Spaces:
Runtime error

Runtime error
Add project
Browse files- Makefile +4 -0
- app.py +32 -0
- data dashboard.png +0 -0
- data/data.csv +9 -0
- model/__init__.py +0 -0
- model/config/__init__.py +0 -0
- model/config/config.py +3 -0
- model/model.py +39 -0
- model/processing/__init__.py +0 -0
- model/processing/data_manager.py +26 -0
- model/processing/pipeline_qa.py +79 -0
- poetry.lock +0 -0
- pyproject.toml +24 -0
- requirements.txt +8 -0
Makefile
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##@ Clean-up
|
| 2 |
+
clean: ## remove output files from pytest & coverage
|
| 3 |
+
@find . | grep -E "(__pycache__|\.pyc|\.pyo)" | xargs rm -rf
|
| 4 |
+
@find . | grep -E ".ipynb_checkpoints" | xargs rm -rf
|
app.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
from model.model import model
|
| 4 |
+
|
| 5 |
+
# Making question examples
|
| 6 |
+
example1 = "Apa dashboard terkait KPI operational?"
|
| 7 |
+
example2 = "Apa link Dashboard Operational KPIs 2023?"
|
| 8 |
+
example3 = "Mau lihat data performance cabang, ada di dashboard apa?"
|
| 9 |
+
example4 = "Apa saja data di Dashboard Transactions?"
|
| 10 |
+
|
| 11 |
+
# Making UI
|
| 12 |
+
with gr.Blocks() as demo:
|
| 13 |
+
gr.Markdown(
|
| 14 |
+
"""
|
| 15 |
+
# Chatbot Dashboard
|
| 16 |
+
This project is a chatbot based on LLM using the RAG method.
|
| 17 |
+
This chatbot will answer questions related to the company's dashboard.
|
| 18 |
+
You can ask questions according to the dashboard data below.
|
| 19 |
+
""")
|
| 20 |
+
gr.Interface(fn=model,
|
| 21 |
+
inputs="text",
|
| 22 |
+
outputs="text",
|
| 23 |
+
theme=gr.themes.Monochrome(),
|
| 24 |
+
examples = [example1, example2, example3, example4])
|
| 25 |
+
gr.Markdown(
|
| 26 |
+
"""
|
| 27 |
+
## Data dashboard
|
| 28 |
+
""")
|
| 29 |
+
gr.HTML("<img src='https://huggingface.co/spaces/Aldo07/chatbot_dashboard/resolve/main/data%20dashboard.png' width='500'>")
|
| 30 |
+
|
| 31 |
+
demo.launch()
|
| 32 |
+
|
data dashboard.png
ADDED
|
data/data.csv
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
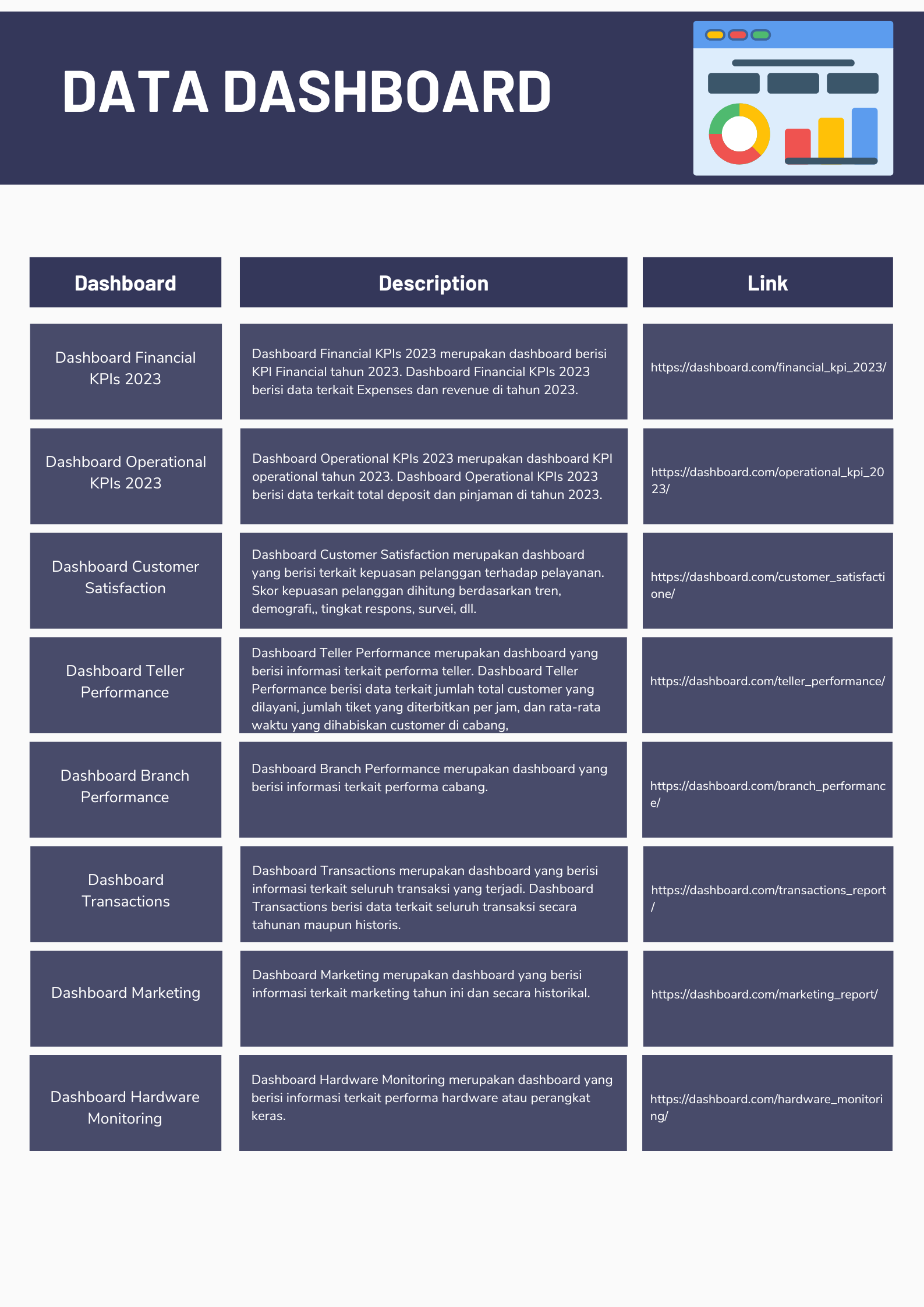
"Dashboard Financial KPIs 2023 merupakan dashboard berisi KPI Financial tahun 2023. Dashboard Financial KPIs 2023 berisi data terkait Expenses dan revenue di tahun 2023.
|
| 2 |
+
Link Dashboard Financial KPIs 2023 adalah https://dashboard.com/financial_kpi_2023/"
|
| 3 |
+
Dashboard Operational KPIs 2023 merupakan dashboard KPI operational tahun 2023. Dashboard Operational KPIs 2023 berisi data terkait total deposit dan pinjaman di tahun 2023. Link Dashboard Operational KPIs 2023 adalah https://dashboard.com/operational_kpi_2023/
|
| 4 |
+
"Dashboard Customer Satisfaction merupakan dashboard yang berisi terkait kepuasan pelanggan terhadap pelayanan. Skor kepuasan pelanggan dihitung berdasarkan tren, demografi,, tingkat respons, survei, dll. Link Dashboard Customer Satisfaction adalah https://dashboard.com/customer_satisfactione/"
|
| 5 |
+
"Dashboard Teller Performance merupakan dashboard yang berisi informasi terkait performa teller. Dashboard Teller Performance berisi data terkait jumlah total customer yang dilayani, jumlah tiket yang diterbitkan per jam, dan rata-rata waktu yang dihabiskan customer di cabang, Link Dashboard Teller Performance adalah https://dashboard.com/teller_performance/"
|
| 6 |
+
Dashboard Branch Performance merupakan dashboard yang berisi informasi terkait performa cabang. Link Dashboard Branch Performance adalah https://dashboard.com/branch_performance/
|
| 7 |
+
Dashboard Transactions merupakan dashboard yang berisi informasi terkait seluruh transaksi yang terjadi. Dashboard Transactions berisi data terkait seluruh transaksi secara tahunan maupun historis. Link Dashboard Transactions adalah https://dashboard.com/transactions_report/
|
| 8 |
+
Dashboard Marketing merupakan dashboard yang berisi informasi terkait marketing tahun ini dan secara historikal.Link Dashboard Marketing adalah https://dashboard.com/marketing_report/
|
| 9 |
+
Dashboard Hardware Monitoring merupakan dashboard yang berisi informasi terkait performa hardware atau perangkat keras.Link Dashboard Hardware Monitoring adalah https://dashboard.com/hardware_monitoring/
|
model/__init__.py
ADDED
|
File without changes
|
model/config/__init__.py
ADDED
|
File without changes
|
model/config/config.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
modelPath = 'firqaaa/indo-sentence-bert-base'
|
| 2 |
+
model_kwargs = {'device':'cpu'}
|
| 3 |
+
encode_kwargs = {'normalize_embeddings': False}
|
model/model.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.embeddings import HuggingFaceEmbeddings
|
| 2 |
+
from langchain.vectorstores import FAISS
|
| 3 |
+
from langchain import HuggingFacePipeline
|
| 4 |
+
from langchain.chains import RetrievalQA
|
| 5 |
+
from sentence_transformers import SentenceTransformer
|
| 6 |
+
import pandas as pd
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
from model.config.config import modelPath, model_kwargs, encode_kwargs
|
| 10 |
+
from model.processing.data_manager import text_chunk
|
| 11 |
+
from model.processing.pipeline_qa import pipeline
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def embedding():
|
| 15 |
+
embeddings = HuggingFaceEmbeddings(
|
| 16 |
+
model_name=modelPath,
|
| 17 |
+
model_kwargs=model_kwargs,
|
| 18 |
+
encode_kwargs=encode_kwargs
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
return embeddings
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def model(question):
|
| 25 |
+
text_chunks = text_chunk()
|
| 26 |
+
embeddings =embedding()
|
| 27 |
+
|
| 28 |
+
db = FAISS.from_documents(text_chunks, embeddings)
|
| 29 |
+
|
| 30 |
+
pipe = pipeline()
|
| 31 |
+
|
| 32 |
+
retriever = db.as_retriever(search_kwargs={"k": 1})
|
| 33 |
+
docs = retriever.get_relevant_documents(question)
|
| 34 |
+
|
| 35 |
+
answer = pipe({
|
| 36 |
+
'context': docs[0],
|
| 37 |
+
'question': question})
|
| 38 |
+
|
| 39 |
+
return answer
|
model/processing/__init__.py
ADDED
|
File without changes
|
model/processing/data_manager.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from langchain.document_loaders import DataFrameLoader
|
| 6 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def load_data():
|
| 10 |
+
|
| 11 |
+
data_folder = Path("data")
|
| 12 |
+
data_path = os.path.join(data_folder, 'data.csv')
|
| 13 |
+
data = pd.read_csv(data_path, header=None, names=['description'])
|
| 14 |
+
data = pd.DataFrame(data)
|
| 15 |
+
|
| 16 |
+
return data
|
| 17 |
+
|
| 18 |
+
def text_chunk():
|
| 19 |
+
data = load_data()
|
| 20 |
+
text_chunks = DataFrameLoader(
|
| 21 |
+
data, page_content_column="description").load_and_split(
|
| 22 |
+
text_splitter=RecursiveCharacterTextSplitter(
|
| 23 |
+
chunk_size=1000, chunk_overlap=0, length_function=len
|
| 24 |
+
))
|
| 25 |
+
|
| 26 |
+
return text_chunks
|
model/processing/pipeline_qa.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import itertools
|
| 2 |
+
from typing import Dict, Union
|
| 3 |
+
|
| 4 |
+
from nltk import sent_tokenize
|
| 5 |
+
import nltk
|
| 6 |
+
nltk.download('punkt')
|
| 7 |
+
import torch
|
| 8 |
+
from transformers import(
|
| 9 |
+
AutoModelForSeq2SeqLM,
|
| 10 |
+
AutoTokenizer
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
class QAPipeline:
|
| 14 |
+
|
| 15 |
+
def __init__(
|
| 16 |
+
self
|
| 17 |
+
):
|
| 18 |
+
|
| 19 |
+
self.model = AutoModelForSeq2SeqLM.from_pretrained("muchad/idt5-qa-qg")
|
| 20 |
+
self.tokenizer = AutoTokenizer.from_pretrained("muchad/idt5-qa-qg")
|
| 21 |
+
self.qg_format = "highlight"
|
| 22 |
+
self.device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 23 |
+
self.model.to(self.device)
|
| 24 |
+
assert self.model.__class__.__name__ in ["T5ForConditionalGeneration"]
|
| 25 |
+
self.model_type = "t5"
|
| 26 |
+
|
| 27 |
+
def __call__(self, inputs: str):
|
| 28 |
+
inputs = " ".join(inputs.split())
|
| 29 |
+
answers = self._extract_answers(inputs)
|
| 30 |
+
flat_answers = list(itertools.chain(*answers))
|
| 31 |
+
|
| 32 |
+
if len(flat_answers) == 0:
|
| 33 |
+
return []
|
| 34 |
+
|
| 35 |
+
def _tokenize(self,
|
| 36 |
+
inputs,
|
| 37 |
+
padding=True,
|
| 38 |
+
truncation=True,
|
| 39 |
+
add_special_tokens=True,
|
| 40 |
+
max_length=512
|
| 41 |
+
):
|
| 42 |
+
inputs = self.tokenizer.batch_encode_plus(
|
| 43 |
+
inputs,
|
| 44 |
+
max_length=max_length,
|
| 45 |
+
add_special_tokens=add_special_tokens,
|
| 46 |
+
truncation=truncation,
|
| 47 |
+
padding="max_length" if padding else False,
|
| 48 |
+
pad_to_max_length=padding,
|
| 49 |
+
return_tensors="pt"
|
| 50 |
+
)
|
| 51 |
+
return inputs
|
| 52 |
+
|
| 53 |
+
class TaskPipeline(QAPipeline):
|
| 54 |
+
def __init__(self, **kwargs):
|
| 55 |
+
super().__init__(**kwargs)
|
| 56 |
+
|
| 57 |
+
def __call__(self, inputs: Union[Dict, str]):
|
| 58 |
+
return self._extract_answer(inputs["question"], inputs["context"])
|
| 59 |
+
|
| 60 |
+
def _prepare_inputs(self, question, context):
|
| 61 |
+
source_text = f"question: {question} context: {context}"
|
| 62 |
+
source_text = source_text + " </s>"
|
| 63 |
+
return source_text
|
| 64 |
+
|
| 65 |
+
def _extract_answer(self, question, context):
|
| 66 |
+
source_text = self._prepare_inputs(question, context)
|
| 67 |
+
inputs = self._tokenize([source_text], padding=False)
|
| 68 |
+
|
| 69 |
+
outs = self.model.generate(
|
| 70 |
+
input_ids=inputs['input_ids'].to(self.device),
|
| 71 |
+
attention_mask=inputs['attention_mask'].to(self.device),
|
| 72 |
+
max_length=80,
|
| 73 |
+
)
|
| 74 |
+
answer = self.tokenizer.decode(outs[0], skip_special_tokens=True)
|
| 75 |
+
return answer
|
| 76 |
+
|
| 77 |
+
def pipeline():
|
| 78 |
+
task = TaskPipeline
|
| 79 |
+
return task()
|
poetry.lock
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pyproject.toml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[tool.poetry]
|
| 2 |
+
name = "chatbot data"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = ""
|
| 5 |
+
authors = ["Your Name <you@example.com>"]
|
| 6 |
+
readme = "README.md"
|
| 7 |
+
packages = [{include = "model"}]
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
[tool.poetry.dependencies]
|
| 11 |
+
python = "^3.9"
|
| 12 |
+
transformers = "^4.38.1"
|
| 13 |
+
langchain = "^0.1.9"
|
| 14 |
+
sentence-transformers = "^2.4.0"
|
| 15 |
+
faiss-cpu = "^1.7.4"
|
| 16 |
+
gradio = "^4.19.2"
|
| 17 |
+
pandas = "^2.2.1"
|
| 18 |
+
torch = "^2.2.1"
|
| 19 |
+
nltk = "^3.8.1"
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
[build-system]
|
| 23 |
+
requires = ["poetry-core"]
|
| 24 |
+
build-backend = "poetry.core.masonry.api"
|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers
|
| 2 |
+
langchain
|
| 3 |
+
sentence-transformers
|
| 4 |
+
faiss-cpu
|
| 5 |
+
gradio
|
| 6 |
+
pandas
|
| 7 |
+
torch
|
| 8 |
+
nltk
|