
Commit
•
a3d05c5
1
Parent(s):
ebf60ee
Initial commit
Browse files- api_data.py +36 -0
- app.py +70 -0
- data_processing.py +69 -0
- results/hum_model.h5 +3 -0
- results/hum_model_plot.png +0 -0
- results/mean_std.pkl +3 -0
- results/temp_model.h5 +3 -0
- results/temp_model_plot.png +0 -0
api_data.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
import datetime
|
| 3 |
+
|
| 4 |
+
def fetch_data(
|
| 5 |
+
lookback,
|
| 6 |
+
span = 24,
|
| 7 |
+
offset = 3, # data from the api is only upto 3 hours before now
|
| 8 |
+
|
| 9 |
+
url = "https://visual-crossing-weather.p.rapidapi.com/history",
|
| 10 |
+
headers = {
|
| 11 |
+
"X-RapidAPI-Key": "12c5552beamshb548b266489323cp1c7cb2jsnf8b18027cebc",
|
| 12 |
+
"X-RapidAPI-Host": "visual-crossing-weather.p.rapidapi.com"
|
| 13 |
+
}
|
| 14 |
+
):
|
| 15 |
+
# Calculate the start and end date and time for the last 24 hours
|
| 16 |
+
end_datetime = datetime.datetime.now() - datetime.timedelta(hours=lookback)
|
| 17 |
+
start_datetime = end_datetime - datetime.timedelta(hours=(span+offset))
|
| 18 |
+
querystring = {
|
| 19 |
+
"startDateTime": start_datetime.strftime("%Y-%m-%dT%H:%M:%S"),
|
| 20 |
+
"aggregateHours": "1",
|
| 21 |
+
"location": "Kolkata",
|
| 22 |
+
"endDateTime": end_datetime.strftime("%Y-%m-%dT%H:%M:%S"),
|
| 23 |
+
"unitGroup": "us",
|
| 24 |
+
"dayStartTime": "00:00:00",
|
| 25 |
+
"contentType": "csv",
|
| 26 |
+
"dayEndTime": "23:59:00",
|
| 27 |
+
"shortColumnNames": "0"
|
| 28 |
+
}
|
| 29 |
+
response = requests.get(url, headers=headers, params=querystring)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
if response.status_code == 200:
|
| 33 |
+
# Parse the CSV response
|
| 34 |
+
return response
|
| 35 |
+
else:
|
| 36 |
+
print("Error:", response.status_code)
|
app.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from data_processing import process_data, standardizeX
|
| 2 |
+
from api_data import fetch_data
|
| 3 |
+
from tensorflow import keras
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import gradio as gr
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pickle
|
| 8 |
+
import io
|
| 9 |
+
|
| 10 |
+
#========================================================================================================================
|
| 11 |
+
# load the models
|
| 12 |
+
#========================================================================================================================
|
| 13 |
+
temp_model = keras.models.load_model('results/temp_model.h5')
|
| 14 |
+
hum_model = keras.models.load_model('results/hum_model.h5')
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
#========================================================================================================================
|
| 18 |
+
# retrieve mean and std
|
| 19 |
+
#========================================================================================================================
|
| 20 |
+
scale = pickle.load(open("results/mean_std.pkl", "rb"))
|
| 21 |
+
mean = scale["mean"]
|
| 22 |
+
std = scale["std"]
|
| 23 |
+
|
| 24 |
+
temp_mean = mean[0]
|
| 25 |
+
temp_std = std[0]
|
| 26 |
+
|
| 27 |
+
hum_mean = mean[2]
|
| 28 |
+
hum_std = std[2]
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
#========================================================================================================================
|
| 32 |
+
# predict function
|
| 33 |
+
#========================================================================================================================
|
| 34 |
+
def forecast(time):
|
| 35 |
+
time = int(time)
|
| 36 |
+
if time>9 or time<0:
|
| 37 |
+
return "please enter valid time", "0 to 9"
|
| 38 |
+
|
| 39 |
+
response = fetch_data(9-time)
|
| 40 |
+
if response is not None:
|
| 41 |
+
# processing data to better fit the model
|
| 42 |
+
df = pd.read_csv(io.StringIO(response.content.decode('utf-8')))
|
| 43 |
+
df = process_data(df)
|
| 44 |
+
X = np.array(df[-24:]).reshape(-1, 24, 16)
|
| 45 |
+
X = standardizeX(X, mean, std)
|
| 46 |
+
|
| 47 |
+
# predictions
|
| 48 |
+
temp = temp_model.predict(X)
|
| 49 |
+
hum = hum_model.predict(X)
|
| 50 |
+
|
| 51 |
+
# reverse scaling
|
| 52 |
+
temp = (temp[0][0]*temp_std) + temp_mean
|
| 53 |
+
hum = (hum[0][0]*hum_std) + hum_mean
|
| 54 |
+
|
| 55 |
+
# output formatting
|
| 56 |
+
temp = str(round(((temp-32)*5)/9, 2)) + " c"
|
| 57 |
+
hum = str(round(hum, 2)) + " %"
|
| 58 |
+
|
| 59 |
+
return temp, hum
|
| 60 |
+
|
| 61 |
+
else:
|
| 62 |
+
return "API access denied"
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
gr.Interface(fn=forecast,
|
| 66 |
+
inputs = gr.Textbox(placeholder="Provide value between 0 to 9, 0 means present, 9 means 9 hrs in future "),
|
| 67 |
+
outputs = [gr.Textbox(label="Temperature"),gr.Textbox(label="Humidity")]
|
| 68 |
+
).launch()
|
| 69 |
+
|
| 70 |
+
|
data_processing.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pandas as pd
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
# function to map weather values to numerical values
|
| 6 |
+
def map_weather_to_numerical(weather, ordinal_values):
|
| 7 |
+
val = 0
|
| 8 |
+
for w in weather.split(","):
|
| 9 |
+
w = w.strip()
|
| 10 |
+
if w in ordinal_values:
|
| 11 |
+
val = max(ordinal_values[w], val)
|
| 12 |
+
|
| 13 |
+
return val
|
| 14 |
+
|
| 15 |
+
def standardizeX(X, mean, std):
|
| 16 |
+
for i in range(len(mean)):
|
| 17 |
+
X[:,:,i] = (X[:, :, i]-mean[i])/std[i]
|
| 18 |
+
return X
|
| 19 |
+
|
| 20 |
+
def process_data(df):
|
| 21 |
+
# Drop redundant columns
|
| 22 |
+
redundant_cols = [col for col in ["Unnamed: 0", "Minimum Temperature",
|
| 23 |
+
"Maximum Temperature", "Snow Depth", "Heat Index",
|
| 24 |
+
"Precipitation Cover", "Wind Gust", "Wind Chill",
|
| 25 |
+
"Snow Depth", "Info", "Latitude",
|
| 26 |
+
"Longitude", "Address", "Resolved Address", "Name"] if col in df.columns]
|
| 27 |
+
df.drop(redundant_cols, axis=1, inplace=True)
|
| 28 |
+
|
| 29 |
+
# Interpolate missing values
|
| 30 |
+
df = df.interpolate()
|
| 31 |
+
|
| 32 |
+
# Fill missing values in 'Conditions' and 'Weather Type' columns
|
| 33 |
+
df['Conditions'].fillna("Clear", inplace=True)
|
| 34 |
+
df['Weather Type'].fillna("", inplace=True)
|
| 35 |
+
|
| 36 |
+
# Rename column and convert to datetime format
|
| 37 |
+
df.rename(columns={"Relative Humidity": "Humidity"}, inplace=True)
|
| 38 |
+
df['DATETIME'] = pd.to_datetime(df['Date time'])
|
| 39 |
+
|
| 40 |
+
# Drop 'Date time' column
|
| 41 |
+
df.drop(["Date time"], axis=1, inplace=True)
|
| 42 |
+
|
| 43 |
+
# Map weather values to numerical values
|
| 44 |
+
rain_values = {'Heavy Rain': 7, 'Snow And Rain Showers': 6, 'Rain Showers': 5, 'Rain': 4, 'Light Rain': 3, 'Light Drizzle': 2, 'Drizzle': 1}
|
| 45 |
+
storm_values = {'Dust storm': 1, 'Lightning Without Thunder': 2, 'Thunderstorm Without Precipitation': 3, 'Thunderstorm': 4}
|
| 46 |
+
overview = {'Clear': 1, 'Partially cloudy': 2, 'Rain': 2, 'Overcast': 3}
|
| 47 |
+
|
| 48 |
+
df["Rain"] = df['Weather Type'].apply(lambda s: map_weather_to_numerical(s, rain_values))
|
| 49 |
+
df["Storm"] = df['Weather Type'].apply(lambda s: map_weather_to_numerical(s, storm_values))
|
| 50 |
+
df["Overview"] = df['Conditions'].apply(lambda s: map_weather_to_numerical(s, overview))
|
| 51 |
+
|
| 52 |
+
# Drop 'Weather Type' and 'Conditions' columns
|
| 53 |
+
df.drop(["Weather Type", "Conditions"], axis=1, inplace=True)
|
| 54 |
+
|
| 55 |
+
# Convert DATETIME to seconds
|
| 56 |
+
df["seconds"] = df["DATETIME"].map(pd.Timestamp.timestamp)
|
| 57 |
+
df.drop("DATETIME", axis=1, inplace=True)
|
| 58 |
+
|
| 59 |
+
# Process seconds to represent periodic nature of days and years
|
| 60 |
+
day_in_seconds = 24 * 3600
|
| 61 |
+
year_in_seconds = day_in_seconds * 365.2425
|
| 62 |
+
df["sin(day)"] = np.sin((df["seconds"] * (2 * np.pi)) / day_in_seconds)
|
| 63 |
+
df["cos(day)"] = np.cos((df["seconds"] * (2 * np.pi)) / day_in_seconds)
|
| 64 |
+
df["sin(year)"] = np.sin((df["seconds"] * (2 * np.pi)) / year_in_seconds)
|
| 65 |
+
df["cos(year)"] = np.cos((df["seconds"] * (2 * np.pi)) / year_in_seconds)
|
| 66 |
+
df.drop("seconds", axis=1, inplace=True)
|
| 67 |
+
|
| 68 |
+
return df
|
| 69 |
+
|
results/hum_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:15fffdccc415ec750c92c590fa82078587b8a5c822586844c2f9520d0fe851b7
|
| 3 |
+
size 297364
|
results/hum_model_plot.png
ADDED
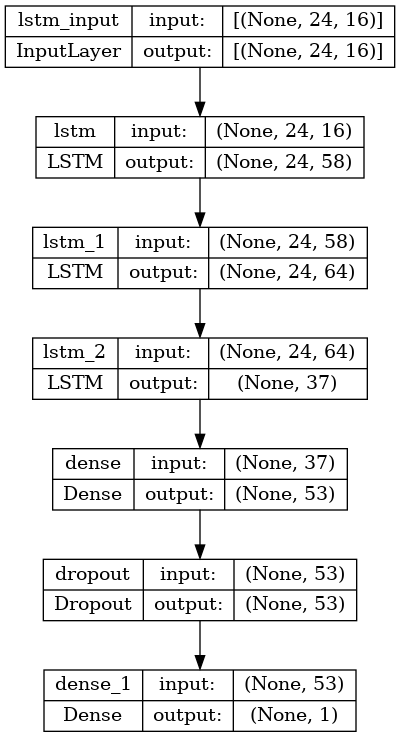
|
results/mean_std.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:869b4cbb687b1c0fbbaad80a6e716b8c8ce724c2ebfb7c097130550006955be2
|
| 3 |
+
size 450
|
results/temp_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:74c3e6df11e3afa2c66fd7411212be198772d7c0f708f2d8f624d19a14c3db21
|
| 3 |
+
size 100200
|
results/temp_model_plot.png
ADDED
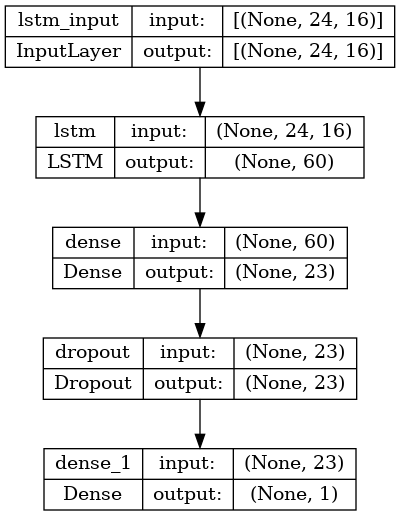
|