

Commit
·
7095a34
1
Parent(s):
69ab4f3
first commit
Browse files- .gitignore +7 -0
- app.py +774 -0
- images/1.png +0 -0
- images/10.png +0 -0
- images/11.png +0 -0
- images/2.png +0 -0
- images/3.png +0 -0
- images/4.png +0 -0
- images/5.png +0 -0
- images/6.png +0 -0
- images/7.png +0 -0
- images/8.png +0 -0
- images/9.png +0 -0
- requirements.txt +8 -0
.gitignore
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.json
|
| 2 |
+
mapping
|
| 3 |
+
*.ipynb
|
| 4 |
+
test.py
|
| 5 |
+
results/
|
| 6 |
+
.notebook/
|
| 7 |
+
__pycache__/
|
app.py
ADDED
|
@@ -0,0 +1,774 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import io
|
| 3 |
+
import base64
|
| 4 |
+
import librosa
|
| 5 |
+
import tempfile
|
| 6 |
+
import os
|
| 7 |
+
import random
|
| 8 |
+
from datetime import timedelta
|
| 9 |
+
import shutil
|
| 10 |
+
import csv
|
| 11 |
+
from audio_recorder_streamlit import audio_recorder
|
| 12 |
+
import pandas as pd
|
| 13 |
+
import plotly.express as px
|
| 14 |
+
import plotly.graph_objects as go
|
| 15 |
+
import numpy as np
|
| 16 |
+
import time
|
| 17 |
+
import re
|
| 18 |
+
import requests
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
SAVE_PATH = "results/results.csv"
|
| 22 |
+
TEMP_DIR = "results/audios"
|
| 23 |
+
|
| 24 |
+
if not os.path.exists("results"):
|
| 25 |
+
os.mkdir("results")
|
| 26 |
+
|
| 27 |
+
if not os.path.exists(SAVE_PATH):
|
| 28 |
+
open(SAVE_PATH,"w").close()
|
| 29 |
+
|
| 30 |
+
if not os.path.exists(TEMP_DIR):
|
| 31 |
+
os.mkdir(TEMP_DIR)
|
| 32 |
+
|
| 33 |
+
CREATE_TASK_URL = "https://ai-voice-test.voicegenie.ai/task"
|
| 34 |
+
|
| 35 |
+
def decode_audio_array(base64_string):
|
| 36 |
+
bytes_data = base64.b64decode(base64_string)
|
| 37 |
+
|
| 38 |
+
buffer = io.BytesIO(bytes_data)
|
| 39 |
+
audio_array = np.load(buffer)
|
| 40 |
+
|
| 41 |
+
return audio_array
|
| 42 |
+
|
| 43 |
+
def send_task(payload):
|
| 44 |
+
response = requests.post(CREATE_TASK_URL,json=payload)
|
| 45 |
+
response = response.json()
|
| 46 |
+
|
| 47 |
+
if payload["task"] == "transcribe_with_fastapi":
|
| 48 |
+
return response["text"]
|
| 49 |
+
|
| 50 |
+
elif payload["task"] == "fetch_audio":
|
| 51 |
+
array = response["array"]
|
| 52 |
+
array = decode_audio_array(array)
|
| 53 |
+
sampling_rate = response["sample_rate"]
|
| 54 |
+
filepath = response["filepath"]
|
| 55 |
+
return array,sampling_rate,filepath
|
| 56 |
+
|
| 57 |
+
def convert_seconds_to_timestamp(seconds):
|
| 58 |
+
time_delta = timedelta(seconds=seconds)
|
| 59 |
+
return str(time_delta).split('.')[0]
|
| 60 |
+
|
| 61 |
+
def transcribe_whisper(model, path):
|
| 62 |
+
return model.transcribe(path)["text"]
|
| 63 |
+
|
| 64 |
+
class ResultWriter:
|
| 65 |
+
def __init__(self, save_path):
|
| 66 |
+
self.save_path = save_path
|
| 67 |
+
self.headers = [
|
| 68 |
+
'email',
|
| 69 |
+
'path',
|
| 70 |
+
'Ori Apex_score', 'Ori Apex XT_score', 'deepgram_score', 'Ori Swift_score', 'Ori Prime_score',
|
| 71 |
+
'Ori Apex_appearance', 'Ori Apex XT_appearance', 'deepgram_appearance', 'Ori Swift_appearance', 'Ori Prime_appearance',
|
| 72 |
+
'Ori Apex_duration', 'Ori Apex XT_duration', 'deepgram_duration', 'Ori Swift_duration', 'Ori Prime_duration','azure_score','azure_appearance','azure_duration'
|
| 73 |
+
]
|
| 74 |
+
|
| 75 |
+
if not os.path.exists(save_path):
|
| 76 |
+
with open(save_path, 'w', newline='') as f:
|
| 77 |
+
writer = csv.DictWriter(f, fieldnames=self.headers)
|
| 78 |
+
writer.writeheader()
|
| 79 |
+
|
| 80 |
+
def write_result(self,user_email ,audio_path,option_1_duration_info,option_2_duration_info ,winner_model=None, loser_model=None, both_preferred=False, none_preferred=False):
|
| 81 |
+
result = {
|
| 82 |
+
'email': user_email,
|
| 83 |
+
'path': audio_path,
|
| 84 |
+
'Ori Apex_score': 0, 'Ori Apex XT_score': 0, 'deepgram_score': 0, 'Ori Swift_score': 0, 'Ori Prime_score': 0,
|
| 85 |
+
'Ori Apex_appearance': 0, 'Ori Apex XT_appearance': 0, 'deepgram_appearance': 0, 'Ori Swift_appearance': 0, 'Ori Prime_appearance': 0,
|
| 86 |
+
'Ori Apex_duration':0, 'Ori Apex XT_duration':0, 'deepgram_duration':0, 'Ori Swift_duration':0, 'Ori Prime_duration':0,'azure_score':0,'azure_appearance':0,'azure_duration':0
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
if winner_model:
|
| 90 |
+
result[f'{winner_model}_appearance'] = 1
|
| 91 |
+
|
| 92 |
+
if loser_model:
|
| 93 |
+
result[f'{loser_model}_appearance'] = 1
|
| 94 |
+
|
| 95 |
+
if both_preferred:
|
| 96 |
+
if winner_model:
|
| 97 |
+
result[f'{winner_model}_score'] = 1
|
| 98 |
+
if loser_model:
|
| 99 |
+
result[f'{loser_model}_score'] = 1
|
| 100 |
+
elif not none_preferred and winner_model:
|
| 101 |
+
result[f'{winner_model}_score'] = 1
|
| 102 |
+
|
| 103 |
+
if option_1_duration_info and option_1_duration_info[0]:
|
| 104 |
+
duration_key, duration_value = option_1_duration_info[0] # Unpack the tuple
|
| 105 |
+
if duration_key in self.headers:
|
| 106 |
+
result[duration_key] = float(duration_value)
|
| 107 |
+
|
| 108 |
+
if option_2_duration_info and option_2_duration_info[0]:
|
| 109 |
+
duration_key, duration_value = option_2_duration_info[0] # Unpack the tuple
|
| 110 |
+
if duration_key in self.headers:
|
| 111 |
+
result[duration_key] = float(duration_value)
|
| 112 |
+
|
| 113 |
+
with open(self.save_path, 'a', newline='\n') as f:
|
| 114 |
+
writer = csv.DictWriter(f, fieldnames=self.headers)
|
| 115 |
+
writer.writerow(result)
|
| 116 |
+
|
| 117 |
+
result_writer = ResultWriter(SAVE_PATH)
|
| 118 |
+
|
| 119 |
+
def reset_state():
|
| 120 |
+
st.session_state.option_1 = ""
|
| 121 |
+
st.session_state.option_2 = ""
|
| 122 |
+
st.session_state.transcribed = False
|
| 123 |
+
st.session_state.choice = ""
|
| 124 |
+
st.session_state.option_selected = False
|
| 125 |
+
st.session_state.current_audio_path = None
|
| 126 |
+
st.session_state.option_1_model_name = None
|
| 127 |
+
st.session_state.option_2_model_name = None
|
| 128 |
+
st.session_state.option_1_model_name_state = None
|
| 129 |
+
st.session_state.option_2_model_name_state = None
|
| 130 |
+
st.session_state.option_2_response_time = None
|
| 131 |
+
st.session_state.option_1_response_time = None
|
| 132 |
+
st.session_state.audio_tab = None
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def process_random_file(audio_file):
|
| 136 |
+
models_list = ["Ori Apex", "Ori Apex XT", "deepgram", "Ori Swift", "Ori Prime","azure"]
|
| 137 |
+
option_1_model_name, option_2_model_name = random.sample(models_list, 2)
|
| 138 |
+
|
| 139 |
+
st.session_state.current_audio_path = audio_file
|
| 140 |
+
|
| 141 |
+
st.session_state.option_1_model_name = option_1_model_name
|
| 142 |
+
st.session_state.option_2_model_name = option_2_model_name
|
| 143 |
+
|
| 144 |
+
return process_normal_audio(audio_file,option_1_model_name,option_2_model_name,"loaded_models")
|
| 145 |
+
|
| 146 |
+
def process_audio_file(audio_file):
|
| 147 |
+
with tempfile.NamedTemporaryFile(delete=False, suffix=os.path.splitext(audio_file.name)[1]) as tmp_file:
|
| 148 |
+
tmp_file.write(audio_file.getvalue())
|
| 149 |
+
permanent_path = os.path.join(TEMP_DIR, os.path.basename(tmp_file.name))
|
| 150 |
+
os.makedirs(TEMP_DIR, exist_ok=True)
|
| 151 |
+
shutil.move(tmp_file.name, permanent_path)
|
| 152 |
+
|
| 153 |
+
st.session_state.current_audio_path = permanent_path
|
| 154 |
+
|
| 155 |
+
models_list = ["Ori Apex", "Ori Apex XT", "deepgram", "Ori Swift", "Ori Prime","azure"]
|
| 156 |
+
option_1_model_name, option_2_model_name = random.sample(models_list, 2)
|
| 157 |
+
|
| 158 |
+
st.session_state.option_1_model_name = option_1_model_name
|
| 159 |
+
st.session_state.option_2_model_name = option_2_model_name
|
| 160 |
+
|
| 161 |
+
return process_normal_audio(permanent_path, option_1_model_name, option_2_model_name, "loaded_models")
|
| 162 |
+
|
| 163 |
+
def encode_audio_array(audio_array):
|
| 164 |
+
buffer = io.BytesIO()
|
| 165 |
+
np.save(buffer, audio_array)
|
| 166 |
+
buffer.seek(0)
|
| 167 |
+
|
| 168 |
+
base64_bytes = base64.b64encode(buffer.read())
|
| 169 |
+
base64_string = base64_bytes.decode('utf-8')
|
| 170 |
+
|
| 171 |
+
return base64_string
|
| 172 |
+
|
| 173 |
+
def call_function(model_name,audio_path):
|
| 174 |
+
if st.session_state.audio_tab:
|
| 175 |
+
y,_ = librosa.load(audio_path,sr=22050,mono=True)
|
| 176 |
+
encoded_array = encode_audio_array(y)
|
| 177 |
+
payload = {
|
| 178 |
+
"task":"transcribe_with_fastapi",
|
| 179 |
+
"payload":{
|
| 180 |
+
"file_path":encoded_array,
|
| 181 |
+
"model_name":model_name,
|
| 182 |
+
"audio_b64":True
|
| 183 |
+
}}
|
| 184 |
+
else:
|
| 185 |
+
payload = {
|
| 186 |
+
"task":"transcribe_with_fastapi",
|
| 187 |
+
"payload":{
|
| 188 |
+
"file_path":audio_path,
|
| 189 |
+
"model_name":model_name,
|
| 190 |
+
"audio_b64":False
|
| 191 |
+
}}
|
| 192 |
+
|
| 193 |
+
transcript = send_task(payload)
|
| 194 |
+
return transcript
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
def process_normal_audio(audio_path, model1_name, model2_name, loaded_models):
|
| 199 |
+
time_1 = time.time()
|
| 200 |
+
transcript1 = call_function(model1_name,audio_path)
|
| 201 |
+
time_2 = time.time()
|
| 202 |
+
transcript2 = call_function(model2_name,audio_path)
|
| 203 |
+
time_3 = time.time()
|
| 204 |
+
|
| 205 |
+
st.session_state.option_2_response_time = round(time_3 - time_2,3)
|
| 206 |
+
st.session_state.option_1_response_time = round(time_2 - time_1,3)
|
| 207 |
+
|
| 208 |
+
return transcript1, transcript2
|
| 209 |
+
|
| 210 |
+
def process_recorded_audio(audio_bytes):
|
| 211 |
+
with tempfile.NamedTemporaryFile(delete=False, suffix='.wav') as tmp_file:
|
| 212 |
+
tmp_file.write(audio_bytes)
|
| 213 |
+
permanent_path = os.path.join(TEMP_DIR, f"recorded_{os.path.basename(tmp_file.name)}")
|
| 214 |
+
os.makedirs(TEMP_DIR, exist_ok=True)
|
| 215 |
+
shutil.move(tmp_file.name, permanent_path)
|
| 216 |
+
|
| 217 |
+
st.session_state.current_audio_path = permanent_path
|
| 218 |
+
|
| 219 |
+
models_list = ["Ori Apex", "Ori Apex XT", "deepgram", "Ori Swift", "Ori Prime","azure"]
|
| 220 |
+
option_1_model_name, option_2_model_name = random.sample(models_list, 2)
|
| 221 |
+
|
| 222 |
+
st.session_state.option_1_model_name = option_1_model_name
|
| 223 |
+
st.session_state.option_2_model_name = option_2_model_name
|
| 224 |
+
|
| 225 |
+
# loaded_models = load_models()
|
| 226 |
+
|
| 227 |
+
return process_normal_audio(permanent_path, option_1_model_name, option_2_model_name, "loaded_models")
|
| 228 |
+
|
| 229 |
+
def get_model_abbreviation(model_name):
|
| 230 |
+
abbrev_map = {
|
| 231 |
+
'Ori Apex': 'Ori Apex',
|
| 232 |
+
'Ori Apex XT': 'Ori Apex XT',
|
| 233 |
+
'deepgram': 'DG',
|
| 234 |
+
'Ori Swift': 'Ori Swift',
|
| 235 |
+
'Ori Prime': 'Ori Prime',
|
| 236 |
+
'azure' : 'Azure'
|
| 237 |
+
}
|
| 238 |
+
return abbrev_map.get(model_name, model_name)
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def calculate_metrics(df):
|
| 242 |
+
models = ['Ori Apex', 'Ori Apex XT', 'deepgram', 'Ori Swift', 'Ori Prime', 'azure']
|
| 243 |
+
metrics = {}
|
| 244 |
+
|
| 245 |
+
for model in models:
|
| 246 |
+
appearances = df[f'{model}_appearance'].sum()
|
| 247 |
+
wins = df[f'{model}_score'].sum()
|
| 248 |
+
durations = df[df[f'{model}_appearance'] == 1][f'{model}_duration']
|
| 249 |
+
|
| 250 |
+
if appearances > 0:
|
| 251 |
+
win_rate = (wins / appearances) * 100
|
| 252 |
+
avg_duration = durations.mean()
|
| 253 |
+
duration_std = durations.std()
|
| 254 |
+
else:
|
| 255 |
+
win_rate = 0
|
| 256 |
+
avg_duration = 0
|
| 257 |
+
duration_std = 0
|
| 258 |
+
|
| 259 |
+
metrics[model] = {
|
| 260 |
+
'appearances': appearances,
|
| 261 |
+
'wins': wins,
|
| 262 |
+
'win_rate': win_rate,
|
| 263 |
+
'avg_response_time': avg_duration,
|
| 264 |
+
'response_time_std': duration_std
|
| 265 |
+
}
|
| 266 |
+
|
| 267 |
+
return metrics
|
| 268 |
+
|
| 269 |
+
def create_win_rate_chart(metrics):
|
| 270 |
+
models = list(metrics.keys())
|
| 271 |
+
win_rates = [metrics[model]['win_rate'] for model in models]
|
| 272 |
+
|
| 273 |
+
fig = go.Figure(data=[
|
| 274 |
+
go.Bar(
|
| 275 |
+
x=[get_model_abbreviation(model) for model in models],
|
| 276 |
+
y=win_rates,
|
| 277 |
+
text=[f'{rate:.1f}%' for rate in win_rates],
|
| 278 |
+
textposition='auto',
|
| 279 |
+
hovertext=models
|
| 280 |
+
)
|
| 281 |
+
])
|
| 282 |
+
|
| 283 |
+
fig.update_layout(
|
| 284 |
+
title='Win Rate by Model',
|
| 285 |
+
xaxis_title='Model',
|
| 286 |
+
yaxis_title='Win Rate (%)',
|
| 287 |
+
yaxis_range=[0, 100]
|
| 288 |
+
)
|
| 289 |
+
|
| 290 |
+
return fig
|
| 291 |
+
|
| 292 |
+
def create_appearance_chart(metrics):
|
| 293 |
+
models = list(metrics.keys())
|
| 294 |
+
appearances = [metrics[model]['appearances'] for model in models]
|
| 295 |
+
|
| 296 |
+
fig = px.pie(
|
| 297 |
+
values=appearances,
|
| 298 |
+
names=[get_model_abbreviation(model) for model in models],
|
| 299 |
+
title='Model Appearances Distribution',
|
| 300 |
+
hover_data=[models]
|
| 301 |
+
)
|
| 302 |
+
|
| 303 |
+
return fig
|
| 304 |
+
|
| 305 |
+
def create_head_to_head_matrix(df):
|
| 306 |
+
models = ['Ori Apex', 'Ori Apex XT', 'deepgram', 'Ori Swift', 'Ori Prime', 'azure']
|
| 307 |
+
matrix = np.zeros((len(models), len(models)))
|
| 308 |
+
|
| 309 |
+
for i, model1 in enumerate(models):
|
| 310 |
+
for j, model2 in enumerate(models):
|
| 311 |
+
if i != j:
|
| 312 |
+
matches = df[
|
| 313 |
+
(df[f'{model1}_appearance'] == 1) &
|
| 314 |
+
(df[f'{model2}_appearance'] == 1)
|
| 315 |
+
]
|
| 316 |
+
if len(matches) > 0:
|
| 317 |
+
win_rate = (matches[f'{model1}_score'].sum() / len(matches)) * 100
|
| 318 |
+
matrix[i][j] = win_rate
|
| 319 |
+
|
| 320 |
+
fig = go.Figure(data=go.Heatmap(
|
| 321 |
+
z=matrix,
|
| 322 |
+
x=[get_model_abbreviation(model) for model in models],
|
| 323 |
+
y=[get_model_abbreviation(model) for model in models],
|
| 324 |
+
text=[[f'{val:.1f}%' if val > 0 else '' for val in row] for row in matrix],
|
| 325 |
+
texttemplate='%{text}',
|
| 326 |
+
colorscale='RdYlBu',
|
| 327 |
+
zmin=0,
|
| 328 |
+
zmax=100
|
| 329 |
+
))
|
| 330 |
+
|
| 331 |
+
fig.update_layout(
|
| 332 |
+
title='Head-to-Head Win Rates',
|
| 333 |
+
xaxis_title='Opponent Model',
|
| 334 |
+
yaxis_title='Model'
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
return fig
|
| 338 |
+
|
| 339 |
+
def create_metric_container(label, value, full_name=None):
|
| 340 |
+
container = st.container()
|
| 341 |
+
with container:
|
| 342 |
+
st.markdown(f"**{label}**")
|
| 343 |
+
if full_name:
|
| 344 |
+
st.markdown(f"<h3 style='margin-top: 0;'>{value}</h3>", unsafe_allow_html=True)
|
| 345 |
+
st.caption(f"Full name: {full_name}")
|
| 346 |
+
else:
|
| 347 |
+
st.markdown(f"<h3 style='margin-top: 0;'>{value}</h3>", unsafe_allow_html=True)
|
| 348 |
+
|
| 349 |
+
def on_option_1_click():
|
| 350 |
+
if st.session_state.transcribed and not st.session_state.option_selected:
|
| 351 |
+
st.session_state.option_1_model_name_state = f"👑 {st.session_state.option_1_model_name} 👑"
|
| 352 |
+
st.session_state.option_2_model_name_state = f"👎 {st.session_state.option_2_model_name} 👎"
|
| 353 |
+
st.session_state.choice = f"You chose Option 1. Option 1 was {st.session_state.option_1_model_name} Option 2 was {st.session_state.option_2_model_name}"
|
| 354 |
+
result_writer.write_result(
|
| 355 |
+
st.session_state.user_email,
|
| 356 |
+
st.session_state.current_audio_path,
|
| 357 |
+
winner_model=st.session_state.option_1_model_name,
|
| 358 |
+
loser_model=st.session_state.option_2_model_name,
|
| 359 |
+
option_1_duration_info=[(f"{st.session_state.option_1_model_name}_duration",st.session_state.option_1_response_time)],
|
| 360 |
+
option_2_duration_info=[(f"{st.session_state.option_2_model_name}_duration",st.session_state.option_2_response_time)]
|
| 361 |
+
)
|
| 362 |
+
st.session_state.option_selected = True
|
| 363 |
+
|
| 364 |
+
def on_option_2_click():
|
| 365 |
+
if st.session_state.transcribed and not st.session_state.option_selected:
|
| 366 |
+
st.session_state.option_2_model_name_state = f"👑 {st.session_state.option_2_model_name} 👑"
|
| 367 |
+
st.session_state.option_1_model_name_state = f"👎 {st.session_state.option_1_model_name} 👎"
|
| 368 |
+
st.session_state.choice = f"You chose Option 2. Option 1 was {st.session_state.option_1_model_name} Option 2 was {st.session_state.option_2_model_name}"
|
| 369 |
+
result_writer.write_result(
|
| 370 |
+
st.session_state.user_email,
|
| 371 |
+
st.session_state.current_audio_path,
|
| 372 |
+
winner_model=st.session_state.option_2_model_name,
|
| 373 |
+
loser_model=st.session_state.option_1_model_name,
|
| 374 |
+
option_1_duration_info=[(f"{st.session_state.option_1_model_name}_duration",st.session_state.option_1_response_time)],
|
| 375 |
+
option_2_duration_info=[(f"{st.session_state.option_2_model_name}_duration",st.session_state.option_2_response_time)]
|
| 376 |
+
)
|
| 377 |
+
st.session_state.option_selected = True
|
| 378 |
+
|
| 379 |
+
def on_option_both_click():
|
| 380 |
+
if st.session_state.transcribed and not st.session_state.option_selected:
|
| 381 |
+
st.session_state.option_2_model_name_state = f"👑 {st.session_state.option_2_model_name} 👑"
|
| 382 |
+
st.session_state.option_1_model_name_state = f"👑 {st.session_state.option_1_model_name} 👑"
|
| 383 |
+
st.session_state.choice = f"You chose Prefer both. Option 1 was {st.session_state.option_1_model_name} Option 2 was {st.session_state.option_2_model_name}"
|
| 384 |
+
result_writer.write_result(
|
| 385 |
+
st.session_state.user_email,
|
| 386 |
+
st.session_state.current_audio_path,
|
| 387 |
+
winner_model=st.session_state.option_1_model_name,
|
| 388 |
+
loser_model=st.session_state.option_2_model_name,
|
| 389 |
+
option_1_duration_info=[(f"{st.session_state.option_1_model_name}_duration",st.session_state.option_1_response_time)],
|
| 390 |
+
option_2_duration_info=[(f"{st.session_state.option_2_model_name}_duration",st.session_state.option_2_response_time)],
|
| 391 |
+
both_preferred=True
|
| 392 |
+
)
|
| 393 |
+
st.session_state.option_selected = True
|
| 394 |
+
|
| 395 |
+
def on_option_none_click():
|
| 396 |
+
if st.session_state.transcribed and not st.session_state.option_selected:
|
| 397 |
+
st.session_state.option_1_model_name_state = f"👎 {st.session_state.option_1_model_name} 👎"
|
| 398 |
+
st.session_state.option_2_model_name_state = f"👎 {st.session_state.option_2_model_name} 👎"
|
| 399 |
+
st.session_state.choice = f"You chose none option. Option 1 was {st.session_state.option_1_model_name} Option 2 was {st.session_state.option_2_model_name}"
|
| 400 |
+
result_writer.write_result(
|
| 401 |
+
st.session_state.user_email,
|
| 402 |
+
st.session_state.current_audio_path,
|
| 403 |
+
winner_model=st.session_state.option_1_model_name,
|
| 404 |
+
loser_model=st.session_state.option_2_model_name,
|
| 405 |
+
option_1_duration_info=[(f"{st.session_state.option_1_model_name}_duration",st.session_state.option_1_response_time)],
|
| 406 |
+
option_2_duration_info=[(f"{st.session_state.option_2_model_name}_duration",st.session_state.option_2_response_time)],
|
| 407 |
+
none_preferred=True
|
| 408 |
+
)
|
| 409 |
+
st.session_state.option_selected = True
|
| 410 |
+
|
| 411 |
+
def on_reset_click():
|
| 412 |
+
st.session_state.choice = ""
|
| 413 |
+
st.session_state.option_selected = False
|
| 414 |
+
reset_state()
|
| 415 |
+
|
| 416 |
+
def arena():
|
| 417 |
+
if 'logged_in' not in st.session_state:
|
| 418 |
+
st.session_state.logged_in = False
|
| 419 |
+
|
| 420 |
+
if st.session_state.logged_in:
|
| 421 |
+
|
| 422 |
+
# load_models()
|
| 423 |
+
st.title("⚔️ Ori Speech-To-Text Arena ⚔️")
|
| 424 |
+
|
| 425 |
+
if 'option_1' not in st.session_state:
|
| 426 |
+
st.session_state.option_1 = ""
|
| 427 |
+
if 'option_2' not in st.session_state:
|
| 428 |
+
st.session_state.option_2 = ""
|
| 429 |
+
if 'transcribed' not in st.session_state:
|
| 430 |
+
st.session_state.transcribed = False
|
| 431 |
+
if 'choice' not in st.session_state:
|
| 432 |
+
st.session_state.choice = ""
|
| 433 |
+
if 'option_selected' not in st.session_state:
|
| 434 |
+
st.session_state.option_selected = False
|
| 435 |
+
if 'current_file_id' not in st.session_state:
|
| 436 |
+
st.session_state.current_file_id = None
|
| 437 |
+
if 'current_audio_path' not in st.session_state:
|
| 438 |
+
st.session_state.current_audio_path = None
|
| 439 |
+
if "option_1_model_name" not in st.session_state:
|
| 440 |
+
st.session_state.option_1_model_name = None
|
| 441 |
+
if "option_2_model_name" not in st.session_state:
|
| 442 |
+
st.session_state.option_2_model_name = None
|
| 443 |
+
if "last_recorded_audio" not in st.session_state:
|
| 444 |
+
st.session_state.last_recorded_audio = None
|
| 445 |
+
if "last_random_audio" not in st.session_state:
|
| 446 |
+
st.session_state.last_random_audio = None
|
| 447 |
+
if "option_1_model_name_state" not in st.session_state:
|
| 448 |
+
st.session_state.option_1_model_name_state = None
|
| 449 |
+
if "option_2_model_name_state" not in st.session_state:
|
| 450 |
+
st.session_state.option_2_model_name_state = None
|
| 451 |
+
if "option_1_response_time" not in st.session_state:
|
| 452 |
+
st.session_state.option_1_response_time = None
|
| 453 |
+
if "option_2_response_time" not in st.session_state:
|
| 454 |
+
st.session_state.option_2_response_time = None
|
| 455 |
+
if "audio_tab" not in st.session_state:
|
| 456 |
+
st.session_state.audio_tab = None
|
| 457 |
+
|
| 458 |
+
tab2, tab3,tab4 = st.tabs(["Upload Audio", "Record Audio","Random Audio Example"])
|
| 459 |
+
|
| 460 |
+
with tab2:
|
| 461 |
+
normal_audio = st.file_uploader("Upload Normal Audio File", type=['wav', 'mp3'], key='normal_audio')
|
| 462 |
+
if normal_audio:
|
| 463 |
+
if st.session_state.get('last_normal_file') != normal_audio.name:
|
| 464 |
+
reset_state()
|
| 465 |
+
st.session_state.last_normal_file = normal_audio.name
|
| 466 |
+
st.session_state.current_file_id = normal_audio.name
|
| 467 |
+
|
| 468 |
+
st.audio(normal_audio)
|
| 469 |
+
|
| 470 |
+
if st.button("Transcribe File"):
|
| 471 |
+
reset_state()
|
| 472 |
+
st.session_state.choice = ""
|
| 473 |
+
st.session_state.option_selected = False
|
| 474 |
+
st.session_state.audio_tab = "Upload"
|
| 475 |
+
option_1_text, option_2_text = process_audio_file(normal_audio)
|
| 476 |
+
st.session_state.option_1 = option_1_text
|
| 477 |
+
st.session_state.option_2 = option_2_text
|
| 478 |
+
st.session_state.transcribed = True
|
| 479 |
+
|
| 480 |
+
with tab3:
|
| 481 |
+
audio_bytes = audio_recorder(text="Click 🎙️ to record ((Recording active when icon is red))",pause_threshold=3,icon_size="2x")
|
| 482 |
+
|
| 483 |
+
if audio_bytes and audio_bytes != st.session_state.last_recorded_audio:
|
| 484 |
+
reset_state()
|
| 485 |
+
st.session_state.last_recorded_audio = audio_bytes
|
| 486 |
+
st.session_state.current_file_id = "recorded_audio"
|
| 487 |
+
|
| 488 |
+
st.audio(audio_bytes, format='audio/wav')
|
| 489 |
+
|
| 490 |
+
if st.button("Transcribe Recorded Audio"):
|
| 491 |
+
if audio_bytes:
|
| 492 |
+
reset_state()
|
| 493 |
+
st.session_state.choice = ""
|
| 494 |
+
st.session_state.option_selected = False
|
| 495 |
+
st.session_state.audio_tab = "Upload"
|
| 496 |
+
option_1_text, option_2_text = process_recorded_audio(audio_bytes)
|
| 497 |
+
st.session_state.option_1 = option_1_text
|
| 498 |
+
st.session_state.option_2 = option_2_text
|
| 499 |
+
st.session_state.transcribed = True
|
| 500 |
+
|
| 501 |
+
with tab4:
|
| 502 |
+
fetch_audio_payload = {
|
| 503 |
+
"task":"fetch_audio"
|
| 504 |
+
}
|
| 505 |
+
array,sampling_rate,filepath = send_task(fetch_audio_payload)
|
| 506 |
+
if "current_random_audio" not in st.session_state:
|
| 507 |
+
st.session_state.current_random_audio = filepath
|
| 508 |
+
if "current_array" not in st.session_state:
|
| 509 |
+
st.session_state.current_array = array
|
| 510 |
+
if "current_sampling_rate" not in st.session_state:
|
| 511 |
+
st.session_state.current_sampling_rate = sampling_rate
|
| 512 |
+
|
| 513 |
+
if "current_random_audio" not in st.session_state:
|
| 514 |
+
st.session_state.current_random_audio = filepath
|
| 515 |
+
|
| 516 |
+
if st.button("Next File"):
|
| 517 |
+
reset_state()
|
| 518 |
+
fetch_audio_payload = {
|
| 519 |
+
"task":"fetch_audio"
|
| 520 |
+
}
|
| 521 |
+
array,sampling_rate,filepath = send_task(fetch_audio_payload)
|
| 522 |
+
st.session_state.current_random_audio = filepath
|
| 523 |
+
st.session_state.current_array = array
|
| 524 |
+
st.session_state.current_sampling_rate = sampling_rate
|
| 525 |
+
st.session_state.last_random_audio = None
|
| 526 |
+
|
| 527 |
+
audio = st.session_state.current_random_audio
|
| 528 |
+
|
| 529 |
+
if audio and audio != st.session_state.last_random_audio:
|
| 530 |
+
st.session_state.choice = ""
|
| 531 |
+
st.session_state.option_selected = False
|
| 532 |
+
st.session_state.last_random_audio = audio
|
| 533 |
+
st.session_state.current_file_id = audio
|
| 534 |
+
|
| 535 |
+
st.audio(data=st.session_state.current_array,
|
| 536 |
+
sample_rate=st.session_state.current_sampling_rate,
|
| 537 |
+
format="audio/wav")
|
| 538 |
+
|
| 539 |
+
if st.button("Transcribe Random Audio"):
|
| 540 |
+
if audio:
|
| 541 |
+
st.session_state.option_selected = False
|
| 542 |
+
option_1_text, option_2_text = process_random_file(audio)
|
| 543 |
+
st.session_state.option_1 = option_1_text
|
| 544 |
+
st.session_state.option_2 = option_2_text
|
| 545 |
+
st.session_state.transcribed = True
|
| 546 |
+
|
| 547 |
+
text_containers = st.columns([1, 1])
|
| 548 |
+
name_containers = st.columns([1, 1])
|
| 549 |
+
|
| 550 |
+
with text_containers[0]:
|
| 551 |
+
st.text_area("Option 1", value=st.session_state.option_1, height=300)
|
| 552 |
+
|
| 553 |
+
with text_containers[1]:
|
| 554 |
+
st.text_area("Option 2", value=st.session_state.option_2, height=300)
|
| 555 |
+
|
| 556 |
+
with name_containers[0]:
|
| 557 |
+
if st.session_state.option_1_model_name_state:
|
| 558 |
+
st.markdown(f"<div style='text-align: center'>{st.session_state.option_1_model_name_state}</div>", unsafe_allow_html=True)
|
| 559 |
+
|
| 560 |
+
with name_containers[1]:
|
| 561 |
+
if st.session_state.option_2_model_name_state:
|
| 562 |
+
st.markdown(f"<div style='text-align: center'>{st.session_state.option_2_model_name_state}</div>", unsafe_allow_html=True)
|
| 563 |
+
|
| 564 |
+
c1, c2, c3, c4 = st.columns(4)
|
| 565 |
+
|
| 566 |
+
with c1:
|
| 567 |
+
st.button("Prefer Option 1",on_click=on_option_1_click)
|
| 568 |
+
|
| 569 |
+
with c2:
|
| 570 |
+
st.button("Prefer Option 2",on_click=on_option_2_click)
|
| 571 |
+
|
| 572 |
+
with c3:
|
| 573 |
+
st.button("Prefer Both",on_click=on_option_both_click)
|
| 574 |
+
|
| 575 |
+
with c4:
|
| 576 |
+
st.button("Prefer None",on_click=on_option_none_click)
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
st.button("Reset Choice",on_click=on_reset_click)
|
| 580 |
+
|
| 581 |
+
else:
|
| 582 |
+
st.write('You have not entered your email and name yet')
|
| 583 |
+
st.write('Please Navigate to login page in the dropdown menu')
|
| 584 |
+
|
| 585 |
+
|
| 586 |
+
def dashboard():
|
| 587 |
+
if 'logged_in' not in st.session_state:
|
| 588 |
+
st.session_state.logged_in = False
|
| 589 |
+
|
| 590 |
+
if st.session_state.logged_in:
|
| 591 |
+
st.title('Model Arena Scoreboard')
|
| 592 |
+
|
| 593 |
+
df = pd.read_csv(SAVE_PATH)
|
| 594 |
+
metrics = calculate_metrics(df)
|
| 595 |
+
|
| 596 |
+
MODEL_DESCRIPTIONS = {
|
| 597 |
+
"Ori Prime": "Foundational, large, and stable.",
|
| 598 |
+
"Ori Swift": "Lighter and faster than Ori Prime.",
|
| 599 |
+
"Ori Apex": "The top-performing model, fast and stable.",
|
| 600 |
+
"Ori Apex XT": "Enhanced with more training, though slightly less stable than Ori Apex.",
|
| 601 |
+
"DG" : "Deepgram Nova-2 API",
|
| 602 |
+
"Azure" : "Azure Speech Services API"
|
| 603 |
+
}
|
| 604 |
+
|
| 605 |
+
st.header('Model Descriptions')
|
| 606 |
+
|
| 607 |
+
cols = st.columns(2)
|
| 608 |
+
for idx, (model, description) in enumerate(MODEL_DESCRIPTIONS.items()):
|
| 609 |
+
with cols[idx % 2]:
|
| 610 |
+
st.markdown(f"""
|
| 611 |
+
<div style='padding: 1rem; border: 1px solid #e1e4e8; border-radius: 6px; margin-bottom: 1rem;'>
|
| 612 |
+
<h3 style='margin: 0; margin-bottom: 0.5rem;'>{model}</h3>
|
| 613 |
+
<p style='margin: 0; color: #6e7681;'>{description}</p>
|
| 614 |
+
</div>
|
| 615 |
+
""", unsafe_allow_html=True)
|
| 616 |
+
|
| 617 |
+
st.header('Overall Performance')
|
| 618 |
+
|
| 619 |
+
col1, col2, col3= st.columns(3)
|
| 620 |
+
|
| 621 |
+
with col1:
|
| 622 |
+
create_metric_container("Total Matches", len(df))
|
| 623 |
+
|
| 624 |
+
best_model = max(metrics.items(), key=lambda x: x[1]['win_rate'])[0]
|
| 625 |
+
with col2:
|
| 626 |
+
create_metric_container(
|
| 627 |
+
"Best Model",
|
| 628 |
+
get_model_abbreviation(best_model),
|
| 629 |
+
full_name=best_model
|
| 630 |
+
)
|
| 631 |
+
|
| 632 |
+
most_appearances = max(metrics.items(), key=lambda x: x[1]['appearances'])[0]
|
| 633 |
+
with col3:
|
| 634 |
+
create_metric_container(
|
| 635 |
+
"Most Used",
|
| 636 |
+
get_model_abbreviation(most_appearances),
|
| 637 |
+
full_name=most_appearances
|
| 638 |
+
)
|
| 639 |
+
|
| 640 |
+
st.header('Win Rates')
|
| 641 |
+
win_rate_chart = create_win_rate_chart(metrics)
|
| 642 |
+
st.plotly_chart(win_rate_chart, use_container_width=True)
|
| 643 |
+
|
| 644 |
+
st.header('Appearance Distribution')
|
| 645 |
+
appearance_chart = create_appearance_chart(metrics)
|
| 646 |
+
st.plotly_chart(appearance_chart, use_container_width=True)
|
| 647 |
+
|
| 648 |
+
st.header('Head-to-Head Analysis')
|
| 649 |
+
matrix_chart = create_head_to_head_matrix(df)
|
| 650 |
+
st.plotly_chart(matrix_chart, use_container_width=True)
|
| 651 |
+
|
| 652 |
+
st.header('Detailed Metrics')
|
| 653 |
+
metrics_df = pd.DataFrame.from_dict(metrics, orient='index')
|
| 654 |
+
metrics_df['win_rate'] = metrics_df['win_rate'].round(2)
|
| 655 |
+
metrics_df.drop(["avg_response_time","response_time_std"],axis=1,inplace=True)
|
| 656 |
+
# metrics_df['avg_response_time'] = metrics_df['avg_response_time'].round(3)
|
| 657 |
+
metrics_df.index = [get_model_abbreviation(model) for model in metrics_df.index]
|
| 658 |
+
st.dataframe(metrics_df)
|
| 659 |
+
|
| 660 |
+
st.header('Full Dataframe')
|
| 661 |
+
df = df.drop('path', axis=1)
|
| 662 |
+
df = df.drop(['Ori Apex_duration', 'Ori Apex XT_duration', 'deepgram_duration', 'Ori Swift_duration', 'Ori Prime_duration','azure_duration','email'],axis=1)
|
| 663 |
+
st.dataframe(df)
|
| 664 |
+
else:
|
| 665 |
+
st.write('You have not entered your email and name yet')
|
| 666 |
+
st.write('Please Navigate to login page in the dropdown menu')
|
| 667 |
+
|
| 668 |
+
def help():
|
| 669 |
+
st.title("Help")
|
| 670 |
+
|
| 671 |
+
st.markdown(
|
| 672 |
+
"""
|
| 673 |
+
# Ori Speech-To-Text Arena
|
| 674 |
+
|
| 675 |
+
## Introduction
|
| 676 |
+
|
| 677 |
+
Below are the general instructions for participating in the Ori Speech-To-Text Arena.
|
| 678 |
+
|
| 679 |
+
## Options:
|
| 680 |
+
There are three options for participating in the Ori Speech-To-Text Arena:
|
| 681 |
+
|
| 682 |
+
1. Compare different model by uploading your own audio file and submit it to the Arena
|
| 683 |
+
2. Compare different model by recording your own audio file and submit it to the Arena
|
| 684 |
+
3. Choose and compare from one of our randomly selected audio files
|
| 685 |
+
|
| 686 |
+
### 1. Compare different model by uploading your own audio file and submit it to the Arena
|
| 687 |
+
|
| 688 |
+
Steps:
|
| 689 |
+
1. Select the upload audio file option
|
| 690 |
+
""")
|
| 691 |
+
|
| 692 |
+
st.image("./images/1.png")
|
| 693 |
+
st.image("./images/2.png")
|
| 694 |
+
st.image("./images/3.png")
|
| 695 |
+
st.image("./images/4.png")
|
| 696 |
+
|
| 697 |
+
st.markdown("""
|
| 698 |
+
### 2. Compare different model by recording your own audio file and submit it to the Arena
|
| 699 |
+
|
| 700 |
+
Steps:
|
| 701 |
+
1. Select the record audio file option
|
| 702 |
+
""")
|
| 703 |
+
|
| 704 |
+
st.image("./images/5.png")
|
| 705 |
+
st.image("./images/6.png")
|
| 706 |
+
st.image("./images/7.png")
|
| 707 |
+
|
| 708 |
+
st.markdown("""
|
| 709 |
+
4. Rest of the steps remain same as above
|
| 710 |
+
|
| 711 |
+
### 3. Choose and compare from one of our randomly selected audio files
|
| 712 |
+
|
| 713 |
+
Steps:
|
| 714 |
+
1. Select the random audio file option
|
| 715 |
+
""")
|
| 716 |
+
|
| 717 |
+
st.image("./images/8.png")
|
| 718 |
+
st.image("./images/9.png")
|
| 719 |
+
|
| 720 |
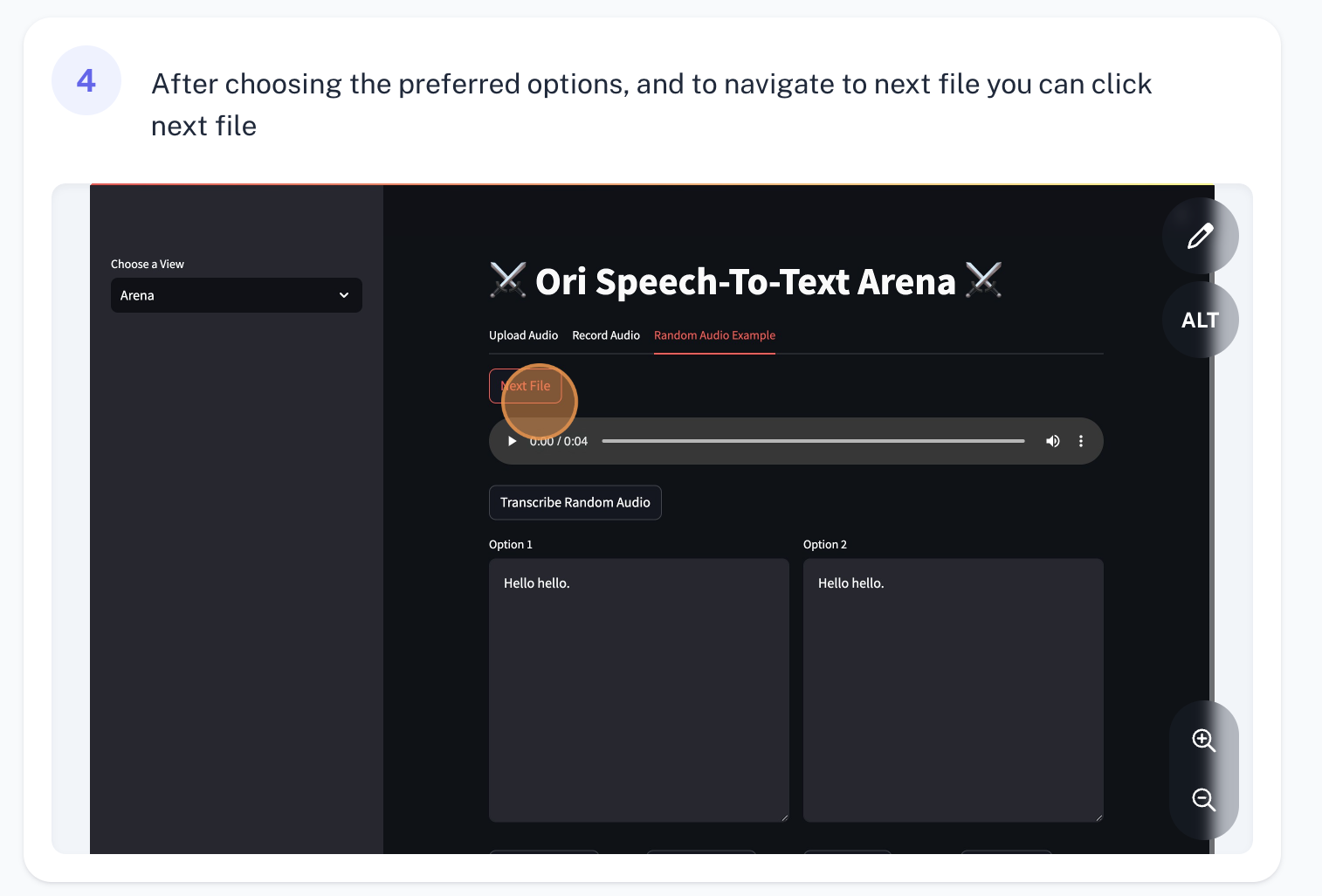
+
st.markdown("""
|
| 721 |
+
4. Rest of the steps remain same as above
|
| 722 |
+
""")
|
| 723 |
+
|
| 724 |
+
st.image("./images/10.png")
|
| 725 |
+
|
| 726 |
+
def validate_email(email):
|
| 727 |
+
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
|
| 728 |
+
return re.match(pattern, email) is not None
|
| 729 |
+
|
| 730 |
+
def validate_name(name):
|
| 731 |
+
pattern = r'^[a-zA-Z\s-]{2,}$'
|
| 732 |
+
return re.match(pattern, name) is not None
|
| 733 |
+
|
| 734 |
+
def create_login_page():
|
| 735 |
+
st.title("Welcome to the App")
|
| 736 |
+
|
| 737 |
+
if 'logged_in' not in st.session_state:
|
| 738 |
+
st.session_state.logged_in = False
|
| 739 |
+
|
| 740 |
+
if not st.session_state.logged_in:
|
| 741 |
+
with st.form("login_form"):
|
| 742 |
+
st.subheader("Please Login")
|
| 743 |
+
|
| 744 |
+
email = st.text_input("Email")
|
| 745 |
+
name = st.text_input("Name")
|
| 746 |
+
|
| 747 |
+
submit_button = st.form_submit_button("Login")
|
| 748 |
+
|
| 749 |
+
if submit_button:
|
| 750 |
+
if not email or not name:
|
| 751 |
+
st.error("Please fill in all fields")
|
| 752 |
+
else:
|
| 753 |
+
if not validate_email(email):
|
| 754 |
+
st.error("Please enter a valid email address")
|
| 755 |
+
elif not validate_name(name):
|
| 756 |
+
st.error("Please enter a valid name (letters, spaces, and hyphens only)")
|
| 757 |
+
else:
|
| 758 |
+
st.session_state.logged_in = True
|
| 759 |
+
st.session_state.user_email = email
|
| 760 |
+
st.session_state.user_name = name
|
| 761 |
+
st.success("Login successful! You can now navigate to the Arena using the dropdown in the sidebar")
|
| 762 |
+
else:
|
| 763 |
+
st.success("You have already logged in. You can now navigate to the Arena using the dropdown in the sidebar")
|
| 764 |
+
|
| 765 |
+
|
| 766 |
+
page_names_to_funcs = {
|
| 767 |
+
"Login" : create_login_page,
|
| 768 |
+
"Arena": arena,
|
| 769 |
+
"Scoreboard": dashboard,
|
| 770 |
+
"Help": help
|
| 771 |
+
}
|
| 772 |
+
|
| 773 |
+
demo_name = st.sidebar.selectbox("Choose a View\nTo view the help page choose the help view", page_names_to_funcs.keys())
|
| 774 |
+
page_names_to_funcs[demo_name]()
|
images/1.png
ADDED

|
images/10.png
ADDED
|
images/11.png
ADDED

|
images/2.png
ADDED

|
images/3.png
ADDED
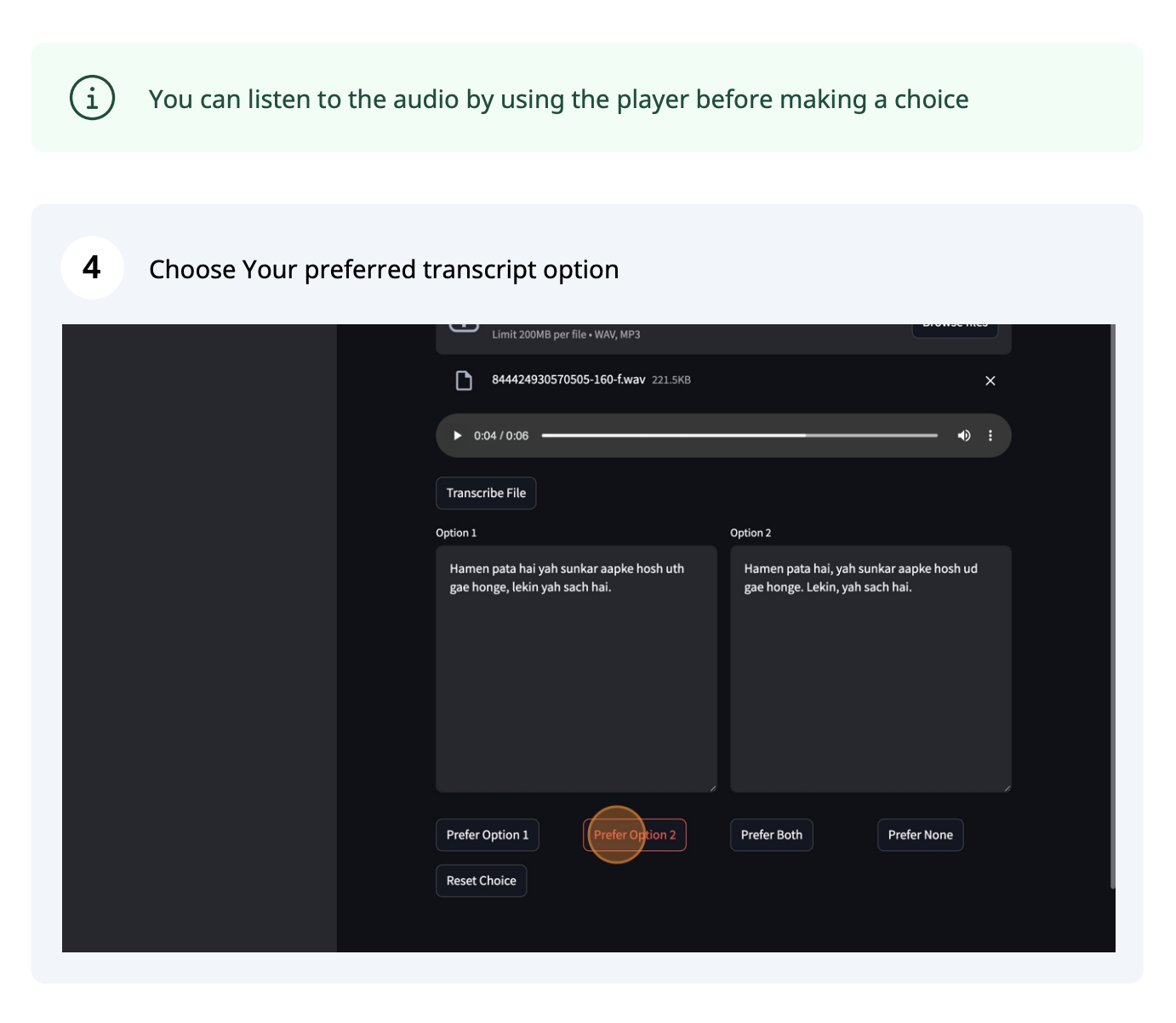
|
images/4.png
ADDED

|
images/5.png
ADDED
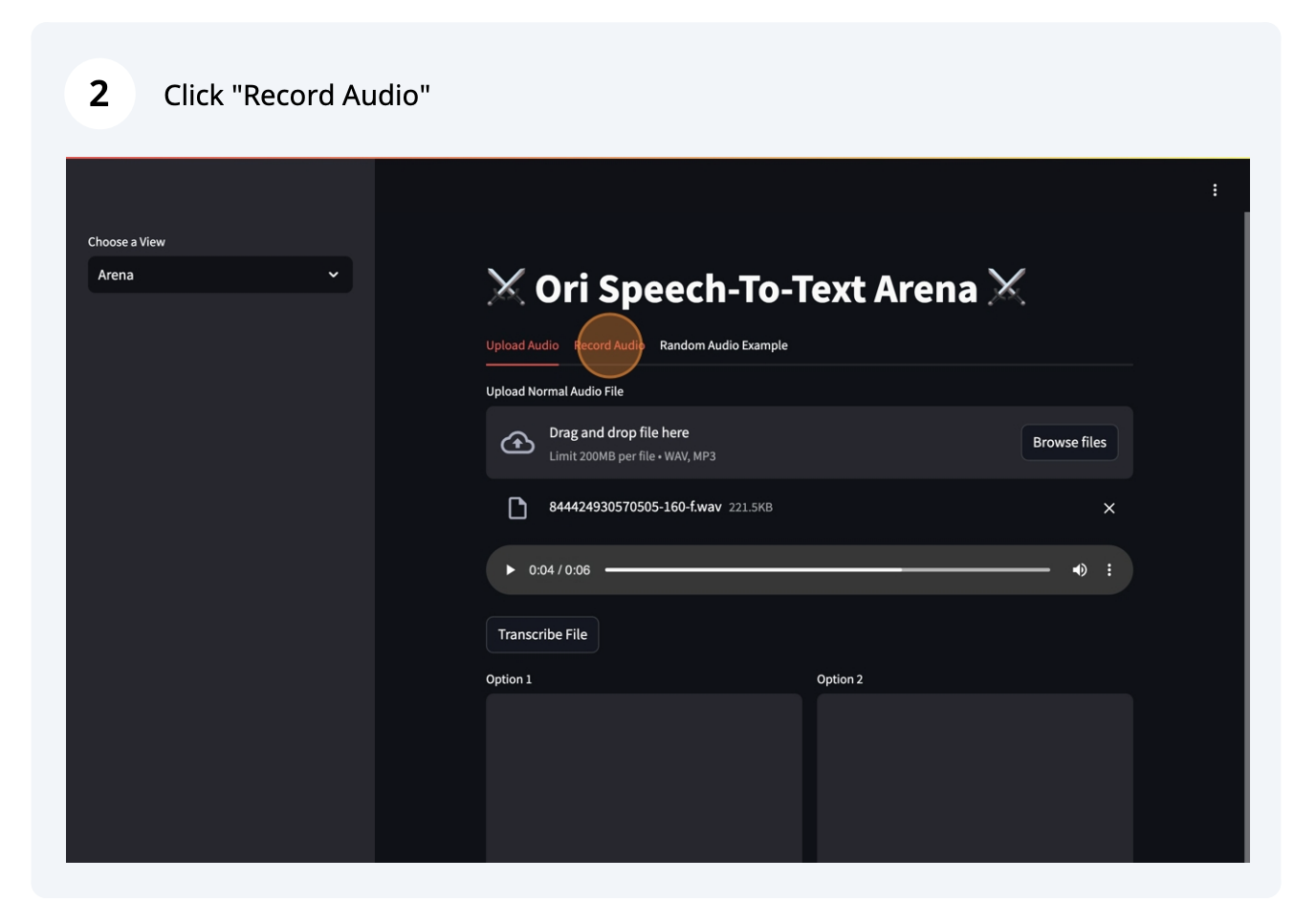
|
images/6.png
ADDED

|
images/7.png
ADDED

|
images/8.png
ADDED

|
images/9.png
ADDED

|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
audio-recorder-streamlit==0.0.10
|
| 2 |
+
librosa
|
| 3 |
+
numpy==1.26.4
|
| 4 |
+
pandas==2.2.3
|
| 5 |
+
plotly==5.24.1
|
| 6 |
+
requests==2.32.3
|
| 7 |
+
scipy
|
| 8 |
+
streamlit==1.40.2
|