Spaces:
Sleeping

Sleeping

add bkse
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- diffusion-posterior-sampling/bkse/LICENSE +203 -0
- diffusion-posterior-sampling/bkse/README.md +181 -0
- diffusion-posterior-sampling/bkse/data/GOPRO_dataset.py +135 -0
- diffusion-posterior-sampling/bkse/data/REDS_dataset.py +139 -0
- diffusion-posterior-sampling/bkse/data/__init__.py +53 -0
- diffusion-posterior-sampling/bkse/data/data_sampler.py +72 -0
- diffusion-posterior-sampling/bkse/data/mix_dataset.py +104 -0
- diffusion-posterior-sampling/bkse/data/util.py +574 -0
- diffusion-posterior-sampling/bkse/data_augmentation.py +145 -0
- diffusion-posterior-sampling/bkse/domain_specific_deblur.py +89 -0
- diffusion-posterior-sampling/bkse/experiments/pretrained/kernel.pth +0 -0
- diffusion-posterior-sampling/bkse/generate_blur.py +53 -0
- diffusion-posterior-sampling/bkse/generic_deblur.py +28 -0
- diffusion-posterior-sampling/bkse/imgs/blur_faces/face01.png +0 -0
- diffusion-posterior-sampling/bkse/imgs/blur_imgs/blur1.png +0 -0
- diffusion-posterior-sampling/bkse/imgs/blur_imgs/blur2.png +0 -0
- diffusion-posterior-sampling/bkse/imgs/results/augmentation.jpg +0 -0
- diffusion-posterior-sampling/bkse/imgs/results/domain_specific_deblur.jpg +0 -0
- diffusion-posterior-sampling/bkse/imgs/results/general_deblurring.jpg +0 -0
- diffusion-posterior-sampling/bkse/imgs/results/generate_blur.jpg +0 -0
- diffusion-posterior-sampling/bkse/imgs/results/kernel_encoding_wGT.png +0 -0
- diffusion-posterior-sampling/bkse/imgs/sharp_imgs/mushishi.png +0 -0
- diffusion-posterior-sampling/bkse/imgs/teaser.jpg +0 -0
- diffusion-posterior-sampling/bkse/models/__init__.py +15 -0
- diffusion-posterior-sampling/bkse/models/arch_util.py +58 -0
- diffusion-posterior-sampling/bkse/models/backbones/resnet.py +89 -0
- diffusion-posterior-sampling/bkse/models/backbones/skip/concat.py +39 -0
- diffusion-posterior-sampling/bkse/models/backbones/skip/downsampler.py +241 -0
- diffusion-posterior-sampling/bkse/models/backbones/skip/non_local_dot_product.py +130 -0
- diffusion-posterior-sampling/bkse/models/backbones/skip/skip.py +133 -0
- diffusion-posterior-sampling/bkse/models/backbones/skip/util.py +65 -0
- diffusion-posterior-sampling/bkse/models/backbones/unet_parts.py +109 -0
- diffusion-posterior-sampling/bkse/models/deblurring/image_deblur.py +71 -0
- diffusion-posterior-sampling/bkse/models/deblurring/joint_deblur.py +63 -0
- diffusion-posterior-sampling/bkse/models/dips.py +83 -0
- diffusion-posterior-sampling/bkse/models/dsd/bicubic.py +76 -0
- diffusion-posterior-sampling/bkse/models/dsd/dsd.py +194 -0
- diffusion-posterior-sampling/bkse/models/dsd/dsd_stylegan.py +81 -0
- diffusion-posterior-sampling/bkse/models/dsd/dsd_stylegan2.py +78 -0
- diffusion-posterior-sampling/bkse/models/dsd/op/__init__.py +0 -0
- diffusion-posterior-sampling/bkse/models/dsd/op/fused_act.py +107 -0
- diffusion-posterior-sampling/bkse/models/dsd/op/fused_bias_act.cpp +21 -0
- diffusion-posterior-sampling/bkse/models/dsd/op/fused_bias_act_kernel.cu +99 -0
- diffusion-posterior-sampling/bkse/models/dsd/op/upfirdn2d.cpp +23 -0
- diffusion-posterior-sampling/bkse/models/dsd/op/upfirdn2d.py +184 -0
- diffusion-posterior-sampling/bkse/models/dsd/op/upfirdn2d_kernel.cu +369 -0
- diffusion-posterior-sampling/bkse/models/dsd/spherical_optimizer.py +29 -0
- diffusion-posterior-sampling/bkse/models/dsd/stylegan.py +474 -0
- diffusion-posterior-sampling/bkse/models/dsd/stylegan2.py +621 -0
- diffusion-posterior-sampling/bkse/models/kernel_encoding/base_model.py +131 -0
diffusion-posterior-sampling/bkse/LICENSE
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
| 202 |
+
'+
|
| 203 |
+
|
diffusion-posterior-sampling/bkse/README.md
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Exploring Image Deblurring via Encoded Blur Kernel Space
|
| 2 |
+
|
| 3 |
+
## About the project
|
| 4 |
+
|
| 5 |
+
We introduce a method to encode the blur operators of an arbitrary dataset of sharp-blur image pairs into a blur kernel space. Assuming the encoded kernel space is close enough to in-the-wild blur operators, we propose an alternating optimization algorithm for blind image deblurring. It approximates an unseen blur operator by a kernel in the encoded space and searches for the corresponding sharp image. Due to the method's design, the encoded kernel space is fully differentiable, thus can be easily adopted in deep neural network models.
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+
|
| 9 |
+
Detail of the method and experimental results can be found in [our following paper](https://arxiv.org/abs/2104.00317):
|
| 10 |
+
```
|
| 11 |
+
@inproceedings{m_Tran-etal-CVPR21,
|
| 12 |
+
author = {Phong Tran and Anh Tran and Quynh Phung and Minh Hoai},
|
| 13 |
+
title = {Explore Image Deblurring via Encoded Blur Kernel Space},
|
| 14 |
+
year = {2021},
|
| 15 |
+
booktitle = {Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition (CVPR)}
|
| 16 |
+
}
|
| 17 |
+
```
|
| 18 |
+
Please CITE our paper whenever this repository is used to help produce published results or incorporated into other software.
|
| 19 |
+
|
| 20 |
+
[](https://colab.research.google.com/drive/1GDvbr4WQUibaEhQVzYPPObV4STn9NAot?usp=sharing)
|
| 21 |
+
|
| 22 |
+
## Table of Content
|
| 23 |
+
|
| 24 |
+
* [About the Project](#about-the-project)
|
| 25 |
+
* [Getting Started](#getting-started)
|
| 26 |
+
* [Prerequisites](#prerequisites)
|
| 27 |
+
* [Installation](#installation)
|
| 28 |
+
* [Using the pretrained model](#Using-the-pretrained-model)
|
| 29 |
+
* [Training and evaluation](#Training-and-evaluation)
|
| 30 |
+
* [Model Zoo](#Model-zoo)
|
| 31 |
+
|
| 32 |
+
## Getting started
|
| 33 |
+
|
| 34 |
+
### Prerequisites
|
| 35 |
+
|
| 36 |
+
* Python >= 3.7
|
| 37 |
+
* Pytorch >= 1.4.0
|
| 38 |
+
* CUDA >= 10.0
|
| 39 |
+
|
| 40 |
+
### Installation
|
| 41 |
+
|
| 42 |
+
``` sh
|
| 43 |
+
git clone https://github.com/VinAIResearch/blur-kernel-space-exploring.git
|
| 44 |
+
cd blur-kernel-space-exploring
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
conda create -n BlurKernelSpace -y python=3.7
|
| 48 |
+
conda activate BlurKernelSpace
|
| 49 |
+
conda install --file requirements.txt
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
## Training and evaluation
|
| 53 |
+
### Preparing datasets
|
| 54 |
+
You can download the datasets in the [model zoo section](#model-zoo).
|
| 55 |
+
|
| 56 |
+
To use your customized dataset, your dataset must be organized as follow:
|
| 57 |
+
```
|
| 58 |
+
root
|
| 59 |
+
├── blur_imgs
|
| 60 |
+
├── 000
|
| 61 |
+
├──── 00000000.png
|
| 62 |
+
├──── 00000001.png
|
| 63 |
+
├──── ...
|
| 64 |
+
├── 001
|
| 65 |
+
├──── 00000000.png
|
| 66 |
+
├──── 00000001.png
|
| 67 |
+
├──── ...
|
| 68 |
+
├── sharp_imgs
|
| 69 |
+
├── 000
|
| 70 |
+
├──── 00000000.png
|
| 71 |
+
├──── 00000001.png
|
| 72 |
+
├──── ...
|
| 73 |
+
├── 001
|
| 74 |
+
├──── 00000000.png
|
| 75 |
+
├──── 00000001.png
|
| 76 |
+
├──── ...
|
| 77 |
+
```
|
| 78 |
+
where `root`, `blur_imgs`, and `sharp_imgs` folders can have arbitrary names. For example, let `root, blur_imgs, sharp_imgs` be `REDS, train_blur, train_sharp` respectively (That is, you are using the REDS training set), then use the following scripts to create the lmdb dataset:
|
| 79 |
+
```sh
|
| 80 |
+
python create_lmdb.py --H 720 --W 1280 --C 3 --img_folder REDS/train_sharp --name train_sharp_wval --save_path ../datasets/REDS/train_sharp_wval.lmdb
|
| 81 |
+
python create_lmdb.py --H 720 --W 1280 --C 3 --img_folder REDS/train_blur --name train_blur_wval --save_path ../datasets/REDS/train_blur_wval.lmdb
|
| 82 |
+
```
|
| 83 |
+
where `(H, C, W)` is the shape of the images (note that all images in the dataset must have the same shape), `img_folder` is the folder that contains the images, `name` is the name of the dataset, and `save_path` is the save destination (`save_path` must end with `.lmdb`).
|
| 84 |
+
|
| 85 |
+
When the script is finished, two folders `train_sharp_wval.lmdb` and `train_blur_wval.lmdb` will be created in `./REDS`.
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
### Training
|
| 89 |
+
To do image deblurring, data augmentation, and blur generation, you first need to train the blur encoding network (The F function in the paper). This is the only network that you need to train. After creating the dataset, change the value of `dataroot_HQ` and `dataroot_LQ` in `options/kernel_encoding/REDS/woVAE.yml` to the paths of the sharp and blur lmdb datasets that were created before, then use the following script to train the model:
|
| 90 |
+
```
|
| 91 |
+
python train.py -opt options/kernel_encoding/REDS/woVAE.yml
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
where `opt` is the path to yaml file that contains training configurations. You can find some default configurations in the `options` folder. Checkpoints, training states, and logs will be saved in `experiments/modelName`. You can change the configurations (learning rate, hyper-parameters, network structure, etc) in the yaml file.
|
| 95 |
+
|
| 96 |
+
### Testing
|
| 97 |
+
#### Data augmentation
|
| 98 |
+
To augment a given dataset, first, create an lmdb dataset using `scripts/create_lmdb.py` as before. Then use the following script:
|
| 99 |
+
```
|
| 100 |
+
python data_augmentation.py --target_H=720 --target_W=1280 \
|
| 101 |
+
--source_H=720 --source_W=1280\
|
| 102 |
+
--augmented_H=256 --augmented_W=256\
|
| 103 |
+
--source_LQ_root=datasets/REDS/train_blur_wval.lmdb \
|
| 104 |
+
--source_HQ_root=datasets/REDS/train_sharp_wval.lmdb \
|
| 105 |
+
--target_HQ_root=datasets/REDS/test_sharp_wval.lmdb \
|
| 106 |
+
--save_path=results/GOPRO_augmented \
|
| 107 |
+
--num_images=10 \
|
| 108 |
+
--yml_path=options/data_augmentation/default.yml
|
| 109 |
+
```
|
| 110 |
+
`(target_H, target_W)`, `(source_H, source_W)`, and `(augmented_H, augmented_W)` are the desired shapes of the target images, source images, and augmented images respectively. `source_LQ_root`, `source_HQ_root`, and `target_HQ_root` are the paths of the lmdb datasets for the reference blur-sharp pairs and the input sharp images that were created before. `num_images` is the size of the augmented dataset. `model_path` is the path of the trained model. `yml_path` is the path to the model configuration file. Results will be saved in `save_path`.
|
| 111 |
+
|
| 112 |
+

|
| 113 |
+
|
| 114 |
+
#### Generate novel blur kernels
|
| 115 |
+
To generate a blur image given a sharp image, use the following command:
|
| 116 |
+
```sh
|
| 117 |
+
python generate_blur.py --yml_path=options/generate_blur/default.yml \
|
| 118 |
+
--image_path=imgs/sharp_imgs/mushishi.png \
|
| 119 |
+
--num_samples=10
|
| 120 |
+
--save_path=./res.png
|
| 121 |
+
```
|
| 122 |
+
where `model_path` is the path of the pre-trained model, `yml_path` is the path of the configuration file. `image_path` is the path of the sharp image. After running the script, a blur image corresponding to the sharp image will be saved in `save_path`. Here is some expected output:
|
| 123 |
+

|
| 124 |
+
**Note**: This only works with models that were trained with `--VAE` flag. The size of input images must be divisible by 128.
|
| 125 |
+
|
| 126 |
+
#### Generic Deblurring
|
| 127 |
+
To deblur a blurry image, use the following command:
|
| 128 |
+
```sh
|
| 129 |
+
python generic_deblur.py --image_path imgs/blur_imgs/blur1.png --yml_path options/generic_deblur/default.yml --save_path ./res.png
|
| 130 |
+
```
|
| 131 |
+
where `image_path` is the path of the blurry image. `yml_path` is the path of the configuration file. The deblurred image will be saved to `save_path`.
|
| 132 |
+
|
| 133 |
+

|
| 134 |
+
|
| 135 |
+
#### Deblurring using sharp image prior
|
| 136 |
+
[mapping]: https://drive.google.com/uc?id=14R6iHGf5iuVx3DMNsACAl7eBr7Vdpd0k
|
| 137 |
+
[synthesis]: https://drive.google.com/uc?id=1TCViX1YpQyRsklTVYEJwdbmK91vklCo8
|
| 138 |
+
[pretrained model]: https://drive.google.com/file/d/1PQutd-JboOCOZqmd95XWxWrO8gGEvRcO/view
|
| 139 |
+
First, you need to download the pre-trained styleGAN or styleGAN2 networks. If you want to use styleGAN, download the [mapping] and [synthesis] networks, then rename and copy them to `experiments/pretrained/stylegan_mapping.pt` and `experiments/pretrained/stylegan_synthesis.pt` respectively. If you want to use styleGAN2 instead, download the [pretrained model], then rename and copy it to `experiments/pretrained/stylegan2.pt`.
|
| 140 |
+
|
| 141 |
+
To deblur a blurry image using styleGAN latent space as the sharp image prior, you can use one of the following commands:
|
| 142 |
+
```sh
|
| 143 |
+
python domain_specific_deblur.py --input_dir imgs/blur_faces \
|
| 144 |
+
--output_dir experiments/domain_specific_deblur/results \
|
| 145 |
+
--yml_path options/domain_specific_deblur/stylegan.yml # Use latent space of stylegan
|
| 146 |
+
python domain_specific_deblur.py --input_dir imgs/blur_faces \
|
| 147 |
+
--output_dir experiments/domain_specific_deblur/results \
|
| 148 |
+
--yml_path options/domain_specific_deblur/stylegan2.yml # Use latent space of stylegan2
|
| 149 |
+
```
|
| 150 |
+
Results will be saved in `experiments/domain_specific_deblur/results`.
|
| 151 |
+
**Note**: Generally, the code still works with images that have the size divisible by 128. However, since our blur kernels are not uniform, the size of the kernel increases as the size of the image increases.
|
| 152 |
+
|
| 153 |
+

|
| 154 |
+
|
| 155 |
+
## Model Zoo
|
| 156 |
+
Pretrained models and corresponding datasets are provided in the below table. After downloading the datasets and models, follow the instructions in the [testing section](#testing) to do data augmentation, generating blur images, or image deblurring.
|
| 157 |
+
|
| 158 |
+
[REDS]: https://seungjunnah.github.io/Datasets/reds.html
|
| 159 |
+
[GOPRO]: https://seungjunnah.github.io/Datasets/gopro
|
| 160 |
+
|
| 161 |
+
[REDS woVAE]: https://drive.google.com/file/d/12ZhjXWcYhAZjBnMtF0ai0R5PQydZct61/view?usp=sharing
|
| 162 |
+
[GOPRO woVAE]: https://drive.google.com/file/d/1WrVALP-woJgtiZyvQ7NOkaZssHbHwKYn/view?usp=sharing
|
| 163 |
+
[GOPRO wVAE]: https://drive.google.com/file/d/1QMUY8mxUMgEJty2Gk7UY0WYmyyYRY7vS/view?usp=sharing
|
| 164 |
+
[GOPRO + REDS woVAE]: https://drive.google.com/file/d/169R0hEs3rNeloj-m1rGS4YjW38pu-LFD/view?usp=sharing
|
| 165 |
+
|
| 166 |
+
|Model name | dataset(s) | status |
|
| 167 |
+
|:-----------------------|:---------------:|-------------------------:|
|
| 168 |
+
|[REDS woVAE] | [REDS] | :heavy_check_mark: |
|
| 169 |
+
|[GOPRO woVAE] | [GOPRO] | :heavy_check_mark: |
|
| 170 |
+
|[GOPRO wVAE] | [GOPRO] | :heavy_check_mark: |
|
| 171 |
+
|[GOPRO + REDS woVAE] | [GOPRO], [REDS] | :heavy_check_mark: |
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
## Notes and references
|
| 175 |
+
The training code is borrowed from the EDVR project: https://github.com/xinntao/EDVR
|
| 176 |
+
|
| 177 |
+
The backbone code is borrowed from the DeblurGAN project: https://github.com/KupynOrest/DeblurGAN
|
| 178 |
+
|
| 179 |
+
The styleGAN code is borrowed from the PULSE project: https://github.com/adamian98/pulse
|
| 180 |
+
|
| 181 |
+
The stylegan2 code is borrowed from https://github.com/rosinality/stylegan2-pytorch
|
diffusion-posterior-sampling/bkse/data/GOPRO_dataset.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
GOPRO dataset
|
| 3 |
+
support reading images from lmdb, image folder and memcached
|
| 4 |
+
"""
|
| 5 |
+
import logging
|
| 6 |
+
import os.path as osp
|
| 7 |
+
import pickle
|
| 8 |
+
import random
|
| 9 |
+
|
| 10 |
+
import cv2
|
| 11 |
+
import data.util as util
|
| 12 |
+
import lmdb
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import torch.utils.data as data
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
try:
|
| 19 |
+
import mc # import memcached
|
| 20 |
+
except ImportError:
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
logger = logging.getLogger("base")
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class GOPRODataset(data.Dataset):
|
| 27 |
+
"""
|
| 28 |
+
Reading the training GOPRO dataset
|
| 29 |
+
key example: 000_00000000
|
| 30 |
+
HQ: Ground-Truth;
|
| 31 |
+
LQ: Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames
|
| 32 |
+
support reading N LQ frames, N = 1, 3, 5, 7
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
def __init__(self, opt):
|
| 36 |
+
super(GOPRODataset, self).__init__()
|
| 37 |
+
self.opt = opt
|
| 38 |
+
# temporal augmentation
|
| 39 |
+
|
| 40 |
+
self.HQ_root, self.LQ_root = opt["dataroot_HQ"], opt["dataroot_LQ"]
|
| 41 |
+
self.N_frames = opt["N_frames"]
|
| 42 |
+
self.data_type = self.opt["data_type"]
|
| 43 |
+
# directly load image keys
|
| 44 |
+
if self.data_type == "lmdb":
|
| 45 |
+
self.paths_HQ, _ = util.get_image_paths(self.data_type, opt["dataroot_HQ"])
|
| 46 |
+
logger.info("Using lmdb meta info for cache keys.")
|
| 47 |
+
elif opt["cache_keys"]:
|
| 48 |
+
logger.info("Using cache keys: {}".format(opt["cache_keys"]))
|
| 49 |
+
self.paths_HQ = pickle.load(open(opt["cache_keys"], "rb"))["keys"]
|
| 50 |
+
else:
|
| 51 |
+
raise ValueError(
|
| 52 |
+
"Need to create cache keys (meta_info.pkl) \
|
| 53 |
+
by running [create_lmdb.py]"
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
assert self.paths_HQ, "Error: HQ path is empty."
|
| 57 |
+
|
| 58 |
+
if self.data_type == "lmdb":
|
| 59 |
+
self.HQ_env, self.LQ_env = None, None
|
| 60 |
+
elif self.data_type == "mc": # memcached
|
| 61 |
+
self.mclient = None
|
| 62 |
+
elif self.data_type == "img":
|
| 63 |
+
pass
|
| 64 |
+
else:
|
| 65 |
+
raise ValueError("Wrong data type: {}".format(self.data_type))
|
| 66 |
+
|
| 67 |
+
def _init_lmdb(self):
|
| 68 |
+
# https://github.com/chainer/chainermn/issues/129
|
| 69 |
+
self.HQ_env = lmdb.open(self.opt["dataroot_HQ"], readonly=True, lock=False, readahead=False, meminit=False)
|
| 70 |
+
self.LQ_env = lmdb.open(self.opt["dataroot_LQ"], readonly=True, lock=False, readahead=False, meminit=False)
|
| 71 |
+
|
| 72 |
+
def _ensure_memcached(self):
|
| 73 |
+
if self.mclient is None:
|
| 74 |
+
# specify the config files
|
| 75 |
+
server_list_config_file = None
|
| 76 |
+
client_config_file = None
|
| 77 |
+
self.mclient = mc.MemcachedClient.GetInstance(server_list_config_file, client_config_file)
|
| 78 |
+
|
| 79 |
+
def _read_img_mc(self, path):
|
| 80 |
+
""" Return BGR, HWC, [0, 255], uint8"""
|
| 81 |
+
value = mc.pyvector()
|
| 82 |
+
self.mclient.Get(path, value)
|
| 83 |
+
value_buf = mc.ConvertBuffer(value)
|
| 84 |
+
img_array = np.frombuffer(value_buf, np.uint8)
|
| 85 |
+
img = cv2.imdecode(img_array, cv2.IMREAD_UNCHANGED)
|
| 86 |
+
return img
|
| 87 |
+
|
| 88 |
+
def _read_img_mc_BGR(self, path, name_a, name_b):
|
| 89 |
+
"""
|
| 90 |
+
Read BGR channels separately and then combine for 1M limits in cluster
|
| 91 |
+
"""
|
| 92 |
+
img_B = self._read_img_mc(osp.join(path + "_B", name_a, name_b + ".png"))
|
| 93 |
+
img_G = self._read_img_mc(osp.join(path + "_G", name_a, name_b + ".png"))
|
| 94 |
+
img_R = self._read_img_mc(osp.join(path + "_R", name_a, name_b + ".png"))
|
| 95 |
+
img = cv2.merge((img_B, img_G, img_R))
|
| 96 |
+
return img
|
| 97 |
+
|
| 98 |
+
def __getitem__(self, index):
|
| 99 |
+
if self.data_type == "mc":
|
| 100 |
+
self._ensure_memcached()
|
| 101 |
+
elif self.data_type == "lmdb" and (self.HQ_env is None or self.LQ_env is None):
|
| 102 |
+
self._init_lmdb()
|
| 103 |
+
|
| 104 |
+
HQ_size = self.opt["HQ_size"]
|
| 105 |
+
key = self.paths_HQ[index]
|
| 106 |
+
|
| 107 |
+
# get the HQ image (as the center frame)
|
| 108 |
+
img_HQ = util.read_img(self.HQ_env, key, (3, 720, 1280))
|
| 109 |
+
|
| 110 |
+
# get LQ images
|
| 111 |
+
img_LQ = util.read_img(self.LQ_env, key, (3, 720, 1280))
|
| 112 |
+
|
| 113 |
+
if self.opt["phase"] == "train":
|
| 114 |
+
_, H, W = 3, 720, 1280 # LQ size
|
| 115 |
+
# randomly crop
|
| 116 |
+
rnd_h = random.randint(0, max(0, H - HQ_size))
|
| 117 |
+
rnd_w = random.randint(0, max(0, W - HQ_size))
|
| 118 |
+
img_LQ = img_LQ[rnd_h : rnd_h + HQ_size, rnd_w : rnd_w + HQ_size, :]
|
| 119 |
+
img_HQ = img_HQ[rnd_h : rnd_h + HQ_size, rnd_w : rnd_w + HQ_size, :]
|
| 120 |
+
|
| 121 |
+
# augmentation - flip, rotate
|
| 122 |
+
imgs = [img_HQ, img_LQ]
|
| 123 |
+
rlt = util.augment(imgs, self.opt["use_flip"], self.opt["use_rot"])
|
| 124 |
+
img_HQ = rlt[0]
|
| 125 |
+
img_LQ = rlt[1]
|
| 126 |
+
|
| 127 |
+
# BGR to RGB, HWC to CHW, numpy to tensor
|
| 128 |
+
img_LQ = img_LQ[:, :, [2, 1, 0]]
|
| 129 |
+
img_HQ = img_HQ[:, :, [2, 1, 0]]
|
| 130 |
+
img_LQ = torch.from_numpy(np.ascontiguousarray(np.transpose(img_LQ, (2, 0, 1)))).float()
|
| 131 |
+
img_HQ = torch.from_numpy(np.ascontiguousarray(np.transpose(img_HQ, (2, 0, 1)))).float()
|
| 132 |
+
return {"LQ": img_LQ, "HQ": img_HQ, "key": key}
|
| 133 |
+
|
| 134 |
+
def __len__(self):
|
| 135 |
+
return len(self.paths_HQ)
|
diffusion-posterior-sampling/bkse/data/REDS_dataset.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
REDS dataset
|
| 3 |
+
support reading images from lmdb, image folder and memcached
|
| 4 |
+
"""
|
| 5 |
+
import logging
|
| 6 |
+
import os.path as osp
|
| 7 |
+
import pickle
|
| 8 |
+
import random
|
| 9 |
+
|
| 10 |
+
import cv2
|
| 11 |
+
import data.util as util
|
| 12 |
+
import lmdb
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import torch.utils.data as data
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
try:
|
| 19 |
+
import mc # import memcached
|
| 20 |
+
except ImportError:
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
logger = logging.getLogger("base")
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class REDSDataset(data.Dataset):
|
| 27 |
+
"""
|
| 28 |
+
Reading the training REDS dataset
|
| 29 |
+
key example: 000_00000000
|
| 30 |
+
HQ: Ground-Truth;
|
| 31 |
+
LQ: Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames
|
| 32 |
+
support reading N LQ frames, N = 1, 3, 5, 7
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
def __init__(self, opt):
|
| 36 |
+
super(REDSDataset, self).__init__()
|
| 37 |
+
self.opt = opt
|
| 38 |
+
# temporal augmentation
|
| 39 |
+
|
| 40 |
+
self.HQ_root, self.LQ_root = opt["dataroot_HQ"], opt["dataroot_LQ"]
|
| 41 |
+
self.N_frames = opt["N_frames"]
|
| 42 |
+
self.data_type = self.opt["data_type"]
|
| 43 |
+
# directly load image keys
|
| 44 |
+
if self.data_type == "lmdb":
|
| 45 |
+
self.paths_HQ, _ = util.get_image_paths(self.data_type, opt["dataroot_HQ"])
|
| 46 |
+
logger.info("Using lmdb meta info for cache keys.")
|
| 47 |
+
elif opt["cache_keys"]:
|
| 48 |
+
logger.info("Using cache keys: {}".format(opt["cache_keys"]))
|
| 49 |
+
self.paths_HQ = pickle.load(open(opt["cache_keys"], "rb"))["keys"]
|
| 50 |
+
else:
|
| 51 |
+
raise ValueError(
|
| 52 |
+
"Need to create cache keys (meta_info.pkl) \
|
| 53 |
+
by running [create_lmdb.py]"
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
# remove the REDS4 for testing
|
| 57 |
+
self.paths_HQ = [v for v in self.paths_HQ if v.split("_")[0] not in ["000", "011", "015", "020"]]
|
| 58 |
+
assert self.paths_HQ, "Error: HQ path is empty."
|
| 59 |
+
|
| 60 |
+
if self.data_type == "lmdb":
|
| 61 |
+
self.HQ_env, self.LQ_env = None, None
|
| 62 |
+
elif self.data_type == "mc": # memcached
|
| 63 |
+
self.mclient = None
|
| 64 |
+
elif self.data_type == "img":
|
| 65 |
+
pass
|
| 66 |
+
else:
|
| 67 |
+
raise ValueError("Wrong data type: {}".format(self.data_type))
|
| 68 |
+
|
| 69 |
+
def _init_lmdb(self):
|
| 70 |
+
# https://github.com/chainer/chainermn/issues/129
|
| 71 |
+
self.HQ_env = lmdb.open(self.opt["dataroot_HQ"], readonly=True, lock=False, readahead=False, meminit=False)
|
| 72 |
+
self.LQ_env = lmdb.open(self.opt["dataroot_LQ"], readonly=True, lock=False, readahead=False, meminit=False)
|
| 73 |
+
|
| 74 |
+
def _ensure_memcached(self):
|
| 75 |
+
if self.mclient is None:
|
| 76 |
+
# specify the config files
|
| 77 |
+
server_list_config_file = None
|
| 78 |
+
client_config_file = None
|
| 79 |
+
self.mclient = mc.MemcachedClient.GetInstance(server_list_config_file, client_config_file)
|
| 80 |
+
|
| 81 |
+
def _read_img_mc(self, path):
|
| 82 |
+
""" Return BGR, HWC, [0, 255], uint8"""
|
| 83 |
+
value = mc.pyvector()
|
| 84 |
+
self.mclient.Get(path, value)
|
| 85 |
+
value_buf = mc.ConvertBuffer(value)
|
| 86 |
+
img_array = np.frombuffer(value_buf, np.uint8)
|
| 87 |
+
img = cv2.imdecode(img_array, cv2.IMREAD_UNCHANGED)
|
| 88 |
+
return img
|
| 89 |
+
|
| 90 |
+
def _read_img_mc_BGR(self, path, name_a, name_b):
|
| 91 |
+
"""
|
| 92 |
+
Read BGR channels separately and then combine for 1M limits in cluster
|
| 93 |
+
"""
|
| 94 |
+
img_B = self._read_img_mc(osp.join(path + "_B", name_a, name_b + ".png"))
|
| 95 |
+
img_G = self._read_img_mc(osp.join(path + "_G", name_a, name_b + ".png"))
|
| 96 |
+
img_R = self._read_img_mc(osp.join(path + "_R", name_a, name_b + ".png"))
|
| 97 |
+
img = cv2.merge((img_B, img_G, img_R))
|
| 98 |
+
return img
|
| 99 |
+
|
| 100 |
+
def __getitem__(self, index):
|
| 101 |
+
if self.data_type == "mc":
|
| 102 |
+
self._ensure_memcached()
|
| 103 |
+
elif self.data_type == "lmdb" and (self.HQ_env is None or self.LQ_env is None):
|
| 104 |
+
self._init_lmdb()
|
| 105 |
+
|
| 106 |
+
HQ_size = self.opt["HQ_size"]
|
| 107 |
+
key = self.paths_HQ[index]
|
| 108 |
+
name_a, name_b = key.split("_")
|
| 109 |
+
|
| 110 |
+
# get the HQ image
|
| 111 |
+
img_HQ = util.read_img(self.HQ_env, key, (3, 720, 1280))
|
| 112 |
+
|
| 113 |
+
# get the LQ image
|
| 114 |
+
img_LQ = util.read_img(self.LQ_env, key, (3, 720, 1280))
|
| 115 |
+
|
| 116 |
+
if self.opt["phase"] == "train":
|
| 117 |
+
_, H, W = 3, 720, 1280 # LQ size
|
| 118 |
+
# randomly crop
|
| 119 |
+
rnd_h = random.randint(0, max(0, H - HQ_size))
|
| 120 |
+
rnd_w = random.randint(0, max(0, W - HQ_size))
|
| 121 |
+
img_LQ = img_LQ[rnd_h : rnd_h + HQ_size, rnd_w : rnd_w + HQ_size, :]
|
| 122 |
+
img_HQ = img_HQ[rnd_h : rnd_h + HQ_size, rnd_w : rnd_w + HQ_size, :]
|
| 123 |
+
|
| 124 |
+
# augmentation - flip, rotate
|
| 125 |
+
imgs = [img_HQ, img_LQ]
|
| 126 |
+
rlt = util.augment(imgs, self.opt["use_flip"], self.opt["use_rot"])
|
| 127 |
+
img_HQ = rlt[0]
|
| 128 |
+
img_LQ = rlt[1]
|
| 129 |
+
|
| 130 |
+
# BGR to RGB, HWC to CHW, numpy to tensor
|
| 131 |
+
img_LQ = img_LQ[:, :, [2, 1, 0]]
|
| 132 |
+
img_HQ = img_HQ[:, :, [2, 1, 0]]
|
| 133 |
+
img_LQ = torch.from_numpy(np.ascontiguousarray(np.transpose(img_LQ, (2, 0, 1)))).float()
|
| 134 |
+
img_HQ = torch.from_numpy(np.ascontiguousarray(np.transpose(img_HQ, (2, 0, 1)))).float()
|
| 135 |
+
|
| 136 |
+
return {"LQ": img_LQ, "HQ": img_HQ}
|
| 137 |
+
|
| 138 |
+
def __len__(self):
|
| 139 |
+
return len(self.paths_HQ)
|
diffusion-posterior-sampling/bkse/data/__init__.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""create dataset and dataloader"""
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.utils.data
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def create_dataloader(dataset, dataset_opt, opt=None, sampler=None):
|
| 9 |
+
phase = dataset_opt["phase"]
|
| 10 |
+
if phase == "train":
|
| 11 |
+
if opt["dist"]:
|
| 12 |
+
world_size = torch.distributed.get_world_size()
|
| 13 |
+
num_workers = dataset_opt["n_workers"]
|
| 14 |
+
assert dataset_opt["batch_size"] % world_size == 0
|
| 15 |
+
batch_size = dataset_opt["batch_size"] // world_size
|
| 16 |
+
shuffle = False
|
| 17 |
+
else:
|
| 18 |
+
num_workers = dataset_opt["n_workers"] * len(opt["gpu_ids"])
|
| 19 |
+
batch_size = dataset_opt["batch_size"]
|
| 20 |
+
shuffle = True
|
| 21 |
+
return torch.utils.data.DataLoader(
|
| 22 |
+
dataset,
|
| 23 |
+
batch_size=batch_size,
|
| 24 |
+
shuffle=shuffle,
|
| 25 |
+
num_workers=num_workers,
|
| 26 |
+
sampler=sampler,
|
| 27 |
+
drop_last=True,
|
| 28 |
+
pin_memory=False,
|
| 29 |
+
)
|
| 30 |
+
else:
|
| 31 |
+
return torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=1, pin_memory=False)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def create_dataset(dataset_opt):
|
| 35 |
+
mode = dataset_opt["mode"]
|
| 36 |
+
# datasets for image restoration
|
| 37 |
+
if mode == "REDS":
|
| 38 |
+
from data.REDS_dataset import REDSDataset as D
|
| 39 |
+
elif mode == "GOPRO":
|
| 40 |
+
from data.GOPRO_dataset import GOPRODataset as D
|
| 41 |
+
elif mode == "fewshot":
|
| 42 |
+
from data.fewshot_dataset import FewShotDataset as D
|
| 43 |
+
elif mode == "levin":
|
| 44 |
+
from data.levin_dataset import LevinDataset as D
|
| 45 |
+
elif mode == "mix":
|
| 46 |
+
from data.mix_dataset import MixDataset as D
|
| 47 |
+
else:
|
| 48 |
+
raise NotImplementedError(f"Dataset {mode} is not recognized.")
|
| 49 |
+
dataset = D(dataset_opt)
|
| 50 |
+
|
| 51 |
+
logger = logging.getLogger("base")
|
| 52 |
+
logger.info("Dataset [{:s} - {:s}] is created.".format(dataset.__class__.__name__, dataset_opt["name"]))
|
| 53 |
+
return dataset
|
diffusion-posterior-sampling/bkse/data/data_sampler.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Modified from torch.utils.data.distributed.DistributedSampler
|
| 3 |
+
Support enlarging the dataset for *iteration-oriented* training,
|
| 4 |
+
for saving time when restart the dataloader after each epoch
|
| 5 |
+
"""
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.distributed as dist
|
| 10 |
+
from torch.utils.data.sampler import Sampler
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class DistIterSampler(Sampler):
|
| 14 |
+
"""Sampler that restricts data loading to a subset of the dataset.
|
| 15 |
+
|
| 16 |
+
It is especially useful in conjunction with
|
| 17 |
+
:class:`torch.nn.parallel.DistributedDataParallel`. In such case, each
|
| 18 |
+
process can pass a DistributedSampler instance as a DataLoader sampler,
|
| 19 |
+
and load a subset of the original dataset that is exclusive to it.
|
| 20 |
+
|
| 21 |
+
.. note::
|
| 22 |
+
Dataset is assumed to be of constant size.
|
| 23 |
+
|
| 24 |
+
Arguments:
|
| 25 |
+
dataset: Dataset used for sampling.
|
| 26 |
+
num_replicas (optional): Number of processes participating in
|
| 27 |
+
distributed training.
|
| 28 |
+
rank (optional): Rank of the current process within num_replicas.
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
def __init__(self, dataset, num_replicas=None, rank=None, ratio=100):
|
| 32 |
+
if num_replicas is None:
|
| 33 |
+
if not dist.is_available():
|
| 34 |
+
raise RuntimeError(
|
| 35 |
+
"Requires distributed \
|
| 36 |
+
package to be available"
|
| 37 |
+
)
|
| 38 |
+
num_replicas = dist.get_world_size()
|
| 39 |
+
if rank is None:
|
| 40 |
+
if not dist.is_available():
|
| 41 |
+
raise RuntimeError(
|
| 42 |
+
"Requires distributed \
|
| 43 |
+
package to be available"
|
| 44 |
+
)
|
| 45 |
+
rank = dist.get_rank()
|
| 46 |
+
self.dataset = dataset
|
| 47 |
+
self.num_replicas = num_replicas
|
| 48 |
+
self.rank = rank
|
| 49 |
+
self.epoch = 0
|
| 50 |
+
self.num_samples = int(math.ceil(len(self.dataset) * ratio / self.num_replicas))
|
| 51 |
+
self.total_size = self.num_samples * self.num_replicas
|
| 52 |
+
|
| 53 |
+
def __iter__(self):
|
| 54 |
+
# deterministically shuffle based on epoch
|
| 55 |
+
g = torch.Generator()
|
| 56 |
+
g.manual_seed(self.epoch)
|
| 57 |
+
indices = torch.randperm(self.total_size, generator=g).tolist()
|
| 58 |
+
|
| 59 |
+
dsize = len(self.dataset)
|
| 60 |
+
indices = [v % dsize for v in indices]
|
| 61 |
+
|
| 62 |
+
# subsample
|
| 63 |
+
indices = indices[self.rank : self.total_size : self.num_replicas]
|
| 64 |
+
assert len(indices) == self.num_samples
|
| 65 |
+
|
| 66 |
+
return iter(indices)
|
| 67 |
+
|
| 68 |
+
def __len__(self):
|
| 69 |
+
return self.num_samples
|
| 70 |
+
|
| 71 |
+
def set_epoch(self, epoch):
|
| 72 |
+
self.epoch = epoch
|
diffusion-posterior-sampling/bkse/data/mix_dataset.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Mix dataset
|
| 3 |
+
support reading images from lmdb
|
| 4 |
+
"""
|
| 5 |
+
import logging
|
| 6 |
+
import random
|
| 7 |
+
|
| 8 |
+
import data.util as util
|
| 9 |
+
import lmdb
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import torch.utils.data as data
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
logger = logging.getLogger("base")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class MixDataset(data.Dataset):
|
| 19 |
+
"""
|
| 20 |
+
Reading the training REDS dataset
|
| 21 |
+
key example: 000_00000000
|
| 22 |
+
HQ: Ground-Truth;
|
| 23 |
+
LQ: Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames
|
| 24 |
+
support reading N LQ frames, N = 1, 3, 5, 7
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
def __init__(self, opt):
|
| 28 |
+
super(MixDataset, self).__init__()
|
| 29 |
+
self.opt = opt
|
| 30 |
+
# temporal augmentation
|
| 31 |
+
|
| 32 |
+
self.HQ_roots = opt["dataroots_HQ"]
|
| 33 |
+
self.LQ_roots = opt["dataroots_LQ"]
|
| 34 |
+
self.use_identical = opt["identical_loss"]
|
| 35 |
+
dataset_weights = opt["dataset_weights"]
|
| 36 |
+
self.data_type = "lmdb"
|
| 37 |
+
# directly load image keys
|
| 38 |
+
self.HQ_envs, self.LQ_envs = None, None
|
| 39 |
+
self.paths_HQ = []
|
| 40 |
+
for idx, (HQ_root, LQ_root) in enumerate(zip(self.HQ_roots, self.LQ_roots)):
|
| 41 |
+
paths_HQ, _ = util.get_image_paths(self.data_type, HQ_root)
|
| 42 |
+
self.paths_HQ += list(zip([idx] * len(paths_HQ), paths_HQ)) * dataset_weights[idx]
|
| 43 |
+
random.shuffle(self.paths_HQ)
|
| 44 |
+
logger.info("Using lmdb meta info for cache keys.")
|
| 45 |
+
|
| 46 |
+
def _init_lmdb(self):
|
| 47 |
+
self.HQ_envs, self.LQ_envs = [], []
|
| 48 |
+
for HQ_root, LQ_root in zip(self.HQ_roots, self.LQ_roots):
|
| 49 |
+
self.HQ_envs.append(lmdb.open(HQ_root, readonly=True, lock=False, readahead=False, meminit=False))
|
| 50 |
+
self.LQ_envs.append(lmdb.open(LQ_root, readonly=True, lock=False, readahead=False, meminit=False))
|
| 51 |
+
|
| 52 |
+
def __getitem__(self, index):
|
| 53 |
+
if self.HQ_envs is None:
|
| 54 |
+
self._init_lmdb()
|
| 55 |
+
|
| 56 |
+
HQ_size = self.opt["HQ_size"]
|
| 57 |
+
env_idx, key = self.paths_HQ[index]
|
| 58 |
+
name_a, name_b = key.split("_")
|
| 59 |
+
target_frame_idx = int(name_b)
|
| 60 |
+
|
| 61 |
+
# determine the neighbor frames
|
| 62 |
+
# ensure not exceeding the borders
|
| 63 |
+
neighbor_list = [target_frame_idx]
|
| 64 |
+
name_b = "{:08d}".format(neighbor_list[0])
|
| 65 |
+
|
| 66 |
+
# get the HQ image (as the center frame)
|
| 67 |
+
img_HQ_l = []
|
| 68 |
+
for v in neighbor_list:
|
| 69 |
+
img_HQ = util.read_img(self.HQ_envs[env_idx], "{}_{:08d}".format(name_a, v), (3, 720, 1280))
|
| 70 |
+
img_HQ_l.append(img_HQ)
|
| 71 |
+
|
| 72 |
+
# get LQ images
|
| 73 |
+
img_LQ = util.read_img(self.LQ_envs[env_idx], "{}_{:08d}".format(name_a, neighbor_list[-1]), (3, 720, 1280))
|
| 74 |
+
if self.opt["phase"] == "train":
|
| 75 |
+
_, H, W = 3, 720, 1280 # LQ size
|
| 76 |
+
# randomly crop
|
| 77 |
+
rnd_h = random.randint(0, max(0, H - HQ_size))
|
| 78 |
+
rnd_w = random.randint(0, max(0, W - HQ_size))
|
| 79 |
+
img_LQ = img_LQ[rnd_h : rnd_h + HQ_size, rnd_w : rnd_w + HQ_size, :]
|
| 80 |
+
img_HQ_l = [v[rnd_h : rnd_h + HQ_size, rnd_w : rnd_w + HQ_size, :] for v in img_HQ_l]
|
| 81 |
+
|
| 82 |
+
# augmentation - flip, rotate
|
| 83 |
+
img_HQ_l.append(img_LQ)
|
| 84 |
+
rlt = util.augment(img_HQ_l, self.opt["use_flip"], self.opt["use_rot"])
|
| 85 |
+
img_HQ_l = rlt[0:-1]
|
| 86 |
+
img_LQ = rlt[-1]
|
| 87 |
+
|
| 88 |
+
# stack LQ images to NHWC, N is the frame number
|
| 89 |
+
img_HQs = np.stack(img_HQ_l, axis=0)
|
| 90 |
+
# BGR to RGB, HWC to CHW, numpy to tensor
|
| 91 |
+
img_LQ = img_LQ[:, :, [2, 1, 0]]
|
| 92 |
+
img_HQs = img_HQs[:, :, :, [2, 1, 0]]
|
| 93 |
+
img_LQ = torch.from_numpy(np.ascontiguousarray(np.transpose(img_LQ, (2, 0, 1)))).float()
|
| 94 |
+
img_HQs = torch.from_numpy(np.ascontiguousarray(np.transpose(img_HQs, (0, 3, 1, 2)))).float()
|
| 95 |
+
# print(img_LQ.shape, img_HQs.shape)
|
| 96 |
+
|
| 97 |
+
if self.use_identical and np.random.randint(0, 10) == 0:
|
| 98 |
+
img_LQ = img_HQs[-1, :, :, :]
|
| 99 |
+
return {"LQ": img_LQ, "HQs": img_HQs, "identical_w": 10}
|
| 100 |
+
|
| 101 |
+
return {"LQ": img_LQ, "HQs": img_HQs, "identical_w": 0}
|
| 102 |
+
|
| 103 |
+
def __len__(self):
|
| 104 |
+
return len(self.paths_HQ)
|
diffusion-posterior-sampling/bkse/data/util.py
ADDED
|
@@ -0,0 +1,574 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import math
|
| 3 |
+
import os
|
| 4 |
+
import pickle
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
import cv2
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
####################
|
| 13 |
+
# Files & IO
|
| 14 |
+
####################
|
| 15 |
+
|
| 16 |
+
# get image path list
|
| 17 |
+
IMG_EXTENSIONS = [".jpg", ".JPG", ".jpeg", ".JPEG", ".png", ".PNG", ".ppm", ".PPM", ".bmp", ".BMP"]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def is_image_file(filename):
|
| 21 |
+
return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def _get_paths_from_images(path):
|
| 25 |
+
"""get image path list from image folder"""
|
| 26 |
+
assert os.path.isdir(path), "{:s} is not a valid directory".format(path)
|
| 27 |
+
images = []
|
| 28 |
+
for dirpath, _, fnames in sorted(os.walk(path)):
|
| 29 |
+
for fname in sorted(fnames):
|
| 30 |
+
if is_image_file(fname):
|
| 31 |
+
img_path = os.path.join(dirpath, fname)
|
| 32 |
+
images.append(img_path)
|
| 33 |
+
assert images, "{:s} has no valid image file".format(path)
|
| 34 |
+
return images
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def _get_paths_from_lmdb(dataroot):
|
| 38 |
+
"""get image path list from lmdb meta info"""
|
| 39 |
+
meta_info = pickle.load(open(os.path.join(dataroot, "meta_info.pkl"), "rb"))
|
| 40 |
+
paths = meta_info["keys"]
|
| 41 |
+
sizes = meta_info["resolution"]
|
| 42 |
+
if len(sizes) == 1:
|
| 43 |
+
sizes = sizes * len(paths)
|
| 44 |
+
return paths, sizes
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_image_paths(data_type, dataroot):
|
| 48 |
+
"""get image path list
|
| 49 |
+
support lmdb or image files"""
|
| 50 |
+
paths, sizes = None, None
|
| 51 |
+
if dataroot is not None:
|
| 52 |
+
if data_type == "lmdb":
|
| 53 |
+
paths, sizes = _get_paths_from_lmdb(dataroot)
|
| 54 |
+
elif data_type == "img":
|
| 55 |
+
paths = sorted(_get_paths_from_images(dataroot))
|
| 56 |
+
else:
|
| 57 |
+
raise NotImplementedError(
|
| 58 |
+
f"data_type {data_type} \
|
| 59 |
+
is not recognized."
|
| 60 |
+
)
|
| 61 |
+
return paths, sizes
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def glob_file_list(root):
|
| 65 |
+
return sorted(glob.glob(os.path.join(root, "*")))
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
# read images
|
| 69 |
+
def _read_img_lmdb(env, key, size):
|
| 70 |
+
"""read image from lmdb with key (w/ and w/o fixed size)
|
| 71 |
+
size: (C, H, W) tuple"""
|
| 72 |
+
with env.begin(write=False) as txn:
|
| 73 |
+
buf = txn.get(key.encode("ascii"))
|
| 74 |
+
if buf is None:
|
| 75 |
+
print(key)
|
| 76 |
+
img_flat = np.frombuffer(buf, dtype=np.uint8)
|
| 77 |
+
C, H, W = size
|
| 78 |
+
img = img_flat.reshape(H, W, C)
|
| 79 |
+
return img
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def read_img(env, path, size=None):
|
| 83 |
+
"""read image by cv2 or from lmdb
|
| 84 |
+
return: Numpy float32, HWC, BGR, [0,1]"""
|
| 85 |
+
if env is None: # img
|
| 86 |
+
img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
|
| 87 |
+
else:
|
| 88 |
+
img = _read_img_lmdb(env, path, size)
|
| 89 |
+
img = img.astype(np.float32) / 255.0
|
| 90 |
+
if img.ndim == 2:
|
| 91 |
+
img = np.expand_dims(img, axis=2)
|
| 92 |
+
# some images have 4 channels
|
| 93 |
+
if img.shape[2] > 3:
|
| 94 |
+
img = img[:, :, :3]
|
| 95 |
+
return img
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def read_img_gray(env, path, size=None):
|
| 99 |
+
"""read image by cv2 or from lmdb
|
| 100 |
+
return: Numpy float32, HWC, BGR, [0,1]"""
|
| 101 |
+
img = _read_img_lmdb(env, path, size)
|
| 102 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
|
| 103 |
+
img = img.astype(np.float32) / 255.0
|
| 104 |
+
img = img[:, :, np.newaxis]
|
| 105 |
+
return img
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def read_img_seq(path):
|
| 109 |
+
"""Read a sequence of images from a given folder path
|
| 110 |
+
Args:
|
| 111 |
+
path (list/str): list of image paths/image folder path
|
| 112 |
+
|
| 113 |
+
Returns:
|
| 114 |
+
imgs (Tensor): size (T, C, H, W), RGB, [0, 1]
|
| 115 |
+
"""
|
| 116 |
+
if type(path) is list:
|
| 117 |
+
img_path_l = path
|
| 118 |
+
else:
|
| 119 |
+
img_path_l = sorted(glob.glob(os.path.join(path, "*")))
|
| 120 |
+
img_l = [read_img(None, v) for v in img_path_l]
|
| 121 |
+
# stack to Torch tensor
|
| 122 |
+
imgs = np.stack(img_l, axis=0)
|
| 123 |
+
imgs = imgs[:, :, :, [2, 1, 0]]
|
| 124 |
+
imgs = torch.from_numpy(np.ascontiguousarray(np.transpose(imgs, (0, 3, 1, 2)))).float()
|
| 125 |
+
return imgs
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def index_generation(crt_i, max_n, N, padding="reflection"):
|
| 129 |
+
"""Generate an index list for reading N frames from a sequence of images
|
| 130 |
+
Args:
|
| 131 |
+
crt_i (int): current center index
|
| 132 |
+
max_n (int): max number of the sequence of images (calculated from 1)
|
| 133 |
+
N (int): reading N frames
|
| 134 |
+
padding (str): padding mode, one of
|
| 135 |
+
replicate | reflection | new_info | circle
|
| 136 |
+
Example: crt_i = 0, N = 5
|
| 137 |
+
replicate: [0, 0, 0, 1, 2]
|
| 138 |
+
reflection: [2, 1, 0, 1, 2]
|
| 139 |
+
new_info: [4, 3, 0, 1, 2]
|
| 140 |
+
circle: [3, 4, 0, 1, 2]
|
| 141 |
+
|
| 142 |
+
Returns:
|
| 143 |
+
return_l (list [int]): a list of indexes
|
| 144 |
+
"""
|
| 145 |
+
max_n = max_n - 1
|
| 146 |
+
n_pad = N // 2
|
| 147 |
+
return_l = []
|
| 148 |
+
|
| 149 |
+
for i in range(crt_i - n_pad, crt_i + n_pad + 1):
|
| 150 |
+
if i < 0:
|
| 151 |
+
if padding == "replicate":
|
| 152 |
+
add_idx = 0
|
| 153 |
+
elif padding == "reflection":
|
| 154 |
+
add_idx = -i
|
| 155 |
+
elif padding == "new_info":
|
| 156 |
+
add_idx = (crt_i + n_pad) + (-i)
|
| 157 |
+
elif padding == "circle":
|
| 158 |
+
add_idx = N + i
|
| 159 |
+
else:
|
| 160 |
+
raise ValueError("Wrong padding mode")
|
| 161 |
+
elif i > max_n:
|
| 162 |
+
if padding == "replicate":
|
| 163 |
+
add_idx = max_n
|
| 164 |
+
elif padding == "reflection":
|
| 165 |
+
add_idx = max_n * 2 - i
|
| 166 |
+
elif padding == "new_info":
|
| 167 |
+
add_idx = (crt_i - n_pad) - (i - max_n)
|
| 168 |
+
elif padding == "circle":
|
| 169 |
+
add_idx = i - N
|
| 170 |
+
else:
|
| 171 |
+
raise ValueError("Wrong padding mode")
|
| 172 |
+
else:
|
| 173 |
+
add_idx = i
|
| 174 |
+
return_l.append(add_idx)
|
| 175 |
+
return return_l
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
####################
|
| 179 |
+
# image processing
|
| 180 |
+
# process on numpy image
|
| 181 |
+
####################
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def augment(img_list, hflip=True, rot=True):
|
| 185 |
+
"""horizontal flip OR rotate (0, 90, 180, 270 degrees)"""
|
| 186 |
+
hflip = hflip and random.random() < 0.5
|
| 187 |
+
vflip = rot and random.random() < 0.5
|
| 188 |
+
rot90 = rot and random.random() < 0.5
|
| 189 |
+
|
| 190 |
+
def _augment(img):
|
| 191 |
+
if hflip:
|
| 192 |
+
img = img[:, ::-1, :]
|
| 193 |
+
if vflip:
|
| 194 |
+
img = img[::-1, :, :]
|
| 195 |
+
if rot90:
|
| 196 |
+
img = img.transpose(1, 0, 2)
|
| 197 |
+
return img
|
| 198 |
+
|
| 199 |
+
return [_augment(img) for img in img_list]
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def augment_flow(img_list, flow_list, hflip=True, rot=True):
|
| 203 |
+
"""horizontal flip OR rotate (0, 90, 180, 270 degrees) with flows"""
|
| 204 |
+
hflip = hflip and random.random() < 0.5
|
| 205 |
+
vflip = rot and random.random() < 0.5
|
| 206 |
+
rot90 = rot and random.random() < 0.5
|
| 207 |
+
|
| 208 |
+
def _augment(img):
|
| 209 |
+
if hflip:
|
| 210 |
+
img = img[:, ::-1, :]
|
| 211 |
+
if vflip:
|
| 212 |
+
img = img[::-1, :, :]
|
| 213 |
+
if rot90:
|
| 214 |
+
img = img.transpose(1, 0, 2)
|
| 215 |
+
return img
|
| 216 |
+
|
| 217 |
+
def _augment_flow(flow):
|
| 218 |
+
if hflip:
|
| 219 |
+
flow = flow[:, ::-1, :]
|
| 220 |
+
flow[:, :, 0] *= -1
|
| 221 |
+
if vflip:
|
| 222 |
+
flow = flow[::-1, :, :]
|
| 223 |
+
flow[:, :, 1] *= -1
|
| 224 |
+
if rot90:
|
| 225 |
+
flow = flow.transpose(1, 0, 2)
|
| 226 |
+
flow = flow[:, :, [1, 0]]
|
| 227 |
+
return flow
|
| 228 |
+
|
| 229 |
+
rlt_img_list = [_augment(img) for img in img_list]
|
| 230 |
+
rlt_flow_list = [_augment_flow(flow) for flow in flow_list]
|
| 231 |
+
|
| 232 |
+
return rlt_img_list, rlt_flow_list
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def channel_convert(in_c, tar_type, img_list):
|
| 236 |
+
"""conversion among BGR, gray and y"""
|
| 237 |
+
if in_c == 3 and tar_type == "gray": # BGR to gray
|
| 238 |
+
gray_list = [cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) for img in img_list]
|
| 239 |
+
return [np.expand_dims(img, axis=2) for img in gray_list]
|
| 240 |
+
elif in_c == 3 and tar_type == "y": # BGR to y
|
| 241 |
+
y_list = [bgr2ycbcr(img, only_y=True) for img in img_list]
|
| 242 |
+
return [np.expand_dims(img, axis=2) for img in y_list]
|
| 243 |
+
elif in_c == 1 and tar_type == "RGB": # gray/y to BGR
|
| 244 |
+
return [cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) for img in img_list]
|
| 245 |
+
else:
|
| 246 |
+
return img_list
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
def rgb2ycbcr(img, only_y=True):
|
| 250 |
+
"""same as matlab rgb2ycbcr
|
| 251 |
+
only_y: only return Y channel
|
| 252 |
+
Input:
|
| 253 |
+
uint8, [0, 255]
|
| 254 |
+
float, [0, 1]
|
| 255 |
+
"""
|
| 256 |
+
in_img_type = img.dtype
|
| 257 |
+
img.astype(np.float32)
|
| 258 |
+
if in_img_type != np.uint8:
|
| 259 |
+
img *= 255.0
|
| 260 |
+
# convert
|
| 261 |
+
if only_y:
|
| 262 |
+
rlt = np.dot(img, [65.481, 128.553, 24.966]) / 255.0 + 16.0
|
| 263 |
+
else:
|
| 264 |
+
rlt = np.matmul(
|
| 265 |
+
img, [[65.481, -37.797, 112.0], [128.553, -74.203, -93.786], [24.966, 112.0, -18.214]]
|
| 266 |
+
) / 255.0 + [16, 128, 128]
|
| 267 |
+
if in_img_type == np.uint8:
|
| 268 |
+
rlt = rlt.round()
|
| 269 |
+
else:
|
| 270 |
+
rlt /= 255.0
|
| 271 |
+
return rlt.astype(in_img_type)
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
def bgr2ycbcr(img, only_y=True):
|
| 275 |
+
"""bgr version of rgb2ycbcr
|
| 276 |
+
only_y: only return Y channel
|
| 277 |
+
Input:
|
| 278 |
+
uint8, [0, 255]
|
| 279 |
+
float, [0, 1]
|
| 280 |
+
"""
|
| 281 |
+
in_img_type = img.dtype
|
| 282 |
+
img.astype(np.float32)
|
| 283 |
+
if in_img_type != np.uint8:
|
| 284 |
+
img *= 255.0
|
| 285 |
+
# convert
|
| 286 |
+
if only_y:
|
| 287 |
+
rlt = np.dot(img, [24.966, 128.553, 65.481]) / 255.0 + 16.0
|
| 288 |
+
else:
|
| 289 |
+
rlt = np.matmul(
|
| 290 |
+
img, [[24.966, 112.0, -18.214], [128.553, -74.203, -93.786], [65.481, -37.797, 112.0]]
|
| 291 |
+
) / 255.0 + [16, 128, 128]
|
| 292 |
+
if in_img_type == np.uint8:
|
| 293 |
+
rlt = rlt.round()
|
| 294 |
+
else:
|
| 295 |
+
rlt /= 255.0
|
| 296 |
+
return rlt.astype(in_img_type)
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
def ycbcr2rgb(img):
|
| 300 |
+
"""same as matlab ycbcr2rgb
|
| 301 |
+
Input:
|
| 302 |
+
uint8, [0, 255]
|
| 303 |
+
float, [0, 1]
|
| 304 |
+
"""
|
| 305 |
+
in_img_type = img.dtype
|
| 306 |
+
img.astype(np.float32)
|
| 307 |
+
if in_img_type != np.uint8:
|
| 308 |
+
img *= 255.0
|
| 309 |
+
# convert
|
| 310 |
+
rlt = np.matmul(
|
| 311 |
+
img, [[0.00456621, 0.00456621, 0.00456621], [0, -0.00153632, 0.00791071], [0.00625893, -0.00318811, 0]]
|
| 312 |
+
) * 255.0 + [-222.921, 135.576, -276.836]
|
| 313 |
+
if in_img_type == np.uint8:
|
| 314 |
+
rlt = rlt.round()
|
| 315 |
+
else:
|
| 316 |
+
rlt /= 255.0
|
| 317 |
+
return rlt.astype(in_img_type)
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
def modcrop(img_in, scale):
|
| 321 |
+
"""img_in: Numpy, HWC or HW"""
|
| 322 |
+
img = np.copy(img_in)
|
| 323 |
+
if img.ndim == 2:
|
| 324 |
+
H, W = img.shape
|
| 325 |
+
H_r, W_r = H % scale, W % scale
|
| 326 |
+
img = img[: H - H_r, : W - W_r]
|
| 327 |
+
elif img.ndim == 3:
|
| 328 |
+
H, W, C = img.shape
|
| 329 |
+
H_r, W_r = H % scale, W % scale
|
| 330 |
+
img = img[: H - H_r, : W - W_r, :]
|
| 331 |
+
else:
|
| 332 |
+
raise ValueError("Wrong img ndim: [{:d}].".format(img.ndim))
|
| 333 |
+
return img
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
####################
|
| 337 |
+
# Functions
|
| 338 |
+
####################
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
# matlab 'imresize' function, now only support 'bicubic'
|
| 342 |
+
def cubic(x):
|
| 343 |
+
absx = torch.abs(x)
|
| 344 |
+
absx2 = absx ** 2
|
| 345 |
+
absx3 = absx ** 3
|
| 346 |
+
return (1.5 * absx3 - 2.5 * absx2 + 1) * ((absx <= 1).type_as(absx)) + (
|
| 347 |
+
-0.5 * absx3 + 2.5 * absx2 - 4 * absx + 2
|
| 348 |
+
) * (((absx > 1) * (absx <= 2)).type_as(absx))
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
def calculate_weights_indices(in_length, out_length, scale, kernel, kernel_width, antialiasing):
|
| 352 |
+
if (scale < 1) and (antialiasing):
|
| 353 |
+
"""
|
| 354 |
+
Use a modified kernel to simultaneously interpolate
|
| 355 |
+
and antialias- larger kernel width
|
| 356 |
+
"""
|
| 357 |
+
kernel_width = kernel_width / scale
|
| 358 |
+
|
| 359 |
+
# Output-space coordinates
|
| 360 |
+
x = torch.linspace(1, out_length, out_length)
|
| 361 |
+
|
| 362 |
+
# Input-space coordinates. Calculate the inverse mapping such that 0.5
|
| 363 |
+
# in output space maps to 0.5 in input space, and 0.5+scale in output
|
| 364 |
+
# space maps to 1.5 in input space.
|
| 365 |
+
u = x / scale + 0.5 * (1 - 1 / scale)
|
| 366 |
+
|
| 367 |
+
# What is the left-most pixel that can be involved in the computation?
|
| 368 |
+
left = torch.floor(u - kernel_width / 2)
|
| 369 |
+
|
| 370 |
+
# What is the maximum number of pixels that can be involved in the
|
| 371 |
+
# computation? Note: it's OK to use an extra pixel here; if the
|
| 372 |
+
# corresponding weights are all zero, it will be eliminated at the end
|
| 373 |
+
# of this function.
|
| 374 |
+
P = math.ceil(kernel_width) + 2
|
| 375 |
+
|
| 376 |
+
# The indices of the input pixels involved in computing the k-th output
|
| 377 |
+
# pixel are in row k of the indices matrix.
|
| 378 |
+
indices = left.view(out_length, 1).expand(out_length, P) + torch.linspace(0, P - 1, P).view(1, P).expand(
|
| 379 |
+
out_length, P
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
# The weights used to compute the k-th output pixel are in row k of the
|
| 383 |
+
# weights matrix.
|
| 384 |
+
distance_to_center = u.view(out_length, 1).expand(out_length, P) - indices
|
| 385 |
+
# apply cubic kernel
|
| 386 |
+
if (scale < 1) and (antialiasing):
|
| 387 |
+
weights = scale * cubic(distance_to_center * scale)
|
| 388 |
+
else:
|
| 389 |
+
weights = cubic(distance_to_center)
|
| 390 |
+
# Normalize the weights matrix so that each row sums to 1.
|
| 391 |
+
weights_sum = torch.sum(weights, 1).view(out_length, 1)
|
| 392 |
+
weights = weights / weights_sum.expand(out_length, P)
|
| 393 |
+
|
| 394 |
+
# If a column in weights is all zero, get rid of it.
|
| 395 |
+
# Only consider the first and last column.
|
| 396 |
+
weights_zero_tmp = torch.sum((weights == 0), 0)
|
| 397 |
+
if not math.isclose(weights_zero_tmp[0], 0, rel_tol=1e-6):
|
| 398 |
+
indices = indices.narrow(1, 1, P - 2)
|
| 399 |
+
weights = weights.narrow(1, 1, P - 2)
|
| 400 |
+
if not math.isclose(weights_zero_tmp[-1], 0, rel_tol=1e-6):
|
| 401 |
+
indices = indices.narrow(1, 0, P - 2)
|
| 402 |
+
weights = weights.narrow(1, 0, P - 2)
|
| 403 |
+
weights = weights.contiguous()
|
| 404 |
+
indices = indices.contiguous()
|
| 405 |
+
sym_len_s = -indices.min() + 1
|
| 406 |
+
sym_len_e = indices.max() - in_length
|
| 407 |
+
indices = indices + sym_len_s - 1
|
| 408 |
+
return weights, indices, int(sym_len_s), int(sym_len_e)
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
def imresize(img, scale, antialiasing=True):
|
| 412 |
+
# Now the scale should be the same for H and W
|
| 413 |
+
# input: img: CHW RGB [0,1]
|
| 414 |
+
# output: CHW RGB [0,1] w/o round
|
| 415 |
+
|
| 416 |
+
in_C, in_H, in_W = img.size()
|
| 417 |
+
_, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
|
| 418 |
+
kernel_width = 4
|
| 419 |
+
kernel = "cubic"
|
| 420 |
+
|
| 421 |
+
# Return the desired dimension order for performing the resize. The
|
| 422 |
+
# strategy is to perform the resize first along the dimension with the
|
| 423 |
+
# smallest scale factor.
|
| 424 |
+
# Now we do not support this.
|
| 425 |
+
|
| 426 |
+
# get weights and indices
|
| 427 |
+
weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
|
| 428 |
+
in_H, out_H, scale, kernel, kernel_width, antialiasing
|
| 429 |
+
)
|
| 430 |
+
weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
|
| 431 |
+
in_W, out_W, scale, kernel, kernel_width, antialiasing
|
| 432 |
+
)
|
| 433 |
+
# process H dimension
|
| 434 |
+
# symmetric copying
|
| 435 |
+
img_aug = torch.FloatTensor(in_C, in_H + sym_len_Hs + sym_len_He, in_W)
|
| 436 |
+
img_aug.narrow(1, sym_len_Hs, in_H).copy_(img)
|
| 437 |
+
|
| 438 |
+
sym_patch = img[:, :sym_len_Hs, :]
|
| 439 |
+
inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
|
| 440 |
+
sym_patch_inv = sym_patch.index_select(1, inv_idx)
|
| 441 |
+
img_aug.narrow(1, 0, sym_len_Hs).copy_(sym_patch_inv)
|
| 442 |
+
|
| 443 |
+
sym_patch = img[:, -sym_len_He:, :]
|
| 444 |
+
inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
|
| 445 |
+
sym_patch_inv = sym_patch.index_select(1, inv_idx)
|
| 446 |
+
img_aug.narrow(1, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
|
| 447 |
+
|
| 448 |
+
out_1 = torch.FloatTensor(in_C, out_H, in_W)
|
| 449 |
+
kernel_width = weights_H.size(1)
|
| 450 |
+
for i in range(out_H):
|
| 451 |
+
idx = int(indices_H[i][0])
|
| 452 |
+
out_1[0, i, :] = img_aug[0, idx : idx + kernel_width, :].transpose(0, 1).mv(weights_H[i])
|
| 453 |
+
out_1[1, i, :] = img_aug[1, idx : idx + kernel_width, :].transpose(0, 1).mv(weights_H[i])
|
| 454 |
+
out_1[2, i, :] = img_aug[2, idx : idx + kernel_width, :].transpose(0, 1).mv(weights_H[i])
|
| 455 |
+
|
| 456 |
+
# process W dimension
|
| 457 |
+
# symmetric copying
|
| 458 |
+
out_1_aug = torch.FloatTensor(in_C, out_H, in_W + sym_len_Ws + sym_len_We)
|
| 459 |
+
out_1_aug.narrow(2, sym_len_Ws, in_W).copy_(out_1)
|
| 460 |
+
|
| 461 |
+
sym_patch = out_1[:, :, :sym_len_Ws]
|
| 462 |
+
inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
|
| 463 |
+
sym_patch_inv = sym_patch.index_select(2, inv_idx)
|
| 464 |
+
out_1_aug.narrow(2, 0, sym_len_Ws).copy_(sym_patch_inv)
|
| 465 |
+
|
| 466 |
+
sym_patch = out_1[:, :, -sym_len_We:]
|
| 467 |
+
inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
|
| 468 |
+
sym_patch_inv = sym_patch.index_select(2, inv_idx)
|
| 469 |
+
out_1_aug.narrow(2, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
|
| 470 |
+
|
| 471 |
+
out_2 = torch.FloatTensor(in_C, out_H, out_W)
|
| 472 |
+
kernel_width = weights_W.size(1)
|
| 473 |
+
for i in range(out_W):
|
| 474 |
+
idx = int(indices_W[i][0])
|
| 475 |
+
out_2[0, :, i] = out_1_aug[0, :, idx : idx + kernel_width].mv(weights_W[i])
|
| 476 |
+
out_2[1, :, i] = out_1_aug[1, :, idx : idx + kernel_width].mv(weights_W[i])
|
| 477 |
+
out_2[2, :, i] = out_1_aug[2, :, idx : idx + kernel_width].mv(weights_W[i])
|
| 478 |
+
|
| 479 |
+
return out_2
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
def imresize_np(img, scale, antialiasing=True):
|
| 483 |
+
# Now the scale should be the same for H and W
|
| 484 |
+
# input: img: Numpy, HWC BGR [0,1]
|
| 485 |
+
# output: HWC BGR [0,1] w/o round
|
| 486 |
+
img = torch.from_numpy(img)
|
| 487 |
+
|
| 488 |
+
in_H, in_W, in_C = img.size()
|
| 489 |
+
_, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
|
| 490 |
+
kernel_width = 4
|
| 491 |
+
kernel = "cubic"
|
| 492 |
+
|
| 493 |
+
# Return the desired dimension order for performing the resize. The
|
| 494 |
+
# strategy is to perform the resize first along the dimension with the
|
| 495 |
+
# smallest scale factor.
|
| 496 |
+
# Now we do not support this.
|
| 497 |
+
|
| 498 |
+
# get weights and indices
|
| 499 |
+
weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
|
| 500 |
+
in_H, out_H, scale, kernel, kernel_width, antialiasing
|
| 501 |
+
)
|
| 502 |
+
weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
|
| 503 |
+
in_W, out_W, scale, kernel, kernel_width, antialiasing
|
| 504 |
+
)
|
| 505 |
+
# process H dimension
|
| 506 |
+
# symmetric copying
|
| 507 |
+
img_aug = torch.FloatTensor(in_H + sym_len_Hs + sym_len_He, in_W, in_C)
|
| 508 |
+
img_aug.narrow(0, sym_len_Hs, in_H).copy_(img)
|
| 509 |
+
|
| 510 |
+
sym_patch = img[:sym_len_Hs, :, :]
|
| 511 |
+
inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
|
| 512 |
+
sym_patch_inv = sym_patch.index_select(0, inv_idx)
|
| 513 |
+
img_aug.narrow(0, 0, sym_len_Hs).copy_(sym_patch_inv)
|
| 514 |
+
|
| 515 |
+
sym_patch = img[-sym_len_He:, :, :]
|
| 516 |
+
inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
|
| 517 |
+
sym_patch_inv = sym_patch.index_select(0, inv_idx)
|
| 518 |
+
img_aug.narrow(0, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
|
| 519 |
+
|
| 520 |
+
out_1 = torch.FloatTensor(out_H, in_W, in_C)
|
| 521 |
+
kernel_width = weights_H.size(1)
|
| 522 |
+
for i in range(out_H):
|
| 523 |
+
idx = int(indices_H[i][0])
|
| 524 |
+
out_1[i, :, 0] = img_aug[idx : idx + kernel_width, :, 0].transpose(0, 1).mv(weights_H[i])
|
| 525 |
+
out_1[i, :, 1] = img_aug[idx : idx + kernel_width, :, 1].transpose(0, 1).mv(weights_H[i])
|
| 526 |
+
out_1[i, :, 2] = img_aug[idx : idx + kernel_width, :, 2].transpose(0, 1).mv(weights_H[i])
|
| 527 |
+
|
| 528 |
+
# process W dimension
|
| 529 |
+
# symmetric copying
|
| 530 |
+
out_1_aug = torch.FloatTensor(out_H, in_W + sym_len_Ws + sym_len_We, in_C)
|
| 531 |
+
out_1_aug.narrow(1, sym_len_Ws, in_W).copy_(out_1)
|
| 532 |
+
|
| 533 |
+
sym_patch = out_1[:, :sym_len_Ws, :]
|
| 534 |
+
inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
|
| 535 |
+
sym_patch_inv = sym_patch.index_select(1, inv_idx)
|
| 536 |
+
out_1_aug.narrow(1, 0, sym_len_Ws).copy_(sym_patch_inv)
|
| 537 |
+
|
| 538 |
+
sym_patch = out_1[:, -sym_len_We:, :]
|
| 539 |
+
inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
|
| 540 |
+
sym_patch_inv = sym_patch.index_select(1, inv_idx)
|
| 541 |
+
out_1_aug.narrow(1, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
|
| 542 |
+
|
| 543 |
+
out_2 = torch.FloatTensor(out_H, out_W, in_C)
|
| 544 |
+
kernel_width = weights_W.size(1)
|
| 545 |
+
for i in range(out_W):
|
| 546 |
+
idx = int(indices_W[i][0])
|
| 547 |
+
out_2[:, i, 0] = out_1_aug[:, idx : idx + kernel_width, 0].mv(weights_W[i])
|
| 548 |
+
out_2[:, i, 1] = out_1_aug[:, idx : idx + kernel_width, 1].mv(weights_W[i])
|
| 549 |
+
out_2[:, i, 2] = out_1_aug[:, idx : idx + kernel_width, 2].mv(weights_W[i])
|
| 550 |
+
|
| 551 |
+
return out_2.numpy()
|
| 552 |
+
|
| 553 |
+
|
| 554 |
+
if __name__ == "__main__":
|
| 555 |
+
# test imresize function
|
| 556 |
+
# read images
|
| 557 |
+
img = cv2.imread("test.png")
|
| 558 |
+
img = img * 1.0 / 255
|
| 559 |
+
img = torch.from_numpy(np.transpose(img[:, :, [2, 1, 0]], (2, 0, 1))).float()
|
| 560 |
+
# imresize
|
| 561 |
+
scale = 1 / 4
|
| 562 |
+
import time
|
| 563 |
+
|
| 564 |
+
total_time = 0
|
| 565 |
+
for i in range(10):
|
| 566 |
+
start_time = time.time()
|
| 567 |
+
rlt = imresize(img, scale, antialiasing=True)
|
| 568 |
+
use_time = time.time() - start_time
|
| 569 |
+
total_time += use_time
|
| 570 |
+
print("average time: {}".format(total_time / 10))
|
| 571 |
+
|
| 572 |
+
import torchvision.utils
|
| 573 |
+
|
| 574 |
+
torchvision.utils.save_image((rlt * 255).round() / 255, "rlt.png", nrow=1, padding=0, normalize=False)
|
diffusion-posterior-sampling/bkse/data_augmentation.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import os.path as osp
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
import cv2
|
| 8 |
+
import data.util as data_util
|
| 9 |
+
import lmdb
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import utils.util as util
|
| 13 |
+
import yaml
|
| 14 |
+
from models.kernel_encoding.kernel_wizard import KernelWizard
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def read_image(env, key, x, y, h, w):
|
| 18 |
+
img = data_util.read_img(env, key, (3, 720, 1280))
|
| 19 |
+
img = np.transpose(img[x : x + h, y : y + w, [2, 1, 0]], (2, 0, 1))
|
| 20 |
+
return img
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def main():
|
| 24 |
+
device = torch.device("cuda")
|
| 25 |
+
|
| 26 |
+
parser = argparse.ArgumentParser(description="Kernel extractor testing")
|
| 27 |
+
|
| 28 |
+
parser.add_argument("--source_H", action="store", help="source image height", type=int, required=True)
|
| 29 |
+
parser.add_argument("--source_W", action="store", help="source image width", type=int, required=True)
|
| 30 |
+
parser.add_argument("--target_H", action="store", help="target image height", type=int, required=True)
|
| 31 |
+
parser.add_argument("--target_W", action="store", help="target image width", type=int, required=True)
|
| 32 |
+
parser.add_argument(
|
| 33 |
+
"--augmented_H", action="store", help="desired height of the augmented images", type=int, required=True
|
| 34 |
+
)
|
| 35 |
+
parser.add_argument(
|
| 36 |
+
"--augmented_W", action="store", help="desired width of the augmented images", type=int, required=True
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"--source_LQ_root", action="store", help="source low-quality dataroot", type=str, required=True
|
| 41 |
+
)
|
| 42 |
+
parser.add_argument(
|
| 43 |
+
"--source_HQ_root", action="store", help="source high-quality dataroot", type=str, required=True
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument(
|
| 46 |
+
"--target_HQ_root", action="store", help="target high-quality dataroot", type=str, required=True
|
| 47 |
+
)
|
| 48 |
+
parser.add_argument("--save_path", action="store", help="save path", type=str, required=True)
|
| 49 |
+
parser.add_argument("--yml_path", action="store", help="yml path", type=str, required=True)
|
| 50 |
+
parser.add_argument(
|
| 51 |
+
"--num_images", action="store", help="number of desire augmented images", type=int, required=True
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
args = parser.parse_args()
|
| 55 |
+
|
| 56 |
+
source_LQ_root = args.source_LQ_root
|
| 57 |
+
source_HQ_root = args.source_HQ_root
|
| 58 |
+
target_HQ_root = args.target_HQ_root
|
| 59 |
+
|
| 60 |
+
save_path = args.save_path
|
| 61 |
+
source_H, source_W = args.source_H, args.source_W
|
| 62 |
+
target_H, target_W = args.target_H, args.target_W
|
| 63 |
+
augmented_H, augmented_W = args.augmented_H, args.augmented_W
|
| 64 |
+
yml_path = args.yml_path
|
| 65 |
+
num_images = args.num_images
|
| 66 |
+
|
| 67 |
+
# Initializing logger
|
| 68 |
+
logger = logging.getLogger("base")
|
| 69 |
+
os.makedirs(save_path, exist_ok=True)
|
| 70 |
+
util.setup_logger("base", save_path, "test", level=logging.INFO, screen=True, tofile=True)
|
| 71 |
+
logger.info("source LQ root: {}".format(source_LQ_root))
|
| 72 |
+
logger.info("source HQ root: {}".format(source_HQ_root))
|
| 73 |
+
logger.info("target HQ root: {}".format(target_HQ_root))
|
| 74 |
+
logger.info("augmented height: {}".format(augmented_H))
|
| 75 |
+
logger.info("augmented width: {}".format(augmented_W))
|
| 76 |
+
logger.info("Number of augmented images: {}".format(num_images))
|
| 77 |
+
|
| 78 |
+
# Initializing mode
|
| 79 |
+
logger.info("Loading model...")
|
| 80 |
+
with open(yml_path, "r") as f:
|
| 81 |
+
print(yml_path)
|
| 82 |
+
opt = yaml.load(f)["KernelWizard"]
|
| 83 |
+
model_path = opt["pretrained"]
|
| 84 |
+
model = KernelWizard(opt)
|
| 85 |
+
model.eval()
|
| 86 |
+
model.load_state_dict(torch.load(model_path))
|
| 87 |
+
model = model.to(device)
|
| 88 |
+
logger.info("Done")
|
| 89 |
+
|
| 90 |
+
# processing data
|
| 91 |
+
source_HQ_env = lmdb.open(source_HQ_root, readonly=True, lock=False, readahead=False, meminit=False)
|
| 92 |
+
source_LQ_env = lmdb.open(source_LQ_root, readonly=True, lock=False, readahead=False, meminit=False)
|
| 93 |
+
target_HQ_env = lmdb.open(target_HQ_root, readonly=True, lock=False, readahead=False, meminit=False)
|
| 94 |
+
paths_source_HQ, _ = data_util.get_image_paths("lmdb", source_HQ_root)
|
| 95 |
+
paths_target_HQ, _ = data_util.get_image_paths("lmdb", target_HQ_root)
|
| 96 |
+
|
| 97 |
+
psnr_avg = 0
|
| 98 |
+
|
| 99 |
+
for i in range(num_images):
|
| 100 |
+
source_key = np.random.choice(paths_source_HQ)
|
| 101 |
+
target_key = np.random.choice(paths_target_HQ)
|
| 102 |
+
|
| 103 |
+
source_rnd_h = random.randint(0, max(0, source_H - augmented_H))
|
| 104 |
+
source_rnd_w = random.randint(0, max(0, source_W - augmented_W))
|
| 105 |
+
target_rnd_h = random.randint(0, max(0, target_H - augmented_H))
|
| 106 |
+
target_rnd_w = random.randint(0, max(0, target_W - augmented_W))
|
| 107 |
+
|
| 108 |
+
source_LQ = read_image(source_LQ_env, source_key, source_rnd_h, source_rnd_w, augmented_H, augmented_W)
|
| 109 |
+
source_HQ = read_image(source_HQ_env, source_key, source_rnd_h, source_rnd_w, augmented_H, augmented_W)
|
| 110 |
+
target_HQ = read_image(target_HQ_env, target_key, target_rnd_h, target_rnd_w, augmented_H, augmented_W)
|
| 111 |
+
|
| 112 |
+
source_LQ = torch.Tensor(source_LQ).unsqueeze(0).to(device)
|
| 113 |
+
source_HQ = torch.Tensor(source_HQ).unsqueeze(0).to(device)
|
| 114 |
+
target_HQ = torch.Tensor(target_HQ).unsqueeze(0).to(device)
|
| 115 |
+
|
| 116 |
+
with torch.no_grad():
|
| 117 |
+
kernel_mean, kernel_sigma = model(source_HQ, source_LQ)
|
| 118 |
+
kernel = kernel_mean + kernel_sigma * torch.randn_like(kernel_mean)
|
| 119 |
+
fake_source_LQ = model.adaptKernel(source_HQ, kernel)
|
| 120 |
+
target_LQ = model.adaptKernel(target_HQ, kernel)
|
| 121 |
+
|
| 122 |
+
LQ_img = util.tensor2img(source_LQ)
|
| 123 |
+
fake_LQ_img = util.tensor2img(fake_source_LQ)
|
| 124 |
+
target_LQ_img = util.tensor2img(target_LQ)
|
| 125 |
+
target_HQ_img = util.tensor2img(target_HQ)
|
| 126 |
+
|
| 127 |
+
target_HQ_dst = osp.join(save_path, "sharp/{:03d}/{:08d}.png".format(i // 100, i % 100))
|
| 128 |
+
target_LQ_dst = osp.join(save_path, "blur/{:03d}/{:08d}.png".format(i // 100, i % 100))
|
| 129 |
+
|
| 130 |
+
os.makedirs(osp.dirname(target_HQ_dst), exist_ok=True)
|
| 131 |
+
os.makedirs(osp.dirname(target_LQ_dst), exist_ok=True)
|
| 132 |
+
|
| 133 |
+
cv2.imwrite(target_HQ_dst, target_HQ_img)
|
| 134 |
+
cv2.imwrite(target_LQ_dst, target_LQ_img)
|
| 135 |
+
# torch.save(kernel, osp.join(osp.dirname(target_LQ_dst), f'kernel{i:03d}.pth'))
|
| 136 |
+
|
| 137 |
+
psnr = util.calculate_psnr(LQ_img, fake_LQ_img)
|
| 138 |
+
|
| 139 |
+
logger.info("Reconstruction PSNR of image #{:03d}/{:03d}: {:.2f}db".format(i, num_images, psnr))
|
| 140 |
+
psnr_avg += psnr
|
| 141 |
+
|
| 142 |
+
logger.info("Average reconstruction PSNR: {:.2f}db".format(psnr_avg / num_images))
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
main()
|
diffusion-posterior-sampling/bkse/domain_specific_deblur.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from math import ceil, log10
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import torchvision
|
| 6 |
+
import yaml
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from torch.nn import DataParallel
|
| 9 |
+
from torch.utils.data import DataLoader, Dataset
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class Images(Dataset):
|
| 13 |
+
def __init__(self, root_dir, duplicates):
|
| 14 |
+
self.root_path = Path(root_dir)
|
| 15 |
+
self.image_list = list(self.root_path.glob("*.png"))
|
| 16 |
+
self.duplicates = (
|
| 17 |
+
duplicates # Number of times to duplicate the image in the dataset to produce multiple HR images
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
def __len__(self):
|
| 21 |
+
return self.duplicates * len(self.image_list)
|
| 22 |
+
|
| 23 |
+
def __getitem__(self, idx):
|
| 24 |
+
img_path = self.image_list[idx // self.duplicates]
|
| 25 |
+
image = torchvision.transforms.ToTensor()(Image.open(img_path))
|
| 26 |
+
if self.duplicates == 1:
|
| 27 |
+
return image, img_path.stem
|
| 28 |
+
else:
|
| 29 |
+
return image, img_path.stem + f"_{(idx % self.duplicates)+1}"
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
parser = argparse.ArgumentParser(description="PULSE")
|
| 33 |
+
|
| 34 |
+
# I/O arguments
|
| 35 |
+
parser.add_argument("--input_dir", type=str, default="imgs/blur_faces", help="input data directory")
|
| 36 |
+
parser.add_argument(
|
| 37 |
+
"--output_dir", type=str, default="experiments/domain_specific_deblur/results", help="output data directory"
|
| 38 |
+
)
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"--cache_dir",
|
| 41 |
+
type=str,
|
| 42 |
+
default="experiments/domain_specific_deblur/cache",
|
| 43 |
+
help="cache directory for model weights",
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument(
|
| 46 |
+
"--yml_path", type=str, default="options/domain_specific_deblur/stylegan2.yml", help="configuration file"
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
kwargs = vars(parser.parse_args())
|
| 50 |
+
|
| 51 |
+
with open(kwargs["yml_path"], "rb") as f:
|
| 52 |
+
opt = yaml.safe_load(f)
|
| 53 |
+
|
| 54 |
+
dataset = Images(kwargs["input_dir"], duplicates=opt["duplicates"])
|
| 55 |
+
out_path = Path(kwargs["output_dir"])
|
| 56 |
+
out_path.mkdir(parents=True, exist_ok=True)
|
| 57 |
+
|
| 58 |
+
dataloader = DataLoader(dataset, batch_size=opt["batch_size"])
|
| 59 |
+
|
| 60 |
+
if opt["stylegan_ver"] == 1:
|
| 61 |
+
from models.dsd.dsd_stylegan import DSDStyleGAN
|
| 62 |
+
|
| 63 |
+
model = DSDStyleGAN(opt=opt, cache_dir=kwargs["cache_dir"])
|
| 64 |
+
else:
|
| 65 |
+
from models.dsd.dsd_stylegan2 import DSDStyleGAN2
|
| 66 |
+
|
| 67 |
+
model = DSDStyleGAN2(opt=opt, cache_dir=kwargs["cache_dir"])
|
| 68 |
+
|
| 69 |
+
model = DataParallel(model)
|
| 70 |
+
|
| 71 |
+
toPIL = torchvision.transforms.ToPILImage()
|
| 72 |
+
|
| 73 |
+
for ref_im, ref_im_name in dataloader:
|
| 74 |
+
if opt["save_intermediate"]:
|
| 75 |
+
padding = ceil(log10(100))
|
| 76 |
+
for i in range(opt["batch_size"]):
|
| 77 |
+
int_path_HR = Path(out_path / ref_im_name[i] / "HR")
|
| 78 |
+
int_path_LR = Path(out_path / ref_im_name[i] / "LR")
|
| 79 |
+
int_path_HR.mkdir(parents=True, exist_ok=True)
|
| 80 |
+
int_path_LR.mkdir(parents=True, exist_ok=True)
|
| 81 |
+
for j, (HR, LR) in enumerate(model(ref_im)):
|
| 82 |
+
for i in range(opt["batch_size"]):
|
| 83 |
+
toPIL(HR[i].cpu().detach().clamp(0, 1)).save(int_path_HR / f"{ref_im_name[i]}_{j:0{padding}}.png")
|
| 84 |
+
toPIL(LR[i].cpu().detach().clamp(0, 1)).save(int_path_LR / f"{ref_im_name[i]}_{j:0{padding}}.png")
|
| 85 |
+
else:
|
| 86 |
+
# out_im = model(ref_im,**kwargs)
|
| 87 |
+
for j, (HR, LR) in enumerate(model(ref_im)):
|
| 88 |
+
for i in range(opt["batch_size"]):
|
| 89 |
+
toPIL(HR[i].cpu().detach().clamp(0, 1)).save(out_path / f"{ref_im_name[i]}.png")
|
diffusion-posterior-sampling/bkse/experiments/pretrained/kernel.pth
ADDED
|
Binary file (9.02 kB). View file
|
|
|
diffusion-posterior-sampling/bkse/generate_blur.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os.path as osp
|
| 6 |
+
import torch
|
| 7 |
+
import utils.util as util
|
| 8 |
+
import yaml
|
| 9 |
+
from models.kernel_encoding.kernel_wizard import KernelWizard
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def main():
|
| 13 |
+
device = torch.device("cuda")
|
| 14 |
+
|
| 15 |
+
parser = argparse.ArgumentParser(description="Kernel extractor testing")
|
| 16 |
+
|
| 17 |
+
parser.add_argument("--image_path", action="store", help="image path", type=str, required=True)
|
| 18 |
+
parser.add_argument("--yml_path", action="store", help="yml path", type=str, required=True)
|
| 19 |
+
parser.add_argument("--save_path", action="store", help="save path", type=str, default=".")
|
| 20 |
+
parser.add_argument("--num_samples", action="store", help="number of samples", type=int, default=1)
|
| 21 |
+
|
| 22 |
+
args = parser.parse_args()
|
| 23 |
+
|
| 24 |
+
image_path = args.image_path
|
| 25 |
+
yml_path = args.yml_path
|
| 26 |
+
num_samples = args.num_samples
|
| 27 |
+
|
| 28 |
+
# Initializing mode
|
| 29 |
+
with open(yml_path, "r") as f:
|
| 30 |
+
opt = yaml.load(f)["KernelWizard"]
|
| 31 |
+
model_path = opt["pretrained"]
|
| 32 |
+
model = KernelWizard(opt)
|
| 33 |
+
model.eval()
|
| 34 |
+
model.load_state_dict(torch.load(model_path))
|
| 35 |
+
model = model.to(device)
|
| 36 |
+
|
| 37 |
+
HQ = cv2.cvtColor(cv2.imread(image_path), cv2.COLOR_BGR2RGB) / 255.0
|
| 38 |
+
HQ = np.transpose(HQ, (2, 0, 1))
|
| 39 |
+
HQ_tensor = torch.Tensor(HQ).unsqueeze(0).to(device).cuda()
|
| 40 |
+
|
| 41 |
+
for i in range(num_samples):
|
| 42 |
+
print(f"Sample #{i}/{num_samples}")
|
| 43 |
+
with torch.no_grad():
|
| 44 |
+
kernel = torch.randn((1, 512, 2, 2)).cuda() * 1.2
|
| 45 |
+
LQ_tensor = model.adaptKernel(HQ_tensor, kernel)
|
| 46 |
+
|
| 47 |
+
dst = osp.join(args.save_path, f"blur{i:03d}.png")
|
| 48 |
+
LQ_img = util.tensor2img(LQ_tensor)
|
| 49 |
+
|
| 50 |
+
cv2.imwrite(dst, LQ_img)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
main()
|
diffusion-posterior-sampling/bkse/generic_deblur.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import yaml
|
| 5 |
+
from models.deblurring.joint_deblur import JointDeblur
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def main():
|
| 9 |
+
parser = argparse.ArgumentParser(description="Kernel extractor testing")
|
| 10 |
+
|
| 11 |
+
parser.add_argument("--image_path", action="store", help="image path", type=str, required=True)
|
| 12 |
+
parser.add_argument("--save_path", action="store", help="save path", type=str, default="res.png")
|
| 13 |
+
parser.add_argument("--yml_path", action="store", help="yml path", type=str, required=True)
|
| 14 |
+
|
| 15 |
+
args = parser.parse_args()
|
| 16 |
+
|
| 17 |
+
# Initializing mode
|
| 18 |
+
with open(args.yml_path, "rb") as f:
|
| 19 |
+
opt = yaml.safe_load(f)
|
| 20 |
+
model = JointDeblur(opt)
|
| 21 |
+
|
| 22 |
+
blur_img = cv2.cvtColor(cv2.imread(args.image_path), cv2.COLOR_BGR2RGB)
|
| 23 |
+
sharp_img = model.deblur(blur_img)
|
| 24 |
+
|
| 25 |
+
cv2.imwrite(args.save_path, sharp_img)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
main()
|
diffusion-posterior-sampling/bkse/imgs/blur_faces/face01.png
ADDED

|
diffusion-posterior-sampling/bkse/imgs/blur_imgs/blur1.png
ADDED

|
diffusion-posterior-sampling/bkse/imgs/blur_imgs/blur2.png
ADDED

|
diffusion-posterior-sampling/bkse/imgs/results/augmentation.jpg
ADDED

|
diffusion-posterior-sampling/bkse/imgs/results/domain_specific_deblur.jpg
ADDED

|
diffusion-posterior-sampling/bkse/imgs/results/general_deblurring.jpg
ADDED

|
diffusion-posterior-sampling/bkse/imgs/results/generate_blur.jpg
ADDED

|
diffusion-posterior-sampling/bkse/imgs/results/kernel_encoding_wGT.png
ADDED
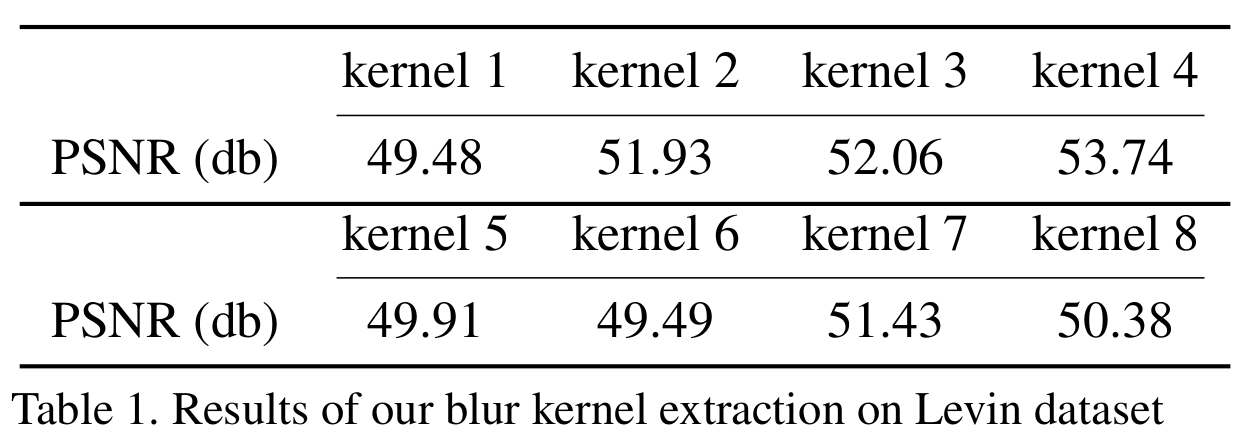
|
diffusion-posterior-sampling/bkse/imgs/sharp_imgs/mushishi.png
ADDED

|
diffusion-posterior-sampling/bkse/imgs/teaser.jpg
ADDED
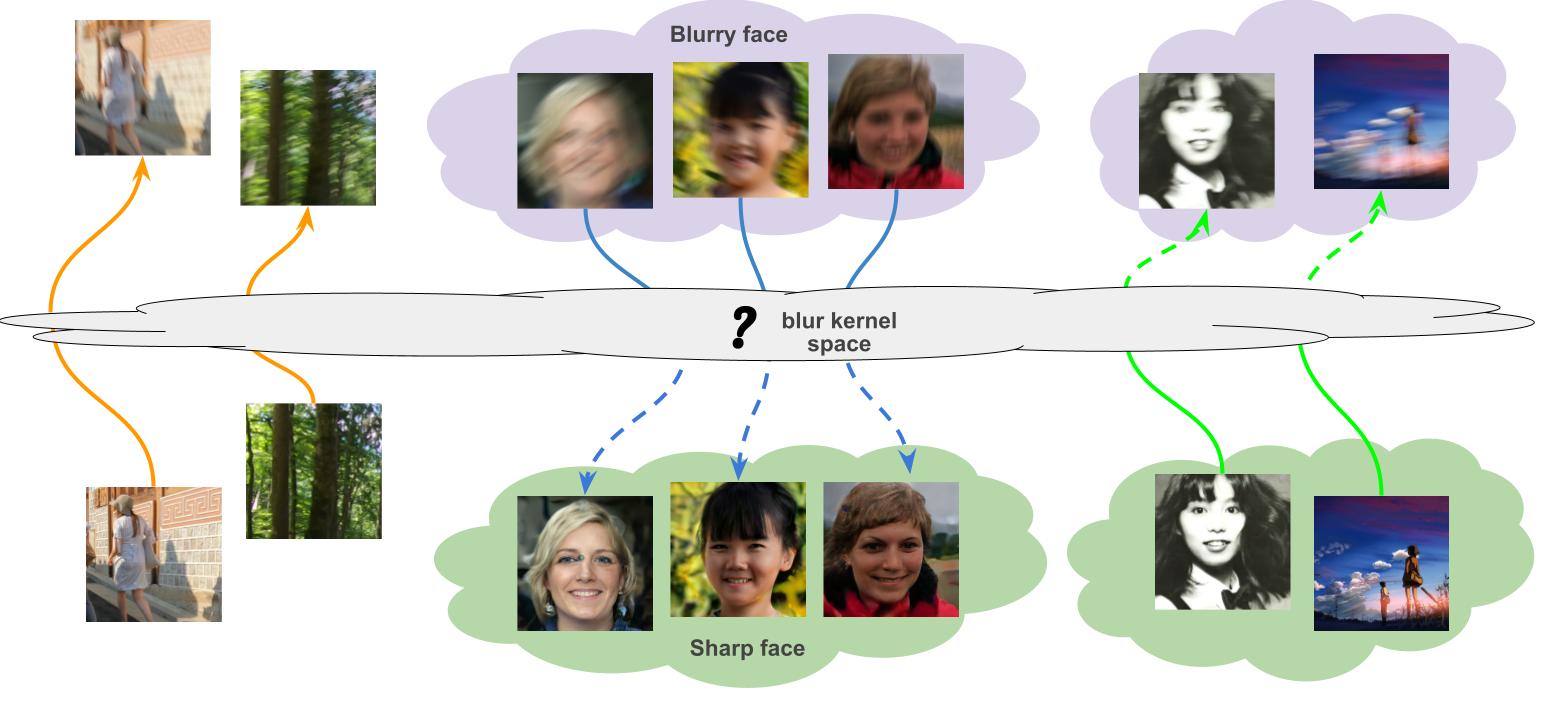
|
diffusion-posterior-sampling/bkse/models/__init__.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
logger = logging.getLogger("base")
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def create_model(opt):
|
| 8 |
+
model = opt["model"]
|
| 9 |
+
if model == "image_base":
|
| 10 |
+
from models.kernel_encoding.image_base_model import ImageBaseModel as M
|
| 11 |
+
else:
|
| 12 |
+
raise NotImplementedError("Model [{:s}] not recognized.".format(model))
|
| 13 |
+
m = M(opt)
|
| 14 |
+
logger.info("Model [{:s}] is created.".format(m.__class__.__name__))
|
| 15 |
+
return m
|
diffusion-posterior-sampling/bkse/models/arch_util.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import functools
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.init as init
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class Identity(nn.Module):
|
| 8 |
+
def forward(self, x):
|
| 9 |
+
return x
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_norm_layer(norm_type="instance"):
|
| 13 |
+
"""Return a normalization layer
|
| 14 |
+
Parameters:
|
| 15 |
+
norm_type (str) -- the name of the normalization
|
| 16 |
+
layer: batch | instance | none
|
| 17 |
+
|
| 18 |
+
For BatchNorm, we use learnable affine parameters and
|
| 19 |
+
track running statistics (mean/stddev).
|
| 20 |
+
|
| 21 |
+
For InstanceNorm, we do not use learnable affine
|
| 22 |
+
parameters. We do not track running statistics.
|
| 23 |
+
"""
|
| 24 |
+
if norm_type == "batch":
|
| 25 |
+
norm_layer = functools.partial(nn.BatchNorm2d, affine=True, track_running_stats=True)
|
| 26 |
+
elif norm_type == "instance":
|
| 27 |
+
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
|
| 28 |
+
elif norm_type == "none":
|
| 29 |
+
|
| 30 |
+
def norm_layer(x):
|
| 31 |
+
return Identity()
|
| 32 |
+
|
| 33 |
+
else:
|
| 34 |
+
raise NotImplementedError(
|
| 35 |
+
f"normalization layer {norm_type}\
|
| 36 |
+
is not found"
|
| 37 |
+
)
|
| 38 |
+
return norm_layer
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def initialize_weights(net_l, scale=1):
|
| 42 |
+
if not isinstance(net_l, list):
|
| 43 |
+
net_l = [net_l]
|
| 44 |
+
for net in net_l:
|
| 45 |
+
for m in net.modules():
|
| 46 |
+
if isinstance(m, nn.Conv2d):
|
| 47 |
+
init.kaiming_normal_(m.weight, a=0, mode="fan_in")
|
| 48 |
+
m.weight.data *= scale # for residual block
|
| 49 |
+
if m.bias is not None:
|
| 50 |
+
m.bias.data.zero_()
|
| 51 |
+
elif isinstance(m, nn.Linear):
|
| 52 |
+
init.kaiming_normal_(m.weight, a=0, mode="fan_in")
|
| 53 |
+
m.weight.data *= scale
|
| 54 |
+
if m.bias is not None:
|
| 55 |
+
m.bias.data.zero_()
|
| 56 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 57 |
+
init.constant_(m.weight, 1)
|
| 58 |
+
init.constant_(m.bias.data, 0.0)
|
diffusion-posterior-sampling/bkse/models/backbones/resnet.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
from models.arch_util import initialize_weights
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ResnetBlock(nn.Module):
|
| 7 |
+
"""Define a Resnet block"""
|
| 8 |
+
|
| 9 |
+
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
|
| 10 |
+
"""Initialize the Resnet block
|
| 11 |
+
A resnet block is a conv block with skip connections
|
| 12 |
+
We construct a conv block with build_conv_block function,
|
| 13 |
+
and implement skip connections in <forward> function.
|
| 14 |
+
Original Resnet paper: https://arxiv.org/pdf/1512.03385.pdf
|
| 15 |
+
"""
|
| 16 |
+
super(ResnetBlock, self).__init__()
|
| 17 |
+
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias)
|
| 18 |
+
|
| 19 |
+
def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias):
|
| 20 |
+
"""Construct a convolutional block.
|
| 21 |
+
Parameters:
|
| 22 |
+
dim (int) -- the number of channels in the conv layer.
|
| 23 |
+
padding_type (str) -- the name of padding
|
| 24 |
+
layer: reflect | replicate | zero
|
| 25 |
+
norm_layer -- normalization layer
|
| 26 |
+
use_dropout (bool) -- if use dropout layers.
|
| 27 |
+
use_bias (bool) -- if the conv layer uses bias or not
|
| 28 |
+
Returns a conv block (with a conv layer, a normalization layer,
|
| 29 |
+
and a non-linearity layer (ReLU))
|
| 30 |
+
"""
|
| 31 |
+
conv_block = []
|
| 32 |
+
p = 0
|
| 33 |
+
if padding_type == "reflect":
|
| 34 |
+
conv_block += [nn.ReflectionPad2d(1)]
|
| 35 |
+
elif padding_type == "replicate":
|
| 36 |
+
conv_block += [nn.ReplicationPad2d(1)]
|
| 37 |
+
elif padding_type == "zero":
|
| 38 |
+
p = 1
|
| 39 |
+
else:
|
| 40 |
+
raise NotImplementedError(
|
| 41 |
+
f"padding {padding_type} \
|
| 42 |
+
is not implemented"
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
|
| 46 |
+
if use_dropout:
|
| 47 |
+
conv_block += [nn.Dropout(0.5)]
|
| 48 |
+
|
| 49 |
+
p = 0
|
| 50 |
+
if padding_type == "reflect":
|
| 51 |
+
conv_block += [nn.ReflectionPad2d(1)]
|
| 52 |
+
elif padding_type == "replicate":
|
| 53 |
+
conv_block += [nn.ReplicationPad2d(1)]
|
| 54 |
+
elif padding_type == "zero":
|
| 55 |
+
p = 1
|
| 56 |
+
else:
|
| 57 |
+
raise NotImplementedError(
|
| 58 |
+
f"padding {padding_type} \
|
| 59 |
+
is not implemented"
|
| 60 |
+
)
|
| 61 |
+
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
|
| 62 |
+
|
| 63 |
+
return nn.Sequential(*conv_block)
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
"""Forward function (with skip connections)"""
|
| 67 |
+
out = x + self.conv_block(x) # add skip connections
|
| 68 |
+
return out
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class ResidualBlock_noBN(nn.Module):
|
| 72 |
+
"""Residual block w/o BN
|
| 73 |
+
---Conv-ReLU-Conv-+-
|
| 74 |
+
|________________|
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
def __init__(self, nf=64):
|
| 78 |
+
super(ResidualBlock_noBN, self).__init__()
|
| 79 |
+
self.conv1 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
|
| 80 |
+
self.conv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
|
| 81 |
+
|
| 82 |
+
# initialization
|
| 83 |
+
initialize_weights([self.conv1, self.conv2], 0.1)
|
| 84 |
+
|
| 85 |
+
def forward(self, x):
|
| 86 |
+
identity = x
|
| 87 |
+
out = F.relu(self.conv1(x), inplace=False)
|
| 88 |
+
out = self.conv2(out)
|
| 89 |
+
return identity + out
|
diffusion-posterior-sampling/bkse/models/backbones/skip/concat.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Concat(nn.Module):
|
| 7 |
+
def __init__(self, dim, *args):
|
| 8 |
+
super(Concat, self).__init__()
|
| 9 |
+
self.dim = dim
|
| 10 |
+
|
| 11 |
+
for idx, module in enumerate(args):
|
| 12 |
+
self.add_module(str(idx), module)
|
| 13 |
+
|
| 14 |
+
def forward(self, input):
|
| 15 |
+
inputs = []
|
| 16 |
+
for module in self._modules.values():
|
| 17 |
+
inputs.append(module(input))
|
| 18 |
+
|
| 19 |
+
inputs_shapes2 = [x.shape[2] for x in inputs]
|
| 20 |
+
inputs_shapes3 = [x.shape[3] for x in inputs]
|
| 21 |
+
|
| 22 |
+
if np.all(np.array(inputs_shapes2) == min(inputs_shapes2)) and np.all(
|
| 23 |
+
np.array(inputs_shapes3) == min(inputs_shapes3)
|
| 24 |
+
):
|
| 25 |
+
inputs_ = inputs
|
| 26 |
+
else:
|
| 27 |
+
target_shape2 = min(inputs_shapes2)
|
| 28 |
+
target_shape3 = min(inputs_shapes3)
|
| 29 |
+
|
| 30 |
+
inputs_ = []
|
| 31 |
+
for inp in inputs:
|
| 32 |
+
diff2 = (inp.size(2) - target_shape2) // 2
|
| 33 |
+
diff3 = (inp.size(3) - target_shape3) // 2
|
| 34 |
+
inputs_.append(inp[:, :, diff2 : diff2 + target_shape2, diff3 : diff3 + target_shape3])
|
| 35 |
+
|
| 36 |
+
return torch.cat(inputs_, dim=self.dim)
|
| 37 |
+
|
| 38 |
+
def __len__(self):
|
| 39 |
+
return len(self._modules)
|
diffusion-posterior-sampling/bkse/models/backbones/skip/downsampler.py
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Downsampler(nn.Module):
|
| 7 |
+
"""
|
| 8 |
+
http://www.realitypixels.com/turk/computergraphics/ResamplingFilters.pdf
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
def __init__(
|
| 12 |
+
self, n_planes, factor, kernel_type, phase=0, kernel_width=None, support=None, sigma=None, preserve_size=False
|
| 13 |
+
):
|
| 14 |
+
super(Downsampler, self).__init__()
|
| 15 |
+
|
| 16 |
+
assert phase in [0, 0.5], "phase should be 0 or 0.5"
|
| 17 |
+
|
| 18 |
+
if kernel_type == "lanczos2":
|
| 19 |
+
support = 2
|
| 20 |
+
kernel_width = 4 * factor + 1
|
| 21 |
+
kernel_type_ = "lanczos"
|
| 22 |
+
|
| 23 |
+
elif kernel_type == "lanczos3":
|
| 24 |
+
support = 3
|
| 25 |
+
kernel_width = 6 * factor + 1
|
| 26 |
+
kernel_type_ = "lanczos"
|
| 27 |
+
|
| 28 |
+
elif kernel_type == "gauss12":
|
| 29 |
+
kernel_width = 7
|
| 30 |
+
sigma = 1 / 2
|
| 31 |
+
kernel_type_ = "gauss"
|
| 32 |
+
|
| 33 |
+
elif kernel_type == "gauss1sq2":
|
| 34 |
+
kernel_width = 9
|
| 35 |
+
sigma = 1.0 / np.sqrt(2)
|
| 36 |
+
kernel_type_ = "gauss"
|
| 37 |
+
|
| 38 |
+
elif kernel_type in ["lanczos", "gauss", "box"]:
|
| 39 |
+
kernel_type_ = kernel_type
|
| 40 |
+
|
| 41 |
+
else:
|
| 42 |
+
assert False, "wrong name kernel"
|
| 43 |
+
|
| 44 |
+
# note that `kernel width` will be different to actual size for phase = 1/2
|
| 45 |
+
self.kernel = get_kernel(factor, kernel_type_, phase, kernel_width, support=support, sigma=sigma)
|
| 46 |
+
|
| 47 |
+
downsampler = nn.Conv2d(n_planes, n_planes, kernel_size=self.kernel.shape, stride=factor, padding=0)
|
| 48 |
+
downsampler.weight.data[:] = 0
|
| 49 |
+
downsampler.bias.data[:] = 0
|
| 50 |
+
|
| 51 |
+
kernel_torch = torch.from_numpy(self.kernel)
|
| 52 |
+
for i in range(n_planes):
|
| 53 |
+
downsampler.weight.data[i, i] = kernel_torch
|
| 54 |
+
|
| 55 |
+
self.downsampler_ = downsampler
|
| 56 |
+
|
| 57 |
+
if preserve_size:
|
| 58 |
+
|
| 59 |
+
if self.kernel.shape[0] % 2 == 1:
|
| 60 |
+
pad = int((self.kernel.shape[0] - 1) / 2.0)
|
| 61 |
+
else:
|
| 62 |
+
pad = int((self.kernel.shape[0] - factor) / 2.0)
|
| 63 |
+
|
| 64 |
+
self.padding = nn.ReplicationPad2d(pad)
|
| 65 |
+
|
| 66 |
+
self.preserve_size = preserve_size
|
| 67 |
+
|
| 68 |
+
def forward(self, input):
|
| 69 |
+
if self.preserve_size:
|
| 70 |
+
x = self.padding(input)
|
| 71 |
+
else:
|
| 72 |
+
x = input
|
| 73 |
+
self.x = x
|
| 74 |
+
return self.downsampler_(x)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class Blurconv(nn.Module):
|
| 78 |
+
"""
|
| 79 |
+
http://www.realitypixels.com/turk/computergraphics/ResamplingFilters.pdf
|
| 80 |
+
"""
|
| 81 |
+
|
| 82 |
+
def __init__(self, n_planes=1, preserve_size=False):
|
| 83 |
+
super(Blurconv, self).__init__()
|
| 84 |
+
|
| 85 |
+
# self.kernel = kernel
|
| 86 |
+
# blurconv = nn.Conv2d(n_planes, n_planes, kernel_size=self.kernel.shape, stride=1, padding=0)
|
| 87 |
+
# blurconvr.weight.data = self.kernel
|
| 88 |
+
# blurconv.bias.data[:] = 0
|
| 89 |
+
self.n_planes = n_planes
|
| 90 |
+
self.preserve_size = preserve_size
|
| 91 |
+
|
| 92 |
+
# kernel_torch = torch.from_numpy(self.kernel)
|
| 93 |
+
# for i in range(n_planes):
|
| 94 |
+
# blurconv.weight.data[i, i] = kernel_torch
|
| 95 |
+
|
| 96 |
+
# self.blurconv_ = blurconv
|
| 97 |
+
#
|
| 98 |
+
# if preserve_size:
|
| 99 |
+
#
|
| 100 |
+
# if self.kernel.shape[0] % 2 == 1:
|
| 101 |
+
# pad = int((self.kernel.shape[0] - 1) / 2.)
|
| 102 |
+
# else:
|
| 103 |
+
# pad = int((self.kernel.shape[0] - factor) / 2.)
|
| 104 |
+
#
|
| 105 |
+
# self.padding = nn.ReplicationPad2d(pad)
|
| 106 |
+
#
|
| 107 |
+
# self.preserve_size = preserve_size
|
| 108 |
+
|
| 109 |
+
def forward(self, input, kernel):
|
| 110 |
+
if self.preserve_size:
|
| 111 |
+
if kernel.shape[0] % 2 == 1:
|
| 112 |
+
pad = int((kernel.shape[3] - 1) / 2.0)
|
| 113 |
+
else:
|
| 114 |
+
pad = int((kernel.shape[3] - 1.0) / 2.0)
|
| 115 |
+
padding = nn.ReplicationPad2d(pad)
|
| 116 |
+
x = padding(input)
|
| 117 |
+
else:
|
| 118 |
+
x = input
|
| 119 |
+
|
| 120 |
+
blurconv = nn.Conv2d(
|
| 121 |
+
self.n_planes, self.n_planes, kernel_size=kernel.size(3), stride=1, padding=0, bias=False
|
| 122 |
+
).cuda()
|
| 123 |
+
|
| 124 |
+
blurconv.weight.data[:] = kernel
|
| 125 |
+
|
| 126 |
+
return blurconv(x)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
class Blurconv2(nn.Module):
|
| 130 |
+
"""
|
| 131 |
+
http://www.realitypixels.com/turk/computergraphics/ResamplingFilters.pdf
|
| 132 |
+
"""
|
| 133 |
+
|
| 134 |
+
def __init__(self, n_planes=1, preserve_size=False, k_size=21):
|
| 135 |
+
super(Blurconv2, self).__init__()
|
| 136 |
+
|
| 137 |
+
self.n_planes = n_planes
|
| 138 |
+
self.k_size = k_size
|
| 139 |
+
self.preserve_size = preserve_size
|
| 140 |
+
self.blurconv = nn.Conv2d(self.n_planes, self.n_planes, kernel_size=k_size, stride=1, padding=0, bias=False)
|
| 141 |
+
|
| 142 |
+
# self.blurconv.weight.data[:] /= self.blurconv.weight.data.sum()
|
| 143 |
+
def forward(self, input):
|
| 144 |
+
if self.preserve_size:
|
| 145 |
+
pad = int((self.k_size - 1.0) / 2.0)
|
| 146 |
+
padding = nn.ReplicationPad2d(pad)
|
| 147 |
+
x = padding(input)
|
| 148 |
+
else:
|
| 149 |
+
x = input
|
| 150 |
+
# self.blurconv.weight.data[:] /= self.blurconv.weight.data.sum()
|
| 151 |
+
return self.blurconv(x)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def get_kernel(factor, kernel_type, phase, kernel_width, support=None, sigma=None):
|
| 155 |
+
assert kernel_type in ["lanczos", "gauss", "box"]
|
| 156 |
+
|
| 157 |
+
# factor = float(factor)
|
| 158 |
+
if phase == 0.5 and kernel_type != "box":
|
| 159 |
+
kernel = np.zeros([kernel_width - 1, kernel_width - 1])
|
| 160 |
+
else:
|
| 161 |
+
kernel = np.zeros([kernel_width, kernel_width])
|
| 162 |
+
|
| 163 |
+
if kernel_type == "box":
|
| 164 |
+
assert phase == 0.5, "Box filter is always half-phased"
|
| 165 |
+
kernel[:] = 1.0 / (kernel_width * kernel_width)
|
| 166 |
+
|
| 167 |
+
elif kernel_type == "gauss":
|
| 168 |
+
assert sigma, "sigma is not specified"
|
| 169 |
+
assert phase != 0.5, "phase 1/2 for gauss not implemented"
|
| 170 |
+
|
| 171 |
+
center = (kernel_width + 1.0) / 2.0
|
| 172 |
+
print(center, kernel_width)
|
| 173 |
+
sigma_sq = sigma * sigma
|
| 174 |
+
|
| 175 |
+
for i in range(1, kernel.shape[0] + 1):
|
| 176 |
+
for j in range(1, kernel.shape[1] + 1):
|
| 177 |
+
di = (i - center) / 2.0
|
| 178 |
+
dj = (j - center) / 2.0
|
| 179 |
+
kernel[i - 1][j - 1] = np.exp(-(di * di + dj * dj) / (2 * sigma_sq))
|
| 180 |
+
kernel[i - 1][j - 1] = kernel[i - 1][j - 1] / (2.0 * np.pi * sigma_sq)
|
| 181 |
+
elif kernel_type == "lanczos":
|
| 182 |
+
assert support, "support is not specified"
|
| 183 |
+
center = (kernel_width + 1) / 2.0
|
| 184 |
+
|
| 185 |
+
for i in range(1, kernel.shape[0] + 1):
|
| 186 |
+
for j in range(1, kernel.shape[1] + 1):
|
| 187 |
+
|
| 188 |
+
if phase == 0.5:
|
| 189 |
+
di = abs(i + 0.5 - center) / factor
|
| 190 |
+
dj = abs(j + 0.5 - center) / factor
|
| 191 |
+
else:
|
| 192 |
+
di = abs(i - center) / factor
|
| 193 |
+
dj = abs(j - center) / factor
|
| 194 |
+
|
| 195 |
+
val = 1
|
| 196 |
+
if di != 0:
|
| 197 |
+
val = val * support * np.sin(np.pi * di) * np.sin(np.pi * di / support)
|
| 198 |
+
val = val / (np.pi * np.pi * di * di)
|
| 199 |
+
|
| 200 |
+
if dj != 0:
|
| 201 |
+
val = val * support * np.sin(np.pi * dj) * np.sin(np.pi * dj / support)
|
| 202 |
+
val = val / (np.pi * np.pi * dj * dj)
|
| 203 |
+
|
| 204 |
+
kernel[i - 1][j - 1] = val
|
| 205 |
+
|
| 206 |
+
else:
|
| 207 |
+
assert False, "wrong method name"
|
| 208 |
+
|
| 209 |
+
kernel /= kernel.sum()
|
| 210 |
+
|
| 211 |
+
return kernel
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
# a = Downsampler(n_planes=3, factor=2, kernel_type='lanczos2', phase='1', preserve_size=True)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
#################
|
| 218 |
+
# Learnable downsampler
|
| 219 |
+
|
| 220 |
+
# KS = 32
|
| 221 |
+
# dow = nn.Sequential(nn.ReplicationPad2d(int((KS - factor) / 2.)), nn.Conv2d(1,1,KS,factor))
|
| 222 |
+
|
| 223 |
+
# class Apply(nn.Module):
|
| 224 |
+
# def __init__(self, what, dim, *args):
|
| 225 |
+
# super(Apply, self).__init__()
|
| 226 |
+
# self.dim = dim
|
| 227 |
+
|
| 228 |
+
# self.what = what
|
| 229 |
+
|
| 230 |
+
# def forward(self, input):
|
| 231 |
+
# inputs = []
|
| 232 |
+
# for i in range(input.size(self.dim)):
|
| 233 |
+
# inputs.append(self.what(input.narrow(self.dim, i, 1)))
|
| 234 |
+
|
| 235 |
+
# return torch.cat(inputs, dim=self.dim)
|
| 236 |
+
|
| 237 |
+
# def __len__(self):
|
| 238 |
+
# return len(self._modules)
|
| 239 |
+
|
| 240 |
+
# downs = Apply(dow, 1)
|
| 241 |
+
# downs.type(dtype)(net_input.type(dtype)).size()
|
diffusion-posterior-sampling/bkse/models/backbones/skip/non_local_dot_product.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class _NonLocalBlockND(nn.Module):
|
| 6 |
+
def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True):
|
| 7 |
+
super(_NonLocalBlockND, self).__init__()
|
| 8 |
+
|
| 9 |
+
assert dimension in [1, 2, 3]
|
| 10 |
+
|
| 11 |
+
self.dimension = dimension
|
| 12 |
+
self.sub_sample = sub_sample
|
| 13 |
+
|
| 14 |
+
self.in_channels = in_channels
|
| 15 |
+
self.inter_channels = inter_channels
|
| 16 |
+
|
| 17 |
+
if self.inter_channels is None:
|
| 18 |
+
self.inter_channels = in_channels // 2
|
| 19 |
+
if self.inter_channels == 0:
|
| 20 |
+
self.inter_channels = 1
|
| 21 |
+
|
| 22 |
+
if dimension == 3:
|
| 23 |
+
conv_nd = nn.Conv3d
|
| 24 |
+
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
|
| 25 |
+
bn = nn.BatchNorm3d
|
| 26 |
+
elif dimension == 2:
|
| 27 |
+
conv_nd = nn.Conv2d
|
| 28 |
+
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
|
| 29 |
+
bn = nn.BatchNorm2d
|
| 30 |
+
else:
|
| 31 |
+
conv_nd = nn.Conv1d
|
| 32 |
+
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
|
| 33 |
+
bn = nn.BatchNorm1d
|
| 34 |
+
|
| 35 |
+
self.g = conv_nd(
|
| 36 |
+
in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
if bn_layer:
|
| 40 |
+
self.W = nn.Sequential(
|
| 41 |
+
conv_nd(
|
| 42 |
+
in_channels=self.inter_channels, out_channels=self.in_channels, kernel_size=1, stride=1, padding=0
|
| 43 |
+
),
|
| 44 |
+
bn(self.in_channels),
|
| 45 |
+
)
|
| 46 |
+
nn.init.constant_(self.W[1].weight, 0)
|
| 47 |
+
nn.init.constant_(self.W[1].bias, 0)
|
| 48 |
+
else:
|
| 49 |
+
self.W = conv_nd(
|
| 50 |
+
in_channels=self.inter_channels, out_channels=self.in_channels, kernel_size=1, stride=1, padding=0
|
| 51 |
+
)
|
| 52 |
+
nn.init.constant_(self.W.weight, 0)
|
| 53 |
+
nn.init.constant_(self.W.bias, 0)
|
| 54 |
+
|
| 55 |
+
self.theta = conv_nd(
|
| 56 |
+
in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
self.phi = conv_nd(
|
| 60 |
+
in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
if sub_sample:
|
| 64 |
+
self.g = nn.Sequential(self.g, max_pool_layer)
|
| 65 |
+
self.phi = nn.Sequential(self.phi, max_pool_layer)
|
| 66 |
+
|
| 67 |
+
def forward(self, x):
|
| 68 |
+
"""
|
| 69 |
+
:param x: (b, c, t, h, w)
|
| 70 |
+
:return:
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
batch_size = x.size(0)
|
| 74 |
+
|
| 75 |
+
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
|
| 76 |
+
g_x = g_x.permute(0, 2, 1)
|
| 77 |
+
|
| 78 |
+
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
|
| 79 |
+
theta_x = theta_x.permute(0, 2, 1)
|
| 80 |
+
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
|
| 81 |
+
f = torch.matmul(theta_x, phi_x)
|
| 82 |
+
N = f.size(-1)
|
| 83 |
+
f_div_C = f / N
|
| 84 |
+
|
| 85 |
+
y = torch.matmul(f_div_C, g_x)
|
| 86 |
+
y = y.permute(0, 2, 1).contiguous()
|
| 87 |
+
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
|
| 88 |
+
W_y = self.W(y)
|
| 89 |
+
z = W_y + x
|
| 90 |
+
|
| 91 |
+
return z
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class NONLocalBlock1D(_NonLocalBlockND):
|
| 95 |
+
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
|
| 96 |
+
super(NONLocalBlock1D, self).__init__(
|
| 97 |
+
in_channels, inter_channels=inter_channels, dimension=1, sub_sample=sub_sample, bn_layer=bn_layer
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class NONLocalBlock2D(_NonLocalBlockND):
|
| 102 |
+
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
|
| 103 |
+
super(NONLocalBlock2D, self).__init__(
|
| 104 |
+
in_channels, inter_channels=inter_channels, dimension=2, sub_sample=sub_sample, bn_layer=bn_layer
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class NONLocalBlock3D(_NonLocalBlockND):
|
| 109 |
+
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
|
| 110 |
+
super(NONLocalBlock3D, self).__init__(
|
| 111 |
+
in_channels, inter_channels=inter_channels, dimension=3, sub_sample=sub_sample, bn_layer=bn_layer
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
if __name__ == "__main__":
|
| 116 |
+
for (sub_sample, bn_layer) in [(True, True), (False, False), (True, False), (False, True)]:
|
| 117 |
+
img = torch.zeros(2, 3, 20)
|
| 118 |
+
net = NONLocalBlock1D(3, sub_sample=sub_sample, bn_layer=bn_layer)
|
| 119 |
+
out = net(img)
|
| 120 |
+
print(out.size())
|
| 121 |
+
|
| 122 |
+
img = torch.zeros(2, 3, 20, 20)
|
| 123 |
+
net = NONLocalBlock2D(3, sub_sample=sub_sample, bn_layer=bn_layer)
|
| 124 |
+
out = net(img)
|
| 125 |
+
print(out.size())
|
| 126 |
+
|
| 127 |
+
img = torch.randn(2, 3, 8, 20, 20)
|
| 128 |
+
net = NONLocalBlock3D(3, sub_sample=sub_sample, bn_layer=bn_layer)
|
| 129 |
+
out = net(img)
|
| 130 |
+
print(out.size())
|
diffusion-posterior-sampling/bkse/models/backbones/skip/skip.py
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from .concat import Concat
|
| 5 |
+
from .non_local_dot_product import NONLocalBlock2D
|
| 6 |
+
from .util import get_activation, get_conv
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def add_module(self, module):
|
| 10 |
+
self.add_module(str(len(self) + 1), module)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
torch.nn.Module.add = add_module
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def skip(
|
| 17 |
+
num_input_channels=2,
|
| 18 |
+
num_output_channels=3,
|
| 19 |
+
num_channels_down=[16, 32, 64, 128, 128],
|
| 20 |
+
num_channels_up=[16, 32, 64, 128, 128],
|
| 21 |
+
num_channels_skip=[4, 4, 4, 4, 4],
|
| 22 |
+
filter_size_down=3,
|
| 23 |
+
filter_size_up=3,
|
| 24 |
+
filter_skip_size=1,
|
| 25 |
+
need_sigmoid=True,
|
| 26 |
+
need_bias=True,
|
| 27 |
+
pad="zero",
|
| 28 |
+
upsample_mode="nearest",
|
| 29 |
+
downsample_mode="stride",
|
| 30 |
+
act_fun="LeakyReLU",
|
| 31 |
+
need1x1_up=True,
|
| 32 |
+
):
|
| 33 |
+
"""Assembles encoder-decoder with skip connections.
|
| 34 |
+
|
| 35 |
+
Arguments:
|
| 36 |
+
act_fun: Either string 'LeakyReLU|Swish|ELU|none' or module (e.g. nn.ReLU)
|
| 37 |
+
pad (string): zero|reflection (default: 'zero')
|
| 38 |
+
upsample_mode (string): 'nearest|bilinear' (default: 'nearest')
|
| 39 |
+
downsample_mode (string): 'stride|avg|max|lanczos2' (default: 'stride')
|
| 40 |
+
|
| 41 |
+
"""
|
| 42 |
+
assert len(num_channels_down) == len(num_channels_up) == len(num_channels_skip)
|
| 43 |
+
|
| 44 |
+
n_scales = len(num_channels_down)
|
| 45 |
+
|
| 46 |
+
if not (isinstance(upsample_mode, list) or isinstance(upsample_mode, tuple)):
|
| 47 |
+
upsample_mode = [upsample_mode] * n_scales
|
| 48 |
+
|
| 49 |
+
if not (isinstance(downsample_mode, list) or isinstance(downsample_mode, tuple)):
|
| 50 |
+
downsample_mode = [downsample_mode] * n_scales
|
| 51 |
+
|
| 52 |
+
if not (isinstance(filter_size_down, list) or isinstance(filter_size_down, tuple)):
|
| 53 |
+
filter_size_down = [filter_size_down] * n_scales
|
| 54 |
+
|
| 55 |
+
if not (isinstance(filter_size_up, list) or isinstance(filter_size_up, tuple)):
|
| 56 |
+
filter_size_up = [filter_size_up] * n_scales
|
| 57 |
+
|
| 58 |
+
last_scale = n_scales - 1
|
| 59 |
+
|
| 60 |
+
model = nn.Sequential()
|
| 61 |
+
model_tmp = model
|
| 62 |
+
|
| 63 |
+
input_depth = num_input_channels
|
| 64 |
+
for i in range(len(num_channels_down)):
|
| 65 |
+
|
| 66 |
+
deeper = nn.Sequential()
|
| 67 |
+
skip = nn.Sequential()
|
| 68 |
+
|
| 69 |
+
if num_channels_skip[i] != 0:
|
| 70 |
+
model_tmp.add(Concat(1, skip, deeper))
|
| 71 |
+
else:
|
| 72 |
+
model_tmp.add(deeper)
|
| 73 |
+
|
| 74 |
+
model_tmp.add(
|
| 75 |
+
nn.BatchNorm2d(num_channels_skip[i] + (num_channels_up[i + 1] if i < last_scale else num_channels_down[i]))
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
if num_channels_skip[i] != 0:
|
| 79 |
+
skip.add(get_conv(input_depth, num_channels_skip[i], filter_skip_size, bias=need_bias, pad=pad))
|
| 80 |
+
skip.add(nn.BatchNorm2d(num_channels_skip[i]))
|
| 81 |
+
skip.add(get_activation(act_fun))
|
| 82 |
+
|
| 83 |
+
# skip.add(Concat(2, GenNoise(nums_noise[i]), skip_part))
|
| 84 |
+
|
| 85 |
+
deeper.add(
|
| 86 |
+
get_conv(
|
| 87 |
+
input_depth,
|
| 88 |
+
num_channels_down[i],
|
| 89 |
+
filter_size_down[i],
|
| 90 |
+
2,
|
| 91 |
+
bias=need_bias,
|
| 92 |
+
pad=pad,
|
| 93 |
+
downsample_mode=downsample_mode[i],
|
| 94 |
+
)
|
| 95 |
+
)
|
| 96 |
+
deeper.add(nn.BatchNorm2d(num_channels_down[i]))
|
| 97 |
+
deeper.add(get_activation(act_fun))
|
| 98 |
+
if i > 1:
|
| 99 |
+
deeper.add(NONLocalBlock2D(in_channels=num_channels_down[i]))
|
| 100 |
+
deeper.add(get_conv(num_channels_down[i], num_channels_down[i], filter_size_down[i], bias=need_bias, pad=pad))
|
| 101 |
+
deeper.add(nn.BatchNorm2d(num_channels_down[i]))
|
| 102 |
+
deeper.add(get_activation(act_fun))
|
| 103 |
+
|
| 104 |
+
deeper_main = nn.Sequential()
|
| 105 |
+
|
| 106 |
+
if i == len(num_channels_down) - 1:
|
| 107 |
+
# The deepest
|
| 108 |
+
k = num_channels_down[i]
|
| 109 |
+
else:
|
| 110 |
+
deeper.add(deeper_main)
|
| 111 |
+
k = num_channels_up[i + 1]
|
| 112 |
+
|
| 113 |
+
deeper.add(nn.Upsample(scale_factor=2, mode=upsample_mode[i]))
|
| 114 |
+
|
| 115 |
+
model_tmp.add(
|
| 116 |
+
get_conv(num_channels_skip[i] + k, num_channels_up[i], filter_size_up[i], 1, bias=need_bias, pad=pad)
|
| 117 |
+
)
|
| 118 |
+
model_tmp.add(nn.BatchNorm2d(num_channels_up[i]))
|
| 119 |
+
model_tmp.add(get_activation(act_fun))
|
| 120 |
+
|
| 121 |
+
if need1x1_up:
|
| 122 |
+
model_tmp.add(get_conv(num_channels_up[i], num_channels_up[i], 1, bias=need_bias, pad=pad))
|
| 123 |
+
model_tmp.add(nn.BatchNorm2d(num_channels_up[i]))
|
| 124 |
+
model_tmp.add(get_activation(act_fun))
|
| 125 |
+
|
| 126 |
+
input_depth = num_channels_down[i]
|
| 127 |
+
model_tmp = deeper_main
|
| 128 |
+
|
| 129 |
+
model.add(get_conv(num_channels_up[0], num_output_channels, 1, bias=need_bias, pad=pad))
|
| 130 |
+
if need_sigmoid:
|
| 131 |
+
model.add(nn.Sigmoid())
|
| 132 |
+
|
| 133 |
+
return model
|
diffusion-posterior-sampling/bkse/models/backbones/skip/util.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
|
| 3 |
+
from .downsampler import Downsampler
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Swish(nn.Module):
|
| 7 |
+
"""
|
| 8 |
+
https://arxiv.org/abs/1710.05941
|
| 9 |
+
The hype was so huge that I could not help but try it
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
def __init__(self):
|
| 13 |
+
super(Swish, self).__init__()
|
| 14 |
+
self.s = nn.Sigmoid()
|
| 15 |
+
|
| 16 |
+
def forward(self, x):
|
| 17 |
+
return x * self.s(x)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_conv(in_f, out_f, kernel_size, stride=1, bias=True, pad="zero", downsample_mode="stride"):
|
| 21 |
+
downsampler = None
|
| 22 |
+
if stride != 1 and downsample_mode != "stride":
|
| 23 |
+
|
| 24 |
+
if downsample_mode == "avg":
|
| 25 |
+
downsampler = nn.AvgPool2d(stride, stride)
|
| 26 |
+
elif downsample_mode == "max":
|
| 27 |
+
downsampler = nn.MaxPool2d(stride, stride)
|
| 28 |
+
elif downsample_mode in ["lanczos2", "lanczos3"]:
|
| 29 |
+
downsampler = Downsampler(
|
| 30 |
+
n_planes=out_f, factor=stride, kernel_type=downsample_mode, phase=0.5, preserve_size=True
|
| 31 |
+
)
|
| 32 |
+
else:
|
| 33 |
+
assert False
|
| 34 |
+
|
| 35 |
+
stride = 1
|
| 36 |
+
|
| 37 |
+
padder = None
|
| 38 |
+
to_pad = int((kernel_size - 1) / 2)
|
| 39 |
+
if pad == "reflection":
|
| 40 |
+
padder = nn.ReflectionPad2d(to_pad)
|
| 41 |
+
to_pad = 0
|
| 42 |
+
|
| 43 |
+
convolver = nn.Conv2d(in_f, out_f, kernel_size, stride, padding=to_pad, bias=bias)
|
| 44 |
+
|
| 45 |
+
layers = filter(lambda x: x is not None, [padder, convolver, downsampler])
|
| 46 |
+
return nn.Sequential(*layers)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def get_activation(act_fun="LeakyReLU"):
|
| 50 |
+
"""
|
| 51 |
+
Either string defining an activation function or module (e.g. nn.ReLU)
|
| 52 |
+
"""
|
| 53 |
+
if isinstance(act_fun, str):
|
| 54 |
+
if act_fun == "LeakyReLU":
|
| 55 |
+
return nn.LeakyReLU(0.2, inplace=True)
|
| 56 |
+
elif act_fun == "Swish":
|
| 57 |
+
return Swish()
|
| 58 |
+
elif act_fun == "ELU":
|
| 59 |
+
return nn.ELU()
|
| 60 |
+
elif act_fun == "none":
|
| 61 |
+
return nn.Sequential()
|
| 62 |
+
else:
|
| 63 |
+
assert False
|
| 64 |
+
else:
|
| 65 |
+
return act_fun()
|
diffusion-posterior-sampling/bkse/models/backbones/unet_parts.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" Parts of the U-Net model """
|
| 2 |
+
|
| 3 |
+
import functools
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class DoubleConv(nn.Module):
|
| 10 |
+
"""(convolution => [BN] => ReLU) * 2"""
|
| 11 |
+
|
| 12 |
+
def __init__(self, in_channels, out_channels, mid_channels=None):
|
| 13 |
+
super().__init__()
|
| 14 |
+
if not mid_channels:
|
| 15 |
+
mid_channels = out_channels
|
| 16 |
+
self.double_conv = nn.Sequential(
|
| 17 |
+
nn.Conv2d(in_channels, mid_channels, kernel_size=5, padding=2),
|
| 18 |
+
nn.ReLU(inplace=True),
|
| 19 |
+
nn.Conv2d(mid_channels, out_channels, kernel_size=5, padding=2),
|
| 20 |
+
nn.ReLU(inplace=True),
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
def forward(self, x):
|
| 24 |
+
return self.double_conv(x)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class UnetSkipConnectionBlock(nn.Module):
|
| 28 |
+
"""Defines the Unet submodule with skip connection.
|
| 29 |
+
X -------------------identity----------------------
|
| 30 |
+
|-- downsampling -- |submodule| -- upsampling --|
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
def __init__(
|
| 34 |
+
self,
|
| 35 |
+
outer_nc,
|
| 36 |
+
inner_nc,
|
| 37 |
+
input_nc=None,
|
| 38 |
+
submodule=None,
|
| 39 |
+
outermost=False,
|
| 40 |
+
innermost=False,
|
| 41 |
+
norm_layer=nn.BatchNorm2d,
|
| 42 |
+
use_dropout=False,
|
| 43 |
+
):
|
| 44 |
+
"""Construct a Unet submodule with skip connections.
|
| 45 |
+
Parameters:
|
| 46 |
+
outer_nc (int) -- the number of filters in the outer conv layer
|
| 47 |
+
inner_nc (int) -- the number of filters in the inner conv layer
|
| 48 |
+
input_nc (int) -- the number of channels in input images/features
|
| 49 |
+
submodule (UnetSkipConnectionBlock) --previously defined submodules
|
| 50 |
+
outermost (bool) -- if this module is the outermost module
|
| 51 |
+
innermost (bool) -- if this module is the innermost module
|
| 52 |
+
norm_layer -- normalization layer
|
| 53 |
+
use_dropout (bool) -- if use dropout layers.
|
| 54 |
+
"""
|
| 55 |
+
super(UnetSkipConnectionBlock, self).__init__()
|
| 56 |
+
self.outermost = outermost
|
| 57 |
+
self.innermost = innermost
|
| 58 |
+
if type(norm_layer) == functools.partial:
|
| 59 |
+
use_bias = norm_layer.func == nn.InstanceNorm2d
|
| 60 |
+
else:
|
| 61 |
+
use_bias = norm_layer == nn.InstanceNorm2d
|
| 62 |
+
if input_nc is None:
|
| 63 |
+
input_nc = outer_nc
|
| 64 |
+
downconv = nn.Conv2d(input_nc, inner_nc, kernel_size=4, stride=2, padding=1, bias=use_bias)
|
| 65 |
+
downrelu = nn.LeakyReLU(0.2, True)
|
| 66 |
+
downnorm = norm_layer(inner_nc)
|
| 67 |
+
uprelu = nn.ReLU(True)
|
| 68 |
+
upnorm = norm_layer(outer_nc)
|
| 69 |
+
|
| 70 |
+
if outermost:
|
| 71 |
+
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc, kernel_size=4, stride=2, padding=1)
|
| 72 |
+
# upsample = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
|
| 73 |
+
# upconv = DoubleConv(inner_nc * 2, outer_nc)
|
| 74 |
+
up = [uprelu, upconv, nn.Tanh()]
|
| 75 |
+
down = [downconv]
|
| 76 |
+
self.down = nn.Sequential(*down)
|
| 77 |
+
self.submodule = submodule
|
| 78 |
+
self.up = nn.Sequential(*up)
|
| 79 |
+
elif innermost:
|
| 80 |
+
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc, kernel_size=4, stride=2, padding=1, bias=use_bias)
|
| 81 |
+
# upsample = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
|
| 82 |
+
# upconv = DoubleConv(inner_nc * 2, outer_nc)
|
| 83 |
+
down = [downrelu, downconv]
|
| 84 |
+
up = [uprelu, upconv, upnorm]
|
| 85 |
+
self.down = nn.Sequential(*down)
|
| 86 |
+
self.up = nn.Sequential(*up)
|
| 87 |
+
else:
|
| 88 |
+
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc, kernel_size=4, stride=2, padding=1, bias=use_bias)
|
| 89 |
+
# upsample = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
|
| 90 |
+
# upconv = DoubleConv(inner_nc * 2, outer_nc)
|
| 91 |
+
down = [downrelu, downconv, downnorm]
|
| 92 |
+
up = [uprelu, upconv, upnorm]
|
| 93 |
+
if use_dropout:
|
| 94 |
+
up += [nn.Dropout(0.5)]
|
| 95 |
+
|
| 96 |
+
self.down = nn.Sequential(*down)
|
| 97 |
+
self.submodule = submodule
|
| 98 |
+
self.up = nn.Sequential(*up)
|
| 99 |
+
|
| 100 |
+
def forward(self, x, noise):
|
| 101 |
+
|
| 102 |
+
if self.outermost:
|
| 103 |
+
return self.up(self.submodule(self.down(x), noise))
|
| 104 |
+
elif self.innermost: # add skip connections
|
| 105 |
+
if noise is None:
|
| 106 |
+
noise = torch.randn((1, 512, 8, 8)).cuda() * 0.0007
|
| 107 |
+
return torch.cat((self.up(torch.cat((self.down(x), noise), dim=1)), x), dim=1)
|
| 108 |
+
else:
|
| 109 |
+
return torch.cat((self.up(self.submodule(self.down(x), noise)), x), dim=1)
|
diffusion-posterior-sampling/bkse/models/deblurring/image_deblur.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import utils.util as util
|
| 4 |
+
from models.dips import ImageDIP, KernelDIP
|
| 5 |
+
from models.kernel_encoding.kernel_wizard import KernelWizard
|
| 6 |
+
from models.losses.hyper_laplacian_penalty import HyperLaplacianPenalty
|
| 7 |
+
from models.losses.perceptual_loss import PerceptualLoss
|
| 8 |
+
from models.losses.ssim_loss import SSIM
|
| 9 |
+
from torch.optim.lr_scheduler import StepLR
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class ImageDeblur:
|
| 14 |
+
def __init__(self, opt):
|
| 15 |
+
self.opt = opt
|
| 16 |
+
|
| 17 |
+
# losses
|
| 18 |
+
self.ssim_loss = SSIM().cuda()
|
| 19 |
+
self.mse = nn.MSELoss().cuda()
|
| 20 |
+
self.perceptual_loss = PerceptualLoss().cuda()
|
| 21 |
+
self.laplace_penalty = HyperLaplacianPenalty(3, 0.66).cuda()
|
| 22 |
+
|
| 23 |
+
self.kernel_wizard = KernelWizard(opt["KernelWizard"]).cuda()
|
| 24 |
+
self.kernel_wizard.load_state_dict(torch.load(opt["KernelWizard"]["pretrained"]))
|
| 25 |
+
|
| 26 |
+
for k, v in self.kernel_wizard.named_parameters():
|
| 27 |
+
v.requires_grad = False
|
| 28 |
+
|
| 29 |
+
def reset_optimizers(self):
|
| 30 |
+
self.x_optimizer = torch.optim.Adam(self.x_dip.parameters(), lr=self.opt["x_lr"])
|
| 31 |
+
self.k_optimizer = torch.optim.Adam(self.k_dip.parameters(), lr=self.opt["k_lr"])
|
| 32 |
+
|
| 33 |
+
self.x_scheduler = StepLR(self.x_optimizer, step_size=self.opt["num_iters"] // 5, gamma=0.7)
|
| 34 |
+
|
| 35 |
+
self.k_scheduler = StepLR(self.k_optimizer, step_size=self.opt["num_iters"] // 5, gamma=0.7)
|
| 36 |
+
|
| 37 |
+
def prepare_DIPs(self):
|
| 38 |
+
# x is stand for the sharp image, k is stand for the kernel
|
| 39 |
+
self.x_dip = ImageDIP(self.opt["ImageDIP"]).cuda()
|
| 40 |
+
self.k_dip = KernelDIP(self.opt["KernelDIP"]).cuda()
|
| 41 |
+
|
| 42 |
+
# fixed input vectors of DIPs
|
| 43 |
+
# zk and zx are the length of the corresponding vectors
|
| 44 |
+
self.dip_zk = util.get_noise(64, "noise", (64, 64)).cuda()
|
| 45 |
+
self.dip_zx = util.get_noise(8, "noise", self.opt["img_size"]).cuda()
|
| 46 |
+
|
| 47 |
+
def warmup(self, warmup_x, warmup_k):
|
| 48 |
+
# Input vector of DIPs is sampled from N(z, I)
|
| 49 |
+
reg_noise_std = self.opt["reg_noise_std"]
|
| 50 |
+
|
| 51 |
+
for step in tqdm(range(self.opt["num_warmup_iters"])):
|
| 52 |
+
self.x_optimizer.zero_grad()
|
| 53 |
+
dip_zx_rand = self.dip_zx + reg_noise_std * torch.randn_like(self.dip_zx).cuda()
|
| 54 |
+
x = self.x_dip(dip_zx_rand)
|
| 55 |
+
|
| 56 |
+
loss = self.mse(x, warmup_x)
|
| 57 |
+
loss.backward()
|
| 58 |
+
self.x_optimizer.step()
|
| 59 |
+
|
| 60 |
+
print("Warming up k DIP")
|
| 61 |
+
for step in tqdm(range(self.opt["num_warmup_iters"])):
|
| 62 |
+
self.k_optimizer.zero_grad()
|
| 63 |
+
dip_zk_rand = self.dip_zk + reg_noise_std * torch.randn_like(self.dip_zk).cuda()
|
| 64 |
+
k = self.k_dip(dip_zk_rand)
|
| 65 |
+
|
| 66 |
+
loss = self.mse(k, warmup_k)
|
| 67 |
+
loss.backward()
|
| 68 |
+
self.k_optimizer.step()
|
| 69 |
+
|
| 70 |
+
def deblur(self, img):
|
| 71 |
+
pass
|
diffusion-posterior-sampling/bkse/models/deblurring/joint_deblur.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import utils.util as util
|
| 3 |
+
from models.deblurring.image_deblur import ImageDeblur
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class JointDeblur(ImageDeblur):
|
| 8 |
+
def __init__(self, opt):
|
| 9 |
+
super(JointDeblur, self).__init__(opt)
|
| 10 |
+
|
| 11 |
+
def deblur(self, y):
|
| 12 |
+
"""Deblur image
|
| 13 |
+
Args:
|
| 14 |
+
y: Blur image
|
| 15 |
+
"""
|
| 16 |
+
y = util.img2tensor(y).unsqueeze(0).cuda()
|
| 17 |
+
|
| 18 |
+
self.prepare_DIPs()
|
| 19 |
+
self.reset_optimizers()
|
| 20 |
+
|
| 21 |
+
warmup_k = torch.load(self.opt["warmup_k_path"]).cuda()
|
| 22 |
+
self.warmup(y, warmup_k)
|
| 23 |
+
|
| 24 |
+
# Input vector of DIPs is sampled from N(z, I)
|
| 25 |
+
|
| 26 |
+
print("Deblurring")
|
| 27 |
+
reg_noise_std = self.opt["reg_noise_std"]
|
| 28 |
+
for step in tqdm(range(self.opt["num_iters"])):
|
| 29 |
+
dip_zx_rand = self.dip_zx + reg_noise_std * torch.randn_like(self.dip_zx).cuda()
|
| 30 |
+
dip_zk_rand = self.dip_zk + reg_noise_std * torch.randn_like(self.dip_zk).cuda()
|
| 31 |
+
|
| 32 |
+
self.x_optimizer.zero_grad()
|
| 33 |
+
self.k_optimizer.zero_grad()
|
| 34 |
+
|
| 35 |
+
self.x_scheduler.step()
|
| 36 |
+
self.k_scheduler.step()
|
| 37 |
+
|
| 38 |
+
x = self.x_dip(dip_zx_rand)
|
| 39 |
+
k = self.k_dip(dip_zk_rand)
|
| 40 |
+
|
| 41 |
+
fake_y = self.kernel_wizard.adaptKernel(x, k)
|
| 42 |
+
|
| 43 |
+
if step < self.opt["num_iters"] // 2:
|
| 44 |
+
total_loss = 6e-1 * self.perceptual_loss(fake_y, y)
|
| 45 |
+
total_loss += 1 - self.ssim_loss(fake_y, y)
|
| 46 |
+
total_loss += 5e-5 * torch.norm(k)
|
| 47 |
+
total_loss += 2e-2 * self.laplace_penalty(x)
|
| 48 |
+
else:
|
| 49 |
+
total_loss = self.perceptual_loss(fake_y, y)
|
| 50 |
+
total_loss += 5e-2 * self.laplace_penalty(x)
|
| 51 |
+
total_loss += 5e-4 * torch.norm(k)
|
| 52 |
+
|
| 53 |
+
total_loss.backward()
|
| 54 |
+
|
| 55 |
+
self.x_optimizer.step()
|
| 56 |
+
self.k_optimizer.step()
|
| 57 |
+
|
| 58 |
+
# debugging
|
| 59 |
+
# if step % 100 == 0:
|
| 60 |
+
# print(torch.norm(k))
|
| 61 |
+
# print(f"{self.k_optimizer.param_groups[0]['lr']:.3e}")
|
| 62 |
+
|
| 63 |
+
return util.tensor2img(x.detach())
|
diffusion-posterior-sampling/bkse/models/dips.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import models.arch_util as arch_util
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from models.backbones.resnet import ResnetBlock
|
| 4 |
+
from models.backbones.skip.skip import skip
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class KernelDIP(nn.Module):
|
| 8 |
+
"""
|
| 9 |
+
DIP (Deep Image Prior) for blur kernel
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
def __init__(self, opt):
|
| 13 |
+
super(KernelDIP, self).__init__()
|
| 14 |
+
|
| 15 |
+
norm_layer = arch_util.get_norm_layer("none")
|
| 16 |
+
n_blocks = opt["n_blocks"]
|
| 17 |
+
nf = opt["nf"]
|
| 18 |
+
padding_type = opt["padding_type"]
|
| 19 |
+
use_dropout = opt["use_dropout"]
|
| 20 |
+
kernel_dim = opt["kernel_dim"]
|
| 21 |
+
|
| 22 |
+
input_nc = 64
|
| 23 |
+
model = [
|
| 24 |
+
nn.ReflectionPad2d(3),
|
| 25 |
+
nn.Conv2d(input_nc, nf, kernel_size=7, padding=0, bias=True),
|
| 26 |
+
norm_layer(nf),
|
| 27 |
+
nn.ReLU(True),
|
| 28 |
+
]
|
| 29 |
+
|
| 30 |
+
n_downsampling = 5
|
| 31 |
+
for i in range(n_downsampling): # add downsampling layers
|
| 32 |
+
mult = 2 ** i
|
| 33 |
+
input_nc = min(nf * mult, kernel_dim)
|
| 34 |
+
output_nc = min(nf * mult * 2, kernel_dim)
|
| 35 |
+
model += [
|
| 36 |
+
nn.Conv2d(input_nc, output_nc, kernel_size=3, stride=2, padding=1, bias=True),
|
| 37 |
+
norm_layer(nf * mult * 2),
|
| 38 |
+
nn.ReLU(True),
|
| 39 |
+
]
|
| 40 |
+
|
| 41 |
+
for i in range(n_blocks): # add ResNet blocks
|
| 42 |
+
model += [
|
| 43 |
+
ResnetBlock(
|
| 44 |
+
kernel_dim,
|
| 45 |
+
padding_type=padding_type,
|
| 46 |
+
norm_layer=norm_layer,
|
| 47 |
+
use_dropout=use_dropout,
|
| 48 |
+
use_bias=True,
|
| 49 |
+
)
|
| 50 |
+
]
|
| 51 |
+
|
| 52 |
+
self.model = nn.Sequential(*model)
|
| 53 |
+
|
| 54 |
+
def forward(self, noise):
|
| 55 |
+
return self.model(noise)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class ImageDIP(nn.Module):
|
| 59 |
+
"""
|
| 60 |
+
DIP (Deep Image Prior) for sharp image
|
| 61 |
+
"""
|
| 62 |
+
|
| 63 |
+
def __init__(self, opt):
|
| 64 |
+
super(ImageDIP, self).__init__()
|
| 65 |
+
|
| 66 |
+
input_nc = opt["input_nc"]
|
| 67 |
+
output_nc = opt["output_nc"]
|
| 68 |
+
|
| 69 |
+
self.model = skip(
|
| 70 |
+
input_nc,
|
| 71 |
+
output_nc,
|
| 72 |
+
num_channels_down=[128, 128, 128, 128, 128],
|
| 73 |
+
num_channels_up=[128, 128, 128, 128, 128],
|
| 74 |
+
num_channels_skip=[16, 16, 16, 16, 16],
|
| 75 |
+
upsample_mode="bilinear",
|
| 76 |
+
need_sigmoid=True,
|
| 77 |
+
need_bias=True,
|
| 78 |
+
pad=opt["padding_type"],
|
| 79 |
+
act_fun="LeakyReLU",
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
def forward(self, img):
|
| 83 |
+
return self.model(img)
|
diffusion-posterior-sampling/bkse/models/dsd/bicubic.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class BicubicDownSample(nn.Module):
|
| 7 |
+
def bicubic_kernel(self, x, a=-0.50):
|
| 8 |
+
"""
|
| 9 |
+
This equation is exactly copied from the website below:
|
| 10 |
+
https://clouard.users.greyc.fr/Pantheon/experiments/rescaling/index-en.html#bicubic
|
| 11 |
+
"""
|
| 12 |
+
abs_x = torch.abs(x)
|
| 13 |
+
if abs_x <= 1.0:
|
| 14 |
+
return (a + 2.0) * torch.pow(abs_x, 3.0) - (a + 3.0) * torch.pow(abs_x, 2.0) + 1
|
| 15 |
+
elif 1.0 < abs_x < 2.0:
|
| 16 |
+
return a * torch.pow(abs_x, 3) - 5.0 * a * torch.pow(abs_x, 2.0) + 8.0 * a * abs_x - 4.0 * a
|
| 17 |
+
else:
|
| 18 |
+
return 0.0
|
| 19 |
+
|
| 20 |
+
def __init__(self, factor=4, cuda=True, padding="reflect"):
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.factor = factor
|
| 23 |
+
size = factor * 4
|
| 24 |
+
k = torch.tensor(
|
| 25 |
+
[self.bicubic_kernel((i - torch.floor(torch.tensor(size / 2)) + 0.5) / factor) for i in range(size)],
|
| 26 |
+
dtype=torch.float32,
|
| 27 |
+
)
|
| 28 |
+
k = k / torch.sum(k)
|
| 29 |
+
# k = torch.einsum('i,j->ij', (k, k))
|
| 30 |
+
k1 = torch.reshape(k, shape=(1, 1, size, 1))
|
| 31 |
+
self.k1 = torch.cat([k1, k1, k1], dim=0)
|
| 32 |
+
k2 = torch.reshape(k, shape=(1, 1, 1, size))
|
| 33 |
+
self.k2 = torch.cat([k2, k2, k2], dim=0)
|
| 34 |
+
self.cuda = ".cuda" if cuda else ""
|
| 35 |
+
self.padding = padding
|
| 36 |
+
for param in self.parameters():
|
| 37 |
+
param.requires_grad = False
|
| 38 |
+
|
| 39 |
+
def forward(self, x, nhwc=False, clip_round=False, byte_output=False):
|
| 40 |
+
# x = torch.from_numpy(x).type('torch.FloatTensor')
|
| 41 |
+
filter_height = self.factor * 4
|
| 42 |
+
filter_width = self.factor * 4
|
| 43 |
+
stride = self.factor
|
| 44 |
+
|
| 45 |
+
pad_along_height = max(filter_height - stride, 0)
|
| 46 |
+
pad_along_width = max(filter_width - stride, 0)
|
| 47 |
+
filters1 = self.k1.type("torch{}.FloatTensor".format(self.cuda))
|
| 48 |
+
filters2 = self.k2.type("torch{}.FloatTensor".format(self.cuda))
|
| 49 |
+
|
| 50 |
+
# compute actual padding values for each side
|
| 51 |
+
pad_top = pad_along_height // 2
|
| 52 |
+
pad_bottom = pad_along_height - pad_top
|
| 53 |
+
pad_left = pad_along_width // 2
|
| 54 |
+
pad_right = pad_along_width - pad_left
|
| 55 |
+
|
| 56 |
+
# apply mirror padding
|
| 57 |
+
if nhwc:
|
| 58 |
+
x = torch.transpose(torch.transpose(x, 2, 3), 1, 2) # NHWC to NCHW
|
| 59 |
+
|
| 60 |
+
# downscaling performed by 1-d convolution
|
| 61 |
+
x = F.pad(x, (0, 0, pad_top, pad_bottom), self.padding)
|
| 62 |
+
x = F.conv2d(input=x, weight=filters1, stride=(stride, 1), groups=3)
|
| 63 |
+
if clip_round:
|
| 64 |
+
x = torch.clamp(torch.round(x), 0.0, 255.0)
|
| 65 |
+
|
| 66 |
+
x = F.pad(x, (pad_left, pad_right, 0, 0), self.padding)
|
| 67 |
+
x = F.conv2d(input=x, weight=filters2, stride=(1, stride), groups=3)
|
| 68 |
+
if clip_round:
|
| 69 |
+
x = torch.clamp(torch.round(x), 0.0, 255.0)
|
| 70 |
+
|
| 71 |
+
if nhwc:
|
| 72 |
+
x = torch.transpose(torch.transpose(x, 1, 3), 1, 2)
|
| 73 |
+
if byte_output:
|
| 74 |
+
return x.type("torch.{}.ByteTensor".format(self.cuda))
|
| 75 |
+
else:
|
| 76 |
+
return x
|
diffusion-posterior-sampling/bkse/models/dsd/dsd.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import utils.util as util
|
| 8 |
+
from models.dips import KernelDIP
|
| 9 |
+
from models.dsd.spherical_optimizer import SphericalOptimizer
|
| 10 |
+
from torch.optim.lr_scheduler import StepLR
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class DSD(torch.nn.Module):
|
| 15 |
+
def __init__(self, opt, cache_dir):
|
| 16 |
+
super(DSD, self).__init__()
|
| 17 |
+
|
| 18 |
+
self.opt = opt
|
| 19 |
+
|
| 20 |
+
self.verbose = opt["verbose"]
|
| 21 |
+
cache_dir = Path(cache_dir)
|
| 22 |
+
cache_dir.mkdir(parents=True, exist_ok=True)
|
| 23 |
+
|
| 24 |
+
# Initialize synthesis network
|
| 25 |
+
if self.verbose:
|
| 26 |
+
print("Loading Synthesis Network")
|
| 27 |
+
self.load_synthesis_network()
|
| 28 |
+
if self.verbose:
|
| 29 |
+
print("Synthesis Network loaded!")
|
| 30 |
+
|
| 31 |
+
self.lrelu = torch.nn.LeakyReLU(negative_slope=0.2)
|
| 32 |
+
|
| 33 |
+
self.initialize_mapping_network()
|
| 34 |
+
|
| 35 |
+
def initialize_dip(self):
|
| 36 |
+
self.dip_zk = util.get_noise(64, "noise", (64, 64)).cuda().detach()
|
| 37 |
+
self.k_dip = KernelDIP(self.opt["KernelDIP"]).cuda()
|
| 38 |
+
|
| 39 |
+
def initialize_latent_space(self):
|
| 40 |
+
pass
|
| 41 |
+
|
| 42 |
+
def initialize_optimizers(self):
|
| 43 |
+
# Optimizer for k
|
| 44 |
+
self.optimizer_k = torch.optim.Adam(self.k_dip.parameters(), lr=self.opt["k_lr"])
|
| 45 |
+
self.scheduler_k = StepLR(
|
| 46 |
+
self.optimizer_k, step_size=self.opt["num_epochs"] * self.opt["num_k_iters"] // 5, gamma=0.7
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
# Optimizer for x
|
| 50 |
+
optimizer_dict = {
|
| 51 |
+
"sgd": torch.optim.SGD,
|
| 52 |
+
"adam": torch.optim.Adam,
|
| 53 |
+
"sgdm": partial(torch.optim.SGD, momentum=0.9),
|
| 54 |
+
"adamax": torch.optim.Adamax,
|
| 55 |
+
}
|
| 56 |
+
optimizer_func = optimizer_dict[self.opt["optimizer_name"]]
|
| 57 |
+
self.optimizer_x = SphericalOptimizer(optimizer_func, self.latent_x_var_list, lr=self.opt["x_lr"])
|
| 58 |
+
|
| 59 |
+
steps = self.opt["num_epochs"] * self.opt["num_x_iters"]
|
| 60 |
+
schedule_dict = {
|
| 61 |
+
"fixed": lambda x: 1,
|
| 62 |
+
"linear1cycle": lambda x: (9 * (1 - np.abs(x / steps - 1 / 2) * 2) + 1) / 10,
|
| 63 |
+
"linear1cycledrop": lambda x: (9 * (1 - np.abs(x / (0.9 * steps) - 1 / 2) * 2) + 1) / 10
|
| 64 |
+
if x < 0.9 * steps
|
| 65 |
+
else 1 / 10 + (x - 0.9 * steps) / (0.1 * steps) * (1 / 1000 - 1 / 10),
|
| 66 |
+
}
|
| 67 |
+
schedule_func = schedule_dict[self.opt["lr_schedule"]]
|
| 68 |
+
self.scheduler_x = torch.optim.lr_scheduler.LambdaLR(self.optimizer_x.opt, schedule_func)
|
| 69 |
+
|
| 70 |
+
def warmup_dip(self):
|
| 71 |
+
self.reg_noise_std = self.opt["reg_noise_std"]
|
| 72 |
+
warmup_k = torch.load("experiments/pretrained/kernel.pth")
|
| 73 |
+
|
| 74 |
+
mse = nn.MSELoss().cuda()
|
| 75 |
+
|
| 76 |
+
print("Warming up k DIP")
|
| 77 |
+
for step in tqdm(range(self.opt["num_warmup_iters"])):
|
| 78 |
+
self.optimizer_k.zero_grad()
|
| 79 |
+
dip_zk_rand = self.dip_zk + self.reg_noise_std * torch.randn_like(self.dip_zk).cuda()
|
| 80 |
+
k = self.k_dip(dip_zk_rand)
|
| 81 |
+
|
| 82 |
+
loss = mse(k, warmup_k)
|
| 83 |
+
loss.backward()
|
| 84 |
+
self.optimizer_k.step()
|
| 85 |
+
|
| 86 |
+
def optimize_k_step(self, epoch):
|
| 87 |
+
# Optimize k
|
| 88 |
+
tq_k = tqdm(range(self.opt["num_k_iters"]))
|
| 89 |
+
for j in tq_k:
|
| 90 |
+
for p in self.k_dip.parameters():
|
| 91 |
+
p.requires_grad = True
|
| 92 |
+
for p in self.latent_x_var_list:
|
| 93 |
+
p.requires_grad = False
|
| 94 |
+
|
| 95 |
+
self.optimizer_k.zero_grad()
|
| 96 |
+
|
| 97 |
+
# Duplicate latent in case tile_latent = True
|
| 98 |
+
if self.opt["tile_latent"]:
|
| 99 |
+
latent_in = self.latent.expand(-1, 14, -1)
|
| 100 |
+
else:
|
| 101 |
+
latent_in = self.latent
|
| 102 |
+
|
| 103 |
+
dip_zk_rand = self.dip_zk + self.reg_noise_std * torch.randn_like(self.dip_zk).cuda()
|
| 104 |
+
# Apply learned linear mapping to match latent distribution to that of the mapping network
|
| 105 |
+
latent_in = self.lrelu(latent_in * self.gaussian_fit["std"] + self.gaussian_fit["mean"])
|
| 106 |
+
|
| 107 |
+
# Normalize image to [0,1] instead of [-1,1]
|
| 108 |
+
self.gen_im = self.get_gen_im(latent_in)
|
| 109 |
+
self.gen_ker = self.k_dip(dip_zk_rand)
|
| 110 |
+
|
| 111 |
+
# Calculate Losses
|
| 112 |
+
loss, loss_dict = self.loss_builder(latent_in, self.gen_im, self.gen_ker, epoch)
|
| 113 |
+
self.cur_loss = loss.cpu().detach().numpy()
|
| 114 |
+
|
| 115 |
+
loss.backward()
|
| 116 |
+
self.optimizer_k.step()
|
| 117 |
+
self.scheduler_k.step()
|
| 118 |
+
|
| 119 |
+
msg = " | ".join("{}: {:.4f}".format(k, v) for k, v in loss_dict.items())
|
| 120 |
+
tq_k.set_postfix(loss=msg)
|
| 121 |
+
|
| 122 |
+
def optimize_x_step(self, epoch):
|
| 123 |
+
tq_x = tqdm(range(self.opt["num_x_iters"]))
|
| 124 |
+
for j in tq_x:
|
| 125 |
+
for p in self.k_dip.parameters():
|
| 126 |
+
p.requires_grad = False
|
| 127 |
+
for p in self.latent_x_var_list:
|
| 128 |
+
p.requires_grad = True
|
| 129 |
+
|
| 130 |
+
self.optimizer_x.opt.zero_grad()
|
| 131 |
+
|
| 132 |
+
# Duplicate latent in case tile_latent = True
|
| 133 |
+
if self.opt["tile_latent"]:
|
| 134 |
+
latent_in = self.latent.expand(-1, 14, -1)
|
| 135 |
+
else:
|
| 136 |
+
latent_in = self.latent
|
| 137 |
+
|
| 138 |
+
dip_zk_rand = self.dip_zk + self.reg_noise_std * torch.randn_like(self.dip_zk).cuda()
|
| 139 |
+
# Apply learned linear mapping to match latent distribution to that of the mapping network
|
| 140 |
+
latent_in = self.lrelu(latent_in * self.gaussian_fit["std"] + self.gaussian_fit["mean"])
|
| 141 |
+
|
| 142 |
+
# Normalize image to [0,1] instead of [-1,1]
|
| 143 |
+
self.gen_im = self.get_gen_im(latent_in)
|
| 144 |
+
self.gen_ker = self.k_dip(dip_zk_rand)
|
| 145 |
+
|
| 146 |
+
# Calculate Losses
|
| 147 |
+
loss, loss_dict = self.loss_builder(latent_in, self.gen_im, self.gen_ker, epoch)
|
| 148 |
+
self.cur_loss = loss.cpu().detach().numpy()
|
| 149 |
+
|
| 150 |
+
loss.backward()
|
| 151 |
+
self.optimizer_x.step()
|
| 152 |
+
self.scheduler_x.step()
|
| 153 |
+
|
| 154 |
+
msg = " | ".join("{}: {:.4f}".format(k, v) for k, v in loss_dict.items())
|
| 155 |
+
tq_x.set_postfix(loss=msg)
|
| 156 |
+
|
| 157 |
+
def log(self):
|
| 158 |
+
if self.cur_loss < self.min_loss:
|
| 159 |
+
self.min_loss = self.cur_loss
|
| 160 |
+
self.best_im = self.gen_im.clone()
|
| 161 |
+
self.best_ker = self.gen_ker.clone()
|
| 162 |
+
|
| 163 |
+
def forward(self, ref_im):
|
| 164 |
+
if self.opt["seed"]:
|
| 165 |
+
seed = self.opt["seed"]
|
| 166 |
+
torch.manual_seed(seed)
|
| 167 |
+
torch.cuda.manual_seed(seed)
|
| 168 |
+
torch.backends.cudnn.deterministic = True
|
| 169 |
+
|
| 170 |
+
self.initialize_dip()
|
| 171 |
+
self.initialize_latent_space()
|
| 172 |
+
self.initialize_optimizers()
|
| 173 |
+
self.warmup_dip()
|
| 174 |
+
|
| 175 |
+
self.min_loss = np.inf
|
| 176 |
+
self.gen_im = None
|
| 177 |
+
self.initialize_loss(ref_im)
|
| 178 |
+
|
| 179 |
+
if self.verbose:
|
| 180 |
+
print("Optimizing")
|
| 181 |
+
|
| 182 |
+
for epoch in range(self.opt["num_epochs"]):
|
| 183 |
+
print("Step: {}".format(epoch + 1))
|
| 184 |
+
|
| 185 |
+
self.optimize_x_step(epoch)
|
| 186 |
+
self.log()
|
| 187 |
+
self.optimize_k_step(epoch)
|
| 188 |
+
self.log()
|
| 189 |
+
|
| 190 |
+
if self.opt["save_intermediate"]:
|
| 191 |
+
yield (
|
| 192 |
+
self.best_im.cpu().detach().clamp(0, 1),
|
| 193 |
+
self.loss_builder.get_blur_img(self.best_im, self.best_ker),
|
| 194 |
+
)
|
diffusion-posterior-sampling/bkse/models/dsd/dsd_stylegan.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from models.dsd.dsd import DSD
|
| 5 |
+
from models.dsd.stylegan import G_mapping, G_synthesis
|
| 6 |
+
from models.losses.dsd_loss import LossBuilderStyleGAN
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class DSDStyleGAN(DSD):
|
| 10 |
+
def __init__(self, opt, cache_dir):
|
| 11 |
+
super(DSDStyleGAN, self).__init__(opt, cache_dir)
|
| 12 |
+
|
| 13 |
+
def load_synthesis_network(self):
|
| 14 |
+
self.synthesis = G_synthesis().cuda()
|
| 15 |
+
self.synthesis.load_state_dict(torch.load("experiments/pretrained/stylegan_synthesis.pt"))
|
| 16 |
+
for v in self.synthesis.parameters():
|
| 17 |
+
v.requires_grad = False
|
| 18 |
+
|
| 19 |
+
def initialize_mapping_network(self):
|
| 20 |
+
if Path("experiments/pretrained/gaussian_fit_stylegan.pt").exists():
|
| 21 |
+
self.gaussian_fit = torch.load("experiments/pretrained/gaussian_fit_stylegan.pt")
|
| 22 |
+
else:
|
| 23 |
+
if self.verbose:
|
| 24 |
+
print("\tRunning Mapping Network")
|
| 25 |
+
|
| 26 |
+
mapping = G_mapping().cuda()
|
| 27 |
+
mapping.load_state_dict(torch.load("experiments/pretrained/stylegan_mapping.pt"))
|
| 28 |
+
with torch.no_grad():
|
| 29 |
+
torch.manual_seed(0)
|
| 30 |
+
latent = torch.randn((1000000, 512), dtype=torch.float32, device="cuda")
|
| 31 |
+
latent_out = torch.nn.LeakyReLU(5)(mapping(latent))
|
| 32 |
+
self.gaussian_fit = {"mean": latent_out.mean(0), "std": latent_out.std(0)}
|
| 33 |
+
torch.save(self.gaussian_fit, "experiments/pretrained/gaussian_fit_stylegan.pt")
|
| 34 |
+
if self.verbose:
|
| 35 |
+
print('\tSaved "gaussian_fit_stylegan.pt"')
|
| 36 |
+
|
| 37 |
+
def initialize_latent_space(self):
|
| 38 |
+
batch_size = self.opt["batch_size"]
|
| 39 |
+
|
| 40 |
+
# Generate latent tensor
|
| 41 |
+
if self.opt["tile_latent"]:
|
| 42 |
+
self.latent = torch.randn((batch_size, 1, 512), dtype=torch.float, requires_grad=True, device="cuda")
|
| 43 |
+
else:
|
| 44 |
+
self.latent = torch.randn((batch_size, 18, 512), dtype=torch.float, requires_grad=True, device="cuda")
|
| 45 |
+
|
| 46 |
+
# Generate list of noise tensors
|
| 47 |
+
noise = [] # stores all of the noise tensors
|
| 48 |
+
noise_vars = [] # stores the noise tensors that we want to optimize on
|
| 49 |
+
|
| 50 |
+
noise_type = self.opt["noise_type"]
|
| 51 |
+
bad_noise_layers = self.opt["bad_noise_layers"]
|
| 52 |
+
for i in range(18):
|
| 53 |
+
# dimension of the ith noise tensor
|
| 54 |
+
res = (batch_size, 1, 2 ** (i // 2 + 2), 2 ** (i // 2 + 2))
|
| 55 |
+
|
| 56 |
+
if noise_type == "zero" or i in [int(layer) for layer in bad_noise_layers.split(".")]:
|
| 57 |
+
new_noise = torch.zeros(res, dtype=torch.float, device="cuda")
|
| 58 |
+
new_noise.requires_grad = False
|
| 59 |
+
elif noise_type == "fixed":
|
| 60 |
+
new_noise = torch.randn(res, dtype=torch.float, device="cuda")
|
| 61 |
+
new_noise.requires_grad = False
|
| 62 |
+
elif noise_type == "trainable":
|
| 63 |
+
new_noise = torch.randn(res, dtype=torch.float, device="cuda")
|
| 64 |
+
if i < self.opt["num_trainable_noise_layers"]:
|
| 65 |
+
new_noise.requires_grad = True
|
| 66 |
+
noise_vars.append(new_noise)
|
| 67 |
+
else:
|
| 68 |
+
new_noise.requires_grad = False
|
| 69 |
+
else:
|
| 70 |
+
raise Exception("unknown noise type")
|
| 71 |
+
|
| 72 |
+
noise.append(new_noise)
|
| 73 |
+
|
| 74 |
+
self.latent_x_var_list = [self.latent] + noise_vars
|
| 75 |
+
self.noise = noise
|
| 76 |
+
|
| 77 |
+
def initialize_loss(self, ref_im):
|
| 78 |
+
self.loss_builder = LossBuilderStyleGAN(ref_im, self.opt).cuda()
|
| 79 |
+
|
| 80 |
+
def get_gen_im(self, latent_in):
|
| 81 |
+
return (self.synthesis(latent_in, self.noise) + 1) / 2
|
diffusion-posterior-sampling/bkse/models/dsd/dsd_stylegan2.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from models.dsd.dsd import DSD
|
| 5 |
+
from models.dsd.stylegan2 import Generator
|
| 6 |
+
from models.losses.dsd_loss import LossBuilderStyleGAN2
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class DSDStyleGAN2(DSD):
|
| 10 |
+
def __init__(self, opt, cache_dir):
|
| 11 |
+
super(DSDStyleGAN2, self).__init__(opt, cache_dir)
|
| 12 |
+
|
| 13 |
+
def load_synthesis_network(self):
|
| 14 |
+
self.synthesis = Generator(size=256, style_dim=512, n_mlp=8).cuda()
|
| 15 |
+
self.synthesis.load_state_dict(torch.load("experiments/pretrained/stylegan2.pt")["g_ema"], strict=False)
|
| 16 |
+
for v in self.synthesis.parameters():
|
| 17 |
+
v.requires_grad = False
|
| 18 |
+
|
| 19 |
+
def initialize_mapping_network(self):
|
| 20 |
+
if Path("experiments/pretrained/gaussian_fit_stylegan2.pt").exists():
|
| 21 |
+
self.gaussian_fit = torch.load("experiments/pretrained/gaussian_fit_stylegan2.pt")
|
| 22 |
+
else:
|
| 23 |
+
if self.verbose:
|
| 24 |
+
print("\tRunning Mapping Network")
|
| 25 |
+
with torch.no_grad():
|
| 26 |
+
torch.manual_seed(0)
|
| 27 |
+
latent = torch.randn((1000000, 512), dtype=torch.float32, device="cuda")
|
| 28 |
+
latent_out = torch.nn.LeakyReLU(5)(self.synthesis.get_latent(latent))
|
| 29 |
+
self.gaussian_fit = {"mean": latent_out.mean(0), "std": latent_out.std(0)}
|
| 30 |
+
torch.save(self.gaussian_fit, "experiments/pretrained/gaussian_fit_stylegan2.pt")
|
| 31 |
+
if self.verbose:
|
| 32 |
+
print('\tSaved "gaussian_fit_stylegan2.pt"')
|
| 33 |
+
|
| 34 |
+
def initialize_latent_space(self):
|
| 35 |
+
batch_size = self.opt["batch_size"]
|
| 36 |
+
|
| 37 |
+
# Generate latent tensor
|
| 38 |
+
if self.opt["tile_latent"]:
|
| 39 |
+
self.latent = torch.randn((batch_size, 1, 512), dtype=torch.float, requires_grad=True, device="cuda")
|
| 40 |
+
else:
|
| 41 |
+
self.latent = torch.randn((batch_size, 14, 512), dtype=torch.float, requires_grad=True, device="cuda")
|
| 42 |
+
|
| 43 |
+
# Generate list of noise tensors
|
| 44 |
+
noise = [] # stores all of the noise tensors
|
| 45 |
+
noise_vars = [] # stores the noise tensors that we want to optimize on
|
| 46 |
+
|
| 47 |
+
for i in range(14):
|
| 48 |
+
res = (i + 5) // 2
|
| 49 |
+
res = [1, 1, 2 ** res, 2 ** res]
|
| 50 |
+
|
| 51 |
+
noise_type = self.opt["noise_type"]
|
| 52 |
+
bad_noise_layers = self.opt["bad_noise_layers"]
|
| 53 |
+
if noise_type == "zero" or i in [int(layer) for layer in bad_noise_layers.split(".")]:
|
| 54 |
+
new_noise = torch.zeros(res, dtype=torch.float, device="cuda")
|
| 55 |
+
new_noise.requires_grad = False
|
| 56 |
+
elif noise_type == "fixed":
|
| 57 |
+
new_noise = torch.randn(res, dtype=torch.float, device="cuda")
|
| 58 |
+
new_noise.requires_grad = False
|
| 59 |
+
elif noise_type == "trainable":
|
| 60 |
+
new_noise = torch.randn(res, dtype=torch.float, device="cuda")
|
| 61 |
+
if i < self.opt["num_trainable_noise_layers"]:
|
| 62 |
+
new_noise.requires_grad = True
|
| 63 |
+
noise_vars.append(new_noise)
|
| 64 |
+
else:
|
| 65 |
+
new_noise.requires_grad = False
|
| 66 |
+
else:
|
| 67 |
+
raise Exception("unknown noise type")
|
| 68 |
+
|
| 69 |
+
noise.append(new_noise)
|
| 70 |
+
|
| 71 |
+
self.latent_x_var_list = [self.latent] + noise_vars
|
| 72 |
+
self.noise = noise
|
| 73 |
+
|
| 74 |
+
def initialize_loss(self, ref_im):
|
| 75 |
+
self.loss_builder = LossBuilderStyleGAN2(ref_im, self.opt).cuda()
|
| 76 |
+
|
| 77 |
+
def get_gen_im(self, latent_in):
|
| 78 |
+
return (self.synthesis([latent_in], input_is_latent=True, noise=self.noise)[0] + 1) / 2
|
diffusion-posterior-sampling/bkse/models/dsd/op/__init__.py
ADDED
|
File without changes
|
diffusion-posterior-sampling/bkse/models/dsd/op/fused_act.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.autograd import Function
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
from torch.utils.cpp_extension import load
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
module_path = os.path.dirname(__file__)
|
| 11 |
+
fused = load(
|
| 12 |
+
"fused",
|
| 13 |
+
sources=[
|
| 14 |
+
os.path.join(module_path, "fused_bias_act.cpp"),
|
| 15 |
+
os.path.join(module_path, "fused_bias_act_kernel.cu"),
|
| 16 |
+
],
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class FusedLeakyReLUFunctionBackward(Function):
|
| 21 |
+
@staticmethod
|
| 22 |
+
def forward(ctx, grad_output, out, bias, negative_slope, scale):
|
| 23 |
+
ctx.save_for_backward(out)
|
| 24 |
+
ctx.negative_slope = negative_slope
|
| 25 |
+
ctx.scale = scale
|
| 26 |
+
|
| 27 |
+
empty = grad_output.new_empty(0)
|
| 28 |
+
|
| 29 |
+
grad_input = fused.fused_bias_act(grad_output, empty, out, 3, 1, negative_slope, scale)
|
| 30 |
+
|
| 31 |
+
dim = [0]
|
| 32 |
+
|
| 33 |
+
if grad_input.ndim > 2:
|
| 34 |
+
dim += list(range(2, grad_input.ndim))
|
| 35 |
+
|
| 36 |
+
if bias:
|
| 37 |
+
grad_bias = grad_input.sum(dim).detach()
|
| 38 |
+
|
| 39 |
+
else:
|
| 40 |
+
grad_bias = None
|
| 41 |
+
|
| 42 |
+
return grad_input, grad_bias
|
| 43 |
+
|
| 44 |
+
@staticmethod
|
| 45 |
+
def backward(ctx, gradgrad_input, gradgrad_bias):
|
| 46 |
+
(out,) = ctx.saved_tensors
|
| 47 |
+
gradgrad_out = fused.fused_bias_act(gradgrad_input, gradgrad_bias, out, 3, 1, ctx.negative_slope, ctx.scale)
|
| 48 |
+
|
| 49 |
+
return gradgrad_out, None, None, None, None
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class FusedLeakyReLUFunction(Function):
|
| 53 |
+
@staticmethod
|
| 54 |
+
def forward(ctx, input, bias, negative_slope, scale):
|
| 55 |
+
empty = input.new_empty(0)
|
| 56 |
+
|
| 57 |
+
if bias is None:
|
| 58 |
+
bias = empty
|
| 59 |
+
|
| 60 |
+
ctx.bias = bias is not None
|
| 61 |
+
|
| 62 |
+
out = fused.fused_bias_act(input, bias, empty, 3, 0, negative_slope, scale)
|
| 63 |
+
ctx.save_for_backward(out)
|
| 64 |
+
ctx.negative_slope = negative_slope
|
| 65 |
+
ctx.scale = scale
|
| 66 |
+
|
| 67 |
+
return out
|
| 68 |
+
|
| 69 |
+
@staticmethod
|
| 70 |
+
def backward(ctx, grad_output):
|
| 71 |
+
(out,) = ctx.saved_tensors
|
| 72 |
+
|
| 73 |
+
grad_input, grad_bias = FusedLeakyReLUFunctionBackward.apply(
|
| 74 |
+
grad_output, out, ctx.bias, ctx.negative_slope, ctx.scale
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
return grad_input, grad_bias, None, None
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class FusedLeakyReLU(nn.Module):
|
| 81 |
+
def __init__(self, channel, bias=True, negative_slope=0.2, scale=2 ** 0.5):
|
| 82 |
+
super().__init__()
|
| 83 |
+
|
| 84 |
+
if bias:
|
| 85 |
+
self.bias = nn.Parameter(torch.zeros(channel))
|
| 86 |
+
|
| 87 |
+
else:
|
| 88 |
+
self.bias = None
|
| 89 |
+
|
| 90 |
+
self.negative_slope = negative_slope
|
| 91 |
+
self.scale = scale
|
| 92 |
+
|
| 93 |
+
def forward(self, input):
|
| 94 |
+
return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def fused_leaky_relu(input, bias=None, negative_slope=0.2, scale=2 ** 0.5):
|
| 98 |
+
if input.device.type == "cpu":
|
| 99 |
+
if bias is not None:
|
| 100 |
+
rest_dim = [1] * (input.ndim - bias.ndim - 1)
|
| 101 |
+
return F.leaky_relu(input + bias.view(1, bias.shape[0], *rest_dim), negative_slope=0.2) * scale
|
| 102 |
+
|
| 103 |
+
else:
|
| 104 |
+
return F.leaky_relu(input, negative_slope=0.2) * scale
|
| 105 |
+
|
| 106 |
+
else:
|
| 107 |
+
return FusedLeakyReLUFunction.apply(input, bias, negative_slope, scale)
|
diffusion-posterior-sampling/bkse/models/dsd/op/fused_bias_act.cpp
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <torch/extension.h>
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
|
| 5 |
+
int act, int grad, float alpha, float scale);
|
| 6 |
+
|
| 7 |
+
#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
|
| 8 |
+
#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
|
| 9 |
+
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
|
| 10 |
+
|
| 11 |
+
torch::Tensor fused_bias_act(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
|
| 12 |
+
int act, int grad, float alpha, float scale) {
|
| 13 |
+
CHECK_CUDA(input);
|
| 14 |
+
CHECK_CUDA(bias);
|
| 15 |
+
|
| 16 |
+
return fused_bias_act_op(input, bias, refer, act, grad, alpha, scale);
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 20 |
+
m.def("fused_bias_act", &fused_bias_act, "fused bias act (CUDA)");
|
| 21 |
+
}
|
diffusion-posterior-sampling/bkse/models/dsd/op/fused_bias_act_kernel.cu
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// This work is made available under the Nvidia Source Code License-NC.
|
| 4 |
+
// To view a copy of this license, visit
|
| 5 |
+
// https://nvlabs.github.io/stylegan2/license.html
|
| 6 |
+
|
| 7 |
+
#include <torch/types.h>
|
| 8 |
+
|
| 9 |
+
#include <ATen/ATen.h>
|
| 10 |
+
#include <ATen/AccumulateType.h>
|
| 11 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 12 |
+
#include <ATen/cuda/CUDAApplyUtils.cuh>
|
| 13 |
+
|
| 14 |
+
#include <cuda.h>
|
| 15 |
+
#include <cuda_runtime.h>
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
template <typename scalar_t>
|
| 19 |
+
static __global__ void fused_bias_act_kernel(scalar_t* out, const scalar_t* p_x, const scalar_t* p_b, const scalar_t* p_ref,
|
| 20 |
+
int act, int grad, scalar_t alpha, scalar_t scale, int loop_x, int size_x, int step_b, int size_b, int use_bias, int use_ref) {
|
| 21 |
+
int xi = blockIdx.x * loop_x * blockDim.x + threadIdx.x;
|
| 22 |
+
|
| 23 |
+
scalar_t zero = 0.0;
|
| 24 |
+
|
| 25 |
+
for (int loop_idx = 0; loop_idx < loop_x && xi < size_x; loop_idx++, xi += blockDim.x) {
|
| 26 |
+
scalar_t x = p_x[xi];
|
| 27 |
+
|
| 28 |
+
if (use_bias) {
|
| 29 |
+
x += p_b[(xi / step_b) % size_b];
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
scalar_t ref = use_ref ? p_ref[xi] : zero;
|
| 33 |
+
|
| 34 |
+
scalar_t y;
|
| 35 |
+
|
| 36 |
+
switch (act * 10 + grad) {
|
| 37 |
+
default:
|
| 38 |
+
case 10: y = x; break;
|
| 39 |
+
case 11: y = x; break;
|
| 40 |
+
case 12: y = 0.0; break;
|
| 41 |
+
|
| 42 |
+
case 30: y = (x > 0.0) ? x : x * alpha; break;
|
| 43 |
+
case 31: y = (ref > 0.0) ? x : x * alpha; break;
|
| 44 |
+
case 32: y = 0.0; break;
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
out[xi] = y * scale;
|
| 48 |
+
}
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
|
| 53 |
+
int act, int grad, float alpha, float scale) {
|
| 54 |
+
int curDevice = -1;
|
| 55 |
+
cudaGetDevice(&curDevice);
|
| 56 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
|
| 57 |
+
|
| 58 |
+
auto x = input.contiguous();
|
| 59 |
+
auto b = bias.contiguous();
|
| 60 |
+
auto ref = refer.contiguous();
|
| 61 |
+
|
| 62 |
+
int use_bias = b.numel() ? 1 : 0;
|
| 63 |
+
int use_ref = ref.numel() ? 1 : 0;
|
| 64 |
+
|
| 65 |
+
int size_x = x.numel();
|
| 66 |
+
int size_b = b.numel();
|
| 67 |
+
int step_b = 1;
|
| 68 |
+
|
| 69 |
+
for (int i = 1 + 1; i < x.dim(); i++) {
|
| 70 |
+
step_b *= x.size(i);
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
int loop_x = 4;
|
| 74 |
+
int block_size = 4 * 32;
|
| 75 |
+
int grid_size = (size_x - 1) / (loop_x * block_size) + 1;
|
| 76 |
+
|
| 77 |
+
auto y = torch::empty_like(x);
|
| 78 |
+
|
| 79 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "fused_bias_act_kernel", [&] {
|
| 80 |
+
fused_bias_act_kernel<scalar_t><<<grid_size, block_size, 0, stream>>>(
|
| 81 |
+
y.data_ptr<scalar_t>(),
|
| 82 |
+
x.data_ptr<scalar_t>(),
|
| 83 |
+
b.data_ptr<scalar_t>(),
|
| 84 |
+
ref.data_ptr<scalar_t>(),
|
| 85 |
+
act,
|
| 86 |
+
grad,
|
| 87 |
+
alpha,
|
| 88 |
+
scale,
|
| 89 |
+
loop_x,
|
| 90 |
+
size_x,
|
| 91 |
+
step_b,
|
| 92 |
+
size_b,
|
| 93 |
+
use_bias,
|
| 94 |
+
use_ref
|
| 95 |
+
);
|
| 96 |
+
});
|
| 97 |
+
|
| 98 |
+
return y;
|
| 99 |
+
}
|
diffusion-posterior-sampling/bkse/models/dsd/op/upfirdn2d.cpp
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <torch/extension.h>
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
|
| 5 |
+
int up_x, int up_y, int down_x, int down_y,
|
| 6 |
+
int pad_x0, int pad_x1, int pad_y0, int pad_y1);
|
| 7 |
+
|
| 8 |
+
#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
|
| 9 |
+
#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
|
| 10 |
+
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
|
| 11 |
+
|
| 12 |
+
torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
|
| 13 |
+
int up_x, int up_y, int down_x, int down_y,
|
| 14 |
+
int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
|
| 15 |
+
CHECK_CUDA(input);
|
| 16 |
+
CHECK_CUDA(kernel);
|
| 17 |
+
|
| 18 |
+
return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1);
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 22 |
+
m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
|
| 23 |
+
}
|
diffusion-posterior-sampling/bkse/models/dsd/op/upfirdn2d.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch.autograd import Function
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
from torch.utils.cpp_extension import load
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
module_path = os.path.dirname(__file__)
|
| 10 |
+
upfirdn2d_op = load(
|
| 11 |
+
"upfirdn2d",
|
| 12 |
+
sources=[
|
| 13 |
+
os.path.join(module_path, "upfirdn2d.cpp"),
|
| 14 |
+
os.path.join(module_path, "upfirdn2d_kernel.cu"),
|
| 15 |
+
],
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class UpFirDn2dBackward(Function):
|
| 20 |
+
@staticmethod
|
| 21 |
+
def forward(ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size):
|
| 22 |
+
|
| 23 |
+
up_x, up_y = up
|
| 24 |
+
down_x, down_y = down
|
| 25 |
+
g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
|
| 26 |
+
|
| 27 |
+
grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
|
| 28 |
+
|
| 29 |
+
grad_input = upfirdn2d_op.upfirdn2d(
|
| 30 |
+
grad_output,
|
| 31 |
+
grad_kernel,
|
| 32 |
+
down_x,
|
| 33 |
+
down_y,
|
| 34 |
+
up_x,
|
| 35 |
+
up_y,
|
| 36 |
+
g_pad_x0,
|
| 37 |
+
g_pad_x1,
|
| 38 |
+
g_pad_y0,
|
| 39 |
+
g_pad_y1,
|
| 40 |
+
)
|
| 41 |
+
grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
|
| 42 |
+
|
| 43 |
+
ctx.save_for_backward(kernel)
|
| 44 |
+
|
| 45 |
+
pad_x0, pad_x1, pad_y0, pad_y1 = pad
|
| 46 |
+
|
| 47 |
+
ctx.up_x = up_x
|
| 48 |
+
ctx.up_y = up_y
|
| 49 |
+
ctx.down_x = down_x
|
| 50 |
+
ctx.down_y = down_y
|
| 51 |
+
ctx.pad_x0 = pad_x0
|
| 52 |
+
ctx.pad_x1 = pad_x1
|
| 53 |
+
ctx.pad_y0 = pad_y0
|
| 54 |
+
ctx.pad_y1 = pad_y1
|
| 55 |
+
ctx.in_size = in_size
|
| 56 |
+
ctx.out_size = out_size
|
| 57 |
+
|
| 58 |
+
return grad_input
|
| 59 |
+
|
| 60 |
+
@staticmethod
|
| 61 |
+
def backward(ctx, gradgrad_input):
|
| 62 |
+
(kernel,) = ctx.saved_tensors
|
| 63 |
+
|
| 64 |
+
gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
|
| 65 |
+
|
| 66 |
+
gradgrad_out = upfirdn2d_op.upfirdn2d(
|
| 67 |
+
gradgrad_input,
|
| 68 |
+
kernel,
|
| 69 |
+
ctx.up_x,
|
| 70 |
+
ctx.up_y,
|
| 71 |
+
ctx.down_x,
|
| 72 |
+
ctx.down_y,
|
| 73 |
+
ctx.pad_x0,
|
| 74 |
+
ctx.pad_x1,
|
| 75 |
+
ctx.pad_y0,
|
| 76 |
+
ctx.pad_y1,
|
| 77 |
+
)
|
| 78 |
+
# gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
|
| 79 |
+
gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1])
|
| 80 |
+
|
| 81 |
+
return gradgrad_out, None, None, None, None, None, None, None, None
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class UpFirDn2d(Function):
|
| 85 |
+
@staticmethod
|
| 86 |
+
def forward(ctx, input, kernel, up, down, pad):
|
| 87 |
+
up_x, up_y = up
|
| 88 |
+
down_x, down_y = down
|
| 89 |
+
pad_x0, pad_x1, pad_y0, pad_y1 = pad
|
| 90 |
+
|
| 91 |
+
kernel_h, kernel_w = kernel.shape
|
| 92 |
+
batch, channel, in_h, in_w = input.shape
|
| 93 |
+
ctx.in_size = input.shape
|
| 94 |
+
|
| 95 |
+
input = input.reshape(-1, in_h, in_w, 1)
|
| 96 |
+
|
| 97 |
+
ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
|
| 98 |
+
|
| 99 |
+
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
|
| 100 |
+
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
|
| 101 |
+
ctx.out_size = (out_h, out_w)
|
| 102 |
+
|
| 103 |
+
ctx.up = (up_x, up_y)
|
| 104 |
+
ctx.down = (down_x, down_y)
|
| 105 |
+
ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
|
| 106 |
+
|
| 107 |
+
g_pad_x0 = kernel_w - pad_x0 - 1
|
| 108 |
+
g_pad_y0 = kernel_h - pad_y0 - 1
|
| 109 |
+
g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
|
| 110 |
+
g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
|
| 111 |
+
|
| 112 |
+
ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
|
| 113 |
+
|
| 114 |
+
out = upfirdn2d_op.upfirdn2d(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1)
|
| 115 |
+
# out = out.view(major, out_h, out_w, minor)
|
| 116 |
+
out = out.view(-1, channel, out_h, out_w)
|
| 117 |
+
|
| 118 |
+
return out
|
| 119 |
+
|
| 120 |
+
@staticmethod
|
| 121 |
+
def backward(ctx, grad_output):
|
| 122 |
+
kernel, grad_kernel = ctx.saved_tensors
|
| 123 |
+
|
| 124 |
+
grad_input = UpFirDn2dBackward.apply(
|
| 125 |
+
grad_output,
|
| 126 |
+
kernel,
|
| 127 |
+
grad_kernel,
|
| 128 |
+
ctx.up,
|
| 129 |
+
ctx.down,
|
| 130 |
+
ctx.pad,
|
| 131 |
+
ctx.g_pad,
|
| 132 |
+
ctx.in_size,
|
| 133 |
+
ctx.out_size,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
return grad_input, None, None, None, None
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
|
| 140 |
+
if input.device.type == "cpu":
|
| 141 |
+
out = upfirdn2d_native(input, kernel, up, up, down, down, pad[0], pad[1], pad[0], pad[1])
|
| 142 |
+
|
| 143 |
+
else:
|
| 144 |
+
out = UpFirDn2d.apply(input, kernel, (up, up), (down, down), (pad[0], pad[1], pad[0], pad[1]))
|
| 145 |
+
|
| 146 |
+
return out
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def upfirdn2d_native(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1):
|
| 150 |
+
_, channel, in_h, in_w = input.shape
|
| 151 |
+
input = input.reshape(-1, in_h, in_w, 1)
|
| 152 |
+
|
| 153 |
+
_, in_h, in_w, minor = input.shape
|
| 154 |
+
kernel_h, kernel_w = kernel.shape
|
| 155 |
+
|
| 156 |
+
out = input.view(-1, in_h, 1, in_w, 1, minor)
|
| 157 |
+
out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
|
| 158 |
+
out = out.view(-1, in_h * up_y, in_w * up_x, minor)
|
| 159 |
+
|
| 160 |
+
out = F.pad(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
|
| 161 |
+
out = out[
|
| 162 |
+
:,
|
| 163 |
+
max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
|
| 164 |
+
max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
|
| 165 |
+
:,
|
| 166 |
+
]
|
| 167 |
+
|
| 168 |
+
out = out.permute(0, 3, 1, 2)
|
| 169 |
+
out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
|
| 170 |
+
w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
|
| 171 |
+
out = F.conv2d(out, w)
|
| 172 |
+
out = out.reshape(
|
| 173 |
+
-1,
|
| 174 |
+
minor,
|
| 175 |
+
in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
|
| 176 |
+
in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
|
| 177 |
+
)
|
| 178 |
+
out = out.permute(0, 2, 3, 1)
|
| 179 |
+
out = out[:, ::down_y, ::down_x, :]
|
| 180 |
+
|
| 181 |
+
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
|
| 182 |
+
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
|
| 183 |
+
|
| 184 |
+
return out.view(-1, channel, out_h, out_w)
|
diffusion-posterior-sampling/bkse/models/dsd/op/upfirdn2d_kernel.cu
ADDED
|
@@ -0,0 +1,369 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// This work is made available under the Nvidia Source Code License-NC.
|
| 4 |
+
// To view a copy of this license, visit
|
| 5 |
+
// https://nvlabs.github.io/stylegan2/license.html
|
| 6 |
+
|
| 7 |
+
#include <torch/types.h>
|
| 8 |
+
|
| 9 |
+
#include <ATen/ATen.h>
|
| 10 |
+
#include <ATen/AccumulateType.h>
|
| 11 |
+
#include <ATen/cuda/CUDAApplyUtils.cuh>
|
| 12 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 13 |
+
|
| 14 |
+
#include <cuda.h>
|
| 15 |
+
#include <cuda_runtime.h>
|
| 16 |
+
|
| 17 |
+
static __host__ __device__ __forceinline__ int floor_div(int a, int b) {
|
| 18 |
+
int c = a / b;
|
| 19 |
+
|
| 20 |
+
if (c * b > a) {
|
| 21 |
+
c--;
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
return c;
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
struct UpFirDn2DKernelParams {
|
| 28 |
+
int up_x;
|
| 29 |
+
int up_y;
|
| 30 |
+
int down_x;
|
| 31 |
+
int down_y;
|
| 32 |
+
int pad_x0;
|
| 33 |
+
int pad_x1;
|
| 34 |
+
int pad_y0;
|
| 35 |
+
int pad_y1;
|
| 36 |
+
|
| 37 |
+
int major_dim;
|
| 38 |
+
int in_h;
|
| 39 |
+
int in_w;
|
| 40 |
+
int minor_dim;
|
| 41 |
+
int kernel_h;
|
| 42 |
+
int kernel_w;
|
| 43 |
+
int out_h;
|
| 44 |
+
int out_w;
|
| 45 |
+
int loop_major;
|
| 46 |
+
int loop_x;
|
| 47 |
+
};
|
| 48 |
+
|
| 49 |
+
template <typename scalar_t>
|
| 50 |
+
__global__ void upfirdn2d_kernel_large(scalar_t *out, const scalar_t *input,
|
| 51 |
+
const scalar_t *kernel,
|
| 52 |
+
const UpFirDn2DKernelParams p) {
|
| 53 |
+
int minor_idx = blockIdx.x * blockDim.x + threadIdx.x;
|
| 54 |
+
int out_y = minor_idx / p.minor_dim;
|
| 55 |
+
minor_idx -= out_y * p.minor_dim;
|
| 56 |
+
int out_x_base = blockIdx.y * p.loop_x * blockDim.y + threadIdx.y;
|
| 57 |
+
int major_idx_base = blockIdx.z * p.loop_major;
|
| 58 |
+
|
| 59 |
+
if (out_x_base >= p.out_w || out_y >= p.out_h ||
|
| 60 |
+
major_idx_base >= p.major_dim) {
|
| 61 |
+
return;
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
int mid_y = out_y * p.down_y + p.up_y - 1 - p.pad_y0;
|
| 65 |
+
int in_y = min(max(floor_div(mid_y, p.up_y), 0), p.in_h);
|
| 66 |
+
int h = min(max(floor_div(mid_y + p.kernel_h, p.up_y), 0), p.in_h) - in_y;
|
| 67 |
+
int kernel_y = mid_y + p.kernel_h - (in_y + 1) * p.up_y;
|
| 68 |
+
|
| 69 |
+
for (int loop_major = 0, major_idx = major_idx_base;
|
| 70 |
+
loop_major < p.loop_major && major_idx < p.major_dim;
|
| 71 |
+
loop_major++, major_idx++) {
|
| 72 |
+
for (int loop_x = 0, out_x = out_x_base;
|
| 73 |
+
loop_x < p.loop_x && out_x < p.out_w; loop_x++, out_x += blockDim.y) {
|
| 74 |
+
int mid_x = out_x * p.down_x + p.up_x - 1 - p.pad_x0;
|
| 75 |
+
int in_x = min(max(floor_div(mid_x, p.up_x), 0), p.in_w);
|
| 76 |
+
int w = min(max(floor_div(mid_x + p.kernel_w, p.up_x), 0), p.in_w) - in_x;
|
| 77 |
+
int kernel_x = mid_x + p.kernel_w - (in_x + 1) * p.up_x;
|
| 78 |
+
|
| 79 |
+
const scalar_t *x_p =
|
| 80 |
+
&input[((major_idx * p.in_h + in_y) * p.in_w + in_x) * p.minor_dim +
|
| 81 |
+
minor_idx];
|
| 82 |
+
const scalar_t *k_p = &kernel[kernel_y * p.kernel_w + kernel_x];
|
| 83 |
+
int x_px = p.minor_dim;
|
| 84 |
+
int k_px = -p.up_x;
|
| 85 |
+
int x_py = p.in_w * p.minor_dim;
|
| 86 |
+
int k_py = -p.up_y * p.kernel_w;
|
| 87 |
+
|
| 88 |
+
scalar_t v = 0.0f;
|
| 89 |
+
|
| 90 |
+
for (int y = 0; y < h; y++) {
|
| 91 |
+
for (int x = 0; x < w; x++) {
|
| 92 |
+
v += static_cast<scalar_t>(*x_p) * static_cast<scalar_t>(*k_p);
|
| 93 |
+
x_p += x_px;
|
| 94 |
+
k_p += k_px;
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
x_p += x_py - w * x_px;
|
| 98 |
+
k_p += k_py - w * k_px;
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim +
|
| 102 |
+
minor_idx] = v;
|
| 103 |
+
}
|
| 104 |
+
}
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
template <typename scalar_t, int up_x, int up_y, int down_x, int down_y,
|
| 108 |
+
int kernel_h, int kernel_w, int tile_out_h, int tile_out_w>
|
| 109 |
+
__global__ void upfirdn2d_kernel(scalar_t *out, const scalar_t *input,
|
| 110 |
+
const scalar_t *kernel,
|
| 111 |
+
const UpFirDn2DKernelParams p) {
|
| 112 |
+
const int tile_in_h = ((tile_out_h - 1) * down_y + kernel_h - 1) / up_y + 1;
|
| 113 |
+
const int tile_in_w = ((tile_out_w - 1) * down_x + kernel_w - 1) / up_x + 1;
|
| 114 |
+
|
| 115 |
+
__shared__ volatile float sk[kernel_h][kernel_w];
|
| 116 |
+
__shared__ volatile float sx[tile_in_h][tile_in_w];
|
| 117 |
+
|
| 118 |
+
int minor_idx = blockIdx.x;
|
| 119 |
+
int tile_out_y = minor_idx / p.minor_dim;
|
| 120 |
+
minor_idx -= tile_out_y * p.minor_dim;
|
| 121 |
+
tile_out_y *= tile_out_h;
|
| 122 |
+
int tile_out_x_base = blockIdx.y * p.loop_x * tile_out_w;
|
| 123 |
+
int major_idx_base = blockIdx.z * p.loop_major;
|
| 124 |
+
|
| 125 |
+
if (tile_out_x_base >= p.out_w | tile_out_y >= p.out_h |
|
| 126 |
+
major_idx_base >= p.major_dim) {
|
| 127 |
+
return;
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
for (int tap_idx = threadIdx.x; tap_idx < kernel_h * kernel_w;
|
| 131 |
+
tap_idx += blockDim.x) {
|
| 132 |
+
int ky = tap_idx / kernel_w;
|
| 133 |
+
int kx = tap_idx - ky * kernel_w;
|
| 134 |
+
scalar_t v = 0.0;
|
| 135 |
+
|
| 136 |
+
if (kx < p.kernel_w & ky < p.kernel_h) {
|
| 137 |
+
v = kernel[(p.kernel_h - 1 - ky) * p.kernel_w + (p.kernel_w - 1 - kx)];
|
| 138 |
+
}
|
| 139 |
+
|
| 140 |
+
sk[ky][kx] = v;
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
for (int loop_major = 0, major_idx = major_idx_base;
|
| 144 |
+
loop_major < p.loop_major & major_idx < p.major_dim;
|
| 145 |
+
loop_major++, major_idx++) {
|
| 146 |
+
for (int loop_x = 0, tile_out_x = tile_out_x_base;
|
| 147 |
+
loop_x < p.loop_x & tile_out_x < p.out_w;
|
| 148 |
+
loop_x++, tile_out_x += tile_out_w) {
|
| 149 |
+
int tile_mid_x = tile_out_x * down_x + up_x - 1 - p.pad_x0;
|
| 150 |
+
int tile_mid_y = tile_out_y * down_y + up_y - 1 - p.pad_y0;
|
| 151 |
+
int tile_in_x = floor_div(tile_mid_x, up_x);
|
| 152 |
+
int tile_in_y = floor_div(tile_mid_y, up_y);
|
| 153 |
+
|
| 154 |
+
__syncthreads();
|
| 155 |
+
|
| 156 |
+
for (int in_idx = threadIdx.x; in_idx < tile_in_h * tile_in_w;
|
| 157 |
+
in_idx += blockDim.x) {
|
| 158 |
+
int rel_in_y = in_idx / tile_in_w;
|
| 159 |
+
int rel_in_x = in_idx - rel_in_y * tile_in_w;
|
| 160 |
+
int in_x = rel_in_x + tile_in_x;
|
| 161 |
+
int in_y = rel_in_y + tile_in_y;
|
| 162 |
+
|
| 163 |
+
scalar_t v = 0.0;
|
| 164 |
+
|
| 165 |
+
if (in_x >= 0 & in_y >= 0 & in_x < p.in_w & in_y < p.in_h) {
|
| 166 |
+
v = input[((major_idx * p.in_h + in_y) * p.in_w + in_x) *
|
| 167 |
+
p.minor_dim +
|
| 168 |
+
minor_idx];
|
| 169 |
+
}
|
| 170 |
+
|
| 171 |
+
sx[rel_in_y][rel_in_x] = v;
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
__syncthreads();
|
| 175 |
+
for (int out_idx = threadIdx.x; out_idx < tile_out_h * tile_out_w;
|
| 176 |
+
out_idx += blockDim.x) {
|
| 177 |
+
int rel_out_y = out_idx / tile_out_w;
|
| 178 |
+
int rel_out_x = out_idx - rel_out_y * tile_out_w;
|
| 179 |
+
int out_x = rel_out_x + tile_out_x;
|
| 180 |
+
int out_y = rel_out_y + tile_out_y;
|
| 181 |
+
|
| 182 |
+
int mid_x = tile_mid_x + rel_out_x * down_x;
|
| 183 |
+
int mid_y = tile_mid_y + rel_out_y * down_y;
|
| 184 |
+
int in_x = floor_div(mid_x, up_x);
|
| 185 |
+
int in_y = floor_div(mid_y, up_y);
|
| 186 |
+
int rel_in_x = in_x - tile_in_x;
|
| 187 |
+
int rel_in_y = in_y - tile_in_y;
|
| 188 |
+
int kernel_x = (in_x + 1) * up_x - mid_x - 1;
|
| 189 |
+
int kernel_y = (in_y + 1) * up_y - mid_y - 1;
|
| 190 |
+
|
| 191 |
+
scalar_t v = 0.0;
|
| 192 |
+
|
| 193 |
+
#pragma unroll
|
| 194 |
+
for (int y = 0; y < kernel_h / up_y; y++)
|
| 195 |
+
#pragma unroll
|
| 196 |
+
for (int x = 0; x < kernel_w / up_x; x++)
|
| 197 |
+
v += sx[rel_in_y + y][rel_in_x + x] *
|
| 198 |
+
sk[kernel_y + y * up_y][kernel_x + x * up_x];
|
| 199 |
+
|
| 200 |
+
if (out_x < p.out_w & out_y < p.out_h) {
|
| 201 |
+
out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim +
|
| 202 |
+
minor_idx] = v;
|
| 203 |
+
}
|
| 204 |
+
}
|
| 205 |
+
}
|
| 206 |
+
}
|
| 207 |
+
}
|
| 208 |
+
|
| 209 |
+
torch::Tensor upfirdn2d_op(const torch::Tensor &input,
|
| 210 |
+
const torch::Tensor &kernel, int up_x, int up_y,
|
| 211 |
+
int down_x, int down_y, int pad_x0, int pad_x1,
|
| 212 |
+
int pad_y0, int pad_y1) {
|
| 213 |
+
int curDevice = -1;
|
| 214 |
+
cudaGetDevice(&curDevice);
|
| 215 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
|
| 216 |
+
|
| 217 |
+
UpFirDn2DKernelParams p;
|
| 218 |
+
|
| 219 |
+
auto x = input.contiguous();
|
| 220 |
+
auto k = kernel.contiguous();
|
| 221 |
+
|
| 222 |
+
p.major_dim = x.size(0);
|
| 223 |
+
p.in_h = x.size(1);
|
| 224 |
+
p.in_w = x.size(2);
|
| 225 |
+
p.minor_dim = x.size(3);
|
| 226 |
+
p.kernel_h = k.size(0);
|
| 227 |
+
p.kernel_w = k.size(1);
|
| 228 |
+
p.up_x = up_x;
|
| 229 |
+
p.up_y = up_y;
|
| 230 |
+
p.down_x = down_x;
|
| 231 |
+
p.down_y = down_y;
|
| 232 |
+
p.pad_x0 = pad_x0;
|
| 233 |
+
p.pad_x1 = pad_x1;
|
| 234 |
+
p.pad_y0 = pad_y0;
|
| 235 |
+
p.pad_y1 = pad_y1;
|
| 236 |
+
|
| 237 |
+
p.out_h = (p.in_h * p.up_y + p.pad_y0 + p.pad_y1 - p.kernel_h + p.down_y) /
|
| 238 |
+
p.down_y;
|
| 239 |
+
p.out_w = (p.in_w * p.up_x + p.pad_x0 + p.pad_x1 - p.kernel_w + p.down_x) /
|
| 240 |
+
p.down_x;
|
| 241 |
+
|
| 242 |
+
auto out =
|
| 243 |
+
at::empty({p.major_dim, p.out_h, p.out_w, p.minor_dim}, x.options());
|
| 244 |
+
|
| 245 |
+
int mode = -1;
|
| 246 |
+
|
| 247 |
+
int tile_out_h = -1;
|
| 248 |
+
int tile_out_w = -1;
|
| 249 |
+
|
| 250 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 &&
|
| 251 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 252 |
+
mode = 1;
|
| 253 |
+
tile_out_h = 16;
|
| 254 |
+
tile_out_w = 64;
|
| 255 |
+
}
|
| 256 |
+
|
| 257 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 &&
|
| 258 |
+
p.kernel_h <= 3 && p.kernel_w <= 3) {
|
| 259 |
+
mode = 2;
|
| 260 |
+
tile_out_h = 16;
|
| 261 |
+
tile_out_w = 64;
|
| 262 |
+
}
|
| 263 |
+
|
| 264 |
+
if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 &&
|
| 265 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 266 |
+
mode = 3;
|
| 267 |
+
tile_out_h = 16;
|
| 268 |
+
tile_out_w = 64;
|
| 269 |
+
}
|
| 270 |
+
|
| 271 |
+
if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 &&
|
| 272 |
+
p.kernel_h <= 2 && p.kernel_w <= 2) {
|
| 273 |
+
mode = 4;
|
| 274 |
+
tile_out_h = 16;
|
| 275 |
+
tile_out_w = 64;
|
| 276 |
+
}
|
| 277 |
+
|
| 278 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 &&
|
| 279 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 280 |
+
mode = 5;
|
| 281 |
+
tile_out_h = 8;
|
| 282 |
+
tile_out_w = 32;
|
| 283 |
+
}
|
| 284 |
+
|
| 285 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 &&
|
| 286 |
+
p.kernel_h <= 2 && p.kernel_w <= 2) {
|
| 287 |
+
mode = 6;
|
| 288 |
+
tile_out_h = 8;
|
| 289 |
+
tile_out_w = 32;
|
| 290 |
+
}
|
| 291 |
+
|
| 292 |
+
dim3 block_size;
|
| 293 |
+
dim3 grid_size;
|
| 294 |
+
|
| 295 |
+
if (tile_out_h > 0 && tile_out_w > 0) {
|
| 296 |
+
p.loop_major = (p.major_dim - 1) / 16384 + 1;
|
| 297 |
+
p.loop_x = 1;
|
| 298 |
+
block_size = dim3(32 * 8, 1, 1);
|
| 299 |
+
grid_size = dim3(((p.out_h - 1) / tile_out_h + 1) * p.minor_dim,
|
| 300 |
+
(p.out_w - 1) / (p.loop_x * tile_out_w) + 1,
|
| 301 |
+
(p.major_dim - 1) / p.loop_major + 1);
|
| 302 |
+
} else {
|
| 303 |
+
p.loop_major = (p.major_dim - 1) / 16384 + 1;
|
| 304 |
+
p.loop_x = 4;
|
| 305 |
+
block_size = dim3(4, 32, 1);
|
| 306 |
+
grid_size = dim3((p.out_h * p.minor_dim - 1) / block_size.x + 1,
|
| 307 |
+
(p.out_w - 1) / (p.loop_x * block_size.y) + 1,
|
| 308 |
+
(p.major_dim - 1) / p.loop_major + 1);
|
| 309 |
+
}
|
| 310 |
+
|
| 311 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] {
|
| 312 |
+
switch (mode) {
|
| 313 |
+
case 1:
|
| 314 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 1, 1, 4, 4, 16, 64>
|
| 315 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 316 |
+
x.data_ptr<scalar_t>(),
|
| 317 |
+
k.data_ptr<scalar_t>(), p);
|
| 318 |
+
|
| 319 |
+
break;
|
| 320 |
+
|
| 321 |
+
case 2:
|
| 322 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 1, 1, 3, 3, 16, 64>
|
| 323 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 324 |
+
x.data_ptr<scalar_t>(),
|
| 325 |
+
k.data_ptr<scalar_t>(), p);
|
| 326 |
+
|
| 327 |
+
break;
|
| 328 |
+
|
| 329 |
+
case 3:
|
| 330 |
+
upfirdn2d_kernel<scalar_t, 2, 2, 1, 1, 4, 4, 16, 64>
|
| 331 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 332 |
+
x.data_ptr<scalar_t>(),
|
| 333 |
+
k.data_ptr<scalar_t>(), p);
|
| 334 |
+
|
| 335 |
+
break;
|
| 336 |
+
|
| 337 |
+
case 4:
|
| 338 |
+
upfirdn2d_kernel<scalar_t, 2, 2, 1, 1, 2, 2, 16, 64>
|
| 339 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 340 |
+
x.data_ptr<scalar_t>(),
|
| 341 |
+
k.data_ptr<scalar_t>(), p);
|
| 342 |
+
|
| 343 |
+
break;
|
| 344 |
+
|
| 345 |
+
case 5:
|
| 346 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 2, 2, 4, 4, 8, 32>
|
| 347 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 348 |
+
x.data_ptr<scalar_t>(),
|
| 349 |
+
k.data_ptr<scalar_t>(), p);
|
| 350 |
+
|
| 351 |
+
break;
|
| 352 |
+
|
| 353 |
+
case 6:
|
| 354 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 2, 2, 4, 4, 8, 32>
|
| 355 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 356 |
+
x.data_ptr<scalar_t>(),
|
| 357 |
+
k.data_ptr<scalar_t>(), p);
|
| 358 |
+
|
| 359 |
+
break;
|
| 360 |
+
|
| 361 |
+
default:
|
| 362 |
+
upfirdn2d_kernel_large<scalar_t><<<grid_size, block_size, 0, stream>>>(
|
| 363 |
+
out.data_ptr<scalar_t>(), x.data_ptr<scalar_t>(),
|
| 364 |
+
k.data_ptr<scalar_t>(), p);
|
| 365 |
+
}
|
| 366 |
+
});
|
| 367 |
+
|
| 368 |
+
return out;
|
| 369 |
+
}
|
diffusion-posterior-sampling/bkse/models/dsd/spherical_optimizer.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.optim import Optimizer
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
# Spherical Optimizer Class
|
| 6 |
+
# Uses the first two dimensions as batch information
|
| 7 |
+
# Optimizes over the surface of a sphere using the initial radius throughout
|
| 8 |
+
#
|
| 9 |
+
# Example Usage:
|
| 10 |
+
# opt = SphericalOptimizer(torch.optim.SGD, [x], lr=0.01)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class SphericalOptimizer(Optimizer):
|
| 14 |
+
def __init__(self, optimizer, params, **kwargs):
|
| 15 |
+
self.opt = optimizer(params, **kwargs)
|
| 16 |
+
self.params = params
|
| 17 |
+
with torch.no_grad():
|
| 18 |
+
self.radii = {
|
| 19 |
+
param: (param.pow(2).sum(tuple(range(2, param.ndim)), keepdim=True) + 1e-9).sqrt() for param in params
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
@torch.no_grad()
|
| 23 |
+
def step(self, closure=None):
|
| 24 |
+
loss = self.opt.step(closure)
|
| 25 |
+
for param in self.params:
|
| 26 |
+
param.data.div_((param.pow(2).sum(tuple(range(2, param.ndim)), keepdim=True) + 1e-9).sqrt())
|
| 27 |
+
param.mul_(self.radii[param])
|
| 28 |
+
|
| 29 |
+
return loss
|
diffusion-posterior-sampling/bkse/models/dsd/stylegan.py
ADDED
|
@@ -0,0 +1,474 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from https://github.com/lernapparat/lernapparat/
|
| 2 |
+
|
| 3 |
+
from collections import OrderedDict
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class MyLinear(nn.Module):
|
| 12 |
+
"""Linear layer with equalized learning rate and custom learning rate multiplier."""
|
| 13 |
+
|
| 14 |
+
def __init__(self, input_size, output_size, gain=2 ** (0.5), use_wscale=False, lrmul=1, bias=True):
|
| 15 |
+
super().__init__()
|
| 16 |
+
he_std = gain * input_size ** (-0.5) # He init
|
| 17 |
+
# Equalized learning rate and custom learning rate multiplier.
|
| 18 |
+
if use_wscale:
|
| 19 |
+
init_std = 1.0 / lrmul
|
| 20 |
+
self.w_mul = he_std * lrmul
|
| 21 |
+
else:
|
| 22 |
+
init_std = he_std / lrmul
|
| 23 |
+
self.w_mul = lrmul
|
| 24 |
+
self.weight = torch.nn.Parameter(torch.randn(output_size, input_size) * init_std)
|
| 25 |
+
if bias:
|
| 26 |
+
self.bias = torch.nn.Parameter(torch.zeros(output_size))
|
| 27 |
+
self.b_mul = lrmul
|
| 28 |
+
else:
|
| 29 |
+
self.bias = None
|
| 30 |
+
|
| 31 |
+
def forward(self, x):
|
| 32 |
+
bias = self.bias
|
| 33 |
+
if bias is not None:
|
| 34 |
+
bias = bias * self.b_mul
|
| 35 |
+
return F.linear(x, self.weight * self.w_mul, bias)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class MyConv2d(nn.Module):
|
| 39 |
+
"""Conv layer with equalized learning rate and custom learning rate multiplier."""
|
| 40 |
+
|
| 41 |
+
def __init__(
|
| 42 |
+
self,
|
| 43 |
+
input_channels,
|
| 44 |
+
output_channels,
|
| 45 |
+
kernel_size,
|
| 46 |
+
gain=2 ** (0.5),
|
| 47 |
+
use_wscale=False,
|
| 48 |
+
lrmul=1,
|
| 49 |
+
bias=True,
|
| 50 |
+
intermediate=None,
|
| 51 |
+
upscale=False,
|
| 52 |
+
):
|
| 53 |
+
super().__init__()
|
| 54 |
+
if upscale:
|
| 55 |
+
self.upscale = Upscale2d()
|
| 56 |
+
else:
|
| 57 |
+
self.upscale = None
|
| 58 |
+
he_std = gain * (input_channels * kernel_size ** 2) ** (-0.5) # He init
|
| 59 |
+
self.kernel_size = kernel_size
|
| 60 |
+
if use_wscale:
|
| 61 |
+
init_std = 1.0 / lrmul
|
| 62 |
+
self.w_mul = he_std * lrmul
|
| 63 |
+
else:
|
| 64 |
+
init_std = he_std / lrmul
|
| 65 |
+
self.w_mul = lrmul
|
| 66 |
+
self.weight = torch.nn.Parameter(
|
| 67 |
+
torch.randn(output_channels, input_channels, kernel_size, kernel_size) * init_std
|
| 68 |
+
)
|
| 69 |
+
if bias:
|
| 70 |
+
self.bias = torch.nn.Parameter(torch.zeros(output_channels))
|
| 71 |
+
self.b_mul = lrmul
|
| 72 |
+
else:
|
| 73 |
+
self.bias = None
|
| 74 |
+
self.intermediate = intermediate
|
| 75 |
+
|
| 76 |
+
def forward(self, x):
|
| 77 |
+
bias = self.bias
|
| 78 |
+
if bias is not None:
|
| 79 |
+
bias = bias * self.b_mul
|
| 80 |
+
|
| 81 |
+
have_convolution = False
|
| 82 |
+
if self.upscale is not None and min(x.shape[2:]) * 2 >= 128:
|
| 83 |
+
# this is the fused upscale + conv from StyleGAN, sadly this seems incompatible with the non-fused way
|
| 84 |
+
# this really needs to be cleaned up and go into the conv...
|
| 85 |
+
w = self.weight * self.w_mul
|
| 86 |
+
w = w.permute(1, 0, 2, 3)
|
| 87 |
+
# probably applying a conv on w would be more efficient. also this quadruples the weight (average)?!
|
| 88 |
+
w = F.pad(w, (1, 1, 1, 1))
|
| 89 |
+
w = w[:, :, 1:, 1:] + w[:, :, :-1, 1:] + w[:, :, 1:, :-1] + w[:, :, :-1, :-1]
|
| 90 |
+
x = F.conv_transpose2d(x, w, stride=2, padding=int((w.size(-1) - 1) // 2))
|
| 91 |
+
have_convolution = True
|
| 92 |
+
elif self.upscale is not None:
|
| 93 |
+
x = self.upscale(x)
|
| 94 |
+
|
| 95 |
+
if not have_convolution and self.intermediate is None:
|
| 96 |
+
return F.conv2d(x, self.weight * self.w_mul, bias, padding=int(self.kernel_size // 2))
|
| 97 |
+
elif not have_convolution:
|
| 98 |
+
x = F.conv2d(x, self.weight * self.w_mul, None, padding=int(self.kernel_size // 2))
|
| 99 |
+
|
| 100 |
+
if self.intermediate is not None:
|
| 101 |
+
x = self.intermediate(x)
|
| 102 |
+
if bias is not None:
|
| 103 |
+
x = x + bias.view(1, -1, 1, 1)
|
| 104 |
+
return x
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class NoiseLayer(nn.Module):
|
| 108 |
+
"""adds noise. noise is per pixel (constant over channels) with per-channel weight"""
|
| 109 |
+
|
| 110 |
+
def __init__(self, channels):
|
| 111 |
+
super().__init__()
|
| 112 |
+
self.weight = nn.Parameter(torch.zeros(channels))
|
| 113 |
+
self.noise = None
|
| 114 |
+
|
| 115 |
+
def forward(self, x, noise=None):
|
| 116 |
+
if noise is None and self.noise is None:
|
| 117 |
+
noise = torch.randn(x.size(0), 1, x.size(2), x.size(3), device=x.device, dtype=x.dtype)
|
| 118 |
+
elif noise is None:
|
| 119 |
+
# here is a little trick: if you get all the noiselayers and set each
|
| 120 |
+
# modules .noise attribute, you can have pre-defined noise.
|
| 121 |
+
# Very useful for analysis
|
| 122 |
+
noise = self.noise
|
| 123 |
+
x = x + self.weight.view(1, -1, 1, 1) * noise
|
| 124 |
+
return x
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class StyleMod(nn.Module):
|
| 128 |
+
def __init__(self, latent_size, channels, use_wscale):
|
| 129 |
+
super(StyleMod, self).__init__()
|
| 130 |
+
self.lin = MyLinear(latent_size, channels * 2, gain=1.0, use_wscale=use_wscale)
|
| 131 |
+
|
| 132 |
+
def forward(self, x, latent):
|
| 133 |
+
style = self.lin(latent) # style => [batch_size, n_channels*2]
|
| 134 |
+
shape = [-1, 2, x.size(1)] + (x.dim() - 2) * [1]
|
| 135 |
+
style = style.view(shape) # [batch_size, 2, n_channels, ...]
|
| 136 |
+
x = x * (style[:, 0] + 1.0) + style[:, 1]
|
| 137 |
+
return x
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
class PixelNormLayer(nn.Module):
|
| 141 |
+
def __init__(self, epsilon=1e-8):
|
| 142 |
+
super().__init__()
|
| 143 |
+
self.epsilon = epsilon
|
| 144 |
+
|
| 145 |
+
def forward(self, x):
|
| 146 |
+
return x * torch.rsqrt(torch.mean(x ** 2, dim=1, keepdim=True) + self.epsilon)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class BlurLayer(nn.Module):
|
| 150 |
+
def __init__(self, kernel=[1, 2, 1], normalize=True, flip=False, stride=1):
|
| 151 |
+
super(BlurLayer, self).__init__()
|
| 152 |
+
kernel = [1, 2, 1]
|
| 153 |
+
kernel = torch.tensor(kernel, dtype=torch.float32)
|
| 154 |
+
kernel = kernel[:, None] * kernel[None, :]
|
| 155 |
+
kernel = kernel[None, None]
|
| 156 |
+
if normalize:
|
| 157 |
+
kernel = kernel / kernel.sum()
|
| 158 |
+
if flip:
|
| 159 |
+
kernel = kernel[:, :, ::-1, ::-1]
|
| 160 |
+
self.register_buffer("kernel", kernel)
|
| 161 |
+
self.stride = stride
|
| 162 |
+
|
| 163 |
+
def forward(self, x):
|
| 164 |
+
# expand kernel channels
|
| 165 |
+
kernel = self.kernel.expand(x.size(1), -1, -1, -1)
|
| 166 |
+
x = F.conv2d(x, kernel, stride=self.stride, padding=int((self.kernel.size(2) - 1) / 2), groups=x.size(1))
|
| 167 |
+
return x
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def upscale2d(x, factor=2, gain=1):
|
| 171 |
+
assert x.dim() == 4
|
| 172 |
+
if gain != 1:
|
| 173 |
+
x = x * gain
|
| 174 |
+
if factor != 1:
|
| 175 |
+
shape = x.shape
|
| 176 |
+
x = x.view(shape[0], shape[1], shape[2], 1, shape[3], 1).expand(-1, -1, -1, factor, -1, factor)
|
| 177 |
+
x = x.contiguous().view(shape[0], shape[1], factor * shape[2], factor * shape[3])
|
| 178 |
+
return x
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
class Upscale2d(nn.Module):
|
| 182 |
+
def __init__(self, factor=2, gain=1):
|
| 183 |
+
super().__init__()
|
| 184 |
+
assert isinstance(factor, int) and factor >= 1
|
| 185 |
+
self.gain = gain
|
| 186 |
+
self.factor = factor
|
| 187 |
+
|
| 188 |
+
def forward(self, x):
|
| 189 |
+
return upscale2d(x, factor=self.factor, gain=self.gain)
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
class G_mapping(nn.Sequential):
|
| 193 |
+
def __init__(self, nonlinearity="lrelu", use_wscale=True):
|
| 194 |
+
act, gain = {"relu": (torch.relu, np.sqrt(2)), "lrelu": (nn.LeakyReLU(negative_slope=0.2), np.sqrt(2))}[
|
| 195 |
+
nonlinearity
|
| 196 |
+
]
|
| 197 |
+
layers = [
|
| 198 |
+
("pixel_norm", PixelNormLayer()),
|
| 199 |
+
("dense0", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 200 |
+
("dense0_act", act),
|
| 201 |
+
("dense1", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 202 |
+
("dense1_act", act),
|
| 203 |
+
("dense2", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 204 |
+
("dense2_act", act),
|
| 205 |
+
("dense3", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 206 |
+
("dense3_act", act),
|
| 207 |
+
("dense4", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 208 |
+
("dense4_act", act),
|
| 209 |
+
("dense5", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 210 |
+
("dense5_act", act),
|
| 211 |
+
("dense6", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 212 |
+
("dense6_act", act),
|
| 213 |
+
("dense7", MyLinear(512, 512, gain=gain, lrmul=0.01, use_wscale=use_wscale)),
|
| 214 |
+
("dense7_act", act),
|
| 215 |
+
]
|
| 216 |
+
super().__init__(OrderedDict(layers))
|
| 217 |
+
|
| 218 |
+
def forward(self, x):
|
| 219 |
+
x = super().forward(x)
|
| 220 |
+
return x
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
class Truncation(nn.Module):
|
| 224 |
+
def __init__(self, avg_latent, max_layer=8, threshold=0.7):
|
| 225 |
+
super().__init__()
|
| 226 |
+
self.max_layer = max_layer
|
| 227 |
+
self.threshold = threshold
|
| 228 |
+
self.register_buffer("avg_latent", avg_latent)
|
| 229 |
+
|
| 230 |
+
def forward(self, x):
|
| 231 |
+
assert x.dim() == 3
|
| 232 |
+
interp = torch.lerp(self.avg_latent, x, self.threshold)
|
| 233 |
+
do_trunc = (torch.arange(x.size(1)) < self.max_layer).view(1, -1, 1)
|
| 234 |
+
return torch.where(do_trunc, interp, x)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
class LayerEpilogue(nn.Module):
|
| 238 |
+
"""Things to do at the end of each layer."""
|
| 239 |
+
|
| 240 |
+
def __init__(
|
| 241 |
+
self,
|
| 242 |
+
channels,
|
| 243 |
+
dlatent_size,
|
| 244 |
+
use_wscale,
|
| 245 |
+
use_noise,
|
| 246 |
+
use_pixel_norm,
|
| 247 |
+
use_instance_norm,
|
| 248 |
+
use_styles,
|
| 249 |
+
activation_layer,
|
| 250 |
+
):
|
| 251 |
+
super().__init__()
|
| 252 |
+
layers = []
|
| 253 |
+
if use_noise:
|
| 254 |
+
self.noise = NoiseLayer(channels)
|
| 255 |
+
else:
|
| 256 |
+
self.noise = None
|
| 257 |
+
layers.append(("activation", activation_layer))
|
| 258 |
+
if use_pixel_norm:
|
| 259 |
+
layers.append(("pixel_norm", PixelNormLayer()))
|
| 260 |
+
if use_instance_norm:
|
| 261 |
+
layers.append(("instance_norm", nn.InstanceNorm2d(channels)))
|
| 262 |
+
|
| 263 |
+
self.top_epi = nn.Sequential(OrderedDict(layers))
|
| 264 |
+
if use_styles:
|
| 265 |
+
self.style_mod = StyleMod(dlatent_size, channels, use_wscale=use_wscale)
|
| 266 |
+
else:
|
| 267 |
+
self.style_mod = None
|
| 268 |
+
|
| 269 |
+
def forward(self, x, dlatents_in_slice=None, noise_in_slice=None):
|
| 270 |
+
if self.noise is not None:
|
| 271 |
+
x = self.noise(x, noise=noise_in_slice)
|
| 272 |
+
x = self.top_epi(x)
|
| 273 |
+
if self.style_mod is not None:
|
| 274 |
+
x = self.style_mod(x, dlatents_in_slice)
|
| 275 |
+
else:
|
| 276 |
+
assert dlatents_in_slice is None
|
| 277 |
+
return x
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class InputBlock(nn.Module):
|
| 281 |
+
def __init__(
|
| 282 |
+
self,
|
| 283 |
+
nf,
|
| 284 |
+
dlatent_size,
|
| 285 |
+
const_input_layer,
|
| 286 |
+
gain,
|
| 287 |
+
use_wscale,
|
| 288 |
+
use_noise,
|
| 289 |
+
use_pixel_norm,
|
| 290 |
+
use_instance_norm,
|
| 291 |
+
use_styles,
|
| 292 |
+
activation_layer,
|
| 293 |
+
):
|
| 294 |
+
super().__init__()
|
| 295 |
+
self.const_input_layer = const_input_layer
|
| 296 |
+
self.nf = nf
|
| 297 |
+
if self.const_input_layer:
|
| 298 |
+
# called 'const' in tf
|
| 299 |
+
self.const = nn.Parameter(torch.ones(1, nf, 4, 4))
|
| 300 |
+
self.bias = nn.Parameter(torch.ones(nf))
|
| 301 |
+
else:
|
| 302 |
+
# tweak gain to match the official implementation of Progressing GAN
|
| 303 |
+
self.dense = MyLinear(dlatent_size, nf * 16, gain=gain / 4, use_wscale=use_wscale)
|
| 304 |
+
self.epi1 = LayerEpilogue(
|
| 305 |
+
nf, dlatent_size, use_wscale, use_noise, use_pixel_norm, use_instance_norm, use_styles, activation_layer
|
| 306 |
+
)
|
| 307 |
+
self.conv = MyConv2d(nf, nf, 3, gain=gain, use_wscale=use_wscale)
|
| 308 |
+
self.epi2 = LayerEpilogue(
|
| 309 |
+
nf, dlatent_size, use_wscale, use_noise, use_pixel_norm, use_instance_norm, use_styles, activation_layer
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
def forward(self, dlatents_in_range, noise_in_range):
|
| 313 |
+
batch_size = dlatents_in_range.size(0)
|
| 314 |
+
if self.const_input_layer:
|
| 315 |
+
x = self.const.expand(batch_size, -1, -1, -1)
|
| 316 |
+
x = x + self.bias.view(1, -1, 1, 1)
|
| 317 |
+
else:
|
| 318 |
+
x = self.dense(dlatents_in_range[:, 0]).view(batch_size, self.nf, 4, 4)
|
| 319 |
+
x = self.epi1(x, dlatents_in_range[:, 0], noise_in_range[0])
|
| 320 |
+
x = self.conv(x)
|
| 321 |
+
x = self.epi2(x, dlatents_in_range[:, 1], noise_in_range[1])
|
| 322 |
+
return x
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
class GSynthesisBlock(nn.Module):
|
| 326 |
+
def __init__(
|
| 327 |
+
self,
|
| 328 |
+
in_channels,
|
| 329 |
+
out_channels,
|
| 330 |
+
blur_filter,
|
| 331 |
+
dlatent_size,
|
| 332 |
+
gain,
|
| 333 |
+
use_wscale,
|
| 334 |
+
use_noise,
|
| 335 |
+
use_pixel_norm,
|
| 336 |
+
use_instance_norm,
|
| 337 |
+
use_styles,
|
| 338 |
+
activation_layer,
|
| 339 |
+
):
|
| 340 |
+
# 2**res x 2**res # res = 3..resolution_log2
|
| 341 |
+
super().__init__()
|
| 342 |
+
if blur_filter:
|
| 343 |
+
blur = BlurLayer(blur_filter)
|
| 344 |
+
else:
|
| 345 |
+
blur = None
|
| 346 |
+
self.conv0_up = MyConv2d(
|
| 347 |
+
in_channels, out_channels, kernel_size=3, gain=gain, use_wscale=use_wscale, intermediate=blur, upscale=True
|
| 348 |
+
)
|
| 349 |
+
self.epi1 = LayerEpilogue(
|
| 350 |
+
out_channels,
|
| 351 |
+
dlatent_size,
|
| 352 |
+
use_wscale,
|
| 353 |
+
use_noise,
|
| 354 |
+
use_pixel_norm,
|
| 355 |
+
use_instance_norm,
|
| 356 |
+
use_styles,
|
| 357 |
+
activation_layer,
|
| 358 |
+
)
|
| 359 |
+
self.conv1 = MyConv2d(out_channels, out_channels, kernel_size=3, gain=gain, use_wscale=use_wscale)
|
| 360 |
+
self.epi2 = LayerEpilogue(
|
| 361 |
+
out_channels,
|
| 362 |
+
dlatent_size,
|
| 363 |
+
use_wscale,
|
| 364 |
+
use_noise,
|
| 365 |
+
use_pixel_norm,
|
| 366 |
+
use_instance_norm,
|
| 367 |
+
use_styles,
|
| 368 |
+
activation_layer,
|
| 369 |
+
)
|
| 370 |
+
|
| 371 |
+
def forward(self, x, dlatents_in_range, noise_in_range):
|
| 372 |
+
x = self.conv0_up(x)
|
| 373 |
+
x = self.epi1(x, dlatents_in_range[:, 0], noise_in_range[0])
|
| 374 |
+
x = self.conv1(x)
|
| 375 |
+
x = self.epi2(x, dlatents_in_range[:, 1], noise_in_range[1])
|
| 376 |
+
return x
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
class G_synthesis(nn.Module):
|
| 380 |
+
def __init__(
|
| 381 |
+
self,
|
| 382 |
+
# Disentangled latent (W) dimensionality.
|
| 383 |
+
dlatent_size=512,
|
| 384 |
+
num_channels=3, # Number of output color channels.
|
| 385 |
+
resolution=1024, # Output resolution.
|
| 386 |
+
# Overall multiplier for the number of feature maps.
|
| 387 |
+
fmap_base=8192,
|
| 388 |
+
# log2 feature map reduction when doubling the resolution.
|
| 389 |
+
fmap_decay=1.0,
|
| 390 |
+
# Maximum number of feature maps in any layer.
|
| 391 |
+
fmap_max=512,
|
| 392 |
+
use_styles=True, # Enable style inputs?
|
| 393 |
+
const_input_layer=True, # First layer is a learned constant?
|
| 394 |
+
use_noise=True, # Enable noise inputs?
|
| 395 |
+
# True = randomize noise inputs every time (non-deterministic), False = read noise inputs from variables.
|
| 396 |
+
randomize_noise=True,
|
| 397 |
+
nonlinearity="lrelu", # Activation function: 'relu', 'lrelu'
|
| 398 |
+
use_wscale=True, # Enable equalized learning rate?
|
| 399 |
+
use_pixel_norm=False, # Enable pixelwise feature vector normalization?
|
| 400 |
+
use_instance_norm=True, # Enable instance normalization?
|
| 401 |
+
# Data type to use for activations and outputs.
|
| 402 |
+
dtype=torch.float32,
|
| 403 |
+
# Low-pass filter to apply when resampling activations. None = no filtering.
|
| 404 |
+
blur_filter=[1, 2, 1],
|
| 405 |
+
):
|
| 406 |
+
|
| 407 |
+
super().__init__()
|
| 408 |
+
|
| 409 |
+
def nf(stage):
|
| 410 |
+
return min(int(fmap_base / (2.0 ** (stage * fmap_decay))), fmap_max)
|
| 411 |
+
|
| 412 |
+
self.dlatent_size = dlatent_size
|
| 413 |
+
resolution_log2 = int(np.log2(resolution))
|
| 414 |
+
assert resolution == 2 ** resolution_log2 and resolution >= 4
|
| 415 |
+
|
| 416 |
+
act, gain = {"relu": (torch.relu, np.sqrt(2)), "lrelu": (nn.LeakyReLU(negative_slope=0.2), np.sqrt(2))}[
|
| 417 |
+
nonlinearity
|
| 418 |
+
]
|
| 419 |
+
blocks = []
|
| 420 |
+
for res in range(2, resolution_log2 + 1):
|
| 421 |
+
channels = nf(res - 1)
|
| 422 |
+
name = "{s}x{s}".format(s=2 ** res)
|
| 423 |
+
if res == 2:
|
| 424 |
+
blocks.append(
|
| 425 |
+
(
|
| 426 |
+
name,
|
| 427 |
+
InputBlock(
|
| 428 |
+
channels,
|
| 429 |
+
dlatent_size,
|
| 430 |
+
const_input_layer,
|
| 431 |
+
gain,
|
| 432 |
+
use_wscale,
|
| 433 |
+
use_noise,
|
| 434 |
+
use_pixel_norm,
|
| 435 |
+
use_instance_norm,
|
| 436 |
+
use_styles,
|
| 437 |
+
act,
|
| 438 |
+
),
|
| 439 |
+
)
|
| 440 |
+
)
|
| 441 |
+
|
| 442 |
+
else:
|
| 443 |
+
blocks.append(
|
| 444 |
+
(
|
| 445 |
+
name,
|
| 446 |
+
GSynthesisBlock(
|
| 447 |
+
last_channels,
|
| 448 |
+
channels,
|
| 449 |
+
blur_filter,
|
| 450 |
+
dlatent_size,
|
| 451 |
+
gain,
|
| 452 |
+
use_wscale,
|
| 453 |
+
use_noise,
|
| 454 |
+
use_pixel_norm,
|
| 455 |
+
use_instance_norm,
|
| 456 |
+
use_styles,
|
| 457 |
+
act,
|
| 458 |
+
),
|
| 459 |
+
)
|
| 460 |
+
)
|
| 461 |
+
last_channels = channels
|
| 462 |
+
self.torgb = MyConv2d(channels, num_channels, 1, gain=1, use_wscale=use_wscale)
|
| 463 |
+
self.blocks = nn.ModuleDict(OrderedDict(blocks))
|
| 464 |
+
|
| 465 |
+
def forward(self, dlatents_in, noise_in):
|
| 466 |
+
# Input: Disentangled latents (W) [minibatch, num_layers, dlatent_size].
|
| 467 |
+
# lod_in = tf.cast(tf.get_variable('lod', initializer=np.float32(0), trainable=False), dtype)
|
| 468 |
+
for i, m in enumerate(self.blocks.values()):
|
| 469 |
+
if i == 0:
|
| 470 |
+
x = m(dlatents_in[:, 2 * i : 2 * i + 2], noise_in[2 * i : 2 * i + 2])
|
| 471 |
+
else:
|
| 472 |
+
x = m(x, dlatents_in[:, 2 * i : 2 * i + 2], noise_in[2 * i : 2 * i + 2])
|
| 473 |
+
rgb = self.torgb(x)
|
| 474 |
+
return rgb
|
diffusion-posterior-sampling/bkse/models/dsd/stylegan2.py
ADDED
|
@@ -0,0 +1,621 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import random
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from models.dsd.op.fused_act import FusedLeakyReLU, fused_leaky_relu
|
| 6 |
+
from models.dsd.op.upfirdn2d import upfirdn2d
|
| 7 |
+
from torch import nn
|
| 8 |
+
from torch.nn import functional as F
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class PixelNorm(nn.Module):
|
| 12 |
+
def __init__(self):
|
| 13 |
+
super().__init__()
|
| 14 |
+
|
| 15 |
+
def forward(self, input):
|
| 16 |
+
return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def make_kernel(k):
|
| 20 |
+
k = torch.tensor(k, dtype=torch.float32)
|
| 21 |
+
|
| 22 |
+
if k.ndim == 1:
|
| 23 |
+
k = k[None, :] * k[:, None]
|
| 24 |
+
|
| 25 |
+
k /= k.sum()
|
| 26 |
+
|
| 27 |
+
return k
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class Upsample(nn.Module):
|
| 31 |
+
def __init__(self, kernel, factor=2):
|
| 32 |
+
super().__init__()
|
| 33 |
+
|
| 34 |
+
self.factor = factor
|
| 35 |
+
kernel = make_kernel(kernel) * (factor ** 2)
|
| 36 |
+
self.register_buffer("kernel", kernel)
|
| 37 |
+
|
| 38 |
+
p = kernel.shape[0] - factor
|
| 39 |
+
|
| 40 |
+
pad0 = (p + 1) // 2 + factor - 1
|
| 41 |
+
pad1 = p // 2
|
| 42 |
+
|
| 43 |
+
self.pad = (pad0, pad1)
|
| 44 |
+
|
| 45 |
+
def forward(self, input):
|
| 46 |
+
out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
|
| 47 |
+
|
| 48 |
+
return out
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class Downsample(nn.Module):
|
| 52 |
+
def __init__(self, kernel, factor=2):
|
| 53 |
+
super().__init__()
|
| 54 |
+
|
| 55 |
+
self.factor = factor
|
| 56 |
+
kernel = make_kernel(kernel)
|
| 57 |
+
self.register_buffer("kernel", kernel)
|
| 58 |
+
|
| 59 |
+
p = kernel.shape[0] - factor
|
| 60 |
+
|
| 61 |
+
pad0 = (p + 1) // 2
|
| 62 |
+
pad1 = p // 2
|
| 63 |
+
|
| 64 |
+
self.pad = (pad0, pad1)
|
| 65 |
+
|
| 66 |
+
def forward(self, input):
|
| 67 |
+
out = upfirdn2d(input, self.kernel, up=1, down=self.factor, pad=self.pad)
|
| 68 |
+
|
| 69 |
+
return out
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class Blur(nn.Module):
|
| 73 |
+
def __init__(self, kernel, pad, upsample_factor=1):
|
| 74 |
+
super().__init__()
|
| 75 |
+
|
| 76 |
+
kernel = make_kernel(kernel)
|
| 77 |
+
|
| 78 |
+
if upsample_factor > 1:
|
| 79 |
+
kernel = kernel * (upsample_factor ** 2)
|
| 80 |
+
|
| 81 |
+
self.register_buffer("kernel", kernel)
|
| 82 |
+
|
| 83 |
+
self.pad = pad
|
| 84 |
+
|
| 85 |
+
def forward(self, input):
|
| 86 |
+
out = upfirdn2d(input, self.kernel, pad=self.pad)
|
| 87 |
+
|
| 88 |
+
return out
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class EqualConv2d(nn.Module):
|
| 92 |
+
def __init__(self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True):
|
| 93 |
+
super().__init__()
|
| 94 |
+
|
| 95 |
+
self.weight = nn.Parameter(torch.randn(out_channel, in_channel, kernel_size, kernel_size))
|
| 96 |
+
self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
|
| 97 |
+
|
| 98 |
+
self.stride = stride
|
| 99 |
+
self.padding = padding
|
| 100 |
+
|
| 101 |
+
if bias:
|
| 102 |
+
self.bias = nn.Parameter(torch.zeros(out_channel))
|
| 103 |
+
|
| 104 |
+
else:
|
| 105 |
+
self.bias = None
|
| 106 |
+
|
| 107 |
+
def forward(self, input):
|
| 108 |
+
out = F.conv2d(
|
| 109 |
+
input,
|
| 110 |
+
self.weight * self.scale,
|
| 111 |
+
bias=self.bias,
|
| 112 |
+
stride=self.stride,
|
| 113 |
+
padding=self.padding,
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
return out
|
| 117 |
+
|
| 118 |
+
def __repr__(self):
|
| 119 |
+
return (
|
| 120 |
+
f"{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},"
|
| 121 |
+
f" {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})"
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class EqualLinear(nn.Module):
|
| 126 |
+
def __init__(self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None):
|
| 127 |
+
super().__init__()
|
| 128 |
+
|
| 129 |
+
self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
|
| 130 |
+
|
| 131 |
+
if bias:
|
| 132 |
+
self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
|
| 133 |
+
|
| 134 |
+
else:
|
| 135 |
+
self.bias = None
|
| 136 |
+
|
| 137 |
+
self.activation = activation
|
| 138 |
+
|
| 139 |
+
self.scale = (1 / math.sqrt(in_dim)) * lr_mul
|
| 140 |
+
self.lr_mul = lr_mul
|
| 141 |
+
|
| 142 |
+
def forward(self, input):
|
| 143 |
+
if self.activation:
|
| 144 |
+
out = F.linear(input, self.weight * self.scale)
|
| 145 |
+
out = fused_leaky_relu(out, self.bias * self.lr_mul)
|
| 146 |
+
|
| 147 |
+
else:
|
| 148 |
+
out = F.linear(input, self.weight * self.scale, bias=self.bias * self.lr_mul)
|
| 149 |
+
|
| 150 |
+
return out
|
| 151 |
+
|
| 152 |
+
def __repr__(self):
|
| 153 |
+
return f"{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})"
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
class ModulatedConv2d(nn.Module):
|
| 157 |
+
def __init__(
|
| 158 |
+
self,
|
| 159 |
+
in_channel,
|
| 160 |
+
out_channel,
|
| 161 |
+
kernel_size,
|
| 162 |
+
style_dim,
|
| 163 |
+
demodulate=True,
|
| 164 |
+
upsample=False,
|
| 165 |
+
downsample=False,
|
| 166 |
+
blur_kernel=[1, 3, 3, 1],
|
| 167 |
+
):
|
| 168 |
+
super().__init__()
|
| 169 |
+
|
| 170 |
+
self.eps = 1e-8
|
| 171 |
+
self.kernel_size = kernel_size
|
| 172 |
+
self.in_channel = in_channel
|
| 173 |
+
self.out_channel = out_channel
|
| 174 |
+
self.upsample = upsample
|
| 175 |
+
self.downsample = downsample
|
| 176 |
+
|
| 177 |
+
if upsample:
|
| 178 |
+
factor = 2
|
| 179 |
+
p = (len(blur_kernel) - factor) - (kernel_size - 1)
|
| 180 |
+
pad0 = (p + 1) // 2 + factor - 1
|
| 181 |
+
pad1 = p // 2 + 1
|
| 182 |
+
|
| 183 |
+
self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
|
| 184 |
+
|
| 185 |
+
if downsample:
|
| 186 |
+
factor = 2
|
| 187 |
+
p = (len(blur_kernel) - factor) + (kernel_size - 1)
|
| 188 |
+
pad0 = (p + 1) // 2
|
| 189 |
+
pad1 = p // 2
|
| 190 |
+
|
| 191 |
+
self.blur = Blur(blur_kernel, pad=(pad0, pad1))
|
| 192 |
+
|
| 193 |
+
fan_in = in_channel * kernel_size ** 2
|
| 194 |
+
self.scale = 1 / math.sqrt(fan_in)
|
| 195 |
+
self.padding = kernel_size // 2
|
| 196 |
+
|
| 197 |
+
self.weight = nn.Parameter(torch.randn(1, out_channel, in_channel, kernel_size, kernel_size))
|
| 198 |
+
|
| 199 |
+
self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
|
| 200 |
+
|
| 201 |
+
self.demodulate = demodulate
|
| 202 |
+
|
| 203 |
+
def __repr__(self):
|
| 204 |
+
return (
|
| 205 |
+
f"{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, "
|
| 206 |
+
f"upsample={self.upsample}, downsample={self.downsample})"
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
def forward(self, input, style):
|
| 210 |
+
batch, in_channel, height, width = input.shape
|
| 211 |
+
|
| 212 |
+
style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
|
| 213 |
+
weight = self.scale * self.weight * style
|
| 214 |
+
|
| 215 |
+
if self.demodulate:
|
| 216 |
+
demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
|
| 217 |
+
weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
|
| 218 |
+
|
| 219 |
+
weight = weight.view(batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size)
|
| 220 |
+
|
| 221 |
+
if self.upsample:
|
| 222 |
+
input = input.view(1, batch * in_channel, height, width)
|
| 223 |
+
weight = weight.view(batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size)
|
| 224 |
+
weight = weight.transpose(1, 2).reshape(
|
| 225 |
+
batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
|
| 226 |
+
)
|
| 227 |
+
out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
|
| 228 |
+
_, _, height, width = out.shape
|
| 229 |
+
out = out.view(batch, self.out_channel, height, width)
|
| 230 |
+
out = self.blur(out)
|
| 231 |
+
|
| 232 |
+
elif self.downsample:
|
| 233 |
+
input = self.blur(input)
|
| 234 |
+
_, _, height, width = input.shape
|
| 235 |
+
input = input.view(1, batch * in_channel, height, width)
|
| 236 |
+
out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
|
| 237 |
+
_, _, height, width = out.shape
|
| 238 |
+
out = out.view(batch, self.out_channel, height, width)
|
| 239 |
+
|
| 240 |
+
else:
|
| 241 |
+
input = input.view(1, batch * in_channel, height, width)
|
| 242 |
+
out = F.conv2d(input, weight, padding=self.padding, groups=batch)
|
| 243 |
+
_, _, height, width = out.shape
|
| 244 |
+
out = out.view(batch, self.out_channel, height, width)
|
| 245 |
+
|
| 246 |
+
return out
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
class NoiseInjection(nn.Module):
|
| 250 |
+
def __init__(self):
|
| 251 |
+
super().__init__()
|
| 252 |
+
|
| 253 |
+
self.weight = nn.Parameter(torch.zeros(1))
|
| 254 |
+
|
| 255 |
+
def forward(self, image, noise=None):
|
| 256 |
+
if noise is None:
|
| 257 |
+
batch, _, height, width = image.shape
|
| 258 |
+
noise = image.new_empty(batch, 1, height, width).normal_()
|
| 259 |
+
|
| 260 |
+
return image + self.weight * noise
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
class ConstantInput(nn.Module):
|
| 264 |
+
def __init__(self, channel, size=4):
|
| 265 |
+
super().__init__()
|
| 266 |
+
|
| 267 |
+
self.input = nn.Parameter(torch.randn(1, channel, size, size))
|
| 268 |
+
|
| 269 |
+
def forward(self, input):
|
| 270 |
+
batch = input.shape[0]
|
| 271 |
+
out = self.input.repeat(batch, 1, 1, 1)
|
| 272 |
+
|
| 273 |
+
return out
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
class StyledConv(nn.Module):
|
| 277 |
+
def __init__(
|
| 278 |
+
self,
|
| 279 |
+
in_channel,
|
| 280 |
+
out_channel,
|
| 281 |
+
kernel_size,
|
| 282 |
+
style_dim,
|
| 283 |
+
upsample=False,
|
| 284 |
+
blur_kernel=[1, 3, 3, 1],
|
| 285 |
+
demodulate=True,
|
| 286 |
+
):
|
| 287 |
+
super().__init__()
|
| 288 |
+
|
| 289 |
+
self.conv = ModulatedConv2d(
|
| 290 |
+
in_channel,
|
| 291 |
+
out_channel,
|
| 292 |
+
kernel_size,
|
| 293 |
+
style_dim,
|
| 294 |
+
upsample=upsample,
|
| 295 |
+
blur_kernel=blur_kernel,
|
| 296 |
+
demodulate=demodulate,
|
| 297 |
+
)
|
| 298 |
+
|
| 299 |
+
self.noise = NoiseInjection()
|
| 300 |
+
# self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
|
| 301 |
+
# self.activate = ScaledLeakyReLU(0.2)
|
| 302 |
+
self.activate = FusedLeakyReLU(out_channel)
|
| 303 |
+
|
| 304 |
+
def forward(self, input, style, noise=None):
|
| 305 |
+
out = self.conv(input, style)
|
| 306 |
+
out = self.noise(out, noise=noise)
|
| 307 |
+
# out = out + self.bias
|
| 308 |
+
out = self.activate(out)
|
| 309 |
+
|
| 310 |
+
return out
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
class ToRGB(nn.Module):
|
| 314 |
+
def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
|
| 315 |
+
super().__init__()
|
| 316 |
+
|
| 317 |
+
if upsample:
|
| 318 |
+
self.upsample = Upsample(blur_kernel)
|
| 319 |
+
|
| 320 |
+
self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
|
| 321 |
+
self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
|
| 322 |
+
|
| 323 |
+
def forward(self, input, style, skip=None):
|
| 324 |
+
out = self.conv(input, style)
|
| 325 |
+
out = out + self.bias
|
| 326 |
+
|
| 327 |
+
if skip is not None:
|
| 328 |
+
skip = self.upsample(skip)
|
| 329 |
+
|
| 330 |
+
out = out + skip
|
| 331 |
+
|
| 332 |
+
return out
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
class Generator(nn.Module):
|
| 336 |
+
def __init__(
|
| 337 |
+
self,
|
| 338 |
+
size,
|
| 339 |
+
style_dim,
|
| 340 |
+
n_mlp,
|
| 341 |
+
channel_multiplier=2,
|
| 342 |
+
blur_kernel=[1, 3, 3, 1],
|
| 343 |
+
lr_mlp=0.01,
|
| 344 |
+
):
|
| 345 |
+
super().__init__()
|
| 346 |
+
|
| 347 |
+
self.size = size
|
| 348 |
+
|
| 349 |
+
self.style_dim = style_dim
|
| 350 |
+
|
| 351 |
+
layers = [PixelNorm()]
|
| 352 |
+
|
| 353 |
+
for i in range(n_mlp):
|
| 354 |
+
layers.append(EqualLinear(style_dim, style_dim, lr_mul=lr_mlp, activation="fused_lrelu"))
|
| 355 |
+
|
| 356 |
+
self.style = nn.Sequential(*layers)
|
| 357 |
+
|
| 358 |
+
self.channels = {
|
| 359 |
+
4: 512,
|
| 360 |
+
8: 512,
|
| 361 |
+
16: 512,
|
| 362 |
+
32: 512,
|
| 363 |
+
64: 256 * channel_multiplier,
|
| 364 |
+
128: 128 * channel_multiplier,
|
| 365 |
+
256: 64 * channel_multiplier,
|
| 366 |
+
512: 32 * channel_multiplier,
|
| 367 |
+
1024: 16 * channel_multiplier,
|
| 368 |
+
}
|
| 369 |
+
|
| 370 |
+
self.input = ConstantInput(self.channels[4])
|
| 371 |
+
self.conv1 = StyledConv(self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel)
|
| 372 |
+
self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)
|
| 373 |
+
|
| 374 |
+
self.log_size = int(math.log(size, 2))
|
| 375 |
+
self.num_layers = (self.log_size - 2) * 2 + 1
|
| 376 |
+
|
| 377 |
+
self.convs = nn.ModuleList()
|
| 378 |
+
self.upsamples = nn.ModuleList()
|
| 379 |
+
self.to_rgbs = nn.ModuleList()
|
| 380 |
+
self.noises = nn.Module()
|
| 381 |
+
|
| 382 |
+
in_channel = self.channels[4]
|
| 383 |
+
|
| 384 |
+
for layer_idx in range(self.num_layers):
|
| 385 |
+
res = (layer_idx + 5) // 2
|
| 386 |
+
shape = [1, 1, 2 ** res, 2 ** res]
|
| 387 |
+
self.noises.register_buffer(f"noise_{layer_idx}", torch.randn(*shape))
|
| 388 |
+
|
| 389 |
+
for i in range(3, self.log_size + 1):
|
| 390 |
+
out_channel = self.channels[2 ** i]
|
| 391 |
+
|
| 392 |
+
self.convs.append(
|
| 393 |
+
StyledConv(
|
| 394 |
+
in_channel,
|
| 395 |
+
out_channel,
|
| 396 |
+
3,
|
| 397 |
+
style_dim,
|
| 398 |
+
upsample=True,
|
| 399 |
+
blur_kernel=blur_kernel,
|
| 400 |
+
)
|
| 401 |
+
)
|
| 402 |
+
|
| 403 |
+
self.convs.append(StyledConv(out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel))
|
| 404 |
+
|
| 405 |
+
self.to_rgbs.append(ToRGB(out_channel, style_dim))
|
| 406 |
+
|
| 407 |
+
in_channel = out_channel
|
| 408 |
+
|
| 409 |
+
self.n_latent = self.log_size * 2 - 2
|
| 410 |
+
|
| 411 |
+
def make_noise(self):
|
| 412 |
+
device = self.input.input.device
|
| 413 |
+
|
| 414 |
+
noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
|
| 415 |
+
|
| 416 |
+
for i in range(3, self.log_size + 1):
|
| 417 |
+
for _ in range(2):
|
| 418 |
+
noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
|
| 419 |
+
|
| 420 |
+
return noises
|
| 421 |
+
|
| 422 |
+
def mean_latent(self, n_latent):
|
| 423 |
+
latent_in = torch.randn(n_latent, self.style_dim, device=self.input.input.device)
|
| 424 |
+
latent = self.style(latent_in).mean(0, keepdim=True)
|
| 425 |
+
|
| 426 |
+
return latent
|
| 427 |
+
|
| 428 |
+
def get_latent(self, input):
|
| 429 |
+
return self.style(input)
|
| 430 |
+
|
| 431 |
+
def forward(
|
| 432 |
+
self,
|
| 433 |
+
styles,
|
| 434 |
+
return_latents=False,
|
| 435 |
+
inject_index=None,
|
| 436 |
+
truncation=1,
|
| 437 |
+
truncation_latent=None,
|
| 438 |
+
input_is_latent=False,
|
| 439 |
+
noise=None,
|
| 440 |
+
randomize_noise=True,
|
| 441 |
+
):
|
| 442 |
+
if not input_is_latent:
|
| 443 |
+
styles = [self.style(s) for s in styles]
|
| 444 |
+
|
| 445 |
+
if noise is None:
|
| 446 |
+
if randomize_noise:
|
| 447 |
+
noise = [None] * self.num_layers
|
| 448 |
+
else:
|
| 449 |
+
noise = [getattr(self.noises, f"noise_{i}") for i in range(self.num_layers)]
|
| 450 |
+
|
| 451 |
+
if truncation < 1:
|
| 452 |
+
style_t = []
|
| 453 |
+
|
| 454 |
+
for style in styles:
|
| 455 |
+
style_t.append(truncation_latent + truncation * (style - truncation_latent))
|
| 456 |
+
|
| 457 |
+
styles = style_t
|
| 458 |
+
|
| 459 |
+
if len(styles) < 2:
|
| 460 |
+
inject_index = self.n_latent
|
| 461 |
+
|
| 462 |
+
if styles[0].ndim < 3:
|
| 463 |
+
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
|
| 464 |
+
|
| 465 |
+
else:
|
| 466 |
+
latent = styles[0]
|
| 467 |
+
|
| 468 |
+
else:
|
| 469 |
+
if inject_index is None:
|
| 470 |
+
inject_index = random.randint(1, self.n_latent - 1)
|
| 471 |
+
|
| 472 |
+
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
|
| 473 |
+
latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
|
| 474 |
+
|
| 475 |
+
latent = torch.cat([latent, latent2], 1)
|
| 476 |
+
|
| 477 |
+
out = self.input(latent)
|
| 478 |
+
out = self.conv1(out, latent[:, 0], noise=noise[0])
|
| 479 |
+
|
| 480 |
+
skip = self.to_rgb1(out, latent[:, 1])
|
| 481 |
+
|
| 482 |
+
i = 1
|
| 483 |
+
for conv1, conv2, noise1, noise2, to_rgb in zip(
|
| 484 |
+
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
|
| 485 |
+
):
|
| 486 |
+
out = conv1(out, latent[:, i], noise=noise1)
|
| 487 |
+
out = conv2(out, latent[:, i + 1], noise=noise2)
|
| 488 |
+
skip = to_rgb(out, latent[:, i + 2], skip)
|
| 489 |
+
|
| 490 |
+
i += 2
|
| 491 |
+
|
| 492 |
+
image = skip
|
| 493 |
+
|
| 494 |
+
if return_latents:
|
| 495 |
+
return image, latent
|
| 496 |
+
|
| 497 |
+
else:
|
| 498 |
+
return image, None
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
class ConvLayer(nn.Sequential):
|
| 502 |
+
def __init__(
|
| 503 |
+
self,
|
| 504 |
+
in_channel,
|
| 505 |
+
out_channel,
|
| 506 |
+
kernel_size,
|
| 507 |
+
downsample=False,
|
| 508 |
+
blur_kernel=[1, 3, 3, 1],
|
| 509 |
+
bias=True,
|
| 510 |
+
activate=True,
|
| 511 |
+
):
|
| 512 |
+
layers = []
|
| 513 |
+
|
| 514 |
+
if downsample:
|
| 515 |
+
factor = 2
|
| 516 |
+
p = (len(blur_kernel) - factor) + (kernel_size - 1)
|
| 517 |
+
pad0 = (p + 1) // 2
|
| 518 |
+
pad1 = p // 2
|
| 519 |
+
|
| 520 |
+
layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
|
| 521 |
+
|
| 522 |
+
stride = 2
|
| 523 |
+
self.padding = 0
|
| 524 |
+
|
| 525 |
+
else:
|
| 526 |
+
stride = 1
|
| 527 |
+
self.padding = kernel_size // 2
|
| 528 |
+
|
| 529 |
+
layers.append(
|
| 530 |
+
EqualConv2d(
|
| 531 |
+
in_channel,
|
| 532 |
+
out_channel,
|
| 533 |
+
kernel_size,
|
| 534 |
+
padding=self.padding,
|
| 535 |
+
stride=stride,
|
| 536 |
+
bias=bias and not activate,
|
| 537 |
+
)
|
| 538 |
+
)
|
| 539 |
+
|
| 540 |
+
if activate:
|
| 541 |
+
layers.append(FusedLeakyReLU(out_channel, bias=bias))
|
| 542 |
+
|
| 543 |
+
super().__init__(*layers)
|
| 544 |
+
|
| 545 |
+
|
| 546 |
+
class ResBlock(nn.Module):
|
| 547 |
+
def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
|
| 548 |
+
super().__init__()
|
| 549 |
+
|
| 550 |
+
self.conv1 = ConvLayer(in_channel, in_channel, 3)
|
| 551 |
+
self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
|
| 552 |
+
|
| 553 |
+
self.skip = ConvLayer(in_channel, out_channel, 1, downsample=True, activate=False, bias=False)
|
| 554 |
+
|
| 555 |
+
def forward(self, input):
|
| 556 |
+
out = self.conv1(input)
|
| 557 |
+
out = self.conv2(out)
|
| 558 |
+
|
| 559 |
+
skip = self.skip(input)
|
| 560 |
+
out = (out + skip) / math.sqrt(2)
|
| 561 |
+
|
| 562 |
+
return out
|
| 563 |
+
|
| 564 |
+
|
| 565 |
+
class Discriminator(nn.Module):
|
| 566 |
+
def __init__(self, size, channel_multiplier=2, blur_kernel=[1, 3, 3, 1]):
|
| 567 |
+
super().__init__()
|
| 568 |
+
|
| 569 |
+
channels = {
|
| 570 |
+
4: 512,
|
| 571 |
+
8: 512,
|
| 572 |
+
16: 512,
|
| 573 |
+
32: 512,
|
| 574 |
+
64: 256 * channel_multiplier,
|
| 575 |
+
128: 128 * channel_multiplier,
|
| 576 |
+
256: 64 * channel_multiplier,
|
| 577 |
+
512: 32 * channel_multiplier,
|
| 578 |
+
1024: 16 * channel_multiplier,
|
| 579 |
+
}
|
| 580 |
+
|
| 581 |
+
convs = [ConvLayer(3, channels[size], 1)]
|
| 582 |
+
|
| 583 |
+
log_size = int(math.log(size, 2))
|
| 584 |
+
|
| 585 |
+
in_channel = channels[size]
|
| 586 |
+
|
| 587 |
+
for i in range(log_size, 2, -1):
|
| 588 |
+
out_channel = channels[2 ** (i - 1)]
|
| 589 |
+
|
| 590 |
+
convs.append(ResBlock(in_channel, out_channel, blur_kernel))
|
| 591 |
+
|
| 592 |
+
in_channel = out_channel
|
| 593 |
+
|
| 594 |
+
self.convs = nn.Sequential(*convs)
|
| 595 |
+
|
| 596 |
+
self.stddev_group = 4
|
| 597 |
+
self.stddev_feat = 1
|
| 598 |
+
|
| 599 |
+
self.final_conv = ConvLayer(in_channel + 1, channels[4], 3)
|
| 600 |
+
self.final_linear = nn.Sequential(
|
| 601 |
+
EqualLinear(channels[4] * 4 * 4, channels[4], activation="fused_lrelu"),
|
| 602 |
+
EqualLinear(channels[4], 1),
|
| 603 |
+
)
|
| 604 |
+
|
| 605 |
+
def forward(self, input):
|
| 606 |
+
out = self.convs(input)
|
| 607 |
+
|
| 608 |
+
batch, channel, height, width = out.shape
|
| 609 |
+
group = min(batch, self.stddev_group)
|
| 610 |
+
stddev = out.view(group, -1, self.stddev_feat, channel // self.stddev_feat, height, width)
|
| 611 |
+
stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
|
| 612 |
+
stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
|
| 613 |
+
stddev = stddev.repeat(group, 1, height, width)
|
| 614 |
+
out = torch.cat([out, stddev], 1)
|
| 615 |
+
|
| 616 |
+
out = self.final_conv(out)
|
| 617 |
+
|
| 618 |
+
out = out.view(batch, -1)
|
| 619 |
+
out = self.final_linear(out)
|
| 620 |
+
|
| 621 |
+
return out
|
diffusion-posterior-sampling/bkse/models/kernel_encoding/base_model.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from collections import OrderedDict
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from torch.nn.parallel import DistributedDataParallel
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BaseModel:
|
| 10 |
+
def __init__(self, opt):
|
| 11 |
+
self.opt = opt
|
| 12 |
+
self.device = torch.device("cuda" if opt["gpu_ids"] is not None else "cpu")
|
| 13 |
+
self.is_train = opt["is_train"]
|
| 14 |
+
self.schedulers = []
|
| 15 |
+
self.optimizers = []
|
| 16 |
+
|
| 17 |
+
def feed_data(self, data):
|
| 18 |
+
pass
|
| 19 |
+
|
| 20 |
+
def optimize_parameters(self):
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
def get_current_visuals(self):
|
| 24 |
+
pass
|
| 25 |
+
|
| 26 |
+
def get_current_losses(self):
|
| 27 |
+
pass
|
| 28 |
+
|
| 29 |
+
def print_network(self):
|
| 30 |
+
pass
|
| 31 |
+
|
| 32 |
+
def save(self, label):
|
| 33 |
+
pass
|
| 34 |
+
|
| 35 |
+
def load(self):
|
| 36 |
+
pass
|
| 37 |
+
|
| 38 |
+
def _set_lr(self, lr_groups_l):
|
| 39 |
+
"""Set learning rate for warmup
|
| 40 |
+
lr_groups_l: list for lr_groups. each for a optimizer"""
|
| 41 |
+
for optimizer, lr_groups in zip(self.optimizers, lr_groups_l):
|
| 42 |
+
for param_group, lr in zip(optimizer.param_groups, lr_groups):
|
| 43 |
+
param_group["lr"] = lr
|
| 44 |
+
|
| 45 |
+
def _get_init_lr(self):
|
| 46 |
+
"""Get the initial lr, which is set by the scheduler"""
|
| 47 |
+
init_lr_groups_l = []
|
| 48 |
+
for optimizer in self.optimizers:
|
| 49 |
+
init_lr_groups_l.append([v["initial_lr"] for v in optimizer.param_groups])
|
| 50 |
+
return init_lr_groups_l
|
| 51 |
+
|
| 52 |
+
def update_learning_rate(self, cur_iter, warmup_iter=-1):
|
| 53 |
+
for scheduler in self.schedulers:
|
| 54 |
+
scheduler.step()
|
| 55 |
+
# set up warm-up learning rate
|
| 56 |
+
if cur_iter < warmup_iter:
|
| 57 |
+
# get initial lr for each group
|
| 58 |
+
init_lr_g_l = self._get_init_lr()
|
| 59 |
+
# modify warming-up learning rates
|
| 60 |
+
warm_up_lr_l = []
|
| 61 |
+
for init_lr_g in init_lr_g_l:
|
| 62 |
+
warm_up_lr_l.append([v / warmup_iter * cur_iter for v in init_lr_g])
|
| 63 |
+
# set learning rate
|
| 64 |
+
self._set_lr(warm_up_lr_l)
|
| 65 |
+
|
| 66 |
+
def get_current_learning_rate(self):
|
| 67 |
+
return [param_group["lr"] for param_group in self.optimizers[0].param_groups]
|
| 68 |
+
|
| 69 |
+
def get_network_description(self, network):
|
| 70 |
+
"""Get the string and total parameters of the network"""
|
| 71 |
+
if isinstance(network, nn.DataParallel) or isinstance(network, DistributedDataParallel):
|
| 72 |
+
network = network.module
|
| 73 |
+
return str(network), sum(map(lambda x: x.numel(), network.parameters()))
|
| 74 |
+
|
| 75 |
+
def save_network(self, network, network_label, iter_label):
|
| 76 |
+
save_filename = "{}_{}.pth".format(iter_label, network_label)
|
| 77 |
+
save_path = os.path.join(self.opt["path"]["models"], save_filename)
|
| 78 |
+
if isinstance(network, nn.DataParallel) or isinstance(network, DistributedDataParallel):
|
| 79 |
+
network = network.module
|
| 80 |
+
state_dict = network.state_dict()
|
| 81 |
+
for key, param in state_dict.items():
|
| 82 |
+
state_dict[key] = param.cpu()
|
| 83 |
+
torch.save(state_dict, save_path)
|
| 84 |
+
|
| 85 |
+
def load_network(self, load_path, network, strict=True, prefix=""):
|
| 86 |
+
if isinstance(network, nn.DataParallel) or isinstance(network, DistributedDataParallel):
|
| 87 |
+
network = network.module
|
| 88 |
+
load_net = torch.load(load_path)
|
| 89 |
+
load_net_clean = OrderedDict() # remove unnecessary 'module.'
|
| 90 |
+
for k, v in load_net.items():
|
| 91 |
+
if k.startswith("module."):
|
| 92 |
+
load_net_clean[k[7:]] = v
|
| 93 |
+
else:
|
| 94 |
+
load_net_clean[k] = v
|
| 95 |
+
load_net.update(load_net_clean)
|
| 96 |
+
|
| 97 |
+
model_dict = network.state_dict()
|
| 98 |
+
for k, v in load_net.items():
|
| 99 |
+
k = prefix + k
|
| 100 |
+
if (k in model_dict) and (v.shape == model_dict[k].shape):
|
| 101 |
+
model_dict[k] = v
|
| 102 |
+
else:
|
| 103 |
+
print("Load failed:", k)
|
| 104 |
+
|
| 105 |
+
network.load_state_dict(model_dict, strict=True)
|
| 106 |
+
|
| 107 |
+
def save_training_state(self, epoch, iter_step):
|
| 108 |
+
"""
|
| 109 |
+
Save training state during training,
|
| 110 |
+
which will be used for resuming
|
| 111 |
+
"""
|
| 112 |
+
|
| 113 |
+
state = {"epoch": epoch, "iter": iter_step, "schedulers": [], "optimizers": []}
|
| 114 |
+
for s in self.schedulers:
|
| 115 |
+
state["schedulers"].append(s.state_dict())
|
| 116 |
+
for o in self.optimizers:
|
| 117 |
+
state["optimizers"].append(o.state_dict())
|
| 118 |
+
save_filename = "{}.state".format(iter_step)
|
| 119 |
+
save_path = os.path.join(self.opt["path"]["training_state"], save_filename)
|
| 120 |
+
torch.save(state, save_path)
|
| 121 |
+
|
| 122 |
+
def resume_training(self, resume_state):
|
| 123 |
+
"""Resume the optimizers and schedulers for training"""
|
| 124 |
+
resume_optimizers = resume_state["optimizers"]
|
| 125 |
+
resume_schedulers = resume_state["schedulers"]
|
| 126 |
+
assert len(resume_optimizers) == len(self.optimizers), "Wrong lengths of optimizers"
|
| 127 |
+
assert len(resume_schedulers) == len(self.schedulers), "Wrong lengths of schedulers"
|
| 128 |
+
for i, o in enumerate(resume_optimizers):
|
| 129 |
+
self.optimizers[i].load_state_dict(o)
|
| 130 |
+
for i, s in enumerate(resume_schedulers):
|
| 131 |
+
self.schedulers[i].load_state_dict(s)
|