Spaces:
Runtime error

Runtime error
Commit
•
83c6c56
1
Parent(s):
8578e68
Streamlit app
Browse files- .env +1 -0
- Images/Interface.png +0 -0
- Images/Output.png +0 -0
- Images/Youtube_Helper.jpg +0 -0
- langchain_helper.py +59 -0
- main.py +39 -0
- requirements.txt +7 -0
.env
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
OPENAI_API_KEY= "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"
|
Images/Interface.png
ADDED

|
Images/Output.png
ADDED
|
Images/Youtube_Helper.jpg
ADDED

|
langchain_helper.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.document_loaders import YoutubeLoader
|
| 2 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 3 |
+
from langchain.embeddings.openai import OpenAIEmbeddings
|
| 4 |
+
from langchain.vectorstores import FAISS
|
| 5 |
+
from langchain.llms import OpenAI
|
| 6 |
+
from langchain import PromptTemplate
|
| 7 |
+
from langchain.chains import LLMChain
|
| 8 |
+
from dotenv import load_dotenv
|
| 9 |
+
|
| 10 |
+
# Initiating the dotenv
|
| 11 |
+
load_dotenv()
|
| 12 |
+
embeddings = OpenAIEmbeddings()
|
| 13 |
+
|
| 14 |
+
# A function to create a db using FAISS
|
| 15 |
+
def create_db_from_youtube_video_url(video_url: str) -> FAISS:
|
| 16 |
+
# Loading the video
|
| 17 |
+
loader = YoutubeLoader.from_youtube_url(video_url)
|
| 18 |
+
transcript = loader.load()
|
| 19 |
+
# Splitting the document into chunks
|
| 20 |
+
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
|
| 21 |
+
docs = text_splitter.split_documents(transcript)
|
| 22 |
+
# Saving the chunks into vector store
|
| 23 |
+
db = FAISS.from_documents(docs, embeddings)
|
| 24 |
+
return db
|
| 25 |
+
|
| 26 |
+
# A function to get the response from the query passed
|
| 27 |
+
def get_response_from_query(db, query, k=4):
|
| 28 |
+
"""
|
| 29 |
+
text-davinci-003 can handle up to 4097 tokens. Setting the chunksize to 1000 and k to 4 maximizes
|
| 30 |
+
the number of tokens to analyze.
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
docs = db.similarity_search(query, k=k)
|
| 34 |
+
docs_page_content = " ".join([d.page_content for d in docs])
|
| 35 |
+
|
| 36 |
+
llm = OpenAI(model_name="text-davinci-003")
|
| 37 |
+
|
| 38 |
+
prompt = PromptTemplate(
|
| 39 |
+
input_variables=["question", "docs"],
|
| 40 |
+
template="""
|
| 41 |
+
You are a helpful assistant that that can answer questions about youtube videos
|
| 42 |
+
based on the video's transcript.
|
| 43 |
+
|
| 44 |
+
Answer the following question: {question}
|
| 45 |
+
By searching the following video transcript: {docs}
|
| 46 |
+
|
| 47 |
+
Only use the factual information from the transcript to answer the question.
|
| 48 |
+
|
| 49 |
+
If you feel like you don't have enough information to answer the question, say "I don't know".
|
| 50 |
+
|
| 51 |
+
Your answers should be verbose and detailed.
|
| 52 |
+
""",
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
chain = LLMChain(llm=llm, prompt=prompt)
|
| 56 |
+
|
| 57 |
+
response = chain.run(question=query, docs=docs_page_content)
|
| 58 |
+
response = response.replace("\n", "")
|
| 59 |
+
return response, docs
|
main.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import langchain_helper as lch
|
| 3 |
+
import textwrap
|
| 4 |
+
|
| 5 |
+
st.title("YouTube Assistant")
|
| 6 |
+
st.write("""I'm here to assist you in answering questions about the Youtube video you share.
|
| 7 |
+
Just paste the link to the Youtube video and feel free to ask me anything!""")
|
| 8 |
+
|
| 9 |
+
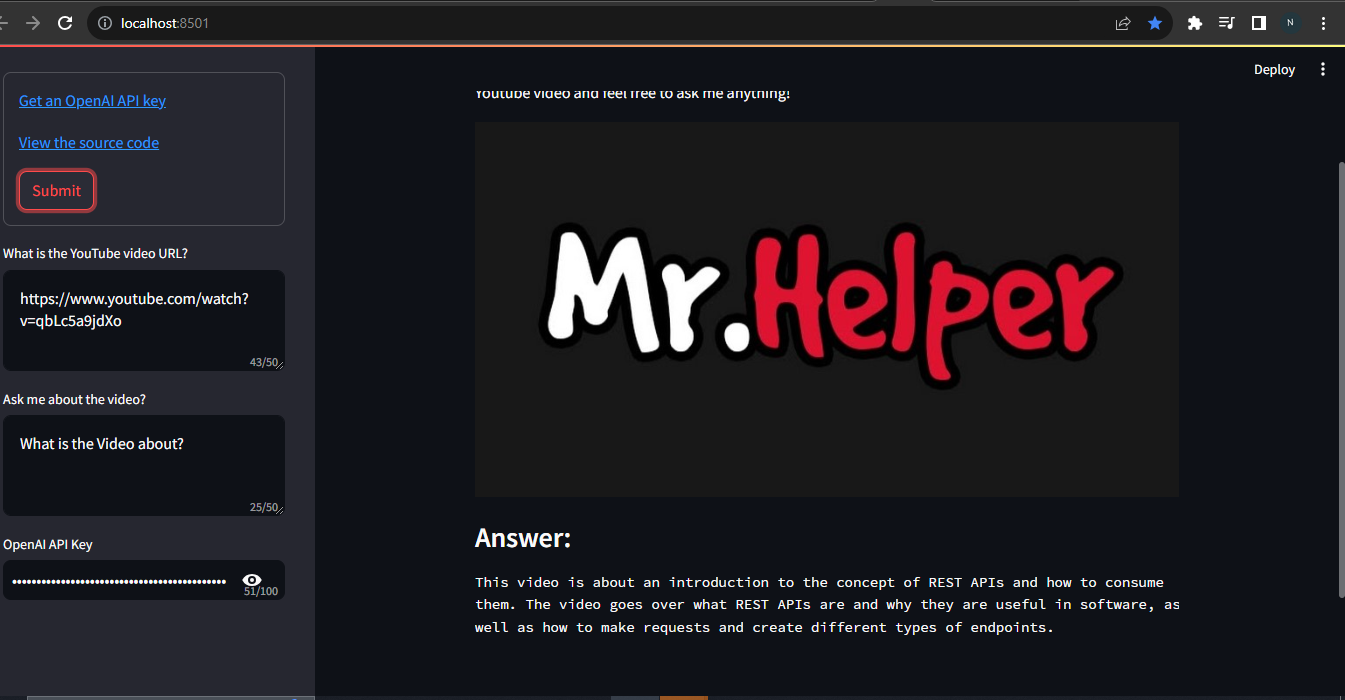
st.image("Images/Youtube_Helper.jpg")
|
| 10 |
+
with st.sidebar:
|
| 11 |
+
with st.form(key='my_form'):
|
| 12 |
+
youtube_url = st.sidebar.text_area(
|
| 13 |
+
label="What is the YouTube video URL?",
|
| 14 |
+
max_chars=50
|
| 15 |
+
)
|
| 16 |
+
query = st.sidebar.text_area(
|
| 17 |
+
label="Ask me about the video?",
|
| 18 |
+
max_chars=50,
|
| 19 |
+
key="query"
|
| 20 |
+
)
|
| 21 |
+
openai_api_key = st.sidebar.text_input(
|
| 22 |
+
label="OpenAI API Key",
|
| 23 |
+
key="langchain_search_api_key_openai",
|
| 24 |
+
max_chars=100,
|
| 25 |
+
type="password"
|
| 26 |
+
)
|
| 27 |
+
"[Get an OpenAI API key](https://platform.openai.com/account/api-keys)"
|
| 28 |
+
"[View the source code](https://github.com/Newton23-nk/Youtube_Helper_Langchain)"
|
| 29 |
+
submit_button = st.form_submit_button(label='Submit')
|
| 30 |
+
|
| 31 |
+
if query and youtube_url:
|
| 32 |
+
if not openai_api_key:
|
| 33 |
+
st.info("Please add your OpenAI API key to continue.")
|
| 34 |
+
st.stop()
|
| 35 |
+
else:
|
| 36 |
+
db = lch.create_db_from_youtube_video_url(youtube_url)
|
| 37 |
+
response, docs = lch.get_response_from_query(db, query)
|
| 38 |
+
st.subheader("Answer:")
|
| 39 |
+
st.text(textwrap.fill(response, width=85))
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python-dotenv
|
| 2 |
+
langchain
|
| 3 |
+
openai
|
| 4 |
+
youtube-transcript-api
|
| 5 |
+
faiss-cpu
|
| 6 |
+
streamlit
|
| 7 |
+
tiktoken
|