Spaces:
Paused

Paused
Doron Adler
commited on
Commit
·
5b2843c
1
Parent(s):
63cbe24
Turn a face into the face of a "Comics hero"
Browse files- .gitattributes +2 -0
- Example00001.jpg +0 -0
- Example00002.jpg +0 -0
- Example00003.jpg +0 -0
- Example00004.jpg +0 -0
- Example00005.jpg +0 -0
- Example00006.jpg +0 -0
- README.md +4 -4
- Sample00001.jpg +0 -0
- Sample00002.jpg +0 -0
- Sample00003.jpg +0 -0
- Sample00004.jpg +0 -0
- Sample00005.jpg +0 -0
- Sample00006.jpg +0 -0
- app.py +87 -0
- comics-heroes_p2s2p_model_from_scripted-simp.quant.onnx +3 -0
- face_detection.py +140 -0
- requirements.txt +9 -0
- shape_predictor_5_face_landmarks.dat +3 -0
.gitattributes
CHANGED
|
@@ -25,3 +25,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 25 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 25 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
comics-heroes_p2s2p_model_from_scripted-simp.quant.onnx filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
shape_predictor_5_face_landmarks.dat filter=lfs diff=lfs merge=lfs -text
|
Example00001.jpg
ADDED

|
Example00002.jpg
ADDED

|
Example00003.jpg
ADDED

|
Example00004.jpg
ADDED

|
Example00005.jpg
ADDED

|
Example00006.jpg
ADDED

|
README.md
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
app_file: app.py
|
| 8 |
pinned: false
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Comics Hero HD
|
| 3 |
+
emoji: 🦸🏽♀️
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
app_file: app.py
|
| 8 |
pinned: false
|
Sample00001.jpg
ADDED
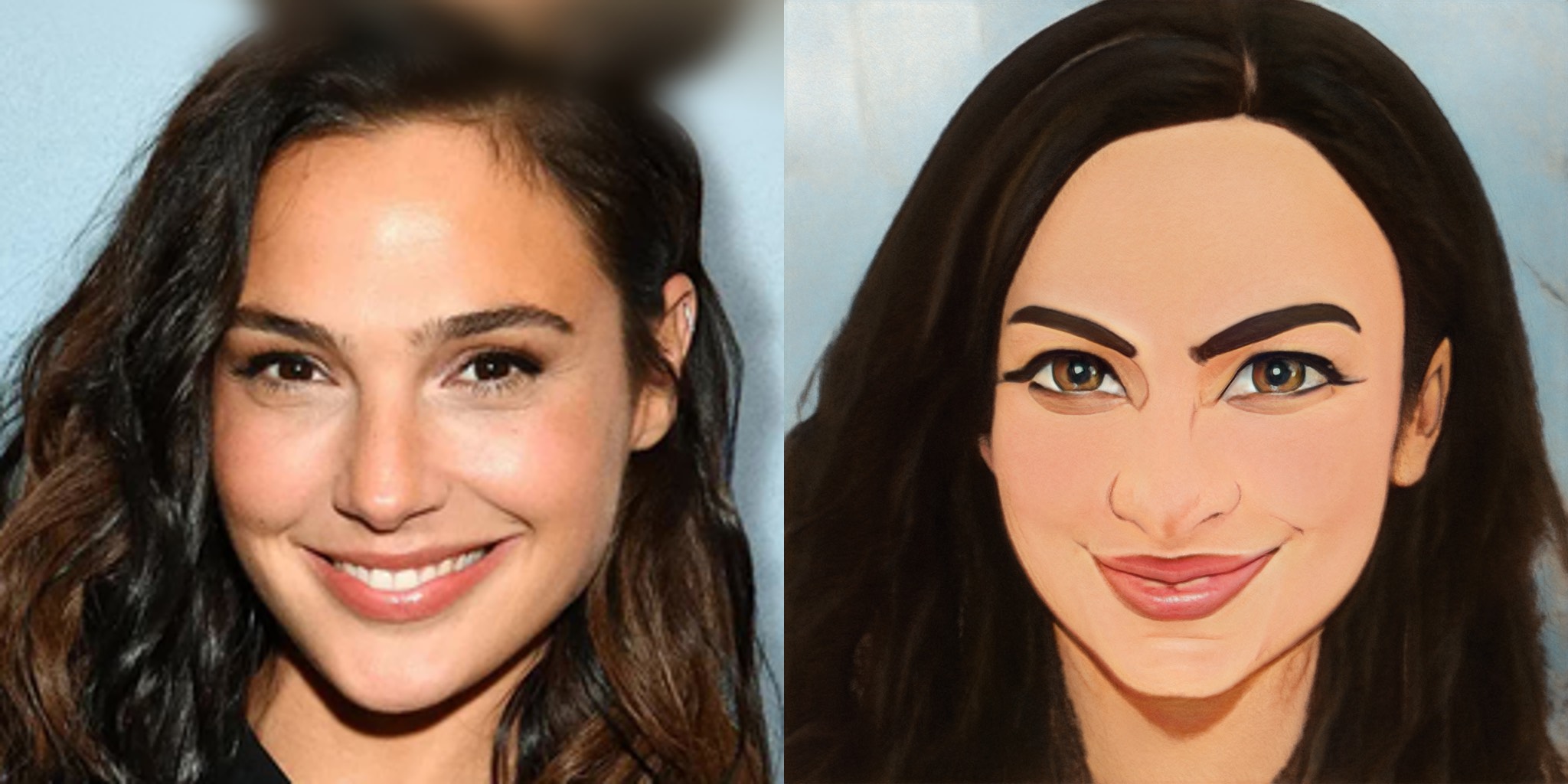
|
Sample00002.jpg
ADDED

|
Sample00003.jpg
ADDED

|
Sample00004.jpg
ADDED

|
Sample00005.jpg
ADDED

|
Sample00006.jpg
ADDED

|
app.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
os.system("pip install dlib")
|
| 3 |
+
import sys
|
| 4 |
+
import PIL
|
| 5 |
+
from PIL import Image, ImageOps, ImageFile
|
| 6 |
+
import numpy as np
|
| 7 |
+
import onnxruntime as rt
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
import collections
|
| 10 |
+
from typing import Union, List
|
| 11 |
+
import scipy.ndimage
|
| 12 |
+
import requests
|
| 13 |
+
import face_detection
|
| 14 |
+
|
| 15 |
+
MODEL_FILE = "comics-heroes_p2s2p_model_from_scripted-simp.quant.onnx"
|
| 16 |
+
session = rt.InferenceSession(MODEL_FILE)
|
| 17 |
+
input_name = session.get_inputs()[0].name
|
| 18 |
+
print("input_name = " + str(input_name))
|
| 19 |
+
output_name = session.get_outputs()[0].name
|
| 20 |
+
print("output_name = " + str(output_name))
|
| 21 |
+
|
| 22 |
+
def array_to_image(array_in):
|
| 23 |
+
array_in = np.squeeze(255*(array_in + 1)/2)
|
| 24 |
+
array_in = np.transpose(array_in, (1, 2, 0))
|
| 25 |
+
im = Image.fromarray(array_in.astype(np.uint8))
|
| 26 |
+
return im
|
| 27 |
+
|
| 28 |
+
def image_as_array(image_in):
|
| 29 |
+
im_array = np.array(image_in, np.float32)
|
| 30 |
+
im_array = (im_array/255)*2 - 1
|
| 31 |
+
im_array = np.transpose(im_array, (2, 0, 1))
|
| 32 |
+
im_array = np.expand_dims(im_array, 0)
|
| 33 |
+
return im_array
|
| 34 |
+
|
| 35 |
+
def find_aligned_face(image_in, size=256):
|
| 36 |
+
aligned_image, n_faces, quad = face_detection.align(image_in, face_index=0, output_size=size)
|
| 37 |
+
return aligned_image, n_faces, quad
|
| 38 |
+
|
| 39 |
+
def align_first_face(image_in, size=256):
|
| 40 |
+
aligned_image, n_faces, quad = find_aligned_face(image_in,size=size)
|
| 41 |
+
if n_faces == 0:
|
| 42 |
+
try:
|
| 43 |
+
image_in = ImageOps.exif_transpose(image_in)
|
| 44 |
+
except:
|
| 45 |
+
print("exif problem, not rotating")
|
| 46 |
+
image_in = image_in.resize((size, size))
|
| 47 |
+
im_array = image_as_array(image_in)
|
| 48 |
+
else:
|
| 49 |
+
im_array = image_as_array(aligned_image)
|
| 50 |
+
|
| 51 |
+
return im_array
|
| 52 |
+
|
| 53 |
+
def img_concat_h(im1, im2):
|
| 54 |
+
dst = Image.new('RGB', (im1.width + im2.width, im1.height))
|
| 55 |
+
dst.paste(im1, (0, 0))
|
| 56 |
+
dst.paste(im2, (im1.width, 0))
|
| 57 |
+
return dst
|
| 58 |
+
|
| 59 |
+
import gradio as gr
|
| 60 |
+
|
| 61 |
+
def face2hero(
|
| 62 |
+
img: Image.Image,
|
| 63 |
+
size: int
|
| 64 |
+
) -> Image.Image:
|
| 65 |
+
|
| 66 |
+
aligned_img = align_first_face(img)
|
| 67 |
+
if aligned_img is None:
|
| 68 |
+
output=None
|
| 69 |
+
else:
|
| 70 |
+
output = session.run([output_name], {input_name: aligned_img})[0]
|
| 71 |
+
output = array_to_image(output)
|
| 72 |
+
aligned_img = array_to_image(aligned_img).resize((output.width, output.height))
|
| 73 |
+
output = img_concat_h(aligned_img, output)
|
| 74 |
+
|
| 75 |
+
return output
|
| 76 |
+
|
| 77 |
+
def inference(img):
|
| 78 |
+
out = face2hero(img, 256)
|
| 79 |
+
return out
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
title = "Comics hero HD"
|
| 83 |
+
description = "Turn a face into the face of a \"Comics hero\". Upload an image with a face, or click on one of the examples below. If a face could not be detected, an image will still be created."
|
| 84 |
+
article = "<hr><p style='text-align: center'>See the <a href='https://github.com/justinpinkney/pixel2style2pixel/tree/nw' target='_blank'>Github Repo</a></p><p style='text-align: center'>samples: <img src='https://hf.space/gradioiframe/Norod78/ComicsHeroHD/file/Sample00001.jpg' alt='Sample00001'/><img src='https://hf.space/gradioiframe/Norod78/ComicsHeroHD/file/Sample00002.jpg' alt='Sample00002'/><img src='https://hf.space/gradioiframe/Norod78/ComicsHeroHD/file/Sample00003.jpg' alt='Sample00003'/><img src='https://hf.space/gradioiframe/Norod78/ComicsHeroHD/file/Sample00004.jpg' alt='Sample00004'/><img src='https://hf.space/gradioiframe/Norod78/ComicsHeroHD/file/Sample00005.jpg' alt='Sample00005'/></p><p>The \"Comics Hero HD\" model was fine tuned on a pre-trained Pixel2Style2Pixel model by <a href='https://linktr.ee/Norod78' target='_blank'>Doron Adler</a></p>"
|
| 85 |
+
|
| 86 |
+
examples=[['Example00001.jpg'],['Example00002.jpg'],['Example00003.jpg'],['Example00004.jpg'],['Example00005.jpg'], ['Example00006.jpg']]
|
| 87 |
+
gr.Interface(inference, gr.inputs.Image(type="pil",shape=(1024,1024)), gr.outputs.Image(type="pil"),title=title,description=description,article=article,examples=examples,enable_queue=True).launch()
|
comics-heroes_p2s2p_model_from_scripted-simp.quant.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:74cc8ebc3a4777532b93ae770c8be90dd19e92f571d10bc4a3df00c89adff86c
|
| 3 |
+
size 378274615
|
face_detection.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021 Justin Pinkney
|
| 2 |
+
|
| 3 |
+
import dlib
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from PIL import ImageOps
|
| 8 |
+
from scipy.ndimage import gaussian_filter
|
| 9 |
+
import cv2
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
MODEL_PATH = "shape_predictor_5_face_landmarks.dat"
|
| 13 |
+
detector = dlib.get_frontal_face_detector()
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def align(image_in, face_index=0, output_size=256):
|
| 17 |
+
try:
|
| 18 |
+
image_in = ImageOps.exif_transpose(image_in)
|
| 19 |
+
except:
|
| 20 |
+
print("exif problem, not rotating")
|
| 21 |
+
|
| 22 |
+
landmarks = list(get_landmarks(image_in))
|
| 23 |
+
n_faces = len(landmarks)
|
| 24 |
+
face_index = min(n_faces-1, face_index)
|
| 25 |
+
if n_faces == 0:
|
| 26 |
+
aligned_image = image_in
|
| 27 |
+
quad = None
|
| 28 |
+
else:
|
| 29 |
+
aligned_image, quad = image_align(image_in, landmarks[face_index], output_size=output_size)
|
| 30 |
+
|
| 31 |
+
return aligned_image, n_faces, quad
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def composite_images(quad, img, output):
|
| 35 |
+
"""Composite an image into and output canvas according to transformed co-ords"""
|
| 36 |
+
output = output.convert("RGBA")
|
| 37 |
+
img = img.convert("RGBA")
|
| 38 |
+
input_size = img.size
|
| 39 |
+
src = np.array(((0, 0), (0, input_size[1]), input_size, (input_size[0], 0)), dtype=np.float32)
|
| 40 |
+
dst = np.float32(quad)
|
| 41 |
+
mtx = cv2.getPerspectiveTransform(dst, src)
|
| 42 |
+
img = img.transform(output.size, Image.PERSPECTIVE, mtx.flatten(), Image.BILINEAR)
|
| 43 |
+
output.alpha_composite(img)
|
| 44 |
+
|
| 45 |
+
return output.convert("RGB")
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def get_landmarks(image):
|
| 49 |
+
"""Get landmarks from PIL image"""
|
| 50 |
+
shape_predictor = dlib.shape_predictor(MODEL_PATH)
|
| 51 |
+
|
| 52 |
+
max_size = max(image.size)
|
| 53 |
+
reduction_scale = int(max_size/512)
|
| 54 |
+
if reduction_scale == 0:
|
| 55 |
+
reduction_scale = 1
|
| 56 |
+
downscaled = image.reduce(reduction_scale)
|
| 57 |
+
img = np.array(downscaled)
|
| 58 |
+
detections = detector(img, 0)
|
| 59 |
+
|
| 60 |
+
for detection in detections:
|
| 61 |
+
try:
|
| 62 |
+
face_landmarks = [(reduction_scale*item.x, reduction_scale*item.y) for item in shape_predictor(img, detection).parts()]
|
| 63 |
+
yield face_landmarks
|
| 64 |
+
except Exception as e:
|
| 65 |
+
print(e)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def image_align(src_img, face_landmarks, output_size=512, transform_size=2048, enable_padding=True, x_scale=1, y_scale=1, em_scale=0.1, alpha=False):
|
| 69 |
+
# Align function modified from ffhq-dataset
|
| 70 |
+
# See https://github.com/NVlabs/ffhq-dataset for license
|
| 71 |
+
|
| 72 |
+
lm = np.array(face_landmarks)
|
| 73 |
+
lm_eye_left = lm[2:3] # left-clockwise
|
| 74 |
+
lm_eye_right = lm[0:1] # left-clockwise
|
| 75 |
+
|
| 76 |
+
# Calculate auxiliary vectors.
|
| 77 |
+
eye_left = np.mean(lm_eye_left, axis=0)
|
| 78 |
+
eye_right = np.mean(lm_eye_right, axis=0)
|
| 79 |
+
eye_avg = (eye_left + eye_right) * 0.5
|
| 80 |
+
eye_to_eye = 0.71*(eye_right - eye_left)
|
| 81 |
+
mouth_avg = lm[4]
|
| 82 |
+
eye_to_mouth = 1.35*(mouth_avg - eye_avg)
|
| 83 |
+
|
| 84 |
+
# Choose oriented crop rectangle.
|
| 85 |
+
x = eye_to_eye.copy()
|
| 86 |
+
x /= np.hypot(*x)
|
| 87 |
+
x *= max(np.hypot(*eye_to_eye) * 2.0, np.hypot(*eye_to_mouth) * 1.8)
|
| 88 |
+
x *= x_scale
|
| 89 |
+
y = np.flipud(x) * [-y_scale, y_scale]
|
| 90 |
+
c = eye_avg + eye_to_mouth * em_scale
|
| 91 |
+
quad = np.stack([c - x - y, c - x + y, c + x + y, c + x - y])
|
| 92 |
+
quad_orig = quad.copy()
|
| 93 |
+
qsize = np.hypot(*x) * 2
|
| 94 |
+
|
| 95 |
+
img = src_img.convert('RGBA').convert('RGB')
|
| 96 |
+
|
| 97 |
+
# Shrink.
|
| 98 |
+
shrink = int(np.floor(qsize / output_size * 0.5))
|
| 99 |
+
if shrink > 1:
|
| 100 |
+
rsize = (int(np.rint(float(img.size[0]) / shrink)), int(np.rint(float(img.size[1]) / shrink)))
|
| 101 |
+
img = img.resize(rsize, Image.ANTIALIAS)
|
| 102 |
+
quad /= shrink
|
| 103 |
+
qsize /= shrink
|
| 104 |
+
|
| 105 |
+
# Crop.
|
| 106 |
+
border = max(int(np.rint(qsize * 0.1)), 3)
|
| 107 |
+
crop = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1]))))
|
| 108 |
+
crop = (max(crop[0] - border, 0), max(crop[1] - border, 0), min(crop[2] + border, img.size[0]), min(crop[3] + border, img.size[1]))
|
| 109 |
+
if crop[2] - crop[0] < img.size[0] or crop[3] - crop[1] < img.size[1]:
|
| 110 |
+
img = img.crop(crop)
|
| 111 |
+
quad -= crop[0:2]
|
| 112 |
+
|
| 113 |
+
# Pad.
|
| 114 |
+
pad = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1]))))
|
| 115 |
+
pad = (max(-pad[0] + border, 0), max(-pad[1] + border, 0), max(pad[2] - img.size[0] + border, 0), max(pad[3] - img.size[1] + border, 0))
|
| 116 |
+
if enable_padding and max(pad) > border - 4:
|
| 117 |
+
pad = np.maximum(pad, int(np.rint(qsize * 0.3)))
|
| 118 |
+
img = np.pad(np.float32(img), ((pad[1], pad[3]), (pad[0], pad[2]), (0, 0)), 'reflect')
|
| 119 |
+
h, w, _ = img.shape
|
| 120 |
+
y, x, _ = np.ogrid[:h, :w, :1]
|
| 121 |
+
mask = np.maximum(1.0 - np.minimum(np.float32(x) / pad[0], np.float32(w-1-x) / pad[2]), 1.0 - np.minimum(np.float32(y) / pad[1], np.float32(h-1-y) / pad[3]))
|
| 122 |
+
blur = qsize * 0.02
|
| 123 |
+
img += (gaussian_filter(img, [blur, blur, 0]) - img) * np.clip(mask * 3.0 + 1.0, 0.0, 1.0)
|
| 124 |
+
img += (np.median(img, axis=(0,1)) - img) * np.clip(mask, 0.0, 1.0)
|
| 125 |
+
img = np.uint8(np.clip(np.rint(img), 0, 255))
|
| 126 |
+
if alpha:
|
| 127 |
+
mask = 1-np.clip(3.0 * mask, 0.0, 1.0)
|
| 128 |
+
mask = np.uint8(np.clip(np.rint(mask*255), 0, 255))
|
| 129 |
+
img = np.concatenate((img, mask), axis=2)
|
| 130 |
+
img = Image.fromarray(img, 'RGBA')
|
| 131 |
+
else:
|
| 132 |
+
img = Image.fromarray(img, 'RGB')
|
| 133 |
+
quad += pad[:2]
|
| 134 |
+
|
| 135 |
+
# Transform.
|
| 136 |
+
img = img.transform((transform_size, transform_size), Image.QUAD, (quad + 0.5).flatten(), Image.BILINEAR)
|
| 137 |
+
if output_size < transform_size:
|
| 138 |
+
img = img.resize((output_size, output_size), Image.ANTIALIAS)
|
| 139 |
+
|
| 140 |
+
return img, quad_orig
|
requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
opencv-python-headless
|
| 3 |
+
Pillow
|
| 4 |
+
scikit-image
|
| 5 |
+
torch
|
| 6 |
+
torchvision
|
| 7 |
+
ninja
|
| 8 |
+
scipy
|
| 9 |
+
cmake
|
shape_predictor_5_face_landmarks.dat
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c4b1e9804792707d3a405c2c16a80a20269e6675021f64a41d30fffafbc41888
|
| 3 |
+
size 9150489
|