Spaces:
Runtime error


Runtime error
Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- .github/ISSUE_TEMPLATE/bug_report.yaml +63 -0
- .github/ISSUE_TEMPLATE/config.yml +1 -0
- .github/ISSUE_TEMPLATE/feature_request.yml +26 -0
- FAQ.md +15 -0
- MODEL_LICENSE +65 -0
- README.md +336 -8
- README_EN.md +256 -0
- api.py +60 -0
- cli_demo.py +60 -0
- evaluation/README.md +10 -0
- evaluation/evaluate_ceval.py +60 -0
- openai_api.py +174 -0
- requirements.txt +8 -0
- resources/WECHAT.md +7 -0
- resources/cli-demo.png +0 -0
- resources/knowledge.png +0 -0
- resources/long-context.png +3 -0
- resources/math.png +0 -0
- resources/web-demo.gif +3 -0
- resources/web-demo.png +0 -0
- resources/wechat.jpg +0 -0
- utils.py +59 -0
- web_demo.py +108 -0
- web_demo2.py +75 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
resources/long-context.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
resources/web-demo.gif filter=lfs diff=lfs merge=lfs -text
|
.github/ISSUE_TEMPLATE/bug_report.yaml
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: 🐞 Bug/Help
|
| 2 |
+
description: File a bug/issue
|
| 3 |
+
title: "[BUG/Help] <title>"
|
| 4 |
+
labels: []
|
| 5 |
+
body:
|
| 6 |
+
- type: checkboxes
|
| 7 |
+
attributes:
|
| 8 |
+
label: Is there an existing issue for this?
|
| 9 |
+
description: Please search to see if an issue already exists for the bug you encountered.
|
| 10 |
+
options:
|
| 11 |
+
- label: I have searched the existing issues
|
| 12 |
+
required: true
|
| 13 |
+
- type: textarea
|
| 14 |
+
attributes:
|
| 15 |
+
label: Current Behavior
|
| 16 |
+
description: |
|
| 17 |
+
A concise description of what you're experiencing, with screenshot attached if possible.
|
| 18 |
+
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
| 19 |
+
validations:
|
| 20 |
+
required: true
|
| 21 |
+
- type: textarea
|
| 22 |
+
attributes:
|
| 23 |
+
label: Expected Behavior
|
| 24 |
+
description: A concise description of what you expected to happen.
|
| 25 |
+
validations:
|
| 26 |
+
required: false
|
| 27 |
+
- type: textarea
|
| 28 |
+
attributes:
|
| 29 |
+
label: Steps To Reproduce
|
| 30 |
+
description: Steps to reproduce the behavior.
|
| 31 |
+
placeholder: |
|
| 32 |
+
1. In this environment...
|
| 33 |
+
2. With this config...
|
| 34 |
+
3. Run '...'
|
| 35 |
+
4. See error...
|
| 36 |
+
validations:
|
| 37 |
+
required: true
|
| 38 |
+
- type: textarea
|
| 39 |
+
attributes:
|
| 40 |
+
label: Environment
|
| 41 |
+
description: |
|
| 42 |
+
examples:
|
| 43 |
+
- **OS**: Ubuntu 20.04
|
| 44 |
+
- **Python**: 3.8
|
| 45 |
+
- **Transformers**: 4.26.1
|
| 46 |
+
- **PyTorch**: 1.12
|
| 47 |
+
- **CUDA Support**: True
|
| 48 |
+
value: |
|
| 49 |
+
- OS:
|
| 50 |
+
- Python:
|
| 51 |
+
- Transformers:
|
| 52 |
+
- PyTorch:
|
| 53 |
+
- CUDA Support (`python -c "import torch; print(torch.cuda.is_available())"`) :
|
| 54 |
+
render: markdown
|
| 55 |
+
validations:
|
| 56 |
+
required: true
|
| 57 |
+
- type: textarea
|
| 58 |
+
attributes:
|
| 59 |
+
label: Anything else?
|
| 60 |
+
description: |
|
| 61 |
+
Links? References? Anything that will give us more context about the issue you are encountering!
|
| 62 |
+
validations:
|
| 63 |
+
required: false
|
.github/ISSUE_TEMPLATE/config.yml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
blank_issues_enabled: false
|
.github/ISSUE_TEMPLATE/feature_request.yml
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Feature request
|
| 2 |
+
description: Suggest an idea for this project
|
| 3 |
+
title: "[Feature] <title>"
|
| 4 |
+
labels: []
|
| 5 |
+
body:
|
| 6 |
+
- type: textarea
|
| 7 |
+
attributes:
|
| 8 |
+
label: Is your feature request related to a problem? Please describe.
|
| 9 |
+
description: |
|
| 10 |
+
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
| 11 |
+
validations:
|
| 12 |
+
required: false
|
| 13 |
+
- type: textarea
|
| 14 |
+
attributes:
|
| 15 |
+
label: Solutions
|
| 16 |
+
description: |
|
| 17 |
+
Describe the solution you'd like
|
| 18 |
+
A clear and concise description of what you want to happen.
|
| 19 |
+
validations:
|
| 20 |
+
required: true
|
| 21 |
+
- type: textarea
|
| 22 |
+
attributes:
|
| 23 |
+
label: Additional context
|
| 24 |
+
description: Add any other context or screenshots about the feature request here.
|
| 25 |
+
validations:
|
| 26 |
+
required: false
|
FAQ.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Q1
|
| 2 |
+
|
| 3 |
+
**Mac直接加载量化后的模型出现提示 `clang: error: unsupported option '-fopenmp'**
|
| 4 |
+
|
| 5 |
+
这是由于Mac由于本身缺乏omp导致的,此时可运行但是单核。需要单独安装 openmp 依赖,即可在Mac下使用OMP:
|
| 6 |
+
|
| 7 |
+
```bash
|
| 8 |
+
# 参考`https://mac.r-project.org/openmp/`
|
| 9 |
+
## 假设: gcc(clang)是14.x版本,其他版本见R-Project提供的表格
|
| 10 |
+
curl -O https://mac.r-project.org/openmp/openmp-14.0.6-darwin20-Release.tar.gz
|
| 11 |
+
sudo tar fvxz openmp-14.0.6-darwin20-Release.tar.gz -C /
|
| 12 |
+
```
|
| 13 |
+
此时会安装下面几个文件:`/usr/local/lib/libomp.dylib`, `/usr/local/include/ompt.h`, `/usr/local/include/omp.h`, `/usr/local/include/omp-tools.h`。
|
| 14 |
+
|
| 15 |
+
> 注意:如果你之前运行`ChatGLM`项目失败过,最好清一下Hugging Face的缓存,i.e. 默认下是 `rm -rf ${HOME}/.cache/huggingface/modules/transformers_modules/chatglm-6b-int4`。由于使用了`rm`命令,请明确知道自己在删除什么。
|
MODEL_LICENSE
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The ChatGLM-6B License
|
| 2 |
+
|
| 3 |
+
一、定义
|
| 4 |
+
|
| 5 |
+
“许可方”是指分发其软件的 ChatGLM2-6B 模型团队。
|
| 6 |
+
|
| 7 |
+
“软件”是指根据本许可提供的 ChatGLM2-6B 模型参数。
|
| 8 |
+
|
| 9 |
+
2. 许可授予
|
| 10 |
+
|
| 11 |
+
根据本许可的条款和条件,许可方特此授予您非排他性、全球性、不可转让、不可再许可、可撤销、免版税的版权许可,仅用于您的非商业研究目的。
|
| 12 |
+
|
| 13 |
+
上述版权声明和本许可声明应包含在本软件的所有副本或重要部分中。
|
| 14 |
+
|
| 15 |
+
3.限制
|
| 16 |
+
|
| 17 |
+
您不得出于任何商业、军事或非法目的使用、复制、修改、合并、发布、分发、复制或创建本软件的全部或部分衍生作品。
|
| 18 |
+
|
| 19 |
+
您不得利用本软件从事任何危害国家安全和国家统一、危害社会公共利益、侵犯人身权益的行为。
|
| 20 |
+
|
| 21 |
+
4.免责声明
|
| 22 |
+
|
| 23 |
+
本软件“按原样”提供,不提供任何明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和非侵权性的保证。 在任何情况下,作者或版权持有人均不对任何索赔、损害或其他责任负责,无论是在合同诉讼、侵权行为还是其他方面,由软件或软件的使用或其他交易引起、由软件引起或与之相关 软件。
|
| 24 |
+
|
| 25 |
+
5. 责任限制
|
| 26 |
+
|
| 27 |
+
除适用法律禁止的范围外,在任何情况下且根据任何法律理论,无论是基于侵权行为、疏忽、合同、责任或其他原因,任何许可方均不对您承担任何直接、间接、特殊、偶然、示范性、 或间接损害,或任何其他商业损失,即使许可人已被告知此类损害的可能性。
|
| 28 |
+
|
| 29 |
+
6.争议解决
|
| 30 |
+
|
| 31 |
+
本许可受中华人民共和国法律管辖并按其解释。 因本许可引起的或与本许可有关的任何争议应提交北京市海淀区人民法院。
|
| 32 |
+
|
| 33 |
+
请注意,许可证可能会更新到更全面的版本。 有关许可和版权的任何问题,请通过 glm-130b@googlegroups.com 与我们联系。
|
| 34 |
+
|
| 35 |
+
1. Definitions
|
| 36 |
+
|
| 37 |
+
“Licensor” means the ChatGLM2-6B Model Team that distributes its Software.
|
| 38 |
+
|
| 39 |
+
“Software” means the ChatGLM2-6B model parameters made available under this license.
|
| 40 |
+
|
| 41 |
+
2. License Grant
|
| 42 |
+
|
| 43 |
+
Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software solely for your non-commercial research purposes.
|
| 44 |
+
|
| 45 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 46 |
+
|
| 47 |
+
3. Restriction
|
| 48 |
+
|
| 49 |
+
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any commercial, military, or illegal purposes.
|
| 50 |
+
|
| 51 |
+
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
|
| 52 |
+
|
| 53 |
+
4. Disclaimer
|
| 54 |
+
|
| 55 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 56 |
+
|
| 57 |
+
5. Limitation of Liability
|
| 58 |
+
|
| 59 |
+
EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
|
| 60 |
+
|
| 61 |
+
6. Dispute Resolution
|
| 62 |
+
|
| 63 |
+
This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
|
| 64 |
+
|
| 65 |
+
Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us at glm-130b@googlegroups.com.
|
README.md
CHANGED
|
@@ -1,13 +1,341 @@
|
|
| 1 |
---
|
| 2 |
-
title: ChatGLM2
|
| 3 |
-
|
| 4 |
-
colorFrom: red
|
| 5 |
-
colorTo: green
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 3.35.2
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: unknown
|
| 11 |
---
|
|
|
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: ChatGLM2-6B
|
| 3 |
+
app_file: web_demo.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 3.35.2
|
|
|
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# ChatGLM2-6B
|
| 8 |
|
| 9 |
+
<p align="center">
|
| 10 |
+
🤗 <a href="https://huggingface.co/THUDM/chatglm2-6b" target="_blank">HF Repo</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2210.02414" target="_blank">[GLM-130B@ICLR 23]</a> <a href="https://github.com/THUDM/GLM-130B" target="_blank">[GitHub]</a> <br>
|
| 11 |
+
</p>
|
| 12 |
+
<p align="center">
|
| 13 |
+
👋 加入我们的 <a href="https://join.slack.com/t/chatglm/shared_invite/zt-1udqapmrr-ocT1DS_mxWe6dDY8ahRWzg" target="_blank">Slack</a> 和 <a href="resources/WECHAT.md" target="_blank">WeChat</a>
|
| 14 |
+
</p>
|
| 15 |
+
|
| 16 |
+
*Read this in [English](README_EN.md)*
|
| 17 |
+
|
| 18 |
+
## 介绍
|
| 19 |
+
|
| 20 |
+
ChatGLM**2**-6B 是开源中英双语对话模型 [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM**2**-6B 引入了如下新特性:
|
| 21 |
+
|
| 22 |
+
1. **更强大的性能**:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 [GLM](https://github.com/THUDM/GLM) 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,[评测结果](#评测结果)显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
|
| 23 |
+
2. **更长的上下文**:基于 [FlashAttention](https://github.com/HazyResearch/flash-attention) 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
|
| 24 |
+
3. **更高效的推理**:基于 [Multi-Query Attention](http://arxiv.org/abs/1911.02150) 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
|
| 25 |
+
4. **更开放的协议**:ChatGLM2-6B 权重对学术研究**完全开放**,在获得官方的书面许可后,亦**允许商业使用**。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
|
| 26 |
+
|
| 27 |
+
-----
|
| 28 |
+
|
| 29 |
+
ChatGLM2-6B 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守[开源协议](MODEL_LICENSE),勿将开源模型和代码及基于开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务。**目前,本项目团队未基于 ChatGLM2-6B 开发任何应用,包括网页端、安卓、苹果 iOS 及 Windows App 等应用。**
|
| 30 |
+
|
| 31 |
+
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM2-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导。**本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。**
|
| 32 |
+
|
| 33 |
+
## 评测结果
|
| 34 |
+
我们选取了部分中英文典型数据集进行了评测,以下为 ChatGLM2-6B 模型在 [MMLU](https://github.com/hendrycks/test) (英文)、[C-Eval](https://cevalbenchmark.com/static/leaderboard.html)(中文)、[GSM8K](https://github.com/openai/grade-school-math)(数学)、[BBH](https://github.com/suzgunmirac/BIG-Bench-Hard)(英文) 上的测评结果。在 [evaluation](./evaluation/README.md) 中提供了在 C-Eval 上进行测评的脚本。
|
| 35 |
+
|
| 36 |
+
### MMLU
|
| 37 |
+
|
| 38 |
+
| Model | Average | STEM | Social Sciences | Humanities | Others |
|
| 39 |
+
| ----- | ----- | ---- | ----- | ----- | ----- |
|
| 40 |
+
| ChatGLM-6B | 40.63 | 33.89 | 44.84 | 39.02 | 45.71 |
|
| 41 |
+
| ChatGLM2-6B (base) | 47.86 | 41.20 | 54.44 | 43.66 | 54.46 |
|
| 42 |
+
| ChatGLM2-6B | 45.46 | 40.06 | 51.61 | 41.23 | 51.24 |
|
| 43 |
+
|
| 44 |
+
> Chat 模型使用 zero-shot CoT (Chain-of-Thought) 的方法测试,Base 模型使用 few-shot answer-only 的方法测试
|
| 45 |
+
|
| 46 |
+
### C-Eval
|
| 47 |
+
|
| 48 |
+
| Model | Average | STEM | Social Sciences | Humanities | Others |
|
| 49 |
+
| ----- | ---- | ---- | ----- | ----- | ----- |
|
| 50 |
+
| ChatGLM-6B | 38.9 | 33.3 | 48.3 | 41.3 | 38.0 |
|
| 51 |
+
| ChatGLM2-6B (base) | 51.7 | 48.6 | 60.5 | 51.3 | 49.8 |
|
| 52 |
+
| ChatGLM2-6B | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
|
| 53 |
+
|
| 54 |
+
> Chat 模型使用 zero-shot CoT 的方法测试,Base 模型使用 few-shot answer only 的方法测试
|
| 55 |
+
|
| 56 |
+
### GSM8K
|
| 57 |
+
|
| 58 |
+
| Model | Accuracy | Accuracy (Chinese)* |
|
| 59 |
+
| ----- | ----- | ----- |
|
| 60 |
+
| ChatGLM-6B | 4.82 | 5.85 |
|
| 61 |
+
| ChatGLM2-6B (base) | 32.37 | 28.95 |
|
| 62 |
+
| ChatGLM2-6B | 28.05 | 20.45 |
|
| 63 |
+
|
| 64 |
+
> 所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 http://arxiv.org/abs/2201.11903
|
| 65 |
+
>
|
| 66 |
+
> \* 我们使用翻译 API 翻译了 GSM8K 中的 500 道题目和 CoT prompt 并进行了人工校对
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
### BBH
|
| 70 |
+
|
| 71 |
+
| Model | Accuracy |
|
| 72 |
+
| ----- | ----- |
|
| 73 |
+
| ChatGLM-6B | 18.73 |
|
| 74 |
+
| ChatGLM2-6B (base) | 33.68 |
|
| 75 |
+
| ChatGLM2-6B | 30.00 |
|
| 76 |
+
|
| 77 |
+
> 所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 https://github.com/suzgunmirac/BIG-Bench-Hard/tree/main/cot-prompts
|
| 78 |
+
|
| 79 |
+
## 推理性能
|
| 80 |
+
ChatGLM2-6B 使用了 [Multi-Query Attention](http://arxiv.org/abs/1911.02150),提高了生成速度。生成 2000 个字符的平均速度对比如下
|
| 81 |
+
|
| 82 |
+
| Model | 推理速度 (字符/秒) |
|
| 83 |
+
| ---- | ----- |
|
| 84 |
+
| ChatGLM-6B | 31.49 |
|
| 85 |
+
| ChatGLM2-6B | 44.62 |
|
| 86 |
+
|
| 87 |
+
> 使用官方实现,batch size = 1,max length = 2048,bf16 精度,测试硬件为 A100-SXM4-80G,软件环境为 PyTorch 2.0.1
|
| 88 |
+
|
| 89 |
+
Multi-Query Attention 同时也降低了生成过程中 KV Cache 的显存占用,此外,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。因此,使用 6GB 显存的显卡进行 INT4 量化的推理时,初代的 ChatGLM-6B 模型最多能够生成 1119 个字符就会提示显存耗尽,而 ChatGLM2-6B 能够生成至少 8192 个字符。
|
| 90 |
+
|
| 91 |
+
| **量化等级** | **编码 2048 长度的最小显存** | **生成 8192 长度的最小显存** |
|
| 92 |
+
| -------------- |---------------------|---------------------|
|
| 93 |
+
| FP16 / BF16 | 13.1 GB | 12.8 GB |
|
| 94 |
+
| INT8 | 8.2 GB | 8.1 GB |
|
| 95 |
+
| INT4 | 5.5 GB | 5.1 GB |
|
| 96 |
+
|
| 97 |
+
> ChatGLM2-6B 利用了 PyTorch 2.0 引入的 `torch.nn.functional.scaled_dot_product_attention` 实现高效的 Attention 计算,如果 PyTorch 版本较低则会 fallback 到朴素的 Attention 实现,出现显存占用高于上表的情况。
|
| 98 |
+
|
| 99 |
+
我们也测试了量化对模型性能的影响。结果表明,量化对模型性能的影响在可接受范围内。
|
| 100 |
+
|
| 101 |
+
| 量化等级 | Accuracy (MMLU) | Accuracy (C-Eval dev) |
|
| 102 |
+
| ----- | ----- |-----------------------|
|
| 103 |
+
| BF16 | 45.47 | 53.57 |
|
| 104 |
+
| INT4 | 43.13 | 50.30 |
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
## ChatGLM2-6B 示例
|
| 109 |
+
|
| 110 |
+
相比于初代模型,ChatGLM2-6B 多个维度的能力都取得了提升,以下是一些对比示例。更多 ChatGLM2-6B 的可能,等待你来探索发现!
|
| 111 |
+
|
| 112 |
+
<details><summary><b>数理逻辑</b></summary>
|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
</details>
|
| 117 |
+
|
| 118 |
+
<details><summary><b>知识推理</b></summary>
|
| 119 |
+
|
| 120 |
+

|
| 121 |
+
|
| 122 |
+
</details>
|
| 123 |
+
|
| 124 |
+
<details><summary><b>长文档理解</b></summary>
|
| 125 |
+
|
| 126 |
+

|
| 127 |
+
|
| 128 |
+
</details>
|
| 129 |
+
|
| 130 |
+
## 使用方式
|
| 131 |
+
### 环境安装
|
| 132 |
+
首先需要下载本仓库:
|
| 133 |
+
```shell
|
| 134 |
+
git clone https://github.com/THUDM/ChatGLM2-6B
|
| 135 |
+
cd ChatGLM2-6B
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
然后使用 pip 安装依赖:`pip install -r requirements.txt`,其中 `transformers` 库版本推荐为 `4.30.2`,`torch` 推荐使用 2.0 以上的版本,以获得最佳的推理性能。
|
| 139 |
+
|
| 140 |
+
### 代码调用
|
| 141 |
+
|
| 142 |
+
可以通过如下代码调用 ChatGLM2-6B 模型来生成对话:
|
| 143 |
+
|
| 144 |
+
```python
|
| 145 |
+
>>> from transformers import AutoTokenizer, AutoModel
|
| 146 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 147 |
+
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
|
| 148 |
+
>>> model = model.eval()
|
| 149 |
+
>>> response, history = model.chat(tokenizer, "你好", history=[])
|
| 150 |
+
>>> print(response)
|
| 151 |
+
你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
|
| 152 |
+
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
|
| 153 |
+
>>> print(response)
|
| 154 |
+
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
|
| 155 |
+
|
| 156 |
+
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
|
| 157 |
+
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
|
| 158 |
+
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
|
| 159 |
+
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
|
| 160 |
+
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
|
| 161 |
+
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡���试着慢慢吸气,保持几秒钟,然后缓慢呼气。
|
| 162 |
+
|
| 163 |
+
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
#### 从本地加载模型
|
| 167 |
+
以上代码会由 `transformers` 自动下载模型实现和参数。完整的模型实现在 [Hugging Face Hub](https://huggingface.co/THUDM/chatglm2-6b)。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
|
| 168 |
+
|
| 169 |
+
从 Hugging Face Hub 下载模型需要先[安装Git LFS](https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage),然后运行
|
| 170 |
+
```Shell
|
| 171 |
+
git clone https://huggingface.co/THUDM/chatglm2-6b
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
如果你从 Hugging Face Hub 上下载 checkpoint 的速度较慢,可以只下载模型实现
|
| 175 |
+
```Shell
|
| 176 |
+
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
|
| 177 |
+
```
|
| 178 |
+
然后从[这里](https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/)手动下载模型参数文件,并将下载的文件替换到本地的 `chatglm2-6b` 目录下。
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
将模型下载到本地之后,将以上代码中的 `THUDM/chatglm2-6b` 替换为你本地的 `chatglm2-6b` 文件夹的路径,即可从本地加载模型。
|
| 182 |
+
|
| 183 |
+
模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在 `from_pretrained` 的调用中增加 `revision="v1.0"` 参数。`v1.0` 是当前最新的版本号,完整的版本列表参见 [Change Log](https://huggingface.co/THUDM/chatglm2-6b#change-log)。
|
| 184 |
+
|
| 185 |
+
### 网页版 Demo
|
| 186 |
+
|
| 187 |
+

|
| 188 |
+
|
| 189 |
+
首先安装 Gradio:`pip install gradio`,然后运行仓库中的 [web_demo.py](web_demo.py):
|
| 190 |
+
|
| 191 |
+
```shell
|
| 192 |
+
python web_demo.py
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。
|
| 196 |
+
> 默认使用了 `share=False` 启动,不会生成公网链接。如有需要公网访问的需求,可以修改为 `share=True` 启动。
|
| 197 |
+
>
|
| 198 |
+
|
| 199 |
+
感谢 [@AdamBear](https://github.com/AdamBear) 实现了基于 Streamlit 的网页版 Demo `web_demo2.py`。使用时首先需要额外安装以下依赖:
|
| 200 |
+
```shell
|
| 201 |
+
pip install streamlit streamlit-chat
|
| 202 |
+
```
|
| 203 |
+
然后通过以下命令运行:
|
| 204 |
+
```shell
|
| 205 |
+
streamlit run web_demo2.py
|
| 206 |
+
```
|
| 207 |
+
经测试,如果输入的 prompt 较长的话,使用基于 Streamlit 的网页版 Demo 会更流畅。
|
| 208 |
+
|
| 209 |
+
### 命令行 Demo
|
| 210 |
+
|
| 211 |
+

|
| 212 |
+
|
| 213 |
+
运行仓库中 [cli_demo.py](cli_demo.py):
|
| 214 |
+
|
| 215 |
+
```shell
|
| 216 |
+
python cli_demo.py
|
| 217 |
+
```
|
| 218 |
+
|
| 219 |
+
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 `clear` 可以清空对话历史,输入 `stop` 终止程序。
|
| 220 |
+
|
| 221 |
+
### API 部署
|
| 222 |
+
首先需要安装额外的依赖 `pip install fastapi uvicorn`,然后运行仓库中的 [api.py](api.py):
|
| 223 |
+
```shell
|
| 224 |
+
python api.py
|
| 225 |
+
```
|
| 226 |
+
默认部署在本地的 8000 端口,通过 POST 方法进行调用
|
| 227 |
+
```shell
|
| 228 |
+
curl -X POST "http://127.0.0.1:8000" \
|
| 229 |
+
-H 'Content-Type: application/json' \
|
| 230 |
+
-d '{"prompt": "你好", "history": []}'
|
| 231 |
+
```
|
| 232 |
+
得到的返回值为
|
| 233 |
+
```shell
|
| 234 |
+
{
|
| 235 |
+
"response":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。",
|
| 236 |
+
"history":[["你好","你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。"]],
|
| 237 |
+
"status":200,
|
| 238 |
+
"time":"2023-03-23 21:38:40"
|
| 239 |
+
}
|
| 240 |
+
```
|
| 241 |
+
感谢 [@hiyouga]() 实现了 OpenAI 格式的流式 API 部署,可以作为任意基于 ChatGPT 的应用的后端,比如 [ChatGPT-Next-Web](https://github.com/Yidadaa/ChatGPT-Next-Web)。可以通过运行仓库中的[openai_api.py](openai_api.py) 进行部署:
|
| 242 |
+
```shell
|
| 243 |
+
python openai_api.py
|
| 244 |
+
```
|
| 245 |
+
进行 API 调用的示例代码为
|
| 246 |
+
```python
|
| 247 |
+
import openai
|
| 248 |
+
if __name__ == "__main__":
|
| 249 |
+
openai.api_base = "http://localhost:8000/v1"
|
| 250 |
+
openai.api_key = "none"
|
| 251 |
+
for chunk in openai.ChatCompletion.create(
|
| 252 |
+
model="chatglm2-6b",
|
| 253 |
+
messages=[
|
| 254 |
+
{"role": "user", "content": "你好"}
|
| 255 |
+
],
|
| 256 |
+
stream=True
|
| 257 |
+
):
|
| 258 |
+
if hasattr(chunk.choices[0].delta, "content"):
|
| 259 |
+
print(chunk.choices[0].delta.content, end="", flush=True)
|
| 260 |
+
```
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
## 低成本部署
|
| 264 |
+
|
| 265 |
+
### 模型量化
|
| 266 |
+
|
| 267 |
+
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
|
| 268 |
+
|
| 269 |
+
```python
|
| 270 |
+
# 按需修改,目前只支持 4/8 bit 量化
|
| 271 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(8).cuda()
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
模型量化会带来一定的性能损失,经过测试,ChatGLM2-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
|
| 275 |
+
|
| 276 |
+
如果你的内存不足,可以直接加载量化后的模型:
|
| 277 |
+
```python
|
| 278 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).cuda()
|
| 279 |
+
```
|
| 280 |
+
|
| 281 |
+
<!-- 量化模型的参数文件也可以从[这里](https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/)手动下载。 -->
|
| 282 |
+
|
| 283 |
+
### CPU 部署
|
| 284 |
+
|
| 285 |
+
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
|
| 286 |
+
```python
|
| 287 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
|
| 288 |
+
```
|
| 289 |
+
如果你的内存不足的话,也可以使用量化后的模型
|
| 290 |
+
```python
|
| 291 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()
|
| 292 |
+
```
|
| 293 |
+
在 cpu 上运行量化后的模型需要安装 `gcc` 与 `openmp`。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 [TDM-GCC](https://jmeubank.github.io/tdm-gcc/) 时勾选 `openmp`。 Windows 测试环境 `gcc` 版本为 `TDM-GCC 10.3.0`, Linux 为 `gcc 11.3.0`。在 MacOS 上请参考 [Q1](FAQ.md#q1)。
|
| 294 |
+
|
| 295 |
+
### Mac 部署
|
| 296 |
+
|
| 297 |
+
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM2-6B。需要参考 Apple 的 [官方说明](https://developer.apple.com/metal/pytorch) 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
|
| 298 |
+
|
| 299 |
+
目前在 MacOS 上只支持[从本地加载模型](README.md#从本地加载模型)。将代码中的模型加载改为从本地加载,并使用 mps 后端:
|
| 300 |
+
```python
|
| 301 |
+
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
|
| 302 |
+
```
|
| 303 |
+
|
| 304 |
+
加载半精度的 ChatGLM2-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。
|
| 305 |
+
此时可以使用量化后的模型 chatglm2-6b-int4。因为 GPU 上量化的 kernel 是使用 CUDA 编写的,因此无法在 MacOS 上使用,只能使用 CPU 进行推理。
|
| 306 |
+
为了充分使用 CPU 并行,还需要[单独安装 OpenMP](FAQ.md#q1)。
|
| 307 |
+
|
| 308 |
+
### 多卡部署
|
| 309 |
+
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: `pip install accelerate`,然后通过如下方法加载模型:
|
| 310 |
+
```python
|
| 311 |
+
from utils import load_model_on_gpus
|
| 312 |
+
model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
|
| 313 |
+
```
|
| 314 |
+
即可将模型部署到两张 GPU 上进行推理。你可以将 `num_gpus` 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 `device_map` 参数来自己指定。
|
| 315 |
+
|
| 316 |
+
## 协议
|
| 317 |
+
|
| 318 |
+
本仓库的代码依照 [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) 协议开源,ChatGLM2-6B 模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE)。ChatGLM2-6B 权重对学术研究**完全开放**,在获得官方的书面许可后,亦**允许商业使用**。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。申请商用许可与捐赠请联系 [yiwen.xu@zhipuai.cn](mailto:yiwen.xu@zhipuai.cn)。
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
## 引用
|
| 322 |
+
|
| 323 |
+
如果你觉得我们的工作有帮助的话,请考虑引用下列论文,ChatGLM2-6B 的论文会在近期公布,敬请期待~
|
| 324 |
+
|
| 325 |
+
```
|
| 326 |
+
@article{zeng2022glm,
|
| 327 |
+
title={Glm-130b: An open bilingual pre-trained model},
|
| 328 |
+
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
| 329 |
+
journal={arXiv preprint arXiv:2210.02414},
|
| 330 |
+
year={2022}
|
| 331 |
+
}
|
| 332 |
+
```
|
| 333 |
+
```
|
| 334 |
+
@inproceedings{du2022glm,
|
| 335 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 336 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 337 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 338 |
+
pages={320--335},
|
| 339 |
+
year={2022}
|
| 340 |
+
}
|
| 341 |
+
```
|
README_EN.md
ADDED
|
@@ -0,0 +1,256 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center">
|
| 2 |
+
🤗 <a href="https://huggingface.co/THUDM/chatglm2-6b" target="_blank">HF Repo</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2210.02414" target="_blank">[GLM-130B@ICLR 23]</a> <a href="https://github.com/THUDM/GLM-130B" target="_blank">[GitHub]</a> <br>
|
| 3 |
+
</p>
|
| 4 |
+
<p align="center">
|
| 5 |
+
👋 Join our <a href="https://join.slack.com/t/chatglm/shared_invite/zt-1udqapmrr-ocT1DS_mxWe6dDY8ahRWzg" target="_blank">Slack</a> and <a href="resources/WECHAT.md" target="_blank">WeChat</a>
|
| 6 |
+
</p>
|
| 7 |
+
|
| 8 |
+
## Introduction
|
| 9 |
+
|
| 10 |
+
ChatGLM**2**-6B is the second-generation version of the open-source bilingual (Chinese-English) chat model [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B). It retains the smooth conversation flow and low deployment threshold of the first-generation model, while introducing the following new features:
|
| 11 |
+
|
| 12 |
+
1. **Stronger Performance**: Based on the development experience of the first-generation ChatGLM model, we have fully upgraded the base model of ChatGLM2-6B. ChatGLM2-6B uses the hybrid objective function of [GLM](https://github.com/THUDM/GLM), and has undergone pre-training with 1.4T bilingual tokens and human preference alignment training. The [evaluation results](README.md#evaluation-results) show that, compared to the first-generation model, ChatGLM2-6B has achieved substantial improvements in performance on datasets like MMLU (+23%), CEval (+33%), GSM8K (+571%), BBH (+60%), showing strong competitiveness among models of the same size.
|
| 13 |
+
2. **Longer Context**: Based on [FlashAttention](https://github.com/HazyResearch/flash-attention) technique, we have extended the context length of the base model from 2K in ChatGLM-6B to 32K, and trained with a context length of 8K during the dialogue alignment, allowing for more rounds of dialogue. However, the current version of ChatGLM2-6B has limited understanding of single-round ultra-long documents, which we will focus on optimizing in future iterations.
|
| 14 |
+
3. **More Efficient Inference**: Based on [Multi-Query Attention](http://arxiv.org/abs/1911.02150) technique, ChatGLM2-6B has more efficient inference speed and lower GPU memory usage: under the official implementation, the inference speed has increased by 42% compared to the first generation; under INT4 quantization, the dialogue length supported by 6G GPU memory has increased from 1K to 8K.
|
| 15 |
+
4. **More Open License**: The weights of ChatGLM2-6B are **fully open** to academic research, and with our official written permission, the weights of ChatGLM2-6B are also **permitted for commercial use**. If you find our open-source model useful for your business, we welcome your donation towards the development of the next-generation model ChatGLM3.
|
| 16 |
+
|
| 17 |
+
-----
|
| 18 |
+
|
| 19 |
+
The open-source ChatGLM2-6B is intended to promote the development of LLMs together with the open-source community. We earnestly request developers and everyone to abide by the [open-source license](MODEL_LICENSE). Do not use the open-source model, code, or any derivatives from the open-source project for any purposes that may harm nations or societies, or for any services that have not undergone safety assessments and legal approval. **At present, our project team has not developed any applications based on ChatGLM2-6B, including web, Android, Apple iOS, and Windows App applications.**
|
| 20 |
+
|
| 21 |
+
Although the model strives to ensure the compliance and accuracy of data at each stage of training, due to the smaller scale of the ChatGLM2-6B model, and its susceptibility to probabilistic randomness, the accuracy of output content cannot be guaranteed, and the model can easily be misled. **Our project does not assume any risks or responsibilities arising from data security, public opinion risks, or any instances of the model being misled, abused, disseminated, or improperly used due to the open-source model and code.**
|
| 22 |
+
|
| 23 |
+
## Evaluation
|
| 24 |
+
We selected some typical Chinese and English datasets for evaluation. Below are the evaluation results of the ChatGLM2-6B model on [MMLU](https://github.com/hendrycks/test) (English), [C-Eval](https://cevalbenchmark.com/static/leaderboard.html) (Chinese), [GSM8K](https://github.com/openai/grade-school-math) (Mathematics), [BBH](https://github.com/suzgunmirac/BIG-Bench-Hard) (English).
|
| 25 |
+
|
| 26 |
+
### MMLU
|
| 27 |
+
|
| 28 |
+
| Model | Average | STEM | Social Sciences | Humanities | Others |
|
| 29 |
+
| ----- | ----- | ---- | ----- | ----- | ----- |
|
| 30 |
+
| ChatGLM-6B | 40.63 | 33.89 | 44.84 | 39.02 | 45.71 |
|
| 31 |
+
| ChatGLM2-6B (base) | 47.86 | 41.20 | 54.44 | 43.66 | 54.46 |
|
| 32 |
+
| ChatGLM2-6B | 45.46 | 40.06 | 51.61 | 41.23 | 51.24 |
|
| 33 |
+
|
| 34 |
+
> Chat-aligned version is evaluated under zero-shot CoT (Chain-of-Thought), and Base version is evaluated under few-shot answer-only
|
| 35 |
+
|
| 36 |
+
### C-Eval
|
| 37 |
+
|
| 38 |
+
| Model | Average | STEM | Social Sciences | Humanities | Others |
|
| 39 |
+
| ----- | ---- | ---- | ----- | ----- | ----- |
|
| 40 |
+
| ChatGLM-6B | 38.9 | 33.3 | 48.3 | 41.3 | 38.0 |
|
| 41 |
+
| ChatGLM2-6B (base) | 51.7 | 48.6 | 60.5 | 51.3 | 49.8 |
|
| 42 |
+
| ChatGLM2-6B | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
|
| 43 |
+
|
| 44 |
+
> Chat-aligned version is evaluated under zero-shot CoT (Chain-of-Thought), and Base version is evaluated under few-shot answer-only
|
| 45 |
+
|
| 46 |
+
### GSM8K
|
| 47 |
+
|
| 48 |
+
| Model | Accuracy | Accuracy (Chinese)* |
|
| 49 |
+
| ----- | ----- | ----- |
|
| 50 |
+
| ChatGLM-6B | 4.82 | 5.85 |
|
| 51 |
+
| ChatGLM2-6B (base) | 32.37 | 28.95 |
|
| 52 |
+
| ChatGLM2-6B | 28.05 | 20.45 |
|
| 53 |
+
|
| 54 |
+
> All model versions are evaluated under few-shot CoT, and CoT prompts are from http://arxiv.org/abs/2201.11903
|
| 55 |
+
> \* We translate a 500-query subset of GSM8K and its corresponding CoT prompts using machine translation API and subsequent human proofreading.
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
### BBH
|
| 59 |
+
|
| 60 |
+
| Model | Accuracy |
|
| 61 |
+
| ----- | ----- |
|
| 62 |
+
| ChatGLM-6B | 18.73 |
|
| 63 |
+
| ChatGLM2-6B (base) | 33.68 |
|
| 64 |
+
| ChatGLM2-6B | 30.00 |
|
| 65 |
+
|
| 66 |
+
> All model versions are evaluated under few-shot CoT, and CoT prompts are from https://github.com/suzgunmirac/BIG-Bench-Hard/tree/main/cot-prompts
|
| 67 |
+
|
| 68 |
+
## Inference Efficiency
|
| 69 |
+
ChatGLM2-6B employs [Multi-Query Attention](http://arxiv.org/abs/1911.02150) to improve inference speed. Here is a comparison of the average speed for generating 2000 tokens.
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
| Model | Inference Speed (tokens/s) |
|
| 73 |
+
| ---- | ----- |
|
| 74 |
+
| ChatGLM-6B | 31.49 |
|
| 75 |
+
| ChatGLM2-6B | 44.62 |
|
| 76 |
+
|
| 77 |
+
> Under our official implementation, batch size = 1, max length = 2048, bf16 precision, tested with an A100-SXM-80G and PyTorch 2.0 environment
|
| 78 |
+
|
| 79 |
+
Multi-Query Attention also reduces the GPU memory usage of the KV Cache during inference. Additionally, ChatGLM2-6B uses Causal Mask for dialogue training, which allows the reuse of the KV Cache from previous rounds in continuous dialogues, further optimizing GPU memory usage. Therefore, when performing INT4 quantization inference with a 6GB GPU, while the first-generation ChatGLM-6B can only generate a maximum of 1119 tokens before running out of memory, ChatGLM2-6B can generate at least 8192 tokens.
|
| 80 |
+
|
| 81 |
+
| **Quantization** | **Encoding 2048 Tokens** | **Decoding 8192 Tokens** |
|
| 82 |
+
| -------------- | --------------------- | --------------- |
|
| 83 |
+
| FP16 / BF16 | 13.1 GB | 12.8 GB |
|
| 84 |
+
| INT8 | 8.2 GB | 8.1 GB |
|
| 85 |
+
| INT4 | 5.5 GB | 5.1 GB |
|
| 86 |
+
|
| 87 |
+
> ChatGLM2-6B takes advantage of `torch.nn.functional.scaled_dot_product_attention` introduced in PyTorch 2.0 for efficient Attention computation. If the PyTorch version is lower, it will fallback to the naive Attention implementation, which may result in higher GPU memory usage than shown in the table above.
|
| 88 |
+
|
| 89 |
+
We also tested the impact of quantization on model performance. The results show that the impact of quantization on model performance is within an acceptable range.
|
| 90 |
+
|
| 91 |
+
| Quantization | Accuracy (MMLU) | Accuracy (C-Eval dev) |
|
| 92 |
+
| ----- | ----- |-----------------------|
|
| 93 |
+
| BF16 | 45.47 | 53.57 |
|
| 94 |
+
| INT4 | 43.13 | 50.30 |
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
## ChatGLM2-6B Examples
|
| 98 |
+
|
| 99 |
+
Compared to the first-generation model, ChatGLM2-6B has made improvements in multiple dimensions. Below are some comparison examples. More possibilities with ChatGLM2-6B are waiting for you to explore and discover!
|
| 100 |
+
|
| 101 |
+
<details><summary><b>Mathematics and Logic</b></summary>
|
| 102 |
+
|
| 103 |
+

|
| 104 |
+
|
| 105 |
+
</details>
|
| 106 |
+
|
| 107 |
+
<details><summary><b>Knowledge Reasoning</b></summary>
|
| 108 |
+
|
| 109 |
+

|
| 110 |
+
|
| 111 |
+
</details>
|
| 112 |
+
|
| 113 |
+
<details><summary><b>Long Document Understanding</b></summary>
|
| 114 |
+
|
| 115 |
+

|
| 116 |
+
|
| 117 |
+
</details>
|
| 118 |
+
|
| 119 |
+
## Getting Started
|
| 120 |
+
### Environment Setup
|
| 121 |
+
|
| 122 |
+
Install dependencies with pip: `pip install -r requirements.txt`. It's recommended to use version `4.27.1` for the `transformers` library and use version 2.0 or higher for `torch` to achieve the best inference performance.
|
| 123 |
+
|
| 124 |
+
We provide a web page demo and a command line demo. You need to download this repository to use them:
|
| 125 |
+
|
| 126 |
+
```shell
|
| 127 |
+
git clone https://github.com/THUDM/ChatGLM2-6B
|
| 128 |
+
cd ChatGLM2-6B
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
### Usage
|
| 132 |
+
|
| 133 |
+
Generate dialogue with the following code:
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
>>> from transformers import AutoTokenizer, AutoModel
|
| 137 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 138 |
+
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda').eval()
|
| 139 |
+
>>> response, history = model.chat(tokenizer, "你好", history=[])
|
| 140 |
+
>>> print(response)
|
| 141 |
+
你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
|
| 142 |
+
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
|
| 143 |
+
>>> print(response)
|
| 144 |
+
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
|
| 145 |
+
|
| 146 |
+
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
|
| 147 |
+
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
|
| 148 |
+
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
|
| 149 |
+
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
|
| 150 |
+
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
|
| 151 |
+
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
|
| 152 |
+
|
| 153 |
+
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
|
| 154 |
+
```
|
| 155 |
+
The implementation of the model is still in development. If you want to fix the used model implementation to ensure compatibility, you can add the `revision="v1.0"` parameter in the `from_pretrained` call. `v1.0` is the latest version number. For a complete list of versions, see [Change Log](https://huggingface.co/THUDM/chatglm2-6b#change-log).
|
| 156 |
+
|
| 157 |
+
### Web Demo
|
| 158 |
+
|
| 159 |
+

|
| 160 |
+
|
| 161 |
+
Install Gradio `pip install gradio`,and run [web_demo.py](web_demo.py):
|
| 162 |
+
|
| 163 |
+
```shell
|
| 164 |
+
python web_demo.py
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
The program runs a web server and outputs the URL. Open the URL in the browser to use the web demo.
|
| 168 |
+
|
| 169 |
+
#### CLI Demo
|
| 170 |
+
|
| 171 |
+

|
| 172 |
+
|
| 173 |
+
Run [cli_demo.py](cli_demo.py) in the repo:
|
| 174 |
+
|
| 175 |
+
```shell
|
| 176 |
+
python cli_demo.py
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
The command runs an interactive program in the shell. Type your instruction in the shell and hit enter to generate the response. Type `clear` to clear the dialogue history and `stop` to terminate the program.
|
| 180 |
+
|
| 181 |
+
## API Deployment
|
| 182 |
+
First install the additional dependency `pip install fastapi uvicorn`. The run [api.py](api.py) in the repo.
|
| 183 |
+
```shell
|
| 184 |
+
python api.py
|
| 185 |
+
```
|
| 186 |
+
By default the api runs at the`8000`port of the local machine. You can call the API via
|
| 187 |
+
```shell
|
| 188 |
+
curl -X POST "http://127.0.0.1:8000" \
|
| 189 |
+
-H 'Content-Type: application/json' \
|
| 190 |
+
-d '{"prompt": "你好", "history": []}'
|
| 191 |
+
```
|
| 192 |
+
The returned value is
|
| 193 |
+
```shell
|
| 194 |
+
{
|
| 195 |
+
"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。",
|
| 196 |
+
"history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],
|
| 197 |
+
"status":200,
|
| 198 |
+
"time":"2023-03-23 21:38:40"
|
| 199 |
+
}
|
| 200 |
+
```
|
| 201 |
+
## Deployment
|
| 202 |
+
|
| 203 |
+
### Quantization
|
| 204 |
+
|
| 205 |
+
By default, the model parameters are loaded with FP16 precision, which require about 13GB of GPU memory. It your GPU memory is limited, you can try to load the model parameters with quantization:
|
| 206 |
+
|
| 207 |
+
```python
|
| 208 |
+
# hange according to your hardware. Only support 4/8 bit quantization now.
|
| 209 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(8).cuda()
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
Model quantization will bring some performance loss on datasets. But after testing, ChatGLM2-6B can still perform natural and smooth generation under 4-bit quantization.
|
| 213 |
+
|
| 214 |
+
### CPU Deployment
|
| 215 |
+
|
| 216 |
+
If your computer is not equipped with GPU, you can also conduct inference on CPU, but the inference speed is slow (and taking about 32GB of memory):
|
| 217 |
+
```python
|
| 218 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
### Inference on Mac
|
| 222 |
+
|
| 223 |
+
For Macs (and MacBooks) with Apple Silicon, it is possible to use the MPS backend to run ChatGLM-6B on the GPU. First, you need to refer to Apple's [official instructions](https://developer.apple.com/metal/pytorch) to install PyTorch-Nightly. (The correct version number should be 2.1.0.dev2023xxxx, not 2.0.0).
|
| 224 |
+
|
| 225 |
+
Currently you must [load the model locally](README_en.md#load-the-model-locally) on MacOS. Change the code to load the model from your local path, and use the mps backend:
|
| 226 |
+
```python
|
| 227 |
+
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
Loading a FP16 ChatGLM-6B model requires about 13GB of memory. Machines with less memory (such as a MacBook Pro with 16GB of memory) will use the virtual memory on the hard disk when there is insufficient free memory, resulting in a serious slowdown in inference speed.
|
| 231 |
+
|
| 232 |
+
## License
|
| 233 |
+
|
| 234 |
+
The code of this repository is licensed under [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0). The use of the ChatGLM2-6B model weights is subject to the [Model License](MODEL_LICENSE). ChatGLM2-6B weights are **completely open** for academic research, and **commercial use** is also allowed after **obtaining official written permission**. If you find our open source model useful for your business, we welcome your donations towards the development of the next generation model, ChatGLM3. For related matters, please contact [yiwen.xu@zhipuai.cn](mailto:yiwen.xu@zhipuai.cn).
|
| 235 |
+
|
| 236 |
+
## Citation
|
| 237 |
+
|
| 238 |
+
If you find our work useful, please consider citing the following papers. The technical report for ChatGLM2-6B will be out soon.
|
| 239 |
+
|
| 240 |
+
```
|
| 241 |
+
@article{zeng2022glm,
|
| 242 |
+
title={Glm-130b: An open bilingual pre-trained model},
|
| 243 |
+
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
| 244 |
+
journal={arXiv preprint arXiv:2210.02414},
|
| 245 |
+
year={2022}
|
| 246 |
+
}
|
| 247 |
+
```
|
| 248 |
+
```
|
| 249 |
+
@inproceedings{du2022glm,
|
| 250 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 251 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 252 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 253 |
+
pages={320--335},
|
| 254 |
+
year={2022}
|
| 255 |
+
}
|
| 256 |
+
```
|
api.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import FastAPI, Request
|
| 2 |
+
from transformers import AutoTokenizer, AutoModel
|
| 3 |
+
import uvicorn, json, datetime
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
DEVICE = "cuda"
|
| 7 |
+
DEVICE_ID = "0"
|
| 8 |
+
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def torch_gc():
|
| 12 |
+
if torch.cuda.is_available():
|
| 13 |
+
with torch.cuda.device(CUDA_DEVICE):
|
| 14 |
+
torch.cuda.empty_cache()
|
| 15 |
+
torch.cuda.ipc_collect()
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
app = FastAPI()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@app.post("/")
|
| 22 |
+
async def create_item(request: Request):
|
| 23 |
+
global model, tokenizer
|
| 24 |
+
json_post_raw = await request.json()
|
| 25 |
+
json_post = json.dumps(json_post_raw)
|
| 26 |
+
json_post_list = json.loads(json_post)
|
| 27 |
+
prompt = json_post_list.get('prompt')
|
| 28 |
+
history = json_post_list.get('history')
|
| 29 |
+
max_length = json_post_list.get('max_length')
|
| 30 |
+
top_p = json_post_list.get('top_p')
|
| 31 |
+
temperature = json_post_list.get('temperature')
|
| 32 |
+
response, history = model.chat(tokenizer,
|
| 33 |
+
prompt,
|
| 34 |
+
history=history,
|
| 35 |
+
max_length=max_length if max_length else 2048,
|
| 36 |
+
top_p=top_p if top_p else 0.7,
|
| 37 |
+
temperature=temperature if temperature else 0.95)
|
| 38 |
+
now = datetime.datetime.now()
|
| 39 |
+
time = now.strftime("%Y-%m-%d %H:%M:%S")
|
| 40 |
+
answer = {
|
| 41 |
+
"response": response,
|
| 42 |
+
"history": history,
|
| 43 |
+
"status": 200,
|
| 44 |
+
"time": time
|
| 45 |
+
}
|
| 46 |
+
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
|
| 47 |
+
print(log)
|
| 48 |
+
torch_gc()
|
| 49 |
+
return answer
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == '__main__':
|
| 53 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 54 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
|
| 55 |
+
# 多显卡支持,使用下面三行代替上面两行,将num_gpus改为你实际的显卡数量
|
| 56 |
+
# model_path = "THUDM/chatglm2-6b"
|
| 57 |
+
# tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
| 58 |
+
# model = load_model_on_gpus(model_path, num_gpus=2)
|
| 59 |
+
model.eval()
|
| 60 |
+
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
|
cli_demo.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import platform
|
| 3 |
+
import signal
|
| 4 |
+
from transformers import AutoTokenizer, AutoModel
|
| 5 |
+
import readline
|
| 6 |
+
|
| 7 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 8 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
|
| 9 |
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
|
| 10 |
+
# from utils import load_model_on_gpus
|
| 11 |
+
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
|
| 12 |
+
model = model.eval()
|
| 13 |
+
|
| 14 |
+
os_name = platform.system()
|
| 15 |
+
clear_command = 'cls' if os_name == 'Windows' else 'clear'
|
| 16 |
+
stop_stream = False
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def build_prompt(history):
|
| 20 |
+
prompt = "欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
|
| 21 |
+
for query, response in history:
|
| 22 |
+
prompt += f"\n\n用户:{query}"
|
| 23 |
+
prompt += f"\n\nChatGLM2-6B:{response}"
|
| 24 |
+
return prompt
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def signal_handler(signal, frame):
|
| 28 |
+
global stop_stream
|
| 29 |
+
stop_stream = True
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def main():
|
| 33 |
+
past_key_values, history = None, []
|
| 34 |
+
global stop_stream
|
| 35 |
+
print("欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
|
| 36 |
+
while True:
|
| 37 |
+
query = input("\n用户:")
|
| 38 |
+
if query.strip() == "stop":
|
| 39 |
+
break
|
| 40 |
+
if query.strip() == "clear":
|
| 41 |
+
past_key_values, history = None, []
|
| 42 |
+
os.system(clear_command)
|
| 43 |
+
print("欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
|
| 44 |
+
continue
|
| 45 |
+
print("\nChatGLM:", end="")
|
| 46 |
+
current_length = 0
|
| 47 |
+
for response, history, past_key_values in model.stream_chat(tokenizer, query, history=history,
|
| 48 |
+
past_key_values=past_key_values,
|
| 49 |
+
return_past_key_values=True):
|
| 50 |
+
if stop_stream:
|
| 51 |
+
stop_stream = False
|
| 52 |
+
break
|
| 53 |
+
else:
|
| 54 |
+
print(response[current_length:], end="", flush=True)
|
| 55 |
+
current_length = len(response)
|
| 56 |
+
print("")
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
if __name__ == "__main__":
|
| 60 |
+
main()
|
evaluation/README.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
首先从 [Tsinghua Cloud](https://cloud.tsinghua.edu.cn/f/e84444333b6d434ea7b0) 下载处理好的 C-Eval 数据集,解压到 `evaluation` 目录下。然后运行
|
| 2 |
+
|
| 3 |
+
```shell
|
| 4 |
+
cd evaluation
|
| 5 |
+
python evaluate_ceval.py
|
| 6 |
+
```
|
| 7 |
+
|
| 8 |
+
这个脚本会在C-Eval的验证集上进行预测并输出准确率。如果想要得到测试集上的结果可以将代码中的 `./CEval/val/**/*.jsonl` 改为 `./CEval/test/**/*.jsonl`,并按照 C-Eval 规定的格式保存结果并在 [官网](https://cevalbenchmark.com/) 上提交。
|
| 9 |
+
|
| 10 |
+
汇报的结果使用的是内部的并行测试框架,结果可能会有轻微波动。
|
evaluation/evaluate_ceval.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
import re
|
| 4 |
+
import json
|
| 5 |
+
import torch
|
| 6 |
+
import torch.utils.data
|
| 7 |
+
from transformers import AutoTokenizer, AutoModel
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 11 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).bfloat16().cuda()
|
| 12 |
+
|
| 13 |
+
choices = ["A", "B", "C", "D"]
|
| 14 |
+
choice_tokens = [tokenizer.encode(choice, add_special_tokens=False)[0] for choice in choices]
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def build_prompt(text):
|
| 18 |
+
return "[Round {}]\n\n问:{}\n\n答:".format(1, text)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
extraction_prompt = '综上所述,ABCD中正确的选项是:'
|
| 22 |
+
|
| 23 |
+
accuracy_dict, count_dict = {}, {}
|
| 24 |
+
with torch.no_grad():
|
| 25 |
+
for entry in glob.glob("./CEval/val/**/*.jsonl", recursive=True):
|
| 26 |
+
dataset = []
|
| 27 |
+
with open(entry, encoding='utf-8') as file:
|
| 28 |
+
for line in file:
|
| 29 |
+
dataset.append(json.loads(line))
|
| 30 |
+
correct = 0
|
| 31 |
+
dataloader = torch.utils.data.DataLoader(dataset, batch_size=8)
|
| 32 |
+
for batch in tqdm(dataloader):
|
| 33 |
+
texts = batch["inputs_pretokenized"]
|
| 34 |
+
queries = [build_prompt(query) for query in texts]
|
| 35 |
+
inputs = tokenizer(queries, padding=True, return_tensors="pt", truncation=True, max_length=2048).to('cuda')
|
| 36 |
+
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=512)
|
| 37 |
+
intermediate_outputs = []
|
| 38 |
+
for idx in range(len(outputs)):
|
| 39 |
+
output = outputs.tolist()[idx][len(inputs["input_ids"][idx]):]
|
| 40 |
+
response = tokenizer.decode(output)
|
| 41 |
+
intermediate_outputs.append(response)
|
| 42 |
+
answer_texts = [text + intermediate + "\n" + extraction_prompt for text, intermediate in
|
| 43 |
+
zip(texts, intermediate_outputs)]
|
| 44 |
+
input_tokens = [build_prompt(answer_text) for answer_text in answer_texts]
|
| 45 |
+
inputs = tokenizer(input_tokens, padding=True, return_tensors="pt", truncation=True, max_length=2048).to('cuda')
|
| 46 |
+
outputs = model(**inputs, return_last_logit=True)
|
| 47 |
+
logits = outputs.logits[:, -1]
|
| 48 |
+
logits = logits[:, choice_tokens]
|
| 49 |
+
preds = logits.argmax(dim=-1)
|
| 50 |
+
correct += (preds.cpu() == batch["label"]).sum().item()
|
| 51 |
+
accuracy = correct / len(dataset)
|
| 52 |
+
print(entry, accuracy)
|
| 53 |
+
accuracy_dict[entry] = accuracy
|
| 54 |
+
count_dict[entry] = len(dataset)
|
| 55 |
+
|
| 56 |
+
acc_total, count_total = 0.0, 0
|
| 57 |
+
for key in accuracy_dict:
|
| 58 |
+
acc_total += accuracy_dict[key] * count_dict[key]
|
| 59 |
+
count_total += count_dict[key]
|
| 60 |
+
print(acc_total / count_total)
|
openai_api.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Implements API for ChatGLM2-6B in OpenAI's format. (https://platform.openai.com/docs/api-reference/chat)
|
| 3 |
+
# Usage: python openai_api.py
|
| 4 |
+
# Visit http://localhost:8000/docs for documents.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
import time
|
| 8 |
+
import torch
|
| 9 |
+
import uvicorn
|
| 10 |
+
from pydantic import BaseModel, Field
|
| 11 |
+
from fastapi import FastAPI, HTTPException
|
| 12 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 13 |
+
from contextlib import asynccontextmanager
|
| 14 |
+
from starlette.responses import StreamingResponse
|
| 15 |
+
from typing import Any, Dict, List, Literal, Optional, Union
|
| 16 |
+
from transformers import AutoTokenizer, AutoModel
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@asynccontextmanager
|
| 20 |
+
async def lifespan(app: FastAPI): # collects GPU memory
|
| 21 |
+
yield
|
| 22 |
+
if torch.cuda.is_available():
|
| 23 |
+
torch.cuda.empty_cache()
|
| 24 |
+
torch.cuda.ipc_collect()
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
app = FastAPI(lifespan=lifespan)
|
| 28 |
+
|
| 29 |
+
app.add_middleware(
|
| 30 |
+
CORSMiddleware,
|
| 31 |
+
allow_origins=["*"],
|
| 32 |
+
allow_credentials=True,
|
| 33 |
+
allow_methods=["*"],
|
| 34 |
+
allow_headers=["*"],
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
class ModelCard(BaseModel):
|
| 38 |
+
id: str
|
| 39 |
+
object: str = "model"
|
| 40 |
+
created: int = Field(default_factory=lambda: int(time.time()))
|
| 41 |
+
owned_by: str = "owner"
|
| 42 |
+
root: Optional[str] = None
|
| 43 |
+
parent: Optional[str] = None
|
| 44 |
+
permission: Optional[list] = None
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class ModelList(BaseModel):
|
| 48 |
+
object: str = "list"
|
| 49 |
+
data: List[ModelCard] = []
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class ChatMessage(BaseModel):
|
| 53 |
+
role: Literal["user", "assistant", "system"]
|
| 54 |
+
content: str
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class DeltaMessage(BaseModel):
|
| 58 |
+
role: Optional[Literal["user", "assistant", "system"]] = None
|
| 59 |
+
content: Optional[str] = None
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class ChatCompletionRequest(BaseModel):
|
| 63 |
+
model: str
|
| 64 |
+
messages: List[ChatMessage]
|
| 65 |
+
temperature: Optional[float] = None
|
| 66 |
+
top_p: Optional[float] = None
|
| 67 |
+
max_length: Optional[int] = None
|
| 68 |
+
stream: Optional[bool] = False
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class ChatCompletionResponseChoice(BaseModel):
|
| 72 |
+
index: int
|
| 73 |
+
message: ChatMessage
|
| 74 |
+
finish_reason: Literal["stop", "length"]
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class ChatCompletionResponseStreamChoice(BaseModel):
|
| 78 |
+
index: int
|
| 79 |
+
delta: DeltaMessage
|
| 80 |
+
finish_reason: Optional[Literal["stop", "length"]]
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class ChatCompletionResponse(BaseModel):
|
| 84 |
+
model: str
|
| 85 |
+
object: Literal["chat.completion", "chat.completion.chunk"]
|
| 86 |
+
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
|
| 87 |
+
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
@app.get("/v1/models", response_model=ModelList)
|
| 91 |
+
async def list_models():
|
| 92 |
+
global model_args
|
| 93 |
+
model_card = ModelCard(id="gpt-3.5-turbo")
|
| 94 |
+
return ModelList(data=[model_card])
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
|
| 98 |
+
async def create_chat_completion(request: ChatCompletionRequest):
|
| 99 |
+
global model, tokenizer
|
| 100 |
+
|
| 101 |
+
if request.messages[-1].role != "user":
|
| 102 |
+
raise HTTPException(status_code=400, detail="Invalid request")
|
| 103 |
+
query = request.messages[-1].content
|
| 104 |
+
|
| 105 |
+
prev_messages = request.messages[:-1]
|
| 106 |
+
if len(prev_messages) > 0 and prev_messages[0].role == "system":
|
| 107 |
+
query = prev_messages.pop(0).content + query
|
| 108 |
+
|
| 109 |
+
history = []
|
| 110 |
+
if len(prev_messages) % 2 == 0:
|
| 111 |
+
for i in range(0, len(prev_messages), 2):
|
| 112 |
+
if prev_messages[i].role == "user" and prev_messages[i+1].role == "assistant":
|
| 113 |
+
history.append([prev_messages[i].content, prev_messages[i+1].content])
|
| 114 |
+
|
| 115 |
+
if request.stream:
|
| 116 |
+
generate = predict(query, history, request.model)
|
| 117 |
+
return StreamingResponse(generate, media_type="text/event-stream")
|
| 118 |
+
|
| 119 |
+
response, _ = model.chat(tokenizer, query, history=history)
|
| 120 |
+
choice_data = ChatCompletionResponseChoice(
|
| 121 |
+
index=0,
|
| 122 |
+
message=ChatMessage(role="assistant", content=response),
|
| 123 |
+
finish_reason="stop"
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion")
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
async def predict(query: str, history: List[List[str]], model_id: str):
|
| 130 |
+
global model, tokenizer
|
| 131 |
+
|
| 132 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 133 |
+
index=0,
|
| 134 |
+
delta=DeltaMessage(role="assistant"),
|
| 135 |
+
finish_reason=None
|
| 136 |
+
)
|
| 137 |
+
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
|
| 138 |
+
yield "data: {}\n\n".format(chunk.json(exclude_unset=True, ensure_ascii=False))
|
| 139 |
+
|
| 140 |
+
current_length = 0
|
| 141 |
+
|
| 142 |
+
for new_response, _ in model.stream_chat(tokenizer, query, history):
|
| 143 |
+
if len(new_response) == current_length:
|
| 144 |
+
continue
|
| 145 |
+
|
| 146 |
+
new_text = new_response[current_length:]
|
| 147 |
+
current_length = len(new_response)
|
| 148 |
+
|
| 149 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 150 |
+
index=0,
|
| 151 |
+
delta=DeltaMessage(content=new_text),
|
| 152 |
+
finish_reason=None
|
| 153 |
+
)
|
| 154 |
+
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
|
| 155 |
+
yield "data: {}\n\n".format(chunk.json(exclude_unset=True, ensure_ascii=False))
|
| 156 |
+
|
| 157 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 158 |
+
index=0,
|
| 159 |
+
delta=DeltaMessage(),
|
| 160 |
+
finish_reason="stop"
|
| 161 |
+
)
|
| 162 |
+
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
|
| 163 |
+
yield "data: {}\n\n".format(chunk.json(exclude_unset=True, ensure_ascii=False))
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
if __name__ == "__main__":
|
| 167 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 168 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
|
| 169 |
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
|
| 170 |
+
# from utils import load_model_on_gpus
|
| 171 |
+
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
|
| 172 |
+
model.eval()
|
| 173 |
+
|
| 174 |
+
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
protobuf
|
| 2 |
+
transformers==4.30.2
|
| 3 |
+
cpm_kernels
|
| 4 |
+
torch>=2.0
|
| 5 |
+
gradio
|
| 6 |
+
mdtex2html
|
| 7 |
+
sentencepiece
|
| 8 |
+
accelerate
|
resources/WECHAT.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src=wechat.jpg width="60%"/>
|
| 3 |
+
|
| 4 |
+
<p> 扫码关注公众号,加入「ChatGLM交流群」 </p>
|
| 5 |
+
<p> Scan the QR code to follow the official account and join the "ChatGLM Discussion Group" </p>
|
| 6 |
+
</div>
|
| 7 |
+
|
resources/cli-demo.png
ADDED
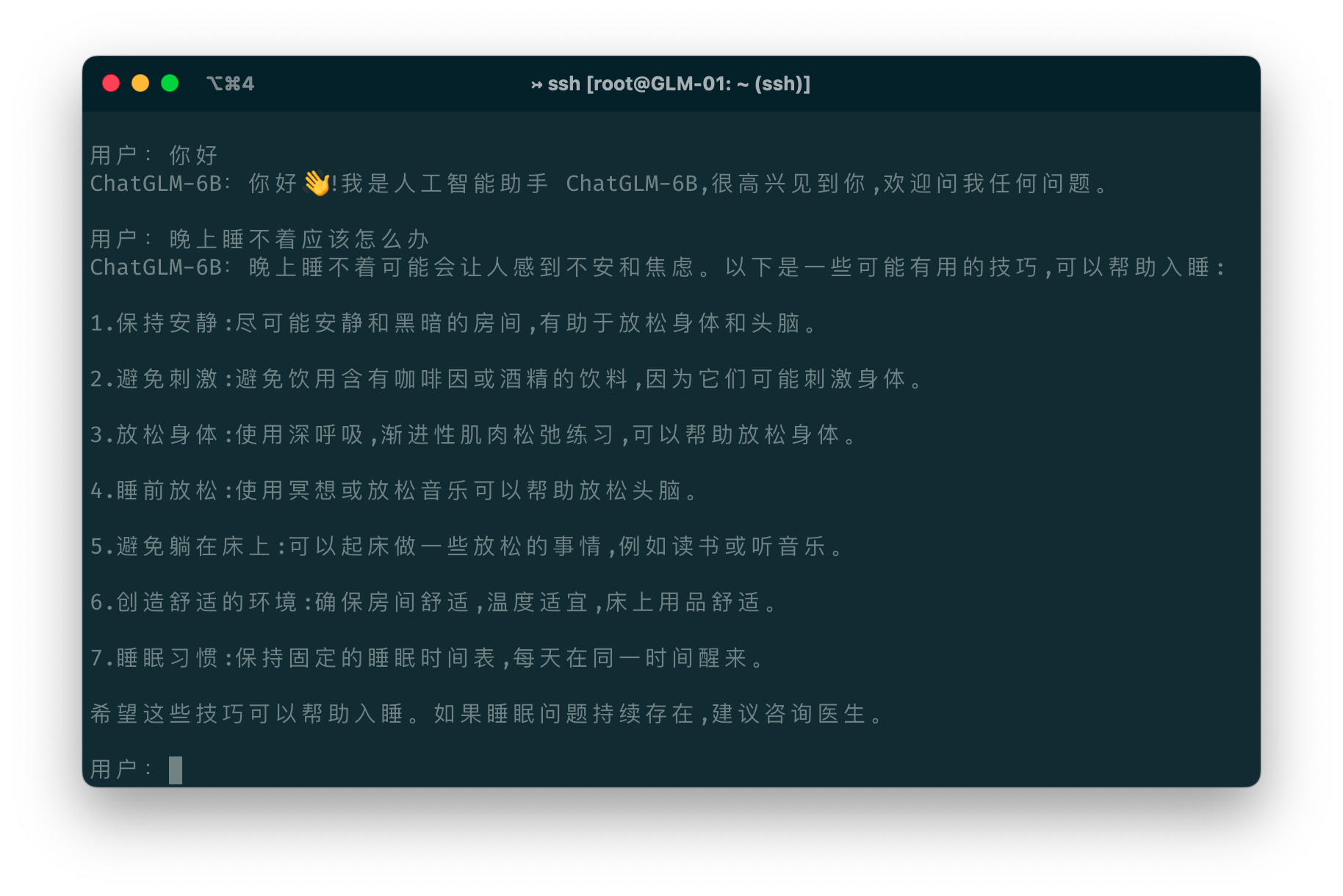
|
resources/knowledge.png
ADDED

|
resources/long-context.png
ADDED

|
Git LFS Details
|
resources/math.png
ADDED

|
resources/web-demo.gif
ADDED

|
Git LFS Details
|
resources/web-demo.png
ADDED
|
resources/wechat.jpg
ADDED

|
utils.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import Dict, Tuple, Union, Optional
|
| 3 |
+
|
| 4 |
+
from torch.nn import Module
|
| 5 |
+
from transformers import AutoModel
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def auto_configure_device_map(num_gpus: int) -> Dict[str, int]:
|
| 9 |
+
# transformer.word_embeddings 占用1层
|
| 10 |
+
# transformer.final_layernorm 和 lm_head 占用1层
|
| 11 |
+
# transformer.layers 占用 28 层
|
| 12 |
+
# 总共30层分配到num_gpus张卡上
|
| 13 |
+
num_trans_layers = 28
|
| 14 |
+
per_gpu_layers = 30 / num_gpus
|
| 15 |
+
|
| 16 |
+
# bugfix: 在linux中调用torch.embedding传入的weight,input不在同一device上,导致RuntimeError
|
| 17 |
+
# windows下 model.device 会被设置成 transformer.word_embeddings.device
|
| 18 |
+
# linux下 model.device 会被设置成 lm_head.device
|
| 19 |
+
# 在调用chat或者stream_chat时,input_ids会被放到model.device上
|
| 20 |
+
# 如果transformer.word_embeddings.device和model.device不同,则会导致RuntimeError
|
| 21 |
+
# 因此这里将transformer.word_embeddings,transformer.final_layernorm,lm_head都放到第一张卡上
|
| 22 |
+
# 本文件来源于https://github.com/THUDM/ChatGLM-6B/blob/main/utils.py
|
| 23 |
+
# 仅此处做少许修改以支持ChatGLM2
|
| 24 |
+
device_map = {
|
| 25 |
+
'transformer.embedding.word_embeddings': 0,
|
| 26 |
+
'transformer.encoder.final_layernorm': 0,
|
| 27 |
+
'transformer.output_layer': 0,
|
| 28 |
+
'transformer.rotary_pos_emb': 0,
|
| 29 |
+
'lm_head': 0
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
used = 2
|
| 33 |
+
gpu_target = 0
|
| 34 |
+
for i in range(num_trans_layers):
|
| 35 |
+
if used >= per_gpu_layers:
|
| 36 |
+
gpu_target += 1
|
| 37 |
+
used = 0
|
| 38 |
+
assert gpu_target < num_gpus
|
| 39 |
+
device_map[f'transformer.encoder.layers.{i}'] = gpu_target
|
| 40 |
+
used += 1
|
| 41 |
+
|
| 42 |
+
return device_map
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def load_model_on_gpus(checkpoint_path: Union[str, os.PathLike], num_gpus: int = 2,
|
| 46 |
+
device_map: Optional[Dict[str, int]] = None, **kwargs) -> Module:
|
| 47 |
+
if num_gpus < 2 and device_map is None:
|
| 48 |
+
model = AutoModel.from_pretrained(checkpoint_path, trust_remote_code=True, **kwargs).half().cuda()
|
| 49 |
+
else:
|
| 50 |
+
from accelerate import dispatch_model
|
| 51 |
+
|
| 52 |
+
model = AutoModel.from_pretrained(checkpoint_path, trust_remote_code=True, **kwargs).half()
|
| 53 |
+
|
| 54 |
+
if device_map is None:
|
| 55 |
+
device_map = auto_configure_device_map(num_gpus)
|
| 56 |
+
|
| 57 |
+
model = dispatch_model(model, device_map=device_map)
|
| 58 |
+
|
| 59 |
+
return model
|
web_demo.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoModel, AutoTokenizer
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import mdtex2html
|
| 4 |
+
from utils import load_model_on_gpus
|
| 5 |
+
|
| 6 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 7 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
|
| 8 |
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
|
| 9 |
+
# from utils import load_model_on_gpus
|
| 10 |
+
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
|
| 11 |
+
model = model.eval()
|
| 12 |
+
|
| 13 |
+
"""Override Chatbot.postprocess"""
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def postprocess(self, y):
|
| 17 |
+
if y is None:
|
| 18 |
+
return []
|
| 19 |
+
for i, (message, response) in enumerate(y):
|
| 20 |
+
y[i] = (
|
| 21 |
+
None if message is None else mdtex2html.convert((message)),
|
| 22 |
+
None if response is None else mdtex2html.convert(response),
|
| 23 |
+
)
|
| 24 |
+
return y
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
gr.Chatbot.postprocess = postprocess
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def parse_text(text):
|
| 31 |
+
"""copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""
|
| 32 |
+
lines = text.split("\n")
|
| 33 |
+
lines = [line for line in lines if line != ""]
|
| 34 |
+
count = 0
|
| 35 |
+
for i, line in enumerate(lines):
|
| 36 |
+
if "```" in line:
|
| 37 |
+
count += 1
|
| 38 |
+
items = line.split('`')
|
| 39 |
+
if count % 2 == 1:
|
| 40 |
+
lines[i] = f'<pre><code class="language-{items[-1]}">'
|
| 41 |
+
else:
|
| 42 |
+
lines[i] = f'<br></code></pre>'
|
| 43 |
+
else:
|
| 44 |
+
if i > 0:
|
| 45 |
+
if count % 2 == 1:
|
| 46 |
+
line = line.replace("`", "\`")
|
| 47 |
+
line = line.replace("<", "<")
|
| 48 |
+
line = line.replace(">", ">")
|
| 49 |
+
line = line.replace(" ", " ")
|
| 50 |
+
line = line.replace("*", "*")
|
| 51 |
+
line = line.replace("_", "_")
|
| 52 |
+
line = line.replace("-", "-")
|
| 53 |
+
line = line.replace(".", ".")
|
| 54 |
+
line = line.replace("!", "!")
|
| 55 |
+
line = line.replace("(", "(")
|
| 56 |
+
line = line.replace(")", ")")
|
| 57 |
+
line = line.replace("$", "$")
|
| 58 |
+
lines[i] = "<br>"+line
|
| 59 |
+
text = "".join(lines)
|
| 60 |
+
return text
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def predict(input, chatbot, max_length, top_p, temperature, history, past_key_values):
|
| 64 |
+
chatbot.append((parse_text(input), ""))
|
| 65 |
+
for response, history, past_key_values in model.stream_chat(tokenizer, input, history, past_key_values=past_key_values,
|
| 66 |
+
return_past_key_values=True,
|
| 67 |
+
max_length=max_length, top_p=top_p,
|
| 68 |
+
temperature=temperature):
|
| 69 |
+
chatbot[-1] = (parse_text(input), parse_text(response))
|
| 70 |
+
|
| 71 |
+
yield chatbot, history, past_key_values
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def reset_user_input():
|
| 75 |
+
return gr.update(value='')
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def reset_state():
|
| 79 |
+
return [], [], None
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
with gr.Blocks() as demo:
|
| 83 |
+
gr.HTML("""<h1 align="center">ChatGLM2-6B</h1>""")
|
| 84 |
+
|
| 85 |
+
chatbot = gr.Chatbot()
|
| 86 |
+
with gr.Row():
|
| 87 |
+
with gr.Column(scale=4):
|
| 88 |
+
with gr.Column(scale=12):
|
| 89 |
+
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
|
| 90 |
+
container=False)
|
| 91 |
+
with gr.Column(min_width=32, scale=1):
|
| 92 |
+
submitBtn = gr.Button("Submit", variant="primary")
|
| 93 |
+
with gr.Column(scale=1):
|
| 94 |
+
emptyBtn = gr.Button("Clear History")
|
| 95 |
+
max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)
|
| 96 |
+
top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)
|
| 97 |
+
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
|
| 98 |
+
|
| 99 |
+
history = gr.State([])
|
| 100 |
+
past_key_values = gr.State(None)
|
| 101 |
+
|
| 102 |
+
submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history, past_key_values],
|
| 103 |
+
[chatbot, history, past_key_values], show_progress=True)
|
| 104 |
+
submitBtn.click(reset_user_input, [], [user_input])
|
| 105 |
+
|
| 106 |
+
emptyBtn.click(reset_state, outputs=[chatbot, history, past_key_values], show_progress=True)
|
| 107 |
+
|
| 108 |
+
demo.queue().launch(share=False, inbrowser=True)
|
web_demo2.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoModel, AutoTokenizer
|
| 2 |
+
import streamlit as st
|
| 3 |
+
from streamlit_chat import message
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
st.set_page_config(
|
| 7 |
+
page_title="ChatGLM2-6b 演示",
|
| 8 |
+
page_icon=":robot:",
|
| 9 |
+
layout='wide'
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@st.cache_resource
|
| 14 |
+
def get_model():
|
| 15 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
|
| 16 |
+
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
|
| 17 |
+
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
|
| 18 |
+
# from utils import load_model_on_gpus
|
| 19 |
+
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
|
| 20 |
+
model = model.eval()
|
| 21 |
+
return tokenizer, model
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
MAX_TURNS = 20
|
| 25 |
+
MAX_BOXES = MAX_TURNS * 2
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def predict(input, max_length, top_p, temperature, history=None):
|
| 29 |
+
tokenizer, model = get_model()
|
| 30 |
+
if history is None:
|
| 31 |
+
history = []
|
| 32 |
+
|
| 33 |
+
with container:
|
| 34 |
+
if len(history) > 0:
|
| 35 |
+
if len(history)>MAX_BOXES:
|
| 36 |
+
history = history[-MAX_TURNS:]
|
| 37 |
+
for i, (query, response) in enumerate(history):
|
| 38 |
+
message(query, avatar_style="big-smile", key=str(i) + "_user")
|
| 39 |
+
message(response, avatar_style="bottts", key=str(i))
|
| 40 |
+
|
| 41 |
+
message(input, avatar_style="big-smile", key=str(len(history)) + "_user")
|
| 42 |
+
st.write("AI正在回复:")
|
| 43 |
+
with st.empty():
|
| 44 |
+
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
|
| 45 |
+
temperature=temperature):
|
| 46 |
+
query, response = history[-1]
|
| 47 |
+
st.write(response)
|
| 48 |
+
|
| 49 |
+
return history
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
container = st.container()
|
| 53 |
+
|
| 54 |
+
# create a prompt text for the text generation
|
| 55 |
+
prompt_text = st.text_area(label="用户命令输入",
|
| 56 |
+
height = 100,
|
| 57 |
+
placeholder="请在这儿输入您的命令")
|
| 58 |
+
|
| 59 |
+
max_length = st.sidebar.slider(
|
| 60 |
+
'max_length', 0, 32768, 8192, step=1
|
| 61 |
+
)
|
| 62 |
+
top_p = st.sidebar.slider(
|
| 63 |
+
'top_p', 0.0, 1.0, 0.8, step=0.01
|
| 64 |
+
)
|
| 65 |
+
temperature = st.sidebar.slider(
|
| 66 |
+
'temperature', 0.0, 1.0, 0.95, step=0.01
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
if 'state' not in st.session_state:
|
| 70 |
+
st.session_state['state'] = []
|
| 71 |
+
|
| 72 |
+
if st.button("发送", key="predict"):
|
| 73 |
+
with st.spinner("AI正在思考,请稍等........"):
|
| 74 |
+
# text generation
|
| 75 |
+
st.session_state["state"] = predict(prompt_text, max_length, top_p, temperature, st.session_state["state"])
|