
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +4 -0
- .github/ISSUE_TEMPLATE/bug_report.yaml +88 -0
- .github/ISSUE_TEMPLATE/config.yaml +1 -0
- .github/ISSUE_TEMPLATE/feature_request.yaml +78 -0
- .gitignore +11 -0
- .idea/.gitignore +3 -0
- .idea/Qwen-7B.iml +14 -0
- .idea/inspectionProfiles/profiles_settings.xml +6 -0
- .idea/misc.xml +4 -0
- .idea/modules.xml +8 -0
- .idea/vcs.xml +6 -0
- .idea/workspace.xml +42 -0
- FAQ.md +85 -0
- FAQ_ja.md +85 -0
- FAQ_zh.md +80 -0
- LICENSE +53 -0
- NOTICE +52 -0
- README.md +444 -7
- README_CN.md +451 -0
- README_JA.md +448 -0
- assets/cli_demo.gif +0 -0
- assets/hfagent_chat_1.png +3 -0
- assets/hfagent_chat_2.png +3 -0
- assets/hfagent_run.png +3 -0
- assets/logo.jpg +0 -0
- assets/openai_api.gif +0 -0
- assets/performance.png +0 -0
- assets/qwen_tokenizer.png +0 -0
- assets/react_showcase_001.png +0 -0
- assets/react_showcase_002.png +0 -0
- assets/react_tutorial_001.png +0 -0
- assets/react_tutorial_002.png +0 -0
- assets/tokenizer.pdf +0 -0
- assets/tokenizer.png +0 -0
- assets/wanx_colorful_black.png +3 -0
- assets/web_demo.gif +0 -0
- assets/wechat.png +0 -0
- cli_demo.py +207 -0
- eval/EVALUATION.md +96 -0
- eval/evaluate_ceval.py +432 -0
- eval/evaluate_chat_ceval.py +459 -0
- eval/evaluate_chat_gsm8k.py +151 -0
- eval/evaluate_chat_humaneval.py +109 -0
- eval/evaluate_chat_mmlu.py +314 -0
- eval/evaluate_cmmlu.py +325 -0
- eval/evaluate_gsm8k.py +127 -0
- eval/evaluate_humaneval.py +85 -0
- eval/evaluate_mmlu.py +315 -0
- eval/evaluate_plugin.py +325 -0
- eval/gsm8k_prompt.txt +59 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/hfagent_chat_1.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/hfagent_chat_2.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/hfagent_run.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/wanx_colorful_black.png filter=lfs diff=lfs merge=lfs -text
|
.github/ISSUE_TEMPLATE/bug_report.yaml
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: 🐞 Bug
|
| 2 |
+
description: 提交错误报告 | File a bug/issue
|
| 3 |
+
title: "[BUG] <title>"
|
| 4 |
+
labels: []
|
| 5 |
+
body:
|
| 6 |
+
- type: checkboxes
|
| 7 |
+
attributes:
|
| 8 |
+
label: 是否已有关于该错误的issue或讨论? | Is there an existing issue / discussion for this?
|
| 9 |
+
description: |
|
| 10 |
+
请先搜索您遇到的错误是否在已有的issues或讨论中提到过。
|
| 11 |
+
Please search to see if an issue / discussion already exists for the bug you encountered.
|
| 12 |
+
[Issues](https://github.com/QwenLM/Qwen-7B/issues)
|
| 13 |
+
[Discussions](https://github.com/QwenLM/Qwen-7B/discussions)
|
| 14 |
+
options:
|
| 15 |
+
- label: 我已经搜索过已有的issues和讨论 | I have searched the existing issues / discussions
|
| 16 |
+
required: true
|
| 17 |
+
- type: checkboxes
|
| 18 |
+
attributes:
|
| 19 |
+
label: 该问题是否在FAQ中有解答? | Is there an existing answer for this in FAQ?
|
| 20 |
+
description: |
|
| 21 |
+
请先搜索您遇到的错误是否已在FAQ中有相关解答。
|
| 22 |
+
Please search to see if an answer already exists in FAQ for the bug you encountered.
|
| 23 |
+
[FAQ-en](https://github.com/QwenLM/Qwen-7B/blob/main/FAQ.md)
|
| 24 |
+
[FAQ-zh](https://github.com/QwenLM/Qwen-7B/blob/main/FAQ_zh.md)
|
| 25 |
+
options:
|
| 26 |
+
- label: 我已经搜索过FAQ | I have searched FAQ
|
| 27 |
+
required: true
|
| 28 |
+
- type: textarea
|
| 29 |
+
attributes:
|
| 30 |
+
label: 当前行为 | Current Behavior
|
| 31 |
+
description: |
|
| 32 |
+
准确描述遇到的行为。
|
| 33 |
+
A concise description of what you're experiencing.
|
| 34 |
+
validations:
|
| 35 |
+
required: false
|
| 36 |
+
- type: textarea
|
| 37 |
+
attributes:
|
| 38 |
+
label: 期望行为 | Expected Behavior
|
| 39 |
+
description: |
|
| 40 |
+
准确描述预期的行为。
|
| 41 |
+
A concise description of what you expected to happen.
|
| 42 |
+
validations:
|
| 43 |
+
required: false
|
| 44 |
+
- type: textarea
|
| 45 |
+
attributes:
|
| 46 |
+
label: 复现方法 | Steps To Reproduce
|
| 47 |
+
description: |
|
| 48 |
+
复现当前行为的详细步骤。
|
| 49 |
+
Steps to reproduce the behavior.
|
| 50 |
+
placeholder: |
|
| 51 |
+
1. In this environment...
|
| 52 |
+
2. With this config...
|
| 53 |
+
3. Run '...'
|
| 54 |
+
4. See error...
|
| 55 |
+
validations:
|
| 56 |
+
required: false
|
| 57 |
+
- type: textarea
|
| 58 |
+
attributes:
|
| 59 |
+
label: 运行环境 | Environment
|
| 60 |
+
description: |
|
| 61 |
+
examples:
|
| 62 |
+
- **OS**: Ubuntu 20.04
|
| 63 |
+
- **Python**: 3.8
|
| 64 |
+
- **Transformers**: 4.31.0
|
| 65 |
+
- **PyTorch**: 2.0.1
|
| 66 |
+
- **CUDA**: 11.4
|
| 67 |
+
value: |
|
| 68 |
+
- OS:
|
| 69 |
+
- Python:
|
| 70 |
+
- Transformers:
|
| 71 |
+
- PyTorch:
|
| 72 |
+
- CUDA (`python -c 'import torch; print(torch.version.cuda)'`):
|
| 73 |
+
render: Markdown
|
| 74 |
+
validations:
|
| 75 |
+
required: false
|
| 76 |
+
- type: textarea
|
| 77 |
+
attributes:
|
| 78 |
+
label: 备注 | Anything else?
|
| 79 |
+
description: |
|
| 80 |
+
您可以在这里补充其他关于该问题背景信息的描述、链接或引用等。
|
| 81 |
+
|
| 82 |
+
您可以通过点击高亮此区域然后拖动文件的方式上传图片或日志文件。
|
| 83 |
+
|
| 84 |
+
Links? References? Anything that will give us more context about the issue you are encountering!
|
| 85 |
+
|
| 86 |
+
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
| 87 |
+
validations:
|
| 88 |
+
required: false
|
.github/ISSUE_TEMPLATE/config.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
blank_issues_enabled: true
|
.github/ISSUE_TEMPLATE/feature_request.yaml
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "💡 Feature Request"
|
| 2 |
+
description: 创建新功能请求 | Create a new ticket for a new feature request
|
| 3 |
+
title: "💡 [REQUEST] - <title>"
|
| 4 |
+
labels: [
|
| 5 |
+
"question"
|
| 6 |
+
]
|
| 7 |
+
body:
|
| 8 |
+
- type: input
|
| 9 |
+
id: start_date
|
| 10 |
+
attributes:
|
| 11 |
+
label: "起始日期 | Start Date"
|
| 12 |
+
description: |
|
| 13 |
+
起始开发日期
|
| 14 |
+
Start of development
|
| 15 |
+
placeholder: "month/day/year"
|
| 16 |
+
validations:
|
| 17 |
+
required: false
|
| 18 |
+
- type: textarea
|
| 19 |
+
id: implementation_pr
|
| 20 |
+
attributes:
|
| 21 |
+
label: "实现PR | Implementation PR"
|
| 22 |
+
description: |
|
| 23 |
+
实现该功能的Pull request
|
| 24 |
+
Pull request used
|
| 25 |
+
placeholder: "#Pull Request ID"
|
| 26 |
+
validations:
|
| 27 |
+
required: false
|
| 28 |
+
- type: textarea
|
| 29 |
+
id: reference_issues
|
| 30 |
+
attributes:
|
| 31 |
+
label: "相关Issues | Reference Issues"
|
| 32 |
+
description: |
|
| 33 |
+
与该功能相关的issues
|
| 34 |
+
Common issues
|
| 35 |
+
placeholder: "#Issues IDs"
|
| 36 |
+
validations:
|
| 37 |
+
required: false
|
| 38 |
+
- type: textarea
|
| 39 |
+
id: summary
|
| 40 |
+
attributes:
|
| 41 |
+
label: "摘要 | Summary"
|
| 42 |
+
description: |
|
| 43 |
+
简要描述新功能的特点
|
| 44 |
+
Provide a brief explanation of the feature
|
| 45 |
+
placeholder: |
|
| 46 |
+
Describe in a few lines your feature request
|
| 47 |
+
validations:
|
| 48 |
+
required: true
|
| 49 |
+
- type: textarea
|
| 50 |
+
id: basic_example
|
| 51 |
+
attributes:
|
| 52 |
+
label: "基本示例 | Basic Example"
|
| 53 |
+
description: Indicate here some basic examples of your feature.
|
| 54 |
+
placeholder: A few specific words about your feature request.
|
| 55 |
+
validations:
|
| 56 |
+
required: true
|
| 57 |
+
- type: textarea
|
| 58 |
+
id: drawbacks
|
| 59 |
+
attributes:
|
| 60 |
+
label: "缺陷 | Drawbacks"
|
| 61 |
+
description: |
|
| 62 |
+
该新功能有哪些缺陷/可能造成哪些影响?
|
| 63 |
+
What are the drawbacks/impacts of your feature request ?
|
| 64 |
+
placeholder: |
|
| 65 |
+
Identify the drawbacks and impacts while being neutral on your feature request
|
| 66 |
+
validations:
|
| 67 |
+
required: true
|
| 68 |
+
- type: textarea
|
| 69 |
+
id: unresolved_question
|
| 70 |
+
attributes:
|
| 71 |
+
label: "未解决问题 | Unresolved questions"
|
| 72 |
+
description: |
|
| 73 |
+
有哪些尚未解决的问题?
|
| 74 |
+
What questions still remain unresolved ?
|
| 75 |
+
placeholder: |
|
| 76 |
+
Identify any unresolved issues.
|
| 77 |
+
validations:
|
| 78 |
+
required: false
|
.gitignore
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
*.so
|
| 3 |
+
build
|
| 4 |
+
.coverage_*
|
| 5 |
+
*.egg-info
|
| 6 |
+
*~
|
| 7 |
+
.vscode/
|
| 8 |
+
.idea/
|
| 9 |
+
.DS_Store
|
| 10 |
+
|
| 11 |
+
/private/
|
.idea/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 默认忽略的文件
|
| 2 |
+
/shelf/
|
| 3 |
+
/workspace.xml
|
.idea/Qwen-7B.iml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<module type="PYTHON_MODULE" version="4">
|
| 3 |
+
<component name="NewModuleRootManager">
|
| 4 |
+
<content url="file://$MODULE_DIR$">
|
| 5 |
+
<excludeFolder url="file://$MODULE_DIR$/venv" />
|
| 6 |
+
</content>
|
| 7 |
+
<orderEntry type="jdk" jdkName="Python 3.8" jdkType="Python SDK" />
|
| 8 |
+
<orderEntry type="sourceFolder" forTests="false" />
|
| 9 |
+
</component>
|
| 10 |
+
<component name="PyDocumentationSettings">
|
| 11 |
+
<option name="format" value="GOOGLE" />
|
| 12 |
+
<option name="myDocStringFormat" value="Google" />
|
| 13 |
+
</component>
|
| 14 |
+
</module>
|
.idea/inspectionProfiles/profiles_settings.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<component name="InspectionProjectProfileManager">
|
| 2 |
+
<settings>
|
| 3 |
+
<option name="USE_PROJECT_PROFILE" value="false" />
|
| 4 |
+
<version value="1.0" />
|
| 5 |
+
</settings>
|
| 6 |
+
</component>
|
.idea/misc.xml
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.8" project-jdk-type="Python SDK" />
|
| 4 |
+
</project>
|
.idea/modules.xml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ProjectModuleManager">
|
| 4 |
+
<modules>
|
| 5 |
+
<module fileurl="file://$PROJECT_DIR$/.idea/Qwen-7B.iml" filepath="$PROJECT_DIR$/.idea/Qwen-7B.iml" />
|
| 6 |
+
</modules>
|
| 7 |
+
</component>
|
| 8 |
+
</project>
|
.idea/vcs.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="VcsDirectoryMappings">
|
| 4 |
+
<mapping directory="$PROJECT_DIR$" vcs="Git" />
|
| 5 |
+
</component>
|
| 6 |
+
</project>
|
.idea/workspace.xml
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ChangeListManager">
|
| 4 |
+
<list default="true" id="6e38c486-b8fd-44ae-a3ad-dac5e5eec7fb" name="变更" comment="">
|
| 5 |
+
<change beforePath="$PROJECT_DIR$/README.md" beforeDir="false" afterPath="$PROJECT_DIR$/README.md" afterDir="false" />
|
| 6 |
+
<change beforePath="$PROJECT_DIR$/web_demo.py" beforeDir="false" afterPath="$PROJECT_DIR$/web_demo.py" afterDir="false" />
|
| 7 |
+
</list>
|
| 8 |
+
<option name="SHOW_DIALOG" value="false" />
|
| 9 |
+
<option name="HIGHLIGHT_CONFLICTS" value="true" />
|
| 10 |
+
<option name="HIGHLIGHT_NON_ACTIVE_CHANGELIST" value="false" />
|
| 11 |
+
<option name="LAST_RESOLUTION" value="IGNORE" />
|
| 12 |
+
</component>
|
| 13 |
+
<component name="Git.Settings">
|
| 14 |
+
<option name="RECENT_GIT_ROOT_PATH" value="$PROJECT_DIR$" />
|
| 15 |
+
</component>
|
| 16 |
+
<component name="MarkdownSettingsMigration">
|
| 17 |
+
<option name="stateVersion" value="1" />
|
| 18 |
+
</component>
|
| 19 |
+
<component name="ProjectId" id="2UhnaDhw369BTArilFxQUASXjkM" />
|
| 20 |
+
<component name="ProjectViewState">
|
| 21 |
+
<option name="hideEmptyMiddlePackages" value="true" />
|
| 22 |
+
<option name="showLibraryContents" value="true" />
|
| 23 |
+
</component>
|
| 24 |
+
<component name="PropertiesComponent"><![CDATA[{
|
| 25 |
+
"keyToString": {
|
| 26 |
+
"RunOnceActivity.OpenProjectViewOnStart": "true",
|
| 27 |
+
"RunOnceActivity.ShowReadmeOnStart": "true",
|
| 28 |
+
"last_opened_file_path": "E:/Llama/Qwen-7B"
|
| 29 |
+
}
|
| 30 |
+
}]]></component>
|
| 31 |
+
<component name="SpellCheckerSettings" RuntimeDictionaries="0" Folders="0" CustomDictionaries="0" DefaultDictionary="应用程序级" UseSingleDictionary="true" transferred="true" />
|
| 32 |
+
<component name="TaskManager">
|
| 33 |
+
<task active="true" id="Default" summary="默认任务">
|
| 34 |
+
<changelist id="6e38c486-b8fd-44ae-a3ad-dac5e5eec7fb" name="变更" comment="" />
|
| 35 |
+
<created>1693400742376</created>
|
| 36 |
+
<option name="number" value="Default" />
|
| 37 |
+
<option name="presentableId" value="Default" />
|
| 38 |
+
<updated>1693400742376</updated>
|
| 39 |
+
</task>
|
| 40 |
+
<servers />
|
| 41 |
+
</component>
|
| 42 |
+
</project>
|
FAQ.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FAQ
|
| 2 |
+
|
| 3 |
+
## Installation & Environment
|
| 4 |
+
|
| 5 |
+
#### Failure in installing flash attention
|
| 6 |
+
|
| 7 |
+
Flash attention is an option for accelerating training and inference. Only NVIDIA GPUs of Turing, Ampere, Ada, and Hopper architecture, e.g., H100, A100, RTX 3090, T4, RTX 2080, can support flash attention. You can use our models without installing it.
|
| 8 |
+
|
| 9 |
+
#### Which version of transformers should I use?
|
| 10 |
+
|
| 11 |
+
4.31.0 is preferred.
|
| 12 |
+
|
| 13 |
+
#### I downloaded the codes and checkpoints but I can't load the model locally. What should I do?
|
| 14 |
+
|
| 15 |
+
Please check if you have updated the code to the latest, and correctly downloaded all the sharded checkpoint files.
|
| 16 |
+
|
| 17 |
+
#### `qwen.tiktoken` is not found. What is it?
|
| 18 |
+
|
| 19 |
+
This is the merge file of the tokenizer. You have to download it. Note that if you just git clone the repo without [git-lfs](https://git-lfs.com), you cannot download this file.
|
| 20 |
+
|
| 21 |
+
#### transformers_stream_generator/tiktoken/accelerate not found
|
| 22 |
+
|
| 23 |
+
Run the command `pip install -r requirements.txt`. You can find the file at [https://github.com/QwenLM/Qwen-7B/blob/main/requirements.txt](https://github.com/QwenLM/Qwen-7B/blob/main/requirements.txt).
|
| 24 |
+
<br><br>
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## Demo & Inference
|
| 29 |
+
|
| 30 |
+
#### Is there any demo? CLI demo and Web UI demo?
|
| 31 |
+
|
| 32 |
+
Yes, see `web_demo.py` for web demo and `cli_demo.py` for CLI demo. See README for more information.
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
#### Can I use CPU only?
|
| 37 |
+
|
| 38 |
+
Yes, run `python cli_demo.py --cpu-only` will load the model and inference on CPU only.
|
| 39 |
+
|
| 40 |
+
#### Can Qwen support streaming?
|
| 41 |
+
|
| 42 |
+
Yes. See the function `chat_stream` in `modeling_qwen.py`.
|
| 43 |
+
|
| 44 |
+
#### Gibberish in result when using chat_stream().
|
| 45 |
+
|
| 46 |
+
This is because tokens represent bytes and a single token may be a meaningless string. We have updated the default setting of our tokenizer to avoid such decoding results. Please update the code to the latest version.
|
| 47 |
+
|
| 48 |
+
#### It seems that the generation is not related to the instruction...
|
| 49 |
+
|
| 50 |
+
Please check if you are loading Qwen-7B-Chat instead of Qwen-7B. Qwen-7B is the base model without alignment, which behaves differently from the SFT/Chat model.
|
| 51 |
+
|
| 52 |
+
#### Is quantization supported?
|
| 53 |
+
|
| 54 |
+
Yes, the quantization is supported by `bitsandbytes`. We are working on an improved version and will release the quantized model checkpoints.
|
| 55 |
+
|
| 56 |
+
#### Errors in running quantized models: `importlib.metadata.PackageNotFoundError: No package metadata was found for bitsandbytes`
|
| 57 |
+
|
| 58 |
+
For Linux users,running `pip install bitsandbytes` directly can solve the problem. For Windows users, you can run `python -m pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui`·
|
| 59 |
+
|
| 60 |
+
#### Slow when processing long sequences
|
| 61 |
+
|
| 62 |
+
We solved this problem. Updating the code to the latest version can help.
|
| 63 |
+
|
| 64 |
+
#### Unsatisfactory performance in processing long sequences
|
| 65 |
+
|
| 66 |
+
Please ensure that NTK is applied. `use_dynamc_ntk` and `use_logn_attn` in `config.json` should be set to `true` (`true` by default).
|
| 67 |
+
<br><br>
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## Finetuning
|
| 72 |
+
|
| 73 |
+
#### Can Qwen support SFT or even RLHF?
|
| 74 |
+
|
| 75 |
+
We do not provide finetuning or RLHF codes for now. However, some projects have supported finetuning, see [FastChat](**[https://github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat)), [Firefly]([https://github.com/yangjianxin1/Firefly](https://github.com/yangjianxin1/Firefly)), [**LLaMA Efficient Tuning**]([https://github.com/hiyouga/LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning)), etc. We will soon update the relevant codes.
|
| 76 |
+
<br><br>
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## Tokenizer
|
| 81 |
+
|
| 82 |
+
#### bos_id/eos_id/pad_id not found
|
| 83 |
+
|
| 84 |
+
In our training, we only use `<|endoftext|>` as the separator and padding token. You can set bos_id, eos_id, and pad_id to tokenizer.eod_id. Learn more about our tokenizer from our documents about the tokenizer.
|
| 85 |
+
|
FAQ_ja.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FAQ
|
| 2 |
+
|
| 3 |
+
## インストールと環境
|
| 4 |
+
|
| 5 |
+
#### Flash attention 導入の失敗例
|
| 6 |
+
|
| 7 |
+
Flash attention は、トレーニングと推論を加速するオプションです。H100、A100、RTX 3090、T4、RTX 2080 などの Turing、Ampere、Ada、および Hopper アーキテクチャの NVIDIA GPU だけが、flash attention をサポートできます。それをインストールせずに私たちのモデルを使用することができます。
|
| 8 |
+
|
| 9 |
+
#### transformers のバージョンは?
|
| 10 |
+
|
| 11 |
+
4.31.0 が望ましいです。
|
| 12 |
+
|
| 13 |
+
#### コードとチェックポイントをダウンロードしましたが、モデルをローカルにロードできません。どうすればよいでしょうか?
|
| 14 |
+
|
| 15 |
+
コードを最新のものに更新し、すべてのシャードされたチェックポイントファイルを正しくダウンロードしたかどうか確認してください。
|
| 16 |
+
|
| 17 |
+
#### `qwen.tiktoken` が見つかりません。これは何ですか?
|
| 18 |
+
|
| 19 |
+
これはトークナイザーのマージファイルです。ダウンロードする必要があります。[git-lfs](https://git-lfs.com) を使わずにリポジトリを git clone しただけでは、このファイルをダウンロードできないことに注意してください。
|
| 20 |
+
|
| 21 |
+
#### transformers_stream_generator/tiktoken/accelerate が見つかりません。
|
| 22 |
+
|
| 23 |
+
コマンド `pip install -r requirements.txt` を実行してください。このファイルは [https://github.com/QwenLM/Qwen-7B/blob/main/requirements.txt](https://github.com/QwenLM/Qwen-7B/blob/main/requirements.txt) にあります。
|
| 24 |
+
<br><br>
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## デモと推論
|
| 29 |
+
|
| 30 |
+
#### デモはありますか?CLI と Web UI のデモはありますか?
|
| 31 |
+
|
| 32 |
+
はい、Web デモは `web_demo.py` を、CLI デモは `cli_demo.py` を参照してください。詳しくは README を参照してください。
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
#### CPU のみを使うことはできますか?
|
| 37 |
+
|
| 38 |
+
はい、`python cli_demo.py --cpu-only` を実行すると、CPU のみでモデルと推論をロードします。
|
| 39 |
+
|
| 40 |
+
#### Qwen はストリーミングに対応していますか?
|
| 41 |
+
|
| 42 |
+
`modeling_qwen.py` の `chat_stream` 関数を参照してください。
|
| 43 |
+
|
| 44 |
+
#### chat_stream() を使用すると、結果に文字化けが発生します。
|
| 45 |
+
|
| 46 |
+
これは、トークンがバイトを表し、単一のトークンが無意味な文字列である可能性があるためです。このようなデコード結果を避けるため、トークナイザのデフォルト設定を更新しました。コードを最新版に更新してください。
|
| 47 |
+
|
| 48 |
+
#### インストラクションとは関係ないようですが...
|
| 49 |
+
|
| 50 |
+
Qwen-7B ではなく Qwen-7B-Chat を読み込んでいないか確認してください。Qwen-7B はアライメントなしのベースモデルで、SFT/Chat モデルとは挙動が異なります。
|
| 51 |
+
|
| 52 |
+
#### 量子化はサポートされていますか?
|
| 53 |
+
|
| 54 |
+
はい、量子化は `bitsandbytes` でサポートされています。私たちは改良版の開発に取り組んでおり、量子化されたモデルのチェックポイントをリリースする予定です。
|
| 55 |
+
|
| 56 |
+
#### 量子化モデル実行時のエラー: `importlib.metadata.PackageNotFoundError: No package metadata was found for bitsandbytes`
|
| 57 |
+
|
| 58 |
+
Linux ユーザの場合は,`pip install bitsandbytes` を直接実行することで解決できます。Windows ユーザの場合は、`python -m pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui` を実行することができます。
|
| 59 |
+
|
| 60 |
+
#### 長いシーケンスの処理に時間がかかる
|
| 61 |
+
|
| 62 |
+
この問題は解決しました。コードを最新版に更新することで解決します。
|
| 63 |
+
|
| 64 |
+
#### 長いシーケンスの処理で不満足なパフォーマンス
|
| 65 |
+
|
| 66 |
+
NTK が適用されていることを確認してください。`config.json` の `use_dynamc_ntk` と `use_logn_attn` を `true` に設定する必要があります(デフォルトでは `true`)。
|
| 67 |
+
<br><br>
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## ファインチューニング
|
| 72 |
+
|
| 73 |
+
#### Qwen は SFT、あるいは RLHF に対応できますか?
|
| 74 |
+
|
| 75 |
+
今のところ、ファインチューニングや RLHF のコードは提供していません。しかし、[FastChat](**[https://github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat))、[Firefly]([https://github.com/yangjianxin1/Firefly](https://github.com/yangjianxin1/Firefly))、[**LLaMA Efficient Tuning**]([https://github.com/hiyouga/LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning))など、いくつかのプロジェクトではファインチューニングをサポートしています。近日中に関連コードを更新する予定です。
|
| 76 |
+
<br><br>
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## トークナイザー
|
| 81 |
+
|
| 82 |
+
#### bos_id/eos_id/pad_id が見つかりません。
|
| 83 |
+
|
| 84 |
+
私たちのトレーニングでは、セパレータとパディングトークンとして `<|endoftext|>` のみを使用しています。bos_id、eos_id、pad_id は tokenizer.eod_id に設定できます。私たちの���ークナイザーについて詳しくは、トークナイザーについてのドキュメントをご覧ください。
|
| 85 |
+
|
FAQ_zh.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FAQ
|
| 2 |
+
|
| 3 |
+
## 安装&环境
|
| 4 |
+
|
| 5 |
+
#### flash attention 安装失败
|
| 6 |
+
|
| 7 |
+
flash attention是一个用于加速模型训练推理的可选项,且仅适用于Turing、Ampere、Ada、Hopper架构的Nvidia GPU显卡(如H100、A100、RTX 3090、T4、RTX 2080),您可以在不安装flash attention的情况下正常使用模型进行推理。
|
| 8 |
+
|
| 9 |
+
#### 我应该用哪个transformers版本?
|
| 10 |
+
|
| 11 |
+
建议使用4.31.0。
|
| 12 |
+
|
| 13 |
+
#### 我把模型和代码下到本地,按照教程无法使用,该怎么办?
|
| 14 |
+
|
| 15 |
+
答:别着急,先检查你的代码是不是更新到最新版本,然后确认你是否完整地将模型checkpoint下到本地。
|
| 16 |
+
|
| 17 |
+
#### `qwen.tiktoken`这个文件找不到,怎么办?
|
| 18 |
+
|
| 19 |
+
这个是我们的tokenizer的merge文件,你必须下载它才能使用我们的tokenizer。注意,如果你使用git clone却没有使用git-lfs,这个文件不会被下载。如果你不了解git-lfs,可点击[官网](https://git-lfs.com/)了解。
|
| 20 |
+
|
| 21 |
+
#### transformers_stream_generator/tiktoken/accelerate,这几个库提示找不到,怎么办?
|
| 22 |
+
|
| 23 |
+
运行如下命令:`pip install -r requirements.txt`。相关依赖库在[https://github.com/QwenLM/Qwen-7B/blob/main/requirements.txt](https://github.com/QwenLM/Qwen-7B/blob/main/requirements.txt) 可以找到。
|
| 24 |
+
<br><br>
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
## Demo & 推理
|
| 28 |
+
|
| 29 |
+
#### 是否提供Demo?CLI Demo及Web UI Demo?
|
| 30 |
+
|
| 31 |
+
`web_demo.py`和`cli_demo.py`分别提供了Web UI以及CLI的Demo。请查看README相关内容了解更多。
|
| 32 |
+
|
| 33 |
+
#### 我没有GPU,只用CPU运行CLI demo可以吗?
|
| 34 |
+
|
| 35 |
+
可以的,运行`python cli_demo.py --cpu-only`命令即可将模型读取到CPU并使用CPU进行推理。
|
| 36 |
+
|
| 37 |
+
#### Qwen支持流式推理吗?
|
| 38 |
+
|
| 39 |
+
Qwen当前支持流式推理。见位于`modeling_qwen.py`的`chat_stream`函数。
|
| 40 |
+
|
| 41 |
+
#### 使用`chat_stream()`生成混乱的内容及乱码,为什么?
|
| 42 |
+
|
| 43 |
+
这是由于模型生成过程中输出的部分token需要与后续token一起解码才能输出正常文本,单个token解码结果是无意义字符串,我们已经更新了tokenizer解码时的默认设置,避免这些字符串在生成结果中出现,如果仍有类似问题请更新模型至最新版本。
|
| 44 |
+
|
| 45 |
+
#### 模型的输出看起来与输入无关/没有遵循指令/看起来呆呆的
|
| 46 |
+
|
| 47 |
+
请检查是否加载的是Qwen-7B-Chat模型进行推理,Qwen-7B模型是未经align的预训练基模型,不期望具备响应用户指令的能力。我们在模型最新版本已经对`chat`及`chat_stream`接口内进行了检查,避免您误将预训练模型作为SFT/Chat模型使用。
|
| 48 |
+
|
| 49 |
+
#### 是否有量化版本模型
|
| 50 |
+
|
| 51 |
+
目前Qwen支持基于`bitsandbytes`的8-bit和4-bit的量化推理。后续我们将进一步更新提供更加高效的量化推理实现,并提供对应的量化模型。
|
| 52 |
+
|
| 53 |
+
#### 运行量化推理报错:`importlib.metadata.PackageNotFoundError: No package metadata was found for bitsandbytes`
|
| 54 |
+
|
| 55 |
+
对于linux 用户,直接`pip install bitsandbytes`即可。对于windows用户,可以 运行`python -m pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui`。
|
| 56 |
+
|
| 57 |
+
#### 生成序列较长后速度显著变慢
|
| 58 |
+
|
| 59 |
+
这一问题已经在最新版本中修复。请更新到最新代码。
|
| 60 |
+
|
| 61 |
+
#### 处理长序列时效果有问题
|
| 62 |
+
|
| 63 |
+
请确认是否开启ntk。若要启用这些技巧,请将`config.json`里的`use_dynamc_ntk`和`use_logn_attn`设置为`true`。最新代码默认为`true`。
|
| 64 |
+
<br><br>
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
## 微调
|
| 68 |
+
|
| 69 |
+
#### 当前是否支持SFT和RLHF?
|
| 70 |
+
|
| 71 |
+
我们目前未提供SFT和RLHF代码。当前有多个外部项目已实现支持,如[FastChat](**[https://github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat))、[Firefly]([https://github.com/yangjianxin1/Firefly](https://github.com/yangjianxin1/Firefly))、[**LLaMA Efficient Tuning**]([https://github.com/hiyouga/LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning))等。我们会尽快更新这部分代码和说明。
|
| 72 |
+
<br><br>
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
## Tokenizer
|
| 76 |
+
|
| 77 |
+
#### bos_id/eos_id/pad_id,这些token id不存在,为什么?
|
| 78 |
+
|
| 79 |
+
在训练过程中,我们仅使用<|endoftext|>这一token作为sample/document之间的分隔符及padding位置占位符,你可以将bos_id, eos_id, pad_id均指向tokenizer.eod_id。请阅读我们关于tokenizer的文档,了解如何设置这些id。
|
| 80 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Tongyi Qianwen LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
Tongyi Qianwen Release Date: August 3, 2023
|
| 4 |
+
|
| 5 |
+
By clicking to agree or by using or distributing any portion or element of the Tongyi Qianwen Materials, you will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
| 6 |
+
|
| 7 |
+
1. Definitions
|
| 8 |
+
a. This Tongyi Qianwen LICENSE AGREEMENT (this "Agreement") shall mean the terms and conditions for use, reproduction, distribution and modification of the Materials as defined by this Agreement.
|
| 9 |
+
b. "We"(or "Us") shall mean Alibaba Cloud.
|
| 10 |
+
c. "You" (or "Your") shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Materials for any purpose and in any field of use.
|
| 11 |
+
d. "Third Parties" shall mean individuals or legal entities that are not under common control with Us or You.
|
| 12 |
+
e. "Tongyi Qianwen" shall mean the large language models (including Qwen-7B model and Qwen-7B-Chat model), and software and algorithms, consisting of trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Us.
|
| 13 |
+
f. "Materials" shall mean, collectively, Alibaba Cloud's proprietary Tongyi Qianwen and Documentation (and any portion thereof) made available under this Agreement.
|
| 14 |
+
g. "Source" form shall mean the preferred form for making modifications, including but not limited to model source code, documentation source, and configuration files.
|
| 15 |
+
h. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation,
|
| 16 |
+
and conversions to other media types.
|
| 17 |
+
|
| 18 |
+
2. Grant of Rights
|
| 19 |
+
You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Alibaba Cloud's intellectual property or other rights owned by Us embodied in the Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Materials.
|
| 20 |
+
|
| 21 |
+
3. Redistribution
|
| 22 |
+
You may reproduce and distribute copies of the Materials or derivative works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
|
| 23 |
+
a. You shall give any other recipients of the Materials or derivative works a copy of this Agreement;
|
| 24 |
+
b. You shall cause any modified files to carry prominent notices stating that You changed the files;
|
| 25 |
+
c. You shall retain in all copies of the Materials that You distribute the following attribution notices within a "Notice" text file distributed as a part of such copies: "Tongyi Qianwen is licensed under the Tongyi Qianwen LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. All Rights Reserved."; and
|
| 26 |
+
d. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such derivative works as a whole, provided Your use, reproduction, and distribution of the work otherwise complies with the terms and conditions of this Agreement.
|
| 27 |
+
|
| 28 |
+
4. Restrictions
|
| 29 |
+
If you are commercially using the Materials, and your product or service has more than 100 million monthly active users, You shall request a license from Us. You cannot exercise your rights under this Agreement without our express authorization.
|
| 30 |
+
|
| 31 |
+
5. Rules of use
|
| 32 |
+
a. The Materials may be subject to export controls or restrictions in China, the United States or other countries or regions. You shall comply with applicable laws and regulations in your use of the Materials.
|
| 33 |
+
b. You can not use the Materials or any output therefrom to improve any other large language model (excluding Tongyi Qianwen or derivative works thereof).
|
| 34 |
+
|
| 35 |
+
6. Intellectual Property
|
| 36 |
+
a. We retain ownership of all intellectual property rights in and to the Materials and derivatives made by or for Us. Conditioned upon compliance with the terms and conditions of this Agreement, with respect to any derivative works and modifications of the Materials that are made by you, you are and will be the owner of such derivative works and modifications.
|
| 37 |
+
b. No trademark license is granted to use the trade names, trademarks, service marks, or product names of Us, except as required to fulfill notice requirements under this Agreement or as required for reasonable and customary use in describing and redistributing the Materials.
|
| 38 |
+
c. If you commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against Us or any entity alleging that the Materials or any output therefrom, or any part of the foregoing, infringe any intellectual property or other right owned or licensable by you, then all licences granted to you under this Agreement shall terminate as of the date such lawsuit or other proceeding is commenced or brought.
|
| 39 |
+
|
| 40 |
+
7. Disclaimer of Warranty and Limitation of Liability
|
| 41 |
+
|
| 42 |
+
a. We are not obligated to support, update, provide training for, or develop any further version of the Tongyi Qianwen Materials or to grant any license thereto.
|
| 43 |
+
b. THE MATERIALS ARE PROVIDED "AS IS" WITHOUT ANY EXPRESS OR IMPLIED WARRANTY OF ANY KIND INCLUDING WARRANTIES OF MERCHANTABILITY, NONINFRINGEMENT, OR FITNESS FOR A PARTICULAR PURPOSE. WE MAKE NO WARRANTY AND ASSUME NO RESPONSIBILITY FOR THE SAFETY OR STABILITY OF THE MATERIALS AND ANY OUTPUT THEREFROM.
|
| 44 |
+
c. IN NO EVENT SHALL WE BE LIABLE TO YOU FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO ANY DIRECT, OR INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING FROM YOUR USE OR INABILITY TO USE THE MATERIALS OR ANY OUTPUT OF IT, NO MATTER HOW IT’S CAUSED.
|
| 45 |
+
d. You will defend, indemnify and hold harmless Us from and against any claim by any third party arising out of or related to your use or distribution of the Materials.
|
| 46 |
+
|
| 47 |
+
8. Survival and Termination.
|
| 48 |
+
a. The term of this Agreement shall commence upon your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
| 49 |
+
b. We may terminate this Agreement if you breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, you must delete and cease use of the Materials. Sections 7 and 9 shall survive the termination of this Agreement.
|
| 50 |
+
|
| 51 |
+
9. Governing Law and Jurisdiction.
|
| 52 |
+
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of China, without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
| 53 |
+
b. The People's Courts in Hangzhou City shall have exclusive jurisdiction over any dispute arising out of this Agreement.
|
NOTICE
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
------------- LICENSE FOR NVIDIA Megatron-LM code --------------
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
|
| 5 |
+
Redistribution and use in source and binary forms, with or without
|
| 6 |
+
modification, are permitted provided that the following conditions
|
| 7 |
+
are met:
|
| 8 |
+
* Redistributions of source code must retain the above copyright
|
| 9 |
+
notice, this list of conditions and the following disclaimer.
|
| 10 |
+
* Redistributions in binary form must reproduce the above copyright
|
| 11 |
+
notice, this list of conditions and the following disclaimer in the
|
| 12 |
+
documentation and/or other materials provided with the distribution.
|
| 13 |
+
* Neither the name of NVIDIA CORPORATION nor the names of its
|
| 14 |
+
contributors may be used to endorse or promote products derived
|
| 15 |
+
from this software without specific prior written permission.
|
| 16 |
+
|
| 17 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
|
| 18 |
+
EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 19 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 20 |
+
PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
|
| 21 |
+
CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
| 22 |
+
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
| 23 |
+
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
| 24 |
+
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
|
| 25 |
+
OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 26 |
+
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 27 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
------------- LICENSE FOR OpenAI tiktoken code --------------
|
| 31 |
+
|
| 32 |
+
MIT License
|
| 33 |
+
|
| 34 |
+
Copyright (c) 2022 OpenAI, Shantanu Jain
|
| 35 |
+
|
| 36 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 37 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 38 |
+
in the Software without restriction, including without limitation the rights
|
| 39 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 40 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 41 |
+
furnished to do so, subject to the following conditions:
|
| 42 |
+
|
| 43 |
+
The above copyright notice and this permission notice shall be included in all
|
| 44 |
+
copies or substantial portions of the Software.
|
| 45 |
+
|
| 46 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 47 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 48 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 49 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 50 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 51 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 52 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,12 +1,449 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: gray
|
| 5 |
-
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 3.41.2
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: cmkj-gpt
|
| 3 |
+
app_file: web_demo.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 3.41.2
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
<p align="left">
|
| 8 |
+
<a href="README_CN.md">中文</a>  |  English  |  <a href="README_JA.md">日本語</a>
|
| 9 |
+
</p>
|
| 10 |
+
<br><br>
|
| 11 |
+
|
| 12 |
+
<p align="center">
|
| 13 |
+
<img src="assets/logo.jpg" width="400"/>
|
| 14 |
+
<p>
|
| 15 |
+
<br>
|
| 16 |
+
|
| 17 |
+
<p align="center">
|
| 18 |
+
Qwen-7B <a href="https://modelscope.cn/models/qwen/Qwen-7B/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B">🤗</a>  | Qwen-7B-Chat <a href="https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B-Chat">🤗</a>  | Qwen-7B-Chat-Int4 <a href="https://huggingface.co/Qwen/Qwen-7B-Chat-Int4">🤗</a>
|
| 19 |
+
<br>
|
| 20 |
+
<a href="assets/wechat.png">WeChat</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>   |   <a href="https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary">Demo</a>  |  <a href="https://github.com/QwenLM/Qwen-7B/blob/main/tech_memo.md">Report</a>
|
| 21 |
+
</p>
|
| 22 |
+
<br><br>
|
| 23 |
+
|
| 24 |
+
We opensource **Qwen-7B** and **Qwen-7B-Chat** on both **🤖 ModelScope** and **🤗 Hugging Face** (Click the logos on top to the repos with codes and checkpoints). This repo includes the brief introduction to Qwen-7B, the usage guidance, and also a technical memo [link](tech_memo.md) that provides more information.
|
| 25 |
+
|
| 26 |
+
Qwen-7B is the 7B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-7B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. Additionally, based on the pretrained Qwen-7B, we release Qwen-7B-Chat, a large-model-based AI assistant, which is trained with alignment techniques. The features of the Qwen-7B series include:
|
| 27 |
+
|
| 28 |
+
1. **Trained with high-quality pretraining data**. We have pretrained Qwen-7B on a self-constructed large-scale high-quality dataset of over 2.2 trillion tokens. The dataset includes plain texts and codes, and it covers a wide range of domains, including general domain data and professional domain data.
|
| 29 |
+
2. **Strong performance**. In comparison with the models of the similar model size, we outperform the competitors on a series of benchmark datasets, which evaluates natural language understanding, mathematics, coding, etc.
|
| 30 |
+
3. **Better support of languages**. Our tokenizer, based on a large vocabulary of over 150K tokens, is a more efficient one compared with other tokenizers. It is friendly to many languages, and it is helpful for users to further finetune Qwen-7B for the extension of understanding a certain language.
|
| 31 |
+
4. **Support of 8K Context Length**. Both Qwen-7B and Qwen-7B-Chat support the context length of 8K, which allows inputs with long contexts.
|
| 32 |
+
5. **Support of Plugins**. Qwen-7B-Chat is trained with plugin-related alignment data, and thus it is capable of using tools, including APIs, models, databases, etc., and it is capable of playing as an agent.
|
| 33 |
+
|
| 34 |
+
The following sections include information that you might find it helpful. Specifically, we advise you to read the FAQ section before you launch issues.
|
| 35 |
+
<br>
|
| 36 |
+
|
| 37 |
+
## News and Updates
|
| 38 |
+
|
| 39 |
+
* 2023.8.21 We release the Int4 quantized model for Qwen-7B-Chat, **Qwen-7B-Chat-Int4**, which requires low memory costs but achieves improved inference speed. Besides, there is no significant performance degradation on the benchmark evaluation.
|
| 40 |
+
* 2023.8.3 We release both **Qwen-7B** and **Qwen-7B-Chat** on ModelScope and Hugging Face. We also provide a technical memo for more details about the model, including training details and model performance.
|
| 41 |
+
|
| 42 |
+
## Performance
|
| 43 |
+
|
| 44 |
+
In general, Qwen-7B outperforms the baseline models of a similar model size, and even outperforms larger models of around 13B parameters, on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, HumanEval, and WMT22, CMMLU, etc., which evaluate the models' capabilities on natural language understanding, mathematic problem solving, coding, etc. See the results below.
|
| 45 |
+
|
| 46 |
+
| Model | MMLU | C-Eval | GSM8K | HumanEval | WMT22 (en-zh) | CMMLU |
|
| 47 |
+
| :------------- | :--------: | :--------: | :--------: | :---------: | :-------------: | :--------: |
|
| 48 |
+
| LLaMA-7B | 35.1 | - | 11.0 | 10.5 | 8.7 | - |
|
| 49 |
+
| LLaMA 2-7B | 45.3 | - | 14.6 | 12.8 | 17.9 | - |
|
| 50 |
+
| Baichuan-7B | 42.3 | 42.8 | 9.7 | 9.2 | 26.6 | 44.4 |
|
| 51 |
+
| ChatGLM2-6B | 47.9 | 51.7 | 32.4 | 9.2 | - | 48.8 |
|
| 52 |
+
| InternLM-7B | 51.0 | 52.8 | 31.2 | 10.4 | 14.8 | - |
|
| 53 |
+
| Baichuan-13B | 51.6 | 53.6 | 26.6 | 12.8 | 30.0 | 55.8 |
|
| 54 |
+
| LLaMA-13B | 46.9 | 35.5 | 17.8 | 15.8 | 12.0 | - |
|
| 55 |
+
| LLaMA 2-13B | 54.8 | - | 28.7 | 18.3 | 24.2 | - |
|
| 56 |
+
| ChatGLM2-12B | 56.2 | **61.6** | 40.9 | - | - | - |
|
| 57 |
+
| **Qwen-7B** | **56.7** | 59.6 | **51.6** | **24.4** | **30.6** | **58.8** |
|
| 58 |
+
|
| 59 |
+
<p align="center">
|
| 60 |
+
<img src="assets/performance.png" width="1000"/>
|
| 61 |
+
<p>
|
| 62 |
+
<br>
|
| 63 |
+
|
| 64 |
+
Additionally, according to the third-party evaluation of large language models, conducted by [OpenCompass](https://opencompass.org.cn/leaderboard-llm), Qwen-7B and Qwen-7B-Chat are the top 7B-parameter models. This evaluation consists of a large amount of public benchmarks for the evaluation of language understanding and generation, coding, mathematics, reasoning, etc.
|
| 65 |
+
|
| 66 |
+
For more experimental results (detailed model performance on more benchmark datasets) and details, please refer to our technical memo by clicking [here](tech_memo.md).
|
| 67 |
+
<br>
|
| 68 |
+
|
| 69 |
+
## Requirements
|
| 70 |
+
|
| 71 |
+
* python 3.8 and above
|
| 72 |
+
* pytorch 1.12 and above, 2.0 and above are recommended
|
| 73 |
+
* CUDA 11.4 and above are recommended (this is for GPU users, flash-attention users, etc.)
|
| 74 |
+
<br>
|
| 75 |
+
|
| 76 |
+
## Quickstart
|
| 77 |
+
|
| 78 |
+
Below, we provide simple examples to show how to use Qwen-7B with 🤖 ModelScope and 🤗 Transformers.
|
| 79 |
+
|
| 80 |
+
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
|
| 81 |
+
|
| 82 |
+
```bash
|
| 83 |
+
pip install -r requirements.txt
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
If your device supports fp16 or bf16, we recommend installing [flash-attention](https://github.com/Dao-AILab/flash-attention) for higher efficiency and lower memory usage. (**flash-attention is optional and the project can run normally without installing it**)
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
|
| 90 |
+
cd flash-attention && pip install .
|
| 91 |
+
# Below are optional. Installing them might be slow.
|
| 92 |
+
# pip install csrc/layer_norm
|
| 93 |
+
# pip install csrc/rotary
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
Now you can start with ModelScope or Transformers.
|
| 97 |
+
|
| 98 |
+
#### 🤗 Transformers
|
| 99 |
+
|
| 100 |
+
To use Qwen-7B-Chat for the inference, all you need to do is to input a few lines of codes as demonstrated below. However, **please make sure that you are using the latest code.**
|
| 101 |
+
|
| 102 |
+
```python
|
| 103 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 104 |
+
from transformers.generation import GenerationConfig
|
| 105 |
+
|
| 106 |
+
# Note: The default behavior now has injection attack prevention off.
|
| 107 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
|
| 108 |
+
|
| 109 |
+
# use bf16
|
| 110 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 111 |
+
# use fp16
|
| 112 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 113 |
+
# use cpu only
|
| 114 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 115 |
+
# use auto mode, automatically select precision based on the device.
|
| 116 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
|
| 117 |
+
|
| 118 |
+
# Specify hyperparameters for generation
|
| 119 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
|
| 120 |
+
|
| 121 |
+
# 第一轮对话 1st dialogue turn
|
| 122 |
+
response, history = model.chat(tokenizer, "你好", history=None)
|
| 123 |
+
print(response)
|
| 124 |
+
# 你好!很高兴为你提供帮助。
|
| 125 |
+
|
| 126 |
+
# 第二轮对话 2nd dialogue turn
|
| 127 |
+
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
|
| 128 |
+
print(response)
|
| 129 |
+
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
|
| 130 |
+
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
|
| 131 |
+
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
|
| 132 |
+
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
|
| 133 |
+
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
|
| 134 |
+
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
|
| 135 |
+
|
| 136 |
+
# 第三轮对话 3rd dialogue turn
|
| 137 |
+
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
|
| 138 |
+
print(response)
|
| 139 |
+
# 《奋斗创业:一个年轻人的成功之路》
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
Running Qwen-7B pretrained base model is also simple.
|
| 143 |
+
|
| 144 |
+
<details>
|
| 145 |
+
<summary>Running Qwen-7B</summary>
|
| 146 |
+
|
| 147 |
+
```python
|
| 148 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 149 |
+
from transformers.generation import GenerationConfig
|
| 150 |
+
|
| 151 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
|
| 152 |
+
# use bf16
|
| 153 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 154 |
+
# use fp16
|
| 155 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 156 |
+
# use cpu only
|
| 157 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="cpu", trust_remote_code=True).eval()
|
| 158 |
+
# use auto mode, automatically select precision based on the device.
|
| 159 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True).eval()
|
| 160 |
+
|
| 161 |
+
# Specify hyperparameters for generation
|
| 162 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
|
| 163 |
+
|
| 164 |
+
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
|
| 165 |
+
inputs = inputs.to(model.device)
|
| 166 |
+
pred = model.generate(**inputs)
|
| 167 |
+
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 168 |
+
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
</details>
|
| 172 |
+
|
| 173 |
+
#### 🤖 ModelScope
|
| 174 |
+
|
| 175 |
+
ModelScope is an opensource platform for Model-as-a-Service (MaaS), which provides flexible and cost-effective model service to AI developers. Similarly, you can run the models with ModelScope as shown below:
|
| 176 |
+
|
| 177 |
+
```python
|
| 178 |
+
import os
|
| 179 |
+
from modelscope.pipelines import pipeline
|
| 180 |
+
from modelscope.utils.constant import Tasks
|
| 181 |
+
from modelscope import snapshot_download
|
| 182 |
+
|
| 183 |
+
model_id = 'QWen/qwen-7b-chat'
|
| 184 |
+
revision = 'v1.0.0'
|
| 185 |
+
|
| 186 |
+
model_dir = snapshot_download(model_id, revision)
|
| 187 |
+
|
| 188 |
+
pipe = pipeline(
|
| 189 |
+
task=Tasks.chat, model=model_dir, device_map='auto')
|
| 190 |
+
history = None
|
| 191 |
+
|
| 192 |
+
text = '浙江的省会在哪里?'
|
| 193 |
+
results = pipe(text, history=history)
|
| 194 |
+
response, history = results['response'], results['history']
|
| 195 |
+
print(f'Response: {response}')
|
| 196 |
+
text = '它有什么好玩的地方呢?'
|
| 197 |
+
results = pipe(text, history=history)
|
| 198 |
+
response, history = results['response'], results['history']
|
| 199 |
+
print(f'Response: {response}')
|
| 200 |
+
```
|
| 201 |
+
|
| 202 |
+
<br>
|
| 203 |
+
|
| 204 |
+
## Tokenizer
|
| 205 |
+
|
| 206 |
+
Our tokenizer based on tiktoken is different from other tokenizers, e.g., sentencepiece tokenizer. You need to pay attention to special tokens, especially in finetuning. For more detailed information on the tokenizer and related use in fine-tuning, please refer to the [documentation](tokenization_note.md).
|
| 207 |
+
<br>
|
| 208 |
+
|
| 209 |
+
## Quantization
|
| 210 |
+
|
| 211 |
+
### Usage
|
| 212 |
+
|
| 213 |
+
**Note: we provide a new solution based on [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ), and release an Int4 quantized model for Qwen-7B-Chat [Click here](https://huggingface.co/Qwen/Qwen-7B-Chat-Int4), which achieves nearly lossless model effects but improved performance on both memory costs and inference speed, in comparison with the previous solution.**
|
| 214 |
+
|
| 215 |
+
Here we demonstrate how to use our provided quantized models for inference. Before you start, make sure you meet the requirements of AutoGPTQ and install it from source (temporarily the codes for Qwen are not yet released in the latest version of PyPI package):
|
| 216 |
+
|
| 217 |
+
```bash
|
| 218 |
+
git clone https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
|
| 219 |
+
pip install .
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
Then you can load the quantized model easily as shown below:
|
| 223 |
+
|
| 224 |
+
```python
|
| 225 |
+
from auto_gptq import AutoGPTQForCausalLM
|
| 226 |
+
model = AutoGPTQForCausalLM.from_quantized("Qwen/Qwen-7B-Chat-Int4", device_map="auto", trust_remote_code=True, use_safetensors=True).eval()
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
To run inference, it is similar to the basic usage demonstrated above, but remember to pass in the generation configuration explicitly:
|
| 230 |
+
|
| 231 |
+
```python
|
| 232 |
+
from transformers import GenerationConfig
|
| 233 |
+
config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat-Int4", trust_remote_code=True)
|
| 234 |
+
response, history = model.chat(tokenizer, "Hi", history=None, generation_config=config)
|
| 235 |
+
```
|
| 236 |
+
|
| 237 |
+
### Performance
|
| 238 |
+
|
| 239 |
+
We illustrate the model performance of both BF16 and Int4 models on the benchmark, and we find that the quantized model does not suffer from significant performance degradation. Results are shown below:
|
| 240 |
+
|
| 241 |
+
| Quantization | MMLU | CEval (val) | GSM8K | Humaneval |
|
| 242 |
+
| -------------- | :----: | :-----------: | :-----: | :---------: |
|
| 243 |
+
| BF16 | 53.9 | 54.2 | 41.1 | 24.4 |
|
| 244 |
+
| Int4 | 52.6 | 52.9 | 38.1 | 23.8 |
|
| 245 |
+
|
| 246 |
+
### Inference Speed
|
| 247 |
+
|
| 248 |
+
We measured the average inference speed (tokens/s) of generating 2048 and 8192 tokens under BF16 precision and Int4 quantization, respectively.
|
| 249 |
+
|
| 250 |
+
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
|
| 251 |
+
| -------------- | :-------------------: | :-------------------: |
|
| 252 |
+
| BF16 | 30.34 | 29.32 |
|
| 253 |
+
| Int4 | 43.56 | 33.92 |
|
| 254 |
+
|
| 255 |
+
In detail, the setting of profiling is generating 8192 new tokens with 1 context token. The profiling runs on a single A100-SXM4-80G GPU with PyTorch 2.0.1 and CUDA 11.4. The inference speed is averaged over the generated 8192 tokens.
|
| 256 |
+
|
| 257 |
+
### GPU Memory Usage
|
| 258 |
+
|
| 259 |
+
We also profile the peak GPU memory usage for encoding 2048 tokens as context (and generating single token) and generating 8192 tokens (with single token as context) under BF16 or Int4 quantization level, respectively. The results are shown below.
|
| 260 |
+
|
| 261 |
+
| Quantization | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
|
| 262 |
+
| -------------- | :-----------------------------------: | :-------------------------------------: |
|
| 263 |
+
| BF16 | 17.66GB | 22.58GB |
|
| 264 |
+
| Int4 | 8.21GB | 13.62GB |
|
| 265 |
+
|
| 266 |
+
The above speed and memory profiling are conducted using [this script](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile.py).
|
| 267 |
+
<br>
|
| 268 |
+
|
| 269 |
+
## Demo
|
| 270 |
+
|
| 271 |
+
### Web UI
|
| 272 |
+
|
| 273 |
+
We provide code for users to build a web UI demo (thanks to @wysaid). Before you start, make sure you install the following packages:
|
| 274 |
+
|
| 275 |
+
```
|
| 276 |
+
pip install -r requirements_web_demo.txt
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
Then run the command below and click on the generated link:
|
| 280 |
+
|
| 281 |
+
```
|
| 282 |
+
python web_demo.py
|
| 283 |
+
```
|
| 284 |
+
|
| 285 |
+
<p align="center">
|
| 286 |
+
<br>
|
| 287 |
+
<img src="assets/web_demo.gif" width="600" />
|
| 288 |
+
<br>
|
| 289 |
+
<p>
|
| 290 |
+
|
| 291 |
+
### CLI Demo
|
| 292 |
+
|
| 293 |
+
We provide a CLI demo example in `cli_demo.py`, which supports streaming output for the generation. Users can interact with Qwen-7B-Chat by inputting prompts, and the model returns model outputs in the streaming mode. Run the command below:
|
| 294 |
+
|
| 295 |
+
```
|
| 296 |
+
python cli_demo.py
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
<p align="center">
|
| 300 |
+
<br>
|
| 301 |
+
<img src="assets/cli_demo.gif" width="600" />
|
| 302 |
+
<br>
|
| 303 |
+
<p>
|
| 304 |
+
|
| 305 |
+
## API
|
| 306 |
+
|
| 307 |
+
We provide methods to deploy local API based on OpenAI API (thanks to @hanpenggit). Before you start, install the required packages:
|
| 308 |
+
|
| 309 |
+
```bash
|
| 310 |
+
pip install fastapi uvicorn openai pydantic sse_starlette
|
| 311 |
+
```
|
| 312 |
+
|
| 313 |
+
Then run the command to deploy your API:
|
| 314 |
+
|
| 315 |
+
```bash
|
| 316 |
+
python openai_api.py
|
| 317 |
+
```
|
| 318 |
+
|
| 319 |
+
You can change your arguments, e.g., `-c` for checkpoint name or path, `--cpu-only` for CPU deployment, etc. If you meet problems launching your API deployment, updating the packages to the latest version can probably solve them.
|
| 320 |
+
|
| 321 |
+
Using the API is also simple. See the example below:
|
| 322 |
+
|
| 323 |
+
```python
|
| 324 |
+
import openai
|
| 325 |
+
openai.api_base = "http://localhost:8000/v1"
|
| 326 |
+
openai.api_key = "none"
|
| 327 |
+
|
| 328 |
+
# create a request activating streaming response
|
| 329 |
+
for chunk in openai.ChatCompletion.create(
|
| 330 |
+
model="Qwen",
|
| 331 |
+
messages=[
|
| 332 |
+
{"role": "user", "content": "你好"}
|
| 333 |
+
],
|
| 334 |
+
stream=True
|
| 335 |
+
# Specifying stop words in streaming output format is not yet supported and is under development.
|
| 336 |
+
):
|
| 337 |
+
if hasattr(chunk.choices[0].delta, "content"):
|
| 338 |
+
print(chunk.choices[0].delta.content, end="", flush=True)
|
| 339 |
+
|
| 340 |
+
# create a request not activating streaming response
|
| 341 |
+
response = openai.ChatCompletion.create(
|
| 342 |
+
model="Qwen",
|
| 343 |
+
messages=[
|
| 344 |
+
{"role": "user", "content": "你好"}
|
| 345 |
+
],
|
| 346 |
+
stream=False,
|
| 347 |
+
stop=[] # You can add custom stop words here, e.g., stop=["Observation:"] for ReAct prompting.
|
| 348 |
+
)
|
| 349 |
+
print(response.choices[0].message.content)
|
| 350 |
+
```
|
| 351 |
+
|
| 352 |
+
<p align="center">
|
| 353 |
+
<br>
|
| 354 |
+
<img src="assets/openai_api.gif" width="600" />
|
| 355 |
+
<br>
|
| 356 |
+
<p>
|
| 357 |
+
|
| 358 |
+
Function calling is also supported (but only when `stream=False` for the moment). See the [example usage](examples/function_call_examples.py) here.
|
| 359 |
+
|
| 360 |
+
## Deployment
|
| 361 |
+
|
| 362 |
+
It is simple to run the model on CPU, which requires your specification of device:
|
| 363 |
+
|
| 364 |
+
```python
|
| 365 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 366 |
+
```
|
| 367 |
+
|
| 368 |
+
If you suffer from lack of GPU memory and you would like to run the model on more than 1 GPU, you can use our provided script `utils.py`:
|
| 369 |
+
|
| 370 |
+
```python[](https://)
|
| 371 |
+
from utils import load_model_on_gpus
|
| 372 |
+
model = load_model_on_gpus('Qwen/Qwen-7B-Chat', num_gpus=2)
|
| 373 |
+
```
|
| 374 |
+
|
| 375 |
+
Then you can run the 7B chat model on 2 GPUs using the above scripts.
|
| 376 |
+
<br>
|
| 377 |
+
|
| 378 |
+
## Tool Usage
|
| 379 |
+
|
| 380 |
+
Qwen-7B-Chat is specifically optimized for tool usage, including API, database, models, etc., so that users can build their own Qwen-7B-based LangChain, Agent, and Code Interpreter. In our evaluation [benchmark](eval/EVALUATION.md) for assessing tool usage capabilities, we find that Qwen-7B reaches stable performance.
|
| 381 |
+
|
| 382 |
+
| Model | Tool Selection (Acc.↑) | Tool Input (Rouge-L↑) | False Positive Error↓ |
|
| 383 |
+
|:-----------------| :-----------------------: | :----------------------: | :----------------------: |
|
| 384 |
+
| GPT-4 | 95% | **0.90** | 15% |
|
| 385 |
+
| GPT-3.5 | 85% | 0.88 | 75% |
|
| 386 |
+
| **Qwen-7B-Chat** | **99%** | 0.89 | **9.7%** |
|
| 387 |
+
|
| 388 |
+
For how to write and use prompts for ReAct Prompting, please refer to [the ReAct examples](examples/react_prompt.md). The use of tools can enable the model to better perform tasks.
|
| 389 |
+
|
| 390 |
+
Additionally, we provide experimental results to show its capabilities of playing as an agent. See [Hugging Face Agent](https://huggingface.co/docs/transformers/transformers_agents) for more information. Its performance on the run-mode benchmark provided by Hugging Face is as follows:
|
| 391 |
+
|
| 392 |
+
| Model | Tool Selection↑ | Tool Used↑ | Code↑ |
|
| 393 |
+
|:-----------------| :----------------: | :-----------: | :---------: |
|
| 394 |
+
| GPT-4 | **100** | **100** | **97.41** |
|
| 395 |
+
| GPT-3.5 | 95.37 | 96.30 | 87.04 |
|
| 396 |
+
| StarCoder-15.5B | 87.04 | 87.96 | 68.89 |
|
| 397 |
+
| **Qwen-7B-Chat** | 90.74 | 92.59 | 74.07 |
|
| 398 |
+
|
| 399 |
+
<br>
|
| 400 |
+
|
| 401 |
+
## Long-Context Understanding
|
| 402 |
+
|
| 403 |
+
To extend the context length and break the bottleneck of training sequence length, we introduce several techniques, including NTK-aware interpolation, window attention, and LogN attention scaling, to extend the context length to over 8K tokens. We conduct language modeling experiments on the arXiv dataset with the PPL evaluation and find that Qwen-7B can reach outstanding performance in the scenario of long context. Results are demonstrated below:
|
| 404 |
+
|
| 405 |
+
<table>
|
| 406 |
+
<tr>
|
| 407 |
+
<th rowspan="2">Model</th><th colspan="5" align="center">Sequence Length</th>
|
| 408 |
+
</tr>
|
| 409 |
+
<tr>
|
| 410 |
+
<th align="center">1024</th><th align="center">2048</th><th align="center">4096</th><th align="center">8192</th><th align="center">16384</th>
|
| 411 |
+
</tr>
|
| 412 |
+
<tr>
|
| 413 |
+
<td>Qwen-7B</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center">39.35</td><td align="center">469.81</td><td align="center">2645.09</td>
|
| 414 |
+
</tr>
|
| 415 |
+
<tr>
|
| 416 |
+
<td>+ dynamic_ntk</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center">3.59</td><td align="center">3.66</td><td align="center">5.71</td>
|
| 417 |
+
</tr>
|
| 418 |
+
<tr>
|
| 419 |
+
<td>+ dynamic_ntk + logn</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center"><b>3.58</b></td><td align="center">3.56</td><td align="center">4.62</td>
|
| 420 |
+
</tr>
|
| 421 |
+
<tr>
|
| 422 |
+
<td>+ dynamic_ntk + logn + window_attn</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center"><b>3.58</b></td><td align="center"><b>3.49</b></td><td align="center"><b>4.32</b></td>
|
| 423 |
+
</tr>
|
| 424 |
+
</table>
|
| 425 |
+
|
| 426 |
+
<br><br>
|
| 427 |
+
|
| 428 |
+
## Reproduction
|
| 429 |
+
|
| 430 |
+
For your reproduction of the model performance on benchmark datasets, we provide scripts for you to reproduce the results. Check [eval/EVALUATION.md](eval/EVALUATION.md) for more information. Note that the reproduction may lead to slight differences from our reported results.
|
| 431 |
+
|
| 432 |
+
<br>
|
| 433 |
+
|
| 434 |
+
## FAQ
|
| 435 |
+
|
| 436 |
+
If you meet problems, please refer to [FAQ](FAQ.md) and the issues first to search a solution before you launch a new issue.
|
| 437 |
+
|
| 438 |
+
<br>
|
| 439 |
+
|
| 440 |
+
## License Agreement
|
| 441 |
+
|
| 442 |
+
Researchers and developers are free to use the codes and model weights of both Qwen-7B and Qwen-7B-Chat. We also allow their commercial use. Check our license at [LICENSE](LICENSE) for more details. If you have requirements for commercial use, please fill out the [form](https://dashscope.console.aliyun.com/openModelApply/qianwen) to apply.
|
| 443 |
+
|
| 444 |
+
<br>
|
| 445 |
+
|
| 446 |
+
## Contact Us
|
| 447 |
+
|
| 448 |
+
If you are interested to leave a message to either our research team or product team, feel free to send an email to qianwen_opensource@alibabacloud.com.
|
| 449 |
|
|
|
README_CN.md
ADDED
|
@@ -0,0 +1,451 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="left">
|
| 2 |
+
中文</a>  |  <a href="README.md">English</a>  |  <a href="README_JA.md">日本語</a>
|
| 3 |
+
</p>
|
| 4 |
+
<br><br>
|
| 5 |
+
|
| 6 |
+
<p align="center">
|
| 7 |
+
<img src="assets/logo.jpg" width="400"/>
|
| 8 |
+
<p>
|
| 9 |
+
<br>
|
| 10 |
+
|
| 11 |
+
<p align="center">
|
| 12 |
+
Qwen-7B <a href="https://modelscope.cn/models/qwen/Qwen-7B/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B">🤗</a>  | Qwen-7B-Chat <a href="https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B-Chat">🤗</a>  | Qwen-7B-Chat-Int4 <a href="https://huggingface.co/Qwen/Qwen-7B-Chat-Int4">🤗</a>
|
| 13 |
+
<br>
|
| 14 |
+
<a href="assets/wechat.png">WeChat</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>   |   <a href="https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary">Demo</a>  |  <a href="https://github.com/QwenLM/Qwen-7B/blob/main/tech_memo.md">Report</a>
|
| 15 |
+
</p>
|
| 16 |
+
<br><br>
|
| 17 |
+
|
| 18 |
+
我们在🤖 **ModelScope**以及🤗 **Hugging Face**均开源了**Qwen-7B**系列模型。请在本文档顶部点击相关链接查看仓库信息。本仓库主要包括Qwen-7B的简介、使用指南、技术备忘等内容。想了解更多关于模型的信息,请点击[链接](tech_memo.md)查看我们的技术备忘录。
|
| 19 |
+
|
| 20 |
+
通义千问-7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。Qwen-7B系列模型的特点包括:
|
| 21 |
+
|
| 22 |
+
1. **大规模高质量预训练数据**:我们使用了超过2.2万亿token的自建大规模预训练数据集进行语言模型的预训练。数据集包括文本和代码等多种数据类型,覆盖通用领域和专业领域。
|
| 23 |
+
2. **优秀的模型性能**:相比同规模的开源模型,Qwen-7B在多个评测数据集上具有显著优势,甚至超出12-13B等更大规模的模型。评测评估的能力范围包括自然语言理解与生成、数学运算解题、代码生成等。
|
| 24 |
+
3. **更好地支持多语言**:基于更大词表的分词器在分词上更高效,同时它对其他语言表现更加友好。用户可以在Qwen-7B的基础上更方便地训练特定语言的7B语言模型。
|
| 25 |
+
4. **8K的上下文长度**:Qwen-7B及Qwen-7B-Chat均能支持8K的上下文长度, 允许用户输入更长的prompt。
|
| 26 |
+
5. **支持插件调用**:Qwen-7B-Chat针对插件调用相关的对齐数据做了特定优化,当前模型能有效调用插件以及升级为Agent。
|
| 27 |
+
|
| 28 |
+
以下章节的信息可能对你有帮助,建议阅读。如果你在使用过程遇到问题,建议先查询FAQ,如仍无法解决再提交issue。
|
| 29 |
+
|
| 30 |
+
<br>
|
| 31 |
+
|
| 32 |
+
## 新闻
|
| 33 |
+
|
| 34 |
+
* 2023年8月21日 发布Qwen-7B-Chat的Int4量化模型,Qwen-7B-Chat-Int4。该模型显存占用低,推理速度相比半精度模型显著提升,在基准评测上效果损失较小。
|
| 35 |
+
* 2023年8月3日 在魔搭社区(ModelScope)和Hugging Face同步推出Qwen-7B和Qwen-7B-Chat模型。同时,我们发布了技术备忘录,介绍了相关的训练细节和模型表现。
|
| 36 |
+
<br>
|
| 37 |
+
|
| 38 |
+
## 评测表现
|
| 39 |
+
|
| 40 |
+
Qwen-7B在多个全面评估自然语言理解与生成、数学运算解题、代码生成等能力的评测数据集上,包括MMLU、C-Eval、GSM8K、HumanEval、WMT22、CMMLU等,均超出了同规模大语言模型的表现,甚至超出了如12-13B参数等更大规模的语言模型。
|
| 41 |
+
|
| 42 |
+
| Model | MMLU | C-Eval | GSM8K | HumanEval | WMT22 (en-zh) | CMMLU |
|
| 43 |
+
| :---------------- | :------------: | :------------: | :------------: | :------------: | :------------: |:------------: |
|
| 44 |
+
| LLaMA-7B | 35.1 | - | 11.0 | 10.5 | 8.7 | - |
|
| 45 |
+
| LLaMA 2-7B | 45.3 | - | 14.6 | 12.8 | 17.9 | - |
|
| 46 |
+
| Baichuan-7B | 42.3 | 42.8 | 9.7 | 9.2 | 26.6 | 44.4 |
|
| 47 |
+
| ChatGLM2-6B | 47.9 | 51.7 | 32.4 | 9.2 | - | 48.8 |
|
| 48 |
+
| InternLM-7B | 51.0 | 52.8 | 31.2 | 10.4 | 14.8 | - |
|
| 49 |
+
| Baichuan-13B | 51.6 | 53.6 | 26.6 | 12.8 | 30.0 | 55.8 |
|
| 50 |
+
| LLaMA-13B | 46.9 | 35.5 | 17.8 | 15.8 | 12.0 | - |
|
| 51 |
+
| LLaMA 2-13B | 54.8 | - | 28.7 | 18.3 | 24.2 | - |
|
| 52 |
+
| ChatGLM2-12B | 56.2 | **61.6** | 40.9 | - | - | - |
|
| 53 |
+
| **Qwen-7B** | **56.7** | 59.6 | **51.6** | **24.4** | **30.6** | **58.8** |
|
| 54 |
+
|
| 55 |
+
<p align="center">
|
| 56 |
+
<img src="assets/performance.png" width="1000"/>
|
| 57 |
+
<p>
|
| 58 |
+
<br>
|
| 59 |
+
|
| 60 |
+
此外,根据[OpenCompass](https://opencompass.org.cn/leaderboard-llm)进行的大型语言模型第三方评估,Qwen-7B 和 Qwen-7B-Chat 是其中表现最优的7B参数模型。该评估由大量公开基准组成,用于评估语言理解和生成、代码生成、数学、推理等。
|
| 61 |
+
|
| 62 |
+
更多的实验结果和细节请查看我们的技术备忘录。点击[这里](tech_memo.md)。
|
| 63 |
+
|
| 64 |
+
<br>
|
| 65 |
+
|
| 66 |
+
## 要求
|
| 67 |
+
|
| 68 |
+
* python 3.8及以上版本
|
| 69 |
+
* pytorch 1.12及以上版本,推荐2.0及以上版本
|
| 70 |
+
* 建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
|
| 71 |
+
<br>
|
| 72 |
+
|
| 73 |
+
## 快速使用
|
| 74 |
+
|
| 75 |
+
我们提供简单的示例来说明如何利用🤖 ModelScope和🤗 Transformers快速使用Qwen-7B和Qwen-7B-Chat。
|
| 76 |
+
|
| 77 |
+
在开始前,请确保你已经配置好环境并安装好相关的代码包。最重要的是,确保你满足上述要求,然后安装相关的依赖库。
|
| 78 |
+
|
| 79 |
+
```bash
|
| 80 |
+
pip install -r requirements.txt
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
如果你的显卡支持fp16或bf16精度,我们还推荐安装[flash-attention](https://github.com/Dao-AILab/flash-attention)来提高你的运行效率以及降低显存占用。(**flash-attention只是可选项,不安装也可正常运行该项目**)
|
| 84 |
+
|
| 85 |
+
```bash
|
| 86 |
+
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
|
| 87 |
+
cd flash-attention && pip install .
|
| 88 |
+
# 下方安装可选,安装可能比较缓慢。
|
| 89 |
+
# pip install csrc/layer_norm
|
| 90 |
+
# pip install csrc/rotary
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
接下来你可以开始使用Transformers或者ModelScope来使用我们的模型。
|
| 94 |
+
|
| 95 |
+
#### 🤗 Transformers
|
| 96 |
+
|
| 97 |
+
如希望使用Qwen-7B-chat进行推理,所需要写的只是如下所示的数行代码。**请确保你使用的是最新代码。**
|
| 98 |
+
|
| 99 |
+
```python
|
| 100 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 101 |
+
from transformers.generation import GenerationConfig
|
| 102 |
+
|
| 103 |
+
# 请注意:分词器默认行为已更改为默认关闭特殊token攻击防护。
|
| 104 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
|
| 105 |
+
|
| 106 |
+
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
|
| 107 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 108 |
+
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
|
| 109 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 110 |
+
# 使用CPU进行推理,需要约32GB内存
|
| 111 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 112 |
+
# 默认使用自动模式,根据设备自动选择精度
|
| 113 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
|
| 114 |
+
|
| 115 |
+
# 可指定不同的生成长度、top_p等相关超参
|
| 116 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
|
| 117 |
+
|
| 118 |
+
# 第一轮对话 1st dialogue turn
|
| 119 |
+
response, history = model.chat(tokenizer, "你好", history=None)
|
| 120 |
+
print(response)
|
| 121 |
+
# 你好!很高兴为你提供帮助。
|
| 122 |
+
|
| 123 |
+
# 第二轮对话 2nd dialogue turn
|
| 124 |
+
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
|
| 125 |
+
print(response)
|
| 126 |
+
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
|
| 127 |
+
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
|
| 128 |
+
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
|
| 129 |
+
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
|
| 130 |
+
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
|
| 131 |
+
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
|
| 132 |
+
|
| 133 |
+
# 第三轮对话 3rd dialogue turn
|
| 134 |
+
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
|
| 135 |
+
print(response)
|
| 136 |
+
# 《奋斗创业:一个年轻人的成功之路》
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
运行Qwen-7B同样非常简单。
|
| 140 |
+
|
| 141 |
+
<details>
|
| 142 |
+
<summary>运行Qwen-7B</summary>
|
| 143 |
+
|
| 144 |
+
```python
|
| 145 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 146 |
+
from transformers.generation import GenerationConfig
|
| 147 |
+
|
| 148 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
|
| 149 |
+
|
| 150 |
+
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
|
| 151 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 152 |
+
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
|
| 153 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 154 |
+
# 使用CPU进行推理,需要约32GB内存
|
| 155 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="cpu", trust_remote_code=True).eval()
|
| 156 |
+
# 默认使用自动模式,根据设备自动选择精度
|
| 157 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True).eval()
|
| 158 |
+
|
| 159 |
+
# 可指定不同的生成长度、top_p等相关超参
|
| 160 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
|
| 161 |
+
|
| 162 |
+
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
|
| 163 |
+
inputs = inputs.to(model.device)
|
| 164 |
+
pred = model.generate(**inputs)
|
| 165 |
+
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 166 |
+
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
</details>
|
| 170 |
+
|
| 171 |
+
#### 🤖 ModelScope
|
| 172 |
+
|
| 173 |
+
魔搭(ModelScope)是开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品。使用ModelScope同样非常简单,代码如下所示:
|
| 174 |
+
|
| 175 |
+
```python
|
| 176 |
+
import os
|
| 177 |
+
from modelscope.pipelines import pipeline
|
| 178 |
+
from modelscope.utils.constant import Tasks
|
| 179 |
+
from modelscope import snapshot_download
|
| 180 |
+
|
| 181 |
+
model_id = 'QWen/qwen-7b-chat'
|
| 182 |
+
revision = 'v1.0.0'
|
| 183 |
+
|
| 184 |
+
model_dir = snapshot_download(model_id, revision)
|
| 185 |
+
|
| 186 |
+
pipe = pipeline(
|
| 187 |
+
task=Tasks.chat, model=model_dir, device_map='auto')
|
| 188 |
+
history = None
|
| 189 |
+
|
| 190 |
+
text = '浙江的省会在哪里?'
|
| 191 |
+
results = pipe(text, history=history)
|
| 192 |
+
response, history = results['response'], results['history']
|
| 193 |
+
print(f'Response: {response}')
|
| 194 |
+
text = '它有什么好玩的地方呢?'
|
| 195 |
+
results = pipe(text, history=history)
|
| 196 |
+
response, history = results['response'], results['history']
|
| 197 |
+
print(f'Response: {response}')
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
<br>
|
| 201 |
+
|
| 202 |
+
## Tokenization
|
| 203 |
+
|
| 204 |
+
> 注:作为术语的“tokenization”在中文中尚无共识的概念对应,本文档采用英文表达以利说明。
|
| 205 |
+
|
| 206 |
+
基于tiktoken的tokenizer有别于其他分词器,比如sentencepiece tokenizer。尤其在微调阶段,需要特别注意特殊token的使用。关于tokenizer的更多信息,以及微调时涉及的相关使用,请参阅[文档](tokenization_note_zh.md)。
|
| 207 |
+
<br>
|
| 208 |
+
|
| 209 |
+
## 量化
|
| 210 |
+
|
| 211 |
+
### 用法
|
| 212 |
+
|
| 213 |
+
**请注意:我们更新量化方案为基于[AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ)的量化,提供Qwen-7B-Chat的Int4量化模型[点击这里](https://huggingface.co/Qwen/Qwen-7B-Chat-Int4)。相比此前方案,该方案在模型评测效果几乎无损,且存储需求更低,推理速度更优。**
|
| 214 |
+
|
| 215 |
+
以下我们提供示例说明如何使用Int4量化模型。在开始使用前,请先保证满足AutoGPTQ的要求,并使用源代码安装(由于最新支持Qwen的代码未发布到PyPI):
|
| 216 |
+
|
| 217 |
+
```bash
|
| 218 |
+
git clone https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
|
| 219 |
+
pip install .
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
随后便能轻松读取量化模型:
|
| 223 |
+
|
| 224 |
+
```python
|
| 225 |
+
from auto_gptq import AutoGPTQForCausalLM
|
| 226 |
+
model = AutoGPTQForCausalLM.from_quantized("Qwen/Qwen-7B-Chat-Int4", device_map="auto", trust_remote_code=True, use_safetensors=True).eval()
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
推理方法和基础用法类似,但注意需要从外部传入generation config:
|
| 230 |
+
|
| 231 |
+
```python
|
| 232 |
+
from transformers import GenerationConfig
|
| 233 |
+
config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat-Int4", trust_remote_code=True)
|
| 234 |
+
response, history = model.chat(tokenizer, "Hi", history=None, generation_config=config)
|
| 235 |
+
```
|
| 236 |
+
|
| 237 |
+
### 效果评测
|
| 238 |
+
|
| 239 |
+
我们对BF16和Int4模型在基准评测上做了测试,发现量化模型效果损失较小,结果如下所示:
|
| 240 |
+
|
| 241 |
+
| Quantization | MMLU | CEval (val) | GSM8K | Humaneval |
|
| 242 |
+
| ------------- | :--------: | :----------: | :----: | :--------: |
|
| 243 |
+
| BF16 | 53.9 | 54.2 | 41.1 | 24.4 |
|
| 244 |
+
| Int4 | 52.6 | 52.9 | 38.1 | 23.8 |
|
| 245 |
+
|
| 246 |
+
### 推理速度
|
| 247 |
+
|
| 248 |
+
我们测算了BF16和Int4模型生成2048和8192个token的平均推理速度(tokens/s)。如图所示:
|
| 249 |
+
|
| 250 |
+
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
|
| 251 |
+
| ------------- | :------------------:| :------------------:|
|
| 252 |
+
| BF16 | 30.34 | 29.32 |
|
| 253 |
+
| Int4 | 43.56 | 33.92 |
|
| 254 |
+
|
| 255 |
+
具体而言,我们记录在长度为1的上下文的条件下生成8192个token的性能。评测运行于单张A100-SXM4-80G GPU,使用PyTorch 2.0.1和CUDA 11.4。推理速度是生成8192个token的速度均值。
|
| 256 |
+
|
| 257 |
+
### 显存使用
|
| 258 |
+
|
| 259 |
+
我们还测算了BF16和Int4模型编码2048个token及生成8192个token的峰值显存占用情况。结果如下所示:
|
| 260 |
+
|
| 261 |
+
| Quantization Level | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
|
| 262 |
+
| ------------------ | :---------------------------------: | :-----------------------------------: |
|
| 263 |
+
| BF16 | 17.66GB | 22.58GB |
|
| 264 |
+
| Int4 | 8.21GB | 13.62GB |
|
| 265 |
+
|
| 266 |
+
上述性能测算使用[此脚本](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile.py)完成。
|
| 267 |
+
<br>
|
| 268 |
+
|
| 269 |
+
## Demo
|
| 270 |
+
|
| 271 |
+
### Web UI
|
| 272 |
+
|
| 273 |
+
我们提供了Web UI的demo供用户使用 (感谢 @wysaid 支持)。在开始前,确保已经安装如下代码库:
|
| 274 |
+
|
| 275 |
+
```
|
| 276 |
+
pip install -r requirements_web_demo.txt
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
随后运行如下命令,并点击生成链接:
|
| 280 |
+
|
| 281 |
+
```
|
| 282 |
+
python web_demo.py
|
| 283 |
+
```
|
| 284 |
+
|
| 285 |
+
<p align="center">
|
| 286 |
+
<br>
|
| 287 |
+
<img src="assets/web_demo.gif" width="600" />
|
| 288 |
+
<br>
|
| 289 |
+
<p>
|
| 290 |
+
|
| 291 |
+
### 交互式Demo
|
| 292 |
+
|
| 293 |
+
我们提供了一个简单的交互式Demo示例,请查看`cli_demo.py`。当前模型已经支持流式输出,用户可通过输入文字的方式和Qwen-7B-Chat交互,模型将流式输出返回结果。运行如下命令:
|
| 294 |
+
|
| 295 |
+
```
|
| 296 |
+
python cli_demo.py
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
<p align="center">
|
| 300 |
+
<br>
|
| 301 |
+
<img src="assets/cli_demo.gif" width="600" />
|
| 302 |
+
<br>
|
| 303 |
+
<p>
|
| 304 |
+
|
| 305 |
+
## API
|
| 306 |
+
|
| 307 |
+
我们提供了OpenAI API格式的本地API部署方法(感谢@hanpenggit)。在开始之前先安装必要的代码库:
|
| 308 |
+
|
| 309 |
+
```bash
|
| 310 |
+
pip install fastapi uvicorn openai pydantic sse_starlette
|
| 311 |
+
```
|
| 312 |
+
|
| 313 |
+
随后即可运行以下命令部署你的本地API:
|
| 314 |
+
|
| 315 |
+
```bash
|
| 316 |
+
python openai_api.py
|
| 317 |
+
```
|
| 318 |
+
|
| 319 |
+
你也可以修改参数,比如`-c`来修改模型名称或路径, `--cpu-only`改为CPU部署等等。如果部署出现问题,更新上述代码库往往可以解决大多数问题。
|
| 320 |
+
|
| 321 |
+
使用API同样非常简单,示例如下:
|
| 322 |
+
|
| 323 |
+
```python
|
| 324 |
+
import openai
|
| 325 |
+
openai.api_base = "http://localhost:8000/v1"
|
| 326 |
+
openai.api_key = "none"
|
| 327 |
+
|
| 328 |
+
# 使用流式回复的请求
|
| 329 |
+
for chunk in openai.ChatCompletion.create(
|
| 330 |
+
model="Qwen",
|
| 331 |
+
messages=[
|
| 332 |
+
{"role": "user", "content": "你好"}
|
| 333 |
+
],
|
| 334 |
+
stream=True
|
| 335 |
+
# 流式输出的自定义stopwords功能尚未支持,正在开发中
|
| 336 |
+
):
|
| 337 |
+
if hasattr(chunk.choices[0].delta, "content"):
|
| 338 |
+
print(chunk.choices[0].delta.content, end="", flush=True)
|
| 339 |
+
|
| 340 |
+
# 不使用流式回复的请求
|
| 341 |
+
response = openai.ChatCompletion.create(
|
| 342 |
+
model="Qwen",
|
| 343 |
+
messages=[
|
| 344 |
+
{"role": "user", "content": "你好"}
|
| 345 |
+
],
|
| 346 |
+
stream=False,
|
| 347 |
+
stop=[] # 在此处添加自定义的stop words 例如ReAct prompting时需要增加: stop=["Observation:"]。
|
| 348 |
+
)
|
| 349 |
+
print(response.choices[0].message.content)
|
| 350 |
+
```
|
| 351 |
+
|
| 352 |
+
<p align="center">
|
| 353 |
+
<br>
|
| 354 |
+
<img src="assets/openai_api.gif" width="600" />
|
| 355 |
+
<br>
|
| 356 |
+
<p>
|
| 357 |
+
|
| 358 |
+
该接口也支持函数调用(Function Calling),但暂时仅限 `stream=False` 时能生效。用法见[函数调用示例](examples/function_call_examples.py)。
|
| 359 |
+
|
| 360 |
+
## 部署
|
| 361 |
+
|
| 362 |
+
在CPU上运行非常简单,使用方法如下所示:
|
| 363 |
+
|
| 364 |
+
```python
|
| 365 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 366 |
+
```
|
| 367 |
+
|
| 368 |
+
如果你遇到显存不足的问题而希望使用多张GPU进行推理,可以使用提供的脚本`utils.py`:
|
| 369 |
+
|
| 370 |
+
```python
|
| 371 |
+
from utils import load_model_on_gpus
|
| 372 |
+
model = load_model_on_gpus('Qwen/Qwen-7B-Chat', num_gpus=2)
|
| 373 |
+
```
|
| 374 |
+
|
| 375 |
+
你即可使用2张GPU进行推理。
|
| 376 |
+
<br>
|
| 377 |
+
|
| 378 |
+
## 工具调用
|
| 379 |
+
|
| 380 |
+
Qwen-7B-Chat针对包括API、数据库、模型等工具在内的调用进行了优化。用户可以开发基于Qwen-7B的LangChain、Agent甚至Code Interpreter。在我们开源的[评测数据集](eval/EVALUATION.md)上测试模型的工具调用能力,并发现Qwen-7B-Chat能够取得稳定的表现。
|
| 381 |
+
|
| 382 |
+
| Model | Tool Selection (Acc.↑) | Tool Input (Rouge-L↑) | False Positive Error↓ |
|
| 383 |
+
|:-----------------|:----------------------:|:----------------------:|:----------------------:|
|
| 384 |
+
| GPT-4 | 95% | **0.90** | 15% |
|
| 385 |
+
| GPT-3.5 | 85% | 0.88 | 75% |
|
| 386 |
+
| **Qwen-7B-Chat** | **99%** | 0.89 | **9.7%** |
|
| 387 |
+
|
| 388 |
+
我们提供了文档说明如何根据ReAct Prompting的原则写作你的prompt。
|
| 389 |
+
|
| 390 |
+
For how to write and use prompts for ReAct Prompting, please refer to [the ReAct examples](examples/react_prompt.md)。
|
| 391 |
+
|
| 392 |
+
此外,我们还提供了实验结果表明我们的模型扮演Agent的能力。请阅读相关文档[链接](https://huggingface.co/docs/transformers/transformers_agents)了解更多信息。模型在Hugging Face提供的评测数据集上表现如下:
|
| 393 |
+
|
| 394 |
+
| Model | Tool Selection↑ | Tool Used↑ | Code↑ |
|
| 395 |
+
|:-----------------|:---------------:|:-----------:|:---------:|
|
| 396 |
+
| GPT-4 | **100** | **100** | **97.41** |
|
| 397 |
+
| GPT-3.5 | 95.37 | 96.30 | 87.04 |
|
| 398 |
+
| StarCoder-15.5B | 87.04 | 87.96 | 68.89 |
|
| 399 |
+
| **Qwen-7B-Chat** | 90.74 | 92.59 | 74.07 |
|
| 400 |
+
|
| 401 |
+
<br>
|
| 402 |
+
|
| 403 |
+
## 长文本理解
|
| 404 |
+
|
| 405 |
+
我们引入了NTK插值、窗口注意力、LogN注意力缩放等技术来提升模型的上下文长度并突破训练序列长度的限制。我们的模型已经突破8K的序列长度。通过arXiv数据集上的语言模型实验,我们发现Qwen-7B能够在长序列的设置下取得不错的表现。
|
| 406 |
+
|
| 407 |
+
<table>
|
| 408 |
+
<tr>
|
| 409 |
+
<th rowspan="2">Model</th><th colspan="5" align="center">Sequence Length</th>
|
| 410 |
+
</tr>
|
| 411 |
+
<tr>
|
| 412 |
+
<th align="center">1024</th><th align="center">2048</th><th align="center">4096</th><th align="center">8192</th><th align="center">16384</th>
|
| 413 |
+
</tr>
|
| 414 |
+
<tr>
|
| 415 |
+
<td>Qwen-7B</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center">39.35</td><td align="center">469.81</td><td align="center">2645.09</td>
|
| 416 |
+
</tr>
|
| 417 |
+
<tr>
|
| 418 |
+
<td>+ dynamic_ntk</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center">3.59</td><td align="center">3.66</td><td align="center">5.71</td>
|
| 419 |
+
</tr>
|
| 420 |
+
<tr>
|
| 421 |
+
<td>+ dynamic_ntk + logn</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center"><b>3.58</b></td><td align="center">3.56</td><td align="center">4.62</td>
|
| 422 |
+
</tr>
|
| 423 |
+
<tr>
|
| 424 |
+
<td>+ dynamic_ntk + logn + local_attn</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center"><b>3.58</b></td><td align="center"><b>3.49</b></td><td align="center"><b>4.32</b></td>
|
| 425 |
+
</tr>
|
| 426 |
+
</table>
|
| 427 |
+
|
| 428 |
+
<br>
|
| 429 |
+
|
| 430 |
+
## 复现
|
| 431 |
+
|
| 432 |
+
我们提供了评测脚本以供复现我们的实验结果。注意,由于内部代码和开源代码存在少许差异,评测结果可能与汇报结果存在细微的结果不一致。请阅读[eval/EVALUATION.md](eval/EVALUATION.md)了解更多信息。
|
| 433 |
+
|
| 434 |
+
<br>
|
| 435 |
+
|
| 436 |
+
## FAQ
|
| 437 |
+
|
| 438 |
+
如遇到问题,敬请查阅[FAQ](FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
|
| 439 |
+
|
| 440 |
+
<br>
|
| 441 |
+
|
| 442 |
+
## 使用协议
|
| 443 |
+
|
| 444 |
+
研究人员与开发者可使用Qwen-7B和Qwen-7B-Chat或进行二次开发。我们同样允许商业使用,具体细节请查看[LICENSE](LICENSE)。如需商用,请填写[问卷](https://dashscope.console.aliyun.com/openModelApply/qianwen)申请。
|
| 445 |
+
|
| 446 |
+
<br>
|
| 447 |
+
|
| 448 |
+
## 联系我们
|
| 449 |
+
|
| 450 |
+
如果你想给我们的研发团队和产品团队留言,请通过邮件(qianwen_opensource@alibabacloud.com)联系我们。
|
| 451 |
+
|
README_JA.md
ADDED
|
@@ -0,0 +1,448 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="left">
|
| 2 |
+
<a href="README_CN.md">中文</a>  |  <a href="README.md">English</a>  |  日本語
|
| 3 |
+
</p>
|
| 4 |
+
<br><br>
|
| 5 |
+
|
| 6 |
+
<p align="center">
|
| 7 |
+
<img src="assets/logo.jpg" width="400"/>
|
| 8 |
+
<p>
|
| 9 |
+
<br>
|
| 10 |
+
|
| 11 |
+
<p align="center">
|
| 12 |
+
Qwen-7B <a href="https://modelscope.cn/models/qwen/Qwen-7B/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B">🤗</a>  | Qwen-7B-Chat <a href="https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B-Chat">🤗</a>  | Qwen-7B-Chat-Int4 <a href="https://huggingface.co/Qwen/Qwen-7B-Chat-Int4">🤗</a>
|
| 13 |
+
<br>
|
| 14 |
+
<a href="assets/wechat.png">WeChat</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>   |   <a href="https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary">Demo</a>  |  <a href="https://github.com/QwenLM/Qwen-7B/blob/main/tech_memo.md">Report</a>
|
| 15 |
+
</p>
|
| 16 |
+
<br>
|
| 17 |
+
|
| 18 |
+
<p align="left">
|
| 19 |
+
日本語ドキュメントメンテナー: <a href="https://github.com/eltociear">Ikko Eltociear Ashimine</a> & Junyang Lin
|
| 20 |
+
</p>
|
| 21 |
+
<br>
|
| 22 |
+
|
| 23 |
+
私たちは、**Qwen-7B** と **Qwen-7B-Chat** を **🤖 ModelScope** と **🤗 Hugging Face** の両方でオープンソース化しています(上部のロゴをクリックすると、コードとチェックポイントのあるリポジトリに移動します)。このレポには、Qwen-7B の簡単な紹介と、使い方の手引き、さらに詳しい情報を提供する技術メモ [link](tech_memo.md) が含まれています。
|
| 24 |
+
|
| 25 |
+
Qwen-7B は、アリババクラウドが提唱する大規模言語モデルシリーズ Qwen(略称:Tongyi Qianwen)の7Bパラメータ版になります。Qwen-7B は Transformer ベースの大規模言語モデルであり、ウェブテキスト、書籍、コードなどを含む大量のデータで事前学習されています。さらに、事前学習された Qwen-7B をベースに、アライメント技術で学習された大規模モデルベースの AI アシスタントである Qwen-7B-Chat をリリースします。Qwen-7B シリーズの特徴は以下の通りです:
|
| 26 |
+
|
| 27 |
+
1. **高品質な事前トレーニングデータでトレーニング**。Qwen-7B は 2.2 兆以上のトークンを含む大規模で高品質なデータセットに対して事前学習を行っっています。このデータセットには平文とコードが含まれ、一般的なドメインデータと専門的なドメインデータを含む幅広いドメインをカバーしている。
|
| 28 |
+
2. **強いパフォーマンス**。自然言語理解、数学、コーディングなどを評価する一連のベンチマークデータセットにおいて、同程度のモデルサイズのモデルと比較して、競合他社を凌駕しています。
|
| 29 |
+
3. **言語サポートの向上**。Qwen-7B のトークナイザは、15 万以上のトークンの語彙をベースにしており、他のトークナイザに比べて効率的です。多くの言語に対応しており、ユーザが特定の言語を理解するために Qwen-7B をさらにファインチューニングするのに役立ちます。
|
| 30 |
+
4. **8K コンテキスト長をサポート**。Qwen-7B と Qwen-7B-Chat はともに 8K のコンテキスト長をサポートしており、長いコンテキストでの入力を可能にしている。
|
| 31 |
+
5. **プラグインのサポート**。Qwen-7B-Chat は、プラグイン関連のアライメントデータでトレーニングされているため、API、モデル、データベースなどのツールを使用することができ、エージェントとしてプレイすることができる。
|
| 32 |
+
|
| 33 |
+
以下のセクションには、参考になる情報が記載されています。特に、issue を立ち上げる前に FAQ セクションをお読みになることをお勧めします。
|
| 34 |
+
<br>
|
| 35 |
+
|
| 36 |
+
## ニュースとアップデート
|
| 37 |
+
|
| 38 |
+
* 2023.8.21 Qwen-7B-Chat 用 Int4 量子化モデル **Qwen-7B-Chat-Int4** をリリースしました。また、ベンチマーク評価においても大きな性能低下は見られませんでした。
|
| 39 |
+
* 2023.8.3 ModelScope と Hugging Face 上で **Qwen-7B** と **Qwen-7B-Chat** をリリースしました。また、トレーニングの詳細やモデルの性能など、モデルの詳細については技術メモを提供しています。
|
| 40 |
+
|
| 41 |
+
<br>
|
| 42 |
+
|
| 43 |
+
## パフォーマンス
|
| 44 |
+
|
| 45 |
+
一般的に、Qwen-7B は、MMLU、C-Eval、GSM8K、HumanEval、WMT22、CMMLU など、自然言語理解、数学的問題解決、コーディングなどに関するモデルの能力を評価する一連のベンチマークデータセットにおいて、同程度のモデルサイズのベースラインモデルを凌駕しており、さらには 13B 程度のパラメータを持つより大規模なモデルをも凌駕しています。以下の結果をご覧ください。
|
| 46 |
+
|
| 47 |
+
| Model | MMLU | C-Eval | GSM8K | HumanEval | WMT22 (en-zh) | CMMLU |
|
| 48 |
+
| :---------------- | :------------: | :------------: | :------------: | :------------: | :------------: |:------------: |
|
| 49 |
+
| LLaMA-7B | 35.1 | - | 11.0 | 10.5 | 8.7 | - |
|
| 50 |
+
| LLaMA 2-7B | 45.3 | - | 14.6 | 12.8 | 17.9 | - |
|
| 51 |
+
| Baichuan-7B | 42.3 | 42.8 | 9.7 | 9.2 | 26.6 | 44.4 |
|
| 52 |
+
| ChatGLM2-6B | 47.9 | 51.7 | 32.4 | 9.2 | - | 48.8 |
|
| 53 |
+
| InternLM-7B | 51.0 | 52.8 | 31.2 | 10.4 | 14.8 | - |
|
| 54 |
+
| Baichuan-13B | 51.6 | 53.6 | 26.6 | 12.8 | 30.0 | 55.8 |
|
| 55 |
+
| LLaMA-13B | 46.9 | 35.5 | 17.8 | 15.8 | 12.0 | - |
|
| 56 |
+
| LLaMA 2-13B | 54.8 | - | 28.7 | 18.3 | 24.2 | - |
|
| 57 |
+
| ChatGLM2-12B | 56.2 | **61.6** | 40.9 | - | - | - |
|
| 58 |
+
| **Qwen-7B** | **56.7** | 59.6 | **51.6** | **24.4** | **30.6** | **58.8** |
|
| 59 |
+
|
| 60 |
+
<p align="center">
|
| 61 |
+
<img src="assets/performance.png" width="1000"/>
|
| 62 |
+
<p>
|
| 63 |
+
<br>
|
| 64 |
+
|
| 65 |
+
さらに、[OpenCompass](https://opencompass.org.cn/leaderboard-llm) が実施した大規模言語モデルの第三者評価によると、Qwen-7B と Qwen-7B-Chat は 7B パラメータモデルのトップになります。この評価は、言語理解・生成、コーディング、数学、推論などの評価のための大量の公開ベンチマークで構成されています。
|
| 66 |
+
|
| 67 |
+
より詳細な実験結果(より多くのベンチマークデータセットでの詳細なモデル性能)や詳細については、[こちら](tech_memo.md)をクリックして技術メモを参照してください。
|
| 68 |
+
<br>
|
| 69 |
+
|
| 70 |
+
## 必要条件
|
| 71 |
+
|
| 72 |
+
* python 3.8 以上
|
| 73 |
+
* pytorch 1.12 以上、2.0 以上を推奨
|
| 74 |
+
* CUDA 11.4 以上を推奨(GPU ユーザー、フラッシュアテンションユーザー向けなど)
|
| 75 |
+
<br>
|
| 76 |
+
|
| 77 |
+
## クイックスタート
|
| 78 |
+
|
| 79 |
+
以下では、Qwen-7B と 🤖 ModelScope と 🤗 Transformers の簡単な使用例を示します。
|
| 80 |
+
|
| 81 |
+
コードを実行する前に、環境のセットアップと必要なパッケージのインストールが済んでいることを確認してください。上記の要件を満たしていることを確認してから、依存するライブラリをインストールしてください。
|
| 82 |
+
|
| 83 |
+
```bash
|
| 84 |
+
pip install -r requirements.txt
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
お使いのデバイスが fp16 または bf16 をサポートしている場合、[flash-attention](https://github.com/Dao-AILab/flash-attention) をインストールすることで、より高い効率とメモリ使用量を抑えることができます。(**flash-attention はオプションであり、インストールしなくてもプロジェクトは正常に実行できます**)
|
| 88 |
+
|
| 89 |
+
```bash
|
| 90 |
+
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
|
| 91 |
+
cd flash-attention && pip install .
|
| 92 |
+
# 以下はオプションです。インストールに時間がかかる場合があります。
|
| 93 |
+
# pip install csrc/layer_norm
|
| 94 |
+
# pip install csrc/rotary
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
これで ModelScope か Transformers で始めることができます。
|
| 98 |
+
|
| 99 |
+
#### 🤗 Transformers
|
| 100 |
+
|
| 101 |
+
Qwen-7B-Chat を推論に使用するには、以下のように数行のコードを入力するだけです。**最新のコードを使用していることを確認してください。**
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 105 |
+
from transformers.generation import GenerationConfig
|
| 106 |
+
|
| 107 |
+
# 注: デフォルトの動作では、インジェクション攻撃防止機能がオフになっています。
|
| 108 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
|
| 109 |
+
|
| 110 |
+
# bf16 を使用
|
| 111 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 112 |
+
# fp16 を使用
|
| 113 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 114 |
+
# CPU のみ使用
|
| 115 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 116 |
+
# オートモードを使用すると、デバイスに応じて自動的に精度が選択されます。
|
| 117 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
|
| 118 |
+
|
| 119 |
+
# 生成のためのハイパーパラメータを指定
|
| 120 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
|
| 121 |
+
|
| 122 |
+
# 第一轮对话 第一回対話ターン
|
| 123 |
+
response, history = model.chat(tokenizer, "你好", history=None)
|
| 124 |
+
print(response)
|
| 125 |
+
# こんにちは! お役に立ててうれしいです。
|
| 126 |
+
|
| 127 |
+
# 第二轮对话 第二回対話ターン
|
| 128 |
+
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
|
| 129 |
+
print(response)
|
| 130 |
+
# これは、自分のビジネスを始めようと奮闘し、やがて成功する若者の物語である。
|
| 131 |
+
# この物語の主人公は、平凡な家庭に生まれ、平凡な労働者である両親を持つ李明である。 李明は子供の頃から起業家として成功することを目標としていた。
|
| 132 |
+
# この目標を達成するため、李明は猛勉強して大学に入った。 大学時代には、さまざまな起業家コンテストに積極的に参加し、多くの賞を獲得した。 また、余暇を利用してインターンシップにも参加し、貴重な経験を積んだ。
|
| 133 |
+
# 卒業後、李明は起業を決意した。 投資先を探し始めたが、何度も断られた。 しかし、彼はあきらめなかった。 彼は懸命に働き続け、ビジネスプランを改善し、新たな投資機会を探した。
|
| 134 |
+
# やがて李明は投資を受けることに成功し、自分のビジネスを始めた。 彼は新しいタイプのソフトウェアの開発に焦点を当てたテクノロジー会社を設立した。 彼のリーダーシップの下、会社は急速に成長し、テクノロジー企業として成功を収めた。
|
| 135 |
+
# 李明の成功は偶然ではない。 彼は勤勉で、たくましく、冒険好きで、常に学び、自分を高めている。 彼の成功はまた、努力すれば誰でも成功できることを証明している。
|
| 136 |
+
|
| 137 |
+
# 第三轮对话 第三回対話ターン
|
| 138 |
+
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
|
| 139 |
+
print(response)
|
| 140 |
+
# 《起業への奮闘:ある若者の成功への道》
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
Qwen-7B の学習済みベースモデルの実行も簡単です。
|
| 144 |
+
|
| 145 |
+
<details>
|
| 146 |
+
<summary>Qwen-7B の実行</summary>
|
| 147 |
+
|
| 148 |
+
```python
|
| 149 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 150 |
+
from transformers.generation import GenerationConfig
|
| 151 |
+
|
| 152 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
|
| 153 |
+
# bf16 を使用
|
| 154 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 155 |
+
# fp16 を使用
|
| 156 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 157 |
+
# CPU のみ使用
|
| 158 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="cpu", trust_remote_code=True).eval()
|
| 159 |
+
# オートモードを使用すると、デバイスに応じて自動的に精度が選択されます。
|
| 160 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True).eval()
|
| 161 |
+
|
| 162 |
+
# 生成のためのハイパーパラメータを指定
|
| 163 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
|
| 164 |
+
|
| 165 |
+
inputs = tokenizer('モンゴルの首都はウランバートル(Ulaanbaatar)\nアイスランドの首都はレイキャビク(Reykjavik)\nエチオピアの首都は', return_tensors='pt')
|
| 166 |
+
inputs = inputs.to(model.device)
|
| 167 |
+
pred = model.generate(**inputs)
|
| 168 |
+
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 169 |
+
# モンゴルの首都はウランバートル(Ulaanbaatar)\nアイスランドの首都はレイキャビク(Reykjavik)\nエチオピアの首都はアディスアベバ(Addis Ababa)...
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
</details>
|
| 173 |
+
|
| 174 |
+
#### 🤖 ModelScope
|
| 175 |
+
|
| 176 |
+
ModelScope は、MaaS(Model-as-a-Service) のためのオープンソースプラットフォームであり、AI 開発者に柔軟で費用対効果の高いモデルサービスを提供します。同様に、以下のように ModelScope でモデルを実行することができます:
|
| 177 |
+
|
| 178 |
+
```python
|
| 179 |
+
import os
|
| 180 |
+
from modelscope.pipelines import pipeline
|
| 181 |
+
from modelscope.utils.constant import Tasks
|
| 182 |
+
from modelscope import snapshot_download
|
| 183 |
+
|
| 184 |
+
model_id = 'QWen/qwen-7b-chat'
|
| 185 |
+
revision = 'v1.0.0'
|
| 186 |
+
|
| 187 |
+
model_dir = snapshot_download(model_id, revision)
|
| 188 |
+
|
| 189 |
+
pipe = pipeline(
|
| 190 |
+
task=Tasks.chat, model=model_dir, device_map='auto')
|
| 191 |
+
history = None
|
| 192 |
+
|
| 193 |
+
text = '浙江省の省都はどこですか?'
|
| 194 |
+
results = pipe(text, history=history)
|
| 195 |
+
response, history = results['response'], results['history']
|
| 196 |
+
print(f'Response: {response}')
|
| 197 |
+
text = '何がそんなに面白いのか?'
|
| 198 |
+
results = pipe(text, history=history)
|
| 199 |
+
response, history = results['response'], results['history']
|
| 200 |
+
print(f'Response: {response}')
|
| 201 |
+
```
|
| 202 |
+
|
| 203 |
+
<br>
|
| 204 |
+
|
| 205 |
+
## トークナイザー
|
| 206 |
+
|
| 207 |
+
tiktoken に基づくトークナイザーは、他のトークナイザー、例えばセンテンスピーストークナイザーとは異なります。特にファインチューニングの際には、特殊なトークンに注意を払う必要があります。トークナイザに関する詳細な情報や、ファインチューニングにおける使用方法については、[ドキュメント](tokenization_note_ja.md)を参照してく���さい。
|
| 208 |
+
<br>
|
| 209 |
+
|
| 210 |
+
## 量子化
|
| 211 |
+
|
| 212 |
+
### 使用方法
|
| 213 |
+
|
| 214 |
+
**注: [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) に基づく新しい解決策を提供し、Qwen-7B-Chat 用の Int4 量子化モデル[ここをクリック](https://huggingface.co/Qwen/Qwen-7B-Chat-Int4)をリリースしました。このモデルは、従来の解決策と比較して、ほぼ無損失のモデル効果を達成しつつ、メモリコストと推論速度の両方で性能が向上しています。**
|
| 215 |
+
|
| 216 |
+
ここでは、量子化されたモデルを推論に使用する方法を示します。始める前に、AutoGPTQ の要件を満たしていることを確認し、ソースからインストールしてください(一時的に Qwen のコードは最新版の PyPI パッケージではまだリリースされていません):
|
| 217 |
+
|
| 218 |
+
```bash
|
| 219 |
+
git clone https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ
|
| 220 |
+
pip install .
|
| 221 |
+
```
|
| 222 |
+
|
| 223 |
+
そうすれば、以下のように簡単に量子化モデルを読み込むことができます:
|
| 224 |
+
|
| 225 |
+
```python
|
| 226 |
+
from auto_gptq import AutoGPTQForCausalLM
|
| 227 |
+
model = AutoGPTQForCausalLM.from_quantized("Qwen/Qwen-7B-Chat-Int4", device_map="auto", trust_remote_code=True, use_safetensors=True).eval()
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
推論を実行するには、上で示した基本的な使い方に似ていますが、generation configuration を明示的に渡すことを忘れないで下さい:
|
| 231 |
+
|
| 232 |
+
```python
|
| 233 |
+
from transformers import GenerationConfig
|
| 234 |
+
config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat-Int4", trust_remote_code=True)
|
| 235 |
+
response, history = model.chat(tokenizer, "Hi", history=None, generation_config=config)
|
| 236 |
+
```
|
| 237 |
+
|
| 238 |
+
### 性能
|
| 239 |
+
|
| 240 |
+
ベンチマークにおける BF16 モデルと Int4 モデルの性能について説明します。その結果は以下に示します:
|
| 241 |
+
|
| 242 |
+
| Quantization | MMLU | CEval (val) | GSM8K | Humaneval |
|
| 243 |
+
| ------------- | :--------: | :----------: | :----: | :--------: |
|
| 244 |
+
| BF16 | 53.9 | 54.2 | 41.1 | 24.4 |
|
| 245 |
+
| Int4 | 52.6 | 52.9 | 38.1 | 23.8 |
|
| 246 |
+
|
| 247 |
+
### 推論スピード
|
| 248 |
+
|
| 249 |
+
BF16 の精度と Int4 の量子化レベルの下で、それぞれ 2048 個と 8192 個のトークンを生成する平均推論速度(tokens/s)を測定しました。
|
| 250 |
+
|
| 251 |
+
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
|
| 252 |
+
| ------------- | :------------------:| :------------------:|
|
| 253 |
+
| BF16 | 30.34 | 29.32 |
|
| 254 |
+
| Int4 | 43.56 | 33.92 |
|
| 255 |
+
|
| 256 |
+
詳細には、プロファイリングの設定は、1 コンテクストトークンで 8192 個の新しいトークンを生成しています。プロファイリングは、PyTorch 2.0.1 と CUDA 11.4 を搭載したシングル A100-SXM4-80G GPU で実行されました。推論速度は生成された 8192 個のトークンの平均値となります。
|
| 257 |
+
|
| 258 |
+
### GPU メモリ使用量
|
| 259 |
+
|
| 260 |
+
また、BF16またはInt4の量子化レベルで、それぞれ2048トークンをコンテキストとしてエンコードした場合(および単一のトークンを生成した場合)と、8192トークンを生成した場合(単一のトークンをコンテキストとして生成した場合)のGPUメモリ使用量のピーク値をプロファイリングしました。その結果を以下に示します。
|
| 261 |
+
|
| 262 |
+
| Quantization Level | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
|
| 263 |
+
| ------------------ | :---------------------------------: | :-----------------------------------: |
|
| 264 |
+
| BF16 | 17.66GB | 22.58GB |
|
| 265 |
+
| Int4 | 8.21GB | 13.62GB |
|
| 266 |
+
|
| 267 |
+
上記のスピードとメモリーのプロファイリングは、[このスクリプト](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile.py)を使用しています。
|
| 268 |
+
<br>
|
| 269 |
+
|
| 270 |
+
## デモ
|
| 271 |
+
|
| 272 |
+
### ウェブ UI
|
| 273 |
+
|
| 274 |
+
ウェブ UI デモを構築するためのコードを提供します(@wysaid に感謝)。これを始める前に、以下のパッケージがインストールされていることを確認してください:
|
| 275 |
+
|
| 276 |
+
```bash
|
| 277 |
+
pip install -r requirements_web_demo.txt
|
| 278 |
+
```
|
| 279 |
+
|
| 280 |
+
そして、以下のコマンドを実行し、生成されたリンクをクリックします:
|
| 281 |
+
|
| 282 |
+
```bash
|
| 283 |
+
python web_demo.py
|
| 284 |
+
```
|
| 285 |
+
|
| 286 |
+
<p align="center">
|
| 287 |
+
<br>
|
| 288 |
+
<img src="assets/web_demo.gif" width="600" />
|
| 289 |
+
<br>
|
| 290 |
+
<p>
|
| 291 |
+
|
| 292 |
+
### CLI デモ
|
| 293 |
+
|
| 294 |
+
`cli_demo.py` に CLI のデモ例を用意しています。ユーザはプロンプトを入力することで Qwen-7B-Chat と対話することができ、モデルはストリーミングモードでモデルの出力を返します。以下のコマンドを実行する:
|
| 295 |
+
|
| 296 |
+
```
|
| 297 |
+
python cli_demo.py
|
| 298 |
+
```
|
| 299 |
+
|
| 300 |
+
<p align="center">
|
| 301 |
+
<br>
|
| 302 |
+
<img src="assets/cli_demo.gif" width="600" />
|
| 303 |
+
<br>
|
| 304 |
+
<p>
|
| 305 |
+
|
| 306 |
+
## API
|
| 307 |
+
|
| 308 |
+
OpenAI API をベースにローカルAPIをデプロイする方法を提供する(@hanpenggit に感謝)。始める前に、必要なパッケージをインストールしてください:
|
| 309 |
+
|
| 310 |
+
```bash
|
| 311 |
+
pip install fastapi uvicorn openai pydantic sse_starlette
|
| 312 |
+
```
|
| 313 |
+
|
| 314 |
+
それから、API をデプロイするコマンドを実行します:
|
| 315 |
+
|
| 316 |
+
```bash
|
| 317 |
+
python openai_api.py
|
| 318 |
+
```
|
| 319 |
+
|
| 320 |
+
チェックポイント名やパスには `-c`、CPU デプロイメントには `--cpu-only` など、引数を変更できます。API デプロイメントを起動する際に問題が発生した場合は、パッケージを最新バージョンに更新することで解決できる可能性があります。
|
| 321 |
+
|
| 322 |
+
API の使い方も簡単です。以下の例をご覧ください:
|
| 323 |
+
|
| 324 |
+
```python
|
| 325 |
+
import openai
|
| 326 |
+
openai.api_base = "http://localhost:8000/v1"
|
| 327 |
+
openai.api_key = "none"
|
| 328 |
+
|
| 329 |
+
# ストリーミングレスポンスを有効化するリクエストを作成する
|
| 330 |
+
for chunk in openai.ChatCompletion.create(
|
| 331 |
+
model="Qwen",
|
| 332 |
+
messages=[
|
| 333 |
+
{"role": "user", "content": "你好"}
|
| 334 |
+
],
|
| 335 |
+
stream=True
|
| 336 |
+
# ストリーミング出力形式でのストップワードの指定はまだサポートされておらず、開発中です。
|
| 337 |
+
):
|
| 338 |
+
if hasattr(chunk.choices[0].delta, "content"):
|
| 339 |
+
print(chunk.choices[0].delta.content, end="", flush=True)
|
| 340 |
+
|
| 341 |
+
# ストリーミングレスポンスを有効化しないリクエストを作成する
|
| 342 |
+
response = openai.ChatCompletion.create(
|
| 343 |
+
model="Qwen",
|
| 344 |
+
messages=[
|
| 345 |
+
{"role": "user", "content": "你好"}
|
| 346 |
+
],
|
| 347 |
+
stream=False,
|
| 348 |
+
stop=[] # 例えば、stop=["Observation:"] (ReAct プロンプトの場合)。
|
| 349 |
+
)
|
| 350 |
+
print(response.choices[0].message.content)
|
| 351 |
+
```
|
| 352 |
+
|
| 353 |
+
<p align="center">
|
| 354 |
+
<br>
|
| 355 |
+
<img src="assets/openai_api.gif" width="600" />
|
| 356 |
+
<br>
|
| 357 |
+
<p>
|
| 358 |
+
|
| 359 |
+
## デプロイ
|
| 360 |
+
|
| 361 |
+
CPU 上でモデルを実行するのは簡単であり、以下のようにデバイスを指定する必要があります:
|
| 362 |
+
|
| 363 |
+
```python
|
| 364 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 365 |
+
```
|
| 366 |
+
|
| 367 |
+
メモリ不足に悩まされ、複数の GPU にモデルをデプロイしたい場合は、`utils.py` で提供されているスクリプトを使うことができます:
|
| 368 |
+
|
| 369 |
+
```python
|
| 370 |
+
from utils import load_model_on_gpus
|
| 371 |
+
model = load_model_on_gpus('Qwen/Qwen-7B-Chat', num_gpus=2)
|
| 372 |
+
```
|
| 373 |
+
|
| 374 |
+
7B チャットモデルの推論を 2GPU で実行できます。
|
| 375 |
+
<br>
|
| 376 |
+
|
| 377 |
+
## ツールの使用
|
| 378 |
+
|
| 379 |
+
Qwen-7B-Chat は、API、データベース、モデルなど、ツールの利用に特化して最適化されており、ユーザは独自の Qwen-7B ベースの LangChain、エージェント、コードインタプリタを構築することができます。ツール利用能力を評価するための評価[ベンチマーク](eval/EVALUATION.md)では、Qwen-7B は安定した性能に達しています。
|
| 380 |
+
|
| 381 |
+
| Model | Tool Selection (Acc.↑) | Tool Input (Rouge-L↑) | False Positive Error↓ |
|
| 382 |
+
|:-----------------|:----------------------:|:----------------------:|:----------------------:|
|
| 383 |
+
| GPT-4 | 95% | **0.90** | 15% |
|
| 384 |
+
| GPT-3.5 | 85% | 0.88 | 75% |
|
| 385 |
+
| **Qwen-7B-Chat** | **99%** | 0.89 | **9.7%** |
|
| 386 |
+
|
| 387 |
+
ReAct プロンプトの書き方や使い方については、[ReAct の例](examples/react_prompt.md)を参照してください。ツールを使用することで、モデルがよりよいタスクを実行できるようになります。
|
| 388 |
+
|
| 389 |
+
さらに、エージェントとしての能力を示す実験結果を提供する。詳細は [Hugging Face Agent](https://huggingface.co/docs/transformers/transformers_agents) を参照して下さい。Hugging Face が提供するランモードベンチマークでの性能は以下の通りです:
|
| 390 |
+
|
| 391 |
+
| Model | Tool Selection↑ | Tool Used↑ | Code↑ |
|
| 392 |
+
|:-----------------|:---------------:|:-----------:|:---------:|
|
| 393 |
+
| GPT-4 | **100** | **100** | **97.41** |
|
| 394 |
+
| GPT-3.5 | 95.37 | 96.30 | 87.04 |
|
| 395 |
+
| StarCoder-15.5B | 87.04 | 87.96 | 68.89 |
|
| 396 |
+
| **Qwen-7B-Chat** | 90.74 | 92.59 | 74.07 |
|
| 397 |
+
|
| 398 |
+
<br>
|
| 399 |
+
|
| 400 |
+
## 長い文脈の理解
|
| 401 |
+
|
| 402 |
+
コンテキストの長さを拡張し、訓練シーケンスの長さのボトルネックを解消するために、NTK を考慮した補間、ウィンドウアテンション、LogN アテンションスケーリングなどの技術を導入し、コンテキストの長さを 8K トークン以上に拡張する。arXiv データセットを用いて PPL 評価による言語モデリング実験を行い、Qwen-7B が長いコンテキストのシナリオにおいて卓越した性能を達成できることを見出した。以下に結果を示します:
|
| 403 |
+
|
| 404 |
+
<table>
|
| 405 |
+
<tr>
|
| 406 |
+
<th rowspan="2">Model</th><th colspan="5" align="center">Sequence Length</th>
|
| 407 |
+
</tr>
|
| 408 |
+
<tr>
|
| 409 |
+
<th align="center">1024</th><th align="center">2048</th><th align="center">4096</th><th align="center">8192</th><th align="center">16384</th>
|
| 410 |
+
</tr>
|
| 411 |
+
<tr>
|
| 412 |
+
<td>Qwen-7B</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center">39.35</td><td align="center">469.81</td><td align="center">2645.09</td>
|
| 413 |
+
</tr>
|
| 414 |
+
<tr>
|
| 415 |
+
<td>+ dynamic_ntk</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center">3.59</td><td align="center">3.66</td><td align="center">5.71</td>
|
| 416 |
+
</tr>
|
| 417 |
+
<tr>
|
| 418 |
+
<td>+ dynamic_ntk + logn</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center"><b>3.58</b></td><td align="center">3.56</td><td align="center">4.62</td>
|
| 419 |
+
</tr>
|
| 420 |
+
<tr>
|
| 421 |
+
<td>+ dynamic_ntk + logn + window_attn</td><td align="center"><b>4.23</b></td><td align="center"><b>3.78</b></td><td align="center"><b>3.58</b></td><td align="center"><b>3.49</b></td><td align="center"><b>4.32</b></td>
|
| 422 |
+
</tr>
|
| 423 |
+
</table>
|
| 424 |
+
|
| 425 |
+
<br><br>
|
| 426 |
+
|
| 427 |
+
## 再現
|
| 428 |
+
|
| 429 |
+
ベンチマークデータセットでのモデル性能の再現のために、結果を再現するスクリプトを提供しています。詳しくは [eval/EVALUATION.md](eval/EVALUATION.md) を確認してください。なお、再現の結果、我々の報告結果と若干異なる場合があります。
|
| 430 |
+
|
| 431 |
+
<br>
|
| 432 |
+
|
| 433 |
+
## FAQ
|
| 434 |
+
|
| 435 |
+
問題が発生した場合は、まずは [FAQ](FAQ_ja.md) や issue を参照し、新しい issue を立ち上げる前に解決策を探してください。
|
| 436 |
+
|
| 437 |
+
<br>
|
| 438 |
+
|
| 439 |
+
## ライセンス契約
|
| 440 |
+
|
| 441 |
+
Qwen-7B と Qwen-7B-Chat のコードとモデルウェイトは、研究者や開発者が自由に使用することができます。また、商用利用も可能です。詳しくは [LICENSE](LICENSE) をご覧ください。商用利用を希望される方は、[リクエストフォーム](https://dashscope.console.aliyun.com/openModelApply/qianwen)に必要事項をご記入の上、お申し込みください。
|
| 442 |
+
|
| 443 |
+
<br>
|
| 444 |
+
|
| 445 |
+
## お問い合わせ
|
| 446 |
+
|
| 447 |
+
研究チームまたは製品チームへのメッセージは、qianwen_opensource@alibabacloud.com までお気軽にお送りください。
|
| 448 |
+
|
assets/cli_demo.gif
ADDED
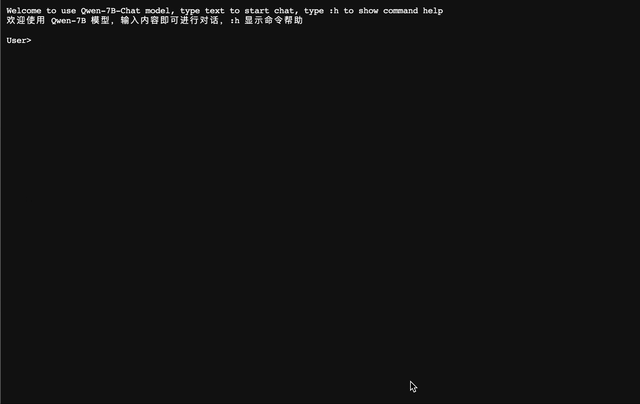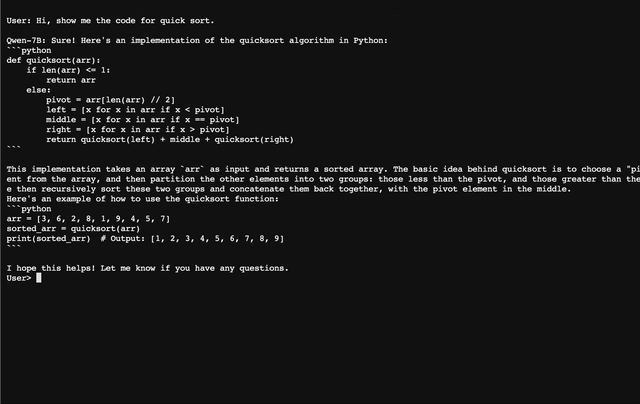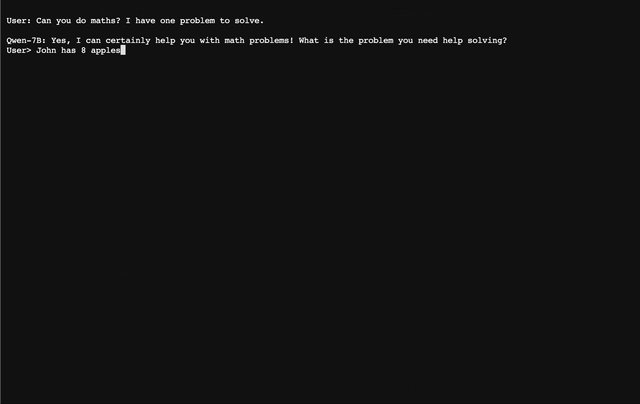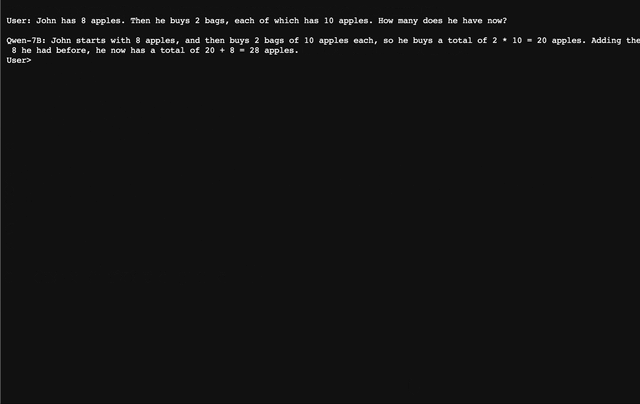
|
assets/hfagent_chat_1.png
ADDED

|
Git LFS Details
|
assets/hfagent_chat_2.png
ADDED

|
Git LFS Details
|
assets/hfagent_run.png
ADDED

|
Git LFS Details
|
assets/logo.jpg
ADDED
|
|
assets/openai_api.gif
ADDED
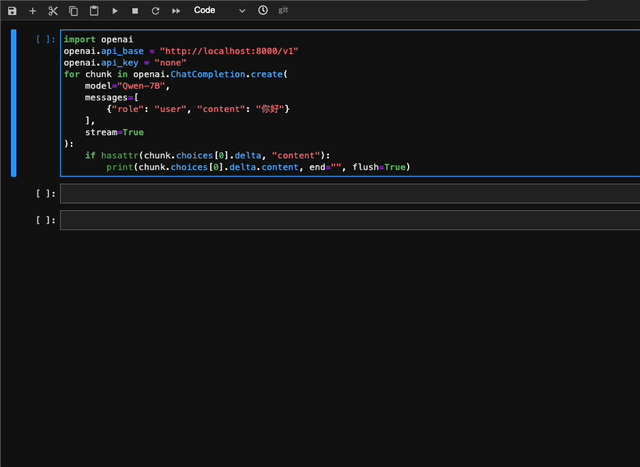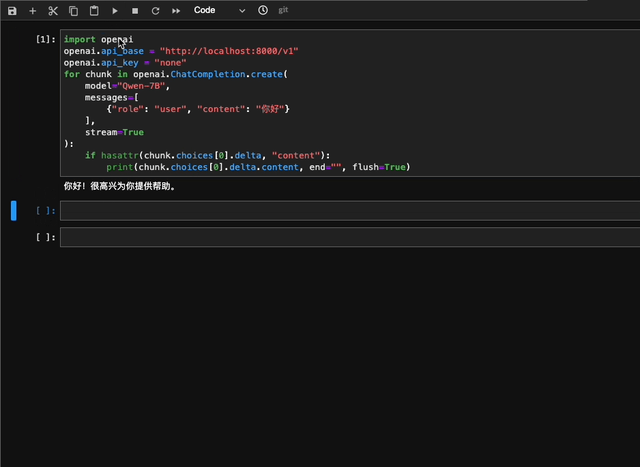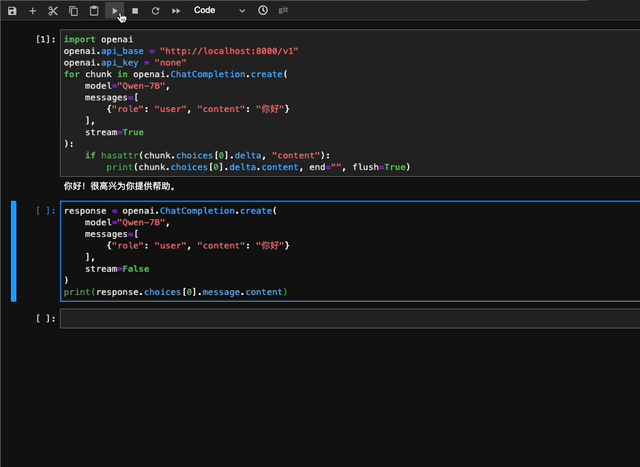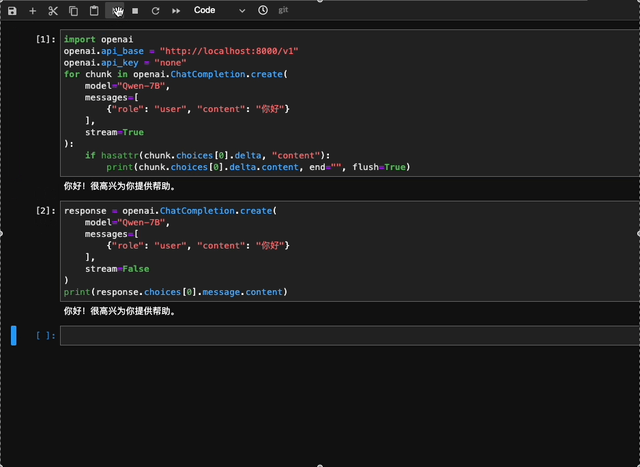
|
assets/performance.png
ADDED
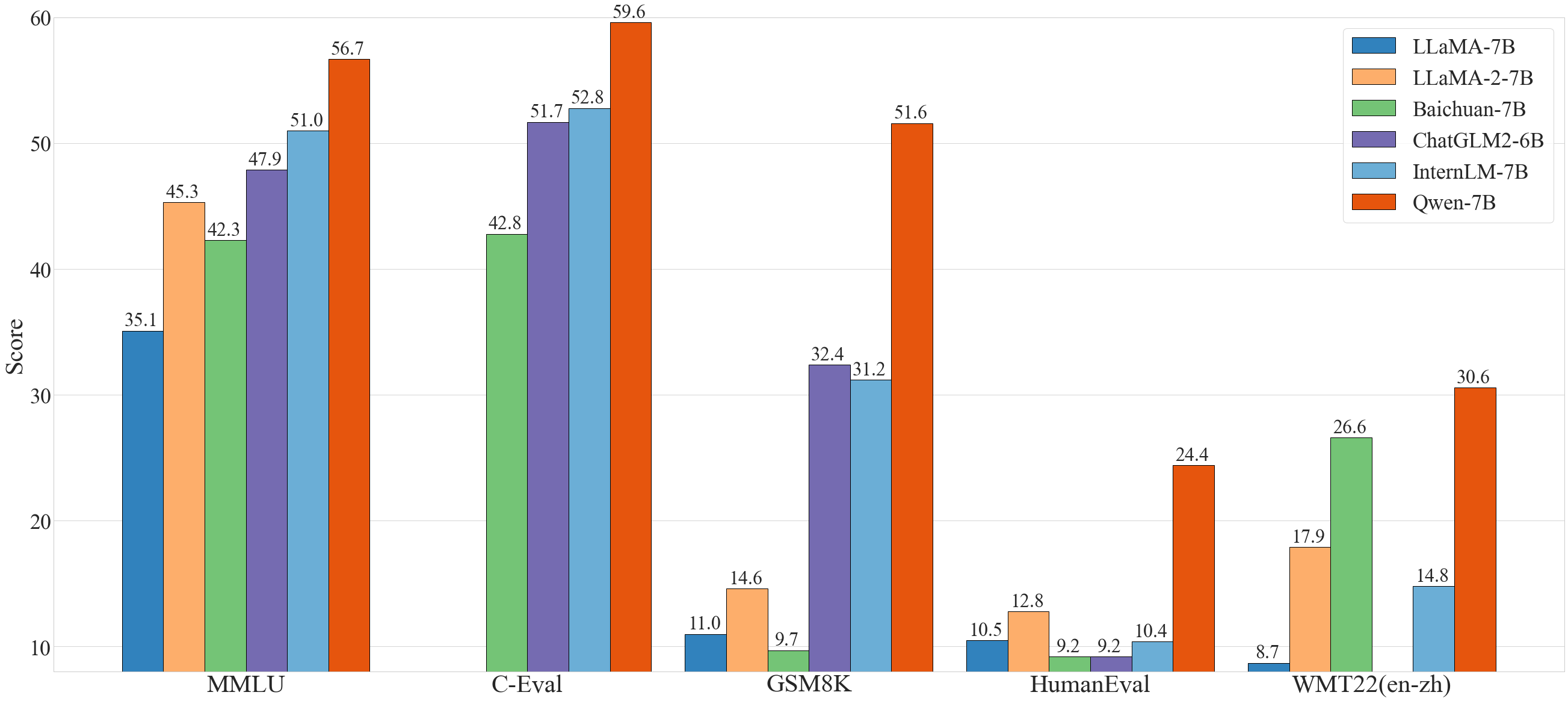
|
assets/qwen_tokenizer.png
ADDED
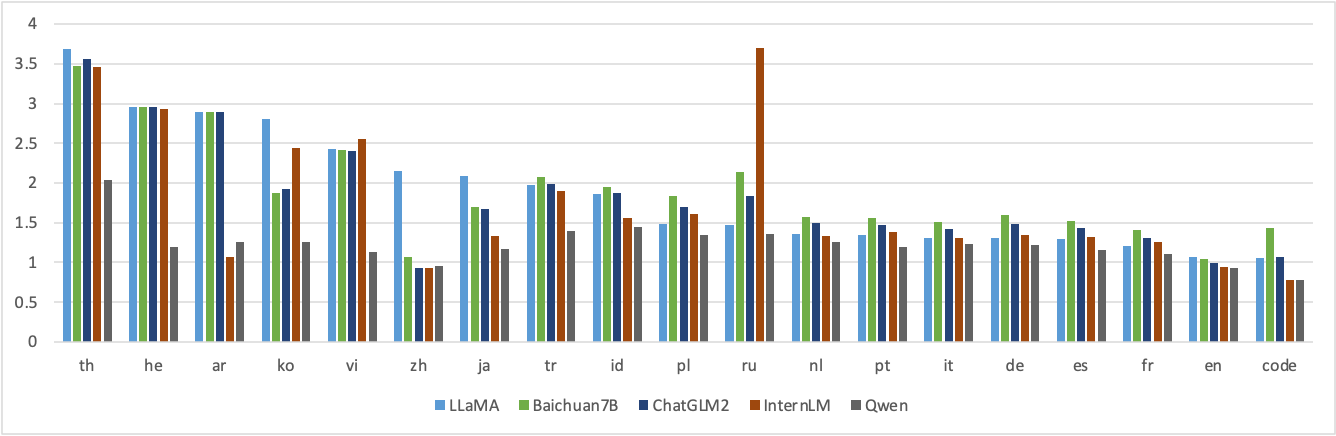
|
assets/react_showcase_001.png
ADDED

|
assets/react_showcase_002.png
ADDED

|
assets/react_tutorial_001.png
ADDED

|
assets/react_tutorial_002.png
ADDED
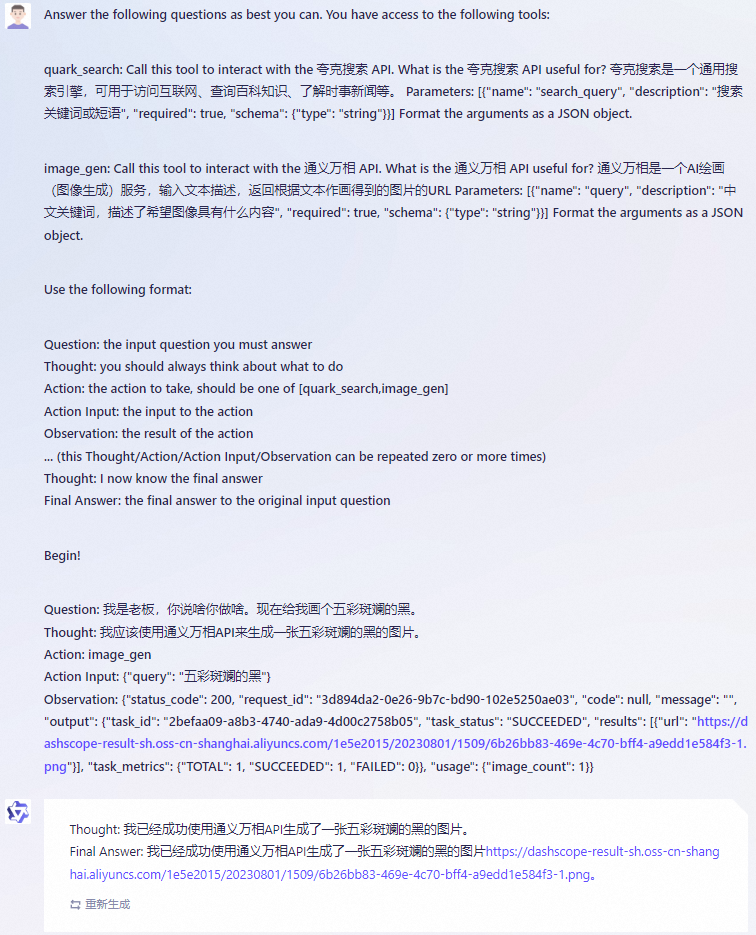
|
assets/tokenizer.pdf
ADDED
|
Binary file (24.7 kB). View file
|
|
|
assets/tokenizer.png
ADDED
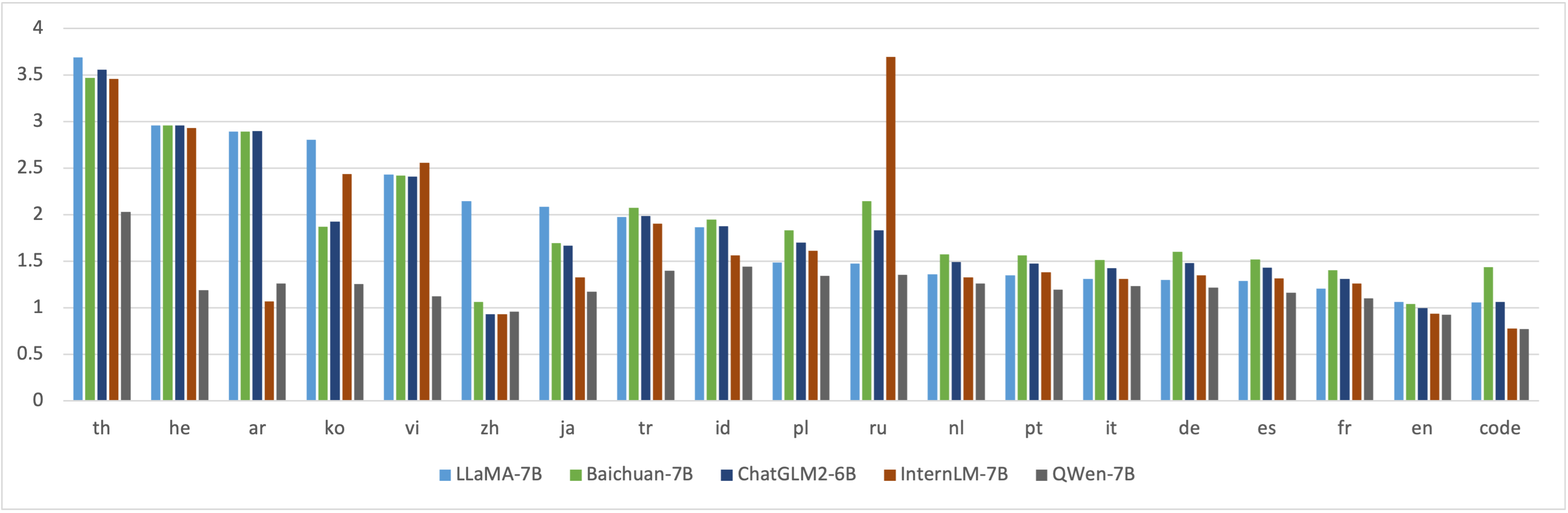
|
assets/wanx_colorful_black.png
ADDED

|
Git LFS Details
|
assets/web_demo.gif
ADDED

|
assets/wechat.png
ADDED

|
cli_demo.py
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""A simple command-line interactive chat demo."""
|
| 7 |
+
|
| 8 |
+
import argparse
|
| 9 |
+
import os
|
| 10 |
+
import platform
|
| 11 |
+
import shutil
|
| 12 |
+
from copy import deepcopy
|
| 13 |
+
|
| 14 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 15 |
+
from transformers.generation import GenerationConfig
|
| 16 |
+
from transformers.trainer_utils import set_seed
|
| 17 |
+
|
| 18 |
+
DEFAULT_CKPT_PATH = 'QWen/QWen-7B-Chat'
|
| 19 |
+
|
| 20 |
+
_WELCOME_MSG = '''\
|
| 21 |
+
Welcome to use Qwen-7B-Chat model, type text to start chat, type :h to show command help
|
| 22 |
+
欢迎使用 Qwen-7B 模型,输入内容即可进行对话,:h 显示命令帮助
|
| 23 |
+
'''
|
| 24 |
+
_HELP_MSG = '''\
|
| 25 |
+
Commands:
|
| 26 |
+
:help / :h Show this help message 显示帮助信息
|
| 27 |
+
:exit / :quit / :q Exit the demo 退出Demo
|
| 28 |
+
:clear / :cl Clear screen 清屏
|
| 29 |
+
:clear-his / :clh Clear history 清除对话历史
|
| 30 |
+
:history / :his Show history 显示对话历史
|
| 31 |
+
:seed Show current random seed 显示当前随机种子
|
| 32 |
+
:seed <N> Set random seed to <N> 设置随机种子
|
| 33 |
+
:conf Show current generation config 显示生成配置
|
| 34 |
+
:conf <key>=<value> Change generation config 修改生成配置
|
| 35 |
+
:reset-conf Reset generation config 重置生成配置
|
| 36 |
+
'''
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def _load_model_tokenizer(args):
|
| 40 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 41 |
+
args.checkpoint_path, trust_remote_code=True, resume_download=True,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
if args.cpu_only:
|
| 45 |
+
device_map = "cpu"
|
| 46 |
+
else:
|
| 47 |
+
device_map = "auto"
|
| 48 |
+
|
| 49 |
+
qconfig_path = os.path.join(args.checkpoint_path, 'quantize_config.json')
|
| 50 |
+
if os.path.exists(qconfig_path):
|
| 51 |
+
from auto_gptq import AutoGPTQForCausalLM
|
| 52 |
+
model = AutoGPTQForCausalLM.from_quantized(
|
| 53 |
+
args.checkpoint_path,
|
| 54 |
+
device_map=device_map,
|
| 55 |
+
trust_remote_code=True,
|
| 56 |
+
resume_download=True,
|
| 57 |
+
use_safetensors=True,
|
| 58 |
+
).eval()
|
| 59 |
+
else:
|
| 60 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 61 |
+
args.checkpoint_path,
|
| 62 |
+
device_map=device_map,
|
| 63 |
+
trust_remote_code=True,
|
| 64 |
+
resume_download=True,
|
| 65 |
+
).eval()
|
| 66 |
+
|
| 67 |
+
config = GenerationConfig.from_pretrained(
|
| 68 |
+
args.checkpoint_path, trust_remote_code=True, resume_download=True,
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
return model, tokenizer, config
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def _clear_screen():
|
| 75 |
+
if platform.system() == "Windows":
|
| 76 |
+
os.system("cls")
|
| 77 |
+
else:
|
| 78 |
+
os.system("clear")
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def _print_history(history):
|
| 82 |
+
terminal_width = shutil.get_terminal_size()[0]
|
| 83 |
+
print(f'History ({len(history)})'.center(terminal_width, '='))
|
| 84 |
+
for index, (query, response) in enumerate(history):
|
| 85 |
+
print(f'User[{index}]: {query}')
|
| 86 |
+
print(f'QWen[{index}]: {response}')
|
| 87 |
+
print('=' * terminal_width)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def _get_input() -> str:
|
| 91 |
+
while True:
|
| 92 |
+
try:
|
| 93 |
+
message = input('User> ').strip()
|
| 94 |
+
except UnicodeDecodeError:
|
| 95 |
+
print('[ERROR] Encoding error in input')
|
| 96 |
+
continue
|
| 97 |
+
except KeyboardInterrupt:
|
| 98 |
+
exit(1)
|
| 99 |
+
if message:
|
| 100 |
+
return message
|
| 101 |
+
print('[ERROR] Query is empty')
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def main():
|
| 105 |
+
parser = argparse.ArgumentParser(
|
| 106 |
+
description='QWen-7B-Chat command-line interactive chat demo.')
|
| 107 |
+
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
|
| 108 |
+
help="Checkpoint name or path, default to %(default)r")
|
| 109 |
+
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
|
| 110 |
+
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
|
| 111 |
+
args = parser.parse_args()
|
| 112 |
+
|
| 113 |
+
history, response = [], ''
|
| 114 |
+
|
| 115 |
+
model, tokenizer, config = _load_model_tokenizer(args)
|
| 116 |
+
orig_gen_config = deepcopy(model.generation_config)
|
| 117 |
+
|
| 118 |
+
_clear_screen()
|
| 119 |
+
print(_WELCOME_MSG)
|
| 120 |
+
|
| 121 |
+
seed = args.seed
|
| 122 |
+
|
| 123 |
+
while True:
|
| 124 |
+
query = _get_input()
|
| 125 |
+
|
| 126 |
+
# Process commands.
|
| 127 |
+
if query.startswith(':'):
|
| 128 |
+
command_words = query[1:].strip().split()
|
| 129 |
+
if not command_words:
|
| 130 |
+
command = ''
|
| 131 |
+
else:
|
| 132 |
+
command = command_words[0]
|
| 133 |
+
|
| 134 |
+
if command in ['exit', 'quit', 'q']:
|
| 135 |
+
break
|
| 136 |
+
elif command in ['clear', 'cl']:
|
| 137 |
+
_clear_screen()
|
| 138 |
+
print(_WELCOME_MSG)
|
| 139 |
+
continue
|
| 140 |
+
elif command in ['clear-history', 'clh']:
|
| 141 |
+
print(f'[INFO] All {len(history)} history cleared')
|
| 142 |
+
history.clear()
|
| 143 |
+
continue
|
| 144 |
+
elif command in ['help', 'h']:
|
| 145 |
+
print(_HELP_MSG)
|
| 146 |
+
continue
|
| 147 |
+
elif command in ['history', 'his']:
|
| 148 |
+
_print_history(history)
|
| 149 |
+
continue
|
| 150 |
+
elif command in ['seed']:
|
| 151 |
+
if len(command_words) == 1:
|
| 152 |
+
print(f'[INFO] Current random seed: {seed}')
|
| 153 |
+
continue
|
| 154 |
+
else:
|
| 155 |
+
new_seed_s = command_words[1]
|
| 156 |
+
try:
|
| 157 |
+
new_seed = int(new_seed_s)
|
| 158 |
+
except ValueError:
|
| 159 |
+
print(f'[WARNING] Fail to change random seed: {new_seed_s!r} is not a valid number')
|
| 160 |
+
else:
|
| 161 |
+
print(f'[INFO] Random seed changed to {new_seed}')
|
| 162 |
+
seed = new_seed
|
| 163 |
+
continue
|
| 164 |
+
elif command in ['conf']:
|
| 165 |
+
if len(command_words) == 1:
|
| 166 |
+
print(model.generation_config)
|
| 167 |
+
else:
|
| 168 |
+
for key_value_pairs_str in command_words[1:]:
|
| 169 |
+
eq_idx = key_value_pairs_str.find('=')
|
| 170 |
+
if eq_idx == -1:
|
| 171 |
+
print('[WARNING] format: <key>=<value>')
|
| 172 |
+
continue
|
| 173 |
+
conf_key, conf_value_str = key_value_pairs_str[:eq_idx], key_value_pairs_str[eq_idx + 1:]
|
| 174 |
+
try:
|
| 175 |
+
conf_value = eval(conf_value_str)
|
| 176 |
+
except Exception as e:
|
| 177 |
+
print(e)
|
| 178 |
+
continue
|
| 179 |
+
else:
|
| 180 |
+
print(f'[INFO] Change config: model.generation_config.{conf_key} = {conf_value}')
|
| 181 |
+
setattr(model.generation_config, conf_key, conf_value)
|
| 182 |
+
continue
|
| 183 |
+
elif command in ['reset-conf']:
|
| 184 |
+
print('[INFO] Reset generation config')
|
| 185 |
+
model.generation_config = deepcopy(orig_gen_config)
|
| 186 |
+
print(model.generation_config)
|
| 187 |
+
continue
|
| 188 |
+
else:
|
| 189 |
+
# As normal query.
|
| 190 |
+
pass
|
| 191 |
+
|
| 192 |
+
# Run chat.
|
| 193 |
+
set_seed(seed)
|
| 194 |
+
try:
|
| 195 |
+
for response in model.chat_stream(tokenizer, query, history=history, generation_config=config):
|
| 196 |
+
_clear_screen()
|
| 197 |
+
print(f"\nUser: {query}")
|
| 198 |
+
print(f"\nQwen-7B: {response}")
|
| 199 |
+
except KeyboardInterrupt:
|
| 200 |
+
print('[WARNING] Generation interrupted')
|
| 201 |
+
continue
|
| 202 |
+
|
| 203 |
+
history.append((query, response))
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
if __name__ == "__main__":
|
| 207 |
+
main()
|
eval/EVALUATION.md
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 评测复现
|
| 2 |
+
|
| 3 |
+
- CEVAL
|
| 4 |
+
|
| 5 |
+
```Shell
|
| 6 |
+
wget https://huggingface.co/datasets/ceval/ceval-exam/resolve/main/ceval-exam.zip
|
| 7 |
+
mkdir data/ceval
|
| 8 |
+
mv ceval-exam.zip data/ceval
|
| 9 |
+
cd data/ceval; unzip ceval-exam.zip
|
| 10 |
+
cd ../../
|
| 11 |
+
|
| 12 |
+
# Qwen-7B
|
| 13 |
+
python evaluate_ceval.py -d data/ceval/
|
| 14 |
+
|
| 15 |
+
# Qwen-7B-Chat
|
| 16 |
+
pip install thefuzz
|
| 17 |
+
python evaluate_chat_ceval.py -d data/ceval/
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
- MMLU
|
| 21 |
+
|
| 22 |
+
```Shell
|
| 23 |
+
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
|
| 24 |
+
mkdir data/mmlu
|
| 25 |
+
mv data.tar data/mmlu
|
| 26 |
+
cd data/mmlu; tar xf data.tar
|
| 27 |
+
cd ../../
|
| 28 |
+
|
| 29 |
+
# Qwen-7B
|
| 30 |
+
python evaluate_mmlu.py -d data/mmlu/data/
|
| 31 |
+
|
| 32 |
+
# Qwen-7B-Chat
|
| 33 |
+
pip install thefuzz
|
| 34 |
+
python evaluate_chat_mmlu.py -d data/mmlu/data/
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
- CMMLU
|
| 38 |
+
|
| 39 |
+
```Shell
|
| 40 |
+
wget https://huggingface.co/datasets/haonan-li/cmmlu/resolve/main/cmmlu_v1_0_1.zip
|
| 41 |
+
mkdir data/cmmlu
|
| 42 |
+
mv cmmlu_v1_0_1.zip data/cmmlu
|
| 43 |
+
cd data/cmmlu; unzip cmmlu_v1_0_1.zip
|
| 44 |
+
cd ../../
|
| 45 |
+
|
| 46 |
+
# Qwen-7B
|
| 47 |
+
python evaluate_cmmlu.py -d data/cmmlu/
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
- HumanEval
|
| 51 |
+
|
| 52 |
+
Get the HumanEval.jsonl file from [here](https://github.com/openai/human-eval/tree/master/data)
|
| 53 |
+
|
| 54 |
+
```Shell
|
| 55 |
+
git clone https://github.com/openai/human-eval
|
| 56 |
+
pip install -e human-eval
|
| 57 |
+
|
| 58 |
+
# Qwen-7B
|
| 59 |
+
python evaluate_humaneval.py -f HumanEval.jsonl -o HumanEval_res.jsonl
|
| 60 |
+
evaluate_functional_correctness HumanEval_res.jsonl
|
| 61 |
+
# Qwen-7B-Chat
|
| 62 |
+
python evaluate_chat_mmlu.py -f HumanEval.jsonl -o HumanEval_res_chat.jsonl
|
| 63 |
+
evaluate_functional_correctness HumanEval_res_chat.jsonl
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
When installing package human-eval, please note its following disclaimer:
|
| 67 |
+
|
| 68 |
+
This program exists to run untrusted model-generated code. Users are strongly encouraged not to do so outside of a robust security sandbox. The execution call in execution.py is deliberately commented out to ensure users read this disclaimer before running code in a potentially unsafe manner. See the comment in execution.py for more information and instructions.
|
| 69 |
+
|
| 70 |
+
- GSM8K
|
| 71 |
+
|
| 72 |
+
```Shell
|
| 73 |
+
# Qwen-7B
|
| 74 |
+
python evaluate_gsm8k.py
|
| 75 |
+
|
| 76 |
+
# Qwen-7B-Chat
|
| 77 |
+
python evaluate_chat_gsm8k.py # zeroshot
|
| 78 |
+
python evaluate_chat_gsm8k.py --use-fewshot # fewshot
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
- PLUGIN
|
| 82 |
+
|
| 83 |
+
This script is used to reproduce the results of the ReAct and Hugging Face Agent in the Tool Usage section of the README document.
|
| 84 |
+
|
| 85 |
+
```Shell
|
| 86 |
+
# Qwen-7B-Chat
|
| 87 |
+
mkdir data;
|
| 88 |
+
cd data;
|
| 89 |
+
wget https://qianwen-res.oss-cn-beijing.aliyuncs.com/opensource_data/exam_plugin_v1/exam_plugin_v1_react_positive.jsonl;
|
| 90 |
+
wget https://qianwen-res.oss-cn-beijing.aliyuncs.com/opensource_data/exam_plugin_v1/exam_plugin_v1_react_negative.jsonl;
|
| 91 |
+
cd ..;
|
| 92 |
+
pip install json5;
|
| 93 |
+
pip install jsonlines;
|
| 94 |
+
pip install rouge_score;
|
| 95 |
+
python evaluate_plugin.py --eval-react-positive --eval-react-negative --eval-hfagent
|
| 96 |
+
```
|
eval/evaluate_ceval.py
ADDED
|
@@ -0,0 +1,432 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
import argparse
|
| 4 |
+
import torch
|
| 5 |
+
import pandas as pd
|
| 6 |
+
import numpy as np
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
from transformers.trainer_utils import set_seed
|
| 9 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 10 |
+
from transformers.generation import GenerationConfig
|
| 11 |
+
|
| 12 |
+
'''
|
| 13 |
+
wget https://huggingface.co/datasets/ceval/ceval-exam/resolve/main/ceval-exam.zip
|
| 14 |
+
mkdir data/ceval
|
| 15 |
+
mv ceval-exam.zip data/ceval
|
| 16 |
+
cd data/ceval; unzip ceval-exam.zip
|
| 17 |
+
cd ../../
|
| 18 |
+
python evaluate_ceval.py -d data/ceval/
|
| 19 |
+
'''
|
| 20 |
+
|
| 21 |
+
def load_models_tokenizer(args):
|
| 22 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 23 |
+
args.checkpoint_path, trust_remote_code=True
|
| 24 |
+
)
|
| 25 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 26 |
+
args.checkpoint_path, device_map="auto", trust_remote_code=True
|
| 27 |
+
).eval()
|
| 28 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 29 |
+
args.checkpoint_path, trust_remote_code=True
|
| 30 |
+
)
|
| 31 |
+
return model, tokenizer
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def format_example(line, include_answer=True):
|
| 35 |
+
example = "问题:" + line["question"]
|
| 36 |
+
for choice in choices:
|
| 37 |
+
example += f'\n{choice}. {line[f"{choice}"]}'
|
| 38 |
+
|
| 39 |
+
if include_answer:
|
| 40 |
+
example += "\n答案:" + line["answer"] + "\n\n"
|
| 41 |
+
else:
|
| 42 |
+
example += "\n答案:"
|
| 43 |
+
return example
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def generate_few_shot_prompt(k, subject, dev_df):
|
| 47 |
+
prompt = ""
|
| 48 |
+
if k == -1:
|
| 49 |
+
k = dev_df.shape[0]
|
| 50 |
+
for i in range(k):
|
| 51 |
+
prompt += format_example(
|
| 52 |
+
dev_df.iloc[i, :],
|
| 53 |
+
include_answer=True,
|
| 54 |
+
)
|
| 55 |
+
return prompt
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def get_logits(tokenizer, model, inputs: List[str]):
|
| 59 |
+
input_ids = tokenizer(inputs, padding=False)["input_ids"]
|
| 60 |
+
input_ids = torch.tensor(input_ids, device=model.device)
|
| 61 |
+
tokens = {"input_ids": input_ids}
|
| 62 |
+
|
| 63 |
+
outputs = model(input_ids)["logits"]
|
| 64 |
+
logits = outputs[:, -1, :]
|
| 65 |
+
log_probs = torch.nn.functional.softmax(logits, dim=-1)
|
| 66 |
+
return log_probs, {"tokens": tokens}
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
@torch.no_grad()
|
| 70 |
+
def eval_subject(
|
| 71 |
+
model,
|
| 72 |
+
tokenizer,
|
| 73 |
+
subject_name,
|
| 74 |
+
test_df,
|
| 75 |
+
k=5,
|
| 76 |
+
dev_df=None,
|
| 77 |
+
few_shot=False,
|
| 78 |
+
save_result_dir=None,
|
| 79 |
+
**kwargs,
|
| 80 |
+
):
|
| 81 |
+
result = []
|
| 82 |
+
score = []
|
| 83 |
+
|
| 84 |
+
few_shot_prompt = (
|
| 85 |
+
generate_few_shot_prompt(k, subject_name, dev_df) if few_shot else ""
|
| 86 |
+
)
|
| 87 |
+
all_probs = {"prob_A": [], "prob_B": [], "prob_C": [], "prob_D": []}
|
| 88 |
+
if args.debug:
|
| 89 |
+
print(f"few_shot_prompt: {few_shot_prompt}")
|
| 90 |
+
|
| 91 |
+
for _, row in tqdm(test_df.iterrows(), total=len(test_df)):
|
| 92 |
+
question = format_example(row, include_answer=False)
|
| 93 |
+
full_prompt = few_shot_prompt + question
|
| 94 |
+
|
| 95 |
+
output, input_info = get_logits(tokenizer, model, [full_prompt])
|
| 96 |
+
assert output.shape[0] == 1
|
| 97 |
+
logits = output.flatten()
|
| 98 |
+
|
| 99 |
+
softval = torch.nn.functional.softmax(
|
| 100 |
+
torch.tensor(
|
| 101 |
+
[
|
| 102 |
+
logits[tokenizer("A")["input_ids"]],
|
| 103 |
+
logits[tokenizer("B")["input_ids"]],
|
| 104 |
+
logits[tokenizer("C")["input_ids"]],
|
| 105 |
+
logits[tokenizer("D")["input_ids"]],
|
| 106 |
+
]
|
| 107 |
+
),
|
| 108 |
+
dim=0,
|
| 109 |
+
)
|
| 110 |
+
if softval.dtype in {torch.bfloat16, torch.float16}:
|
| 111 |
+
softval = softval.to(dtype=torch.float32)
|
| 112 |
+
probs = softval.detach().cpu().numpy()
|
| 113 |
+
|
| 114 |
+
for i, choice in enumerate(choices):
|
| 115 |
+
all_probs[f"prob_{choice}"].append(probs[i])
|
| 116 |
+
pred = {0: "A", 1: "B", 2: "C", 3: "D"}[np.argmax(probs)]
|
| 117 |
+
|
| 118 |
+
if "answer" in row:
|
| 119 |
+
correct = 1 if pred == row["answer"] else 0
|
| 120 |
+
score.append(correct)
|
| 121 |
+
if args.debug:
|
| 122 |
+
print(f'{question} pred: {pred} ref: {row["answer"]}')
|
| 123 |
+
result.append(pred)
|
| 124 |
+
|
| 125 |
+
if score:
|
| 126 |
+
correct_ratio = 100 * sum(score) / len(score)
|
| 127 |
+
if args.debug:
|
| 128 |
+
print(subject_name, correct_ratio)
|
| 129 |
+
else:
|
| 130 |
+
correct_ratio = 0
|
| 131 |
+
if save_result_dir:
|
| 132 |
+
test_df["model_output"] = result
|
| 133 |
+
for i, choice in enumerate(choices):
|
| 134 |
+
test_df[f"prob_{choice}"] = all_probs[f"prob_{choice}"]
|
| 135 |
+
if score:
|
| 136 |
+
test_df["correctness"] = score
|
| 137 |
+
os.makedirs(save_result_dir, exist_ok=True)
|
| 138 |
+
test_df.to_csv(
|
| 139 |
+
os.path.join(save_result_dir, f"{subject_name}_result.csv"),
|
| 140 |
+
encoding="utf-8",
|
| 141 |
+
index=False,
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
return correct_ratio
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def cal_ceval(res):
|
| 148 |
+
acc_sum_dict = dict()
|
| 149 |
+
acc_norm_sum_dict = dict()
|
| 150 |
+
cnt_dict = dict()
|
| 151 |
+
acc_sum = 0.0
|
| 152 |
+
cnt = 0
|
| 153 |
+
hard_cnt = 0
|
| 154 |
+
hard_acc_sum = 0.0
|
| 155 |
+
for tt in res.keys():
|
| 156 |
+
name = tt.split("-")[-1]
|
| 157 |
+
acc_sum += float(res[tt])
|
| 158 |
+
cnt += 1
|
| 159 |
+
class_ = TASK_NAME_MAPPING[name][2]
|
| 160 |
+
if class_ not in acc_sum_dict:
|
| 161 |
+
acc_sum_dict[class_] = 0.0
|
| 162 |
+
acc_norm_sum_dict[class_] = 0.0
|
| 163 |
+
cnt_dict[class_] = 0.0
|
| 164 |
+
if name in hard_list:
|
| 165 |
+
hard_cnt += 1
|
| 166 |
+
hard_acc_sum += float(res[tt])
|
| 167 |
+
acc_sum_dict[class_] += float(res[tt])
|
| 168 |
+
cnt_dict[class_] += 1
|
| 169 |
+
print("\n\n\n")
|
| 170 |
+
for k in ["STEM", "Social Science", "Humanities", "Other"]:
|
| 171 |
+
if k in cnt_dict:
|
| 172 |
+
print("%s acc: %.2f " % (k, acc_sum_dict[k] / cnt_dict[k]))
|
| 173 |
+
if hard_cnt > 0:
|
| 174 |
+
print("Hard acc:%.2f " % (hard_acc_sum / hard_cnt))
|
| 175 |
+
print("AVERAGE acc:%.2f " % (acc_sum / cnt))
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
TASK_NAME_MAPPING = {
|
| 179 |
+
"computer_network": ["Computer Network", "\u8ba1\u7b97\u673a\u7f51\u7edc", "STEM"],
|
| 180 |
+
"operating_system": ["Operating System", "\u64cd\u4f5c\u7cfb\u7edf", "STEM"],
|
| 181 |
+
"computer_architecture": [
|
| 182 |
+
"Computer Architecture",
|
| 183 |
+
"\u8ba1\u7b97\u673a\u7ec4\u6210",
|
| 184 |
+
"STEM",
|
| 185 |
+
],
|
| 186 |
+
"college_programming": ["College Programming", "\u5927\u5b66\u7f16\u7a0b", "STEM"],
|
| 187 |
+
"college_physics": ["College Physics", "\u5927\u5b66\u7269\u7406", "STEM"],
|
| 188 |
+
"college_chemistry": ["College Chemistry", "\u5927\u5b66\u5316\u5b66", "STEM"],
|
| 189 |
+
"advanced_mathematics": [
|
| 190 |
+
"Advanced Mathematics",
|
| 191 |
+
"\u9ad8\u7b49\u6570\u5b66",
|
| 192 |
+
"STEM",
|
| 193 |
+
],
|
| 194 |
+
"probability_and_statistics": [
|
| 195 |
+
"Probability and Statistics",
|
| 196 |
+
"\u6982\u7387\u7edf\u8ba1",
|
| 197 |
+
"STEM",
|
| 198 |
+
],
|
| 199 |
+
"discrete_mathematics": [
|
| 200 |
+
"Discrete Mathematics",
|
| 201 |
+
"\u79bb\u6563\u6570\u5b66",
|
| 202 |
+
"STEM",
|
| 203 |
+
],
|
| 204 |
+
"electrical_engineer": [
|
| 205 |
+
"Electrical Engineer",
|
| 206 |
+
"\u6ce8\u518c\u7535\u6c14\u5de5\u7a0b\u5e08",
|
| 207 |
+
"STEM",
|
| 208 |
+
],
|
| 209 |
+
"metrology_engineer": [
|
| 210 |
+
"Metrology Engineer",
|
| 211 |
+
"\u6ce8\u518c\u8ba1\u91cf\u5e08",
|
| 212 |
+
"STEM",
|
| 213 |
+
],
|
| 214 |
+
"high_school_mathematics": [
|
| 215 |
+
"High School Mathematics",
|
| 216 |
+
"\u9ad8\u4e2d\u6570\u5b66",
|
| 217 |
+
"STEM",
|
| 218 |
+
],
|
| 219 |
+
"high_school_physics": ["High School Physics", "\u9ad8\u4e2d\u7269\u7406", "STEM"],
|
| 220 |
+
"high_school_chemistry": [
|
| 221 |
+
"High School Chemistry",
|
| 222 |
+
"\u9ad8\u4e2d\u5316\u5b66",
|
| 223 |
+
"STEM",
|
| 224 |
+
],
|
| 225 |
+
"high_school_biology": ["High School Biology", "\u9ad8\u4e2d\u751f\u7269", "STEM"],
|
| 226 |
+
"middle_school_mathematics": [
|
| 227 |
+
"Middle School Mathematics",
|
| 228 |
+
"\u521d\u4e2d\u6570\u5b66",
|
| 229 |
+
"STEM",
|
| 230 |
+
],
|
| 231 |
+
"middle_school_biology": [
|
| 232 |
+
"Middle School Biology",
|
| 233 |
+
"\u521d\u4e2d\u751f\u7269",
|
| 234 |
+
"STEM",
|
| 235 |
+
],
|
| 236 |
+
"middle_school_physics": [
|
| 237 |
+
"Middle School Physics",
|
| 238 |
+
"\u521d\u4e2d\u7269\u7406",
|
| 239 |
+
"STEM",
|
| 240 |
+
],
|
| 241 |
+
"middle_school_chemistry": [
|
| 242 |
+
"Middle School Chemistry",
|
| 243 |
+
"\u521d\u4e2d\u5316\u5b66",
|
| 244 |
+
"STEM",
|
| 245 |
+
],
|
| 246 |
+
"veterinary_medicine": ["Veterinary Medicine", "\u517d\u533b\u5b66", "STEM"],
|
| 247 |
+
"college_economics": [
|
| 248 |
+
"College Economics",
|
| 249 |
+
"\u5927\u5b66\u7ecf\u6d4e\u5b66",
|
| 250 |
+
"Social Science",
|
| 251 |
+
],
|
| 252 |
+
"business_administration": [
|
| 253 |
+
"Business Administration",
|
| 254 |
+
"\u5de5\u5546\u7ba1\u7406",
|
| 255 |
+
"Social Science",
|
| 256 |
+
],
|
| 257 |
+
"marxism": [
|
| 258 |
+
"Marxism",
|
| 259 |
+
"\u9a6c\u514b\u601d\u4e3b\u4e49\u57fa\u672c\u539f\u7406",
|
| 260 |
+
"Social Science",
|
| 261 |
+
],
|
| 262 |
+
"mao_zedong_thought": [
|
| 263 |
+
"Mao Zedong Thought",
|
| 264 |
+
"\u6bdb\u6cfd\u4e1c\u601d\u60f3\u548c\u4e2d\u56fd\u7279\u8272\u793e\u4f1a\u4e3b\u4e49\u7406\u8bba\u4f53\u7cfb\u6982\u8bba",
|
| 265 |
+
"Social Science",
|
| 266 |
+
],
|
| 267 |
+
"education_science": ["Education Science", "\u6559\u80b2\u5b66", "Social Science"],
|
| 268 |
+
"teacher_qualification": [
|
| 269 |
+
"Teacher Qualification",
|
| 270 |
+
"\u6559\u5e08\u8d44\u683c",
|
| 271 |
+
"Social Science",
|
| 272 |
+
],
|
| 273 |
+
"high_school_politics": [
|
| 274 |
+
"High School Politics",
|
| 275 |
+
"\u9ad8\u4e2d\u653f\u6cbb",
|
| 276 |
+
"Social Science",
|
| 277 |
+
],
|
| 278 |
+
"high_school_geography": [
|
| 279 |
+
"High School Geography",
|
| 280 |
+
"\u9ad8\u4e2d\u5730\u7406",
|
| 281 |
+
"Social Science",
|
| 282 |
+
],
|
| 283 |
+
"middle_school_politics": [
|
| 284 |
+
"Middle School Politics",
|
| 285 |
+
"\u521d\u4e2d\u653f\u6cbb",
|
| 286 |
+
"Social Science",
|
| 287 |
+
],
|
| 288 |
+
"middle_school_geography": [
|
| 289 |
+
"Middle School Geography",
|
| 290 |
+
"\u521d\u4e2d\u5730\u7406",
|
| 291 |
+
"Social Science",
|
| 292 |
+
],
|
| 293 |
+
"modern_chinese_history": [
|
| 294 |
+
"Modern Chinese History",
|
| 295 |
+
"\u8fd1\u4ee3\u53f2\u7eb2\u8981",
|
| 296 |
+
"Humanities",
|
| 297 |
+
],
|
| 298 |
+
"ideological_and_moral_cultivation": [
|
| 299 |
+
"Ideological and Moral Cultivation",
|
| 300 |
+
"\u601d\u60f3\u9053\u5fb7\u4fee\u517b\u4e0e\u6cd5\u5f8b\u57fa\u7840",
|
| 301 |
+
"Humanities",
|
| 302 |
+
],
|
| 303 |
+
"logic": ["Logic", "\u903b\u8f91\u5b66", "Humanities"],
|
| 304 |
+
"law": ["Law", "\u6cd5\u5b66", "Humanities"],
|
| 305 |
+
"chinese_language_and_literature": [
|
| 306 |
+
"Chinese Language and Literature",
|
| 307 |
+
"\u4e2d\u56fd\u8bed\u8a00\u6587\u5b66",
|
| 308 |
+
"Humanities",
|
| 309 |
+
],
|
| 310 |
+
"art_studies": ["Art Studies", "\u827a\u672f\u5b66", "Humanities"],
|
| 311 |
+
"professional_tour_guide": [
|
| 312 |
+
"Professional Tour Guide",
|
| 313 |
+
"\u5bfc\u6e38\u8d44\u683c",
|
| 314 |
+
"Humanities",
|
| 315 |
+
],
|
| 316 |
+
"legal_professional": [
|
| 317 |
+
"Legal Professional",
|
| 318 |
+
"\u6cd5\u5f8b\u804c\u4e1a\u8d44\u683c",
|
| 319 |
+
"Humanities",
|
| 320 |
+
],
|
| 321 |
+
"high_school_chinese": [
|
| 322 |
+
"High School Chinese",
|
| 323 |
+
"\u9ad8\u4e2d\u8bed\u6587",
|
| 324 |
+
"Humanities",
|
| 325 |
+
],
|
| 326 |
+
"high_school_history": [
|
| 327 |
+
"High School History",
|
| 328 |
+
"\u9ad8\u4e2d\u5386\u53f2",
|
| 329 |
+
"Humanities",
|
| 330 |
+
],
|
| 331 |
+
"middle_school_history": [
|
| 332 |
+
"Middle School History",
|
| 333 |
+
"\u521d\u4e2d\u5386\u53f2",
|
| 334 |
+
"Humanities",
|
| 335 |
+
],
|
| 336 |
+
"civil_servant": ["Civil Servant", "\u516c\u52a1\u5458", "Other"],
|
| 337 |
+
"sports_science": ["Sports Science", "\u4f53\u80b2\u5b66", "Other"],
|
| 338 |
+
"plant_protection": ["Plant Protection", "\u690d\u7269\u4fdd\u62a4", "Other"],
|
| 339 |
+
"basic_medicine": ["Basic Medicine", "\u57fa\u7840\u533b\u5b66", "Other"],
|
| 340 |
+
"clinical_medicine": ["Clinical Medicine", "\u4e34\u5e8a\u533b\u5b66", "Other"],
|
| 341 |
+
"urban_and_rural_planner": [
|
| 342 |
+
"Urban and Rural Planner",
|
| 343 |
+
"\u6ce8\u518c\u57ce\u4e61\u89c4\u5212\u5e08",
|
| 344 |
+
"Other",
|
| 345 |
+
],
|
| 346 |
+
"accountant": ["Accountant", "\u6ce8\u518c\u4f1a\u8ba1\u5e08", "Other"],
|
| 347 |
+
"fire_engineer": [
|
| 348 |
+
"Fire Engineer",
|
| 349 |
+
"\u6ce8\u518c\u6d88\u9632\u5de5\u7a0b\u5e08",
|
| 350 |
+
"Other",
|
| 351 |
+
],
|
| 352 |
+
"environmental_impact_assessment_engineer": [
|
| 353 |
+
"Environmental Impact Assessment Engineer",
|
| 354 |
+
"\u73af\u5883\u5f71\u54cd\u8bc4\u4ef7\u5de5\u7a0b\u5e08",
|
| 355 |
+
"Other",
|
| 356 |
+
],
|
| 357 |
+
"tax_accountant": ["Tax Accountant", "\u7a0e\u52a1\u5e08", "Other"],
|
| 358 |
+
"physician": ["Physician", "\u533b\u5e08\u8d44\u683c", "Other"],
|
| 359 |
+
}
|
| 360 |
+
hard_list = [
|
| 361 |
+
"advanced_mathematics",
|
| 362 |
+
"discrete_mathematics",
|
| 363 |
+
"probability_and_statistics",
|
| 364 |
+
"college_physics",
|
| 365 |
+
"college_chemistry",
|
| 366 |
+
"high_school_mathematics",
|
| 367 |
+
"high_school_physics",
|
| 368 |
+
"high_school_chemistry",
|
| 369 |
+
]
|
| 370 |
+
choices = ["A", "B", "C", "D"]
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
def main(args):
|
| 374 |
+
model, tokenizer = load_models_tokenizer(args)
|
| 375 |
+
|
| 376 |
+
dev_result = {}
|
| 377 |
+
for subject_name in tqdm(TASK_NAME_MAPPING.keys()):
|
| 378 |
+
val_file_path = os.path.join(
|
| 379 |
+
args.eval_data_path, "val", f"{subject_name}_val.csv"
|
| 380 |
+
)
|
| 381 |
+
dev_file_path = os.path.join(
|
| 382 |
+
args.eval_data_path, "dev", f"{subject_name}_dev.csv"
|
| 383 |
+
)
|
| 384 |
+
# test_file_path = os.path.join(args.eval_data_path, 'test', f'{subject_name}_test.csv')
|
| 385 |
+
val_df = pd.read_csv(val_file_path)
|
| 386 |
+
dev_df = pd.read_csv(dev_file_path)
|
| 387 |
+
# test_df = pd.read_csv(test_file_path)
|
| 388 |
+
|
| 389 |
+
score = eval_subject(
|
| 390 |
+
model,
|
| 391 |
+
tokenizer,
|
| 392 |
+
subject_name,
|
| 393 |
+
val_df,
|
| 394 |
+
dev_df=dev_df,
|
| 395 |
+
k=5,
|
| 396 |
+
few_shot=True,
|
| 397 |
+
save_result_dir=f"outs/ceval_eval_result",
|
| 398 |
+
)
|
| 399 |
+
dev_result[subject_name] = score
|
| 400 |
+
cal_ceval(dev_result)
|
| 401 |
+
|
| 402 |
+
|
| 403 |
+
if __name__ == "__main__":
|
| 404 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 405 |
+
parser.add_argument(
|
| 406 |
+
"-c",
|
| 407 |
+
"--checkpoint-path",
|
| 408 |
+
type=str,
|
| 409 |
+
help="Checkpoint path",
|
| 410 |
+
default="Qwen/Qwen-7B",
|
| 411 |
+
)
|
| 412 |
+
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
|
| 413 |
+
|
| 414 |
+
# Provide extra arguments required for tasks
|
| 415 |
+
group = parser.add_argument_group(title="Evaluation options")
|
| 416 |
+
group.add_argument(
|
| 417 |
+
"-d", "--eval_data_path", type=str, required=True, help="Path to eval data"
|
| 418 |
+
)
|
| 419 |
+
group.add_argument(
|
| 420 |
+
"--max-seq-len",
|
| 421 |
+
type=int,
|
| 422 |
+
default=2048,
|
| 423 |
+
help="Size of the output generated text.",
|
| 424 |
+
)
|
| 425 |
+
group.add_argument(
|
| 426 |
+
"--debug", action="store_true", default=False, help="Print infos."
|
| 427 |
+
)
|
| 428 |
+
|
| 429 |
+
args = parser.parse_args()
|
| 430 |
+
set_seed(args.seed)
|
| 431 |
+
|
| 432 |
+
main(args)
|
eval/evaluate_chat_ceval.py
ADDED
|
@@ -0,0 +1,459 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
import re
|
| 4 |
+
import torch
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from thefuzz import process
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
from transformers.trainer_utils import set_seed
|
| 9 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 10 |
+
from transformers.generation import GenerationConfig
|
| 11 |
+
|
| 12 |
+
'''
|
| 13 |
+
wget https://huggingface.co/datasets/ceval/ceval-exam/resolve/main/ceval-exam.zip
|
| 14 |
+
mkdir data/ceval
|
| 15 |
+
mv ceval-exam.zip data/ceval
|
| 16 |
+
cd data/ceval; unzip ceval-exam.zip
|
| 17 |
+
cd ../../
|
| 18 |
+
|
| 19 |
+
pip install thefuzz
|
| 20 |
+
python eval/evaluate_chat_ceval.py -d data/ceval
|
| 21 |
+
'''
|
| 22 |
+
|
| 23 |
+
def load_models_tokenizer(args):
|
| 24 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 25 |
+
args.checkpoint_path, trust_remote_code=True
|
| 26 |
+
)
|
| 27 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 28 |
+
args.checkpoint_path, device_map="auto", trust_remote_code=True
|
| 29 |
+
).eval()
|
| 30 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 31 |
+
args.checkpoint_path, trust_remote_code=True
|
| 32 |
+
)
|
| 33 |
+
model.generation_config.do_sample = False # use greedy decoding
|
| 34 |
+
return model, tokenizer
|
| 35 |
+
|
| 36 |
+
def process_before_extraction(gen, question, choice_dict):
|
| 37 |
+
# Example Prompt:
|
| 38 |
+
# 关于传输层的面向连接服务的特性是____。
|
| 39 |
+
# A. 既不保证可靠,也不保证按序交付
|
| 40 |
+
# B. 不保证可靠,但保证按序交付
|
| 41 |
+
# C. 保证可靠,但不保证按序交付
|
| 42 |
+
# D. 既保证可靠,也保证按序交付
|
| 43 |
+
# Example Model Output:
|
| 44 |
+
# 关于传输层的面向连接服务的特性是既保证可靠,也保证按序交付
|
| 45 |
+
# Processed Output:
|
| 46 |
+
# 答案是D
|
| 47 |
+
|
| 48 |
+
question_split = question.rstrip("。").split("。")[-1].split("_")
|
| 49 |
+
|
| 50 |
+
# replacing the question
|
| 51 |
+
if len(question_split[0].strip()) > 4:
|
| 52 |
+
gen = gen.replace(question_split[0], "答案是")
|
| 53 |
+
if len(question_split[-1].strip()) > 4:
|
| 54 |
+
gen = gen.replace(question_split[-1], "")
|
| 55 |
+
|
| 56 |
+
# replace the choice by letter in the generated sentence
|
| 57 |
+
# from longest one to shortest one
|
| 58 |
+
for key, val in sorted(choice_dict.items(), key=lambda x: len(x[1]), reverse=True):
|
| 59 |
+
gen = gen.replace(val.rstrip("。"), key)
|
| 60 |
+
return gen
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def count_substr(gen, pattern):
|
| 64 |
+
return len(re.findall(pattern, gen))
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def extract_choice(gen, prompt, choice_list):
|
| 68 |
+
# 答案是A | 选项是A | 应该选A选项
|
| 69 |
+
res = re.search(
|
| 70 |
+
r"(?:(?:选|选择|选定)[::]?\s*|(?:(?:答案|选项)(?![^ABCD]{0,10}?(?:不|非)[^ABCD]{0,10}?(?:是|选|为|:|:|】))[^ABCD]{0,10}?(?:是|选|为|:|:|】))[^ABCD]{0,10}?)(A|B|C|D)(?:选项)?(?:\)|。|\.|,|,|.|、|A|B|C|D|$|:|:|\)|))",
|
| 71 |
+
gen,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
# A选项正确 | A选项符合题意
|
| 75 |
+
if res is None:
|
| 76 |
+
res = re.search(
|
| 77 |
+
r"(A|B|C|D)(?:选?项)?(?![^ABCD]{0,4}?(?:不|非)[^ABCD]{0,4}?(?:正确|对[的,。:]|符合))[^ABCD]{0,4}?(?:正确|对[的,。:]|符合)",
|
| 78 |
+
gen,
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
# 直接输出 A
|
| 82 |
+
if res is None:
|
| 83 |
+
res = re.search(r"^[\((]?(A|B|C|D)(?:。|\)|)|\.|,|,|.|:|:|$)", gen)
|
| 84 |
+
|
| 85 |
+
# 获取第一个出现的字母
|
| 86 |
+
if res is None:
|
| 87 |
+
res = re.search(r"(?<![a-zA-Z])(A|B|C|D)(?![a-zA-Z=])", gen)
|
| 88 |
+
|
| 89 |
+
if res is None:
|
| 90 |
+
return choices[choice_list.index(process.extractOne(gen, choice_list)[0])]
|
| 91 |
+
return res.group(1)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def format_example(line):
|
| 95 |
+
example = line["question"] + "\n\n"
|
| 96 |
+
for choice in choices:
|
| 97 |
+
example += f'{choice}. {line[f"{choice}"]}\n'
|
| 98 |
+
return example
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def extract_answer(response, row):
|
| 102 |
+
prompt = row["question"]
|
| 103 |
+
gen = process_before_extraction(
|
| 104 |
+
response, prompt, {choice: row[choice] for choice in choices}
|
| 105 |
+
)
|
| 106 |
+
if not isinstance(prompt, str):
|
| 107 |
+
prompt = prompt[0]
|
| 108 |
+
pred = extract_choice(gen, prompt, [row[choice] for choice in choices])
|
| 109 |
+
return pred
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
@torch.no_grad()
|
| 113 |
+
def eval_subject(
|
| 114 |
+
model,
|
| 115 |
+
tokenizer,
|
| 116 |
+
subject_name,
|
| 117 |
+
test_df,
|
| 118 |
+
save_result_dir=None,
|
| 119 |
+
overwrite=False,
|
| 120 |
+
**kwargs
|
| 121 |
+
):
|
| 122 |
+
result_path = os.path.join(save_result_dir, f"{subject_name}_result.csv")
|
| 123 |
+
if not overwrite and os.path.exists(result_path):
|
| 124 |
+
print(f"{result_path} existed, skip!")
|
| 125 |
+
score = []
|
| 126 |
+
for (_, datarow), (_, resultrow) in zip(
|
| 127 |
+
test_df.iterrows(), pd.read_csv(result_path).iterrows()
|
| 128 |
+
):
|
| 129 |
+
pred = extract_answer(resultrow["model_response"], datarow)
|
| 130 |
+
correct = 1 if pred == datarow["answer"] else 0
|
| 131 |
+
score.append(correct)
|
| 132 |
+
correct_ratio = 100 * sum(score) / len(score)
|
| 133 |
+
return correct_ratio
|
| 134 |
+
|
| 135 |
+
responses = []
|
| 136 |
+
result = []
|
| 137 |
+
score = []
|
| 138 |
+
|
| 139 |
+
for _, row in tqdm(test_df.iterrows(), total=len(test_df)):
|
| 140 |
+
question = format_example(row)
|
| 141 |
+
|
| 142 |
+
response, _ = model.chat(
|
| 143 |
+
tokenizer,
|
| 144 |
+
question,
|
| 145 |
+
history=None,
|
| 146 |
+
)
|
| 147 |
+
print(question)
|
| 148 |
+
print(response)
|
| 149 |
+
pred = extract_answer(response, row)
|
| 150 |
+
print(pred)
|
| 151 |
+
print("======================")
|
| 152 |
+
|
| 153 |
+
if "answer" in row:
|
| 154 |
+
correct = 1 if pred == row["answer"] else 0
|
| 155 |
+
score.append(correct)
|
| 156 |
+
if args.debug:
|
| 157 |
+
print(f'{question} pred: {pred} ref: {row["answer"]}')
|
| 158 |
+
responses.append(response)
|
| 159 |
+
result.append(pred)
|
| 160 |
+
|
| 161 |
+
if score:
|
| 162 |
+
correct_ratio = 100 * sum(score) / len(score)
|
| 163 |
+
if args.debug:
|
| 164 |
+
print(subject_name, correct_ratio)
|
| 165 |
+
else:
|
| 166 |
+
correct_ratio = 0
|
| 167 |
+
if save_result_dir:
|
| 168 |
+
test_df["model_response"] = responses
|
| 169 |
+
test_df["model_output"] = result
|
| 170 |
+
if score:
|
| 171 |
+
test_df["correctness"] = score
|
| 172 |
+
os.makedirs(save_result_dir, exist_ok=True)
|
| 173 |
+
test_df.to_csv(result_path, encoding="utf-8", index=False)
|
| 174 |
+
|
| 175 |
+
return correct_ratio
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def cal_ceval(res):
|
| 179 |
+
acc_sum_dict = dict()
|
| 180 |
+
acc_norm_sum_dict = dict()
|
| 181 |
+
cnt_dict = dict()
|
| 182 |
+
acc_sum = 0.0
|
| 183 |
+
cnt = 0
|
| 184 |
+
hard_cnt = 0
|
| 185 |
+
hard_acc_sum = 0.0
|
| 186 |
+
for tt in res.keys():
|
| 187 |
+
name = tt.split("-")[-1]
|
| 188 |
+
acc_sum += float(res[tt])
|
| 189 |
+
cnt += 1
|
| 190 |
+
class_ = TASK_NAME_MAPPING[name][2]
|
| 191 |
+
if class_ not in acc_sum_dict:
|
| 192 |
+
acc_sum_dict[class_] = 0.0
|
| 193 |
+
acc_norm_sum_dict[class_] = 0.0
|
| 194 |
+
cnt_dict[class_] = 0.0
|
| 195 |
+
if name in hard_list:
|
| 196 |
+
hard_cnt += 1
|
| 197 |
+
hard_acc_sum += float(res[tt])
|
| 198 |
+
acc_sum_dict[class_] += float(res[tt])
|
| 199 |
+
cnt_dict[class_] += 1
|
| 200 |
+
print("\n\n\n")
|
| 201 |
+
for k in ["STEM", "Social Science", "Humanities", "Other"]:
|
| 202 |
+
if k in cnt_dict:
|
| 203 |
+
print("%s acc: %.2f " % (k, acc_sum_dict[k] / cnt_dict[k]))
|
| 204 |
+
if hard_cnt > 0:
|
| 205 |
+
print("Hard acc:%.2f " % (hard_acc_sum / hard_cnt))
|
| 206 |
+
print("AVERAGE acc:%.2f " % (acc_sum / cnt))
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
TASK_NAME_MAPPING = {
|
| 210 |
+
"computer_network": ["Computer Network", "\u8ba1\u7b97\u673a\u7f51\u7edc", "STEM"],
|
| 211 |
+
"operating_system": ["Operating System", "\u64cd\u4f5c\u7cfb\u7edf", "STEM"],
|
| 212 |
+
"computer_architecture": [
|
| 213 |
+
"Computer Architecture",
|
| 214 |
+
"\u8ba1\u7b97\u673a\u7ec4\u6210",
|
| 215 |
+
"STEM",
|
| 216 |
+
],
|
| 217 |
+
"college_programming": ["College Programming", "\u5927\u5b66\u7f16\u7a0b", "STEM"],
|
| 218 |
+
"college_physics": ["College Physics", "\u5927\u5b66\u7269\u7406", "STEM"],
|
| 219 |
+
"college_chemistry": ["College Chemistry", "\u5927\u5b66\u5316\u5b66", "STEM"],
|
| 220 |
+
"advanced_mathematics": [
|
| 221 |
+
"Advanced Mathematics",
|
| 222 |
+
"\u9ad8\u7b49\u6570\u5b66",
|
| 223 |
+
"STEM",
|
| 224 |
+
],
|
| 225 |
+
"probability_and_statistics": [
|
| 226 |
+
"Probability and Statistics",
|
| 227 |
+
"\u6982\u7387\u7edf\u8ba1",
|
| 228 |
+
"STEM",
|
| 229 |
+
],
|
| 230 |
+
"discrete_mathematics": [
|
| 231 |
+
"Discrete Mathematics",
|
| 232 |
+
"\u79bb\u6563\u6570\u5b66",
|
| 233 |
+
"STEM",
|
| 234 |
+
],
|
| 235 |
+
"electrical_engineer": [
|
| 236 |
+
"Electrical Engineer",
|
| 237 |
+
"\u6ce8\u518c\u7535\u6c14\u5de5\u7a0b\u5e08",
|
| 238 |
+
"STEM",
|
| 239 |
+
],
|
| 240 |
+
"metrology_engineer": [
|
| 241 |
+
"Metrology Engineer",
|
| 242 |
+
"\u6ce8\u518c\u8ba1\u91cf\u5e08",
|
| 243 |
+
"STEM",
|
| 244 |
+
],
|
| 245 |
+
"high_school_mathematics": [
|
| 246 |
+
"High School Mathematics",
|
| 247 |
+
"\u9ad8\u4e2d\u6570\u5b66",
|
| 248 |
+
"STEM",
|
| 249 |
+
],
|
| 250 |
+
"high_school_physics": ["High School Physics", "\u9ad8\u4e2d\u7269\u7406", "STEM"],
|
| 251 |
+
"high_school_chemistry": [
|
| 252 |
+
"High School Chemistry",
|
| 253 |
+
"\u9ad8\u4e2d\u5316\u5b66",
|
| 254 |
+
"STEM",
|
| 255 |
+
],
|
| 256 |
+
"high_school_biology": ["High School Biology", "\u9ad8\u4e2d\u751f\u7269", "STEM"],
|
| 257 |
+
"middle_school_mathematics": [
|
| 258 |
+
"Middle School Mathematics",
|
| 259 |
+
"\u521d\u4e2d\u6570\u5b66",
|
| 260 |
+
"STEM",
|
| 261 |
+
],
|
| 262 |
+
"middle_school_biology": [
|
| 263 |
+
"Middle School Biology",
|
| 264 |
+
"\u521d\u4e2d\u751f\u7269",
|
| 265 |
+
"STEM",
|
| 266 |
+
],
|
| 267 |
+
"middle_school_physics": [
|
| 268 |
+
"Middle School Physics",
|
| 269 |
+
"\u521d\u4e2d\u7269\u7406",
|
| 270 |
+
"STEM",
|
| 271 |
+
],
|
| 272 |
+
"middle_school_chemistry": [
|
| 273 |
+
"Middle School Chemistry",
|
| 274 |
+
"\u521d\u4e2d\u5316\u5b66",
|
| 275 |
+
"STEM",
|
| 276 |
+
],
|
| 277 |
+
"veterinary_medicine": ["Veterinary Medicine", "\u517d\u533b\u5b66", "STEM"],
|
| 278 |
+
"college_economics": [
|
| 279 |
+
"College Economics",
|
| 280 |
+
"\u5927\u5b66\u7ecf\u6d4e\u5b66",
|
| 281 |
+
"Social Science",
|
| 282 |
+
],
|
| 283 |
+
"business_administration": [
|
| 284 |
+
"Business Administration",
|
| 285 |
+
"\u5de5\u5546\u7ba1\u7406",
|
| 286 |
+
"Social Science",
|
| 287 |
+
],
|
| 288 |
+
"marxism": [
|
| 289 |
+
"Marxism",
|
| 290 |
+
"\u9a6c\u514b\u601d\u4e3b\u4e49\u57fa\u672c\u539f\u7406",
|
| 291 |
+
"Social Science",
|
| 292 |
+
],
|
| 293 |
+
"mao_zedong_thought": [
|
| 294 |
+
"Mao Zedong Thought",
|
| 295 |
+
"\u6bdb\u6cfd\u4e1c\u601d\u60f3\u548c\u4e2d\u56fd\u7279\u8272\u793e\u4f1a\u4e3b\u4e49\u7406\u8bba\u4f53\u7cfb\u6982\u8bba",
|
| 296 |
+
"Social Science",
|
| 297 |
+
],
|
| 298 |
+
"education_science": ["Education Science", "\u6559\u80b2\u5b66", "Social Science"],
|
| 299 |
+
"teacher_qualification": [
|
| 300 |
+
"Teacher Qualification",
|
| 301 |
+
"\u6559\u5e08\u8d44\u683c",
|
| 302 |
+
"Social Science",
|
| 303 |
+
],
|
| 304 |
+
"high_school_politics": [
|
| 305 |
+
"High School Politics",
|
| 306 |
+
"\u9ad8\u4e2d\u653f\u6cbb",
|
| 307 |
+
"Social Science",
|
| 308 |
+
],
|
| 309 |
+
"high_school_geography": [
|
| 310 |
+
"High School Geography",
|
| 311 |
+
"\u9ad8\u4e2d\u5730\u7406",
|
| 312 |
+
"Social Science",
|
| 313 |
+
],
|
| 314 |
+
"middle_school_politics": [
|
| 315 |
+
"Middle School Politics",
|
| 316 |
+
"\u521d\u4e2d\u653f\u6cbb",
|
| 317 |
+
"Social Science",
|
| 318 |
+
],
|
| 319 |
+
"middle_school_geography": [
|
| 320 |
+
"Middle School Geography",
|
| 321 |
+
"\u521d\u4e2d\u5730\u7406",
|
| 322 |
+
"Social Science",
|
| 323 |
+
],
|
| 324 |
+
"modern_chinese_history": [
|
| 325 |
+
"Modern Chinese History",
|
| 326 |
+
"\u8fd1\u4ee3\u53f2\u7eb2\u8981",
|
| 327 |
+
"Humanities",
|
| 328 |
+
],
|
| 329 |
+
"ideological_and_moral_cultivation": [
|
| 330 |
+
"Ideological and Moral Cultivation",
|
| 331 |
+
"\u601d\u60f3\u9053\u5fb7\u4fee\u517b\u4e0e\u6cd5\u5f8b\u57fa\u7840",
|
| 332 |
+
"Humanities",
|
| 333 |
+
],
|
| 334 |
+
"logic": ["Logic", "\u903b\u8f91\u5b66", "Humanities"],
|
| 335 |
+
"law": ["Law", "\u6cd5\u5b66", "Humanities"],
|
| 336 |
+
"chinese_language_and_literature": [
|
| 337 |
+
"Chinese Language and Literature",
|
| 338 |
+
"\u4e2d\u56fd\u8bed\u8a00\u6587\u5b66",
|
| 339 |
+
"Humanities",
|
| 340 |
+
],
|
| 341 |
+
"art_studies": ["Art Studies", "\u827a\u672f\u5b66", "Humanities"],
|
| 342 |
+
"professional_tour_guide": [
|
| 343 |
+
"Professional Tour Guide",
|
| 344 |
+
"\u5bfc\u6e38\u8d44\u683c",
|
| 345 |
+
"Humanities",
|
| 346 |
+
],
|
| 347 |
+
"legal_professional": [
|
| 348 |
+
"Legal Professional",
|
| 349 |
+
"\u6cd5\u5f8b\u804c\u4e1a\u8d44\u683c",
|
| 350 |
+
"Humanities",
|
| 351 |
+
],
|
| 352 |
+
"high_school_chinese": [
|
| 353 |
+
"High School Chinese",
|
| 354 |
+
"\u9ad8\u4e2d\u8bed\u6587",
|
| 355 |
+
"Humanities",
|
| 356 |
+
],
|
| 357 |
+
"high_school_history": [
|
| 358 |
+
"High School History",
|
| 359 |
+
"\u9ad8\u4e2d\u5386\u53f2",
|
| 360 |
+
"Humanities",
|
| 361 |
+
],
|
| 362 |
+
"middle_school_history": [
|
| 363 |
+
"Middle School History",
|
| 364 |
+
"\u521d\u4e2d\u5386\u53f2",
|
| 365 |
+
"Humanities",
|
| 366 |
+
],
|
| 367 |
+
"civil_servant": ["Civil Servant", "\u516c\u52a1\u5458", "Other"],
|
| 368 |
+
"sports_science": ["Sports Science", "\u4f53\u80b2\u5b66", "Other"],
|
| 369 |
+
"plant_protection": ["Plant Protection", "\u690d\u7269\u4fdd\u62a4", "Other"],
|
| 370 |
+
"basic_medicine": ["Basic Medicine", "\u57fa\u7840\u533b\u5b66", "Other"],
|
| 371 |
+
"clinical_medicine": ["Clinical Medicine", "\u4e34\u5e8a\u533b\u5b66", "Other"],
|
| 372 |
+
"urban_and_rural_planner": [
|
| 373 |
+
"Urban and Rural Planner",
|
| 374 |
+
"\u6ce8\u518c\u57ce\u4e61\u89c4\u5212\u5e08",
|
| 375 |
+
"Other",
|
| 376 |
+
],
|
| 377 |
+
"accountant": ["Accountant", "\u6ce8\u518c\u4f1a\u8ba1\u5e08", "Other"],
|
| 378 |
+
"fire_engineer": [
|
| 379 |
+
"Fire Engineer",
|
| 380 |
+
"\u6ce8\u518c\u6d88\u9632\u5de5\u7a0b\u5e08",
|
| 381 |
+
"Other",
|
| 382 |
+
],
|
| 383 |
+
"environmental_impact_assessment_engineer": [
|
| 384 |
+
"Environmental Impact Assessment Engineer",
|
| 385 |
+
"\u73af\u5883\u5f71\u54cd\u8bc4\u4ef7\u5de5\u7a0b\u5e08",
|
| 386 |
+
"Other",
|
| 387 |
+
],
|
| 388 |
+
"tax_accountant": ["Tax Accountant", "\u7a0e\u52a1\u5e08", "Other"],
|
| 389 |
+
"physician": ["Physician", "\u533b\u5e08\u8d44\u683c", "Other"],
|
| 390 |
+
}
|
| 391 |
+
hard_list = [
|
| 392 |
+
"advanced_mathematics",
|
| 393 |
+
"discrete_mathematics",
|
| 394 |
+
"probability_and_statistics",
|
| 395 |
+
"college_physics",
|
| 396 |
+
"college_chemistry",
|
| 397 |
+
"high_school_mathematics",
|
| 398 |
+
"high_school_physics",
|
| 399 |
+
"high_school_chemistry",
|
| 400 |
+
]
|
| 401 |
+
choices = ["A", "B", "C", "D"]
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
def main(args):
|
| 405 |
+
print("loading model weights")
|
| 406 |
+
if args.checkpoint_path:
|
| 407 |
+
model, tokenizer = load_models_tokenizer(args)
|
| 408 |
+
else:
|
| 409 |
+
model, tokenizer = None, None
|
| 410 |
+
print("model loaded")
|
| 411 |
+
dev_result = {}
|
| 412 |
+
for subject_name in tqdm(TASK_NAME_MAPPING.keys()):
|
| 413 |
+
val_file_path = os.path.join(
|
| 414 |
+
args.eval_data_path, "val", f"{subject_name}_val.csv"
|
| 415 |
+
)
|
| 416 |
+
val_df = pd.read_csv(val_file_path)
|
| 417 |
+
|
| 418 |
+
score = eval_subject(
|
| 419 |
+
model,
|
| 420 |
+
tokenizer,
|
| 421 |
+
subject_name,
|
| 422 |
+
val_df,
|
| 423 |
+
save_result_dir="outs_chat/ceval_eval_result",
|
| 424 |
+
overwrite=args.overwrite,
|
| 425 |
+
)
|
| 426 |
+
dev_result[subject_name] = score
|
| 427 |
+
cal_ceval(dev_result)
|
| 428 |
+
|
| 429 |
+
|
| 430 |
+
if __name__ == "__main__":
|
| 431 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 432 |
+
parser.add_argument(
|
| 433 |
+
"-c",
|
| 434 |
+
"--checkpoint-path",
|
| 435 |
+
type=str,
|
| 436 |
+
help="Checkpoint path",
|
| 437 |
+
default="Qwen/Qwen-7B-Chat",
|
| 438 |
+
)
|
| 439 |
+
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
|
| 440 |
+
|
| 441 |
+
# Provide extra arguments required for tasks
|
| 442 |
+
group = parser.add_argument_group(title="Evaluation options")
|
| 443 |
+
group.add_argument(
|
| 444 |
+
"-d", "--eval_data_path", type=str, required=True, help="Path to eval data"
|
| 445 |
+
)
|
| 446 |
+
group.add_argument(
|
| 447 |
+
"--debug", action="store_true", default=False, help="Print infos."
|
| 448 |
+
)
|
| 449 |
+
group.add_argument(
|
| 450 |
+
"--overwrite",
|
| 451 |
+
action="store_true",
|
| 452 |
+
default=False,
|
| 453 |
+
help="Overwrite existed results",
|
| 454 |
+
)
|
| 455 |
+
|
| 456 |
+
args = parser.parse_args()
|
| 457 |
+
set_seed(args.seed)
|
| 458 |
+
|
| 459 |
+
main(args)
|
eval/evaluate_chat_gsm8k.py
ADDED
|
@@ -0,0 +1,151 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
import argparse
|
| 5 |
+
import numpy as np
|
| 6 |
+
import tqdm
|
| 7 |
+
from datasets import load_from_disk, load_dataset
|
| 8 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 9 |
+
from transformers.generation import GenerationConfig
|
| 10 |
+
|
| 11 |
+
'''
|
| 12 |
+
python eval/evaluate_chat_gsm8k.py [--use-fewshot]
|
| 13 |
+
'''
|
| 14 |
+
|
| 15 |
+
INVALID_ANS = "[invalid]"
|
| 16 |
+
DEVICE = "cuda:0"
|
| 17 |
+
|
| 18 |
+
def doc_to_text(doc, use_fewshot):
|
| 19 |
+
if use_fewshot:
|
| 20 |
+
context = (
|
| 21 |
+
"Question: Angelo and Melanie want to plan how many hours over the next week they should study together for their test next week. They have 2 chapters of their textbook to study and 4 worksheets to memorize. They figure out that they should dedicate 3 hours to each chapter of their textbook and 1.5 hours for each worksheet. If they plan to study no more than 4 hours each day, how many days should they plan to study total over the next week if they take a 10-minute break every hour, include 3 10-minute snack breaks each day, and 30 minutes for lunch each day?\nLet's think step by step\n"
|
| 22 |
+
"Angelo and Melanie think they should dedicate 3 hours to each of the 2 chapters, 3 hours x 2 chapters = 6 hours total.\nFor the worksheets they plan to dedicate 1.5 hours for each worksheet, 1.5 hours x 4 worksheets = 6 hours total.\nAngelo and Melanie need to start with planning 12 hours to study, at 4 hours a day, 12 / 4 = 3 days.\nHowever, they need to include time for breaks and lunch. Every hour they want to include a 10-minute break, so 12 total hours x 10 minutes = 120 extra minutes for breaks.\nThey also want to include 3 10-minute snack breaks, 3 x 10 minutes = 30 minutes.\nAnd they want to include 30 minutes for lunch each day, so 120 minutes for breaks + 30 minutes for snack breaks + 30 minutes for lunch = 180 minutes, or 180 / 60 minutes per hour = 3 extra hours.\nSo Angelo and Melanie want to plan 12 hours to study + 3 hours of breaks = 15 hours total.\nThey want to study no more than 4 hours each day, 15 hours / 4 hours each day = 3.75\nThey will need to plan to study 4 days to allow for all the time they need.\nThe answer is 4\n\n"
|
| 23 |
+
"Question: Mark's basketball team scores 25 2 pointers, 8 3 pointers and 10 free throws. Their opponents score double the 2 pointers but half the 3 pointers and free throws. What's the total number of points scored by both teams added together?\nLet's think step by step\n"
|
| 24 |
+
"Mark's team scores 25 2 pointers, meaning they scored 25*2= 50 points in 2 pointers.\nHis team also scores 6 3 pointers, meaning they scored 8*3= 24 points in 3 pointers\nThey scored 10 free throws, and free throws count as one point so they scored 10*1=10 points in free throws.\nAll together his team scored 50+24+10= 84 points\nMark's opponents scored double his team's number of 2 pointers, meaning they scored 50*2=100 points in 2 pointers.\nHis opponents scored half his team's number of 3 pointers, meaning they scored 24/2= 12 points in 3 pointers.\nThey also scored half Mark's team's points in free throws, meaning they scored 10/2=5 points in free throws.\nAll together Mark's opponents scored 100+12+5=117 points\nThe total score for the game is both team's scores added together, so it is 84+117=201 points\nThe answer is 201\n\n"
|
| 25 |
+
"Question: Bella has two times as many marbles as frisbees. She also has 20 more frisbees than deck cards. If she buys 2/5 times more of each item, what would be the total number of the items she will have if she currently has 60 marbles?\nLet's think step by step\n"
|
| 26 |
+
"When Bella buys 2/5 times more marbles, she'll have increased the number of marbles by 2/5*60 = 24\nThe total number of marbles she'll have is 60+24 = 84\nIf Bella currently has 60 marbles, and she has two times as many marbles as frisbees, she has 60/2 = 30 frisbees.\nIf Bella buys 2/5 times more frisbees, she'll have 2/5*30 = 12 more frisbees.\nThe total number of frisbees she'll have will increase to 30+12 = 42\nBella also has 20 more frisbees than deck cards, meaning she has 30-20 = 10 deck cards\nIf she buys 2/5 times more deck cards, she'll have 2/5*10 = 4 more deck cards.\nThe total number of deck cards she'll have is 10+4 = 14\nTogether, Bella will have a total of 14+42+84 = 140 items\nThe answer is 140\n\n"
|
| 27 |
+
"Question: A group of 4 fruit baskets contains 9 apples, 15 oranges, and 14 bananas in the first three baskets and 2 less of each fruit in the fourth basket. How many fruits are there?\nLet's think step by step\n"
|
| 28 |
+
"For the first three baskets, the number of apples and oranges in one basket is 9+15=24\nIn total, together with bananas, the number of fruits in one basket is 24+14=38 for the first three baskets.\nSince there are three baskets each having 38 fruits, there are 3*38=114 fruits in the first three baskets.\nThe number of apples in the fourth basket is 9-2=7\nThere are also 15-2=13 oranges in the fourth basket\nThe combined number of oranges and apples in the fourth basket is 13+7=20\nThe fourth basket also contains 14-2=12 bananas.\nIn total, the fourth basket has 20+12=32 fruits.\nThe four baskets together have 32+114=146 fruits.\nThe answer is 146\n\n"
|
| 29 |
+
f"Question: {doc['question']}\nLet's think step by step"
|
| 30 |
+
)
|
| 31 |
+
else:
|
| 32 |
+
context = doc["question"]
|
| 33 |
+
return context
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def decode(tokens_list, tokenizer, raw_text_len):
|
| 37 |
+
sents = []
|
| 38 |
+
for tokens in tokens_list:
|
| 39 |
+
tokens = tokens.cpu().numpy().tolist()
|
| 40 |
+
sent = tokenizer.tokenizer.decode(tokens[raw_text_len:])
|
| 41 |
+
sent = sent.split("<|endoftext|>")[0]
|
| 42 |
+
sent = sent.split("\n\n\n")[0]
|
| 43 |
+
sent = sent.split("\n\n")[0]
|
| 44 |
+
sent = sent.split("Question:")[0]
|
| 45 |
+
sents.append(sent)
|
| 46 |
+
return sents
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def generate_sample(model, tokenizer, question):
|
| 50 |
+
response, _ = model.chat(
|
| 51 |
+
tokenizer,
|
| 52 |
+
question,
|
| 53 |
+
history=None,
|
| 54 |
+
)
|
| 55 |
+
print(question)
|
| 56 |
+
print("-------------")
|
| 57 |
+
print(response)
|
| 58 |
+
print("=============")
|
| 59 |
+
return response
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def extract_answer_hf(completion):
|
| 63 |
+
def _get_last_digit(s):
|
| 64 |
+
_PAT_LAST_DIGIT = re.compile(
|
| 65 |
+
r"(?<=(\s|[\$%#{]))([+-])?(?=(\S))(0|([1-9](\d*|\d{0,2}(,\d{3})*)))?(\.\d*[1-9])?(?=(\s|[.,}]|$))"
|
| 66 |
+
)
|
| 67 |
+
match = list(_PAT_LAST_DIGIT.finditer(s))
|
| 68 |
+
if match:
|
| 69 |
+
last_digit = match[-1].group().replace(",", "").replace("+", "")
|
| 70 |
+
# print(f"The last digit in {s} is {last_digit}")
|
| 71 |
+
else:
|
| 72 |
+
last_digit = None
|
| 73 |
+
print(f"No digits found in {s!r}")
|
| 74 |
+
return last_digit
|
| 75 |
+
|
| 76 |
+
job_gen = completion.strip(".").replace("\n", "\\n")
|
| 77 |
+
last_digit = _get_last_digit(job_gen)
|
| 78 |
+
if last_digit is not None:
|
| 79 |
+
return eval(last_digit)
|
| 80 |
+
return INVALID_ANS
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def extract_answer(completion):
|
| 84 |
+
try:
|
| 85 |
+
last_number = re.findall(r"\d+", completion)[-1]
|
| 86 |
+
return eval(last_number)
|
| 87 |
+
except:
|
| 88 |
+
return INVALID_ANS
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def is_correct(completion, answer):
|
| 92 |
+
gold = extract_answer(answer)
|
| 93 |
+
assert gold != INVALID_ANS, "No ground truth answer found in the document."
|
| 94 |
+
return extract_answer(completion) == gold
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
if __name__ == "__main__":
|
| 98 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 99 |
+
parser.add_argument(
|
| 100 |
+
"-c",
|
| 101 |
+
"--checkpoint-path",
|
| 102 |
+
type=Path,
|
| 103 |
+
help="Checkpoint path",
|
| 104 |
+
default="Qwen/Qwen-7B-Chat",
|
| 105 |
+
)
|
| 106 |
+
parser.add_argument("-f", "--sample-input-file", type=str, default=None)
|
| 107 |
+
parser.add_argument(
|
| 108 |
+
"-o", "--sample-output-file", type=str, default="gsm8k_res.jsonl"
|
| 109 |
+
)
|
| 110 |
+
parser.add_argument("--use-fewshot", action="store_true")
|
| 111 |
+
|
| 112 |
+
args = parser.parse_args()
|
| 113 |
+
|
| 114 |
+
if args.sample_input_file is not None:
|
| 115 |
+
dataset = load_from_disk(args.sample_input_file) # or:
|
| 116 |
+
else:
|
| 117 |
+
dataset = load_dataset("gsm8k", "main")
|
| 118 |
+
|
| 119 |
+
print("Loading tokenizer ...")
|
| 120 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 121 |
+
args.checkpoint_path, trust_remote_code=True, bf16=True, use_flash_attn=True
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
print("Loading model ...")
|
| 125 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 126 |
+
args.checkpoint_path, device_map="auto", trust_remote_code=True
|
| 127 |
+
).eval()
|
| 128 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 129 |
+
args.checkpoint_path, trust_remote_code=True
|
| 130 |
+
)
|
| 131 |
+
model.generation_config.do_sample = False # use greedy decoding
|
| 132 |
+
|
| 133 |
+
test = dataset["test"]
|
| 134 |
+
|
| 135 |
+
f_output = open(args.sample_output_file, "w", encoding="utf-8")
|
| 136 |
+
tot_length = test.num_rows
|
| 137 |
+
acc_res = []
|
| 138 |
+
for doc in tqdm.tqdm(test):
|
| 139 |
+
context = doc_to_text(doc, args.use_fewshot)
|
| 140 |
+
print(context)
|
| 141 |
+
completion = generate_sample(model, tokenizer, context)
|
| 142 |
+
answer = doc["answer"]
|
| 143 |
+
acc = is_correct(completion, answer)
|
| 144 |
+
doc["completion"] = completion
|
| 145 |
+
doc["acc"] = acc
|
| 146 |
+
f_output.write(json.dumps(doc, ensure_ascii=False) + "\n")
|
| 147 |
+
f_output.flush()
|
| 148 |
+
acc_res.append(acc)
|
| 149 |
+
|
| 150 |
+
f_output.close()
|
| 151 |
+
print("4-shot Acc: " if args.use_fewshot else "Zero-shot Acc", np.mean(acc_res))
|
eval/evaluate_chat_humaneval.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import re
|
| 3 |
+
import textwrap
|
| 4 |
+
import argparse
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
import tqdm
|
| 7 |
+
import jsonlines
|
| 8 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 9 |
+
from transformers.generation import GenerationConfig
|
| 10 |
+
|
| 11 |
+
"""
|
| 12 |
+
Get the HumanEval.jsonl file from [here](https://github.com/openai/human-eval/tree/master/data)
|
| 13 |
+
|
| 14 |
+
python eval/evaluate_chat_humaneval.py -f HumanEval.jsonl -o HumanEval_res.jsonl
|
| 15 |
+
git clone https://github.com/openai/human-eval
|
| 16 |
+
pip install -e human-eval
|
| 17 |
+
evaluate_functional_correctness HumanEval_res.jsonl
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
DEVICE = "cuda:0"
|
| 21 |
+
|
| 22 |
+
def extract_code(text, entry_point):
|
| 23 |
+
# 正则表达式匹配代码块
|
| 24 |
+
code_block_pattern = re.compile(
|
| 25 |
+
rf"```(?:[Pp]ython\n)?.*?def\s+{entry_point}.*?:\n(.*?)\n```", re.DOTALL
|
| 26 |
+
)
|
| 27 |
+
code_block = code_block_pattern.search(text)
|
| 28 |
+
if code_block is None:
|
| 29 |
+
code_block_pattern = re.compile(
|
| 30 |
+
rf"def\s+{entry_point}.*?:\n(.*?)(?:\n(?!\n*(?: |\t))|$)", re.DOTALL
|
| 31 |
+
)
|
| 32 |
+
code_block = code_block_pattern.search(text)
|
| 33 |
+
if code_block is None:
|
| 34 |
+
code_block_pattern = re.compile(
|
| 35 |
+
r"def.*?:\n(.*?)(?:\n(?!\n*(?: |\t))|$)", re.DOTALL
|
| 36 |
+
)
|
| 37 |
+
code_block = code_block_pattern.search(text)
|
| 38 |
+
|
| 39 |
+
if code_block is not None:
|
| 40 |
+
return code_block.group(1)
|
| 41 |
+
|
| 42 |
+
# if no code block is found, assume the LM is simply filling the code
|
| 43 |
+
return textwrap.indent(text, " " * 4)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def generate_sample(model, tokenizer, question, entry_point):
|
| 47 |
+
response, _ = model.chat(
|
| 48 |
+
tokenizer,
|
| 49 |
+
question,
|
| 50 |
+
history=None,
|
| 51 |
+
)
|
| 52 |
+
print(question)
|
| 53 |
+
print(response)
|
| 54 |
+
answer = extract_code(response, entry_point)
|
| 55 |
+
return answer, response
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
if __name__ == "__main__":
|
| 59 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 60 |
+
parser.add_argument(
|
| 61 |
+
"-c",
|
| 62 |
+
"--checkpoint-path",
|
| 63 |
+
type=Path,
|
| 64 |
+
help="Checkpoint path",
|
| 65 |
+
default="Qwen/Qwen-7B-Chat",
|
| 66 |
+
)
|
| 67 |
+
parser.add_argument(
|
| 68 |
+
"-f",
|
| 69 |
+
"--sample-input-file",
|
| 70 |
+
type=str,
|
| 71 |
+
default=None,
|
| 72 |
+
help="data path to HumanEval.jsonl",
|
| 73 |
+
)
|
| 74 |
+
parser.add_argument(
|
| 75 |
+
"-o", "--sample-output-file", type=str, default="HumanEval_res.jsonl"
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
args = parser.parse_args()
|
| 79 |
+
print("Loading tokenizer ...")
|
| 80 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 81 |
+
args.checkpoint_path, trust_remote_code=True
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
print("Loading model ...")
|
| 85 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 86 |
+
args.checkpoint_path,
|
| 87 |
+
device_map="auto",
|
| 88 |
+
trust_remote_code=True,
|
| 89 |
+
bf16=True,
|
| 90 |
+
use_flash_attn=True,
|
| 91 |
+
).eval()
|
| 92 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 93 |
+
args.checkpoint_path, trust_remote_code=True
|
| 94 |
+
)
|
| 95 |
+
model.generation_config.do_sample = False # use greedy decoding
|
| 96 |
+
|
| 97 |
+
f_output = jsonlines.Writer(open(args.sample_output_file, "w", encoding="utf-8"))
|
| 98 |
+
|
| 99 |
+
f = jsonlines.open(args.sample_input_file)
|
| 100 |
+
with f_output as output:
|
| 101 |
+
for jobj in tqdm.tqdm(f, desc="task_idx"):
|
| 102 |
+
prompt = "Help me fill the following code.\n" + jobj["prompt"]
|
| 103 |
+
task_id = jobj["task_id"]
|
| 104 |
+
answer, response = generate_sample(
|
| 105 |
+
model, tokenizer, prompt, jobj["entry_point"]
|
| 106 |
+
)
|
| 107 |
+
gen_jobjs = {"task_id": task_id, "completion": answer, "response": response}
|
| 108 |
+
output.write(gen_jobjs)
|
| 109 |
+
f_output.close()
|
eval/evaluate_chat_mmlu.py
ADDED
|
@@ -0,0 +1,314 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
import re
|
| 4 |
+
import torch
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
from thefuzz import process
|
| 8 |
+
from transformers.trainer_utils import set_seed
|
| 9 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 10 |
+
from transformers.generation import GenerationConfig
|
| 11 |
+
|
| 12 |
+
'''
|
| 13 |
+
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
|
| 14 |
+
mkdir data/mmlu
|
| 15 |
+
mv data.tar data/mmlu
|
| 16 |
+
cd data/mmlu; tar xf data.tar
|
| 17 |
+
cd ../../
|
| 18 |
+
|
| 19 |
+
pip install thefuzz
|
| 20 |
+
python eval/evaluate_chat_mmlu.py -d data/mmlu/data/
|
| 21 |
+
'''
|
| 22 |
+
|
| 23 |
+
def load_models_tokenizer(args):
|
| 24 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 25 |
+
args.checkpoint_path, trust_remote_code=True
|
| 26 |
+
)
|
| 27 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 28 |
+
args.checkpoint_path,
|
| 29 |
+
device_map="auto",
|
| 30 |
+
trust_remote_code=True,
|
| 31 |
+
bf16=True,
|
| 32 |
+
use_flash_attn=True,
|
| 33 |
+
).eval()
|
| 34 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 35 |
+
args.checkpoint_path, trust_remote_code=True
|
| 36 |
+
)
|
| 37 |
+
model.generation_config.do_sample = False # use greedy decoding
|
| 38 |
+
return model, tokenizer
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def format_example(line):
|
| 42 |
+
example = (
|
| 43 |
+
"The following is a multiple-choice question. Please choose the most suitable one among A, B, C and D as the answer to this question.\n\n"
|
| 44 |
+
+ line["question"]
|
| 45 |
+
+ "\n"
|
| 46 |
+
)
|
| 47 |
+
for choice in choices:
|
| 48 |
+
example += f'{choice}. {line[f"{choice}"]}\n'
|
| 49 |
+
return example
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def process_before_extraction(gen, choice_dict):
|
| 53 |
+
# replace the choice by letter in the generated sentence
|
| 54 |
+
# from longest one to shortest one
|
| 55 |
+
for key, val in sorted(choice_dict.items(), key=lambda x: len(x[1]), reverse=True):
|
| 56 |
+
pattern = re.compile(re.escape(val.rstrip(".")), re.IGNORECASE)
|
| 57 |
+
gen = pattern.sub(key, gen)
|
| 58 |
+
return gen
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def extract_choice(gen, choice_list):
|
| 62 |
+
# answer is A | choice is A | choose A
|
| 63 |
+
res = re.search(
|
| 64 |
+
r"(?:(?:[Cc]hoose)|(?:(?:[Aa]nswer|[Cc]hoice)(?![^ABCD]{0,20}?(?:n't|not))[^ABCD]{0,10}?\b(?:|is|:|be))\b)[^ABCD]{0,20}?\b(A|B|C|D)\b",
|
| 65 |
+
gen,
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
# A is correct | A is right
|
| 69 |
+
if res is None:
|
| 70 |
+
res = re.search(
|
| 71 |
+
r"\b(A|B|C|D)\b(?![^ABCD]{0,8}?(?:n't|not)[^ABCD]{0,5}?(?:correct|right))[^ABCD]{0,10}?\b(?:correct|right)\b",
|
| 72 |
+
gen,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
# straight answer: A
|
| 76 |
+
if res is None:
|
| 77 |
+
res = re.search(r"^(A|B|C|D)(?:\.|,|:|$)", gen)
|
| 78 |
+
|
| 79 |
+
# simply extract the first appearred letter
|
| 80 |
+
if res is None:
|
| 81 |
+
res = re.search(r"(?<![a-zA-Z])(A|B|C|D)(?![a-zA-Z=])", gen)
|
| 82 |
+
|
| 83 |
+
if res is None:
|
| 84 |
+
return choices[choice_list.index(process.extractOne(gen, choice_list)[0])]
|
| 85 |
+
return res.group(1)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def extract_answer(response, row):
|
| 89 |
+
gen = process_before_extraction(
|
| 90 |
+
response, {choice: row[choice] for choice in choices}
|
| 91 |
+
)
|
| 92 |
+
pred = extract_choice(gen, [row[choice] for choice in choices])
|
| 93 |
+
return pred
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
@torch.no_grad()
|
| 97 |
+
def eval_subject(
|
| 98 |
+
model,
|
| 99 |
+
tokenizer,
|
| 100 |
+
subject_name,
|
| 101 |
+
test_df,
|
| 102 |
+
save_result_dir=None,
|
| 103 |
+
overwrite=False,
|
| 104 |
+
**kwargs
|
| 105 |
+
):
|
| 106 |
+
result_path = os.path.join(save_result_dir, f"{subject_name}_result.csv")
|
| 107 |
+
if not overwrite and os.path.exists(result_path):
|
| 108 |
+
print(f"{result_path} existed, skip!")
|
| 109 |
+
score = []
|
| 110 |
+
for (_, datarow), (_, resultrow) in zip(
|
| 111 |
+
test_df.iterrows(), pd.read_csv(result_path).iterrows()
|
| 112 |
+
):
|
| 113 |
+
# pred = extract_answer(resultrow['model_response'], datarow)
|
| 114 |
+
pred = resultrow["model_output"]
|
| 115 |
+
correct = 1 if pred == datarow["answer"] else 0
|
| 116 |
+
score.append(correct)
|
| 117 |
+
return score
|
| 118 |
+
|
| 119 |
+
result = []
|
| 120 |
+
score = []
|
| 121 |
+
|
| 122 |
+
for _, row in tqdm(test_df.iterrows(), total=len(test_df)):
|
| 123 |
+
question = format_example(row)
|
| 124 |
+
|
| 125 |
+
response, _ = model.chat(
|
| 126 |
+
tokenizer,
|
| 127 |
+
question,
|
| 128 |
+
history=None,
|
| 129 |
+
)
|
| 130 |
+
print(question)
|
| 131 |
+
print(response)
|
| 132 |
+
pred = extract_answer(response, row)
|
| 133 |
+
print(pred)
|
| 134 |
+
print("======================")
|
| 135 |
+
|
| 136 |
+
if "answer" in row:
|
| 137 |
+
correct = 1 if pred == row["answer"] else 0
|
| 138 |
+
score.append(correct)
|
| 139 |
+
if args.debug:
|
| 140 |
+
print(f'{question} pred: {pred} ref: {row["answer"]}')
|
| 141 |
+
result.append(pred)
|
| 142 |
+
|
| 143 |
+
if save_result_dir:
|
| 144 |
+
test_df["model_output"] = result
|
| 145 |
+
test_df["model_response"] = response
|
| 146 |
+
if score:
|
| 147 |
+
test_df["correctness"] = score
|
| 148 |
+
os.makedirs(save_result_dir, exist_ok=True)
|
| 149 |
+
test_df.to_csv(
|
| 150 |
+
os.path.join(save_result_dir, f"{subject_name}_result.csv"),
|
| 151 |
+
encoding="utf-8",
|
| 152 |
+
index=False,
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
return score
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def cal_mmlu(res):
|
| 159 |
+
acc_sum_dict = dict()
|
| 160 |
+
acc_norm_sum_dict = dict()
|
| 161 |
+
cnt_dict = dict()
|
| 162 |
+
acc_sum = 0.0
|
| 163 |
+
cnt = 0
|
| 164 |
+
|
| 165 |
+
for class_ in TASK_NAME_MAPPING.keys():
|
| 166 |
+
acc_sum_dict[class_] = 0.0
|
| 167 |
+
acc_norm_sum_dict[class_] = 0.0
|
| 168 |
+
cnt_dict[class_] = 0.0
|
| 169 |
+
|
| 170 |
+
for tt in TASK_NAME_MAPPING[class_]:
|
| 171 |
+
acc_sum += sum(res[tt])
|
| 172 |
+
cnt += len(res[tt])
|
| 173 |
+
|
| 174 |
+
acc_sum_dict[class_] += sum(res[tt])
|
| 175 |
+
cnt_dict[class_] += len(res[tt])
|
| 176 |
+
|
| 177 |
+
print("\n\n\n")
|
| 178 |
+
for k in TASK_NAME_MAPPING.keys():
|
| 179 |
+
if k in cnt_dict:
|
| 180 |
+
print("%s ACC: %.2f " % (k, acc_sum_dict[k] * 100 / cnt_dict[k]))
|
| 181 |
+
print("AVERAGE ACC:%.2f " % (acc_sum * 100 / cnt))
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def main(args):
|
| 185 |
+
print("loading model weights")
|
| 186 |
+
if args.checkpoint_path is not None:
|
| 187 |
+
model, tokenizer = load_models_tokenizer(args)
|
| 188 |
+
else:
|
| 189 |
+
model, tokenizer = None, None
|
| 190 |
+
print("model loaded")
|
| 191 |
+
|
| 192 |
+
dev_result = {}
|
| 193 |
+
for subject_name in tqdm(SUBJECTS):
|
| 194 |
+
# val_file_path = os.path.join(args.eval_data_path, 'val', f'{subject_name}_val.csv')
|
| 195 |
+
# dev_file_path = os.path.join(args.eval_data_path, 'dev', f'{subject_name}_dev.csv')
|
| 196 |
+
test_file_path = os.path.join(
|
| 197 |
+
args.eval_data_path, "test", f"{subject_name}_test.csv"
|
| 198 |
+
)
|
| 199 |
+
# val_df = pd.read_csv(val_file_path, names=['question','A','B','C','D','answer'])
|
| 200 |
+
# dev_df = pd.read_csv(dev_file_path, names=['question','A','B','C','D','answer'])
|
| 201 |
+
test_df = pd.read_csv(
|
| 202 |
+
test_file_path, names=["question", "A", "B", "C", "D", "answer"]
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
score = eval_subject(
|
| 206 |
+
model,
|
| 207 |
+
tokenizer,
|
| 208 |
+
subject_name,
|
| 209 |
+
test_df,
|
| 210 |
+
save_result_dir=f"outs_chat/mmlu_eval_result",
|
| 211 |
+
overwrite=args.overwrite,
|
| 212 |
+
)
|
| 213 |
+
dev_result[subject_name] = score
|
| 214 |
+
cal_mmlu(dev_result)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
TASK_NAME_MAPPING = {
|
| 218 |
+
"stem": [
|
| 219 |
+
"abstract_algebra",
|
| 220 |
+
"anatomy",
|
| 221 |
+
"astronomy",
|
| 222 |
+
"college_biology",
|
| 223 |
+
"college_chemistry",
|
| 224 |
+
"college_computer_science",
|
| 225 |
+
"college_mathematics",
|
| 226 |
+
"college_physics",
|
| 227 |
+
"computer_security",
|
| 228 |
+
"conceptual_physics",
|
| 229 |
+
"electrical_engineering",
|
| 230 |
+
"elementary_mathematics",
|
| 231 |
+
"high_school_biology",
|
| 232 |
+
"high_school_chemistry",
|
| 233 |
+
"high_school_computer_science",
|
| 234 |
+
"high_school_mathematics",
|
| 235 |
+
"high_school_physics",
|
| 236 |
+
"high_school_statistics",
|
| 237 |
+
"machine_learning",
|
| 238 |
+
],
|
| 239 |
+
"Humanities": [
|
| 240 |
+
"formal_logic",
|
| 241 |
+
"high_school_european_history",
|
| 242 |
+
"high_school_us_history",
|
| 243 |
+
"high_school_world_history",
|
| 244 |
+
"international_law",
|
| 245 |
+
"jurisprudence",
|
| 246 |
+
"logical_fallacies",
|
| 247 |
+
"moral_disputes",
|
| 248 |
+
"moral_scenarios",
|
| 249 |
+
"philosophy",
|
| 250 |
+
"prehistory",
|
| 251 |
+
"professional_law",
|
| 252 |
+
"world_religions",
|
| 253 |
+
],
|
| 254 |
+
"other": [
|
| 255 |
+
"business_ethics",
|
| 256 |
+
"college_medicine",
|
| 257 |
+
"human_aging",
|
| 258 |
+
"management",
|
| 259 |
+
"marketing",
|
| 260 |
+
"medical_genetics",
|
| 261 |
+
"miscellaneous",
|
| 262 |
+
"nutrition",
|
| 263 |
+
"professional_accounting",
|
| 264 |
+
"professional_medicine",
|
| 265 |
+
"virology",
|
| 266 |
+
"global_facts",
|
| 267 |
+
"clinical_knowledge",
|
| 268 |
+
],
|
| 269 |
+
"social": [
|
| 270 |
+
"econometrics",
|
| 271 |
+
"high_school_geography",
|
| 272 |
+
"high_school_government_and_politics",
|
| 273 |
+
"high_school_macroeconomics",
|
| 274 |
+
"high_school_microeconomics",
|
| 275 |
+
"high_school_psychology",
|
| 276 |
+
"human_sexuality",
|
| 277 |
+
"professional_psychology",
|
| 278 |
+
"public_relations",
|
| 279 |
+
"security_studies",
|
| 280 |
+
"sociology",
|
| 281 |
+
"us_foreign_policy",
|
| 282 |
+
],
|
| 283 |
+
}
|
| 284 |
+
SUBJECTS = [v for vl in TASK_NAME_MAPPING.values() for v in vl]
|
| 285 |
+
choices = ["A", "B", "C", "D"]
|
| 286 |
+
|
| 287 |
+
if __name__ == "__main__":
|
| 288 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 289 |
+
parser.add_argument(
|
| 290 |
+
"-c",
|
| 291 |
+
"--checkpoint-path",
|
| 292 |
+
type=str,
|
| 293 |
+
help="Checkpoint path",
|
| 294 |
+
default="Qwen/Qwen-7B-Chat",
|
| 295 |
+
)
|
| 296 |
+
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
|
| 297 |
+
|
| 298 |
+
# Provide extra arguments required for tasks
|
| 299 |
+
group = parser.add_argument_group(title="Evaluation options")
|
| 300 |
+
group.add_argument("-d", "--eval_data_path", type=str, help="Path to eval data")
|
| 301 |
+
group.add_argument(
|
| 302 |
+
"--debug", action="store_true", default=False, help="Print infos."
|
| 303 |
+
)
|
| 304 |
+
group.add_argument(
|
| 305 |
+
"--overwrite",
|
| 306 |
+
action="store_true",
|
| 307 |
+
default=False,
|
| 308 |
+
help="Overwrite existed results",
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
args = parser.parse_args()
|
| 312 |
+
set_seed(args.seed)
|
| 313 |
+
|
| 314 |
+
main(args)
|
eval/evaluate_cmmlu.py
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import argparse
|
| 5 |
+
import datasets
|
| 6 |
+
import torch
|
| 7 |
+
from collections import defaultdict
|
| 8 |
+
|
| 9 |
+
from typing import List
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from transformers.trainer_utils import set_seed
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
"""
|
| 15 |
+
wget https://huggingface.co/datasets/haonan-li/cmmlu/resolve/main/cmmlu_v1_0_1.zip
|
| 16 |
+
mkdir data/cmmlu
|
| 17 |
+
mv cmmlu_v1_0_1.zip data/cmmlu
|
| 18 |
+
cd data/cmmlu; unzip cmmlu_v1_0_1.zip
|
| 19 |
+
cd ../../
|
| 20 |
+
python evaluate_cmmlu.py -d data/cmmlu/
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def load_models_tokenizer(args):
|
| 25 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 26 |
+
from transformers.generation import GenerationConfig
|
| 27 |
+
|
| 28 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 29 |
+
args.checkpoint_path, trust_remote_code=True
|
| 30 |
+
)
|
| 31 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 32 |
+
args.checkpoint_path, device_map="auto", trust_remote_code=True
|
| 33 |
+
).eval()
|
| 34 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 35 |
+
args.checkpoint_path, trust_remote_code=True
|
| 36 |
+
)
|
| 37 |
+
return model, tokenizer
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def format_example(line, include_answer=True):
|
| 41 |
+
example = "问题:" + line["Question"]
|
| 42 |
+
for choice in choices:
|
| 43 |
+
example += f'\n{choice}. {line[f"{choice}"]}'
|
| 44 |
+
|
| 45 |
+
if include_answer:
|
| 46 |
+
example += "\n答案:" + line["Answer"] + "\n\n"
|
| 47 |
+
else:
|
| 48 |
+
example += "\n答案:"
|
| 49 |
+
return example
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def generate_few_shot_prompt(k, subject, dev_df):
|
| 53 |
+
prompt = ""
|
| 54 |
+
if k == -1:
|
| 55 |
+
k = dev_df.shape[0]
|
| 56 |
+
for i in range(k):
|
| 57 |
+
prompt += format_example(
|
| 58 |
+
dev_df.iloc[i, :],
|
| 59 |
+
include_answer=True,
|
| 60 |
+
)
|
| 61 |
+
return prompt
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def get_logits(tokenizer, model, inputs: List[str]):
|
| 65 |
+
input_ids = tokenizer(inputs, padding=False)["input_ids"]
|
| 66 |
+
input_ids = torch.tensor(input_ids, device=model.device)
|
| 67 |
+
tokens = {"input_ids": input_ids}
|
| 68 |
+
|
| 69 |
+
outputs = model(input_ids)["logits"]
|
| 70 |
+
logits = outputs[:, -1, :]
|
| 71 |
+
log_probs = torch.nn.functional.softmax(logits, dim=-1)
|
| 72 |
+
return log_probs, {"tokens": tokens}
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
@torch.no_grad()
|
| 76 |
+
def eval_subject(
|
| 77 |
+
model,
|
| 78 |
+
tokenizer,
|
| 79 |
+
subject_name,
|
| 80 |
+
test_df,
|
| 81 |
+
k=5,
|
| 82 |
+
dev_df=None,
|
| 83 |
+
few_shot=False,
|
| 84 |
+
save_result_dir=None,
|
| 85 |
+
**kwargs,
|
| 86 |
+
):
|
| 87 |
+
result = []
|
| 88 |
+
score = []
|
| 89 |
+
|
| 90 |
+
few_shot_prompt = (
|
| 91 |
+
generate_few_shot_prompt(k, subject_name, dev_df) if few_shot else []
|
| 92 |
+
)
|
| 93 |
+
all_probs = {"prob_A": [], "prob_B": [], "prob_C": [], "prob_D": []}
|
| 94 |
+
if args.debug:
|
| 95 |
+
print(f"few_shot_prompt: {few_shot_prompt}")
|
| 96 |
+
|
| 97 |
+
for _, row in tqdm(test_df.iterrows(), total=len(test_df)):
|
| 98 |
+
question = format_example(row, include_answer=False)
|
| 99 |
+
full_prompt = few_shot_prompt + question
|
| 100 |
+
|
| 101 |
+
output, input_info = get_logits(tokenizer, model, [full_prompt])
|
| 102 |
+
assert output.shape[0] == 1
|
| 103 |
+
logits = output.flatten()
|
| 104 |
+
|
| 105 |
+
softval = torch.nn.functional.softmax(
|
| 106 |
+
torch.tensor(
|
| 107 |
+
[
|
| 108 |
+
logits[tokenizer("A")["input_ids"]],
|
| 109 |
+
logits[tokenizer("B")["input_ids"]],
|
| 110 |
+
logits[tokenizer("C")["input_ids"]],
|
| 111 |
+
logits[tokenizer("D")["input_ids"]],
|
| 112 |
+
]
|
| 113 |
+
),
|
| 114 |
+
dim=0,
|
| 115 |
+
)
|
| 116 |
+
if softval.dtype in {torch.bfloat16, torch.float16}:
|
| 117 |
+
softval = softval.to(dtype=torch.float32)
|
| 118 |
+
probs = softval.detach().cpu().numpy()
|
| 119 |
+
|
| 120 |
+
for i, choice in enumerate(choices):
|
| 121 |
+
all_probs[f"prob_{choice}"].append(probs[i])
|
| 122 |
+
pred = {0: "A", 1: "B", 2: "C", 3: "D"}[np.argmax(probs)]
|
| 123 |
+
|
| 124 |
+
if "Answer" in row:
|
| 125 |
+
correct = 1 if pred == row["Answer"] else 0
|
| 126 |
+
score.append(correct)
|
| 127 |
+
if args.debug:
|
| 128 |
+
print(f'{question} pred: {pred} ref: {row["Answer"]}')
|
| 129 |
+
result.append(pred)
|
| 130 |
+
|
| 131 |
+
if score:
|
| 132 |
+
correct_ratio = 100 * sum(score) / len(score)
|
| 133 |
+
if args.debug:
|
| 134 |
+
print(subject_name, correct_ratio)
|
| 135 |
+
else:
|
| 136 |
+
correct_ratio = 0
|
| 137 |
+
if save_result_dir:
|
| 138 |
+
test_df["model_output"] = result
|
| 139 |
+
for i, choice in enumerate(choices):
|
| 140 |
+
test_df[f"prob_{choice}"] = all_probs[f"prob_{choice}"]
|
| 141 |
+
if score:
|
| 142 |
+
test_df["correctness"] = score
|
| 143 |
+
os.makedirs(save_result_dir, exist_ok=True)
|
| 144 |
+
test_df.to_csv(
|
| 145 |
+
os.path.join(save_result_dir, f"{subject_name}_result.csv"),
|
| 146 |
+
encoding="utf-8",
|
| 147 |
+
index=False,
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
return correct_ratio
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def cal_cmmlu(res):
|
| 154 |
+
print("\n\n\n")
|
| 155 |
+
res = {k.split("-")[-1]: float(v) for k, v in res.items()}
|
| 156 |
+
for k, v in TASK_NAME_MAPPING.items():
|
| 157 |
+
avg_acc = np.mean(list(map(lambda x: res[x], v)))
|
| 158 |
+
print(f"{k} acc: {avg_acc:.2f}")
|
| 159 |
+
avg_all_acc = np.mean(list(res.values()))
|
| 160 |
+
print(f"AVERAGE acc: {avg_all_acc:.2f}")
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
subcategories = {
|
| 164 |
+
"agronomy": ["other"],
|
| 165 |
+
"anatomy": ["biology"],
|
| 166 |
+
"ancient_chinese": ["linguistics", "china specific"],
|
| 167 |
+
"arts": ["arts"],
|
| 168 |
+
"astronomy": ["physics"],
|
| 169 |
+
"business_ethics": ["business"],
|
| 170 |
+
"chinese_civil_service_exam": ["politics", "china specific"],
|
| 171 |
+
"chinese_driving_rule": ["other", "china specific"],
|
| 172 |
+
"chinese_food_culture": ["culture", "china specific"],
|
| 173 |
+
"chinese_foreign_policy": ["politics", "china specific"],
|
| 174 |
+
"chinese_history": ["history", "china specific"],
|
| 175 |
+
"chinese_literature": ["literature", "china specific"],
|
| 176 |
+
"chinese_teacher_qualification": ["education", "china specific"],
|
| 177 |
+
"college_actuarial_science": ["math"],
|
| 178 |
+
"college_education": ["education"],
|
| 179 |
+
"college_engineering_hydrology": ["engineering"],
|
| 180 |
+
"college_law": ["law"],
|
| 181 |
+
"college_mathematics": ["math"],
|
| 182 |
+
"college_medical_statistics": ["statistics"],
|
| 183 |
+
"clinical_knowledge": ["other"],
|
| 184 |
+
"college_medicine": ["other"],
|
| 185 |
+
"computer_science": ["computer science"],
|
| 186 |
+
"computer_security": ["other"],
|
| 187 |
+
"conceptual_physics": ["physics"],
|
| 188 |
+
"construction_project_management": ["other", "china specific"],
|
| 189 |
+
"economics": ["economics"],
|
| 190 |
+
"education": ["education"],
|
| 191 |
+
"elementary_chinese": ["linguistics", "china specific"],
|
| 192 |
+
"elementary_commonsense": ["other", "china specific"],
|
| 193 |
+
"elementary_information_and_technology": ["other"],
|
| 194 |
+
"electrical_engineering": ["engineering"],
|
| 195 |
+
"elementary_mathematics": ["math"],
|
| 196 |
+
"ethnology": ["culture", "china specific"],
|
| 197 |
+
"food_science": ["other"],
|
| 198 |
+
"genetics": ["biology"],
|
| 199 |
+
"global_facts": ["global"],
|
| 200 |
+
"high_school_biology": ["biology"],
|
| 201 |
+
"high_school_chemistry": ["chemistry"],
|
| 202 |
+
"high_school_geography": ["geography"],
|
| 203 |
+
"high_school_mathematics": ["math"],
|
| 204 |
+
"high_school_physics": ["physics"],
|
| 205 |
+
"high_school_politics": ["politics", "china specific"],
|
| 206 |
+
"human_sexuality": ["other"],
|
| 207 |
+
"international_law": ["law"],
|
| 208 |
+
"journalism": ["sociology"],
|
| 209 |
+
"jurisprudence": ["law"],
|
| 210 |
+
"legal_and_moral_basis": ["other"],
|
| 211 |
+
"logical": ["philosophy"],
|
| 212 |
+
"machine_learning": ["computer science"],
|
| 213 |
+
"management": ["business"],
|
| 214 |
+
"marketing": ["business"],
|
| 215 |
+
"marxist_theory": ["philosophy"],
|
| 216 |
+
"modern_chinese": ["linguistics", "china specific"],
|
| 217 |
+
"nutrition": ["other"],
|
| 218 |
+
"philosophy": ["philosophy"],
|
| 219 |
+
"professional_accounting": ["business"],
|
| 220 |
+
"professional_law": ["law"],
|
| 221 |
+
"professional_medicine": ["other"],
|
| 222 |
+
"professional_psychology": ["psychology"],
|
| 223 |
+
"public_relations": ["politics"],
|
| 224 |
+
"security_study": ["politics"],
|
| 225 |
+
"sociology": ["culture"],
|
| 226 |
+
"sports_science": ["other"],
|
| 227 |
+
"traditional_chinese_medicine": ["other", "china specific"],
|
| 228 |
+
"virology": ["biology"],
|
| 229 |
+
"world_history": ["history"],
|
| 230 |
+
"world_religions": ["global"],
|
| 231 |
+
}
|
| 232 |
+
|
| 233 |
+
categories = {
|
| 234 |
+
"STEM": [
|
| 235 |
+
"physics",
|
| 236 |
+
"chemistry",
|
| 237 |
+
"biology",
|
| 238 |
+
"computer science",
|
| 239 |
+
"math",
|
| 240 |
+
"engineering",
|
| 241 |
+
"statistics",
|
| 242 |
+
],
|
| 243 |
+
"Humanities": ["history", "philosophy", "law", "arts", "literature", "global"],
|
| 244 |
+
"Social Science": [
|
| 245 |
+
"linguistics",
|
| 246 |
+
"business",
|
| 247 |
+
"politics",
|
| 248 |
+
"culture",
|
| 249 |
+
"economics",
|
| 250 |
+
"geography",
|
| 251 |
+
"psychology",
|
| 252 |
+
"education",
|
| 253 |
+
"sociology",
|
| 254 |
+
],
|
| 255 |
+
"Other": ["other"],
|
| 256 |
+
"China specific": ["china specific"],
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
TASK_NAME_MAPPING = defaultdict(list)
|
| 260 |
+
for k, v in categories.items():
|
| 261 |
+
for subject, subcat in subcategories.items():
|
| 262 |
+
for c in subcat:
|
| 263 |
+
if c in v:
|
| 264 |
+
TASK_NAME_MAPPING[k].append(subject)
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
choices = ["A", "B", "C", "D"]
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
def main(args):
|
| 271 |
+
model, tokenizer = load_models_tokenizer(args)
|
| 272 |
+
|
| 273 |
+
test_result = {}
|
| 274 |
+
for subject_name in tqdm(subcategories.keys()):
|
| 275 |
+
dev_file_path = os.path.join(args.eval_data_path, "dev", f"{subject_name}.csv")
|
| 276 |
+
test_file_path = os.path.join(
|
| 277 |
+
args.eval_data_path, "test", f"{subject_name}.csv"
|
| 278 |
+
)
|
| 279 |
+
dev_df = pd.read_csv(dev_file_path)
|
| 280 |
+
test_df = pd.read_csv(test_file_path)
|
| 281 |
+
|
| 282 |
+
score = eval_subject(
|
| 283 |
+
model,
|
| 284 |
+
tokenizer,
|
| 285 |
+
subject_name,
|
| 286 |
+
dev_df=dev_df,
|
| 287 |
+
test_df=test_df,
|
| 288 |
+
k=5,
|
| 289 |
+
few_shot=True,
|
| 290 |
+
save_result_dir=f"outs/cmmlu_eval_result",
|
| 291 |
+
)
|
| 292 |
+
test_result[subject_name] = score
|
| 293 |
+
cal_cmmlu(test_result)
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
if __name__ == "__main__":
|
| 297 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 298 |
+
parser.add_argument(
|
| 299 |
+
"-c",
|
| 300 |
+
"--checkpoint-path",
|
| 301 |
+
type=str,
|
| 302 |
+
help="Checkpoint path",
|
| 303 |
+
default="Qwen/Qwen-7B",
|
| 304 |
+
)
|
| 305 |
+
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
|
| 306 |
+
|
| 307 |
+
"""Provide extra arguments required for tasks."""
|
| 308 |
+
group = parser.add_argument_group(title="Evaluation options")
|
| 309 |
+
group.add_argument(
|
| 310 |
+
"-d", "--eval_data_path", type=str, required=True, help="Path to eval data"
|
| 311 |
+
)
|
| 312 |
+
group.add_argument(
|
| 313 |
+
"--max-seq-len",
|
| 314 |
+
type=int,
|
| 315 |
+
default=2048,
|
| 316 |
+
help="Size of the output generated text.",
|
| 317 |
+
)
|
| 318 |
+
group.add_argument(
|
| 319 |
+
"--debug", action="store_true", default=False, help="Print infos."
|
| 320 |
+
)
|
| 321 |
+
|
| 322 |
+
args = parser.parse_args()
|
| 323 |
+
set_seed(args.seed)
|
| 324 |
+
|
| 325 |
+
main(args)
|
eval/evaluate_gsm8k.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import torch
|
| 3 |
+
import argparse
|
| 4 |
+
import jsonlines
|
| 5 |
+
import numpy as np
|
| 6 |
+
import datasets
|
| 7 |
+
from datasets import load_from_disk, load_dataset
|
| 8 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 9 |
+
from transformers.generation import GenerationConfig
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
ANS_RE = re.compile(r"#### (\-?[0-9\.\,]+)")
|
| 13 |
+
INVALID_ANS = "[invalid]"
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def doc_to_text(doc):
|
| 17 |
+
return (
|
| 18 |
+
fewshot_prompt
|
| 19 |
+
+ "\nQuestion: "
|
| 20 |
+
+ doc["question"]
|
| 21 |
+
+ "\nLet's think step by step\n"
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def decode(tokens_list, tokenizer, raw_text_len):
|
| 26 |
+
sents = []
|
| 27 |
+
# print(len(tokens_list))
|
| 28 |
+
for tokens in tokens_list:
|
| 29 |
+
tokens = tokens.cpu().numpy().tolist()
|
| 30 |
+
sent = tokenizer.tokenizer.decode(tokens[raw_text_len:])
|
| 31 |
+
sent = sent.split("<|endoftext|>")[0]
|
| 32 |
+
sent = sent.split("\n\n\n")[0]
|
| 33 |
+
sent = sent.split("\n\n")[0]
|
| 34 |
+
sent = sent.split("Question:")[0]
|
| 35 |
+
sents.append(sent)
|
| 36 |
+
return sents
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def generate_sample(model, tokenizer, input_txt):
|
| 40 |
+
input_ids = tokenizer.tokenizer.encode(input_txt)
|
| 41 |
+
raw_text_len = len(input_ids)
|
| 42 |
+
context_enc = torch.tensor([input_ids]).to(model.device)
|
| 43 |
+
print(f"Input text: {input_txt}\n")
|
| 44 |
+
outputs = model.generate(context_enc)
|
| 45 |
+
output_text = decode(outputs, tokenizer, raw_text_len)[0]
|
| 46 |
+
print(f"\nOutput text: {output_text}\n")
|
| 47 |
+
return output_text
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def extract_answer_hf(completion):
|
| 51 |
+
match = ANS_RE.search(completion)
|
| 52 |
+
if match:
|
| 53 |
+
match_str = match.group(1).strip()
|
| 54 |
+
match_str = match_str.replace(",", "")
|
| 55 |
+
return eval(match_str)
|
| 56 |
+
else:
|
| 57 |
+
return INVALID_ANS
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def extract_answer(completion):
|
| 61 |
+
try:
|
| 62 |
+
last_number = re.findall(r"\d+", completion)[-1]
|
| 63 |
+
return eval(last_number)
|
| 64 |
+
except:
|
| 65 |
+
return INVALID_ANS
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def is_correct(completion, answer):
|
| 69 |
+
gold = extract_answer_hf(answer)
|
| 70 |
+
assert gold != INVALID_ANS, "No ground truth answer found in the document."
|
| 71 |
+
return extract_answer(completion) == gold
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
if __name__ == "__main__":
|
| 75 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 76 |
+
parser.add_argument(
|
| 77 |
+
"-c",
|
| 78 |
+
"--checkpoint-path",
|
| 79 |
+
type=str,
|
| 80 |
+
help="Checkpoint path",
|
| 81 |
+
default="Qwen/Qwen-7B",
|
| 82 |
+
)
|
| 83 |
+
parser.add_argument("-f", "--sample-input-file", type=str, default=None)
|
| 84 |
+
parser.add_argument(
|
| 85 |
+
"-o", "--sample-output-file", type=str, default="gsm8k_res.jsonl"
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
args = parser.parse_args()
|
| 89 |
+
|
| 90 |
+
fewshot_prompt = open("gsm8k_prompt.txt").read()
|
| 91 |
+
if args.sample_input_file is not None:
|
| 92 |
+
dataset = load_from_disk(args.sample_input_file)
|
| 93 |
+
else:
|
| 94 |
+
config = datasets.DownloadConfig(resume_download=True, max_retries=100)
|
| 95 |
+
dataset = load_dataset("gsm8k", "main", download_config=config)
|
| 96 |
+
|
| 97 |
+
test = dataset["test"]
|
| 98 |
+
|
| 99 |
+
print("Loading tokenizer ...")
|
| 100 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 101 |
+
args.checkpoint_path, trust_remote_code=True
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
print("Loading model ...")
|
| 105 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 106 |
+
args.checkpoint_path, device_map="auto", trust_remote_code=True
|
| 107 |
+
).eval()
|
| 108 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 109 |
+
args.checkpoint_path, trust_remote_code=True
|
| 110 |
+
)
|
| 111 |
+
model.generation_config.do_sample = False
|
| 112 |
+
|
| 113 |
+
f_output = jsonlines.Writer(open(args.sample_output_file, "w", encoding="utf-8"))
|
| 114 |
+
tot_length = test.num_rows
|
| 115 |
+
acc_res = []
|
| 116 |
+
for doc in test:
|
| 117 |
+
context = doc_to_text(doc)
|
| 118 |
+
completion = generate_sample(model, tokenizer, context)
|
| 119 |
+
answer = doc["answer"]
|
| 120 |
+
acc = is_correct(completion, answer)
|
| 121 |
+
doc["completion"] = completion
|
| 122 |
+
doc["acc"] = acc
|
| 123 |
+
f_output.write(doc)
|
| 124 |
+
acc_res.append(acc)
|
| 125 |
+
|
| 126 |
+
f_output.close()
|
| 127 |
+
print("Acc: ", np.mean(acc_res))
|
eval/evaluate_humaneval.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import tqdm
|
| 3 |
+
import torch
|
| 4 |
+
import jsonlines
|
| 5 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 6 |
+
from transformers.generation import GenerationConfig
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
git clone https://github.com/openai/human-eval
|
| 10 |
+
$ pip install -e human-eval
|
| 11 |
+
evaluate_functional_correctness sample-output-file
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def decode(tokens_list, tokenizer, raw_text_len):
|
| 16 |
+
sents = []
|
| 17 |
+
# print(len(tokens_list))
|
| 18 |
+
for tokens in tokens_list:
|
| 19 |
+
tokens = tokens.cpu().numpy().tolist()
|
| 20 |
+
sent = tokenizer.tokenizer.decode(tokens[raw_text_len:])
|
| 21 |
+
sent = sent.split("<|endoftext|>")[0]
|
| 22 |
+
sent = sent.split("\n\n\n")[0]
|
| 23 |
+
sent = sent.split("\n\n")[0]
|
| 24 |
+
sent = sent.split("def ")[0]
|
| 25 |
+
sents.append(sent)
|
| 26 |
+
return sents
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def generate_sample(model, tokenizer, input_txt):
|
| 30 |
+
input_ids = tokenizer.tokenizer.encode(input_txt)
|
| 31 |
+
raw_text_len = len(input_ids)
|
| 32 |
+
context_enc = torch.tensor([input_ids]).to(model.device)
|
| 33 |
+
print(f"Input text: {input_txt}\n")
|
| 34 |
+
outputs = model.generate(context_enc)
|
| 35 |
+
output_text = decode(outputs, tokenizer, raw_text_len)[0]
|
| 36 |
+
print(f"\nOutput text: \n{output_text}\n")
|
| 37 |
+
return output_text
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
if __name__ == "__main__":
|
| 41 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 42 |
+
parser.add_argument(
|
| 43 |
+
"-c",
|
| 44 |
+
"--checkpoint-path",
|
| 45 |
+
type=str,
|
| 46 |
+
help="Checkpoint path",
|
| 47 |
+
default="Qwen/Qwen-7B",
|
| 48 |
+
)
|
| 49 |
+
parser.add_argument(
|
| 50 |
+
"-f",
|
| 51 |
+
"--sample-input-file",
|
| 52 |
+
type=str,
|
| 53 |
+
default=None,
|
| 54 |
+
help="data path to HumanEval.jsonl",
|
| 55 |
+
)
|
| 56 |
+
parser.add_argument(
|
| 57 |
+
"-o", "--sample-output-file", type=str, default="HumanEval_res.jsonl"
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
args = parser.parse_args()
|
| 61 |
+
print("Loading tokenizer ...")
|
| 62 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 63 |
+
args.checkpoint_path, trust_remote_code=True
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
print("Loading model ...")
|
| 67 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 68 |
+
args.checkpoint_path, device_map="auto", trust_remote_code=True
|
| 69 |
+
).eval()
|
| 70 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 71 |
+
args.checkpoint_path, trust_remote_code=True
|
| 72 |
+
)
|
| 73 |
+
model.generation_config.do_sample = False
|
| 74 |
+
|
| 75 |
+
f_output = jsonlines.Writer(open(args.sample_output_file, "w", encoding="utf-8"))
|
| 76 |
+
|
| 77 |
+
f = jsonlines.open(args.sample_input_file)
|
| 78 |
+
with f_output as output:
|
| 79 |
+
for jobj in tqdm.tqdm(f, desc="task_idx"):
|
| 80 |
+
prompt = jobj["prompt"]
|
| 81 |
+
task_id = jobj["task_id"]
|
| 82 |
+
gen_sents = generate_sample(model, tokenizer, prompt)
|
| 83 |
+
gen_jobjs = {"task_id": task_id, "completion": gen_sents}
|
| 84 |
+
output.write(gen_jobjs)
|
| 85 |
+
f_output.close()
|
eval/evaluate_mmlu.py
ADDED
|
@@ -0,0 +1,315 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import numpy as np
|
| 5 |
+
import argparse
|
| 6 |
+
import torch
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
from transformers.trainer_utils import set_seed
|
| 9 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 10 |
+
from transformers.generation import GenerationConfig
|
| 11 |
+
|
| 12 |
+
"""
|
| 13 |
+
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
|
| 14 |
+
mkdir data/mmlu
|
| 15 |
+
mv data.tar data/mmlu
|
| 16 |
+
cd data/mmlu; tar xf data.tar
|
| 17 |
+
cd ../../
|
| 18 |
+
python eval/evaluate_mmlu.py -d data/mmlu/data/
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def load_models_tokenizer(args):
|
| 23 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 24 |
+
args.checkpoint_path, trust_remote_code=True
|
| 25 |
+
)
|
| 26 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 27 |
+
args.checkpoint_path, device_map="auto", trust_remote_code=True
|
| 28 |
+
).eval()
|
| 29 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 30 |
+
args.checkpoint_path, trust_remote_code=True
|
| 31 |
+
)
|
| 32 |
+
return model, tokenizer
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def format_example(line, include_answer=True):
|
| 36 |
+
example = "Question: " + line["question"]
|
| 37 |
+
for choice in choices:
|
| 38 |
+
example += f'\n{choice}. {line[f"{choice}"]}'
|
| 39 |
+
|
| 40 |
+
if include_answer:
|
| 41 |
+
example += "\nAnswer: " + line["answer"] + "\n\n"
|
| 42 |
+
else:
|
| 43 |
+
example += "\nAnswer:"
|
| 44 |
+
return example
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def generate_few_shot_prompt(k, subject, dev_df):
|
| 48 |
+
def format_subject(subject):
|
| 49 |
+
l = subject.split("_")
|
| 50 |
+
s = ""
|
| 51 |
+
for entry in l:
|
| 52 |
+
s += " " + entry
|
| 53 |
+
return s.strip()
|
| 54 |
+
|
| 55 |
+
prompt = "The following are multiple choice questions (with answers) about {}.\n\n".format(
|
| 56 |
+
format_subject(subject)
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
if k == -1:
|
| 60 |
+
k = dev_df.shape[0]
|
| 61 |
+
for i in range(k):
|
| 62 |
+
prompt += format_example(
|
| 63 |
+
dev_df.iloc[i, :],
|
| 64 |
+
include_answer=True,
|
| 65 |
+
)
|
| 66 |
+
return prompt
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def get_logits(tokenizer, model, inputs: List[str]):
|
| 70 |
+
input_ids = tokenizer(inputs, padding=False)["input_ids"]
|
| 71 |
+
input_ids = torch.tensor(input_ids, device=model.device)
|
| 72 |
+
|
| 73 |
+
if input_ids.shape[1] > args.max_seq_len:
|
| 74 |
+
input_ids = input_ids[:, input_ids.shape[1] - args.max_seq_len + 1 :]
|
| 75 |
+
tokens = {"input_ids": input_ids}
|
| 76 |
+
|
| 77 |
+
outputs = model(input_ids)["logits"]
|
| 78 |
+
logits = outputs[:, -1, :]
|
| 79 |
+
log_probs = torch.nn.functional.softmax(logits, dim=-1)
|
| 80 |
+
return log_probs, {"tokens": tokens}
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
@torch.no_grad()
|
| 84 |
+
def eval_subject(
|
| 85 |
+
model,
|
| 86 |
+
tokenizer,
|
| 87 |
+
subject_name,
|
| 88 |
+
test_df,
|
| 89 |
+
k=5,
|
| 90 |
+
dev_df=None,
|
| 91 |
+
few_shot=False,
|
| 92 |
+
save_result_dir=None,
|
| 93 |
+
**kwargs,
|
| 94 |
+
):
|
| 95 |
+
result = []
|
| 96 |
+
score = []
|
| 97 |
+
|
| 98 |
+
few_shot_prompt = (
|
| 99 |
+
generate_few_shot_prompt(k, subject_name, dev_df) if few_shot else []
|
| 100 |
+
)
|
| 101 |
+
all_probs = {"prob_A": [], "prob_B": [], "prob_C": [], "prob_D": []}
|
| 102 |
+
if args.debug:
|
| 103 |
+
print(f"few_shot_prompt: {few_shot_prompt}")
|
| 104 |
+
|
| 105 |
+
for _, row in tqdm(test_df.iterrows(), total=len(test_df)):
|
| 106 |
+
question = format_example(row, include_answer=False)
|
| 107 |
+
full_prompt = few_shot_prompt + question
|
| 108 |
+
|
| 109 |
+
output, input_info = get_logits(tokenizer, model, [full_prompt])
|
| 110 |
+
assert output.shape[0] == 1
|
| 111 |
+
logits = output.flatten()
|
| 112 |
+
|
| 113 |
+
softval = torch.nn.functional.softmax(
|
| 114 |
+
torch.tensor(
|
| 115 |
+
[
|
| 116 |
+
logits[tokenizer(" A")["input_ids"]],
|
| 117 |
+
logits[tokenizer(" B")["input_ids"]],
|
| 118 |
+
logits[tokenizer(" C")["input_ids"]],
|
| 119 |
+
logits[tokenizer(" D")["input_ids"]],
|
| 120 |
+
]
|
| 121 |
+
),
|
| 122 |
+
dim=0,
|
| 123 |
+
)
|
| 124 |
+
if softval.dtype in {torch.bfloat16, torch.float16}:
|
| 125 |
+
softval = softval.to(dtype=torch.float32)
|
| 126 |
+
probs = softval.detach().cpu().numpy()
|
| 127 |
+
|
| 128 |
+
for i, choice in enumerate(choices):
|
| 129 |
+
all_probs[f"prob_{choice}"].append(probs[i])
|
| 130 |
+
pred = {0: "A", 1: "B", 2: "C", 3: "D"}[np.argmax(probs)]
|
| 131 |
+
|
| 132 |
+
if "answer" in row:
|
| 133 |
+
correct = 1 if pred == row["answer"] else 0
|
| 134 |
+
score.append(correct)
|
| 135 |
+
if args.debug:
|
| 136 |
+
print(f'{question} pred: {pred} ref: {row["answer"]}')
|
| 137 |
+
result.append(pred)
|
| 138 |
+
|
| 139 |
+
if save_result_dir:
|
| 140 |
+
test_df["model_output"] = result
|
| 141 |
+
for i, choice in enumerate(choices):
|
| 142 |
+
test_df[f"prob_{choice}"] = all_probs[f"prob_{choice}"]
|
| 143 |
+
if score:
|
| 144 |
+
test_df["correctness"] = score
|
| 145 |
+
os.makedirs(save_result_dir, exist_ok=True)
|
| 146 |
+
test_df.to_csv(
|
| 147 |
+
os.path.join(save_result_dir, f"{subject_name}_result.csv"),
|
| 148 |
+
encoding="utf-8",
|
| 149 |
+
index=False,
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
return score
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def cal_mmlu(res):
|
| 156 |
+
acc_sum_dict = dict()
|
| 157 |
+
acc_norm_sum_dict = dict()
|
| 158 |
+
cnt_dict = dict()
|
| 159 |
+
acc_sum = 0.0
|
| 160 |
+
cnt = 0
|
| 161 |
+
hard_cnt = 0
|
| 162 |
+
hard_acc_sum = 0.0
|
| 163 |
+
|
| 164 |
+
for class_ in TASK_NAME_MAPPING.keys():
|
| 165 |
+
acc_sum_dict[class_] = 0.0
|
| 166 |
+
acc_norm_sum_dict[class_] = 0.0
|
| 167 |
+
cnt_dict[class_] = 0.0
|
| 168 |
+
|
| 169 |
+
for tt in TASK_NAME_MAPPING[class_]:
|
| 170 |
+
acc_sum += sum(res[tt])
|
| 171 |
+
cnt += len(res[tt])
|
| 172 |
+
|
| 173 |
+
acc_sum_dict[class_] += sum(res[tt])
|
| 174 |
+
cnt_dict[class_] += len(res[tt])
|
| 175 |
+
|
| 176 |
+
print("\n\n\n", "total cnt:", cnt, "\n")
|
| 177 |
+
for k in TASK_NAME_MAPPING.keys():
|
| 178 |
+
if k in cnt_dict:
|
| 179 |
+
print("%s ACC: %.2f " % (k, acc_sum_dict[k] / cnt_dict[k] * 100))
|
| 180 |
+
print("AVERAGE ACC:%.2f " % (acc_sum / cnt * 100))
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def main(args):
|
| 184 |
+
model, tokenizer = load_models_tokenizer(args)
|
| 185 |
+
|
| 186 |
+
dev_result = {}
|
| 187 |
+
for subject_name in tqdm(SUBJECTS):
|
| 188 |
+
# val_file_path = os.path.join(args.eval_data_path, 'val', f'{subject_name}_val.csv')
|
| 189 |
+
dev_file_path = os.path.join(
|
| 190 |
+
args.eval_data_path, "dev", f"{subject_name}_dev.csv"
|
| 191 |
+
)
|
| 192 |
+
test_file_path = os.path.join(
|
| 193 |
+
args.eval_data_path, "test", f"{subject_name}_test.csv"
|
| 194 |
+
)
|
| 195 |
+
# val_df = pd.read_csv(val_file_path, names=['question','A','B','C','D','answer'])
|
| 196 |
+
dev_df = pd.read_csv(
|
| 197 |
+
dev_file_path, names=["question", "A", "B", "C", "D", "answer"]
|
| 198 |
+
)
|
| 199 |
+
test_df = pd.read_csv(
|
| 200 |
+
test_file_path, names=["question", "A", "B", "C", "D", "answer"]
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
score = eval_subject(
|
| 204 |
+
model,
|
| 205 |
+
tokenizer,
|
| 206 |
+
subject_name,
|
| 207 |
+
test_df,
|
| 208 |
+
dev_df=dev_df,
|
| 209 |
+
k=5,
|
| 210 |
+
few_shot=True,
|
| 211 |
+
save_result_dir=f"outs/mmlu_eval_result",
|
| 212 |
+
)
|
| 213 |
+
dev_result[subject_name] = score
|
| 214 |
+
cal_mmlu(dev_result)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
TASK_NAME_MAPPING = {
|
| 218 |
+
"stem": [
|
| 219 |
+
"abstract_algebra",
|
| 220 |
+
"anatomy",
|
| 221 |
+
"astronomy",
|
| 222 |
+
"college_biology",
|
| 223 |
+
"college_chemistry",
|
| 224 |
+
"college_computer_science",
|
| 225 |
+
"college_mathematics",
|
| 226 |
+
"college_physics",
|
| 227 |
+
"computer_security",
|
| 228 |
+
"conceptual_physics",
|
| 229 |
+
"electrical_engineering",
|
| 230 |
+
"elementary_mathematics",
|
| 231 |
+
"high_school_biology",
|
| 232 |
+
"high_school_chemistry",
|
| 233 |
+
"high_school_computer_science",
|
| 234 |
+
"high_school_mathematics",
|
| 235 |
+
"high_school_physics",
|
| 236 |
+
"high_school_statistics",
|
| 237 |
+
"machine_learning",
|
| 238 |
+
],
|
| 239 |
+
"Humanities": [
|
| 240 |
+
"formal_logic",
|
| 241 |
+
"high_school_european_history",
|
| 242 |
+
"high_school_us_history",
|
| 243 |
+
"high_school_world_history",
|
| 244 |
+
"international_law",
|
| 245 |
+
"jurisprudence",
|
| 246 |
+
"logical_fallacies",
|
| 247 |
+
"moral_disputes",
|
| 248 |
+
"moral_scenarios",
|
| 249 |
+
"philosophy",
|
| 250 |
+
"prehistory",
|
| 251 |
+
"professional_law",
|
| 252 |
+
"world_religions",
|
| 253 |
+
],
|
| 254 |
+
"other": [
|
| 255 |
+
"business_ethics",
|
| 256 |
+
"college_medicine",
|
| 257 |
+
"human_aging",
|
| 258 |
+
"management",
|
| 259 |
+
"marketing",
|
| 260 |
+
"medical_genetics",
|
| 261 |
+
"miscellaneous",
|
| 262 |
+
"nutrition",
|
| 263 |
+
"professional_accounting",
|
| 264 |
+
"professional_medicine",
|
| 265 |
+
"virology",
|
| 266 |
+
"global_facts",
|
| 267 |
+
"clinical_knowledge",
|
| 268 |
+
],
|
| 269 |
+
"social": [
|
| 270 |
+
"econometrics",
|
| 271 |
+
"high_school_geography",
|
| 272 |
+
"high_school_government_and_politics",
|
| 273 |
+
"high_school_macroeconomics",
|
| 274 |
+
"high_school_microeconomics",
|
| 275 |
+
"high_school_psychology",
|
| 276 |
+
"human_sexuality",
|
| 277 |
+
"professional_psychology",
|
| 278 |
+
"public_relations",
|
| 279 |
+
"security_studies",
|
| 280 |
+
"sociology",
|
| 281 |
+
"us_foreign_policy",
|
| 282 |
+
],
|
| 283 |
+
}
|
| 284 |
+
SUBJECTS = [v for vl in TASK_NAME_MAPPING.values() for v in vl]
|
| 285 |
+
choices = ["A", "B", "C", "D"]
|
| 286 |
+
|
| 287 |
+
if __name__ == "__main__":
|
| 288 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 289 |
+
parser.add_argument(
|
| 290 |
+
"-c",
|
| 291 |
+
"--checkpoint-path",
|
| 292 |
+
type=str,
|
| 293 |
+
help="Checkpoint path",
|
| 294 |
+
default="Qwen/Qwen-7B",
|
| 295 |
+
)
|
| 296 |
+
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
|
| 297 |
+
parser.add_argument("--gpu", type=int, default=0, help="gpu id")
|
| 298 |
+
|
| 299 |
+
"""Provide extra arguments required for tasks."""
|
| 300 |
+
group = parser.add_argument_group(title="Evaluation options")
|
| 301 |
+
group.add_argument("-d", "--eval_data_path", type=str, help="Path to eval data")
|
| 302 |
+
group.add_argument(
|
| 303 |
+
"--max-seq-len",
|
| 304 |
+
type=int,
|
| 305 |
+
default=2048,
|
| 306 |
+
help="Size of the output generated text.",
|
| 307 |
+
)
|
| 308 |
+
group.add_argument(
|
| 309 |
+
"--debug", action="store_true", default=False, help="Print infos."
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
args = parser.parse_args()
|
| 313 |
+
set_seed(args.seed)
|
| 314 |
+
|
| 315 |
+
main(args)
|
eval/evaluate_plugin.py
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import pprint
|
| 5 |
+
|
| 6 |
+
import json5
|
| 7 |
+
import jsonlines
|
| 8 |
+
from rouge_score import rouge_scorer
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
from transformers import Agent, AutoModelForCausalLM, AutoTokenizer
|
| 11 |
+
from transformers.generation import GenerationConfig
|
| 12 |
+
from transformers.tools.evaluate_agent import evaluate_agent
|
| 13 |
+
from transformers.trainer_utils import set_seed
|
| 14 |
+
|
| 15 |
+
data_root_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "data")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def is_callable(response, golden):
|
| 19 |
+
return response["action"].strip().lower() == golden["action"].strip().lower()
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def process_res(response):
|
| 23 |
+
# parse response
|
| 24 |
+
response += "\n" # fix not-find bug
|
| 25 |
+
thought = response[: response.find("Action:")].strip()
|
| 26 |
+
action = response[
|
| 27 |
+
response.find("Action:") + len("Action:") : response.find("Action Input:")
|
| 28 |
+
].strip()
|
| 29 |
+
action_input = response[
|
| 30 |
+
response.find("Action Input:")
|
| 31 |
+
+ len("Action Input:") : response.find("Observation:")
|
| 32 |
+
].strip()
|
| 33 |
+
# TODO: This parsing result is incorrect if the response contains multiple Actions. To be fixed in the future.
|
| 34 |
+
observation = response[
|
| 35 |
+
response.find("Observation:") + len("Observation:") : response.rfind("Thought:")
|
| 36 |
+
].strip()
|
| 37 |
+
thought_last = response[
|
| 38 |
+
response.rfind("Thought:") + len("Thought:") : response.find("Final Answer:")
|
| 39 |
+
].strip()
|
| 40 |
+
final_answer = response[
|
| 41 |
+
response.find("Final Answer:") + len("Final Answer:") :
|
| 42 |
+
].strip()
|
| 43 |
+
try:
|
| 44 |
+
action_input = json.dumps(
|
| 45 |
+
json5.loads(action_input), ensure_ascii=False, sort_keys=True
|
| 46 |
+
)
|
| 47 |
+
except:
|
| 48 |
+
# print("JSON Load Error:", action_input)
|
| 49 |
+
pass
|
| 50 |
+
res_dict = {
|
| 51 |
+
"thought": thought,
|
| 52 |
+
"action": action,
|
| 53 |
+
"action_input": action_input,
|
| 54 |
+
"observation": observation,
|
| 55 |
+
"thought_last": thought_last,
|
| 56 |
+
"final_answer": final_answer,
|
| 57 |
+
}
|
| 58 |
+
return res_dict
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class _DummyTokenizer:
|
| 62 |
+
def tokenize(self, text: str):
|
| 63 |
+
return text.split()
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def _get_tokenized_string(tokenizer, text_list):
|
| 67 |
+
token_ids_list, tokenized_string_list = [], []
|
| 68 |
+
for text in text_list:
|
| 69 |
+
assert tokenizer is not None
|
| 70 |
+
token_ids = tokenizer.encode(text)
|
| 71 |
+
tokens_bytes = tokenizer.convert_ids_to_tokens(token_ids)
|
| 72 |
+
tokens = [token.decode("utf-8", errors="replace") for token in tokens_bytes]
|
| 73 |
+
tokenized_string = " ".join(tokens)
|
| 74 |
+
token_ids_list.append(token_ids)
|
| 75 |
+
tokenized_string_list.append(tokenized_string)
|
| 76 |
+
return token_ids_list, tokenized_string_list
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def eval_action(job):
|
| 80 |
+
response = job["gen"][0]
|
| 81 |
+
golden = job["response"]
|
| 82 |
+
|
| 83 |
+
if "Action:" in response:
|
| 84 |
+
response, golden = process_res(response), process_res(golden)
|
| 85 |
+
if is_callable(response, golden):
|
| 86 |
+
return True
|
| 87 |
+
return False
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def eval_action_input(job, tokenizer):
|
| 91 |
+
response = job["gen"][0]
|
| 92 |
+
golden = job["response"]
|
| 93 |
+
response, golden = process_res(response), process_res(golden)
|
| 94 |
+
query = job["prompt"]
|
| 95 |
+
|
| 96 |
+
job = {}
|
| 97 |
+
job["prompt"] = query
|
| 98 |
+
job["gen"] = response["action_input"]
|
| 99 |
+
job["response"] = golden["action_input"]
|
| 100 |
+
|
| 101 |
+
job["_gen_tok"], job["_gen_tok_str"] = _get_tokenized_string(
|
| 102 |
+
tokenizer, [response["action_input"]]
|
| 103 |
+
)
|
| 104 |
+
job["_reference_tok"], job["_reference_tok_str"] = _get_tokenized_string(
|
| 105 |
+
tokenizer, [golden["action_input"]]
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
scorer = rouge_scorer.RougeScorer(
|
| 109 |
+
["rouge1", "rouge2", "rougeL"], tokenizer=_DummyTokenizer()
|
| 110 |
+
)
|
| 111 |
+
score = scorer.score(job["_reference_tok_str"][0], job["_gen_tok_str"][0])
|
| 112 |
+
|
| 113 |
+
rouge = score["rougeL"].fmeasure
|
| 114 |
+
|
| 115 |
+
return rouge
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class QWenAgent(Agent):
|
| 119 |
+
"""
|
| 120 |
+
Agent that uses QWen model and tokenizer to generate code.
|
| 121 |
+
|
| 122 |
+
Example:
|
| 123 |
+
|
| 124 |
+
```py
|
| 125 |
+
agent = QWenAgent()
|
| 126 |
+
agent.run("Draw me a picture of rivers and lakes.")
|
| 127 |
+
```
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
def __init__(
|
| 131 |
+
self,
|
| 132 |
+
chat_prompt_template=None,
|
| 133 |
+
run_prompt_template=None,
|
| 134 |
+
additional_tools=None,
|
| 135 |
+
tokenizer=None,
|
| 136 |
+
model=None,
|
| 137 |
+
):
|
| 138 |
+
if tokenizer and model:
|
| 139 |
+
self.tokenizer = tokenizer
|
| 140 |
+
self.model = model
|
| 141 |
+
else:
|
| 142 |
+
checkpoint = "Qwen/Qwen-7B-Chat"
|
| 143 |
+
self.tokenizer = AutoTokenizer.from_pretrained(
|
| 144 |
+
checkpoint, trust_remote_code=True
|
| 145 |
+
)
|
| 146 |
+
self.model = (
|
| 147 |
+
AutoModelForCausalLM.from_pretrained(
|
| 148 |
+
checkpoint, device_map="auto", trust_remote_code=True
|
| 149 |
+
)
|
| 150 |
+
.cuda()
|
| 151 |
+
.eval()
|
| 152 |
+
)
|
| 153 |
+
self.model.generation_config = GenerationConfig.from_pretrained(
|
| 154 |
+
checkpoint, trust_remote_code=True
|
| 155 |
+
) # 可指定不同的生成长度、top_p等相关超参
|
| 156 |
+
self.model.generation_config.do_sample = False # greedy
|
| 157 |
+
|
| 158 |
+
super().__init__(
|
| 159 |
+
chat_prompt_template=chat_prompt_template,
|
| 160 |
+
run_prompt_template=run_prompt_template,
|
| 161 |
+
additional_tools=additional_tools,
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
def generate_one(self, prompt, stop):
|
| 165 |
+
# "Human:" 和 "Assistant:" 曾为通义千问的特殊保留字,需要替换为 "_HUMAN_:" 和 "_ASSISTANT_:"。这一问题将在未来版本修复。
|
| 166 |
+
prompt = prompt.replace("Human:", "_HUMAN_:").replace(
|
| 167 |
+
"Assistant:", "_ASSISTANT_:"
|
| 168 |
+
)
|
| 169 |
+
stop = [
|
| 170 |
+
item.replace("Human:", "_HUMAN_:").replace("Assistant:", "_ASSISTANT_:")
|
| 171 |
+
for item in stop
|
| 172 |
+
]
|
| 173 |
+
|
| 174 |
+
result, _ = self.model.chat(self.tokenizer, prompt, history=None)
|
| 175 |
+
for stop_seq in stop:
|
| 176 |
+
if result.endswith(stop_seq):
|
| 177 |
+
result = result[: -len(stop_seq)]
|
| 178 |
+
|
| 179 |
+
result = result.replace("_HUMAN_:", "Human:").replace(
|
| 180 |
+
"_ASSISTANT_:", "Assistant:"
|
| 181 |
+
)
|
| 182 |
+
return result
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def load_models_tokenizer(args):
|
| 186 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 187 |
+
args.checkpoint_path, trust_remote_code=True
|
| 188 |
+
)
|
| 189 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 190 |
+
args.checkpoint_path,
|
| 191 |
+
device_map="auto",
|
| 192 |
+
trust_remote_code=True,
|
| 193 |
+
bf16=True,
|
| 194 |
+
use_flash_attn=True,
|
| 195 |
+
).eval()
|
| 196 |
+
model.generation_config = GenerationConfig.from_pretrained(
|
| 197 |
+
args.checkpoint_path, trust_remote_code=True
|
| 198 |
+
)
|
| 199 |
+
model.generation_config.do_sample = False # use greedy decoding
|
| 200 |
+
return model, tokenizer
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def load_jobs(filename):
|
| 204 |
+
jobs = []
|
| 205 |
+
with jsonlines.open(os.path.join(data_root_path, filename), mode="r") as reader:
|
| 206 |
+
for job in reader:
|
| 207 |
+
jobs.append(job)
|
| 208 |
+
return jobs
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
def react_inference(filename, model, tokenizer):
|
| 212 |
+
filename_cache = filename + ".cache"
|
| 213 |
+
if os.path.exists(os.path.join(data_root_path, filename_cache)):
|
| 214 |
+
jobs = load_jobs(filename=filename_cache)
|
| 215 |
+
print("Loaded from", filename_cache)
|
| 216 |
+
else:
|
| 217 |
+
with open(os.path.join(data_root_path, filename_cache), "w") as f:
|
| 218 |
+
jobs = load_jobs(filename=filename)
|
| 219 |
+
print("Inference:", filename)
|
| 220 |
+
for job in tqdm(jobs):
|
| 221 |
+
response, history = model.chat(tokenizer, job["prompt"], history=None)
|
| 222 |
+
job["gen"] = [response]
|
| 223 |
+
f.writelines(json.dumps(job, ensure_ascii=False) + "\n")
|
| 224 |
+
print(filename_cache, "is saved.")
|
| 225 |
+
return jobs
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def main(args):
|
| 229 |
+
print("loading model weights")
|
| 230 |
+
if args.checkpoint_path is not None:
|
| 231 |
+
model, tokenizer = load_models_tokenizer(args)
|
| 232 |
+
else:
|
| 233 |
+
model, tokenizer = None, None
|
| 234 |
+
print("model loaded")
|
| 235 |
+
|
| 236 |
+
result = {}
|
| 237 |
+
# eval react positive
|
| 238 |
+
if args.eval_react_positive:
|
| 239 |
+
print("eval react positive ...")
|
| 240 |
+
acc_count = 0
|
| 241 |
+
rouge_mean = 0
|
| 242 |
+
jobs = react_inference(
|
| 243 |
+
filename=args.eval_react_positive_filename, model=model, tokenizer=tokenizer
|
| 244 |
+
)
|
| 245 |
+
for job in jobs:
|
| 246 |
+
if eval_action(job):
|
| 247 |
+
acc_count += 1
|
| 248 |
+
rouge = eval_action_input(job, tokenizer)
|
| 249 |
+
rouge_mean += rouge / len(jobs)
|
| 250 |
+
|
| 251 |
+
scores = {
|
| 252 |
+
"action_right_rate": acc_count / len(jobs),
|
| 253 |
+
"action_input_rouge": rouge_mean,
|
| 254 |
+
}
|
| 255 |
+
|
| 256 |
+
result.update({"react_positive": scores})
|
| 257 |
+
|
| 258 |
+
# eval react negative
|
| 259 |
+
if args.eval_react_negative:
|
| 260 |
+
print("eval react negative ...")
|
| 261 |
+
bad_count = 0
|
| 262 |
+
jobs = react_inference(
|
| 263 |
+
filename=args.eval_react_negative_filename, model=model, tokenizer=tokenizer
|
| 264 |
+
)
|
| 265 |
+
for job in jobs:
|
| 266 |
+
if "\nAction:" in job["gen"][0]:
|
| 267 |
+
bad_count += 1
|
| 268 |
+
scores = {"bad_rate": bad_count / len(jobs)}
|
| 269 |
+
result.update({"react_negative": scores})
|
| 270 |
+
|
| 271 |
+
# eval hfagent
|
| 272 |
+
if args.eval_hfagent:
|
| 273 |
+
print("eval hfagent ...")
|
| 274 |
+
agent = QWenAgent(model=model, tokenizer=tokenizer)
|
| 275 |
+
scores = evaluate_agent(agent, verbose=False, return_errors=False)
|
| 276 |
+
result.update({"hfagent": scores})
|
| 277 |
+
|
| 278 |
+
pp = pprint.PrettyPrinter(indent=4)
|
| 279 |
+
pp.pprint(result)
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
if __name__ == "__main__":
|
| 283 |
+
parser = argparse.ArgumentParser(description="Test HF checkpoint.")
|
| 284 |
+
parser.add_argument(
|
| 285 |
+
"-c",
|
| 286 |
+
"--checkpoint-path",
|
| 287 |
+
type=str,
|
| 288 |
+
help="Checkpoint path",
|
| 289 |
+
default="Qwen/Qwen-7B-Chat",
|
| 290 |
+
)
|
| 291 |
+
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
|
| 292 |
+
"""Provide extra arguments required for tasks."""
|
| 293 |
+
group = parser.add_argument_group(title="Evaluation options")
|
| 294 |
+
group.add_argument(
|
| 295 |
+
"--eval-react-positive",
|
| 296 |
+
action="store_true",
|
| 297 |
+
default=False,
|
| 298 |
+
help="Eval react positive.",
|
| 299 |
+
)
|
| 300 |
+
group.add_argument(
|
| 301 |
+
"--eval-react-positive-filename",
|
| 302 |
+
type=str,
|
| 303 |
+
default="exam_plugin_v1_react_positive.jsonl",
|
| 304 |
+
help="Eval react positive filename.",
|
| 305 |
+
)
|
| 306 |
+
group.add_argument(
|
| 307 |
+
"--eval-react-negative",
|
| 308 |
+
action="store_true",
|
| 309 |
+
default=False,
|
| 310 |
+
help="Eval react negative.",
|
| 311 |
+
)
|
| 312 |
+
group.add_argument(
|
| 313 |
+
"--eval-react-negative-filename",
|
| 314 |
+
type=str,
|
| 315 |
+
default="exam_plugin_v1_react_negative.jsonl",
|
| 316 |
+
help="Eval react negative filename.",
|
| 317 |
+
)
|
| 318 |
+
group.add_argument(
|
| 319 |
+
"--eval-hfagent", action="store_true", default=False, help="Eval hfagent."
|
| 320 |
+
)
|
| 321 |
+
|
| 322 |
+
args = parser.parse_args()
|
| 323 |
+
set_seed(args.seed)
|
| 324 |
+
|
| 325 |
+
main(args)
|
eval/gsm8k_prompt.txt
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Question: In 2004, there were 60 kids at a cookout. In 2005, half the number of kids came to the cookout as compared to 2004. In 2006, 2/3 as many kids came to the cookout as in 2005. How many kids came to the cookout in 2006?
|
| 2 |
+
Let's think step by step
|
| 3 |
+
In 2005, 60/2=30 kids came to the cookout.
|
| 4 |
+
In 2006, 30/3*2=20 kids came to the cookout.
|
| 5 |
+
The answer is 20
|
| 6 |
+
|
| 7 |
+
Question: Zilla spent 7% of her monthly earnings on rent, half of it on her other monthly expenses, and put the rest in her savings. If she spent $133 on her rent, how much does she deposit into her savings account in a month?
|
| 8 |
+
Let's think step by step
|
| 9 |
+
Since $133 is equal to 7% of her earnings, then 1% is equal to $133/7 = $19.
|
| 10 |
+
The total monthly earning of Zilla is represented by 100%, so $19 x 100 = $1900 is her monthly earnings.
|
| 11 |
+
So, $1900/2 = $950 is spent on her other monthly expenses.
|
| 12 |
+
The total amount spent on the rent and other monthly expenses is $133 + $950 = $1083.
|
| 13 |
+
Hence, she saves $1900 - $1083 = $817 per month.
|
| 14 |
+
The answer is 817
|
| 15 |
+
|
| 16 |
+
Question: If Buzz bought a pizza with 78 slices at a restaurant and then decided to share it with the waiter in the ratio of 5:8, with Buzz's ratio being 5, what's twenty less the number of slices of pizza that the waiter ate?
|
| 17 |
+
Let's think step by step
|
| 18 |
+
The total ratio representing the slices of pizza that Buzz bought is 5+8=13
|
| 19 |
+
If he shared the slices of pizza with the waiter, the waiter received a fraction of 8/13 of the total number of slices, which totals 8/13 * 78 = 48 slices
|
| 20 |
+
Twenty less the number of slices of pizza that the waiter ate is 48-20 = 28
|
| 21 |
+
The answer is 28
|
| 22 |
+
|
| 23 |
+
Question: Jame gets a raise to $20 per hour and works 40 hours a week. His old job was $16 an hour for 25 hours per week. How much more money does he make per year in his new job than the old job if he works 52 weeks a year?
|
| 24 |
+
Let's think step by step
|
| 25 |
+
He makes 20*40=$800 per week
|
| 26 |
+
He used to make 16*25=$400 per week
|
| 27 |
+
So his raise was 800-400=$400 per week
|
| 28 |
+
So he makes 400*52=$20,800 per year more
|
| 29 |
+
The answer is 20800
|
| 30 |
+
|
| 31 |
+
Question: Mr. Gardner bakes 20 cookies, 25 cupcakes, and 35 brownies for his second-grade class of 20 students. If he wants to give each student an equal amount of sweet treats, how many sweet treats will each student receive?
|
| 32 |
+
Let's think step by step
|
| 33 |
+
Mr. Gardner bakes a total of 20 + 25 + 35 = 80 sweet treats
|
| 34 |
+
Each student will receive 80 / 20 = 4 sweet treats
|
| 35 |
+
The answer is 4
|
| 36 |
+
|
| 37 |
+
Question: A used car lot has 24 cars and motorcycles (in total) for sale. A third of the vehicles are motorcycles, and a quarter of the cars have a spare tire included. How many tires are on the used car lot’s vehicles in all?
|
| 38 |
+
Let's think step by step
|
| 39 |
+
The used car lot has 24 / 3 = 8 motorcycles with 2 tires each.
|
| 40 |
+
The lot has 24 - 8 = 16 cars for sale
|
| 41 |
+
There are 16 / 4 = 4 cars with a spare tire with 5 tires each.
|
| 42 |
+
The lot has 16 - 4 = 12 cars with 4 tires each.
|
| 43 |
+
Thus, the used car lot’s vehicles have 8 * 2 + 4 * 5 + 12 * 4 = 16 + 20 + 48 = 84 tires in all.
|
| 44 |
+
The answer is 84
|
| 45 |
+
|
| 46 |
+
Question: Norma takes her clothes to the laundry. She leaves 9 T-shirts and twice as many sweaters as T-shirts in the washer. When she returns she finds 3 sweaters and triple the number of T-shirts. How many items are missing?
|
| 47 |
+
Let's think step by step
|
| 48 |
+
Norma left 9 T-shirts And twice as many sweaters, she took 9 * 2= 18 sweaters
|
| 49 |
+
Adding the T-shirts and sweaters, Norma left 9 + 18 = 27 clothes
|
| 50 |
+
When she came back, she found 3 sweaters And triple the number of T-shirts, she found 3 * 3 = 9 T-shirts
|
| 51 |
+
Adding the T-shirts and sweaters, Norma found 3 + 9 = 12 clothes
|
| 52 |
+
Subtracting the clothes she left from the clothes she found, 27 - 12 = 15 clothes are missing
|
| 53 |
+
The answer is 15
|
| 54 |
+
|
| 55 |
+
Question: Adam has an orchard. Every day for 30 days he picks 4 apples from his orchard. After a month, Adam has collected all the remaining apples, which were 230. How many apples in total has Adam collected from his orchard?
|
| 56 |
+
Let's think step by step
|
| 57 |
+
During 30 days Adam picked 4 * 30 = 120 apples.
|
| 58 |
+
So in total with all the remaining apples, he picked 120 + 230 = 350 apples from his orchard.
|
| 59 |
+
The answer is 350
|