

Upload 5 files
Browse files- Energy_Forecast_LTSM.ipynb +0 -0
- Energy_Forecast_LTSM.py +290 -0
- LTSM.png +0 -0
- Readme.md +18 -0
- model.png +0 -0
Energy_Forecast_LTSM.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Energy_Forecast_LTSM.py
ADDED
|
@@ -0,0 +1,290 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#LSTM Model for time series forecast, (c) infinimesh and affiliates, 2020
|
| 2 |
+
# Apache License 2.0
|
| 3 |
+
#Some functions were copied from TensforFlow website time-series tutorial, see: https://www.tensorflow.org/tutorials/structured_data/time_series#top_of_page
|
| 4 |
+
#GitHub: https://github.com/tensorflow/docs/blob/master/site/en/tutorials/structured_data/time_series.ipynb
|
| 5 |
+
#-----------------------------------
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import datetime
|
| 9 |
+
import logging
|
| 10 |
+
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
|
| 11 |
+
import IPython
|
| 12 |
+
import IPython.display
|
| 13 |
+
import matplotlib as mpl
|
| 14 |
+
import matplotlib.pyplot as plt
|
| 15 |
+
import numpy as np
|
| 16 |
+
import pandas as pd
|
| 17 |
+
import seaborn as sns
|
| 18 |
+
import tensorflow as tf
|
| 19 |
+
import datetime as dt
|
| 20 |
+
from sklearn.preprocessing import MinMaxScaler
|
| 21 |
+
mpl.rcParams['figure.figsize'] = (8, 6)
|
| 22 |
+
mpl.rcParams['axes.grid'] = False
|
| 23 |
+
|
| 24 |
+
import warnings
|
| 25 |
+
warnings.filterwarnings("ignore")
|
| 26 |
+
from tensorflow.python.client import device_lib
|
| 27 |
+
|
| 28 |
+
#Some settings
|
| 29 |
+
strategy = tf.distribute.MirroredStrategy()
|
| 30 |
+
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
|
| 31 |
+
print(device_lib.list_local_devices())
|
| 32 |
+
tf.keras.backend.set_floatx('float64')
|
| 33 |
+
|
| 34 |
+
for chunk in pd.read_csv("smartmeter.csv", chunksize= 10**6):
|
| 35 |
+
print(chunk)
|
| 36 |
+
|
| 37 |
+
data = pd.DataFrame(chunk)
|
| 38 |
+
data = data.drop(['device_id', 'device_name', 'property'], axis = 1)
|
| 39 |
+
|
| 40 |
+
# Creating daytime input
|
| 41 |
+
def time_d(x):
|
| 42 |
+
k = datetime.datetime.strptime(x, "%H:%M:%S")
|
| 43 |
+
y = k - datetime.datetime(1900, 1, 1)
|
| 44 |
+
return y.total_seconds()
|
| 45 |
+
|
| 46 |
+
daytime = data['timestamp'].str.slice(start = 11 ,stop=19)
|
| 47 |
+
secondsperday = daytime.map(lambda i: time_d(i))
|
| 48 |
+
data['timestamp'] = data['timestamp'].str.slice(stop=19)
|
| 49 |
+
data['timestamp'] = data['timestamp'].map(lambda i: dt.datetime.strptime(i, '%Y-%m-%d %H:%M:%S'))
|
| 50 |
+
parse_dates = [data['timestamp']]
|
| 51 |
+
|
| 52 |
+
# Creating Weekday input
|
| 53 |
+
wd_input = np.array(data['timestamp'].map(lambda i: int(i.weekday())))
|
| 54 |
+
|
| 55 |
+
# Creating inputs sin\cos
|
| 56 |
+
seconds_in_day = 24*60*60
|
| 57 |
+
data_seconds = np.array(data['timestamp'].map(lambda i: i.weekday()))
|
| 58 |
+
input_sin = np.array(np.sin(2*np.pi*secondsperday/seconds_in_day))
|
| 59 |
+
input_cos = np.array(np.cos(2*np.pi*secondsperday/seconds_in_day))
|
| 60 |
+
|
| 61 |
+
# Putting inputs together in array
|
| 62 |
+
df = pd.DataFrame(data = {'value':data['value'], 'input_sin':input_sin, 'input_cos':input_cos, 'input_wd': wd_input})
|
| 63 |
+
column_indices = {name: i for i, name in enumerate(data.columns)}
|
| 64 |
+
n = len(df)
|
| 65 |
+
train_df = pd.DataFrame(df[0:int(n*0.7)])
|
| 66 |
+
val_df = pd.DataFrame(df[int(n*0.7):int(n*0.9)])
|
| 67 |
+
test_df = pd.DataFrame(df[int(n*0.9):])
|
| 68 |
+
num_features = df.shape[1]
|
| 69 |
+
|
| 70 |
+
# Standardization
|
| 71 |
+
train_mean = train_df['value'].mean()
|
| 72 |
+
train_std = train_df['value'].std()
|
| 73 |
+
train_df['value'] = (train_df['value'] - train_mean) / train_std
|
| 74 |
+
val_df['value'] = (val_df['value'] - train_mean) / train_std
|
| 75 |
+
test_df['value'] = (test_df['value'] - train_mean) / train_std
|
| 76 |
+
|
| 77 |
+
# 1st degree differencing
|
| 78 |
+
train_df['value'] = train_df['value'] - train_df['value'].shift()
|
| 79 |
+
|
| 80 |
+
# Handle negative values in 'value' for loging
|
| 81 |
+
train_df['value'] = train_df['value'].map(lambda i: abs(i))
|
| 82 |
+
train_df.loc[train_df.value <= 0, 'value'] = 0.000000001
|
| 83 |
+
train_df['value'] = train_df['value'].map(lambda i: np.log(i))
|
| 84 |
+
train_df = train_df.replace(np.nan, 0.000000001)
|
| 85 |
+
|
| 86 |
+
# 1st degree differencing
|
| 87 |
+
val_df['value'] = val_df['value'] - val_df['value'].shift()
|
| 88 |
+
|
| 89 |
+
# Handle negative values in 'value' for loging
|
| 90 |
+
val_df['value'] = val_df['value'].map(lambda i: abs(i))
|
| 91 |
+
val_df.loc[val_df.value <= 0, 'value'] = 0.000000001
|
| 92 |
+
val_df['value'] = val_df['value'].map(lambda i: np.log(i))
|
| 93 |
+
val_df = val_df.replace(np.nan, 0.000000001)
|
| 94 |
+
|
| 95 |
+
# 1st degree differencing
|
| 96 |
+
test_df['value'] = test_df['value'] - test_df['value'].shift()
|
| 97 |
+
|
| 98 |
+
# Handle negative values in 'value' for loging
|
| 99 |
+
test_df['value'] = test_df['value'].map(lambda i: abs(i))
|
| 100 |
+
test_df.loc[test_df.value <= 0, 'value'] = 0.000000001
|
| 101 |
+
test_df['value'] = test_df['value'].map(lambda i: np.log(i))
|
| 102 |
+
test_df = test_df.replace(np.nan, 0.000000001)
|
| 103 |
+
|
| 104 |
+
# Creating data window for forecast based on window size
|
| 105 |
+
|
| 106 |
+
class WindowGenerator():
|
| 107 |
+
def __init__(self, input_width, label_width, shift,
|
| 108 |
+
train_df=train_df, val_df=val_df, test_df=test_df,
|
| 109 |
+
label_columns=None):
|
| 110 |
+
# Store the raw data.
|
| 111 |
+
self.train_df = train_df
|
| 112 |
+
self.val_df = val_df
|
| 113 |
+
self.test_df = test_df
|
| 114 |
+
|
| 115 |
+
# Work out the label column indices.
|
| 116 |
+
self.label_columns = label_columns
|
| 117 |
+
if label_columns is not None:
|
| 118 |
+
self.label_columns_indices = {name: i for i, name in
|
| 119 |
+
enumerate(label_columns)}
|
| 120 |
+
self.column_indices = {name: i for i, name in
|
| 121 |
+
enumerate(train_df.columns)}
|
| 122 |
+
|
| 123 |
+
# Work out the window parameters.
|
| 124 |
+
self.input_width = input_width
|
| 125 |
+
self.label_width = label_width
|
| 126 |
+
self.shift = shift
|
| 127 |
+
|
| 128 |
+
self.total_window_size = input_width + shift
|
| 129 |
+
|
| 130 |
+
self.input_slice = slice(0, input_width)
|
| 131 |
+
self.input_indices = np.arange(self.total_window_size)[self.input_slice]
|
| 132 |
+
|
| 133 |
+
self.label_start = self.total_window_size - self.label_width
|
| 134 |
+
self.labels_slice = slice(self.label_start, None)
|
| 135 |
+
self.label_indices = np.arange(self.total_window_size)[self.labels_slice]
|
| 136 |
+
|
| 137 |
+
def __repr__(self):
|
| 138 |
+
return '\n'.join([
|
| 139 |
+
f'Total window size: {self.total_window_size}',
|
| 140 |
+
f'Input indices: {self.input_indices}',
|
| 141 |
+
f'Label indices: {self.label_indices}',
|
| 142 |
+
f'Label column name(s): {self.label_columns}'])
|
| 143 |
+
|
| 144 |
+
def split_window(self, features):
|
| 145 |
+
inputs = features[:, self.input_slice, :]
|
| 146 |
+
labels = features[:, self.labels_slice, :]
|
| 147 |
+
if self.label_columns is not None:
|
| 148 |
+
labels = tf.stack(
|
| 149 |
+
[labels[:, :, self.column_indices[name]] for name in self.label_columns],
|
| 150 |
+
axis=-1)
|
| 151 |
+
|
| 152 |
+
# Slicing doesn't preserve static shape information, so set the shapes
|
| 153 |
+
# manually. This way the `tf.data.Datasets` are easier to inspect.
|
| 154 |
+
inputs.set_shape([None, self.input_width, None])
|
| 155 |
+
labels.set_shape([None, self.label_width, None])
|
| 156 |
+
|
| 157 |
+
return inputs, labels
|
| 158 |
+
|
| 159 |
+
WindowGenerator.split_window = split_window
|
| 160 |
+
|
| 161 |
+
# Plotting function
|
| 162 |
+
def plot(self, model=None, plot_col='value', max_subplots=3):
|
| 163 |
+
inputs, labels = self.example
|
| 164 |
+
plt.figure(figsize=(12, 8))
|
| 165 |
+
plot_col_index = self.column_indices[plot_col]
|
| 166 |
+
max_n = min(max_subplots, len(inputs))
|
| 167 |
+
for n in range(max_n):
|
| 168 |
+
plt.subplot(3, 1, n+1)
|
| 169 |
+
plt.ylabel(f'{plot_col} [normed]')
|
| 170 |
+
plt.plot(self.input_indices, inputs[n, :, plot_col_index],
|
| 171 |
+
label='Inputs', marker='.', zorder=-10)
|
| 172 |
+
if self.label_columns:
|
| 173 |
+
label_col_index = self.label_columns_indices.get(plot_col, None)
|
| 174 |
+
else:
|
| 175 |
+
label_col_index = plot_col_index
|
| 176 |
+
if label_col_index is None:
|
| 177 |
+
continue
|
| 178 |
+
plt.scatter(self.label_indices, labels[n, :, label_col_index],
|
| 179 |
+
edgecolors='k', label='Labels', c='#2ca02c', s=64)
|
| 180 |
+
if model is not None:
|
| 181 |
+
predictions = model(inputs)
|
| 182 |
+
plt.scatter(self.label_indices, predictions[n, :, label_col_index],
|
| 183 |
+
marker='X', edgecolors='k', label='Predictions',
|
| 184 |
+
c='#ff7f0e', s=64)
|
| 185 |
+
if n == 0:
|
| 186 |
+
plt.legend()
|
| 187 |
+
plt.xlabel('Time [h]')
|
| 188 |
+
WindowGenerator.plot = plot
|
| 189 |
+
|
| 190 |
+
# Transforming data into tf dataset
|
| 191 |
+
def make_dataset(self, data):
|
| 192 |
+
data = np.array(data, dtype=np.float64)
|
| 193 |
+
ds = tf.keras.preprocessing.timeseries_dataset_from_array(
|
| 194 |
+
data=data,
|
| 195 |
+
targets=None,
|
| 196 |
+
sequence_length=self.total_window_size,
|
| 197 |
+
sequence_stride=1,
|
| 198 |
+
shuffle=True,
|
| 199 |
+
batch_size=32,)
|
| 200 |
+
|
| 201 |
+
ds = ds.map(self.split_window)
|
| 202 |
+
return ds
|
| 203 |
+
WindowGenerator.make_dataset = make_dataset
|
| 204 |
+
|
| 205 |
+
@property
|
| 206 |
+
def train(self):
|
| 207 |
+
return self.make_dataset(self.train_df)
|
| 208 |
+
|
| 209 |
+
@property
|
| 210 |
+
def val(self):
|
| 211 |
+
return self.make_dataset(self.val_df)
|
| 212 |
+
|
| 213 |
+
@property
|
| 214 |
+
def test(self):
|
| 215 |
+
return self.make_dataset(self.test_df)
|
| 216 |
+
|
| 217 |
+
@property
|
| 218 |
+
def example(self):
|
| 219 |
+
"""Get and cache an example batch of `inputs, labels` for plotting."""
|
| 220 |
+
result = getattr(self, '_example', None)
|
| 221 |
+
if result is None:
|
| 222 |
+
# No example batch was found, so get one from the `.train` dataset
|
| 223 |
+
result = next(iter(self.train))
|
| 224 |
+
# And cache it for next time
|
| 225 |
+
self._example = result
|
| 226 |
+
return result
|
| 227 |
+
WindowGenerator.train = train
|
| 228 |
+
WindowGenerator.val = val
|
| 229 |
+
WindowGenerator.test = test
|
| 230 |
+
WindowGenerator.example = example
|
| 231 |
+
single_step_window = WindowGenerator(
|
| 232 |
+
input_width=1, label_width=1, shift=1,
|
| 233 |
+
label_columns=['value'])
|
| 234 |
+
|
| 235 |
+
# Baseline model for comparison
|
| 236 |
+
class Baseline(tf.keras.Model):
|
| 237 |
+
def __init__(self, label_index=None):
|
| 238 |
+
super().__init__()
|
| 239 |
+
self.label_index = label_index
|
| 240 |
+
|
| 241 |
+
def call(self, inputs):
|
| 242 |
+
if self.label_index is None:
|
| 243 |
+
return inputs
|
| 244 |
+
result = inputs[:, :, self.label_index]
|
| 245 |
+
return result[:, :, tf.newaxis]
|
| 246 |
+
|
| 247 |
+
baseline = Baseline(label_index=column_indices['value'])
|
| 248 |
+
baseline.compile(loss=tf.losses.MeanSquaredError(),
|
| 249 |
+
metrics=[tf.metrics.MeanAbsoluteError()])
|
| 250 |
+
val_performance = {}
|
| 251 |
+
performance = {}
|
| 252 |
+
val_performance['Baseline'] = baseline.evaluate(single_step_window.val)
|
| 253 |
+
performance['Baseline'] = baseline.evaluate(single_step_window.test, verbose=0)
|
| 254 |
+
wide_window = WindowGenerator(
|
| 255 |
+
input_width=25, label_width=25, shift=1,
|
| 256 |
+
label_columns=['value'])
|
| 257 |
+
wide_window.plot(baseline)
|
| 258 |
+
|
| 259 |
+
# Function for compiling and fitting model and data
|
| 260 |
+
MAX_EPOCHS = 20
|
| 261 |
+
def compile_and_fit(model, window, patience=2):
|
| 262 |
+
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss',
|
| 263 |
+
patience=patience,
|
| 264 |
+
mode='min')
|
| 265 |
+
|
| 266 |
+
model.compile(loss=tf.losses.MeanSquaredError(),
|
| 267 |
+
optimizer=tf.optimizers.SGD(),
|
| 268 |
+
metrics=[tf.metrics.MeanAbsoluteError()])
|
| 269 |
+
|
| 270 |
+
history = model.fit(window.train, epochs=MAX_EPOCHS,
|
| 271 |
+
validation_data=window.val,
|
| 272 |
+
callbacks=[early_stopping])
|
| 273 |
+
return history
|
| 274 |
+
|
| 275 |
+
### LSTM ###
|
| 276 |
+
# Main Focus here is THIS model. Simple 2-layer LSTM for basic ts forecast.
|
| 277 |
+
lstm_model = tf.keras.models.Sequential([
|
| 278 |
+
# Shape [batch, time, features] => [batch, time, lstm_units]
|
| 279 |
+
tf.keras.layers.LSTM(32, return_sequences=True),
|
| 280 |
+
# Shape => [batch, time, features]
|
| 281 |
+
tf.keras.layers.Dense(units=1)
|
| 282 |
+
])
|
| 283 |
+
wide_window = WindowGenerator(
|
| 284 |
+
input_width=50, label_width=50, shift=1,
|
| 285 |
+
label_columns=['value'])
|
| 286 |
+
history = compile_and_fit(lstm_model, wide_window)
|
| 287 |
+
IPython.display.clear_output()
|
| 288 |
+
val_performance['LSTM'] = lstm_model.evaluate(wide_window.val)
|
| 289 |
+
performance['LSTM'] = lstm_model.evaluate(wide_window.test, verbose=0)
|
| 290 |
+
wide_window.plot(lstm_model)
|
LTSM.png
ADDED
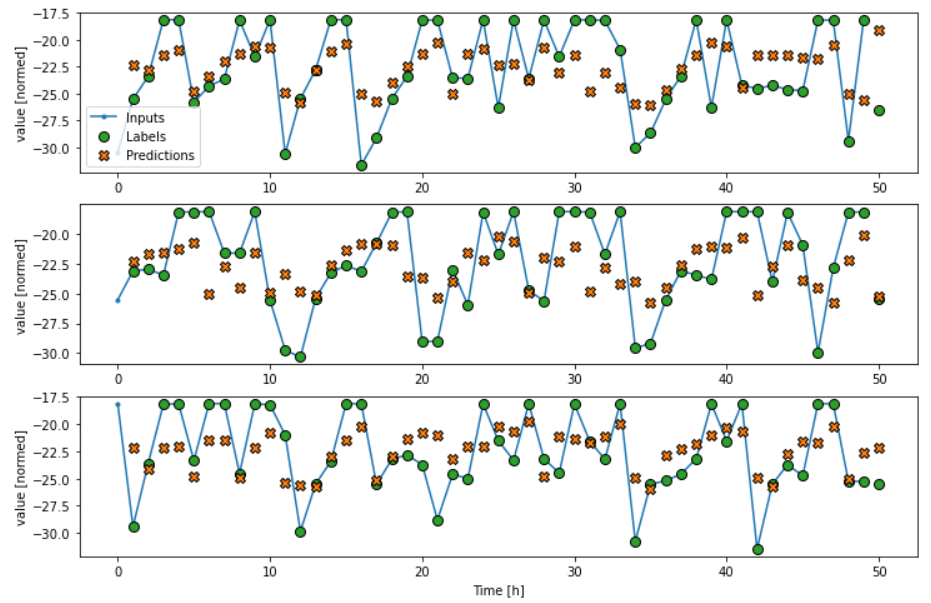
|
Readme.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### AI Energy Forecast using LTSM
|
| 2 |
+
|
| 3 |
+
It basically takes some smartmeter data (5 cols, > 12mil. instances, cols: id, device_name, property, value, timestamp) and creates a custom forecast based on selected window.
|
| 4 |
+
The file is available in .py and .ipynb format, so you can choose according to your preferences.
|
| 5 |
+
|
| 6 |
+
Please notice that once you load up the smartmeter data, there are inputs created on the timestamp col like wd_input (the weekday of the timestamp), as well as a cos(inus) and sin(us)
|
| 7 |
+
time inputs, giving the model the ability to keep track of the daytime of each instance. Finally, the inputs are merged to an input df, standardized and differenced.
|
| 8 |
+
After that, some functions are used to give the user the ability to use time windows from the data. Based on these, the model generates forecasts.
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
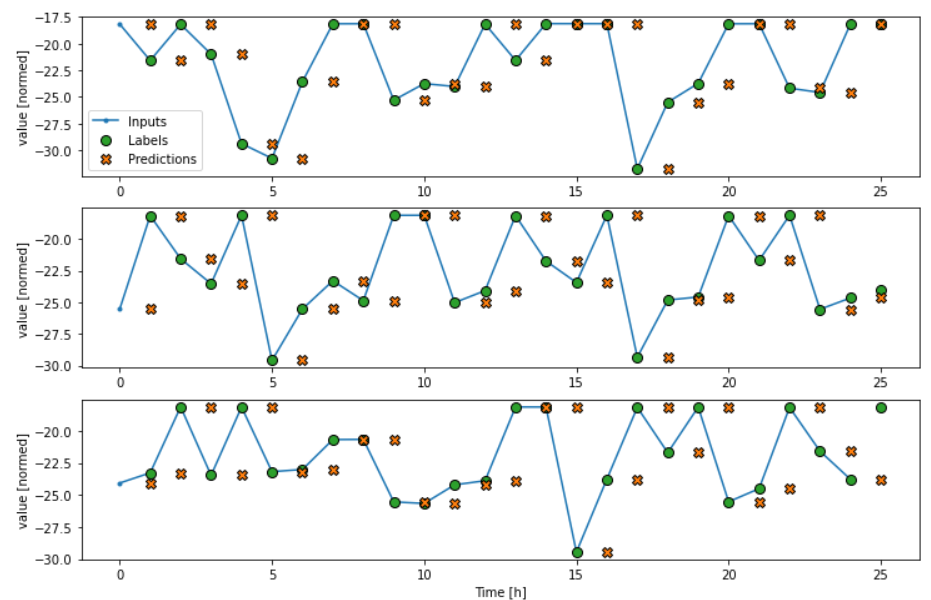
The first models created are a simple baseline model, used for evaluating the performance of the later on built LTSM model. The baseline model simply shifts the values by t=1. Hence,
|
| 13 |
+
there is no t=0 and each timestamp uses the value from t-1.
|
| 14 |
+
Finally, there's the 2-layer plain vanilla LTSM. After 11 epochs, I reached a loss of 10.86 which is rather mediocre. However, the main idea here is to build a basic forecasting model
|
| 15 |
+
for which this seems appropriate.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+

|
model.png
ADDED
|