Spaces:
Running
on
Zero

Running
on
Zero
Upload 61 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- assets/model_diagram.png +0 -0
- assets/sa_v_dataset.jpg +0 -0
- build/lib.linux-x86_64-cpython-310/sam2/_C.so +3 -0
- build/temp.linux-x86_64-cpython-310/build.ninja +32 -0
- build/temp.linux-x86_64-cpython-310/sam2/csrc/connected_components.o +3 -0
- checkpoints/sam2.1_hiera_base_plus.pt +3 -0
- checkpoints/sam2.1_hiera_small.pt +3 -0
- checkpoints/sam2.1_hiera_tiny.pt +3 -0
- sam2/_C.so +3 -0
- sam2/__init__.py +11 -0
- sam2/__pycache__/__init__.cpython-310.pyc +0 -0
- sam2/__pycache__/build_sam.cpython-310.pyc +0 -0
- sam2/__pycache__/sam2_image_predictor.cpython-310.pyc +0 -0
- sam2/__pycache__/sam2_video_predictor.cpython-310.pyc +0 -0
- sam2/automatic_mask_generator.py +454 -0
- sam2/build_sam.py +167 -0
- sam2/configs/sam2.1/sam2.1_hiera_b+.yaml +116 -0
- sam2/configs/sam2.1/sam2.1_hiera_l.yaml +120 -0
- sam2/configs/sam2.1/sam2.1_hiera_s.yaml +119 -0
- sam2/configs/sam2.1/sam2.1_hiera_t.yaml +121 -0
- sam2/configs/sam2.1_training/sam2.1_hiera_b+_MOSE_finetune.yaml +339 -0
- sam2/csrc/connected_components.cu +289 -0
- sam2/modeling/__init__.py +5 -0
- sam2/modeling/__pycache__/__init__.cpython-310.pyc +0 -0
- sam2/modeling/__pycache__/memory_attention.cpython-310.pyc +0 -0
- sam2/modeling/__pycache__/memory_encoder.cpython-310.pyc +0 -0
- sam2/modeling/__pycache__/position_encoding.cpython-310.pyc +0 -0
- sam2/modeling/__pycache__/sam2_base.cpython-310.pyc +0 -0
- sam2/modeling/__pycache__/sam2_utils.cpython-310.pyc +0 -0
- sam2/modeling/backbones/__init__.py +5 -0
- sam2/modeling/backbones/__pycache__/__init__.cpython-310.pyc +0 -0
- sam2/modeling/backbones/__pycache__/hieradet.cpython-310.pyc +0 -0
- sam2/modeling/backbones/__pycache__/image_encoder.cpython-310.pyc +0 -0
- sam2/modeling/backbones/__pycache__/utils.cpython-310.pyc +0 -0
- sam2/modeling/backbones/hieradet.py +317 -0
- sam2/modeling/backbones/image_encoder.py +134 -0
- sam2/modeling/backbones/utils.py +95 -0
- sam2/modeling/memory_attention.py +205 -0
- sam2/modeling/memory_encoder.py +181 -0
- sam2/modeling/position_encoding.py +221 -0
- sam2/modeling/sam/__init__.py +5 -0
- sam2/modeling/sam/__pycache__/__init__.cpython-310.pyc +0 -0
- sam2/modeling/sam/__pycache__/mask_decoder.cpython-310.pyc +0 -0
- sam2/modeling/sam/__pycache__/prompt_encoder.cpython-310.pyc +0 -0
- sam2/modeling/sam/__pycache__/transformer.cpython-310.pyc +0 -0
- sam2/modeling/sam/mask_decoder.py +300 -0
- sam2/modeling/sam/prompt_encoder.py +182 -0
- sam2/modeling/sam/transformer.py +360 -0
- sam2/modeling/sam2_base.py +943 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
build/lib.linux-x86_64-cpython-310/sam2/_C.so filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
build/temp.linux-x86_64-cpython-310/sam2/csrc/connected_components.o filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
sam2/_C.so filter=lfs diff=lfs merge=lfs -text
|
assets/model_diagram.png
ADDED
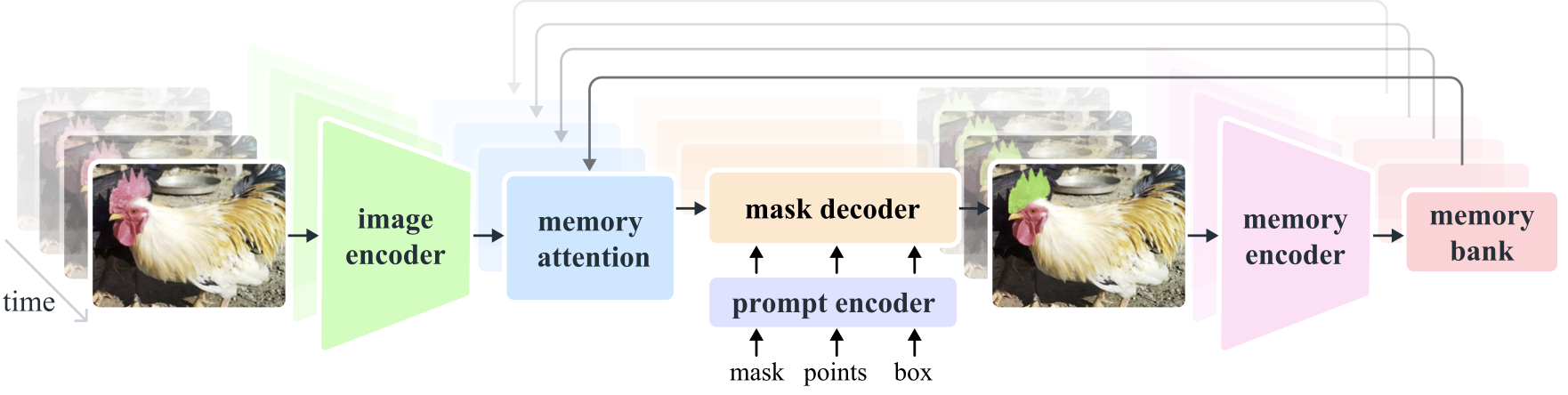
|
assets/sa_v_dataset.jpg
ADDED

|
build/lib.linux-x86_64-cpython-310/sam2/_C.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:67c0d5588c99e7a7d44c2325a98877c585934c8a1e8cd35be793a6ee266f235a
|
| 3 |
+
size 1873536
|
build/temp.linux-x86_64-cpython-310/build.ninja
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ninja_required_version = 1.3
|
| 2 |
+
cxx = /mnt/petrelfs/share/gcc/gcc-10.2.0/bin/c++
|
| 3 |
+
nvcc = /mnt/petrelfs/share/cuda-11.8/bin/nvcc
|
| 4 |
+
|
| 5 |
+
cflags = -Wno-unused-result -Wsign-compare -DNDEBUG -fwrapv -O2 -Wall -fPIC -O2 -isystem /mnt/cache/dingshuangrui/anaconda3/envs/sam/include -fPIC -O2 -isystem /mnt/cache/dingshuangrui/anaconda3/envs/sam/include -fPIC -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include/TH -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include/THC -I/mnt/petrelfs/share/cuda-11.8/include -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/include/python3.10 -c
|
| 6 |
+
post_cflags = -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=_C -D_GLIBCXX_USE_CXX11_ABI=0 -std=c++17
|
| 7 |
+
cuda_cflags = -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include/TH -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/lib/python3.10/site-packages/torch/include/THC -I/mnt/petrelfs/share/cuda-11.8/include -I/mnt/cache/dingshuangrui/anaconda3/envs/sam/include/python3.10 -c
|
| 8 |
+
cuda_post_cflags = -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr --compiler-options ''"'"'-fPIC'"'"'' -DCUDA_HAS_FP16=1 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=_C -D_GLIBCXX_USE_CXX11_ABI=0 -gencode=arch=compute_80,code=compute_80 -gencode=arch=compute_80,code=sm_80 -ccbin /mnt/petrelfs/share/gcc/gcc-10.2.0/bin/gcc -std=c++17
|
| 9 |
+
cuda_dlink_post_cflags =
|
| 10 |
+
ldflags =
|
| 11 |
+
|
| 12 |
+
rule compile
|
| 13 |
+
command = $cxx -MMD -MF $out.d $cflags -c $in -o $out $post_cflags
|
| 14 |
+
depfile = $out.d
|
| 15 |
+
deps = gcc
|
| 16 |
+
|
| 17 |
+
rule cuda_compile
|
| 18 |
+
depfile = $out.d
|
| 19 |
+
deps = gcc
|
| 20 |
+
command = $nvcc --generate-dependencies-with-compile --dependency-output $out.d $cuda_cflags -c $in -o $out $cuda_post_cflags
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
build /mnt/petrelfs/dingshuangrui/SAM2-Video-Predictor/build/temp.linux-x86_64-cpython-310/sam2/csrc/connected_components.o: cuda_compile /mnt/petrelfs/dingshuangrui/SAM2-Video-Predictor/sam2/csrc/connected_components.cu
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
build/temp.linux-x86_64-cpython-310/sam2/csrc/connected_components.o
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7ae64fe80f05eca117159083e8ab58fbdd187d8414578c7a99257fda7a5a123e
|
| 3 |
+
size 2734904
|
checkpoints/sam2.1_hiera_base_plus.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a2345aede8715ab1d5d31b4a509fb160c5a4af1970f199d9054ccfb746c004c5
|
| 3 |
+
size 323606802
|
checkpoints/sam2.1_hiera_small.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6d1aa6f30de5c92224f8172114de081d104bbd23dd9dc5c58996f0cad5dc4d38
|
| 3 |
+
size 184416285
|
checkpoints/sam2.1_hiera_tiny.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7402e0d864fa82708a20fbd15bc84245c2f26dff0eb43a4b5b93452deb34be69
|
| 3 |
+
size 156008466
|
sam2/_C.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:67c0d5588c99e7a7d44c2325a98877c585934c8a1e8cd35be793a6ee266f235a
|
| 3 |
+
size 1873536
|
sam2/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from hydra import initialize_config_module
|
| 8 |
+
from hydra.core.global_hydra import GlobalHydra
|
| 9 |
+
|
| 10 |
+
if not GlobalHydra.instance().is_initialized():
|
| 11 |
+
initialize_config_module("sam2", version_base="1.2")
|
sam2/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (358 Bytes). View file
|
|
|
sam2/__pycache__/build_sam.cpython-310.pyc
ADDED
|
Binary file (3.91 kB). View file
|
|
|
sam2/__pycache__/sam2_image_predictor.cpython-310.pyc
ADDED
|
Binary file (15.3 kB). View file
|
|
|
sam2/__pycache__/sam2_video_predictor.cpython-310.pyc
ADDED
|
Binary file (26.5 kB). View file
|
|
|
sam2/automatic_mask_generator.py
ADDED
|
@@ -0,0 +1,454 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
# Adapted from https://github.com/facebookresearch/segment-anything/blob/main/segment_anything/automatic_mask_generator.py
|
| 8 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from torchvision.ops.boxes import batched_nms, box_area # type: ignore
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_base import SAM2Base
|
| 15 |
+
from sam2.sam2_image_predictor import SAM2ImagePredictor
|
| 16 |
+
from sam2.utils.amg import (
|
| 17 |
+
area_from_rle,
|
| 18 |
+
batch_iterator,
|
| 19 |
+
batched_mask_to_box,
|
| 20 |
+
box_xyxy_to_xywh,
|
| 21 |
+
build_all_layer_point_grids,
|
| 22 |
+
calculate_stability_score,
|
| 23 |
+
coco_encode_rle,
|
| 24 |
+
generate_crop_boxes,
|
| 25 |
+
is_box_near_crop_edge,
|
| 26 |
+
mask_to_rle_pytorch,
|
| 27 |
+
MaskData,
|
| 28 |
+
remove_small_regions,
|
| 29 |
+
rle_to_mask,
|
| 30 |
+
uncrop_boxes_xyxy,
|
| 31 |
+
uncrop_masks,
|
| 32 |
+
uncrop_points,
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class SAM2AutomaticMaskGenerator:
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
model: SAM2Base,
|
| 40 |
+
points_per_side: Optional[int] = 32,
|
| 41 |
+
points_per_batch: int = 64,
|
| 42 |
+
pred_iou_thresh: float = 0.8,
|
| 43 |
+
stability_score_thresh: float = 0.95,
|
| 44 |
+
stability_score_offset: float = 1.0,
|
| 45 |
+
mask_threshold: float = 0.0,
|
| 46 |
+
box_nms_thresh: float = 0.7,
|
| 47 |
+
crop_n_layers: int = 0,
|
| 48 |
+
crop_nms_thresh: float = 0.7,
|
| 49 |
+
crop_overlap_ratio: float = 512 / 1500,
|
| 50 |
+
crop_n_points_downscale_factor: int = 1,
|
| 51 |
+
point_grids: Optional[List[np.ndarray]] = None,
|
| 52 |
+
min_mask_region_area: int = 0,
|
| 53 |
+
output_mode: str = "binary_mask",
|
| 54 |
+
use_m2m: bool = False,
|
| 55 |
+
multimask_output: bool = True,
|
| 56 |
+
**kwargs,
|
| 57 |
+
) -> None:
|
| 58 |
+
"""
|
| 59 |
+
Using a SAM 2 model, generates masks for the entire image.
|
| 60 |
+
Generates a grid of point prompts over the image, then filters
|
| 61 |
+
low quality and duplicate masks. The default settings are chosen
|
| 62 |
+
for SAM 2 with a HieraL backbone.
|
| 63 |
+
|
| 64 |
+
Arguments:
|
| 65 |
+
model (Sam): The SAM 2 model to use for mask prediction.
|
| 66 |
+
points_per_side (int or None): The number of points to be sampled
|
| 67 |
+
along one side of the image. The total number of points is
|
| 68 |
+
points_per_side**2. If None, 'point_grids' must provide explicit
|
| 69 |
+
point sampling.
|
| 70 |
+
points_per_batch (int): Sets the number of points run simultaneously
|
| 71 |
+
by the model. Higher numbers may be faster but use more GPU memory.
|
| 72 |
+
pred_iou_thresh (float): A filtering threshold in [0,1], using the
|
| 73 |
+
model's predicted mask quality.
|
| 74 |
+
stability_score_thresh (float): A filtering threshold in [0,1], using
|
| 75 |
+
the stability of the mask under changes to the cutoff used to binarize
|
| 76 |
+
the model's mask predictions.
|
| 77 |
+
stability_score_offset (float): The amount to shift the cutoff when
|
| 78 |
+
calculated the stability score.
|
| 79 |
+
mask_threshold (float): Threshold for binarizing the mask logits
|
| 80 |
+
box_nms_thresh (float): The box IoU cutoff used by non-maximal
|
| 81 |
+
suppression to filter duplicate masks.
|
| 82 |
+
crop_n_layers (int): If >0, mask prediction will be run again on
|
| 83 |
+
crops of the image. Sets the number of layers to run, where each
|
| 84 |
+
layer has 2**i_layer number of image crops.
|
| 85 |
+
crop_nms_thresh (float): The box IoU cutoff used by non-maximal
|
| 86 |
+
suppression to filter duplicate masks between different crops.
|
| 87 |
+
crop_overlap_ratio (float): Sets the degree to which crops overlap.
|
| 88 |
+
In the first crop layer, crops will overlap by this fraction of
|
| 89 |
+
the image length. Later layers with more crops scale down this overlap.
|
| 90 |
+
crop_n_points_downscale_factor (int): The number of points-per-side
|
| 91 |
+
sampled in layer n is scaled down by crop_n_points_downscale_factor**n.
|
| 92 |
+
point_grids (list(np.ndarray) or None): A list over explicit grids
|
| 93 |
+
of points used for sampling, normalized to [0,1]. The nth grid in the
|
| 94 |
+
list is used in the nth crop layer. Exclusive with points_per_side.
|
| 95 |
+
min_mask_region_area (int): If >0, postprocessing will be applied
|
| 96 |
+
to remove disconnected regions and holes in masks with area smaller
|
| 97 |
+
than min_mask_region_area. Requires opencv.
|
| 98 |
+
output_mode (str): The form masks are returned in. Can be 'binary_mask',
|
| 99 |
+
'uncompressed_rle', or 'coco_rle'. 'coco_rle' requires pycocotools.
|
| 100 |
+
For large resolutions, 'binary_mask' may consume large amounts of
|
| 101 |
+
memory.
|
| 102 |
+
use_m2m (bool): Whether to add a one step refinement using previous mask predictions.
|
| 103 |
+
multimask_output (bool): Whether to output multimask at each point of the grid.
|
| 104 |
+
"""
|
| 105 |
+
|
| 106 |
+
assert (points_per_side is None) != (
|
| 107 |
+
point_grids is None
|
| 108 |
+
), "Exactly one of points_per_side or point_grid must be provided."
|
| 109 |
+
if points_per_side is not None:
|
| 110 |
+
self.point_grids = build_all_layer_point_grids(
|
| 111 |
+
points_per_side,
|
| 112 |
+
crop_n_layers,
|
| 113 |
+
crop_n_points_downscale_factor,
|
| 114 |
+
)
|
| 115 |
+
elif point_grids is not None:
|
| 116 |
+
self.point_grids = point_grids
|
| 117 |
+
else:
|
| 118 |
+
raise ValueError("Can't have both points_per_side and point_grid be None.")
|
| 119 |
+
|
| 120 |
+
assert output_mode in [
|
| 121 |
+
"binary_mask",
|
| 122 |
+
"uncompressed_rle",
|
| 123 |
+
"coco_rle",
|
| 124 |
+
], f"Unknown output_mode {output_mode}."
|
| 125 |
+
if output_mode == "coco_rle":
|
| 126 |
+
try:
|
| 127 |
+
from pycocotools import mask as mask_utils # type: ignore # noqa: F401
|
| 128 |
+
except ImportError as e:
|
| 129 |
+
print("Please install pycocotools")
|
| 130 |
+
raise e
|
| 131 |
+
|
| 132 |
+
self.predictor = SAM2ImagePredictor(
|
| 133 |
+
model,
|
| 134 |
+
max_hole_area=min_mask_region_area,
|
| 135 |
+
max_sprinkle_area=min_mask_region_area,
|
| 136 |
+
)
|
| 137 |
+
self.points_per_batch = points_per_batch
|
| 138 |
+
self.pred_iou_thresh = pred_iou_thresh
|
| 139 |
+
self.stability_score_thresh = stability_score_thresh
|
| 140 |
+
self.stability_score_offset = stability_score_offset
|
| 141 |
+
self.mask_threshold = mask_threshold
|
| 142 |
+
self.box_nms_thresh = box_nms_thresh
|
| 143 |
+
self.crop_n_layers = crop_n_layers
|
| 144 |
+
self.crop_nms_thresh = crop_nms_thresh
|
| 145 |
+
self.crop_overlap_ratio = crop_overlap_ratio
|
| 146 |
+
self.crop_n_points_downscale_factor = crop_n_points_downscale_factor
|
| 147 |
+
self.min_mask_region_area = min_mask_region_area
|
| 148 |
+
self.output_mode = output_mode
|
| 149 |
+
self.use_m2m = use_m2m
|
| 150 |
+
self.multimask_output = multimask_output
|
| 151 |
+
|
| 152 |
+
@classmethod
|
| 153 |
+
def from_pretrained(cls, model_id: str, **kwargs) -> "SAM2AutomaticMaskGenerator":
|
| 154 |
+
"""
|
| 155 |
+
Load a pretrained model from the Hugging Face hub.
|
| 156 |
+
|
| 157 |
+
Arguments:
|
| 158 |
+
model_id (str): The Hugging Face repository ID.
|
| 159 |
+
**kwargs: Additional arguments to pass to the model constructor.
|
| 160 |
+
|
| 161 |
+
Returns:
|
| 162 |
+
(SAM2AutomaticMaskGenerator): The loaded model.
|
| 163 |
+
"""
|
| 164 |
+
from sam2.build_sam import build_sam2_hf
|
| 165 |
+
|
| 166 |
+
sam_model = build_sam2_hf(model_id, **kwargs)
|
| 167 |
+
return cls(sam_model, **kwargs)
|
| 168 |
+
|
| 169 |
+
@torch.no_grad()
|
| 170 |
+
def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:
|
| 171 |
+
"""
|
| 172 |
+
Generates masks for the given image.
|
| 173 |
+
|
| 174 |
+
Arguments:
|
| 175 |
+
image (np.ndarray): The image to generate masks for, in HWC uint8 format.
|
| 176 |
+
|
| 177 |
+
Returns:
|
| 178 |
+
list(dict(str, any)): A list over records for masks. Each record is
|
| 179 |
+
a dict containing the following keys:
|
| 180 |
+
segmentation (dict(str, any) or np.ndarray): The mask. If
|
| 181 |
+
output_mode='binary_mask', is an array of shape HW. Otherwise,
|
| 182 |
+
is a dictionary containing the RLE.
|
| 183 |
+
bbox (list(float)): The box around the mask, in XYWH format.
|
| 184 |
+
area (int): The area in pixels of the mask.
|
| 185 |
+
predicted_iou (float): The model's own prediction of the mask's
|
| 186 |
+
quality. This is filtered by the pred_iou_thresh parameter.
|
| 187 |
+
point_coords (list(list(float))): The point coordinates input
|
| 188 |
+
to the model to generate this mask.
|
| 189 |
+
stability_score (float): A measure of the mask's quality. This
|
| 190 |
+
is filtered on using the stability_score_thresh parameter.
|
| 191 |
+
crop_box (list(float)): The crop of the image used to generate
|
| 192 |
+
the mask, given in XYWH format.
|
| 193 |
+
"""
|
| 194 |
+
|
| 195 |
+
# Generate masks
|
| 196 |
+
mask_data = self._generate_masks(image)
|
| 197 |
+
|
| 198 |
+
# Encode masks
|
| 199 |
+
if self.output_mode == "coco_rle":
|
| 200 |
+
mask_data["segmentations"] = [
|
| 201 |
+
coco_encode_rle(rle) for rle in mask_data["rles"]
|
| 202 |
+
]
|
| 203 |
+
elif self.output_mode == "binary_mask":
|
| 204 |
+
mask_data["segmentations"] = [rle_to_mask(rle) for rle in mask_data["rles"]]
|
| 205 |
+
else:
|
| 206 |
+
mask_data["segmentations"] = mask_data["rles"]
|
| 207 |
+
|
| 208 |
+
# Write mask records
|
| 209 |
+
curr_anns = []
|
| 210 |
+
for idx in range(len(mask_data["segmentations"])):
|
| 211 |
+
ann = {
|
| 212 |
+
"segmentation": mask_data["segmentations"][idx],
|
| 213 |
+
"area": area_from_rle(mask_data["rles"][idx]),
|
| 214 |
+
"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),
|
| 215 |
+
"predicted_iou": mask_data["iou_preds"][idx].item(),
|
| 216 |
+
"point_coords": [mask_data["points"][idx].tolist()],
|
| 217 |
+
"stability_score": mask_data["stability_score"][idx].item(),
|
| 218 |
+
"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),
|
| 219 |
+
}
|
| 220 |
+
curr_anns.append(ann)
|
| 221 |
+
|
| 222 |
+
return curr_anns
|
| 223 |
+
|
| 224 |
+
def _generate_masks(self, image: np.ndarray) -> MaskData:
|
| 225 |
+
orig_size = image.shape[:2]
|
| 226 |
+
crop_boxes, layer_idxs = generate_crop_boxes(
|
| 227 |
+
orig_size, self.crop_n_layers, self.crop_overlap_ratio
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
# Iterate over image crops
|
| 231 |
+
data = MaskData()
|
| 232 |
+
for crop_box, layer_idx in zip(crop_boxes, layer_idxs):
|
| 233 |
+
crop_data = self._process_crop(image, crop_box, layer_idx, orig_size)
|
| 234 |
+
data.cat(crop_data)
|
| 235 |
+
|
| 236 |
+
# Remove duplicate masks between crops
|
| 237 |
+
if len(crop_boxes) > 1:
|
| 238 |
+
# Prefer masks from smaller crops
|
| 239 |
+
scores = 1 / box_area(data["crop_boxes"])
|
| 240 |
+
scores = scores.to(data["boxes"].device)
|
| 241 |
+
keep_by_nms = batched_nms(
|
| 242 |
+
data["boxes"].float(),
|
| 243 |
+
scores,
|
| 244 |
+
torch.zeros_like(data["boxes"][:, 0]), # categories
|
| 245 |
+
iou_threshold=self.crop_nms_thresh,
|
| 246 |
+
)
|
| 247 |
+
data.filter(keep_by_nms)
|
| 248 |
+
data.to_numpy()
|
| 249 |
+
return data
|
| 250 |
+
|
| 251 |
+
def _process_crop(
|
| 252 |
+
self,
|
| 253 |
+
image: np.ndarray,
|
| 254 |
+
crop_box: List[int],
|
| 255 |
+
crop_layer_idx: int,
|
| 256 |
+
orig_size: Tuple[int, ...],
|
| 257 |
+
) -> MaskData:
|
| 258 |
+
# Crop the image and calculate embeddings
|
| 259 |
+
x0, y0, x1, y1 = crop_box
|
| 260 |
+
cropped_im = image[y0:y1, x0:x1, :]
|
| 261 |
+
cropped_im_size = cropped_im.shape[:2]
|
| 262 |
+
self.predictor.set_image(cropped_im)
|
| 263 |
+
|
| 264 |
+
# Get points for this crop
|
| 265 |
+
points_scale = np.array(cropped_im_size)[None, ::-1]
|
| 266 |
+
points_for_image = self.point_grids[crop_layer_idx] * points_scale
|
| 267 |
+
|
| 268 |
+
# Generate masks for this crop in batches
|
| 269 |
+
data = MaskData()
|
| 270 |
+
for (points,) in batch_iterator(self.points_per_batch, points_for_image):
|
| 271 |
+
batch_data = self._process_batch(
|
| 272 |
+
points, cropped_im_size, crop_box, orig_size, normalize=True
|
| 273 |
+
)
|
| 274 |
+
data.cat(batch_data)
|
| 275 |
+
del batch_data
|
| 276 |
+
self.predictor.reset_predictor()
|
| 277 |
+
|
| 278 |
+
# Remove duplicates within this crop.
|
| 279 |
+
keep_by_nms = batched_nms(
|
| 280 |
+
data["boxes"].float(),
|
| 281 |
+
data["iou_preds"],
|
| 282 |
+
torch.zeros_like(data["boxes"][:, 0]), # categories
|
| 283 |
+
iou_threshold=self.box_nms_thresh,
|
| 284 |
+
)
|
| 285 |
+
data.filter(keep_by_nms)
|
| 286 |
+
|
| 287 |
+
# Return to the original image frame
|
| 288 |
+
data["boxes"] = uncrop_boxes_xyxy(data["boxes"], crop_box)
|
| 289 |
+
data["points"] = uncrop_points(data["points"], crop_box)
|
| 290 |
+
data["crop_boxes"] = torch.tensor([crop_box for _ in range(len(data["rles"]))])
|
| 291 |
+
|
| 292 |
+
return data
|
| 293 |
+
|
| 294 |
+
def _process_batch(
|
| 295 |
+
self,
|
| 296 |
+
points: np.ndarray,
|
| 297 |
+
im_size: Tuple[int, ...],
|
| 298 |
+
crop_box: List[int],
|
| 299 |
+
orig_size: Tuple[int, ...],
|
| 300 |
+
normalize=False,
|
| 301 |
+
) -> MaskData:
|
| 302 |
+
orig_h, orig_w = orig_size
|
| 303 |
+
|
| 304 |
+
# Run model on this batch
|
| 305 |
+
points = torch.as_tensor(
|
| 306 |
+
points, dtype=torch.float32, device=self.predictor.device
|
| 307 |
+
)
|
| 308 |
+
in_points = self.predictor._transforms.transform_coords(
|
| 309 |
+
points, normalize=normalize, orig_hw=im_size
|
| 310 |
+
)
|
| 311 |
+
in_labels = torch.ones(
|
| 312 |
+
in_points.shape[0], dtype=torch.int, device=in_points.device
|
| 313 |
+
)
|
| 314 |
+
masks, iou_preds, low_res_masks = self.predictor._predict(
|
| 315 |
+
in_points[:, None, :],
|
| 316 |
+
in_labels[:, None],
|
| 317 |
+
multimask_output=self.multimask_output,
|
| 318 |
+
return_logits=True,
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
# Serialize predictions and store in MaskData
|
| 322 |
+
data = MaskData(
|
| 323 |
+
masks=masks.flatten(0, 1),
|
| 324 |
+
iou_preds=iou_preds.flatten(0, 1),
|
| 325 |
+
points=points.repeat_interleave(masks.shape[1], dim=0),
|
| 326 |
+
low_res_masks=low_res_masks.flatten(0, 1),
|
| 327 |
+
)
|
| 328 |
+
del masks
|
| 329 |
+
|
| 330 |
+
if not self.use_m2m:
|
| 331 |
+
# Filter by predicted IoU
|
| 332 |
+
if self.pred_iou_thresh > 0.0:
|
| 333 |
+
keep_mask = data["iou_preds"] > self.pred_iou_thresh
|
| 334 |
+
data.filter(keep_mask)
|
| 335 |
+
|
| 336 |
+
# Calculate and filter by stability score
|
| 337 |
+
data["stability_score"] = calculate_stability_score(
|
| 338 |
+
data["masks"], self.mask_threshold, self.stability_score_offset
|
| 339 |
+
)
|
| 340 |
+
if self.stability_score_thresh > 0.0:
|
| 341 |
+
keep_mask = data["stability_score"] >= self.stability_score_thresh
|
| 342 |
+
data.filter(keep_mask)
|
| 343 |
+
else:
|
| 344 |
+
# One step refinement using previous mask predictions
|
| 345 |
+
in_points = self.predictor._transforms.transform_coords(
|
| 346 |
+
data["points"], normalize=normalize, orig_hw=im_size
|
| 347 |
+
)
|
| 348 |
+
labels = torch.ones(
|
| 349 |
+
in_points.shape[0], dtype=torch.int, device=in_points.device
|
| 350 |
+
)
|
| 351 |
+
masks, ious = self.refine_with_m2m(
|
| 352 |
+
in_points, labels, data["low_res_masks"], self.points_per_batch
|
| 353 |
+
)
|
| 354 |
+
data["masks"] = masks.squeeze(1)
|
| 355 |
+
data["iou_preds"] = ious.squeeze(1)
|
| 356 |
+
|
| 357 |
+
if self.pred_iou_thresh > 0.0:
|
| 358 |
+
keep_mask = data["iou_preds"] > self.pred_iou_thresh
|
| 359 |
+
data.filter(keep_mask)
|
| 360 |
+
|
| 361 |
+
data["stability_score"] = calculate_stability_score(
|
| 362 |
+
data["masks"], self.mask_threshold, self.stability_score_offset
|
| 363 |
+
)
|
| 364 |
+
if self.stability_score_thresh > 0.0:
|
| 365 |
+
keep_mask = data["stability_score"] >= self.stability_score_thresh
|
| 366 |
+
data.filter(keep_mask)
|
| 367 |
+
|
| 368 |
+
# Threshold masks and calculate boxes
|
| 369 |
+
data["masks"] = data["masks"] > self.mask_threshold
|
| 370 |
+
data["boxes"] = batched_mask_to_box(data["masks"])
|
| 371 |
+
|
| 372 |
+
# Filter boxes that touch crop boundaries
|
| 373 |
+
keep_mask = ~is_box_near_crop_edge(
|
| 374 |
+
data["boxes"], crop_box, [0, 0, orig_w, orig_h]
|
| 375 |
+
)
|
| 376 |
+
if not torch.all(keep_mask):
|
| 377 |
+
data.filter(keep_mask)
|
| 378 |
+
|
| 379 |
+
# Compress to RLE
|
| 380 |
+
data["masks"] = uncrop_masks(data["masks"], crop_box, orig_h, orig_w)
|
| 381 |
+
data["rles"] = mask_to_rle_pytorch(data["masks"])
|
| 382 |
+
del data["masks"]
|
| 383 |
+
|
| 384 |
+
return data
|
| 385 |
+
|
| 386 |
+
@staticmethod
|
| 387 |
+
def postprocess_small_regions(
|
| 388 |
+
mask_data: MaskData, min_area: int, nms_thresh: float
|
| 389 |
+
) -> MaskData:
|
| 390 |
+
"""
|
| 391 |
+
Removes small disconnected regions and holes in masks, then reruns
|
| 392 |
+
box NMS to remove any new duplicates.
|
| 393 |
+
|
| 394 |
+
Edits mask_data in place.
|
| 395 |
+
|
| 396 |
+
Requires open-cv as a dependency.
|
| 397 |
+
"""
|
| 398 |
+
if len(mask_data["rles"]) == 0:
|
| 399 |
+
return mask_data
|
| 400 |
+
|
| 401 |
+
# Filter small disconnected regions and holes
|
| 402 |
+
new_masks = []
|
| 403 |
+
scores = []
|
| 404 |
+
for rle in mask_data["rles"]:
|
| 405 |
+
mask = rle_to_mask(rle)
|
| 406 |
+
|
| 407 |
+
mask, changed = remove_small_regions(mask, min_area, mode="holes")
|
| 408 |
+
unchanged = not changed
|
| 409 |
+
mask, changed = remove_small_regions(mask, min_area, mode="islands")
|
| 410 |
+
unchanged = unchanged and not changed
|
| 411 |
+
|
| 412 |
+
new_masks.append(torch.as_tensor(mask).unsqueeze(0))
|
| 413 |
+
# Give score=0 to changed masks and score=1 to unchanged masks
|
| 414 |
+
# so NMS will prefer ones that didn't need postprocessing
|
| 415 |
+
scores.append(float(unchanged))
|
| 416 |
+
|
| 417 |
+
# Recalculate boxes and remove any new duplicates
|
| 418 |
+
masks = torch.cat(new_masks, dim=0)
|
| 419 |
+
boxes = batched_mask_to_box(masks)
|
| 420 |
+
keep_by_nms = batched_nms(
|
| 421 |
+
boxes.float(),
|
| 422 |
+
torch.as_tensor(scores),
|
| 423 |
+
torch.zeros_like(boxes[:, 0]), # categories
|
| 424 |
+
iou_threshold=nms_thresh,
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
# Only recalculate RLEs for masks that have changed
|
| 428 |
+
for i_mask in keep_by_nms:
|
| 429 |
+
if scores[i_mask] == 0.0:
|
| 430 |
+
mask_torch = masks[i_mask].unsqueeze(0)
|
| 431 |
+
mask_data["rles"][i_mask] = mask_to_rle_pytorch(mask_torch)[0]
|
| 432 |
+
mask_data["boxes"][i_mask] = boxes[i_mask] # update res directly
|
| 433 |
+
mask_data.filter(keep_by_nms)
|
| 434 |
+
|
| 435 |
+
return mask_data
|
| 436 |
+
|
| 437 |
+
def refine_with_m2m(self, points, point_labels, low_res_masks, points_per_batch):
|
| 438 |
+
new_masks = []
|
| 439 |
+
new_iou_preds = []
|
| 440 |
+
|
| 441 |
+
for cur_points, cur_point_labels, low_res_mask in batch_iterator(
|
| 442 |
+
points_per_batch, points, point_labels, low_res_masks
|
| 443 |
+
):
|
| 444 |
+
best_masks, best_iou_preds, _ = self.predictor._predict(
|
| 445 |
+
cur_points[:, None, :],
|
| 446 |
+
cur_point_labels[:, None],
|
| 447 |
+
mask_input=low_res_mask[:, None, :],
|
| 448 |
+
multimask_output=False,
|
| 449 |
+
return_logits=True,
|
| 450 |
+
)
|
| 451 |
+
new_masks.append(best_masks)
|
| 452 |
+
new_iou_preds.append(best_iou_preds)
|
| 453 |
+
masks = torch.cat(new_masks, dim=0)
|
| 454 |
+
return masks, torch.cat(new_iou_preds, dim=0)
|
sam2/build_sam.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
import os
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
from hydra import compose
|
| 12 |
+
from hydra.utils import instantiate
|
| 13 |
+
from omegaconf import OmegaConf
|
| 14 |
+
|
| 15 |
+
import sam2
|
| 16 |
+
|
| 17 |
+
# Check if the user is running Python from the parent directory of the sam2 repo
|
| 18 |
+
# (i.e. the directory where this repo is cloned into) -- this is not supported since
|
| 19 |
+
# it could shadow the sam2 package and cause issues.
|
| 20 |
+
if os.path.isdir(os.path.join(sam2.__path__[0], "sam2")):
|
| 21 |
+
# If the user has "sam2/sam2" in their path, they are likey importing the repo itself
|
| 22 |
+
# as "sam2" rather than importing the "sam2" python package (i.e. "sam2/sam2" directory).
|
| 23 |
+
# This typically happens because the user is running Python from the parent directory
|
| 24 |
+
# that contains the sam2 repo they cloned.
|
| 25 |
+
raise RuntimeError(
|
| 26 |
+
"You're likely running Python from the parent directory of the sam2 repository "
|
| 27 |
+
"(i.e. the directory where https://github.com/facebookresearch/sam2 is cloned into). "
|
| 28 |
+
"This is not supported since the `sam2` Python package could be shadowed by the "
|
| 29 |
+
"repository name (the repository is also named `sam2` and contains the Python package "
|
| 30 |
+
"in `sam2/sam2`). Please run Python from another directory (e.g. from the repo dir "
|
| 31 |
+
"rather than its parent dir, or from your home directory) after installing SAM 2."
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
HF_MODEL_ID_TO_FILENAMES = {
|
| 36 |
+
"facebook/sam2-hiera-tiny": (
|
| 37 |
+
"configs/sam2/sam2_hiera_t.yaml",
|
| 38 |
+
"sam2_hiera_tiny.pt",
|
| 39 |
+
),
|
| 40 |
+
"facebook/sam2-hiera-small": (
|
| 41 |
+
"configs/sam2/sam2_hiera_s.yaml",
|
| 42 |
+
"sam2_hiera_small.pt",
|
| 43 |
+
),
|
| 44 |
+
"facebook/sam2-hiera-base-plus": (
|
| 45 |
+
"configs/sam2/sam2_hiera_b+.yaml",
|
| 46 |
+
"sam2_hiera_base_plus.pt",
|
| 47 |
+
),
|
| 48 |
+
"facebook/sam2-hiera-large": (
|
| 49 |
+
"configs/sam2/sam2_hiera_l.yaml",
|
| 50 |
+
"sam2_hiera_large.pt",
|
| 51 |
+
),
|
| 52 |
+
"facebook/sam2.1-hiera-tiny": (
|
| 53 |
+
"configs/sam2.1/sam2.1_hiera_t.yaml",
|
| 54 |
+
"sam2.1_hiera_tiny.pt",
|
| 55 |
+
),
|
| 56 |
+
"facebook/sam2.1-hiera-small": (
|
| 57 |
+
"configs/sam2.1/sam2.1_hiera_s.yaml",
|
| 58 |
+
"sam2.1_hiera_small.pt",
|
| 59 |
+
),
|
| 60 |
+
"facebook/sam2.1-hiera-base-plus": (
|
| 61 |
+
"configs/sam2.1/sam2.1_hiera_b+.yaml",
|
| 62 |
+
"sam2.1_hiera_base_plus.pt",
|
| 63 |
+
),
|
| 64 |
+
"facebook/sam2.1-hiera-large": (
|
| 65 |
+
"configs/sam2.1/sam2.1_hiera_l.yaml",
|
| 66 |
+
"sam2.1_hiera_large.pt",
|
| 67 |
+
),
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def build_sam2(
|
| 72 |
+
config_file,
|
| 73 |
+
ckpt_path=None,
|
| 74 |
+
device="cuda",
|
| 75 |
+
mode="eval",
|
| 76 |
+
hydra_overrides_extra=[],
|
| 77 |
+
apply_postprocessing=True,
|
| 78 |
+
**kwargs,
|
| 79 |
+
):
|
| 80 |
+
|
| 81 |
+
if apply_postprocessing:
|
| 82 |
+
hydra_overrides_extra = hydra_overrides_extra.copy()
|
| 83 |
+
hydra_overrides_extra += [
|
| 84 |
+
# dynamically fall back to multi-mask if the single mask is not stable
|
| 85 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_via_stability=true",
|
| 86 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_delta=0.05",
|
| 87 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_thresh=0.98",
|
| 88 |
+
]
|
| 89 |
+
# Read config and init model
|
| 90 |
+
cfg = compose(config_name=config_file, overrides=hydra_overrides_extra)
|
| 91 |
+
OmegaConf.resolve(cfg)
|
| 92 |
+
model = instantiate(cfg.model, _recursive_=True)
|
| 93 |
+
_load_checkpoint(model, ckpt_path)
|
| 94 |
+
model = model.to(device)
|
| 95 |
+
if mode == "eval":
|
| 96 |
+
model.eval()
|
| 97 |
+
return model
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def build_sam2_video_predictor(
|
| 101 |
+
config_file,
|
| 102 |
+
ckpt_path=None,
|
| 103 |
+
device="cuda",
|
| 104 |
+
mode="eval",
|
| 105 |
+
hydra_overrides_extra=[],
|
| 106 |
+
apply_postprocessing=True,
|
| 107 |
+
**kwargs,
|
| 108 |
+
):
|
| 109 |
+
hydra_overrides = [
|
| 110 |
+
"++model._target_=sam2.sam2_video_predictor.SAM2VideoPredictor",
|
| 111 |
+
]
|
| 112 |
+
if apply_postprocessing:
|
| 113 |
+
hydra_overrides_extra = hydra_overrides_extra.copy()
|
| 114 |
+
hydra_overrides_extra += [
|
| 115 |
+
# dynamically fall back to multi-mask if the single mask is not stable
|
| 116 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_via_stability=true",
|
| 117 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_delta=0.05",
|
| 118 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_thresh=0.98",
|
| 119 |
+
# the sigmoid mask logits on interacted frames with clicks in the memory encoder so that the encoded masks are exactly as what users see from clicking
|
| 120 |
+
"++model.binarize_mask_from_pts_for_mem_enc=true",
|
| 121 |
+
# fill small holes in the low-res masks up to `fill_hole_area` (before resizing them to the original video resolution)
|
| 122 |
+
"++model.fill_hole_area=8",
|
| 123 |
+
]
|
| 124 |
+
hydra_overrides.extend(hydra_overrides_extra)
|
| 125 |
+
|
| 126 |
+
# Read config and init model
|
| 127 |
+
cfg = compose(config_name=config_file, overrides=hydra_overrides)
|
| 128 |
+
OmegaConf.resolve(cfg)
|
| 129 |
+
model = instantiate(cfg.model, _recursive_=True)
|
| 130 |
+
_load_checkpoint(model, ckpt_path)
|
| 131 |
+
model = model.to(device)
|
| 132 |
+
if mode == "eval":
|
| 133 |
+
model.eval()
|
| 134 |
+
return model
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def _hf_download(model_id):
|
| 138 |
+
from huggingface_hub import hf_hub_download
|
| 139 |
+
|
| 140 |
+
config_name, checkpoint_name = HF_MODEL_ID_TO_FILENAMES[model_id]
|
| 141 |
+
ckpt_path = hf_hub_download(repo_id=model_id, filename=checkpoint_name)
|
| 142 |
+
return config_name, ckpt_path
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def build_sam2_hf(model_id, **kwargs):
|
| 146 |
+
config_name, ckpt_path = _hf_download(model_id)
|
| 147 |
+
return build_sam2(config_file=config_name, ckpt_path=ckpt_path, **kwargs)
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def build_sam2_video_predictor_hf(model_id, **kwargs):
|
| 151 |
+
config_name, ckpt_path = _hf_download(model_id)
|
| 152 |
+
return build_sam2_video_predictor(
|
| 153 |
+
config_file=config_name, ckpt_path=ckpt_path, **kwargs
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def _load_checkpoint(model, ckpt_path):
|
| 158 |
+
if ckpt_path is not None:
|
| 159 |
+
sd = torch.load(ckpt_path, map_location="cpu", weights_only=True)["model"]
|
| 160 |
+
missing_keys, unexpected_keys = model.load_state_dict(sd)
|
| 161 |
+
if missing_keys:
|
| 162 |
+
logging.error(missing_keys)
|
| 163 |
+
raise RuntimeError()
|
| 164 |
+
if unexpected_keys:
|
| 165 |
+
logging.error(unexpected_keys)
|
| 166 |
+
raise RuntimeError()
|
| 167 |
+
logging.info("Loaded checkpoint sucessfully")
|
sam2/configs/sam2.1/sam2.1_hiera_b+.yaml
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 112
|
| 12 |
+
num_heads: 2
|
| 13 |
+
neck:
|
| 14 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 15 |
+
position_encoding:
|
| 16 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 17 |
+
num_pos_feats: 256
|
| 18 |
+
normalize: true
|
| 19 |
+
scale: null
|
| 20 |
+
temperature: 10000
|
| 21 |
+
d_model: 256
|
| 22 |
+
backbone_channel_list: [896, 448, 224, 112]
|
| 23 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 24 |
+
fpn_interp_model: nearest
|
| 25 |
+
|
| 26 |
+
memory_attention:
|
| 27 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 28 |
+
d_model: 256
|
| 29 |
+
pos_enc_at_input: true
|
| 30 |
+
layer:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 32 |
+
activation: relu
|
| 33 |
+
dim_feedforward: 2048
|
| 34 |
+
dropout: 0.1
|
| 35 |
+
pos_enc_at_attn: false
|
| 36 |
+
self_attention:
|
| 37 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 38 |
+
rope_theta: 10000.0
|
| 39 |
+
feat_sizes: [32, 32]
|
| 40 |
+
embedding_dim: 256
|
| 41 |
+
num_heads: 1
|
| 42 |
+
downsample_rate: 1
|
| 43 |
+
dropout: 0.1
|
| 44 |
+
d_model: 256
|
| 45 |
+
pos_enc_at_cross_attn_keys: true
|
| 46 |
+
pos_enc_at_cross_attn_queries: false
|
| 47 |
+
cross_attention:
|
| 48 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 49 |
+
rope_theta: 10000.0
|
| 50 |
+
feat_sizes: [32, 32]
|
| 51 |
+
rope_k_repeat: True
|
| 52 |
+
embedding_dim: 256
|
| 53 |
+
num_heads: 1
|
| 54 |
+
downsample_rate: 1
|
| 55 |
+
dropout: 0.1
|
| 56 |
+
kv_in_dim: 64
|
| 57 |
+
num_layers: 4
|
| 58 |
+
|
| 59 |
+
memory_encoder:
|
| 60 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 61 |
+
out_dim: 64
|
| 62 |
+
position_encoding:
|
| 63 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 64 |
+
num_pos_feats: 64
|
| 65 |
+
normalize: true
|
| 66 |
+
scale: null
|
| 67 |
+
temperature: 10000
|
| 68 |
+
mask_downsampler:
|
| 69 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 70 |
+
kernel_size: 3
|
| 71 |
+
stride: 2
|
| 72 |
+
padding: 1
|
| 73 |
+
fuser:
|
| 74 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 75 |
+
layer:
|
| 76 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 77 |
+
dim: 256
|
| 78 |
+
kernel_size: 7
|
| 79 |
+
padding: 3
|
| 80 |
+
layer_scale_init_value: 1e-6
|
| 81 |
+
use_dwconv: True # depth-wise convs
|
| 82 |
+
num_layers: 2
|
| 83 |
+
|
| 84 |
+
num_maskmem: 7
|
| 85 |
+
image_size: 1024
|
| 86 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 87 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 88 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 89 |
+
use_mask_input_as_output_without_sam: true
|
| 90 |
+
# Memory
|
| 91 |
+
directly_add_no_mem_embed: true
|
| 92 |
+
no_obj_embed_spatial: true
|
| 93 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 94 |
+
use_high_res_features_in_sam: true
|
| 95 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 96 |
+
multimask_output_in_sam: true
|
| 97 |
+
# SAM heads
|
| 98 |
+
iou_prediction_use_sigmoid: True
|
| 99 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 100 |
+
use_obj_ptrs_in_encoder: true
|
| 101 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 102 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 103 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 104 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 105 |
+
# object occlusion prediction
|
| 106 |
+
pred_obj_scores: true
|
| 107 |
+
pred_obj_scores_mlp: true
|
| 108 |
+
fixed_no_obj_ptr: true
|
| 109 |
+
# multimask tracking settings
|
| 110 |
+
multimask_output_for_tracking: true
|
| 111 |
+
use_multimask_token_for_obj_ptr: true
|
| 112 |
+
multimask_min_pt_num: 0
|
| 113 |
+
multimask_max_pt_num: 1
|
| 114 |
+
use_mlp_for_obj_ptr_proj: true
|
| 115 |
+
# Compilation flag
|
| 116 |
+
compile_image_encoder: False
|
sam2/configs/sam2.1/sam2.1_hiera_l.yaml
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 144
|
| 12 |
+
num_heads: 2
|
| 13 |
+
stages: [2, 6, 36, 4]
|
| 14 |
+
global_att_blocks: [23, 33, 43]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
window_spec: [8, 4, 16, 8]
|
| 17 |
+
neck:
|
| 18 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 19 |
+
position_encoding:
|
| 20 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 21 |
+
num_pos_feats: 256
|
| 22 |
+
normalize: true
|
| 23 |
+
scale: null
|
| 24 |
+
temperature: 10000
|
| 25 |
+
d_model: 256
|
| 26 |
+
backbone_channel_list: [1152, 576, 288, 144]
|
| 27 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 28 |
+
fpn_interp_model: nearest
|
| 29 |
+
|
| 30 |
+
memory_attention:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 32 |
+
d_model: 256
|
| 33 |
+
pos_enc_at_input: true
|
| 34 |
+
layer:
|
| 35 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 36 |
+
activation: relu
|
| 37 |
+
dim_feedforward: 2048
|
| 38 |
+
dropout: 0.1
|
| 39 |
+
pos_enc_at_attn: false
|
| 40 |
+
self_attention:
|
| 41 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 42 |
+
rope_theta: 10000.0
|
| 43 |
+
feat_sizes: [32, 32]
|
| 44 |
+
embedding_dim: 256
|
| 45 |
+
num_heads: 1
|
| 46 |
+
downsample_rate: 1
|
| 47 |
+
dropout: 0.1
|
| 48 |
+
d_model: 256
|
| 49 |
+
pos_enc_at_cross_attn_keys: true
|
| 50 |
+
pos_enc_at_cross_attn_queries: false
|
| 51 |
+
cross_attention:
|
| 52 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 53 |
+
rope_theta: 10000.0
|
| 54 |
+
feat_sizes: [32, 32]
|
| 55 |
+
rope_k_repeat: True
|
| 56 |
+
embedding_dim: 256
|
| 57 |
+
num_heads: 1
|
| 58 |
+
downsample_rate: 1
|
| 59 |
+
dropout: 0.1
|
| 60 |
+
kv_in_dim: 64
|
| 61 |
+
num_layers: 4
|
| 62 |
+
|
| 63 |
+
memory_encoder:
|
| 64 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 65 |
+
out_dim: 64
|
| 66 |
+
position_encoding:
|
| 67 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 68 |
+
num_pos_feats: 64
|
| 69 |
+
normalize: true
|
| 70 |
+
scale: null
|
| 71 |
+
temperature: 10000
|
| 72 |
+
mask_downsampler:
|
| 73 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 74 |
+
kernel_size: 3
|
| 75 |
+
stride: 2
|
| 76 |
+
padding: 1
|
| 77 |
+
fuser:
|
| 78 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 79 |
+
layer:
|
| 80 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 81 |
+
dim: 256
|
| 82 |
+
kernel_size: 7
|
| 83 |
+
padding: 3
|
| 84 |
+
layer_scale_init_value: 1e-6
|
| 85 |
+
use_dwconv: True # depth-wise convs
|
| 86 |
+
num_layers: 2
|
| 87 |
+
|
| 88 |
+
num_maskmem: 7
|
| 89 |
+
image_size: 1024
|
| 90 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
no_obj_embed_spatial: true
|
| 97 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 98 |
+
use_high_res_features_in_sam: true
|
| 99 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 100 |
+
multimask_output_in_sam: true
|
| 101 |
+
# SAM heads
|
| 102 |
+
iou_prediction_use_sigmoid: True
|
| 103 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 104 |
+
use_obj_ptrs_in_encoder: true
|
| 105 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 106 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 107 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 108 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 109 |
+
# object occlusion prediction
|
| 110 |
+
pred_obj_scores: true
|
| 111 |
+
pred_obj_scores_mlp: true
|
| 112 |
+
fixed_no_obj_ptr: true
|
| 113 |
+
# multimask tracking settings
|
| 114 |
+
multimask_output_for_tracking: true
|
| 115 |
+
use_multimask_token_for_obj_ptr: true
|
| 116 |
+
multimask_min_pt_num: 0
|
| 117 |
+
multimask_max_pt_num: 1
|
| 118 |
+
use_mlp_for_obj_ptr_proj: true
|
| 119 |
+
# Compilation flag
|
| 120 |
+
compile_image_encoder: False
|
sam2/configs/sam2.1/sam2.1_hiera_s.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 11, 2]
|
| 14 |
+
global_att_blocks: [7, 10, 13]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [32, 32]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [32, 32]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 91 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 92 |
+
use_mask_input_as_output_without_sam: true
|
| 93 |
+
# Memory
|
| 94 |
+
directly_add_no_mem_embed: true
|
| 95 |
+
no_obj_embed_spatial: true
|
| 96 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 97 |
+
use_high_res_features_in_sam: true
|
| 98 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 99 |
+
multimask_output_in_sam: true
|
| 100 |
+
# SAM heads
|
| 101 |
+
iou_prediction_use_sigmoid: True
|
| 102 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 103 |
+
use_obj_ptrs_in_encoder: true
|
| 104 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 105 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 106 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 107 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 108 |
+
# object occlusion prediction
|
| 109 |
+
pred_obj_scores: true
|
| 110 |
+
pred_obj_scores_mlp: true
|
| 111 |
+
fixed_no_obj_ptr: true
|
| 112 |
+
# multimask tracking settings
|
| 113 |
+
multimask_output_for_tracking: true
|
| 114 |
+
use_multimask_token_for_obj_ptr: true
|
| 115 |
+
multimask_min_pt_num: 0
|
| 116 |
+
multimask_max_pt_num: 1
|
| 117 |
+
use_mlp_for_obj_ptr_proj: true
|
| 118 |
+
# Compilation flag
|
| 119 |
+
compile_image_encoder: False
|
sam2/configs/sam2.1/sam2.1_hiera_t.yaml
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 7, 2]
|
| 14 |
+
global_att_blocks: [5, 7, 9]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [32, 32]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [32, 32]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
# SAM decoder
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
no_obj_embed_spatial: true
|
| 97 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 98 |
+
use_high_res_features_in_sam: true
|
| 99 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 100 |
+
multimask_output_in_sam: true
|
| 101 |
+
# SAM heads
|
| 102 |
+
iou_prediction_use_sigmoid: True
|
| 103 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 104 |
+
use_obj_ptrs_in_encoder: true
|
| 105 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 106 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 107 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 108 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 109 |
+
# object occlusion prediction
|
| 110 |
+
pred_obj_scores: true
|
| 111 |
+
pred_obj_scores_mlp: true
|
| 112 |
+
fixed_no_obj_ptr: true
|
| 113 |
+
# multimask tracking settings
|
| 114 |
+
multimask_output_for_tracking: true
|
| 115 |
+
use_multimask_token_for_obj_ptr: true
|
| 116 |
+
multimask_min_pt_num: 0
|
| 117 |
+
multimask_max_pt_num: 1
|
| 118 |
+
use_mlp_for_obj_ptr_proj: true
|
| 119 |
+
# Compilation flag
|
| 120 |
+
# HieraT does not currently support compilation, should always be set to False
|
| 121 |
+
compile_image_encoder: False
|
sam2/configs/sam2.1_training/sam2.1_hiera_b+_MOSE_finetune.yaml
ADDED
|
@@ -0,0 +1,339 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
scratch:
|
| 4 |
+
resolution: 1024
|
| 5 |
+
train_batch_size: 1
|
| 6 |
+
num_train_workers: 10
|
| 7 |
+
num_frames: 8
|
| 8 |
+
max_num_objects: 3
|
| 9 |
+
base_lr: 5.0e-6
|
| 10 |
+
vision_lr: 3.0e-06
|
| 11 |
+
phases_per_epoch: 1
|
| 12 |
+
num_epochs: 40
|
| 13 |
+
|
| 14 |
+
dataset:
|
| 15 |
+
# PATHS to Dataset
|
| 16 |
+
img_folder: /fsx-onevision/shared/data/academic_vos_data/MOSE/train/JPEGImages # PATH to MOSE JPEGImages folder
|
| 17 |
+
gt_folder: /fsx-onevision/shared/data/academic_vos_data/MOSE/train/Annotations/ # PATH to MOSE Annotations folder
|
| 18 |
+
file_list_txt: training/assets/MOSE_sample_train_list.txt # Optional PATH to filelist containing a subset of videos to be used for training
|
| 19 |
+
multiplier: 2
|
| 20 |
+
|
| 21 |
+
# Video transforms
|
| 22 |
+
vos:
|
| 23 |
+
train_transforms:
|
| 24 |
+
- _target_: training.dataset.transforms.ComposeAPI
|
| 25 |
+
transforms:
|
| 26 |
+
- _target_: training.dataset.transforms.RandomHorizontalFlip
|
| 27 |
+
consistent_transform: True
|
| 28 |
+
- _target_: training.dataset.transforms.RandomAffine
|
| 29 |
+
degrees: 25
|
| 30 |
+
shear: 20
|
| 31 |
+
image_interpolation: bilinear
|
| 32 |
+
consistent_transform: True
|
| 33 |
+
- _target_: training.dataset.transforms.RandomResizeAPI
|
| 34 |
+
sizes: ${scratch.resolution}
|
| 35 |
+
square: true
|
| 36 |
+
consistent_transform: True
|
| 37 |
+
- _target_: training.dataset.transforms.ColorJitter
|
| 38 |
+
consistent_transform: True
|
| 39 |
+
brightness: 0.1
|
| 40 |
+
contrast: 0.03
|
| 41 |
+
saturation: 0.03
|
| 42 |
+
hue: null
|
| 43 |
+
- _target_: training.dataset.transforms.RandomGrayscale
|
| 44 |
+
p: 0.05
|
| 45 |
+
consistent_transform: True
|
| 46 |
+
- _target_: training.dataset.transforms.ColorJitter
|
| 47 |
+
consistent_transform: False
|
| 48 |
+
brightness: 0.1
|
| 49 |
+
contrast: 0.05
|
| 50 |
+
saturation: 0.05
|
| 51 |
+
hue: null
|
| 52 |
+
- _target_: training.dataset.transforms.ToTensorAPI
|
| 53 |
+
- _target_: training.dataset.transforms.NormalizeAPI
|
| 54 |
+
mean: [0.485, 0.456, 0.406]
|
| 55 |
+
std: [0.229, 0.224, 0.225]
|
| 56 |
+
|
| 57 |
+
trainer:
|
| 58 |
+
_target_: training.trainer.Trainer
|
| 59 |
+
mode: train_only
|
| 60 |
+
max_epochs: ${times:${scratch.num_epochs},${scratch.phases_per_epoch}}
|
| 61 |
+
accelerator: cuda
|
| 62 |
+
seed_value: 123
|
| 63 |
+
|
| 64 |
+
model:
|
| 65 |
+
_target_: training.model.sam2.SAM2Train
|
| 66 |
+
image_encoder:
|
| 67 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 68 |
+
scalp: 1
|
| 69 |
+
trunk:
|
| 70 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 71 |
+
embed_dim: 112
|
| 72 |
+
num_heads: 2
|
| 73 |
+
drop_path_rate: 0.1
|
| 74 |
+
neck:
|
| 75 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 76 |
+
position_encoding:
|
| 77 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 78 |
+
num_pos_feats: 256
|
| 79 |
+
normalize: true
|
| 80 |
+
scale: null
|
| 81 |
+
temperature: 10000
|
| 82 |
+
d_model: 256
|
| 83 |
+
backbone_channel_list: [896, 448, 224, 112]
|
| 84 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 85 |
+
fpn_interp_model: nearest
|
| 86 |
+
|
| 87 |
+
memory_attention:
|
| 88 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 89 |
+
d_model: 256
|
| 90 |
+
pos_enc_at_input: true
|
| 91 |
+
layer:
|
| 92 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 93 |
+
activation: relu
|
| 94 |
+
dim_feedforward: 2048
|
| 95 |
+
dropout: 0.1
|
| 96 |
+
pos_enc_at_attn: false
|
| 97 |
+
self_attention:
|
| 98 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 99 |
+
rope_theta: 10000.0
|
| 100 |
+
feat_sizes: [32, 32]
|
| 101 |
+
embedding_dim: 256
|
| 102 |
+
num_heads: 1
|
| 103 |
+
downsample_rate: 1
|
| 104 |
+
dropout: 0.1
|
| 105 |
+
d_model: 256
|
| 106 |
+
pos_enc_at_cross_attn_keys: true
|
| 107 |
+
pos_enc_at_cross_attn_queries: false
|
| 108 |
+
cross_attention:
|
| 109 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 110 |
+
rope_theta: 10000.0
|
| 111 |
+
feat_sizes: [32, 32]
|
| 112 |
+
rope_k_repeat: True
|
| 113 |
+
embedding_dim: 256
|
| 114 |
+
num_heads: 1
|
| 115 |
+
downsample_rate: 1
|
| 116 |
+
dropout: 0.1
|
| 117 |
+
kv_in_dim: 64
|
| 118 |
+
num_layers: 4
|
| 119 |
+
|
| 120 |
+
memory_encoder:
|
| 121 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 122 |
+
out_dim: 64
|
| 123 |
+
position_encoding:
|
| 124 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 125 |
+
num_pos_feats: 64
|
| 126 |
+
normalize: true
|
| 127 |
+
scale: null
|
| 128 |
+
temperature: 10000
|
| 129 |
+
mask_downsampler:
|
| 130 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 131 |
+
kernel_size: 3
|
| 132 |
+
stride: 2
|
| 133 |
+
padding: 1
|
| 134 |
+
fuser:
|
| 135 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 136 |
+
layer:
|
| 137 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 138 |
+
dim: 256
|
| 139 |
+
kernel_size: 7
|
| 140 |
+
padding: 3
|
| 141 |
+
layer_scale_init_value: 1e-6
|
| 142 |
+
use_dwconv: True # depth-wise convs
|
| 143 |
+
num_layers: 2
|
| 144 |
+
|
| 145 |
+
num_maskmem: 7
|
| 146 |
+
image_size: ${scratch.resolution}
|
| 147 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 148 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 149 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 150 |
+
use_mask_input_as_output_without_sam: true
|
| 151 |
+
# Memory
|
| 152 |
+
directly_add_no_mem_embed: true
|
| 153 |
+
no_obj_embed_spatial: true
|
| 154 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 155 |
+
use_high_res_features_in_sam: true
|
| 156 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 157 |
+
multimask_output_in_sam: true
|
| 158 |
+
# SAM heads
|
| 159 |
+
iou_prediction_use_sigmoid: True
|
| 160 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 161 |
+
use_obj_ptrs_in_encoder: true
|
| 162 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 163 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 164 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 165 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 166 |
+
# object occlusion prediction
|
| 167 |
+
pred_obj_scores: true
|
| 168 |
+
pred_obj_scores_mlp: true
|
| 169 |
+
fixed_no_obj_ptr: true
|
| 170 |
+
# multimask tracking settings
|
| 171 |
+
multimask_output_for_tracking: true
|
| 172 |
+
use_multimask_token_for_obj_ptr: true
|
| 173 |
+
multimask_min_pt_num: 0
|
| 174 |
+
multimask_max_pt_num: 1
|
| 175 |
+
use_mlp_for_obj_ptr_proj: true
|
| 176 |
+
# Compilation flag
|
| 177 |
+
# compile_image_encoder: False
|
| 178 |
+
|
| 179 |
+
####### Training specific params #######
|
| 180 |
+
# box/point input and corrections
|
| 181 |
+
prob_to_use_pt_input_for_train: 0.5
|
| 182 |
+
prob_to_use_pt_input_for_eval: 0.0
|
| 183 |
+
prob_to_use_box_input_for_train: 0.5 # 0.5*0.5 = 0.25 prob to use box instead of points
|
| 184 |
+
prob_to_use_box_input_for_eval: 0.0
|
| 185 |
+
prob_to_sample_from_gt_for_train: 0.1 # with a small prob, sampling correction points from GT mask instead of prediction errors
|
| 186 |
+
num_frames_to_correct_for_train: 2 # iteratively sample on random 1~2 frames (always include the first frame)
|
| 187 |
+
num_frames_to_correct_for_eval: 1 # only iteratively sample on first frame
|
| 188 |
+
rand_frames_to_correct_for_train: True # random #init-cond-frame ~ 2
|
| 189 |
+
add_all_frames_to_correct_as_cond: True # when a frame receives a correction click, it becomes a conditioning frame (even if it's not initially a conditioning frame)
|
| 190 |
+
# maximum 2 initial conditioning frames
|
| 191 |
+
num_init_cond_frames_for_train: 2
|
| 192 |
+
rand_init_cond_frames_for_train: True # random 1~2
|
| 193 |
+
num_correction_pt_per_frame: 7
|
| 194 |
+
use_act_ckpt_iterative_pt_sampling: false
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
num_init_cond_frames_for_eval: 1 # only mask on the first frame
|
| 199 |
+
forward_backbone_per_frame_for_eval: True
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
data:
|
| 203 |
+
train:
|
| 204 |
+
_target_: training.dataset.sam2_datasets.TorchTrainMixedDataset
|
| 205 |
+
phases_per_epoch: ${scratch.phases_per_epoch}
|
| 206 |
+
batch_sizes:
|
| 207 |
+
- ${scratch.train_batch_size}
|
| 208 |
+
|
| 209 |
+
datasets:
|
| 210 |
+
- _target_: training.dataset.utils.RepeatFactorWrapper
|
| 211 |
+
dataset:
|
| 212 |
+
_target_: training.dataset.utils.ConcatDataset
|
| 213 |
+
datasets:
|
| 214 |
+
- _target_: training.dataset.vos_dataset.VOSDataset
|
| 215 |
+
transforms: ${vos.train_transforms}
|
| 216 |
+
training: true
|
| 217 |
+
video_dataset:
|
| 218 |
+
_target_: training.dataset.vos_raw_dataset.PNGRawDataset
|
| 219 |
+
img_folder: ${dataset.img_folder}
|
| 220 |
+
gt_folder: ${dataset.gt_folder}
|
| 221 |
+
file_list_txt: ${dataset.file_list_txt}
|
| 222 |
+
sampler:
|
| 223 |
+
_target_: training.dataset.vos_sampler.RandomUniformSampler
|
| 224 |
+
num_frames: ${scratch.num_frames}
|
| 225 |
+
max_num_objects: ${scratch.max_num_objects}
|
| 226 |
+
multiplier: ${dataset.multiplier}
|
| 227 |
+
shuffle: True
|
| 228 |
+
num_workers: ${scratch.num_train_workers}
|
| 229 |
+
pin_memory: True
|
| 230 |
+
drop_last: True
|
| 231 |
+
collate_fn:
|
| 232 |
+
_target_: training.utils.data_utils.collate_fn
|
| 233 |
+
_partial_: true
|
| 234 |
+
dict_key: all
|
| 235 |
+
|
| 236 |
+
optim:
|
| 237 |
+
amp:
|
| 238 |
+
enabled: True
|
| 239 |
+
amp_dtype: bfloat16
|
| 240 |
+
|
| 241 |
+
optimizer:
|
| 242 |
+
_target_: torch.optim.AdamW
|
| 243 |
+
|
| 244 |
+
gradient_clip:
|
| 245 |
+
_target_: training.optimizer.GradientClipper
|
| 246 |
+
max_norm: 0.1
|
| 247 |
+
norm_type: 2
|
| 248 |
+
|
| 249 |
+
param_group_modifiers:
|
| 250 |
+
- _target_: training.optimizer.layer_decay_param_modifier
|
| 251 |
+
_partial_: True
|
| 252 |
+
layer_decay_value: 0.9
|
| 253 |
+
apply_to: 'image_encoder.trunk'
|
| 254 |
+
overrides:
|
| 255 |
+
- pattern: '*pos_embed*'
|
| 256 |
+
value: 1.0
|
| 257 |
+
|
| 258 |
+
options:
|
| 259 |
+
lr:
|
| 260 |
+
- scheduler:
|
| 261 |
+
_target_: fvcore.common.param_scheduler.CosineParamScheduler
|
| 262 |
+
start_value: ${scratch.base_lr}
|
| 263 |
+
end_value: ${divide:${scratch.base_lr},10}
|
| 264 |
+
- scheduler:
|
| 265 |
+
_target_: fvcore.common.param_scheduler.CosineParamScheduler
|
| 266 |
+
start_value: ${scratch.vision_lr}
|
| 267 |
+
end_value: ${divide:${scratch.vision_lr},10}
|
| 268 |
+
param_names:
|
| 269 |
+
- 'image_encoder.*'
|
| 270 |
+
weight_decay:
|
| 271 |
+
- scheduler:
|
| 272 |
+
_target_: fvcore.common.param_scheduler.ConstantParamScheduler
|
| 273 |
+
value: 0.1
|
| 274 |
+
- scheduler:
|
| 275 |
+
_target_: fvcore.common.param_scheduler.ConstantParamScheduler
|
| 276 |
+
value: 0.0
|
| 277 |
+
param_names:
|
| 278 |
+
- '*bias*'
|
| 279 |
+
module_cls_names: ['torch.nn.LayerNorm']
|
| 280 |
+
|
| 281 |
+
loss:
|
| 282 |
+
all:
|
| 283 |
+
_target_: training.loss_fns.MultiStepMultiMasksAndIous
|
| 284 |
+
weight_dict:
|
| 285 |
+
loss_mask: 20
|
| 286 |
+
loss_dice: 1
|
| 287 |
+
loss_iou: 1
|
| 288 |
+
loss_class: 1
|
| 289 |
+
supervise_all_iou: true
|
| 290 |
+
iou_use_l1_loss: true
|
| 291 |
+
pred_obj_scores: true
|
| 292 |
+
focal_gamma_obj_score: 0.0
|
| 293 |
+
focal_alpha_obj_score: -1.0
|
| 294 |
+
|
| 295 |
+
distributed:
|
| 296 |
+
backend: nccl
|
| 297 |
+
find_unused_parameters: True
|
| 298 |
+
|
| 299 |
+
logging:
|
| 300 |
+
tensorboard_writer:
|
| 301 |
+
_target_: training.utils.logger.make_tensorboard_logger
|
| 302 |
+
log_dir: ${launcher.experiment_log_dir}/tensorboard
|
| 303 |
+
flush_secs: 120
|
| 304 |
+
should_log: True
|
| 305 |
+
log_dir: ${launcher.experiment_log_dir}/logs
|
| 306 |
+
log_freq: 10
|
| 307 |
+
|
| 308 |
+
# initialize from a SAM 2 checkpoint
|
| 309 |
+
checkpoint:
|
| 310 |
+
save_dir: ${launcher.experiment_log_dir}/checkpoints
|
| 311 |
+
save_freq: 0 # 0 only last checkpoint is saved.
|
| 312 |
+
model_weight_initializer:
|
| 313 |
+
_partial_: True
|
| 314 |
+
_target_: training.utils.checkpoint_utils.load_state_dict_into_model
|
| 315 |
+
strict: True
|
| 316 |
+
ignore_unexpected_keys: null
|
| 317 |
+
ignore_missing_keys: null
|
| 318 |
+
|
| 319 |
+
state_dict:
|
| 320 |
+
_target_: training.utils.checkpoint_utils.load_checkpoint_and_apply_kernels
|
| 321 |
+
checkpoint_path: ./checkpoints/sam2.1_hiera_base_plus.pt # PATH to SAM 2.1 checkpoint
|
| 322 |
+
ckpt_state_dict_keys: ['model']
|
| 323 |
+
|
| 324 |
+
launcher:
|
| 325 |
+
num_nodes: 1
|
| 326 |
+
gpus_per_node: 8
|
| 327 |
+
experiment_log_dir: null # Path to log directory, defaults to ./sam2_logs/${config_name}
|
| 328 |
+
|
| 329 |
+
# SLURM args if running on a cluster
|
| 330 |
+
submitit:
|
| 331 |
+
partition: null
|
| 332 |
+
account: null
|
| 333 |
+
qos: null
|
| 334 |
+
cpus_per_task: 10
|
| 335 |
+
use_cluster: false
|
| 336 |
+
timeout_hour: 24
|
| 337 |
+
name: null
|
| 338 |
+
port_range: [10000, 65000]
|
| 339 |
+
|
sam2/csrc/connected_components.cu
ADDED
|
@@ -0,0 +1,289 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
// All rights reserved.
|
| 3 |
+
|
| 4 |
+
// This source code is licensed under the license found in the
|
| 5 |
+
// LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
// adapted from https://github.com/zsef123/Connected_components_PyTorch
|
| 8 |
+
// with license found in the LICENSE_cctorch file in the root directory.
|
| 9 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 10 |
+
#include <cuda.h>
|
| 11 |
+
#include <cuda_runtime.h>
|
| 12 |
+
#include <torch/extension.h>
|
| 13 |
+
#include <torch/script.h>
|
| 14 |
+
#include <vector>
|
| 15 |
+
|
| 16 |
+
// 2d
|
| 17 |
+
#define BLOCK_ROWS 16
|
| 18 |
+
#define BLOCK_COLS 16
|
| 19 |
+
|
| 20 |
+
namespace cc2d {
|
| 21 |
+
|
| 22 |
+
template <typename T>
|
| 23 |
+
__device__ __forceinline__ unsigned char hasBit(T bitmap, unsigned char pos) {
|
| 24 |
+
return (bitmap >> pos) & 1;
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
__device__ int32_t find(const int32_t* s_buf, int32_t n) {
|
| 28 |
+
while (s_buf[n] != n)
|
| 29 |
+
n = s_buf[n];
|
| 30 |
+
return n;
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
__device__ int32_t find_n_compress(int32_t* s_buf, int32_t n) {
|
| 34 |
+
const int32_t id = n;
|
| 35 |
+
while (s_buf[n] != n) {
|
| 36 |
+
n = s_buf[n];
|
| 37 |
+
s_buf[id] = n;
|
| 38 |
+
}
|
| 39 |
+
return n;
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
__device__ void union_(int32_t* s_buf, int32_t a, int32_t b) {
|
| 43 |
+
bool done;
|
| 44 |
+
do {
|
| 45 |
+
a = find(s_buf, a);
|
| 46 |
+
b = find(s_buf, b);
|
| 47 |
+
|
| 48 |
+
if (a < b) {
|
| 49 |
+
int32_t old = atomicMin(s_buf + b, a);
|
| 50 |
+
done = (old == b);
|
| 51 |
+
b = old;
|
| 52 |
+
} else if (b < a) {
|
| 53 |
+
int32_t old = atomicMin(s_buf + a, b);
|
| 54 |
+
done = (old == a);
|
| 55 |
+
a = old;
|
| 56 |
+
} else
|
| 57 |
+
done = true;
|
| 58 |
+
|
| 59 |
+
} while (!done);
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
__global__ void
|
| 63 |
+
init_labeling(int32_t* label, const uint32_t W, const uint32_t H) {
|
| 64 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 65 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 66 |
+
const uint32_t idx = row * W + col;
|
| 67 |
+
|
| 68 |
+
if (row < H && col < W)
|
| 69 |
+
label[idx] = idx;
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
__global__ void
|
| 73 |
+
merge(uint8_t* img, int32_t* label, const uint32_t W, const uint32_t H) {
|
| 74 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 75 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 76 |
+
const uint32_t idx = row * W + col;
|
| 77 |
+
|
| 78 |
+
if (row >= H || col >= W)
|
| 79 |
+
return;
|
| 80 |
+
|
| 81 |
+
uint32_t P = 0;
|
| 82 |
+
|
| 83 |
+
if (img[idx])
|
| 84 |
+
P |= 0x777;
|
| 85 |
+
if (row + 1 < H && img[idx + W])
|
| 86 |
+
P |= 0x777 << 4;
|
| 87 |
+
if (col + 1 < W && img[idx + 1])
|
| 88 |
+
P |= 0x777 << 1;
|
| 89 |
+
|
| 90 |
+
if (col == 0)
|
| 91 |
+
P &= 0xEEEE;
|
| 92 |
+
if (col + 1 >= W)
|
| 93 |
+
P &= 0x3333;
|
| 94 |
+
else if (col + 2 >= W)
|
| 95 |
+
P &= 0x7777;
|
| 96 |
+
|
| 97 |
+
if (row == 0)
|
| 98 |
+
P &= 0xFFF0;
|
| 99 |
+
if (row + 1 >= H)
|
| 100 |
+
P &= 0xFF;
|
| 101 |
+
|
| 102 |
+
if (P > 0) {
|
| 103 |
+
// If need check about top-left pixel(if flag the first bit) and hit the
|
| 104 |
+
// top-left pixel
|
| 105 |
+
if (hasBit(P, 0) && img[idx - W - 1]) {
|
| 106 |
+
union_(label, idx, idx - 2 * W - 2); // top left block
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
if ((hasBit(P, 1) && img[idx - W]) || (hasBit(P, 2) && img[idx - W + 1]))
|
| 110 |
+
union_(label, idx, idx - 2 * W); // top bottom block
|
| 111 |
+
|
| 112 |
+
if (hasBit(P, 3) && img[idx + 2 - W])
|
| 113 |
+
union_(label, idx, idx - 2 * W + 2); // top right block
|
| 114 |
+
|
| 115 |
+
if ((hasBit(P, 4) && img[idx - 1]) || (hasBit(P, 8) && img[idx + W - 1]))
|
| 116 |
+
union_(label, idx, idx - 2); // just left block
|
| 117 |
+
}
|
| 118 |
+
}
|
| 119 |
+
|
| 120 |
+
__global__ void compression(int32_t* label, const int32_t W, const int32_t H) {
|
| 121 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 122 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 123 |
+
const uint32_t idx = row * W + col;
|
| 124 |
+
|
| 125 |
+
if (row < H && col < W)
|
| 126 |
+
find_n_compress(label, idx);
|
| 127 |
+
}
|
| 128 |
+
|
| 129 |
+
__global__ void final_labeling(
|
| 130 |
+
const uint8_t* img,
|
| 131 |
+
int32_t* label,
|
| 132 |
+
const int32_t W,
|
| 133 |
+
const int32_t H) {
|
| 134 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 135 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 136 |
+
const uint32_t idx = row * W + col;
|
| 137 |
+
|
| 138 |
+
if (row >= H || col >= W)
|
| 139 |
+
return;
|
| 140 |
+
|
| 141 |
+
int32_t y = label[idx] + 1;
|
| 142 |
+
|
| 143 |
+
if (img[idx])
|
| 144 |
+
label[idx] = y;
|
| 145 |
+
else
|
| 146 |
+
label[idx] = 0;
|
| 147 |
+
|
| 148 |
+
if (col + 1 < W) {
|
| 149 |
+
if (img[idx + 1])
|
| 150 |
+
label[idx + 1] = y;
|
| 151 |
+
else
|
| 152 |
+
label[idx + 1] = 0;
|
| 153 |
+
|
| 154 |
+
if (row + 1 < H) {
|
| 155 |
+
if (img[idx + W + 1])
|
| 156 |
+
label[idx + W + 1] = y;
|
| 157 |
+
else
|
| 158 |
+
label[idx + W + 1] = 0;
|
| 159 |
+
}
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
if (row + 1 < H) {
|
| 163 |
+
if (img[idx + W])
|
| 164 |
+
label[idx + W] = y;
|
| 165 |
+
else
|
| 166 |
+
label[idx + W] = 0;
|
| 167 |
+
}
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
__global__ void init_counting(
|
| 171 |
+
const int32_t* label,
|
| 172 |
+
int32_t* count_init,
|
| 173 |
+
const int32_t W,
|
| 174 |
+
const int32_t H) {
|
| 175 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y);
|
| 176 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x);
|
| 177 |
+
const uint32_t idx = row * W + col;
|
| 178 |
+
|
| 179 |
+
if (row >= H || col >= W)
|
| 180 |
+
return;
|
| 181 |
+
|
| 182 |
+
int32_t y = label[idx];
|
| 183 |
+
if (y > 0) {
|
| 184 |
+
int32_t count_idx = y - 1;
|
| 185 |
+
atomicAdd(count_init + count_idx, 1);
|
| 186 |
+
}
|
| 187 |
+
}
|
| 188 |
+
|
| 189 |
+
__global__ void final_counting(
|
| 190 |
+
const int32_t* label,
|
| 191 |
+
const int32_t* count_init,
|
| 192 |
+
int32_t* count_final,
|
| 193 |
+
const int32_t W,
|
| 194 |
+
const int32_t H) {
|
| 195 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y);
|
| 196 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x);
|
| 197 |
+
const uint32_t idx = row * W + col;
|
| 198 |
+
|
| 199 |
+
if (row >= H || col >= W)
|
| 200 |
+
return;
|
| 201 |
+
|
| 202 |
+
int32_t y = label[idx];
|
| 203 |
+
if (y > 0) {
|
| 204 |
+
int32_t count_idx = y - 1;
|
| 205 |
+
count_final[idx] = count_init[count_idx];
|
| 206 |
+
} else {
|
| 207 |
+
count_final[idx] = 0;
|
| 208 |
+
}
|
| 209 |
+
}
|
| 210 |
+
|
| 211 |
+
} // namespace cc2d
|
| 212 |
+
|
| 213 |
+
std::vector<torch::Tensor> get_connected_componnets(
|
| 214 |
+
const torch::Tensor& inputs) {
|
| 215 |
+
AT_ASSERTM(inputs.is_cuda(), "inputs must be a CUDA tensor");
|
| 216 |
+
AT_ASSERTM(inputs.ndimension() == 4, "inputs must be [N, 1, H, W] shape");
|
| 217 |
+
AT_ASSERTM(
|
| 218 |
+
inputs.scalar_type() == torch::kUInt8, "inputs must be a uint8 type");
|
| 219 |
+
|
| 220 |
+
const uint32_t N = inputs.size(0);
|
| 221 |
+
const uint32_t C = inputs.size(1);
|
| 222 |
+
const uint32_t H = inputs.size(2);
|
| 223 |
+
const uint32_t W = inputs.size(3);
|
| 224 |
+
|
| 225 |
+
AT_ASSERTM(C == 1, "inputs must be [N, 1, H, W] shape");
|
| 226 |
+
AT_ASSERTM((H % 2) == 0, "height must be an even number");
|
| 227 |
+
AT_ASSERTM((W % 2) == 0, "width must be an even number");
|
| 228 |
+
|
| 229 |
+
// label must be uint32_t
|
| 230 |
+
auto label_options =
|
| 231 |
+
torch::TensorOptions().dtype(torch::kInt32).device(inputs.device());
|
| 232 |
+
torch::Tensor labels = torch::zeros({N, C, H, W}, label_options);
|
| 233 |
+
torch::Tensor counts_init = torch::zeros({N, C, H, W}, label_options);
|
| 234 |
+
torch::Tensor counts_final = torch::zeros({N, C, H, W}, label_options);
|
| 235 |
+
|
| 236 |
+
dim3 grid = dim3(
|
| 237 |
+
((W + 1) / 2 + BLOCK_COLS - 1) / BLOCK_COLS,
|
| 238 |
+
((H + 1) / 2 + BLOCK_ROWS - 1) / BLOCK_ROWS);
|
| 239 |
+
dim3 block = dim3(BLOCK_COLS, BLOCK_ROWS);
|
| 240 |
+
dim3 grid_count =
|
| 241 |
+
dim3((W + BLOCK_COLS) / BLOCK_COLS, (H + BLOCK_ROWS) / BLOCK_ROWS);
|
| 242 |
+
dim3 block_count = dim3(BLOCK_COLS, BLOCK_ROWS);
|
| 243 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 244 |
+
|
| 245 |
+
for (int n = 0; n < N; n++) {
|
| 246 |
+
uint32_t offset = n * H * W;
|
| 247 |
+
|
| 248 |
+
cc2d::init_labeling<<<grid, block, 0, stream>>>(
|
| 249 |
+
labels.data_ptr<int32_t>() + offset, W, H);
|
| 250 |
+
cc2d::merge<<<grid, block, 0, stream>>>(
|
| 251 |
+
inputs.data_ptr<uint8_t>() + offset,
|
| 252 |
+
labels.data_ptr<int32_t>() + offset,
|
| 253 |
+
W,
|
| 254 |
+
H);
|
| 255 |
+
cc2d::compression<<<grid, block, 0, stream>>>(
|
| 256 |
+
labels.data_ptr<int32_t>() + offset, W, H);
|
| 257 |
+
cc2d::final_labeling<<<grid, block, 0, stream>>>(
|
| 258 |
+
inputs.data_ptr<uint8_t>() + offset,
|
| 259 |
+
labels.data_ptr<int32_t>() + offset,
|
| 260 |
+
W,
|
| 261 |
+
H);
|
| 262 |
+
|
| 263 |
+
// get the counting of each pixel
|
| 264 |
+
cc2d::init_counting<<<grid_count, block_count, 0, stream>>>(
|
| 265 |
+
labels.data_ptr<int32_t>() + offset,
|
| 266 |
+
counts_init.data_ptr<int32_t>() + offset,
|
| 267 |
+
W,
|
| 268 |
+
H);
|
| 269 |
+
cc2d::final_counting<<<grid_count, block_count, 0, stream>>>(
|
| 270 |
+
labels.data_ptr<int32_t>() + offset,
|
| 271 |
+
counts_init.data_ptr<int32_t>() + offset,
|
| 272 |
+
counts_final.data_ptr<int32_t>() + offset,
|
| 273 |
+
W,
|
| 274 |
+
H);
|
| 275 |
+
}
|
| 276 |
+
|
| 277 |
+
// returned values are [labels, counts]
|
| 278 |
+
std::vector<torch::Tensor> outputs;
|
| 279 |
+
outputs.push_back(labels);
|
| 280 |
+
outputs.push_back(counts_final);
|
| 281 |
+
return outputs;
|
| 282 |
+
}
|
| 283 |
+
|
| 284 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 285 |
+
m.def(
|
| 286 |
+
"get_connected_componnets",
|
| 287 |
+
&get_connected_componnets,
|
| 288 |
+
"get_connected_componnets");
|
| 289 |
+
}
|
sam2/modeling/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
sam2/modeling/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (167 Bytes). View file
|
|
|
sam2/modeling/__pycache__/memory_attention.cpython-310.pyc
ADDED
|
Binary file (5 kB). View file
|
|
|
sam2/modeling/__pycache__/memory_encoder.cpython-310.pyc
ADDED
|
Binary file (4.99 kB). View file
|
|
|
sam2/modeling/__pycache__/position_encoding.cpython-310.pyc
ADDED
|
Binary file (7.55 kB). View file
|
|
|
sam2/modeling/__pycache__/sam2_base.cpython-310.pyc
ADDED
|
Binary file (19.4 kB). View file
|
|
|
sam2/modeling/__pycache__/sam2_utils.cpython-310.pyc
ADDED
|
Binary file (11 kB). View file
|
|
|
sam2/modeling/backbones/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
sam2/modeling/backbones/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (177 Bytes). View file
|
|
|
sam2/modeling/backbones/__pycache__/hieradet.cpython-310.pyc
ADDED
|
Binary file (7.74 kB). View file
|
|
|
sam2/modeling/backbones/__pycache__/image_encoder.cpython-310.pyc
ADDED
|
Binary file (3.44 kB). View file
|
|
|
sam2/modeling/backbones/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (3.25 kB). View file
|
|
|
sam2/modeling/backbones/hieradet.py
ADDED
|
@@ -0,0 +1,317 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
from functools import partial
|
| 9 |
+
from typing import List, Tuple, Union
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
from iopath.common.file_io import g_pathmgr
|
| 15 |
+
|
| 16 |
+
from sam2.modeling.backbones.utils import (
|
| 17 |
+
PatchEmbed,
|
| 18 |
+
window_partition,
|
| 19 |
+
window_unpartition,
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
from sam2.modeling.sam2_utils import DropPath, MLP
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def do_pool(x: torch.Tensor, pool: nn.Module, norm: nn.Module = None) -> torch.Tensor:
|
| 26 |
+
if pool is None:
|
| 27 |
+
return x
|
| 28 |
+
# (B, H, W, C) -> (B, C, H, W)
|
| 29 |
+
x = x.permute(0, 3, 1, 2)
|
| 30 |
+
x = pool(x)
|
| 31 |
+
# (B, C, H', W') -> (B, H', W', C)
|
| 32 |
+
x = x.permute(0, 2, 3, 1)
|
| 33 |
+
if norm:
|
| 34 |
+
x = norm(x)
|
| 35 |
+
|
| 36 |
+
return x
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class MultiScaleAttention(nn.Module):
|
| 40 |
+
def __init__(
|
| 41 |
+
self,
|
| 42 |
+
dim: int,
|
| 43 |
+
dim_out: int,
|
| 44 |
+
num_heads: int,
|
| 45 |
+
q_pool: nn.Module = None,
|
| 46 |
+
):
|
| 47 |
+
super().__init__()
|
| 48 |
+
|
| 49 |
+
self.dim = dim
|
| 50 |
+
self.dim_out = dim_out
|
| 51 |
+
self.num_heads = num_heads
|
| 52 |
+
self.q_pool = q_pool
|
| 53 |
+
self.qkv = nn.Linear(dim, dim_out * 3)
|
| 54 |
+
self.proj = nn.Linear(dim_out, dim_out)
|
| 55 |
+
|
| 56 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 57 |
+
B, H, W, _ = x.shape
|
| 58 |
+
# qkv with shape (B, H * W, 3, nHead, C)
|
| 59 |
+
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1)
|
| 60 |
+
# q, k, v with shape (B, H * W, nheads, C)
|
| 61 |
+
q, k, v = torch.unbind(qkv, 2)
|
| 62 |
+
|
| 63 |
+
# Q pooling (for downsample at stage changes)
|
| 64 |
+
if self.q_pool:
|
| 65 |
+
q = do_pool(q.reshape(B, H, W, -1), self.q_pool)
|
| 66 |
+
H, W = q.shape[1:3] # downsampled shape
|
| 67 |
+
q = q.reshape(B, H * W, self.num_heads, -1)
|
| 68 |
+
|
| 69 |
+
# Torch's SDPA expects [B, nheads, H*W, C] so we transpose
|
| 70 |
+
x = F.scaled_dot_product_attention(
|
| 71 |
+
q.transpose(1, 2),
|
| 72 |
+
k.transpose(1, 2),
|
| 73 |
+
v.transpose(1, 2),
|
| 74 |
+
)
|
| 75 |
+
# Transpose back
|
| 76 |
+
x = x.transpose(1, 2)
|
| 77 |
+
x = x.reshape(B, H, W, -1)
|
| 78 |
+
|
| 79 |
+
x = self.proj(x)
|
| 80 |
+
|
| 81 |
+
return x
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class MultiScaleBlock(nn.Module):
|
| 85 |
+
def __init__(
|
| 86 |
+
self,
|
| 87 |
+
dim: int,
|
| 88 |
+
dim_out: int,
|
| 89 |
+
num_heads: int,
|
| 90 |
+
mlp_ratio: float = 4.0,
|
| 91 |
+
drop_path: float = 0.0,
|
| 92 |
+
norm_layer: Union[nn.Module, str] = "LayerNorm",
|
| 93 |
+
q_stride: Tuple[int, int] = None,
|
| 94 |
+
act_layer: nn.Module = nn.GELU,
|
| 95 |
+
window_size: int = 0,
|
| 96 |
+
):
|
| 97 |
+
super().__init__()
|
| 98 |
+
|
| 99 |
+
if isinstance(norm_layer, str):
|
| 100 |
+
norm_layer = partial(getattr(nn, norm_layer), eps=1e-6)
|
| 101 |
+
|
| 102 |
+
self.dim = dim
|
| 103 |
+
self.dim_out = dim_out
|
| 104 |
+
self.norm1 = norm_layer(dim)
|
| 105 |
+
|
| 106 |
+
self.window_size = window_size
|
| 107 |
+
|
| 108 |
+
self.pool, self.q_stride = None, q_stride
|
| 109 |
+
if self.q_stride:
|
| 110 |
+
self.pool = nn.MaxPool2d(
|
| 111 |
+
kernel_size=q_stride, stride=q_stride, ceil_mode=False
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
self.attn = MultiScaleAttention(
|
| 115 |
+
dim,
|
| 116 |
+
dim_out,
|
| 117 |
+
num_heads=num_heads,
|
| 118 |
+
q_pool=self.pool,
|
| 119 |
+
)
|
| 120 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 121 |
+
|
| 122 |
+
self.norm2 = norm_layer(dim_out)
|
| 123 |
+
self.mlp = MLP(
|
| 124 |
+
dim_out,
|
| 125 |
+
int(dim_out * mlp_ratio),
|
| 126 |
+
dim_out,
|
| 127 |
+
num_layers=2,
|
| 128 |
+
activation=act_layer,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
if dim != dim_out:
|
| 132 |
+
self.proj = nn.Linear(dim, dim_out)
|
| 133 |
+
|
| 134 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 135 |
+
shortcut = x # B, H, W, C
|
| 136 |
+
x = self.norm1(x)
|
| 137 |
+
|
| 138 |
+
# Skip connection
|
| 139 |
+
if self.dim != self.dim_out:
|
| 140 |
+
shortcut = do_pool(self.proj(x), self.pool)
|
| 141 |
+
|
| 142 |
+
# Window partition
|
| 143 |
+
window_size = self.window_size
|
| 144 |
+
if window_size > 0:
|
| 145 |
+
H, W = x.shape[1], x.shape[2]
|
| 146 |
+
x, pad_hw = window_partition(x, window_size)
|
| 147 |
+
|
| 148 |
+
# Window Attention + Q Pooling (if stage change)
|
| 149 |
+
x = self.attn(x)
|
| 150 |
+
if self.q_stride:
|
| 151 |
+
# Shapes have changed due to Q pooling
|
| 152 |
+
window_size = self.window_size // self.q_stride[0]
|
| 153 |
+
H, W = shortcut.shape[1:3]
|
| 154 |
+
|
| 155 |
+
pad_h = (window_size - H % window_size) % window_size
|
| 156 |
+
pad_w = (window_size - W % window_size) % window_size
|
| 157 |
+
pad_hw = (H + pad_h, W + pad_w)
|
| 158 |
+
|
| 159 |
+
# Reverse window partition
|
| 160 |
+
if self.window_size > 0:
|
| 161 |
+
x = window_unpartition(x, window_size, pad_hw, (H, W))
|
| 162 |
+
|
| 163 |
+
x = shortcut + self.drop_path(x)
|
| 164 |
+
# MLP
|
| 165 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 166 |
+
return x
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
class Hiera(nn.Module):
|
| 170 |
+
"""
|
| 171 |
+
Reference: https://arxiv.org/abs/2306.00989
|
| 172 |
+
"""
|
| 173 |
+
|
| 174 |
+
def __init__(
|
| 175 |
+
self,
|
| 176 |
+
embed_dim: int = 96, # initial embed dim
|
| 177 |
+
num_heads: int = 1, # initial number of heads
|
| 178 |
+
drop_path_rate: float = 0.0, # stochastic depth
|
| 179 |
+
q_pool: int = 3, # number of q_pool stages
|
| 180 |
+
q_stride: Tuple[int, int] = (2, 2), # downsample stride bet. stages
|
| 181 |
+
stages: Tuple[int, ...] = (2, 3, 16, 3), # blocks per stage
|
| 182 |
+
dim_mul: float = 2.0, # dim_mul factor at stage shift
|
| 183 |
+
head_mul: float = 2.0, # head_mul factor at stage shift
|
| 184 |
+
window_pos_embed_bkg_spatial_size: Tuple[int, int] = (14, 14),
|
| 185 |
+
# window size per stage, when not using global att.
|
| 186 |
+
window_spec: Tuple[int, ...] = (
|
| 187 |
+
8,
|
| 188 |
+
4,
|
| 189 |
+
14,
|
| 190 |
+
7,
|
| 191 |
+
),
|
| 192 |
+
# global attn in these blocks
|
| 193 |
+
global_att_blocks: Tuple[int, ...] = (
|
| 194 |
+
12,
|
| 195 |
+
16,
|
| 196 |
+
20,
|
| 197 |
+
),
|
| 198 |
+
weights_path=None,
|
| 199 |
+
return_interm_layers=True, # return feats from every stage
|
| 200 |
+
):
|
| 201 |
+
super().__init__()
|
| 202 |
+
|
| 203 |
+
assert len(stages) == len(window_spec)
|
| 204 |
+
self.window_spec = window_spec
|
| 205 |
+
|
| 206 |
+
depth = sum(stages)
|
| 207 |
+
self.q_stride = q_stride
|
| 208 |
+
self.stage_ends = [sum(stages[:i]) - 1 for i in range(1, len(stages) + 1)]
|
| 209 |
+
assert 0 <= q_pool <= len(self.stage_ends[:-1])
|
| 210 |
+
self.q_pool_blocks = [x + 1 for x in self.stage_ends[:-1]][:q_pool]
|
| 211 |
+
self.return_interm_layers = return_interm_layers
|
| 212 |
+
|
| 213 |
+
self.patch_embed = PatchEmbed(
|
| 214 |
+
embed_dim=embed_dim,
|
| 215 |
+
)
|
| 216 |
+
# Which blocks have global att?
|
| 217 |
+
self.global_att_blocks = global_att_blocks
|
| 218 |
+
|
| 219 |
+
# Windowed positional embedding (https://arxiv.org/abs/2311.05613)
|
| 220 |
+
self.window_pos_embed_bkg_spatial_size = window_pos_embed_bkg_spatial_size
|
| 221 |
+
self.pos_embed = nn.Parameter(
|
| 222 |
+
torch.zeros(1, embed_dim, *self.window_pos_embed_bkg_spatial_size)
|
| 223 |
+
)
|
| 224 |
+
self.pos_embed_window = nn.Parameter(
|
| 225 |
+
torch.zeros(1, embed_dim, self.window_spec[0], self.window_spec[0])
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
dpr = [
|
| 229 |
+
x.item() for x in torch.linspace(0, drop_path_rate, depth)
|
| 230 |
+
] # stochastic depth decay rule
|
| 231 |
+
|
| 232 |
+
cur_stage = 1
|
| 233 |
+
self.blocks = nn.ModuleList()
|
| 234 |
+
|
| 235 |
+
for i in range(depth):
|
| 236 |
+
dim_out = embed_dim
|
| 237 |
+
# lags by a block, so first block of
|
| 238 |
+
# next stage uses an initial window size
|
| 239 |
+
# of previous stage and final window size of current stage
|
| 240 |
+
window_size = self.window_spec[cur_stage - 1]
|
| 241 |
+
|
| 242 |
+
if self.global_att_blocks is not None:
|
| 243 |
+
window_size = 0 if i in self.global_att_blocks else window_size
|
| 244 |
+
|
| 245 |
+
if i - 1 in self.stage_ends:
|
| 246 |
+
dim_out = int(embed_dim * dim_mul)
|
| 247 |
+
num_heads = int(num_heads * head_mul)
|
| 248 |
+
cur_stage += 1
|
| 249 |
+
|
| 250 |
+
block = MultiScaleBlock(
|
| 251 |
+
dim=embed_dim,
|
| 252 |
+
dim_out=dim_out,
|
| 253 |
+
num_heads=num_heads,
|
| 254 |
+
drop_path=dpr[i],
|
| 255 |
+
q_stride=self.q_stride if i in self.q_pool_blocks else None,
|
| 256 |
+
window_size=window_size,
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
embed_dim = dim_out
|
| 260 |
+
self.blocks.append(block)
|
| 261 |
+
|
| 262 |
+
self.channel_list = (
|
| 263 |
+
[self.blocks[i].dim_out for i in self.stage_ends[::-1]]
|
| 264 |
+
if return_interm_layers
|
| 265 |
+
else [self.blocks[-1].dim_out]
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
if weights_path is not None:
|
| 269 |
+
with g_pathmgr.open(weights_path, "rb") as f:
|
| 270 |
+
chkpt = torch.load(f, map_location="cpu")
|
| 271 |
+
logging.info("loading Hiera", self.load_state_dict(chkpt, strict=False))
|
| 272 |
+
|
| 273 |
+
def _get_pos_embed(self, hw: Tuple[int, int]) -> torch.Tensor:
|
| 274 |
+
h, w = hw
|
| 275 |
+
window_embed = self.pos_embed_window
|
| 276 |
+
pos_embed = F.interpolate(self.pos_embed, size=(h, w), mode="bicubic")
|
| 277 |
+
pos_embed = pos_embed + window_embed.tile(
|
| 278 |
+
[x // y for x, y in zip(pos_embed.shape, window_embed.shape)]
|
| 279 |
+
)
|
| 280 |
+
pos_embed = pos_embed.permute(0, 2, 3, 1)
|
| 281 |
+
return pos_embed
|
| 282 |
+
|
| 283 |
+
def forward(self, x: torch.Tensor) -> List[torch.Tensor]:
|
| 284 |
+
x = self.patch_embed(x)
|
| 285 |
+
# x: (B, H, W, C)
|
| 286 |
+
|
| 287 |
+
# Add pos embed
|
| 288 |
+
x = x + self._get_pos_embed(x.shape[1:3])
|
| 289 |
+
|
| 290 |
+
outputs = []
|
| 291 |
+
for i, blk in enumerate(self.blocks):
|
| 292 |
+
x = blk(x)
|
| 293 |
+
if (i == self.stage_ends[-1]) or (
|
| 294 |
+
i in self.stage_ends and self.return_interm_layers
|
| 295 |
+
):
|
| 296 |
+
feats = x.permute(0, 3, 1, 2)
|
| 297 |
+
outputs.append(feats)
|
| 298 |
+
|
| 299 |
+
return outputs
|
| 300 |
+
|
| 301 |
+
def get_layer_id(self, layer_name):
|
| 302 |
+
# https://github.com/microsoft/unilm/blob/master/beit/optim_factory.py#L33
|
| 303 |
+
num_layers = self.get_num_layers()
|
| 304 |
+
|
| 305 |
+
if layer_name.find("rel_pos") != -1:
|
| 306 |
+
return num_layers + 1
|
| 307 |
+
elif layer_name.find("pos_embed") != -1:
|
| 308 |
+
return 0
|
| 309 |
+
elif layer_name.find("patch_embed") != -1:
|
| 310 |
+
return 0
|
| 311 |
+
elif layer_name.find("blocks") != -1:
|
| 312 |
+
return int(layer_name.split("blocks")[1].split(".")[1]) + 1
|
| 313 |
+
else:
|
| 314 |
+
return num_layers + 1
|
| 315 |
+
|
| 316 |
+
def get_num_layers(self) -> int:
|
| 317 |
+
return len(self.blocks)
|
sam2/modeling/backbones/image_encoder.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import List, Optional
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class ImageEncoder(nn.Module):
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
trunk: nn.Module,
|
| 18 |
+
neck: nn.Module,
|
| 19 |
+
scalp: int = 0,
|
| 20 |
+
):
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.trunk = trunk
|
| 23 |
+
self.neck = neck
|
| 24 |
+
self.scalp = scalp
|
| 25 |
+
assert (
|
| 26 |
+
self.trunk.channel_list == self.neck.backbone_channel_list
|
| 27 |
+
), f"Channel dims of trunk and neck do not match. Trunk: {self.trunk.channel_list}, neck: {self.neck.backbone_channel_list}"
|
| 28 |
+
|
| 29 |
+
def forward(self, sample: torch.Tensor):
|
| 30 |
+
# Forward through backbone
|
| 31 |
+
features, pos = self.neck(self.trunk(sample))
|
| 32 |
+
if self.scalp > 0:
|
| 33 |
+
# Discard the lowest resolution features
|
| 34 |
+
features, pos = features[: -self.scalp], pos[: -self.scalp]
|
| 35 |
+
|
| 36 |
+
src = features[-1]
|
| 37 |
+
output = {
|
| 38 |
+
"vision_features": src,
|
| 39 |
+
"vision_pos_enc": pos,
|
| 40 |
+
"backbone_fpn": features,
|
| 41 |
+
}
|
| 42 |
+
return output
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class FpnNeck(nn.Module):
|
| 46 |
+
"""
|
| 47 |
+
A modified variant of Feature Pyramid Network (FPN) neck
|
| 48 |
+
(we remove output conv and also do bicubic interpolation similar to ViT
|
| 49 |
+
pos embed interpolation)
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(
|
| 53 |
+
self,
|
| 54 |
+
position_encoding: nn.Module,
|
| 55 |
+
d_model: int,
|
| 56 |
+
backbone_channel_list: List[int],
|
| 57 |
+
kernel_size: int = 1,
|
| 58 |
+
stride: int = 1,
|
| 59 |
+
padding: int = 0,
|
| 60 |
+
fpn_interp_model: str = "bilinear",
|
| 61 |
+
fuse_type: str = "sum",
|
| 62 |
+
fpn_top_down_levels: Optional[List[int]] = None,
|
| 63 |
+
):
|
| 64 |
+
"""Initialize the neck
|
| 65 |
+
:param trunk: the backbone
|
| 66 |
+
:param position_encoding: the positional encoding to use
|
| 67 |
+
:param d_model: the dimension of the model
|
| 68 |
+
:param neck_norm: the normalization to use
|
| 69 |
+
"""
|
| 70 |
+
super().__init__()
|
| 71 |
+
self.position_encoding = position_encoding
|
| 72 |
+
self.convs = nn.ModuleList()
|
| 73 |
+
self.backbone_channel_list = backbone_channel_list
|
| 74 |
+
self.d_model = d_model
|
| 75 |
+
for dim in backbone_channel_list:
|
| 76 |
+
current = nn.Sequential()
|
| 77 |
+
current.add_module(
|
| 78 |
+
"conv",
|
| 79 |
+
nn.Conv2d(
|
| 80 |
+
in_channels=dim,
|
| 81 |
+
out_channels=d_model,
|
| 82 |
+
kernel_size=kernel_size,
|
| 83 |
+
stride=stride,
|
| 84 |
+
padding=padding,
|
| 85 |
+
),
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
self.convs.append(current)
|
| 89 |
+
self.fpn_interp_model = fpn_interp_model
|
| 90 |
+
assert fuse_type in ["sum", "avg"]
|
| 91 |
+
self.fuse_type = fuse_type
|
| 92 |
+
|
| 93 |
+
# levels to have top-down features in its outputs
|
| 94 |
+
# e.g. if fpn_top_down_levels is [2, 3], then only outputs of level 2 and 3
|
| 95 |
+
# have top-down propagation, while outputs of level 0 and level 1 have only
|
| 96 |
+
# lateral features from the same backbone level.
|
| 97 |
+
if fpn_top_down_levels is None:
|
| 98 |
+
# default is to have top-down features on all levels
|
| 99 |
+
fpn_top_down_levels = range(len(self.convs))
|
| 100 |
+
self.fpn_top_down_levels = list(fpn_top_down_levels)
|
| 101 |
+
|
| 102 |
+
def forward(self, xs: List[torch.Tensor]):
|
| 103 |
+
|
| 104 |
+
out = [None] * len(self.convs)
|
| 105 |
+
pos = [None] * len(self.convs)
|
| 106 |
+
assert len(xs) == len(self.convs)
|
| 107 |
+
# fpn forward pass
|
| 108 |
+
# see https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/fpn.py
|
| 109 |
+
prev_features = None
|
| 110 |
+
# forward in top-down order (from low to high resolution)
|
| 111 |
+
n = len(self.convs) - 1
|
| 112 |
+
for i in range(n, -1, -1):
|
| 113 |
+
x = xs[i]
|
| 114 |
+
lateral_features = self.convs[n - i](x)
|
| 115 |
+
if i in self.fpn_top_down_levels and prev_features is not None:
|
| 116 |
+
top_down_features = F.interpolate(
|
| 117 |
+
prev_features.to(dtype=torch.float32),
|
| 118 |
+
scale_factor=2.0,
|
| 119 |
+
mode=self.fpn_interp_model,
|
| 120 |
+
align_corners=(
|
| 121 |
+
None if self.fpn_interp_model == "nearest" else False
|
| 122 |
+
),
|
| 123 |
+
antialias=False,
|
| 124 |
+
)
|
| 125 |
+
prev_features = lateral_features + top_down_features
|
| 126 |
+
if self.fuse_type == "avg":
|
| 127 |
+
prev_features /= 2
|
| 128 |
+
else:
|
| 129 |
+
prev_features = lateral_features
|
| 130 |
+
x_out = prev_features
|
| 131 |
+
out[i] = x_out
|
| 132 |
+
pos[i] = self.position_encoding(x_out).to(x_out.dtype)
|
| 133 |
+
|
| 134 |
+
return out, pos
|
sam2/modeling/backbones/utils.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
"""Some utilities for backbones, in particular for windowing"""
|
| 8 |
+
|
| 9 |
+
from typing import Tuple
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def window_partition(x, window_size):
|
| 17 |
+
"""
|
| 18 |
+
Partition into non-overlapping windows with padding if needed.
|
| 19 |
+
Args:
|
| 20 |
+
x (tensor): input tokens with [B, H, W, C].
|
| 21 |
+
window_size (int): window size.
|
| 22 |
+
Returns:
|
| 23 |
+
windows: windows after partition with [B * num_windows, window_size, window_size, C].
|
| 24 |
+
(Hp, Wp): padded height and width before partition
|
| 25 |
+
"""
|
| 26 |
+
B, H, W, C = x.shape
|
| 27 |
+
|
| 28 |
+
pad_h = (window_size - H % window_size) % window_size
|
| 29 |
+
pad_w = (window_size - W % window_size) % window_size
|
| 30 |
+
if pad_h > 0 or pad_w > 0:
|
| 31 |
+
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
|
| 32 |
+
Hp, Wp = H + pad_h, W + pad_w
|
| 33 |
+
|
| 34 |
+
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
|
| 35 |
+
windows = (
|
| 36 |
+
x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
|
| 37 |
+
)
|
| 38 |
+
return windows, (Hp, Wp)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def window_unpartition(windows, window_size, pad_hw, hw):
|
| 42 |
+
"""
|
| 43 |
+
Window unpartition into original sequences and removing padding.
|
| 44 |
+
Args:
|
| 45 |
+
x (tensor): input tokens with [B * num_windows, window_size, window_size, C].
|
| 46 |
+
window_size (int): window size.
|
| 47 |
+
pad_hw (Tuple): padded height and width (Hp, Wp).
|
| 48 |
+
hw (Tuple): original height and width (H, W) before padding.
|
| 49 |
+
Returns:
|
| 50 |
+
x: unpartitioned sequences with [B, H, W, C].
|
| 51 |
+
"""
|
| 52 |
+
Hp, Wp = pad_hw
|
| 53 |
+
H, W = hw
|
| 54 |
+
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
|
| 55 |
+
x = windows.view(
|
| 56 |
+
B, Hp // window_size, Wp // window_size, window_size, window_size, -1
|
| 57 |
+
)
|
| 58 |
+
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
|
| 59 |
+
|
| 60 |
+
if Hp > H or Wp > W:
|
| 61 |
+
x = x[:, :H, :W, :].contiguous()
|
| 62 |
+
return x
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class PatchEmbed(nn.Module):
|
| 66 |
+
"""
|
| 67 |
+
Image to Patch Embedding.
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
def __init__(
|
| 71 |
+
self,
|
| 72 |
+
kernel_size: Tuple[int, ...] = (7, 7),
|
| 73 |
+
stride: Tuple[int, ...] = (4, 4),
|
| 74 |
+
padding: Tuple[int, ...] = (3, 3),
|
| 75 |
+
in_chans: int = 3,
|
| 76 |
+
embed_dim: int = 768,
|
| 77 |
+
):
|
| 78 |
+
"""
|
| 79 |
+
Args:
|
| 80 |
+
kernel_size (Tuple): kernel size of the projection layer.
|
| 81 |
+
stride (Tuple): stride of the projection layer.
|
| 82 |
+
padding (Tuple): padding size of the projection layer.
|
| 83 |
+
in_chans (int): Number of input image channels.
|
| 84 |
+
embed_dim (int): embed_dim (int): Patch embedding dimension.
|
| 85 |
+
"""
|
| 86 |
+
super().__init__()
|
| 87 |
+
self.proj = nn.Conv2d(
|
| 88 |
+
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 92 |
+
x = self.proj(x)
|
| 93 |
+
# B C H W -> B H W C
|
| 94 |
+
x = x.permute(0, 2, 3, 1)
|
| 95 |
+
return x
|
sam2/modeling/memory_attention.py
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import Optional
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch import nn, Tensor
|
| 11 |
+
|
| 12 |
+
from sam2.modeling.sam.transformer import RoPEAttention
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_utils import get_activation_fn, get_clones
|
| 15 |
+
import pdb
|
| 16 |
+
|
| 17 |
+
class MemoryAttentionLayer(nn.Module):
|
| 18 |
+
|
| 19 |
+
def __init__(
|
| 20 |
+
self,
|
| 21 |
+
activation: str,
|
| 22 |
+
cross_attention: nn.Module,
|
| 23 |
+
d_model: int,
|
| 24 |
+
dim_feedforward: int,
|
| 25 |
+
dropout: float,
|
| 26 |
+
pos_enc_at_attn: bool,
|
| 27 |
+
pos_enc_at_cross_attn_keys: bool,
|
| 28 |
+
pos_enc_at_cross_attn_queries: bool,
|
| 29 |
+
self_attention: nn.Module,
|
| 30 |
+
):
|
| 31 |
+
super().__init__()
|
| 32 |
+
self.d_model = d_model
|
| 33 |
+
self.dim_feedforward = dim_feedforward
|
| 34 |
+
self.dropout_value = dropout
|
| 35 |
+
self.self_attn = self_attention
|
| 36 |
+
self.cross_attn_image = cross_attention
|
| 37 |
+
|
| 38 |
+
# Implementation of Feedforward model
|
| 39 |
+
self.linear1 = nn.Linear(d_model, dim_feedforward)
|
| 40 |
+
self.dropout = nn.Dropout(dropout)
|
| 41 |
+
self.linear2 = nn.Linear(dim_feedforward, d_model)
|
| 42 |
+
|
| 43 |
+
self.norm1 = nn.LayerNorm(d_model)
|
| 44 |
+
self.norm2 = nn.LayerNorm(d_model)
|
| 45 |
+
self.norm3 = nn.LayerNorm(d_model)
|
| 46 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 47 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 48 |
+
self.dropout3 = nn.Dropout(dropout)
|
| 49 |
+
|
| 50 |
+
self.activation_str = activation
|
| 51 |
+
self.activation = get_activation_fn(activation)
|
| 52 |
+
|
| 53 |
+
# Where to add pos enc
|
| 54 |
+
self.pos_enc_at_attn = pos_enc_at_attn
|
| 55 |
+
self.pos_enc_at_cross_attn_queries = pos_enc_at_cross_attn_queries
|
| 56 |
+
self.pos_enc_at_cross_attn_keys = pos_enc_at_cross_attn_keys
|
| 57 |
+
|
| 58 |
+
def _forward_sa(self, tgt, query_pos):
|
| 59 |
+
# Self-Attention
|
| 60 |
+
tgt2 = self.norm1(tgt)
|
| 61 |
+
q = k = tgt2 + query_pos if self.pos_enc_at_attn else tgt2
|
| 62 |
+
tgt2 = self.self_attn(q, k, v=tgt2)
|
| 63 |
+
tgt = tgt + self.dropout1(tgt2)
|
| 64 |
+
return tgt
|
| 65 |
+
|
| 66 |
+
def _forward_ca(self, tgt, memory, query_pos, pos, num_k_exclude_rope=0, object_frame_scores=None, object_ptr_scores=None):
|
| 67 |
+
kwds = {}
|
| 68 |
+
if num_k_exclude_rope > 0:
|
| 69 |
+
assert isinstance(self.cross_attn_image, RoPEAttention)
|
| 70 |
+
kwds = {"num_k_exclude_rope": num_k_exclude_rope}
|
| 71 |
+
|
| 72 |
+
# Cross-Attention
|
| 73 |
+
tgt2 = self.norm2(tgt)
|
| 74 |
+
if object_frame_scores is None:
|
| 75 |
+
key = memory + pos if self.pos_enc_at_cross_attn_keys else memory
|
| 76 |
+
else: # relative
|
| 77 |
+
key_original = memory + pos if self.pos_enc_at_cross_attn_keys else memory
|
| 78 |
+
num_frame, num_ptr = len(object_frame_scores), len(object_ptr_scores)
|
| 79 |
+
num_frame_ = int(num_frame*4096)
|
| 80 |
+
num_object = key_original.shape[0]
|
| 81 |
+
key_frame = key_original[:, :num_frame_].reshape(num_object, num_frame, 4096, -1)
|
| 82 |
+
key_ptr = key_original[:, num_frame_:].reshape(num_object, num_ptr, 4, -1)
|
| 83 |
+
scaling_low = 0.95
|
| 84 |
+
scaling_high = 1.05
|
| 85 |
+
if num_frame == 1:
|
| 86 |
+
key = key_original
|
| 87 |
+
else:
|
| 88 |
+
weight_frame = torch.stack(object_frame_scores, dim=1) # num_object, num_frame
|
| 89 |
+
weight_ptr = torch.stack(object_ptr_scores, dim=1) # num_object, num_ptr
|
| 90 |
+
|
| 91 |
+
standard_weight_frame = torch.linspace(scaling_low, scaling_high, num_frame).to(weight_frame) # num_frame
|
| 92 |
+
standard_weight_ptr = torch.linspace(scaling_low, scaling_high, num_ptr).to(weight_ptr) # num_ptr
|
| 93 |
+
|
| 94 |
+
new_weight_frame = torch.zeros_like(weight_frame)
|
| 95 |
+
new_weight_ptr = torch.zeros_like(weight_ptr)
|
| 96 |
+
|
| 97 |
+
new_weight_frame.scatter_(1, torch.argsort(weight_frame, dim=1), standard_weight_frame.unsqueeze(0).repeat([num_object, 1]))
|
| 98 |
+
new_weight_ptr.scatter_(1, torch.argsort(weight_ptr, dim=1), standard_weight_ptr.unsqueeze(0).repeat([num_object, 1]))
|
| 99 |
+
|
| 100 |
+
key_frame_scale = (new_weight_frame[:, :, None, None].to(key_frame.device) * key_frame)
|
| 101 |
+
key_ptr_scale = (new_weight_ptr[:, :, None, None].to(key_ptr.device) * key_ptr)
|
| 102 |
+
key = torch.cat([key_frame_scale.reshape(num_object, num_frame_, -1), key_ptr_scale.reshape(num_object, int(num_ptr*4), -1)], dim=1)
|
| 103 |
+
# key = memory + pos if self.pos_enc_at_cross_attn_keys else memory
|
| 104 |
+
tgt2 = self.cross_attn_image(
|
| 105 |
+
q=tgt2 + query_pos if self.pos_enc_at_cross_attn_queries else tgt2,
|
| 106 |
+
k=key,
|
| 107 |
+
v=memory,
|
| 108 |
+
**kwds,
|
| 109 |
+
)
|
| 110 |
+
tgt = tgt + self.dropout2(tgt2)
|
| 111 |
+
return tgt
|
| 112 |
+
|
| 113 |
+
def forward(
|
| 114 |
+
self,
|
| 115 |
+
tgt,
|
| 116 |
+
memory,
|
| 117 |
+
pos: Optional[Tensor] = None,
|
| 118 |
+
query_pos: Optional[Tensor] = None,
|
| 119 |
+
num_k_exclude_rope: int = 0,
|
| 120 |
+
object_frame_scores = None,
|
| 121 |
+
object_ptr_scores = None,
|
| 122 |
+
) -> torch.Tensor:
|
| 123 |
+
|
| 124 |
+
# Self-Attn, Cross-Attn
|
| 125 |
+
tgt = self._forward_sa(tgt, query_pos)
|
| 126 |
+
tgt = self._forward_ca(tgt, memory, query_pos, pos, num_k_exclude_rope, object_frame_scores, object_ptr_scores)
|
| 127 |
+
# MLP
|
| 128 |
+
tgt2 = self.norm3(tgt)
|
| 129 |
+
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
|
| 130 |
+
tgt = tgt + self.dropout3(tgt2)
|
| 131 |
+
return tgt
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
class MemoryAttention(nn.Module):
|
| 135 |
+
def __init__(
|
| 136 |
+
self,
|
| 137 |
+
d_model: int,
|
| 138 |
+
pos_enc_at_input: bool,
|
| 139 |
+
layer: nn.Module,
|
| 140 |
+
num_layers: int,
|
| 141 |
+
batch_first: bool = True, # Do layers expect batch first input?
|
| 142 |
+
):
|
| 143 |
+
super().__init__()
|
| 144 |
+
self.d_model = d_model
|
| 145 |
+
self.layers = get_clones(layer, num_layers)
|
| 146 |
+
self.num_layers = num_layers
|
| 147 |
+
self.norm = nn.LayerNorm(d_model)
|
| 148 |
+
self.pos_enc_at_input = pos_enc_at_input
|
| 149 |
+
self.batch_first = batch_first
|
| 150 |
+
|
| 151 |
+
def forward(
|
| 152 |
+
self,
|
| 153 |
+
curr: torch.Tensor, # self-attention inputs
|
| 154 |
+
memory: torch.Tensor, # cross-attention inputs
|
| 155 |
+
curr_pos: Optional[Tensor] = None, # pos_enc for self-attention inputs
|
| 156 |
+
memory_pos: Optional[Tensor] = None, # pos_enc for cross-attention inputs
|
| 157 |
+
num_obj_ptr_tokens: int = 0, # number of object pointer *tokens*
|
| 158 |
+
object_frame_scores=None,
|
| 159 |
+
object_ptr_scores=None,
|
| 160 |
+
):
|
| 161 |
+
if isinstance(curr, list):
|
| 162 |
+
assert isinstance(curr_pos, list)
|
| 163 |
+
assert len(curr) == len(curr_pos) == 1
|
| 164 |
+
curr, curr_pos = (
|
| 165 |
+
curr[0],
|
| 166 |
+
curr_pos[0],
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
assert (
|
| 170 |
+
curr.shape[1] == memory.shape[1]
|
| 171 |
+
), "Batch size must be the same for curr and memory"
|
| 172 |
+
|
| 173 |
+
output = curr
|
| 174 |
+
if self.pos_enc_at_input and curr_pos is not None:
|
| 175 |
+
output = output + 0.1 * curr_pos
|
| 176 |
+
|
| 177 |
+
if self.batch_first:
|
| 178 |
+
# Convert to batch first
|
| 179 |
+
output = output.transpose(0, 1)
|
| 180 |
+
curr_pos = curr_pos.transpose(0, 1)
|
| 181 |
+
memory = memory.transpose(0, 1)
|
| 182 |
+
memory_pos = memory_pos.transpose(0, 1)
|
| 183 |
+
|
| 184 |
+
for layer in self.layers:
|
| 185 |
+
kwds = {}
|
| 186 |
+
if isinstance(layer.cross_attn_image, RoPEAttention):
|
| 187 |
+
kwds = {"num_k_exclude_rope": num_obj_ptr_tokens,
|
| 188 |
+
"object_frame_scores": object_frame_scores,
|
| 189 |
+
"object_ptr_scores":object_ptr_scores}
|
| 190 |
+
|
| 191 |
+
output = layer(
|
| 192 |
+
tgt=output,
|
| 193 |
+
memory=memory,
|
| 194 |
+
pos=memory_pos,
|
| 195 |
+
query_pos=curr_pos,
|
| 196 |
+
**kwds,
|
| 197 |
+
)
|
| 198 |
+
normed_output = self.norm(output)
|
| 199 |
+
|
| 200 |
+
if self.batch_first:
|
| 201 |
+
# Convert back to seq first
|
| 202 |
+
normed_output = normed_output.transpose(0, 1)
|
| 203 |
+
curr_pos = curr_pos.transpose(0, 1)
|
| 204 |
+
|
| 205 |
+
return normed_output
|
sam2/modeling/memory_encoder.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
from typing import Tuple
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_utils import DropPath, get_clones, LayerNorm2d
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class MaskDownSampler(nn.Module):
|
| 18 |
+
"""
|
| 19 |
+
Progressively downsample a mask by total_stride, each time by stride.
|
| 20 |
+
Note that LayerNorm is applied per *token*, like in ViT.
|
| 21 |
+
|
| 22 |
+
With each downsample (by a factor stride**2), channel capacity increases by the same factor.
|
| 23 |
+
In the end, we linearly project to embed_dim channels.
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
def __init__(
|
| 27 |
+
self,
|
| 28 |
+
embed_dim=256,
|
| 29 |
+
kernel_size=4,
|
| 30 |
+
stride=4,
|
| 31 |
+
padding=0,
|
| 32 |
+
total_stride=16,
|
| 33 |
+
activation=nn.GELU,
|
| 34 |
+
):
|
| 35 |
+
super().__init__()
|
| 36 |
+
num_layers = int(math.log2(total_stride) // math.log2(stride))
|
| 37 |
+
assert stride**num_layers == total_stride
|
| 38 |
+
self.encoder = nn.Sequential()
|
| 39 |
+
mask_in_chans, mask_out_chans = 1, 1
|
| 40 |
+
for _ in range(num_layers):
|
| 41 |
+
mask_out_chans = mask_in_chans * (stride**2)
|
| 42 |
+
self.encoder.append(
|
| 43 |
+
nn.Conv2d(
|
| 44 |
+
mask_in_chans,
|
| 45 |
+
mask_out_chans,
|
| 46 |
+
kernel_size=kernel_size,
|
| 47 |
+
stride=stride,
|
| 48 |
+
padding=padding,
|
| 49 |
+
)
|
| 50 |
+
)
|
| 51 |
+
self.encoder.append(LayerNorm2d(mask_out_chans))
|
| 52 |
+
self.encoder.append(activation())
|
| 53 |
+
mask_in_chans = mask_out_chans
|
| 54 |
+
|
| 55 |
+
self.encoder.append(nn.Conv2d(mask_out_chans, embed_dim, kernel_size=1))
|
| 56 |
+
|
| 57 |
+
def forward(self, x):
|
| 58 |
+
return self.encoder(x)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# Lightly adapted from ConvNext (https://github.com/facebookresearch/ConvNeXt)
|
| 62 |
+
class CXBlock(nn.Module):
|
| 63 |
+
r"""ConvNeXt Block. There are two equivalent implementations:
|
| 64 |
+
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
|
| 65 |
+
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
|
| 66 |
+
We use (2) as we find it slightly faster in PyTorch
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
dim (int): Number of input channels.
|
| 70 |
+
drop_path (float): Stochastic depth rate. Default: 0.0
|
| 71 |
+
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
def __init__(
|
| 75 |
+
self,
|
| 76 |
+
dim,
|
| 77 |
+
kernel_size=7,
|
| 78 |
+
padding=3,
|
| 79 |
+
drop_path=0.0,
|
| 80 |
+
layer_scale_init_value=1e-6,
|
| 81 |
+
use_dwconv=True,
|
| 82 |
+
):
|
| 83 |
+
super().__init__()
|
| 84 |
+
self.dwconv = nn.Conv2d(
|
| 85 |
+
dim,
|
| 86 |
+
dim,
|
| 87 |
+
kernel_size=kernel_size,
|
| 88 |
+
padding=padding,
|
| 89 |
+
groups=dim if use_dwconv else 1,
|
| 90 |
+
) # depthwise conv
|
| 91 |
+
self.norm = LayerNorm2d(dim, eps=1e-6)
|
| 92 |
+
self.pwconv1 = nn.Linear(
|
| 93 |
+
dim, 4 * dim
|
| 94 |
+
) # pointwise/1x1 convs, implemented with linear layers
|
| 95 |
+
self.act = nn.GELU()
|
| 96 |
+
self.pwconv2 = nn.Linear(4 * dim, dim)
|
| 97 |
+
self.gamma = (
|
| 98 |
+
nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
|
| 99 |
+
if layer_scale_init_value > 0
|
| 100 |
+
else None
|
| 101 |
+
)
|
| 102 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 103 |
+
|
| 104 |
+
def forward(self, x):
|
| 105 |
+
input = x
|
| 106 |
+
x = self.dwconv(x)
|
| 107 |
+
x = self.norm(x)
|
| 108 |
+
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
|
| 109 |
+
x = self.pwconv1(x)
|
| 110 |
+
x = self.act(x)
|
| 111 |
+
x = self.pwconv2(x)
|
| 112 |
+
if self.gamma is not None:
|
| 113 |
+
x = self.gamma * x
|
| 114 |
+
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
|
| 115 |
+
|
| 116 |
+
x = input + self.drop_path(x)
|
| 117 |
+
return x
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class Fuser(nn.Module):
|
| 121 |
+
def __init__(self, layer, num_layers, dim=None, input_projection=False):
|
| 122 |
+
super().__init__()
|
| 123 |
+
self.proj = nn.Identity()
|
| 124 |
+
self.layers = get_clones(layer, num_layers)
|
| 125 |
+
|
| 126 |
+
if input_projection:
|
| 127 |
+
assert dim is not None
|
| 128 |
+
self.proj = nn.Conv2d(dim, dim, kernel_size=1)
|
| 129 |
+
|
| 130 |
+
def forward(self, x):
|
| 131 |
+
# normally x: (N, C, H, W)
|
| 132 |
+
x = self.proj(x)
|
| 133 |
+
for layer in self.layers:
|
| 134 |
+
x = layer(x)
|
| 135 |
+
return x
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class MemoryEncoder(nn.Module):
|
| 139 |
+
def __init__(
|
| 140 |
+
self,
|
| 141 |
+
out_dim,
|
| 142 |
+
mask_downsampler,
|
| 143 |
+
fuser,
|
| 144 |
+
position_encoding,
|
| 145 |
+
in_dim=256, # in_dim of pix_feats
|
| 146 |
+
):
|
| 147 |
+
super().__init__()
|
| 148 |
+
|
| 149 |
+
self.mask_downsampler = mask_downsampler
|
| 150 |
+
|
| 151 |
+
self.pix_feat_proj = nn.Conv2d(in_dim, in_dim, kernel_size=1)
|
| 152 |
+
self.fuser = fuser
|
| 153 |
+
self.position_encoding = position_encoding
|
| 154 |
+
self.out_proj = nn.Identity()
|
| 155 |
+
if out_dim != in_dim:
|
| 156 |
+
self.out_proj = nn.Conv2d(in_dim, out_dim, kernel_size=1)
|
| 157 |
+
|
| 158 |
+
def forward(
|
| 159 |
+
self,
|
| 160 |
+
pix_feat: torch.Tensor,
|
| 161 |
+
masks: torch.Tensor,
|
| 162 |
+
skip_mask_sigmoid: bool = False,
|
| 163 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 164 |
+
## Process masks
|
| 165 |
+
# sigmoid, so that less domain shift from gt masks which are bool
|
| 166 |
+
if not skip_mask_sigmoid:
|
| 167 |
+
masks = F.sigmoid(masks)
|
| 168 |
+
masks = self.mask_downsampler(masks)
|
| 169 |
+
|
| 170 |
+
## Fuse pix_feats and downsampled masks
|
| 171 |
+
# in case the visual features are on CPU, cast them to CUDA
|
| 172 |
+
pix_feat = pix_feat.to(masks.device)
|
| 173 |
+
|
| 174 |
+
x = self.pix_feat_proj(pix_feat)
|
| 175 |
+
x = x + masks
|
| 176 |
+
x = self.fuser(x)
|
| 177 |
+
x = self.out_proj(x)
|
| 178 |
+
|
| 179 |
+
pos = self.position_encoding(x).to(x.dtype)
|
| 180 |
+
|
| 181 |
+
return {"vision_features": x, "vision_pos_enc": [pos]}
|
sam2/modeling/position_encoding.py
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
from typing import Any, Optional, Tuple
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
from torch import nn
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class PositionEmbeddingSine(nn.Module):
|
| 17 |
+
"""
|
| 18 |
+
This is a more standard version of the position embedding, very similar to the one
|
| 19 |
+
used by the Attention Is All You Need paper, generalized to work on images.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
num_pos_feats,
|
| 25 |
+
temperature: int = 10000,
|
| 26 |
+
normalize: bool = True,
|
| 27 |
+
scale: Optional[float] = None,
|
| 28 |
+
):
|
| 29 |
+
super().__init__()
|
| 30 |
+
assert num_pos_feats % 2 == 0, "Expecting even model width"
|
| 31 |
+
self.num_pos_feats = num_pos_feats // 2
|
| 32 |
+
self.temperature = temperature
|
| 33 |
+
self.normalize = normalize
|
| 34 |
+
if scale is not None and normalize is False:
|
| 35 |
+
raise ValueError("normalize should be True if scale is passed")
|
| 36 |
+
if scale is None:
|
| 37 |
+
scale = 2 * math.pi
|
| 38 |
+
self.scale = scale
|
| 39 |
+
|
| 40 |
+
self.cache = {}
|
| 41 |
+
|
| 42 |
+
def _encode_xy(self, x, y):
|
| 43 |
+
# The positions are expected to be normalized
|
| 44 |
+
assert len(x) == len(y) and x.ndim == y.ndim == 1
|
| 45 |
+
x_embed = x * self.scale
|
| 46 |
+
y_embed = y * self.scale
|
| 47 |
+
|
| 48 |
+
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 49 |
+
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
|
| 50 |
+
|
| 51 |
+
pos_x = x_embed[:, None] / dim_t
|
| 52 |
+
pos_y = y_embed[:, None] / dim_t
|
| 53 |
+
pos_x = torch.stack(
|
| 54 |
+
(pos_x[:, 0::2].sin(), pos_x[:, 1::2].cos()), dim=2
|
| 55 |
+
).flatten(1)
|
| 56 |
+
pos_y = torch.stack(
|
| 57 |
+
(pos_y[:, 0::2].sin(), pos_y[:, 1::2].cos()), dim=2
|
| 58 |
+
).flatten(1)
|
| 59 |
+
return pos_x, pos_y
|
| 60 |
+
|
| 61 |
+
@torch.no_grad()
|
| 62 |
+
def encode_boxes(self, x, y, w, h):
|
| 63 |
+
pos_x, pos_y = self._encode_xy(x, y)
|
| 64 |
+
pos = torch.cat((pos_y, pos_x, h[:, None], w[:, None]), dim=1)
|
| 65 |
+
return pos
|
| 66 |
+
|
| 67 |
+
encode = encode_boxes # Backwards compatibility
|
| 68 |
+
|
| 69 |
+
@torch.no_grad()
|
| 70 |
+
def encode_points(self, x, y, labels):
|
| 71 |
+
(bx, nx), (by, ny), (bl, nl) = x.shape, y.shape, labels.shape
|
| 72 |
+
assert bx == by and nx == ny and bx == bl and nx == nl
|
| 73 |
+
pos_x, pos_y = self._encode_xy(x.flatten(), y.flatten())
|
| 74 |
+
pos_x, pos_y = pos_x.reshape(bx, nx, -1), pos_y.reshape(by, ny, -1)
|
| 75 |
+
pos = torch.cat((pos_y, pos_x, labels[:, :, None]), dim=2)
|
| 76 |
+
return pos
|
| 77 |
+
|
| 78 |
+
@torch.no_grad()
|
| 79 |
+
def forward(self, x: torch.Tensor):
|
| 80 |
+
cache_key = (x.shape[-2], x.shape[-1])
|
| 81 |
+
if cache_key in self.cache:
|
| 82 |
+
return self.cache[cache_key][None].repeat(x.shape[0], 1, 1, 1)
|
| 83 |
+
y_embed = (
|
| 84 |
+
torch.arange(1, x.shape[-2] + 1, dtype=torch.float32, device=x.device)
|
| 85 |
+
.view(1, -1, 1)
|
| 86 |
+
.repeat(x.shape[0], 1, x.shape[-1])
|
| 87 |
+
)
|
| 88 |
+
x_embed = (
|
| 89 |
+
torch.arange(1, x.shape[-1] + 1, dtype=torch.float32, device=x.device)
|
| 90 |
+
.view(1, 1, -1)
|
| 91 |
+
.repeat(x.shape[0], x.shape[-2], 1)
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
if self.normalize:
|
| 95 |
+
eps = 1e-6
|
| 96 |
+
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
|
| 97 |
+
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
|
| 98 |
+
|
| 99 |
+
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 100 |
+
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
|
| 101 |
+
|
| 102 |
+
pos_x = x_embed[:, :, :, None] / dim_t
|
| 103 |
+
pos_y = y_embed[:, :, :, None] / dim_t
|
| 104 |
+
pos_x = torch.stack(
|
| 105 |
+
(pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4
|
| 106 |
+
).flatten(3)
|
| 107 |
+
pos_y = torch.stack(
|
| 108 |
+
(pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4
|
| 109 |
+
).flatten(3)
|
| 110 |
+
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
|
| 111 |
+
self.cache[cache_key] = pos[0]
|
| 112 |
+
return pos
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
class PositionEmbeddingRandom(nn.Module):
|
| 116 |
+
"""
|
| 117 |
+
Positional encoding using random spatial frequencies.
|
| 118 |
+
"""
|
| 119 |
+
|
| 120 |
+
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
|
| 121 |
+
super().__init__()
|
| 122 |
+
if scale is None or scale <= 0.0:
|
| 123 |
+
scale = 1.0
|
| 124 |
+
self.register_buffer(
|
| 125 |
+
"positional_encoding_gaussian_matrix",
|
| 126 |
+
scale * torch.randn((2, num_pos_feats)),
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
|
| 130 |
+
"""Positionally encode points that are normalized to [0,1]."""
|
| 131 |
+
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
|
| 132 |
+
coords = 2 * coords - 1
|
| 133 |
+
coords = coords @ self.positional_encoding_gaussian_matrix
|
| 134 |
+
coords = 2 * np.pi * coords
|
| 135 |
+
# outputs d_1 x ... x d_n x C shape
|
| 136 |
+
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
|
| 137 |
+
|
| 138 |
+
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
|
| 139 |
+
"""Generate positional encoding for a grid of the specified size."""
|
| 140 |
+
h, w = size
|
| 141 |
+
device: Any = self.positional_encoding_gaussian_matrix.device
|
| 142 |
+
grid = torch.ones((h, w), device=device, dtype=torch.float32)
|
| 143 |
+
y_embed = grid.cumsum(dim=0) - 0.5
|
| 144 |
+
x_embed = grid.cumsum(dim=1) - 0.5
|
| 145 |
+
y_embed = y_embed / h
|
| 146 |
+
x_embed = x_embed / w
|
| 147 |
+
|
| 148 |
+
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
|
| 149 |
+
return pe.permute(2, 0, 1) # C x H x W
|
| 150 |
+
|
| 151 |
+
def forward_with_coords(
|
| 152 |
+
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
|
| 153 |
+
) -> torch.Tensor:
|
| 154 |
+
"""Positionally encode points that are not normalized to [0,1]."""
|
| 155 |
+
coords = coords_input.clone()
|
| 156 |
+
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
|
| 157 |
+
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
|
| 158 |
+
return self._pe_encoding(coords.to(torch.float)) # B x N x C
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
# Rotary Positional Encoding, adapted from:
|
| 162 |
+
# 1. https://github.com/meta-llama/codellama/blob/main/llama/model.py
|
| 163 |
+
# 2. https://github.com/naver-ai/rope-vit
|
| 164 |
+
# 3. https://github.com/lucidrains/rotary-embedding-torch
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def init_t_xy(end_x: int, end_y: int):
|
| 168 |
+
t = torch.arange(end_x * end_y, dtype=torch.float32)
|
| 169 |
+
t_x = (t % end_x).float()
|
| 170 |
+
t_y = torch.div(t, end_x, rounding_mode="floor").float()
|
| 171 |
+
return t_x, t_y
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def compute_axial_cis(dim: int, end_x: int, end_y: int, theta: float = 10000.0):
|
| 175 |
+
freqs_x = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim))
|
| 176 |
+
freqs_y = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim))
|
| 177 |
+
|
| 178 |
+
t_x, t_y = init_t_xy(end_x, end_y)
|
| 179 |
+
freqs_x = torch.outer(t_x, freqs_x)
|
| 180 |
+
freqs_y = torch.outer(t_y, freqs_y)
|
| 181 |
+
freqs_cis_x = torch.polar(torch.ones_like(freqs_x), freqs_x)
|
| 182 |
+
freqs_cis_y = torch.polar(torch.ones_like(freqs_y), freqs_y)
|
| 183 |
+
return torch.cat([freqs_cis_x, freqs_cis_y], dim=-1)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
|
| 187 |
+
ndim = x.ndim
|
| 188 |
+
assert 0 <= 1 < ndim
|
| 189 |
+
assert freqs_cis.shape == (x.shape[-2], x.shape[-1])
|
| 190 |
+
shape = [d if i >= ndim - 2 else 1 for i, d in enumerate(x.shape)]
|
| 191 |
+
return freqs_cis.view(*shape)
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def apply_rotary_enc(
|
| 195 |
+
xq: torch.Tensor,
|
| 196 |
+
xk: torch.Tensor,
|
| 197 |
+
freqs_cis: torch.Tensor,
|
| 198 |
+
repeat_freqs_k: bool = False,
|
| 199 |
+
):
|
| 200 |
+
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
|
| 201 |
+
xk_ = (
|
| 202 |
+
torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
|
| 203 |
+
if xk.shape[-2] != 0
|
| 204 |
+
else None
|
| 205 |
+
)
|
| 206 |
+
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
|
| 207 |
+
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
|
| 208 |
+
if xk_ is None:
|
| 209 |
+
# no keys to rotate, due to dropout
|
| 210 |
+
return xq_out.type_as(xq).to(xq.device), xk
|
| 211 |
+
# repeat freqs along seq_len dim to match k seq_len
|
| 212 |
+
if repeat_freqs_k:
|
| 213 |
+
r = xk_.shape[-2] // xq_.shape[-2]
|
| 214 |
+
if freqs_cis.is_cuda:
|
| 215 |
+
freqs_cis = freqs_cis.repeat(*([1] * (freqs_cis.ndim - 2)), r, 1)
|
| 216 |
+
else:
|
| 217 |
+
# torch.repeat on complex numbers may not be supported on non-CUDA devices
|
| 218 |
+
# (freqs_cis has 4 dims and we repeat on dim 2) so we use expand + flatten
|
| 219 |
+
freqs_cis = freqs_cis.unsqueeze(2).expand(-1, -1, r, -1, -1).flatten(2, 3)
|
| 220 |
+
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
|
| 221 |
+
return xq_out.type_as(xq).to(xq.device), xk_out.type_as(xk).to(xk.device)
|
sam2/modeling/sam/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
sam2/modeling/sam/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (171 Bytes). View file
|
|
|
sam2/modeling/sam/__pycache__/mask_decoder.cpython-310.pyc
ADDED
|
Binary file (7.82 kB). View file
|
|
|
sam2/modeling/sam/__pycache__/prompt_encoder.cpython-310.pyc
ADDED
|
Binary file (5.92 kB). View file
|
|
|
sam2/modeling/sam/__pycache__/transformer.cpython-310.pyc
ADDED
|
Binary file (9.65 kB). View file
|
|
|
sam2/modeling/sam/mask_decoder.py
ADDED
|
@@ -0,0 +1,300 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import List, Optional, Tuple, Type
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch import nn
|
| 11 |
+
import pdb
|
| 12 |
+
from fvcore.nn import FlopCountAnalysis
|
| 13 |
+
from sam2.modeling.sam2_utils import LayerNorm2d, MLP
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class MaskDecoder(nn.Module):
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
*,
|
| 20 |
+
transformer_dim: int,
|
| 21 |
+
transformer: nn.Module,
|
| 22 |
+
num_multimask_outputs: int = 3,
|
| 23 |
+
activation: Type[nn.Module] = nn.GELU,
|
| 24 |
+
iou_head_depth: int = 3,
|
| 25 |
+
iou_head_hidden_dim: int = 256,
|
| 26 |
+
use_high_res_features: bool = False,
|
| 27 |
+
iou_prediction_use_sigmoid=False,
|
| 28 |
+
dynamic_multimask_via_stability=False,
|
| 29 |
+
dynamic_multimask_stability_delta=0.05,
|
| 30 |
+
dynamic_multimask_stability_thresh=0.98,
|
| 31 |
+
pred_obj_scores: bool = False,
|
| 32 |
+
pred_obj_scores_mlp: bool = False,
|
| 33 |
+
use_multimask_token_for_obj_ptr: bool = False,
|
| 34 |
+
) -> None:
|
| 35 |
+
"""
|
| 36 |
+
Predicts masks given an image and prompt embeddings, using a
|
| 37 |
+
transformer architecture.
|
| 38 |
+
|
| 39 |
+
Arguments:
|
| 40 |
+
transformer_dim (int): the channel dimension of the transformer
|
| 41 |
+
transformer (nn.Module): the transformer used to predict masks
|
| 42 |
+
num_multimask_outputs (int): the number of masks to predict
|
| 43 |
+
when disambiguating masks
|
| 44 |
+
activation (nn.Module): the type of activation to use when
|
| 45 |
+
upscaling masks
|
| 46 |
+
iou_head_depth (int): the depth of the MLP used to predict
|
| 47 |
+
mask quality
|
| 48 |
+
iou_head_hidden_dim (int): the hidden dimension of the MLP
|
| 49 |
+
used to predict mask quality
|
| 50 |
+
"""
|
| 51 |
+
super().__init__()
|
| 52 |
+
self.transformer_dim = transformer_dim
|
| 53 |
+
self.transformer = transformer
|
| 54 |
+
|
| 55 |
+
self.num_multimask_outputs = num_multimask_outputs
|
| 56 |
+
|
| 57 |
+
self.iou_token = nn.Embedding(1, transformer_dim)
|
| 58 |
+
self.num_mask_tokens = num_multimask_outputs + 1
|
| 59 |
+
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
|
| 60 |
+
|
| 61 |
+
self.pred_obj_scores = pred_obj_scores
|
| 62 |
+
if self.pred_obj_scores:
|
| 63 |
+
self.obj_score_token = nn.Embedding(1, transformer_dim)
|
| 64 |
+
self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr
|
| 65 |
+
|
| 66 |
+
self.output_upscaling = nn.Sequential(
|
| 67 |
+
nn.ConvTranspose2d(
|
| 68 |
+
transformer_dim, transformer_dim // 4, kernel_size=2, stride=2
|
| 69 |
+
),
|
| 70 |
+
LayerNorm2d(transformer_dim // 4),
|
| 71 |
+
activation(),
|
| 72 |
+
nn.ConvTranspose2d(
|
| 73 |
+
transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2
|
| 74 |
+
),
|
| 75 |
+
activation(),
|
| 76 |
+
)
|
| 77 |
+
self.use_high_res_features = use_high_res_features
|
| 78 |
+
if use_high_res_features:
|
| 79 |
+
self.conv_s0 = nn.Conv2d(
|
| 80 |
+
transformer_dim, transformer_dim // 8, kernel_size=1, stride=1
|
| 81 |
+
)
|
| 82 |
+
self.conv_s1 = nn.Conv2d(
|
| 83 |
+
transformer_dim, transformer_dim // 4, kernel_size=1, stride=1
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
self.output_hypernetworks_mlps = nn.ModuleList(
|
| 87 |
+
[
|
| 88 |
+
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
|
| 89 |
+
for i in range(self.num_mask_tokens)
|
| 90 |
+
]
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
self.iou_prediction_head = MLP(
|
| 94 |
+
transformer_dim,
|
| 95 |
+
iou_head_hidden_dim,
|
| 96 |
+
self.num_mask_tokens,
|
| 97 |
+
iou_head_depth,
|
| 98 |
+
sigmoid_output=iou_prediction_use_sigmoid,
|
| 99 |
+
)
|
| 100 |
+
if self.pred_obj_scores:
|
| 101 |
+
self.pred_obj_score_head = nn.Linear(transformer_dim, 1)
|
| 102 |
+
if pred_obj_scores_mlp:
|
| 103 |
+
self.pred_obj_score_head = MLP(transformer_dim, transformer_dim, 1, 3)
|
| 104 |
+
|
| 105 |
+
# When outputting a single mask, optionally we can dynamically fall back to the best
|
| 106 |
+
# multimask output token if the single mask output token gives low stability scores.
|
| 107 |
+
self.dynamic_multimask_via_stability = dynamic_multimask_via_stability
|
| 108 |
+
self.dynamic_multimask_stability_delta = dynamic_multimask_stability_delta
|
| 109 |
+
self.dynamic_multimask_stability_thresh = dynamic_multimask_stability_thresh
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def forward(
|
| 114 |
+
self,
|
| 115 |
+
image_embeddings: torch.Tensor,
|
| 116 |
+
image_pe: torch.Tensor,
|
| 117 |
+
sparse_prompt_embeddings: torch.Tensor,
|
| 118 |
+
dense_prompt_embeddings: torch.Tensor,
|
| 119 |
+
multimask_output: bool,
|
| 120 |
+
repeat_image: bool,
|
| 121 |
+
high_res_features: Optional[List[torch.Tensor]] = None,
|
| 122 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 123 |
+
"""
|
| 124 |
+
Predict masks given image and prompt embeddings.
|
| 125 |
+
|
| 126 |
+
Arguments:
|
| 127 |
+
image_embeddings (torch.Tensor): the embeddings from the image encoder
|
| 128 |
+
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
|
| 129 |
+
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
|
| 130 |
+
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
|
| 131 |
+
multimask_output (bool): Whether to return multiple masks or a single
|
| 132 |
+
mask.
|
| 133 |
+
|
| 134 |
+
Returns:
|
| 135 |
+
torch.Tensor: batched predicted masks
|
| 136 |
+
torch.Tensor: batched predictions of mask quality
|
| 137 |
+
torch.Tensor: batched SAM token for mask output
|
| 138 |
+
"""
|
| 139 |
+
masks, iou_pred, mask_tokens_out, object_score_logits = self.predict_masks(
|
| 140 |
+
image_embeddings=image_embeddings,
|
| 141 |
+
image_pe=image_pe,
|
| 142 |
+
sparse_prompt_embeddings=sparse_prompt_embeddings,
|
| 143 |
+
dense_prompt_embeddings=dense_prompt_embeddings,
|
| 144 |
+
repeat_image=repeat_image,
|
| 145 |
+
high_res_features=high_res_features,
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
# Select the correct mask or masks for output
|
| 149 |
+
if multimask_output:
|
| 150 |
+
masks = masks[:, 1:, :, :]
|
| 151 |
+
iou_pred = iou_pred[:, 1:]
|
| 152 |
+
elif self.dynamic_multimask_via_stability and not self.training:
|
| 153 |
+
masks, iou_pred = self._dynamic_multimask_via_stability(masks, iou_pred)
|
| 154 |
+
else:
|
| 155 |
+
masks = masks[:, 0:1, :, :]
|
| 156 |
+
iou_pred = iou_pred[:, 0:1]
|
| 157 |
+
|
| 158 |
+
if multimask_output and self.use_multimask_token_for_obj_ptr:
|
| 159 |
+
sam_tokens_out = mask_tokens_out[:, 1:] # [b, 3, c] shape
|
| 160 |
+
else:
|
| 161 |
+
# Take the mask output token. Here we *always* use the token for single mask output.
|
| 162 |
+
# At test time, even if we track after 1-click (and using multimask_output=True),
|
| 163 |
+
# we still take the single mask token here. The rationale is that we always track
|
| 164 |
+
# after multiple clicks during training, so the past tokens seen during training
|
| 165 |
+
# are always the single mask token (and we'll let it be the object-memory token).
|
| 166 |
+
sam_tokens_out = mask_tokens_out[:, 0:1] # [b, 1, c] shape
|
| 167 |
+
|
| 168 |
+
# Prepare output
|
| 169 |
+
return masks, iou_pred, sam_tokens_out, object_score_logits
|
| 170 |
+
|
| 171 |
+
def predict_masks(
|
| 172 |
+
self,
|
| 173 |
+
image_embeddings: torch.Tensor,
|
| 174 |
+
image_pe: torch.Tensor,
|
| 175 |
+
sparse_prompt_embeddings: torch.Tensor,
|
| 176 |
+
dense_prompt_embeddings: torch.Tensor,
|
| 177 |
+
repeat_image: bool,
|
| 178 |
+
high_res_features: Optional[List[torch.Tensor]] = None,
|
| 179 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 180 |
+
"""Predicts masks. See 'forward' for more details."""
|
| 181 |
+
# Concatenate output tokens
|
| 182 |
+
s = 0
|
| 183 |
+
if self.pred_obj_scores:
|
| 184 |
+
output_tokens = torch.cat(
|
| 185 |
+
[
|
| 186 |
+
self.obj_score_token.weight,
|
| 187 |
+
self.iou_token.weight,
|
| 188 |
+
self.mask_tokens.weight,
|
| 189 |
+
],
|
| 190 |
+
dim=0,
|
| 191 |
+
)
|
| 192 |
+
s = 1
|
| 193 |
+
else:
|
| 194 |
+
output_tokens = torch.cat(
|
| 195 |
+
[self.iou_token.weight, self.mask_tokens.weight], dim=0
|
| 196 |
+
)
|
| 197 |
+
output_tokens = output_tokens.unsqueeze(0).expand(
|
| 198 |
+
sparse_prompt_embeddings.size(0), -1, -1
|
| 199 |
+
)
|
| 200 |
+
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
|
| 201 |
+
|
| 202 |
+
# Expand per-image data in batch direction to be per-mask
|
| 203 |
+
if repeat_image:
|
| 204 |
+
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
|
| 205 |
+
else:
|
| 206 |
+
assert image_embeddings.shape[0] == tokens.shape[0]
|
| 207 |
+
src = image_embeddings
|
| 208 |
+
src = src + dense_prompt_embeddings
|
| 209 |
+
assert (
|
| 210 |
+
image_pe.size(0) == 1
|
| 211 |
+
), "image_pe should have size 1 in batch dim (from `get_dense_pe()`)"
|
| 212 |
+
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
|
| 213 |
+
b, c, h, w = src.shape
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
# Run the transformer
|
| 218 |
+
hs, src = self.transformer(src, pos_src, tokens)
|
| 219 |
+
iou_token_out = hs[:, s, :]
|
| 220 |
+
mask_tokens_out = hs[:, s + 1 : (s + 1 + self.num_mask_tokens), :]
|
| 221 |
+
|
| 222 |
+
# Upscale mask embeddings and predict masks using the mask tokens
|
| 223 |
+
src = src.transpose(1, 2).view(b, c, h, w)
|
| 224 |
+
if not self.use_high_res_features:
|
| 225 |
+
upscaled_embedding = self.output_upscaling(src)
|
| 226 |
+
else:
|
| 227 |
+
dc1, ln1, act1, dc2, act2 = self.output_upscaling
|
| 228 |
+
feat_s0, feat_s1 = high_res_features
|
| 229 |
+
upscaled_embedding = act1(ln1(dc1(src) + feat_s1))
|
| 230 |
+
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)
|
| 231 |
+
|
| 232 |
+
hyper_in_list: List[torch.Tensor] = []
|
| 233 |
+
for i in range(self.num_mask_tokens):
|
| 234 |
+
hyper_in_list.append(
|
| 235 |
+
self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])
|
| 236 |
+
)
|
| 237 |
+
hyper_in = torch.stack(hyper_in_list, dim=1)
|
| 238 |
+
b, c, h, w = upscaled_embedding.shape
|
| 239 |
+
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
|
| 240 |
+
|
| 241 |
+
# Generate mask quality predictions
|
| 242 |
+
iou_pred = self.iou_prediction_head(iou_token_out)
|
| 243 |
+
if self.pred_obj_scores:
|
| 244 |
+
assert s == 1
|
| 245 |
+
object_score_logits = self.pred_obj_score_head(hs[:, 0, :])
|
| 246 |
+
else:
|
| 247 |
+
# Obj scores logits - default to 10.0, i.e. assuming the object is present, sigmoid(10)=1
|
| 248 |
+
object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape[0], 1)
|
| 249 |
+
|
| 250 |
+
return masks, iou_pred, mask_tokens_out, object_score_logits
|
| 251 |
+
|
| 252 |
+
def _get_stability_scores(self, mask_logits):
|
| 253 |
+
"""
|
| 254 |
+
Compute stability scores of the mask logits based on the IoU between upper and
|
| 255 |
+
lower thresholds.
|
| 256 |
+
"""
|
| 257 |
+
mask_logits = mask_logits.flatten(-2)
|
| 258 |
+
stability_delta = self.dynamic_multimask_stability_delta
|
| 259 |
+
area_i = torch.sum(mask_logits > stability_delta, dim=-1).float()
|
| 260 |
+
area_u = torch.sum(mask_logits > -stability_delta, dim=-1).float()
|
| 261 |
+
stability_scores = torch.where(area_u > 0, area_i / area_u, 1.0)
|
| 262 |
+
return stability_scores
|
| 263 |
+
|
| 264 |
+
def _dynamic_multimask_via_stability(self, all_mask_logits, all_iou_scores):
|
| 265 |
+
"""
|
| 266 |
+
When outputting a single mask, if the stability score from the current single-mask
|
| 267 |
+
output (based on output token 0) falls below a threshold, we instead select from
|
| 268 |
+
multi-mask outputs (based on output token 1~3) the mask with the highest predicted
|
| 269 |
+
IoU score. This is intended to ensure a valid mask for both clicking and tracking.
|
| 270 |
+
"""
|
| 271 |
+
# The best mask from multimask output tokens (1~3)
|
| 272 |
+
multimask_logits = all_mask_logits[:, 1:, :, :]
|
| 273 |
+
multimask_iou_scores = all_iou_scores[:, 1:]
|
| 274 |
+
best_scores_inds = torch.argmax(multimask_iou_scores, dim=-1)
|
| 275 |
+
batch_inds = torch.arange(
|
| 276 |
+
multimask_iou_scores.size(0), device=all_iou_scores.device
|
| 277 |
+
)
|
| 278 |
+
best_multimask_logits = multimask_logits[batch_inds, best_scores_inds]
|
| 279 |
+
best_multimask_logits = best_multimask_logits.unsqueeze(1)
|
| 280 |
+
best_multimask_iou_scores = multimask_iou_scores[batch_inds, best_scores_inds]
|
| 281 |
+
best_multimask_iou_scores = best_multimask_iou_scores.unsqueeze(1)
|
| 282 |
+
|
| 283 |
+
# The mask from singlemask output token 0 and its stability score
|
| 284 |
+
singlemask_logits = all_mask_logits[:, 0:1, :, :]
|
| 285 |
+
singlemask_iou_scores = all_iou_scores[:, 0:1]
|
| 286 |
+
stability_scores = self._get_stability_scores(singlemask_logits)
|
| 287 |
+
is_stable = stability_scores >= self.dynamic_multimask_stability_thresh
|
| 288 |
+
|
| 289 |
+
# Dynamically fall back to best multimask output upon low stability scores.
|
| 290 |
+
mask_logits_out = torch.where(
|
| 291 |
+
is_stable[..., None, None].expand_as(singlemask_logits),
|
| 292 |
+
singlemask_logits,
|
| 293 |
+
best_multimask_logits,
|
| 294 |
+
)
|
| 295 |
+
iou_scores_out = torch.where(
|
| 296 |
+
is_stable.expand_as(singlemask_iou_scores),
|
| 297 |
+
singlemask_iou_scores,
|
| 298 |
+
best_multimask_iou_scores,
|
| 299 |
+
)
|
| 300 |
+
return mask_logits_out, iou_scores_out
|
sam2/modeling/sam/prompt_encoder.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import Optional, Tuple, Type
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch import nn
|
| 11 |
+
|
| 12 |
+
from sam2.modeling.position_encoding import PositionEmbeddingRandom
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_utils import LayerNorm2d
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class PromptEncoder(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
embed_dim: int,
|
| 21 |
+
image_embedding_size: Tuple[int, int],
|
| 22 |
+
input_image_size: Tuple[int, int],
|
| 23 |
+
mask_in_chans: int,
|
| 24 |
+
activation: Type[nn.Module] = nn.GELU,
|
| 25 |
+
) -> None:
|
| 26 |
+
"""
|
| 27 |
+
Encodes prompts for input to SAM's mask decoder.
|
| 28 |
+
|
| 29 |
+
Arguments:
|
| 30 |
+
embed_dim (int): The prompts' embedding dimension
|
| 31 |
+
image_embedding_size (tuple(int, int)): The spatial size of the
|
| 32 |
+
image embedding, as (H, W).
|
| 33 |
+
input_image_size (int): The padded size of the image as input
|
| 34 |
+
to the image encoder, as (H, W).
|
| 35 |
+
mask_in_chans (int): The number of hidden channels used for
|
| 36 |
+
encoding input masks.
|
| 37 |
+
activation (nn.Module): The activation to use when encoding
|
| 38 |
+
input masks.
|
| 39 |
+
"""
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.embed_dim = embed_dim
|
| 42 |
+
self.input_image_size = input_image_size
|
| 43 |
+
self.image_embedding_size = image_embedding_size
|
| 44 |
+
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
|
| 45 |
+
|
| 46 |
+
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
|
| 47 |
+
point_embeddings = [
|
| 48 |
+
nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)
|
| 49 |
+
]
|
| 50 |
+
self.point_embeddings = nn.ModuleList(point_embeddings)
|
| 51 |
+
self.not_a_point_embed = nn.Embedding(1, embed_dim)
|
| 52 |
+
|
| 53 |
+
self.mask_input_size = (
|
| 54 |
+
4 * image_embedding_size[0],
|
| 55 |
+
4 * image_embedding_size[1],
|
| 56 |
+
)
|
| 57 |
+
self.mask_downscaling = nn.Sequential(
|
| 58 |
+
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
|
| 59 |
+
LayerNorm2d(mask_in_chans // 4),
|
| 60 |
+
activation(),
|
| 61 |
+
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
|
| 62 |
+
LayerNorm2d(mask_in_chans),
|
| 63 |
+
activation(),
|
| 64 |
+
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
|
| 65 |
+
)
|
| 66 |
+
self.no_mask_embed = nn.Embedding(1, embed_dim)
|
| 67 |
+
|
| 68 |
+
def get_dense_pe(self) -> torch.Tensor:
|
| 69 |
+
"""
|
| 70 |
+
Returns the positional encoding used to encode point prompts,
|
| 71 |
+
applied to a dense set of points the shape of the image encoding.
|
| 72 |
+
|
| 73 |
+
Returns:
|
| 74 |
+
torch.Tensor: Positional encoding with shape
|
| 75 |
+
1x(embed_dim)x(embedding_h)x(embedding_w)
|
| 76 |
+
"""
|
| 77 |
+
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
|
| 78 |
+
|
| 79 |
+
def _embed_points(
|
| 80 |
+
self,
|
| 81 |
+
points: torch.Tensor,
|
| 82 |
+
labels: torch.Tensor,
|
| 83 |
+
pad: bool,
|
| 84 |
+
) -> torch.Tensor:
|
| 85 |
+
"""Embeds point prompts."""
|
| 86 |
+
points = points + 0.5 # Shift to center of pixel
|
| 87 |
+
if pad:
|
| 88 |
+
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
|
| 89 |
+
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
|
| 90 |
+
points = torch.cat([points, padding_point], dim=1)
|
| 91 |
+
labels = torch.cat([labels, padding_label], dim=1)
|
| 92 |
+
point_embedding = self.pe_layer.forward_with_coords(
|
| 93 |
+
points, self.input_image_size
|
| 94 |
+
)
|
| 95 |
+
point_embedding[labels == -1] = 0.0
|
| 96 |
+
point_embedding[labels == -1] += self.not_a_point_embed.weight
|
| 97 |
+
point_embedding[labels == 0] += self.point_embeddings[0].weight
|
| 98 |
+
point_embedding[labels == 1] += self.point_embeddings[1].weight
|
| 99 |
+
point_embedding[labels == 2] += self.point_embeddings[2].weight
|
| 100 |
+
point_embedding[labels == 3] += self.point_embeddings[3].weight
|
| 101 |
+
return point_embedding
|
| 102 |
+
|
| 103 |
+
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
|
| 104 |
+
"""Embeds box prompts."""
|
| 105 |
+
boxes = boxes + 0.5 # Shift to center of pixel
|
| 106 |
+
coords = boxes.reshape(-1, 2, 2)
|
| 107 |
+
corner_embedding = self.pe_layer.forward_with_coords(
|
| 108 |
+
coords, self.input_image_size
|
| 109 |
+
)
|
| 110 |
+
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
|
| 111 |
+
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
|
| 112 |
+
return corner_embedding
|
| 113 |
+
|
| 114 |
+
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
|
| 115 |
+
"""Embeds mask inputs."""
|
| 116 |
+
mask_embedding = self.mask_downscaling(masks)
|
| 117 |
+
return mask_embedding
|
| 118 |
+
|
| 119 |
+
def _get_batch_size(
|
| 120 |
+
self,
|
| 121 |
+
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
|
| 122 |
+
boxes: Optional[torch.Tensor],
|
| 123 |
+
masks: Optional[torch.Tensor],
|
| 124 |
+
) -> int:
|
| 125 |
+
"""
|
| 126 |
+
Gets the batch size of the output given the batch size of the input prompts.
|
| 127 |
+
"""
|
| 128 |
+
if points is not None:
|
| 129 |
+
return points[0].shape[0]
|
| 130 |
+
elif boxes is not None:
|
| 131 |
+
return boxes.shape[0]
|
| 132 |
+
elif masks is not None:
|
| 133 |
+
return masks.shape[0]
|
| 134 |
+
else:
|
| 135 |
+
return 1
|
| 136 |
+
|
| 137 |
+
def _get_device(self) -> torch.device:
|
| 138 |
+
return self.point_embeddings[0].weight.device
|
| 139 |
+
|
| 140 |
+
def forward(
|
| 141 |
+
self,
|
| 142 |
+
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
|
| 143 |
+
boxes: Optional[torch.Tensor],
|
| 144 |
+
masks: Optional[torch.Tensor],
|
| 145 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 146 |
+
"""
|
| 147 |
+
Embeds different types of prompts, returning both sparse and dense
|
| 148 |
+
embeddings.
|
| 149 |
+
|
| 150 |
+
Arguments:
|
| 151 |
+
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
|
| 152 |
+
and labels to embed.
|
| 153 |
+
boxes (torch.Tensor or none): boxes to embed
|
| 154 |
+
masks (torch.Tensor or none): masks to embed
|
| 155 |
+
|
| 156 |
+
Returns:
|
| 157 |
+
torch.Tensor: sparse embeddings for the points and boxes, with shape
|
| 158 |
+
BxNx(embed_dim), where N is determined by the number of input points
|
| 159 |
+
and boxes.
|
| 160 |
+
torch.Tensor: dense embeddings for the masks, in the shape
|
| 161 |
+
Bx(embed_dim)x(embed_H)x(embed_W)
|
| 162 |
+
"""
|
| 163 |
+
bs = self._get_batch_size(points, boxes, masks)
|
| 164 |
+
sparse_embeddings = torch.empty(
|
| 165 |
+
(bs, 0, self.embed_dim), device=self._get_device()
|
| 166 |
+
)
|
| 167 |
+
if points is not None:
|
| 168 |
+
coords, labels = points
|
| 169 |
+
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
|
| 170 |
+
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
|
| 171 |
+
if boxes is not None:
|
| 172 |
+
box_embeddings = self._embed_boxes(boxes)
|
| 173 |
+
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
|
| 174 |
+
|
| 175 |
+
if masks is not None:
|
| 176 |
+
dense_embeddings = self._embed_masks(masks)
|
| 177 |
+
else:
|
| 178 |
+
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
|
| 179 |
+
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
return sparse_embeddings, dense_embeddings
|
sam2/modeling/sam/transformer.py
ADDED
|
@@ -0,0 +1,360 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import contextlib
|
| 8 |
+
import math
|
| 9 |
+
import warnings
|
| 10 |
+
from functools import partial
|
| 11 |
+
from typing import Tuple, Type
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
from torch import nn, Tensor
|
| 16 |
+
|
| 17 |
+
from sam2.modeling.position_encoding import apply_rotary_enc, compute_axial_cis
|
| 18 |
+
from sam2.modeling.sam2_utils import MLP
|
| 19 |
+
from sam2.utils.misc import get_sdpa_settings
|
| 20 |
+
|
| 21 |
+
warnings.simplefilter(action="ignore", category=FutureWarning)
|
| 22 |
+
# Check whether Flash Attention is available (and use it by default)
|
| 23 |
+
OLD_GPU, USE_FLASH_ATTN, MATH_KERNEL_ON = get_sdpa_settings()
|
| 24 |
+
# A fallback setting to allow all available kernels if Flash Attention fails
|
| 25 |
+
ALLOW_ALL_KERNELS = False
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def sdp_kernel_context(dropout_p):
|
| 29 |
+
"""
|
| 30 |
+
Get the context for the attention scaled dot-product kernel. We use Flash Attention
|
| 31 |
+
by default, but fall back to all available kernels if Flash Attention fails.
|
| 32 |
+
"""
|
| 33 |
+
if ALLOW_ALL_KERNELS:
|
| 34 |
+
return contextlib.nullcontext()
|
| 35 |
+
|
| 36 |
+
return torch.backends.cuda.sdp_kernel(
|
| 37 |
+
enable_flash=USE_FLASH_ATTN,
|
| 38 |
+
# if Flash attention kernel is off, then math kernel needs to be enabled
|
| 39 |
+
enable_math=(OLD_GPU and dropout_p > 0.0) or MATH_KERNEL_ON,
|
| 40 |
+
enable_mem_efficient=OLD_GPU,
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class TwoWayTransformer(nn.Module):
|
| 45 |
+
def __init__(
|
| 46 |
+
self,
|
| 47 |
+
depth: int,
|
| 48 |
+
embedding_dim: int,
|
| 49 |
+
num_heads: int,
|
| 50 |
+
mlp_dim: int,
|
| 51 |
+
activation: Type[nn.Module] = nn.ReLU,
|
| 52 |
+
attention_downsample_rate: int = 2,
|
| 53 |
+
) -> None:
|
| 54 |
+
"""
|
| 55 |
+
A transformer decoder that attends to an input image using
|
| 56 |
+
queries whose positional embedding is supplied.
|
| 57 |
+
|
| 58 |
+
Args:
|
| 59 |
+
depth (int): number of layers in the transformer
|
| 60 |
+
embedding_dim (int): the channel dimension for the input embeddings
|
| 61 |
+
num_heads (int): the number of heads for multihead attention. Must
|
| 62 |
+
divide embedding_dim
|
| 63 |
+
mlp_dim (int): the channel dimension internal to the MLP block
|
| 64 |
+
activation (nn.Module): the activation to use in the MLP block
|
| 65 |
+
"""
|
| 66 |
+
super().__init__()
|
| 67 |
+
self.depth = depth
|
| 68 |
+
self.embedding_dim = embedding_dim
|
| 69 |
+
self.num_heads = num_heads
|
| 70 |
+
self.mlp_dim = mlp_dim
|
| 71 |
+
self.layers = nn.ModuleList()
|
| 72 |
+
|
| 73 |
+
for i in range(depth):
|
| 74 |
+
self.layers.append(
|
| 75 |
+
TwoWayAttentionBlock(
|
| 76 |
+
embedding_dim=embedding_dim,
|
| 77 |
+
num_heads=num_heads,
|
| 78 |
+
mlp_dim=mlp_dim,
|
| 79 |
+
activation=activation,
|
| 80 |
+
attention_downsample_rate=attention_downsample_rate,
|
| 81 |
+
skip_first_layer_pe=(i == 0),
|
| 82 |
+
)
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
self.final_attn_token_to_image = Attention(
|
| 86 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 87 |
+
)
|
| 88 |
+
self.norm_final_attn = nn.LayerNorm(embedding_dim)
|
| 89 |
+
|
| 90 |
+
def forward(
|
| 91 |
+
self,
|
| 92 |
+
image_embedding: Tensor,
|
| 93 |
+
image_pe: Tensor,
|
| 94 |
+
point_embedding: Tensor,
|
| 95 |
+
) -> Tuple[Tensor, Tensor]:
|
| 96 |
+
"""
|
| 97 |
+
Args:
|
| 98 |
+
image_embedding (torch.Tensor): image to attend to. Should be shape
|
| 99 |
+
B x embedding_dim x h x w for any h and w.
|
| 100 |
+
image_pe (torch.Tensor): the positional encoding to add to the image. Must
|
| 101 |
+
have the same shape as image_embedding.
|
| 102 |
+
point_embedding (torch.Tensor): the embedding to add to the query points.
|
| 103 |
+
Must have shape B x N_points x embedding_dim for any N_points.
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
torch.Tensor: the processed point_embedding
|
| 107 |
+
torch.Tensor: the processed image_embedding
|
| 108 |
+
"""
|
| 109 |
+
# BxCxHxW -> BxHWxC == B x N_image_tokens x C
|
| 110 |
+
bs, c, h, w = image_embedding.shape
|
| 111 |
+
image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
|
| 112 |
+
image_pe = image_pe.flatten(2).permute(0, 2, 1)
|
| 113 |
+
|
| 114 |
+
# Prepare queries
|
| 115 |
+
queries = point_embedding
|
| 116 |
+
keys = image_embedding
|
| 117 |
+
|
| 118 |
+
# Apply transformer blocks and final layernorm
|
| 119 |
+
for layer in self.layers:
|
| 120 |
+
queries, keys = layer(
|
| 121 |
+
queries=queries,
|
| 122 |
+
keys=keys,
|
| 123 |
+
query_pe=point_embedding,
|
| 124 |
+
key_pe=image_pe,
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
# Apply the final attention layer from the points to the image
|
| 128 |
+
q = queries + point_embedding
|
| 129 |
+
k = keys + image_pe
|
| 130 |
+
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
|
| 131 |
+
queries = queries + attn_out
|
| 132 |
+
queries = self.norm_final_attn(queries)
|
| 133 |
+
|
| 134 |
+
return queries, keys
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class TwoWayAttentionBlock(nn.Module):
|
| 138 |
+
def __init__(
|
| 139 |
+
self,
|
| 140 |
+
embedding_dim: int,
|
| 141 |
+
num_heads: int,
|
| 142 |
+
mlp_dim: int = 2048,
|
| 143 |
+
activation: Type[nn.Module] = nn.ReLU,
|
| 144 |
+
attention_downsample_rate: int = 2,
|
| 145 |
+
skip_first_layer_pe: bool = False,
|
| 146 |
+
) -> None:
|
| 147 |
+
"""
|
| 148 |
+
A transformer block with four layers: (1) self-attention of sparse
|
| 149 |
+
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
|
| 150 |
+
block on sparse inputs, and (4) cross attention of dense inputs to sparse
|
| 151 |
+
inputs.
|
| 152 |
+
|
| 153 |
+
Arguments:
|
| 154 |
+
embedding_dim (int): the channel dimension of the embeddings
|
| 155 |
+
num_heads (int): the number of heads in the attention layers
|
| 156 |
+
mlp_dim (int): the hidden dimension of the mlp block
|
| 157 |
+
activation (nn.Module): the activation of the mlp block
|
| 158 |
+
skip_first_layer_pe (bool): skip the PE on the first layer
|
| 159 |
+
"""
|
| 160 |
+
super().__init__()
|
| 161 |
+
self.self_attn = Attention(embedding_dim, num_heads)
|
| 162 |
+
self.norm1 = nn.LayerNorm(embedding_dim)
|
| 163 |
+
|
| 164 |
+
self.cross_attn_token_to_image = Attention(
|
| 165 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 166 |
+
)
|
| 167 |
+
self.norm2 = nn.LayerNorm(embedding_dim)
|
| 168 |
+
|
| 169 |
+
self.mlp = MLP(
|
| 170 |
+
embedding_dim, mlp_dim, embedding_dim, num_layers=2, activation=activation
|
| 171 |
+
)
|
| 172 |
+
self.norm3 = nn.LayerNorm(embedding_dim)
|
| 173 |
+
|
| 174 |
+
self.norm4 = nn.LayerNorm(embedding_dim)
|
| 175 |
+
self.cross_attn_image_to_token = Attention(
|
| 176 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
self.skip_first_layer_pe = skip_first_layer_pe
|
| 180 |
+
|
| 181 |
+
def forward(
|
| 182 |
+
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
|
| 183 |
+
) -> Tuple[Tensor, Tensor]:
|
| 184 |
+
# Self attention block
|
| 185 |
+
if self.skip_first_layer_pe:
|
| 186 |
+
queries = self.self_attn(q=queries, k=queries, v=queries)
|
| 187 |
+
else:
|
| 188 |
+
q = queries + query_pe
|
| 189 |
+
attn_out = self.self_attn(q=q, k=q, v=queries)
|
| 190 |
+
queries = queries + attn_out
|
| 191 |
+
queries = self.norm1(queries)
|
| 192 |
+
|
| 193 |
+
# Cross attention block, tokens attending to image embedding
|
| 194 |
+
q = queries + query_pe
|
| 195 |
+
k = keys + key_pe
|
| 196 |
+
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
|
| 197 |
+
queries = queries + attn_out
|
| 198 |
+
queries = self.norm2(queries)
|
| 199 |
+
|
| 200 |
+
# MLP block
|
| 201 |
+
mlp_out = self.mlp(queries)
|
| 202 |
+
queries = queries + mlp_out
|
| 203 |
+
queries = self.norm3(queries)
|
| 204 |
+
|
| 205 |
+
# Cross attention block, image embedding attending to tokens
|
| 206 |
+
q = queries + query_pe
|
| 207 |
+
k = keys + key_pe
|
| 208 |
+
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
|
| 209 |
+
keys = keys + attn_out
|
| 210 |
+
keys = self.norm4(keys)
|
| 211 |
+
|
| 212 |
+
return queries, keys
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
class Attention(nn.Module):
|
| 216 |
+
"""
|
| 217 |
+
An attention layer that allows for downscaling the size of the embedding
|
| 218 |
+
after projection to queries, keys, and values.
|
| 219 |
+
"""
|
| 220 |
+
|
| 221 |
+
def __init__(
|
| 222 |
+
self,
|
| 223 |
+
embedding_dim: int,
|
| 224 |
+
num_heads: int,
|
| 225 |
+
downsample_rate: int = 1,
|
| 226 |
+
dropout: float = 0.0,
|
| 227 |
+
kv_in_dim: int = None,
|
| 228 |
+
) -> None:
|
| 229 |
+
super().__init__()
|
| 230 |
+
self.embedding_dim = embedding_dim
|
| 231 |
+
self.kv_in_dim = kv_in_dim if kv_in_dim is not None else embedding_dim
|
| 232 |
+
self.internal_dim = embedding_dim // downsample_rate
|
| 233 |
+
self.num_heads = num_heads
|
| 234 |
+
assert (
|
| 235 |
+
self.internal_dim % num_heads == 0
|
| 236 |
+
), "num_heads must divide embedding_dim."
|
| 237 |
+
|
| 238 |
+
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
|
| 239 |
+
self.k_proj = nn.Linear(self.kv_in_dim, self.internal_dim)
|
| 240 |
+
self.v_proj = nn.Linear(self.kv_in_dim, self.internal_dim)
|
| 241 |
+
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
|
| 242 |
+
|
| 243 |
+
self.dropout_p = dropout
|
| 244 |
+
|
| 245 |
+
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
|
| 246 |
+
b, n, c = x.shape
|
| 247 |
+
x = x.reshape(b, n, num_heads, c // num_heads)
|
| 248 |
+
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
|
| 249 |
+
|
| 250 |
+
def _recombine_heads(self, x: Tensor) -> Tensor:
|
| 251 |
+
b, n_heads, n_tokens, c_per_head = x.shape
|
| 252 |
+
x = x.transpose(1, 2)
|
| 253 |
+
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
|
| 254 |
+
|
| 255 |
+
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
|
| 256 |
+
# Input projections
|
| 257 |
+
q = self.q_proj(q)
|
| 258 |
+
k = self.k_proj(k)
|
| 259 |
+
v = self.v_proj(v)
|
| 260 |
+
|
| 261 |
+
# Separate into heads
|
| 262 |
+
q = self._separate_heads(q, self.num_heads)
|
| 263 |
+
k = self._separate_heads(k, self.num_heads)
|
| 264 |
+
v = self._separate_heads(v, self.num_heads)
|
| 265 |
+
|
| 266 |
+
dropout_p = self.dropout_p if self.training else 0.0
|
| 267 |
+
# Attention
|
| 268 |
+
try:
|
| 269 |
+
with sdp_kernel_context(dropout_p):
|
| 270 |
+
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
|
| 271 |
+
except Exception as e:
|
| 272 |
+
# Fall back to all kernels if the Flash attention kernel fails
|
| 273 |
+
warnings.warn(
|
| 274 |
+
f"Flash Attention kernel failed due to: {e}\nFalling back to all available "
|
| 275 |
+
f"kernels for scaled_dot_product_attention (which may have a slower speed).",
|
| 276 |
+
category=UserWarning,
|
| 277 |
+
stacklevel=2,
|
| 278 |
+
)
|
| 279 |
+
global ALLOW_ALL_KERNELS
|
| 280 |
+
ALLOW_ALL_KERNELS = True
|
| 281 |
+
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
|
| 282 |
+
|
| 283 |
+
out = self._recombine_heads(out)
|
| 284 |
+
out = self.out_proj(out)
|
| 285 |
+
|
| 286 |
+
return out
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
class RoPEAttention(Attention):
|
| 290 |
+
"""Attention with rotary position encoding."""
|
| 291 |
+
|
| 292 |
+
def __init__(
|
| 293 |
+
self,
|
| 294 |
+
*args,
|
| 295 |
+
rope_theta=10000.0,
|
| 296 |
+
# whether to repeat q rope to match k length
|
| 297 |
+
# this is needed for cross-attention to memories
|
| 298 |
+
rope_k_repeat=False,
|
| 299 |
+
feat_sizes=(32, 32), # [w, h] for stride 16 feats at 512 resolution
|
| 300 |
+
**kwargs,
|
| 301 |
+
):
|
| 302 |
+
super().__init__(*args, **kwargs)
|
| 303 |
+
|
| 304 |
+
self.compute_cis = partial(
|
| 305 |
+
compute_axial_cis, dim=self.internal_dim // self.num_heads, theta=rope_theta
|
| 306 |
+
)
|
| 307 |
+
freqs_cis = self.compute_cis(end_x=feat_sizes[0], end_y=feat_sizes[1])
|
| 308 |
+
self.freqs_cis = freqs_cis
|
| 309 |
+
self.rope_k_repeat = rope_k_repeat
|
| 310 |
+
|
| 311 |
+
def forward(
|
| 312 |
+
self, q: Tensor, k: Tensor, v: Tensor, num_k_exclude_rope: int = 0
|
| 313 |
+
) -> Tensor:
|
| 314 |
+
# Input projections
|
| 315 |
+
q = self.q_proj(q)
|
| 316 |
+
k = self.k_proj(k)
|
| 317 |
+
v = self.v_proj(v)
|
| 318 |
+
|
| 319 |
+
# Separate into heads
|
| 320 |
+
q = self._separate_heads(q, self.num_heads)
|
| 321 |
+
k = self._separate_heads(k, self.num_heads)
|
| 322 |
+
v = self._separate_heads(v, self.num_heads)
|
| 323 |
+
|
| 324 |
+
# Apply rotary position encoding
|
| 325 |
+
w = h = math.sqrt(q.shape[-2])
|
| 326 |
+
self.freqs_cis = self.freqs_cis.to(q.device)
|
| 327 |
+
if self.freqs_cis.shape[0] != q.shape[-2]:
|
| 328 |
+
self.freqs_cis = self.compute_cis(end_x=w, end_y=h).to(q.device)
|
| 329 |
+
if q.shape[-2] != k.shape[-2]:
|
| 330 |
+
assert self.rope_k_repeat
|
| 331 |
+
|
| 332 |
+
num_k_rope = k.size(-2) - num_k_exclude_rope
|
| 333 |
+
q, k[:, :, :num_k_rope] = apply_rotary_enc(
|
| 334 |
+
q,
|
| 335 |
+
k[:, :, :num_k_rope],
|
| 336 |
+
freqs_cis=self.freqs_cis,
|
| 337 |
+
repeat_freqs_k=self.rope_k_repeat,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
dropout_p = self.dropout_p if self.training else 0.0
|
| 341 |
+
# Attention
|
| 342 |
+
try:
|
| 343 |
+
with sdp_kernel_context(dropout_p):
|
| 344 |
+
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
|
| 345 |
+
except Exception as e:
|
| 346 |
+
# Fall back to all kernels if the Flash attention kernel fails
|
| 347 |
+
warnings.warn(
|
| 348 |
+
f"Flash Attention kernel failed due to: {e}\nFalling back to all available "
|
| 349 |
+
f"kernels for scaled_dot_product_attention (which may have a slower speed).",
|
| 350 |
+
category=UserWarning,
|
| 351 |
+
stacklevel=2,
|
| 352 |
+
)
|
| 353 |
+
global ALLOW_ALL_KERNELS
|
| 354 |
+
ALLOW_ALL_KERNELS = True
|
| 355 |
+
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
|
| 356 |
+
|
| 357 |
+
out = self._recombine_heads(out)
|
| 358 |
+
out = self.out_proj(out)
|
| 359 |
+
|
| 360 |
+
return out
|
sam2/modeling/sam2_base.py
ADDED
|
@@ -0,0 +1,943 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.distributed
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
from torch.nn.init import trunc_normal_
|
| 12 |
+
|
| 13 |
+
from sam2.modeling.sam.mask_decoder import MaskDecoder
|
| 14 |
+
from sam2.modeling.sam.prompt_encoder import PromptEncoder
|
| 15 |
+
from sam2.modeling.sam.transformer import TwoWayTransformer
|
| 16 |
+
from sam2.modeling.sam2_utils import get_1d_sine_pe, MLP, select_closest_cond_frames
|
| 17 |
+
import pdb
|
| 18 |
+
from fvcore.nn import FlopCountAnalysis
|
| 19 |
+
# a large negative value as a placeholder score for missing objects
|
| 20 |
+
NO_OBJ_SCORE = -1024.0
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class SAM2Base(torch.nn.Module):
|
| 24 |
+
def __init__(
|
| 25 |
+
self,
|
| 26 |
+
image_encoder,
|
| 27 |
+
memory_attention,
|
| 28 |
+
memory_encoder,
|
| 29 |
+
num_maskmem=7, # default 1 input frame + 6 previous frames
|
| 30 |
+
image_size=512,
|
| 31 |
+
backbone_stride=16, # stride of the image backbone output
|
| 32 |
+
sigmoid_scale_for_mem_enc=1.0, # scale factor for mask sigmoid prob
|
| 33 |
+
sigmoid_bias_for_mem_enc=0.0, # bias factor for mask sigmoid prob
|
| 34 |
+
# During evaluation, whether to binarize the sigmoid mask logits on interacted frames with clicks
|
| 35 |
+
binarize_mask_from_pts_for_mem_enc=False,
|
| 36 |
+
use_mask_input_as_output_without_sam=False, # on frames with mask input, whether to directly output the input mask without using a SAM prompt encoder + mask decoder
|
| 37 |
+
# The maximum number of conditioning frames to participate in the memory attention (-1 means no limit; if there are more conditioning frames than this limit,
|
| 38 |
+
# we only cross-attend to the temporally closest `max_cond_frames_in_attn` conditioning frames in the encoder when tracking each frame). This gives the model
|
| 39 |
+
# a temporal locality when handling a large number of annotated frames (since closer frames should be more important) and also avoids GPU OOM.
|
| 40 |
+
max_cond_frames_in_attn=-1,
|
| 41 |
+
# on the first frame, whether to directly add the no-memory embedding to the image feature
|
| 42 |
+
# (instead of using the transformer encoder)
|
| 43 |
+
directly_add_no_mem_embed=False,
|
| 44 |
+
# whether to use high-resolution feature maps in the SAM mask decoder
|
| 45 |
+
use_high_res_features_in_sam=False,
|
| 46 |
+
# whether to output multiple (3) masks for the first click on initial conditioning frames
|
| 47 |
+
multimask_output_in_sam=False,
|
| 48 |
+
# the minimum and maximum number of clicks to use multimask_output_in_sam (only relevant when `multimask_output_in_sam=True`;
|
| 49 |
+
# default is 1 for both, meaning that only the first click gives multimask output; also note that a box counts as two points)
|
| 50 |
+
multimask_min_pt_num=1,
|
| 51 |
+
multimask_max_pt_num=1,
|
| 52 |
+
# whether to also use multimask output for tracking (not just for the first click on initial conditioning frames; only relevant when `multimask_output_in_sam=True`)
|
| 53 |
+
multimask_output_for_tracking=False,
|
| 54 |
+
# Whether to use multimask tokens for obj ptr; Only relevant when both
|
| 55 |
+
# use_obj_ptrs_in_encoder=True and multimask_output_for_tracking=True
|
| 56 |
+
use_multimask_token_for_obj_ptr: bool = False,
|
| 57 |
+
# whether to use sigmoid to restrict ious prediction to [0-1]
|
| 58 |
+
iou_prediction_use_sigmoid=False,
|
| 59 |
+
# The memory bank's temporal stride during evaluation (i.e. the `r` parameter in XMem and Cutie; XMem and Cutie use r=5).
|
| 60 |
+
# For r>1, the (self.num_maskmem - 1) non-conditioning memory frames consist of
|
| 61 |
+
# (self.num_maskmem - 2) nearest frames from every r-th frames, plus the last frame.
|
| 62 |
+
memory_temporal_stride_for_eval=1,
|
| 63 |
+
# whether to apply non-overlapping constraints on the object masks in the memory encoder during evaluation (to avoid/alleviate superposing masks)
|
| 64 |
+
non_overlap_masks_for_mem_enc=False,
|
| 65 |
+
# whether to cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 66 |
+
use_obj_ptrs_in_encoder=False,
|
| 67 |
+
# the maximum number of object pointers from other frames in encoder cross attention (only relevant when `use_obj_ptrs_in_encoder=True`)
|
| 68 |
+
max_obj_ptrs_in_encoder=16,
|
| 69 |
+
# whether to add temporal positional encoding to the object pointers in the encoder (only relevant when `use_obj_ptrs_in_encoder=True`)
|
| 70 |
+
add_tpos_enc_to_obj_ptrs=True,
|
| 71 |
+
# whether to add an extra linear projection layer for the temporal positional encoding in the object pointers to avoid potential interference
|
| 72 |
+
# with spatial positional encoding (only relevant when both `use_obj_ptrs_in_encoder=True` and `add_tpos_enc_to_obj_ptrs=True`)
|
| 73 |
+
proj_tpos_enc_in_obj_ptrs=False,
|
| 74 |
+
# whether to use signed distance (instead of unsigned absolute distance) in the temporal positional encoding in the object pointers
|
| 75 |
+
# (only relevant when both `use_obj_ptrs_in_encoder=True` and `add_tpos_enc_to_obj_ptrs=True`)
|
| 76 |
+
use_signed_tpos_enc_to_obj_ptrs=False,
|
| 77 |
+
# whether to only attend to object pointers in the past (before the current frame) in the encoder during evaluation
|
| 78 |
+
# (only relevant when `use_obj_ptrs_in_encoder=True`; this might avoid pointer information too far in the future to distract the initial tracking)
|
| 79 |
+
only_obj_ptrs_in_the_past_for_eval=False,
|
| 80 |
+
# Whether to predict if there is an object in the frame
|
| 81 |
+
pred_obj_scores: bool = False,
|
| 82 |
+
# Whether to use an MLP to predict object scores
|
| 83 |
+
pred_obj_scores_mlp: bool = False,
|
| 84 |
+
# Only relevant if pred_obj_scores=True and use_obj_ptrs_in_encoder=True;
|
| 85 |
+
# Whether to have a fixed no obj pointer when there is no object present
|
| 86 |
+
# or to use it as an additive embedding with obj_ptr produced by decoder
|
| 87 |
+
fixed_no_obj_ptr: bool = False,
|
| 88 |
+
# Soft no object, i.e. mix in no_obj_ptr softly,
|
| 89 |
+
# hope to make recovery easier if there is a mistake and mitigate accumulation of errors
|
| 90 |
+
soft_no_obj_ptr: bool = False,
|
| 91 |
+
use_mlp_for_obj_ptr_proj: bool = False,
|
| 92 |
+
# add no obj embedding to spatial frames
|
| 93 |
+
no_obj_embed_spatial: bool = False,
|
| 94 |
+
# extra arguments used to construct the SAM mask decoder; if not None, it should be a dict of kwargs to be passed into `MaskDecoder` class.
|
| 95 |
+
sam_mask_decoder_extra_args=None,
|
| 96 |
+
compile_image_encoder: bool = False,
|
| 97 |
+
):
|
| 98 |
+
super().__init__()
|
| 99 |
+
# Part 1: the image backbone
|
| 100 |
+
self.image_encoder = image_encoder
|
| 101 |
+
# Use level 0, 1, 2 for high-res setting, or just level 2 for the default setting
|
| 102 |
+
self.use_high_res_features_in_sam = use_high_res_features_in_sam
|
| 103 |
+
self.num_feature_levels = 3 if use_high_res_features_in_sam else 1
|
| 104 |
+
self.use_obj_ptrs_in_encoder = use_obj_ptrs_in_encoder
|
| 105 |
+
self.max_obj_ptrs_in_encoder = max_obj_ptrs_in_encoder
|
| 106 |
+
if use_obj_ptrs_in_encoder:
|
| 107 |
+
# A conv layer to downsample the mask prompt to stride 4 (the same stride as
|
| 108 |
+
# low-res SAM mask logits) and to change its scales from 0~1 to SAM logit scale,
|
| 109 |
+
# so that it can be fed into the SAM mask decoder to generate a pointer.
|
| 110 |
+
self.mask_downsample = torch.nn.Conv2d(1, 1, kernel_size=4, stride=4)
|
| 111 |
+
self.add_tpos_enc_to_obj_ptrs = add_tpos_enc_to_obj_ptrs
|
| 112 |
+
if proj_tpos_enc_in_obj_ptrs:
|
| 113 |
+
assert add_tpos_enc_to_obj_ptrs # these options need to be used together
|
| 114 |
+
self.proj_tpos_enc_in_obj_ptrs = proj_tpos_enc_in_obj_ptrs
|
| 115 |
+
self.use_signed_tpos_enc_to_obj_ptrs = use_signed_tpos_enc_to_obj_ptrs
|
| 116 |
+
self.only_obj_ptrs_in_the_past_for_eval = only_obj_ptrs_in_the_past_for_eval
|
| 117 |
+
|
| 118 |
+
# Part 2: memory attention to condition current frame's visual features
|
| 119 |
+
# with memories (and obj ptrs) from past frames
|
| 120 |
+
self.memory_attention = memory_attention
|
| 121 |
+
self.hidden_dim = image_encoder.neck.d_model
|
| 122 |
+
|
| 123 |
+
# Part 3: memory encoder for the previous frame's outputs
|
| 124 |
+
self.memory_encoder = memory_encoder
|
| 125 |
+
self.mem_dim = self.hidden_dim
|
| 126 |
+
if hasattr(self.memory_encoder, "out_proj") and hasattr(
|
| 127 |
+
self.memory_encoder.out_proj, "weight"
|
| 128 |
+
):
|
| 129 |
+
# if there is compression of memories along channel dim
|
| 130 |
+
self.mem_dim = self.memory_encoder.out_proj.weight.shape[0]
|
| 131 |
+
self.num_maskmem = num_maskmem # Number of memories accessible
|
| 132 |
+
# Temporal encoding of the memories
|
| 133 |
+
self.maskmem_tpos_enc = torch.nn.Parameter(
|
| 134 |
+
torch.zeros(num_maskmem, 1, 1, self.mem_dim)
|
| 135 |
+
)
|
| 136 |
+
trunc_normal_(self.maskmem_tpos_enc, std=0.02)
|
| 137 |
+
# a single token to indicate no memory embedding from previous frames
|
| 138 |
+
self.no_mem_embed = torch.nn.Parameter(torch.zeros(1, 1, self.hidden_dim))
|
| 139 |
+
self.no_mem_pos_enc = torch.nn.Parameter(torch.zeros(1, 1, self.hidden_dim))
|
| 140 |
+
trunc_normal_(self.no_mem_embed, std=0.02)
|
| 141 |
+
trunc_normal_(self.no_mem_pos_enc, std=0.02)
|
| 142 |
+
self.directly_add_no_mem_embed = directly_add_no_mem_embed
|
| 143 |
+
# Apply sigmoid to the output raw mask logits (to turn them from
|
| 144 |
+
# range (-inf, +inf) to range (0, 1)) before feeding them into the memory encoder
|
| 145 |
+
self.sigmoid_scale_for_mem_enc = sigmoid_scale_for_mem_enc
|
| 146 |
+
self.sigmoid_bias_for_mem_enc = sigmoid_bias_for_mem_enc
|
| 147 |
+
self.binarize_mask_from_pts_for_mem_enc = binarize_mask_from_pts_for_mem_enc
|
| 148 |
+
self.non_overlap_masks_for_mem_enc = non_overlap_masks_for_mem_enc
|
| 149 |
+
self.memory_temporal_stride_for_eval = memory_temporal_stride_for_eval
|
| 150 |
+
# On frames with mask input, whether to directly output the input mask without
|
| 151 |
+
# using a SAM prompt encoder + mask decoder
|
| 152 |
+
self.use_mask_input_as_output_without_sam = use_mask_input_as_output_without_sam
|
| 153 |
+
self.multimask_output_in_sam = multimask_output_in_sam
|
| 154 |
+
self.multimask_min_pt_num = multimask_min_pt_num
|
| 155 |
+
self.multimask_max_pt_num = multimask_max_pt_num
|
| 156 |
+
self.multimask_output_for_tracking = multimask_output_for_tracking
|
| 157 |
+
self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr
|
| 158 |
+
self.iou_prediction_use_sigmoid = iou_prediction_use_sigmoid
|
| 159 |
+
|
| 160 |
+
# Part 4: SAM-style prompt encoder (for both mask and point inputs)
|
| 161 |
+
# and SAM-style mask decoder for the final mask output
|
| 162 |
+
self.image_size = image_size
|
| 163 |
+
self.backbone_stride = backbone_stride
|
| 164 |
+
self.sam_mask_decoder_extra_args = sam_mask_decoder_extra_args
|
| 165 |
+
self.pred_obj_scores = pred_obj_scores
|
| 166 |
+
self.pred_obj_scores_mlp = pred_obj_scores_mlp
|
| 167 |
+
self.fixed_no_obj_ptr = fixed_no_obj_ptr
|
| 168 |
+
self.soft_no_obj_ptr = soft_no_obj_ptr
|
| 169 |
+
if self.fixed_no_obj_ptr:
|
| 170 |
+
assert self.pred_obj_scores
|
| 171 |
+
assert self.use_obj_ptrs_in_encoder
|
| 172 |
+
if self.pred_obj_scores and self.use_obj_ptrs_in_encoder:
|
| 173 |
+
self.no_obj_ptr = torch.nn.Parameter(torch.zeros(1, self.hidden_dim))
|
| 174 |
+
trunc_normal_(self.no_obj_ptr, std=0.02)
|
| 175 |
+
self.use_mlp_for_obj_ptr_proj = use_mlp_for_obj_ptr_proj
|
| 176 |
+
self.no_obj_embed_spatial = None
|
| 177 |
+
if no_obj_embed_spatial:
|
| 178 |
+
self.no_obj_embed_spatial = torch.nn.Parameter(torch.zeros(1, self.mem_dim))
|
| 179 |
+
trunc_normal_(self.no_obj_embed_spatial, std=0.02)
|
| 180 |
+
|
| 181 |
+
self._build_sam_heads()
|
| 182 |
+
self.max_cond_frames_in_attn = max_cond_frames_in_attn
|
| 183 |
+
|
| 184 |
+
# Model compilation
|
| 185 |
+
if compile_image_encoder:
|
| 186 |
+
# Compile the forward function (not the full module) to allow loading checkpoints.
|
| 187 |
+
print(
|
| 188 |
+
"Image encoder compilation is enabled. First forward pass will be slow."
|
| 189 |
+
)
|
| 190 |
+
self.image_encoder.forward = torch.compile(
|
| 191 |
+
self.image_encoder.forward,
|
| 192 |
+
mode="max-autotune",
|
| 193 |
+
fullgraph=True,
|
| 194 |
+
dynamic=False,
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
@property
|
| 198 |
+
def device(self):
|
| 199 |
+
return next(self.parameters()).device
|
| 200 |
+
|
| 201 |
+
def forward(self, *args, **kwargs):
|
| 202 |
+
raise NotImplementedError(
|
| 203 |
+
"Please use the corresponding methods in SAM2VideoPredictor for inference or SAM2Train for training/fine-tuning"
|
| 204 |
+
"See notebooks/video_predictor_example.ipynb for an inference example."
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
def _build_sam_heads(self):
|
| 208 |
+
"""Build SAM-style prompt encoder and mask decoder."""
|
| 209 |
+
self.sam_prompt_embed_dim = self.hidden_dim
|
| 210 |
+
self.sam_image_embedding_size = self.image_size // self.backbone_stride
|
| 211 |
+
|
| 212 |
+
# build PromptEncoder and MaskDecoder from SAM
|
| 213 |
+
# (their hyperparameters like `mask_in_chans=16` are from SAM code)
|
| 214 |
+
self.sam_prompt_encoder = PromptEncoder(
|
| 215 |
+
embed_dim=self.sam_prompt_embed_dim,
|
| 216 |
+
image_embedding_size=(
|
| 217 |
+
self.sam_image_embedding_size,
|
| 218 |
+
self.sam_image_embedding_size,
|
| 219 |
+
),
|
| 220 |
+
input_image_size=(self.image_size, self.image_size),
|
| 221 |
+
mask_in_chans=16,
|
| 222 |
+
)
|
| 223 |
+
self.sam_mask_decoder = MaskDecoder(
|
| 224 |
+
num_multimask_outputs=3,
|
| 225 |
+
transformer=TwoWayTransformer(
|
| 226 |
+
depth=2,
|
| 227 |
+
embedding_dim=self.sam_prompt_embed_dim,
|
| 228 |
+
mlp_dim=2048,
|
| 229 |
+
num_heads=8,
|
| 230 |
+
),
|
| 231 |
+
transformer_dim=self.sam_prompt_embed_dim,
|
| 232 |
+
iou_head_depth=3,
|
| 233 |
+
iou_head_hidden_dim=256,
|
| 234 |
+
use_high_res_features=self.use_high_res_features_in_sam,
|
| 235 |
+
iou_prediction_use_sigmoid=self.iou_prediction_use_sigmoid,
|
| 236 |
+
pred_obj_scores=self.pred_obj_scores,
|
| 237 |
+
pred_obj_scores_mlp=self.pred_obj_scores_mlp,
|
| 238 |
+
use_multimask_token_for_obj_ptr=self.use_multimask_token_for_obj_ptr,
|
| 239 |
+
**(self.sam_mask_decoder_extra_args or {}),
|
| 240 |
+
)
|
| 241 |
+
if self.use_obj_ptrs_in_encoder:
|
| 242 |
+
# a linear projection on SAM output tokens to turn them into object pointers
|
| 243 |
+
self.obj_ptr_proj = torch.nn.Linear(self.hidden_dim, self.hidden_dim)
|
| 244 |
+
if self.use_mlp_for_obj_ptr_proj:
|
| 245 |
+
self.obj_ptr_proj = MLP(
|
| 246 |
+
self.hidden_dim, self.hidden_dim, self.hidden_dim, 3
|
| 247 |
+
)
|
| 248 |
+
else:
|
| 249 |
+
self.obj_ptr_proj = torch.nn.Identity()
|
| 250 |
+
if self.proj_tpos_enc_in_obj_ptrs:
|
| 251 |
+
# a linear projection on temporal positional encoding in object pointers to
|
| 252 |
+
# avoid potential interference with spatial positional encoding
|
| 253 |
+
self.obj_ptr_tpos_proj = torch.nn.Linear(self.hidden_dim, self.mem_dim)
|
| 254 |
+
else:
|
| 255 |
+
self.obj_ptr_tpos_proj = torch.nn.Identity()
|
| 256 |
+
|
| 257 |
+
def _forward_sam_heads(
|
| 258 |
+
self,
|
| 259 |
+
backbone_features,
|
| 260 |
+
point_inputs=None,
|
| 261 |
+
mask_inputs=None,
|
| 262 |
+
high_res_features=None,
|
| 263 |
+
multimask_output=False,
|
| 264 |
+
):
|
| 265 |
+
"""
|
| 266 |
+
Forward SAM prompt encoders and mask heads.
|
| 267 |
+
|
| 268 |
+
Inputs:
|
| 269 |
+
- backbone_features: image features of [B, C, H, W] shape
|
| 270 |
+
- point_inputs: a dictionary with "point_coords" and "point_labels", where
|
| 271 |
+
1) "point_coords" has [B, P, 2] shape and float32 dtype and contains the
|
| 272 |
+
absolute pixel-unit coordinate in (x, y) format of the P input points
|
| 273 |
+
2) "point_labels" has shape [B, P] and int32 dtype, where 1 means
|
| 274 |
+
positive clicks, 0 means negative clicks, and -1 means padding
|
| 275 |
+
- mask_inputs: a mask of [B, 1, H*16, W*16] shape, float or bool, with the
|
| 276 |
+
same spatial size as the image.
|
| 277 |
+
- high_res_features: either 1) None or 2) or a list of length 2 containing
|
| 278 |
+
two feature maps of [B, C, 4*H, 4*W] and [B, C, 2*H, 2*W] shapes respectively,
|
| 279 |
+
which will be used as high-resolution feature maps for SAM decoder.
|
| 280 |
+
- multimask_output: if it's True, we output 3 candidate masks and their 3
|
| 281 |
+
corresponding IoU estimates, and if it's False, we output only 1 mask and
|
| 282 |
+
its corresponding IoU estimate.
|
| 283 |
+
|
| 284 |
+
Outputs:
|
| 285 |
+
- low_res_multimasks: [B, M, H*4, W*4] shape (where M = 3 if
|
| 286 |
+
`multimask_output=True` and M = 1 if `multimask_output=False`), the SAM
|
| 287 |
+
output mask logits (before sigmoid) for the low-resolution masks, with 4x
|
| 288 |
+
the resolution (1/4 stride) of the input backbone_features.
|
| 289 |
+
- high_res_multimasks: [B, M, H*16, W*16] shape (where M = 3
|
| 290 |
+
if `multimask_output=True` and M = 1 if `multimask_output=False`),
|
| 291 |
+
upsampled from the low-resolution masks, with shape size as the image
|
| 292 |
+
(stride is 1 pixel).
|
| 293 |
+
- ious, [B, M] shape, where (where M = 3 if `multimask_output=True` and M = 1
|
| 294 |
+
if `multimask_output=False`), the estimated IoU of each output mask.
|
| 295 |
+
- low_res_masks: [B, 1, H*4, W*4] shape, the best mask in `low_res_multimasks`.
|
| 296 |
+
If `multimask_output=True`, it's the mask with the highest IoU estimate.
|
| 297 |
+
If `multimask_output=False`, it's the same as `low_res_multimasks`.
|
| 298 |
+
- high_res_masks: [B, 1, H*16, W*16] shape, the best mask in `high_res_multimasks`.
|
| 299 |
+
If `multimask_output=True`, it's the mask with the highest IoU estimate.
|
| 300 |
+
If `multimask_output=False`, it's the same as `high_res_multimasks`.
|
| 301 |
+
- obj_ptr: [B, C] shape, the object pointer vector for the output mask, extracted
|
| 302 |
+
based on the output token from the SAM mask decoder.
|
| 303 |
+
"""
|
| 304 |
+
B = backbone_features.size(0)
|
| 305 |
+
device = backbone_features.device
|
| 306 |
+
assert backbone_features.size(1) == self.sam_prompt_embed_dim
|
| 307 |
+
assert backbone_features.size(2) == self.sam_image_embedding_size
|
| 308 |
+
assert backbone_features.size(3) == self.sam_image_embedding_size
|
| 309 |
+
|
| 310 |
+
# a) Handle point prompts
|
| 311 |
+
if point_inputs is not None:
|
| 312 |
+
sam_point_coords = point_inputs["point_coords"]
|
| 313 |
+
sam_point_labels = point_inputs["point_labels"]
|
| 314 |
+
assert sam_point_coords.size(0) == B and sam_point_labels.size(0) == B
|
| 315 |
+
else:
|
| 316 |
+
# If no points are provide, pad with an empty point (with label -1)
|
| 317 |
+
sam_point_coords = torch.zeros(B, 1, 2, device=device)
|
| 318 |
+
sam_point_labels = -torch.ones(B, 1, dtype=torch.int32, device=device)
|
| 319 |
+
|
| 320 |
+
# b) Handle mask prompts
|
| 321 |
+
if mask_inputs is not None:
|
| 322 |
+
# If mask_inputs is provided, downsize it into low-res mask input if needed
|
| 323 |
+
# and feed it as a dense mask prompt into the SAM mask encoder
|
| 324 |
+
assert len(mask_inputs.shape) == 4 and mask_inputs.shape[:2] == (B, 1)
|
| 325 |
+
if mask_inputs.shape[-2:] != self.sam_prompt_encoder.mask_input_size:
|
| 326 |
+
sam_mask_prompt = F.interpolate(
|
| 327 |
+
mask_inputs.float(),
|
| 328 |
+
size=self.sam_prompt_encoder.mask_input_size,
|
| 329 |
+
align_corners=False,
|
| 330 |
+
mode="bilinear",
|
| 331 |
+
antialias=True, # use antialias for downsampling
|
| 332 |
+
)
|
| 333 |
+
else:
|
| 334 |
+
sam_mask_prompt = mask_inputs
|
| 335 |
+
else:
|
| 336 |
+
# Otherwise, simply feed None (and SAM's prompt encoder will add
|
| 337 |
+
# a learned `no_mask_embed` to indicate no mask input in this case).
|
| 338 |
+
sam_mask_prompt = None
|
| 339 |
+
|
| 340 |
+
sparse_embeddings, dense_embeddings = self.sam_prompt_encoder(
|
| 341 |
+
points=(sam_point_coords, sam_point_labels),
|
| 342 |
+
boxes=None,
|
| 343 |
+
masks=sam_mask_prompt,
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
(
|
| 349 |
+
low_res_multimasks,
|
| 350 |
+
ious,
|
| 351 |
+
sam_output_tokens,
|
| 352 |
+
object_score_logits,
|
| 353 |
+
) = self.sam_mask_decoder(
|
| 354 |
+
image_embeddings=backbone_features,
|
| 355 |
+
image_pe=self.sam_prompt_encoder.get_dense_pe(),
|
| 356 |
+
sparse_prompt_embeddings=sparse_embeddings,
|
| 357 |
+
dense_prompt_embeddings=dense_embeddings,
|
| 358 |
+
multimask_output=multimask_output,
|
| 359 |
+
repeat_image=False, # the image is already batched
|
| 360 |
+
high_res_features=high_res_features,
|
| 361 |
+
)
|
| 362 |
+
if self.pred_obj_scores:
|
| 363 |
+
is_obj_appearing = object_score_logits > 0
|
| 364 |
+
|
| 365 |
+
# Mask used for spatial memories is always a *hard* choice between obj and no obj,
|
| 366 |
+
# consistent with the actual mask prediction
|
| 367 |
+
low_res_multimasks = torch.where(
|
| 368 |
+
is_obj_appearing[:, None, None],
|
| 369 |
+
low_res_multimasks,
|
| 370 |
+
NO_OBJ_SCORE,
|
| 371 |
+
)
|
| 372 |
+
|
| 373 |
+
# convert masks from possibly bfloat16 (or float16) to float32
|
| 374 |
+
# (older PyTorch versions before 2.1 don't support `interpolate` on bf16)
|
| 375 |
+
low_res_multimasks = low_res_multimasks.float()
|
| 376 |
+
high_res_multimasks = F.interpolate(
|
| 377 |
+
low_res_multimasks,
|
| 378 |
+
size=(self.image_size, self.image_size),
|
| 379 |
+
mode="bilinear",
|
| 380 |
+
align_corners=False,
|
| 381 |
+
)
|
| 382 |
+
|
| 383 |
+
sam_output_token = sam_output_tokens[:, 0]
|
| 384 |
+
if multimask_output:
|
| 385 |
+
# take the best mask prediction (with the highest IoU estimation)
|
| 386 |
+
best_iou_inds = torch.argmax(ious, dim=-1)
|
| 387 |
+
batch_inds = torch.arange(B, device=device)
|
| 388 |
+
low_res_masks = low_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)
|
| 389 |
+
high_res_masks = high_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)
|
| 390 |
+
if sam_output_tokens.size(1) > 1:
|
| 391 |
+
sam_output_token = sam_output_tokens[batch_inds, best_iou_inds]
|
| 392 |
+
else:
|
| 393 |
+
low_res_masks, high_res_masks = low_res_multimasks, high_res_multimasks
|
| 394 |
+
|
| 395 |
+
# Extract object pointer from the SAM output token (with occlusion handling)
|
| 396 |
+
obj_ptr = self.obj_ptr_proj(sam_output_token)
|
| 397 |
+
if self.pred_obj_scores:
|
| 398 |
+
# Allow *soft* no obj ptr, unlike for masks
|
| 399 |
+
if self.soft_no_obj_ptr:
|
| 400 |
+
lambda_is_obj_appearing = object_score_logits.sigmoid()
|
| 401 |
+
else:
|
| 402 |
+
lambda_is_obj_appearing = is_obj_appearing.float()
|
| 403 |
+
|
| 404 |
+
if self.fixed_no_obj_ptr:
|
| 405 |
+
obj_ptr = lambda_is_obj_appearing * obj_ptr
|
| 406 |
+
obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
#######SAM2Long########
|
| 410 |
+
obj_ptrs = self.obj_ptr_proj(sam_output_tokens)
|
| 411 |
+
lambda_is_obj_appearing = is_obj_appearing.float()[:, None]
|
| 412 |
+
obj_ptrs = lambda_is_obj_appearing * obj_ptrs
|
| 413 |
+
obj_ptrs = obj_ptrs + (1 - lambda_is_obj_appearing) * self.no_obj_ptr
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
return (
|
| 417 |
+
low_res_multimasks,
|
| 418 |
+
high_res_multimasks,
|
| 419 |
+
ious,
|
| 420 |
+
low_res_masks,
|
| 421 |
+
high_res_masks,
|
| 422 |
+
obj_ptr,
|
| 423 |
+
object_score_logits,
|
| 424 |
+
obj_ptrs,
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
def _use_mask_as_output(self, backbone_features, high_res_features, mask_inputs):
|
| 428 |
+
"""
|
| 429 |
+
Directly turn binary `mask_inputs` into a output mask logits without using SAM.
|
| 430 |
+
(same input and output shapes as in _forward_sam_heads above).
|
| 431 |
+
"""
|
| 432 |
+
# Use -10/+10 as logits for neg/pos pixels (very close to 0/1 in prob after sigmoid).
|
| 433 |
+
out_scale, out_bias = 20.0, -10.0 # sigmoid(-10.0)=4.5398e-05
|
| 434 |
+
mask_inputs_float = mask_inputs.float()
|
| 435 |
+
high_res_masks = mask_inputs_float * out_scale + out_bias
|
| 436 |
+
low_res_masks = F.interpolate(
|
| 437 |
+
high_res_masks,
|
| 438 |
+
size=(high_res_masks.size(-2) // 4, high_res_masks.size(-1) // 4),
|
| 439 |
+
align_corners=False,
|
| 440 |
+
mode="bilinear",
|
| 441 |
+
antialias=True, # use antialias for downsampling
|
| 442 |
+
)
|
| 443 |
+
# a dummy IoU prediction of all 1's under mask input
|
| 444 |
+
ious = mask_inputs.new_ones(mask_inputs.size(0), 1).float()
|
| 445 |
+
if not self.use_obj_ptrs_in_encoder:
|
| 446 |
+
# all zeros as a dummy object pointer (of shape [B, C])
|
| 447 |
+
obj_ptr = torch.zeros(
|
| 448 |
+
mask_inputs.size(0), self.hidden_dim, device=mask_inputs.device
|
| 449 |
+
)
|
| 450 |
+
else:
|
| 451 |
+
# produce an object pointer using the SAM decoder from the mask input
|
| 452 |
+
_, _, _, _, _, obj_ptr, _, _ = self._forward_sam_heads(
|
| 453 |
+
backbone_features=backbone_features,
|
| 454 |
+
mask_inputs=self.mask_downsample(mask_inputs_float),
|
| 455 |
+
high_res_features=high_res_features,
|
| 456 |
+
)
|
| 457 |
+
# In this method, we are treating mask_input as output, e.g. using it directly to create spatial mem;
|
| 458 |
+
# Below, we follow the same design axiom to use mask_input to decide if obj appears or not instead of relying
|
| 459 |
+
# on the object_scores from the SAM decoder.
|
| 460 |
+
is_obj_appearing = torch.any(mask_inputs.flatten(1).float() > 0.0, dim=1)
|
| 461 |
+
is_obj_appearing = is_obj_appearing[..., None]
|
| 462 |
+
lambda_is_obj_appearing = is_obj_appearing.float()
|
| 463 |
+
object_score_logits = out_scale * lambda_is_obj_appearing + out_bias
|
| 464 |
+
if self.pred_obj_scores:
|
| 465 |
+
if self.fixed_no_obj_ptr:
|
| 466 |
+
obj_ptr = lambda_is_obj_appearing * obj_ptr
|
| 467 |
+
obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr
|
| 468 |
+
|
| 469 |
+
return (
|
| 470 |
+
low_res_masks,
|
| 471 |
+
high_res_masks,
|
| 472 |
+
ious,
|
| 473 |
+
low_res_masks,
|
| 474 |
+
high_res_masks,
|
| 475 |
+
obj_ptr,
|
| 476 |
+
object_score_logits,
|
| 477 |
+
None,
|
| 478 |
+
)
|
| 479 |
+
|
| 480 |
+
def forward_image(self, img_batch: torch.Tensor):
|
| 481 |
+
"""Get the image feature on the input batch."""
|
| 482 |
+
backbone_out = self.image_encoder(img_batch)
|
| 483 |
+
if self.use_high_res_features_in_sam:
|
| 484 |
+
# precompute projected level 0 and level 1 features in SAM decoder
|
| 485 |
+
# to avoid running it again on every SAM click
|
| 486 |
+
backbone_out["backbone_fpn"][0] = self.sam_mask_decoder.conv_s0(
|
| 487 |
+
backbone_out["backbone_fpn"][0]
|
| 488 |
+
)
|
| 489 |
+
backbone_out["backbone_fpn"][1] = self.sam_mask_decoder.conv_s1(
|
| 490 |
+
backbone_out["backbone_fpn"][1]
|
| 491 |
+
)
|
| 492 |
+
return backbone_out
|
| 493 |
+
|
| 494 |
+
def _prepare_backbone_features(self, backbone_out):
|
| 495 |
+
"""Prepare and flatten visual features."""
|
| 496 |
+
backbone_out = backbone_out.copy()
|
| 497 |
+
assert len(backbone_out["backbone_fpn"]) == len(backbone_out["vision_pos_enc"])
|
| 498 |
+
assert len(backbone_out["backbone_fpn"]) >= self.num_feature_levels
|
| 499 |
+
|
| 500 |
+
feature_maps = backbone_out["backbone_fpn"][-self.num_feature_levels :]
|
| 501 |
+
vision_pos_embeds = backbone_out["vision_pos_enc"][-self.num_feature_levels :]
|
| 502 |
+
|
| 503 |
+
feat_sizes = [(x.shape[-2], x.shape[-1]) for x in vision_pos_embeds]
|
| 504 |
+
# flatten NxCxHxW to HWxNxC
|
| 505 |
+
vision_feats = [x.flatten(2).permute(2, 0, 1) for x in feature_maps]
|
| 506 |
+
vision_pos_embeds = [x.flatten(2).permute(2, 0, 1) for x in vision_pos_embeds]
|
| 507 |
+
|
| 508 |
+
return backbone_out, vision_feats, vision_pos_embeds, feat_sizes
|
| 509 |
+
|
| 510 |
+
def _prepare_memory_conditioned_features(
|
| 511 |
+
self,
|
| 512 |
+
frame_idx,
|
| 513 |
+
is_init_cond_frame,
|
| 514 |
+
current_vision_feats,
|
| 515 |
+
current_vision_pos_embeds,
|
| 516 |
+
feat_sizes,
|
| 517 |
+
output_dict,
|
| 518 |
+
num_frames,
|
| 519 |
+
track_in_reverse=False, # tracking in reverse time order (for demo usage)
|
| 520 |
+
mem_pick_index=0,
|
| 521 |
+
start_frame_idx=0,
|
| 522 |
+
iou_thre=0.1,
|
| 523 |
+
):
|
| 524 |
+
"""Fuse the current frame's visual feature map with previous memory."""
|
| 525 |
+
B = current_vision_feats[-1].size(1) # batch size on this frame
|
| 526 |
+
C = self.hidden_dim
|
| 527 |
+
H, W = feat_sizes[-1] # top-level (lowest-resolution) feature size
|
| 528 |
+
device = current_vision_feats[-1].device
|
| 529 |
+
# The case of `self.num_maskmem == 0` below is primarily used for reproducing SAM on images.
|
| 530 |
+
# In this case, we skip the fusion with any memory.
|
| 531 |
+
if self.num_maskmem == 0: # Disable memory and skip fusion
|
| 532 |
+
pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W)
|
| 533 |
+
return pix_feat
|
| 534 |
+
|
| 535 |
+
num_obj_ptr_tokens = 0
|
| 536 |
+
tpos_sign_mul = -1 if track_in_reverse else 1
|
| 537 |
+
# Step 1: condition the visual features of the current frame on previous memories
|
| 538 |
+
if not is_init_cond_frame:
|
| 539 |
+
# Retrieve the memories encoded with the maskmem backbone
|
| 540 |
+
to_cat_memory, to_cat_memory_pos_embed = [], []
|
| 541 |
+
# Add conditioning frames's output first (all cond frames have t_pos=0 for
|
| 542 |
+
# when getting temporal positional embedding below)
|
| 543 |
+
assert len(output_dict["cond_frame_outputs"]) > 0
|
| 544 |
+
# Select a maximum number of temporally closest cond frames for cross attention
|
| 545 |
+
cond_outputs = output_dict["cond_frame_outputs"]
|
| 546 |
+
selected_cond_outputs, unselected_cond_outputs = select_closest_cond_frames(
|
| 547 |
+
frame_idx, cond_outputs, self.max_cond_frames_in_attn
|
| 548 |
+
)
|
| 549 |
+
t_pos_and_prevs = [(0, out) for out in selected_cond_outputs.values()]
|
| 550 |
+
# Add last (self.num_maskmem - 1) frames before current frame for non-conditioning memory
|
| 551 |
+
# the earliest one has t_pos=1 and the latest one has t_pos=self.num_maskmem-1
|
| 552 |
+
# We also allow taking the memory frame non-consecutively (with stride>1), in which case
|
| 553 |
+
# we take (self.num_maskmem - 2) frames among every stride-th frames plus the last frame.
|
| 554 |
+
stride = 1 if self.training else self.memory_temporal_stride_for_eval
|
| 555 |
+
|
| 556 |
+
max_obj_ptrs_in_encoder = min(num_frames, self.max_obj_ptrs_in_encoder)
|
| 557 |
+
num_object = int(cond_outputs[start_frame_idx]['obj_ptr'].shape[0]) ##always one
|
| 558 |
+
|
| 559 |
+
|
| 560 |
+
if frame_idx <= start_frame_idx+1 or mem_pick_index==0:
|
| 561 |
+
valid_indices = []
|
| 562 |
+
else:
|
| 563 |
+
valid_indices = []
|
| 564 |
+
for i in range(frame_idx - 1, start_frame_idx, -1):
|
| 565 |
+
object_score = output_dict["non_cond_frame_outputs"][i]['object_score_logits'][...,mem_pick_index[i]]
|
| 566 |
+
iou = output_dict["non_cond_frame_outputs"][i]['ious'][...,mem_pick_index[i]]
|
| 567 |
+
# print("threshold", iou_thre)
|
| 568 |
+
if iou.item() > iou_thre and object_score.item() > 0:
|
| 569 |
+
valid_indices.insert(0, i)
|
| 570 |
+
if len(valid_indices) >= max_obj_ptrs_in_encoder - 1:
|
| 571 |
+
break
|
| 572 |
+
if frame_idx - 1 not in valid_indices: ##pick last frame
|
| 573 |
+
valid_indices.append(frame_idx-1)
|
| 574 |
+
|
| 575 |
+
prev_idxs = [start_frame_idx]
|
| 576 |
+
for t_pos in range(1, self.num_maskmem):
|
| 577 |
+
idx = t_pos - self.num_maskmem
|
| 578 |
+
if idx < -len(valid_indices):
|
| 579 |
+
continue
|
| 580 |
+
out = output_dict["non_cond_frame_outputs"].get(valid_indices[idx], None)
|
| 581 |
+
if out is None:
|
| 582 |
+
out = unselected_cond_outputs.get(valid_indices[idx], None)
|
| 583 |
+
t_pos_and_prevs.append((t_pos, out))
|
| 584 |
+
prev_idxs.append(valid_indices[idx])
|
| 585 |
+
|
| 586 |
+
object_frame_score = [torch.ones(num_object).to(cond_outputs[start_frame_idx]['obj_ptr'].device, torch.bfloat16)*10]
|
| 587 |
+
for (t_pos, prev), prev_idx in zip(t_pos_and_prevs, prev_idxs):
|
| 588 |
+
if prev is None:
|
| 589 |
+
continue # skip padding frames
|
| 590 |
+
# "maskmem_features" might have been offloaded to CPU in demo use cases,
|
| 591 |
+
# so we load it back to GPU (it's a no-op if it's already on GPU).
|
| 592 |
+
if t_pos > 0 and mem_pick_index != 0:
|
| 593 |
+
object_frame_score.append(prev["object_score_logits"][...,mem_pick_index[prev_idx]].view(-1))
|
| 594 |
+
feats = prev["maskmem_features"][...,mem_pick_index[prev_idx]].to(device, non_blocking=True)
|
| 595 |
+
else:
|
| 596 |
+
feats = prev["maskmem_features"].to(device, non_blocking=True)
|
| 597 |
+
to_cat_memory.append(feats.flatten(2).permute(2, 0, 1))
|
| 598 |
+
# Spatial positional encoding (it might have been offloaded to CPU in eval)
|
| 599 |
+
maskmem_enc = prev["maskmem_pos_enc"][-1].to(device)
|
| 600 |
+
maskmem_enc = maskmem_enc.flatten(2).permute(2, 0, 1)
|
| 601 |
+
# Temporal positional encoding
|
| 602 |
+
maskmem_enc = (
|
| 603 |
+
maskmem_enc + self.maskmem_tpos_enc[self.num_maskmem - t_pos - 1]
|
| 604 |
+
)
|
| 605 |
+
to_cat_memory_pos_embed.append(maskmem_enc)
|
| 606 |
+
|
| 607 |
+
# Construct the list of past object pointers
|
| 608 |
+
if self.use_obj_ptrs_in_encoder:
|
| 609 |
+
max_obj_ptrs_in_encoder = min(num_frames, self.max_obj_ptrs_in_encoder)
|
| 610 |
+
# First add those object pointers from selected conditioning frames
|
| 611 |
+
# (optionally, only include object pointers in the past during evaluation)
|
| 612 |
+
if not self.training and self.only_obj_ptrs_in_the_past_for_eval:
|
| 613 |
+
ptr_cond_outputs = {
|
| 614 |
+
t: out
|
| 615 |
+
for t, out in selected_cond_outputs.items()
|
| 616 |
+
if (t >= frame_idx if track_in_reverse else t <= frame_idx)
|
| 617 |
+
}
|
| 618 |
+
else:
|
| 619 |
+
ptr_cond_outputs = selected_cond_outputs
|
| 620 |
+
pos_and_ptrs = [
|
| 621 |
+
# Temporal pos encoding contains how far away each pointer is from current frame
|
| 622 |
+
(abs(frame_idx - t), out["obj_ptr"])
|
| 623 |
+
for t, out in ptr_cond_outputs.items()
|
| 624 |
+
]
|
| 625 |
+
# Add up to (max_obj_ptrs_in_encoder - 1) non-conditioning frames before current frame
|
| 626 |
+
object_ptr_score = [torch.ones(num_object).to(cond_outputs[start_frame_idx]['obj_ptr'].device, torch.bfloat16)*10]
|
| 627 |
+
for t_diff in range(1, max_obj_ptrs_in_encoder):
|
| 628 |
+
if -t_diff <= -len(valid_indices):
|
| 629 |
+
break
|
| 630 |
+
out = output_dict["non_cond_frame_outputs"].get(
|
| 631 |
+
valid_indices[-t_diff], unselected_cond_outputs.get(valid_indices[-t_diff], None))
|
| 632 |
+
if out is not None:
|
| 633 |
+
mem_idx = mem_pick_index[valid_indices[-t_diff]]
|
| 634 |
+
object_ptr_score.append(out['object_score_logits'][...,mem_idx].view(-1))
|
| 635 |
+
pos_and_ptrs.append((t_diff, out["obj_ptr"][...,mem_idx]))
|
| 636 |
+
# object_ptr_score.append(output_dict["non_cond_frame_outputs"][valid_indices[-t_diff]]['object_score'].item())
|
| 637 |
+
# If we have at least one object pointer, add them to the across attention
|
| 638 |
+
if len(pos_and_ptrs) > 0:
|
| 639 |
+
pos_list, ptrs_list = zip(*pos_and_ptrs)
|
| 640 |
+
# stack object pointers along dim=0 into [ptr_seq_len, B, C] shape
|
| 641 |
+
obj_ptrs = torch.stack(ptrs_list, dim=0)
|
| 642 |
+
# a temporal positional embedding based on how far each object pointer is from
|
| 643 |
+
# the current frame (sine embedding normalized by the max pointer num).
|
| 644 |
+
if self.add_tpos_enc_to_obj_ptrs:
|
| 645 |
+
t_diff_max = max_obj_ptrs_in_encoder - 1
|
| 646 |
+
tpos_dim = C if self.proj_tpos_enc_in_obj_ptrs else self.mem_dim
|
| 647 |
+
obj_pos = torch.tensor(pos_list, device=device)
|
| 648 |
+
obj_pos = get_1d_sine_pe(obj_pos / t_diff_max, dim=tpos_dim)
|
| 649 |
+
obj_pos = self.obj_ptr_tpos_proj(obj_pos)
|
| 650 |
+
obj_pos = obj_pos.unsqueeze(1).expand(-1, B, self.mem_dim)
|
| 651 |
+
else:
|
| 652 |
+
obj_pos = obj_ptrs.new_zeros(len(pos_list), B, self.mem_dim)
|
| 653 |
+
if self.mem_dim < C:
|
| 654 |
+
# split a pointer into (C // self.mem_dim) tokens for self.mem_dim < C
|
| 655 |
+
obj_ptrs = obj_ptrs.reshape(
|
| 656 |
+
-1, B, C // self.mem_dim, self.mem_dim
|
| 657 |
+
)
|
| 658 |
+
obj_ptrs = obj_ptrs.permute(0, 2, 1, 3).flatten(0, 1)
|
| 659 |
+
obj_pos = obj_pos.repeat_interleave(C // self.mem_dim, dim=0)
|
| 660 |
+
to_cat_memory.append(obj_ptrs)
|
| 661 |
+
to_cat_memory_pos_embed.append(obj_pos)
|
| 662 |
+
num_obj_ptr_tokens = obj_ptrs.shape[0]
|
| 663 |
+
else:
|
| 664 |
+
num_obj_ptr_tokens = 0
|
| 665 |
+
else:
|
| 666 |
+
# for initial conditioning frames, encode them without using any previous memory
|
| 667 |
+
if self.directly_add_no_mem_embed:
|
| 668 |
+
# directly add no-mem embedding (instead of using the transformer encoder)
|
| 669 |
+
pix_feat_with_mem = current_vision_feats[-1] + self.no_mem_embed
|
| 670 |
+
pix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W)
|
| 671 |
+
return pix_feat_with_mem
|
| 672 |
+
|
| 673 |
+
# Use a dummy token on the first frame (to avoid empty memory input to tranformer encoder)
|
| 674 |
+
to_cat_memory = [self.no_mem_embed.expand(1, B, self.mem_dim)]
|
| 675 |
+
to_cat_memory_pos_embed = [self.no_mem_pos_enc.expand(1, B, self.mem_dim)]
|
| 676 |
+
|
| 677 |
+
# Step 2: Concatenate the memories and forward through the transformer encoder
|
| 678 |
+
memory = torch.cat(to_cat_memory, dim=0)
|
| 679 |
+
memory_pos_embed = torch.cat(to_cat_memory_pos_embed, dim=0)
|
| 680 |
+
|
| 681 |
+
pix_feat_with_mem = self.memory_attention(
|
| 682 |
+
curr=current_vision_feats,
|
| 683 |
+
curr_pos=current_vision_pos_embeds,
|
| 684 |
+
memory=memory,
|
| 685 |
+
memory_pos=memory_pos_embed,
|
| 686 |
+
num_obj_ptr_tokens=num_obj_ptr_tokens,
|
| 687 |
+
object_frame_scores=object_frame_score,
|
| 688 |
+
object_ptr_scores=object_ptr_score,
|
| 689 |
+
)
|
| 690 |
+
# reshape the output (HW)BC => BCHW
|
| 691 |
+
pix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W)
|
| 692 |
+
|
| 693 |
+
return pix_feat_with_mem
|
| 694 |
+
|
| 695 |
+
def _encode_new_memory(
|
| 696 |
+
self,
|
| 697 |
+
current_vision_feats,
|
| 698 |
+
feat_sizes,
|
| 699 |
+
pred_masks_high_res,
|
| 700 |
+
object_score_logits,
|
| 701 |
+
is_mask_from_pts,
|
| 702 |
+
):
|
| 703 |
+
"""Encode the current image and its prediction into a memory feature."""
|
| 704 |
+
B = current_vision_feats[-1].size(1) # batch size on this frame
|
| 705 |
+
C = self.hidden_dim
|
| 706 |
+
H, W = feat_sizes[-1] # top-level (lowest-resolution) feature size
|
| 707 |
+
# top-level feature, (HW)BC => BCHW
|
| 708 |
+
pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W)
|
| 709 |
+
if self.non_overlap_masks_for_mem_enc and not self.training:
|
| 710 |
+
# optionally, apply non-overlapping constraints to the masks (it's applied
|
| 711 |
+
# in the batch dimension and should only be used during eval, where all
|
| 712 |
+
# the objects come from the same video under batch size 1).
|
| 713 |
+
pred_masks_high_res = self._apply_non_overlapping_constraints(
|
| 714 |
+
pred_masks_high_res
|
| 715 |
+
)
|
| 716 |
+
# scale the raw mask logits with a temperature before applying sigmoid
|
| 717 |
+
binarize = self.binarize_mask_from_pts_for_mem_enc and is_mask_from_pts
|
| 718 |
+
if binarize and not self.training:
|
| 719 |
+
mask_for_mem = (pred_masks_high_res > 0).float()
|
| 720 |
+
else:
|
| 721 |
+
# apply sigmoid on the raw mask logits to turn them into range (0, 1)
|
| 722 |
+
mask_for_mem = torch.sigmoid(pred_masks_high_res)
|
| 723 |
+
# apply scale and bias terms to the sigmoid probabilities
|
| 724 |
+
if self.sigmoid_scale_for_mem_enc != 1.0:
|
| 725 |
+
mask_for_mem = mask_for_mem * self.sigmoid_scale_for_mem_enc
|
| 726 |
+
if self.sigmoid_bias_for_mem_enc != 0.0:
|
| 727 |
+
mask_for_mem = mask_for_mem + self.sigmoid_bias_for_mem_enc
|
| 728 |
+
|
| 729 |
+
maskmem_out = self.memory_encoder(
|
| 730 |
+
pix_feat, mask_for_mem, skip_mask_sigmoid=True # sigmoid already applied
|
| 731 |
+
)
|
| 732 |
+
maskmem_features = maskmem_out["vision_features"]
|
| 733 |
+
maskmem_pos_enc = maskmem_out["vision_pos_enc"]
|
| 734 |
+
# add a no-object embedding to the spatial memory to indicate that the frame
|
| 735 |
+
# is predicted to be occluded (i.e. no object is appearing in the frame)
|
| 736 |
+
if self.no_obj_embed_spatial is not None:
|
| 737 |
+
is_obj_appearing = (object_score_logits > 0).float()
|
| 738 |
+
maskmem_features += (
|
| 739 |
+
1 - is_obj_appearing[..., None, None]
|
| 740 |
+
) * self.no_obj_embed_spatial[..., None, None].expand(
|
| 741 |
+
*maskmem_features.shape
|
| 742 |
+
)
|
| 743 |
+
|
| 744 |
+
return maskmem_features, maskmem_pos_enc
|
| 745 |
+
|
| 746 |
+
def _track_step(
|
| 747 |
+
self,
|
| 748 |
+
frame_idx,
|
| 749 |
+
is_init_cond_frame,
|
| 750 |
+
current_vision_feats,
|
| 751 |
+
current_vision_pos_embeds,
|
| 752 |
+
feat_sizes,
|
| 753 |
+
point_inputs,
|
| 754 |
+
mask_inputs,
|
| 755 |
+
output_dict,
|
| 756 |
+
num_frames,
|
| 757 |
+
track_in_reverse,
|
| 758 |
+
prev_sam_mask_logits,
|
| 759 |
+
mem_pick_index=0,
|
| 760 |
+
start_frame_idx=0,
|
| 761 |
+
iou_thre=0.1,
|
| 762 |
+
):
|
| 763 |
+
current_out = {"point_inputs": point_inputs, "mask_inputs": mask_inputs}
|
| 764 |
+
# High-resolution feature maps for the SAM head, reshape (HW)BC => BCHW
|
| 765 |
+
if len(current_vision_feats) > 1:
|
| 766 |
+
high_res_features = [
|
| 767 |
+
x.permute(1, 2, 0).view(x.size(1), x.size(2), *s)
|
| 768 |
+
for x, s in zip(current_vision_feats[:-1], feat_sizes[:-1])
|
| 769 |
+
]
|
| 770 |
+
else:
|
| 771 |
+
high_res_features = None
|
| 772 |
+
if mask_inputs is not None and self.use_mask_input_as_output_without_sam:
|
| 773 |
+
# When use_mask_input_as_output_without_sam=True, we directly output the mask input
|
| 774 |
+
# (see it as a GT mask) without using a SAM prompt encoder + mask decoder.
|
| 775 |
+
pix_feat = current_vision_feats[-1].permute(1, 2, 0)
|
| 776 |
+
pix_feat = pix_feat.view(-1, self.hidden_dim, *feat_sizes[-1])
|
| 777 |
+
sam_outputs = self._use_mask_as_output(
|
| 778 |
+
pix_feat, high_res_features, mask_inputs
|
| 779 |
+
)
|
| 780 |
+
else:
|
| 781 |
+
# fused the visual feature with previous memory features in the memory bank
|
| 782 |
+
pix_feat = self._prepare_memory_conditioned_features(
|
| 783 |
+
frame_idx=frame_idx,
|
| 784 |
+
is_init_cond_frame=is_init_cond_frame,
|
| 785 |
+
current_vision_feats=current_vision_feats[-1:],
|
| 786 |
+
current_vision_pos_embeds=current_vision_pos_embeds[-1:],
|
| 787 |
+
feat_sizes=feat_sizes[-1:],
|
| 788 |
+
output_dict=output_dict,
|
| 789 |
+
num_frames=num_frames,
|
| 790 |
+
track_in_reverse=track_in_reverse,
|
| 791 |
+
mem_pick_index=mem_pick_index,
|
| 792 |
+
start_frame_idx=start_frame_idx,
|
| 793 |
+
iou_thre=iou_thre,
|
| 794 |
+
)
|
| 795 |
+
# apply SAM-style segmentation head
|
| 796 |
+
# here we might feed previously predicted low-res SAM mask logits into the SAM mask decoder,
|
| 797 |
+
# e.g. in demo where such logits come from earlier interaction instead of correction sampling
|
| 798 |
+
# (in this case, any `mask_inputs` shouldn't reach here as they are sent to _use_mask_as_output instead)
|
| 799 |
+
if prev_sam_mask_logits is not None:
|
| 800 |
+
assert point_inputs is not None and mask_inputs is None
|
| 801 |
+
mask_inputs = prev_sam_mask_logits
|
| 802 |
+
multimask_output = self._use_multimask(is_init_cond_frame, point_inputs)
|
| 803 |
+
sam_outputs = self._forward_sam_heads(
|
| 804 |
+
backbone_features=pix_feat,
|
| 805 |
+
point_inputs=point_inputs,
|
| 806 |
+
mask_inputs=mask_inputs,
|
| 807 |
+
high_res_features=high_res_features,
|
| 808 |
+
multimask_output=multimask_output,
|
| 809 |
+
)
|
| 810 |
+
|
| 811 |
+
return current_out, sam_outputs, high_res_features, pix_feat
|
| 812 |
+
|
| 813 |
+
def _encode_memory_in_output(
|
| 814 |
+
self,
|
| 815 |
+
current_vision_feats,
|
| 816 |
+
feat_sizes,
|
| 817 |
+
point_inputs,
|
| 818 |
+
run_mem_encoder,
|
| 819 |
+
high_res_masks,
|
| 820 |
+
object_score_logits,
|
| 821 |
+
current_out,
|
| 822 |
+
):
|
| 823 |
+
if run_mem_encoder and self.num_maskmem > 0:
|
| 824 |
+
high_res_masks_for_mem_enc = high_res_masks
|
| 825 |
+
maskmem_features, maskmem_pos_enc = self._encode_new_memory(
|
| 826 |
+
current_vision_feats=current_vision_feats,
|
| 827 |
+
feat_sizes=feat_sizes,
|
| 828 |
+
pred_masks_high_res=high_res_masks_for_mem_enc,
|
| 829 |
+
object_score_logits=object_score_logits,
|
| 830 |
+
is_mask_from_pts=(point_inputs is not None),
|
| 831 |
+
)
|
| 832 |
+
current_out["maskmem_features"] = maskmem_features
|
| 833 |
+
current_out["maskmem_pos_enc"] = maskmem_pos_enc
|
| 834 |
+
else:
|
| 835 |
+
current_out["maskmem_features"] = None
|
| 836 |
+
current_out["maskmem_pos_enc"] = None
|
| 837 |
+
|
| 838 |
+
def track_step(
|
| 839 |
+
self,
|
| 840 |
+
frame_idx,
|
| 841 |
+
is_init_cond_frame,
|
| 842 |
+
current_vision_feats,
|
| 843 |
+
current_vision_pos_embeds,
|
| 844 |
+
feat_sizes,
|
| 845 |
+
point_inputs,
|
| 846 |
+
mask_inputs,
|
| 847 |
+
output_dict,
|
| 848 |
+
num_frames,
|
| 849 |
+
track_in_reverse=False, # tracking in reverse time order (for demo usage)
|
| 850 |
+
# Whether to run the memory encoder on the predicted masks. Sometimes we might want
|
| 851 |
+
# to skip the memory encoder with `run_mem_encoder=False`. For example,
|
| 852 |
+
# in demo we might call `track_step` multiple times for each user click,
|
| 853 |
+
# and only encode the memory when the user finalizes their clicks. And in ablation
|
| 854 |
+
# settings like SAM training on static images, we don't need the memory encoder.
|
| 855 |
+
run_mem_encoder=True,
|
| 856 |
+
# The previously predicted SAM mask logits (which can be fed together with new clicks in demo).
|
| 857 |
+
prev_sam_mask_logits=None,
|
| 858 |
+
mem_pick_index=0,
|
| 859 |
+
start_frame_idx=0,
|
| 860 |
+
iou_thre=0.1,
|
| 861 |
+
):
|
| 862 |
+
current_out, sam_outputs, _, _ = self._track_step(
|
| 863 |
+
frame_idx,
|
| 864 |
+
is_init_cond_frame,
|
| 865 |
+
current_vision_feats,
|
| 866 |
+
current_vision_pos_embeds,
|
| 867 |
+
feat_sizes,
|
| 868 |
+
point_inputs,
|
| 869 |
+
mask_inputs,
|
| 870 |
+
output_dict,
|
| 871 |
+
num_frames,
|
| 872 |
+
track_in_reverse,
|
| 873 |
+
prev_sam_mask_logits,
|
| 874 |
+
mem_pick_index,
|
| 875 |
+
start_frame_idx,
|
| 876 |
+
iou_thre,
|
| 877 |
+
)
|
| 878 |
+
|
| 879 |
+
(
|
| 880 |
+
low_res_multimasks,
|
| 881 |
+
high_res_multimasks,
|
| 882 |
+
ious,
|
| 883 |
+
low_res_masks,
|
| 884 |
+
high_res_masks,
|
| 885 |
+
obj_ptr,
|
| 886 |
+
object_score_logits,
|
| 887 |
+
obj_ptrs,
|
| 888 |
+
) = sam_outputs
|
| 889 |
+
|
| 890 |
+
|
| 891 |
+
if mem_pick_index == 0:
|
| 892 |
+
current_out["pred_masks"] = low_res_masks
|
| 893 |
+
current_out["ious"] = ious.max(-1)[0]
|
| 894 |
+
current_out["object_score"] = object_score_logits[:,0]
|
| 895 |
+
current_out["obj_ptr"] = obj_ptr
|
| 896 |
+
current_out["pred_masks_high_res"] = high_res_masks
|
| 897 |
+
else:
|
| 898 |
+
current_out["pred_masks"] = low_res_multimasks
|
| 899 |
+
current_out["ious"] = ious
|
| 900 |
+
current_out["object_score"] = object_score_logits[:,0]
|
| 901 |
+
current_out["obj_ptr"] = obj_ptrs
|
| 902 |
+
current_out["pred_masks_high_res"] = high_res_multimasks
|
| 903 |
+
|
| 904 |
+
|
| 905 |
+
|
| 906 |
+
|
| 907 |
+
if not self.training:
|
| 908 |
+
# Only add this in inference (to avoid unused param in activation checkpointing;
|
| 909 |
+
# it's mainly used in the demo to encode spatial memories w/ consolidated masks)
|
| 910 |
+
current_out["object_score_logits"] = object_score_logits
|
| 911 |
+
|
| 912 |
+
|
| 913 |
+
return current_out
|
| 914 |
+
|
| 915 |
+
def _use_multimask(self, is_init_cond_frame, point_inputs):
|
| 916 |
+
"""Whether to use multimask output in the SAM head."""
|
| 917 |
+
num_pts = 0 if point_inputs is None else point_inputs["point_labels"].size(1)
|
| 918 |
+
multimask_output = (
|
| 919 |
+
self.multimask_output_in_sam
|
| 920 |
+
and (is_init_cond_frame or self.multimask_output_for_tracking)
|
| 921 |
+
and (self.multimask_min_pt_num <= num_pts <= self.multimask_max_pt_num)
|
| 922 |
+
)
|
| 923 |
+
return multimask_output
|
| 924 |
+
|
| 925 |
+
def _apply_non_overlapping_constraints(self, pred_masks):
|
| 926 |
+
"""
|
| 927 |
+
Apply non-overlapping constraints to the object scores in pred_masks. Here we
|
| 928 |
+
keep only the highest scoring object at each spatial location in pred_masks.
|
| 929 |
+
"""
|
| 930 |
+
batch_size = pred_masks.size(0)
|
| 931 |
+
if batch_size == 1:
|
| 932 |
+
return pred_masks
|
| 933 |
+
|
| 934 |
+
device = pred_masks.device
|
| 935 |
+
# "max_obj_inds": object index of the object with the highest score at each location
|
| 936 |
+
max_obj_inds = torch.argmax(pred_masks, dim=0, keepdim=True)
|
| 937 |
+
# "batch_obj_inds": object index of each object slice (along dim 0) in `pred_masks`
|
| 938 |
+
batch_obj_inds = torch.arange(batch_size, device=device)[:, None, None, None]
|
| 939 |
+
keep = max_obj_inds == batch_obj_inds
|
| 940 |
+
# suppress overlapping regions' scores below -10.0 so that the foreground regions
|
| 941 |
+
# don't overlap (here sigmoid(-10.0)=4.5398e-05)
|
| 942 |
+
pred_masks = torch.where(keep, pred_masks, torch.clamp(pred_masks, max=-10.0))
|
| 943 |
+
return pred_masks
|