Spaces:
Running
on
CPU Upgrade

Running
on
CPU Upgrade

add cogagent
Browse files- .gitignore +10 -0
- app.py +55 -67
- examples/1.jpeg +0 -0
- examples/2.jpeg +0 -0
- examples/3.jpeg +0 -0
- examples/3.jpg +0 -0
- examples/{6.jpg → 4.jpg} +0 -0
- examples/4.png +0 -0
- examples/5.jpeg +0 -0
- examples/5.jpg +0 -0
- examples/6.jpeg +0 -0
- examples/example_inputs.jsonl +6 -6
- utils.py +338 -1
.gitignore
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
en_core_web_sm-3.6.0/*
|
| 2 |
+
daily_receive.*
|
| 3 |
+
weekly_train_generate.*
|
| 4 |
+
app[2-3].py
|
| 5 |
+
test_gradio_client.py
|
| 6 |
+
boxes.py
|
| 7 |
+
*.tar.gz
|
| 8 |
+
*.pyi
|
| 9 |
+
__pycache__/
|
| 10 |
+
examples/*grounding*
|
app.py
CHANGED
|
@@ -2,77 +2,38 @@
|
|
| 2 |
|
| 3 |
import gradio as gr
|
| 4 |
import os
|
| 5 |
-
import
|
| 6 |
-
|
| 7 |
-
import
|
| 8 |
-
|
|
|
|
| 9 |
|
| 10 |
-
|
| 11 |
|
| 12 |
MAINTENANCE_NOTICE1 = 'Hint 1: If the app report "Something went wrong, connection error out", please turn off your proxy and retry.<br>Hint 2: If you upload a large size of image like 10MB, it may take some time to upload and process. Please be patient and wait.'
|
| 13 |
|
| 14 |
-
GROUNDING_NOTICE = 'Hint: When you check "Grounding", please use the <a href="https://github.com/THUDM/CogVLM/blob/main/utils/template.py#L344">corresponding prompt</a> or the examples below.'
|
| 15 |
|
|
|
|
| 16 |
|
| 17 |
-
NOTES = 'This app is adapted from <a href="https://github.com/THUDM/CogVLM">https://github.com/THUDM/CogVLM</a>. It would be recommended to check out the repo if you want to see the detail of our model.'
|
| 18 |
-
|
| 19 |
-
import json
|
| 20 |
-
import requests
|
| 21 |
-
import base64
|
| 22 |
-
import hashlib
|
| 23 |
-
from utils import parse_response
|
| 24 |
|
| 25 |
default_chatbox = [("", "Hi, What do you want to know about this image?")]
|
| 26 |
|
| 27 |
URL = os.environ.get("URL")
|
| 28 |
|
| 29 |
-
def process_image(image_prompt):
|
| 30 |
-
image = Image.open(image_prompt)
|
| 31 |
-
print(f"height:{image.height}, width:{image.width}")
|
| 32 |
-
resized_image = image.resize((224, 224), )
|
| 33 |
-
timestamp = int(time.time())
|
| 34 |
-
file_ext = os.path.splitext(image_prompt)[1]
|
| 35 |
-
filename = f"examples/{timestamp}{file_ext}"
|
| 36 |
-
resized_image.save(filename)
|
| 37 |
-
print(f"temporal filename {filename}")
|
| 38 |
-
with open(filename, "rb") as image_file:
|
| 39 |
-
bytes = base64.b64encode(image_file.read())
|
| 40 |
-
encoded_img = str(bytes, encoding='utf-8')
|
| 41 |
-
image_hash = hashlib.sha256(bytes).hexdigest()
|
| 42 |
-
os.remove(filename)
|
| 43 |
-
return encoded_img, image_hash
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
def process_image_without_resize(image_prompt):
|
| 47 |
-
image = Image.open(image_prompt)
|
| 48 |
-
print(f"height:{image.height}, width:{image.width}")
|
| 49 |
-
timestamp = int(time.time())
|
| 50 |
-
file_ext = os.path.splitext(image_prompt)[1]
|
| 51 |
-
filename = f"examples/{timestamp}{file_ext}"
|
| 52 |
-
filename_grounding = f"examples/{timestamp}_grounding{file_ext}"
|
| 53 |
-
image.save(filename)
|
| 54 |
-
print(f"temporal filename {filename}")
|
| 55 |
-
with open(filename, "rb") as image_file:
|
| 56 |
-
bytes = base64.b64encode(image_file.read())
|
| 57 |
-
encoded_img = str(bytes, encoding='utf-8')
|
| 58 |
-
image_hash = hashlib.sha256(bytes).hexdigest()
|
| 59 |
-
os.remove(filename)
|
| 60 |
-
return image, encoded_img, image_hash, filename_grounding
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
def is_chinese(text):
|
| 64 |
-
zh_pattern = re.compile(u'[\u4e00-\u9fa5]+')
|
| 65 |
-
return zh_pattern.search(text)
|
| 66 |
-
|
| 67 |
|
| 68 |
def post(
|
| 69 |
input_text,
|
| 70 |
temperature,
|
| 71 |
top_p,
|
|
|
|
| 72 |
image_prompt,
|
| 73 |
result_previous,
|
| 74 |
hidden_image,
|
| 75 |
-
grounding
|
|
|
|
|
|
|
|
|
|
| 76 |
):
|
| 77 |
result_text = [(ele[0], ele[1]) for ele in result_previous]
|
| 78 |
for i in range(len(result_text)-1, -1, -1):
|
|
@@ -107,16 +68,35 @@ def post(
|
|
| 107 |
result_text = []
|
| 108 |
hidden_image = image_hash
|
| 109 |
else:
|
| 110 |
-
encoded_img = None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
|
| 112 |
-
|
|
|
|
|
|
|
|
|
|
| 113 |
data = json.dumps({
|
| 114 |
-
'
|
|
|
|
|
|
|
|
|
|
| 115 |
'image': encoded_img,
|
| 116 |
'temperature': temperature,
|
| 117 |
'top_p': top_p,
|
| 118 |
-
'
|
| 119 |
-
'
|
|
|
|
| 120 |
})
|
| 121 |
try:
|
| 122 |
response = requests.request("POST", URL, headers=headers, data=data, timeout=(60, 100)).json()
|
|
@@ -161,6 +141,9 @@ def main():
|
|
| 161 |
|
| 162 |
with gr.Blocks(css='style.css') as demo:
|
| 163 |
|
|
|
|
|
|
|
|
|
|
| 164 |
with gr.Row():
|
| 165 |
with gr.Column(scale=4.5):
|
| 166 |
with gr.Group():
|
|
@@ -172,28 +155,33 @@ def main():
|
|
| 172 |
image_prompt = gr.Image(type="filepath", label="Image Prompt", value=None)
|
| 173 |
with gr.Row():
|
| 174 |
grounding = gr.Checkbox(label="Grounding")
|
|
|
|
| 175 |
with gr.Row():
|
| 176 |
-
grounding_notice = gr.Markdown(GROUNDING_NOTICE)
|
|
|
|
|
|
|
|
|
|
| 177 |
|
| 178 |
with gr.Row():
|
| 179 |
-
temperature = gr.Slider(maximum=1, value=0.
|
| 180 |
-
top_p = gr.Slider(maximum=1, value=0.
|
|
|
|
|
|
|
| 181 |
with gr.Column(scale=5.5):
|
| 182 |
-
result_text = gr.components.Chatbot(label='Multi-round conversation History', value=[("", "Hi, What do you want to know about this image?")]
|
| 183 |
hidden_image_hash = gr.Textbox(visible=False)
|
| 184 |
|
| 185 |
-
gr_examples = gr.Examples(examples=[[example["text"], example["image"]] for example in examples],
|
| 186 |
-
inputs=[input_text, image_prompt],
|
| 187 |
label="Example Inputs (Click to insert an examplet into the input box)",
|
| 188 |
examples_per_page=6)
|
| 189 |
|
| 190 |
gr.Markdown(MAINTENANCE_NOTICE1)
|
| 191 |
-
gr.Markdown(NOTES)
|
| 192 |
|
| 193 |
print(gr.__version__)
|
| 194 |
-
run_button.click(fn=post,inputs=[input_text, temperature, top_p, image_prompt, result_text, hidden_image_hash, grounding],
|
| 195 |
outputs=[input_text, result_text, hidden_image_hash])
|
| 196 |
-
input_text.submit(fn=post,inputs=[input_text, temperature, top_p, image_prompt, result_text, hidden_image_hash, grounding],
|
| 197 |
outputs=[input_text, result_text, hidden_image_hash])
|
| 198 |
clear_button.click(fn=clear_fn, inputs=clear_button, outputs=[input_text, result_text, image_prompt])
|
| 199 |
image_prompt.upload(fn=clear_fn2, inputs=clear_button, outputs=[result_text])
|
|
@@ -202,7 +190,7 @@ def main():
|
|
| 202 |
print(gr.__version__)
|
| 203 |
|
| 204 |
demo.queue(concurrency_count=10)
|
| 205 |
-
demo.launch()
|
| 206 |
|
| 207 |
if __name__ == '__main__':
|
| 208 |
main()
|
|
|
|
| 2 |
|
| 3 |
import gradio as gr
|
| 4 |
import os
|
| 5 |
+
import json
|
| 6 |
+
import requests
|
| 7 |
+
from utils import is_chinese, process_image_without_resize, parse_response, templates_agent_cogagent, template_grounding_cogvlm, postprocess_text
|
| 8 |
+
|
| 9 |
+
DESCRIPTION = '''<h2 style='text-align: center'> <a href="https://github.com/THUDM/CogVLM"> CogVLM & CogAgent Chat Demo</a> </h2>'''
|
| 10 |
|
| 11 |
+
NOTES = 'This app is adapted from <a href="https://github.com/THUDM/CogVLM">https://github.com/THUDM/CogVLM</a>. It would be recommended to check out the repo if you want to see the detail of our model.\n\n该demo仅作为测试使用,不支持批量请求。如有大批量需求,欢迎联系[智谱AI](mailto:business@zhipuai.cn)。\n\n请注意CoogVLM-17B目前仅支持英文。'
|
| 12 |
|
| 13 |
MAINTENANCE_NOTICE1 = 'Hint 1: If the app report "Something went wrong, connection error out", please turn off your proxy and retry.<br>Hint 2: If you upload a large size of image like 10MB, it may take some time to upload and process. Please be patient and wait.'
|
| 14 |
|
| 15 |
+
GROUNDING_NOTICE = 'Hint: When you check "Grounding", please use the <a href="https://github.com/THUDM/CogVLM/blob/main/utils/utils/template.py#L344">corresponding prompt</a> or the examples below.'
|
| 16 |
|
| 17 |
+
AGENT_NOTICE = 'Hint: When you check "CogAgent", please use the <a href="https://github.com/THUDM/CogVLM/blob/main/utils/utils/template.py#L761C1-L761C17">corresponding prompt</a> or the examples below.'
|
| 18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
|
| 20 |
default_chatbox = [("", "Hi, What do you want to know about this image?")]
|
| 21 |
|
| 22 |
URL = os.environ.get("URL")
|
| 23 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
|
| 25 |
def post(
|
| 26 |
input_text,
|
| 27 |
temperature,
|
| 28 |
top_p,
|
| 29 |
+
top_k,
|
| 30 |
image_prompt,
|
| 31 |
result_previous,
|
| 32 |
hidden_image,
|
| 33 |
+
grounding,
|
| 34 |
+
cogagent,
|
| 35 |
+
grounding_template,
|
| 36 |
+
agent_template
|
| 37 |
):
|
| 38 |
result_text = [(ele[0], ele[1]) for ele in result_previous]
|
| 39 |
for i in range(len(result_text)-1, -1, -1):
|
|
|
|
| 68 |
result_text = []
|
| 69 |
hidden_image = image_hash
|
| 70 |
else:
|
| 71 |
+
encoded_img = None
|
| 72 |
+
|
| 73 |
+
model_use = "vlm_chat"
|
| 74 |
+
if not cogagent and grounding:
|
| 75 |
+
model_use = "vlm_grounding"
|
| 76 |
+
if grounding_template:
|
| 77 |
+
input_text = postprocess_text(grounding_template, input_text)
|
| 78 |
+
elif cogagent:
|
| 79 |
+
model_use = "agent_chat"
|
| 80 |
+
if agent_template:
|
| 81 |
+
input_text = postprocess_text(agent_template, input_text)
|
| 82 |
+
|
| 83 |
+
prompt = input_text
|
| 84 |
|
| 85 |
+
if grounding:
|
| 86 |
+
prompt += "(with grounding)"
|
| 87 |
+
|
| 88 |
+
print(f'request {model_use} model... with prompt {prompt}, grounding_template {grounding_template}, agent_template {agent_template}')
|
| 89 |
data = json.dumps({
|
| 90 |
+
'model_use': model_use,
|
| 91 |
+
'is_grounding': grounding,
|
| 92 |
+
'text': prompt,
|
| 93 |
+
'history': result_text,
|
| 94 |
'image': encoded_img,
|
| 95 |
'temperature': temperature,
|
| 96 |
'top_p': top_p,
|
| 97 |
+
'top_k': top_k,
|
| 98 |
+
'do_sample': True,
|
| 99 |
+
'max_new_tokens': 2048
|
| 100 |
})
|
| 101 |
try:
|
| 102 |
response = requests.request("POST", URL, headers=headers, data=data, timeout=(60, 100)).json()
|
|
|
|
| 141 |
|
| 142 |
with gr.Blocks(css='style.css') as demo:
|
| 143 |
|
| 144 |
+
gr.Markdown(DESCRIPTION)
|
| 145 |
+
gr.Markdown(NOTES)
|
| 146 |
+
|
| 147 |
with gr.Row():
|
| 148 |
with gr.Column(scale=4.5):
|
| 149 |
with gr.Group():
|
|
|
|
| 155 |
image_prompt = gr.Image(type="filepath", label="Image Prompt", value=None)
|
| 156 |
with gr.Row():
|
| 157 |
grounding = gr.Checkbox(label="Grounding")
|
| 158 |
+
cogagent = gr.Checkbox(label="CogAgent")
|
| 159 |
with gr.Row():
|
| 160 |
+
# grounding_notice = gr.Markdown(GROUNDING_NOTICE)
|
| 161 |
+
grounding_template = gr.Dropdown(choices=template_grounding_cogvlm, label="Grounding Template", value=template_grounding_cogvlm[0])
|
| 162 |
+
# agent_notice = gr.Markdown(AGENT_NOTICE)
|
| 163 |
+
agent_template = gr.Dropdown(choices=templates_agent_cogagent, label="Agent Template", value=templates_agent_cogagent[0])
|
| 164 |
|
| 165 |
with gr.Row():
|
| 166 |
+
temperature = gr.Slider(maximum=1, value=0.9, minimum=0, label='Temperature')
|
| 167 |
+
top_p = gr.Slider(maximum=1, value=0.8, minimum=0, label='Top P')
|
| 168 |
+
top_k = gr.Slider(maximum=50, value=5, minimum=1, step=1, label='Top K')
|
| 169 |
+
|
| 170 |
with gr.Column(scale=5.5):
|
| 171 |
+
result_text = gr.components.Chatbot(label='Multi-round conversation History', value=[("", "Hi, What do you want to know about this image?")], height=550)
|
| 172 |
hidden_image_hash = gr.Textbox(visible=False)
|
| 173 |
|
| 174 |
+
gr_examples = gr.Examples(examples=[[example["text"], example["image"], example["grounding"], example["cogagent"]] for example in examples],
|
| 175 |
+
inputs=[input_text, image_prompt, grounding, cogagent],
|
| 176 |
label="Example Inputs (Click to insert an examplet into the input box)",
|
| 177 |
examples_per_page=6)
|
| 178 |
|
| 179 |
gr.Markdown(MAINTENANCE_NOTICE1)
|
|
|
|
| 180 |
|
| 181 |
print(gr.__version__)
|
| 182 |
+
run_button.click(fn=post,inputs=[input_text, temperature, top_p, top_k, image_prompt, result_text, hidden_image_hash, grounding, cogagent, grounding_template, agent_template],
|
| 183 |
outputs=[input_text, result_text, hidden_image_hash])
|
| 184 |
+
input_text.submit(fn=post,inputs=[input_text, temperature, top_p, top_k, image_prompt, result_text, hidden_image_hash, grounding, cogagent, grounding_template, agent_template],
|
| 185 |
outputs=[input_text, result_text, hidden_image_hash])
|
| 186 |
clear_button.click(fn=clear_fn, inputs=clear_button, outputs=[input_text, result_text, image_prompt])
|
| 187 |
image_prompt.upload(fn=clear_fn2, inputs=clear_button, outputs=[result_text])
|
|
|
|
| 190 |
print(gr.__version__)
|
| 191 |
|
| 192 |
demo.queue(concurrency_count=10)
|
| 193 |
+
demo.launch(server_port=7862)
|
| 194 |
|
| 195 |
if __name__ == '__main__':
|
| 196 |
main()
|
examples/1.jpeg
DELETED
|
Binary file (236 kB)
|
|
|
examples/2.jpeg
DELETED
|
Binary file (6.7 kB)
|
|
|
examples/3.jpeg
DELETED
|
Binary file (53.9 kB)
|
|
|
examples/3.jpg
CHANGED

|

|
examples/{6.jpg → 4.jpg}
RENAMED
|
File without changes
|
examples/4.png
DELETED
|
Binary file (196 kB)
|
|
|
examples/5.jpeg
ADDED
|
examples/5.jpg
DELETED
|
Binary file (343 kB)
|
|
|
examples/6.jpeg
ADDED
|
examples/example_inputs.jsonl
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
-
{"id":1, "text": "Describe this image", "image": "examples/1.png"}
|
| 2 |
-
{"id":2, "text": "What is written in the image?", "image": "examples/2.jpg"}
|
| 3 |
-
{"id":3, "text": "
|
| 4 |
-
{"id":4, "text": "
|
| 5 |
-
{"id":5, "text": "
|
| 6 |
-
{"id":6, "text": "
|
|
|
|
| 1 |
+
{"id":1, "text": "Describe this image", "image": "examples/1.png", "grounding": false, "cogagent": false}
|
| 2 |
+
{"id":2, "text": "What is written in the image?", "image": "examples/2.jpg", "grounding": false, "cogagent": false}
|
| 3 |
+
{"id":3, "text": "the tree closer to the sun", "image": "examples/3.jpg", "grounding": true, "cogagent": false}
|
| 4 |
+
{"id":4, "text": "What color are the clothes of the girl whose hands are holding flowers? Let's think step by step", "image": "examples/4.jpg", "grounding": true, "cogagent": false}
|
| 5 |
+
{"id":5, "text": "search CogVLM", "image": "examples/5.jpeg", "grounding": true, "cogagent": true}
|
| 6 |
+
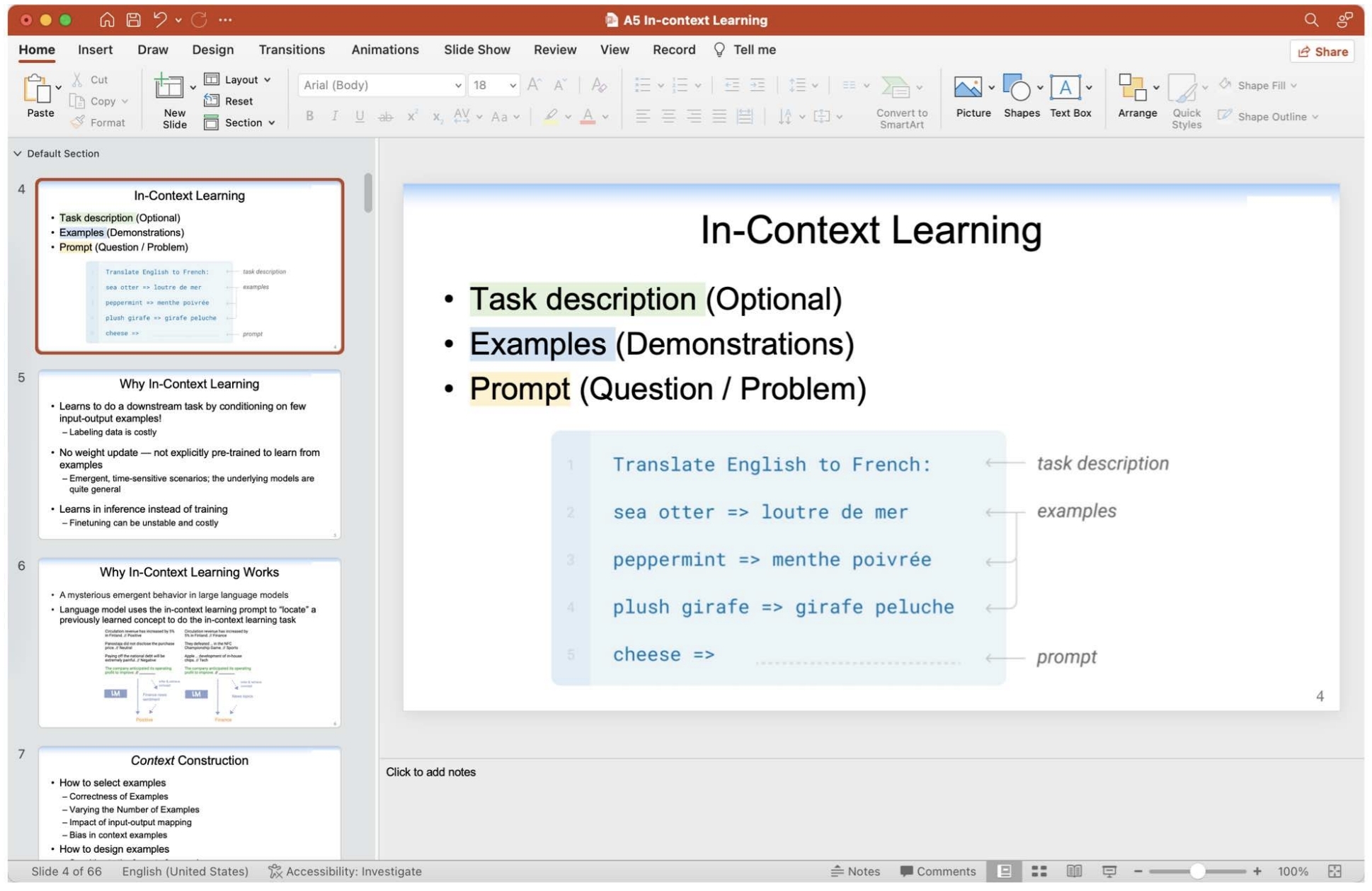
{"id":6, "text": "Insert a new slide named 'In-context learning: Details' with a Two Content layout after the current slide.", "image": "examples/6.jpeg", "grounding": false, "cogagent": true}
|
utils.py
CHANGED
|
@@ -3,9 +3,38 @@ from PIL import Image, ImageDraw, ImageFont
|
|
| 3 |
import matplotlib.font_manager
|
| 4 |
import spacy
|
| 5 |
import re
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
|
| 7 |
nlp = spacy.load("en_core_web_sm-3.6.0")
|
| 8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
def draw_boxes(image, boxes, texts, output_fn='output.png'):
|
| 10 |
box_width = 5
|
| 11 |
color_palette = sns.color_palette("husl", len(boxes))
|
|
@@ -83,4 +112,312 @@ def parse_response(img, response, output_fn='output.png'):
|
|
| 83 |
boxes = []
|
| 84 |
else:
|
| 85 |
texts, boxes = zip(*dic.items())
|
| 86 |
-
draw_boxes(new_img, boxes, texts, output_fn=output_fn)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
import matplotlib.font_manager
|
| 4 |
import spacy
|
| 5 |
import re
|
| 6 |
+
import base64
|
| 7 |
+
import time
|
| 8 |
+
import re
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import base64
|
| 11 |
+
import hashlib
|
| 12 |
+
import os
|
| 13 |
|
| 14 |
nlp = spacy.load("en_core_web_sm-3.6.0")
|
| 15 |
|
| 16 |
+
def process_image_without_resize(image_prompt):
|
| 17 |
+
image = Image.open(image_prompt)
|
| 18 |
+
print(f"height:{image.height}, width:{image.width}")
|
| 19 |
+
timestamp = time.time()
|
| 20 |
+
file_ext = os.path.splitext(image_prompt)[1]
|
| 21 |
+
filename = f"examples/{timestamp}{file_ext}"
|
| 22 |
+
filename_grounding = f"examples/{timestamp}_grounding{file_ext}"
|
| 23 |
+
image.save(filename)
|
| 24 |
+
print(f"temporal filename {filename}")
|
| 25 |
+
with open(filename, "rb") as image_file:
|
| 26 |
+
bytes = base64.b64encode(image_file.read())
|
| 27 |
+
encoded_img = str(bytes, encoding='utf-8')
|
| 28 |
+
image_hash = hashlib.sha256(bytes).hexdigest()
|
| 29 |
+
os.remove(filename)
|
| 30 |
+
return image, encoded_img, image_hash, filename_grounding
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def is_chinese(text):
|
| 34 |
+
zh_pattern = re.compile(u'[\u4e00-\u9fa5]+')
|
| 35 |
+
return zh_pattern.search(text)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
def draw_boxes(image, boxes, texts, output_fn='output.png'):
|
| 39 |
box_width = 5
|
| 40 |
color_palette = sns.color_palette("husl", len(boxes))
|
|
|
|
| 112 |
boxes = []
|
| 113 |
else:
|
| 114 |
texts, boxes = zip(*dic.items())
|
| 115 |
+
draw_boxes(new_img, boxes, texts, output_fn=output_fn)
|
| 116 |
+
|
| 117 |
+
def postprocess_text(template, text):
|
| 118 |
+
quoted_text = f'"{text.strip()}"'
|
| 119 |
+
return template.replace("<TASK>", quoted_text).strip() if template != "" else text.strip()
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
# The templates is for CogAgent_Agent Template
|
| 123 |
+
templates_agent_cogagent = [
|
| 124 |
+
"Can you advise me on how to <TASK>?",
|
| 125 |
+
"I'm looking for guidance on how to <TASK>.",
|
| 126 |
+
"What steps do I need to take to <TASK>?",
|
| 127 |
+
"Could you provide instructions for <TASK>?",
|
| 128 |
+
"I'm wondering what the process is for <TASK>.",
|
| 129 |
+
"How can I go about <TASK>?",
|
| 130 |
+
"I need assistance with planning to <TASK>.",
|
| 131 |
+
"Do you have any recommendations for <TASK>?",
|
| 132 |
+
"Please share some tips for <TASK>.",
|
| 133 |
+
"I'd like to know the best way to <TASK>.",
|
| 134 |
+
"What's the most effective way to <TASK>?",
|
| 135 |
+
"I'm seeking advice on accomplishing <TASK>.",
|
| 136 |
+
"Could you guide me through the steps to <TASK>?",
|
| 137 |
+
"I'm unsure how to start with <TASK>.",
|
| 138 |
+
"Is there a strategy for successfully <TASK>?",
|
| 139 |
+
"What's the proper procedure for <TASK>?",
|
| 140 |
+
"How should I prepare for <TASK>?",
|
| 141 |
+
"I'm not sure where to begin with <TASK>.",
|
| 142 |
+
"I need some insights on <TASK>.",
|
| 143 |
+
"Can you explain how to tackle <TASK>?",
|
| 144 |
+
"I'm interested in the process of <TASK>.",
|
| 145 |
+
"Could you enlighten me on <TASK>?",
|
| 146 |
+
"What are the recommended steps for <TASK>?",
|
| 147 |
+
"Is there a preferred method for <TASK>?",
|
| 148 |
+
"I'd appreciate your advice on <TASK>.",
|
| 149 |
+
"Can you shed light on <TASK>?",
|
| 150 |
+
"What would be the best approach to <TASK>?",
|
| 151 |
+
"How do I get started with <TASK>?",
|
| 152 |
+
"I'm inquiring about the procedure for <TASK>.",
|
| 153 |
+
"Could you share your expertise on <TASK>?",
|
| 154 |
+
"I'd like some guidance on <TASK>.",
|
| 155 |
+
"What's your recommendation for <TASK>?",
|
| 156 |
+
"I'm seeking your input on how to <TASK>.",
|
| 157 |
+
"Can you provide some insights into <TASK>?",
|
| 158 |
+
"How can I successfully accomplish <TASK>?",
|
| 159 |
+
"What steps are involved in <TASK>?",
|
| 160 |
+
"I'm curious about the best way to <TASK>.",
|
| 161 |
+
"Could you show me the ropes for <TASK>?",
|
| 162 |
+
"I need to know how to go about <TASK>.",
|
| 163 |
+
"What are the essential steps for <TASK>?",
|
| 164 |
+
"Is there a specific method for <TASK>?",
|
| 165 |
+
"I'd like to get some advice on <TASK>.",
|
| 166 |
+
"Can you explain the process of <TASK>?",
|
| 167 |
+
"I'm looking for guidance on how to approach <TASK>.",
|
| 168 |
+
"What's the proper way to handle <TASK>?",
|
| 169 |
+
"How should I proceed with <TASK>?",
|
| 170 |
+
"I'm interested in your expertise on <TASK>.",
|
| 171 |
+
"Could you walk me through the steps for <TASK>?",
|
| 172 |
+
"I'm not sure where to begin when it comes to <TASK>.",
|
| 173 |
+
"What should I prioritize when doing <TASK>?",
|
| 174 |
+
"How can I ensure success with <TASK>?",
|
| 175 |
+
"I'd appreciate some tips on <TASK>.",
|
| 176 |
+
"Can you provide a roadmap for <TASK>?",
|
| 177 |
+
"What's the recommended course of action for <TASK>?",
|
| 178 |
+
"I'm seeking your guidance on <TASK>.",
|
| 179 |
+
"Could you offer some suggestions for <TASK>?",
|
| 180 |
+
"I'd like to know the steps to take for <TASK>.",
|
| 181 |
+
"What's the most effective way to achieve <TASK>?",
|
| 182 |
+
"How can I make the most of <TASK>?",
|
| 183 |
+
"I'm wondering about the best approach to <TASK>.",
|
| 184 |
+
"Can you share your insights on <TASK>?",
|
| 185 |
+
"What steps should I follow to complete <TASK>?",
|
| 186 |
+
"I'm looking for advice on <TASK>.",
|
| 187 |
+
"What's the strategy for successfully completing <TASK>?",
|
| 188 |
+
"How should I prepare myself for <TASK>?",
|
| 189 |
+
"I'm not sure where to start with <TASK>.",
|
| 190 |
+
"What's the procedure for <TASK>?",
|
| 191 |
+
"Could you provide some guidance on <TASK>?",
|
| 192 |
+
"I'd like to get some tips on how to <TASK>.",
|
| 193 |
+
"Can you explain how to tackle <TASK> step by step?",
|
| 194 |
+
"I'm interested in understanding the process of <TASK>.",
|
| 195 |
+
"What are the key steps to <TASK>?",
|
| 196 |
+
"Is there a specific method that works for <TASK>?",
|
| 197 |
+
"I'd appreciate your advice on successfully completing <TASK>.",
|
| 198 |
+
"Can you shed light on the best way to <TASK>?",
|
| 199 |
+
"What would you recommend as the first step to <TASK>?",
|
| 200 |
+
"How do I initiate <TASK>?",
|
| 201 |
+
"I'm inquiring about the recommended steps for <TASK>.",
|
| 202 |
+
"Could you share some insights into <TASK>?",
|
| 203 |
+
"I'm seeking your expertise on <TASK>.",
|
| 204 |
+
"What's your recommended approach for <TASK>?",
|
| 205 |
+
"I'd like some guidance on where to start with <TASK>.",
|
| 206 |
+
"Can you provide recommendations for <TASK>?",
|
| 207 |
+
"What's your advice for someone looking to <TASK>?",
|
| 208 |
+
"I'm seeking your input on the process of <TASK>.",
|
| 209 |
+
"How can I achieve success with <TASK>?",
|
| 210 |
+
"What's the best way to navigate <TASK>?",
|
| 211 |
+
"I'm curious about the steps required for <TASK>.",
|
| 212 |
+
"Could you show me the proper way to <TASK>?",
|
| 213 |
+
"I need to know the necessary steps for <TASK>.",
|
| 214 |
+
"What's the most efficient method for <TASK>?",
|
| 215 |
+
"I'd appreciate your guidance on <TASK>.",
|
| 216 |
+
"Can you explain the steps involved in <TASK>?",
|
| 217 |
+
"I'm looking for recommendations on how to approach <TASK>.",
|
| 218 |
+
"What's the right way to handle <TASK>?",
|
| 219 |
+
"How should I manage <TASK>?",
|
| 220 |
+
"I'm interested in your insights on <TASK>.",
|
| 221 |
+
"Could you provide a step-by-step guide for <TASK>?",
|
| 222 |
+
"I'm not sure how to start when it comes to <TASK>.",
|
| 223 |
+
"What are the key factors to consider for <TASK>?",
|
| 224 |
+
"How can I ensure a successful outcome with <TASK>?",
|
| 225 |
+
"I'd like some tips and tricks for <TASK>.",
|
| 226 |
+
"Can you offer a roadmap for accomplishing <TASK>?",
|
| 227 |
+
"What's the preferred course of action for <TASK>?",
|
| 228 |
+
"I'm seeking your expert advice on <TASK>.",
|
| 229 |
+
"Could you suggest some best practices for <TASK>?",
|
| 230 |
+
"I'd like to understand the necessary steps to complete <TASK>.",
|
| 231 |
+
"What's the most effective strategy for <TASK>?",
|
| 232 |
+
]
|
| 233 |
+
|
| 234 |
+
template_grounding_cogvlm = [
|
| 235 |
+
"Where is <TASK>?",
|
| 236 |
+
"Where is <TASK> in the image?",
|
| 237 |
+
"Where is <TASK>? answer in [[x0,y0,x1,y1]] format.",
|
| 238 |
+
"Can you point out <TASK> in the image and provide the bounding boxes of its location?",
|
| 239 |
+
"Help me to locate <TASK> in and give me its bounding boxes, please.",
|
| 240 |
+
"In the given, could you find and tell me the bounding boxes of <TASK>?",
|
| 241 |
+
"Guide me to the location of <TASK> within the image by providing its bounding boxes.",
|
| 242 |
+
"I'd like to know the exact bounding boxes of <TASK> in the photo.",
|
| 243 |
+
"Would you kindly provide the bounding boxes of <TASK> located in the picture?",
|
| 244 |
+
"Can you find <TASK> in and give me the bounding boxes of where it is located?",
|
| 245 |
+
"I'm trying to locate <TASK> in. Can you determine its bounding boxes for me?",
|
| 246 |
+
"What are the bounding boxes of <TASK> in the image?",
|
| 247 |
+
"Can you disclose the position of <TASK> in the photograph by stating its bounding boxes?",
|
| 248 |
+
"In, could you let me know the location of <TASK> in the form of bounding boxes?",
|
| 249 |
+
"I need the bounding boxes of <TASK> in, can you please assist me with that?",
|
| 250 |
+
"Where in is <TASK> located? Provide me with its bounding boxes, please.",
|
| 251 |
+
"May I have the bounding boxes of <TASK>?",
|
| 252 |
+
"In the photograph, could you pinpoint the location of <TASK> and tell me its bounding boxes?",
|
| 253 |
+
"Can you please search and find <TASK> in, then let me know its bounding boxes?",
|
| 254 |
+
"Please, point out the position of <TASK> in the image by giving its bounding boxes.",
|
| 255 |
+
"What are the exact bounding boxes of <TASK> in the provided picture?",
|
| 256 |
+
"Detect the location of <TASK> in and share the bounding boxes with me, please.",
|
| 257 |
+
"In the picture, I'd like you to locate <TASK> and provide its coordinates.",
|
| 258 |
+
"Please indicate the location of <TASK> in the photo by giving bounding boxes.",
|
| 259 |
+
"Find <TASK> in and share its coordinates with me.",
|
| 260 |
+
"Could you please help me find the bounding boxes of <TASK> in the image?",
|
| 261 |
+
"I am looking for the position of <TASK> in. Can you provide its bounding boxes?",
|
| 262 |
+
"In the image, can you locate <TASK> and let me know its coordinates?",
|
| 263 |
+
"I'd appreciate if you could find and tell me the bounding boxes of <TASK>.",
|
| 264 |
+
"In, I need the bounding box bounding boxes of <TASK>.",
|
| 265 |
+
"Point me to the location of <TASK> in the picture by providing its bounding boxes.",
|
| 266 |
+
"Could you trace <TASK> in and tell me its bounding boxes?",
|
| 267 |
+
"Can you assist me in locating <TASK> in, and then provide its bounding boxes?",
|
| 268 |
+
"I'm curious, what are the bounding boxes of <TASK> in the photo?",
|
| 269 |
+
"Kindly share the bounding boxes of <TASK> located in the image.",
|
| 270 |
+
"I would like to find <TASK> in. Can you give me its bounding boxes?",
|
| 271 |
+
"Can you spot <TASK> in and disclose its bounding boxes to me?",
|
| 272 |
+
"Please, reveal the location of <TASK> in the provided photograph as coordinates.",
|
| 273 |
+
"Help me locate and determine the bounding boxes of <TASK>.",
|
| 274 |
+
"I request the bounding boxes of <TASK> in the image.",
|
| 275 |
+
"In the given, can you find <TASK> and tell me its bounding boxes?",
|
| 276 |
+
"I need to know the position of <TASK> in as bounding boxes.",
|
| 277 |
+
"Locate <TASK> in and provide its bounding boxes, please.",
|
| 278 |
+
"Assist me in finding <TASK> in the photo and provide the bounding box bounding boxes.",
|
| 279 |
+
"In, can you guide me to the location of <TASK> by providing bounding boxes?",
|
| 280 |
+
"I'd like the bounding boxes of <TASK> as it appears in the image.",
|
| 281 |
+
"What location does <TASK> hold in the picture? Inform me of its bounding boxes.",
|
| 282 |
+
"Identify the position of <TASK> in and share its bounding boxes.",
|
| 283 |
+
"I'd like to request the bounding boxes of <TASK> within the photo.",
|
| 284 |
+
"How can I locate <TASK> in the image? Please provide the bounding boxes.",
|
| 285 |
+
"I am interested in knowing the bounding boxes of <TASK> in the picture.",
|
| 286 |
+
"Assist me in locating the position of <TASK> in the photograph and its bounding box bounding boxes.",
|
| 287 |
+
"In the image, I need to find <TASK> and know its bounding boxes. Can you please help?"
|
| 288 |
+
"Can you give me a description of the region <TASK> in image?",
|
| 289 |
+
"In the provided image, would you mind describing the selected area <TASK>?",
|
| 290 |
+
"I need details about the area <TASK> located within image.",
|
| 291 |
+
"Could you please share some information on the region <TASK> in this photograph?",
|
| 292 |
+
"Describe what's happening within the coordinates <TASK> of the given image.",
|
| 293 |
+
"What can you tell me about the selected region <TASK> in the photo?",
|
| 294 |
+
"Please, can you help me understand what's inside the region <TASK> in image?",
|
| 295 |
+
"Give me a comprehensive description of the specified area <TASK> in the picture.",
|
| 296 |
+
"I'm curious about the area <TASK> in the following image. Can you describe it?",
|
| 297 |
+
"Please elaborate on the area with the coordinates <TASK> in the visual.",
|
| 298 |
+
"In the displayed image, help me understand the region defined by <TASK>.",
|
| 299 |
+
"Regarding the image, what's going on in the section <TASK>?",
|
| 300 |
+
"In the given photograph, can you explain the area with coordinates <TASK>?",
|
| 301 |
+
"Kindly describe what I should be seeing in the area <TASK> of image.",
|
| 302 |
+
"Within the input image, what can be found in the region defined by <TASK>?",
|
| 303 |
+
"Tell me what you see within the designated area <TASK> in the picture.",
|
| 304 |
+
"Please detail the contents of the chosen region <TASK> in the visual input.",
|
| 305 |
+
"What's inside the area <TASK> of the provided graphic?",
|
| 306 |
+
"I'd like some information about the specific region <TASK> in the image.",
|
| 307 |
+
"Help me understand the details within the area <TASK> in photograph.",
|
| 308 |
+
"Can you break down the region <TASK> in the image for me?",
|
| 309 |
+
"What is taking place within the specified area <TASK> in this capture?",
|
| 310 |
+
"Care to elaborate on the targeted area <TASK> in the visual illustration?",
|
| 311 |
+
"What insights can you provide about the area <TASK> in the selected picture?",
|
| 312 |
+
"What does the area <TASK> within the given visual contain?",
|
| 313 |
+
"Analyze and describe the region <TASK> in the included photo.",
|
| 314 |
+
"Please provide details for the area marked as <TASK> in this photographic.",
|
| 315 |
+
"For the image, can you assess and describe what's happening at <TASK>?",
|
| 316 |
+
"Fill me in about the selected portion <TASK> within the presented image.",
|
| 317 |
+
"In the image, elaborate on the details found within the section <TASK>.",
|
| 318 |
+
"Please interpret and describe the area <TASK> inside the given picture.",
|
| 319 |
+
"What information can you give me about the coordinates <TASK> in image?",
|
| 320 |
+
"Regarding the coordinates <TASK> in image, can you provide a description?",
|
| 321 |
+
"In the photo, can you delve into the details of the region <TASK>?",
|
| 322 |
+
"Please provide insights on the specified area <TASK> within the graphic.",
|
| 323 |
+
"Detail the chosen region <TASK> in the depicted scene.",
|
| 324 |
+
"Can you discuss the entities within the region <TASK> of image?",
|
| 325 |
+
"I'd appreciate a breakdown of the area <TASK> in the displayed image.",
|
| 326 |
+
"What's the story in the section <TASK> of the included visual?",
|
| 327 |
+
"Please enlighten me about the region <TASK> in the given photo.",
|
| 328 |
+
"Offer a thorough description of the area <TASK> within the illustration.",
|
| 329 |
+
"What can you share about the area <TASK> in the presented image?",
|
| 330 |
+
"Help me grasp the context of the region <TASK> within image.",
|
| 331 |
+
"Kindly give an overview of the section <TASK> in photo.",
|
| 332 |
+
"What details can you provide about the region <TASK> in the snapshot?",
|
| 333 |
+
"Can you divulge the contents of the area <TASK> within the given image?",
|
| 334 |
+
"In the submitted image, please give a synopsis of the area <TASK>.",
|
| 335 |
+
"In the image, please describe the bounding box <TASK>.",
|
| 336 |
+
"Please describe the region <TASK> in the picture.",
|
| 337 |
+
"Describe the bbox <TASK> in the provided photo.",
|
| 338 |
+
"What can you tell me about the area <TASK> within the image?",
|
| 339 |
+
"Could you give me a description of the rectangular region <TASK> found in?",
|
| 340 |
+
"In, what elements can be found within the coordinates <TASK>?",
|
| 341 |
+
"Please provide details for the area within the bounding box <TASK> in.",
|
| 342 |
+
"Can you generate a description for the selected region <TASK> in the image?",
|
| 343 |
+
"Kindly describe the objects or scenery in the bounding box <TASK> within.",
|
| 344 |
+
"What details can you provide for the rectangle defined by the coordinates <TASK> in?",
|
| 345 |
+
"In relation to the picture, please describe the content of the area marked by <TASK>.",
|
| 346 |
+
"I'd like to know more about the area <TASK> in the given image. Can you describe it?",
|
| 347 |
+
"Can you help me by describing the part of that lies within the bounding box <TASK>?",
|
| 348 |
+
"What's happening in the section of the photo enclosed by the coordinates <TASK>?",
|
| 349 |
+
"Describe the image content present in the specified rectangular area <TASK> of.",
|
| 350 |
+
"Please provide information about the area within the bounding box <TASK> in the picture.",
|
| 351 |
+
"Could you offer a description of the contents in the selected area <TASK> of the image?",
|
| 352 |
+
"I'm curious about the area <TASK> in. Can you provide a description of it?",
|
| 353 |
+
"What can be observed in the rectangular region <TASK> in the photograph?",
|
| 354 |
+
"Please explain what is contained in the portion of defined by the box <TASK>.",
|
| 355 |
+
"In the photograph, can you describe the objects or scenery enclosed by <TASK>?",
|
| 356 |
+
"Can you give a brief explanation of the specified area <TASK> in the image?",
|
| 357 |
+
"What does the area <TASK> look like in the context of the image?",
|
| 358 |
+
"Could you please describe the contents of the bounding box <TASK> in the given image?",
|
| 359 |
+
"I would like to know more about the rectangular region <TASK> within the picture. Can you describe it?",
|
| 360 |
+
"Please tell me about the area <TASK> in the image. What does it contain?",
|
| 361 |
+
"Help me understand what's happening in the selected bounding box <TASK> within.",
|
| 362 |
+
"Can you provide a description of the area <TASK> in the image?",
|
| 363 |
+
"What sort of things can be seen in the region <TASK> of the photo?",
|
| 364 |
+
"Describe what can be found within the bounds of <TASK> in the image.",
|
| 365 |
+
"In, can you paint a picture of the area enclosed by coordinates <TASK>?",
|
| 366 |
+
"Please provide a detailed account of the area covered by the bounding box <TASK> in.",
|
| 367 |
+
"Give me a vivid description of what's happening in the area <TASK> within the snapshot.",
|
| 368 |
+
"In the image, what do you observe within the rectangular box defined by the coordinates <TASK>?",
|
| 369 |
+
"Could you give me a breakdown of the content in the specified area <TASK> of the picture?",
|
| 370 |
+
"Please elucidate the area<TASK> of the image.",
|
| 371 |
+
"I'd appreciate it if you could describe the portion of that lies within the rectangle <TASK>.",
|
| 372 |
+
"Can you share some insights about the rectangular region <TASK> in the image?",
|
| 373 |
+
"Help me visualize the section of the photo enclosed by the bounding box <TASK>.",
|
| 374 |
+
"Would you kindly provide a description for the content within the rectangular area <TASK> of?",
|
| 375 |
+
"In, can you tell me more about the area specified by the bounding box <TASK>?",
|
| 376 |
+
"Please describe what can be seen in the rectangular region <TASK> of the image.",
|
| 377 |
+
"Can you analyze the content of the area <TASK> within the photograph?",
|
| 378 |
+
"In the provided image, please explain the content within the region <TASK>.",
|
| 379 |
+
"I'm interested in the selected rectangle <TASK> in. Can you tell me more about it?",
|
| 380 |
+
"Explain what can be found in the bounding box <TASK> in the context of the image.",
|
| 381 |
+
"Kindly share your observations about the rectangular region <TASK> within.",
|
| 382 |
+
"I'd like a thorough description of the area <TASK> in the image.",
|
| 383 |
+
"Could you please provide a description of the rectangular area <TASK> in?",
|
| 384 |
+
"Please describe the section of the picture defined by the bbox <TASK>.",
|
| 385 |
+
"Tell me more about the scenery or objects within the rectangular region <TASK> in.",
|
| 386 |
+
"Would you kindly describe the content of the area enclosed by <TASK> in the image?",
|
| 387 |
+
"Help me understand the objects or scenery within the bounding box <TASK> in the image.",
|
| 388 |
+
"I would like to know about the section of the image enclosed by the rectangle <TASK>. Can you describe it?",
|
| 389 |
+
"Describe the selected rectangular area <TASK> in the photo.",
|
| 390 |
+
"Tell me about the region <TASK> of the image.",
|
| 391 |
+
"I request a description of the area <TASK> in the picture.",
|
| 392 |
+
"Can you elaborate on the content of the bounding box <TASK> in?",
|
| 393 |
+
"Please share details about the rectangular region <TASK> within the image.",
|
| 394 |
+
"What can I find in the bbox <TASK> of the provided image?",
|
| 395 |
+
"In the image, could you provide a description for the coordinates <TASK>?",
|
| 396 |
+
"Could you tell me more about the area <TASK> in the snapshot?",
|
| 397 |
+
"Fill me in on the details of the rectangular box <TASK> within the image.",
|
| 398 |
+
"What's going on in the section of contained within the bounding box <TASK>?",
|
| 399 |
+
"I would like a description of the content within the bbox <TASK> in.",
|
| 400 |
+
"Please enlighten me about the area <TASK> in the photograph.",
|
| 401 |
+
"Can you give me a visual rundown of the area <TASK> in?",
|
| 402 |
+
"Describe the visual elements within the selected area <TASK> of the image.",
|
| 403 |
+
"Tell me what you see in the area <TASK> within the context of the image.",
|
| 404 |
+
"Explain the content within the rectangular region <TASK> of the image.",
|
| 405 |
+
"I'd like some information about the bounding box <TASK> in the photo.",
|
| 406 |
+
"What is happening within the rectangle defined by coordinates <TASK> in the image?",
|
| 407 |
+
"Please describe the content within the area <TASK> displayed in the image.",
|
| 408 |
+
"What can be seen in the bounding box <TASK> in the context of the provided image?",
|
| 409 |
+
"Share some details about the objects or environment within the bounding box <TASK> in.",
|
| 410 |
+
"Please describe the area <TASK> in the image for me.",
|
| 411 |
+
"Can you generate a description of the contents within the selected region <TASK> in?",
|
| 412 |
+
"What objects or scenery can be found in the area <TASK> in the image?",
|
| 413 |
+
"Please tell me more about the rectangular section <TASK> in the photo.",
|
| 414 |
+
"Could you describe the content of the bbox <TASK> in the image?",
|
| 415 |
+
"What does the selected region <TASK> in the image encompass?",
|
| 416 |
+
"I am interested in the region <TASK> of the image; please describe it.",
|
| 417 |
+
"Can you provide some context for the area <TASK> within the picture?",
|
| 418 |
+
"Please give me some details about the rectangle <TASK> in the image.",
|
| 419 |
+
"In the photo, what can you see within the region defined by the bounding box <TASK>?",
|
| 420 |
+
"I would like a detailed description of the portion of enclosed by the bbox <TASK>.",
|
| 421 |
+
"Please help me understand the content present within the rectangle <TASK> in.",
|
| 422 |
+
"Would you mind describing the rectangular area <TASK> in the provided image?"
|
| 423 |
+
]
|