
Upload 7 files
Browse files- Home.py +53 -0
- README.md +30 -13
- clients.py +160 -0
- pages/app_api_completion.py +128 -0
- pages/app_langchain_completion.py +135 -0
- requirements.txt +11 -0
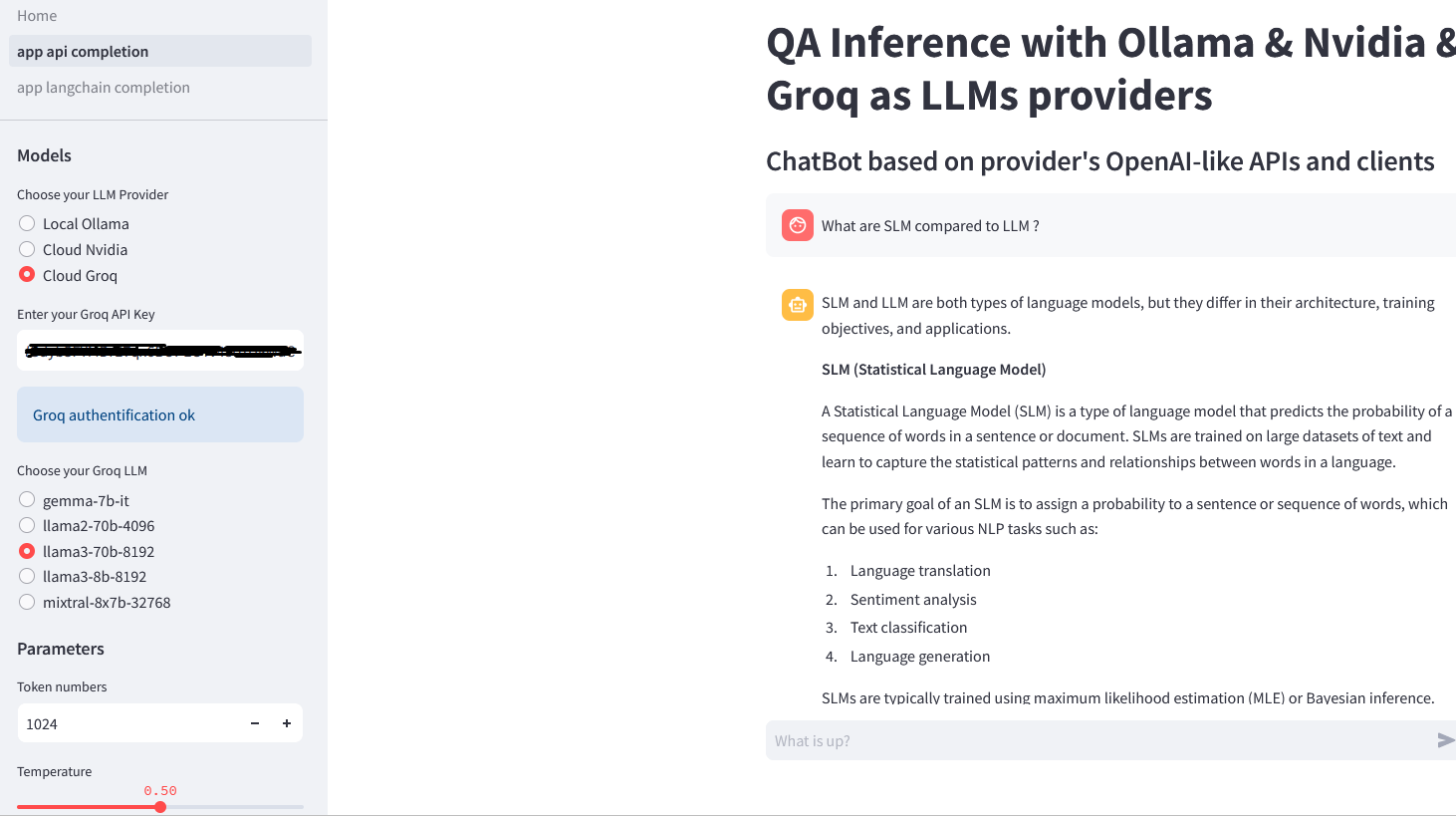
- screenshot.png +0 -0
Home.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.set_page_config(page_title="QA Inference Streamlit App using Ollama, Nvidia and Groq", layout="wide")
|
| 4 |
+
|
| 5 |
+
st.write("# QA Inference with Ollama & Nvidia & Groq as LLMs providers")
|
| 6 |
+
st.markdown(
|
| 7 |
+
"""
|
| 8 |
+
This app is a demo for showing how to interact with LLMs in the case of three providers : Ollama, the Nvidia Cloud and Groq.
|
| 9 |
+
|
| 10 |
+
You can use one, two or the three LLMs hosting solutions according to your environment :
|
| 11 |
+
|
| 12 |
+
- **[Ollama](https://ollama.com/)** : a local Ollama instance must be running on http://localhost:11434 (change the base_url in clients.py if needed)
|
| 13 |
+
- **[Nvidia Cloud](https://build.nvidia.com/explore/discover)** : if you want to test the LLMs hosted on Nvidia Cloud and mostly the no-latency QA process on Nvidia GPU, you need to create an (free) account and generate an API key
|
| 14 |
+
- **[Groq Cloud](https://console.groq.com/playground)** : if you want to test the LLMs hosted on Groq and especially the speed of execution of the inference process on Groq LPU, you need to create an (free) account and generate an API key
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
The app contains two pages implementing the same kind of chatbot, the only difference is how to achieve the LLM answer
|
| 18 |
+
|
| 19 |
+
- 👉 **App API completion** page : this page illustrates how to query a LLM by using OpenAI-like APIs or the OpenAI client
|
| 20 |
+
- 👉 **App Langchain completion** page : this page illustrates how to query a LLM using appropriate Langchain components
|
| 21 |
+
|
| 22 |
+
"""
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
footer="""<style>
|
| 26 |
+
a:link , a:visited{
|
| 27 |
+
color: blue;
|
| 28 |
+
background-color: transparent;
|
| 29 |
+
text-decoration: underline;
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
a:hover, a:active {
|
| 33 |
+
color: red;
|
| 34 |
+
background-color: transparent;
|
| 35 |
+
text-decoration: underline;
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
.footer {
|
| 39 |
+
position: fixed;
|
| 40 |
+
left: 0;
|
| 41 |
+
bottom: 0;
|
| 42 |
+
width: 100%;
|
| 43 |
+
background-color: white;
|
| 44 |
+
color: black;
|
| 45 |
+
text-align: center;
|
| 46 |
+
}
|
| 47 |
+
</style>
|
| 48 |
+
<div class="footer">
|
| 49 |
+
<p>Contact 🤙 <a style='display: block; text-align: center;' href="mailto:geraldine.geoffroy@epdl.ch" target="_blank">Géraldine Geoffroy</a></p>
|
| 50 |
+
</div>
|
| 51 |
+
"""
|
| 52 |
+
st.markdown(footer,unsafe_allow_html=True)
|
| 53 |
+
|
README.md
CHANGED
|
@@ -1,13 +1,30 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Streamlit simple QA Inference App with Ollama, Nvidia Cloud and Groq
|
| 2 |
+
|
| 3 |
+
> Post :
|
| 4 |
+
|
| 5 |
+
> Deployed : no
|
| 6 |
+
|
| 7 |
+
Two different ways to develop the same chatbot application
|
| 8 |
+
- app_api_completion.py : make QA inference with LLMs by choosing between the native Chat API completion endpoints provided by Ollama, Nvidia or Groq
|
| 9 |
+
- app_langchain_completion.py : make QA inference with LLMs with the dedicated Langchain wrappers for Ollama, Nvidia or Groq
|
| 10 |
+
|
| 11 |
+
You can use one, two or the three LLMs hosting solutions according to your environment :
|
| 12 |
+
|
| 13 |
+
- a running Ollama instance : the default base_url is http://localhost:11434 but if needed (remote or dockerized Ollama instance for example) you change it in the OllamaClient in clients.py
|
| 14 |
+
*and/or*
|
| 15 |
+
- a valid API key on the Nvidia Cloud : [https://build.nvidia.com/explore/discover](https://build.nvidia.com/explore/discover)
|
| 16 |
+
*and/or*
|
| 17 |
+
- a valid API key on Groq Cloud : [https://console.groq.com/playground](https://console.groq.com/playground)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
git clone
|
| 23 |
+
pip install -r requirements.txt
|
| 24 |
+
streamlit run Home.py
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
Running on http://localhost:8501
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+
|
clients.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
import json
|
| 3 |
+
from openai import OpenAI
|
| 4 |
+
from groq import Groq
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class OllamaClient:
|
| 8 |
+
def __init__(
|
| 9 |
+
self,
|
| 10 |
+
api_key=None,
|
| 11 |
+
model=None,
|
| 12 |
+
):
|
| 13 |
+
self.base_url = "http://localhost:11434"
|
| 14 |
+
self.headers = {"Content-Type": "application/json"}
|
| 15 |
+
self.api_key = api_key
|
| 16 |
+
self.model = model
|
| 17 |
+
|
| 18 |
+
def list_models(self):
|
| 19 |
+
url = f"{self.base_url}/api/tags"
|
| 20 |
+
try:
|
| 21 |
+
response = requests.get(url)
|
| 22 |
+
response.raise_for_status() # Raise an exception for HTTP errors (status codes 4xx and 5xx)
|
| 23 |
+
return response.json() # returns the response is in JSON format
|
| 24 |
+
except requests.exceptions.HTTPError as http_err:
|
| 25 |
+
print(f'HTTP error occurred: {http_err}')
|
| 26 |
+
except Exception as err:
|
| 27 |
+
print(f'Other error occurred: {err}')
|
| 28 |
+
|
| 29 |
+
def api_chat_completion(self,prompt,**options):
|
| 30 |
+
url = f"{self.base_url}/api/chat"
|
| 31 |
+
options = options if options is not None else {"max_tokens":1024,"top_p":0.7,"temperature":0.7}
|
| 32 |
+
payload = json.dumps(
|
| 33 |
+
{
|
| 34 |
+
"model": self.model,
|
| 35 |
+
"messages": [{"role": "user", "content": prompt}],
|
| 36 |
+
"option": {
|
| 37 |
+
"num_ctx": self.options["max_tokens"],
|
| 38 |
+
"top_p": self.options["top_p"],
|
| 39 |
+
"temperature": self.options["temperature"],
|
| 40 |
+
# stop_sequences=["<|prompter|>","<|assistant|>","</s>"]
|
| 41 |
+
},
|
| 42 |
+
"stream": False,
|
| 43 |
+
}
|
| 44 |
+
)
|
| 45 |
+
response = requests.request("POST", url, headers=self.headers, data=payload)
|
| 46 |
+
return response.json()["message"]["content"]
|
| 47 |
+
|
| 48 |
+
def client_chat_completion(self,prompt,**options):
|
| 49 |
+
options = options if options is not None else {"max_tokens":1024,"top_p":0.7,"temperature":0.7}
|
| 50 |
+
client = OpenAI(
|
| 51 |
+
base_url=self.base_url,
|
| 52 |
+
api_key=self.api_key,
|
| 53 |
+
)
|
| 54 |
+
completion = client.chat.completions.create(
|
| 55 |
+
model=self.model,
|
| 56 |
+
messages=[{"role": "user", "content": prompt}],
|
| 57 |
+
temperature=options["temperature"],
|
| 58 |
+
top_p=options["top_p"],
|
| 59 |
+
max_tokens=options["max_tokens"],
|
| 60 |
+
stream=False,
|
| 61 |
+
)
|
| 62 |
+
return completion.choices[0].message.content
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class NvidiaClient:
|
| 66 |
+
def __init__(self, api_key=None, model=None):
|
| 67 |
+
self.base_url = "https://integrate.api.nvidia.com/v1"
|
| 68 |
+
self.api_key = api_key
|
| 69 |
+
self.headers = {
|
| 70 |
+
"Content-Type": "application/json",
|
| 71 |
+
"Authorization": f"Bearer {self.api_key}",
|
| 72 |
+
}
|
| 73 |
+
self.model = model
|
| 74 |
+
|
| 75 |
+
def list_models(self):
|
| 76 |
+
url = f"{self.base_url}/models"
|
| 77 |
+
response = requests.request("GET", url) # api_key is not needed to list the available models
|
| 78 |
+
return response.json()
|
| 79 |
+
|
| 80 |
+
def api_chat_completion(self,prompt,**options):
|
| 81 |
+
url = f"{self.base_url}/chat/completions"
|
| 82 |
+
options = options if options is not None else {"max_tokens":1024,"top_p":0.7,"temperature":0.7}
|
| 83 |
+
payload = json.dumps(
|
| 84 |
+
{
|
| 85 |
+
"model": self.model,
|
| 86 |
+
"messages": [{"role": "user", "content": prompt}],
|
| 87 |
+
"temperature": options["temperature"],
|
| 88 |
+
"top_p": options["top_p"],
|
| 89 |
+
"max_tokens": options["max_tokens"],
|
| 90 |
+
"stream": False,
|
| 91 |
+
}
|
| 92 |
+
)
|
| 93 |
+
response = requests.request("POST", url, headers=self.headers, data=payload)
|
| 94 |
+
return response.json()["choices"][0]["message"]["content"]
|
| 95 |
+
|
| 96 |
+
def client_chat_completion(self,prompt,**options):
|
| 97 |
+
options = options if options is not None else {"max_tokens":1024,"top_p":0.7,"temperature":0.7}
|
| 98 |
+
client = OpenAI(
|
| 99 |
+
base_url=self.base_url,
|
| 100 |
+
api_key=self.api_key,
|
| 101 |
+
)
|
| 102 |
+
completion = client.chat.completions.create(
|
| 103 |
+
model=self.model,
|
| 104 |
+
messages=[{"role": "user", "content": prompt}],
|
| 105 |
+
temperature=self.options["temperature"],
|
| 106 |
+
top_p=self.options["top_p"],
|
| 107 |
+
max_tokens=self.options["max_tokens"],
|
| 108 |
+
stream=False,
|
| 109 |
+
)
|
| 110 |
+
return completion.choices[0].message.content
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class GroqClient:
|
| 114 |
+
def __init__(self, api_key=None, model=None):
|
| 115 |
+
self.base_url = "https://api.groq.com/openai/v1"
|
| 116 |
+
self.api_key = api_key
|
| 117 |
+
self.headers = {
|
| 118 |
+
"Content-Type": "application/json",
|
| 119 |
+
"Authorization": f"Bearer {self.api_key}",
|
| 120 |
+
}
|
| 121 |
+
self.model = model
|
| 122 |
+
|
| 123 |
+
def list_models(self):
|
| 124 |
+
url = f"{self.base_url}/models"
|
| 125 |
+
response = requests.request("GET", url, headers=self.headers)
|
| 126 |
+
return response.json()
|
| 127 |
+
|
| 128 |
+
def api_chat_completion(self,prompt,**options):
|
| 129 |
+
url = f"{self.base_url}/chat/completions"
|
| 130 |
+
options = options if options is not None else {"max_tokens":1024,"top_p":0.7,"temperature":0.7}
|
| 131 |
+
payload = json.dumps(
|
| 132 |
+
{
|
| 133 |
+
"model": self.model,
|
| 134 |
+
"messages": [{"role": "user", "content": prompt}],
|
| 135 |
+
"temperature": options["temperature"],
|
| 136 |
+
"top_p": options["top_p"],
|
| 137 |
+
"max_tokens": options["max_tokens"],
|
| 138 |
+
"stream": False,
|
| 139 |
+
}
|
| 140 |
+
)
|
| 141 |
+
response = requests.request("POST", url, headers=self.headers, data=payload)
|
| 142 |
+
return response.json()["choices"][0]["message"]["content"]
|
| 143 |
+
|
| 144 |
+
def client_chat_completion(self,prompt,**options):
|
| 145 |
+
options = options if options is not None else {"max_tokens":1024,"top_p":0.7,"temperature":0.7}
|
| 146 |
+
client = Groq(
|
| 147 |
+
api_key=self.api_key,
|
| 148 |
+
)
|
| 149 |
+
completion = client.chat.completions.create(
|
| 150 |
+
model=self.model,
|
| 151 |
+
messages=[
|
| 152 |
+
{"role": "system", "content": "you are a helpful assistant."},
|
| 153 |
+
{"role": "user", "content": prompt},
|
| 154 |
+
],
|
| 155 |
+
temperature=self.options["temperature"],
|
| 156 |
+
top_p=self.options["top_p"],
|
| 157 |
+
max_tokens=self.options["max_tokens"],
|
| 158 |
+
stream=False,
|
| 159 |
+
)
|
| 160 |
+
return completion.choices[0].message.content
|
pages/app_api_completion.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import streamlit as st
|
| 5 |
+
from clients import OllamaClient, NvidiaClient, GroqClient
|
| 6 |
+
|
| 7 |
+
st.set_page_config(
|
| 8 |
+
page_title="QA Inference Streamlit App using Ollama, Nvidia and Groq APIs"
|
| 9 |
+
)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# Cache the header of the app to prevent re-rendering on each load
|
| 13 |
+
@st.cache_resource
|
| 14 |
+
def display_app_header():
|
| 15 |
+
"""Display the header of the Streamlit app."""
|
| 16 |
+
st.title("QA Inference with Ollama & Nvidia & Groq as LLMs providers")
|
| 17 |
+
st.subheader("ChatBot based on provider's OpenAI-like APIs and clients")
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# Display the header of the app
|
| 21 |
+
display_app_header()
|
| 22 |
+
|
| 23 |
+
# UI sidebar ##########################################
|
| 24 |
+
st.sidebar.subheader("Models")
|
| 25 |
+
|
| 26 |
+
# LLM
|
| 27 |
+
llm_providers = {
|
| 28 |
+
"Local Ollama": "ollama",
|
| 29 |
+
"Cloud Nvidia": "nvidia",
|
| 30 |
+
"Cloud Groq": "groq",
|
| 31 |
+
}
|
| 32 |
+
llm_provider = st.sidebar.radio(
|
| 33 |
+
"Choose your LLM Provider", llm_providers.keys(), key="llm_provider"
|
| 34 |
+
)
|
| 35 |
+
if llm_provider == "Local Ollama":
|
| 36 |
+
ollama_list_models = OllamaClient().list_models()
|
| 37 |
+
if ollama_list_models:
|
| 38 |
+
ollama_models = [x["name"] for x in ollama_list_models["models"]]
|
| 39 |
+
ollama_llm = st.sidebar.radio(
|
| 40 |
+
"Select your Ollama model", ollama_models, key="ollama_llm"
|
| 41 |
+
) # retrive with st.session_state["ollama_llm"]
|
| 42 |
+
else:
|
| 43 |
+
st.sidebar.error('Ollama is not running')
|
| 44 |
+
elif llm_provider == "Cloud Nvidia":
|
| 45 |
+
if nvidia_api_token := st.sidebar.text_input("Enter your Nvidia API Key"):
|
| 46 |
+
st.sidebar.info("Nvidia authentification ok")
|
| 47 |
+
nvidia_list_models = NvidiaClient().list_models() # api_key is not needed to list the available models
|
| 48 |
+
nvidia_models = [x["id"] for x in nvidia_list_models["data"]]
|
| 49 |
+
nvidia_llm = st.sidebar.radio(
|
| 50 |
+
"Select your Nvidia LLM", nvidia_models, key="nvidia_llm"
|
| 51 |
+
)
|
| 52 |
+
else:
|
| 53 |
+
st.sidebar.warning("You must enter your Nvidia API key")
|
| 54 |
+
elif llm_provider == "Cloud Groq":
|
| 55 |
+
if groq_api_token := st.sidebar.text_input("Enter your Groq API Key"):
|
| 56 |
+
st.sidebar.info("Groq authentification ok")
|
| 57 |
+
groq_list_models = GroqClient(api_key=groq_api_token).list_models()
|
| 58 |
+
groq_models = [x["id"] for x in groq_list_models["data"]]
|
| 59 |
+
groq_llm = st.sidebar.radio("Choose your Groq LLM", groq_models, key="groq_llm")
|
| 60 |
+
else:
|
| 61 |
+
st.sidebar.warning("You must enter your Groq API key")
|
| 62 |
+
|
| 63 |
+
# LLM parameters
|
| 64 |
+
st.sidebar.subheader("Parameters")
|
| 65 |
+
max_tokens = st.sidebar.number_input("Token numbers", value=1024, key="max_tokens")
|
| 66 |
+
temperature = st.sidebar.slider(
|
| 67 |
+
"Temperature", min_value=0.0, max_value=1.0, value=0.5, step=0.1, key="temperature"
|
| 68 |
+
)
|
| 69 |
+
top_p = st.sidebar.slider(
|
| 70 |
+
"Top P", min_value=0.0, max_value=1.0, value=0.7, step=0.1, key="top_p"
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
# LLM response function ########################################
|
| 75 |
+
def get_llm_response(provider, prompt):
|
| 76 |
+
options = dict(
|
| 77 |
+
max_tokens=st.session_state["max_tokens"],
|
| 78 |
+
top_p=st.session_state["top_p"],
|
| 79 |
+
temperature=st.session_state["temperature"],
|
| 80 |
+
)
|
| 81 |
+
if provider == "ollama":
|
| 82 |
+
return OllamaClient(
|
| 83 |
+
api_key="ollama",
|
| 84 |
+
model=st.session_state["ollama_llm"],
|
| 85 |
+
).api_chat_completion(
|
| 86 |
+
prompt, **options
|
| 87 |
+
) # or .client_chat_completion(prompt,**options)
|
| 88 |
+
elif provider == "nvidia":
|
| 89 |
+
return NvidiaClient(
|
| 90 |
+
api_key=nvidia_api_token,
|
| 91 |
+
model=st.session_state["nvidia_llm"],
|
| 92 |
+
).api_chat_completion(
|
| 93 |
+
prompt, **options
|
| 94 |
+
) # or .client_chat_completion(prompt,**options)
|
| 95 |
+
elif provider == "groq":
|
| 96 |
+
return GroqClient(
|
| 97 |
+
api_key=groq_api_token,
|
| 98 |
+
model=st.session_state["groq_llm"],
|
| 99 |
+
).api_chat_completion(
|
| 100 |
+
prompt, **options
|
| 101 |
+
) # or .client_chat_completion(prompt,**options)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
# UI main #####################################################
|
| 105 |
+
# Initialize chat history
|
| 106 |
+
if "messages" not in st.session_state:
|
| 107 |
+
st.session_state.messages = []
|
| 108 |
+
|
| 109 |
+
# Display chat messages from history on app rerun
|
| 110 |
+
for message in st.session_state.messages:
|
| 111 |
+
with st.chat_message(message["role"]):
|
| 112 |
+
st.markdown(message["content"])
|
| 113 |
+
|
| 114 |
+
# React to user input
|
| 115 |
+
if prompt := st.chat_input("What is up?"):
|
| 116 |
+
# Display user message in chat message container
|
| 117 |
+
with st.chat_message("user"):
|
| 118 |
+
st.markdown(prompt)
|
| 119 |
+
# Add user message to chat history
|
| 120 |
+
st.session_state.messages.append({"role": "user", "content": prompt})
|
| 121 |
+
|
| 122 |
+
response = f"Echo: {prompt}"
|
| 123 |
+
# Display assistant response in chat message container
|
| 124 |
+
with st.chat_message("assistant"):
|
| 125 |
+
response = get_llm_response(llm_providers[st.session_state["llm_provider"]], prompt)
|
| 126 |
+
st.markdown(response)
|
| 127 |
+
# Add assistant response to chat history
|
| 128 |
+
st.session_state.messages.append({"role": "assistant", "content": response})
|
pages/app_langchain_completion.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import streamlit as st
|
| 5 |
+
from langchain_community.llms import Ollama
|
| 6 |
+
from langchain_nvidia_ai_endpoints import ChatNVIDIA
|
| 7 |
+
from langchain_groq import ChatGroq
|
| 8 |
+
from langchain.chains import ConversationChain
|
| 9 |
+
from langchain.memory import ConversationBufferMemory
|
| 10 |
+
from clients import OllamaClient, GroqClient
|
| 11 |
+
|
| 12 |
+
st.set_page_config(
|
| 13 |
+
page_title="QA Inference Streamlit App using Ollama, Nvidia and Groq with Langchain framework"
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# Cache the header of the app to prevent re-rendering on each load
|
| 18 |
+
@st.cache_resource
|
| 19 |
+
def display_app_header():
|
| 20 |
+
"""Display the header of the Streamlit app."""
|
| 21 |
+
st.title("QA Inference with Ollama & Nvidia & Groq as LLMs providers")
|
| 22 |
+
st.subheader("ChatBot based on Langchain framework")
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Display the header of the app
|
| 26 |
+
display_app_header()
|
| 27 |
+
|
| 28 |
+
# UI sidebar ##########################################
|
| 29 |
+
st.sidebar.subheader("Models")
|
| 30 |
+
# LLM
|
| 31 |
+
llm_providers = {
|
| 32 |
+
"Local Ollama": "ollama",
|
| 33 |
+
"Cloud Nvidia": "nvidia",
|
| 34 |
+
"Cloud Groq": "groq",
|
| 35 |
+
}
|
| 36 |
+
# hard coded because models returned by NvidiaClient().list_models() are not well formed for Langchain ChatNVIDIA class
|
| 37 |
+
llms_from_nvidia = [
|
| 38 |
+
"ai-llama3-70b",
|
| 39 |
+
"ai-mistral-large",
|
| 40 |
+
"ai-gemma-7b",
|
| 41 |
+
"ai-codellama-70b",
|
| 42 |
+
]
|
| 43 |
+
llm_provider = st.sidebar.radio(
|
| 44 |
+
"Choose your LLM Provider", llm_providers.keys(), key="llm_provider"
|
| 45 |
+
)
|
| 46 |
+
if llm_provider == "Local Ollama":
|
| 47 |
+
ollama_list_models = OllamaClient().list_models()
|
| 48 |
+
ollama_models = [x["name"] for x in ollama_list_models["models"]]
|
| 49 |
+
ollama_llm = st.sidebar.radio(
|
| 50 |
+
"Select your Ollama model", ollama_models, key="ollama_llm"
|
| 51 |
+
) # retrive with st.session_state["ollama_llm"]
|
| 52 |
+
elif llm_provider == "Cloud Nvidia":
|
| 53 |
+
if nvidia_api_token := st.sidebar.text_input("Enter your Nvidia API Key"):
|
| 54 |
+
os.environ["NVIDIA_API_KEY"] = nvidia_api_token
|
| 55 |
+
st.sidebar.info("nvidia authentification ok")
|
| 56 |
+
# nvidia_models = [model.model_name for model in list_nvidia_models() if (model.model_type == "chat") & (model.model_name is not None)] # list is false
|
| 57 |
+
nvidia_models = llms_from_nvidia
|
| 58 |
+
nvidia_llm = st.sidebar.radio(
|
| 59 |
+
"Select your Nvidia LLM", nvidia_models, key="nvidia_llm"
|
| 60 |
+
)
|
| 61 |
+
else:
|
| 62 |
+
st.sidebar.warning("You must enter your Nvidia API key")
|
| 63 |
+
elif llm_provider == "Cloud Groq":
|
| 64 |
+
if groq_api_token := st.sidebar.text_input("Enter your Groq API Key"):
|
| 65 |
+
st.sidebar.info("Groq authentification ok")
|
| 66 |
+
groq_list_models = GroqClient(api_key=groq_api_token).list_models()
|
| 67 |
+
groq_models = [x["id"] for x in groq_list_models["data"]]
|
| 68 |
+
groq_llm = st.sidebar.radio("Choose your Groq LLM", groq_models, key="groq_llm")
|
| 69 |
+
else:
|
| 70 |
+
st.sidebar.warning("You must enter your Groq API key")
|
| 71 |
+
|
| 72 |
+
# LLM parameters
|
| 73 |
+
st.sidebar.subheader("Parameters")
|
| 74 |
+
max_tokens = st.sidebar.number_input("Token numbers", value=1024, key="max_tokens")
|
| 75 |
+
temperature = st.sidebar.slider(
|
| 76 |
+
"Temperature", min_value=0.0, max_value=1.0, value=0.5, step=0.1, key="temperature"
|
| 77 |
+
)
|
| 78 |
+
top_p = st.sidebar.slider(
|
| 79 |
+
"Top P", min_value=0.0, max_value=1.0, value=0.7, step=0.1, key="top_p"
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
# LLM client #########################################
|
| 84 |
+
class LlmProvider:
|
| 85 |
+
def __init__(self, provider):
|
| 86 |
+
if provider == "ollama":
|
| 87 |
+
self.llm = Ollama(
|
| 88 |
+
model=st.session_state["ollama_llm"],
|
| 89 |
+
temperature=st.session_state["temperature"],
|
| 90 |
+
max_tokens=st.session_state["max_tokens"],
|
| 91 |
+
top_p=st.session_state["top_p"],
|
| 92 |
+
)
|
| 93 |
+
elif provider == "nvidia":
|
| 94 |
+
self.llm = ChatNVIDIA(
|
| 95 |
+
model=st.session_state["nvidia_llm"],
|
| 96 |
+
temperature=st.session_state["temperature"],
|
| 97 |
+
max_tokens=st.session_state["max_tokens"],
|
| 98 |
+
top_p=st.session_state["top_p"],
|
| 99 |
+
)
|
| 100 |
+
elif provider == "groq":
|
| 101 |
+
self.llm = ChatGroq(
|
| 102 |
+
groq_api_key = groq_api_token,
|
| 103 |
+
model_name=st.session_state["groq_llm"],
|
| 104 |
+
temperature=st.session_state["temperature"],
|
| 105 |
+
max_tokens=st.session_state["max_tokens"],
|
| 106 |
+
top_p=st.session_state["top_p"],
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
# Initialize chat history
|
| 111 |
+
if "messages" not in st.session_state:
|
| 112 |
+
st.session_state.messages = []
|
| 113 |
+
|
| 114 |
+
# Display chat messages from history on app rerun
|
| 115 |
+
for message in st.session_state.messages:
|
| 116 |
+
with st.chat_message(message["role"]):
|
| 117 |
+
st.markdown(message["content"])
|
| 118 |
+
|
| 119 |
+
# React to user input
|
| 120 |
+
if prompt := st.chat_input("What is up?"):
|
| 121 |
+
# Display user message in chat message container
|
| 122 |
+
with st.chat_message("user"):
|
| 123 |
+
st.markdown(prompt)
|
| 124 |
+
conversation = ConversationChain(
|
| 125 |
+
llm=LlmProvider(llm_providers[st.session_state["llm_provider"]]).llm,
|
| 126 |
+
memory=ConversationBufferMemory(),
|
| 127 |
+
)
|
| 128 |
+
response = f"Echo: {prompt}"
|
| 129 |
+
# Display assistant response in chat message container
|
| 130 |
+
with st.chat_message("assistant"):
|
| 131 |
+
# response = LlmProvider1(llm_providers[llm_provider], prompt=prompt).response
|
| 132 |
+
response = conversation.invoke(prompt)["response"]
|
| 133 |
+
st.markdown(response)
|
| 134 |
+
# Add assistant response to chat history
|
| 135 |
+
st.session_state.messages.append({"role": "assistant", "content": response})
|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
huggingface_hub
|
| 2 |
+
langchain
|
| 3 |
+
langchain-community
|
| 4 |
+
langchain-nvidia-ai-endpoints
|
| 5 |
+
numpy
|
| 6 |
+
pandas
|
| 7 |
+
requests
|
| 8 |
+
streamlit
|
| 9 |
+
ollama
|
| 10 |
+
groq
|
| 11 |
+
langchain-groq
|
screenshot.png
ADDED
|