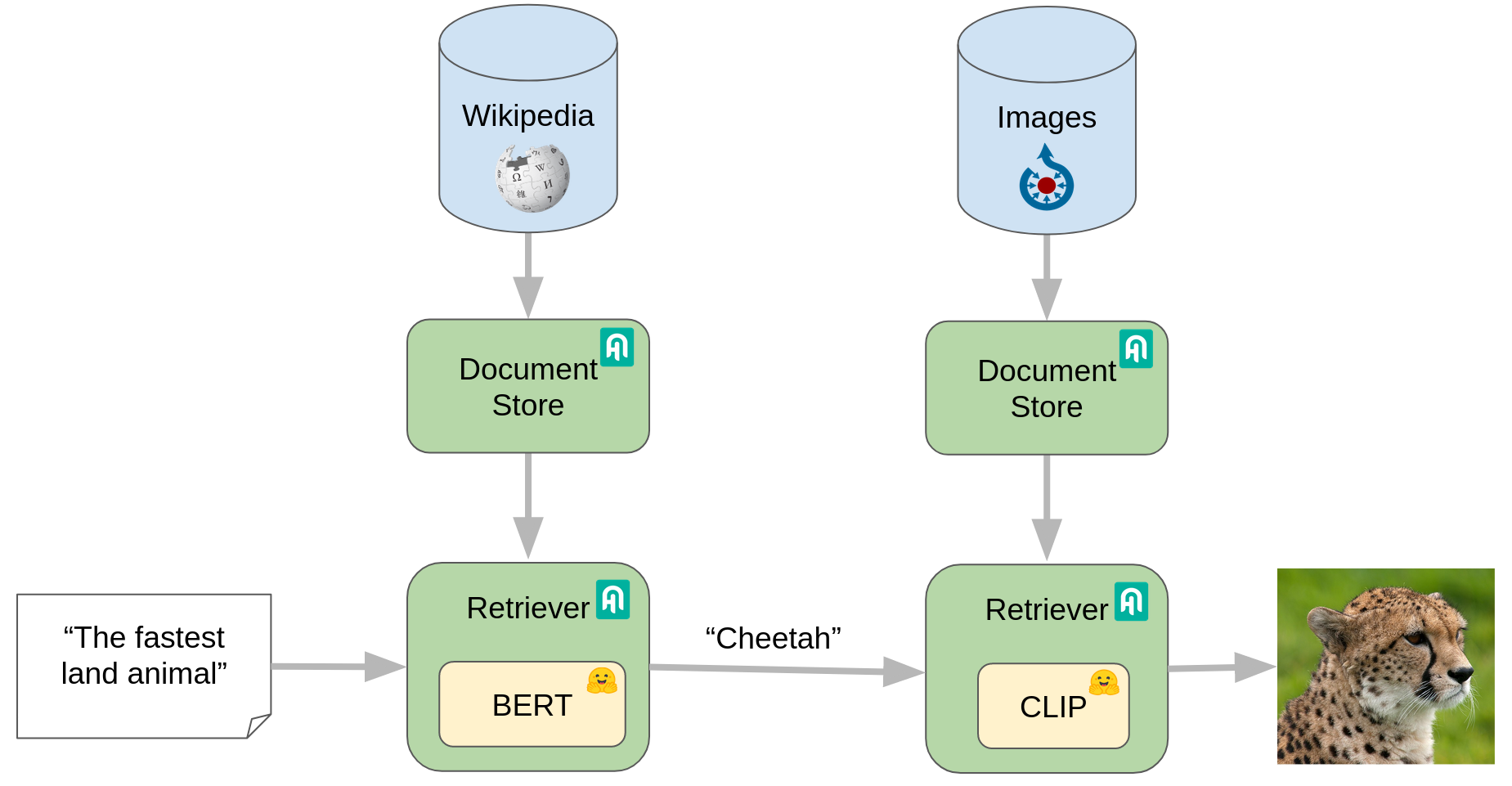
# Better Image Retrieval With Reinforced CLIP 🧠
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
CLIP is a neural network trained on image-text pairs that can predict how semantically close images are with some text
|
| 8 |
+
But, although CLIP understands what it sees, it doesn't know its properties. While other models can understand text that contains such information, like Wikipedia.
|
| 9 |
+
|
| 10 |
+
In this demo application, we see if we can 'help' CLIP by reinforcing it with another model.""")
|
| 11 |
+
|
| 12 |
+
st.image("diagram.png")
|
requirements.txt
CHANGED
|
@@ -1,2 +1,4 @@
|
|
| 1 |
farm-haystack[faiss]==1.11.1
|
| 2 |
streamlit==1.12.0
|
|
|
|
|
|
|
|
|
| 1 |
farm-haystack[faiss]==1.11.1
|
| 2 |
streamlit==1.12.0
|
| 3 |
+
markdown
|
| 4 |
+
st-annotated-text
|
utils/frontend.py
CHANGED
|
@@ -5,6 +5,4 @@ def set_state_if_absent(key, value):
|
|
| 5 |
st.session_state[key] = value
|
| 6 |
|
| 7 |
def reset_results(*args):
|
| 8 |
-
st.write("Called reset")
|
| 9 |
-
st.session_state.answer = None
|
| 10 |
st.session_state.results = None
|
|
|
|
| 5 |
st.session_state[key] = value
|
| 6 |
|
| 7 |
def reset_results(*args):
|
|
|
|
|
|
|
| 8 |
st.session_state.results = None
|
utils/haystack.py
CHANGED
|
@@ -73,7 +73,7 @@ pipe = start_haystack()
|
|
| 73 |
|
| 74 |
@st.cache(allow_output_mutation=True)
|
| 75 |
def query(statement: str, text_retriever_top_k: int = 5, image_retriever_top_k = 1):
|
| 76 |
-
"""Run query
|
| 77 |
params = {"image_retriever": {"top_k": image_retriever_top_k},"text_retriever": {"top_k": text_retriever_top_k} }
|
| 78 |
results = pipe.run(statement, params=params)
|
| 79 |
return results
|
|
|
|
| 73 |
|
| 74 |
@st.cache(allow_output_mutation=True)
|
| 75 |
def query(statement: str, text_retriever_top_k: int = 5, image_retriever_top_k = 1):
|
| 76 |
+
"""Run query"""
|
| 77 |
params = {"image_retriever": {"top_k": image_retriever_top_k},"text_retriever": {"top_k": text_retriever_top_k} }
|
| 78 |
results = pipe.run(statement, params=params)
|
| 79 |
return results
|
app.py → 🏡_Home.py
RENAMED
|
@@ -3,18 +3,40 @@ import time
|
|
| 3 |
import logging
|
| 4 |
from json import JSONDecodeError
|
| 5 |
from PIL import Image
|
| 6 |
-
|
| 7 |
-
|
| 8 |
from utils.haystack import query
|
| 9 |
from utils.frontend import reset_results, set_state_if_absent
|
| 10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
def main():
|
| 12 |
|
| 13 |
set_state_if_absent("statement", "What is the fastest animal?")
|
| 14 |
set_state_if_absent("results", None)
|
| 15 |
|
| 16 |
st.write("# Look for images with MultiModalRetrieval 🐅")
|
| 17 |
-
st.write()
|
| 18 |
st.markdown(
|
| 19 |
"""
|
| 20 |
##### Enter a question about animals
|
|
@@ -41,15 +63,13 @@ def main():
|
|
| 41 |
time_start = time.time()
|
| 42 |
reset_results()
|
| 43 |
st.session_state.statement = statement
|
| 44 |
-
with st.spinner("
|
| 45 |
try:
|
| 46 |
docs = query(statement)
|
| 47 |
-
st.write(docs["documents"])
|
| 48 |
for doc in docs["documents"]:
|
| 49 |
image = Image.open(doc.content)
|
| 50 |
st.image(image)
|
| 51 |
-
|
| 52 |
-
st.write(answer)
|
| 53 |
print(f"S: {statement}")
|
| 54 |
time_end = time.time()
|
| 55 |
print(time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime()))
|
|
@@ -62,19 +82,24 @@ def main():
|
|
| 62 |
except Exception as e:
|
| 63 |
logging.exception(e)
|
| 64 |
st.error("🐞 An error occurred during the request.")
|
| 65 |
-
|
| 66 |
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 79 |
|
| 80 |
main()
|
|
|
|
| 3 |
import logging
|
| 4 |
from json import JSONDecodeError
|
| 5 |
from PIL import Image
|
| 6 |
+
from markdown import markdown
|
| 7 |
+
from annotated_text import annotation
|
| 8 |
from utils.haystack import query
|
| 9 |
from utils.frontend import reset_results, set_state_if_absent
|
| 10 |
|
| 11 |
+
def create_answer_objects(predictions):
|
| 12 |
+
results = []
|
| 13 |
+
for answer in predictions:
|
| 14 |
+
answer = answer.to_dict()
|
| 15 |
+
if answer["answer"]:
|
| 16 |
+
results.append(
|
| 17 |
+
{
|
| 18 |
+
"context": "..." + answer["context"] + "...",
|
| 19 |
+
"answer": answer["answer"],
|
| 20 |
+
"relevance": round(answer["score"] * 100, 2),
|
| 21 |
+
"offset_start_in_doc": answer["offsets_in_document"][0]["start"],
|
| 22 |
+
}
|
| 23 |
+
)
|
| 24 |
+
else:
|
| 25 |
+
results.append(
|
| 26 |
+
{
|
| 27 |
+
"context": None,
|
| 28 |
+
"answer": None,
|
| 29 |
+
"relevance": round(answer["score"] * 100, 2),
|
| 30 |
+
}
|
| 31 |
+
)
|
| 32 |
+
return results
|
| 33 |
+
|
| 34 |
def main():
|
| 35 |
|
| 36 |
set_state_if_absent("statement", "What is the fastest animal?")
|
| 37 |
set_state_if_absent("results", None)
|
| 38 |
|
| 39 |
st.write("# Look for images with MultiModalRetrieval 🐅")
|
|
|
|
| 40 |
st.markdown(
|
| 41 |
"""
|
| 42 |
##### Enter a question about animals
|
|
|
|
| 63 |
time_start = time.time()
|
| 64 |
reset_results()
|
| 65 |
st.session_state.statement = statement
|
| 66 |
+
with st.spinner("🔎 🐼🐷🦊 Looking for the right animal"):
|
| 67 |
try:
|
| 68 |
docs = query(statement)
|
|
|
|
| 69 |
for doc in docs["documents"]:
|
| 70 |
image = Image.open(doc.content)
|
| 71 |
st.image(image)
|
| 72 |
+
st.session_state.results = create_answer_objects(docs["answers"])
|
|
|
|
| 73 |
print(f"S: {statement}")
|
| 74 |
time_end = time.time()
|
| 75 |
print(time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime()))
|
|
|
|
| 82 |
except Exception as e:
|
| 83 |
logging.exception(e)
|
| 84 |
st.error("🐞 An error occurred during the request.")
|
| 85 |
+
return
|
| 86 |
|
| 87 |
+
if st.session_state.results:
|
| 88 |
+
st.write('## Why this image?')
|
| 89 |
+
answers = st.session_state.results
|
| 90 |
+
for count, answer in enumerate(answers):
|
| 91 |
+
if answer["answer"]:
|
| 92 |
+
text, context = answer["answer"], answer["context"]
|
| 93 |
+
start_idx = context.find(text)
|
| 94 |
+
end_idx = start_idx + len(text)
|
| 95 |
+
st.write(
|
| 96 |
+
markdown(context[:start_idx] + str(annotation(body=text, label="ANSWER", background="#964448", color='#ffffff')) + context[end_idx:]),
|
| 97 |
+
unsafe_allow_html=True,
|
| 98 |
+
)
|
| 99 |
+
st.markdown(f"**Relevance:** {answer['relevance']}")
|
| 100 |
+
else:
|
| 101 |
+
st.info(
|
| 102 |
+
"🤔 Haystack is unsure whether any of the documents contain an answer to your question. Try to reformulate it!"
|
| 103 |
+
)
|
| 104 |
|
| 105 |
main()
|