
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- ko
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# KR-FinBert & KR-FinBert-SC
|
| 8 |
+
|
| 9 |
+
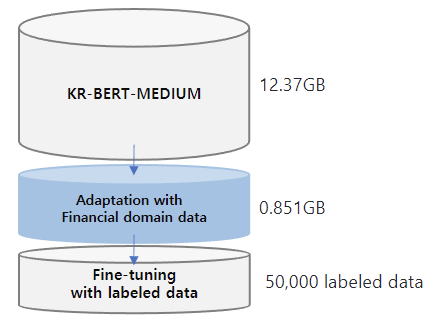
Much progress has been made in the NLP (Natural Language Processing) field, with numerous studies showing that domain adaptation using small-scale corpus and fine-tuning with labeled data is effective for overall performance improvement.
|
| 10 |
+
we proposed KR-FinBert for the financial domain by further pre-training it on a financial corpus and fine-tuning it for sentiment analysis. As many studies have shown, the performance improvement through adaptation and conducting the downstream task was also clear in this experiment.
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## Data
|
| 15 |
+
|
| 16 |
+
The training data for this model is expanded from those of **KR-BERT-MEDIUM**, texts from Korean Wikipedia, general news articles, legal texts crawled from the National Law Information Center and [Korean Comments dataset](https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments). For the transfer learning, **corporate related economic news articles from 72 media sources** such as the Financial Times, The Korean Economy Daily, etc and **analyst reports from 16 securities companies** such as Kiwoom Securities, Samsung Securities, etc are added. Included in the dataset is 440,067 news titles with their content and 11,237 analyst reports. **The total data size is about 13.22GB.** For mlm training, we split the data line by line and **the total no. of lines is 6,379,315.**
|
| 17 |
+
KR-FinBert is trained for 5.5M steps with the maxlen of 512, training batch size of 32, and learning rate of 5e-5, taking 67.48 hours to train the model using NVIDIA TITAN XP.
|