Spaces:
Sleeping

Sleeping
Upload 20 files
Browse files- __init__/__init__.py +0 -0
- app.py +84 -0
- data/Note_des_classes_6e_5e.xlsx +0 -0
- images/SIPE_sketch.jpg +0 -0
- images/massock.jpg +0 -0
- images/tree.dot +37 -0
- module/__pycache__/cards.cpython-310.pyc +0 -0
- module/__pycache__/cards.cpython-37.pyc +0 -0
- module/__pycache__/data_viz.cpython-310.pyc +0 -0
- module/__pycache__/data_viz.cpython-37.pyc +0 -0
- module/__pycache__/dataset.cpython-310.pyc +0 -0
- module/__pycache__/dataset.cpython-37.pyc +0 -0
- module/__pycache__/load_data.cpython-310.pyc +0 -0
- module/__pycache__/load_data.cpython-37.pyc +0 -0
- module/cards.py +75 -0
- module/data_viz.py +272 -0
- module/dataset.py +243 -0
- module/load_data.py +9 -0
- requirements.txt +9 -0
__init__/__init__.py
ADDED
|
File without changes
|
app.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from module.cards import welcome, about_me
|
| 3 |
+
from module.dataset import eda
|
| 4 |
+
from module.load_data import data
|
| 5 |
+
from module.data_viz import visualization
|
| 6 |
+
import numpy as np
|
| 7 |
+
from datetime import datetime
|
| 8 |
+
|
| 9 |
+
global LOW, HIGH, SEQUENCE, RESET
|
| 10 |
+
|
| 11 |
+
LOW = 10.0*np.ones((46,7))
|
| 12 |
+
HIGH = 20.0*np.ones((46,7))
|
| 13 |
+
SEQUENCE = ['seq 1','seq 2','seq 3','seq 4','seq 5','seq 6','average_marks']
|
| 14 |
+
RESET = True
|
| 15 |
+
|
| 16 |
+
st.set_page_config(
|
| 17 |
+
page_title="ICT Mark's Dashboard",
|
| 18 |
+
page_icon="📢",
|
| 19 |
+
layout="wide")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
st.title("📊 :red[ICT Mark's] Dashboard")
|
| 24 |
+
|
| 25 |
+
welcome()
|
| 26 |
+
about_me()
|
| 27 |
+
|
| 28 |
+
date = f"{datetime.today().date()} {datetime.today().hour}:{datetime.today().minute}:{datetime.today().second}"
|
| 29 |
+
|
| 30 |
+
#page = st.selectbox('Select page:', ['Dataset','EDA', 'Data Viz'])
|
| 31 |
+
tab1, tab2, tab3 = st.tabs(['**Dataset**','**EDA**', '**Data Viz**'])
|
| 32 |
+
|
| 33 |
+
with tab1:
|
| 34 |
+
|
| 35 |
+
st.info(f"You select Dataset page at the {date}", icon="💂")
|
| 36 |
+
col1, col2, col3, col4 = st.columns(4)
|
| 37 |
+
|
| 38 |
+
if col1.button(':orange[**highlight >10/20**]'):
|
| 39 |
+
st.dataframe(data.style.highlight_between(axis=None, color="#fffd75", left=LOW, right=HIGH,
|
| 40 |
+
subset=SEQUENCE), use_container_width=True)
|
| 41 |
+
RESET = False
|
| 42 |
+
|
| 43 |
+
if col2.button(':orange[**highlight max**]'):
|
| 44 |
+
st.dataframe(data.style.highlight_max(color="green", subset=SEQUENCE), use_container_width=True)
|
| 45 |
+
RESET = False
|
| 46 |
+
|
| 47 |
+
if col3.button(':orange[**highlight min**]'):
|
| 48 |
+
st.dataframe(data.style.highlight_min(color="red", subset=SEQUENCE), use_container_width=True)
|
| 49 |
+
RESET = False
|
| 50 |
+
|
| 51 |
+
if RESET:
|
| 52 |
+
st.dataframe(data, use_container_width=True)
|
| 53 |
+
|
| 54 |
+
if col4.button(':black[**reset**]'):
|
| 55 |
+
st.dataframe(data, use_container_width=True)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
with st.expander("👁 Read more"):
|
| 60 |
+
st.markdown("""
|
| 61 |
+
This dataset is an :red[ICT Mark's] data come from the evaluation of the Tebap students. The attributes are defined as follows:
|
| 62 |
+
|
| 63 |
+
> 1. :orange[$seq_{i, i = (1,2,3,4,5,6)}$]: are the 6 sequences that
|
| 64 |
+
Tebap student's had undergone during school year 2018-2019.
|
| 65 |
+
> 2. :orange[age]: the age of the students.
|
| 66 |
+
> 3. :orange[gender]: the gender of the students (M or F).
|
| 67 |
+
> 4. :orange[form]: the class of students.
|
| 68 |
+
> 5. :orange[average_marks]: the annual ICT mark's of each student.
|
| 69 |
+
""")
|
| 70 |
+
|
| 71 |
+
with tab2 :
|
| 72 |
+
st.info(f"You select EDA page at the {date}", icon="💂")
|
| 73 |
+
st.header('Exploratory Data Analysis')
|
| 74 |
+
eda()
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
with tab3:
|
| 78 |
+
st.info(f"You select Data Viz page at the {date}", icon="💂")
|
| 79 |
+
st.header('Visualization')
|
| 80 |
+
visualization()
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
|
data/Note_des_classes_6e_5e.xlsx
ADDED
|
Binary file (7.95 kB). View file
|
|
|
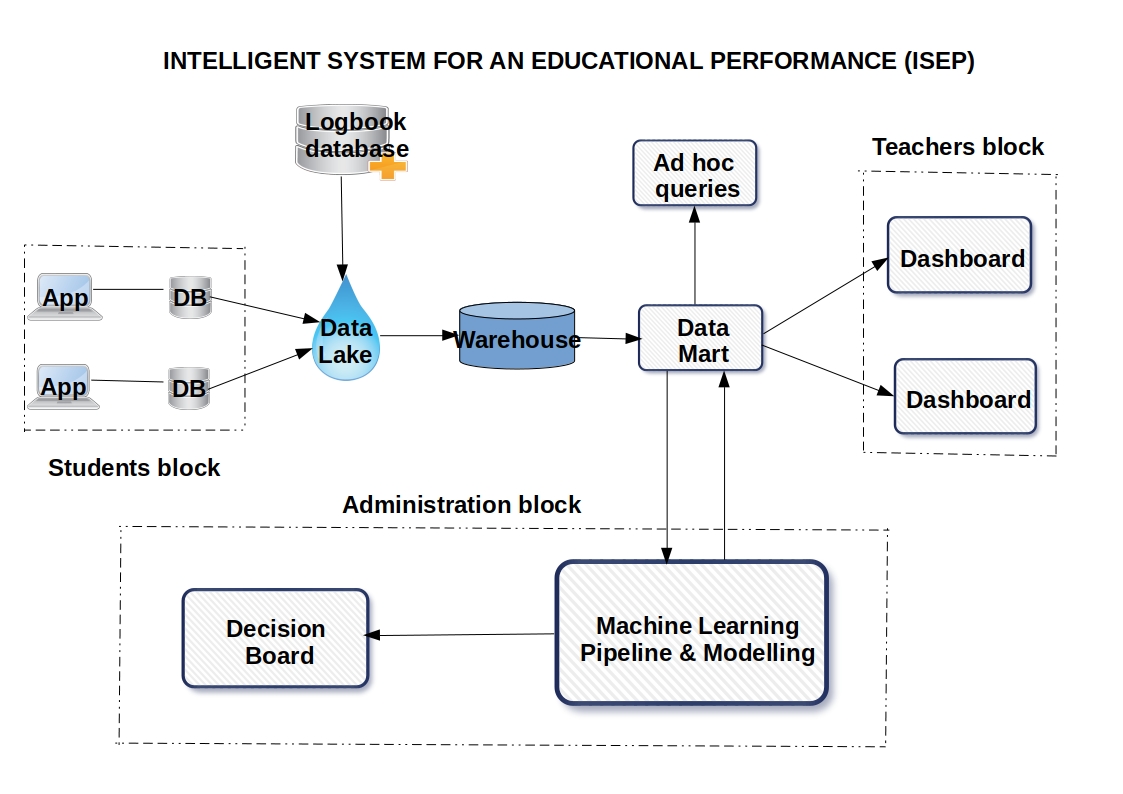
images/SIPE_sketch.jpg
ADDED
|
images/massock.jpg
ADDED

|
images/tree.dot
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
digraph Tree {
|
| 2 |
+
node [shape=box, style="filled, rounded", color="black", fontname="helvetica"] ;
|
| 3 |
+
edge [fontname="helvetica"] ;
|
| 4 |
+
0 [label="seq 6 <= 11.375\nsamples = 46\nvalue = [23, 23]\nclass = Female", fillcolor="#ffffff"] ;
|
| 5 |
+
1 [label="seq 1 <= 1.25\nsamples = 36\nvalue = [13, 23]\nclass = Male", fillcolor="#a9d4f4"] ;
|
| 6 |
+
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
|
| 7 |
+
2 [label="samples = 4\nvalue = [4, 0]\nclass = Female", fillcolor="#e58139"] ;
|
| 8 |
+
1 -> 2 ;
|
| 9 |
+
3 [label="seq 2 <= 3.125\nsamples = 32\nvalue = [9, 23]\nclass = Male", fillcolor="#86c3ef"] ;
|
| 10 |
+
1 -> 3 ;
|
| 11 |
+
4 [label="seq 4 <= 2.75\nsamples = 5\nvalue = [4, 1]\nclass = Female", fillcolor="#eca06a"] ;
|
| 12 |
+
3 -> 4 ;
|
| 13 |
+
5 [label="samples = 1\nvalue = [0, 1]\nclass = Male", fillcolor="#399de5"] ;
|
| 14 |
+
4 -> 5 ;
|
| 15 |
+
6 [label="samples = 4\nvalue = [4, 0]\nclass = Female", fillcolor="#e58139"] ;
|
| 16 |
+
4 -> 6 ;
|
| 17 |
+
7 [label="seq 1 <= 13.5\nsamples = 27\nvalue = [5, 22]\nclass = Male", fillcolor="#66b3eb"] ;
|
| 18 |
+
3 -> 7 ;
|
| 19 |
+
8 [label="seq 1 <= 4.375\nsamples = 25\nvalue = [3, 22]\nclass = Male", fillcolor="#54aae9"] ;
|
| 20 |
+
7 -> 8 ;
|
| 21 |
+
9 [label="samples = 15\nvalue = [0, 15]\nclass = Male", fillcolor="#399de5"] ;
|
| 22 |
+
8 -> 9 ;
|
| 23 |
+
10 [label="seq 1 <= 5.625\nsamples = 10\nvalue = [3, 7]\nclass = Male", fillcolor="#8ec7f0"] ;
|
| 24 |
+
8 -> 10 ;
|
| 25 |
+
11 [label="samples = 2\nvalue = [2, 0]\nclass = Female", fillcolor="#e58139"] ;
|
| 26 |
+
10 -> 11 ;
|
| 27 |
+
12 [label="seq 6 <= 5.0\nsamples = 8\nvalue = [1, 7]\nclass = Male", fillcolor="#55abe9"] ;
|
| 28 |
+
10 -> 12 ;
|
| 29 |
+
13 [label="samples = 1\nvalue = [1, 0]\nclass = Female", fillcolor="#e58139"] ;
|
| 30 |
+
12 -> 13 ;
|
| 31 |
+
14 [label="samples = 7\nvalue = [0, 7]\nclass = Male", fillcolor="#399de5"] ;
|
| 32 |
+
12 -> 14 ;
|
| 33 |
+
15 [label="samples = 2\nvalue = [2, 0]\nclass = Female", fillcolor="#e58139"] ;
|
| 34 |
+
7 -> 15 ;
|
| 35 |
+
16 [label="samples = 10\nvalue = [10, 0]\nclass = Female", fillcolor="#e58139"] ;
|
| 36 |
+
0 -> 16 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
|
| 37 |
+
}
|
module/__pycache__/cards.cpython-310.pyc
ADDED
|
Binary file (2.37 kB). View file
|
|
|
module/__pycache__/cards.cpython-37.pyc
ADDED
|
Binary file (2.32 kB). View file
|
|
|
module/__pycache__/data_viz.cpython-310.pyc
ADDED
|
Binary file (9.44 kB). View file
|
|
|
module/__pycache__/data_viz.cpython-37.pyc
ADDED
|
Binary file (9.36 kB). View file
|
|
|
module/__pycache__/dataset.cpython-310.pyc
ADDED
|
Binary file (7.24 kB). View file
|
|
|
module/__pycache__/dataset.cpython-37.pyc
ADDED
|
Binary file (6.91 kB). View file
|
|
|
module/__pycache__/load_data.cpython-310.pyc
ADDED
|
Binary file (390 Bytes). View file
|
|
|
module/__pycache__/load_data.cpython-37.pyc
ADDED
|
Binary file (380 Bytes). View file
|
|
|
module/cards.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
image_file = "images/massock.jpg"
|
| 6 |
+
path_image = "images/SIPE_sketch.jpg"
|
| 7 |
+
image = Image.open(image_file)
|
| 8 |
+
|
| 9 |
+
text1 = """
|
| 10 |
+
*I am a young Cameroonian named **Massock Batalong Maurice Blaise** with a *Masters in specialty Materials/
|
| 11 |
+
Mechanics option Mechanics at the University of Yaoundé I* and a *Master in Science Mathematics at the
|
| 12 |
+
African Institute for Mathematical Sciences (AIMS-Cameroon)*. And holder of a *Certificate in Big Data
|
| 13 |
+
Analytics with python issued by AIMS-Cameroon*. I am also a Kaggle Notebook & Discussion Expert.*
|
| 14 |
+
|
| 15 |
+
- **LinkedIn**: Massock Batalong Maurice Blaise
|
| 16 |
+
- **Email**: lumierebatalong@gmail.com
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
text2 = """
|
| 20 |
+
*This dashboard is one little part of my project :green[**Creation of Intelligent system for an Education Performance (ISEP)**].*
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
text3 = """
|
| 24 |
+
To construct an intelligent system able to evaluate an educational performance of students of an
|
| 25 |
+
establishment (school, secondary school, training center, university,...) given and to help respectively the
|
| 26 |
+
teacher staff and the administrative staff to arrest well an evolution of school teaching of theirs students.
|
| 27 |
+
Because in future, these students will be human ressources qualified able to releive the challenge and stakes
|
| 28 |
+
of Africa in the domain such that education, health, water, energy, agriculture, infrastructure, etc ...
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def welcome():
|
| 34 |
+
|
| 35 |
+
placeholder = st.empty()
|
| 36 |
+
|
| 37 |
+
with placeholder.container():
|
| 38 |
+
kp1, kp2, kp3, kp4, kp5 = st.columns(5)
|
| 39 |
+
|
| 40 |
+
kp1.metric(
|
| 41 |
+
label= "🗓 **:red[School year]**",
|
| 42 |
+
value = "2018-2019",
|
| 43 |
+
delta = ""
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
kp2.metric(
|
| 47 |
+
label= "👨🎓 :red[**College**]",
|
| 48 |
+
value = "Tebap",
|
| 49 |
+
delta = ""
|
| 50 |
+
)
|
| 51 |
+
kp3.metric(
|
| 52 |
+
label="👩🏫 :red[**Form**]",
|
| 53 |
+
value="6e-5e",
|
| 54 |
+
delta = ""
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
kp4.metric(
|
| 58 |
+
label="🏛 :red[**City**]",
|
| 59 |
+
value="Yaounde",
|
| 60 |
+
delta = ""
|
| 61 |
+
)
|
| 62 |
+
kp5.metric(
|
| 63 |
+
label="🏴 :red[**Country**] ",
|
| 64 |
+
value = "Cameroon",
|
| 65 |
+
delta = ""
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
def about_me():
|
| 69 |
+
st.sidebar.image(image)
|
| 70 |
+
st.sidebar.markdown(text1)
|
| 71 |
+
st.sidebar.markdown(text2)
|
| 72 |
+
st.sidebar.header("Abstract")
|
| 73 |
+
st.sidebar.markdown(text3)
|
| 74 |
+
st.sidebar.image(path_image)
|
| 75 |
+
|
module/data_viz.py
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import plotly.express as px
|
| 3 |
+
import pandas as pd
|
| 4 |
+
from module.load_data import data
|
| 5 |
+
from module.dataset import create_data
|
| 6 |
+
import plotly.express as px
|
| 7 |
+
from sklearn.tree import DecisionTreeClassifier, export_graphviz
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
|
| 10 |
+
#plt.style.use('seaborn-dark-palette')
|
| 11 |
+
|
| 12 |
+
def grades(mark):
|
| 13 |
+
if mark >= 0 and mark < 5:
|
| 14 |
+
return 'U'
|
| 15 |
+
elif mark >= 5 and mark < 9:
|
| 16 |
+
return 'E'
|
| 17 |
+
elif mark >= 9 and mark < 12:
|
| 18 |
+
return 'D'
|
| 19 |
+
elif mark >= 12 and mark < 15:
|
| 20 |
+
return 'C'
|
| 21 |
+
elif mark >= 15 and mark < 18:
|
| 22 |
+
return 'B'
|
| 23 |
+
else:
|
| 24 |
+
return 'A'
|
| 25 |
+
|
| 26 |
+
def segmentation(data:pd.DataFrame):
|
| 27 |
+
df = data.copy()
|
| 28 |
+
factor = pd.factorize(df.form)
|
| 29 |
+
df['form'] = factor[0]; definition=factor[1]
|
| 30 |
+
|
| 31 |
+
cols = [f'seq {i+1}' for i in range(6)] + ['age','form']
|
| 32 |
+
tree = DecisionTreeClassifier(random_state=31012020)
|
| 33 |
+
tree.fit(df[cols], df['gender'])
|
| 34 |
+
|
| 35 |
+
export_graphviz(tree, out_file="images/tree.dot", class_names=["Female", "Male"],
|
| 36 |
+
feature_names=cols, impurity=False, filled=True,rounded=True)
|
| 37 |
+
result = pd.DataFrame({"Feature":cols, "Gain":tree.feature_importances_})
|
| 38 |
+
return result
|
| 39 |
+
|
| 40 |
+
def scatterplot(female=None, male=None, line_separator=None, x_axis=None, y_axis=None):
|
| 41 |
+
fig = plt.figure(figsize=(5,5))
|
| 42 |
+
plt.scatter(female[x_axis], female[y_axis], marker='v', color='red', label="Girl", lw=1.2)
|
| 43 |
+
plt.scatter(male[x_axis], male[y_axis], marker='o', color='blue', label="Boy",lw=1.2)
|
| 44 |
+
plt.xlabel(x_axis); plt.ylabel(y_axis)
|
| 45 |
+
plt.title("Decision line", fontweight="bold")
|
| 46 |
+
for u in line_separator[0]:
|
| 47 |
+
plt.vlines(line_separator[0], 0, female[y_axis].max(), color="black",
|
| 48 |
+
linestyles="-.", lw=1.75)
|
| 49 |
+
|
| 50 |
+
for v in line_separator[1] :
|
| 51 |
+
plt.hlines(line_separator[1], -1, female[y_axis].max(), color="black",
|
| 52 |
+
linestyles="dashed", lw=1.75)
|
| 53 |
+
|
| 54 |
+
plt.legend(loc="best", frameon=True, fancybox=True, shadow=True, title="Gender")
|
| 55 |
+
return fig
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
df_trim = create_data(data)
|
| 59 |
+
total_students = len(data)
|
| 60 |
+
average_age = data.age.mean()
|
| 61 |
+
gca1 = df_trim["trimester 1"].mean()
|
| 62 |
+
gca2 = df_trim["trimester 2"].mean()
|
| 63 |
+
gca3 = df_trim["trimester 3"].mean()
|
| 64 |
+
annual_gca = (gca1+gca2+gca3)/3
|
| 65 |
+
|
| 66 |
+
evaluations = ['seq 1', 'seq 2','seq 3','seq 4','seq 5','seq 6']
|
| 67 |
+
|
| 68 |
+
sgca = pd.DataFrame(columns=['Male','Female'], index=evaluations)
|
| 69 |
+
|
| 70 |
+
sgca['Male'] = data[data.gender == 'M'][evaluations].mean()
|
| 71 |
+
sgca['Female'] = data[data.gender == 'F'][evaluations].mean()
|
| 72 |
+
|
| 73 |
+
form_counts = data.form.value_counts()
|
| 74 |
+
gender_counts = data.gender.value_counts()
|
| 75 |
+
|
| 76 |
+
progression = sgca.diff()
|
| 77 |
+
|
| 78 |
+
pass_or_fail =pd.DataFrame({seq:data[seq].apply(lambda x: 'Passed' if x >= 10.0 else 'Failed').value_counts().to_dict() for seq in evaluations})
|
| 79 |
+
|
| 80 |
+
student_grade = pd.DataFrame({seq:data[seq].apply(grades).value_counts().to_dict() for seq in evaluations})
|
| 81 |
+
|
| 82 |
+
##print(student_grade)
|
| 83 |
+
|
| 84 |
+
bar_polar = px.bar_polar(data_frame=sgca, r='Male',
|
| 85 |
+
theta=sgca.index, color='Female',
|
| 86 |
+
title='General Class Average (GCA) for each evaluation',
|
| 87 |
+
barmode="overlay",width=1200, height=500)
|
| 88 |
+
pie_form = px.pie(data_frame=form_counts, names=form_counts.index, values=form_counts,
|
| 89 |
+
title="Form", hole=0.25, width=500, height=500)
|
| 90 |
+
pie_gender = px.pie(data_frame=gender_counts, names=gender_counts.index, values=gender_counts,
|
| 91 |
+
title="Gender", hole=0.25, width=500, height=500)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
feature_importances = segmentation(data)
|
| 95 |
+
|
| 96 |
+
bar_feature_importance = px.bar(data_frame=feature_importances, x="Feature", y="Gain",
|
| 97 |
+
title="Feature importances bar", width=500)
|
| 98 |
+
|
| 99 |
+
with open("images/tree.dot") as f:
|
| 100 |
+
dot_graph = f.read()
|
| 101 |
+
|
| 102 |
+
female = data[data.gender == "F"]
|
| 103 |
+
male = data[data.gender == "M"]
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def visualization():
|
| 107 |
+
placeholder1 = st.empty()
|
| 108 |
+
|
| 109 |
+
with placeholder1.container():
|
| 110 |
+
kp1, kp2, kp3, kp4, kp5, kp6 = st.columns(6)
|
| 111 |
+
|
| 112 |
+
kp1.metric(
|
| 113 |
+
label= "**:red[👬 Total students]**",
|
| 114 |
+
value = total_students,
|
| 115 |
+
delta = ""
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
kp2.metric(
|
| 119 |
+
label= ":red[**⏳ Average age**]",
|
| 120 |
+
value = f"{average_age:.2f}" ,
|
| 121 |
+
delta = ""
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
kp3.metric(
|
| 125 |
+
label=":red[**✍ GCA-trimester 1**]",
|
| 126 |
+
value=f"{gca1:.2f}/20",
|
| 127 |
+
delta = 0.0
|
| 128 |
+
)
|
| 129 |
+
kp4.metric(
|
| 130 |
+
label=":red[**✍ GCA-trimester 2**]",
|
| 131 |
+
value = f"{gca2:.2f}/20",
|
| 132 |
+
delta = round(gca2-gca1, 3)
|
| 133 |
+
)
|
| 134 |
+
kp5.metric(
|
| 135 |
+
label =":red[**✍ GCA-trimester 3**]",
|
| 136 |
+
value = f"{gca3:.2f}/20",
|
| 137 |
+
delta = round(gca3-gca2, 3)
|
| 138 |
+
)
|
| 139 |
+
kp6.metric(
|
| 140 |
+
label =":red[**🎓 Annual-GCA**]",
|
| 141 |
+
value = f"{annual_gca:.2f}/20",
|
| 142 |
+
delta = ""
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
placeholder2 = st.empty()
|
| 147 |
+
with placeholder2.container():
|
| 148 |
+
col1, col2 = st.columns(2)
|
| 149 |
+
col1.plotly_chart(pie_gender)
|
| 150 |
+
col1.caption('**We represent the gender of students in form 6e-5e (francophone section one of the cameroonian education system).**')
|
| 151 |
+
col2.plotly_chart(pie_form)
|
| 152 |
+
col2.caption("""**We represent the number of students in each form 6e and 5e**.
|
| 153 |
+
**NB**: **Cameroon have two sub-education systems one is a francophone and a second is an anglosaxone.**
|
| 154 |
+
""")
|
| 155 |
+
|
| 156 |
+
tab1, tab2, tab3 = st.tabs([':orange[**Performance**]', ':orange[**Distribution**]', ':orange[**Miscelaneous**]'])
|
| 157 |
+
|
| 158 |
+
with tab1:
|
| 159 |
+
tab1.plotly_chart(bar_polar)
|
| 160 |
+
tab1.caption("""We represent the general class average of students in each sequence. Colors bar shows the marks
|
| 161 |
+
for female gender and bar polar also shows the marks for male gender.""")
|
| 162 |
+
tab1.subheader('Progression')
|
| 163 |
+
tab1.line_chart(progression)
|
| 164 |
+
tab1.caption("""This chart shows a progression of students during the six evaluations.
|
| 165 |
+
We just make a difference between the previous sequence and the next sequence.
|
| 166 |
+
The x-axis represent a sequence and the y-axis represent the growth of students.""")
|
| 167 |
+
|
| 168 |
+
tab1.subheader('Passed or Failed')
|
| 169 |
+
col1, col2 = tab1.columns(2)
|
| 170 |
+
col1.caption(':red[💃 passed or failed table 👉]')
|
| 171 |
+
col1.dataframe(pass_or_fail)
|
| 172 |
+
col1.caption("""
|
| 173 |
+
- In left: We got this table to compute the number of students that the mark is >10 (passed) or <10 (failed) for
|
| 174 |
+
each sequence.
|
| 175 |
+
- In right: We plot this table. The chart explains how a student make some effort to succeed a ICT course.
|
| 176 |
+
- In general, we can appreciate the effort of the students in the form 6e and 5e for each evaluation.
|
| 177 |
+
""")
|
| 178 |
+
col2.bar_chart(pass_or_fail.T)
|
| 179 |
+
|
| 180 |
+
tab1.subheader("Student grades")
|
| 181 |
+
col3, col4 = tab1.columns(2)
|
| 182 |
+
col3.caption(':red[💃 grades table 👉]')
|
| 183 |
+
col3.dataframe(student_grade.fillna(0))
|
| 184 |
+
col3.caption("""
|
| 185 |
+
The student grade respect this decision:
|
| 186 |
+
- U -> [0 - 5[; E -> [5 - 9[
|
| 187 |
+
- D -> [9 - 12[; C -> [12 - 15[
|
| 188 |
+
- B -> [15 - 18[; A -> [18 - 20[
|
| 189 |
+
""")
|
| 190 |
+
col4.bar_chart(student_grade.T)
|
| 191 |
+
col4.caption('This bar chart shows the number of student in each grade for each sequence.')
|
| 192 |
+
|
| 193 |
+
with tab2:
|
| 194 |
+
tab2.subheader('evaluation and age distribution')
|
| 195 |
+
tab2.caption('Histogram')
|
| 196 |
+
var1 = tab2.selectbox('Choose items', evaluations+['age'], key=6)
|
| 197 |
+
fig1 = px.histogram(data_frame=data, x=var1, width=1200, height=500, opacity=0.75)
|
| 198 |
+
tab2.plotly_chart(fig1)
|
| 199 |
+
col1, col2 = tab2.columns(2)
|
| 200 |
+
col1.caption('Boxplot'); col2.caption('Violin')
|
| 201 |
+
var2 = col1.selectbox('Choose items', evaluations+['age'], key=7)
|
| 202 |
+
var3 = col2.selectbox('Choose items', evaluations+['age'], key=8)
|
| 203 |
+
col1.plotly_chart(px.box(data_frame=data, y=var2, width=500, height=500))
|
| 204 |
+
col2.plotly_chart(px.violin(data_frame=data, x=var3, width=500, height=500))
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
with tab3:
|
| 208 |
+
st.subheader('Relation graph')
|
| 209 |
+
container = tab3.empty()
|
| 210 |
+
vcol1, vcol2, vcol3 = container.columns(3)
|
| 211 |
+
|
| 212 |
+
trim1 = px.scatter(data_frame=df_trim, x="trimester 1", y="trimester 2", width=350,
|
| 213 |
+
height=350,title="trimester 1 & 2")
|
| 214 |
+
vcol1.plotly_chart(trim1)
|
| 215 |
+
|
| 216 |
+
trim2 = px.scatter(data_frame=df_trim, x="trimester 2", y="trimester 3", width=350, height=350,title="trimester 3 & 2")
|
| 217 |
+
vcol2.plotly_chart(trim2)
|
| 218 |
+
|
| 219 |
+
trim3 = px.scatter(data_frame=df_trim, x="trimester 3", y="trimester 1", width=350, height=350,title="trimester 1 & 3")
|
| 220 |
+
vcol3.plotly_chart(trim3)
|
| 221 |
+
|
| 222 |
+
tab3.caption("""
|
| 223 |
+
The three charts shows the monotony of the relation function between the three trimesters.
|
| 224 |
+
Each chart prove that the students for form 6e-5e francophone education systems at the Tebap college make considerably
|
| 225 |
+
an effort to succeed an ICT's course.
|
| 226 |
+
""")
|
| 227 |
+
tab3.subheader('Supervised segmentation with tree')
|
| 228 |
+
tab3.caption("""
|
| 229 |
+
In this section, we are making a supervised segmentation to segment the population of student into subgroups
|
| 230 |
+
that have different values for the target gender. To find a subgroups, we are using a tree structured model.
|
| 231 |
+
We cannot make a classification here because our dataset is just a size equal to 46. Let's go! 💂
|
| 232 |
+
""")
|
| 233 |
+
block = tab3.empty()
|
| 234 |
+
hcol1, hcol2 = block.columns(2)
|
| 235 |
+
hcol1.caption('**Feature importance table**👉')
|
| 236 |
+
hcol1.dataframe(feature_importances)
|
| 237 |
+
hcol1.caption("""
|
| 238 |
+
The table shows the features that the tree structured model
|
| 239 |
+
consider very importance for segmenting students
|
| 240 |
+
population in to subgroups.
|
| 241 |
+
""")
|
| 242 |
+
|
| 243 |
+
hcol2.plotly_chart(bar_feature_importance)
|
| 244 |
+
tab3.subheader('Dot graph')
|
| 245 |
+
tab3.graphviz_chart(dot_graph)
|
| 246 |
+
tab3.caption("""
|
| 247 |
+
Let's us interprete this graph.
|
| 248 |
+
|
| 249 |
+
- node 0: the student that the mark in seq 6 <= 11.375 are female gender; the answer is False. In each node, we have
|
| 250 |
+
a condition where the next node give an answers.
|
| 251 |
+
|
| 252 |
+
Let's plot the line separating the region.
|
| 253 |
+
""")
|
| 254 |
+
|
| 255 |
+
bcol1, bcol2 = tab3.columns(2)
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
var1 = bcol1.selectbox("Choose x-axis (line[i])", ['seq 1', "seq 2", "seq 4", "seq 6"])
|
| 259 |
+
var2 = bcol1.selectbox("Choose y-axis (line[i+1])", reversed(['seq 1', "seq 2", "seq 4", "seq 6"]))
|
| 260 |
+
|
| 261 |
+
line1 = bcol2.multiselect("Line separator for x-axis", [1.25, 2.75, 3.125, 4.375,5.0, 5.625, 11.375,13.5])
|
| 262 |
+
line2 = bcol2.multiselect("Line separator for y-axis", [1.25, 2.75, 3.125, 4.375,5.0, 5.625, 11.375,13.5])
|
| 263 |
+
tab3.caption("""
|
| 264 |
+
We have eight lines line 1 (node 0) to line 8 (node 12). We start to line 1 and line 2.
|
| 265 |
+
""")
|
| 266 |
+
gplot = scatterplot(female, male, line_separator=[line1, line2], x_axis=var1, y_axis=var2)
|
| 267 |
+
tab3.pyplot(gplot)
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
|
module/dataset.py
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import numpy as np
|
| 3 |
+
import pandas as pd
|
| 4 |
+
from module.load_data import data
|
| 5 |
+
from scipy import stats
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def create_data(data:pd.DataFrame) -> pd.DataFrame:
|
| 10 |
+
df = pd.DataFrame({"trimester 1": round((data['seq 1']+data['seq 2'])/2, 2),
|
| 11 |
+
"trimester 2": round((data['seq 3']+data['seq 4'])/2, 2),
|
| 12 |
+
"trimester 3": round((data['seq 5']+data['seq 6'])/2, 2),
|
| 13 |
+
"age":data["age"]})
|
| 14 |
+
return df
|
| 15 |
+
|
| 16 |
+
def subdata(data:pd.DataFrame, items:list) -> pd.DataFrame:
|
| 17 |
+
if len(items) == 3:
|
| 18 |
+
return data[(data[items[0][0]] == items[0][1]) & (data[items[1][0]] == items[1][1]) & (data[items[2][0]] == items[2][1])]['average_marks']
|
| 19 |
+
|
| 20 |
+
if len(items) == 2:
|
| 21 |
+
return data[(data[items[0][0]] == items[0][1]) & (data[items[1][0]] == items[1][1])]['average_marks']
|
| 22 |
+
|
| 23 |
+
if len(items) == 1:
|
| 24 |
+
return data[(data[items[0][0]] == items[0][1])]['average_marks']
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def hypothesis_testing(group1:pd.DataFrame, group2:pd.DataFrame, label1:list, label2:list) -> list:
|
| 28 |
+
|
| 29 |
+
mean1, std1, nobs1 = group1.mean(), group1.std(), group1.count()
|
| 30 |
+
mean2, std2, nobs2 = group2.mean(), group2.std(), group2.count()
|
| 31 |
+
|
| 32 |
+
res = stats.ttest_ind_from_stats(mean1=mean1, std1=std1, nobs1=nobs1,
|
| 33 |
+
mean2=mean2, std2=std2, nobs2=nobs2,equal_var=False)
|
| 34 |
+
|
| 35 |
+
tvalue = res.statistic
|
| 36 |
+
pvalue = res.pvalue
|
| 37 |
+
|
| 38 |
+
diff = mean1 - mean2
|
| 39 |
+
std_error = np.sqrt((std1**2/nobs1) + (std2**2/nobs2))
|
| 40 |
+
low_bound = diff - tvalue*std_error
|
| 41 |
+
upper_bound = diff + tvalue*std_error
|
| 42 |
+
|
| 43 |
+
text1 = f"""
|
| 44 |
+
:green[**Welch two-sample t-test**]
|
| 45 |
+
|
| 46 |
+
**data**: group1={label1} and group2={label2}
|
| 47 |
+
|
| 48 |
+
t = {tvalue:.4f}, diff = {diff:.4f}, p-value = {pvalue:.4f}
|
| 49 |
+
|
| 50 |
+
**alternative hypothesis**: true difference in means is not equal to 0
|
| 51 |
+
|
| 52 |
+
**95% confidence interval**: ({low_bound}, {upper_bound})
|
| 53 |
+
|
| 54 |
+
**mean of group1**: {mean1:.3f}
|
| 55 |
+
|
| 56 |
+
**mean of group2**: {mean2:.3f}
|
| 57 |
+
"""
|
| 58 |
+
|
| 59 |
+
text2 = f"""
|
| 60 |
+
:green[**Welch two-sample t-test**]
|
| 61 |
+
|
| 62 |
+
**data**: group1={label1} and group2={label2}
|
| 63 |
+
|
| 64 |
+
t = {tvalue:.8f}, diff = {diff:.8f}, p-value = {pvalue:.8f}
|
| 65 |
+
|
| 66 |
+
**null hypothesis**: true difference in means is equal to 0
|
| 67 |
+
|
| 68 |
+
**mean of group1**: {mean1:.3f}
|
| 69 |
+
|
| 70 |
+
**mean of group2**: {mean2:.3f}
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
return text1 if pvalue < 0.05 else text2
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def eda():
|
| 78 |
+
df = pd.DataFrame({"trimester 1": round((data['seq 1']+data['seq 2'])/2, 2),
|
| 79 |
+
"trimester 2": round((data['seq 3']+data['seq 4'])/2, 2),
|
| 80 |
+
"trimester 3": round((data['seq 5']+data['seq 6'])/2, 2),
|
| 81 |
+
"age":data["age"]})
|
| 82 |
+
corr = df.corr()
|
| 83 |
+
|
| 84 |
+
vif = np.linalg.inv(corr.to_numpy()).diagonal()
|
| 85 |
+
vifs = pd.Series(np.round(vif,2), index=df.columns.tolist(), name="VIF")
|
| 86 |
+
|
| 87 |
+
female = data[data.gender == 'F']
|
| 88 |
+
male = data[data.gender == 'M']
|
| 89 |
+
|
| 90 |
+
df_female = create_data(female)
|
| 91 |
+
df_male = create_data(male)
|
| 92 |
+
|
| 93 |
+
items = ['F','M','6e','5e']
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
st.subheader('Sequence')
|
| 97 |
+
placeholder1 = st.empty()
|
| 98 |
+
|
| 99 |
+
with placeholder1.container():
|
| 100 |
+
col1, col2 = st.columns(2)
|
| 101 |
+
col1.caption(':red[**Descriptive statistics**]')
|
| 102 |
+
col1.dataframe(round(data.describe(), 2))
|
| 103 |
+
col2.caption(':red[**Correlation**]')
|
| 104 |
+
col2.dataframe(round(data.corr(), 2))
|
| 105 |
+
|
| 106 |
+
st.subheader("Trimester")
|
| 107 |
+
st.caption(':red[**Descriptive statistics**]')
|
| 108 |
+
st.dataframe(round(df.describe(), 2), use_container_width=True)
|
| 109 |
+
placeholder2 = st.empty()
|
| 110 |
+
with placeholder2.container():
|
| 111 |
+
col1, col2 = st.columns(2)
|
| 112 |
+
col1.caption(':red[**Correlation**]')
|
| 113 |
+
col1.dataframe(round(corr, 2))
|
| 114 |
+
col2.caption(':red[**Variance Inflation Factor**]')
|
| 115 |
+
col2.dataframe(vifs)
|
| 116 |
+
|
| 117 |
+
with st.expander("👁 Read more"):
|
| 118 |
+
st.markdown("""
|
| 119 |
+
> 1. :orange[Descriptive statistics] help to define mean, standard deviation, minimun, maximun, median, etc..
|
| 120 |
+
such that we can summarize the dataset and discover the patterns.
|
| 121 |
+
> 2. :orange[Correlation] help to find the tendance or colinearity between two or more attributes in the dataset.
|
| 122 |
+
> 3. :orange[VIF] is a mesure of colinearity among predictor variables within a multiple regression.
|
| 123 |
+
>> 1. If outcome is 1, it's okay.
|
| 124 |
+
>> 2. If it is between 1 and 5, it show low to average colinearity, and above 5 generally means highly redundant
|
| 125 |
+
and variable should be dropped.
|
| 126 |
+
""")
|
| 127 |
+
|
| 128 |
+
st.subheader('Sequence by gender')
|
| 129 |
+
placeholder3 = st.empty()
|
| 130 |
+
placeholder4 = st.empty()
|
| 131 |
+
with placeholder3.container():
|
| 132 |
+
col1, col2 = st.columns(2)
|
| 133 |
+
col1.caption(':orange[**Descriptive statistics: Female**]')
|
| 134 |
+
col1.dataframe(round(female.describe(), 2))
|
| 135 |
+
col2.caption(':orange[**Descriptive statistics: Male**]')
|
| 136 |
+
col2.dataframe(round(male.describe(), 2))
|
| 137 |
+
|
| 138 |
+
with placeholder4.container():
|
| 139 |
+
col1, col2 = st.columns(2)
|
| 140 |
+
col1.caption(':orange[**Correlation: Female**]')
|
| 141 |
+
col1.dataframe(round(female.corr(), 2))
|
| 142 |
+
col2.caption(':orange[**Correlation: Male**]')
|
| 143 |
+
col2.dataframe(round(male.corr(), 2))
|
| 144 |
+
|
| 145 |
+
st.subheader('Trimester by gender')
|
| 146 |
+
placeholder5 = st.empty()
|
| 147 |
+
placeholder6 = st.empty()
|
| 148 |
+
with placeholder5.container():
|
| 149 |
+
col1, col2 = st.columns(2)
|
| 150 |
+
col1.caption(':orange[**Descriptive statistics: Female**]')
|
| 151 |
+
col1.dataframe(round(df_female.describe(), 2))
|
| 152 |
+
col2.caption(':orange[**Descriptive statistics: Male**]')
|
| 153 |
+
col2.dataframe(round(df_male.describe(), 2))
|
| 154 |
+
|
| 155 |
+
with placeholder6.container():
|
| 156 |
+
col1, col2 = st.columns(2)
|
| 157 |
+
col1.caption(':orange[**Correlation: Female**]')
|
| 158 |
+
col1.dataframe(round(df_female.corr(), 2))
|
| 159 |
+
col2.caption(':orange[**Correlation: Male**]')
|
| 160 |
+
col2.dataframe(round(df_male.corr(), 2))
|
| 161 |
+
|
| 162 |
+
st.subheader('Assumption')
|
| 163 |
+
st.markdown("""
|
| 164 |
+
In this section, you can make your assumption to know which group is best than other group in this ICT course.
|
| 165 |
+
For example: According to table trimester evaluation by gender, we have two groups (female students and male students).
|
| 166 |
+
|
| 167 |
+
By the observation,
|
| 168 |
+
> **Is it true that female students are best than male students in the ICT course for Tebap college?**
|
| 169 |
+
|
| 170 |
+
This question we allow us to compare the general annual class average (mean) for one group to other group. That's lead to
|
| 171 |
+
compute the difference between the two means. We have two hypothesis:
|
| 172 |
+
|
| 173 |
+
1. **Null hypothesis:** :blue[ true difference in means is equal to 0].
|
| 174 |
+
|
| 175 |
+
2. **Alternative hypothesis:** :blue[ true difference in means is not equal to 0]
|
| 176 |
+
|
| 177 |
+
**NB**: difference = $\mu$(group1) - $\mu$(group2)
|
| 178 |
+
|
| 179 |
+
We choose the right hypothesis as follows:
|
| 180 |
+
- **if p-value < 5% then we reject null hypothesis**
|
| 181 |
+
- **if p-value > 5% then we accept null hypothesis**
|
| 182 |
+
""")
|
| 183 |
+
placeholder7 = st.empty()
|
| 184 |
+
with placeholder7.container():
|
| 185 |
+
col1, col2 = st.columns(2)
|
| 186 |
+
|
| 187 |
+
with col1:
|
| 188 |
+
label1 = []
|
| 189 |
+
st.caption(':red[Create group A]')
|
| 190 |
+
scol1, scol2, scol3 = st.columns(3)
|
| 191 |
+
|
| 192 |
+
gender1 = scol1.selectbox('Gender', ['Choose an option', 'F', 'M'])
|
| 193 |
+
form1 = scol2.selectbox('Form', ['Choose an option', '6e', '5e'])
|
| 194 |
+
age1 = scol3.selectbox('Age', ['Choose an option',]+sorted(data.age.unique().tolist()))
|
| 195 |
+
|
| 196 |
+
if gender1 != 'Choose an option':
|
| 197 |
+
label1.append(('gender', gender1))
|
| 198 |
+
if form1 != 'Choose an option':
|
| 199 |
+
label1.append(('form', form1))
|
| 200 |
+
if age1 != 'Choose an option':
|
| 201 |
+
label1.append(('age', age1))
|
| 202 |
+
|
| 203 |
+
group1 = subdata(data, label1)
|
| 204 |
+
if type(group1) == pd.Series:
|
| 205 |
+
scol2.write(group1)
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
with col2:
|
| 209 |
+
label2 = []
|
| 210 |
+
st.caption(':red[Create group B]')
|
| 211 |
+
tcol1, tcol2, tcol3 = st.columns(3)
|
| 212 |
+
|
| 213 |
+
gender2 = tcol1.selectbox('Gender', ['Choose an option', 'F', 'M'], key=1)
|
| 214 |
+
form2 = tcol2.selectbox('Form', ['Choose an option', '6e', '5e'], key=2)
|
| 215 |
+
age2 = tcol3.selectbox('Age', ['Choose an option',]+sorted(data.age.unique().tolist()), key=3)
|
| 216 |
+
|
| 217 |
+
if gender2 != 'Choose an option':
|
| 218 |
+
label2.append(('gender', gender2))
|
| 219 |
+
if form2 != 'Choose an option':
|
| 220 |
+
label2.append(('form', form2))
|
| 221 |
+
if age2 != 'Choose an option':
|
| 222 |
+
label2.append(('age', age2))
|
| 223 |
+
|
| 224 |
+
group2 = subdata(data, label2)
|
| 225 |
+
if type(group2) == pd.Series:
|
| 226 |
+
tcol2.write(group2)
|
| 227 |
+
|
| 228 |
+
st.caption('Choose only one or two item(s) per group. For example group A = (F, 5e) or group B = (M)')
|
| 229 |
+
|
| 230 |
+
if (sorted(label2) == sorted(label1)) and not(len(label1) == 0 or len(label2) == 0):
|
| 231 |
+
st.info(f'You cannot create two different groups with same items: label1 = {label1} & label2 = {label2}.')
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
if st.button('t-test'):
|
| 235 |
+
res = hypothesis_testing(group1, group2, label1, label2)
|
| 236 |
+
st.write(res)
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
|
module/load_data.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def get_data():
|
| 5 |
+
data = pd.read_excel('data/Note_des_classes_6e_5e.xlsx')
|
| 6 |
+
data['average_marks'] = round(data['average_marks'], 2)
|
| 7 |
+
return data
|
| 8 |
+
|
| 9 |
+
data = get_data()
|
requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
scipy==1.7.3
|
| 2 |
+
matplotlib==3.5.3
|
| 3 |
+
plotly==5.14.0
|
| 4 |
+
numpy==1.21.6
|
| 5 |
+
pandas==1.3.5
|
| 6 |
+
streamlit==1.23.1
|
| 7 |
+
Pillow
|
| 8 |
+
openpyxl
|
| 9 |
+
scikit_learn==1.3.2
|