Spaces:
Sleeping


Sleeping
init
Browse files- G_49200.pth +3 -0
- LICENSE +21 -0
- all_emotions.npy +3 -0
- app.py +111 -0
- attentions.py +303 -0
- commons.py +161 -0
- configs/vtubers.json +53 -0
- data_utils.py +261 -0
- emotion_extract.py +112 -0
- filelists/train.txt +0 -0
- filelists/train.txt.cleaned +0 -0
- filelists/val.txt +63 -0
- filelists/val.txt.cleaned +63 -0
- losses.py +61 -0
- mel_processing.py +119 -0
- models.py +537 -0
- modules.py +390 -0
- monotonic_align/__init__.py +19 -0
- monotonic_align/core.pyx +42 -0
- monotonic_align/setup.py +9 -0
- preprocess.py +25 -0
- requirements.txt +13 -0
- resources/fig_1a.png +0 -0
- resources/fig_1b.png +0 -0
- resources/training.png +0 -0
- text/LICENSE +19 -0
- text/__init__.py +56 -0
- text/cleaners.py +178 -0
- text/japanese.py +153 -0
- text/mandarin.py +328 -0
- text/symbols.py +69 -0
- train_ms.py +296 -0
- transforms.py +193 -0
- utils.py +267 -0
G_49200.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:da931601660595a5ab841b25668faf97ee66e10d3ae5da03f69c5e61f28476fd
|
| 3 |
+
size 479164585
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Jaehyeon Kim
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
all_emotions.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:48e81667f1fc4ce2b2eaed80fadd0871e1ddfc8933767915954c39ac854d5724
|
| 3 |
+
size 22356096
|
app.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
import commons
|
| 4 |
+
import utils
|
| 5 |
+
from models import SynthesizerTrn
|
| 6 |
+
from text.symbols import symbols
|
| 7 |
+
from text import text_to_sequence
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_text(text, hps):
|
| 12 |
+
text_norm = text_to_sequence(text, hps.data.text_cleaners)
|
| 13 |
+
if hps.data.add_blank:
|
| 14 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 15 |
+
text_norm = torch.LongTensor(text_norm)
|
| 16 |
+
return text_norm
|
| 17 |
+
hps = utils.get_hparams_from_file("./configs/vtubers.json")
|
| 18 |
+
net_g = SynthesizerTrn(
|
| 19 |
+
len(symbols),
|
| 20 |
+
hps.data.filter_length // 2 + 1,
|
| 21 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 22 |
+
n_speakers=hps.data.n_speakers,
|
| 23 |
+
**hps.model)
|
| 24 |
+
_ = net_g.eval()
|
| 25 |
+
|
| 26 |
+
_ = utils.load_checkpoint("./G_49200.pth", net_g, None)
|
| 27 |
+
all_emotions = np.load("all_emotions.npy")
|
| 28 |
+
emotion_dict = {
|
| 29 |
+
"小声": 2077,
|
| 30 |
+
"激动": 111,
|
| 31 |
+
"平静1": 434,
|
| 32 |
+
"平静2": 3554
|
| 33 |
+
}
|
| 34 |
+
import random
|
| 35 |
+
def tts(txt, emotion):
|
| 36 |
+
stn_tst = get_text(txt, hps)
|
| 37 |
+
randsample = None
|
| 38 |
+
with torch.no_grad():
|
| 39 |
+
x_tst = stn_tst.unsqueeze(0)
|
| 40 |
+
x_tst_lengths = torch.LongTensor([stn_tst.size(0)])
|
| 41 |
+
sid = torch.LongTensor([0])
|
| 42 |
+
if type(emotion) ==int:
|
| 43 |
+
emo = torch.FloatTensor(all_emotions[emotion]).unsqueeze(0)
|
| 44 |
+
elif emotion == "random":
|
| 45 |
+
emo = torch.randn([1,1024])
|
| 46 |
+
elif emotion == "random_sample":
|
| 47 |
+
randint = random.randint(0, all_emotions.shape[0])
|
| 48 |
+
emo = torch.FloatTensor(all_emotions[randint]).unsqueeze(0)
|
| 49 |
+
randsample = randint
|
| 50 |
+
elif emotion.endswith("wav"):
|
| 51 |
+
import emotion_extract
|
| 52 |
+
emo = torch.FloatTensor(emotion_extract.extract_wav(emotion))
|
| 53 |
+
else:
|
| 54 |
+
emo = torch.FloatTensor(all_emotions[emotion_dict[emotion]]).unsqueeze(0)
|
| 55 |
+
|
| 56 |
+
audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=0.667, noise_scale_w=0.8, length_scale=1, emo=emo)[0][0,0].data.float().numpy()
|
| 57 |
+
return audio, randsample
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def tts1(text, emotion):
|
| 61 |
+
if len(text) > 150:
|
| 62 |
+
return "Error: Text is too long", None
|
| 63 |
+
audio, _ = tts(text, emotion)
|
| 64 |
+
return "Success", (hps.data.sampling_rate, audio)
|
| 65 |
+
|
| 66 |
+
def tts2(text):
|
| 67 |
+
if len(text) > 150:
|
| 68 |
+
return "Error: Text is too long", None
|
| 69 |
+
audio, randsample = tts(text, "random_sample")
|
| 70 |
+
|
| 71 |
+
return str(randsample), (hps.data.sampling_rate, audio)
|
| 72 |
+
|
| 73 |
+
def tts3(text, sample):
|
| 74 |
+
if len(text) > 150:
|
| 75 |
+
return "Error: Text is too long", None
|
| 76 |
+
try:
|
| 77 |
+
audio, _ = tts(text, int(sample))
|
| 78 |
+
return "Success", (hps.data.sampling_rate, audio)
|
| 79 |
+
except:
|
| 80 |
+
return "输入参数不为整数或其他错误"
|
| 81 |
+
|
| 82 |
+
app = gr.Blocks()
|
| 83 |
+
with app:
|
| 84 |
+
with gr.Tabs():
|
| 85 |
+
with gr.TabItem("使用预制情感合成"):
|
| 86 |
+
tts_input1 = gr.TextArea(label="日语文本", value="こんにちは。私わあやちねねです。")
|
| 87 |
+
tts_input2 = gr.Dropdown(label="情感", choices=list(emotion_dict.keys()), value="平静1")
|
| 88 |
+
tts_submit = gr.Button("合成音频", variant="primary")
|
| 89 |
+
tts_output1 = gr.Textbox(label="Message")
|
| 90 |
+
tts_output2 = gr.Audio(label="Output")
|
| 91 |
+
tts_submit.click(tts1, [tts_input1, tts_input2], [tts_output1, tts_output2])
|
| 92 |
+
with gr.TabItem("随机抽取训练集样本作为情感参数"):
|
| 93 |
+
tts_input1 = gr.TextArea(label="日语文本", value="こんにちは。私わあやちねねです。")
|
| 94 |
+
tts_submit = gr.Button("合成音频", variant="primary")
|
| 95 |
+
tts_output1 = gr.Textbox(label="随机样本id(可用于第三个tab中合成)")
|
| 96 |
+
tts_output2 = gr.Audio(label="Output")
|
| 97 |
+
tts_submit.click(tts2, [tts_input1], [tts_output1, tts_output2])
|
| 98 |
+
|
| 99 |
+
with gr.TabItem("使用情感样本id作为情感参数"):
|
| 100 |
+
|
| 101 |
+
tts_input1 = gr.TextArea(label="日语文本", value="こんにちは。私わあやちねねです。")
|
| 102 |
+
tts_input2 = gr.Number(label="情感样本id", value=2004)
|
| 103 |
+
tts_submit = gr.Button("合成音频", variant="primary")
|
| 104 |
+
tts_output1 = gr.Textbox(label="Message")
|
| 105 |
+
tts_output2 = gr.Audio(label="Output")
|
| 106 |
+
tts_submit.click(tts3, [tts_input1, tts_input2], [tts_output1, tts_output2])
|
| 107 |
+
|
| 108 |
+
with gr.TabItem("使用参考音频作为情感参数"):
|
| 109 |
+
tts_input1 = gr.TextArea(label="text", value="暂未实现")
|
| 110 |
+
|
| 111 |
+
app.launch()
|
attentions.py
ADDED
|
@@ -0,0 +1,303 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
import commons
|
| 9 |
+
import modules
|
| 10 |
+
from modules import LayerNorm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Encoder(nn.Module):
|
| 14 |
+
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., window_size=4, **kwargs):
|
| 15 |
+
super().__init__()
|
| 16 |
+
self.hidden_channels = hidden_channels
|
| 17 |
+
self.filter_channels = filter_channels
|
| 18 |
+
self.n_heads = n_heads
|
| 19 |
+
self.n_layers = n_layers
|
| 20 |
+
self.kernel_size = kernel_size
|
| 21 |
+
self.p_dropout = p_dropout
|
| 22 |
+
self.window_size = window_size
|
| 23 |
+
|
| 24 |
+
self.drop = nn.Dropout(p_dropout)
|
| 25 |
+
self.attn_layers = nn.ModuleList()
|
| 26 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 27 |
+
self.ffn_layers = nn.ModuleList()
|
| 28 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 29 |
+
for i in range(self.n_layers):
|
| 30 |
+
self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, window_size=window_size))
|
| 31 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 32 |
+
self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout))
|
| 33 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 34 |
+
|
| 35 |
+
def forward(self, x, x_mask):
|
| 36 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 37 |
+
x = x * x_mask
|
| 38 |
+
for i in range(self.n_layers):
|
| 39 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 40 |
+
y = self.drop(y)
|
| 41 |
+
x = self.norm_layers_1[i](x + y)
|
| 42 |
+
|
| 43 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 44 |
+
y = self.drop(y)
|
| 45 |
+
x = self.norm_layers_2[i](x + y)
|
| 46 |
+
x = x * x_mask
|
| 47 |
+
return x
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class Decoder(nn.Module):
|
| 51 |
+
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., proximal_bias=False, proximal_init=True, **kwargs):
|
| 52 |
+
super().__init__()
|
| 53 |
+
self.hidden_channels = hidden_channels
|
| 54 |
+
self.filter_channels = filter_channels
|
| 55 |
+
self.n_heads = n_heads
|
| 56 |
+
self.n_layers = n_layers
|
| 57 |
+
self.kernel_size = kernel_size
|
| 58 |
+
self.p_dropout = p_dropout
|
| 59 |
+
self.proximal_bias = proximal_bias
|
| 60 |
+
self.proximal_init = proximal_init
|
| 61 |
+
|
| 62 |
+
self.drop = nn.Dropout(p_dropout)
|
| 63 |
+
self.self_attn_layers = nn.ModuleList()
|
| 64 |
+
self.norm_layers_0 = nn.ModuleList()
|
| 65 |
+
self.encdec_attn_layers = nn.ModuleList()
|
| 66 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 67 |
+
self.ffn_layers = nn.ModuleList()
|
| 68 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 69 |
+
for i in range(self.n_layers):
|
| 70 |
+
self.self_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, proximal_bias=proximal_bias, proximal_init=proximal_init))
|
| 71 |
+
self.norm_layers_0.append(LayerNorm(hidden_channels))
|
| 72 |
+
self.encdec_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout))
|
| 73 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 74 |
+
self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout, causal=True))
|
| 75 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 76 |
+
|
| 77 |
+
def forward(self, x, x_mask, h, h_mask):
|
| 78 |
+
"""
|
| 79 |
+
x: decoder input
|
| 80 |
+
h: encoder output
|
| 81 |
+
"""
|
| 82 |
+
self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(device=x.device, dtype=x.dtype)
|
| 83 |
+
encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 84 |
+
x = x * x_mask
|
| 85 |
+
for i in range(self.n_layers):
|
| 86 |
+
y = self.self_attn_layers[i](x, x, self_attn_mask)
|
| 87 |
+
y = self.drop(y)
|
| 88 |
+
x = self.norm_layers_0[i](x + y)
|
| 89 |
+
|
| 90 |
+
y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
|
| 91 |
+
y = self.drop(y)
|
| 92 |
+
x = self.norm_layers_1[i](x + y)
|
| 93 |
+
|
| 94 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 95 |
+
y = self.drop(y)
|
| 96 |
+
x = self.norm_layers_2[i](x + y)
|
| 97 |
+
x = x * x_mask
|
| 98 |
+
return x
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MultiHeadAttention(nn.Module):
|
| 102 |
+
def __init__(self, channels, out_channels, n_heads, p_dropout=0., window_size=None, heads_share=True, block_length=None, proximal_bias=False, proximal_init=False):
|
| 103 |
+
super().__init__()
|
| 104 |
+
assert channels % n_heads == 0
|
| 105 |
+
|
| 106 |
+
self.channels = channels
|
| 107 |
+
self.out_channels = out_channels
|
| 108 |
+
self.n_heads = n_heads
|
| 109 |
+
self.p_dropout = p_dropout
|
| 110 |
+
self.window_size = window_size
|
| 111 |
+
self.heads_share = heads_share
|
| 112 |
+
self.block_length = block_length
|
| 113 |
+
self.proximal_bias = proximal_bias
|
| 114 |
+
self.proximal_init = proximal_init
|
| 115 |
+
self.attn = None
|
| 116 |
+
|
| 117 |
+
self.k_channels = channels // n_heads
|
| 118 |
+
self.conv_q = nn.Conv1d(channels, channels, 1)
|
| 119 |
+
self.conv_k = nn.Conv1d(channels, channels, 1)
|
| 120 |
+
self.conv_v = nn.Conv1d(channels, channels, 1)
|
| 121 |
+
self.conv_o = nn.Conv1d(channels, out_channels, 1)
|
| 122 |
+
self.drop = nn.Dropout(p_dropout)
|
| 123 |
+
|
| 124 |
+
if window_size is not None:
|
| 125 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 126 |
+
rel_stddev = self.k_channels**-0.5
|
| 127 |
+
self.emb_rel_k = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 128 |
+
self.emb_rel_v = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 129 |
+
|
| 130 |
+
nn.init.xavier_uniform_(self.conv_q.weight)
|
| 131 |
+
nn.init.xavier_uniform_(self.conv_k.weight)
|
| 132 |
+
nn.init.xavier_uniform_(self.conv_v.weight)
|
| 133 |
+
if proximal_init:
|
| 134 |
+
with torch.no_grad():
|
| 135 |
+
self.conv_k.weight.copy_(self.conv_q.weight)
|
| 136 |
+
self.conv_k.bias.copy_(self.conv_q.bias)
|
| 137 |
+
|
| 138 |
+
def forward(self, x, c, attn_mask=None):
|
| 139 |
+
q = self.conv_q(x)
|
| 140 |
+
k = self.conv_k(c)
|
| 141 |
+
v = self.conv_v(c)
|
| 142 |
+
|
| 143 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 144 |
+
|
| 145 |
+
x = self.conv_o(x)
|
| 146 |
+
return x
|
| 147 |
+
|
| 148 |
+
def attention(self, query, key, value, mask=None):
|
| 149 |
+
# reshape [b, d, t] -> [b, n_h, t, d_k]
|
| 150 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 151 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 152 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 153 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 154 |
+
|
| 155 |
+
scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
|
| 156 |
+
if self.window_size is not None:
|
| 157 |
+
assert t_s == t_t, "Relative attention is only available for self-attention."
|
| 158 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 159 |
+
rel_logits = self._matmul_with_relative_keys(query /math.sqrt(self.k_channels), key_relative_embeddings)
|
| 160 |
+
scores_local = self._relative_position_to_absolute_position(rel_logits)
|
| 161 |
+
scores = scores + scores_local
|
| 162 |
+
if self.proximal_bias:
|
| 163 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 164 |
+
scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device, dtype=scores.dtype)
|
| 165 |
+
if mask is not None:
|
| 166 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 167 |
+
if self.block_length is not None:
|
| 168 |
+
assert t_s == t_t, "Local attention is only available for self-attention."
|
| 169 |
+
block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length)
|
| 170 |
+
scores = scores.masked_fill(block_mask == 0, -1e4)
|
| 171 |
+
p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
|
| 172 |
+
p_attn = self.drop(p_attn)
|
| 173 |
+
output = torch.matmul(p_attn, value)
|
| 174 |
+
if self.window_size is not None:
|
| 175 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 176 |
+
value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)
|
| 177 |
+
output = output + self._matmul_with_relative_values(relative_weights, value_relative_embeddings)
|
| 178 |
+
output = output.transpose(2, 3).contiguous().view(b, d, t_t) # [b, n_h, t_t, d_k] -> [b, d, t_t]
|
| 179 |
+
return output, p_attn
|
| 180 |
+
|
| 181 |
+
def _matmul_with_relative_values(self, x, y):
|
| 182 |
+
"""
|
| 183 |
+
x: [b, h, l, m]
|
| 184 |
+
y: [h or 1, m, d]
|
| 185 |
+
ret: [b, h, l, d]
|
| 186 |
+
"""
|
| 187 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 188 |
+
return ret
|
| 189 |
+
|
| 190 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 191 |
+
"""
|
| 192 |
+
x: [b, h, l, d]
|
| 193 |
+
y: [h or 1, m, d]
|
| 194 |
+
ret: [b, h, l, m]
|
| 195 |
+
"""
|
| 196 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 197 |
+
return ret
|
| 198 |
+
|
| 199 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 200 |
+
max_relative_position = 2 * self.window_size + 1
|
| 201 |
+
# Pad first before slice to avoid using cond ops.
|
| 202 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 203 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 204 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 205 |
+
if pad_length > 0:
|
| 206 |
+
padded_relative_embeddings = F.pad(
|
| 207 |
+
relative_embeddings,
|
| 208 |
+
commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]))
|
| 209 |
+
else:
|
| 210 |
+
padded_relative_embeddings = relative_embeddings
|
| 211 |
+
used_relative_embeddings = padded_relative_embeddings[:,slice_start_position:slice_end_position]
|
| 212 |
+
return used_relative_embeddings
|
| 213 |
+
|
| 214 |
+
def _relative_position_to_absolute_position(self, x):
|
| 215 |
+
"""
|
| 216 |
+
x: [b, h, l, 2*l-1]
|
| 217 |
+
ret: [b, h, l, l]
|
| 218 |
+
"""
|
| 219 |
+
batch, heads, length, _ = x.size()
|
| 220 |
+
# Concat columns of pad to shift from relative to absolute indexing.
|
| 221 |
+
x = F.pad(x, commons.convert_pad_shape([[0,0],[0,0],[0,0],[0,1]]))
|
| 222 |
+
|
| 223 |
+
# Concat extra elements so to add up to shape (len+1, 2*len-1).
|
| 224 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 225 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0,0],[0,0],[0,length-1]]))
|
| 226 |
+
|
| 227 |
+
# Reshape and slice out the padded elements.
|
| 228 |
+
x_final = x_flat.view([batch, heads, length+1, 2*length-1])[:, :, :length, length-1:]
|
| 229 |
+
return x_final
|
| 230 |
+
|
| 231 |
+
def _absolute_position_to_relative_position(self, x):
|
| 232 |
+
"""
|
| 233 |
+
x: [b, h, l, l]
|
| 234 |
+
ret: [b, h, l, 2*l-1]
|
| 235 |
+
"""
|
| 236 |
+
batch, heads, length, _ = x.size()
|
| 237 |
+
# padd along column
|
| 238 |
+
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length-1]]))
|
| 239 |
+
x_flat = x.view([batch, heads, length**2 + length*(length -1)])
|
| 240 |
+
# add 0's in the beginning that will skew the elements after reshape
|
| 241 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 242 |
+
x_final = x_flat.view([batch, heads, length, 2*length])[:,:,:,1:]
|
| 243 |
+
return x_final
|
| 244 |
+
|
| 245 |
+
def _attention_bias_proximal(self, length):
|
| 246 |
+
"""Bias for self-attention to encourage attention to close positions.
|
| 247 |
+
Args:
|
| 248 |
+
length: an integer scalar.
|
| 249 |
+
Returns:
|
| 250 |
+
a Tensor with shape [1, 1, length, length]
|
| 251 |
+
"""
|
| 252 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 253 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 254 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
class FFN(nn.Module):
|
| 258 |
+
def __init__(self, in_channels, out_channels, filter_channels, kernel_size, p_dropout=0., activation=None, causal=False):
|
| 259 |
+
super().__init__()
|
| 260 |
+
self.in_channels = in_channels
|
| 261 |
+
self.out_channels = out_channels
|
| 262 |
+
self.filter_channels = filter_channels
|
| 263 |
+
self.kernel_size = kernel_size
|
| 264 |
+
self.p_dropout = p_dropout
|
| 265 |
+
self.activation = activation
|
| 266 |
+
self.causal = causal
|
| 267 |
+
|
| 268 |
+
if causal:
|
| 269 |
+
self.padding = self._causal_padding
|
| 270 |
+
else:
|
| 271 |
+
self.padding = self._same_padding
|
| 272 |
+
|
| 273 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
|
| 274 |
+
self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
|
| 275 |
+
self.drop = nn.Dropout(p_dropout)
|
| 276 |
+
|
| 277 |
+
def forward(self, x, x_mask):
|
| 278 |
+
x = self.conv_1(self.padding(x * x_mask))
|
| 279 |
+
if self.activation == "gelu":
|
| 280 |
+
x = x * torch.sigmoid(1.702 * x)
|
| 281 |
+
else:
|
| 282 |
+
x = torch.relu(x)
|
| 283 |
+
x = self.drop(x)
|
| 284 |
+
x = self.conv_2(self.padding(x * x_mask))
|
| 285 |
+
return x * x_mask
|
| 286 |
+
|
| 287 |
+
def _causal_padding(self, x):
|
| 288 |
+
if self.kernel_size == 1:
|
| 289 |
+
return x
|
| 290 |
+
pad_l = self.kernel_size - 1
|
| 291 |
+
pad_r = 0
|
| 292 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 293 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 294 |
+
return x
|
| 295 |
+
|
| 296 |
+
def _same_padding(self, x):
|
| 297 |
+
if self.kernel_size == 1:
|
| 298 |
+
return x
|
| 299 |
+
pad_l = (self.kernel_size - 1) // 2
|
| 300 |
+
pad_r = self.kernel_size // 2
|
| 301 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 302 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 303 |
+
return x
|
commons.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 9 |
+
classname = m.__class__.__name__
|
| 10 |
+
if classname.find("Conv") != -1:
|
| 11 |
+
m.weight.data.normal_(mean, std)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_padding(kernel_size, dilation=1):
|
| 15 |
+
return int((kernel_size*dilation - dilation)/2)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def convert_pad_shape(pad_shape):
|
| 19 |
+
l = pad_shape[::-1]
|
| 20 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 21 |
+
return pad_shape
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def intersperse(lst, item):
|
| 25 |
+
result = [item] * (len(lst) * 2 + 1)
|
| 26 |
+
result[1::2] = lst
|
| 27 |
+
return result
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def kl_divergence(m_p, logs_p, m_q, logs_q):
|
| 31 |
+
"""KL(P||Q)"""
|
| 32 |
+
kl = (logs_q - logs_p) - 0.5
|
| 33 |
+
kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q)
|
| 34 |
+
return kl
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def rand_gumbel(shape):
|
| 38 |
+
"""Sample from the Gumbel distribution, protect from overflows."""
|
| 39 |
+
uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
|
| 40 |
+
return -torch.log(-torch.log(uniform_samples))
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def rand_gumbel_like(x):
|
| 44 |
+
g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
|
| 45 |
+
return g
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def slice_segments(x, ids_str, segment_size=4):
|
| 49 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 50 |
+
for i in range(x.size(0)):
|
| 51 |
+
idx_str = ids_str[i]
|
| 52 |
+
idx_end = idx_str + segment_size
|
| 53 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 54 |
+
return ret
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def rand_slice_segments(x, x_lengths=None, segment_size=4):
|
| 58 |
+
b, d, t = x.size()
|
| 59 |
+
if x_lengths is None:
|
| 60 |
+
x_lengths = t
|
| 61 |
+
ids_str_max = x_lengths - segment_size + 1
|
| 62 |
+
ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
|
| 63 |
+
ret = slice_segments(x, ids_str, segment_size)
|
| 64 |
+
return ret, ids_str
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def get_timing_signal_1d(
|
| 68 |
+
length, channels, min_timescale=1.0, max_timescale=1.0e4):
|
| 69 |
+
position = torch.arange(length, dtype=torch.float)
|
| 70 |
+
num_timescales = channels // 2
|
| 71 |
+
log_timescale_increment = (
|
| 72 |
+
math.log(float(max_timescale) / float(min_timescale)) /
|
| 73 |
+
(num_timescales - 1))
|
| 74 |
+
inv_timescales = min_timescale * torch.exp(
|
| 75 |
+
torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment)
|
| 76 |
+
scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
|
| 77 |
+
signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
|
| 78 |
+
signal = F.pad(signal, [0, 0, 0, channels % 2])
|
| 79 |
+
signal = signal.view(1, channels, length)
|
| 80 |
+
return signal
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
|
| 84 |
+
b, channels, length = x.size()
|
| 85 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 86 |
+
return x + signal.to(dtype=x.dtype, device=x.device)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
|
| 90 |
+
b, channels, length = x.size()
|
| 91 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 92 |
+
return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def subsequent_mask(length):
|
| 96 |
+
mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
|
| 97 |
+
return mask
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@torch.jit.script
|
| 101 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 102 |
+
n_channels_int = n_channels[0]
|
| 103 |
+
in_act = input_a + input_b
|
| 104 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 105 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 106 |
+
acts = t_act * s_act
|
| 107 |
+
return acts
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def convert_pad_shape(pad_shape):
|
| 111 |
+
l = pad_shape[::-1]
|
| 112 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 113 |
+
return pad_shape
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def shift_1d(x):
|
| 117 |
+
x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def sequence_mask(length, max_length=None):
|
| 122 |
+
if max_length is None:
|
| 123 |
+
max_length = length.max()
|
| 124 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 125 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def generate_path(duration, mask):
|
| 129 |
+
"""
|
| 130 |
+
duration: [b, 1, t_x]
|
| 131 |
+
mask: [b, 1, t_y, t_x]
|
| 132 |
+
"""
|
| 133 |
+
device = duration.device
|
| 134 |
+
|
| 135 |
+
b, _, t_y, t_x = mask.shape
|
| 136 |
+
cum_duration = torch.cumsum(duration, -1)
|
| 137 |
+
|
| 138 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 139 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 140 |
+
path = path.view(b, t_x, t_y)
|
| 141 |
+
path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
| 142 |
+
path = path.unsqueeze(1).transpose(2,3) * mask
|
| 143 |
+
return path
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def clip_grad_value_(parameters, clip_value, norm_type=2):
|
| 147 |
+
if isinstance(parameters, torch.Tensor):
|
| 148 |
+
parameters = [parameters]
|
| 149 |
+
parameters = list(filter(lambda p: p.grad is not None, parameters))
|
| 150 |
+
norm_type = float(norm_type)
|
| 151 |
+
if clip_value is not None:
|
| 152 |
+
clip_value = float(clip_value)
|
| 153 |
+
|
| 154 |
+
total_norm = 0
|
| 155 |
+
for p in parameters:
|
| 156 |
+
param_norm = p.grad.data.norm(norm_type)
|
| 157 |
+
total_norm += param_norm.item() ** norm_type
|
| 158 |
+
if clip_value is not None:
|
| 159 |
+
p.grad.data.clamp_(min=-clip_value, max=clip_value)
|
| 160 |
+
total_norm = total_norm ** (1. / norm_type)
|
| 161 |
+
return total_norm
|
configs/vtubers.json
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 400,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 8,
|
| 11 |
+
"fp16_run": false,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/train.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/val.txt.cleaned",
|
| 22 |
+
"text_cleaners":["japanese_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 7,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
}
|
| 53 |
+
}
|
data_utils.py
ADDED
|
@@ -0,0 +1,261 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.utils.data
|
| 7 |
+
|
| 8 |
+
import commons
|
| 9 |
+
from mel_processing import spectrogram_torch
|
| 10 |
+
from utils import load_wav_to_torch, load_filepaths_and_text
|
| 11 |
+
from text import text_to_sequence, cleaned_text_to_sequence
|
| 12 |
+
|
| 13 |
+
"""Multi speaker version"""
|
| 14 |
+
class TextAudioSpeakerLoader(torch.utils.data.Dataset):
|
| 15 |
+
"""
|
| 16 |
+
1) loads audio, speaker_id, text pairs
|
| 17 |
+
2) normalizes text and converts them to sequences of integers
|
| 18 |
+
3) computes spectrograms from audio files.
|
| 19 |
+
"""
|
| 20 |
+
def __init__(self, audiopaths_sid_text, hparams):
|
| 21 |
+
self.audiopaths_sid_text = load_filepaths_and_text(audiopaths_sid_text)
|
| 22 |
+
self.text_cleaners = hparams.text_cleaners
|
| 23 |
+
self.max_wav_value = hparams.max_wav_value
|
| 24 |
+
self.sampling_rate = hparams.sampling_rate
|
| 25 |
+
self.filter_length = hparams.filter_length
|
| 26 |
+
self.hop_length = hparams.hop_length
|
| 27 |
+
self.win_length = hparams.win_length
|
| 28 |
+
self.sampling_rate = hparams.sampling_rate
|
| 29 |
+
|
| 30 |
+
self.cleaned_text = getattr(hparams, "cleaned_text", False)
|
| 31 |
+
|
| 32 |
+
self.add_blank = hparams.add_blank
|
| 33 |
+
self.min_text_len = getattr(hparams, "min_text_len", 1)
|
| 34 |
+
self.max_text_len = getattr(hparams, "max_text_len", 190)
|
| 35 |
+
|
| 36 |
+
random.seed(1234)
|
| 37 |
+
random.shuffle(self.audiopaths_sid_text)
|
| 38 |
+
self._filter()
|
| 39 |
+
|
| 40 |
+
def _filter(self):
|
| 41 |
+
"""
|
| 42 |
+
Filter text & store spec lengths
|
| 43 |
+
"""
|
| 44 |
+
# Store spectrogram lengths for Bucketing
|
| 45 |
+
# wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
|
| 46 |
+
# spec_length = wav_length // hop_length
|
| 47 |
+
|
| 48 |
+
audiopaths_sid_text_new = []
|
| 49 |
+
lengths = []
|
| 50 |
+
for audiopath, sid, text in self.audiopaths_sid_text:
|
| 51 |
+
if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
|
| 52 |
+
audiopaths_sid_text_new.append([audiopath, sid, text])
|
| 53 |
+
lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
|
| 54 |
+
self.audiopaths_sid_text = audiopaths_sid_text_new
|
| 55 |
+
self.lengths = lengths
|
| 56 |
+
|
| 57 |
+
def get_audio_text_speaker_pair(self, audiopath_sid_text):
|
| 58 |
+
# separate filename, speaker_id and text
|
| 59 |
+
audiopath, sid, text = audiopath_sid_text[0], audiopath_sid_text[1], audiopath_sid_text[2]
|
| 60 |
+
text = self.get_text(text)
|
| 61 |
+
spec, wav = self.get_audio(audiopath)
|
| 62 |
+
sid = self.get_sid(sid)
|
| 63 |
+
emo = torch.FloatTensor(np.load(audiopath+".emo.npy"))
|
| 64 |
+
return (text, spec, wav, sid, emo)
|
| 65 |
+
|
| 66 |
+
def get_audio(self, filename):
|
| 67 |
+
audio, sampling_rate = load_wav_to_torch(filename)
|
| 68 |
+
if sampling_rate != self.sampling_rate:
|
| 69 |
+
raise ValueError("{} {} SR doesn't match target {} SR".format(
|
| 70 |
+
sampling_rate, self.sampling_rate))
|
| 71 |
+
audio_norm = audio / self.max_wav_value
|
| 72 |
+
audio_norm = audio_norm.unsqueeze(0)
|
| 73 |
+
spec_filename = filename.replace(".wav", ".spec.pt")
|
| 74 |
+
if os.path.exists(spec_filename):
|
| 75 |
+
spec = torch.load(spec_filename)
|
| 76 |
+
else:
|
| 77 |
+
spec = spectrogram_torch(audio_norm, self.filter_length,
|
| 78 |
+
self.sampling_rate, self.hop_length, self.win_length,
|
| 79 |
+
center=False)
|
| 80 |
+
spec = torch.squeeze(spec, 0)
|
| 81 |
+
torch.save(spec, spec_filename)
|
| 82 |
+
return spec, audio_norm
|
| 83 |
+
|
| 84 |
+
def get_text(self, text):
|
| 85 |
+
if self.cleaned_text:
|
| 86 |
+
text_norm = cleaned_text_to_sequence(text)
|
| 87 |
+
else:
|
| 88 |
+
text_norm = text_to_sequence(text, self.text_cleaners)
|
| 89 |
+
if self.add_blank:
|
| 90 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 91 |
+
text_norm = torch.LongTensor(text_norm)
|
| 92 |
+
return text_norm
|
| 93 |
+
|
| 94 |
+
def get_sid(self, sid):
|
| 95 |
+
sid = torch.LongTensor([int(sid)])
|
| 96 |
+
return sid
|
| 97 |
+
|
| 98 |
+
def __getitem__(self, index):
|
| 99 |
+
return self.get_audio_text_speaker_pair(self.audiopaths_sid_text[index])
|
| 100 |
+
|
| 101 |
+
def __len__(self):
|
| 102 |
+
return len(self.audiopaths_sid_text)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class TextAudioSpeakerCollate():
|
| 106 |
+
""" Zero-pads model inputs and targets
|
| 107 |
+
"""
|
| 108 |
+
def __init__(self, return_ids=False):
|
| 109 |
+
self.return_ids = return_ids
|
| 110 |
+
|
| 111 |
+
def __call__(self, batch):
|
| 112 |
+
"""Collate's training batch from normalized text, audio and speaker identities
|
| 113 |
+
PARAMS
|
| 114 |
+
------
|
| 115 |
+
batch: [text_normalized, spec_normalized, wav_normalized, sid]
|
| 116 |
+
"""
|
| 117 |
+
# Right zero-pad all one-hot text sequences to max input length
|
| 118 |
+
_, ids_sorted_decreasing = torch.sort(
|
| 119 |
+
torch.LongTensor([x[1].size(1) for x in batch]),
|
| 120 |
+
dim=0, descending=True)
|
| 121 |
+
|
| 122 |
+
max_text_len = max([len(x[0]) for x in batch])
|
| 123 |
+
max_spec_len = max([x[1].size(1) for x in batch])
|
| 124 |
+
max_wav_len = max([x[2].size(1) for x in batch])
|
| 125 |
+
|
| 126 |
+
text_lengths = torch.LongTensor(len(batch))
|
| 127 |
+
spec_lengths = torch.LongTensor(len(batch))
|
| 128 |
+
wav_lengths = torch.LongTensor(len(batch))
|
| 129 |
+
sid = torch.LongTensor(len(batch))
|
| 130 |
+
|
| 131 |
+
text_padded = torch.LongTensor(len(batch), max_text_len)
|
| 132 |
+
spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
|
| 133 |
+
wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
|
| 134 |
+
emo = torch.FloatTensor(len(batch), 1024)
|
| 135 |
+
|
| 136 |
+
text_padded.zero_()
|
| 137 |
+
spec_padded.zero_()
|
| 138 |
+
wav_padded.zero_()
|
| 139 |
+
emo.zero_()
|
| 140 |
+
|
| 141 |
+
for i in range(len(ids_sorted_decreasing)):
|
| 142 |
+
row = batch[ids_sorted_decreasing[i]]
|
| 143 |
+
|
| 144 |
+
text = row[0]
|
| 145 |
+
text_padded[i, :text.size(0)] = text
|
| 146 |
+
text_lengths[i] = text.size(0)
|
| 147 |
+
|
| 148 |
+
spec = row[1]
|
| 149 |
+
spec_padded[i, :, :spec.size(1)] = spec
|
| 150 |
+
spec_lengths[i] = spec.size(1)
|
| 151 |
+
|
| 152 |
+
wav = row[2]
|
| 153 |
+
wav_padded[i, :, :wav.size(1)] = wav
|
| 154 |
+
wav_lengths[i] = wav.size(1)
|
| 155 |
+
|
| 156 |
+
sid[i] = row[3]
|
| 157 |
+
|
| 158 |
+
emo[i, :] = row[4]
|
| 159 |
+
|
| 160 |
+
if self.return_ids:
|
| 161 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid, ids_sorted_decreasing
|
| 162 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid,emo
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
class DistributedBucketSampler(torch.utils.data.distributed.DistributedSampler):
|
| 166 |
+
"""
|
| 167 |
+
Maintain similar input lengths in a batch.
|
| 168 |
+
Length groups are specified by boundaries.
|
| 169 |
+
Ex) boundaries = [b1, b2, b3] -> any batch is included either {x | b1 < length(x) <=b2} or {x | b2 < length(x) <= b3}.
|
| 170 |
+
|
| 171 |
+
It removes samples which are not included in the boundaries.
|
| 172 |
+
Ex) boundaries = [b1, b2, b3] -> any x s.t. length(x) <= b1 or length(x) > b3 are discarded.
|
| 173 |
+
"""
|
| 174 |
+
def __init__(self, dataset, batch_size, boundaries, num_replicas=None, rank=None, shuffle=True):
|
| 175 |
+
super().__init__(dataset, num_replicas=num_replicas, rank=rank, shuffle=shuffle)
|
| 176 |
+
self.lengths = dataset.lengths
|
| 177 |
+
self.batch_size = batch_size
|
| 178 |
+
self.boundaries = boundaries
|
| 179 |
+
|
| 180 |
+
self.buckets, self.num_samples_per_bucket = self._create_buckets()
|
| 181 |
+
self.total_size = sum(self.num_samples_per_bucket)
|
| 182 |
+
self.num_samples = self.total_size // self.num_replicas
|
| 183 |
+
|
| 184 |
+
def _create_buckets(self):
|
| 185 |
+
buckets = [[] for _ in range(len(self.boundaries) - 1)]
|
| 186 |
+
for i in range(len(self.lengths)):
|
| 187 |
+
length = self.lengths[i]
|
| 188 |
+
idx_bucket = self._bisect(length)
|
| 189 |
+
if idx_bucket != -1:
|
| 190 |
+
buckets[idx_bucket].append(i)
|
| 191 |
+
|
| 192 |
+
for i in range(len(buckets) - 1, 0, -1):
|
| 193 |
+
if len(buckets[i]) == 0:
|
| 194 |
+
buckets.pop(i)
|
| 195 |
+
self.boundaries.pop(i+1)
|
| 196 |
+
|
| 197 |
+
num_samples_per_bucket = []
|
| 198 |
+
for i in range(len(buckets)):
|
| 199 |
+
len_bucket = len(buckets[i])
|
| 200 |
+
total_batch_size = self.num_replicas * self.batch_size
|
| 201 |
+
rem = (total_batch_size - (len_bucket % total_batch_size)) % total_batch_size
|
| 202 |
+
num_samples_per_bucket.append(len_bucket + rem)
|
| 203 |
+
return buckets, num_samples_per_bucket
|
| 204 |
+
|
| 205 |
+
def __iter__(self):
|
| 206 |
+
# deterministically shuffle based on epoch
|
| 207 |
+
g = torch.Generator()
|
| 208 |
+
g.manual_seed(self.epoch)
|
| 209 |
+
|
| 210 |
+
indices = []
|
| 211 |
+
if self.shuffle:
|
| 212 |
+
for bucket in self.buckets:
|
| 213 |
+
indices.append(torch.randperm(len(bucket), generator=g).tolist())
|
| 214 |
+
else:
|
| 215 |
+
for bucket in self.buckets:
|
| 216 |
+
indices.append(list(range(len(bucket))))
|
| 217 |
+
|
| 218 |
+
batches = []
|
| 219 |
+
for i in range(len(self.buckets)):
|
| 220 |
+
bucket = self.buckets[i]
|
| 221 |
+
len_bucket = len(bucket)
|
| 222 |
+
ids_bucket = indices[i]
|
| 223 |
+
num_samples_bucket = self.num_samples_per_bucket[i]
|
| 224 |
+
|
| 225 |
+
# add extra samples to make it evenly divisible
|
| 226 |
+
rem = num_samples_bucket - len_bucket
|
| 227 |
+
ids_bucket = ids_bucket + ids_bucket * (rem // len_bucket) + ids_bucket[:(rem % len_bucket)]
|
| 228 |
+
|
| 229 |
+
# subsample
|
| 230 |
+
ids_bucket = ids_bucket[self.rank::self.num_replicas]
|
| 231 |
+
|
| 232 |
+
# batching
|
| 233 |
+
for j in range(len(ids_bucket) // self.batch_size):
|
| 234 |
+
batch = [bucket[idx] for idx in ids_bucket[j*self.batch_size:(j+1)*self.batch_size]]
|
| 235 |
+
batches.append(batch)
|
| 236 |
+
|
| 237 |
+
if self.shuffle:
|
| 238 |
+
batch_ids = torch.randperm(len(batches), generator=g).tolist()
|
| 239 |
+
batches = [batches[i] for i in batch_ids]
|
| 240 |
+
self.batches = batches
|
| 241 |
+
|
| 242 |
+
assert len(self.batches) * self.batch_size == self.num_samples
|
| 243 |
+
return iter(self.batches)
|
| 244 |
+
|
| 245 |
+
def _bisect(self, x, lo=0, hi=None):
|
| 246 |
+
if hi is None:
|
| 247 |
+
hi = len(self.boundaries) - 1
|
| 248 |
+
|
| 249 |
+
if hi > lo:
|
| 250 |
+
mid = (hi + lo) // 2
|
| 251 |
+
if self.boundaries[mid] < x and x <= self.boundaries[mid+1]:
|
| 252 |
+
return mid
|
| 253 |
+
elif x <= self.boundaries[mid]:
|
| 254 |
+
return self._bisect(x, lo, mid)
|
| 255 |
+
else:
|
| 256 |
+
return self._bisect(x, mid + 1, hi)
|
| 257 |
+
else:
|
| 258 |
+
return -1
|
| 259 |
+
|
| 260 |
+
def __len__(self):
|
| 261 |
+
return self.num_samples // self.batch_size
|
emotion_extract.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from transformers import Wav2Vec2Processor
|
| 4 |
+
from transformers.models.wav2vec2.modeling_wav2vec2 import (
|
| 5 |
+
Wav2Vec2Model,
|
| 6 |
+
Wav2Vec2PreTrainedModel,
|
| 7 |
+
)
|
| 8 |
+
import os
|
| 9 |
+
import librosa
|
| 10 |
+
import numpy as np
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class RegressionHead(nn.Module):
|
| 14 |
+
r"""Classification head."""
|
| 15 |
+
|
| 16 |
+
def __init__(self, config):
|
| 17 |
+
super().__init__()
|
| 18 |
+
|
| 19 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 20 |
+
self.dropout = nn.Dropout(config.final_dropout)
|
| 21 |
+
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
|
| 22 |
+
|
| 23 |
+
def forward(self, features, **kwargs):
|
| 24 |
+
x = features
|
| 25 |
+
x = self.dropout(x)
|
| 26 |
+
x = self.dense(x)
|
| 27 |
+
x = torch.tanh(x)
|
| 28 |
+
x = self.dropout(x)
|
| 29 |
+
x = self.out_proj(x)
|
| 30 |
+
|
| 31 |
+
return x
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class EmotionModel(Wav2Vec2PreTrainedModel):
|
| 35 |
+
r"""Speech emotion classifier."""
|
| 36 |
+
|
| 37 |
+
def __init__(self, config):
|
| 38 |
+
super().__init__(config)
|
| 39 |
+
|
| 40 |
+
self.config = config
|
| 41 |
+
self.wav2vec2 = Wav2Vec2Model(config)
|
| 42 |
+
self.classifier = RegressionHead(config)
|
| 43 |
+
self.init_weights()
|
| 44 |
+
|
| 45 |
+
def forward(
|
| 46 |
+
self,
|
| 47 |
+
input_values,
|
| 48 |
+
):
|
| 49 |
+
outputs = self.wav2vec2(input_values)
|
| 50 |
+
hidden_states = outputs[0]
|
| 51 |
+
hidden_states = torch.mean(hidden_states, dim=1)
|
| 52 |
+
logits = self.classifier(hidden_states)
|
| 53 |
+
|
| 54 |
+
return hidden_states, logits
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
# load model from hub
|
| 58 |
+
device = 'cuda' if torch.cuda.is_available() else "cpu"
|
| 59 |
+
model_name = 'audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim'
|
| 60 |
+
processor = Wav2Vec2Processor.from_pretrained(model_name)
|
| 61 |
+
model = EmotionModel.from_pretrained(model_name).to(device)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def process_func(
|
| 65 |
+
x: np.ndarray,
|
| 66 |
+
sampling_rate: int,
|
| 67 |
+
embeddings: bool = False,
|
| 68 |
+
) -> np.ndarray:
|
| 69 |
+
r"""Predict emotions or extract embeddings from raw audio signal."""
|
| 70 |
+
|
| 71 |
+
# run through processor to normalize signal
|
| 72 |
+
# always returns a batch, so we just get the first entry
|
| 73 |
+
# then we put it on the device
|
| 74 |
+
y = processor(x, sampling_rate=sampling_rate)
|
| 75 |
+
y = y['input_values'][0]
|
| 76 |
+
y = torch.from_numpy(y).to(device)
|
| 77 |
+
|
| 78 |
+
# run through model
|
| 79 |
+
with torch.no_grad():
|
| 80 |
+
y = model(y)[0 if embeddings else 1]
|
| 81 |
+
|
| 82 |
+
# convert to numpy
|
| 83 |
+
y = y.detach().cpu().numpy()
|
| 84 |
+
|
| 85 |
+
return y
|
| 86 |
+
#
|
| 87 |
+
#
|
| 88 |
+
# def disp(rootpath, wavname):
|
| 89 |
+
# wav, sr = librosa.load(f"{rootpath}/{wavname}", 16000)
|
| 90 |
+
# display(ipd.Audio(wav, rate=sr))
|
| 91 |
+
|
| 92 |
+
rootpath = "dataset/nene"
|
| 93 |
+
embs = []
|
| 94 |
+
wavnames = []
|
| 95 |
+
def extract_dir(path):
|
| 96 |
+
rootpath = path
|
| 97 |
+
for idx, wavname in enumerate(os.listdir(rootpath)):
|
| 98 |
+
wav, sr =librosa.load(f"{rootpath}/{wavname}", 16000)
|
| 99 |
+
emb = process_func(np.expand_dims(wav, 0), sr, embeddings=True)
|
| 100 |
+
embs.append(emb)
|
| 101 |
+
wavnames.append(wavname)
|
| 102 |
+
np.save(f"{rootpath}/{wavname}.emo.npy", emb.squeeze(0))
|
| 103 |
+
print(idx, wavname)
|
| 104 |
+
|
| 105 |
+
def extract_wav(path):
|
| 106 |
+
wav, sr = librosa.load(path, 16000)
|
| 107 |
+
emb = process_func(np.expand_dims(wav, 0), sr, embeddings=True)
|
| 108 |
+
return emb
|
| 109 |
+
|
| 110 |
+
if __name__ == '__main__':
|
| 111 |
+
for spk in ["serena", "koni", "nyaru","shanoa", "mana"]:
|
| 112 |
+
extract_dir(f"dataset/{spk}")
|
filelists/train.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
filelists/train.txt.cleaned
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
filelists/val.txt
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset/nene/nen001_001.wav|0|はい?呼びました?
|
| 2 |
+
dataset/nene/nen001_002.wav|0|驚かせたならごめんなさい。通りかかったときにちょうど名前が聞こえてきたので
|
| 3 |
+
dataset/nene/nen001_003.wav|0|私に何か用ですか?
|
| 4 |
+
dataset/nene/nen001_004.wav|0|いえ、少し気になっただけですから、別に怒っているわけじゃないです。気にしないで下さい
|
| 5 |
+
dataset/nene/nen001_005.wav|0|それより仮屋さん、例の件ですが――
|
| 6 |
+
dataset/nene/nen001_006.wav|0|喜んでもらえたならなによりです
|
| 7 |
+
dataset/nene/nen001_007.wav|0|また何かあったら、いつでも部室に来て下さい
|
| 8 |
+
dataset/nene/nen001_008.wav|0|大したことじゃないので。それより体調の方はもういいんですか?
|
| 9 |
+
dataset/nene/nen001_009.wav|0|それはよかったです。他に困ったことはありますか?
|
| 10 |
+
dataset/nene/nen001_010.wav|0|何かあったらいつでも話して下さい。学院のことじゃなく、私事に関することでも何でも
|
| 11 |
+
dataset/nene/nen001_011.wav|0|はい、いつでもどうぞ
|
| 12 |
+
dataset/nene/nen001_012.wav|0|保科君も
|
| 13 |
+
dataset/nene/nen001_013.wav|0|もし何か困ったことがあれば、力になりますから
|
| 14 |
+
dataset/nene/nen001_014.wav|0|そうですか?私には、なにか悩み事があるように見えたりしましたけど……
|
| 15 |
+
dataset/nene/nen001_015.wav|0|――なんて、言ってみただけですから、深い意味はありませんよ
|
| 16 |
+
dataset/nene/nen001_016.wav|0|いえ、そういうわけじゃなくって……ただ何となく。そんな気がしただけですから
|
| 17 |
+
dataset/nene/nen001_017.wav|0|あ、いえ、絶対に秘密というわけじゃないので気にしないで下さい
|
| 18 |
+
dataset/nene/nen001_018.wav|0|好奇心だけで来られると困るので、本当に悩んでる人以外には、広めないようにお願いしているだけです
|
| 19 |
+
dataset/nene/nen001_019.wav|0|そんな仰々しい話じゃなく……私は、オカ研に所属しているんです
|
| 20 |
+
dataset/nene/nen001_020.wav|0|はい。そのオカ研です
|
| 21 |
+
dataset/nene/nen001_021.wav|0|そうですよ。実は私たちが入学する前からあった部活なんです。今は部員がいなくて、所属してるのは私一人ですが
|
| 22 |
+
dataset/nene/nen001_022.wav|0|なので最近は、学生会の方からは結構つつかれてて……活動も、発表などを意欲的にしているわけじゃありませんからね
|
| 23 |
+
dataset/nene/nen001_023.wav|0|いえ、私は占いを。オカルトと言っても幅は広いので。それに部には私しかいませんから、結構好きにできるんです
|
| 24 |
+
dataset/nene/nen001_024.wav|0|さすがに白蛇占いはできませんよ
|
| 25 |
+
dataset/nene/nen001_025.wav|0|一応。知ってはいますけど、私にできるのはタロットぐらいです。あくまで趣味程度ですから
|
| 26 |
+
dataset/nene/nen001_026.wav|0|あくまで占いの延長線上のものですから。人生相談なんていうほど大層な物じゃありません
|
| 27 |
+
dataset/nene/nen001_027.wav|0|でも……もし保科君も嫌いでなければ、いつでも部室に来て下さい
|
| 28 |
+
dataset/nene/nen001_028.wav|0|あ、はい。すぐに行きます
|
| 29 |
+
dataset/nene/nen001_029.wav|0|それじゃあ私はこれで
|
| 30 |
+
dataset/nene/nen001_030.wav|0|あの、先生
|
| 31 |
+
dataset/nene/nen001_031.wav|0|はい。気付いたらこんな時間になってしまって
|
| 32 |
+
dataset/nene/nen001_032.wav|0|図書室は……もう誰もいないんですか?
|
| 33 |
+
dataset/nene/nen001_033.wav|0|その前にちょっと調べ物をさせて欲しいんですが、鍵を貸してもらえませんか?
|
| 34 |
+
dataset/nene/nen001_034.wav|0|タロットカードのことで少々。時間はかかりません。5分……は無理かも……でも20分もあれば終わりますから……お願いします
|
| 35 |
+
dataset/nene/nen001_035.wav|0|わかりました。ありがとう……ございます
|
| 36 |
+
dataset/nene/nen001_036.wav|0|は、はい………気をつけます……ハァ、ハァ……
|
| 37 |
+
dataset/nene/nen001_037.wav|0|……ハァ……ハァ……
|
| 38 |
+
dataset/nene/nen001_038.wav|0|……大丈夫、ですよね……んっ……
|
| 39 |
+
dataset/nene/nen001_039.wav|0|……ハァ……ハァ……
|
| 40 |
+
dataset/nene/nen001_040.wav|0|んっ、んん……
|
| 41 |
+
dataset/nene/nen001_041.wav|0|あ……あっ、んっ……んんン、んッ、んッ、んぅぅッ……
|
| 42 |
+
dataset/nene/nen001_042.wav|0|んっ、ふぅぅ……はぁ、はぁ、あっ、ああぁぁ……ふぁぁぁ……
|
| 43 |
+
dataset/nene/nen001_043.wav|0|はぁ、はぁぁ……ん、ん、んっ……はぁぁ……ぁ、ぁ、ぁ……ぁぁ……ンッ……!
|
| 44 |
+
dataset/nene/nen001_044.wav|0|あぁ、もう……こ、んなの、最低ですッ……はぁ、はぁ……学院内で、おっ、オナニー……をするなんてっ、ん、んんっ
|
| 45 |
+
dataset/nene/nen001_045.wav|0|あっ、ああぁぁ……はぁ、はぁ、はぁぁぁ……ん、んンッッ
|
| 46 |
+
dataset/nene/nen001_046.wav|0|はぁ、はぁ……私、��んてこと……あっ、あぁぁ……でも、気持ちよくて止まりません……ん、んんッ、ふぁ、あ、あぁぁぁ……
|
| 47 |
+
dataset/nene/nen001_047.wav|0|うっ……あ、あ、あっ、あっ、ひあっ、ん、んはっ……はっ、はっ、んんぅぅッ
|
| 48 |
+
dataset/nene/nen001_048.wav|0|はぁ……はぁ……んっ、んんん……んぁ、んぁ、あっ……んっ、ぃぃぃッ
|
| 49 |
+
dataset/nene/nen001_049.wav|0|んっ、んっ、んくっ……ひっ、あっ、ぁっ、ぁっ、んんーーッ……
|
| 50 |
+
dataset/nene/nen001_050.wav|0|はぁぁぁ……はぁ、はぁ……んんっ、んっ、んんん、んぁ……んぁ、ぁ、ぁ、ぁぁぁぁ……ッ!
|
| 51 |
+
dataset/nene/nen001_051.wav|0|だめ、早く、しないと……先生が、戻って、きます……こんなところ、見られたら……んっ、んっ、んぁ、んぁ、あ、あ、あ、あ、あ……
|
| 52 |
+
dataset/nene/nen001_052.wav|0|あ、あ、ん、んんんッ……はっ、はぁ、はぁ、あぁぁもう、本当に、最低ですっ……
|
| 53 |
+
dataset/nene/nen001_053.wav|0|んッ……んはぁッ、はぁ、はぁ……ンン、んぁ、んぁぁ……あ、あ、あぁぁ……
|
| 54 |
+
dataset/nene/nen001_054.wav|0|はぁー、はぁーーぁぁ、気持ちいい……あっ、あぃ、あぃっ、いい……本当に……んん
|
| 55 |
+
dataset/nene/nen001_055.wav|0|早く……こんなこと、早く……先生が、また様子を……見に、きたりしない、内に……はぁ、はぁ、はぁ、はぁ
|
| 56 |
+
dataset/nene/nen001_056.wav|0|はぁ、はぁ、はぁっ、はぁぁぁ……ぁ、ぁ、ぁ……ぁぁ……ぁぁんッ、んっ、んーッ
|
| 57 |
+
dataset/nene/nen001_057.wav|0|んんッ、ん、んはぁぁぁーー……はぁ、はぁ、はぁァン、あッ、あん、あぁぁンッ
|
| 58 |
+
dataset/nene/nen001_058.wav|0|はぁ、はぁ、はぁぁ……ヨダレ、でちゃう……じゅる……んぁっ、はぁ、はぁぁ……はっ、はっ、はっ……じゅる
|
| 59 |
+
dataset/nene/nen001_059.wav|0|こんな、に、気持ちいいなんて、最低です……本当、図書室でオナニーなんて、最低すぎます……でも、でも
|
| 60 |
+
dataset/nene/nen001_060.wav|0|あああぁぁ……今は、止められなくて……じゅる……はぁ、はぁぁ……あぁぁぁあぁ……
|
| 61 |
+
dataset/nene/nen001_061.wav|0|はぁ、はぁ、はぁ……早く……あっ、あっ、あぁぁ……ぁぁぁ、早く、早く
|
| 62 |
+
dataset/nene/nen001_062.wav|0|早く、イきたい、イきたい……このままイきたいぃ……はぁ、はぁ、はぁ、ぁぁ、ぁっ、ぁっ、あっ、あっ、あぁッ!
|
| 63 |
+
dataset/nene/nen001_063.wav|0|あっ、あっ、ああぁぁ……痺れて、きたぁ……だめ、イきそう……んっ、だめじゃなくて、あっ、あっ、早く、このまま……早く早く早く
|
filelists/val.txt.cleaned
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset/nene/nen001_001.wav|0|ha↓i? yo↑bima↓ʃIta?
|
| 2 |
+
dataset/nene/nen001_002.wav|0|o↑doro↓kasetanara go↑meNnasa↓i. to↑orikaka↓Qta to↓kini ʧo↑odo na↑maega kI↑koete ki↓tanode.
|
| 3 |
+
dataset/nene/nen001_003.wav|0|wa↑taʃini na↑nika↓yoodesUka?
|
| 4 |
+
dataset/nene/nen001_004.wav|0|i↓e, sU↑ko↓ʃI ki↑ni na↓QtadakedesUkara, be↑tsuni o↑ko↓Qte i↑ru wa↓kejanaidesU. ki↑ni ʃi↑na↓ide ku↑dasa↓i.
|
| 5 |
+
dataset/nene/nen001_005.wav|0|so↑reyo↓ri ka↑riyasaN, re↓eno ke↓NdesUga----
|
| 6 |
+
dataset/nene/nen001_006.wav|0|yo↑roko↓Nde mo↑raeta↓nara na↓niyoridesU.
|
| 7 |
+
dataset/nene/nen001_007.wav|0|ma↑ta na↓nika a↓Qtara, i↓tsudemo bu↑ʃItsuni ki↓te ku↑dasa↓i.
|
| 8 |
+
dataset/nene/nen001_008.wav|0|ta↓iʃIta ko↑to↓janainode. so↑reyo↓ri ta↑iʧoono ho↓owa mo↓o i↓i N↓desUka?
|
| 9 |
+
dataset/nene/nen001_009.wav|0|so↑rewa yo↓kaQtadesU. ta↓ni ko↑ma↓Qta ko↑to↓wa a↑rima↓sUka?
|
| 10 |
+
dataset/nene/nen001_010.wav|0|na↓nika a↓Qtara i↓tsudemo ha↑na↓ʃIte ku↑dasa↓i. ga↑kuiNno ko↑to↓janaku, ʃi↓jini ka↑Nsu↓ru ko↑to↓demo na↓nidemo.
|
| 11 |
+
dataset/nene/nen001_011.wav|0|ha↓i, i↓tsudemo do↓ozo.
|
| 12 |
+
dataset/nene/nen001_012.wav|0|ho↓ʃinakuNmo.
|
| 13 |
+
dataset/nene/nen001_013.wav|0|mo↓ʃi na↓nika ko↑ma↓Qta ko↑to↓ga a↑re↓ba, ʧI↑kara↓ni na↑rima↓sUkara.
|
| 14 |
+
dataset/nene/nen001_014.wav|0|so↑odesU↓ka? wa↑taʃiniwa, na↓nika na↑yami↓gotoga a↓ru yo↓oni mi↑eta↓ri ʃi↑ma↓ʃItakedo......
|
| 15 |
+
dataset/nene/nen001_015.wav|0|---- na↓Nte, i↑Qte mi↓tadakedesUkara, fU↑ka↓i i↑miwaarimase↓Nyo.
|
| 16 |
+
dataset/nene/nen001_016.wav|0|i↓e, so↑oyuu wa↓kejanakuQte...... ta↓da na↑Ntona↓ku. so↑Nna ki↑ga ʃI↑ta↓dakedesUkara.
|
| 17 |
+
dataset/nene/nen001_017.wav|0|a, i↓e, ze↑Qtaini hi↑mitsUto i↑u wa↓kejanainode ki↑ni ʃi↑na↓ide ku↑dasa↓i.
|
| 18 |
+
dataset/nene/nen001_018.wav|0|ko↑okIʃiNdakede ko↑rare↓ruto ko↑ma↓runode, ho↑Ntooni na↑ya↓Nde ru↑niNi↓gainiwa, hi↑romenai yo↓oni o↑negai ʃI↑te i↑rudakedesU.
|
| 19 |
+
dataset/nene/nen001_019.wav|0|so↑Nna gyo↑ogyooʃi↓i ha↑naʃi↓janaku...... wa↑taʃiwa, o↑kakeNni ʃo↑zoku ʃI↑te i↑ru N↓desU.
|
| 20 |
+
dataset/nene/nen001_020.wav|0|ha↓i. so↑no o↑kakeNde↓sU.
|
| 21 |
+
dataset/nene/nen001_021.wav|0|so↑odesUyo. ji↑tsu↓wa wa↑taʃi↓taʧiga nyu↑ugakU su↑ru ma↓ekara a↓Qta bu↑katsuna N↓desU. i↓mawa bu↑iNga i↑nakUte, ʃo↑zoku ʃI↑te↓ru no↑wa wa↑taʃI hi↑to↓ridesUga.
|
| 22 |
+
dataset/nene/nen001_022.wav|0|na↑node sa↑ikiNwa, ga↑kUsee↓kaino ho↓okarawa ke↓Qkoo tsU↑tsu↓karetete...... ka↑tsudoomo, ha↑Qpyoona↓doo i↑yoku↓tekini ʃI↑te i↑ru wa↑kejaarimase↓Nkarane.
|
| 23 |
+
dataset/nene/nen001_023.wav|0|i↓e, wa↑taʃiwa u↑ranaio. o↑karutoto i↑Qtemo ha↑bawa hi↑ro↓inode. so↑reni bu↓niwa wa↑taʃIʃi↓ka i↑mase↓Nkara, ke↓Qkoo sU↑ki↓ni de↑ki↓ru N↓desU.
|
| 24 |
+
dataset/nene/nen001_024.wav|0|sa↑sugani ʃi↑rohebiu↓ranaiwa de↑kimase↓Nyo.
|
| 25 |
+
dataset/nene/nen001_025.wav|0|i↑ʧioo. ʃi↑Qte ha↑ima↓sUkedo, wa↑taʃini de↑ki↓ru no↑wa ta↑roQtogu↓raidesU. a↑ku↓made ʃu↑mite↓edodesUkara.
|
| 26 |
+
dataset/nene/nen001_026.wav|0|a↑ku↓made u↑ranaino e↑NʧooseNjoono mo↑no↓desUkara. ji↑Nseeso↓odaNnaNte i↑uhodo ta↓isoona mo↑nojaarimase↓N.
|
| 27 |
+
dataset/nene/nen001_027.wav|0|de↓mo...... mo↓ʃI ho↓ʃinakuNmo ki↑raidenakere↓ba, i↓tsudemo bu↑ʃItsuni ki↓te ku↑dasa↓i.
|
| 28 |
+
dataset/nene/nen001_028.wav|0|a, ha↓i. su↓guni i↑kima↓sU.
|
| 29 |
+
dataset/nene/nen001_029.wav|0|so↑reja↓a wa↑taʃiwa ko↑rede.
|
| 30 |
+
dataset/nene/nen001_030.wav|0|a↑no, se↑Nse↓e.
|
| 31 |
+
dataset/nene/nen001_031.wav|0|ha↓i. ki↑zu↓itara ko↑Nna ji↑kaNni na↓Qte ʃi↑ma↓Qte.
|
| 32 |
+
dataset/nene/nen001_032.wav|0|to↑ʃo↓ʃItsuwa...... mo↓o da↓remo i↑nai N↓desUka?
|
| 33 |
+
dataset/nene/nen001_033.wav|0|so↑no ma↓eni ʧo↓Qto ʃi↑rabebutsuo sa↑setehoʃii N↓desUga, ka↑gi↓o ka↑ʃIte mo↑raemase↓Nka?
|
| 34 |
+
dataset/nene/nen001_034.wav|0|ta↑roQtoka↓adono ko↑to↓de ʃo↓oʃoo. ji↑kaNwa ka↑karimase↓N. go↓fuN...... w a mu↓rikamo...... de↓mo ni↑juQ↓puNmo a↑re↓ba o↑warima↓sUkara...... o↑negai ʃi↑ma↓sU.
|
| 35 |
+
dataset/nene/nen001_035.wav|0|wa↑karima↓ʃIta. a↑ri↓gatoo...... go↑zaima↓sU.
|
| 36 |
+
dataset/nene/nen001_036.wav|0|w a, ha↓i......... ki↑o tsU↑kema↓sU...... ha↓a, ha↓a......
|
| 37 |
+
dataset/nene/nen001_037.wav|0|...... ha↓a...... ha↓a......
|
| 38 |
+
dataset/nene/nen001_038.wav|0|...... da↑ijo↓obu, de↓sUyone...... N↓Q......
|
| 39 |
+
dataset/nene/nen001_039.wav|0|...... ha↓a...... ha↓a......
|
| 40 |
+
dataset/nene/nen001_040.wav|0|N↓Q, N↓N......
|
| 41 |
+
dataset/nene/nen001_041.wav|0|a...... a↓Q, N↓Q...... N↓N N, N↓Q, N↓Q, N↓uuQ......
|
| 42 |
+
dataset/nene/nen001_042.wav|0|N↓Q, fu↓uu...... ha↓a, ha↓a, a↓Q, a↓aaa...... fa↓aa......
|
| 43 |
+
dataset/nene/nen001_043.wav|0|ha↓a, ha↓aa...... N, N, N↓Q...... ha↓aa...... a, a, a...... a↓a...... N↓Q......!
|
| 44 |
+
dataset/nene/nen001_044.wav|0|a↓a, mo↓o...... k o, N↑na n o, sa↑iteede su↓Q...... ha↓a, ha↓a...... ga↑kuiN↓naide, o↑Q, o↓nanii...... o su↑ru↓naNteQ, N, N↓NQ.
|
| 45 |
+
dataset/nene/nen001_045.wav|0|a↓Q, a↓aaa...... ha↓a, ha↓a, ha↓aaa...... N, N↓NQQ.
|
| 46 |
+
dataset/nene/nen001_046.wav|0|ha↓a, ha↓a...... wa↑taʃi, na↓Nte ko↑to...... a↓Q, a↓aa...... de↓mo, ki↑moʧiyo↓kUte to↑marimase↓N...... N, N↓NQ, f a, a, a↓aaa......
|
| 47 |
+
dataset/nene/nen001_047.wav|0|u↓Q...... a, a, a↓Q, a↓Q, hi↓aQ, N, N↓haQ...... ha↓Q, ha↓Q, N↓NuuQ.
|
| 48 |
+
dataset/nene/nen001_048.wav|0|ha↓a...... ha↓a...... N↓Q, N↓NN...... N↓a, N↓a, a↓Q...... N↓Q, i↓iiQ.
|
| 49 |
+
dataset/nene/nen001_049.wav|0|N↓Q, N↓Q, N ku↓Q...... hi↓Q, a↓Q, a↓Q, a↓Q, N↓NNNQ......
|
| 50 |
+
dataset/nene/nen001_050.wav|0|ha↓aaa...... ha↓a, ha↓a...... N↓NQ, N↓Q, N↓NN, N↓a...... N↓a, a, a, a↓aaa...... Q!
|
| 51 |
+
dataset/nene/nen001_051.wav|0|da↑me, ha↓yaku, ʃi↑naito...... se↑Nse↓ega, mo↑do↓Qte, ki↑ma↓sU...... ko↑Nna to↑koro, mi↓raretara...... N↓Q, N↓Q, N↓a, N↓a, a, a, a, a, a......
|
| 52 |
+
dataset/nene/nen001_052.wav|0|a, a, N, N↓NN Q...... ha↓Q, ha↓a, ha↓a, a↓aa mo↓o, ho↑Ntooni, sa↑iteede su↓Q......
|
| 53 |
+
dataset/nene/nen001_053.wav|0|N↓Q...... N↓haaQ, ha↓a, ha↓a...... N↓N, N↓a, N↓aa...... a, a, a↓aa......
|
| 54 |
+
dataset/nene/nen001_054.wav|0|ha↓aa, ha↓aaaaa, ki↑moʧii↓i...... a↓Q, a↓i, a↓iQ, i↓i...... ho↑Ntooni...... N↓N.
|
| 55 |
+
dataset/nene/nen001_055.wav|0|ha↓yaku...... ko↑Nna ko↑to, ha↓yaku...... se↑Nse↓ega, ma↑ta yo↑osuo...... mi↑ni, kI↑tariʃi↓nai, u↑ʧini...... ha↓a, ha↓a, ha↓a, ha↓a.
|
| 56 |
+
dataset/nene/nen001_056.wav|0|ha↓a, ha↓a, ha↓aQ, ha↓aaa...... a, a, a...... a↓a...... a↓aNQ, N↓Q, N↓NQ.
|
| 57 |
+
dataset/nene/nen001_057.wav|0|N↓NQ, N, N↓haaaaaa...... ha↓a, ha↓a, ha↓aaN, a↓Q, a↑N, a↓aaNQ.
|
| 58 |
+
dataset/nene/nen001_058.wav|0|ha↓a, ha↓a, ha↓aa...... yo↑dare, de↑ʧau...... ju↑ru...... N↓aQ, ha↓a, ha↓aa...... ha↓Q, ha↓Q, ha↓Q...... ju↑ru.
|
| 59 |
+
dataset/nene/nen001_059.wav|0|ko↑Nna, n i, ki↑moʧii↓inaNte, sa↑iteede↓sU...... ho↑Ntoo, to↑ʃo↓ʃItsude o↓naniinaNte, sa↑itee su↑gima↓sU...... de↓mo, de↓mo.
|
| 60 |
+
dataset/nene/nen001_060.wav|0|a↑a↓aaa...... i↓mawa, to↑merarenakUte...... ju↑ru...... ha↓a, ha↓aa...... a↑aaa↓aa......
|
| 61 |
+
dataset/nene/nen001_061.wav|0|ha↓a, ha↓a, ha↓a...... ha↓yaku...... a↓Q, a↓Q, a↓aa...... a↓aa, ha↓yaku, ha↓yaku.
|
| 62 |
+
dataset/nene/nen001_062.wav|0|ha↓yaku, i↑ki↓tai, i↑ki↓tai...... ko↑no ma↑maiki↓taii...... ha↓a, ha↓a, ha↓a, a↓a, a↓Q, a↓Q, a↓Q, a↓Q, a↓aQ!
|
| 63 |
+
dataset/nene/nen001_063.wav|0|a↓Q, a↓Q, a↓aaa...... ʃi↑bire↓te, ki↓ta a...... da↑me, i↓kIsou...... N↓Q, da↑me↓janakUte, a↓Q, a↓Q, ha↓yaku, ko↑no ma↑ma...... ha↓yakUhayakUhayaku.
|
losses.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
import commons
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def feature_loss(fmap_r, fmap_g):
|
| 8 |
+
loss = 0
|
| 9 |
+
for dr, dg in zip(fmap_r, fmap_g):
|
| 10 |
+
for rl, gl in zip(dr, dg):
|
| 11 |
+
rl = rl.float().detach()
|
| 12 |
+
gl = gl.float()
|
| 13 |
+
loss += torch.mean(torch.abs(rl - gl))
|
| 14 |
+
|
| 15 |
+
return loss * 2
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def discriminator_loss(disc_real_outputs, disc_generated_outputs):
|
| 19 |
+
loss = 0
|
| 20 |
+
r_losses = []
|
| 21 |
+
g_losses = []
|
| 22 |
+
for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
|
| 23 |
+
dr = dr.float()
|
| 24 |
+
dg = dg.float()
|
| 25 |
+
r_loss = torch.mean((1-dr)**2)
|
| 26 |
+
g_loss = torch.mean(dg**2)
|
| 27 |
+
loss += (r_loss + g_loss)
|
| 28 |
+
r_losses.append(r_loss.item())
|
| 29 |
+
g_losses.append(g_loss.item())
|
| 30 |
+
|
| 31 |
+
return loss, r_losses, g_losses
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def generator_loss(disc_outputs):
|
| 35 |
+
loss = 0
|
| 36 |
+
gen_losses = []
|
| 37 |
+
for dg in disc_outputs:
|
| 38 |
+
dg = dg.float()
|
| 39 |
+
l = torch.mean((1-dg)**2)
|
| 40 |
+
gen_losses.append(l)
|
| 41 |
+
loss += l
|
| 42 |
+
|
| 43 |
+
return loss, gen_losses
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
|
| 47 |
+
"""
|
| 48 |
+
z_p, logs_q: [b, h, t_t]
|
| 49 |
+
m_p, logs_p: [b, h, t_t]
|
| 50 |
+
"""
|
| 51 |
+
z_p = z_p.float()
|
| 52 |
+
logs_q = logs_q.float()
|
| 53 |
+
m_p = m_p.float()
|
| 54 |
+
logs_p = logs_p.float()
|
| 55 |
+
z_mask = z_mask.float()
|
| 56 |
+
|
| 57 |
+
kl = logs_p - logs_q - 0.5
|
| 58 |
+
kl += 0.5 * ((z_p - m_p)**2) * torch.exp(-2. * logs_p)
|
| 59 |
+
kl = torch.sum(kl * z_mask)
|
| 60 |
+
l = kl / torch.sum(z_mask)
|
| 61 |
+
return l
|
mel_processing.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import torch.utils.data
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
import logging
|
| 11 |
+
|
| 12 |
+
numba_logger = logging.getLogger('numba')
|
| 13 |
+
numba_logger.setLevel(logging.WARNING)
|
| 14 |
+
import warnings
|
| 15 |
+
warnings.filterwarnings('ignore')
|
| 16 |
+
import librosa
|
| 17 |
+
import librosa.util as librosa_util
|
| 18 |
+
from librosa.util import normalize, pad_center, tiny
|
| 19 |
+
from scipy.signal import get_window
|
| 20 |
+
from scipy.io.wavfile import read
|
| 21 |
+
from librosa.filters import mel as librosa_mel_fn
|
| 22 |
+
|
| 23 |
+
MAX_WAV_VALUE = 32768.0
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
|
| 27 |
+
"""
|
| 28 |
+
PARAMS
|
| 29 |
+
------
|
| 30 |
+
C: compression factor
|
| 31 |
+
"""
|
| 32 |
+
return torch.log(torch.clamp(x, min=clip_val) * C)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def dynamic_range_decompression_torch(x, C=1):
|
| 36 |
+
"""
|
| 37 |
+
PARAMS
|
| 38 |
+
------
|
| 39 |
+
C: compression factor used to compress
|
| 40 |
+
"""
|
| 41 |
+
return torch.exp(x) / C
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def spectral_normalize_torch(magnitudes):
|
| 45 |
+
output = dynamic_range_compression_torch(magnitudes)
|
| 46 |
+
return output
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def spectral_de_normalize_torch(magnitudes):
|
| 50 |
+
output = dynamic_range_decompression_torch(magnitudes)
|
| 51 |
+
return output
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
mel_basis = {}
|
| 55 |
+
hann_window = {}
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
| 59 |
+
if torch.min(y) < -1.:
|
| 60 |
+
print('min value is ', torch.min(y))
|
| 61 |
+
if torch.max(y) > 1.:
|
| 62 |
+
print('max value is ', torch.max(y))
|
| 63 |
+
|
| 64 |
+
global hann_window
|
| 65 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 66 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 67 |
+
if wnsize_dtype_device not in hann_window:
|
| 68 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 69 |
+
|
| 70 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 71 |
+
y = y.squeeze(1)
|
| 72 |
+
|
| 73 |
+
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 74 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True)
|
| 75 |
+
|
| 76 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 77 |
+
return spec
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
|
| 81 |
+
global mel_basis
|
| 82 |
+
dtype_device = str(spec.dtype) + '_' + str(spec.device)
|
| 83 |
+
fmax_dtype_device = str(fmax) + '_' + dtype_device
|
| 84 |
+
if fmax_dtype_device not in mel_basis:
|
| 85 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 86 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device)
|
| 87 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 88 |
+
spec = spectral_normalize_torch(spec)
|
| 89 |
+
return spec
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False):
|
| 93 |
+
if torch.min(y) < -1.:
|
| 94 |
+
print('min value is ', torch.min(y))
|
| 95 |
+
if torch.max(y) > 1.:
|
| 96 |
+
print('max value is ', torch.max(y))
|
| 97 |
+
|
| 98 |
+
global mel_basis, hann_window
|
| 99 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 100 |
+
fmax_dtype_device = str(fmax) + '_' + dtype_device
|
| 101 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 102 |
+
if fmax_dtype_device not in mel_basis:
|
| 103 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 104 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device)
|
| 105 |
+
if wnsize_dtype_device not in hann_window:
|
| 106 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 107 |
+
|
| 108 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 109 |
+
y = y.squeeze(1)
|
| 110 |
+
|
| 111 |
+
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 112 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True)
|
| 113 |
+
|
| 114 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 115 |
+
|
| 116 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 117 |
+
spec = spectral_normalize_torch(spec)
|
| 118 |
+
|
| 119 |
+
return spec
|
models.py
ADDED
|
@@ -0,0 +1,537 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
import commons
|
| 8 |
+
import modules
|
| 9 |
+
import attentions
|
| 10 |
+
# import monotonic_align
|
| 11 |
+
|
| 12 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 13 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 14 |
+
from commons import init_weights, get_padding
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class StochasticDurationPredictor(nn.Module):
|
| 18 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0):
|
| 19 |
+
super().__init__()
|
| 20 |
+
filter_channels = in_channels # it needs to be removed from future version.
|
| 21 |
+
self.in_channels = in_channels
|
| 22 |
+
self.filter_channels = filter_channels
|
| 23 |
+
self.kernel_size = kernel_size
|
| 24 |
+
self.p_dropout = p_dropout
|
| 25 |
+
self.n_flows = n_flows
|
| 26 |
+
self.gin_channels = gin_channels
|
| 27 |
+
|
| 28 |
+
self.log_flow = modules.Log()
|
| 29 |
+
self.flows = nn.ModuleList()
|
| 30 |
+
self.flows.append(modules.ElementwiseAffine(2))
|
| 31 |
+
for i in range(n_flows):
|
| 32 |
+
self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 33 |
+
self.flows.append(modules.Flip())
|
| 34 |
+
|
| 35 |
+
self.post_pre = nn.Conv1d(1, filter_channels, 1)
|
| 36 |
+
self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 37 |
+
self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 38 |
+
self.post_flows = nn.ModuleList()
|
| 39 |
+
self.post_flows.append(modules.ElementwiseAffine(2))
|
| 40 |
+
for i in range(4):
|
| 41 |
+
self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 42 |
+
self.post_flows.append(modules.Flip())
|
| 43 |
+
|
| 44 |
+
self.pre = nn.Conv1d(in_channels, filter_channels, 1)
|
| 45 |
+
self.proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 46 |
+
self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 47 |
+
if gin_channels != 0:
|
| 48 |
+
self.cond = nn.Conv1d(gin_channels, filter_channels, 1)
|
| 49 |
+
|
| 50 |
+
def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
|
| 51 |
+
x = torch.detach(x)
|
| 52 |
+
x = self.pre(x)
|
| 53 |
+
if g is not None:
|
| 54 |
+
g = torch.detach(g)
|
| 55 |
+
x = x + self.cond(g)
|
| 56 |
+
x = self.convs(x, x_mask)
|
| 57 |
+
x = self.proj(x) * x_mask
|
| 58 |
+
|
| 59 |
+
if not reverse:
|
| 60 |
+
flows = self.flows
|
| 61 |
+
assert w is not None
|
| 62 |
+
|
| 63 |
+
logdet_tot_q = 0
|
| 64 |
+
h_w = self.post_pre(w)
|
| 65 |
+
h_w = self.post_convs(h_w, x_mask)
|
| 66 |
+
h_w = self.post_proj(h_w) * x_mask
|
| 67 |
+
e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask
|
| 68 |
+
z_q = e_q
|
| 69 |
+
for flow in self.post_flows:
|
| 70 |
+
z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w))
|
| 71 |
+
logdet_tot_q += logdet_q
|
| 72 |
+
z_u, z1 = torch.split(z_q, [1, 1], 1)
|
| 73 |
+
u = torch.sigmoid(z_u) * x_mask
|
| 74 |
+
z0 = (w - u) * x_mask
|
| 75 |
+
logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1,2])
|
| 76 |
+
logq = torch.sum(-0.5 * (math.log(2*math.pi) + (e_q**2)) * x_mask, [1,2]) - logdet_tot_q
|
| 77 |
+
|
| 78 |
+
logdet_tot = 0
|
| 79 |
+
z0, logdet = self.log_flow(z0, x_mask)
|
| 80 |
+
logdet_tot += logdet
|
| 81 |
+
z = torch.cat([z0, z1], 1)
|
| 82 |
+
for flow in flows:
|
| 83 |
+
z, logdet = flow(z, x_mask, g=x, reverse=reverse)
|
| 84 |
+
logdet_tot = logdet_tot + logdet
|
| 85 |
+
nll = torch.sum(0.5 * (math.log(2*math.pi) + (z**2)) * x_mask, [1,2]) - logdet_tot
|
| 86 |
+
return nll + logq # [b]
|
| 87 |
+
else:
|
| 88 |
+
flows = list(reversed(self.flows))
|
| 89 |
+
flows = flows[:-2] + [flows[-1]] # remove a useless vflow
|
| 90 |
+
z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale
|
| 91 |
+
for flow in flows:
|
| 92 |
+
z = flow(z, x_mask, g=x, reverse=reverse)
|
| 93 |
+
z0, z1 = torch.split(z, [1, 1], 1)
|
| 94 |
+
logw = z0
|
| 95 |
+
return logw
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class DurationPredictor(nn.Module):
|
| 99 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, gin_channels=0):
|
| 100 |
+
super().__init__()
|
| 101 |
+
|
| 102 |
+
self.in_channels = in_channels
|
| 103 |
+
self.filter_channels = filter_channels
|
| 104 |
+
self.kernel_size = kernel_size
|
| 105 |
+
self.p_dropout = p_dropout
|
| 106 |
+
self.gin_channels = gin_channels
|
| 107 |
+
|
| 108 |
+
self.drop = nn.Dropout(p_dropout)
|
| 109 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size//2)
|
| 110 |
+
self.norm_1 = modules.LayerNorm(filter_channels)
|
| 111 |
+
self.conv_2 = nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size//2)
|
| 112 |
+
self.norm_2 = modules.LayerNorm(filter_channels)
|
| 113 |
+
self.proj = nn.Conv1d(filter_channels, 1, 1)
|
| 114 |
+
|
| 115 |
+
if gin_channels != 0:
|
| 116 |
+
self.cond = nn.Conv1d(gin_channels, in_channels, 1)
|
| 117 |
+
|
| 118 |
+
def forward(self, x, x_mask, g=None):
|
| 119 |
+
x = torch.detach(x)
|
| 120 |
+
if g is not None:
|
| 121 |
+
g = torch.detach(g)
|
| 122 |
+
x = x + self.cond(g)
|
| 123 |
+
x = self.conv_1(x * x_mask)
|
| 124 |
+
x = torch.relu(x)
|
| 125 |
+
x = self.norm_1(x)
|
| 126 |
+
x = self.drop(x)
|
| 127 |
+
x = self.conv_2(x * x_mask)
|
| 128 |
+
x = torch.relu(x)
|
| 129 |
+
x = self.norm_2(x)
|
| 130 |
+
x = self.drop(x)
|
| 131 |
+
x = self.proj(x * x_mask)
|
| 132 |
+
return x * x_mask
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class TextEncoder(nn.Module):
|
| 136 |
+
def __init__(self,
|
| 137 |
+
n_vocab,
|
| 138 |
+
out_channels,
|
| 139 |
+
hidden_channels,
|
| 140 |
+
filter_channels,
|
| 141 |
+
n_heads,
|
| 142 |
+
n_layers,
|
| 143 |
+
kernel_size,
|
| 144 |
+
p_dropout):
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.n_vocab = n_vocab
|
| 147 |
+
self.out_channels = out_channels
|
| 148 |
+
self.hidden_channels = hidden_channels
|
| 149 |
+
self.filter_channels = filter_channels
|
| 150 |
+
self.n_heads = n_heads
|
| 151 |
+
self.n_layers = n_layers
|
| 152 |
+
self.kernel_size = kernel_size
|
| 153 |
+
self.p_dropout = p_dropout
|
| 154 |
+
|
| 155 |
+
self.emb = nn.Embedding(n_vocab, hidden_channels)
|
| 156 |
+
self.emo_proj = nn.Linear(1024, hidden_channels)
|
| 157 |
+
|
| 158 |
+
nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5)
|
| 159 |
+
|
| 160 |
+
self.encoder = attentions.Encoder(
|
| 161 |
+
hidden_channels,
|
| 162 |
+
filter_channels,
|
| 163 |
+
n_heads,
|
| 164 |
+
n_layers,
|
| 165 |
+
kernel_size,
|
| 166 |
+
p_dropout)
|
| 167 |
+
self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 168 |
+
|
| 169 |
+
def forward(self, x, x_lengths, emo):
|
| 170 |
+
x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 171 |
+
x = x + self.emo_proj(emo.unsqueeze(1))
|
| 172 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 173 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 174 |
+
|
| 175 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 176 |
+
stats = self.proj(x) * x_mask
|
| 177 |
+
|
| 178 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 179 |
+
return x, m, logs, x_mask
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
class ResidualCouplingBlock(nn.Module):
|
| 183 |
+
def __init__(self,
|
| 184 |
+
channels,
|
| 185 |
+
hidden_channels,
|
| 186 |
+
kernel_size,
|
| 187 |
+
dilation_rate,
|
| 188 |
+
n_layers,
|
| 189 |
+
n_flows=4,
|
| 190 |
+
gin_channels=0):
|
| 191 |
+
super().__init__()
|
| 192 |
+
self.channels = channels
|
| 193 |
+
self.hidden_channels = hidden_channels
|
| 194 |
+
self.kernel_size = kernel_size
|
| 195 |
+
self.dilation_rate = dilation_rate
|
| 196 |
+
self.n_layers = n_layers
|
| 197 |
+
self.n_flows = n_flows
|
| 198 |
+
self.gin_channels = gin_channels
|
| 199 |
+
|
| 200 |
+
self.flows = nn.ModuleList()
|
| 201 |
+
for i in range(n_flows):
|
| 202 |
+
self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True))
|
| 203 |
+
self.flows.append(modules.Flip())
|
| 204 |
+
|
| 205 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 206 |
+
if not reverse:
|
| 207 |
+
for flow in self.flows:
|
| 208 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 209 |
+
else:
|
| 210 |
+
for flow in reversed(self.flows):
|
| 211 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 212 |
+
return x
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
class PosteriorEncoder(nn.Module):
|
| 216 |
+
def __init__(self,
|
| 217 |
+
in_channels,
|
| 218 |
+
out_channels,
|
| 219 |
+
hidden_channels,
|
| 220 |
+
kernel_size,
|
| 221 |
+
dilation_rate,
|
| 222 |
+
n_layers,
|
| 223 |
+
gin_channels=0):
|
| 224 |
+
super().__init__()
|
| 225 |
+
self.in_channels = in_channels
|
| 226 |
+
self.out_channels = out_channels
|
| 227 |
+
self.hidden_channels = hidden_channels
|
| 228 |
+
self.kernel_size = kernel_size
|
| 229 |
+
self.dilation_rate = dilation_rate
|
| 230 |
+
self.n_layers = n_layers
|
| 231 |
+
self.gin_channels = gin_channels
|
| 232 |
+
|
| 233 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 234 |
+
self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels)
|
| 235 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 236 |
+
|
| 237 |
+
def forward(self, x, x_lengths, g=None):
|
| 238 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 239 |
+
x = self.pre(x) * x_mask
|
| 240 |
+
x = self.enc(x, x_mask, g=g)
|
| 241 |
+
stats = self.proj(x) * x_mask
|
| 242 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 243 |
+
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
|
| 244 |
+
return z, m, logs, x_mask
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class Generator(torch.nn.Module):
|
| 248 |
+
def __init__(self, initial_channel, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=0):
|
| 249 |
+
super(Generator, self).__init__()
|
| 250 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 251 |
+
self.num_upsamples = len(upsample_rates)
|
| 252 |
+
self.conv_pre = Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3)
|
| 253 |
+
resblock = modules.ResBlock1 if resblock == '1' else modules.ResBlock2
|
| 254 |
+
|
| 255 |
+
self.ups = nn.ModuleList()
|
| 256 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 257 |
+
self.ups.append(weight_norm(
|
| 258 |
+
ConvTranspose1d(upsample_initial_channel//(2**i), upsample_initial_channel//(2**(i+1)),
|
| 259 |
+
k, u, padding=(k-u)//2)))
|
| 260 |
+
|
| 261 |
+
self.resblocks = nn.ModuleList()
|
| 262 |
+
for i in range(len(self.ups)):
|
| 263 |
+
ch = upsample_initial_channel//(2**(i+1))
|
| 264 |
+
for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):
|
| 265 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 266 |
+
|
| 267 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 268 |
+
self.ups.apply(init_weights)
|
| 269 |
+
|
| 270 |
+
if gin_channels != 0:
|
| 271 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 272 |
+
|
| 273 |
+
def forward(self, x, g=None):
|
| 274 |
+
x = self.conv_pre(x)
|
| 275 |
+
if g is not None:
|
| 276 |
+
x = x + self.cond(g)
|
| 277 |
+
|
| 278 |
+
for i in range(self.num_upsamples):
|
| 279 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 280 |
+
x = self.ups[i](x)
|
| 281 |
+
xs = None
|
| 282 |
+
for j in range(self.num_kernels):
|
| 283 |
+
if xs is None:
|
| 284 |
+
xs = self.resblocks[i*self.num_kernels+j](x)
|
| 285 |
+
else:
|
| 286 |
+
xs += self.resblocks[i*self.num_kernels+j](x)
|
| 287 |
+
x = xs / self.num_kernels
|
| 288 |
+
x = F.leaky_relu(x)
|
| 289 |
+
x = self.conv_post(x)
|
| 290 |
+
x = torch.tanh(x)
|
| 291 |
+
|
| 292 |
+
return x
|
| 293 |
+
|
| 294 |
+
def remove_weight_norm(self):
|
| 295 |
+
print('Removing weight norm...')
|
| 296 |
+
for l in self.ups:
|
| 297 |
+
remove_weight_norm(l)
|
| 298 |
+
for l in self.resblocks:
|
| 299 |
+
l.remove_weight_norm()
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
class DiscriminatorP(torch.nn.Module):
|
| 303 |
+
def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
|
| 304 |
+
super(DiscriminatorP, self).__init__()
|
| 305 |
+
self.period = period
|
| 306 |
+
self.use_spectral_norm = use_spectral_norm
|
| 307 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 308 |
+
self.convs = nn.ModuleList([
|
| 309 |
+
norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 310 |
+
norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 311 |
+
norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 312 |
+
norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 313 |
+
norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))),
|
| 314 |
+
])
|
| 315 |
+
self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
|
| 316 |
+
|
| 317 |
+
def forward(self, x):
|
| 318 |
+
fmap = []
|
| 319 |
+
|
| 320 |
+
# 1d to 2d
|
| 321 |
+
b, c, t = x.shape
|
| 322 |
+
if t % self.period != 0: # pad first
|
| 323 |
+
n_pad = self.period - (t % self.period)
|
| 324 |
+
x = F.pad(x, (0, n_pad), "reflect")
|
| 325 |
+
t = t + n_pad
|
| 326 |
+
x = x.view(b, c, t // self.period, self.period)
|
| 327 |
+
|
| 328 |
+
for l in self.convs:
|
| 329 |
+
x = l(x)
|
| 330 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 331 |
+
fmap.append(x)
|
| 332 |
+
x = self.conv_post(x)
|
| 333 |
+
fmap.append(x)
|
| 334 |
+
x = torch.flatten(x, 1, -1)
|
| 335 |
+
|
| 336 |
+
return x, fmap
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
class DiscriminatorS(torch.nn.Module):
|
| 340 |
+
def __init__(self, use_spectral_norm=False):
|
| 341 |
+
super(DiscriminatorS, self).__init__()
|
| 342 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 343 |
+
self.convs = nn.ModuleList([
|
| 344 |
+
norm_f(Conv1d(1, 16, 15, 1, padding=7)),
|
| 345 |
+
norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
|
| 346 |
+
norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
|
| 347 |
+
norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
|
| 348 |
+
norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
|
| 349 |
+
norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
|
| 350 |
+
])
|
| 351 |
+
self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
|
| 352 |
+
|
| 353 |
+
def forward(self, x):
|
| 354 |
+
fmap = []
|
| 355 |
+
|
| 356 |
+
for l in self.convs:
|
| 357 |
+
x = l(x)
|
| 358 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 359 |
+
fmap.append(x)
|
| 360 |
+
x = self.conv_post(x)
|
| 361 |
+
fmap.append(x)
|
| 362 |
+
x = torch.flatten(x, 1, -1)
|
| 363 |
+
|
| 364 |
+
return x, fmap
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
class MultiPeriodDiscriminator(torch.nn.Module):
|
| 368 |
+
def __init__(self, use_spectral_norm=False):
|
| 369 |
+
super(MultiPeriodDiscriminator, self).__init__()
|
| 370 |
+
periods = [2,3,5,7,11]
|
| 371 |
+
|
| 372 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 373 |
+
discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]
|
| 374 |
+
self.discriminators = nn.ModuleList(discs)
|
| 375 |
+
|
| 376 |
+
def forward(self, y, y_hat):
|
| 377 |
+
y_d_rs = []
|
| 378 |
+
y_d_gs = []
|
| 379 |
+
fmap_rs = []
|
| 380 |
+
fmap_gs = []
|
| 381 |
+
for i, d in enumerate(self.discriminators):
|
| 382 |
+
y_d_r, fmap_r = d(y)
|
| 383 |
+
y_d_g, fmap_g = d(y_hat)
|
| 384 |
+
y_d_rs.append(y_d_r)
|
| 385 |
+
y_d_gs.append(y_d_g)
|
| 386 |
+
fmap_rs.append(fmap_r)
|
| 387 |
+
fmap_gs.append(fmap_g)
|
| 388 |
+
|
| 389 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 390 |
+
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
class SynthesizerTrn(nn.Module):
|
| 394 |
+
"""
|
| 395 |
+
Synthesizer for Training
|
| 396 |
+
"""
|
| 397 |
+
|
| 398 |
+
def __init__(self,
|
| 399 |
+
n_vocab,
|
| 400 |
+
spec_channels,
|
| 401 |
+
segment_size,
|
| 402 |
+
inter_channels,
|
| 403 |
+
hidden_channels,
|
| 404 |
+
filter_channels,
|
| 405 |
+
n_heads,
|
| 406 |
+
n_layers,
|
| 407 |
+
kernel_size,
|
| 408 |
+
p_dropout,
|
| 409 |
+
resblock,
|
| 410 |
+
resblock_kernel_sizes,
|
| 411 |
+
resblock_dilation_sizes,
|
| 412 |
+
upsample_rates,
|
| 413 |
+
upsample_initial_channel,
|
| 414 |
+
upsample_kernel_sizes,
|
| 415 |
+
n_speakers=0,
|
| 416 |
+
gin_channels=0,
|
| 417 |
+
use_sdp=True,
|
| 418 |
+
**kwargs):
|
| 419 |
+
|
| 420 |
+
super().__init__()
|
| 421 |
+
self.n_vocab = n_vocab
|
| 422 |
+
self.spec_channels = spec_channels
|
| 423 |
+
self.inter_channels = inter_channels
|
| 424 |
+
self.hidden_channels = hidden_channels
|
| 425 |
+
self.filter_channels = filter_channels
|
| 426 |
+
self.n_heads = n_heads
|
| 427 |
+
self.n_layers = n_layers
|
| 428 |
+
self.kernel_size = kernel_size
|
| 429 |
+
self.p_dropout = p_dropout
|
| 430 |
+
self.resblock = resblock
|
| 431 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 432 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 433 |
+
self.upsample_rates = upsample_rates
|
| 434 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 435 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 436 |
+
self.segment_size = segment_size
|
| 437 |
+
self.n_speakers = n_speakers
|
| 438 |
+
self.gin_channels = gin_channels
|
| 439 |
+
|
| 440 |
+
self.use_sdp = use_sdp
|
| 441 |
+
|
| 442 |
+
self.enc_p = TextEncoder(n_vocab,
|
| 443 |
+
inter_channels,
|
| 444 |
+
hidden_channels,
|
| 445 |
+
filter_channels,
|
| 446 |
+
n_heads,
|
| 447 |
+
n_layers,
|
| 448 |
+
kernel_size,
|
| 449 |
+
p_dropout)
|
| 450 |
+
self.dec = Generator(inter_channels, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=gin_channels)
|
| 451 |
+
self.enc_q = PosteriorEncoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels)
|
| 452 |
+
self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
|
| 453 |
+
|
| 454 |
+
if use_sdp:
|
| 455 |
+
self.dp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels)
|
| 456 |
+
else:
|
| 457 |
+
self.dp = DurationPredictor(hidden_channels, 256, 3, 0.5, gin_channels=gin_channels)
|
| 458 |
+
|
| 459 |
+
if n_speakers > 1:
|
| 460 |
+
self.emb_g = nn.Embedding(n_speakers, gin_channels)
|
| 461 |
+
|
| 462 |
+
def forward(self, x, x_lengths, y, y_lengths, sid=None, emo=None):
|
| 463 |
+
|
| 464 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths, emo)
|
| 465 |
+
if self.n_speakers > 0:
|
| 466 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 467 |
+
else:
|
| 468 |
+
g = None
|
| 469 |
+
|
| 470 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
| 471 |
+
z_p = self.flow(z, y_mask, g=g)
|
| 472 |
+
|
| 473 |
+
with torch.no_grad():
|
| 474 |
+
# negative cross-entropy
|
| 475 |
+
s_p_sq_r = torch.exp(-2 * logs_p) # [b, d, t]
|
| 476 |
+
neg_cent1 = torch.sum(-0.5 * math.log(2 * math.pi) - logs_p, [1], keepdim=True) # [b, 1, t_s]
|
| 477 |
+
neg_cent2 = torch.matmul(-0.5 * (z_p ** 2).transpose(1, 2), s_p_sq_r) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s]
|
| 478 |
+
neg_cent3 = torch.matmul(z_p.transpose(1, 2), (m_p * s_p_sq_r)) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s]
|
| 479 |
+
neg_cent4 = torch.sum(-0.5 * (m_p ** 2) * s_p_sq_r, [1], keepdim=True) # [b, 1, t_s]
|
| 480 |
+
neg_cent = neg_cent1 + neg_cent2 + neg_cent3 + neg_cent4
|
| 481 |
+
|
| 482 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 483 |
+
attn = monotonic_align.maximum_path(neg_cent, attn_mask.squeeze(1)).unsqueeze(1).detach()
|
| 484 |
+
|
| 485 |
+
w = attn.sum(2)
|
| 486 |
+
if self.use_sdp:
|
| 487 |
+
l_length = self.dp(x, x_mask, w, g=g)
|
| 488 |
+
l_length = l_length / torch.sum(x_mask)
|
| 489 |
+
else:
|
| 490 |
+
logw_ = torch.log(w + 1e-6) * x_mask
|
| 491 |
+
logw = self.dp(x, x_mask, g=g)
|
| 492 |
+
l_length = torch.sum((logw - logw_)**2, [1,2]) / torch.sum(x_mask) # for averaging
|
| 493 |
+
|
| 494 |
+
# expand prior
|
| 495 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2)
|
| 496 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2)
|
| 497 |
+
|
| 498 |
+
z_slice, ids_slice = commons.rand_slice_segments(z, y_lengths, self.segment_size)
|
| 499 |
+
o = self.dec(z_slice, g=g)
|
| 500 |
+
return o, l_length, attn, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
| 501 |
+
|
| 502 |
+
def infer(self, x, x_lengths, sid=None, emo=None, noise_scale=1, length_scale=1, noise_scale_w=1., max_len=None):
|
| 503 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths,emo)
|
| 504 |
+
if self.n_speakers > 0:
|
| 505 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 506 |
+
else:
|
| 507 |
+
g = None
|
| 508 |
+
|
| 509 |
+
if self.use_sdp:
|
| 510 |
+
logw = self.dp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w)
|
| 511 |
+
else:
|
| 512 |
+
logw = self.dp(x, x_mask, g=g)
|
| 513 |
+
w = torch.exp(logw) * x_mask * length_scale
|
| 514 |
+
w_ceil = torch.ceil(w)
|
| 515 |
+
y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long()
|
| 516 |
+
y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype)
|
| 517 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 518 |
+
attn = commons.generate_path(w_ceil, attn_mask)
|
| 519 |
+
|
| 520 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 521 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 522 |
+
|
| 523 |
+
z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale
|
| 524 |
+
z = self.flow(z_p, y_mask, g=g, reverse=True)
|
| 525 |
+
o = self.dec((z * y_mask)[:,:,:max_len], g=g)
|
| 526 |
+
return o, attn, y_mask, (z, z_p, m_p, logs_p)
|
| 527 |
+
|
| 528 |
+
def voice_conversion(self, y, y_lengths, sid_src, sid_tgt):
|
| 529 |
+
assert self.n_speakers > 0, "n_speakers have to be larger than 0."
|
| 530 |
+
g_src = self.emb_g(sid_src).unsqueeze(-1)
|
| 531 |
+
g_tgt = self.emb_g(sid_tgt).unsqueeze(-1)
|
| 532 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g_src)
|
| 533 |
+
z_p = self.flow(z, y_mask, g=g_src)
|
| 534 |
+
z_hat = self.flow(z_p, y_mask, g=g_tgt, reverse=True)
|
| 535 |
+
o_hat = self.dec(z_hat * y_mask, g=g_tgt)
|
| 536 |
+
return o_hat, y_mask, (z, z_p, z_hat)
|
| 537 |
+
|
modules.py
ADDED
|
@@ -0,0 +1,390 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import scipy
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
|
| 9 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 10 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 11 |
+
|
| 12 |
+
import commons
|
| 13 |
+
from commons import init_weights, get_padding
|
| 14 |
+
from transforms import piecewise_rational_quadratic_transform
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
LRELU_SLOPE = 0.1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class LayerNorm(nn.Module):
|
| 21 |
+
def __init__(self, channels, eps=1e-5):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.channels = channels
|
| 24 |
+
self.eps = eps
|
| 25 |
+
|
| 26 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 27 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 28 |
+
|
| 29 |
+
def forward(self, x):
|
| 30 |
+
x = x.transpose(1, -1)
|
| 31 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 32 |
+
return x.transpose(1, -1)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ConvReluNorm(nn.Module):
|
| 36 |
+
def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
|
| 37 |
+
super().__init__()
|
| 38 |
+
self.in_channels = in_channels
|
| 39 |
+
self.hidden_channels = hidden_channels
|
| 40 |
+
self.out_channels = out_channels
|
| 41 |
+
self.kernel_size = kernel_size
|
| 42 |
+
self.n_layers = n_layers
|
| 43 |
+
self.p_dropout = p_dropout
|
| 44 |
+
assert n_layers > 1, "Number of layers should be larger than 0."
|
| 45 |
+
|
| 46 |
+
self.conv_layers = nn.ModuleList()
|
| 47 |
+
self.norm_layers = nn.ModuleList()
|
| 48 |
+
self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
|
| 49 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 50 |
+
self.relu_drop = nn.Sequential(
|
| 51 |
+
nn.ReLU(),
|
| 52 |
+
nn.Dropout(p_dropout))
|
| 53 |
+
for _ in range(n_layers-1):
|
| 54 |
+
self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
|
| 55 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 56 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 57 |
+
self.proj.weight.data.zero_()
|
| 58 |
+
self.proj.bias.data.zero_()
|
| 59 |
+
|
| 60 |
+
def forward(self, x, x_mask):
|
| 61 |
+
x_org = x
|
| 62 |
+
for i in range(self.n_layers):
|
| 63 |
+
x = self.conv_layers[i](x * x_mask)
|
| 64 |
+
x = self.norm_layers[i](x)
|
| 65 |
+
x = self.relu_drop(x)
|
| 66 |
+
x = x_org + self.proj(x)
|
| 67 |
+
return x * x_mask
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class DDSConv(nn.Module):
|
| 71 |
+
"""
|
| 72 |
+
Dialted and Depth-Separable Convolution
|
| 73 |
+
"""
|
| 74 |
+
def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
|
| 75 |
+
super().__init__()
|
| 76 |
+
self.channels = channels
|
| 77 |
+
self.kernel_size = kernel_size
|
| 78 |
+
self.n_layers = n_layers
|
| 79 |
+
self.p_dropout = p_dropout
|
| 80 |
+
|
| 81 |
+
self.drop = nn.Dropout(p_dropout)
|
| 82 |
+
self.convs_sep = nn.ModuleList()
|
| 83 |
+
self.convs_1x1 = nn.ModuleList()
|
| 84 |
+
self.norms_1 = nn.ModuleList()
|
| 85 |
+
self.norms_2 = nn.ModuleList()
|
| 86 |
+
for i in range(n_layers):
|
| 87 |
+
dilation = kernel_size ** i
|
| 88 |
+
padding = (kernel_size * dilation - dilation) // 2
|
| 89 |
+
self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
|
| 90 |
+
groups=channels, dilation=dilation, padding=padding
|
| 91 |
+
))
|
| 92 |
+
self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
|
| 93 |
+
self.norms_1.append(LayerNorm(channels))
|
| 94 |
+
self.norms_2.append(LayerNorm(channels))
|
| 95 |
+
|
| 96 |
+
def forward(self, x, x_mask, g=None):
|
| 97 |
+
if g is not None:
|
| 98 |
+
x = x + g
|
| 99 |
+
for i in range(self.n_layers):
|
| 100 |
+
y = self.convs_sep[i](x * x_mask)
|
| 101 |
+
y = self.norms_1[i](y)
|
| 102 |
+
y = F.gelu(y)
|
| 103 |
+
y = self.convs_1x1[i](y)
|
| 104 |
+
y = self.norms_2[i](y)
|
| 105 |
+
y = F.gelu(y)
|
| 106 |
+
y = self.drop(y)
|
| 107 |
+
x = x + y
|
| 108 |
+
return x * x_mask
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class WN(torch.nn.Module):
|
| 112 |
+
def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
|
| 113 |
+
super(WN, self).__init__()
|
| 114 |
+
assert(kernel_size % 2 == 1)
|
| 115 |
+
self.hidden_channels =hidden_channels
|
| 116 |
+
self.kernel_size = kernel_size,
|
| 117 |
+
self.dilation_rate = dilation_rate
|
| 118 |
+
self.n_layers = n_layers
|
| 119 |
+
self.gin_channels = gin_channels
|
| 120 |
+
self.p_dropout = p_dropout
|
| 121 |
+
|
| 122 |
+
self.in_layers = torch.nn.ModuleList()
|
| 123 |
+
self.res_skip_layers = torch.nn.ModuleList()
|
| 124 |
+
self.drop = nn.Dropout(p_dropout)
|
| 125 |
+
|
| 126 |
+
if gin_channels != 0:
|
| 127 |
+
cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
|
| 128 |
+
self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
|
| 129 |
+
|
| 130 |
+
for i in range(n_layers):
|
| 131 |
+
dilation = dilation_rate ** i
|
| 132 |
+
padding = int((kernel_size * dilation - dilation) / 2)
|
| 133 |
+
in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
|
| 134 |
+
dilation=dilation, padding=padding)
|
| 135 |
+
in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
|
| 136 |
+
self.in_layers.append(in_layer)
|
| 137 |
+
|
| 138 |
+
# last one is not necessary
|
| 139 |
+
if i < n_layers - 1:
|
| 140 |
+
res_skip_channels = 2 * hidden_channels
|
| 141 |
+
else:
|
| 142 |
+
res_skip_channels = hidden_channels
|
| 143 |
+
|
| 144 |
+
res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
|
| 145 |
+
res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
|
| 146 |
+
self.res_skip_layers.append(res_skip_layer)
|
| 147 |
+
|
| 148 |
+
def forward(self, x, x_mask, g=None, **kwargs):
|
| 149 |
+
output = torch.zeros_like(x)
|
| 150 |
+
n_channels_tensor = torch.IntTensor([self.hidden_channels])
|
| 151 |
+
|
| 152 |
+
if g is not None:
|
| 153 |
+
g = self.cond_layer(g)
|
| 154 |
+
|
| 155 |
+
for i in range(self.n_layers):
|
| 156 |
+
x_in = self.in_layers[i](x)
|
| 157 |
+
if g is not None:
|
| 158 |
+
cond_offset = i * 2 * self.hidden_channels
|
| 159 |
+
g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
|
| 160 |
+
else:
|
| 161 |
+
g_l = torch.zeros_like(x_in)
|
| 162 |
+
|
| 163 |
+
acts = commons.fused_add_tanh_sigmoid_multiply(
|
| 164 |
+
x_in,
|
| 165 |
+
g_l,
|
| 166 |
+
n_channels_tensor)
|
| 167 |
+
acts = self.drop(acts)
|
| 168 |
+
|
| 169 |
+
res_skip_acts = self.res_skip_layers[i](acts)
|
| 170 |
+
if i < self.n_layers - 1:
|
| 171 |
+
res_acts = res_skip_acts[:,:self.hidden_channels,:]
|
| 172 |
+
x = (x + res_acts) * x_mask
|
| 173 |
+
output = output + res_skip_acts[:,self.hidden_channels:,:]
|
| 174 |
+
else:
|
| 175 |
+
output = output + res_skip_acts
|
| 176 |
+
return output * x_mask
|
| 177 |
+
|
| 178 |
+
def remove_weight_norm(self):
|
| 179 |
+
if self.gin_channels != 0:
|
| 180 |
+
torch.nn.utils.remove_weight_norm(self.cond_layer)
|
| 181 |
+
for l in self.in_layers:
|
| 182 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 183 |
+
for l in self.res_skip_layers:
|
| 184 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class ResBlock1(torch.nn.Module):
|
| 188 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
|
| 189 |
+
super(ResBlock1, self).__init__()
|
| 190 |
+
self.convs1 = nn.ModuleList([
|
| 191 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 192 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 193 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 194 |
+
padding=get_padding(kernel_size, dilation[1]))),
|
| 195 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
|
| 196 |
+
padding=get_padding(kernel_size, dilation[2])))
|
| 197 |
+
])
|
| 198 |
+
self.convs1.apply(init_weights)
|
| 199 |
+
|
| 200 |
+
self.convs2 = nn.ModuleList([
|
| 201 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 202 |
+
padding=get_padding(kernel_size, 1))),
|
| 203 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 204 |
+
padding=get_padding(kernel_size, 1))),
|
| 205 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 206 |
+
padding=get_padding(kernel_size, 1)))
|
| 207 |
+
])
|
| 208 |
+
self.convs2.apply(init_weights)
|
| 209 |
+
|
| 210 |
+
def forward(self, x, x_mask=None):
|
| 211 |
+
for c1, c2 in zip(self.convs1, self.convs2):
|
| 212 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 213 |
+
if x_mask is not None:
|
| 214 |
+
xt = xt * x_mask
|
| 215 |
+
xt = c1(xt)
|
| 216 |
+
xt = F.leaky_relu(xt, LRELU_SLOPE)
|
| 217 |
+
if x_mask is not None:
|
| 218 |
+
xt = xt * x_mask
|
| 219 |
+
xt = c2(xt)
|
| 220 |
+
x = xt + x
|
| 221 |
+
if x_mask is not None:
|
| 222 |
+
x = x * x_mask
|
| 223 |
+
return x
|
| 224 |
+
|
| 225 |
+
def remove_weight_norm(self):
|
| 226 |
+
for l in self.convs1:
|
| 227 |
+
remove_weight_norm(l)
|
| 228 |
+
for l in self.convs2:
|
| 229 |
+
remove_weight_norm(l)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
class ResBlock2(torch.nn.Module):
|
| 233 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
|
| 234 |
+
super(ResBlock2, self).__init__()
|
| 235 |
+
self.convs = nn.ModuleList([
|
| 236 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 237 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 238 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 239 |
+
padding=get_padding(kernel_size, dilation[1])))
|
| 240 |
+
])
|
| 241 |
+
self.convs.apply(init_weights)
|
| 242 |
+
|
| 243 |
+
def forward(self, x, x_mask=None):
|
| 244 |
+
for c in self.convs:
|
| 245 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 246 |
+
if x_mask is not None:
|
| 247 |
+
xt = xt * x_mask
|
| 248 |
+
xt = c(xt)
|
| 249 |
+
x = xt + x
|
| 250 |
+
if x_mask is not None:
|
| 251 |
+
x = x * x_mask
|
| 252 |
+
return x
|
| 253 |
+
|
| 254 |
+
def remove_weight_norm(self):
|
| 255 |
+
for l in self.convs:
|
| 256 |
+
remove_weight_norm(l)
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
class Log(nn.Module):
|
| 260 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 261 |
+
if not reverse:
|
| 262 |
+
y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
|
| 263 |
+
logdet = torch.sum(-y, [1, 2])
|
| 264 |
+
return y, logdet
|
| 265 |
+
else:
|
| 266 |
+
x = torch.exp(x) * x_mask
|
| 267 |
+
return x
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
class Flip(nn.Module):
|
| 271 |
+
def forward(self, x, *args, reverse=False, **kwargs):
|
| 272 |
+
x = torch.flip(x, [1])
|
| 273 |
+
if not reverse:
|
| 274 |
+
logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
|
| 275 |
+
return x, logdet
|
| 276 |
+
else:
|
| 277 |
+
return x
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class ElementwiseAffine(nn.Module):
|
| 281 |
+
def __init__(self, channels):
|
| 282 |
+
super().__init__()
|
| 283 |
+
self.channels = channels
|
| 284 |
+
self.m = nn.Parameter(torch.zeros(channels,1))
|
| 285 |
+
self.logs = nn.Parameter(torch.zeros(channels,1))
|
| 286 |
+
|
| 287 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 288 |
+
if not reverse:
|
| 289 |
+
y = self.m + torch.exp(self.logs) * x
|
| 290 |
+
y = y * x_mask
|
| 291 |
+
logdet = torch.sum(self.logs * x_mask, [1,2])
|
| 292 |
+
return y, logdet
|
| 293 |
+
else:
|
| 294 |
+
x = (x - self.m) * torch.exp(-self.logs) * x_mask
|
| 295 |
+
return x
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class ResidualCouplingLayer(nn.Module):
|
| 299 |
+
def __init__(self,
|
| 300 |
+
channels,
|
| 301 |
+
hidden_channels,
|
| 302 |
+
kernel_size,
|
| 303 |
+
dilation_rate,
|
| 304 |
+
n_layers,
|
| 305 |
+
p_dropout=0,
|
| 306 |
+
gin_channels=0,
|
| 307 |
+
mean_only=False):
|
| 308 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 309 |
+
super().__init__()
|
| 310 |
+
self.channels = channels
|
| 311 |
+
self.hidden_channels = hidden_channels
|
| 312 |
+
self.kernel_size = kernel_size
|
| 313 |
+
self.dilation_rate = dilation_rate
|
| 314 |
+
self.n_layers = n_layers
|
| 315 |
+
self.half_channels = channels // 2
|
| 316 |
+
self.mean_only = mean_only
|
| 317 |
+
|
| 318 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 319 |
+
self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
|
| 320 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 321 |
+
self.post.weight.data.zero_()
|
| 322 |
+
self.post.bias.data.zero_()
|
| 323 |
+
|
| 324 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 325 |
+
x0, x1 = torch.split(x, [self.half_channels]*2, 1)
|
| 326 |
+
h = self.pre(x0) * x_mask
|
| 327 |
+
h = self.enc(h, x_mask, g=g)
|
| 328 |
+
stats = self.post(h) * x_mask
|
| 329 |
+
if not self.mean_only:
|
| 330 |
+
m, logs = torch.split(stats, [self.half_channels]*2, 1)
|
| 331 |
+
else:
|
| 332 |
+
m = stats
|
| 333 |
+
logs = torch.zeros_like(m)
|
| 334 |
+
|
| 335 |
+
if not reverse:
|
| 336 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 337 |
+
x = torch.cat([x0, x1], 1)
|
| 338 |
+
logdet = torch.sum(logs, [1,2])
|
| 339 |
+
return x, logdet
|
| 340 |
+
else:
|
| 341 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 342 |
+
x = torch.cat([x0, x1], 1)
|
| 343 |
+
return x
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
class ConvFlow(nn.Module):
|
| 347 |
+
def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
|
| 348 |
+
super().__init__()
|
| 349 |
+
self.in_channels = in_channels
|
| 350 |
+
self.filter_channels = filter_channels
|
| 351 |
+
self.kernel_size = kernel_size
|
| 352 |
+
self.n_layers = n_layers
|
| 353 |
+
self.num_bins = num_bins
|
| 354 |
+
self.tail_bound = tail_bound
|
| 355 |
+
self.half_channels = in_channels // 2
|
| 356 |
+
|
| 357 |
+
self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
|
| 358 |
+
self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
|
| 359 |
+
self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
|
| 360 |
+
self.proj.weight.data.zero_()
|
| 361 |
+
self.proj.bias.data.zero_()
|
| 362 |
+
|
| 363 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 364 |
+
x0, x1 = torch.split(x, [self.half_channels]*2, 1)
|
| 365 |
+
h = self.pre(x0)
|
| 366 |
+
h = self.convs(h, x_mask, g=g)
|
| 367 |
+
h = self.proj(h) * x_mask
|
| 368 |
+
|
| 369 |
+
b, c, t = x0.shape
|
| 370 |
+
h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
|
| 371 |
+
|
| 372 |
+
unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
|
| 373 |
+
unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
|
| 374 |
+
unnormalized_derivatives = h[..., 2 * self.num_bins:]
|
| 375 |
+
|
| 376 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(x1,
|
| 377 |
+
unnormalized_widths,
|
| 378 |
+
unnormalized_heights,
|
| 379 |
+
unnormalized_derivatives,
|
| 380 |
+
inverse=reverse,
|
| 381 |
+
tails='linear',
|
| 382 |
+
tail_bound=self.tail_bound
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 386 |
+
logdet = torch.sum(logabsdet * x_mask, [1,2])
|
| 387 |
+
if not reverse:
|
| 388 |
+
return x, logdet
|
| 389 |
+
else:
|
| 390 |
+
return x
|
monotonic_align/__init__.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from .monotonic_align.core import maximum_path_c
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def maximum_path(neg_cent, mask):
|
| 7 |
+
""" Cython optimized version.
|
| 8 |
+
neg_cent: [b, t_t, t_s]
|
| 9 |
+
mask: [b, t_t, t_s]
|
| 10 |
+
"""
|
| 11 |
+
device = neg_cent.device
|
| 12 |
+
dtype = neg_cent.dtype
|
| 13 |
+
neg_cent = neg_cent.data.cpu().numpy().astype(np.float32)
|
| 14 |
+
path = np.zeros(neg_cent.shape, dtype=np.int32)
|
| 15 |
+
|
| 16 |
+
t_t_max = mask.sum(1)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 17 |
+
t_s_max = mask.sum(2)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 18 |
+
maximum_path_c(path, neg_cent, t_t_max, t_s_max)
|
| 19 |
+
return torch.from_numpy(path).to(device=device, dtype=dtype)
|
monotonic_align/core.pyx
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cimport cython
|
| 2 |
+
from cython.parallel import prange
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
@cython.boundscheck(False)
|
| 6 |
+
@cython.wraparound(False)
|
| 7 |
+
cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil:
|
| 8 |
+
cdef int x
|
| 9 |
+
cdef int y
|
| 10 |
+
cdef float v_prev
|
| 11 |
+
cdef float v_cur
|
| 12 |
+
cdef float tmp
|
| 13 |
+
cdef int index = t_x - 1
|
| 14 |
+
|
| 15 |
+
for y in range(t_y):
|
| 16 |
+
for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
|
| 17 |
+
if x == y:
|
| 18 |
+
v_cur = max_neg_val
|
| 19 |
+
else:
|
| 20 |
+
v_cur = value[y-1, x]
|
| 21 |
+
if x == 0:
|
| 22 |
+
if y == 0:
|
| 23 |
+
v_prev = 0.
|
| 24 |
+
else:
|
| 25 |
+
v_prev = max_neg_val
|
| 26 |
+
else:
|
| 27 |
+
v_prev = value[y-1, x-1]
|
| 28 |
+
value[y, x] += max(v_prev, v_cur)
|
| 29 |
+
|
| 30 |
+
for y in range(t_y - 1, -1, -1):
|
| 31 |
+
path[y, index] = 1
|
| 32 |
+
if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
|
| 33 |
+
index = index - 1
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
@cython.boundscheck(False)
|
| 37 |
+
@cython.wraparound(False)
|
| 38 |
+
cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil:
|
| 39 |
+
cdef int b = paths.shape[0]
|
| 40 |
+
cdef int i
|
| 41 |
+
for i in prange(b, nogil=True):
|
| 42 |
+
maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
|
monotonic_align/setup.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from distutils.core import setup
|
| 2 |
+
from Cython.Build import cythonize
|
| 3 |
+
import numpy
|
| 4 |
+
|
| 5 |
+
setup(
|
| 6 |
+
name = 'monotonic_align',
|
| 7 |
+
ext_modules = cythonize("core.pyx"),
|
| 8 |
+
include_dirs=[numpy.get_include()]
|
| 9 |
+
)
|
preprocess.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import text
|
| 3 |
+
from utils import load_filepaths_and_text
|
| 4 |
+
|
| 5 |
+
if __name__ == '__main__':
|
| 6 |
+
parser = argparse.ArgumentParser()
|
| 7 |
+
parser.add_argument("--out_extension", default="cleaned")
|
| 8 |
+
parser.add_argument("--text_index", default=1, type=int)
|
| 9 |
+
parser.add_argument("--filelists", nargs="+", default=["filelists/ljs_audio_text_val_filelist.txt", "filelists/ljs_audio_text_test_filelist.txt"])
|
| 10 |
+
parser.add_argument("--text_cleaners", nargs="+", default=["english_cleaners2"])
|
| 11 |
+
|
| 12 |
+
args = parser.parse_args()
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
for filelist in args.filelists:
|
| 16 |
+
print("START:", filelist)
|
| 17 |
+
filepaths_and_text = load_filepaths_and_text(filelist)
|
| 18 |
+
for i in range(len(filepaths_and_text)):
|
| 19 |
+
original_text = filepaths_and_text[i][args.text_index]
|
| 20 |
+
cleaned_text = text._clean_text(original_text, args.text_cleaners)
|
| 21 |
+
filepaths_and_text[i][args.text_index] = cleaned_text
|
| 22 |
+
|
| 23 |
+
new_filelist = filelist + "." + args.out_extension
|
| 24 |
+
with open(new_filelist, "w", encoding="utf-8") as f:
|
| 25 |
+
f.writelines(["|".join(x) + "\n" for x in filepaths_and_text])
|
requirements.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Cython
|
| 2 |
+
librosa
|
| 3 |
+
matplotlib
|
| 4 |
+
numpy
|
| 5 |
+
phonemizer
|
| 6 |
+
scipy
|
| 7 |
+
tensorboard
|
| 8 |
+
torch
|
| 9 |
+
torchvision
|
| 10 |
+
Unidecode
|
| 11 |
+
jieba
|
| 12 |
+
cn2an
|
| 13 |
+
pypinyin
|
resources/fig_1a.png
ADDED
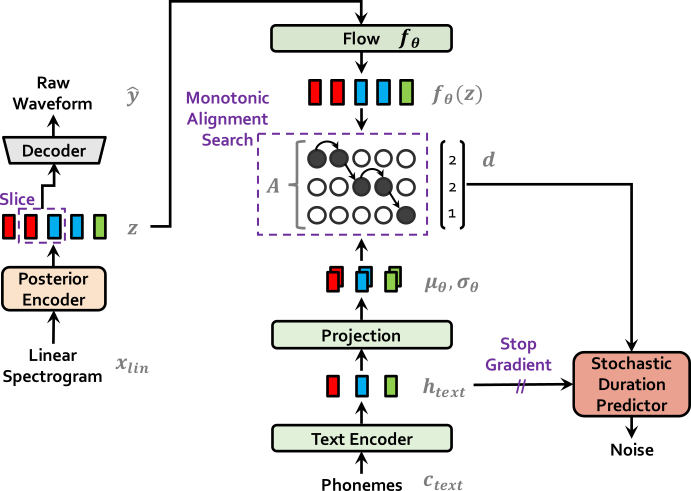
|
resources/fig_1b.png
ADDED
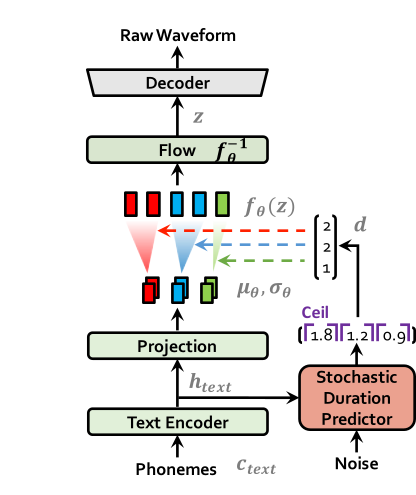
|
resources/training.png
ADDED
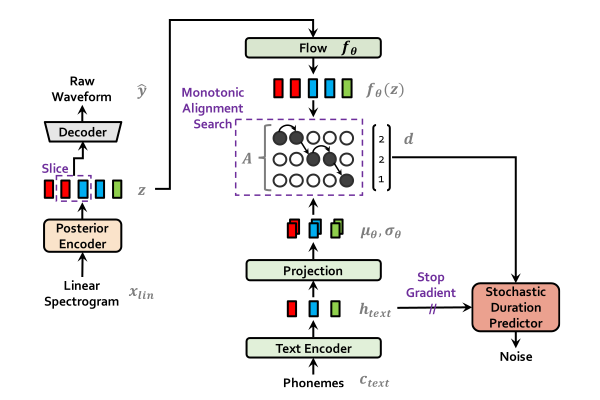
|
text/LICENSE
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2017 Keith Ito
|
| 2 |
+
|
| 3 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 4 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 5 |
+
in the Software without restriction, including without limitation the rights
|
| 6 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 7 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 8 |
+
furnished to do so, subject to the following conditions:
|
| 9 |
+
|
| 10 |
+
The above copyright notice and this permission notice shall be included in
|
| 11 |
+
all copies or substantial portions of the Software.
|
| 12 |
+
|
| 13 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 19 |
+
THE SOFTWARE.
|
text/__init__.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
from text import cleaners
|
| 3 |
+
from text.symbols import symbols
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# Mappings from symbol to numeric ID and vice versa:
|
| 7 |
+
_symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 8 |
+
_id_to_symbol = {i: s for i, s in enumerate(symbols)}
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def text_to_sequence(text, cleaner_names):
|
| 12 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 13 |
+
Args:
|
| 14 |
+
text: string to convert to a sequence
|
| 15 |
+
cleaner_names: names of the cleaner functions to run the text through
|
| 16 |
+
Returns:
|
| 17 |
+
List of integers corresponding to the symbols in the text
|
| 18 |
+
'''
|
| 19 |
+
sequence = []
|
| 20 |
+
|
| 21 |
+
clean_text = _clean_text(text, cleaner_names)
|
| 22 |
+
for symbol in clean_text:
|
| 23 |
+
if symbol not in _symbol_to_id.keys():
|
| 24 |
+
continue
|
| 25 |
+
symbol_id = _symbol_to_id[symbol]
|
| 26 |
+
sequence += [symbol_id]
|
| 27 |
+
return sequence
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def cleaned_text_to_sequence(cleaned_text):
|
| 31 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 32 |
+
Args:
|
| 33 |
+
text: string to convert to a sequence
|
| 34 |
+
Returns:
|
| 35 |
+
List of integers corresponding to the symbols in the text
|
| 36 |
+
'''
|
| 37 |
+
sequence = [_symbol_to_id[symbol] for symbol in cleaned_text if symbol in _symbol_to_id.keys()]
|
| 38 |
+
return sequence
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def sequence_to_text(sequence):
|
| 42 |
+
'''Converts a sequence of IDs back to a string'''
|
| 43 |
+
result = ''
|
| 44 |
+
for symbol_id in sequence:
|
| 45 |
+
s = _id_to_symbol[symbol_id]
|
| 46 |
+
result += s
|
| 47 |
+
return result
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def _clean_text(text, cleaner_names):
|
| 51 |
+
for name in cleaner_names:
|
| 52 |
+
cleaner = getattr(cleaners, name)
|
| 53 |
+
if not cleaner:
|
| 54 |
+
raise Exception('Unknown cleaner: %s' % name)
|
| 55 |
+
text = cleaner(text)
|
| 56 |
+
return text
|
text/cleaners.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
try:
|
| 3 |
+
from text.japanese import japanese_to_romaji_with_accent, japanese_to_ipa, japanese_to_ipa2, japanese_to_ipa3
|
| 4 |
+
from text.mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo, chinese_to_romaji, chinese_to_lazy_ipa, chinese_to_ipa, chinese_to_ipa2
|
| 5 |
+
except:
|
| 6 |
+
pass
|
| 7 |
+
# from text.sanskrit import devanagari_to_ipa
|
| 8 |
+
# from text.english import english_to_lazy_ipa, english_to_ipa2, english_to_lazy_ipa2
|
| 9 |
+
# from text.thai import num_to_thai, latin_to_thai
|
| 10 |
+
# from text.shanghainese import shanghainese_to_ipa
|
| 11 |
+
# from text.cantonese import cantonese_to_ipa
|
| 12 |
+
# from text.ngu_dialect import ngu_dialect_to_ipa
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def japanese_cleaners(text):
|
| 16 |
+
text = japanese_to_romaji_with_accent(text)
|
| 17 |
+
if re.match('[A-Za-z]', text[-1]):
|
| 18 |
+
text += '.'
|
| 19 |
+
return text
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def japanese_cleaners2(text):
|
| 23 |
+
return japanese_cleaners(text).replace('ts', 'ʦ').replace('...', '…')
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def korean_cleaners(text):
|
| 27 |
+
'''Pipeline for Korean text'''
|
| 28 |
+
text = latin_to_hangul(text)
|
| 29 |
+
text = number_to_hangul(text)
|
| 30 |
+
text = divide_hangul(text)
|
| 31 |
+
if re.match('[\u3131-\u3163]', text[-1]):
|
| 32 |
+
text += '.'
|
| 33 |
+
return text
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def chinese_cleaners(text):
|
| 37 |
+
'''Pipeline for Chinese text'''
|
| 38 |
+
text = number_to_chinese(text)
|
| 39 |
+
text = chinese_to_bopomofo(text)
|
| 40 |
+
text = latin_to_bopomofo(text)
|
| 41 |
+
if re.match('[ˉˊˇˋ˙]', text[-1]):
|
| 42 |
+
text += '。'
|
| 43 |
+
return text
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def zh_ja_mixture_cleaners(text):
|
| 47 |
+
chinese_texts = re.findall(r'\[ZH\].*?\[ZH\]', text)
|
| 48 |
+
japanese_texts = re.findall(r'\[JA\].*?\[JA\]', text)
|
| 49 |
+
for chinese_text in chinese_texts:
|
| 50 |
+
cleaned_text = chinese_to_romaji(chinese_text[4:-4])
|
| 51 |
+
text = text.replace(chinese_text, cleaned_text+' ', 1)
|
| 52 |
+
for japanese_text in japanese_texts:
|
| 53 |
+
cleaned_text = japanese_to_romaji_with_accent(
|
| 54 |
+
japanese_text[4:-4]).replace('ts', 'ʦ').replace('u', 'ɯ').replace('...', '…')
|
| 55 |
+
text = text.replace(japanese_text, cleaned_text+' ', 1)
|
| 56 |
+
text = text[:-1]
|
| 57 |
+
if re.match('[A-Za-zɯɹəɥ→↓↑]', text[-1]):
|
| 58 |
+
text += '.'
|
| 59 |
+
return text
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def sanskrit_cleaners(text):
|
| 63 |
+
text = text.replace('॥', '।').replace('ॐ', 'ओम्')
|
| 64 |
+
if text[-1] != '।':
|
| 65 |
+
text += ' ।'
|
| 66 |
+
return text
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def cjks_cleaners(text):
|
| 70 |
+
chinese_texts = re.findall(r'\[ZH\].*?\[ZH\]', text)
|
| 71 |
+
japanese_texts = re.findall(r'\[JA\].*?\[JA\]', text)
|
| 72 |
+
korean_texts = re.findall(r'\[KO\].*?\[KO\]', text)
|
| 73 |
+
sanskrit_texts = re.findall(r'\[SA\].*?\[SA\]', text)
|
| 74 |
+
english_texts = re.findall(r'\[EN\].*?\[EN\]', text)
|
| 75 |
+
for chinese_text in chinese_texts:
|
| 76 |
+
cleaned_text = chinese_to_lazy_ipa(chinese_text[4:-4])
|
| 77 |
+
text = text.replace(chinese_text, cleaned_text+' ', 1)
|
| 78 |
+
for japanese_text in japanese_texts:
|
| 79 |
+
cleaned_text = japanese_to_ipa(japanese_text[4:-4])
|
| 80 |
+
text = text.replace(japanese_text, cleaned_text+' ', 1)
|
| 81 |
+
for korean_text in korean_texts:
|
| 82 |
+
cleaned_text = korean_to_lazy_ipa(korean_text[4:-4])
|
| 83 |
+
text = text.replace(korean_text, cleaned_text+' ', 1)
|
| 84 |
+
for sanskrit_text in sanskrit_texts:
|
| 85 |
+
cleaned_text = devanagari_to_ipa(sanskrit_text[4:-4])
|
| 86 |
+
text = text.replace(sanskrit_text, cleaned_text+' ', 1)
|
| 87 |
+
for english_text in english_texts:
|
| 88 |
+
cleaned_text = english_to_lazy_ipa(english_text[4:-4])
|
| 89 |
+
text = text.replace(english_text, cleaned_text+' ', 1)
|
| 90 |
+
text = text[:-1]
|
| 91 |
+
if re.match(r'[^\.,!\?\-…~]', text[-1]):
|
| 92 |
+
text += '.'
|
| 93 |
+
return text
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def cjke_cleaners(text):
|
| 97 |
+
chinese_texts = re.findall(r'\[ZH\].*?\[ZH\]', text)
|
| 98 |
+
japanese_texts = re.findall(r'\[JA\].*?\[JA\]', text)
|
| 99 |
+
korean_texts = re.findall(r'\[KO\].*?\[KO\]', text)
|
| 100 |
+
english_texts = re.findall(r'\[EN\].*?\[EN\]', text)
|
| 101 |
+
for chinese_text in chinese_texts:
|
| 102 |
+
cleaned_text = chinese_to_lazy_ipa(chinese_text[4:-4])
|
| 103 |
+
cleaned_text = cleaned_text.replace(
|
| 104 |
+
'ʧ', 'tʃ').replace('ʦ', 'ts').replace('ɥan', 'ɥæn')
|
| 105 |
+
text = text.replace(chinese_text, cleaned_text+' ', 1)
|
| 106 |
+
for japanese_text in japanese_texts:
|
| 107 |
+
cleaned_text = japanese_to_ipa(japanese_text[4:-4])
|
| 108 |
+
cleaned_text = cleaned_text.replace('ʧ', 'tʃ').replace(
|
| 109 |
+
'ʦ', 'ts').replace('ɥan', 'ɥæn').replace('ʥ', 'dz')
|
| 110 |
+
text = text.replace(japanese_text, cleaned_text+' ', 1)
|
| 111 |
+
for korean_text in korean_texts:
|
| 112 |
+
cleaned_text = korean_to_ipa(korean_text[4:-4])
|
| 113 |
+
text = text.replace(korean_text, cleaned_text+' ', 1)
|
| 114 |
+
for english_text in english_texts:
|
| 115 |
+
cleaned_text = english_to_ipa2(english_text[4:-4])
|
| 116 |
+
cleaned_text = cleaned_text.replace('ɑ', 'a').replace(
|
| 117 |
+
'ɔ', 'o').replace('ɛ', 'e').replace('ɪ', 'i').replace('ʊ', 'u')
|
| 118 |
+
text = text.replace(english_text, cleaned_text+' ', 1)
|
| 119 |
+
text = text[:-1]
|
| 120 |
+
if re.match(r'[^\.,!\?\-…~]', text[-1]):
|
| 121 |
+
text += '.'
|
| 122 |
+
return text
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def cjke_cleaners2(text):
|
| 126 |
+
chinese_texts = re.findall(r'\[ZH\].*?\[ZH\]', text)
|
| 127 |
+
japanese_texts = re.findall(r'\[JA\].*?\[JA\]', text)
|
| 128 |
+
korean_texts = re.findall(r'\[KO\].*?\[KO\]', text)
|
| 129 |
+
english_texts = re.findall(r'\[EN\].*?\[EN\]', text)
|
| 130 |
+
for chinese_text in chinese_texts:
|
| 131 |
+
cleaned_text = chinese_to_ipa(chinese_text[4:-4])
|
| 132 |
+
text = text.replace(chinese_text, cleaned_text+' ', 1)
|
| 133 |
+
for japanese_text in japanese_texts:
|
| 134 |
+
cleaned_text = japanese_to_ipa2(japanese_text[4:-4])
|
| 135 |
+
text = text.replace(japanese_text, cleaned_text+' ', 1)
|
| 136 |
+
for korean_text in korean_texts:
|
| 137 |
+
cleaned_text = korean_to_ipa(korean_text[4:-4])
|
| 138 |
+
text = text.replace(korean_text, cleaned_text+' ', 1)
|
| 139 |
+
for english_text in english_texts:
|
| 140 |
+
cleaned_text = english_to_ipa2(english_text[4:-4])
|
| 141 |
+
text = text.replace(english_text, cleaned_text+' ', 1)
|
| 142 |
+
text = text[:-1]
|
| 143 |
+
if re.match(r'[^\.,!\?\-…~]', text[-1]):
|
| 144 |
+
text += '.'
|
| 145 |
+
return text
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def thai_cleaners(text):
|
| 149 |
+
text = num_to_thai(text)
|
| 150 |
+
text = latin_to_thai(text)
|
| 151 |
+
return text
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def shanghainese_cleaners(text):
|
| 155 |
+
text = shanghainese_to_ipa(text)
|
| 156 |
+
if re.match(r'[^\.,!\?\-…~]', text[-1]):
|
| 157 |
+
text += '.'
|
| 158 |
+
return text
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def chinese_dialect_cleaners(text):
|
| 162 |
+
text = re.sub(r'\[MD\](.*?)\[MD\]',
|
| 163 |
+
lambda x: chinese_to_ipa2(x.group(1))+' ', text)
|
| 164 |
+
text = re.sub(r'\[TW\](.*?)\[TW\]',
|
| 165 |
+
lambda x: chinese_to_ipa2(x.group(1), True)+' ', text)
|
| 166 |
+
text = re.sub(r'\[JA\](.*?)\[JA\]',
|
| 167 |
+
lambda x: japanese_to_ipa3(x.group(1)).replace('Q', 'ʔ')+' ', text)
|
| 168 |
+
text = re.sub(r'\[SH\](.*?)\[SH\]', lambda x: shanghainese_to_ipa(x.group(1)).replace('1', '˥˧').replace('5',
|
| 169 |
+
'˧˧˦').replace('6', '˩˩˧').replace('7', '˥').replace('8', '˩˨').replace('ᴀ', 'ɐ').replace('ᴇ', 'e')+' ', text)
|
| 170 |
+
text = re.sub(r'\[GD\](.*?)\[GD\]',
|
| 171 |
+
lambda x: cantonese_to_ipa(x.group(1))+' ', text)
|
| 172 |
+
text = re.sub(r'\[EN\](.*?)\[EN\]',
|
| 173 |
+
lambda x: english_to_lazy_ipa2(x.group(1))+' ', text)
|
| 174 |
+
text = re.sub(r'\[([A-Z]{2})\](.*?)\[\1\]', lambda x: ngu_dialect_to_ipa(x.group(2), x.group(
|
| 175 |
+
1)).replace('ʣ', 'dz').replace('ʥ', 'dʑ').replace('ʦ', 'ts').replace('ʨ', 'tɕ')+' ', text)
|
| 176 |
+
text = re.sub(r'\s+$', '', text)
|
| 177 |
+
text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
|
| 178 |
+
return text
|
text/japanese.py
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from unidecode import unidecode
|
| 3 |
+
import pyopenjtalk
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# Regular expression matching Japanese without punctuation marks:
|
| 7 |
+
_japanese_characters = re.compile(
|
| 8 |
+
r'[A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 9 |
+
|
| 10 |
+
# Regular expression matching non-Japanese characters or punctuation marks:
|
| 11 |
+
_japanese_marks = re.compile(
|
| 12 |
+
r'[^A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 13 |
+
|
| 14 |
+
# List of (symbol, Japanese) pairs for marks:
|
| 15 |
+
_symbols_to_japanese = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 16 |
+
('%', 'パーセント')
|
| 17 |
+
]]
|
| 18 |
+
|
| 19 |
+
# List of (romaji, ipa) pairs for marks:
|
| 20 |
+
_romaji_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 21 |
+
('ts', 'ʦ'),
|
| 22 |
+
('u', 'ɯ'),
|
| 23 |
+
('j', 'ʥ'),
|
| 24 |
+
('y', 'j'),
|
| 25 |
+
('ni', 'n^i'),
|
| 26 |
+
('nj', 'n^'),
|
| 27 |
+
('hi', 'çi'),
|
| 28 |
+
('hj', 'ç'),
|
| 29 |
+
('f', 'ɸ'),
|
| 30 |
+
('I', 'i*'),
|
| 31 |
+
('U', 'ɯ*'),
|
| 32 |
+
('r', 'ɾ')
|
| 33 |
+
]]
|
| 34 |
+
|
| 35 |
+
# List of (romaji, ipa2) pairs for marks:
|
| 36 |
+
_romaji_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 37 |
+
('u', 'ɯ'),
|
| 38 |
+
('ʧ', 'tʃ'),
|
| 39 |
+
('j', 'dʑ'),
|
| 40 |
+
('y', 'j'),
|
| 41 |
+
('ni', 'n^i'),
|
| 42 |
+
('nj', 'n^'),
|
| 43 |
+
('hi', 'çi'),
|
| 44 |
+
('hj', 'ç'),
|
| 45 |
+
('f', 'ɸ'),
|
| 46 |
+
('I', 'i*'),
|
| 47 |
+
('U', 'ɯ*'),
|
| 48 |
+
('r', 'ɾ')
|
| 49 |
+
]]
|
| 50 |
+
|
| 51 |
+
# List of (consonant, sokuon) pairs:
|
| 52 |
+
_real_sokuon = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 53 |
+
(r'Q([↑↓]*[kg])', r'k#\1'),
|
| 54 |
+
(r'Q([↑↓]*[tdjʧ])', r't#\1'),
|
| 55 |
+
(r'Q([↑↓]*[sʃ])', r's\1'),
|
| 56 |
+
(r'Q([↑↓]*[pb])', r'p#\1')
|
| 57 |
+
]]
|
| 58 |
+
|
| 59 |
+
# List of (consonant, hatsuon) pairs:
|
| 60 |
+
_real_hatsuon = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 61 |
+
(r'N([↑↓]*[pbm])', r'm\1'),
|
| 62 |
+
(r'N([↑↓]*[ʧʥj])', r'n^\1'),
|
| 63 |
+
(r'N([↑↓]*[tdn])', r'n\1'),
|
| 64 |
+
(r'N([↑↓]*[kg])', r'ŋ\1')
|
| 65 |
+
]]
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def symbols_to_japanese(text):
|
| 69 |
+
for regex, replacement in _symbols_to_japanese:
|
| 70 |
+
text = re.sub(regex, replacement, text)
|
| 71 |
+
return text
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def japanese_to_romaji_with_accent(text):
|
| 75 |
+
'''Reference https://r9y9.github.io/ttslearn/latest/notebooks/ch10_Recipe-Tacotron.html'''
|
| 76 |
+
text = symbols_to_japanese(text)
|
| 77 |
+
sentences = re.split(_japanese_marks, text)
|
| 78 |
+
marks = re.findall(_japanese_marks, text)
|
| 79 |
+
text = ''
|
| 80 |
+
for i, sentence in enumerate(sentences):
|
| 81 |
+
if re.match(_japanese_characters, sentence):
|
| 82 |
+
if text != '':
|
| 83 |
+
text += ' '
|
| 84 |
+
labels = pyopenjtalk.extract_fullcontext(sentence)
|
| 85 |
+
for n, label in enumerate(labels):
|
| 86 |
+
phoneme = re.search(r'\-([^\+]*)\+', label).group(1)
|
| 87 |
+
if phoneme not in ['sil', 'pau']:
|
| 88 |
+
text += phoneme.replace('ch', 'ʧ').replace('sh',
|
| 89 |
+
'ʃ').replace('cl', 'Q')
|
| 90 |
+
else:
|
| 91 |
+
continue
|
| 92 |
+
# n_moras = int(re.search(r'/F:(\d+)_', label).group(1))
|
| 93 |
+
a1 = int(re.search(r"/A:(\-?[0-9]+)\+", label).group(1))
|
| 94 |
+
a2 = int(re.search(r"\+(\d+)\+", label).group(1))
|
| 95 |
+
a3 = int(re.search(r"\+(\d+)/", label).group(1))
|
| 96 |
+
if re.search(r'\-([^\+]*)\+', labels[n + 1]).group(1) in ['sil', 'pau']:
|
| 97 |
+
a2_next = -1
|
| 98 |
+
else:
|
| 99 |
+
a2_next = int(
|
| 100 |
+
re.search(r"\+(\d+)\+", labels[n + 1]).group(1))
|
| 101 |
+
# Accent phrase boundary
|
| 102 |
+
if a3 == 1 and a2_next == 1:
|
| 103 |
+
text += ' '
|
| 104 |
+
# Falling
|
| 105 |
+
elif a1 == 0 and a2_next == a2 + 1:
|
| 106 |
+
text += '↓'
|
| 107 |
+
# Rising
|
| 108 |
+
elif a2 == 1 and a2_next == 2:
|
| 109 |
+
text += '↑'
|
| 110 |
+
if i < len(marks):
|
| 111 |
+
text += unidecode(marks[i]).replace(' ', '')
|
| 112 |
+
return text
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def get_real_sokuon(text):
|
| 116 |
+
for regex, replacement in _real_sokuon:
|
| 117 |
+
text = re.sub(regex, replacement, text)
|
| 118 |
+
return text
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def get_real_hatsuon(text):
|
| 122 |
+
for regex, replacement in _real_hatsuon:
|
| 123 |
+
text = re.sub(regex, replacement, text)
|
| 124 |
+
return text
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def japanese_to_ipa(text):
|
| 128 |
+
text = japanese_to_romaji_with_accent(text).replace('...', '…')
|
| 129 |
+
text = re.sub(
|
| 130 |
+
r'([aiueo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
|
| 131 |
+
text = get_real_sokuon(text)
|
| 132 |
+
text = get_real_hatsuon(text)
|
| 133 |
+
for regex, replacement in _romaji_to_ipa:
|
| 134 |
+
text = re.sub(regex, replacement, text)
|
| 135 |
+
return text
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def japanese_to_ipa2(text):
|
| 139 |
+
text = japanese_to_romaji_with_accent(text).replace('...', '…')
|
| 140 |
+
text = get_real_sokuon(text)
|
| 141 |
+
text = get_real_hatsuon(text)
|
| 142 |
+
for regex, replacement in _romaji_to_ipa2:
|
| 143 |
+
text = re.sub(regex, replacement, text)
|
| 144 |
+
return text
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def japanese_to_ipa3(text):
|
| 148 |
+
text = japanese_to_ipa2(text).replace('n^', 'ȵ').replace(
|
| 149 |
+
'ʃ', 'ɕ').replace('*', '\u0325').replace('#', '\u031a')
|
| 150 |
+
text = re.sub(
|
| 151 |
+
r'([aiɯeo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
|
| 152 |
+
text = re.sub(r'((?:^|\s)(?:ts|tɕ|[kpt]))', r'\1ʰ', text)
|
| 153 |
+
return text
|
text/mandarin.py
ADDED
|
@@ -0,0 +1,328 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import re
|
| 4 |
+
from pypinyin import lazy_pinyin, BOPOMOFO
|
| 5 |
+
import jieba
|
| 6 |
+
import cn2an
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
# List of (Latin alphabet, bopomofo) pairs:
|
| 10 |
+
_latin_to_bopomofo = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 11 |
+
('a', 'ㄟˉ'),
|
| 12 |
+
('b', 'ㄅㄧˋ'),
|
| 13 |
+
('c', 'ㄙㄧˉ'),
|
| 14 |
+
('d', 'ㄉㄧˋ'),
|
| 15 |
+
('e', 'ㄧˋ'),
|
| 16 |
+
('f', 'ㄝˊㄈㄨˋ'),
|
| 17 |
+
('g', 'ㄐㄧˋ'),
|
| 18 |
+
('h', 'ㄝˇㄑㄩˋ'),
|
| 19 |
+
('i', 'ㄞˋ'),
|
| 20 |
+
('j', 'ㄐㄟˋ'),
|
| 21 |
+
('k', 'ㄎㄟˋ'),
|
| 22 |
+
('l', 'ㄝˊㄛˋ'),
|
| 23 |
+
('m', 'ㄝˊㄇㄨˋ'),
|
| 24 |
+
('n', 'ㄣˉ'),
|
| 25 |
+
('o', 'ㄡˉ'),
|
| 26 |
+
('p', 'ㄆㄧˉ'),
|
| 27 |
+
('q', 'ㄎㄧㄡˉ'),
|
| 28 |
+
('r', 'ㄚˋ'),
|
| 29 |
+
('s', 'ㄝˊㄙˋ'),
|
| 30 |
+
('t', 'ㄊㄧˋ'),
|
| 31 |
+
('u', 'ㄧㄡˉ'),
|
| 32 |
+
('v', 'ㄨㄧˉ'),
|
| 33 |
+
('w', 'ㄉㄚˋㄅㄨˋㄌㄧㄡˋ'),
|
| 34 |
+
('x', 'ㄝˉㄎㄨˋㄙˋ'),
|
| 35 |
+
('y', 'ㄨㄞˋ'),
|
| 36 |
+
('z', 'ㄗㄟˋ')
|
| 37 |
+
]]
|
| 38 |
+
|
| 39 |
+
# List of (bopomofo, romaji) pairs:
|
| 40 |
+
_bopomofo_to_romaji = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 41 |
+
('ㄅㄛ', 'p⁼wo'),
|
| 42 |
+
('ㄆㄛ', 'pʰwo'),
|
| 43 |
+
('ㄇㄛ', 'mwo'),
|
| 44 |
+
('ㄈㄛ', 'fwo'),
|
| 45 |
+
('ㄅ', 'p⁼'),
|
| 46 |
+
('ㄆ', 'pʰ'),
|
| 47 |
+
('ㄇ', 'm'),
|
| 48 |
+
('ㄈ', 'f'),
|
| 49 |
+
('ㄉ', 't⁼'),
|
| 50 |
+
('ㄊ', 'tʰ'),
|
| 51 |
+
('ㄋ', 'n'),
|
| 52 |
+
('ㄌ', 'l'),
|
| 53 |
+
('ㄍ', 'k⁼'),
|
| 54 |
+
('ㄎ', 'kʰ'),
|
| 55 |
+
('ㄏ', 'h'),
|
| 56 |
+
('ㄐ', 'ʧ⁼'),
|
| 57 |
+
('ㄑ', 'ʧʰ'),
|
| 58 |
+
('ㄒ', 'ʃ'),
|
| 59 |
+
('ㄓ', 'ʦ`⁼'),
|
| 60 |
+
('ㄔ', 'ʦ`ʰ'),
|
| 61 |
+
('ㄕ', 's`'),
|
| 62 |
+
('ㄖ', 'ɹ`'),
|
| 63 |
+
('ㄗ', 'ʦ⁼'),
|
| 64 |
+
('ㄘ', 'ʦʰ'),
|
| 65 |
+
('ㄙ', 's'),
|
| 66 |
+
('ㄚ', 'a'),
|
| 67 |
+
('ㄛ', 'o'),
|
| 68 |
+
('ㄜ', 'ə'),
|
| 69 |
+
('ㄝ', 'e'),
|
| 70 |
+
('ㄞ', 'ai'),
|
| 71 |
+
('ㄟ', 'ei'),
|
| 72 |
+
('ㄠ', 'au'),
|
| 73 |
+
('ㄡ', 'ou'),
|
| 74 |
+
('ㄧㄢ', 'yeNN'),
|
| 75 |
+
('ㄢ', 'aNN'),
|
| 76 |
+
('ㄧㄣ', 'iNN'),
|
| 77 |
+
('ㄣ', 'əNN'),
|
| 78 |
+
('ㄤ', 'aNg'),
|
| 79 |
+
('ㄧㄥ', 'iNg'),
|
| 80 |
+
('ㄨㄥ', 'uNg'),
|
| 81 |
+
('ㄩㄥ', 'yuNg'),
|
| 82 |
+
('ㄥ', 'əNg'),
|
| 83 |
+
('ㄦ', 'əɻ'),
|
| 84 |
+
('ㄧ', 'i'),
|
| 85 |
+
('ㄨ', 'u'),
|
| 86 |
+
('ㄩ', 'ɥ'),
|
| 87 |
+
('ˉ', '→'),
|
| 88 |
+
('ˊ', '↑'),
|
| 89 |
+
('ˇ', '↓↑'),
|
| 90 |
+
('ˋ', '↓'),
|
| 91 |
+
('˙', ''),
|
| 92 |
+
(',', ','),
|
| 93 |
+
('。', '.'),
|
| 94 |
+
('!', '!'),
|
| 95 |
+
('?', '?'),
|
| 96 |
+
('—', '-')
|
| 97 |
+
]]
|
| 98 |
+
|
| 99 |
+
# List of (romaji, ipa) pairs:
|
| 100 |
+
_romaji_to_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 101 |
+
('ʃy', 'ʃ'),
|
| 102 |
+
('ʧʰy', 'ʧʰ'),
|
| 103 |
+
('ʧ⁼y', 'ʧ⁼'),
|
| 104 |
+
('NN', 'n'),
|
| 105 |
+
('Ng', 'ŋ'),
|
| 106 |
+
('y', 'j'),
|
| 107 |
+
('h', 'x')
|
| 108 |
+
]]
|
| 109 |
+
|
| 110 |
+
# List of (bopomofo, ipa) pairs:
|
| 111 |
+
_bopomofo_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 112 |
+
('ㄅㄛ', 'p⁼wo'),
|
| 113 |
+
('ㄆㄛ', 'pʰwo'),
|
| 114 |
+
('ㄇㄛ', 'mwo'),
|
| 115 |
+
('ㄈㄛ', 'fwo'),
|
| 116 |
+
('ㄅ', 'p⁼'),
|
| 117 |
+
('ㄆ', 'pʰ'),
|
| 118 |
+
('ㄇ', 'm'),
|
| 119 |
+
('ㄈ', 'f'),
|
| 120 |
+
('ㄉ', 't⁼'),
|
| 121 |
+
('ㄊ', 'tʰ'),
|
| 122 |
+
('ㄋ', 'n'),
|
| 123 |
+
('ㄌ', 'l'),
|
| 124 |
+
('ㄍ', 'k⁼'),
|
| 125 |
+
('ㄎ', 'kʰ'),
|
| 126 |
+
('ㄏ', 'x'),
|
| 127 |
+
('ㄐ', 'tʃ⁼'),
|
| 128 |
+
('ㄑ', 'tʃʰ'),
|
| 129 |
+
('ㄒ', 'ʃ'),
|
| 130 |
+
('ㄓ', 'ts`⁼'),
|
| 131 |
+
('ㄔ', 'ts`ʰ'),
|
| 132 |
+
('ㄕ', 's`'),
|
| 133 |
+
('ㄖ', 'ɹ`'),
|
| 134 |
+
('ㄗ', 'ts⁼'),
|
| 135 |
+
('ㄘ', 'tsʰ'),
|
| 136 |
+
('ㄙ', 's'),
|
| 137 |
+
('ㄚ', 'a'),
|
| 138 |
+
('ㄛ', 'o'),
|
| 139 |
+
('ㄜ', 'ə'),
|
| 140 |
+
('ㄝ', 'ɛ'),
|
| 141 |
+
('ㄞ', 'aɪ'),
|
| 142 |
+
('ㄟ', 'eɪ'),
|
| 143 |
+
('ㄠ', 'ɑʊ'),
|
| 144 |
+
('ㄡ', 'oʊ'),
|
| 145 |
+
('ㄧㄢ', 'jɛn'),
|
| 146 |
+
('ㄩㄢ', 'ɥæn'),
|
| 147 |
+
('ㄢ', 'an'),
|
| 148 |
+
('ㄧㄣ', 'in'),
|
| 149 |
+
('ㄩㄣ', 'ɥn'),
|
| 150 |
+
('ㄣ', 'ən'),
|
| 151 |
+
('ㄤ', 'ɑŋ'),
|
| 152 |
+
('ㄧㄥ', 'iŋ'),
|
| 153 |
+
('ㄨㄥ', 'ʊŋ'),
|
| 154 |
+
('ㄩㄥ', 'jʊŋ'),
|
| 155 |
+
('ㄥ', 'əŋ'),
|
| 156 |
+
('ㄦ', 'əɻ'),
|
| 157 |
+
('ㄧ', 'i'),
|
| 158 |
+
('ㄨ', 'u'),
|
| 159 |
+
('ㄩ', 'ɥ'),
|
| 160 |
+
('ˉ', '→'),
|
| 161 |
+
('ˊ', '↑'),
|
| 162 |
+
('ˇ', '↓↑'),
|
| 163 |
+
('ˋ', '↓'),
|
| 164 |
+
('˙', ''),
|
| 165 |
+
(',', ','),
|
| 166 |
+
('。', '.'),
|
| 167 |
+
('!', '!'),
|
| 168 |
+
('?', '?'),
|
| 169 |
+
('—', '-')
|
| 170 |
+
]]
|
| 171 |
+
|
| 172 |
+
# List of (bopomofo, ipa2) pairs:
|
| 173 |
+
_bopomofo_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 174 |
+
('ㄅㄛ', 'pwo'),
|
| 175 |
+
('ㄆㄛ', 'pʰwo'),
|
| 176 |
+
('ㄇㄛ', 'mwo'),
|
| 177 |
+
('ㄈㄛ', 'fwo'),
|
| 178 |
+
('ㄅ', 'p'),
|
| 179 |
+
('ㄆ', 'pʰ'),
|
| 180 |
+
('ㄇ', 'm'),
|
| 181 |
+
('ㄈ', 'f'),
|
| 182 |
+
('ㄉ', 't'),
|
| 183 |
+
('ㄊ', 'tʰ'),
|
| 184 |
+
('ㄋ', 'n'),
|
| 185 |
+
('ㄌ', 'l'),
|
| 186 |
+
('ㄍ', 'k'),
|
| 187 |
+
('ㄎ', 'kʰ'),
|
| 188 |
+
('ㄏ', 'h'),
|
| 189 |
+
('ㄐ', 'tɕ'),
|
| 190 |
+
('ㄑ', 'tɕʰ'),
|
| 191 |
+
('ㄒ', 'ɕ'),
|
| 192 |
+
('ㄓ', 'tʂ'),
|
| 193 |
+
('ㄔ', 'tʂʰ'),
|
| 194 |
+
('ㄕ', 'ʂ'),
|
| 195 |
+
('ㄖ', 'ɻ'),
|
| 196 |
+
('ㄗ', 'ts'),
|
| 197 |
+
('ㄘ', 'tsʰ'),
|
| 198 |
+
('ㄙ', 's'),
|
| 199 |
+
('ㄚ', 'a'),
|
| 200 |
+
('ㄛ', 'o'),
|
| 201 |
+
('ㄜ', 'ɤ'),
|
| 202 |
+
('ㄝ', 'ɛ'),
|
| 203 |
+
('ㄞ', 'aɪ'),
|
| 204 |
+
('ㄟ', 'eɪ'),
|
| 205 |
+
('ㄠ', 'ɑʊ'),
|
| 206 |
+
('ㄡ', 'oʊ'),
|
| 207 |
+
('ㄧㄢ', 'jɛn'),
|
| 208 |
+
('ㄩㄢ', 'yæn'),
|
| 209 |
+
('ㄢ', 'an'),
|
| 210 |
+
('ㄧㄣ', 'in'),
|
| 211 |
+
('ㄩㄣ', 'yn'),
|
| 212 |
+
('ㄣ', 'ən'),
|
| 213 |
+
('ㄤ', 'ɑŋ'),
|
| 214 |
+
('ㄧㄥ', 'iŋ'),
|
| 215 |
+
('ㄨㄥ', 'ʊŋ'),
|
| 216 |
+
('ㄩㄥ', 'jʊŋ'),
|
| 217 |
+
('ㄥ', 'ɤŋ'),
|
| 218 |
+
('ㄦ', 'əɻ'),
|
| 219 |
+
('ㄧ', 'i'),
|
| 220 |
+
('ㄨ', 'u'),
|
| 221 |
+
('ㄩ', 'y'),
|
| 222 |
+
('ˉ', '˥'),
|
| 223 |
+
('ˊ', '˧˥'),
|
| 224 |
+
('ˇ', '˨˩˦'),
|
| 225 |
+
('ˋ', '˥˩'),
|
| 226 |
+
('˙', ''),
|
| 227 |
+
(',', ','),
|
| 228 |
+
('。', '.'),
|
| 229 |
+
('!', '!'),
|
| 230 |
+
('?', '?'),
|
| 231 |
+
('—', '-')
|
| 232 |
+
]]
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def number_to_chinese(text):
|
| 236 |
+
numbers = re.findall(r'\d+(?:\.?\d+)?', text)
|
| 237 |
+
for number in numbers:
|
| 238 |
+
text = text.replace(number, cn2an.an2cn(number), 1)
|
| 239 |
+
return text
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def chinese_to_bopomofo(text, taiwanese=False):
|
| 243 |
+
text = text.replace('、', ',').replace(';', ',').replace(':', ',')
|
| 244 |
+
words = jieba.lcut(text, cut_all=False)
|
| 245 |
+
text = ''
|
| 246 |
+
for word in words:
|
| 247 |
+
bopomofos = lazy_pinyin(word, BOPOMOFO)
|
| 248 |
+
if not re.search('[\u4e00-\u9fff]', word):
|
| 249 |
+
text += word
|
| 250 |
+
continue
|
| 251 |
+
for i in range(len(bopomofos)):
|
| 252 |
+
bopomofos[i] = re.sub(r'([\u3105-\u3129])$', r'\1ˉ', bopomofos[i])
|
| 253 |
+
if text != '':
|
| 254 |
+
text += ' '
|
| 255 |
+
if taiwanese:
|
| 256 |
+
text += '#'+'#'.join(bopomofos)
|
| 257 |
+
else:
|
| 258 |
+
text += ''.join(bopomofos)
|
| 259 |
+
return text
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
def latin_to_bopomofo(text):
|
| 263 |
+
for regex, replacement in _latin_to_bopomofo:
|
| 264 |
+
text = re.sub(regex, replacement, text)
|
| 265 |
+
return text
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
def bopomofo_to_romaji(text):
|
| 269 |
+
for regex, replacement in _bopomofo_to_romaji:
|
| 270 |
+
text = re.sub(regex, replacement, text)
|
| 271 |
+
return text
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
def bopomofo_to_ipa(text):
|
| 275 |
+
for regex, replacement in _bopomofo_to_ipa:
|
| 276 |
+
text = re.sub(regex, replacement, text)
|
| 277 |
+
return text
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
def bopomofo_to_ipa2(text):
|
| 281 |
+
for regex, replacement in _bopomofo_to_ipa2:
|
| 282 |
+
text = re.sub(regex, replacement, text)
|
| 283 |
+
return text
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
def chinese_to_romaji(text):
|
| 287 |
+
text = number_to_chinese(text)
|
| 288 |
+
text = chinese_to_bopomofo(text)
|
| 289 |
+
text = latin_to_bopomofo(text)
|
| 290 |
+
text = bopomofo_to_romaji(text)
|
| 291 |
+
text = re.sub('i([aoe])', r'y\1', text)
|
| 292 |
+
text = re.sub('u([aoəe])', r'w\1', text)
|
| 293 |
+
text = re.sub('([ʦsɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
|
| 294 |
+
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
|
| 295 |
+
text = re.sub('([ʦs][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
|
| 296 |
+
return text
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
def chinese_to_lazy_ipa(text):
|
| 300 |
+
text = chinese_to_romaji(text)
|
| 301 |
+
for regex, replacement in _romaji_to_ipa:
|
| 302 |
+
text = re.sub(regex, replacement, text)
|
| 303 |
+
return text
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
def chinese_to_ipa(text):
|
| 307 |
+
text = number_to_chinese(text)
|
| 308 |
+
text = chinese_to_bopomofo(text)
|
| 309 |
+
text = latin_to_bopomofo(text)
|
| 310 |
+
text = bopomofo_to_ipa(text)
|
| 311 |
+
text = re.sub('i([aoe])', r'j\1', text)
|
| 312 |
+
text = re.sub('u([aoəe])', r'w\1', text)
|
| 313 |
+
text = re.sub('([sɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
|
| 314 |
+
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
|
| 315 |
+
text = re.sub('([s][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
|
| 316 |
+
return text
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def chinese_to_ipa2(text, taiwanese=False):
|
| 320 |
+
text = number_to_chinese(text)
|
| 321 |
+
text = chinese_to_bopomofo(text, taiwanese)
|
| 322 |
+
text = latin_to_bopomofo(text)
|
| 323 |
+
text = bopomofo_to_ipa2(text)
|
| 324 |
+
text = re.sub(r'i([aoe])', r'j\1', text)
|
| 325 |
+
text = re.sub(r'u([aoəe])', r'w\1', text)
|
| 326 |
+
text = re.sub(r'([ʂɹ]ʰ?)([˩˨˧˦˥ ]+|$)', r'\1ʅ\2', text)
|
| 327 |
+
text = re.sub(r'(sʰ?)([˩˨˧˦˥ ]+|$)', r'\1ɿ\2', text)
|
| 328 |
+
return text
|
text/symbols.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Defines the set of symbols used in text input to the model.
|
| 3 |
+
'''
|
| 4 |
+
|
| 5 |
+
_pad = '_'
|
| 6 |
+
_punctuation = ',.!?-'
|
| 7 |
+
_letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧ↓↑ '
|
| 8 |
+
|
| 9 |
+
'''
|
| 10 |
+
# japanese_cleaners2
|
| 11 |
+
_pad = '_'
|
| 12 |
+
_punctuation = ',.!?-~…'
|
| 13 |
+
_letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ '
|
| 14 |
+
'''
|
| 15 |
+
|
| 16 |
+
'''# korean_cleaners
|
| 17 |
+
_pad = '_'
|
| 18 |
+
_punctuation = ',.!?…~'
|
| 19 |
+
_letters = 'ㄱㄴㄷㄹㅁㅂㅅㅇㅈㅊㅋㅌㅍㅎㄲㄸㅃㅆㅉㅏㅓㅗㅜㅡㅣㅐㅔ '
|
| 20 |
+
'''
|
| 21 |
+
|
| 22 |
+
'''# chinese_cleaners
|
| 23 |
+
_pad = '_'
|
| 24 |
+
_punctuation = ',。!?—…'
|
| 25 |
+
_letters = 'ㄅㄆㄇㄈㄉㄊㄋㄌㄍㄎㄏㄐㄑㄒㄓㄔㄕㄖㄗㄘㄙㄚㄛㄜㄝㄞㄟㄠㄡㄢㄣㄤㄥㄦㄧㄨㄩˉˊˇˋ˙ '
|
| 26 |
+
'''
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
'''# sanskrit_cleaners
|
| 30 |
+
_pad = '_'
|
| 31 |
+
_punctuation = '।'
|
| 32 |
+
_letters = 'ँंःअआइईउऊऋएऐओऔकखगघङचछजझञटठडढणतथदधनपफबभमयरलळवशषसहऽािीुूृॄेैोौ्ॠॢ '
|
| 33 |
+
'''
|
| 34 |
+
|
| 35 |
+
'''# cjks_cleaners
|
| 36 |
+
_pad = '_'
|
| 37 |
+
_punctuation = ',.!?-~…'
|
| 38 |
+
_letters = 'NQabdefghijklmnopstuvwxyzʃʧʥʦɯɹəɥçɸɾβŋɦː⁼ʰ`^#*=→↓↑ '
|
| 39 |
+
'''
|
| 40 |
+
|
| 41 |
+
'''# thai_cleaners
|
| 42 |
+
_pad = '_'
|
| 43 |
+
_punctuation = '.!? '
|
| 44 |
+
_letters = 'กขฃคฆงจฉชซฌญฎฏฐฑฒณดตถทธนบปผฝพฟภมยรฤลวศษสหฬอฮฯะัาำิีึืุูเแโใไๅๆ็่้๊๋์'
|
| 45 |
+
'''
|
| 46 |
+
|
| 47 |
+
'''# cjke_cleaners2
|
| 48 |
+
_pad = '_'
|
| 49 |
+
_punctuation = ',.!?-~…'
|
| 50 |
+
_letters = 'NQabdefghijklmnopstuvwxyzɑæʃʑçɯɪɔɛɹðəɫɥɸʊɾʒθβŋɦ⁼ʰ`^#*=ˈˌ→↓↑ '
|
| 51 |
+
'''
|
| 52 |
+
|
| 53 |
+
'''# shanghainese_cleaners
|
| 54 |
+
_pad = '_'
|
| 55 |
+
_punctuation = ',.!?…'
|
| 56 |
+
_letters = 'abdfghiklmnopstuvyzøŋȵɑɔɕəɤɦɪɿʑʔʰ̩̃ᴀᴇ15678 '
|
| 57 |
+
'''
|
| 58 |
+
|
| 59 |
+
'''# chinese_dialect_cleaners
|
| 60 |
+
_pad = '_'
|
| 61 |
+
_punctuation = ',.!?~…─'
|
| 62 |
+
_letters = '#Nabdefghijklmnoprstuvwxyzæçøŋœȵɐɑɒɓɔɕɗɘəɚɛɜɣɤɦɪɭɯɵɷɸɻɾɿʂʅʊʋʌʏʑʔʦʮʰʷˀː˥˦˧˨˩̥̩̃̚αᴀᴇ↑↓∅ⱼ '
|
| 63 |
+
'''
|
| 64 |
+
|
| 65 |
+
# Export all symbols:
|
| 66 |
+
symbols = [_pad] + list(_punctuation) + list(_letters)
|
| 67 |
+
|
| 68 |
+
# Special symbol ids
|
| 69 |
+
SPACE_ID = symbols.index(" ")
|
train_ms.py
ADDED
|
@@ -0,0 +1,296 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import argparse
|
| 4 |
+
import itertools
|
| 5 |
+
import math
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn, optim
|
| 8 |
+
from torch.nn import functional as F
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 11 |
+
import torch.multiprocessing as mp
|
| 12 |
+
import torch.distributed as dist
|
| 13 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 14 |
+
from torch.cuda.amp import autocast, GradScaler
|
| 15 |
+
|
| 16 |
+
import commons
|
| 17 |
+
import utils
|
| 18 |
+
from data_utils import (
|
| 19 |
+
TextAudioSpeakerLoader,
|
| 20 |
+
TextAudioSpeakerCollate,
|
| 21 |
+
DistributedBucketSampler
|
| 22 |
+
)
|
| 23 |
+
from models import (
|
| 24 |
+
SynthesizerTrn,
|
| 25 |
+
MultiPeriodDiscriminator,
|
| 26 |
+
)
|
| 27 |
+
from losses import (
|
| 28 |
+
generator_loss,
|
| 29 |
+
discriminator_loss,
|
| 30 |
+
feature_loss,
|
| 31 |
+
kl_loss
|
| 32 |
+
)
|
| 33 |
+
from mel_processing import mel_spectrogram_torch, spec_to_mel_torch
|
| 34 |
+
from text.symbols import symbols
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
torch.backends.cudnn.benchmark = True
|
| 38 |
+
global_step = 0
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main():
|
| 42 |
+
"""Assume Single Node Multi GPUs Training Only"""
|
| 43 |
+
assert torch.cuda.is_available(), "CPU training is not allowed."
|
| 44 |
+
|
| 45 |
+
n_gpus = torch.cuda.device_count()
|
| 46 |
+
os.environ['MASTER_ADDR'] = 'localhost'
|
| 47 |
+
os.environ['MASTER_PORT'] = '8899'
|
| 48 |
+
|
| 49 |
+
hps = utils.get_hparams()
|
| 50 |
+
mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def run(rank, n_gpus, hps):
|
| 54 |
+
global global_step
|
| 55 |
+
if rank == 0:
|
| 56 |
+
logger = utils.get_logger(hps.model_dir)
|
| 57 |
+
print(hps) or logger.info(hps)
|
| 58 |
+
utils.check_git_hash(hps.model_dir)
|
| 59 |
+
writer = SummaryWriter(log_dir=hps.model_dir)
|
| 60 |
+
writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
|
| 61 |
+
|
| 62 |
+
dist.init_process_group(backend='nccl', init_method='env://', world_size=n_gpus, rank=rank)
|
| 63 |
+
torch.manual_seed(hps.train.seed)
|
| 64 |
+
torch.cuda.set_device(rank)
|
| 65 |
+
|
| 66 |
+
train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps.data)
|
| 67 |
+
train_sampler = DistributedBucketSampler(
|
| 68 |
+
train_dataset,
|
| 69 |
+
hps.train.batch_size,
|
| 70 |
+
[32,300,400,500,600,700,800,900,1000],
|
| 71 |
+
num_replicas=n_gpus,
|
| 72 |
+
rank=rank,
|
| 73 |
+
shuffle=True)
|
| 74 |
+
collate_fn = TextAudioSpeakerCollate()
|
| 75 |
+
train_loader = DataLoader(train_dataset, num_workers=8, shuffle=False, pin_memory=True,
|
| 76 |
+
collate_fn=collate_fn, batch_sampler=train_sampler)
|
| 77 |
+
if rank == 0:
|
| 78 |
+
eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps.data)
|
| 79 |
+
eval_loader = DataLoader(eval_dataset, num_workers=8, shuffle=False,
|
| 80 |
+
batch_size=hps.train.batch_size, pin_memory=True,
|
| 81 |
+
drop_last=False, collate_fn=collate_fn)
|
| 82 |
+
|
| 83 |
+
net_g = SynthesizerTrn(
|
| 84 |
+
len(symbols),
|
| 85 |
+
hps.data.filter_length // 2 + 1,
|
| 86 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 87 |
+
n_speakers=hps.data.n_speakers,
|
| 88 |
+
**hps.model).cuda(rank)
|
| 89 |
+
net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
|
| 90 |
+
optim_g = torch.optim.AdamW(
|
| 91 |
+
net_g.parameters(),
|
| 92 |
+
hps.train.learning_rate,
|
| 93 |
+
betas=hps.train.betas,
|
| 94 |
+
eps=hps.train.eps)
|
| 95 |
+
optim_d = torch.optim.AdamW(
|
| 96 |
+
net_d.parameters(),
|
| 97 |
+
hps.train.learning_rate,
|
| 98 |
+
betas=hps.train.betas,
|
| 99 |
+
eps=hps.train.eps)
|
| 100 |
+
net_g = DDP(net_g, device_ids=[rank])
|
| 101 |
+
net_d = DDP(net_d, device_ids=[rank])
|
| 102 |
+
|
| 103 |
+
try:
|
| 104 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g)
|
| 105 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d, optim_d)
|
| 106 |
+
global_step = (epoch_str - 1) * len(train_loader)
|
| 107 |
+
except:
|
| 108 |
+
epoch_str = 1
|
| 109 |
+
global_step = 0
|
| 110 |
+
|
| 111 |
+
scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
|
| 112 |
+
scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
|
| 113 |
+
|
| 114 |
+
scaler = GradScaler(enabled=hps.train.fp16_run)
|
| 115 |
+
|
| 116 |
+
for epoch in range(epoch_str, hps.train.epochs + 1):
|
| 117 |
+
if rank==0:
|
| 118 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, eval_loader], logger, [writer, writer_eval])
|
| 119 |
+
else:
|
| 120 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, None], None, None)
|
| 121 |
+
scheduler_g.step()
|
| 122 |
+
scheduler_d.step()
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
|
| 126 |
+
net_g, net_d = nets
|
| 127 |
+
optim_g, optim_d = optims
|
| 128 |
+
scheduler_g, scheduler_d = schedulers
|
| 129 |
+
train_loader, eval_loader = loaders
|
| 130 |
+
if writers is not None:
|
| 131 |
+
writer, writer_eval = writers
|
| 132 |
+
|
| 133 |
+
train_loader.batch_sampler.set_epoch(epoch)
|
| 134 |
+
global global_step
|
| 135 |
+
|
| 136 |
+
net_g.train()
|
| 137 |
+
net_d.train()
|
| 138 |
+
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers, emo) in enumerate(train_loader):
|
| 139 |
+
x, x_lengths = x.cuda(rank, non_blocking=True), x_lengths.cuda(rank, non_blocking=True)
|
| 140 |
+
spec, spec_lengths = spec.cuda(rank, non_blocking=True), spec_lengths.cuda(rank, non_blocking=True)
|
| 141 |
+
y, y_lengths = y.cuda(rank, non_blocking=True), y_lengths.cuda(rank, non_blocking=True)
|
| 142 |
+
speakers = speakers.cuda(rank, non_blocking=True)
|
| 143 |
+
emo = emo.cuda(rank, non_blocking=True)
|
| 144 |
+
|
| 145 |
+
with autocast(enabled=hps.train.fp16_run):
|
| 146 |
+
y_hat, l_length, attn, ids_slice, x_mask, z_mask,\
|
| 147 |
+
(z, z_p, m_p, logs_p, m_q, logs_q) = net_g(x, x_lengths, spec, spec_lengths, speakers, emo)
|
| 148 |
+
|
| 149 |
+
mel = spec_to_mel_torch(
|
| 150 |
+
spec,
|
| 151 |
+
hps.data.filter_length,
|
| 152 |
+
hps.data.n_mel_channels,
|
| 153 |
+
hps.data.sampling_rate,
|
| 154 |
+
hps.data.mel_fmin,
|
| 155 |
+
hps.data.mel_fmax)
|
| 156 |
+
y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
|
| 157 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 158 |
+
y_hat.squeeze(1),
|
| 159 |
+
hps.data.filter_length,
|
| 160 |
+
hps.data.n_mel_channels,
|
| 161 |
+
hps.data.sampling_rate,
|
| 162 |
+
hps.data.hop_length,
|
| 163 |
+
hps.data.win_length,
|
| 164 |
+
hps.data.mel_fmin,
|
| 165 |
+
hps.data.mel_fmax
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
|
| 169 |
+
|
| 170 |
+
# Discriminator
|
| 171 |
+
y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
|
| 172 |
+
with autocast(enabled=False):
|
| 173 |
+
loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
|
| 174 |
+
loss_disc_all = loss_disc
|
| 175 |
+
optim_d.zero_grad()
|
| 176 |
+
scaler.scale(loss_disc_all).backward()
|
| 177 |
+
scaler.unscale_(optim_d)
|
| 178 |
+
grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
|
| 179 |
+
scaler.step(optim_d)
|
| 180 |
+
|
| 181 |
+
with autocast(enabled=hps.train.fp16_run):
|
| 182 |
+
# Generator
|
| 183 |
+
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
|
| 184 |
+
with autocast(enabled=False):
|
| 185 |
+
loss_dur = torch.sum(l_length.float())
|
| 186 |
+
loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
|
| 187 |
+
loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
|
| 188 |
+
|
| 189 |
+
loss_fm = feature_loss(fmap_r, fmap_g)
|
| 190 |
+
loss_gen, losses_gen = generator_loss(y_d_hat_g)
|
| 191 |
+
loss_gen_all = loss_gen + loss_fm + loss_mel + loss_dur + loss_kl
|
| 192 |
+
optim_g.zero_grad()
|
| 193 |
+
scaler.scale(loss_gen_all.float()).backward()
|
| 194 |
+
scaler.unscale_(optim_g)
|
| 195 |
+
grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
|
| 196 |
+
scaler.step(optim_g)
|
| 197 |
+
scaler.update()
|
| 198 |
+
|
| 199 |
+
if rank==0:
|
| 200 |
+
if global_step % hps.train.log_interval == 0:
|
| 201 |
+
lr = optim_g.param_groups[0]['lr']
|
| 202 |
+
losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_dur, loss_kl]
|
| 203 |
+
logger.info('Train Epoch: {} [{:.0f}%]'.format(
|
| 204 |
+
epoch,
|
| 205 |
+
100. * batch_idx / len(train_loader)))
|
| 206 |
+
print([x.item() for x in losses] + [global_step, lr]) or logger.info([x.item() for x in losses] + [global_step, lr])
|
| 207 |
+
|
| 208 |
+
scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr, "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
|
| 209 |
+
scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/dur": loss_dur, "loss/g/kl": loss_kl})
|
| 210 |
+
|
| 211 |
+
scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
|
| 212 |
+
scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
|
| 213 |
+
scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
|
| 214 |
+
image_dict = {
|
| 215 |
+
"slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
|
| 216 |
+
"slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
|
| 217 |
+
"all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()),
|
| 218 |
+
"all/attn": utils.plot_alignment_to_numpy(attn[0,0].data.cpu().numpy())
|
| 219 |
+
}
|
| 220 |
+
utils.summarize(
|
| 221 |
+
writer=writer,
|
| 222 |
+
global_step=global_step,
|
| 223 |
+
images=image_dict,
|
| 224 |
+
scalars=scalar_dict)
|
| 225 |
+
|
| 226 |
+
if global_step % hps.train.eval_interval == 0:
|
| 227 |
+
evaluate(hps, net_g, eval_loader, writer_eval)
|
| 228 |
+
utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
|
| 229 |
+
utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
|
| 230 |
+
global_step += 1
|
| 231 |
+
|
| 232 |
+
if rank == 0:
|
| 233 |
+
print('====> Epoch: {}'.format(epoch)) or logger.info('====> Epoch: {}'.format(epoch))
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def evaluate(hps, generator, eval_loader, writer_eval):
|
| 237 |
+
generator.eval()
|
| 238 |
+
with torch.no_grad():
|
| 239 |
+
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers, emo) in enumerate(eval_loader):
|
| 240 |
+
x, x_lengths = x.cuda(0), x_lengths.cuda(0)
|
| 241 |
+
spec, spec_lengths = spec.cuda(0), spec_lengths.cuda(0)
|
| 242 |
+
y, y_lengths = y.cuda(0), y_lengths.cuda(0)
|
| 243 |
+
speakers = speakers.cuda(0)
|
| 244 |
+
emo = emo.cuda(0)
|
| 245 |
+
# remove else
|
| 246 |
+
x = x[:1]
|
| 247 |
+
x_lengths = x_lengths[:1]
|
| 248 |
+
spec = spec[:1]
|
| 249 |
+
spec_lengths = spec_lengths[:1]
|
| 250 |
+
y = y[:1]
|
| 251 |
+
y_lengths = y_lengths[:1]
|
| 252 |
+
speakers = speakers[:1]
|
| 253 |
+
emo = emo[:1]
|
| 254 |
+
break
|
| 255 |
+
y_hat, attn, mask, *_ = generator.module.infer(x, x_lengths, speakers,emo, max_len=1000)
|
| 256 |
+
y_hat_lengths = mask.sum([1,2]).long() * hps.data.hop_length
|
| 257 |
+
|
| 258 |
+
mel = spec_to_mel_torch(
|
| 259 |
+
spec,
|
| 260 |
+
hps.data.filter_length,
|
| 261 |
+
hps.data.n_mel_channels,
|
| 262 |
+
hps.data.sampling_rate,
|
| 263 |
+
hps.data.mel_fmin,
|
| 264 |
+
hps.data.mel_fmax)
|
| 265 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 266 |
+
y_hat.squeeze(1).float(),
|
| 267 |
+
hps.data.filter_length,
|
| 268 |
+
hps.data.n_mel_channels,
|
| 269 |
+
hps.data.sampling_rate,
|
| 270 |
+
hps.data.hop_length,
|
| 271 |
+
hps.data.win_length,
|
| 272 |
+
hps.data.mel_fmin,
|
| 273 |
+
hps.data.mel_fmax
|
| 274 |
+
)
|
| 275 |
+
image_dict = {
|
| 276 |
+
"gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy())
|
| 277 |
+
}
|
| 278 |
+
audio_dict = {
|
| 279 |
+
"gen/audio": y_hat[0,:,:y_hat_lengths[0]]
|
| 280 |
+
}
|
| 281 |
+
if global_step == 0:
|
| 282 |
+
image_dict.update({"gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())})
|
| 283 |
+
audio_dict.update({"gt/audio": y[0,:,:y_lengths[0]]})
|
| 284 |
+
|
| 285 |
+
utils.summarize(
|
| 286 |
+
writer=writer_eval,
|
| 287 |
+
global_step=global_step,
|
| 288 |
+
images=image_dict,
|
| 289 |
+
audios=audio_dict,
|
| 290 |
+
audio_sampling_rate=hps.data.sampling_rate
|
| 291 |
+
)
|
| 292 |
+
generator.train()
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
if __name__ == "__main__":
|
| 296 |
+
main()
|
transforms.py
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
DEFAULT_MIN_BIN_WIDTH = 1e-3
|
| 8 |
+
DEFAULT_MIN_BIN_HEIGHT = 1e-3
|
| 9 |
+
DEFAULT_MIN_DERIVATIVE = 1e-3
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def piecewise_rational_quadratic_transform(inputs,
|
| 13 |
+
unnormalized_widths,
|
| 14 |
+
unnormalized_heights,
|
| 15 |
+
unnormalized_derivatives,
|
| 16 |
+
inverse=False,
|
| 17 |
+
tails=None,
|
| 18 |
+
tail_bound=1.,
|
| 19 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 20 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 21 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 22 |
+
|
| 23 |
+
if tails is None:
|
| 24 |
+
spline_fn = rational_quadratic_spline
|
| 25 |
+
spline_kwargs = {}
|
| 26 |
+
else:
|
| 27 |
+
spline_fn = unconstrained_rational_quadratic_spline
|
| 28 |
+
spline_kwargs = {
|
| 29 |
+
'tails': tails,
|
| 30 |
+
'tail_bound': tail_bound
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
outputs, logabsdet = spline_fn(
|
| 34 |
+
inputs=inputs,
|
| 35 |
+
unnormalized_widths=unnormalized_widths,
|
| 36 |
+
unnormalized_heights=unnormalized_heights,
|
| 37 |
+
unnormalized_derivatives=unnormalized_derivatives,
|
| 38 |
+
inverse=inverse,
|
| 39 |
+
min_bin_width=min_bin_width,
|
| 40 |
+
min_bin_height=min_bin_height,
|
| 41 |
+
min_derivative=min_derivative,
|
| 42 |
+
**spline_kwargs
|
| 43 |
+
)
|
| 44 |
+
return outputs, logabsdet
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def searchsorted(bin_locations, inputs, eps=1e-6):
|
| 48 |
+
bin_locations[..., -1] += eps
|
| 49 |
+
return torch.sum(
|
| 50 |
+
inputs[..., None] >= bin_locations,
|
| 51 |
+
dim=-1
|
| 52 |
+
) - 1
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def unconstrained_rational_quadratic_spline(inputs,
|
| 56 |
+
unnormalized_widths,
|
| 57 |
+
unnormalized_heights,
|
| 58 |
+
unnormalized_derivatives,
|
| 59 |
+
inverse=False,
|
| 60 |
+
tails='linear',
|
| 61 |
+
tail_bound=1.,
|
| 62 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 63 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 64 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 65 |
+
inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
|
| 66 |
+
outside_interval_mask = ~inside_interval_mask
|
| 67 |
+
|
| 68 |
+
outputs = torch.zeros_like(inputs)
|
| 69 |
+
logabsdet = torch.zeros_like(inputs)
|
| 70 |
+
|
| 71 |
+
if tails == 'linear':
|
| 72 |
+
unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
|
| 73 |
+
constant = np.log(np.exp(1 - min_derivative) - 1)
|
| 74 |
+
unnormalized_derivatives[..., 0] = constant
|
| 75 |
+
unnormalized_derivatives[..., -1] = constant
|
| 76 |
+
|
| 77 |
+
outputs[outside_interval_mask] = inputs[outside_interval_mask]
|
| 78 |
+
logabsdet[outside_interval_mask] = 0
|
| 79 |
+
else:
|
| 80 |
+
raise RuntimeError('{} tails are not implemented.'.format(tails))
|
| 81 |
+
|
| 82 |
+
outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
|
| 83 |
+
inputs=inputs[inside_interval_mask],
|
| 84 |
+
unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
|
| 85 |
+
unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
|
| 86 |
+
unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
|
| 87 |
+
inverse=inverse,
|
| 88 |
+
left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
|
| 89 |
+
min_bin_width=min_bin_width,
|
| 90 |
+
min_bin_height=min_bin_height,
|
| 91 |
+
min_derivative=min_derivative
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
return outputs, logabsdet
|
| 95 |
+
|
| 96 |
+
def rational_quadratic_spline(inputs,
|
| 97 |
+
unnormalized_widths,
|
| 98 |
+
unnormalized_heights,
|
| 99 |
+
unnormalized_derivatives,
|
| 100 |
+
inverse=False,
|
| 101 |
+
left=0., right=1., bottom=0., top=1.,
|
| 102 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 103 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 104 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 105 |
+
if torch.min(inputs) < left or torch.max(inputs) > right:
|
| 106 |
+
raise ValueError('Input to a transform is not within its domain')
|
| 107 |
+
|
| 108 |
+
num_bins = unnormalized_widths.shape[-1]
|
| 109 |
+
|
| 110 |
+
if min_bin_width * num_bins > 1.0:
|
| 111 |
+
raise ValueError('Minimal bin width too large for the number of bins')
|
| 112 |
+
if min_bin_height * num_bins > 1.0:
|
| 113 |
+
raise ValueError('Minimal bin height too large for the number of bins')
|
| 114 |
+
|
| 115 |
+
widths = F.softmax(unnormalized_widths, dim=-1)
|
| 116 |
+
widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
|
| 117 |
+
cumwidths = torch.cumsum(widths, dim=-1)
|
| 118 |
+
cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
|
| 119 |
+
cumwidths = (right - left) * cumwidths + left
|
| 120 |
+
cumwidths[..., 0] = left
|
| 121 |
+
cumwidths[..., -1] = right
|
| 122 |
+
widths = cumwidths[..., 1:] - cumwidths[..., :-1]
|
| 123 |
+
|
| 124 |
+
derivatives = min_derivative + F.softplus(unnormalized_derivatives)
|
| 125 |
+
|
| 126 |
+
heights = F.softmax(unnormalized_heights, dim=-1)
|
| 127 |
+
heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
|
| 128 |
+
cumheights = torch.cumsum(heights, dim=-1)
|
| 129 |
+
cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
|
| 130 |
+
cumheights = (top - bottom) * cumheights + bottom
|
| 131 |
+
cumheights[..., 0] = bottom
|
| 132 |
+
cumheights[..., -1] = top
|
| 133 |
+
heights = cumheights[..., 1:] - cumheights[..., :-1]
|
| 134 |
+
|
| 135 |
+
if inverse:
|
| 136 |
+
bin_idx = searchsorted(cumheights, inputs)[..., None]
|
| 137 |
+
else:
|
| 138 |
+
bin_idx = searchsorted(cumwidths, inputs)[..., None]
|
| 139 |
+
|
| 140 |
+
input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
|
| 141 |
+
input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
|
| 142 |
+
|
| 143 |
+
input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
|
| 144 |
+
delta = heights / widths
|
| 145 |
+
input_delta = delta.gather(-1, bin_idx)[..., 0]
|
| 146 |
+
|
| 147 |
+
input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
|
| 148 |
+
input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
|
| 149 |
+
|
| 150 |
+
input_heights = heights.gather(-1, bin_idx)[..., 0]
|
| 151 |
+
|
| 152 |
+
if inverse:
|
| 153 |
+
a = (((inputs - input_cumheights) * (input_derivatives
|
| 154 |
+
+ input_derivatives_plus_one
|
| 155 |
+
- 2 * input_delta)
|
| 156 |
+
+ input_heights * (input_delta - input_derivatives)))
|
| 157 |
+
b = (input_heights * input_derivatives
|
| 158 |
+
- (inputs - input_cumheights) * (input_derivatives
|
| 159 |
+
+ input_derivatives_plus_one
|
| 160 |
+
- 2 * input_delta))
|
| 161 |
+
c = - input_delta * (inputs - input_cumheights)
|
| 162 |
+
|
| 163 |
+
discriminant = b.pow(2) - 4 * a * c
|
| 164 |
+
assert (discriminant >= 0).all()
|
| 165 |
+
|
| 166 |
+
root = (2 * c) / (-b - torch.sqrt(discriminant))
|
| 167 |
+
outputs = root * input_bin_widths + input_cumwidths
|
| 168 |
+
|
| 169 |
+
theta_one_minus_theta = root * (1 - root)
|
| 170 |
+
denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 171 |
+
* theta_one_minus_theta)
|
| 172 |
+
derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
|
| 173 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 174 |
+
+ input_derivatives * (1 - root).pow(2))
|
| 175 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 176 |
+
|
| 177 |
+
return outputs, -logabsdet
|
| 178 |
+
else:
|
| 179 |
+
theta = (inputs - input_cumwidths) / input_bin_widths
|
| 180 |
+
theta_one_minus_theta = theta * (1 - theta)
|
| 181 |
+
|
| 182 |
+
numerator = input_heights * (input_delta * theta.pow(2)
|
| 183 |
+
+ input_derivatives * theta_one_minus_theta)
|
| 184 |
+
denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 185 |
+
* theta_one_minus_theta)
|
| 186 |
+
outputs = input_cumheights + numerator / denominator
|
| 187 |
+
|
| 188 |
+
derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
|
| 189 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 190 |
+
+ input_derivatives * (1 - theta).pow(2))
|
| 191 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 192 |
+
|
| 193 |
+
return outputs, logabsdet
|
utils.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
import sys
|
| 4 |
+
import argparse
|
| 5 |
+
import logging
|
| 6 |
+
import json
|
| 7 |
+
import subprocess
|
| 8 |
+
import numpy as np
|
| 9 |
+
from scipy.io.wavfile import read
|
| 10 |
+
import torch
|
| 11 |
+
|
| 12 |
+
MATPLOTLIB_FLAG = False
|
| 13 |
+
|
| 14 |
+
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
|
| 15 |
+
logger = logging
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def load_checkpoint(checkpoint_path, model, optimizer=None):
|
| 19 |
+
assert os.path.isfile(checkpoint_path)
|
| 20 |
+
checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
|
| 21 |
+
iteration = checkpoint_dict['iteration']
|
| 22 |
+
learning_rate = checkpoint_dict['learning_rate']
|
| 23 |
+
if optimizer is not None:
|
| 24 |
+
optimizer.load_state_dict(checkpoint_dict['optimizer'])
|
| 25 |
+
saved_state_dict = checkpoint_dict['model']
|
| 26 |
+
if hasattr(model, 'module'):
|
| 27 |
+
state_dict = model.module.state_dict()
|
| 28 |
+
else:
|
| 29 |
+
state_dict = model.state_dict()
|
| 30 |
+
new_state_dict= {}
|
| 31 |
+
for k, v in state_dict.items():
|
| 32 |
+
try:
|
| 33 |
+
new_state_dict[k] = saved_state_dict[k]
|
| 34 |
+
except:
|
| 35 |
+
print("%s is not in the checkpoint" % k) or logger.info("%s is not in the checkpoint" % k)
|
| 36 |
+
new_state_dict[k] = v
|
| 37 |
+
if hasattr(model, 'module'):
|
| 38 |
+
model.module.load_state_dict(new_state_dict)
|
| 39 |
+
else:
|
| 40 |
+
model.load_state_dict(new_state_dict)
|
| 41 |
+
logger.info("Loaded checkpoint '{}' (iteration {})" .format(
|
| 42 |
+
checkpoint_path, iteration))
|
| 43 |
+
print("Loaded checkpoint '{}' (iteration {}) " .format(
|
| 44 |
+
checkpoint_path, iteration))
|
| 45 |
+
return model, optimizer, learning_rate, iteration
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
|
| 49 |
+
ckptname = checkpoint_path.split("/")[-1]
|
| 50 |
+
newest_step = int(ckptname.split(".")[0].split("_")[1])
|
| 51 |
+
last_ckptname = checkpoint_path.replace(str(newest_step), str(newest_step-1200))
|
| 52 |
+
if newest_step >= 1200:
|
| 53 |
+
os.system(f"rm {last_ckptname}")
|
| 54 |
+
logger.info("Saving model and optimizer state at iteration {} to {}".format(
|
| 55 |
+
iteration, checkpoint_path))
|
| 56 |
+
print("Saving model and optimizer state at iteration {} to {}".format(
|
| 57 |
+
iteration, checkpoint_path))
|
| 58 |
+
if hasattr(model, 'module'):
|
| 59 |
+
state_dict = model.module.state_dict()
|
| 60 |
+
else:
|
| 61 |
+
state_dict = model.state_dict()
|
| 62 |
+
torch.save({'model': state_dict,
|
| 63 |
+
'iteration': iteration,
|
| 64 |
+
'optimizer': optimizer.state_dict(),
|
| 65 |
+
'learning_rate': learning_rate}, checkpoint_path)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050):
|
| 69 |
+
for k, v in scalars.items():
|
| 70 |
+
writer.add_scalar(k, v, global_step)
|
| 71 |
+
for k, v in histograms.items():
|
| 72 |
+
writer.add_histogram(k, v, global_step)
|
| 73 |
+
for k, v in images.items():
|
| 74 |
+
writer.add_image(k, v, global_step, dataformats='HWC')
|
| 75 |
+
for k, v in audios.items():
|
| 76 |
+
writer.add_audio(k, v, global_step, audio_sampling_rate)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def latest_checkpoint_path(dir_path, regex="G_*.pth"):
|
| 80 |
+
f_list = glob.glob(os.path.join(dir_path, regex))
|
| 81 |
+
f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
|
| 82 |
+
x = f_list[-1]
|
| 83 |
+
print(x)
|
| 84 |
+
return x
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def plot_spectrogram_to_numpy(spectrogram):
|
| 88 |
+
global MATPLOTLIB_FLAG
|
| 89 |
+
if not MATPLOTLIB_FLAG:
|
| 90 |
+
import matplotlib
|
| 91 |
+
matplotlib.use("Agg")
|
| 92 |
+
MATPLOTLIB_FLAG = True
|
| 93 |
+
mpl_logger = logging.getLogger('matplotlib')
|
| 94 |
+
mpl_logger.setLevel(logging.WARNING)
|
| 95 |
+
import matplotlib.pylab as plt
|
| 96 |
+
import numpy as np
|
| 97 |
+
|
| 98 |
+
fig, ax = plt.subplots(figsize=(10,2))
|
| 99 |
+
im = ax.imshow(spectrogram, aspect="auto", origin="lower",
|
| 100 |
+
interpolation='none')
|
| 101 |
+
plt.colorbar(im, ax=ax)
|
| 102 |
+
plt.xlabel("Frames")
|
| 103 |
+
plt.ylabel("Channels")
|
| 104 |
+
plt.tight_layout()
|
| 105 |
+
|
| 106 |
+
fig.canvas.draw()
|
| 107 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 108 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 109 |
+
plt.close()
|
| 110 |
+
return data
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def plot_alignment_to_numpy(alignment, info=None):
|
| 114 |
+
global MATPLOTLIB_FLAG
|
| 115 |
+
if not MATPLOTLIB_FLAG:
|
| 116 |
+
import matplotlib
|
| 117 |
+
matplotlib.use("Agg")
|
| 118 |
+
MATPLOTLIB_FLAG = True
|
| 119 |
+
mpl_logger = logging.getLogger('matplotlib')
|
| 120 |
+
mpl_logger.setLevel(logging.WARNING)
|
| 121 |
+
import matplotlib.pylab as plt
|
| 122 |
+
import numpy as np
|
| 123 |
+
|
| 124 |
+
fig, ax = plt.subplots(figsize=(6, 4))
|
| 125 |
+
im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
|
| 126 |
+
interpolation='none')
|
| 127 |
+
fig.colorbar(im, ax=ax)
|
| 128 |
+
xlabel = 'Decoder timestep'
|
| 129 |
+
if info is not None:
|
| 130 |
+
xlabel += '\n\n' + info
|
| 131 |
+
plt.xlabel(xlabel)
|
| 132 |
+
plt.ylabel('Encoder timestep')
|
| 133 |
+
plt.tight_layout()
|
| 134 |
+
|
| 135 |
+
fig.canvas.draw()
|
| 136 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 137 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 138 |
+
plt.close()
|
| 139 |
+
return data
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def load_wav_to_torch(full_path):
|
| 143 |
+
sampling_rate, data = read(full_path)
|
| 144 |
+
return torch.FloatTensor(data.astype(np.float32)), sampling_rate
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def load_filepaths_and_text(filename, split="|"):
|
| 148 |
+
with open(filename, encoding='utf-8') as f:
|
| 149 |
+
filepaths_and_text = [line.strip().split(split) for line in f]
|
| 150 |
+
return filepaths_and_text
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def get_hparams(init=True):
|
| 154 |
+
parser = argparse.ArgumentParser()
|
| 155 |
+
parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
|
| 156 |
+
help='JSON file for configuration')
|
| 157 |
+
parser.add_argument('-m', '--model', type=str, required=True,
|
| 158 |
+
help='Model name')
|
| 159 |
+
|
| 160 |
+
args = parser.parse_args()
|
| 161 |
+
model_dir = os.path.join("./logs", args.model)
|
| 162 |
+
|
| 163 |
+
if not os.path.exists(model_dir):
|
| 164 |
+
os.makedirs(model_dir)
|
| 165 |
+
|
| 166 |
+
config_path = args.config
|
| 167 |
+
config_save_path = os.path.join(model_dir, "config.json")
|
| 168 |
+
if init:
|
| 169 |
+
with open(config_path, "r") as f:
|
| 170 |
+
data = f.read()
|
| 171 |
+
with open(config_save_path, "w") as f:
|
| 172 |
+
f.write(data)
|
| 173 |
+
else:
|
| 174 |
+
with open(config_save_path, "r") as f:
|
| 175 |
+
data = f.read()
|
| 176 |
+
config = json.loads(data)
|
| 177 |
+
|
| 178 |
+
hparams = HParams(**config)
|
| 179 |
+
hparams.model_dir = model_dir
|
| 180 |
+
return hparams
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def get_hparams_from_dir(model_dir):
|
| 184 |
+
config_save_path = os.path.join(model_dir, "config.json")
|
| 185 |
+
with open(config_save_path, "r") as f:
|
| 186 |
+
data = f.read()
|
| 187 |
+
config = json.loads(data)
|
| 188 |
+
|
| 189 |
+
hparams =HParams(**config)
|
| 190 |
+
hparams.model_dir = model_dir
|
| 191 |
+
return hparams
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def get_hparams_from_file(config_path):
|
| 195 |
+
with open(config_path, "r") as f:
|
| 196 |
+
data = f.read()
|
| 197 |
+
config = json.loads(data)
|
| 198 |
+
|
| 199 |
+
hparams =HParams(**config)
|
| 200 |
+
return hparams
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def check_git_hash(model_dir):
|
| 204 |
+
source_dir = os.path.dirname(os.path.realpath(__file__))
|
| 205 |
+
if not os.path.exists(os.path.join(source_dir, ".git")):
|
| 206 |
+
logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
|
| 207 |
+
source_dir
|
| 208 |
+
))
|
| 209 |
+
return
|
| 210 |
+
|
| 211 |
+
cur_hash = subprocess.getoutput("git rev-parse HEAD")
|
| 212 |
+
|
| 213 |
+
path = os.path.join(model_dir, "githash")
|
| 214 |
+
if os.path.exists(path):
|
| 215 |
+
saved_hash = open(path).read()
|
| 216 |
+
if saved_hash != cur_hash:
|
| 217 |
+
logger.warn("git hash values are different. {}(saved) != {}(current)".format(
|
| 218 |
+
saved_hash[:8], cur_hash[:8]))
|
| 219 |
+
else:
|
| 220 |
+
open(path, "w").write(cur_hash)
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def get_logger(model_dir, filename="train.log"):
|
| 224 |
+
global logger
|
| 225 |
+
logger = logging.getLogger(os.path.basename(model_dir))
|
| 226 |
+
logger.setLevel(logging.DEBUG)
|
| 227 |
+
|
| 228 |
+
formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
|
| 229 |
+
if not os.path.exists(model_dir):
|
| 230 |
+
os.makedirs(model_dir)
|
| 231 |
+
h = logging.FileHandler(os.path.join(model_dir, filename))
|
| 232 |
+
h.setLevel(logging.DEBUG)
|
| 233 |
+
h.setFormatter(formatter)
|
| 234 |
+
logger.addHandler(h)
|
| 235 |
+
return logger
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
class HParams():
|
| 239 |
+
def __init__(self, **kwargs):
|
| 240 |
+
for k, v in kwargs.items():
|
| 241 |
+
if type(v) == dict:
|
| 242 |
+
v = HParams(**v)
|
| 243 |
+
self[k] = v
|
| 244 |
+
|
| 245 |
+
def keys(self):
|
| 246 |
+
return self.__dict__.keys()
|
| 247 |
+
|
| 248 |
+
def items(self):
|
| 249 |
+
return self.__dict__.items()
|
| 250 |
+
|
| 251 |
+
def values(self):
|
| 252 |
+
return self.__dict__.values()
|
| 253 |
+
|
| 254 |
+
def __len__(self):
|
| 255 |
+
return len(self.__dict__)
|
| 256 |
+
|
| 257 |
+
def __getitem__(self, key):
|
| 258 |
+
return getattr(self, key)
|
| 259 |
+
|
| 260 |
+
def __setitem__(self, key, value):
|
| 261 |
+
return setattr(self, key, value)
|
| 262 |
+
|
| 263 |
+
def __contains__(self, key):
|
| 264 |
+
return key in self.__dict__
|
| 265 |
+
|
| 266 |
+
def __repr__(self):
|
| 267 |
+
return self.__dict__.__repr__()
|