
Commit
•
f5eb6b9
1
Parent(s):
484d56b
added tokenizer files
Browse files- tokenizer/__init__.py +4 -0
- tokenizer/kmer.py +58 -0
- tokenizer/kmer_bpe.py +139 -0
- tokenizer/main.py +215 -0
- tokenizer/perChar.py +43 -0
- tokenizer/tokenizer.md +62 -0
- tokenizer/trained models/base_4mer.json +0 -0
- tokenizer/trained models/base_4mer.model +3 -0
- tokenizer/trained models/base_5k.json +1 -0
tokenizer/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .main import DNAtokenizer
|
| 2 |
+
from .perChar import PerCharTokenizer
|
| 3 |
+
from .kmer_bpe import KmerPairTokenizer
|
| 4 |
+
from .kmer import KMerTokenizer
|
tokenizer/kmer.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from tqdm import tqdm
|
| 3 |
+
import json
|
| 4 |
+
|
| 5 |
+
class KMerTokenizer:
|
| 6 |
+
def __init__(self, k_mers: int=4):
|
| 7 |
+
self.k_mers = k_mers
|
| 8 |
+
self.vocab = {}
|
| 9 |
+
self.id_to_token = []
|
| 10 |
+
self.token_to_id = {}
|
| 11 |
+
|
| 12 |
+
def tokenize_sequence(self, sequence):
|
| 13 |
+
kmers = [sequence[i:i+self.k_mers] for i in tqdm(range(0, len(sequence), self.k_mers), desc="tokenizing k-mers")]
|
| 14 |
+
return kmers
|
| 15 |
+
|
| 16 |
+
def build_vocab(self, sequences):
|
| 17 |
+
all_kmers = []
|
| 18 |
+
for sequence in sequences:
|
| 19 |
+
all_kmers.extend(self.tokenize_sequence(sequence))
|
| 20 |
+
token_count = {}
|
| 21 |
+
for kmer in all_kmers:
|
| 22 |
+
if kmer in token_count:
|
| 23 |
+
token_count[kmer] += 1
|
| 24 |
+
else:
|
| 25 |
+
token_count[kmer] = 1
|
| 26 |
+
sorted_tokens = sorted(token_count.items(), key=lambda x: x[1], reverse=True)
|
| 27 |
+
for token, _ in sorted_tokens:
|
| 28 |
+
self.token_to_id[token] = len(self.token_to_id)
|
| 29 |
+
self.id_to_token.append(token)
|
| 30 |
+
self.vocab = self.token_to_id
|
| 31 |
+
|
| 32 |
+
def encode(self, sequence):
|
| 33 |
+
encoded_sequence = []
|
| 34 |
+
kmers = self.tokenize_sequence(sequence)
|
| 35 |
+
for kmer in tqdm(kmers, desc="encoding sequences"):
|
| 36 |
+
if kmer in self.token_to_id:
|
| 37 |
+
encoded_sequence.append(self.token_to_id[kmer])
|
| 38 |
+
else:
|
| 39 |
+
encoded_sequence.append(len(self.vocab))
|
| 40 |
+
return encoded_sequence
|
| 41 |
+
|
| 42 |
+
def decode(self, encoded_sequence):
|
| 43 |
+
decoded_sequence = [self.id_to_token[token_id] for token_id in encoded_sequence]
|
| 44 |
+
return decoded_sequence
|
| 45 |
+
|
| 46 |
+
def save_model(self, model_path):
|
| 47 |
+
vocab_file = f"{model_path}/base_{self.k_mers}k.json"
|
| 48 |
+
with open(vocab_file, 'w') as f:
|
| 49 |
+
json.dump(self.vocab, f)
|
| 50 |
+
|
| 51 |
+
def load_model(self, path):
|
| 52 |
+
assert path.endswith('.json')
|
| 53 |
+
with open(path, 'r') as f:
|
| 54 |
+
vocab = json.load(f)
|
| 55 |
+
|
| 56 |
+
self.vocab = vocab
|
| 57 |
+
self.token_to_id = self.vocab
|
| 58 |
+
self.vocab_size = len(vocab)
|
tokenizer/kmer_bpe.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
current_dir = os.path.dirname(os.path.realpath(__file__))
|
| 3 |
+
os.chdir(current_dir)
|
| 4 |
+
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import json
|
| 7 |
+
|
| 8 |
+
class KmerPairTokenizer:
|
| 9 |
+
def __init__(self):
|
| 10 |
+
self.k_mers = 4
|
| 11 |
+
self.vocab = {}
|
| 12 |
+
self.merges = {}
|
| 13 |
+
self.vocab_size = 0
|
| 14 |
+
self.init_vocab = {"\n": 1, "A": 2, "T": 3, "G": 4, "C": 5, "P": 6, "M": 7, "U": 8, " ": 9}
|
| 15 |
+
|
| 16 |
+
def _tokenize_seq(self, sequence):
|
| 17 |
+
kmers = [sequence[i:i+self.k_mers] for i in tqdm(range(0, len(sequence), self.k_mers), desc="tokenizing k-mers")]
|
| 18 |
+
return kmers
|
| 19 |
+
|
| 20 |
+
def _get_stats(self, ids, counts=None):
|
| 21 |
+
"""
|
| 22 |
+
takes list of integers and returns dictionary of counts of pairs(consecutive ones)
|
| 23 |
+
eg: [1, 2, 3, 1, 2] -> {(1, 2): 2, (2, 3): 1, (3, 1): 1}
|
| 24 |
+
allows to update an existing dictionary of counts
|
| 25 |
+
"""
|
| 26 |
+
counts = {} if counts is None else counts
|
| 27 |
+
for pair in zip(ids, ids[1:]):
|
| 28 |
+
counts[pair] = counts.get(pair, 0) + 1
|
| 29 |
+
return counts
|
| 30 |
+
|
| 31 |
+
def _merge(self, ids, pair, idx):
|
| 32 |
+
"""
|
| 33 |
+
in the list of integers, replaces all consecutive pair with the new integer token idx
|
| 34 |
+
eg: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx=4 -> [4, 3, 4]
|
| 35 |
+
"""
|
| 36 |
+
new_ids = []
|
| 37 |
+
i = 0
|
| 38 |
+
while i < len(ids):
|
| 39 |
+
if i+1 < len(ids) and ids[i] == pair[0] and ids[i+1] == pair[1]:
|
| 40 |
+
new_ids.append(idx)
|
| 41 |
+
i += 2
|
| 42 |
+
else:
|
| 43 |
+
new_ids.append(ids[i])
|
| 44 |
+
i += 1
|
| 45 |
+
return new_ids
|
| 46 |
+
|
| 47 |
+
def get_ids(self, data):
|
| 48 |
+
all_kmers = []
|
| 49 |
+
seq_to_no = {}
|
| 50 |
+
ass_no = []
|
| 51 |
+
i = 1
|
| 52 |
+
for seq in data:
|
| 53 |
+
all_kmers.extend(self._tokenize_seq(seq))
|
| 54 |
+
|
| 55 |
+
for seq in all_kmers:
|
| 56 |
+
if seq not in seq_to_no:
|
| 57 |
+
seq_to_no[seq] = i
|
| 58 |
+
i += 1
|
| 59 |
+
ass_no.append(seq_to_no[seq])
|
| 60 |
+
|
| 61 |
+
del all_kmers, i
|
| 62 |
+
return ass_no, seq_to_no
|
| 63 |
+
|
| 64 |
+
def train_tokenizer(self, data: str, max_vocab: int):
|
| 65 |
+
n_merges = max_vocab
|
| 66 |
+
text_pairs, init_vocab = self.get_ids([data])
|
| 67 |
+
ids = list(text_pairs)
|
| 68 |
+
|
| 69 |
+
del text_pairs, max_vocab
|
| 70 |
+
merges = {}
|
| 71 |
+
ids_len = len(init_vocab)
|
| 72 |
+
|
| 73 |
+
for i in tqdm(range(n_merges), desc="training the tokenizer"):
|
| 74 |
+
stats = self._get_stats(ids)
|
| 75 |
+
pair = max(stats, key=stats.get)
|
| 76 |
+
idx = ids_len + i + 1
|
| 77 |
+
ids = self._merge(ids, pair, idx)
|
| 78 |
+
merges[pair] = idx
|
| 79 |
+
|
| 80 |
+
vocab = {value: key for key, value in init_vocab.items()}
|
| 81 |
+
for (p0, p1), idx in merges.items():
|
| 82 |
+
vocab[idx] = vocab[p0] + vocab[p1]
|
| 83 |
+
|
| 84 |
+
self.vocab = vocab
|
| 85 |
+
self.merges = merges
|
| 86 |
+
self.vocab_size = len(self.vocab)
|
| 87 |
+
|
| 88 |
+
del vocab, merges, ids, stats, pair, idx
|
| 89 |
+
|
| 90 |
+
def encode(self, text):
|
| 91 |
+
text_pairs, _ = self.get_ids([text])
|
| 92 |
+
ids = list(text_pairs)
|
| 93 |
+
total_pairs = len(ids) - 1
|
| 94 |
+
|
| 95 |
+
with tqdm(total=total_pairs, desc="Encoding text") as pbar:
|
| 96 |
+
while len(ids) >= 2:
|
| 97 |
+
stats = self._get_stats(ids)
|
| 98 |
+
pair = min(stats, key=lambda p: self.merges.get(p, float('inf')))
|
| 99 |
+
if pair not in self.merges:
|
| 100 |
+
break
|
| 101 |
+
idx = self.merges[pair]
|
| 102 |
+
ids = self._merge(ids, pair, idx)
|
| 103 |
+
pbar.update(1)
|
| 104 |
+
return ids
|
| 105 |
+
|
| 106 |
+
def decode(self, ids):
|
| 107 |
+
tokens = [self.vocab[idx] for idx in ids]
|
| 108 |
+
sequence = ''.join(tokens)
|
| 109 |
+
return sequence
|
| 110 |
+
|
| 111 |
+
def save_model(self, file_path):
|
| 112 |
+
model_file = file_path + f"/base_mer.model"
|
| 113 |
+
vocab_file = file_path + f"/base_kmer.json"
|
| 114 |
+
|
| 115 |
+
with open(model_file, 'w', encoding='utf-8') as f:
|
| 116 |
+
for ids1, ids2 in self.merges:
|
| 117 |
+
f.write(f"{ids1} {ids2}\n")
|
| 118 |
+
with open(vocab_file, 'w') as f:
|
| 119 |
+
json.dump(self.vocab, f)
|
| 120 |
+
print('model file saved successfully!')
|
| 121 |
+
|
| 122 |
+
def load(self, model_path, vocab_path):
|
| 123 |
+
assert model_path.endswith('.model')
|
| 124 |
+
assert vocab_path.endswith('.json')
|
| 125 |
+
|
| 126 |
+
with open(vocab_path, 'r') as f:
|
| 127 |
+
vocab_data = json.load(f)
|
| 128 |
+
|
| 129 |
+
self.vocab = vocab_data
|
| 130 |
+
self.vocab_size = len(vocab_data)
|
| 131 |
+
|
| 132 |
+
merges = {}
|
| 133 |
+
idx = 256 + 1
|
| 134 |
+
with open(model_path, 'r', encoding='utf-8') as fread:
|
| 135 |
+
for line in fread:
|
| 136 |
+
idx1, idx2 = map(int, line.split())
|
| 137 |
+
merges[(idx1, idx2)] = idx
|
| 138 |
+
idx += 1
|
| 139 |
+
self.merges = merges
|
tokenizer/main.py
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
r"""
|
| 2 |
+
- basic bpe-tokenizer that doesn't uses byte pairing, insted uses set of initial unique characters
|
| 3 |
+
to train the new vocab
|
| 4 |
+
- set of initial characters = ["\n", "A", "C", "G", "T", " "] that can be present in a file or are
|
| 5 |
+
needed for the tokenizer
|
| 6 |
+
- save and load functions, saves two files, '.model' and 'vocab.json' and only '.model' file is loaded
|
| 7 |
+
'vocab.json' is just for human interpretation
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
import json
|
| 12 |
+
import os
|
| 13 |
+
current_dir = os.path.dirname(os.path.realpath(__file__))
|
| 14 |
+
os.chdir(current_dir)
|
| 15 |
+
|
| 16 |
+
class DNAtokenizer:
|
| 17 |
+
def __init__(self):
|
| 18 |
+
"""
|
| 19 |
+
inital variables:
|
| 20 |
+
- chars = set of unique characters that could be present in the file, that are needed
|
| 21 |
+
- merges, vocab = empty dictonaries to store future merges and final vocab
|
| 22 |
+
- vocab_size = initially it's equal to 6 or len(chars), updated later
|
| 23 |
+
- str_to_idx, idx_to_str = functions enumerate chars to idx and idx to chars
|
| 24 |
+
"""
|
| 25 |
+
super().__init__()
|
| 26 |
+
self.chars = ["\n", "A", "C", "G", "T", " "]
|
| 27 |
+
self.vocab_size = len(self.chars)
|
| 28 |
+
self.merges = {}
|
| 29 |
+
self.vocab = {}
|
| 30 |
+
self.string_to_index = {char: idx for idx, char in enumerate(self.chars)}
|
| 31 |
+
self.index_to_string = {idx: char for idx, char in enumerate(self.chars)}
|
| 32 |
+
|
| 33 |
+
def _encode(self, string):
|
| 34 |
+
"""
|
| 35 |
+
encoder: takes a string, returns a list of integers
|
| 36 |
+
eg. AATGC --> ['2', '2', '5', '4', '3']
|
| 37 |
+
"""
|
| 38 |
+
encoded = [self.string_to_index[char] for char in string]
|
| 39 |
+
return encoded
|
| 40 |
+
|
| 41 |
+
def _decode(self, integer):
|
| 42 |
+
"""
|
| 43 |
+
decoder: takes a list of integers, returns a string
|
| 44 |
+
eg. ['2', '2', '5', '4', '3'] --> AATGC
|
| 45 |
+
"""
|
| 46 |
+
decoded = ''.join([self.index_to_string[i] for i in integer])
|
| 47 |
+
return decoded
|
| 48 |
+
|
| 49 |
+
def _get_stats(self, ids, counts=None):
|
| 50 |
+
"""
|
| 51 |
+
takes list of integers and returns dictionary of counts of pairs(consecutive ones)
|
| 52 |
+
eg: [1, 2, 3, 1, 2] -> {(1, 2): 2, (2, 3): 1, (3, 1): 1}
|
| 53 |
+
allows to update an existing dictionary of counts
|
| 54 |
+
"""
|
| 55 |
+
counts = {} if counts is None else counts
|
| 56 |
+
for pair in zip(ids, ids[1:]):
|
| 57 |
+
counts[pair] = counts.get(pair, 0) + 1
|
| 58 |
+
return counts
|
| 59 |
+
|
| 60 |
+
def _merge(self, ids, pair, idx):
|
| 61 |
+
"""
|
| 62 |
+
in the list of integers, replaces all consecutive pair with the new integer token idx
|
| 63 |
+
eg: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx=4 -> [4, 3, 4]
|
| 64 |
+
"""
|
| 65 |
+
new_ids = []
|
| 66 |
+
i = 0
|
| 67 |
+
while i < len(ids):
|
| 68 |
+
if i+1 < len(ids) and ids[i] == pair[0] and ids[i+1] == pair[1]:
|
| 69 |
+
new_ids.append(idx)
|
| 70 |
+
i += 2
|
| 71 |
+
else:
|
| 72 |
+
new_ids.append(ids[i])
|
| 73 |
+
i += 1
|
| 74 |
+
return new_ids
|
| 75 |
+
|
| 76 |
+
def _build_vocab(self):
|
| 77 |
+
"""
|
| 78 |
+
it was causing some bugs, if not used, so I had to use it
|
| 79 |
+
"""
|
| 80 |
+
return {i: ids for i, ids in enumerate(self.chars)}
|
| 81 |
+
|
| 82 |
+
def train(self, train_data, target_vocab):
|
| 83 |
+
"""
|
| 84 |
+
- takes in the data, encodes it using _encode() function, converts each unique char to index
|
| 85 |
+
eg. AATGC --> ['2', '2', '5', '4', '3']
|
| 86 |
+
- performs iteration till n_merges i.e. target_vocab - self.vocab_size
|
| 87 |
+
- each iteration, makes dictonary of 2 consecutive pairs and then merges the max occuring
|
| 88 |
+
pair together
|
| 89 |
+
- at the end uses merges to build final vocab
|
| 90 |
+
|
| 91 |
+
Args:
|
| 92 |
+
train_data (str): a big file containing lots of dna sequence
|
| 93 |
+
target_vocab (integer): name tells you fucking idiot
|
| 94 |
+
"""
|
| 95 |
+
vocab = self._build_vocab()
|
| 96 |
+
tokens = self._encode(train_data)
|
| 97 |
+
ids = list(tokens)
|
| 98 |
+
|
| 99 |
+
merges = {}
|
| 100 |
+
n_merges = target_vocab - self.vocab_size + 1
|
| 101 |
+
for i in tqdm(range(n_merges), desc='Training the tokenizer\t'):
|
| 102 |
+
stats = self._get_stats(ids)
|
| 103 |
+
pair = max(stats, key=stats.get)
|
| 104 |
+
idx = self.vocab_size + i
|
| 105 |
+
ids = self._merge(ids, pair, idx)
|
| 106 |
+
merges[pair] = idx
|
| 107 |
+
|
| 108 |
+
for (p0, p1), idx in merges.items():
|
| 109 |
+
vocab[idx] = vocab[p0] + vocab[p1]
|
| 110 |
+
|
| 111 |
+
self.vocab = vocab
|
| 112 |
+
self.merges = merges
|
| 113 |
+
self.vocab_size = len(vocab)
|
| 114 |
+
|
| 115 |
+
def continue_train(self, train_data, n_merges):
|
| 116 |
+
"""
|
| 117 |
+
- takes in the data, performs iteration till n_merges
|
| 118 |
+
- continues from the last index of the loaded merges
|
| 119 |
+
- each iteration, makes dictonary of 2 consecutive pairs and then merges the max occuring
|
| 120 |
+
pair together (same as train())
|
| 121 |
+
- at the end uses merges to build final vocab
|
| 122 |
+
|
| 123 |
+
Args:
|
| 124 |
+
train_data (str): a big file containing lots of dna sequence
|
| 125 |
+
n_merges (integer): no of merges
|
| 126 |
+
|
| 127 |
+
** this function has some problems
|
| 128 |
+
"""
|
| 129 |
+
tokens = self._encode(train_data)
|
| 130 |
+
ids = list(tokens)
|
| 131 |
+
for i in tqdm(range(n_merges), desc='Training continue'):
|
| 132 |
+
stats = self._get_stats(ids)
|
| 133 |
+
pair = max(stats, key=stats.get)
|
| 134 |
+
idx = self.vocab_size + i
|
| 135 |
+
ids = self._merge(ids, pair, idx)
|
| 136 |
+
self.merges[pair] = idx
|
| 137 |
+
|
| 138 |
+
for (p0, p1), idx in self.merges.items():
|
| 139 |
+
self.vocab[idx] = self.vocab[p0] + self.vocab[p1]
|
| 140 |
+
|
| 141 |
+
self.vocab_size = len(self.vocab)
|
| 142 |
+
|
| 143 |
+
def encode(self, text):
|
| 144 |
+
"""
|
| 145 |
+
- takes in the input string, encodes it using initial vocab '_encode()' function
|
| 146 |
+
- fetches merges from saved or loaded merges
|
| 147 |
+
|
| 148 |
+
Args:
|
| 149 |
+
train_data (str): string of dna sequence
|
| 150 |
+
self.merges (dictonary): contains merges
|
| 151 |
+
"""
|
| 152 |
+
tokens = self._encode(text)
|
| 153 |
+
ids = list(tokens)
|
| 154 |
+
while len(ids) >= 2:
|
| 155 |
+
stats = self._get_stats(ids)
|
| 156 |
+
pair = min(stats, key=lambda p: self.merges.get(p, float('inf')))
|
| 157 |
+
if pair not in self.merges:
|
| 158 |
+
break
|
| 159 |
+
|
| 160 |
+
idx = self.merges[pair]
|
| 161 |
+
ids = self._merge(ids, pair, idx)
|
| 162 |
+
return ids
|
| 163 |
+
|
| 164 |
+
def decode(self, de_text):
|
| 165 |
+
tokens = [self.vocab[idx] for idx in de_text]
|
| 166 |
+
text = ''.join(tokens)
|
| 167 |
+
return text
|
| 168 |
+
|
| 169 |
+
def save_model(self, model_prefix):
|
| 170 |
+
"""
|
| 171 |
+
- basic save_model() funtion, saves two files, '.model' & 'vocab.json'
|
| 172 |
+
- '.model' contians all the final merges, each on next line
|
| 173 |
+
- 'vocab.json' contians the final vocab, for human interpretation
|
| 174 |
+
|
| 175 |
+
Args:
|
| 176 |
+
model_prefix (str): prefix along with the path
|
| 177 |
+
self.merges (dict): contains final merges
|
| 178 |
+
self.vocab (dict): contains final vocab
|
| 179 |
+
"""
|
| 180 |
+
model_file = model_prefix + '.model'
|
| 181 |
+
|
| 182 |
+
with open(model_file, 'w', encoding='utf-8') as fwrite:
|
| 183 |
+
for ids1, ids2 in self.merges:
|
| 184 |
+
fwrite.write(f"{ids1} {ids2}\n")
|
| 185 |
+
vocab_file = model_prefix + '_vocab.json'
|
| 186 |
+
with open(vocab_file, 'w') as f:
|
| 187 |
+
json.dump(self.vocab, f)
|
| 188 |
+
print('model file saved successfully!')
|
| 189 |
+
|
| 190 |
+
def load_model(self, model_path):
|
| 191 |
+
"""
|
| 192 |
+
- loads the '.model' file
|
| 193 |
+
- re-writes the merges in the new merges dict
|
| 194 |
+
- builds the vocab again for further use
|
| 195 |
+
|
| 196 |
+
Args:
|
| 197 |
+
model_path (str): path to the '.model' file
|
| 198 |
+
"""
|
| 199 |
+
assert model_path.endswith('.model')
|
| 200 |
+
|
| 201 |
+
merges = {}
|
| 202 |
+
idx = self.vocab_size
|
| 203 |
+
with open(model_path, 'r', encoding='utf-8') as fread:
|
| 204 |
+
for line in fread:
|
| 205 |
+
idx1, idx2 = map(int, line.split())
|
| 206 |
+
merges[(idx1, idx2)] = idx
|
| 207 |
+
idx += 1
|
| 208 |
+
vocab = self._build_vocab()
|
| 209 |
+
|
| 210 |
+
for (p0, p1), idx in merges.items():
|
| 211 |
+
vocab[idx] = vocab[p0] + vocab[p1]
|
| 212 |
+
|
| 213 |
+
self.merges = merges
|
| 214 |
+
self.vocab = vocab
|
| 215 |
+
self.vocab_size = len(self.vocab)
|
tokenizer/perChar.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
current_dir = os.path.dirname(os.path.realpath(__file__))
|
| 3 |
+
os.chdir(current_dir)
|
| 4 |
+
|
| 5 |
+
class PerCharTokenizer:
|
| 6 |
+
"""
|
| 7 |
+
Args:
|
| 8 |
+
- chars (list): all bases along with special tokens represented as characters
|
| 9 |
+
- vocab_size (int): size of vocabulary
|
| 10 |
+
|
| 11 |
+
Working:
|
| 12 |
+
- vocab contains all the bases and ['P', 'M', 'U'] as padding, mask and unknown token
|
| 13 |
+
- encode(): iterates over each character a time and the looks up for the position in vocab
|
| 14 |
+
and returns it's position as integer
|
| 15 |
+
- decode(): takes input of a list of integers and returns the specific item from vocab
|
| 16 |
+
"""
|
| 17 |
+
def __init__(self):
|
| 18 |
+
super().__init__()
|
| 19 |
+
self.chars = ['\n', 'A', 'T', 'G', 'C', 'P', 'M', 'U', ' ']
|
| 20 |
+
self.vocab_size = len(self.chars)
|
| 21 |
+
self.string_to_index = {ch: i for i, ch in enumerate(self.chars)}
|
| 22 |
+
self.index_to_string = {i: ch for i, ch in enumerate(self.chars)}
|
| 23 |
+
|
| 24 |
+
def encode(self, string):
|
| 25 |
+
encoded = []
|
| 26 |
+
for char in string:
|
| 27 |
+
if char in self.string_to_index:
|
| 28 |
+
encoded.append(self.string_to_index[char])
|
| 29 |
+
else:
|
| 30 |
+
special_index = len(self.string_to_index)
|
| 31 |
+
self.string_to_index[char] = special_index
|
| 32 |
+
self.index_to_string[special_index] = char
|
| 33 |
+
encoded.append(special_index)
|
| 34 |
+
return encoded
|
| 35 |
+
|
| 36 |
+
def decode(self, integer):
|
| 37 |
+
decoded = []
|
| 38 |
+
for i in integer:
|
| 39 |
+
if i in self.index_to_string:
|
| 40 |
+
decoded.append(self.index_to_string[i])
|
| 41 |
+
else:
|
| 42 |
+
continue
|
| 43 |
+
return ''.join(decoded)
|
tokenizer/tokenizer.md
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# tokenizing DNA sequences
|
| 2 |
+
|
| 3 |
+
Tokenizers for DNA tokenization for enigma-1.5b model.
|
| 4 |
+
## Overview
|
| 5 |
+
DNA-(Dexoy-ribo Nucleic Acid) has 4 nucleobases named Adenine, Thymine, Guanine, Cytosine or A, T, G, C. Just like in english we have most basic things: alphabets, in DNA, these nucleobases are most basic things. We need to tokenize them on the basis of these pairs and characters. So this means, our initial vocab is going to be ['A', 'T', 'G', 'C'] instead of 256 utf-8 characters.
|
| 6 |
+
|
| 7 |
+
Read more about DNA: [Wikipedia/DNA](https://en.wikipedia.org/wiki/DNA)
|
| 8 |
+
|
| 9 |
+
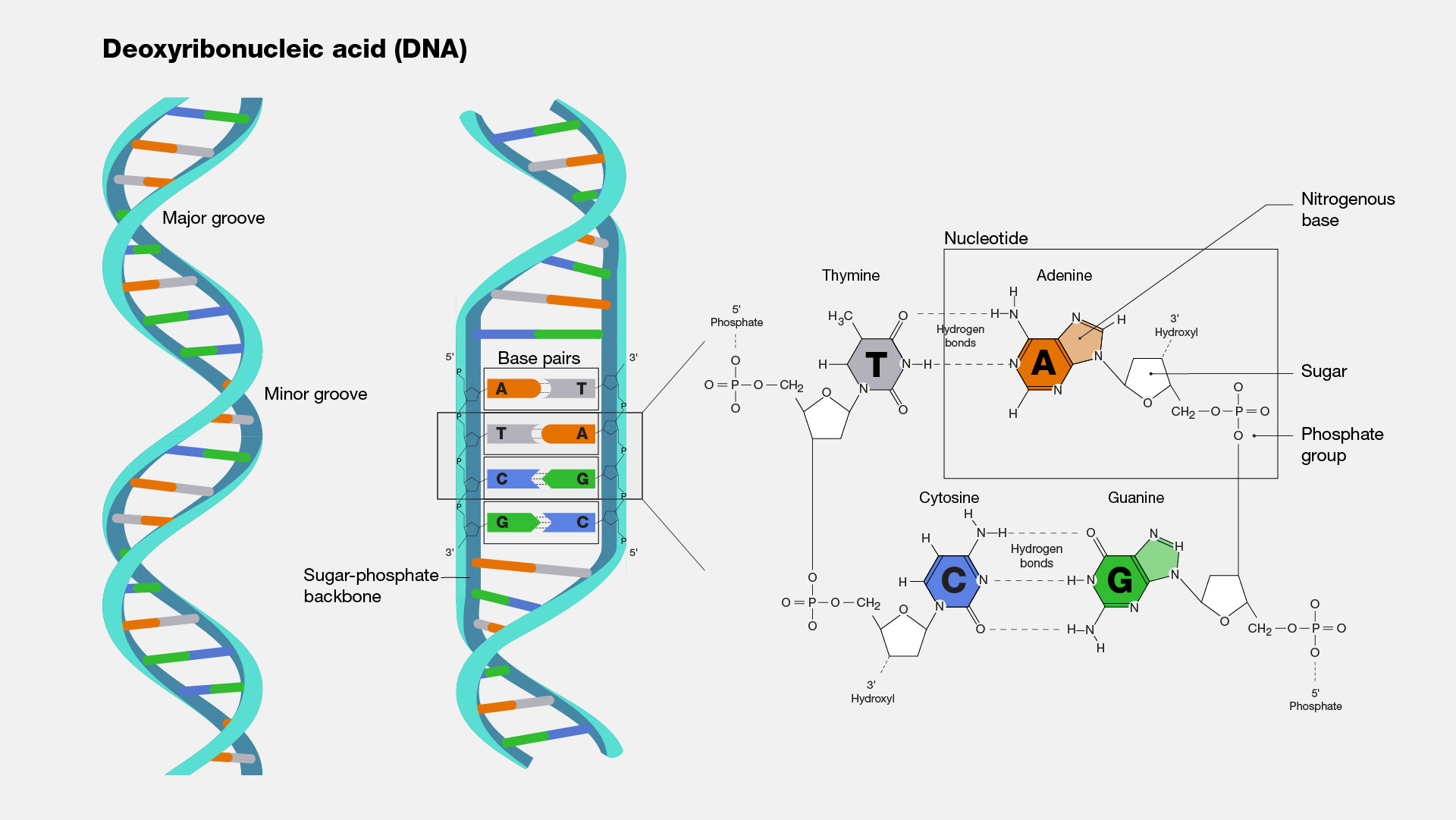
|
| 10 |
+
|
| 11 |
+
## Tokenizer:
|
| 12 |
+
|
| 13 |
+
### Base Level
|
| 14 |
+
It's very basic in working, just like per-character tokenizer which enumerates each and every unique character present in the train file. In our case, we'll have only 4-bases along with '`\n`' and 4-special tokens represented as characters. P, M, U, S as padding, mask, unknown & space token, respectively.
|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
self.init_vocab = {"\n": 1, "A": 2, "T": 3, "G": 4, "C": 5, "P": 6, "M": 7, "U": 8, "S": 9}
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
For encoding and decoding purpose, two functions `string_to_index` & `index_to_string` convert each character into a number from 1 to 9 and decoder takes those 1 to 9 numbers and returns the joint string of respective characters.
|
| 21 |
+
```python
|
| 22 |
+
self.string_to_index = {ch: i for i, ch in enumerate(self.chars)}
|
| 23 |
+
self.index_to_string = {i: ch for i, ch in enumerate(self.chars)}
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
### K-Mer Tokenization
|
| 27 |
+
Let's say we have a long sequence of DNA. This tokenizer splits that sequence into sections of consecutively occurring bases, and each section has length of value equal to `k_mer` which is by default set to 4.
|
| 28 |
+
`build_vocab()` function then builds a vocab out of all tokenized sequences by storing them into a new dictionary, seq as key and index as value. And finally, you can save the generated vocab using `save_model()` function and can be loaded later for use.
|
| 29 |
+
```python
|
| 30 |
+
tokenizer.load_model('../tokenizer/trained models/base_5k.json')
|
| 31 |
+
```
|
| 32 |
+
I used this tokenizer to train decoder-only model, here is how to use it:
|
| 33 |
+
```python
|
| 34 |
+
from tokenizer import KMerTokenizer
|
| 35 |
+
|
| 36 |
+
tokenizer = KMerTokenizer(k_mers=5)
|
| 37 |
+
tokenizer.build_vocab([train_data])
|
| 38 |
+
tokenizer.save_model('../tokenizer/trained models')
|
| 39 |
+
|
| 40 |
+
encoded_tokens = tokenizer.encode(test_data)
|
| 41 |
+
decoded_tokens = tokenizer.decode(encoded_tokens)
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
### Sub-K-Mer Level
|
| 45 |
+
It works kind of same as BPE tokenizer, however has some changes in the way it builds its vocab. It first splits it's training into sequences containing only 4 consecutive letters of DNA (same as K-Mer tokenizer with k=4) and then it trains the tokenizer to build new merges based on the frequency of those pairs, like it would have done with the BPE tokenizer.
|
| 46 |
+
It can be trained quiet easily and then model file can be saved in two different files; *'.model': contains merges* & *'.json: contains vocab'*.
|
| 47 |
+
Encoding and decoding works same as the BPE.
|
| 48 |
+
```python
|
| 49 |
+
from tokenizer import KmerPairTokenizer
|
| 50 |
+
|
| 51 |
+
tokenizer = KmerPairTokenizer()
|
| 52 |
+
tokenizer.train(train_data)
|
| 53 |
+
tokenizer.save_model('../tokenizer/trained models')
|
| 54 |
+
|
| 55 |
+
encoded_tokens = tokenizer.encode(test_data)
|
| 56 |
+
decoded_tokens = tokenizer.decode(encoded_tokens)
|
| 57 |
+
```
|
| 58 |
+
This tokenizer works fine but it has one problem in decode function, it outputs more tokens than actual present tokens, means:
|
| 59 |
+
```shell
|
| 60 |
+
test_data == decoded_tokens is False
|
| 61 |
+
```
|
| 62 |
+
I'll try to fix it and make this work soon, but for now, it's not suitable for use, at-least not for decoding.
|
tokenizer/trained models/base_4mer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/trained models/base_4mer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e2b954834b3038fac7bbb072cb3a556ab897bdcdb11edc936810cc44cad74b73
|
| 3 |
+
size 6680
|
tokenizer/trained models/base_5k.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"TTTTT": 0, "AAAAA": 1, "CCCAG": 2, "CTGGG": 3, "CCTGG": 4, "CCAGG": 5, "GGAGG": 6, "CCTCC": 7, "GCTGG": 8, "CCAGC": 9, "CAGCC": 10, "GGCTG": 11, "GCCTG": 12, "ATTTT": 13, "AAAAT": 14, "CAGGC": 15, "CTCCC": 16, "TGGGA": 17, "TCCCA": 18, "GGGAG": 19, "GCCTC": 20, "GAGGC": 21, "CAGGA": 22, "TCCTG": 23, "AGGAG": 24, "CTCCT": 25, "CTCAG": 26, "CTGAG": 27, "CTCTG": 28, "CAGAG": 29, "AGCCT": 30, "TTTCT": 31, "GGCAG": 32, "CTGCC": 33, "AGGCT": 34, "GGTGG": 35, "AGAAA": 36, "CCACC": 37, "CAGGG": 38, "CCCTG": 39, "TGCCT": 40, "CCCCA": 41, "TCTCT": 42, "AGGCA": 43, "TTTTG": 44, "TGGGG": 45, "TAAAA": 46, "TTTTA": 47, "CAAAA": 48, "AGAGA": 49, "CCTGC": 50, "GCAGG": 51, "TGGAG": 52, "CTGCA": 53, "TGCAG": 54, "CAGCT": 55, "AGCTG": 56, "AAATA": 57, "TATTT": 58, "CTCCA": 59, "TGAGG": 60, "CCTCA": 61, "CTGGA": 62, "CAGTG": 63, "CACTG": 64, "CAGCA": 65, "AGCCA": 66, "TGGCT": 67, "GCCAG": 68, "CTGGC": 69, "TCCAG": 70, "CTGTG": 71, "TGCTG": 72, "CCTGT": 73, "CACAG": 74, "TTCTT": 75, "TCTTT": 76, "ACAGG": 77, "AGGTG": 78, "TGGTG": 79, "CACCA": 80, "TGGGC": 81, "CACAC": 82, "CCTCT": 83, "TGAGA": 84, "CTTTT": 85, "ACACA": 86, "AAGAA": 87, "TGTGT": 88, "GGCCA": 89, "GCCCA": 90, "AAAGA": 91, "TTTTC": 92, "TTTGT": 93, "TGGCC": 94, "AGAGG": 95, "GTGTG": 96, "GGAGA": 97, "TCTCA": 98, "TCTCC": 99, "CACCT": 100, "TTCCT": 101, "AAAAG": 102, "ACAAA": 103, "AGGAA": 104, "TCTGT": 105, "ACAGA": 106, "GAAAA": 107, "CCCAC": 108, "TCAGG": 109, "TGAGC": 110, "CCTGA": 111, "TGTTT": 112, "AAACA": 113, "GGAAG": 114, "GTGAG": 115, "GTGGG": 116, "AGCAG": 117, "AGGGA": 118, "TCCCT": 119, "CCCTC": 120, "CTTCC": 121, "GGCTC": 122, "TTCTC": 123, "GCTCA": 124, "CACCC": 125, "TGCCC": 126, "GAGCC": 127, "CTGCT": 128, "GGGCA": 129, "AAATT": 130, "GAGAA": 131, "CTCAC": 132, "AATTT": 133, "GAGGG": 134, "GGCCT": 135, "ATAAA": 136, "CATTT": 137, "TTTAT": 138, "GTGGC": 139, "AGGCC": 140, "CAGGT": 141, "GAGGA": 142, "TCCTC": 143, "GAGAG": 144, "TTCTG": 145, "ACCTG": 146, "GCCAC": 147, "CTCTC": 148, "GGGTG": 149, "AATAA": 150, "CAGAA": 151, "GTCTC": 152, "AAATG": 153, "TTATT": 154, "TTTCA": 155, "AGTGA": 156, "CCACA": 157, "CTTCT": 158, "TCACT": 159, "TCAGC": 160, "GAGAC": 161, "TCTGG": 162, "TGAAA": 163, "GCTGA": 164, "TTTAA": 165, "TTAAA": 166, "GGGGA": 167, "TGTGG": 168, "CCAGA": 169, "AGAAG": 170, "TCCCC": 171, "TTGGG": 172, "CTTTG": 173, "GCAGA": 174, "GACAG": 175, "TCTGC": 176, "GGAAA": 177, "GAGGT": 178, "AGGGG": 179, "GGGCT": 180, "ACCTC": 181, "GTTTT": 182, "AGCCC": 183, "CCCAA": 184, "TTTGG": 185, "CCCCT": 186, "TTTCC": 187, "TGTCT": 188, "CTTGG": 189, "CAAAG": 190, "AGACA": 191, "CTGTC": 192, "CCACT": 193, "ACCCA": 194, "GGGGC": 195, "AAAAC": 196, "AGTGG": 197, "TGCCA": 198, "GCCCC": 199, "CCAAG": 200, "TGGCA": 201, "TGGGT": 202, "CCAAA": 203, "GAAGG": 204, "GGGAA": 205, "TCCTT": 206, "AAGGA": 207, "CATCT": 208, "TGGAA": 209, "TTCCC": 210, "CATGG": 211, "GCTGC": 212, "GCAGC": 213, "ACTCC": 214, "AGATG": 215, "CCATG": 216, "CCTTC": 217, "GGAGT": 218, "TTGAG": 219, "CACTT": 220, "TTTGA": 221, "TTCCA": 222, "AAGTG": 223, "AACAA": 224, "TCAAA": 225, "GATGG": 226, "GGTGA": 227, "CTCTT": 228, "TTGTT": 229, "TCACC": 230, "CTCAA": 231, "AAGAG": 232, "CCATC": 233, "GGCCC": 234, "GGGCC": 235, "TCTTG": 236, "ACTTT": 237, "CTTTC": 238, "ATTCT": 239, "CCCCC": 240, "GCAGT": 241, "AAAGT": 242, "GAAAG": 243, "GCCCT": 244, "ACTGC": 245, "TCACA": 246, "AGAAT": 247, "AGGGC": 248, "GAGAT": 249, "TGTGA": 250, "GGGGG": 251, "CAAGA": 252, "CCTTT": 253, "TCTTC": 254, "AAAGG": 255, "CACTC": 256, "TCTGA": 257, "ATCTC": 258, "CTGTA": 259, "TAAAT": 260, "GAGTG": 261, "TACAG": 262, "CCTTG": 263, "GCTCT": 264, "AGAGC": 265, "TGCTT": 266, "CTGGT": 267, "TCAAG": 268, "ACCAG": 269, "ATTTA": 270, "CAAGG": 271, "ACCCC": 272, "TGTTG": 273, "CTTGA": 274, "TTCAG": 275, "TTGAA": 276, "GAGCT": 277, "GAAGA": 278, "CAACA": 279, "TTGCT": 280, "GAGCA": 281, "AAGCA": 282, "ACAGC": 283, "AATTA": 284, "TCAGA": 285, "CTGAA": 286, "GGAGC": 287, "TTCAA": 288, "AGCTC": 289, "GTGGT": 290, "AGTTT": 291, "TAATT": 292, "ACCAC": 293, "CTGTT": 294, "AGTGC": 295, "GCTCC": 296, "GGGGT": 297, "ATGGA": 298, "GCACT": 299, "AACAG": 300, "AGCAC": 301, "AGCAA": 302, "TCATT": 303, "TGTGC": 304, "GTGCC": 305, "AATGA": 306, "GGGAT": 307, "ATGGG": 308, "AAACT": 309, "GCACA": 310, "GTGCA": 311, "ATCCC": 312, "ACATG": 313, "TTCAT": 314, "ATTTC": 315, "CCCAT": 316, "GCTGT": 317, "TGCAC": 318, "CATGT": 319, "GCATG": 320, "TTACA": 321, "TGAAG": 322, "AAGGG": 323, "ATGAA": 324, "GTGCT": 325, "GAAAT": 326, "CCCTT": 327, "TGTAA": 328, "CTTCA": 329, "GGCAC": 330, "GTGGA": 331, "GGATG": 332, "TGCTC": 333, "TCCAC": 334, "CATGC": 335, "CTCAT": 336, "TCCAT": 337, "GGTCT": 338, "ATGAG": 339, "ATCTG": 340, "AGACC": 341, "ATGTG": 342, "CACAT": 343, "TTGCA": 344, "GGTTT": 345, "ATGTT": 346, "CATCC": 347, "TGCAA": 348, "AGGGT": 349, "GGATT": 350, "AATCC": 351, "TTGGC": 352, "CTGAC": 353, "GAAAC": 354, "AACAT": 355, "AAACC": 356, "ATTTG": 357, "GTTTC": 358, "AACCC": 359, "GGGTT": 360, "CAGAT": 361, "GTGAA": 362, "ACCCT": 363, "GCCAA": 364, "CAAAT": 365, "AAGGC": 366, "CCATT": 367, "AGGAT": 368, "ACCAT": 369, "TTCAC": 370, "TCATG": 371, "GTCAG": 372, "ATGGT": 373, "GTCCC": 374, "TGAGT": 375, "CATGA": 376, "GCACC": 377, "ATGCC": 378, "ACTCA": 379, "TGTCC": 380, "GGCAT": 381, "GGACA": 382, "CCAGT": 383, "GGGAC": 384, "ACTCT": 385, "AGAGT": 386, "GCCTT": 387, "GTCTG": 388, "ACTGG": 389, "ATCCT": 390, "AACCT": 391, "AGGTT": 392, "TGACA": 393, "AATGG": 394, "GCTTT": 395, "TGGAT": 396, "ATTCA": 397, "GGCTT": 398, "AGTCT": 399, "AATAT": 400, "ACACC": 401, "ATATT": 402, "TGTCA": 403, "GTGAT": 404, "ATCAC": 405, "AAGCC": 406, "AGACT": 407, "TATAT": 408, "CAGAC": 409, "GGTGC": 410, "TGGTC": 411, "TGAAT": 412, "AAAGC": 413, "CATCA": 414, "ACAGT": 415, "ATATA": 416, "GGTCA": 417, "TGATG": 418, "TTGTG": 419, "TTTGC": 420, "TGACC": 421, "GGTGT": 422, "ACTGT": 423, "ATCCA": 424, "GTCTT": 425, "ATTAT": 426, "GAGTT": 427, "CAAGT": 428, "GACCA": 429, "GCTTC": 430, "GCAAA": 431, "GCTTG": 432, "CACAA": 433, "GAAGC": 434, "ACATT": 435, "TTGGA": 436, "TTGCC": 437, "ATAAT": 438, "TCAGT": 439, "ATACA": 440, "GTTCA": 441, "TGTAT": 442, "CATTC": 443, "ACTTG": 444, "GACCT": 445, "GAATG": 446, "AGTAG": 447, "AACTC": 448, "AGCTT": 449, "TCCAA": 450, "CAAGC": 451, "AAGAC": 452, "AATGT": 453, "GGCAA": 454, "ACTGA": 455, "TGATT": 456, "TGAAC": 457, "AAGCT": 458, "ATCTT": 459, "AGGTC": 460, "AAGAT": 461, "GTTTG": 462, "CAAAC": 463, "CTACT": 464, "TTAAT": 465, "TTTAG": 466, "CTAAA": 467, "CAGTT": 468, "AACTG": 469, "GCCAT": 470, "GATTT": 471, "TTGTA": 472, "ATTAA": 473, "AATCA": 474, "GTCCT": 475, "TGGTT": 476, "AGGAC": 477, "CTCTA": 478, "ATGGC": 479, "TACAA": 480, "AAATC": 481, "AGCTA": 482, "TGCAT": 483, "TAGCT": 484, "AATCT": 485, "ATGCA": 486, "TAGAG": 487, "TCATC": 488, "CTTGC": 489, "GATGA": 490, "AGATT": 491, "AACCA": 492, "AGCAT": 493, "CTTGT": 494, "GCAAG": 495, "TGACT": 496, "TGATC": 497, "AATTC": 498, "GAACA": 499, "GATCA": 500, "AGTCA": 501, "ACAAG": 502, "GGGTC": 503, "GTTGG": 504, "TGTTC": 505, "AACAC": 506, "ACACT": 507, "GAATT": 508, "CCAAC": 509, "CTTTA": 510, "GACCC": 511, "TTCTA": 512, "GTTCT": 513, "CAGTC": 514, "TAGAA": 515, "ACCTT": 516, "ATGCT": 517, "GGAAT": 518, "GTGTT": 519, "AGTTC": 520, "AAGGT": 521, "GAACT": 522, "AGTGT": 523, "AGAAC": 524, "GGACT": 525, "AGTCC": 526, "GATCT": 527, "ATCAG": 528, "GATTA": 529, "ATCAT": 530, "CTGAT": 531, "TAAAG": 532, "TAATC": 533, "AGATC": 534, "GACTG": 535, "GAAGT": 536, "ACTTC": 537, "AACTT": 538, "AAGTT": 539, "ATGAT": 540, "ATTCC": 541, "GTAAT": 542, "GACTC": 543, "TTGGT": 544, "CAACC": 545, "TATAA": 546, "GTCAC": 547, "GAGTC": 548, "ATTAC": 549, "TTATA": 550, "TATTA": 551, "TAATA": 552, "GGTTG": 553, "GTGAC": 554, "GGTTC": 555, "ACCAA": 556, "GAACC": 557, "GTATT": 558, "GTGTC": 559, "ACATA": 560, "CATTG": 561, "ATTAG": 562, "GACAC": 563, "CTAAT": 564, "TGTAG": 565, "TATGT": 566, "TGGAC": 567, "AAGTA": 568, "CTACA": 569, "ATTGT": 570, "AATAC": 571, "GCAAC": 572, "ACAAT": 573, "CAATG": 574, "TACTT": 575, "GTTGC": 576, "GCATT": 577, "GTCCA": 578, "TCTTA": 579, "CCCGG": 580, "TTGTC": 581, "CCGGG": 582, "GACAA": 583, "AATGC": 584, "TAAGA": 585, "TAGGA": 586, "GCTAA": 587, "GACTT": 588, "AAGTC": 589, "GTAGA": 590, "TTTAC": 591, "TCCTA": 592, "TGTTA": 593, "TTAGC": 594, "GGTCC": 595, "TCTAC": 596, "GGAAC": 597, "CAATT": 598, "GTAAA": 599, "TAACA": 600, "CTTAA": 601, "AATTG": 602, "ATTGC": 603, "AGATA": 604, "GGACC": 605, "GTTCC": 606, "GGATC": 607, "AGTAA": 608, "GAATC": 609, "TTAAG": 610, "TTACT": 611, "GATCC": 612, "TTAGA": 613, "ACTAA": 614, "TATCT": 615, "GATTC": 616, "TTGAT": 617, "GCATC": 618, "GATGT": 619, "GCAAT": 620, "TCTAA": 621, "TTAGT": 622, "TACAT": 623, "CCTAG": 624, "CTAGG": 625, "ACATC": 626, "ATGTA": 627, "CTATT": 628, "ATCAA": 629, "AGTTG": 630, "GACAT": 631, "ATGTC": 632, "CCGCC": 633, "CAACT": 634, "TCTAT": 635, "AATAG": 636, "TAGCC": 637, "ATATG": 638, "AGGCG": 639, "GGCGG": 640, "CATAT": 641, "TTATG": 642, "GATGC": 643, "CGCCT": 644, "ATAGA": 645, "TATTC": 646, "ATTGA": 647, "GGCTA": 648, "GAATA": 649, "TACCT": 650, "ACAAC": 651, "TAATG": 652, "CATTA": 653, "CTAGA": 654, "CATAA": 655, "TAAAC": 656, "TCTAG": 657, "AGGTA": 658, "CAGTA": 659, "TCAAT": 660, "GTTGT": 661, "GTTTA": 662, "TACTG": 663, "TTAGG": 664, "TGCTA": 665, "ATGAC": 666, "CCTAA": 667, "GTCAT": 668, "TATTG": 669, "TCATA": 670, "CTTAG": 671, "TAGCA": 672, "TGGTA": 673, "GTAGC": 674, "GCTAC": 675, "CCCCG": 676, "GATTG": 677, "CAATA": 678, "TAGGG": 679, "TATGA": 680, "TACCA": 681, "CCCTA": 682, "ATTGG": 683, "TACTC": 684, "CTAAG": 685, "GAGTA": 686, "CGCCC": 687, "CGGGG": 688, "CTTAT": 689, "CAATC": 690, "AGTTA": 691, "CCTTA": 692, "ATAAG": 693, "TAAGT": 694, "TAACT": 695, "ACTTA": 696, "GTTGA": 697, "TTATC": 698, "TATCA": 699, "TAAGG": 700, "CCAAT": 701, "TACTA": 702, "CATAG": 703, "GATAA": 704, "TCAAC": 705, "CTATG": 706, "CCGAG": 707, "GGGCG": 708, "TAGTA": 709, "CTCGG": 710, "AACTA": 711, "ATCTA": 712, "TGATA": 713, "CGGCC": 714, "GGCCG": 715, "TAGTT": 716, "CTACC": 717, "TAGAT": 718, "TTGAC": 719, "TATGG": 720, "GGTAG": 721, "GTCAA": 722, "TTAAC": 723, "CACTA": 724, "CCATA": 725, "CCTAT": 726, "GTTAA": 727, "GCGTG": 728, "TACAC": 729, "CCCGC": 730, "GCCTA": 731, "CACGC": 732, "GCGGG": 733, "ATAGG": 734, "TAGTG": 735, "GTGTA": 736, "GCCCG": 737, "AGTAT": 738, "GTAGG": 739, "CGGGC": 740, "TAGGC": 741, "CCTAC": 742, "ATACT": 743, "ACTAT": 744, "ATAGT": 745, "TTACC": 746, "CCGGC": 747, "TAGGT": 748, "GTACA": 749, "GCCGG": 750, "TGTAC": 751, "ACCTA": 752, "CGTGG": 753, "TACCC": 754, "GGTAA": 755, "CTATA": 756, "GTAAG": 757, "ACTAC": 758, "GTAGT": 759, "TATAG": 760, "TAAGC": 761, "CCACG": 762, "CTTAC": 763, "TCCCG": 764, "GGGTA": 765, "GCTTA": 766, "CCTCG": 767, "CGGGA": 768, "GTTAT": 769, "GGATA": 770, "CTAGC": 771, "ATAAC": 772, "GCTAG": 773, "GATAT": 774, "CGAGG": 775, "ATAGC": 776, "CATAC": 777, "GCTAT": 778, "TATCC": 779, "GGCGC": 780, "ATATC": 781, "GCGCC": 782, "TAGTC": 783, "GACTA": 784, "GTATG": 785, "CTCCG": 786, "AGCCG": 787, "CGAGA": 788, "GGTTA": 789, "CGGAG": 790, "CGGCT": 791, "CTAAC": 792, "TAACC": 793, "TCTCG": 794, "GTTAG": 795, "TATAC": 796, "GGCGT": 797, "ACGCC": 798, "GCATA": 799, "CTATC": 800, "GATAG": 801, "TATGC": 802, "ATACC": 803, "GGTAT": 804, "GTATA": 805, "TGGCG": 806, "CTAGT": 807, "CACGG": 808, "CGCCA": 809, "CCGTG": 810, "ACTAG": 811, "GTACT": 812, "CGTGA": 813, "TAGAC": 814, "AGTAC": 815, "GTCTA": 816, "CGGTG": 817, "CACCG": 818, "TCACG": 819, "GTTAC": 820, "GTAAC": 821, "CAGCG": 822, "CGCTG": 823, "TCGGC": 824, "CGTCT": 825, "AGACG": 826, "CGCAG": 827, "GCCGA": 828, "CCGTC": 829, "CACGT": 830, "CTGCG": 831, "CGTGC": 832, "GCCGC": 833, "GTATC": 834, "ACGTG": 835, "GGTAC": 836, "GCACG": 837, "CCCGT": 838, "GTACC": 839, "ACGGG": 840, "CGGGT": 841, "GCGGC": 842, "CCCGA": 843, "GACGG": 844, "TCGGG": 845, "GATAC": 846, "ACCCG": 847, "CGTGT": 848, "ACACG": 849, "TCCGC": 850, "GCGGA": 851, "AGCGA": 852, "TCGCT": 853, "GCGAG": 854, "CGCTC": 855, "GAGCG": 856, "CCGCA": 857, "TGCGG": 858, "CTCGC": 859, "CCGCT": 860, "AGCGG": 861, "GGCGA": 862, "TGCCG": 863, "CGGCA": 864, "TCGTG": 865, "CTCGA": 866, "CGCTT": 867, "GTGCG": 868, "CACGA": 869, "TCGAG": 870, "CGCAC": 871, "TCGCC": 872, "TCCGT": 873, "TCCGG": 874, "CGTCC": 875, "AAGCG": 876, "GGACG": 877, "CCGGA": 878, "ACCGC": 879, "GCGCA": 880, "ACGGA": 881, "TGCGC": 882, "CTCGT": 883, "GCGGT": 884, "CGAGT": 885, "ATCGC": 886, "CGAGC": 887, "AGCGC": 888, "ACTCG": 889, "ACGCA": 890, "GCGAT": 891, "ACGAG": 892, "ACGGC": 893, "GCCGT": 894, "ACGGT": 895, "GCGCT": 896, "TGCGT": 897, "ACCGT": 898, "AAACG": 899, "CGTTT": 900, "GCTCG": 901, "AGCGT": 902, "GATCG": 903, "ACGCT": 904, "CGATC": 905, "CGCGC": 906, "GCGCG": 907, "TTCCG": 908, "CGGAA": 909, "ATCCG": 910, "CGACA": 911, "CGCGG": 912, "ACCGG": 913, "TGTCG": 914, "CTTCG": 915, "GACGC": 916, "GCGTC": 917, "CGTCA": 918, "CCGCG": 919, "CGGAT": 920, "CCGGT": 921, "TGACG": 922, "ACGTT": 923, "CGAAG": 924, "TCGAA": 925, "TTCGA": 926, "AACGT": 927, "CGATT": 928, "CATCG": 929, "CCGAC": 930, "GACGT": 931, "CGATG": 932, "AATCG": 933, "CGAAA": 934, "ACGTC": 935, "GTCGG": 936, "GAACG": 937, "CGCCG": 938, "CGGTC": 939, "CGTTC": 940, "CGGCG": 941, "GTCGC": 942, "GCGAC": 943, "AACGG": 944, "TTTCG": 945, "GACCG": 946, "CCGTT": 947, "TCCGA": 948, "CGACC": 949, "TTCGG": 950, "CGTTG": 951, "GGTCG": 952, "CCGAA": 953, "CGAAC": 954, "CGCAT": 955, "GTTCG": 956, "TCGGA": 957, "CGGAC": 958, "TCGCA": 959, "TGCGA": 960, "ACCGA": 961, "GTCCG": 962, "ATGCG": 963, "ATCGT": 964, "CAACG": 965, "TTCGT": 966, "TCGTC": 967, "TCGGT": 968, "TCGTT": 969, "ACGAA": 970, "ACGAT": 971, "AACCG": 972, "AACGA": 973, "CGCAA": 974, "TTGCG": 975, "CGGTT": 976, "GACGA": 977, "AACGC": 978, "GCGAA": 979, "AGTCG": 980, "GCGTT": 981, "CGACT": 982, "TTCGC": 983, "ACGTA": 984, "TACGT": 985, "TCGAT": 986, "ATCGA": 987, "CGAAT": 988, "ATCGG": 989, "ATTCG": 990, "GTCGT": 991, "CCGAT": 992, "CTACG": 993, "CGTAG": 994, "ATACG": 995, "ACGAC": 996, "TTACG": 997, "CCGTA": 998, "CGTAT": 999, "TACGG": 1000, "CGTAA": 1001, "TAGCG": 1002, "TAACG": 1003, "CGTTA": 1004, "CGGTA": 1005, "CGCTA": 1006, "TCGAC": 1007, "TACCG": 1008, "GTCGA": 1009, "TCGTA": 1010, "TACGA": 1011, "ACGCG": 1012, "TACGC": 1013, "GCGTA": 1014, "CGCGT": 1015, "CGCGA": 1016, "TCGCG": 1017, "CGTAC": 1018, "GTACG": 1019, "TATCG": 1020, "CGATA": 1021, "CGTCG": 1022, "CGACG": 1023, "\nCAGG": 1024, "\nCCTG": 1025, "AAAA\n": 1026, "\nTTTT": 1027, "\nAAAA": 1028, "C\nCAG": 1029, "\nCCCA": 1030, "A\nACA": 1031, "GGAG\n": 1032, "A\nTGT": 1033, "CAGC\n": 1034, "TTTT\n": 1035, "CCTG\n": 1036, "AAGG\n": 1037, "CCAG\n": 1038, "AA\nTT": 1039, "GGGA\n": 1040, "G\nCTG": 1041, "A\nTGC": 1042, "AA\nTC": 1043, "TGTG\n": 1044, "CTC\nG": 1045, "GGG\nC": 1046, "AAA\nA": 1047, "CCCA\n": 1048, "\nAGGC": 1049, "\nCTGG": 1050, "CCA\nT": 1051, "C\nCTT": 1052, "\nGAGA": 1053, "TGGC\n": 1054, "TT\nCA": 1055, "CT\nAA": 1056, "AG\nCA": 1057, "\nTGTC": 1058, "CTC\nT": 1059, "\nTGAG": 1060, "AGAA\n": 1061, "CAGA\n": 1062, "GGA\nT": 1063, "A\nCAA": 1064, "GG\nTG": 1065, "\nATTT": 1066, "T\nTTT": 1067, "T\nTCT": 1068, "CAAA\n": 1069, "GG\nAG": 1070, "CACC\n": 1071, "CCAC\n": 1072, "C\nCTC": 1073, "AG\nAG": 1074, "G\nCAG": 1075, "CTGG\n": 1076, "TCCT\n": 1077, "AGCC\n": 1078, "G\nTTT": 1079, "CC\nTG": 1080, "\nGCCC": 1081, "TTTG\n": 1082, "TTT\nT": 1083, "\nGCAG": 1084, "GCTG\n": 1085, "\nCAAA": 1086, "AGA\nT": 1087, "CCAT\n": 1088, "A\nCTG": 1089, "CT\nAG": 1090, "CACA\n": 1091, "CA\nGG": 1092, "TT\nGG": 1093, "GG\nCC": 1094, "\nGTGG": 1095, "A\nTTT": 1096, "\nCCAG": 1097, "C\nAGG": 1098, "TT\nCT": 1099, "\nCCCC": 1100, "GC\nCC": 1101, "\nTCCT": 1102, "TCAG\n": 1103, "CAG\nC": 1104, "\nGGGA": 1105, "TTT\nA": 1106, "A\nCAG": 1107, "GAA\nT": 1108, "T\nTGA": 1109, "TTTA\n": 1110, "\nTAAA": 1111, "\nTCTG": 1112, "CC\nCC": 1113, "C\nGTG": 1114, "CTG\nA": 1115, "TAAT\n": 1116, "GCCT\n": 1117, "C\nAAA": 1118, "TGCA\n": 1119, "CCT\nA": 1120, "G\nCCT": 1121, "GCAG\n": 1122, "GAGA\n": 1123, "AAGA\n": 1124, "\nAAGT": 1125, "CACT\n": 1126, "\nAGAC": 1127, "\nCTGC": 1128, "TGG\nC": 1129, "CT\nGA": 1130, "CTG\nG": 1131, "G\nAGG": 1132, "CAC\nT": 1133, "\nTTCT": 1134, "GGC\nC": 1135, "AGG\nG": 1136, "AGCA\n": 1137, "\nATGA": 1138, "TT\nTT": 1139, "GG\nTT": 1140, "TTG\nG": 1141, "CCA\nA": 1142, "\nTGAA": 1143, "CC\nGA": 1144, "GCCA\n": 1145, "AAA\nT": 1146, "GTG\nT": 1147, "CTG\nC": 1148, "CTGC\n": 1149, "\nGCAC": 1150, "CAG\nT": 1151, "C\nTGG": 1152, "T\nTGG": 1153, "TG\nTT": 1154, "GA\nCA": 1155, "TG\nTG": 1156, "TG\nGC": 1157, "C\nGAG": 1158, "\nAGGG": 1159, "TC\nTT": 1160, "G\nCCA": 1161, "GGGG\n": 1162, "\nCAGC": 1163, "TCC\nG": 1164, "CT\nGG": 1165, "GGTG\n": 1166, "TGAG\n": 1167, "AGGA\n": 1168, "CCT\nT": 1169, "CTCT\n": 1170, "CC\nTC": 1171, "CCC\nC": 1172, "G\nTCC": 1173, "ATAA\n": 1174, "A\nCAC": 1175, "GG\nAA": 1176, "GG\nGC": 1177, "ATG\nA": 1178, "\nTCTC": 1179, "A\nTGA": 1180, "\nAGGT": 1181, "\nGGAA": 1182, "T\nTTC": 1183, "\nAGAA": 1184, "GGG\nT": 1185, "GA\nAA": 1186, "A\nTCT": 1187, "AAG\nC": 1188, "A\nACT": 1189, "GCT\nT": 1190, "\nGAGG": 1191, "TGG\nT": 1192, "\nATTA": 1193, "T\nTGT": 1194, "C\nTCA": 1195, "\nTCAG": 1196, "TTA\nA": 1197, "\nTTTG": 1198, "AGAC\n": 1199, "TCT\nA": 1200, "GC\nTG": 1201, "T\nCTG": 1202, "CAT\nT": 1203, "C\nGCA": 1204, "AC\nGA": 1205, "TG\nGT": 1206, "\nGACC": 1207, "TT\nAT": 1208, "TGT\nT": 1209, "CCC\nA": 1210, "CTTT\n": 1211, "\nTATT": 1212, "\nCTCA": 1213, "TT\nTG": 1214, "T\nAAA": 1215, "\nCAGA": 1216, "TGTA\n": 1217, "CT\nTT": 1218, "GA\nGA": 1219, "\nCCCT": 1220, "\nAGTT": 1221, "\nGAAG": 1222, "C\nCCA": 1223, "GGC\nG": 1224, "GTGT\n": 1225, "CTC\nA": 1226, "CTCC\n": 1227, "TTTC\n": 1228, "TGGG\n": 1229, "CAC\nC": 1230, "TTC\nC": 1231, "GA\nTT": 1232, "AGG\nT": 1233, "A\nAGA": 1234, "\nAGAG": 1235, "GC\nCA": 1236, "CCA\nG": 1237, "GCA\nA": 1238, "TT\nTC": 1239, "GTG\nC": 1240, "ATT\nG": 1241, "T\nGCA": 1242, "\nTTCA": 1243, "\nACAG": 1244, "GC\nGG": 1245, "A\nTGG": 1246, "ACAC\n": 1247, "CATG\n": 1248, "TGG\nG": 1249, "AGGG\n": 1250, "GCCC\n": 1251, "\nGACA": 1252, "\nGCCT": 1253, "AAA\nC": 1254, "TT\nAA": 1255, "G\nCCC": 1256, "\nCATG": 1257, "\nGAAA": 1258, "AT\nCA": 1259, "TTG\nA": 1260, "A\nTTG": 1261, "TG\nCA": 1262, "\nCTTC": 1263, "A\nATT": 1264, "\nACCA": 1265, "\nATGT": 1266, "\nAAAG": 1267, "\nATAT": 1268, "TGG\nA": 1269, "T\nCCT": 1270, "AG\nCT": 1271, "GAG\nT": 1272, "\nGGAG": 1273, "CA\nAT": 1274, "G\nAAT": 1275, "TCTT\n": 1276, "T\nGCC": 1277, "ATCA\n": 1278, "GA\nTG": 1279, "AG\nAA": 1280, "\nTTCC": 1281, "GA\nCT": 1282, "TG\nGG": 1283, "CAGT\n": 1284, "G\nTCT": 1285, "\nCCAT": 1286, "TG\nCT": 1287, "C\nATT": 1288, "\nGGGC": 1289, "GTG\nA": 1290, "GGC\nA": 1291, "CAGG\n": 1292, "\nGTGC": 1293, "\nAGCA": 1294, "A\nGAA": 1295, "TGT\nG": 1296, "TG\nGA": 1297, "AAAT\n": 1298, "TC\nGG": 1299, "CA\nCT": 1300, "C\nTGA": 1301, "GAG\nC": 1302, "ATT\nT": 1303, "G\nGCT": 1304, "CC\nGG": 1305, "GCA\nC": 1306, "A\nGAC": 1307, "C\nCCT": 1308, "\nGGGG": 1309, "A\nGGG": 1310, "GGTC\n": 1311, "\nACAT": 1312, "\nCATT": 1313, "\nGGCC": 1314, "C\nGGC": 1315, "CAG\nG": 1316, "CAA\nC": 1317, "\nGGTG": 1318, "\nAAAC": 1319, "\nGAAC": 1320, "C\nTTA": 1321, "GGCC\n": 1322, "CTT\nG": 1323, "CA\nGC": 1324, "\nAACT": 1325, "TTT\nG": 1326, "CCT\nG": 1327, "GGA\nC": 1328, "G\nGGG": 1329, "GGCT\n": 1330, "CCC\nT": 1331, "TCCC\n": 1332, "AG\nGG": 1333, "\nCTTT": 1334, "TT\nGA": 1335, "GGG\nA": 1336, "AGA\nG": 1337, "TCTG\n": 1338, "CT\nTG": 1339, "T\nTGC": 1340, "AG\nGA": 1341, "A\nAAA": 1342, "AGTG\n": 1343, "\nCAGT": 1344, "AT\nAT": 1345, "CA\nAG": 1346, "A\nATG": 1347, "AAAC\n": 1348, "\nTTAA": 1349, "CCT\nC": 1350, "\nGTGT": 1351, "TGT\nA": 1352, "C\nGCC": 1353, "\nTCAT": 1354, "G\nGGC": 1355, "ACCA\n": 1356, "TCA\nT": 1357, "GG\nCA": 1358, "T\nTCC": 1359, "AGG\nC": 1360, "AC\nAC": 1361, "CTTC\n": 1362, "GATG\n": 1363, "A\nGGC": 1364, "G\nCAA": 1365, "CCTC\n": 1366, "\nTGCC": 1367, "G\nAGA": 1368, "CAC\nG": 1369, "CTG\nT": 1370, "AGCT\n": 1371, "TC\nCA": 1372, "AAG\nT": 1373, "C\nTGC": 1374, "AGGC\n": 1375, "TG\nAG": 1376, "AGG\nA": 1377, "AT\nGC": 1378, "GT\nTG": 1379, "\nGCTT": 1380, "AA\nGA": 1381, "GTC\nG": 1382, "GG\nAT": 1383, "\nACTC": 1384, "AGC\nC": 1385, "GGG\nG": 1386, "GCC\nT": 1387, "GTCT\n": 1388, "TCCA\n": 1389, "TGTT\n": 1390, "\nAACA": 1391, "GAGG\n": 1392, "TT\nCC": 1393, "GGGC\n": 1394, "GTGC\n": 1395, "G\nGAG": 1396, "\nTTGC": 1397, "CCCC\n": 1398, "CTCA\n": 1399, "\nGTCA": 1400, "CAC\nA": 1401, "GG\nTC": 1402, "\nGGCT": 1403, "GA\nAT": 1404, "GTTT\n": 1405, "CCTT\n": 1406, "TG\nCC": 1407, "GCT\nA": 1408, "AATA\n": 1409, "\nAAGA": 1410, "TTG\nT": 1411, "AATT\n": 1412, "\nTCCA": 1413, "TCT\nT": 1414, "AC\nAA": 1415, "A\nTTA": 1416, "AA\nCA": 1417, "AT\nTT": 1418, "\nCTGA": 1419, "A\nATA": 1420, "\nCCTT": 1421, "CTTG\n": 1422, "CT\nAT": 1423, "\nGCTC": 1424, "\nTGGA": 1425, "\nCCTA": 1426, "TA\nCT": 1427, "T\nAGC": 1428, "GA\nTC": 1429, "TAT\nT": 1430, "TGCC\n": 1431, "T\nAGA": 1432, "AA\nTG": 1433, "ATAT\n": 1434, "G\nCTC": 1435, "\nATAA": 1436, "GCC\nA": 1437, "CA\nTC": 1438, "\nACTT": 1439, "GAGT\n": 1440, "CAT\nC": 1441, "CA\nCA": 1442, "TGC\nA": 1443, "GC\nGT": 1444, "CAA\nG": 1445, "TTAT\n": 1446, "TGT\nC": 1447, "AT\nGA": 1448, "CCCT\n": 1449, "AG\nCC": 1450, "G\nGGA": 1451, "\nGTCT": 1452, "AGT\nG": 1453, "T\nGGC": 1454, "AG\nGC": 1455, "TA\nCA": 1456, "\nGGGT": 1457, "G\nTGG": 1458, "AC\nGG": 1459, "CC\nGC": 1460, "T\nGAC": 1461, "GG\nGT": 1462, "T\nGGG": 1463, "\nCTGT": 1464, "TTA\nT": 1465, "GAC\nT": 1466, "\nTGCT": 1467, "C\nCCC": 1468, "T\nGGA": 1469, "A\nAGC": 1470, "GG\nCT": 1471, "ACC\nA": 1472, "\nGATG": 1473, "AGC\nG": 1474, "\nGCCA": 1475, "G\nTCA": 1476, "TTGA\n": 1477, "CA\nAA": 1478, "TTT\nC": 1479, "TCC\nT": 1480, "TT\nAC": 1481, "\nCTTG": 1482, "\nTTTA": 1483, "TGAA\n": 1484, "AA\nAG": 1485, "GG\nGG": 1486, "GT\nCA": 1487, "CC\nAA": 1488, "TGAC\n": 1489, "A\nAAC": 1490, "CTGT\n": 1491, "GGT\nT": 1492, "TGCT\n": 1493, "\nGGAC": 1494, "\nAATT": 1495, "C\nTTG": 1496, "GGTT\n": 1497, "TG\nAA": 1498, "AG\nTG": 1499, "ACAG\n": 1500, "A\nCTC": 1501, "TC\nAG": 1502, "C\nGCT": 1503, "ACA\nT": 1504, "GAA\nC": 1505, "GT\nTC": 1506, "C\nGTT": 1507, "\nCCTC": 1508, "T\nTTA": 1509, "AA\nCT": 1510, "C\nATC": 1511, "\nCTCC": 1512, "T\nCCA": 1513, "\nAGAT": 1514, "C\nTAA": 1515, "GG\nAC": 1516, "AAG\nG": 1517, "CC\nCA": 1518, "\nAGGA": 1519, "AAC\nT": 1520, "CAG\nA": 1521, "T\nATT": 1522, "C\nAAG": 1523, "CTAA\n": 1524, "G\nTAG": 1525, "GA\nGT": 1526, "CA\nTT": 1527, "T\nCTT": 1528, "CC\nAG": 1529, "AC\nTT": 1530, "\nTACA": 1531, "AG\nTC": 1532, "\nAGTG": 1533, "A\nTTC": 1534, "\nAGCT": 1535, "ATC\nG": 1536, "TT\nAG": 1537, "\nTGGG": 1538, "ATT\nC": 1539, "\nAGTA": 1540, "TTCC\n": 1541, "T\nACA": 1542, "TTGG\n": 1543, "A\nCCA": 1544, "AG\nTA": 1545, "\nACTG": 1546, "GTT\nT": 1547, "AGC\nT": 1548, "CT\nTC": 1549, "AGAT\n": 1550, "\nAATC": 1551, "A\nGAT": 1552, "TAAA\n": 1553, "AA\nGG": 1554, "TC\nAA": 1555, "A\nCTT": 1556, "AATG\n": 1557, "T\nACT": 1558, "AA\nAA": 1559, "CAT\nG": 1560, "CC\nAT": 1561, "CAA\nA": 1562, "G\nAAA": 1563, "\nGCAA": 1564, "C\nGGA": 1565, "AGT\nA": 1566, "C\nCAC": 1567, "A\nTAA": 1568, "GCT\nG": 1569, "GAT\nA": 1570, "GAAT\n": 1571, "TCC\nC": 1572, "GT\nCC": 1573, "TCAC\n": 1574, "A\nAGG": 1575, "GT\nAA": 1576, "C\nACA": 1577, "CCC\nG": 1578, "A\nGGT": 1579, "TGAT\n": 1580, "GATT\n": 1581, "GAAA\n": 1582, "ATG\nC": 1583, "CTC\nC": 1584, "AAA\nG": 1585, "TGGT\n": 1586, "A\nTCA": 1587, "TC\nCT": 1588, "\nACAC": 1589, "ATG\nT": 1590, "G\nGCA": 1591, "\nATTC": 1592, "C\nGGG": 1593, "ACTG\n": 1594, "AC\nTC": 1595, "A\nGAG": 1596, "\nATGC": 1597, "G\nTAT": 1598, "TCA\nG": 1599, "\nATGG": 1600, "ACCT\n": 1601, "TCT\nC": 1602, "AC\nCC": 1603, "C\nTCC": 1604, "TT\nGC": 1605, "\nTTAG": 1606, "GGGT\n": 1607, "G\nCAC": 1608, "ACC\nG": 1609, "T\nAGT": 1610, "ATGT\n": 1611, "CT\nCA": 1612, "\nTGAT": 1613, "CATT\n": 1614, "C\nTCT": 1615, "A\nGCT": 1616, "\nTTGG": 1617, "G\nTTC": 1618, "G\nGTG": 1619, "TGGA\n": 1620, "T\nTCA": 1621, "T\nCAC": 1622, "T\nGAA": 1623, "\nTTGA": 1624, "GAG\nG": 1625, "AAAG\n": 1626, "A\nCCC": 1627, "TCA\nA": 1628, "\nTCAC": 1629, "ACA\nC": 1630, "CA\nGA": 1631, "T\nGAG": 1632, "TTGT\n": 1633, "AT\nAG": 1634, "T\nAAG": 1635, "A\nAAT": 1636, "\nTGTG": 1637, "ATT\nA": 1638, "GC\nAA": 1639, "TTCT\n": 1640, "TT\nTA": 1641, "A\nCCT": 1642, "AAT\nT": 1643, "GTAG\n": 1644, "AT\nAA": 1645, "GAAG\n": 1646, "GAT\nT": 1647, "GC\nCT": 1648, "TAT\nA": 1649, "C\nGAA": 1650, "\nTGTT": 1651, "GT\nAC": 1652, "GTCC\n": 1653, "\nCACT": 1654, "AG\nAC": 1655, "\nTGGC": 1656, "TATA\n": 1657, "GTTC\n": 1658, "CT\nCC": 1659, "\nATCC": 1660, "CAT\nA": 1661, "ATTA\n": 1662, "ATCT\n": 1663, "\nCACC": 1664, "A\nACC": 1665, "CT\nCT": 1666, "GG\nGA": 1667, "AGT\nC": 1668, "\nTCTT": 1669, "GCTT\n": 1670, "T\nAGG": 1671, "\nCACA": 1672, "C\nGAT": 1673, "\nGAGC": 1674, "C\nGTC": 1675, "GT\nCT": 1676, "\nACCC": 1677, "CC\nTT": 1678, "AG\nGT": 1679, "ATGA\n": 1680, "C\nACC": 1681, "CC\nCT": 1682, "T\nATG": 1683, "AACA\n": 1684, "GGCA\n": 1685, "\nTTAT": 1686, "AA\nCC": 1687, "ATGC\n": 1688, "GGC\nT": 1689, "AGTA\n": 1690, "AGTC\n": 1691, "AGA\nC": 1692, "G\nGAA": 1693, "GAT\nG": 1694, "TGC\nG": 1695, "ATTC\n": 1696, "G\nACC": 1697, "C\nGAC": 1698, "AC\nAG": 1699, "T\nAAC": 1700, "T\nGGT": 1701, "GTT\nG": 1702, "GA\nGG": 1703, "TC\nTA": 1704, "\nCAAC": 1705, "ACA\nA": 1706, "TGA\nT": 1707, "T\nTTG": 1708, "\nTTAC": 1709, "T\nATC": 1710, "TC\nGA": 1711, "A\nAGT": 1712, "AT\nTC": 1713, "\nACCT": 1714, "T\nGCT": 1715, "TA\nTG": 1716, "GTGA\n": 1717, "CT\nGT": 1718, "AACT\n": 1719, "TTCA\n": 1720, "TAT\nC": 1721, "TG\nTC": 1722, "T\nCAT": 1723, "CTGA\n": 1724, "CT\nGC": 1725, "T\nGTG": 1726, "GCAA\n": 1727, "G\nAGC": 1728, "C\nTTC": 1729, "GTCA\n": 1730, "ATA\nC": 1731, "\nCAAG": 1732, "ACT\nG": 1733, "AG\nTT": 1734, "ATCC\n": 1735, "TG\nAT": 1736, "GTGG\n": 1737, "A\nGCC": 1738, "GA\nGC": 1739, "GGT\nA": 1740, "CCAA\n": 1741, "\nTTTC": 1742, "\nGGAT": 1743, "GCAT\n": 1744, "GATC\n": 1745, "AA\nAT": 1746, "TGC\nT": 1747, "T\nTAG": 1748, "G\nCAT": 1749, "ATTT\n": 1750, "CC\nTA": 1751, "TA\nCC": 1752, "G\nGTT": 1753, "AG\nAT": 1754, "TA\nGA": 1755, "GTA\nT": 1756, "\nCTCT": 1757, "AGAG\n": 1758, "G\nTTA": 1759, "G\nAGT": 1760, "CAA\nT": 1761, "CTT\nA": 1762, "\nGGCA": 1763, "AT\nGG": 1764, "ACAA\n": 1765, "TACA\n": 1766, "A\nATC": 1767, "A\nGCA": 1768, "CTT\nT": 1769, "AGGT\n": 1770, "T\nCTC": 1771, "C\nCAT": 1772, "TCTA\n": 1773, "GCAC\n": 1774, "\nTGTA": 1775, "ACC\nT": 1776, "G\nTAA": 1777, "AGTT\n": 1778, "\nGCTG": 1779, "GA\nAC": 1780, "CAAG\n": 1781, "GCTC\n": 1782, "T\nGTC": 1783, "TC\nAC": 1784, "T\nCAG": 1785, "TC\nTC": 1786, "\nTCCC": 1787, "CA\nCC": 1788, "A\nAAG": 1789, "G\nGGT": 1790, "GAAC\n": 1791, "TAG\nG": 1792, "GC\nTA": 1793, "AA\nGC": 1794, "TTA\nG": 1795, "C\nACT": 1796, "CCG\nC": 1797, "GTG\nG": 1798, "ACCC\n": 1799, "GTT\nC": 1800, "G\nACA": 1801, "C\nAGC": 1802, "CC\nGT": 1803, "A\nGGA": 1804, "GCCG\n": 1805, "TC\nGC": 1806, "AAGT\n": 1807, "AGC\nA": 1808, "G\nGTA": 1809, "AA\nGT": 1810, "CCGC\n": 1811, "GCA\nG": 1812, "CC\nAC": 1813, "AAGC\n": 1814, "CA\nAC": 1815, "CT\nAC": 1816, "\nCCAA": 1817, "GCC\nG": 1818, "CG\nTT": 1819, "AT\nCC": 1820, "T\nCAA": 1821, "GAGC\n": 1822, "A\nGTT": 1823, "\nTCAA": 1824, "TGA\nC": 1825, "TC\nTG": 1826, "TAA\nT": 1827, "TCTC\n": 1828, "G\nGCC": 1829, "GC\nGC": 1830, "\nAGCC": 1831, "GCT\nC": 1832, "\nTAAT": 1833, "TGA\nG": 1834, "G\nTGA": 1835, "TTCG\n": 1836, "GT\nGG": 1837, "\nCATC": 1838, "AA\nAC": 1839, "TCAT\n": 1840, "\nTAGG": 1841, "T\nAAT": 1842, "GGA\nA": 1843, "A\nCAT": 1844, "\nTATA": 1845, "TCA\nC": 1846, "TAG\nA": 1847, "AAG\nA": 1848, "AT\nCT": 1849, "ATGG\n": 1850, "AGA\nA": 1851, "C\nTTT": 1852, "\nAAAT": 1853, "GAA\nA": 1854, "\nCTAA": 1855, "TC\nAT": 1856, "T\nTAT": 1857, "T\nCTA": 1858, "TAT\nG": 1859, "TGA\nA": 1860, "AAC\nC": 1861, "C\nAAC": 1862, "TAC\nT": 1863, "G\nATA": 1864, "TAAC\n": 1865, "T\nGAT": 1866, "\nGATA": 1867, "CATA\n": 1868, "A\nGTG": 1869, "GTC\nT": 1870, "ACTT\n": 1871, "\nGTGA": 1872, "AAC\nA": 1873, "CA\nTA": 1874, "TGC\nC": 1875, "CGAG\n": 1876, "A\nCCG": 1877, "\nGAGT": 1878, "TAGC\n": 1879, "CAAC\n": 1880, "ACT\nT": 1881, "CTAT\n": 1882, "CTA\nT": 1883, "GAT\nC": 1884, "\nCGCC": 1885, "ATA\nA": 1886, "G\nTAC": 1887, "T\nTAA": 1888, "GC\nGA": 1889, "AAT\nG": 1890, "AC\nTG": 1891, "AACC\n": 1892, "TTAA\n": 1893, "\nTGAC": 1894, "C\nAGA": 1895, "\nAAGG": 1896, "GTC\nC": 1897, "T\nCCC": 1898, "AAT\nA": 1899, "GT\nAT": 1900, "\nTGGT": 1901, "C\nCTG": 1902, "\nGATC": 1903, "\nCCCG": 1904, "GACC\n": 1905, "\nTTGT": 1906, "\nTAAC": 1907, "AC\nAT": 1908, "GA\nCC": 1909, "GC\nTC": 1910, "GGAA\n": 1911, "CTA\nG": 1912, "AC\nCT": 1913, "ACA\nG": 1914, "\nGTTG": 1915, "CGGG\n": 1916, "GTC\nA": 1917, "\nATCT": 1918, "\nTCTA": 1919, "CG\nCC": 1920, "TCT\nG": 1921, "G\nTGT": 1922, "ACT\nC": 1923, "A\nTCC": 1924, "GGT\nC": 1925, "GGAC\n": 1926, "C\nATG": 1927, "GAA\nG": 1928, "TCCG\n": 1929, "ACAT\n": 1930, "GC\nAG": 1931, "\nCCGG": 1932, "GT\nTA": 1933, "A\nACG": 1934, "GGA\nG": 1935, "\nAACC": 1936, "G\nAAG": 1937, "CGA\nT": 1938, "AT\nTG": 1939, "ATA\nT": 1940, "\nTAGA": 1941, "\nGTTC": 1942, "\nGTAA": 1943, "GTA\nC": 1944, "TAGG\n": 1945, "CCA\nC": 1946, "G\nAAC": 1947, "TTG\nC": 1948, "TACC\n": 1949, "TATG\n": 1950, "C\nAGT": 1951, "CTAG\n": 1952, "GAC\nC": 1953, "TCG\nA": 1954, "TTC\nG": 1955, "GG\nTA": 1956, "TA\nGC": 1957, "TTA\nC": 1958, "\nGATT": 1959, "AC\nCA": 1960, "G\nTGC": 1961, "\nACTA": 1962, "TCC\nA": 1963, "GGT\nG": 1964, "TAA\nA": 1965, "\nGGCG": 1966, "CA\nTG": 1967, "CTAC\n": 1968, "TAC\nA": 1969, "CT\nTA": 1970, "G\nTTG": 1971, "\nTATG": 1972, "AAT\nC": 1973, "C\nATA": 1974, "C\nCAA": 1975, "TAGA\n": 1976, "\nAATG": 1977, "T\nACC": 1978, "TACT\n": 1979, "\nCTAG": 1980, "G\nGAC": 1981, "TAG\nT": 1982, "TTC\nA": 1983, "A\nGTA": 1984, "TA\nGG": 1985, "\nGTTA": 1986, "GT\nGT": 1987, "\nACAA": 1988, "G\nACT": 1989, "CCGG\n": 1990, "A\nGTC": 1991, "GCTA\n": 1992, "\nCCGC": 1993, "\nCGGG": 1994, "TGTC\n": 1995, "CG\nGC": 1996, "C\nGGT": 1997, "TC\nCC": 1998, "GCA\nT": 1999, "C\nAAT": 2000, "CGGT\n": 2001, "CGG\nT": 2002, "TTC\nT": 2003, "TTAC\n": 2004, "TC\nGT": 2005, "CC\nCG": 2006, "TG\nAC": 2007, "GAC\nG": 2008, "AC\nTA": 2009, "ACG\nA": 2010, "GT\nTT": 2011, "GCGG\n": 2012, "CTT\nC": 2013, "\nAGTC": 2014, "CA\nGT": 2015, "GACA\n": 2016, "G\nCCG": 2017, "GA\nCG": 2018, "GTTG\n": 2019, "TAA\nG": 2020, "\nGGTA": 2021, "\nCTCG": 2022, "\nGTCC": 2023, "\nCTTA": 2024, "\nGGTC": 2025, "TATT\n": 2026, "G\nGTC": 2027, "\nTAAG": 2028, "GAC\nA": 2029, "AC\nGT": 2030, "\nCATA": 2031, "\nCTAC": 2032, "T\nGTA": 2033, "GT\nGA": 2034, "\nGCAT": 2035, "\nTACT": 2036, "CATC\n": 2037, "G\nACG": 2038, "AGT\nT": 2039, "GATA\n": 2040, "\nGACT": 2041, "ATC\nA": 2042, "\nTACC": 2043, "CCTA\n": 2044, "AATC\n": 2045, "CTA\nC": 2046, "\nTAGC": 2047, "T\nCCG": 2048, "A\nCTA": 2049, "GACT\n": 2050, "GGAT\n": 2051, "ATG\nG": 2052, "TCAA\n": 2053, "C\nGCG": 2054, "TT\nGT": 2055, "ATA\nG": 2056, "\nACGA": 2057, "GT\nAG": 2058, "ATTG\n": 2059, "C\nTGT": 2060, "TAAG\n": 2061, "\nGTAG": 2062, "TA\nAA": 2063, "\nGGTT": 2064, "GC\nAC": 2065, "C\nCTA": 2066, "\nCCAC": 2067, "AAC\nG": 2068, "C\nTAC": 2069, "T\nATA": 2070, "GTT\nA": 2071, "TCG\nT": 2072, "C\nTAG": 2073, "ACTC\n": 2074, "TA\nAC": 2075, "CGG\nG": 2076, "GAG\nA": 2077, "\nTCGG": 2078, "ACT\nA": 2079, "\nCGTG": 2080, "TAC\nG": 2081, "CCG\nG": 2082, "GT\nGC": 2083, "AGCG\n": 2084, "ATAC\n": 2085, "CGCC\n": 2086, "GA\nAG": 2087, "CG\nAA": 2088, "ACGT\n": 2089, "CCG\nT": 2090, "GCG\nA": 2091, "TG\nTA": 2092, "\nCGGA": 2093, "C\nCCG": 2094, "AA\nTA": 2095, "A\nTAC": 2096, "CCCG\n": 2097, "CGC\nA": 2098, "AT\nGT": 2099, "ACTA\n": 2100, "GTAC\n": 2101, "G\nATG": 2102, "G\nCTA": 2103, "A\nTAT": 2104, "CGC\nT": 2105, "GC\nTT": 2106, "CGGC\n": 2107, "G\nCGG": 2108, "CGC\nC": 2109, "\nTATC": 2110, "GC\nAT": 2111, "TAG\nC": 2112, "CGT\nG": 2113, "G\nCTT": 2114, "GTA\nG": 2115, "C\nACG": 2116, "ATC\nC": 2117, "ATC\nT": 2118, "\nGAAT": 2119, "GA\nTA": 2120, "\nAAGC": 2121, "\nCTAT": 2122, "AT\nAC": 2123, "\nTGCA": 2124, "A\nCGT": 2125, "\nATAC": 2126, "GCC\nC": 2127, "CG\nAT": 2128, "\nGTAT": 2129, "\nCGTA": 2130, "GTAT\n": 2131, "\nTAGT": 2132, "CG\nCT": 2133, "CTTA\n": 2134, "A\nCGG": 2135, "\nATTG": 2136, "CGCA\n": 2137, "GCG\nG": 2138, "TA\nTA": 2139, "\nGACG": 2140, "ACG\nC": 2141, "GG\nCG": 2142, "TCGG\n": 2143, "\nCGGT": 2144, "TA\nAT": 2145, "CGA\nC": 2146, "\nAACG": 2147, "T\nCGT": 2148, "CG\nCA": 2149, "CGAT\n": 2150, "\nGTAC": 2151, "CGG\nA": 2152, "\nAATA": 2153, "C\nCGA": 2154, "\nTCCG": 2155, "ACGC\n": 2156, "GC\nCG": 2157, "C\nGTA": 2158, "AG\nCG": 2159, "GCG\nC": 2160, "CGT\nT": 2161, "T\nCGG": 2162, "G\nGAT": 2163, "CGG\nC": 2164, "GGTA\n": 2165, "CG\nGT": 2166, "TA\nAG": 2167, "GTAA\n": 2168, "C\nTAT": 2169, "TAGT\n": 2170, "CTCG\n": 2171, "TATC\n": 2172, "\nGTTT": 2173, "\nTGCG": 2174, "CCGT\n": 2175, "TA\nTT": 2176, "A\nCGC": 2177, "G\nCGA": 2178, "CG\nTA": 2179, "\nGCGT": 2180, "AC\nGC": 2181, "GCGT\n": 2182, "CG\nAG": 2183, "CGCT\n": 2184, "\nTACG": 2185, "ACC\nC": 2186, "CG\nTG": 2187, "TCG\nC": 2188, "G\nATT": 2189, "\nGCTA": 2190, "CGTG\n": 2191, "ATAG\n": 2192, "TCGT\n": 2193, "TAC\nC": 2194, "\nGCGG": 2195, "CGTA\n": 2196, "CGA\nG": 2197, "GCGC\n": 2198, "\nATCG": 2199, "TT\nCG": 2200, "CCGA\n": 2201, "TA\nTC": 2202, "CCG\nA": 2203, "A\nCGA": 2204, "\nCCGT": 2205, "AT\nTA": 2206, "\nTCGA": 2207, "\nCAAT": 2208, "GCGA\n": 2209, "ACGG\n": 2210, "T\nGTT": 2211, "\nCACG": 2212, "\nATAG": 2213, "AC\nCG": 2214, "CGC\nG": 2215, "\nCGAC": 2216, "\nCGCG": 2217, "T\nCGC": 2218, "CG\nTC": 2219, "CGT\nC": 2220, "AACG\n": 2221, "ATCG\n": 2222, "\nCGTT": 2223, "C\nCGC": 2224, "ACG\nG": 2225, "CGT\nA": 2226, "\nCGGC": 2227, "\nCGAG": 2228, "GCG\nT": 2229, "CGAC\n": 2230, "G\nATC": 2231, "\nATCA": 2232, "TTAG\n": 2233, "T\nTCG": 2234, "TG\nCG": 2235, "CGCG\n": 2236, "\nTCGT": 2237, "GGCG\n": 2238, "GT\nCG": 2239, "AT\nCG": 2240, "TAA\nC": 2241, "CGTC\n": 2242, "\nGCCG": 2243, "CG\nGG": 2244, "\nGTCG": 2245, "CG\nGA": 2246, "CA\nCG": 2247, "GTA\nA": 2248, "A\nTCG": 2249, "TA\nGT": 2250, "CTA\nA": 2251, "G\nCGT": 2252, "C\nCGT": 2253, "C\nTCG": 2254, "T\nCGA": 2255, "\nCCGA": 2256, "\nCGAT": 2257, "TCGA\n": 2258, "G\nGCG": 2259, "\nAGCG": 2260, "CG\nAC": 2261, "T\nGCG": 2262, "TTGC\n": 2263, "CGA\nA": 2264, "CAAT\n": 2265, "GTTA\n": 2266, "GACG\n": 2267, "\nGCGA": 2268, "A\nTAG": 2269, "CACG\n": 2270, "T\nACG": 2271, "TGCG\n": 2272, "\nCGAA": 2273, "\nCGTC": 2274, "\nTCGC": 2275, "AA\nCG": 2276, "\nTTCG": 2277, "ACG\nT": 2278, "T\nTAC": 2279, "TCG\nG": 2280, "ATCA": 2281}
|