Spaces:
Sleeping

Sleeping
Upload 8 files
Browse files
.gitattributes
CHANGED
|
@@ -49,3 +49,4 @@ b.mp4 filter=lfs diff=lfs merge=lfs -text
|
|
| 49 |
cut_a_2.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 50 |
cut_b_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 51 |
tresa.mp4 filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 49 |
cut_a_2.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 50 |
cut_b_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 51 |
tresa.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
Img-1.png filter=lfs diff=lfs merge=lfs -text
|
Img-1.png
ADDED

|
Git LFS Details
|
Img-2.png
ADDED
|
Img-3.png
ADDED
|
Img-4.png
ADDED
|
README.md
CHANGED
|
@@ -1,13 +1,44 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Inference of Vehicle detection using Yolov9
|
| 2 |
+
|
| 3 |
+
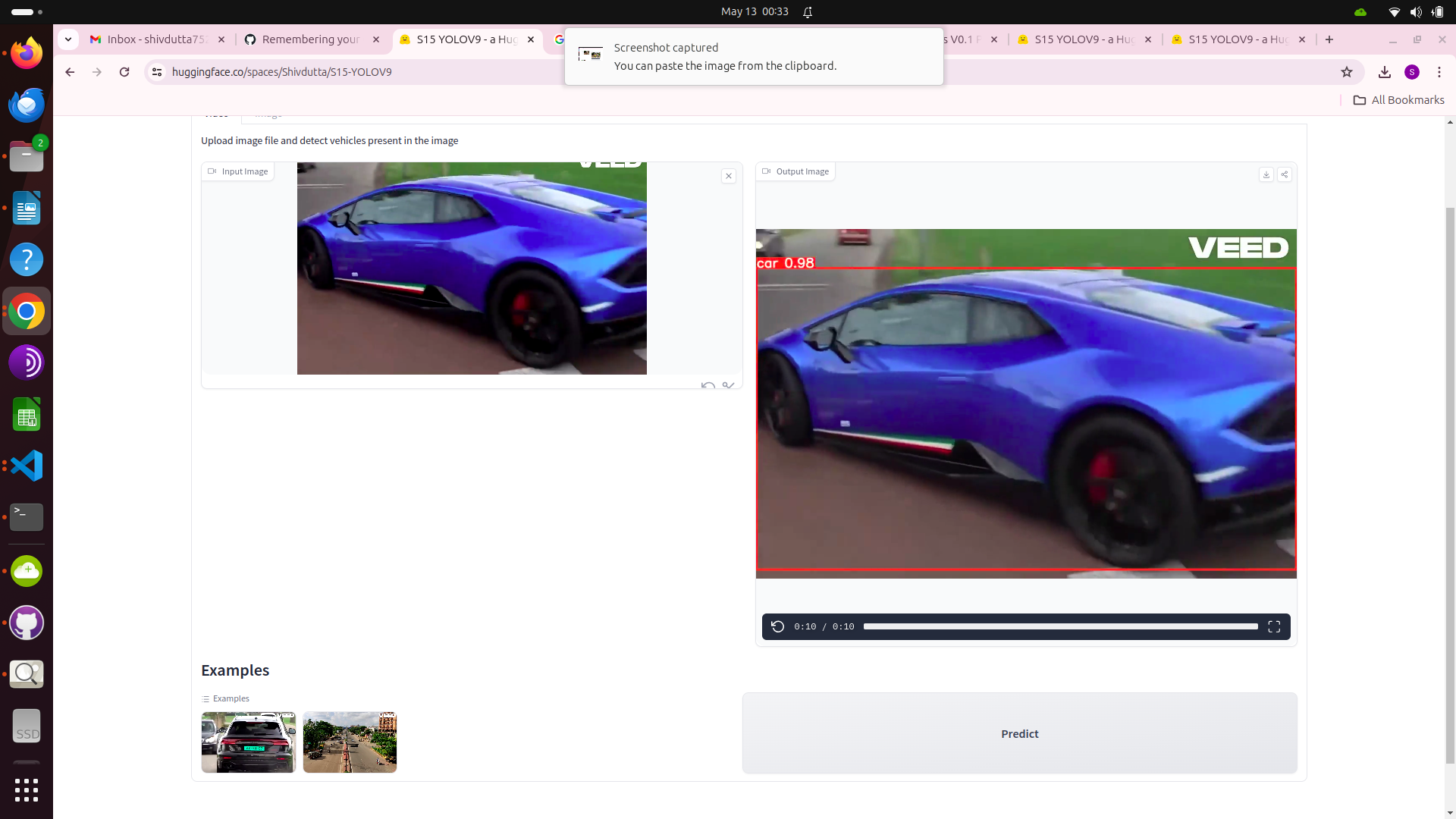
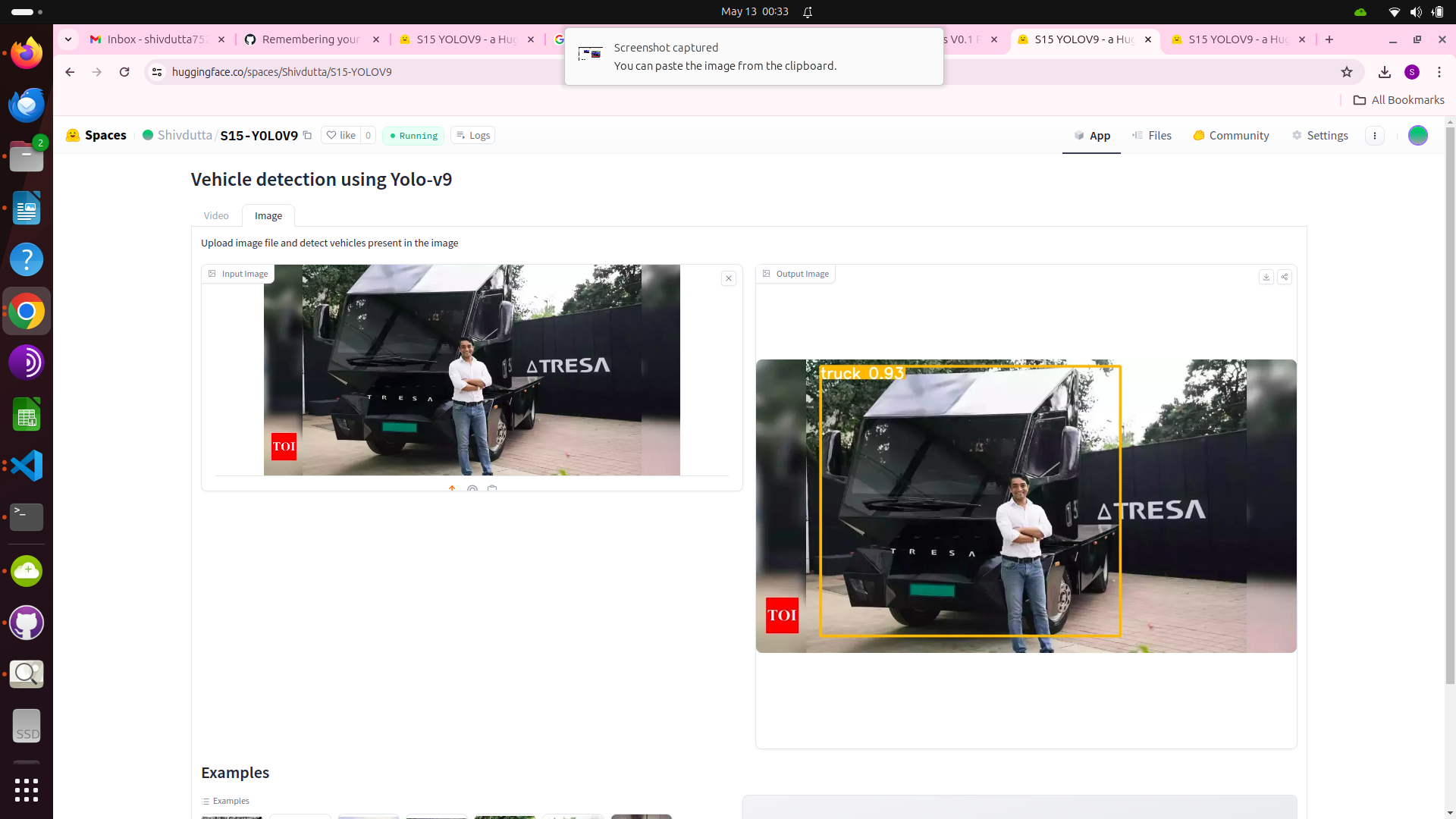
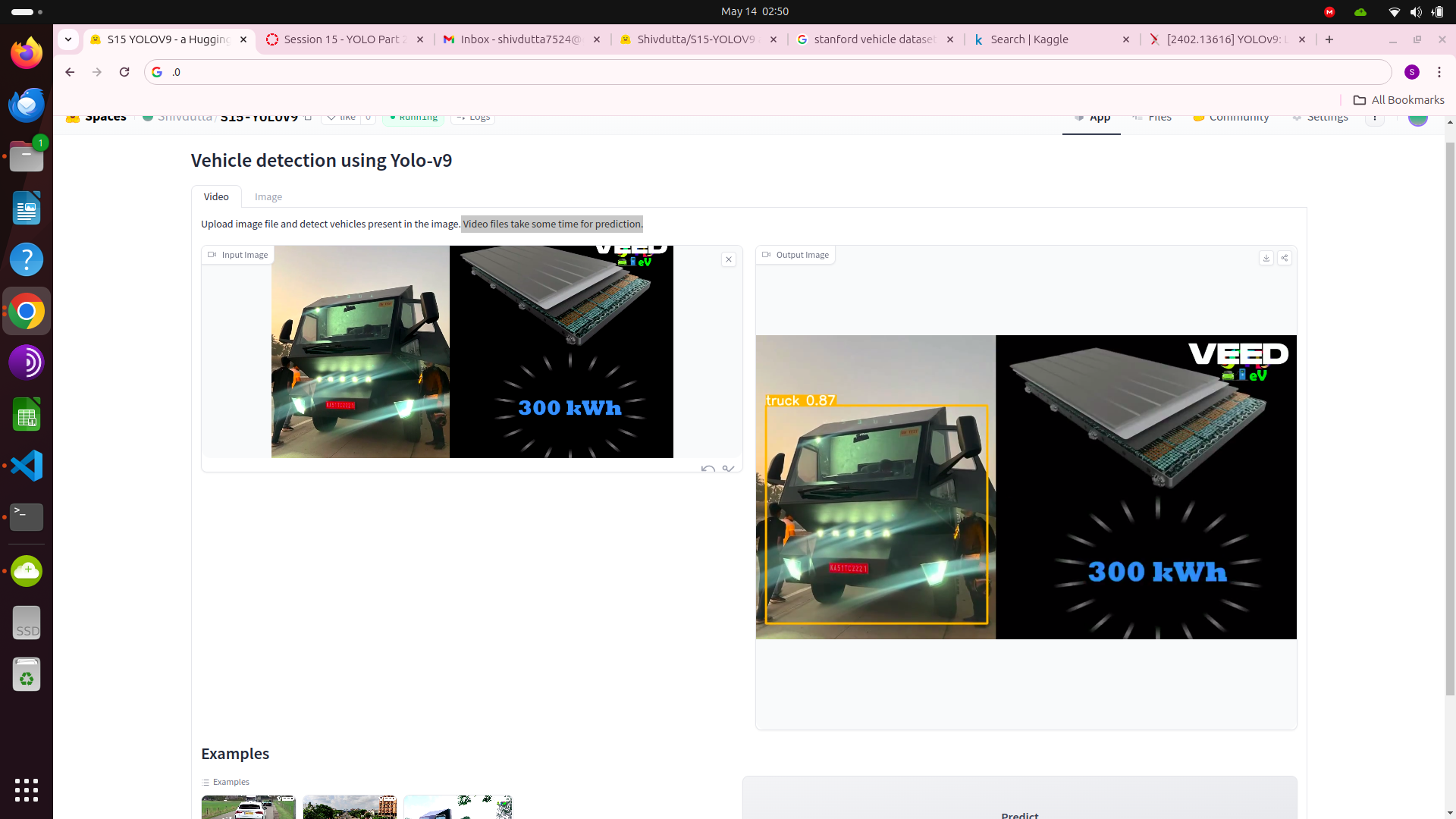
- This application showcases the inference capabilities of a Yolo v9 trained on the vehicle dataset from kaggle.
|
| 4 |
+
[Vehicle Dataset Repo Link](https://www.kaggle.com/datasets/nadinpethiyagoda/vehicle-dataset-for-yolo)
|
| 5 |
+
- The model is trained on 6 classes:
|
| 6 |
+
- car
|
| 7 |
+
- threewheel
|
| 8 |
+
- bus
|
| 9 |
+
- truck
|
| 10 |
+
- motorbike
|
| 11 |
+
- van
|
| 12 |
+
- The architecture is based on Yolo v9 papar https://arxiv.org/abs/2402.13616 and model is
|
| 13 |
+
trained using https://github.com/WongKinYiu/yolov9.git
|
| 14 |
+
- detect.py file used for inference.
|
| 15 |
+
- From gradio applicaiton call is made to detect.py using command line shell with unique folder name passed as argument
|
| 16 |
+
- After processing, image/video is picked from same location.
|
| 17 |
+
|
| 18 |
+
Mentioned below is the link for Training Repository [Training Repo Link](https://github.com/Shivdutta/ERA2-Session15-Yolov9)
|
| 19 |
+
|
| 20 |
+
- Post training process, the model is saved locally and then uploaded to Gradio Spaces.
|
| 21 |
+
- Attached below is the link to [download model file](https://huggingface.co/spaces/Shivdutta/S15-YOLOV9/blob/main/yolov9/runs/train/exp/weights/best.pt)
|
| 22 |
+
|
| 23 |
+
- This app has two features :
|
| 24 |
+
|
| 25 |
+
- **Video Prediction:**
|
| 26 |
+
" - This feature will allow detection of moving vehicles in the the video
|
| 27 |
+
- **Image Prediction:**
|
| 28 |
+
- This feature will allow detection of vehicle in the the image
|
| 29 |
+
|
| 30 |
+
## Usage:
|
| 31 |
+
|
| 32 |
+
- **Video Prediction:**
|
| 33 |
+
" - Upload video file and detect vehicles present in the video.
|
| 34 |
+
- Inferencing is done using CPU therefore it takes more time.
|
| 35 |
+
- **Image Prediction:**
|
| 36 |
+
- Upload image file and detect vehicles present in the image.
|
| 37 |
+
|
| 38 |
+

|
| 39 |
+
|
| 40 |
+

|
| 41 |
+
|
| 42 |
+

|
| 43 |
+
Thank you
|
| 44 |
+
|
app.ipynb
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
app.py
CHANGED
|
@@ -25,8 +25,8 @@ with gr.Blocks() as demo:
|
|
| 25 |
with gr.Tab("Video"):
|
| 26 |
gr.Markdown(
|
| 27 |
"""
|
| 28 |
-
Upload
|
| 29 |
-
|
| 30 |
"""
|
| 31 |
)
|
| 32 |
with gr.Row():
|
|
@@ -36,11 +36,10 @@ with gr.Blocks() as demo:
|
|
| 36 |
gr.Markdown("## Examples")
|
| 37 |
|
| 38 |
with gr.Row():
|
| 39 |
-
gr.Examples([
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
inputs=img_input, fn=inference)
|
| 44 |
|
| 45 |
image_button = gr.Button("Predict")
|
| 46 |
image_button.click(inference, inputs=img_input, outputs=pred_outputs)
|
|
|
|
| 25 |
with gr.Tab("Video"):
|
| 26 |
gr.Markdown(
|
| 27 |
"""
|
| 28 |
+
Upload video file and detect vehicles present in the video.
|
| 29 |
+
Inferencing is done using CPU therefore it takes more time.
|
| 30 |
"""
|
| 31 |
)
|
| 32 |
with gr.Row():
|
|
|
|
| 36 |
gr.Markdown("## Examples")
|
| 37 |
|
| 38 |
with gr.Row():
|
| 39 |
+
gr.Examples([
|
| 40 |
+
'cut_a_2.mp4',
|
| 41 |
+
'cut_b_1.mp4','tresa.mp4'],
|
| 42 |
+
inputs=img_input, fn=inference)
|
|
|
|
| 43 |
|
| 44 |
image_button = gr.Button("Predict")
|
| 45 |
image_button.click(inference, inputs=img_input, outputs=pred_outputs)
|