Spaces:
Running

Running
finalizing
Browse files- air_quality_model/images/feature_importance.png +0 -0
- air_quality_model/images/pm25_hindcast.png +0 -0
- air_quality_model/model.json +0 -0
- app_streamlit.py +12 -11
- backfill.ipynb +587 -0
- backfill.py +0 -62
- data/lahore.csv +0 -0
- debug.ipynb +64 -363
- functions/__pycache__/util.cpython-312.pyc +0 -0
- functions/{merge_df.py → retrieve.py} +4 -1
- functions/util.py +13 -9
- inference_pipeline.py +1 -95
- training.py +270 -0
air_quality_model/images/feature_importance.png
ADDED
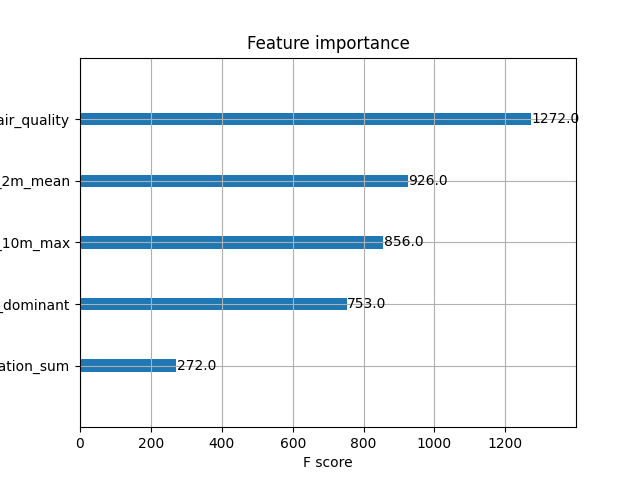
|
air_quality_model/images/pm25_hindcast.png
ADDED
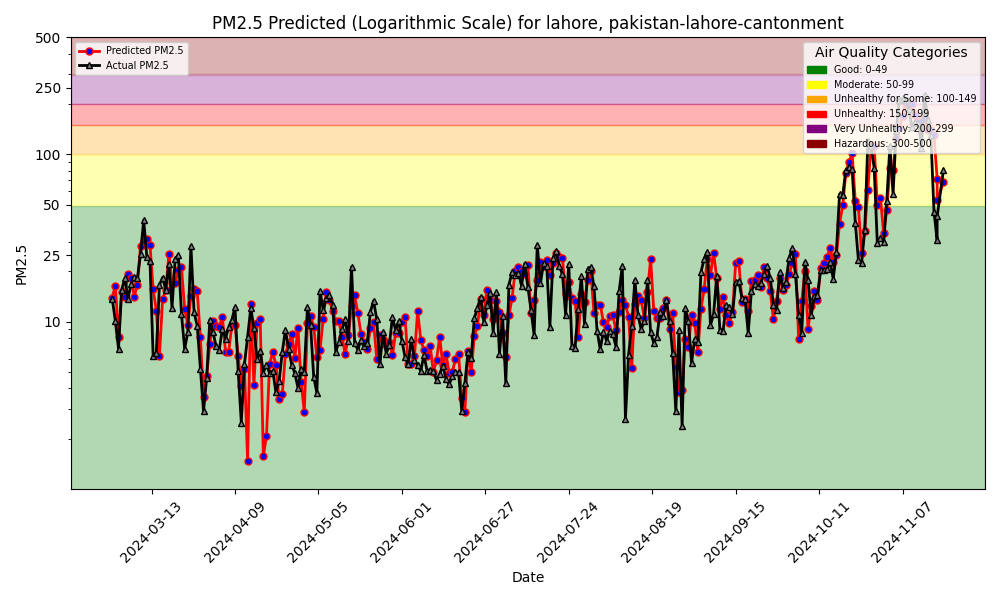
|
air_quality_model/model.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
app_streamlit.py
CHANGED
|
@@ -3,7 +3,7 @@ import pandas as pd
|
|
| 3 |
import numpy as np
|
| 4 |
import datetime
|
| 5 |
import hopsworks
|
| 6 |
-
from functions import figure,
|
| 7 |
import os
|
| 8 |
import pickle
|
| 9 |
import plotly.express as px
|
|
@@ -13,17 +13,18 @@ import os
|
|
| 13 |
|
| 14 |
|
| 15 |
# Real data
|
| 16 |
-
|
|
|
|
|
|
|
| 17 |
|
| 18 |
# Dummmy data
|
| 19 |
-
size = 400
|
| 20 |
-
data = {
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
}
|
| 25 |
-
df = pd.DataFrame(data)
|
| 26 |
-
|
| 27 |
|
| 28 |
# Page configuration
|
| 29 |
|
|
@@ -42,5 +43,5 @@ st.subheader('Forecast and hindcast')
|
|
| 42 |
st.subheader('Unit: PM25 - particle matter of diameter < 2.5 micrometers')
|
| 43 |
|
| 44 |
# Plotting
|
| 45 |
-
fig = figure.plot(df)
|
| 46 |
st.plotly_chart(fig, use_container_width=True)
|
|
|
|
| 3 |
import numpy as np
|
| 4 |
import datetime
|
| 5 |
import hopsworks
|
| 6 |
+
from functions import figure, retrieve
|
| 7 |
import os
|
| 8 |
import pickle
|
| 9 |
import plotly.express as px
|
|
|
|
| 13 |
|
| 14 |
|
| 15 |
# Real data
|
| 16 |
+
today = datetime.today().strftime('%Y-%m-%d')
|
| 17 |
+
df = retrieve.get_merged_dataframe()
|
| 18 |
+
n = len(df[df['pm25'].isna()]) - 1
|
| 19 |
|
| 20 |
# Dummmy data
|
| 21 |
+
# size = 400
|
| 22 |
+
# data = {
|
| 23 |
+
# 'date': pd.date_range(start='2023-01-01', periods=size, freq='D'),
|
| 24 |
+
# 'pm25': np.random.randint(50, 150, size=size),
|
| 25 |
+
# 'predicted_pm25': np.random.randint(50, 150, size=size)
|
| 26 |
+
# }
|
| 27 |
+
# df = pd.DataFrame(data)
|
|
|
|
| 28 |
|
| 29 |
# Page configuration
|
| 30 |
|
|
|
|
| 43 |
st.subheader('Unit: PM25 - particle matter of diameter < 2.5 micrometers')
|
| 44 |
|
| 45 |
# Plotting
|
| 46 |
+
fig = figure.plot(df, n=n)
|
| 47 |
st.plotly_chart(fig, use_container_width=True)
|
backfill.ipynb
ADDED
|
@@ -0,0 +1,587 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"name": "stdout",
|
| 10 |
+
"output_type": "stream",
|
| 11 |
+
"text": [
|
| 12 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"Logged in to project, explore it here https://c.app.hopsworks.ai:443/p/1160340\n",
|
| 15 |
+
"2024-11-21 05:38:56,037 WARNING: using legacy validation callback\n",
|
| 16 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 17 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 18 |
+
"Deleted air_quality_fv/1\n",
|
| 19 |
+
"Deleted air_quality/1\n",
|
| 20 |
+
"Deleted weather/1\n",
|
| 21 |
+
"Deleted aq_predictions/1\n",
|
| 22 |
+
"Deleted model air_quality_xgboost_model/1\n",
|
| 23 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 24 |
+
"No SENSOR_LOCATION_JSON secret found\n"
|
| 25 |
+
]
|
| 26 |
+
}
|
| 27 |
+
],
|
| 28 |
+
"source": [
|
| 29 |
+
"import datetime\n",
|
| 30 |
+
"import requests\n",
|
| 31 |
+
"import pandas as pd\n",
|
| 32 |
+
"import hopsworks\n",
|
| 33 |
+
"import datetime\n",
|
| 34 |
+
"from pathlib import Path\n",
|
| 35 |
+
"from functions import util\n",
|
| 36 |
+
"import json\n",
|
| 37 |
+
"import re\n",
|
| 38 |
+
"import os\n",
|
| 39 |
+
"import warnings\n",
|
| 40 |
+
"warnings.filterwarnings(\"ignore\")\n",
|
| 41 |
+
"\n",
|
| 42 |
+
"AQI_API_KEY = os.getenv('AQI_API_KEY')\n",
|
| 43 |
+
"api_key = os.getenv('HOPSWORKS_API_KEY')\n",
|
| 44 |
+
"project_name = os.getenv('HOPSWORKS_PROJECT')\n",
|
| 45 |
+
"project = hopsworks.login(project=project_name, api_key_value=api_key)\n",
|
| 46 |
+
"util.purge_project(project)"
|
| 47 |
+
]
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"cell_type": "code",
|
| 51 |
+
"execution_count": 2,
|
| 52 |
+
"metadata": {},
|
| 53 |
+
"outputs": [
|
| 54 |
+
{
|
| 55 |
+
"name": "stdout",
|
| 56 |
+
"output_type": "stream",
|
| 57 |
+
"text": [
|
| 58 |
+
"File successfully found at the path: data/lahore.csv\n"
|
| 59 |
+
]
|
| 60 |
+
}
|
| 61 |
+
],
|
| 62 |
+
"source": [
|
| 63 |
+
"country=\"pakistan\"\n",
|
| 64 |
+
"city = \"lahore\"\n",
|
| 65 |
+
"street = \"pakistan-lahore-cantonment\"\n",
|
| 66 |
+
"aqicn_url=\"https://api.waqi.info/feed/A74005\"\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"latitude, longitude = util.get_city_coordinates(city)\n",
|
| 69 |
+
"today = datetime.date.today()\n",
|
| 70 |
+
"\n",
|
| 71 |
+
"csv_file=\"data/lahore.csv\"\n",
|
| 72 |
+
"util.check_file_path(csv_file)"
|
| 73 |
+
]
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"cell_type": "code",
|
| 77 |
+
"execution_count": 3,
|
| 78 |
+
"metadata": {},
|
| 79 |
+
"outputs": [
|
| 80 |
+
{
|
| 81 |
+
"name": "stdout",
|
| 82 |
+
"output_type": "stream",
|
| 83 |
+
"text": [
|
| 84 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n"
|
| 85 |
+
]
|
| 86 |
+
}
|
| 87 |
+
],
|
| 88 |
+
"source": [
|
| 89 |
+
"secrets = util.secrets_api(project.name)\n",
|
| 90 |
+
"try:\n",
|
| 91 |
+
" secrets.create_secret(\"AQI_API_KEY\", AQI_API_KEY)\n",
|
| 92 |
+
"except hopsworks.RestAPIError:\n",
|
| 93 |
+
" AQI_API_KEY = secrets.get_secret(\"AQI_API_KEY\").value"
|
| 94 |
+
]
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"cell_type": "code",
|
| 98 |
+
"execution_count": 4,
|
| 99 |
+
"metadata": {},
|
| 100 |
+
"outputs": [],
|
| 101 |
+
"source": [
|
| 102 |
+
"try:\n",
|
| 103 |
+
" aq_today_df = util.get_pm25(aqicn_url, country, city, street, today, AQI_API_KEY)\n",
|
| 104 |
+
"except hopsworks.RestAPIError:\n",
|
| 105 |
+
" print(\"It looks like the AQI_API_KEY doesn't work for your sensor. Is the API key correct? Is the sensor URL correct?\")\n"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": null,
|
| 111 |
+
"metadata": {},
|
| 112 |
+
"outputs": [
|
| 113 |
+
{
|
| 114 |
+
"name": "stdout",
|
| 115 |
+
"output_type": "stream",
|
| 116 |
+
"text": [
|
| 117 |
+
"<class 'pandas.core.frame.DataFrame'>\n",
|
| 118 |
+
"RangeIndex: 1802 entries, 0 to 1801\n",
|
| 119 |
+
"Data columns (total 2 columns):\n",
|
| 120 |
+
" # Column Non-Null Count Dtype \n",
|
| 121 |
+
"--- ------ -------------- ----- \n",
|
| 122 |
+
" 0 date 1802 non-null object \n",
|
| 123 |
+
" 1 pm25 1802 non-null float32\n",
|
| 124 |
+
"dtypes: float32(1), object(1)\n",
|
| 125 |
+
"memory usage: 21.2+ KB\n"
|
| 126 |
+
]
|
| 127 |
+
},
|
| 128 |
+
{
|
| 129 |
+
"data": {
|
| 130 |
+
"text/plain": [
|
| 131 |
+
"'2019-12-09'"
|
| 132 |
+
]
|
| 133 |
+
},
|
| 134 |
+
"execution_count": 6,
|
| 135 |
+
"metadata": {},
|
| 136 |
+
"output_type": "execute_result"
|
| 137 |
+
}
|
| 138 |
+
],
|
| 139 |
+
"source": [
|
| 140 |
+
"aq_today_df.head()\n",
|
| 141 |
+
"\n",
|
| 142 |
+
"df = pd.read_csv(csv_file, parse_dates=['date'], skipinitialspace=True)\n",
|
| 143 |
+
"\n",
|
| 144 |
+
"# These commands will succeed if your CSV file didn't have a `median` or `timestamp` column\n",
|
| 145 |
+
"df = df.rename(columns={\"median\": \"pm25\"})\n",
|
| 146 |
+
"# df = df.rename(columns={\"timestamp\": \"date\"})\n",
|
| 147 |
+
"df['date'] = pd.to_datetime(df['date']).dt.date\n",
|
| 148 |
+
"\n",
|
| 149 |
+
"df_aq = df[['date', 'pm25']]\n",
|
| 150 |
+
"df_aq['pm25'] = df_aq['pm25'].astype('float32')\n",
|
| 151 |
+
"df_aq.info()\n",
|
| 152 |
+
"df_aq.dropna(inplace=True)\n",
|
| 153 |
+
"df_aq['country']=country\n",
|
| 154 |
+
"df_aq['city']=city\n",
|
| 155 |
+
"df_aq['street']=street\n",
|
| 156 |
+
"df_aq['url']=aqicn_url\n",
|
| 157 |
+
"df_aq\n",
|
| 158 |
+
"\n",
|
| 159 |
+
"df_aq =df_aq.set_index(\"date\")\n",
|
| 160 |
+
"df_aq['past_air_quality'] = df_aq['pm25'].rolling(3).mean()\n",
|
| 161 |
+
"df_aq[\"past_air_quality\"] = df_aq[\"past_air_quality\"].fillna(df_aq[\"past_air_quality\"].mean())\n",
|
| 162 |
+
"df_aq = df_aq.reset_index()\n",
|
| 163 |
+
"df_aq.date.describe()\n",
|
| 164 |
+
"\n",
|
| 165 |
+
"earliest_aq_date = pd.Series.min(df_aq['date'])\n",
|
| 166 |
+
"earliest_aq_date = earliest_aq_date.strftime('%Y-%m-%d')\n",
|
| 167 |
+
"earliest_aq_date"
|
| 168 |
+
]
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"cell_type": "code",
|
| 172 |
+
"execution_count": null,
|
| 173 |
+
"metadata": {},
|
| 174 |
+
"outputs": [
|
| 175 |
+
{
|
| 176 |
+
"data": {
|
| 177 |
+
"text/plain": [
|
| 178 |
+
"datetime.date(2024, 11, 20)"
|
| 179 |
+
]
|
| 180 |
+
},
|
| 181 |
+
"execution_count": 8,
|
| 182 |
+
"metadata": {},
|
| 183 |
+
"output_type": "execute_result"
|
| 184 |
+
}
|
| 185 |
+
],
|
| 186 |
+
"source": [
|
| 187 |
+
"today"
|
| 188 |
+
]
|
| 189 |
+
},
|
| 190 |
+
{
|
| 191 |
+
"cell_type": "code",
|
| 192 |
+
"execution_count": null,
|
| 193 |
+
"metadata": {},
|
| 194 |
+
"outputs": [
|
| 195 |
+
{
|
| 196 |
+
"name": "stdout",
|
| 197 |
+
"output_type": "stream",
|
| 198 |
+
"text": [
|
| 199 |
+
"Coordinates 31.59929656982422°N 74.26347351074219°E\n",
|
| 200 |
+
"Elevation 215.0 m asl\n",
|
| 201 |
+
"Timezone None None\n",
|
| 202 |
+
"Timezone difference to GMT+0 0 s\n",
|
| 203 |
+
"<class 'pandas.core.frame.DataFrame'>\n",
|
| 204 |
+
"Index: 1807 entries, 0 to 1806\n",
|
| 205 |
+
"Data columns (total 6 columns):\n",
|
| 206 |
+
" # Column Non-Null Count Dtype \n",
|
| 207 |
+
"--- ------ -------------- ----- \n",
|
| 208 |
+
" 0 date 1807 non-null datetime64[ns]\n",
|
| 209 |
+
" 1 temperature_2m_mean 1807 non-null float32 \n",
|
| 210 |
+
" 2 precipitation_sum 1807 non-null float32 \n",
|
| 211 |
+
" 3 wind_speed_10m_max 1807 non-null float32 \n",
|
| 212 |
+
" 4 wind_direction_10m_dominant 1807 non-null float32 \n",
|
| 213 |
+
" 5 city 1807 non-null object \n",
|
| 214 |
+
"dtypes: datetime64[ns](1), float32(4), object(1)\n",
|
| 215 |
+
"memory usage: 70.6+ KB\n"
|
| 216 |
+
]
|
| 217 |
+
}
|
| 218 |
+
],
|
| 219 |
+
"source": [
|
| 220 |
+
"weather_df = util.get_historical_weather(city, earliest_aq_date, str(today - datetime.timedelta(days=1)), latitude, longitude)\n",
|
| 221 |
+
"# weather_df = util.get_historical_weather(city, earliest_aq_date, \"2024-11-05\", latitude, longitude)\n",
|
| 222 |
+
"weather_df.info()"
|
| 223 |
+
]
|
| 224 |
+
},
|
| 225 |
+
{
|
| 226 |
+
"cell_type": "code",
|
| 227 |
+
"execution_count": 10,
|
| 228 |
+
"metadata": {},
|
| 229 |
+
"outputs": [
|
| 230 |
+
{
|
| 231 |
+
"data": {
|
| 232 |
+
"text/plain": [
|
| 233 |
+
"{\"expectation_type\": \"expect_column_min_to_be_between\", \"kwargs\": {\"column\": \"pm25\", \"min_value\": -0.1, \"max_value\": 500.0, \"strict_min\": true}, \"meta\": {}}"
|
| 234 |
+
]
|
| 235 |
+
},
|
| 236 |
+
"execution_count": 10,
|
| 237 |
+
"metadata": {},
|
| 238 |
+
"output_type": "execute_result"
|
| 239 |
+
}
|
| 240 |
+
],
|
| 241 |
+
"source": [
|
| 242 |
+
"\n",
|
| 243 |
+
"import great_expectations as ge\n",
|
| 244 |
+
"aq_expectation_suite = ge.core.ExpectationSuite(\n",
|
| 245 |
+
" expectation_suite_name=\"aq_expectation_suite\"\n",
|
| 246 |
+
")\n",
|
| 247 |
+
"\n",
|
| 248 |
+
"aq_expectation_suite.add_expectation(\n",
|
| 249 |
+
" ge.core.ExpectationConfiguration(\n",
|
| 250 |
+
" expectation_type=\"expect_column_min_to_be_between\",\n",
|
| 251 |
+
" kwargs={\n",
|
| 252 |
+
" \"column\":\"pm25\",\n",
|
| 253 |
+
" \"min_value\":-0.1,\n",
|
| 254 |
+
" \"max_value\":500.0,\n",
|
| 255 |
+
" \"strict_min\":True\n",
|
| 256 |
+
" }\n",
|
| 257 |
+
" )\n",
|
| 258 |
+
")\n"
|
| 259 |
+
]
|
| 260 |
+
},
|
| 261 |
+
{
|
| 262 |
+
"cell_type": "code",
|
| 263 |
+
"execution_count": 11,
|
| 264 |
+
"metadata": {},
|
| 265 |
+
"outputs": [],
|
| 266 |
+
"source": [
|
| 267 |
+
"import great_expectations as ge\n",
|
| 268 |
+
"weather_expectation_suite = ge.core.ExpectationSuite(\n",
|
| 269 |
+
" expectation_suite_name=\"weather_expectation_suite\"\n",
|
| 270 |
+
")\n",
|
| 271 |
+
"\n",
|
| 272 |
+
"def expect_greater_than_zero(col):\n",
|
| 273 |
+
" weather_expectation_suite.add_expectation(\n",
|
| 274 |
+
" ge.core.ExpectationConfiguration(\n",
|
| 275 |
+
" expectation_type=\"expect_column_min_to_be_between\",\n",
|
| 276 |
+
" kwargs={\n",
|
| 277 |
+
" \"column\":col,\n",
|
| 278 |
+
" \"min_value\":-0.1,\n",
|
| 279 |
+
" \"max_value\":1000.0,\n",
|
| 280 |
+
" \"strict_min\":True\n",
|
| 281 |
+
" }\n",
|
| 282 |
+
" )\n",
|
| 283 |
+
" )\n",
|
| 284 |
+
"expect_greater_than_zero(\"precipitation_sum\")\n",
|
| 285 |
+
"expect_greater_than_zero(\"wind_speed_10m_max\")"
|
| 286 |
+
]
|
| 287 |
+
},
|
| 288 |
+
{
|
| 289 |
+
"cell_type": "code",
|
| 290 |
+
"execution_count": 12,
|
| 291 |
+
"metadata": {},
|
| 292 |
+
"outputs": [
|
| 293 |
+
{
|
| 294 |
+
"name": "stdout",
|
| 295 |
+
"output_type": "stream",
|
| 296 |
+
"text": [
|
| 297 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n"
|
| 298 |
+
]
|
| 299 |
+
}
|
| 300 |
+
],
|
| 301 |
+
"source": [
|
| 302 |
+
"fs = project.get_feature_store() "
|
| 303 |
+
]
|
| 304 |
+
},
|
| 305 |
+
{
|
| 306 |
+
"cell_type": "code",
|
| 307 |
+
"execution_count": 13,
|
| 308 |
+
"metadata": {},
|
| 309 |
+
"outputs": [
|
| 310 |
+
{
|
| 311 |
+
"name": "stdout",
|
| 312 |
+
"output_type": "stream",
|
| 313 |
+
"text": [
|
| 314 |
+
"Secret created successfully, explore it at https://c.app.hopsworks.ai:443/account/secrets\n"
|
| 315 |
+
]
|
| 316 |
+
}
|
| 317 |
+
],
|
| 318 |
+
"source": [
|
| 319 |
+
"dict_obj = {\n",
|
| 320 |
+
" \"country\": country,\n",
|
| 321 |
+
" \"city\": city,\n",
|
| 322 |
+
" \"street\": street,\n",
|
| 323 |
+
" \"aqicn_url\": aqicn_url,\n",
|
| 324 |
+
" \"latitude\": latitude,\n",
|
| 325 |
+
" \"longitude\": longitude\n",
|
| 326 |
+
"}\n",
|
| 327 |
+
"\n",
|
| 328 |
+
"# Convert the dictionary to a JSON string\n",
|
| 329 |
+
"str_dict = json.dumps(dict_obj)\n",
|
| 330 |
+
"\n",
|
| 331 |
+
"try:\n",
|
| 332 |
+
" secrets.create_secret(\"SENSOR_LOCATION_JSON\", str_dict)\n",
|
| 333 |
+
"except hopsworks.RestAPIError:\n",
|
| 334 |
+
" print(\"SENSOR_LOCATION_JSON already exists. To update, delete the secret in the UI (https://c.app.hopsworks.ai/account/secrets) and re-run this cell.\")\n",
|
| 335 |
+
" existing_key = secrets.get_secret(\"SENSOR_LOCATION_JSON\").value\n",
|
| 336 |
+
" print(f\"{existing_key}\")\n"
|
| 337 |
+
]
|
| 338 |
+
},
|
| 339 |
+
{
|
| 340 |
+
"cell_type": "code",
|
| 341 |
+
"execution_count": 15,
|
| 342 |
+
"metadata": {},
|
| 343 |
+
"outputs": [],
|
| 344 |
+
"source": [
|
| 345 |
+
"air_quality_fg = fs.get_or_create_feature_group(\n",
|
| 346 |
+
" name='air_quality',\n",
|
| 347 |
+
" description='Air Quality characteristics of each day',\n",
|
| 348 |
+
" version=1,\n",
|
| 349 |
+
" primary_key=['city', 'street', 'date'],\n",
|
| 350 |
+
" event_time=\"date\",\n",
|
| 351 |
+
" expectation_suite=aq_expectation_suite\n",
|
| 352 |
+
")\n"
|
| 353 |
+
]
|
| 354 |
+
},
|
| 355 |
+
{
|
| 356 |
+
"cell_type": "code",
|
| 357 |
+
"execution_count": 16,
|
| 358 |
+
"metadata": {},
|
| 359 |
+
"outputs": [
|
| 360 |
+
{
|
| 361 |
+
"name": "stdout",
|
| 362 |
+
"output_type": "stream",
|
| 363 |
+
"text": [
|
| 364 |
+
"Feature Group created successfully, explore it at \n",
|
| 365 |
+
"https://c.app.hopsworks.ai:443/p/1160340/fs/1151043/fg/1362254\n",
|
| 366 |
+
"2024-11-21 05:44:54,527 INFO: \t1 expectation(s) included in expectation_suite.\n",
|
| 367 |
+
"Validation succeeded.\n",
|
| 368 |
+
"Validation Report saved successfully, explore a summary at https://c.app.hopsworks.ai:443/p/1160340/fs/1151043/fg/1362254\n"
|
| 369 |
+
]
|
| 370 |
+
},
|
| 371 |
+
{
|
| 372 |
+
"data": {
|
| 373 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 374 |
+
"model_id": "506badbe42224a17b3ccc6d6b1ae7927",
|
| 375 |
+
"version_major": 2,
|
| 376 |
+
"version_minor": 0
|
| 377 |
+
},
|
| 378 |
+
"text/plain": [
|
| 379 |
+
"Uploading Dataframe: 0.00% | | Rows 0/1802 | Elapsed Time: 00:00 | Remaining Time: ?"
|
| 380 |
+
]
|
| 381 |
+
},
|
| 382 |
+
"metadata": {},
|
| 383 |
+
"output_type": "display_data"
|
| 384 |
+
},
|
| 385 |
+
{
|
| 386 |
+
"name": "stdout",
|
| 387 |
+
"output_type": "stream",
|
| 388 |
+
"text": [
|
| 389 |
+
"Launching job: air_quality_1_offline_fg_materialization\n",
|
| 390 |
+
"Job started successfully, you can follow the progress at \n",
|
| 391 |
+
"https://c.app.hopsworks.ai/p/1160340/jobs/named/air_quality_1_offline_fg_materialization/executions\n"
|
| 392 |
+
]
|
| 393 |
+
},
|
| 394 |
+
{
|
| 395 |
+
"data": {
|
| 396 |
+
"text/plain": [
|
| 397 |
+
"(<hsfs.core.job.Job at 0x74c9c7eb8c20>,\n",
|
| 398 |
+
" {\n",
|
| 399 |
+
" \"success\": true,\n",
|
| 400 |
+
" \"results\": [\n",
|
| 401 |
+
" {\n",
|
| 402 |
+
" \"success\": true,\n",
|
| 403 |
+
" \"expectation_config\": {\n",
|
| 404 |
+
" \"expectation_type\": \"expect_column_min_to_be_between\",\n",
|
| 405 |
+
" \"kwargs\": {\n",
|
| 406 |
+
" \"column\": \"pm25\",\n",
|
| 407 |
+
" \"min_value\": -0.1,\n",
|
| 408 |
+
" \"max_value\": 500.0,\n",
|
| 409 |
+
" \"strict_min\": true\n",
|
| 410 |
+
" },\n",
|
| 411 |
+
" \"meta\": {\n",
|
| 412 |
+
" \"expectationId\": 686087\n",
|
| 413 |
+
" }\n",
|
| 414 |
+
" },\n",
|
| 415 |
+
" \"result\": {\n",
|
| 416 |
+
" \"observed_value\": 1.9899998903274536,\n",
|
| 417 |
+
" \"element_count\": 1802,\n",
|
| 418 |
+
" \"missing_count\": null,\n",
|
| 419 |
+
" \"missing_percent\": null\n",
|
| 420 |
+
" },\n",
|
| 421 |
+
" \"meta\": {\n",
|
| 422 |
+
" \"ingestionResult\": \"INGESTED\",\n",
|
| 423 |
+
" \"validationTime\": \"2024-11-20T09:44:54.000525Z\"\n",
|
| 424 |
+
" },\n",
|
| 425 |
+
" \"exception_info\": {\n",
|
| 426 |
+
" \"raised_exception\": false,\n",
|
| 427 |
+
" \"exception_message\": null,\n",
|
| 428 |
+
" \"exception_traceback\": null\n",
|
| 429 |
+
" }\n",
|
| 430 |
+
" }\n",
|
| 431 |
+
" ],\n",
|
| 432 |
+
" \"evaluation_parameters\": {},\n",
|
| 433 |
+
" \"statistics\": {\n",
|
| 434 |
+
" \"evaluated_expectations\": 1,\n",
|
| 435 |
+
" \"successful_expectations\": 1,\n",
|
| 436 |
+
" \"unsuccessful_expectations\": 0,\n",
|
| 437 |
+
" \"success_percent\": 100.0\n",
|
| 438 |
+
" },\n",
|
| 439 |
+
" \"meta\": {\n",
|
| 440 |
+
" \"great_expectations_version\": \"0.18.12\",\n",
|
| 441 |
+
" \"expectation_suite_name\": \"aq_expectation_suite\",\n",
|
| 442 |
+
" \"run_id\": {\n",
|
| 443 |
+
" \"run_name\": null,\n",
|
| 444 |
+
" \"run_time\": \"2024-11-21T05:44:54.526004+08:00\"\n",
|
| 445 |
+
" },\n",
|
| 446 |
+
" \"batch_kwargs\": {\n",
|
| 447 |
+
" \"ge_batch_id\": \"adcf6d76-a788-11ef-a237-1091d10619ea\"\n",
|
| 448 |
+
" },\n",
|
| 449 |
+
" \"batch_markers\": {},\n",
|
| 450 |
+
" \"batch_parameters\": {},\n",
|
| 451 |
+
" \"validation_time\": \"20241120T214454.525505Z\",\n",
|
| 452 |
+
" \"expectation_suite_meta\": {\n",
|
| 453 |
+
" \"great_expectations_version\": \"0.18.12\"\n",
|
| 454 |
+
" }\n",
|
| 455 |
+
" }\n",
|
| 456 |
+
" })"
|
| 457 |
+
]
|
| 458 |
+
},
|
| 459 |
+
"execution_count": 16,
|
| 460 |
+
"metadata": {},
|
| 461 |
+
"output_type": "execute_result"
|
| 462 |
+
}
|
| 463 |
+
],
|
| 464 |
+
"source": [
|
| 465 |
+
"air_quality_fg.insert(df_aq)"
|
| 466 |
+
]
|
| 467 |
+
},
|
| 468 |
+
{
|
| 469 |
+
"cell_type": "code",
|
| 470 |
+
"execution_count": 17,
|
| 471 |
+
"metadata": {},
|
| 472 |
+
"outputs": [
|
| 473 |
+
{
|
| 474 |
+
"data": {
|
| 475 |
+
"text/plain": [
|
| 476 |
+
"<hsfs.feature_group.FeatureGroup at 0x74c9c7ed3d10>"
|
| 477 |
+
]
|
| 478 |
+
},
|
| 479 |
+
"execution_count": 17,
|
| 480 |
+
"metadata": {},
|
| 481 |
+
"output_type": "execute_result"
|
| 482 |
+
}
|
| 483 |
+
],
|
| 484 |
+
"source": [
|
| 485 |
+
"air_quality_fg.update_feature_description(\"date\", \"Date of measurement of air quality\")\n",
|
| 486 |
+
"air_quality_fg.update_feature_description(\"country\", \"Country where the air quality was measured (sometimes a city in acqcn.org)\")\n",
|
| 487 |
+
"air_quality_fg.update_feature_description(\"city\", \"City where the air quality was measured\")\n",
|
| 488 |
+
"air_quality_fg.update_feature_description(\"street\", \"Street in the city where the air quality was measured\")\n",
|
| 489 |
+
"air_quality_fg.update_feature_description(\"pm25\", \"Particles less than 2.5 micrometers in diameter (fine particles) pose health risk\")\n",
|
| 490 |
+
"air_quality_fg.update_feature_description(\"past_air_quality\", \"mean air quality of the past 3 days\")\n"
|
| 491 |
+
]
|
| 492 |
+
},
|
| 493 |
+
{
|
| 494 |
+
"cell_type": "code",
|
| 495 |
+
"execution_count": 18,
|
| 496 |
+
"metadata": {},
|
| 497 |
+
"outputs": [
|
| 498 |
+
{
|
| 499 |
+
"name": "stdout",
|
| 500 |
+
"output_type": "stream",
|
| 501 |
+
"text": [
|
| 502 |
+
"Feature Group created successfully, explore it at \n",
|
| 503 |
+
"https://c.app.hopsworks.ai:443/p/1160340/fs/1151043/fg/1362255\n",
|
| 504 |
+
"2024-11-21 05:56:51,769 INFO: \t2 expectation(s) included in expectation_suite.\n",
|
| 505 |
+
"Validation succeeded.\n",
|
| 506 |
+
"Validation Report saved successfully, explore a summary at https://c.app.hopsworks.ai:443/p/1160340/fs/1151043/fg/1362255\n"
|
| 507 |
+
]
|
| 508 |
+
},
|
| 509 |
+
{
|
| 510 |
+
"data": {
|
| 511 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 512 |
+
"model_id": "455439f2dd8643b4b06da1d3851d2f8c",
|
| 513 |
+
"version_major": 2,
|
| 514 |
+
"version_minor": 0
|
| 515 |
+
},
|
| 516 |
+
"text/plain": [
|
| 517 |
+
"Uploading Dataframe: 0.00% | | Rows 0/1807 | Elapsed Time: 00:00 | Remaining Time: ?"
|
| 518 |
+
]
|
| 519 |
+
},
|
| 520 |
+
"metadata": {},
|
| 521 |
+
"output_type": "display_data"
|
| 522 |
+
},
|
| 523 |
+
{
|
| 524 |
+
"name": "stdout",
|
| 525 |
+
"output_type": "stream",
|
| 526 |
+
"text": [
|
| 527 |
+
"Launching job: weather_1_offline_fg_materialization\n",
|
| 528 |
+
"Job started successfully, you can follow the progress at \n",
|
| 529 |
+
"https://c.app.hopsworks.ai/p/1160340/jobs/named/weather_1_offline_fg_materialization/executions\n"
|
| 530 |
+
]
|
| 531 |
+
},
|
| 532 |
+
{
|
| 533 |
+
"data": {
|
| 534 |
+
"text/plain": [
|
| 535 |
+
"<hsfs.feature_group.FeatureGroup at 0x74c9c7ebaea0>"
|
| 536 |
+
]
|
| 537 |
+
},
|
| 538 |
+
"execution_count": 18,
|
| 539 |
+
"metadata": {},
|
| 540 |
+
"output_type": "execute_result"
|
| 541 |
+
}
|
| 542 |
+
],
|
| 543 |
+
"source": [
|
| 544 |
+
"weather_fg = fs.get_or_create_feature_group(\n",
|
| 545 |
+
" name='weather',\n",
|
| 546 |
+
" description='Weather characteristics of each day',\n",
|
| 547 |
+
" version=1,\n",
|
| 548 |
+
" primary_key=['city', 'date'],\n",
|
| 549 |
+
" event_time=\"date\",\n",
|
| 550 |
+
" expectation_suite=weather_expectation_suite\n",
|
| 551 |
+
") \n",
|
| 552 |
+
"\n",
|
| 553 |
+
"weather_fg.insert(weather_df)\n",
|
| 554 |
+
"\n",
|
| 555 |
+
"weather_fg.update_feature_description(\"date\", \"Date of measurement of weather\")\n",
|
| 556 |
+
"weather_fg.update_feature_description(\"city\", \"City where weather is measured/forecast for\")\n",
|
| 557 |
+
"weather_fg.update_feature_description(\"temperature_2m_mean\", \"Temperature in Celsius\")\n",
|
| 558 |
+
"weather_fg.update_feature_description(\"precipitation_sum\", \"Precipitation (rain/snow) in mm\")\n",
|
| 559 |
+
"weather_fg.update_feature_description(\"wind_speed_10m_max\", \"Wind speed at 10m abouve ground\")\n",
|
| 560 |
+
"weather_fg.update_feature_description(\"wind_direction_10m_dominant\", \"Dominant Wind direction over the dayd\")\n",
|
| 561 |
+
"\n",
|
| 562 |
+
"\n"
|
| 563 |
+
]
|
| 564 |
+
}
|
| 565 |
+
],
|
| 566 |
+
"metadata": {
|
| 567 |
+
"kernelspec": {
|
| 568 |
+
"display_name": ".venv",
|
| 569 |
+
"language": "python",
|
| 570 |
+
"name": "python3"
|
| 571 |
+
},
|
| 572 |
+
"language_info": {
|
| 573 |
+
"codemirror_mode": {
|
| 574 |
+
"name": "ipython",
|
| 575 |
+
"version": 3
|
| 576 |
+
},
|
| 577 |
+
"file_extension": ".py",
|
| 578 |
+
"mimetype": "text/x-python",
|
| 579 |
+
"name": "python",
|
| 580 |
+
"nbconvert_exporter": "python",
|
| 581 |
+
"pygments_lexer": "ipython3",
|
| 582 |
+
"version": "3.12.4"
|
| 583 |
+
}
|
| 584 |
+
},
|
| 585 |
+
"nbformat": 4,
|
| 586 |
+
"nbformat_minor": 2
|
| 587 |
+
}
|
backfill.py
DELETED
|
@@ -1,62 +0,0 @@
|
|
| 1 |
-
import datetime
|
| 2 |
-
import requests
|
| 3 |
-
import pandas as pd
|
| 4 |
-
import hopsworks
|
| 5 |
-
import datetime
|
| 6 |
-
from pathlib import Path
|
| 7 |
-
from functions import util
|
| 8 |
-
import json
|
| 9 |
-
import re
|
| 10 |
-
import os
|
| 11 |
-
import warnings
|
| 12 |
-
import pandas as pd
|
| 13 |
-
|
| 14 |
-
api_key = os.getenv('HOPSWORKS_API_KEY')
|
| 15 |
-
project_name = os.getenv('HOPSWORKS_PROJECT')
|
| 16 |
-
|
| 17 |
-
project = hopsworks.login(project=project_name, api_key_value=api_key)
|
| 18 |
-
fs = project.get_feature_store()
|
| 19 |
-
secrets = util.secrets_api(project.name)
|
| 20 |
-
|
| 21 |
-
AQI_API_KEY = secrets.get_secret("AQI_API_KEY").value
|
| 22 |
-
location_str = secrets.get_secret("SENSOR_LOCATION_JSON").value
|
| 23 |
-
location = json.loads(location_str)
|
| 24 |
-
|
| 25 |
-
country=location['country']
|
| 26 |
-
city=location['city']
|
| 27 |
-
street=location['street']
|
| 28 |
-
aqicn_url=location['aqicn_url']
|
| 29 |
-
latitude=location['latitude']
|
| 30 |
-
longitude=location['longitude']
|
| 31 |
-
|
| 32 |
-
today = datetime.date.today()
|
| 33 |
-
|
| 34 |
-
# Retrieve feature groups
|
| 35 |
-
air_quality_fg = fs.get_feature_group(
|
| 36 |
-
name='air_quality',
|
| 37 |
-
version=1,
|
| 38 |
-
)
|
| 39 |
-
weather_fg = fs.get_feature_group(
|
| 40 |
-
name='weather',
|
| 41 |
-
version=1,
|
| 42 |
-
)
|
| 43 |
-
|
| 44 |
-
aq_today_df = util.get_pm25(aqicn_url, country, city, street, today, AQI_API_KEY)
|
| 45 |
-
#aq_today_df = util.get_pm25(aqicn_url, country, city, street, "2024-11-15", AQI_API_KEY)
|
| 46 |
-
aq_today_df['date'] = pd.to_datetime(aq_today_df['date']).dt.date
|
| 47 |
-
aq_today_df
|
| 48 |
-
|
| 49 |
-
# Get weather forecast data
|
| 50 |
-
|
| 51 |
-
hourly_df = util.get_hourly_weather_forecast(city, latitude, longitude)
|
| 52 |
-
hourly_df = hourly_df.set_index('date')
|
| 53 |
-
|
| 54 |
-
# We will only make 1 daily prediction, so we will replace the hourly forecasts with a single daily forecast
|
| 55 |
-
# We only want the daily weather data, so only get weather at 12:00
|
| 56 |
-
daily_df = hourly_df.between_time('11:59', '12:01')
|
| 57 |
-
daily_df = daily_df.reset_index()
|
| 58 |
-
daily_df['date'] = pd.to_datetime(daily_df['date']).dt.date
|
| 59 |
-
daily_df['date'] = pd.to_datetime(daily_df['date'])
|
| 60 |
-
# daily_df['date'] = daily_df['date'].astype(str)
|
| 61 |
-
daily_df['city'] = city
|
| 62 |
-
daily_df
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
data/lahore.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
debug.ipynb
CHANGED
|
@@ -2,7 +2,7 @@
|
|
| 2 |
"cells": [
|
| 3 |
{
|
| 4 |
"cell_type": "code",
|
| 5 |
-
"execution_count":
|
| 6 |
"metadata": {},
|
| 7 |
"outputs": [
|
| 8 |
{
|
|
@@ -10,266 +10,70 @@
|
|
| 10 |
"output_type": "stream",
|
| 11 |
"text": [
|
| 12 |
"Connection closed.\n",
|
| 13 |
-
"Connected. Call `.close()` to terminate connection gracefully.\n"
|
| 14 |
-
]
|
| 15 |
-
},
|
| 16 |
-
{
|
| 17 |
-
"name": "stdout",
|
| 18 |
-
"output_type": "stream",
|
| 19 |
-
"text": [
|
| 20 |
"\n",
|
| 21 |
"Logged in to project, explore it here https://c.app.hopsworks.ai:443/p/1160344\n",
|
| 22 |
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 23 |
-
"Connected. Call `.close()` to terminate connection gracefully.\n"
|
|
|
|
|
|
|
| 24 |
]
|
| 25 |
}
|
| 26 |
],
|
| 27 |
"source": [
|
| 28 |
-
"import
|
| 29 |
"import pandas as pd\n",
|
| 30 |
-
"
|
|
|
|
| 31 |
"import hopsworks\n",
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
"import json\n",
|
| 33 |
-
"from
|
| 34 |
"import os\n",
|
| 35 |
"\n",
|
| 36 |
-
"# Set up\n",
|
| 37 |
-
"\n",
|
| 38 |
-
"api_key = os.getenv('HOPSWORKS_API_KEY')\n",
|
| 39 |
-
"project_name = os.getenv('HOPSWORKS_PROJECT')\n",
|
| 40 |
-
"project = hopsworks.login(project=project_name, api_key_value=api_key)\n",
|
| 41 |
-
"fs = project.get_feature_store() \n",
|
| 42 |
-
"secrets = util.secrets_api(project.name)\n",
|
| 43 |
-
"location_str = secrets.get_secret(\"SENSOR_LOCATION_JSON\").value\n",
|
| 44 |
-
"location = json.loads(location_str)\n",
|
| 45 |
-
"country=location['country']\n",
|
| 46 |
-
"city=location['city']\n",
|
| 47 |
-
"street=location['street']\n",
|
| 48 |
-
"\n",
|
| 49 |
-
"AQI_API_KEY = secrets.get_secret(\"AQI_API_KEY\").value\n",
|
| 50 |
-
"location_str = secrets.get_secret(\"SENSOR_LOCATION_JSON\").value\n",
|
| 51 |
-
"location = json.loads(location_str)\n",
|
| 52 |
"\n",
|
| 53 |
-
"
|
|
|
|
|
|
|
| 54 |
]
|
| 55 |
},
|
| 56 |
{
|
| 57 |
"cell_type": "code",
|
| 58 |
-
"execution_count":
|
| 59 |
"metadata": {},
|
| 60 |
"outputs": [
|
| 61 |
{
|
| 62 |
"name": "stdout",
|
| 63 |
"output_type": "stream",
|
| 64 |
"text": [
|
|
|
|
| 65 |
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 66 |
-
"
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
" version=1,\n",
|
| 78 |
-
")\n",
|
| 79 |
-
"\n",
|
| 80 |
-
"saved_model_dir = retrieved_model.download()\n",
|
| 81 |
-
"retrieved_xgboost_model = XGBRegressor()\n",
|
| 82 |
-
"retrieved_xgboost_model.load_model(saved_model_dir + \"/model.json\")\n",
|
| 83 |
-
"\n",
|
| 84 |
-
"### Retrieve features \n",
|
| 85 |
-
"\n",
|
| 86 |
-
"weather_fg = fs.get_feature_group(\n",
|
| 87 |
-
" name='weather',\n",
|
| 88 |
-
" version=1,\n",
|
| 89 |
-
")\n",
|
| 90 |
-
"\n",
|
| 91 |
-
"today_timestamp = pd.to_datetime(today)\n",
|
| 92 |
-
"batch_data = weather_fg.filter(weather_fg.date >= today_timestamp ).read().sort_values(by=['date'])"
|
| 93 |
-
]
|
| 94 |
-
},
|
| 95 |
-
{
|
| 96 |
-
"cell_type": "code",
|
| 97 |
-
"execution_count": 7,
|
| 98 |
-
"metadata": {},
|
| 99 |
-
"outputs": [
|
| 100 |
-
{
|
| 101 |
-
"data": {
|
| 102 |
-
"text/html": [
|
| 103 |
-
"<div>\n",
|
| 104 |
-
"<style scoped>\n",
|
| 105 |
-
" .dataframe tbody tr th:only-of-type {\n",
|
| 106 |
-
" vertical-align: middle;\n",
|
| 107 |
-
" }\n",
|
| 108 |
-
"\n",
|
| 109 |
-
" .dataframe tbody tr th {\n",
|
| 110 |
-
" vertical-align: top;\n",
|
| 111 |
-
" }\n",
|
| 112 |
-
"\n",
|
| 113 |
-
" .dataframe thead th {\n",
|
| 114 |
-
" text-align: right;\n",
|
| 115 |
-
" }\n",
|
| 116 |
-
"</style>\n",
|
| 117 |
-
"<table border=\"1\" class=\"dataframe\">\n",
|
| 118 |
-
" <thead>\n",
|
| 119 |
-
" <tr style=\"text-align: right;\">\n",
|
| 120 |
-
" <th></th>\n",
|
| 121 |
-
" <th>date</th>\n",
|
| 122 |
-
" <th>temperature_2m_mean</th>\n",
|
| 123 |
-
" <th>precipitation_sum</th>\n",
|
| 124 |
-
" <th>wind_speed_10m_max</th>\n",
|
| 125 |
-
" <th>wind_direction_10m_dominant</th>\n",
|
| 126 |
-
" <th>city</th>\n",
|
| 127 |
-
" </tr>\n",
|
| 128 |
-
" </thead>\n",
|
| 129 |
-
" <tbody>\n",
|
| 130 |
-
" <tr>\n",
|
| 131 |
-
" <th>1</th>\n",
|
| 132 |
-
" <td>2024-11-21 00:00:00+00:00</td>\n",
|
| 133 |
-
" <td>21.700001</td>\n",
|
| 134 |
-
" <td>0.0</td>\n",
|
| 135 |
-
" <td>1.138420</td>\n",
|
| 136 |
-
" <td>71.564964</td>\n",
|
| 137 |
-
" <td>lahore</td>\n",
|
| 138 |
-
" </tr>\n",
|
| 139 |
-
" <tr>\n",
|
| 140 |
-
" <th>4</th>\n",
|
| 141 |
-
" <td>2024-11-22 00:00:00+00:00</td>\n",
|
| 142 |
-
" <td>21.850000</td>\n",
|
| 143 |
-
" <td>0.0</td>\n",
|
| 144 |
-
" <td>4.610250</td>\n",
|
| 145 |
-
" <td>128.659836</td>\n",
|
| 146 |
-
" <td>lahore</td>\n",
|
| 147 |
-
" </tr>\n",
|
| 148 |
-
" <tr>\n",
|
| 149 |
-
" <th>7</th>\n",
|
| 150 |
-
" <td>2024-11-23 00:00:00+00:00</td>\n",
|
| 151 |
-
" <td>22.250000</td>\n",
|
| 152 |
-
" <td>0.0</td>\n",
|
| 153 |
-
" <td>5.091168</td>\n",
|
| 154 |
-
" <td>44.999897</td>\n",
|
| 155 |
-
" <td>lahore</td>\n",
|
| 156 |
-
" </tr>\n",
|
| 157 |
-
" <tr>\n",
|
| 158 |
-
" <th>6</th>\n",
|
| 159 |
-
" <td>2024-11-24 00:00:00+00:00</td>\n",
|
| 160 |
-
" <td>21.400000</td>\n",
|
| 161 |
-
" <td>0.0</td>\n",
|
| 162 |
-
" <td>4.334974</td>\n",
|
| 163 |
-
" <td>318.366547</td>\n",
|
| 164 |
-
" <td>lahore</td>\n",
|
| 165 |
-
" </tr>\n",
|
| 166 |
-
" <tr>\n",
|
| 167 |
-
" <th>5</th>\n",
|
| 168 |
-
" <td>2024-11-25 00:00:00+00:00</td>\n",
|
| 169 |
-
" <td>20.750000</td>\n",
|
| 170 |
-
" <td>0.0</td>\n",
|
| 171 |
-
" <td>6.439876</td>\n",
|
| 172 |
-
" <td>296.564972</td>\n",
|
| 173 |
-
" <td>lahore</td>\n",
|
| 174 |
-
" </tr>\n",
|
| 175 |
-
" <tr>\n",
|
| 176 |
-
" <th>2</th>\n",
|
| 177 |
-
" <td>2024-11-26 00:00:00+00:00</td>\n",
|
| 178 |
-
" <td>20.750000</td>\n",
|
| 179 |
-
" <td>0.0</td>\n",
|
| 180 |
-
" <td>4.680000</td>\n",
|
| 181 |
-
" <td>270.000000</td>\n",
|
| 182 |
-
" <td>lahore</td>\n",
|
| 183 |
-
" </tr>\n",
|
| 184 |
-
" <tr>\n",
|
| 185 |
-
" <th>0</th>\n",
|
| 186 |
-
" <td>2024-11-27 00:00:00+00:00</td>\n",
|
| 187 |
-
" <td>20.350000</td>\n",
|
| 188 |
-
" <td>0.0</td>\n",
|
| 189 |
-
" <td>4.104631</td>\n",
|
| 190 |
-
" <td>37.875053</td>\n",
|
| 191 |
-
" <td>lahore</td>\n",
|
| 192 |
-
" </tr>\n",
|
| 193 |
-
" <tr>\n",
|
| 194 |
-
" <th>3</th>\n",
|
| 195 |
-
" <td>2024-11-28 00:00:00+00:00</td>\n",
|
| 196 |
-
" <td>19.799999</td>\n",
|
| 197 |
-
" <td>0.0</td>\n",
|
| 198 |
-
" <td>2.189795</td>\n",
|
| 199 |
-
" <td>9.462248</td>\n",
|
| 200 |
-
" <td>lahore</td>\n",
|
| 201 |
-
" </tr>\n",
|
| 202 |
-
" </tbody>\n",
|
| 203 |
-
"</table>\n",
|
| 204 |
-
"</div>"
|
| 205 |
-
],
|
| 206 |
-
"text/plain": [
|
| 207 |
-
" date temperature_2m_mean precipitation_sum \\\n",
|
| 208 |
-
"1 2024-11-21 00:00:00+00:00 21.700001 0.0 \n",
|
| 209 |
-
"4 2024-11-22 00:00:00+00:00 21.850000 0.0 \n",
|
| 210 |
-
"7 2024-11-23 00:00:00+00:00 22.250000 0.0 \n",
|
| 211 |
-
"6 2024-11-24 00:00:00+00:00 21.400000 0.0 \n",
|
| 212 |
-
"5 2024-11-25 00:00:00+00:00 20.750000 0.0 \n",
|
| 213 |
-
"2 2024-11-26 00:00:00+00:00 20.750000 0.0 \n",
|
| 214 |
-
"0 2024-11-27 00:00:00+00:00 20.350000 0.0 \n",
|
| 215 |
-
"3 2024-11-28 00:00:00+00:00 19.799999 0.0 \n",
|
| 216 |
-
"\n",
|
| 217 |
-
" wind_speed_10m_max wind_direction_10m_dominant city \n",
|
| 218 |
-
"1 1.138420 71.564964 lahore \n",
|
| 219 |
-
"4 4.610250 128.659836 lahore \n",
|
| 220 |
-
"7 5.091168 44.999897 lahore \n",
|
| 221 |
-
"6 4.334974 318.366547 lahore \n",
|
| 222 |
-
"5 6.439876 296.564972 lahore \n",
|
| 223 |
-
"2 4.680000 270.000000 lahore \n",
|
| 224 |
-
"0 4.104631 37.875053 lahore \n",
|
| 225 |
-
"3 2.189795 9.462248 lahore "
|
| 226 |
-
]
|
| 227 |
-
},
|
| 228 |
-
"execution_count": 7,
|
| 229 |
-
"metadata": {},
|
| 230 |
-
"output_type": "execute_result"
|
| 231 |
-
}
|
| 232 |
-
],
|
| 233 |
-
"source": [
|
| 234 |
-
"batch_data"
|
| 235 |
-
]
|
| 236 |
-
},
|
| 237 |
-
{
|
| 238 |
-
"cell_type": "code",
|
| 239 |
-
"execution_count": 6,
|
| 240 |
-
"metadata": {},
|
| 241 |
-
"outputs": [
|
| 242 |
-
{
|
| 243 |
-
"ename": "ValueError",
|
| 244 |
-
"evalue": "feature_names mismatch: ['past_air_quality', 'temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant'] ['temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']\nexpected past_air_quality in input data",
|
| 245 |
-
"output_type": "error",
|
| 246 |
-
"traceback": [
|
| 247 |
-
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 248 |
-
"\u001b[0;31mValueError\u001b[0m Traceback (most recent call last)",
|
| 249 |
-
"Cell \u001b[0;32mIn[6], line 3\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[38;5;66;03m### Predict and upload\u001b[39;00m\n\u001b[0;32m----> 3\u001b[0m batch_data[\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mpredicted_pm25\u001b[39m\u001b[38;5;124m'\u001b[39m] \u001b[38;5;241m=\u001b[39m \u001b[43mretrieved_xgboost_model\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mpredict\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 4\u001b[0m \u001b[43m \u001b[49m\u001b[43mbatch_data\u001b[49m\u001b[43m[\u001b[49m\u001b[43m[\u001b[49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[38;5;124;43mtemperature_2m_mean\u001b[39;49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[38;5;124;43mprecipitation_sum\u001b[39;49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[38;5;124;43mwind_speed_10m_max\u001b[39;49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[38;5;124;43mwind_direction_10m_dominant\u001b[39;49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[43m]\u001b[49m\u001b[43m]\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 6\u001b[0m batch_data[\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mstreet\u001b[39m\u001b[38;5;124m'\u001b[39m] \u001b[38;5;241m=\u001b[39m street\n\u001b[1;32m 7\u001b[0m batch_data[\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mcity\u001b[39m\u001b[38;5;124m'\u001b[39m] \u001b[38;5;241m=\u001b[39m city\n",
|
| 250 |
-
"File \u001b[0;32m~/Documents/scalable-ml/lab1-new/hbg-weather/.venv/lib/python3.12/site-packages/xgboost/sklearn.py:1168\u001b[0m, in \u001b[0;36mXGBModel.predict\u001b[0;34m(self, X, output_margin, validate_features, base_margin, iteration_range)\u001b[0m\n\u001b[1;32m 1166\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_can_use_inplace_predict():\n\u001b[1;32m 1167\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m-> 1168\u001b[0m predts \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mget_booster\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43minplace_predict\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1169\u001b[0m \u001b[43m \u001b[49m\u001b[43mdata\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mX\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1170\u001b[0m \u001b[43m \u001b[49m\u001b[43miteration_range\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43miteration_range\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1171\u001b[0m \u001b[43m \u001b[49m\u001b[43mpredict_type\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43mmargin\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m \u001b[49m\u001b[38;5;28;43;01mif\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[43moutput_margin\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;28;43;01melse\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43mvalue\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1172\u001b[0m \u001b[43m \u001b[49m\u001b[43mmissing\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mmissing\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1173\u001b[0m \u001b[43m \u001b[49m\u001b[43mbase_margin\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mbase_margin\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1174\u001b[0m \u001b[43m \u001b[49m\u001b[43mvalidate_features\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mvalidate_features\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1175\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 1176\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m _is_cupy_array(predts):\n\u001b[1;32m 1177\u001b[0m \u001b[38;5;28;01mimport\u001b[39;00m \u001b[38;5;21;01mcupy\u001b[39;00m \u001b[38;5;66;03m# pylint: disable=import-error\u001b[39;00m\n",
|
| 251 |
-
"File \u001b[0;32m~/Documents/scalable-ml/lab1-new/hbg-weather/.venv/lib/python3.12/site-packages/xgboost/core.py:2418\u001b[0m, in \u001b[0;36mBooster.inplace_predict\u001b[0;34m(self, data, iteration_range, predict_type, missing, validate_features, base_margin, strict_shape)\u001b[0m\n\u001b[1;32m 2416\u001b[0m data, fns, _ \u001b[38;5;241m=\u001b[39m _transform_pandas_df(data, enable_categorical)\n\u001b[1;32m 2417\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m validate_features:\n\u001b[0;32m-> 2418\u001b[0m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_validate_features\u001b[49m\u001b[43m(\u001b[49m\u001b[43mfns\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 2419\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m _is_list(data) \u001b[38;5;129;01mor\u001b[39;00m _is_tuple(data):\n\u001b[1;32m 2420\u001b[0m data \u001b[38;5;241m=\u001b[39m np\u001b[38;5;241m.\u001b[39marray(data)\n",
|
| 252 |
-
"File \u001b[0;32m~/Documents/scalable-ml/lab1-new/hbg-weather/.venv/lib/python3.12/site-packages/xgboost/core.py:2970\u001b[0m, in \u001b[0;36mBooster._validate_features\u001b[0;34m(self, feature_names)\u001b[0m\n\u001b[1;32m 2964\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m my_missing:\n\u001b[1;32m 2965\u001b[0m msg \u001b[38;5;241m+\u001b[39m\u001b[38;5;241m=\u001b[39m (\n\u001b[1;32m 2966\u001b[0m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;130;01m\\n\u001b[39;00m\u001b[38;5;124mtraining data did not have the following fields: \u001b[39m\u001b[38;5;124m\"\u001b[39m\n\u001b[1;32m 2967\u001b[0m \u001b[38;5;241m+\u001b[39m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124m, \u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;241m.\u001b[39mjoin(\u001b[38;5;28mstr\u001b[39m(s) \u001b[38;5;28;01mfor\u001b[39;00m s \u001b[38;5;129;01min\u001b[39;00m my_missing)\n\u001b[1;32m 2968\u001b[0m )\n\u001b[0;32m-> 2970\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mValueError\u001b[39;00m(msg\u001b[38;5;241m.\u001b[39mformat(\u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39mfeature_names, feature_names))\n",
|
| 253 |
-
"\u001b[0;31mValueError\u001b[0m: feature_names mismatch: ['past_air_quality', 'temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant'] ['temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']\nexpected past_air_quality in input data"
|
| 254 |
]
|
| 255 |
}
|
| 256 |
],
|
| 257 |
"source": [
|
| 258 |
-
"
|
| 259 |
-
"\n",
|
| 260 |
-
"batch_data['predicted_pm25'] = retrieved_xgboost_model.predict(\n",
|
| 261 |
-
" batch_data[['temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']])\n",
|
| 262 |
-
"\n",
|
| 263 |
-
"batch_data['street'] = street\n",
|
| 264 |
-
"batch_data['city'] = city\n",
|
| 265 |
-
"batch_data['country'] = country\n",
|
| 266 |
-
"# Fill in the number of days before the date on which you made the forecast (base_date)\n",
|
| 267 |
-
"batch_data['days_before_forecast_day'] = range(1, len(batch_data)+1)\n",
|
| 268 |
-
"batch_data = batch_data.sort_values(by=['date'])\n",
|
| 269 |
-
"#batch_data['date'] = batch_data['date'].dt.tz_convert(None).astype('datetime64[ns]')\n",
|
| 270 |
"\n",
|
| 271 |
-
"
|
| 272 |
-
"
|
|
|
|
|
|
|
|
|
|
| 273 |
]
|
| 274 |
},
|
| 275 |
{
|
|
@@ -277,156 +81,53 @@
|
|
| 277 |
"execution_count": null,
|
| 278 |
"metadata": {},
|
| 279 |
"outputs": [
|
| 280 |
-
{
|
| 281 |
-
"name": "stdout",
|
| 282 |
-
"output_type": "stream",
|
| 283 |
-
"text": [
|
| 284 |
-
"Batch data: date temperature_2m_mean precipitation_sum \\\n",
|
| 285 |
-
"0 2024-11-21 00:00:00+00:00 3.40 0.2 \n",
|
| 286 |
-
"3 2024-11-22 00:00:00+00:00 4.05 0.7 \n",
|
| 287 |
-
"2 2024-11-23 00:00:00+00:00 5.45 0.0 \n",
|
| 288 |
-
"1 2024-11-24 00:00:00+00:00 5.60 0.0 \n",
|
| 289 |
-
"\n",
|
| 290 |
-
" wind_speed_10m_max wind_direction_10m_dominant city \\\n",
|
| 291 |
-
"0 19.995398 246.665939 Helsingborg \n",
|
| 292 |
-
"3 23.540806 246.571289 Helsingborg \n",
|
| 293 |
-
"2 30.631746 240.422256 Helsingborg \n",
|
| 294 |
-
"1 13.755580 276.008911 Helsingborg \n",
|
| 295 |
-
"\n",
|
| 296 |
-
" predicted_pm25 street country days_before_forecast_day \n",
|
| 297 |
-
"0 39.168438 Drottninggatan Sweden 1 \n",
|
| 298 |
-
"3 20.740093 Drottninggatan Sweden 2 \n",
|
| 299 |
-
"2 46.448105 Drottninggatan Sweden 3 \n",
|
| 300 |
-
"1 61.713448 Drottninggatan Sweden 4 \n"
|
| 301 |
-
]
|
| 302 |
-
},
|
| 303 |
{
|
| 304 |
"data": {
|
| 305 |
-
"application/vnd.jupyter.widget-view+json": {
|
| 306 |
-
"model_id": "0c3e8fd8c8f545a597e504acf5f077e8",
|
| 307 |
-
"version_major": 2,
|
| 308 |
-
"version_minor": 0
|
| 309 |
-
},
|
| 310 |
"text/plain": [
|
| 311 |
-
"
|
| 312 |
]
|
| 313 |
},
|
|
|
|
| 314 |
"metadata": {},
|
| 315 |
-
"output_type": "
|
| 316 |
-
},
|
| 317 |
-
{
|
| 318 |
-
"name": "stdout",
|
| 319 |
-
"output_type": "stream",
|
| 320 |
-
"text": [
|
| 321 |
-
"Launching job: aq_predictions_1_offline_fg_materialization\n",
|
| 322 |
-
"Job started successfully, you can follow the progress at \n",
|
| 323 |
-
"https://c.app.hopsworks.ai/p/1160340/jobs/named/aq_predictions_1_offline_fg_materialization/executions\n",
|
| 324 |
-
"Finished: Reading data from Hopsworks, using Hopsworks Feature Query Service (0.95s) \n",
|
| 325 |
-
"Finished: Reading data from Hopsworks, using Hopsworks Feature Query Service (1.85s) \n"
|
| 326 |
-
]
|
| 327 |
-
}
|
| 328 |
-
],
|
| 329 |
-
"source": [
|
| 330 |
-
"monitor_fg = fs.get_or_create_feature_group(\n",
|
| 331 |
-
" name='aq_predictions',\n",
|
| 332 |
-
" description='Air Quality prediction monitoring',\n",
|
| 333 |
-
" version=1,\n",
|
| 334 |
-
" primary_key=['city','street','date','days_before_forecast_day'],\n",
|
| 335 |
-
" event_time=\"date\"\n",
|
| 336 |
-
")\n",
|
| 337 |
-
"\n",
|
| 338 |
-
"print(f\"Batch data: {batch_data}\")\n",
|
| 339 |
-
"\n",
|
| 340 |
-
"monitor_fg.insert(batch_data, write_options={\"wait_for_job\": True})\n",
|
| 341 |
-
"monitoring_df = monitor_fg.filter(monitor_fg.days_before_forecast_day == 1).read()\n",
|
| 342 |
-
"\n",
|
| 343 |
-
"# Hindcast monitoring\n",
|
| 344 |
-
"\n",
|
| 345 |
-
"air_quality_fg = fs.get_feature_group(\n",
|
| 346 |
-
" name='air_quality',\n",
|
| 347 |
-
" version=1,\n",
|
| 348 |
-
")\n",
|
| 349 |
-
"air_quality_df = air_quality_fg.read()\n",
|
| 350 |
-
"\n",
|
| 351 |
-
"outcome_df = air_quality_df[['date', 'pm25']]\n",
|
| 352 |
-
"preds_df = monitoring_df[['date', 'predicted_pm25']]"
|
| 353 |
-
]
|
| 354 |
-
},
|
| 355 |
-
{
|
| 356 |
-
"cell_type": "code",
|
| 357 |
-
"execution_count": null,
|
| 358 |
-
"metadata": {},
|
| 359 |
-
"outputs": [
|
| 360 |
-
{
|
| 361 |
-
"ename": "ValueError",
|
| 362 |
-
"evalue": "You are trying to merge on datetime64[us, UTC] and object columns for key 'date'. If you wish to proceed you should use pd.concat",
|
| 363 |
-
"output_type": "error",
|
| 364 |
-
"traceback": [
|
| 365 |
-
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 366 |
-
"\u001b[0;31mValueError\u001b[0m Traceback (most recent call last)",
|
| 367 |
-
"Cell \u001b[0;32mIn[5], line 1\u001b[0m\n\u001b[0;32m----> 1\u001b[0m hindcast_df \u001b[38;5;241m=\u001b[39m \u001b[43mpd\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mmerge\u001b[49m\u001b[43m(\u001b[49m\u001b[43mpreds_df\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43moutcome_df\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mon\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43mdate\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m)\u001b[49m\n\u001b[1;32m 2\u001b[0m hindcast_df \u001b[38;5;241m=\u001b[39m hindcast_df\u001b[38;5;241m.\u001b[39msort_values(by\u001b[38;5;241m=\u001b[39m[\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mdate\u001b[39m\u001b[38;5;124m'\u001b[39m])\n\u001b[1;32m 4\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28mlen\u001b[39m(hindcast_df) \u001b[38;5;241m==\u001b[39m \u001b[38;5;241m0\u001b[39m:\n",
|
| 368 |
-
"File \u001b[0;32m~/Documents/scalable-ml/lab1-new/hbg-weather/.venv/lib/python3.12/site-packages/pandas/core/reshape/merge.py:169\u001b[0m, in \u001b[0;36mmerge\u001b[0;34m(left, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)\u001b[0m\n\u001b[1;32m 154\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m _cross_merge(\n\u001b[1;32m 155\u001b[0m left_df,\n\u001b[1;32m 156\u001b[0m right_df,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 166\u001b[0m copy\u001b[38;5;241m=\u001b[39mcopy,\n\u001b[1;32m 167\u001b[0m )\n\u001b[1;32m 168\u001b[0m \u001b[38;5;28;01melse\u001b[39;00m:\n\u001b[0;32m--> 169\u001b[0m op \u001b[38;5;241m=\u001b[39m \u001b[43m_MergeOperation\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 170\u001b[0m \u001b[43m \u001b[49m\u001b[43mleft_df\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 171\u001b[0m \u001b[43m \u001b[49m\u001b[43mright_df\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 172\u001b[0m \u001b[43m \u001b[49m\u001b[43mhow\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mhow\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 173\u001b[0m \u001b[43m \u001b[49m\u001b[43mon\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mon\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 174\u001b[0m \u001b[43m \u001b[49m\u001b[43mleft_on\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mleft_on\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 175\u001b[0m \u001b[43m \u001b[49m\u001b[43mright_on\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mright_on\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 176\u001b[0m \u001b[43m \u001b[49m\u001b[43mleft_index\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mleft_index\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 177\u001b[0m \u001b[43m \u001b[49m\u001b[43mright_index\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mright_index\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 178\u001b[0m \u001b[43m \u001b[49m\u001b[43msort\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43msort\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 179\u001b[0m \u001b[43m \u001b[49m\u001b[43msuffixes\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43msuffixes\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 180\u001b[0m \u001b[43m \u001b[49m\u001b[43mindicator\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mindicator\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 181\u001b[0m \u001b[43m \u001b[49m\u001b[43mvalidate\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mvalidate\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 182\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 183\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m op\u001b[38;5;241m.\u001b[39mget_result(copy\u001b[38;5;241m=\u001b[39mcopy)\n",
|
| 369 |
-
"File \u001b[0;32m~/Documents/scalable-ml/lab1-new/hbg-weather/.venv/lib/python3.12/site-packages/pandas/core/reshape/merge.py:804\u001b[0m, in \u001b[0;36m_MergeOperation.__init__\u001b[0;34m(self, left, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, indicator, validate)\u001b[0m\n\u001b[1;32m 800\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_validate_tolerance(\u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39mleft_join_keys)\n\u001b[1;32m 802\u001b[0m \u001b[38;5;66;03m# validate the merge keys dtypes. We may need to coerce\u001b[39;00m\n\u001b[1;32m 803\u001b[0m \u001b[38;5;66;03m# to avoid incompatible dtypes\u001b[39;00m\n\u001b[0;32m--> 804\u001b[0m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_maybe_coerce_merge_keys\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 806\u001b[0m \u001b[38;5;66;03m# If argument passed to validate,\u001b[39;00m\n\u001b[1;32m 807\u001b[0m \u001b[38;5;66;03m# check if columns specified as unique\u001b[39;00m\n\u001b[1;32m 808\u001b[0m \u001b[38;5;66;03m# are in fact unique.\u001b[39;00m\n\u001b[1;32m 809\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m validate \u001b[38;5;129;01mis\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m:\n",
|
| 370 |
-
"File \u001b[0;32m~/Documents/scalable-ml/lab1-new/hbg-weather/.venv/lib/python3.12/site-packages/pandas/core/reshape/merge.py:1483\u001b[0m, in \u001b[0;36m_MergeOperation._maybe_coerce_merge_keys\u001b[0;34m(self)\u001b[0m\n\u001b[1;32m 1481\u001b[0m \u001b[38;5;66;03m# datetimelikes must match exactly\u001b[39;00m\n\u001b[1;32m 1482\u001b[0m \u001b[38;5;28;01melif\u001b[39;00m needs_i8_conversion(lk\u001b[38;5;241m.\u001b[39mdtype) \u001b[38;5;129;01mand\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m needs_i8_conversion(rk\u001b[38;5;241m.\u001b[39mdtype):\n\u001b[0;32m-> 1483\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mValueError\u001b[39;00m(msg)\n\u001b[1;32m 1484\u001b[0m \u001b[38;5;28;01melif\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m needs_i8_conversion(lk\u001b[38;5;241m.\u001b[39mdtype) \u001b[38;5;129;01mand\u001b[39;00m needs_i8_conversion(rk\u001b[38;5;241m.\u001b[39mdtype):\n\u001b[1;32m 1485\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mValueError\u001b[39;00m(msg)\n",
|
| 371 |
-
"\u001b[0;31mValueError\u001b[0m: You are trying to merge on datetime64[us, UTC] and object columns for key 'date'. If you wish to proceed you should use pd.concat"
|
| 372 |
-
]
|
| 373 |
}
|
| 374 |
],
|
| 375 |
"source": [
|
| 376 |
-
"
|
| 377 |
-
"
|
| 378 |
-
"\n",
|
| 379 |
-
"
|
| 380 |
-
"
|
| 381 |
-
"\n",
|
| 382 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 383 |
]
|
| 384 |
},
|
| 385 |
{
|
| 386 |
"cell_type": "code",
|
| 387 |
"execution_count": null,
|
| 388 |
"metadata": {},
|
| 389 |
-
"outputs": [
|
| 390 |
-
|
| 391 |
-
"name": "stdout",
|
| 392 |
-
"output_type": "stream",
|
| 393 |
-
"text": [
|
| 394 |
-
"2024-11-20 14:23:12,559 WARNING: SettingWithCopyWarning: \n",
|
| 395 |
-
"A value is trying to be set on a copy of a slice from a DataFrame.\n",
|
| 396 |
-
"Try using .loc[row_indexer,col_indexer] = value instead\n",
|
| 397 |
-
"\n",
|
| 398 |
-
"See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n",
|
| 399 |
-
"\n"
|
| 400 |
-
]
|
| 401 |
-
}
|
| 402 |
-
],
|
| 403 |
-
"source": [
|
| 404 |
-
"import numpy as np\n",
|
| 405 |
-
"\n",
|
| 406 |
-
"scale = 5\n",
|
| 407 |
-
"outcome_df['predicted_pm25'] = outcome_df['pm25'] + scale * np.random.uniform(-1, 1, outcome_df.shape[0])\n",
|
| 408 |
-
"outcome_df.sort_values(by=['date'])\n",
|
| 409 |
-
"outcome_df.to_pickle('outcome_df.pkl')"
|
| 410 |
-
]
|
| 411 |
}
|
| 412 |
],
|
| 413 |
"metadata": {
|
| 414 |
-
"kernelspec": {
|
| 415 |
-
"display_name": ".venv",
|
| 416 |
-
"language": "python",
|
| 417 |
-
"name": "python3"
|
| 418 |
-
},
|
| 419 |
"language_info": {
|
| 420 |
-
"
|
| 421 |
-
"name": "ipython",
|
| 422 |
-
"version": 3
|
| 423 |
-
},
|
| 424 |
-
"file_extension": ".py",
|
| 425 |
-
"mimetype": "text/x-python",
|
| 426 |
-
"name": "python",
|
| 427 |
-
"nbconvert_exporter": "python",
|
| 428 |
-
"pygments_lexer": "ipython3",
|
| 429 |
-
"version": "3.12.4"
|
| 430 |
}
|
| 431 |
},
|
| 432 |
"nbformat": 4,
|
|
|
|
| 2 |
"cells": [
|
| 3 |
{
|
| 4 |
"cell_type": "code",
|
| 5 |
+
"execution_count": 8,
|
| 6 |
"metadata": {},
|
| 7 |
"outputs": [
|
| 8 |
{
|
|
|
|
| 10 |
"output_type": "stream",
|
| 11 |
"text": [
|
| 12 |
"Connection closed.\n",
|
| 13 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
"\n",
|
| 15 |
"Logged in to project, explore it here https://c.app.hopsworks.ai:443/p/1160344\n",
|
| 16 |
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 17 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 18 |
+
"Finished: Reading data from Hopsworks, using Hopsworks Feature Query Service (3.28s) \n",
|
| 19 |
+
"Finished: Reading data from Hopsworks, using Hopsworks Feature Query Service (1.04s) \n"
|
| 20 |
]
|
| 21 |
}
|
| 22 |
],
|
| 23 |
"source": [
|
| 24 |
+
"import streamlit as st\n",
|
| 25 |
"import pandas as pd\n",
|
| 26 |
+
"import numpy as np\n",
|
| 27 |
+
"import datetime\n",
|
| 28 |
"import hopsworks\n",
|
| 29 |
+
"from functions import figure, retrieve\n",
|
| 30 |
+
"import os\n",
|
| 31 |
+
"import pickle\n",
|
| 32 |
+
"import plotly.express as px\n",
|
| 33 |
"import json\n",
|
| 34 |
+
"from datetime import datetime\n",
|
| 35 |
"import os\n",
|
| 36 |
"\n",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
"\n",
|
| 38 |
+
"# Real data\n",
|
| 39 |
+
"today = datetime.today().strftime('%Y-%m-%d')\n",
|
| 40 |
+
"df = retrieve.get_merged_dataframe()"
|
| 41 |
]
|
| 42 |
},
|
| 43 |
{
|
| 44 |
"cell_type": "code",
|
| 45 |
+
"execution_count": 17,
|
| 46 |
"metadata": {},
|
| 47 |
"outputs": [
|
| 48 |
{
|
| 49 |
"name": "stdout",
|
| 50 |
"output_type": "stream",
|
| 51 |
"text": [
|
| 52 |
+
"Connection closed.\n",
|
| 53 |
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"Logged in to project, explore it here https://c.app.hopsworks.ai:443/p/1160344\n",
|
| 56 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 57 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 58 |
+
"No air_quality_fv feature view found\n",
|
| 59 |
+
"No air_quality feature group found\n",
|
| 60 |
+
"No weather feature group found\n",
|
| 61 |
+
"No aq_predictions feature group found\n",
|
| 62 |
+
"No air_quality_xgboost_model model found\n",
|
| 63 |
+
"Connected. Call `.close()` to terminate connection gracefully.\n",
|
| 64 |
+
"Deleted secret SENSOR_LOCATION_JSON\n"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 65 |
]
|
| 66 |
}
|
| 67 |
],
|
| 68 |
"source": [
|
| 69 |
+
"import hopsworks\n",
|
| 70 |
+
"import os\n",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
"\n",
|
| 72 |
+
"from functions import util\n",
|
| 73 |
+
"api_key = os.getenv('HOPSWORKS_API_KEY')\n",
|
| 74 |
+
"project_name = os.getenv('HOPSWORKS_PROJECT')\n",
|
| 75 |
+
"project = hopsworks.login(project=project_name, api_key_value=api_key)\n",
|
| 76 |
+
"util.purge_project(project)"
|
| 77 |
]
|
| 78 |
},
|
| 79 |
{
|
|
|
|
| 81 |
"execution_count": null,
|
| 82 |
"metadata": {},
|
| 83 |
"outputs": [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 84 |
{
|
| 85 |
"data": {
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 86 |
"text/plain": [
|
| 87 |
+
"9"
|
| 88 |
]
|
| 89 |
},
|
| 90 |
+
"execution_count": 16,
|
| 91 |
"metadata": {},
|
| 92 |
+
"output_type": "execute_result"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 93 |
}
|
| 94 |
],
|
| 95 |
"source": [
|
| 96 |
+
"def backfill_predictions_for_monitoring(weather_fg, air_quality_df, monitor_fg, model):\n",
|
| 97 |
+
" weather_df = weather_fg.read()\n",
|
| 98 |
+
" weather_df = weather_df.sort_values(by=['date'], ascending=True)\n",
|
| 99 |
+
" weather_df['date'] = weather_df['date'].dt.tz_convert(None).astype('datetime64[ns]')\n",
|
| 100 |
+
" air_quality_df_filter = air_quality_df[['date', 'past_air_quality']]\n",
|
| 101 |
+
" monitor_fg_filter = monitor_fg.read()[['date','past_air_quality']]\n",
|
| 102 |
+
" combined_df = pd.concat([air_quality_df_filter, monitor_fg_filter])\n",
|
| 103 |
+
" combined_df['date'] = pd.to_datetime(combined_df['date'], utc=True)\n",
|
| 104 |
+
" combined_df['date'] = combined_df['date'].dt.tz_convert(None).astype('datetime64[ns]')\n",
|
| 105 |
+
" features_df = pd.merge(weather_df, combined_df, on='date', how='left')\n",
|
| 106 |
+
" \n",
|
| 107 |
+
" features_df = features_df.tail(10)\n",
|
| 108 |
+
" features_df['predicted_pm25'] = model.predict(features_df[['past_air_quality','temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']])\n",
|
| 109 |
+
" air_quality_df['date'] = pd.to_datetime(air_quality_df['date'])\n",
|
| 110 |
+
" # features_df['date'] = features_df['date'].dt.tz_convert(None).astype('datetime64[ns]')\n",
|
| 111 |
+
" \n",
|
| 112 |
+
" df = pd.merge(features_df, air_quality_df[['date','pm25','street','country']], on=\"date\")\n",
|
| 113 |
+
" df['days_before_forecast_day'] = 1\n",
|
| 114 |
+
" hindcast_df = df\n",
|
| 115 |
+
" df = df.drop('pm25', axis=1)\n",
|
| 116 |
+
" monitor_fg.insert(df, write_options={\"wait_for_job\": True})\n",
|
| 117 |
+
" return hindcast_df"
|
| 118 |
]
|
| 119 |
},
|
| 120 |
{
|
| 121 |
"cell_type": "code",
|
| 122 |
"execution_count": null,
|
| 123 |
"metadata": {},
|
| 124 |
+
"outputs": [],
|
| 125 |
+
"source": []
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 126 |
}
|
| 127 |
],
|
| 128 |
"metadata": {
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 129 |
"language_info": {
|
| 130 |
+
"name": "python"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 131 |
}
|
| 132 |
},
|
| 133 |
"nbformat": 4,
|
functions/__pycache__/util.cpython-312.pyc
CHANGED
|
Binary files a/functions/__pycache__/util.cpython-312.pyc and b/functions/__pycache__/util.cpython-312.pyc differ
|
|
|
functions/{merge_df.py → retrieve.py}
RENAMED
|
@@ -50,15 +50,17 @@ def get_merged_dataframe():
|
|
| 50 |
selected_features = air_quality_fg.select_all(['pm25', 'past_air_quality']).join(weather_fg.select(['temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']), on=['city'])
|
| 51 |
selected_features = selected_features.read()
|
| 52 |
selected_features['date'] = pd.to_datetime(selected_features['date'], utc=True).dt.tz_convert(None).astype('datetime64[ns]')
|
|
|
|
| 53 |
|
| 54 |
predicted_data = monitor_fg.read()
|
| 55 |
predicted_data = predicted_data[['date','predicted_pm25']]
|
| 56 |
predicted_data['date'] = predicted_data['date'].dt.tz_convert(None).astype('datetime64[ns]')
|
| 57 |
predicted_data = predicted_data.sort_values(by=['date'], ascending=True).reset_index(drop=True)
|
|
|
|
| 58 |
|
| 59 |
|
| 60 |
#get historical predicted pm25
|
| 61 |
-
selected_features['predicted_pm25'] = retrieved_xgboost_model.predict(selected_features[['past_air_quality','temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']])
|
| 62 |
|
| 63 |
#merge data
|
| 64 |
selected_features = selected_features[['date', 'pm25', 'predicted_pm25']]
|
|
@@ -70,5 +72,6 @@ def get_merged_dataframe():
|
|
| 70 |
|
| 71 |
# Drop the individual columns after merging
|
| 72 |
combined_df = combined_df.drop(columns=['predicted_pm25_x', 'predicted_pm25_y'])
|
|
|
|
| 73 |
|
| 74 |
return combined_df
|
|
|
|
| 50 |
selected_features = air_quality_fg.select_all(['pm25', 'past_air_quality']).join(weather_fg.select(['temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']), on=['city'])
|
| 51 |
selected_features = selected_features.read()
|
| 52 |
selected_features['date'] = pd.to_datetime(selected_features['date'], utc=True).dt.tz_convert(None).astype('datetime64[ns]')
|
| 53 |
+
selected_features = selected_features.tail(100)
|
| 54 |
|
| 55 |
predicted_data = monitor_fg.read()
|
| 56 |
predicted_data = predicted_data[['date','predicted_pm25']]
|
| 57 |
predicted_data['date'] = predicted_data['date'].dt.tz_convert(None).astype('datetime64[ns]')
|
| 58 |
predicted_data = predicted_data.sort_values(by=['date'], ascending=True).reset_index(drop=True)
|
| 59 |
+
|
| 60 |
|
| 61 |
|
| 62 |
#get historical predicted pm25
|
| 63 |
+
selected_features['predicted_pm25'] = retrieved_xgboost_model.predict(selected_features[['past_air_quality','temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']])
|
| 64 |
|
| 65 |
#merge data
|
| 66 |
selected_features = selected_features[['date', 'pm25', 'predicted_pm25']]
|
|
|
|
| 72 |
|
| 73 |
# Drop the individual columns after merging
|
| 74 |
combined_df = combined_df.drop(columns=['predicted_pm25_x', 'predicted_pm25_y'])
|
| 75 |
+
combined_df = combined_df.drop_duplicates(subset=['date']).reset_index(drop=True)
|
| 76 |
|
| 77 |
return combined_df
|
functions/util.py
CHANGED
|
@@ -15,10 +15,6 @@ import hopsworks
|
|
| 15 |
import hsfs
|
| 16 |
from pathlib import Path
|
| 17 |
|
| 18 |
-
import sys
|
| 19 |
-
print(sys.path)
|
| 20 |
-
|
| 21 |
-
|
| 22 |
def get_historical_weather(city, start_date, end_date, latitude, longitude):
|
| 23 |
# latitude, longitude = get_city_coordinates(city)
|
| 24 |
|
|
@@ -300,16 +296,24 @@ def check_file_path(file_path):
|
|
| 300 |
print(f"File successfully found at the path: {file_path}")
|
| 301 |
|
| 302 |
def backfill_predictions_for_monitoring(weather_fg, air_quality_df, monitor_fg, model):
|
| 303 |
-
|
| 304 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 305 |
features_df = features_df.tail(10)
|
| 306 |
-
features_df['predicted_pm25'] = model.predict(features_df[['temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']])
|
| 307 |
air_quality_df['date'] = pd.to_datetime(air_quality_df['date'])
|
| 308 |
-
features_df['date'] = features_df['date'].dt.tz_convert(None).astype('datetime64[ns]')
|
| 309 |
|
| 310 |
df = pd.merge(features_df, air_quality_df[['date','pm25','street','country']], on="date")
|
| 311 |
df['days_before_forecast_day'] = 1
|
| 312 |
hindcast_df = df
|
| 313 |
df = df.drop('pm25', axis=1)
|
| 314 |
monitor_fg.insert(df, write_options={"wait_for_job": True})
|
| 315 |
-
return hindcast_df
|
|
|
|
| 15 |
import hsfs
|
| 16 |
from pathlib import Path
|
| 17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
def get_historical_weather(city, start_date, end_date, latitude, longitude):
|
| 19 |
# latitude, longitude = get_city_coordinates(city)
|
| 20 |
|
|
|
|
| 296 |
print(f"File successfully found at the path: {file_path}")
|
| 297 |
|
| 298 |
def backfill_predictions_for_monitoring(weather_fg, air_quality_df, monitor_fg, model):
|
| 299 |
+
weather_df = weather_fg.read()
|
| 300 |
+
weather_df = weather_df.sort_values(by=['date'], ascending=True)
|
| 301 |
+
weather_df['date'] = weather_df['date'].dt.tz_convert(None).astype('datetime64[ns]')
|
| 302 |
+
air_quality_df_filter = air_quality_df[['date', 'past_air_quality']]
|
| 303 |
+
monitor_fg_filter = monitor_fg.read()[['date','past_air_quality']]
|
| 304 |
+
combined_df = pd.concat([air_quality_df_filter, monitor_fg_filter])
|
| 305 |
+
combined_df['date'] = pd.to_datetime(combined_df['date'], utc=True)
|
| 306 |
+
combined_df['date'] = combined_df['date'].dt.tz_convert(None).astype('datetime64[ns]')
|
| 307 |
+
features_df = pd.merge(weather_df, combined_df, on='date', how='left')
|
| 308 |
+
|
| 309 |
features_df = features_df.tail(10)
|
| 310 |
+
features_df['predicted_pm25'] = model.predict(features_df[['past_air_quality','temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']])
|
| 311 |
air_quality_df['date'] = pd.to_datetime(air_quality_df['date'])
|
| 312 |
+
# features_df['date'] = features_df['date'].dt.tz_convert(None).astype('datetime64[ns]')
|
| 313 |
|
| 314 |
df = pd.merge(features_df, air_quality_df[['date','pm25','street','country']], on="date")
|
| 315 |
df['days_before_forecast_day'] = 1
|
| 316 |
hindcast_df = df
|
| 317 |
df = df.drop('pm25', axis=1)
|
| 318 |
monitor_fg.insert(df, write_options={"wait_for_job": True})
|
| 319 |
+
return hindcast_df
|
inference_pipeline.py
CHANGED
|
@@ -30,9 +30,6 @@ today = datetime.datetime.now() - datetime.timedelta(0)
|
|
| 30 |
tomorrow = today + datetime.timedelta(days = 1)
|
| 31 |
today
|
| 32 |
|
| 33 |
-
|
| 34 |
-
# ## <span style="color:#ff5f27;"> 📡 Connect to Hopsworks Feature Store </span>
|
| 35 |
-
|
| 36 |
# In[3]:
|
| 37 |
|
| 38 |
|
|
@@ -50,10 +47,6 @@ country=location['country']
|
|
| 50 |
city=location['city']
|
| 51 |
street=location['street']
|
| 52 |
|
| 53 |
-
|
| 54 |
-
# ## <span style="color:#ff5f27;"> ⚙️ Feature View Retrieval</span>
|
| 55 |
-
#
|
| 56 |
-
|
| 57 |
# In[4]:
|
| 58 |
|
| 59 |
|
|
@@ -62,9 +55,6 @@ feature_view = fs.get_feature_view(
|
|
| 62 |
version=1,
|
| 63 |
)
|
| 64 |
|
| 65 |
-
|
| 66 |
-
# ## <span style="color:#ff5f27;">🪝 Download the model from Model Registry</span>
|
| 67 |
-
|
| 68 |
# In[5]:
|
| 69 |
|
| 70 |
|
|
@@ -74,38 +64,22 @@ retrieved_model = mr.get_model(
|
|
| 74 |
name="air_quality_xgboost_model",
|
| 75 |
version=1,
|
| 76 |
)
|
| 77 |
-
|
| 78 |
-
# Download the saved model artifacts to a local directory
|
| 79 |
saved_model_dir = retrieved_model.download()
|
| 80 |
|
| 81 |
|
| 82 |
# In[6]:
|
| 83 |
|
| 84 |
|
| 85 |
-
# Loading the XGBoost regressor model and label encoder from the saved model directory
|
| 86 |
-
# retrieved_xgboost_model = joblib.load(saved_model_dir + "/xgboost_regressor.pkl")
|
| 87 |
retrieved_xgboost_model = XGBRegressor()
|
| 88 |
-
|
| 89 |
retrieved_xgboost_model.load_model(saved_model_dir + "/model.json")
|
| 90 |
-
|
| 91 |
-
# Displaying the retrieved XGBoost regressor model
|
| 92 |
retrieved_xgboost_model
|
| 93 |
|
| 94 |
|
| 95 |
# In[7]:
|
| 96 |
|
| 97 |
-
|
| 98 |
-
# Access the feature names of the trained XGBoost model
|
| 99 |
feature_names = retrieved_xgboost_model.get_booster().feature_names
|
| 100 |
-
|
| 101 |
-
# Print the feature names
|
| 102 |
print("Feature names:", feature_names)
|
| 103 |
|
| 104 |
-
|
| 105 |
-
# ## <span style="color:#ff5f27;">✨ Get Weather Forecast Features with Feature View </span>
|
| 106 |
-
#
|
| 107 |
-
#
|
| 108 |
-
|
| 109 |
# In[8]:
|
| 110 |
|
| 111 |
|
|
@@ -117,12 +91,8 @@ today_timestamp = pd.to_datetime(today)
|
|
| 117 |
batch_data = weather_fg.filter(weather_fg.date >= today_timestamp ).read()
|
| 118 |
batch_data
|
| 119 |
|
| 120 |
-
|
| 121 |
-
# ### Get Mean air quality for past days
|
| 122 |
-
|
| 123 |
# In[9]:
|
| 124 |
|
| 125 |
-
|
| 126 |
air_quality_fg = fs.get_feature_group(
|
| 127 |
name='air_quality',
|
| 128 |
version=1,
|
|
@@ -130,39 +100,22 @@ air_quality_fg = fs.get_feature_group(
|
|
| 130 |
selected_features = air_quality_fg.select_all() #(['pm25']).join(weather_fg.select_all(), on=['city'])
|
| 131 |
selected_features = selected_features.read()
|
| 132 |
|
| 133 |
-
|
| 134 |
# In[10]:
|
| 135 |
|
| 136 |
-
|
| 137 |
selected_features = selected_features.sort_values(by='date').reset_index(drop=True)
|
| 138 |
|
| 139 |
-
|
| 140 |
# In[11]:
|
| 141 |
|
| 142 |
-
|
| 143 |
past_air_q_list = selected_features[['date', 'pm25']][-3:]['pm25'].tolist()
|
| 144 |
|
| 145 |
-
|
| 146 |
# In[12]:
|
| 147 |
|
| 148 |
-
|
| 149 |
batch_data = batch_data.sort_values(by='date').reset_index(drop=True)
|
| 150 |
|
| 151 |
-
|
| 152 |
# In[13]:
|
| 153 |
|
| 154 |
-
|
| 155 |
batch_data['past_air_quality'] = None
|
| 156 |
|
| 157 |
-
|
| 158 |
-
# In[14]:
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
batch_data
|
| 162 |
-
|
| 163 |
-
|
| 164 |
-
# ### <span style="color:#ff5f27;">🤖 Making the predictions</span>
|
| 165 |
-
|
| 166 |
# In[15]:
|
| 167 |
|
| 168 |
|
|
@@ -196,23 +149,11 @@ batch_data['predicted_pm25'] = predictions
|
|
| 196 |
# Display the updated DataFrame
|
| 197 |
batch_data
|
| 198 |
|
| 199 |
-
|
| 200 |
-
# In[16]:
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
# batch_data['predicted_pm25'] = retrieved_xgboost_model.predict(
|
| 204 |
-
# batch_data[['temperature_2m_mean', 'precipitation_sum', 'wind_speed_10m_max', 'wind_direction_10m_dominant']])
|
| 205 |
-
# batch_data
|
| 206 |
-
|
| 207 |
-
|
| 208 |
# In[17]:
|
| 209 |
|
| 210 |
|
| 211 |
batch_data.info()
|
| 212 |
|
| 213 |
-
|
| 214 |
-
# ### <span style="color:#ff5f27;">🤖 Saving the predictions (for monitoring) to a Feature Group</span>
|
| 215 |
-
|
| 216 |
# In[18]:
|
| 217 |
|
| 218 |
|
|
@@ -226,24 +167,6 @@ batch_data['date'] = batch_data['date'].dt.tz_convert(None).astype('datetime64[n
|
|
| 226 |
batch_data
|
| 227 |
|
| 228 |
|
| 229 |
-
# In[19]:
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
batch_data.info()
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
# ### Create Forecast Graph
|
| 236 |
-
# Draw a graph of the predictions with dates as a PNG and save it to the github repo
|
| 237 |
-
# Show it on github pages
|
| 238 |
-
|
| 239 |
-
# In[20]:
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
file_path = "img/pm25_forecast.png"
|
| 243 |
-
plt = util.plot_air_quality_forecast(city, street, batch_data, file_path)
|
| 244 |
-
plt.show()
|
| 245 |
-
|
| 246 |
-
|
| 247 |
# In[21]:
|
| 248 |
|
| 249 |
|
|
@@ -268,8 +191,6 @@ monitor_fg.insert(batch_data, write_options={"wait_for_job": True})
|
|
| 268 |
|
| 269 |
# We will create a hindcast chart for only the forecasts made 1 day beforehand
|
| 270 |
monitoring_df = monitor_fg.filter(monitor_fg.days_before_forecast_day == 1).read()
|
| 271 |
-
monitoring_df
|
| 272 |
-
|
| 273 |
|
| 274 |
# In[24]:
|
| 275 |
|
|
@@ -331,19 +252,4 @@ hindcast_df = hindcast_df.sort_values(by=['date'])
|
|
| 331 |
# If there are no outcomes for predictions yet, generate some predictions/outcomes from existing data
|
| 332 |
if len(hindcast_df) == 0:
|
| 333 |
hindcast_df = util.backfill_predictions_for_monitoring(weather_fg, air_quality_df, monitor_fg, retrieved_xgboost_model)
|
| 334 |
-
hindcast_df
|
| 335 |
-
|
| 336 |
-
|
| 337 |
-
# ### Plot the Hindcast comparing predicted with forecasted values (1-day prior forecast)
|
| 338 |
-
#
|
| 339 |
-
# __This graph will be empty to begin with - this is normal.__
|
| 340 |
-
#
|
| 341 |
-
# After a few days of predictions and observations, you will get data points in this graph.
|
| 342 |
-
|
| 343 |
-
# In[32]:
|
| 344 |
-
|
| 345 |
-
|
| 346 |
-
file_path = "img/pm25_hindcast_1day.png"
|
| 347 |
-
plt = util.plot_air_quality_forecast(city, street, hindcast_df, file_path, hindcast=True)
|
| 348 |
-
plt.show()
|
| 349 |
-
# %%
|
|
|
|
| 30 |
tomorrow = today + datetime.timedelta(days = 1)
|
| 31 |
today
|
| 32 |
|
|
|
|
|
|
|
|
|
|
| 33 |
# In[3]:
|
| 34 |
|
| 35 |
|
|
|
|
| 47 |
city=location['city']
|
| 48 |
street=location['street']
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
# In[4]:
|
| 51 |
|
| 52 |
|
|
|
|
| 55 |
version=1,
|
| 56 |
)
|
| 57 |
|
|
|
|
|
|
|
|
|
|
| 58 |
# In[5]:
|
| 59 |
|
| 60 |
|
|
|
|
| 64 |
name="air_quality_xgboost_model",
|
| 65 |
version=1,
|
| 66 |
)
|
|
|
|
|
|
|
| 67 |
saved_model_dir = retrieved_model.download()
|
| 68 |
|
| 69 |
|
| 70 |
# In[6]:
|
| 71 |
|
| 72 |
|
|
|
|
|
|
|
| 73 |
retrieved_xgboost_model = XGBRegressor()
|
|
|
|
| 74 |
retrieved_xgboost_model.load_model(saved_model_dir + "/model.json")
|
|
|
|
|
|
|
| 75 |
retrieved_xgboost_model
|
| 76 |
|
| 77 |
|
| 78 |
# In[7]:
|
| 79 |
|
|
|
|
|
|
|
| 80 |
feature_names = retrieved_xgboost_model.get_booster().feature_names
|
|
|
|
|
|
|
| 81 |
print("Feature names:", feature_names)
|
| 82 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 83 |
# In[8]:
|
| 84 |
|
| 85 |
|
|
|
|
| 91 |
batch_data = weather_fg.filter(weather_fg.date >= today_timestamp ).read()
|
| 92 |
batch_data
|
| 93 |
|
|
|
|
|
|
|
|
|
|
| 94 |
# In[9]:
|
| 95 |
|
|
|
|
| 96 |
air_quality_fg = fs.get_feature_group(
|
| 97 |
name='air_quality',
|
| 98 |
version=1,
|
|
|
|
| 100 |
selected_features = air_quality_fg.select_all() #(['pm25']).join(weather_fg.select_all(), on=['city'])
|
| 101 |
selected_features = selected_features.read()
|
| 102 |
|
|
|
|
| 103 |
# In[10]:
|
| 104 |
|
|
|
|
| 105 |
selected_features = selected_features.sort_values(by='date').reset_index(drop=True)
|
| 106 |
|
|
|
|
| 107 |
# In[11]:
|
| 108 |
|
|
|
|
| 109 |
past_air_q_list = selected_features[['date', 'pm25']][-3:]['pm25'].tolist()
|
| 110 |
|
|
|
|
| 111 |
# In[12]:
|
| 112 |
|
|
|
|
| 113 |
batch_data = batch_data.sort_values(by='date').reset_index(drop=True)
|
| 114 |
|
|
|
|
| 115 |
# In[13]:
|
| 116 |
|
|
|
|
| 117 |
batch_data['past_air_quality'] = None
|
| 118 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 119 |
# In[15]:
|
| 120 |
|
| 121 |
|
|
|
|
| 149 |
# Display the updated DataFrame
|
| 150 |
batch_data
|
| 151 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 152 |
# In[17]:
|
| 153 |
|
| 154 |
|
| 155 |
batch_data.info()
|
| 156 |
|
|
|
|
|
|
|
|
|
|
| 157 |
# In[18]:
|
| 158 |
|
| 159 |
|
|
|
|
| 167 |
batch_data
|
| 168 |
|
| 169 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 170 |
# In[21]:
|
| 171 |
|
| 172 |
|
|
|
|
| 191 |
|
| 192 |
# We will create a hindcast chart for only the forecasts made 1 day beforehand
|
| 193 |
monitoring_df = monitor_fg.filter(monitor_fg.days_before_forecast_day == 1).read()
|
|
|
|
|
|
|
| 194 |
|
| 195 |
# In[24]:
|
| 196 |
|
|
|
|
| 252 |
# If there are no outcomes for predictions yet, generate some predictions/outcomes from existing data
|
| 253 |
if len(hindcast_df) == 0:
|
| 254 |
hindcast_df = util.backfill_predictions_for_monitoring(weather_fg, air_quality_df, monitor_fg, retrieved_xgboost_model)
|
| 255 |
+
hindcast_df
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
training.py
ADDED
|
@@ -0,0 +1,270 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# coding: utf-8
|
| 3 |
+
|
| 4 |
+
# # <span style="font-width:bold; font-size: 3rem; color:#333;">Training Pipeline</span>
|
| 5 |
+
#
|
| 6 |
+
# ## 🗒️ This notebook is divided into the following sections:
|
| 7 |
+
#
|
| 8 |
+
# 1. Select features for the model and create a Feature View with the selected features
|
| 9 |
+
# 2. Create training data using the feature view
|
| 10 |
+
# 3. Train model
|
| 11 |
+
# 4. Evaluate model performance
|
| 12 |
+
# 5. Save model to model registry
|
| 13 |
+
|
| 14 |
+
# ### <span style='color:#ff5f27'> 📝 Imports
|
| 15 |
+
|
| 16 |
+
# In[1]:
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import os
|
| 20 |
+
from datetime import datetime, timedelta
|
| 21 |
+
import pandas as pd
|
| 22 |
+
import matplotlib.pyplot as plt
|
| 23 |
+
from xgboost import XGBRegressor
|
| 24 |
+
from xgboost import plot_importance
|
| 25 |
+
from sklearn.metrics import mean_squared_error, r2_score
|
| 26 |
+
import hopsworks
|
| 27 |
+
from functions import util
|
| 28 |
+
|
| 29 |
+
import warnings
|
| 30 |
+
warnings.filterwarnings("ignore")
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# ## <span style="color:#ff5f27;"> 📡 Connect to Hopsworks Feature Store </span>
|
| 34 |
+
|
| 35 |
+
# In[2]:
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
project = hopsworks.login()
|
| 39 |
+
api_key = os.getenv('HOPSWORKS_API_KEY')
|
| 40 |
+
project_name = os.getenv('HOPSWORKS_PROJECT')
|
| 41 |
+
project = hopsworks.login(project=project_name, api_key_value=api_key)
|
| 42 |
+
fs = project.get_feature_store()
|
| 43 |
+
secrets = util.secrets_api(project.name)
|
| 44 |
+
|
| 45 |
+
# In[3]:
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# Retrieve feature groups
|
| 49 |
+
air_quality_fg = fs.get_feature_group(
|
| 50 |
+
name='air_quality',
|
| 51 |
+
version=1,
|
| 52 |
+
)
|
| 53 |
+
weather_fg = fs.get_feature_group(
|
| 54 |
+
name='weather',
|
| 55 |
+
version=1,
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# ---
|
| 60 |
+
#
|
| 61 |
+
# ## <span style="color:#ff5f27;"> 🖍 Feature View Creation and Retrieving </span>
|
| 62 |
+
|
| 63 |
+
# In[4]:
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
# Select features for training data.
|
| 67 |
+
selected_features = air_quality_fg.select(['pm25', 'past_air_quality']).join(weather_fg.select_all(), on=['city'])
|
| 68 |
+
selected_features.show(10)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
# In[9]:
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
feature_view = fs.get_or_create_feature_view(
|
| 75 |
+
name='air_quality_fv',
|
| 76 |
+
description="weather features with air quality as the target",
|
| 77 |
+
version=1,
|
| 78 |
+
labels=['pm25'],
|
| 79 |
+
query=selected_features,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# In[10]:
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
start_date_test_data = "2024-03-01"
|
| 86 |
+
# Convert string to datetime object
|
| 87 |
+
test_start = datetime.strptime(start_date_test_data, "%Y-%m-%d")
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
# In[11]:
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
X_train, X_test, y_train, y_test = feature_view.train_test_split(
|
| 94 |
+
test_start=test_start
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
# In[12]:
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
X_train
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
# In[13]:
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
# Drop the index columns - 'date' (event_time) and 'city' (primary key)
|
| 108 |
+
|
| 109 |
+
train_features = X_train.drop(['date', 'city'], axis=1)
|
| 110 |
+
test_features = X_test.drop(['date', 'city'], axis=1)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# In[14]:
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
y_train
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# The `Feature View` is now saved in Hopsworks and you can retrieve it using `FeatureStore.get_feature_view(name='...', version=1)`.
|
| 120 |
+
|
| 121 |
+
# ---
|
| 122 |
+
|
| 123 |
+
# ## <span style="color:#ff5f27;">🧬 Modeling</span>
|
| 124 |
+
#
|
| 125 |
+
# We will train a regression model to predict pm25 using our 4 features (wind_speed, wind_dir, temp, precipitation)
|
| 126 |
+
|
| 127 |
+
# In[16]:
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
# Creating an instance of the XGBoost Regressor
|
| 131 |
+
xgb_regressor = XGBRegressor()
|
| 132 |
+
|
| 133 |
+
# Fitting the XGBoost Regressor to the training data
|
| 134 |
+
xgb_regressor.fit(train_features, y_train)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# In[17]:
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
# Predicting target values on the test set
|
| 141 |
+
y_pred = xgb_regressor.predict(test_features)
|
| 142 |
+
|
| 143 |
+
# Calculating Mean Squared Error (MSE) using sklearn
|
| 144 |
+
mse = mean_squared_error(y_test.iloc[:,0], y_pred)
|
| 145 |
+
print("MSE:", mse)
|
| 146 |
+
|
| 147 |
+
# Calculating R squared using sklearn
|
| 148 |
+
r2 = r2_score(y_test.iloc[:,0], y_pred)
|
| 149 |
+
print("R squared:", r2)
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
# In[18]:
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
df = y_test
|
| 156 |
+
df['predicted_pm25'] = y_pred
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
# In[19]:
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
df['date'] = X_test['date']
|
| 163 |
+
df = df.sort_values(by=['date'])
|
| 164 |
+
df.head(5)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
# In[20]:
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
# Creating a directory for the model artifacts if it doesn't exist
|
| 171 |
+
model_dir = "air_quality_model"
|
| 172 |
+
if not os.path.exists(model_dir):
|
| 173 |
+
os.mkdir(model_dir)
|
| 174 |
+
images_dir = model_dir + "/images"
|
| 175 |
+
if not os.path.exists(images_dir):
|
| 176 |
+
os.mkdir(images_dir)
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# In[21]:
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
file_path = images_dir + "/pm25_hindcast.png"
|
| 183 |
+
plt = util.plot_air_quality_forecast("lahore", "pakistan-lahore-cantonment", df, file_path, hindcast=True)
|
| 184 |
+
plt.show()
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
# In[22]:
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
# Plotting feature importances using the plot_importance function from XGBoost
|
| 191 |
+
plot_importance(xgb_regressor, max_num_features=5)
|
| 192 |
+
feature_importance_path = images_dir + "/feature_importance.png"
|
| 193 |
+
plt.savefig(feature_importance_path)
|
| 194 |
+
plt.show()
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
# ---
|
| 198 |
+
|
| 199 |
+
# ## <span style='color:#ff5f27'>🗄 Model Registry</span>
|
| 200 |
+
#
|
| 201 |
+
# One of the features in Hopsworks is the model registry. This is where you can store different versions of models and compare their performance. Models from the registry can then be served as API endpoints.
|
| 202 |
+
|
| 203 |
+
# ### <span style="color:#ff5f27;">⚙️ Model Schema</span>
|
| 204 |
+
|
| 205 |
+
# The model needs to be set up with a [Model Schema](https://docs.hopsworks.ai/machine-learning-api/latest/generated/model_schema/), which describes the inputs and outputs for a model.
|
| 206 |
+
#
|
| 207 |
+
# A Model Schema can be automatically generated from training examples, as shown below.
|
| 208 |
+
|
| 209 |
+
# In[23]:
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
from hsml.schema import Schema
|
| 213 |
+
from hsml.model_schema import ModelSchema
|
| 214 |
+
|
| 215 |
+
# Creating input and output schemas using the 'Schema' class for features (X) and target variable (y)
|
| 216 |
+
input_schema = Schema(X_train)
|
| 217 |
+
output_schema = Schema(y_train)
|
| 218 |
+
|
| 219 |
+
# Creating a model schema using 'ModelSchema' with the input and output schemas
|
| 220 |
+
model_schema = ModelSchema(input_schema=input_schema, output_schema=output_schema)
|
| 221 |
+
|
| 222 |
+
# Converting the model schema to a dictionary representation
|
| 223 |
+
schema_dict = model_schema.to_dict()
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
# In[24]:
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
# Saving the XGBoost regressor object as a json file in the model directory
|
| 230 |
+
xgb_regressor.save_model(model_dir + "/model.json")
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
# In[25]:
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
res_dict = {
|
| 237 |
+
"MSE": str(mse),
|
| 238 |
+
"R squared": str(r2),
|
| 239 |
+
}
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
# In[26]:
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
mr = project.get_model_registry()
|
| 246 |
+
|
| 247 |
+
# Creating a Python model in the model registry named 'air_quality_xgboost_model'
|
| 248 |
+
|
| 249 |
+
aq_model = mr.python.create_model(
|
| 250 |
+
name="air_quality_xgboost_model",
|
| 251 |
+
metrics= res_dict,
|
| 252 |
+
model_schema=model_schema,
|
| 253 |
+
input_example=X_test.sample().values,
|
| 254 |
+
description="Air Quality (PM2.5) predictor",
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
# Saving the model artifacts to the 'air_quality_model' directory in the model registry
|
| 258 |
+
aq_model.save(model_dir)
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
# ---
|
| 262 |
+
# ## <span style="color:#ff5f27;">⏭️ **Next:** Part 04: Batch Inference</span>
|
| 263 |
+
#
|
| 264 |
+
# In the following notebook you will use your model for Batch Inference.
|
| 265 |
+
#
|
| 266 |
+
|
| 267 |
+
# In[ ]:
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
|