Spaces:
No application file

No application file
Commit
•
2f5e00f
1
Parent(s):
d549a0f
Upload 10 files
Browse files- LSTM.py +82 -0
- Train_ANN.py +139 -0
- Train_CNN.py +184 -0
- Train_LSTM2.py +185 -0
- cnn_model.h5 +3 -0
- g1.jpg +0 -0
- lstm_model.h5 +3 -0
- manage.py +22 -0
- tokenizer.pickle +3 -0
- train.csv +0 -0
LSTM.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import pickle
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import tqdm
|
| 6 |
+
import numpy as np
|
| 7 |
+
import os
|
| 8 |
+
import matplotlib
|
| 9 |
+
matplotlib.use('Agg')
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
from tensorflow.keras.preprocessing.text import Tokenizer
|
| 12 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 13 |
+
from tensorflow.keras.utils import to_categorical
|
| 14 |
+
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard
|
| 15 |
+
from sklearn.model_selection import train_test_split
|
| 16 |
+
#from tensorflow.keras.layers import Embedding, Dropout, Dense
|
| 17 |
+
from tensorflow.keras.models import Sequential
|
| 18 |
+
from keras.models import load_model
|
| 19 |
+
|
| 20 |
+
from sklearn.metrics import f1_score, precision_score, accuracy_score, recall_score
|
| 21 |
+
|
| 22 |
+
from tensorflow.keras.layers import LSTM, GlobalMaxPooling1D, Dropout, Dense, Input, Embedding, MaxPooling1D, Flatten,BatchNormalization
|
| 23 |
+
|
| 24 |
+
SEQUENCE_LENGTH = 100 # the length of all sequences (number of words per sample)
|
| 25 |
+
EMBEDDING_SIZE = 100 # Using 100-Dimensional GloVe embedding vectors
|
| 26 |
+
TEST_SIZE = 0.25 # ratio of testing set
|
| 27 |
+
|
| 28 |
+
BATCH_SIZE = 64
|
| 29 |
+
EPOCHS = 20 # number of epochs
|
| 30 |
+
|
| 31 |
+
label2int = {"frustrated": 0, "negative": 1,"neutral":2,"positive":3,"satisfied":4}
|
| 32 |
+
|
| 33 |
+
int2label = {0: "frustrated", 1: "negative",2:"neutral",3:"positive",4:"satisfied"}
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_embedding_vectors(tokenizer, dim=100):
|
| 42 |
+
embedding_index = {}
|
| 43 |
+
with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:
|
| 44 |
+
for line in tqdm.tqdm(f, "Reading GloVe"):
|
| 45 |
+
values = line.split()
|
| 46 |
+
word = values[0]
|
| 47 |
+
vectors = np.asarray(values[1:], dtype='float32')
|
| 48 |
+
embedding_index[word] = vectors
|
| 49 |
+
|
| 50 |
+
word_index = tokenizer.word_index
|
| 51 |
+
embedding_matrix = np.zeros((len(word_index) + 1, dim))
|
| 52 |
+
for word, i in word_index.items():
|
| 53 |
+
embedding_vector = embedding_index.get(word)
|
| 54 |
+
if embedding_vector is not None:
|
| 55 |
+
# words not found will be 0s
|
| 56 |
+
embedding_matrix[i] = embedding_vector
|
| 57 |
+
|
| 58 |
+
return embedding_matrix
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def get_predictions(text):
|
| 63 |
+
tokenizer = Tokenizer()
|
| 64 |
+
|
| 65 |
+
model_path = 'lstm_model.h5'
|
| 66 |
+
model = load_model(model_path)
|
| 67 |
+
sequence = tokenizer.texts_to_sequences(text)
|
| 68 |
+
# pad the sequence
|
| 69 |
+
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
|
| 70 |
+
# get the prediction
|
| 71 |
+
prediction = model.predict(sequence)
|
| 72 |
+
|
| 73 |
+
res=[]
|
| 74 |
+
|
| 75 |
+
for p1 in prediction:
|
| 76 |
+
res.append(int2label[np.argmax(p1)])
|
| 77 |
+
return res
|
| 78 |
+
|
| 79 |
+
if __name__ == '__main__':
|
| 80 |
+
t=[' Sooo SAD I will miss you here in San Diego!!!', 'Stolen iPhone 15 pro', 'iPhone 15 Pro and iPhone 15 Pro Max Feature Increased 8GB of RAM', 'Apple announces iPhone 15 Pro and Pro Max', 'Temperature of my iPhone 15 Pro Max while on the phone for 5 mins.', 'I traded in my iPhone 14 Pro for the iPhone 15 Pro Max, then FedEx lost the old phone', 'iPhone 15 Pro Max crushes Google Pixel 8 Pro in speed test', 'Apple Design Team Making The New iPhone 15 Pro Max', 'iPhone 15 Pro Could Be Most Lightweight Pro Model Since iPhone XS', ' iPhone 15 Pro/Pro Max is so sad']
|
| 81 |
+
print(get_predictions(t))
|
| 82 |
+
|
Train_ANN.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import pickle
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import tqdm
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
import matplotlib
|
| 9 |
+
matplotlib.use('Agg')
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
from tensorflow.keras.preprocessing.text import Tokenizer
|
| 12 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 13 |
+
from tensorflow.keras.utils import to_categorical
|
| 14 |
+
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard
|
| 15 |
+
from sklearn.model_selection import train_test_split
|
| 16 |
+
#from tensorflow.keras.layers import Embedding, Dropout, Dense
|
| 17 |
+
from tensorflow.keras.models import Sequential
|
| 18 |
+
#from tensorflow.keras.metrics import Recall, Precision
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
from sklearn.metrics import f1_score, precision_score, accuracy_score, recall_score
|
| 23 |
+
|
| 24 |
+
from tensorflow.keras.layers import Conv1D, GlobalMaxPooling1D, Dropout, Dense, Input, Embedding, MaxPooling1D, Flatten
|
| 25 |
+
|
| 26 |
+
SEQUENCE_LENGTH = 500 # the length of all sequences (number of words per sample)
|
| 27 |
+
EMBEDDING_SIZE = 100 # Using 100-Dimensional GloVe embedding vectors
|
| 28 |
+
TEST_SIZE = 0.25 # ratio of testing set
|
| 29 |
+
|
| 30 |
+
BATCH_SIZE = 64
|
| 31 |
+
EPOCHS = 10 # number of epochs
|
| 32 |
+
|
| 33 |
+
maxlen = 80
|
| 34 |
+
batch_size = 32
|
| 35 |
+
|
| 36 |
+
label2int = {"frustrated": 0, "negative": 1,"neutral":2,"positive":3,"satisfied":4}
|
| 37 |
+
|
| 38 |
+
int2label = {0: "frustrated", 1: "negative",2:"neutral",3:"positive",4:"satisfied"}
|
| 39 |
+
|
| 40 |
+
def load_data():
|
| 41 |
+
"""
|
| 42 |
+
Loads SMS Spam Collection dataset
|
| 43 |
+
"""
|
| 44 |
+
data = pd.read_csv("train.csv",encoding='latin-1')
|
| 45 |
+
|
| 46 |
+
texts = data['feedback'].values
|
| 47 |
+
|
| 48 |
+
labels=data['sentiment'].values
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
return texts, labels
|
| 52 |
+
|
| 53 |
+
def dl_evaluation_process():
|
| 54 |
+
print("loading data")
|
| 55 |
+
X, y = load_data()
|
| 56 |
+
|
| 57 |
+
# Text tokenization
|
| 58 |
+
# vectorizing text, turning each text into sequence of integers
|
| 59 |
+
tokenizer = Tokenizer()
|
| 60 |
+
tokenizer.fit_on_texts(X)
|
| 61 |
+
# lets dump it to a file, so we can use it in testing
|
| 62 |
+
pickle.dump(tokenizer, open("tokenizer.pickle", "wb"))
|
| 63 |
+
# convert to sequence of integers
|
| 64 |
+
X = tokenizer.texts_to_sequences(X)
|
| 65 |
+
|
| 66 |
+
# convert to numpy arrays
|
| 67 |
+
X = np.array(X)
|
| 68 |
+
y = np.array(y)
|
| 69 |
+
# pad sequences at the beginning of each sequence with 0's
|
| 70 |
+
# for example if SEQUENCE_LENGTH=4:
|
| 71 |
+
# [[5, 3, 2], [5, 1, 2, 3], [3, 4]]
|
| 72 |
+
# will be transformed to:
|
| 73 |
+
# [[0, 5, 3, 2], [5, 1, 2, 3], [0, 0, 3, 4]]
|
| 74 |
+
X = pad_sequences(X, maxlen=SEQUENCE_LENGTH)
|
| 75 |
+
|
| 76 |
+
# One Hot encoding labels
|
| 77 |
+
# [spam, ham, spam, ham, ham] will be converted to:
|
| 78 |
+
# [1, 0, 1, 0, 1] and then to:
|
| 79 |
+
# [[0, 1], [1, 0], [0, 1], [1, 0], [0, 1]]
|
| 80 |
+
|
| 81 |
+
y = [label2int[label] for label in y]
|
| 82 |
+
y = to_categorical(y)
|
| 83 |
+
|
| 84 |
+
# split and shuffle
|
| 85 |
+
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=7)
|
| 86 |
+
# print our data shapes
|
| 87 |
+
'''print("X_train.shape:", X_train.shape)
|
| 88 |
+
print("X_test.shape:", X_test.shape)
|
| 89 |
+
print("y_train.shape:", y_train.shape)
|
| 90 |
+
print("y_test.shape:", y_test.shape)'''
|
| 91 |
+
|
| 92 |
+
#print("EMD Matrix")
|
| 93 |
+
|
| 94 |
+
print("Starting...")
|
| 95 |
+
# Define the model
|
| 96 |
+
print('Build model...')
|
| 97 |
+
model = Sequential()
|
| 98 |
+
model.add(Flatten(input_shape=(500,)))
|
| 99 |
+
model.add(Dense(128, activation='relu'))
|
| 100 |
+
model.add(Dense(5, activation='softmax'))
|
| 101 |
+
|
| 102 |
+
# Compile the model
|
| 103 |
+
model.compile(loss='categorical_crossentropy',
|
| 104 |
+
optimizer='adam',
|
| 105 |
+
metrics=['accuracy'])
|
| 106 |
+
|
| 107 |
+
# Train the model
|
| 108 |
+
print('Train...')
|
| 109 |
+
model.fit(X, y,
|
| 110 |
+
batch_size=batch_size,
|
| 111 |
+
epochs=2,
|
| 112 |
+
validation_data=(X_test, y_test))
|
| 113 |
+
|
| 114 |
+
y_test = np.argmax(y_test, axis=1)
|
| 115 |
+
y_pred = np.argmax(model.predict(X_test), axis=1)
|
| 116 |
+
|
| 117 |
+
acc = accuracy_score(y_test, y_pred) * 100
|
| 118 |
+
|
| 119 |
+
precsn = precision_score(y_test, y_pred, average="macro") * 100
|
| 120 |
+
|
| 121 |
+
recall = recall_score(y_test, y_pred, average="macro") * 100
|
| 122 |
+
|
| 123 |
+
f1score = f1_score(y_test, y_pred, average="macro") * 100
|
| 124 |
+
|
| 125 |
+
print("acc=", acc)
|
| 126 |
+
|
| 127 |
+
print("precsn=", precsn)
|
| 128 |
+
|
| 129 |
+
print("recall=", recall)
|
| 130 |
+
|
| 131 |
+
print("f1score=", f1score)
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
return acc, precsn, recall, f1score
|
| 137 |
+
|
| 138 |
+
if __name__ == '__main__':
|
| 139 |
+
dl_evaluation_process()
|
Train_CNN.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import pickle
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import tqdm
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
import matplotlib
|
| 9 |
+
matplotlib.use('Agg')
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
from tensorflow.keras.preprocessing.text import Tokenizer
|
| 12 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 13 |
+
from tensorflow.keras.utils import to_categorical
|
| 14 |
+
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard
|
| 15 |
+
from sklearn.model_selection import train_test_split
|
| 16 |
+
#from tensorflow.keras.layers import Embedding, Dropout, Dense
|
| 17 |
+
from tensorflow.keras.models import Sequential
|
| 18 |
+
#from tensorflow.keras.metrics import Recall, Precision
|
| 19 |
+
|
| 20 |
+
from sklearn.metrics import f1_score, precision_score, accuracy_score, recall_score
|
| 21 |
+
|
| 22 |
+
from tensorflow.keras.layers import Conv1D, GlobalMaxPooling1D, Dropout, Dense, Input, Embedding, MaxPooling1D, Flatten
|
| 23 |
+
|
| 24 |
+
SEQUENCE_LENGTH = 100 # the length of all sequences (number of words per sample)
|
| 25 |
+
EMBEDDING_SIZE = 100 # Using 100-Dimensional GloVe embedding vectors
|
| 26 |
+
TEST_SIZE = 0.25 # ratio of testing set
|
| 27 |
+
|
| 28 |
+
BATCH_SIZE = 64
|
| 29 |
+
EPOCHS = 10 # number of epochs
|
| 30 |
+
|
| 31 |
+
label2int = {"frustrated": 0, "negative": 1,"neutral":2,"positive":3,"satisfied":4}
|
| 32 |
+
|
| 33 |
+
int2label = {0: "frustrated", 1: "negative",2:"neutral",3:"positive",4:"satisfied"}
|
| 34 |
+
|
| 35 |
+
def load_data():
|
| 36 |
+
"""
|
| 37 |
+
Loads SMS Spam Collection dataset
|
| 38 |
+
"""
|
| 39 |
+
data = pd.read_csv("train.csv",encoding='latin-1')
|
| 40 |
+
|
| 41 |
+
texts = data['feedback'].values
|
| 42 |
+
|
| 43 |
+
labels=data['sentiment'].values
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
return texts, labels
|
| 47 |
+
|
| 48 |
+
def dl_evaluation_process():
|
| 49 |
+
print("loading data")
|
| 50 |
+
X, y = load_data()
|
| 51 |
+
|
| 52 |
+
# Text tokenization
|
| 53 |
+
# vectorizing text, turning each text into sequence of integers
|
| 54 |
+
tokenizer = Tokenizer()
|
| 55 |
+
tokenizer.fit_on_texts(X)
|
| 56 |
+
# lets dump it to a file, so we can use it in testing
|
| 57 |
+
pickle.dump(tokenizer, open("tokenizer.pickle", "wb"))
|
| 58 |
+
# convert to sequence of integers
|
| 59 |
+
X = tokenizer.texts_to_sequences(X)
|
| 60 |
+
|
| 61 |
+
# convert to numpy arrays
|
| 62 |
+
X = np.array(X)
|
| 63 |
+
y = np.array(y)
|
| 64 |
+
# pad sequences at the beginning of each sequence with 0's
|
| 65 |
+
# for example if SEQUENCE_LENGTH=4:
|
| 66 |
+
# [[5, 3, 2], [5, 1, 2, 3], [3, 4]]
|
| 67 |
+
# will be transformed to:
|
| 68 |
+
# [[0, 5, 3, 2], [5, 1, 2, 3], [0, 0, 3, 4]]
|
| 69 |
+
X = pad_sequences(X, maxlen=SEQUENCE_LENGTH)
|
| 70 |
+
|
| 71 |
+
# One Hot encoding labels
|
| 72 |
+
# [spam, ham, spam, ham, ham] will be converted to:
|
| 73 |
+
# [1, 0, 1, 0, 1] and then to:
|
| 74 |
+
# [[0, 1], [1, 0], [0, 1], [1, 0], [0, 1]]
|
| 75 |
+
|
| 76 |
+
y = [label2int[label] for label in y]
|
| 77 |
+
y = to_categorical(y)
|
| 78 |
+
|
| 79 |
+
# split and shuffle
|
| 80 |
+
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=7)
|
| 81 |
+
# print our data shapes
|
| 82 |
+
'''print("X_train.shape:", X_train.shape)
|
| 83 |
+
print("X_test.shape:", X_test.shape)
|
| 84 |
+
print("y_train.shape:", y_train.shape)
|
| 85 |
+
print("y_test.shape:", y_test.shape)'''
|
| 86 |
+
|
| 87 |
+
#print("EMD Matrix")
|
| 88 |
+
embedding_matrix = get_embedding_vectors(tokenizer)
|
| 89 |
+
print("Starting...",len(tokenizer.word_index))
|
| 90 |
+
model = Sequential()
|
| 91 |
+
model.add(Embedding(len(tokenizer.word_index) + 1,
|
| 92 |
+
EMBEDDING_SIZE,
|
| 93 |
+
weights=[embedding_matrix],
|
| 94 |
+
trainable=False,
|
| 95 |
+
input_length=SEQUENCE_LENGTH))
|
| 96 |
+
model.add(Conv1D(128, 3, activation='relu'))
|
| 97 |
+
model.add(GlobalMaxPooling1D())
|
| 98 |
+
model.add(Dense(64, activation='relu'))
|
| 99 |
+
model.add(Dense(5, activation="softmax"))
|
| 100 |
+
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
|
| 101 |
+
|
| 102 |
+
model.fit(X, y, epochs=20, verbose=1, validation_data=(X_test, y_test), batch_size=128)
|
| 103 |
+
#print("saving")
|
| 104 |
+
model.save('cnn_model.h5')
|
| 105 |
+
#model.summary()
|
| 106 |
+
|
| 107 |
+
y_test = np.argmax(y_test, axis=1)
|
| 108 |
+
y_pred = np.argmax(model.predict(X_test), axis=1)
|
| 109 |
+
|
| 110 |
+
acc = accuracy_score(y_test, y_pred) * 100
|
| 111 |
+
|
| 112 |
+
precsn = precision_score(y_test, y_pred, average="macro") * 100
|
| 113 |
+
|
| 114 |
+
recall = recall_score(y_test, y_pred, average="macro") * 100
|
| 115 |
+
|
| 116 |
+
f1score = f1_score(y_test, y_pred, average="macro") * 100
|
| 117 |
+
|
| 118 |
+
print("acc=", acc)
|
| 119 |
+
|
| 120 |
+
print("precsn=", precsn)
|
| 121 |
+
|
| 122 |
+
print("recall=", recall)
|
| 123 |
+
|
| 124 |
+
print("f1score=", f1score)
|
| 125 |
+
|
| 126 |
+
accuracy_list = [acc,precsn,recall,f1score]
|
| 127 |
+
|
| 128 |
+
'''bars = ('Accuracy', 'Precision', 'Recall', 'F1_Score')
|
| 129 |
+
y_pos = np.arange(len(bars))
|
| 130 |
+
plt.bar(y_pos, accuracy_list, color=['red', 'green', 'blue', 'orange'])
|
| 131 |
+
plt.xticks(y_pos, bars)
|
| 132 |
+
plt.xlabel('Performance Metrics')
|
| 133 |
+
plt.ylabel('Scores')
|
| 134 |
+
plt.title('DL Model Evaluation')
|
| 135 |
+
plt.savefig('static/accuracy.png')
|
| 136 |
+
plt.clf()'''
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
return acc, precsn, recall, f1score
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def get_embedding_vectors(tokenizer, dim=100):
|
| 143 |
+
embedding_index = {}
|
| 144 |
+
with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:
|
| 145 |
+
for line in tqdm.tqdm(f, "Reading GloVe"):
|
| 146 |
+
values = line.split()
|
| 147 |
+
word = values[0]
|
| 148 |
+
vectors = np.asarray(values[1:], dtype='float32')
|
| 149 |
+
embedding_index[word] = vectors
|
| 150 |
+
|
| 151 |
+
word_index = tokenizer.word_index
|
| 152 |
+
embedding_matrix = np.zeros((len(word_index) + 1, dim))
|
| 153 |
+
for word, i in word_index.items():
|
| 154 |
+
embedding_vector = embedding_index.get(word)
|
| 155 |
+
if embedding_vector is not None:
|
| 156 |
+
# words not found will be 0s
|
| 157 |
+
embedding_matrix[i] = embedding_vector
|
| 158 |
+
|
| 159 |
+
return embedding_matrix
|
| 160 |
+
|
| 161 |
+
# get the loss and metrics
|
| 162 |
+
#result = model.evaluate(X_test, y_test)
|
| 163 |
+
# extract those
|
| 164 |
+
#loss = result[0]
|
| 165 |
+
#accuracy = result[1]
|
| 166 |
+
#precision = result[2]
|
| 167 |
+
#recall = result[3]
|
| 168 |
+
|
| 169 |
+
#print(f"[+] Accuracy: {accuracy*100:.2f}%")
|
| 170 |
+
#print("Model created")
|
| 171 |
+
|
| 172 |
+
'''def get_predictions(text):
|
| 173 |
+
sequence = tokenizer.texts_to_sequences([text])
|
| 174 |
+
# pad the sequence
|
| 175 |
+
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
|
| 176 |
+
# get the prediction
|
| 177 |
+
prediction = model.predict(sequence)[0]
|
| 178 |
+
# one-hot encoded vector, revert using np.argmax
|
| 179 |
+
return int2label[np.argmax(prediction)]
|
| 180 |
+
|
| 181 |
+
text = "Need a loan? We offer quick and easy approval. Apply now for cash in minutes!."
|
| 182 |
+
print(get_predictions(text))'''
|
| 183 |
+
|
| 184 |
+
dl_evaluation_process()
|
Train_LSTM2.py
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import pickle
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import tqdm
|
| 6 |
+
import numpy as np
|
| 7 |
+
import os
|
| 8 |
+
import matplotlib
|
| 9 |
+
matplotlib.use('Agg')
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
from tensorflow.keras.preprocessing.text import Tokenizer
|
| 12 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 13 |
+
from tensorflow.keras.utils import to_categorical
|
| 14 |
+
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard
|
| 15 |
+
from sklearn.model_selection import train_test_split
|
| 16 |
+
#from tensorflow.keras.layers import Embedding, Dropout, Dense
|
| 17 |
+
from tensorflow.keras.models import Sequential
|
| 18 |
+
from keras.models import load_model
|
| 19 |
+
|
| 20 |
+
from sklearn.metrics import f1_score, precision_score, accuracy_score, recall_score
|
| 21 |
+
|
| 22 |
+
from tensorflow.keras.layers import LSTM, GlobalMaxPooling1D, Dropout, Dense, Input, Embedding, MaxPooling1D, Flatten,BatchNormalization
|
| 23 |
+
|
| 24 |
+
SEQUENCE_LENGTH = 100 # the length of all sequences (number of words per sample)
|
| 25 |
+
EMBEDDING_SIZE = 100 # Using 100-Dimensional GloVe embedding vectors
|
| 26 |
+
TEST_SIZE = 0.25 # ratio of testing set
|
| 27 |
+
|
| 28 |
+
BATCH_SIZE = 64
|
| 29 |
+
EPOCHS = 20 # number of epochs
|
| 30 |
+
|
| 31 |
+
label2int = {"frustrated": 0, "negative": 1,"neutral":2,"positive":3,"satisfied":4}
|
| 32 |
+
|
| 33 |
+
int2label = {0: "frustrated", 1: "negative",2:"neutral",3:"positive",4:"satisfied"}
|
| 34 |
+
|
| 35 |
+
def load_data():
|
| 36 |
+
data = pd.read_csv("train.csv",encoding='latin-1')
|
| 37 |
+
texts = data['feedback'].values
|
| 38 |
+
labels=data['sentiment'].values
|
| 39 |
+
return texts, labels
|
| 40 |
+
|
| 41 |
+
def dl_evaluation_process():
|
| 42 |
+
print("loading data")
|
| 43 |
+
X, y = load_data()
|
| 44 |
+
|
| 45 |
+
# Text tokenization
|
| 46 |
+
# vectorizing text, turning each text into sequence of integers
|
| 47 |
+
tokenizer = Tokenizer()
|
| 48 |
+
tokenizer.fit_on_texts(X)
|
| 49 |
+
# lets dump it to a file, so we can use it in testing
|
| 50 |
+
pickle.dump(tokenizer, open("tokenizer.pickle", "wb"))
|
| 51 |
+
# convert to sequence of integers
|
| 52 |
+
X = tokenizer.texts_to_sequences(X)
|
| 53 |
+
|
| 54 |
+
# convert to numpy arrays
|
| 55 |
+
X = np.array(X)
|
| 56 |
+
y = np.array(y)
|
| 57 |
+
# pad sequences at the beginning of each sequence with 0's
|
| 58 |
+
# for example if SEQUENCE_LENGTH=4:
|
| 59 |
+
# [[5, 3, 2], [5, 1, 2, 3], [3, 4]]
|
| 60 |
+
# will be transformed to:
|
| 61 |
+
# [[0, 5, 3, 2], [5, 1, 2, 3], [0, 0, 3, 4]]
|
| 62 |
+
X = pad_sequences(X, maxlen=SEQUENCE_LENGTH)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
y = [label2int[label] for label in y]
|
| 67 |
+
y = to_categorical(y)
|
| 68 |
+
|
| 69 |
+
# split and shuffle
|
| 70 |
+
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=7)
|
| 71 |
+
|
| 72 |
+
#print("EMD Matrix")
|
| 73 |
+
print("Starting...")
|
| 74 |
+
embedding_matrix = get_embedding_vectors(tokenizer)
|
| 75 |
+
|
| 76 |
+
if os.path.exists("lstm_model.h5"):
|
| 77 |
+
|
| 78 |
+
model_path = 'lstm_model.h5'
|
| 79 |
+
|
| 80 |
+
model = load_model(model_path)
|
| 81 |
+
|
| 82 |
+
y_test = np.argmax(y_test, axis=1)
|
| 83 |
+
|
| 84 |
+
y_pred = np.argmax(model.predict(X_test), axis=1)
|
| 85 |
+
|
| 86 |
+
acc = accuracy_score(y_test, y_pred) * 100
|
| 87 |
+
|
| 88 |
+
precsn = precision_score(y_test, y_pred, average="macro") * 100
|
| 89 |
+
|
| 90 |
+
recall = recall_score(y_test, y_pred, average="macro") * 100
|
| 91 |
+
|
| 92 |
+
f1score = f1_score(y_test, y_pred, average="macro") * 100
|
| 93 |
+
|
| 94 |
+
print("acc=", acc)
|
| 95 |
+
|
| 96 |
+
print("precsn=", precsn)
|
| 97 |
+
|
| 98 |
+
print("recall=", recall)
|
| 99 |
+
|
| 100 |
+
print("f1score=", f1score)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
else:
|
| 104 |
+
model = Sequential()
|
| 105 |
+
model.add(Embedding(len(tokenizer.word_index) + 1,
|
| 106 |
+
EMBEDDING_SIZE,
|
| 107 |
+
weights=[embedding_matrix],
|
| 108 |
+
trainable=False,
|
| 109 |
+
input_length=SEQUENCE_LENGTH))
|
| 110 |
+
|
| 111 |
+
model.add(LSTM(32, return_sequences=True))
|
| 112 |
+
model.add(BatchNormalization())
|
| 113 |
+
|
| 114 |
+
model.add(LSTM(64))
|
| 115 |
+
model.add(BatchNormalization())
|
| 116 |
+
|
| 117 |
+
model.add(Dense(64, activation='relu'))
|
| 118 |
+
model.add(Dense(5, activation="softmax"))
|
| 119 |
+
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
|
| 120 |
+
|
| 121 |
+
model.fit(X, y, epochs=50, verbose=1, validation_data=(X_test, y_test), batch_size=64)
|
| 122 |
+
#print("saving")
|
| 123 |
+
#model.save('lstm_model.h5')
|
| 124 |
+
#model.summary()
|
| 125 |
+
|
| 126 |
+
y_test = np.argmax(y_test, axis=1)
|
| 127 |
+
y_pred = np.argmax(model.predict(X_test), axis=1)
|
| 128 |
+
|
| 129 |
+
acc = accuracy_score(y_test, y_pred) * 100
|
| 130 |
+
|
| 131 |
+
precsn = precision_score(y_test, y_pred, average="macro") * 100
|
| 132 |
+
|
| 133 |
+
recall = recall_score(y_test, y_pred, average="macro") * 100
|
| 134 |
+
|
| 135 |
+
f1score = f1_score(y_test, y_pred, average="macro") * 100
|
| 136 |
+
|
| 137 |
+
print("acc=", acc)
|
| 138 |
+
|
| 139 |
+
print("precsn=", precsn)
|
| 140 |
+
|
| 141 |
+
print("recall=", recall)
|
| 142 |
+
|
| 143 |
+
print("f1score=", f1score)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
return acc, precsn, recall, f1score
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def get_embedding_vectors(tokenizer, dim=100):
|
| 152 |
+
embedding_index = {}
|
| 153 |
+
with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:
|
| 154 |
+
for line in tqdm.tqdm(f, "Reading GloVe"):
|
| 155 |
+
values = line.split()
|
| 156 |
+
word = values[0]
|
| 157 |
+
vectors = np.asarray(values[1:], dtype='float32')
|
| 158 |
+
embedding_index[word] = vectors
|
| 159 |
+
|
| 160 |
+
word_index = tokenizer.word_index
|
| 161 |
+
embedding_matrix = np.zeros((len(word_index) + 1, dim))
|
| 162 |
+
for word, i in word_index.items():
|
| 163 |
+
embedding_vector = embedding_index.get(word)
|
| 164 |
+
if embedding_vector is not None:
|
| 165 |
+
# words not found will be 0s
|
| 166 |
+
embedding_matrix[i] = embedding_vector
|
| 167 |
+
|
| 168 |
+
return embedding_matrix
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
'''def get_predictions(text):
|
| 173 |
+
sequence = tokenizer.texts_to_sequences([text])
|
| 174 |
+
# pad the sequence
|
| 175 |
+
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
|
| 176 |
+
# get the prediction
|
| 177 |
+
prediction = model.predict(sequence)[0]
|
| 178 |
+
# one-hot encoded vector, revert using np.argmax
|
| 179 |
+
return int2label[np.argmax(prediction)]
|
| 180 |
+
|
| 181 |
+
text = "Need a loan? We offer quick and easy approval. Apply now for cash in minutes!."
|
| 182 |
+
print(get_predictions(text))'''
|
| 183 |
+
|
| 184 |
+
if __name__ == '__main__':
|
| 185 |
+
dl_evaluation_process()
|
cnn_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a3a713c55572fb6127d0b32bf73b82cc31f4292c1bdbe3f8196d5c98aafade83
|
| 3 |
+
size 11241160
|
g1.jpg
ADDED
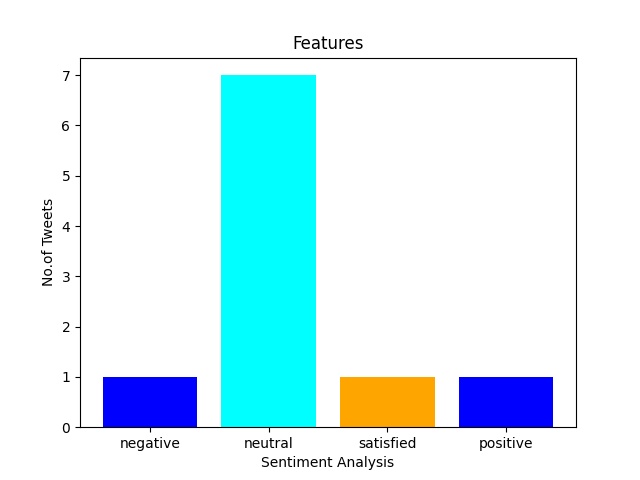
|
lstm_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:013719aceb3bf3dd458ac32b0fc6e19683543f8247f1da1709fb44fc6811ca24
|
| 3 |
+
size 11269336
|
manage.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
"""Django's command-line utility for administrative tasks."""
|
| 3 |
+
import os
|
| 4 |
+
import sys
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def main():
|
| 8 |
+
"""Run administrative tasks."""
|
| 9 |
+
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Sentiment.settings')
|
| 10 |
+
try:
|
| 11 |
+
from django.core.management import execute_from_command_line
|
| 12 |
+
except ImportError as exc:
|
| 13 |
+
raise ImportError(
|
| 14 |
+
"Couldn't import Django. Are you sure it's installed and "
|
| 15 |
+
"available on your PYTHONPATH environment variable? Did you "
|
| 16 |
+
"forget to activate a virtual environment?"
|
| 17 |
+
) from exc
|
| 18 |
+
execute_from_command_line(sys.argv)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
if __name__ == '__main__':
|
| 22 |
+
main()
|
tokenizer.pickle
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d6c42fa972b1570608c2571aa0d9409bc9c5775ec97e3312cd409a09c8d2c4f6
|
| 3 |
+
size 1234700
|
train.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|