Spaces:
Sleeping

Sleeping
Commit
•
833a1dc
1
Parent(s):
e66a60a
Tested summary refine using ollama locally
Browse files- examples/techniques/Contextual_RAG.ipynb +62 -20
- examples/techniques/Contextual_RAG.py +112 -0
- modules/ollama_sum_refine.py +105 -0
- ollama_inference.py +14 -0
examples/techniques/Contextual_RAG.ipynb
CHANGED
|
@@ -112,7 +112,7 @@
|
|
| 112 |
},
|
| 113 |
{
|
| 114 |
"cell_type": "code",
|
| 115 |
-
"execution_count":
|
| 116 |
"metadata": {},
|
| 117 |
"outputs": [],
|
| 118 |
"source": [
|
|
@@ -121,7 +121,7 @@
|
|
| 121 |
},
|
| 122 |
{
|
| 123 |
"cell_type": "code",
|
| 124 |
-
"execution_count":
|
| 125 |
"metadata": {},
|
| 126 |
"outputs": [],
|
| 127 |
"source": [
|
|
@@ -166,7 +166,16 @@
|
|
| 166 |
},
|
| 167 |
{
|
| 168 |
"cell_type": "code",
|
| 169 |
-
"execution_count":
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 170 |
"metadata": {},
|
| 171 |
"outputs": [],
|
| 172 |
"source": [
|
|
@@ -175,31 +184,39 @@
|
|
| 175 |
},
|
| 176 |
{
|
| 177 |
"cell_type": "code",
|
| 178 |
-
"execution_count":
|
| 179 |
"metadata": {},
|
| 180 |
"outputs": [
|
| 181 |
{
|
| 182 |
"data": {
|
| 183 |
"text/markdown": [
|
| 184 |
-
"Here is a summary of the text:\n",
|
| 185 |
"\n",
|
| 186 |
-
"A state machine is a mathematical model that
|
| 187 |
"\n",
|
| 188 |
-
"
|
| 189 |
-
"
|
| 190 |
-
"
|
| 191 |
-
"
|
| 192 |
-
"
|
| 193 |
"\n",
|
| 194 |
-
"
|
| 195 |
"\n",
|
| 196 |
-
"The key
|
| 197 |
"\n",
|
| 198 |
-
"*
|
| 199 |
-
"*
|
| 200 |
-
"* The
|
| 201 |
"\n",
|
| 202 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 203 |
],
|
| 204 |
"text/plain": [
|
| 205 |
"<IPython.core.display.Markdown object>"
|
|
@@ -210,15 +227,18 @@
|
|
| 210 |
}
|
| 211 |
],
|
| 212 |
"source": [
|
| 213 |
-
"display(Markdown(
|
| 214 |
]
|
| 215 |
},
|
| 216 |
{
|
| 217 |
"cell_type": "code",
|
| 218 |
-
"execution_count":
|
| 219 |
"metadata": {},
|
| 220 |
"outputs": [],
|
| 221 |
-
"source": [
|
|
|
|
|
|
|
|
|
|
| 222 |
},
|
| 223 |
{
|
| 224 |
"cell_type": "markdown",
|
|
@@ -239,6 +259,28 @@
|
|
| 239 |
"The best approach will be to use local models to achive this kind of heavy inference. For that we will turn to either **Ollama** or hugging face **Transformers**."
|
| 240 |
]
|
| 241 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 242 |
{
|
| 243 |
"cell_type": "code",
|
| 244 |
"execution_count": null,
|
|
|
|
| 112 |
},
|
| 113 |
{
|
| 114 |
"cell_type": "code",
|
| 115 |
+
"execution_count": 26,
|
| 116 |
"metadata": {},
|
| 117 |
"outputs": [],
|
| 118 |
"source": [
|
|
|
|
| 121 |
},
|
| 122 |
{
|
| 123 |
"cell_type": "code",
|
| 124 |
+
"execution_count": 27,
|
| 125 |
"metadata": {},
|
| 126 |
"outputs": [],
|
| 127 |
"source": [
|
|
|
|
| 166 |
},
|
| 167 |
{
|
| 168 |
"cell_type": "code",
|
| 169 |
+
"execution_count": 28,
|
| 170 |
+
"metadata": {},
|
| 171 |
+
"outputs": [],
|
| 172 |
+
"source": [
|
| 173 |
+
"output_text = result[output_key]"
|
| 174 |
+
]
|
| 175 |
+
},
|
| 176 |
+
{
|
| 177 |
+
"cell_type": "code",
|
| 178 |
+
"execution_count": 29,
|
| 179 |
"metadata": {},
|
| 180 |
"outputs": [],
|
| 181 |
"source": [
|
|
|
|
| 184 |
},
|
| 185 |
{
|
| 186 |
"cell_type": "code",
|
| 187 |
+
"execution_count": 30,
|
| 188 |
"metadata": {},
|
| 189 |
"outputs": [
|
| 190 |
{
|
| 191 |
"data": {
|
| 192 |
"text/markdown": [
|
| 193 |
+
"Here is a comprehensive summary of the text:\n",
|
| 194 |
"\n",
|
| 195 |
+
"A state machine is a mathematical model that represents an automaton or computer program that operates on inputs and produces outputs in steps. The 5-tuple StateMachine = (States, Inputs, Outputs, update, initialState) defines these five components.\n",
|
| 196 |
"\n",
|
| 197 |
+
"**States**: Represent the current state of the system.\n",
|
| 198 |
+
"**Inputs**: Represent the input signals that affect the system's behavior.\n",
|
| 199 |
+
"**Outputs**: Represent the output signals produced by the system as a result of processing the inputs.\n",
|
| 200 |
+
"**update**: A function that determines the next state based on the current state and input.\n",
|
| 201 |
+
"**initialState**: The initial state of the system, which defines its starting point.\n",
|
| 202 |
"\n",
|
| 203 |
+
"A state machine can be thought of as a sequence of steps where each step represents one symbol in an infinite sequence of symbols (e.g., x(n)) being processed. This sequence defines the function that describes how to process those inputs to produce outputs.\n",
|
| 204 |
"\n",
|
| 205 |
+
"The key characteristics of a state machine are:\n",
|
| 206 |
"\n",
|
| 207 |
+
"* One event occurs before another event\n",
|
| 208 |
+
"* Time is not specified between events\n",
|
| 209 |
+
"* The system can have different states at any given time\n",
|
| 210 |
"\n",
|
| 211 |
+
"State machines can be used to model complex systems, such as communication protocols, computer algorithms, and control systems. They provide a mathematical framework for analyzing and designing these systems.\n",
|
| 212 |
+
"\n",
|
| 213 |
+
"The 5-tuple StateMachine = (States, Inputs, Outputs, update, initialState) is the most common way to represent a state machine in mathematical terms. It consists of:\n",
|
| 214 |
+
"\n",
|
| 215 |
+
"* States: The set of possible states\n",
|
| 216 |
+
"* Inputs: The set of possible input symbols\n",
|
| 217 |
+
"* Outputs: The set of possible output symbols\n",
|
| 218 |
+
"* update: A function that determines the next state based on the current state and input\n",
|
| 219 |
+
"* initialState: The initial state of the system"
|
| 220 |
],
|
| 221 |
"text/plain": [
|
| 222 |
"<IPython.core.display.Markdown object>"
|
|
|
|
| 227 |
}
|
| 228 |
],
|
| 229 |
"source": [
|
| 230 |
+
"display(Markdown(output_text))"
|
| 231 |
]
|
| 232 |
},
|
| 233 |
{
|
| 234 |
"cell_type": "code",
|
| 235 |
+
"execution_count": 31,
|
| 236 |
"metadata": {},
|
| 237 |
"outputs": [],
|
| 238 |
+
"source": [
|
| 239 |
+
"with open(\"data/document_summary.txt\", \"w\", encoding=\"utf-8\") as fp:\n",
|
| 240 |
+
" fp.write(output_text)"
|
| 241 |
+
]
|
| 242 |
},
|
| 243 |
{
|
| 244 |
"cell_type": "markdown",
|
|
|
|
| 259 |
"The best approach will be to use local models to achive this kind of heavy inference. For that we will turn to either **Ollama** or hugging face **Transformers**."
|
| 260 |
]
|
| 261 |
},
|
| 262 |
+
{
|
| 263 |
+
"cell_type": "markdown",
|
| 264 |
+
"metadata": {
|
| 265 |
+
"vscode": {
|
| 266 |
+
"languageId": "html"
|
| 267 |
+
}
|
| 268 |
+
},
|
| 269 |
+
"source": [
|
| 270 |
+
"<h2 align=center> Proper Contextual RAG </h2>\n",
|
| 271 |
+
"\n",
|
| 272 |
+
"NOw that we have an executive summary to provide the context for each chunk, we proceed to the main implementation."
|
| 273 |
+
]
|
| 274 |
+
},
|
| 275 |
+
{
|
| 276 |
+
"cell_type": "code",
|
| 277 |
+
"execution_count": 32,
|
| 278 |
+
"metadata": {},
|
| 279 |
+
"outputs": [],
|
| 280 |
+
"source": [
|
| 281 |
+
"document_summary = output_text"
|
| 282 |
+
]
|
| 283 |
+
},
|
| 284 |
{
|
| 285 |
"cell_type": "code",
|
| 286 |
"execution_count": null,
|
examples/techniques/Contextual_RAG.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# %% [markdown]
|
| 2 |
+
# <h1 align=center> Contextual RAG </h1>
|
| 3 |
+
#
|
| 4 |
+
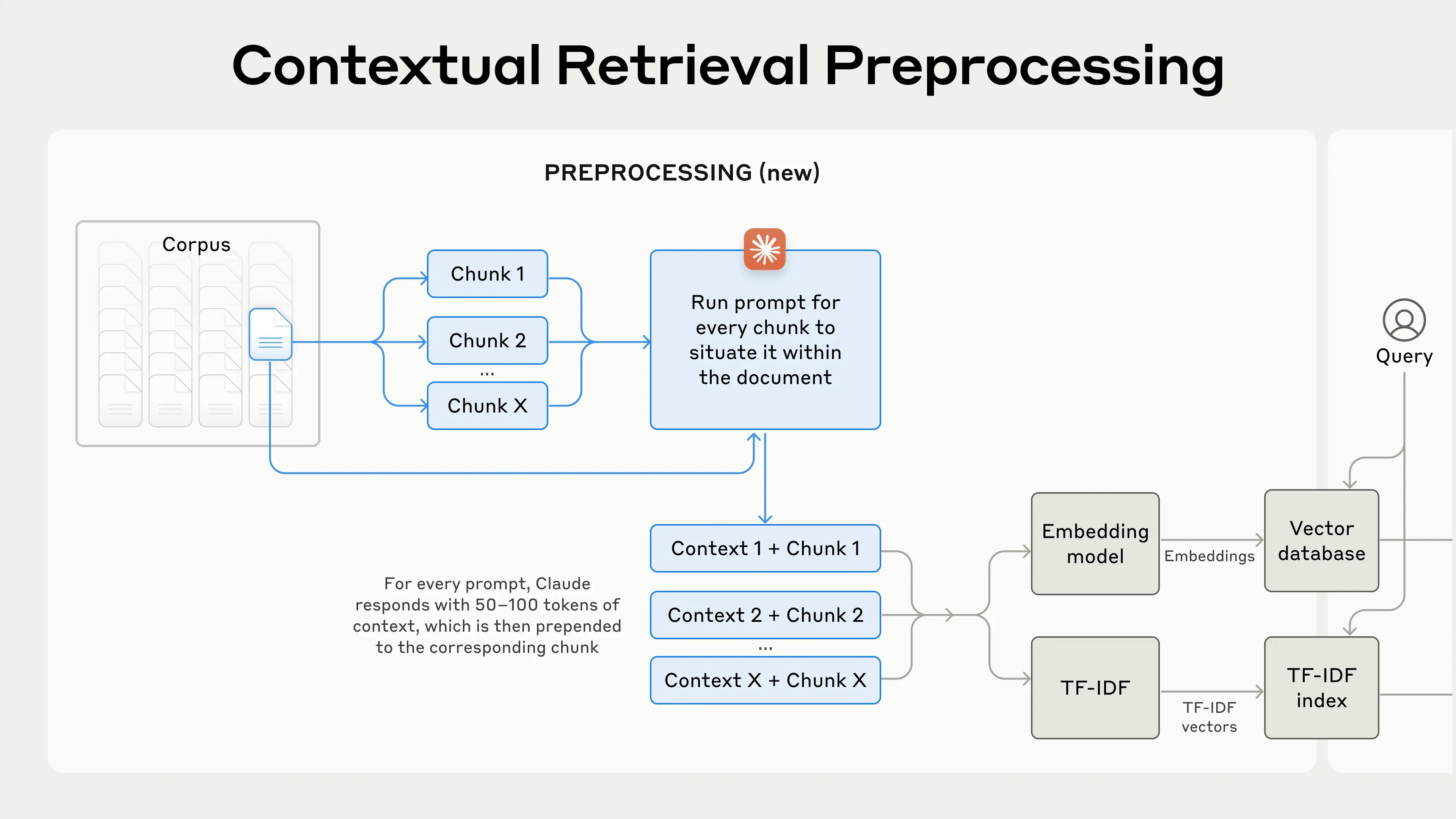
# 
|
| 5 |
+
#
|
| 6 |
+
# This is an approach proposed by Anthropic in a recent [blog poas](https://www.anthropic.com/news/contextual-retrieval). It involves improving retrieval by providing each document chunk with an in context summary.
|
| 7 |
+
|
| 8 |
+
# %% [markdown]
|
| 9 |
+
# <h2 align=center> Problems </h2>
|
| 10 |
+
#
|
| 11 |
+
# As one may gather from the explanation, there is a requirement that each chunk be appropriately contextualized with respect to the rest of the document. So essentially the whole document has to be passed into the prompt each time along with the chunk. There are two problems with this:
|
| 12 |
+
#
|
| 13 |
+
# 1. This would be very expensive in terms of input token count.
|
| 14 |
+
# 2. For models with smaller context windows, the whole document may exceed it.( Further, there is a sense in which fitting a whole document into a models context width defeats the point of performing RAG.)
|
| 15 |
+
#
|
| 16 |
+
|
| 17 |
+
# %% [markdown]
|
| 18 |
+
# <h2 align=center> Whole Document Summarization </h2>
|
| 19 |
+
#
|
| 20 |
+
# The solution I have come up with is to instead summarize the document into a more manageable size.
|
| 21 |
+
|
| 22 |
+
# %% [markdown]
|
| 23 |
+
# <h3 align=center> Refine </h3>
|
| 24 |
+
|
| 25 |
+
# %%
|
| 26 |
+
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
|
| 27 |
+
from langchain.chains.llm import LLMChain
|
| 28 |
+
from langchain.prompts import PromptTemplate
|
| 29 |
+
from langchain_text_splitters import CharacterTextSplitter
|
| 30 |
+
from langchain.document_loaders import PyMuPDFLoader
|
| 31 |
+
|
| 32 |
+
# %%
|
| 33 |
+
from langchain.chains.summarize import load_summarize_chain
|
| 34 |
+
|
| 35 |
+
# %%
|
| 36 |
+
# from langchain_google_genai import ChatGoogleGenerativeAI
|
| 37 |
+
# import os
|
| 38 |
+
# from dotenv import load_dotenv
|
| 39 |
+
|
| 40 |
+
# if not load_dotenv():
|
| 41 |
+
# print("API keys may not have been loaded succesfully")
|
| 42 |
+
# google_api_key = os.getenv("GOOGLE_API_KEY")
|
| 43 |
+
|
| 44 |
+
# llm = ChatGoogleGenerativeAI(model="gemini-pro", api_key=google_api_key)
|
| 45 |
+
|
| 46 |
+
# %%
|
| 47 |
+
from langchain_ollama.llms import OllamaLLM
|
| 48 |
+
|
| 49 |
+
# A lightweigh model for local inference
|
| 50 |
+
llm = OllamaLLM(model="llama3.2:1b-instruct-q4_K_M")
|
| 51 |
+
|
| 52 |
+
# %%
|
| 53 |
+
loader = PyMuPDFLoader("data/State Machines.pdf")
|
| 54 |
+
docs = loader.load()
|
| 55 |
+
|
| 56 |
+
# %%
|
| 57 |
+
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)
|
| 58 |
+
split_docs = text_splitter.split_documents(docs)
|
| 59 |
+
|
| 60 |
+
# %%
|
| 61 |
+
prompt = """
|
| 62 |
+
Please provide a summary of the following text.
|
| 63 |
+
TEXT: {text}
|
| 64 |
+
SUMMARY:
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
question_prompt = PromptTemplate(
|
| 68 |
+
template=prompt, input_variables=["text"]
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
refine_prompt_template = """
|
| 72 |
+
Write a concise summary of the following text delimited by triple backquotes.
|
| 73 |
+
Return your response in bullet points which covers the key points of the text.
|
| 74 |
+
```{text}```
|
| 75 |
+
BULLET POINT SUMMARY:
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
refine_template = PromptTemplate(
|
| 79 |
+
template=refine_prompt_template, input_variables=["text"]
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# Load refine chain
|
| 83 |
+
chain = load_summarize_chain(
|
| 84 |
+
llm=llm,
|
| 85 |
+
chain_type="refine",
|
| 86 |
+
question_prompt=question_prompt,
|
| 87 |
+
refine_prompt=refine_template,
|
| 88 |
+
return_intermediate_steps=True,
|
| 89 |
+
input_key="input_documents",
|
| 90 |
+
output_key="output_text",
|
| 91 |
+
)
|
| 92 |
+
result = chain({"input_documents": split_docs}, return_only_outputs=True)
|
| 93 |
+
|
| 94 |
+
# %% [markdown]
|
| 95 |
+
# <h3 align=center> Remarks </h3>
|
| 96 |
+
#
|
| 97 |
+
# Refine is properly configured but we ran into this error.
|
| 98 |
+
#
|
| 99 |
+
# ```python
|
| 100 |
+
# ResourceExhausted: 429 Resource has been exhausted (e.g. check quota).
|
| 101 |
+
# ```
|
| 102 |
+
#
|
| 103 |
+
# This is a problem on the part of our llm provider not the code.
|
| 104 |
+
#
|
| 105 |
+
# <h3 align=center> Next Steps </h3>
|
| 106 |
+
#
|
| 107 |
+
# The best approach will be to use local models to achive this kind of heavy inference. For that we will turn to either **Ollama** or hugging face **Transformers**.
|
| 108 |
+
|
| 109 |
+
# %%
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
modules/ollama_sum_refine.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.prompts import PromptTemplate
|
| 2 |
+
from langchain_text_splitters import RecursiveCharacterTextSplitter
|
| 3 |
+
from langchain.chains.summarize import load_summarize_chain
|
| 4 |
+
from langchain.docstore.document import Document
|
| 5 |
+
|
| 6 |
+
from langchain_ollama.llms import OllamaLLM
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
llm = OllamaLLM(model="llama3.2:1b-instruct-q4_K_M")
|
| 10 |
+
|
| 11 |
+
def refine(text: str, prompt=None, refine_prompt=None) -> str:
|
| 12 |
+
"""
|
| 13 |
+
use the refine method to summarize text. More can be learned here:
|
| 14 |
+
https://python.langchain.com/v0.1/docs/use_cases/summarization/#option-3-refine
|
| 15 |
+
"""
|
| 16 |
+
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n\n", "\n\n", "\n"],
|
| 17 |
+
# chunk_size=128, chunk_overlap=0
|
| 18 |
+
)
|
| 19 |
+
split_texts = text_splitter.split_text(text)
|
| 20 |
+
|
| 21 |
+
# Convert into langchain docs for downstream chain
|
| 22 |
+
split_docs = []
|
| 23 |
+
for text in split_texts:
|
| 24 |
+
page = Document(page_content=text,
|
| 25 |
+
metadata = {"source": "local"})
|
| 26 |
+
split_docs.append(page)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
if prompt is None:
|
| 30 |
+
prompt = """
|
| 31 |
+
Please provide a very comprehensive summary of the following text.
|
| 32 |
+
WHile maintaining lower level detail
|
| 33 |
+
|
| 34 |
+
TEXT: {text}
|
| 35 |
+
|
| 36 |
+
Begin by summarizing the topic at hand briefly
|
| 37 |
+
in the same way an abstract explains a paper
|
| 38 |
+
|
| 39 |
+
SUMMARY:
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
question_prompt = PromptTemplate(
|
| 43 |
+
template=prompt, input_variables=["text"]
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
if refine_prompt is None:
|
| 47 |
+
refine_prompt = """
|
| 48 |
+
You are tasked with refining and improving an existing summary. We have an initial summary that is accurate but may lack details from the new context below.
|
| 49 |
+
|
| 50 |
+
---
|
| 51 |
+
Existing Summary:
|
| 52 |
+
{existing_answer}
|
| 53 |
+
|
| 54 |
+
New Context:
|
| 55 |
+
{text}
|
| 56 |
+
---
|
| 57 |
+
|
| 58 |
+
Please refine the existing summary by incorporating relevant information from the new context. Ensure the refined summary remains clear, concise, and cohesive. If the new context does not provide useful details, keep the original summary unchanged. Avoid repeating information unnecessarily. Return the improved summary below.
|
| 59 |
+
s
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
refine_template = PromptTemplate(
|
| 64 |
+
template=refine_prompt, input_variables=["text", "existing_answer"]
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
output_key = "output_text"
|
| 68 |
+
|
| 69 |
+
# Load refine chain
|
| 70 |
+
chain = load_summarize_chain(
|
| 71 |
+
llm=llm,
|
| 72 |
+
chain_type="refine",
|
| 73 |
+
question_prompt=question_prompt,
|
| 74 |
+
refine_prompt=refine_template,
|
| 75 |
+
return_intermediate_steps=True,
|
| 76 |
+
input_key="input_documents",
|
| 77 |
+
output_key=output_key,
|
| 78 |
+
)
|
| 79 |
+
result = chain({"input_documents": split_docs}, return_only_outputs=True)
|
| 80 |
+
return result[output_key]
|
| 81 |
+
|
| 82 |
+
if __name__ == "__main__":
|
| 83 |
+
long_text = """
|
| 84 |
+
And Hector quickly reached for his son. But the boy
|
| 85 |
+
recoiled, crying out to his nurse,
|
| 86 |
+
terrified by his father’s bronze-encased appearance—
|
| 87 |
+
the crest of the horsehair helmet
|
| 88 |
+
shone so bright it frightened him.
|
| 89 |
+
At that, Hector and his wife both burst out laughing,
|
| 90 |
+
and from his head Hector lifted off the helmet,
|
| 91 |
+
and set it on the ground, all shimmering with light.
|
| 92 |
+
Then he kissed his dear son, tossing him in his arms,
|
| 93 |
+
lifting a prayer to Zeus and the other gods:
|
| 94 |
+
'Zeus, and all gods, grant this boy of mine
|
| 95 |
+
to be, like me, preeminent in Troy,
|
| 96 |
+
strong and brave, and ruling Ilium with might.
|
| 97 |
+
Then one day men will say of him,
|
| 98 |
+
as he returns from war, bearing the bloodstained gear of slaughtered foes,
|
| 99 |
+
"A far better man than his father!"'
|
| 100 |
+
And Hector placed his son in his wife's arms,
|
| 101 |
+
and she embraced him, smiling through her tears.
|
| 102 |
+
"""
|
| 103 |
+
|
| 104 |
+
print(refine(long_text))
|
| 105 |
+
|
ollama_inference.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from modules.ollama_sum_refine import refine
|
| 3 |
+
|
| 4 |
+
st.write("### Get an Ollama Response ✨")
|
| 5 |
+
|
| 6 |
+
text = st.text_area("Input your Text tHere", height=300)
|
| 7 |
+
|
| 8 |
+
@st.cache_data
|
| 9 |
+
def summarize(content):
|
| 10 |
+
return refine(content)
|
| 11 |
+
|
| 12 |
+
if text:
|
| 13 |
+
response = summarize(text)
|
| 14 |
+
response
|