Spaces:
Runtime error

Runtime error
First commit
Browse files- demo.py +157 -0
- requirements.txt +5 -0
- test_images/001.jpg +0 -0
- test_images/005.jpg +0 -0
- test_images/007.jpg +0 -0
- test_images/062.jpg +0 -0
- test_images/119.jpg +0 -0
- test_images/150.jpg +0 -0
- test_images/TEST_0019.jpg +0 -0
- test_images/TRAIN_00001.jpg +0 -0
- test_images/VALIDATION_0011.jpg +0 -0
- test_images/VALIDATION_0022.jpg +0 -0
demo.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
"""Demo.ipynb
|
| 3 |
+
|
| 4 |
+
Automatically generated by Colaboratory.
|
| 5 |
+
|
| 6 |
+
Original file is located at
|
| 7 |
+
https://colab.research.google.com/drive/1Icb8zeoaudyTDOKM1QySNay1cXzltRAp
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
!pip install -q -U gradio peft
|
| 11 |
+
|
| 12 |
+
import gradio as gr
|
| 13 |
+
from tqdm.notebook import tqdm
|
| 14 |
+
from PIL import Image
|
| 15 |
+
import re
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
from warnings import simplefilter
|
| 20 |
+
|
| 21 |
+
simplefilter('ignore')
|
| 22 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 23 |
+
|
| 24 |
+
# Seting up the model
|
| 25 |
+
from peft import PeftConfig, PeftModel
|
| 26 |
+
numeric_lora_config = PeftConfig.from_pretrained("Edgar404/donut-sroie-lora-r8-x3")
|
| 27 |
+
|
| 28 |
+
from transformers import VisionEncoderDecoderConfig
|
| 29 |
+
|
| 30 |
+
image_size = [720,960]
|
| 31 |
+
max_length = 512
|
| 32 |
+
|
| 33 |
+
config = VisionEncoderDecoderConfig.from_pretrained(numeric_lora_config.base_model_name_or_path)
|
| 34 |
+
config.encoder.image_size = image_size
|
| 35 |
+
config.decoder.max_length = max_length
|
| 36 |
+
|
| 37 |
+
from transformers import DonutProcessor, VisionEncoderDecoderModel
|
| 38 |
+
model = VisionEncoderDecoderModel.from_pretrained(numeric_lora_config.base_model_name_or_path ,config = config )
|
| 39 |
+
numeric_processor = DonutProcessor.from_pretrained("Edgar404/donut-sroie-lora-r8-x3")
|
| 40 |
+
|
| 41 |
+
model.config.pad_token_id = numeric_processor.tokenizer.pad_token_id
|
| 42 |
+
model.config.decoder_start_token_id = numeric_processor.tokenizer.convert_tokens_to_ids(['<s_cord-v2>'])[0]
|
| 43 |
+
model.decoder.resize_token_embeddings(len(numeric_processor.tokenizer))
|
| 44 |
+
|
| 45 |
+
model = PeftModel.from_pretrained(model, model_id = "Edgar404/donut-sroie-lora-r8-x3", adapter_name = 'numeric')
|
| 46 |
+
model.to(device)
|
| 47 |
+
|
| 48 |
+
# Handwritten setting
|
| 49 |
+
|
| 50 |
+
hand_processor = DonutProcessor.from_pretrained("Edgar404/donut-lora-r8-x2")
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def resize_token_handwritten():
|
| 54 |
+
|
| 55 |
+
try :
|
| 56 |
+
model.load_adapter("Edgar404/donut-lora-r8-x2" ,'handwritten')
|
| 57 |
+
|
| 58 |
+
except Exception :
|
| 59 |
+
# resizing the handwritten embedding layer
|
| 60 |
+
embedding_layer = model.decoder.model.decoder.embed_tokens.modules_to_save.handwritten
|
| 61 |
+
old_num_tokens, old_embedding_dim = embedding_layer.weight.shape
|
| 62 |
+
|
| 63 |
+
new_embeddings = nn.Embedding(
|
| 64 |
+
len(hand_processor.tokenizer), old_embedding_dim
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
new_embeddings.to(
|
| 68 |
+
embedding_layer.weight.device,
|
| 69 |
+
dtype=embedding_layer.weight.dtype,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
model.decoder.model.decoder.embed_tokens.modules_to_save.handwritten = new_embeddings
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# Resizing the handwritten lm_head layer
|
| 76 |
+
lm_layer = model.decoder.lm_head.modules_to_save.handwritten
|
| 77 |
+
|
| 78 |
+
old_num_tokens, old_input_dim = lm_layer.weight.shape
|
| 79 |
+
|
| 80 |
+
new_lm_head = nn.Linear(
|
| 81 |
+
old_input_dim, len(hand_processor.tokenizer),
|
| 82 |
+
bias = False
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
new_lm_head.to(
|
| 86 |
+
lm_layer.weight.device,
|
| 87 |
+
dtype=lm_layer.weight.dtype,
|
| 88 |
+
)
|
| 89 |
+
model.decoder.lm_head.modules_to_save.handwritten = new_lm_head
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
resize_token_handwritten()
|
| 93 |
+
|
| 94 |
+
model.load_adapter("Edgar404/donut-lora-r8-x2" ,'handwritten')
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def process_image(image , mode = 'numeric' ):
|
| 98 |
+
""" Function that takes an image and perform an OCR using the model DonUT via the task document
|
| 99 |
+
parsing
|
| 100 |
+
|
| 101 |
+
parameters
|
| 102 |
+
__________
|
| 103 |
+
image : a machine readable image of class PIL or numpy"""
|
| 104 |
+
|
| 105 |
+
model.set_adapter(mode)
|
| 106 |
+
processor = numeric_processor if mode == 'numeric' else hand_processor
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
task_prompt = "<s_cord-v2>"
|
| 111 |
+
decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
|
| 112 |
+
|
| 113 |
+
pixel_values = processor(image, return_tensors="pt").pixel_values
|
| 114 |
+
|
| 115 |
+
outputs = model.generate(
|
| 116 |
+
pixel_values.to(device),
|
| 117 |
+
decoder_input_ids=decoder_input_ids.to(device),
|
| 118 |
+
max_length=model.decoder.config.max_position_embeddings,
|
| 119 |
+
pad_token_id=processor.tokenizer.pad_token_id,
|
| 120 |
+
eos_token_id=processor.tokenizer.eos_token_id,
|
| 121 |
+
use_cache=True,
|
| 122 |
+
bad_words_ids=[[processor.tokenizer.unk_token_id]],
|
| 123 |
+
return_dict_in_generate=True,
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
sequence = processor.batch_decode(outputs.sequences)[0]
|
| 127 |
+
sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
|
| 128 |
+
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip()
|
| 129 |
+
output = processor.token2json(sequence)
|
| 130 |
+
|
| 131 |
+
return output
|
| 132 |
+
|
| 133 |
+
import gradio as gr
|
| 134 |
+
|
| 135 |
+
def image_classifier(image , mode):
|
| 136 |
+
return process_image(image , mode)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
examples_list = [['./test_images/TRAIN_00001.jpg' ,"handwritten"] ,
|
| 141 |
+
['./test_images/001.jpg','numeric'],
|
| 142 |
+
['./test_images/TEST_0019.jpg' ,"handwritten"],
|
| 143 |
+
['./test_images/005.jpg','numeric'],
|
| 144 |
+
['./test_images/007.jpg','numeric'],
|
| 145 |
+
['./test_images/VALIDATION_0011.jpg' ,"handwritten"],
|
| 146 |
+
['./test_images/VALIDATION_0022.jpg' ,"handwritten"],
|
| 147 |
+
['./test_images/062.jpg','numeric'],
|
| 148 |
+
['./test_images/119.jpg','numeric'],
|
| 149 |
+
['./test_images/150.jpg','numeric']
|
| 150 |
+
]
|
| 151 |
+
|
| 152 |
+
demo = gr.Interface(fn=image_classifier, inputs=["image",
|
| 153 |
+
gr.Radio(["handwritten", "numeric"], label="mode")],
|
| 154 |
+
outputs="text",
|
| 155 |
+
examples = examples_list )
|
| 156 |
+
|
| 157 |
+
demo.launch(share = True)
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers
|
| 2 |
+
torch
|
| 3 |
+
pillow
|
| 4 |
+
gradio
|
| 5 |
+
peft
|
test_images/001.jpg
ADDED

|
test_images/005.jpg
ADDED

|
test_images/007.jpg
ADDED

|
test_images/062.jpg
ADDED
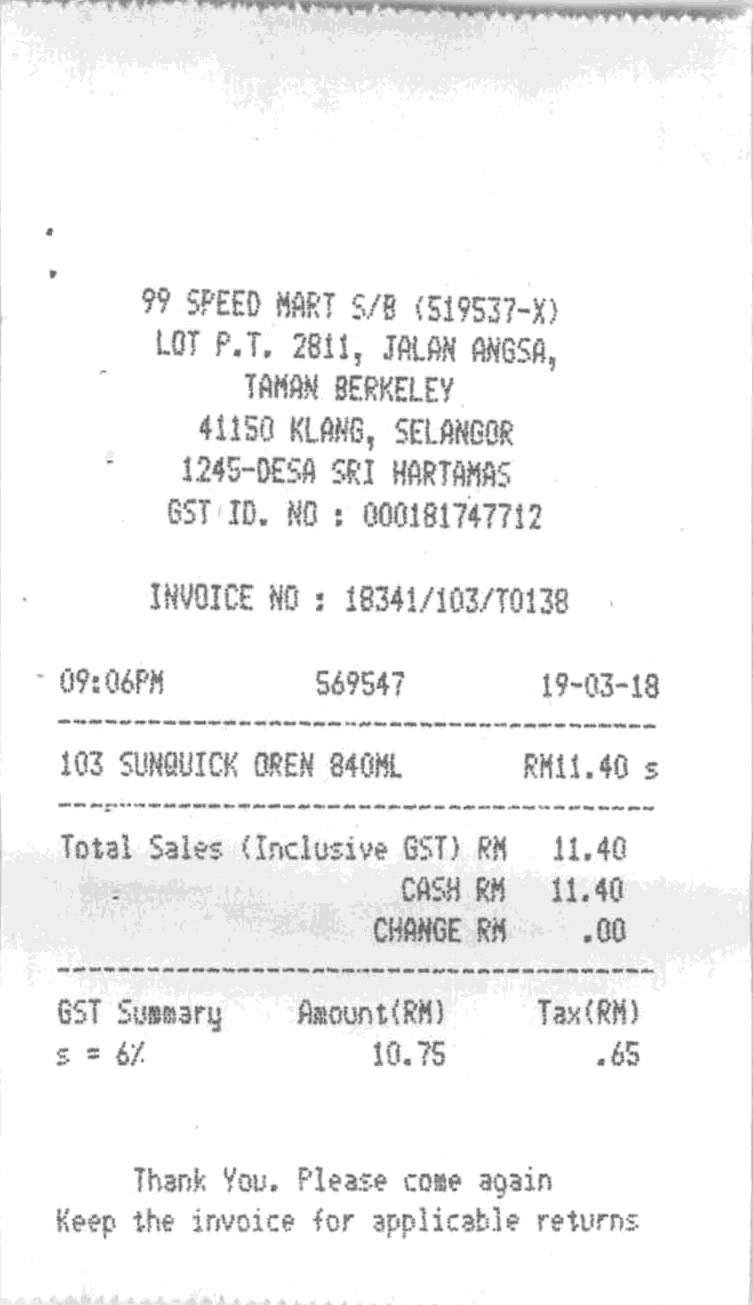
|
test_images/119.jpg
ADDED
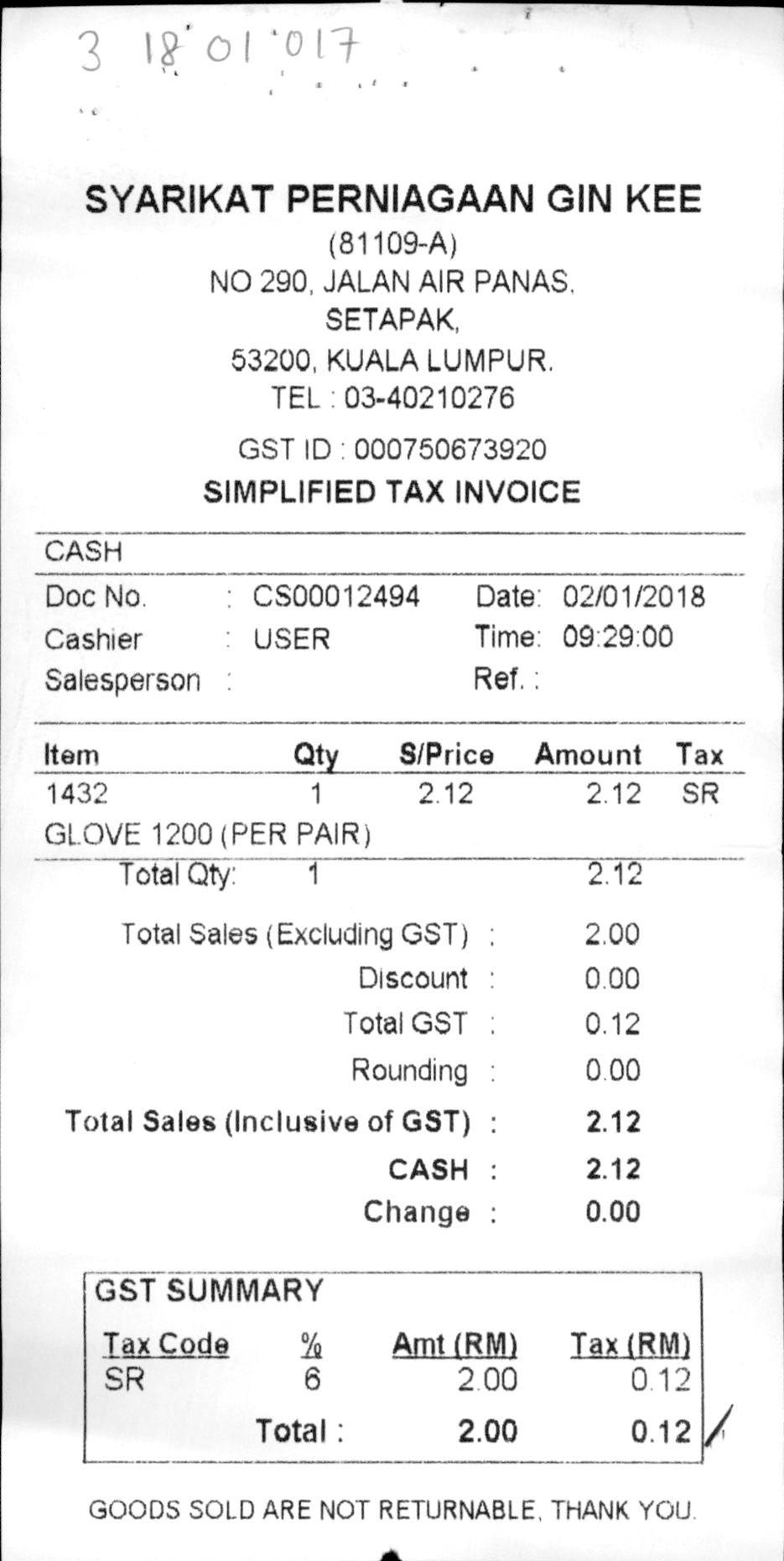
|
test_images/150.jpg
ADDED

|
test_images/TEST_0019.jpg
ADDED
|
test_images/TRAIN_00001.jpg
ADDED
|
test_images/VALIDATION_0011.jpg
ADDED
|
test_images/VALIDATION_0022.jpg
ADDED

|