
Анастасия
commited on
Commit
•
b8458b8
1
Parent(s):
aa2e3cb
project_streamlit_app
Browse files- images/1.jpeg +0 -0
- images/2.jpeg +0 -0
- images/3.jpeg +0 -0
- images/4.jpeg +0 -0
- images/5.jpeg +0 -0
- images/mem.jpg +0 -0
- pages/01_🎥_Serials.py +4 -4
- pages/02_🔥_Results.py +23 -4
images/1.jpeg
ADDED
|
images/2.jpeg
ADDED
|
images/3.jpeg
ADDED

|
images/4.jpeg
ADDED

|
images/5.jpeg
ADDED
|
images/mem.jpg
ADDED

|
pages/01_🎥_Serials.py
CHANGED
|
@@ -40,7 +40,7 @@ ganres_lst = sorted(['драма', 'документальный', 'биогра
|
|
| 40 |
st.sidebar.header('Панель инструментов :gear:')
|
| 41 |
choice_g = st.sidebar.multiselect("Выберите жанры", options=ganres_lst)
|
| 42 |
n = st.sidebar.selectbox("Количество отображаемых элементов на странице", options=[5, 10, 15, 20, 30])
|
| 43 |
-
st.sidebar.info("Для наилучшего соответствия, запрос должен быть максимально развернутым")
|
| 44 |
|
| 45 |
text = st.text_input('Введите описание для рекомендации')
|
| 46 |
|
|
@@ -86,16 +86,16 @@ if text and button:
|
|
| 86 |
|
| 87 |
# Отображение изображений и названий
|
| 88 |
for i in n_lst:
|
| 89 |
-
col1, col2 = st.columns([
|
| 90 |
with col1:
|
| 91 |
-
st.image(df['poster'][i], width=
|
| 92 |
with col2:
|
| 93 |
st.write(f"***Название:*** {df['title'][i]}")
|
| 94 |
st.write(f"***Жанр:*** {', '.join(df['ganres'][i])}")
|
| 95 |
st.write(f"***Описание:*** {df['description'][i]}")
|
| 96 |
# similarity = float(confidence)
|
| 97 |
# st.write(f"***Cosine Similarity : {round(similarity, 3)}***")
|
| 98 |
-
st.
|
| 99 |
st.write(f"")
|
| 100 |
end_time = time.time()
|
| 101 |
st.write(f"<small>*Степень соответствия по косинусному сходству: {conf_dict[i]:.4f}*</small>", unsafe_allow_html=True)
|
|
|
|
| 40 |
st.sidebar.header('Панель инструментов :gear:')
|
| 41 |
choice_g = st.sidebar.multiselect("Выберите жанры", options=ganres_lst)
|
| 42 |
n = st.sidebar.selectbox("Количество отображаемых элементов на странице", options=[5, 10, 15, 20, 30])
|
| 43 |
+
st.sidebar.info("📚 Для наилучшего соответствия, запрос должен быть максимально развернутым")
|
| 44 |
|
| 45 |
text = st.text_input('Введите описание для рекомендации')
|
| 46 |
|
|
|
|
| 86 |
|
| 87 |
# Отображение изображений и названий
|
| 88 |
for i in n_lst:
|
| 89 |
+
col1, col2 = st.columns([2, 5])
|
| 90 |
with col1:
|
| 91 |
+
st.image(df['poster'][i], width=200)
|
| 92 |
with col2:
|
| 93 |
st.write(f"***Название:*** {df['title'][i]}")
|
| 94 |
st.write(f"***Жанр:*** {', '.join(df['ganres'][i])}")
|
| 95 |
st.write(f"***Описание:*** {df['description'][i]}")
|
| 96 |
# similarity = float(confidence)
|
| 97 |
# st.write(f"***Cosine Similarity : {round(similarity, 3)}***")
|
| 98 |
+
st.markdown(f"[***ссылка на сериал***]({df['url'][i]})")
|
| 99 |
st.write(f"")
|
| 100 |
end_time = time.time()
|
| 101 |
st.write(f"<small>*Степень соответствия по косинусному сходству: {conf_dict[i]:.4f}*</small>", unsafe_allow_html=True)
|
pages/02_🔥_Results.py
CHANGED
|
@@ -1,15 +1,34 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
-
from PIL import Image
|
|
|
|
| 3 |
|
| 4 |
st.write("""
|
| 5 |
## 📝 Итоги проекта Рекомендательные системы.
|
| 6 |
""")
|
| 7 |
"""
|
| 8 |
-
###### 1. Парсинг профильных
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
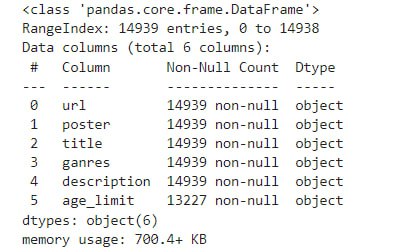
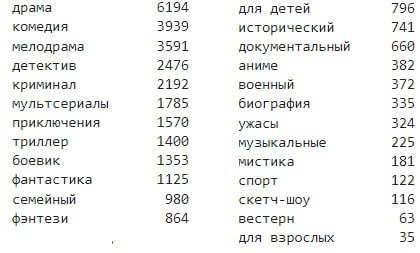
###### 2. Сбор и анализ информации с киносервисов. Формирование датасета. Итоговый размер - 14939 объектов.
|
| 10 |
-
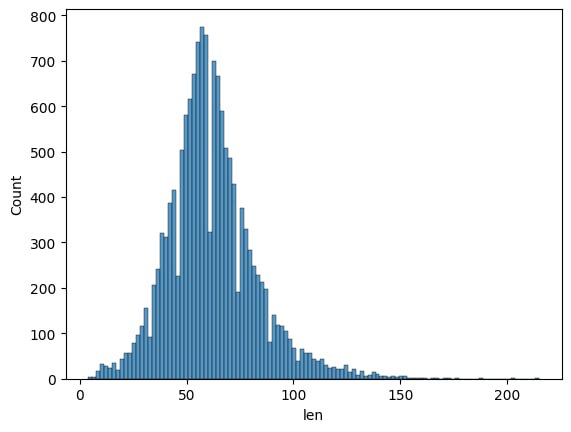
###### 3. Предобработка данных от лишных символов и пропусков.
|
| 11 |
-
###### 4. Векторизация с использованием модели rubert-tiny2.
|
| 12 |
"""
|
|
|
|
| 13 |
|
|
|
|
|
|
|
| 14 |
|
|
|
|
|
|
|
|
|
|
| 15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
+
from PIL import Image, ImageOps
|
| 3 |
+
import matplotlib.pyplot as plt
|
| 4 |
|
| 5 |
st.write("""
|
| 6 |
## 📝 Итоги проекта Рекомендательные системы.
|
| 7 |
""")
|
| 8 |
"""
|
| 9 |
+
###### 1. Парсинг профильных сайтов, итоговый с kino.mail.ru.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
st.image('images/mem.jpg', width=400)
|
| 13 |
+
|
| 14 |
+
"""
|
| 15 |
###### 2. Сбор и анализ информации с киносервисов. Формирование датасета. Итоговый размер - 14939 объектов.
|
|
|
|
|
|
|
| 16 |
"""
|
| 17 |
+
col1, col2 = st.columns(2)
|
| 18 |
|
| 19 |
+
with col1:
|
| 20 |
+
st.image('images/1.jpeg')
|
| 21 |
|
| 22 |
+
with col2:
|
| 23 |
+
st.image('images/2.jpeg')
|
| 24 |
+
# st.image('images/1.png')
|
| 25 |
|
| 26 |
+
"""
|
| 27 |
+
###### 3. Предобработка данных от лишных символов и пропусков.
|
| 28 |
+
"""
|
| 29 |
+
st.image('images/3.jpeg')
|
| 30 |
+
st.image('images/4.jpeg')
|
| 31 |
+
|
| 32 |
+
"""
|
| 33 |
+
###### 4. Векторизация с использованием модели RuBERT (Russian, cased, 12-layer, 768-hidden, 12-heads, 180M parameters)
|
| 34 |
+
"""
|