

optimize sripts
Browse files- assets/images/clusters.png +0 -0
- dist/assets/images/clusters.png +0 -0
- dist/index.html +612 -4
- dist/main.bundle.js +0 -0
- dist/main.bundle.js.map +0 -0
- src/index.html +2 -0
- src/plotting.js +2 -3
- webpack.config.js +1 -3
assets/images/clusters.png
CHANGED
|
|
dist/assets/images/clusters.png
CHANGED
|

|
dist/index.html
CHANGED
|
@@ -1,4 +1,16 @@
|
|
| 1 |
-
<!doctype html
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
* TOC
|
| 3 |
******************************************/
|
| 4 |
@media (max-width: 1199px) {
|
|
@@ -98,7 +110,14 @@
|
|
| 98 |
d-contents nav > div > a:hover,
|
| 99 |
d-contents nav > ul > li > a:hover {
|
| 100 |
text-decoration: none;
|
| 101 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 102 |
"title": "🍷 FineWeb: decanting the web for the finest text data at scale",
|
| 103 |
"description": "This blog covers a discussion on processing and evaluating data quality at scale, the 🍷 FineWeb recipe (listing and explaining all of our design choices), and the process followed to create 📚 FineWeb-Edu.",
|
| 104 |
"published": "May 28, 2024",
|
|
@@ -138,7 +157,594 @@
|
|
| 138 |
{"left": "$$", "right": "$$", "display": false}
|
| 139 |
]
|
| 140 |
}
|
| 141 |
-
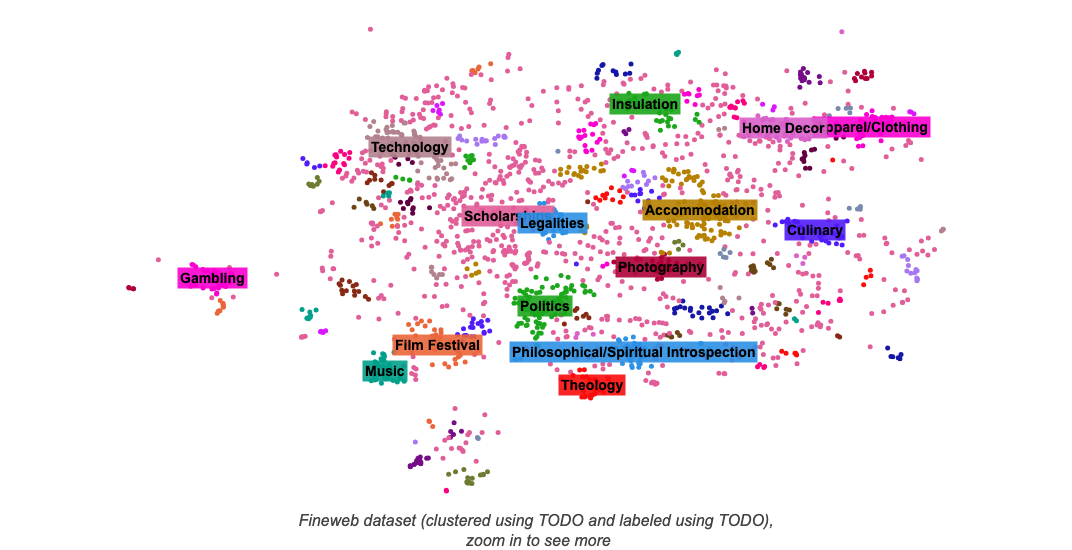
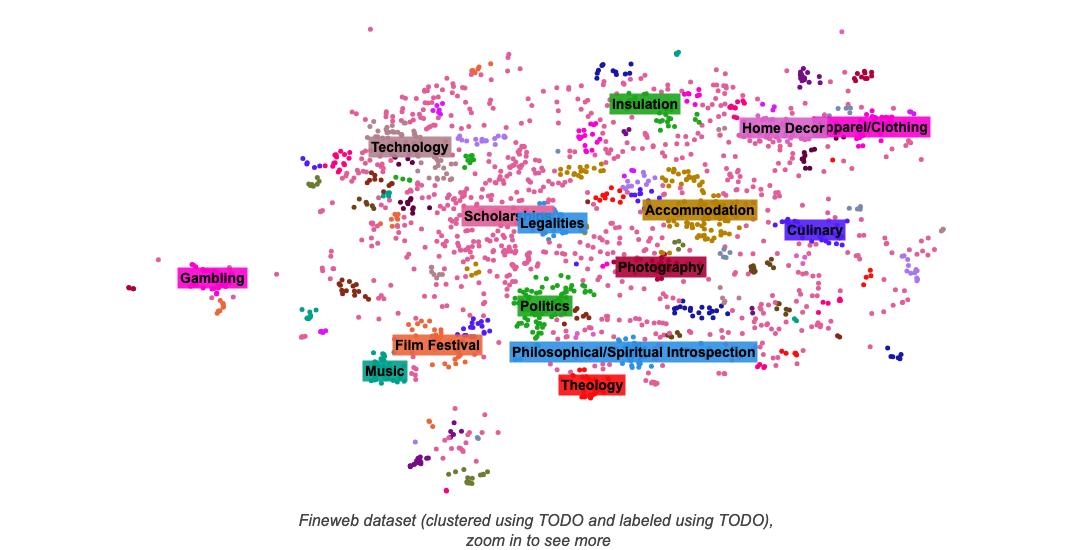
}</script></d-front-matter><d-title><h1 class="l-page" style="text-align: center;">🍷 FineWeb: decanting the web for the finest text data at scale</h1><div id="title-plot" class="main-plot-container l-screen"><figure><img src="assets/images/banner.png" alt="FineWeb"></figure><div id="clusters-plot"><img src="assets/images/clusters.png" alt="Clusters"></div></div></d-title><d-byline></d-byline><d-article><d-contents></d-contents><p>We have recently released <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb"><strong>🍷 FineWeb</strong></a>, our new large scale (<strong>15T gpt2 tokens, 44TB disk space</strong>) dataset of clean text sourced from the web for LLM pretraining. You can download it <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb">here</a>.</p><p>The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3<d-cite bibtex-key="llama3modelcard"></d-cite>and Mixtral<d-cite bibtex-key="jiang2024mixtral"></d-cite>are not publicly available and very little is known about how they were created.</p><p>🍷 FineWeb, a 15-trillion token dataset derived from 96 <a href="https://commoncrawl.org/">CommonCrawl</a> snapshots, produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies.</p><p>We are also excited to announce the release of <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu"><strong>📚 FineWeb-Edu</strong></a>, a version of 🍷 FineWeb that was filtered for educational content, available in two sizes: <strong>1.3 trillion (very high quality) and 5.4 trillion (high quality) tokens</strong>. 📚 FineWeb-Edu outperforms all existing public web datasets, with models pretrained on it showing notable improvements on knowledge- and reasoning-intensive benchmarks like MMLU, ARC, and OpenBookQA. You can download it <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu">here</a>.</p><p>Both datasets are released under the permissive <strong><a href="https://opendatacommons.org/licenses/by/1-0/">ODC-By 1.0 license</a></strong></p><p>As 🍷 FineWeb has gathered a lot of interest from the community, we decided to further explain the steps involved in creating it, our processing decisions and some lessons learned along the way. Read on for all the juicy details on large text dataset creation!</p><p><strong>TLDR:</strong> This blog covers a discussion on processing and evaluating data quality at scale, the 🍷 FineWeb recipe (listing and explaining all of our design choices), and the process followed to create 📚 FineWeb-Edu.</p><h2>General considerations on web data</h2><h3>Sourcing the data</h3><p>A common question we see asked regarding web datasets used to train LLMs is “where do they even get all that data?” There are generally two options:</p><ul><li>you either crawl it yourself, like <a href="https://platform.openai.com/docs/gptbot">OpenAI</a> or <a href="https://darkvisitors.com/agents/claudebot">Anthropic</a> seem to do</li></ul><ul><li>you use a public repository of crawled webpages, like the one maintained by the non-profit <a href="https://commoncrawl.org/">CommonCrawl</a></li></ul><p>For 🍷 FineWeb, similarly to what was done for a large number of other public datasets, we used <a href="https://commoncrawl.org/">CommonCrawl</a> as a starting point. They have been crawling the web since 2007 (long before LLMs became widespread) and release a new dump usually every 1 or 2 months, which can be freely downloaded.</p><p>As an example, their latest crawl (2024-18) contains 2.7 billion web pages, totaling 386 TiB of uncompressed HTML text content (the size changes from dump to dump). There are 96 dumps since 2013 and 3 dumps from 2008 to 2012, which are in a different (older) format.<d-footnote>We have not processed these 3 older dumps.</d-footnote></p><h3>Processing at scale</h3><p>Given the sheer size of the data involved, one of the main challenges we had to overcome was having a modular, scalable codebase that would allow us to quickly iterate on our processing decisions and easily try out new ideas, while appropriately parallelizing our workloads and providing clear insights into the data.</p><p>For this purpose, we developed <a href="https://github.com/huggingface/datatrove"><code>datatrove</code></a><d-cite bibtex-key="penedo2024datatrove"></d-cite>, an open-source data processing library that allowed us to seamlessly scale our filtering and deduplication setup to thousands of CPU cores. All the data processing steps involved in the creation of 🍷 FineWeb used this <a href="https://github.com/huggingface/datatrove">library</a>.</p><h3>What is clean, good data?</h3><p>This is probably the main question to keep in mind when creating a dataset. In the context of large language model pretraining, "high quality" is not a very well defined term<d-cite bibtex-key="albalak2024survey"></d-cite>, and often not a property of documents that can be easily perceived through direct observation alone.<d-cite bibtex-key="longpre2023pretrainers"></d-cite></p><p>It is still common to train a model on a given corpus (wikipedia, or some other web dataset considered clean) and use it to check the perplexity on the dataset that we were trying to curate<d-cite bibtex-key="wenzek2019ccnet"></d-cite>. Unfortunately this does not always correlate with performance on downstream tasks<d-cite bibtex-key="soldaini2024dolma"></d-cite>, and so another often used approach is to train small models (small because training models is expensive and time consuming, and we want to be able to quickly iterate) on a representative subset of our dataset and evaluate them on a set of evaluation tasks. As we are curating a dataset for pretraining a generalist LLM, it is important to choose a diverse set of tasks and try not to overfit to any one individual benchmark.</p><p>Another way to evaluate different datasets would be to train a model on each one and have humans rate and compare their outputs (like on the <a href="https://chat.lmsys.org/">LMSYS Chatbot Arena</a>)<d-cite bibtex-key="chiang2024chatbot"></d-cite>. This would arguably provide the most reliable results in terms of representing real model usage, but getting ablation results this way is too expensive and slow. It also often requires that the models have undergone at least an instruction finetuning stage, as pretrained models have difficulty following instructions.<d-cite bibtex-key="ouyang2022training"></d-cite></p><p>The approach we ultimately went with was to train small models and evaluate them on a set of benchmark tasks. We believe this is a reasonable proxy for the quality of the data used to train these models.</p><h3>Ablations and evaluation setup</h3><p>To be able to compare the impact of a given processing step, we would train 2 models, one where the data included the extra step and another where this step was ablated (cut/removed). These 2 models would have the same number of parameters, architecture, and be trained on an equal number of randomly sampled tokens from each step's data, for a single epoch, and with the same hyperparameters — the only difference would be in the training data. We would then evaluate each model on the same set of tasks and compare the average scores.</p><p>Our ablation models were trained using <a href="https://github.com/huggingface/nanotron"><code>nanotron</code></a> with this config [<strong>TODO: INSERT SIMPLIFIED NANOTRON CONFIG HERE</strong>]. The models had 1.82B parameters, used the Llama architecture with a 2048 sequence length, and a global batch size of ~2 million tokens. For filtering ablations we mostly trained on ~28B tokens (which is roughly the Chinchilla<d-cite bibtex-key="hoffmann2022training"></d-cite>optimal training size for this model size).</p><p>We evaluated the models using <a href="https://github.com/huggingface/lighteval/"><code>lighteval</code></a>. We tried selecting benchmarks that would provide good signal at a relatively small scale (small models trained on only a few billion tokens). Furthermore, we also used the following criteria when selecting benchmarks:</p><ul><li>small variance between runs trained on different samplings of the same dataset: we want our runs on a subset of the data to be representative of the whole dataset, and the resulting scores to have as little evaluation noise as possible</li></ul><ul><li>performance increasing monotonically (or close) over a training run: ideally, as the number of seen tokens increases, the performance on this benchmark should not decrease (which would be indicative of unreliable results at a small scale)</li></ul><p>We selected the following list of benchmarks:</p><ul><li>CommonSense QA<d-cite bibtex-key="talmor-etal-2019-commonsenseqa"></d-cite></li><li>HellaSwag<d-cite bibtex-key="zellers-etal-2019-hellaswag"></d-cite></li><li>OpenBook QA<d-cite bibtex-key="OpenBookQA2018"></d-cite></li><li>PIQA<d-cite bibtex-key="bisk2019piqa"></d-cite></li><li>SIQA<d-cite bibtex-key="sap2019socialiqa"></d-cite></li><li>WinoGrande<d-cite bibtex-key="sakaguchi2019winogrande"></d-cite></li><li>ARC<d-cite bibtex-key="clark2018think"></d-cite></li><li>MMLU<d-cite bibtex-key="hendrycks2021measuring"></d-cite></li></ul><p>To have results quickly we capped longer benchmarks at 1000 samples (wall-clock evaluation taking less than 5 min on a single node of 8 GPUs - done in parallel to the training).</p><aside>You can find the full list of tasks and prompts we used <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb/blob/main/lighteval_tasks.py">here</a>.</aside><h2>The 🍷 FineWeb recipe</h2><p>In the next subsections we will explain each of the steps taken to produce the FineWeb dataset.</p><figure class="l-body"><img src="assets/images/fineweb-recipe.png"/></figure><aside>You can find a fully reproducible <code>datatrove</code> config <a href="https://github.com/huggingface/datatrove/blob/main/examples/fineweb.py">here</a>.</aside><h3>Starting point: text extraction</h3><p>CommonCrawl data is available in two main formats: WARC and WET. <strong>WARC </strong>(Web ARChive format) files contain the raw data from the crawl, including the full page HTML and request metadata. <strong>WET</strong> (WARC Encapsulated Text) files provide a text only version of those websites.</p><p>A large number of datasets take the WET files as their starting point. In our experience the default text extraction (extracting the main text of a webpage from its HTML) used to create these WET files is suboptimal and there are a variety of open-source libraries that provide better text extraction (by, namely, keeping less boilerplate content/navigation menus). We extracted the text content from the WARC files using the trafilatura library<d-cite bibtex-key="barbaresi-2021-trafilatura"></d-cite>, which from visual inspection of the results provided good quality extraction when compared to other libraries.</p><aside>You can also find a benchmark on text extraction libraries <a href="https://github.com/scrapinghub/article-extraction-benchmark/blob/master/README.rst">here</a>.</aside><p>To validate this decision, we processed the 2019-18 dump directly using the WET files and with text extracted from WARC files using trafilatura<d-footnote>We used trafilatura default options with <code>favour_precision=True</code>.</d-footnote>. We applied the same processing to each one (our base filtering+minhash, detailed below) and trained two models. While the resulting dataset is about 25% larger for the WET data (around 254 billion tokens), it proves to be of much worse quality than the one that used trafilatura to extract text from WARC files (which is around 200 billion tokens). Visual inspection of some samples confirms that many of these additional tokens on the WET files are unnecessary page boilerplate.</p><p>It is important to note, however, that text extraction is one of the most costly steps of our processing, so we believe that using the readily available WET data could be a reasonable trade-off for lower budget teams.</p><div class="main-plot-container"><figure><img src="assets/images/wet_comparison.png"/></figure><div id="plot-wet_comparison"></div></div><h3>Base filtering</h3><p>Filtering is an important part of the curation process. It removes part of the data (be it words, lines, or full documents) that would harm performance and is thus deemed to be “lower quality”.</p><p>As a basis for our filtering we used part of the setup from RefinedWeb<d-cite bibtex-key="penedo2023refinedweb"></d-cite>. Namely, we:</p><ul><li>Applied URL filtering using a <a href="https://dsi.ut-capitole.fr/blacklists/">blocklist</a> to remove adult content</li></ul><ul><li>Applied a <a href="https://fasttext.cc/docs/en/language-identification.html">fastText language classifier</a><d-cite bibtex-key="joulin2016bag"></d-cite><d-cite bibtex-key="joulin2016fasttext"></d-cite>to keep only English text with a score ≥ 0.65</li></ul><ul><li>Applied quality and repetition filters from MassiveText<d-cite bibtex-key="rae2022scaling"></d-cite>(using the default thresholds)</li></ul><p>After applying this filtering to each of the text extracted dumps (there are currently 96 dumps) we obtained roughly 36 trillion tokens of data (when tokenized with the <code>gpt2</code> tokenizer).</p><h3>Deduplication</h3><p>Deduplication is one of the most important steps when creating large web datasets for LLM pretraining. Methods to deduplicate datasets attempt to identify and remove redundant/repeated data from the dataset.</p><h4>Why deduplicate?</h4><p>The web has many aggregators, mirrors, templated pages or just otherwise repeated content spread over different domains and webpages. Often, these duplicated pages can be introduced by the crawler itself, when different links point to the same page.</p><p>Removing these duplicates (deduplicating) has been linked to an improvement in model performance<d-cite bibtex-key="lee2022deduplicating"></d-cite>and a reduction in memorization of pretraining data<d-cite bibtex-key="carlini2023quantifying"></d-cite>, which might allow for better generalization. Additionally, the performance uplift obtained through deduplication can also be tied to increased training efficiency: by removing duplicated content, for the same number of training tokens, a model will have seen more diverse data.<d-cite bibtex-key="muennighoff2023scaling"></d-cite><d-cite bibtex-key="hernandez2022scaling"></d-cite></p><p>There are different ways to identify and even define duplicated data. Common approaches rely on hashing techniques to speed up the process, or on building efficient data structures to index the data (like suffix arrays). Methods can also be “fuzzy”, by using some similarity metric to mark documents as duplicates, or “exact” by checking for exact matches between two documents (or lines, paragraphs, or whatever other granularity level being used).</p><h4>Our deduplication parameters</h4><p>Similarly to RefinedWeb<d-cite bibtex-key="penedo2023refinedweb"></d-cite>, we decided to apply MinHash, a fuzzy hash based deduplication technique that scales well and allows us to tune similarity thresholds (by changing the number and size of buckets) and the granularity of the matches (by changing the n-gram size). We chose to compute minhashes on each document’s 5-grams, using 112 hash functions in total, split into 14 buckets of 8 hashes each — targeting documents that are at least 75% similar. Documents with the same 8 minhashes in any bucket are considered a duplicate of each other.</p><p>This would mean that for two documents with a similarity ($$s$$) of 0.7, 0.75, 0.8 and 0.85, the probability that they would be identified as duplicates would be 56%, 77%, 92% and 98.8% respectively ($$1-(1-s^8)^{14}$$). See the plot below for a match probability comparison between our setup with 112 hashes and the one from RefinedWeb, with 9000 hashes, divided into 450 buckets of 20 hashes (that requires a substantially larger amount of compute resources, as each individual hash must be computed, stored and then compared with hashes from other documents):</p><div class="main-plot-container"><figure><img src="assets/images/minhash_params.png"/></figure><div id="plot-minhash_params"></div></div><p>While the high number of hash functions in RefinedWeb allows for a steeper, more well defined cut off (documents with real similarity near the threshold are more likely to be correctly identified), we believe the compute and storage savings are a reasonable trade off.</p><p>It should also be noted that intra-document deduplication is already handled by our repetition filter, which removes documents with many repeated lines and paragraphs.</p><h4>More deduplication is always better, right?</h4><p>Our initial approach was to take the entire dataset (all 90+ dumps) and deduplicate them together as one big dataset using MinHash.</p><p>We did this in an iterative manner: starting with the most recent dump (which at the time was 2023-50) and proceeding chronologically until the oldest one, we would deduplicate each dump not only within itself, but we would also remove any matches with documents from the previously processed (more recent) dumps.</p><p>For instance, for the second most recent dump (2023-40 at the time), we deduplicated it against the most recent one in addition to within itself. In particular, the oldest dump was deduplicated against all other dumps. As a result, more data was removed from the oldest dumps (last to be deduplicated) than from the most recent ones.</p><p>Deduplicating the dataset in this manner resulted in 4 trillion tokens of data, but, quite surprisingly for us, when training on a randomly sampled 350 billion tokens subset, the model showed no improvement over one trained on the non deduplicated data (see orange and green curves below), scoring far below its predecessor RefinedWeb on our aggregate of tasks.</p><div class="main-plot-container"><figure><img src="assets/images/dedup_all_dumps_bad.png"/></figure><div id="plot-all_dumps_bad"></div></div><p>This was quite puzzling as our intuition regarding web data was that more deduplication would always result in improved performance. We decided to take a closer look at one of the oldest dumps, dump 2013-48:</p><ul><li>pre deduplication, this dump had ~490 billion tokens</li></ul><ul><li>after our iterative MinHash, ~31 billion tokens remained (94% of data had been removed)</li></ul><p>As an experiment, we tried training two models on 28 billion tokens sampled from the following data from 2013-48:</p><ul><li>the fully deduplicated remaining ~31 billion tokens (<em>originally kept data</em>)</li></ul><ul><li>171 billion tokens obtained by individually deduplicating (without considering the other dumps) the ~460 billion tokens that had been removed from this dump in the iterative dedup process (<em>originally removed data</em>)<d-footnote>While there may be documents in <em>originally kept data</em> similar to documents in <em>originally removed data</em>, we estimate the overlap to be small (around 4 billion tokens)</d-footnote></li></ul><div class="main-plot-container"><figure><img src="assets/images/removed_data_cross_dedup.png"/></figure><div id="plot-removed_data_dedup"></div></div><p>These results show that, for this older dump from which we had removed over 90% of the original data, the data that was kept was actually <em>worse</em> than the data removed (considered independently of all the other dumps). This is also confirmed by visual inspection: <em>originally kept data</em> contains far more ads, lists of keywords and generally badly formatted text than <em>originally removed data</em>.</p><h4>Taking a step back: individual dump dedup</h4><p>We then tried an alternative approach: we deduplicated each dump with MinHash individually (without considering the other dumps). This resulted in 20 trillion tokens of data.</p><p>When training on a random sample from this dataset we see that it now matches RefinedWeb’s performance (blue and red curves below):</p><div class="main-plot-container"><figure><img src="assets/images/cross_ind_unfiltered_comparison.png"/></figure><div id="plot-ind_dedup_better"></div></div><p>We hypothesize that the main improvement gained from deduplication is the removal of very large clusters that are present in every single dump (you will find some examples of these clusters on the RefinedWeb paper, each containing <em>hundreds of thousands</em> of documents) and that further deduplication for clusters with a low number of duplicates (less than ~100 i.e. the number of dumps) actually harms performance: data that does not find a duplicate match in any other dump might actually be worse quality/more out of distribution (as evidenced by the results on the 2013-48 data).</p><p>While you might see some performance improvement when deduplicating a few dumps together, at the scale of the entire dataset (all the dumps), the effect from this upsampling of lower quality data side effect seems to be more impactful.</p><p>One possibility to consider is that as filtering quality improves, this effect may not be as prevalent, since the filtering might be able to remove some of this lower quality data. We also experimented with applying different, and often “lighter”, deduplication approaches on top of the individually deduplicated dumps. You can read about them further below.</p><h4>A note on measuring the effect of deduplication</h4><p>Given the nature of deduplication, its effect is not always very visible in a smaller slice of the dataset (such as 28B tokens, the size we used for our filtering ablations). Furthermore, one must consider the fact that there are specific effects at play when deduplicating across all CommonCrawl dumps, as some URLs/pages are recrawled from one dump to the next.</p><p>To visualize the effect of scaling the number of training tokens on measuring deduplication impact, we considered the following (very extreme and unrealistic regarding the degree of duplication observed) theoretical scenario:</p><ul><li>there are 100 CommonCrawl dumps (roughly accurate)</li></ul><ul><li>each dump has been perfectly individually deduplicated (every single document in it is unique)</li></ul><ul><li>each dump is a perfect copy of each other (maximum possible duplication across dumps, effectively the worst case scenario)</li></ul><ul><li>each dump has 200 billion tokens (for a total of 20 trillion, the resulting size of our individual dedup above)</li></ul><ul><li>each dump is made up of documents of 1k tokens (200M documents per dump)</li></ul><p>We then simulated uniformly sampling documents from this entire dataset of 20 trillion tokens, to obtain subsets of 1B, 10B, 100B, 350B and 1T tokens. In the image below you can see how often each document would be repeated.</p><div class="main-plot-container"><figure><img src="assets/images/duplicates_simul.png"/></figure><div id="plot-duplicates-simul"></div></div><p>For 1B almost all documents would be unique (#duplicates=1), despite the fact that in the entire dataset each document is repeated 100 times (once per dump). We start seeing some changes at the 100B scale (0.5% of the total dataset), with a large number of documents being repeated twice, and a few even 4-8 times. At the larger scale of 1T (5% of the total dataset), the majority of the documents are repeated up to 8 times, with some being repeated up to 16 times.</p><p>We ran our performance evaluations for the deduplicated data at the 350B scale, which would, under this theoretical scenario, be made up of a significant portion of documents duplicated up to 8 times. This simulation illustrates the inherent difficulties associated with measuring deduplication impact on the training of LLMs, once the biggest duplicate clusters have been removed.</p><h4>Other (failed) global approaches</h4><p>We attempted to improve the performance of the independently minhash deduped 20 trillion tokens of data by further deduplicating it (globally, over all dumps) with the following methods:</p><ul><li>URL deduplication, where we only kept one document per normalized (lowercased) URL (71.5% of tokens removed, 5.6T left) — <em>FineWeb URL dedup</em></li></ul><ul><li>Line deduplication:<ul><li>remove all but 1 (randomly chosen) occurrence of each duplicated line (77.8% of tokens dropped, 4.4T left) — <em>FineWeb line dedup</em></li></ul><ul><li>same as above, but only removing duplicate lines with at least 10 words and dropping documents with fewer than 3 sentences after deduplication (85% of tokens dropped, 2.9T left) — <em>FineWeb line dedup w/ min words</em></li></ul><ul><li>remove all but 1 occurrence of each span of 3 duplicated lines with each number treated as 0 when finding duplicates, (80.9% of tokens removed, 3.7T left) — <em>FineWeb 3-line dedup</em></li></ul></li></ul><p>The performance of the models trained on each of these was consistently worse (even if to different degrees) than that of the original independently deduplicated data:</p><div class="main-plot-container"><figure><img src="assets/images/dedup_attempts.png"/></figure><div id="plot-dedup_attempts"></div></div><h3>Additional filtering</h3><p>By this point we had reached the same performance as RefinedWeb with base filtering + independent MinHash, but on our aggregate of tasks, another heavily filtered dataset, the C4 dataset<d-cite bibtex-key="raffel2023exploring"></d-cite>, still showed stronger performance (with the caveat that it is a relatively small dataset for current web-scale standards).</p><p>We therefore set out to find new filtering steps that would, at first, allow us to match the performance of C4 and, at a second stage, surpass it. A natural starting point was to look into the processing of C4 itself.</p><h4>C4: A dataset that has stood the test of time</h4><p>The <a href="https://huggingface.co/datasets/c4">C4 dataset</a> was first released in 2019. It was obtained from the <code>2019-18</code> CommonCrawl dump by removing non english data, applying some heuristic filters on both the line and document level, deduplicating on the line level, and removing documents containing words from a word blocklist.</p><p>Despite its age and limited size for current standards (around 175B gpt2 tokens), this dataset is, to this day, a common sub-set of typical LLM training, being used in models such as the relatively recent Llama1<d-cite bibtex-key="touvron2023llama"></d-cite>. This success is due to the strong performance that models trained on this dataset exhibit, excelling in particular on the Hellaswag benchmark<d-cite bibtex-key="zellers-etal-2019-hellaswag"></d-cite>, one of the benchmarks in our “early signal” group with the highest signal-to-noise ratio. We experimented applying each of the different filters used in C4 to a baseline of the independently deduped FineWeb 2019-18 dump:</p><div class="main-plot-container"><figure><img src="assets/images/c4_filters_hellaswag.png"/></figure><div id="plot-c4_filters_hellaswag"></div></div><ul><li>applying “All filters” (drop lines not ending on punctuation marks, mentioning javascript and cookie notices + drop documents outside length thresholds, containing “lorem ipsum” or a curly bracket, <code>{</code>) allows us to match C4’s HellaSwag performance (purple versus pink curves).</li></ul><ul><li>The curly bracket filter, and the word lengths filter only give a small boost, removing 2.8% and 4.3% of tokens, respectively</li></ul><ul><li>The terminal punctuation filter, by itself, gives the biggest individual boost, but removes <em>around 30%</em> of all tokens (!)</li></ul><ul><li>The lorem_ipsum, javascript and policy rules each remove <0.5% of training tokens, so we did not train on them individually</li></ul><ul><li>"All filters except the (very destructive) terminal_punct" performs better than terminal_punct by itself, while removing less in total (~7%)</li></ul><p>We decided to apply all C4 filters mentioned above except the terminal punctuation one. We validated these results with a longer run, which you will find in a plot in the next section.</p><h4>A statistical approach to develop heuristic filters</h4><p>To develop new heuristic filters and select their thresholds we devised a systematic process:</p><ol><li>we started by collecting a very large list of high level statistics (over <strong>50</strong>) ranging from common document-level metrics (e.g. number of lines, avg. line/word length, etc) to inter-document repetition metrics (MassiveText inspired), on both a high quality and a lower quality web dataset;</li><li>we selected the metrics for which the Wasserstein distance between the two distributions (of the metric computed on each dataset) was larger;</li><li>we inspected the histograms of the two distributions and empirically chose a threshold that would make the lower quality dataset more closely resemble the higher quality one on this metric;</li><li>we validated the resulting filter (metric-threshold pair) by using it on a reference dataset and running small ablations.</li></ol><p>Due to our assumption that global MinHash greatly upsamples lower quality data in the oldest dumps, we computed metrics on both the independently MinHashed and the (worse quality) global MinHashed versions of the 2013-48 and 2015-22 crawls (two older crawls). We then compared the statistics at a macro level, by looking at the distribution of these metrics for each one.</p><p>Perhaps not too surprisingly given our findings for deduplication, we found significant disparities in most of the metrics for the two deduplication methods. For instance, the <code>line-char-duplicates</code> metric (nb. of characters in duplicated lines / nb. characters), roughly doubled from the independent dedup (0.0053 for 2015-22 and 0.0058 for 2013-48), to the global dedup (0.011 for 2015-22 and 0.01 for 2013-48), indicating that the latter had higher inter-document repetition.</p><p>Following the process listed above for these datasets yielded 17 candidate metric-threshold pairs. In the image below, you can see 3 of these histograms:</p><div class="main-plot-container"><figure><img src="assets/images/custom_filters.png"/></figure><div id="plot-stats"></div></div><p>As an example, we inspected the histograms of "fraction of lines ending with punctuation" (see the image above) and observed an increased document density of global MinHash at around 0.12. We then filtered with this threshold and found that the removed data had a higher amount of short lists or consisted of only document layout text ("Home", "Sign up", etc).</p><p>We then assessed the effectiveness of these 17 newly created filters, by conducting <strong>28B tokens</strong> ablation runs on the <strong>2019-18 crawl</strong>. Out of all those runs, we identified three filters (the ones based on the histograms above) that demonstrated the most significant improvements on the aggregate score:</p><ul><li>Remove documents where the fraction of lines ending with punctuation ≤ 0.12 (10.14% of tokens removed) — vs the 30% from the original C4 terminal punct filter</li></ul><ul><li>Remove documents where the fraction of characters in duplicated lines ≥ 0.1 (12.47% of tokens removed) — the original MassiveText threshold for this ratio is ≥ 0.2</li></ul><ul><li>Remove documents where the fraction of lines shorter than 30 characters ≥ 0.67 (3.73% of tokens removed)</li></ul><ul><li>When applying the 3 together, ~22% of tokens were removed.</li></ul><div class="main-plot-container"><figure><img src="assets/images/custom_filters.png"/></figure><div id="plot-custom_filters"></div></div><p>These filters allowed us to further improve performance and to, notably, surpass the C4 dataset performance.</p><h2>The final dataset</h2><p>The final 🍷 FineWeb dataset comprises 15T tokens and includes the following previously mentioned steps, in order, each providing a performance boost on our group of benchmark tasks:</p><ul><li>base filtering</li></ul><ul><li>independent MinHash deduplication per dump</li></ul><ul><li>a selection of C4 filters</li></ul><ul><li>our custom filters (mentioned in the previous section)</li></ul><div class="main-plot-container"><figure><img src="assets/images/filtering_steps.png"/></figure><div id="plot-all_filtering_steps"></div></div><p>We compared 🍷 FineWeb with the following datasets:</p><ul><li><a href="https://huggingface.co/datasets/tiiuae/falcon-refinedweb">RefinedWeb</a><d-cite bibtex-key="penedo2023refinedweb"></d-cite></li></ul><ul><li><a href="https://huggingface.co/datasets/allenai/c4">C4</a><d-cite bibtex-key="raffel2023exploring"></d-cite></li></ul><ul><li><a href="https://huggingface.co/datasets/allenai/dolma">Dolma v1.6</a> (the CommonCrawl part)<d-cite bibtex-key="dolma"></d-cite></li></ul><ul><li><a href="https://huggingface.co/datasets/EleutherAI/pile">The Pile</a><d-cite bibtex-key="gao2020pile"></d-cite></li></ul><ul><li><a href="https://huggingface.co/datasets/cerebras/SlimPajama-627B">SlimPajama</a><d-cite bibtex-key="cerebras2023slimpajama"></d-cite></li></ul><ul><li><a href="https://huggingface.co/datasets/togethercomputer/RedPajama-Data-V2">RedPajama2</a><d-cite bibtex-key="together2023redpajama"></d-cite>(deduplicated)</li></ul><p>You will find these models on <a href="https://huggingface.co/collections/HuggingFaceFW/ablation-models-662457b0d213e8c14fe47f32">this collection</a>. We have uploaded checkpoints at every 1000 training steps. You will also find our full <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb/blob/main/eval_results.csv">evaluation results here</a>.</p><div class="main-plot-container"><figure><img src="assets/images/dataset_ablations.png"/></figure><div id="plot-dataset_ablations"></div></div><p>Large language models pretrained on 🍷 FineWeb, the largest publicly available clean LLM pretraining dataset, are better-performing than other open pretraining datasets.</p><h2>📚 FineWeb-Edu</h2><p>A new approach has recently emerged for filtering LLM training datasets: using synthetic data to develop classifiers for identifying educational content. This technique was used in the trainings of Llama 3<d-cite bibtex-key="llama3modelcard"></d-cite>and Phi3<d-cite bibtex-key="abdin2024phi"></d-cite>but its large-scale impact on web data filtering hasn't been fully explored or published.</p><p>The popular Phi3 models were trained on 3.3 and 4.8 trillion tokens, with the paper<d-cite bibtex-key="abdin2024phi"></d-cite>stating:</p><blockquote>Our training data consists of heavily filtered publicly available web data (according to the 'educational level') from various open internet sources, as well as synthetic LLM-generated data.</blockquote><p>Similarly, Llama 3 blog post<d-cite bibtex-key="meta2024responsible"></d-cite>notes:</p><blockquote>We found that previous generations of Llama are good at identifying high-quality data, so we used Llama 2 to help build the text-quality classifiers that are powering Llama 3.</blockquote><p>However, these classifiers and filtered datasets are not publicly available. To further enhance 🍷 FineWeb's quality, we developed an educational quality classifier using annotations generated by <a href="https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct">Llama-3-70B-Instruct</a> to create <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu"><strong>📚 FineWeb-Edu</strong></a>.</p><h3>Annotation</h3><p>We used Llama-3-70B-Instruct to annotate 500k samples from 🍷 FineWeb, scoring each for their educational quality on a scale from 0 to 5.</p><p>We explored various prompts and found that the additive scale by Yuan et al.<d-cite bibtex-key="yuan2024self"></d-cite>worked best. This scale allows the LLM to reason about each additional point awarded, unlike the single-rating Likert scale which fits samples into predefined boxes. Then, to avoid the LLM favoring highly technical pages like arXiv abstracts and submissions, we focused on grade-school and middle-school level knowledge. By setting a threshold of 3 (on a scale of 0 to 5) during the filtering process, we were able to also retain some high-level educational pages.</p><div style="text-align: center; margin: 20px 0;"><img src="https://cdn-uploads.huggingface.co/production/uploads/61c141342aac764ce1654e43/fjZQ4izIj1rx1xQnBTKKr.png" alt="Prompt for LLM annotation" style="width: 90%; max-width: 800px; height: auto;"><figcaption style="font-style: italic; margin-top: 10px;">Prompt used for Llama3 annotations of the educational score, also available <a href="https://huggingface.co/HuggingFaceFW/fineweb-edu-classifier/blob/main/utils/prompt.txt">here</a>.</figcaption></div><p>We also experimented with <a href="https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1">Mixtral-8x-7B-Instruct</a> and <a href="https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1">Mixtral-8x22B-Instruct</a> and a jury of all three models<d-cite bibtex-key="verga2024replacing"></d-cite>but found that Llama3 alone gave the most reliable results.</p><h3>Classifier Training</h3><p>We added a classification head with a single regression output to <a href="https://huggingface.co/Snowflake/snowflake-arctic-embed-m">Snowflake-arctic-embed</a> and trained it on 450,000 Llama 3 annotations for 20 epochs with a learning rate of 3e-4, freezing the embedding and encoder layers. We saved the checkpoint with the highest F1 score on our held-out validation set of 45k samples, treating Llama 3 annotations as ground-truth. After training, we rounded the scores to integers from 0 to 5.</p><p>We then converted the problem to a binary classification task by using a fixed threshold to determine if a file is educational. With a threshold of 3, the model achieved an F1 score of 82% on the validation set, indicating strong performance in distinguishing high-quality educational content.</p><p>The classifier is available at: <a href="https://huggingface.co/HuggingFaceFW/fineweb-edu-classifier">HuggingFaceFW/fineweb-edu-classifier</a>. The training and inference code is available on <a href="https://github.com/huggingface/cosmopedia/tree/main/classification">GitHub</a>.</p><h3>Filtering and results</h3><p>We applied the classifier to the 15T tokens of 🍷 FineWeb, a process that required 6,000 H100 GPU hours. We investigated the impact of using different thresholds for the filtering and found that threshold 3 gave the best overall results. Although using a threshold higher than 3 improves performance on knowledge and reasoning intensive benchmarks, it significantly degrades performance on HellaSwag and PIQA. The plot below shows the performance of each threshold compared to FineWeb on six different benchmarks; it uses a 1.82B model trained on 8B tokens.</p><div class="main-plot-container"><figure><img src="assets/images/edu-8k.png"></figure><div id="plot-edu-8k"></div></div><p>We then built 📚 FineWeb-Edu by filtering out samples with scores lower than 3. This removed 92% of the dataset, leaving us with 1.3 trillion educational tokens. To evaluate the effectiveness of this filtering at a larger scale, we conducted an ablation using a 1.82B model trained on 350 billion tokens, similar to the FineWeb filtering ablation mentioned above:</p><div class="main-plot-container"><figure><img src="assets/images/edu-100k.png"></figure><div id="plot-edu-100k"></div></div><p>Here are the key highlights of the ablation results above:</p><ul><li>📚 FineWeb-Edu surpasses 🍷 FineWeb and all other open web datasets, with remarkable improvements on educational benchmarks such as MMLU, ARC, and OpenBookQA.</li><li>It achieves the same performance with significantly less data, requiring 10x fewer tokens compared to C4 and Dolma to match MMLU results.</li><li>This demonstrates the effectiveness of using classifiers trained on LLM annotations for large-scale data filtering.</li></ul><p>Given that a threshold of 2 also demonstrated strong performance while retaining more data, we are releasing an additional dataset filtered with this threshold, containing 5.4 trillion tokens under <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu-score-2">HuggingFaceFW/fineweb-edu-score-2</a>.</p><p>You can find the two datasets along with the classifier used for the filtering in this <a href="https://huggingface.co/collections/HuggingFaceFW/fineweb-edu-6659c3f3d399d0e1d648adfd">collection</a>.</p><h2>Next steps</h2><p>Through our open data efforts we hope to give every model trainer the ability to create state-of-the-art large language models. As part of this process, we plan to continue iterating on FineWeb and to release more specialised filtered subsets of web data, in a fully open and reproducible manner.</p><p>While English currently dominates the large language model landscape, we believe that making high quality training data for other languages more easily accessible would allow millions of non english speakers to benefit from these technologies and, as such, will also strive to adapt the FineWeb Recipe to a multilingual version.</p></d-article><d-appendix><d-bibliography src="bibliography.bib"></d-bibliography></d-appendix><script>const article = document.querySelector('d-article');
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 142 |
const toc = document.querySelector('d-contents');
|
| 143 |
if (toc) {
|
| 144 |
const headings = article.querySelectorAll('h2, h3, h4');
|
|
@@ -198,4 +804,6 @@
|
|
| 198 |
}
|
| 199 |
}
|
| 200 |
});
|
| 201 |
-
}
|
|
|
|
|
|
|
|
|
| 1 |
+
<!doctype html>
|
| 2 |
+
|
| 3 |
+
<head>
|
| 4 |
+
<link rel="stylesheet" href="style.css">
|
| 5 |
+
<script src="distill.bundle.js" fetchpriority="high" blocking></script>
|
| 6 |
+
<script src="main.bundle.js" type="module" fetchpriority="low" defer></script>
|
| 7 |
+
<meta name="viewport" content="width=device-width, initial-scale=1">
|
| 8 |
+
<meta charset="utf8">
|
| 9 |
+
<base target="_blank">
|
| 10 |
+
<title>FineWeb: decanting the web for the finest text data at scale</title>
|
| 11 |
+
<style>
|
| 12 |
+
|
| 13 |
+
/* ****************************************
|
| 14 |
* TOC
|
| 15 |
******************************************/
|
| 16 |
@media (max-width: 1199px) {
|
|
|
|
| 110 |
d-contents nav > div > a:hover,
|
| 111 |
d-contents nav > ul > li > a:hover {
|
| 112 |
text-decoration: none;
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
</style>
|
| 116 |
+
</head>
|
| 117 |
+
|
| 118 |
+
<body>
|
| 119 |
+
<d-front-matter>
|
| 120 |
+
<script id='distill-front-matter' type="text/json">{
|
| 121 |
"title": "🍷 FineWeb: decanting the web for the finest text data at scale",
|
| 122 |
"description": "This blog covers a discussion on processing and evaluating data quality at scale, the 🍷 FineWeb recipe (listing and explaining all of our design choices), and the process followed to create 📚 FineWeb-Edu.",
|
| 123 |
"published": "May 28, 2024",
|
|
|
|
| 157 |
{"left": "$$", "right": "$$", "display": false}
|
| 158 |
]
|
| 159 |
}
|
| 160 |
+
}
|
| 161 |
+
</script>
|
| 162 |
+
</d-front-matter>
|
| 163 |
+
<d-title>
|
| 164 |
+
<h1 class="l-page" style="text-align: center;">🍷 FineWeb: decanting the web for the finest text data at scale</h1>
|
| 165 |
+
<div id="title-plot" class="main-plot-container l-screen">
|
| 166 |
+
<figure>
|
| 167 |
+
<img src="assets/images/banner.png" alt="FineWeb">
|
| 168 |
+
</figure>
|
| 169 |
+
<div id="clusters-plot">
|
| 170 |
+
<img src="assets/images/clusters.png" alt="Clusters">
|
| 171 |
+
</div>
|
| 172 |
+
</div>
|
| 173 |
+
</d-title>
|
| 174 |
+
<d-byline></d-byline>
|
| 175 |
+
<d-article>
|
| 176 |
+
<d-contents>
|
| 177 |
+
</d-contents>
|
| 178 |
+
|
| 179 |
+
<p>We have recently released <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb"><strong>🍷 FineWeb</strong></a>, our new large scale
|
| 180 |
+
(<strong>15T gpt2 tokens, 44TB disk space</strong>) dataset of clean text sourced from the web for LLM pretraining. You can
|
| 181 |
+
download it <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb">here</a>.</p>
|
| 182 |
+
<p>The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3<d-cite bibtex-key="llama3modelcard"></d-cite> and Mixtral<d-cite bibtex-key="jiang2024mixtral"></d-cite> are not publicly available and very little is known about how they were created.</p>
|
| 183 |
+
<p>🍷 FineWeb, a 15-trillion token dataset derived from 96 <a href="https://commoncrawl.org/">CommonCrawl</a> snapshots, produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies.</p>
|
| 184 |
+
<p>We are also excited to announce the release of <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu"><strong>📚 FineWeb-Edu</strong></a>, a version of 🍷 FineWeb that was filtered for educational content, available in two sizes: <strong>1.3 trillion (very high quality) and 5.4 trillion (high quality) tokens</strong>. 📚 FineWeb-Edu outperforms all existing public web datasets, with models pretrained on it showing notable improvements on knowledge- and reasoning-intensive benchmarks like MMLU, ARC, and OpenBookQA. You can
|
| 185 |
+
download it <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu">here</a>.</p>
|
| 186 |
+
<p>Both datasets are released under the permissive <strong><a href="https://opendatacommons.org/licenses/by/1-0/">ODC-By 1.0 license</a></strong></p>
|
| 187 |
+
|
| 188 |
+
<p>As 🍷 FineWeb has gathered a lot of interest from the
|
| 189 |
+
community, we decided to further explain the steps involved in creating it, our processing decisions and
|
| 190 |
+
some lessons learned along the way. Read on for all the juicy details on large text dataset creation!</p>
|
| 191 |
+
<p><strong>TLDR:</strong> This blog covers a discussion on processing and evaluating data quality at scale, the 🍷 FineWeb
|
| 192 |
+
recipe (listing and explaining all of our design choices), and the process followed to create 📚 FineWeb-Edu.</p>
|
| 193 |
+
|
| 194 |
+
<h2>General considerations on web data</h2>
|
| 195 |
+
<h3>Sourcing the data</h3>
|
| 196 |
+
<p>A common question we see asked regarding web datasets used
|
| 197 |
+
to train LLMs is “where do they even get all that data?” There are generally two options:</p>
|
| 198 |
+
<ul>
|
| 199 |
+
<li>you either crawl it yourself, like <a
|
| 200 |
+
href="https://platform.openai.com/docs/gptbot">OpenAI</a> or <a
|
| 201 |
+
href="https://darkvisitors.com/agents/claudebot">Anthropic</a> seem to do
|
| 202 |
+
</li>
|
| 203 |
+
</ul>
|
| 204 |
+
<ul>
|
| 205 |
+
<li>you use a public repository of crawled webpages, like the one maintained by
|
| 206 |
+
the non-profit <a href="https://commoncrawl.org/">CommonCrawl</a></li>
|
| 207 |
+
</ul>
|
| 208 |
+
<p>For 🍷 FineWeb, similarly to what was done for a large number
|
| 209 |
+
of other public datasets, we used <a href="https://commoncrawl.org/">CommonCrawl</a> as a starting point.
|
| 210 |
+
They have been crawling the web since 2007 (long before LLMs became widespread) and release a new dump usually
|
| 211 |
+
every 1 or 2 months, which can be freely downloaded. </p>
|
| 212 |
+
<p>As an example, their latest crawl (2024-18) contains 2.7
|
| 213 |
+
billion web pages, totaling 386 TiB of uncompressed HTML text content (the size changes from dump to dump). There
|
| 214 |
+
are 96 dumps since 2013 and 3 dumps from 2008 to 2012, which are in a different (older) format.<d-footnote>We have not processed these 3 older dumps.</d-footnote> </p>
|
| 215 |
+
<h3>Processing at scale</h3>
|
| 216 |
+
<p>Given the sheer size of the data involved, one of the main
|
| 217 |
+
challenges we had to overcome was having a modular, scalable codebase that would allow us to quickly iterate
|
| 218 |
+
on our processing decisions and easily try out new ideas, while appropriately parallelizing our workloads
|
| 219 |
+
and providing clear insights into the data. </p>
|
| 220 |
+
<p>For this purpose, we developed <a
|
| 221 |
+
href="https://github.com/huggingface/datatrove"><code>datatrove</code></a><d-cite bibtex-key="penedo2024datatrove"></d-cite>, an open-source data
|
| 222 |
+
processing library that allowed us to seamlessly scale our filtering and deduplication setup to thousands of
|
| 223 |
+
CPU cores. All the data processing steps involved in the creation of 🍷 FineWeb used this <a
|
| 224 |
+
href="https://github.com/huggingface/datatrove">library</a>.</p>
|
| 225 |
+
<h3>What is clean, good data?</h3>
|
| 226 |
+
<p>This is probably the main question to keep in mind when
|
| 227 |
+
creating a dataset. In the context of large language model pretraining, "high quality" is not a very well defined term<d-cite bibtex-key="albalak2024survey"></d-cite>, and often not a property of documents that can be easily perceived through direct observation alone.<d-cite bibtex-key="longpre2023pretrainers"></d-cite></p>
|
| 228 |
+
<p>It is still common to train a model on a given corpus
|
| 229 |
+
(wikipedia, or some other web dataset considered clean) and use it to check the perplexity on the dataset
|
| 230 |
+
that we were trying to curate<d-cite bibtex-key="wenzek2019ccnet"></d-cite>. Unfortunately this does not always correlate with performance on downstream
|
| 231 |
+
tasks<d-cite bibtex-key="soldaini2024dolma"></d-cite>, and so another often used approach is to train small models (small because training models is
|
| 232 |
+
expensive and time consuming, and we want to be able to quickly iterate) on a representative subset of our dataset and evaluate them on
|
| 233 |
+
a set of evaluation tasks. As we are curating a dataset for pretraining a generalist LLM, it is important to
|
| 234 |
+
choose a diverse set of tasks and try not to overfit to any one individual benchmark.</p>
|
| 235 |
+
<p>Another way to evaluate different datasets would be to
|
| 236 |
+
train a model on each one and have humans rate and compare their outputs (like on the <a
|
| 237 |
+
href="https://chat.lmsys.org/">LMSYS Chatbot Arena</a>)<d-cite bibtex-key="chiang2024chatbot"></d-cite>. This would arguably provide the most
|
| 238 |
+
reliable results in terms of representing real model usage, but getting ablation results this way is too
|
| 239 |
+
expensive and slow. It also often requires that the models have undergone at least an instruction finetuning stage, as pretrained models have difficulty following instructions.<d-cite bibtex-key="ouyang2022training"></d-cite></p>
|
| 240 |
+
<p>The approach we ultimately went with was to train small
|
| 241 |
+
models and evaluate them on a set of benchmark tasks. We believe this is a reasonable proxy for the quality
|
| 242 |
+
of the data used to train these models.</p>
|
| 243 |
+
<h3>Ablations and evaluation setup</h3>
|
| 244 |
+
<p>To be able to compare the impact of a given processing
|
| 245 |
+
step, we would train 2 models, one where the data included the extra step and another where this step was
|
| 246 |
+
ablated (cut/removed). These 2 models would have the same number of parameters, architecture, and be trained
|
| 247 |
+
on an equal number of randomly sampled tokens from each step's data, for a single epoch, and with the same hyperparameters — the only difference would be in the
|
| 248 |
+
training data. We would then evaluate each model on the same set of tasks and compare the average
|
| 249 |
+
scores.</p>
|
| 250 |
+
<p>Our ablation models were trained using <a
|
| 251 |
+
href="https://github.com/huggingface/nanotron"><code>nanotron</code></a> with this config [<strong>TODO:
|
| 252 |
+
INSERT SIMPLIFIED NANOTRON CONFIG HERE</strong>]. The models had 1.82B parameters, used the Llama
|
| 253 |
+
architecture with a 2048 sequence length, and a global batch size of ~2 million tokens. For filtering
|
| 254 |
+
ablations we mostly trained on ~28B tokens (which is roughly the Chinchilla<d-cite bibtex-key="hoffmann2022training"></d-cite> optimal training size for this
|
| 255 |
+
model size).</p>
|
| 256 |
+
<p>We evaluated the models using <a
|
| 257 |
+
href="https://github.com/huggingface/lighteval/"><code>lighteval</code></a>. We tried selecting
|
| 258 |
+
benchmarks that would provide good signal at a relatively small scale (small models trained on only a few
|
| 259 |
+
billion tokens). Furthermore, we also used the following criteria when selecting benchmarks:</p>
|
| 260 |
+
<ul>
|
| 261 |
+
<li>small variance between runs trained on different samplings of the same
|
| 262 |
+
dataset: we want our runs on a subset of the data to be representative of the whole dataset, and the
|
| 263 |
+
resulting scores to have as little evaluation noise as possible
|
| 264 |
+
</li>
|
| 265 |
+
</ul>
|
| 266 |
+
<ul>
|
| 267 |
+
<li>performance increasing monotonically (or close) over a training run:
|
| 268 |
+
ideally, as the number of seen tokens increases, the performance on this benchmark should not decrease
|
| 269 |
+
(which would be indicative of unreliable results at a small scale)
|
| 270 |
+
</li>
|
| 271 |
+
</ul>
|
| 272 |
+
<p>We selected the following list of benchmarks:</p>
|
| 273 |
+
<ul>
|
| 274 |
+
<li>CommonSense QA<d-cite bibtex-key="talmor-etal-2019-commonsenseqa"></d-cite></li>
|
| 275 |
+
<li>HellaSwag<d-cite bibtex-key="zellers-etal-2019-hellaswag"></d-cite></li>
|
| 276 |
+
<li>OpenBook QA<d-cite bibtex-key="OpenBookQA2018"></d-cite></li>
|
| 277 |
+
<li>PIQA<d-cite bibtex-key="bisk2019piqa"></d-cite></li>
|
| 278 |
+
<li>SIQA<d-cite bibtex-key="sap2019socialiqa"></d-cite></li>
|
| 279 |
+
<li>WinoGrande<d-cite bibtex-key="sakaguchi2019winogrande"></d-cite></li>
|
| 280 |
+
<li>ARC<d-cite bibtex-key="clark2018think"></d-cite></li>
|
| 281 |
+
<li>MMLU<d-cite bibtex-key="hendrycks2021measuring"></d-cite></li>
|
| 282 |
+
</ul>
|
| 283 |
+
<p>To
|
| 284 |
+
have results quickly we capped longer benchmarks at 1000 samples (wall-clock evaluation taking less than 5
|
| 285 |
+
min on a single node of 8 GPUs - done in parallel to the training).</p>
|
| 286 |
+
<aside>You can find the full list of tasks and prompts we used <a
|
| 287 |
+
href="https://huggingface.co/datasets/HuggingFaceFW/fineweb/blob/main/lighteval_tasks.py">here</a>.</aside>
|
| 288 |
+
<h2>The 🍷 FineWeb recipe</h2>
|
| 289 |
+
<p>In the next subsections we will explain each of the steps
|
| 290 |
+
taken to produce the FineWeb dataset.</p>
|
| 291 |
+
<figure class="l-body">
|
| 292 |
+
<img src="assets/images/fineweb-recipe.png"/>
|
| 293 |
+
</figure>
|
| 294 |
+
<aside>You can find a fully reproducible <code>datatrove</code> config <a
|
| 295 |
+
href="https://github.com/huggingface/datatrove/blob/main/examples/fineweb.py">here</a>.</aside>
|
| 296 |
+
<h3>Starting point: text extraction</h3>
|
| 297 |
+
<p>CommonCrawl data is available in two main formats: WARC
|
| 298 |
+
and WET. <strong>WARC </strong>(Web ARChive format) files contain the raw data from the crawl, including the
|
| 299 |
+
full page HTML and request metadata. <strong>WET</strong> (WARC Encapsulated Text) files provide a text only
|
| 300 |
+
version of those websites.</p>
|
| 301 |
+
<p>A large number of datasets take the WET files as their
|
| 302 |
+
starting point. In our experience the default text extraction (extracting the main text of a webpage from
|
| 303 |
+
its HTML) used to create these WET files is suboptimal and there are a variety of open-source libraries that
|
| 304 |
+
provide better text extraction (by, namely, keeping less boilerplate content/navigation menus). We extracted
|
| 305 |
+
the text content from the WARC files using the trafilatura library<d-cite bibtex-key="barbaresi-2021-trafilatura"></d-cite>, which from visual inspection of the results provided good quality extraction when compared to other libraries.</p><aside>You can also find a benchmark on text extraction libraries <a href="https://github.com/scrapinghub/article-extraction-benchmark/blob/master/README.rst">here</a>.</aside>
|
| 306 |
+
<p>To validate this decision, we processed the 2019-18 dump
|
| 307 |
+
directly using the WET files and with text extracted from WARC files using trafilatura<d-footnote>We used trafilatura default options with <code>favour_precision=True</code>.</d-footnote>. We applied the same
|
| 308 |
+
processing to each one (our base filtering+minhash, detailed below) and trained two models. While the
|
| 309 |
+
resulting dataset is about 25% larger for the WET data (around 254 billion tokens), it proves to be of much worse
|
| 310 |
+
quality than the one that used trafilatura to extract text from WARC files (which is around 200 billion tokens). Visual inspection of some samples confirms that many of
|
| 311 |
+
these additional tokens on the WET files are unnecessary page boilerplate.</p>
|
| 312 |
+
<p>It is important to note, however, that text extraction is one of the most costly steps of our
|
| 313 |
+
processing, so we believe that using the readily available WET data could be a reasonable trade-off for
|
| 314 |
+
lower budget teams.</p>
|
| 315 |
+
<div class="main-plot-container">
|
| 316 |
+
<figure><img src="assets/images/wet_comparison.png"/></figure>
|
| 317 |
+
<div id="plot-wet_comparison"></div>
|
| 318 |
+
</div>
|
| 319 |
+
<h3>Base filtering</h3>
|
| 320 |
+
<p>Filtering is an important part of the curation process. It
|
| 321 |
+
removes part of the data (be it words, lines, or full documents) that would harm performance and is thus
|
| 322 |
+
deemed to be “lower quality”.</p>
|
| 323 |
+
<p>As a basis for our filtering we used part of the setup
|
| 324 |
+
from RefinedWeb<d-cite bibtex-key="penedo2023refinedweb"></d-cite>. Namely, we:</p>
|
| 325 |
+
<ul>
|
| 326 |
+
<li>Applied URL filtering using a <a
|
| 327 |
+
href="https://dsi.ut-capitole.fr/blacklists/">blocklist</a> to remove adult content
|
| 328 |
+
</li>
|
| 329 |
+
</ul>
|
| 330 |
+
<ul>
|
| 331 |
+
<li>Applied a <a
|
| 332 |
+
href="https://fasttext.cc/docs/en/language-identification.html">fastText language classifier</a><d-cite bibtex-key="joulin2016bag"></d-cite><d-cite bibtex-key="joulin2016fasttext"></d-cite> to
|
| 333 |
+
keep only English text with a score ≥ 0.65
|
| 334 |
+
</li>
|
| 335 |
+
</ul>
|
| 336 |
+
<ul>
|
| 337 |
+
<li>Applied quality and repetition filters from MassiveText<d-cite bibtex-key="rae2022scaling"></d-cite> (using the default thresholds)
|
| 338 |
+
</li>
|
| 339 |
+
</ul>
|
| 340 |
+
<p>After applying this filtering to each of the text
|
| 341 |
+
extracted dumps (there are currently 96 dumps) we obtained roughly 36 trillion tokens of data (when
|
| 342 |
+
tokenized with the <code>gpt2</code> tokenizer).</p>
|
| 343 |
+
<h3>Deduplication</h3>
|
| 344 |
+
<p>Deduplication is one of the most important steps when creating large web datasets for LLM pretraining. Methods to deduplicate datasets attempt to identify and remove redundant/repeated data from the dataset. </p>
|
| 345 |
+
<h4>Why deduplicate?</h4>
|
| 346 |
+
<p>The web has many aggregators, mirrors, templated pages or
|
| 347 |
+
just otherwise repeated content spread over different domains and webpages. Often, these duplicated pages
|
| 348 |
+
can be introduced by the crawler itself, when different links point to the same page. </p>
|
| 349 |
+
<p>Removing these duplicates (deduplicating) has been linked to an improvement in model performance<d-cite bibtex-key="lee2022deduplicating"></d-cite> and a reduction in memorization of pretraining data<d-cite bibtex-key="carlini2023quantifying"></d-cite>, which might
|
| 350 |
+
allow for better generalization. Additionally, the performance uplift obtained through deduplication can also be tied to increased training
|
| 351 |
+
efficiency: by removing duplicated content, for the same number of training tokens, a model will have seen
|
| 352 |
+
more diverse data.<d-cite bibtex-key="muennighoff2023scaling"></d-cite><d-cite bibtex-key="hernandez2022scaling"></d-cite></p>
|
| 353 |
+
<p>There are different ways to identify and even define
|
| 354 |
+
duplicated data. Common approaches rely on hashing techniques to speed up the process, or on building
|
| 355 |
+
efficient data structures to index the data (like suffix arrays). Methods can also be “fuzzy”, by using some
|
| 356 |
+
similarity metric to mark documents as duplicates, or “exact” by checking for exact matches between two
|
| 357 |
+
documents (or lines, paragraphs, or whatever other granularity level being used).</p>
|
| 358 |
+
<h4>Our deduplication parameters</h4>
|
| 359 |
+
<p>Similarly to RefinedWeb<d-cite bibtex-key="penedo2023refinedweb"></d-cite>, we decided to apply MinHash, a
|
| 360 |
+
fuzzy hash based deduplication technique that scales well and allows us to tune similarity thresholds (by changing the number and size of buckets) and the granularity of the matches (by changing the n-gram size). We chose to compute minhashes on each document’s 5-grams, using
|
| 361 |
+
112 hash functions in total, split into 14 buckets of 8 hashes each — targeting documents that are at least
|
| 362 |
+
75% similar. Documents with the same 8 minhashes in any bucket are considered a duplicate of each other.</p>
|
| 363 |
+
<p>This would mean that for two documents with a similarity ($$s$$)
|
| 364 |
+
of 0.7, 0.75, 0.8 and 0.85, the probability that they would be identified as duplicates would be 56%, 77%,
|
| 365 |
+
92% and 98.8% respectively ($$1-(1-s^8)^{14}$$). See the plot below for a match probability
|
| 366 |
+
comparison between our setup with 112 hashes and the one from RefinedWeb, with 9000 hashes, divided into 450
|
| 367 |
+
buckets of 20 hashes (that requires a substantially larger amount of compute resources, as each individual hash must be computed, stored and then compared with hashes from other documents):</p>
|
| 368 |
+
<div class="main-plot-container">
|
| 369 |
+
<figure><img src="assets/images/minhash_params.png"/></figure>
|
| 370 |
+
<div id="plot-minhash_params"></div>
|
| 371 |
+
</div>
|
| 372 |
+
<p>While the high number of hash functions in RefinedWeb
|
| 373 |
+
allows for a steeper, more well defined cut off (documents with real similarity near the threshold are more likely to be correctly identified), we believe the compute and storage savings are a reasonable
|
| 374 |
+
trade off.</p>
|
| 375 |
+
<p>It should also be noted that intra-document deduplication is already handled by our repetition filter, which removes documents with many repeated lines and paragraphs.</p>
|
| 376 |
+
<h4>More deduplication is always better, right?</h4>
|
| 377 |
+
<p>Our initial approach was to take the entire dataset (all
|
| 378 |
+
90+ dumps) and deduplicate them together as one big dataset using MinHash.</p>
|
| 379 |
+
<p>We did this in an iterative manner: starting with the most
|
| 380 |
+
recent dump (which at the time was 2023-50) and proceeding chronologically until the oldest one, we would deduplicate each dump
|
| 381 |
+
not only within itself, but we would also remove any matches with documents from the previously processed (more recent)
|
| 382 |
+
dumps. </p>
|
| 383 |
+
<p>For instance, for the second most recent dump (2023-40 at
|
| 384 |
+
the time), we deduplicated it against the most recent one in addition to within itself. In particular, the oldest
|
| 385 |
+
dump was deduplicated against all other dumps. As a result, more data was removed from the oldest dumps (last
|
| 386 |
+
to be deduplicated) than from the most recent ones.</p>
|
| 387 |
+
<p>Deduplicating the dataset in this manner resulted in 4
|
| 388 |
+
trillion tokens of data, but, quite surprisingly for us, when training on a randomly sampled 350 billion
|
| 389 |
+
tokens subset, the model showed no improvement over one trained on the non deduplicated data (see orange and
|
| 390 |
+
green curves below), scoring far below its predecessor RefinedWeb on our aggregate of tasks.</p>
|
| 391 |
+
<div class="main-plot-container">
|
| 392 |
+
<figure><img src="assets/images/dedup_all_dumps_bad.png"/></figure>
|
| 393 |
+
<div id="plot-all_dumps_bad"></div>
|
| 394 |
+
</div>
|
| 395 |
+
<p>This was quite puzzling as our intuition regarding web
|
| 396 |
+
data was that more deduplication would always result in improved performance. We decided to take a closer
|
| 397 |
+
look at one of the oldest dumps, dump 2013-48:</p>
|
| 398 |
+
<ul>
|
| 399 |
+
<li>pre deduplication, this dump had ~490 billion tokens</li>
|
| 400 |
+
</ul>
|
| 401 |
+
<ul>
|
| 402 |
+
<li>after our iterative MinHash, ~31 billion tokens remained (94% of data had been
|
| 403 |
+
removed)
|
| 404 |
+
</li>
|
| 405 |
+
</ul>
|
| 406 |
+
<p>As an experiment, we tried training two models on 28 billion tokens
|
| 407 |
+
sampled from the following data from 2013-48:</p>
|
| 408 |
+
<ul>
|
| 409 |
+
<li>the fully deduplicated remaining ~31 billion tokens (<em>originally kept
|
| 410 |
+
data</em>)
|
| 411 |
+
</li>
|
| 412 |
+
</ul>
|
| 413 |
+
<ul>
|
| 414 |
+
<li>171 billion tokens obtained by individually deduplicating (without
|
| 415 |
+
considering the other dumps) the ~460 billion tokens that had been removed from this dump in the
|
| 416 |
+
iterative dedup process (<em>originally removed data</em>)<d-footnote>While there may be documents in <em>originally kept
|
| 417 |
+
data</em> similar to documents in <em>originally removed data</em>, we estimate the overlap to be small (around 4 billion tokens)</d-footnote>
|
| 418 |
+
</li>
|
| 419 |
+
</ul>
|
| 420 |
+
<div class="main-plot-container">
|
| 421 |
+
<figure><img src="assets/images/removed_data_cross_dedup.png"/></figure>
|
| 422 |
+
<div id="plot-removed_data_dedup"></div>
|
| 423 |
+
</div>
|
| 424 |
+
<p>These results show that, for this older dump from which we had
|
| 425 |
+
removed over 90% of the original data, the data that was kept was actually <em>worse</em> than the data
|
| 426 |
+
removed (considered independently of all the other dumps). This is also confirmed by visual inspection: <em>originally kept
|
| 427 |
+
data</em> contains far more ads, lists of keywords and generally badly formatted text than <em>originally removed data</em>.</p>
|
| 428 |
+
<h4>Taking a step back: individual dump dedup</h4>
|
| 429 |
+
<p>We then tried an alternative approach: we deduplicated
|
| 430 |
+
each dump with MinHash individually (without considering the other dumps). This resulted in 20 trillion
|
| 431 |
+
tokens of data.</p>
|
| 432 |
+
<p>When training on a random sample from this dataset we see
|
| 433 |
+
that it now matches RefinedWeb’s performance (blue and red curves below):</p>
|
| 434 |
+
<div class="main-plot-container">
|
| 435 |
+
<figure><img src="assets/images/cross_ind_unfiltered_comparison.png"/></figure>
|
| 436 |
+
<div id="plot-ind_dedup_better"></div>
|
| 437 |
+
</div>
|
| 438 |
+
<p>We hypothesize that the main improvement gained from
|
| 439 |
+
deduplication is the removal of very large clusters that are present in every single dump (you will find
|
| 440 |
+
some examples of these clusters on the RefinedWeb paper, each containing <em>hundreds of thousands</em> of
|
| 441 |
+
documents) and that further deduplication for clusters with a low number of duplicates (less than ~100 i.e. the number
|
| 442 |
+
of dumps) actually harms performance: data that does not find a duplicate match in any other dump might
|
| 443 |
+
actually be worse quality/more out of distribution (as evidenced by the results on the 2013-48 data). </p>
|
| 444 |
+
<p>While you might see some performance improvement when
|
| 445 |
+
deduplicating a few dumps together, at the scale of the entire dataset (all the dumps), the effect from this upsampling of lower quality data side
|
| 446 |
+
effect seems to be more impactful.</p>
|
| 447 |
+
<p>One possibility to consider is that as filtering quality
|
| 448 |
+
improves, this effect may not be as prevalent, since the filtering might be able to remove some of this
|
| 449 |
+
lower quality data. We also experimented with applying different, and often “lighter”, deduplication
|
| 450 |
+
approaches on top of the individually deduplicated dumps. You can read about them further below.</p>
|
| 451 |
+
<h4>A note on measuring the effect of deduplication</h4>
|
| 452 |
+
<p>Given the nature of deduplication, its effect is not
|
| 453 |
+
always very visible in a smaller slice of the dataset (such as 28B tokens, the size we used for our
|
| 454 |
+
filtering ablations). Furthermore, one must consider the fact that there are specific effects at play when
|
| 455 |
+
deduplicating across all CommonCrawl dumps, as some URLs/pages are recrawled from one dump to the next.</p>
|
| 456 |
+
<p>To visualize the effect of scaling the number of training
|
| 457 |
+
tokens on measuring deduplication impact, we considered the following (very extreme and unrealistic
|
| 458 |
+
regarding the degree of duplication observed) theoretical scenario:</p>
|
| 459 |
+
<ul>
|
| 460 |
+
<li>there are 100 CommonCrawl dumps (roughly accurate)</li>
|
| 461 |
+
</ul>
|
| 462 |
+
<ul>
|
| 463 |
+
<li>each dump has been perfectly individually deduplicated (every single
|
| 464 |
+
document in it is unique)
|
| 465 |
+
</li>
|
| 466 |
+
</ul>
|
| 467 |
+
<ul>
|
| 468 |
+
<li>each dump is a perfect copy of each other (maximum possible duplication
|
| 469 |
+
across dumps, effectively the worst case scenario)
|
| 470 |
+
</li>
|
| 471 |
+
</ul>
|
| 472 |
+
<ul>
|
| 473 |
+
<li>each dump has 200 billion tokens (for a total of 20 trillion, the resulting
|
| 474 |
+
size of our individual dedup above)
|
| 475 |
+
</li>
|
| 476 |
+
</ul>
|
| 477 |
+
<ul>
|
| 478 |
+
<li>each dump is made up of documents of 1k tokens (200M documents per dump)
|
| 479 |
+
</li>
|
| 480 |
+
</ul>
|
| 481 |
+
<p>We then simulated uniformly sampling documents from this
|
| 482 |
+
entire dataset of 20 trillion tokens, to obtain subsets of 1B, 10B, 100B, 350B and 1T tokens. In the image
|
| 483 |
+
below you can see how often each document would be repeated.</p>
|
| 484 |
+
<div class="main-plot-container">
|
| 485 |
+
<figure><img src="assets/images/duplicates_simul.png"/></figure>
|
| 486 |
+
<div id="plot-duplicates-simul"></div>
|
| 487 |
+
</div>
|
| 488 |
+
<p>For 1B almost all documents would be unique
|
| 489 |
+
(#duplicates=1), despite the fact that in the entire dataset each document is repeated 100 times (once per
|
| 490 |
+
dump). We start seeing some changes at the 100B scale (0.5% of the total dataset), with a large number of
|
| 491 |
+
documents being repeated twice, and a few even 4-8 times. At the larger scale of 1T (5% of the total
|
| 492 |
+
dataset), the majority of the documents are repeated up to 8 times, with some being repeated up to 16
|
| 493 |
+
times. </p>
|
| 494 |
+
<p>We ran our performance evaluations for the deduplicated
|
| 495 |
+
data at the 350B scale, which would, under this theoretical scenario, be made up of a significant portion of
|
| 496 |
+
documents duplicated up to 8 times. This simulation illustrates the inherent difficulties associated with
|
| 497 |
+
measuring deduplication impact on the training of LLMs, once the biggest duplicate clusters have been
|
| 498 |
+
removed.</p>
|
| 499 |
+
<h4>Other (failed) global approaches</h4>
|
| 500 |
+
<p>We attempted to improve the performance of the
|
| 501 |
+
independently minhash deduped 20 trillion tokens of data by further deduplicating it (globally, over all dumps) with the following methods:</p>
|
| 502 |
+
<ul>
|
| 503 |
+
<li>URL deduplication, where we only kept one document per normalized
|
| 504 |
+
(lowercased) URL (71.5% of tokens removed, 5.6T left) — <em>FineWeb URL dedup</em></li>
|
| 505 |
+
</ul>
|
| 506 |
+
<ul>
|
| 507 |
+
<li>Line deduplication:
|
| 508 |
+
<ul>
|
| 509 |
+
<li>remove all but 1 (randomly chosen) occurrence of each duplicated line (77.8% of
|
| 510 |
+
tokens dropped, 4.4T left) — <em>FineWeb line dedup</em></li>
|
| 511 |
+
</ul>
|
| 512 |
+
<ul>
|
| 513 |
+
<li>same as above, but only removing duplicate lines with at least 10
|
| 514 |
+
words and dropping documents with fewer than 3 sentences after deduplication (85% of tokens
|
| 515 |
+
dropped, 2.9T left) — <em>FineWeb line dedup w/ min words</em></li>
|
| 516 |
+
</ul>
|
| 517 |
+
<ul>
|
| 518 |
+
<li>remove all but 1 occurrence of each span of 3 duplicated lines
|
| 519 |
+
with each number treated as 0 when finding duplicates, (80.9% of tokens removed, 3.7T left) — <em>FineWeb 3-line
|
| 520 |
+
dedup</em></li>
|
| 521 |
+
</ul>
|
| 522 |
+
</li>
|
| 523 |
+
</ul>
|
| 524 |
+
<p>The performance of the models trained on each of these was
|
| 525 |
+
consistently worse (even if to different degrees) than that of the original independently deduplicated
|
| 526 |
+
data:</p>
|
| 527 |
+
<div class="main-plot-container">
|
| 528 |
+
<figure><img src="assets/images/dedup_attempts.png"/></figure>
|
| 529 |
+
<div id="plot-dedup_attempts"></div>
|
| 530 |
+
</div>
|
| 531 |
+
<h3>Additional filtering</h3>
|
| 532 |
+
<p>By this point we had reached the same performance as
|
| 533 |
+
RefinedWeb with base filtering + independent MinHash, but on our aggregate of tasks, another heavily filtered dataset, the C4 dataset<d-cite bibtex-key="raffel2023exploring"></d-cite>, still showed stronger performance (with
|
| 534 |
+
the caveat that it is a relatively small dataset for current web-scale standards).</p>
|
| 535 |
+
<p>We therefore set out to find new filtering steps that
|
| 536 |
+
would, at first, allow us to match the performance of C4 and, at a second stage, surpass it. A natural starting point
|
| 537 |
+
was to look into the processing of C4 itself.</p>
|
| 538 |
+
<h4>C4: A dataset that has stood the test of time</h4>
|
| 539 |
+
<p>The <a href="https://huggingface.co/datasets/c4">C4
|
| 540 |
+
dataset</a> was first released in 2019. It was obtained from the <code>2019-18</code> CommonCrawl dump by
|
| 541 |
+
removing non english data, applying some heuristic filters on both the line and document level,
|
| 542 |
+
deduplicating on the line level, and removing documents containing words from a word blocklist.</p>
|
| 543 |
+
<p>Despite its age and limited size for current standards (around 175B gpt2 tokens), this dataset is, to this day, a common sub-set of typical LLM training, being used in models such as the relatively recent Llama1<d-cite bibtex-key="touvron2023llama"></d-cite>.
|
| 544 |
+
This success is due to the strong performance that models trained on this dataset exhibit, excelling in particular on the Hellaswag
|
| 545 |
+
benchmark <d-cite bibtex-key="zellers-etal-2019-hellaswag"></d-cite>, one of the benchmarks in our “early signal” group with the highest
|
| 546 |
+
signal-to-noise ratio. We experimented applying
|
| 547 |
+
each of the different filters used in C4 to a baseline of the independently deduped FineWeb 2019-18 dump:</p>
|
| 548 |
+
<div class="main-plot-container">
|
| 549 |
+
<figure><img src="assets/images/c4_filters_hellaswag.png"/></figure>
|
| 550 |
+
<div id="plot-c4_filters_hellaswag"></div>
|
| 551 |
+
</div>
|
| 552 |
+
<ul>
|
| 553 |
+
<li>applying “All filters” (drop lines not ending on punctuation marks,
|
| 554 |
+
mentioning javascript and cookie notices + drop documents outside length thresholds, containing “lorem
|
| 555 |
+
ipsum” or a curly bracket, <code>{</code>) allows us to match C4’s HellaSwag performance (purple versus
|
| 556 |
+
pink curves).
|
| 557 |
+
</li>
|
| 558 |
+
</ul>
|
| 559 |
+
<ul>
|
| 560 |
+
<li>The curly bracket filter, and the word lengths filter only give a small
|
| 561 |
+
boost, removing 2.8% and 4.3% of tokens, respectively
|
| 562 |
+
</li>
|
| 563 |
+
</ul>
|
| 564 |
+
<ul>
|
| 565 |
+
<li>The terminal punctuation filter, by itself, gives the biggest individual
|
| 566 |
+
boost, but removes <em>around 30%</em> of all tokens (!)
|
| 567 |
+
</li>
|
| 568 |
+
</ul>
|
| 569 |
+
<ul>
|
| 570 |
+
<li>The lorem_ipsum, javascript and policy rules each remove <0.5% of
|
| 571 |
+
training tokens, so we did not train on them individually
|
| 572 |
+
</li>
|
| 573 |
+
</ul>
|
| 574 |
+
<ul>
|
| 575 |
+
<li>"All filters except the (very destructive) terminal_punct" performs better than
|
| 576 |
+
terminal_punct by itself, while removing less in total (~7%)
|
| 577 |
+
</li>
|
| 578 |
+
</ul>
|
| 579 |
+
<p>We decided to apply all C4 filters mentioned above except
|
| 580 |
+
the terminal punctuation one. We validated these results with a longer run, which you will find in a plot in
|
| 581 |
+
the next section.</p>
|
| 582 |
+
<h4>A statistical approach to develop heuristic filters</h4>
|
| 583 |
+
<p>To develop new heuristic filters and select their thresholds we devised a systematic process:</p>
|
| 584 |
+
<ol><li>we started by collecting a very large list of high level statistics (over <strong>50</strong>) ranging from common document-level
|
| 585 |
+
metrics (e.g. number of lines, avg. line/word length, etc) to inter-document repetition metrics (MassiveText
|
| 586 |
+
inspired), on both a high quality and a lower quality web dataset;</li>
|
| 587 |
+
<li>we selected the metrics for which the Wasserstein distance between the two distributions (of the metric computed on each dataset) was larger;</li>
|
| 588 |
+
<li>we inspected the histograms of the two distributions and empirically chose a threshold that would make the lower quality dataset more closely resemble the higher quality one on this metric;</li>
|
| 589 |
+
<li>we validated the resulting filter (metric-threshold pair) by using it on a reference dataset and running small ablations.</li>
|
| 590 |
+
</ol>
|
| 591 |
+
<p>Due to our assumption that global MinHash greatly upsamples lower quality data in the oldest dumps, we computed metrics on both the independently
|
| 592 |
+
MinHashed and the (worse quality) global MinHashed versions of the 2013-48 and 2015-22 crawls (two older crawls). We then compared the
|
| 593 |
+
statistics at a macro level, by looking at the distribution of these metrics for each one.</p>
|
| 594 |
+
<p>Perhaps not too surprisingly given our findings for deduplication, we found significant
|
| 595 |
+
disparities in most of the metrics for the two deduplication methods. For instance, the <code>line-char-duplicates</code>
|
| 596 |
+
metric (nb. of characters in duplicated lines / nb. characters), roughly doubled from the independent dedup
|
| 597 |
+
(0.0053 for 2015-22 and 0.0058 for 2013-48), to the global dedup (0.011 for 2015-22 and 0.01 for 2013-48),
|
| 598 |
+
indicating that the latter had higher inter-document repetition.</p>
|
| 599 |
+
<p>Following the process listed above for these datasets yielded 17 candidate
|
| 600 |
+
metric-threshold pairs. In the image below, you can see 3 of these histograms:</p>
|
| 601 |
+
<div class="main-plot-container">
|
| 602 |
+
<figure><img src="assets/images/custom_filters.png"/></figure>
|
| 603 |
+
<div id="plot-stats"></div>
|
| 604 |
+
</div>
|
| 605 |
+
|
| 606 |
+
<p>As an example, we inspected the histograms of "fraction of lines ending with punctuation" (see the image above) and observed an increased document density of global MinHash at around 0.12.
|
| 607 |
+
We then filtered with this threshold and found that the removed data had a higher amount of short lists or consisted of only document layout text ("Home", "Sign up", etc).
|
| 608 |
+
</p>
|
| 609 |
+
|
| 610 |
+
<p>We then assessed the effectiveness of these 17 newly created
|
| 611 |
+
filters, by conducting <strong>28B tokens</strong> ablation runs on the <strong>2019-18 crawl</strong>. Out
|
| 612 |
+
of all those runs, we identified three filters (the ones based on the histograms above) that demonstrated
|
| 613 |
+
the most significant improvements on the aggregate score:</p>
|
| 614 |
+
<ul>
|
| 615 |
+
<li>Remove documents where the fraction of lines ending with punctuation ≤ 0.12
|
| 616 |
+
(10.14% of tokens removed) — vs the 30% from the original C4 terminal punct filter
|
| 617 |
+
</li>
|
| 618 |
+
</ul>
|
| 619 |
+
<ul>
|
| 620 |
+
<li>Remove documents where the fraction of characters in duplicated lines ≥ 0.1
|
| 621 |
+
(12.47% of tokens removed) — the original MassiveText threshold for this ratio is ≥ 0.2
|
| 622 |
+
</li>
|
| 623 |
+
</ul>
|
| 624 |
+
<ul>
|
| 625 |
+
<li>Remove documents where the fraction of lines shorter than 30 characters ≥
|
| 626 |
+
0.67 (3.73% of tokens removed)
|
| 627 |
+
</li>
|
| 628 |
+
</ul>
|
| 629 |
+
<ul>
|
| 630 |
+
<li>When applying the 3 together, ~22% of tokens were removed.</li>
|
| 631 |
+
</ul>
|
| 632 |
+
<div class="main-plot-container">
|
| 633 |
+
<figure><img src="assets/images/custom_filters.png"/></figure>
|
| 634 |
+
<div id="plot-custom_filters"></div>
|
| 635 |
+
</div>
|
| 636 |
+
<p>These filters allowed us to further improve performance and to, notably, surpass the C4 dataset performance.</p>
|
| 637 |
+
<h2>The final dataset</h2>
|
| 638 |
+
<p>The final 🍷 FineWeb dataset comprises 15T tokens and
|
| 639 |
+
includes the following previously mentioned steps, in order, each providing a performance boost on our group
|
| 640 |
+
of benchmark tasks:</p>
|
| 641 |
+
<ul>
|
| 642 |
+
<li>base filtering</li>
|
| 643 |
+
</ul>
|
| 644 |
+
<ul>
|
| 645 |
+
<li>independent MinHash deduplication per dump</li>
|
| 646 |
+
</ul>
|
| 647 |
+
<ul>
|
| 648 |
+
<li>a selection of C4 filters</li>
|
| 649 |
+
</ul>
|
| 650 |
+
<ul>
|
| 651 |
+
<li>our custom filters (mentioned in the previous section)</li>
|
| 652 |
+
</ul>
|
| 653 |
+
<div class="main-plot-container">
|
| 654 |
+
<figure><img src="assets/images/filtering_steps.png"/></figure>
|
| 655 |
+
<div id="plot-all_filtering_steps"></div>
|
| 656 |
+
</div>
|
| 657 |
+
<p>We compared 🍷 FineWeb with the following datasets:</p>
|
| 658 |
+
<ul>
|
| 659 |
+
<li><a
|
| 660 |
+
href="https://huggingface.co/datasets/tiiuae/falcon-refinedweb">RefinedWeb</a><d-cite bibtex-key="penedo2023refinedweb"></d-cite>
|
| 661 |
+
</li>
|
| 662 |
+
</ul>
|
| 663 |
+
<ul>
|
| 664 |
+
<li><a href="https://huggingface.co/datasets/allenai/c4">C4</a><d-cite bibtex-key="raffel2023exploring"></d-cite></li>
|
| 665 |
+
</ul>
|
| 666 |
+
<ul>
|
| 667 |
+
<li><a href="https://huggingface.co/datasets/allenai/dolma">Dolma v1.6</a> (the
|
| 668 |
+
CommonCrawl part) <d-cite bibtex-key="dolma"></d-cite>
|
| 669 |
+
</li>
|
| 670 |
+
</ul>
|
| 671 |
+
<ul>
|
| 672 |
+
<li><a href="https://huggingface.co/datasets/EleutherAI/pile">The Pile</a> <d-cite bibtex-key="gao2020pile"></d-cite></li>
|
| 673 |
+
</ul>
|
| 674 |
+
<ul>
|
| 675 |
+
<li><a
|
| 676 |
+
href="https://huggingface.co/datasets/cerebras/SlimPajama-627B">SlimPajama</a> <d-cite bibtex-key="cerebras2023slimpajama"></d-cite>
|
| 677 |
+
</li>
|
| 678 |
+
</ul>
|
| 679 |
+
<ul>
|
| 680 |
+
<li><a
|
| 681 |
+
href="https://huggingface.co/datasets/togethercomputer/RedPajama-Data-V2">RedPajama2</a> <d-cite bibtex-key="together2023redpajama"></d-cite>
|
| 682 |
+
(deduplicated)
|
| 683 |
+
</li>
|
| 684 |
+
</ul>
|
| 685 |
+
<p>You will find these models on <a
|
| 686 |
+
href="https://huggingface.co/collections/HuggingFaceFW/ablation-models-662457b0d213e8c14fe47f32">this
|
| 687 |
+
collection</a>. We have uploaded checkpoints at every 1000 training steps. You will also find our full <a
|
| 688 |
+
href="https://huggingface.co/datasets/HuggingFaceFW/fineweb/blob/main/eval_results.csv">evaluation
|
| 689 |
+
results here</a>.</p>
|
| 690 |
+
<div class="main-plot-container">
|
| 691 |
+
<figure><img src="assets/images/dataset_ablations.png"/></figure>
|
| 692 |
+
<div id="plot-dataset_ablations"></div>
|
| 693 |
+
</div>
|
| 694 |
+
<p>Large language models pretrained on 🍷 FineWeb, the largest publicly available clean LLM pretraining dataset, are better-performing than other open pretraining datasets.</p>
|
| 695 |
+
<h2>📚 FineWeb-Edu</h2>
|
| 696 |
+
<p>A new approach has recently emerged for filtering LLM training datasets: using synthetic data to develop classifiers for identifying educational content. This technique was used in the trainings of Llama 3<d-cite bibtex-key="llama3modelcard"></d-cite> and Phi3<d-cite bibtex-key="abdin2024phi"></d-cite> but its large-scale impact on web data filtering hasn't been fully explored or published.</p>
|
| 697 |
+
<p>The popular Phi3 models were trained on 3.3 and 4.8 trillion tokens, with the paper<d-cite bibtex-key="abdin2024phi"></d-cite> stating:</p>
|
| 698 |
+
<blockquote>Our training data consists of heavily filtered publicly available web data (according to the 'educational level') from various open internet sources, as well as synthetic LLM-generated data.</blockquote>
|
| 699 |
+
<p>Similarly, Llama 3 blog post<d-cite bibtex-key="meta2024responsible"></d-cite> notes:</p>
|
| 700 |
+
<blockquote>We found that previous generations of Llama are good at identifying high-quality data, so we used Llama 2 to help build the text-quality classifiers that are powering Llama 3.</blockquote>
|
| 701 |
+
<p>However, these classifiers and filtered datasets are not publicly available. To further enhance 🍷 FineWeb's quality, we developed an educational quality classifier using annotations generated by <a href="https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct">Llama-3-70B-Instruct</a> to create <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu"><strong>📚 FineWeb-Edu</strong></a>.</p>
|
| 702 |
+
<h3>Annotation</h3>
|
| 703 |
+
<p>We used Llama-3-70B-Instruct to annotate 500k samples from 🍷 FineWeb, scoring each for their educational quality on a scale from 0 to 5.</p>
|
| 704 |
+
<p>We explored various prompts and found that the additive scale by Yuan et al.<d-cite bibtex-key="yuan2024self"></d-cite> worked best. This scale allows the LLM to reason about each additional point awarded, unlike the single-rating Likert scale which fits samples into predefined boxes. Then, to avoid the LLM favoring highly technical pages like arXiv abstracts and submissions, we focused on grade-school and middle-school level knowledge. By setting a threshold of 3 (on a scale of 0 to 5) during the filtering process, we were able to also retain some high-level educational pages.</p>
|
| 705 |
+
<div style="text-align: center; margin: 20px 0;">
|
| 706 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/61c141342aac764ce1654e43/fjZQ4izIj1rx1xQnBTKKr.png" alt="Prompt for LLM annotation" style="width: 90%; max-width: 800px; height: auto;">
|
| 707 |
+
<figcaption style="font-style: italic; margin-top: 10px;">Prompt used for Llama3 annotations of the educational score, also available <a href="https://huggingface.co/HuggingFaceFW/fineweb-edu-classifier/blob/main/utils/prompt.txt">here</a>.</figcaption>
|
| 708 |
+
</div>
|
| 709 |
+
<p>We also experimented with <a href="https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1">Mixtral-8x-7B-Instruct</a> and <a href="https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1">Mixtral-8x22B-Instruct</a> and a jury of all three models<d-cite bibtex-key="verga2024replacing"></d-cite> but found that Llama3 alone gave the most reliable results.</p>
|
| 710 |
+
<h3>Classifier Training</h3>
|
| 711 |
+
<p>We added a classification head with a single regression output to <a href="https://huggingface.co/Snowflake/snowflake-arctic-embed-m">Snowflake-arctic-embed</a> and trained it on 450,000 Llama 3 annotations for 20 epochs with a learning rate of 3e-4, freezing the embedding and encoder layers. We saved the checkpoint with the highest F1 score on our held-out validation set of 45k samples, treating Llama 3 annotations as ground-truth. After training, we rounded the scores to integers from 0 to 5.</p>
|
| 712 |
+
<p>We then converted the problem to a binary classification task by using a fixed threshold to determine if a file is educational. With a threshold of 3, the model achieved an F1 score of 82% on the validation set, indicating strong performance in distinguishing high-quality educational content.</p>
|
| 713 |
+
<p>The classifier is available at: <a href="https://huggingface.co/HuggingFaceFW/fineweb-edu-classifier">HuggingFaceFW/fineweb-edu-classifier</a>. The training and inference code is available on <a href="https://github.com/huggingface/cosmopedia/tree/main/classification">GitHub</a>.</p>
|
| 714 |
+
<h3>Filtering and results</h3>
|
| 715 |
+
<p>We applied the classifier to the 15T tokens of ��� FineWeb, a process that required 6,000 H100 GPU hours. We investigated the impact of using different thresholds for the filtering and found that threshold 3 gave the best overall results. Although using a threshold higher than 3 improves performance on knowledge and reasoning intensive benchmarks, it significantly degrades performance on HellaSwag and PIQA. The plot below shows the performance of each threshold compared to FineWeb on six different benchmarks; it uses a 1.82B model trained on 8B tokens.</p>
|
| 716 |
+
<div class="main-plot-container">
|
| 717 |
+
<figure>
|
| 718 |
+
<img src="assets/images/edu-8k.png">
|
| 719 |
+
</figure>
|
| 720 |
+
<div id="plot-edu-8k"></div>
|
| 721 |
+
</div>
|
| 722 |
+
<p>We then built 📚 FineWeb-Edu by filtering out samples with scores lower than 3. This removed 92% of the dataset, leaving us with 1.3 trillion educational tokens. To evaluate the effectiveness of this filtering at a larger scale, we conducted an ablation using a 1.82B model trained on 350 billion tokens, similar to the FineWeb filtering ablation mentioned above:</p>
|
| 723 |
+
<div class="main-plot-container">
|
| 724 |
+
<figure>
|
| 725 |
+
<img src="assets/images/edu-100k.png">
|
| 726 |
+
</figure>
|
| 727 |
+
<div id="plot-edu-100k"></div>
|
| 728 |
+
</div>
|
| 729 |
+
<p>Here are the key highlights of the ablation results above:</p>
|
| 730 |
+
<ul>
|
| 731 |
+
<li>📚 FineWeb-Edu surpasses 🍷 FineWeb and all other open web datasets, with remarkable improvements on educational benchmarks such as MMLU, ARC, and OpenBookQA.</li>
|
| 732 |
+
<li>It achieves the same performance with significantly less data, requiring 10x fewer tokens compared to C4 and Dolma to match MMLU results.</li>
|
| 733 |
+
<li>This demonstrates the effectiveness of using classifiers trained on LLM annotations for large-scale data filtering.</li>
|
| 734 |
+
</ul>
|
| 735 |
+
<p>Given that a threshold of 2 also demonstrated strong performance while retaining more data, we are releasing an additional dataset filtered with this threshold, containing 5.4 trillion tokens under <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu-score-2">HuggingFaceFW/fineweb-edu-score-2</a>.</p>
|
| 736 |
+
<p>You can find the two datasets along with the classifier used for the filtering in this <a href="https://huggingface.co/collections/HuggingFaceFW/fineweb-edu-6659c3f3d399d0e1d648adfd">collection</a>.</p>
|
| 737 |
+
<h2>Next steps</h2>
|
| 738 |
+
<p>Through our open data efforts we hope to give every model trainer the ability to create state-of-the-art large language models. As part of this process, we plan to continue iterating on FineWeb and to release more specialised filtered subsets of web data, in a fully open and reproducible manner.</p>
|
| 739 |
+
<p>While English currently dominates the large language model landscape, we believe that making high quality training data for other languages more easily accessible would allow millions of non english speakers to benefit from these technologies and, as such, will also strive to adapt the FineWeb Recipe to a multilingual version.</p>
|
| 740 |
+
</d-article>
|
| 741 |
+
|
| 742 |
+
<d-appendix>
|
| 743 |
+
<d-bibliography src="bibliography.bib"></d-bibliography>
|
| 744 |
+
</d-appendix>
|
| 745 |
+
|
| 746 |
+
<script>
|
| 747 |
+
const article = document.querySelector('d-article');
|
| 748 |
const toc = document.querySelector('d-contents');
|
| 749 |
if (toc) {
|
| 750 |
const headings = article.querySelectorAll('h2, h3, h4');
|
|
|
|
| 804 |
}
|
| 805 |
}
|
| 806 |
});
|
| 807 |
+
}
|
| 808 |
+
</script>
|
| 809 |
+
</body>
|
dist/main.bundle.js
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/main.bundle.js.map
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
src/index.html
CHANGED
|
@@ -2,6 +2,8 @@
|
|
| 2 |
|
| 3 |
<head>
|
| 4 |
<link rel="stylesheet" href="style.css">
|
|
|
|
|
|
|
| 5 |
<meta name="viewport" content="width=device-width, initial-scale=1">
|
| 6 |
<meta charset="utf8">
|
| 7 |
<base target="_blank">
|
|
|
|
| 2 |
|
| 3 |
<head>
|
| 4 |
<link rel="stylesheet" href="style.css">
|
| 5 |
+
<script src="distill.bundle.js" fetchpriority="high" blocking></script>
|
| 6 |
+
<script src="main.bundle.js" type="module" fetchpriority="low" defer></script>
|
| 7 |
<meta name="viewport" content="width=device-width, initial-scale=1">
|
| 8 |
<meta charset="utf8">
|
| 9 |
<base target="_blank">
|
src/plotting.js
CHANGED
|
@@ -272,7 +272,7 @@ export const init_ablation_plot = function () {
|
|
| 272 |
const y = rollingWindow(traceData.y, sliderValue);
|
| 273 |
const x = traceData.x.slice(0, y.length);
|
| 274 |
const plotSettings = settings.type === "bar" ? BAR_SETTINGS : LINE_SETTINGS;
|
| 275 |
-
const trace = {
|
| 276 |
x: x,
|
| 277 |
y: y,
|
| 278 |
name: traceData.label ?? DATASET_ID_TO_NAME[key] ?? key,
|
|
@@ -282,8 +282,7 @@ export const init_ablation_plot = function () {
|
|
| 282 |
line: {
|
| 283 |
color: getColor(index),
|
| 284 |
},
|
| 285 |
-
|
| 286 |
-
};
|
| 287 |
traces.push(trace);
|
| 288 |
}
|
| 289 |
console.log(traces)
|
|
|
|
| 272 |
const y = rollingWindow(traceData.y, sliderValue);
|
| 273 |
const x = traceData.x.slice(0, y.length);
|
| 274 |
const plotSettings = settings.type === "bar" ? BAR_SETTINGS : LINE_SETTINGS;
|
| 275 |
+
const trace = _.merge({}, {
|
| 276 |
x: x,
|
| 277 |
y: y,
|
| 278 |
name: traceData.label ?? DATASET_ID_TO_NAME[key] ?? key,
|
|
|
|
| 282 |
line: {
|
| 283 |
color: getColor(index),
|
| 284 |
},
|
| 285 |
+
}, plotSettings);
|
|
|
|
| 286 |
traces.push(trace);
|
| 287 |
}
|
| 288 |
console.log(traces)
|
webpack.config.js
CHANGED
|
@@ -59,9 +59,6 @@ module.exports = {
|
|
| 59 |
},
|
| 60 |
plugins: [
|
| 61 |
new CleanWebpackPlugin(),
|
| 62 |
-
new HtmlWebpackPlugin({
|
| 63 |
-
template: "./src/index.html", // Path to your source template
|
| 64 |
-
}),
|
| 65 |
new CopyPlugin({
|
| 66 |
patterns: [
|
| 67 |
{
|
|
@@ -71,6 +68,7 @@ module.exports = {
|
|
| 71 |
},
|
| 72 |
{ from: "src/style.css", to: "style.css" },
|
| 73 |
{ from: "src/bibliography.bib", to: "bibliography.bib" },
|
|
|
|
| 74 |
],
|
| 75 |
}),
|
| 76 |
],
|
|
|
|
| 59 |
},
|
| 60 |
plugins: [
|
| 61 |
new CleanWebpackPlugin(),
|
|
|
|
|
|
|
|
|
|
| 62 |
new CopyPlugin({
|
| 63 |
patterns: [
|
| 64 |
{
|
|
|
|
| 68 |
},
|
| 69 |
{ from: "src/style.css", to: "style.css" },
|
| 70 |
{ from: "src/bibliography.bib", to: "bibliography.bib" },
|
| 71 |
+
{ from: "src/index.html", to: "index.html" },
|
| 72 |
],
|
| 73 |
}),
|
| 74 |
],
|