Spaces:
Runtime error

Runtime error

Commit
•
08afbac
1
Parent(s):
b549679
update@web_demo
Browse files- README.md +3 -2
- app_modules/__pycache__/presets.cpython-310.pyc +0 -0
- app_modules/__pycache__/presets.cpython-39.pyc +0 -0
- app_modules/overwrites.py +7 -15
- app_modules/utils.py +5 -160
- clc/__pycache__/langchain_application.cpython-39.pyc +0 -0
- clc/__pycache__/source_service.cpython-310.pyc +0 -0
- clc/__pycache__/source_service.cpython-39.pyc +0 -0
- images/web_demo_new.png +0 -0
- main.py +16 -13
- requirements.txt +4 -1
README.md
CHANGED
|
@@ -11,8 +11,9 @@
|
|
| 11 |
|
| 12 |
## 🚀 特性
|
| 13 |
|
| 14 |
-
-
|
| 15 |
-
-
|
|
|
|
| 16 |
- 🚀 2023/04/18 修复推理预测超时5s报错问题
|
| 17 |
- 🎉 2023/04/17 支持多种文档上传与内容解析:pdf、docx,ppt等
|
| 18 |
- 🎉 2023/04/17 支持知识增量更新
|
|
|
|
| 11 |
|
| 12 |
## 🚀 特性
|
| 13 |
|
| 14 |
+
- 🐯 2023/04/19 引入ChuanhuChatGPT皮肤
|
| 15 |
+
- 📱 2023/04/19 增加web search功能,需要确保网络畅通!
|
| 16 |
+
- 📚 2023/04/18 webui增加知识库选择功能
|
| 17 |
- 🚀 2023/04/18 修复推理预测超时5s报错问题
|
| 18 |
- 🎉 2023/04/17 支持多种文档上传与内容解析:pdf、docx,ppt等
|
| 19 |
- 🎉 2023/04/17 支持知识增量更新
|
app_modules/__pycache__/presets.cpython-310.pyc
ADDED
|
Binary file (2.26 kB). View file
|
|
|
app_modules/__pycache__/presets.cpython-39.pyc
ADDED
|
Binary file (2.26 kB). View file
|
|
|
app_modules/overwrites.py
CHANGED
|
@@ -1,25 +1,12 @@
|
|
| 1 |
from __future__ import annotations
|
| 2 |
-
import logging
|
| 3 |
|
| 4 |
-
from llama_index import Prompt
|
| 5 |
from typing import List, Tuple
|
| 6 |
-
import mdtex2html
|
| 7 |
|
| 8 |
-
from app_modules.presets import *
|
| 9 |
from app_modules.utils import *
|
| 10 |
|
| 11 |
-
def compact_text_chunks(self, prompt: Prompt, text_chunks: List[str]) -> List[str]:
|
| 12 |
-
logging.debug("Compacting text chunks...🚀🚀🚀")
|
| 13 |
-
combined_str = [c.strip() for c in text_chunks if c.strip()]
|
| 14 |
-
combined_str = [f"[{index+1}] {c}" for index, c in enumerate(combined_str)]
|
| 15 |
-
combined_str = "\n\n".join(combined_str)
|
| 16 |
-
# resplit based on self.max_chunk_overlap
|
| 17 |
-
text_splitter = self.get_text_splitter_given_prompt(prompt, 1, padding=1)
|
| 18 |
-
return text_splitter.split_text(combined_str)
|
| 19 |
-
|
| 20 |
|
| 21 |
def postprocess(
|
| 22 |
-
|
| 23 |
) -> List[Tuple[str | None, str | None]]:
|
| 24 |
"""
|
| 25 |
Parameters:
|
|
@@ -39,13 +26,17 @@ def postprocess(
|
|
| 39 |
temp.append((user, bot))
|
| 40 |
return temp
|
| 41 |
|
| 42 |
-
|
|
|
|
|
|
|
| 43 |
customJS = f.read()
|
| 44 |
kelpyCodos = f2.read()
|
| 45 |
|
|
|
|
| 46 |
def reload_javascript():
|
| 47 |
print("Reloading javascript...")
|
| 48 |
js = f'<script>{customJS}</script><script>{kelpyCodos}</script>'
|
|
|
|
| 49 |
def template_response(*args, **kwargs):
|
| 50 |
res = GradioTemplateResponseOriginal(*args, **kwargs)
|
| 51 |
res.body = res.body.replace(b'</html>', f'{js}</html>'.encode("utf8"))
|
|
@@ -54,4 +45,5 @@ def reload_javascript():
|
|
| 54 |
|
| 55 |
gr.routes.templates.TemplateResponse = template_response
|
| 56 |
|
|
|
|
| 57 |
GradioTemplateResponseOriginal = gr.routes.templates.TemplateResponse
|
|
|
|
| 1 |
from __future__ import annotations
|
|
|
|
| 2 |
|
|
|
|
| 3 |
from typing import List, Tuple
|
|
|
|
| 4 |
|
|
|
|
| 5 |
from app_modules.utils import *
|
| 6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
|
| 8 |
def postprocess(
|
| 9 |
+
self, y: List[Tuple[str | None, str | None]]
|
| 10 |
) -> List[Tuple[str | None, str | None]]:
|
| 11 |
"""
|
| 12 |
Parameters:
|
|
|
|
| 26 |
temp.append((user, bot))
|
| 27 |
return temp
|
| 28 |
|
| 29 |
+
|
| 30 |
+
with open("./assets/custom.js", "r", encoding="utf-8") as f, open("./assets/Kelpy-Codos.js", "r",
|
| 31 |
+
encoding="utf-8") as f2:
|
| 32 |
customJS = f.read()
|
| 33 |
kelpyCodos = f2.read()
|
| 34 |
|
| 35 |
+
|
| 36 |
def reload_javascript():
|
| 37 |
print("Reloading javascript...")
|
| 38 |
js = f'<script>{customJS}</script><script>{kelpyCodos}</script>'
|
| 39 |
+
|
| 40 |
def template_response(*args, **kwargs):
|
| 41 |
res = GradioTemplateResponseOriginal(*args, **kwargs)
|
| 42 |
res.body = res.body.replace(b'</html>', f'{js}</html>'.encode("utf8"))
|
|
|
|
| 45 |
|
| 46 |
gr.routes.templates.TemplateResponse = template_response
|
| 47 |
|
| 48 |
+
|
| 49 |
GradioTemplateResponseOriginal = gr.routes.templates.TemplateResponse
|
app_modules/utils.py
CHANGED
|
@@ -1,32 +1,16 @@
|
|
| 1 |
# -*- coding:utf-8 -*-
|
| 2 |
from __future__ import annotations
|
| 3 |
-
|
|
|
|
| 4 |
import logging
|
| 5 |
-
import json
|
| 6 |
-
import os
|
| 7 |
-
import datetime
|
| 8 |
-
import hashlib
|
| 9 |
-
import csv
|
| 10 |
-
import requests
|
| 11 |
import re
|
| 12 |
-
|
| 13 |
-
import markdown2
|
| 14 |
-
import torch
|
| 15 |
-
import sys
|
| 16 |
-
import gc
|
| 17 |
-
from pygments.lexers import guess_lexer, ClassNotFound
|
| 18 |
-
|
| 19 |
-
import gradio as gr
|
| 20 |
-
from pypinyin import lazy_pinyin
|
| 21 |
-
import tiktoken
|
| 22 |
import mdtex2html
|
| 23 |
from markdown import markdown
|
| 24 |
from pygments import highlight
|
| 25 |
-
from pygments.lexers import guess_lexer, get_lexer_by_name
|
| 26 |
from pygments.formatters import HtmlFormatter
|
| 27 |
-
import
|
| 28 |
-
from
|
| 29 |
-
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
|
| 30 |
|
| 31 |
from app_modules.presets import *
|
| 32 |
|
|
@@ -241,142 +225,3 @@ class State:
|
|
| 241 |
|
| 242 |
|
| 243 |
shared_state = State()
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
# Greedy Search
|
| 247 |
-
def greedy_search(input_ids: torch.Tensor,
|
| 248 |
-
model: torch.nn.Module,
|
| 249 |
-
tokenizer: transformers.PreTrainedTokenizer,
|
| 250 |
-
stop_words: list,
|
| 251 |
-
max_length: int,
|
| 252 |
-
temperature: float = 1.0,
|
| 253 |
-
top_p: float = 1.0,
|
| 254 |
-
top_k: int = 25) -> Iterator[str]:
|
| 255 |
-
generated_tokens = []
|
| 256 |
-
past_key_values = None
|
| 257 |
-
current_length = 1
|
| 258 |
-
for i in range(max_length):
|
| 259 |
-
with torch.no_grad():
|
| 260 |
-
if past_key_values is None:
|
| 261 |
-
outputs = model(input_ids)
|
| 262 |
-
else:
|
| 263 |
-
outputs = model(input_ids[:, -1:], past_key_values=past_key_values)
|
| 264 |
-
logits = outputs.logits[:, -1, :]
|
| 265 |
-
past_key_values = outputs.past_key_values
|
| 266 |
-
|
| 267 |
-
# apply temperature
|
| 268 |
-
logits /= temperature
|
| 269 |
-
|
| 270 |
-
probs = torch.softmax(logits, dim=-1)
|
| 271 |
-
# apply top_p
|
| 272 |
-
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
|
| 273 |
-
probs_sum = torch.cumsum(probs_sort, dim=-1)
|
| 274 |
-
mask = probs_sum - probs_sort > top_p
|
| 275 |
-
probs_sort[mask] = 0.0
|
| 276 |
-
|
| 277 |
-
# apply top_k
|
| 278 |
-
# if top_k is not None:
|
| 279 |
-
# probs_sort1, _ = torch.topk(probs_sort, top_k)
|
| 280 |
-
# min_top_probs_sort = torch.min(probs_sort1, dim=-1, keepdim=True).values
|
| 281 |
-
# probs_sort = torch.where(probs_sort < min_top_probs_sort, torch.full_like(probs_sort, float(0.0)), probs_sort)
|
| 282 |
-
|
| 283 |
-
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
|
| 284 |
-
next_token = torch.multinomial(probs_sort, num_samples=1)
|
| 285 |
-
next_token = torch.gather(probs_idx, -1, next_token)
|
| 286 |
-
|
| 287 |
-
input_ids = torch.cat((input_ids, next_token), dim=-1)
|
| 288 |
-
|
| 289 |
-
generated_tokens.append(next_token[0].item())
|
| 290 |
-
text = tokenizer.decode(generated_tokens)
|
| 291 |
-
|
| 292 |
-
yield text
|
| 293 |
-
if any([x in text for x in stop_words]):
|
| 294 |
-
del past_key_values
|
| 295 |
-
del logits
|
| 296 |
-
del probs
|
| 297 |
-
del probs_sort
|
| 298 |
-
del probs_idx
|
| 299 |
-
del probs_sum
|
| 300 |
-
gc.collect()
|
| 301 |
-
return
|
| 302 |
-
|
| 303 |
-
|
| 304 |
-
def generate_prompt_with_history(text, history, tokenizer, max_length=2048):
|
| 305 |
-
prompt = "The following is a conversation between a human and an AI assistant named Baize (named after a mythical creature in Chinese folklore). Baize is an open-source AI assistant developed by UCSD and Sun Yat-Sen University. The human and the AI assistant take turns chatting. Human statements start with [|Human|] and AI assistant statements start with [|AI|]. The AI assistant always provides responses in as much detail as possible, and in Markdown format. The AI assistant always declines to engage with topics, questions and instructions related to unethical, controversial, or sensitive issues. Complete the transcript in exactly that format.\n[|Human|]Hello!\n[|AI|]Hi!"
|
| 306 |
-
history = ["\n[|Human|]{}\n[|AI|]{}".format(x[0], x[1]) for x in history]
|
| 307 |
-
history.append("\n[|Human|]{}\n[|AI|]".format(text))
|
| 308 |
-
history_text = ""
|
| 309 |
-
flag = False
|
| 310 |
-
for x in history[::-1]:
|
| 311 |
-
if tokenizer(prompt + history_text + x, return_tensors="pt")['input_ids'].size(-1) <= max_length:
|
| 312 |
-
history_text = x + history_text
|
| 313 |
-
flag = True
|
| 314 |
-
else:
|
| 315 |
-
break
|
| 316 |
-
if flag:
|
| 317 |
-
return prompt + history_text, tokenizer(prompt + history_text, return_tensors="pt")
|
| 318 |
-
else:
|
| 319 |
-
return None
|
| 320 |
-
|
| 321 |
-
|
| 322 |
-
def is_stop_word_or_prefix(s: str, stop_words: list) -> bool:
|
| 323 |
-
for stop_word in stop_words:
|
| 324 |
-
if s.endswith(stop_word):
|
| 325 |
-
return True
|
| 326 |
-
for i in range(1, len(stop_word)):
|
| 327 |
-
if s.endswith(stop_word[:i]):
|
| 328 |
-
return True
|
| 329 |
-
return False
|
| 330 |
-
|
| 331 |
-
|
| 332 |
-
def load_tokenizer_and_model(base_model, adapter_model, load_8bit=False):
|
| 333 |
-
if torch.cuda.is_available():
|
| 334 |
-
device = "cuda"
|
| 335 |
-
else:
|
| 336 |
-
device = "cpu"
|
| 337 |
-
|
| 338 |
-
try:
|
| 339 |
-
if torch.backends.mps.is_available():
|
| 340 |
-
device = "mps"
|
| 341 |
-
except: # noqa: E722
|
| 342 |
-
pass
|
| 343 |
-
tokenizer = LlamaTokenizer.from_pretrained(base_model)
|
| 344 |
-
if device == "cuda":
|
| 345 |
-
model = LlamaForCausalLM.from_pretrained(
|
| 346 |
-
base_model,
|
| 347 |
-
load_in_8bit=load_8bit,
|
| 348 |
-
torch_dtype=torch.float16,
|
| 349 |
-
device_map="auto",
|
| 350 |
-
)
|
| 351 |
-
model = PeftModel.from_pretrained(
|
| 352 |
-
model,
|
| 353 |
-
adapter_model,
|
| 354 |
-
torch_dtype=torch.float16,
|
| 355 |
-
)
|
| 356 |
-
elif device == "mps":
|
| 357 |
-
model = LlamaForCausalLM.from_pretrained(
|
| 358 |
-
base_model,
|
| 359 |
-
device_map={"": device},
|
| 360 |
-
torch_dtype=torch.float16,
|
| 361 |
-
)
|
| 362 |
-
model = PeftModel.from_pretrained(
|
| 363 |
-
model,
|
| 364 |
-
adapter_model,
|
| 365 |
-
device_map={"": device},
|
| 366 |
-
torch_dtype=torch.float16,
|
| 367 |
-
)
|
| 368 |
-
else:
|
| 369 |
-
model = LlamaForCausalLM.from_pretrained(
|
| 370 |
-
base_model, device_map={"": device}, low_cpu_mem_usage=True
|
| 371 |
-
)
|
| 372 |
-
model = PeftModel.from_pretrained(
|
| 373 |
-
model,
|
| 374 |
-
adapter_model,
|
| 375 |
-
device_map={"": device},
|
| 376 |
-
)
|
| 377 |
-
|
| 378 |
-
if not load_8bit:
|
| 379 |
-
model.half() # seems to fix bugs for some users.
|
| 380 |
-
|
| 381 |
-
model.eval()
|
| 382 |
-
return tokenizer, model, device
|
|
|
|
| 1 |
# -*- coding:utf-8 -*-
|
| 2 |
from __future__ import annotations
|
| 3 |
+
|
| 4 |
+
import html
|
| 5 |
import logging
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
import re
|
| 7 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
import mdtex2html
|
| 9 |
from markdown import markdown
|
| 10 |
from pygments import highlight
|
|
|
|
| 11 |
from pygments.formatters import HtmlFormatter
|
| 12 |
+
from pygments.lexers import ClassNotFound
|
| 13 |
+
from pygments.lexers import guess_lexer, get_lexer_by_name
|
|
|
|
| 14 |
|
| 15 |
from app_modules.presets import *
|
| 16 |
|
|
|
|
| 225 |
|
| 226 |
|
| 227 |
shared_state = State()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
clc/__pycache__/langchain_application.cpython-39.pyc
CHANGED
|
Binary files a/clc/__pycache__/langchain_application.cpython-39.pyc and b/clc/__pycache__/langchain_application.cpython-39.pyc differ
|
|
|
clc/__pycache__/source_service.cpython-310.pyc
CHANGED
|
Binary files a/clc/__pycache__/source_service.cpython-310.pyc and b/clc/__pycache__/source_service.cpython-310.pyc differ
|
|
|
clc/__pycache__/source_service.cpython-39.pyc
CHANGED
|
Binary files a/clc/__pycache__/source_service.cpython-39.pyc and b/clc/__pycache__/source_service.cpython-39.pyc differ
|
|
|
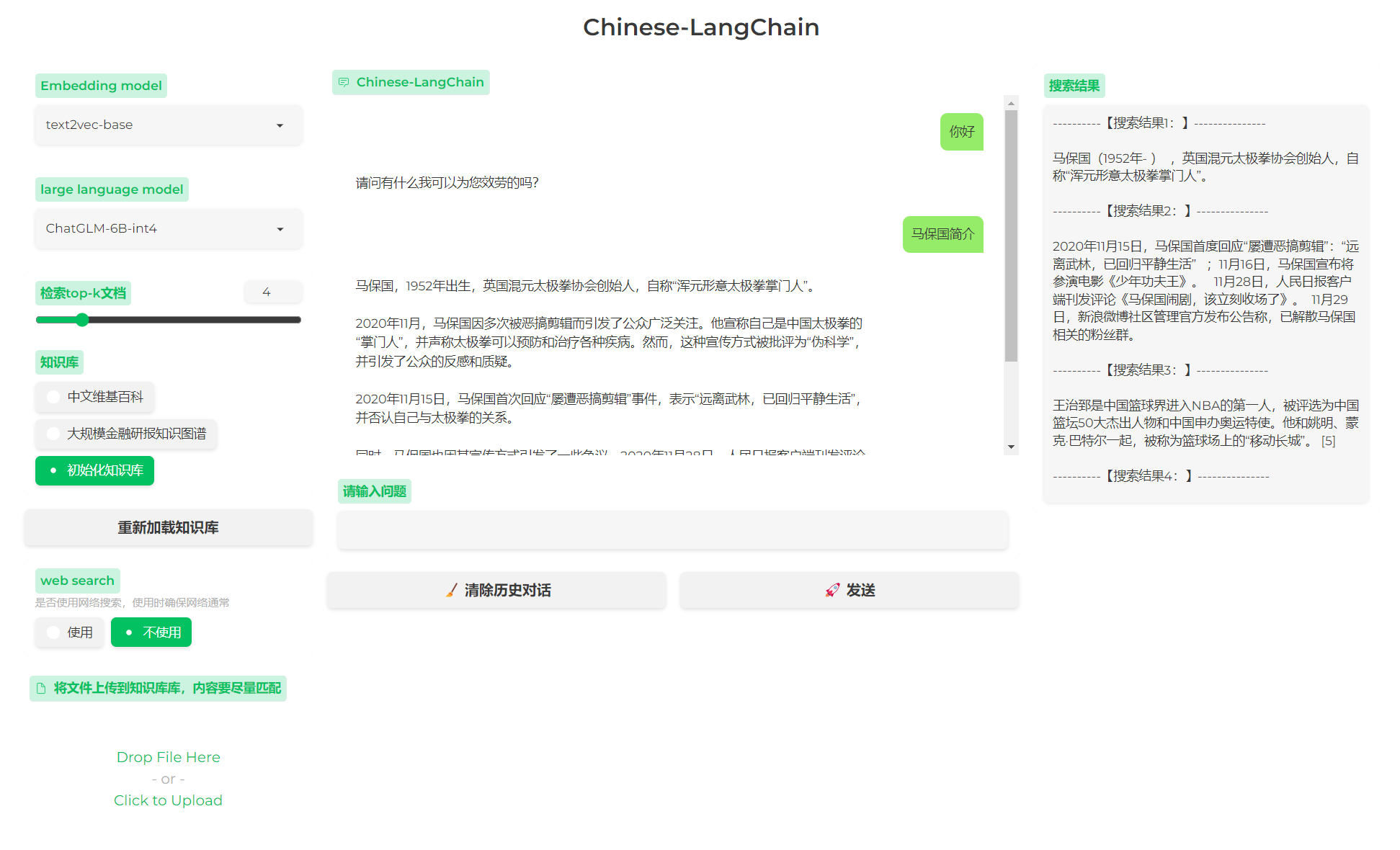
images/web_demo_new.png
CHANGED
|
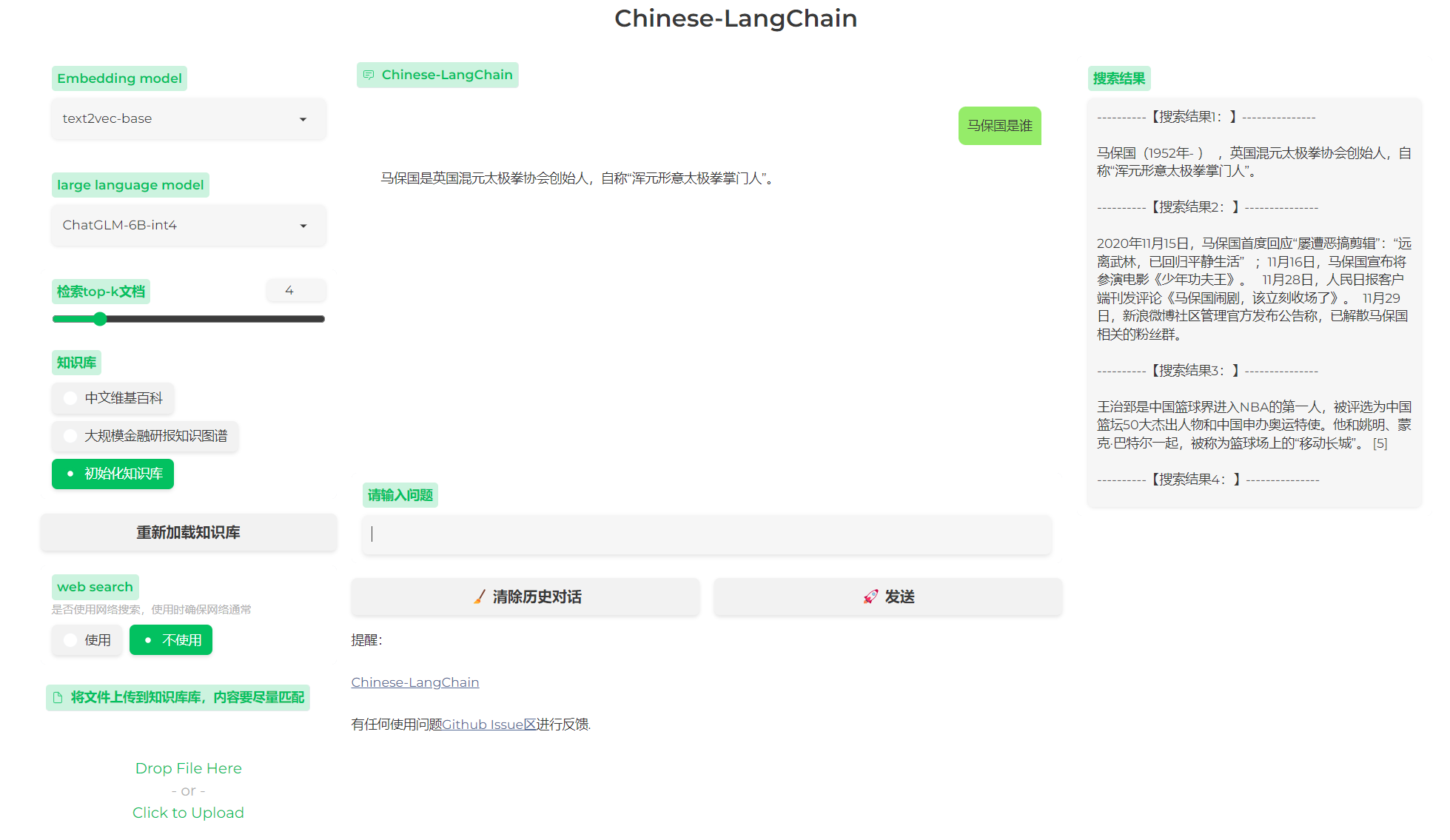
|
main.py
CHANGED
|
@@ -1,7 +1,6 @@
|
|
| 1 |
import os
|
| 2 |
import shutil
|
| 3 |
|
| 4 |
-
import gradio as gr
|
| 5 |
from app_modules.presets import *
|
| 6 |
from clc.langchain_application import LangChainApplication
|
| 7 |
|
|
@@ -93,6 +92,7 @@ def predict(input,
|
|
| 93 |
search_text += web_content
|
| 94 |
return '', history, history, search_text
|
| 95 |
|
|
|
|
| 96 |
with open("assets/custom.css", "r", encoding="utf-8") as f:
|
| 97 |
customCSS = f.read()
|
| 98 |
with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
|
|
@@ -147,14 +147,20 @@ with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
|
|
| 147 |
outputs=None)
|
| 148 |
with gr.Column(scale=4):
|
| 149 |
with gr.Row():
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 158 |
set_kg_btn.click(
|
| 159 |
set_knowledge,
|
| 160 |
show_progress=True,
|
|
@@ -185,10 +191,7 @@ with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
|
|
| 185 |
state
|
| 186 |
],
|
| 187 |
outputs=[message, chatbot, state, search])
|
| 188 |
-
|
| 189 |
-
[Chinese-LangChain](https://github.com/yanqiangmiffy/Chinese-LangChain) <br>
|
| 190 |
-
有任何使用问题[Github Issue区](https://github.com/yanqiangmiffy/Chinese-LangChain)进行反馈. <br>
|
| 191 |
-
""")
|
| 192 |
demo.queue(concurrency_count=2).launch(
|
| 193 |
server_name='0.0.0.0',
|
| 194 |
server_port=8888,
|
|
|
|
| 1 |
import os
|
| 2 |
import shutil
|
| 3 |
|
|
|
|
| 4 |
from app_modules.presets import *
|
| 5 |
from clc.langchain_application import LangChainApplication
|
| 6 |
|
|
|
|
| 92 |
search_text += web_content
|
| 93 |
return '', history, history, search_text
|
| 94 |
|
| 95 |
+
|
| 96 |
with open("assets/custom.css", "r", encoding="utf-8") as f:
|
| 97 |
customCSS = f.read()
|
| 98 |
with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
|
|
|
|
| 147 |
outputs=None)
|
| 148 |
with gr.Column(scale=4):
|
| 149 |
with gr.Row():
|
| 150 |
+
chatbot = gr.Chatbot(label='Chinese-LangChain').style(height=400)
|
| 151 |
+
with gr.Row():
|
| 152 |
+
message = gr.Textbox(label='请输入问题')
|
| 153 |
+
with gr.Row():
|
| 154 |
+
clear_history = gr.Button("🧹 清除历史对话")
|
| 155 |
+
send = gr.Button("🚀 发送")
|
| 156 |
+
with gr.Row():
|
| 157 |
+
gr.Markdown("""提醒:<br>
|
| 158 |
+
[Chinese-LangChain](https://github.com/yanqiangmiffy/Chinese-LangChain) <br>
|
| 159 |
+
有任何使用问题[Github Issue区](https://github.com/yanqiangmiffy/Chinese-LangChain)进行反馈. <br>
|
| 160 |
+
""")
|
| 161 |
+
with gr.Column(scale=2):
|
| 162 |
+
search = gr.Textbox(label='搜索结果')
|
| 163 |
+
|
| 164 |
set_kg_btn.click(
|
| 165 |
set_knowledge,
|
| 166 |
show_progress=True,
|
|
|
|
| 191 |
state
|
| 192 |
],
|
| 193 |
outputs=[message, chatbot, state, search])
|
| 194 |
+
|
|
|
|
|
|
|
|
|
|
| 195 |
demo.queue(concurrency_count=2).launch(
|
| 196 |
server_name='0.0.0.0',
|
| 197 |
server_port=8888,
|
requirements.txt
CHANGED
|
@@ -4,4 +4,7 @@ transformers
|
|
| 4 |
sentence_transformers
|
| 5 |
faiss-cpu
|
| 6 |
unstructured
|
| 7 |
-
duckduckgo_search
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
sentence_transformers
|
| 5 |
faiss-cpu
|
| 6 |
unstructured
|
| 7 |
+
duckduckgo_search
|
| 8 |
+
mdtex2html
|
| 9 |
+
chardet
|
| 10 |
+
cchardet
|