Spaces:
Runtime error

Runtime error
Commit
•
a992504
1
Parent(s):
1ce7f5c
upload files
Browse files- .gitattributes +3 -0
- Images/IMG-20220413-WA0005.jpg +0 -0
- Images/analytics.png +0 -0
- Images/pipeline.png +0 -0
- app.py +167 -0
- videos/Fairly-used.mp4 +3 -0
- videos/movie-recommender.mp4 +3 -0
- videos/music-mood.mp4 +3 -0
- videos/requirements.txt +1 -0
.gitattributes
CHANGED
|
@@ -35,3 +35,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 35 |
my_portfolio/videos/Fairly-used.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 36 |
my_portfolio/videos/movie-recommender.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
my_portfolio/videos/music-mood.mp4 filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
my_portfolio/videos/Fairly-used.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 36 |
my_portfolio/videos/movie-recommender.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
my_portfolio/videos/music-mood.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
videos/Fairly-used.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
videos/movie-recommender.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
videos/music-mood.mp4 filter=lfs diff=lfs merge=lfs -text
|
Images/IMG-20220413-WA0005.jpg
ADDED

|
Images/analytics.png
ADDED

|
Images/pipeline.png
ADDED
|
app.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
st.title(' _Welcome to my Projects Portfolio_ ')
|
| 8 |
+
|
| 9 |
+
with st.sidebar:
|
| 10 |
+
image = Image.open("/Images/IMG-20220413-WA0005.jpg")
|
| 11 |
+
st.image(image)
|
| 12 |
+
st.subheader("Interest")
|
| 13 |
+
st.markdown("""
|
| 14 |
+
- Football
|
| 15 |
+
- Reading
|
| 16 |
+
- Cycling
|
| 17 |
+
""")
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
col1, col2 = st.columns(2)
|
| 22 |
+
with col1:
|
| 23 |
+
st.write("Name: Abubakar Muhammed Muktar")
|
| 24 |
+
st.write("Status: Masters Student, Data Science & Analytics")
|
| 25 |
+
st.write("School: EPITA")
|
| 26 |
+
with col2:
|
| 27 |
+
st.write("Strength: Serial learning, knowing I can always improve.")
|
| 28 |
+
st.write("Favourite Quote: In God we trust, Everyone else bring data!")
|
| 29 |
+
st.header("Data Science and Engineering Project Section")
|
| 30 |
+
with st.expander("PROJECT 1: Fairly Used Car Prediction Platform"):
|
| 31 |
+
st.subheader('Fairly Used Car Prediction Platform')
|
| 32 |
+
st.write("This project is ...")
|
| 33 |
+
st.markdown("""
|
| 34 |
+
- Created a price estimation model for fairly used car using Linear Regression
|
| 35 |
+
- Developed a web platform Using Streamlit and deployed the model as a service\n
|
| 36 |
+
- Platform can predict take direct input from a user or take a csv file and run predictions on them\n
|
| 37 |
+
- Used postgres to save user predictions and user can query past prediction from the database\n
|
| 38 |
+
- Airflow to schedule data ingestion and prediction jobs\n
|
| 39 |
+
- Used Grafana to monitor model and MLFlow for retraining.
|
| 40 |
+
""")
|
| 41 |
+
|
| 42 |
+
st.markdown("[Project CODE](https://github.com/sadiksmart0/Used-Car-ML)")
|
| 43 |
+
video_file = open('C:/Users/A.M. MUKTAR/my_portfolio/videos/Fairly-used.mp4', 'rb')
|
| 44 |
+
video_bytes = video_file.read()
|
| 45 |
+
st.video(video_bytes)
|
| 46 |
+
|
| 47 |
+
with st.expander("PROJECT 2: Music Emotion Recognition and Recommendatation."):
|
| 48 |
+
st.subheader('Music Emotion Recognition and Recommendatation')
|
| 49 |
+
st.write("This project is ...")
|
| 50 |
+
st.markdown("""
|
| 51 |
+
- Collaborated and developed a state-of-the-art deep learning model using BERT and gensims Doc2Vec for recognizing song emotion and give recommendations based on that given lyrics, song title and artist name.
|
| 52 |
+
- Deployed the model on Heroku and serve the it using FastApi.
|
| 53 |
+
- Develop and deployed the app on streamlit.
|
| 54 |
+
- Presented the work as part of our masters thesis.
|
| 55 |
+
""")
|
| 56 |
+
|
| 57 |
+
st.markdown("[Project CODE](https://github.com/anthonybassaf/music-mood-recognition)")
|
| 58 |
+
video_file = open('videos/music-mood.mp4', 'rb')
|
| 59 |
+
video_bytes = video_file.read()
|
| 60 |
+
st.video(video_bytes)
|
| 61 |
+
|
| 62 |
+
with st.expander("PROJECT 3: Brain Tumor Segmentation"):
|
| 63 |
+
st.subheader('Brain Tumor Segmentation')
|
| 64 |
+
st.write("This project is ...")
|
| 65 |
+
st.markdown("""
|
| 66 |
+
- Created a deep learning model based on the U-net architecture to segment brain tumor images.
|
| 67 |
+
- Used tensorflow in the implementation.
|
| 68 |
+
- Engineered the data into desired format.
|
| 69 |
+
- Evaluated model performance based on Dice loss
|
| 70 |
+
""")
|
| 71 |
+
|
| 72 |
+
st.markdown("[Project CODE](https://github.com/sadiksmart0/Image-seg)")
|
| 73 |
+
video_file = open('videos/Fairly-used.mp4', 'rb')
|
| 74 |
+
video_bytes = video_file.read()
|
| 75 |
+
st.video(video_bytes)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
with st.expander("PROJECT 4: Movie Recommendatation system."):
|
| 79 |
+
st.subheader('Movie Recommendatation system.')
|
| 80 |
+
st.write("This project is ...")
|
| 81 |
+
st.markdown("""
|
| 82 |
+
- Implemented a movie recommendation system for using the cosine similarity, users and movie rating.
|
| 83 |
+
- Scrape the web for movie posters and details using BeautifulSoup
|
| 84 |
+
- Built a streamlit app for the recommendation plaform
|
| 85 |
+
- Employed TF-IDF for tokenization.
|
| 86 |
+
""")
|
| 87 |
+
|
| 88 |
+
st.markdown("[Project CODE](https://github.com/sadiksmart0/Movie-Recommender)")
|
| 89 |
+
video_file = open('videos/movie-recommender.mp4', 'rb')
|
| 90 |
+
video_bytes = video_file.read()
|
| 91 |
+
st.video(video_bytes)
|
| 92 |
+
|
| 93 |
+
with st.expander("PROJECT 5: End-to-End Data Engineering Project using Kaggle YouTube Trending Dataset"):
|
| 94 |
+
st.subheader('Movie Recommendatation system.')
|
| 95 |
+
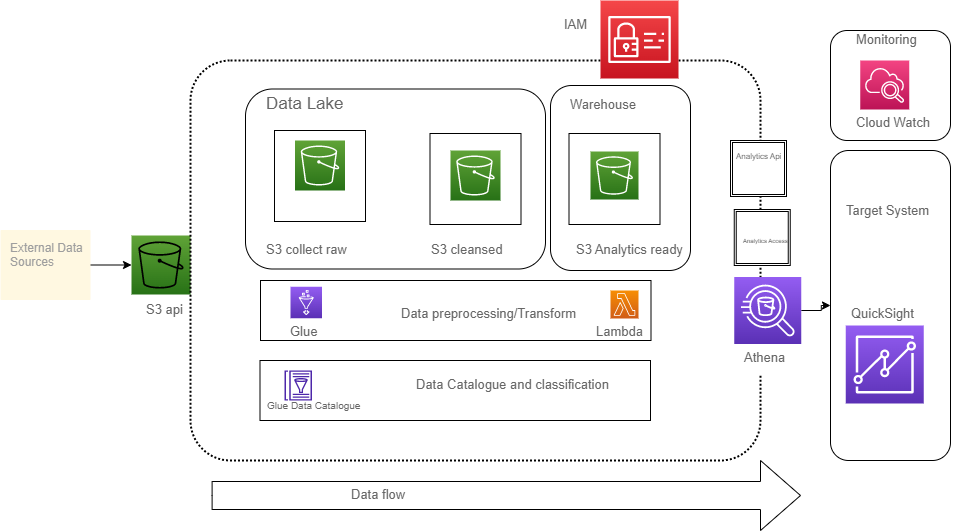
st.write("This project intends to manage, simplify, and analyze structured and semi-structured YouTube video data based on video categories and trending metrics in a secure manner.")
|
| 96 |
+
st.markdown("""
|
| 97 |
+
- Implement the data pipeline completely using AWS cloud.
|
| 98 |
+
- Data Lake to hold raw ingested data using Amazon S3
|
| 99 |
+
- Used AWS Lambda to preprocess the data to a parquet.
|
| 100 |
+
- Data Warehouse to hold cleansed data in Amazon S3
|
| 101 |
+
- Catalogue the data using AWS Glue.
|
| 102 |
+
- Used Athena to query the data.
|
| 103 |
+
- Used IAM to create rule and policies to allow access accross these tools
|
| 104 |
+
- Used QuickSight to run analysis on our final data
|
| 105 |
+
- Used cloudwatch to monitor all of the processes for easy tracking.
|
| 106 |
+
""")
|
| 107 |
+
image1 = Image.open("C:/Users/A.M. MUKTAR/my_portfolio/Images/pipeline.png")
|
| 108 |
+
image2 = Image.open("C:/Users/A.M. MUKTAR/my_portfolio/Images/analytics.png")
|
| 109 |
+
st.image(image1)
|
| 110 |
+
st.image(image2)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
st.header("Data Analysis Project Section")
|
| 114 |
+
st.subheader('Pandas')
|
| 115 |
+
with st.expander("PROJECT 1: Analysis of Ligue 1 From 2010-2021"):
|
| 116 |
+
st.subheader('Analysis of Ligue 1 From 2010-2021')
|
| 117 |
+
st.write("This project intends to ...")
|
| 118 |
+
st.markdown("""
|
| 119 |
+
- Collaborated and developed a state-of-the-art deep learning model using BERT and gensims Doc2Vec for recognizing song emotion and give recommendations based on that given lyrics, song title and artist name.
|
| 120 |
+
- Deployed the model on Heroku and serve the it using FastApi.
|
| 121 |
+
- Develop and deployed the app on streamlit.
|
| 122 |
+
- Presented the work as part of our masters thesis.
|
| 123 |
+
""")
|
| 124 |
+
# # st.image("https://static.streamlit.io/examples/dice.jpg")
|
| 125 |
+
st.markdown("[Project CODE](https://github.com/sadiksmart0/DataVisualizationProject)")
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
with st.expander("PROJECT 1: Analysis of Google play Apps"):
|
| 129 |
+
st.subheader('Analysis of Google play Apps')
|
| 130 |
+
st.write("This project intends to ...")
|
| 131 |
+
st.markdown("""
|
| 132 |
+
- Collaborated and developed a state-of-the-art deep learning model using BERT and gensims Doc2Vec for recognizing song emotion and give recommendations based on that given lyrics, song title and artist name.
|
| 133 |
+
- Deployed the model on Heroku and serve the it using FastApi.
|
| 134 |
+
- Develop and deployed the app on streamlit.
|
| 135 |
+
- Presented the work as part of our masters thesis.
|
| 136 |
+
""")
|
| 137 |
+
# # st.image("https://static.streamlit.io/examples/dice.jpg")
|
| 138 |
+
st.markdown("[Project CODE](https://github.com/sadiksmart0/Android-App-Market/blob/main/Android%20App%20Market.ipynb)")
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
with st.expander("PROJECT 1: Analysis of Netflix movies"):
|
| 142 |
+
st.subheader('Analysis of Netflix movies')
|
| 143 |
+
st.write("This project intends to ...")
|
| 144 |
+
st.markdown("""
|
| 145 |
+
- Collaborated and developed a state-of-the-art deep learning model using BERT and gensims Doc2Vec for recognizing song emotion and give recommendations based on that given lyrics, song title and artist name.
|
| 146 |
+
- Deployed the model on Heroku and serve the it using FastApi.
|
| 147 |
+
- Develop and deployed the app on streamlit.
|
| 148 |
+
- Presented the work as part of our masters thesis.
|
| 149 |
+
""")
|
| 150 |
+
# # st.image("https://static.streamlit.io/examples/dice.jpg")
|
| 151 |
+
st.markdown("[Project CODE](https://github.com/sadiksmart0/Netflix-Movies/blob/main/Netflix-Movies.ipynb)")
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
with st.expander("PROJECT 1: Analysis of Nobel Prize Winners"):
|
| 155 |
+
st.subheader('Analysis of Nobel Prize Winners')
|
| 156 |
+
st.write("This project intends to ...")
|
| 157 |
+
st.markdown("""
|
| 158 |
+
- Collaborated and developed a state-of-the-art deep learning model using BERT and gensims Doc2Vec for recognizing song emotion and give recommendations based on that given lyrics, song title and artist name.
|
| 159 |
+
- Deployed the model on Heroku and serve the it using FastApi.
|
| 160 |
+
- Develop and deployed the app on streamlit.
|
| 161 |
+
- Presented the work as part of our masters thesis.
|
| 162 |
+
""")
|
| 163 |
+
# # st.image("https://static.streamlit.io/examples/dice.jpg")
|
| 164 |
+
st.markdown("[Project CODE](https://github.com/sadiksmart0/Nobel-Prize/blob/main/Nobel_Prize.ipynb)")
|
| 165 |
+
|
| 166 |
+
st.subheader('Tableau')
|
| 167 |
+
st.subheader('Dataiku')
|
videos/Fairly-used.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a8af4fe6ef00f765a7f1496652d94ee307edef547ea560811daeae7e9b57a71
|
| 3 |
+
size 27906155
|
videos/movie-recommender.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ed8dfb4881b256ce9dea8690195ed66c2a1d56cd40ebdcd00cee4ceb8871e04b
|
| 3 |
+
size 19207311
|
videos/music-mood.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:422eac24929a3a900f1d4354b7987846dc0948625e5efe2f30e4f97bdee4fef0
|
| 3 |
+
size 19784159
|
videos/requirements.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
streamlit==1.19.0
|