Spaces:
Configuration error

Configuration error
Upload 7 files
Browse files- .gitattributes +1 -0
- App.py +436 -0
- Courses.py +63 -0
- README.md +54 -13
- requirements.txt +13 -0
- sc1.png +3 -0
- sc2.png +0 -0
- yt_thumb.jpg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
sc1.png filter=lfs diff=lfs merge=lfs -text
|
App.py
ADDED
|
@@ -0,0 +1,436 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import nltk
|
| 3 |
+
import spacy
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import base64, random
|
| 6 |
+
import time, datetime
|
| 7 |
+
from pyresparser import ResumeParser
|
| 8 |
+
from pdfminer3.layout import LAParams, LTTextBox
|
| 9 |
+
from pdfminer3.pdfpage import PDFPage
|
| 10 |
+
from pdfminer3.pdfinterp import PDFResourceManager
|
| 11 |
+
from pdfminer3.pdfinterp import PDFPageInterpreter
|
| 12 |
+
from pdfminer3.converter import TextConverter
|
| 13 |
+
import io, random
|
| 14 |
+
from streamlit_tags import st_tags
|
| 15 |
+
from PIL import Image
|
| 16 |
+
import pymysql
|
| 17 |
+
from Courses import ds_course, web_course, android_course, ios_course, uiux_course, resume_videos, interview_videos
|
| 18 |
+
import pafy
|
| 19 |
+
import plotly.express as px
|
| 20 |
+
import youtube_dl
|
| 21 |
+
nltk.download('punkt')
|
| 22 |
+
nltk.download('stopwords')
|
| 23 |
+
spacy.load('en_core_web_sm')
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def fetch_yt_video(link):
|
| 27 |
+
video = pafy.new(link)
|
| 28 |
+
return video.title
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def get_table_download_link(df, filename, text):
|
| 32 |
+
"""Generates a link allowing the data in a given panda dataframe to be downloaded
|
| 33 |
+
in: dataframe
|
| 34 |
+
out: href string
|
| 35 |
+
"""
|
| 36 |
+
csv = df.to_csv(index=False)
|
| 37 |
+
b64 = base64.b64encode(csv.encode()).decode() # some strings <-> bytes conversions necessary here
|
| 38 |
+
# href = f'<a href="data:file/csv;base64,{b64}">Download Report</a>'
|
| 39 |
+
href = f'<a href="data:file/csv;base64,{b64}" download="{filename}">{text}</a>'
|
| 40 |
+
return href
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def pdf_reader(file):
|
| 44 |
+
resource_manager = PDFResourceManager()
|
| 45 |
+
fake_file_handle = io.StringIO()
|
| 46 |
+
converter = TextConverter(resource_manager, fake_file_handle, laparams=LAParams())
|
| 47 |
+
page_interpreter = PDFPageInterpreter(resource_manager, converter)
|
| 48 |
+
with open(file, 'rb') as fh:
|
| 49 |
+
for page in PDFPage.get_pages(fh,
|
| 50 |
+
caching=True,
|
| 51 |
+
check_extractable=True):
|
| 52 |
+
page_interpreter.process_page(page)
|
| 53 |
+
print(page)
|
| 54 |
+
text = fake_file_handle.getvalue()
|
| 55 |
+
|
| 56 |
+
# close open handles
|
| 57 |
+
converter.close()
|
| 58 |
+
fake_file_handle.close()
|
| 59 |
+
return text
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def show_pdf(file_path):
|
| 63 |
+
with open(file_path, "rb") as f:
|
| 64 |
+
base64_pdf = base64.b64encode(f.read()).decode('utf-8')
|
| 65 |
+
# pdf_display = f'<embed src="data:application/pdf;base64,{base64_pdf}" width="700" height="1000" type="application/pdf">'
|
| 66 |
+
pdf_display = F'<iframe src="data:application/pdf;base64,{base64_pdf}" width="700" height="1000" type="application/pdf"></iframe>'
|
| 67 |
+
st.markdown(pdf_display, unsafe_allow_html=True)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def course_recommender(course_list):
|
| 71 |
+
st.subheader("**Courses & Certificates🎓 Recommendations**")
|
| 72 |
+
c = 0
|
| 73 |
+
rec_course = []
|
| 74 |
+
no_of_reco = st.slider('Choose Number of Course Recommendations:', 1, 10, 4)
|
| 75 |
+
random.shuffle(course_list)
|
| 76 |
+
for c_name, c_link in course_list:
|
| 77 |
+
c += 1
|
| 78 |
+
st.markdown(f"({c}) [{c_name}]({c_link})")
|
| 79 |
+
rec_course.append(c_name)
|
| 80 |
+
if c == no_of_reco:
|
| 81 |
+
break
|
| 82 |
+
return rec_course
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
connection = pymysql.connect(host='localhost', user='root', password='')
|
| 86 |
+
cursor = connection.cursor()
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def insert_data(name, email, res_score, timestamp, no_of_pages, reco_field, cand_level, skills, recommended_skills,
|
| 90 |
+
courses):
|
| 91 |
+
DB_table_name = 'user_data'
|
| 92 |
+
insert_sql = "insert into " + DB_table_name + """
|
| 93 |
+
values (0,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"""
|
| 94 |
+
rec_values = (
|
| 95 |
+
name, email, str(res_score), timestamp, str(no_of_pages), reco_field, cand_level, skills, recommended_skills,
|
| 96 |
+
courses)
|
| 97 |
+
cursor.execute(insert_sql, rec_values)
|
| 98 |
+
connection.commit()
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
st.set_page_config(
|
| 102 |
+
page_title="Smart Resume Analyzer",
|
| 103 |
+
page_icon='./Logo/SRA_Logo.ico',
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def run():
|
| 108 |
+
st.title("Smart Resume Analyser")
|
| 109 |
+
st.sidebar.markdown("# Choose User")
|
| 110 |
+
activities = ["Normal User", "Admin"]
|
| 111 |
+
choice = st.sidebar.selectbox("Choose among the given options:", activities)
|
| 112 |
+
# link = '[©Developed by Spidy20](http://github.com/spidy20)'
|
| 113 |
+
# st.sidebar.markdown(link, unsafe_allow_html=True)
|
| 114 |
+
img = Image.open('./Logo/SRA_Logo.jpg')
|
| 115 |
+
img = img.resize((250, 250))
|
| 116 |
+
st.image(img)
|
| 117 |
+
|
| 118 |
+
# Create the DB
|
| 119 |
+
db_sql = """CREATE DATABASE IF NOT EXISTS SRA;"""
|
| 120 |
+
cursor.execute(db_sql)
|
| 121 |
+
connection.select_db("sra")
|
| 122 |
+
|
| 123 |
+
# Create table
|
| 124 |
+
DB_table_name = 'user_data'
|
| 125 |
+
table_sql = "CREATE TABLE IF NOT EXISTS " + DB_table_name + """
|
| 126 |
+
(ID INT NOT NULL AUTO_INCREMENT,
|
| 127 |
+
Name varchar(100) NOT NULL,
|
| 128 |
+
Email_ID VARCHAR(50) NOT NULL,
|
| 129 |
+
resume_score VARCHAR(8) NOT NULL,
|
| 130 |
+
Timestamp VARCHAR(50) NOT NULL,
|
| 131 |
+
Page_no VARCHAR(5) NOT NULL,
|
| 132 |
+
Predicted_Field VARCHAR(25) NOT NULL,
|
| 133 |
+
User_level VARCHAR(30) NOT NULL,
|
| 134 |
+
Actual_skills VARCHAR(300) NOT NULL,
|
| 135 |
+
Recommended_skills VARCHAR(300) NOT NULL,
|
| 136 |
+
Recommended_courses VARCHAR(600) NOT NULL,
|
| 137 |
+
PRIMARY KEY (ID));
|
| 138 |
+
"""
|
| 139 |
+
cursor.execute(table_sql)
|
| 140 |
+
if choice == 'Normal User':
|
| 141 |
+
# st.markdown('''<h4 style='text-align: left; color: #d73b5c;'>* Upload your resume, and get smart recommendation based on it."</h4>''',
|
| 142 |
+
# unsafe_allow_html=True)
|
| 143 |
+
pdf_file = st.file_uploader("Choose your Resume", type=["pdf"])
|
| 144 |
+
if pdf_file is not None:
|
| 145 |
+
# with st.spinner('Uploading your Resume....'):
|
| 146 |
+
# time.sleep(4)
|
| 147 |
+
save_image_path = './Uploaded_Resumes/' + pdf_file.name
|
| 148 |
+
with open(save_image_path, "wb") as f:
|
| 149 |
+
f.write(pdf_file.getbuffer())
|
| 150 |
+
show_pdf(save_image_path)
|
| 151 |
+
resume_data = ResumeParser(save_image_path).get_extracted_data()
|
| 152 |
+
if resume_data:
|
| 153 |
+
## Get the whole resume data
|
| 154 |
+
resume_text = pdf_reader(save_image_path)
|
| 155 |
+
|
| 156 |
+
st.header("**Resume Analysis**")
|
| 157 |
+
st.success("Hello " + resume_data['name'])
|
| 158 |
+
st.subheader("**Your Basic info**")
|
| 159 |
+
try:
|
| 160 |
+
st.text('Name: ' + resume_data['name'])
|
| 161 |
+
st.text('Email: ' + resume_data['email'])
|
| 162 |
+
st.text('Contact: ' + resume_data['mobile_number'])
|
| 163 |
+
st.text('Resume pages: ' + str(resume_data['no_of_pages']))
|
| 164 |
+
except:
|
| 165 |
+
pass
|
| 166 |
+
cand_level = ''
|
| 167 |
+
if resume_data['no_of_pages'] == 1:
|
| 168 |
+
cand_level = "Fresher"
|
| 169 |
+
st.markdown('''<h4 style='text-align: left; color: #d73b5c;'>You are looking Fresher.</h4>''',
|
| 170 |
+
unsafe_allow_html=True)
|
| 171 |
+
elif resume_data['no_of_pages'] == 2:
|
| 172 |
+
cand_level = "Intermediate"
|
| 173 |
+
st.markdown('''<h4 style='text-align: left; color: #1ed760;'>You are at intermediate level!</h4>''',
|
| 174 |
+
unsafe_allow_html=True)
|
| 175 |
+
elif resume_data['no_of_pages'] >= 3:
|
| 176 |
+
cand_level = "Experienced"
|
| 177 |
+
st.markdown('''<h4 style='text-align: left; color: #fba171;'>You are at experience level!''',
|
| 178 |
+
unsafe_allow_html=True)
|
| 179 |
+
|
| 180 |
+
st.subheader("**Skills Recommendation💡**")
|
| 181 |
+
## Skill shows
|
| 182 |
+
keywords = st_tags(label='### Skills that you have',
|
| 183 |
+
text='See our skills recommendation',
|
| 184 |
+
value=resume_data['skills'], key='1')
|
| 185 |
+
|
| 186 |
+
## recommendation
|
| 187 |
+
ds_keyword = ['tensorflow', 'keras', 'pytorch', 'machine learning', 'deep Learning', 'flask',
|
| 188 |
+
'streamlit']
|
| 189 |
+
web_keyword = ['react', 'django', 'node jS', 'react js', 'php', 'laravel', 'magento', 'wordpress',
|
| 190 |
+
'javascript', 'angular js', 'c#', 'flask']
|
| 191 |
+
android_keyword = ['android', 'android development', 'flutter', 'kotlin', 'xml', 'kivy']
|
| 192 |
+
ios_keyword = ['ios', 'ios development', 'swift', 'cocoa', 'cocoa touch', 'xcode']
|
| 193 |
+
uiux_keyword = ['ux', 'adobe xd', 'figma', 'zeplin', 'balsamiq', 'ui', 'prototyping', 'wireframes',
|
| 194 |
+
'storyframes', 'adobe photoshop', 'photoshop', 'editing', 'adobe illustrator',
|
| 195 |
+
'illustrator', 'adobe after effects', 'after effects', 'adobe premier pro',
|
| 196 |
+
'premier pro', 'adobe indesign', 'indesign', 'wireframe', 'solid', 'grasp',
|
| 197 |
+
'user research', 'user experience']
|
| 198 |
+
|
| 199 |
+
recommended_skills = []
|
| 200 |
+
reco_field = ''
|
| 201 |
+
rec_course = ''
|
| 202 |
+
## Courses recommendation
|
| 203 |
+
for i in resume_data['skills']:
|
| 204 |
+
## Data science recommendation
|
| 205 |
+
if i.lower() in ds_keyword:
|
| 206 |
+
print(i.lower())
|
| 207 |
+
reco_field = 'Data Science'
|
| 208 |
+
st.success("** Our analysis says you are looking for Data Science Jobs.**")
|
| 209 |
+
recommended_skills = ['Data Visualization', 'Predictive Analysis', 'Statistical Modeling',
|
| 210 |
+
'Data Mining', 'Clustering & Classification', 'Data Analytics',
|
| 211 |
+
'Quantitative Analysis', 'Web Scraping', 'ML Algorithms', 'Keras',
|
| 212 |
+
'Pytorch', 'Probability', 'Scikit-learn', 'Tensorflow', "Flask",
|
| 213 |
+
'Streamlit']
|
| 214 |
+
recommended_keywords = st_tags(label='### Recommended skills for you.',
|
| 215 |
+
text='Recommended skills generated from System',
|
| 216 |
+
value=recommended_skills, key='2')
|
| 217 |
+
st.markdown(
|
| 218 |
+
'''<h4 style='text-align: left; color: #1ed760;'>Adding this skills to resume will boost🚀 the chances of getting a Job💼</h4>''',
|
| 219 |
+
unsafe_allow_html=True)
|
| 220 |
+
rec_course = course_recommender(ds_course)
|
| 221 |
+
break
|
| 222 |
+
|
| 223 |
+
## Web development recommendation
|
| 224 |
+
elif i.lower() in web_keyword:
|
| 225 |
+
print(i.lower())
|
| 226 |
+
reco_field = 'Web Development'
|
| 227 |
+
st.success("** Our analysis says you are looking for Web Development Jobs **")
|
| 228 |
+
recommended_skills = ['React', 'Django', 'Node JS', 'React JS', 'php', 'laravel', 'Magento',
|
| 229 |
+
'wordpress', 'Javascript', 'Angular JS', 'c#', 'Flask', 'SDK']
|
| 230 |
+
recommended_keywords = st_tags(label='### Recommended skills for you.',
|
| 231 |
+
text='Recommended skills generated from System',
|
| 232 |
+
value=recommended_skills, key='3')
|
| 233 |
+
st.markdown(
|
| 234 |
+
'''<h4 style='text-align: left; color: #1ed760;'>Adding this skills to resume will boost🚀 the chances of getting a Job💼</h4>''',
|
| 235 |
+
unsafe_allow_html=True)
|
| 236 |
+
rec_course = course_recommender(web_course)
|
| 237 |
+
break
|
| 238 |
+
|
| 239 |
+
## Android App Development
|
| 240 |
+
elif i.lower() in android_keyword:
|
| 241 |
+
print(i.lower())
|
| 242 |
+
reco_field = 'Android Development'
|
| 243 |
+
st.success("** Our analysis says you are looking for Android App Development Jobs **")
|
| 244 |
+
recommended_skills = ['Android', 'Android development', 'Flutter', 'Kotlin', 'XML', 'Java',
|
| 245 |
+
'Kivy', 'GIT', 'SDK', 'SQLite']
|
| 246 |
+
recommended_keywords = st_tags(label='### Recommended skills for you.',
|
| 247 |
+
text='Recommended skills generated from System',
|
| 248 |
+
value=recommended_skills, key='4')
|
| 249 |
+
st.markdown(
|
| 250 |
+
'''<h4 style='text-align: left; color: #1ed760;'>Adding this skills to resume will boost🚀 the chances of getting a Job💼</h4>''',
|
| 251 |
+
unsafe_allow_html=True)
|
| 252 |
+
rec_course = course_recommender(android_course)
|
| 253 |
+
break
|
| 254 |
+
|
| 255 |
+
## IOS App Development
|
| 256 |
+
elif i.lower() in ios_keyword:
|
| 257 |
+
print(i.lower())
|
| 258 |
+
reco_field = 'IOS Development'
|
| 259 |
+
st.success("** Our analysis says you are looking for IOS App Development Jobs **")
|
| 260 |
+
recommended_skills = ['IOS', 'IOS Development', 'Swift', 'Cocoa', 'Cocoa Touch', 'Xcode',
|
| 261 |
+
'Objective-C', 'SQLite', 'Plist', 'StoreKit', "UI-Kit", 'AV Foundation',
|
| 262 |
+
'Auto-Layout']
|
| 263 |
+
recommended_keywords = st_tags(label='### Recommended skills for you.',
|
| 264 |
+
text='Recommended skills generated from System',
|
| 265 |
+
value=recommended_skills, key='5')
|
| 266 |
+
st.markdown(
|
| 267 |
+
'''<h4 style='text-align: left; color: #1ed760;'>Adding this skills to resume will boost🚀 the chances of getting a Job💼</h4>''',
|
| 268 |
+
unsafe_allow_html=True)
|
| 269 |
+
rec_course = course_recommender(ios_course)
|
| 270 |
+
break
|
| 271 |
+
|
| 272 |
+
## Ui-UX Recommendation
|
| 273 |
+
elif i.lower() in uiux_keyword:
|
| 274 |
+
print(i.lower())
|
| 275 |
+
reco_field = 'UI-UX Development'
|
| 276 |
+
st.success("** Our analysis says you are looking for UI-UX Development Jobs **")
|
| 277 |
+
recommended_skills = ['UI', 'User Experience', 'Adobe XD', 'Figma', 'Zeplin', 'Balsamiq',
|
| 278 |
+
'Prototyping', 'Wireframes', 'Storyframes', 'Adobe Photoshop', 'Editing',
|
| 279 |
+
'Illustrator', 'After Effects', 'Premier Pro', 'Indesign', 'Wireframe',
|
| 280 |
+
'Solid', 'Grasp', 'User Research']
|
| 281 |
+
recommended_keywords = st_tags(label='### Recommended skills for you.',
|
| 282 |
+
text='Recommended skills generated from System',
|
| 283 |
+
value=recommended_skills, key='6')
|
| 284 |
+
st.markdown(
|
| 285 |
+
'''<h4 style='text-align: left; color: #1ed760;'>Adding this skills to resume will boost🚀 the chances of getting a Job💼</h4>''',
|
| 286 |
+
unsafe_allow_html=True)
|
| 287 |
+
rec_course = course_recommender(uiux_course)
|
| 288 |
+
break
|
| 289 |
+
|
| 290 |
+
#
|
| 291 |
+
## Insert into table
|
| 292 |
+
ts = time.time()
|
| 293 |
+
cur_date = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d')
|
| 294 |
+
cur_time = datetime.datetime.fromtimestamp(ts).strftime('%H:%M:%S')
|
| 295 |
+
timestamp = str(cur_date + '_' + cur_time)
|
| 296 |
+
|
| 297 |
+
### Resume writing recommendation
|
| 298 |
+
st.subheader("**Resume Tips & Ideas💡**")
|
| 299 |
+
resume_score = 0
|
| 300 |
+
if 'Objective' in resume_text:
|
| 301 |
+
resume_score = resume_score + 20
|
| 302 |
+
st.markdown(
|
| 303 |
+
'''<h4 style='text-align: left; color: #1ed760;'>[+] Awesome! You have added Objective</h4>''',
|
| 304 |
+
unsafe_allow_html=True)
|
| 305 |
+
else:
|
| 306 |
+
st.markdown(
|
| 307 |
+
'''<h4 style='text-align: left; color: #fabc10;'>[-] According to our recommendation please add your career objective, it will give your career intension to the Recruiters.</h4>''',
|
| 308 |
+
unsafe_allow_html=True)
|
| 309 |
+
|
| 310 |
+
if 'Declaration' in resume_text:
|
| 311 |
+
resume_score = resume_score + 20
|
| 312 |
+
st.markdown(
|
| 313 |
+
'''<h4 style='text-align: left; color: #1ed760;'>[+] Awesome! You have added Delcaration✍/h4>''',
|
| 314 |
+
unsafe_allow_html=True)
|
| 315 |
+
else:
|
| 316 |
+
st.markdown(
|
| 317 |
+
'''<h4 style='text-align: left; color: #fabc10;'>[-] According to our recommendation please add Declaration✍. It will give the assurance that everything written on your resume is true and fully acknowledged by you</h4>''',
|
| 318 |
+
unsafe_allow_html=True)
|
| 319 |
+
|
| 320 |
+
if 'Hobbies' or 'Interests' in resume_text:
|
| 321 |
+
resume_score = resume_score + 20
|
| 322 |
+
st.markdown(
|
| 323 |
+
'''<h4 style='text-align: left; color: #1ed760;'>[+] Awesome! You have added your Hobbies⚽</h4>''',
|
| 324 |
+
unsafe_allow_html=True)
|
| 325 |
+
else:
|
| 326 |
+
st.markdown(
|
| 327 |
+
'''<h4 style='text-align: left; color: #fabc10;'>[-] According to our recommendation please add Hobbies⚽. It will show your persnality to the Recruiters and give the assurance that you are fit for this role or not.</h4>''',
|
| 328 |
+
unsafe_allow_html=True)
|
| 329 |
+
|
| 330 |
+
if 'Achievements' in resume_text:
|
| 331 |
+
resume_score = resume_score + 20
|
| 332 |
+
st.markdown(
|
| 333 |
+
'''<h4 style='text-align: left; color: #1ed760;'>[+] Awesome! You have added your Achievements🏅 </h4>''',
|
| 334 |
+
unsafe_allow_html=True)
|
| 335 |
+
else:
|
| 336 |
+
st.markdown(
|
| 337 |
+
'''<h4 style='text-align: left; color: #fabc10;'>[-] According to our recommendation please add Achievements🏅. It will show that you are capable for the required position.</h4>''',
|
| 338 |
+
unsafe_allow_html=True)
|
| 339 |
+
|
| 340 |
+
if 'Projects' in resume_text:
|
| 341 |
+
resume_score = resume_score + 20
|
| 342 |
+
st.markdown(
|
| 343 |
+
'''<h4 style='text-align: left; color: #1ed760;'>[+] Awesome! You have added your Projects👨💻 </h4>''',
|
| 344 |
+
unsafe_allow_html=True)
|
| 345 |
+
else:
|
| 346 |
+
st.markdown(
|
| 347 |
+
'''<h4 style='text-align: left; color: #fabc10;'>[-] According to our recommendation please add Projects👨💻. It will show that you have done work related the required position or not.</h4>''',
|
| 348 |
+
unsafe_allow_html=True)
|
| 349 |
+
|
| 350 |
+
st.subheader("**Resume Score📝**")
|
| 351 |
+
st.markdown(
|
| 352 |
+
"""
|
| 353 |
+
<style>
|
| 354 |
+
.stProgress > div > div > div > div {
|
| 355 |
+
background-color: #d73b5c;
|
| 356 |
+
}
|
| 357 |
+
</style>""",
|
| 358 |
+
unsafe_allow_html=True,
|
| 359 |
+
)
|
| 360 |
+
my_bar = st.progress(0)
|
| 361 |
+
score = 0
|
| 362 |
+
for percent_complete in range(resume_score):
|
| 363 |
+
score += 1
|
| 364 |
+
time.sleep(0.1)
|
| 365 |
+
my_bar.progress(percent_complete + 1)
|
| 366 |
+
st.success('** Your Resume Writing Score: ' + str(score) + '**')
|
| 367 |
+
st.warning(
|
| 368 |
+
"** Note: This score is calculated based on the content that you have added in your Resume. **")
|
| 369 |
+
st.balloons()
|
| 370 |
+
|
| 371 |
+
insert_data(resume_data['name'], resume_data['email'], str(resume_score), timestamp,
|
| 372 |
+
str(resume_data['no_of_pages']), reco_field, cand_level, str(resume_data['skills']),
|
| 373 |
+
str(recommended_skills), str(rec_course))
|
| 374 |
+
|
| 375 |
+
## Resume writing video
|
| 376 |
+
st.header("**Bonus Video for Resume Writing Tips💡**")
|
| 377 |
+
resume_vid = random.choice(resume_videos)
|
| 378 |
+
res_vid_title = fetch_yt_video(resume_vid)
|
| 379 |
+
st.subheader("✅ **" + res_vid_title + "**")
|
| 380 |
+
st.video(resume_vid)
|
| 381 |
+
|
| 382 |
+
## Interview Preparation Video
|
| 383 |
+
st.header("**Bonus Video for Interview👨💼 Tips💡**")
|
| 384 |
+
interview_vid = random.choice(interview_videos)
|
| 385 |
+
int_vid_title = fetch_yt_video(interview_vid)
|
| 386 |
+
st.subheader("✅ **" + int_vid_title + "**")
|
| 387 |
+
st.video(interview_vid)
|
| 388 |
+
|
| 389 |
+
connection.commit()
|
| 390 |
+
else:
|
| 391 |
+
st.error('Something went wrong..')
|
| 392 |
+
else:
|
| 393 |
+
## Admin Side
|
| 394 |
+
st.success('Welcome to Admin Side')
|
| 395 |
+
# st.sidebar.subheader('**ID / Password Required!**')
|
| 396 |
+
|
| 397 |
+
ad_user = st.text_input("Username")
|
| 398 |
+
ad_password = st.text_input("Password", type='password')
|
| 399 |
+
if st.button('Login'):
|
| 400 |
+
if ad_user == 'machine_learning_hub' and ad_password == 'mlhub123':
|
| 401 |
+
st.success("Welcome Kushal")
|
| 402 |
+
# Display Data
|
| 403 |
+
cursor.execute('''SELECT*FROM user_data''')
|
| 404 |
+
data = cursor.fetchall()
|
| 405 |
+
st.header("**User's👨💻 Data**")
|
| 406 |
+
df = pd.DataFrame(data, columns=['ID', 'Name', 'Email', 'Resume Score', 'Timestamp', 'Total Page',
|
| 407 |
+
'Predicted Field', 'User Level', 'Actual Skills', 'Recommended Skills',
|
| 408 |
+
'Recommended Course'])
|
| 409 |
+
st.dataframe(df)
|
| 410 |
+
st.markdown(get_table_download_link(df, 'User_Data.csv', 'Download Report'), unsafe_allow_html=True)
|
| 411 |
+
## Admin Side Data
|
| 412 |
+
query = 'select * from user_data;'
|
| 413 |
+
plot_data = pd.read_sql(query, connection)
|
| 414 |
+
|
| 415 |
+
## Pie chart for predicted field recommendations
|
| 416 |
+
labels = plot_data.Predicted_Field.unique()
|
| 417 |
+
print(labels)
|
| 418 |
+
values = plot_data.Predicted_Field.value_counts()
|
| 419 |
+
print(values)
|
| 420 |
+
st.subheader("📈 **Pie-Chart for Predicted Field Recommendations**")
|
| 421 |
+
fig = px.pie(df, values=values, names=labels, title='Predicted Field according to the Skills')
|
| 422 |
+
st.plotly_chart(fig)
|
| 423 |
+
|
| 424 |
+
### Pie chart for User's👨💻 Experienced Level
|
| 425 |
+
labels = plot_data.User_level.unique()
|
| 426 |
+
values = plot_data.User_level.value_counts()
|
| 427 |
+
st.subheader("📈 ** Pie-Chart for User's👨💻 Experienced Level**")
|
| 428 |
+
fig = px.pie(df, values=values, names=labels, title="Pie-Chart📈 for User's👨💻 Experienced Level")
|
| 429 |
+
st.plotly_chart(fig)
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
else:
|
| 433 |
+
st.error("Wrong ID & Password Provided")
|
| 434 |
+
|
| 435 |
+
|
| 436 |
+
run()
|
Courses.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ds_course = [['Machine Learning Crash Course by Google [Free]', 'https://developers.google.com/machine-learning/crash-course'],
|
| 2 |
+
['Machine Learning A-Z by Udemy','https://www.udemy.com/course/machinelearning/'],
|
| 3 |
+
['Machine Learning by Andrew NG','https://www.coursera.org/learn/machine-learning'],
|
| 4 |
+
['Data Scientist Master Program of Simplilearn (IBM)','https://www.simplilearn.com/big-data-and-analytics/senior-data-scientist-masters-program-training'],
|
| 5 |
+
['Data Science Foundations: Fundamentals by LinkedIn','https://www.linkedin.com/learning/data-science-foundations-fundamentals-5'],
|
| 6 |
+
['Data Scientist with Python','https://www.datacamp.com/tracks/data-scientist-with-python'],
|
| 7 |
+
['Programming for Data Science with Python','https://www.udacity.com/course/programming-for-data-science-nanodegree--nd104'],
|
| 8 |
+
['Programming for Data Science with R','https://www.udacity.com/course/programming-for-data-science-nanodegree-with-R--nd118'],
|
| 9 |
+
['Introduction to Data Science','https://www.udacity.com/course/introduction-to-data-science--cd0017'],
|
| 10 |
+
['Intro to Machine Learning with TensorFlow','https://www.udacity.com/course/intro-to-machine-learning-with-tensorflow-nanodegree--nd230']]
|
| 11 |
+
|
| 12 |
+
web_course = [['Django Crash course [Free]','https://youtu.be/e1IyzVyrLSU'],
|
| 13 |
+
['Python and Django Full Stack Web Developer Bootcamp','https://www.udemy.com/course/python-and-django-full-stack-web-developer-bootcamp'],
|
| 14 |
+
['React Crash Course [Free]','https://youtu.be/Dorf8i6lCuk'],
|
| 15 |
+
['ReactJS Project Development Training','https://www.dotnettricks.com/training/masters-program/reactjs-certification-training'],
|
| 16 |
+
['Full Stack Web Developer - MEAN Stack','https://www.simplilearn.com/full-stack-web-developer-mean-stack-certification-training'],
|
| 17 |
+
['Node.js and Express.js [Free]','https://youtu.be/Oe421EPjeBE'],
|
| 18 |
+
['Flask: Develop Web Applications in Python','https://www.educative.io/courses/flask-develop-web-applications-in-python'],
|
| 19 |
+
['Full Stack Web Developer by Udacity','https://www.udacity.com/course/full-stack-web-developer-nanodegree--nd0044'],
|
| 20 |
+
['Front End Web Developer by Udacity','https://www.udacity.com/course/front-end-web-developer-nanodegree--nd0011'],
|
| 21 |
+
['Become a React Developer by Udacity','https://www.udacity.com/course/react-nanodegree--nd019']]
|
| 22 |
+
|
| 23 |
+
android_course = [['Android Development for Beginners [Free]','https://youtu.be/fis26HvvDII'],
|
| 24 |
+
['Android App Development Specialization','https://www.coursera.org/specializations/android-app-development'],
|
| 25 |
+
['Associate Android Developer Certification','https://grow.google/androiddev/#?modal_active=none'],
|
| 26 |
+
['Become an Android Kotlin Developer by Udacity','https://www.udacity.com/course/android-kotlin-developer-nanodegree--nd940'],
|
| 27 |
+
['Android Basics by Google','https://www.udacity.com/course/android-basics-nanodegree-by-google--nd803'],
|
| 28 |
+
['The Complete Android Developer Course','https://www.udemy.com/course/complete-android-n-developer-course/'],
|
| 29 |
+
['Building an Android App with Architecture Components','https://www.linkedin.com/learning/building-an-android-app-with-architecture-components'],
|
| 30 |
+
['Android App Development Masterclass using Kotlin','https://www.udemy.com/course/android-oreo-kotlin-app-masterclass/'],
|
| 31 |
+
['Flutter & Dart - The Complete Flutter App Development Course','https://www.udemy.com/course/flutter-dart-the-complete-flutter-app-development-course/'],
|
| 32 |
+
['Flutter App Development Course [Free]','https://youtu.be/rZLR5olMR64']]
|
| 33 |
+
|
| 34 |
+
ios_course = [['IOS App Development by LinkedIn','https://www.linkedin.com/learning/subscription/topics/ios'],
|
| 35 |
+
['iOS & Swift - The Complete iOS App Development Bootcamp','https://www.udemy.com/course/ios-13-app-development-bootcamp/'],
|
| 36 |
+
['Become an iOS Developer','https://www.udacity.com/course/ios-developer-nanodegree--nd003'],
|
| 37 |
+
['iOS App Development with Swift Specialization','https://www.coursera.org/specializations/app-development'],
|
| 38 |
+
['Mobile App Development with Swift','https://www.edx.org/professional-certificate/curtinx-mobile-app-development-with-swift'],
|
| 39 |
+
['Swift Course by LinkedIn','https://www.linkedin.com/learning/subscription/topics/swift-2'],
|
| 40 |
+
['Objective-C Crash Course for Swift Developers','https://www.udemy.com/course/objectivec/'],
|
| 41 |
+
['Learn Swift by Codecademy','https://www.codecademy.com/learn/learn-swift'],
|
| 42 |
+
['Swift Tutorial - Full Course for Beginners [Free]','https://youtu.be/comQ1-x2a1Q'],
|
| 43 |
+
['Learn Swift Fast - [Free]','https://youtu.be/FcsY1YPBwzQ']]
|
| 44 |
+
uiux_course = [['Google UX Design Professional Certificate','https://www.coursera.org/professional-certificates/google-ux-design'],
|
| 45 |
+
['UI / UX Design Specialization','https://www.coursera.org/specializations/ui-ux-design'],
|
| 46 |
+
['The Complete App Design Course - UX, UI and Design Thinking','https://www.udemy.com/course/the-complete-app-design-course-ux-and-ui-design/'],
|
| 47 |
+
['UX & Web Design Master Course: Strategy, Design, Development','https://www.udemy.com/course/ux-web-design-master-course-strategy-design-development/'],
|
| 48 |
+
['The Complete App Design Course - UX, UI and Design Thinking','https://www.udemy.com/course/the-complete-app-design-course-ux-and-ui-design/'],
|
| 49 |
+
['DESIGN RULES: Principles + Practices for Great UI Design','https://www.udemy.com/course/design-rules/'],
|
| 50 |
+
['Become a UX Designer by Udacity','https://www.udacity.com/course/ux-designer-nanodegree--nd578'],
|
| 51 |
+
['Adobe XD Tutorial: User Experience Design Course [Free]','https://youtu.be/68w2VwalD5w'],
|
| 52 |
+
['Adobe XD for Beginners [Free]','https://youtu.be/WEljsc2jorI'],
|
| 53 |
+
['Adobe XD in Simple Way','https://learnux.io/course/adobe-xd']]
|
| 54 |
+
|
| 55 |
+
resume_videos = ['https://youtu.be/y8YH0Qbu5h4','https://youtu.be/J-4Fv8nq1iA',
|
| 56 |
+
'https://youtu.be/yp693O87GmM','https://youtu.be/UeMmCex9uTU',
|
| 57 |
+
'https://youtu.be/dQ7Q8ZdnuN0','https://youtu.be/HQqqQx5BCFY',
|
| 58 |
+
'https://youtu.be/CLUsplI4xMU','https://youtu.be/pbczsLkv7Cc']
|
| 59 |
+
|
| 60 |
+
interview_videos = ['https://youtu.be/Ji46s5BHdr0','https://youtu.be/seVxXHi2YMs',
|
| 61 |
+
'https://youtu.be/9FgfsLa_SmY','https://youtu.be/2HQmjLu-6RQ',
|
| 62 |
+
'https://youtu.be/DQd_AlIvHUw','https://youtu.be/oVVdezJ0e7w'
|
| 63 |
+
'https://youtu.be/JZK1MZwUyUU','https://youtu.be/CyXLhHQS3KY']
|
README.md
CHANGED
|
@@ -1,13 +1,54 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Smart Resume Analyser App
|
| 2 |
+
|
| 3 |
+
[](https://www.python.org/)
|
| 4 |
+
[](https://www.python.org/downloads/release/python-360/)
|
| 5 |
+
|
| 6 |
+
## [Watch Tutorial for this project](https://youtu.be/hqu5EYMLCUw)
|
| 7 |
+
<img src="https://github.com/Spidy20/Smart_Resume_Analyser_App/blob/master/yt_thumb.jpg">
|
| 8 |
+
|
| 9 |
+
## [Get the project Report, PPT, and Diagrams](https://kushalbhavsar1820.stores.instamojo.com/product/864991/smart-resume-analyzer-ppt-report-and-diagram-c091f/)
|
| 10 |
+
## Source
|
| 11 |
+
- Extracting user's information from the Resume, I used [PyResparser](https://omkarpathak.in/pyresparser/)
|
| 12 |
+
- Extracting Resume PDF into Text, I used [PDFMiner](https://pypi.org/project/pdfminer/).
|
| 13 |
+
|
| 14 |
+
## Features
|
| 15 |
+
- User's & Admin Section
|
| 16 |
+
- Resume Score
|
| 17 |
+
- Career Recommendations
|
| 18 |
+
- Resume writing Tips suggestions
|
| 19 |
+
- Courses Recommendations
|
| 20 |
+
- Skills Recommendations
|
| 21 |
+
- Youtube video recommendations
|
| 22 |
+
|
| 23 |
+
## Usage
|
| 24 |
+
- Clone my repository.
|
| 25 |
+
- Open CMD in working directory.
|
| 26 |
+
- Run following command.
|
| 27 |
+
```
|
| 28 |
+
pip install -r requirements.txt
|
| 29 |
+
```
|
| 30 |
+
- `App.py` is the main Python file of Streamlit Web-Application.
|
| 31 |
+
- `Courses.py` is the Python file that contains courses and youtube video links.
|
| 32 |
+
- Download XAMP or any other control panel, and turn on the Apache & SQL service.
|
| 33 |
+
- To run app, write following command in CMD. or use any IDE.
|
| 34 |
+
```
|
| 35 |
+
streamlit run App.py
|
| 36 |
+
```
|
| 37 |
+
- `Uploaded_Resumes` folder is contaning the user's uploaded resumes.
|
| 38 |
+
- `Classifier.py` is the main file which is containing a KNN Algorithm.
|
| 39 |
+
- For more explanation of this project see the tutorial on Machine Learning Hub YouTube channel.
|
| 40 |
+
- Admin side credentials is `machine_learning_hub` and password is `mlhub123`.
|
| 41 |
+
|
| 42 |
+
## Screenshots
|
| 43 |
+
|
| 44 |
+
## User side
|
| 45 |
+
<img src="https://github.com/Spidy20/Smart_Resume_Analyser_App/blob/master/sc1.png">
|
| 46 |
+
|
| 47 |
+
## Admin Side
|
| 48 |
+
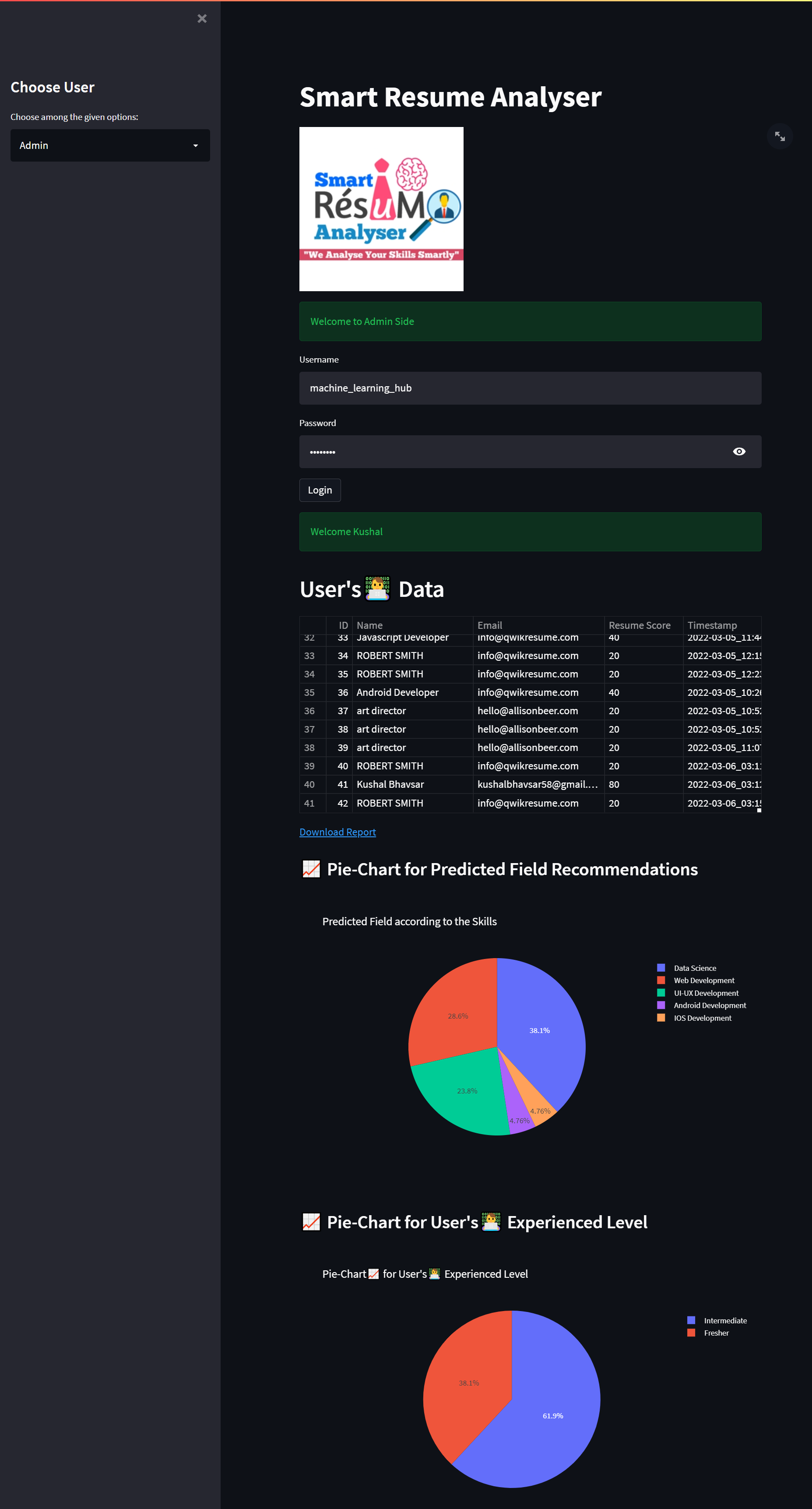
<img src="https://github.com/Spidy20/Smart_Resume_Analyser_App/blob/master/sc2.png">
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
## Just follow☝️ me and Star⭐ my repository
|
| 52 |
+
|
| 53 |
+
# [Buy me a Coffee☕](https://www.buymeacoffee.com/spidy20)
|
| 54 |
+
## [Donate me on PayPal(It will inspire me to do more projects)](https://www.paypal.me/spidy1820)
|
requirements.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pdfminer3
|
| 2 |
+
pyresparser
|
| 3 |
+
streamlit
|
| 4 |
+
pandas
|
| 5 |
+
pafy
|
| 6 |
+
plotly
|
| 7 |
+
pymysql
|
| 8 |
+
streamlit-tags
|
| 9 |
+
Pillow
|
| 10 |
+
youtube-dl
|
| 11 |
+
nltk
|
| 12 |
+
pdfminer3
|
| 13 |
+
spacy==2.3.5
|
sc1.png
ADDED

|
Git LFS Details
|
sc2.png
ADDED
|
yt_thumb.jpg
ADDED

|