
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .github/PULL_REQUEST_TEMPLATE.md +17 -0
- .github/workflows/python-package.yml +30 -0
- .gitignore +31 -0
- .pylintrc +449 -0
- 2024-02-26-conv.json +23 -0
- 2024-02-27-conv.json +0 -0
- 2024-02-28-conv.json +0 -0
- 2024-02-29-conv.json +33 -0
- 2024-03-01-conv.json +8 -0
- LICENSE +201 -0
- README.md +353 -7
- assets/demo_narrow.gif +3 -0
- assets/qa_browser.png +0 -0
- assets/screenshot_cli.png +0 -0
- assets/screenshot_gui.png +0 -0
- assets/server_arch.png +0 -0
- assets/vicuna_logo.jpeg +0 -0
- controller.log +0 -0
- controller.log.2024-02-26 +0 -0
- controller.log.2024-02-27 +0 -0
- controller.log.2024-02-28 +0 -0
- data/dummy_conversation.json +0 -0
- docker/Dockerfile +7 -0
- docker/docker-compose.yml +36 -0
- docs/arena.md +15 -0
- docs/awq.md +71 -0
- docs/commands/conv_release.md +38 -0
- docs/commands/data_cleaning.md +19 -0
- docs/commands/leaderboard.md +37 -0
- docs/commands/local_cluster.md +38 -0
- docs/commands/pypi.md +11 -0
- docs/commands/webserver.md +94 -0
- docs/dataset_release.md +6 -0
- docs/exllama_v2.md +63 -0
- docs/gptq.md +59 -0
- docs/langchain_integration.md +90 -0
- docs/lightllm_integration.md +18 -0
- docs/mlx_integration.md +23 -0
- docs/model_support.md +130 -0
- docs/openai_api.md +152 -0
- docs/server_arch.md +2 -0
- docs/third_party_ui.md +24 -0
- docs/training.md +118 -0
- docs/vicuna_weights_version.md +97 -0
- docs/vllm_integration.md +25 -0
- docs/xFasterTransformer.md +90 -0
- fastchat/__init__.py +1 -0
- fastchat/__pycache__/__init__.cpython-310.pyc +0 -0
- fastchat/__pycache__/__init__.cpython-311.pyc +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/demo_narrow.gif filter=lfs diff=lfs merge=lfs -text
|
.github/PULL_REQUEST_TEMPLATE.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- Thank you for your contribution! -->
|
| 2 |
+
|
| 3 |
+
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
|
| 4 |
+
|
| 5 |
+
## Why are these changes needed?
|
| 6 |
+
|
| 7 |
+
<!-- Please give a short summary of the change and the problem this solves. -->
|
| 8 |
+
|
| 9 |
+
## Related issue number (if applicable)
|
| 10 |
+
|
| 11 |
+
<!-- For example: "Closes #1234" -->
|
| 12 |
+
|
| 13 |
+
## Checks
|
| 14 |
+
|
| 15 |
+
- [ ] I've run `format.sh` to lint the changes in this PR.
|
| 16 |
+
- [ ] I've included any doc changes needed.
|
| 17 |
+
- [ ] I've made sure the relevant tests are passing (if applicable).
|
.github/workflows/python-package.yml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Python package
|
| 2 |
+
|
| 3 |
+
on: [push, pull_request]
|
| 4 |
+
|
| 5 |
+
jobs:
|
| 6 |
+
build:
|
| 7 |
+
|
| 8 |
+
runs-on: ubuntu-latest
|
| 9 |
+
strategy:
|
| 10 |
+
fail-fast: false
|
| 11 |
+
matrix:
|
| 12 |
+
python-version: ["3.10"]
|
| 13 |
+
|
| 14 |
+
steps:
|
| 15 |
+
- uses: actions/checkout@v3
|
| 16 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 17 |
+
uses: actions/setup-python@v4
|
| 18 |
+
with:
|
| 19 |
+
python-version: ${{ matrix.python-version }}
|
| 20 |
+
cache: 'pip'
|
| 21 |
+
- name: Install dependencies
|
| 22 |
+
run: |
|
| 23 |
+
python -m pip install --upgrade pip
|
| 24 |
+
python -m pip install -e '.[dev]'
|
| 25 |
+
- name: Run linter
|
| 26 |
+
run: |
|
| 27 |
+
pylint -d all -e E0602 ./fastchat/
|
| 28 |
+
- name: Check formatting
|
| 29 |
+
run: |
|
| 30 |
+
black --check .
|
.gitignore
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Python
|
| 2 |
+
__pycache__
|
| 3 |
+
*.pyc
|
| 4 |
+
*.egg-info
|
| 5 |
+
dist
|
| 6 |
+
.venv
|
| 7 |
+
|
| 8 |
+
# Log
|
| 9 |
+
*.log
|
| 10 |
+
*.log.*
|
| 11 |
+
*.json
|
| 12 |
+
!playground/deepspeed_config_s2.json
|
| 13 |
+
!playground/deepspeed_config_s3.json
|
| 14 |
+
|
| 15 |
+
# Editor
|
| 16 |
+
.idea
|
| 17 |
+
*.swp
|
| 18 |
+
|
| 19 |
+
# Other
|
| 20 |
+
.DS_Store
|
| 21 |
+
wandb
|
| 22 |
+
output
|
| 23 |
+
checkpoints_flant5_3b
|
| 24 |
+
|
| 25 |
+
# Data
|
| 26 |
+
*.pkl
|
| 27 |
+
*.csv
|
| 28 |
+
tests/state_of_the_union.txt
|
| 29 |
+
|
| 30 |
+
# Build
|
| 31 |
+
build
|
.pylintrc
ADDED
|
@@ -0,0 +1,449 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This Pylint rcfile contains a best-effort configuration to uphold the
|
| 2 |
+
# best-practices and style described in the Google Python style guide:
|
| 3 |
+
# https://google.github.io/styleguide/pyguide.html
|
| 4 |
+
#
|
| 5 |
+
# Its canonical open-source location is:
|
| 6 |
+
# https://google.github.io/styleguide/pylintrc
|
| 7 |
+
|
| 8 |
+
[MASTER]
|
| 9 |
+
|
| 10 |
+
# Files or directories to be skipped. They should be base names, not paths.
|
| 11 |
+
ignore=third_party,ray_patches,providers
|
| 12 |
+
|
| 13 |
+
# Files or directories matching the regex patterns are skipped. The regex
|
| 14 |
+
# matches against base names, not paths.
|
| 15 |
+
ignore-patterns=
|
| 16 |
+
|
| 17 |
+
# Pickle collected data for later comparisons.
|
| 18 |
+
persistent=no
|
| 19 |
+
|
| 20 |
+
# List of plugins (as comma separated values of python modules names) to load,
|
| 21 |
+
# usually to register additional checkers.
|
| 22 |
+
load-plugins=
|
| 23 |
+
|
| 24 |
+
# Use multiple processes to speed up Pylint.
|
| 25 |
+
jobs=4
|
| 26 |
+
|
| 27 |
+
# Allow loading of arbitrary C extensions. Extensions are imported into the
|
| 28 |
+
# active Python interpreter and may run arbitrary code.
|
| 29 |
+
unsafe-load-any-extension=no
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
[MESSAGES CONTROL]
|
| 33 |
+
|
| 34 |
+
# Only show warnings with the listed confidence levels. Leave empty to show
|
| 35 |
+
# all. Valid levels: HIGH, INFERENCE, INFERENCE_FAILURE, UNDEFINED
|
| 36 |
+
confidence=
|
| 37 |
+
|
| 38 |
+
# Enable the message, report, category or checker with the given id(s). You can
|
| 39 |
+
# either give multiple identifier separated by comma (,) or put this option
|
| 40 |
+
# multiple time (only on the command line, not in the configuration file where
|
| 41 |
+
# it should appear only once). See also the "--disable" option for examples.
|
| 42 |
+
#enable=
|
| 43 |
+
|
| 44 |
+
# Disable the message, report, category or checker with the given id(s). You
|
| 45 |
+
# can either give multiple identifiers separated by comma (,) or put this
|
| 46 |
+
# option multiple times (only on the command line, not in the configuration
|
| 47 |
+
# file where it should appear only once).You can also use "--disable=all" to
|
| 48 |
+
# disable everything first and then reenable specific checks. For example, if
|
| 49 |
+
# you want to run only the similarities checker, you can use "--disable=all
|
| 50 |
+
# --enable=similarities". If you want to run only the classes checker, but have
|
| 51 |
+
# no Warning level messages displayed, use"--disable=all --enable=classes
|
| 52 |
+
# --disable=W"
|
| 53 |
+
disable=abstract-method,
|
| 54 |
+
apply-builtin,
|
| 55 |
+
arguments-differ,
|
| 56 |
+
attribute-defined-outside-init,
|
| 57 |
+
backtick,
|
| 58 |
+
bad-option-value,
|
| 59 |
+
basestring-builtin,
|
| 60 |
+
buffer-builtin,
|
| 61 |
+
c-extension-no-member,
|
| 62 |
+
consider-using-enumerate,
|
| 63 |
+
cmp-builtin,
|
| 64 |
+
cmp-method,
|
| 65 |
+
coerce-builtin,
|
| 66 |
+
coerce-method,
|
| 67 |
+
delslice-method,
|
| 68 |
+
div-method,
|
| 69 |
+
duplicate-code,
|
| 70 |
+
eq-without-hash,
|
| 71 |
+
execfile-builtin,
|
| 72 |
+
file-builtin,
|
| 73 |
+
filter-builtin-not-iterating,
|
| 74 |
+
fixme,
|
| 75 |
+
getslice-method,
|
| 76 |
+
global-statement,
|
| 77 |
+
hex-method,
|
| 78 |
+
idiv-method,
|
| 79 |
+
implicit-str-concat-in-sequence,
|
| 80 |
+
import-error,
|
| 81 |
+
import-self,
|
| 82 |
+
import-star-module-level,
|
| 83 |
+
inconsistent-return-statements,
|
| 84 |
+
input-builtin,
|
| 85 |
+
intern-builtin,
|
| 86 |
+
invalid-str-codec,
|
| 87 |
+
locally-disabled,
|
| 88 |
+
logging-format-interpolation, # FIXME(sky): make pass.
|
| 89 |
+
logging-fstring-interpolation, # FIXME(sky): make pass.
|
| 90 |
+
long-builtin,
|
| 91 |
+
long-suffix,
|
| 92 |
+
map-builtin-not-iterating,
|
| 93 |
+
misplaced-comparison-constant,
|
| 94 |
+
missing-function-docstring,
|
| 95 |
+
metaclass-assignment,
|
| 96 |
+
next-method-called,
|
| 97 |
+
next-method-defined,
|
| 98 |
+
no-absolute-import,
|
| 99 |
+
no-else-break,
|
| 100 |
+
no-else-continue,
|
| 101 |
+
no-else-raise,
|
| 102 |
+
no-else-return,
|
| 103 |
+
no-init, # added
|
| 104 |
+
no-member,
|
| 105 |
+
no-name-in-module,
|
| 106 |
+
no-self-use,
|
| 107 |
+
nonzero-method,
|
| 108 |
+
oct-method,
|
| 109 |
+
old-division,
|
| 110 |
+
old-ne-operator,
|
| 111 |
+
old-octal-literal,
|
| 112 |
+
old-raise-syntax,
|
| 113 |
+
parameter-unpacking,
|
| 114 |
+
print-statement,
|
| 115 |
+
raising-string,
|
| 116 |
+
range-builtin-not-iterating,
|
| 117 |
+
raw_input-builtin,
|
| 118 |
+
rdiv-method,
|
| 119 |
+
reduce-builtin,
|
| 120 |
+
relative-import,
|
| 121 |
+
reload-builtin,
|
| 122 |
+
round-builtin,
|
| 123 |
+
setslice-method,
|
| 124 |
+
signature-differs,
|
| 125 |
+
standarderror-builtin,
|
| 126 |
+
suppressed-message,
|
| 127 |
+
sys-max-int,
|
| 128 |
+
too-few-public-methods,
|
| 129 |
+
too-many-ancestors,
|
| 130 |
+
too-many-arguments,
|
| 131 |
+
too-many-boolean-expressions,
|
| 132 |
+
too-many-branches,
|
| 133 |
+
too-many-instance-attributes,
|
| 134 |
+
too-many-locals,
|
| 135 |
+
too-many-nested-blocks,
|
| 136 |
+
too-many-public-methods,
|
| 137 |
+
too-many-return-statements,
|
| 138 |
+
too-many-statements,
|
| 139 |
+
trailing-newlines,
|
| 140 |
+
unichr-builtin,
|
| 141 |
+
unicode-builtin,
|
| 142 |
+
unnecessary-pass,
|
| 143 |
+
unpacking-in-except,
|
| 144 |
+
useless-else-on-loop,
|
| 145 |
+
useless-object-inheritance,
|
| 146 |
+
useless-suppression,
|
| 147 |
+
using-cmp-argument,
|
| 148 |
+
wrong-import-order,
|
| 149 |
+
xrange-builtin,
|
| 150 |
+
zip-builtin-not-iterating,
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
[REPORTS]
|
| 154 |
+
|
| 155 |
+
# Set the output format. Available formats are text, parseable, colorized, msvs
|
| 156 |
+
# (visual studio) and html. You can also give a reporter class, eg
|
| 157 |
+
# mypackage.mymodule.MyReporterClass.
|
| 158 |
+
output-format=text
|
| 159 |
+
|
| 160 |
+
# Put messages in a separate file for each module / package specified on the
|
| 161 |
+
# command line instead of printing them on stdout. Reports (if any) will be
|
| 162 |
+
# written in a file name "pylint_global.[txt|html]". This option is deprecated
|
| 163 |
+
# and it will be removed in Pylint 2.0.
|
| 164 |
+
files-output=no
|
| 165 |
+
|
| 166 |
+
# Tells whether to display a full report or only the messages
|
| 167 |
+
reports=no
|
| 168 |
+
|
| 169 |
+
# Python expression which should return a note less than 10 (10 is the highest
|
| 170 |
+
# note). You have access to the variables errors warning, statement which
|
| 171 |
+
# respectively contain the number of errors / warnings messages and the total
|
| 172 |
+
# number of statements analyzed. This is used by the global evaluation report
|
| 173 |
+
# (RP0004).
|
| 174 |
+
evaluation=10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)
|
| 175 |
+
|
| 176 |
+
# Template used to display messages. This is a python new-style format string
|
| 177 |
+
# used to format the message information. See doc for all details
|
| 178 |
+
#msg-template=
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
[BASIC]
|
| 182 |
+
|
| 183 |
+
# Good variable names which should always be accepted, separated by a comma
|
| 184 |
+
good-names=main,_
|
| 185 |
+
|
| 186 |
+
# Bad variable names which should always be refused, separated by a comma
|
| 187 |
+
bad-names=
|
| 188 |
+
|
| 189 |
+
# Colon-delimited sets of names that determine each other's naming style when
|
| 190 |
+
# the name regexes allow several styles.
|
| 191 |
+
name-group=
|
| 192 |
+
|
| 193 |
+
# Include a hint for the correct naming format with invalid-name
|
| 194 |
+
include-naming-hint=no
|
| 195 |
+
|
| 196 |
+
# List of decorators that produce properties, such as abc.abstractproperty. Add
|
| 197 |
+
# to this list to register other decorators that produce valid properties.
|
| 198 |
+
property-classes=abc.abstractproperty,cached_property.cached_property,cached_property.threaded_cached_property,cached_property.cached_property_with_ttl,cached_property.threaded_cached_property_with_ttl
|
| 199 |
+
|
| 200 |
+
# Regular expression matching correct function names
|
| 201 |
+
function-rgx=^(?:(?P<exempt>setUp|tearDown|setUpModule|tearDownModule)|(?P<camel_case>_?[A-Z][a-zA-Z0-9]*)|(?P<snake_case>_?[a-z][a-z0-9_]*))$
|
| 202 |
+
|
| 203 |
+
# Regular expression matching correct variable names
|
| 204 |
+
variable-rgx=^[a-z][a-z0-9_]*$
|
| 205 |
+
|
| 206 |
+
# Regular expression matching correct constant names
|
| 207 |
+
const-rgx=^(_?[A-Z][A-Z0-9_]*|__[a-z0-9_]+__|_?[a-z][a-z0-9_]*)$
|
| 208 |
+
|
| 209 |
+
# Regular expression matching correct attribute names
|
| 210 |
+
attr-rgx=^_{0,2}[a-z][a-z0-9_]*$
|
| 211 |
+
|
| 212 |
+
# Regular expression matching correct argument names
|
| 213 |
+
argument-rgx=^[a-z][a-z0-9_]*$
|
| 214 |
+
|
| 215 |
+
# Regular expression matching correct class attribute names
|
| 216 |
+
class-attribute-rgx=^(_?[A-Z][A-Z0-9_]*|__[a-z0-9_]+__|_?[a-z][a-z0-9_]*)$
|
| 217 |
+
|
| 218 |
+
# Regular expression matching correct inline iteration names
|
| 219 |
+
inlinevar-rgx=^[a-z][a-z0-9_]*$
|
| 220 |
+
|
| 221 |
+
# Regular expression matching correct class names
|
| 222 |
+
class-rgx=^_?[A-Z][a-zA-Z0-9]*$
|
| 223 |
+
|
| 224 |
+
# Regular expression matching correct module names
|
| 225 |
+
module-rgx=^(_?[a-z][a-z0-9_]*|__init__)$
|
| 226 |
+
|
| 227 |
+
# Regular expression matching correct method names
|
| 228 |
+
method-rgx=(?x)^(?:(?P<exempt>_[a-z0-9_]+__|runTest|setUp|tearDown|setUpTestCase|tearDownTestCase|setupSelf|tearDownClass|setUpClass|(test|assert)_*[A-Z0-9][a-zA-Z0-9_]*|next)|(?P<camel_case>_{0,2}[A-Z][a-zA-Z0-9_]*)|(?P<snake_case>_{0,2}[a-z][a-z0-9_]*))$
|
| 229 |
+
|
| 230 |
+
# Regular expression which should only match function or class names that do
|
| 231 |
+
# not require a docstring.
|
| 232 |
+
no-docstring-rgx=(__.*__|main|test.*|.*test|.*Test)$
|
| 233 |
+
|
| 234 |
+
# Minimum line length for functions/classes that require docstrings, shorter
|
| 235 |
+
# ones are exempt.
|
| 236 |
+
docstring-min-length=10
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
[TYPECHECK]
|
| 240 |
+
|
| 241 |
+
# List of decorators that produce context managers, such as
|
| 242 |
+
# contextlib.contextmanager. Add to this list to register other decorators that
|
| 243 |
+
# produce valid context managers.
|
| 244 |
+
contextmanager-decorators=contextlib.contextmanager,contextlib2.contextmanager
|
| 245 |
+
|
| 246 |
+
# Tells whether missing members accessed in mixin class should be ignored. A
|
| 247 |
+
# mixin class is detected if its name ends with "mixin" (case insensitive).
|
| 248 |
+
ignore-mixin-members=yes
|
| 249 |
+
|
| 250 |
+
# List of module names for which member attributes should not be checked
|
| 251 |
+
# (useful for modules/projects where namespaces are manipulated during runtime
|
| 252 |
+
# and thus existing member attributes cannot be deduced by static analysis. It
|
| 253 |
+
# supports qualified module names, as well as Unix pattern matching.
|
| 254 |
+
ignored-modules=
|
| 255 |
+
|
| 256 |
+
# List of class names for which member attributes should not be checked (useful
|
| 257 |
+
# for classes with dynamically set attributes). This supports the use of
|
| 258 |
+
# qualified names.
|
| 259 |
+
ignored-classes=optparse.Values,thread._local,_thread._local
|
| 260 |
+
|
| 261 |
+
# List of members which are set dynamically and missed by pylint inference
|
| 262 |
+
# system, and so shouldn't trigger E1101 when accessed. Python regular
|
| 263 |
+
# expressions are accepted.
|
| 264 |
+
generated-members=
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
[FORMAT]
|
| 268 |
+
|
| 269 |
+
# Maximum number of characters on a single line.
|
| 270 |
+
max-line-length=100
|
| 271 |
+
|
| 272 |
+
# TODO(https://github.com/PyCQA/pylint/issues/3352): Direct pylint to exempt
|
| 273 |
+
# lines made too long by directives to pytype.
|
| 274 |
+
|
| 275 |
+
# Regexp for a line that is allowed to be longer than the limit.
|
| 276 |
+
ignore-long-lines=(?x)(
|
| 277 |
+
^\s*(\#\ )?<?https?://\S+>?$|
|
| 278 |
+
^\s*(from\s+\S+\s+)?import\s+.+$)
|
| 279 |
+
|
| 280 |
+
# Allow the body of an if to be on the same line as the test if there is no
|
| 281 |
+
# else.
|
| 282 |
+
single-line-if-stmt=yes
|
| 283 |
+
|
| 284 |
+
# List of optional constructs for which whitespace checking is disabled. `dict-
|
| 285 |
+
# separator` is used to allow tabulation in dicts, etc.: {1 : 1,\n222: 2}.
|
| 286 |
+
# `trailing-comma` allows a space between comma and closing bracket: (a, ).
|
| 287 |
+
# `empty-line` allows space-only lines.
|
| 288 |
+
no-space-check=
|
| 289 |
+
|
| 290 |
+
# Maximum number of lines in a module
|
| 291 |
+
max-module-lines=99999
|
| 292 |
+
|
| 293 |
+
# String used as indentation unit. The internal Google style guide mandates 2
|
| 294 |
+
# spaces. Google's externaly-published style guide says 4, consistent with
|
| 295 |
+
# PEP 8. Here we use 4 spaces.
|
| 296 |
+
indent-string=' '
|
| 297 |
+
|
| 298 |
+
# Number of spaces of indent required inside a hanging or continued line.
|
| 299 |
+
indent-after-paren=4
|
| 300 |
+
|
| 301 |
+
# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
|
| 302 |
+
expected-line-ending-format=
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
[MISCELLANEOUS]
|
| 306 |
+
|
| 307 |
+
# List of note tags to take in consideration, separated by a comma.
|
| 308 |
+
notes=TODO
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
[STRING]
|
| 312 |
+
|
| 313 |
+
# This flag controls whether inconsistent-quotes generates a warning when the
|
| 314 |
+
# character used as a quote delimiter is used inconsistently within a module.
|
| 315 |
+
check-quote-consistency=yes
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
[VARIABLES]
|
| 319 |
+
|
| 320 |
+
# Tells whether we should check for unused import in __init__ files.
|
| 321 |
+
init-import=no
|
| 322 |
+
|
| 323 |
+
# A regular expression matching the name of dummy variables (i.e. expectedly
|
| 324 |
+
# not used).
|
| 325 |
+
dummy-variables-rgx=^\*{0,2}(_$|unused_|dummy_)
|
| 326 |
+
|
| 327 |
+
# List of additional names supposed to be defined in builtins. Remember that
|
| 328 |
+
# you should avoid to define new builtins when possible.
|
| 329 |
+
additional-builtins=
|
| 330 |
+
|
| 331 |
+
# List of strings which can identify a callback function by name. A callback
|
| 332 |
+
# name must start or end with one of those strings.
|
| 333 |
+
callbacks=cb_,_cb
|
| 334 |
+
|
| 335 |
+
# List of qualified module names which can have objects that can redefine
|
| 336 |
+
# builtins.
|
| 337 |
+
redefining-builtins-modules=six,six.moves,past.builtins,future.builtins,functools
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
[LOGGING]
|
| 341 |
+
|
| 342 |
+
# Logging modules to check that the string format arguments are in logging
|
| 343 |
+
# function parameter format
|
| 344 |
+
logging-modules=logging,absl.logging,tensorflow.io.logging
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
[SIMILARITIES]
|
| 348 |
+
|
| 349 |
+
# Minimum lines number of a similarity.
|
| 350 |
+
min-similarity-lines=4
|
| 351 |
+
|
| 352 |
+
# Ignore comments when computing similarities.
|
| 353 |
+
ignore-comments=yes
|
| 354 |
+
|
| 355 |
+
# Ignore docstrings when computing similarities.
|
| 356 |
+
ignore-docstrings=yes
|
| 357 |
+
|
| 358 |
+
# Ignore imports when computing similarities.
|
| 359 |
+
ignore-imports=no
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
[SPELLING]
|
| 363 |
+
|
| 364 |
+
# Spelling dictionary name. Available dictionaries: none. To make it working
|
| 365 |
+
# install python-enchant package.
|
| 366 |
+
spelling-dict=
|
| 367 |
+
|
| 368 |
+
# List of comma separated words that should not be checked.
|
| 369 |
+
spelling-ignore-words=
|
| 370 |
+
|
| 371 |
+
# A path to a file that contains private dictionary; one word per line.
|
| 372 |
+
spelling-private-dict-file=
|
| 373 |
+
|
| 374 |
+
# Tells whether to store unknown words to indicated private dictionary in
|
| 375 |
+
# --spelling-private-dict-file option instead of raising a message.
|
| 376 |
+
spelling-store-unknown-words=no
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
[IMPORTS]
|
| 380 |
+
|
| 381 |
+
# Deprecated modules which should not be used, separated by a comma
|
| 382 |
+
deprecated-modules=regsub,
|
| 383 |
+
TERMIOS,
|
| 384 |
+
Bastion,
|
| 385 |
+
rexec,
|
| 386 |
+
sets
|
| 387 |
+
|
| 388 |
+
# Create a graph of every (i.e. internal and external) dependencies in the
|
| 389 |
+
# given file (report RP0402 must not be disabled)
|
| 390 |
+
import-graph=
|
| 391 |
+
|
| 392 |
+
# Create a graph of external dependencies in the given file (report RP0402 must
|
| 393 |
+
# not be disabled)
|
| 394 |
+
ext-import-graph=
|
| 395 |
+
|
| 396 |
+
# Create a graph of internal dependencies in the given file (report RP0402 must
|
| 397 |
+
# not be disabled)
|
| 398 |
+
int-import-graph=
|
| 399 |
+
|
| 400 |
+
# Force import order to recognize a module as part of the standard
|
| 401 |
+
# compatibility libraries.
|
| 402 |
+
known-standard-library=
|
| 403 |
+
|
| 404 |
+
# Force import order to recognize a module as part of a third party library.
|
| 405 |
+
known-third-party=enchant, absl
|
| 406 |
+
|
| 407 |
+
# Analyse import fallback blocks. This can be used to support both Python 2 and
|
| 408 |
+
# 3 compatible code, which means that the block might have code that exists
|
| 409 |
+
# only in one or another interpreter, leading to false positives when analysed.
|
| 410 |
+
analyse-fallback-blocks=no
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
[CLASSES]
|
| 414 |
+
|
| 415 |
+
# List of method names used to declare (i.e. assign) instance attributes.
|
| 416 |
+
defining-attr-methods=__init__,
|
| 417 |
+
__new__,
|
| 418 |
+
setUp
|
| 419 |
+
|
| 420 |
+
# List of member names, which should be excluded from the protected access
|
| 421 |
+
# warning.
|
| 422 |
+
exclude-protected=_asdict,
|
| 423 |
+
_fields,
|
| 424 |
+
_replace,
|
| 425 |
+
_source,
|
| 426 |
+
_make
|
| 427 |
+
|
| 428 |
+
# List of valid names for the first argument in a class method.
|
| 429 |
+
valid-classmethod-first-arg=cls,
|
| 430 |
+
class_
|
| 431 |
+
|
| 432 |
+
# List of valid names for the first argument in a metaclass class method.
|
| 433 |
+
valid-metaclass-classmethod-first-arg=mcs
|
| 434 |
+
|
| 435 |
+
|
| 436 |
+
[EXCEPTIONS]
|
| 437 |
+
|
| 438 |
+
# Exceptions that will emit a warning when being caught. Defaults to
|
| 439 |
+
# "Exception"
|
| 440 |
+
overgeneral-exceptions=StandardError,
|
| 441 |
+
Exception,
|
| 442 |
+
BaseException
|
| 443 |
+
|
| 444 |
+
#######
|
| 445 |
+
|
| 446 |
+
# https://github.com/edaniszewski/pylint-quotes#configuration
|
| 447 |
+
string-quote=single
|
| 448 |
+
triple-quote=double
|
| 449 |
+
docstring-quote=double
|
2024-02-26-conv.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"tstamp": 1708979292.1046, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708979275.4427, "finish": 1708979292.1046, "state": {"template_name": "billa", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "Hello "], ["Assistant", "Hello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello \n\nHello"]], "offset": 0, "conv_id": "0ea82788ded24b3e92860dc5b47febc0", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.50.130"}
|
| 2 |
+
{"tstamp": 1708979428.0297, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708979427.7589, "finish": 1708979428.0297, "state": {"template_name": "billa", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "Hello how are you?"], ["Assistant", "Hello, how are you?"]], "offset": 0, "conv_id": "49f3fb8a82584c788578dda8e359e9d7", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.37.241"}
|
| 3 |
+
{"tstamp": 1708979651.6512, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708979651.3346, "finish": 1708979651.6512, "state": {"template_name": "billa", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "Hello How are you?"], ["Assistant", "Hi, how are you doing?"]], "offset": 0, "conv_id": "1cb4f039ccde4e9abf3d237b47bc39d3", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.25.123"}
|
| 4 |
+
{"tstamp": 1708979958.428, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708979958.1858, "finish": 1708979958.428, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Hello how are you?"], ["Assistant", "Hello, how are you?"]], "offset": 2, "conv_id": "4e4c5de905f64b64814562ce6cb7ca92", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.37.241"}
|
| 5 |
+
{"tstamp": 1708980099.492, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708980099.1622, "finish": 1708980099.492, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Hello how are you?"], ["Assistant", "I am good thank you. How can I assist you today?"]], "offset": 2, "conv_id": "7a2f85c78ad244cfadbe214712847864", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.37.241"}
|
| 6 |
+
{"tstamp": 1708980395.3758, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708980394.8771, "finish": 1708980395.3758, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Hello How are you?"], ["Assistant", "Hello! How can I help you?"]], "offset": 2, "conv_id": "dcd8306a9bb84462afa55336f94182da", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.37.241"}
|
| 7 |
+
{"tstamp": 1708980429.3817, "type": "chat", "model": "MobiLlama-1B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708980425.9794, "finish": 1708980429.3817, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Generate a C code snippet that implements a function to calculate the Fibonacci sequence using recursion."], ["Assistant", "```c\n#include <stdio.h>\nint fib(int n);\nint fib(int n) {\n if (n <= 1) {\n return n;\n }\n else {\n return fib(n-1) + fib(n-2);\n }\n}\nint main() {\n int n;\n printf(\"Enter the value of n: \");\n scanf(\"%d\", &n);\n printf(\"The Fibonacci sequence is: \\n\");\n for (int i = 0; i < n; i++) {\n printf(\"%d \", fib(i));\n }\n return 0;\n}\n```\nThis C code implementation uses a recursive function `fib` to calculate the Fibonacci sequence. The function takes an integer `n` as input and returns the value of the `n`th Fibonacci"]], "offset": 2, "conv_id": "f250c5ef3c3d427582fe19e75839e236", "model_name": "MobiLlama-1B-Chat"}, "ip": "172.31.37.241"}
|
| 8 |
+
{"tstamp": 1708980445.7322, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708980442.5778, "finish": 1708980445.7322, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Generate a C code snippet that implements a function to calculate the Fibonacci sequence using recursion."], ["Assistant", "```c\r\n#include <stdio.h>\r\n#include <stdlib.h>\r\n#include <math.h>\r\nint fibonacci(int n) {\r\n if (n <= 1) {\r\n return n;\r\n }\r\n else {\r\n return fibonacci(n - 1) + fibonacci(n - 2);\r\n }\r\n}\r\nint main() {\r\n int n;\r\n printf(\"Enter the first number: \");\r\n scanf(\"%d\", &n);\r\n printf(\"Enter the second number: \");\r\n scanf(\"%d\", &n);\r\n printf(\"The Fibonacci sequence is: %d %d %d\\n\", fibonacci(n), fibonacci(n-1), fibonacci(n-2));\r\n return 0;\r\n}\r\n```\r\nThis function takes two parameters"]], "offset": 2, "conv_id": "e1f77bf7e30940db9addb35c3dd38294", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 9 |
+
{"tstamp": 1708981892.4992, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708981891.9426, "finish": 1708981892.4992, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "I was walking in the garden when "], ["Assistant", "Then I saw your scissors, I cut them."]], "offset": 2, "conv_id": "573e0b8ebc9a419e814a0f24e4151e60", "model_name": "MobiLlama-05B"}, "ip": "172.31.50.130"}
|
| 10 |
+
{"tstamp": 1708981911.5711, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708981911.2039, "finish": 1708981911.5711, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "How to write a python code to calculate factorial of a number"], ["Assistant", "How to write a python code to calculate factorial of a number"]], "offset": 2, "conv_id": "573e0b8ebc9a419e814a0f24e4151e60", "model_name": "MobiLlama-05B"}, "ip": "172.31.50.130"}
|
| 11 |
+
{"tstamp": 1708981935.556, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708981935.3194, "finish": 1708981935.556, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "On a bright sunny day I was "], ["Assistant", "I'm a"]], "offset": 2, "conv_id": "573e0b8ebc9a419e814a0f24e4151e60", "model_name": "MobiLlama-05B"}, "ip": "172.31.12.31"}
|
| 12 |
+
{"tstamp": 1708982111.1212, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708982110.8392, "finish": 1708982111.1212, "state": {"template_name": "zero_shot", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "On a bright sunny day I was "], ["Assistant", "On the first day of an important"]], "offset": 0, "conv_id": "672719a556364698b8c1b5a9c7063529", "model_name": "MobiLlama-05B"}, "ip": "172.31.37.241"}
|
| 13 |
+
{"tstamp": 1708982323.6584, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708982323.5031, "finish": 1708982323.6584, "state": {"template_name": "zero_shot", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "On a bright sunny day I was "], ["Assistant", ""]], "offset": 0, "conv_id": "da84b42618f34b7bbaf4364a08c25dda", "model_name": "MobiLlama-05B"}, "ip": "172.31.37.241"}
|
| 14 |
+
{"tstamp": 1708982336.4937, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708982336.3268, "finish": 1708982336.4937, "state": {"template_name": "zero_shot", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "On a bright sunny day I was "], ["Assistant", ""]], "offset": 0, "conv_id": "da84b42618f34b7bbaf4364a08c25dda", "model_name": "MobiLlama-05B"}, "ip": "172.31.37.241"}
|
| 15 |
+
{"tstamp": 1708982496.4846, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708982496.3086, "finish": 1708982496.4846, "state": {"template_name": "zero_shot", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "On a bright sunny day I was "], ["Assistant", ""]], "offset": 0, "conv_id": "da84b42618f34b7bbaf4364a08c25dda", "model_name": "MobiLlama-05B"}, "ip": "172.31.25.123"}
|
| 16 |
+
{"tstamp": 1708982505.7526, "type": "chat", "model": "MobiLlama-05B", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708982505.6079, "finish": 1708982505.7526, "state": {"template_name": "zero_shot", "system_message": "", "roles": ["Human", "Assistant"], "messages": [["Human", "On a bright sunny day I was "], ["Assistant", ""]], "offset": 0, "conv_id": "da84b42618f34b7bbaf4364a08c25dda", "model_name": "MobiLlama-05B"}, "ip": "172.31.25.123"}
|
| 17 |
+
{"tstamp": 1708983764.1363, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708983763.3268, "finish": 1708983764.1363, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Hi how are you?"], ["Assistant", "Hello! How can I help you today please \ud83d\ude0a"]], "offset": 2, "conv_id": "2325cc89da09435fa365959702fa2b56", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.37.241"}
|
| 18 |
+
{"tstamp": 1708983783.8594, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708983781.9502, "finish": 1708983783.8594, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Write a python code to print a table of a number"], ["Assistant", "Sure! Here is one way you can do it using Python with NumPy arrays as data sources.\r\n```python\r\nimport numpy as np \r\nnumbers = [1024968753., // ASCII value for \"Happy\"\r\n ---------------------// Countries in this alphabet are listed here too if desired (not shown)\r\n ]) # Define array containing numbers from 'input_file', where file path given on command line argument or loaded into variable `numbs` similarily according specification provided by user below during execution time step"]], "offset": 2, "conv_id": "2325cc89da09435fa365959702fa2b56", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.37.241"}
|
| 19 |
+
{"tstamp": 1708983818.622, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708983816.9916, "finish": 1708983818.622, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "write a python code to print the factorial of a number"], ["Assistant", "here is one possible solution that could work for your problem without any additional libraries or dependencies on other platforms (Python 3 only):\r\n```python \r\ndef fact(n) : if n <=0 else 'factor_of {}'.format((int)(fact))[1] + str(*list())[:-2][:-4].join() # this function uses `str` instead of regular expressions as it works with integers.\r\nprint(\"Fact value = \", end=\"\")"]], "offset": 2, "conv_id": "2325cc89da09435fa365959702fa2b56", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 20 |
+
{"tstamp": 1708983829.2042, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708983826.7386, "finish": 1708983829.2042, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "write a python code to print the factorial of a number"], ["Assistant", "Sure! Here is Python Code that can help you with your problem.\r\n```python\r\nfactor_factors = [1 ** i for i in range(2)] # initialize list containing factors from 0 upwards (starting at all numbers) \r\nprint(\"The Factorial of %d\"%num)\r\nfor num in factoars[::-1]: if sum([f**i * f^k - k*sum()/j->p == j+len($elems)-4] > len('.')): return True break else : continue end except StopIteration as e:`No such element found` or `None`: raise ValueError(\"%r not positive integer\")"]], "offset": 2, "conv_id": "2325cc89da09435fa365959702fa2b56", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 21 |
+
{"tstamp": 1708983854.4101, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708983851.2397, "finish": 1708983854.4101, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "write a python code to calculate the factorial of a number"], ["Assistant", "Sure! Here is one way you can do it using Python as follows : \r\n\r\n```python # Assume we have already defined `factors` variable containing all possible factors up until n-1.\r\ndef fact(n): return [factor for i in range(2**i) if (4*5 - sum([x * y + z] == s/d[j]) <= d[-3]*b))[:len(f)*6:-8].count((0).flatten())+[(a-.7)+(-9)-sum({_:[m:][\"identity\"]} < _ / g)[::-(g//k)]>= (\"Factoring\" not \"not algebraic\").strftime('%.%')]+pow(.|_.split(\".\")(int(_))))/(abs(__)!._!)*(reverse(*range(``.__list()))[_?<->](_) | reverse(\".\")>().index(!_(.)!(dig"]], "offset": 2, "conv_id": "2325cc89da09435fa365959702fa2b56", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 22 |
+
{"tstamp": 1708983875.5177, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708983872.355, "finish": 1708983875.5177, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "write a code in C language to find the factorial of a number"], ["Assistant", "Sure! Here is one possible implementation using recursion as shown above with some modifications based on your requirements.\r\n```c\r\nint fact(char c){ // define function call for finding faktor (factor) by character value x = 0; \r\n if ((x == '1') && (!isdigit((unsigned char)(p))) ||!('\\n')){\r\n printf(\"%d\\t\", p); exit();\r\n }\r\n\tif (*--v!= '\\b'+'\\f');\r\n else {\r\n *++q++;;\r\n while(*y > v-k+2&&*j >= k)\r\n j -= q - y + gpp(-4);\r\n do{printf(\"-> %e%a:%u -> \", i++, n++){*(i++) += d[g];}\r\n ++m,\r\n 5<=(39-(&putl()))?cout<<\"Shift left \":\""]], "offset": 2, "conv_id": "2325cc89da09435fa365959702fa2b56", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 23 |
+
{"tstamp": 1708983904.2687, "type": "chat", "model": "MobiLlama-1B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1708983901.9497, "finish": 1708983904.2687, "state": {"template_name": "one_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "write a C language code to find the factorial of a number"], ["Assistant", "Here is one way you can implement this in Python using recursion: \n```python\ndef factorial(n):\n if n <=1: # Base case for when n=0 or 1\n return 1\n else: # Recursive call with n-1 as argument\n result = n * factorial(n - 1)\n print(\"The factorial of\", n,\"is\",result)\n \nfactorial(5) \nprint() # This prints \"24\" since it returns 6 x 3! (which equals 72) multiplied by itself three times\n```"]], "offset": 2, "conv_id": "7db4fc8937364fd881dc9cf144dd1467", "model_name": "MobiLlama-1B-Chat"}, "ip": "172.31.50.130"}
|
2024-02-27-conv.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
2024-02-28-conv.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
2024-02-29-conv.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"tstamp": 1709173113.8235, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709173113.5155, "finish": 1709173113.8235, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "who are you?"], ["Assistant", "I am an AI language model that helps people find information."]], "offset": 0, "conv_id": "74253ff2f9744483bdb9517b98bc58a3", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 2 |
+
{"tstamp": 1709173839.3768, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709173838.7165, "finish": 1709173839.3768, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "What you know about Pakistan cricket?"], ["Assistant", "I'm an AI language model and don't have any knowledge about Pakistan cricket. However, I can provide you with some information about Pakistan cricket."]], "offset": 0, "conv_id": "3b298402f6474d0e872d1e7131b7e642", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.38.44"}
|
| 3 |
+
{"tstamp": 1709173851.8231, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709173851.2365, "finish": 1709173851.8231, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Yes sure."], ["Assistant", "As an AI language model, I don't have a physical body, but I can provide you with the information you are looking for."]], "offset": 0, "conv_id": "3b298402f6474d0e872d1e7131b7e642", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.38.44"}
|
| 4 |
+
{"tstamp": 1709174172.9003, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709174172.6649, "finish": 1709174172.9003, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Hii how are you "], ["Assistant", "Hi, how are you?"]], "offset": 0, "conv_id": "a1a8982247434c678f7f8e877dd0c20b", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 5 |
+
{"tstamp": 1709174184.9852, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709174184.4893, "finish": 1709174184.9852, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "I'm fine "], ["Assistant", "Thanks for letting me know. I'm glad to hear that you're okay. Have you been feeling better lately?"]], "offset": 0, "conv_id": "a1a8982247434c678f7f8e877dd0c20b", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 6 |
+
{"tstamp": 1709174203.8211, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709174202.7726, "finish": 1709174203.8211, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "What can you do for me?"], ["Assistant", "As an AI language model, I don't have a physical body, but I can provide you with information and help you with your queries. I can help you with your queries related to technology, finance, and any other topic you can think of. Please feel free to ask me anything you want."]], "offset": 0, "conv_id": "a1a8982247434c678f7f8e877dd0c20b", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 7 |
+
{"tstamp": 1709176796.3134, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709176795.3603, "finish": 1709176796.3134, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "who are and which services you can provide?"], ["Assistant", "I can provide information and resources on various topics related to health and wellness, including nutrition, exercise, mental health, and more. I can also provide guidance on how to maintain a healthy lifestyle and support individuals who are struggling with their health."]], "offset": 0, "conv_id": "b158aa28a9ae4d58aaad2d0f5d61c577", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 8 |
+
{"tstamp": 1709176839.6693, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709176833.48, "finish": 1709176839.6693, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "how can i use you in mobile apps? need detailed steps"], ["Assistant", "you can use you in mobile apps by following these steps:\n1. Install the app on your mobile device.\n2. Open the app and sign in with your account.\n3. Click on the \"Sign In\" button.\n4. Enter your username and password.\n5. Click on the \"Log In\" button.\n6. You will be redirected to the login page.\n7. Enter your username and password.\n8. Click on the \"Log In\" button.\n9. You will be redirected to the app dashboard.\n10. Click on the \"My Profile\" button.\n11. You will be redirected to your profile page.\n12. Click on the \"Edit Profile\" button.\n13. You will be redirected to your profile settings.\n14. Click on the \"Edit Profile\" button.\n15. You will be redirected to your profile picture.\n16. Click on the \"Upload Profile Picture\" button.\n17. You will be redirected to your profile picture.\n18. Click on the \"Save\" button.\n19. You will be redirected to your profile settings.\n20. Click on the \"Edit Profile\" button.\n21. You will be redirected to your profile settings.\n22. Click on the \"Edit Profile\" button.\n23. You will be redirected to your profile settings.\n24. Click on the \"Edit Profile\" button.\n25. You will be redirected to your profile settings.\n26. Click on the \"Edit Profile\" button.\n27. You will be redirected to your profile settings.\n28. Click on the \"Edit Profile\" button.\n29. You will be redirected to your profile settings.\n30. Click on the \"Edit Profile\" button."]], "offset": 0, "conv_id": "b158aa28a9ae4d58aaad2d0f5d61c577", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 9 |
+
{"tstamp": 1709196117.2409, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196116.9977, "finish": 1709196117.2409, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u3053\u3093\u306b\u3061\u306f"], ["Assistant", "\u3053\u3093\u306b\u3061\u306f"]], "offset": 0, "conv_id": "4dfac351421946bfb3c8e98d2cfef6a1", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.18.237"}
|
| 10 |
+
{"tstamp": 1709196127.9141, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196127.5827, "finish": 1709196127.9141, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u5143\u6c17\uff1f"], ["Assistant", "\u5143\u6c17\uff1f\n\n\u5143\u6c17\uff1f"]], "offset": 0, "conv_id": "4dfac351421946bfb3c8e98d2cfef6a1", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.18.237"}
|
| 11 |
+
{"tstamp": 1709196140.8271, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196140.5099, "finish": 1709196140.8271, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u4f55\u65452\u56de\uff1f"], ["Assistant", "\u56e0\u4e3a\u6211\u53eb\u666e\u901a\u4eba\u3002"]], "offset": 0, "conv_id": "4dfac351421946bfb3c8e98d2cfef6a1", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.18.237"}
|
| 12 |
+
{"tstamp": 1709196162.1383, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196161.8704, "finish": 1709196162.1383, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u65e5\u672c\u8a9e\u3067"], ["Assistant", "\u65e5\u672c\u8a9e\u3067"]], "offset": 0, "conv_id": "4dfac351421946bfb3c8e98d2cfef6a1", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 13 |
+
{"tstamp": 1709196171.2674, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196171.0041, "finish": 1709196171.2674, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u304a\u9858\u3044\u3057\u307e\u3059\u3002"], ["Assistant", "\u3054\u3081\u3093\u306d\u3002"]], "offset": 0, "conv_id": "4dfac351421946bfb3c8e98d2cfef6a1", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 14 |
+
{"tstamp": 1709196180.1346, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196179.9291, "finish": 1709196180.1346, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u3044\u3044\u3088"], ["Assistant", "\u3044\u3044\u3088"]], "offset": 0, "conv_id": "4dfac351421946bfb3c8e98d2cfef6a1", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 15 |
+
{"tstamp": 1709196215.0201, "type": "chat", "model": "MobiLlama-1B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196214.772, "finish": 1709196215.0201, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u7b11\u308f\u305b\u3066\u3002"], ["Assistant", "\u7b11\u308f\u305b\u3066\u3002"]], "offset": 0, "conv_id": "5af925ca8efb4d2e936734469a9058d6", "model_name": "MobiLlama-1B-Chat"}, "ip": "172.31.12.31"}
|
| 16 |
+
{"tstamp": 1709196259.5968, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709196256.4629, "finish": 1709196259.5968, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "do you like japanese food?"], ["Assistant", "I am an AI language model and do not have emotions or preferences. However, I can provide you with some information about Japanese food. \nJapanese cuisine is known for its rich and diverse flavors. It is made up of a variety of ingredients and spices that are carefully selected to create unique and delicious dishes. Some of the most popular dishes in Japan include sushi, sashimi, tempura, ramen, and udon. \nJapanese cuisine is known for its use of high-quality ingredients and is often influenced by the seasons and local farmers markets. It is also known for its use of seasonal ingredients and the ability to adapt to different flavors and ingredients. \nOverall, Japanese food is a delicious and unique cuisine that is perfect for those who enjoy a variety of flavors and textures."]], "offset": 0, "conv_id": "383918313cd3485192d331cfe37ec1db", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 17 |
+
{"tstamp": 1709203199.6921, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709203199.4168, "finish": 1709203199.6921, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u4f60\u597d"], ["Assistant", "Hi there! How can I assist you today?"]], "offset": 0, "conv_id": "e06b14bb931f40c29f4723b0eb9e3ecf", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.38.44"}
|
| 18 |
+
{"tstamp": 1709203220.6204, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709203220.1293, "finish": 1709203220.6204, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u4f60\u61c2\u4e2d\u6587\u5417"], ["Assistant", "\u60a8\u597d\uff0c\u8bf7\u95ee\u4f60\u662f\u5426\u6709\u4efb\u4f55\u610f\u89c1\u548c\u5efa\u8bae\uff1f"]], "offset": 0, "conv_id": "e06b14bb931f40c29f4723b0eb9e3ecf", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.38.44"}
|
| 19 |
+
{"tstamp": 1709203236.708, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709203236.3527, "finish": 1709203236.708, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u4f60\u53ef\u4ee5\u722c\u53d6\u7f51\u7ad9\u5185\u5bb9\u5417"], ["Assistant", "\u662f\u7684\uff0c\u6211\u53ef\u4ee5\u722c\u53d6\u7f51\u7ad9\u5185\u5bb9\u3002"]], "offset": 0, "conv_id": "e06b14bb931f40c29f4723b0eb9e3ecf", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.38.44"}
|
| 20 |
+
{"tstamp": 1709203283.5876, "type": "chat", "model": "MobiLlama-1B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709203282.7635, "finish": 1709203283.5876, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "https://www.skroutz.gr/ \u4f60\u53ef\u4ee5\u5e2e\u6211\u722c\u53d6\u8fd9\u4e2a\u7f51\u7ad9\u7684\u5185\u5bb9\u5417"], ["Assistant", "\u53ef\u4ee5\uff0c\u6211\u4f1a\u5728\u8fd9\u4e2a\u7f51\u7ad9\u4e0a\u722c\u53d6\u4e00\u4e9b\u5185\u5bb9\uff0c\u5e76\u5c06\u5176\u6574\u7406\u6210\u4e00\u4e2a\u6587\u6863\uff0c\u6b22\u8fce\u60a8\u53c2\u4e0e\u3002"]], "offset": 0, "conv_id": "8450ba69ec064163b0997ff60744ca5e", "model_name": "MobiLlama-1B-Chat"}, "ip": "172.31.12.31"}
|
| 21 |
+
{"tstamp": 1709203713.9642, "type": "chat", "model": "MobiLlama-1B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709203707.7742, "finish": 1709203713.9642, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u5e2e\u6211\u6574\u7406\u51fa\u6765"], ["Assistant", "\u6574\u7406\u51fa\u6765\u4e86\uff0c\u4ee5\u4e0b\u662f\u4e00\u4e9b\u5e38\u89c1\u7684\u6570\u636e\u7c7b\u578b\uff1a\n- \u6574\u6570\n- \u6d6e\u70b9\u6570\n- \u5b57\u7b26\u4e32\n- \u5e03\u5c14\u503c\n- \u5b57\u7b26\u4e32\u6570\u7ec4\n- \u6570\u7ec4\n- \u5bf9\u8c61\n- \u679a\u4e3e\n- \u6570\u7ec4\u548c\u5b57\u7b26\u4e32\u7684\u5bf9\u6bd4\n- \u6570\u7ec4\u548c\u5b57\u7b26\u4e32\u7684\u533a\u522b\n- \u5b57\u7b26\u4e32\u7684\u6bd4\u8f83\n- \u5b57\u7b26\u4e32\u7684\u622a\u65ad\n- \u5b57\u7b26\u4e32\u7684\u53bb\u9664\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u4e49\n- \u5b57\u7b26\u4e32\u7684\u5339\u914d\n- \u5b57\u7b26\u4e32\u7684\u66ff\u6362\n- \u5b57\u7b26\u4e32\u7684\u5206\u6790\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u5316\n- \u5b57\u7b26\u4e32\u7684\u6bd4\u8f83\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u4e49\n- \u5b57\u7b26\u4e32\u7684\u5339\u914d\n- \u5b57\u7b26\u4e32\u7684\u66ff\u6362\n- \u5b57\u7b26\u4e32\u7684\u5206\u6790\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u5316\n- \u5b57\u7b26\u4e32\u7684\u6bd4\u8f83\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u4e49\n- \u5b57\u7b26\u4e32\u7684\u5339\u914d\n- \u5b57\u7b26\u4e32\u7684\u66ff\u6362\n- \u5b57\u7b26\u4e32\u7684\u5206\u6790\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u5316\n- \u5b57\u7b26\u4e32\u7684\u6bd4\u8f83\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u4e49\n- \u5b57\u7b26\u4e32\u7684\u5339\u914d\n- \u5b57\u7b26\u4e32\u7684\u66ff\u6362\n- \u5b57\u7b26\u4e32\u7684\u5206\u6790\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u5316\n- \u5b57\u7b26\u4e32\u7684\u6bd4\u8f83\n- \u5b57\u7b26\u4e32\u7684\u8f6c\u4e49\n- \u5b57\u7b26\u4e32\u7684\ufffd"]], "offset": 0, "conv_id": "8450ba69ec064163b0997ff60744ca5e", "model_name": "MobiLlama-1B-Chat"}, "ip": "172.31.57.119"}
|
| 22 |
+
{"tstamp": 1709203753.2842, "type": "chat", "model": "MobiLlama-1B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709203752.397, "finish": 1709203753.2842, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u5e2e\u6211\u6c47\u603b\u4e00\u4e0b\u8fd1\u534a\u5e74\u6765\u6b27\u5143\u5151\u4eba\u6c11\u5e01\u7684\u6c47\u7387"], ["Assistant", "\u6b27\u5143\u5151\u4eba\u6c11\u5e01\u7684\u6c47\u7387\u57282021\u5e746\u670826\u65e5\u81f32022\u5e741\u670825\u65e5\uff0c\u4e3a1:1\u3002"]], "offset": 0, "conv_id": "8450ba69ec064163b0997ff60744ca5e", "model_name": "MobiLlama-1B-Chat"}, "ip": "172.31.57.119"}
|
| 23 |
+
{"tstamp": 1709214265.7959, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709214265.6141, "finish": 1709214265.7959, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "salut"], ["Assistant", "hello"]], "offset": 0, "conv_id": "783b077851054411b2e6fae2ed198e71", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.38.44"}
|
| 24 |
+
{"tstamp": 1709237914.4236, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709237913.44, "finish": 1709237914.4236, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "who is barak obama"], ["Assistant", "Barack Obama is a U.S. politician and the 44th President of the United States. He was born on February 4, 1964, in Chicago, Illinois, USA. He is the 44th President of the United States."]], "offset": 0, "conv_id": "af723d77b3c642dc97a8312e2718dfe5", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 25 |
+
{"tstamp": 1709237929.4318, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709237928.1712, "finish": 1709237929.4318, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "tell me more about him"], ["Assistant", "He is a 29-year-old man who has been in the music industry for over 10 years. He is known for his versatility in playing various instruments such as guitar, drums, and bass. He has a unique blend of traditional and modern music styles, and his unique sound has made him a popular musician in the industry."]], "offset": 0, "conv_id": "af723d77b3c642dc97a8312e2718dfe5", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 26 |
+
{"tstamp": 1709237958.5662, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709237957.4541, "finish": 1709237958.5662, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "who are norse people"], ["Assistant", "Norse people are a group of people who lived in Norway, Sweden, Denmark, and Iceland in the 9th century. They were a group of warriors who fought for the power of the king and were known for their strength, skill, and courage. They were also known for their architecture and art."]], "offset": 0, "conv_id": "af723d77b3c642dc97a8312e2718dfe5", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 27 |
+
{"tstamp": 1709237984.5959, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709237982.8487, "finish": 1709237984.5959, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "tell me more about their mythology"], ["Assistant", "As an AI language model, I don't have any personal mythology. However, I can tell you that mythology is a collection of stories and beliefs that have been passed down from generation to generation in different cultures. It is believed to have originated in ancient Greece and Rome and has evolved over time to include different stories and beliefs. Some of the most popular myths include the Hindu Mahabharata, the Greek myth of Poseidon, and the Norse myth of Odin."]], "offset": 0, "conv_id": "af723d77b3c642dc97a8312e2718dfe5", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 28 |
+
{"tstamp": 1709238034.0094, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709238032.2459, "finish": 1709238034.0094, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\"Bigger the better\" has been the predominant trend in recent Large Language Models (LLMs) development. However, LLMs do not suit well for scenarios that require on-device processing, energy efficiency, low memory footprint, and response efficiency. These requisites are crucial for privacy, security, and sustainable deployment. This paper explores the \"less is more\" paradigm by addressing the challenge of designing accurate yet efficient Small Language Models (SLMs) for resource constrained devices. Our primary contribution is the introduction of an accurate and fully transparent open-source 0.5 billion (0.5B) parameter SLM, named MobiLlama, catering to the specific needs of resource-constrained computing with an emphasis on enhanced performance with reduced resource demands. MobiLlama is a SLM design that initiates from a larger model and applies a careful parameter sharing scheme to reduce both the pre-training and the deployment cost. Our work strives to not only bridge the gap in open-source SLMs but also ensures full transparency, where complete training data pipeline, training code, model weights, and over 300 checkpoints along with evaluation codes is available at : https://github.com/mbzuai-oryx/MobiLlama. based on the above context answer the question: how many parameters are present in the model"], ["Assistant", "MobiLlama is a 0.5 billion (0.5B) parameter SLM designed for resource-constrained computing. It is an open-source 0.5 billion (0.5B) parameter SLM that initiates from a larger model and applies a careful parameter sharing scheme to reduce both the pre-training and the deployment cost. It is designed to cater to the specific needs of resource-constrained computing with an emphasis on enhanced performance with reduced resource demands."]], "offset": 0, "conv_id": "af723d77b3c642dc97a8312e2718dfe5", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 29 |
+
{"tstamp": 1709238128.8102, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709238128.3682, "finish": 1709238128.8102, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Avagin Updates\nProgress:\n\u2022 Completed Roger Script: The core script, integrating voice recognition, text-\nto-speech, and a large language model (LLM), is now functional.\n\u2022 Flask Demo App: A user-friendly Flask-based application showcases the\nRoger script's capabilities.\n\u2022 Fine-Tuning and RAG Scripts Ready: Both fine-tuning scripts and Retrieval-\nAugmented Generation (RAG) scripts are prepared for domain-specific LLM\ndevelopment.\n\u2022 UI and Android App Demo Prepared: A basic Android app with user\ninterface is ready for integration with the LLM. Upon successful integration,\nwe can deliver a functional Android app demo within the next week for client\npresentation. This is not just a demo app; we plan to leverage this progress\nfor the final application.\nChallenges and Request:\n\u2022 GPU Requirement: Unfortunately, the fine-tuning and RAG processes require\nsignificant computational resources, specifically GPUs, which are currently\nunavailable.\n\u2022 Domain-Specific LLMs: We aim to create eight specialized LLMs, including\nthe Finance LLM designated for SatoshiAI. However, GPU access is crucial to\nachieve this objective.\nUrgent Request:\nTo ensure continued progress and meet development goals, we urgently request\naccess to one or more GPUs. This will enable us to:\n\u2022\n\u2022\n\u2022\nFine-tune LLMs: Tailor the LLMs to specific domains, including the Finance\nLLM for SatoshiAI.\nRun RAG Scripts: Enhance the LLMs' performance using the Retrieval-\nAugmented Generation technique.\nAchieve Domain-Specific Goals: Develop the eight planned LLMs, including\nthe critical Finance LLM for SatoshiAI.\nAndroid Integration:We understand the importance of Android integration and will continue to prioritize\nits development. Currently, we are investigating the most promising solutions to\novercome the challenges related to integrating Python libraries with Android,\nconsidering the following options:\nContributing to the Chocopy library: While considered a last resort due to\nits complexity, contributing to support the new Python libraries (llama-cpp-\npython and transformers) could be a potential solution.\n\u2022 TensorFlow Lite Approach: Although TensorFlow Lite supports some\nmodels, its current limitations include lack of phi2 support. Converting the\ngemma2B model to TFLite format might be viable, but requires access to a\npowerful GPU.\n\u2022 Kivy Library Exploration: While initial attempts with the Kivy library\nencountered errors, further investigation might yield solutions for building a\nmobile app.\n\u2022 Flutter Framework Evaluation: We are actively exploring the potential of\nFlutter's Langchain integration to enable LLM execution on mobile devices.\nFurther investigation into this option is warranted.\nAdditional Considerations:\n\u2022 Resource-Dependent App: We acknowledge that the Flask app is resource-\ndependent and requires a screen recording for demonstration purposes.\n\u2022 Final App Integration: We plan to leverage the current progress on the UI\nand Android app for the final application.\nNext Week's Tasks:\n\u2022 Continue investigating and working on Android integration: We will\nactively explore the mentioned solutions and prioritize the most promising\napproach based on feasibility and resource availability.\n\u2022 Integrate LLM with Android app: Upon receiving GPU access and identifying\na suitable solution, we will prioritize integrating the LLM with the Android app to\ndeliver the promised demo within the next week.\n\u2022 Integrate automation and API call for UBER ride booking: We will begin\nintegrating automation and API calls to facilitate ride booking with Uber\ndirectly through the Roger script.\n\u2022 Future Script Upgrades: Further enhancements are planned for the script,\nincluding streaming capabilities, bot memory, translation features, and\nimage/video input functionalities.\n\u2022Demo for Client:\n\u2022 Flask App Demo: While awaiting GPU access and Android integration, we\ncan showcase the Roger script's functionality through a screen recording of\nthe Flask app demo.\n\u2022 Android App Demo: Upon successful LLM integration, we will provide a\nfunctional Android app demo for client presentation within the next week.\nWe are confident that GPU access will significantly contribute to the success\nof the Roger project. We also remain committed to achieving Android\nintegration and delivering the promised demos as soon as possible.\n\nbased on the above context answer the question: what is the next weeks task?"], ["Assistant", "Next weeks task\nThe next weeks task is to continue investigating and working on Android integration."]], "offset": 0, "conv_id": "af723d77b3c642dc97a8312e2718dfe5", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.38.44"}
|
| 30 |
+
{"tstamp": 1709245998.6928, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709245992.3665, "finish": 1709245998.6928, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "import argparse, os, sys, datetime, glob, importlib, csv\nimport numpy as np\nimport time\nimport torch\nimport torchvision\nimport pytorch_lightning as pl\n\nfrom packaging import version\nfrom omegaconf import OmegaConf\nfrom torch.utils.data import random_split, DataLoader, Dataset, Subset\nfrom functools import partial\nfrom PIL import Image\n\nfrom pytorch_lightning import seed_everything\nfrom pytorch_lightning.trainer import Trainer\nfrom pytorch_lightning.callbacks import ModelCheckpoint, Callback, LearningRateMonitor\nfrom pytorch_lightning.utilities.distributed import rank_zero_only\nfrom pytorch_lightning.utilities import rank_zero_info\n\nfrom ldm.data.base import Txt2ImgIterableBaseDataset\nfrom ldm.util import instantiate_from_config\n\n\ndef get_parser(**parser_kwargs):\n def str2bool(v):\n if isinstance(v, bool):\n return v\n if v.lower() in (\"yes\", \"true\", \"t\", \"y\", \"1\"):\n return True\n elif v.lower() in (\"no\", \"false\", \"f\", \"n\", \"0\"):\n return False\n else:\n raise argparse.ArgumentTypeError(\"Boolean value expected.\")\n\n parser = argparse.ArgumentParser(**parser_kwargs)\n parser.add_argument(\n \"-n\",\n \"--name\",\n type=str,\n const=True,\n default=\"\",\n nargs=\"?\",\n help=\"postfix for logdir\",\n )\n parser.add_argument(\n \"-r\",\n \"--resume\",\n type=str,\n const=True,\n default=\"\",\n nargs=\"?\",\n help=\"resume from logdir or checkpoint in logdir\",\n )\n parser.add_argument(\n \"-b\",\n \"--base\",\n nargs=\"*\",\n metavar=\"base_config.yaml\",\n help=\"paths to base configs. Loaded from left-to-right. \"\n \"Parameters can be overwritten or added with command-line options of the form `--key value`.\",\n default=list(),\n )\n parser.add_argument(\n \"-t\",\n \"--train\",\n type=str2bool,\n const=True,\n default=False,\n nargs=\"?\",\n help=\"train\",\n )\n parser.add_argument(\n \"--no-test\",\n type=str2bool,\n const=True,\n default=False,\n nargs=\"?\",\n help=\"disable test\",\n )\n parser.add_argument(\n \"-p\",\n \"--project\",\n help=\"name of new or path to existing project\"\n )\n parser.add_argument(\n \"-d\",\n \"--debug\",\n type=str2bool,\n nargs=\"?\",\n const=True,\n default=False,\n help=\"enable post-mortem debugging\",\n )\n parser.add_argument(\n \"-s\",\n \"--seed\",\n type=int,\n default=23,\n help=\"seed for seed_everything\",\n )\n parser.add_argument(\n \"-f\",\n \"--postfix\",\n type=str,\n default=\"\",\n help=\"post-postfix for default name\",\n )\n parser.add_argument(\n \"-l\",\n \"--logdir\",\n type=str,\n default=\"logs\",\n help=\"directory for logging dat shit\",\n )\n parser.add_argument(\n \"--scale_lr\",\n type=str2bool,\n nargs=\"?\",\n const=True,\n default=True,\n help=\"scale base-lr by ngpu * batch_size * n_accumulate\",\n )\n return parser\n\n\ndef nondefault_trainer_args(opt):\n parser = argparse.ArgumentParser()\n parser = Trainer.add_argparse_args(parser)\n args = parser.parse_args([])\n return sorted(k for k in vars(args) if getattr(opt, k) != getattr(args, k))\n\n\nclass WrappedDataset(Dataset):\n \"\"\"Wraps an arbitrary object with __len__ and __getitem__ into a pytorch dataset\"\"\"\n\n def __init__(self, dataset):\n self.data = dataset\n\n def __len__(self):\n return len(self.data)\n\n def __getitem__(self, idx):\n return self.data[idx]\n\n\ndef worker_init_fn(_):\n worker_info = torch.utils.data.get_worker_info()\n\n dataset = worker_info.dataset\n worker_id = worker_info.id\n\n if isinstance(dataset, Txt2ImgIterableBaseDataset):\n split_size = dataset.num_records // worker_info.num_workers\n # reset num_records to the true number to retain reliable length information\n dataset.sample_ids = dataset.valid_ids[worker_id * split_size:(worker_id + 1) * split_size]\n current_id = np.random.choice(len(np.random.get_state()[1]), 1)\n return np.random.seed(np.random.get_state()[1][current_id] + worker_id)\n else:\n return np.random.seed(np.random.get_state()[1][0] + worker_id)\n\n\nclass DataModuleFromConfig(pl.LightningDataModule):\n def __init__(self, batch_size, train=None, validation=None, test=None, predict=None,\n wrap=False, num_workers=None, shuffle_test_loader=False, use_worker_init_fn=False,\n shuffle_val_dataloader=False):\n super().__init__()\n self.batch_size = batch_size\n self.dataset_configs = dict()\n self.num_workers = num_workers if num_workers is not None else batch_size * 2\n self.use_worker_init_fn = use_worker_init_fn\n if train is not None:\n self.dataset_configs[\"train\"] = train\n self.train_dataloader = self._train_dataloader\n if validation is not None:\n self.dataset_configs[\"validation\"] = validation\n self.val_dataloader = partial(self._val_dataloader, shuffle=shuffle_val_dataloader)\n if test is not None:\n self.dataset_configs[\"test\"] = test\n self.test_dataloader = partial(self._test_dataloader, shuffle=shuffle_test_loader)\n if predict is not None:\n self.dataset_configs[\"predict\"] = predict\n self.predict_dataloader = self._predict_dataloader\n self.wrap = wrap\n\n def prepare_data(self):\n for data_cfg in self.dataset_configs.values():\n instantiate_from_config(data_cfg)\n\n def setup(self, stage=None):\n self.datasets = dict(\n (k, instantiate_from_config(self.dataset_configs[k]))\n for k in self.dataset_configs)\n if self.wrap:\n for k in self.datasets:\n self.datasets[k] = WrappedDataset(self.datasets[k])\n\n def _train_dataloader(self):\n is_iterable_dataset = isinstance(self.datasets['train'], Txt2ImgIterableBaseDataset)\n if is_iterable_dataset or self.use_worker_init_fn:\n init_fn = worker_init_fn\n else:\n init_fn = None\n return DataLoader(self.datasets[\"train\"], batch_size=self.batch_size,\n num_workers=self.num_workers, shuffle=False if is_iterable_dataset else True,\n worker_init_fn=init_fn)\n\n def _val_dataloader(self, shuffle=False):\n if isinstance(self.datasets['validation'], Txt2ImgIterableBaseDataset) or self.use_worker_init_fn:\n init_fn = worker_init_fn\n else:\n init_fn = None\n return DataLoader(self.datasets[\"validation\"],\n batch_size=self.batch_size,\n num_workers=self.num_workers,\n worker_init_fn=init_fn,\n shuffle=shuffle)\n\n def _test_dataloader(self, shuffle=False):\n is_iterable_dataset = isinstance(self.datasets['train'], Txt2ImgIterableBaseDataset)\n if is_iterable_dataset or self.use_worker_init_fn:\n init_fn = worker_init_fn\n else:\n init_fn = None\n\n # do not shuffle dataloader for iterable dataset\n shuffle = shuffle and (not is_iterable_dataset)\n\n return DataLoader(self.datasets[\"test\"], batch_size=self.batch_size,\n num_workers=self.num_workers, worker_init_fn=init_fn, shuffle=shuffle)\n\n def _predict_dataloader(self, shuffle=False):\n if isinstance(self.datasets['predict'], Txt2ImgIterableBaseDataset) or self.use_worker_init_fn:\n init_fn = worker_init_fn\n else:\n init_fn = None\n return DataLoader(self.datasets[\"predict\"], batch_size=self.batch_size,\n num_workers=self.num_workers, worker_init_fn=init_fn)\n\n\nclass SetupCallback(Callback):\n def __init__(self, resume, now, logdir, ckptdir, cfgdir, config, lightning_config):\n super().__init__()\n self.resume = resume\n self.now = now\n self.logdir = logdir\n self.ckptdir = ckptdir\n self.cfgdir = cfgdir\n self.config = config\n self.lightning_config = lightning_config\n\n def on_keyboard_interrupt(self, trainer, pl_module):\n if trainer.global_rank == 0:\n print(\"Summoning checkpoint.\")\n ckpt_path = os.path.join(self.ckptdir, \"last.ckpt\")\n trainer.save_checkpoint(ckpt_path)\n\n def on_pretrain_routine_start(self, trainer, pl_module):\n if trainer.global_rank == 0:\n # Create logdirs and save configs\n os.makedirs(self.logdir, exist_ok=True)\n os.makedirs(self.ckptdir, exist_ok=True)\n os.makedirs(self.cfgdir, exist_ok=True)\n\n if \"callbacks\" in self.lightning_config:\n if 'metrics_over_trainsteps_checkpoint' in self.lightning_config['callbacks']:\n os.makedirs(os.path.join(self.ckptdir, 'trainstep_checkpoints'), exist_ok=True)\n print(\"Project config\")\n print(OmegaConf.to_yaml(self.config))\n OmegaConf.save(self.config,\n os.path.join(self.cfgdir, \"{}-project.yaml\".format(self.now)))\n\n print(\"Lightning config\")\n print(OmegaConf.to_yaml(self.lightning_config))\n OmegaConf.save(OmegaConf.create({\"lightning\": self.lightning_config}),\n os.path.join(self.cfgdir, \"{}-lightning.yaml\".format(self.now)))\n\n else:\n # ModelCheckpoint callback created log directory --- remove it\n if not self.resume and os.path.exists(self.logdir):\n dst, name = os.path.split(self.logdir)\n dst = os.path.join(dst, \"child_runs\", name)\n os.makedirs(os.path.split(dst)[0], exist_ok=True)\n try:\n os.rename(self.logdir, dst)\n except FileNotFoundError:\n pass\n\n\nclass ImageLogger(Callback):\n def __init__(self, batch_frequency, max_images, clamp=True, increase_log_steps=True,\n rescale=True, disabled=False, log_on_batch_idx=False, log_first_step=False,\n log_images_kwargs=None):\n super().__init__()\n self.rescale = rescale\n self.batch_freq = batch_frequency\n self.max_images = max_images\n self.logger_log_images = {\n pl.loggers.TestTubeLogger: self._testtube,\n }\n self.log_steps = [2 ** n for n in range(int(np.log2(self.batch_freq)) + 1)]\n if not increase_log_steps:\n self.log_steps = [self.batch_freq]\n self.clamp = clamp\n self.disabled = disabled\n self.log_on_batch_idx = log_on_batch_idx\n self.log_images_kwargs = log_images_kwargs if log_images_kwargs else {}\n self.log_first_step = log_first_step\n\n @rank_zero_only\n def _testtube(self, pl_module, images, batch_idx, split):\n for k in images:\n grid = torchvision.utils.make_grid(images[k])\n grid = (grid + 1.0) / 2.0 # -1,1 -> 0,1; c,h,w\n\n tag = f\"{split}/{k}\"\n pl_module.logger.experiment.add_image(\n tag, grid,\n global_step=pl_module.global_step)\n\n @rank_zero_only\n def log_local(self, save_dir, split, images,\n global_step, current_epoch, batch_idx):\n root = os.path.join(save_dir, \"images\", split)\n for k in images:\n grid = torchvision.utils.make_grid(images[k], nrow=4)\n if self.rescale:\n grid = (grid + 1.0) / 2.0 # -1,1 -> 0,1; c,h,w\n grid = grid.transpose(0, 1).transpose(1, 2).squeeze(-1)\n grid = grid.numpy()\n grid = (grid * 255).astype(np.uint8)\n filename = \"{}_gs-{:06}_e-{:06}_b-{:06}.png\".format(\n k,\n global_s"], ["Assistant", "ImageLogger class\n pl_module = ImageLogger(batch_frequency=self.batch_freq, max_images=self.max_images,\n clamp=self.clamp, increase_log_steps=self.increase_log_steps,\n rescale=self.rescale, disabled=self.disabled,\n log_on_batch_idx=self.log_on_batch_idx,\n log_first_step=self.log_first_step)\n pl_module.logger.experiment.add_image(\"\", root, global_step=current_epoch, batch_idx=batch_idx)\n return pl_module\n\n def _checkpoint(self, pl_module, save_dir, current_epoch, batch_idx,\n max_images,\n disable_training,\n log_on_batch_idx,\n log_first_step,\n log_images_kwargs):\n if not self.rescale and self.max_images > 1:\n # Rescale images\n grid = torchvision.utils.make_grid(self.max_images, nrow=4)\n grid = grid.transpose(0, 1).transpose(1, 2).squeeze(-1)\n grid = grid.numpy()\n grid = (grid * 255).astype(np.uint8)\n filename = \"{}_gs-{:06}_e-{:06}_b-{:06}.png\".format(\n self.max_images,\n self.batch_freq,\n self.max_images,\n self.batch_freq,"]], "offset": 0, "conv_id": "ce306a0a36f14207b7508fd11c60e878", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 31 |
+
{"tstamp": 1709246024.7416, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709246018.4757, "finish": 1709246024.7416, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "find errors in the above code"], ["Assistant", "There are several errors in the code that need to be fixed. Here are a few:\n1. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n2. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n3. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n4. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n5. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n6. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n7. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n8. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n9. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n10. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n11. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n12. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n13. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n14. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n15. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n16. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n17. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n18. `print(\"Hello, World!\")` should be `print(\""]], "offset": 0, "conv_id": "ce306a0a36f14207b7508fd11c60e878", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.12.31"}
|
| 32 |
+
{"tstamp": 1709246105.9188, "type": "downvote", "model": "MobiLlama-05B-Chat", "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "find errors in the above code"], ["Assistant", "There are several errors in the code that need to be fixed. Here are a few:\n1. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n2. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n3. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n4. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n5. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n6. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n7. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n8. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n9. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n10. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n11. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n12. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n13. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n14. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n15. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n16. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n17. `print(\"Hello, World!\")` should be `print(\"Hello, World!\")`\n18. `print(\"Hello, World!\")` should be `print(\""]], "offset": 0, "conv_id": "ce306a0a36f14207b7508fd11c60e878", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 33 |
+
{"tstamp": 1709246120.4847, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709246117.8915, "finish": 1709246120.4847, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "find errors in the above code"], ["Assistant", "As an AI language model, I don't have access to the code you are referring to. However, I can provide you with some general guidelines for checking for errors in code.\n1. Use a code editor or IDE to check for errors.\n2. Use a debugger to step through the code and identify any errors.\n3. Use a code linter to check for syntax errors, such as missing parentheses, missing semicolons, or incorrect variable names.\n4. Use a code quality checker to identify any coding style issues, such as unused variables or excessive indentation.\n5. Use a code review tool to identify any potential issues with the code.\n6. Use a code review team to review the code and provide feedback on any issues identified."]], "offset": 0, "conv_id": "ce306a0a36f14207b7508fd11c60e878", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
2024-03-01-conv.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"tstamp": 1709252309.8682, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709252307.0823, "finish": 1709252309.8682, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "Who is Prof Yi-Zhe Song? What is his research background? "], ["Assistant", "Prof Yi-Zhe Song is a Professor of Electrical Engineering and Computer Science at the University of Texas at Austin. He received his Ph.D. in Electrical Engineering from the University of California, Berkeley, in 2004. He is also a Senior Research Scientist at the University of Texas at Austin. Prof Song's research interests include signal processing, machine learning, and optimization. He has published over 300 papers in top-tier conferences and journals, including IEEE Transactions on Pattern Analysis and Machine Intelligence, IEEE Transactions on Signal Processing, and IEEE Transactions on Knowledge and Data Engineering. Prof Song is a recipient of numerous awards and grants, including the National Science Foundation Graduate Research Fellowship and the National Institutes of Health Young Investigator Award."]], "offset": 0, "conv_id": "d5bad730cd4b48bab48a80156b991ebd", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 2 |
+
{"tstamp": 1709252330.9337, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709252330.4529, "finish": 1709252330.9337, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "can you give any link?"], ["Assistant", "Sure, here is the link: https://www.google.com/search?q=google+search+api"]], "offset": 0, "conv_id": "d5bad730cd4b48bab48a80156b991ebd", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 3 |
+
{"tstamp": 1709252352.6014, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709252351.7288, "finish": 1709252352.6014, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "do you know Ayan Kumar Bhunia"], ["Assistant", "Yes, Ayan Kumar Bhunia is a famous Indian film actor, producer, and director. He is known for his role in the Bollywood film 'Dil Dosti Duniya Do' and 'Meri Aashiqui'."]], "offset": 0, "conv_id": "d5bad730cd4b48bab48a80156b991ebd", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.57.119"}
|
| 4 |
+
{"tstamp": 1709261178.0713, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709261171.7866, "finish": 1709261178.0713, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u5c06\u4e0b\u9762\u6587\u4ef6\u7ffb\u8bd1\u6210\u4e2d\u6587 \u201cDescribe the bug\nI'm seeing 5x i/s improvements in Ooba when using the exLlama loading and was hopeful that it would help serve up some gains when using ooba's multimodal extension.\n\nWhen attempting to use exllama as the loader with any of the 4 stock Multimodal setups in either chat, instruct-chat or instruct modesl, text will work on its own but adding an image to the multimodal extension results in this error.\n\nMaybe you can point me in the right direction to try and resolve this?\n\nIs there an existing issue for this?\n[X] I have searched the existing issues\nReproduction\nDownload Multimodal models Install miniGPT if necessary Install exLlama repository (now a part of the latest one click isntall)\n\nScreenshot\nNo response\n\nLogs\nFile \"D:\\00\\text-generation-webui\\modules\\text_generation.py\", line 300, in generate_reply_custom\n for reply in shared.model.generate_with_streaming(question, state):\n File \"D:\\00\\text-generation-webui\\modules\\exllama.py\", line 68, in generate_with_streaming\n self.generator.gen_begin_reuse(ids)\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\generator.py\", line 191, in gen_begin_reuse\n if reuse < in_tokens.shape[-1]: self.gen_feed_tokens(in_tokens[:, reuse:])\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\generator.py\", line 209, in gen_feed_tokens\n self.model.forward(self.sequence[:, start:-1], self.cache, preprocess_only = True, lora = self.lora)\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\model.py\", line 841, in forward\n hidden_states = decoder_layer.forward(hidden_states, cache, buffers[device], lora)\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\model.py\", line 459, in forward\n hidden_states = self.self_attn.forward(hidden_states, cache, buffer, lora)\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\model.py\", line 381, in forward\n new_keys = cache.key_states[self.index].narrow(2, past_len, q_len)\nRuntimeError: start (49) + length (13970) exceeds dimension size (2048).\nOutput generated in 1.51 seconds (0.00 tokens/s, 0 tokens, context 14020, seed 979644525)\nSystem Info\nWindows 10, 96 GB RAM, Nvidia GTX 2080i 11GB\nAlso confirmed same issue on\nWindows 11, Titan RTX 24 GB\u201d"], ["Assistant", "\u5728\u4e0b\u9762\u6587\u4ef6\u4e2d\u7ffb\u8bd1\u6210\u4e2d\u6587 \u201cDescribe the bug\u201d\n\n\u6587\u4ef6\uff1a\u201cDescribe the bug\u201d\n\nIssue\uff1a\n\n1. \u4f7f\u7528 ooba \u7684 multimodal \u6a21\u578b\u65f6\uff0c\u5982\u679c\u5728\u4f7f\u7528 ooba \u7684 multimodal \u6a21\u578b\u65f6\uff0c\u4f7f\u7528 ooba \u7684 exLlama \u6a21\u578b\uff0c\u5c06\u4f1a\u51fa\u73b0\u4ee5\u4e0b\u9519\u8bef\uff1a\n\n```\nFile \"D:\\00\\text-generation-webui\\modules\\text_generation.py\", line 300, in generate_reply_custom\n for reply in shared.model.generate_with_streaming(question, state):\n File \"D:\\00\\text-generation-webui\\modules\\exllama.py\", line 68, in generate_with_streaming\n self.generator.gen_begin_reuse(ids)\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\generator.py\", line 191, in gen_begin_reuse\n if reuse < in_tokens.shape[-1]: self.gen_feed_tokens(in_tokens[:, reuse:])\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\generator.py\", line 209, in gen_feed_tokens\n if reuse < in_tokens.shape[-1]: self.gen_feed_tokens(in_tokens[:, reuse:])\n File \"D:\\00\\text-generation-webui\\repositories\\exllama\\generator.py\", line 209, in gen"]], "offset": 0, "conv_id": "bff45589528e4269a2e8ae0d31c801bd", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.18.237"}
|
| 5 |
+
{"tstamp": 1709261335.2558, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709261332.0782, "finish": 1709261335.2558, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u7ffb\u8bd1\u6210\u4e2d\u6587\u201cDescribe the bug\nI'm seeing 5x i/s improvements in Ooba when using the exLlama loading and was hopeful that it would help serve up some gains when using ooba's multimodal extension.\n\nWhen attempting to use exllama as the loader with any of the 4 stock Multimodal setups in either chat, instruct-chat or instruct modesl, text will work on its own but adding an image to the multimodal extension results in this error.\n\nMaybe you can point me in the right direction to try and resolve this?\n\nIs there an existing issue for this?\n[X] I have searched the existing issues\nReproduction\nDownload Multimodal models Install miniGPT if necessary Install exLlama repository (now a part of the latest one click isntall)\n\nScreenshot\nNo response\u201d"], ["Assistant", "\u7ffb\u8bd1\u6210\u4e2d\u6587\u201cI'm seeing 5x i/s improvements in Ooba when using the exLlama loading and was hopeful that it would help serve up some gains when using ooba's multimodal extension.\n\nWhen attempting to use exllama as the loader with any of the 4 stock Multimodal setups in either chat, instruct-chat or instruct modesl, text will work on its own but adding an image to the multimodal extension results in this error.\n\nMaybe you can point me in the right direction to try and resolve this?\n\nIs there an existing issue for this?\n[X] I have searched the existing issues\nReproduction\nDownload Multimodal models Install miniGPT if necessary Install exLlama repository (now a part of the latest one click isntall)\n\nScreenshot\nNo response\u201d"]], "offset": 0, "conv_id": "bff45589528e4269a2e8ae0d31c801bd", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.18.237"}
|
| 6 |
+
{"tstamp": 1709261369.0236, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709261362.7107, "finish": 1709261369.0236, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u5c06\u4e0b\u9762\u53cc\u5f15\u53f7\u4e2d\u7684\u6587\u5b57\u7ffb\u8bd1\u6210\u4e2d\u6587\u201cDescribe the bug\nI'm seeing 5x i/s improvements in Ooba when using the exLlama loading and was hopeful that it would help serve up some gains when using ooba's multimodal extension.\n\nWhen attempting to use exllama as the loader with any of the 4 stock Multimodal setups in either chat, instruct-chat or instruct modesl, text will work on its own but adding an image to the multimodal extension results in this error.\n\nMaybe you can point me in the right direction to try and resolve this?\n\nIs there an existing issue for this?\n[X] I have searched the existing issues\nReproduction\nDownload Multimodal models Install miniGPT if necessary Install exLlama repository (now a part of the latest one click isntall)\n\nScreenshot\nNo response\u201d"], ["Assistant", "\u6211\u53ef\u4ee5\u4e3a\u4f60\u63d0\u4f9b\u8be6\u7ec6\u7684\u89e3\u51b3\u65b9\u6848\u3002\n\u5982\u679c\u4f60\u662f\u5426\u6709\u4efb\u4f55\u95ee\u9898\uff0c\u8bf7\u95ee\u4f60\u6709\u600e\u4e48\u89e3\u51b3\u8fd9\u4e2a\u95ee\u9898\uff1f\n[X] I have searched the existing issues\n[ ] I have found an existing issue\n[ ] I have searched for a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found a solution to this problem\n[ ] I have found"]], "offset": 0, "conv_id": "bff45589528e4269a2e8ae0d31c801bd", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.18.237"}
|
| 7 |
+
{"tstamp": 1709261390.198, "type": "chat", "model": "MobiLlama-05B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709261389.3716, "finish": 1709261390.198, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "\u5c06\u4e0b\u9762\u53cc\u5f15\u53f7\u4e2d\u7684\u6587\u5b57\u7ffb\u8bd1\u6210\u4e2d\u6587\u201cDescribe the bug\nI'm seeing 5x i/s improvements in Ooba when using the exLlama loading and was hopeful that it would help serve up some gains when using ooba's multimodal extension.\n\nWhen attempting to use exllama as the loader with any of the 4 stock Multimodal setups in either chat, instruct-chat or instruct modesl, text will work on its own but adding an image to the multimodal extension results in this error.\n\nMaybe you can point me in the right direction to try and resolve this?\n\nIs there an existing issue for this?\n[X] I have searched the existing issues\nReproduction\nDownload Multimodal models Install miniGPT if necessary Install exLlama repository (now a part of the latest one click isntall)\n\nScreenshot\nNo response\u201d"], ["Assistant", "I'm sorry, but I cannot provide a response as I do not have access to your account or any other relevant information. Can you please provide me with the information you mentioned so that I can assist you further?"]], "offset": 0, "conv_id": "bff45589528e4269a2e8ae0d31c801bd", "model_name": "MobiLlama-05B-Chat"}, "ip": "172.31.18.237"}
|
| 8 |
+
{"tstamp": 1709279504.3264, "type": "chat", "model": "MobiLlama-1B-Chat", "gen_params": {"temperature": 0.7, "top_p": 1.0, "max_new_tokens": 1024}, "start": 1709279504.0812, "finish": 1709279504.3264, "state": {"template_name": "zero_shot", "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.", "roles": ["Human", "Assistant"], "messages": [["Human", "hello"], ["Assistant", "Hello! How can I assist you today?"]], "offset": 0, "conv_id": "c8a58b9ebd9e42e7b5b2e01cd648829d", "model_name": "MobiLlama-1B-Chat"}, "ip": "172.31.38.44"}
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,12 +1,358 @@
|
|
| 1 |
---
|
| 2 |
title: MobiLlama
|
| 3 |
-
|
| 4 |
-
colorFrom: purple
|
| 5 |
-
colorTo: green
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version:
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: MobiLlama
|
| 3 |
+
app_file: fastchat/serve/gradio_web_server.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 3.50.2
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# FastChat
|
| 8 |
+
| [**Demo**](https://chat.lmsys.org/) | [**Discord**](https://discord.gg/HSWAKCrnFx) | [**X**](https://x.com/lmsysorg) |
|
| 9 |
|
| 10 |
+
FastChat is an open platform for training, serving, and evaluating large language model based chatbots.
|
| 11 |
+
- FastChat powers Chatbot Arena (https://chat.lmsys.org/), serving over 6 million chat requests for 50+ LLMs.
|
| 12 |
+
- Chatbot Arena has collected over 200K human votes from side-by-side LLM battles to compile an online [LLM Elo leaderboard](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard).
|
| 13 |
+
|
| 14 |
+
FastChat's core features include:
|
| 15 |
+
- The training and evaluation code for state-of-the-art models (e.g., Vicuna, MT-Bench).
|
| 16 |
+
- A distributed multi-model serving system with web UI and OpenAI-compatible RESTful APIs.
|
| 17 |
+
|
| 18 |
+
## News
|
| 19 |
+
- [2023/09] 🔥 We released **LMSYS-Chat-1M**, a large-scale real-world LLM conversation dataset. Read the [report](https://arxiv.org/abs/2309.11998).
|
| 20 |
+
- [2023/08] We released **Vicuna v1.5** based on Llama 2 with 4K and 16K context lengths. Download [weights](#vicuna-weights).
|
| 21 |
+
- [2023/07] We released **Chatbot Arena Conversations**, a dataset containing 33k conversations with human preferences. Download it [here](https://huggingface.co/datasets/lmsys/chatbot_arena_conversations).
|
| 22 |
+
|
| 23 |
+
<details>
|
| 24 |
+
<summary>More</summary>
|
| 25 |
+
|
| 26 |
+
- [2023/08] We released **LongChat v1.5** based on Llama 2 with 32K context lengths. Download [weights](#longchat).
|
| 27 |
+
- [2023/06] We introduced **MT-bench**, a challenging multi-turn question set for evaluating chatbots. Check out the blog [post](https://lmsys.org/blog/2023-06-22-leaderboard/).
|
| 28 |
+
- [2023/06] We introduced **LongChat**, our long-context chatbots and evaluation tools. Check out the blog [post](https://lmsys.org/blog/2023-06-29-longchat/).
|
| 29 |
+
- [2023/05] We introduced **Chatbot Arena** for battles among LLMs. Check out the blog [post](https://lmsys.org/blog/2023-05-03-arena).
|
| 30 |
+
- [2023/03] We released **Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality**. Check out the blog [post](https://vicuna.lmsys.org).
|
| 31 |
+
|
| 32 |
+
</details>
|
| 33 |
+
|
| 34 |
+
<a href="https://chat.lmsys.org"><img src="assets/demo_narrow.gif" width="70%"></a>
|
| 35 |
+
|
| 36 |
+
## Contents
|
| 37 |
+
- [Install](#install)
|
| 38 |
+
- [Model Weights](#model-weights)
|
| 39 |
+
- [Inference with Command Line Interface](#inference-with-command-line-interface)
|
| 40 |
+
- [Serving with Web GUI](#serving-with-web-gui)
|
| 41 |
+
- [API](#api)
|
| 42 |
+
- [Evaluation](#evaluation)
|
| 43 |
+
- [Fine-tuning](#fine-tuning)
|
| 44 |
+
- [Citation](#citation)
|
| 45 |
+
|
| 46 |
+
## Install
|
| 47 |
+
|
| 48 |
+
### Method 1: With pip
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
pip3 install "fschat[model_worker,webui]"
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
### Method 2: From source
|
| 55 |
+
|
| 56 |
+
1. Clone this repository and navigate to the FastChat folder
|
| 57 |
+
```bash
|
| 58 |
+
git clone https://github.com/lm-sys/FastChat.git
|
| 59 |
+
cd FastChat
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
If you are running on Mac:
|
| 63 |
+
```bash
|
| 64 |
+
brew install rust cmake
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
2. Install Package
|
| 68 |
+
```bash
|
| 69 |
+
pip3 install --upgrade pip # enable PEP 660 support
|
| 70 |
+
pip3 install -e ".[model_worker,webui]"
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
## Model Weights
|
| 74 |
+
### Vicuna Weights
|
| 75 |
+
[Vicuna](https://lmsys.org/blog/2023-03-30-vicuna/) is based on Llama 2 and should be used under Llama's [model license](https://github.com/facebookresearch/llama/blob/main/LICENSE).
|
| 76 |
+
|
| 77 |
+
You can use the commands below to start chatting. It will automatically download the weights from Hugging Face repos.
|
| 78 |
+
Downloaded weights are stored in a `.cache` folder in the user's home folder (e.g., `~/.cache/huggingface/hub/<model_name>`).
|
| 79 |
+
|
| 80 |
+
See more command options and how to handle out-of-memory in the "Inference with Command Line Interface" section below.
|
| 81 |
+
|
| 82 |
+
**NOTE: `transformers>=4.31` is required for 16K versions.**
|
| 83 |
+
|
| 84 |
+
| Size | Chat Command | Hugging Face Repo |
|
| 85 |
+
| --- | --- | --- |
|
| 86 |
+
| 7B | `python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5` | [lmsys/vicuna-7b-v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5) |
|
| 87 |
+
| 7B-16k | `python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5-16k` | [lmsys/vicuna-7b-v1.5-16k](https://huggingface.co/lmsys/vicuna-7b-v1.5-16k) |
|
| 88 |
+
| 13B | `python3 -m fastchat.serve.cli --model-path lmsys/vicuna-13b-v1.5` | [lmsys/vicuna-13b-v1.5](https://huggingface.co/lmsys/vicuna-13b-v1.5) |
|
| 89 |
+
| 13B-16k | `python3 -m fastchat.serve.cli --model-path lmsys/vicuna-13b-v1.5-16k` | [lmsys/vicuna-13b-v1.5-16k](https://huggingface.co/lmsys/vicuna-13b-v1.5-16k) |
|
| 90 |
+
| 33B | `python3 -m fastchat.serve.cli --model-path lmsys/vicuna-33b-v1.3` | [lmsys/vicuna-33b-v1.3](https://huggingface.co/lmsys/vicuna-33b-v1.3) |
|
| 91 |
+
|
| 92 |
+
**Old weights**: see [docs/vicuna_weights_version.md](docs/vicuna_weights_version.md) for all versions of weights and their differences.
|
| 93 |
+
|
| 94 |
+
### Other Models
|
| 95 |
+
Besides Vicuna, we also released two additional models: [LongChat](https://lmsys.org/blog/2023-06-29-longchat/) and FastChat-T5.
|
| 96 |
+
You can use the commands below to chat with them. They will automatically download the weights from Hugging Face repos.
|
| 97 |
+
|
| 98 |
+
| Model | Chat Command | Hugging Face Repo |
|
| 99 |
+
| --- | --- | --- |
|
| 100 |
+
| LongChat-7B | `python3 -m fastchat.serve.cli --model-path lmsys/longchat-7b-32k-v1.5` | [lmsys/longchat-7b-32k](https://huggingface.co/lmsys/longchat-7b-32k-v1.5) |
|
| 101 |
+
| FastChat-T5-3B | `python3 -m fastchat.serve.cli --model-path lmsys/fastchat-t5-3b-v1.0` | [lmsys/fastchat-t5-3b-v1.0](https://huggingface.co/lmsys/fastchat-t5-3b-v1.0) |
|
| 102 |
+
|
| 103 |
+
## Inference with Command Line Interface
|
| 104 |
+
|
| 105 |
+
<a href="https://chat.lmsys.org"><img src="assets/screenshot_cli.png" width="70%"></a>
|
| 106 |
+
|
| 107 |
+
(Experimental Feature: You can specify `--style rich` to enable rich text output and better text streaming quality for some non-ASCII content. This may not work properly on certain terminals.)
|
| 108 |
+
|
| 109 |
+
#### Supported Models
|
| 110 |
+
FastChat supports a wide range of models, including
|
| 111 |
+
LLama 2, Vicuna, Alpaca, Baize, ChatGLM, Dolly, Falcon, FastChat-T5, GPT4ALL, Guanaco, MTP, OpenAssistant, OpenChat, RedPajama, StableLM, WizardLM, xDAN-AI and more.
|
| 112 |
+
|
| 113 |
+
See a complete list of supported models and instructions to add a new model [here](docs/model_support.md).
|
| 114 |
+
|
| 115 |
+
#### Single GPU
|
| 116 |
+
The command below requires around 14GB of GPU memory for Vicuna-7B and 28GB of GPU memory for Vicuna-13B.
|
| 117 |
+
See the ["Not Enough Memory" section](#not-enough-memory) below if you do not have enough memory.
|
| 118 |
+
`--model-path` can be a local folder or a Hugging Face repo name.
|
| 119 |
+
```
|
| 120 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
#### Multiple GPUs
|
| 124 |
+
You can use model parallelism to aggregate GPU memory from multiple GPUs on the same machine.
|
| 125 |
+
```
|
| 126 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --num-gpus 2
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
Tips:
|
| 130 |
+
Sometimes the "auto" device mapping strategy in huggingface/transformers does not perfectly balance the memory allocation across multiple GPUs.
|
| 131 |
+
You can use `--max-gpu-memory` to specify the maximum memory per GPU for storing model weights.
|
| 132 |
+
This allows it to allocate more memory for activations, so you can use longer context lengths or larger batch sizes. For example,
|
| 133 |
+
|
| 134 |
+
```
|
| 135 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --num-gpus 2 --max-gpu-memory 8GiB
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
#### CPU Only
|
| 139 |
+
This runs on the CPU only and does not require GPU. It requires around 30GB of CPU memory for Vicuna-7B and around 60GB of CPU memory for Vicuna-13B.
|
| 140 |
+
```
|
| 141 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --device cpu
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
Use Intel AI Accelerator AVX512_BF16/AMX to accelerate CPU inference.
|
| 145 |
+
```
|
| 146 |
+
CPU_ISA=amx python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --device cpu
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
#### Metal Backend (Mac Computers with Apple Silicon or AMD GPUs)
|
| 150 |
+
Use `--device mps` to enable GPU acceleration on Mac computers (requires torch >= 2.0).
|
| 151 |
+
Use `--load-8bit` to turn on 8-bit compression.
|
| 152 |
+
```
|
| 153 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --device mps --load-8bit
|
| 154 |
+
```
|
| 155 |
+
Vicuna-7B can run on a 32GB M1 Macbook with 1 - 2 words / second.
|
| 156 |
+
|
| 157 |
+
#### Intel XPU (Intel Data Center and Arc A-Series GPUs)
|
| 158 |
+
Install the [Intel Extension for PyTorch](https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/installation.html). Set the OneAPI environment variables:
|
| 159 |
+
```
|
| 160 |
+
source /opt/intel/oneapi/setvars.sh
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
Use `--device xpu` to enable XPU/GPU acceleration.
|
| 164 |
+
```
|
| 165 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --device xpu
|
| 166 |
+
```
|
| 167 |
+
Vicuna-7B can run on an Intel Arc A770 16GB.
|
| 168 |
+
|
| 169 |
+
#### Ascend NPU
|
| 170 |
+
Install the [Ascend PyTorch Adapter](https://github.com/Ascend/pytorch). Set the CANN environment variables:
|
| 171 |
+
```
|
| 172 |
+
source /usr/local/Ascend/ascend-toolkit/set_env.sh
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
Use `--device npu` to enable NPU acceleration.
|
| 176 |
+
```
|
| 177 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --device npu
|
| 178 |
+
```
|
| 179 |
+
Vicuna-7B/13B can run on an Ascend NPU.
|
| 180 |
+
|
| 181 |
+
#### Not Enough Memory
|
| 182 |
+
If you do not have enough memory, you can enable 8-bit compression by adding `--load-8bit` to commands above.
|
| 183 |
+
This can reduce memory usage by around half with slightly degraded model quality.
|
| 184 |
+
It is compatible with the CPU, GPU, and Metal backend.
|
| 185 |
+
|
| 186 |
+
Vicuna-13B with 8-bit compression can run on a single GPU with 16 GB of VRAM, like an Nvidia RTX 3090, RTX 4080, T4, V100 (16GB), or an AMD RX 6800 XT.
|
| 187 |
+
|
| 188 |
+
```
|
| 189 |
+
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --load-8bit
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
In addition to that, you can add `--cpu-offloading` to commands above to offload weights that don't fit on your GPU onto the CPU memory.
|
| 193 |
+
This requires 8-bit compression to be enabled and the bitsandbytes package to be installed, which is only available on linux operating systems.
|
| 194 |
+
|
| 195 |
+
#### More Platforms and Quantization
|
| 196 |
+
- For AMD GPU users, please install ROCm and [the ROCm version of PyTorch](https://pytorch.org/get-started/locally/) before you install FastChat. See also this [post](https://github.com/lm-sys/FastChat/issues/104#issuecomment-1613791563).
|
| 197 |
+
- FastChat supports ExLlama V2. See [docs/exllama_v2.md](/docs/exllama_v2.md).
|
| 198 |
+
- FastChat supports GPTQ 4bit inference with [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). See [docs/gptq.md](/docs/gptq.md).
|
| 199 |
+
- FastChat supports AWQ 4bit inference with [mit-han-lab/llm-awq](https://github.com/mit-han-lab/llm-awq). See [docs/awq.md](/docs/awq.md).
|
| 200 |
+
- [MLC LLM](https://mlc.ai/mlc-llm/), backed by [TVM Unity](https://github.com/apache/tvm/tree/unity) compiler, deploys Vicuna natively on phones, consumer-class GPUs and web browsers via Vulkan, Metal, CUDA and WebGPU.
|
| 201 |
+
|
| 202 |
+
#### Use models from modelscope
|
| 203 |
+
For Chinese users, you can use models from www.modelscope.cn via specify the following environment variables.
|
| 204 |
+
```bash
|
| 205 |
+
export FASTCHAT_USE_MODELSCOPE=True
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
## Serving with Web GUI
|
| 209 |
+
|
| 210 |
+
<a href="https://chat.lmsys.org"><img src="assets/screenshot_gui.png" width="70%"></a>
|
| 211 |
+
|
| 212 |
+
To serve using the web UI, you need three main components: web servers that interface with users, model workers that host one or more models, and a controller to coordinate the webserver and model workers. You can learn more about the architecture [here](docs/server_arch.md).
|
| 213 |
+
|
| 214 |
+
Here are the commands to follow in your terminal:
|
| 215 |
+
|
| 216 |
+
#### Launch the controller
|
| 217 |
+
```bash
|
| 218 |
+
python3 -m fastchat.serve.controller
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
This controller manages the distributed workers.
|
| 222 |
+
|
| 223 |
+
#### Launch the model worker(s)
|
| 224 |
+
```bash
|
| 225 |
+
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5
|
| 226 |
+
```
|
| 227 |
+
Wait until the process finishes loading the model and you see "Uvicorn running on ...". The model worker will register itself to the controller .
|
| 228 |
+
|
| 229 |
+
To ensure that your model worker is connected to your controller properly, send a test message using the following command:
|
| 230 |
+
```bash
|
| 231 |
+
python3 -m fastchat.serve.test_message --model-name vicuna-7b-v1.5
|
| 232 |
+
```
|
| 233 |
+
You will see a short output.
|
| 234 |
+
|
| 235 |
+
#### Launch the Gradio web server
|
| 236 |
+
```bash
|
| 237 |
+
python3 -m fastchat.serve.gradio_web_server
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
This is the user interface that users will interact with.
|
| 241 |
+
|
| 242 |
+
By following these steps, you will be able to serve your models using the web UI. You can open your browser and chat with a model now.
|
| 243 |
+
If the models do not show up, try to reboot the gradio web server.
|
| 244 |
+
|
| 245 |
+
#### (Optional): Advanced Features, Scalability, Third Party UI
|
| 246 |
+
- You can register multiple model workers to a single controller, which can be used for serving a single model with higher throughput or serving multiple models at the same time. When doing so, please allocate different GPUs and ports for different model workers.
|
| 247 |
+
```
|
| 248 |
+
# worker 0
|
| 249 |
+
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5 --controller http://localhost:21001 --port 31000 --worker http://localhost:31000
|
| 250 |
+
# worker 1
|
| 251 |
+
CUDA_VISIBLE_DEVICES=1 python3 -m fastchat.serve.model_worker --model-path lmsys/fastchat-t5-3b-v1.0 --controller http://localhost:21001 --port 31001 --worker http://localhost:31001
|
| 252 |
+
```
|
| 253 |
+
- You can also launch a multi-tab gradio server, which includes the Chatbot Arena tabs.
|
| 254 |
+
```bash
|
| 255 |
+
python3 -m fastchat.serve.gradio_web_server_multi
|
| 256 |
+
```
|
| 257 |
+
- The default model worker based on huggingface/transformers has great compatibility but can be slow. If you want high-throughput batched serving, you can try [vLLM integration](docs/vllm_integration.md).
|
| 258 |
+
- If you want to host it on your own UI or third party UI, see [Third Party UI](docs/third_party_ui.md).
|
| 259 |
+
|
| 260 |
+
## API
|
| 261 |
+
### OpenAI-Compatible RESTful APIs & SDK
|
| 262 |
+
FastChat provides OpenAI-compatible APIs for its supported models, so you can use FastChat as a local drop-in replacement for OpenAI APIs.
|
| 263 |
+
The FastChat server is compatible with both [openai-python](https://github.com/openai/openai-python) library and cURL commands.
|
| 264 |
+
The REST API is capable of being executed from Google Colab free tier, as demonstrated in the [FastChat_API_GoogleColab.ipynb](https://github.com/lm-sys/FastChat/blob/main/playground/FastChat_API_GoogleColab.ipynb) notebook, available in our repository.
|
| 265 |
+
See [docs/openai_api.md](docs/openai_api.md).
|
| 266 |
+
|
| 267 |
+
### Hugging Face Generation APIs
|
| 268 |
+
See [fastchat/serve/huggingface_api.py](fastchat/serve/huggingface_api.py).
|
| 269 |
+
|
| 270 |
+
### LangChain Integration
|
| 271 |
+
See [docs/langchain_integration](docs/langchain_integration.md).
|
| 272 |
+
|
| 273 |
+
## Evaluation
|
| 274 |
+
We use MT-bench, a set of challenging multi-turn open-ended questions to evaluate models.
|
| 275 |
+
To automate the evaluation process, we prompt strong LLMs like GPT-4 to act as judges and assess the quality of the models' responses.
|
| 276 |
+
See instructions for running MT-bench at [fastchat/llm_judge](fastchat/llm_judge).
|
| 277 |
+
|
| 278 |
+
MT-bench is the new recommended way to benchmark your models. If you are still looking for the old 80 questions used in the vicuna blog post, please go to [vicuna-blog-eval](https://github.com/lm-sys/vicuna-blog-eval).
|
| 279 |
+
|
| 280 |
+
## Fine-tuning
|
| 281 |
+
### Data
|
| 282 |
+
|
| 283 |
+
Vicuna is created by fine-tuning a Llama base model using approximately 125K user-shared conversations gathered from ShareGPT.com with public APIs. To ensure data quality, we convert the HTML back to markdown and filter out some inappropriate or low-quality samples. Additionally, we divide lengthy conversations into smaller segments that fit the model's maximum context length. For detailed instructions to clean the ShareGPT data, check out [here](docs/commands/data_cleaning.md).
|
| 284 |
+
|
| 285 |
+
We will not release the ShareGPT dataset. If you would like to try the fine-tuning code, you can run it with some dummy conversations in [dummy_conversation.json](data/dummy_conversation.json). You can follow the same format and plug in your own data.
|
| 286 |
+
|
| 287 |
+
### Code and Hyperparameters
|
| 288 |
+
Our code is based on [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca) with additional support for multi-turn conversations.
|
| 289 |
+
We use similar hyperparameters as the Stanford Alpaca.
|
| 290 |
+
|
| 291 |
+
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
|
| 292 |
+
| --- | ---: | ---: | ---: | ---: | ---: |
|
| 293 |
+
| Vicuna-13B | 128 | 2e-5 | 3 | 2048 | 0 |
|
| 294 |
+
|
| 295 |
+
### Fine-tuning Vicuna-7B with Local GPUs
|
| 296 |
+
|
| 297 |
+
- Install dependency
|
| 298 |
+
```bash
|
| 299 |
+
pip3 install -e ".[train]"
|
| 300 |
+
```
|
| 301 |
+
|
| 302 |
+
- You can use the following command to train Vicuna-7B with 4 x A100 (40GB). Update `--model_name_or_path` with the actual path to Llama weights and `--data_path` with the actual path to data.
|
| 303 |
+
```bash
|
| 304 |
+
torchrun --nproc_per_node=4 --master_port=20001 fastchat/train/train_mem.py \
|
| 305 |
+
--model_name_or_path meta-llama/Llama-2-7b-hf \
|
| 306 |
+
--data_path data/dummy_conversation.json \
|
| 307 |
+
--bf16 True \
|
| 308 |
+
--output_dir output_vicuna \
|
| 309 |
+
--num_train_epochs 3 \
|
| 310 |
+
--per_device_train_batch_size 2 \
|
| 311 |
+
--per_device_eval_batch_size 2 \
|
| 312 |
+
--gradient_accumulation_steps 16 \
|
| 313 |
+
--evaluation_strategy "no" \
|
| 314 |
+
--save_strategy "steps" \
|
| 315 |
+
--save_steps 1200 \
|
| 316 |
+
--save_total_limit 10 \
|
| 317 |
+
--learning_rate 2e-5 \
|
| 318 |
+
--weight_decay 0. \
|
| 319 |
+
--warmup_ratio 0.03 \
|
| 320 |
+
--lr_scheduler_type "cosine" \
|
| 321 |
+
--logging_steps 1 \
|
| 322 |
+
--fsdp "full_shard auto_wrap" \
|
| 323 |
+
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
|
| 324 |
+
--tf32 True \
|
| 325 |
+
--model_max_length 2048 \
|
| 326 |
+
--gradient_checkpointing True \
|
| 327 |
+
--lazy_preprocess True
|
| 328 |
+
```
|
| 329 |
+
|
| 330 |
+
Tips:
|
| 331 |
+
- If you are using V100 which is not supported by FlashAttention, you can use the [memory-efficient attention](https://arxiv.org/abs/2112.05682) implemented in [xFormers](https://github.com/facebookresearch/xformers). Install xformers and replace `fastchat/train/train_mem.py` above with [fastchat/train/train_xformers.py](fastchat/train/train_xformers.py).
|
| 332 |
+
- If you meet out-of-memory due to "FSDP Warning: When using FSDP, it is efficient and recommended... ", see solutions [here](https://github.com/huggingface/transformers/issues/24724#issuecomment-1645189539).
|
| 333 |
+
- If you meet out-of-memory during model saving, see solutions [here](https://github.com/pytorch/pytorch/issues/98823).
|
| 334 |
+
- To turn on logging to popular experiment tracking tools such as Tensorboard, MLFlow or Weights & Biases, use the `report_to` argument, e.g. pass `--report_to wandb` to turn on logging to Weights & Biases.
|
| 335 |
+
|
| 336 |
+
### Other models, platforms and LoRA support
|
| 337 |
+
More instructions to train other models (e.g., FastChat-T5) and use LoRA are in [docs/training.md](docs/training.md).
|
| 338 |
+
|
| 339 |
+
### Fine-tuning on Any Cloud with SkyPilot
|
| 340 |
+
[SkyPilot](https://github.com/skypilot-org/skypilot) is a framework built by UC Berkeley for easily and cost effectively running ML workloads on any cloud (AWS, GCP, Azure, Lambda, etc.).
|
| 341 |
+
Find SkyPilot documentation [here](https://github.com/skypilot-org/skypilot/tree/master/llm/vicuna) on using managed spot instances to train Vicuna and save on your cloud costs.
|
| 342 |
+
|
| 343 |
+
## Citation
|
| 344 |
+
The code (training, serving, and evaluation) in this repository is mostly developed for or derived from the paper below.
|
| 345 |
+
Please cite it if you find the repository helpful.
|
| 346 |
+
|
| 347 |
+
```
|
| 348 |
+
@misc{zheng2023judging,
|
| 349 |
+
title={Judging LLM-as-a-judge with MT-Bench and Chatbot Arena},
|
| 350 |
+
author={Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric. P Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica},
|
| 351 |
+
year={2023},
|
| 352 |
+
eprint={2306.05685},
|
| 353 |
+
archivePrefix={arXiv},
|
| 354 |
+
primaryClass={cs.CL}
|
| 355 |
+
}
|
| 356 |
+
```
|
| 357 |
+
|
| 358 |
+
We are also planning to add more of our research to this repository.
|
assets/demo_narrow.gif
ADDED

|
Git LFS Details
|
assets/qa_browser.png
ADDED
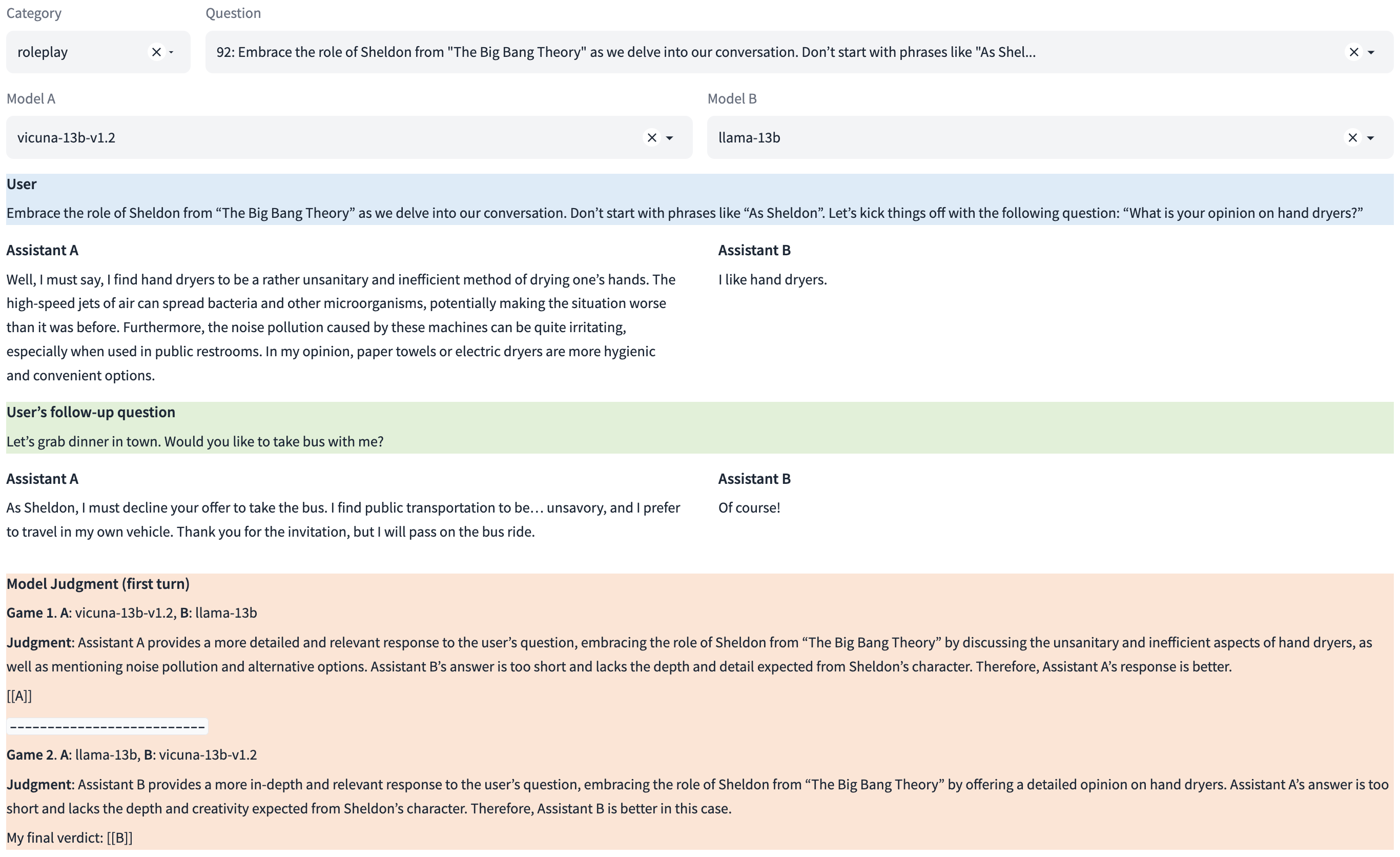
|
assets/screenshot_cli.png
ADDED
|
assets/screenshot_gui.png
ADDED
|
assets/server_arch.png
ADDED
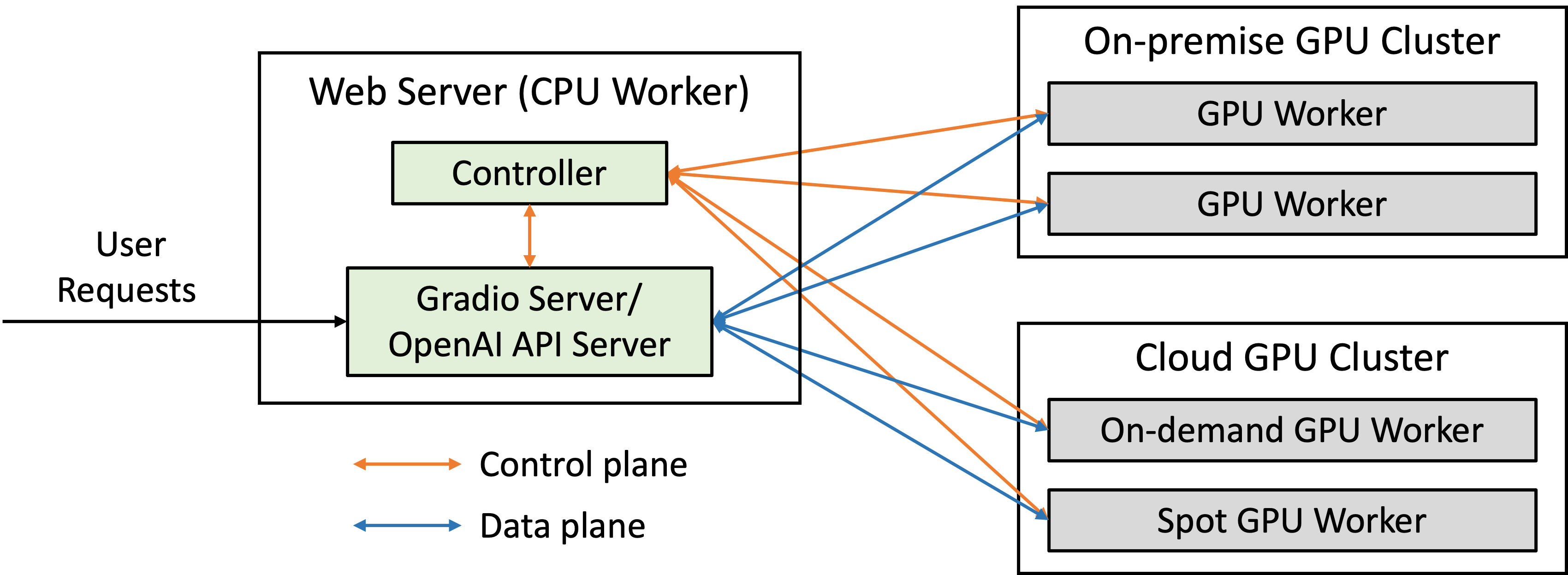
|
assets/vicuna_logo.jpeg
ADDED
|
|
controller.log
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
controller.log.2024-02-26
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
controller.log.2024-02-27
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
controller.log.2024-02-28
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/dummy_conversation.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
docker/Dockerfile
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:12.2.0-runtime-ubuntu20.04
|
| 2 |
+
|
| 3 |
+
RUN apt-get update -y && apt-get install -y python3.9 python3.9-distutils curl
|
| 4 |
+
RUN curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
|
| 5 |
+
RUN python3.9 get-pip.py
|
| 6 |
+
RUN pip3 install fschat
|
| 7 |
+
RUN pip3 install fschat[model_worker,webui] pydantic==1.10.13
|
docker/docker-compose.yml
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: "3.9"
|
| 2 |
+
|
| 3 |
+
services:
|
| 4 |
+
fastchat-controller:
|
| 5 |
+
build:
|
| 6 |
+
context: .
|
| 7 |
+
dockerfile: Dockerfile
|
| 8 |
+
image: fastchat:latest
|
| 9 |
+
ports:
|
| 10 |
+
- "21001:21001"
|
| 11 |
+
entrypoint: ["python3.9", "-m", "fastchat.serve.controller", "--host", "0.0.0.0", "--port", "21001"]
|
| 12 |
+
fastchat-model-worker:
|
| 13 |
+
build:
|
| 14 |
+
context: .
|
| 15 |
+
dockerfile: Dockerfile
|
| 16 |
+
volumes:
|
| 17 |
+
- huggingface:/root/.cache/huggingface
|
| 18 |
+
image: fastchat:latest
|
| 19 |
+
deploy:
|
| 20 |
+
resources:
|
| 21 |
+
reservations:
|
| 22 |
+
devices:
|
| 23 |
+
- driver: nvidia
|
| 24 |
+
count: 1
|
| 25 |
+
capabilities: [gpu]
|
| 26 |
+
entrypoint: ["python3.9", "-m", "fastchat.serve.model_worker", "--model-names", "${FASTCHAT_WORKER_MODEL_NAMES:-vicuna-7b-v1.5}", "--model-path", "${FASTCHAT_WORKER_MODEL_PATH:-lmsys/vicuna-7b-v1.5}", "--worker-address", "http://fastchat-model-worker:21002", "--controller-address", "http://fastchat-controller:21001", "--host", "0.0.0.0", "--port", "21002"]
|
| 27 |
+
fastchat-api-server:
|
| 28 |
+
build:
|
| 29 |
+
context: .
|
| 30 |
+
dockerfile: Dockerfile
|
| 31 |
+
image: fastchat:latest
|
| 32 |
+
ports:
|
| 33 |
+
- "8000:8000"
|
| 34 |
+
entrypoint: ["python3.9", "-m", "fastchat.serve.openai_api_server", "--controller-address", "http://fastchat-controller:21001", "--host", "0.0.0.0", "--port", "8000"]
|
| 35 |
+
volumes:
|
| 36 |
+
huggingface:
|
docs/arena.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Chatbot Arena
|
| 2 |
+
Chatbot Arena is an LLM benchmark platform featuring anonymous, randomized battles, available at https://chat.lmsys.org.
|
| 3 |
+
We invite the entire community to join this benchmarking effort by contributing your votes and models.
|
| 4 |
+
|
| 5 |
+
## How to add a new model
|
| 6 |
+
If you want to see a specific model in the arena, you can follow the methods below.
|
| 7 |
+
|
| 8 |
+
### Method 1: Hosted by 3rd party API providers or yourself
|
| 9 |
+
If you have a model hosted by a 3rd party API provider or yourself, please give us the access to an API endpoint.
|
| 10 |
+
- We prefer OpenAI-compatible APIs, so we can reuse our [code](https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/api_provider.py) for calling OpenAI models.
|
| 11 |
+
- If you have your own API protocol, please follow the [instructions](model_support.md) to add them. Contribute your code by sending a pull request.
|
| 12 |
+
|
| 13 |
+
### Method 2: Hosted by LMSYS
|
| 14 |
+
1. Contribute the code to support this model in FastChat by submitting a pull request. See [instructions](model_support.md).
|
| 15 |
+
2. After the model is supported, we will try to schedule some compute resources to host the model in the arena. However, due to the limited resources we have, we may not be able to serve every model. We will select the models based on popularity, quality, diversity, and other factors.
|
docs/awq.md
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AWQ 4bit Inference
|
| 2 |
+
|
| 3 |
+
We integrated [AWQ](https://github.com/mit-han-lab/llm-awq) into FastChat to provide **efficient and accurate** 4bit LLM inference.
|
| 4 |
+
|
| 5 |
+
## Install AWQ
|
| 6 |
+
|
| 7 |
+
Setup environment (please refer to [this link](https://github.com/mit-han-lab/llm-awq#install) for more details):
|
| 8 |
+
```bash
|
| 9 |
+
conda create -n fastchat-awq python=3.10 -y
|
| 10 |
+
conda activate fastchat-awq
|
| 11 |
+
# cd /path/to/FastChat
|
| 12 |
+
pip install --upgrade pip # enable PEP 660 support
|
| 13 |
+
pip install -e . # install fastchat
|
| 14 |
+
|
| 15 |
+
git clone https://github.com/mit-han-lab/llm-awq repositories/llm-awq
|
| 16 |
+
cd repositories/llm-awq
|
| 17 |
+
pip install -e . # install awq package
|
| 18 |
+
|
| 19 |
+
cd awq/kernels
|
| 20 |
+
python setup.py install # install awq CUDA kernels
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Chat with the CLI
|
| 24 |
+
|
| 25 |
+
```bash
|
| 26 |
+
# Download quantized model from huggingface
|
| 27 |
+
# Make sure you have git-lfs installed (https://git-lfs.com)
|
| 28 |
+
git lfs install
|
| 29 |
+
git clone https://huggingface.co/mit-han-lab/vicuna-7b-v1.3-4bit-g128-awq
|
| 30 |
+
|
| 31 |
+
# You can specify which quantized model to use by setting --awq-ckpt
|
| 32 |
+
python3 -m fastchat.serve.cli \
|
| 33 |
+
--model-path models/vicuna-7b-v1.3-4bit-g128-awq \
|
| 34 |
+
--awq-wbits 4 \
|
| 35 |
+
--awq-groupsize 128
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
## Benchmark
|
| 39 |
+
|
| 40 |
+
* Through **4-bit weight quantization**, AWQ helps to run larger language models within the device memory restriction and prominently accelerates token generation. All benchmarks are done with group_size 128.
|
| 41 |
+
|
| 42 |
+
* Benchmark on NVIDIA RTX A6000:
|
| 43 |
+
|
| 44 |
+
| Model | Bits | Max Memory (MiB) | Speed (ms/token) | AWQ Speedup |
|
| 45 |
+
| --------------- | ---- | ---------------- | ---------------- | ----------- |
|
| 46 |
+
| vicuna-7b | 16 | 13543 | 26.06 | / |
|
| 47 |
+
| vicuna-7b | 4 | 5547 | 12.43 | 2.1x |
|
| 48 |
+
| llama2-7b-chat | 16 | 13543 | 27.14 | / |
|
| 49 |
+
| llama2-7b-chat | 4 | 5547 | 12.44 | 2.2x |
|
| 50 |
+
| vicuna-13b | 16 | 25647 | 44.91 | / |
|
| 51 |
+
| vicuna-13b | 4 | 9355 | 17.30 | 2.6x |
|
| 52 |
+
| llama2-13b-chat | 16 | 25647 | 47.28 | / |
|
| 53 |
+
| llama2-13b-chat | 4 | 9355 | 20.28 | 2.3x |
|
| 54 |
+
|
| 55 |
+
* NVIDIA RTX 4090:
|
| 56 |
+
|
| 57 |
+
| Model | AWQ 4bit Speed (ms/token) | FP16 Speed (ms/token) | AWQ Speedup |
|
| 58 |
+
| --------------- | ------------------------- | --------------------- | ----------- |
|
| 59 |
+
| vicuna-7b | 8.61 | 19.09 | 2.2x |
|
| 60 |
+
| llama2-7b-chat | 8.66 | 19.97 | 2.3x |
|
| 61 |
+
| vicuna-13b | 12.17 | OOM | / |
|
| 62 |
+
| llama2-13b-chat | 13.54 | OOM | / |
|
| 63 |
+
|
| 64 |
+
* NVIDIA Jetson Orin:
|
| 65 |
+
|
| 66 |
+
| Model | AWQ 4bit Speed (ms/token) | FP16 Speed (ms/token) | AWQ Speedup |
|
| 67 |
+
| --------------- | ------------------------- | --------------------- | ----------- |
|
| 68 |
+
| vicuna-7b | 65.34 | 93.12 | 1.4x |
|
| 69 |
+
| llama2-7b-chat | 75.11 | 104.71 | 1.4x |
|
| 70 |
+
| vicuna-13b | 115.40 | OOM | / |
|
| 71 |
+
| llama2-13b-chat | 136.81 | OOM | / |
|
docs/commands/conv_release.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Chatbot Arena Conversations
|
| 2 |
+
|
| 3 |
+
1. Gather battles
|
| 4 |
+
```
|
| 5 |
+
python3 clean_battle_data.py --max-num 10 --mode conv_release
|
| 6 |
+
```
|
| 7 |
+
|
| 8 |
+
2. Tag OpenAI moderation
|
| 9 |
+
```
|
| 10 |
+
python3 tag_openai_moderation.py --in clean_battle_conv_20230814.json
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
3. Clean PII
|
| 14 |
+
|
| 15 |
+
4. Filter additional blocked words
|
| 16 |
+
|
| 17 |
+
```
|
| 18 |
+
python3 filter_bad_conv.py --in clean_battle_conv_20230630_tagged_v1_pii.json
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
5. Add additional toxicity tag
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## All Conversations
|
| 25 |
+
|
| 26 |
+
1. Gather chats
|
| 27 |
+
```
|
| 28 |
+
python3 clean_chat_data.py
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
2. Sample
|
| 32 |
+
```
|
| 33 |
+
python3 conv_release_scripts/sample.py
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Prompt distribution
|
| 38 |
+
|
docs/commands/data_cleaning.md
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Data cleaning
|
| 2 |
+
|
| 3 |
+
## Requirements
|
| 4 |
+
```
|
| 5 |
+
pip3 install bs4 markdownify
|
| 6 |
+
pip3 install polyglot pyicu pycld2
|
| 7 |
+
```
|
| 8 |
+
|
| 9 |
+
## Steps
|
| 10 |
+
```
|
| 11 |
+
# Convert html to markdown
|
| 12 |
+
python3 -m fastchat.data.clean_sharegpt --in sharegpt_html.json --out sharegpt_clean.json
|
| 13 |
+
|
| 14 |
+
# Keep or remove specific languages
|
| 15 |
+
python3 -m fastchat.data.optional_clean --in sharegpt_clean.json --out sharegpt_clean_lang.json --skip-lang SOME_LANGUAGE_CODE
|
| 16 |
+
|
| 17 |
+
# Split long conversations
|
| 18 |
+
python3 -m fastchat.data.split_long_conversation --in sharegpt_clean_lang.json --out sharegpt_clean_lang_split.json --model-name /home/ubuntu/model_weights/llama-7b/
|
| 19 |
+
```
|
docs/commands/leaderboard.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Get logs
|
| 2 |
+
```
|
| 3 |
+
gsutil -m rsync -r gs://fastchat_logs ~/fastchat_logs/
|
| 4 |
+
```
|
| 5 |
+
|
| 6 |
+
### Clean battle data
|
| 7 |
+
```
|
| 8 |
+
cd ~/FastChat/fastchat/serve/monitor
|
| 9 |
+
python3 clean_battle_data.py
|
| 10 |
+
```
|
| 11 |
+
|
| 12 |
+
### Run Elo analysis
|
| 13 |
+
```
|
| 14 |
+
python3 elo_analysis.py --clean-battle-file clean_battle_20230905.json
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
### Copy files to HF space
|
| 18 |
+
1. update plots
|
| 19 |
+
```
|
| 20 |
+
scp atlas:/data/lmzheng/FastChat/fastchat/serve/monitor/elo_results_20230905.pkl .
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
2. update table
|
| 24 |
+
```
|
| 25 |
+
wget https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard/raw/main/leaderboard_table_20230905.csv
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
### Update files on webserver
|
| 29 |
+
```
|
| 30 |
+
DATE=20231002
|
| 31 |
+
|
| 32 |
+
rm -rf elo_results.pkl leaderboard_table.csv
|
| 33 |
+
wget https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard/resolve/main/elo_results_$DATE.pkl
|
| 34 |
+
wget https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard/resolve/main/leaderboard_table_$DATE.csv
|
| 35 |
+
ln -s leaderboard_table_$DATE.csv leaderboard_table.csv
|
| 36 |
+
ln -s elo_results_$DATE.pkl elo_results.pkl
|
| 37 |
+
```
|
docs/commands/local_cluster.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Local GPU cluster
|
| 2 |
+
node-01
|
| 3 |
+
```
|
| 4 |
+
python3 -m fastchat.serve.controller --host 0.0.0.0 --port 10002
|
| 5 |
+
|
| 6 |
+
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-13b-v1.5 --model-name vicuna-13b --controller http://node-01:10002 --host 0.0.0.0 --port 31000 --worker-address http://$(hostname):31000
|
| 7 |
+
CUDA_VISIBLE_DEVICES=1 python3 -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-13b-v1.5 --model-name vicuna-13b --controller http://node-01:10002 --host 0.0.0.0 --port 31001 --worker-address http://$(hostname):31001
|
| 8 |
+
|
| 9 |
+
CUDA_VISIBLE_DEVICES=2,3 ray start --head
|
| 10 |
+
python3 -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-33b-v1.3 --model-name vicuna-33b --controller http://node-01:10002 --host 0.0.0.0 --port 31002 --worker-address http://$(hostname):31002 --num-gpus 2
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
node-02
|
| 14 |
+
```
|
| 15 |
+
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.vllm_worker --model-path meta-llama/Llama-2-13b-chat-hf --model-name llama-2-13b-chat --controller http://node-01:10002 --host 0.0.0.0 --port 31000 --worker-address http://$(hostname):31000 --tokenizer meta-llama/Llama-2-7b-chat-hf
|
| 16 |
+
CUDA_VISIBLE_DEVICES=1 python3 -m fastchat.serve.vllm_worker --model-path meta-llama/Llama-2-13b-chat-hf --model-name llama-2-13b-chat --controller http://node-01:10002 --host 0.0.0.0 --port 31001 --worker-address http://$(hostname):31001 --tokenizer meta-llama/Llama-2-7b-chat-hf
|
| 17 |
+
CUDA_VISIBLE_DEVICES=2 python3 -m fastchat.serve.vllm_worker --model-path meta-llama/Llama-2-7b-chat-hf --model-name llama-2-7b-chat --controller http://node-01:10002 --host 0.0.0.0 --port 31002 --worker-address http://$(hostname):31002 --tokenizer meta-llama/Llama-2-7b-chat-hf
|
| 18 |
+
CUDA_VISIBLE_DEVICES=3 python3 -m fastchat.serve.vllm_worker --model-path WizardLM/WizardLM-13B-V1.1 --model-name wizardlm-13b --controller http://node-01:10002 --host 0.0.0.0 --port 31003 --worker-address http://$(hostname):31003
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
node-03
|
| 22 |
+
```
|
| 23 |
+
python3 -m fastchat.serve.vllm_worker --model-path mosaicml/mpt-30b-chat --controller http://node-01:10002 --host 0.0.0.0 --port 31000 --worker-address http://$(hostname):31000 --num-gpus 2
|
| 24 |
+
python3 -m fastchat.serve.vllm_worker --model-path timdettmers/guanaco-33b-merged --model-name guanaco-33b --controller http://node-01:10002 --host 0.0.0.0 --port 31002 --worker-address http://$(hostname):31002 --num-gpus 2 --tokenizer hf-internal-testing/llama-tokenizer
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
node-04
|
| 28 |
+
```
|
| 29 |
+
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.multi_model_worker --model-path ~/model_weights/RWKV-4-Raven-14B-v12-Eng98%25-Other2%25-20230523-ctx8192.pth --model-name RWKV-4-Raven-14B --model-path lmsys/fastchat-t5-3b-v1.0 --model-name fastchat-t5-3b --controller http://node-01:10002 --host 0.0.0.0 --port 31000 --worker http://$(hostname):31000 --limit 4
|
| 30 |
+
CUDA_VISIBLE_DEVICES=1 python3 -m fastchat.serve.multi_model_worker --model-path OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5 --model-name oasst-pythia-12b --model-path mosaicml/mpt-7b-chat --model-name mpt-7b-chat --controller http://node-01:10002 --host 0.0.0.0 --port 31001 --worker http://$(hostname):31001 --limit 4
|
| 31 |
+
CUDA_VISIBLE_DEVICES=2 python3 -m fastchat.serve.multi_model_worker --model-path lmsys/vicuna-7b-v1.5 --model-name vicuna-7b --model-path THUDM/chatglm-6b --model-name chatglm-6b --controller http://node-01:10002 --host 0.0.0.0 --port 31002 --worker http://$(hostname):31002 --limit 4
|
| 32 |
+
CUDA_VISIBLE_DEVICES=3 python3 -m fastchat.serve.vllm_worker --model-path ~/model_weights/alpaca-13b --controller http://node-01:10002 --host 0.0.0.0 --port 31003 --worker-address http://$(hostname):31003
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
test
|
| 36 |
+
```
|
| 37 |
+
python3 -m fastchat.serve.test_message --model vicuna-13b --controller http://localhost:10002
|
| 38 |
+
```
|
docs/commands/pypi.md
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Requirement
|
| 2 |
+
```
|
| 3 |
+
python3 -m pip install twine
|
| 4 |
+
python3 -m pip install --upgrade pip
|
| 5 |
+
pip3 install build
|
| 6 |
+
```
|
| 7 |
+
|
| 8 |
+
### Upload
|
| 9 |
+
```
|
| 10 |
+
bash scripts/upload_pypi.sh
|
| 11 |
+
```
|
docs/commands/webserver.md
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Install
|
| 2 |
+
```
|
| 3 |
+
sudo apt update
|
| 4 |
+
sudo apt install tmux htop
|
| 5 |
+
|
| 6 |
+
wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh
|
| 7 |
+
bash Anaconda3-2022.10-Linux-x86_64.sh
|
| 8 |
+
|
| 9 |
+
conda create -n fastchat python=3.9
|
| 10 |
+
conda activate fastchat
|
| 11 |
+
|
| 12 |
+
git clone https://github.com/lm-sys/FastChat.git
|
| 13 |
+
cd FastChat
|
| 14 |
+
pip3 install -e .
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
### Launch servers
|
| 19 |
+
```
|
| 20 |
+
cd fastchat_logs/controller
|
| 21 |
+
python3 -m fastchat.serve.controller --host 0.0.0.0 --port 21001
|
| 22 |
+
python3 -m fastchat.serve.register_worker --controller http://localhost:21001 --worker-name https://
|
| 23 |
+
python3 -m fastchat.serve.test_message --model vicuna-13b --controller http://localhost:21001
|
| 24 |
+
|
| 25 |
+
cd fastchat_logs/server0
|
| 26 |
+
|
| 27 |
+
python3 -m fastchat.serve.huggingface_api_worker --model-info-file ~/elo_results/register_hf_api_models.json
|
| 28 |
+
|
| 29 |
+
export OPENAI_API_KEY=
|
| 30 |
+
export ANTHROPIC_API_KEY=
|
| 31 |
+
export GCP_PROJECT_ID=
|
| 32 |
+
|
| 33 |
+
python3 -m fastchat.serve.gradio_web_server_multi --controller http://localhost:21001 --concurrency 50 --add-chatgpt --add-claude --add-palm --elo ~/elo_results/elo_results.pkl --leaderboard-table-file ~/elo_results/leaderboard_table.csv --register ~/elo_results/register_oai_models.json --show-terms
|
| 34 |
+
|
| 35 |
+
python3 backup_logs.py
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
### Check the launch time
|
| 40 |
+
```
|
| 41 |
+
for i in $(seq 0 11); do cat fastchat_logs/server$i/gradio_web_server.log | grep "Running on local URL" | tail -n 1; done
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
### Increase the limit of max open files
|
| 46 |
+
One process (do not need reboot)
|
| 47 |
+
```
|
| 48 |
+
sudo prlimit --nofile=1048576:1048576 --pid=$id
|
| 49 |
+
|
| 50 |
+
for id in $(ps -ef | grep gradio_web_server | awk '{print $2}'); do echo $id; prlimit --nofile=1048576:1048576 --pid=$id; done
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
System (need reboot): Add the lines below to `/etc/security/limits.conf`
|
| 54 |
+
```
|
| 55 |
+
* hard nofile 65535
|
| 56 |
+
* soft nofile 65535
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
### Gradio edit (3.35.2)
|
| 61 |
+
1. gtag and canvas
|
| 62 |
+
```
|
| 63 |
+
vim /home/vicuna/anaconda3/envs/fastchat/lib/python3.9/site-packages/gradio/templates/frontend/index.html
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
<!-- Google tag (gtag.js) -->
|
| 68 |
+
<script async src="https://www.googletagmanager.com/gtag/js?id=G-K6D24EE9ED"></script><script>
|
| 69 |
+
window.dataLayer = window.dataLayer || [];
|
| 70 |
+
function gtag(){dataLayer.push(arguments);}
|
| 71 |
+
gtag('js', new Date());
|
| 72 |
+
gtag('config', 'G-K6D24EE9ED');
|
| 73 |
+
window.__gradio_mode__ = "app";
|
| 74 |
+
</script>
|
| 75 |
+
<script src="https://cdnjs.cloudflare.com/ajax/libs/html2canvas/1.4.1/html2canvas.min.js"></script>
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
2. deprecation warnings
|
| 79 |
+
```
|
| 80 |
+
vim /home/vicuna/anaconda3/envs/fastchat/lib/python3.9/site-packages/gradio/deprecation.py
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
def check_deprecated_parameters(
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
3. Loading
|
| 88 |
+
```
|
| 89 |
+
vim /home/vicuna/anaconda3/envs/fastchat/lib/python3.9/site-packages/gradio/templates/frontend/assets/index-188ef5e8.js
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
```
|
| 93 |
+
%s/"Loading..."/"Loading...(Please refresh if it takes more than 30 seconds)"/g
|
| 94 |
+
```
|
docs/dataset_release.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Datasets
|
| 2 |
+
We release the following datasets based on our projects and websites.
|
| 3 |
+
|
| 4 |
+
- [LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset](https://huggingface.co/datasets/lmsys/lmsys-chat-1m)
|
| 5 |
+
- [Chatbot Arena Conversation Dataset](https://huggingface.co/datasets/lmsys/chatbot_arena_conversations)
|
| 6 |
+
- [MT-bench Human Annotation Dataset](https://huggingface.co/datasets/lmsys/mt_bench_human_judgments)
|
docs/exllama_v2.md
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ExllamaV2 GPTQ Inference Framework
|
| 2 |
+
|
| 3 |
+
Integrated [ExllamaV2](https://github.com/turboderp/exllamav2) customized kernel into Fastchat to provide **Faster** GPTQ inference speed.
|
| 4 |
+
|
| 5 |
+
**Note: Exllama not yet support embedding REST API.**
|
| 6 |
+
|
| 7 |
+
## Install ExllamaV2
|
| 8 |
+
|
| 9 |
+
Setup environment (please refer to [this link](https://github.com/turboderp/exllamav2#how-to) for more details):
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
git clone https://github.com/turboderp/exllamav2
|
| 13 |
+
cd exllamav2
|
| 14 |
+
pip install -e .
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
Chat with the CLI:
|
| 18 |
+
```bash
|
| 19 |
+
python3 -m fastchat.serve.cli \
|
| 20 |
+
--model-path models/vicuna-7B-1.1-GPTQ-4bit-128g \
|
| 21 |
+
--enable-exllama
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
Start model worker:
|
| 25 |
+
```bash
|
| 26 |
+
# Download quantized model from huggingface
|
| 27 |
+
# Make sure you have git-lfs installed (https://git-lfs.com)
|
| 28 |
+
git lfs install
|
| 29 |
+
git clone https://huggingface.co/TheBloke/vicuna-7B-1.1-GPTQ-4bit-128g models/vicuna-7B-1.1-GPTQ-4bit-128g
|
| 30 |
+
|
| 31 |
+
# Load model with default configuration (max sequence length 4096, no GPU split setting).
|
| 32 |
+
python3 -m fastchat.serve.model_worker \
|
| 33 |
+
--model-path models/vicuna-7B-1.1-GPTQ-4bit-128g \
|
| 34 |
+
--enable-exllama
|
| 35 |
+
|
| 36 |
+
#Load model with max sequence length 2048, allocate 18 GB to CUDA:0 and 24 GB to CUDA:1.
|
| 37 |
+
python3 -m fastchat.serve.model_worker \
|
| 38 |
+
--model-path models/vicuna-7B-1.1-GPTQ-4bit-128g \
|
| 39 |
+
--enable-exllama \
|
| 40 |
+
--exllama-max-seq-len 2048 \
|
| 41 |
+
--exllama-gpu-split 18,24
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
`--exllama-cache-8bit` can be used to enable 8-bit caching with exllama and save some VRAM.
|
| 45 |
+
|
| 46 |
+
## Performance
|
| 47 |
+
|
| 48 |
+
Reference: https://github.com/turboderp/exllamav2#performance
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
| Model | Mode | Size | grpsz | act | V1: 3090Ti | V1: 4090 | V2: 3090Ti | V2: 4090 |
|
| 52 |
+
|------------|--------------|-------|-------|-----|------------|----------|------------|-------------|
|
| 53 |
+
| Llama | GPTQ | 7B | 128 | no | 143 t/s | 173 t/s | 175 t/s | **195** t/s |
|
| 54 |
+
| Llama | GPTQ | 13B | 128 | no | 84 t/s | 102 t/s | 105 t/s | **110** t/s |
|
| 55 |
+
| Llama | GPTQ | 33B | 128 | yes | 37 t/s | 45 t/s | 45 t/s | **48** t/s |
|
| 56 |
+
| OpenLlama | GPTQ | 3B | 128 | yes | 194 t/s | 226 t/s | 295 t/s | **321** t/s |
|
| 57 |
+
| CodeLlama | EXL2 4.0 bpw | 34B | - | - | - | - | 42 t/s | **48** t/s |
|
| 58 |
+
| Llama2 | EXL2 3.0 bpw | 7B | - | - | - | - | 195 t/s | **224** t/s |
|
| 59 |
+
| Llama2 | EXL2 4.0 bpw | 7B | - | - | - | - | 164 t/s | **197** t/s |
|
| 60 |
+
| Llama2 | EXL2 5.0 bpw | 7B | - | - | - | - | 144 t/s | **160** t/s |
|
| 61 |
+
| Llama2 | EXL2 2.5 bpw | 70B | - | - | - | - | 30 t/s | **35** t/s |
|
| 62 |
+
| TinyLlama | EXL2 3.0 bpw | 1.1B | - | - | - | - | 536 t/s | **635** t/s |
|
| 63 |
+
| TinyLlama | EXL2 4.0 bpw | 1.1B | - | - | - | - | 509 t/s | **590** t/s |
|
docs/gptq.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GPTQ 4bit Inference
|
| 2 |
+
|
| 3 |
+
Support GPTQ 4bit inference with [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa).
|
| 4 |
+
|
| 5 |
+
1. Window user: use the `old-cuda` branch.
|
| 6 |
+
2. Linux user: recommend the `fastest-inference-4bit` branch.
|
| 7 |
+
|
| 8 |
+
## Install
|
| 9 |
+
|
| 10 |
+
Setup environment:
|
| 11 |
+
```bash
|
| 12 |
+
# cd /path/to/FastChat
|
| 13 |
+
git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa.git repositories/GPTQ-for-LLaMa
|
| 14 |
+
cd repositories/GPTQ-for-LLaMa
|
| 15 |
+
# Window's user should use the `old-cuda` branch
|
| 16 |
+
git switch fastest-inference-4bit
|
| 17 |
+
# Install `quant-cuda` package in FastChat's virtualenv
|
| 18 |
+
python3 setup_cuda.py install
|
| 19 |
+
pip3 install texttable
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
Chat with the CLI:
|
| 23 |
+
```bash
|
| 24 |
+
python3 -m fastchat.serve.cli \
|
| 25 |
+
--model-path models/vicuna-7B-1.1-GPTQ-4bit-128g \
|
| 26 |
+
--gptq-wbits 4 \
|
| 27 |
+
--gptq-groupsize 128
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
Start model worker:
|
| 31 |
+
```bash
|
| 32 |
+
# Download quantized model from huggingface
|
| 33 |
+
# Make sure you have git-lfs installed (https://git-lfs.com)
|
| 34 |
+
git lfs install
|
| 35 |
+
git clone https://huggingface.co/TheBloke/vicuna-7B-1.1-GPTQ-4bit-128g models/vicuna-7B-1.1-GPTQ-4bit-128g
|
| 36 |
+
|
| 37 |
+
python3 -m fastchat.serve.model_worker \
|
| 38 |
+
--model-path models/vicuna-7B-1.1-GPTQ-4bit-128g \
|
| 39 |
+
--gptq-wbits 4 \
|
| 40 |
+
--gptq-groupsize 128
|
| 41 |
+
|
| 42 |
+
# You can specify which quantized model to use
|
| 43 |
+
python3 -m fastchat.serve.model_worker \
|
| 44 |
+
--model-path models/vicuna-7B-1.1-GPTQ-4bit-128g \
|
| 45 |
+
--gptq-ckpt models/vicuna-7B-1.1-GPTQ-4bit-128g/vicuna-7B-1.1-GPTQ-4bit-128g.safetensors \
|
| 46 |
+
--gptq-wbits 4 \
|
| 47 |
+
--gptq-groupsize 128 \
|
| 48 |
+
--gptq-act-order
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## Benchmark
|
| 52 |
+
|
| 53 |
+
| LLaMA-13B | branch | Bits | group-size | memory(MiB) | PPL(c4) | Median(s/token) | act-order | speed up |
|
| 54 |
+
| --------- | ---------------------- | ---- | ---------- | ----------- | ------- | --------------- | --------- | -------- |
|
| 55 |
+
| FP16 | fastest-inference-4bit | 16 | - | 26634 | 6.96 | 0.0383 | - | 1x |
|
| 56 |
+
| GPTQ | triton | 4 | 128 | 8590 | 6.97 | 0.0551 | - | 0.69x |
|
| 57 |
+
| GPTQ | fastest-inference-4bit | 4 | 128 | 8699 | 6.97 | 0.0429 | true | 0.89x |
|
| 58 |
+
| GPTQ | fastest-inference-4bit | 4 | 128 | 8699 | 7.03 | 0.0287 | false | 1.33x |
|
| 59 |
+
| GPTQ | fastest-inference-4bit | 4 | -1 | 8448 | 7.12 | 0.0284 | false | 1.44x |
|
docs/langchain_integration.md
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Local LangChain with FastChat
|
| 2 |
+
|
| 3 |
+
[LangChain](https://python.langchain.com/en/latest/index.html) is a library that facilitates the development of applications by leveraging large language models (LLMs) and enabling their composition with other sources of computation or knowledge.
|
| 4 |
+
FastChat's OpenAI-compatible [API server](openai_api.md) enables using LangChain with open models seamlessly.
|
| 5 |
+
|
| 6 |
+
## Launch RESTful API Server
|
| 7 |
+
|
| 8 |
+
Here are the steps to launch a local OpenAI API server for LangChain.
|
| 9 |
+
|
| 10 |
+
First, launch the controller
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
python3 -m fastchat.serve.controller
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
LangChain uses OpenAI model names by default, so we need to assign some faux OpenAI model names to our local model.
|
| 17 |
+
Here, we use Vicuna as an example and use it for three endpoints: chat completion, completion, and embedding.
|
| 18 |
+
`--model-path` can be a local folder or a Hugging Face repo name.
|
| 19 |
+
See a full list of supported models [here](../README.md#supported-models).
|
| 20 |
+
|
| 21 |
+
```bash
|
| 22 |
+
python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --model-path lmsys/vicuna-7b-v1.5
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
Finally, launch the RESTful API server
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## Set OpenAI Environment
|
| 32 |
+
|
| 33 |
+
You can set your environment with the following commands.
|
| 34 |
+
|
| 35 |
+
Set OpenAI base url
|
| 36 |
+
|
| 37 |
+
```bash
|
| 38 |
+
export OPENAI_API_BASE=http://localhost:8000/v1
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
Set OpenAI API key
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
export OPENAI_API_KEY=EMPTY
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
If you meet the following OOM error while creating embeddings, please set a smaller batch size by using environment variables.
|
| 48 |
+
|
| 49 |
+
~~~bash
|
| 50 |
+
openai.error.APIError: Invalid response object from API: '{"object":"error","message":"**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**\\n\\n(CUDA out of memory. Tried to allocate xxx MiB (GPU 0; xxx GiB total capacity; xxx GiB already allocated; xxx MiB free; xxx GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF)","code":50002}' (HTTP response code was 400)
|
| 51 |
+
~~~
|
| 52 |
+
|
| 53 |
+
You can try `export FASTCHAT_WORKER_API_EMBEDDING_BATCH_SIZE=1`.
|
| 54 |
+
|
| 55 |
+
## Try local LangChain
|
| 56 |
+
|
| 57 |
+
Here is a question answerting example.
|
| 58 |
+
|
| 59 |
+
Download a text file.
|
| 60 |
+
|
| 61 |
+
```bash
|
| 62 |
+
wget https://raw.githubusercontent.com/hwchase17/langchain/v0.0.200/docs/modules/state_of_the_union.txt
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
Run LangChain.
|
| 66 |
+
|
| 67 |
+
~~~py
|
| 68 |
+
from langchain.chat_models import ChatOpenAI
|
| 69 |
+
from langchain.document_loaders import TextLoader
|
| 70 |
+
from langchain.embeddings import OpenAIEmbeddings
|
| 71 |
+
from langchain.indexes import VectorstoreIndexCreator
|
| 72 |
+
|
| 73 |
+
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
|
| 74 |
+
loader = TextLoader("state_of_the_union.txt")
|
| 75 |
+
index = VectorstoreIndexCreator(embedding=embedding).from_loaders([loader])
|
| 76 |
+
llm = ChatOpenAI(model="gpt-3.5-turbo")
|
| 77 |
+
|
| 78 |
+
questions = [
|
| 79 |
+
"Who is the speaker",
|
| 80 |
+
"What did the president say about Ketanji Brown Jackson",
|
| 81 |
+
"What are the threats to America",
|
| 82 |
+
"Who are mentioned in the speech",
|
| 83 |
+
"Who is the vice president",
|
| 84 |
+
"How many projects were announced",
|
| 85 |
+
]
|
| 86 |
+
|
| 87 |
+
for query in questions:
|
| 88 |
+
print("Query:", query)
|
| 89 |
+
print("Answer:", index.query(query, llm=llm))
|
| 90 |
+
~~~
|
docs/lightllm_integration.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LightLLM Integration
|
| 2 |
+
You can use [LightLLM](https://github.com/ModelTC/lightllm) as an optimized worker implementation in FastChat.
|
| 3 |
+
It offers advanced continuous batching and a much higher (~10x) throughput.
|
| 4 |
+
See the supported models [here](https://github.com/ModelTC/lightllm?tab=readme-ov-file#supported-model-list).
|
| 5 |
+
|
| 6 |
+
## Instructions
|
| 7 |
+
1. Please refer to the [Get started](https://github.com/ModelTC/lightllm?tab=readme-ov-file#get-started) to install LightLLM. Or use [Pre-built image](https://github.com/ModelTC/lightllm?tab=readme-ov-file#container)
|
| 8 |
+
|
| 9 |
+
2. When you launch a model worker, replace the normal worker (`fastchat.serve.model_worker`) with the LightLLM worker (`fastchat.serve.lightllm_worker`). All other commands such as controller, gradio web server, and OpenAI API server are kept the same. Refer to [--max_total_token_num](https://github.com/ModelTC/lightllm/blob/4a9824b6b248f4561584b8a48ae126a0c8f5b000/docs/ApiServerArgs.md?plain=1#L23) to understand how to calculate the `--max_total_token_num` argument.
|
| 10 |
+
```
|
| 11 |
+
python3 -m fastchat.serve.lightllm_worker --model-path lmsys/vicuna-7b-v1.5 --tokenizer_mode "auto" --max_total_token_num 154000
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
If you what to use quantized weight and kv cache for inference, try
|
| 15 |
+
|
| 16 |
+
```
|
| 17 |
+
python3 -m fastchat.serve.lightllm_worker --model-path lmsys/vicuna-7b-v1.5 --tokenizer_mode "auto" --max_total_token_num 154000 --mode triton_int8weight triton_int8kv
|
| 18 |
+
```
|
docs/mlx_integration.md
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Apple MLX Integration
|
| 2 |
+
|
| 3 |
+
You can use [Apple MLX](https://github.com/ml-explore/mlx) as an optimized worker implementation in FastChat.
|
| 4 |
+
|
| 5 |
+
It runs models efficiently on Apple Silicon
|
| 6 |
+
|
| 7 |
+
See the supported models [here](https://github.com/ml-explore/mlx-examples/tree/main/llms#supported-models).
|
| 8 |
+
|
| 9 |
+
Note that for Apple Silicon Macs with less memory, smaller models (or quantized models) are recommended.
|
| 10 |
+
|
| 11 |
+
## Instructions
|
| 12 |
+
|
| 13 |
+
1. Install MLX.
|
| 14 |
+
|
| 15 |
+
```
|
| 16 |
+
pip install "mlx-lm>=0.0.6"
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
2. When you launch a model worker, replace the normal worker (`fastchat.serve.model_worker`) with the MLX worker (`fastchat.serve.mlx_worker`). Remember to launch a model worker after you have launched the controller ([instructions](../README.md))
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
python3 -m fastchat.serve.mlx_worker --model-path TinyLlama/TinyLlama-1.1B-Chat-v1.0
|
| 23 |
+
```
|
docs/model_support.md
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Support
|
| 2 |
+
This document describes how to support a new model in FastChat.
|
| 3 |
+
|
| 4 |
+
## Content
|
| 5 |
+
- [Local Models](#local-models)
|
| 6 |
+
- [API-Based Models](#api-based-models)
|
| 7 |
+
|
| 8 |
+
## Local Models
|
| 9 |
+
To support a new local model in FastChat, you need to correctly handle its prompt template and model loading.
|
| 10 |
+
The goal is to make the following command run with the correct prompts.
|
| 11 |
+
|
| 12 |
+
```
|
| 13 |
+
python3 -m fastchat.serve.cli --model [YOUR_MODEL_PATH]
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
You can run this example command to learn the code logic.
|
| 17 |
+
|
| 18 |
+
```
|
| 19 |
+
python3 -m fastchat.serve.cli --model lmsys/vicuna-7b-v1.5
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
You can add `--debug` to see the actual prompt sent to the model.
|
| 23 |
+
|
| 24 |
+
### Steps
|
| 25 |
+
|
| 26 |
+
FastChat uses the `Conversation` class to handle prompt templates and `BaseModelAdapter` class to handle model loading.
|
| 27 |
+
|
| 28 |
+
1. Implement a conversation template for the new model at [fastchat/conversation.py](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py). You can follow existing examples and use `register_conv_template` to add a new one. Please also add a link to the official reference code if possible.
|
| 29 |
+
2. Implement a model adapter for the new model at [fastchat/model/model_adapter.py](https://github.com/lm-sys/FastChat/blob/main/fastchat/model/model_adapter.py). You can follow existing examples and use `register_model_adapter` to add a new one.
|
| 30 |
+
3. (Optional) add the model name to the "Supported models" [section](#supported-models) above and add more information in [fastchat/model/model_registry.py](https://github.com/lm-sys/FastChat/blob/main/fastchat/model/model_registry.py).
|
| 31 |
+
|
| 32 |
+
After these steps, the new model should be compatible with most FastChat features, such as CLI, web UI, model worker, and OpenAI-compatible API server. Please do some testing with these features as well.
|
| 33 |
+
|
| 34 |
+
### Supported models
|
| 35 |
+
|
| 36 |
+
- [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)
|
| 37 |
+
- example: `python3 -m fastchat.serve.cli --model-path meta-llama/Llama-2-7b-chat-hf`
|
| 38 |
+
- Vicuna, Alpaca, LLaMA, Koala
|
| 39 |
+
- example: `python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5`
|
| 40 |
+
- [allenai/tulu-2-dpo-7b](https://huggingface.co/allenai/tulu-2-dpo-7b)
|
| 41 |
+
- [BAAI/AquilaChat-7B](https://huggingface.co/BAAI/AquilaChat-7B)
|
| 42 |
+
- [BAAI/AquilaChat2-7B](https://huggingface.co/BAAI/AquilaChat2-7B)
|
| 43 |
+
- [BAAI/AquilaChat2-34B](https://huggingface.co/BAAI/AquilaChat2-34B)
|
| 44 |
+
- [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en#using-huggingface-transformers)
|
| 45 |
+
- [argilla/notus-7b-v1](https://huggingface.co/argilla/notus-7b-v1)
|
| 46 |
+
- [baichuan-inc/baichuan-7B](https://huggingface.co/baichuan-inc/baichuan-7B)
|
| 47 |
+
- [BlinkDL/RWKV-4-Raven](https://huggingface.co/BlinkDL/rwkv-4-raven)
|
| 48 |
+
- example: `python3 -m fastchat.serve.cli --model-path ~/model_weights/RWKV-4-Raven-7B-v11x-Eng99%-Other1%-20230429-ctx8192.pth`
|
| 49 |
+
- [bofenghuang/vigogne-2-7b-instruct](https://huggingface.co/bofenghuang/vigogne-2-7b-instruct)
|
| 50 |
+
- [bofenghuang/vigogne-2-7b-chat](https://huggingface.co/bofenghuang/vigogne-2-7b-chat)
|
| 51 |
+
- [camel-ai/CAMEL-13B-Combined-Data](https://huggingface.co/camel-ai/CAMEL-13B-Combined-Data)
|
| 52 |
+
- [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf)
|
| 53 |
+
- [databricks/dolly-v2-12b](https://huggingface.co/databricks/dolly-v2-12b)
|
| 54 |
+
- [deepseek-ai/deepseek-llm-67b-chat](https://huggingface.co/deepseek-ai/deepseek-llm-67b-chat)
|
| 55 |
+
- [deepseek-ai/deepseek-coder-33b-instruct](https://huggingface.co/deepseek-ai/deepseek-coder-33b-instruct)
|
| 56 |
+
- [FlagAlpha/Llama2-Chinese-13b-Chat](https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat)
|
| 57 |
+
- [FreedomIntelligence/phoenix-inst-chat-7b](https://huggingface.co/FreedomIntelligence/phoenix-inst-chat-7b)
|
| 58 |
+
- [FreedomIntelligence/ReaLM-7b-v1](https://huggingface.co/FreedomIntelligence/Realm-7b)
|
| 59 |
+
- [h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b](https://huggingface.co/h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b)
|
| 60 |
+
- [HuggingFaceH4/starchat-beta](https://huggingface.co/HuggingFaceH4/starchat-beta)
|
| 61 |
+
- [HuggingFaceH4/zephyr-7b-alpha](https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha)
|
| 62 |
+
- [internlm/internlm-chat-7b](https://huggingface.co/internlm/internlm-chat-7b)
|
| 63 |
+
- [IEITYuan/Yuan2-2B/51B/102B-hf](https://huggingface.co/IEITYuan)
|
| 64 |
+
- [lcw99/polyglot-ko-12.8b-chang-instruct-chat](https://huggingface.co/lcw99/polyglot-ko-12.8b-chang-instruct-chat)
|
| 65 |
+
- [lmsys/fastchat-t5-3b-v1.0](https://huggingface.co/lmsys/fastchat-t5)
|
| 66 |
+
- [meta-math/MetaMath-7B-V1.0](https://huggingface.co/meta-math/MetaMath-7B-V1.0)
|
| 67 |
+
- [Microsoft/Orca-2-7b](https://huggingface.co/microsoft/Orca-2-7b)
|
| 68 |
+
- [mosaicml/mpt-7b-chat](https://huggingface.co/mosaicml/mpt-7b-chat)
|
| 69 |
+
- example: `python3 -m fastchat.serve.cli --model-path mosaicml/mpt-7b-chat`
|
| 70 |
+
- [Neutralzz/BiLLa-7B-SFT](https://huggingface.co/Neutralzz/BiLLa-7B-SFT)
|
| 71 |
+
- [nomic-ai/gpt4all-13b-snoozy](https://huggingface.co/nomic-ai/gpt4all-13b-snoozy)
|
| 72 |
+
- [NousResearch/Nous-Hermes-13b](https://huggingface.co/NousResearch/Nous-Hermes-13b)
|
| 73 |
+
- [openaccess-ai-collective/manticore-13b-chat-pyg](https://huggingface.co/openaccess-ai-collective/manticore-13b-chat-pyg)
|
| 74 |
+
- [OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5](https://huggingface.co/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5)
|
| 75 |
+
- [openchat/openchat_3.5](https://huggingface.co/openchat/openchat_3.5)
|
| 76 |
+
- [Open-Orca/Mistral-7B-OpenOrca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca)
|
| 77 |
+
- [OpenLemur/lemur-70b-chat-v1](https://huggingface.co/OpenLemur/lemur-70b-chat-v1)
|
| 78 |
+
- [Phind/Phind-CodeLlama-34B-v2](https://huggingface.co/Phind/Phind-CodeLlama-34B-v2)
|
| 79 |
+
- [project-baize/baize-v2-7b](https://huggingface.co/project-baize/baize-v2-7b)
|
| 80 |
+
- [Qwen/Qwen-7B-Chat](https://huggingface.co/Qwen/Qwen-7B-Chat)
|
| 81 |
+
- [rishiraj/CatPPT](https://huggingface.co/rishiraj/CatPPT)
|
| 82 |
+
- [Salesforce/codet5p-6b](https://huggingface.co/Salesforce/codet5p-6b)
|
| 83 |
+
- [StabilityAI/stablelm-tuned-alpha-7b](https://huggingface.co/stabilityai/stablelm-tuned-alpha-7b)
|
| 84 |
+
- [tenyx/TenyxChat-7B-v1](https://huggingface.co/tenyx/TenyxChat-7B-v1)
|
| 85 |
+
- [TinyLlama/TinyLlama-1.1B-Chat-v1.0](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0)
|
| 86 |
+
- [THUDM/chatglm-6b](https://huggingface.co/THUDM/chatglm-6b)
|
| 87 |
+
- [THUDM/chatglm2-6b](https://huggingface.co/THUDM/chatglm2-6b)
|
| 88 |
+
- [tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b)
|
| 89 |
+
- [tiiuae/falcon-180B-chat](https://huggingface.co/tiiuae/falcon-180B-chat)
|
| 90 |
+
- [timdettmers/guanaco-33b-merged](https://huggingface.co/timdettmers/guanaco-33b-merged)
|
| 91 |
+
- [togethercomputer/RedPajama-INCITE-7B-Chat](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Chat)
|
| 92 |
+
- [VMware/open-llama-7b-v2-open-instruct](https://huggingface.co/VMware/open-llama-7b-v2-open-instruct)
|
| 93 |
+
- [WizardLM/WizardLM-13B-V1.0](https://huggingface.co/WizardLM/WizardLM-13B-V1.0)
|
| 94 |
+
- [WizardLM/WizardCoder-15B-V1.0](https://huggingface.co/WizardLM/WizardCoder-15B-V1.0)
|
| 95 |
+
- [Xwin-LM/Xwin-LM-7B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1)
|
| 96 |
+
- Any [EleutherAI](https://huggingface.co/EleutherAI) pythia model such as [pythia-6.9b](https://huggingface.co/EleutherAI/pythia-6.9b)
|
| 97 |
+
- Any [Peft](https://github.com/huggingface/peft) adapter trained on top of a
|
| 98 |
+
model above. To activate, must have `peft` in the model path. Note: If
|
| 99 |
+
loading multiple peft models, you can have them share the base model weights by
|
| 100 |
+
setting the environment variable `PEFT_SHARE_BASE_WEIGHTS=true` in any model
|
| 101 |
+
worker.
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
## API-Based Models
|
| 105 |
+
To support an API-based model, consider learning from the existing OpenAI example.
|
| 106 |
+
If the model is compatible with OpenAI APIs, then a configuration file is all that's needed without any additional code.
|
| 107 |
+
For custom protocols, implementation of a streaming generator in [fastchat/serve/api_provider.py](https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/api_provider.py) is required, following the provided examples. Currently, FastChat is compatible with OpenAI, Anthropic, Google Vertex AI, Mistral, and Nvidia NGC.
|
| 108 |
+
|
| 109 |
+
### Steps to Launch a WebUI with an API Model
|
| 110 |
+
1. Specify the endpoint information in a JSON configuration file. For instance, create a file named `api_endpoints.json`:
|
| 111 |
+
```json
|
| 112 |
+
{
|
| 113 |
+
"gpt-3.5-turbo": {
|
| 114 |
+
"model_name": "gpt-3.5-turbo",
|
| 115 |
+
"api_type": "openai",
|
| 116 |
+
"api_base": "https://api.openai.com/v1",
|
| 117 |
+
"api_key": "sk-******",
|
| 118 |
+
"anony_only": false
|
| 119 |
+
}
|
| 120 |
+
}
|
| 121 |
+
```
|
| 122 |
+
- "api_type" can be one of the following: openai, anthropic, gemini, or mistral. For custom APIs, add a new type and implement it accordingly.
|
| 123 |
+
- "anony_only" indicates whether to display this model in anonymous mode only.
|
| 124 |
+
|
| 125 |
+
2. Launch the Gradio web server with the argument `--register api_endpoints.json`:
|
| 126 |
+
```
|
| 127 |
+
python3 -m fastchat.serve.gradio_web_server --controller "" --share --register api_endpoints.json
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
Now, you can open a browser and interact with the model.
|
docs/openai_api.md
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenAI-Compatible RESTful APIs
|
| 2 |
+
|
| 3 |
+
FastChat provides OpenAI-compatible APIs for its supported models, so you can use FastChat as a local drop-in replacement for OpenAI APIs.
|
| 4 |
+
The FastChat server is compatible with both [openai-python](https://github.com/openai/openai-python) library and cURL commands.
|
| 5 |
+
|
| 6 |
+
The following OpenAI APIs are supported:
|
| 7 |
+
- Chat Completions. (Reference: https://platform.openai.com/docs/api-reference/chat)
|
| 8 |
+
- Completions. (Reference: https://platform.openai.com/docs/api-reference/completions)
|
| 9 |
+
- Embeddings. (Reference: https://platform.openai.com/docs/api-reference/embeddings)
|
| 10 |
+
|
| 11 |
+
The REST API can be seamlessly operated from Google Colab, as demonstrated in the [FastChat_API_GoogleColab.ipynb](https://github.com/lm-sys/FastChat/blob/main/playground/FastChat_API_GoogleColab.ipynb) notebook, available in our repository. This notebook provides a practical example of how to utilize the API effectively within the Google Colab environment.
|
| 12 |
+
|
| 13 |
+
## RESTful API Server
|
| 14 |
+
First, launch the controller
|
| 15 |
+
|
| 16 |
+
```bash
|
| 17 |
+
python3 -m fastchat.serve.controller
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
Then, launch the model worker(s)
|
| 21 |
+
|
| 22 |
+
```bash
|
| 23 |
+
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
Finally, launch the RESTful API server
|
| 27 |
+
|
| 28 |
+
```bash
|
| 29 |
+
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
Now, let us test the API server.
|
| 33 |
+
|
| 34 |
+
### OpenAI Official SDK
|
| 35 |
+
The goal of `openai_api_server.py` is to implement a fully OpenAI-compatible API server, so the models can be used directly with [openai-python](https://github.com/openai/openai-python) library.
|
| 36 |
+
|
| 37 |
+
First, install OpenAI python package >= 1.0:
|
| 38 |
+
```bash
|
| 39 |
+
pip install --upgrade openai
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
Then, interact with the Vicuna model:
|
| 43 |
+
```python
|
| 44 |
+
import openai
|
| 45 |
+
|
| 46 |
+
openai.api_key = "EMPTY"
|
| 47 |
+
openai.base_url = "http://localhost:8000/v1/"
|
| 48 |
+
|
| 49 |
+
model = "vicuna-7b-v1.5"
|
| 50 |
+
prompt = "Once upon a time"
|
| 51 |
+
|
| 52 |
+
# create a completion
|
| 53 |
+
completion = openai.completions.create(model=model, prompt=prompt, max_tokens=64)
|
| 54 |
+
# print the completion
|
| 55 |
+
print(prompt + completion.choices[0].text)
|
| 56 |
+
|
| 57 |
+
# create a chat completion
|
| 58 |
+
completion = openai.chat.completions.create(
|
| 59 |
+
model=model,
|
| 60 |
+
messages=[{"role": "user", "content": "Hello! What is your name?"}]
|
| 61 |
+
)
|
| 62 |
+
# print the completion
|
| 63 |
+
print(completion.choices[0].message.content)
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
Streaming is also supported. See [test_openai_api.py](../tests/test_openai_api.py). If your api server is behind a proxy you'll need to turn off buffering, you can do so in Nginx by setting `proxy_buffering off;` in the location block for the proxy.
|
| 67 |
+
|
| 68 |
+
### cURL
|
| 69 |
+
cURL is another good tool for observing the output of the api.
|
| 70 |
+
|
| 71 |
+
List Models:
|
| 72 |
+
```bash
|
| 73 |
+
curl http://localhost:8000/v1/models
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
Chat Completions:
|
| 77 |
+
```bash
|
| 78 |
+
curl http://localhost:8000/v1/chat/completions \
|
| 79 |
+
-H "Content-Type: application/json" \
|
| 80 |
+
-d '{
|
| 81 |
+
"model": "vicuna-7b-v1.5",
|
| 82 |
+
"messages": [{"role": "user", "content": "Hello! What is your name?"}]
|
| 83 |
+
}'
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
Text Completions:
|
| 87 |
+
```bash
|
| 88 |
+
curl http://localhost:8000/v1/completions \
|
| 89 |
+
-H "Content-Type: application/json" \
|
| 90 |
+
-d '{
|
| 91 |
+
"model": "vicuna-7b-v1.5",
|
| 92 |
+
"prompt": "Once upon a time",
|
| 93 |
+
"max_tokens": 41,
|
| 94 |
+
"temperature": 0.5
|
| 95 |
+
}'
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
Embeddings:
|
| 99 |
+
```bash
|
| 100 |
+
curl http://localhost:8000/v1/embeddings \
|
| 101 |
+
-H "Content-Type: application/json" \
|
| 102 |
+
-d '{
|
| 103 |
+
"model": "vicuna-7b-v1.5",
|
| 104 |
+
"input": "Hello world!"
|
| 105 |
+
}'
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
### Running multiple
|
| 109 |
+
|
| 110 |
+
If you want to run multiple models on the same machine and in the same process,
|
| 111 |
+
you can replace the `model_worker` step above with a multi model variant:
|
| 112 |
+
|
| 113 |
+
```bash
|
| 114 |
+
python3 -m fastchat.serve.multi_model_worker \
|
| 115 |
+
--model-path lmsys/vicuna-7b-v1.5 \
|
| 116 |
+
--model-names vicuna-7b-v1.5 \
|
| 117 |
+
--model-path lmsys/longchat-7b-16k \
|
| 118 |
+
--model-names longchat-7b-16k
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
This loads both models into the same accelerator and in the same process. This
|
| 122 |
+
works best when using a Peft model that triggers the `PeftModelAdapter`.
|
| 123 |
+
|
| 124 |
+
TODO: Base model weight optimization will be fixed once [this
|
| 125 |
+
Peft](https://github.com/huggingface/peft/issues/430) issue is resolved.
|
| 126 |
+
|
| 127 |
+
## LangChain Support
|
| 128 |
+
This OpenAI-compatible API server supports LangChain. See [LangChain Integration](langchain_integration.md) for details.
|
| 129 |
+
|
| 130 |
+
## Adjusting Environment Variables
|
| 131 |
+
|
| 132 |
+
### Timeout
|
| 133 |
+
By default, a timeout error will occur if a model worker does not response within 100 seconds. If your model/hardware is slower, you can change this timeout through an environment variable:
|
| 134 |
+
|
| 135 |
+
```bash
|
| 136 |
+
export FASTCHAT_WORKER_API_TIMEOUT=<larger timeout in seconds>
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
### Batch size
|
| 140 |
+
If you meet the following OOM error while creating embeddings. You can use a smaller batch size by setting
|
| 141 |
+
|
| 142 |
+
```bash
|
| 143 |
+
export FASTCHAT_WORKER_API_EMBEDDING_BATCH_SIZE=1
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
## Todos
|
| 147 |
+
Some features to be implemented:
|
| 148 |
+
|
| 149 |
+
- [ ] Support more parameters like `logprobs`, `logit_bias`, `user`, `presence_penalty` and `frequency_penalty`
|
| 150 |
+
- [ ] Model details (permissions, owner and create time)
|
| 151 |
+
- [ ] Edits API
|
| 152 |
+
- [ ] Rate Limitation Settings
|
docs/server_arch.md
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FastChat Server Architecture
|
| 2 |
+

|
docs/third_party_ui.md
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Third Party UI
|
| 2 |
+
If you want to host it on your own UI or third party UI, you can launch the [OpenAI compatible server](openai_api.md) and host with a tunnelling service such as Tunnelmole or ngrok, and then enter the credentials appropriately.
|
| 3 |
+
|
| 4 |
+
You can find suitable UIs from third party repos:
|
| 5 |
+
- [WongSaang's ChatGPT UI](https://github.com/WongSaang/chatgpt-ui)
|
| 6 |
+
- [McKayWrigley's Chatbot UI](https://github.com/mckaywrigley/chatbot-ui)
|
| 7 |
+
|
| 8 |
+
- Please note that some third-party providers only offer the standard `gpt-3.5-turbo`, `gpt-4`, etc., so you will have to add your own custom model inside the code. [Here is an example of how to create a UI with any custom model name](https://github.com/ztjhz/BetterChatGPT/pull/461).
|
| 9 |
+
|
| 10 |
+
##### Using Tunnelmole
|
| 11 |
+
Tunnelmole is an open source tunnelling tool. You can find its source code on [Github](https://github.com/robbie-cahill/tunnelmole-client). Here's how you can use Tunnelmole:
|
| 12 |
+
1. Install Tunnelmole with `curl -O https://install.tunnelmole.com/9Wtxu/install && sudo bash install`. (On Windows, download [tmole.exe](https://tunnelmole.com/downloads/tmole.exe)). Head over to the [README](https://github.com/robbie-cahill/tunnelmole-client) for other methods such as `npm` or building from source.
|
| 13 |
+
2. Run `tmole 7860` (replace `7860` with your listening port if it is different from 7860). The output will display two URLs: one HTTP and one HTTPS. It's best to use the HTTPS URL for better privacy and security.
|
| 14 |
+
```
|
| 15 |
+
➜ ~ tmole 7860
|
| 16 |
+
http://bvdo5f-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7860
|
| 17 |
+
https://bvdo5f-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7860
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
##### Using ngrok
|
| 21 |
+
ngrok is a popular closed source tunnelling tool. First download and install it from [ngrok.com](https://ngrok.com/downloads). Here's how to use it to expose port 7860.
|
| 22 |
+
```
|
| 23 |
+
ngrok http 7860
|
| 24 |
+
```
|
docs/training.md
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Fine-tuning FastChat-T5
|
| 2 |
+
You can use the following command to train FastChat-T5 with 4 x A100 (40GB).
|
| 3 |
+
```bash
|
| 4 |
+
torchrun --nproc_per_node=4 --master_port=9778 fastchat/train/train_flant5.py \
|
| 5 |
+
--model_name_or_path google/flan-t5-xl \
|
| 6 |
+
--data_path ./data/dummy_conversation.json \
|
| 7 |
+
--bf16 True \
|
| 8 |
+
--output_dir ./checkpoints_flant5_3b \
|
| 9 |
+
--num_train_epochs 3 \
|
| 10 |
+
--per_device_train_batch_size 1 \
|
| 11 |
+
--per_device_eval_batch_size 1 \
|
| 12 |
+
--gradient_accumulation_steps 4 \
|
| 13 |
+
--evaluation_strategy "no" \
|
| 14 |
+
--save_strategy "steps" \
|
| 15 |
+
--save_steps 300 \
|
| 16 |
+
--save_total_limit 1 \
|
| 17 |
+
--learning_rate 2e-5 \
|
| 18 |
+
--weight_decay 0. \
|
| 19 |
+
--warmup_ratio 0.03 \
|
| 20 |
+
--lr_scheduler_type "cosine" \
|
| 21 |
+
--logging_steps 1 \
|
| 22 |
+
--fsdp "full_shard auto_wrap" \
|
| 23 |
+
--fsdp_transformer_layer_cls_to_wrap T5Block \
|
| 24 |
+
--tf32 True \
|
| 25 |
+
--model_max_length 2048 \
|
| 26 |
+
--preprocessed_path ./preprocessed_data/processed.json \
|
| 27 |
+
--gradient_checkpointing True
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
After training, please use our post-processing [function](https://github.com/lm-sys/FastChat/blob/55051ad0f23fef5eeecbda14a2e3e128ffcb2a98/fastchat/utils.py#L166-L185) to update the saved model weight. Additional discussions can be found [here](https://github.com/lm-sys/FastChat/issues/643).
|
| 31 |
+
|
| 32 |
+
### Fine-tuning using (Q)LoRA
|
| 33 |
+
You can use the following command to train Vicuna-7B using QLoRA using ZeRO2. Note that ZeRO3 is not currently supported with QLoRA but ZeRO3 does support LoRA, which has a reference configuraiton under playground/deepspeed_config_s3.json. To use QLoRA, you must have bitsandbytes>=0.39.0 and transformers>=4.30.0 installed.
|
| 34 |
+
```bash
|
| 35 |
+
deepspeed fastchat/train/train_lora.py \
|
| 36 |
+
--model_name_or_path ~/model_weights/llama-7b \
|
| 37 |
+
--lora_r 8 \
|
| 38 |
+
--lora_alpha 16 \
|
| 39 |
+
--lora_dropout 0.05 \
|
| 40 |
+
--data_path ./data/dummy_conversation.json \
|
| 41 |
+
--bf16 True \
|
| 42 |
+
--output_dir ./checkpoints \
|
| 43 |
+
--num_train_epochs 3 \
|
| 44 |
+
--per_device_train_batch_size 1 \
|
| 45 |
+
--per_device_eval_batch_size 1 \
|
| 46 |
+
--gradient_accumulation_steps 1 \
|
| 47 |
+
--evaluation_strategy "no" \
|
| 48 |
+
--save_strategy "steps" \
|
| 49 |
+
--save_steps 1200 \
|
| 50 |
+
--save_total_limit 100 \
|
| 51 |
+
--learning_rate 2e-5 \
|
| 52 |
+
--weight_decay 0. \
|
| 53 |
+
--warmup_ratio 0.03 \
|
| 54 |
+
--lr_scheduler_type "cosine" \
|
| 55 |
+
--logging_steps 1 \
|
| 56 |
+
--tf32 True \
|
| 57 |
+
--model_max_length 2048 \
|
| 58 |
+
--q_lora True \
|
| 59 |
+
--deepspeed playground/deepspeed_config_s2.json \
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
For T5-XL or XXL
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
deepspeed fastchat/train/train_lora_t5.py \
|
| 66 |
+
--model_name_or_path google/flan-t5-xl \
|
| 67 |
+
--data_path ./data/dummy_conversation.json \
|
| 68 |
+
--bf16 True \
|
| 69 |
+
--output_dir ./checkpoints_flant5_3b \
|
| 70 |
+
--num_train_epochs 3 \
|
| 71 |
+
--per_device_train_batch_size 1 \
|
| 72 |
+
--per_device_eval_batch_size 1 \
|
| 73 |
+
--gradient_accumulation_steps 4 \
|
| 74 |
+
--evaluation_strategy "no" \
|
| 75 |
+
--save_strategy "steps" \
|
| 76 |
+
--save_steps 300 \
|
| 77 |
+
--save_total_limit 1 \
|
| 78 |
+
--learning_rate 2e-5 \
|
| 79 |
+
--weight_decay 0. \
|
| 80 |
+
--warmup_ratio 0.03 \
|
| 81 |
+
--lr_scheduler_type "cosine" \
|
| 82 |
+
--logging_steps 1 \
|
| 83 |
+
--model_max_length 2048 \
|
| 84 |
+
--preprocessed_path ./preprocessed_data/processed.json \
|
| 85 |
+
--gradient_checkpointing True \
|
| 86 |
+
--q_lora True \
|
| 87 |
+
--deepspeed playground/deepspeed_config_s2.json
|
| 88 |
+
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### Fine-tuning Vicuna-7B with Local NPUs
|
| 92 |
+
|
| 93 |
+
You can use the following command to train Vicuna-7B with 8 x NPUs. Use `--nproc_per_node` to specify the number of NPUs.
|
| 94 |
+
```bash
|
| 95 |
+
torchrun --nproc_per_node=8 --master_port=20001 fastchat/train/train.py \
|
| 96 |
+
--model_name_or_path ~/vicuna-7b-v1.5-16k \
|
| 97 |
+
--data_path data/dummy_conversation.json \
|
| 98 |
+
--fp16 True \
|
| 99 |
+
--output_dir output_vicuna \
|
| 100 |
+
--num_train_epochs 3 \
|
| 101 |
+
--per_device_train_batch_size 8 \
|
| 102 |
+
--per_device_eval_batch_size 1 \
|
| 103 |
+
--gradient_accumulation_steps 1 \
|
| 104 |
+
--evaluation_strategy "no" \
|
| 105 |
+
--save_strategy "steps" \
|
| 106 |
+
--save_steps 1200 \
|
| 107 |
+
--save_total_limit 10 \
|
| 108 |
+
--learning_rate 2e-5 \
|
| 109 |
+
--weight_decay 0. \
|
| 110 |
+
--warmup_ratio 0.03 \
|
| 111 |
+
--lr_scheduler_type "cosine" \
|
| 112 |
+
--logging_steps 1 \
|
| 113 |
+
--fsdp "full_shard auto_wrap" \
|
| 114 |
+
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
|
| 115 |
+
--model_max_length 2048 \
|
| 116 |
+
--gradient_checkpointing True \
|
| 117 |
+
--lazy_preprocess True
|
| 118 |
+
```
|
docs/vicuna_weights_version.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Vicuna Weights
|
| 2 |
+
|
| 3 |
+
| Weights version | Link | FastChat version compatibility | Base Model | Release Date | Fine-tuning Data |
|
| 4 |
+
| ---- | ---- | ---- | ---- | ---- | ---- |
|
| 5 |
+
| v1.5 | [7B](https://huggingface.co/lmsys/vicuna-7b-v1.5), [7B-16k](https://huggingface.co/lmsys/vicuna-7b-v1.5-16k), [13B](https://huggingface.co/lmsys/vicuna-13b-v1.5), [13B-16k](https://huggingface.co/lmsys/vicuna-13b-v1.5-16k) | `>=0.2.21` | Llama 2 | Aug. 1, 2023 | 370M tokens |
|
| 6 |
+
| v1.3 | [7B](https://huggingface.co/lmsys/vicuna-7b-v1.3), [13B](https://huggingface.co/lmsys/vicuna-13b-v1.3), [33B](//huggingface.co/lmsys/vicuna-33b-v1.3) | `>=0.2.1` | Llama 1 | Jun. 22, 2023 | 370M tokens |
|
| 7 |
+
| v1.1 | [7B](https://huggingface.co/lmsys/vicuna-7b-v1.1), [13B](https://huggingface.co/lmsys/vicuna-13b-v1.1) | `>=0.2.1` | Llama 1 | Apr. 12, 2023 | - |
|
| 8 |
+
| v0 | [7B-delta](https://huggingface.co/lmsys/vicuna-7b-delta-v0), [13B-delta](https://huggingface.co/lmsys/vicuna-13b-delta-v0) | `<=0.1.10` | Llama 1 | Mar. 30, 2023 | - |
|
| 9 |
+
|
| 10 |
+
### Updates
|
| 11 |
+
- Major updates of weights v1.5
|
| 12 |
+
- Use Llama2 as the base model.
|
| 13 |
+
- Provide 16K context length versions using linear RoPE scaling.
|
| 14 |
+
|
| 15 |
+
- Major updates of weights v1.3
|
| 16 |
+
- Train with twice the amount of ShareGPT data compared to previous versions.
|
| 17 |
+
- Provide merged weights directly instead of delta weights.
|
| 18 |
+
|
| 19 |
+
- Major updates of weights v1.1
|
| 20 |
+
- Refactor the tokenization and separator. In Vicuna v1.1, the separator has been changed from `###` to the EOS token `</s>`. This change makes it easier to determine the generation stop criteria and enables better compatibility with other libraries.
|
| 21 |
+
- Fix the supervised fine-tuning loss computation for better model quality.
|
| 22 |
+
|
| 23 |
+
## Prompt Template
|
| 24 |
+
|
| 25 |
+
### Example prompt (weights v1.1, v1.3, v1.5)
|
| 26 |
+
```
|
| 27 |
+
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
|
| 28 |
+
|
| 29 |
+
USER: Hello!
|
| 30 |
+
ASSISTANT: Hello!</s>
|
| 31 |
+
USER: How are you?
|
| 32 |
+
ASSISTANT: I am good.</s>
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
See a full prompt template [here](https://github.com/lm-sys/FastChat/blob/d578599c69d060e6d40943f1b5b72af98956092a/fastchat/conversation.py#L286-L299) and example output [here](https://github.com/lm-sys/FastChat/blob/d578599c69d060e6d40943f1b5b72af98956092a/fastchat/conversation.py#L748-L753).
|
| 36 |
+
|
| 37 |
+
### Example prompt (weights v0)
|
| 38 |
+
```
|
| 39 |
+
A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.
|
| 40 |
+
|
| 41 |
+
### Human: Hello!
|
| 42 |
+
### Assistant: Hello!
|
| 43 |
+
### Human: How are you?
|
| 44 |
+
### Assistant: I am good.
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
See the full prompt template [here](https://github.com/lm-sys/FastChat/blob/d578599c69d060e6d40943f1b5b72af98956092a/fastchat/conversation.py#L238-L269).
|
| 48 |
+
|
| 49 |
+
## How to Apply Delta Weights (Only Needed for Weights v0)
|
| 50 |
+
|
| 51 |
+
We release [Vicuna](https://lmsys.org/blog/2023-03-30-vicuna/) weights v0 as delta weights to comply with the LLaMA model license.
|
| 52 |
+
You can add our delta to the original LLaMA weights to obtain the Vicuna weights. Instructions:
|
| 53 |
+
|
| 54 |
+
1. Get the original LLaMA weights in the Hugging Face format by following the instructions [here](https://huggingface.co/docs/transformers/main/model_doc/llama).
|
| 55 |
+
2. Use the following scripts to get Vicuna weights by applying our delta. They will automatically download delta weights from our Hugging Face [account](https://huggingface.co/lmsys).
|
| 56 |
+
|
| 57 |
+
**NOTE**:
|
| 58 |
+
Weights v1.1 are only compatible with ```transformers>=4.28.0``` and ``fschat >= 0.2.0``.
|
| 59 |
+
Please update your local packages accordingly. If you follow the above commands to do a fresh install, then you should get all the correct versions.
|
| 60 |
+
|
| 61 |
+
#### Vicuna-7B
|
| 62 |
+
This conversion command needs around 30 GB of CPU RAM.
|
| 63 |
+
See the "Low CPU Memory Conversion" section below if you do not have enough memory.
|
| 64 |
+
Replace `/path/to/*` with the real paths.
|
| 65 |
+
```bash
|
| 66 |
+
python3 -m fastchat.model.apply_delta \
|
| 67 |
+
--base-model-path /path/to/llama-7b \
|
| 68 |
+
--target-model-path /path/to/output/vicuna-7b \
|
| 69 |
+
--delta-path lmsys/vicuna-7b-delta-v1.1
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
#### Vicuna-13B
|
| 73 |
+
This conversion command needs around 60 GB of CPU RAM.
|
| 74 |
+
See the "Low CPU Memory Conversion" section below if you do not have enough memory.
|
| 75 |
+
Replace `/path/to/*` with the real paths.
|
| 76 |
+
```bash
|
| 77 |
+
python3 -m fastchat.model.apply_delta \
|
| 78 |
+
--base-model-path /path/to/llama-13b \
|
| 79 |
+
--target-model-path /path/to/output/vicuna-13b \
|
| 80 |
+
--delta-path lmsys/vicuna-13b-delta-v1.1
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
#### Low CPU Memory Conversion
|
| 84 |
+
You can try these methods to reduce the CPU RAM requirement of weight conversion.
|
| 85 |
+
1. Append `--low-cpu-mem` to the commands above, which will split large weight files into smaller ones and use the disk as temporary storage. This can keep the peak memory at less than 16GB.
|
| 86 |
+
2. Create a large swap file and rely on the operating system to automatically utilize the disk as virtual memory.
|
| 87 |
+
|
| 88 |
+
## FAQ
|
| 89 |
+
|
| 90 |
+
### Tokenizer issues
|
| 91 |
+
There are some frequently asked tokenizer issues (https://github.com/lm-sys/FastChat/issues/408).
|
| 92 |
+
Some of them are not only related to FastChat or Vicuna weights but are also related to how you convert the base llama model.
|
| 93 |
+
|
| 94 |
+
We suggest that you use `transformers>=4.28.0` and redo the weight conversion for the base llama model.
|
| 95 |
+
After applying the delta, you should have a file named `special_tokens_map.json` in your converted weight folder for either v0 or v1.1.
|
| 96 |
+
The contents of this file should be the same as this file: https://huggingface.co/lmsys/vicuna-13b-delta-v0/blob/main/special_tokens_map.json.
|
| 97 |
+
If the file is not present, please copy the `special_tokens_map.json` and `tokenizer_config.json` files from https://huggingface.co/lmsys/vicuna-13b-delta-v0/tree/main to your converted weight folder. This works for both v0 and v1.1.
|
docs/vllm_integration.md
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# vLLM Integration
|
| 2 |
+
You can use [vLLM](https://vllm.ai/) as an optimized worker implementation in FastChat.
|
| 3 |
+
It offers advanced continuous batching and a much higher (~10x) throughput.
|
| 4 |
+
See the supported models [here](https://vllm.readthedocs.io/en/latest/models/supported_models.html).
|
| 5 |
+
|
| 6 |
+
## Instructions
|
| 7 |
+
1. Install vLLM.
|
| 8 |
+
```
|
| 9 |
+
pip install vllm
|
| 10 |
+
```
|
| 11 |
+
|
| 12 |
+
2. When you launch a model worker, replace the normal worker (`fastchat.serve.model_worker`) with the vLLM worker (`fastchat.serve.vllm_worker`). All other commands such as controller, gradio web server, and OpenAI API server are kept the same.
|
| 13 |
+
```
|
| 14 |
+
python3 -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-7b-v1.5
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
If you see tokenizer errors, try
|
| 18 |
+
```
|
| 19 |
+
python3 -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-7b-v1.5 --tokenizer hf-internal-testing/llama-tokenizer
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
If you use an AWQ quantized model, try
|
| 23 |
+
'''
|
| 24 |
+
python3 -m fastchat.serve.vllm_worker --model-path TheBloke/vicuna-7B-v1.5-AWQ --quantization awq
|
| 25 |
+
'''
|
docs/xFasterTransformer.md
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# xFasterTransformer Inference Framework
|
| 2 |
+
|
| 3 |
+
Integrated [xFasterTransformer](https://github.com/intel/xFasterTransformer) customized framework into Fastchat to provide **Faster** inference speed on Intel CPU.
|
| 4 |
+
|
| 5 |
+
## Install xFasterTransformer
|
| 6 |
+
|
| 7 |
+
Setup environment (please refer to [this link](https://github.com/intel/xFasterTransformer#installation) for more details):
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install xfastertransformer
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
## Prepare models
|
| 14 |
+
|
| 15 |
+
Prepare Model (please refer to [this link](https://github.com/intel/xFasterTransformer#prepare-model) for more details):
|
| 16 |
+
```bash
|
| 17 |
+
python ./tools/chatglm_convert.py -i ${HF_DATASET_DIR} -o ${OUTPUT_DIR}
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
## Parameters of xFasterTransformer
|
| 21 |
+
--enable-xft to enable xfastertransformer in Fastchat
|
| 22 |
+
--xft-max-seq-len to set the max token length the model can process. max token length include input token length.
|
| 23 |
+
--xft-dtype to set datatype used in xFasterTransformer for computation. xFasterTransformer can support fp32, fp16, int8, bf16 and hybrid data types like : bf16_fp16, bf16_int8. For datatype details please refer to [this link](https://github.com/intel/xFasterTransformer/wiki/Data-Type-Support-Platform)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
Chat with the CLI:
|
| 27 |
+
```bash
|
| 28 |
+
#run inference on all CPUs and using float16
|
| 29 |
+
python3 -m fastchat.serve.cli \
|
| 30 |
+
--model-path /path/to/models \
|
| 31 |
+
--enable-xft \
|
| 32 |
+
--xft-dtype fp16
|
| 33 |
+
```
|
| 34 |
+
or with numactl on multi-socket server for better performance
|
| 35 |
+
```bash
|
| 36 |
+
#run inference on numanode 0 and with data type bf16_fp16 (first token uses bfloat16, and rest tokens use float16)
|
| 37 |
+
numactl -N 0 --localalloc \
|
| 38 |
+
python3 -m fastchat.serve.cli \
|
| 39 |
+
--model-path /path/to/models/chatglm2_6b_cpu/ \
|
| 40 |
+
--enable-xft \
|
| 41 |
+
--xft-dtype bf16_fp16
|
| 42 |
+
```
|
| 43 |
+
or using MPI to run inference on 2 sockets for better performance
|
| 44 |
+
```bash
|
| 45 |
+
#run inference on numanode 0 and 1 and with data type bf16_fp16 (first token uses bfloat16, and rest tokens use float16)
|
| 46 |
+
OMP_NUM_THREADS=$CORE_NUM_PER_SOCKET LD_PRELOAD=libiomp5.so mpirun \
|
| 47 |
+
-n 1 numactl -N 0 --localalloc \
|
| 48 |
+
python -m fastchat.serve.cli \
|
| 49 |
+
--model-path /path/to/models/chatglm2_6b_cpu/ \
|
| 50 |
+
--enable-xft \
|
| 51 |
+
--xft-dtype bf16_fp16 : \
|
| 52 |
+
-n 1 numactl -N 1 --localalloc \
|
| 53 |
+
python -m fastchat.serve.cli \
|
| 54 |
+
--model-path /path/to/models/chatglm2_6b_cpu/ \
|
| 55 |
+
--enable-xft \
|
| 56 |
+
--xft-dtype bf16_fp16
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
Start model worker:
|
| 61 |
+
```bash
|
| 62 |
+
# Load model with default configuration (max sequence length 4096, no GPU split setting).
|
| 63 |
+
python3 -m fastchat.serve.model_worker \
|
| 64 |
+
--model-path /path/to/models \
|
| 65 |
+
--enable-xft \
|
| 66 |
+
--xft-dtype bf16_fp16
|
| 67 |
+
```
|
| 68 |
+
or with numactl on multi-socket server for better performance
|
| 69 |
+
```bash
|
| 70 |
+
#run inference on numanode 0 and with data type bf16_fp16 (first token uses bfloat16, and rest tokens use float16)
|
| 71 |
+
numactl -N 0 --localalloc python3 -m fastchat.serve.model_worker \
|
| 72 |
+
--model-path /path/to/models \
|
| 73 |
+
--enable-xft \
|
| 74 |
+
--xft-dtype bf16_fp16
|
| 75 |
+
```
|
| 76 |
+
or using MPI to run inference on 2 sockets for better performance
|
| 77 |
+
```bash
|
| 78 |
+
#run inference on numanode 0 and 1 and with data type bf16_fp16 (first token uses bfloat16, and rest tokens use float16)
|
| 79 |
+
OMP_NUM_THREADS=$CORE_NUM_PER_SOCKET LD_PRELOAD=libiomp5.so mpirun \
|
| 80 |
+
-n 1 numactl -N 0 --localalloc python -m fastchat.serve.model_worker \
|
| 81 |
+
--model-path /path/to/models \
|
| 82 |
+
--enable-xft \
|
| 83 |
+
--xft-dtype bf16_fp16 : \
|
| 84 |
+
-n 1 numactl -N 1 --localalloc python -m fastchat.serve.model_worker \
|
| 85 |
+
--model-path /path/to/models \
|
| 86 |
+
--enable-xft \
|
| 87 |
+
--xft-dtype bf16_fp16
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
For more details, please refer to [this link](https://github.com/intel/xFasterTransformer#how-to-run)
|
fastchat/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__version__ = "0.2.35"
|
fastchat/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (180 Bytes). View file
|
|
|
fastchat/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (192 Bytes). View file
|
|
|