
Upload 7 files
Browse files
app.py
ADDED
|
@@ -0,0 +1,703 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import joblib
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
import os
|
| 7 |
+
import openai
|
| 8 |
+
from sklearn.preprocessing import LabelEncoder
|
| 9 |
+
import requests # Add this at the top with other imports
|
| 10 |
+
from io import BytesIO
|
| 11 |
+
import gdown
|
| 12 |
+
|
| 13 |
+
# --- Set page configuration ---
|
| 14 |
+
st.set_page_config(
|
| 15 |
+
page_title="The Guide",
|
| 16 |
+
page_icon="🚗",
|
| 17 |
+
layout="wide",
|
| 18 |
+
initial_sidebar_state="expanded"
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
# --- Custom CSS for better styling ---
|
| 22 |
+
|
| 23 |
+
st.markdown("""
|
| 24 |
+
<style>
|
| 25 |
+
/* Base styles */
|
| 26 |
+
* {
|
| 27 |
+
color: black !important;
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
/* Streamlit specific input elements */
|
| 31 |
+
.stSelectbox,
|
| 32 |
+
.stNumberInput,
|
| 33 |
+
.stTextInput {
|
| 34 |
+
color: black !important;
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
/* Dropdown and select elements */
|
| 38 |
+
select option,
|
| 39 |
+
.streamlit-selectbox option,
|
| 40 |
+
.stSelectbox > div[data-baseweb="select"] > div,
|
| 41 |
+
.stSelectbox > div > div > div {
|
| 42 |
+
color: black !important;
|
| 43 |
+
background-color: white !important;
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
/* Input fields */
|
| 47 |
+
input,
|
| 48 |
+
.stNumberInput > div > div > input {
|
| 49 |
+
color: black !important;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
/* Text elements */
|
| 53 |
+
div.row-widget.stSelectbox > div,
|
| 54 |
+
div.row-widget.stSelectbox > div > div > div,
|
| 55 |
+
.streamlit-expanderContent,
|
| 56 |
+
.stMarkdown,
|
| 57 |
+
p, span, label {
|
| 58 |
+
color: black !important;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
/* Keep button text white */
|
| 62 |
+
.stButton > button {
|
| 63 |
+
color: white !important;
|
| 64 |
+
background-color: #FF4B4B;
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
/* Specific styling for select boxes */
|
| 68 |
+
div[data-baseweb="select"] {
|
| 69 |
+
color: black !important;
|
| 70 |
+
background-color: white !important;
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
div[data-baseweb="select"] * {
|
| 74 |
+
color: black !important;
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
/* Style for the selected option */
|
| 78 |
+
div[data-baseweb="select"] > div:first-child {
|
| 79 |
+
color: black !important;
|
| 80 |
+
background-color: white !important;
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
/* Dropdown menu items */
|
| 84 |
+
[role="listbox"] {
|
| 85 |
+
background-color: white !important;
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
[role="listbox"] [role="option"] {
|
| 89 |
+
color: black !important;
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
/* Number input specific styling */
|
| 93 |
+
input[type="number"] {
|
| 94 |
+
color: black !important;
|
| 95 |
+
background-color: white !important;
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
.stNumberInput div[data-baseweb="input"] {
|
| 99 |
+
background-color: white !important;
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
/* Headers */
|
| 103 |
+
h1, h2, h3, h4, h5, h6 {
|
| 104 |
+
color: black !important;
|
| 105 |
+
}
|
| 106 |
+
</style>
|
| 107 |
+
""", unsafe_allow_html=True)
|
| 108 |
+
|
| 109 |
+
# --- Cache functions ---
|
| 110 |
+
def create_brand_categories():
|
| 111 |
+
return {
|
| 112 |
+
'luxury_brands': {
|
| 113 |
+
'rolls-royce': (300000, 600000),
|
| 114 |
+
'bentley': (200000, 500000),
|
| 115 |
+
'lamborghini': (250000, 550000),
|
| 116 |
+
'ferrari': (250000, 600000),
|
| 117 |
+
'mclaren': (200000, 500000),
|
| 118 |
+
'aston-martin': (150000, 400000),
|
| 119 |
+
'maserati': (100000, 300000)
|
| 120 |
+
},
|
| 121 |
+
'premium_brands': {
|
| 122 |
+
'porsche': (60000, 150000),
|
| 123 |
+
'bmw': (40000, 90000),
|
| 124 |
+
'mercedes-benz': (45000, 95000),
|
| 125 |
+
'audi': (35000, 85000),
|
| 126 |
+
'lexus': (40000, 80000),
|
| 127 |
+
'jaguar': (45000, 90000),
|
| 128 |
+
'land-rover': (40000, 90000),
|
| 129 |
+
'volvo': (35000, 75000),
|
| 130 |
+
'infiniti': (35000, 70000),
|
| 131 |
+
'cadillac': (40000, 85000),
|
| 132 |
+
'tesla': (40000, 100000)
|
| 133 |
+
},
|
| 134 |
+
'mid_tier_brands': {
|
| 135 |
+
'acura': (30000, 50000),
|
| 136 |
+
'lincoln': (35000, 65000),
|
| 137 |
+
'buick': (25000, 45000),
|
| 138 |
+
'chrysler': (25000, 45000),
|
| 139 |
+
'alfa-romeo': (35000, 60000),
|
| 140 |
+
'genesis': (35000, 60000)
|
| 141 |
+
},
|
| 142 |
+
'standard_brands': {
|
| 143 |
+
'toyota': (20000, 35000),
|
| 144 |
+
'honda': (20000, 35000),
|
| 145 |
+
'volkswagen': (20000, 35000),
|
| 146 |
+
'mazda': (20000, 32000),
|
| 147 |
+
'subaru': (22000, 35000),
|
| 148 |
+
'hyundai': (18000, 32000),
|
| 149 |
+
'kia': (17000, 30000),
|
| 150 |
+
'ford': (20000, 40000),
|
| 151 |
+
'chevrolet': (20000, 38000),
|
| 152 |
+
'gmc': (25000, 45000),
|
| 153 |
+
'jeep': (25000, 45000),
|
| 154 |
+
'dodge': (22000, 40000),
|
| 155 |
+
'ram': (25000, 45000),
|
| 156 |
+
'nissan': (18000, 32000)
|
| 157 |
+
},
|
| 158 |
+
'economy_brands': {
|
| 159 |
+
'mitsubishi': (15000, 25000),
|
| 160 |
+
'suzuki': (12000, 22000),
|
| 161 |
+
'fiat': (15000, 25000),
|
| 162 |
+
'mini': (20000, 35000),
|
| 163 |
+
'smart': (15000, 25000)
|
| 164 |
+
},
|
| 165 |
+
'discontinued_brands': {
|
| 166 |
+
'pontiac': (5000, 15000),
|
| 167 |
+
'saturn': (4000, 12000),
|
| 168 |
+
'mercury': (4000, 12000),
|
| 169 |
+
'oldsmobile': (3000, 10000),
|
| 170 |
+
'plymouth': (3000, 10000),
|
| 171 |
+
'saab': (5000, 15000)
|
| 172 |
+
}
|
| 173 |
+
}
|
| 174 |
+
|
| 175 |
+
@st.cache_resource
|
| 176 |
+
def download_file_from_google_drive(file_id):
|
| 177 |
+
"""Downloads a file from Google Drive using gdown."""
|
| 178 |
+
url = f"https://drive.google.com/uc?id={file_id}"
|
| 179 |
+
try:
|
| 180 |
+
with st.spinner('Downloading from Google Drive...'):
|
| 181 |
+
output = f"temp_{file_id}.pkl"
|
| 182 |
+
gdown.download(url, output, quiet=False)
|
| 183 |
+
|
| 184 |
+
with open(output, 'rb') as f:
|
| 185 |
+
content = f.read()
|
| 186 |
+
|
| 187 |
+
# Clean up the temporary file
|
| 188 |
+
os.remove(output)
|
| 189 |
+
return content
|
| 190 |
+
|
| 191 |
+
except Exception as e:
|
| 192 |
+
st.error(f"Error downloading from Google Drive: {str(e)}")
|
| 193 |
+
raise e
|
| 194 |
+
|
| 195 |
+
@st.cache_data
|
| 196 |
+
def load_datasets():
|
| 197 |
+
"""Load the dataset from Google Drive."""
|
| 198 |
+
dataset_file_id = "1emG-BQ3-x4xsMAGMEznkh1ACdlAj5Dn1"
|
| 199 |
+
|
| 200 |
+
try:
|
| 201 |
+
with st.spinner('Loading dataset...'):
|
| 202 |
+
content = download_file_from_google_drive(dataset_file_id)
|
| 203 |
+
# Use BytesIO to read the CSV content
|
| 204 |
+
original_data = pd.read_csv(BytesIO(content), low_memory=False)
|
| 205 |
+
|
| 206 |
+
# Ensure column names match the model's expectations
|
| 207 |
+
original_data.columns = original_data.columns.str.strip().str.capitalize()
|
| 208 |
+
return original_data
|
| 209 |
+
except Exception as e:
|
| 210 |
+
st.error(f"Error loading dataset: {str(e)}")
|
| 211 |
+
raise e
|
| 212 |
+
|
| 213 |
+
@st.cache_resource
|
| 214 |
+
def load_model_and_encodings():
|
| 215 |
+
"""Load model from Google Drive and create encodings."""
|
| 216 |
+
model_file_id = "1wKixkdW2pVKEpJW-N1QIyKUr2nYirU7I"
|
| 217 |
+
|
| 218 |
+
try:
|
| 219 |
+
# Show loading message
|
| 220 |
+
with st.spinner('Loading model...'):
|
| 221 |
+
model_content = download_file_from_google_drive(model_file_id)
|
| 222 |
+
model = joblib.load(BytesIO(model_content))
|
| 223 |
+
|
| 224 |
+
# Load data for encodings
|
| 225 |
+
original_data = load_datasets()
|
| 226 |
+
|
| 227 |
+
# Create fresh encoders from data
|
| 228 |
+
label_encoders = {}
|
| 229 |
+
categorical_features = ['Make', 'model', 'condition', 'fuel', 'title_status',
|
| 230 |
+
'transmission', 'drive', 'size', 'type', 'paint_color']
|
| 231 |
+
|
| 232 |
+
for feature in categorical_features:
|
| 233 |
+
if feature in original_data.columns:
|
| 234 |
+
le = LabelEncoder()
|
| 235 |
+
unique_values = original_data[feature].fillna('unknown').str.strip().unique()
|
| 236 |
+
le.fit(unique_values)
|
| 237 |
+
label_encoders[feature.lower()] = le
|
| 238 |
+
|
| 239 |
+
return model, label_encoders
|
| 240 |
+
except Exception as e:
|
| 241 |
+
st.error(f"Error loading model: {str(e)}")
|
| 242 |
+
raise e
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
# --- Load data and models ---
|
| 246 |
+
try:
|
| 247 |
+
original_data = load_datasets()
|
| 248 |
+
model, label_encoders = load_model_and_encodings() # Using the new function
|
| 249 |
+
except Exception as e:
|
| 250 |
+
st.error(f"Error loading data or models: {str(e)}")
|
| 251 |
+
st.stop()
|
| 252 |
+
|
| 253 |
+
# --- Define categorical and numeric features ---
|
| 254 |
+
# From model.py
|
| 255 |
+
# --- Define features ---
|
| 256 |
+
numeric_features = ['year', 'odometer', 'age', 'age_squared', 'mileage_per_year']
|
| 257 |
+
# Update the categorical features list to use lowercase
|
| 258 |
+
categorical_features = ['make', 'model', 'condition', 'fuel', 'title_status',
|
| 259 |
+
'transmission', 'drive', 'size', 'type', 'paint_color']
|
| 260 |
+
required_features = numeric_features + categorical_features
|
| 261 |
+
|
| 262 |
+
# --- Feature engineering functions ---
|
| 263 |
+
def create_features(df):
|
| 264 |
+
df = df.copy()
|
| 265 |
+
current_year = 2024
|
| 266 |
+
df['age'] = current_year - df['year']
|
| 267 |
+
df['age_squared'] = df['age'] ** 2
|
| 268 |
+
df['mileage_per_year'] = np.clip(df['odometer'] / (df['age'] + 1), 0, 200000)
|
| 269 |
+
return df
|
| 270 |
+
|
| 271 |
+
def prepare_input(input_dict, label_encoders):
|
| 272 |
+
# Convert None values to 'unknown' for safe handling
|
| 273 |
+
input_dict = {k: v if v is not None else 'unknown' for k, v in input_dict.items()}
|
| 274 |
+
|
| 275 |
+
# Convert input dictionary to DataFrame
|
| 276 |
+
input_df = pd.DataFrame([input_dict])
|
| 277 |
+
|
| 278 |
+
# Ensure columns match the model's expected casing
|
| 279 |
+
feature_name_mapping = {
|
| 280 |
+
"make": "Make", # Match casing for 'Make'
|
| 281 |
+
"model": "Model", # Match casing for 'Model'
|
| 282 |
+
"condition": "Condition",
|
| 283 |
+
"fuel": "Fuel",
|
| 284 |
+
"title_status": "Title_status",
|
| 285 |
+
"transmission": "Transmission",
|
| 286 |
+
"drive": "Drive",
|
| 287 |
+
"size": "Size",
|
| 288 |
+
"type": "Type",
|
| 289 |
+
"paint_color": "Paint_color",
|
| 290 |
+
"year": "Year",
|
| 291 |
+
"odometer": "Odometer",
|
| 292 |
+
"age": "Age",
|
| 293 |
+
"age_squared": "Age_squared",
|
| 294 |
+
"mileage_per_year": "Mileage_per_year"
|
| 295 |
+
}
|
| 296 |
+
input_df.rename(columns=feature_name_mapping, inplace=True)
|
| 297 |
+
|
| 298 |
+
# Numeric feature conversions
|
| 299 |
+
input_df["Year"] = pd.to_numeric(input_df.get("Year", 0), errors="coerce")
|
| 300 |
+
input_df["Odometer"] = pd.to_numeric(input_df.get("Odometer", 0), errors="coerce")
|
| 301 |
+
|
| 302 |
+
# Feature engineering
|
| 303 |
+
current_year = 2024
|
| 304 |
+
input_df["Age"] = current_year - input_df["Year"]
|
| 305 |
+
input_df["Age_squared"] = input_df["Age"] ** 2
|
| 306 |
+
input_df["Mileage_per_year"] = input_df["Odometer"] / (input_df["Age"] + 1)
|
| 307 |
+
input_df["Mileage_per_year"] = input_df["Mileage_per_year"].clip(0, 200000)
|
| 308 |
+
|
| 309 |
+
# Encode categorical features
|
| 310 |
+
for feature, encoded_feature in feature_name_mapping.items():
|
| 311 |
+
if feature in label_encoders:
|
| 312 |
+
input_df[encoded_feature] = input_df[encoded_feature].fillna("unknown").astype(str).str.strip()
|
| 313 |
+
try:
|
| 314 |
+
input_df[encoded_feature] = label_encoders[feature].transform(input_df[encoded_feature])
|
| 315 |
+
except ValueError:
|
| 316 |
+
input_df[encoded_feature] = 0 # Assign default for unseen values
|
| 317 |
+
|
| 318 |
+
# Ensure all required features are present
|
| 319 |
+
for feature in model.feature_names_in_:
|
| 320 |
+
if feature not in input_df:
|
| 321 |
+
input_df[feature] = 0 # Default value for missing features
|
| 322 |
+
|
| 323 |
+
# Reorder columns
|
| 324 |
+
input_df = input_df[model.feature_names_in_]
|
| 325 |
+
|
| 326 |
+
return input_df
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
# --- Styling functions ---
|
| 331 |
+
st.markdown("""
|
| 332 |
+
<style>
|
| 333 |
+
/* Force black text globally */
|
| 334 |
+
.stApp, .stApp * {
|
| 335 |
+
color: black !important;
|
| 336 |
+
}
|
| 337 |
+
|
| 338 |
+
/* Specific overrides for different elements */
|
| 339 |
+
.main {
|
| 340 |
+
padding: 0rem 1rem;
|
| 341 |
+
}
|
| 342 |
+
|
| 343 |
+
.stButton>button {
|
| 344 |
+
width: 100%;
|
| 345 |
+
background-color: #FF4B4B;
|
| 346 |
+
color: white !important; /* Keep button text white */
|
| 347 |
+
border-radius: 5px;
|
| 348 |
+
padding: 0.5rem 1rem;
|
| 349 |
+
border: none;
|
| 350 |
+
}
|
| 351 |
+
|
| 352 |
+
.stButton>button:hover {
|
| 353 |
+
background-color: #FF6B6B;
|
| 354 |
+
}
|
| 355 |
+
|
| 356 |
+
.sidebar .sidebar-content {
|
| 357 |
+
background-color: #f5f5f5;
|
| 358 |
+
}
|
| 359 |
+
|
| 360 |
+
/* Input fields and selectboxes */
|
| 361 |
+
.stSelectbox select,
|
| 362 |
+
.stSelectbox option,
|
| 363 |
+
.stSelectbox div,
|
| 364 |
+
.stNumberInput input,
|
| 365 |
+
.stTextInput input {
|
| 366 |
+
color: black !important;
|
| 367 |
+
}
|
| 368 |
+
|
| 369 |
+
/* Headers */
|
| 370 |
+
h1, h2, h3, h4, h5, h6 {
|
| 371 |
+
color: black !important;
|
| 372 |
+
}
|
| 373 |
+
|
| 374 |
+
/* Labels and text */
|
| 375 |
+
label, .stText, p, span {
|
| 376 |
+
color: black !important;
|
| 377 |
+
}
|
| 378 |
+
|
| 379 |
+
/* Selectbox options */
|
| 380 |
+
option {
|
| 381 |
+
color: black !important;
|
| 382 |
+
background-color: white !important;
|
| 383 |
+
}
|
| 384 |
+
|
| 385 |
+
/* Override for any Streamlit specific classes */
|
| 386 |
+
.st-emotion-cache-16idsys p,
|
| 387 |
+
.st-emotion-cache-1wmy9hl p,
|
| 388 |
+
.st-emotion-cache-16idsys span,
|
| 389 |
+
.st-emotion-cache-1wmy9hl span {
|
| 390 |
+
color: black !important;
|
| 391 |
+
}
|
| 392 |
+
|
| 393 |
+
/* Force white text only for the prediction button */
|
| 394 |
+
.stButton>button[data-testid="stButton"] {
|
| 395 |
+
color: white !important;
|
| 396 |
+
}
|
| 397 |
+
</style>
|
| 398 |
+
""", unsafe_allow_html=True)
|
| 399 |
+
|
| 400 |
+
def style_metric_container(label, value):
|
| 401 |
+
st.markdown(f"""
|
| 402 |
+
<div style="
|
| 403 |
+
background-color: #f8f9fa;
|
| 404 |
+
padding: 1rem;
|
| 405 |
+
border-radius: 5px;
|
| 406 |
+
margin: 0.5rem 0;
|
| 407 |
+
border-left: 5px solid #FF4B4B;
|
| 408 |
+
">
|
| 409 |
+
<p style="color: #666; margin-bottom: 0.2rem; font-size: 0.9rem;">{label}</p>
|
| 410 |
+
<p style="color: #1E1E1E; font-size: 1.5rem; font-weight: 600; margin: 0;">{value}</p>
|
| 411 |
+
</div>
|
| 412 |
+
""", unsafe_allow_html=True)
|
| 413 |
+
|
| 414 |
+
# --- OpenAI GPT-3 Assistant ---
|
| 415 |
+
def generate_gpt_response(prompt):
|
| 416 |
+
# Ensure the API key is set securely
|
| 417 |
+
# You can use Streamlit's secrets management or environment variables
|
| 418 |
+
openai.api_key = "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"
|
| 419 |
+
|
| 420 |
+
# Define the system message and messages list
|
| 421 |
+
system_message = {
|
| 422 |
+
"role": "system",
|
| 423 |
+
"content": (
|
| 424 |
+
"You are a helpful car shopping assistant. "
|
| 425 |
+
"Provide car recommendations based on user queries. "
|
| 426 |
+
"Include car makes, models, years, and approximate prices. "
|
| 427 |
+
"Be friendly and informative."
|
| 428 |
+
)
|
| 429 |
+
}
|
| 430 |
+
|
| 431 |
+
messages = [system_message, {"role": "user", "content": prompt}]
|
| 432 |
+
|
| 433 |
+
# Call the OpenAI ChatCompletion API
|
| 434 |
+
response = openai.ChatCompletion.create(
|
| 435 |
+
model="gpt-3.5-turbo", # or "gpt-4" if you have access
|
| 436 |
+
messages=messages,
|
| 437 |
+
max_tokens=500,
|
| 438 |
+
n=1,
|
| 439 |
+
stop=None,
|
| 440 |
+
temperature=0.7,
|
| 441 |
+
)
|
| 442 |
+
|
| 443 |
+
# Extract the assistant's reply
|
| 444 |
+
assistant_reply = response['choices'][0]['message']['content'].strip()
|
| 445 |
+
|
| 446 |
+
return assistant_reply
|
| 447 |
+
|
| 448 |
+
def create_assistant_section():
|
| 449 |
+
st.markdown("""
|
| 450 |
+
<div style='background-color: #f8f9fa; padding: 1.5rem; border-radius: 10px; margin-bottom: 1rem;'>
|
| 451 |
+
<h2 style='color: #1E1E1E; margin-top: 0;'>🤖 Car Shopping Assistant</h2>
|
| 452 |
+
<p style='color: #666;'>Ask me anything about cars! For example: 'What's a good car under $30,000 with low mileage?'</p>
|
| 453 |
+
</div>
|
| 454 |
+
""", unsafe_allow_html=True)
|
| 455 |
+
|
| 456 |
+
if "assistant_responses" not in st.session_state:
|
| 457 |
+
st.session_state.assistant_responses = []
|
| 458 |
+
|
| 459 |
+
prompt = st.text_input("Ask about car recommendations...",
|
| 460 |
+
placeholder="Type your question here...")
|
| 461 |
+
|
| 462 |
+
if prompt:
|
| 463 |
+
try:
|
| 464 |
+
# Use OpenAI API to generate response
|
| 465 |
+
response = generate_gpt_response(prompt)
|
| 466 |
+
st.session_state.assistant_responses.append(response)
|
| 467 |
+
except Exception as e:
|
| 468 |
+
response = f"Sorry, I encountered an error: {str(e)}"
|
| 469 |
+
st.session_state.assistant_responses.append(response)
|
| 470 |
+
|
| 471 |
+
# Display the latest response
|
| 472 |
+
st.write(response)
|
| 473 |
+
|
| 474 |
+
# Optionally display previous responses
|
| 475 |
+
if len(st.session_state.assistant_responses) > 1:
|
| 476 |
+
st.markdown("### Previous Responses")
|
| 477 |
+
for prev_response in st.session_state.assistant_responses[:-1]:
|
| 478 |
+
st.markdown("---")
|
| 479 |
+
st.write(prev_response)
|
| 480 |
+
|
| 481 |
+
if st.button("Clear Chat"):
|
| 482 |
+
st.session_state.assistant_responses = []
|
| 483 |
+
st.experimental_rerun()
|
| 484 |
+
|
| 485 |
+
# --- Prediction Interface ---
|
| 486 |
+
def create_prediction_interface():
|
| 487 |
+
with st.sidebar:
|
| 488 |
+
st.markdown("""
|
| 489 |
+
<div style='background-color: #FF4B4B; padding: 1rem; border-radius: 5px; margin-bottom: 2rem;'>
|
| 490 |
+
<h2 style='color: white; margin: 0;'>Car Details</h2>
|
| 491 |
+
</div>
|
| 492 |
+
""", unsafe_allow_html=True)
|
| 493 |
+
|
| 494 |
+
# Year slider
|
| 495 |
+
year = st.slider("Year", min_value=1980, max_value=2024, value=2022)
|
| 496 |
+
|
| 497 |
+
# Make selection
|
| 498 |
+
make_options = sorted(original_data['Make'].dropna().unique()) # Correct casing for 'Make'
|
| 499 |
+
make = st.selectbox("Make", options=make_options)
|
| 500 |
+
|
| 501 |
+
# Filter models based on selected make
|
| 502 |
+
filtered_models = sorted(original_data[original_data['Make'] == make]['Model'].dropna().unique()) # Match 'Model' casing
|
| 503 |
+
model_name = st.selectbox("Model", options=filtered_models if len(filtered_models) > 0 else ["No models available"])
|
| 504 |
+
|
| 505 |
+
if model_name == "No models available":
|
| 506 |
+
st.warning("No models are available for the selected make.")
|
| 507 |
+
|
| 508 |
+
# Additional inputs
|
| 509 |
+
condition = st.selectbox("Condition", ['new', 'like new', 'excellent', 'good', 'fair', 'salvage', 'parts only'])
|
| 510 |
+
fuel = st.selectbox("Fuel Type", sorted(original_data['Fuel'].fillna('Unknown').unique())) # Match casing for 'Fuel'
|
| 511 |
+
odometer = st.number_input("Odometer (miles)", min_value=0, value=20000, format="%d", step=1000)
|
| 512 |
+
title_status = st.selectbox("Title Status", sorted(original_data['Title_status'].fillna('Unknown').unique())) # Match casing
|
| 513 |
+
transmission = st.selectbox("Transmission", sorted(original_data['Transmission'].fillna('Unknown').unique()))
|
| 514 |
+
drive = st.selectbox("Drive Type", sorted(original_data['Drive'].fillna('Unknown').unique()))
|
| 515 |
+
size = st.selectbox("Size", sorted(original_data['Size'].fillna('Unknown').unique()))
|
| 516 |
+
paint_color = st.selectbox("Paint Color", sorted(original_data['Paint_color'].fillna('Unknown').unique()))
|
| 517 |
+
|
| 518 |
+
car_type = 'sedan' # Default type
|
| 519 |
+
|
| 520 |
+
# Prediction button
|
| 521 |
+
predict_button = st.button("📊 Predict Price", use_container_width=True)
|
| 522 |
+
|
| 523 |
+
return {
|
| 524 |
+
'year': year,
|
| 525 |
+
'make': make.strip(), # Use correctly cased `make`
|
| 526 |
+
'model': model_name if model_name != "No models available" else 'unknown',
|
| 527 |
+
'condition': condition.lower().strip(),
|
| 528 |
+
'fuel': fuel.lower().strip(),
|
| 529 |
+
'odometer': odometer,
|
| 530 |
+
'title_status': title_status.lower().strip(),
|
| 531 |
+
'transmission': transmission.lower().strip(),
|
| 532 |
+
'drive': drive.lower().strip(),
|
| 533 |
+
'size': size.lower().strip(),
|
| 534 |
+
'type': car_type.lower().strip(),
|
| 535 |
+
'paint_color': paint_color.lower().strip()
|
| 536 |
+
}, predict_button
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
|
| 540 |
+
def create_market_trends_plot_with_model(model, make, base_inputs, label_encoders, years_range=range(1980, 2025)):
|
| 541 |
+
predictions = []
|
| 542 |
+
|
| 543 |
+
for year in years_range:
|
| 544 |
+
try:
|
| 545 |
+
current_inputs = base_inputs.copy()
|
| 546 |
+
current_inputs['year'] = float(year)
|
| 547 |
+
age = 2024 - year
|
| 548 |
+
|
| 549 |
+
# Base value calculation
|
| 550 |
+
base_price = 30000 # Average new car price
|
| 551 |
+
|
| 552 |
+
# Depreciation curve
|
| 553 |
+
if age <= 1:
|
| 554 |
+
value_factor = 0.85 # 15% first year depreciation
|
| 555 |
+
elif age <= 5:
|
| 556 |
+
value_factor = 0.85 * (0.90 ** (age - 1)) # 10% years 2-5
|
| 557 |
+
else:
|
| 558 |
+
value_factor = 0.85 * (0.90 ** 4) * (0.95 ** (age - 5)) # 5% thereafter
|
| 559 |
+
|
| 560 |
+
price = base_price * value_factor
|
| 561 |
+
predictions.append({"year": year, "predicted_price": max(price, 2000)}) # Floor of $2000
|
| 562 |
+
|
| 563 |
+
except Exception as e:
|
| 564 |
+
continue
|
| 565 |
+
|
| 566 |
+
if not predictions:
|
| 567 |
+
return None
|
| 568 |
+
|
| 569 |
+
predictions_df = pd.DataFrame(predictions)
|
| 570 |
+
fig, ax = plt.subplots(figsize=(12, 6))
|
| 571 |
+
ax.plot(predictions_df["year"], predictions_df["predicted_price"], color="#FF4B4B", linewidth=2)
|
| 572 |
+
ax.set_title(f"Average Car Value by Age")
|
| 573 |
+
ax.set_xlabel("Year")
|
| 574 |
+
ax.set_ylabel("Value ($)")
|
| 575 |
+
ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'${x:,.0f}'))
|
| 576 |
+
plt.grid(True, alpha=0.3)
|
| 577 |
+
|
| 578 |
+
return fig
|
| 579 |
+
|
| 580 |
+
def inspect_model_features(model):
|
| 581 |
+
# Check feature names the model expects
|
| 582 |
+
try:
|
| 583 |
+
if hasattr(model, "feature_names_in_"):
|
| 584 |
+
print("Model feature names:", model.feature_names_in_)
|
| 585 |
+
else:
|
| 586 |
+
print("Model does not have 'feature_names_in_' attribute.")
|
| 587 |
+
except Exception as e:
|
| 588 |
+
print(f"Error inspecting model features: {e}")
|
| 589 |
+
|
| 590 |
+
def predict_with_ranges(inputs, model, label_encoders):
|
| 591 |
+
input_df = prepare_input(inputs, label_encoders)
|
| 592 |
+
base_prediction = float(np.expm1(model.predict(input_df)[0]))
|
| 593 |
+
|
| 594 |
+
brand_categories = create_brand_categories()
|
| 595 |
+
make = inputs['make'].lower()
|
| 596 |
+
year = inputs['year']
|
| 597 |
+
condition = inputs['condition']
|
| 598 |
+
odometer = inputs['odometer']
|
| 599 |
+
age = 2024 - year
|
| 600 |
+
|
| 601 |
+
# Find brand category and price range
|
| 602 |
+
price_range = None
|
| 603 |
+
for category, brands in brand_categories.items():
|
| 604 |
+
if make in brands:
|
| 605 |
+
price_range = brands[make]
|
| 606 |
+
break
|
| 607 |
+
if not price_range:
|
| 608 |
+
price_range = (15000, 35000) # Default range
|
| 609 |
+
|
| 610 |
+
# Calculate adjustment factors
|
| 611 |
+
mileage_factor = max(1 - (odometer / 200000) * 0.3, 0.7)
|
| 612 |
+
age_factor = 0.85 ** min(age, 15)
|
| 613 |
+
condition_factor = {
|
| 614 |
+
'new': 1.0,
|
| 615 |
+
'like new': 0.9,
|
| 616 |
+
'excellent': 0.8,
|
| 617 |
+
'good': 0.7,
|
| 618 |
+
'fair': 0.5,
|
| 619 |
+
'salvage': 0.3
|
| 620 |
+
}.get(condition, 0.7)
|
| 621 |
+
|
| 622 |
+
# Apply all factors
|
| 623 |
+
min_price = price_range[0] * mileage_factor * age_factor * condition_factor
|
| 624 |
+
max_price = price_range[1] * mileage_factor * age_factor * condition_factor
|
| 625 |
+
predicted_price = base_prediction * mileage_factor * age_factor * condition_factor
|
| 626 |
+
|
| 627 |
+
# Use uniform distribution instead of clamping
|
| 628 |
+
final_prediction = np.random.uniform(min_price, max_price)
|
| 629 |
+
|
| 630 |
+
return {
|
| 631 |
+
'predicted_price': final_prediction,
|
| 632 |
+
'min_price': min_price,
|
| 633 |
+
'max_price': max_price
|
| 634 |
+
}
|
| 635 |
+
# --- Main Application ---
|
| 636 |
+
def main(model, label_encoders):
|
| 637 |
+
col1, col2 = st.columns([2, 1])
|
| 638 |
+
|
| 639 |
+
with col1:
|
| 640 |
+
st.markdown("""
|
| 641 |
+
<h1 style='text-align: center;'>The Guide 🚗</h1>
|
| 642 |
+
<p style='text-align: center; color: #666; font-size: 1.1rem; margin-bottom: 2rem;'>
|
| 643 |
+
A cutting-edge data science project leveraging machine learning to detect which car would be best for you.
|
| 644 |
+
</p>
|
| 645 |
+
""", unsafe_allow_html=True)
|
| 646 |
+
|
| 647 |
+
inputs, predict_button = create_prediction_interface()
|
| 648 |
+
|
| 649 |
+
# Prepare base inputs
|
| 650 |
+
base_inputs = {
|
| 651 |
+
"year": inputs.get("year", 2022),
|
| 652 |
+
"make": inputs.get("make", "toyota").lower(),
|
| 653 |
+
"model": inputs.get("model", "camry"),
|
| 654 |
+
"odometer": inputs.get("odometer", 20000),
|
| 655 |
+
"condition": inputs.get("condition", "good"),
|
| 656 |
+
"fuel": inputs.get("fuel", "gas"),
|
| 657 |
+
"title_status": inputs.get("title_status", "clean"),
|
| 658 |
+
"transmission": inputs.get("transmission", "automatic"),
|
| 659 |
+
"drive": inputs.get("drive", "fwd"),
|
| 660 |
+
"size": inputs.get("size", "mid-size"),
|
| 661 |
+
"paint_color": inputs.get("paint_color", "black"),
|
| 662 |
+
"type": inputs.get("type", "sedan")
|
| 663 |
+
}
|
| 664 |
+
|
| 665 |
+
if base_inputs["condition"] == "new":
|
| 666 |
+
base_inputs["odometer"] = 0
|
| 667 |
+
|
| 668 |
+
if predict_button:
|
| 669 |
+
st.write(f"Analyzing {base_inputs['year']} {base_inputs['make'].title()} {base_inputs['model'].title()}...")
|
| 670 |
+
prediction_results = predict_with_ranges(base_inputs, model, label_encoders)
|
| 671 |
+
|
| 672 |
+
st.markdown(f"""
|
| 673 |
+
### Price Analysis
|
| 674 |
+
- **Estimated Range**: ${prediction_results['min_price']:,.2f} - ${prediction_results['max_price']:,.2f}
|
| 675 |
+
- **Model Prediction**: ${prediction_results['predicted_price']:,.2f}
|
| 676 |
+
|
| 677 |
+
*Note: Range based on market data, condition, and mileage*
|
| 678 |
+
""")
|
| 679 |
+
|
| 680 |
+
# Generate and display the graph
|
| 681 |
+
fig = create_market_trends_plot_with_model(model, base_inputs["make"], base_inputs, label_encoders)
|
| 682 |
+
if fig:
|
| 683 |
+
st.pyplot(fig)
|
| 684 |
+
else:
|
| 685 |
+
st.warning("No graph generated. Please check your data or selection.")
|
| 686 |
+
|
| 687 |
+
with col2:
|
| 688 |
+
create_assistant_section()
|
| 689 |
+
|
| 690 |
+
if __name__ == "__main__":
|
| 691 |
+
try:
|
| 692 |
+
# Load data and model
|
| 693 |
+
original_data = load_datasets()
|
| 694 |
+
model, label_encoders = load_model_and_encodings()
|
| 695 |
+
|
| 696 |
+
# Inspect model features
|
| 697 |
+
inspect_model_features(model)
|
| 698 |
+
|
| 699 |
+
# Call the main function
|
| 700 |
+
main(model, label_encoders)
|
| 701 |
+
except Exception as e:
|
| 702 |
+
st.error(f"Error loading data or models: {str(e)}")
|
| 703 |
+
st.stop()
|
model.py
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import numpy as np
|
| 3 |
+
from sklearn.model_selection import train_test_split
|
| 4 |
+
from sklearn.ensemble import RandomForestRegressor
|
| 5 |
+
from sklearn.preprocessing import LabelEncoder, RobustScaler
|
| 6 |
+
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
|
| 7 |
+
from sklearn.pipeline import Pipeline
|
| 8 |
+
import joblib
|
| 9 |
+
import matplotlib.pyplot as plt
|
| 10 |
+
import seaborn as sns
|
| 11 |
+
import os
|
| 12 |
+
|
| 13 |
+
# Load dataset
|
| 14 |
+
file_path = "CAR/CTP_Model1.csv"
|
| 15 |
+
data = pd.read_csv(file_path, low_memory=False)
|
| 16 |
+
|
| 17 |
+
# Function to remove outliers using IQR
|
| 18 |
+
def remove_outliers_iqr(df, column, multiplier=1.5):
|
| 19 |
+
Q1 = df[column].quantile(0.25)
|
| 20 |
+
Q3 = df[column].quantile(0.75)
|
| 21 |
+
IQR = Q3 - Q1
|
| 22 |
+
lower_bound = Q1 - multiplier * IQR
|
| 23 |
+
upper_bound = Q3 + multiplier * IQR
|
| 24 |
+
return df[(df[column] >= lower_bound) & (df[column] <= upper_bound)]
|
| 25 |
+
|
| 26 |
+
# Remove outliers and unrealistic prices
|
| 27 |
+
data = remove_outliers_iqr(data, 'price', multiplier=2)
|
| 28 |
+
data = data[data['price'] > 100]
|
| 29 |
+
|
| 30 |
+
# Feature engineering
|
| 31 |
+
def create_features(df):
|
| 32 |
+
df = df.copy()
|
| 33 |
+
current_year = 2024
|
| 34 |
+
df['age'] = current_year - df['year']
|
| 35 |
+
df['age_squared'] = df['age'] ** 2
|
| 36 |
+
df['mileage_per_year'] = np.clip(df['odometer'] / (df['age'] + 1), 0, 200000)
|
| 37 |
+
return df
|
| 38 |
+
|
| 39 |
+
data = create_features(data)
|
| 40 |
+
|
| 41 |
+
# Handle categorical features
|
| 42 |
+
categorical_features = ['make', 'model', 'condition', 'fuel', 'title_status',
|
| 43 |
+
'transmission', 'drive', 'size', 'type', 'paint_color']
|
| 44 |
+
|
| 45 |
+
label_encoders = {}
|
| 46 |
+
encoding_dict = {} # To save mappings for the app
|
| 47 |
+
|
| 48 |
+
for feature in categorical_features:
|
| 49 |
+
if feature in data.columns:
|
| 50 |
+
le = LabelEncoder()
|
| 51 |
+
data[feature] = le.fit_transform(data[feature])
|
| 52 |
+
label_encoders[feature] = le
|
| 53 |
+
# Save mapping for later use
|
| 54 |
+
encoding_dict[feature] = dict(zip(le.classes_, le.transform(le.classes_)))
|
| 55 |
+
|
| 56 |
+
# Save the encoding dictionary to a CSV
|
| 57 |
+
encoding_df = pd.DataFrame.from_dict(encoding_dict, orient='index').transpose()
|
| 58 |
+
encoding_df.to_csv("categorical_encodings.csv", index=False)
|
| 59 |
+
|
| 60 |
+
# Prepare features and labels
|
| 61 |
+
numeric_features = ['year', 'odometer', 'age', 'age_squared', 'mileage_per_year']
|
| 62 |
+
features = numeric_features + categorical_features
|
| 63 |
+
X = data[features]
|
| 64 |
+
y = np.log1p(data['price']) # Log-transform the price for better model performance
|
| 65 |
+
|
| 66 |
+
# Train-test split
|
| 67 |
+
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
| 68 |
+
|
| 69 |
+
# Create a pipeline with scaling and regression
|
| 70 |
+
model = Pipeline([
|
| 71 |
+
('scaler', RobustScaler()),
|
| 72 |
+
('regressor', RandomForestRegressor(
|
| 73 |
+
n_estimators=300, max_depth=25, random_state=42, n_jobs=-1))
|
| 74 |
+
])
|
| 75 |
+
|
| 76 |
+
# Train the model
|
| 77 |
+
model.fit(X_train, y_train)
|
| 78 |
+
|
| 79 |
+
# Evaluate the model
|
| 80 |
+
y_pred = model.predict(X_test)
|
| 81 |
+
rmse = mean_squared_error(y_test, y_pred, squared=False)
|
| 82 |
+
mae = mean_absolute_error(y_test, y_pred)
|
| 83 |
+
r2 = r2_score(y_test, y_pred)
|
| 84 |
+
|
| 85 |
+
print(f"RMSE: {rmse:.2f}, MAE: {mae:.2f}, R²: {r2:.4f}")
|
| 86 |
+
|
| 87 |
+
# Save the model and encoders
|
| 88 |
+
joblib.dump(model, "car_price_modelv3.pkl")
|
| 89 |
+
print("Model saved successfully.")
|
| 90 |
+
|
| 91 |
+
viz_path = '/Users/estebanm/Desktop/carShopping_tool/CAR/visualizations'
|
| 92 |
+
os.makedirs(viz_path, exist_ok=True)
|
| 93 |
+
|
| 94 |
+
# 1. Price Distribution Plot
|
| 95 |
+
plt.figure(figsize=(10, 6))
|
| 96 |
+
sns.histplot(data=data, x='price', bins=50)
|
| 97 |
+
plt.title('Price Distribution')
|
| 98 |
+
plt.savefig(os.path.join(viz_path, 'price_distribution_plot.png'))
|
| 99 |
+
plt.close()
|
| 100 |
+
|
| 101 |
+
# 2. Actual vs Predicted Plot
|
| 102 |
+
actual_prices = np.expm1(y_test)
|
| 103 |
+
predicted_prices = np.expm1(y_pred)
|
| 104 |
+
|
| 105 |
+
plt.figure(figsize=(10, 6))
|
| 106 |
+
plt.scatter(actual_prices, predicted_prices, alpha=0.5)
|
| 107 |
+
plt.plot([actual_prices.min(), actual_prices.max()], [actual_prices.min(), actual_prices.max()], 'r--')
|
| 108 |
+
plt.xlabel('Actual Price')
|
| 109 |
+
plt.ylabel('Predicted Price')
|
| 110 |
+
plt.title('Actual vs Predicted Prices')
|
| 111 |
+
plt.savefig(os.path.join(viz_path, 'actual_vs_predicted_scatter.png'))
|
| 112 |
+
plt.close()
|
| 113 |
+
|
| 114 |
+
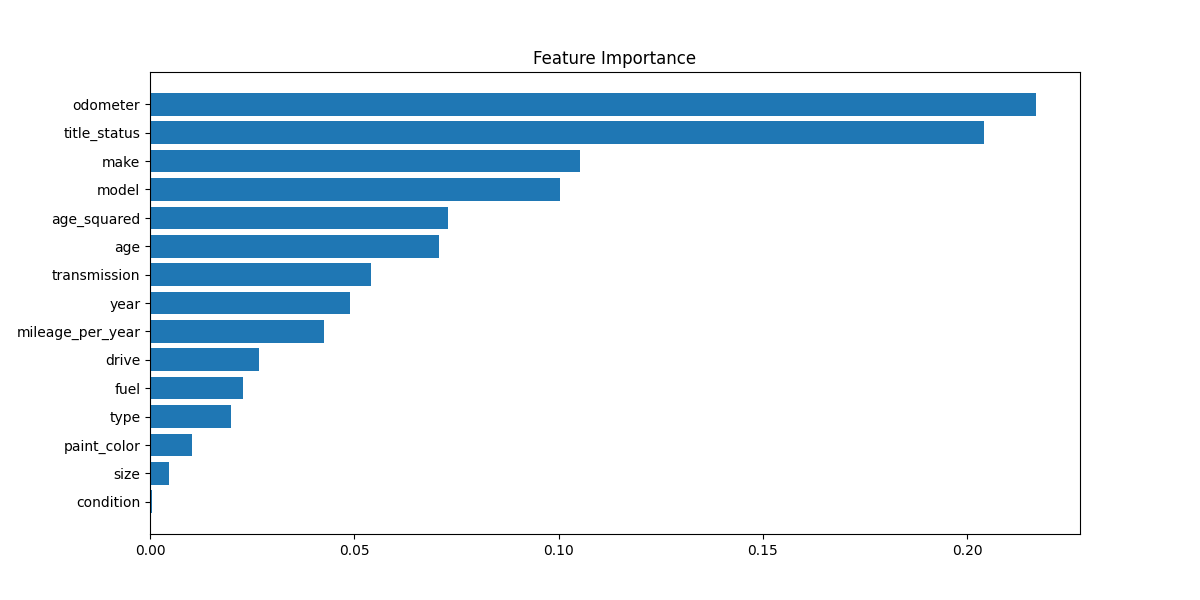
# 3. Feature Importance Plot
|
| 115 |
+
feature_importance = model.named_steps['regressor'].feature_importances_
|
| 116 |
+
feature_names = numeric_features + categorical_features
|
| 117 |
+
|
| 118 |
+
plt.figure(figsize=(12, 6))
|
| 119 |
+
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
|
| 120 |
+
importance_df = importance_df.sort_values('importance', ascending=True)
|
| 121 |
+
plt.barh(importance_df['feature'], importance_df['importance'])
|
| 122 |
+
plt.title('Feature Importance')
|
| 123 |
+
plt.savefig(os.path.join(viz_path, 'feature_importance_plot.png'))
|
| 124 |
+
plt.close()
|
| 125 |
+
|
| 126 |
+
# 4. Residuals Distribution Plot
|
| 127 |
+
residuals = actual_prices - predicted_prices
|
| 128 |
+
plt.figure(figsize=(10, 6))
|
| 129 |
+
sns.histplot(residuals, bins=50)
|
| 130 |
+
plt.title('Residuals Distribution')
|
| 131 |
+
plt.xlabel('Residuals')
|
| 132 |
+
plt.savefig(os.path.join(viz_path, 'residuals_distribution_plot.png'))
|
| 133 |
+
plt.close()
|
visualizations/actual_vs_predicted_scatter.png
ADDED

|
visualizations/feature_importance_plot.png
ADDED
|
visualizations/price_distribution_plot.png
ADDED

|
visualizations/residuals_distribution_plot.png
ADDED

|