Spaces:
Runtime error

Runtime error
dafajudin
commited on
Commit
•
f7701c2
1
Parent(s):
c645901
first commit
Browse files- app.py +215 -4
- img/Model-Architecture.png +0 -0
- requirements.txt +10 -0
app.py
CHANGED
|
@@ -1,7 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import gradio as gr
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
-
|
| 4 |
-
|
|
|
|
| 5 |
|
| 6 |
-
|
| 7 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import subprocess
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import io
|
| 5 |
import gradio as gr
|
| 6 |
+
from transformers import AutoProcessor, TextIteratorStreamer
|
| 7 |
+
from transformers import Idefics2ForConditionalGeneration
|
| 8 |
+
import torch
|
| 9 |
+
from peft import LoraConfig
|
| 10 |
+
from transformers import AutoProcessor, BitsAndBytesConfig, IdeficsForVisionText2Text
|
| 11 |
|
| 12 |
+
# Project description
|
| 13 |
+
description = """
|
| 14 |
+
# Kalbe Farma - Visual Question Answering (VQA) for Medical Imaging
|
| 15 |
|
| 16 |
+
## Overview
|
| 17 |
+
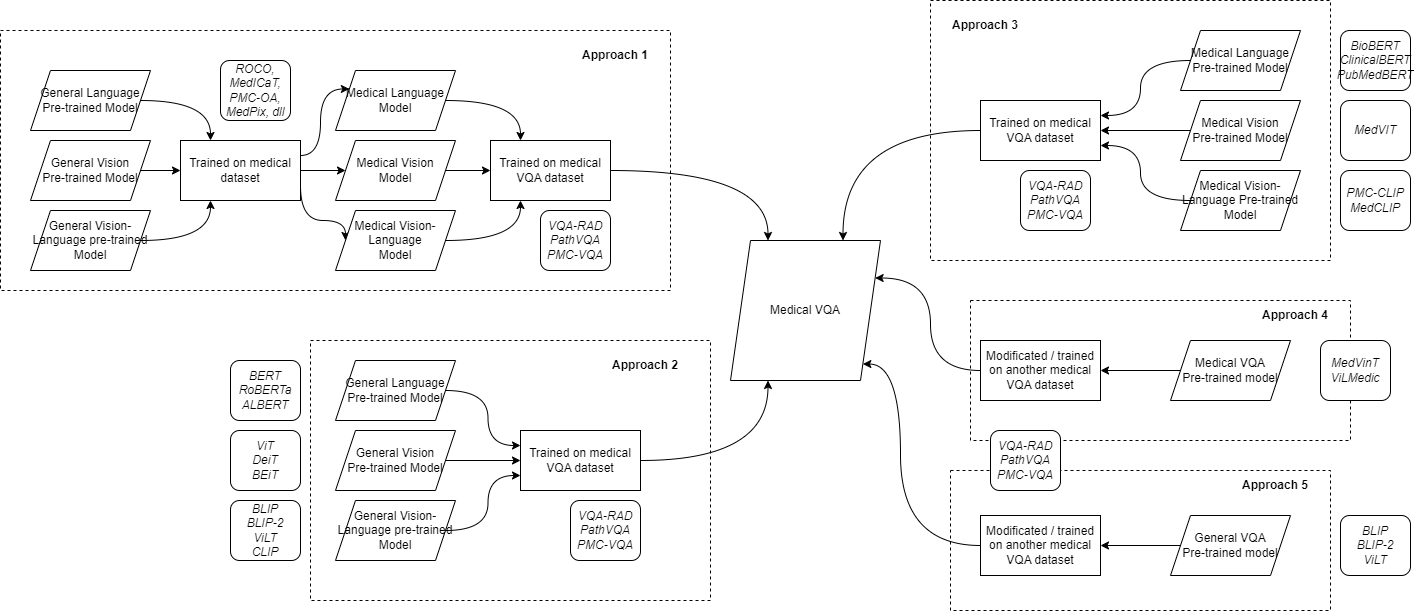
The project addresses the challenge of accurate and efficient medical imaging analysis in healthcare, aiming to reduce human error and workload for radiologists. The proposed solution involves developing advanced AI models for Visual Question Answering (VQA) to assist healthcare professionals in analyzing medical images quickly and accurately. These models will be integrated into a user-friendly web application, providing a practical tool for real-world healthcare settings.
|
| 18 |
+
|
| 19 |
+
## Dataset
|
| 20 |
+
The model is trained using the [Hugging face](https://huggingface.co/datasets/flaviagiammarino/vqa-rad/viewer).
|
| 21 |
+
|
| 22 |
+
Reference: [ScienceDirect](https://www.sciencedirect.com/science/article/abs/pii/S0933365723001252)
|
| 23 |
+
|
| 24 |
+
## Model Architecture
|
| 25 |
+
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
Reference: [ScienceDirect](https://www.sciencedirect.com/science/article/abs/pii/S0933365723001252)
|
| 29 |
+
|
| 30 |
+
## Demo
|
| 31 |
+
Please select the example below or upload 4 pairs of mammography exam results.
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
DEVICE = torch.device("cuda")
|
| 35 |
+
|
| 36 |
+
USE_LORA = False
|
| 37 |
+
USE_QLORA = True
|
| 38 |
+
|
| 39 |
+
if USE_QLORA or USE_LORA:
|
| 40 |
+
lora_config = LoraConfig(
|
| 41 |
+
r=8,
|
| 42 |
+
lora_alpha=8,
|
| 43 |
+
lora_dropout=0.1,
|
| 44 |
+
target_modules='.*(text_model|modality_projection|perceiver_resampler).*(down_proj|gate_proj|up_proj|k_proj|q_proj|v_proj|o_proj).*$',
|
| 45 |
+
use_dora=False if USE_QLORA else True,
|
| 46 |
+
init_lora_weights="gaussian"
|
| 47 |
+
)
|
| 48 |
+
if USE_QLORA:
|
| 49 |
+
bnb_config = BitsAndBytesConfig(
|
| 50 |
+
load_in_4bit=True,
|
| 51 |
+
bnb_4bit_quant_type="nf4",
|
| 52 |
+
bnb_4bit_compute_dtype=torch.float16
|
| 53 |
+
)
|
| 54 |
+
# Model
|
| 55 |
+
model = Idefics2ForConditionalGeneration.from_pretrained(
|
| 56 |
+
"jihadzakki/idefics2-8b-vqarad-delta",
|
| 57 |
+
torch_dtype=torch.float16,
|
| 58 |
+
quantization_config=bnb_config
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
processor = AutoProcessor.from_pretrained(
|
| 63 |
+
"HuggingFaceM4/idefics2-8b",
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
def format_answer(image, question, history):
|
| 67 |
+
try:
|
| 68 |
+
messages = [
|
| 69 |
+
{
|
| 70 |
+
"role": "user",
|
| 71 |
+
"content": [
|
| 72 |
+
{"type": "image"},
|
| 73 |
+
{"type": "text", "text": question}
|
| 74 |
+
]
|
| 75 |
+
}
|
| 76 |
+
]
|
| 77 |
+
|
| 78 |
+
text = processor.apply_chat_template(messages, add_generation_prompt=True)
|
| 79 |
+
inputs = processor(text=[text.strip()], images=[image], return_tensors="pt", padding=True)
|
| 80 |
+
inputs = {key: value.to(DEVICE) for key, value in inputs.items()}
|
| 81 |
+
generated_ids = model.generate(**inputs, max_new_tokens=64)
|
| 82 |
+
generated_texts = processor.batch_decode(generated_ids[:, inputs["input_ids"].size(1):], skip_special_tokens=True)[0]
|
| 83 |
+
|
| 84 |
+
history.append((image, f"Question: {question} | Answer: {generated_texts}"))
|
| 85 |
+
|
| 86 |
+
# Store the predicted answer in a variable before deleting intermediate variables
|
| 87 |
+
predicted_answer = f"Predicted Answer: {generated_texts}"
|
| 88 |
+
|
| 89 |
+
# Clear the cache and delete unnecessary variables
|
| 90 |
+
del inputs
|
| 91 |
+
del generated_ids
|
| 92 |
+
del generated_texts
|
| 93 |
+
torch.cuda.empty_cache()
|
| 94 |
+
|
| 95 |
+
return predicted_answer, history
|
| 96 |
+
except Exception as e:
|
| 97 |
+
# Clear the cache in case of an error
|
| 98 |
+
torch.cuda.empty_cache()
|
| 99 |
+
return f"Error: {str(e)}", history
|
| 100 |
+
|
| 101 |
+
def clear_history():
|
| 102 |
+
return "", []
|
| 103 |
+
|
| 104 |
+
def undo_last(history):
|
| 105 |
+
if history:
|
| 106 |
+
history.pop()
|
| 107 |
+
return "", history
|
| 108 |
+
|
| 109 |
+
def retry_last(image, question, history):
|
| 110 |
+
if history:
|
| 111 |
+
last_image, last_entry = history[-1]
|
| 112 |
+
return format_answer(last_image, question, history[:-1])
|
| 113 |
+
return "No previous analysis to retry.", history
|
| 114 |
+
|
| 115 |
+
def switch_theme(mode):
|
| 116 |
+
if mode == "Light Mode":
|
| 117 |
+
return gr.themes.Default()
|
| 118 |
+
else:
|
| 119 |
+
return gr.themes.Soft(primary_hue=gr.themes.colors.blue, secondary_hue=gr.themes.colors.orange)
|
| 120 |
+
|
| 121 |
+
def save_feedback(feedback):
|
| 122 |
+
return "Thank you for your feedback!"
|
| 123 |
+
|
| 124 |
+
def display_history(history):
|
| 125 |
+
log_entries = []
|
| 126 |
+
for img, text in history:
|
| 127 |
+
log_entries.append((img, text))
|
| 128 |
+
return log_entries
|
| 129 |
+
|
| 130 |
+
# Build the Visual QA application using Gradio with improvements
|
| 131 |
+
with gr.Blocks(
|
| 132 |
+
theme=gr.themes.Soft(
|
| 133 |
+
font=[gr.themes.GoogleFont("Inconsolata"), "Arial", "sans-serif"],
|
| 134 |
+
primary_hue=gr.themes.colors.blue,
|
| 135 |
+
secondary_hue=gr.themes.colors.red,
|
| 136 |
+
)
|
| 137 |
+
) as VisualQAApp:
|
| 138 |
+
gr.Markdown(description, elem_classes="title") # Display the project description
|
| 139 |
+
|
| 140 |
+
gr.Markdown("## Demo")
|
| 141 |
+
|
| 142 |
+
with gr.Row():
|
| 143 |
+
with gr.Column():
|
| 144 |
+
image_input = gr.Image(label="Upload image", type="pil")
|
| 145 |
+
question_input = gr.Textbox(show_label=False, placeholder="Enter your question here...")
|
| 146 |
+
submit_button = gr.Button("Submit", variant="primary")
|
| 147 |
+
|
| 148 |
+
with gr.Column():
|
| 149 |
+
answer_output = gr.Textbox(label="Result Prediction")
|
| 150 |
+
|
| 151 |
+
history_state = gr.State([]) # Initialize the history state
|
| 152 |
+
|
| 153 |
+
submit_button.click(
|
| 154 |
+
format_answer,
|
| 155 |
+
inputs=[image_input, question_input, history_state],
|
| 156 |
+
outputs=[answer_output, history_state],
|
| 157 |
+
show_progress=True
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
with gr.Row():
|
| 161 |
+
retry_button = gr.Button("Retry")
|
| 162 |
+
undo_button = gr.Button("Undo")
|
| 163 |
+
clear_button = gr.Button("Clear")
|
| 164 |
+
|
| 165 |
+
retry_button.click(
|
| 166 |
+
retry_last,
|
| 167 |
+
inputs=[image_input, question_input, history_state],
|
| 168 |
+
outputs=[answer_output, history_state]
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
undo_button.click(
|
| 172 |
+
undo_last,
|
| 173 |
+
inputs=[history_state],
|
| 174 |
+
outputs=[answer_output, history_state]
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
clear_button.click(
|
| 178 |
+
clear_history,
|
| 179 |
+
inputs=[],
|
| 180 |
+
outputs=[answer_output, history_state]
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
with gr.Row():
|
| 184 |
+
history_gallery = gr.Gallery(label="History Log", elem_id="history_log")
|
| 185 |
+
submit_button.click(
|
| 186 |
+
display_history,
|
| 187 |
+
inputs=[history_state],
|
| 188 |
+
outputs=[history_gallery]
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
with gr.Accordion("Help", open=False):
|
| 192 |
+
gr.Markdown("**Upload image**: Select the chest X-ray image you want to analyze.")
|
| 193 |
+
gr.Markdown("**Enter your question**: Type the question you have about the image, such as 'Is there any sign of pneumonia?'")
|
| 194 |
+
gr.Markdown("**Submit**: Click the submit button to get the prediction from the model.")
|
| 195 |
+
|
| 196 |
+
with gr.Accordion("User Preferences", open=False):
|
| 197 |
+
gr.Markdown("**Mode**: Choose between light and dark mode for your comfort.")
|
| 198 |
+
mode_selector = gr.Radio(choices=["Light Mode", "Dark Mode"], label="Select Mode")
|
| 199 |
+
apply_theme_button = gr.Button("Apply Theme")
|
| 200 |
+
|
| 201 |
+
apply_theme_button.click(
|
| 202 |
+
switch_theme,
|
| 203 |
+
inputs=[mode_selector],
|
| 204 |
+
outputs=[],
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
with gr.Accordion("Feedback", open=False):
|
| 208 |
+
gr.Markdown("**We value your feedback!** Please provide any feedback you have about this application.")
|
| 209 |
+
feedback_input = gr.Textbox(label="Feedback", lines=4)
|
| 210 |
+
submit_feedback_button = gr.Button("Submit Feedback")
|
| 211 |
+
|
| 212 |
+
submit_feedback_button.click(
|
| 213 |
+
save_feedback,
|
| 214 |
+
inputs=[feedback_input],
|
| 215 |
+
outputs=[feedback_input]
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
VisualQAApp.launch(share=True, debug=True)
|
img/Model-Architecture.png
ADDED
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers
|
| 2 |
+
gradio
|
| 3 |
+
plotly
|
| 4 |
+
torch
|
| 5 |
+
tensorflow
|
| 6 |
+
tf-keras
|
| 7 |
+
peft
|
| 8 |
+
bitsandbytes
|
| 9 |
+
accelerate
|
| 10 |
+
pillow
|