Spaces:
Running
on
Zero


Running
on
Zero
SingleZombie
commited on
Commit
·
ff715ca
1
Parent(s):
21b374f
upload files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- LICENSE.md +14 -0
- README.md +208 -0
- config/config_boxer.yaml +27 -0
- config/config_carturn.yaml +30 -0
- config/config_dog.yaml +27 -0
- config/config_music.yaml +27 -0
- install.py +95 -0
- requirements.txt +11 -0
- run_fresco.ipynb +0 -0
- run_fresco.py +318 -0
- src/ControlNet/annotator/canny/__init__.py +6 -0
- src/ControlNet/annotator/ckpts/ckpts.txt +1 -0
- src/ControlNet/annotator/hed/__init__.py +96 -0
- src/ControlNet/annotator/midas/LICENSE +21 -0
- src/ControlNet/annotator/midas/__init__.py +42 -0
- src/ControlNet/annotator/midas/api.py +169 -0
- src/ControlNet/annotator/midas/midas/__init__.py +0 -0
- src/ControlNet/annotator/midas/midas/base_model.py +16 -0
- src/ControlNet/annotator/midas/midas/blocks.py +342 -0
- src/ControlNet/annotator/midas/midas/dpt_depth.py +109 -0
- src/ControlNet/annotator/midas/midas/midas_net.py +76 -0
- src/ControlNet/annotator/midas/midas/midas_net_custom.py +128 -0
- src/ControlNet/annotator/midas/midas/transforms.py +234 -0
- src/ControlNet/annotator/midas/midas/vit.py +491 -0
- src/ControlNet/annotator/midas/utils.py +189 -0
- src/ControlNet/annotator/mlsd/LICENSE +201 -0
- src/ControlNet/annotator/mlsd/__init__.py +43 -0
- src/ControlNet/annotator/mlsd/models/mbv2_mlsd_large.py +292 -0
- src/ControlNet/annotator/mlsd/models/mbv2_mlsd_tiny.py +275 -0
- src/ControlNet/annotator/mlsd/utils.py +580 -0
- src/ControlNet/annotator/openpose/LICENSE +108 -0
- src/ControlNet/annotator/openpose/__init__.py +49 -0
- src/ControlNet/annotator/openpose/body.py +219 -0
- src/ControlNet/annotator/openpose/hand.py +86 -0
- src/ControlNet/annotator/openpose/model.py +219 -0
- src/ControlNet/annotator/openpose/util.py +164 -0
- src/ControlNet/annotator/util.py +38 -0
- src/EGNet/README.md +49 -0
- src/EGNet/dataset.py +283 -0
- src/EGNet/model.py +208 -0
- src/EGNet/resnet.py +301 -0
- src/EGNet/run.py +68 -0
- src/EGNet/sal2edge.m +34 -0
- src/EGNet/solver.py +230 -0
- src/EGNet/vgg.py +273 -0
- src/diffusion_hacked.py +957 -0
- src/ebsynth/blender/guide.py +104 -0
- src/ebsynth/blender/histogram_blend.py +50 -0
- src/ebsynth/blender/poisson_fusion.py +93 -0
- src/ebsynth/blender/video_sequence.py +187 -0
LICENSE.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# S-Lab License 1.0
|
| 2 |
+
|
| 3 |
+
Copyright 2024 S-Lab
|
| 4 |
+
|
| 5 |
+
Redistribution and use for non-commercial purpose in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 6 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 7 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 8 |
+
3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.\
|
| 9 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 10 |
+
4. In the event that redistribution and/or use for commercial purpose in source or binary forms, with or without modification is required, please contact the contributor(s) of the work.
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
---
|
| 14 |
+
For the commercial use of the code, please consult Prof. Chen Change Loy (ccloy@ntu.edu.sg)
|
README.md
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FRESCO - Official PyTorch Implementation
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
**FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation**<br>
|
| 5 |
+
[Shuai Yang](https://williamyang1991.github.io/), [Yifan Zhou](https://zhouyifan.net/), [Ziwei Liu](https://liuziwei7.github.io/) and [Chen Change Loy](https://www.mmlab-ntu.com/person/ccloy/)<br>
|
| 6 |
+
in CVPR 2024 <br>
|
| 7 |
+
[**Project Page**](https://www.mmlab-ntu.com/project/fresco/) | [**Paper**](https://arxiv.org/abs/2403.12962) | [**Supplementary Video**](https://youtu.be/jLnGx5H-wLw) | [**Input Data and Video Results**](https://drive.google.com/file/d/12BFx3hp8_jp9m0EmKpw-cus2SABPQx2Q/view?usp=sharing) <br>
|
| 8 |
+
|
| 9 |
+
**Abstract:** *The remarkable efficacy of text-to-image diffusion models has motivated extensive exploration of their potential application in video domains.
|
| 10 |
+
Zero-shot methods seek to extend image diffusion models to videos without necessitating model training.
|
| 11 |
+
Recent methods mainly focus on incorporating inter-frame correspondence into attention mechanisms. However, the soft constraint imposed on determining where to attend to valid features can sometimes be insufficient, resulting in temporal inconsistency.
|
| 12 |
+
In this paper, we introduce FRESCO, intra-frame correspondence alongside inter-frame correspondence to establish a more robust spatial-temporal constraint. This enhancement ensures a more consistent transformation of semantically similar content across frames. Beyond mere attention guidance, our approach involves an explicit update of features to achieve high spatial-temporal consistency with the input video, significantly improving the visual coherence of the resulting translated videos.
|
| 13 |
+
Extensive experiments demonstrate the effectiveness of our proposed framework in producing high-quality, coherent videos, marking a notable improvement over existing zero-shot methods.*
|
| 14 |
+
|
| 15 |
+
**Features**:<br>
|
| 16 |
+
- **Temporal consistency**: use intra-and inter-frame constraint with better consistency and coverage than optical flow alone.
|
| 17 |
+
- Compared with our previous work [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video), FRESCO is more robust to large and quick motion.
|
| 18 |
+
- **Zero-shot**: no training or fine-tuning required.
|
| 19 |
+
- **Flexibility**: compatible with off-the-shelf models (e.g., [ControlNet](https://github.com/lllyasviel/ControlNet), [LoRA](https://civitai.com/)) for customized translation.
|
| 20 |
+
|
| 21 |
+
https://github.com/williamyang1991/FRESCO/assets/18130694/aad358af-4d27-4f18-b069-89a1abd94d38
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## Updates
|
| 25 |
+
- [03/2023] Paper is released.
|
| 26 |
+
- [03/2023] Code is released.
|
| 27 |
+
- [03/2024] This website is created.
|
| 28 |
+
|
| 29 |
+
### TODO
|
| 30 |
+
- [ ] Integrate into Diffusers
|
| 31 |
+
- [ ] Add Huggingface web demo
|
| 32 |
+
- [x] ~~Add webUI.~~
|
| 33 |
+
- [x] ~~Update readme~~
|
| 34 |
+
- [x] ~~Upload paper to arXiv, release related material~~
|
| 35 |
+
|
| 36 |
+
## Installation
|
| 37 |
+
|
| 38 |
+
1. Clone the repository.
|
| 39 |
+
|
| 40 |
+
```shell
|
| 41 |
+
git clone https://github.com/williamyang1991/FRESCO.git
|
| 42 |
+
cd FRESCO
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
2. You can simply set up the environment with pip based on [requirements.txt](https://github.com/williamyang1991/FRESCO/blob/main/requirements.txt)
|
| 46 |
+
- Create a conda environment and install torch >= 2.0.0. Here is an example script to install torch 2.0.0 + CUDA 11.8 :
|
| 47 |
+
```
|
| 48 |
+
conda create --name diffusers python==3.8.5
|
| 49 |
+
conda activate diffusers
|
| 50 |
+
pip install torch==2.0.0 torchvision==0.15.1 --index-url https://download.pytorch.org/whl/cu118
|
| 51 |
+
```
|
| 52 |
+
- Run `pip install -r requirements.txt` in an environment where torch is installed.
|
| 53 |
+
- We have tested on torch 2.0.0/2.1.0 and diffusers 0.19.3
|
| 54 |
+
- If you use new versions of diffusers, you need to modify [my_forward()](https://github.com/williamyang1991/FRESCO/blob/fb991262615665de88f7a8f2cc903d9539e1b234/src/diffusion_hacked.py#L496)
|
| 55 |
+
|
| 56 |
+
3. Run the installation script. The required models will be downloaded in `./model`, `./src/ControlNet/annotator` and `./src/ebsynth/deps/ebsynth/bin`.
|
| 57 |
+
- Requires access to huggingface.co
|
| 58 |
+
|
| 59 |
+
```shell
|
| 60 |
+
python install.py
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
4. You can run the demo with `run_fresco.py`
|
| 64 |
+
|
| 65 |
+
```shell
|
| 66 |
+
python run_fresco.py ./config/config_music.yaml
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
5. For issues with Ebsynth, please refer to [issues](https://github.com/williamyang1991/Rerender_A_Video#issues)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
## (1) Inference
|
| 73 |
+
|
| 74 |
+
### WebUI (recommended)
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
python webUI.py
|
| 78 |
+
```
|
| 79 |
+
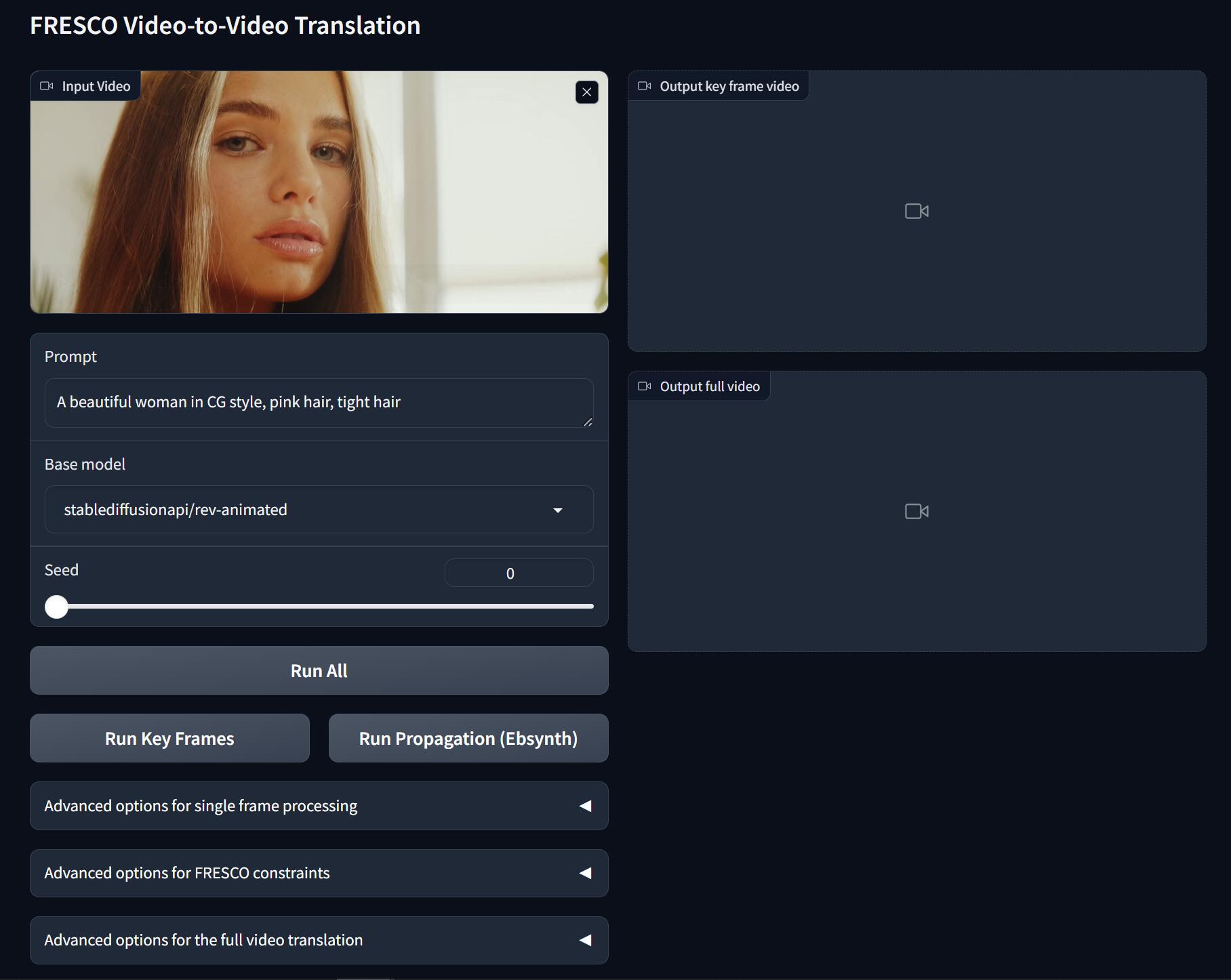
The Gradio app also allows you to flexibly change the inference options. Just try it for more details.
|
| 80 |
+
|
| 81 |
+
Upload your video, input the prompt, select the model and seed, and hit:
|
| 82 |
+
- **Run Key Frames**: detect keyframes, translate all keyframes.
|
| 83 |
+
- **Run Propagation**: propagate the keyframes to other frames for full video translation
|
| 84 |
+
- **Run All**: **Run Key Frames** and **Run Propagation**
|
| 85 |
+
|
| 86 |
+
Select the model:
|
| 87 |
+
- **Base model**: base Stable Diffusion model (SD 1.5)
|
| 88 |
+
- Stable Diffusion 1.5: official model
|
| 89 |
+
- [rev-Animated](https://huggingface.co/stablediffusionapi/rev-animated): a semi-realistic (2.5D) model
|
| 90 |
+
- [realistic-Vision](https://huggingface.co/SG161222/Realistic_Vision_V2.0): a photo-realistic model
|
| 91 |
+
- [flat2d-animerge](https://huggingface.co/stablediffusionapi/flat-2d-animerge): a cartoon model
|
| 92 |
+
- You can add other models on huggingface.co by modifying this [line](https://github.com/williamyang1991/FRESCO/blob/1afcca9c7b1bc1ac68254f900be9bd768fbb6988/webUI.py#L362)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
We provide abundant advanced options to play with
|
| 97 |
+
|
| 98 |
+
</details>
|
| 99 |
+
|
| 100 |
+
<details id="option1">
|
| 101 |
+
<summary> <b>Advanced options for single frame processing</b></summary>
|
| 102 |
+
|
| 103 |
+
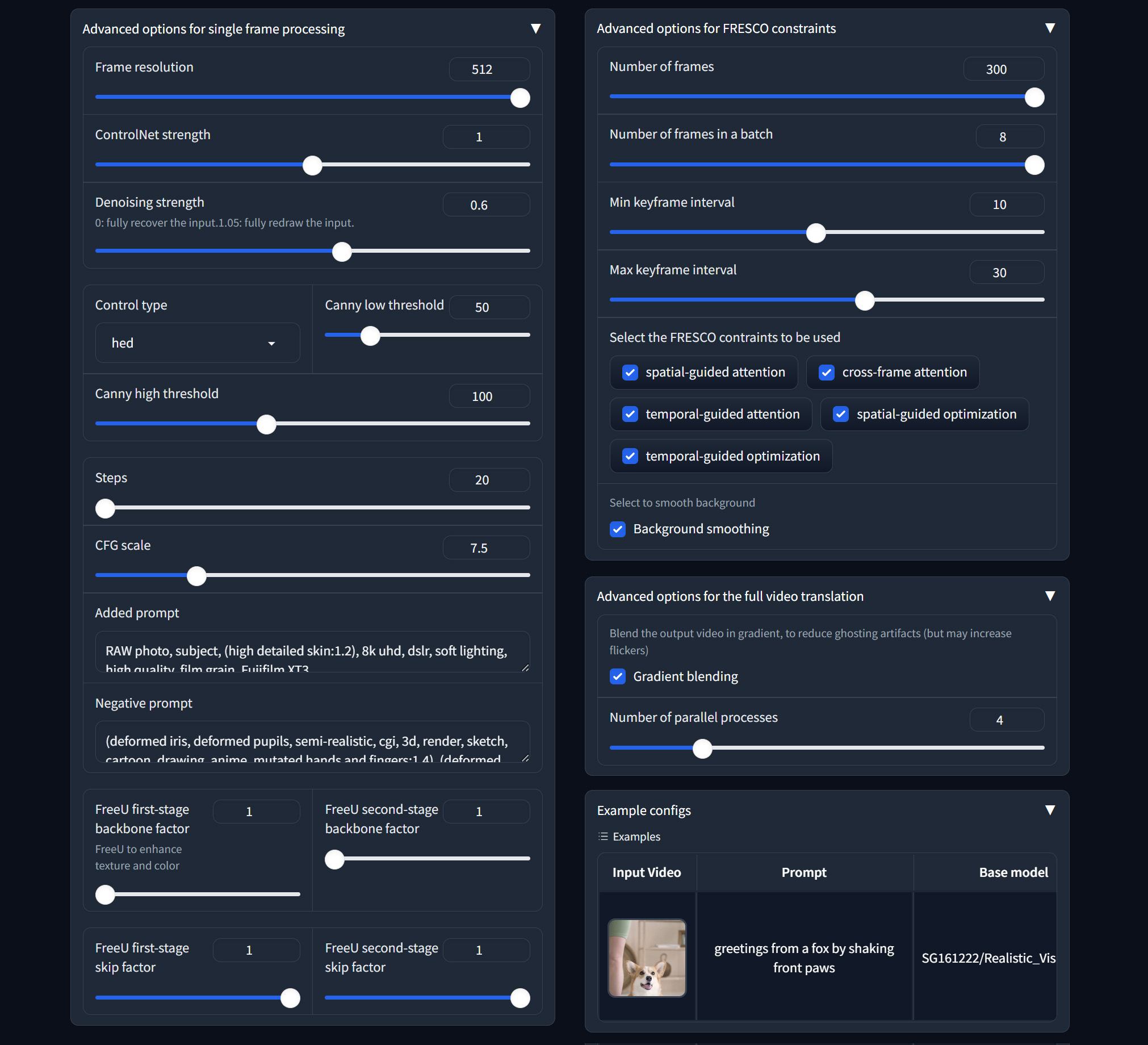
1. **Frame resolution**: resize the short side of the video to 512.
|
| 104 |
+
2. ControlNet related:
|
| 105 |
+
- **ControlNet strength**: how well the output matches the input control edges
|
| 106 |
+
- **Control type**: HED edge, Canny edge, Depth map
|
| 107 |
+
- **Canny low/high threshold**: low values for more edge details
|
| 108 |
+
3. SDEdit related:
|
| 109 |
+
- **Denoising strength**: repaint degree (low value to make the output look more like the original video)
|
| 110 |
+
- **Preserve color**: preserve the color of the original video
|
| 111 |
+
4. SD related:
|
| 112 |
+
- **Steps**: denoising step
|
| 113 |
+
- **CFG scale**: how well the output matches the prompt
|
| 114 |
+
- **Added prompt/Negative prompt**: supplementary prompts
|
| 115 |
+
5. FreeU related:
|
| 116 |
+
- **FreeU first/second-stage backbone factor**: =1 do nothing; >1 enhance output color and details
|
| 117 |
+
- **FreeU first/second-stage skip factor**: =1 do nothing; <1 enhance output color and details
|
| 118 |
+
|
| 119 |
+
</details>
|
| 120 |
+
|
| 121 |
+
<details id="option2">
|
| 122 |
+
<summary> <b>Advanced options for FRESCO constraints</b></summary>
|
| 123 |
+
|
| 124 |
+
1. Keyframe related
|
| 125 |
+
- **Number of frames**: Total frames to be translated
|
| 126 |
+
- **Number of frames in a batch**: To avoid out-of-memory, use small batch size
|
| 127 |
+
- **Min keyframe interval (s_min)**: The keyframes will be detected at least every s_min frames
|
| 128 |
+
- **Max keyframe interval (s_max)**: The keyframes will be detected at most every s_max frames
|
| 129 |
+
2. FRESCO constraints
|
| 130 |
+
- FRESCO-guided Attention:
|
| 131 |
+
- **spatial-guided attention**: Check to enable spatial-guided attention
|
| 132 |
+
- **cross-frame attention**: Check to enable efficient cross-frame attention
|
| 133 |
+
- **temporal-guided attention**: Check to enable temporal-guided attention
|
| 134 |
+
- FRESCO-guided optimization:
|
| 135 |
+
- **spatial-guided optimization**: Check to enable spatial-guided optimization
|
| 136 |
+
- **temporal-guided optimization**: Check to enable temporal-guided optimization
|
| 137 |
+
3. **Background smoothing**: Check to enable background smoothing (best for static background)
|
| 138 |
+
|
| 139 |
+
</details>
|
| 140 |
+
|
| 141 |
+
<details id="option3">
|
| 142 |
+
<summary> <b>Advanced options for the full video translation</b></summary>
|
| 143 |
+
|
| 144 |
+
1. **Gradient blending**: apply Poisson Blending to reduce ghosting artifacts. May slow the process and increase flickers.
|
| 145 |
+
2. **Number of parallel processes**: multiprocessing to speed up the process. Large value (4) is recommended.
|
| 146 |
+
</details>
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
### Command Line
|
| 151 |
+
|
| 152 |
+
We provide a flexible script `run_fresco.py` to run our method.
|
| 153 |
+
|
| 154 |
+
Set the options via a config file. For example,
|
| 155 |
+
```shell
|
| 156 |
+
python run_fresco.py ./config/config_music.yaml
|
| 157 |
+
```
|
| 158 |
+
We provide some examples of the config in `config` directory.
|
| 159 |
+
Most options in the config is the same as those in WebUI.
|
| 160 |
+
Please check the explanations in the WebUI section.
|
| 161 |
+
|
| 162 |
+
We provide a separate Ebsynth python script `video_blend.py` with the temporal blending algorithm introduced in
|
| 163 |
+
[Stylizing Video by Example](https://dcgi.fel.cvut.cz/home/sykorad/ebsynth.html) for interpolating style between key frames.
|
| 164 |
+
It can work on your own stylized key frames independently of our FRESCO algorithm.
|
| 165 |
+
For the details, please refer to our previous work [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video/tree/main?tab=readme-ov-file#our-ebsynth-implementation)
|
| 166 |
+
|
| 167 |
+
## (2) Results
|
| 168 |
+
|
| 169 |
+
### Key frame translation
|
| 170 |
+
|
| 171 |
+
<table class="center">
|
| 172 |
+
<tr>
|
| 173 |
+
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/e8d5776a-37c5-49ae-8ab4-15669df6f572" raw=true></td>
|
| 174 |
+
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/8a792af6-555c-4e82-ac1e-5c2e1ee35fdb" raw=true></td>
|
| 175 |
+
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/10f9a964-85ac-4433-84c5-1611a6c2c434" raw=true></td>
|
| 176 |
+
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/0ec0fbf9-90dd-4d8b-964d-945b5f6687c2" raw=true></td>
|
| 177 |
+
</tr>
|
| 178 |
+
<tr>
|
| 179 |
+
<td width=26.5% align="center">a red car turns in the winter</td>
|
| 180 |
+
<td width=26.5% align="center">an African American boxer wearing black boxing gloves punches towards the camera, cartoon style</td>
|
| 181 |
+
<td width=26.5% align="center">a cartoon spiderman in black suit, black shoes and white gloves is dancing</td>
|
| 182 |
+
<td width=20.5% align="center">a beautiful woman holding her glasses in CG style</td>
|
| 183 |
+
</tr>
|
| 184 |
+
</table>
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
### Full video translation
|
| 188 |
+
|
| 189 |
+
https://github.com/williamyang1991/FRESCO/assets/18130694/bf8bfb82-5cb7-4b2f-8169-cf8dbf408b54
|
| 190 |
+
|
| 191 |
+
## Citation
|
| 192 |
+
|
| 193 |
+
If you find this work useful for your research, please consider citing our paper:
|
| 194 |
+
|
| 195 |
+
```bibtex
|
| 196 |
+
@inproceedings{yang2024fresco,
|
| 197 |
+
title = {FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation},
|
| 198 |
+
author = {Yang, Shuai and Zhou, Yifan and Liu, Ziwei and and Loy, Chen Change},
|
| 199 |
+
booktitle = {CVPR},
|
| 200 |
+
year = {2024},
|
| 201 |
+
}
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
## Acknowledgments
|
| 205 |
+
|
| 206 |
+
The code is mainly developed based on [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video), [ControlNet](https://github.com/lllyasviel/ControlNet), [Stable Diffusion](https://github.com/Stability-AI/stablediffusion), [GMFlow](https://github.com/haofeixu/gmflow) and [Ebsynth](https://github.com/jamriska/ebsynth).
|
| 207 |
+
|
| 208 |
+
|
config/config_boxer.yaml
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# data
|
| 2 |
+
file_path: './data/boxer-punching-towards-camera.mp4'
|
| 3 |
+
save_path: './output/boxer-punching-towards-camera/'
|
| 4 |
+
mininterv: 2 # for keyframe selection
|
| 5 |
+
maxinterv: 2 # for keyframe selection
|
| 6 |
+
|
| 7 |
+
# diffusion
|
| 8 |
+
seed: 0
|
| 9 |
+
prompt: 'An African American boxer wearing black boxing gloves punches towards the camera, cartoon style'
|
| 10 |
+
sd_path: 'stablediffusionapi/flat-2d-animerge'
|
| 11 |
+
use_controlnet: True
|
| 12 |
+
controlnet_type: 'depth' # 'hed', 'canny'
|
| 13 |
+
cond_scale: 0.7
|
| 14 |
+
use_freeu: False
|
| 15 |
+
|
| 16 |
+
# video-to-video translation
|
| 17 |
+
batch_size: 8
|
| 18 |
+
num_inference_steps: 20
|
| 19 |
+
num_warmup_steps: 5
|
| 20 |
+
end_opt_step: 15
|
| 21 |
+
run_ebsynth: False
|
| 22 |
+
max_process: 4
|
| 23 |
+
|
| 24 |
+
# supporting model
|
| 25 |
+
gmflow_path: './model/gmflow_sintel-0c07dcb3.pth'
|
| 26 |
+
sod_path: './model/epoch_resnet.pth'
|
| 27 |
+
use_salinecy: True
|
config/config_carturn.yaml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# data
|
| 2 |
+
file_path: './data/car-turn.mp4'
|
| 3 |
+
save_path: './output/car-turn/'
|
| 4 |
+
mininterv: 5 # for keyframe selection
|
| 5 |
+
maxinterv: 5 # for keyframe selection
|
| 6 |
+
|
| 7 |
+
# diffusion
|
| 8 |
+
seed: 0
|
| 9 |
+
prompt: 'a red car turns in the winter'
|
| 10 |
+
# sd_path: 'runwayml/stable-diffusion-v1-5'
|
| 11 |
+
# sd_path: 'stablediffusionapi/rev-animated'
|
| 12 |
+
# sd_path: 'stablediffusionapi/flat-2d-animerge'
|
| 13 |
+
sd_path: 'SG161222/Realistic_Vision_V2.0'
|
| 14 |
+
use_controlnet: True
|
| 15 |
+
controlnet_type: 'hed' # 'depth', 'canny'
|
| 16 |
+
cond_scale: 0.7
|
| 17 |
+
use_freeu: False
|
| 18 |
+
|
| 19 |
+
# video-to-video translation
|
| 20 |
+
batch_size: 8
|
| 21 |
+
num_inference_steps: 20
|
| 22 |
+
num_warmup_steps: 5
|
| 23 |
+
end_opt_step: 15
|
| 24 |
+
run_ebsynth: False
|
| 25 |
+
max_process: 4
|
| 26 |
+
|
| 27 |
+
# supporting model
|
| 28 |
+
gmflow_path: './model/gmflow_sintel-0c07dcb3.pth'
|
| 29 |
+
sod_path: './model/epoch_resnet.pth'
|
| 30 |
+
use_salinecy: True
|
config/config_dog.yaml
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# data
|
| 2 |
+
file_path: './data/dog.mp4'
|
| 3 |
+
save_path: './output/dog/'
|
| 4 |
+
mininterv: 10 # for keyframe selection
|
| 5 |
+
maxinterv: 30 # for keyframe selection
|
| 6 |
+
|
| 7 |
+
# diffusion
|
| 8 |
+
seed: 0
|
| 9 |
+
prompt: 'greetings from a fox by shaking front paws'
|
| 10 |
+
sd_path: 'SG161222/Realistic_Vision_V2.0'
|
| 11 |
+
use_controlnet: True
|
| 12 |
+
controlnet_type: 'hed' # 'depth', 'canny'
|
| 13 |
+
cond_scale: 1.0
|
| 14 |
+
use_freeu: False
|
| 15 |
+
|
| 16 |
+
# video-to-video translation
|
| 17 |
+
batch_size: 8
|
| 18 |
+
num_inference_steps: 20
|
| 19 |
+
num_warmup_steps: 8
|
| 20 |
+
end_opt_step: 15
|
| 21 |
+
run_ebsynth: False
|
| 22 |
+
max_process: 4
|
| 23 |
+
|
| 24 |
+
# supporting model
|
| 25 |
+
gmflow_path: './model/gmflow_sintel-0c07dcb3.pth'
|
| 26 |
+
sod_path: './model/epoch_resnet.pth'
|
| 27 |
+
use_salinecy: True
|
config/config_music.yaml
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# data
|
| 2 |
+
file_path: './data/music.mp4'
|
| 3 |
+
save_path: './output/music/'
|
| 4 |
+
mininterv: 10 # for keyframe selection
|
| 5 |
+
maxinterv: 30 # for keyframe selection
|
| 6 |
+
|
| 7 |
+
# diffusion
|
| 8 |
+
seed: 0
|
| 9 |
+
prompt: 'A beautiful woman with headphones listening to music in CG cyberpunk style, neon, closed eyes, colorful'
|
| 10 |
+
sd_path: 'stablediffusionapi/rev-animated'
|
| 11 |
+
use_controlnet: True
|
| 12 |
+
controlnet_type: 'hed' # 'depth', 'canny'
|
| 13 |
+
cond_scale: 1.0
|
| 14 |
+
use_freeu: False
|
| 15 |
+
|
| 16 |
+
# video-to-video translation
|
| 17 |
+
batch_size: 8
|
| 18 |
+
num_inference_steps: 20
|
| 19 |
+
num_warmup_steps: 3
|
| 20 |
+
end_opt_step: 15
|
| 21 |
+
run_ebsynth: False
|
| 22 |
+
max_process: 4
|
| 23 |
+
|
| 24 |
+
# supporting model
|
| 25 |
+
gmflow_path: './model/gmflow_sintel-0c07dcb3.pth'
|
| 26 |
+
sod_path: './model/epoch_resnet.pth'
|
| 27 |
+
use_salinecy: True
|
install.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import platform
|
| 3 |
+
|
| 4 |
+
import requests
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def build_ebsynth():
|
| 8 |
+
if os.path.exists('src/ebsynth/deps/ebsynth/bin/ebsynth'):
|
| 9 |
+
print('Ebsynth has been built.')
|
| 10 |
+
return
|
| 11 |
+
|
| 12 |
+
os_str = platform.system()
|
| 13 |
+
|
| 14 |
+
if os_str == 'Windows':
|
| 15 |
+
print('Build Ebsynth Windows 64 bit.',
|
| 16 |
+
'If you want to build for 32 bit, please modify install.py.')
|
| 17 |
+
cmd = '.\\build-win64-cpu+cuda.bat'
|
| 18 |
+
exe_file = 'src/ebsynth/deps/ebsynth/bin/ebsynth.exe'
|
| 19 |
+
elif os_str == 'Linux':
|
| 20 |
+
cmd = 'bash build-linux-cpu+cuda.sh'
|
| 21 |
+
exe_file = 'src/ebsynth/deps/ebsynth/bin/ebsynth'
|
| 22 |
+
elif os_str == 'Darwin':
|
| 23 |
+
cmd = 'sh build-macos-cpu_only.sh'
|
| 24 |
+
exe_file = 'src/ebsynth/deps/ebsynth/bin/ebsynth.app'
|
| 25 |
+
else:
|
| 26 |
+
print('Cannot recognize OS. Ebsynth installation stopped.')
|
| 27 |
+
return
|
| 28 |
+
|
| 29 |
+
os.chdir('src/ebsynth/deps/ebsynth')
|
| 30 |
+
print(cmd)
|
| 31 |
+
os.system(cmd)
|
| 32 |
+
os.chdir('../../../..')
|
| 33 |
+
if os.path.exists(exe_file):
|
| 34 |
+
print('Ebsynth installed successfully.')
|
| 35 |
+
else:
|
| 36 |
+
print('Failed to install Ebsynth.')
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def download(url, dir, name=None):
|
| 40 |
+
os.makedirs(dir, exist_ok=True)
|
| 41 |
+
if name is None:
|
| 42 |
+
name = url.split('/')[-1]
|
| 43 |
+
path = os.path.join(dir, name)
|
| 44 |
+
if not os.path.exists(path):
|
| 45 |
+
print(f'Install {name} ...')
|
| 46 |
+
open(path, 'wb').write(requests.get(url).content)
|
| 47 |
+
print('Install successfully.')
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def download_gmflow_ckpt():
|
| 51 |
+
url = ('https://huggingface.co/PKUWilliamYang/Rerender/'
|
| 52 |
+
'resolve/main/models/gmflow_sintel-0c07dcb3.pth')
|
| 53 |
+
download(url, 'model')
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def download_egnet_ckpt():
|
| 57 |
+
url = ('https://huggingface.co/PKUWilliamYang/Rerender/'
|
| 58 |
+
'resolve/main/models/epoch_resnet.pth')
|
| 59 |
+
download(url, 'model')
|
| 60 |
+
|
| 61 |
+
def download_hed_ckpt():
|
| 62 |
+
url = ('https://huggingface.co/lllyasviel/Annotators/'
|
| 63 |
+
'resolve/main/ControlNetHED.pth')
|
| 64 |
+
download(url, 'src/ControlNet/annotator/ckpts')
|
| 65 |
+
|
| 66 |
+
def download_depth_ckpt():
|
| 67 |
+
url = ('https://huggingface.co/lllyasviel/ControlNet/'
|
| 68 |
+
'resolve/main/annotator/ckpts/dpt_hybrid-midas-501f0c75.pt')
|
| 69 |
+
download(url, 'src/ControlNet/annotator/ckpts')
|
| 70 |
+
|
| 71 |
+
def download_ebsynth_ckpt():
|
| 72 |
+
os_str = platform.system()
|
| 73 |
+
if os_str == 'Linux':
|
| 74 |
+
url = ('https://huggingface.co/PKUWilliamYang/Rerender/'
|
| 75 |
+
'resolve/main/models/ebsynth')
|
| 76 |
+
download(url, 'src/ebsynth/deps/ebsynth/bin')
|
| 77 |
+
elif os_str == 'Windows':
|
| 78 |
+
url = ('https://huggingface.co/PKUWilliamYang/Rerender/'
|
| 79 |
+
'resolve/main/models/ebsynth.exe')
|
| 80 |
+
download(url, 'src/ebsynth/deps/ebsynth/bin')
|
| 81 |
+
url = ('https://huggingface.co/PKUWilliamYang/Rerender/'
|
| 82 |
+
'resolve/main/models/ebsynth_cpu.dll')
|
| 83 |
+
download(url, 'src/ebsynth/deps/ebsynth/bin')
|
| 84 |
+
url = ('https://huggingface.co/PKUWilliamYang/Rerender/'
|
| 85 |
+
'resolve/main/models/ebsynth_cpu.exe')
|
| 86 |
+
download(url, 'src/ebsynth/deps/ebsynth/bin')
|
| 87 |
+
else:
|
| 88 |
+
print('No available compiled Ebsynth.')
|
| 89 |
+
|
| 90 |
+
#build_ebsynth()
|
| 91 |
+
download_ebsynth_ckpt()
|
| 92 |
+
download_gmflow_ckpt()
|
| 93 |
+
download_egnet_ckpt()
|
| 94 |
+
download_hed_ckpt()
|
| 95 |
+
download_depth_ckpt()
|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
diffusers[torch]==0.19.3
|
| 2 |
+
transformers
|
| 3 |
+
opencv-python
|
| 4 |
+
einops
|
| 5 |
+
matplotlib
|
| 6 |
+
timm
|
| 7 |
+
av
|
| 8 |
+
basicsr==1.4.2
|
| 9 |
+
numba==0.57.0
|
| 10 |
+
imageio-ffmpeg
|
| 11 |
+
gradio==3.44.4
|
run_fresco.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
run_fresco.py
ADDED
|
@@ -0,0 +1,318 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
#os.environ['CUDA_VISIBLE_DEVICES'] = "6"
|
| 3 |
+
|
| 4 |
+
# In China, set this to use huggingface
|
| 5 |
+
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
|
| 6 |
+
|
| 7 |
+
import cv2
|
| 8 |
+
import io
|
| 9 |
+
import gc
|
| 10 |
+
import yaml
|
| 11 |
+
import argparse
|
| 12 |
+
import torch
|
| 13 |
+
import torchvision
|
| 14 |
+
import diffusers
|
| 15 |
+
from diffusers import StableDiffusionPipeline, AutoencoderKL, DDPMScheduler, ControlNetModel
|
| 16 |
+
|
| 17 |
+
from src.utils import *
|
| 18 |
+
from src.keyframe_selection import get_keyframe_ind
|
| 19 |
+
from src.diffusion_hacked import apply_FRESCO_attn, apply_FRESCO_opt, disable_FRESCO_opt
|
| 20 |
+
from src.diffusion_hacked import get_flow_and_interframe_paras, get_intraframe_paras
|
| 21 |
+
from src.pipe_FRESCO import inference
|
| 22 |
+
|
| 23 |
+
def get_models(config):
|
| 24 |
+
print('\n' + '=' * 100)
|
| 25 |
+
print('creating models...')
|
| 26 |
+
import sys
|
| 27 |
+
sys.path.append("./src/ebsynth/deps/gmflow/")
|
| 28 |
+
sys.path.append("./src/EGNet/")
|
| 29 |
+
sys.path.append("./src/ControlNet/")
|
| 30 |
+
|
| 31 |
+
from gmflow.gmflow import GMFlow
|
| 32 |
+
from model import build_model
|
| 33 |
+
from annotator.hed import HEDdetector
|
| 34 |
+
from annotator.canny import CannyDetector
|
| 35 |
+
from annotator.midas import MidasDetector
|
| 36 |
+
|
| 37 |
+
# optical flow
|
| 38 |
+
flow_model = GMFlow(feature_channels=128,
|
| 39 |
+
num_scales=1,
|
| 40 |
+
upsample_factor=8,
|
| 41 |
+
num_head=1,
|
| 42 |
+
attention_type='swin',
|
| 43 |
+
ffn_dim_expansion=4,
|
| 44 |
+
num_transformer_layers=6,
|
| 45 |
+
).to('cuda')
|
| 46 |
+
|
| 47 |
+
checkpoint = torch.load(config['gmflow_path'], map_location=lambda storage, loc: storage)
|
| 48 |
+
weights = checkpoint['model'] if 'model' in checkpoint else checkpoint
|
| 49 |
+
flow_model.load_state_dict(weights, strict=False)
|
| 50 |
+
flow_model.eval()
|
| 51 |
+
print('create optical flow estimation model successfully!')
|
| 52 |
+
|
| 53 |
+
# saliency detection
|
| 54 |
+
sod_model = build_model('resnet')
|
| 55 |
+
sod_model.load_state_dict(torch.load(config['sod_path']))
|
| 56 |
+
sod_model.to("cuda").eval()
|
| 57 |
+
print('create saliency detection model successfully!')
|
| 58 |
+
|
| 59 |
+
# controlnet
|
| 60 |
+
if config['controlnet_type'] not in ['hed', 'depth', 'canny']:
|
| 61 |
+
print('unsupported control type, set to hed')
|
| 62 |
+
config['controlnet_type'] = 'hed'
|
| 63 |
+
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-"+config['controlnet_type'],
|
| 64 |
+
torch_dtype=torch.float16)
|
| 65 |
+
controlnet.to("cuda")
|
| 66 |
+
if config['controlnet_type'] == 'depth':
|
| 67 |
+
detector = MidasDetector()
|
| 68 |
+
elif config['controlnet_type'] == 'canny':
|
| 69 |
+
detector = CannyDetector()
|
| 70 |
+
else:
|
| 71 |
+
detector = HEDdetector()
|
| 72 |
+
print('create controlnet model-' + config['controlnet_type'] + ' successfully!')
|
| 73 |
+
|
| 74 |
+
# diffusion model
|
| 75 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse", torch_dtype=torch.float16)
|
| 76 |
+
pipe = StableDiffusionPipeline.from_pretrained(config['sd_path'], vae=vae, torch_dtype=torch.float16)
|
| 77 |
+
pipe.scheduler = DDPMScheduler.from_config(pipe.scheduler.config)
|
| 78 |
+
#noise_scheduler = DDPMScheduler.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="scheduler")
|
| 79 |
+
pipe.to("cuda")
|
| 80 |
+
pipe.scheduler.set_timesteps(config['num_inference_steps'], device=pipe._execution_device)
|
| 81 |
+
|
| 82 |
+
if config['use_freeu']:
|
| 83 |
+
from src.free_lunch_utils import apply_freeu
|
| 84 |
+
apply_freeu(pipe, b1=1.2, b2=1.5, s1=1.0, s2=1.0)
|
| 85 |
+
|
| 86 |
+
frescoProc = apply_FRESCO_attn(pipe)
|
| 87 |
+
frescoProc.controller.disable_controller()
|
| 88 |
+
apply_FRESCO_opt(pipe)
|
| 89 |
+
print('create diffusion model ' + config['sd_path'] + ' successfully!')
|
| 90 |
+
|
| 91 |
+
for param in flow_model.parameters():
|
| 92 |
+
param.requires_grad = False
|
| 93 |
+
for param in sod_model.parameters():
|
| 94 |
+
param.requires_grad = False
|
| 95 |
+
for param in controlnet.parameters():
|
| 96 |
+
param.requires_grad = False
|
| 97 |
+
for param in pipe.unet.parameters():
|
| 98 |
+
param.requires_grad = False
|
| 99 |
+
|
| 100 |
+
return pipe, frescoProc, controlnet, detector, flow_model, sod_model
|
| 101 |
+
|
| 102 |
+
def apply_control(x, detector, config):
|
| 103 |
+
if config['controlnet_type'] == 'depth':
|
| 104 |
+
detected_map, _ = detector(x)
|
| 105 |
+
elif config['controlnet_type'] == 'canny':
|
| 106 |
+
detected_map = detector(x, 50, 100)
|
| 107 |
+
else:
|
| 108 |
+
detected_map = detector(x)
|
| 109 |
+
return detected_map
|
| 110 |
+
|
| 111 |
+
def run_keyframe_translation(config):
|
| 112 |
+
pipe, frescoProc, controlnet, detector, flow_model, sod_model = get_models(config)
|
| 113 |
+
device = pipe._execution_device
|
| 114 |
+
guidance_scale = 7.5
|
| 115 |
+
do_classifier_free_guidance = guidance_scale > 1
|
| 116 |
+
assert(do_classifier_free_guidance)
|
| 117 |
+
timesteps = pipe.scheduler.timesteps
|
| 118 |
+
cond_scale = [config['cond_scale']] * config['num_inference_steps']
|
| 119 |
+
dilate = Dilate(device=device)
|
| 120 |
+
|
| 121 |
+
base_prompt = config['prompt']
|
| 122 |
+
if 'Realistic' in config['sd_path'] or 'realistic' in config['sd_path']:
|
| 123 |
+
a_prompt = ', RAW photo, subject, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3, '
|
| 124 |
+
n_prompt = '(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation'
|
| 125 |
+
else:
|
| 126 |
+
a_prompt = ', best quality, extremely detailed, '
|
| 127 |
+
n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing finger, extra digit, fewer digits, cropped, worst quality, low quality'
|
| 128 |
+
|
| 129 |
+
print('\n' + '=' * 100)
|
| 130 |
+
print('key frame selection for \"%s\"...'%(config['file_path']))
|
| 131 |
+
|
| 132 |
+
video_cap = cv2.VideoCapture(config['file_path'])
|
| 133 |
+
frame_num = int(video_cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 134 |
+
|
| 135 |
+
# you can set extra_prompts for individual keyframe
|
| 136 |
+
# for example, extra_prompts[38] = ', closed eyes' to specify the person frame38 closes the eyes
|
| 137 |
+
extra_prompts = [''] * frame_num
|
| 138 |
+
|
| 139 |
+
keys = get_keyframe_ind(config['file_path'], frame_num, config['mininterv'], config['maxinterv'])
|
| 140 |
+
|
| 141 |
+
os.makedirs(config['save_path'], exist_ok=True)
|
| 142 |
+
os.makedirs(config['save_path']+'keys', exist_ok=True)
|
| 143 |
+
os.makedirs(config['save_path']+'video', exist_ok=True)
|
| 144 |
+
|
| 145 |
+
sublists = [keys[i:i+config['batch_size']-2] for i in range(2, len(keys), config['batch_size']-2)]
|
| 146 |
+
sublists[0].insert(0, keys[0])
|
| 147 |
+
sublists[0].insert(1, keys[1])
|
| 148 |
+
if len(sublists) > 1 and len(sublists[-1]) < 3:
|
| 149 |
+
add_num = 3 - len(sublists[-1])
|
| 150 |
+
sublists[-1] = sublists[-2][-add_num:] + sublists[-1]
|
| 151 |
+
sublists[-2] = sublists[-2][:-add_num]
|
| 152 |
+
|
| 153 |
+
if not sublists[-2]:
|
| 154 |
+
del sublists[-2]
|
| 155 |
+
|
| 156 |
+
print('processing %d batches:\nkeyframe indexes'%(len(sublists)), sublists)
|
| 157 |
+
|
| 158 |
+
print('\n' + '=' * 100)
|
| 159 |
+
print('video to video translation...')
|
| 160 |
+
|
| 161 |
+
batch_ind = 0
|
| 162 |
+
propagation_mode = batch_ind > 0
|
| 163 |
+
imgs = []
|
| 164 |
+
record_latents = []
|
| 165 |
+
video_cap = cv2.VideoCapture(config['file_path'])
|
| 166 |
+
for i in range(frame_num):
|
| 167 |
+
# prepare a batch of frame based on sublists
|
| 168 |
+
success, frame = video_cap.read()
|
| 169 |
+
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
|
| 170 |
+
img = resize_image(frame, 512)
|
| 171 |
+
H, W, C = img.shape
|
| 172 |
+
Image.fromarray(img).save(os.path.join(config['save_path'], 'video/%04d.png'%(i)))
|
| 173 |
+
if i not in sublists[batch_ind]:
|
| 174 |
+
continue
|
| 175 |
+
|
| 176 |
+
imgs += [img]
|
| 177 |
+
if i != sublists[batch_ind][-1]:
|
| 178 |
+
continue
|
| 179 |
+
|
| 180 |
+
print('processing batch [%d/%d] with %d frames'%(batch_ind+1, len(sublists), len(sublists[batch_ind])))
|
| 181 |
+
|
| 182 |
+
# prepare input
|
| 183 |
+
batch_size = len(imgs)
|
| 184 |
+
n_prompts = [n_prompt] * len(imgs)
|
| 185 |
+
prompts = [base_prompt + a_prompt + extra_prompts[ind] for ind in sublists[batch_ind]]
|
| 186 |
+
if propagation_mode: # restore the extra_prompts from previous batch
|
| 187 |
+
assert len(imgs) == len(sublists[batch_ind]) + 2
|
| 188 |
+
prompts = ref_prompt + prompts
|
| 189 |
+
|
| 190 |
+
prompt_embeds = pipe._encode_prompt(
|
| 191 |
+
prompts,
|
| 192 |
+
device,
|
| 193 |
+
1,
|
| 194 |
+
do_classifier_free_guidance,
|
| 195 |
+
n_prompts,
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
imgs_torch = torch.cat([numpy2tensor(img) for img in imgs], dim=0)
|
| 199 |
+
edges = torch.cat([numpy2tensor(apply_control(img, detector, config)[:, :, None]) for img in imgs], dim=0)
|
| 200 |
+
edges = edges.repeat(1,3,1,1).cuda() * 0.5 + 0.5
|
| 201 |
+
if do_classifier_free_guidance:
|
| 202 |
+
edges = torch.cat([edges.to(pipe.unet.dtype)] * 2)
|
| 203 |
+
|
| 204 |
+
if config['use_salinecy']:
|
| 205 |
+
saliency = get_saliency(imgs, sod_model, dilate)
|
| 206 |
+
else:
|
| 207 |
+
saliency = None
|
| 208 |
+
|
| 209 |
+
# prepare parameters for inter-frame and intra-frame consistency
|
| 210 |
+
flows, occs, attn_mask, interattn_paras = get_flow_and_interframe_paras(flow_model, imgs)
|
| 211 |
+
correlation_matrix = get_intraframe_paras(pipe, imgs_torch, frescoProc,
|
| 212 |
+
prompt_embeds, seed = config['seed'])
|
| 213 |
+
|
| 214 |
+
'''
|
| 215 |
+
Flexible settings for attention:
|
| 216 |
+
* Turn off FRESCO-guided attention: frescoProc.controller.disable_controller()
|
| 217 |
+
Then you can turn on one specific attention submodule
|
| 218 |
+
* Turn on Cross-frame attention: frescoProc.controller.enable_cfattn(attn_mask)
|
| 219 |
+
* Turn on Spatial-guided attention: frescoProc.controller.enable_intraattn()
|
| 220 |
+
* Turn on Temporal-guided attention: frescoProc.controller.enable_interattn(interattn_paras)
|
| 221 |
+
|
| 222 |
+
Flexible settings for optimization:
|
| 223 |
+
* Turn off Spatial-guided optimization: set optimize_temporal = False in apply_FRESCO_opt()
|
| 224 |
+
* Turn off Temporal-guided optimization: set correlation_matrix = [] in apply_FRESCO_opt()
|
| 225 |
+
* Turn off FRESCO-guided optimization: disable_FRESCO_opt(pipe)
|
| 226 |
+
|
| 227 |
+
Flexible settings for background smoothing:
|
| 228 |
+
* Turn off background smoothing: set saliency = None in apply_FRESCO_opt()
|
| 229 |
+
'''
|
| 230 |
+
# Turn on all FRESCO support
|
| 231 |
+
frescoProc.controller.enable_controller(interattn_paras=interattn_paras, attn_mask=attn_mask)
|
| 232 |
+
apply_FRESCO_opt(pipe, steps = timesteps[:config['end_opt_step']],
|
| 233 |
+
flows = flows, occs = occs, correlation_matrix=correlation_matrix,
|
| 234 |
+
saliency=saliency, optimize_temporal = True)
|
| 235 |
+
|
| 236 |
+
gc.collect()
|
| 237 |
+
torch.cuda.empty_cache()
|
| 238 |
+
|
| 239 |
+
# run!
|
| 240 |
+
latents = inference(pipe, controlnet, frescoProc,
|
| 241 |
+
imgs_torch, prompt_embeds, edges, timesteps,
|
| 242 |
+
cond_scale, config['num_inference_steps'], config['num_warmup_steps'],
|
| 243 |
+
do_classifier_free_guidance, config['seed'], guidance_scale, config['use_controlnet'],
|
| 244 |
+
record_latents, propagation_mode,
|
| 245 |
+
flows = flows, occs = occs, saliency=saliency, repeat_noise=True)
|
| 246 |
+
|
| 247 |
+
gc.collect()
|
| 248 |
+
torch.cuda.empty_cache()
|
| 249 |
+
|
| 250 |
+
with torch.no_grad():
|
| 251 |
+
image = pipe.vae.decode(latents / pipe.vae.config.scaling_factor, return_dict=False)[0]
|
| 252 |
+
image = torch.clamp(image, -1 , 1)
|
| 253 |
+
save_imgs = tensor2numpy(image)
|
| 254 |
+
bias = 2 if propagation_mode else 0
|
| 255 |
+
for ind, num in enumerate(sublists[batch_ind]):
|
| 256 |
+
Image.fromarray(save_imgs[ind+bias]).save(os.path.join(config['save_path'], 'keys/%04d.png'%(num)))
|
| 257 |
+
|
| 258 |
+
gc.collect()
|
| 259 |
+
torch.cuda.empty_cache()
|
| 260 |
+
|
| 261 |
+
batch_ind += 1
|
| 262 |
+
# current batch uses the last frame of the previous batch as ref
|
| 263 |
+
ref_prompt= [prompts[0], prompts[-1]]
|
| 264 |
+
imgs = [imgs[0], imgs[-1]]
|
| 265 |
+
propagation_mode = batch_ind > 0
|
| 266 |
+
if batch_ind == len(sublists):
|
| 267 |
+
gc.collect()
|
| 268 |
+
torch.cuda.empty_cache()
|
| 269 |
+
break
|
| 270 |
+
return keys
|
| 271 |
+
|
| 272 |
+
def run_full_video_translation(config, keys):
|
| 273 |
+
print('\n' + '=' * 100)
|
| 274 |
+
if not config['run_ebsynth']:
|
| 275 |
+
print('to translate full video with ebsynth, install ebsynth and run:')
|
| 276 |
+
else:
|
| 277 |
+
print('translating full video with:')
|
| 278 |
+
|
| 279 |
+
video_cap = cv2.VideoCapture(config['file_path'])
|
| 280 |
+
fps = int(video_cap.get(cv2.CAP_PROP_FPS))
|
| 281 |
+
o_video = os.path.join(config['save_path'], 'blend.mp4')
|
| 282 |
+
max_process = config['max_process']
|
| 283 |
+
save_path = config['save_path']
|
| 284 |
+
key_ind = io.StringIO()
|
| 285 |
+
for k in keys:
|
| 286 |
+
print('%d'%(k), end=' ', file=key_ind)
|
| 287 |
+
cmd = (
|
| 288 |
+
f'python video_blend.py {save_path} --key keys '
|
| 289 |
+
f'--key_ind {key_ind.getvalue()} --output {o_video} --fps {fps} '
|
| 290 |
+
f'--n_proc {max_process} -ps')
|
| 291 |
+
|
| 292 |
+
print('\n```')
|
| 293 |
+
print(cmd)
|
| 294 |
+
print('```')
|
| 295 |
+
|
| 296 |
+
if config['run_ebsynth']:
|
| 297 |
+
os.system(cmd)
|
| 298 |
+
|
| 299 |
+
print('\n' + '=' * 100)
|
| 300 |
+
print('Done')
|
| 301 |
+
|
| 302 |
+
if __name__ == '__main__':
|
| 303 |
+
parser = argparse.ArgumentParser()
|
| 304 |
+
parser.add_argument('config_path', type=str,
|
| 305 |
+
default='./config/config_carturn.yaml',
|
| 306 |
+
help='The configuration file.')
|
| 307 |
+
opt = parser.parse_args()
|
| 308 |
+
|
| 309 |
+
print('=' * 100)
|
| 310 |
+
print('loading configuration...')
|
| 311 |
+
with open(opt.config_path, "r") as f:
|
| 312 |
+
config = yaml.safe_load(f)
|
| 313 |
+
|
| 314 |
+
for name, value in sorted(config.items()):
|
| 315 |
+
print('%s: %s' % (str(name), str(value)))
|
| 316 |
+
|
| 317 |
+
keys = run_keyframe_translation(config)
|
| 318 |
+
run_full_video_translation(config, keys)
|
src/ControlNet/annotator/canny/__init__.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class CannyDetector:
|
| 5 |
+
def __call__(self, img, low_threshold, high_threshold):
|
| 6 |
+
return cv2.Canny(img, low_threshold, high_threshold)
|
src/ControlNet/annotator/ckpts/ckpts.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Weights here.
|
src/ControlNet/annotator/hed/__init__.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This is an improved version and model of HED edge detection with Apache License, Version 2.0.
|
| 2 |
+
# Please use this implementation in your products
|
| 3 |
+
# This implementation may produce slightly different results from Saining Xie's official implementations,
|
| 4 |
+
# but it generates smoother edges and is more suitable for ControlNet as well as other image-to-image translations.
|
| 5 |
+
# Different from official models and other implementations, this is an RGB-input model (rather than BGR)
|
| 6 |
+
# and in this way it works better for gradio's RGB protocol
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import cv2
|
| 10 |
+
import torch
|
| 11 |
+
import numpy as np
|
| 12 |
+
|
| 13 |
+
from einops import rearrange
|
| 14 |
+
from annotator.util import annotator_ckpts_path
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class DoubleConvBlock(torch.nn.Module):
|
| 18 |
+
def __init__(self, input_channel, output_channel, layer_number):
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.convs = torch.nn.Sequential()
|
| 21 |
+
self.convs.append(torch.nn.Conv2d(in_channels=input_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
|
| 22 |
+
for i in range(1, layer_number):
|
| 23 |
+
self.convs.append(torch.nn.Conv2d(in_channels=output_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
|
| 24 |
+
self.projection = torch.nn.Conv2d(in_channels=output_channel, out_channels=1, kernel_size=(1, 1), stride=(1, 1), padding=0)
|
| 25 |
+
|
| 26 |
+
def __call__(self, x, down_sampling=False):
|
| 27 |
+
h = x
|
| 28 |
+
if down_sampling:
|
| 29 |
+
h = torch.nn.functional.max_pool2d(h, kernel_size=(2, 2), stride=(2, 2))
|
| 30 |
+
for conv in self.convs:
|
| 31 |
+
h = conv(h)
|
| 32 |
+
h = torch.nn.functional.relu(h)
|
| 33 |
+
return h, self.projection(h)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class ControlNetHED_Apache2(torch.nn.Module):
|
| 37 |
+
def __init__(self):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.norm = torch.nn.Parameter(torch.zeros(size=(1, 3, 1, 1)))
|
| 40 |
+
self.block1 = DoubleConvBlock(input_channel=3, output_channel=64, layer_number=2)
|
| 41 |
+
self.block2 = DoubleConvBlock(input_channel=64, output_channel=128, layer_number=2)
|
| 42 |
+
self.block3 = DoubleConvBlock(input_channel=128, output_channel=256, layer_number=3)
|
| 43 |
+
self.block4 = DoubleConvBlock(input_channel=256, output_channel=512, layer_number=3)
|
| 44 |
+
self.block5 = DoubleConvBlock(input_channel=512, output_channel=512, layer_number=3)
|
| 45 |
+
|
| 46 |
+
def __call__(self, x):
|
| 47 |
+
h = x - self.norm
|
| 48 |
+
h, projection1 = self.block1(h)
|
| 49 |
+
h, projection2 = self.block2(h, down_sampling=True)
|
| 50 |
+
h, projection3 = self.block3(h, down_sampling=True)
|
| 51 |
+
h, projection4 = self.block4(h, down_sampling=True)
|
| 52 |
+
h, projection5 = self.block5(h, down_sampling=True)
|
| 53 |
+
return projection1, projection2, projection3, projection4, projection5
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class HEDdetector:
|
| 57 |
+
def __init__(self):
|
| 58 |
+
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/ControlNetHED.pth"
|
| 59 |
+
modelpath = os.path.join(annotator_ckpts_path, "ControlNetHED.pth")
|
| 60 |
+
if not os.path.exists(modelpath):
|
| 61 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 62 |
+
load_file_from_url(remote_model_path, model_dir=annotator_ckpts_path)
|
| 63 |
+
self.netNetwork = ControlNetHED_Apache2().float().cuda().eval()
|
| 64 |
+
self.netNetwork.load_state_dict(torch.load(modelpath))
|
| 65 |
+
|
| 66 |
+
def __call__(self, input_image):
|
| 67 |
+
assert input_image.ndim == 3
|
| 68 |
+
H, W, C = input_image.shape
|
| 69 |
+
with torch.no_grad():
|
| 70 |
+
image_hed = torch.from_numpy(input_image.copy()).float().cuda()
|
| 71 |
+
image_hed = rearrange(image_hed, 'h w c -> 1 c h w')
|
| 72 |
+
edges = self.netNetwork(image_hed)
|
| 73 |
+
edges = [e.detach().cpu().numpy().astype(np.float32)[0, 0] for e in edges]
|
| 74 |
+
edges = [cv2.resize(e, (W, H), interpolation=cv2.INTER_LINEAR) for e in edges]
|
| 75 |
+
edges = np.stack(edges, axis=2)
|
| 76 |
+
edge = 1 / (1 + np.exp(-np.mean(edges, axis=2).astype(np.float64)))
|
| 77 |
+
edge = (edge * 255.0).clip(0, 255).astype(np.uint8)
|
| 78 |
+
return edge
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def nms(x, t, s):
|
| 82 |
+
x = cv2.GaussianBlur(x.astype(np.float32), (0, 0), s)
|
| 83 |
+
|
| 84 |
+
f1 = np.array([[0, 0, 0], [1, 1, 1], [0, 0, 0]], dtype=np.uint8)
|
| 85 |
+
f2 = np.array([[0, 1, 0], [0, 1, 0], [0, 1, 0]], dtype=np.uint8)
|
| 86 |
+
f3 = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]], dtype=np.uint8)
|
| 87 |
+
f4 = np.array([[0, 0, 1], [0, 1, 0], [1, 0, 0]], dtype=np.uint8)
|
| 88 |
+
|
| 89 |
+
y = np.zeros_like(x)
|
| 90 |
+
|
| 91 |
+
for f in [f1, f2, f3, f4]:
|
| 92 |
+
np.putmask(y, cv2.dilate(x, kernel=f) == x, x)
|
| 93 |
+
|
| 94 |
+
z = np.zeros_like(y, dtype=np.uint8)
|
| 95 |
+
z[y > t] = 255
|
| 96 |
+
return z
|
src/ControlNet/annotator/midas/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2019 Intel ISL (Intel Intelligent Systems Lab)
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
src/ControlNet/annotator/midas/__init__.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Midas Depth Estimation
|
| 2 |
+
# From https://github.com/isl-org/MiDaS
|
| 3 |
+
# MIT LICENSE
|
| 4 |
+
|
| 5 |
+
import cv2
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from einops import rearrange
|
| 10 |
+
from .api import MiDaSInference
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class MidasDetector:
|
| 14 |
+
def __init__(self):
|
| 15 |
+
self.model = MiDaSInference(model_type="dpt_hybrid").cuda()
|
| 16 |
+
|
| 17 |
+
def __call__(self, input_image, a=np.pi * 2.0, bg_th=0.1):
|
| 18 |
+
assert input_image.ndim == 3
|
| 19 |
+
image_depth = input_image
|
| 20 |
+
with torch.no_grad():
|
| 21 |
+
image_depth = torch.from_numpy(image_depth).float().cuda()
|
| 22 |
+
image_depth = image_depth / 127.5 - 1.0
|
| 23 |
+
image_depth = rearrange(image_depth, 'h w c -> 1 c h w')
|
| 24 |
+
depth = self.model(image_depth)[0]
|
| 25 |
+
|
| 26 |
+
depth_pt = depth.clone()
|
| 27 |
+
depth_pt -= torch.min(depth_pt)
|
| 28 |
+
depth_pt /= torch.max(depth_pt)
|
| 29 |
+
depth_pt = depth_pt.cpu().numpy()
|
| 30 |
+
depth_image = (depth_pt * 255.0).clip(0, 255).astype(np.uint8)
|
| 31 |
+
|
| 32 |
+
depth_np = depth.cpu().numpy()
|
| 33 |
+
x = cv2.Sobel(depth_np, cv2.CV_32F, 1, 0, ksize=3)
|
| 34 |
+
y = cv2.Sobel(depth_np, cv2.CV_32F, 0, 1, ksize=3)
|
| 35 |
+
z = np.ones_like(x) * a
|
| 36 |
+
x[depth_pt < bg_th] = 0
|
| 37 |
+
y[depth_pt < bg_th] = 0
|
| 38 |
+
normal = np.stack([x, y, z], axis=2)
|
| 39 |
+
normal /= np.sum(normal ** 2.0, axis=2, keepdims=True) ** 0.5
|
| 40 |
+
normal_image = (normal * 127.5 + 127.5).clip(0, 255).astype(np.uint8)
|
| 41 |
+
|
| 42 |
+
return depth_image, normal_image
|
src/ControlNet/annotator/midas/api.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# based on https://github.com/isl-org/MiDaS
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import os
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
from torchvision.transforms import Compose
|
| 8 |
+
|
| 9 |
+
from .midas.dpt_depth import DPTDepthModel
|
| 10 |
+
from .midas.midas_net import MidasNet
|
| 11 |
+
from .midas.midas_net_custom import MidasNet_small
|
| 12 |
+
from .midas.transforms import Resize, NormalizeImage, PrepareForNet
|
| 13 |
+
from annotator.util import annotator_ckpts_path
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
ISL_PATHS = {
|
| 17 |
+
"dpt_large": os.path.join(annotator_ckpts_path, "dpt_large-midas-2f21e586.pt"),
|
| 18 |
+
"dpt_hybrid": os.path.join(annotator_ckpts_path, "dpt_hybrid-midas-501f0c75.pt"),
|
| 19 |
+
"midas_v21": "",
|
| 20 |
+
"midas_v21_small": "",
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
remote_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/dpt_hybrid-midas-501f0c75.pt"
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def disabled_train(self, mode=True):
|
| 27 |
+
"""Overwrite model.train with this function to make sure train/eval mode
|
| 28 |
+
does not change anymore."""
|
| 29 |
+
return self
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def load_midas_transform(model_type):
|
| 33 |
+
# https://github.com/isl-org/MiDaS/blob/master/run.py
|
| 34 |
+
# load transform only
|
| 35 |
+
if model_type == "dpt_large": # DPT-Large
|
| 36 |
+
net_w, net_h = 384, 384
|
| 37 |
+
resize_mode = "minimal"
|
| 38 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 39 |
+
|
| 40 |
+
elif model_type == "dpt_hybrid": # DPT-Hybrid
|
| 41 |
+
net_w, net_h = 384, 384
|
| 42 |
+
resize_mode = "minimal"
|
| 43 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 44 |
+
|
| 45 |
+
elif model_type == "midas_v21":
|
| 46 |
+
net_w, net_h = 384, 384
|
| 47 |
+
resize_mode = "upper_bound"
|
| 48 |
+
normalization = NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
|
| 49 |
+
|
| 50 |
+
elif model_type == "midas_v21_small":
|
| 51 |
+
net_w, net_h = 256, 256
|
| 52 |
+
resize_mode = "upper_bound"
|
| 53 |
+
normalization = NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
|
| 54 |
+
|
| 55 |
+
else:
|
| 56 |
+
assert False, f"model_type '{model_type}' not implemented, use: --model_type large"
|
| 57 |
+
|
| 58 |
+
transform = Compose(
|
| 59 |
+
[
|
| 60 |
+
Resize(
|
| 61 |
+
net_w,
|
| 62 |
+
net_h,
|
| 63 |
+
resize_target=None,
|
| 64 |
+
keep_aspect_ratio=True,
|
| 65 |
+
ensure_multiple_of=32,
|
| 66 |
+
resize_method=resize_mode,
|
| 67 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 68 |
+
),
|
| 69 |
+
normalization,
|
| 70 |
+
PrepareForNet(),
|
| 71 |
+
]
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
return transform
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def load_model(model_type):
|
| 78 |
+
# https://github.com/isl-org/MiDaS/blob/master/run.py
|
| 79 |
+
# load network
|
| 80 |
+
model_path = ISL_PATHS[model_type]
|
| 81 |
+
if model_type == "dpt_large": # DPT-Large
|
| 82 |
+
model = DPTDepthModel(
|
| 83 |
+
path=model_path,
|
| 84 |
+
backbone="vitl16_384",
|
| 85 |
+
non_negative=True,
|
| 86 |
+
)
|
| 87 |
+
net_w, net_h = 384, 384
|
| 88 |
+
resize_mode = "minimal"
|
| 89 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 90 |
+
|
| 91 |
+
elif model_type == "dpt_hybrid": # DPT-Hybrid
|
| 92 |
+
if not os.path.exists(model_path):
|
| 93 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 94 |
+
load_file_from_url(remote_model_path, model_dir=annotator_ckpts_path)
|
| 95 |
+
|
| 96 |
+
model = DPTDepthModel(
|
| 97 |
+
path=model_path,
|
| 98 |
+
backbone="vitb_rn50_384",
|
| 99 |
+
non_negative=True,
|
| 100 |
+
)
|
| 101 |
+
net_w, net_h = 384, 384
|
| 102 |
+
resize_mode = "minimal"
|
| 103 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 104 |
+
|
| 105 |
+
elif model_type == "midas_v21":
|
| 106 |
+
model = MidasNet(model_path, non_negative=True)
|
| 107 |
+
net_w, net_h = 384, 384
|
| 108 |
+
resize_mode = "upper_bound"
|
| 109 |
+
normalization = NormalizeImage(
|
| 110 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
elif model_type == "midas_v21_small":
|
| 114 |
+
model = MidasNet_small(model_path, features=64, backbone="efficientnet_lite3", exportable=True,
|
| 115 |
+
non_negative=True, blocks={'expand': True})
|
| 116 |
+
net_w, net_h = 256, 256
|
| 117 |
+
resize_mode = "upper_bound"
|
| 118 |
+
normalization = NormalizeImage(
|
| 119 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
else:
|
| 123 |
+
print(f"model_type '{model_type}' not implemented, use: --model_type large")
|
| 124 |
+
assert False
|
| 125 |
+
|
| 126 |
+
transform = Compose(
|
| 127 |
+
[
|
| 128 |
+
Resize(
|
| 129 |
+
net_w,
|
| 130 |
+
net_h,
|
| 131 |
+
resize_target=None,
|
| 132 |
+
keep_aspect_ratio=True,
|
| 133 |
+
ensure_multiple_of=32,
|
| 134 |
+
resize_method=resize_mode,
|
| 135 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 136 |
+
),
|
| 137 |
+
normalization,
|
| 138 |
+
PrepareForNet(),
|
| 139 |
+
]
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
return model.eval(), transform
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class MiDaSInference(nn.Module):
|
| 146 |
+
MODEL_TYPES_TORCH_HUB = [
|
| 147 |
+
"DPT_Large",
|
| 148 |
+
"DPT_Hybrid",
|
| 149 |
+
"MiDaS_small"
|
| 150 |
+
]
|
| 151 |
+
MODEL_TYPES_ISL = [
|
| 152 |
+
"dpt_large",
|
| 153 |
+
"dpt_hybrid",
|
| 154 |
+
"midas_v21",
|
| 155 |
+
"midas_v21_small",
|
| 156 |
+
]
|
| 157 |
+
|
| 158 |
+
def __init__(self, model_type):
|
| 159 |
+
super().__init__()
|
| 160 |
+
assert (model_type in self.MODEL_TYPES_ISL)
|
| 161 |
+
model, _ = load_model(model_type)
|
| 162 |
+
self.model = model
|
| 163 |
+
self.model.train = disabled_train
|
| 164 |
+
|
| 165 |
+
def forward(self, x):
|
| 166 |
+
with torch.no_grad():
|
| 167 |
+
prediction = self.model(x)
|
| 168 |
+
return prediction
|
| 169 |
+
|
src/ControlNet/annotator/midas/midas/__init__.py
ADDED
|
File without changes
|
src/ControlNet/annotator/midas/midas/base_model.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BaseModel(torch.nn.Module):
|
| 5 |
+
def load(self, path):
|
| 6 |
+
"""Load model from file.
|
| 7 |
+
|
| 8 |
+
Args:
|
| 9 |
+
path (str): file path
|
| 10 |
+
"""
|
| 11 |
+
parameters = torch.load(path, map_location=torch.device('cpu'))
|
| 12 |
+
|
| 13 |
+
if "optimizer" in parameters:
|
| 14 |
+
parameters = parameters["model"]
|
| 15 |
+
|
| 16 |
+
self.load_state_dict(parameters)
|
src/ControlNet/annotator/midas/midas/blocks.py
ADDED
|
@@ -0,0 +1,342 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from .vit import (
|
| 5 |
+
_make_pretrained_vitb_rn50_384,
|
| 6 |
+
_make_pretrained_vitl16_384,
|
| 7 |
+
_make_pretrained_vitb16_384,
|
| 8 |
+
forward_vit,
|
| 9 |
+
)
|
| 10 |
+
|
| 11 |
+
def _make_encoder(backbone, features, use_pretrained, groups=1, expand=False, exportable=True, hooks=None, use_vit_only=False, use_readout="ignore",):
|
| 12 |
+
if backbone == "vitl16_384":
|
| 13 |
+
pretrained = _make_pretrained_vitl16_384(
|
| 14 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 15 |
+
)
|
| 16 |
+
scratch = _make_scratch(
|
| 17 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 18 |
+
) # ViT-L/16 - 85.0% Top1 (backbone)
|
| 19 |
+
elif backbone == "vitb_rn50_384":
|
| 20 |
+
pretrained = _make_pretrained_vitb_rn50_384(
|
| 21 |
+
use_pretrained,
|
| 22 |
+
hooks=hooks,
|
| 23 |
+
use_vit_only=use_vit_only,
|
| 24 |
+
use_readout=use_readout,
|
| 25 |
+
)
|
| 26 |
+
scratch = _make_scratch(
|
| 27 |
+
[256, 512, 768, 768], features, groups=groups, expand=expand
|
| 28 |
+
) # ViT-H/16 - 85.0% Top1 (backbone)
|
| 29 |
+
elif backbone == "vitb16_384":
|
| 30 |
+
pretrained = _make_pretrained_vitb16_384(
|
| 31 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 32 |
+
)
|
| 33 |
+
scratch = _make_scratch(
|
| 34 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 35 |
+
) # ViT-B/16 - 84.6% Top1 (backbone)
|
| 36 |
+
elif backbone == "resnext101_wsl":
|
| 37 |
+
pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
|
| 38 |
+
scratch = _make_scratch([256, 512, 1024, 2048], features, groups=groups, expand=expand) # efficientnet_lite3
|
| 39 |
+
elif backbone == "efficientnet_lite3":
|
| 40 |
+
pretrained = _make_pretrained_efficientnet_lite3(use_pretrained, exportable=exportable)
|
| 41 |
+
scratch = _make_scratch([32, 48, 136, 384], features, groups=groups, expand=expand) # efficientnet_lite3
|
| 42 |
+
else:
|
| 43 |
+
print(f"Backbone '{backbone}' not implemented")
|
| 44 |
+
assert False
|
| 45 |
+
|
| 46 |
+
return pretrained, scratch
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def _make_scratch(in_shape, out_shape, groups=1, expand=False):
|
| 50 |
+
scratch = nn.Module()
|
| 51 |
+
|
| 52 |
+
out_shape1 = out_shape
|
| 53 |
+
out_shape2 = out_shape
|
| 54 |
+
out_shape3 = out_shape
|
| 55 |
+
out_shape4 = out_shape
|
| 56 |
+
if expand==True:
|
| 57 |
+
out_shape1 = out_shape
|
| 58 |
+
out_shape2 = out_shape*2
|
| 59 |
+
out_shape3 = out_shape*4
|
| 60 |
+
out_shape4 = out_shape*8
|
| 61 |
+
|
| 62 |
+
scratch.layer1_rn = nn.Conv2d(
|
| 63 |
+
in_shape[0], out_shape1, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 64 |
+
)
|
| 65 |
+
scratch.layer2_rn = nn.Conv2d(
|
| 66 |
+
in_shape[1], out_shape2, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 67 |
+
)
|
| 68 |
+
scratch.layer3_rn = nn.Conv2d(
|
| 69 |
+
in_shape[2], out_shape3, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 70 |
+
)
|
| 71 |
+
scratch.layer4_rn = nn.Conv2d(
|
| 72 |
+
in_shape[3], out_shape4, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
return scratch
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def _make_pretrained_efficientnet_lite3(use_pretrained, exportable=False):
|
| 79 |
+
efficientnet = torch.hub.load(
|
| 80 |
+
"rwightman/gen-efficientnet-pytorch",
|
| 81 |
+
"tf_efficientnet_lite3",
|
| 82 |
+
pretrained=use_pretrained,
|
| 83 |
+
exportable=exportable
|
| 84 |
+
)
|
| 85 |
+
return _make_efficientnet_backbone(efficientnet)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def _make_efficientnet_backbone(effnet):
|
| 89 |
+
pretrained = nn.Module()
|
| 90 |
+
|
| 91 |
+
pretrained.layer1 = nn.Sequential(
|
| 92 |
+
effnet.conv_stem, effnet.bn1, effnet.act1, *effnet.blocks[0:2]
|
| 93 |
+
)
|
| 94 |
+
pretrained.layer2 = nn.Sequential(*effnet.blocks[2:3])
|
| 95 |
+
pretrained.layer3 = nn.Sequential(*effnet.blocks[3:5])
|
| 96 |
+
pretrained.layer4 = nn.Sequential(*effnet.blocks[5:9])
|
| 97 |
+
|
| 98 |
+
return pretrained
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def _make_resnet_backbone(resnet):
|
| 102 |
+
pretrained = nn.Module()
|
| 103 |
+
pretrained.layer1 = nn.Sequential(
|
| 104 |
+
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
pretrained.layer2 = resnet.layer2
|
| 108 |
+
pretrained.layer3 = resnet.layer3
|
| 109 |
+
pretrained.layer4 = resnet.layer4
|
| 110 |
+
|
| 111 |
+
return pretrained
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def _make_pretrained_resnext101_wsl(use_pretrained):
|
| 115 |
+
resnet = torch.hub.load("facebookresearch/WSL-Images", "resnext101_32x8d_wsl")
|
| 116 |
+
return _make_resnet_backbone(resnet)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class Interpolate(nn.Module):
|
| 121 |
+
"""Interpolation module.
|
| 122 |
+
"""
|
| 123 |
+
|
| 124 |
+
def __init__(self, scale_factor, mode, align_corners=False):
|
| 125 |
+
"""Init.
|
| 126 |
+
|
| 127 |
+
Args:
|
| 128 |
+
scale_factor (float): scaling
|
| 129 |
+
mode (str): interpolation mode
|
| 130 |
+
"""
|
| 131 |
+
super(Interpolate, self).__init__()
|
| 132 |
+
|
| 133 |
+
self.interp = nn.functional.interpolate
|
| 134 |
+
self.scale_factor = scale_factor
|
| 135 |
+
self.mode = mode
|
| 136 |
+
self.align_corners = align_corners
|
| 137 |
+
|
| 138 |
+
def forward(self, x):
|
| 139 |
+
"""Forward pass.
|
| 140 |
+
|
| 141 |
+
Args:
|
| 142 |
+
x (tensor): input
|
| 143 |
+
|
| 144 |
+
Returns:
|
| 145 |
+
tensor: interpolated data
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
x = self.interp(
|
| 149 |
+
x, scale_factor=self.scale_factor, mode=self.mode, align_corners=self.align_corners
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
return x
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
class ResidualConvUnit(nn.Module):
|
| 156 |
+
"""Residual convolution module.
|
| 157 |
+
"""
|
| 158 |
+
|
| 159 |
+
def __init__(self, features):
|
| 160 |
+
"""Init.
|
| 161 |
+
|
| 162 |
+
Args:
|
| 163 |
+
features (int): number of features
|
| 164 |
+
"""
|
| 165 |
+
super().__init__()
|
| 166 |
+
|
| 167 |
+
self.conv1 = nn.Conv2d(
|
| 168 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
self.conv2 = nn.Conv2d(
|
| 172 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
self.relu = nn.ReLU(inplace=True)
|
| 176 |
+
|
| 177 |
+
def forward(self, x):
|
| 178 |
+
"""Forward pass.
|
| 179 |
+
|
| 180 |
+
Args:
|
| 181 |
+
x (tensor): input
|
| 182 |
+
|
| 183 |
+
Returns:
|
| 184 |
+
tensor: output
|
| 185 |
+
"""
|
| 186 |
+
out = self.relu(x)
|
| 187 |
+
out = self.conv1(out)
|
| 188 |
+
out = self.relu(out)
|
| 189 |
+
out = self.conv2(out)
|
| 190 |
+
|
| 191 |
+
return out + x
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
class FeatureFusionBlock(nn.Module):
|
| 195 |
+
"""Feature fusion block.
|
| 196 |
+
"""
|
| 197 |
+
|
| 198 |
+
def __init__(self, features):
|
| 199 |
+
"""Init.
|
| 200 |
+
|
| 201 |
+
Args:
|
| 202 |
+
features (int): number of features
|
| 203 |
+
"""
|
| 204 |
+
super(FeatureFusionBlock, self).__init__()
|
| 205 |
+
|
| 206 |
+
self.resConfUnit1 = ResidualConvUnit(features)
|
| 207 |
+
self.resConfUnit2 = ResidualConvUnit(features)
|
| 208 |
+
|
| 209 |
+
def forward(self, *xs):
|
| 210 |
+
"""Forward pass.
|
| 211 |
+
|
| 212 |
+
Returns:
|
| 213 |
+
tensor: output
|
| 214 |
+
"""
|
| 215 |
+
output = xs[0]
|
| 216 |
+
|
| 217 |
+
if len(xs) == 2:
|
| 218 |
+
output += self.resConfUnit1(xs[1])
|
| 219 |
+
|
| 220 |
+
output = self.resConfUnit2(output)
|
| 221 |
+
|
| 222 |
+
output = nn.functional.interpolate(
|
| 223 |
+
output, scale_factor=2, mode="bilinear", align_corners=True
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
return output
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
class ResidualConvUnit_custom(nn.Module):
|
| 232 |
+
"""Residual convolution module.
|
| 233 |
+
"""
|
| 234 |
+
|
| 235 |
+
def __init__(self, features, activation, bn):
|
| 236 |
+
"""Init.
|
| 237 |
+
|
| 238 |
+
Args:
|
| 239 |
+
features (int): number of features
|
| 240 |
+
"""
|
| 241 |
+
super().__init__()
|
| 242 |
+
|
| 243 |
+
self.bn = bn
|
| 244 |
+
|
| 245 |
+
self.groups=1
|
| 246 |
+
|
| 247 |
+
self.conv1 = nn.Conv2d(
|
| 248 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
self.conv2 = nn.Conv2d(
|
| 252 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
if self.bn==True:
|
| 256 |
+
self.bn1 = nn.BatchNorm2d(features)
|
| 257 |
+
self.bn2 = nn.BatchNorm2d(features)
|
| 258 |
+
|
| 259 |
+
self.activation = activation
|
| 260 |
+
|
| 261 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 262 |
+
|
| 263 |
+
def forward(self, x):
|
| 264 |
+
"""Forward pass.
|
| 265 |
+
|
| 266 |
+
Args:
|
| 267 |
+
x (tensor): input
|
| 268 |
+
|
| 269 |
+
Returns:
|
| 270 |
+
tensor: output
|
| 271 |
+
"""
|
| 272 |
+
|
| 273 |
+
out = self.activation(x)
|
| 274 |
+
out = self.conv1(out)
|
| 275 |
+
if self.bn==True:
|
| 276 |
+
out = self.bn1(out)
|
| 277 |
+
|
| 278 |
+
out = self.activation(out)
|
| 279 |
+
out = self.conv2(out)
|
| 280 |
+
if self.bn==True:
|
| 281 |
+
out = self.bn2(out)
|
| 282 |
+
|
| 283 |
+
if self.groups > 1:
|
| 284 |
+
out = self.conv_merge(out)
|
| 285 |
+
|
| 286 |
+
return self.skip_add.add(out, x)
|
| 287 |
+
|
| 288 |
+
# return out + x
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class FeatureFusionBlock_custom(nn.Module):
|
| 292 |
+
"""Feature fusion block.
|
| 293 |
+
"""
|
| 294 |
+
|
| 295 |
+
def __init__(self, features, activation, deconv=False, bn=False, expand=False, align_corners=True):
|
| 296 |
+
"""Init.
|
| 297 |
+
|
| 298 |
+
Args:
|
| 299 |
+
features (int): number of features
|
| 300 |
+
"""
|
| 301 |
+
super(FeatureFusionBlock_custom, self).__init__()
|
| 302 |
+
|
| 303 |
+
self.deconv = deconv
|
| 304 |
+
self.align_corners = align_corners
|
| 305 |
+
|
| 306 |
+
self.groups=1
|
| 307 |
+
|
| 308 |
+
self.expand = expand
|
| 309 |
+
out_features = features
|
| 310 |
+
if self.expand==True:
|
| 311 |
+
out_features = features//2
|
| 312 |
+
|
| 313 |
+
self.out_conv = nn.Conv2d(features, out_features, kernel_size=1, stride=1, padding=0, bias=True, groups=1)
|
| 314 |
+
|
| 315 |
+
self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
|
| 316 |
+
self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
|
| 317 |
+
|
| 318 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 319 |
+
|
| 320 |
+
def forward(self, *xs):
|
| 321 |
+
"""Forward pass.
|
| 322 |
+
|
| 323 |
+
Returns:
|
| 324 |
+
tensor: output
|
| 325 |
+
"""
|
| 326 |
+
output = xs[0]
|
| 327 |
+
|
| 328 |
+
if len(xs) == 2:
|
| 329 |
+
res = self.resConfUnit1(xs[1])
|
| 330 |
+
output = self.skip_add.add(output, res)
|
| 331 |
+
# output += res
|
| 332 |
+
|
| 333 |
+
output = self.resConfUnit2(output)
|
| 334 |
+
|
| 335 |
+
output = nn.functional.interpolate(
|
| 336 |
+
output, scale_factor=2, mode="bilinear", align_corners=self.align_corners
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
output = self.out_conv(output)
|
| 340 |
+
|
| 341 |
+
return output
|
| 342 |
+
|
src/ControlNet/annotator/midas/midas/dpt_depth.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from .base_model import BaseModel
|
| 6 |
+
from .blocks import (
|
| 7 |
+
FeatureFusionBlock,
|
| 8 |
+
FeatureFusionBlock_custom,
|
| 9 |
+
Interpolate,
|
| 10 |
+
_make_encoder,
|
| 11 |
+
forward_vit,
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def _make_fusion_block(features, use_bn):
|
| 16 |
+
return FeatureFusionBlock_custom(
|
| 17 |
+
features,
|
| 18 |
+
nn.ReLU(False),
|
| 19 |
+
deconv=False,
|
| 20 |
+
bn=use_bn,
|
| 21 |
+
expand=False,
|
| 22 |
+
align_corners=True,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class DPT(BaseModel):
|
| 27 |
+
def __init__(
|
| 28 |
+
self,
|
| 29 |
+
head,
|
| 30 |
+
features=256,
|
| 31 |
+
backbone="vitb_rn50_384",
|
| 32 |
+
readout="project",
|
| 33 |
+
channels_last=False,
|
| 34 |
+
use_bn=False,
|
| 35 |
+
):
|
| 36 |
+
|
| 37 |
+
super(DPT, self).__init__()
|
| 38 |
+
|
| 39 |
+
self.channels_last = channels_last
|
| 40 |
+
|
| 41 |
+
hooks = {
|
| 42 |
+
"vitb_rn50_384": [0, 1, 8, 11],
|
| 43 |
+
"vitb16_384": [2, 5, 8, 11],
|
| 44 |
+
"vitl16_384": [5, 11, 17, 23],
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
# Instantiate backbone and reassemble blocks
|
| 48 |
+
self.pretrained, self.scratch = _make_encoder(
|
| 49 |
+
backbone,
|
| 50 |
+
features,
|
| 51 |
+
False, # Set to true of you want to train from scratch, uses ImageNet weights
|
| 52 |
+
groups=1,
|
| 53 |
+
expand=False,
|
| 54 |
+
exportable=False,
|
| 55 |
+
hooks=hooks[backbone],
|
| 56 |
+
use_readout=readout,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
self.scratch.refinenet1 = _make_fusion_block(features, use_bn)
|
| 60 |
+
self.scratch.refinenet2 = _make_fusion_block(features, use_bn)
|
| 61 |
+
self.scratch.refinenet3 = _make_fusion_block(features, use_bn)
|
| 62 |
+
self.scratch.refinenet4 = _make_fusion_block(features, use_bn)
|
| 63 |
+
|
| 64 |
+
self.scratch.output_conv = head
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def forward(self, x):
|
| 68 |
+
if self.channels_last == True:
|
| 69 |
+
x.contiguous(memory_format=torch.channels_last)
|
| 70 |
+
|
| 71 |
+
layer_1, layer_2, layer_3, layer_4 = forward_vit(self.pretrained, x)
|
| 72 |
+
|
| 73 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 74 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 75 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 76 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 77 |
+
|
| 78 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 79 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 80 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 81 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 82 |
+
|
| 83 |
+
out = self.scratch.output_conv(path_1)
|
| 84 |
+
|
| 85 |
+
return out
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class DPTDepthModel(DPT):
|
| 89 |
+
def __init__(self, path=None, non_negative=True, **kwargs):
|
| 90 |
+
features = kwargs["features"] if "features" in kwargs else 256
|
| 91 |
+
|
| 92 |
+
head = nn.Sequential(
|
| 93 |
+
nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1),
|
| 94 |
+
Interpolate(scale_factor=2, mode="bilinear", align_corners=True),
|
| 95 |
+
nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
|
| 96 |
+
nn.ReLU(True),
|
| 97 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 98 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 99 |
+
nn.Identity(),
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
super().__init__(head, **kwargs)
|
| 103 |
+
|
| 104 |
+
if path is not None:
|
| 105 |
+
self.load(path)
|
| 106 |
+
|
| 107 |
+
def forward(self, x):
|
| 108 |
+
return super().forward(x).squeeze(dim=1)
|
| 109 |
+
|
src/ControlNet/annotator/midas/midas/midas_net.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
| 2 |
+
This file contains code that is adapted from
|
| 3 |
+
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
from .base_model import BaseModel
|
| 9 |
+
from .blocks import FeatureFusionBlock, Interpolate, _make_encoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MidasNet(BaseModel):
|
| 13 |
+
"""Network for monocular depth estimation.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, path=None, features=256, non_negative=True):
|
| 17 |
+
"""Init.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
path (str, optional): Path to saved model. Defaults to None.
|
| 21 |
+
features (int, optional): Number of features. Defaults to 256.
|
| 22 |
+
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
| 23 |
+
"""
|
| 24 |
+
print("Loading weights: ", path)
|
| 25 |
+
|
| 26 |
+
super(MidasNet, self).__init__()
|
| 27 |
+
|
| 28 |
+
use_pretrained = False if path is None else True
|
| 29 |
+
|
| 30 |
+
self.pretrained, self.scratch = _make_encoder(backbone="resnext101_wsl", features=features, use_pretrained=use_pretrained)
|
| 31 |
+
|
| 32 |
+
self.scratch.refinenet4 = FeatureFusionBlock(features)
|
| 33 |
+
self.scratch.refinenet3 = FeatureFusionBlock(features)
|
| 34 |
+
self.scratch.refinenet2 = FeatureFusionBlock(features)
|
| 35 |
+
self.scratch.refinenet1 = FeatureFusionBlock(features)
|
| 36 |
+
|
| 37 |
+
self.scratch.output_conv = nn.Sequential(
|
| 38 |
+
nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1),
|
| 39 |
+
Interpolate(scale_factor=2, mode="bilinear"),
|
| 40 |
+
nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1),
|
| 41 |
+
nn.ReLU(True),
|
| 42 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 43 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
if path:
|
| 47 |
+
self.load(path)
|
| 48 |
+
|
| 49 |
+
def forward(self, x):
|
| 50 |
+
"""Forward pass.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
x (tensor): input data (image)
|
| 54 |
+
|
| 55 |
+
Returns:
|
| 56 |
+
tensor: depth
|
| 57 |
+
"""
|
| 58 |
+
|
| 59 |
+
layer_1 = self.pretrained.layer1(x)
|
| 60 |
+
layer_2 = self.pretrained.layer2(layer_1)
|
| 61 |
+
layer_3 = self.pretrained.layer3(layer_2)
|
| 62 |
+
layer_4 = self.pretrained.layer4(layer_3)
|
| 63 |
+
|
| 64 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 65 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 66 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 67 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 68 |
+
|
| 69 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 70 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 71 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 72 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 73 |
+
|
| 74 |
+
out = self.scratch.output_conv(path_1)
|
| 75 |
+
|
| 76 |
+
return torch.squeeze(out, dim=1)
|
src/ControlNet/annotator/midas/midas/midas_net_custom.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
| 2 |
+
This file contains code that is adapted from
|
| 3 |
+
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
from .base_model import BaseModel
|
| 9 |
+
from .blocks import FeatureFusionBlock, FeatureFusionBlock_custom, Interpolate, _make_encoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MidasNet_small(BaseModel):
|
| 13 |
+
"""Network for monocular depth estimation.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, path=None, features=64, backbone="efficientnet_lite3", non_negative=True, exportable=True, channels_last=False, align_corners=True,
|
| 17 |
+
blocks={'expand': True}):
|
| 18 |
+
"""Init.
|
| 19 |
+
|
| 20 |
+
Args:
|
| 21 |
+
path (str, optional): Path to saved model. Defaults to None.
|
| 22 |
+
features (int, optional): Number of features. Defaults to 256.
|
| 23 |
+
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
| 24 |
+
"""
|
| 25 |
+
print("Loading weights: ", path)
|
| 26 |
+
|
| 27 |
+
super(MidasNet_small, self).__init__()
|
| 28 |
+
|
| 29 |
+
use_pretrained = False if path else True
|
| 30 |
+
|
| 31 |
+
self.channels_last = channels_last
|
| 32 |
+
self.blocks = blocks
|
| 33 |
+
self.backbone = backbone
|
| 34 |
+
|
| 35 |
+
self.groups = 1
|
| 36 |
+
|
| 37 |
+
features1=features
|
| 38 |
+
features2=features
|
| 39 |
+
features3=features
|
| 40 |
+
features4=features
|
| 41 |
+
self.expand = False
|
| 42 |
+
if "expand" in self.blocks and self.blocks['expand'] == True:
|
| 43 |
+
self.expand = True
|
| 44 |
+
features1=features
|
| 45 |
+
features2=features*2
|
| 46 |
+
features3=features*4
|
| 47 |
+
features4=features*8
|
| 48 |
+
|
| 49 |
+
self.pretrained, self.scratch = _make_encoder(self.backbone, features, use_pretrained, groups=self.groups, expand=self.expand, exportable=exportable)
|
| 50 |
+
|
| 51 |
+
self.scratch.activation = nn.ReLU(False)
|
| 52 |
+
|
| 53 |
+
self.scratch.refinenet4 = FeatureFusionBlock_custom(features4, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 54 |
+
self.scratch.refinenet3 = FeatureFusionBlock_custom(features3, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 55 |
+
self.scratch.refinenet2 = FeatureFusionBlock_custom(features2, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 56 |
+
self.scratch.refinenet1 = FeatureFusionBlock_custom(features1, self.scratch.activation, deconv=False, bn=False, align_corners=align_corners)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
self.scratch.output_conv = nn.Sequential(
|
| 60 |
+
nn.Conv2d(features, features//2, kernel_size=3, stride=1, padding=1, groups=self.groups),
|
| 61 |
+
Interpolate(scale_factor=2, mode="bilinear"),
|
| 62 |
+
nn.Conv2d(features//2, 32, kernel_size=3, stride=1, padding=1),
|
| 63 |
+
self.scratch.activation,
|
| 64 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 65 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 66 |
+
nn.Identity(),
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
if path:
|
| 70 |
+
self.load(path)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
"""Forward pass.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
x (tensor): input data (image)
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
tensor: depth
|
| 81 |
+
"""
|
| 82 |
+
if self.channels_last==True:
|
| 83 |
+
print("self.channels_last = ", self.channels_last)
|
| 84 |
+
x.contiguous(memory_format=torch.channels_last)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
layer_1 = self.pretrained.layer1(x)
|
| 88 |
+
layer_2 = self.pretrained.layer2(layer_1)
|
| 89 |
+
layer_3 = self.pretrained.layer3(layer_2)
|
| 90 |
+
layer_4 = self.pretrained.layer4(layer_3)
|
| 91 |
+
|
| 92 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 93 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 94 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 95 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 99 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 100 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 101 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 102 |
+
|
| 103 |
+
out = self.scratch.output_conv(path_1)
|
| 104 |
+
|
| 105 |
+
return torch.squeeze(out, dim=1)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def fuse_model(m):
|
| 110 |
+
prev_previous_type = nn.Identity()
|
| 111 |
+
prev_previous_name = ''
|
| 112 |
+
previous_type = nn.Identity()
|
| 113 |
+
previous_name = ''
|
| 114 |
+
for name, module in m.named_modules():
|
| 115 |
+
if prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d and type(module) == nn.ReLU:
|
| 116 |
+
# print("FUSED ", prev_previous_name, previous_name, name)
|
| 117 |
+
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name, name], inplace=True)
|
| 118 |
+
elif prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d:
|
| 119 |
+
# print("FUSED ", prev_previous_name, previous_name)
|
| 120 |
+
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name], inplace=True)
|
| 121 |
+
# elif previous_type == nn.Conv2d and type(module) == nn.ReLU:
|
| 122 |
+
# print("FUSED ", previous_name, name)
|
| 123 |
+
# torch.quantization.fuse_modules(m, [previous_name, name], inplace=True)
|
| 124 |
+
|
| 125 |
+
prev_previous_type = previous_type
|
| 126 |
+
prev_previous_name = previous_name
|
| 127 |
+
previous_type = type(module)
|
| 128 |
+
previous_name = name
|
src/ControlNet/annotator/midas/midas/transforms.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import cv2
|
| 3 |
+
import math
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def apply_min_size(sample, size, image_interpolation_method=cv2.INTER_AREA):
|
| 7 |
+
"""Rezise the sample to ensure the given size. Keeps aspect ratio.
|
| 8 |
+
|
| 9 |
+
Args:
|
| 10 |
+
sample (dict): sample
|
| 11 |
+
size (tuple): image size
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
tuple: new size
|
| 15 |
+
"""
|
| 16 |
+
shape = list(sample["disparity"].shape)
|
| 17 |
+
|
| 18 |
+
if shape[0] >= size[0] and shape[1] >= size[1]:
|
| 19 |
+
return sample
|
| 20 |
+
|
| 21 |
+
scale = [0, 0]
|
| 22 |
+
scale[0] = size[0] / shape[0]
|
| 23 |
+
scale[1] = size[1] / shape[1]
|
| 24 |
+
|
| 25 |
+
scale = max(scale)
|
| 26 |
+
|
| 27 |
+
shape[0] = math.ceil(scale * shape[0])
|
| 28 |
+
shape[1] = math.ceil(scale * shape[1])
|
| 29 |
+
|
| 30 |
+
# resize
|
| 31 |
+
sample["image"] = cv2.resize(
|
| 32 |
+
sample["image"], tuple(shape[::-1]), interpolation=image_interpolation_method
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
sample["disparity"] = cv2.resize(
|
| 36 |
+
sample["disparity"], tuple(shape[::-1]), interpolation=cv2.INTER_NEAREST
|
| 37 |
+
)
|
| 38 |
+
sample["mask"] = cv2.resize(
|
| 39 |
+
sample["mask"].astype(np.float32),
|
| 40 |
+
tuple(shape[::-1]),
|
| 41 |
+
interpolation=cv2.INTER_NEAREST,
|
| 42 |
+
)
|
| 43 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 44 |
+
|
| 45 |
+
return tuple(shape)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class Resize(object):
|
| 49 |
+
"""Resize sample to given size (width, height).
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(
|
| 53 |
+
self,
|
| 54 |
+
width,
|
| 55 |
+
height,
|
| 56 |
+
resize_target=True,
|
| 57 |
+
keep_aspect_ratio=False,
|
| 58 |
+
ensure_multiple_of=1,
|
| 59 |
+
resize_method="lower_bound",
|
| 60 |
+
image_interpolation_method=cv2.INTER_AREA,
|
| 61 |
+
):
|
| 62 |
+
"""Init.
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
width (int): desired output width
|
| 66 |
+
height (int): desired output height
|
| 67 |
+
resize_target (bool, optional):
|
| 68 |
+
True: Resize the full sample (image, mask, target).
|
| 69 |
+
False: Resize image only.
|
| 70 |
+
Defaults to True.
|
| 71 |
+
keep_aspect_ratio (bool, optional):
|
| 72 |
+
True: Keep the aspect ratio of the input sample.
|
| 73 |
+
Output sample might not have the given width and height, and
|
| 74 |
+
resize behaviour depends on the parameter 'resize_method'.
|
| 75 |
+
Defaults to False.
|
| 76 |
+
ensure_multiple_of (int, optional):
|
| 77 |
+
Output width and height is constrained to be multiple of this parameter.
|
| 78 |
+
Defaults to 1.
|
| 79 |
+
resize_method (str, optional):
|
| 80 |
+
"lower_bound": Output will be at least as large as the given size.
|
| 81 |
+
"upper_bound": Output will be at max as large as the given size. (Output size might be smaller than given size.)
|
| 82 |
+
"minimal": Scale as least as possible. (Output size might be smaller than given size.)
|
| 83 |
+
Defaults to "lower_bound".
|
| 84 |
+
"""
|
| 85 |
+
self.__width = width
|
| 86 |
+
self.__height = height
|
| 87 |
+
|
| 88 |
+
self.__resize_target = resize_target
|
| 89 |
+
self.__keep_aspect_ratio = keep_aspect_ratio
|
| 90 |
+
self.__multiple_of = ensure_multiple_of
|
| 91 |
+
self.__resize_method = resize_method
|
| 92 |
+
self.__image_interpolation_method = image_interpolation_method
|
| 93 |
+
|
| 94 |
+
def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
|
| 95 |
+
y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 96 |
+
|
| 97 |
+
if max_val is not None and y > max_val:
|
| 98 |
+
y = (np.floor(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 99 |
+
|
| 100 |
+
if y < min_val:
|
| 101 |
+
y = (np.ceil(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 102 |
+
|
| 103 |
+
return y
|
| 104 |
+
|
| 105 |
+
def get_size(self, width, height):
|
| 106 |
+
# determine new height and width
|
| 107 |
+
scale_height = self.__height / height
|
| 108 |
+
scale_width = self.__width / width
|
| 109 |
+
|
| 110 |
+
if self.__keep_aspect_ratio:
|
| 111 |
+
if self.__resize_method == "lower_bound":
|
| 112 |
+
# scale such that output size is lower bound
|
| 113 |
+
if scale_width > scale_height:
|
| 114 |
+
# fit width
|
| 115 |
+
scale_height = scale_width
|
| 116 |
+
else:
|
| 117 |
+
# fit height
|
| 118 |
+
scale_width = scale_height
|
| 119 |
+
elif self.__resize_method == "upper_bound":
|
| 120 |
+
# scale such that output size is upper bound
|
| 121 |
+
if scale_width < scale_height:
|
| 122 |
+
# fit width
|
| 123 |
+
scale_height = scale_width
|
| 124 |
+
else:
|
| 125 |
+
# fit height
|
| 126 |
+
scale_width = scale_height
|
| 127 |
+
elif self.__resize_method == "minimal":
|
| 128 |
+
# scale as least as possbile
|
| 129 |
+
if abs(1 - scale_width) < abs(1 - scale_height):
|
| 130 |
+
# fit width
|
| 131 |
+
scale_height = scale_width
|
| 132 |
+
else:
|
| 133 |
+
# fit height
|
| 134 |
+
scale_width = scale_height
|
| 135 |
+
else:
|
| 136 |
+
raise ValueError(
|
| 137 |
+
f"resize_method {self.__resize_method} not implemented"
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
if self.__resize_method == "lower_bound":
|
| 141 |
+
new_height = self.constrain_to_multiple_of(
|
| 142 |
+
scale_height * height, min_val=self.__height
|
| 143 |
+
)
|
| 144 |
+
new_width = self.constrain_to_multiple_of(
|
| 145 |
+
scale_width * width, min_val=self.__width
|
| 146 |
+
)
|
| 147 |
+
elif self.__resize_method == "upper_bound":
|
| 148 |
+
new_height = self.constrain_to_multiple_of(
|
| 149 |
+
scale_height * height, max_val=self.__height
|
| 150 |
+
)
|
| 151 |
+
new_width = self.constrain_to_multiple_of(
|
| 152 |
+
scale_width * width, max_val=self.__width
|
| 153 |
+
)
|
| 154 |
+
elif self.__resize_method == "minimal":
|
| 155 |
+
new_height = self.constrain_to_multiple_of(scale_height * height)
|
| 156 |
+
new_width = self.constrain_to_multiple_of(scale_width * width)
|
| 157 |
+
else:
|
| 158 |
+
raise ValueError(f"resize_method {self.__resize_method} not implemented")
|
| 159 |
+
|
| 160 |
+
return (new_width, new_height)
|
| 161 |
+
|
| 162 |
+
def __call__(self, sample):
|
| 163 |
+
width, height = self.get_size(
|
| 164 |
+
sample["image"].shape[1], sample["image"].shape[0]
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
# resize sample
|
| 168 |
+
sample["image"] = cv2.resize(
|
| 169 |
+
sample["image"],
|
| 170 |
+
(width, height),
|
| 171 |
+
interpolation=self.__image_interpolation_method,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
if self.__resize_target:
|
| 175 |
+
if "disparity" in sample:
|
| 176 |
+
sample["disparity"] = cv2.resize(
|
| 177 |
+
sample["disparity"],
|
| 178 |
+
(width, height),
|
| 179 |
+
interpolation=cv2.INTER_NEAREST,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
if "depth" in sample:
|
| 183 |
+
sample["depth"] = cv2.resize(
|
| 184 |
+
sample["depth"], (width, height), interpolation=cv2.INTER_NEAREST
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
sample["mask"] = cv2.resize(
|
| 188 |
+
sample["mask"].astype(np.float32),
|
| 189 |
+
(width, height),
|
| 190 |
+
interpolation=cv2.INTER_NEAREST,
|
| 191 |
+
)
|
| 192 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 193 |
+
|
| 194 |
+
return sample
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class NormalizeImage(object):
|
| 198 |
+
"""Normlize image by given mean and std.
|
| 199 |
+
"""
|
| 200 |
+
|
| 201 |
+
def __init__(self, mean, std):
|
| 202 |
+
self.__mean = mean
|
| 203 |
+
self.__std = std
|
| 204 |
+
|
| 205 |
+
def __call__(self, sample):
|
| 206 |
+
sample["image"] = (sample["image"] - self.__mean) / self.__std
|
| 207 |
+
|
| 208 |
+
return sample
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class PrepareForNet(object):
|
| 212 |
+
"""Prepare sample for usage as network input.
|
| 213 |
+
"""
|
| 214 |
+
|
| 215 |
+
def __init__(self):
|
| 216 |
+
pass
|
| 217 |
+
|
| 218 |
+
def __call__(self, sample):
|
| 219 |
+
image = np.transpose(sample["image"], (2, 0, 1))
|
| 220 |
+
sample["image"] = np.ascontiguousarray(image).astype(np.float32)
|
| 221 |
+
|
| 222 |
+
if "mask" in sample:
|
| 223 |
+
sample["mask"] = sample["mask"].astype(np.float32)
|
| 224 |
+
sample["mask"] = np.ascontiguousarray(sample["mask"])
|
| 225 |
+
|
| 226 |
+
if "disparity" in sample:
|
| 227 |
+
disparity = sample["disparity"].astype(np.float32)
|
| 228 |
+
sample["disparity"] = np.ascontiguousarray(disparity)
|
| 229 |
+
|
| 230 |
+
if "depth" in sample:
|
| 231 |
+
depth = sample["depth"].astype(np.float32)
|
| 232 |
+
sample["depth"] = np.ascontiguousarray(depth)
|
| 233 |
+
|
| 234 |
+
return sample
|
src/ControlNet/annotator/midas/midas/vit.py
ADDED
|
@@ -0,0 +1,491 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import timm
|
| 4 |
+
import types
|
| 5 |
+
import math
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Slice(nn.Module):
|
| 10 |
+
def __init__(self, start_index=1):
|
| 11 |
+
super(Slice, self).__init__()
|
| 12 |
+
self.start_index = start_index
|
| 13 |
+
|
| 14 |
+
def forward(self, x):
|
| 15 |
+
return x[:, self.start_index :]
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class AddReadout(nn.Module):
|
| 19 |
+
def __init__(self, start_index=1):
|
| 20 |
+
super(AddReadout, self).__init__()
|
| 21 |
+
self.start_index = start_index
|
| 22 |
+
|
| 23 |
+
def forward(self, x):
|
| 24 |
+
if self.start_index == 2:
|
| 25 |
+
readout = (x[:, 0] + x[:, 1]) / 2
|
| 26 |
+
else:
|
| 27 |
+
readout = x[:, 0]
|
| 28 |
+
return x[:, self.start_index :] + readout.unsqueeze(1)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class ProjectReadout(nn.Module):
|
| 32 |
+
def __init__(self, in_features, start_index=1):
|
| 33 |
+
super(ProjectReadout, self).__init__()
|
| 34 |
+
self.start_index = start_index
|
| 35 |
+
|
| 36 |
+
self.project = nn.Sequential(nn.Linear(2 * in_features, in_features), nn.GELU())
|
| 37 |
+
|
| 38 |
+
def forward(self, x):
|
| 39 |
+
readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index :])
|
| 40 |
+
features = torch.cat((x[:, self.start_index :], readout), -1)
|
| 41 |
+
|
| 42 |
+
return self.project(features)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class Transpose(nn.Module):
|
| 46 |
+
def __init__(self, dim0, dim1):
|
| 47 |
+
super(Transpose, self).__init__()
|
| 48 |
+
self.dim0 = dim0
|
| 49 |
+
self.dim1 = dim1
|
| 50 |
+
|
| 51 |
+
def forward(self, x):
|
| 52 |
+
x = x.transpose(self.dim0, self.dim1)
|
| 53 |
+
return x
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def forward_vit(pretrained, x):
|
| 57 |
+
b, c, h, w = x.shape
|
| 58 |
+
|
| 59 |
+
glob = pretrained.model.forward_flex(x)
|
| 60 |
+
|
| 61 |
+
layer_1 = pretrained.activations["1"]
|
| 62 |
+
layer_2 = pretrained.activations["2"]
|
| 63 |
+
layer_3 = pretrained.activations["3"]
|
| 64 |
+
layer_4 = pretrained.activations["4"]
|
| 65 |
+
|
| 66 |
+
layer_1 = pretrained.act_postprocess1[0:2](layer_1)
|
| 67 |
+
layer_2 = pretrained.act_postprocess2[0:2](layer_2)
|
| 68 |
+
layer_3 = pretrained.act_postprocess3[0:2](layer_3)
|
| 69 |
+
layer_4 = pretrained.act_postprocess4[0:2](layer_4)
|
| 70 |
+
|
| 71 |
+
unflatten = nn.Sequential(
|
| 72 |
+
nn.Unflatten(
|
| 73 |
+
2,
|
| 74 |
+
torch.Size(
|
| 75 |
+
[
|
| 76 |
+
h // pretrained.model.patch_size[1],
|
| 77 |
+
w // pretrained.model.patch_size[0],
|
| 78 |
+
]
|
| 79 |
+
),
|
| 80 |
+
)
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
if layer_1.ndim == 3:
|
| 84 |
+
layer_1 = unflatten(layer_1)
|
| 85 |
+
if layer_2.ndim == 3:
|
| 86 |
+
layer_2 = unflatten(layer_2)
|
| 87 |
+
if layer_3.ndim == 3:
|
| 88 |
+
layer_3 = unflatten(layer_3)
|
| 89 |
+
if layer_4.ndim == 3:
|
| 90 |
+
layer_4 = unflatten(layer_4)
|
| 91 |
+
|
| 92 |
+
layer_1 = pretrained.act_postprocess1[3 : len(pretrained.act_postprocess1)](layer_1)
|
| 93 |
+
layer_2 = pretrained.act_postprocess2[3 : len(pretrained.act_postprocess2)](layer_2)
|
| 94 |
+
layer_3 = pretrained.act_postprocess3[3 : len(pretrained.act_postprocess3)](layer_3)
|
| 95 |
+
layer_4 = pretrained.act_postprocess4[3 : len(pretrained.act_postprocess4)](layer_4)
|
| 96 |
+
|
| 97 |
+
return layer_1, layer_2, layer_3, layer_4
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def _resize_pos_embed(self, posemb, gs_h, gs_w):
|
| 101 |
+
posemb_tok, posemb_grid = (
|
| 102 |
+
posemb[:, : self.start_index],
|
| 103 |
+
posemb[0, self.start_index :],
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
gs_old = int(math.sqrt(len(posemb_grid)))
|
| 107 |
+
|
| 108 |
+
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
|
| 109 |
+
posemb_grid = F.interpolate(posemb_grid, size=(gs_h, gs_w), mode="bilinear")
|
| 110 |
+
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_h * gs_w, -1)
|
| 111 |
+
|
| 112 |
+
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
|
| 113 |
+
|
| 114 |
+
return posemb
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def forward_flex(self, x):
|
| 118 |
+
b, c, h, w = x.shape
|
| 119 |
+
|
| 120 |
+
pos_embed = self._resize_pos_embed(
|
| 121 |
+
self.pos_embed, h // self.patch_size[1], w // self.patch_size[0]
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
B = x.shape[0]
|
| 125 |
+
|
| 126 |
+
if hasattr(self.patch_embed, "backbone"):
|
| 127 |
+
x = self.patch_embed.backbone(x)
|
| 128 |
+
if isinstance(x, (list, tuple)):
|
| 129 |
+
x = x[-1] # last feature if backbone outputs list/tuple of features
|
| 130 |
+
|
| 131 |
+
x = self.patch_embed.proj(x).flatten(2).transpose(1, 2)
|
| 132 |
+
|
| 133 |
+
if getattr(self, "dist_token", None) is not None:
|
| 134 |
+
cls_tokens = self.cls_token.expand(
|
| 135 |
+
B, -1, -1
|
| 136 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 137 |
+
dist_token = self.dist_token.expand(B, -1, -1)
|
| 138 |
+
x = torch.cat((cls_tokens, dist_token, x), dim=1)
|
| 139 |
+
else:
|
| 140 |
+
cls_tokens = self.cls_token.expand(
|
| 141 |
+
B, -1, -1
|
| 142 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 143 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 144 |
+
|
| 145 |
+
x = x + pos_embed
|
| 146 |
+
x = self.pos_drop(x)
|
| 147 |
+
|
| 148 |
+
for blk in self.blocks:
|
| 149 |
+
x = blk(x)
|
| 150 |
+
|
| 151 |
+
x = self.norm(x)
|
| 152 |
+
|
| 153 |
+
return x
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
activations = {}
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def get_activation(name):
|
| 160 |
+
def hook(model, input, output):
|
| 161 |
+
activations[name] = output
|
| 162 |
+
|
| 163 |
+
return hook
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def get_readout_oper(vit_features, features, use_readout, start_index=1):
|
| 167 |
+
if use_readout == "ignore":
|
| 168 |
+
readout_oper = [Slice(start_index)] * len(features)
|
| 169 |
+
elif use_readout == "add":
|
| 170 |
+
readout_oper = [AddReadout(start_index)] * len(features)
|
| 171 |
+
elif use_readout == "project":
|
| 172 |
+
readout_oper = [
|
| 173 |
+
ProjectReadout(vit_features, start_index) for out_feat in features
|
| 174 |
+
]
|
| 175 |
+
else:
|
| 176 |
+
assert (
|
| 177 |
+
False
|
| 178 |
+
), "wrong operation for readout token, use_readout can be 'ignore', 'add', or 'project'"
|
| 179 |
+
|
| 180 |
+
return readout_oper
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def _make_vit_b16_backbone(
|
| 184 |
+
model,
|
| 185 |
+
features=[96, 192, 384, 768],
|
| 186 |
+
size=[384, 384],
|
| 187 |
+
hooks=[2, 5, 8, 11],
|
| 188 |
+
vit_features=768,
|
| 189 |
+
use_readout="ignore",
|
| 190 |
+
start_index=1,
|
| 191 |
+
):
|
| 192 |
+
pretrained = nn.Module()
|
| 193 |
+
|
| 194 |
+
pretrained.model = model
|
| 195 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 196 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 197 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 198 |
+
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 199 |
+
|
| 200 |
+
pretrained.activations = activations
|
| 201 |
+
|
| 202 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
| 203 |
+
|
| 204 |
+
# 32, 48, 136, 384
|
| 205 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 206 |
+
readout_oper[0],
|
| 207 |
+
Transpose(1, 2),
|
| 208 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 209 |
+
nn.Conv2d(
|
| 210 |
+
in_channels=vit_features,
|
| 211 |
+
out_channels=features[0],
|
| 212 |
+
kernel_size=1,
|
| 213 |
+
stride=1,
|
| 214 |
+
padding=0,
|
| 215 |
+
),
|
| 216 |
+
nn.ConvTranspose2d(
|
| 217 |
+
in_channels=features[0],
|
| 218 |
+
out_channels=features[0],
|
| 219 |
+
kernel_size=4,
|
| 220 |
+
stride=4,
|
| 221 |
+
padding=0,
|
| 222 |
+
bias=True,
|
| 223 |
+
dilation=1,
|
| 224 |
+
groups=1,
|
| 225 |
+
),
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 229 |
+
readout_oper[1],
|
| 230 |
+
Transpose(1, 2),
|
| 231 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 232 |
+
nn.Conv2d(
|
| 233 |
+
in_channels=vit_features,
|
| 234 |
+
out_channels=features[1],
|
| 235 |
+
kernel_size=1,
|
| 236 |
+
stride=1,
|
| 237 |
+
padding=0,
|
| 238 |
+
),
|
| 239 |
+
nn.ConvTranspose2d(
|
| 240 |
+
in_channels=features[1],
|
| 241 |
+
out_channels=features[1],
|
| 242 |
+
kernel_size=2,
|
| 243 |
+
stride=2,
|
| 244 |
+
padding=0,
|
| 245 |
+
bias=True,
|
| 246 |
+
dilation=1,
|
| 247 |
+
groups=1,
|
| 248 |
+
),
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 252 |
+
readout_oper[2],
|
| 253 |
+
Transpose(1, 2),
|
| 254 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 255 |
+
nn.Conv2d(
|
| 256 |
+
in_channels=vit_features,
|
| 257 |
+
out_channels=features[2],
|
| 258 |
+
kernel_size=1,
|
| 259 |
+
stride=1,
|
| 260 |
+
padding=0,
|
| 261 |
+
),
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 265 |
+
readout_oper[3],
|
| 266 |
+
Transpose(1, 2),
|
| 267 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 268 |
+
nn.Conv2d(
|
| 269 |
+
in_channels=vit_features,
|
| 270 |
+
out_channels=features[3],
|
| 271 |
+
kernel_size=1,
|
| 272 |
+
stride=1,
|
| 273 |
+
padding=0,
|
| 274 |
+
),
|
| 275 |
+
nn.Conv2d(
|
| 276 |
+
in_channels=features[3],
|
| 277 |
+
out_channels=features[3],
|
| 278 |
+
kernel_size=3,
|
| 279 |
+
stride=2,
|
| 280 |
+
padding=1,
|
| 281 |
+
),
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
pretrained.model.start_index = start_index
|
| 285 |
+
pretrained.model.patch_size = [16, 16]
|
| 286 |
+
|
| 287 |
+
# We inject this function into the VisionTransformer instances so that
|
| 288 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 289 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 290 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 291 |
+
_resize_pos_embed, pretrained.model
|
| 292 |
+
)
|
| 293 |
+
|
| 294 |
+
return pretrained
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
def _make_pretrained_vitl16_384(pretrained, use_readout="ignore", hooks=None):
|
| 298 |
+
model = timm.create_model("vit_large_patch16_384", pretrained=pretrained)
|
| 299 |
+
|
| 300 |
+
hooks = [5, 11, 17, 23] if hooks == None else hooks
|
| 301 |
+
return _make_vit_b16_backbone(
|
| 302 |
+
model,
|
| 303 |
+
features=[256, 512, 1024, 1024],
|
| 304 |
+
hooks=hooks,
|
| 305 |
+
vit_features=1024,
|
| 306 |
+
use_readout=use_readout,
|
| 307 |
+
)
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
def _make_pretrained_vitb16_384(pretrained, use_readout="ignore", hooks=None):
|
| 311 |
+
model = timm.create_model("vit_base_patch16_384", pretrained=pretrained)
|
| 312 |
+
|
| 313 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 314 |
+
return _make_vit_b16_backbone(
|
| 315 |
+
model, features=[96, 192, 384, 768], hooks=hooks, use_readout=use_readout
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def _make_pretrained_deitb16_384(pretrained, use_readout="ignore", hooks=None):
|
| 320 |
+
model = timm.create_model("vit_deit_base_patch16_384", pretrained=pretrained)
|
| 321 |
+
|
| 322 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 323 |
+
return _make_vit_b16_backbone(
|
| 324 |
+
model, features=[96, 192, 384, 768], hooks=hooks, use_readout=use_readout
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
def _make_pretrained_deitb16_distil_384(pretrained, use_readout="ignore", hooks=None):
|
| 329 |
+
model = timm.create_model(
|
| 330 |
+
"vit_deit_base_distilled_patch16_384", pretrained=pretrained
|
| 331 |
+
)
|
| 332 |
+
|
| 333 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 334 |
+
return _make_vit_b16_backbone(
|
| 335 |
+
model,
|
| 336 |
+
features=[96, 192, 384, 768],
|
| 337 |
+
hooks=hooks,
|
| 338 |
+
use_readout=use_readout,
|
| 339 |
+
start_index=2,
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
def _make_vit_b_rn50_backbone(
|
| 344 |
+
model,
|
| 345 |
+
features=[256, 512, 768, 768],
|
| 346 |
+
size=[384, 384],
|
| 347 |
+
hooks=[0, 1, 8, 11],
|
| 348 |
+
vit_features=768,
|
| 349 |
+
use_vit_only=False,
|
| 350 |
+
use_readout="ignore",
|
| 351 |
+
start_index=1,
|
| 352 |
+
):
|
| 353 |
+
pretrained = nn.Module()
|
| 354 |
+
|
| 355 |
+
pretrained.model = model
|
| 356 |
+
|
| 357 |
+
if use_vit_only == True:
|
| 358 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 359 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 360 |
+
else:
|
| 361 |
+
pretrained.model.patch_embed.backbone.stages[0].register_forward_hook(
|
| 362 |
+
get_activation("1")
|
| 363 |
+
)
|
| 364 |
+
pretrained.model.patch_embed.backbone.stages[1].register_forward_hook(
|
| 365 |
+
get_activation("2")
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 369 |
+
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 370 |
+
|
| 371 |
+
pretrained.activations = activations
|
| 372 |
+
|
| 373 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
| 374 |
+
|
| 375 |
+
if use_vit_only == True:
|
| 376 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 377 |
+
readout_oper[0],
|
| 378 |
+
Transpose(1, 2),
|
| 379 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 380 |
+
nn.Conv2d(
|
| 381 |
+
in_channels=vit_features,
|
| 382 |
+
out_channels=features[0],
|
| 383 |
+
kernel_size=1,
|
| 384 |
+
stride=1,
|
| 385 |
+
padding=0,
|
| 386 |
+
),
|
| 387 |
+
nn.ConvTranspose2d(
|
| 388 |
+
in_channels=features[0],
|
| 389 |
+
out_channels=features[0],
|
| 390 |
+
kernel_size=4,
|
| 391 |
+
stride=4,
|
| 392 |
+
padding=0,
|
| 393 |
+
bias=True,
|
| 394 |
+
dilation=1,
|
| 395 |
+
groups=1,
|
| 396 |
+
),
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 400 |
+
readout_oper[1],
|
| 401 |
+
Transpose(1, 2),
|
| 402 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 403 |
+
nn.Conv2d(
|
| 404 |
+
in_channels=vit_features,
|
| 405 |
+
out_channels=features[1],
|
| 406 |
+
kernel_size=1,
|
| 407 |
+
stride=1,
|
| 408 |
+
padding=0,
|
| 409 |
+
),
|
| 410 |
+
nn.ConvTranspose2d(
|
| 411 |
+
in_channels=features[1],
|
| 412 |
+
out_channels=features[1],
|
| 413 |
+
kernel_size=2,
|
| 414 |
+
stride=2,
|
| 415 |
+
padding=0,
|
| 416 |
+
bias=True,
|
| 417 |
+
dilation=1,
|
| 418 |
+
groups=1,
|
| 419 |
+
),
|
| 420 |
+
)
|
| 421 |
+
else:
|
| 422 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 423 |
+
nn.Identity(), nn.Identity(), nn.Identity()
|
| 424 |
+
)
|
| 425 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 426 |
+
nn.Identity(), nn.Identity(), nn.Identity()
|
| 427 |
+
)
|
| 428 |
+
|
| 429 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 430 |
+
readout_oper[2],
|
| 431 |
+
Transpose(1, 2),
|
| 432 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 433 |
+
nn.Conv2d(
|
| 434 |
+
in_channels=vit_features,
|
| 435 |
+
out_channels=features[2],
|
| 436 |
+
kernel_size=1,
|
| 437 |
+
stride=1,
|
| 438 |
+
padding=0,
|
| 439 |
+
),
|
| 440 |
+
)
|
| 441 |
+
|
| 442 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 443 |
+
readout_oper[3],
|
| 444 |
+
Transpose(1, 2),
|
| 445 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 446 |
+
nn.Conv2d(
|
| 447 |
+
in_channels=vit_features,
|
| 448 |
+
out_channels=features[3],
|
| 449 |
+
kernel_size=1,
|
| 450 |
+
stride=1,
|
| 451 |
+
padding=0,
|
| 452 |
+
),
|
| 453 |
+
nn.Conv2d(
|
| 454 |
+
in_channels=features[3],
|
| 455 |
+
out_channels=features[3],
|
| 456 |
+
kernel_size=3,
|
| 457 |
+
stride=2,
|
| 458 |
+
padding=1,
|
| 459 |
+
),
|
| 460 |
+
)
|
| 461 |
+
|
| 462 |
+
pretrained.model.start_index = start_index
|
| 463 |
+
pretrained.model.patch_size = [16, 16]
|
| 464 |
+
|
| 465 |
+
# We inject this function into the VisionTransformer instances so that
|
| 466 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 467 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 468 |
+
|
| 469 |
+
# We inject this function into the VisionTransformer instances so that
|
| 470 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 471 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 472 |
+
_resize_pos_embed, pretrained.model
|
| 473 |
+
)
|
| 474 |
+
|
| 475 |
+
return pretrained
|
| 476 |
+
|
| 477 |
+
|
| 478 |
+
def _make_pretrained_vitb_rn50_384(
|
| 479 |
+
pretrained, use_readout="ignore", hooks=None, use_vit_only=False
|
| 480 |
+
):
|
| 481 |
+
model = timm.create_model("vit_base_resnet50_384", pretrained=pretrained)
|
| 482 |
+
|
| 483 |
+
hooks = [0, 1, 8, 11] if hooks == None else hooks
|
| 484 |
+
return _make_vit_b_rn50_backbone(
|
| 485 |
+
model,
|
| 486 |
+
features=[256, 512, 768, 768],
|
| 487 |
+
size=[384, 384],
|
| 488 |
+
hooks=hooks,
|
| 489 |
+
use_vit_only=use_vit_only,
|
| 490 |
+
use_readout=use_readout,
|
| 491 |
+
)
|
src/ControlNet/annotator/midas/utils.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Utils for monoDepth."""
|
| 2 |
+
import sys
|
| 3 |
+
import re
|
| 4 |
+
import numpy as np
|
| 5 |
+
import cv2
|
| 6 |
+
import torch
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def read_pfm(path):
|
| 10 |
+
"""Read pfm file.
|
| 11 |
+
|
| 12 |
+
Args:
|
| 13 |
+
path (str): path to file
|
| 14 |
+
|
| 15 |
+
Returns:
|
| 16 |
+
tuple: (data, scale)
|
| 17 |
+
"""
|
| 18 |
+
with open(path, "rb") as file:
|
| 19 |
+
|
| 20 |
+
color = None
|
| 21 |
+
width = None
|
| 22 |
+
height = None
|
| 23 |
+
scale = None
|
| 24 |
+
endian = None
|
| 25 |
+
|
| 26 |
+
header = file.readline().rstrip()
|
| 27 |
+
if header.decode("ascii") == "PF":
|
| 28 |
+
color = True
|
| 29 |
+
elif header.decode("ascii") == "Pf":
|
| 30 |
+
color = False
|
| 31 |
+
else:
|
| 32 |
+
raise Exception("Not a PFM file: " + path)
|
| 33 |
+
|
| 34 |
+
dim_match = re.match(r"^(\d+)\s(\d+)\s$", file.readline().decode("ascii"))
|
| 35 |
+
if dim_match:
|
| 36 |
+
width, height = list(map(int, dim_match.groups()))
|
| 37 |
+
else:
|
| 38 |
+
raise Exception("Malformed PFM header.")
|
| 39 |
+
|
| 40 |
+
scale = float(file.readline().decode("ascii").rstrip())
|
| 41 |
+
if scale < 0:
|
| 42 |
+
# little-endian
|
| 43 |
+
endian = "<"
|
| 44 |
+
scale = -scale
|
| 45 |
+
else:
|
| 46 |
+
# big-endian
|
| 47 |
+
endian = ">"
|
| 48 |
+
|
| 49 |
+
data = np.fromfile(file, endian + "f")
|
| 50 |
+
shape = (height, width, 3) if color else (height, width)
|
| 51 |
+
|
| 52 |
+
data = np.reshape(data, shape)
|
| 53 |
+
data = np.flipud(data)
|
| 54 |
+
|
| 55 |
+
return data, scale
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def write_pfm(path, image, scale=1):
|
| 59 |
+
"""Write pfm file.
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
path (str): pathto file
|
| 63 |
+
image (array): data
|
| 64 |
+
scale (int, optional): Scale. Defaults to 1.
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
with open(path, "wb") as file:
|
| 68 |
+
color = None
|
| 69 |
+
|
| 70 |
+
if image.dtype.name != "float32":
|
| 71 |
+
raise Exception("Image dtype must be float32.")
|
| 72 |
+
|
| 73 |
+
image = np.flipud(image)
|
| 74 |
+
|
| 75 |
+
if len(image.shape) == 3 and image.shape[2] == 3: # color image
|
| 76 |
+
color = True
|
| 77 |
+
elif (
|
| 78 |
+
len(image.shape) == 2 or len(image.shape) == 3 and image.shape[2] == 1
|
| 79 |
+
): # greyscale
|
| 80 |
+
color = False
|
| 81 |
+
else:
|
| 82 |
+
raise Exception("Image must have H x W x 3, H x W x 1 or H x W dimensions.")
|
| 83 |
+
|
| 84 |
+
file.write("PF\n" if color else "Pf\n".encode())
|
| 85 |
+
file.write("%d %d\n".encode() % (image.shape[1], image.shape[0]))
|
| 86 |
+
|
| 87 |
+
endian = image.dtype.byteorder
|
| 88 |
+
|
| 89 |
+
if endian == "<" or endian == "=" and sys.byteorder == "little":
|
| 90 |
+
scale = -scale
|
| 91 |
+
|
| 92 |
+
file.write("%f\n".encode() % scale)
|
| 93 |
+
|
| 94 |
+
image.tofile(file)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def read_image(path):
|
| 98 |
+
"""Read image and output RGB image (0-1).
|
| 99 |
+
|
| 100 |
+
Args:
|
| 101 |
+
path (str): path to file
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
array: RGB image (0-1)
|
| 105 |
+
"""
|
| 106 |
+
img = cv2.imread(path)
|
| 107 |
+
|
| 108 |
+
if img.ndim == 2:
|
| 109 |
+
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
| 110 |
+
|
| 111 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) / 255.0
|
| 112 |
+
|
| 113 |
+
return img
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def resize_image(img):
|
| 117 |
+
"""Resize image and make it fit for network.
|
| 118 |
+
|
| 119 |
+
Args:
|
| 120 |
+
img (array): image
|
| 121 |
+
|
| 122 |
+
Returns:
|
| 123 |
+
tensor: data ready for network
|
| 124 |
+
"""
|
| 125 |
+
height_orig = img.shape[0]
|
| 126 |
+
width_orig = img.shape[1]
|
| 127 |
+
|
| 128 |
+
if width_orig > height_orig:
|
| 129 |
+
scale = width_orig / 384
|
| 130 |
+
else:
|
| 131 |
+
scale = height_orig / 384
|
| 132 |
+
|
| 133 |
+
height = (np.ceil(height_orig / scale / 32) * 32).astype(int)
|
| 134 |
+
width = (np.ceil(width_orig / scale / 32) * 32).astype(int)
|
| 135 |
+
|
| 136 |
+
img_resized = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA)
|
| 137 |
+
|
| 138 |
+
img_resized = (
|
| 139 |
+
torch.from_numpy(np.transpose(img_resized, (2, 0, 1))).contiguous().float()
|
| 140 |
+
)
|
| 141 |
+
img_resized = img_resized.unsqueeze(0)
|
| 142 |
+
|
| 143 |
+
return img_resized
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def resize_depth(depth, width, height):
|
| 147 |
+
"""Resize depth map and bring to CPU (numpy).
|
| 148 |
+
|
| 149 |
+
Args:
|
| 150 |
+
depth (tensor): depth
|
| 151 |
+
width (int): image width
|
| 152 |
+
height (int): image height
|
| 153 |
+
|
| 154 |
+
Returns:
|
| 155 |
+
array: processed depth
|
| 156 |
+
"""
|
| 157 |
+
depth = torch.squeeze(depth[0, :, :, :]).to("cpu")
|
| 158 |
+
|
| 159 |
+
depth_resized = cv2.resize(
|
| 160 |
+
depth.numpy(), (width, height), interpolation=cv2.INTER_CUBIC
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
return depth_resized
|
| 164 |
+
|
| 165 |
+
def write_depth(path, depth, bits=1):
|
| 166 |
+
"""Write depth map to pfm and png file.
|
| 167 |
+
|
| 168 |
+
Args:
|
| 169 |
+
path (str): filepath without extension
|
| 170 |
+
depth (array): depth
|
| 171 |
+
"""
|
| 172 |
+
write_pfm(path + ".pfm", depth.astype(np.float32))
|
| 173 |
+
|
| 174 |
+
depth_min = depth.min()
|
| 175 |
+
depth_max = depth.max()
|
| 176 |
+
|
| 177 |
+
max_val = (2**(8*bits))-1
|
| 178 |
+
|
| 179 |
+
if depth_max - depth_min > np.finfo("float").eps:
|
| 180 |
+
out = max_val * (depth - depth_min) / (depth_max - depth_min)
|
| 181 |
+
else:
|
| 182 |
+
out = np.zeros(depth.shape, dtype=depth.type)
|
| 183 |
+
|
| 184 |
+
if bits == 1:
|
| 185 |
+
cv2.imwrite(path + ".png", out.astype("uint8"))
|
| 186 |
+
elif bits == 2:
|
| 187 |
+
cv2.imwrite(path + ".png", out.astype("uint16"))
|
| 188 |
+
|
| 189 |
+
return
|
src/ControlNet/annotator/mlsd/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "{}"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2021-present NAVER Corp.
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
src/ControlNet/annotator/mlsd/__init__.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MLSD Line Detection
|
| 2 |
+
# From https://github.com/navervision/mlsd
|
| 3 |
+
# Apache-2.0 license
|
| 4 |
+
|
| 5 |
+
import cv2
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import os
|
| 9 |
+
|
| 10 |
+
from einops import rearrange
|
| 11 |
+
from .models.mbv2_mlsd_tiny import MobileV2_MLSD_Tiny
|
| 12 |
+
from .models.mbv2_mlsd_large import MobileV2_MLSD_Large
|
| 13 |
+
from .utils import pred_lines
|
| 14 |
+
|
| 15 |
+
from annotator.util import annotator_ckpts_path
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
remote_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/mlsd_large_512_fp32.pth"
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class MLSDdetector:
|
| 22 |
+
def __init__(self):
|
| 23 |
+
model_path = os.path.join(annotator_ckpts_path, "mlsd_large_512_fp32.pth")
|
| 24 |
+
if not os.path.exists(model_path):
|
| 25 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 26 |
+
load_file_from_url(remote_model_path, model_dir=annotator_ckpts_path)
|
| 27 |
+
model = MobileV2_MLSD_Large()
|
| 28 |
+
model.load_state_dict(torch.load(model_path), strict=True)
|
| 29 |
+
self.model = model.cuda().eval()
|
| 30 |
+
|
| 31 |
+
def __call__(self, input_image, thr_v, thr_d):
|
| 32 |
+
assert input_image.ndim == 3
|
| 33 |
+
img = input_image
|
| 34 |
+
img_output = np.zeros_like(img)
|
| 35 |
+
try:
|
| 36 |
+
with torch.no_grad():
|
| 37 |
+
lines = pred_lines(img, self.model, [img.shape[0], img.shape[1]], thr_v, thr_d)
|
| 38 |
+
for line in lines:
|
| 39 |
+
x_start, y_start, x_end, y_end = [int(val) for val in line]
|
| 40 |
+
cv2.line(img_output, (x_start, y_start), (x_end, y_end), [255, 255, 255], 1)
|
| 41 |
+
except Exception as e:
|
| 42 |
+
pass
|
| 43 |
+
return img_output[:, :, 0]
|
src/ControlNet/annotator/mlsd/models/mbv2_mlsd_large.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.utils.model_zoo as model_zoo
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BlockTypeA(nn.Module):
|
| 10 |
+
def __init__(self, in_c1, in_c2, out_c1, out_c2, upscale = True):
|
| 11 |
+
super(BlockTypeA, self).__init__()
|
| 12 |
+
self.conv1 = nn.Sequential(
|
| 13 |
+
nn.Conv2d(in_c2, out_c2, kernel_size=1),
|
| 14 |
+
nn.BatchNorm2d(out_c2),
|
| 15 |
+
nn.ReLU(inplace=True)
|
| 16 |
+
)
|
| 17 |
+
self.conv2 = nn.Sequential(
|
| 18 |
+
nn.Conv2d(in_c1, out_c1, kernel_size=1),
|
| 19 |
+
nn.BatchNorm2d(out_c1),
|
| 20 |
+
nn.ReLU(inplace=True)
|
| 21 |
+
)
|
| 22 |
+
self.upscale = upscale
|
| 23 |
+
|
| 24 |
+
def forward(self, a, b):
|
| 25 |
+
b = self.conv1(b)
|
| 26 |
+
a = self.conv2(a)
|
| 27 |
+
if self.upscale:
|
| 28 |
+
b = F.interpolate(b, scale_factor=2.0, mode='bilinear', align_corners=True)
|
| 29 |
+
return torch.cat((a, b), dim=1)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class BlockTypeB(nn.Module):
|
| 33 |
+
def __init__(self, in_c, out_c):
|
| 34 |
+
super(BlockTypeB, self).__init__()
|
| 35 |
+
self.conv1 = nn.Sequential(
|
| 36 |
+
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
| 37 |
+
nn.BatchNorm2d(in_c),
|
| 38 |
+
nn.ReLU()
|
| 39 |
+
)
|
| 40 |
+
self.conv2 = nn.Sequential(
|
| 41 |
+
nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
|
| 42 |
+
nn.BatchNorm2d(out_c),
|
| 43 |
+
nn.ReLU()
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
def forward(self, x):
|
| 47 |
+
x = self.conv1(x) + x
|
| 48 |
+
x = self.conv2(x)
|
| 49 |
+
return x
|
| 50 |
+
|
| 51 |
+
class BlockTypeC(nn.Module):
|
| 52 |
+
def __init__(self, in_c, out_c):
|
| 53 |
+
super(BlockTypeC, self).__init__()
|
| 54 |
+
self.conv1 = nn.Sequential(
|
| 55 |
+
nn.Conv2d(in_c, in_c, kernel_size=3, padding=5, dilation=5),
|
| 56 |
+
nn.BatchNorm2d(in_c),
|
| 57 |
+
nn.ReLU()
|
| 58 |
+
)
|
| 59 |
+
self.conv2 = nn.Sequential(
|
| 60 |
+
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
| 61 |
+
nn.BatchNorm2d(in_c),
|
| 62 |
+
nn.ReLU()
|
| 63 |
+
)
|
| 64 |
+
self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1)
|
| 65 |
+
|
| 66 |
+
def forward(self, x):
|
| 67 |
+
x = self.conv1(x)
|
| 68 |
+
x = self.conv2(x)
|
| 69 |
+
x = self.conv3(x)
|
| 70 |
+
return x
|
| 71 |
+
|
| 72 |
+
def _make_divisible(v, divisor, min_value=None):
|
| 73 |
+
"""
|
| 74 |
+
This function is taken from the original tf repo.
|
| 75 |
+
It ensures that all layers have a channel number that is divisible by 8
|
| 76 |
+
It can be seen here:
|
| 77 |
+
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
|
| 78 |
+
:param v:
|
| 79 |
+
:param divisor:
|
| 80 |
+
:param min_value:
|
| 81 |
+
:return:
|
| 82 |
+
"""
|
| 83 |
+
if min_value is None:
|
| 84 |
+
min_value = divisor
|
| 85 |
+
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
|
| 86 |
+
# Make sure that round down does not go down by more than 10%.
|
| 87 |
+
if new_v < 0.9 * v:
|
| 88 |
+
new_v += divisor
|
| 89 |
+
return new_v
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class ConvBNReLU(nn.Sequential):
|
| 93 |
+
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
|
| 94 |
+
self.channel_pad = out_planes - in_planes
|
| 95 |
+
self.stride = stride
|
| 96 |
+
#padding = (kernel_size - 1) // 2
|
| 97 |
+
|
| 98 |
+
# TFLite uses slightly different padding than PyTorch
|
| 99 |
+
if stride == 2:
|
| 100 |
+
padding = 0
|
| 101 |
+
else:
|
| 102 |
+
padding = (kernel_size - 1) // 2
|
| 103 |
+
|
| 104 |
+
super(ConvBNReLU, self).__init__(
|
| 105 |
+
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
|
| 106 |
+
nn.BatchNorm2d(out_planes),
|
| 107 |
+
nn.ReLU6(inplace=True)
|
| 108 |
+
)
|
| 109 |
+
self.max_pool = nn.MaxPool2d(kernel_size=stride, stride=stride)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def forward(self, x):
|
| 113 |
+
# TFLite uses different padding
|
| 114 |
+
if self.stride == 2:
|
| 115 |
+
x = F.pad(x, (0, 1, 0, 1), "constant", 0)
|
| 116 |
+
#print(x.shape)
|
| 117 |
+
|
| 118 |
+
for module in self:
|
| 119 |
+
if not isinstance(module, nn.MaxPool2d):
|
| 120 |
+
x = module(x)
|
| 121 |
+
return x
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class InvertedResidual(nn.Module):
|
| 125 |
+
def __init__(self, inp, oup, stride, expand_ratio):
|
| 126 |
+
super(InvertedResidual, self).__init__()
|
| 127 |
+
self.stride = stride
|
| 128 |
+
assert stride in [1, 2]
|
| 129 |
+
|
| 130 |
+
hidden_dim = int(round(inp * expand_ratio))
|
| 131 |
+
self.use_res_connect = self.stride == 1 and inp == oup
|
| 132 |
+
|
| 133 |
+
layers = []
|
| 134 |
+
if expand_ratio != 1:
|
| 135 |
+
# pw
|
| 136 |
+
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
|
| 137 |
+
layers.extend([
|
| 138 |
+
# dw
|
| 139 |
+
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
|
| 140 |
+
# pw-linear
|
| 141 |
+
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
|
| 142 |
+
nn.BatchNorm2d(oup),
|
| 143 |
+
])
|
| 144 |
+
self.conv = nn.Sequential(*layers)
|
| 145 |
+
|
| 146 |
+
def forward(self, x):
|
| 147 |
+
if self.use_res_connect:
|
| 148 |
+
return x + self.conv(x)
|
| 149 |
+
else:
|
| 150 |
+
return self.conv(x)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class MobileNetV2(nn.Module):
|
| 154 |
+
def __init__(self, pretrained=True):
|
| 155 |
+
"""
|
| 156 |
+
MobileNet V2 main class
|
| 157 |
+
Args:
|
| 158 |
+
num_classes (int): Number of classes
|
| 159 |
+
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
|
| 160 |
+
inverted_residual_setting: Network structure
|
| 161 |
+
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
|
| 162 |
+
Set to 1 to turn off rounding
|
| 163 |
+
block: Module specifying inverted residual building block for mobilenet
|
| 164 |
+
"""
|
| 165 |
+
super(MobileNetV2, self).__init__()
|
| 166 |
+
|
| 167 |
+
block = InvertedResidual
|
| 168 |
+
input_channel = 32
|
| 169 |
+
last_channel = 1280
|
| 170 |
+
width_mult = 1.0
|
| 171 |
+
round_nearest = 8
|
| 172 |
+
|
| 173 |
+
inverted_residual_setting = [
|
| 174 |
+
# t, c, n, s
|
| 175 |
+
[1, 16, 1, 1],
|
| 176 |
+
[6, 24, 2, 2],
|
| 177 |
+
[6, 32, 3, 2],
|
| 178 |
+
[6, 64, 4, 2],
|
| 179 |
+
[6, 96, 3, 1],
|
| 180 |
+
#[6, 160, 3, 2],
|
| 181 |
+
#[6, 320, 1, 1],
|
| 182 |
+
]
|
| 183 |
+
|
| 184 |
+
# only check the first element, assuming user knows t,c,n,s are required
|
| 185 |
+
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
|
| 186 |
+
raise ValueError("inverted_residual_setting should be non-empty "
|
| 187 |
+
"or a 4-element list, got {}".format(inverted_residual_setting))
|
| 188 |
+
|
| 189 |
+
# building first layer
|
| 190 |
+
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
|
| 191 |
+
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
|
| 192 |
+
features = [ConvBNReLU(4, input_channel, stride=2)]
|
| 193 |
+
# building inverted residual blocks
|
| 194 |
+
for t, c, n, s in inverted_residual_setting:
|
| 195 |
+
output_channel = _make_divisible(c * width_mult, round_nearest)
|
| 196 |
+
for i in range(n):
|
| 197 |
+
stride = s if i == 0 else 1
|
| 198 |
+
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
|
| 199 |
+
input_channel = output_channel
|
| 200 |
+
|
| 201 |
+
self.features = nn.Sequential(*features)
|
| 202 |
+
self.fpn_selected = [1, 3, 6, 10, 13]
|
| 203 |
+
# weight initialization
|
| 204 |
+
for m in self.modules():
|
| 205 |
+
if isinstance(m, nn.Conv2d):
|
| 206 |
+
nn.init.kaiming_normal_(m.weight, mode='fan_out')
|
| 207 |
+
if m.bias is not None:
|
| 208 |
+
nn.init.zeros_(m.bias)
|
| 209 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 210 |
+
nn.init.ones_(m.weight)
|
| 211 |
+
nn.init.zeros_(m.bias)
|
| 212 |
+
elif isinstance(m, nn.Linear):
|
| 213 |
+
nn.init.normal_(m.weight, 0, 0.01)
|
| 214 |
+
nn.init.zeros_(m.bias)
|
| 215 |
+
if pretrained:
|
| 216 |
+
self._load_pretrained_model()
|
| 217 |
+
|
| 218 |
+
def _forward_impl(self, x):
|
| 219 |
+
# This exists since TorchScript doesn't support inheritance, so the superclass method
|
| 220 |
+
# (this one) needs to have a name other than `forward` that can be accessed in a subclass
|
| 221 |
+
fpn_features = []
|
| 222 |
+
for i, f in enumerate(self.features):
|
| 223 |
+
if i > self.fpn_selected[-1]:
|
| 224 |
+
break
|
| 225 |
+
x = f(x)
|
| 226 |
+
if i in self.fpn_selected:
|
| 227 |
+
fpn_features.append(x)
|
| 228 |
+
|
| 229 |
+
c1, c2, c3, c4, c5 = fpn_features
|
| 230 |
+
return c1, c2, c3, c4, c5
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
def forward(self, x):
|
| 234 |
+
return self._forward_impl(x)
|
| 235 |
+
|
| 236 |
+
def _load_pretrained_model(self):
|
| 237 |
+
pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/mobilenet_v2-b0353104.pth')
|
| 238 |
+
model_dict = {}
|
| 239 |
+
state_dict = self.state_dict()
|
| 240 |
+
for k, v in pretrain_dict.items():
|
| 241 |
+
if k in state_dict:
|
| 242 |
+
model_dict[k] = v
|
| 243 |
+
state_dict.update(model_dict)
|
| 244 |
+
self.load_state_dict(state_dict)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class MobileV2_MLSD_Large(nn.Module):
|
| 248 |
+
def __init__(self):
|
| 249 |
+
super(MobileV2_MLSD_Large, self).__init__()
|
| 250 |
+
|
| 251 |
+
self.backbone = MobileNetV2(pretrained=False)
|
| 252 |
+
## A, B
|
| 253 |
+
self.block15 = BlockTypeA(in_c1= 64, in_c2= 96,
|
| 254 |
+
out_c1= 64, out_c2=64,
|
| 255 |
+
upscale=False)
|
| 256 |
+
self.block16 = BlockTypeB(128, 64)
|
| 257 |
+
|
| 258 |
+
## A, B
|
| 259 |
+
self.block17 = BlockTypeA(in_c1 = 32, in_c2 = 64,
|
| 260 |
+
out_c1= 64, out_c2= 64)
|
| 261 |
+
self.block18 = BlockTypeB(128, 64)
|
| 262 |
+
|
| 263 |
+
## A, B
|
| 264 |
+
self.block19 = BlockTypeA(in_c1=24, in_c2=64,
|
| 265 |
+
out_c1=64, out_c2=64)
|
| 266 |
+
self.block20 = BlockTypeB(128, 64)
|
| 267 |
+
|
| 268 |
+
## A, B, C
|
| 269 |
+
self.block21 = BlockTypeA(in_c1=16, in_c2=64,
|
| 270 |
+
out_c1=64, out_c2=64)
|
| 271 |
+
self.block22 = BlockTypeB(128, 64)
|
| 272 |
+
|
| 273 |
+
self.block23 = BlockTypeC(64, 16)
|
| 274 |
+
|
| 275 |
+
def forward(self, x):
|
| 276 |
+
c1, c2, c3, c4, c5 = self.backbone(x)
|
| 277 |
+
|
| 278 |
+
x = self.block15(c4, c5)
|
| 279 |
+
x = self.block16(x)
|
| 280 |
+
|
| 281 |
+
x = self.block17(c3, x)
|
| 282 |
+
x = self.block18(x)
|
| 283 |
+
|
| 284 |
+
x = self.block19(c2, x)
|
| 285 |
+
x = self.block20(x)
|
| 286 |
+
|
| 287 |
+
x = self.block21(c1, x)
|
| 288 |
+
x = self.block22(x)
|
| 289 |
+
x = self.block23(x)
|
| 290 |
+
x = x[:, 7:, :, :]
|
| 291 |
+
|
| 292 |
+
return x
|
src/ControlNet/annotator/mlsd/models/mbv2_mlsd_tiny.py
ADDED
|
@@ -0,0 +1,275 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.utils.model_zoo as model_zoo
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BlockTypeA(nn.Module):
|
| 10 |
+
def __init__(self, in_c1, in_c2, out_c1, out_c2, upscale = True):
|
| 11 |
+
super(BlockTypeA, self).__init__()
|
| 12 |
+
self.conv1 = nn.Sequential(
|
| 13 |
+
nn.Conv2d(in_c2, out_c2, kernel_size=1),
|
| 14 |
+
nn.BatchNorm2d(out_c2),
|
| 15 |
+
nn.ReLU(inplace=True)
|
| 16 |
+
)
|
| 17 |
+
self.conv2 = nn.Sequential(
|
| 18 |
+
nn.Conv2d(in_c1, out_c1, kernel_size=1),
|
| 19 |
+
nn.BatchNorm2d(out_c1),
|
| 20 |
+
nn.ReLU(inplace=True)
|
| 21 |
+
)
|
| 22 |
+
self.upscale = upscale
|
| 23 |
+
|
| 24 |
+
def forward(self, a, b):
|
| 25 |
+
b = self.conv1(b)
|
| 26 |
+
a = self.conv2(a)
|
| 27 |
+
b = F.interpolate(b, scale_factor=2.0, mode='bilinear', align_corners=True)
|
| 28 |
+
return torch.cat((a, b), dim=1)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class BlockTypeB(nn.Module):
|
| 32 |
+
def __init__(self, in_c, out_c):
|
| 33 |
+
super(BlockTypeB, self).__init__()
|
| 34 |
+
self.conv1 = nn.Sequential(
|
| 35 |
+
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
| 36 |
+
nn.BatchNorm2d(in_c),
|
| 37 |
+
nn.ReLU()
|
| 38 |
+
)
|
| 39 |
+
self.conv2 = nn.Sequential(
|
| 40 |
+
nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
|
| 41 |
+
nn.BatchNorm2d(out_c),
|
| 42 |
+
nn.ReLU()
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
def forward(self, x):
|
| 46 |
+
x = self.conv1(x) + x
|
| 47 |
+
x = self.conv2(x)
|
| 48 |
+
return x
|
| 49 |
+
|
| 50 |
+
class BlockTypeC(nn.Module):
|
| 51 |
+
def __init__(self, in_c, out_c):
|
| 52 |
+
super(BlockTypeC, self).__init__()
|
| 53 |
+
self.conv1 = nn.Sequential(
|
| 54 |
+
nn.Conv2d(in_c, in_c, kernel_size=3, padding=5, dilation=5),
|
| 55 |
+
nn.BatchNorm2d(in_c),
|
| 56 |
+
nn.ReLU()
|
| 57 |
+
)
|
| 58 |
+
self.conv2 = nn.Sequential(
|
| 59 |
+
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
| 60 |
+
nn.BatchNorm2d(in_c),
|
| 61 |
+
nn.ReLU()
|
| 62 |
+
)
|
| 63 |
+
self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1)
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
x = self.conv1(x)
|
| 67 |
+
x = self.conv2(x)
|
| 68 |
+
x = self.conv3(x)
|
| 69 |
+
return x
|
| 70 |
+
|
| 71 |
+
def _make_divisible(v, divisor, min_value=None):
|
| 72 |
+
"""
|
| 73 |
+
This function is taken from the original tf repo.
|
| 74 |
+
It ensures that all layers have a channel number that is divisible by 8
|
| 75 |
+
It can be seen here:
|
| 76 |
+
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
|
| 77 |
+
:param v:
|
| 78 |
+
:param divisor:
|
| 79 |
+
:param min_value:
|
| 80 |
+
:return:
|
| 81 |
+
"""
|
| 82 |
+
if min_value is None:
|
| 83 |
+
min_value = divisor
|
| 84 |
+
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
|
| 85 |
+
# Make sure that round down does not go down by more than 10%.
|
| 86 |
+
if new_v < 0.9 * v:
|
| 87 |
+
new_v += divisor
|
| 88 |
+
return new_v
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class ConvBNReLU(nn.Sequential):
|
| 92 |
+
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
|
| 93 |
+
self.channel_pad = out_planes - in_planes
|
| 94 |
+
self.stride = stride
|
| 95 |
+
#padding = (kernel_size - 1) // 2
|
| 96 |
+
|
| 97 |
+
# TFLite uses slightly different padding than PyTorch
|
| 98 |
+
if stride == 2:
|
| 99 |
+
padding = 0
|
| 100 |
+
else:
|
| 101 |
+
padding = (kernel_size - 1) // 2
|
| 102 |
+
|
| 103 |
+
super(ConvBNReLU, self).__init__(
|
| 104 |
+
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
|
| 105 |
+
nn.BatchNorm2d(out_planes),
|
| 106 |
+
nn.ReLU6(inplace=True)
|
| 107 |
+
)
|
| 108 |
+
self.max_pool = nn.MaxPool2d(kernel_size=stride, stride=stride)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def forward(self, x):
|
| 112 |
+
# TFLite uses different padding
|
| 113 |
+
if self.stride == 2:
|
| 114 |
+
x = F.pad(x, (0, 1, 0, 1), "constant", 0)
|
| 115 |
+
#print(x.shape)
|
| 116 |
+
|
| 117 |
+
for module in self:
|
| 118 |
+
if not isinstance(module, nn.MaxPool2d):
|
| 119 |
+
x = module(x)
|
| 120 |
+
return x
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class InvertedResidual(nn.Module):
|
| 124 |
+
def __init__(self, inp, oup, stride, expand_ratio):
|
| 125 |
+
super(InvertedResidual, self).__init__()
|
| 126 |
+
self.stride = stride
|
| 127 |
+
assert stride in [1, 2]
|
| 128 |
+
|
| 129 |
+
hidden_dim = int(round(inp * expand_ratio))
|
| 130 |
+
self.use_res_connect = self.stride == 1 and inp == oup
|
| 131 |
+
|
| 132 |
+
layers = []
|
| 133 |
+
if expand_ratio != 1:
|
| 134 |
+
# pw
|
| 135 |
+
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
|
| 136 |
+
layers.extend([
|
| 137 |
+
# dw
|
| 138 |
+
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
|
| 139 |
+
# pw-linear
|
| 140 |
+
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
|
| 141 |
+
nn.BatchNorm2d(oup),
|
| 142 |
+
])
|
| 143 |
+
self.conv = nn.Sequential(*layers)
|
| 144 |
+
|
| 145 |
+
def forward(self, x):
|
| 146 |
+
if self.use_res_connect:
|
| 147 |
+
return x + self.conv(x)
|
| 148 |
+
else:
|
| 149 |
+
return self.conv(x)
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
class MobileNetV2(nn.Module):
|
| 153 |
+
def __init__(self, pretrained=True):
|
| 154 |
+
"""
|
| 155 |
+
MobileNet V2 main class
|
| 156 |
+
Args:
|
| 157 |
+
num_classes (int): Number of classes
|
| 158 |
+
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
|
| 159 |
+
inverted_residual_setting: Network structure
|
| 160 |
+
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
|
| 161 |
+
Set to 1 to turn off rounding
|
| 162 |
+
block: Module specifying inverted residual building block for mobilenet
|
| 163 |
+
"""
|
| 164 |
+
super(MobileNetV2, self).__init__()
|
| 165 |
+
|
| 166 |
+
block = InvertedResidual
|
| 167 |
+
input_channel = 32
|
| 168 |
+
last_channel = 1280
|
| 169 |
+
width_mult = 1.0
|
| 170 |
+
round_nearest = 8
|
| 171 |
+
|
| 172 |
+
inverted_residual_setting = [
|
| 173 |
+
# t, c, n, s
|
| 174 |
+
[1, 16, 1, 1],
|
| 175 |
+
[6, 24, 2, 2],
|
| 176 |
+
[6, 32, 3, 2],
|
| 177 |
+
[6, 64, 4, 2],
|
| 178 |
+
#[6, 96, 3, 1],
|
| 179 |
+
#[6, 160, 3, 2],
|
| 180 |
+
#[6, 320, 1, 1],
|
| 181 |
+
]
|
| 182 |
+
|
| 183 |
+
# only check the first element, assuming user knows t,c,n,s are required
|
| 184 |
+
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
|
| 185 |
+
raise ValueError("inverted_residual_setting should be non-empty "
|
| 186 |
+
"or a 4-element list, got {}".format(inverted_residual_setting))
|
| 187 |
+
|
| 188 |
+
# building first layer
|
| 189 |
+
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
|
| 190 |
+
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
|
| 191 |
+
features = [ConvBNReLU(4, input_channel, stride=2)]
|
| 192 |
+
# building inverted residual blocks
|
| 193 |
+
for t, c, n, s in inverted_residual_setting:
|
| 194 |
+
output_channel = _make_divisible(c * width_mult, round_nearest)
|
| 195 |
+
for i in range(n):
|
| 196 |
+
stride = s if i == 0 else 1
|
| 197 |
+
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
|
| 198 |
+
input_channel = output_channel
|
| 199 |
+
self.features = nn.Sequential(*features)
|
| 200 |
+
|
| 201 |
+
self.fpn_selected = [3, 6, 10]
|
| 202 |
+
# weight initialization
|
| 203 |
+
for m in self.modules():
|
| 204 |
+
if isinstance(m, nn.Conv2d):
|
| 205 |
+
nn.init.kaiming_normal_(m.weight, mode='fan_out')
|
| 206 |
+
if m.bias is not None:
|
| 207 |
+
nn.init.zeros_(m.bias)
|
| 208 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 209 |
+
nn.init.ones_(m.weight)
|
| 210 |
+
nn.init.zeros_(m.bias)
|
| 211 |
+
elif isinstance(m, nn.Linear):
|
| 212 |
+
nn.init.normal_(m.weight, 0, 0.01)
|
| 213 |
+
nn.init.zeros_(m.bias)
|
| 214 |
+
|
| 215 |
+
#if pretrained:
|
| 216 |
+
# self._load_pretrained_model()
|
| 217 |
+
|
| 218 |
+
def _forward_impl(self, x):
|
| 219 |
+
# This exists since TorchScript doesn't support inheritance, so the superclass method
|
| 220 |
+
# (this one) needs to have a name other than `forward` that can be accessed in a subclass
|
| 221 |
+
fpn_features = []
|
| 222 |
+
for i, f in enumerate(self.features):
|
| 223 |
+
if i > self.fpn_selected[-1]:
|
| 224 |
+
break
|
| 225 |
+
x = f(x)
|
| 226 |
+
if i in self.fpn_selected:
|
| 227 |
+
fpn_features.append(x)
|
| 228 |
+
|
| 229 |
+
c2, c3, c4 = fpn_features
|
| 230 |
+
return c2, c3, c4
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
def forward(self, x):
|
| 234 |
+
return self._forward_impl(x)
|
| 235 |
+
|
| 236 |
+
def _load_pretrained_model(self):
|
| 237 |
+
pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/mobilenet_v2-b0353104.pth')
|
| 238 |
+
model_dict = {}
|
| 239 |
+
state_dict = self.state_dict()
|
| 240 |
+
for k, v in pretrain_dict.items():
|
| 241 |
+
if k in state_dict:
|
| 242 |
+
model_dict[k] = v
|
| 243 |
+
state_dict.update(model_dict)
|
| 244 |
+
self.load_state_dict(state_dict)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class MobileV2_MLSD_Tiny(nn.Module):
|
| 248 |
+
def __init__(self):
|
| 249 |
+
super(MobileV2_MLSD_Tiny, self).__init__()
|
| 250 |
+
|
| 251 |
+
self.backbone = MobileNetV2(pretrained=True)
|
| 252 |
+
|
| 253 |
+
self.block12 = BlockTypeA(in_c1= 32, in_c2= 64,
|
| 254 |
+
out_c1= 64, out_c2=64)
|
| 255 |
+
self.block13 = BlockTypeB(128, 64)
|
| 256 |
+
|
| 257 |
+
self.block14 = BlockTypeA(in_c1 = 24, in_c2 = 64,
|
| 258 |
+
out_c1= 32, out_c2= 32)
|
| 259 |
+
self.block15 = BlockTypeB(64, 64)
|
| 260 |
+
|
| 261 |
+
self.block16 = BlockTypeC(64, 16)
|
| 262 |
+
|
| 263 |
+
def forward(self, x):
|
| 264 |
+
c2, c3, c4 = self.backbone(x)
|
| 265 |
+
|
| 266 |
+
x = self.block12(c3, c4)
|
| 267 |
+
x = self.block13(x)
|
| 268 |
+
x = self.block14(c2, x)
|
| 269 |
+
x = self.block15(x)
|
| 270 |
+
x = self.block16(x)
|
| 271 |
+
x = x[:, 7:, :, :]
|
| 272 |
+
#print(x.shape)
|
| 273 |
+
x = F.interpolate(x, scale_factor=2.0, mode='bilinear', align_corners=True)
|
| 274 |
+
|
| 275 |
+
return x
|
src/ControlNet/annotator/mlsd/utils.py
ADDED
|
@@ -0,0 +1,580 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
modified by lihaoweicv
|
| 3 |
+
pytorch version
|
| 4 |
+
'''
|
| 5 |
+
|
| 6 |
+
'''
|
| 7 |
+
M-LSD
|
| 8 |
+
Copyright 2021-present NAVER Corp.
|
| 9 |
+
Apache License v2.0
|
| 10 |
+
'''
|
| 11 |
+
|
| 12 |
+
import os
|
| 13 |
+
import numpy as np
|
| 14 |
+
import cv2
|
| 15 |
+
import torch
|
| 16 |
+
from torch.nn import functional as F
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def deccode_output_score_and_ptss(tpMap, topk_n = 200, ksize = 5):
|
| 20 |
+
'''
|
| 21 |
+
tpMap:
|
| 22 |
+
center: tpMap[1, 0, :, :]
|
| 23 |
+
displacement: tpMap[1, 1:5, :, :]
|
| 24 |
+
'''
|
| 25 |
+
b, c, h, w = tpMap.shape
|
| 26 |
+
assert b==1, 'only support bsize==1'
|
| 27 |
+
displacement = tpMap[:, 1:5, :, :][0]
|
| 28 |
+
center = tpMap[:, 0, :, :]
|
| 29 |
+
heat = torch.sigmoid(center)
|
| 30 |
+
hmax = F.max_pool2d( heat, (ksize, ksize), stride=1, padding=(ksize-1)//2)
|
| 31 |
+
keep = (hmax == heat).float()
|
| 32 |
+
heat = heat * keep
|
| 33 |
+
heat = heat.reshape(-1, )
|
| 34 |
+
|
| 35 |
+
scores, indices = torch.topk(heat, topk_n, dim=-1, largest=True)
|
| 36 |
+
yy = torch.floor_divide(indices, w).unsqueeze(-1)
|
| 37 |
+
xx = torch.fmod(indices, w).unsqueeze(-1)
|
| 38 |
+
ptss = torch.cat((yy, xx),dim=-1)
|
| 39 |
+
|
| 40 |
+
ptss = ptss.detach().cpu().numpy()
|
| 41 |
+
scores = scores.detach().cpu().numpy()
|
| 42 |
+
displacement = displacement.detach().cpu().numpy()
|
| 43 |
+
displacement = displacement.transpose((1,2,0))
|
| 44 |
+
return ptss, scores, displacement
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def pred_lines(image, model,
|
| 48 |
+
input_shape=[512, 512],
|
| 49 |
+
score_thr=0.10,
|
| 50 |
+
dist_thr=20.0):
|
| 51 |
+
h, w, _ = image.shape
|
| 52 |
+
h_ratio, w_ratio = [h / input_shape[0], w / input_shape[1]]
|
| 53 |
+
|
| 54 |
+
resized_image = np.concatenate([cv2.resize(image, (input_shape[1], input_shape[0]), interpolation=cv2.INTER_AREA),
|
| 55 |
+
np.ones([input_shape[0], input_shape[1], 1])], axis=-1)
|
| 56 |
+
|
| 57 |
+
resized_image = resized_image.transpose((2,0,1))
|
| 58 |
+
batch_image = np.expand_dims(resized_image, axis=0).astype('float32')
|
| 59 |
+
batch_image = (batch_image / 127.5) - 1.0
|
| 60 |
+
|
| 61 |
+
batch_image = torch.from_numpy(batch_image).float().cuda()
|
| 62 |
+
outputs = model(batch_image)
|
| 63 |
+
pts, pts_score, vmap = deccode_output_score_and_ptss(outputs, 200, 3)
|
| 64 |
+
start = vmap[:, :, :2]
|
| 65 |
+
end = vmap[:, :, 2:]
|
| 66 |
+
dist_map = np.sqrt(np.sum((start - end) ** 2, axis=-1))
|
| 67 |
+
|
| 68 |
+
segments_list = []
|
| 69 |
+
for center, score in zip(pts, pts_score):
|
| 70 |
+
y, x = center
|
| 71 |
+
distance = dist_map[y, x]
|
| 72 |
+
if score > score_thr and distance > dist_thr:
|
| 73 |
+
disp_x_start, disp_y_start, disp_x_end, disp_y_end = vmap[y, x, :]
|
| 74 |
+
x_start = x + disp_x_start
|
| 75 |
+
y_start = y + disp_y_start
|
| 76 |
+
x_end = x + disp_x_end
|
| 77 |
+
y_end = y + disp_y_end
|
| 78 |
+
segments_list.append([x_start, y_start, x_end, y_end])
|
| 79 |
+
|
| 80 |
+
lines = 2 * np.array(segments_list) # 256 > 512
|
| 81 |
+
lines[:, 0] = lines[:, 0] * w_ratio
|
| 82 |
+
lines[:, 1] = lines[:, 1] * h_ratio
|
| 83 |
+
lines[:, 2] = lines[:, 2] * w_ratio
|
| 84 |
+
lines[:, 3] = lines[:, 3] * h_ratio
|
| 85 |
+
|
| 86 |
+
return lines
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def pred_squares(image,
|
| 90 |
+
model,
|
| 91 |
+
input_shape=[512, 512],
|
| 92 |
+
params={'score': 0.06,
|
| 93 |
+
'outside_ratio': 0.28,
|
| 94 |
+
'inside_ratio': 0.45,
|
| 95 |
+
'w_overlap': 0.0,
|
| 96 |
+
'w_degree': 1.95,
|
| 97 |
+
'w_length': 0.0,
|
| 98 |
+
'w_area': 1.86,
|
| 99 |
+
'w_center': 0.14}):
|
| 100 |
+
'''
|
| 101 |
+
shape = [height, width]
|
| 102 |
+
'''
|
| 103 |
+
h, w, _ = image.shape
|
| 104 |
+
original_shape = [h, w]
|
| 105 |
+
|
| 106 |
+
resized_image = np.concatenate([cv2.resize(image, (input_shape[0], input_shape[1]), interpolation=cv2.INTER_AREA),
|
| 107 |
+
np.ones([input_shape[0], input_shape[1], 1])], axis=-1)
|
| 108 |
+
resized_image = resized_image.transpose((2, 0, 1))
|
| 109 |
+
batch_image = np.expand_dims(resized_image, axis=0).astype('float32')
|
| 110 |
+
batch_image = (batch_image / 127.5) - 1.0
|
| 111 |
+
|
| 112 |
+
batch_image = torch.from_numpy(batch_image).float().cuda()
|
| 113 |
+
outputs = model(batch_image)
|
| 114 |
+
|
| 115 |
+
pts, pts_score, vmap = deccode_output_score_and_ptss(outputs, 200, 3)
|
| 116 |
+
start = vmap[:, :, :2] # (x, y)
|
| 117 |
+
end = vmap[:, :, 2:] # (x, y)
|
| 118 |
+
dist_map = np.sqrt(np.sum((start - end) ** 2, axis=-1))
|
| 119 |
+
|
| 120 |
+
junc_list = []
|
| 121 |
+
segments_list = []
|
| 122 |
+
for junc, score in zip(pts, pts_score):
|
| 123 |
+
y, x = junc
|
| 124 |
+
distance = dist_map[y, x]
|
| 125 |
+
if score > params['score'] and distance > 20.0:
|
| 126 |
+
junc_list.append([x, y])
|
| 127 |
+
disp_x_start, disp_y_start, disp_x_end, disp_y_end = vmap[y, x, :]
|
| 128 |
+
d_arrow = 1.0
|
| 129 |
+
x_start = x + d_arrow * disp_x_start
|
| 130 |
+
y_start = y + d_arrow * disp_y_start
|
| 131 |
+
x_end = x + d_arrow * disp_x_end
|
| 132 |
+
y_end = y + d_arrow * disp_y_end
|
| 133 |
+
segments_list.append([x_start, y_start, x_end, y_end])
|
| 134 |
+
|
| 135 |
+
segments = np.array(segments_list)
|
| 136 |
+
|
| 137 |
+
####### post processing for squares
|
| 138 |
+
# 1. get unique lines
|
| 139 |
+
point = np.array([[0, 0]])
|
| 140 |
+
point = point[0]
|
| 141 |
+
start = segments[:, :2]
|
| 142 |
+
end = segments[:, 2:]
|
| 143 |
+
diff = start - end
|
| 144 |
+
a = diff[:, 1]
|
| 145 |
+
b = -diff[:, 0]
|
| 146 |
+
c = a * start[:, 0] + b * start[:, 1]
|
| 147 |
+
|
| 148 |
+
d = np.abs(a * point[0] + b * point[1] - c) / np.sqrt(a ** 2 + b ** 2 + 1e-10)
|
| 149 |
+
theta = np.arctan2(diff[:, 0], diff[:, 1]) * 180 / np.pi
|
| 150 |
+
theta[theta < 0.0] += 180
|
| 151 |
+
hough = np.concatenate([d[:, None], theta[:, None]], axis=-1)
|
| 152 |
+
|
| 153 |
+
d_quant = 1
|
| 154 |
+
theta_quant = 2
|
| 155 |
+
hough[:, 0] //= d_quant
|
| 156 |
+
hough[:, 1] //= theta_quant
|
| 157 |
+
_, indices, counts = np.unique(hough, axis=0, return_index=True, return_counts=True)
|
| 158 |
+
|
| 159 |
+
acc_map = np.zeros([512 // d_quant + 1, 360 // theta_quant + 1], dtype='float32')
|
| 160 |
+
idx_map = np.zeros([512 // d_quant + 1, 360 // theta_quant + 1], dtype='int32') - 1
|
| 161 |
+
yx_indices = hough[indices, :].astype('int32')
|
| 162 |
+
acc_map[yx_indices[:, 0], yx_indices[:, 1]] = counts
|
| 163 |
+
idx_map[yx_indices[:, 0], yx_indices[:, 1]] = indices
|
| 164 |
+
|
| 165 |
+
acc_map_np = acc_map
|
| 166 |
+
# acc_map = acc_map[None, :, :, None]
|
| 167 |
+
#
|
| 168 |
+
# ### fast suppression using tensorflow op
|
| 169 |
+
# acc_map = tf.constant(acc_map, dtype=tf.float32)
|
| 170 |
+
# max_acc_map = tf.keras.layers.MaxPool2D(pool_size=(5, 5), strides=1, padding='same')(acc_map)
|
| 171 |
+
# acc_map = acc_map * tf.cast(tf.math.equal(acc_map, max_acc_map), tf.float32)
|
| 172 |
+
# flatten_acc_map = tf.reshape(acc_map, [1, -1])
|
| 173 |
+
# topk_values, topk_indices = tf.math.top_k(flatten_acc_map, k=len(pts))
|
| 174 |
+
# _, h, w, _ = acc_map.shape
|
| 175 |
+
# y = tf.expand_dims(topk_indices // w, axis=-1)
|
| 176 |
+
# x = tf.expand_dims(topk_indices % w, axis=-1)
|
| 177 |
+
# yx = tf.concat([y, x], axis=-1)
|
| 178 |
+
|
| 179 |
+
### fast suppression using pytorch op
|
| 180 |
+
acc_map = torch.from_numpy(acc_map_np).unsqueeze(0).unsqueeze(0)
|
| 181 |
+
_,_, h, w = acc_map.shape
|
| 182 |
+
max_acc_map = F.max_pool2d(acc_map,kernel_size=5, stride=1, padding=2)
|
| 183 |
+
acc_map = acc_map * ( (acc_map == max_acc_map).float() )
|
| 184 |
+
flatten_acc_map = acc_map.reshape([-1, ])
|
| 185 |
+
|
| 186 |
+
scores, indices = torch.topk(flatten_acc_map, len(pts), dim=-1, largest=True)
|
| 187 |
+
yy = torch.div(indices, w, rounding_mode='floor').unsqueeze(-1)
|
| 188 |
+
xx = torch.fmod(indices, w).unsqueeze(-1)
|
| 189 |
+
yx = torch.cat((yy, xx), dim=-1)
|
| 190 |
+
|
| 191 |
+
yx = yx.detach().cpu().numpy()
|
| 192 |
+
|
| 193 |
+
topk_values = scores.detach().cpu().numpy()
|
| 194 |
+
indices = idx_map[yx[:, 0], yx[:, 1]]
|
| 195 |
+
basis = 5 // 2
|
| 196 |
+
|
| 197 |
+
merged_segments = []
|
| 198 |
+
for yx_pt, max_indice, value in zip(yx, indices, topk_values):
|
| 199 |
+
y, x = yx_pt
|
| 200 |
+
if max_indice == -1 or value == 0:
|
| 201 |
+
continue
|
| 202 |
+
segment_list = []
|
| 203 |
+
for y_offset in range(-basis, basis + 1):
|
| 204 |
+
for x_offset in range(-basis, basis + 1):
|
| 205 |
+
indice = idx_map[y + y_offset, x + x_offset]
|
| 206 |
+
cnt = int(acc_map_np[y + y_offset, x + x_offset])
|
| 207 |
+
if indice != -1:
|
| 208 |
+
segment_list.append(segments[indice])
|
| 209 |
+
if cnt > 1:
|
| 210 |
+
check_cnt = 1
|
| 211 |
+
current_hough = hough[indice]
|
| 212 |
+
for new_indice, new_hough in enumerate(hough):
|
| 213 |
+
if (current_hough == new_hough).all() and indice != new_indice:
|
| 214 |
+
segment_list.append(segments[new_indice])
|
| 215 |
+
check_cnt += 1
|
| 216 |
+
if check_cnt == cnt:
|
| 217 |
+
break
|
| 218 |
+
group_segments = np.array(segment_list).reshape([-1, 2])
|
| 219 |
+
sorted_group_segments = np.sort(group_segments, axis=0)
|
| 220 |
+
x_min, y_min = sorted_group_segments[0, :]
|
| 221 |
+
x_max, y_max = sorted_group_segments[-1, :]
|
| 222 |
+
|
| 223 |
+
deg = theta[max_indice]
|
| 224 |
+
if deg >= 90:
|
| 225 |
+
merged_segments.append([x_min, y_max, x_max, y_min])
|
| 226 |
+
else:
|
| 227 |
+
merged_segments.append([x_min, y_min, x_max, y_max])
|
| 228 |
+
|
| 229 |
+
# 2. get intersections
|
| 230 |
+
new_segments = np.array(merged_segments) # (x1, y1, x2, y2)
|
| 231 |
+
start = new_segments[:, :2] # (x1, y1)
|
| 232 |
+
end = new_segments[:, 2:] # (x2, y2)
|
| 233 |
+
new_centers = (start + end) / 2.0
|
| 234 |
+
diff = start - end
|
| 235 |
+
dist_segments = np.sqrt(np.sum(diff ** 2, axis=-1))
|
| 236 |
+
|
| 237 |
+
# ax + by = c
|
| 238 |
+
a = diff[:, 1]
|
| 239 |
+
b = -diff[:, 0]
|
| 240 |
+
c = a * start[:, 0] + b * start[:, 1]
|
| 241 |
+
pre_det = a[:, None] * b[None, :]
|
| 242 |
+
det = pre_det - np.transpose(pre_det)
|
| 243 |
+
|
| 244 |
+
pre_inter_y = a[:, None] * c[None, :]
|
| 245 |
+
inter_y = (pre_inter_y - np.transpose(pre_inter_y)) / (det + 1e-10)
|
| 246 |
+
pre_inter_x = c[:, None] * b[None, :]
|
| 247 |
+
inter_x = (pre_inter_x - np.transpose(pre_inter_x)) / (det + 1e-10)
|
| 248 |
+
inter_pts = np.concatenate([inter_x[:, :, None], inter_y[:, :, None]], axis=-1).astype('int32')
|
| 249 |
+
|
| 250 |
+
# 3. get corner information
|
| 251 |
+
# 3.1 get distance
|
| 252 |
+
'''
|
| 253 |
+
dist_segments:
|
| 254 |
+
| dist(0), dist(1), dist(2), ...|
|
| 255 |
+
dist_inter_to_segment1:
|
| 256 |
+
| dist(inter,0), dist(inter,0), dist(inter,0), ... |
|
| 257 |
+
| dist(inter,1), dist(inter,1), dist(inter,1), ... |
|
| 258 |
+
...
|
| 259 |
+
dist_inter_to_semgnet2:
|
| 260 |
+
| dist(inter,0), dist(inter,1), dist(inter,2), ... |
|
| 261 |
+
| dist(inter,0), dist(inter,1), dist(inter,2), ... |
|
| 262 |
+
...
|
| 263 |
+
'''
|
| 264 |
+
|
| 265 |
+
dist_inter_to_segment1_start = np.sqrt(
|
| 266 |
+
np.sum(((inter_pts - start[:, None, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
| 267 |
+
dist_inter_to_segment1_end = np.sqrt(
|
| 268 |
+
np.sum(((inter_pts - end[:, None, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
| 269 |
+
dist_inter_to_segment2_start = np.sqrt(
|
| 270 |
+
np.sum(((inter_pts - start[None, :, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
| 271 |
+
dist_inter_to_segment2_end = np.sqrt(
|
| 272 |
+
np.sum(((inter_pts - end[None, :, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
| 273 |
+
|
| 274 |
+
# sort ascending
|
| 275 |
+
dist_inter_to_segment1 = np.sort(
|
| 276 |
+
np.concatenate([dist_inter_to_segment1_start, dist_inter_to_segment1_end], axis=-1),
|
| 277 |
+
axis=-1) # [n_batch, n_batch, 2]
|
| 278 |
+
dist_inter_to_segment2 = np.sort(
|
| 279 |
+
np.concatenate([dist_inter_to_segment2_start, dist_inter_to_segment2_end], axis=-1),
|
| 280 |
+
axis=-1) # [n_batch, n_batch, 2]
|
| 281 |
+
|
| 282 |
+
# 3.2 get degree
|
| 283 |
+
inter_to_start = new_centers[:, None, :] - inter_pts
|
| 284 |
+
deg_inter_to_start = np.arctan2(inter_to_start[:, :, 1], inter_to_start[:, :, 0]) * 180 / np.pi
|
| 285 |
+
deg_inter_to_start[deg_inter_to_start < 0.0] += 360
|
| 286 |
+
inter_to_end = new_centers[None, :, :] - inter_pts
|
| 287 |
+
deg_inter_to_end = np.arctan2(inter_to_end[:, :, 1], inter_to_end[:, :, 0]) * 180 / np.pi
|
| 288 |
+
deg_inter_to_end[deg_inter_to_end < 0.0] += 360
|
| 289 |
+
|
| 290 |
+
'''
|
| 291 |
+
B -- G
|
| 292 |
+
| |
|
| 293 |
+
C -- R
|
| 294 |
+
B : blue / G: green / C: cyan / R: red
|
| 295 |
+
|
| 296 |
+
0 -- 1
|
| 297 |
+
| |
|
| 298 |
+
3 -- 2
|
| 299 |
+
'''
|
| 300 |
+
# rename variables
|
| 301 |
+
deg1_map, deg2_map = deg_inter_to_start, deg_inter_to_end
|
| 302 |
+
# sort deg ascending
|
| 303 |
+
deg_sort = np.sort(np.concatenate([deg1_map[:, :, None], deg2_map[:, :, None]], axis=-1), axis=-1)
|
| 304 |
+
|
| 305 |
+
deg_diff_map = np.abs(deg1_map - deg2_map)
|
| 306 |
+
# we only consider the smallest degree of intersect
|
| 307 |
+
deg_diff_map[deg_diff_map > 180] = 360 - deg_diff_map[deg_diff_map > 180]
|
| 308 |
+
|
| 309 |
+
# define available degree range
|
| 310 |
+
deg_range = [60, 120]
|
| 311 |
+
|
| 312 |
+
corner_dict = {corner_info: [] for corner_info in range(4)}
|
| 313 |
+
inter_points = []
|
| 314 |
+
for i in range(inter_pts.shape[0]):
|
| 315 |
+
for j in range(i + 1, inter_pts.shape[1]):
|
| 316 |
+
# i, j > line index, always i < j
|
| 317 |
+
x, y = inter_pts[i, j, :]
|
| 318 |
+
deg1, deg2 = deg_sort[i, j, :]
|
| 319 |
+
deg_diff = deg_diff_map[i, j]
|
| 320 |
+
|
| 321 |
+
check_degree = deg_diff > deg_range[0] and deg_diff < deg_range[1]
|
| 322 |
+
|
| 323 |
+
outside_ratio = params['outside_ratio'] # over ratio >>> drop it!
|
| 324 |
+
inside_ratio = params['inside_ratio'] # over ratio >>> drop it!
|
| 325 |
+
check_distance = ((dist_inter_to_segment1[i, j, 1] >= dist_segments[i] and \
|
| 326 |
+
dist_inter_to_segment1[i, j, 0] <= dist_segments[i] * outside_ratio) or \
|
| 327 |
+
(dist_inter_to_segment1[i, j, 1] <= dist_segments[i] and \
|
| 328 |
+
dist_inter_to_segment1[i, j, 0] <= dist_segments[i] * inside_ratio)) and \
|
| 329 |
+
((dist_inter_to_segment2[i, j, 1] >= dist_segments[j] and \
|
| 330 |
+
dist_inter_to_segment2[i, j, 0] <= dist_segments[j] * outside_ratio) or \
|
| 331 |
+
(dist_inter_to_segment2[i, j, 1] <= dist_segments[j] and \
|
| 332 |
+
dist_inter_to_segment2[i, j, 0] <= dist_segments[j] * inside_ratio))
|
| 333 |
+
|
| 334 |
+
if check_degree and check_distance:
|
| 335 |
+
corner_info = None
|
| 336 |
+
|
| 337 |
+
if (deg1 >= 0 and deg1 <= 45 and deg2 >= 45 and deg2 <= 120) or \
|
| 338 |
+
(deg2 >= 315 and deg1 >= 45 and deg1 <= 120):
|
| 339 |
+
corner_info, color_info = 0, 'blue'
|
| 340 |
+
elif (deg1 >= 45 and deg1 <= 125 and deg2 >= 125 and deg2 <= 225):
|
| 341 |
+
corner_info, color_info = 1, 'green'
|
| 342 |
+
elif (deg1 >= 125 and deg1 <= 225 and deg2 >= 225 and deg2 <= 315):
|
| 343 |
+
corner_info, color_info = 2, 'black'
|
| 344 |
+
elif (deg1 >= 0 and deg1 <= 45 and deg2 >= 225 and deg2 <= 315) or \
|
| 345 |
+
(deg2 >= 315 and deg1 >= 225 and deg1 <= 315):
|
| 346 |
+
corner_info, color_info = 3, 'cyan'
|
| 347 |
+
else:
|
| 348 |
+
corner_info, color_info = 4, 'red' # we don't use it
|
| 349 |
+
continue
|
| 350 |
+
|
| 351 |
+
corner_dict[corner_info].append([x, y, i, j])
|
| 352 |
+
inter_points.append([x, y])
|
| 353 |
+
|
| 354 |
+
square_list = []
|
| 355 |
+
connect_list = []
|
| 356 |
+
segments_list = []
|
| 357 |
+
for corner0 in corner_dict[0]:
|
| 358 |
+
for corner1 in corner_dict[1]:
|
| 359 |
+
connect01 = False
|
| 360 |
+
for corner0_line in corner0[2:]:
|
| 361 |
+
if corner0_line in corner1[2:]:
|
| 362 |
+
connect01 = True
|
| 363 |
+
break
|
| 364 |
+
if connect01:
|
| 365 |
+
for corner2 in corner_dict[2]:
|
| 366 |
+
connect12 = False
|
| 367 |
+
for corner1_line in corner1[2:]:
|
| 368 |
+
if corner1_line in corner2[2:]:
|
| 369 |
+
connect12 = True
|
| 370 |
+
break
|
| 371 |
+
if connect12:
|
| 372 |
+
for corner3 in corner_dict[3]:
|
| 373 |
+
connect23 = False
|
| 374 |
+
for corner2_line in corner2[2:]:
|
| 375 |
+
if corner2_line in corner3[2:]:
|
| 376 |
+
connect23 = True
|
| 377 |
+
break
|
| 378 |
+
if connect23:
|
| 379 |
+
for corner3_line in corner3[2:]:
|
| 380 |
+
if corner3_line in corner0[2:]:
|
| 381 |
+
# SQUARE!!!
|
| 382 |
+
'''
|
| 383 |
+
0 -- 1
|
| 384 |
+
| |
|
| 385 |
+
3 -- 2
|
| 386 |
+
square_list:
|
| 387 |
+
order: 0 > 1 > 2 > 3
|
| 388 |
+
| x0, y0, x1, y1, x2, y2, x3, y3 |
|
| 389 |
+
| x0, y0, x1, y1, x2, y2, x3, y3 |
|
| 390 |
+
...
|
| 391 |
+
connect_list:
|
| 392 |
+
order: 01 > 12 > 23 > 30
|
| 393 |
+
| line_idx01, line_idx12, line_idx23, line_idx30 |
|
| 394 |
+
| line_idx01, line_idx12, line_idx23, line_idx30 |
|
| 395 |
+
...
|
| 396 |
+
segments_list:
|
| 397 |
+
order: 0 > 1 > 2 > 3
|
| 398 |
+
| line_idx0_i, line_idx0_j, line_idx1_i, line_idx1_j, line_idx2_i, line_idx2_j, line_idx3_i, line_idx3_j |
|
| 399 |
+
| line_idx0_i, line_idx0_j, line_idx1_i, line_idx1_j, line_idx2_i, line_idx2_j, line_idx3_i, line_idx3_j |
|
| 400 |
+
...
|
| 401 |
+
'''
|
| 402 |
+
square_list.append(corner0[:2] + corner1[:2] + corner2[:2] + corner3[:2])
|
| 403 |
+
connect_list.append([corner0_line, corner1_line, corner2_line, corner3_line])
|
| 404 |
+
segments_list.append(corner0[2:] + corner1[2:] + corner2[2:] + corner3[2:])
|
| 405 |
+
|
| 406 |
+
def check_outside_inside(segments_info, connect_idx):
|
| 407 |
+
# return 'outside or inside', min distance, cover_param, peri_param
|
| 408 |
+
if connect_idx == segments_info[0]:
|
| 409 |
+
check_dist_mat = dist_inter_to_segment1
|
| 410 |
+
else:
|
| 411 |
+
check_dist_mat = dist_inter_to_segment2
|
| 412 |
+
|
| 413 |
+
i, j = segments_info
|
| 414 |
+
min_dist, max_dist = check_dist_mat[i, j, :]
|
| 415 |
+
connect_dist = dist_segments[connect_idx]
|
| 416 |
+
if max_dist > connect_dist:
|
| 417 |
+
return 'outside', min_dist, 0, 1
|
| 418 |
+
else:
|
| 419 |
+
return 'inside', min_dist, -1, -1
|
| 420 |
+
|
| 421 |
+
top_square = None
|
| 422 |
+
|
| 423 |
+
try:
|
| 424 |
+
map_size = input_shape[0] / 2
|
| 425 |
+
squares = np.array(square_list).reshape([-1, 4, 2])
|
| 426 |
+
score_array = []
|
| 427 |
+
connect_array = np.array(connect_list)
|
| 428 |
+
segments_array = np.array(segments_list).reshape([-1, 4, 2])
|
| 429 |
+
|
| 430 |
+
# get degree of corners:
|
| 431 |
+
squares_rollup = np.roll(squares, 1, axis=1)
|
| 432 |
+
squares_rolldown = np.roll(squares, -1, axis=1)
|
| 433 |
+
vec1 = squares_rollup - squares
|
| 434 |
+
normalized_vec1 = vec1 / (np.linalg.norm(vec1, axis=-1, keepdims=True) + 1e-10)
|
| 435 |
+
vec2 = squares_rolldown - squares
|
| 436 |
+
normalized_vec2 = vec2 / (np.linalg.norm(vec2, axis=-1, keepdims=True) + 1e-10)
|
| 437 |
+
inner_products = np.sum(normalized_vec1 * normalized_vec2, axis=-1) # [n_squares, 4]
|
| 438 |
+
squares_degree = np.arccos(inner_products) * 180 / np.pi # [n_squares, 4]
|
| 439 |
+
|
| 440 |
+
# get square score
|
| 441 |
+
overlap_scores = []
|
| 442 |
+
degree_scores = []
|
| 443 |
+
length_scores = []
|
| 444 |
+
|
| 445 |
+
for connects, segments, square, degree in zip(connect_array, segments_array, squares, squares_degree):
|
| 446 |
+
'''
|
| 447 |
+
0 -- 1
|
| 448 |
+
| |
|
| 449 |
+
3 -- 2
|
| 450 |
+
|
| 451 |
+
# segments: [4, 2]
|
| 452 |
+
# connects: [4]
|
| 453 |
+
'''
|
| 454 |
+
|
| 455 |
+
###################################### OVERLAP SCORES
|
| 456 |
+
cover = 0
|
| 457 |
+
perimeter = 0
|
| 458 |
+
# check 0 > 1 > 2 > 3
|
| 459 |
+
square_length = []
|
| 460 |
+
|
| 461 |
+
for start_idx in range(4):
|
| 462 |
+
end_idx = (start_idx + 1) % 4
|
| 463 |
+
|
| 464 |
+
connect_idx = connects[start_idx] # segment idx of segment01
|
| 465 |
+
start_segments = segments[start_idx]
|
| 466 |
+
end_segments = segments[end_idx]
|
| 467 |
+
|
| 468 |
+
start_point = square[start_idx]
|
| 469 |
+
end_point = square[end_idx]
|
| 470 |
+
|
| 471 |
+
# check whether outside or inside
|
| 472 |
+
start_position, start_min, start_cover_param, start_peri_param = check_outside_inside(start_segments,
|
| 473 |
+
connect_idx)
|
| 474 |
+
end_position, end_min, end_cover_param, end_peri_param = check_outside_inside(end_segments, connect_idx)
|
| 475 |
+
|
| 476 |
+
cover += dist_segments[connect_idx] + start_cover_param * start_min + end_cover_param * end_min
|
| 477 |
+
perimeter += dist_segments[connect_idx] + start_peri_param * start_min + end_peri_param * end_min
|
| 478 |
+
|
| 479 |
+
square_length.append(
|
| 480 |
+
dist_segments[connect_idx] + start_peri_param * start_min + end_peri_param * end_min)
|
| 481 |
+
|
| 482 |
+
overlap_scores.append(cover / perimeter)
|
| 483 |
+
######################################
|
| 484 |
+
###################################### DEGREE SCORES
|
| 485 |
+
'''
|
| 486 |
+
deg0 vs deg2
|
| 487 |
+
deg1 vs deg3
|
| 488 |
+
'''
|
| 489 |
+
deg0, deg1, deg2, deg3 = degree
|
| 490 |
+
deg_ratio1 = deg0 / deg2
|
| 491 |
+
if deg_ratio1 > 1.0:
|
| 492 |
+
deg_ratio1 = 1 / deg_ratio1
|
| 493 |
+
deg_ratio2 = deg1 / deg3
|
| 494 |
+
if deg_ratio2 > 1.0:
|
| 495 |
+
deg_ratio2 = 1 / deg_ratio2
|
| 496 |
+
degree_scores.append((deg_ratio1 + deg_ratio2) / 2)
|
| 497 |
+
######################################
|
| 498 |
+
###################################### LENGTH SCORES
|
| 499 |
+
'''
|
| 500 |
+
len0 vs len2
|
| 501 |
+
len1 vs len3
|
| 502 |
+
'''
|
| 503 |
+
len0, len1, len2, len3 = square_length
|
| 504 |
+
len_ratio1 = len0 / len2 if len2 > len0 else len2 / len0
|
| 505 |
+
len_ratio2 = len1 / len3 if len3 > len1 else len3 / len1
|
| 506 |
+
length_scores.append((len_ratio1 + len_ratio2) / 2)
|
| 507 |
+
|
| 508 |
+
######################################
|
| 509 |
+
|
| 510 |
+
overlap_scores = np.array(overlap_scores)
|
| 511 |
+
overlap_scores /= np.max(overlap_scores)
|
| 512 |
+
|
| 513 |
+
degree_scores = np.array(degree_scores)
|
| 514 |
+
# degree_scores /= np.max(degree_scores)
|
| 515 |
+
|
| 516 |
+
length_scores = np.array(length_scores)
|
| 517 |
+
|
| 518 |
+
###################################### AREA SCORES
|
| 519 |
+
area_scores = np.reshape(squares, [-1, 4, 2])
|
| 520 |
+
area_x = area_scores[:, :, 0]
|
| 521 |
+
area_y = area_scores[:, :, 1]
|
| 522 |
+
correction = area_x[:, -1] * area_y[:, 0] - area_y[:, -1] * area_x[:, 0]
|
| 523 |
+
area_scores = np.sum(area_x[:, :-1] * area_y[:, 1:], axis=-1) - np.sum(area_y[:, :-1] * area_x[:, 1:], axis=-1)
|
| 524 |
+
area_scores = 0.5 * np.abs(area_scores + correction)
|
| 525 |
+
area_scores /= (map_size * map_size) # np.max(area_scores)
|
| 526 |
+
######################################
|
| 527 |
+
|
| 528 |
+
###################################### CENTER SCORES
|
| 529 |
+
centers = np.array([[256 // 2, 256 // 2]], dtype='float32') # [1, 2]
|
| 530 |
+
# squares: [n, 4, 2]
|
| 531 |
+
square_centers = np.mean(squares, axis=1) # [n, 2]
|
| 532 |
+
center2center = np.sqrt(np.sum((centers - square_centers) ** 2))
|
| 533 |
+
center_scores = center2center / (map_size / np.sqrt(2.0))
|
| 534 |
+
|
| 535 |
+
'''
|
| 536 |
+
score_w = [overlap, degree, area, center, length]
|
| 537 |
+
'''
|
| 538 |
+
score_w = [0.0, 1.0, 10.0, 0.5, 1.0]
|
| 539 |
+
score_array = params['w_overlap'] * overlap_scores \
|
| 540 |
+
+ params['w_degree'] * degree_scores \
|
| 541 |
+
+ params['w_area'] * area_scores \
|
| 542 |
+
- params['w_center'] * center_scores \
|
| 543 |
+
+ params['w_length'] * length_scores
|
| 544 |
+
|
| 545 |
+
best_square = []
|
| 546 |
+
|
| 547 |
+
sorted_idx = np.argsort(score_array)[::-1]
|
| 548 |
+
score_array = score_array[sorted_idx]
|
| 549 |
+
squares = squares[sorted_idx]
|
| 550 |
+
|
| 551 |
+
except Exception as e:
|
| 552 |
+
pass
|
| 553 |
+
|
| 554 |
+
'''return list
|
| 555 |
+
merged_lines, squares, scores
|
| 556 |
+
'''
|
| 557 |
+
|
| 558 |
+
try:
|
| 559 |
+
new_segments[:, 0] = new_segments[:, 0] * 2 / input_shape[1] * original_shape[1]
|
| 560 |
+
new_segments[:, 1] = new_segments[:, 1] * 2 / input_shape[0] * original_shape[0]
|
| 561 |
+
new_segments[:, 2] = new_segments[:, 2] * 2 / input_shape[1] * original_shape[1]
|
| 562 |
+
new_segments[:, 3] = new_segments[:, 3] * 2 / input_shape[0] * original_shape[0]
|
| 563 |
+
except:
|
| 564 |
+
new_segments = []
|
| 565 |
+
|
| 566 |
+
try:
|
| 567 |
+
squares[:, :, 0] = squares[:, :, 0] * 2 / input_shape[1] * original_shape[1]
|
| 568 |
+
squares[:, :, 1] = squares[:, :, 1] * 2 / input_shape[0] * original_shape[0]
|
| 569 |
+
except:
|
| 570 |
+
squares = []
|
| 571 |
+
score_array = []
|
| 572 |
+
|
| 573 |
+
try:
|
| 574 |
+
inter_points = np.array(inter_points)
|
| 575 |
+
inter_points[:, 0] = inter_points[:, 0] * 2 / input_shape[1] * original_shape[1]
|
| 576 |
+
inter_points[:, 1] = inter_points[:, 1] * 2 / input_shape[0] * original_shape[0]
|
| 577 |
+
except:
|
| 578 |
+
inter_points = []
|
| 579 |
+
|
| 580 |
+
return new_segments, squares, score_array, inter_points
|
src/ControlNet/annotator/openpose/LICENSE
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
OPENPOSE: MULTIPERSON KEYPOINT DETECTION
|
| 2 |
+
SOFTWARE LICENSE AGREEMENT
|
| 3 |
+
ACADEMIC OR NON-PROFIT ORGANIZATION NONCOMMERCIAL RESEARCH USE ONLY
|
| 4 |
+
|
| 5 |
+
BY USING OR DOWNLOADING THE SOFTWARE, YOU ARE AGREEING TO THE TERMS OF THIS LICENSE AGREEMENT. IF YOU DO NOT AGREE WITH THESE TERMS, YOU MAY NOT USE OR DOWNLOAD THE SOFTWARE.
|
| 6 |
+
|
| 7 |
+
This is a license agreement ("Agreement") between your academic institution or non-profit organization or self (called "Licensee" or "You" in this Agreement) and Carnegie Mellon University (called "Licensor" in this Agreement). All rights not specifically granted to you in this Agreement are reserved for Licensor.
|
| 8 |
+
|
| 9 |
+
RESERVATION OF OWNERSHIP AND GRANT OF LICENSE:
|
| 10 |
+
Licensor retains exclusive ownership of any copy of the Software (as defined below) licensed under this Agreement and hereby grants to Licensee a personal, non-exclusive,
|
| 11 |
+
non-transferable license to use the Software for noncommercial research purposes, without the right to sublicense, pursuant to the terms and conditions of this Agreement. As used in this Agreement, the term "Software" means (i) the actual copy of all or any portion of code for program routines made accessible to Licensee by Licensor pursuant to this Agreement, inclusive of backups, updates, and/or merged copies permitted hereunder or subsequently supplied by Licensor, including all or any file structures, programming instructions, user interfaces and screen formats and sequences as well as any and all documentation and instructions related to it, and (ii) all or any derivatives and/or modifications created or made by You to any of the items specified in (i).
|
| 12 |
+
|
| 13 |
+
CONFIDENTIALITY: Licensee acknowledges that the Software is proprietary to Licensor, and as such, Licensee agrees to receive all such materials in confidence and use the Software only in accordance with the terms of this Agreement. Licensee agrees to use reasonable effort to protect the Software from unauthorized use, reproduction, distribution, or publication.
|
| 14 |
+
|
| 15 |
+
COPYRIGHT: The Software is owned by Licensor and is protected by United
|
| 16 |
+
States copyright laws and applicable international treaties and/or conventions.
|
| 17 |
+
|
| 18 |
+
PERMITTED USES: The Software may be used for your own noncommercial internal research purposes. You understand and agree that Licensor is not obligated to implement any suggestions and/or feedback you might provide regarding the Software, but to the extent Licensor does so, you are not entitled to any compensation related thereto.
|
| 19 |
+
|
| 20 |
+
DERIVATIVES: You may create derivatives of or make modifications to the Software, however, You agree that all and any such derivatives and modifications will be owned by Licensor and become a part of the Software licensed to You under this Agreement. You may only use such derivatives and modifications for your own noncommercial internal research purposes, and you may not otherwise use, distribute or copy such derivatives and modifications in violation of this Agreement.
|
| 21 |
+
|
| 22 |
+
BACKUPS: If Licensee is an organization, it may make that number of copies of the Software necessary for internal noncommercial use at a single site within its organization provided that all information appearing in or on the original labels, including the copyright and trademark notices are copied onto the labels of the copies.
|
| 23 |
+
|
| 24 |
+
USES NOT PERMITTED: You may not distribute, copy or use the Software except as explicitly permitted herein. Licensee has not been granted any trademark license as part of this Agreement and may not use the name or mark “OpenPose", "Carnegie Mellon" or any renditions thereof without the prior written permission of Licensor.
|
| 25 |
+
|
| 26 |
+
You may not sell, rent, lease, sublicense, lend, time-share or transfer, in whole or in part, or provide third parties access to prior or present versions (or any parts thereof) of the Software.
|
| 27 |
+
|
| 28 |
+
ASSIGNMENT: You may not assign this Agreement or your rights hereunder without the prior written consent of Licensor. Any attempted assignment without such consent shall be null and void.
|
| 29 |
+
|
| 30 |
+
TERM: The term of the license granted by this Agreement is from Licensee's acceptance of this Agreement by downloading the Software or by using the Software until terminated as provided below.
|
| 31 |
+
|
| 32 |
+
The Agreement automatically terminates without notice if you fail to comply with any provision of this Agreement. Licensee may terminate this Agreement by ceasing using the Software. Upon any termination of this Agreement, Licensee will delete any and all copies of the Software. You agree that all provisions which operate to protect the proprietary rights of Licensor shall remain in force should breach occur and that the obligation of confidentiality described in this Agreement is binding in perpetuity and, as such, survives the term of the Agreement.
|
| 33 |
+
|
| 34 |
+
FEE: Provided Licensee abides completely by the terms and conditions of this Agreement, there is no fee due to Licensor for Licensee's use of the Software in accordance with this Agreement.
|
| 35 |
+
|
| 36 |
+
DISCLAIMER OF WARRANTIES: THE SOFTWARE IS PROVIDED "AS-IS" WITHOUT WARRANTY OF ANY KIND INCLUDING ANY WARRANTIES OF PERFORMANCE OR MERCHANTABILITY OR FITNESS FOR A PARTICULAR USE OR PURPOSE OR OF NON-INFRINGEMENT. LICENSEE BEARS ALL RISK RELATING TO QUALITY AND PERFORMANCE OF THE SOFTWARE AND RELATED MATERIALS.
|
| 37 |
+
|
| 38 |
+
SUPPORT AND MAINTENANCE: No Software support or training by the Licensor is provided as part of this Agreement.
|
| 39 |
+
|
| 40 |
+
EXCLUSIVE REMEDY AND LIMITATION OF LIABILITY: To the maximum extent permitted under applicable law, Licensor shall not be liable for direct, indirect, special, incidental, or consequential damages or lost profits related to Licensee's use of and/or inability to use the Software, even if Licensor is advised of the possibility of such damage.
|
| 41 |
+
|
| 42 |
+
EXPORT REGULATION: Licensee agrees to comply with any and all applicable
|
| 43 |
+
U.S. export control laws, regulations, and/or other laws related to embargoes and sanction programs administered by the Office of Foreign Assets Control.
|
| 44 |
+
|
| 45 |
+
SEVERABILITY: If any provision(s) of this Agreement shall be held to be invalid, illegal, or unenforceable by a court or other tribunal of competent jurisdiction, the validity, legality and enforceability of the remaining provisions shall not in any way be affected or impaired thereby.
|
| 46 |
+
|
| 47 |
+
NO IMPLIED WAIVERS: No failure or delay by Licensor in enforcing any right or remedy under this Agreement shall be construed as a waiver of any future or other exercise of such right or remedy by Licensor.
|
| 48 |
+
|
| 49 |
+
GOVERNING LAW: This Agreement shall be construed and enforced in accordance with the laws of the Commonwealth of Pennsylvania without reference to conflict of laws principles. You consent to the personal jurisdiction of the courts of this County and waive their rights to venue outside of Allegheny County, Pennsylvania.
|
| 50 |
+
|
| 51 |
+
ENTIRE AGREEMENT AND AMENDMENTS: This Agreement constitutes the sole and entire agreement between Licensee and Licensor as to the matter set forth herein and supersedes any previous agreements, understandings, and arrangements between the parties relating hereto.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
************************************************************************
|
| 56 |
+
|
| 57 |
+
THIRD-PARTY SOFTWARE NOTICES AND INFORMATION
|
| 58 |
+
|
| 59 |
+
This project incorporates material from the project(s) listed below (collectively, "Third Party Code"). This Third Party Code is licensed to you under their original license terms set forth below. We reserves all other rights not expressly granted, whether by implication, estoppel or otherwise.
|
| 60 |
+
|
| 61 |
+
1. Caffe, version 1.0.0, (https://github.com/BVLC/caffe/)
|
| 62 |
+
|
| 63 |
+
COPYRIGHT
|
| 64 |
+
|
| 65 |
+
All contributions by the University of California:
|
| 66 |
+
Copyright (c) 2014-2017 The Regents of the University of California (Regents)
|
| 67 |
+
All rights reserved.
|
| 68 |
+
|
| 69 |
+
All other contributions:
|
| 70 |
+
Copyright (c) 2014-2017, the respective contributors
|
| 71 |
+
All rights reserved.
|
| 72 |
+
|
| 73 |
+
Caffe uses a shared copyright model: each contributor holds copyright over
|
| 74 |
+
their contributions to Caffe. The project versioning records all such
|
| 75 |
+
contribution and copyright details. If a contributor wants to further mark
|
| 76 |
+
their specific copyright on a particular contribution, they should indicate
|
| 77 |
+
their copyright solely in the commit message of the change when it is
|
| 78 |
+
committed.
|
| 79 |
+
|
| 80 |
+
LICENSE
|
| 81 |
+
|
| 82 |
+
Redistribution and use in source and binary forms, with or without
|
| 83 |
+
modification, are permitted provided that the following conditions are met:
|
| 84 |
+
|
| 85 |
+
1. Redistributions of source code must retain the above copyright notice, this
|
| 86 |
+
list of conditions and the following disclaimer.
|
| 87 |
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
| 88 |
+
this list of conditions and the following disclaimer in the documentation
|
| 89 |
+
and/or other materials provided with the distribution.
|
| 90 |
+
|
| 91 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
|
| 92 |
+
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
|
| 93 |
+
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 94 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
|
| 95 |
+
ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
|
| 96 |
+
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
|
| 97 |
+
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
|
| 98 |
+
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 99 |
+
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
|
| 100 |
+
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 101 |
+
|
| 102 |
+
CONTRIBUTION AGREEMENT
|
| 103 |
+
|
| 104 |
+
By contributing to the BVLC/caffe repository through pull-request, comment,
|
| 105 |
+
or otherwise, the contributor releases their content to the
|
| 106 |
+
license and copyright terms herein.
|
| 107 |
+
|
| 108 |
+
************END OF THIRD-PARTY SOFTWARE NOTICES AND INFORMATION**********
|
src/ControlNet/annotator/openpose/__init__.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Openpose
|
| 2 |
+
# Original from CMU https://github.com/CMU-Perceptual-Computing-Lab/openpose
|
| 3 |
+
# 2nd Edited by https://github.com/Hzzone/pytorch-openpose
|
| 4 |
+
# 3rd Edited by ControlNet
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import numpy as np
|
| 11 |
+
from . import util
|
| 12 |
+
from .body import Body
|
| 13 |
+
from .hand import Hand
|
| 14 |
+
from annotator.util import annotator_ckpts_path
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
body_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/body_pose_model.pth"
|
| 18 |
+
hand_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/hand_pose_model.pth"
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class OpenposeDetector:
|
| 22 |
+
def __init__(self):
|
| 23 |
+
body_modelpath = os.path.join(annotator_ckpts_path, "body_pose_model.pth")
|
| 24 |
+
hand_modelpath = os.path.join(annotator_ckpts_path, "hand_pose_model.pth")
|
| 25 |
+
|
| 26 |
+
if not os.path.exists(hand_modelpath):
|
| 27 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 28 |
+
load_file_from_url(body_model_path, model_dir=annotator_ckpts_path)
|
| 29 |
+
load_file_from_url(hand_model_path, model_dir=annotator_ckpts_path)
|
| 30 |
+
|
| 31 |
+
self.body_estimation = Body(body_modelpath)
|
| 32 |
+
self.hand_estimation = Hand(hand_modelpath)
|
| 33 |
+
|
| 34 |
+
def __call__(self, oriImg, hand=False):
|
| 35 |
+
oriImg = oriImg[:, :, ::-1].copy()
|
| 36 |
+
with torch.no_grad():
|
| 37 |
+
candidate, subset = self.body_estimation(oriImg)
|
| 38 |
+
canvas = np.zeros_like(oriImg)
|
| 39 |
+
canvas = util.draw_bodypose(canvas, candidate, subset)
|
| 40 |
+
if hand:
|
| 41 |
+
hands_list = util.handDetect(candidate, subset, oriImg)
|
| 42 |
+
all_hand_peaks = []
|
| 43 |
+
for x, y, w, is_left in hands_list:
|
| 44 |
+
peaks = self.hand_estimation(oriImg[y:y+w, x:x+w, :])
|
| 45 |
+
peaks[:, 0] = np.where(peaks[:, 0] == 0, peaks[:, 0], peaks[:, 0] + x)
|
| 46 |
+
peaks[:, 1] = np.where(peaks[:, 1] == 0, peaks[:, 1], peaks[:, 1] + y)
|
| 47 |
+
all_hand_peaks.append(peaks)
|
| 48 |
+
canvas = util.draw_handpose(canvas, all_hand_peaks)
|
| 49 |
+
return canvas, dict(candidate=candidate.tolist(), subset=subset.tolist())
|
src/ControlNet/annotator/openpose/body.py
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
import math
|
| 4 |
+
import time
|
| 5 |
+
from scipy.ndimage.filters import gaussian_filter
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import matplotlib
|
| 8 |
+
import torch
|
| 9 |
+
from torchvision import transforms
|
| 10 |
+
|
| 11 |
+
from . import util
|
| 12 |
+
from .model import bodypose_model
|
| 13 |
+
|
| 14 |
+
class Body(object):
|
| 15 |
+
def __init__(self, model_path):
|
| 16 |
+
self.model = bodypose_model()
|
| 17 |
+
if torch.cuda.is_available():
|
| 18 |
+
self.model = self.model.cuda()
|
| 19 |
+
print('cuda')
|
| 20 |
+
model_dict = util.transfer(self.model, torch.load(model_path))
|
| 21 |
+
self.model.load_state_dict(model_dict)
|
| 22 |
+
self.model.eval()
|
| 23 |
+
|
| 24 |
+
def __call__(self, oriImg):
|
| 25 |
+
# scale_search = [0.5, 1.0, 1.5, 2.0]
|
| 26 |
+
scale_search = [0.5]
|
| 27 |
+
boxsize = 368
|
| 28 |
+
stride = 8
|
| 29 |
+
padValue = 128
|
| 30 |
+
thre1 = 0.1
|
| 31 |
+
thre2 = 0.05
|
| 32 |
+
multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
|
| 33 |
+
heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 19))
|
| 34 |
+
paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
|
| 35 |
+
|
| 36 |
+
for m in range(len(multiplier)):
|
| 37 |
+
scale = multiplier[m]
|
| 38 |
+
imageToTest = cv2.resize(oriImg, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
|
| 39 |
+
imageToTest_padded, pad = util.padRightDownCorner(imageToTest, stride, padValue)
|
| 40 |
+
im = np.transpose(np.float32(imageToTest_padded[:, :, :, np.newaxis]), (3, 2, 0, 1)) / 256 - 0.5
|
| 41 |
+
im = np.ascontiguousarray(im)
|
| 42 |
+
|
| 43 |
+
data = torch.from_numpy(im).float()
|
| 44 |
+
if torch.cuda.is_available():
|
| 45 |
+
data = data.cuda()
|
| 46 |
+
# data = data.permute([2, 0, 1]).unsqueeze(0).float()
|
| 47 |
+
with torch.no_grad():
|
| 48 |
+
Mconv7_stage6_L1, Mconv7_stage6_L2 = self.model(data)
|
| 49 |
+
Mconv7_stage6_L1 = Mconv7_stage6_L1.cpu().numpy()
|
| 50 |
+
Mconv7_stage6_L2 = Mconv7_stage6_L2.cpu().numpy()
|
| 51 |
+
|
| 52 |
+
# extract outputs, resize, and remove padding
|
| 53 |
+
# heatmap = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[1]].data), (1, 2, 0)) # output 1 is heatmaps
|
| 54 |
+
heatmap = np.transpose(np.squeeze(Mconv7_stage6_L2), (1, 2, 0)) # output 1 is heatmaps
|
| 55 |
+
heatmap = cv2.resize(heatmap, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
|
| 56 |
+
heatmap = heatmap[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
|
| 57 |
+
heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
|
| 58 |
+
|
| 59 |
+
# paf = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[0]].data), (1, 2, 0)) # output 0 is PAFs
|
| 60 |
+
paf = np.transpose(np.squeeze(Mconv7_stage6_L1), (1, 2, 0)) # output 0 is PAFs
|
| 61 |
+
paf = cv2.resize(paf, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
|
| 62 |
+
paf = paf[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
|
| 63 |
+
paf = cv2.resize(paf, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
|
| 64 |
+
|
| 65 |
+
heatmap_avg += heatmap_avg + heatmap / len(multiplier)
|
| 66 |
+
paf_avg += + paf / len(multiplier)
|
| 67 |
+
|
| 68 |
+
all_peaks = []
|
| 69 |
+
peak_counter = 0
|
| 70 |
+
|
| 71 |
+
for part in range(18):
|
| 72 |
+
map_ori = heatmap_avg[:, :, part]
|
| 73 |
+
one_heatmap = gaussian_filter(map_ori, sigma=3)
|
| 74 |
+
|
| 75 |
+
map_left = np.zeros(one_heatmap.shape)
|
| 76 |
+
map_left[1:, :] = one_heatmap[:-1, :]
|
| 77 |
+
map_right = np.zeros(one_heatmap.shape)
|
| 78 |
+
map_right[:-1, :] = one_heatmap[1:, :]
|
| 79 |
+
map_up = np.zeros(one_heatmap.shape)
|
| 80 |
+
map_up[:, 1:] = one_heatmap[:, :-1]
|
| 81 |
+
map_down = np.zeros(one_heatmap.shape)
|
| 82 |
+
map_down[:, :-1] = one_heatmap[:, 1:]
|
| 83 |
+
|
| 84 |
+
peaks_binary = np.logical_and.reduce(
|
| 85 |
+
(one_heatmap >= map_left, one_heatmap >= map_right, one_heatmap >= map_up, one_heatmap >= map_down, one_heatmap > thre1))
|
| 86 |
+
peaks = list(zip(np.nonzero(peaks_binary)[1], np.nonzero(peaks_binary)[0])) # note reverse
|
| 87 |
+
peaks_with_score = [x + (map_ori[x[1], x[0]],) for x in peaks]
|
| 88 |
+
peak_id = range(peak_counter, peak_counter + len(peaks))
|
| 89 |
+
peaks_with_score_and_id = [peaks_with_score[i] + (peak_id[i],) for i in range(len(peak_id))]
|
| 90 |
+
|
| 91 |
+
all_peaks.append(peaks_with_score_and_id)
|
| 92 |
+
peak_counter += len(peaks)
|
| 93 |
+
|
| 94 |
+
# find connection in the specified sequence, center 29 is in the position 15
|
| 95 |
+
limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \
|
| 96 |
+
[10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \
|
| 97 |
+
[1, 16], [16, 18], [3, 17], [6, 18]]
|
| 98 |
+
# the middle joints heatmap correpondence
|
| 99 |
+
mapIdx = [[31, 32], [39, 40], [33, 34], [35, 36], [41, 42], [43, 44], [19, 20], [21, 22], \
|
| 100 |
+
[23, 24], [25, 26], [27, 28], [29, 30], [47, 48], [49, 50], [53, 54], [51, 52], \
|
| 101 |
+
[55, 56], [37, 38], [45, 46]]
|
| 102 |
+
|
| 103 |
+
connection_all = []
|
| 104 |
+
special_k = []
|
| 105 |
+
mid_num = 10
|
| 106 |
+
|
| 107 |
+
for k in range(len(mapIdx)):
|
| 108 |
+
score_mid = paf_avg[:, :, [x - 19 for x in mapIdx[k]]]
|
| 109 |
+
candA = all_peaks[limbSeq[k][0] - 1]
|
| 110 |
+
candB = all_peaks[limbSeq[k][1] - 1]
|
| 111 |
+
nA = len(candA)
|
| 112 |
+
nB = len(candB)
|
| 113 |
+
indexA, indexB = limbSeq[k]
|
| 114 |
+
if (nA != 0 and nB != 0):
|
| 115 |
+
connection_candidate = []
|
| 116 |
+
for i in range(nA):
|
| 117 |
+
for j in range(nB):
|
| 118 |
+
vec = np.subtract(candB[j][:2], candA[i][:2])
|
| 119 |
+
norm = math.sqrt(vec[0] * vec[0] + vec[1] * vec[1])
|
| 120 |
+
norm = max(0.001, norm)
|
| 121 |
+
vec = np.divide(vec, norm)
|
| 122 |
+
|
| 123 |
+
startend = list(zip(np.linspace(candA[i][0], candB[j][0], num=mid_num), \
|
| 124 |
+
np.linspace(candA[i][1], candB[j][1], num=mid_num)))
|
| 125 |
+
|
| 126 |
+
vec_x = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 0] \
|
| 127 |
+
for I in range(len(startend))])
|
| 128 |
+
vec_y = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 1] \
|
| 129 |
+
for I in range(len(startend))])
|
| 130 |
+
|
| 131 |
+
score_midpts = np.multiply(vec_x, vec[0]) + np.multiply(vec_y, vec[1])
|
| 132 |
+
score_with_dist_prior = sum(score_midpts) / len(score_midpts) + min(
|
| 133 |
+
0.5 * oriImg.shape[0] / norm - 1, 0)
|
| 134 |
+
criterion1 = len(np.nonzero(score_midpts > thre2)[0]) > 0.8 * len(score_midpts)
|
| 135 |
+
criterion2 = score_with_dist_prior > 0
|
| 136 |
+
if criterion1 and criterion2:
|
| 137 |
+
connection_candidate.append(
|
| 138 |
+
[i, j, score_with_dist_prior, score_with_dist_prior + candA[i][2] + candB[j][2]])
|
| 139 |
+
|
| 140 |
+
connection_candidate = sorted(connection_candidate, key=lambda x: x[2], reverse=True)
|
| 141 |
+
connection = np.zeros((0, 5))
|
| 142 |
+
for c in range(len(connection_candidate)):
|
| 143 |
+
i, j, s = connection_candidate[c][0:3]
|
| 144 |
+
if (i not in connection[:, 3] and j not in connection[:, 4]):
|
| 145 |
+
connection = np.vstack([connection, [candA[i][3], candB[j][3], s, i, j]])
|
| 146 |
+
if (len(connection) >= min(nA, nB)):
|
| 147 |
+
break
|
| 148 |
+
|
| 149 |
+
connection_all.append(connection)
|
| 150 |
+
else:
|
| 151 |
+
special_k.append(k)
|
| 152 |
+
connection_all.append([])
|
| 153 |
+
|
| 154 |
+
# last number in each row is the total parts number of that person
|
| 155 |
+
# the second last number in each row is the score of the overall configuration
|
| 156 |
+
subset = -1 * np.ones((0, 20))
|
| 157 |
+
candidate = np.array([item for sublist in all_peaks for item in sublist])
|
| 158 |
+
|
| 159 |
+
for k in range(len(mapIdx)):
|
| 160 |
+
if k not in special_k:
|
| 161 |
+
partAs = connection_all[k][:, 0]
|
| 162 |
+
partBs = connection_all[k][:, 1]
|
| 163 |
+
indexA, indexB = np.array(limbSeq[k]) - 1
|
| 164 |
+
|
| 165 |
+
for i in range(len(connection_all[k])): # = 1:size(temp,1)
|
| 166 |
+
found = 0
|
| 167 |
+
subset_idx = [-1, -1]
|
| 168 |
+
for j in range(len(subset)): # 1:size(subset,1):
|
| 169 |
+
if subset[j][indexA] == partAs[i] or subset[j][indexB] == partBs[i]:
|
| 170 |
+
subset_idx[found] = j
|
| 171 |
+
found += 1
|
| 172 |
+
|
| 173 |
+
if found == 1:
|
| 174 |
+
j = subset_idx[0]
|
| 175 |
+
if subset[j][indexB] != partBs[i]:
|
| 176 |
+
subset[j][indexB] = partBs[i]
|
| 177 |
+
subset[j][-1] += 1
|
| 178 |
+
subset[j][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
|
| 179 |
+
elif found == 2: # if found 2 and disjoint, merge them
|
| 180 |
+
j1, j2 = subset_idx
|
| 181 |
+
membership = ((subset[j1] >= 0).astype(int) + (subset[j2] >= 0).astype(int))[:-2]
|
| 182 |
+
if len(np.nonzero(membership == 2)[0]) == 0: # merge
|
| 183 |
+
subset[j1][:-2] += (subset[j2][:-2] + 1)
|
| 184 |
+
subset[j1][-2:] += subset[j2][-2:]
|
| 185 |
+
subset[j1][-2] += connection_all[k][i][2]
|
| 186 |
+
subset = np.delete(subset, j2, 0)
|
| 187 |
+
else: # as like found == 1
|
| 188 |
+
subset[j1][indexB] = partBs[i]
|
| 189 |
+
subset[j1][-1] += 1
|
| 190 |
+
subset[j1][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
|
| 191 |
+
|
| 192 |
+
# if find no partA in the subset, create a new subset
|
| 193 |
+
elif not found and k < 17:
|
| 194 |
+
row = -1 * np.ones(20)
|
| 195 |
+
row[indexA] = partAs[i]
|
| 196 |
+
row[indexB] = partBs[i]
|
| 197 |
+
row[-1] = 2
|
| 198 |
+
row[-2] = sum(candidate[connection_all[k][i, :2].astype(int), 2]) + connection_all[k][i][2]
|
| 199 |
+
subset = np.vstack([subset, row])
|
| 200 |
+
# delete some rows of subset which has few parts occur
|
| 201 |
+
deleteIdx = []
|
| 202 |
+
for i in range(len(subset)):
|
| 203 |
+
if subset[i][-1] < 4 or subset[i][-2] / subset[i][-1] < 0.4:
|
| 204 |
+
deleteIdx.append(i)
|
| 205 |
+
subset = np.delete(subset, deleteIdx, axis=0)
|
| 206 |
+
|
| 207 |
+
# subset: n*20 array, 0-17 is the index in candidate, 18 is the total score, 19 is the total parts
|
| 208 |
+
# candidate: x, y, score, id
|
| 209 |
+
return candidate, subset
|
| 210 |
+
|
| 211 |
+
if __name__ == "__main__":
|
| 212 |
+
body_estimation = Body('../model/body_pose_model.pth')
|
| 213 |
+
|
| 214 |
+
test_image = '../images/ski.jpg'
|
| 215 |
+
oriImg = cv2.imread(test_image) # B,G,R order
|
| 216 |
+
candidate, subset = body_estimation(oriImg)
|
| 217 |
+
canvas = util.draw_bodypose(oriImg, candidate, subset)
|
| 218 |
+
plt.imshow(canvas[:, :, [2, 1, 0]])
|
| 219 |
+
plt.show()
|
src/ControlNet/annotator/openpose/hand.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import json
|
| 3 |
+
import numpy as np
|
| 4 |
+
import math
|
| 5 |
+
import time
|
| 6 |
+
from scipy.ndimage.filters import gaussian_filter
|
| 7 |
+
import matplotlib.pyplot as plt
|
| 8 |
+
import matplotlib
|
| 9 |
+
import torch
|
| 10 |
+
from skimage.measure import label
|
| 11 |
+
|
| 12 |
+
from .model import handpose_model
|
| 13 |
+
from . import util
|
| 14 |
+
|
| 15 |
+
class Hand(object):
|
| 16 |
+
def __init__(self, model_path):
|
| 17 |
+
self.model = handpose_model()
|
| 18 |
+
if torch.cuda.is_available():
|
| 19 |
+
self.model = self.model.cuda()
|
| 20 |
+
print('cuda')
|
| 21 |
+
model_dict = util.transfer(self.model, torch.load(model_path))
|
| 22 |
+
self.model.load_state_dict(model_dict)
|
| 23 |
+
self.model.eval()
|
| 24 |
+
|
| 25 |
+
def __call__(self, oriImg):
|
| 26 |
+
scale_search = [0.5, 1.0, 1.5, 2.0]
|
| 27 |
+
# scale_search = [0.5]
|
| 28 |
+
boxsize = 368
|
| 29 |
+
stride = 8
|
| 30 |
+
padValue = 128
|
| 31 |
+
thre = 0.05
|
| 32 |
+
multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
|
| 33 |
+
heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 22))
|
| 34 |
+
# paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
|
| 35 |
+
|
| 36 |
+
for m in range(len(multiplier)):
|
| 37 |
+
scale = multiplier[m]
|
| 38 |
+
imageToTest = cv2.resize(oriImg, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
|
| 39 |
+
imageToTest_padded, pad = util.padRightDownCorner(imageToTest, stride, padValue)
|
| 40 |
+
im = np.transpose(np.float32(imageToTest_padded[:, :, :, np.newaxis]), (3, 2, 0, 1)) / 256 - 0.5
|
| 41 |
+
im = np.ascontiguousarray(im)
|
| 42 |
+
|
| 43 |
+
data = torch.from_numpy(im).float()
|
| 44 |
+
if torch.cuda.is_available():
|
| 45 |
+
data = data.cuda()
|
| 46 |
+
# data = data.permute([2, 0, 1]).unsqueeze(0).float()
|
| 47 |
+
with torch.no_grad():
|
| 48 |
+
output = self.model(data).cpu().numpy()
|
| 49 |
+
# output = self.model(data).numpy()q
|
| 50 |
+
|
| 51 |
+
# extract outputs, resize, and remove padding
|
| 52 |
+
heatmap = np.transpose(np.squeeze(output), (1, 2, 0)) # output 1 is heatmaps
|
| 53 |
+
heatmap = cv2.resize(heatmap, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
|
| 54 |
+
heatmap = heatmap[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
|
| 55 |
+
heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
|
| 56 |
+
|
| 57 |
+
heatmap_avg += heatmap / len(multiplier)
|
| 58 |
+
|
| 59 |
+
all_peaks = []
|
| 60 |
+
for part in range(21):
|
| 61 |
+
map_ori = heatmap_avg[:, :, part]
|
| 62 |
+
one_heatmap = gaussian_filter(map_ori, sigma=3)
|
| 63 |
+
binary = np.ascontiguousarray(one_heatmap > thre, dtype=np.uint8)
|
| 64 |
+
# 全部小于阈值
|
| 65 |
+
if np.sum(binary) == 0:
|
| 66 |
+
all_peaks.append([0, 0])
|
| 67 |
+
continue
|
| 68 |
+
label_img, label_numbers = label(binary, return_num=True, connectivity=binary.ndim)
|
| 69 |
+
max_index = np.argmax([np.sum(map_ori[label_img == i]) for i in range(1, label_numbers + 1)]) + 1
|
| 70 |
+
label_img[label_img != max_index] = 0
|
| 71 |
+
map_ori[label_img == 0] = 0
|
| 72 |
+
|
| 73 |
+
y, x = util.npmax(map_ori)
|
| 74 |
+
all_peaks.append([x, y])
|
| 75 |
+
return np.array(all_peaks)
|
| 76 |
+
|
| 77 |
+
if __name__ == "__main__":
|
| 78 |
+
hand_estimation = Hand('../model/hand_pose_model.pth')
|
| 79 |
+
|
| 80 |
+
# test_image = '../images/hand.jpg'
|
| 81 |
+
test_image = '../images/hand.jpg'
|
| 82 |
+
oriImg = cv2.imread(test_image) # B,G,R order
|
| 83 |
+
peaks = hand_estimation(oriImg)
|
| 84 |
+
canvas = util.draw_handpose(oriImg, peaks, True)
|
| 85 |
+
cv2.imshow('', canvas)
|
| 86 |
+
cv2.waitKey(0)
|
src/ControlNet/annotator/openpose/model.py
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from collections import OrderedDict
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
|
| 7 |
+
def make_layers(block, no_relu_layers):
|
| 8 |
+
layers = []
|
| 9 |
+
for layer_name, v in block.items():
|
| 10 |
+
if 'pool' in layer_name:
|
| 11 |
+
layer = nn.MaxPool2d(kernel_size=v[0], stride=v[1],
|
| 12 |
+
padding=v[2])
|
| 13 |
+
layers.append((layer_name, layer))
|
| 14 |
+
else:
|
| 15 |
+
conv2d = nn.Conv2d(in_channels=v[0], out_channels=v[1],
|
| 16 |
+
kernel_size=v[2], stride=v[3],
|
| 17 |
+
padding=v[4])
|
| 18 |
+
layers.append((layer_name, conv2d))
|
| 19 |
+
if layer_name not in no_relu_layers:
|
| 20 |
+
layers.append(('relu_'+layer_name, nn.ReLU(inplace=True)))
|
| 21 |
+
|
| 22 |
+
return nn.Sequential(OrderedDict(layers))
|
| 23 |
+
|
| 24 |
+
class bodypose_model(nn.Module):
|
| 25 |
+
def __init__(self):
|
| 26 |
+
super(bodypose_model, self).__init__()
|
| 27 |
+
|
| 28 |
+
# these layers have no relu layer
|
| 29 |
+
no_relu_layers = ['conv5_5_CPM_L1', 'conv5_5_CPM_L2', 'Mconv7_stage2_L1',\
|
| 30 |
+
'Mconv7_stage2_L2', 'Mconv7_stage3_L1', 'Mconv7_stage3_L2',\
|
| 31 |
+
'Mconv7_stage4_L1', 'Mconv7_stage4_L2', 'Mconv7_stage5_L1',\
|
| 32 |
+
'Mconv7_stage5_L2', 'Mconv7_stage6_L1', 'Mconv7_stage6_L1']
|
| 33 |
+
blocks = {}
|
| 34 |
+
block0 = OrderedDict([
|
| 35 |
+
('conv1_1', [3, 64, 3, 1, 1]),
|
| 36 |
+
('conv1_2', [64, 64, 3, 1, 1]),
|
| 37 |
+
('pool1_stage1', [2, 2, 0]),
|
| 38 |
+
('conv2_1', [64, 128, 3, 1, 1]),
|
| 39 |
+
('conv2_2', [128, 128, 3, 1, 1]),
|
| 40 |
+
('pool2_stage1', [2, 2, 0]),
|
| 41 |
+
('conv3_1', [128, 256, 3, 1, 1]),
|
| 42 |
+
('conv3_2', [256, 256, 3, 1, 1]),
|
| 43 |
+
('conv3_3', [256, 256, 3, 1, 1]),
|
| 44 |
+
('conv3_4', [256, 256, 3, 1, 1]),
|
| 45 |
+
('pool3_stage1', [2, 2, 0]),
|
| 46 |
+
('conv4_1', [256, 512, 3, 1, 1]),
|
| 47 |
+
('conv4_2', [512, 512, 3, 1, 1]),
|
| 48 |
+
('conv4_3_CPM', [512, 256, 3, 1, 1]),
|
| 49 |
+
('conv4_4_CPM', [256, 128, 3, 1, 1])
|
| 50 |
+
])
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# Stage 1
|
| 54 |
+
block1_1 = OrderedDict([
|
| 55 |
+
('conv5_1_CPM_L1', [128, 128, 3, 1, 1]),
|
| 56 |
+
('conv5_2_CPM_L1', [128, 128, 3, 1, 1]),
|
| 57 |
+
('conv5_3_CPM_L1', [128, 128, 3, 1, 1]),
|
| 58 |
+
('conv5_4_CPM_L1', [128, 512, 1, 1, 0]),
|
| 59 |
+
('conv5_5_CPM_L1', [512, 38, 1, 1, 0])
|
| 60 |
+
])
|
| 61 |
+
|
| 62 |
+
block1_2 = OrderedDict([
|
| 63 |
+
('conv5_1_CPM_L2', [128, 128, 3, 1, 1]),
|
| 64 |
+
('conv5_2_CPM_L2', [128, 128, 3, 1, 1]),
|
| 65 |
+
('conv5_3_CPM_L2', [128, 128, 3, 1, 1]),
|
| 66 |
+
('conv5_4_CPM_L2', [128, 512, 1, 1, 0]),
|
| 67 |
+
('conv5_5_CPM_L2', [512, 19, 1, 1, 0])
|
| 68 |
+
])
|
| 69 |
+
blocks['block1_1'] = block1_1
|
| 70 |
+
blocks['block1_2'] = block1_2
|
| 71 |
+
|
| 72 |
+
self.model0 = make_layers(block0, no_relu_layers)
|
| 73 |
+
|
| 74 |
+
# Stages 2 - 6
|
| 75 |
+
for i in range(2, 7):
|
| 76 |
+
blocks['block%d_1' % i] = OrderedDict([
|
| 77 |
+
('Mconv1_stage%d_L1' % i, [185, 128, 7, 1, 3]),
|
| 78 |
+
('Mconv2_stage%d_L1' % i, [128, 128, 7, 1, 3]),
|
| 79 |
+
('Mconv3_stage%d_L1' % i, [128, 128, 7, 1, 3]),
|
| 80 |
+
('Mconv4_stage%d_L1' % i, [128, 128, 7, 1, 3]),
|
| 81 |
+
('Mconv5_stage%d_L1' % i, [128, 128, 7, 1, 3]),
|
| 82 |
+
('Mconv6_stage%d_L1' % i, [128, 128, 1, 1, 0]),
|
| 83 |
+
('Mconv7_stage%d_L1' % i, [128, 38, 1, 1, 0])
|
| 84 |
+
])
|
| 85 |
+
|
| 86 |
+
blocks['block%d_2' % i] = OrderedDict([
|
| 87 |
+
('Mconv1_stage%d_L2' % i, [185, 128, 7, 1, 3]),
|
| 88 |
+
('Mconv2_stage%d_L2' % i, [128, 128, 7, 1, 3]),
|
| 89 |
+
('Mconv3_stage%d_L2' % i, [128, 128, 7, 1, 3]),
|
| 90 |
+
('Mconv4_stage%d_L2' % i, [128, 128, 7, 1, 3]),
|
| 91 |
+
('Mconv5_stage%d_L2' % i, [128, 128, 7, 1, 3]),
|
| 92 |
+
('Mconv6_stage%d_L2' % i, [128, 128, 1, 1, 0]),
|
| 93 |
+
('Mconv7_stage%d_L2' % i, [128, 19, 1, 1, 0])
|
| 94 |
+
])
|
| 95 |
+
|
| 96 |
+
for k in blocks.keys():
|
| 97 |
+
blocks[k] = make_layers(blocks[k], no_relu_layers)
|
| 98 |
+
|
| 99 |
+
self.model1_1 = blocks['block1_1']
|
| 100 |
+
self.model2_1 = blocks['block2_1']
|
| 101 |
+
self.model3_1 = blocks['block3_1']
|
| 102 |
+
self.model4_1 = blocks['block4_1']
|
| 103 |
+
self.model5_1 = blocks['block5_1']
|
| 104 |
+
self.model6_1 = blocks['block6_1']
|
| 105 |
+
|
| 106 |
+
self.model1_2 = blocks['block1_2']
|
| 107 |
+
self.model2_2 = blocks['block2_2']
|
| 108 |
+
self.model3_2 = blocks['block3_2']
|
| 109 |
+
self.model4_2 = blocks['block4_2']
|
| 110 |
+
self.model5_2 = blocks['block5_2']
|
| 111 |
+
self.model6_2 = blocks['block6_2']
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def forward(self, x):
|
| 115 |
+
|
| 116 |
+
out1 = self.model0(x)
|
| 117 |
+
|
| 118 |
+
out1_1 = self.model1_1(out1)
|
| 119 |
+
out1_2 = self.model1_2(out1)
|
| 120 |
+
out2 = torch.cat([out1_1, out1_2, out1], 1)
|
| 121 |
+
|
| 122 |
+
out2_1 = self.model2_1(out2)
|
| 123 |
+
out2_2 = self.model2_2(out2)
|
| 124 |
+
out3 = torch.cat([out2_1, out2_2, out1], 1)
|
| 125 |
+
|
| 126 |
+
out3_1 = self.model3_1(out3)
|
| 127 |
+
out3_2 = self.model3_2(out3)
|
| 128 |
+
out4 = torch.cat([out3_1, out3_2, out1], 1)
|
| 129 |
+
|
| 130 |
+
out4_1 = self.model4_1(out4)
|
| 131 |
+
out4_2 = self.model4_2(out4)
|
| 132 |
+
out5 = torch.cat([out4_1, out4_2, out1], 1)
|
| 133 |
+
|
| 134 |
+
out5_1 = self.model5_1(out5)
|
| 135 |
+
out5_2 = self.model5_2(out5)
|
| 136 |
+
out6 = torch.cat([out5_1, out5_2, out1], 1)
|
| 137 |
+
|
| 138 |
+
out6_1 = self.model6_1(out6)
|
| 139 |
+
out6_2 = self.model6_2(out6)
|
| 140 |
+
|
| 141 |
+
return out6_1, out6_2
|
| 142 |
+
|
| 143 |
+
class handpose_model(nn.Module):
|
| 144 |
+
def __init__(self):
|
| 145 |
+
super(handpose_model, self).__init__()
|
| 146 |
+
|
| 147 |
+
# these layers have no relu layer
|
| 148 |
+
no_relu_layers = ['conv6_2_CPM', 'Mconv7_stage2', 'Mconv7_stage3',\
|
| 149 |
+
'Mconv7_stage4', 'Mconv7_stage5', 'Mconv7_stage6']
|
| 150 |
+
# stage 1
|
| 151 |
+
block1_0 = OrderedDict([
|
| 152 |
+
('conv1_1', [3, 64, 3, 1, 1]),
|
| 153 |
+
('conv1_2', [64, 64, 3, 1, 1]),
|
| 154 |
+
('pool1_stage1', [2, 2, 0]),
|
| 155 |
+
('conv2_1', [64, 128, 3, 1, 1]),
|
| 156 |
+
('conv2_2', [128, 128, 3, 1, 1]),
|
| 157 |
+
('pool2_stage1', [2, 2, 0]),
|
| 158 |
+
('conv3_1', [128, 256, 3, 1, 1]),
|
| 159 |
+
('conv3_2', [256, 256, 3, 1, 1]),
|
| 160 |
+
('conv3_3', [256, 256, 3, 1, 1]),
|
| 161 |
+
('conv3_4', [256, 256, 3, 1, 1]),
|
| 162 |
+
('pool3_stage1', [2, 2, 0]),
|
| 163 |
+
('conv4_1', [256, 512, 3, 1, 1]),
|
| 164 |
+
('conv4_2', [512, 512, 3, 1, 1]),
|
| 165 |
+
('conv4_3', [512, 512, 3, 1, 1]),
|
| 166 |
+
('conv4_4', [512, 512, 3, 1, 1]),
|
| 167 |
+
('conv5_1', [512, 512, 3, 1, 1]),
|
| 168 |
+
('conv5_2', [512, 512, 3, 1, 1]),
|
| 169 |
+
('conv5_3_CPM', [512, 128, 3, 1, 1])
|
| 170 |
+
])
|
| 171 |
+
|
| 172 |
+
block1_1 = OrderedDict([
|
| 173 |
+
('conv6_1_CPM', [128, 512, 1, 1, 0]),
|
| 174 |
+
('conv6_2_CPM', [512, 22, 1, 1, 0])
|
| 175 |
+
])
|
| 176 |
+
|
| 177 |
+
blocks = {}
|
| 178 |
+
blocks['block1_0'] = block1_0
|
| 179 |
+
blocks['block1_1'] = block1_1
|
| 180 |
+
|
| 181 |
+
# stage 2-6
|
| 182 |
+
for i in range(2, 7):
|
| 183 |
+
blocks['block%d' % i] = OrderedDict([
|
| 184 |
+
('Mconv1_stage%d' % i, [150, 128, 7, 1, 3]),
|
| 185 |
+
('Mconv2_stage%d' % i, [128, 128, 7, 1, 3]),
|
| 186 |
+
('Mconv3_stage%d' % i, [128, 128, 7, 1, 3]),
|
| 187 |
+
('Mconv4_stage%d' % i, [128, 128, 7, 1, 3]),
|
| 188 |
+
('Mconv5_stage%d' % i, [128, 128, 7, 1, 3]),
|
| 189 |
+
('Mconv6_stage%d' % i, [128, 128, 1, 1, 0]),
|
| 190 |
+
('Mconv7_stage%d' % i, [128, 22, 1, 1, 0])
|
| 191 |
+
])
|
| 192 |
+
|
| 193 |
+
for k in blocks.keys():
|
| 194 |
+
blocks[k] = make_layers(blocks[k], no_relu_layers)
|
| 195 |
+
|
| 196 |
+
self.model1_0 = blocks['block1_0']
|
| 197 |
+
self.model1_1 = blocks['block1_1']
|
| 198 |
+
self.model2 = blocks['block2']
|
| 199 |
+
self.model3 = blocks['block3']
|
| 200 |
+
self.model4 = blocks['block4']
|
| 201 |
+
self.model5 = blocks['block5']
|
| 202 |
+
self.model6 = blocks['block6']
|
| 203 |
+
|
| 204 |
+
def forward(self, x):
|
| 205 |
+
out1_0 = self.model1_0(x)
|
| 206 |
+
out1_1 = self.model1_1(out1_0)
|
| 207 |
+
concat_stage2 = torch.cat([out1_1, out1_0], 1)
|
| 208 |
+
out_stage2 = self.model2(concat_stage2)
|
| 209 |
+
concat_stage3 = torch.cat([out_stage2, out1_0], 1)
|
| 210 |
+
out_stage3 = self.model3(concat_stage3)
|
| 211 |
+
concat_stage4 = torch.cat([out_stage3, out1_0], 1)
|
| 212 |
+
out_stage4 = self.model4(concat_stage4)
|
| 213 |
+
concat_stage5 = torch.cat([out_stage4, out1_0], 1)
|
| 214 |
+
out_stage5 = self.model5(concat_stage5)
|
| 215 |
+
concat_stage6 = torch.cat([out_stage5, out1_0], 1)
|
| 216 |
+
out_stage6 = self.model6(concat_stage6)
|
| 217 |
+
return out_stage6
|
| 218 |
+
|
| 219 |
+
|
src/ControlNet/annotator/openpose/util.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import matplotlib
|
| 4 |
+
import cv2
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def padRightDownCorner(img, stride, padValue):
|
| 8 |
+
h = img.shape[0]
|
| 9 |
+
w = img.shape[1]
|
| 10 |
+
|
| 11 |
+
pad = 4 * [None]
|
| 12 |
+
pad[0] = 0 # up
|
| 13 |
+
pad[1] = 0 # left
|
| 14 |
+
pad[2] = 0 if (h % stride == 0) else stride - (h % stride) # down
|
| 15 |
+
pad[3] = 0 if (w % stride == 0) else stride - (w % stride) # right
|
| 16 |
+
|
| 17 |
+
img_padded = img
|
| 18 |
+
pad_up = np.tile(img_padded[0:1, :, :]*0 + padValue, (pad[0], 1, 1))
|
| 19 |
+
img_padded = np.concatenate((pad_up, img_padded), axis=0)
|
| 20 |
+
pad_left = np.tile(img_padded[:, 0:1, :]*0 + padValue, (1, pad[1], 1))
|
| 21 |
+
img_padded = np.concatenate((pad_left, img_padded), axis=1)
|
| 22 |
+
pad_down = np.tile(img_padded[-2:-1, :, :]*0 + padValue, (pad[2], 1, 1))
|
| 23 |
+
img_padded = np.concatenate((img_padded, pad_down), axis=0)
|
| 24 |
+
pad_right = np.tile(img_padded[:, -2:-1, :]*0 + padValue, (1, pad[3], 1))
|
| 25 |
+
img_padded = np.concatenate((img_padded, pad_right), axis=1)
|
| 26 |
+
|
| 27 |
+
return img_padded, pad
|
| 28 |
+
|
| 29 |
+
# transfer caffe model to pytorch which will match the layer name
|
| 30 |
+
def transfer(model, model_weights):
|
| 31 |
+
transfered_model_weights = {}
|
| 32 |
+
for weights_name in model.state_dict().keys():
|
| 33 |
+
transfered_model_weights[weights_name] = model_weights['.'.join(weights_name.split('.')[1:])]
|
| 34 |
+
return transfered_model_weights
|
| 35 |
+
|
| 36 |
+
# draw the body keypoint and lims
|
| 37 |
+
def draw_bodypose(canvas, candidate, subset):
|
| 38 |
+
stickwidth = 4
|
| 39 |
+
limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \
|
| 40 |
+
[10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \
|
| 41 |
+
[1, 16], [16, 18], [3, 17], [6, 18]]
|
| 42 |
+
|
| 43 |
+
colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
|
| 44 |
+
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \
|
| 45 |
+
[170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
|
| 46 |
+
for i in range(18):
|
| 47 |
+
for n in range(len(subset)):
|
| 48 |
+
index = int(subset[n][i])
|
| 49 |
+
if index == -1:
|
| 50 |
+
continue
|
| 51 |
+
x, y = candidate[index][0:2]
|
| 52 |
+
cv2.circle(canvas, (int(x), int(y)), 4, colors[i], thickness=-1)
|
| 53 |
+
for i in range(17):
|
| 54 |
+
for n in range(len(subset)):
|
| 55 |
+
index = subset[n][np.array(limbSeq[i]) - 1]
|
| 56 |
+
if -1 in index:
|
| 57 |
+
continue
|
| 58 |
+
cur_canvas = canvas.copy()
|
| 59 |
+
Y = candidate[index.astype(int), 0]
|
| 60 |
+
X = candidate[index.astype(int), 1]
|
| 61 |
+
mX = np.mean(X)
|
| 62 |
+
mY = np.mean(Y)
|
| 63 |
+
length = ((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2) ** 0.5
|
| 64 |
+
angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
|
| 65 |
+
polygon = cv2.ellipse2Poly((int(mY), int(mX)), (int(length / 2), stickwidth), int(angle), 0, 360, 1)
|
| 66 |
+
cv2.fillConvexPoly(cur_canvas, polygon, colors[i])
|
| 67 |
+
canvas = cv2.addWeighted(canvas, 0.4, cur_canvas, 0.6, 0)
|
| 68 |
+
# plt.imsave("preview.jpg", canvas[:, :, [2, 1, 0]])
|
| 69 |
+
# plt.imshow(canvas[:, :, [2, 1, 0]])
|
| 70 |
+
return canvas
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
# image drawed by opencv is not good.
|
| 74 |
+
def draw_handpose(canvas, all_hand_peaks, show_number=False):
|
| 75 |
+
edges = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8], [0, 9], [9, 10], \
|
| 76 |
+
[10, 11], [11, 12], [0, 13], [13, 14], [14, 15], [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]]
|
| 77 |
+
|
| 78 |
+
for peaks in all_hand_peaks:
|
| 79 |
+
for ie, e in enumerate(edges):
|
| 80 |
+
if np.sum(np.all(peaks[e], axis=1)==0)==0:
|
| 81 |
+
x1, y1 = peaks[e[0]]
|
| 82 |
+
x2, y2 = peaks[e[1]]
|
| 83 |
+
cv2.line(canvas, (x1, y1), (x2, y2), matplotlib.colors.hsv_to_rgb([ie/float(len(edges)), 1.0, 1.0])*255, thickness=2)
|
| 84 |
+
|
| 85 |
+
for i, keyponit in enumerate(peaks):
|
| 86 |
+
x, y = keyponit
|
| 87 |
+
cv2.circle(canvas, (x, y), 4, (0, 0, 255), thickness=-1)
|
| 88 |
+
if show_number:
|
| 89 |
+
cv2.putText(canvas, str(i), (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 0, 0), lineType=cv2.LINE_AA)
|
| 90 |
+
return canvas
|
| 91 |
+
|
| 92 |
+
# detect hand according to body pose keypoints
|
| 93 |
+
# please refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/src/openpose/hand/handDetector.cpp
|
| 94 |
+
def handDetect(candidate, subset, oriImg):
|
| 95 |
+
# right hand: wrist 4, elbow 3, shoulder 2
|
| 96 |
+
# left hand: wrist 7, elbow 6, shoulder 5
|
| 97 |
+
ratioWristElbow = 0.33
|
| 98 |
+
detect_result = []
|
| 99 |
+
image_height, image_width = oriImg.shape[0:2]
|
| 100 |
+
for person in subset.astype(int):
|
| 101 |
+
# if any of three not detected
|
| 102 |
+
has_left = np.sum(person[[5, 6, 7]] == -1) == 0
|
| 103 |
+
has_right = np.sum(person[[2, 3, 4]] == -1) == 0
|
| 104 |
+
if not (has_left or has_right):
|
| 105 |
+
continue
|
| 106 |
+
hands = []
|
| 107 |
+
#left hand
|
| 108 |
+
if has_left:
|
| 109 |
+
left_shoulder_index, left_elbow_index, left_wrist_index = person[[5, 6, 7]]
|
| 110 |
+
x1, y1 = candidate[left_shoulder_index][:2]
|
| 111 |
+
x2, y2 = candidate[left_elbow_index][:2]
|
| 112 |
+
x3, y3 = candidate[left_wrist_index][:2]
|
| 113 |
+
hands.append([x1, y1, x2, y2, x3, y3, True])
|
| 114 |
+
# right hand
|
| 115 |
+
if has_right:
|
| 116 |
+
right_shoulder_index, right_elbow_index, right_wrist_index = person[[2, 3, 4]]
|
| 117 |
+
x1, y1 = candidate[right_shoulder_index][:2]
|
| 118 |
+
x2, y2 = candidate[right_elbow_index][:2]
|
| 119 |
+
x3, y3 = candidate[right_wrist_index][:2]
|
| 120 |
+
hands.append([x1, y1, x2, y2, x3, y3, False])
|
| 121 |
+
|
| 122 |
+
for x1, y1, x2, y2, x3, y3, is_left in hands:
|
| 123 |
+
# pos_hand = pos_wrist + ratio * (pos_wrist - pos_elbox) = (1 + ratio) * pos_wrist - ratio * pos_elbox
|
| 124 |
+
# handRectangle.x = posePtr[wrist*3] + ratioWristElbow * (posePtr[wrist*3] - posePtr[elbow*3]);
|
| 125 |
+
# handRectangle.y = posePtr[wrist*3+1] + ratioWristElbow * (posePtr[wrist*3+1] - posePtr[elbow*3+1]);
|
| 126 |
+
# const auto distanceWristElbow = getDistance(poseKeypoints, person, wrist, elbow);
|
| 127 |
+
# const auto distanceElbowShoulder = getDistance(poseKeypoints, person, elbow, shoulder);
|
| 128 |
+
# handRectangle.width = 1.5f * fastMax(distanceWristElbow, 0.9f * distanceElbowShoulder);
|
| 129 |
+
x = x3 + ratioWristElbow * (x3 - x2)
|
| 130 |
+
y = y3 + ratioWristElbow * (y3 - y2)
|
| 131 |
+
distanceWristElbow = math.sqrt((x3 - x2) ** 2 + (y3 - y2) ** 2)
|
| 132 |
+
distanceElbowShoulder = math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2)
|
| 133 |
+
width = 1.5 * max(distanceWristElbow, 0.9 * distanceElbowShoulder)
|
| 134 |
+
# x-y refers to the center --> offset to topLeft point
|
| 135 |
+
# handRectangle.x -= handRectangle.width / 2.f;
|
| 136 |
+
# handRectangle.y -= handRectangle.height / 2.f;
|
| 137 |
+
x -= width / 2
|
| 138 |
+
y -= width / 2 # width = height
|
| 139 |
+
# overflow the image
|
| 140 |
+
if x < 0: x = 0
|
| 141 |
+
if y < 0: y = 0
|
| 142 |
+
width1 = width
|
| 143 |
+
width2 = width
|
| 144 |
+
if x + width > image_width: width1 = image_width - x
|
| 145 |
+
if y + width > image_height: width2 = image_height - y
|
| 146 |
+
width = min(width1, width2)
|
| 147 |
+
# the max hand box value is 20 pixels
|
| 148 |
+
if width >= 20:
|
| 149 |
+
detect_result.append([int(x), int(y), int(width), is_left])
|
| 150 |
+
|
| 151 |
+
'''
|
| 152 |
+
return value: [[x, y, w, True if left hand else False]].
|
| 153 |
+
width=height since the network require squared input.
|
| 154 |
+
x, y is the coordinate of top left
|
| 155 |
+
'''
|
| 156 |
+
return detect_result
|
| 157 |
+
|
| 158 |
+
# get max index of 2d array
|
| 159 |
+
def npmax(array):
|
| 160 |
+
arrayindex = array.argmax(1)
|
| 161 |
+
arrayvalue = array.max(1)
|
| 162 |
+
i = arrayvalue.argmax()
|
| 163 |
+
j = arrayindex[i]
|
| 164 |
+
return i, j
|
src/ControlNet/annotator/util.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import cv2
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
annotator_ckpts_path = os.path.join(os.path.dirname(__file__), 'ckpts')
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def HWC3(x):
|
| 10 |
+
assert x.dtype == np.uint8
|
| 11 |
+
if x.ndim == 2:
|
| 12 |
+
x = x[:, :, None]
|
| 13 |
+
assert x.ndim == 3
|
| 14 |
+
H, W, C = x.shape
|
| 15 |
+
assert C == 1 or C == 3 or C == 4
|
| 16 |
+
if C == 3:
|
| 17 |
+
return x
|
| 18 |
+
if C == 1:
|
| 19 |
+
return np.concatenate([x, x, x], axis=2)
|
| 20 |
+
if C == 4:
|
| 21 |
+
color = x[:, :, 0:3].astype(np.float32)
|
| 22 |
+
alpha = x[:, :, 3:4].astype(np.float32) / 255.0
|
| 23 |
+
y = color * alpha + 255.0 * (1.0 - alpha)
|
| 24 |
+
y = y.clip(0, 255).astype(np.uint8)
|
| 25 |
+
return y
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def resize_image(input_image, resolution):
|
| 29 |
+
H, W, C = input_image.shape
|
| 30 |
+
H = float(H)
|
| 31 |
+
W = float(W)
|
| 32 |
+
k = float(resolution) / min(H, W)
|
| 33 |
+
H *= k
|
| 34 |
+
W *= k
|
| 35 |
+
H = int(np.round(H / 64.0)) * 64
|
| 36 |
+
W = int(np.round(W / 64.0)) * 64
|
| 37 |
+
img = cv2.resize(input_image, (W, H), interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA)
|
| 38 |
+
return img
|
src/EGNet/README.md
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# EGNet
|
| 2 |
+
EGNet:Edge Guidance Network for Salient Object Detection (ICCV 2019)
|
| 3 |
+
|
| 4 |
+
We use the sal2edge.m to generate the edge label for training.
|
| 5 |
+
### For training:
|
| 6 |
+
1. Clone this code by `git clone https://github.com/JXingZhao/EGNet.git --recursive`, assume your source code directory is`$EGNet`;
|
| 7 |
+
|
| 8 |
+
2. Download [training data](https://pan.baidu.com/s/1LaQoNRS8-11V7grAfFiHCg) (fsex) ([google drive](https://drive.google.com/open?id=1wduPbFMkxB_3W72LvJckD7N0hWbXsKsj));
|
| 9 |
+
|
| 10 |
+
3. Download [initial model](https://pan.baidu.com/s/1dD2JOY_FBSLzjp5tUPBDBQ) (8ir7) ([google_drive](https://drive.google.com/open?id=1q7FtHWoarRzGNQQXTn9t7QSR8jJL8vk6));
|
| 11 |
+
|
| 12 |
+
4. Change the image path and intial model path in run.py and dataset.py;
|
| 13 |
+
|
| 14 |
+
5. Start to train with `python3 run.py --mode train`.
|
| 15 |
+
|
| 16 |
+
### For testing:
|
| 17 |
+
1. Download [pretrained model](https://pan.baidu.com/s/1s35ZyGDSNVzVIeVd7Aot0Q) (2cf5) ([google drive](https://drive.google.com/open?id=17Ffc6V5EiujtcFKupsJXhtlQ3cLK5OGp));
|
| 18 |
+
|
| 19 |
+
2. Change the test image path in dataset.py
|
| 20 |
+
|
| 21 |
+
3. Generate saliency maps for SOD dataset by `python3 run.py --mode test --sal_mode s`, PASCALS by `python3 run.py --mode test --sal_mode p` and so on;
|
| 22 |
+
|
| 23 |
+
4. Testing code we use is the public open source code. (https://github.com/Andrew-Qibin/SalMetric)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
### Pretrained models, datasets and results:
|
| 28 |
+
| [Page](https://mmcheng.net/jxzhao/) |
|
| 29 |
+
| [Training Set](https://pan.baidu.com/s/1LaQoNRS8-11V7grAfFiHCg) (fsex) ([google drive](https://drive.google.com/open?id=1wduPbFMkxB_3W72LvJckD7N0hWbXsKsj)) |
|
| 30 |
+
| [Pretrained models](https://pan.baidu.com/s/1s35ZyGDSNVzVIeVd7Aot0Q) (2cf5) |
|
| 31 |
+
| [Saliency maps](https://pan.baidu.com/s/1M_dqPJ08oaYWge_zZnHSTQ) (54gi) ([google drive VGG](https://drive.google.com/open?id=1WEuEqNmqMePyxD8anGo0KA4rWK9Nyb9I)) ([google drive resnet](https://drive.google.com/open?id=1h5R8tT3Jq_2S3pLfXREpuWaKvFphQ4K9)) |
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
### If you think this work is helpful, please cite
|
| 35 |
+
```latex
|
| 36 |
+
@inproceedings{zhao2019EGNet,
|
| 37 |
+
title={EGNet:Edge Guidance Network for Salient Object Detection},
|
| 38 |
+
author={Zhao, Jia-Xing and Liu, Jiang-Jiang and Fan, Deng-Ping and Cao, Yang and Yang, Jufeng and Cheng, Ming-Ming},
|
| 39 |
+
booktitle={The IEEE International Conference on Computer Vision (ICCV)},
|
| 40 |
+
month={Oct},
|
| 41 |
+
year={2019},
|
| 42 |
+
}
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
### Other related work
|
| 46 |
+
Contrast Prior and Fluid Pyramid Integration for RGBD Salient Object Detection. (CVPR2019) [page](https://mmcheng.net/rgbdsalpyr/)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
src/EGNet/dataset.py
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import cv2
|
| 4 |
+
import torch
|
| 5 |
+
from torch.utils import data
|
| 6 |
+
from torchvision import transforms
|
| 7 |
+
from torchvision.transforms import functional as F
|
| 8 |
+
import numbers
|
| 9 |
+
import numpy as np
|
| 10 |
+
import random
|
| 11 |
+
|
| 12 |
+
#re_size = (256, 256)
|
| 13 |
+
#cr_size = (224, 224)
|
| 14 |
+
|
| 15 |
+
class ImageDataTrain(data.Dataset):
|
| 16 |
+
def __init__(self):
|
| 17 |
+
|
| 18 |
+
self.sal_root = '/home/liuj/dataset/DUTS/DUTS-TR'
|
| 19 |
+
self.sal_source = '/home/liuj/dataset/DUTS/DUTS-TR/train_pair_edge.lst'
|
| 20 |
+
|
| 21 |
+
with open(self.sal_source, 'r') as f:
|
| 22 |
+
self.sal_list = [x.strip() for x in f.readlines()]
|
| 23 |
+
|
| 24 |
+
self.sal_num = len(self.sal_list)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def __getitem__(self, item):
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
sal_image = load_image(os.path.join(self.sal_root, self.sal_list[item%self.sal_num].split()[0]))
|
| 31 |
+
sal_label = load_sal_label(os.path.join(self.sal_root, self.sal_list[item%self.sal_num].split()[1]))
|
| 32 |
+
sal_edge = load_edge_label(os.path.join(self.sal_root, self.sal_list[item%self.sal_num].split()[2]))
|
| 33 |
+
sal_image, sal_label, sal_edge = cv_random_flip(sal_image, sal_label, sal_edge)
|
| 34 |
+
sal_image = torch.Tensor(sal_image)
|
| 35 |
+
sal_label = torch.Tensor(sal_label)
|
| 36 |
+
sal_edge = torch.Tensor(sal_edge)
|
| 37 |
+
|
| 38 |
+
sample = {'sal_image': sal_image, 'sal_label': sal_label, 'sal_edge': sal_edge}
|
| 39 |
+
return sample
|
| 40 |
+
|
| 41 |
+
def __len__(self):
|
| 42 |
+
# return max(max(self.edge_num, self.sal_num), self.skel_num)
|
| 43 |
+
return self.sal_num
|
| 44 |
+
|
| 45 |
+
class ImageDataTest(data.Dataset):
|
| 46 |
+
def __init__(self, test_mode=1, sal_mode='e'):
|
| 47 |
+
if test_mode == 0:
|
| 48 |
+
# self.image_root = '/home/liuj/dataset/saliency_test/ECSSD/Imgs/'
|
| 49 |
+
# self.image_source = '/home/liuj/dataset/saliency_test/ECSSD/test.lst'
|
| 50 |
+
self.image_root = '/home/liuj/dataset/HED-BSDS_PASCAL/HED-BSDS/test/'
|
| 51 |
+
self.image_source = '/home/liuj/dataset/HED-BSDS_PASCAL/HED-BSDS/test.lst'
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
elif test_mode == 1:
|
| 55 |
+
if sal_mode == 'e':
|
| 56 |
+
self.image_root = '/home/liuj/dataset/saliency_test/ECSSD/Imgs/'
|
| 57 |
+
self.image_source = '/home/liuj/dataset/saliency_test/ECSSD/test.lst'
|
| 58 |
+
self.test_fold = '/media/ubuntu/disk/Result/saliency/ECSSD/'
|
| 59 |
+
elif sal_mode == 'p':
|
| 60 |
+
self.image_root = '/home/liuj/dataset/saliency_test/PASCALS/Imgs/'
|
| 61 |
+
self.image_source = '/home/liuj/dataset/saliency_test/PASCALS/test.lst'
|
| 62 |
+
self.test_fold = '/media/ubuntu/disk/Result/saliency/PASCALS/'
|
| 63 |
+
elif sal_mode == 'd':
|
| 64 |
+
self.image_root = '/home/liuj/dataset/saliency_test/DUTOMRON/Imgs/'
|
| 65 |
+
self.image_source = '/home/liuj/dataset/saliency_test/DUTOMRON/test.lst'
|
| 66 |
+
self.test_fold = '/media/ubuntu/disk/Result/saliency/DUTOMRON/'
|
| 67 |
+
elif sal_mode == 'h':
|
| 68 |
+
self.image_root = '/home/liuj/dataset/saliency_test/HKU-IS/Imgs/'
|
| 69 |
+
self.image_source = '/home/liuj/dataset/saliency_test/HKU-IS/test.lst'
|
| 70 |
+
self.test_fold = '/media/ubuntu/disk/Result/saliency/HKU-IS/'
|
| 71 |
+
elif sal_mode == 's':
|
| 72 |
+
self.image_root = '/home/liuj/dataset/saliency_test/SOD/Imgs/'
|
| 73 |
+
self.image_source = '/home/liuj/dataset/saliency_test/SOD/test.lst'
|
| 74 |
+
self.test_fold = '/media/ubuntu/disk/Result/saliency/SOD/'
|
| 75 |
+
elif sal_mode == 'm':
|
| 76 |
+
self.image_root = '/home/liuj/dataset/saliency_test/MSRA/Imgs/'
|
| 77 |
+
self.image_source = '/home/liuj/dataset/saliency_test/MSRA/test.lst'
|
| 78 |
+
elif sal_mode == 'o':
|
| 79 |
+
self.image_root = '/home/liuj/dataset/saliency_test/SOC/TestSet/Imgs/'
|
| 80 |
+
self.image_source = '/home/liuj/dataset/saliency_test/SOC/TestSet/test.lst'
|
| 81 |
+
self.test_fold = '/media/ubuntu/disk/Result/saliency/SOC/'
|
| 82 |
+
elif sal_mode == 't':
|
| 83 |
+
self.image_root = '/home/liuj/dataset/DUTS/DUTS-TE/DUTS-TE-Image/'
|
| 84 |
+
self.image_source = '/home/liuj/dataset/DUTS/DUTS-TE/test.lst'
|
| 85 |
+
self.test_fold = '/media/ubuntu/disk/Result/saliency/DUTS/'
|
| 86 |
+
elif test_mode == 2:
|
| 87 |
+
|
| 88 |
+
self.image_root = '/home/liuj/dataset/SK-LARGE/images/test/'
|
| 89 |
+
self.image_source = '/home/liuj/dataset/SK-LARGE/test.lst'
|
| 90 |
+
|
| 91 |
+
with open(self.image_source, 'r') as f:
|
| 92 |
+
self.image_list = [x.strip() for x in f.readlines()]
|
| 93 |
+
|
| 94 |
+
self.image_num = len(self.image_list)
|
| 95 |
+
|
| 96 |
+
def __getitem__(self, item):
|
| 97 |
+
image, im_size = load_image_test(os.path.join(self.image_root, self.image_list[item]))
|
| 98 |
+
image = torch.Tensor(image)
|
| 99 |
+
|
| 100 |
+
return {'image': image, 'name': self.image_list[item%self.image_num], 'size': im_size}
|
| 101 |
+
def save_folder(self):
|
| 102 |
+
return self.test_fold
|
| 103 |
+
|
| 104 |
+
def __len__(self):
|
| 105 |
+
# return max(max(self.edge_num, self.skel_num), self.sal_num)
|
| 106 |
+
return self.image_num
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
# get the dataloader (Note: without data augmentation, except saliency with random flip)
|
| 110 |
+
def get_loader(batch_size, mode='train', num_thread=1, test_mode=0, sal_mode='e'):
|
| 111 |
+
shuffle = False
|
| 112 |
+
if mode == 'train':
|
| 113 |
+
shuffle = True
|
| 114 |
+
dataset = ImageDataTrain()
|
| 115 |
+
else:
|
| 116 |
+
dataset = ImageDataTest(test_mode=test_mode, sal_mode=sal_mode)
|
| 117 |
+
|
| 118 |
+
data_loader = data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_thread)
|
| 119 |
+
return data_loader, dataset
|
| 120 |
+
|
| 121 |
+
def load_image(pah):
|
| 122 |
+
if not os.path.exists(pah):
|
| 123 |
+
print('File Not Exists')
|
| 124 |
+
im = cv2.imread(pah)
|
| 125 |
+
in_ = np.array(im, dtype=np.float32)
|
| 126 |
+
# in_ = cv2.resize(in_, im_sz, interpolation=cv2.INTER_CUBIC)
|
| 127 |
+
# in_ = in_[:,:,::-1] # only if use PIL to load image
|
| 128 |
+
in_ -= np.array((104.00699, 116.66877, 122.67892))
|
| 129 |
+
in_ = in_.transpose((2,0,1))
|
| 130 |
+
return in_
|
| 131 |
+
|
| 132 |
+
def load_image_test(pah):
|
| 133 |
+
if not os.path.exists(pah):
|
| 134 |
+
print('File Not Exists')
|
| 135 |
+
im = cv2.imread(pah)
|
| 136 |
+
in_ = np.array(im, dtype=np.float32)
|
| 137 |
+
im_size = tuple(in_.shape[:2])
|
| 138 |
+
# in_ = cv2.resize(in_, (cr_size[1], cr_size[0]), interpolation=cv2.INTER_LINEAR)
|
| 139 |
+
# in_ = in_[:,:,::-1] # only if use PIL to load image
|
| 140 |
+
in_ -= np.array((104.00699, 116.66877, 122.67892))
|
| 141 |
+
in_ = in_.transpose((2,0,1))
|
| 142 |
+
return in_, im_size
|
| 143 |
+
|
| 144 |
+
def load_edge_label(pah):
|
| 145 |
+
"""
|
| 146 |
+
pixels > 0.5 -> 1
|
| 147 |
+
Load label image as 1 x height x width integer array of label indices.
|
| 148 |
+
The leading singleton dimension is required by the loss.
|
| 149 |
+
"""
|
| 150 |
+
if not os.path.exists(pah):
|
| 151 |
+
print('File Not Exists')
|
| 152 |
+
im = Image.open(pah)
|
| 153 |
+
label = np.array(im, dtype=np.float32)
|
| 154 |
+
if len(label.shape) == 3:
|
| 155 |
+
label = label[:,:,0]
|
| 156 |
+
# label = cv2.resize(label, im_sz, interpolation=cv2.INTER_NEAREST)
|
| 157 |
+
label = label / 255.
|
| 158 |
+
label[np.where(label > 0.5)] = 1.
|
| 159 |
+
label = label[np.newaxis, ...]
|
| 160 |
+
return label
|
| 161 |
+
|
| 162 |
+
def load_skel_label(pah):
|
| 163 |
+
"""
|
| 164 |
+
pixels > 0 -> 1
|
| 165 |
+
Load label image as 1 x height x width integer array of label indices.
|
| 166 |
+
The leading singleton dimension is required by the loss.
|
| 167 |
+
"""
|
| 168 |
+
if not os.path.exists(pah):
|
| 169 |
+
print('File Not Exists')
|
| 170 |
+
im = Image.open(pah)
|
| 171 |
+
label = np.array(im, dtype=np.float32)
|
| 172 |
+
if len(label.shape) == 3:
|
| 173 |
+
label = label[:,:,0]
|
| 174 |
+
# label = cv2.resize(label, im_sz, interpolation=cv2.INTER_NEAREST)
|
| 175 |
+
label = label / 255.
|
| 176 |
+
label[np.where(label > 0.)] = 1.
|
| 177 |
+
label = label[np.newaxis, ...]
|
| 178 |
+
return label
|
| 179 |
+
|
| 180 |
+
def load_sal_label(pah):
|
| 181 |
+
"""
|
| 182 |
+
Load label image as 1 x height x width integer array of label indices.
|
| 183 |
+
The leading singleton dimension is required by the loss.
|
| 184 |
+
"""
|
| 185 |
+
if not os.path.exists(pah):
|
| 186 |
+
print('File Not Exists')
|
| 187 |
+
im = Image.open(pah)
|
| 188 |
+
label = np.array(im, dtype=np.float32)
|
| 189 |
+
if len(label.shape) == 3:
|
| 190 |
+
label = label[:,:,0]
|
| 191 |
+
# label = cv2.resize(label, im_sz, interpolation=cv2.INTER_NEAREST)
|
| 192 |
+
label = label / 255.
|
| 193 |
+
label = label[np.newaxis, ...]
|
| 194 |
+
return label
|
| 195 |
+
|
| 196 |
+
def load_sem_label(pah):
|
| 197 |
+
"""
|
| 198 |
+
Load label image as 1 x height x width integer array of label indices.
|
| 199 |
+
The leading singleton dimension is required by the loss.
|
| 200 |
+
"""
|
| 201 |
+
if not os.path.exists(pah):
|
| 202 |
+
print('File Not Exists')
|
| 203 |
+
im = Image.open(pah)
|
| 204 |
+
label = np.array(im, dtype=np.float32)
|
| 205 |
+
if len(label.shape) == 3:
|
| 206 |
+
label = label[:,:,0]
|
| 207 |
+
# label = cv2.resize(label, im_sz, interpolation=cv2.INTER_NEAREST)
|
| 208 |
+
# label = label / 255.
|
| 209 |
+
label = label[np.newaxis, ...]
|
| 210 |
+
return label
|
| 211 |
+
|
| 212 |
+
def edge_thres_transform(x, thres):
|
| 213 |
+
# y0 = torch.zeros(x.size())
|
| 214 |
+
y1 = torch.ones(x.size())
|
| 215 |
+
x = torch.where(x >= thres, y1, x)
|
| 216 |
+
return x
|
| 217 |
+
|
| 218 |
+
def skel_thres_transform(x, thres):
|
| 219 |
+
y0 = torch.zeros(x.size())
|
| 220 |
+
y1 = torch.ones(x.size())
|
| 221 |
+
x = torch.where(x > thres, y1, y0)
|
| 222 |
+
return x
|
| 223 |
+
|
| 224 |
+
def cv_random_flip(img, label, edge):
|
| 225 |
+
flip_flag = random.randint(0, 1)
|
| 226 |
+
if flip_flag == 1:
|
| 227 |
+
img = img[:,:,::-1].copy()
|
| 228 |
+
label = label[:,:,::-1].copy()
|
| 229 |
+
edge = edge[:,:,::-1].copy()
|
| 230 |
+
return img, label, edge
|
| 231 |
+
|
| 232 |
+
def cv_random_crop_flip(img, label, resize_size, crop_size, random_flip=True):
|
| 233 |
+
def get_params(img_size, output_size):
|
| 234 |
+
h, w = img_size
|
| 235 |
+
th, tw = output_size
|
| 236 |
+
if w == tw and h == th:
|
| 237 |
+
return 0, 0, h, w
|
| 238 |
+
i = random.randint(0, h - th)
|
| 239 |
+
j = random.randint(0, w - tw)
|
| 240 |
+
return i, j, th, tw
|
| 241 |
+
if random_flip:
|
| 242 |
+
flip_flag = random.randint(0, 1)
|
| 243 |
+
img = img.transpose((1,2,0)) # H, W, C
|
| 244 |
+
label = label[0,:,:] # H, W
|
| 245 |
+
img = cv2.resize(img, (resize_size[1], resize_size[0]), interpolation=cv2.INTER_LINEAR)
|
| 246 |
+
label = cv2.resize(label, (resize_size[1], resize_size[0]), interpolation=cv2.INTER_NEAREST)
|
| 247 |
+
i, j, h, w = get_params(resize_size, crop_size)
|
| 248 |
+
img = img[i:i+h, j:j+w, :].transpose((2,0,1)) # C, H, W
|
| 249 |
+
label = label[i:i+h, j:j+w][np.newaxis, ...] # 1, H, W
|
| 250 |
+
if flip_flag == 1:
|
| 251 |
+
img = img[:,:,::-1].copy()
|
| 252 |
+
label = label[:,:,::-1].copy()
|
| 253 |
+
return img, label
|
| 254 |
+
|
| 255 |
+
def random_crop(img, label, size, padding=None, pad_if_needed=True, fill_img=(123, 116, 103), fill_label=0, padding_mode='constant'):
|
| 256 |
+
|
| 257 |
+
def get_params(img, output_size):
|
| 258 |
+
w, h = img.size
|
| 259 |
+
th, tw = output_size
|
| 260 |
+
if w == tw and h == th:
|
| 261 |
+
return 0, 0, h, w
|
| 262 |
+
|
| 263 |
+
i = random.randint(0, h - th)
|
| 264 |
+
j = random.randint(0, w - tw)
|
| 265 |
+
return i, j, th, tw
|
| 266 |
+
|
| 267 |
+
if isinstance(size, numbers.Number):
|
| 268 |
+
size = (int(size), int(size))
|
| 269 |
+
if padding is not None:
|
| 270 |
+
img = F.pad(img, padding, fill_img, padding_mode)
|
| 271 |
+
label = F.pad(label, padding, fill_label, padding_mode)
|
| 272 |
+
|
| 273 |
+
# pad the width if needed
|
| 274 |
+
if pad_if_needed and img.size[0] < size[1]:
|
| 275 |
+
img = F.pad(img, (int((1 + size[1] - img.size[0]) / 2), 0), fill_img, padding_mode)
|
| 276 |
+
label = F.pad(label, (int((1 + size[1] - label.size[0]) / 2), 0), fill_label, padding_mode)
|
| 277 |
+
# pad the height if needed
|
| 278 |
+
if pad_if_needed and img.size[1] < size[0]:
|
| 279 |
+
img = F.pad(img, (0, int((1 + size[0] - img.size[1]) / 2)), fill_img, padding_mode)
|
| 280 |
+
label = F.pad(label, (0, int((1 + size[0] - label.size[1]) / 2)), fill_label, padding_mode)
|
| 281 |
+
|
| 282 |
+
i, j, h, w = get_params(img, size)
|
| 283 |
+
return [F.crop(img, i, j, h, w), F.crop(label, i, j, h, w)]
|
src/EGNet/model.py
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from torch.nn import init
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
import math
|
| 6 |
+
from torch.autograd import Variable
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
from resnet import resnet50
|
| 10 |
+
from vgg import vgg16
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
config_vgg = {'convert': [[128,256,512,512,512],[64,128,256,512,512]], 'merge1': [[128, 256, 128, 3,1], [256, 512, 256, 3, 1], [512, 0, 512, 5, 2], [512, 0, 512, 5, 2],[512, 0, 512, 7, 3]], 'merge2': [[128], [256, 512, 512, 512]]} # no convert layer, no conv6
|
| 14 |
+
|
| 15 |
+
config_resnet = {'convert': [[64,256,512,1024,2048],[128,256,512,512,512]], 'deep_pool': [[512, 512, 256, 256, 128], [512, 256, 256, 128, 128], [False, True, True, True, False], [True, True, True, True, False]], 'score': 256, 'edgeinfo':[[16, 16, 16, 16], 128, [16,8,4,2]],'edgeinfoc':[64,128], 'block': [[512, [16]], [256, [16]], [256, [16]], [128, [16]]], 'fuse': [[16, 16, 16, 16], True], 'fuse_ratio': [[16,1], [8,1], [4,1], [2,1]], 'merge1': [[128, 256, 128, 3,1], [256, 512, 256, 3, 1], [512, 0, 512, 5, 2], [512, 0, 512, 5, 2],[512, 0, 512, 7, 3]], 'merge2': [[128], [256, 512, 512, 512]]}
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class ConvertLayer(nn.Module):
|
| 19 |
+
def __init__(self, list_k):
|
| 20 |
+
super(ConvertLayer, self).__init__()
|
| 21 |
+
up0, up1, up2 = [], [], []
|
| 22 |
+
for i in range(len(list_k[0])):
|
| 23 |
+
|
| 24 |
+
up0.append(nn.Sequential(nn.Conv2d(list_k[0][i], list_k[1][i], 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
self.convert0 = nn.ModuleList(up0)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def forward(self, list_x):
|
| 31 |
+
resl = []
|
| 32 |
+
for i in range(len(list_x)):
|
| 33 |
+
resl.append(self.convert0[i](list_x[i]))
|
| 34 |
+
return resl
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class MergeLayer1(nn.Module): # list_k: [[64, 512, 64], [128, 512, 128], [256, 0, 256] ... ]
|
| 40 |
+
def __init__(self, list_k):
|
| 41 |
+
super(MergeLayer1, self).__init__()
|
| 42 |
+
self.list_k = list_k
|
| 43 |
+
trans, up, score = [], [], []
|
| 44 |
+
for ik in list_k:
|
| 45 |
+
if ik[1] > 0:
|
| 46 |
+
trans.append(nn.Sequential(nn.Conv2d(ik[1], ik[0], 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
up.append(nn.Sequential(nn.Conv2d(ik[0], ik[2], ik[3], 1, ik[4]), nn.ReLU(inplace=True), nn.Conv2d(ik[2], ik[2], ik[3], 1, ik[4]), nn.ReLU(inplace=True), nn.Conv2d(ik[2], ik[2], ik[3], 1, ik[4]), nn.ReLU(inplace=True)))
|
| 50 |
+
score.append(nn.Conv2d(ik[2], 1, 3, 1, 1))
|
| 51 |
+
trans.append(nn.Sequential(nn.Conv2d(512, 128, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 52 |
+
self.trans, self.up, self.score = nn.ModuleList(trans), nn.ModuleList(up), nn.ModuleList(score)
|
| 53 |
+
self.relu =nn.ReLU()
|
| 54 |
+
|
| 55 |
+
def forward(self, list_x, x_size):
|
| 56 |
+
up_edge, up_sal, edge_feature, sal_feature = [], [], [], []
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
num_f = len(list_x)
|
| 60 |
+
tmp = self.up[num_f - 1](list_x[num_f-1])
|
| 61 |
+
sal_feature.append(tmp)
|
| 62 |
+
U_tmp = tmp
|
| 63 |
+
up_sal.append(F.interpolate(self.score[num_f - 1](tmp), x_size, mode='bilinear', align_corners=True))
|
| 64 |
+
|
| 65 |
+
for j in range(2, num_f ):
|
| 66 |
+
i = num_f - j
|
| 67 |
+
|
| 68 |
+
if list_x[i].size()[1] < U_tmp.size()[1]:
|
| 69 |
+
U_tmp = list_x[i] + F.interpolate((self.trans[i](U_tmp)), list_x[i].size()[2:], mode='bilinear', align_corners=True)
|
| 70 |
+
else:
|
| 71 |
+
U_tmp = list_x[i] + F.interpolate((U_tmp), list_x[i].size()[2:], mode='bilinear', align_corners=True)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
tmp = self.up[i](U_tmp)
|
| 78 |
+
U_tmp = tmp
|
| 79 |
+
sal_feature.append(tmp)
|
| 80 |
+
up_sal.append(F.interpolate(self.score[i](tmp), x_size, mode='bilinear', align_corners=True))
|
| 81 |
+
|
| 82 |
+
U_tmp = list_x[0] + F.interpolate((self.trans[-1](sal_feature[0])), list_x[0].size()[2:], mode='bilinear', align_corners=True)
|
| 83 |
+
tmp = self.up[0](U_tmp)
|
| 84 |
+
edge_feature.append(tmp)
|
| 85 |
+
|
| 86 |
+
up_edge.append(F.interpolate(self.score[0](tmp), x_size, mode='bilinear', align_corners=True))
|
| 87 |
+
return up_edge, edge_feature, up_sal, sal_feature
|
| 88 |
+
|
| 89 |
+
class MergeLayer2(nn.Module):
|
| 90 |
+
def __init__(self, list_k):
|
| 91 |
+
super(MergeLayer2, self).__init__()
|
| 92 |
+
self.list_k = list_k
|
| 93 |
+
trans, up, score = [], [], []
|
| 94 |
+
for i in list_k[0]:
|
| 95 |
+
tmp = []
|
| 96 |
+
tmp_up = []
|
| 97 |
+
tmp_score = []
|
| 98 |
+
feature_k = [[3,1],[5,2], [5,2], [7,3]]
|
| 99 |
+
for idx, j in enumerate(list_k[1]):
|
| 100 |
+
tmp.append(nn.Sequential(nn.Conv2d(j, i, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 101 |
+
|
| 102 |
+
tmp_up.append(nn.Sequential(nn.Conv2d(i , i, feature_k[idx][0], 1, feature_k[idx][1]), nn.ReLU(inplace=True), nn.Conv2d(i, i, feature_k[idx][0],1 , feature_k[idx][1]), nn.ReLU(inplace=True), nn.Conv2d(i, i, feature_k[idx][0], 1, feature_k[idx][1]), nn.ReLU(inplace=True)))
|
| 103 |
+
tmp_score.append(nn.Conv2d(i, 1, 3, 1, 1))
|
| 104 |
+
trans.append(nn.ModuleList(tmp))
|
| 105 |
+
|
| 106 |
+
up.append(nn.ModuleList(tmp_up))
|
| 107 |
+
score.append(nn.ModuleList(tmp_score))
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
self.trans, self.up, self.score = nn.ModuleList(trans), nn.ModuleList(up), nn.ModuleList(score)
|
| 111 |
+
self.final_score = nn.Sequential(nn.Conv2d(list_k[0][0], list_k[0][0], 5, 1, 2), nn.ReLU(inplace=True), nn.Conv2d(list_k[0][0], 1, 3, 1, 1))
|
| 112 |
+
self.relu =nn.ReLU()
|
| 113 |
+
|
| 114 |
+
def forward(self, list_x, list_y, x_size):
|
| 115 |
+
up_score, tmp_feature = [], []
|
| 116 |
+
list_y = list_y[::-1]
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
for i, i_x in enumerate(list_x):
|
| 120 |
+
for j, j_x in enumerate(list_y):
|
| 121 |
+
tmp = F.interpolate(self.trans[i][j](j_x), i_x.size()[2:], mode='bilinear', align_corners=True) + i_x
|
| 122 |
+
tmp_f = self.up[i][j](tmp)
|
| 123 |
+
up_score.append(F.interpolate(self.score[i][j](tmp_f), x_size, mode='bilinear', align_corners=True))
|
| 124 |
+
tmp_feature.append(tmp_f)
|
| 125 |
+
|
| 126 |
+
tmp_fea = tmp_feature[0]
|
| 127 |
+
for i_fea in range(len(tmp_feature) - 1):
|
| 128 |
+
tmp_fea = self.relu(torch.add(tmp_fea, F.interpolate((tmp_feature[i_fea+1]), tmp_feature[0].size()[2:], mode='bilinear', align_corners=True)))
|
| 129 |
+
up_score.append(F.interpolate(self.final_score(tmp_fea), x_size, mode='bilinear', align_corners=True))
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
return up_score
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# extra part
|
| 138 |
+
def extra_layer(base_model_cfg, vgg):
|
| 139 |
+
if base_model_cfg == 'vgg':
|
| 140 |
+
config = config_vgg
|
| 141 |
+
elif base_model_cfg == 'resnet':
|
| 142 |
+
config = config_resnet
|
| 143 |
+
merge1_layers = MergeLayer1(config['merge1'])
|
| 144 |
+
merge2_layers = MergeLayer2(config['merge2'])
|
| 145 |
+
|
| 146 |
+
return vgg, merge1_layers, merge2_layers
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
# TUN network
|
| 150 |
+
class TUN_bone(nn.Module):
|
| 151 |
+
def __init__(self, base_model_cfg, base, merge1_layers, merge2_layers):
|
| 152 |
+
super(TUN_bone, self).__init__()
|
| 153 |
+
self.base_model_cfg = base_model_cfg
|
| 154 |
+
if self.base_model_cfg == 'vgg':
|
| 155 |
+
|
| 156 |
+
self.base = base
|
| 157 |
+
# self.base_ex = nn.ModuleList(base_ex)
|
| 158 |
+
self.merge1 = merge1_layers
|
| 159 |
+
self.merge2 = merge2_layers
|
| 160 |
+
|
| 161 |
+
elif self.base_model_cfg == 'resnet':
|
| 162 |
+
self.convert = ConvertLayer(config_resnet['convert'])
|
| 163 |
+
self.base = base
|
| 164 |
+
self.merge1 = merge1_layers
|
| 165 |
+
self.merge2 = merge2_layers
|
| 166 |
+
|
| 167 |
+
def forward(self, x):
|
| 168 |
+
x_size = x.size()[2:]
|
| 169 |
+
conv2merge = self.base(x)
|
| 170 |
+
if self.base_model_cfg == 'resnet':
|
| 171 |
+
conv2merge = self.convert(conv2merge)
|
| 172 |
+
up_edge, edge_feature, up_sal, sal_feature = self.merge1(conv2merge, x_size)
|
| 173 |
+
up_sal_final = self.merge2(edge_feature, sal_feature, x_size)
|
| 174 |
+
return up_edge, up_sal, up_sal_final
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
# build the whole network
|
| 178 |
+
def build_model(base_model_cfg='vgg'):
|
| 179 |
+
if base_model_cfg == 'vgg':
|
| 180 |
+
return TUN_bone(base_model_cfg, *extra_layer(base_model_cfg, vgg16()))
|
| 181 |
+
elif base_model_cfg == 'resnet':
|
| 182 |
+
return TUN_bone(base_model_cfg, *extra_layer(base_model_cfg, resnet50()))
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
# weight init
|
| 186 |
+
def xavier(param):
|
| 187 |
+
# init.xavier_uniform(param)
|
| 188 |
+
init.xavier_uniform_(param)
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def weights_init(m):
|
| 192 |
+
if isinstance(m, nn.Conv2d):
|
| 193 |
+
# xavier(m.weight.data)
|
| 194 |
+
m.weight.data.normal_(0, 0.01)
|
| 195 |
+
if m.bias is not None:
|
| 196 |
+
m.bias.data.zero_()
|
| 197 |
+
|
| 198 |
+
if __name__ == '__main__':
|
| 199 |
+
from torch.autograd import Variable
|
| 200 |
+
net = TUN(*extra_layer(vgg(base['tun'], 3), vgg(base['tun_ex'], 512), config['merge_block'], config['fuse'])).cuda()
|
| 201 |
+
img = Variable(torch.randn((1, 3, 256, 256))).cuda()
|
| 202 |
+
out = net(img, mode = 2)
|
| 203 |
+
print(len(out))
|
| 204 |
+
print(len(out[0]))
|
| 205 |
+
print(out[0].shape)
|
| 206 |
+
print(len(out[1]))
|
| 207 |
+
# print(net)
|
| 208 |
+
input('Press Any to Continue...')
|
src/EGNet/resnet.py
ADDED
|
@@ -0,0 +1,301 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import math
|
| 3 |
+
# import torch.utils.model_zoo as model_zoo
|
| 4 |
+
import torch
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
affine_par = True
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# def outS(i):
|
| 11 |
+
# i = int(i)
|
| 12 |
+
# i = (i+1)/2
|
| 13 |
+
# i = int(np.ceil((i+1)/2.0))
|
| 14 |
+
# i = (i+1)/2
|
| 15 |
+
# return i
|
| 16 |
+
def conv3x3(in_planes, out_planes, stride=1):
|
| 17 |
+
"3x3 convolution with padding"
|
| 18 |
+
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
|
| 19 |
+
padding=1, bias=False)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class BasicBlock(nn.Module):
|
| 23 |
+
expansion = 1
|
| 24 |
+
|
| 25 |
+
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
| 26 |
+
super(BasicBlock, self).__init__()
|
| 27 |
+
self.conv1 = conv3x3(inplanes, planes, stride)
|
| 28 |
+
self.bn1 = nn.BatchNorm2d(planes, affine = affine_par)
|
| 29 |
+
self.relu = nn.ReLU(inplace=True)
|
| 30 |
+
self.conv2 = conv3x3(planes, planes)
|
| 31 |
+
self.bn2 = nn.BatchNorm2d(planes, affine = affine_par)
|
| 32 |
+
self.downsample = downsample
|
| 33 |
+
self.stride = stride
|
| 34 |
+
|
| 35 |
+
def forward(self, x):
|
| 36 |
+
residual = x
|
| 37 |
+
|
| 38 |
+
out = self.conv1(x)
|
| 39 |
+
out = self.bn1(out)
|
| 40 |
+
out = self.relu(out)
|
| 41 |
+
|
| 42 |
+
out = self.conv2(out)
|
| 43 |
+
out = self.bn2(out)
|
| 44 |
+
|
| 45 |
+
if self.downsample is not None:
|
| 46 |
+
residual = self.downsample(x)
|
| 47 |
+
|
| 48 |
+
out += residual
|
| 49 |
+
out = self.relu(out)
|
| 50 |
+
|
| 51 |
+
return out
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class Bottleneck(nn.Module):
|
| 55 |
+
expansion = 4
|
| 56 |
+
|
| 57 |
+
def __init__(self, inplanes, planes, stride=1, dilation_ = 1, downsample=None):
|
| 58 |
+
super(Bottleneck, self).__init__()
|
| 59 |
+
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False) # change
|
| 60 |
+
self.bn1 = nn.BatchNorm2d(planes,affine = affine_par)
|
| 61 |
+
for i in self.bn1.parameters():
|
| 62 |
+
i.requires_grad = False
|
| 63 |
+
padding = 1
|
| 64 |
+
if dilation_ == 2:
|
| 65 |
+
padding = 2
|
| 66 |
+
elif dilation_ == 4:
|
| 67 |
+
padding = 4
|
| 68 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, # change
|
| 69 |
+
padding=padding, bias=False, dilation = dilation_)
|
| 70 |
+
self.bn2 = nn.BatchNorm2d(planes,affine = affine_par)
|
| 71 |
+
for i in self.bn2.parameters():
|
| 72 |
+
i.requires_grad = False
|
| 73 |
+
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
|
| 74 |
+
self.bn3 = nn.BatchNorm2d(planes * 4, affine = affine_par)
|
| 75 |
+
for i in self.bn3.parameters():
|
| 76 |
+
i.requires_grad = False
|
| 77 |
+
self.relu = nn.ReLU(inplace=True)
|
| 78 |
+
self.downsample = downsample
|
| 79 |
+
self.stride = stride
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def forward(self, x):
|
| 84 |
+
residual = x
|
| 85 |
+
|
| 86 |
+
out = self.conv1(x)
|
| 87 |
+
out = self.bn1(out)
|
| 88 |
+
out = self.relu(out)
|
| 89 |
+
|
| 90 |
+
out = self.conv2(out)
|
| 91 |
+
out = self.bn2(out)
|
| 92 |
+
out = self.relu(out)
|
| 93 |
+
|
| 94 |
+
out = self.conv3(out)
|
| 95 |
+
out = self.bn3(out)
|
| 96 |
+
|
| 97 |
+
if self.downsample is not None:
|
| 98 |
+
residual = self.downsample(x)
|
| 99 |
+
|
| 100 |
+
out += residual
|
| 101 |
+
out = self.relu(out)
|
| 102 |
+
|
| 103 |
+
return out
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class ResNet(nn.Module):
|
| 110 |
+
def __init__(self, block, layers):
|
| 111 |
+
self.inplanes = 64
|
| 112 |
+
super(ResNet, self).__init__()
|
| 113 |
+
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
|
| 114 |
+
bias=False)
|
| 115 |
+
self.bn1 = nn.BatchNorm2d(64,affine = affine_par)
|
| 116 |
+
for i in self.bn1.parameters():
|
| 117 |
+
i.requires_grad = False
|
| 118 |
+
self.relu = nn.ReLU(inplace=True)
|
| 119 |
+
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True) # change
|
| 120 |
+
self.layer1 = self._make_layer(block, 64, layers[0])
|
| 121 |
+
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
|
| 122 |
+
# self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation__ = 2)
|
| 123 |
+
# self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation__ = 4)
|
| 124 |
+
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
|
| 125 |
+
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation__ = 2)
|
| 126 |
+
|
| 127 |
+
for m in self.modules():
|
| 128 |
+
if isinstance(m, nn.Conv2d):
|
| 129 |
+
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 130 |
+
m.weight.data.normal_(0, 0.01)
|
| 131 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 132 |
+
m.weight.data.fill_(1)
|
| 133 |
+
m.bias.data.zero_()
|
| 134 |
+
# for i in m.parameters():
|
| 135 |
+
# i.requires_grad = False
|
| 136 |
+
|
| 137 |
+
def _make_layer(self, block, planes, blocks, stride=1,dilation__ = 1):
|
| 138 |
+
downsample = None
|
| 139 |
+
if stride != 1 or self.inplanes != planes * block.expansion or dilation__ == 2 or dilation__ == 4:
|
| 140 |
+
downsample = nn.Sequential(
|
| 141 |
+
nn.Conv2d(self.inplanes, planes * block.expansion,
|
| 142 |
+
kernel_size=1, stride=stride, bias=False),
|
| 143 |
+
nn.BatchNorm2d(planes * block.expansion,affine = affine_par),
|
| 144 |
+
)
|
| 145 |
+
for i in downsample._modules['1'].parameters():
|
| 146 |
+
i.requires_grad = False
|
| 147 |
+
layers = []
|
| 148 |
+
layers.append(block(self.inplanes, planes, stride,dilation_=dilation__, downsample = downsample ))
|
| 149 |
+
self.inplanes = planes * block.expansion
|
| 150 |
+
for i in range(1, blocks):
|
| 151 |
+
layers.append(block(self.inplanes, planes,dilation_=dilation__))
|
| 152 |
+
|
| 153 |
+
return nn.Sequential(*layers)
|
| 154 |
+
# def _make_pred_layer(self,block, dilation_series, padding_series,NoLabels):
|
| 155 |
+
# return block(dilation_series,padding_series,NoLabels)
|
| 156 |
+
|
| 157 |
+
def forward(self, x):
|
| 158 |
+
tmp_x = []
|
| 159 |
+
x = self.conv1(x)
|
| 160 |
+
x = self.bn1(x)
|
| 161 |
+
x = self.relu(x)
|
| 162 |
+
tmp_x.append(x)
|
| 163 |
+
x = self.maxpool(x)
|
| 164 |
+
|
| 165 |
+
x = self.layer1(x)
|
| 166 |
+
tmp_x.append(x)
|
| 167 |
+
x = self.layer2(x)
|
| 168 |
+
tmp_x.append(x)
|
| 169 |
+
x = self.layer3(x)
|
| 170 |
+
tmp_x.append(x)
|
| 171 |
+
x = self.layer4(x)
|
| 172 |
+
tmp_x.append(x)
|
| 173 |
+
|
| 174 |
+
return tmp_x
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
class ResNet_locate(nn.Module):
|
| 179 |
+
def __init__(self, block, layers):
|
| 180 |
+
super(ResNet_locate,self).__init__()
|
| 181 |
+
self.resnet = ResNet(block, layers)
|
| 182 |
+
self.in_planes = 512
|
| 183 |
+
self.out_planes = [512, 256, 256, 128]
|
| 184 |
+
|
| 185 |
+
self.ppms_pre = nn.Conv2d(2048, self.in_planes, 1, 1, bias=False)
|
| 186 |
+
ppms, infos = [], []
|
| 187 |
+
for ii in [1, 3, 5]:
|
| 188 |
+
ppms.append(nn.Sequential(nn.AdaptiveAvgPool2d(ii), nn.Conv2d(self.in_planes, self.in_planes, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 189 |
+
self.ppms = nn.ModuleList(ppms)
|
| 190 |
+
|
| 191 |
+
self.ppm_cat = nn.Sequential(nn.Conv2d(self.in_planes * 4, self.in_planes, 3, 1, 1, bias=False), nn.ReLU(inplace=True))
|
| 192 |
+
# self.ppm_score = nn.Conv2d(self.in_planes, 1, 1, 1)
|
| 193 |
+
for ii in self.out_planes:
|
| 194 |
+
infos.append(nn.Sequential(nn.Conv2d(self.in_planes, ii, 3, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 195 |
+
self.infos = nn.ModuleList(infos)
|
| 196 |
+
|
| 197 |
+
for m in self.modules():
|
| 198 |
+
if isinstance(m, nn.Conv2d):
|
| 199 |
+
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 200 |
+
m.weight.data.normal_(0, 0.01)
|
| 201 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 202 |
+
m.weight.data.fill_(1)
|
| 203 |
+
m.bias.data.zero_()
|
| 204 |
+
|
| 205 |
+
def load_pretrained_model(self, model):
|
| 206 |
+
self.resnet.load_state_dict(model)
|
| 207 |
+
|
| 208 |
+
def forward(self, x):
|
| 209 |
+
x_size = x.size()[2:]
|
| 210 |
+
xs = self.resnet(x)
|
| 211 |
+
|
| 212 |
+
xs_1 = self.ppms_pre(xs[-1])
|
| 213 |
+
xls = [xs_1]
|
| 214 |
+
for k in range(len(self.ppms)):
|
| 215 |
+
xls.append(F.interpolate(self.ppms[k](xs_1), xs_1.size()[2:], mode='bilinear', align_corners=True))
|
| 216 |
+
xls = self.ppm_cat(torch.cat(xls, dim=1))
|
| 217 |
+
top_score = None
|
| 218 |
+
# top_score = F.interpolate(self.ppm_score(xls), x_size, mode='bilinear', align_corners=True)
|
| 219 |
+
|
| 220 |
+
infos = []
|
| 221 |
+
for k in range(len(self.infos)):
|
| 222 |
+
infos.append(self.infos[k](F.interpolate(xls, xs[len(self.infos) - 1 - k].size()[2:], mode='bilinear', align_corners=True)))
|
| 223 |
+
|
| 224 |
+
return xs, top_score, infos
|
| 225 |
+
|
| 226 |
+
class BottleneckEZ(nn.Module):
|
| 227 |
+
expansion = 4
|
| 228 |
+
|
| 229 |
+
def __init__(self, inplanes, planes, stride=1, dilation_ = 1, downsample=None):
|
| 230 |
+
super(BottleneckEZ, self).__init__()
|
| 231 |
+
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False) # change
|
| 232 |
+
# self.bn1 = nn.BatchNorm2d(planes,affine = affine_par)
|
| 233 |
+
# for i in self.bn1.parameters():
|
| 234 |
+
# i.requires_grad = False
|
| 235 |
+
padding = 1
|
| 236 |
+
if dilation_ == 2:
|
| 237 |
+
padding = 2
|
| 238 |
+
elif dilation_ == 4:
|
| 239 |
+
padding = 4
|
| 240 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, # change
|
| 241 |
+
padding=padding, bias=False, dilation = dilation_)
|
| 242 |
+
# self.bn2 = nn.BatchNorm2d(planes,affine = affine_par)
|
| 243 |
+
# for i in self.bn2.parameters():
|
| 244 |
+
# i.requires_grad = False
|
| 245 |
+
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
|
| 246 |
+
# self.bn3 = nn.BatchNorm2d(planes * 4, affine = affine_par)
|
| 247 |
+
# for i in self.bn3.parameters():
|
| 248 |
+
# i.requires_grad = False
|
| 249 |
+
self.relu = nn.ReLU(inplace=True)
|
| 250 |
+
self.downsample = downsample
|
| 251 |
+
self.stride = stride
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def forward(self, x):
|
| 256 |
+
residual = x
|
| 257 |
+
|
| 258 |
+
out = self.conv1(x)
|
| 259 |
+
# out = self.bn1(out)
|
| 260 |
+
out = self.relu(out)
|
| 261 |
+
|
| 262 |
+
out = self.conv2(out)
|
| 263 |
+
# out = self.bn2(out)
|
| 264 |
+
out = self.relu(out)
|
| 265 |
+
|
| 266 |
+
out = self.conv3(out)
|
| 267 |
+
# out = self.bn3(out)
|
| 268 |
+
|
| 269 |
+
if self.downsample is not None:
|
| 270 |
+
residual = self.downsample(x)
|
| 271 |
+
|
| 272 |
+
out += residual
|
| 273 |
+
out = self.relu(out)
|
| 274 |
+
|
| 275 |
+
return out
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def resnet50(pretrained=False):
|
| 280 |
+
"""Constructs a ResNet-50 model.
|
| 281 |
+
|
| 282 |
+
Args:
|
| 283 |
+
pretrained (bool): If True, returns a model pre-trained on Places
|
| 284 |
+
"""
|
| 285 |
+
# model = ResNet(Bottleneck, [3, 4, 6, 3])
|
| 286 |
+
model = ResNet(Bottleneck, [3, 4, 6, 3])
|
| 287 |
+
if pretrained:
|
| 288 |
+
model.load_state_dict(load_url(model_urls['resnet50']), strict=False)
|
| 289 |
+
return model
|
| 290 |
+
|
| 291 |
+
def resnet101(pretrained=False):
|
| 292 |
+
"""Constructs a ResNet-101 model.
|
| 293 |
+
|
| 294 |
+
Args:
|
| 295 |
+
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
| 296 |
+
"""
|
| 297 |
+
# model = ResNet(Bottleneck, [3, 4, 23, 3])
|
| 298 |
+
model = ResNet_locate(Bottleneck, [3, 4, 23, 3])
|
| 299 |
+
if pretrained:
|
| 300 |
+
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
|
| 301 |
+
return model
|
src/EGNet/run.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
from dataset import get_loader
|
| 4 |
+
from solver import Solver
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def main(config):
|
| 8 |
+
if config.mode == 'train':
|
| 9 |
+
train_loader, dataset = get_loader(config.batch_size, num_thread=config.num_thread)
|
| 10 |
+
run = "nnet"
|
| 11 |
+
if not os.path.exists("%s/run-%s" % (config.save_fold, run)):
|
| 12 |
+
os.mkdir("%s/run-%s" % (config.save_fold, run))
|
| 13 |
+
os.mkdir("%s/run-%s/logs" % (config.save_fold, run))
|
| 14 |
+
os.mkdir("%s/run-%s/models" % (config.save_fold, run))
|
| 15 |
+
config.save_fold = "%s/run-%s" % (config.save_fold, run)
|
| 16 |
+
train = Solver(train_loader, None, config)
|
| 17 |
+
train.train()
|
| 18 |
+
elif config.mode == 'test':
|
| 19 |
+
test_loader, dataset = get_loader(config.test_batch_size, mode='test',num_thread=config.num_thread, test_mode=config.test_mode, sal_mode=config.sal_mode)
|
| 20 |
+
|
| 21 |
+
test = Solver(None, test_loader, config, dataset.save_folder())
|
| 22 |
+
test.test(test_mode=config.test_mode)
|
| 23 |
+
else:
|
| 24 |
+
raise IOError("illegal input!!!")
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
if __name__ == '__main__':
|
| 29 |
+
|
| 30 |
+
vgg_path = '/home/liuj/code/Messal/weights/vgg16_20M.pth'
|
| 31 |
+
resnet_path = '/home/liuj/code/Messal/weights/resnet50_caffe.pth'
|
| 32 |
+
|
| 33 |
+
parser = argparse.ArgumentParser()
|
| 34 |
+
|
| 35 |
+
# Hyper-parameters
|
| 36 |
+
parser.add_argument('--n_color', type=int, default=3)
|
| 37 |
+
|
| 38 |
+
parser.add_argument('--cuda', type=bool, default=True)
|
| 39 |
+
|
| 40 |
+
# Training settings
|
| 41 |
+
parser.add_argument('--vgg', type=str, default=vgg_path)
|
| 42 |
+
parser.add_argument('--resnet', type=str, default=resnet_path)
|
| 43 |
+
parser.add_argument('--epoch', type=int, default=30) # 12, now x3
|
| 44 |
+
parser.add_argument('--batch_size', type=int, default=1)
|
| 45 |
+
parser.add_argument('--test_batch_size', type=int, default=1)
|
| 46 |
+
parser.add_argument('--num_thread', type=int, default=4)
|
| 47 |
+
parser.add_argument('--load_bone', type=str, default='')
|
| 48 |
+
# parser.add_argument('--load_branch', type=str, default='')
|
| 49 |
+
parser.add_argument('--save_fold', type=str, default='./EGNet')
|
| 50 |
+
# parser.add_argument('--epoch_val', type=int, default=20)
|
| 51 |
+
parser.add_argument('--epoch_save', type=int, default=1) # 2, now x3
|
| 52 |
+
parser.add_argument('--epoch_show', type=int, default=1)
|
| 53 |
+
parser.add_argument('--pre_trained', type=str, default=None)
|
| 54 |
+
|
| 55 |
+
# Testing settings
|
| 56 |
+
parser.add_argument('--model', type=str, default='./epoch_resnet.pth')
|
| 57 |
+
parser.add_argument('--test_fold', type=str, default='./results/test')
|
| 58 |
+
parser.add_argument('--test_mode', type=int, default=1)
|
| 59 |
+
parser.add_argument('--sal_mode', type=str, default='t')
|
| 60 |
+
|
| 61 |
+
# Misc
|
| 62 |
+
parser.add_argument('--mode', type=str, default='train', choices=['train', 'test'])
|
| 63 |
+
parser.add_argument('--visdom', type=bool, default=False)
|
| 64 |
+
|
| 65 |
+
config = parser.parse_args()
|
| 66 |
+
|
| 67 |
+
if not os.path.exists(config.save_fold): os.mkdir(config.save_fold)
|
| 68 |
+
main(config)
|
src/EGNet/sal2edge.m
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data_root = '/home/liuj/dataset/DUTS/DUTS-TR/DUTS-TR-Mask';
|
| 2 |
+
out_root = '/home/liuj/dataset/DUTS/DUTS-TR/DUTS-TR-Mask';
|
| 3 |
+
lst_set = '/home/liuj/dataset/DUTS/DUTS-TR/train'
|
| 4 |
+
index_file = fullfile([lst_set '.lst']);
|
| 5 |
+
|
| 6 |
+
fileID = fopen(index_file);
|
| 7 |
+
im_ids = textscan(fileID, '%s');
|
| 8 |
+
im_ids = im_ids{1};
|
| 9 |
+
fclose(fileID);
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
num_images = length(im_ids);
|
| 13 |
+
|
| 14 |
+
for im_id = 1:10
|
| 15 |
+
|
| 16 |
+
id = im_ids{im_id};
|
| 17 |
+
id = id(1:end-4);
|
| 18 |
+
|
| 19 |
+
% img_path = fullfile(data_root, [id '.jpg']);
|
| 20 |
+
% image = imread(img_path);
|
| 21 |
+
|
| 22 |
+
gt = imread(fullfile(data_root, [id '.png']));
|
| 23 |
+
gt = (gt > 128);
|
| 24 |
+
gt = double(gt);
|
| 25 |
+
|
| 26 |
+
[gy, gx] = gradient(gt);
|
| 27 |
+
temp_edge = gy.*gy + gx.*gx;
|
| 28 |
+
temp_edge(temp_edge~=0)=1;
|
| 29 |
+
bound = uint8(temp_edge*255);
|
| 30 |
+
|
| 31 |
+
save_path = fullfile(out_root, [id '_edge.png']);
|
| 32 |
+
imwrite(bound, save_path);
|
| 33 |
+
|
| 34 |
+
end
|
src/EGNet/solver.py
ADDED
|
@@ -0,0 +1,230 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from collections import OrderedDict
|
| 3 |
+
from torch.nn import utils, functional as F
|
| 4 |
+
from torch.optim import Adam, SGD
|
| 5 |
+
from torch.autograd import Variable
|
| 6 |
+
from torch.backends import cudnn
|
| 7 |
+
from model import build_model, weights_init
|
| 8 |
+
import scipy.misc as sm
|
| 9 |
+
import numpy as np
|
| 10 |
+
import os
|
| 11 |
+
import torchvision.utils as vutils
|
| 12 |
+
import cv2
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import math
|
| 15 |
+
import time
|
| 16 |
+
import sys
|
| 17 |
+
import PIL.Image
|
| 18 |
+
import scipy.io
|
| 19 |
+
import os
|
| 20 |
+
import logging
|
| 21 |
+
EPSILON = 1e-8
|
| 22 |
+
p = OrderedDict()
|
| 23 |
+
|
| 24 |
+
from dataset import get_loader
|
| 25 |
+
base_model_cfg = 'resnet'
|
| 26 |
+
p['lr_bone'] = 5e-5 # Learning rate resnet:5e-5, vgg:2e-5
|
| 27 |
+
p['lr_branch'] = 0.025 # Learning rate
|
| 28 |
+
p['wd'] = 0.0005 # Weight decay
|
| 29 |
+
p['momentum'] = 0.90 # Momentum
|
| 30 |
+
lr_decay_epoch = [15, 24] # [6, 9], now x3 #15
|
| 31 |
+
nAveGrad = 10 # Update the weights once in 'nAveGrad' forward passes
|
| 32 |
+
showEvery = 50
|
| 33 |
+
tmp_path = 'tmp_see'
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class Solver(object):
|
| 37 |
+
def __init__(self, train_loader, test_loader, config, save_fold=None):
|
| 38 |
+
self.train_loader = train_loader
|
| 39 |
+
self.test_loader = test_loader
|
| 40 |
+
self.config = config
|
| 41 |
+
self.save_fold = save_fold
|
| 42 |
+
self.mean = torch.Tensor([123.68, 116.779, 103.939]).view(3, 1, 1) / 255.
|
| 43 |
+
# inference: choose the side map (see paper)
|
| 44 |
+
if config.visdom:
|
| 45 |
+
self.visual = Viz_visdom("trueUnify", 1)
|
| 46 |
+
self.build_model()
|
| 47 |
+
if self.config.pre_trained: self.net.load_state_dict(torch.load(self.config.pre_trained))
|
| 48 |
+
if config.mode == 'train':
|
| 49 |
+
self.log_output = open("%s/logs/log.txt" % config.save_fold, 'w')
|
| 50 |
+
else:
|
| 51 |
+
print('Loading pre-trained model from %s...' % self.config.model)
|
| 52 |
+
self.net_bone.load_state_dict(torch.load(self.config.model))
|
| 53 |
+
self.net_bone.eval()
|
| 54 |
+
|
| 55 |
+
def print_network(self, model, name):
|
| 56 |
+
num_params = 0
|
| 57 |
+
for p in model.parameters():
|
| 58 |
+
num_params += p.numel()
|
| 59 |
+
print(name)
|
| 60 |
+
print(model)
|
| 61 |
+
print("The number of parameters: {}".format(num_params))
|
| 62 |
+
|
| 63 |
+
def get_params(self, base_lr):
|
| 64 |
+
ml = []
|
| 65 |
+
for name, module in self.net_bone.named_children():
|
| 66 |
+
print(name)
|
| 67 |
+
if name == 'loss_weight':
|
| 68 |
+
ml.append({'params': module.parameters(), 'lr': p['lr_branch']})
|
| 69 |
+
else:
|
| 70 |
+
ml.append({'params': module.parameters()})
|
| 71 |
+
return ml
|
| 72 |
+
|
| 73 |
+
# build the network
|
| 74 |
+
def build_model(self):
|
| 75 |
+
self.net_bone = build_model(base_model_cfg)
|
| 76 |
+
if self.config.cuda:
|
| 77 |
+
self.net_bone = self.net_bone.cuda()
|
| 78 |
+
|
| 79 |
+
self.net_bone.eval() # use_global_stats = True
|
| 80 |
+
self.net_bone.apply(weights_init)
|
| 81 |
+
if self.config.mode == 'train':
|
| 82 |
+
if self.config.load_bone == '':
|
| 83 |
+
if base_model_cfg == 'vgg':
|
| 84 |
+
self.net_bone.base.load_pretrained_model(torch.load(self.config.vgg))
|
| 85 |
+
elif base_model_cfg == 'resnet':
|
| 86 |
+
self.net_bone.base.load_state_dict(torch.load(self.config.resnet))
|
| 87 |
+
if self.config.load_bone != '': self.net_bone.load_state_dict(torch.load(self.config.load_bone))
|
| 88 |
+
|
| 89 |
+
self.lr_bone = p['lr_bone']
|
| 90 |
+
self.lr_branch = p['lr_branch']
|
| 91 |
+
self.optimizer_bone = Adam(filter(lambda p: p.requires_grad, self.net_bone.parameters()), lr=self.lr_bone, weight_decay=p['wd'])
|
| 92 |
+
|
| 93 |
+
self.print_network(self.net_bone, 'trueUnify bone part')
|
| 94 |
+
|
| 95 |
+
# update the learning rate
|
| 96 |
+
def update_lr(self, rate):
|
| 97 |
+
for param_group in self.optimizer.param_groups:
|
| 98 |
+
param_group['lr'] = param_group['lr'] * rate
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def test(self, test_mode=0):
|
| 102 |
+
EPSILON = 1e-8
|
| 103 |
+
img_num = len(self.test_loader)
|
| 104 |
+
time_t = 0.0
|
| 105 |
+
name_t = 'EGNet_ResNet50/'
|
| 106 |
+
|
| 107 |
+
if not os.path.exists(os.path.join(self.save_fold, name_t)):
|
| 108 |
+
os.mkdir(os.path.join(self.save_fold, name_t))
|
| 109 |
+
for i, data_batch in enumerate(self.test_loader):
|
| 110 |
+
self.config.test_fold = self.save_fold
|
| 111 |
+
print(self.config.test_fold)
|
| 112 |
+
images_, name, im_size = data_batch['image'], data_batch['name'][0], np.asarray(data_batch['size'])
|
| 113 |
+
|
| 114 |
+
with torch.no_grad():
|
| 115 |
+
|
| 116 |
+
images = Variable(images_)
|
| 117 |
+
if self.config.cuda:
|
| 118 |
+
images = images.cuda()
|
| 119 |
+
print(images.size())
|
| 120 |
+
time_start = time.time()
|
| 121 |
+
up_edge, up_sal, up_sal_f = self.net_bone(images)
|
| 122 |
+
torch.cuda.synchronize()
|
| 123 |
+
time_end = time.time()
|
| 124 |
+
print(time_end - time_start)
|
| 125 |
+
time_t = time_t + time_end - time_start
|
| 126 |
+
pred = np.squeeze(torch.sigmoid(up_sal_f[-1]).cpu().data.numpy())
|
| 127 |
+
multi_fuse = 255 * pred
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
cv2.imwrite(os.path.join(self.config.test_fold,name_t, name[:-4] + '.png'), multi_fuse)
|
| 132 |
+
|
| 133 |
+
print("--- %s seconds ---" % (time_t))
|
| 134 |
+
print('Test Done!')
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# training phase
|
| 138 |
+
def train(self):
|
| 139 |
+
iter_num = len(self.train_loader.dataset) // self.config.batch_size
|
| 140 |
+
aveGrad = 0
|
| 141 |
+
F_v = 0
|
| 142 |
+
if not os.path.exists(tmp_path):
|
| 143 |
+
os.mkdir(tmp_path)
|
| 144 |
+
for epoch in range(self.config.epoch):
|
| 145 |
+
r_edge_loss, r_sal_loss, r_sum_loss= 0,0,0
|
| 146 |
+
self.net_bone.zero_grad()
|
| 147 |
+
for i, data_batch in enumerate(self.train_loader):
|
| 148 |
+
sal_image, sal_label, sal_edge = data_batch['sal_image'], data_batch['sal_label'], data_batch['sal_edge']
|
| 149 |
+
if sal_image.size()[2:] != sal_label.size()[2:]:
|
| 150 |
+
print("Skip this batch")
|
| 151 |
+
continue
|
| 152 |
+
sal_image, sal_label, sal_edge = Variable(sal_image), Variable(sal_label), Variable(sal_edge)
|
| 153 |
+
if self.config.cuda:
|
| 154 |
+
sal_image, sal_label, sal_edge = sal_image.cuda(), sal_label.cuda(), sal_edge.cuda()
|
| 155 |
+
|
| 156 |
+
up_edge, up_sal, up_sal_f = self.net_bone(sal_image)
|
| 157 |
+
# edge part
|
| 158 |
+
edge_loss = []
|
| 159 |
+
for ix in up_edge:
|
| 160 |
+
edge_loss.append(bce2d_new(ix, sal_edge, reduction='sum'))
|
| 161 |
+
edge_loss = sum(edge_loss) / (nAveGrad * self.config.batch_size)
|
| 162 |
+
r_edge_loss += edge_loss.data
|
| 163 |
+
# sal part
|
| 164 |
+
sal_loss1= []
|
| 165 |
+
sal_loss2 = []
|
| 166 |
+
for ix in up_sal:
|
| 167 |
+
sal_loss1.append(F.binary_cross_entropy_with_logits(ix, sal_label, reduction='sum'))
|
| 168 |
+
|
| 169 |
+
for ix in up_sal_f:
|
| 170 |
+
sal_loss2.append(F.binary_cross_entropy_with_logits(ix, sal_label, reduction='sum'))
|
| 171 |
+
sal_loss = (sum(sal_loss1) + sum(sal_loss2)) / (nAveGrad * self.config.batch_size)
|
| 172 |
+
|
| 173 |
+
r_sal_loss += sal_loss.data
|
| 174 |
+
loss = sal_loss + edge_loss
|
| 175 |
+
r_sum_loss += loss.data
|
| 176 |
+
loss.backward()
|
| 177 |
+
aveGrad += 1
|
| 178 |
+
|
| 179 |
+
if aveGrad % nAveGrad == 0:
|
| 180 |
+
|
| 181 |
+
self.optimizer_bone.step()
|
| 182 |
+
self.optimizer_bone.zero_grad()
|
| 183 |
+
aveGrad = 0
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
if i % showEvery == 0:
|
| 187 |
+
|
| 188 |
+
print('epoch: [%2d/%2d], iter: [%5d/%5d] || Edge : %10.4f || Sal : %10.4f || Sum : %10.4f' % (
|
| 189 |
+
epoch, self.config.epoch, i, iter_num, r_edge_loss*(nAveGrad * self.config.batch_size)/showEvery,
|
| 190 |
+
r_sal_loss*(nAveGrad * self.config.batch_size)/showEvery,
|
| 191 |
+
r_sum_loss*(nAveGrad * self.config.batch_size)/showEvery))
|
| 192 |
+
|
| 193 |
+
print('Learning rate: ' + str(self.lr_bone))
|
| 194 |
+
r_edge_loss, r_sal_loss, r_sum_loss= 0,0,0
|
| 195 |
+
|
| 196 |
+
if i % 200 == 0:
|
| 197 |
+
|
| 198 |
+
vutils.save_image(torch.sigmoid(up_sal_f[-1].data), tmp_path+'/iter%d-sal-0.jpg' % i, normalize=True, padding = 0)
|
| 199 |
+
|
| 200 |
+
vutils.save_image(sal_image.data, tmp_path+'/iter%d-sal-data.jpg' % i, padding = 0)
|
| 201 |
+
vutils.save_image(sal_label.data, tmp_path+'/iter%d-sal-target.jpg' % i, padding = 0)
|
| 202 |
+
|
| 203 |
+
if (epoch + 1) % self.config.epoch_save == 0:
|
| 204 |
+
torch.save(self.net_bone.state_dict(), '%s/models/epoch_%d_bone.pth' % (self.config.save_fold, epoch + 1))
|
| 205 |
+
|
| 206 |
+
if epoch in lr_decay_epoch:
|
| 207 |
+
self.lr_bone = self.lr_bone * 0.1
|
| 208 |
+
self.optimizer_bone = Adam(filter(lambda p: p.requires_grad, self.net_bone.parameters()), lr=self.lr_bone, weight_decay=p['wd'])
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
torch.save(self.net_bone.state_dict(), '%s/models/final_bone.pth' % self.config.save_fold)
|
| 212 |
+
|
| 213 |
+
def bce2d_new(input, target, reduction=None):
|
| 214 |
+
assert(input.size() == target.size())
|
| 215 |
+
pos = torch.eq(target, 1).float()
|
| 216 |
+
neg = torch.eq(target, 0).float()
|
| 217 |
+
# ing = ((torch.gt(target, 0) & torch.lt(target, 1))).float()
|
| 218 |
+
|
| 219 |
+
num_pos = torch.sum(pos)
|
| 220 |
+
num_neg = torch.sum(neg)
|
| 221 |
+
num_total = num_pos + num_neg
|
| 222 |
+
|
| 223 |
+
alpha = num_neg / num_total
|
| 224 |
+
beta = 1.1 * num_pos / num_total
|
| 225 |
+
# target pixel = 1 -> weight beta
|
| 226 |
+
# target pixel = 0 -> weight 1-beta
|
| 227 |
+
weights = alpha * pos + beta * neg
|
| 228 |
+
|
| 229 |
+
return F.binary_cross_entropy_with_logits(input, target, weights, reduction=reduction)
|
| 230 |
+
|
src/EGNet/vgg.py
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import math
|
| 3 |
+
# import torch.utils.model_zoo as model_zoo
|
| 4 |
+
import torch
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
# vgg16
|
| 9 |
+
def vgg(cfg, i, batch_norm=False):
|
| 10 |
+
layers = []
|
| 11 |
+
in_channels = i
|
| 12 |
+
stage = 1
|
| 13 |
+
for v in cfg:
|
| 14 |
+
if v == 'M':
|
| 15 |
+
stage += 1
|
| 16 |
+
if stage == 6:
|
| 17 |
+
layers += [nn.MaxPool2d(kernel_size=3, stride=2, padding=1)]
|
| 18 |
+
else:
|
| 19 |
+
layers += [nn.MaxPool2d(kernel_size=3, stride=2, padding=1)]
|
| 20 |
+
else:
|
| 21 |
+
if stage == 6:
|
| 22 |
+
# conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=4, dilation=4, bias=False)
|
| 23 |
+
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
|
| 24 |
+
else:
|
| 25 |
+
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
|
| 26 |
+
if batch_norm:
|
| 27 |
+
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
|
| 28 |
+
else:
|
| 29 |
+
layers += [conv2d, nn.ReLU(inplace=True)]
|
| 30 |
+
in_channels = v
|
| 31 |
+
return layers
|
| 32 |
+
|
| 33 |
+
class vgg16(nn.Module):
|
| 34 |
+
def __init__(self):
|
| 35 |
+
super(vgg16, self).__init__()
|
| 36 |
+
self.cfg = {'tun': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], 'tun_ex': [512, 512, 512]}
|
| 37 |
+
self.extract = [8, 15, 22, 29] # [3, 8, 15, 22, 29]
|
| 38 |
+
self.extract_ex = [5]
|
| 39 |
+
self.base = nn.ModuleList(vgg(self.cfg['tun'], 3))
|
| 40 |
+
self.base_ex = vgg_ex(self.cfg['tun_ex'], 512)
|
| 41 |
+
|
| 42 |
+
for m in self.modules():
|
| 43 |
+
if isinstance(m, nn.Conv2d):
|
| 44 |
+
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 45 |
+
m.weight.data.normal_(0, 0.01)
|
| 46 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 47 |
+
m.weight.data.fill_(1)
|
| 48 |
+
m.bias.data.zero_()
|
| 49 |
+
|
| 50 |
+
def load_pretrained_model(self, model):
|
| 51 |
+
self.base.load_state_dict(model)
|
| 52 |
+
|
| 53 |
+
def forward(self, x, multi=0):
|
| 54 |
+
tmp_x = []
|
| 55 |
+
for k in range(len(self.base)):
|
| 56 |
+
x = self.base[k](x)
|
| 57 |
+
if k in self.extract:
|
| 58 |
+
tmp_x.append(x)
|
| 59 |
+
x = self.base_ex(x)
|
| 60 |
+
tmp_x.append(x)
|
| 61 |
+
if multi == 1:
|
| 62 |
+
tmp_y = []
|
| 63 |
+
tmp_y.append(tmp_x[0])
|
| 64 |
+
return tmp_y
|
| 65 |
+
else:
|
| 66 |
+
return tmp_x
|
| 67 |
+
|
| 68 |
+
class vgg_ex(nn.Module):
|
| 69 |
+
def __init__(self, cfg, incs=512, padding=1, dilation=1):
|
| 70 |
+
super(vgg_ex, self).__init__()
|
| 71 |
+
self.cfg = cfg
|
| 72 |
+
layers = []
|
| 73 |
+
for v in self.cfg:
|
| 74 |
+
# conv2d = nn.Conv2d(incs, v, kernel_size=3, padding=4, dilation=4, bias=False)
|
| 75 |
+
conv2d = nn.Conv2d(incs, v, kernel_size=3, padding=padding, dilation=dilation, bias=False)
|
| 76 |
+
layers += [conv2d, nn.ReLU(inplace=True)]
|
| 77 |
+
incs = v
|
| 78 |
+
self.ex = nn.Sequential(*layers)
|
| 79 |
+
|
| 80 |
+
for m in self.modules():
|
| 81 |
+
if isinstance(m, nn.Conv2d):
|
| 82 |
+
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 83 |
+
m.weight.data.normal_(0, 0.01)
|
| 84 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 85 |
+
m.weight.data.fill_(1)
|
| 86 |
+
m.bias.data.zero_()
|
| 87 |
+
|
| 88 |
+
def forward(self, x):
|
| 89 |
+
x = self.ex(x)
|
| 90 |
+
return x
|
| 91 |
+
|
| 92 |
+
# class vgg16_locate(nn.Module):
|
| 93 |
+
# def __init__(self):
|
| 94 |
+
# super(vgg16_locate,self).__init__()
|
| 95 |
+
# self.cfg = [512, 512, 512]
|
| 96 |
+
# self.vgg16 = vgg16()
|
| 97 |
+
# # self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 98 |
+
# # self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=3, padding=1)
|
| 99 |
+
# self.layer61 = vgg_ex(self.cfg, 512, 3, 3)
|
| 100 |
+
# self.layer62 = vgg_ex(self.cfg, 512, 6, 6)
|
| 101 |
+
# self.layer63 = vgg_ex(self.cfg, 512, 9, 9)
|
| 102 |
+
# self.layer64 = vgg_ex(self.cfg, 512, 12, 12)
|
| 103 |
+
#
|
| 104 |
+
#
|
| 105 |
+
# # self.layer6_convert, self.layer6_trans, self.layer6_score = [],[],[]
|
| 106 |
+
# # for ii in range(3):
|
| 107 |
+
# # self.layer6_convert.append(nn.Conv2d(1024, 512, 3, 1, 1, bias=False))
|
| 108 |
+
# # self.layer6_trans.append(nn.Conv2d(512, 512, 1, 1, bias=False))
|
| 109 |
+
# # self.layer6_score.append(nn.Conv2d(512, 1, 1, 1))
|
| 110 |
+
# # self.layer6_convert, self.layer6_trans, self.layer6_score = nn.ModuleList(self.layer6_convert), nn.ModuleList(self.layer6_trans), nn.ModuleList(self.layer6_score)
|
| 111 |
+
# self.trans = nn.Conv2d(512*5, 512, 3, 1, 1, bias=False)
|
| 112 |
+
# # self.score = nn.Conv2d(3, 1, 1, 1)
|
| 113 |
+
# # self.score = nn.Conv2d(1, 1, 1, 1)
|
| 114 |
+
# self.relu = nn.ReLU(inplace=True)
|
| 115 |
+
#
|
| 116 |
+
# for m in self.modules():
|
| 117 |
+
# if isinstance(m, nn.Conv2d):
|
| 118 |
+
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 119 |
+
# m.weight.data.normal_(0, 0.01)
|
| 120 |
+
# elif isinstance(m, nn.BatchNorm2d):
|
| 121 |
+
# m.weight.data.fill_(1)
|
| 122 |
+
# m.bias.data.zero_()
|
| 123 |
+
#
|
| 124 |
+
# def load_pretrained_model(self, model):
|
| 125 |
+
# self.vgg16.load_pretrained_model(model)
|
| 126 |
+
#
|
| 127 |
+
# def forward(self, x):
|
| 128 |
+
# x_size = x.size()[2:]
|
| 129 |
+
# xs = self.vgg16(x)
|
| 130 |
+
#
|
| 131 |
+
# xls = [xs[-1]]
|
| 132 |
+
# xls.append(self.layer61(xs[-2]))
|
| 133 |
+
# xls.append(self.layer62(xs[-2]))
|
| 134 |
+
# xls.append(self.layer63(xs[-2]))
|
| 135 |
+
# xls.append(self.layer64(xs[-2]))
|
| 136 |
+
#
|
| 137 |
+
# # xls_tmp = [self.layer6_convert[0](xls[0])]
|
| 138 |
+
# # for ii in range(1, 3):
|
| 139 |
+
# # xls_tmp.append(F.interpolate(self.layer6_convert[ii](xls[ii]), xls_tmp[0].size()[2:], mode='bilinear', align_corners=True))
|
| 140 |
+
# #
|
| 141 |
+
# # xls_trans = self.layer6_trans[0](xls_tmp[0])
|
| 142 |
+
# # for ii in range(1, 3):
|
| 143 |
+
# # xls_trans = torch.add(xls_trans, self.layer6_trans[ii](xls_tmp[ii]))
|
| 144 |
+
# score, score_fuse = [], None
|
| 145 |
+
# # for ii in range(3):
|
| 146 |
+
# # score.append(self.layer6_score[ii](xls_tmp[ii]))
|
| 147 |
+
#
|
| 148 |
+
# xls_trans = self.trans(self.relu(torch.cat(xls, dim=1)))
|
| 149 |
+
# xs[-1] = xls_trans
|
| 150 |
+
# # score_fuse = F.interpolate(self.score(torch.cat(score, dim=1)), x_size, mode='bilinear', align_corners=True)
|
| 151 |
+
# # score_fuse = F.interpolate(self.score(torch.add(torch.add(score[0], score[1]), score[2])), x_size, mode='bilinear', align_corners=True)
|
| 152 |
+
#
|
| 153 |
+
# # score = [F.interpolate(ss, x_size, mode='bilinear', align_corners=True) for ss in score]
|
| 154 |
+
#
|
| 155 |
+
# return xs, score_fuse, score
|
| 156 |
+
|
| 157 |
+
class vgg16_locate(nn.Module):
|
| 158 |
+
def __init__(self):
|
| 159 |
+
super(vgg16_locate,self).__init__()
|
| 160 |
+
self.vgg16 = vgg16()
|
| 161 |
+
self.in_planes = 512
|
| 162 |
+
# self.out_planes = [512, 256, 128, 64] # with convert layer, with conv6
|
| 163 |
+
# self.out_planes = [512, 512, 256, 128] # no convert layer, with conv6
|
| 164 |
+
self.out_planes = [512, 256, 128] # no convert layer, no conv6
|
| 165 |
+
|
| 166 |
+
ppms, infos = [], []
|
| 167 |
+
# for ii in [3, 6, 12]:
|
| 168 |
+
# if ii <= 8:
|
| 169 |
+
# ppms.append(nn.Sequential(nn.AvgPool2d(kernel_size=ii, stride=ii), nn.Conv2d(self.in_planes, self.in_planes, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 170 |
+
# else:
|
| 171 |
+
# ppms.append(nn.Sequential(nn.AdaptiveAvgPool2d(1), nn.Conv2d(self.in_planes, self.in_planes, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 172 |
+
for ii in [1, 3, 5]:
|
| 173 |
+
ppms.append(nn.Sequential(nn.AdaptiveAvgPool2d(ii), nn.Conv2d(self.in_planes, self.in_planes, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 174 |
+
self.ppms = nn.ModuleList(ppms)
|
| 175 |
+
|
| 176 |
+
self.ppm_cat = nn.Sequential(nn.Conv2d(self.in_planes * 4, self.in_planes, 3, 1, 1, bias=False), nn.ReLU(inplace=True))
|
| 177 |
+
#self.ppm_cat = nn.Sequential(nn.Conv2d(self.in_planes, self.in_planes, 3, 1, 1, bias=False), nn.ReLU(inplace=True))
|
| 178 |
+
# self.ppm_score = nn.Conv2d(self.in_planes, 1, 1, 1)
|
| 179 |
+
for ii in self.out_planes:
|
| 180 |
+
infos.append(nn.Sequential(nn.Conv2d(self.in_planes, ii, 3, 1, 1, bias=False), nn.ReLU(inplace=True)))
|
| 181 |
+
self.infos = nn.ModuleList(infos)
|
| 182 |
+
|
| 183 |
+
for m in self.modules():
|
| 184 |
+
if isinstance(m, nn.Conv2d):
|
| 185 |
+
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 186 |
+
m.weight.data.normal_(0, 0.01)
|
| 187 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 188 |
+
m.weight.data.fill_(1)
|
| 189 |
+
m.bias.data.zero_()
|
| 190 |
+
|
| 191 |
+
def load_pretrained_model(self, model):
|
| 192 |
+
self.vgg16.load_pretrained_model(model)
|
| 193 |
+
|
| 194 |
+
def forward(self, x):
|
| 195 |
+
x_size = x.size()[2:]
|
| 196 |
+
xs = self.vgg16(x)
|
| 197 |
+
|
| 198 |
+
xls = [xs[-1]]
|
| 199 |
+
#xls = xs[-1]
|
| 200 |
+
for k in range(len(self.ppms)):
|
| 201 |
+
xls.append(F.interpolate(self.ppms[k](xs[-1]), xs[-1].size()[2:], mode='bilinear', align_corners=True))
|
| 202 |
+
#xls = torch.add(xls, F.interpolate(self.ppms[k](xs[-1]), xs[-1].size()[2:], mode='bilinear', align_corners=True))
|
| 203 |
+
xls = self.ppm_cat(torch.cat(xls, dim=1))
|
| 204 |
+
#xls = self.ppm_cat(xls)
|
| 205 |
+
top_score = None
|
| 206 |
+
# top_score = F.interpolate(self.ppm_score(xls), x_size, mode='bilinear', align_corners=True)
|
| 207 |
+
|
| 208 |
+
infos = []
|
| 209 |
+
for k in range(len(self.infos)):
|
| 210 |
+
infos.append(self.infos[k](F.interpolate(xls, xs[len(self.infos) - 1 - k].size()[2:], mode='bilinear', align_corners=True)))
|
| 211 |
+
|
| 212 |
+
return xs, top_score, infos
|
| 213 |
+
|
| 214 |
+
# class vgg16_locate(nn.Module):
|
| 215 |
+
# def __init__(self):
|
| 216 |
+
# super(vgg16_locate,self).__init__()
|
| 217 |
+
# self.cfg = [1024, 1024, 1024]
|
| 218 |
+
# self.vgg16 = vgg16()
|
| 219 |
+
# self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 220 |
+
# self.maxpool5 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 221 |
+
# self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 222 |
+
#
|
| 223 |
+
# self.layer5 = vgg_ex(self.cfg, 1024)
|
| 224 |
+
# self.layer6 = vgg_ex(self.cfg, 1024)
|
| 225 |
+
# self.layer7 = vgg_ex(self.cfg, 1024)
|
| 226 |
+
#
|
| 227 |
+
# self.layer71 = nn.Conv2d(1024, 512, 1, 1, bias=False)
|
| 228 |
+
# self.layer61 = nn.Conv2d(1024, 512, 1, 1, bias=False)
|
| 229 |
+
# self.layer51 = nn.Conv2d(1024, 512, 1, 1, bias=False)
|
| 230 |
+
# self.layer41 = nn.Conv2d(1024, 512, 1, 1, bias=False)
|
| 231 |
+
#
|
| 232 |
+
# self.layer76 = nn.Conv2d(512, 512, 3, 1, 1, bias=False)
|
| 233 |
+
# self.layer65 = nn.Conv2d(512, 512, 3, 1, 1, bias=False)
|
| 234 |
+
# self.layer54 = nn.Sequential(nn.Conv2d(512, 512, 3, 1, 1, bias=False), nn.ReLU(inplace=True), nn.Conv2d(512, 512, 1, 1, bias=False))
|
| 235 |
+
# # self.layer54 = nn.Conv2d(512, 512, 3, 1, 1, bias=False)
|
| 236 |
+
# # self.layer54_ = nn.Sequential(nn.ReLU(inplace=True), nn.Conv2d(512, 512, 1, 1, bias=False))
|
| 237 |
+
# # self.score = nn.Conv2d(512, 1, 1, 1)
|
| 238 |
+
#
|
| 239 |
+
# self.relu = nn.ReLU(inplace=True)
|
| 240 |
+
#
|
| 241 |
+
# for m in self.modules():
|
| 242 |
+
# if isinstance(m, nn.Conv2d):
|
| 243 |
+
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 244 |
+
# m.weight.data.normal_(0, 0.01)
|
| 245 |
+
# elif isinstance(m, nn.BatchNorm2d):
|
| 246 |
+
# m.weight.data.fill_(1)
|
| 247 |
+
# m.bias.data.zero_()
|
| 248 |
+
#
|
| 249 |
+
# def load_pretrained_model(self, model):
|
| 250 |
+
# self.vgg16.load_pretrained_model(model)
|
| 251 |
+
#
|
| 252 |
+
# def forward(self, x):
|
| 253 |
+
# x_size = x.size()[2:]
|
| 254 |
+
# score_fuse, score = None, None
|
| 255 |
+
# xs = self.vgg16(x)
|
| 256 |
+
#
|
| 257 |
+
# x5 = self.layer5(self.maxpool4(xs[-1]))
|
| 258 |
+
# x6 = self.layer6(self.maxpool5(x5))
|
| 259 |
+
# x7 = self.layer7(self.maxpool6(x6))
|
| 260 |
+
#
|
| 261 |
+
# x8 = self.layer76(self.relu(torch.add(F.interpolate(self.layer71(x7) , x6.size()[2:], mode='bilinear', align_corners=True), self.layer61(x6))))
|
| 262 |
+
# x8 = self.layer65(self.relu(torch.add(F.interpolate(x8 , x5.size()[2:], mode='bilinear', align_corners=True), self.layer51(x5))))
|
| 263 |
+
# x8 = self.layer54(self.relu(torch.add(F.interpolate(x8 , xs[-1].size()[2:], mode='bilinear', align_corners=True), self.layer41(xs[-1]))))
|
| 264 |
+
# xs[-1] = x8
|
| 265 |
+
#
|
| 266 |
+
# # x8 = self.layer76(self.relu(torch.add(F.interpolate(self.layer71(x7) , x6.size()[2:], mode='bilinear', align_corners=True), self.layer61(x6))))
|
| 267 |
+
# # x9 = self.layer65(self.relu(torch.add(F.interpolate(x8 , x5.size()[2:], mode='bilinear', align_corners=True), self.layer51(x5))))
|
| 268 |
+
# # x10 = self.layer54(self.relu(torch.add(F.interpolate(x9 , xs[-1].size()[2:], mode='bilinear', align_corners=True), self.layer41(xs[-1]))))
|
| 269 |
+
# # score_fuse = F.interpolate(self.score(self.relu(torch.add(torch.add(F.interpolate(x8 , x10.size()[2:], mode='bilinear', align_corners=True),
|
| 270 |
+
# # F.interpolate(x9 , x10.size()[2:], mode='bilinear', align_corners=True)), x10))), x_size, mode='bilinear', align_corners=True)
|
| 271 |
+
# # xs[-1] = self.layer54_(x10)
|
| 272 |
+
#
|
| 273 |
+
# return xs, score_fuse, score
|
src/diffusion_hacked.py
ADDED
|
@@ -0,0 +1,957 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from einops import rearrange, reduce, repeat
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import torch
|
| 4 |
+
import gc
|
| 5 |
+
from src.utils import *
|
| 6 |
+
from src.flow_utils import get_mapping_ind, warp_tensor
|
| 7 |
+
from diffusers.models.unet_2d_condition import UNet2DConditionOutput
|
| 8 |
+
from diffusers.models.attention_processor import AttnProcessor2_0
|
| 9 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 10 |
+
import sys
|
| 11 |
+
sys.path.append("./src/ebsynth/deps/gmflow/")
|
| 12 |
+
from gmflow.geometry import flow_warp, forward_backward_consistency_check
|
| 13 |
+
|
| 14 |
+
"""
|
| 15 |
+
==========================================================================
|
| 16 |
+
PART I - FRESCO-based attention
|
| 17 |
+
* Class AttentionControl: Control the function of FRESCO-based attention
|
| 18 |
+
* Class FRESCOAttnProcessor2_0: FRESCO-based attention
|
| 19 |
+
* apply_FRESCO_attn(): Apply FRESCO-based attention to a StableDiffusionPipeline
|
| 20 |
+
==========================================================================
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
class AttentionControl():
|
| 24 |
+
"""
|
| 25 |
+
Control FRESCO-based attention
|
| 26 |
+
* enable/diable spatial-guided attention
|
| 27 |
+
* enable/diable temporal-guided attention
|
| 28 |
+
* enable/diable cross-frame attention
|
| 29 |
+
* collect intermediate attention feature (for spatial-guided attention)
|
| 30 |
+
"""
|
| 31 |
+
def __init__(self):
|
| 32 |
+
self.stored_attn = self.get_empty_store()
|
| 33 |
+
self.store = False
|
| 34 |
+
self.index = 0
|
| 35 |
+
self.attn_mask = None
|
| 36 |
+
self.interattn_paras = None
|
| 37 |
+
self.use_interattn = False
|
| 38 |
+
self.use_cfattn = False
|
| 39 |
+
self.use_intraattn = False
|
| 40 |
+
self.intraattn_bias = 0
|
| 41 |
+
self.intraattn_scale_factor = 0.2
|
| 42 |
+
self.interattn_scale_factor = 0.2
|
| 43 |
+
|
| 44 |
+
@staticmethod
|
| 45 |
+
def get_empty_store():
|
| 46 |
+
return {
|
| 47 |
+
'decoder_attn': [],
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
def clear_store(self):
|
| 51 |
+
del self.stored_attn
|
| 52 |
+
torch.cuda.empty_cache()
|
| 53 |
+
gc.collect()
|
| 54 |
+
self.stored_attn = self.get_empty_store()
|
| 55 |
+
self.disable_intraattn()
|
| 56 |
+
|
| 57 |
+
# store attention feature of the input frame for spatial-guided attention
|
| 58 |
+
def enable_store(self):
|
| 59 |
+
self.store = True
|
| 60 |
+
|
| 61 |
+
def disable_store(self):
|
| 62 |
+
self.store = False
|
| 63 |
+
|
| 64 |
+
# spatial-guided attention
|
| 65 |
+
def enable_intraattn(self):
|
| 66 |
+
self.index = 0
|
| 67 |
+
self.use_intraattn = True
|
| 68 |
+
self.disable_store()
|
| 69 |
+
if len(self.stored_attn['decoder_attn']) == 0:
|
| 70 |
+
self.use_intraattn = False
|
| 71 |
+
|
| 72 |
+
def disable_intraattn(self):
|
| 73 |
+
self.index = 0
|
| 74 |
+
self.use_intraattn = False
|
| 75 |
+
self.disable_store()
|
| 76 |
+
|
| 77 |
+
def disable_cfattn(self):
|
| 78 |
+
self.use_cfattn = False
|
| 79 |
+
|
| 80 |
+
# cross frame attention
|
| 81 |
+
def enable_cfattn(self, attn_mask=None):
|
| 82 |
+
if attn_mask:
|
| 83 |
+
if self.attn_mask:
|
| 84 |
+
del self.attn_mask
|
| 85 |
+
torch.cuda.empty_cache()
|
| 86 |
+
self.attn_mask = attn_mask
|
| 87 |
+
self.use_cfattn = True
|
| 88 |
+
else:
|
| 89 |
+
if self.attn_mask:
|
| 90 |
+
self.use_cfattn = True
|
| 91 |
+
else:
|
| 92 |
+
print('Warning: no valid cross-frame attention parameters available!')
|
| 93 |
+
self.disable_cfattn()
|
| 94 |
+
|
| 95 |
+
def disable_interattn(self):
|
| 96 |
+
self.use_interattn = False
|
| 97 |
+
|
| 98 |
+
# temporal-guided attention
|
| 99 |
+
def enable_interattn(self, interattn_paras=None):
|
| 100 |
+
if interattn_paras:
|
| 101 |
+
if self.interattn_paras:
|
| 102 |
+
del self.interattn_paras
|
| 103 |
+
torch.cuda.empty_cache()
|
| 104 |
+
self.interattn_paras = interattn_paras
|
| 105 |
+
self.use_interattn = True
|
| 106 |
+
else:
|
| 107 |
+
if self.interattn_paras:
|
| 108 |
+
self.use_interattn = True
|
| 109 |
+
else:
|
| 110 |
+
print('Warning: no valid temporal-guided attention parameters available!')
|
| 111 |
+
self.disable_interattn()
|
| 112 |
+
|
| 113 |
+
def disable_controller(self):
|
| 114 |
+
self.disable_intraattn()
|
| 115 |
+
self.disable_interattn()
|
| 116 |
+
self.disable_cfattn()
|
| 117 |
+
|
| 118 |
+
def enable_controller(self, interattn_paras=None, attn_mask=None):
|
| 119 |
+
self.enable_intraattn()
|
| 120 |
+
self.enable_interattn(interattn_paras)
|
| 121 |
+
self.enable_cfattn(attn_mask)
|
| 122 |
+
|
| 123 |
+
def forward(self, context):
|
| 124 |
+
if self.store:
|
| 125 |
+
self.stored_attn['decoder_attn'].append(context.detach())
|
| 126 |
+
if self.use_intraattn and len(self.stored_attn['decoder_attn']) > 0:
|
| 127 |
+
tmp = self.stored_attn['decoder_attn'][self.index]
|
| 128 |
+
self.index = self.index + 1
|
| 129 |
+
if self.index >= len(self.stored_attn['decoder_attn']):
|
| 130 |
+
self.index = 0
|
| 131 |
+
self.disable_store()
|
| 132 |
+
return tmp
|
| 133 |
+
return context
|
| 134 |
+
|
| 135 |
+
def __call__(self, context):
|
| 136 |
+
context = self.forward(context)
|
| 137 |
+
return context
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
#import xformers
|
| 141 |
+
#import importlib
|
| 142 |
+
class FRESCOAttnProcessor2_0:
|
| 143 |
+
"""
|
| 144 |
+
Hack self attention to FRESCO-based attention
|
| 145 |
+
* adding spatial-guided attention
|
| 146 |
+
* adding temporal-guided attention
|
| 147 |
+
* adding cross-frame attention
|
| 148 |
+
|
| 149 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 150 |
+
Usage
|
| 151 |
+
frescoProc = FRESCOAttnProcessor2_0(2, attn_mask)
|
| 152 |
+
attnProc = AttnProcessor2_0()
|
| 153 |
+
|
| 154 |
+
attn_processor_dict = {}
|
| 155 |
+
for k in pipe.unet.attn_processors.keys():
|
| 156 |
+
if k.startswith("up_blocks.2") or k.startswith("up_blocks.3"):
|
| 157 |
+
attn_processor_dict[k] = frescoProc
|
| 158 |
+
else:
|
| 159 |
+
attn_processor_dict[k] = attnProc
|
| 160 |
+
pipe.unet.set_attn_processor(attn_processor_dict)
|
| 161 |
+
"""
|
| 162 |
+
|
| 163 |
+
def __init__(self, unet_chunk_size=2, controller=None):
|
| 164 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 165 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 166 |
+
self.unet_chunk_size = unet_chunk_size
|
| 167 |
+
self.controller = controller
|
| 168 |
+
|
| 169 |
+
def __call__(
|
| 170 |
+
self,
|
| 171 |
+
attn,
|
| 172 |
+
hidden_states,
|
| 173 |
+
encoder_hidden_states=None,
|
| 174 |
+
attention_mask=None,
|
| 175 |
+
temb=None,
|
| 176 |
+
):
|
| 177 |
+
residual = hidden_states
|
| 178 |
+
|
| 179 |
+
if attn.spatial_norm is not None:
|
| 180 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 181 |
+
|
| 182 |
+
input_ndim = hidden_states.ndim
|
| 183 |
+
|
| 184 |
+
if input_ndim == 4:
|
| 185 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 186 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 187 |
+
|
| 188 |
+
batch_size, sequence_length, _ = (
|
| 189 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
if attention_mask is not None:
|
| 193 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 194 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 195 |
+
# (batch, heads, source_length, target_length)
|
| 196 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 197 |
+
|
| 198 |
+
if attn.group_norm is not None:
|
| 199 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 200 |
+
|
| 201 |
+
query = attn.to_q(hidden_states)
|
| 202 |
+
|
| 203 |
+
crossattn = False
|
| 204 |
+
if encoder_hidden_states is None:
|
| 205 |
+
encoder_hidden_states = hidden_states
|
| 206 |
+
if self.controller and self.controller.store:
|
| 207 |
+
self.controller(hidden_states.detach().clone())
|
| 208 |
+
else:
|
| 209 |
+
crossattn = True
|
| 210 |
+
if attn.norm_cross:
|
| 211 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 212 |
+
|
| 213 |
+
# BC * HW * 8D
|
| 214 |
+
key = attn.to_k(encoder_hidden_states)
|
| 215 |
+
value = attn.to_v(encoder_hidden_states)
|
| 216 |
+
|
| 217 |
+
query_raw, key_raw = None, None
|
| 218 |
+
if self.controller and self.controller.use_interattn and (not crossattn):
|
| 219 |
+
query_raw, key_raw = query.clone(), key.clone()
|
| 220 |
+
|
| 221 |
+
inner_dim = key.shape[-1] # 8D
|
| 222 |
+
head_dim = inner_dim // attn.heads # D
|
| 223 |
+
|
| 224 |
+
'''for efficient cross-frame attention'''
|
| 225 |
+
if self.controller and self.controller.use_cfattn and (not crossattn):
|
| 226 |
+
video_length = key.size()[0] // self.unet_chunk_size
|
| 227 |
+
former_frame_index = [0] * video_length
|
| 228 |
+
attn_mask = None
|
| 229 |
+
if self.controller.attn_mask is not None:
|
| 230 |
+
for m in self.controller.attn_mask:
|
| 231 |
+
if m.shape[1] == key.shape[1]:
|
| 232 |
+
attn_mask = m
|
| 233 |
+
# BC * HW * 8D --> B * C * HW * 8D
|
| 234 |
+
key = rearrange(key, "(b f) d c -> b f d c", f=video_length)
|
| 235 |
+
# B * C * HW * 8D --> B * C * HW * 8D
|
| 236 |
+
if attn_mask is None:
|
| 237 |
+
key = key[:, former_frame_index]
|
| 238 |
+
else:
|
| 239 |
+
key = repeat(key[:, attn_mask], "b d c -> b f d c", f=video_length)
|
| 240 |
+
# B * C * HW * 8D --> BC * HW * 8D
|
| 241 |
+
key = rearrange(key, "b f d c -> (b f) d c").detach()
|
| 242 |
+
value = rearrange(value, "(b f) d c -> b f d c", f=video_length)
|
| 243 |
+
if attn_mask is None:
|
| 244 |
+
value = value[:, former_frame_index]
|
| 245 |
+
else:
|
| 246 |
+
value = repeat(value[:, attn_mask], "b d c -> b f d c", f=video_length)
|
| 247 |
+
value = rearrange(value, "b f d c -> (b f) d c").detach()
|
| 248 |
+
|
| 249 |
+
# BC * HW * 8D --> BC * HW * 8 * D --> BC * 8 * HW * D
|
| 250 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 251 |
+
# BC * 8 * HW2 * D
|
| 252 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 253 |
+
# BC * 8 * HW2 * D2
|
| 254 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 255 |
+
|
| 256 |
+
'''for spatial-guided intra-frame attention'''
|
| 257 |
+
if self.controller and self.controller.use_intraattn and (not crossattn):
|
| 258 |
+
ref_hidden_states = self.controller(None)
|
| 259 |
+
assert ref_hidden_states.shape == encoder_hidden_states.shape
|
| 260 |
+
query_ = attn.to_q(ref_hidden_states)
|
| 261 |
+
key_ = attn.to_k(ref_hidden_states)
|
| 262 |
+
|
| 263 |
+
'''
|
| 264 |
+
# for xformers implementation
|
| 265 |
+
if importlib.util.find_spec("xformers") is not None:
|
| 266 |
+
# BC * HW * 8D --> BC * HW * 8 * D
|
| 267 |
+
query_ = rearrange(query_, "b d (h c) -> b d h c", h=attn.heads)
|
| 268 |
+
key_ = rearrange(key_, "b d (h c) -> b d h c", h=attn.heads)
|
| 269 |
+
# BC * 8 * HW * D --> 8BC * HW * D
|
| 270 |
+
query = rearrange(query, "b h d c -> b d h c")
|
| 271 |
+
query = xformers.ops.memory_efficient_attention(
|
| 272 |
+
query_, key_ * self.sattn_scale_factor, query,
|
| 273 |
+
attn_bias=torch.eye(query_.size(1), key_.size(1),
|
| 274 |
+
dtype=query.dtype, device=query.device) * self.bias_weight, op=None
|
| 275 |
+
)
|
| 276 |
+
query = rearrange(query, "b d h c -> b h d c").detach()
|
| 277 |
+
'''
|
| 278 |
+
# BC * 8 * HW * D
|
| 279 |
+
query_ = query_.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 280 |
+
key_ = key_.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 281 |
+
query = F.scaled_dot_product_attention(
|
| 282 |
+
query_, key_ * self.controller.intraattn_scale_factor, query,
|
| 283 |
+
attn_mask = torch.eye(query_.size(-2), key_.size(-2),
|
| 284 |
+
dtype=query.dtype, device=query.device) * self.controller.intraattn_bias,
|
| 285 |
+
).detach()
|
| 286 |
+
#print('intra: ', GPU.getGPUs()[1].memoryUsed)
|
| 287 |
+
del query_, key_
|
| 288 |
+
torch.cuda.empty_cache()
|
| 289 |
+
|
| 290 |
+
'''
|
| 291 |
+
# for xformers implementation
|
| 292 |
+
if importlib.util.find_spec("xformers") is not None:
|
| 293 |
+
hidden_states = xformers.ops.memory_efficient_attention(
|
| 294 |
+
rearrange(query, "b h d c -> b d h c"), rearrange(key, "b h d c -> b d h c"),
|
| 295 |
+
rearrange(value, "b h d c -> b d h c"),
|
| 296 |
+
attn_bias=attention_mask, op=None
|
| 297 |
+
)
|
| 298 |
+
hidden_states = rearrange(hidden_states, "b d h c -> b h d c", h=attn.heads)
|
| 299 |
+
'''
|
| 300 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 301 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 302 |
+
# output: BC * 8 * HW * D2
|
| 303 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 304 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 305 |
+
)
|
| 306 |
+
#print('cross: ', GPU.getGPUs()[1].memoryUsed)
|
| 307 |
+
|
| 308 |
+
'''for temporal-guided inter-frame attention (FLATTEN)'''
|
| 309 |
+
if self.controller and self.controller.use_interattn and (not crossattn):
|
| 310 |
+
del query, key, value
|
| 311 |
+
torch.cuda.empty_cache()
|
| 312 |
+
bwd_mapping = None
|
| 313 |
+
fwd_mapping = None
|
| 314 |
+
flattn_mask = None
|
| 315 |
+
for i, f in enumerate(self.controller.interattn_paras['fwd_mappings']):
|
| 316 |
+
if f.shape[2] == hidden_states.shape[2]:
|
| 317 |
+
fwd_mapping = f
|
| 318 |
+
bwd_mapping = self.controller.interattn_paras['bwd_mappings'][i]
|
| 319 |
+
interattn_mask = self.controller.interattn_paras['interattn_masks'][i]
|
| 320 |
+
video_length = key_raw.size()[0] // self.unet_chunk_size
|
| 321 |
+
# BC * HW * 8D --> C * 8BD * HW
|
| 322 |
+
key = rearrange(key_raw, "(b f) d c -> f (b c) d", f=video_length)
|
| 323 |
+
query = rearrange(query_raw, "(b f) d c -> f (b c) d", f=video_length)
|
| 324 |
+
# BC * 8 * HW * D --> C * 8BD * HW
|
| 325 |
+
#key = rearrange(hidden_states, "(b f) h d c -> f (b h c) d", f=video_length) ########
|
| 326 |
+
#query = rearrange(hidden_states, "(b f) h d c -> f (b h c) d", f=video_length) #######
|
| 327 |
+
|
| 328 |
+
value = rearrange(hidden_states, "(b f) h d c -> f (b h c) d", f=video_length)
|
| 329 |
+
key = torch.gather(key, 2, fwd_mapping.expand(-1,key.shape[1],-1))
|
| 330 |
+
query = torch.gather(query, 2, fwd_mapping.expand(-1,query.shape[1],-1))
|
| 331 |
+
value = torch.gather(value, 2, fwd_mapping.expand(-1,value.shape[1],-1))
|
| 332 |
+
# C * 8BD * HW --> BHW, C, 8D
|
| 333 |
+
key = rearrange(key, "f (b c) d -> (b d) f c", b=self.unet_chunk_size)
|
| 334 |
+
query = rearrange(query, "f (b c) d -> (b d) f c", b=self.unet_chunk_size)
|
| 335 |
+
value = rearrange(value, "f (b c) d -> (b d) f c", b=self.unet_chunk_size)
|
| 336 |
+
'''
|
| 337 |
+
# for xformers implementation
|
| 338 |
+
if importlib.util.find_spec("xformers") is not None:
|
| 339 |
+
# BHW * C * 8D --> BHW * C * 8 * D
|
| 340 |
+
query = rearrange(query, "b d (h c) -> b d h c", h=attn.heads)
|
| 341 |
+
key = rearrange(key, "b d (h c) -> b d h c", h=attn.heads)
|
| 342 |
+
value = rearrange(value, "b d (h c) -> b d h c", h=attn.heads)
|
| 343 |
+
B, D, C, _ = flattn_mask.shape
|
| 344 |
+
C1 = int(np.ceil(C / 4) * 4)
|
| 345 |
+
attn_bias = torch.zeros(B, D, C, C1, dtype=value.dtype, device=value.device) # HW * 1 * C * C
|
| 346 |
+
attn_bias[:,:,:,:C].masked_fill_(interattn_mask.logical_not(), float("-inf")) # BHW * C * C
|
| 347 |
+
hidden_states_ = xformers.ops.memory_efficient_attention(
|
| 348 |
+
query, key * self.controller.interattn_scale_factor, value,
|
| 349 |
+
attn_bias=attn_bias.squeeze(1).repeat(self.unet_chunk_size*attn.heads,1,1)[:,:,:C], op=None
|
| 350 |
+
)
|
| 351 |
+
hidden_states_ = rearrange(hidden_states_, "b d h c -> b h d c", h=attn.heads).detach()
|
| 352 |
+
'''
|
| 353 |
+
# BHW * C * 8D --> BHW * C * 8 * D--> BHW * 8 * C * D
|
| 354 |
+
query = query.view(-1, video_length, attn.heads, head_dim).transpose(1, 2).detach()
|
| 355 |
+
key = key.view(-1, video_length, attn.heads, head_dim).transpose(1, 2).detach()
|
| 356 |
+
value = value.view(-1, video_length, attn.heads, head_dim).transpose(1, 2).detach()
|
| 357 |
+
hidden_states_ = F.scaled_dot_product_attention(
|
| 358 |
+
query, key * self.controller.interattn_scale_factor, value,
|
| 359 |
+
attn_mask = (interattn_mask.repeat(self.unet_chunk_size,1,1,1))#.to(query.dtype)-1.0) * 1e6 -
|
| 360 |
+
#torch.eye(interattn_mask.shape[2]).to(query.device).to(query.dtype) * 1e4,
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
# BHW * 8 * C * D --> C * 8BD * HW
|
| 364 |
+
hidden_states_ = rearrange(hidden_states_, "(b d) h f c -> f (b h c) d", b=self.unet_chunk_size)
|
| 365 |
+
hidden_states_ = torch.gather(hidden_states_, 2, bwd_mapping.expand(-1,hidden_states_.shape[1],-1)).detach()
|
| 366 |
+
# C * 8BD * HW --> BC * 8 * HW * D
|
| 367 |
+
hidden_states = rearrange(hidden_states_, "f (b h c) d -> (b f) h d c", b=self.unet_chunk_size, h=attn.heads)
|
| 368 |
+
#print('inter: ', GPU.getGPUs()[1].memoryUsed)
|
| 369 |
+
|
| 370 |
+
# BC * 8 * HW * D --> BC * HW * 8D
|
| 371 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 372 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 373 |
+
|
| 374 |
+
# linear proj
|
| 375 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 376 |
+
# dropout
|
| 377 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 378 |
+
|
| 379 |
+
if input_ndim == 4:
|
| 380 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 381 |
+
|
| 382 |
+
if attn.residual_connection:
|
| 383 |
+
hidden_states = hidden_states + residual
|
| 384 |
+
|
| 385 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 386 |
+
|
| 387 |
+
return hidden_states
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
def apply_FRESCO_attn(pipe):
|
| 391 |
+
"""
|
| 392 |
+
Apply FRESCO-guided attention to a StableDiffusionPipeline
|
| 393 |
+
"""
|
| 394 |
+
frescoProc = FRESCOAttnProcessor2_0(2, AttentionControl())
|
| 395 |
+
attnProc = AttnProcessor2_0()
|
| 396 |
+
attn_processor_dict = {}
|
| 397 |
+
for k in pipe.unet.attn_processors.keys():
|
| 398 |
+
if k.startswith("up_blocks.2") or k.startswith("up_blocks.3"):
|
| 399 |
+
attn_processor_dict[k] = frescoProc
|
| 400 |
+
else:
|
| 401 |
+
attn_processor_dict[k] = attnProc
|
| 402 |
+
pipe.unet.set_attn_processor(attn_processor_dict)
|
| 403 |
+
return frescoProc
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
"""
|
| 407 |
+
==========================================================================
|
| 408 |
+
PART II - FRESCO-based optimization
|
| 409 |
+
* optimize_feature(): function to optimze latent feature
|
| 410 |
+
* my_forward(): hacked pipe.unet.forward(), adding feature optimization
|
| 411 |
+
* apply_FRESCO_opt(): function to apply FRESCO-based optimization to a StableDiffusionPipeline
|
| 412 |
+
* disable_FRESCO_opt(): function to disable the FRESCO-based optimization
|
| 413 |
+
==========================================================================
|
| 414 |
+
"""
|
| 415 |
+
|
| 416 |
+
def optimize_feature(sample, flows, occs, correlation_matrix=[],
|
| 417 |
+
intra_weight = 1e2, iters=20, unet_chunk_size=2, optimize_temporal = True):
|
| 418 |
+
"""
|
| 419 |
+
FRESO-guided latent feature optimization
|
| 420 |
+
* optimize spatial correspondence (match correlation_matrix)
|
| 421 |
+
* optimize temporal correspondence (match warped_image)
|
| 422 |
+
"""
|
| 423 |
+
if (flows is None or occs is None or (not optimize_temporal)) and (intra_weight == 0 or len(correlation_matrix) == 0):
|
| 424 |
+
return sample
|
| 425 |
+
# flows=[fwd_flows, bwd_flows]: (N-1)*2*H1*W1
|
| 426 |
+
# occs=[fwd_occs, bwd_occs]: (N-1)*H1*W1
|
| 427 |
+
# sample: 2N*C*H*W
|
| 428 |
+
torch.cuda.empty_cache()
|
| 429 |
+
video_length = sample.shape[0] // unet_chunk_size
|
| 430 |
+
latent = rearrange(sample.to(torch.float32), "(b f) c h w -> b f c h w", f=video_length)
|
| 431 |
+
|
| 432 |
+
cs = torch.nn.Parameter((latent.detach().clone()))
|
| 433 |
+
optimizer = torch.optim.Adam([cs], lr=0.2)
|
| 434 |
+
|
| 435 |
+
# unify resolution
|
| 436 |
+
if flows is not None and occs is not None:
|
| 437 |
+
scale = sample.shape[2] * 1.0 / flows[0].shape[2]
|
| 438 |
+
kernel = int(1 / scale)
|
| 439 |
+
bwd_flow_ = F.interpolate(flows[1] * scale, scale_factor=scale, mode='bilinear').repeat(unet_chunk_size,1,1,1)
|
| 440 |
+
bwd_occ_ = F.max_pool2d(occs[1].unsqueeze(1), kernel_size=kernel).repeat(unet_chunk_size,1,1,1) # 2(N-1)*1*H1*W1
|
| 441 |
+
fwd_flow_ = F.interpolate(flows[0] * scale, scale_factor=scale, mode='bilinear').repeat(unet_chunk_size,1,1,1)
|
| 442 |
+
fwd_occ_ = F.max_pool2d(occs[0].unsqueeze(1), kernel_size=kernel).repeat(unet_chunk_size,1,1,1) # 2(N-1)*1*H1*W1
|
| 443 |
+
# match frame 0,1,2,3 and frame 1,2,3,0
|
| 444 |
+
reshuffle_list = list(range(1,video_length))+[0]
|
| 445 |
+
|
| 446 |
+
# attention_probs is the GRAM matrix of the normalized feature
|
| 447 |
+
attention_probs = None
|
| 448 |
+
for tmp in correlation_matrix:
|
| 449 |
+
if sample.shape[2] * sample.shape[3] == tmp.shape[1]:
|
| 450 |
+
attention_probs = tmp # 2N*HW*HW
|
| 451 |
+
break
|
| 452 |
+
|
| 453 |
+
n_iter=[0]
|
| 454 |
+
while n_iter[0] < iters:
|
| 455 |
+
def closure():
|
| 456 |
+
optimizer.zero_grad()
|
| 457 |
+
|
| 458 |
+
loss = 0
|
| 459 |
+
|
| 460 |
+
# temporal consistency loss
|
| 461 |
+
if optimize_temporal and flows is not None and occs is not None:
|
| 462 |
+
c1 = rearrange(cs[:,:], "b f c h w -> (b f) c h w")
|
| 463 |
+
c2 = rearrange(cs[:,reshuffle_list], "b f c h w -> (b f) c h w")
|
| 464 |
+
warped_image1 = flow_warp(c1, bwd_flow_)
|
| 465 |
+
warped_image2 = flow_warp(c2, fwd_flow_)
|
| 466 |
+
loss = (abs((c2-warped_image1)*(1-bwd_occ_)) + abs((c1-warped_image2)*(1-fwd_occ_))).mean() * 2
|
| 467 |
+
|
| 468 |
+
# spatial consistency loss
|
| 469 |
+
if attention_probs is not None and intra_weight > 0:
|
| 470 |
+
cs_vector = rearrange(cs, "b f c h w -> (b f) (h w) c")
|
| 471 |
+
#attention_scores = torch.bmm(cs_vector, cs_vector.transpose(-1, -2))
|
| 472 |
+
#cs_attention_probs = attention_scores.softmax(dim=-1)
|
| 473 |
+
cs_vector = cs_vector / ((cs_vector ** 2).sum(dim=2, keepdims=True) ** 0.5)
|
| 474 |
+
cs_attention_probs = torch.bmm(cs_vector, cs_vector.transpose(-1, -2))
|
| 475 |
+
tmp = F.l1_loss(cs_attention_probs, attention_probs) * intra_weight
|
| 476 |
+
loss = tmp + loss
|
| 477 |
+
|
| 478 |
+
loss.backward()
|
| 479 |
+
n_iter[0]+=1
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
if False: # for debug
|
| 483 |
+
print('Iteration: %d, loss: %f'%(n_iter[0]+1, loss.data.mean()))
|
| 484 |
+
return loss
|
| 485 |
+
optimizer.step(closure)
|
| 486 |
+
|
| 487 |
+
torch.cuda.empty_cache()
|
| 488 |
+
return adaptive_instance_normalization(rearrange(cs.data.to(sample.dtype), "b f c h w -> (b f) c h w"), sample)
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
def my_forward(self, steps = [], layers = [0,1,2,3], flows = None, occs = None,
|
| 492 |
+
correlation_matrix=[], intra_weight = 1e2, iters=20, optimize_temporal = True, saliency = None):
|
| 493 |
+
"""
|
| 494 |
+
Hacked pipe.unet.forward()
|
| 495 |
+
copied from https://github.com/huggingface/diffusers/blob/v0.19.3/src/diffusers/models/unet_2d_condition.py#L700
|
| 496 |
+
if you are using a new version of diffusers, please copy the source code and modify it accordingly (find [HACK] in the code)
|
| 497 |
+
* restore and return the decoder features
|
| 498 |
+
* optimize the decoder features
|
| 499 |
+
* perform background smoothing
|
| 500 |
+
"""
|
| 501 |
+
def forward(
|
| 502 |
+
sample: torch.FloatTensor,
|
| 503 |
+
timestep: Union[torch.Tensor, float, int],
|
| 504 |
+
encoder_hidden_states: torch.Tensor,
|
| 505 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 506 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 507 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 508 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 509 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 510 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 511 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 512 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 513 |
+
return_dict: bool = True,
|
| 514 |
+
) -> Union[UNet2DConditionOutput, Tuple]:
|
| 515 |
+
r"""
|
| 516 |
+
The [`UNet2DConditionModel`] forward method.
|
| 517 |
+
|
| 518 |
+
Args:
|
| 519 |
+
sample (`torch.FloatTensor`):
|
| 520 |
+
The noisy input tensor with the following shape `(batch, channel, height, width)`.
|
| 521 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 522 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 523 |
+
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
|
| 524 |
+
encoder_attention_mask (`torch.Tensor`):
|
| 525 |
+
A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
|
| 526 |
+
`True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
|
| 527 |
+
which adds large negative values to the attention scores corresponding to "discard" tokens.
|
| 528 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 529 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 530 |
+
tuple.
|
| 531 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 532 |
+
A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
|
| 533 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 534 |
+
A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
|
| 535 |
+
are passed along to the UNet blocks.
|
| 536 |
+
|
| 537 |
+
Returns:
|
| 538 |
+
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
| 539 |
+
If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
|
| 540 |
+
a `tuple` is returned where the first element is the sample tensor.
|
| 541 |
+
"""
|
| 542 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 543 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
|
| 544 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 545 |
+
# on the fly if necessary.
|
| 546 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 547 |
+
|
| 548 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 549 |
+
forward_upsample_size = False
|
| 550 |
+
upsample_size = None
|
| 551 |
+
|
| 552 |
+
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
| 553 |
+
logger.info("Forward upsample size to force interpolation output size.")
|
| 554 |
+
forward_upsample_size = True
|
| 555 |
+
|
| 556 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension
|
| 557 |
+
# expects mask of shape:
|
| 558 |
+
# [batch, key_tokens]
|
| 559 |
+
# adds singleton query_tokens dimension:
|
| 560 |
+
# [batch, 1, key_tokens]
|
| 561 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 562 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 563 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 564 |
+
if attention_mask is not None:
|
| 565 |
+
# assume that mask is expressed as:
|
| 566 |
+
# (1 = keep, 0 = discard)
|
| 567 |
+
# convert mask into a bias that can be added to attention scores:
|
| 568 |
+
# (keep = +0, discard = -10000.0)
|
| 569 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 570 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 571 |
+
|
| 572 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 573 |
+
if encoder_attention_mask is not None:
|
| 574 |
+
encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
|
| 575 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 576 |
+
|
| 577 |
+
# 0. center input if necessary
|
| 578 |
+
if self.config.center_input_sample:
|
| 579 |
+
sample = 2 * sample - 1.0
|
| 580 |
+
|
| 581 |
+
# 1. time
|
| 582 |
+
timesteps = timestep
|
| 583 |
+
if not torch.is_tensor(timesteps):
|
| 584 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 585 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 586 |
+
is_mps = sample.device.type == "mps"
|
| 587 |
+
if isinstance(timestep, float):
|
| 588 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 589 |
+
else:
|
| 590 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 591 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 592 |
+
elif len(timesteps.shape) == 0:
|
| 593 |
+
timesteps = timesteps[None].to(sample.device)
|
| 594 |
+
|
| 595 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 596 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 597 |
+
|
| 598 |
+
t_emb = self.time_proj(timesteps)
|
| 599 |
+
|
| 600 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 601 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 602 |
+
# there might be better ways to encapsulate this.
|
| 603 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 604 |
+
|
| 605 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 606 |
+
aug_emb = None
|
| 607 |
+
|
| 608 |
+
if self.class_embedding is not None:
|
| 609 |
+
if class_labels is None:
|
| 610 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 611 |
+
|
| 612 |
+
if self.config.class_embed_type == "timestep":
|
| 613 |
+
class_labels = self.time_proj(class_labels)
|
| 614 |
+
|
| 615 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 616 |
+
# there might be better ways to encapsulate this.
|
| 617 |
+
class_labels = class_labels.to(dtype=sample.dtype)
|
| 618 |
+
|
| 619 |
+
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
|
| 620 |
+
|
| 621 |
+
if self.config.class_embeddings_concat:
|
| 622 |
+
emb = torch.cat([emb, class_emb], dim=-1)
|
| 623 |
+
else:
|
| 624 |
+
emb = emb + class_emb
|
| 625 |
+
|
| 626 |
+
if self.config.addition_embed_type == "text":
|
| 627 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 628 |
+
elif self.config.addition_embed_type == "text_image":
|
| 629 |
+
# Kandinsky 2.1 - style
|
| 630 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 631 |
+
raise ValueError(
|
| 632 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 633 |
+
)
|
| 634 |
+
|
| 635 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 636 |
+
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
| 637 |
+
aug_emb = self.add_embedding(text_embs, image_embs)
|
| 638 |
+
elif self.config.addition_embed_type == "text_time":
|
| 639 |
+
# SDXL - style
|
| 640 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 641 |
+
raise ValueError(
|
| 642 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 643 |
+
)
|
| 644 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 645 |
+
if "time_ids" not in added_cond_kwargs:
|
| 646 |
+
raise ValueError(
|
| 647 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 648 |
+
)
|
| 649 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 650 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 651 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 652 |
+
|
| 653 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 654 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 655 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 656 |
+
elif self.config.addition_embed_type == "image":
|
| 657 |
+
# Kandinsky 2.2 - style
|
| 658 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 659 |
+
raise ValueError(
|
| 660 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 661 |
+
)
|
| 662 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 663 |
+
aug_emb = self.add_embedding(image_embs)
|
| 664 |
+
elif self.config.addition_embed_type == "image_hint":
|
| 665 |
+
# Kandinsky 2.2 - style
|
| 666 |
+
if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
|
| 667 |
+
raise ValueError(
|
| 668 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
|
| 669 |
+
)
|
| 670 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 671 |
+
hint = added_cond_kwargs.get("hint")
|
| 672 |
+
aug_emb, hint = self.add_embedding(image_embs, hint)
|
| 673 |
+
sample = torch.cat([sample, hint], dim=1)
|
| 674 |
+
|
| 675 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 676 |
+
|
| 677 |
+
if self.time_embed_act is not None:
|
| 678 |
+
emb = self.time_embed_act(emb)
|
| 679 |
+
|
| 680 |
+
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
| 681 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
| 682 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
| 683 |
+
# Kadinsky 2.1 - style
|
| 684 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 685 |
+
raise ValueError(
|
| 686 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 687 |
+
)
|
| 688 |
+
|
| 689 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 690 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
| 691 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
|
| 692 |
+
# Kandinsky 2.2 - style
|
| 693 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 694 |
+
raise ValueError(
|
| 695 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 696 |
+
)
|
| 697 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 698 |
+
encoder_hidden_states = self.encoder_hid_proj(image_embeds)
|
| 699 |
+
# 2. pre-process
|
| 700 |
+
sample = self.conv_in(sample)
|
| 701 |
+
|
| 702 |
+
# 3. down
|
| 703 |
+
|
| 704 |
+
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
|
| 705 |
+
is_adapter = mid_block_additional_residual is None and down_block_additional_residuals is not None
|
| 706 |
+
|
| 707 |
+
down_block_res_samples = (sample,)
|
| 708 |
+
for downsample_block in self.down_blocks:
|
| 709 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 710 |
+
# For t2i-adapter CrossAttnDownBlock2D
|
| 711 |
+
additional_residuals = {}
|
| 712 |
+
if is_adapter and len(down_block_additional_residuals) > 0:
|
| 713 |
+
additional_residuals["additional_residuals"] = down_block_additional_residuals.pop(0)
|
| 714 |
+
|
| 715 |
+
sample, res_samples = downsample_block(
|
| 716 |
+
hidden_states=sample,
|
| 717 |
+
temb=emb,
|
| 718 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 719 |
+
attention_mask=attention_mask,
|
| 720 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 721 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 722 |
+
**additional_residuals,
|
| 723 |
+
)
|
| 724 |
+
else:
|
| 725 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
| 726 |
+
|
| 727 |
+
if is_adapter and len(down_block_additional_residuals) > 0:
|
| 728 |
+
sample += down_block_additional_residuals.pop(0)
|
| 729 |
+
down_block_res_samples += res_samples
|
| 730 |
+
|
| 731 |
+
if is_controlnet:
|
| 732 |
+
new_down_block_res_samples = ()
|
| 733 |
+
|
| 734 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 735 |
+
down_block_res_samples, down_block_additional_residuals
|
| 736 |
+
):
|
| 737 |
+
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
| 738 |
+
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
|
| 739 |
+
|
| 740 |
+
down_block_res_samples = new_down_block_res_samples
|
| 741 |
+
|
| 742 |
+
# 4. mid
|
| 743 |
+
if self.mid_block is not None:
|
| 744 |
+
sample = self.mid_block(
|
| 745 |
+
sample,
|
| 746 |
+
emb,
|
| 747 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 748 |
+
attention_mask=attention_mask,
|
| 749 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 750 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 751 |
+
)
|
| 752 |
+
|
| 753 |
+
if is_controlnet:
|
| 754 |
+
sample = sample + mid_block_additional_residual
|
| 755 |
+
|
| 756 |
+
# 5. up
|
| 757 |
+
'''
|
| 758 |
+
[HACK] restore the decoder features in up_samples
|
| 759 |
+
'''
|
| 760 |
+
up_samples = ()
|
| 761 |
+
#down_samples = ()
|
| 762 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 763 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 764 |
+
|
| 765 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 766 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 767 |
+
|
| 768 |
+
'''
|
| 769 |
+
[HACK] restore the decoder features in up_samples
|
| 770 |
+
[HACK] optimize the decoder features
|
| 771 |
+
[HACK] perform background smoothing
|
| 772 |
+
'''
|
| 773 |
+
if i in layers:
|
| 774 |
+
up_samples += (sample, )
|
| 775 |
+
if timestep in steps and i in layers:
|
| 776 |
+
sample = optimize_feature(sample, flows, occs, correlation_matrix,
|
| 777 |
+
intra_weight, iters, optimize_temporal = optimize_temporal)
|
| 778 |
+
if saliency is not None:
|
| 779 |
+
sample = warp_tensor(sample, flows, occs, saliency, 2)
|
| 780 |
+
|
| 781 |
+
# if we have not reached the final block and need to forward the
|
| 782 |
+
# upsample size, we do it here
|
| 783 |
+
if not is_final_block and forward_upsample_size:
|
| 784 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 785 |
+
|
| 786 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 787 |
+
sample = upsample_block(
|
| 788 |
+
hidden_states=sample,
|
| 789 |
+
temb=emb,
|
| 790 |
+
res_hidden_states_tuple=res_samples,
|
| 791 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 792 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 793 |
+
upsample_size=upsample_size,
|
| 794 |
+
attention_mask=attention_mask,
|
| 795 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 796 |
+
)
|
| 797 |
+
else:
|
| 798 |
+
sample = upsample_block(
|
| 799 |
+
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
| 800 |
+
)
|
| 801 |
+
|
| 802 |
+
# 6. post-process
|
| 803 |
+
if self.conv_norm_out:
|
| 804 |
+
sample = self.conv_norm_out(sample)
|
| 805 |
+
sample = self.conv_act(sample)
|
| 806 |
+
sample = self.conv_out(sample)
|
| 807 |
+
|
| 808 |
+
'''
|
| 809 |
+
[HACK] return the output feature as well as the decoder features
|
| 810 |
+
'''
|
| 811 |
+
if not return_dict:
|
| 812 |
+
return (sample, ) + up_samples
|
| 813 |
+
|
| 814 |
+
return UNet2DConditionOutput(sample=sample)
|
| 815 |
+
|
| 816 |
+
return forward
|
| 817 |
+
|
| 818 |
+
|
| 819 |
+
def apply_FRESCO_opt(pipe, steps = [], layers = [0,1,2,3], flows = None, occs = None,
|
| 820 |
+
correlation_matrix=[], intra_weight = 1e2, iters=20, optimize_temporal = True, saliency = None):
|
| 821 |
+
"""
|
| 822 |
+
Apply FRESCO-based optimization to a StableDiffusionPipeline
|
| 823 |
+
"""
|
| 824 |
+
pipe.unet.forward = my_forward(pipe.unet, steps, layers, flows, occs,
|
| 825 |
+
correlation_matrix, intra_weight, iters, optimize_temporal, saliency)
|
| 826 |
+
|
| 827 |
+
def disable_FRESCO_opt(pipe):
|
| 828 |
+
"""
|
| 829 |
+
Disable the FRESCO-based optimization
|
| 830 |
+
"""
|
| 831 |
+
apply_FRESCO_opt(pipe)
|
| 832 |
+
|
| 833 |
+
|
| 834 |
+
"""
|
| 835 |
+
=====================================================================================
|
| 836 |
+
PART III - Prepare parameters for FRESCO-guided attention/optimization
|
| 837 |
+
* get_intraframe_paras(): get parameters for spatial-guided attention/optimization
|
| 838 |
+
* get_flow_and_interframe_paras(): get parameters for temporal-guided attention/optimization
|
| 839 |
+
=====================================================================================
|
| 840 |
+
"""
|
| 841 |
+
|
| 842 |
+
@torch.no_grad()
|
| 843 |
+
def get_intraframe_paras(pipe, imgs, frescoProc,
|
| 844 |
+
prompt_embeds, do_classifier_free_guidance=True, seed=0):
|
| 845 |
+
"""
|
| 846 |
+
Get parameters for spatial-guided attention and optimization
|
| 847 |
+
* perform one step denoising
|
| 848 |
+
* collect attention feature, stored in frescoProc.controller.stored_attn['decoder_attn']
|
| 849 |
+
* compute the gram matrix of the normalized feature for spatial consistency loss
|
| 850 |
+
"""
|
| 851 |
+
|
| 852 |
+
noise_scheduler = pipe.scheduler
|
| 853 |
+
timestep = noise_scheduler.timesteps[-1]
|
| 854 |
+
device = pipe._execution_device
|
| 855 |
+
generator = torch.Generator(device=device).manual_seed(seed)
|
| 856 |
+
B, C, H, W = imgs.shape
|
| 857 |
+
|
| 858 |
+
frescoProc.controller.disable_controller()
|
| 859 |
+
disable_FRESCO_opt(pipe)
|
| 860 |
+
frescoProc.controller.clear_store()
|
| 861 |
+
frescoProc.controller.enable_store()
|
| 862 |
+
|
| 863 |
+
latents = pipe.prepare_latents(
|
| 864 |
+
B,
|
| 865 |
+
pipe.unet.config.in_channels,
|
| 866 |
+
H,
|
| 867 |
+
W,
|
| 868 |
+
prompt_embeds.dtype,
|
| 869 |
+
device,
|
| 870 |
+
generator,
|
| 871 |
+
latents = None,
|
| 872 |
+
)
|
| 873 |
+
|
| 874 |
+
latent_x0 = pipe.vae.config.scaling_factor * pipe.vae.encode(imgs.to(pipe.unet.dtype)).latent_dist.sample()
|
| 875 |
+
latents = noise_scheduler.add_noise(latent_x0, latents, timestep).detach()
|
| 876 |
+
|
| 877 |
+
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 878 |
+
model_output = pipe.unet(
|
| 879 |
+
latent_model_input,
|
| 880 |
+
timestep,
|
| 881 |
+
encoder_hidden_states=prompt_embeds,
|
| 882 |
+
cross_attention_kwargs=None,
|
| 883 |
+
return_dict=False,
|
| 884 |
+
)
|
| 885 |
+
|
| 886 |
+
frescoProc.controller.disable_store()
|
| 887 |
+
|
| 888 |
+
# gram matrix of the normalized feature for spatial consistency loss
|
| 889 |
+
correlation_matrix = []
|
| 890 |
+
for tmp in model_output[1:]:
|
| 891 |
+
latent_vector = rearrange(tmp, "b c h w -> b (h w) c")
|
| 892 |
+
latent_vector = latent_vector / ((latent_vector ** 2).sum(dim=2, keepdims=True) ** 0.5)
|
| 893 |
+
attention_probs = torch.bmm(latent_vector, latent_vector.transpose(-1, -2))
|
| 894 |
+
correlation_matrix += [attention_probs.detach().clone().to(torch.float32)]
|
| 895 |
+
del attention_probs, latent_vector, tmp
|
| 896 |
+
del model_output
|
| 897 |
+
|
| 898 |
+
gc.collect()
|
| 899 |
+
torch.cuda.empty_cache()
|
| 900 |
+
|
| 901 |
+
return correlation_matrix
|
| 902 |
+
|
| 903 |
+
|
| 904 |
+
@torch.no_grad()
|
| 905 |
+
def get_flow_and_interframe_paras(flow_model, imgs, visualize_pipeline=False):
|
| 906 |
+
"""
|
| 907 |
+
Get parameters for temporal-guided attention and optimization
|
| 908 |
+
* predict optical flow and occlusion mask
|
| 909 |
+
* compute pixel index correspondence for FLATTEN
|
| 910 |
+
"""
|
| 911 |
+
images = torch.stack([torch.from_numpy(img).permute(2, 0, 1).float() for img in imgs], dim=0).cuda()
|
| 912 |
+
imgs_torch = torch.cat([numpy2tensor(img) for img in imgs], dim=0)
|
| 913 |
+
|
| 914 |
+
reshuffle_list = list(range(1,len(images)))+[0]
|
| 915 |
+
|
| 916 |
+
results_dict = flow_model(images, images[reshuffle_list], attn_splits_list=[2],
|
| 917 |
+
corr_radius_list=[-1], prop_radius_list=[-1], pred_bidir_flow=True)
|
| 918 |
+
flow_pr = results_dict['flow_preds'][-1] # [2*B, 2, H, W]
|
| 919 |
+
fwd_flows, bwd_flows = flow_pr.chunk(2) # [B, 2, H, W]
|
| 920 |
+
fwd_occs, bwd_occs = forward_backward_consistency_check(fwd_flows, bwd_flows) # [B, H, W]
|
| 921 |
+
|
| 922 |
+
warped_image1 = flow_warp(images, bwd_flows)
|
| 923 |
+
bwd_occs = torch.clamp(bwd_occs + (abs(images[reshuffle_list]-warped_image1).mean(dim=1)>255*0.25).float(), 0 ,1)
|
| 924 |
+
|
| 925 |
+
warped_image2 = flow_warp(images[reshuffle_list], fwd_flows)
|
| 926 |
+
fwd_occs = torch.clamp(fwd_occs + (abs(images-warped_image2).mean(dim=1)>255*0.25).float(), 0 ,1)
|
| 927 |
+
|
| 928 |
+
if visualize_pipeline:
|
| 929 |
+
print('visualized occlusion masks based on optical flows')
|
| 930 |
+
viz = torchvision.utils.make_grid(imgs_torch * (1-fwd_occs.unsqueeze(1)), len(images), 1)
|
| 931 |
+
visualize(viz.cpu(), 90)
|
| 932 |
+
viz = torchvision.utils.make_grid(imgs_torch[reshuffle_list] * (1-bwd_occs.unsqueeze(1)), len(images), 1)
|
| 933 |
+
visualize(viz.cpu(), 90)
|
| 934 |
+
|
| 935 |
+
attn_mask = []
|
| 936 |
+
for scale in [8.0, 16.0, 32.0]:
|
| 937 |
+
bwd_occs_ = F.interpolate(bwd_occs[:-1].unsqueeze(1), scale_factor=1./scale, mode='bilinear')
|
| 938 |
+
attn_mask += [torch.cat((bwd_occs_[0:1].reshape(1,-1)>-1, bwd_occs_.reshape(bwd_occs_.shape[0],-1)>0.5), dim=0)]
|
| 939 |
+
|
| 940 |
+
fwd_mappings = []
|
| 941 |
+
bwd_mappings = []
|
| 942 |
+
interattn_masks = []
|
| 943 |
+
for scale in [8.0, 16.0]:
|
| 944 |
+
fwd_mapping, bwd_mapping, interattn_mask = get_mapping_ind(bwd_flows, bwd_occs, imgs_torch, scale=scale)
|
| 945 |
+
fwd_mappings += [fwd_mapping]
|
| 946 |
+
bwd_mappings += [bwd_mapping]
|
| 947 |
+
interattn_masks += [interattn_mask]
|
| 948 |
+
|
| 949 |
+
interattn_paras = {}
|
| 950 |
+
interattn_paras['fwd_mappings'] = fwd_mappings
|
| 951 |
+
interattn_paras['bwd_mappings'] = bwd_mappings
|
| 952 |
+
interattn_paras['interattn_masks'] = interattn_masks
|
| 953 |
+
|
| 954 |
+
gc.collect()
|
| 955 |
+
torch.cuda.empty_cache()
|
| 956 |
+
|
| 957 |
+
return [fwd_flows, bwd_flows], [fwd_occs, bwd_occs], attn_mask, interattn_paras
|
src/ebsynth/blender/guide.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
from flow.flow_utils import flow_calc, read_flow, read_mask
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BaseGuide:
|
| 10 |
+
|
| 11 |
+
def __init__(self):
|
| 12 |
+
...
|
| 13 |
+
|
| 14 |
+
def get_cmd(self, i, weight) -> str:
|
| 15 |
+
return (f'-guide {os.path.abspath(self.imgs[0])} '
|
| 16 |
+
f'{os.path.abspath(self.imgs[i])} -weight {weight}')
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class ColorGuide(BaseGuide):
|
| 20 |
+
|
| 21 |
+
def __init__(self, imgs):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.imgs = imgs
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class PositionalGuide(BaseGuide):
|
| 27 |
+
|
| 28 |
+
def __init__(self, flow_paths, save_paths):
|
| 29 |
+
super().__init__()
|
| 30 |
+
flows = [read_flow(f) for f in flow_paths]
|
| 31 |
+
masks = [read_mask(f) for f in flow_paths]
|
| 32 |
+
# TODO: modify the format of flow to numpy
|
| 33 |
+
H, W = flows[0].shape[2:]
|
| 34 |
+
first_img = PositionalGuide.__generate_first_img(H, W)
|
| 35 |
+
prev_img = first_img
|
| 36 |
+
imgs = [first_img]
|
| 37 |
+
cid = 0
|
| 38 |
+
for flow, mask in zip(flows, masks):
|
| 39 |
+
cur_img = flow_calc.warp(prev_img, flow,
|
| 40 |
+
'nearest').astype(np.uint8)
|
| 41 |
+
cur_img = cv2.inpaint(cur_img, mask, 30, cv2.INPAINT_TELEA)
|
| 42 |
+
prev_img = cur_img
|
| 43 |
+
imgs.append(cur_img)
|
| 44 |
+
cid += 1
|
| 45 |
+
cv2.imwrite(f'guide/{cid}.jpg', mask)
|
| 46 |
+
|
| 47 |
+
for path, img in zip(save_paths, imgs):
|
| 48 |
+
cv2.imwrite(path, img)
|
| 49 |
+
self.imgs = save_paths
|
| 50 |
+
|
| 51 |
+
@staticmethod
|
| 52 |
+
def __generate_first_img(H, W):
|
| 53 |
+
Hs = np.linspace(0, 1, H)
|
| 54 |
+
Ws = np.linspace(0, 1, W)
|
| 55 |
+
i, j = np.meshgrid(Hs, Ws, indexing='ij')
|
| 56 |
+
r = (i * 255).astype(np.uint8)
|
| 57 |
+
g = (j * 255).astype(np.uint8)
|
| 58 |
+
b = np.zeros(r.shape)
|
| 59 |
+
res = np.stack((b, g, r), 2)
|
| 60 |
+
return res
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class EdgeGuide(BaseGuide):
|
| 64 |
+
|
| 65 |
+
def __init__(self, imgs, save_paths):
|
| 66 |
+
super().__init__()
|
| 67 |
+
edges = [EdgeGuide.__generate_edge(cv2.imread(img)) for img in imgs]
|
| 68 |
+
for path, img in zip(save_paths, edges):
|
| 69 |
+
cv2.imwrite(path, img)
|
| 70 |
+
self.imgs = save_paths
|
| 71 |
+
|
| 72 |
+
@staticmethod
|
| 73 |
+
def __generate_edge(img):
|
| 74 |
+
filter = np.array([[0, -1, 0], [-1, 4, -1], [0, -1, 0]])
|
| 75 |
+
res = cv2.filter2D(img, -1, filter)
|
| 76 |
+
return res
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class TemporalGuide(BaseGuide):
|
| 80 |
+
|
| 81 |
+
def __init__(self, key_img, stylized_imgs, flow_paths, save_paths):
|
| 82 |
+
super().__init__()
|
| 83 |
+
self.flows = [read_flow(f) for f in flow_paths]
|
| 84 |
+
self.masks = [read_mask(f) for f in flow_paths]
|
| 85 |
+
self.stylized_imgs = stylized_imgs
|
| 86 |
+
self.imgs = save_paths
|
| 87 |
+
|
| 88 |
+
first_img = cv2.imread(key_img)
|
| 89 |
+
cv2.imwrite(self.imgs[0], first_img)
|
| 90 |
+
|
| 91 |
+
def get_cmd(self, i, weight) -> str:
|
| 92 |
+
if i == 0:
|
| 93 |
+
warped_img = self.stylized_imgs[0]
|
| 94 |
+
else:
|
| 95 |
+
prev_img = cv2.imread(self.stylized_imgs[i - 1])
|
| 96 |
+
warped_img = flow_calc.warp(prev_img, self.flows[i - 1],
|
| 97 |
+
'nearest').astype(np.uint8)
|
| 98 |
+
|
| 99 |
+
warped_img = cv2.inpaint(warped_img, self.masks[i - 1], 30,
|
| 100 |
+
cv2.INPAINT_TELEA)
|
| 101 |
+
|
| 102 |
+
cv2.imwrite(self.imgs[i], warped_img)
|
| 103 |
+
|
| 104 |
+
return super().get_cmd(i, weight)
|
src/ebsynth/blender/histogram_blend.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def histogram_transform(img: np.ndarray, means: np.ndarray, stds: np.ndarray,
|
| 6 |
+
target_means: np.ndarray, target_stds: np.ndarray):
|
| 7 |
+
means = means.reshape((1, 1, 3))
|
| 8 |
+
stds = stds.reshape((1, 1, 3))
|
| 9 |
+
target_means = target_means.reshape((1, 1, 3))
|
| 10 |
+
target_stds = target_stds.reshape((1, 1, 3))
|
| 11 |
+
x = img.astype(np.float32)
|
| 12 |
+
x = (x - means) * target_stds / stds + target_means
|
| 13 |
+
# x = np.round(x)
|
| 14 |
+
# x = np.clip(x, 0, 255)
|
| 15 |
+
# x = x.astype(np.uint8)
|
| 16 |
+
return x
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def blend(a: np.ndarray,
|
| 20 |
+
b: np.ndarray,
|
| 21 |
+
min_error: np.ndarray,
|
| 22 |
+
weight1=0.5,
|
| 23 |
+
weight2=0.5):
|
| 24 |
+
a = cv2.cvtColor(a, cv2.COLOR_BGR2Lab)
|
| 25 |
+
b = cv2.cvtColor(b, cv2.COLOR_BGR2Lab)
|
| 26 |
+
min_error = cv2.cvtColor(min_error, cv2.COLOR_BGR2Lab)
|
| 27 |
+
a_mean = np.mean(a, axis=(0, 1))
|
| 28 |
+
a_std = np.std(a, axis=(0, 1))
|
| 29 |
+
b_mean = np.mean(b, axis=(0, 1))
|
| 30 |
+
b_std = np.std(b, axis=(0, 1))
|
| 31 |
+
min_error_mean = np.mean(min_error, axis=(0, 1))
|
| 32 |
+
min_error_std = np.std(min_error, axis=(0, 1))
|
| 33 |
+
|
| 34 |
+
t_mean_val = 0.5 * 256
|
| 35 |
+
t_std_val = (1 / 36) * 256
|
| 36 |
+
t_mean = np.ones([3], dtype=np.float32) * t_mean_val
|
| 37 |
+
t_std = np.ones([3], dtype=np.float32) * t_std_val
|
| 38 |
+
a = histogram_transform(a, a_mean, a_std, t_mean, t_std)
|
| 39 |
+
|
| 40 |
+
b = histogram_transform(b, b_mean, b_std, t_mean, t_std)
|
| 41 |
+
ab = (a * weight1 + b * weight2 - t_mean_val) / 0.5 + t_mean_val
|
| 42 |
+
ab_mean = np.mean(ab, axis=(0, 1))
|
| 43 |
+
ab_std = np.std(ab, axis=(0, 1))
|
| 44 |
+
ab = histogram_transform(ab, ab_mean, ab_std, min_error_mean,
|
| 45 |
+
min_error_std)
|
| 46 |
+
ab = np.round(ab)
|
| 47 |
+
ab = np.clip(ab, 0, 255)
|
| 48 |
+
ab = ab.astype(np.uint8)
|
| 49 |
+
ab = cv2.cvtColor(ab, cv2.COLOR_Lab2BGR)
|
| 50 |
+
return ab
|
src/ebsynth/blender/poisson_fusion.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
import scipy
|
| 4 |
+
|
| 5 |
+
As = None
|
| 6 |
+
prev_states = None
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def construct_A(h, w, grad_weight):
|
| 10 |
+
indgx_x = []
|
| 11 |
+
indgx_y = []
|
| 12 |
+
indgy_x = []
|
| 13 |
+
indgy_y = []
|
| 14 |
+
vdx = []
|
| 15 |
+
vdy = []
|
| 16 |
+
for i in range(h):
|
| 17 |
+
for j in range(w):
|
| 18 |
+
if i < h - 1:
|
| 19 |
+
indgx_x += [i * w + j]
|
| 20 |
+
indgx_y += [i * w + j]
|
| 21 |
+
vdx += [1]
|
| 22 |
+
indgx_x += [i * w + j]
|
| 23 |
+
indgx_y += [(i + 1) * w + j]
|
| 24 |
+
vdx += [-1]
|
| 25 |
+
if j < w - 1:
|
| 26 |
+
indgy_x += [i * w + j]
|
| 27 |
+
indgy_y += [i * w + j]
|
| 28 |
+
vdy += [1]
|
| 29 |
+
indgy_x += [i * w + j]
|
| 30 |
+
indgy_y += [i * w + j + 1]
|
| 31 |
+
vdy += [-1]
|
| 32 |
+
Ix = scipy.sparse.coo_array(
|
| 33 |
+
(np.ones(h * w), (np.arange(h * w), np.arange(h * w))),
|
| 34 |
+
shape=(h * w, h * w)).tocsc()
|
| 35 |
+
Gx = scipy.sparse.coo_array(
|
| 36 |
+
(np.array(vdx), (np.array(indgx_x), np.array(indgx_y))),
|
| 37 |
+
shape=(h * w, h * w)).tocsc()
|
| 38 |
+
Gy = scipy.sparse.coo_array(
|
| 39 |
+
(np.array(vdy), (np.array(indgy_x), np.array(indgy_y))),
|
| 40 |
+
shape=(h * w, h * w)).tocsc()
|
| 41 |
+
As = []
|
| 42 |
+
for i in range(3):
|
| 43 |
+
As += [
|
| 44 |
+
scipy.sparse.vstack([Gx * grad_weight[i], Gy * grad_weight[i], Ix])
|
| 45 |
+
]
|
| 46 |
+
return As
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# blendI, I1, I2, mask should be RGB unit8 type
|
| 50 |
+
# return poissson fusion result (RGB unit8 type)
|
| 51 |
+
# I1 and I2: propagated results from previous and subsequent key frames
|
| 52 |
+
# mask: pixel selection mask
|
| 53 |
+
# blendI: contrastive-preserving blending results of I1 and I2
|
| 54 |
+
def poisson_fusion(blendI, I1, I2, mask, grad_weight=[2.5, 0.5, 0.5]):
|
| 55 |
+
global As
|
| 56 |
+
global prev_states
|
| 57 |
+
|
| 58 |
+
Iab = cv2.cvtColor(blendI, cv2.COLOR_BGR2LAB).astype(float)
|
| 59 |
+
Ia = cv2.cvtColor(I1, cv2.COLOR_BGR2LAB).astype(float)
|
| 60 |
+
Ib = cv2.cvtColor(I2, cv2.COLOR_BGR2LAB).astype(float)
|
| 61 |
+
m = (mask > 0).astype(float)[:, :, np.newaxis]
|
| 62 |
+
h, w, c = Iab.shape
|
| 63 |
+
|
| 64 |
+
# fuse the gradient of I1 and I2 with mask
|
| 65 |
+
gx = np.zeros_like(Ia)
|
| 66 |
+
gy = np.zeros_like(Ia)
|
| 67 |
+
gx[:-1, :, :] = (Ia[:-1, :, :] - Ia[1:, :, :]) * (1 - m[:-1, :, :]) + (
|
| 68 |
+
Ib[:-1, :, :] - Ib[1:, :, :]) * m[:-1, :, :]
|
| 69 |
+
gy[:, :-1, :] = (Ia[:, :-1, :] - Ia[:, 1:, :]) * (1 - m[:, :-1, :]) + (
|
| 70 |
+
Ib[:, :-1, :] - Ib[:, 1:, :]) * m[:, :-1, :]
|
| 71 |
+
|
| 72 |
+
# construct A for solving Ax=b
|
| 73 |
+
crt_states = (h, w, grad_weight)
|
| 74 |
+
if As is None or crt_states != prev_states:
|
| 75 |
+
As = construct_A(*crt_states)
|
| 76 |
+
prev_states = crt_states
|
| 77 |
+
|
| 78 |
+
final = []
|
| 79 |
+
for i in range(3):
|
| 80 |
+
weight = grad_weight[i]
|
| 81 |
+
im_dx = np.clip(gx[:, :, i].reshape(h * w, 1), -100, 100)
|
| 82 |
+
im_dy = np.clip(gy[:, :, i].reshape(h * w, 1), -100, 100)
|
| 83 |
+
im = Iab[:, :, i].reshape(h * w, 1)
|
| 84 |
+
im_mean = im.mean()
|
| 85 |
+
im = im - im_mean
|
| 86 |
+
A = As[i]
|
| 87 |
+
b = np.vstack([im_dx * weight, im_dy * weight, im])
|
| 88 |
+
out = scipy.sparse.linalg.lsqr(A, b)
|
| 89 |
+
out_im = (out[0] + im_mean).reshape(h, w, 1)
|
| 90 |
+
final += [out_im]
|
| 91 |
+
|
| 92 |
+
final = np.clip(np.concatenate(final, axis=2), 0, 255)
|
| 93 |
+
return cv2.cvtColor(final.astype(np.uint8), cv2.COLOR_LAB2BGR)
|
src/ebsynth/blender/video_sequence.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import shutil
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class VideoSequence:
|
| 6 |
+
|
| 7 |
+
def __init__(self,
|
| 8 |
+
base_dir,
|
| 9 |
+
key_ind,
|
| 10 |
+
input_subdir='videos',
|
| 11 |
+
key_subdir='keys0',
|
| 12 |
+
tmp_subdir='tmp',
|
| 13 |
+
input_format='frame%04d.jpg',
|
| 14 |
+
key_format='%04d.jpg',
|
| 15 |
+
out_subdir_format='out_%d',
|
| 16 |
+
blending_out_subdir='blend',
|
| 17 |
+
output_format='%04d.jpg'):
|
| 18 |
+
#if (end_frame - beg_frame) % interval != 0:
|
| 19 |
+
# end_frame -= (end_frame - beg_frame) % interval
|
| 20 |
+
|
| 21 |
+
self.__base_dir = base_dir
|
| 22 |
+
self.__input_dir = os.path.join(base_dir, input_subdir)
|
| 23 |
+
self.__key_dir = os.path.join(base_dir, key_subdir)
|
| 24 |
+
self.__tmp_dir = os.path.join(base_dir, tmp_subdir)
|
| 25 |
+
self.__input_format = input_format
|
| 26 |
+
self.__blending_out_dir = os.path.join(base_dir, blending_out_subdir)
|
| 27 |
+
self.__key_format = key_format
|
| 28 |
+
self.__out_subdir_format = out_subdir_format
|
| 29 |
+
self.__output_format = output_format
|
| 30 |
+
self.__key_ind = key_ind
|
| 31 |
+
#self.__beg_frame = beg_frame
|
| 32 |
+
#self.__end_frame = end_frame
|
| 33 |
+
#self.__interval = interval
|
| 34 |
+
self.__n_seq = len(key_ind)-1#(end_frame - beg_frame) // interval
|
| 35 |
+
self.__make_out_dirs()
|
| 36 |
+
os.makedirs(self.__tmp_dir, exist_ok=True)
|
| 37 |
+
|
| 38 |
+
@property
|
| 39 |
+
def beg_frame(self):
|
| 40 |
+
return self.__key_ind[0]#self.__beg_frame
|
| 41 |
+
|
| 42 |
+
@property
|
| 43 |
+
def end_frame(self):
|
| 44 |
+
return self.__key_ind[-1]#self.__end_frame
|
| 45 |
+
|
| 46 |
+
@property
|
| 47 |
+
def n_seq(self):
|
| 48 |
+
return self.__n_seq
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def blending_dir(self):
|
| 52 |
+
return os.path.abspath(self.__blending_out_dir)
|
| 53 |
+
|
| 54 |
+
def interval(self, i):
|
| 55 |
+
return self.get_sequence_beg_id(i + 1) - self.get_sequence_beg_id(i)
|
| 56 |
+
|
| 57 |
+
def remove_out_and_tmp(self):
|
| 58 |
+
for i in range(self.n_seq + 1):
|
| 59 |
+
out_dir = self.__get_out_subdir(i)
|
| 60 |
+
shutil.rmtree(out_dir)
|
| 61 |
+
shutil.rmtree(self.__tmp_dir)
|
| 62 |
+
|
| 63 |
+
def get_input_sequence(self, i, is_forward=True):
|
| 64 |
+
beg_id = self.get_sequence_beg_id(i)
|
| 65 |
+
end_id = self.get_sequence_beg_id(i + 1)
|
| 66 |
+
if is_forward:
|
| 67 |
+
id_list = list(range(beg_id, end_id))
|
| 68 |
+
else:
|
| 69 |
+
id_list = list(range(end_id, beg_id, -1))
|
| 70 |
+
path_dir = [
|
| 71 |
+
os.path.join(self.__input_dir, self.__input_format % id)
|
| 72 |
+
for id in id_list
|
| 73 |
+
]
|
| 74 |
+
return path_dir
|
| 75 |
+
|
| 76 |
+
def get_output_sequence(self, i, is_forward=True):
|
| 77 |
+
beg_id = self.get_sequence_beg_id(i)
|
| 78 |
+
end_id = self.get_sequence_beg_id(i + 1)
|
| 79 |
+
if is_forward:
|
| 80 |
+
id_list = list(range(beg_id, end_id))
|
| 81 |
+
else:
|
| 82 |
+
i += 1
|
| 83 |
+
id_list = list(range(end_id, beg_id, -1))
|
| 84 |
+
out_subdir = self.__get_out_subdir(i)
|
| 85 |
+
path_dir = [
|
| 86 |
+
os.path.join(out_subdir, self.__output_format % id)
|
| 87 |
+
for id in id_list
|
| 88 |
+
]
|
| 89 |
+
return path_dir
|
| 90 |
+
|
| 91 |
+
def get_temporal_sequence(self, i, is_forward=True):
|
| 92 |
+
beg_id = self.get_sequence_beg_id(i)
|
| 93 |
+
end_id = self.get_sequence_beg_id(i + 1)
|
| 94 |
+
if is_forward:
|
| 95 |
+
id_list = list(range(beg_id, end_id))
|
| 96 |
+
else:
|
| 97 |
+
i += 1
|
| 98 |
+
id_list = list(range(end_id, beg_id, -1))
|
| 99 |
+
tmp_dir = self.__get_tmp_out_subdir(i)
|
| 100 |
+
path_dir = [
|
| 101 |
+
os.path.join(tmp_dir, 'temporal_' + self.__output_format % id)
|
| 102 |
+
for id in id_list
|
| 103 |
+
]
|
| 104 |
+
return path_dir
|
| 105 |
+
|
| 106 |
+
def get_edge_sequence(self, i, is_forward=True):
|
| 107 |
+
beg_id = self.get_sequence_beg_id(i)
|
| 108 |
+
end_id = self.get_sequence_beg_id(i + 1)
|
| 109 |
+
if is_forward:
|
| 110 |
+
id_list = list(range(beg_id, end_id))
|
| 111 |
+
else:
|
| 112 |
+
i += 1
|
| 113 |
+
id_list = list(range(end_id, beg_id, -1))
|
| 114 |
+
tmp_dir = self.__get_tmp_out_subdir(i)
|
| 115 |
+
path_dir = [
|
| 116 |
+
os.path.join(tmp_dir, 'edge_' + self.__output_format % id)
|
| 117 |
+
for id in id_list
|
| 118 |
+
]
|
| 119 |
+
return path_dir
|
| 120 |
+
|
| 121 |
+
def get_pos_sequence(self, i, is_forward=True):
|
| 122 |
+
beg_id = self.get_sequence_beg_id(i)
|
| 123 |
+
end_id = self.get_sequence_beg_id(i + 1)
|
| 124 |
+
if is_forward:
|
| 125 |
+
id_list = list(range(beg_id, end_id))
|
| 126 |
+
else:
|
| 127 |
+
i += 1
|
| 128 |
+
id_list = list(range(end_id, beg_id, -1))
|
| 129 |
+
tmp_dir = self.__get_tmp_out_subdir(i)
|
| 130 |
+
path_dir = [
|
| 131 |
+
os.path.join(tmp_dir, 'pos_' + self.__output_format % id)
|
| 132 |
+
for id in id_list
|
| 133 |
+
]
|
| 134 |
+
return path_dir
|
| 135 |
+
|
| 136 |
+
def get_flow_sequence(self, i, is_forward=True):
|
| 137 |
+
beg_id = self.get_sequence_beg_id(i)
|
| 138 |
+
end_id = self.get_sequence_beg_id(i + 1)
|
| 139 |
+
if is_forward:
|
| 140 |
+
id_list = list(range(beg_id, end_id - 1))
|
| 141 |
+
path_dir = [
|
| 142 |
+
os.path.join(self.__tmp_dir, 'flow_f_%04d.npy' % id)
|
| 143 |
+
for id in id_list
|
| 144 |
+
]
|
| 145 |
+
else:
|
| 146 |
+
id_list = list(range(end_id, beg_id + 1, -1))
|
| 147 |
+
path_dir = [
|
| 148 |
+
os.path.join(self.__tmp_dir, 'flow_b_%04d.npy' % id)
|
| 149 |
+
for id in id_list
|
| 150 |
+
]
|
| 151 |
+
|
| 152 |
+
return path_dir
|
| 153 |
+
|
| 154 |
+
def get_input_img(self, i):
|
| 155 |
+
return os.path.join(self.__input_dir, self.__input_format % i)
|
| 156 |
+
|
| 157 |
+
def get_key_img(self, i):
|
| 158 |
+
sequence_beg_id = self.get_sequence_beg_id(i)
|
| 159 |
+
return os.path.join(self.__key_dir,
|
| 160 |
+
self.__key_format % sequence_beg_id)
|
| 161 |
+
|
| 162 |
+
def get_blending_img(self, i):
|
| 163 |
+
return os.path.join(self.__blending_out_dir, self.__output_format % i)
|
| 164 |
+
|
| 165 |
+
def get_sequence_beg_id(self, i):
|
| 166 |
+
return self.__key_ind[i]#i * self.__interval + self.__beg_frame
|
| 167 |
+
|
| 168 |
+
def __get_out_subdir(self, i):
|
| 169 |
+
dir_id = self.get_sequence_beg_id(i)
|
| 170 |
+
out_subdir = os.path.join(self.__base_dir,
|
| 171 |
+
self.__out_subdir_format % dir_id)
|
| 172 |
+
return out_subdir
|
| 173 |
+
|
| 174 |
+
def __get_tmp_out_subdir(self, i):
|
| 175 |
+
dir_id = self.get_sequence_beg_id(i)
|
| 176 |
+
tmp_out_subdir = os.path.join(self.__tmp_dir,
|
| 177 |
+
self.__out_subdir_format % dir_id)
|
| 178 |
+
return tmp_out_subdir
|
| 179 |
+
|
| 180 |
+
def __make_out_dirs(self):
|
| 181 |
+
os.makedirs(self.__base_dir, exist_ok=True)
|
| 182 |
+
os.makedirs(self.__blending_out_dir, exist_ok=True)
|
| 183 |
+
for i in range(self.__n_seq + 1):
|
| 184 |
+
out_subdir = self.__get_out_subdir(i)
|
| 185 |
+
tmp_subdir = self.__get_tmp_out_subdir(i)
|
| 186 |
+
os.makedirs(out_subdir, exist_ok=True)
|
| 187 |
+
os.makedirs(tmp_subdir, exist_ok=True)
|