
Rolando
commited on
Commit
·
8718761
1
Parent(s):
e9ccfaf
Set it up
Browse files- .gitignore +129 -0
- LICENSE +21 -0
- README.md +1872 -0
- examples/non-whisper.ipynb +425 -0
- setup.py +40 -0
- silence_suppresion0.png +0 -0
- silence_suppresion1.png +0 -0
- stable_whisper/__init__.py +8 -0
- stable_whisper/__main__.py +3 -0
- stable_whisper/_version.py +1 -0
- stable_whisper/alignment.py +1265 -0
- stable_whisper/audio.py +288 -0
- stable_whisper/decode.py +109 -0
- stable_whisper/non_whisper.py +348 -0
- stable_whisper/quantization.py +40 -0
- stable_whisper/result.py +2281 -0
- stable_whisper/stabilization.py +424 -0
- stable_whisper/text_output.py +620 -0
- stable_whisper/timing.py +275 -0
- stable_whisper/utils.py +78 -0
- stable_whisper/video_output.py +111 -0
- stable_whisper/whisper_compatibility.py +73 -0
- stable_whisper/whisper_word_level.py +1651 -0
.gitignore
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
pip-wheel-metadata/
|
| 24 |
+
share/python-wheels/
|
| 25 |
+
*.egg-info/
|
| 26 |
+
.installed.cfg
|
| 27 |
+
*.egg
|
| 28 |
+
MANIFEST
|
| 29 |
+
|
| 30 |
+
# PyInstaller
|
| 31 |
+
# Usually these files are written by a python script from a template
|
| 32 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 33 |
+
*.manifest
|
| 34 |
+
*.spec
|
| 35 |
+
|
| 36 |
+
# Installer logs
|
| 37 |
+
pip-log.txt
|
| 38 |
+
pip-delete-this-directory.txt
|
| 39 |
+
|
| 40 |
+
# Unit test / coverage reports
|
| 41 |
+
htmlcov/
|
| 42 |
+
.tox/
|
| 43 |
+
.nox/
|
| 44 |
+
.coverage
|
| 45 |
+
.coverage.*
|
| 46 |
+
.cache
|
| 47 |
+
nosetests.xml
|
| 48 |
+
coverage.xml
|
| 49 |
+
*.cover
|
| 50 |
+
*.py,cover
|
| 51 |
+
.hypothesis/
|
| 52 |
+
.pytest_cache/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
target/
|
| 76 |
+
|
| 77 |
+
# Jupyter Notebook
|
| 78 |
+
.ipynb_checkpoints
|
| 79 |
+
|
| 80 |
+
# IPython
|
| 81 |
+
profile_default/
|
| 82 |
+
ipython_config.py
|
| 83 |
+
|
| 84 |
+
# pyenv
|
| 85 |
+
.python-version
|
| 86 |
+
|
| 87 |
+
# pipenv
|
| 88 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 89 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 90 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 91 |
+
# install all needed dependencies.
|
| 92 |
+
#Pipfile.lock
|
| 93 |
+
|
| 94 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 95 |
+
__pypackages__/
|
| 96 |
+
|
| 97 |
+
# Celery stuff
|
| 98 |
+
celerybeat-schedule
|
| 99 |
+
celerybeat.pid
|
| 100 |
+
|
| 101 |
+
# SageMath parsed files
|
| 102 |
+
*.sage.py
|
| 103 |
+
|
| 104 |
+
# Environments
|
| 105 |
+
.env
|
| 106 |
+
.venv
|
| 107 |
+
env/
|
| 108 |
+
venv/
|
| 109 |
+
ENV/
|
| 110 |
+
env.bak/
|
| 111 |
+
venv.bak/
|
| 112 |
+
|
| 113 |
+
# Spyder project settings
|
| 114 |
+
.spyderproject
|
| 115 |
+
.spyproject
|
| 116 |
+
|
| 117 |
+
# Rope project settings
|
| 118 |
+
.ropeproject
|
| 119 |
+
|
| 120 |
+
# mkdocs documentation
|
| 121 |
+
/site
|
| 122 |
+
|
| 123 |
+
# mypy
|
| 124 |
+
.mypy_cache/
|
| 125 |
+
.dmypy.json
|
| 126 |
+
dmypy.json
|
| 127 |
+
|
| 128 |
+
# Pyre type checker
|
| 129 |
+
.pyre/
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 jian
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,1872 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Stabilizing Timestamps for Whisper
|
| 2 |
+
|
| 3 |
+
This library modifies [Whisper](https://github.com/openai/whisper) to produce more reliable timestamps and extends its functionality.
|
| 4 |
+
|
| 5 |
+
https://github.com/jianfch/stable-ts/assets/28970749/7adf0540-3620-4b2b-b2d4-e316906d6dfa
|
| 6 |
+
|
| 7 |
+
* [Setup](#setup)
|
| 8 |
+
* [Usage](#usage)
|
| 9 |
+
* [Transcribe](#transcribe)
|
| 10 |
+
* [Output](#output)
|
| 11 |
+
* [Alignment](#alignment)
|
| 12 |
+
* [Adjustments](#adjustments)
|
| 13 |
+
* [Refinement](#refinement)
|
| 14 |
+
* [Regrouping Words](#regrouping-words)
|
| 15 |
+
* [Editing](#editing)
|
| 16 |
+
* [Locating Words](#locating-words)
|
| 17 |
+
* [Silence Suppression](#silence-suppression)
|
| 18 |
+
* [Tips](#tips)
|
| 19 |
+
* [Visualizing Suppression](#visualizing-suppression)
|
| 20 |
+
* [Encode Comparison](#encode-comparison)
|
| 21 |
+
* [Use with any ASR](#any-asr)
|
| 22 |
+
* [Quick 1.X → 2.X Guide](#quick-1x--2x-guide)
|
| 23 |
+
|
| 24 |
+
## Setup
|
| 25 |
+
```
|
| 26 |
+
pip install -U stable-ts
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
To install the latest commit:
|
| 30 |
+
```
|
| 31 |
+
pip install -U git+https://github.com/jianfch/stable-ts.git
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
## Usage
|
| 35 |
+
|
| 36 |
+
### Transcribe
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
import stable_whisper
|
| 40 |
+
model = stable_whisper.load_model('base')
|
| 41 |
+
result = model.transcribe('audio.mp3')
|
| 42 |
+
result.to_srt_vtt('audio.srt')
|
| 43 |
+
```
|
| 44 |
+
<details>
|
| 45 |
+
<summary>CLI</summary>
|
| 46 |
+
|
| 47 |
+
```commandline
|
| 48 |
+
stable-ts audio.mp3 -o audio.srt
|
| 49 |
+
```
|
| 50 |
+
</details>
|
| 51 |
+
|
| 52 |
+
Docstrings:
|
| 53 |
+
<details>
|
| 54 |
+
<summary>load_model()</summary>
|
| 55 |
+
|
| 56 |
+
Load an instance if :class:`whisper.model.Whisper`.
|
| 57 |
+
|
| 58 |
+
Parameters
|
| 59 |
+
----------
|
| 60 |
+
name : {'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1',
|
| 61 |
+
'large-v2', 'large-v3', or 'large'}
|
| 62 |
+
One of the official model names listed by :func:`whisper.available_models`, or
|
| 63 |
+
path to a model checkpoint containing the model dimensions and the model state_dict.
|
| 64 |
+
device : str or torch.device, optional
|
| 65 |
+
PyTorch device to put the model into.
|
| 66 |
+
download_root : str, optional
|
| 67 |
+
Path to download the model files; by default, it uses "~/.cache/whisper".
|
| 68 |
+
in_memory : bool, default False
|
| 69 |
+
Whether to preload the model weights into host memory.
|
| 70 |
+
cpu_preload : bool, default True
|
| 71 |
+
Load model into CPU memory first then move model to specified device
|
| 72 |
+
to reduce GPU memory usage when loading model
|
| 73 |
+
dq : bool, default False
|
| 74 |
+
Whether to apply Dynamic Quantization to model to reduced memory usage and increase inference speed
|
| 75 |
+
but at the cost of a slight decrease in accuracy. Only for CPU.
|
| 76 |
+
|
| 77 |
+
Returns
|
| 78 |
+
-------
|
| 79 |
+
model : "Whisper"
|
| 80 |
+
The Whisper ASR model instance.
|
| 81 |
+
|
| 82 |
+
Notes
|
| 83 |
+
-----
|
| 84 |
+
The overhead from ``dq = True`` might make inference slower for models smaller than 'large'.
|
| 85 |
+
|
| 86 |
+
</details>
|
| 87 |
+
|
| 88 |
+
<details>
|
| 89 |
+
<summary>transcribe()</summary>
|
| 90 |
+
|
| 91 |
+
Transcribe audio using Whisper.
|
| 92 |
+
|
| 93 |
+
This is a modified version of :func:`whisper.transcribe.transcribe` with slightly different decoding logic while
|
| 94 |
+
allowing additional preprocessing and postprocessing. The preprocessing performed on the audio includes: isolating
|
| 95 |
+
voice / removing noise with Demucs and low/high-pass filter. The postprocessing performed on the transcription
|
| 96 |
+
result includes: adjusting timestamps with VAD and custom regrouping segments based punctuation and speech gaps.
|
| 97 |
+
|
| 98 |
+
Parameters
|
| 99 |
+
----------
|
| 100 |
+
model : whisper.model.Whisper
|
| 101 |
+
An instance of Whisper ASR model.
|
| 102 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 103 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 104 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 105 |
+
verbose : bool or None, default False
|
| 106 |
+
Whether to display the text being decoded to the console.
|
| 107 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 108 |
+
temperature : float or iterable of float, default (0.0, 0.2, 0.4, 0.6, 0.8, 1.0)
|
| 109 |
+
Temperature for sampling. It can be a tuple of temperatures, which will be successfully used
|
| 110 |
+
upon failures according to either ``compression_ratio_threshold`` or ``logprob_threshold``.
|
| 111 |
+
compression_ratio_threshold : float, default 2.4
|
| 112 |
+
If the gzip compression ratio is above this value, treat as failed.
|
| 113 |
+
logprob_threshold : float, default -1
|
| 114 |
+
If the average log probability over sampled tokens is below this value, treat as failed
|
| 115 |
+
no_speech_threshold : float, default 0.6
|
| 116 |
+
If the no_speech probability is higher than this value AND the average log probability
|
| 117 |
+
over sampled tokens is below ``logprob_threshold``, consider the segment as silent
|
| 118 |
+
condition_on_previous_text : bool, default True
|
| 119 |
+
If ``True``, the previous output of the model is provided as a prompt for the next window;
|
| 120 |
+
disabling may make the text inconsistent across windows, but the model becomes less prone to
|
| 121 |
+
getting stuck in a failure loop, such as repetition looping or timestamps going out of sync.
|
| 122 |
+
initial_prompt : str, optional
|
| 123 |
+
Text to provide as a prompt for the first window. This can be used to provide, or
|
| 124 |
+
"prompt-engineer" a context for transcription, e.g. custom vocabularies or proper nouns
|
| 125 |
+
to make it more likely to predict those word correctly.
|
| 126 |
+
word_timestamps : bool, default True
|
| 127 |
+
Extract word-level timestamps using the cross-attention pattern and dynamic time warping,
|
| 128 |
+
and include the timestamps for each word in each segment.
|
| 129 |
+
Disabling this will prevent segments from splitting/merging properly.
|
| 130 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 131 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 132 |
+
Ignored if ``word_timestamps = False``.
|
| 133 |
+
ts_num : int, default 0, meaning disable this option
|
| 134 |
+
Number of extra timestamp inferences to perform then use average of these extra timestamps.
|
| 135 |
+
An experimental option that might hurt performance.
|
| 136 |
+
ts_noise : float, default 0.1
|
| 137 |
+
Percentage of noise to add to audio_features to perform inferences for ``ts_num``.
|
| 138 |
+
suppress_silence : bool, default True
|
| 139 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 140 |
+
suppress_word_ts : bool, default True
|
| 141 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 142 |
+
use_word_position : bool, default True
|
| 143 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 144 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 145 |
+
q_levels : int, default 20
|
| 146 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 147 |
+
Acts as a threshold to marking sound as silent.
|
| 148 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 149 |
+
k_size : int, default 5
|
| 150 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 151 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 152 |
+
time_scale : float, optional
|
| 153 |
+
Factor for scaling audio duration for inference.
|
| 154 |
+
Greater than 1.0 'slows down' the audio, and less than 1.0 'speeds up' the audio. None is same as 1.0.
|
| 155 |
+
A factor of 1.5 will stretch 10s audio to 15s for inference. This increases the effective resolution
|
| 156 |
+
of the model but can increase word error rate.
|
| 157 |
+
demucs : bool or torch.nn.Module, default False
|
| 158 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 159 |
+
a Demucs model to avoid reloading the model for each run.
|
| 160 |
+
Demucs must be installed to use. Official repo. https://github.com/facebookresearch/demucs.
|
| 161 |
+
demucs_output : str, optional
|
| 162 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 163 |
+
Demucs must be installed to use. Official repo. https://github.com/facebookresearch/demucs.
|
| 164 |
+
demucs_options : dict, optional
|
| 165 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 166 |
+
vad : bool, default False
|
| 167 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 168 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 169 |
+
vad_threshold : float, default 0.35
|
| 170 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 171 |
+
vad_onnx : bool, default False
|
| 172 |
+
Whether to use ONNX for Silero VAD.
|
| 173 |
+
min_word_dur : float, default 0.1
|
| 174 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 175 |
+
nonspeech_error : float, default 0.3
|
| 176 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 177 |
+
only_voice_freq : bool, default False
|
| 178 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 179 |
+
prepend_punctuations : str, default '"\'“¿([{-)'
|
| 180 |
+
Punctuations to prepend to next word.
|
| 181 |
+
append_punctuations : str, default '.。,,!!??::”)]}、)'
|
| 182 |
+
Punctuations to append to previous word.
|
| 183 |
+
mel_first : bool, default False
|
| 184 |
+
Process entire audio track into log-Mel spectrogram first instead in chunks.
|
| 185 |
+
Used if odd behavior seen in stable-ts but not in whisper, but use significantly more memory for long audio.
|
| 186 |
+
split_callback : Callable, optional
|
| 187 |
+
Custom callback for grouping tokens up with their corresponding words.
|
| 188 |
+
The callback must take two arguments, list of tokens and tokenizer.
|
| 189 |
+
The callback returns a tuple with a list of words and a corresponding nested list of tokens.
|
| 190 |
+
suppress_ts_tokens : bool, default False
|
| 191 |
+
Whether to suppress timestamp tokens during inference for timestamps are detected at silent.
|
| 192 |
+
Reduces hallucinations in some cases, but also prone to ignore disfluencies and repetitions.
|
| 193 |
+
This option is ignored if ``suppress_silence = False``.
|
| 194 |
+
gap_padding : str, default ' ...'
|
| 195 |
+
Padding prepend to each segments for word timing alignment.
|
| 196 |
+
Used to reduce the probability of model predicting timestamps earlier than the first utterance.
|
| 197 |
+
only_ffmpeg : bool, default False
|
| 198 |
+
Whether to use only FFmpeg (instead of not yt-dlp) for URls
|
| 199 |
+
max_instant_words : float, default 0.5
|
| 200 |
+
If percentage of instantaneous words in a segment exceed this amount, the segment is removed.
|
| 201 |
+
avg_prob_threshold: float or None, default None
|
| 202 |
+
Transcribe the gap after the previous word and if the average word proababiliy of a segment falls below this
|
| 203 |
+
value, discard the segment. If ``None``, skip transcribing the gap to reduce chance of timestamps starting
|
| 204 |
+
before the next utterance.
|
| 205 |
+
progress_callback : Callable, optional
|
| 206 |
+
A function that will be called when transcription progress is updated.
|
| 207 |
+
The callback need two parameters.
|
| 208 |
+
The first parameter is a float for seconds of the audio that has been transcribed.
|
| 209 |
+
The second parameter is a float for total duration of audio in seconds.
|
| 210 |
+
ignore_compatibility : bool, default False
|
| 211 |
+
Whether to ignore warnings for compatibility issues with the detected Whisper version.
|
| 212 |
+
decode_options
|
| 213 |
+
Keyword arguments to construct class:`whisper.decode.DecodingOptions` instances.
|
| 214 |
+
|
| 215 |
+
Returns
|
| 216 |
+
-------
|
| 217 |
+
stable_whisper.result.WhisperResult
|
| 218 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 219 |
+
|
| 220 |
+
See Also
|
| 221 |
+
--------
|
| 222 |
+
stable_whisper.non_whisper.transcribe_any : Return :class:`stable_whisper.result.WhisperResult` containing all the
|
| 223 |
+
data from transcribing audio with unmodified :func:`whisper.transcribe.transcribe` with preprocessing and
|
| 224 |
+
postprocessing.
|
| 225 |
+
stable_whisper.whisper_word_level.load_faster_whisper.faster_transcribe : Return
|
| 226 |
+
:class:`stable_whisper.result.WhisperResult` containing all the data from transcribing audio with
|
| 227 |
+
:meth:`faster_whisper.WhisperModel.transcribe` with preprocessing and postprocessing.
|
| 228 |
+
|
| 229 |
+
Examples
|
| 230 |
+
--------
|
| 231 |
+
>>> import stable_whisper
|
| 232 |
+
>>> model = stable_whisper.load_model('base')
|
| 233 |
+
>>> result = model.transcribe('audio.mp3', vad=True)
|
| 234 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 235 |
+
Saved: audio.srt
|
| 236 |
+
|
| 237 |
+
</details>
|
| 238 |
+
|
| 239 |
+
<details>
|
| 240 |
+
<summary>transcribe_minimal()</summary>
|
| 241 |
+
|
| 242 |
+
Transcribe audio using Whisper.
|
| 243 |
+
|
| 244 |
+
This is uses the original whisper transcribe function, :func:`whisper.transcribe.transcribe`, while still allowing
|
| 245 |
+
additional preprocessing and postprocessing. The preprocessing performed on the audio includes: isolating voice /
|
| 246 |
+
removing noise with Demucs and low/high-pass filter. The postprocessing performed on the transcription
|
| 247 |
+
result includes: adjusting timestamps with VAD and custom regrouping segments based punctuation and speech gaps.
|
| 248 |
+
|
| 249 |
+
Parameters
|
| 250 |
+
----------
|
| 251 |
+
model : whisper.model.Whisper
|
| 252 |
+
An instance of Whisper ASR model.
|
| 253 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 254 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 255 |
+
If audio is ``numpy.ndarray`` or ``torch.Tensor``, the audio must be already at sampled to 16kHz.
|
| 256 |
+
verbose : bool or None, default False
|
| 257 |
+
Whether to display the text being decoded to the console.
|
| 258 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 259 |
+
word_timestamps : bool, default True
|
| 260 |
+
Extract word-level timestamps using the cross-attention pattern and dynamic time warping,
|
| 261 |
+
and include the timestamps for each word in each segment.
|
| 262 |
+
Disabling this will prevent segments from splitting/merging properly.
|
| 263 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 264 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 265 |
+
Ignored if ``word_timestamps = False``.
|
| 266 |
+
suppress_silence : bool, default True
|
| 267 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 268 |
+
suppress_word_ts : bool, default True
|
| 269 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 270 |
+
use_word_position : bool, default True
|
| 271 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 272 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 273 |
+
q_levels : int, default 20
|
| 274 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 275 |
+
Acts as a threshold to marking sound as silent.
|
| 276 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 277 |
+
k_size : int, default 5
|
| 278 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 279 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 280 |
+
demucs : bool or torch.nn.Module, default False
|
| 281 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 282 |
+
a Demucs model to avoid reloading the model for each run.
|
| 283 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 284 |
+
demucs_output : str, optional
|
| 285 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 286 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 287 |
+
demucs_options : dict, optional
|
| 288 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 289 |
+
vad : bool, default False
|
| 290 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 291 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 292 |
+
vad_threshold : float, default 0.35
|
| 293 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 294 |
+
vad_onnx : bool, default False
|
| 295 |
+
Whether to use ONNX for Silero VAD.
|
| 296 |
+
min_word_dur : float, default 0.1
|
| 297 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 298 |
+
nonspeech_error : float, default 0.3
|
| 299 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 300 |
+
only_voice_freq : bool, default False
|
| 301 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 302 |
+
only_ffmpeg : bool, default False
|
| 303 |
+
Whether to use only FFmpeg (instead of not yt-dlp) for URls
|
| 304 |
+
options
|
| 305 |
+
Additional options used for :func:`whisper.transcribe.transcribe` and
|
| 306 |
+
:func:`stable_whisper.non_whisper.transcribe_any`.
|
| 307 |
+
Returns
|
| 308 |
+
-------
|
| 309 |
+
stable_whisper.result.WhisperResult
|
| 310 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 311 |
+
|
| 312 |
+
Examples
|
| 313 |
+
--------
|
| 314 |
+
>>> import stable_whisper
|
| 315 |
+
>>> model = stable_whisper.load_model('base')
|
| 316 |
+
>>> result = model.transcribe_minimal('audio.mp3', vad=True)
|
| 317 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 318 |
+
Saved: audio.srt
|
| 319 |
+
|
| 320 |
+
</details>
|
| 321 |
+
|
| 322 |
+
<br>
|
| 323 |
+
<details>
|
| 324 |
+
<summary>faster-whisper</summary>
|
| 325 |
+
|
| 326 |
+
Use with [faster-whisper](https://github.com/guillaumekln/faster-whisper):
|
| 327 |
+
```python
|
| 328 |
+
model = stable_whisper.load_faster_whisper('base')
|
| 329 |
+
result = model.transcribe_stable('audio.mp3')
|
| 330 |
+
```
|
| 331 |
+
```commandline
|
| 332 |
+
stable-ts audio.mp3 -o audio.srt -fw
|
| 333 |
+
```
|
| 334 |
+
Docstring:
|
| 335 |
+
<details>
|
| 336 |
+
<summary>load_faster_whisper()</summary>
|
| 337 |
+
|
| 338 |
+
Load an instance of :class:`faster_whisper.WhisperModel`.
|
| 339 |
+
|
| 340 |
+
Parameters
|
| 341 |
+
----------
|
| 342 |
+
model_size_or_path : {'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1',
|
| 343 |
+
'large-v2', 'large-v3', or 'large'}
|
| 344 |
+
Size of the model.
|
| 345 |
+
|
| 346 |
+
model_init_options
|
| 347 |
+
Additional options to use for initialization of :class:`faster_whisper.WhisperModel`.
|
| 348 |
+
|
| 349 |
+
Returns
|
| 350 |
+
-------
|
| 351 |
+
faster_whisper.WhisperModel
|
| 352 |
+
A modified instance with :func:`stable_whisper.whisper_word_level.load_faster_whisper.faster_transcribe`
|
| 353 |
+
assigned to :meth:`faster_whisper.WhisperModel.transcribe_stable`.
|
| 354 |
+
|
| 355 |
+
</details>
|
| 356 |
+
|
| 357 |
+
<details>
|
| 358 |
+
<summary>transcribe_stable()</summary>
|
| 359 |
+
|
| 360 |
+
Transcribe audio using faster-whisper (https://github.com/guillaumekln/faster-whisper).
|
| 361 |
+
|
| 362 |
+
This is uses the transcribe method from faster-whisper, :meth:`faster_whisper.WhisperModel.transcribe`, while
|
| 363 |
+
still allowing additional preprocessing and postprocessing. The preprocessing performed on the audio includes:
|
| 364 |
+
isolating voice / removing noise with Demucs and low/high-pass filter. The postprocessing performed on the
|
| 365 |
+
transcription result includes: adjusting timestamps with VAD and custom regrouping segments based punctuation
|
| 366 |
+
and speech gaps.
|
| 367 |
+
|
| 368 |
+
Parameters
|
| 369 |
+
----------
|
| 370 |
+
model : faster_whisper.WhisperModel
|
| 371 |
+
The faster-whisper ASR model instance.
|
| 372 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 373 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 374 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 375 |
+
verbose : bool or None, default False
|
| 376 |
+
Whether to display the text being decoded to the console.
|
| 377 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 378 |
+
word_timestamps : bool, default True
|
| 379 |
+
Extract word-level timestamps using the cross-attention pattern and dynamic time warping,
|
| 380 |
+
and include the timestamps for each word in each segment.
|
| 381 |
+
Disabling this will prevent segments from splitting/merging properly.
|
| 382 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 383 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 384 |
+
Ignored if ``word_timestamps = False``.
|
| 385 |
+
suppress_silence : bool, default True
|
| 386 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 387 |
+
suppress_word_ts : bool, default True
|
| 388 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 389 |
+
use_word_position : bool, default True
|
| 390 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 391 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 392 |
+
q_levels : int, default 20
|
| 393 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 394 |
+
Acts as a threshold to marking sound as silent.
|
| 395 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 396 |
+
k_size : int, default 5
|
| 397 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 398 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 399 |
+
demucs : bool or torch.nn.Module, default False
|
| 400 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance
|
| 401 |
+
of a Demucs model to avoid reloading the model for each run.
|
| 402 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 403 |
+
demucs_output : str, optional
|
| 404 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 405 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 406 |
+
demucs_options : dict, optional
|
| 407 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 408 |
+
vad : bool, default False
|
| 409 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 410 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 411 |
+
vad_threshold : float, default 0.35
|
| 412 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 413 |
+
vad_onnx : bool, default False
|
| 414 |
+
Whether to use ONNX for Silero VAD.
|
| 415 |
+
min_word_dur : float, default 0.1
|
| 416 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 417 |
+
nonspeech_error : float, default 0.3
|
| 418 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 419 |
+
only_voice_freq : bool, default False
|
| 420 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 421 |
+
only_ffmpeg : bool, default False
|
| 422 |
+
Whether to use only FFmpeg (instead of not yt-dlp) for URls
|
| 423 |
+
check_sorted : bool, default True
|
| 424 |
+
Whether to raise an error when timestamps returned by faster-whipser are not in ascending order.
|
| 425 |
+
progress_callback : Callable, optional
|
| 426 |
+
A function that will be called when transcription progress is updated.
|
| 427 |
+
The callback need two parameters.
|
| 428 |
+
The first parameter is a float for seconds of the audio that has been transcribed.
|
| 429 |
+
The second parameter is a float for total duration of audio in seconds.
|
| 430 |
+
options
|
| 431 |
+
Additional options used for :meth:`faster_whisper.WhisperModel.transcribe` and
|
| 432 |
+
:func:`stable_whisper.non_whisper.transcribe_any`.
|
| 433 |
+
|
| 434 |
+
Returns
|
| 435 |
+
-------
|
| 436 |
+
stable_whisper.result.WhisperResult
|
| 437 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 438 |
+
|
| 439 |
+
Examples
|
| 440 |
+
--------
|
| 441 |
+
>>> import stable_whisper
|
| 442 |
+
>>> model = stable_whisper.load_faster_whisper('base')
|
| 443 |
+
>>> result = model.transcribe_stable('audio.mp3', vad=True)
|
| 444 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 445 |
+
Saved: audio.srt
|
| 446 |
+
|
| 447 |
+
</details>
|
| 448 |
+
|
| 449 |
+
</details>
|
| 450 |
+
|
| 451 |
+
### Output
|
| 452 |
+
Stable-ts supports various text output formats.
|
| 453 |
+
```python
|
| 454 |
+
result.to_srt_vtt('audio.srt') #SRT
|
| 455 |
+
result.to_srt_vtt('audio.vtt') #VTT
|
| 456 |
+
result.to_ass('audio.ass') #ASS
|
| 457 |
+
result.to_tsv('audio.tsv') #TSV
|
| 458 |
+
```
|
| 459 |
+
Docstrings:
|
| 460 |
+
<details>
|
| 461 |
+
<summary>result_to_srt_vtt()</summary>
|
| 462 |
+
|
| 463 |
+
Generate SRT/VTT from ``result`` to display segment-level and/or word-level timestamp.
|
| 464 |
+
|
| 465 |
+
Parameters
|
| 466 |
+
----------
|
| 467 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 468 |
+
Result of transcription.
|
| 469 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 470 |
+
Path to save file.
|
| 471 |
+
segment_level : bool, default True
|
| 472 |
+
Whether to use segment-level timestamps in output.
|
| 473 |
+
word_level : bool, default True
|
| 474 |
+
Whether to use word-level timestamps in output.
|
| 475 |
+
min_dur : float, default 0.2
|
| 476 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 477 |
+
tag: tuple of (str, str), default None, meaning ('<font color="#00ff00">', '</font>') if SRT else ('<u>', '</u>')
|
| 478 |
+
Tag used to change the properties a word at its timestamp.
|
| 479 |
+
vtt : bool, default None, meaning determined by extension of ``filepath`` or ``False`` if no valid extension.
|
| 480 |
+
Whether to output VTT.
|
| 481 |
+
strip : bool, default True
|
| 482 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 483 |
+
reverse_text: bool or tuple, default False
|
| 484 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 485 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 486 |
+
|
| 487 |
+
Returns
|
| 488 |
+
-------
|
| 489 |
+
str
|
| 490 |
+
String of the content if ``filepath`` is ``None``.
|
| 491 |
+
|
| 492 |
+
Notes
|
| 493 |
+
-----
|
| 494 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 495 |
+
seems to not suffer from this issue.
|
| 496 |
+
|
| 497 |
+
Examples
|
| 498 |
+
--------
|
| 499 |
+
>>> import stable_whisper
|
| 500 |
+
>>> model = stable_whisper.load_model('base')
|
| 501 |
+
>>> result = model.transcribe('audio.mp3')
|
| 502 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 503 |
+
Saved: audio.srt
|
| 504 |
+
|
| 505 |
+
</details>
|
| 506 |
+
|
| 507 |
+
<details>
|
| 508 |
+
<summary>result_to_ass()</summary>
|
| 509 |
+
|
| 510 |
+
Generate Advanced SubStation Alpha (ASS) file from ``result`` to display segment-level and/or word-level timestamp.
|
| 511 |
+
|
| 512 |
+
Parameters
|
| 513 |
+
----------
|
| 514 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 515 |
+
Result of transcription.
|
| 516 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 517 |
+
Path to save file.
|
| 518 |
+
segment_level : bool, default True
|
| 519 |
+
Whether to use segment-level timestamps in output.
|
| 520 |
+
word_level : bool, default True
|
| 521 |
+
Whether to use word-level timestamps in output.
|
| 522 |
+
min_dur : float, default 0.2
|
| 523 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 524 |
+
tag: tuple of (str, str) or int, default None, meaning use default highlighting
|
| 525 |
+
Tag used to change the properties a word at its timestamp. -1 for individual word highlight tag.
|
| 526 |
+
font : str, default `Arial`
|
| 527 |
+
Word font.
|
| 528 |
+
font_size : int, default 48
|
| 529 |
+
Word font size.
|
| 530 |
+
strip : bool, default True
|
| 531 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 532 |
+
highlight_color : str, default '00ff00'
|
| 533 |
+
Hexadecimal of the color use for default highlights as '<bb><gg><rr>'.
|
| 534 |
+
karaoke : bool, default False
|
| 535 |
+
Whether to use progressive filling highlights (for karaoke effect).
|
| 536 |
+
reverse_text: bool or tuple, default False
|
| 537 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 538 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 539 |
+
kwargs:
|
| 540 |
+
Format styles:
|
| 541 |
+
'Name', 'Fontname', 'Fontsize', 'PrimaryColour', 'SecondaryColour', 'OutlineColour', 'BackColour', 'Bold',
|
| 542 |
+
'Italic', 'Underline', 'StrikeOut', 'ScaleX', 'ScaleY', 'Spacing', 'Angle', 'BorderStyle', 'Outline',
|
| 543 |
+
'Shadow', 'Alignment', 'MarginL', 'MarginR', 'MarginV', 'Encoding'
|
| 544 |
+
|
| 545 |
+
Returns
|
| 546 |
+
-------
|
| 547 |
+
str
|
| 548 |
+
String of the content if ``filepath`` is ``None``.
|
| 549 |
+
|
| 550 |
+
Notes
|
| 551 |
+
-----
|
| 552 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 553 |
+
seems to not suffer from this issue.
|
| 554 |
+
|
| 555 |
+
Examples
|
| 556 |
+
--------
|
| 557 |
+
>>> import stable_whisper
|
| 558 |
+
>>> model = stable_whisper.load_model('base')
|
| 559 |
+
>>> result = model.transcribe('audio.mp3')
|
| 560 |
+
>>> result.to_ass('audio.ass')
|
| 561 |
+
Saved: audio.ass
|
| 562 |
+
|
| 563 |
+
</details>
|
| 564 |
+
|
| 565 |
+
<details>
|
| 566 |
+
<summary>result_to_tsv()</summary>
|
| 567 |
+
|
| 568 |
+
Generate TSV from ``result`` to display segment-level and/or word-level timestamp.
|
| 569 |
+
|
| 570 |
+
Parameters
|
| 571 |
+
----------
|
| 572 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 573 |
+
Result of transcription.
|
| 574 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 575 |
+
Path to save file.
|
| 576 |
+
segment_level : bool, default True
|
| 577 |
+
Whether to use segment-level timestamps in output.
|
| 578 |
+
word_level : bool, default True
|
| 579 |
+
Whether to use word-level timestamps in output.
|
| 580 |
+
min_dur : float, default 0.2
|
| 581 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 582 |
+
strip : bool, default True
|
| 583 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 584 |
+
reverse_text: bool or tuple, default False
|
| 585 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 586 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 587 |
+
|
| 588 |
+
Returns
|
| 589 |
+
-------
|
| 590 |
+
str
|
| 591 |
+
String of the content if ``filepath`` is ``None``.
|
| 592 |
+
|
| 593 |
+
Notes
|
| 594 |
+
-----
|
| 595 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 596 |
+
seems to not suffer from this issue.
|
| 597 |
+
|
| 598 |
+
Examples
|
| 599 |
+
--------
|
| 600 |
+
>>> import stable_whisper
|
| 601 |
+
>>> model = stable_whisper.load_model('base')
|
| 602 |
+
>>> result = model.transcribe('audio.mp3')
|
| 603 |
+
>>> result.to_tsv('audio.tsv')
|
| 604 |
+
Saved: audio.tsv
|
| 605 |
+
|
| 606 |
+
</details>
|
| 607 |
+
|
| 608 |
+
<details>
|
| 609 |
+
<summary>result_to_txt()</summary>
|
| 610 |
+
|
| 611 |
+
Generate plain-text without timestamps from ``result``.
|
| 612 |
+
|
| 613 |
+
Parameters
|
| 614 |
+
----------
|
| 615 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 616 |
+
Result of transcription.
|
| 617 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 618 |
+
Path to save file.
|
| 619 |
+
min_dur : float, default 0.2
|
| 620 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 621 |
+
strip : bool, default True
|
| 622 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 623 |
+
reverse_text: bool or tuple, default False
|
| 624 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 625 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 626 |
+
|
| 627 |
+
Returns
|
| 628 |
+
-------
|
| 629 |
+
str
|
| 630 |
+
String of the content if ``filepath`` is ``None``.
|
| 631 |
+
|
| 632 |
+
Notes
|
| 633 |
+
-----
|
| 634 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 635 |
+
seems to not suffer from this issue.
|
| 636 |
+
|
| 637 |
+
Examples
|
| 638 |
+
--------
|
| 639 |
+
>>> import stable_whisper
|
| 640 |
+
>>> model = stable_whisper.load_model('base')
|
| 641 |
+
>>> result = model.transcribe('audio.mp3')
|
| 642 |
+
>>> result.to_txt('audio.txt')
|
| 643 |
+
Saved: audio.txt
|
| 644 |
+
|
| 645 |
+
</details>
|
| 646 |
+
|
| 647 |
+
<details>
|
| 648 |
+
<summary>save_as_json()</summary>
|
| 649 |
+
|
| 650 |
+
Save ``result`` as JSON file to ``path``.
|
| 651 |
+
|
| 652 |
+
Parameters
|
| 653 |
+
----------
|
| 654 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 655 |
+
Result of transcription.
|
| 656 |
+
path : str
|
| 657 |
+
Path to save file.
|
| 658 |
+
ensure_ascii : bool, default False
|
| 659 |
+
Whether to escape non-ASCII characters.
|
| 660 |
+
|
| 661 |
+
Examples
|
| 662 |
+
--------
|
| 663 |
+
>>> import stable_whisper
|
| 664 |
+
>>> model = stable_whisper.load_model('base')
|
| 665 |
+
>>> result = model.transcribe('audio.mp3')
|
| 666 |
+
>>> result.save_as_json('audio.json')
|
| 667 |
+
Saved: audio.json
|
| 668 |
+
|
| 669 |
+
</details>
|
| 670 |
+
|
| 671 |
+
<br /><br />
|
| 672 |
+
There are word-level and segment-level timestamps. All output formats support them.
|
| 673 |
+
They also support will both levels simultaneously except TSV.
|
| 674 |
+
By default, `segment_level` and `word_level` are both `True` for all the formats that support both simultaneously.<br /><br />
|
| 675 |
+
Examples in VTT.
|
| 676 |
+
|
| 677 |
+
Default: `segment_level=True` + `word_level=True`
|
| 678 |
+
<details>
|
| 679 |
+
<summary>CLI</summary>
|
| 680 |
+
|
| 681 |
+
`--segment_level true` + `--word_level true`
|
| 682 |
+
|
| 683 |
+
</details>
|
| 684 |
+
|
| 685 |
+
```
|
| 686 |
+
00:00:07.760 --> 00:00:09.900
|
| 687 |
+
But<00:00:07.860> when<00:00:08.040> you<00:00:08.280> arrived<00:00:08.580> at<00:00:08.800> that<00:00:09.000> distant<00:00:09.400> world,
|
| 688 |
+
```
|
| 689 |
+
|
| 690 |
+
`segment_level=True` + `word_level=False`
|
| 691 |
+
```
|
| 692 |
+
00:00:07.760 --> 00:00:09.900
|
| 693 |
+
But when you arrived at that distant world,
|
| 694 |
+
```
|
| 695 |
+
|
| 696 |
+
`segment_level=False` + `word_level=True`
|
| 697 |
+
```
|
| 698 |
+
00:00:07.760 --> 00:00:07.860
|
| 699 |
+
But
|
| 700 |
+
|
| 701 |
+
00:00:07.860 --> 00:00:08.040
|
| 702 |
+
when
|
| 703 |
+
|
| 704 |
+
00:00:08.040 --> 00:00:08.280
|
| 705 |
+
you
|
| 706 |
+
|
| 707 |
+
00:00:08.280 --> 00:00:08.580
|
| 708 |
+
arrived
|
| 709 |
+
|
| 710 |
+
...
|
| 711 |
+
```
|
| 712 |
+
|
| 713 |
+
#### JSON
|
| 714 |
+
The result can also be saved as a JSON file to preserve all the data for future reprocessing.
|
| 715 |
+
This is useful for testing different sets of postprocessing arguments without the need to redo inference.
|
| 716 |
+
|
| 717 |
+
```python
|
| 718 |
+
result.save_as_json('audio.json')
|
| 719 |
+
```
|
| 720 |
+
<details>
|
| 721 |
+
<summary>CLI</summary>
|
| 722 |
+
|
| 723 |
+
```commandline
|
| 724 |
+
stable-ts audio.mp3 -o audio.json
|
| 725 |
+
```
|
| 726 |
+
|
| 727 |
+
</details>
|
| 728 |
+
|
| 729 |
+
Processing JSON file of the results into SRT.
|
| 730 |
+
```python
|
| 731 |
+
result = stable_whisper.WhisperResult('audio.json')
|
| 732 |
+
result.to_srt_vtt('audio.srt')
|
| 733 |
+
```
|
| 734 |
+
<details>
|
| 735 |
+
<summary>CLI</summary>
|
| 736 |
+
|
| 737 |
+
```commandline
|
| 738 |
+
stable-ts audio.json -o audio.srt
|
| 739 |
+
```
|
| 740 |
+
|
| 741 |
+
</details>
|
| 742 |
+
|
| 743 |
+
### Alignment
|
| 744 |
+
Audio can be aligned/synced with plain text on word-level.
|
| 745 |
+
```python
|
| 746 |
+
text = 'Machines thinking, breeding. You were to bear us a new, promised land.'
|
| 747 |
+
result = model.align('audio.mp3', text, language='en')
|
| 748 |
+
```
|
| 749 |
+
When the text is correct but the timestamps need more work,
|
| 750 |
+
`align()` is a faster alternative for testing various settings/models.
|
| 751 |
+
```python
|
| 752 |
+
new_result = model.align('audio.mp3', result, language='en')
|
| 753 |
+
```
|
| 754 |
+
<details>
|
| 755 |
+
<summary>CLI</summary>
|
| 756 |
+
|
| 757 |
+
```commandline
|
| 758 |
+
stable-ts audio.mp3 --align text.txt --language en
|
| 759 |
+
```
|
| 760 |
+
`--align` can also a JSON file of a result
|
| 761 |
+
|
| 762 |
+
</details>
|
| 763 |
+
|
| 764 |
+
Docstring:
|
| 765 |
+
<details>
|
| 766 |
+
<summary>align()</summary>
|
| 767 |
+
|
| 768 |
+
Align plain text or tokens with audio at word-level.
|
| 769 |
+
|
| 770 |
+
Since this is significantly faster than transcribing, it is a more efficient method for testing various settings
|
| 771 |
+
without re-transcribing. This is also useful for timing a more correct transcript than one that Whisper can produce.
|
| 772 |
+
|
| 773 |
+
Parameters
|
| 774 |
+
----------
|
| 775 |
+
model : "Whisper"
|
| 776 |
+
The Whisper ASR model modified instance
|
| 777 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 778 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 779 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 780 |
+
text : str or list of int or stable_whisper.result.WhisperResult
|
| 781 |
+
String of plain-text, list of tokens, or instance of :class:`stable_whisper.result.WhisperResult`.
|
| 782 |
+
language : str, default None, uses ``language`` in ``text`` if it is a :class:`stable_whisper.result.WhisperResult`
|
| 783 |
+
Language of ``text``. Required if ``text`` does not contain ``language``.
|
| 784 |
+
remove_instant_words : bool, default False
|
| 785 |
+
Whether to truncate any words with zero duration.
|
| 786 |
+
token_step : int, default 100
|
| 787 |
+
Max number of tokens to align each pass. Use higher values to reduce chance of misalignment.
|
| 788 |
+
original_split : bool, default False
|
| 789 |
+
Whether to preserve the original segment groupings. Segments are spit by line break if ``text`` is plain-text.
|
| 790 |
+
max_word_dur : float or None, default 3.0
|
| 791 |
+
Global maximum word duration in seconds. Re-align words that exceed the global maximum word duration.
|
| 792 |
+
word_dur_factor : float or None, default 2.0
|
| 793 |
+
Factor to compute the Local maximum word duration, which is ``word_dur_factor`` * local medium word duration.
|
| 794 |
+
Words that need re-alignment, are re-algined with duration <= local/global maximum word duration.
|
| 795 |
+
nonspeech_skip : float or None, default 3.0
|
| 796 |
+
Skip non-speech sections that are equal or longer than this duration in seconds. Disable skipping if ``None``.
|
| 797 |
+
fast_mode : bool, default False
|
| 798 |
+
Whether to speed up alignment by re-alignment with local/global maximum word duration.
|
| 799 |
+
``True`` tends produce better timestamps when ``text`` is accurate and there are no large speechless gaps.
|
| 800 |
+
tokenizer : "Tokenizer", default None, meaning a new tokenizer is created according ``language`` and ``model``
|
| 801 |
+
A tokenizer to used tokenizer text and detokenize tokens.
|
| 802 |
+
verbose : bool or None, default False
|
| 803 |
+
Whether to display the text being decoded to the console.
|
| 804 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 805 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 806 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 807 |
+
Ignored if ``word_timestamps = False``.
|
| 808 |
+
suppress_silence : bool, default True
|
| 809 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 810 |
+
suppress_word_ts : bool, default True
|
| 811 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 812 |
+
use_word_position : bool, default True
|
| 813 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 814 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 815 |
+
q_levels : int, default 20
|
| 816 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 817 |
+
Acts as a threshold to marking sound as silent.
|
| 818 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 819 |
+
k_size : int, default 5
|
| 820 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 821 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 822 |
+
demucs : bool or torch.nn.Module, default False
|
| 823 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 824 |
+
a Demucs model to avoid reloading the model for each run.
|
| 825 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 826 |
+
demucs_output : str, optional
|
| 827 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 828 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 829 |
+
demucs_options : dict, optional
|
| 830 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 831 |
+
vad : bool, default False
|
| 832 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 833 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 834 |
+
vad_threshold : float, default 0.35
|
| 835 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 836 |
+
vad_onnx : bool, default False
|
| 837 |
+
Whether to use ONNX for Silero VAD.
|
| 838 |
+
min_word_dur : float, default 0.1
|
| 839 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 840 |
+
nonspeech_error : float, default 0.3
|
| 841 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 842 |
+
only_voice_freq : bool, default False
|
| 843 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 844 |
+
prepend_punctuations : str, default '"'“¿([{-)'
|
| 845 |
+
Punctuations to prepend to next word.
|
| 846 |
+
append_punctuations : str, default '.。,,!!??::”)]}、)'
|
| 847 |
+
Punctuations to append to previous word.
|
| 848 |
+
progress_callback : Callable, optional
|
| 849 |
+
A function that will be called when transcription progress is updated.
|
| 850 |
+
The callback need two parameters.
|
| 851 |
+
The first parameter is a float for seconds of the audio that has been transcribed.
|
| 852 |
+
The second parameter is a float for total duration of audio in seconds.
|
| 853 |
+
ignore_compatibility : bool, default False
|
| 854 |
+
Whether to ignore warnings for compatibility issues with the detected Whisper version.
|
| 855 |
+
|
| 856 |
+
Returns
|
| 857 |
+
-------
|
| 858 |
+
stable_whisper.result.WhisperResult or None
|
| 859 |
+
All timestamps, words, probabilities, and other data from the alignment of ``audio``. Return None if alignment
|
| 860 |
+
fails and ``remove_instant_words = True``.
|
| 861 |
+
|
| 862 |
+
Notes
|
| 863 |
+
-----
|
| 864 |
+
If ``token_step`` is less than 1, ``token_step`` will be set to its maximum value, 442. This value is computed with
|
| 865 |
+
``whisper.model.Whisper.dims.n_text_ctx`` - 6.
|
| 866 |
+
|
| 867 |
+
IF ``original_split = True`` and a line break is found in middle of a word in ``text``, the split will occur after
|
| 868 |
+
that word.
|
| 869 |
+
|
| 870 |
+
``regroup`` is ignored if ``original_split = True``.
|
| 871 |
+
|
| 872 |
+
Examples
|
| 873 |
+
--------
|
| 874 |
+
>>> import stable_whisper
|
| 875 |
+
>>> model = stable_whisper.load_model('base')
|
| 876 |
+
>>> result = model.align('helloworld.mp3', 'Hello, World!', 'English')
|
| 877 |
+
>>> result.to_srt_vtt('helloword.srt')
|
| 878 |
+
Saved 'helloworld.srt'
|
| 879 |
+
|
| 880 |
+
</details>
|
| 881 |
+
|
| 882 |
+
#### Adjustments
|
| 883 |
+
Timestamps are adjusted after the model predicts them.
|
| 884 |
+
When `suppress_silence=True` (default), `transcribe()`/`transcribe_minimal()`/`align()` adjust based on silence/non-speech.
|
| 885 |
+
The timestamps can be further adjusted base on another result with `adjust_by_result()`,
|
| 886 |
+
which acts as a logical AND operation for the timestamps of both results, further reducing duration of each word.
|
| 887 |
+
Note: both results are required to have word timestamps and matching words.
|
| 888 |
+
```python
|
| 889 |
+
# the adjustments are in-place for `result`
|
| 890 |
+
result.adjust_by_result(new_result)
|
| 891 |
+
```
|
| 892 |
+
Docstring:
|
| 893 |
+
<details>
|
| 894 |
+
<summary>adjust_by_result()</summary>
|
| 895 |
+
|
| 896 |
+
Minimize the duration of words using timestamps of another result.
|
| 897 |
+
|
| 898 |
+
Parameters
|
| 899 |
+
----------
|
| 900 |
+
other_result : "WhisperResult"
|
| 901 |
+
Timing data of the same words in a WhisperResult instance.
|
| 902 |
+
min_word_dur : float, default 0.1
|
| 903 |
+
Prevent changes to timestamps if the resultant word duration is less than ``min_word_dur``.
|
| 904 |
+
verbose : bool, default False
|
| 905 |
+
Whether to print out the timestamp changes.
|
| 906 |
+
|
| 907 |
+
</details>
|
| 908 |
+
|
| 909 |
+
### Refinement
|
| 910 |
+
Timestamps can be further improved with `refine()`.
|
| 911 |
+
This method iteratively mutes portions of the audio based on current timestamps
|
| 912 |
+
then compute the probabilities of the tokens.
|
| 913 |
+
Then by monitoring the fluctuation of the probabilities, it tries to find the most precise timestamps.
|
| 914 |
+
"Most precise" in this case means the latest start and earliest end for the word
|
| 915 |
+
such that it still meets the specified conditions.
|
| 916 |
+
```python
|
| 917 |
+
model.refine('audio.mp3', result)
|
| 918 |
+
```
|
| 919 |
+
<details>
|
| 920 |
+
<summary>CLI</summary>
|
| 921 |
+
|
| 922 |
+
```commandline
|
| 923 |
+
stable-ts audio.mp3 --refine -o audio.srt
|
| 924 |
+
```
|
| 925 |
+
Input can also be JSON file of a result.
|
| 926 |
+
```commandline
|
| 927 |
+
stable-ts result.json --refine -o audio.srt --refine_option "audio=audio.mp3"
|
| 928 |
+
```
|
| 929 |
+
|
| 930 |
+
</details>
|
| 931 |
+
|
| 932 |
+
Docstring:
|
| 933 |
+
<details>
|
| 934 |
+
<summary>refine()</summary>
|
| 935 |
+
|
| 936 |
+
Improve existing timestamps.
|
| 937 |
+
|
| 938 |
+
This function iteratively muting portions of the audio and monitoring token probabilities to find the most precise
|
| 939 |
+
timestamps. This "most precise" in this case means the latest start and earliest end of a word that maintains an
|
| 940 |
+
acceptable probability determined by the specified arguments.
|
| 941 |
+
|
| 942 |
+
This is useful readjusting timestamps when they start too early or end too late.
|
| 943 |
+
|
| 944 |
+
Parameters
|
| 945 |
+
----------
|
| 946 |
+
model : "Whisper"
|
| 947 |
+
The Whisper ASR model modified instance
|
| 948 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 949 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 950 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 951 |
+
result : stable_whisper.result.WhisperResult
|
| 952 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 953 |
+
steps : str, default 'se'
|
| 954 |
+
Instructions for refinement. A 's' means refine start-timestamps. An 'e' means refine end-timestamps.
|
| 955 |
+
rel_prob_decrease : float, default 0.3
|
| 956 |
+
Maximum percent decrease in probability relative to original probability which is the probability from muting
|
| 957 |
+
according initial timestamps.
|
| 958 |
+
abs_prob_decrease : float, default 0.05
|
| 959 |
+
Maximum decrease in probability from original probability.
|
| 960 |
+
rel_rel_prob_decrease : float, optional
|
| 961 |
+
Maximum percent decrease in probability relative to previous probability which is the probability from previous
|
| 962 |
+
iteration of muting.
|
| 963 |
+
prob_threshold : float, default 0.5
|
| 964 |
+
Stop refining the timestamp if the probability of its token goes below this value.
|
| 965 |
+
rel_dur_change : float, default 0.5
|
| 966 |
+
Maximum percent change in duration of a word relative to its original duration.
|
| 967 |
+
abs_dur_change : float, optional
|
| 968 |
+
Maximum seconds a word is allowed deviate from its original duration.
|
| 969 |
+
word_level : bool, default True
|
| 970 |
+
Whether to refine timestamps on word-level. If ``False``, only refine start/end timestamps of each segment.
|
| 971 |
+
precision : float, default 0.1
|
| 972 |
+
Precision of refined timestamps in seconds. The lowest precision is 0.02 second.
|
| 973 |
+
single_batch : bool, default False
|
| 974 |
+
Whether to process in only batch size of one to reduce memory usage.
|
| 975 |
+
inplace : bool, default True, meaning return a deepcopy of ``result``
|
| 976 |
+
Whether to alter timestamps in-place.
|
| 977 |
+
demucs : bool or torch.nn.Module, default False
|
| 978 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 979 |
+
a Demucs model to avoid reloading the model for each run.
|
| 980 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 981 |
+
demucs_options : dict, optional
|
| 982 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 983 |
+
only_voice_freq : bool, default False
|
| 984 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 985 |
+
verbose : bool or None, default False
|
| 986 |
+
Whether to display the text being decoded to the console.
|
| 987 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 988 |
+
|
| 989 |
+
Returns
|
| 990 |
+
-------
|
| 991 |
+
stable_whisper.result.WhisperResult
|
| 992 |
+
All timestamps, words, probabilities, and other data from the refinement of ``text`` with ``audio``.
|
| 993 |
+
|
| 994 |
+
Notes
|
| 995 |
+
-----
|
| 996 |
+
The lower the ``precision``, the longer the processing time.
|
| 997 |
+
|
| 998 |
+
Examples
|
| 999 |
+
--------
|
| 1000 |
+
>>> import stable_whisper
|
| 1001 |
+
>>> model = stable_whisper.load_model('base')
|
| 1002 |
+
>>> result = model.transcribe('audio.mp3')
|
| 1003 |
+
>>> model.refine('audio.mp3', result)
|
| 1004 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 1005 |
+
Saved 'audio.srt'
|
| 1006 |
+
|
| 1007 |
+
</details>
|
| 1008 |
+
|
| 1009 |
+
|
| 1010 |
+
### Regrouping Words
|
| 1011 |
+
Stable-ts has a preset for regrouping words into different segments with more natural boundaries.
|
| 1012 |
+
This preset is enabled by `regroup=True` (default).
|
| 1013 |
+
But there are other built-in [regrouping methods](#regrouping-methods) that allow you to customize the regrouping algorithm.
|
| 1014 |
+
This preset is just a predefined combination of those methods.
|
| 1015 |
+
|
| 1016 |
+
https://github.com/jianfch/stable-ts/assets/28970749/7b6164a3-50e2-4368-8b75-853cb14045ec
|
| 1017 |
+
|
| 1018 |
+
```python
|
| 1019 |
+
# The following results are all functionally equivalent:
|
| 1020 |
+
result0 = model.transcribe('audio.mp3', regroup=True) # regroup is True by default
|
| 1021 |
+
result1 = model.transcribe('audio.mp3', regroup=False)
|
| 1022 |
+
(
|
| 1023 |
+
result1
|
| 1024 |
+
.clamp_max()
|
| 1025 |
+
.split_by_punctuation([('.', ' '), '。', '?', '?', (',', ' '), ','])
|
| 1026 |
+
.split_by_gap(.5)
|
| 1027 |
+
.merge_by_gap(.3, max_words=3)
|
| 1028 |
+
.split_by_punctuation([('.', ' '), '。', '?', '?'])
|
| 1029 |
+
)
|
| 1030 |
+
result2 = model.transcribe('audio.mp3', regroup='cm_sp=.* /。/?/?/,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?')
|
| 1031 |
+
|
| 1032 |
+
# To undo all regrouping operations:
|
| 1033 |
+
result0.reset()
|
| 1034 |
+
```
|
| 1035 |
+
Any regrouping algorithm can be expressed as a string. Please feel free share your strings [here](https://github.com/jianfch/stable-ts/discussions/162)
|
| 1036 |
+
#### Regrouping Methods
|
| 1037 |
+
<details>
|
| 1038 |
+
<summary>regroup()</summary>
|
| 1039 |
+
|
| 1040 |
+
Regroup (in-place) words into segments.
|
| 1041 |
+
|
| 1042 |
+
Parameters
|
| 1043 |
+
----------
|
| 1044 |
+
regroup_algo: str or bool, default 'da'
|
| 1045 |
+
String representation of a custom regrouping algorithm or ``True`` use to the default algorithm 'da'.
|
| 1046 |
+
verbose : bool, default False
|
| 1047 |
+
Whether to show all the methods and arguments parsed from ``regroup_algo``.
|
| 1048 |
+
only_show : bool, default False
|
| 1049 |
+
Whether to show the all methods and arguments parsed from ``regroup_algo`` without running the methods
|
| 1050 |
+
|
| 1051 |
+
Returns
|
| 1052 |
+
-------
|
| 1053 |
+
stable_whisper.result.WhisperResult
|
| 1054 |
+
The current instance after the changes.
|
| 1055 |
+
|
| 1056 |
+
Notes
|
| 1057 |
+
-----
|
| 1058 |
+
Syntax for string representation of custom regrouping algorithm.
|
| 1059 |
+
Method keys:
|
| 1060 |
+
sg: split_by_gap
|
| 1061 |
+
sp: split_by_punctuation
|
| 1062 |
+
sl: split_by_length
|
| 1063 |
+
sd: split_by_duration
|
| 1064 |
+
mg: merge_by_gap
|
| 1065 |
+
mp: merge_by_punctuation
|
| 1066 |
+
ms: merge_all_segment
|
| 1067 |
+
cm: clamp_max
|
| 1068 |
+
l: lock
|
| 1069 |
+
us: unlock_all_segments
|
| 1070 |
+
da: default algorithm (cm_sp=.* /。/?/?/,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?)
|
| 1071 |
+
rw: remove_word
|
| 1072 |
+
rs: remove_segment
|
| 1073 |
+
rp: remove_repetition
|
| 1074 |
+
rws: remove_words_by_str
|
| 1075 |
+
fg: fill_in_gaps
|
| 1076 |
+
Metacharacters:
|
| 1077 |
+
= separates a method key and its arguments (not used if no argument)
|
| 1078 |
+
_ separates method keys (after arguments if there are any)
|
| 1079 |
+
+ separates arguments for a method key
|
| 1080 |
+
/ separates an argument into list of strings
|
| 1081 |
+
* separates an item in list of strings into a nested list of strings
|
| 1082 |
+
Notes:
|
| 1083 |
+
-arguments are parsed positionally
|
| 1084 |
+
-if no argument is provided, the default ones will be used
|
| 1085 |
+
-use 1 or 0 to represent True or False
|
| 1086 |
+
Example 1:
|
| 1087 |
+
merge_by_gap(.2, 10, lock=True)
|
| 1088 |
+
mg=.2+10+++1
|
| 1089 |
+
Note: [lock] is the 5th argument hence the 2 missing arguments inbetween the three + before 1
|
| 1090 |
+
Example 2:
|
| 1091 |
+
split_by_punctuation([('.', ' '), '。', '?', '?'], True)
|
| 1092 |
+
sp=.* /。/?/?+1
|
| 1093 |
+
Example 3:
|
| 1094 |
+
merge_all_segments().split_by_gap(.5).merge_by_gap(.15, 3)
|
| 1095 |
+
ms_sg=.5_mg=.15+3
|
| 1096 |
+
|
| 1097 |
+
</details>
|
| 1098 |
+
|
| 1099 |
+
<details>
|
| 1100 |
+
<summary>split_by_gap()</summary>
|
| 1101 |
+
|
| 1102 |
+
Split (in-place) any segment where the gap between two of its words is greater than ``max_gap``.
|
| 1103 |
+
|
| 1104 |
+
Parameters
|
| 1105 |
+
----------
|
| 1106 |
+
max_gap : float, default 0.1
|
| 1107 |
+
Maximum second(s) allowed between two words if the same segment.
|
| 1108 |
+
lock : bool, default False
|
| 1109 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1110 |
+
newline: bool, default False
|
| 1111 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1112 |
+
|
| 1113 |
+
Returns
|
| 1114 |
+
-------
|
| 1115 |
+
stable_whisper.result.WhisperResult
|
| 1116 |
+
The current instance after the changes.
|
| 1117 |
+
|
| 1118 |
+
</details>
|
| 1119 |
+
|
| 1120 |
+
<details>
|
| 1121 |
+
<summary>split_by_punctuation()</summary>
|
| 1122 |
+
|
| 1123 |
+
Split (in-place) segments at words that start/end with ``punctuation``.
|
| 1124 |
+
|
| 1125 |
+
Parameters
|
| 1126 |
+
----------
|
| 1127 |
+
punctuation : list of str of list of tuple of (str, str) or str
|
| 1128 |
+
Punctuation(s) to split segments by.
|
| 1129 |
+
lock : bool, default False
|
| 1130 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1131 |
+
newline : bool, default False
|
| 1132 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1133 |
+
min_words : int, optional
|
| 1134 |
+
Split segments with words >= ``min_words``.
|
| 1135 |
+
min_chars : int, optional
|
| 1136 |
+
Split segments with characters >= ``min_chars``.
|
| 1137 |
+
min_dur : int, optional
|
| 1138 |
+
split segments with duration (in seconds) >= ``min_dur``.
|
| 1139 |
+
|
| 1140 |
+
Returns
|
| 1141 |
+
-------
|
| 1142 |
+
stable_whisper.result.WhisperResult
|
| 1143 |
+
The current instance after the changes.
|
| 1144 |
+
|
| 1145 |
+
</details>
|
| 1146 |
+
|
| 1147 |
+
<details>
|
| 1148 |
+
<summary>split_by_length()</summary>
|
| 1149 |
+
|
| 1150 |
+
Split (in-place) any segment that exceeds ``max_chars`` or ``max_words`` into smaller segments.
|
| 1151 |
+
|
| 1152 |
+
Parameters
|
| 1153 |
+
----------
|
| 1154 |
+
max_chars : int, optional
|
| 1155 |
+
Maximum number of characters allowed in each segment.
|
| 1156 |
+
max_words : int, optional
|
| 1157 |
+
Maximum number of words allowed in each segment.
|
| 1158 |
+
even_split : bool, default True
|
| 1159 |
+
Whether to evenly split a segment in length if it exceeds ``max_chars`` or ``max_words``.
|
| 1160 |
+
force_len : bool, default False
|
| 1161 |
+
Whether to force a constant length for each segment except the last segment.
|
| 1162 |
+
This will ignore all previous non-locked segment boundaries.
|
| 1163 |
+
lock : bool, default False
|
| 1164 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1165 |
+
include_lock: bool, default False
|
| 1166 |
+
Whether to include previous lock before splitting based on max_words, if ``even_split = False``.
|
| 1167 |
+
Splitting will be done after the first non-locked word > ``max_chars`` / ``max_words``.
|
| 1168 |
+
newline: bool, default False
|
| 1169 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1170 |
+
|
| 1171 |
+
Returns
|
| 1172 |
+
-------
|
| 1173 |
+
stable_whisper.result.WhisperResult
|
| 1174 |
+
The current instance after the changes.
|
| 1175 |
+
|
| 1176 |
+
Notes
|
| 1177 |
+
-----
|
| 1178 |
+
If ``even_split = True``, segments can still exceed ``max_chars`` and locked words will be ignored to avoid
|
| 1179 |
+
uneven splitting.
|
| 1180 |
+
|
| 1181 |
+
</details>
|
| 1182 |
+
|
| 1183 |
+
<details>
|
| 1184 |
+
<summary>split_by_duration()</summary>
|
| 1185 |
+
|
| 1186 |
+
Split (in-place) any segment that exceeds ``max_dur`` into smaller segments.
|
| 1187 |
+
|
| 1188 |
+
Parameters
|
| 1189 |
+
----------
|
| 1190 |
+
max_dur : float
|
| 1191 |
+
Maximum duration (in seconds) per segment.
|
| 1192 |
+
even_split : bool, default True
|
| 1193 |
+
Whether to evenly split a segment in length if it exceeds ``max_dur``.
|
| 1194 |
+
force_len : bool, default False
|
| 1195 |
+
Whether to force a constant length for each segment except the last segment.
|
| 1196 |
+
This will ignore all previous non-locked segment boundaries.
|
| 1197 |
+
lock : bool, default False
|
| 1198 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1199 |
+
include_lock: bool, default False
|
| 1200 |
+
Whether to include previous lock before splitting based on max_words, if ``even_split = False``.
|
| 1201 |
+
Splitting will be done after the first non-locked word > ``max_dur``.
|
| 1202 |
+
newline: bool, default False
|
| 1203 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1204 |
+
|
| 1205 |
+
Returns
|
| 1206 |
+
-------
|
| 1207 |
+
stable_whisper.result.WhisperResult
|
| 1208 |
+
The current instance after the changes.
|
| 1209 |
+
|
| 1210 |
+
Notes
|
| 1211 |
+
-----
|
| 1212 |
+
If ``even_split = True``, segments can still exceed ``max_dur`` and locked words will be ignored to avoid
|
| 1213 |
+
uneven splitting.
|
| 1214 |
+
|
| 1215 |
+
</details>
|
| 1216 |
+
|
| 1217 |
+
<details>
|
| 1218 |
+
<summary>merge_by_gap()</summary>
|
| 1219 |
+
|
| 1220 |
+
Merge (in-place) any pair of adjacent segments if the gap between them <= ``min_gap``.
|
| 1221 |
+
|
| 1222 |
+
Parameters
|
| 1223 |
+
----------
|
| 1224 |
+
min_gap : float, default 0.1
|
| 1225 |
+
Minimum second(s) allow between two segment.
|
| 1226 |
+
max_words : int, optional
|
| 1227 |
+
Maximum number of words allowed in each segment.
|
| 1228 |
+
max_chars : int, optional
|
| 1229 |
+
Maximum number of characters allowed in each segment.
|
| 1230 |
+
is_sum_max : bool, default False
|
| 1231 |
+
Whether ``max_words`` and ``max_chars`` is applied to the merged segment instead of the individual segments
|
| 1232 |
+
to be merged.
|
| 1233 |
+
lock : bool, default False
|
| 1234 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1235 |
+
|
| 1236 |
+
Returns
|
| 1237 |
+
-------
|
| 1238 |
+
stable_whisper.result.WhisperResult
|
| 1239 |
+
The current instance after the changes.
|
| 1240 |
+
|
| 1241 |
+
</details>
|
| 1242 |
+
|
| 1243 |
+
<details>
|
| 1244 |
+
<summary>merge_by_punctuation()</summary>
|
| 1245 |
+
|
| 1246 |
+
Merge (in-place) any two segments that has specific punctuations inbetween.
|
| 1247 |
+
|
| 1248 |
+
Parameters
|
| 1249 |
+
----------
|
| 1250 |
+
punctuation : list of str of list of tuple of (str, str) or str
|
| 1251 |
+
Punctuation(s) to merge segments by.
|
| 1252 |
+
max_words : int, optional
|
| 1253 |
+
Maximum number of words allowed in each segment.
|
| 1254 |
+
max_chars : int, optional
|
| 1255 |
+
Maximum number of characters allowed in each segment.
|
| 1256 |
+
is_sum_max : bool, default False
|
| 1257 |
+
Whether ``max_words`` and ``max_chars`` is applied to the merged segment instead of the individual segments
|
| 1258 |
+
to be merged.
|
| 1259 |
+
lock : bool, default False
|
| 1260 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1261 |
+
|
| 1262 |
+
Returns
|
| 1263 |
+
-------
|
| 1264 |
+
stable_whisper.result.WhisperResult
|
| 1265 |
+
The current instance after the changes.
|
| 1266 |
+
|
| 1267 |
+
</details>
|
| 1268 |
+
|
| 1269 |
+
<details>
|
| 1270 |
+
<summary>merge_all_segments()</summary>
|
| 1271 |
+
|
| 1272 |
+
Merge all segments into one segment.
|
| 1273 |
+
|
| 1274 |
+
Returns
|
| 1275 |
+
-------
|
| 1276 |
+
stable_whisper.result.WhisperResult
|
| 1277 |
+
The current instance after the changes.
|
| 1278 |
+
|
| 1279 |
+
</details>
|
| 1280 |
+
|
| 1281 |
+
<details>
|
| 1282 |
+
<summary>clamp_max()</summary>
|
| 1283 |
+
|
| 1284 |
+
Clamp all word durations above certain value.
|
| 1285 |
+
|
| 1286 |
+
This is most effective when applied before and after other regroup operations.
|
| 1287 |
+
|
| 1288 |
+
Parameters
|
| 1289 |
+
----------
|
| 1290 |
+
medium_factor : float, default 2.5
|
| 1291 |
+
Clamp durations above (``medium_factor`` * medium duration) per segment.
|
| 1292 |
+
If ``medium_factor = None/0`` or segment has less than 3 words, it will be ignored and use only ``max_dur``.
|
| 1293 |
+
max_dur : float, optional
|
| 1294 |
+
Clamp durations above ``max_dur``.
|
| 1295 |
+
clip_start : bool or None, default None
|
| 1296 |
+
Whether to clamp the start of a word. If ``None``, clamp the start of first word and end of last word per
|
| 1297 |
+
segment.
|
| 1298 |
+
verbose : bool, default False
|
| 1299 |
+
Whether to print out the timestamp changes.
|
| 1300 |
+
|
| 1301 |
+
Returns
|
| 1302 |
+
-------
|
| 1303 |
+
stable_whisper.result.WhisperResult
|
| 1304 |
+
The current instance after the changes.
|
| 1305 |
+
|
| 1306 |
+
</details>
|
| 1307 |
+
|
| 1308 |
+
<details>
|
| 1309 |
+
<summary>lock()</summary>
|
| 1310 |
+
|
| 1311 |
+
Lock words/segments with matching prefix/suffix to prevent splitting/merging.
|
| 1312 |
+
|
| 1313 |
+
Parameters
|
| 1314 |
+
----------
|
| 1315 |
+
startswith: str or list of str
|
| 1316 |
+
Prefixes to lock.
|
| 1317 |
+
endswith: str or list of str
|
| 1318 |
+
Suffixes to lock.
|
| 1319 |
+
right : bool, default True
|
| 1320 |
+
Whether prevent splits/merges with the next word/segment.
|
| 1321 |
+
left : bool, default False
|
| 1322 |
+
Whether prevent splits/merges with the previous word/segment.
|
| 1323 |
+
case_sensitive : bool, default False
|
| 1324 |
+
Whether to match the case of the prefixes/suffixes with the words/segments.
|
| 1325 |
+
strip : bool, default True
|
| 1326 |
+
Whether to ignore spaces before and after both words/segments and prefixes/suffixes.
|
| 1327 |
+
|
| 1328 |
+
Returns
|
| 1329 |
+
-------
|
| 1330 |
+
stable_whisper.result.WhisperResult
|
| 1331 |
+
The current instance after the changes.
|
| 1332 |
+
|
| 1333 |
+
</details>
|
| 1334 |
+
|
| 1335 |
+
### Editing
|
| 1336 |
+
The editing methods in stable-ts can be chained with [Regrouping Methods](#regrouping-methods) and used in `regroup()`.
|
| 1337 |
+
|
| 1338 |
+
Remove specific instances words or segments:
|
| 1339 |
+
```python
|
| 1340 |
+
# Remove first word of the first segment:
|
| 1341 |
+
first_word = result[0][0]
|
| 1342 |
+
result.remove_word(first_word)
|
| 1343 |
+
# This following is also does the same:
|
| 1344 |
+
del result[0][0]
|
| 1345 |
+
|
| 1346 |
+
# Remove the last segment:
|
| 1347 |
+
last_segment = result[-1]
|
| 1348 |
+
result.remove_segment(last_segment)
|
| 1349 |
+
# This following is also does the same:
|
| 1350 |
+
del result[-1]
|
| 1351 |
+
```
|
| 1352 |
+
Docstrings:
|
| 1353 |
+
<details>
|
| 1354 |
+
<summary>remove_word()</summary>
|
| 1355 |
+
|
| 1356 |
+
Remove a word.
|
| 1357 |
+
|
| 1358 |
+
Parameters
|
| 1359 |
+
----------
|
| 1360 |
+
word : WordTiming or tuple of (int, int)
|
| 1361 |
+
Instance of :class:`stable_whisper.result.WordTiming` or tuple of (segment index, word index).
|
| 1362 |
+
reassign_ids : bool, default True
|
| 1363 |
+
Whether to reassign segment and word ids (indices) after removing ``word``.
|
| 1364 |
+
verbose : bool, default True
|
| 1365 |
+
Whether to print detail of the removed word.
|
| 1366 |
+
|
| 1367 |
+
Returns
|
| 1368 |
+
-------
|
| 1369 |
+
stable_whisper.result.WhisperResult
|
| 1370 |
+
The current instance after the changes.
|
| 1371 |
+
|
| 1372 |
+
</details>
|
| 1373 |
+
|
| 1374 |
+
<details>
|
| 1375 |
+
<summary>remove_segment()</summary>
|
| 1376 |
+
|
| 1377 |
+
Remove a segment.
|
| 1378 |
+
|
| 1379 |
+
Parameters
|
| 1380 |
+
----------
|
| 1381 |
+
segment : Segment or int
|
| 1382 |
+
Instance :class:`stable_whisper.result.Segment` or segment index.
|
| 1383 |
+
reassign_ids : bool, default True
|
| 1384 |
+
Whether to reassign segment IDs (indices) after removing ``segment``.
|
| 1385 |
+
verbose : bool, default True
|
| 1386 |
+
Whether to print detail of the removed word.
|
| 1387 |
+
|
| 1388 |
+
Returns
|
| 1389 |
+
-------
|
| 1390 |
+
stable_whisper.result.WhisperResult
|
| 1391 |
+
The current instance after the changes.
|
| 1392 |
+
|
| 1393 |
+
</details>
|
| 1394 |
+
|
| 1395 |
+
|
| 1396 |
+
Removing repetitions:
|
| 1397 |
+
```python
|
| 1398 |
+
# Example 1: "This is is is a test." -> "This is a test."
|
| 1399 |
+
# The following removes the last two " is":
|
| 1400 |
+
result.remove_repetition(1)
|
| 1401 |
+
|
| 1402 |
+
# Example 2: "This is is is a test this is a test." -> "This is a test."
|
| 1403 |
+
# The following removes the second " is" and third " is", then remove the last "this is a test"
|
| 1404 |
+
# The first parameter `max_words` is `4` because "this is a test" consists 4 words
|
| 1405 |
+
result.remove_repetition(4)
|
| 1406 |
+
```
|
| 1407 |
+
Docstring:
|
| 1408 |
+
<details>
|
| 1409 |
+
<summary>remove_repetition()</summary>
|
| 1410 |
+
|
| 1411 |
+
Remove words that repeat consecutively.
|
| 1412 |
+
|
| 1413 |
+
Parameters
|
| 1414 |
+
----------
|
| 1415 |
+
max_words : int
|
| 1416 |
+
Maximum number of words to look for consecutively.
|
| 1417 |
+
case_sensitive : bool, default False
|
| 1418 |
+
Whether the case of words need to match to be considered as repetition.
|
| 1419 |
+
strip : bool, default True
|
| 1420 |
+
Whether to ignore spaces before and after each word.
|
| 1421 |
+
ignore_punctuations : bool, default '"',.?!'
|
| 1422 |
+
Ending punctuations to ignore.
|
| 1423 |
+
extend_duration: bool, default True
|
| 1424 |
+
Whether to extend the duration of the previous word to cover the duration of the repetition.
|
| 1425 |
+
verbose: bool, default True
|
| 1426 |
+
Whether to print detail of the removed repetitions.
|
| 1427 |
+
|
| 1428 |
+
Returns
|
| 1429 |
+
-------
|
| 1430 |
+
stable_whisper.result.WhisperResult
|
| 1431 |
+
The current instance after the changes.
|
| 1432 |
+
|
| 1433 |
+
</details>
|
| 1434 |
+
|
| 1435 |
+
Removing specific word(s) by string content:
|
| 1436 |
+
```python
|
| 1437 |
+
# Remove all " ok" from " ok ok this is a test."
|
| 1438 |
+
result.remove_words_by_str('ok')
|
| 1439 |
+
|
| 1440 |
+
# Remove all " ok" and " Um..." from " ok this is a test. Um..."
|
| 1441 |
+
result.remove_words_by_str(['ok', 'um'])
|
| 1442 |
+
```
|
| 1443 |
+
Docstring:
|
| 1444 |
+
<details>
|
| 1445 |
+
<summary>remove_words_by_str()</summary>
|
| 1446 |
+
|
| 1447 |
+
Remove words that match ``words``.
|
| 1448 |
+
|
| 1449 |
+
Parameters
|
| 1450 |
+
----------
|
| 1451 |
+
words : str or list of str or None
|
| 1452 |
+
A word or list of words to remove.``None`` for all words to be passed into ``filters``.
|
| 1453 |
+
case_sensitive : bool, default False
|
| 1454 |
+
Whether the case of words need to match to be considered as repetition.
|
| 1455 |
+
strip : bool, default True
|
| 1456 |
+
Whether to ignore spaces before and after each word.
|
| 1457 |
+
ignore_punctuations : bool, default '"',.?!'
|
| 1458 |
+
Ending punctuations to ignore.
|
| 1459 |
+
min_prob : float, optional
|
| 1460 |
+
Acts as the first filter the for the words that match ``words``. Words with probability < ``min_prob`` will
|
| 1461 |
+
be removed if ``filters`` is ``None``, else pass the words into ``filters``. Words without probability will
|
| 1462 |
+
be treated as having probability < ``min_prob``.
|
| 1463 |
+
filters : Callable, optional
|
| 1464 |
+
A function that takes an instance of :class:`stable_whisper.result.WordTiming` as its only argument.
|
| 1465 |
+
This function is custom filter for the words that match ``words`` and were not caught by ``min_prob``.
|
| 1466 |
+
verbose:
|
| 1467 |
+
Whether to print detail of the removed words.
|
| 1468 |
+
|
| 1469 |
+
Returns
|
| 1470 |
+
-------
|
| 1471 |
+
stable_whisper.result.WhisperResult
|
| 1472 |
+
The current instance after the changes.
|
| 1473 |
+
|
| 1474 |
+
</details>
|
| 1475 |
+
|
| 1476 |
+
Filling in segment gaps:
|
| 1477 |
+
```python
|
| 1478 |
+
# result0: [" How are you?"] [" I'm good."] [" Good!"]
|
| 1479 |
+
# result1: [" Hello!"] [" How are you?"] [" How about you?"] [" Good!"]
|
| 1480 |
+
result0.fill_in_gaps(result1)
|
| 1481 |
+
# After filling in the gaps in `result0` with contents in `result1`:
|
| 1482 |
+
# result0: [" Hello!"] [" How are you?"] [" I'm good."] [" How about you?"] [" Good!"]
|
| 1483 |
+
```
|
| 1484 |
+
Docstring:
|
| 1485 |
+
<details>
|
| 1486 |
+
<summary>fill_in_gaps()</summary>
|
| 1487 |
+
|
| 1488 |
+
Fill in segment gaps larger than ``min_gap`` with content from ``other_result`` at the times of gaps.
|
| 1489 |
+
|
| 1490 |
+
Parameters
|
| 1491 |
+
----------
|
| 1492 |
+
other_result : WhisperResult or str
|
| 1493 |
+
Another transcription result as an instance of :class:`stable_whisper.result.WhisperResult` or path to the
|
| 1494 |
+
JSON of the result.
|
| 1495 |
+
min_gap : float, default 0.1
|
| 1496 |
+
The minimum seconds of a gap between segments that must be exceeded to be filled in.
|
| 1497 |
+
case_sensitive : bool, default False
|
| 1498 |
+
Whether to consider the case of the first and last word of the gap to determine overlapping words to remove
|
| 1499 |
+
before filling in.
|
| 1500 |
+
strip : bool, default True
|
| 1501 |
+
Whether to ignore spaces before and after the first and last word of the gap to determine overlapping words
|
| 1502 |
+
to remove before filling in.
|
| 1503 |
+
ignore_punctuations : bool, default '"',.?!'
|
| 1504 |
+
Ending punctuations to ignore in the first and last word of the gap to determine overlapping words to
|
| 1505 |
+
remove before filling in.
|
| 1506 |
+
verbose:
|
| 1507 |
+
Whether to print detail of the filled content.
|
| 1508 |
+
|
| 1509 |
+
Returns
|
| 1510 |
+
-------
|
| 1511 |
+
stable_whisper.result.WhisperResult
|
| 1512 |
+
The current instance after the changes.
|
| 1513 |
+
|
| 1514 |
+
</details>
|
| 1515 |
+
|
| 1516 |
+
### Locating Words
|
| 1517 |
+
There are two ways to locate words.
|
| 1518 |
+
The first way is by approximating time at which the words are spoken
|
| 1519 |
+
then transcribing a few seconds around the approximated time.
|
| 1520 |
+
This also the faster way for locating words.
|
| 1521 |
+
```python
|
| 1522 |
+
matches = model.locate('audio.mp3', 'are', language='en', count=0)
|
| 1523 |
+
for match in matches:
|
| 1524 |
+
print(match.to_display_str())
|
| 1525 |
+
# verbose=True does the same thing as this for-loop.
|
| 1526 |
+
```
|
| 1527 |
+
Docstring:
|
| 1528 |
+
<details>
|
| 1529 |
+
<summary>locate()</summary>
|
| 1530 |
+
|
| 1531 |
+
Locate when specific words are spoken in ``audio`` without fully transcribing.
|
| 1532 |
+
|
| 1533 |
+
This is usefully for quickly finding at what time the specify words or phrases are spoken in an audio. Since it
|
| 1534 |
+
does not need to transcribe the audio to approximate the time, it is significantly faster transcribing then
|
| 1535 |
+
locating the word in the transcript.
|
| 1536 |
+
|
| 1537 |
+
It can also transcribe few seconds around the approximated time to find out what was said around those words or
|
| 1538 |
+
confirm if the word was even spoken near that time.
|
| 1539 |
+
|
| 1540 |
+
Parameters
|
| 1541 |
+
----------
|
| 1542 |
+
model : whisper.model.Whisper
|
| 1543 |
+
An instance of Whisper ASR model.
|
| 1544 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 1545 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 1546 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 1547 |
+
text: str or list of int
|
| 1548 |
+
Words/phrase or list of tokens to search for in ``audio``.
|
| 1549 |
+
language : str
|
| 1550 |
+
Language of the ``text``.
|
| 1551 |
+
count : int, default 1, meaning stop search after 1 match
|
| 1552 |
+
Number of matches to find. Use 0 to look for all.
|
| 1553 |
+
duration_window : float or tuple of (float, float), default 3.0, same as (3.0, 3.0)
|
| 1554 |
+
Seconds before and after the end timestamp approximations to transcribe after mode 1.
|
| 1555 |
+
If tuple pair of values, then the 1st value will be seconds before the end and 2nd value will be seconds after.
|
| 1556 |
+
mode : int, default 0
|
| 1557 |
+
Mode of search.
|
| 1558 |
+
2, Approximates the end timestamp of ``text`` in the audio. This mode does not confirm whether ``text`` is
|
| 1559 |
+
spoken at the timestamp
|
| 1560 |
+
1, Completes mode 2 then transcribes audio within ``duration_window`` to confirm whether `text` is a match at
|
| 1561 |
+
the approximated timestamp by checking if ``text`` at that ``duration_window`` is within
|
| 1562 |
+
``probability_threshold`` or matching the string content if ``text`` with the transcribed text at the
|
| 1563 |
+
``duration_window``.
|
| 1564 |
+
0, Completes mode 1 then add word timestamps to the transcriptions of each match.
|
| 1565 |
+
Modes from fastest to slowest: 2, 1, 0
|
| 1566 |
+
start : float, optional, meaning it starts from 0s
|
| 1567 |
+
Seconds into the audio to start searching for ``text``.
|
| 1568 |
+
end : float, optional
|
| 1569 |
+
Seconds into the audio to stop searching for ``text``.
|
| 1570 |
+
probability_threshold : float, default 0.5
|
| 1571 |
+
Minimum probability of each token in ``text`` for it to be considered a match.
|
| 1572 |
+
eots : int, default 1
|
| 1573 |
+
Number of EOTs to reach before stopping transcription at mode 1. When transcription reach a EOT, it usually
|
| 1574 |
+
means the end of the segment or audio. Once ``text`` is found in the ``duration_window``, the transcription
|
| 1575 |
+
will stop immediately upon reaching a EOT.
|
| 1576 |
+
max_token_per_seg : int, default 20
|
| 1577 |
+
Maximum number of tokens to transcribe in the ``duration_window`` before stopping.
|
| 1578 |
+
exact_token : bool, default False
|
| 1579 |
+
Whether to find a match base on the exact tokens that make up ``text``.
|
| 1580 |
+
case_sensitive : bool, default False
|
| 1581 |
+
Whether to consider the case of ``text`` when matching in string content.
|
| 1582 |
+
verbose : bool or None, default False
|
| 1583 |
+
Whether to display the text being decoded to the console.
|
| 1584 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 1585 |
+
initial_prompt : str, optional
|
| 1586 |
+
Text to provide as a prompt for the first window. This can be used to provide, or
|
| 1587 |
+
"prompt-engineer" a context for transcription, e.g. custom vocabularies or proper nouns
|
| 1588 |
+
to make it more likely to predict those word correctly.
|
| 1589 |
+
suppress_tokens : str or list of int, default '-1', meaning suppress special characters except common punctuations
|
| 1590 |
+
List of tokens to suppress.
|
| 1591 |
+
demucs : bool or torch.nn.Module, default False
|
| 1592 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 1593 |
+
a Demucs model to avoid reloading the model for each run.
|
| 1594 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 1595 |
+
demucs_options : dict, optional
|
| 1596 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 1597 |
+
only_voice_freq : bool, default False
|
| 1598 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 1599 |
+
|
| 1600 |
+
Returns
|
| 1601 |
+
-------
|
| 1602 |
+
stable_whisper.result.Segment or list of dict or list of float
|
| 1603 |
+
Mode 0, list of instances of :class:`stable_whisper.result.Segment`.
|
| 1604 |
+
Mode 1, list of dictionaries with end timestamp approximation of matches and transcribed neighboring words.
|
| 1605 |
+
Mode 2, list of timestamps in seconds for each end timestamp approximation.
|
| 1606 |
+
|
| 1607 |
+
Notes
|
| 1608 |
+
-----
|
| 1609 |
+
For ``text``, the case and spacing matters as 'on', ' on', ' On' are different tokens, therefore chose the one that
|
| 1610 |
+
best suits the context (e.g. ' On' to look for it at the beginning of a sentence).
|
| 1611 |
+
|
| 1612 |
+
Use a sufficiently large first value of ``duration_window`` i.e. the value > time it is expected to speak ``text``.
|
| 1613 |
+
|
| 1614 |
+
If ``exact_token = False`` and the string content matches, then ``probability_threshold`` is not used.
|
| 1615 |
+
|
| 1616 |
+
Examples
|
| 1617 |
+
--------
|
| 1618 |
+
>>> import stable_whisper
|
| 1619 |
+
>>> model = stable_whisper.load_model('base')
|
| 1620 |
+
>>> matches = model.locate('audio.mp3', 'are', 'English', verbose=True)
|
| 1621 |
+
|
| 1622 |
+
Some words can sound the same but have different spellings to increase of the chance of finding such words use
|
| 1623 |
+
``initial_prompt``.
|
| 1624 |
+
|
| 1625 |
+
>>> matches = model.locate('audio.mp3', ' Nickie', 'English', verbose=True, initial_prompt='Nickie')
|
| 1626 |
+
|
| 1627 |
+
</details>
|
| 1628 |
+
|
| 1629 |
+
<details>
|
| 1630 |
+
<summary>CLI</summary>
|
| 1631 |
+
|
| 1632 |
+
```
|
| 1633 |
+
stable-ts audio.mp3 --locate "are" --language en -to "count=0"
|
| 1634 |
+
```
|
| 1635 |
+
|
| 1636 |
+
</details>
|
| 1637 |
+
|
| 1638 |
+
The second way allows you to locate words with regular expression,
|
| 1639 |
+
but it requires the audio to be fully transcribed first.
|
| 1640 |
+
```python
|
| 1641 |
+
result = model.transcribe('audio.mp3')
|
| 1642 |
+
# Find every sentence that contains "and"
|
| 1643 |
+
matches = result.find(r'[^.]+and[^.]+\.')
|
| 1644 |
+
# print the all matches if there are any
|
| 1645 |
+
for match in matches:
|
| 1646 |
+
print(f'match: {match.text_match}\n'
|
| 1647 |
+
f'text: {match.text}\n'
|
| 1648 |
+
f'start: {match.start}\n'
|
| 1649 |
+
f'end: {match.end}\n')
|
| 1650 |
+
|
| 1651 |
+
# Find the word before and after "and" in the matches
|
| 1652 |
+
matches = matches.find(r'\s\S+\sand\s\S+')
|
| 1653 |
+
for match in matches:
|
| 1654 |
+
print(f'match: {match.text_match}\n'
|
| 1655 |
+
f'text: {match.text}\n'
|
| 1656 |
+
f'start: {match.start}\n'
|
| 1657 |
+
f'end: {match.end}\n')
|
| 1658 |
+
```
|
| 1659 |
+
Docstring:
|
| 1660 |
+
<details>
|
| 1661 |
+
<summary>find()</summary>
|
| 1662 |
+
|
| 1663 |
+
Find segments/words and timestamps with regular expression.
|
| 1664 |
+
|
| 1665 |
+
Parameters
|
| 1666 |
+
----------
|
| 1667 |
+
pattern : str
|
| 1668 |
+
RegEx pattern to search for.
|
| 1669 |
+
word_level : bool, default True
|
| 1670 |
+
Whether to search at word-level.
|
| 1671 |
+
flags : optional
|
| 1672 |
+
RegEx flags.
|
| 1673 |
+
|
| 1674 |
+
Returns
|
| 1675 |
+
-------
|
| 1676 |
+
stable_whisper.result.WhisperResultMatches
|
| 1677 |
+
An instance of :class:`stable_whisper.result.WhisperResultMatches` with word/segment that match ``pattern``.
|
| 1678 |
+
|
| 1679 |
+
</details>
|
| 1680 |
+
|
| 1681 |
+
### Silence Suppression
|
| 1682 |
+
While the timestamps predicted by Whisper are generally accurate,
|
| 1683 |
+
it sometimes predicts the start of a word way before the word is spoken
|
| 1684 |
+
or the end of a word long after the word has been spoken.
|
| 1685 |
+
This is where "silence suppression" helps. It is enabled by default (`suppress_silence=True`).
|
| 1686 |
+
The idea is to adjust the timestamps based on the timestamps of non-speech portions of the audio.
|
| 1687 |
+

|
| 1688 |
+
*Note: In 1.X, "silence suppression" refers to the process of suppressing timestamp tokens of the silent portions during inference,
|
| 1689 |
+
but changed to post-inference timestamp adjustments in 2.X, which allows stable-ts to be used with other ASR models.
|
| 1690 |
+
The timestamp token suppression feature is disabled by default, but can still be enabled with `suppress_ts_tokens=True`.*
|
| 1691 |
+
|
| 1692 |
+
By default, stable-ts determines the non-speech timestamps based on
|
| 1693 |
+
how loud a section of the audio is relative to the neighboring sections.
|
| 1694 |
+
This method is most effective for cases, where the speech is significantly louder than the background noise.
|
| 1695 |
+
The other method is to use [Silero VAD](https://github.com/snakers4/silero-vad) (enabled with `vad=True`).
|
| 1696 |
+
To visualize the differences between non-VAD and VAD, see [Visualizing Suppression](#visualizing-suppression).
|
| 1697 |
+
|
| 1698 |
+
Besides the parameters for non-speech detection sensitivity (see [Visualizing Suppression](#visualizing-suppression)),
|
| 1699 |
+
the following parameters are used to combat inaccurate non-speech detection.<br>
|
| 1700 |
+
`min_word_dur` is the shortest duration each word is allowed from adjustments.<br>
|
| 1701 |
+
`nonspeech_error` is the relative error of the non-speech that appears in between a word.<br>
|
| 1702 |
+
`use_word_position` is whether to use word position in segment to determine whether to keep end or start timestamps
|
| 1703 |
+
*Note: `nonspeech_error` was not available before 2.14.0; `use_word_position` was not available before 2.14.2;
|
| 1704 |
+
`min_word_dur` prevented any adjustments that resulted in word duration shorter than `min_word_dur`.*
|
| 1705 |
+
|
| 1706 |
+
For the following example, `min_word_dur=0.5` (default: 0.1) and `nonspeech_error=0.3` (default: 0.3).
|
| 1707 |
+

|
| 1708 |
+
`nonspeech_error=0.3` allows each non-speech section to be treated 1.3 times their actual duration.
|
| 1709 |
+
Either from the start of the corresponding word to the end of the non-speech
|
| 1710 |
+
or from the start of the non-speech to the end of the corresponding word.
|
| 1711 |
+
In the case that both conditions are met, the shorter one is used.
|
| 1712 |
+
Or if both are equal, then the start of the non-speech to the end of the word is used.<br>
|
| 1713 |
+
The second non-speech from 1.375s to 1.75s is ignored for 'world.' because it failed both conditions.<br>
|
| 1714 |
+
The first word, 'Hello', satisfies only the former condition from 0s to 0.625, thus the new start for 'Hello'
|
| 1715 |
+
would be 0.625s. However, `min_word_dur=0.5` requires the resultant duration to be at least 0.5s.
|
| 1716 |
+
As a result, the start of 'Hello' is changed to 0.375s instead of 0.625s.
|
| 1717 |
+
Furthermore, the default setting, `use_word_position=True`, also ensures the start is adjusted for the first word
|
| 1718 |
+
and the end is adjusted for the last word of the segment as long as one of the conditions is true.
|
| 1719 |
+
|
| 1720 |
+
### Tips
|
| 1721 |
+
- do not disable word timestamps with `word_timestamps=False` for reliable segment timestamps
|
| 1722 |
+
- use `vad=True` for more accurate non-speech detection
|
| 1723 |
+
- use `demucs=True` to isolate vocals with [Demucs](https://github.com/facebookresearch/demucs); it is also effective at isolating vocals even if there is no music
|
| 1724 |
+
- use `demucs=True` and `vad=True` for music
|
| 1725 |
+
- set same seed for each transcription (e.g. `random.seed(0)`) for `demucs=True` to produce deterministic outputs
|
| 1726 |
+
- to enable dynamic quantization for inference on CPU use `--dq true` for CLI or `dq=True` for `stable_whisper.load_model`
|
| 1727 |
+
- use `encode_video_comparison()` to encode multiple transcripts into one video for synced comparison; see [Encode Comparison](#encode-comparison)
|
| 1728 |
+
- use `visualize_suppression()` to visualize the differences between non-VAD and VAD options; see [Visualizing Suppression](#visualizing-suppression)
|
| 1729 |
+
- [refinement](#refinement) can an effective (but slow) alternative for polishing timestamps if silence suppression isn't effective
|
| 1730 |
+
|
| 1731 |
+
### Visualizing Suppression
|
| 1732 |
+
You can visualize which parts of the audio will likely be suppressed (i.e. marked as silent).
|
| 1733 |
+
Requires: [Pillow](https://github.com/python-pillow/Pillow) or [opencv-python](https://github.com/opencv/opencv-python).
|
| 1734 |
+
|
| 1735 |
+
#### Without VAD
|
| 1736 |
+
```python
|
| 1737 |
+
import stable_whisper
|
| 1738 |
+
# regions on the waveform colored red are where it will likely be suppressed and marked as silent
|
| 1739 |
+
# [q_levels]=20 and [k_size]=5 (default)
|
| 1740 |
+
stable_whisper.visualize_suppression('audio.mp3', 'image.png', q_levels=20, k_size = 5)
|
| 1741 |
+
```
|
| 1742 |
+

|
| 1743 |
+
|
| 1744 |
+
#### With [Silero VAD](https://github.com/snakers4/silero-vad)
|
| 1745 |
+
```python
|
| 1746 |
+
# [vad_threshold]=0.35 (default)
|
| 1747 |
+
stable_whisper.visualize_suppression('audio.mp3', 'image.png', vad=True, vad_threshold=0.35)
|
| 1748 |
+
```
|
| 1749 |
+

|
| 1750 |
+
Docstring:
|
| 1751 |
+
<details>
|
| 1752 |
+
<summary>visualize_suppression()</summary>
|
| 1753 |
+
|
| 1754 |
+
Visualize regions on the waveform of ``audio`` detected as silent.
|
| 1755 |
+
|
| 1756 |
+
Regions on the waveform colored red are detected as silent.
|
| 1757 |
+
|
| 1758 |
+
Parameters
|
| 1759 |
+
----------
|
| 1760 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 1761 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 1762 |
+
If audio is ``numpy.ndarray`` or ``torch.Tensor``, the audio must be already at sampled to 16kHz.
|
| 1763 |
+
output : str, default None, meaning image will be shown directly via Pillow or opencv-python
|
| 1764 |
+
Path to save visualization.
|
| 1765 |
+
q_levels : int, default 20
|
| 1766 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 1767 |
+
Acts as a threshold to marking sound as silent.
|
| 1768 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 1769 |
+
k_size : int, default 5
|
| 1770 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 1771 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 1772 |
+
vad : bool, default False
|
| 1773 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 1774 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 1775 |
+
vad_threshold : float, default 0.35
|
| 1776 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 1777 |
+
max_width : int, default 1500
|
| 1778 |
+
Maximum width of visualization to avoid overly large image from long audio.
|
| 1779 |
+
Each unit of pixel is equivalent to 1 token. Use -1 to visualize the entire audio track.
|
| 1780 |
+
height : int, default 200
|
| 1781 |
+
Height of visualization.
|
| 1782 |
+
|
| 1783 |
+
</details>
|
| 1784 |
+
|
| 1785 |
+
### Encode Comparison
|
| 1786 |
+
You can encode videos similar to the ones in the doc for comparing transcriptions of the same audio.
|
| 1787 |
+
```python
|
| 1788 |
+
stable_whisper.encode_video_comparison(
|
| 1789 |
+
'audio.mp3',
|
| 1790 |
+
['audio_sub1.srt', 'audio_sub2.srt'],
|
| 1791 |
+
output_videopath='audio.mp4',
|
| 1792 |
+
labels=['Example 1', 'Example 2']
|
| 1793 |
+
)
|
| 1794 |
+
```
|
| 1795 |
+
Docstring:
|
| 1796 |
+
<details>
|
| 1797 |
+
<summary>encode_video_comparison()</summary>
|
| 1798 |
+
|
| 1799 |
+
Encode multiple subtitle files into one video with the subtitles vertically stacked.
|
| 1800 |
+
|
| 1801 |
+
Parameters
|
| 1802 |
+
----------
|
| 1803 |
+
audiofile : str
|
| 1804 |
+
Path of audio file.
|
| 1805 |
+
subtitle_files : list of str
|
| 1806 |
+
List of paths for subtitle file.
|
| 1807 |
+
output_videopath : str, optional
|
| 1808 |
+
Output video path.
|
| 1809 |
+
labels : list of str, default, None, meaning use ``subtitle_files`` as labels
|
| 1810 |
+
List of labels for ``subtitle_files``.
|
| 1811 |
+
height : int, default 90
|
| 1812 |
+
Height for each subtitle section.
|
| 1813 |
+
width : int, default 720
|
| 1814 |
+
Width for each subtitle section.
|
| 1815 |
+
color : str, default 'black'
|
| 1816 |
+
Background color of the video.
|
| 1817 |
+
fontsize: int, default 70
|
| 1818 |
+
Font size for subtitles.
|
| 1819 |
+
border_color : str, default 'white'
|
| 1820 |
+
Border color for separating the sections of subtitle.
|
| 1821 |
+
label_color : str, default 'white'
|
| 1822 |
+
Color of labels.
|
| 1823 |
+
label_size : int, default 14
|
| 1824 |
+
Font size of labels.
|
| 1825 |
+
fps : int, default 25
|
| 1826 |
+
Frame-rate of the video.
|
| 1827 |
+
video_codec : str, optional
|
| 1828 |
+
Video codec opf the video.
|
| 1829 |
+
audio_codec : str, optional
|
| 1830 |
+
Audio codec opf the video.
|
| 1831 |
+
overwrite : bool, default False
|
| 1832 |
+
Whether to overwrite existing video files with the same path as the output video.
|
| 1833 |
+
only_cmd : bool, default False
|
| 1834 |
+
Whether to skip encoding and only return the full command generate from the specified options.
|
| 1835 |
+
verbose : bool, default True
|
| 1836 |
+
Whether to display ffmpeg processing info.
|
| 1837 |
+
|
| 1838 |
+
Returns
|
| 1839 |
+
-------
|
| 1840 |
+
str or None
|
| 1841 |
+
Encoding command as a string if ``only_cmd = True``.
|
| 1842 |
+
|
| 1843 |
+
</details>
|
| 1844 |
+
|
| 1845 |
+
#### Multiple Files with CLI
|
| 1846 |
+
Transcribe multiple audio files then process the results directly into SRT files.
|
| 1847 |
+
```commandline
|
| 1848 |
+
stable-ts audio1.mp3 audio2.mp3 audio3.mp3 -o audio1.srt audio2.srt audio3.srt
|
| 1849 |
+
```
|
| 1850 |
+
|
| 1851 |
+
### Any ASR
|
| 1852 |
+
You can use most of the features of Stable-ts improve the results of any ASR model/APIs.
|
| 1853 |
+
[Just follow this notebook](https://github.com/jianfch/stable-ts/blob/main/examples/non-whisper.ipynb).
|
| 1854 |
+
|
| 1855 |
+
## Quick 1.X → 2.X Guide
|
| 1856 |
+
### What's new in 2.0.0?
|
| 1857 |
+
- updated to use Whisper's more reliable word-level timestamps method.
|
| 1858 |
+
- the more reliable word timestamps allow regrouping all words into segments with more natural boundaries.
|
| 1859 |
+
- can now suppress silence with [Silero VAD](https://github.com/snakers4/silero-vad) (requires PyTorch 1.12.0+)
|
| 1860 |
+
- non-VAD silence suppression is also more robust
|
| 1861 |
+
### Usage changes
|
| 1862 |
+
- `results_to_sentence_srt(result, 'audio.srt')` → `result.to_srt_vtt('audio.srt', word_level=False)`
|
| 1863 |
+
- `results_to_word_srt(result, 'audio.srt')` → `result.to_srt_vtt('output.srt', segment_level=False)`
|
| 1864 |
+
- `results_to_sentence_word_ass(result, 'audio.srt')` → `result.to_ass('output.ass')`
|
| 1865 |
+
- there's no need to stabilize segments after inference because they're already stabilized during inference
|
| 1866 |
+
- `transcribe()` returns a `WhisperResult` object which can be converted to `dict` with `.to_dict()`. e.g `result.to_dict()`
|
| 1867 |
+
|
| 1868 |
+
## License
|
| 1869 |
+
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details
|
| 1870 |
+
|
| 1871 |
+
## Acknowledgments
|
| 1872 |
+
Includes slight modification of the original work: [Whisper](https://github.com/openai/whisper)
|
examples/non-whisper.ipynb
ADDED
|
@@ -0,0 +1,425 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "13dc05a3-de12-4d7a-a926-e99d6d97826e",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## Using Stable-ts with any ASR"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "code",
|
| 13 |
+
"execution_count": null,
|
| 14 |
+
"id": "5cfee322-ebca-4c23-87a4-a109a2f85203",
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"outputs": [],
|
| 17 |
+
"source": [
|
| 18 |
+
"import stable_whisper\n",
|
| 19 |
+
"assert int(stable_whisper.__version__.replace('.', '')) >= 270, f\"Requires Stable-ts 2.7.0+. Current version is {stable_whisper.__version__}.\""
|
| 20 |
+
]
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "markdown",
|
| 24 |
+
"id": "e6c2dab2-f4df-46f9-b2e8-94dd88522c7d",
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"source": [
|
| 27 |
+
"<br />\n",
|
| 28 |
+
"\n",
|
| 29 |
+
"Stable-ts can be used for other ASR models or web APIs by wrapping them as a function then passing it as the first argument to `non_whisper.transcribe_any()`."
|
| 30 |
+
]
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"cell_type": "code",
|
| 34 |
+
"execution_count": 2,
|
| 35 |
+
"id": "7d32fa9f-a54c-4996-97c3-3b360230d029",
|
| 36 |
+
"metadata": {
|
| 37 |
+
"tags": []
|
| 38 |
+
},
|
| 39 |
+
"outputs": [],
|
| 40 |
+
"source": [
|
| 41 |
+
"def inference(audio, **kwargs) -> dict:\n",
|
| 42 |
+
" # run model/API \n",
|
| 43 |
+
" # return data as a dictionary\n",
|
| 44 |
+
" data = {}\n",
|
| 45 |
+
" return data"
|
| 46 |
+
]
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"cell_type": "markdown",
|
| 50 |
+
"id": "856ef1fd-f489-42af-a90c-97323fd05a6b",
|
| 51 |
+
"metadata": {},
|
| 52 |
+
"source": [
|
| 53 |
+
"The data returned by the function must be one of the following:\n",
|
| 54 |
+
"- an instance of `WhisperResult` containing the data\n",
|
| 55 |
+
"- a dictionary in an appropriate mapping\n",
|
| 56 |
+
"- a path of JSON file containing data in an appropriate mapping"
|
| 57 |
+
]
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"cell_type": "markdown",
|
| 61 |
+
"id": "bbdebdad-af1d-4077-8e99-20e767a0fd91",
|
| 62 |
+
"metadata": {},
|
| 63 |
+
"source": [
|
| 64 |
+
"Here are the 3 types of mappings:"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "code",
|
| 69 |
+
"execution_count": 3,
|
| 70 |
+
"id": "06bc4ce7-5117-4674-8eb9-c343c13c18bc",
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"outputs": [],
|
| 73 |
+
"source": [
|
| 74 |
+
"#1:\n",
|
| 75 |
+
"essential_mapping = [\n",
|
| 76 |
+
" [ # 1st Segment\n",
|
| 77 |
+
" {'word': ' And', 'start': 0.0, 'end': 1.28}, \n",
|
| 78 |
+
" {'word': ' when', 'start': 1.28, 'end': 1.52}, \n",
|
| 79 |
+
" {'word': ' no', 'start': 1.52, 'end': 2.26}, \n",
|
| 80 |
+
" {'word': ' ocean,', 'start': 2.26, 'end': 2.68},\n",
|
| 81 |
+
" {'word': ' mountain,', 'start': 3.28, 'end': 3.58}\n",
|
| 82 |
+
" ], \n",
|
| 83 |
+
" [ # 2nd Segment\n",
|
| 84 |
+
" {'word': ' or', 'start': 4.0, 'end': 4.08}, \n",
|
| 85 |
+
" {'word': ' sky', 'start': 4.08, 'end': 4.56}, \n",
|
| 86 |
+
" {'word': ' could', 'start': 4.56, 'end': 4.84}, \n",
|
| 87 |
+
" {'word': ' contain', 'start': 4.84, 'end': 5.26}, \n",
|
| 88 |
+
" {'word': ' us,', 'start': 5.26, 'end': 6.27},\n",
|
| 89 |
+
" {'word': ' our', 'start': 6.27, 'end': 6.58}, \n",
|
| 90 |
+
" {'word': ' gaze', 'start': 6.58, 'end': 6.98}, \n",
|
| 91 |
+
" {'word': ' hungered', 'start': 6.98, 'end': 7.88}, \n",
|
| 92 |
+
" {'word': ' starward.', 'start': 7.88, 'end': 8.64}\n",
|
| 93 |
+
" ]\n",
|
| 94 |
+
"]"
|
| 95 |
+
]
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"cell_type": "markdown",
|
| 99 |
+
"id": "b53bd812-2838-4f47-ab5f-5e729801aaee",
|
| 100 |
+
"metadata": {},
|
| 101 |
+
"source": [
|
| 102 |
+
"<br />\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"If word timings are not available they can be omitted, but operations that can be performed on this data will be limited."
|
| 105 |
+
]
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
"cell_type": "code",
|
| 109 |
+
"execution_count": 4,
|
| 110 |
+
"id": "8c6bf720-5bfd-4e79-90e7-7049a2ca1d3a",
|
| 111 |
+
"metadata": {},
|
| 112 |
+
"outputs": [],
|
| 113 |
+
"source": [
|
| 114 |
+
"#2:\n",
|
| 115 |
+
"no_word_mapping = [\n",
|
| 116 |
+
" {\n",
|
| 117 |
+
" 'start': 0.0, \n",
|
| 118 |
+
" 'end': 3.58, \n",
|
| 119 |
+
" 'text': ' And when no ocean, mountain,',\n",
|
| 120 |
+
" }, \n",
|
| 121 |
+
" {\n",
|
| 122 |
+
" 'start': 4.0, \n",
|
| 123 |
+
" 'end': 8.64, \n",
|
| 124 |
+
" 'text': ' or sky could contain us, our gaze hungered starward.', \n",
|
| 125 |
+
" }\n",
|
| 126 |
+
"]"
|
| 127 |
+
]
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"cell_type": "markdown",
|
| 131 |
+
"id": "108e960f-8bd1-4d2a-92bf-cc8cb56f4615",
|
| 132 |
+
"metadata": {},
|
| 133 |
+
"source": [
|
| 134 |
+
"<br />\n",
|
| 135 |
+
"\n",
|
| 136 |
+
"Below is the full mapping for normal Stable-ts results. `None` takes the place of any omitted values except for `start`, `end`, and `text`/`word` which are required."
|
| 137 |
+
]
|
| 138 |
+
},
|
| 139 |
+
{
|
| 140 |
+
"cell_type": "code",
|
| 141 |
+
"execution_count": 5,
|
| 142 |
+
"id": "2969aad2-c8bf-4043-8015-669a3102e158",
|
| 143 |
+
"metadata": {},
|
| 144 |
+
"outputs": [],
|
| 145 |
+
"source": [
|
| 146 |
+
"#3:\n",
|
| 147 |
+
"full_mapping = {\n",
|
| 148 |
+
" 'language': 'en',\n",
|
| 149 |
+
" 'text': ' And when no ocean, mountain, or sky could contain us, our gaze hungered starward.', \n",
|
| 150 |
+
" 'segments': [\n",
|
| 151 |
+
" {\n",
|
| 152 |
+
" 'seek': 0.0, \n",
|
| 153 |
+
" 'start': 0.0, \n",
|
| 154 |
+
" 'end': 3.58, \n",
|
| 155 |
+
" 'text': ' And when no ocean, mountain,', \n",
|
| 156 |
+
" 'tokens': [400, 562, 572, 7810, 11, 6937, 11], \n",
|
| 157 |
+
" 'temperature': 0.0, \n",
|
| 158 |
+
" 'avg_logprob': -0.48702024376910663, \n",
|
| 159 |
+
" 'compression_ratio': 1.0657894736842106, \n",
|
| 160 |
+
" 'no_speech_prob': 0.3386174440383911, \n",
|
| 161 |
+
" 'id': 0, \n",
|
| 162 |
+
" 'words': [\n",
|
| 163 |
+
" {'word': ' And', 'start': 0.04, 'end': 1.28, 'probability': 0.6481522917747498, 'tokens': [400]}, \n",
|
| 164 |
+
" {'word': ' when', 'start': 1.28, 'end': 1.52, 'probability': 0.9869539141654968, 'tokens': [562]}, \n",
|
| 165 |
+
" {'word': ' no', 'start': 1.52, 'end': 2.26, 'probability': 0.57384192943573, 'tokens': [572]}, \n",
|
| 166 |
+
" {'word': ' ocean,', 'start': 2.26, 'end': 2.68, 'probability': 0.9484889507293701, 'tokens': [7810, 11]},\n",
|
| 167 |
+
" {'word': ' mountain,', 'start': 3.28, 'end': 3.58, 'probability': 0.9581122398376465, 'tokens': [6937, 11]}\n",
|
| 168 |
+
" ]\n",
|
| 169 |
+
" }, \n",
|
| 170 |
+
" {\n",
|
| 171 |
+
" 'seek': 0.0, \n",
|
| 172 |
+
" 'start': 4.0, \n",
|
| 173 |
+
" 'end': 8.64, \n",
|
| 174 |
+
" 'text': ' or sky could contain us, our gaze hungered starward.', \n",
|
| 175 |
+
" 'tokens': [420, 5443, 727, 5304, 505, 11, 527, 24294, 5753, 4073, 3543, 1007, 13], \n",
|
| 176 |
+
" 'temperature': 0.0, \n",
|
| 177 |
+
" 'avg_logprob': -0.48702024376910663, \n",
|
| 178 |
+
" 'compression_ratio': 1.0657894736842106, \n",
|
| 179 |
+
" 'no_speech_prob': 0.3386174440383911, \n",
|
| 180 |
+
" 'id': 1, \n",
|
| 181 |
+
" 'words': [\n",
|
| 182 |
+
" {'word': ' or', 'start': 4.0, 'end': 4.08, 'probability': 0.9937937259674072, 'tokens': [420]}, \n",
|
| 183 |
+
" {'word': ' sky', 'start': 4.08, 'end': 4.56, 'probability': 0.9950089454650879, 'tokens': [5443]}, \n",
|
| 184 |
+
" {'word': ' could', 'start': 4.56, 'end': 4.84, 'probability': 0.9915681481361389, 'tokens': [727]}, \n",
|
| 185 |
+
" {'word': ' contain', 'start': 4.84, 'end': 5.26, 'probability': 0.898974597454071, 'tokens': [5304]}, \n",
|
| 186 |
+
" {'word': ' us,', 'start': 5.26, 'end': 6.27, 'probability': 0.999351441860199, 'tokens': [505, 11]},\n",
|
| 187 |
+
" {'word': ' our', 'start': 6.27, 'end': 6.58, 'probability': 0.9634224772453308, 'tokens': [527]}, \n",
|
| 188 |
+
" {'word': ' gaze', 'start': 6.58, 'end': 6.98, 'probability': 0.8934874534606934, 'tokens': [24294]}, \n",
|
| 189 |
+
" {'word': ' hungered', 'start': 6.98, 'end': 7.88, 'probability': 0.7424876093864441, 'tokens': [5753, 4073]}, \n",
|
| 190 |
+
" {'word': ' starward.', 'start': 7.88, 'end': 8.64, 'probability': 0.464096799492836, 'tokens': [3543, 1007, 13]}\n",
|
| 191 |
+
" ]\n",
|
| 192 |
+
" }\n",
|
| 193 |
+
" ]\n",
|
| 194 |
+
"}"
|
| 195 |
+
]
|
| 196 |
+
},
|
| 197 |
+
{
|
| 198 |
+
"cell_type": "markdown",
|
| 199 |
+
"id": "49d136e4-0f7d-4dcf-84f9-efb6f0eda491",
|
| 200 |
+
"metadata": {},
|
| 201 |
+
"source": [
|
| 202 |
+
"<br />\n",
|
| 203 |
+
"\n",
|
| 204 |
+
"The function must also have `audio` as a parameter."
|
| 205 |
+
]
|
| 206 |
+
},
|
| 207 |
+
{
|
| 208 |
+
"cell_type": "code",
|
| 209 |
+
"execution_count": 6,
|
| 210 |
+
"id": "33f03286-69f9-4ae1-aec0-250fd92a8cb6",
|
| 211 |
+
"metadata": {
|
| 212 |
+
"tags": []
|
| 213 |
+
},
|
| 214 |
+
"outputs": [],
|
| 215 |
+
"source": [
|
| 216 |
+
"def inference(audio, **kwargs) -> dict:\n",
|
| 217 |
+
" # run model/API on the audio\n",
|
| 218 |
+
" # return data in a proper format\n",
|
| 219 |
+
" return essential_mapping"
|
| 220 |
+
]
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"cell_type": "code",
|
| 224 |
+
"execution_count": 7,
|
| 225 |
+
"id": "d6710eb5-5386-42cf-b6e7-02a84b5fad40",
|
| 226 |
+
"metadata": {
|
| 227 |
+
"tags": []
|
| 228 |
+
},
|
| 229 |
+
"outputs": [],
|
| 230 |
+
"source": [
|
| 231 |
+
"result = stable_whisper.transcribe_any(inference, './demo.wav', vad=True)"
|
| 232 |
+
]
|
| 233 |
+
},
|
| 234 |
+
{
|
| 235 |
+
"cell_type": "code",
|
| 236 |
+
"execution_count": 8,
|
| 237 |
+
"id": "6d7f9de6-5c9b-4c73-808d-640b13efb051",
|
| 238 |
+
"metadata": {},
|
| 239 |
+
"outputs": [
|
| 240 |
+
{
|
| 241 |
+
"name": "stdout",
|
| 242 |
+
"output_type": "stream",
|
| 243 |
+
"text": [
|
| 244 |
+
"0\n",
|
| 245 |
+
"00:00:01,122 --> 00:00:02,680\n",
|
| 246 |
+
"And when no ocean,\n",
|
| 247 |
+
"\n",
|
| 248 |
+
"1\n",
|
| 249 |
+
"00:00:03,280 --> 00:00:03,580\n",
|
| 250 |
+
"mountain,\n",
|
| 251 |
+
"\n",
|
| 252 |
+
"2\n",
|
| 253 |
+
"00:00:04,000 --> 00:00:06,046\n",
|
| 254 |
+
"or sky could contain us,\n",
|
| 255 |
+
"\n",
|
| 256 |
+
"3\n",
|
| 257 |
+
"00:00:06,402 --> 00:00:08,640\n",
|
| 258 |
+
"our gaze hungered starward.\n"
|
| 259 |
+
]
|
| 260 |
+
}
|
| 261 |
+
],
|
| 262 |
+
"source": [
|
| 263 |
+
"print(result.to_srt_vtt(word_level=False))"
|
| 264 |
+
]
|
| 265 |
+
},
|
| 266 |
+
{
|
| 267 |
+
"cell_type": "code",
|
| 268 |
+
"execution_count": 9,
|
| 269 |
+
"id": "be5a45e8-1b25-4a70-9af6-94bc5379fc7d",
|
| 270 |
+
"metadata": {},
|
| 271 |
+
"outputs": [
|
| 272 |
+
{
|
| 273 |
+
"name": "stdout",
|
| 274 |
+
"output_type": "stream",
|
| 275 |
+
"text": [
|
| 276 |
+
"\n",
|
| 277 |
+
" Transcribe an audio file using any ASR system.\n",
|
| 278 |
+
"\n",
|
| 279 |
+
" Parameters\n",
|
| 280 |
+
" ----------\n",
|
| 281 |
+
" inference_func: Callable\n",
|
| 282 |
+
" Function that runs ASR when provided the [audio] and return data in the appropriate format.\n",
|
| 283 |
+
" For format examples: https://github.com/jianfch/stable-ts/blob/main/examples/non-whisper.ipynb\n",
|
| 284 |
+
"\n",
|
| 285 |
+
" audio: Union[str, np.ndarray, torch.Tensor, bytes]\n",
|
| 286 |
+
" The path/URL to the audio file, the audio waveform, or bytes of audio file.\n",
|
| 287 |
+
"\n",
|
| 288 |
+
" audio_type: str\n",
|
| 289 |
+
" The type that [audio] needs to be for [inference_func]. (Default: Same type as [audio])\n",
|
| 290 |
+
"\n",
|
| 291 |
+
" Types:\n",
|
| 292 |
+
" None (default)\n",
|
| 293 |
+
" same type as [audio]\n",
|
| 294 |
+
"\n",
|
| 295 |
+
" 'str'\n",
|
| 296 |
+
" a path to the file\n",
|
| 297 |
+
" -if [audio] is a file and not audio preprocessing is done,\n",
|
| 298 |
+
" [audio] will be directly passed into [inference_func]\n",
|
| 299 |
+
" -if audio preprocessing is performed (from [demucs] and/or [only_voice_freq]),\n",
|
| 300 |
+
" the processed audio will be encoded into [temp_file] and then passed into [inference_func]\n",
|
| 301 |
+
"\n",
|
| 302 |
+
" 'byte'\n",
|
| 303 |
+
" bytes (used for APIs or to avoid writing any data to hard drive)\n",
|
| 304 |
+
" -if [audio] is file, the bytes of file is used\n",
|
| 305 |
+
" -if [audio] PyTorch tensor or NumPy array, the bytes of the [audio] encoded into WAV format is used\n",
|
| 306 |
+
"\n",
|
| 307 |
+
" 'torch'\n",
|
| 308 |
+
" a PyTorch tensor containing the audio waveform, in float32 dtype, on CPU\n",
|
| 309 |
+
"\n",
|
| 310 |
+
" 'numpy'\n",
|
| 311 |
+
" a NumPy array containing the audio waveform, in float32 dtype\n",
|
| 312 |
+
"\n",
|
| 313 |
+
" input_sr: int\n",
|
| 314 |
+
" The sample rate of [audio]. (Default: Auto-detected if [audio] is str/bytes)\n",
|
| 315 |
+
"\n",
|
| 316 |
+
" model_sr: int\n",
|
| 317 |
+
" The sample rate to resample the audio into for [inference_func]. (Default: Same as [input_sr])\n",
|
| 318 |
+
" Resampling is only performed when [model_sr] do not match the sample rate of the final audio due to:\n",
|
| 319 |
+
" -[input_sr] not matching\n",
|
| 320 |
+
" -sample rate changed due to audio preprocessing from [demucs]=True\n",
|
| 321 |
+
"\n",
|
| 322 |
+
" inference_kwargs: dict\n",
|
| 323 |
+
" Dictionary of arguments provided to [inference_func]. (Default: None)\n",
|
| 324 |
+
"\n",
|
| 325 |
+
" temp_file: str\n",
|
| 326 |
+
" Temporary path for the preprocessed audio when [audio_type]='str'. (Default: './_temp_stable-ts_audio_.wav')\n",
|
| 327 |
+
"\n",
|
| 328 |
+
" verbose: bool\n",
|
| 329 |
+
" Whether to display the text being decoded to the console. If True, displays all the details,\n",
|
| 330 |
+
" If False, displays progressbar. If None, does not display anything (Default: False)\n",
|
| 331 |
+
"\n",
|
| 332 |
+
" regroup: Union[bool, str]\n",
|
| 333 |
+
" Whether to regroup all words into segments with more natural boundaries. (Default: True)\n",
|
| 334 |
+
" Specify string for customizing the regrouping algorithm.\n",
|
| 335 |
+
" Ignored if [word_timestamps]=False.\n",
|
| 336 |
+
"\n",
|
| 337 |
+
" suppress_silence: bool\n",
|
| 338 |
+
" Whether to suppress timestamp where audio is silent at segment-level\n",
|
| 339 |
+
" and word-level if [suppress_word_ts]=True. (Default: True)\n",
|
| 340 |
+
"\n",
|
| 341 |
+
" suppress_word_ts: bool\n",
|
| 342 |
+
" Whether to suppress timestamps, if [suppress_silence]=True, where audio is silent at word-level. (Default: True)\n",
|
| 343 |
+
"\n",
|
| 344 |
+
" q_levels: int\n",
|
| 345 |
+
" Quantization levels for generating timestamp suppression mask; ignored if [vad]=true. (Default: 20)\n",
|
| 346 |
+
" Acts as a threshold to marking sound as silent.\n",
|
| 347 |
+
" Fewer levels will increase the threshold of volume at which to mark a sound as silent.\n",
|
| 348 |
+
"\n",
|
| 349 |
+
" k_size: int\n",
|
| 350 |
+
" Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if [vad]=true. (Default: 5)\n",
|
| 351 |
+
" Recommend 5 or 3; higher sizes will reduce detection of silence.\n",
|
| 352 |
+
"\n",
|
| 353 |
+
" demucs: bool\n",
|
| 354 |
+
" Whether to preprocess the audio track with Demucs to isolate vocals/remove noise. (Default: False)\n",
|
| 355 |
+
" Demucs must be installed to use. Official repo: https://github.com/facebookresearch/demucs\n",
|
| 356 |
+
"\n",
|
| 357 |
+
" demucs_device: str\n",
|
| 358 |
+
" Device to use for demucs: 'cuda' or 'cpu'. (Default. 'cuda' if torch.cuda.is_available() else 'cpu')\n",
|
| 359 |
+
"\n",
|
| 360 |
+
" demucs_output: str\n",
|
| 361 |
+
" Path to save the vocals isolated by Demucs as WAV file. Ignored if [demucs]=False.\n",
|
| 362 |
+
" Demucs must be installed to use. Official repo: https://github.com/facebookresearch/demucs\n",
|
| 363 |
+
"\n",
|
| 364 |
+
" vad: bool\n",
|
| 365 |
+
" Whether to use Silero VAD to generate timestamp suppression mask. (Default: False)\n",
|
| 366 |
+
" Silero VAD requires PyTorch 1.12.0+. Official repo: https://github.com/snakers4/silero-vad\n",
|
| 367 |
+
"\n",
|
| 368 |
+
" vad_threshold: float\n",
|
| 369 |
+
" Threshold for detecting speech with Silero VAD. (Default: 0.35)\n",
|
| 370 |
+
" Low threshold reduces false positives for silence detection.\n",
|
| 371 |
+
"\n",
|
| 372 |
+
" vad_onnx: bool\n",
|
| 373 |
+
" Whether to use ONNX for Silero VAD. (Default: False)\n",
|
| 374 |
+
"\n",
|
| 375 |
+
" min_word_dur: float\n",
|
| 376 |
+
" Only allow suppressing timestamps that result in word durations greater than this value. (default: 0.1)\n",
|
| 377 |
+
"\n",
|
| 378 |
+
" only_voice_freq: bool\n",
|
| 379 |
+
" Whether to only use sound between 200 - 5000 Hz, where majority of human speech are. (Default: False)\n",
|
| 380 |
+
"\n",
|
| 381 |
+
" only_ffmpeg: bool\n",
|
| 382 |
+
" Whether to use only FFmpeg (and not yt-dlp) for URls. (Default: False)\n",
|
| 383 |
+
"\n",
|
| 384 |
+
" Returns\n",
|
| 385 |
+
" -------\n",
|
| 386 |
+
" An instance of WhisperResult.\n",
|
| 387 |
+
" \n"
|
| 388 |
+
]
|
| 389 |
+
}
|
| 390 |
+
],
|
| 391 |
+
"source": [
|
| 392 |
+
"print(stable_whisper.transcribe_any.__doc__)"
|
| 393 |
+
]
|
| 394 |
+
},
|
| 395 |
+
{
|
| 396 |
+
"cell_type": "code",
|
| 397 |
+
"execution_count": null,
|
| 398 |
+
"id": "a99ee627-6ab4-411d-ba27-d372d3647593",
|
| 399 |
+
"metadata": {},
|
| 400 |
+
"outputs": [],
|
| 401 |
+
"source": []
|
| 402 |
+
}
|
| 403 |
+
],
|
| 404 |
+
"metadata": {
|
| 405 |
+
"kernelspec": {
|
| 406 |
+
"display_name": "Python 3 (ipykernel)",
|
| 407 |
+
"language": "python",
|
| 408 |
+
"name": "python3"
|
| 409 |
+
},
|
| 410 |
+
"language_info": {
|
| 411 |
+
"codemirror_mode": {
|
| 412 |
+
"name": "ipython",
|
| 413 |
+
"version": 3
|
| 414 |
+
},
|
| 415 |
+
"file_extension": ".py",
|
| 416 |
+
"mimetype": "text/x-python",
|
| 417 |
+
"name": "python",
|
| 418 |
+
"nbconvert_exporter": "python",
|
| 419 |
+
"pygments_lexer": "ipython3",
|
| 420 |
+
"version": "3.8.15"
|
| 421 |
+
}
|
| 422 |
+
},
|
| 423 |
+
"nbformat": 4,
|
| 424 |
+
"nbformat_minor": 5
|
| 425 |
+
}
|
setup.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from setuptools import setup
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def version() -> str:
|
| 6 |
+
with open(os.path.join(os.path.dirname(__file__), 'stable_whisper/_version.py')) as f:
|
| 7 |
+
return f.read().split('=')[-1].strip().strip('"').strip("'")
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def read_me() -> str:
|
| 11 |
+
with open('README.md', 'r', encoding='utf-8') as f:
|
| 12 |
+
return f.read()
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
setup(
|
| 16 |
+
name="stable-ts",
|
| 17 |
+
version=version(),
|
| 18 |
+
description="Modifies OpenAI's Whisper to produce more reliable timestamps.",
|
| 19 |
+
long_description=read_me(),
|
| 20 |
+
long_description_content_type='text/markdown',
|
| 21 |
+
python_requires=">=3.8",
|
| 22 |
+
author="Jian",
|
| 23 |
+
url="https://github.com/jianfch/stable-ts",
|
| 24 |
+
license="MIT",
|
| 25 |
+
packages=['stable_whisper'],
|
| 26 |
+
install_requires=[
|
| 27 |
+
"numpy",
|
| 28 |
+
"torch",
|
| 29 |
+
"torchaudio",
|
| 30 |
+
"tqdm",
|
| 31 |
+
"more-itertools",
|
| 32 |
+
"transformers>=4.19.0",
|
| 33 |
+
"ffmpeg-python==0.2.0",
|
| 34 |
+
"openai-whisper==20231117"
|
| 35 |
+
],
|
| 36 |
+
entry_points={
|
| 37 |
+
"console_scripts": ["stable-ts=stable_whisper.whisper_word_level:cli"],
|
| 38 |
+
},
|
| 39 |
+
include_package_data=False
|
| 40 |
+
)
|
silence_suppresion0.png
ADDED
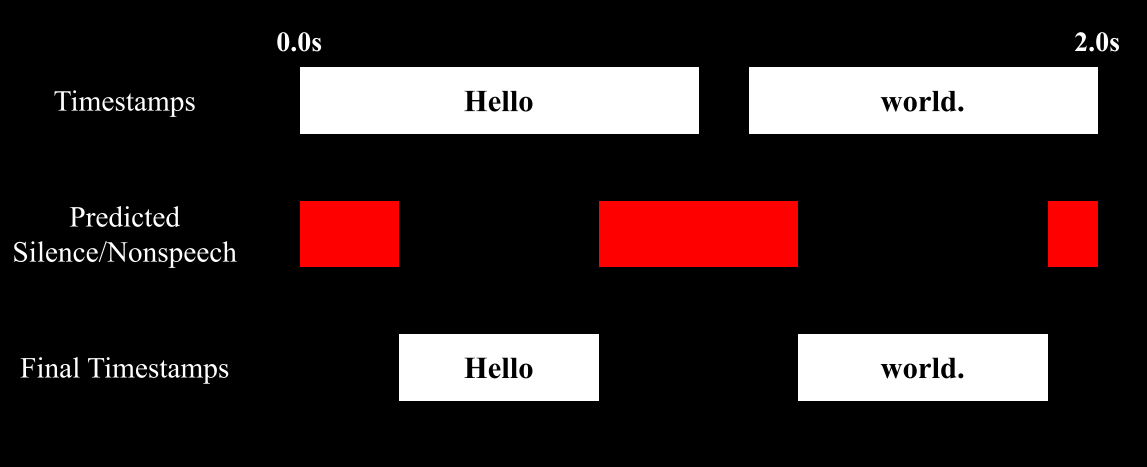
|
silence_suppresion1.png
ADDED

|
stable_whisper/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .whisper_word_level import *
|
| 2 |
+
from .result import *
|
| 3 |
+
from .text_output import *
|
| 4 |
+
from .video_output import *
|
| 5 |
+
from .stabilization import visualize_suppression
|
| 6 |
+
from .non_whisper import transcribe_any
|
| 7 |
+
from ._version import __version__
|
| 8 |
+
from .whisper_compatibility import _required_whisper_ver, _COMPATIBLE_WHISPER_VERSIONS
|
stable_whisper/__main__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .whisper_word_level import cli
|
| 2 |
+
|
| 3 |
+
cli()
|
stable_whisper/_version.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__version__ = "2.14.3"
|
stable_whisper/alignment.py
ADDED
|
@@ -0,0 +1,1265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import re
|
| 3 |
+
import warnings
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import numpy as np
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
from typing import TYPE_CHECKING, Union, List, Callable, Optional, Tuple
|
| 9 |
+
|
| 10 |
+
import whisper
|
| 11 |
+
from whisper.audio import (
|
| 12 |
+
SAMPLE_RATE, N_FRAMES, N_SAMPLES, N_FFT, pad_or_trim, log_mel_spectrogram, FRAMES_PER_SECOND, CHUNK_LENGTH
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
from .result import WhisperResult, Segment
|
| 16 |
+
from .timing import add_word_timestamps_stable, split_word_tokens
|
| 17 |
+
from .audio import prep_audio
|
| 18 |
+
from .utils import safe_print, format_timestamp
|
| 19 |
+
from .whisper_compatibility import warn_compatibility_issues, get_tokenizer
|
| 20 |
+
from .stabilization import get_vad_silence_func, wav2mask, mask2timing
|
| 21 |
+
|
| 22 |
+
if TYPE_CHECKING:
|
| 23 |
+
from whisper.model import Whisper
|
| 24 |
+
|
| 25 |
+
__all__ = ['align', 'refine', 'locate']
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def align(
|
| 29 |
+
model: "Whisper",
|
| 30 |
+
audio: Union[str, np.ndarray, torch.Tensor, bytes],
|
| 31 |
+
text: Union[str, List[int], WhisperResult],
|
| 32 |
+
language: str = None,
|
| 33 |
+
*,
|
| 34 |
+
verbose: Optional[bool] = False,
|
| 35 |
+
regroup: bool = True,
|
| 36 |
+
suppress_silence: bool = True,
|
| 37 |
+
suppress_word_ts: bool = True,
|
| 38 |
+
use_word_position: bool = True,
|
| 39 |
+
min_word_dur: bool = 0.1,
|
| 40 |
+
nonspeech_error: float = 0.3,
|
| 41 |
+
q_levels: int = 20,
|
| 42 |
+
k_size: int = 5,
|
| 43 |
+
vad: bool = False,
|
| 44 |
+
vad_threshold: float = 0.35,
|
| 45 |
+
vad_onnx: bool = False,
|
| 46 |
+
demucs: Union[bool, torch.nn.Module] = False,
|
| 47 |
+
demucs_output: str = None,
|
| 48 |
+
demucs_options: dict = None,
|
| 49 |
+
only_voice_freq: bool = False,
|
| 50 |
+
prepend_punctuations: str = "\"'“¿([{-",
|
| 51 |
+
append_punctuations: str = "\"'.。,,!!??::”)]}、",
|
| 52 |
+
progress_callback: Callable = None,
|
| 53 |
+
ignore_compatibility: bool = False,
|
| 54 |
+
remove_instant_words: bool = False,
|
| 55 |
+
token_step: int = 100,
|
| 56 |
+
original_split: bool = False,
|
| 57 |
+
word_dur_factor: Optional[float] = 2.0,
|
| 58 |
+
max_word_dur: Optional[float] = 3.0,
|
| 59 |
+
nonspeech_skip: Optional[float] = 3.0,
|
| 60 |
+
fast_mode: bool = False,
|
| 61 |
+
tokenizer: "Tokenizer" = None
|
| 62 |
+
) -> Union[WhisperResult, None]:
|
| 63 |
+
"""
|
| 64 |
+
Align plain text or tokens with audio at word-level.
|
| 65 |
+
|
| 66 |
+
Since this is significantly faster than transcribing, it is a more efficient method for testing various settings
|
| 67 |
+
without re-transcribing. This is also useful for timing a more correct transcript than one that Whisper can produce.
|
| 68 |
+
|
| 69 |
+
Parameters
|
| 70 |
+
----------
|
| 71 |
+
model : "Whisper"
|
| 72 |
+
The Whisper ASR model modified instance
|
| 73 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 74 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 75 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 76 |
+
text : str or list of int or stable_whisper.result.WhisperResult
|
| 77 |
+
String of plain-text, list of tokens, or instance of :class:`stable_whisper.result.WhisperResult`.
|
| 78 |
+
language : str, default None, uses ``language`` in ``text`` if it is a :class:`stable_whisper.result.WhisperResult`
|
| 79 |
+
Language of ``text``. Required if ``text`` does not contain ``language``.
|
| 80 |
+
remove_instant_words : bool, default False
|
| 81 |
+
Whether to truncate any words with zero duration.
|
| 82 |
+
token_step : int, default 100
|
| 83 |
+
Max number of tokens to align each pass. Use higher values to reduce chance of misalignment.
|
| 84 |
+
original_split : bool, default False
|
| 85 |
+
Whether to preserve the original segment groupings. Segments are spit by line break if ``text`` is plain-text.
|
| 86 |
+
max_word_dur : float or None, default 3.0
|
| 87 |
+
Global maximum word duration in seconds. Re-align words that exceed the global maximum word duration.
|
| 88 |
+
word_dur_factor : float or None, default 2.0
|
| 89 |
+
Factor to compute the Local maximum word duration, which is ``word_dur_factor`` * local medium word duration.
|
| 90 |
+
Words that need re-alignment, are re-algined with duration <= local/global maximum word duration.
|
| 91 |
+
nonspeech_skip : float or None, default 3.0
|
| 92 |
+
Skip non-speech sections that are equal or longer than this duration in seconds. Disable skipping if ``None``.
|
| 93 |
+
fast_mode : bool, default False
|
| 94 |
+
Whether to speed up alignment by re-alignment with local/global maximum word duration.
|
| 95 |
+
``True`` tends produce better timestamps when ``text`` is accurate and there are no large speechless gaps.
|
| 96 |
+
tokenizer : "Tokenizer", default None, meaning a new tokenizer is created according ``language`` and ``model``
|
| 97 |
+
A tokenizer to used tokenizer text and detokenize tokens.
|
| 98 |
+
verbose : bool or None, default False
|
| 99 |
+
Whether to display the text being decoded to the console.
|
| 100 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 101 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 102 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 103 |
+
Ignored if ``word_timestamps = False``.
|
| 104 |
+
suppress_silence : bool, default True
|
| 105 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 106 |
+
suppress_word_ts : bool, default True
|
| 107 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 108 |
+
use_word_position : bool, default True
|
| 109 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 110 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 111 |
+
q_levels : int, default 20
|
| 112 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 113 |
+
Acts as a threshold to marking sound as silent.
|
| 114 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 115 |
+
k_size : int, default 5
|
| 116 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 117 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 118 |
+
demucs : bool or torch.nn.Module, default False
|
| 119 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 120 |
+
a Demucs model to avoid reloading the model for each run.
|
| 121 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 122 |
+
demucs_output : str, optional
|
| 123 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 124 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 125 |
+
demucs_options : dict, optional
|
| 126 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 127 |
+
vad : bool, default False
|
| 128 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 129 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 130 |
+
vad_threshold : float, default 0.35
|
| 131 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 132 |
+
vad_onnx : bool, default False
|
| 133 |
+
Whether to use ONNX for Silero VAD.
|
| 134 |
+
min_word_dur : float, default 0.1
|
| 135 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 136 |
+
nonspeech_error : float, default 0.3
|
| 137 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 138 |
+
only_voice_freq : bool, default False
|
| 139 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 140 |
+
prepend_punctuations : str, default '"'“¿([{-)'
|
| 141 |
+
Punctuations to prepend to next word.
|
| 142 |
+
append_punctuations : str, default '.。,,!!??::”)]}、)'
|
| 143 |
+
Punctuations to append to previous word.
|
| 144 |
+
progress_callback : Callable, optional
|
| 145 |
+
A function that will be called when transcription progress is updated.
|
| 146 |
+
The callback need two parameters.
|
| 147 |
+
The first parameter is a float for seconds of the audio that has been transcribed.
|
| 148 |
+
The second parameter is a float for total duration of audio in seconds.
|
| 149 |
+
ignore_compatibility : bool, default False
|
| 150 |
+
Whether to ignore warnings for compatibility issues with the detected Whisper version.
|
| 151 |
+
|
| 152 |
+
Returns
|
| 153 |
+
-------
|
| 154 |
+
stable_whisper.result.WhisperResult or None
|
| 155 |
+
All timestamps, words, probabilities, and other data from the alignment of ``audio``. Return None if alignment
|
| 156 |
+
fails and ``remove_instant_words = True``.
|
| 157 |
+
|
| 158 |
+
Notes
|
| 159 |
+
-----
|
| 160 |
+
If ``token_step`` is less than 1, ``token_step`` will be set to its maximum value, 442. This value is computed with
|
| 161 |
+
``whisper.model.Whisper.dims.n_text_ctx`` - 6.
|
| 162 |
+
|
| 163 |
+
IF ``original_split = True`` and a line break is found in middle of a word in ``text``, the split will occur after
|
| 164 |
+
that word.
|
| 165 |
+
|
| 166 |
+
``regroup`` is ignored if ``original_split = True``.
|
| 167 |
+
|
| 168 |
+
Examples
|
| 169 |
+
--------
|
| 170 |
+
>>> import stable_whisper
|
| 171 |
+
>>> model = stable_whisper.load_model('base')
|
| 172 |
+
>>> result = model.align('helloworld.mp3', 'Hello, World!', 'English')
|
| 173 |
+
>>> result.to_srt_vtt('helloword.srt')
|
| 174 |
+
Saved 'helloworld.srt'
|
| 175 |
+
"""
|
| 176 |
+
is_faster_model = model.__module__.startswith('faster_whisper.')
|
| 177 |
+
if demucs_options is None:
|
| 178 |
+
demucs_options = {}
|
| 179 |
+
if demucs_output:
|
| 180 |
+
if 'save_path' not in demucs_options:
|
| 181 |
+
demucs_options['save_path'] = demucs_output
|
| 182 |
+
warnings.warn('``demucs_output`` is deprecated. Use ``demucs_options`` with ``save_path`` instead. '
|
| 183 |
+
'E.g. demucs_options=dict(save_path="demucs_output.mp3")',
|
| 184 |
+
DeprecationWarning, stacklevel=2)
|
| 185 |
+
max_token_step = (model.max_length if is_faster_model else model.dims.n_text_ctx) - 6
|
| 186 |
+
if token_step < 1:
|
| 187 |
+
token_step = max_token_step
|
| 188 |
+
elif token_step > max_token_step:
|
| 189 |
+
raise ValueError(f'The max value for [token_step] is {max_token_step} but got {token_step}.')
|
| 190 |
+
|
| 191 |
+
warn_compatibility_issues(whisper, ignore_compatibility)
|
| 192 |
+
split_indices_by_char = []
|
| 193 |
+
if isinstance(text, WhisperResult):
|
| 194 |
+
if language is None:
|
| 195 |
+
language = text.language
|
| 196 |
+
if original_split and len(text.segments) > 1 and text.has_words:
|
| 197 |
+
split_indices_by_char = np.cumsum([sum(len(w.word) for w in seg.words) for seg in text.segments])
|
| 198 |
+
text = text.all_tokens() if text.has_words and all(w.tokens for w in text.all_words()) else text.text
|
| 199 |
+
elif isinstance(text, str):
|
| 200 |
+
if original_split and '\n' in text:
|
| 201 |
+
text_split = [line if line.startswith(' ') else ' '+line for line in text.splitlines()]
|
| 202 |
+
split_indices_by_char = np.cumsum([len(seg) for seg in text_split])
|
| 203 |
+
text = ''.join(re.sub(r'\s', ' ', seg) for seg in text_split)
|
| 204 |
+
else:
|
| 205 |
+
text = re.sub(r'\s', ' ', text)
|
| 206 |
+
if not text.startswith(' '):
|
| 207 |
+
text = ' ' + text
|
| 208 |
+
if language is None:
|
| 209 |
+
raise TypeError('expected argument for language')
|
| 210 |
+
if tokenizer is None:
|
| 211 |
+
tokenizer = get_tokenizer(model, is_faster_model=is_faster_model, language=language, task='transcribe')
|
| 212 |
+
tokens = tokenizer.encode(text) if isinstance(text, str) else text
|
| 213 |
+
tokens = [t for t in tokens if t < tokenizer.eot]
|
| 214 |
+
_, (words, word_tokens), _ = split_word_tokens([dict(tokens=tokens)], tokenizer)
|
| 215 |
+
|
| 216 |
+
audio = prep_audio(
|
| 217 |
+
audio,
|
| 218 |
+
demucs=demucs,
|
| 219 |
+
demucs_options=demucs_options,
|
| 220 |
+
only_voice_freq=only_voice_freq,
|
| 221 |
+
verbose=verbose
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
sample_padding = int(N_FFT // 2) + 1
|
| 225 |
+
seek_sample = 0
|
| 226 |
+
total_samples = audio.shape[-1]
|
| 227 |
+
total_duration = round(total_samples / SAMPLE_RATE, 2)
|
| 228 |
+
total_words = len(words)
|
| 229 |
+
|
| 230 |
+
if is_faster_model:
|
| 231 |
+
def timestamp_words():
|
| 232 |
+
temp_segment = dict(
|
| 233 |
+
seek=0,
|
| 234 |
+
start=0.0,
|
| 235 |
+
end=round(segment_samples / model.feature_extractor.sampling_rate, 3),
|
| 236 |
+
tokens=[t for wt in curr_word_tokens for t in wt],
|
| 237 |
+
)
|
| 238 |
+
features = model.feature_extractor(audio_segment.numpy())
|
| 239 |
+
encoder_output = model.encode(features[:, : model.feature_extractor.nb_max_frames])
|
| 240 |
+
|
| 241 |
+
model.add_word_timestamps(
|
| 242 |
+
segments=[temp_segment],
|
| 243 |
+
tokenizer=tokenizer,
|
| 244 |
+
encoder_output=encoder_output,
|
| 245 |
+
num_frames=round(segment_samples / model.feature_extractor.hop_length),
|
| 246 |
+
prepend_punctuations=prepend_punctuations,
|
| 247 |
+
append_punctuations=append_punctuations,
|
| 248 |
+
last_speech_timestamp=temp_segment['start'],
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
cumsum_lens = np.cumsum([len(w) for w in curr_words]).tolist()
|
| 252 |
+
final_cumsum_lens = np.cumsum([len(w['word']) for w in temp_segment['words']]).tolist()
|
| 253 |
+
|
| 254 |
+
assert not (set(final_cumsum_lens) - set(cumsum_lens)), 'word mismatch'
|
| 255 |
+
prev_l_idx = 0
|
| 256 |
+
for w_idx, cs_len in enumerate(final_cumsum_lens):
|
| 257 |
+
temp_segment['words'][w_idx]['start'] = round(temp_segment['words'][w_idx]['start'] + time_offset, 3)
|
| 258 |
+
temp_segment['words'][w_idx]['end'] = round(temp_segment['words'][w_idx]['end'] + time_offset, 3)
|
| 259 |
+
l_idx = cumsum_lens.index(cs_len)+1
|
| 260 |
+
temp_segment['words'][w_idx]['tokens'] = [t for wt in curr_word_tokens[prev_l_idx:l_idx] for t in wt]
|
| 261 |
+
prev_l_idx = l_idx
|
| 262 |
+
|
| 263 |
+
return temp_segment
|
| 264 |
+
|
| 265 |
+
else:
|
| 266 |
+
def timestamp_words():
|
| 267 |
+
temp_segment = dict(
|
| 268 |
+
seek=time_offset,
|
| 269 |
+
tokens=(curr_words, curr_word_tokens)
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
mel_segment = log_mel_spectrogram(audio_segment, model.dims.n_mels, padding=sample_padding)
|
| 273 |
+
mel_segment = pad_or_trim(mel_segment, N_FRAMES).to(device=model.device)
|
| 274 |
+
|
| 275 |
+
add_word_timestamps_stable(
|
| 276 |
+
segments=[temp_segment],
|
| 277 |
+
model=model,
|
| 278 |
+
tokenizer=tokenizer,
|
| 279 |
+
mel=mel_segment,
|
| 280 |
+
num_samples=segment_samples,
|
| 281 |
+
split_callback=(lambda x, _: x),
|
| 282 |
+
prepend_punctuations=prepend_punctuations,
|
| 283 |
+
append_punctuations=append_punctuations,
|
| 284 |
+
gap_padding=None
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
return temp_segment
|
| 288 |
+
|
| 289 |
+
def get_curr_words():
|
| 290 |
+
nonlocal words, word_tokens
|
| 291 |
+
curr_tk_count = 0
|
| 292 |
+
w, wt = [], []
|
| 293 |
+
for _ in range(len(words)):
|
| 294 |
+
tk_count = len(word_tokens[0])
|
| 295 |
+
if curr_tk_count + tk_count > token_step and w:
|
| 296 |
+
break
|
| 297 |
+
w.append(words.pop(0))
|
| 298 |
+
wt.append(word_tokens.pop(0))
|
| 299 |
+
curr_tk_count += tk_count
|
| 300 |
+
return w, wt
|
| 301 |
+
result = []
|
| 302 |
+
|
| 303 |
+
nonspeech_timings = [[], []]
|
| 304 |
+
nonspeech_vad_timings = None
|
| 305 |
+
if (suppress_silence or nonspeech_skip is not None) and vad:
|
| 306 |
+
nonspeech_vad_timings = (
|
| 307 |
+
get_vad_silence_func(onnx=vad_onnx, verbose=verbose)(audio, speech_threshold=vad_threshold)
|
| 308 |
+
)
|
| 309 |
+
if nonspeech_vad_timings is not None:
|
| 310 |
+
nonspeech_timings = nonspeech_vad_timings[0].copy(), nonspeech_vad_timings[1].copy()
|
| 311 |
+
|
| 312 |
+
with tqdm(total=total_duration, unit='sec', disable=verbose is not False, desc='Align') as tqdm_pbar:
|
| 313 |
+
|
| 314 |
+
def update_pbar(finish: bool = False):
|
| 315 |
+
tqdm_pbar.update((total_duration if finish else min(round(last_ts, 2), total_duration)) - tqdm_pbar.n)
|
| 316 |
+
if progress_callback is not None:
|
| 317 |
+
progress_callback(seek=tqdm_pbar.n, total=tqdm_pbar.total)
|
| 318 |
+
|
| 319 |
+
def redo_words(_idx: int = None):
|
| 320 |
+
nonlocal seg_words, seg_tokens, seg_words, words, word_tokens, curr_words, temp_word
|
| 321 |
+
if curr_words and temp_word is not None:
|
| 322 |
+
assert curr_words[0]['word'] == temp_word['word']
|
| 323 |
+
if curr_words[0]['probability'] >= temp_word['probability']:
|
| 324 |
+
temp_word = curr_words[0]
|
| 325 |
+
if _idx is None: # redo all
|
| 326 |
+
words = seg_words + words
|
| 327 |
+
word_tokens = seg_tokens + word_tokens
|
| 328 |
+
curr_words = []
|
| 329 |
+
elif _idx != len(seg_words): # redo from _idx
|
| 330 |
+
words = seg_words[_idx:] + words
|
| 331 |
+
word_tokens = seg_tokens[_idx:] + word_tokens
|
| 332 |
+
curr_words = curr_words[:_idx]
|
| 333 |
+
if curr_words:
|
| 334 |
+
if temp_word is not None:
|
| 335 |
+
curr_words[0] = temp_word
|
| 336 |
+
temp_word = None
|
| 337 |
+
words = seg_words[_idx-1:_idx] + words
|
| 338 |
+
word_tokens = seg_tokens[_idx-1:_idx] + word_tokens
|
| 339 |
+
temp_word = curr_words.pop(-1)
|
| 340 |
+
else:
|
| 341 |
+
if temp_word is not None:
|
| 342 |
+
curr_words[0] = temp_word
|
| 343 |
+
temp_word = None
|
| 344 |
+
|
| 345 |
+
n_samples = model.feature_extractor.n_samples if is_faster_model else N_SAMPLES
|
| 346 |
+
|
| 347 |
+
temp_word = None
|
| 348 |
+
|
| 349 |
+
while words and seek_sample < total_samples:
|
| 350 |
+
|
| 351 |
+
time_offset = seek_sample / SAMPLE_RATE
|
| 352 |
+
seek_sample_end = seek_sample + n_samples
|
| 353 |
+
audio_segment = audio[seek_sample:seek_sample_end]
|
| 354 |
+
segment_samples = audio_segment.shape[-1]
|
| 355 |
+
|
| 356 |
+
if nonspeech_skip is not None:
|
| 357 |
+
segment_nonspeech_timings = None
|
| 358 |
+
if not vad:
|
| 359 |
+
ts_token_mask = wav2mask(audio_segment, q_levels=q_levels, k_size=k_size)
|
| 360 |
+
segment_nonspeech_timings = mask2timing(ts_token_mask, time_offset=time_offset)
|
| 361 |
+
if segment_nonspeech_timings is not None:
|
| 362 |
+
nonspeech_timings[0].extend(segment_nonspeech_timings[0])
|
| 363 |
+
nonspeech_timings[1].extend(segment_nonspeech_timings[1])
|
| 364 |
+
elif nonspeech_vad_timings:
|
| 365 |
+
timing_indices = np.logical_and(
|
| 366 |
+
nonspeech_vad_timings[1] > time_offset,
|
| 367 |
+
nonspeech_vad_timings[0] < time_offset + 30.0
|
| 368 |
+
)
|
| 369 |
+
|
| 370 |
+
if timing_indices.any():
|
| 371 |
+
segment_nonspeech_timings = (
|
| 372 |
+
nonspeech_vad_timings[0][timing_indices], nonspeech_vad_timings[1][timing_indices]
|
| 373 |
+
)
|
| 374 |
+
else:
|
| 375 |
+
segment_nonspeech_timings = None
|
| 376 |
+
|
| 377 |
+
if mn := timing_indices.argmax():
|
| 378 |
+
nonspeech_vad_timings = (nonspeech_vad_timings[0][mn:], nonspeech_vad_timings[1][mn:])
|
| 379 |
+
|
| 380 |
+
if segment_nonspeech_timings is not None:
|
| 381 |
+
# segment has no detectable speech
|
| 382 |
+
if (
|
| 383 |
+
(segment_nonspeech_timings[0][0] <= time_offset + min_word_dur) and
|
| 384 |
+
(segment_nonspeech_timings[1][0] >= time_offset + segment_samples - min_word_dur)
|
| 385 |
+
):
|
| 386 |
+
seek_sample += segment_samples
|
| 387 |
+
continue
|
| 388 |
+
|
| 389 |
+
timing_indices = (segment_nonspeech_timings[1] - segment_nonspeech_timings[0]) >= nonspeech_skip
|
| 390 |
+
if any(timing_indices):
|
| 391 |
+
nonspeech_starts = segment_nonspeech_timings[0][timing_indices]
|
| 392 |
+
nonspeech_ends = segment_nonspeech_timings[1][timing_indices]
|
| 393 |
+
|
| 394 |
+
if round(time_offset, 3) >= nonspeech_starts[0]:
|
| 395 |
+
seek_sample = round(nonspeech_ends[0] * SAMPLE_RATE)
|
| 396 |
+
if seek_sample + (min_word_dur * SAMPLE_RATE) >= total_samples:
|
| 397 |
+
seek_sample = total_samples
|
| 398 |
+
continue
|
| 399 |
+
time_offset = seek_sample / SAMPLE_RATE
|
| 400 |
+
|
| 401 |
+
if len(nonspeech_starts) > 1:
|
| 402 |
+
seek_sample_end = (
|
| 403 |
+
seek_sample + round((nonspeech_starts[1] - nonspeech_ends[0]) * SAMPLE_RATE)
|
| 404 |
+
)
|
| 405 |
+
audio_segment = audio[seek_sample:seek_sample_end]
|
| 406 |
+
segment_samples = audio_segment.shape[-1]
|
| 407 |
+
|
| 408 |
+
curr_words, curr_word_tokens = get_curr_words()
|
| 409 |
+
|
| 410 |
+
segment = timestamp_words()
|
| 411 |
+
curr_words = segment['words']
|
| 412 |
+
seg_words = [w['word'] for w in curr_words]
|
| 413 |
+
seg_tokens = [w['tokens'] for w in curr_words]
|
| 414 |
+
durations = np.array([w['end'] - w['start'] for w in curr_words]).round(3)
|
| 415 |
+
nonzero_mask = durations > 0
|
| 416 |
+
nonzero_indices = np.flatnonzero(nonzero_mask)
|
| 417 |
+
if len(nonzero_indices):
|
| 418 |
+
redo_index = nonzero_indices[-1] + 1
|
| 419 |
+
if (
|
| 420 |
+
words and
|
| 421 |
+
redo_index > 1 and
|
| 422 |
+
curr_words[nonzero_indices[-1]]['end'] >= np.floor(time_offset + segment_samples / SAMPLE_RATE)
|
| 423 |
+
):
|
| 424 |
+
nonzero_mask[nonzero_indices[-1]] = False
|
| 425 |
+
nonzero_indices = nonzero_indices[:-1]
|
| 426 |
+
redo_index = nonzero_indices[-1] + 1
|
| 427 |
+
med_dur = np.median(durations[:redo_index])
|
| 428 |
+
|
| 429 |
+
if fast_mode:
|
| 430 |
+
new_start = None
|
| 431 |
+
global_max_dur = None
|
| 432 |
+
else:
|
| 433 |
+
local_max_dur = round(med_dur * word_dur_factor, 3) if word_dur_factor else None
|
| 434 |
+
if max_word_dur:
|
| 435 |
+
local_max_dur = min(local_max_dur, max_word_dur) if local_max_dur else max_word_dur
|
| 436 |
+
global_max_dur = max_word_dur
|
| 437 |
+
else:
|
| 438 |
+
global_max_dur = local_max_dur or None
|
| 439 |
+
if global_max_dur and med_dur > global_max_dur:
|
| 440 |
+
med_dur = global_max_dur
|
| 441 |
+
if (
|
| 442 |
+
local_max_dur and durations[nonzero_indices[0]] > global_max_dur
|
| 443 |
+
):
|
| 444 |
+
new_start = round(max(
|
| 445 |
+
curr_words[nonzero_indices[0]]['end'] - (med_dur * nonzero_indices[0] + local_max_dur),
|
| 446 |
+
curr_words[nonzero_indices[0]]['start']
|
| 447 |
+
), 3)
|
| 448 |
+
if new_start <= time_offset:
|
| 449 |
+
new_start = None
|
| 450 |
+
else:
|
| 451 |
+
new_start = None
|
| 452 |
+
if new_start is None:
|
| 453 |
+
if global_max_dur:
|
| 454 |
+
index_offset = nonzero_indices[0] + 1
|
| 455 |
+
redo_indices = \
|
| 456 |
+
np.flatnonzero(durations[index_offset:redo_index] > global_max_dur) + index_offset
|
| 457 |
+
if len(redo_indices):
|
| 458 |
+
redo_index = redo_indices[0]
|
| 459 |
+
last_ts = curr_words[redo_index - 1]['end']
|
| 460 |
+
redo_words(redo_index)
|
| 461 |
+
else:
|
| 462 |
+
last_ts = new_start
|
| 463 |
+
redo_words()
|
| 464 |
+
seek_sample = round(last_ts * SAMPLE_RATE)
|
| 465 |
+
else:
|
| 466 |
+
seek_sample += audio_segment.shape[-1]
|
| 467 |
+
last_ts = round(seek_sample / SAMPLE_RATE, 2)
|
| 468 |
+
redo_words()
|
| 469 |
+
|
| 470 |
+
update_pbar()
|
| 471 |
+
|
| 472 |
+
result.extend(curr_words)
|
| 473 |
+
|
| 474 |
+
if verbose:
|
| 475 |
+
line = '\n'.join(
|
| 476 |
+
f"[{format_timestamp(word['start'])}] -> "
|
| 477 |
+
f"[{format_timestamp(word['end'])}] \"{word['word']}\""
|
| 478 |
+
for word in curr_words
|
| 479 |
+
)
|
| 480 |
+
safe_print(line)
|
| 481 |
+
update_pbar(True)
|
| 482 |
+
|
| 483 |
+
if temp_word is not None:
|
| 484 |
+
result.append(temp_word)
|
| 485 |
+
if not result:
|
| 486 |
+
warnings.warn('Failed to align text.', stacklevel=2)
|
| 487 |
+
elif words:
|
| 488 |
+
warnings.warn(f'Failed to align the last {len(words)}/{total_words} words after '
|
| 489 |
+
f'{format_timestamp(result[-1]["end"])}.', stacklevel=2)
|
| 490 |
+
|
| 491 |
+
if words and not remove_instant_words:
|
| 492 |
+
result.extend(
|
| 493 |
+
[
|
| 494 |
+
dict(word=w, start=total_duration, end=total_duration, probability=0.0, tokens=wt)
|
| 495 |
+
for w, wt in zip(words, word_tokens)
|
| 496 |
+
]
|
| 497 |
+
)
|
| 498 |
+
|
| 499 |
+
if not result:
|
| 500 |
+
return
|
| 501 |
+
|
| 502 |
+
if len(split_indices_by_char):
|
| 503 |
+
word_lens = np.cumsum([[len(w['word']) for w in result]])
|
| 504 |
+
split_indices = [(word_lens >= i).nonzero()[0][0]+1 for i in split_indices_by_char]
|
| 505 |
+
result = WhisperResult([result[i:j] for i, j in zip([0]+split_indices[:-1], split_indices)])
|
| 506 |
+
else:
|
| 507 |
+
result = WhisperResult([result])
|
| 508 |
+
|
| 509 |
+
if suppress_silence:
|
| 510 |
+
result.suppress_silence(
|
| 511 |
+
*nonspeech_timings,
|
| 512 |
+
min_word_dur=min_word_dur,
|
| 513 |
+
word_level=suppress_word_ts,
|
| 514 |
+
nonspeech_error=nonspeech_error,
|
| 515 |
+
use_word_position=use_word_position
|
| 516 |
+
)
|
| 517 |
+
result.update_nonspeech_sections(*nonspeech_timings)
|
| 518 |
+
if not original_split:
|
| 519 |
+
result.regroup(regroup)
|
| 520 |
+
|
| 521 |
+
if fail_segs := len([None for s in result.segments if s.end-s.start <= 0]):
|
| 522 |
+
warnings.warn(f'{fail_segs}/{len(result.segments)} segments failed to align.', stacklevel=2)
|
| 523 |
+
|
| 524 |
+
return result
|
| 525 |
+
|
| 526 |
+
|
| 527 |
+
def refine(
|
| 528 |
+
model: "Whisper",
|
| 529 |
+
audio: Union[str, np.ndarray, torch.Tensor, bytes],
|
| 530 |
+
result: WhisperResult,
|
| 531 |
+
*,
|
| 532 |
+
steps: str = None,
|
| 533 |
+
rel_prob_decrease: float = .03,
|
| 534 |
+
abs_prob_decrease: float = .05,
|
| 535 |
+
rel_rel_prob_decrease: Optional[float] = None,
|
| 536 |
+
prob_threshold: float = .5,
|
| 537 |
+
rel_dur_change: Optional[float] = .5,
|
| 538 |
+
abs_dur_change: Optional[float] = None,
|
| 539 |
+
word_level: bool = True,
|
| 540 |
+
precision: float = None,
|
| 541 |
+
single_batch: bool = False,
|
| 542 |
+
inplace: bool = True,
|
| 543 |
+
demucs: Union[bool, torch.nn.Module] = False,
|
| 544 |
+
demucs_options: dict = None,
|
| 545 |
+
only_voice_freq: bool = False,
|
| 546 |
+
verbose: Optional[bool] = False
|
| 547 |
+
) -> WhisperResult:
|
| 548 |
+
"""
|
| 549 |
+
Improve existing timestamps.
|
| 550 |
+
|
| 551 |
+
This function iteratively muting portions of the audio and monitoring token probabilities to find the most precise
|
| 552 |
+
timestamps. This "most precise" in this case means the latest start and earliest end of a word that maintains an
|
| 553 |
+
acceptable probability determined by the specified arguments.
|
| 554 |
+
|
| 555 |
+
This is useful readjusting timestamps when they start too early or end too late.
|
| 556 |
+
|
| 557 |
+
Parameters
|
| 558 |
+
----------
|
| 559 |
+
model : "Whisper"
|
| 560 |
+
The Whisper ASR model modified instance
|
| 561 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 562 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 563 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 564 |
+
result : stable_whisper.result.WhisperResult
|
| 565 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 566 |
+
steps : str, default 'se'
|
| 567 |
+
Instructions for refinement. A 's' means refine start-timestamps. An 'e' means refine end-timestamps.
|
| 568 |
+
rel_prob_decrease : float, default 0.3
|
| 569 |
+
Maximum percent decrease in probability relative to original probability which is the probability from muting
|
| 570 |
+
according initial timestamps.
|
| 571 |
+
abs_prob_decrease : float, default 0.05
|
| 572 |
+
Maximum decrease in probability from original probability.
|
| 573 |
+
rel_rel_prob_decrease : float, optional
|
| 574 |
+
Maximum percent decrease in probability relative to previous probability which is the probability from previous
|
| 575 |
+
iteration of muting.
|
| 576 |
+
prob_threshold : float, default 0.5
|
| 577 |
+
Stop refining the timestamp if the probability of its token goes below this value.
|
| 578 |
+
rel_dur_change : float, default 0.5
|
| 579 |
+
Maximum percent change in duration of a word relative to its original duration.
|
| 580 |
+
abs_dur_change : float, optional
|
| 581 |
+
Maximum seconds a word is allowed deviate from its original duration.
|
| 582 |
+
word_level : bool, default True
|
| 583 |
+
Whether to refine timestamps on word-level. If ``False``, only refine start/end timestamps of each segment.
|
| 584 |
+
precision : float, default 0.1
|
| 585 |
+
Precision of refined timestamps in seconds. The lowest precision is 0.02 second.
|
| 586 |
+
single_batch : bool, default False
|
| 587 |
+
Whether to process in only batch size of one to reduce memory usage.
|
| 588 |
+
inplace : bool, default True, meaning return a deepcopy of ``result``
|
| 589 |
+
Whether to alter timestamps in-place.
|
| 590 |
+
demucs : bool or torch.nn.Module, default False
|
| 591 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 592 |
+
a Demucs model to avoid reloading the model for each run.
|
| 593 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 594 |
+
demucs_options : dict, optional
|
| 595 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 596 |
+
only_voice_freq : bool, default False
|
| 597 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 598 |
+
verbose : bool or None, default False
|
| 599 |
+
Whether to display the text being decoded to the console.
|
| 600 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 601 |
+
|
| 602 |
+
Returns
|
| 603 |
+
-------
|
| 604 |
+
stable_whisper.result.WhisperResult
|
| 605 |
+
All timestamps, words, probabilities, and other data from the refinement of ``text`` with ``audio``.
|
| 606 |
+
|
| 607 |
+
Notes
|
| 608 |
+
-----
|
| 609 |
+
The lower the ``precision``, the longer the processing time.
|
| 610 |
+
|
| 611 |
+
Examples
|
| 612 |
+
--------
|
| 613 |
+
>>> import stable_whisper
|
| 614 |
+
>>> model = stable_whisper.load_model('base')
|
| 615 |
+
>>> result = model.transcribe('audio.mp3')
|
| 616 |
+
>>> model.refine('audio.mp3', result)
|
| 617 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 618 |
+
Saved 'audio.srt'
|
| 619 |
+
"""
|
| 620 |
+
if not steps:
|
| 621 |
+
steps = 'se'
|
| 622 |
+
if precision is None:
|
| 623 |
+
precision = 0.1
|
| 624 |
+
if invalid_steps := steps.replace('s', '').replace('e', ''):
|
| 625 |
+
raise ValueError(f'Invalid step(s): {", ".join(invalid_steps)}')
|
| 626 |
+
if not result.has_words:
|
| 627 |
+
raise NotImplementedError(f'Result must have word timestamps.')
|
| 628 |
+
|
| 629 |
+
if not inplace:
|
| 630 |
+
result = copy.deepcopy(result)
|
| 631 |
+
|
| 632 |
+
audio = prep_audio(
|
| 633 |
+
audio,
|
| 634 |
+
demucs=demucs,
|
| 635 |
+
demucs_options=demucs_options,
|
| 636 |
+
only_voice_freq=only_voice_freq,
|
| 637 |
+
verbose=verbose
|
| 638 |
+
)
|
| 639 |
+
max_inference_tokens = model.dims.n_text_ctx - 6
|
| 640 |
+
sample_padding = int(N_FFT // 2) + 1
|
| 641 |
+
frame_precision = max(round(precision * FRAMES_PER_SECOND), 2)
|
| 642 |
+
total_duration = round(audio.shape[-1] / SAMPLE_RATE, 3)
|
| 643 |
+
tokenizer = get_tokenizer(model, language=result.language, task='transcribe')
|
| 644 |
+
|
| 645 |
+
def ts_to_frames(timestamps: Union[np.ndarray, list]) -> np.ndarray:
|
| 646 |
+
if isinstance(timestamps, list):
|
| 647 |
+
timestamps = np.array(timestamps)
|
| 648 |
+
return (timestamps * FRAMES_PER_SECOND).round().astype(int)
|
| 649 |
+
|
| 650 |
+
def curr_segments():
|
| 651 |
+
all_words = result.all_words()
|
| 652 |
+
seg_edge_mask = np.array([
|
| 653 |
+
1 if _i == 0 else (2 if _i == len(seg.words)-1 else 0)
|
| 654 |
+
for seg in result.segments
|
| 655 |
+
for _i, w in enumerate(seg.words)
|
| 656 |
+
])
|
| 657 |
+
start_times = [
|
| 658 |
+
max(
|
| 659 |
+
0 if abs_dur_change is None else (w.start - abs_dur_change),
|
| 660 |
+
0 if rel_dur_change is None else (w.start - w.duration * rel_dur_change),
|
| 661 |
+
0 if i == 0 else max(all_words[i - 1].end, w.end - 14.5, 0)
|
| 662 |
+
)
|
| 663 |
+
for i, w in enumerate(all_words)
|
| 664 |
+
]
|
| 665 |
+
end_times = [
|
| 666 |
+
min(
|
| 667 |
+
total_duration if abs_dur_change is None else (w.end + abs_dur_change),
|
| 668 |
+
total_duration if rel_dur_change is None else (w.end + w.duration * rel_dur_change),
|
| 669 |
+
total_duration if i == len(all_words) else min(all_words[i].start, w.start + 14.5, total_duration)
|
| 670 |
+
)
|
| 671 |
+
for i, w in enumerate(all_words, 1)
|
| 672 |
+
]
|
| 673 |
+
start = start_times[0]
|
| 674 |
+
|
| 675 |
+
prev_i = 0
|
| 676 |
+
curr_words, curr_starts, curr_ends = [], [], []
|
| 677 |
+
|
| 678 |
+
for i, w in enumerate(all_words, 1):
|
| 679 |
+
if (
|
| 680 |
+
(end_times[0] - start > 30) or
|
| 681 |
+
(len(curr_words) + 1 > max_inference_tokens)
|
| 682 |
+
):
|
| 683 |
+
if curr_words:
|
| 684 |
+
yield curr_words, curr_starts, curr_ends, seg_edge_mask[prev_i:prev_i+len(curr_words)]
|
| 685 |
+
curr_words, curr_starts, curr_ends = [], [], []
|
| 686 |
+
start = start_times[0]
|
| 687 |
+
prev_i = i - 1
|
| 688 |
+
|
| 689 |
+
curr_words.append(w)
|
| 690 |
+
curr_starts.append(start_times.pop(0))
|
| 691 |
+
curr_ends.append(end_times.pop(0))
|
| 692 |
+
|
| 693 |
+
if i == len(all_words):
|
| 694 |
+
yield curr_words, curr_starts, curr_ends, seg_edge_mask[prev_i:prev_i+len(curr_words)]
|
| 695 |
+
|
| 696 |
+
def _refine(_step: str):
|
| 697 |
+
|
| 698 |
+
for words, min_starts, max_ends, edge_mask in curr_segments():
|
| 699 |
+
|
| 700 |
+
time_offset = min_starts[0]
|
| 701 |
+
start_sample = round(time_offset * SAMPLE_RATE)
|
| 702 |
+
end_sample = round(max_ends[-1] * SAMPLE_RATE)
|
| 703 |
+
audio_segment = audio[start_sample:end_sample + 1].unsqueeze(0)
|
| 704 |
+
|
| 705 |
+
max_starts = ts_to_frames(np.array([w.end for w in words]) - time_offset)
|
| 706 |
+
min_ends = ts_to_frames(np.array([w.start for w in words]) - time_offset)
|
| 707 |
+
min_starts = ts_to_frames(np.array(min_starts) - time_offset)
|
| 708 |
+
max_ends = ts_to_frames(np.array(max_ends) - time_offset)
|
| 709 |
+
|
| 710 |
+
mid_starts = min_starts + ((max_starts - min_starts) / 2).round().astype(int)
|
| 711 |
+
mid_ends = min_ends + ((max_ends - min_ends) / 2).round().astype(int)
|
| 712 |
+
|
| 713 |
+
text_tokens = [t for w in words for t in w.tokens if t < tokenizer.eot]
|
| 714 |
+
word_tokens = [[t for t in w.tokens if t < tokenizer.eot] for w in words]
|
| 715 |
+
orig_mel_segment = log_mel_spectrogram(audio_segment, model.dims.n_mels, padding=sample_padding)
|
| 716 |
+
orig_mel_segment = pad_or_trim(orig_mel_segment, N_FRAMES).to(device=model.device)
|
| 717 |
+
|
| 718 |
+
def get_prob():
|
| 719 |
+
|
| 720 |
+
tokens = torch.tensor(
|
| 721 |
+
[
|
| 722 |
+
*tokenizer.sot_sequence,
|
| 723 |
+
tokenizer.no_timestamps,
|
| 724 |
+
*text_tokens,
|
| 725 |
+
tokenizer.eot,
|
| 726 |
+
]
|
| 727 |
+
).to(model.device)
|
| 728 |
+
|
| 729 |
+
with torch.no_grad():
|
| 730 |
+
curr_mel_segment = mel_segment if prob_indices else orig_mel_segment
|
| 731 |
+
if single_batch:
|
| 732 |
+
logits = torch.cat(
|
| 733 |
+
[model(_mel.unsqueeze(0), tokens.unsqueeze(0)) for _mel in curr_mel_segment]
|
| 734 |
+
)
|
| 735 |
+
else:
|
| 736 |
+
logits = model(curr_mel_segment, tokens.unsqueeze(0))
|
| 737 |
+
|
| 738 |
+
sampled_logits = logits[:, len(tokenizer.sot_sequence):, : tokenizer.eot]
|
| 739 |
+
token_probs = sampled_logits.softmax(dim=-1)
|
| 740 |
+
|
| 741 |
+
text_token_probs = token_probs[:, np.arange(len(text_tokens)), text_tokens]
|
| 742 |
+
token_positions = token_probs[:, np.arange(len(text_tokens))]
|
| 743 |
+
if logits.shape[0] != 1 and prob_indices is not None:
|
| 744 |
+
indices1 = np.arange(len(prob_indices))
|
| 745 |
+
text_token_probs = text_token_probs[prob_indices, indices1]
|
| 746 |
+
token_positions = token_positions[prob_indices, indices1]
|
| 747 |
+
else:
|
| 748 |
+
text_token_probs.squeeze_(0)
|
| 749 |
+
|
| 750 |
+
text_token_probs = text_token_probs.tolist()
|
| 751 |
+
token_positions = \
|
| 752 |
+
(
|
| 753 |
+
token_positions.sort().indices == tokens[len(tokenizer.sot_sequence) + 1:-1][:, None]
|
| 754 |
+
).nonzero()[:, -1].tolist()
|
| 755 |
+
|
| 756 |
+
word_boundaries = np.pad(np.cumsum([len(t) for t in word_tokens]), (1, 0))
|
| 757 |
+
word_probabilities = np.array([
|
| 758 |
+
text_token_probs[j-1] if is_end_ts else text_token_probs[i]
|
| 759 |
+
for i, j in zip(word_boundaries[:-1], word_boundaries[1:])
|
| 760 |
+
])
|
| 761 |
+
token_positions = [
|
| 762 |
+
token_positions[j-1] if is_end_ts else token_positions[i]
|
| 763 |
+
for i, j in zip(word_boundaries[:-1], word_boundaries[1:])
|
| 764 |
+
]
|
| 765 |
+
|
| 766 |
+
return word_probabilities, token_positions
|
| 767 |
+
|
| 768 |
+
def update_ts():
|
| 769 |
+
if not is_finish[idx] or changes[idx, -1] == -1:
|
| 770 |
+
return
|
| 771 |
+
new_ts = round(time_offset + (changes[idx, -1] / FRAMES_PER_SECOND), 3)
|
| 772 |
+
if changes[idx, 0] and not changes[idx, 1]:
|
| 773 |
+
if is_end_ts:
|
| 774 |
+
if new_ts <= words[idx].end:
|
| 775 |
+
return
|
| 776 |
+
elif new_ts >= words[idx].start:
|
| 777 |
+
return
|
| 778 |
+
if not verbose:
|
| 779 |
+
return
|
| 780 |
+
curr_word = words[idx]
|
| 781 |
+
word_info = (f'[Word="{curr_word.word}"] '
|
| 782 |
+
f'[Segment ID: {curr_word.segment_id}] '
|
| 783 |
+
f'[Word ID: {curr_word.id}]')
|
| 784 |
+
if is_end_ts:
|
| 785 |
+
print(f'End: {words[idx].end} -> {new_ts} {word_info}')
|
| 786 |
+
words[idx].end = new_ts
|
| 787 |
+
else:
|
| 788 |
+
print(f'Start: {words[idx].start} -> {new_ts} {word_info}')
|
| 789 |
+
words[idx].start = new_ts
|
| 790 |
+
|
| 791 |
+
mel_segment = orig_mel_segment.clone().repeat_interleave(2, 0)
|
| 792 |
+
is_end_ts = _step == 'e'
|
| 793 |
+
|
| 794 |
+
prob_indices = []
|
| 795 |
+
is_finish = np.less([w.probability for w in words], prob_threshold)
|
| 796 |
+
is_finish = np.logical_or(is_finish, [w.duration == 0 for w in words])
|
| 797 |
+
if not word_level:
|
| 798 |
+
is_finish[edge_mask != (2 if is_end_ts else 1)] = True
|
| 799 |
+
for idx, _i in enumerate(max_starts if is_end_ts else min_ends):
|
| 800 |
+
row = idx % 2
|
| 801 |
+
prob_indices.extend([row] * len(words[idx].tokens))
|
| 802 |
+
if is_finish[idx]:
|
| 803 |
+
continue
|
| 804 |
+
if is_end_ts:
|
| 805 |
+
_p = mel_segment.shape[-1] if idx == len(words)-1 else mid_ends[idx+1]
|
| 806 |
+
mel_segment[row, :, _i:_p] = 0
|
| 807 |
+
else:
|
| 808 |
+
_p = 0 if idx == 0 else mid_starts[idx-1]
|
| 809 |
+
mel_segment[row, :, _p:_i] = 0
|
| 810 |
+
orig_probs, orig_tk_poss = get_prob()
|
| 811 |
+
changes = np.zeros((orig_probs.shape[-1], 3), dtype=int)
|
| 812 |
+
changes[:, -1] = -1
|
| 813 |
+
frame_indices = (mid_ends, max_starts) if is_end_ts else (min_ends, mid_starts)
|
| 814 |
+
for idx, (_s, _e) in enumerate(zip(*frame_indices)):
|
| 815 |
+
row = idx % 2
|
| 816 |
+
if is_finish[idx]:
|
| 817 |
+
continue
|
| 818 |
+
mel_segment[row, :, _s:_e] = 0
|
| 819 |
+
|
| 820 |
+
new_probs = prev_probs = orig_probs
|
| 821 |
+
while not np.all(is_finish):
|
| 822 |
+
probs, tk_poss = get_prob()
|
| 823 |
+
abs_diffs = orig_probs - probs
|
| 824 |
+
rel_diffs = abs_diffs / orig_probs
|
| 825 |
+
rel_change_diffs = (prev_probs - probs) / prev_probs
|
| 826 |
+
prev_probs = probs
|
| 827 |
+
for idx, (abs_diff, rel_diff, rel_change_diff, prob) \
|
| 828 |
+
in enumerate(zip(abs_diffs, rel_diffs, rel_change_diffs, probs)):
|
| 829 |
+
if is_finish[idx]:
|
| 830 |
+
continue
|
| 831 |
+
if is_end_ts:
|
| 832 |
+
curr_min, curr_max, curr_mid = min_ends[idx], max_ends[idx], mid_ends[idx]
|
| 833 |
+
else:
|
| 834 |
+
curr_min, curr_max, curr_mid = min_starts[idx], max_starts[idx], mid_starts[idx]
|
| 835 |
+
|
| 836 |
+
row = prob_indices[idx]
|
| 837 |
+
best_tks_changed = orig_tk_poss[idx] > tk_poss[idx]
|
| 838 |
+
failed_requirements = (
|
| 839 |
+
abs_diff > abs_prob_decrease or
|
| 840 |
+
rel_diff > rel_prob_decrease or
|
| 841 |
+
(rel_rel_prob_decrease is not None and rel_change_diff > rel_rel_prob_decrease) or
|
| 842 |
+
prob < prob_threshold or
|
| 843 |
+
best_tks_changed
|
| 844 |
+
)
|
| 845 |
+
|
| 846 |
+
if failed_requirements:
|
| 847 |
+
changes[idx][0] = 1
|
| 848 |
+
if is_end_ts:
|
| 849 |
+
curr_min = curr_mid
|
| 850 |
+
else:
|
| 851 |
+
curr_max = curr_mid
|
| 852 |
+
else:
|
| 853 |
+
changes[idx][1] = 1
|
| 854 |
+
if is_end_ts:
|
| 855 |
+
curr_max = curr_mid
|
| 856 |
+
else:
|
| 857 |
+
curr_min = curr_mid
|
| 858 |
+
|
| 859 |
+
if (new_mid_change := round((curr_max - curr_min) / 2)) < frame_precision:
|
| 860 |
+
is_finish[idx] = True
|
| 861 |
+
update_ts()
|
| 862 |
+
continue
|
| 863 |
+
|
| 864 |
+
new_mid = curr_min + new_mid_change
|
| 865 |
+
if failed_requirements:
|
| 866 |
+
if is_end_ts:
|
| 867 |
+
mel_segment[row, :, curr_min:new_mid] = orig_mel_segment[0, :, curr_min:new_mid]
|
| 868 |
+
else:
|
| 869 |
+
mel_segment[row, :, new_mid:curr_max] = orig_mel_segment[0, :, new_mid:curr_max]
|
| 870 |
+
|
| 871 |
+
else:
|
| 872 |
+
if is_end_ts:
|
| 873 |
+
mel_segment[row, :, new_mid:curr_max] = 0
|
| 874 |
+
else:
|
| 875 |
+
mel_segment[row, :, curr_min:new_mid] = 0
|
| 876 |
+
|
| 877 |
+
if is_end_ts:
|
| 878 |
+
min_ends[idx], max_ends[idx], mid_ends[idx] = curr_min, curr_max, new_mid
|
| 879 |
+
else:
|
| 880 |
+
min_starts[idx], max_starts[idx], mid_starts[idx] = curr_min, curr_max, new_mid
|
| 881 |
+
if not best_tks_changed:
|
| 882 |
+
changes[idx][-1] = new_mid
|
| 883 |
+
new_probs[idx] = prob
|
| 884 |
+
|
| 885 |
+
update_pbar(words[-1].end)
|
| 886 |
+
|
| 887 |
+
with tqdm(total=round(total_duration, 2), unit='sec', disable=verbose is not False, desc='Refine') as tqdm_pbar:
|
| 888 |
+
|
| 889 |
+
def update_pbar(last_ts: float):
|
| 890 |
+
nonlocal prev_ts
|
| 891 |
+
tqdm_pbar.update(round(((last_ts - prev_ts) / len(steps)), 2))
|
| 892 |
+
prev_ts = last_ts
|
| 893 |
+
|
| 894 |
+
for step_count, step in enumerate(steps, 1):
|
| 895 |
+
prev_ts = 0
|
| 896 |
+
_refine(step)
|
| 897 |
+
update_pbar(round(tqdm_pbar.total / len(step), 2))
|
| 898 |
+
tqdm_pbar.update(tqdm_pbar.total - tqdm_pbar.n)
|
| 899 |
+
|
| 900 |
+
result.update_all_segs_with_words()
|
| 901 |
+
|
| 902 |
+
return result
|
| 903 |
+
|
| 904 |
+
|
| 905 |
+
def locate(
|
| 906 |
+
model: "Whisper",
|
| 907 |
+
audio: Union[str, np.ndarray, torch.Tensor, bytes],
|
| 908 |
+
text: Union[str, List[int]],
|
| 909 |
+
language: str,
|
| 910 |
+
count: int = 1,
|
| 911 |
+
duration_window: Union[float, Tuple[float, float]] = 3.0,
|
| 912 |
+
*,
|
| 913 |
+
mode: int = 0,
|
| 914 |
+
start: float = None,
|
| 915 |
+
end: float = None,
|
| 916 |
+
probability_threshold: float = 0.5,
|
| 917 |
+
eots: int = 1,
|
| 918 |
+
max_token_per_seg: int = 20,
|
| 919 |
+
exact_token: bool = False,
|
| 920 |
+
case_sensitive: bool = False,
|
| 921 |
+
verbose: bool = False,
|
| 922 |
+
initial_prompt: str = None,
|
| 923 |
+
suppress_tokens: Union[str, List[int]] = '-1',
|
| 924 |
+
demucs: Union[bool, torch.nn.Module] = False,
|
| 925 |
+
demucs_options: dict = None,
|
| 926 |
+
only_voice_freq: bool = False,
|
| 927 |
+
) -> Union[List[Segment], List[dict]]:
|
| 928 |
+
"""
|
| 929 |
+
Locate when specific words are spoken in ``audio`` without fully transcribing.
|
| 930 |
+
|
| 931 |
+
This is usefully for quickly finding at what time the specify words or phrases are spoken in an audio. Since it
|
| 932 |
+
does not need to transcribe the audio to approximate the time, it is significantly faster transcribing then
|
| 933 |
+
locating the word in the transcript.
|
| 934 |
+
|
| 935 |
+
It can also transcribe few seconds around the approximated time to find out what was said around those words or
|
| 936 |
+
confirm if the word was even spoken near that time.
|
| 937 |
+
|
| 938 |
+
Parameters
|
| 939 |
+
----------
|
| 940 |
+
model : whisper.model.Whisper
|
| 941 |
+
An instance of Whisper ASR model.
|
| 942 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 943 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 944 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 945 |
+
text: str or list of int
|
| 946 |
+
Words/phrase or list of tokens to search for in ``audio``.
|
| 947 |
+
language : str
|
| 948 |
+
Language of the ``text``.
|
| 949 |
+
count : int, default 1, meaning stop search after 1 match
|
| 950 |
+
Number of matches to find. Use 0 to look for all.
|
| 951 |
+
duration_window : float or tuple of (float, float), default 3.0, same as (3.0, 3.0)
|
| 952 |
+
Seconds before and after the end timestamp approximations to transcribe after mode 1.
|
| 953 |
+
If tuple pair of values, then the 1st value will be seconds before the end and 2nd value will be seconds after.
|
| 954 |
+
mode : int, default 0
|
| 955 |
+
Mode of search.
|
| 956 |
+
2, Approximates the end timestamp of ``text`` in the audio. This mode does not confirm whether ``text`` is
|
| 957 |
+
spoken at the timestamp
|
| 958 |
+
1, Completes mode 2 then transcribes audio within ``duration_window`` to confirm whether `text` is a match at
|
| 959 |
+
the approximated timestamp by checking if ``text`` at that ``duration_window`` is within
|
| 960 |
+
``probability_threshold`` or matching the string content if ``text`` with the transcribed text at the
|
| 961 |
+
``duration_window``.
|
| 962 |
+
0, Completes mode 1 then add word timestamps to the transcriptions of each match.
|
| 963 |
+
Modes from fastest to slowest: 2, 1, 0
|
| 964 |
+
start : float, optional, meaning it starts from 0s
|
| 965 |
+
Seconds into the audio to start searching for ``text``.
|
| 966 |
+
end : float, optional
|
| 967 |
+
Seconds into the audio to stop searching for ``text``.
|
| 968 |
+
probability_threshold : float, default 0.5
|
| 969 |
+
Minimum probability of each token in ``text`` for it to be considered a match.
|
| 970 |
+
eots : int, default 1
|
| 971 |
+
Number of EOTs to reach before stopping transcription at mode 1. When transcription reach a EOT, it usually
|
| 972 |
+
means the end of the segment or audio. Once ``text`` is found in the ``duration_window``, the transcription
|
| 973 |
+
will stop immediately upon reaching a EOT.
|
| 974 |
+
max_token_per_seg : int, default 20
|
| 975 |
+
Maximum number of tokens to transcribe in the ``duration_window`` before stopping.
|
| 976 |
+
exact_token : bool, default False
|
| 977 |
+
Whether to find a match base on the exact tokens that make up ``text``.
|
| 978 |
+
case_sensitive : bool, default False
|
| 979 |
+
Whether to consider the case of ``text`` when matching in string content.
|
| 980 |
+
verbose : bool or None, default False
|
| 981 |
+
Whether to display the text being decoded to the console.
|
| 982 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 983 |
+
initial_prompt : str, optional
|
| 984 |
+
Text to provide as a prompt for the first window. This can be used to provide, or
|
| 985 |
+
"prompt-engineer" a context for transcription, e.g. custom vocabularies or proper nouns
|
| 986 |
+
to make it more likely to predict those word correctly.
|
| 987 |
+
suppress_tokens : str or list of int, default '-1', meaning suppress special characters except common punctuations
|
| 988 |
+
List of tokens to suppress.
|
| 989 |
+
demucs : bool or torch.nn.Module, default False
|
| 990 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 991 |
+
a Demucs model to avoid reloading the model for each run.
|
| 992 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 993 |
+
demucs_options : dict, optional
|
| 994 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 995 |
+
only_voice_freq : bool, default False
|
| 996 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 997 |
+
|
| 998 |
+
Returns
|
| 999 |
+
-------
|
| 1000 |
+
stable_whisper.result.Segment or list of dict or list of float
|
| 1001 |
+
Mode 0, list of instances of :class:`stable_whisper.result.Segment`.
|
| 1002 |
+
Mode 1, list of dictionaries with end timestamp approximation of matches and transcribed neighboring words.
|
| 1003 |
+
Mode 2, list of timestamps in seconds for each end timestamp approximation.
|
| 1004 |
+
|
| 1005 |
+
Notes
|
| 1006 |
+
-----
|
| 1007 |
+
For ``text``, the case and spacing matters as 'on', ' on', ' On' are different tokens, therefore chose the one that
|
| 1008 |
+
best suits the context (e.g. ' On' to look for it at the beginning of a sentence).
|
| 1009 |
+
|
| 1010 |
+
Use a sufficiently large first value of ``duration_window`` i.e. the value > time it is expected to speak ``text``.
|
| 1011 |
+
|
| 1012 |
+
If ``exact_token = False`` and the string content matches, then ``probability_threshold`` is not used.
|
| 1013 |
+
|
| 1014 |
+
Examples
|
| 1015 |
+
--------
|
| 1016 |
+
>>> import stable_whisper
|
| 1017 |
+
>>> model = stable_whisper.load_model('base')
|
| 1018 |
+
>>> matches = model.locate('audio.mp3', 'are', 'English', verbose=True)
|
| 1019 |
+
|
| 1020 |
+
Some words can sound the same but have different spellings to increase of the chance of finding such words use
|
| 1021 |
+
``initial_prompt``.
|
| 1022 |
+
|
| 1023 |
+
>>> matches = model.locate('audio.mp3', ' Nickie', 'English', verbose=True, initial_prompt='Nickie')
|
| 1024 |
+
"""
|
| 1025 |
+
from whisper.timing import median_filter
|
| 1026 |
+
from whisper.decoding import DecodingTask, DecodingOptions, SuppressTokens
|
| 1027 |
+
from .timing import split_word_tokens
|
| 1028 |
+
|
| 1029 |
+
sample_padding = int(N_FFT // 2) + 1
|
| 1030 |
+
sec_per_emb = model.dims.n_audio_ctx / CHUNK_LENGTH
|
| 1031 |
+
CHUNK_SAMPLES = round(CHUNK_LENGTH * SAMPLE_RATE)
|
| 1032 |
+
if isinstance(duration_window, (float, int)):
|
| 1033 |
+
duration_window = [duration_window] * 2
|
| 1034 |
+
window_sum = sum(duration_window)
|
| 1035 |
+
assert CHUNK_SAMPLES > window_sum, \
|
| 1036 |
+
f'Sum of [duration_window] must be less than {CHUNK_SAMPLES}, got {window_sum}'
|
| 1037 |
+
adjusted_chunk_size = CHUNK_SAMPLES - round(duration_window[0]*SAMPLE_RATE)
|
| 1038 |
+
if initial_prompt:
|
| 1039 |
+
initial_prompt = ' ' + initial_prompt.strip()
|
| 1040 |
+
task = DecodingTask(model, DecodingOptions(
|
| 1041 |
+
language=language, prompt=initial_prompt, suppress_tokens=suppress_tokens, without_timestamps=True,
|
| 1042 |
+
))
|
| 1043 |
+
tokenizer = task.tokenizer
|
| 1044 |
+
initial_tokens = list(task.initial_tokens)
|
| 1045 |
+
text_tokens, text = (tokenizer.encode(text), text) if isinstance(text, str) else (text, tokenizer.decode(text))
|
| 1046 |
+
if not exact_token and not case_sensitive:
|
| 1047 |
+
text = text.lower()
|
| 1048 |
+
|
| 1049 |
+
tk_suppress_masks = [
|
| 1050 |
+
[i for i in fil.suppress_tokens if i < tokenizer.eot]
|
| 1051 |
+
for fil in task.logit_filters if isinstance(fil, SuppressTokens)
|
| 1052 |
+
]
|
| 1053 |
+
|
| 1054 |
+
audio = prep_audio(
|
| 1055 |
+
audio,
|
| 1056 |
+
demucs=demucs,
|
| 1057 |
+
demucs_options=demucs_options,
|
| 1058 |
+
only_voice_freq=only_voice_freq,
|
| 1059 |
+
verbose=verbose
|
| 1060 |
+
)
|
| 1061 |
+
prev_target_end = None
|
| 1062 |
+
found = 0
|
| 1063 |
+
if end:
|
| 1064 |
+
audio = audio[:round(end * SAMPLE_RATE)]
|
| 1065 |
+
seek_sample = round(start * SAMPLE_RATE) if start else 0
|
| 1066 |
+
total_samples = audio.shape[-1]
|
| 1067 |
+
|
| 1068 |
+
def _locate():
|
| 1069 |
+
nonlocal seek_sample, found
|
| 1070 |
+
seek = round(seek_sample / SAMPLE_RATE, 3)
|
| 1071 |
+
audio_segment = audio[seek_sample: seek_sample + CHUNK_SAMPLES]
|
| 1072 |
+
mel_segment = log_mel_spectrogram(audio_segment, model.dims.n_mels, padding=sample_padding)
|
| 1073 |
+
mel_segment = pad_or_trim(mel_segment, N_FRAMES).to(device=model.device)
|
| 1074 |
+
|
| 1075 |
+
QKs = [None] * model.dims.n_text_layer
|
| 1076 |
+
hooks = [
|
| 1077 |
+
block.cross_attn.register_forward_hook(
|
| 1078 |
+
lambda _, ins, outs, index=i: QKs.__setitem__(index, outs[-1])
|
| 1079 |
+
)
|
| 1080 |
+
for i, block in enumerate(model.decoder.blocks)
|
| 1081 |
+
]
|
| 1082 |
+
tokens = torch.tensor([initial_tokens + text_tokens]).to(model.device)
|
| 1083 |
+
with torch.no_grad():
|
| 1084 |
+
audio_features = model.encoder(mel_segment.unsqueeze(0))
|
| 1085 |
+
model.decoder(tokens, audio_features)
|
| 1086 |
+
|
| 1087 |
+
for hook in hooks:
|
| 1088 |
+
hook.remove()
|
| 1089 |
+
|
| 1090 |
+
weights = torch.cat([QKs[_l][:, _h] for _l, _h in model.alignment_heads.indices().T], dim=0)
|
| 1091 |
+
weights = weights.softmax(dim=-1)
|
| 1092 |
+
std, mean = torch.std_mean(weights, dim=-2, keepdim=True, unbiased=False)
|
| 1093 |
+
weights = (weights - mean) / std
|
| 1094 |
+
weights = median_filter(weights, 7)
|
| 1095 |
+
|
| 1096 |
+
matrix = weights.mean(axis=0)
|
| 1097 |
+
target_end = round((matrix[-1].argmax()/sec_per_emb).item(), 3)
|
| 1098 |
+
found_msg = f'"{text}" ending at ~{format_timestamp(target_end+seek)}' if verbose else ''
|
| 1099 |
+
|
| 1100 |
+
if mode == 2:
|
| 1101 |
+
if found_msg:
|
| 1102 |
+
safe_print('Unconfirmed:' + found_msg)
|
| 1103 |
+
nonlocal prev_target_end
|
| 1104 |
+
found += 1
|
| 1105 |
+
if (
|
| 1106 |
+
(seek_sample + CHUNK_SAMPLES >= total_samples) or
|
| 1107 |
+
(count and found >= count) or
|
| 1108 |
+
(prev_target_end == target_end)
|
| 1109 |
+
):
|
| 1110 |
+
seek_sample = total_samples
|
| 1111 |
+
else:
|
| 1112 |
+
seek_sample += round(target_end * SAMPLE_RATE)
|
| 1113 |
+
prev_target_end = target_end
|
| 1114 |
+
return dict(tokens=[], target_end=target_end+seek)
|
| 1115 |
+
|
| 1116 |
+
curr_start = round(max(target_end - duration_window[0], 0.), 3)
|
| 1117 |
+
curr_end = round(target_end + duration_window[1], 3)
|
| 1118 |
+
start_frame = round(curr_start * FRAMES_PER_SECOND)
|
| 1119 |
+
end_frame = round(curr_end * FRAMES_PER_SECOND)
|
| 1120 |
+
mel_segment_section = pad_or_trim(mel_segment[..., start_frame:end_frame], N_FRAMES)
|
| 1121 |
+
temp_tokens = torch.tensor([initial_tokens]).to(model.device)
|
| 1122 |
+
|
| 1123 |
+
predictions = []
|
| 1124 |
+
|
| 1125 |
+
target_token_idx = 0
|
| 1126 |
+
not_end = True
|
| 1127 |
+
found_target = False
|
| 1128 |
+
curr_eots = 0
|
| 1129 |
+
temp_audio_features = model.encoder(mel_segment_section.unsqueeze(0))
|
| 1130 |
+
tokens_to_decode = []
|
| 1131 |
+
replace_found_tokens = []
|
| 1132 |
+
infer_tokens = [temp_tokens[0]]
|
| 1133 |
+
kv_cache, hooks = model.install_kv_cache_hooks()
|
| 1134 |
+
while not_end:
|
| 1135 |
+
with torch.no_grad():
|
| 1136 |
+
logits = model.decoder(temp_tokens, temp_audio_features, kv_cache=kv_cache)[0, -1, :tokenizer.eot+1]
|
| 1137 |
+
for tks in tk_suppress_masks:
|
| 1138 |
+
logits[tks] = -np.inf
|
| 1139 |
+
sorted_logits_idxs = logits.sort(dim=-1).indices[-2:]
|
| 1140 |
+
best_token = sorted_logits_idxs[-1]
|
| 1141 |
+
best_non_eot_token = sorted_logits_idxs[-2] if best_token == tokenizer.eot else best_token
|
| 1142 |
+
|
| 1143 |
+
logits = logits[:tokenizer.eot].softmax(dim=-1)
|
| 1144 |
+
if found_target:
|
| 1145 |
+
target_word_prob = is_match = None
|
| 1146 |
+
else:
|
| 1147 |
+
if exact_token:
|
| 1148 |
+
is_match = False
|
| 1149 |
+
else:
|
| 1150 |
+
tokens_to_decode.append(best_non_eot_token)
|
| 1151 |
+
temp_text = tokenizer.decode(tokens_to_decode)
|
| 1152 |
+
if not case_sensitive:
|
| 1153 |
+
temp_text = temp_text.lower()
|
| 1154 |
+
if is_match := temp_text.endswith(text):
|
| 1155 |
+
tokens_to_decode = []
|
| 1156 |
+
target_word_prob = logits[text_tokens[target_token_idx]].item()
|
| 1157 |
+
if (
|
| 1158 |
+
target_word_prob is not None and
|
| 1159 |
+
(
|
| 1160 |
+
target_word_prob >= probability_threshold or
|
| 1161 |
+
best_non_eot_token == text_tokens[target_token_idx] or
|
| 1162 |
+
is_match
|
| 1163 |
+
)
|
| 1164 |
+
):
|
| 1165 |
+
if is_match:
|
| 1166 |
+
best_token = best_non_eot_token
|
| 1167 |
+
token_prob = logits[best_token].item()
|
| 1168 |
+
found_target = True
|
| 1169 |
+
else:
|
| 1170 |
+
best_token[None] = text_tokens[target_token_idx]
|
| 1171 |
+
if len(replace_found_tokens) or best_non_eot_token != text_tokens[target_token_idx]:
|
| 1172 |
+
replace_found_tokens.append(best_non_eot_token)
|
| 1173 |
+
target_token_idx += 1
|
| 1174 |
+
if target_token_idx == len(text_tokens):
|
| 1175 |
+
found_target = True
|
| 1176 |
+
token_prob = target_word_prob
|
| 1177 |
+
if found_target:
|
| 1178 |
+
found += 1
|
| 1179 |
+
curr_eots = 0
|
| 1180 |
+
else:
|
| 1181 |
+
if not found_target:
|
| 1182 |
+
if len(replace_found_tokens):
|
| 1183 |
+
temp_tokens = torch.cat(infer_tokens)[None]
|
| 1184 |
+
temp_tokens = torch.cat(
|
| 1185 |
+
[temp_tokens[..., :-len(replace_found_tokens)],
|
| 1186 |
+
torch.stack(replace_found_tokens)[None]]
|
| 1187 |
+
)
|
| 1188 |
+
replace_found_tokens = []
|
| 1189 |
+
kv_cache.clear()
|
| 1190 |
+
target_token_idx = 0
|
| 1191 |
+
if best_token == tokenizer.eot:
|
| 1192 |
+
if curr_eots >= eots or found_target:
|
| 1193 |
+
not_end = False
|
| 1194 |
+
else:
|
| 1195 |
+
curr_eots += 1
|
| 1196 |
+
best_token = best_non_eot_token
|
| 1197 |
+
else:
|
| 1198 |
+
curr_eots = 0
|
| 1199 |
+
token_prob = None if best_token == tokenizer.eot else logits[best_token].item()
|
| 1200 |
+
|
| 1201 |
+
predictions.append(dict(token=best_token.item(), prob=token_prob))
|
| 1202 |
+
if len(predictions) > max_token_per_seg:
|
| 1203 |
+
not_end = False
|
| 1204 |
+
if not_end:
|
| 1205 |
+
infer_tokens.append(best_token[None])
|
| 1206 |
+
temp_tokens = best_token[None, None]
|
| 1207 |
+
kv_cache.clear()
|
| 1208 |
+
for hook in hooks:
|
| 1209 |
+
hook.remove()
|
| 1210 |
+
segment = None
|
| 1211 |
+
|
| 1212 |
+
if found_target:
|
| 1213 |
+
if found_msg:
|
| 1214 |
+
safe_print('Confirmed: ' + found_msg, tqdm_pbar.write)
|
| 1215 |
+
final_tokens = [p['token'] for p in predictions]
|
| 1216 |
+
if mode == 1:
|
| 1217 |
+
_, (ws, wts), _ = split_word_tokens([dict(tokens=final_tokens)], tokenizer)
|
| 1218 |
+
final_token_probs = [p['prob'] for p in predictions]
|
| 1219 |
+
wps = [float(np.mean([final_token_probs.pop(0) for _ in wt])) for wt in wts]
|
| 1220 |
+
words = [dict(word=w, tokens=wt, probability=wp) for w, wt, wp in zip(ws, wts, wps)]
|
| 1221 |
+
final_end = target_end+seek
|
| 1222 |
+
near_text = "".join(ws)
|
| 1223 |
+
segment = dict(end=final_end, text=text, duration_window_text=near_text, duration_window_word=words)
|
| 1224 |
+
if verbose:
|
| 1225 |
+
safe_print(f'Duration Window: "{near_text}"\n', tqdm_pbar.write)
|
| 1226 |
+
seek_sample += round(curr_end * SAMPLE_RATE)
|
| 1227 |
+
else:
|
| 1228 |
+
|
| 1229 |
+
segment = dict(
|
| 1230 |
+
seek=0,
|
| 1231 |
+
tokens=final_tokens
|
| 1232 |
+
)
|
| 1233 |
+
|
| 1234 |
+
add_word_timestamps_stable(
|
| 1235 |
+
segments=[segment],
|
| 1236 |
+
model=model,
|
| 1237 |
+
tokenizer=tokenizer,
|
| 1238 |
+
mel=mel_segment,
|
| 1239 |
+
num_samples=round(curr_end*SAMPLE_RATE),
|
| 1240 |
+
gap_padding=None
|
| 1241 |
+
)
|
| 1242 |
+
segment = Segment(0, 0, '', words=segment['words'])
|
| 1243 |
+
segment.update_seg_with_words()
|
| 1244 |
+
seek_sample += round(segment.words[-1].end * SAMPLE_RATE)
|
| 1245 |
+
segment.offset_time(seek)
|
| 1246 |
+
segment.seek = curr_start
|
| 1247 |
+
if verbose:
|
| 1248 |
+
safe_print(segment.to_display_str(), tqdm_pbar.write)
|
| 1249 |
+
|
| 1250 |
+
else:
|
| 1251 |
+
seek_sample += adjusted_chunk_size if audio_segment.shape[-1] == CHUNK_SAMPLES else audio_segment.shape[-1]
|
| 1252 |
+
|
| 1253 |
+
return segment
|
| 1254 |
+
|
| 1255 |
+
total_duration = round(total_samples / SAMPLE_RATE, 2)
|
| 1256 |
+
matches = []
|
| 1257 |
+
with tqdm(total=total_duration, unit='sec', disable=verbose is None, desc='Locate') as tqdm_pbar:
|
| 1258 |
+
while seek_sample < total_samples and (not count or found < count):
|
| 1259 |
+
if match := _locate():
|
| 1260 |
+
matches.append(match)
|
| 1261 |
+
tqdm_pbar.update(round(seek_sample/SAMPLE_RATE, 2) - tqdm_pbar.n)
|
| 1262 |
+
tqdm_pbar.update(tqdm_pbar.total - tqdm_pbar.n)
|
| 1263 |
+
if verbose and not matches:
|
| 1264 |
+
safe_print(f'Failed to locate "{text}".')
|
| 1265 |
+
return matches
|
stable_whisper/audio.py
ADDED
|
@@ -0,0 +1,288 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import subprocess
|
| 2 |
+
import warnings
|
| 3 |
+
import ffmpeg
|
| 4 |
+
import torch
|
| 5 |
+
import torchaudio
|
| 6 |
+
import numpy as np
|
| 7 |
+
from typing import Union, Optional
|
| 8 |
+
|
| 9 |
+
from whisper.audio import SAMPLE_RATE
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def is_ytdlp_available():
|
| 13 |
+
return subprocess.run('yt-dlp -h', shell=True, capture_output=True).returncode == 0
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _load_file(file: Union[str, bytes], verbose: bool = False, only_ffmpeg: bool = False):
|
| 17 |
+
if isinstance(file, str) and '://' in file:
|
| 18 |
+
if is_ytdlp_available():
|
| 19 |
+
verbosity = ' -q' if verbose is None else (' --progress' if verbose else ' --progress -q')
|
| 20 |
+
p = subprocess.run(
|
| 21 |
+
f'yt-dlp "{file}" -f ba/w -I 1{verbosity} -o -',
|
| 22 |
+
shell=True,
|
| 23 |
+
stdout=subprocess.PIPE
|
| 24 |
+
)
|
| 25 |
+
if len(p.stdout) == 0:
|
| 26 |
+
raise RuntimeError(f'Failed to download media from "{file}" with yt-dlp')
|
| 27 |
+
return p.stdout
|
| 28 |
+
else:
|
| 29 |
+
warnings.warn('URL detected but yt-dlp not available. '
|
| 30 |
+
'To handle a greater variety of URLs (i.e. non-direct links), '
|
| 31 |
+
'install yt-dlp, \'pip install yt-dlp\' (repo: https://github.com/yt-dlp/yt-dlp).')
|
| 32 |
+
if not only_ffmpeg:
|
| 33 |
+
if is_ytdlp_available():
|
| 34 |
+
verbosity = ' -q' if verbose is None else (' --progress' if verbose else ' --progress -q')
|
| 35 |
+
p = subprocess.run(
|
| 36 |
+
f'yt-dlp "{file}" -f ba/w -I 1{verbosity} -o -',
|
| 37 |
+
shell=True,
|
| 38 |
+
stdout=subprocess.PIPE
|
| 39 |
+
)
|
| 40 |
+
if p.returncode != 0 or len(p.stdout) == 0:
|
| 41 |
+
raise RuntimeError(f'Failed to download media from "{file}" with yt-dlp')
|
| 42 |
+
return p.stdout
|
| 43 |
+
else:
|
| 44 |
+
warnings.warn('URL detected but yt-dlp not available. '
|
| 45 |
+
'To handle a greater variety of URLs (i.e. non-direct links), '
|
| 46 |
+
'install yt-dlp, \'pip install yt-dlp\' (repo: https://github.com/yt-dlp/yt-dlp).')
|
| 47 |
+
return file
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# modified version of whisper.audio.load_audio
|
| 51 |
+
def load_audio(file: Union[str, bytes], sr: int = SAMPLE_RATE, verbose: bool = True, only_ffmpeg: bool = False):
|
| 52 |
+
"""
|
| 53 |
+
Open an audio file and read as mono waveform then resamples as necessary.
|
| 54 |
+
|
| 55 |
+
Parameters
|
| 56 |
+
----------
|
| 57 |
+
file : str or bytes
|
| 58 |
+
The audio file to open, bytes of file, or URL to audio/video.
|
| 59 |
+
sr : int, default ``whisper.model.SAMPLE_RATE``
|
| 60 |
+
The sample rate to resample the audio if necessary.
|
| 61 |
+
verbose : bool, default True
|
| 62 |
+
Whether to print yt-dlp log.
|
| 63 |
+
only_ffmpeg : bool, default False
|
| 64 |
+
Whether to use only FFmpeg (instead of yt-dlp) for URls.
|
| 65 |
+
|
| 66 |
+
Returns
|
| 67 |
+
-------
|
| 68 |
+
numpy.ndarray
|
| 69 |
+
A array containing the audio waveform in float32.
|
| 70 |
+
"""
|
| 71 |
+
file = _load_file(file, verbose=verbose, only_ffmpeg=only_ffmpeg)
|
| 72 |
+
if isinstance(file, bytes):
|
| 73 |
+
inp, file = file, 'pipe:'
|
| 74 |
+
else:
|
| 75 |
+
inp = None
|
| 76 |
+
try:
|
| 77 |
+
# This launches a subprocess to decode audio while down-mixing and resampling as necessary.
|
| 78 |
+
# Requires the ffmpeg CLI and `ffmpeg-python` package to be installed.
|
| 79 |
+
out, _ = (
|
| 80 |
+
ffmpeg.input(file, threads=0)
|
| 81 |
+
.output("-", format="s16le", acodec="pcm_s16le", ac=1, ar=sr)
|
| 82 |
+
.run(cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True, input=inp)
|
| 83 |
+
)
|
| 84 |
+
except ffmpeg.Error as e:
|
| 85 |
+
raise RuntimeError(f"Failed to load audio: {e.stderr.decode()}") from e
|
| 86 |
+
|
| 87 |
+
return np.frombuffer(out, np.int16).flatten().astype(np.float32) / 32768.0
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def voice_freq_filter(wf: (torch.Tensor, np.ndarray), sr: int,
|
| 91 |
+
upper_freq: int = None,
|
| 92 |
+
lower_freq: int = None) -> torch.Tensor:
|
| 93 |
+
if isinstance(wf, np.ndarray):
|
| 94 |
+
wf = torch.from_numpy(wf)
|
| 95 |
+
if upper_freq is None:
|
| 96 |
+
upper_freq = 5000
|
| 97 |
+
if lower_freq is None:
|
| 98 |
+
lower_freq = 200
|
| 99 |
+
assert upper_freq > lower_freq, f'upper_freq {upper_freq} must but greater than lower_freq {lower_freq}'
|
| 100 |
+
return torchaudio.functional.highpass_biquad(torchaudio.functional.lowpass_biquad(wf, sr, upper_freq),
|
| 101 |
+
sr,
|
| 102 |
+
lower_freq)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def is_demucs_available():
|
| 106 |
+
from importlib.util import find_spec
|
| 107 |
+
if find_spec('demucs') is None:
|
| 108 |
+
raise ModuleNotFoundError("Please install Demucs; "
|
| 109 |
+
"'pip install -U demucs' or "
|
| 110 |
+
"'pip install -U git+https://github.com/facebookresearch/demucs#egg=demucs'; "
|
| 111 |
+
"Official Demucs repo: https://github.com/facebookresearch/demucs")
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def load_demucs_model():
|
| 115 |
+
is_demucs_available()
|
| 116 |
+
from demucs.pretrained import get_model_from_args
|
| 117 |
+
return get_model_from_args(type('args', (object,), dict(name='htdemucs', repo=None))).cpu().eval()
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def demucs_audio(audio: (torch.Tensor, str),
|
| 121 |
+
input_sr: int = None,
|
| 122 |
+
output_sr: int = None,
|
| 123 |
+
model=None,
|
| 124 |
+
device=None,
|
| 125 |
+
verbose: bool = True,
|
| 126 |
+
track_name: str = None,
|
| 127 |
+
save_path: str = None,
|
| 128 |
+
**demucs_options) -> torch.Tensor:
|
| 129 |
+
"""
|
| 130 |
+
Isolates vocals / remove noise from ``audio`` with Demucs.
|
| 131 |
+
|
| 132 |
+
Official repo, https://github.com/facebookresearch/demucs.
|
| 133 |
+
"""
|
| 134 |
+
if model is None:
|
| 135 |
+
model = load_demucs_model()
|
| 136 |
+
else:
|
| 137 |
+
is_demucs_available()
|
| 138 |
+
from demucs.apply import apply_model
|
| 139 |
+
|
| 140 |
+
if track_name:
|
| 141 |
+
track_name = f'"{track_name}"'
|
| 142 |
+
|
| 143 |
+
if isinstance(audio, (str, bytes)):
|
| 144 |
+
if isinstance(audio, str) and not track_name:
|
| 145 |
+
track_name = f'"{audio}"'
|
| 146 |
+
audio = torch.from_numpy(load_audio(audio, model.samplerate))
|
| 147 |
+
elif input_sr != model.samplerate:
|
| 148 |
+
if input_sr is None:
|
| 149 |
+
raise ValueError('No [input_sr] specified for audio tensor.')
|
| 150 |
+
audio = torchaudio.functional.resample(audio,
|
| 151 |
+
orig_freq=input_sr,
|
| 152 |
+
new_freq=model.samplerate)
|
| 153 |
+
if not track_name:
|
| 154 |
+
track_name = 'audio track'
|
| 155 |
+
audio_dims = audio.dim()
|
| 156 |
+
if audio_dims == 1:
|
| 157 |
+
audio = audio[None, None].repeat_interleave(2, -2)
|
| 158 |
+
else:
|
| 159 |
+
if audio.shape[-2] == 1:
|
| 160 |
+
audio = audio.repeat_interleave(2, -2)
|
| 161 |
+
if audio_dims < 3:
|
| 162 |
+
audio = audio[None]
|
| 163 |
+
|
| 164 |
+
if 'mix' in demucs_options:
|
| 165 |
+
audio = demucs_options.pop('mix')
|
| 166 |
+
|
| 167 |
+
if device is None:
|
| 168 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 169 |
+
|
| 170 |
+
vocals_idx = model.sources.index('vocals')
|
| 171 |
+
if verbose:
|
| 172 |
+
print(f'Isolating vocals from {track_name}')
|
| 173 |
+
apply_kwarg = dict(
|
| 174 |
+
model=model,
|
| 175 |
+
mix=audio,
|
| 176 |
+
device=device,
|
| 177 |
+
split=True,
|
| 178 |
+
overlap=.25,
|
| 179 |
+
progress=verbose is not None,
|
| 180 |
+
)
|
| 181 |
+
apply_kwarg.update(demucs_options)
|
| 182 |
+
vocals = apply_model(
|
| 183 |
+
**apply_kwarg
|
| 184 |
+
)[0, vocals_idx].mean(0)
|
| 185 |
+
|
| 186 |
+
if device != 'cpu':
|
| 187 |
+
torch.cuda.empty_cache()
|
| 188 |
+
|
| 189 |
+
if output_sr is not None and model.samplerate != output_sr:
|
| 190 |
+
vocals = torchaudio.functional.resample(vocals,
|
| 191 |
+
orig_freq=model.samplerate,
|
| 192 |
+
new_freq=output_sr)
|
| 193 |
+
|
| 194 |
+
if save_path is not None:
|
| 195 |
+
if isinstance(save_path, str) and not save_path.lower().endswith('.wav'):
|
| 196 |
+
save_path += '.wav'
|
| 197 |
+
torchaudio.save(save_path, vocals[None], output_sr or model.samplerate)
|
| 198 |
+
print(f'Saved: {save_path}')
|
| 199 |
+
|
| 200 |
+
return vocals
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def get_samplerate(audiofile: (str, bytes)) -> (int, None):
|
| 204 |
+
import re
|
| 205 |
+
if isinstance(audiofile, str):
|
| 206 |
+
metadata = subprocess.run(f'ffmpeg -i {audiofile}', capture_output=True, shell=True).stderr.decode()
|
| 207 |
+
else:
|
| 208 |
+
p = subprocess.Popen(f'ffmpeg -i -', stderr=subprocess.PIPE, stdin=subprocess.PIPE, shell=True)
|
| 209 |
+
try:
|
| 210 |
+
p.stdin.write(audiofile)
|
| 211 |
+
except BrokenPipeError:
|
| 212 |
+
pass
|
| 213 |
+
finally:
|
| 214 |
+
metadata = p.communicate()[-1]
|
| 215 |
+
if metadata is not None:
|
| 216 |
+
metadata = metadata.decode()
|
| 217 |
+
sr = re.findall(r'\n.+Stream.+Audio.+\D+(\d+) Hz', metadata)
|
| 218 |
+
if sr:
|
| 219 |
+
return int(sr[0])
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def prep_audio(
|
| 223 |
+
audio: Union[str, np.ndarray, torch.Tensor, bytes],
|
| 224 |
+
demucs: Union[bool, torch.nn.Module] = False,
|
| 225 |
+
demucs_options: dict = None,
|
| 226 |
+
only_voice_freq: bool = False,
|
| 227 |
+
only_ffmpeg: bool = False,
|
| 228 |
+
verbose: Optional[bool] = False,
|
| 229 |
+
sr: int = None
|
| 230 |
+
) -> torch.Tensor:
|
| 231 |
+
"""
|
| 232 |
+
Converts input audio of many types into a mono waveform as a torch.Tensor.
|
| 233 |
+
|
| 234 |
+
Parameters
|
| 235 |
+
----------
|
| 236 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 237 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 238 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 239 |
+
demucs : bool or torch.nn.Module, default False
|
| 240 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 241 |
+
a Demucs model to avoid reloading the model for each run.
|
| 242 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 243 |
+
demucs_options : dict, optional
|
| 244 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 245 |
+
only_voice_freq : bool, default False
|
| 246 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 247 |
+
sr : int, default None, meaning ``whisper.audio.SAMPLE_RATE``, 16kHZ
|
| 248 |
+
The sample rate of ``audio``.
|
| 249 |
+
verbose : bool, default False
|
| 250 |
+
Whether to print yt-dlp log.
|
| 251 |
+
only_ffmpeg: bool, default False
|
| 252 |
+
Whether to use only FFmpeg (and not yt-dlp) for URls.
|
| 253 |
+
|
| 254 |
+
Returns
|
| 255 |
+
-------
|
| 256 |
+
torch.Tensor
|
| 257 |
+
A mono waveform.
|
| 258 |
+
"""
|
| 259 |
+
if not sr:
|
| 260 |
+
sr = SAMPLE_RATE
|
| 261 |
+
if isinstance(audio, (str, bytes)):
|
| 262 |
+
if demucs:
|
| 263 |
+
demucs_kwargs = dict(
|
| 264 |
+
audio=audio,
|
| 265 |
+
output_sr=sr,
|
| 266 |
+
verbose=verbose,
|
| 267 |
+
)
|
| 268 |
+
demucs_kwargs.update(demucs_options or {})
|
| 269 |
+
audio = demucs_audio(**demucs_kwargs)
|
| 270 |
+
else:
|
| 271 |
+
audio = torch.from_numpy(load_audio(audio, sr=sr, verbose=verbose, only_ffmpeg=only_ffmpeg))
|
| 272 |
+
else:
|
| 273 |
+
if isinstance(audio, np.ndarray):
|
| 274 |
+
audio = torch.from_numpy(audio)
|
| 275 |
+
if demucs:
|
| 276 |
+
demucs_kwargs = dict(
|
| 277 |
+
audio=audio,
|
| 278 |
+
input_sr=sr,
|
| 279 |
+
output_sr=sr,
|
| 280 |
+
verbose=verbose,
|
| 281 |
+
)
|
| 282 |
+
demucs_kwargs.update(demucs_options or {})
|
| 283 |
+
audio = demucs_audio(**demucs_kwargs)
|
| 284 |
+
if only_voice_freq:
|
| 285 |
+
audio = voice_freq_filter(audio, sr)
|
| 286 |
+
|
| 287 |
+
return audio
|
| 288 |
+
|
stable_whisper/decode.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import TYPE_CHECKING, List, Union
|
| 2 |
+
from dataclasses import replace
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
from whisper.decoding import DecodingTask, DecodingOptions, DecodingResult
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
if TYPE_CHECKING:
|
| 11 |
+
from whisper.model import Whisper
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def _suppress_ts(ts_logits: torch.Tensor, ts_token_mask: torch.Tensor = None):
|
| 15 |
+
if ts_token_mask is not None:
|
| 16 |
+
ts_logits[:, ts_token_mask] = -np.inf
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# modified version of whisper.decoding.DecodingTask
|
| 20 |
+
class DecodingTaskStable(DecodingTask):
|
| 21 |
+
|
| 22 |
+
def __init__(self, *args, **kwargs):
|
| 23 |
+
self.ts_token_mask: torch.Tensor = kwargs.pop('ts_token_mask', None)
|
| 24 |
+
self.audio_features: torch.Tensor = kwargs.pop('audio_features', None)
|
| 25 |
+
super(DecodingTaskStable, self).__init__(*args, **kwargs)
|
| 26 |
+
|
| 27 |
+
def _get_audio_features(self, mel: torch.Tensor):
|
| 28 |
+
if self.audio_features is None:
|
| 29 |
+
audio_features = super()._get_audio_features(mel)
|
| 30 |
+
self.audio_features = audio_features.detach().clone()
|
| 31 |
+
return audio_features
|
| 32 |
+
return self.audio_features.clone()
|
| 33 |
+
|
| 34 |
+
# modified version of whisper.DecodingTask._main_loop
|
| 35 |
+
def _main_loop(self, audio_features: torch.Tensor, tokens: torch.Tensor):
|
| 36 |
+
n_batch = tokens.shape[0]
|
| 37 |
+
sum_logprobs: torch.Tensor = torch.zeros(n_batch, device=audio_features.device)
|
| 38 |
+
no_speech_probs = [np.nan] * n_batch
|
| 39 |
+
|
| 40 |
+
try:
|
| 41 |
+
for i in range(self.sample_len):
|
| 42 |
+
logits = self.inference.logits(tokens, audio_features)
|
| 43 |
+
|
| 44 |
+
if i == 0 and self.tokenizer.no_speech is not None: # save no_speech_probs
|
| 45 |
+
probs_at_sot = logits[:, self.sot_index].float().softmax(dim=-1)
|
| 46 |
+
no_speech_probs = probs_at_sot[:, self.tokenizer.no_speech].tolist()
|
| 47 |
+
|
| 48 |
+
# now we need to consider the logits at the last token only
|
| 49 |
+
logits = logits[:, -1]
|
| 50 |
+
|
| 51 |
+
# apply the logit filters, e.g. for suppressing or applying penalty to
|
| 52 |
+
for logit_filter in self.logit_filters:
|
| 53 |
+
logit_filter.apply(logits, tokens)
|
| 54 |
+
|
| 55 |
+
# suppress timestamp tokens where the audio is silent so that decoder ignores those timestamps
|
| 56 |
+
_suppress_ts(logits[:, self.tokenizer.timestamp_begin:], self.ts_token_mask)
|
| 57 |
+
|
| 58 |
+
logits.nan_to_num_(-np.inf)
|
| 59 |
+
# expand the tokens tensor with the selected next tokens
|
| 60 |
+
tokens, completed = self.decoder.update(tokens, logits, sum_logprobs)
|
| 61 |
+
|
| 62 |
+
if completed or tokens.shape[-1] > self.n_ctx:
|
| 63 |
+
break
|
| 64 |
+
finally:
|
| 65 |
+
self.inference.cleanup_caching()
|
| 66 |
+
|
| 67 |
+
return tokens, sum_logprobs, no_speech_probs
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
# modified version of whisper.decoding.decode
|
| 71 |
+
@torch.no_grad()
|
| 72 |
+
def decode_stable(model: "Whisper",
|
| 73 |
+
mel: torch.Tensor,
|
| 74 |
+
options: DecodingOptions = DecodingOptions(),
|
| 75 |
+
ts_token_mask: torch.Tensor = None,
|
| 76 |
+
audio_features: torch.Tensor = None,
|
| 77 |
+
**kwargs, ) -> \
|
| 78 |
+
Union[DecodingResult, List[DecodingResult], tuple]:
|
| 79 |
+
"""
|
| 80 |
+
Performs decoding of 30-second audio segment(s), provided as Mel spectrogram(s).
|
| 81 |
+
|
| 82 |
+
Parameters
|
| 83 |
+
----------
|
| 84 |
+
model : whisper.model.Whisper
|
| 85 |
+
An instance of Whisper ASR model.
|
| 86 |
+
mel : torch.Tensor,
|
| 87 |
+
A tensor containing the Mel spectrogram(s). ``mel.shape`` must be (80, 3000) or (*, 80, 3000).
|
| 88 |
+
options : whisper.decode.DecodingOptions, default whisper.decode.DecodingOptions()
|
| 89 |
+
A dataclass that contains all necessary options for decoding 30-second segments
|
| 90 |
+
ts_token_mask : torch.Tensor, optional
|
| 91 |
+
Mask for suppressing to timestamp token(s) for decoding.
|
| 92 |
+
audio_features : torch.Tensor, optional
|
| 93 |
+
Reused ``audio_feature`` from encoder for fallback.
|
| 94 |
+
|
| 95 |
+
Returns
|
| 96 |
+
-------
|
| 97 |
+
whisper.decode.DecodingResult or list whisper.decode.DecodingResult
|
| 98 |
+
The result(s) of decoding contained in ``whisper.decode.DecodingResult`` dataclass instance(s).
|
| 99 |
+
"""
|
| 100 |
+
if single := mel.ndim == 2:
|
| 101 |
+
mel = mel.unsqueeze(0)
|
| 102 |
+
|
| 103 |
+
if kwargs:
|
| 104 |
+
options = replace(options, **kwargs)
|
| 105 |
+
|
| 106 |
+
task = DecodingTaskStable(model, options, ts_token_mask=ts_token_mask, audio_features=audio_features)
|
| 107 |
+
result = task.run(mel)
|
| 108 |
+
|
| 109 |
+
return result[0] if single else result, task.audio_features
|
stable_whisper/non_whisper.py
ADDED
|
@@ -0,0 +1,348 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import warnings
|
| 3 |
+
import io
|
| 4 |
+
import torch
|
| 5 |
+
import torchaudio
|
| 6 |
+
import numpy as np
|
| 7 |
+
from typing import Union, Callable, Optional
|
| 8 |
+
|
| 9 |
+
from .audio import load_audio
|
| 10 |
+
from .result import WhisperResult
|
| 11 |
+
|
| 12 |
+
AUDIO_TYPES = ('str', 'byte', 'torch', 'numpy')
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def transcribe_any(
|
| 16 |
+
inference_func: Callable,
|
| 17 |
+
audio: Union[str, np.ndarray, torch.Tensor, bytes],
|
| 18 |
+
audio_type: str = None,
|
| 19 |
+
input_sr: int = None,
|
| 20 |
+
model_sr: int = None,
|
| 21 |
+
inference_kwargs: dict = None,
|
| 22 |
+
temp_file: str = None,
|
| 23 |
+
verbose: Optional[bool] = False,
|
| 24 |
+
regroup: Union[bool, str] = True,
|
| 25 |
+
suppress_silence: bool = True,
|
| 26 |
+
suppress_word_ts: bool = True,
|
| 27 |
+
q_levels: int = 20,
|
| 28 |
+
k_size: int = 5,
|
| 29 |
+
demucs: bool = False,
|
| 30 |
+
demucs_device: str = None,
|
| 31 |
+
demucs_output: str = None,
|
| 32 |
+
demucs_options: dict = None,
|
| 33 |
+
vad: bool = False,
|
| 34 |
+
vad_threshold: float = 0.35,
|
| 35 |
+
vad_onnx: bool = False,
|
| 36 |
+
min_word_dur: float = 0.1,
|
| 37 |
+
nonspeech_error: float = 0.3,
|
| 38 |
+
use_word_position: bool = True,
|
| 39 |
+
only_voice_freq: bool = False,
|
| 40 |
+
only_ffmpeg: bool = False,
|
| 41 |
+
force_order: bool = False,
|
| 42 |
+
check_sorted: bool = True
|
| 43 |
+
) -> WhisperResult:
|
| 44 |
+
"""
|
| 45 |
+
Transcribe ``audio`` using any ASR system.
|
| 46 |
+
|
| 47 |
+
Parameters
|
| 48 |
+
----------
|
| 49 |
+
inference_func : Callable
|
| 50 |
+
Function that runs ASR when provided the [audio] and return data in the appropriate format.
|
| 51 |
+
For format examples see, https://github.com/jianfch/stable-ts/blob/main/examples/non-whisper.ipynb.
|
| 52 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 53 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 54 |
+
audio_type : {'str', 'byte', 'torch', 'numpy', None}, default None, meaning same type as ``audio``
|
| 55 |
+
The type that ``audio`` needs to be for ``inference_func``.
|
| 56 |
+
'str' is a path to the file.
|
| 57 |
+
'byte' is bytes (used for APIs or to avoid writing any data to hard drive).
|
| 58 |
+
'torch' is an instance of :class:`torch.Tensor` containing the audio waveform, in float32 dtype, on CPU.
|
| 59 |
+
'numpy' is an instance of :class:`numpy.ndarray` containing the audio waveform, in float32 dtype.
|
| 60 |
+
input_sr : int, default None, meaning auto-detected if ``audio`` is ``str`` or ``bytes``
|
| 61 |
+
The sample rate of ``audio``.
|
| 62 |
+
model_sr : int, default None, meaning same sample rate as ``input_sr``
|
| 63 |
+
The sample rate to resample the audio into for ``inference_func``.
|
| 64 |
+
inference_kwargs : dict, optional
|
| 65 |
+
Dictionary of arguments to pass into ``inference_func``.
|
| 66 |
+
temp_file : str, default './_temp_stable-ts_audio_.wav'
|
| 67 |
+
Temporary path for the preprocessed audio when ``audio_type = 'str'``.
|
| 68 |
+
verbose: bool, False
|
| 69 |
+
Whether to displays all the details during transcription, If ``False``, displays progressbar. If ``None``, does
|
| 70 |
+
not display anything.
|
| 71 |
+
regroup: str or bool, default True
|
| 72 |
+
String representation of a custom regrouping algorithm or ``True`` use to the default algorithm 'da'. Only
|
| 73 |
+
applies if ``word_timestamps = False``.
|
| 74 |
+
suppress_silence : bool, default True
|
| 75 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 76 |
+
suppress_word_ts : bool, default True
|
| 77 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 78 |
+
q_levels : int, default 20
|
| 79 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 80 |
+
Acts as a threshold to marking sound as silent.
|
| 81 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 82 |
+
k_size : int, default 5
|
| 83 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 84 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 85 |
+
demucs : bool or torch.nn.Module, default False
|
| 86 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 87 |
+
a Demucs model to avoid reloading the model for each run.
|
| 88 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 89 |
+
demucs_output : str, optional
|
| 90 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 91 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 92 |
+
demucs_options : dict, optional
|
| 93 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 94 |
+
demucs_device : str, default None, meaning 'cuda' if cuda is available with ``torch`` else 'cpu'
|
| 95 |
+
Device to use for demucs.
|
| 96 |
+
vad : bool, default False
|
| 97 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 98 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 99 |
+
vad_threshold : float, default 0.35
|
| 100 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 101 |
+
vad_onnx : bool, default False
|
| 102 |
+
Whether to use ONNX for Silero VAD.
|
| 103 |
+
min_word_dur : float, default 0.1
|
| 104 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 105 |
+
nonspeech_error : float, default 0.3
|
| 106 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 107 |
+
use_word_position : bool, default True
|
| 108 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 109 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 110 |
+
only_voice_freq : bool, default False
|
| 111 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 112 |
+
only_ffmpeg : bool, default False
|
| 113 |
+
Whether to use only FFmpeg (instead of not yt-dlp) for URls
|
| 114 |
+
force_order : bool, default False
|
| 115 |
+
Whether to use adjacent timestamps to replace timestamps that are out of order. Use this parameter only if
|
| 116 |
+
the words/segments returned by ``inference_func`` are expected to be in chronological order.
|
| 117 |
+
check_sorted : bool, default True
|
| 118 |
+
Whether to raise an error when timestamps returned by ``inference_func`` are not in ascending order.
|
| 119 |
+
|
| 120 |
+
Returns
|
| 121 |
+
-------
|
| 122 |
+
stable_whisper.result.WhisperResult
|
| 123 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 124 |
+
|
| 125 |
+
Notes
|
| 126 |
+
-----
|
| 127 |
+
For ``audio_type = 'str'``:
|
| 128 |
+
If ``audio`` is a file and no audio preprocessing is set, ``audio`` will be directly passed into
|
| 129 |
+
``inference_func``.
|
| 130 |
+
If audio preprocessing is ``demucs`` or ``only_voice_freq``, the processed audio will be encoded into
|
| 131 |
+
``temp_file`` and then passed into ``inference_func``.
|
| 132 |
+
|
| 133 |
+
For ``audio_type = 'byte'``:
|
| 134 |
+
If ``audio`` is file, the bytes of file will be passed into ``inference_func``.
|
| 135 |
+
If ``audio`` is :class:`torch.Tensor` or :class:`numpy.ndarray`, the bytes of the ``audio`` will be encoded
|
| 136 |
+
into WAV format then passed into ``inference_func``.
|
| 137 |
+
|
| 138 |
+
Resampling is only performed on ``audio`` when ``model_sr`` does not match the sample rate of the ``audio`` before
|
| 139 |
+
passing into ``inference_func`` due to ``input_sr`` not matching ``model_sr``, or sample rate changes due to
|
| 140 |
+
audio preprocessing from ``demucs = True``.
|
| 141 |
+
"""
|
| 142 |
+
if demucs_options is None:
|
| 143 |
+
demucs_options = {}
|
| 144 |
+
if demucs_output:
|
| 145 |
+
if 'save_path' not in demucs_options:
|
| 146 |
+
demucs_options['save_path'] = demucs_output
|
| 147 |
+
warnings.warn('``demucs_output`` is deprecated. Use ``demucs_options`` with ``save_path`` instead. '
|
| 148 |
+
'E.g. demucs_options=dict(save_path="demucs_output.mp3")',
|
| 149 |
+
DeprecationWarning, stacklevel=2)
|
| 150 |
+
if demucs_device:
|
| 151 |
+
if 'device' not in demucs_options:
|
| 152 |
+
demucs_options['device'] = demucs_device
|
| 153 |
+
warnings.warn('``demucs_device`` is deprecated. Use ``demucs_options`` with ``device`` instead. '
|
| 154 |
+
'E.g. demucs_options=dict(device="cpu")',
|
| 155 |
+
DeprecationWarning, stacklevel=2)
|
| 156 |
+
|
| 157 |
+
if audio_type is not None and (audio_type := audio_type.lower()) not in AUDIO_TYPES:
|
| 158 |
+
raise NotImplementedError(f'[audio_type]={audio_type} is not supported. Types: {AUDIO_TYPES}')
|
| 159 |
+
|
| 160 |
+
if audio_type is None:
|
| 161 |
+
if isinstance(audio, str):
|
| 162 |
+
audio_type = 'str'
|
| 163 |
+
elif isinstance(audio, bytes):
|
| 164 |
+
audio_type = 'byte'
|
| 165 |
+
elif isinstance(audio, torch.Tensor):
|
| 166 |
+
audio_type = 'pytorch'
|
| 167 |
+
elif isinstance(audio, np.ndarray):
|
| 168 |
+
audio_type = 'numpy'
|
| 169 |
+
else:
|
| 170 |
+
raise TypeError(f'{type(audio)} is not supported for [audio].')
|
| 171 |
+
|
| 172 |
+
if (
|
| 173 |
+
input_sr is None and
|
| 174 |
+
isinstance(audio, (np.ndarray, torch.Tensor)) and
|
| 175 |
+
(demucs or only_voice_freq or suppress_silence or model_sr)
|
| 176 |
+
):
|
| 177 |
+
raise ValueError('[input_sr] is required when [audio] is a PyTorch tensor or NumPy array.')
|
| 178 |
+
|
| 179 |
+
if (
|
| 180 |
+
model_sr is None and
|
| 181 |
+
isinstance(audio, (str, bytes)) and
|
| 182 |
+
audio_type in ('torch', 'numpy')
|
| 183 |
+
):
|
| 184 |
+
raise ValueError('[model_sr] is required when [audio_type] is a "pytorch" or "numpy".')
|
| 185 |
+
|
| 186 |
+
if isinstance(audio, str):
|
| 187 |
+
from .audio import _load_file
|
| 188 |
+
audio = _load_file(audio, verbose=verbose, only_ffmpeg=only_ffmpeg)
|
| 189 |
+
|
| 190 |
+
if inference_kwargs is None:
|
| 191 |
+
inference_kwargs = {}
|
| 192 |
+
|
| 193 |
+
temp_file = os.path.abspath(temp_file or './_temp_stable-ts_audio_.wav')
|
| 194 |
+
temp_audio_file = None
|
| 195 |
+
|
| 196 |
+
curr_sr = input_sr
|
| 197 |
+
|
| 198 |
+
if demucs:
|
| 199 |
+
if demucs is True:
|
| 200 |
+
from .audio import load_demucs_model
|
| 201 |
+
demucs_model = load_demucs_model()
|
| 202 |
+
else:
|
| 203 |
+
demucs_model = demucs
|
| 204 |
+
demucs = True
|
| 205 |
+
else:
|
| 206 |
+
demucs_model = None
|
| 207 |
+
|
| 208 |
+
def get_input_sr():
|
| 209 |
+
nonlocal input_sr
|
| 210 |
+
if not input_sr and isinstance(audio, (str, bytes)):
|
| 211 |
+
from .audio import get_samplerate
|
| 212 |
+
input_sr = get_samplerate(audio)
|
| 213 |
+
return input_sr
|
| 214 |
+
|
| 215 |
+
if only_voice_freq:
|
| 216 |
+
from .audio import voice_freq_filter
|
| 217 |
+
if demucs_model is None:
|
| 218 |
+
curr_sr = model_sr or get_input_sr()
|
| 219 |
+
else:
|
| 220 |
+
curr_sr = demucs_model.samplerate
|
| 221 |
+
if model_sr is None:
|
| 222 |
+
model_sr = get_input_sr()
|
| 223 |
+
audio = load_audio(audio, sr=curr_sr, verbose=verbose, only_ffmpeg=only_ffmpeg)
|
| 224 |
+
audio = voice_freq_filter(audio, curr_sr)
|
| 225 |
+
|
| 226 |
+
if demucs:
|
| 227 |
+
from .audio import demucs_audio
|
| 228 |
+
if demucs_device is None:
|
| 229 |
+
demucs_device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 230 |
+
demucs_kwargs = dict(
|
| 231 |
+
audio=audio,
|
| 232 |
+
input_sr=curr_sr,
|
| 233 |
+
model=demucs_model,
|
| 234 |
+
save_path=demucs_output,
|
| 235 |
+
device=demucs_device,
|
| 236 |
+
verbose=verbose
|
| 237 |
+
)
|
| 238 |
+
demucs_kwargs.update(demucs_options or {})
|
| 239 |
+
audio = demucs_audio(
|
| 240 |
+
**demucs_kwargs
|
| 241 |
+
)
|
| 242 |
+
curr_sr = demucs_model.samplerate
|
| 243 |
+
if demucs_output and audio_type == 'str':
|
| 244 |
+
audio = demucs_output
|
| 245 |
+
|
| 246 |
+
final_audio = audio
|
| 247 |
+
|
| 248 |
+
if model_sr is not None:
|
| 249 |
+
|
| 250 |
+
if curr_sr is None:
|
| 251 |
+
curr_sr = get_input_sr()
|
| 252 |
+
|
| 253 |
+
if curr_sr != model_sr:
|
| 254 |
+
if isinstance(final_audio, (str, bytes)):
|
| 255 |
+
final_audio = load_audio(
|
| 256 |
+
final_audio,
|
| 257 |
+
sr=model_sr,
|
| 258 |
+
verbose=verbose,
|
| 259 |
+
only_ffmpeg=only_ffmpeg
|
| 260 |
+
)
|
| 261 |
+
else:
|
| 262 |
+
if isinstance(final_audio, np.ndarray):
|
| 263 |
+
final_audio = torch.from_numpy(final_audio)
|
| 264 |
+
if isinstance(final_audio, torch.Tensor):
|
| 265 |
+
final_audio = torchaudio.functional.resample(
|
| 266 |
+
final_audio,
|
| 267 |
+
orig_freq=curr_sr,
|
| 268 |
+
new_freq=model_sr,
|
| 269 |
+
resampling_method="kaiser_window"
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
if audio_type in ('torch', 'numpy'):
|
| 273 |
+
|
| 274 |
+
if isinstance(final_audio, (str, bytes)):
|
| 275 |
+
final_audio = load_audio(
|
| 276 |
+
final_audio,
|
| 277 |
+
sr=model_sr,
|
| 278 |
+
verbose=verbose,
|
| 279 |
+
only_ffmpeg=only_ffmpeg
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
else:
|
| 283 |
+
if audio_type == 'torch':
|
| 284 |
+
if isinstance(final_audio, np.ndarray):
|
| 285 |
+
final_audio = torch.from_numpy(final_audio)
|
| 286 |
+
elif audio_type == 'numpy' and isinstance(final_audio, torch.Tensor):
|
| 287 |
+
final_audio = final_audio.cpu().numpy()
|
| 288 |
+
|
| 289 |
+
elif audio_type == 'str':
|
| 290 |
+
|
| 291 |
+
if isinstance(final_audio, (torch.Tensor, np.ndarray)):
|
| 292 |
+
if isinstance(final_audio, np.ndarray):
|
| 293 |
+
final_audio = torch.from_numpy(final_audio)
|
| 294 |
+
if final_audio.ndim < 2:
|
| 295 |
+
final_audio = final_audio[None]
|
| 296 |
+
torchaudio.save(temp_file, final_audio, model_sr)
|
| 297 |
+
final_audio = temp_audio_file = temp_file
|
| 298 |
+
|
| 299 |
+
elif isinstance(final_audio, bytes):
|
| 300 |
+
with open(temp_file, 'wb') as f:
|
| 301 |
+
f.write(final_audio)
|
| 302 |
+
final_audio = temp_audio_file = temp_file
|
| 303 |
+
|
| 304 |
+
else: # audio_type == 'byte'
|
| 305 |
+
|
| 306 |
+
if isinstance(final_audio, (torch.Tensor, np.ndarray)):
|
| 307 |
+
if isinstance(final_audio, np.ndarray):
|
| 308 |
+
final_audio = torch.from_numpy(final_audio)
|
| 309 |
+
if final_audio.ndim < 2:
|
| 310 |
+
final_audio = final_audio[None]
|
| 311 |
+
with io.BytesIO() as f:
|
| 312 |
+
torchaudio.save(f, final_audio, model_sr, format="wav")
|
| 313 |
+
f.seek(0)
|
| 314 |
+
final_audio = f.read()
|
| 315 |
+
|
| 316 |
+
elif isinstance(final_audio, str):
|
| 317 |
+
with open(final_audio, 'rb') as f:
|
| 318 |
+
final_audio = f.read()
|
| 319 |
+
|
| 320 |
+
inference_kwargs['audio'] = final_audio
|
| 321 |
+
|
| 322 |
+
result = None
|
| 323 |
+
try:
|
| 324 |
+
result = inference_func(**inference_kwargs)
|
| 325 |
+
if not isinstance(result, WhisperResult):
|
| 326 |
+
result = WhisperResult(result, force_order=force_order, check_sorted=check_sorted)
|
| 327 |
+
if suppress_silence:
|
| 328 |
+
result.adjust_by_silence(
|
| 329 |
+
audio, vad,
|
| 330 |
+
vad_onnx=vad_onnx, vad_threshold=vad_threshold,
|
| 331 |
+
q_levels=q_levels, k_size=k_size,
|
| 332 |
+
sample_rate=curr_sr, min_word_dur=min_word_dur,
|
| 333 |
+
word_level=suppress_word_ts, verbose=True,
|
| 334 |
+
nonspeech_error=nonspeech_error,
|
| 335 |
+
use_word_position=use_word_position
|
| 336 |
+
)
|
| 337 |
+
|
| 338 |
+
if result.has_words and regroup:
|
| 339 |
+
result.regroup(regroup)
|
| 340 |
+
|
| 341 |
+
finally:
|
| 342 |
+
if temp_audio_file is not None:
|
| 343 |
+
try:
|
| 344 |
+
os.unlink(temp_audio_file)
|
| 345 |
+
except Exception as e:
|
| 346 |
+
warnings.warn(f'Failed to remove temporary audio file {temp_audio_file}. {e}')
|
| 347 |
+
|
| 348 |
+
return result
|
stable_whisper/quantization.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from whisper.model import Linear, Conv1d, LayerNorm, Whisper
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def replace_modules(model: nn.Module, only_linear: bool = False):
|
| 7 |
+
"""
|
| 8 |
+
Replace ``Linear``/``Conv1d``/``LayerNorm`` from :class:`whisper.model` with equivalent module in
|
| 9 |
+
:class:`torch.nn`.
|
| 10 |
+
"""
|
| 11 |
+
for m in model.__dict__.get('_modules', []):
|
| 12 |
+
module = model.__getattr__(m)
|
| 13 |
+
update = True
|
| 14 |
+
if isinstance(module, Linear):
|
| 15 |
+
model.__setattr__(m, nn.Linear(module.in_features, module.out_features,
|
| 16 |
+
bias=module.bias is not None))
|
| 17 |
+
elif not only_linear and isinstance(module, Conv1d):
|
| 18 |
+
model.__setattr__(m, nn.Conv1d(module.in_channels, module.out_channels,
|
| 19 |
+
kernel_size=module.kernel_size,
|
| 20 |
+
stride=module.stride,
|
| 21 |
+
padding=module.padding,
|
| 22 |
+
bias=module.bias is not None))
|
| 23 |
+
elif not only_linear and isinstance(module, LayerNorm):
|
| 24 |
+
model.__setattr__(m, nn.LayerNorm(module.normalized_shape[0]))
|
| 25 |
+
else:
|
| 26 |
+
update = False
|
| 27 |
+
replace_modules(module)
|
| 28 |
+
|
| 29 |
+
if update:
|
| 30 |
+
model.__getattr__(m).load_state_dict(module.state_dict())
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def ptdq_linear(model: "Whisper"):
|
| 34 |
+
"""
|
| 35 |
+
Apply Dynamic Quantization to instance of :class:`whisper.model.Whisper`.
|
| 36 |
+
"""
|
| 37 |
+
model.cpu()
|
| 38 |
+
replace_modules(model, only_linear=True)
|
| 39 |
+
torch.quantization.quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8, inplace=True)
|
| 40 |
+
setattr(model, 'dq', True)
|
stable_whisper/result.py
ADDED
|
@@ -0,0 +1,2281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
import re
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from typing import Union, List, Tuple, Optional, Callable
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
from copy import deepcopy
|
| 8 |
+
from itertools import chain
|
| 9 |
+
|
| 10 |
+
from .stabilization import suppress_silence, get_vad_silence_func, mask2timing, wav2mask
|
| 11 |
+
from .text_output import *
|
| 12 |
+
from .utils import str_to_valid_type, format_timestamp, UnsortedException
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
__all__ = ['WhisperResult', 'Segment']
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _combine_attr(obj: object, other_obj: object, attr: str):
|
| 19 |
+
if (val := getattr(obj, attr)) is not None:
|
| 20 |
+
other_val = getattr(other_obj, attr)
|
| 21 |
+
if isinstance(val, list):
|
| 22 |
+
if other_val is None:
|
| 23 |
+
setattr(obj, attr, None)
|
| 24 |
+
else:
|
| 25 |
+
val.extend(other_val)
|
| 26 |
+
else:
|
| 27 |
+
new_val = None if other_val is None else ((val + other_val) / 2)
|
| 28 |
+
setattr(obj, attr, new_val)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def _increment_attr(obj: object, attr: str, val: Union[int, float]):
|
| 32 |
+
if (curr_val := getattr(obj, attr, None)) is not None:
|
| 33 |
+
setattr(obj, attr, curr_val + val)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
@dataclass
|
| 37 |
+
class WordTiming:
|
| 38 |
+
word: str
|
| 39 |
+
start: float
|
| 40 |
+
end: float
|
| 41 |
+
probability: float = None
|
| 42 |
+
tokens: List[int] = None
|
| 43 |
+
left_locked: bool = False
|
| 44 |
+
right_locked: bool = False
|
| 45 |
+
segment_id: Optional[int] = None
|
| 46 |
+
id: Optional[int] = None
|
| 47 |
+
|
| 48 |
+
def __len__(self):
|
| 49 |
+
return len(self.word)
|
| 50 |
+
|
| 51 |
+
def __add__(self, other: 'WordTiming'):
|
| 52 |
+
self_copy = deepcopy(self)
|
| 53 |
+
|
| 54 |
+
self_copy.start = min(self_copy.start, other.start)
|
| 55 |
+
self_copy.end = max(other.end, self_copy.end)
|
| 56 |
+
self_copy.word += other.word
|
| 57 |
+
self_copy.left_locked = self_copy.left_locked or other.left_locked
|
| 58 |
+
self_copy.right_locked = self_copy.right_locked or other.right_locked
|
| 59 |
+
_combine_attr(self_copy, other, 'probability')
|
| 60 |
+
_combine_attr(self_copy, other, 'tokens')
|
| 61 |
+
|
| 62 |
+
return self_copy
|
| 63 |
+
|
| 64 |
+
def __deepcopy__(self, memo=None):
|
| 65 |
+
return self.copy()
|
| 66 |
+
|
| 67 |
+
def copy(self):
|
| 68 |
+
return WordTiming(
|
| 69 |
+
word=self.word,
|
| 70 |
+
start=self.start,
|
| 71 |
+
end=self.end,
|
| 72 |
+
probability=self.probability,
|
| 73 |
+
tokens=None if self.tokens is None else self.tokens.copy(),
|
| 74 |
+
left_locked=self.left_locked,
|
| 75 |
+
right_locked=self.right_locked,
|
| 76 |
+
segment_id=self.segment_id,
|
| 77 |
+
id=self.id
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
@property
|
| 81 |
+
def duration(self):
|
| 82 |
+
return round(self.end - self.start, 3)
|
| 83 |
+
|
| 84 |
+
def round_all_timestamps(self):
|
| 85 |
+
self.start = round(self.start, 3)
|
| 86 |
+
self.end = round(self.end, 3)
|
| 87 |
+
|
| 88 |
+
def offset_time(self, offset_seconds: float):
|
| 89 |
+
self.start = round(self.start + offset_seconds, 3)
|
| 90 |
+
self.end = round(self.end + offset_seconds, 3)
|
| 91 |
+
|
| 92 |
+
def to_dict(self):
|
| 93 |
+
dict_ = deepcopy(self).__dict__
|
| 94 |
+
dict_.pop('left_locked')
|
| 95 |
+
dict_.pop('right_locked')
|
| 96 |
+
return dict_
|
| 97 |
+
|
| 98 |
+
def lock_left(self):
|
| 99 |
+
self.left_locked = True
|
| 100 |
+
|
| 101 |
+
def lock_right(self):
|
| 102 |
+
self.right_locked = True
|
| 103 |
+
|
| 104 |
+
def lock_both(self):
|
| 105 |
+
self.lock_left()
|
| 106 |
+
self.lock_right()
|
| 107 |
+
|
| 108 |
+
def unlock_both(self):
|
| 109 |
+
self.left_locked = False
|
| 110 |
+
self.right_locked = False
|
| 111 |
+
|
| 112 |
+
def suppress_silence(self,
|
| 113 |
+
silent_starts: np.ndarray,
|
| 114 |
+
silent_ends: np.ndarray,
|
| 115 |
+
min_word_dur: float = 0.1,
|
| 116 |
+
nonspeech_error: float = 0.3,
|
| 117 |
+
keep_end: Optional[bool] = True):
|
| 118 |
+
suppress_silence(self, silent_starts, silent_ends, min_word_dur, nonspeech_error, keep_end)
|
| 119 |
+
return self
|
| 120 |
+
|
| 121 |
+
def rescale_time(self, scale_factor: float):
|
| 122 |
+
self.start = round(self.start * scale_factor, 3)
|
| 123 |
+
self.end = round(self.end * scale_factor, 3)
|
| 124 |
+
|
| 125 |
+
def clamp_max(self, max_dur: float, clip_start: bool = False, verbose: bool = False):
|
| 126 |
+
if self.duration > max_dur:
|
| 127 |
+
if clip_start:
|
| 128 |
+
new_start = round(self.end - max_dur, 3)
|
| 129 |
+
if verbose:
|
| 130 |
+
print(f'Start: {self.start} -> {new_start}\nEnd: {self.end}\nText:"{self.word}"\n')
|
| 131 |
+
self.start = new_start
|
| 132 |
+
|
| 133 |
+
else:
|
| 134 |
+
new_end = round(self.start + max_dur, 3)
|
| 135 |
+
if verbose:
|
| 136 |
+
print(f'Start: {self.start}\nEnd: {self.end} -> {new_end}\nText:"{self.word}"\n')
|
| 137 |
+
self.end = new_end
|
| 138 |
+
|
| 139 |
+
def set_segment(self, segment: 'Segment'):
|
| 140 |
+
self._segment = segment
|
| 141 |
+
|
| 142 |
+
def get_segment(self) -> Union['Segment', None]:
|
| 143 |
+
"""
|
| 144 |
+
Return instance of :class:`stable_whisper.result.Segment` that this instance is a part of.
|
| 145 |
+
"""
|
| 146 |
+
return getattr(self, '_segment', None)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def _words_by_lock(words: List[WordTiming], only_text: bool = False, include_single: bool = False):
|
| 150 |
+
"""
|
| 151 |
+
Return a nested list of words such that each sublist contains words that are locked together.
|
| 152 |
+
"""
|
| 153 |
+
all_words = []
|
| 154 |
+
for word in words:
|
| 155 |
+
if len(all_words) == 0 or not (all_words[-1][-1].right_locked or word.left_locked):
|
| 156 |
+
all_words.append([word])
|
| 157 |
+
else:
|
| 158 |
+
all_words[-1].append(word)
|
| 159 |
+
if only_text:
|
| 160 |
+
all_words = list(map(lambda ws: list(map(lambda w: w.word, ws)), all_words))
|
| 161 |
+
if not include_single:
|
| 162 |
+
all_words = [ws for ws in all_words if len(ws) > 1]
|
| 163 |
+
return all_words
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
@dataclass
|
| 167 |
+
class Segment:
|
| 168 |
+
start: float
|
| 169 |
+
end: float
|
| 170 |
+
text: str
|
| 171 |
+
seek: float = None
|
| 172 |
+
tokens: List[int] = None
|
| 173 |
+
temperature: float = None
|
| 174 |
+
avg_logprob: float = None
|
| 175 |
+
compression_ratio: float = None
|
| 176 |
+
no_speech_prob: float = None
|
| 177 |
+
words: Union[List[WordTiming], List[dict]] = None
|
| 178 |
+
ori_has_words: bool = None
|
| 179 |
+
id: int = None
|
| 180 |
+
|
| 181 |
+
def __getitem__(self, index: int) -> WordTiming:
|
| 182 |
+
if self.words is None:
|
| 183 |
+
raise ValueError('segment contains no words')
|
| 184 |
+
return self.words[index]
|
| 185 |
+
|
| 186 |
+
def __delitem__(self, index: int):
|
| 187 |
+
if self.words is None:
|
| 188 |
+
raise ValueError('segment contains no words')
|
| 189 |
+
del self.words[index]
|
| 190 |
+
self.reassign_ids()
|
| 191 |
+
self.update_seg_with_words()
|
| 192 |
+
|
| 193 |
+
def __deepcopy__(self, memo=None):
|
| 194 |
+
return self.copy()
|
| 195 |
+
|
| 196 |
+
def copy(self, new_words: Optional[List[WordTiming]] = None):
|
| 197 |
+
if new_words is None:
|
| 198 |
+
words = None if self.words is None else [w.copy() for w in self.words]
|
| 199 |
+
else:
|
| 200 |
+
words = [w.copy() for w in new_words]
|
| 201 |
+
|
| 202 |
+
new_seg = Segment(
|
| 203 |
+
start=self.start,
|
| 204 |
+
end=self.end,
|
| 205 |
+
text=self.text,
|
| 206 |
+
seek=self.seek,
|
| 207 |
+
tokens=self.tokens,
|
| 208 |
+
temperature=self.temperature,
|
| 209 |
+
avg_logprob=self.avg_logprob,
|
| 210 |
+
compression_ratio=self.compression_ratio,
|
| 211 |
+
no_speech_prob=self.no_speech_prob,
|
| 212 |
+
words=words,
|
| 213 |
+
id=self.id
|
| 214 |
+
)
|
| 215 |
+
new_seg.update_seg_with_words()
|
| 216 |
+
return new_seg
|
| 217 |
+
|
| 218 |
+
def to_display_str(self, only_segment: bool = False):
|
| 219 |
+
line = f'[{format_timestamp(self.start)} --> {format_timestamp(self.end)}] "{self.text}"'
|
| 220 |
+
if self.has_words and not only_segment:
|
| 221 |
+
line += '\n' + '\n'.join(
|
| 222 |
+
f"-[{format_timestamp(w.start)}] -> [{format_timestamp(w.end)}] \"{w.word}\"" for w in self.words
|
| 223 |
+
) + '\n'
|
| 224 |
+
return line
|
| 225 |
+
|
| 226 |
+
@property
|
| 227 |
+
def has_words(self):
|
| 228 |
+
return bool(self.words)
|
| 229 |
+
|
| 230 |
+
@property
|
| 231 |
+
def duration(self):
|
| 232 |
+
return self.end - self.start
|
| 233 |
+
|
| 234 |
+
def word_count(self):
|
| 235 |
+
if self.has_words:
|
| 236 |
+
return len(self.words)
|
| 237 |
+
return -1
|
| 238 |
+
|
| 239 |
+
def char_count(self):
|
| 240 |
+
if self.has_words:
|
| 241 |
+
return sum(len(w) for w in self.words)
|
| 242 |
+
return len(self.text)
|
| 243 |
+
|
| 244 |
+
def __post_init__(self):
|
| 245 |
+
if self.has_words:
|
| 246 |
+
self.words: List[WordTiming] = \
|
| 247 |
+
[WordTiming(**word) if isinstance(word, dict) else word for word in self.words]
|
| 248 |
+
for w in self.words:
|
| 249 |
+
w.set_segment(self)
|
| 250 |
+
if self.ori_has_words is None:
|
| 251 |
+
self.ori_has_words = self.has_words
|
| 252 |
+
self.round_all_timestamps()
|
| 253 |
+
|
| 254 |
+
def __add__(self, other: 'Segment'):
|
| 255 |
+
self_copy = deepcopy(self)
|
| 256 |
+
|
| 257 |
+
self_copy.start = min(self_copy.start, other.start)
|
| 258 |
+
self_copy.end = max(other.end, self_copy.end)
|
| 259 |
+
self_copy.text += other.text
|
| 260 |
+
|
| 261 |
+
_combine_attr(self_copy, other, 'tokens')
|
| 262 |
+
_combine_attr(self_copy, other, 'temperature')
|
| 263 |
+
_combine_attr(self_copy, other, 'avg_logprob')
|
| 264 |
+
_combine_attr(self_copy, other, 'compression_ratio')
|
| 265 |
+
_combine_attr(self_copy, other, 'no_speech_prob')
|
| 266 |
+
if self_copy.has_words:
|
| 267 |
+
if other.has_words:
|
| 268 |
+
self_copy.words.extend(other.words)
|
| 269 |
+
else:
|
| 270 |
+
self_copy.words = None
|
| 271 |
+
|
| 272 |
+
return self_copy
|
| 273 |
+
|
| 274 |
+
def _word_operations(self, operation: str, *args, **kwargs):
|
| 275 |
+
if self.has_words:
|
| 276 |
+
for w in self.words:
|
| 277 |
+
getattr(w, operation)(*args, **kwargs)
|
| 278 |
+
|
| 279 |
+
def round_all_timestamps(self):
|
| 280 |
+
self.start = round(self.start, 3)
|
| 281 |
+
self.end = round(self.end, 3)
|
| 282 |
+
if self.has_words:
|
| 283 |
+
for word in self.words:
|
| 284 |
+
word.round_all_timestamps()
|
| 285 |
+
|
| 286 |
+
def offset_time(self, offset_seconds: float):
|
| 287 |
+
self.start = round(self.start + offset_seconds, 3)
|
| 288 |
+
self.end = round(self.end + offset_seconds, 3)
|
| 289 |
+
_increment_attr(self, 'seek', offset_seconds)
|
| 290 |
+
self._word_operations('offset_time', offset_seconds)
|
| 291 |
+
|
| 292 |
+
def add_words(self, index0: int, index1: int, inplace: bool = False):
|
| 293 |
+
if self.has_words:
|
| 294 |
+
new_word = self.words[index0] + self.words[index1]
|
| 295 |
+
if inplace:
|
| 296 |
+
i0, i1 = sorted([index0, index1])
|
| 297 |
+
self.words[i0] = new_word
|
| 298 |
+
del self.words[i1]
|
| 299 |
+
return new_word
|
| 300 |
+
|
| 301 |
+
def rescale_time(self, scale_factor: float):
|
| 302 |
+
self.start = round(self.start * scale_factor, 3)
|
| 303 |
+
self.end = round(self.end * scale_factor, 3)
|
| 304 |
+
if self.seek is not None:
|
| 305 |
+
self.seek = round(self.seek * scale_factor, 3)
|
| 306 |
+
self._word_operations('rescale_time', scale_factor)
|
| 307 |
+
self.update_seg_with_words()
|
| 308 |
+
|
| 309 |
+
def apply_min_dur(self, min_dur: float, inplace: bool = False):
|
| 310 |
+
"""
|
| 311 |
+
Merge any word with adjacent word if its duration is less than ``min_dur``.
|
| 312 |
+
"""
|
| 313 |
+
segment = self if inplace else deepcopy(self)
|
| 314 |
+
if not self.has_words:
|
| 315 |
+
return segment
|
| 316 |
+
max_i = len(segment.words) - 1
|
| 317 |
+
if max_i == 0:
|
| 318 |
+
return segment
|
| 319 |
+
for i in reversed(range(len(segment.words))):
|
| 320 |
+
if max_i == 0:
|
| 321 |
+
break
|
| 322 |
+
if segment.words[i].duration < min_dur:
|
| 323 |
+
if i == max_i:
|
| 324 |
+
segment.add_words(i-1, i, inplace=True)
|
| 325 |
+
elif i == 0:
|
| 326 |
+
segment.add_words(i, i+1, inplace=True)
|
| 327 |
+
else:
|
| 328 |
+
if segment.words[i+1].duration < segment.words[i-1].duration:
|
| 329 |
+
segment.add_words(i-1, i, inplace=True)
|
| 330 |
+
else:
|
| 331 |
+
segment.add_words(i, i+1, inplace=True)
|
| 332 |
+
max_i -= 1
|
| 333 |
+
return segment
|
| 334 |
+
|
| 335 |
+
def _to_reverse_text(
|
| 336 |
+
self,
|
| 337 |
+
prepend_punctuations: str = None,
|
| 338 |
+
append_punctuations: str = None
|
| 339 |
+
):
|
| 340 |
+
"""
|
| 341 |
+
Return a copy with words reversed order per segment.
|
| 342 |
+
"""
|
| 343 |
+
if prepend_punctuations is None:
|
| 344 |
+
prepend_punctuations = "\"'“¿([{-"
|
| 345 |
+
if prepend_punctuations and ' ' not in prepend_punctuations:
|
| 346 |
+
prepend_punctuations += ' '
|
| 347 |
+
if append_punctuations is None:
|
| 348 |
+
append_punctuations = "\"'.。,,!!??::”)]}、"
|
| 349 |
+
self_copy = deepcopy(self)
|
| 350 |
+
has_prepend = bool(prepend_punctuations)
|
| 351 |
+
has_append = bool(append_punctuations)
|
| 352 |
+
if has_prepend or has_append:
|
| 353 |
+
word_objs = (
|
| 354 |
+
self_copy.words
|
| 355 |
+
if self_copy.has_words else
|
| 356 |
+
[WordTiming(w, 0, 1, 0) for w in self_copy.text.split(' ')]
|
| 357 |
+
)
|
| 358 |
+
for word in word_objs:
|
| 359 |
+
new_append = ''
|
| 360 |
+
if has_prepend:
|
| 361 |
+
for _ in range(len(word)):
|
| 362 |
+
char = word.word[0]
|
| 363 |
+
if char in prepend_punctuations:
|
| 364 |
+
new_append += char
|
| 365 |
+
word.word = word.word[1:]
|
| 366 |
+
else:
|
| 367 |
+
break
|
| 368 |
+
new_prepend = ''
|
| 369 |
+
if has_append:
|
| 370 |
+
for _ in range(len(word)):
|
| 371 |
+
char = word.word[-1]
|
| 372 |
+
if char in append_punctuations:
|
| 373 |
+
new_prepend += char
|
| 374 |
+
word.word = word.word[:-1]
|
| 375 |
+
else:
|
| 376 |
+
break
|
| 377 |
+
word.word = f'{new_prepend}{word.word}{new_append[::-1]}'
|
| 378 |
+
self_copy.text = ''.join(w.word for w in reversed(word_objs))
|
| 379 |
+
|
| 380 |
+
return self_copy
|
| 381 |
+
|
| 382 |
+
def to_dict(self, reverse_text: Union[bool, tuple] = False):
|
| 383 |
+
if reverse_text:
|
| 384 |
+
seg_dict = (
|
| 385 |
+
(self._to_reverse_text(*reverse_text)
|
| 386 |
+
if isinstance(reverse_text, tuple) else
|
| 387 |
+
self._to_reverse_text()).__dict__
|
| 388 |
+
)
|
| 389 |
+
else:
|
| 390 |
+
seg_dict = deepcopy(self).__dict__
|
| 391 |
+
seg_dict.pop('ori_has_words')
|
| 392 |
+
if self.has_words:
|
| 393 |
+
seg_dict['words'] = [w.to_dict() for w in seg_dict['words']]
|
| 394 |
+
elif self.ori_has_words:
|
| 395 |
+
seg_dict['words'] = []
|
| 396 |
+
else:
|
| 397 |
+
seg_dict.pop('words')
|
| 398 |
+
if self.id is None:
|
| 399 |
+
seg_dict.pop('id')
|
| 400 |
+
if reverse_text:
|
| 401 |
+
seg_dict['reversed_text'] = True
|
| 402 |
+
return seg_dict
|
| 403 |
+
|
| 404 |
+
def words_by_lock(self, only_text: bool = True, include_single: bool = False):
|
| 405 |
+
return _words_by_lock(self.words, only_text=only_text, include_single=include_single)
|
| 406 |
+
|
| 407 |
+
@property
|
| 408 |
+
def left_locked(self):
|
| 409 |
+
if self.has_words:
|
| 410 |
+
return self.words[0].left_locked
|
| 411 |
+
return False
|
| 412 |
+
|
| 413 |
+
@property
|
| 414 |
+
def right_locked(self):
|
| 415 |
+
if self.has_words:
|
| 416 |
+
return self.words[-1].right_locked
|
| 417 |
+
return False
|
| 418 |
+
|
| 419 |
+
def lock_left(self):
|
| 420 |
+
if self.has_words:
|
| 421 |
+
self.words[0].lock_left()
|
| 422 |
+
|
| 423 |
+
def lock_right(self):
|
| 424 |
+
if self.has_words:
|
| 425 |
+
self.words[-1].lock_right()
|
| 426 |
+
|
| 427 |
+
def lock_both(self):
|
| 428 |
+
self.lock_left()
|
| 429 |
+
self.lock_right()
|
| 430 |
+
|
| 431 |
+
def unlock_all_words(self):
|
| 432 |
+
self._word_operations('unlock_both')
|
| 433 |
+
|
| 434 |
+
def reassign_ids(self):
|
| 435 |
+
if self.has_words:
|
| 436 |
+
for i, w in enumerate(self.words):
|
| 437 |
+
w.segment_id = self.id
|
| 438 |
+
w.id = i
|
| 439 |
+
|
| 440 |
+
def update_seg_with_words(self):
|
| 441 |
+
if self.has_words:
|
| 442 |
+
self.start = self.words[0].start
|
| 443 |
+
self.end = self.words[-1].end
|
| 444 |
+
self.text = ''.join(w.word for w in self.words)
|
| 445 |
+
self.tokens = (
|
| 446 |
+
None
|
| 447 |
+
if any(w.tokens is None for w in self.words) else
|
| 448 |
+
[t for w in self.words for t in w.tokens]
|
| 449 |
+
)
|
| 450 |
+
for w in self.words:
|
| 451 |
+
w.set_segment(self)
|
| 452 |
+
|
| 453 |
+
def suppress_silence(self,
|
| 454 |
+
silent_starts: np.ndarray,
|
| 455 |
+
silent_ends: np.ndarray,
|
| 456 |
+
min_word_dur: float = 0.1,
|
| 457 |
+
word_level: bool = True,
|
| 458 |
+
nonspeech_error: float = 0.3,
|
| 459 |
+
use_word_position: bool = True):
|
| 460 |
+
if self.has_words:
|
| 461 |
+
words = self.words if word_level or len(self.words) == 1 else [self.words[0], self.words[-1]]
|
| 462 |
+
for i, w in enumerate(words, 1):
|
| 463 |
+
if use_word_position:
|
| 464 |
+
keep_end = True if i == 1 else (False if i == len(words) else None)
|
| 465 |
+
else:
|
| 466 |
+
keep_end = None
|
| 467 |
+
w.suppress_silence(silent_starts, silent_ends, min_word_dur, nonspeech_error, keep_end)
|
| 468 |
+
self.update_seg_with_words()
|
| 469 |
+
else:
|
| 470 |
+
suppress_silence(self,
|
| 471 |
+
silent_starts,
|
| 472 |
+
silent_ends,
|
| 473 |
+
min_word_dur,
|
| 474 |
+
nonspeech_error)
|
| 475 |
+
|
| 476 |
+
return self
|
| 477 |
+
|
| 478 |
+
def get_locked_indices(self):
|
| 479 |
+
locked_indices = [i
|
| 480 |
+
for i, (left, right) in enumerate(zip(self.words[1:], self.words[:-1]))
|
| 481 |
+
if left.left_locked or right.right_locked]
|
| 482 |
+
return locked_indices
|
| 483 |
+
|
| 484 |
+
def get_gaps(self, as_ndarray=False):
|
| 485 |
+
if self.has_words:
|
| 486 |
+
s_ts = np.array([w.start for w in self.words])
|
| 487 |
+
e_ts = np.array([w.end for w in self.words])
|
| 488 |
+
gap = s_ts[1:] - e_ts[:-1]
|
| 489 |
+
return gap if as_ndarray else gap.tolist()
|
| 490 |
+
return []
|
| 491 |
+
|
| 492 |
+
def get_gap_indices(self, max_gap: float = 0.1): # for splitting
|
| 493 |
+
if not self.has_words or len(self.words) < 2:
|
| 494 |
+
return []
|
| 495 |
+
if max_gap is None:
|
| 496 |
+
max_gap = 0
|
| 497 |
+
indices = (self.get_gaps(True) > max_gap).nonzero()[0].tolist()
|
| 498 |
+
return sorted(set(indices) - set(self.get_locked_indices()))
|
| 499 |
+
|
| 500 |
+
def get_punctuation_indices(self, punctuation: Union[List[str], List[Tuple[str, str]], str]): # for splitting
|
| 501 |
+
if not self.has_words or len(self.words) < 2:
|
| 502 |
+
return []
|
| 503 |
+
if isinstance(punctuation, str):
|
| 504 |
+
punctuation = [punctuation]
|
| 505 |
+
indices = []
|
| 506 |
+
for p in punctuation:
|
| 507 |
+
if isinstance(p, str):
|
| 508 |
+
for i, s in enumerate(self.words[:-1]):
|
| 509 |
+
if s.word.endswith(p):
|
| 510 |
+
indices.append(i)
|
| 511 |
+
elif i != 0 and s.word.startswith(p):
|
| 512 |
+
indices.append(i-1)
|
| 513 |
+
else:
|
| 514 |
+
ending, beginning = p
|
| 515 |
+
indices.extend([i for i, (w0, w1) in enumerate(zip(self.words[:-1], self.words[1:]))
|
| 516 |
+
if w0.word.endswith(ending) and w1.word.startswith(beginning)])
|
| 517 |
+
|
| 518 |
+
return sorted(set(indices) - set(self.get_locked_indices()))
|
| 519 |
+
|
| 520 |
+
def get_length_indices(self, max_chars: int = None, max_words: int = None, even_split: bool = True,
|
| 521 |
+
include_lock: bool = False):
|
| 522 |
+
# for splitting
|
| 523 |
+
if not self.has_words or (max_chars is None and max_words is None):
|
| 524 |
+
return []
|
| 525 |
+
assert max_chars != 0 and max_words != 0, \
|
| 526 |
+
f'max_chars and max_words must be greater 0, but got {max_chars} and {max_words}'
|
| 527 |
+
if len(self.words) < 2:
|
| 528 |
+
return []
|
| 529 |
+
indices = []
|
| 530 |
+
if even_split:
|
| 531 |
+
char_count = -1 if max_chars is None else sum(map(len, self.words))
|
| 532 |
+
word_count = -1 if max_words is None else len(self.words)
|
| 533 |
+
exceed_chars = max_chars is not None and char_count > max_chars
|
| 534 |
+
exceed_words = max_words is not None and word_count > max_words
|
| 535 |
+
if exceed_chars:
|
| 536 |
+
splits = np.ceil(char_count / max_chars)
|
| 537 |
+
chars_per_split = char_count / splits
|
| 538 |
+
cum_char_count = np.cumsum([len(w.word) for w in self.words[:-1]])
|
| 539 |
+
indices = [
|
| 540 |
+
(np.abs(cum_char_count-(i*chars_per_split))).argmin()
|
| 541 |
+
for i in range(1, int(splits))
|
| 542 |
+
]
|
| 543 |
+
if max_words is not None:
|
| 544 |
+
exceed_words = any(j-i+1 > max_words for i, j in zip([0]+indices, indices+[len(self.words)]))
|
| 545 |
+
|
| 546 |
+
if exceed_words:
|
| 547 |
+
splits = np.ceil(word_count / max_words)
|
| 548 |
+
words_per_split = word_count / splits
|
| 549 |
+
cum_word_count = np.array(range(1, len(self.words)+1))
|
| 550 |
+
indices = [
|
| 551 |
+
np.abs(cum_word_count-(i*words_per_split)).argmin()
|
| 552 |
+
for i in range(1, int(splits))
|
| 553 |
+
]
|
| 554 |
+
|
| 555 |
+
else:
|
| 556 |
+
curr_words = 0
|
| 557 |
+
curr_chars = 0
|
| 558 |
+
locked_indices = []
|
| 559 |
+
if include_lock:
|
| 560 |
+
locked_indices = self.get_locked_indices()
|
| 561 |
+
for i, word in enumerate(self.words):
|
| 562 |
+
curr_words += 1
|
| 563 |
+
curr_chars += len(word)
|
| 564 |
+
if i != 0:
|
| 565 |
+
if (
|
| 566 |
+
max_chars is not None and curr_chars > max_chars
|
| 567 |
+
or
|
| 568 |
+
max_words is not None and curr_words > max_words
|
| 569 |
+
) and i-1 not in locked_indices:
|
| 570 |
+
indices.append(i-1)
|
| 571 |
+
curr_words = 1
|
| 572 |
+
curr_chars = len(word)
|
| 573 |
+
return indices
|
| 574 |
+
|
| 575 |
+
def get_duration_indices(self, max_dur: float, even_split: bool = True, include_lock: bool = False):
|
| 576 |
+
if not self.has_words or (total_duration := np.sum([w.duration for w in self.words])) <= max_dur:
|
| 577 |
+
return []
|
| 578 |
+
if even_split:
|
| 579 |
+
splits = np.ceil(total_duration / max_dur)
|
| 580 |
+
dur_per_split = total_duration / splits
|
| 581 |
+
cum_dur = np.cumsum([w.duration for w in self.words[:-1]])
|
| 582 |
+
indices = [
|
| 583 |
+
(np.abs(cum_dur - (i * dur_per_split))).argmin()
|
| 584 |
+
for i in range(1, int(splits))
|
| 585 |
+
]
|
| 586 |
+
else:
|
| 587 |
+
indices = []
|
| 588 |
+
curr_total_dur = 0.0
|
| 589 |
+
locked_indices = self.get_locked_indices() if include_lock else []
|
| 590 |
+
for i, word in enumerate(self.words):
|
| 591 |
+
curr_total_dur += word.duration
|
| 592 |
+
if i != 0:
|
| 593 |
+
if curr_total_dur > max_dur and i - 1 not in locked_indices:
|
| 594 |
+
indices.append(i - 1)
|
| 595 |
+
curr_total_dur = word.duration
|
| 596 |
+
return indices
|
| 597 |
+
|
| 598 |
+
def split(self, indices: List[int]):
|
| 599 |
+
if len(indices) == 0:
|
| 600 |
+
return []
|
| 601 |
+
if indices[-1] != len(self.words) - 1:
|
| 602 |
+
indices.append(len(self.words) - 1)
|
| 603 |
+
seg_copies = []
|
| 604 |
+
prev_i = 0
|
| 605 |
+
for i in indices:
|
| 606 |
+
i += 1
|
| 607 |
+
c = deepcopy(self)
|
| 608 |
+
c.words = c.words[prev_i:i]
|
| 609 |
+
c.update_seg_with_words()
|
| 610 |
+
seg_copies.append(c)
|
| 611 |
+
prev_i = i
|
| 612 |
+
return seg_copies
|
| 613 |
+
|
| 614 |
+
def set_result(self, result: 'WhisperResult'):
|
| 615 |
+
self._result = result
|
| 616 |
+
|
| 617 |
+
def get_result(self) -> Union['WhisperResult', None]:
|
| 618 |
+
"""
|
| 619 |
+
Return outer instance of :class:`stable_whisper.result.WhisperResult` that ``self`` is a part of.
|
| 620 |
+
"""
|
| 621 |
+
return getattr(self, '_result', None)
|
| 622 |
+
|
| 623 |
+
|
| 624 |
+
class WhisperResult:
|
| 625 |
+
|
| 626 |
+
def __init__(
|
| 627 |
+
self,
|
| 628 |
+
result: Union[str, dict, list],
|
| 629 |
+
force_order: bool = False,
|
| 630 |
+
check_sorted: Union[bool, str] = True,
|
| 631 |
+
show_unsorted: bool = True
|
| 632 |
+
):
|
| 633 |
+
result, self.path = self._standardize_result(result)
|
| 634 |
+
self.ori_dict = result.get('ori_dict') or result
|
| 635 |
+
self.language = self.ori_dict.get('language')
|
| 636 |
+
self._regroup_history = result.get('regroup_history', '')
|
| 637 |
+
self._nonspeech_sections = result.get('nonspeech_sections', [])
|
| 638 |
+
segments = deepcopy(result.get('segments', self.ori_dict.get('segments')))
|
| 639 |
+
self.segments: List[Segment] = [Segment(**s) for s in segments] if segments else []
|
| 640 |
+
self._forced_order = force_order
|
| 641 |
+
if self._forced_order:
|
| 642 |
+
self.force_order()
|
| 643 |
+
self.raise_for_unsorted(check_sorted, show_unsorted)
|
| 644 |
+
self.remove_no_word_segments(any(seg.has_words for seg in self.segments))
|
| 645 |
+
self.update_all_segs_with_words()
|
| 646 |
+
|
| 647 |
+
def __getitem__(self, index: int) -> Segment:
|
| 648 |
+
return self.segments[index]
|
| 649 |
+
|
| 650 |
+
def __delitem__(self, index: int):
|
| 651 |
+
del self.segments[index]
|
| 652 |
+
self.reassign_ids(True)
|
| 653 |
+
|
| 654 |
+
@staticmethod
|
| 655 |
+
def _standardize_result(result: Union[str, dict, list]):
|
| 656 |
+
path = None
|
| 657 |
+
if isinstance(result, str):
|
| 658 |
+
path = result
|
| 659 |
+
result = load_result(path)
|
| 660 |
+
if isinstance(result, list):
|
| 661 |
+
if isinstance(result[0], list):
|
| 662 |
+
if not isinstance(result[0][0], dict):
|
| 663 |
+
raise NotImplementedError(f'Got list of list of {type(result[0])} but expects list of list of dict')
|
| 664 |
+
result = dict(
|
| 665 |
+
segments=[
|
| 666 |
+
dict(
|
| 667 |
+
start=words[0]['start'],
|
| 668 |
+
end=words[-1]['end'],
|
| 669 |
+
text=''.join(w['word'] for w in words),
|
| 670 |
+
words=words
|
| 671 |
+
)
|
| 672 |
+
for words in result
|
| 673 |
+
]
|
| 674 |
+
)
|
| 675 |
+
|
| 676 |
+
elif isinstance(result[0], dict):
|
| 677 |
+
result = dict(segments=result)
|
| 678 |
+
else:
|
| 679 |
+
raise NotImplementedError(f'Got list of {type(result[0])} but expects list of list/dict')
|
| 680 |
+
return result, path
|
| 681 |
+
|
| 682 |
+
def force_order(self):
|
| 683 |
+
prev_ts_end = 0
|
| 684 |
+
timestamps = self.all_words_or_segments()
|
| 685 |
+
for i, ts in enumerate(timestamps, 1):
|
| 686 |
+
if ts.start < prev_ts_end:
|
| 687 |
+
ts.start = prev_ts_end
|
| 688 |
+
if ts.start > ts.end:
|
| 689 |
+
if prev_ts_end > ts.end:
|
| 690 |
+
warnings.warn('Multiple consecutive timestamps are out of order. Some parts will have no duration.')
|
| 691 |
+
ts.start = ts.end
|
| 692 |
+
for j in range(i-2, -1, -1):
|
| 693 |
+
if timestamps[j].end > ts.end:
|
| 694 |
+
timestamps[j].end = ts.end
|
| 695 |
+
if timestamps[j].start > ts.end:
|
| 696 |
+
timestamps[j].start = ts.end
|
| 697 |
+
else:
|
| 698 |
+
if ts.start != prev_ts_end:
|
| 699 |
+
ts.start = prev_ts_end
|
| 700 |
+
else:
|
| 701 |
+
ts.end = ts.start if i == len(timestamps) else timestamps[i].start
|
| 702 |
+
prev_ts_end = ts.end
|
| 703 |
+
if self.has_words:
|
| 704 |
+
self.update_all_segs_with_words()
|
| 705 |
+
|
| 706 |
+
def raise_for_unsorted(self, check_sorted: Union[bool, str] = True, show_unsorted: bool = True):
|
| 707 |
+
if check_sorted is False:
|
| 708 |
+
return
|
| 709 |
+
all_parts = self.all_words_or_segments()
|
| 710 |
+
has_words = self.has_words
|
| 711 |
+
timestamps = np.array(list(chain.from_iterable((p.start, p.end) for p in all_parts)))
|
| 712 |
+
if len(timestamps) > 1 and (unsorted_mask := timestamps[:-1] > timestamps[1:]).any():
|
| 713 |
+
if show_unsorted:
|
| 714 |
+
def get_part_info(idx):
|
| 715 |
+
curr_part = all_parts[idx]
|
| 716 |
+
seg_id = curr_part.segment_id if has_words else curr_part.id
|
| 717 |
+
word_id_str = f'Word ID: {curr_part.id}\n' if has_words else ''
|
| 718 |
+
return (
|
| 719 |
+
f'Segment ID: {seg_id}\n{word_id_str}'
|
| 720 |
+
f'Start: {curr_part.start}\nEnd: {curr_part.end}\n'
|
| 721 |
+
f'Text: "{curr_part.word if has_words else curr_part.text}"'
|
| 722 |
+
), curr_part.start, curr_part.end
|
| 723 |
+
|
| 724 |
+
for i, unsorted in enumerate(unsorted_mask, 2):
|
| 725 |
+
if unsorted:
|
| 726 |
+
word_id = i//2-1
|
| 727 |
+
part_info, start, end = get_part_info(word_id)
|
| 728 |
+
if i % 2 == 1:
|
| 729 |
+
next_info, next_start, _ = get_part_info(word_id+1)
|
| 730 |
+
part_info += f'\nConflict: end ({end}) > next start ({next_start})\n{next_info}'
|
| 731 |
+
else:
|
| 732 |
+
part_info += f'\nConflict: start ({start}) > end ({end})'
|
| 733 |
+
print(part_info, end='\n\n')
|
| 734 |
+
|
| 735 |
+
data = self.to_dict()
|
| 736 |
+
if check_sorted is True:
|
| 737 |
+
raise UnsortedException(data=data)
|
| 738 |
+
warnings.warn('Timestamps are not in ascending order. '
|
| 739 |
+
'If data is produced by Stable-ts, please submit an issue with the saved data.')
|
| 740 |
+
save_as_json(data, check_sorted)
|
| 741 |
+
|
| 742 |
+
def update_all_segs_with_words(self):
|
| 743 |
+
for seg in self.segments:
|
| 744 |
+
seg.update_seg_with_words()
|
| 745 |
+
seg.set_result(self)
|
| 746 |
+
|
| 747 |
+
def update_nonspeech_sections(self, silent_starts, silent_ends):
|
| 748 |
+
self._nonspeech_sections = [dict(start=s, end=e) for s, e in zip(silent_starts, silent_ends)]
|
| 749 |
+
|
| 750 |
+
def add_segments(self, index0: int, index1: int, inplace: bool = False, lock: bool = False):
|
| 751 |
+
new_seg = self.segments[index0] + self.segments[index1]
|
| 752 |
+
new_seg.update_seg_with_words()
|
| 753 |
+
if lock and self.segments[index0].has_words:
|
| 754 |
+
lock_idx = len(self.segments[index0].words)
|
| 755 |
+
new_seg.words[lock_idx - 1].lock_right()
|
| 756 |
+
if lock_idx < len(new_seg.words):
|
| 757 |
+
new_seg.words[lock_idx].lock_left()
|
| 758 |
+
if inplace:
|
| 759 |
+
i0, i1 = sorted([index0, index1])
|
| 760 |
+
self.segments[i0] = new_seg
|
| 761 |
+
del self.segments[i1]
|
| 762 |
+
return new_seg
|
| 763 |
+
|
| 764 |
+
def rescale_time(self, scale_factor: float):
|
| 765 |
+
for s in self.segments:
|
| 766 |
+
s.rescale_time(scale_factor)
|
| 767 |
+
|
| 768 |
+
def apply_min_dur(self, min_dur: float, inplace: bool = False):
|
| 769 |
+
"""
|
| 770 |
+
Merge any word/segment with adjacent word/segment if its duration is less than ``min_dur``.
|
| 771 |
+
"""
|
| 772 |
+
result = self if inplace else deepcopy(self)
|
| 773 |
+
max_i = len(result.segments) - 1
|
| 774 |
+
if max_i == 0:
|
| 775 |
+
return result
|
| 776 |
+
for i in reversed(range(len(result.segments))):
|
| 777 |
+
if max_i == 0:
|
| 778 |
+
break
|
| 779 |
+
if result.segments[i].duration < min_dur:
|
| 780 |
+
if i == max_i:
|
| 781 |
+
result.add_segments(i-1, i, inplace=True)
|
| 782 |
+
elif i == 0:
|
| 783 |
+
result.add_segments(i, i+1, inplace=True)
|
| 784 |
+
else:
|
| 785 |
+
if result.segments[i+1].duration < result.segments[i-1].duration:
|
| 786 |
+
result.add_segments(i-1, i, inplace=True)
|
| 787 |
+
else:
|
| 788 |
+
result.add_segments(i, i+1, inplace=True)
|
| 789 |
+
max_i -= 1
|
| 790 |
+
result.reassign_ids()
|
| 791 |
+
for s in result.segments:
|
| 792 |
+
s.apply_min_dur(min_dur, inplace=True)
|
| 793 |
+
return result
|
| 794 |
+
|
| 795 |
+
def offset_time(self, offset_seconds: float):
|
| 796 |
+
for s in self.segments:
|
| 797 |
+
s.offset_time(offset_seconds)
|
| 798 |
+
|
| 799 |
+
def suppress_silence(
|
| 800 |
+
self,
|
| 801 |
+
silent_starts: np.ndarray,
|
| 802 |
+
silent_ends: np.ndarray,
|
| 803 |
+
min_word_dur: float = 0.1,
|
| 804 |
+
word_level: bool = True,
|
| 805 |
+
nonspeech_error: float = 0.3,
|
| 806 |
+
use_word_position: bool = True
|
| 807 |
+
) -> "WhisperResult":
|
| 808 |
+
"""
|
| 809 |
+
Move any start/end timestamps in silence parts of audio to the boundaries of the silence.
|
| 810 |
+
|
| 811 |
+
Parameters
|
| 812 |
+
----------
|
| 813 |
+
silent_starts : numpy.ndarray
|
| 814 |
+
An array starting timestamps of silent sections of audio.
|
| 815 |
+
silent_ends : numpy.ndarray
|
| 816 |
+
An array ending timestamps of silent sections of audio.
|
| 817 |
+
min_word_dur : float, default 0.1
|
| 818 |
+
Shortest duration each word is allowed to reach for adjustments.
|
| 819 |
+
word_level : bool, default False
|
| 820 |
+
Whether to settings to word level timestamps.
|
| 821 |
+
nonspeech_error : float, default 0.3
|
| 822 |
+
Relative error of non-speech sections that appear in between a word for adjustments.
|
| 823 |
+
use_word_position : bool, default True
|
| 824 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 825 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 826 |
+
|
| 827 |
+
Returns
|
| 828 |
+
-------
|
| 829 |
+
stable_whisper.result.WhisperResult
|
| 830 |
+
The current instance after the changes.
|
| 831 |
+
"""
|
| 832 |
+
for s in self.segments:
|
| 833 |
+
s.suppress_silence(
|
| 834 |
+
silent_starts,
|
| 835 |
+
silent_ends,
|
| 836 |
+
min_word_dur,
|
| 837 |
+
word_level=word_level,
|
| 838 |
+
nonspeech_error=nonspeech_error,
|
| 839 |
+
use_word_position=use_word_position
|
| 840 |
+
)
|
| 841 |
+
|
| 842 |
+
return self
|
| 843 |
+
|
| 844 |
+
def adjust_by_silence(
|
| 845 |
+
self,
|
| 846 |
+
audio: Union[torch.Tensor, np.ndarray, str, bytes],
|
| 847 |
+
vad: bool = False,
|
| 848 |
+
*,
|
| 849 |
+
verbose: (bool, None) = False,
|
| 850 |
+
sample_rate: int = None,
|
| 851 |
+
vad_onnx: bool = False,
|
| 852 |
+
vad_threshold: float = 0.35,
|
| 853 |
+
q_levels: int = 20,
|
| 854 |
+
k_size: int = 5,
|
| 855 |
+
min_word_dur: float = 0.1,
|
| 856 |
+
word_level: bool = True,
|
| 857 |
+
nonspeech_error: float = 0.3,
|
| 858 |
+
use_word_position: bool = True
|
| 859 |
+
|
| 860 |
+
) -> "WhisperResult":
|
| 861 |
+
"""
|
| 862 |
+
Adjust timestamps base detected speech gaps.
|
| 863 |
+
|
| 864 |
+
This is method combines :meth:`stable_whisper.result.WhisperResult.suppress_silence` with silence detection.
|
| 865 |
+
|
| 866 |
+
Parameters
|
| 867 |
+
----------
|
| 868 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 869 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 870 |
+
vad : bool, default False
|
| 871 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 872 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 873 |
+
verbose : bool or None, default False
|
| 874 |
+
If ``False``, mute messages about hitting local caches. Note that the message about first download cannot be
|
| 875 |
+
muted. Only applies if ``vad = True``.
|
| 876 |
+
sample_rate : int, default None, meaning ``whisper.audio.SAMPLE_RATE``, 16kHZ
|
| 877 |
+
The sample rate of ``audio``.
|
| 878 |
+
vad_onnx : bool, default False
|
| 879 |
+
Whether to use ONNX for Silero VAD.
|
| 880 |
+
vad_threshold : float, default 0.35
|
| 881 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 882 |
+
q_levels : int, default 20
|
| 883 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 884 |
+
Acts as a threshold to marking sound as silent.
|
| 885 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 886 |
+
k_size : int, default 5
|
| 887 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 888 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 889 |
+
min_word_dur : float, default 0.1
|
| 890 |
+
Shortest duration each word is allowed to reach from adjustments.
|
| 891 |
+
word_level : bool, default False
|
| 892 |
+
Whether to settings to word level timestamps.
|
| 893 |
+
nonspeech_error : float, default 0.3
|
| 894 |
+
Relative error of non-speech sections that appear in between a word for adjustments.
|
| 895 |
+
use_word_position : bool, default True
|
| 896 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 897 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 898 |
+
|
| 899 |
+
Returns
|
| 900 |
+
-------
|
| 901 |
+
stable_whisper.result.WhisperResult
|
| 902 |
+
The current instance after the changes.
|
| 903 |
+
|
| 904 |
+
Notes
|
| 905 |
+
-----
|
| 906 |
+
This operation is already performed by :func:`stable_whisper.whisper_word_level.transcribe_stable` /
|
| 907 |
+
:func:`stable_whisper.whisper_word_level.transcribe_minimal`/
|
| 908 |
+
:func:`stable_whisper.non_whisper.transcribe_any` / :func:`stable_whisper.alignment.align`
|
| 909 |
+
if ``suppress_silence = True``.
|
| 910 |
+
"""
|
| 911 |
+
if vad:
|
| 912 |
+
silent_timings = get_vad_silence_func(
|
| 913 |
+
onnx=vad_onnx,
|
| 914 |
+
verbose=verbose
|
| 915 |
+
)(audio, speech_threshold=vad_threshold, sr=sample_rate)
|
| 916 |
+
else:
|
| 917 |
+
silent_timings = mask2timing(
|
| 918 |
+
wav2mask(audio, q_levels=q_levels, k_size=k_size, sr=sample_rate)
|
| 919 |
+
)
|
| 920 |
+
if silent_timings is None:
|
| 921 |
+
return self
|
| 922 |
+
self.suppress_silence(
|
| 923 |
+
*silent_timings,
|
| 924 |
+
min_word_dur=min_word_dur,
|
| 925 |
+
word_level=word_level,
|
| 926 |
+
nonspeech_error=nonspeech_error,
|
| 927 |
+
use_word_position=use_word_position
|
| 928 |
+
)
|
| 929 |
+
self.update_nonspeech_sections(*silent_timings)
|
| 930 |
+
return self
|
| 931 |
+
|
| 932 |
+
def adjust_by_result(
|
| 933 |
+
self,
|
| 934 |
+
other_result: "WhisperResult",
|
| 935 |
+
min_word_dur: float = 0.1,
|
| 936 |
+
verbose: bool = False
|
| 937 |
+
):
|
| 938 |
+
"""
|
| 939 |
+
Minimize the duration of words using timestamps of another result.
|
| 940 |
+
|
| 941 |
+
Parameters
|
| 942 |
+
----------
|
| 943 |
+
other_result : "WhisperResult"
|
| 944 |
+
Timing data of the same words in a WhisperResult instance.
|
| 945 |
+
min_word_dur : float, default 0.1
|
| 946 |
+
Prevent changes to timestamps if the resultant word duration is less than ``min_word_dur``.
|
| 947 |
+
verbose : bool, default False
|
| 948 |
+
Whether to print out the timestamp changes.
|
| 949 |
+
"""
|
| 950 |
+
if not (self.has_words and other_result.has_words):
|
| 951 |
+
raise NotImplementedError('This operation can only be performed on results with word timestamps')
|
| 952 |
+
assert [w.word for w in self.all_words()] == [w.word for w in other_result.all_words()], \
|
| 953 |
+
'The words in [other_result] do not match the current words.'
|
| 954 |
+
for word, other_word in zip(self.all_words(), other_result.all_words()):
|
| 955 |
+
if word.end > other_word.start:
|
| 956 |
+
new_start = max(word.start, other_word.start)
|
| 957 |
+
new_end = min(word.end, other_word.end)
|
| 958 |
+
if new_end - new_start >= min_word_dur:
|
| 959 |
+
line = ''
|
| 960 |
+
if word.start != new_start:
|
| 961 |
+
if verbose:
|
| 962 |
+
line += f'[Start:{word.start:.3f}->{new_start:.3f}] '
|
| 963 |
+
word.start = new_start
|
| 964 |
+
if word.end != new_end:
|
| 965 |
+
if verbose:
|
| 966 |
+
line += f'[End:{word.end:.3f}->{new_end:.3f}] '
|
| 967 |
+
word.end = new_end
|
| 968 |
+
if line:
|
| 969 |
+
print(f'{line}"{word.word}"')
|
| 970 |
+
self.update_all_segs_with_words()
|
| 971 |
+
|
| 972 |
+
def reassign_ids(self, only_segments: bool = False):
|
| 973 |
+
for i, s in enumerate(self.segments):
|
| 974 |
+
s.id = i
|
| 975 |
+
if not only_segments:
|
| 976 |
+
s.reassign_ids()
|
| 977 |
+
|
| 978 |
+
def remove_no_word_segments(self, ignore_ori=False):
|
| 979 |
+
for i in reversed(range(len(self.segments))):
|
| 980 |
+
if (ignore_ori or self.segments[i].ori_has_words) and not self.segments[i].has_words:
|
| 981 |
+
del self.segments[i]
|
| 982 |
+
self.reassign_ids()
|
| 983 |
+
|
| 984 |
+
def get_locked_indices(self):
|
| 985 |
+
locked_indices = [i
|
| 986 |
+
for i, (left, right) in enumerate(zip(self.segments[1:], self.segments[:-1]))
|
| 987 |
+
if left.left_locked or right.right_locked]
|
| 988 |
+
return locked_indices
|
| 989 |
+
|
| 990 |
+
def get_gaps(self, as_ndarray=False):
|
| 991 |
+
s_ts = np.array([s.start for s in self.segments])
|
| 992 |
+
e_ts = np.array([s.end for s in self.segments])
|
| 993 |
+
gap = s_ts[1:] - e_ts[:-1]
|
| 994 |
+
return gap if as_ndarray else gap.tolist()
|
| 995 |
+
|
| 996 |
+
def get_gap_indices(self, min_gap: float = 0.1): # for merging
|
| 997 |
+
if len(self.segments) < 2:
|
| 998 |
+
return []
|
| 999 |
+
if min_gap is None:
|
| 1000 |
+
min_gap = 0
|
| 1001 |
+
indices = (self.get_gaps(True) <= min_gap).nonzero()[0].tolist()
|
| 1002 |
+
return sorted(set(indices) - set(self.get_locked_indices()))
|
| 1003 |
+
|
| 1004 |
+
def get_punctuation_indices(self, punctuation: Union[List[str], List[Tuple[str, str]], str]): # for merging
|
| 1005 |
+
if len(self.segments) < 2:
|
| 1006 |
+
return []
|
| 1007 |
+
if isinstance(punctuation, str):
|
| 1008 |
+
punctuation = [punctuation]
|
| 1009 |
+
indices = []
|
| 1010 |
+
for p in punctuation:
|
| 1011 |
+
if isinstance(p, str):
|
| 1012 |
+
for i, s in enumerate(self.segments[:-1]):
|
| 1013 |
+
if s.text.endswith(p):
|
| 1014 |
+
indices.append(i)
|
| 1015 |
+
elif i != 0 and s.text.startswith(p):
|
| 1016 |
+
indices.append(i-1)
|
| 1017 |
+
else:
|
| 1018 |
+
ending, beginning = p
|
| 1019 |
+
indices.extend([i for i, (s0, s1) in enumerate(zip(self.segments[:-1], self.segments[1:]))
|
| 1020 |
+
if s0.text.endswith(ending) and s1.text.startswith(beginning)])
|
| 1021 |
+
|
| 1022 |
+
return sorted(set(indices) - set(self.get_locked_indices()))
|
| 1023 |
+
|
| 1024 |
+
def all_words(self):
|
| 1025 |
+
return list(chain.from_iterable(s.words for s in self.segments))
|
| 1026 |
+
|
| 1027 |
+
def all_words_or_segments(self):
|
| 1028 |
+
return self.all_words() if self.has_words else self.segments
|
| 1029 |
+
|
| 1030 |
+
def all_words_by_lock(self, only_text: bool = True, by_segment: bool = False, include_single: bool = False):
|
| 1031 |
+
if by_segment:
|
| 1032 |
+
return [
|
| 1033 |
+
segment.words_by_lock(only_text=only_text, include_single=include_single)
|
| 1034 |
+
for segment in self.segments
|
| 1035 |
+
]
|
| 1036 |
+
return _words_by_lock(self.all_words(), only_text=only_text, include_single=include_single)
|
| 1037 |
+
|
| 1038 |
+
def all_tokens(self):
|
| 1039 |
+
return list(chain.from_iterable(s.tokens for s in self.all_words()))
|
| 1040 |
+
|
| 1041 |
+
def to_dict(self):
|
| 1042 |
+
return dict(text=self.text,
|
| 1043 |
+
segments=self.segments_to_dicts(),
|
| 1044 |
+
language=self.language,
|
| 1045 |
+
ori_dict=self.ori_dict,
|
| 1046 |
+
regroup_history=self._regroup_history,
|
| 1047 |
+
nonspeech_sections=self._nonspeech_sections)
|
| 1048 |
+
|
| 1049 |
+
def segments_to_dicts(self, reverse_text: Union[bool, tuple] = False):
|
| 1050 |
+
return [s.to_dict(reverse_text=reverse_text) for s in self.segments]
|
| 1051 |
+
|
| 1052 |
+
def _split_segments(self, get_indices, args: list = None, *, lock: bool = False, newline: bool = False):
|
| 1053 |
+
if args is None:
|
| 1054 |
+
args = []
|
| 1055 |
+
no_words = False
|
| 1056 |
+
for i in reversed(range(0, len(self.segments))):
|
| 1057 |
+
no_words = no_words or not self.segments[i].has_words
|
| 1058 |
+
indices = sorted(set(get_indices(self.segments[i], *args)))
|
| 1059 |
+
if not indices:
|
| 1060 |
+
continue
|
| 1061 |
+
if newline:
|
| 1062 |
+
if indices[-1] == len(self.segments[i].words) - 1:
|
| 1063 |
+
del indices[-1]
|
| 1064 |
+
if not indices:
|
| 1065 |
+
continue
|
| 1066 |
+
|
| 1067 |
+
for word_idx in indices:
|
| 1068 |
+
if self.segments[i].words[word_idx].word.endswith('\n'):
|
| 1069 |
+
continue
|
| 1070 |
+
self.segments[i].words[word_idx].word += '\n'
|
| 1071 |
+
if lock:
|
| 1072 |
+
self.segments[i].words[word_idx].lock_right()
|
| 1073 |
+
if word_idx + 1 < len(self.segments[i].words):
|
| 1074 |
+
self.segments[i].words[word_idx+1].lock_left()
|
| 1075 |
+
self.segments[i].update_seg_with_words()
|
| 1076 |
+
else:
|
| 1077 |
+
new_segments = self.segments[i].split(indices)
|
| 1078 |
+
if lock:
|
| 1079 |
+
for s in new_segments:
|
| 1080 |
+
if s == new_segments[0]:
|
| 1081 |
+
s.lock_right()
|
| 1082 |
+
elif s == new_segments[-1]:
|
| 1083 |
+
s.lock_left()
|
| 1084 |
+
else:
|
| 1085 |
+
s.lock_both()
|
| 1086 |
+
del self.segments[i]
|
| 1087 |
+
for s in reversed(new_segments):
|
| 1088 |
+
self.segments.insert(i, s)
|
| 1089 |
+
if no_words:
|
| 1090 |
+
warnings.warn('Found segment(s) without word timings. These segment(s) cannot be split.')
|
| 1091 |
+
self.remove_no_word_segments()
|
| 1092 |
+
|
| 1093 |
+
def _merge_segments(self, indices: List[int],
|
| 1094 |
+
*, max_words: int = None, max_chars: int = None, is_sum_max: bool = False, lock: bool = False):
|
| 1095 |
+
if len(indices) == 0:
|
| 1096 |
+
return
|
| 1097 |
+
for i in reversed(indices):
|
| 1098 |
+
seg = self.segments[i]
|
| 1099 |
+
if (
|
| 1100 |
+
(
|
| 1101 |
+
max_words and
|
| 1102 |
+
seg.has_words and
|
| 1103 |
+
(
|
| 1104 |
+
(seg.word_count() + self.segments[i + 1].word_count() > max_words)
|
| 1105 |
+
if is_sum_max else
|
| 1106 |
+
(seg.word_count() > max_words and self.segments[i + 1].word_count() > max_words)
|
| 1107 |
+
)
|
| 1108 |
+
) or
|
| 1109 |
+
(
|
| 1110 |
+
max_chars and
|
| 1111 |
+
(
|
| 1112 |
+
(seg.char_count() + self.segments[i + 1].char_count() > max_chars)
|
| 1113 |
+
if is_sum_max else
|
| 1114 |
+
(seg.char_count() > max_chars and self.segments[i + 1].char_count() > max_chars)
|
| 1115 |
+
)
|
| 1116 |
+
)
|
| 1117 |
+
):
|
| 1118 |
+
continue
|
| 1119 |
+
self.add_segments(i, i + 1, inplace=True, lock=lock)
|
| 1120 |
+
self.remove_no_word_segments()
|
| 1121 |
+
|
| 1122 |
+
def get_content_by_time(
|
| 1123 |
+
self,
|
| 1124 |
+
time: Union[float, Tuple[float, float], dict],
|
| 1125 |
+
within: bool = False,
|
| 1126 |
+
segment_level: bool = False
|
| 1127 |
+
) -> Union[List[WordTiming], List[Segment]]:
|
| 1128 |
+
"""
|
| 1129 |
+
Return content in the ``time`` range.
|
| 1130 |
+
|
| 1131 |
+
Parameters
|
| 1132 |
+
----------
|
| 1133 |
+
time : float or tuple of (float, float) or dict
|
| 1134 |
+
Range of time to find content. For tuple of two floats, first value is the start time and second value is
|
| 1135 |
+
the end time. For a single float value, it is treated as both the start and end time.
|
| 1136 |
+
within : bool, default False
|
| 1137 |
+
Whether to only find content fully overlaps with ``time`` range.
|
| 1138 |
+
segment_level : bool, default False
|
| 1139 |
+
Whether to look only on the segment level and return instances of :class:`stable_whisper.result.Segment`
|
| 1140 |
+
instead of :class:`stable_whisper.result.WordTiming`.
|
| 1141 |
+
|
| 1142 |
+
Returns
|
| 1143 |
+
-------
|
| 1144 |
+
list of stable_whisper.result.WordTiming or list of stable_whisper.result.Segment
|
| 1145 |
+
List of contents in the ``time`` range. The contents are instances of
|
| 1146 |
+
:class:`stable_whisper.result.Segment` if ``segment_level = True`` else
|
| 1147 |
+
:class:`stable_whisper.result.WordTiming`.
|
| 1148 |
+
"""
|
| 1149 |
+
if not segment_level and not self.has_words:
|
| 1150 |
+
raise ValueError('Missing word timestamps in result. Use ``segment_level=True`` instead.')
|
| 1151 |
+
contents = self.segments if segment_level else self.all_words()
|
| 1152 |
+
if isinstance(time, (float, int)):
|
| 1153 |
+
time = [time, time]
|
| 1154 |
+
elif isinstance(time, dict):
|
| 1155 |
+
time = [time['start'], time['end']]
|
| 1156 |
+
start, end = time
|
| 1157 |
+
|
| 1158 |
+
if within:
|
| 1159 |
+
def is_in_range(c):
|
| 1160 |
+
return start <= c.start and end >= c.end
|
| 1161 |
+
else:
|
| 1162 |
+
def is_in_range(c):
|
| 1163 |
+
return start <= c.end and end >= c.start
|
| 1164 |
+
|
| 1165 |
+
return [c for c in contents if is_in_range(c)]
|
| 1166 |
+
|
| 1167 |
+
def split_by_gap(
|
| 1168 |
+
self,
|
| 1169 |
+
max_gap: float = 0.1,
|
| 1170 |
+
lock: bool = False,
|
| 1171 |
+
newline: bool = False
|
| 1172 |
+
) -> "WhisperResult":
|
| 1173 |
+
"""
|
| 1174 |
+
Split (in-place) any segment where the gap between two of its words is greater than ``max_gap``.
|
| 1175 |
+
|
| 1176 |
+
Parameters
|
| 1177 |
+
----------
|
| 1178 |
+
max_gap : float, default 0.1
|
| 1179 |
+
Maximum second(s) allowed between two words if the same segment.
|
| 1180 |
+
lock : bool, default False
|
| 1181 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1182 |
+
newline: bool, default False
|
| 1183 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1184 |
+
|
| 1185 |
+
Returns
|
| 1186 |
+
-------
|
| 1187 |
+
stable_whisper.result.WhisperResult
|
| 1188 |
+
The current instance after the changes.
|
| 1189 |
+
"""
|
| 1190 |
+
self._split_segments(lambda x: x.get_gap_indices(max_gap), lock=lock, newline=newline)
|
| 1191 |
+
if self._regroup_history:
|
| 1192 |
+
self._regroup_history += '_'
|
| 1193 |
+
self._regroup_history += f'sg={max_gap}+{int(lock)}+{int(newline)}'
|
| 1194 |
+
return self
|
| 1195 |
+
|
| 1196 |
+
def merge_by_gap(
|
| 1197 |
+
self,
|
| 1198 |
+
min_gap: float = 0.1,
|
| 1199 |
+
max_words: int = None,
|
| 1200 |
+
max_chars: int = None,
|
| 1201 |
+
is_sum_max: bool = False,
|
| 1202 |
+
lock: bool = False
|
| 1203 |
+
) -> "WhisperResult":
|
| 1204 |
+
"""
|
| 1205 |
+
Merge (in-place) any pair of adjacent segments if the gap between them <= ``min_gap``.
|
| 1206 |
+
|
| 1207 |
+
Parameters
|
| 1208 |
+
----------
|
| 1209 |
+
min_gap : float, default 0.1
|
| 1210 |
+
Minimum second(s) allow between two segment.
|
| 1211 |
+
max_words : int, optional
|
| 1212 |
+
Maximum number of words allowed in each segment.
|
| 1213 |
+
max_chars : int, optional
|
| 1214 |
+
Maximum number of characters allowed in each segment.
|
| 1215 |
+
is_sum_max : bool, default False
|
| 1216 |
+
Whether ``max_words`` and ``max_chars`` is applied to the merged segment instead of the individual segments
|
| 1217 |
+
to be merged.
|
| 1218 |
+
lock : bool, default False
|
| 1219 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1220 |
+
|
| 1221 |
+
Returns
|
| 1222 |
+
-------
|
| 1223 |
+
stable_whisper.result.WhisperResult
|
| 1224 |
+
The current instance after the changes.
|
| 1225 |
+
"""
|
| 1226 |
+
indices = self.get_gap_indices(min_gap)
|
| 1227 |
+
self._merge_segments(indices,
|
| 1228 |
+
max_words=max_words, max_chars=max_chars, is_sum_max=is_sum_max, lock=lock)
|
| 1229 |
+
if self._regroup_history:
|
| 1230 |
+
self._regroup_history += '_'
|
| 1231 |
+
self._regroup_history += f'mg={min_gap}+{max_words or ""}+{max_chars or ""}+{int(is_sum_max)}+{int(lock)}'
|
| 1232 |
+
return self
|
| 1233 |
+
|
| 1234 |
+
def split_by_punctuation(
|
| 1235 |
+
self,
|
| 1236 |
+
punctuation: Union[List[str], List[Tuple[str, str]], str],
|
| 1237 |
+
lock: bool = False,
|
| 1238 |
+
newline: bool = False,
|
| 1239 |
+
min_words: Optional[int] = None,
|
| 1240 |
+
min_chars: Optional[int] = None,
|
| 1241 |
+
min_dur: Optional[int] = None
|
| 1242 |
+
) -> "WhisperResult":
|
| 1243 |
+
"""
|
| 1244 |
+
Split (in-place) segments at words that start/end with ``punctuation``.
|
| 1245 |
+
|
| 1246 |
+
Parameters
|
| 1247 |
+
----------
|
| 1248 |
+
punctuation : list of str of list of tuple of (str, str) or str
|
| 1249 |
+
Punctuation(s) to split segments by.
|
| 1250 |
+
lock : bool, default False
|
| 1251 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1252 |
+
newline : bool, default False
|
| 1253 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1254 |
+
min_words : int, optional
|
| 1255 |
+
Split segments with words >= ``min_words``.
|
| 1256 |
+
min_chars : int, optional
|
| 1257 |
+
Split segments with characters >= ``min_chars``.
|
| 1258 |
+
min_dur : int, optional
|
| 1259 |
+
split segments with duration (in seconds) >= ``min_dur``.
|
| 1260 |
+
|
| 1261 |
+
Returns
|
| 1262 |
+
-------
|
| 1263 |
+
stable_whisper.result.WhisperResult
|
| 1264 |
+
The current instance after the changes.
|
| 1265 |
+
"""
|
| 1266 |
+
def _over_max(x: Segment):
|
| 1267 |
+
return (
|
| 1268 |
+
(min_words and len(x.words) >= min_words) or
|
| 1269 |
+
(min_chars and x.char_count() >= min_chars) or
|
| 1270 |
+
(min_dur and x.duration >= min_dur)
|
| 1271 |
+
)
|
| 1272 |
+
|
| 1273 |
+
indices = set(s.id for s in self.segments if _over_max(s)) if any((min_words, min_chars, min_dur)) else None
|
| 1274 |
+
|
| 1275 |
+
def _get_indices(x: Segment):
|
| 1276 |
+
return x.get_punctuation_indices(punctuation) if indices is None or x.id in indices else []
|
| 1277 |
+
|
| 1278 |
+
self._split_segments(_get_indices, lock=lock, newline=newline)
|
| 1279 |
+
if self._regroup_history:
|
| 1280 |
+
self._regroup_history += '_'
|
| 1281 |
+
punct_str = '/'.join(p if isinstance(p, str) else '*'.join(p) for p in punctuation)
|
| 1282 |
+
self._regroup_history += f'sp={punct_str}+{int(lock)}+{int(newline)}'
|
| 1283 |
+
self._regroup_history += f'+{min_words or ""}+{min_chars or ""}+{min_dur or ""}'.rstrip('+')
|
| 1284 |
+
return self
|
| 1285 |
+
|
| 1286 |
+
def merge_by_punctuation(
|
| 1287 |
+
self,
|
| 1288 |
+
punctuation: Union[List[str], List[Tuple[str, str]], str],
|
| 1289 |
+
max_words: int = None,
|
| 1290 |
+
max_chars: int = None,
|
| 1291 |
+
is_sum_max: bool = False,
|
| 1292 |
+
lock: bool = False
|
| 1293 |
+
) -> "WhisperResult":
|
| 1294 |
+
"""
|
| 1295 |
+
Merge (in-place) any two segments that has specific punctuations inbetween.
|
| 1296 |
+
|
| 1297 |
+
Parameters
|
| 1298 |
+
----------
|
| 1299 |
+
punctuation : list of str of list of tuple of (str, str) or str
|
| 1300 |
+
Punctuation(s) to merge segments by.
|
| 1301 |
+
max_words : int, optional
|
| 1302 |
+
Maximum number of words allowed in each segment.
|
| 1303 |
+
max_chars : int, optional
|
| 1304 |
+
Maximum number of characters allowed in each segment.
|
| 1305 |
+
is_sum_max : bool, default False
|
| 1306 |
+
Whether ``max_words`` and ``max_chars`` is applied to the merged segment instead of the individual segments
|
| 1307 |
+
to be merged.
|
| 1308 |
+
lock : bool, default False
|
| 1309 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1310 |
+
|
| 1311 |
+
Returns
|
| 1312 |
+
-------
|
| 1313 |
+
stable_whisper.result.WhisperResult
|
| 1314 |
+
The current instance after the changes.
|
| 1315 |
+
"""
|
| 1316 |
+
indices = self.get_punctuation_indices(punctuation)
|
| 1317 |
+
self._merge_segments(indices,
|
| 1318 |
+
max_words=max_words, max_chars=max_chars, is_sum_max=is_sum_max, lock=lock)
|
| 1319 |
+
if self._regroup_history:
|
| 1320 |
+
self._regroup_history += '_'
|
| 1321 |
+
punct_str = '/'.join(p if isinstance(p, str) else '*'.join(p) for p in punctuation)
|
| 1322 |
+
self._regroup_history += f'mp={punct_str}+{max_words or ""}+{max_chars or ""}+{int(is_sum_max)}+{int(lock)}'
|
| 1323 |
+
return self
|
| 1324 |
+
|
| 1325 |
+
def merge_all_segments(self) -> "WhisperResult":
|
| 1326 |
+
"""
|
| 1327 |
+
Merge all segments into one segment.
|
| 1328 |
+
|
| 1329 |
+
Returns
|
| 1330 |
+
-------
|
| 1331 |
+
stable_whisper.result.WhisperResult
|
| 1332 |
+
The current instance after the changes.
|
| 1333 |
+
"""
|
| 1334 |
+
if not self.segments:
|
| 1335 |
+
return self
|
| 1336 |
+
if self.has_words:
|
| 1337 |
+
self.segments[0].words = self.all_words()
|
| 1338 |
+
else:
|
| 1339 |
+
self.segments[0].text += ''.join(s.text for s in self.segments[1:])
|
| 1340 |
+
if all(s.tokens is not None for s in self.segments):
|
| 1341 |
+
self.segments[0].tokens += list(chain.from_iterable(s.tokens for s in self.segments[1:]))
|
| 1342 |
+
self.segments[0].end = self.segments[-1].end
|
| 1343 |
+
self.segments = [self.segments[0]]
|
| 1344 |
+
self.reassign_ids()
|
| 1345 |
+
self.update_all_segs_with_words()
|
| 1346 |
+
if self._regroup_history:
|
| 1347 |
+
self._regroup_history += '_'
|
| 1348 |
+
self._regroup_history += 'ms'
|
| 1349 |
+
return self
|
| 1350 |
+
|
| 1351 |
+
def split_by_length(
|
| 1352 |
+
self,
|
| 1353 |
+
max_chars: int = None,
|
| 1354 |
+
max_words: int = None,
|
| 1355 |
+
even_split: bool = True,
|
| 1356 |
+
force_len: bool = False,
|
| 1357 |
+
lock: bool = False,
|
| 1358 |
+
include_lock: bool = False,
|
| 1359 |
+
newline: bool = False
|
| 1360 |
+
) -> "WhisperResult":
|
| 1361 |
+
"""
|
| 1362 |
+
Split (in-place) any segment that exceeds ``max_chars`` or ``max_words`` into smaller segments.
|
| 1363 |
+
|
| 1364 |
+
Parameters
|
| 1365 |
+
----------
|
| 1366 |
+
max_chars : int, optional
|
| 1367 |
+
Maximum number of characters allowed in each segment.
|
| 1368 |
+
max_words : int, optional
|
| 1369 |
+
Maximum number of words allowed in each segment.
|
| 1370 |
+
even_split : bool, default True
|
| 1371 |
+
Whether to evenly split a segment in length if it exceeds ``max_chars`` or ``max_words``.
|
| 1372 |
+
force_len : bool, default False
|
| 1373 |
+
Whether to force a constant length for each segment except the last segment.
|
| 1374 |
+
This will ignore all previous non-locked segment boundaries.
|
| 1375 |
+
lock : bool, default False
|
| 1376 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1377 |
+
include_lock: bool, default False
|
| 1378 |
+
Whether to include previous lock before splitting based on max_words, if ``even_split = False``.
|
| 1379 |
+
Splitting will be done after the first non-locked word > ``max_chars`` / ``max_words``.
|
| 1380 |
+
newline: bool, default False
|
| 1381 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1382 |
+
|
| 1383 |
+
Returns
|
| 1384 |
+
-------
|
| 1385 |
+
stable_whisper.result.WhisperResult
|
| 1386 |
+
The current instance after the changes.
|
| 1387 |
+
|
| 1388 |
+
Notes
|
| 1389 |
+
-----
|
| 1390 |
+
If ``even_split = True``, segments can still exceed ``max_chars`` and locked words will be ignored to avoid
|
| 1391 |
+
uneven splitting.
|
| 1392 |
+
"""
|
| 1393 |
+
if force_len:
|
| 1394 |
+
self.merge_all_segments()
|
| 1395 |
+
self._split_segments(
|
| 1396 |
+
lambda x: x.get_length_indices(
|
| 1397 |
+
max_chars=max_chars,
|
| 1398 |
+
max_words=max_words,
|
| 1399 |
+
even_split=even_split,
|
| 1400 |
+
include_lock=include_lock
|
| 1401 |
+
),
|
| 1402 |
+
lock=lock,
|
| 1403 |
+
newline=newline
|
| 1404 |
+
)
|
| 1405 |
+
if self._regroup_history:
|
| 1406 |
+
self._regroup_history += '_'
|
| 1407 |
+
self._regroup_history += (f'sl={max_chars or ""}+{max_words or ""}+{int(even_split)}+{int(force_len)}'
|
| 1408 |
+
f'+{int(lock)}+{int(include_lock)}+{int(newline)}')
|
| 1409 |
+
return self
|
| 1410 |
+
|
| 1411 |
+
def split_by_duration(
|
| 1412 |
+
self,
|
| 1413 |
+
max_dur: float,
|
| 1414 |
+
even_split: bool = True,
|
| 1415 |
+
force_len: bool = False,
|
| 1416 |
+
lock: bool = False,
|
| 1417 |
+
include_lock: bool = False,
|
| 1418 |
+
newline: bool = False
|
| 1419 |
+
) -> "WhisperResult":
|
| 1420 |
+
"""
|
| 1421 |
+
Split (in-place) any segment that exceeds ``max_dur`` into smaller segments.
|
| 1422 |
+
|
| 1423 |
+
Parameters
|
| 1424 |
+
----------
|
| 1425 |
+
max_dur : float
|
| 1426 |
+
Maximum duration (in seconds) per segment.
|
| 1427 |
+
even_split : bool, default True
|
| 1428 |
+
Whether to evenly split a segment in length if it exceeds ``max_dur``.
|
| 1429 |
+
force_len : bool, default False
|
| 1430 |
+
Whether to force a constant length for each segment except the last segment.
|
| 1431 |
+
This will ignore all previous non-locked segment boundaries.
|
| 1432 |
+
lock : bool, default False
|
| 1433 |
+
Whether to prevent future splits/merges from altering changes made by this method.
|
| 1434 |
+
include_lock: bool, default False
|
| 1435 |
+
Whether to include previous lock before splitting based on max_words, if ``even_split = False``.
|
| 1436 |
+
Splitting will be done after the first non-locked word > ``max_dur``.
|
| 1437 |
+
newline: bool, default False
|
| 1438 |
+
Whether to insert line break at the split points instead of splitting into separate segments.
|
| 1439 |
+
|
| 1440 |
+
Returns
|
| 1441 |
+
-------
|
| 1442 |
+
stable_whisper.result.WhisperResult
|
| 1443 |
+
The current instance after the changes.
|
| 1444 |
+
|
| 1445 |
+
Notes
|
| 1446 |
+
-----
|
| 1447 |
+
If ``even_split = True``, segments can still exceed ``max_dur`` and locked words will be ignored to avoid
|
| 1448 |
+
uneven splitting.
|
| 1449 |
+
"""
|
| 1450 |
+
if force_len:
|
| 1451 |
+
self.merge_all_segments()
|
| 1452 |
+
self._split_segments(
|
| 1453 |
+
lambda x: x.get_duration_indices(
|
| 1454 |
+
max_dur=max_dur,
|
| 1455 |
+
even_split=even_split,
|
| 1456 |
+
include_lock=include_lock
|
| 1457 |
+
),
|
| 1458 |
+
lock=lock,
|
| 1459 |
+
newline=newline
|
| 1460 |
+
)
|
| 1461 |
+
if self._regroup_history:
|
| 1462 |
+
self._regroup_history += '_'
|
| 1463 |
+
self._regroup_history += (f'sd={max_dur}+{int(even_split)}+{int(force_len)}'
|
| 1464 |
+
f'+{int(lock)}+{int(include_lock)}+{int(newline)}')
|
| 1465 |
+
return self
|
| 1466 |
+
|
| 1467 |
+
def clamp_max(
|
| 1468 |
+
self,
|
| 1469 |
+
medium_factor: float = 2.5,
|
| 1470 |
+
max_dur: float = None,
|
| 1471 |
+
clip_start: Optional[bool] = None,
|
| 1472 |
+
verbose: bool = False
|
| 1473 |
+
) -> "WhisperResult":
|
| 1474 |
+
"""
|
| 1475 |
+
Clamp all word durations above certain value.
|
| 1476 |
+
|
| 1477 |
+
This is most effective when applied before and after other regroup operations.
|
| 1478 |
+
|
| 1479 |
+
Parameters
|
| 1480 |
+
----------
|
| 1481 |
+
medium_factor : float, default 2.5
|
| 1482 |
+
Clamp durations above (``medium_factor`` * medium duration) per segment.
|
| 1483 |
+
If ``medium_factor = None/0`` or segment has less than 3 words, it will be ignored and use only ``max_dur``.
|
| 1484 |
+
max_dur : float, optional
|
| 1485 |
+
Clamp durations above ``max_dur``.
|
| 1486 |
+
clip_start : bool or None, default None
|
| 1487 |
+
Whether to clamp the start of a word. If ``None``, clamp the start of first word and end of last word per
|
| 1488 |
+
segment.
|
| 1489 |
+
verbose : bool, default False
|
| 1490 |
+
Whether to print out the timestamp changes.
|
| 1491 |
+
|
| 1492 |
+
Returns
|
| 1493 |
+
-------
|
| 1494 |
+
stable_whisper.result.WhisperResult
|
| 1495 |
+
The current instance after the changes.
|
| 1496 |
+
"""
|
| 1497 |
+
if not (medium_factor or max_dur):
|
| 1498 |
+
raise ValueError('At least one of following arguments requires non-zero value: medium_factor; max_dur')
|
| 1499 |
+
|
| 1500 |
+
if not self.has_words:
|
| 1501 |
+
warnings.warn('Cannot clamp due to missing/no word-timestamps')
|
| 1502 |
+
return self
|
| 1503 |
+
|
| 1504 |
+
for seg in self.segments:
|
| 1505 |
+
curr_max_dur = None
|
| 1506 |
+
if medium_factor and len(seg.words) > 2:
|
| 1507 |
+
durations = np.array([word.duration for word in seg.words])
|
| 1508 |
+
durations.sort()
|
| 1509 |
+
curr_max_dur = medium_factor * durations[len(durations)//2 + 1]
|
| 1510 |
+
|
| 1511 |
+
if max_dur and (not curr_max_dur or curr_max_dur > max_dur):
|
| 1512 |
+
curr_max_dur = max_dur
|
| 1513 |
+
|
| 1514 |
+
if not curr_max_dur:
|
| 1515 |
+
continue
|
| 1516 |
+
|
| 1517 |
+
if clip_start is None:
|
| 1518 |
+
seg.words[0].clamp_max(curr_max_dur, clip_start=True, verbose=verbose)
|
| 1519 |
+
seg.words[-1].clamp_max(curr_max_dur, clip_start=False, verbose=verbose)
|
| 1520 |
+
else:
|
| 1521 |
+
for i, word in enumerate(seg.words):
|
| 1522 |
+
word.clamp_max(curr_max_dur, clip_start=clip_start, verbose=verbose)
|
| 1523 |
+
|
| 1524 |
+
seg.update_seg_with_words()
|
| 1525 |
+
if self._regroup_history:
|
| 1526 |
+
self._regroup_history += '_'
|
| 1527 |
+
self._regroup_history += f'cm={medium_factor}+{max_dur or ""}+{clip_start or ""}+{int(verbose)}'
|
| 1528 |
+
return self
|
| 1529 |
+
|
| 1530 |
+
def lock(
|
| 1531 |
+
self,
|
| 1532 |
+
startswith: Union[str, List[str]] = None,
|
| 1533 |
+
endswith: Union[str, List[str]] = None,
|
| 1534 |
+
right: bool = True,
|
| 1535 |
+
left: bool = False,
|
| 1536 |
+
case_sensitive: bool = False,
|
| 1537 |
+
strip: bool = True
|
| 1538 |
+
) -> "WhisperResult":
|
| 1539 |
+
"""
|
| 1540 |
+
Lock words/segments with matching prefix/suffix to prevent splitting/merging.
|
| 1541 |
+
|
| 1542 |
+
Parameters
|
| 1543 |
+
----------
|
| 1544 |
+
startswith: str or list of str
|
| 1545 |
+
Prefixes to lock.
|
| 1546 |
+
endswith: str or list of str
|
| 1547 |
+
Suffixes to lock.
|
| 1548 |
+
right : bool, default True
|
| 1549 |
+
Whether prevent splits/merges with the next word/segment.
|
| 1550 |
+
left : bool, default False
|
| 1551 |
+
Whether prevent splits/merges with the previous word/segment.
|
| 1552 |
+
case_sensitive : bool, default False
|
| 1553 |
+
Whether to match the case of the prefixes/suffixes with the words/segments.
|
| 1554 |
+
strip : bool, default True
|
| 1555 |
+
Whether to ignore spaces before and after both words/segments and prefixes/suffixes.
|
| 1556 |
+
|
| 1557 |
+
Returns
|
| 1558 |
+
-------
|
| 1559 |
+
stable_whisper.result.WhisperResult
|
| 1560 |
+
The current instance after the changes.
|
| 1561 |
+
"""
|
| 1562 |
+
assert startswith or endswith, 'Must specify [startswith] or/and [endswith].'
|
| 1563 |
+
startswith = [] if startswith is None else ([startswith] if isinstance(startswith, str) else startswith)
|
| 1564 |
+
endswith = [] if endswith is None else ([endswith] if isinstance(endswith, str) else endswith)
|
| 1565 |
+
if not case_sensitive:
|
| 1566 |
+
startswith = [t.lower() for t in startswith]
|
| 1567 |
+
endswith = [t.lower() for t in endswith]
|
| 1568 |
+
if strip:
|
| 1569 |
+
startswith = [t.strip() for t in startswith]
|
| 1570 |
+
endswith = [t.strip() for t in endswith]
|
| 1571 |
+
for part in self.all_words_or_segments():
|
| 1572 |
+
text = part.word if hasattr(part, 'word') else part.text
|
| 1573 |
+
if not case_sensitive:
|
| 1574 |
+
text = text.lower()
|
| 1575 |
+
if strip:
|
| 1576 |
+
text = text.strip()
|
| 1577 |
+
for prefix in startswith:
|
| 1578 |
+
if text.startswith(prefix):
|
| 1579 |
+
if right:
|
| 1580 |
+
part.lock_right()
|
| 1581 |
+
if left:
|
| 1582 |
+
part.lock_left()
|
| 1583 |
+
for suffix in endswith:
|
| 1584 |
+
if text.endswith(suffix):
|
| 1585 |
+
if right:
|
| 1586 |
+
part.lock_right()
|
| 1587 |
+
if left:
|
| 1588 |
+
part.lock_left()
|
| 1589 |
+
if self._regroup_history:
|
| 1590 |
+
self._regroup_history += '_'
|
| 1591 |
+
startswith_str = (startswith if isinstance(startswith, str) else '/'.join(startswith)) if startswith else ""
|
| 1592 |
+
endswith_str = (endswith if isinstance(endswith, str) else '/'.join(endswith)) if endswith else ""
|
| 1593 |
+
self._regroup_history += (f'l={startswith_str}+{endswith_str}'
|
| 1594 |
+
f'+{int(right)}+{int(left)}+{int(case_sensitive)}+{int(strip)}')
|
| 1595 |
+
return self
|
| 1596 |
+
|
| 1597 |
+
def remove_word(
|
| 1598 |
+
self,
|
| 1599 |
+
word: Union[WordTiming, Tuple[int, int]],
|
| 1600 |
+
reassign_ids: bool = True,
|
| 1601 |
+
verbose: bool = True
|
| 1602 |
+
) -> 'WhisperResult':
|
| 1603 |
+
"""
|
| 1604 |
+
Remove a word.
|
| 1605 |
+
|
| 1606 |
+
Parameters
|
| 1607 |
+
----------
|
| 1608 |
+
word : WordTiming or tuple of (int, int)
|
| 1609 |
+
Instance of :class:`stable_whisper.result.WordTiming` or tuple of (segment index, word index).
|
| 1610 |
+
reassign_ids : bool, default True
|
| 1611 |
+
Whether to reassign segment and word ids (indices) after removing ``word``.
|
| 1612 |
+
verbose : bool, default True
|
| 1613 |
+
Whether to print detail of the removed word.
|
| 1614 |
+
|
| 1615 |
+
Returns
|
| 1616 |
+
-------
|
| 1617 |
+
stable_whisper.result.WhisperResult
|
| 1618 |
+
The current instance after the changes.
|
| 1619 |
+
"""
|
| 1620 |
+
if isinstance(word, WordTiming):
|
| 1621 |
+
if self[word.segment_id][word.id] is not word:
|
| 1622 |
+
self.reassign_ids()
|
| 1623 |
+
if self[word.segment_id][word.id] is not word:
|
| 1624 |
+
raise ValueError('word not in result')
|
| 1625 |
+
seg_id, word_id = word.segment_id, word.id
|
| 1626 |
+
else:
|
| 1627 |
+
seg_id, word_id = word
|
| 1628 |
+
if verbose:
|
| 1629 |
+
print(f'Removed: {self[seg_id][word_id].to_dict()}')
|
| 1630 |
+
del self.segments[seg_id].words[word_id]
|
| 1631 |
+
if not reassign_ids:
|
| 1632 |
+
return self
|
| 1633 |
+
if self[seg_id].has_words:
|
| 1634 |
+
self[seg_id].reassign_ids()
|
| 1635 |
+
else:
|
| 1636 |
+
self.remove_no_word_segments()
|
| 1637 |
+
return self
|
| 1638 |
+
|
| 1639 |
+
def remove_segment(
|
| 1640 |
+
self,
|
| 1641 |
+
segment: Union[Segment, int],
|
| 1642 |
+
reassign_ids: bool = True,
|
| 1643 |
+
verbose: bool = True
|
| 1644 |
+
) -> 'WhisperResult':
|
| 1645 |
+
"""
|
| 1646 |
+
Remove a segment.
|
| 1647 |
+
|
| 1648 |
+
Parameters
|
| 1649 |
+
----------
|
| 1650 |
+
segment : Segment or int
|
| 1651 |
+
Instance :class:`stable_whisper.result.Segment` or segment index.
|
| 1652 |
+
reassign_ids : bool, default True
|
| 1653 |
+
Whether to reassign segment IDs (indices) after removing ``segment``.
|
| 1654 |
+
verbose : bool, default True
|
| 1655 |
+
Whether to print detail of the removed word.
|
| 1656 |
+
|
| 1657 |
+
Returns
|
| 1658 |
+
-------
|
| 1659 |
+
stable_whisper.result.WhisperResult
|
| 1660 |
+
The current instance after the changes.
|
| 1661 |
+
"""
|
| 1662 |
+
if isinstance(segment, Segment):
|
| 1663 |
+
if self[segment.id] is not segment:
|
| 1664 |
+
self.reassign_ids()
|
| 1665 |
+
if self[segment.id] is not segment:
|
| 1666 |
+
raise ValueError('segment not in result')
|
| 1667 |
+
segment = segment.id
|
| 1668 |
+
if verbose:
|
| 1669 |
+
print(f'Removed: [id:{self[segment].id}] {self[segment].to_display_str(True)}')
|
| 1670 |
+
del self.segments[segment]
|
| 1671 |
+
if not reassign_ids:
|
| 1672 |
+
return self
|
| 1673 |
+
self.reassign_ids(True)
|
| 1674 |
+
return self
|
| 1675 |
+
|
| 1676 |
+
def remove_repetition(
|
| 1677 |
+
self,
|
| 1678 |
+
max_words: int = 1,
|
| 1679 |
+
case_sensitive: bool = False,
|
| 1680 |
+
strip: bool = True,
|
| 1681 |
+
ignore_punctuations: str = "\"',.?!",
|
| 1682 |
+
extend_duration: bool = True,
|
| 1683 |
+
verbose: bool = True
|
| 1684 |
+
) -> 'WhisperResult':
|
| 1685 |
+
"""
|
| 1686 |
+
Remove words that repeat consecutively.
|
| 1687 |
+
|
| 1688 |
+
Parameters
|
| 1689 |
+
----------
|
| 1690 |
+
max_words : int
|
| 1691 |
+
Maximum number of words to look for consecutively.
|
| 1692 |
+
case_sensitive : bool, default False
|
| 1693 |
+
Whether the case of words need to match to be considered as repetition.
|
| 1694 |
+
strip : bool, default True
|
| 1695 |
+
Whether to ignore spaces before and after each word.
|
| 1696 |
+
ignore_punctuations : bool, default '"',.?!'
|
| 1697 |
+
Ending punctuations to ignore.
|
| 1698 |
+
extend_duration: bool, default True
|
| 1699 |
+
Whether to extend the duration of the previous word to cover the duration of the repetition.
|
| 1700 |
+
verbose: bool, default True
|
| 1701 |
+
Whether to print detail of the removed repetitions.
|
| 1702 |
+
|
| 1703 |
+
Returns
|
| 1704 |
+
-------
|
| 1705 |
+
stable_whisper.result.WhisperResult
|
| 1706 |
+
The current instance after the changes.
|
| 1707 |
+
"""
|
| 1708 |
+
if not self.has_words:
|
| 1709 |
+
return self
|
| 1710 |
+
|
| 1711 |
+
for count in range(1, max_words + 1):
|
| 1712 |
+
all_words = self.all_words()
|
| 1713 |
+
if len(all_words) < 2:
|
| 1714 |
+
return self
|
| 1715 |
+
all_words_str = [w.word for w in all_words]
|
| 1716 |
+
if strip:
|
| 1717 |
+
all_words_str = [w.strip() for w in all_words_str]
|
| 1718 |
+
if ignore_punctuations:
|
| 1719 |
+
ptn = f'[{ignore_punctuations}]+$'
|
| 1720 |
+
all_words_str = [re.sub(ptn, '', w) for w in all_words_str]
|
| 1721 |
+
if not case_sensitive:
|
| 1722 |
+
all_words_str = [w.lower() for w in all_words_str]
|
| 1723 |
+
next_i = None
|
| 1724 |
+
changes = []
|
| 1725 |
+
for i in reversed(range(count*2, len(all_words_str)+1)):
|
| 1726 |
+
if next_i is not None:
|
| 1727 |
+
if next_i != i:
|
| 1728 |
+
continue
|
| 1729 |
+
else:
|
| 1730 |
+
next_i = None
|
| 1731 |
+
s = i - count
|
| 1732 |
+
if all_words_str[s - count:s] != all_words_str[s:i]:
|
| 1733 |
+
continue
|
| 1734 |
+
next_i = s
|
| 1735 |
+
if extend_duration:
|
| 1736 |
+
all_words[s-1].end = all_words[i-1].end
|
| 1737 |
+
temp_changes = []
|
| 1738 |
+
for j in reversed(range(s, i)):
|
| 1739 |
+
if verbose:
|
| 1740 |
+
temp_changes.append(f'- {all_words[j].to_dict()}')
|
| 1741 |
+
self.remove_word(all_words[j], False, verbose=False)
|
| 1742 |
+
if temp_changes:
|
| 1743 |
+
changes.append(
|
| 1744 |
+
f'Remove: [{format_timestamp(all_words[s].start)} -> {format_timestamp(all_words[i-1].end)}] '
|
| 1745 |
+
+ ''.join(_w.word for _w in all_words[s:i]) + '\n'
|
| 1746 |
+
+ '\n'.join(reversed(temp_changes)) + '\n'
|
| 1747 |
+
)
|
| 1748 |
+
for i0, i1 in zip(range(s - count, s), range(s, i)):
|
| 1749 |
+
if len(all_words[i0].word) < len(all_words[i1].word):
|
| 1750 |
+
all_words[i1].start = all_words[i0].start
|
| 1751 |
+
all_words[i1].end = all_words[i0].end
|
| 1752 |
+
_sid, _wid = all_words[i0].segment_id, all_words[i0].id
|
| 1753 |
+
self.segments[_sid].words[_wid] = all_words[i1]
|
| 1754 |
+
|
| 1755 |
+
if changes:
|
| 1756 |
+
print('\n'.join(reversed(changes)))
|
| 1757 |
+
|
| 1758 |
+
self.remove_no_word_segments()
|
| 1759 |
+
self.update_all_segs_with_words()
|
| 1760 |
+
|
| 1761 |
+
return self
|
| 1762 |
+
|
| 1763 |
+
def remove_words_by_str(
|
| 1764 |
+
self,
|
| 1765 |
+
words: Union[str, List[str], None],
|
| 1766 |
+
case_sensitive: bool = False,
|
| 1767 |
+
strip: bool = True,
|
| 1768 |
+
ignore_punctuations: str = "\"',.?!",
|
| 1769 |
+
min_prob: float = None,
|
| 1770 |
+
filters: Callable = None,
|
| 1771 |
+
verbose: bool = True
|
| 1772 |
+
) -> 'WhisperResult':
|
| 1773 |
+
"""
|
| 1774 |
+
Remove words that match ``words``.
|
| 1775 |
+
|
| 1776 |
+
Parameters
|
| 1777 |
+
----------
|
| 1778 |
+
words : str or list of str or None
|
| 1779 |
+
A word or list of words to remove.``None`` for all words to be passed into ``filters``.
|
| 1780 |
+
case_sensitive : bool, default False
|
| 1781 |
+
Whether the case of words need to match to be considered as repetition.
|
| 1782 |
+
strip : bool, default True
|
| 1783 |
+
Whether to ignore spaces before and after each word.
|
| 1784 |
+
ignore_punctuations : bool, default '"',.?!'
|
| 1785 |
+
Ending punctuations to ignore.
|
| 1786 |
+
min_prob : float, optional
|
| 1787 |
+
Acts as the first filter the for the words that match ``words``. Words with probability < ``min_prob`` will
|
| 1788 |
+
be removed if ``filters`` is ``None``, else pass the words into ``filters``. Words without probability will
|
| 1789 |
+
be treated as having probability < ``min_prob``.
|
| 1790 |
+
filters : Callable, optional
|
| 1791 |
+
A function that takes an instance of :class:`stable_whisper.result.WordTiming` as its only argument.
|
| 1792 |
+
This function is custom filter for the words that match ``words`` and were not caught by ``min_prob``.
|
| 1793 |
+
verbose:
|
| 1794 |
+
Whether to print detail of the removed words.
|
| 1795 |
+
|
| 1796 |
+
Returns
|
| 1797 |
+
-------
|
| 1798 |
+
stable_whisper.result.WhisperResult
|
| 1799 |
+
The current instance after the changes.
|
| 1800 |
+
"""
|
| 1801 |
+
if not self.has_words:
|
| 1802 |
+
return self
|
| 1803 |
+
if isinstance(words, str):
|
| 1804 |
+
words = [words]
|
| 1805 |
+
all_words = self.all_words()
|
| 1806 |
+
all_words_str = [w.word for w in all_words]
|
| 1807 |
+
if strip:
|
| 1808 |
+
all_words_str = [w.strip() for w in all_words_str]
|
| 1809 |
+
words = [w.strip() for w in words]
|
| 1810 |
+
if ignore_punctuations:
|
| 1811 |
+
ptn = f'[{ignore_punctuations}]+$'
|
| 1812 |
+
all_words_str = [re.sub(ptn, '', w) for w in all_words_str]
|
| 1813 |
+
words = [re.sub(ptn, '', w) for w in words]
|
| 1814 |
+
if not case_sensitive:
|
| 1815 |
+
all_words_str = [w.lower() for w in all_words_str]
|
| 1816 |
+
words = [w.lower() for w in words]
|
| 1817 |
+
|
| 1818 |
+
changes = []
|
| 1819 |
+
for i, w in reversed(list(enumerate(all_words_str))):
|
| 1820 |
+
if not (words is None or any(w == _w for _w in words)):
|
| 1821 |
+
continue
|
| 1822 |
+
if (
|
| 1823 |
+
(min_prob is None or all_words[i].probability is None or min_prob > all_words[i].probability) and
|
| 1824 |
+
(filters is None or filters(all_words[i]))
|
| 1825 |
+
):
|
| 1826 |
+
if verbose:
|
| 1827 |
+
changes.append(f'Removed: {all_words[i].to_dict()}')
|
| 1828 |
+
self.remove_word(all_words[i], False, verbose=False)
|
| 1829 |
+
if changes:
|
| 1830 |
+
print('\n'.join(reversed(changes)))
|
| 1831 |
+
self.remove_no_word_segments()
|
| 1832 |
+
self.update_all_segs_with_words()
|
| 1833 |
+
|
| 1834 |
+
return self
|
| 1835 |
+
|
| 1836 |
+
def fill_in_gaps(
|
| 1837 |
+
self,
|
| 1838 |
+
other_result: Union['WhisperResult', str],
|
| 1839 |
+
min_gap: float = 0.1,
|
| 1840 |
+
case_sensitive: bool = False,
|
| 1841 |
+
strip: bool = True,
|
| 1842 |
+
ignore_punctuations: str = "\"',.?!",
|
| 1843 |
+
verbose: bool = True
|
| 1844 |
+
) -> 'WhisperResult':
|
| 1845 |
+
"""
|
| 1846 |
+
Fill in segment gaps larger than ``min_gap`` with content from ``other_result`` at the times of gaps.
|
| 1847 |
+
|
| 1848 |
+
Parameters
|
| 1849 |
+
----------
|
| 1850 |
+
other_result : WhisperResult or str
|
| 1851 |
+
Another transcription result as an instance of :class:`stable_whisper.result.WhisperResult` or path to the
|
| 1852 |
+
JSON of the result.
|
| 1853 |
+
min_gap : float, default 0.1
|
| 1854 |
+
The minimum seconds of a gap between segments that must be exceeded to be filled in.
|
| 1855 |
+
case_sensitive : bool, default False
|
| 1856 |
+
Whether to consider the case of the first and last word of the gap to determine overlapping words to remove
|
| 1857 |
+
before filling in.
|
| 1858 |
+
strip : bool, default True
|
| 1859 |
+
Whether to ignore spaces before and after the first and last word of the gap to determine overlapping words
|
| 1860 |
+
to remove before filling in.
|
| 1861 |
+
ignore_punctuations : bool, default '"',.?!'
|
| 1862 |
+
Ending punctuations to ignore in the first and last word of the gap to determine overlapping words to
|
| 1863 |
+
remove before filling in.
|
| 1864 |
+
verbose:
|
| 1865 |
+
Whether to print detail of the filled content.
|
| 1866 |
+
|
| 1867 |
+
Returns
|
| 1868 |
+
-------
|
| 1869 |
+
stable_whisper.result.WhisperResult
|
| 1870 |
+
The current instance after the changes.
|
| 1871 |
+
"""
|
| 1872 |
+
if len(self.segments) < 2:
|
| 1873 |
+
return self
|
| 1874 |
+
if isinstance(other_result, str):
|
| 1875 |
+
other_result = WhisperResult(other_result)
|
| 1876 |
+
|
| 1877 |
+
if strip:
|
| 1878 |
+
def strip_space(w):
|
| 1879 |
+
return w.strip()
|
| 1880 |
+
else:
|
| 1881 |
+
def strip_space(w):
|
| 1882 |
+
return w
|
| 1883 |
+
|
| 1884 |
+
if ignore_punctuations:
|
| 1885 |
+
ptn = f'[{ignore_punctuations}]+$'
|
| 1886 |
+
|
| 1887 |
+
def strip_punctuations(w):
|
| 1888 |
+
return re.sub(ptn, '', strip_space(w))
|
| 1889 |
+
else:
|
| 1890 |
+
strip_punctuations = strip_space
|
| 1891 |
+
|
| 1892 |
+
if case_sensitive:
|
| 1893 |
+
strip = strip_punctuations
|
| 1894 |
+
else:
|
| 1895 |
+
def strip(w):
|
| 1896 |
+
return strip_punctuations(w).lower()
|
| 1897 |
+
|
| 1898 |
+
seg_pairs = list(enumerate(zip(self.segments[:-1], self.segments[1:])))
|
| 1899 |
+
seg_pairs.insert(0, (-1, (None, self.segments[0])))
|
| 1900 |
+
seg_pairs.append((seg_pairs[-1][0]+1, (self.segments[-1], None)))
|
| 1901 |
+
|
| 1902 |
+
changes = []
|
| 1903 |
+
for i, (seg0, seg1) in reversed(seg_pairs):
|
| 1904 |
+
first_word = None if seg0 is None else seg0.words[-1]
|
| 1905 |
+
last_word = None if seg1 is None else seg1.words[0]
|
| 1906 |
+
start = (other_result[0].start if first_word is None else first_word.end)
|
| 1907 |
+
end = other_result[-1].end if last_word is None else last_word.start
|
| 1908 |
+
if end - start <= min_gap:
|
| 1909 |
+
continue
|
| 1910 |
+
gap_words = other_result.get_content_by_time((start, end))
|
| 1911 |
+
if first_word is not None and gap_words and strip(first_word.word) == strip(gap_words[0].word):
|
| 1912 |
+
first_word.end = gap_words[0].end
|
| 1913 |
+
gap_words = gap_words[1:]
|
| 1914 |
+
if last_word is not None and gap_words and strip(last_word.word) == strip(gap_words[-1].word):
|
| 1915 |
+
last_word.start = gap_words[-1].start
|
| 1916 |
+
gap_words = gap_words[:-1]
|
| 1917 |
+
if not gap_words:
|
| 1918 |
+
continue
|
| 1919 |
+
if last_word is not None and last_word.start < gap_words[-1].end:
|
| 1920 |
+
last_word.start = gap_words[-1].end
|
| 1921 |
+
new_segments = [other_result[gap_words[0].segment_id].copy([])]
|
| 1922 |
+
for j, new_word in enumerate(gap_words):
|
| 1923 |
+
new_word = deepcopy(new_word)
|
| 1924 |
+
if j == 0 and first_word is not None and first_word.end > gap_words[0].start:
|
| 1925 |
+
new_word.start = first_word.end
|
| 1926 |
+
if new_segments[-1].id != new_word.segment_id:
|
| 1927 |
+
new_segments.append(other_result[new_word.segment_id].copy([]))
|
| 1928 |
+
new_segments[-1].words.append(new_word)
|
| 1929 |
+
if verbose:
|
| 1930 |
+
changes.append('\n'.join('Added: ' + s.to_display_str(True) for s in new_segments))
|
| 1931 |
+
self.segments = self.segments[:i+1] + new_segments + self.segments[i+1:]
|
| 1932 |
+
if changes:
|
| 1933 |
+
print('\n'.join(reversed(changes)))
|
| 1934 |
+
self.reassign_ids()
|
| 1935 |
+
self.update_all_segs_with_words()
|
| 1936 |
+
|
| 1937 |
+
return self
|
| 1938 |
+
|
| 1939 |
+
def regroup(
|
| 1940 |
+
self,
|
| 1941 |
+
regroup_algo: Union[str, bool] = None,
|
| 1942 |
+
verbose: bool = False,
|
| 1943 |
+
only_show: bool = False
|
| 1944 |
+
) -> "WhisperResult":
|
| 1945 |
+
"""
|
| 1946 |
+
Regroup (in-place) words into segments.
|
| 1947 |
+
|
| 1948 |
+
Parameters
|
| 1949 |
+
----------
|
| 1950 |
+
regroup_algo: str or bool, default 'da'
|
| 1951 |
+
String representation of a custom regrouping algorithm or ``True`` use to the default algorithm 'da'.
|
| 1952 |
+
verbose : bool, default False
|
| 1953 |
+
Whether to show all the methods and arguments parsed from ``regroup_algo``.
|
| 1954 |
+
only_show : bool, default False
|
| 1955 |
+
Whether to show the all methods and arguments parsed from ``regroup_algo`` without running the methods
|
| 1956 |
+
|
| 1957 |
+
Returns
|
| 1958 |
+
-------
|
| 1959 |
+
stable_whisper.result.WhisperResult
|
| 1960 |
+
The current instance after the changes.
|
| 1961 |
+
|
| 1962 |
+
Notes
|
| 1963 |
+
-----
|
| 1964 |
+
Syntax for string representation of custom regrouping algorithm.
|
| 1965 |
+
Method keys:
|
| 1966 |
+
sg: split_by_gap
|
| 1967 |
+
sp: split_by_punctuation
|
| 1968 |
+
sl: split_by_length
|
| 1969 |
+
sd: split_by_duration
|
| 1970 |
+
mg: merge_by_gap
|
| 1971 |
+
mp: merge_by_punctuation
|
| 1972 |
+
ms: merge_all_segment
|
| 1973 |
+
cm: clamp_max
|
| 1974 |
+
l: lock
|
| 1975 |
+
us: unlock_all_segments
|
| 1976 |
+
da: default algorithm (cm_sp=.* /。/?/?/,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?)
|
| 1977 |
+
rw: remove_word
|
| 1978 |
+
rs: remove_segment
|
| 1979 |
+
rp: remove_repetition
|
| 1980 |
+
rws: remove_words_by_str
|
| 1981 |
+
fg: fill_in_gaps
|
| 1982 |
+
Metacharacters:
|
| 1983 |
+
= separates a method key and its arguments (not used if no argument)
|
| 1984 |
+
_ separates method keys (after arguments if there are any)
|
| 1985 |
+
+ separates arguments for a method key
|
| 1986 |
+
/ separates an argument into list of strings
|
| 1987 |
+
* separates an item in list of strings into a nested list of strings
|
| 1988 |
+
Notes:
|
| 1989 |
+
-arguments are parsed positionally
|
| 1990 |
+
-if no argument is provided, the default ones will be used
|
| 1991 |
+
-use 1 or 0 to represent True or False
|
| 1992 |
+
Example 1:
|
| 1993 |
+
merge_by_gap(.2, 10, lock=True)
|
| 1994 |
+
mg=.2+10+++1
|
| 1995 |
+
Note: [lock] is the 5th argument hence the 2 missing arguments inbetween the three + before 1
|
| 1996 |
+
Example 2:
|
| 1997 |
+
split_by_punctuation([('.', ' '), '。', '?', '?'], True)
|
| 1998 |
+
sp=.* /。/?/?+1
|
| 1999 |
+
Example 3:
|
| 2000 |
+
merge_all_segments().split_by_gap(.5).merge_by_gap(.15, 3)
|
| 2001 |
+
ms_sg=.5_mg=.15+3
|
| 2002 |
+
"""
|
| 2003 |
+
if regroup_algo is False:
|
| 2004 |
+
return self
|
| 2005 |
+
if regroup_algo is None or regroup_algo is True:
|
| 2006 |
+
regroup_algo = 'da'
|
| 2007 |
+
|
| 2008 |
+
for method, kwargs, msg in self.parse_regroup_algo(regroup_algo, include_str=verbose or only_show):
|
| 2009 |
+
if msg:
|
| 2010 |
+
print(msg)
|
| 2011 |
+
if not only_show:
|
| 2012 |
+
method(**kwargs)
|
| 2013 |
+
|
| 2014 |
+
return self
|
| 2015 |
+
|
| 2016 |
+
def parse_regroup_algo(self, regroup_algo: str, include_str: bool = True) -> List[Tuple[Callable, dict, str]]:
|
| 2017 |
+
methods = dict(
|
| 2018 |
+
sg=self.split_by_gap,
|
| 2019 |
+
sp=self.split_by_punctuation,
|
| 2020 |
+
sl=self.split_by_length,
|
| 2021 |
+
sd=self.split_by_duration,
|
| 2022 |
+
mg=self.merge_by_gap,
|
| 2023 |
+
mp=self.merge_by_punctuation,
|
| 2024 |
+
ms=self.merge_all_segments,
|
| 2025 |
+
cm=self.clamp_max,
|
| 2026 |
+
us=self.unlock_all_segments,
|
| 2027 |
+
l=self.lock,
|
| 2028 |
+
rw=self.remove_word,
|
| 2029 |
+
rs=self.remove_segment,
|
| 2030 |
+
rp=self.remove_repetition,
|
| 2031 |
+
rws=self.remove_words_by_str,
|
| 2032 |
+
fg=self.fill_in_gaps,
|
| 2033 |
+
)
|
| 2034 |
+
if not regroup_algo:
|
| 2035 |
+
return []
|
| 2036 |
+
|
| 2037 |
+
calls = regroup_algo.split('_')
|
| 2038 |
+
if 'da' in calls:
|
| 2039 |
+
default_calls = 'cm_sp=.* /。/?/?/,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?'.split('_')
|
| 2040 |
+
calls = chain.from_iterable(default_calls if method == 'da' else [method] for method in calls)
|
| 2041 |
+
operations = []
|
| 2042 |
+
for method in calls:
|
| 2043 |
+
method, args = method.split('=', maxsplit=1) if '=' in method else (method, '')
|
| 2044 |
+
if method not in methods:
|
| 2045 |
+
raise NotImplementedError(f'{method} is not one of the available methods: {tuple(methods.keys())}')
|
| 2046 |
+
args = [] if len(args) == 0 else list(map(str_to_valid_type, args.split('+')))
|
| 2047 |
+
kwargs = {k: v for k, v in zip(methods[method].__code__.co_varnames[1:], args) if v is not None}
|
| 2048 |
+
if include_str:
|
| 2049 |
+
kwargs_str = ', '.join(f'{k}="{v}"' if isinstance(v, str) else f'{k}={v}' for k, v in kwargs.items())
|
| 2050 |
+
op_str = f'{methods[method].__name__}({kwargs_str})'
|
| 2051 |
+
else:
|
| 2052 |
+
op_str = None
|
| 2053 |
+
operations.append((methods[method], kwargs, op_str))
|
| 2054 |
+
|
| 2055 |
+
return operations
|
| 2056 |
+
|
| 2057 |
+
def find(self, pattern: str, word_level=True, flags=None) -> "WhisperResultMatches":
|
| 2058 |
+
"""
|
| 2059 |
+
Find segments/words and timestamps with regular expression.
|
| 2060 |
+
|
| 2061 |
+
Parameters
|
| 2062 |
+
----------
|
| 2063 |
+
pattern : str
|
| 2064 |
+
RegEx pattern to search for.
|
| 2065 |
+
word_level : bool, default True
|
| 2066 |
+
Whether to search at word-level.
|
| 2067 |
+
flags : optional
|
| 2068 |
+
RegEx flags.
|
| 2069 |
+
|
| 2070 |
+
Returns
|
| 2071 |
+
-------
|
| 2072 |
+
stable_whisper.result.WhisperResultMatches
|
| 2073 |
+
An instance of :class:`stable_whisper.result.WhisperResultMatches` with word/segment that match ``pattern``.
|
| 2074 |
+
"""
|
| 2075 |
+
return WhisperResultMatches(self).find(pattern, word_level=word_level, flags=flags)
|
| 2076 |
+
|
| 2077 |
+
@property
|
| 2078 |
+
def text(self):
|
| 2079 |
+
return ''.join(s.text for s in self.segments)
|
| 2080 |
+
|
| 2081 |
+
@property
|
| 2082 |
+
def regroup_history(self):
|
| 2083 |
+
# same syntax as ``regroup_algo`` for :meth:``result.WhisperResult.regroup`
|
| 2084 |
+
return self._regroup_history
|
| 2085 |
+
|
| 2086 |
+
@property
|
| 2087 |
+
def nonspeech_sections(self):
|
| 2088 |
+
return self._nonspeech_sections
|
| 2089 |
+
|
| 2090 |
+
def show_regroup_history(self):
|
| 2091 |
+
"""
|
| 2092 |
+
Print details of all regrouping operations that been performed on data.
|
| 2093 |
+
"""
|
| 2094 |
+
if not self._regroup_history:
|
| 2095 |
+
print('Result has no history.')
|
| 2096 |
+
for *_, msg in self.parse_regroup_algo(self._regroup_history):
|
| 2097 |
+
print(f'.{msg}')
|
| 2098 |
+
|
| 2099 |
+
def __len__(self):
|
| 2100 |
+
return len(self.segments)
|
| 2101 |
+
|
| 2102 |
+
def unlock_all_segments(self):
|
| 2103 |
+
for s in self.segments:
|
| 2104 |
+
s.unlock_all_words()
|
| 2105 |
+
return self
|
| 2106 |
+
|
| 2107 |
+
def reset(self):
|
| 2108 |
+
"""
|
| 2109 |
+
Restore all values to that at initialization.
|
| 2110 |
+
"""
|
| 2111 |
+
self.language = self.ori_dict.get('language')
|
| 2112 |
+
self._regroup_history = ''
|
| 2113 |
+
segments = self.ori_dict.get('segments')
|
| 2114 |
+
self.segments: List[Segment] = [Segment(**s) for s in segments] if segments else []
|
| 2115 |
+
if self._forced_order:
|
| 2116 |
+
self.force_order()
|
| 2117 |
+
self.remove_no_word_segments(any(seg.has_words for seg in self.segments))
|
| 2118 |
+
self.update_all_segs_with_words()
|
| 2119 |
+
|
| 2120 |
+
@property
|
| 2121 |
+
def has_words(self):
|
| 2122 |
+
return all(seg.has_words for seg in self.segments)
|
| 2123 |
+
|
| 2124 |
+
to_srt_vtt = result_to_srt_vtt
|
| 2125 |
+
to_ass = result_to_ass
|
| 2126 |
+
to_tsv = result_to_tsv
|
| 2127 |
+
to_txt = result_to_txt
|
| 2128 |
+
save_as_json = save_as_json
|
| 2129 |
+
|
| 2130 |
+
|
| 2131 |
+
class SegmentMatch:
|
| 2132 |
+
|
| 2133 |
+
def __init__(
|
| 2134 |
+
self,
|
| 2135 |
+
segments: Union[List[Segment], Segment],
|
| 2136 |
+
_word_indices: List[List[int]] = None,
|
| 2137 |
+
_text_match: str = None
|
| 2138 |
+
):
|
| 2139 |
+
self.segments = [segments] if isinstance(segments, Segment) else segments
|
| 2140 |
+
self.word_indices = [] if _word_indices is None else _word_indices
|
| 2141 |
+
self.words = [self.segments[i].words[j] for i, indices in enumerate(self.word_indices) for j in indices]
|
| 2142 |
+
if len(self.words) != 0:
|
| 2143 |
+
self.text = ''.join(
|
| 2144 |
+
self.segments[i].words[j].word
|
| 2145 |
+
for i, indices in enumerate(self.word_indices)
|
| 2146 |
+
for j in indices
|
| 2147 |
+
)
|
| 2148 |
+
else:
|
| 2149 |
+
self.text = ''.join(seg.text for seg in self.segments)
|
| 2150 |
+
self.text_match = _text_match
|
| 2151 |
+
|
| 2152 |
+
@property
|
| 2153 |
+
def start(self):
|
| 2154 |
+
return (
|
| 2155 |
+
self.words[0].start
|
| 2156 |
+
if len(self.words) != 0 else
|
| 2157 |
+
(self.segments[0].start if len(self.segments) != 0 else None)
|
| 2158 |
+
)
|
| 2159 |
+
|
| 2160 |
+
@property
|
| 2161 |
+
def end(self):
|
| 2162 |
+
return (
|
| 2163 |
+
self.words[-1].end
|
| 2164 |
+
if len(self.words) != 0 else
|
| 2165 |
+
(self.segments[-1].end if len(self.segments) != 0 else None)
|
| 2166 |
+
)
|
| 2167 |
+
|
| 2168 |
+
def __len__(self):
|
| 2169 |
+
return len(self.segments)
|
| 2170 |
+
|
| 2171 |
+
def __repr__(self):
|
| 2172 |
+
return self.__dict__.__repr__()
|
| 2173 |
+
|
| 2174 |
+
def __str__(self):
|
| 2175 |
+
return self.__dict__.__str__()
|
| 2176 |
+
|
| 2177 |
+
|
| 2178 |
+
class WhisperResultMatches:
|
| 2179 |
+
"""
|
| 2180 |
+
RegEx matches for WhisperResults.
|
| 2181 |
+
"""
|
| 2182 |
+
# Use WhisperResult.find() instead of instantiating this class directly.
|
| 2183 |
+
def __init__(
|
| 2184 |
+
self,
|
| 2185 |
+
matches: Union[List[SegmentMatch], WhisperResult],
|
| 2186 |
+
_segment_indices: List[List[int]] = None
|
| 2187 |
+
):
|
| 2188 |
+
if isinstance(matches, WhisperResult):
|
| 2189 |
+
self.matches = list(map(SegmentMatch, matches.segments))
|
| 2190 |
+
self._segment_indices = [[i] for i in range(len(matches.segments))]
|
| 2191 |
+
else:
|
| 2192 |
+
self.matches = matches
|
| 2193 |
+
assert _segment_indices is not None
|
| 2194 |
+
assert len(self.matches) == len(_segment_indices)
|
| 2195 |
+
assert all(len(match.segments) == len(_segment_indices[i]) for i, match in enumerate(self.matches))
|
| 2196 |
+
self._segment_indices = _segment_indices
|
| 2197 |
+
|
| 2198 |
+
@property
|
| 2199 |
+
def segment_indices(self):
|
| 2200 |
+
return self._segment_indices
|
| 2201 |
+
|
| 2202 |
+
def _curr_seg_groups(self) -> List[List[Tuple[int, Segment]]]:
|
| 2203 |
+
seg_groups, curr_segs = [], []
|
| 2204 |
+
curr_max = -1
|
| 2205 |
+
for seg_indices, match in zip(self._segment_indices, self.matches):
|
| 2206 |
+
for i, seg in zip(sorted(seg_indices), match.segments):
|
| 2207 |
+
if i > curr_max:
|
| 2208 |
+
curr_segs.append((i, seg))
|
| 2209 |
+
if i - 1 != curr_max:
|
| 2210 |
+
seg_groups.append(curr_segs)
|
| 2211 |
+
curr_segs = []
|
| 2212 |
+
curr_max = i
|
| 2213 |
+
|
| 2214 |
+
if curr_segs:
|
| 2215 |
+
seg_groups.append(curr_segs)
|
| 2216 |
+
return seg_groups
|
| 2217 |
+
|
| 2218 |
+
def find(self, pattern: str, word_level=True, flags=None) -> "WhisperResultMatches":
|
| 2219 |
+
"""
|
| 2220 |
+
Find segments/words and timestamps with regular expression.
|
| 2221 |
+
|
| 2222 |
+
Parameters
|
| 2223 |
+
----------
|
| 2224 |
+
pattern : str
|
| 2225 |
+
RegEx pattern to search for.
|
| 2226 |
+
word_level : bool, default True
|
| 2227 |
+
Whether to search at word-level.
|
| 2228 |
+
flags : optional
|
| 2229 |
+
RegEx flags.
|
| 2230 |
+
|
| 2231 |
+
Returns
|
| 2232 |
+
-------
|
| 2233 |
+
stable_whisper.result.WhisperResultMatches
|
| 2234 |
+
An instance of :class:`stable_whisper.result.WhisperResultMatches` with word/segment that match ``pattern``.
|
| 2235 |
+
"""
|
| 2236 |
+
|
| 2237 |
+
seg_groups = self._curr_seg_groups()
|
| 2238 |
+
matches: List[SegmentMatch] = []
|
| 2239 |
+
match_seg_indices: List[List[int]] = []
|
| 2240 |
+
if word_level:
|
| 2241 |
+
if not all(all(seg.has_words for seg in match.segments) for match in self.matches):
|
| 2242 |
+
warnings.warn('Cannot perform word-level search with segment(s) missing word timestamps.')
|
| 2243 |
+
word_level = False
|
| 2244 |
+
|
| 2245 |
+
for segs in seg_groups:
|
| 2246 |
+
if word_level:
|
| 2247 |
+
idxs = list(chain.from_iterable(
|
| 2248 |
+
[(i, j)]*len(word.word) for (i, seg) in segs for j, word in enumerate(seg.words)
|
| 2249 |
+
))
|
| 2250 |
+
text = ''.join(word.word for (_, seg) in segs for word in seg.words)
|
| 2251 |
+
else:
|
| 2252 |
+
idxs = list(chain.from_iterable([(i, None)]*len(seg.text) for (i, seg) in segs))
|
| 2253 |
+
text = ''.join(seg.text for (_, seg) in segs)
|
| 2254 |
+
assert len(idxs) == len(text)
|
| 2255 |
+
for curr_match in re.finditer(pattern, text, flags=flags or 0):
|
| 2256 |
+
start, end = curr_match.span()
|
| 2257 |
+
curr_idxs = idxs[start: end]
|
| 2258 |
+
curr_seg_idxs = sorted(set(i[0] for i in curr_idxs))
|
| 2259 |
+
if word_level:
|
| 2260 |
+
curr_word_idxs = [
|
| 2261 |
+
sorted(set(j for i, j in curr_idxs if i == seg_idx))
|
| 2262 |
+
for seg_idx in curr_seg_idxs
|
| 2263 |
+
]
|
| 2264 |
+
else:
|
| 2265 |
+
curr_word_idxs = None
|
| 2266 |
+
matches.append(SegmentMatch(
|
| 2267 |
+
segments=[s for i, s in segs if i in curr_seg_idxs],
|
| 2268 |
+
_word_indices=curr_word_idxs,
|
| 2269 |
+
_text_match=curr_match.group()
|
| 2270 |
+
))
|
| 2271 |
+
match_seg_indices.append(curr_seg_idxs)
|
| 2272 |
+
return WhisperResultMatches(matches, match_seg_indices)
|
| 2273 |
+
|
| 2274 |
+
def __len__(self):
|
| 2275 |
+
return len(self.matches)
|
| 2276 |
+
|
| 2277 |
+
def __bool__(self):
|
| 2278 |
+
return self.__len__() != 0
|
| 2279 |
+
|
| 2280 |
+
def __getitem__(self, idx):
|
| 2281 |
+
return self.matches[idx]
|
stable_whisper/stabilization.py
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
from typing import List, Union, Tuple, Optional
|
| 3 |
+
from itertools import chain
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
from whisper.audio import TOKENS_PER_SECOND, SAMPLE_RATE, N_SAMPLES_PER_TOKEN
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
NONVAD_SAMPLE_RATES = (16000,)
|
| 13 |
+
VAD_SAMPLE_RATES = (16000, 8000)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def is_ascending_sequence(
|
| 17 |
+
seq: List[Union[int, float]],
|
| 18 |
+
verbose=True
|
| 19 |
+
) -> bool:
|
| 20 |
+
"""
|
| 21 |
+
check if a sequence of numbers are in ascending order
|
| 22 |
+
"""
|
| 23 |
+
is_ascending = True
|
| 24 |
+
for idx, (i, j) in enumerate(zip(seq[:-1], seq[1:])):
|
| 25 |
+
if i > j:
|
| 26 |
+
is_ascending = False
|
| 27 |
+
if verbose:
|
| 28 |
+
print(f'[Index{idx}]:{i} > [Index{idx + 1}]:{j}')
|
| 29 |
+
else:
|
| 30 |
+
break
|
| 31 |
+
|
| 32 |
+
return is_ascending
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def valid_ts(
|
| 36 |
+
ts: List[dict],
|
| 37 |
+
warn=True
|
| 38 |
+
) -> bool:
|
| 39 |
+
valid = is_ascending_sequence(list(chain.from_iterable([s['start'], s['end']] for s in ts)), False)
|
| 40 |
+
if warn and not valid:
|
| 41 |
+
warnings.warn(message='Found timestamp(s) jumping backwards in time. '
|
| 42 |
+
'Use word_timestamps=True to avoid the issue.')
|
| 43 |
+
return valid
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def mask2timing(
|
| 47 |
+
silence_mask: (np.ndarray, torch.Tensor),
|
| 48 |
+
time_offset: float = 0.0,
|
| 49 |
+
) -> (Tuple[np.ndarray, np.ndarray], None):
|
| 50 |
+
if silence_mask is None or not silence_mask.any():
|
| 51 |
+
return
|
| 52 |
+
assert silence_mask.ndim == 1
|
| 53 |
+
if isinstance(silence_mask, torch.Tensor):
|
| 54 |
+
silences = silence_mask.cpu().numpy().copy()
|
| 55 |
+
elif isinstance(silence_mask, np.ndarray):
|
| 56 |
+
silences = silence_mask.copy()
|
| 57 |
+
else:
|
| 58 |
+
raise NotImplementedError(f'Expected torch.Tensor or numpy.ndarray, but got {type(silence_mask)}')
|
| 59 |
+
silences[0] = False
|
| 60 |
+
silences[-1] = False
|
| 61 |
+
silent_starts = np.logical_and(~silences[:-1], silences[1:]).nonzero()[0] / TOKENS_PER_SECOND
|
| 62 |
+
silent_ends = (np.logical_and(silences[:-1], ~silences[1:]).nonzero()[0] + 1) / TOKENS_PER_SECOND
|
| 63 |
+
if time_offset:
|
| 64 |
+
silent_starts += time_offset
|
| 65 |
+
silent_ends += time_offset
|
| 66 |
+
return silent_starts, silent_ends
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def timing2mask(
|
| 70 |
+
silent_starts: np.ndarray,
|
| 71 |
+
silent_ends: np.ndarray,
|
| 72 |
+
size: int,
|
| 73 |
+
time_offset: float = None
|
| 74 |
+
) -> torch.Tensor:
|
| 75 |
+
assert len(silent_starts) == len(silent_ends)
|
| 76 |
+
ts_token_mask = torch.zeros(size, dtype=torch.bool)
|
| 77 |
+
if time_offset:
|
| 78 |
+
silent_starts = (silent_starts - time_offset).clip(min=0)
|
| 79 |
+
silent_ends = (silent_ends - time_offset).clip(min=0)
|
| 80 |
+
mask_i = (silent_starts * TOKENS_PER_SECOND).round().astype(np.int16)
|
| 81 |
+
mask_e = (silent_ends * TOKENS_PER_SECOND).round().astype(np.int16)
|
| 82 |
+
for mi, me in zip(mask_i, mask_e):
|
| 83 |
+
ts_token_mask[mi:me+1] = True
|
| 84 |
+
|
| 85 |
+
return ts_token_mask
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def suppress_silence(
|
| 89 |
+
result_obj,
|
| 90 |
+
silent_starts: Union[np.ndarray, List[float]],
|
| 91 |
+
silent_ends: Union[np.ndarray, List[float]],
|
| 92 |
+
min_word_dur: float,
|
| 93 |
+
nonspeech_error: float = 0.3,
|
| 94 |
+
keep_end: Optional[bool] = True
|
| 95 |
+
):
|
| 96 |
+
assert len(silent_starts) == len(silent_ends)
|
| 97 |
+
if len(silent_starts) == 0 or (result_obj.end - result_obj.start) <= min_word_dur:
|
| 98 |
+
return
|
| 99 |
+
if isinstance(silent_starts, list):
|
| 100 |
+
silent_starts = np.array(silent_starts)
|
| 101 |
+
if isinstance(silent_ends, list):
|
| 102 |
+
silent_ends = np.array(silent_ends)
|
| 103 |
+
|
| 104 |
+
start_overlaps = np.all(
|
| 105 |
+
(silent_starts <= result_obj.start, result_obj.start < silent_ends, silent_ends <= result_obj.end),
|
| 106 |
+
axis=0
|
| 107 |
+
).nonzero()[0].tolist()
|
| 108 |
+
if start_overlaps:
|
| 109 |
+
new_start = silent_ends[start_overlaps[0]]
|
| 110 |
+
result_obj.start = min(new_start, round(result_obj.end - min_word_dur, 3))
|
| 111 |
+
if (result_obj.end - result_obj.start) <= min_word_dur:
|
| 112 |
+
return
|
| 113 |
+
|
| 114 |
+
end_overlaps = np.all(
|
| 115 |
+
(result_obj.start <= silent_starts, silent_starts < result_obj.end, result_obj.end <= silent_ends),
|
| 116 |
+
axis=0
|
| 117 |
+
).nonzero()[0].tolist()
|
| 118 |
+
if end_overlaps:
|
| 119 |
+
new_end = silent_starts[end_overlaps[0]]
|
| 120 |
+
result_obj.end = max(new_end, round(result_obj.start + min_word_dur, 3))
|
| 121 |
+
if (result_obj.end - result_obj.start) <= min_word_dur:
|
| 122 |
+
return
|
| 123 |
+
|
| 124 |
+
if nonspeech_error:
|
| 125 |
+
matches = np.logical_and(
|
| 126 |
+
result_obj.start <= silent_starts,
|
| 127 |
+
result_obj.end >= silent_ends,
|
| 128 |
+
).nonzero()[0].tolist()
|
| 129 |
+
if len(matches) == 0:
|
| 130 |
+
return
|
| 131 |
+
silence_start = np.min(silent_starts[matches])
|
| 132 |
+
silence_end = np.max(silent_ends[matches])
|
| 133 |
+
start_extra = silence_start - result_obj.start
|
| 134 |
+
end_extra = result_obj.end - silence_end
|
| 135 |
+
silent_duration = silence_end - silence_start
|
| 136 |
+
start_within_error = (start_extra / silent_duration) <= nonspeech_error
|
| 137 |
+
end_within_error = (end_extra / silent_duration) <= nonspeech_error
|
| 138 |
+
if keep_end is None:
|
| 139 |
+
keep_end = start_extra <= end_extra
|
| 140 |
+
within_error = start_within_error if keep_end else end_within_error
|
| 141 |
+
else:
|
| 142 |
+
within_error = start_within_error or end_within_error
|
| 143 |
+
|
| 144 |
+
if within_error:
|
| 145 |
+
if keep_end:
|
| 146 |
+
result_obj.start = min(silence_end, round(result_obj.end - min_word_dur, 3))
|
| 147 |
+
else:
|
| 148 |
+
result_obj.end = max(silence_start, round(result_obj.start + min_word_dur, 3))
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def standardize_audio(
|
| 152 |
+
audio: Union[torch.Tensor, np.ndarray, str, bytes],
|
| 153 |
+
resample_sr: Tuple[Optional[int], Union[int, Tuple[int]]] = None
|
| 154 |
+
) -> torch.Tensor:
|
| 155 |
+
if isinstance(audio, (str, bytes)):
|
| 156 |
+
from .audio import load_audio
|
| 157 |
+
audio = load_audio(audio)
|
| 158 |
+
if isinstance(audio, np.ndarray):
|
| 159 |
+
audio = torch.from_numpy(audio)
|
| 160 |
+
audio = audio.float()
|
| 161 |
+
if resample_sr:
|
| 162 |
+
in_sr, out_sr = resample_sr
|
| 163 |
+
if in_sr:
|
| 164 |
+
if isinstance(out_sr, int):
|
| 165 |
+
out_sr = [out_sr]
|
| 166 |
+
if in_sr not in out_sr:
|
| 167 |
+
from torchaudio.functional import resample
|
| 168 |
+
audio = resample(audio, in_sr, out_sr[0])
|
| 169 |
+
|
| 170 |
+
return audio
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def audio2loudness(
|
| 174 |
+
audio_tensor: torch.Tensor
|
| 175 |
+
) -> (torch.Tensor, None):
|
| 176 |
+
assert audio_tensor.dim() == 1, f'waveform must be 1D, but got {audio_tensor.dim()}D'
|
| 177 |
+
audio_tensor = audio_tensor.abs()
|
| 178 |
+
k = int(audio_tensor.numel() * 0.001)
|
| 179 |
+
if k:
|
| 180 |
+
top_values, _ = torch.topk(audio_tensor, k)
|
| 181 |
+
threshold = top_values[-1]
|
| 182 |
+
else:
|
| 183 |
+
threshold = audio_tensor.quantile(0.999, dim=-1)
|
| 184 |
+
if (token_count := round(audio_tensor.shape[-1] / N_SAMPLES_PER_TOKEN)+1) > 2:
|
| 185 |
+
if threshold < 1e-5:
|
| 186 |
+
return torch.zeros(token_count, dtype=audio_tensor.dtype, device=audio_tensor.device)
|
| 187 |
+
audio_tensor = audio_tensor / min(1., threshold * 1.75)
|
| 188 |
+
audio_tensor = F.interpolate(
|
| 189 |
+
audio_tensor[None, None],
|
| 190 |
+
size=token_count,
|
| 191 |
+
mode='linear',
|
| 192 |
+
align_corners=False
|
| 193 |
+
)[0, 0]
|
| 194 |
+
return audio_tensor
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def visualize_mask(
|
| 198 |
+
loudness_tensor: torch.Tensor,
|
| 199 |
+
silence_mask: torch.Tensor = None,
|
| 200 |
+
width: int = 1500,
|
| 201 |
+
height: int = 200,
|
| 202 |
+
output: str = None,
|
| 203 |
+
):
|
| 204 |
+
no_silence = silence_mask is None or not silence_mask.any()
|
| 205 |
+
assert no_silence or silence_mask.shape[0] == loudness_tensor.shape[0]
|
| 206 |
+
if loudness_tensor.shape[0] < 2:
|
| 207 |
+
raise NotImplementedError(f'audio size, {loudness_tensor.shape[0]}, is too short to visualize')
|
| 208 |
+
else:
|
| 209 |
+
width = loudness_tensor.shape[0] if width == -1 else width
|
| 210 |
+
im = torch.zeros((height, width, 3), dtype=torch.uint8)
|
| 211 |
+
mid = round(height / 2)
|
| 212 |
+
for i, j in enumerate(loudness_tensor.tolist()):
|
| 213 |
+
j = round(abs(j) * mid)
|
| 214 |
+
if j == 0 or width <= i:
|
| 215 |
+
continue
|
| 216 |
+
im[mid - j:mid + 1, i] = 255
|
| 217 |
+
im[mid + 1:mid + j + 1, i] = 255
|
| 218 |
+
if not no_silence:
|
| 219 |
+
im[:, silence_mask[:width], 1:] = 0
|
| 220 |
+
im = im.cpu().numpy()
|
| 221 |
+
if output and not output.endswith('.png'):
|
| 222 |
+
output += '.png'
|
| 223 |
+
try:
|
| 224 |
+
from PIL import Image
|
| 225 |
+
except ModuleNotFoundError:
|
| 226 |
+
try:
|
| 227 |
+
import cv2
|
| 228 |
+
except ModuleNotFoundError:
|
| 229 |
+
raise ModuleNotFoundError('Failed to import "PIL" or "cv2" to visualize suppression mask. '
|
| 230 |
+
'Try "pip install Pillow" or "pip install opencv-python"')
|
| 231 |
+
else:
|
| 232 |
+
im = im[..., [2, 1, 0]]
|
| 233 |
+
if isinstance(output, str):
|
| 234 |
+
cv2.imwrite(output, im)
|
| 235 |
+
else:
|
| 236 |
+
cv2.imshow('image', im)
|
| 237 |
+
cv2.waitKey(0)
|
| 238 |
+
else:
|
| 239 |
+
im = Image.fromarray(im)
|
| 240 |
+
if isinstance(output, str):
|
| 241 |
+
im.save(output)
|
| 242 |
+
else:
|
| 243 |
+
im.show(im)
|
| 244 |
+
if output:
|
| 245 |
+
print(f'Save: {output}')
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
def wav2mask(
|
| 249 |
+
audio: (torch.Tensor, np.ndarray, str, bytes),
|
| 250 |
+
q_levels: int = 20,
|
| 251 |
+
k_size: int = 5,
|
| 252 |
+
sr: int = None
|
| 253 |
+
) -> (Tuple[torch.Tensor, Tuple[np.ndarray, np.ndarray]], None):
|
| 254 |
+
"""
|
| 255 |
+
Generate 1D mask from waveform for suppressing timestamp tokens.
|
| 256 |
+
"""
|
| 257 |
+
audio = standardize_audio(audio, (sr, NONVAD_SAMPLE_RATES))
|
| 258 |
+
loudness_tensor = audio2loudness(audio)
|
| 259 |
+
if loudness_tensor is None:
|
| 260 |
+
return
|
| 261 |
+
p = k_size // 2 if k_size else 0
|
| 262 |
+
if p and p < loudness_tensor.shape[-1]:
|
| 263 |
+
assert k_size % 2, f'kernel_size must be odd but got {k_size}'
|
| 264 |
+
mask = torch.avg_pool1d(
|
| 265 |
+
F.pad(
|
| 266 |
+
loudness_tensor[None],
|
| 267 |
+
(p, p),
|
| 268 |
+
'reflect'
|
| 269 |
+
),
|
| 270 |
+
kernel_size=k_size,
|
| 271 |
+
stride=1
|
| 272 |
+
)[0]
|
| 273 |
+
else:
|
| 274 |
+
mask = loudness_tensor.clone()
|
| 275 |
+
|
| 276 |
+
if q_levels:
|
| 277 |
+
mask = mask.mul(q_levels).round()
|
| 278 |
+
|
| 279 |
+
mask = mask.bool()
|
| 280 |
+
|
| 281 |
+
if not mask.any(): # entirely silent
|
| 282 |
+
return ~mask
|
| 283 |
+
temp_timings = mask2timing(mask)
|
| 284 |
+
s, e = temp_timings
|
| 285 |
+
se_mask = (e - s) > 0.1
|
| 286 |
+
s = s[se_mask]
|
| 287 |
+
e = e[se_mask]
|
| 288 |
+
mask = ~timing2mask(s, e, loudness_tensor.shape[-1])
|
| 289 |
+
|
| 290 |
+
if not mask.any(): # no silence
|
| 291 |
+
return
|
| 292 |
+
|
| 293 |
+
return mask
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
_model_cache = {}
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
def get_vad_silence_func(
|
| 300 |
+
onnx=False,
|
| 301 |
+
verbose: (bool, None) = False
|
| 302 |
+
):
|
| 303 |
+
if onnx in _model_cache:
|
| 304 |
+
model, get_ts = _model_cache[onnx]
|
| 305 |
+
else:
|
| 306 |
+
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad:master',
|
| 307 |
+
model='silero_vad',
|
| 308 |
+
verbose=verbose,
|
| 309 |
+
onnx=onnx,
|
| 310 |
+
trust_repo=True)
|
| 311 |
+
get_ts = utils[0]
|
| 312 |
+
_model_cache[onnx] = (model, get_ts)
|
| 313 |
+
|
| 314 |
+
warnings.filterwarnings('ignore', message=r'operator \(\) profile_node.*', category=UserWarning)
|
| 315 |
+
|
| 316 |
+
def get_speech_timestamps(wav: torch.Tensor, threshold: float = .35):
|
| 317 |
+
return get_ts(wav, model, threshold, min_speech_duration_ms=100, min_silence_duration_ms=20)
|
| 318 |
+
|
| 319 |
+
def vad_silence_timing(
|
| 320 |
+
audio: (torch.Tensor, np.ndarray, str, bytes),
|
| 321 |
+
speech_threshold: float = .35,
|
| 322 |
+
sr: int = None
|
| 323 |
+
) -> (Tuple[np.ndarray, np.ndarray], None):
|
| 324 |
+
|
| 325 |
+
audio = standardize_audio(audio, (sr, VAD_SAMPLE_RATES))
|
| 326 |
+
|
| 327 |
+
total_duration = round(audio.shape[-1] / SAMPLE_RATE, 3)
|
| 328 |
+
if not total_duration:
|
| 329 |
+
return
|
| 330 |
+
ori_t = torch.get_num_threads()
|
| 331 |
+
if verbose is not None:
|
| 332 |
+
print('Predicting silences(s) with VAD...\r', end='')
|
| 333 |
+
torch.set_num_threads(1) # vad was optimized for single performance
|
| 334 |
+
speech_ts = get_speech_timestamps(audio, speech_threshold)
|
| 335 |
+
if verbose is not None:
|
| 336 |
+
print('Predicted silence(s) with VAD. ')
|
| 337 |
+
torch.set_num_threads(ori_t)
|
| 338 |
+
if len(speech_ts) == 0: # all silent
|
| 339 |
+
return np.array([0.0]), np.array([total_duration])
|
| 340 |
+
silent_starts = []
|
| 341 |
+
silent_ends = []
|
| 342 |
+
for ts in speech_ts:
|
| 343 |
+
start = round(ts['start'] / SAMPLE_RATE, 3)
|
| 344 |
+
end = round(ts['end'] / SAMPLE_RATE, 3)
|
| 345 |
+
if start != 0:
|
| 346 |
+
silent_ends.append(start)
|
| 347 |
+
if len(silent_starts) == 0:
|
| 348 |
+
silent_starts.append(0.0)
|
| 349 |
+
if end < total_duration:
|
| 350 |
+
silent_starts.append(end)
|
| 351 |
+
|
| 352 |
+
if len(silent_starts) == 0 and len(silent_ends) == 0:
|
| 353 |
+
return
|
| 354 |
+
|
| 355 |
+
if len(silent_starts) != 0 and (len(silent_ends) == 0 or silent_ends[-1] < silent_starts[-1]):
|
| 356 |
+
silent_ends.append(total_duration)
|
| 357 |
+
|
| 358 |
+
silent_starts = np.array(silent_starts)
|
| 359 |
+
silent_ends = np.array(silent_ends)
|
| 360 |
+
|
| 361 |
+
return silent_starts, silent_ends
|
| 362 |
+
|
| 363 |
+
return vad_silence_timing
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
def visualize_suppression(
|
| 367 |
+
audio: Union[torch.Tensor, np.ndarray, str, bytes],
|
| 368 |
+
output: str = None,
|
| 369 |
+
q_levels: int = 20,
|
| 370 |
+
k_size: int = 5,
|
| 371 |
+
vad_threshold: float = 0.35,
|
| 372 |
+
vad: bool = False,
|
| 373 |
+
max_width: int = 1500,
|
| 374 |
+
height: int = 200
|
| 375 |
+
):
|
| 376 |
+
"""
|
| 377 |
+
Visualize regions on the waveform of ``audio`` detected as silent.
|
| 378 |
+
|
| 379 |
+
Regions on the waveform colored red are detected as silent.
|
| 380 |
+
|
| 381 |
+
Parameters
|
| 382 |
+
----------
|
| 383 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 384 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 385 |
+
If audio is ``numpy.ndarray`` or ``torch.Tensor``, the audio must be already at sampled to 16kHz.
|
| 386 |
+
output : str, default None, meaning image will be shown directly via Pillow or opencv-python
|
| 387 |
+
Path to save visualization.
|
| 388 |
+
q_levels : int, default 20
|
| 389 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 390 |
+
Acts as a threshold to marking sound as silent.
|
| 391 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 392 |
+
k_size : int, default 5
|
| 393 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 394 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 395 |
+
vad : bool, default False
|
| 396 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 397 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 398 |
+
vad_threshold : float, default 0.35
|
| 399 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 400 |
+
max_width : int, default 1500
|
| 401 |
+
Maximum width of visualization to avoid overly large image from long audio.
|
| 402 |
+
Each unit of pixel is equivalent to 1 token. Use -1 to visualize the entire audio track.
|
| 403 |
+
height : int, default 200
|
| 404 |
+
Height of visualization.
|
| 405 |
+
"""
|
| 406 |
+
max_n_samples = None if max_width == -1 else round(max_width * N_SAMPLES_PER_TOKEN)
|
| 407 |
+
|
| 408 |
+
audio = standardize_audio(audio)
|
| 409 |
+
if max_n_samples is None:
|
| 410 |
+
max_width = audio.shape[-1]
|
| 411 |
+
else:
|
| 412 |
+
audio = audio[:max_n_samples]
|
| 413 |
+
loudness_tensor = audio2loudness(audio)
|
| 414 |
+
width = min(max_width, loudness_tensor.shape[-1])
|
| 415 |
+
if loudness_tensor is None:
|
| 416 |
+
raise NotImplementedError(f'Audio is too short and cannot visualized.')
|
| 417 |
+
|
| 418 |
+
if vad:
|
| 419 |
+
silence_timings = get_vad_silence_func()(audio, vad_threshold)
|
| 420 |
+
silence_mask = None if silence_timings is None else timing2mask(*silence_timings, size=loudness_tensor.shape[0])
|
| 421 |
+
else:
|
| 422 |
+
silence_mask = wav2mask(audio, q_levels=q_levels, k_size=k_size)
|
| 423 |
+
|
| 424 |
+
visualize_mask(loudness_tensor, silence_mask, width=width, height=height, output=output)
|
stable_whisper/text_output.py
ADDED
|
@@ -0,0 +1,620 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import warnings
|
| 4 |
+
from typing import List, Tuple, Union, Callable
|
| 5 |
+
from itertools import chain
|
| 6 |
+
from .stabilization import valid_ts
|
| 7 |
+
|
| 8 |
+
__all__ = ['result_to_srt_vtt', 'result_to_ass', 'result_to_tsv', 'result_to_txt', 'save_as_json', 'load_result']
|
| 9 |
+
SUPPORTED_FORMATS = ('srt', 'vtt', 'ass', 'tsv', 'txt')
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def _save_as_file(content: str, path: str):
|
| 13 |
+
with open(path, 'w', encoding='utf-8') as f:
|
| 14 |
+
f.write(content)
|
| 15 |
+
print(f'Saved: {os.path.abspath(path)}')
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _get_segments(result: (dict, list), min_dur: float, reverse_text: Union[bool, tuple] = False):
|
| 19 |
+
if isinstance(result, dict):
|
| 20 |
+
if reverse_text:
|
| 21 |
+
warnings.warn(f'[reverse_text]=True only applies to WhisperResult but result is {type(result)}')
|
| 22 |
+
return result.get('segments')
|
| 23 |
+
elif not isinstance(result, list) and callable(getattr(result, 'segments_to_dicts', None)):
|
| 24 |
+
return result.apply_min_dur(min_dur, inplace=False).segments_to_dicts(reverse_text=reverse_text)
|
| 25 |
+
return result
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def finalize_text(text: str, strip: bool = True):
|
| 29 |
+
if not strip:
|
| 30 |
+
return text
|
| 31 |
+
return text.strip().replace('\n ', '\n')
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def sec2hhmmss(seconds: (float, int)):
|
| 35 |
+
mm, ss = divmod(seconds, 60)
|
| 36 |
+
hh, mm = divmod(mm, 60)
|
| 37 |
+
return hh, mm, ss
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def sec2milliseconds(seconds: (float, int)) -> int:
|
| 41 |
+
return round(seconds * 1000)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def sec2centiseconds(seconds: (float, int)) -> int:
|
| 45 |
+
return round(seconds * 100)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def sec2vtt(seconds: (float, int)) -> str:
|
| 49 |
+
hh, mm, ss = sec2hhmmss(seconds)
|
| 50 |
+
return f'{hh:0>2.0f}:{mm:0>2.0f}:{ss:0>6.3f}'
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def sec2srt(seconds: (float, int)) -> str:
|
| 54 |
+
return sec2vtt(seconds).replace(".", ",")
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def sec2ass(seconds: (float, int)) -> str:
|
| 58 |
+
hh, mm, ss = sec2hhmmss(seconds)
|
| 59 |
+
return f'{hh:0>1.0f}:{mm:0>2.0f}:{ss:0>2.2f}'
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def segment2vttblock(segment: dict, strip=True) -> str:
|
| 63 |
+
return f'{sec2vtt(segment["start"])} --> {sec2vtt(segment["end"])}\n' \
|
| 64 |
+
f'{finalize_text(segment["text"], strip)}'
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def segment2srtblock(segment: dict, idx: int, strip=True) -> str:
|
| 68 |
+
return f'{idx}\n{sec2srt(segment["start"])} --> {sec2srt(segment["end"])}\n' \
|
| 69 |
+
f'{finalize_text(segment["text"], strip)}'
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def segment2assblock(segment: dict, idx: int, strip=True) -> str:
|
| 73 |
+
return f'Dialogue: {idx},{sec2ass(segment["start"])},{sec2ass(segment["end"])},Default,,0,0,0,,' \
|
| 74 |
+
f'{finalize_text(segment["text"], strip)}'
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def segment2tsvblock(segment: dict, strip=True) -> str:
|
| 78 |
+
return f'{sec2milliseconds(segment["start"])}' \
|
| 79 |
+
f'\t{sec2milliseconds(segment["end"])}' \
|
| 80 |
+
f'\t{segment["text"].strip() if strip else segment["text"]}'
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def words2segments(words: List[dict], tag: Tuple[str, str], reverse_text: bool = False) -> List[dict]:
|
| 84 |
+
def add_tag(idx: int):
|
| 85 |
+
return ''.join(
|
| 86 |
+
(
|
| 87 |
+
f" {tag[0]}{w['word'][1:]}{tag[1]}"
|
| 88 |
+
if w['word'].startswith(' ') else
|
| 89 |
+
f"{tag[0]}{w['word']}{tag[1]}"
|
| 90 |
+
)
|
| 91 |
+
if w['word'] not in ('', ' ') and idx_ == idx else
|
| 92 |
+
w['word']
|
| 93 |
+
for idx_, w in idx_filled_words
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
filled_words = []
|
| 97 |
+
for i, word in enumerate(words):
|
| 98 |
+
curr_end = round(word['end'], 3)
|
| 99 |
+
filled_words.append(dict(word=word['word'], start=round(word['start'], 3), end=curr_end))
|
| 100 |
+
if word != words[-1]:
|
| 101 |
+
next_start = round(words[i + 1]['start'], 3)
|
| 102 |
+
if next_start - curr_end != 0:
|
| 103 |
+
filled_words.append(dict(word='', start=curr_end, end=next_start))
|
| 104 |
+
idx_filled_words = list(enumerate(filled_words))
|
| 105 |
+
if reverse_text:
|
| 106 |
+
idx_filled_words = list(reversed(idx_filled_words))
|
| 107 |
+
|
| 108 |
+
segments = [dict(text=add_tag(i), start=filled_words[i]['start'], end=filled_words[i]['end'])
|
| 109 |
+
for i in range(len(filled_words))]
|
| 110 |
+
return segments
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def to_word_level_segments(segments: List[dict], tag: Tuple[str, str]) -> List[dict]:
|
| 114 |
+
return list(
|
| 115 |
+
chain.from_iterable(
|
| 116 |
+
words2segments(s['words'], tag, reverse_text=s.get('reversed_text'))
|
| 117 |
+
for s in segments
|
| 118 |
+
)
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def to_vtt_word_level_segments(segments: List[dict], tag: Tuple[str, str] = None) -> List[dict]:
|
| 123 |
+
def to_segment_string(segment: dict):
|
| 124 |
+
segment_string = ''
|
| 125 |
+
prev_end = 0
|
| 126 |
+
for i, word in enumerate(segment['words']):
|
| 127 |
+
if i != 0:
|
| 128 |
+
curr_start = word['start']
|
| 129 |
+
if prev_end == curr_start:
|
| 130 |
+
segment_string += f"<{sec2vtt(curr_start)}>"
|
| 131 |
+
else:
|
| 132 |
+
if segment_string.endswith(' '):
|
| 133 |
+
segment_string = segment_string[:-1]
|
| 134 |
+
elif segment['words'][i]['word'].startswith(' '):
|
| 135 |
+
segment['words'][i]['word'] = segment['words'][i]['word'][1:]
|
| 136 |
+
segment_string += f"<{sec2vtt(prev_end)}> <{sec2vtt(curr_start)}>"
|
| 137 |
+
segment_string += word['word']
|
| 138 |
+
prev_end = word['end']
|
| 139 |
+
return segment_string
|
| 140 |
+
|
| 141 |
+
return [
|
| 142 |
+
dict(
|
| 143 |
+
text=to_segment_string(s),
|
| 144 |
+
start=s['start'],
|
| 145 |
+
end=s['end']
|
| 146 |
+
)
|
| 147 |
+
for s in segments
|
| 148 |
+
]
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def to_ass_word_level_segments(segments: List[dict], tag: Tuple[str, str], karaoke: bool = False) -> List[dict]:
|
| 152 |
+
|
| 153 |
+
def to_segment_string(segment: dict):
|
| 154 |
+
segment_string = ''
|
| 155 |
+
for i, word in enumerate(segment['words']):
|
| 156 |
+
curr_word, space = (word['word'][1:], " ") if word['word'].startswith(" ") else (word['word'], "")
|
| 157 |
+
segment_string += (
|
| 158 |
+
space +
|
| 159 |
+
r"{\k" +
|
| 160 |
+
("f" if karaoke else "") +
|
| 161 |
+
f"{sec2centiseconds(word['end']-word['start'])}" +
|
| 162 |
+
r"}" +
|
| 163 |
+
curr_word
|
| 164 |
+
)
|
| 165 |
+
return segment_string
|
| 166 |
+
|
| 167 |
+
return [
|
| 168 |
+
dict(
|
| 169 |
+
text=to_segment_string(s),
|
| 170 |
+
start=s['start'],
|
| 171 |
+
end=s['end']
|
| 172 |
+
)
|
| 173 |
+
for s in segments
|
| 174 |
+
]
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
def to_word_level(segments: List[dict]) -> List[dict]:
|
| 178 |
+
return [dict(text=w['word'], start=w['start'], end=w['end']) for s in segments for w in s['words']]
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def _confirm_word_level(segments: List[dict]) -> bool:
|
| 182 |
+
if not all(bool(s.get('words')) for s in segments):
|
| 183 |
+
warnings.warn('Result is missing word timestamps. Word-level timing cannot be exported. '
|
| 184 |
+
'Use "word_level=False" to avoid this warning')
|
| 185 |
+
return False
|
| 186 |
+
return True
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def _preprocess_args(result: (dict, list),
|
| 190 |
+
segment_level: bool,
|
| 191 |
+
word_level: bool,
|
| 192 |
+
min_dur: float,
|
| 193 |
+
reverse_text: Union[bool, tuple] = False):
|
| 194 |
+
assert segment_level or word_level, '`segment_level` or `word_level` must be True'
|
| 195 |
+
segments = _get_segments(result, min_dur, reverse_text=reverse_text)
|
| 196 |
+
if word_level:
|
| 197 |
+
word_level = _confirm_word_level(segments)
|
| 198 |
+
return segments, segment_level, word_level
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def result_to_any(result: (dict, list),
|
| 202 |
+
filepath: str = None,
|
| 203 |
+
filetype: str = None,
|
| 204 |
+
segments2blocks: Callable = None,
|
| 205 |
+
segment_level=True,
|
| 206 |
+
word_level=True,
|
| 207 |
+
min_dur: float = 0.02,
|
| 208 |
+
tag: Tuple[str, str] = None,
|
| 209 |
+
default_tag: Tuple[str, str] = None,
|
| 210 |
+
strip=True,
|
| 211 |
+
reverse_text: Union[bool, tuple] = False,
|
| 212 |
+
to_word_level_string_callback: Callable = None):
|
| 213 |
+
"""
|
| 214 |
+
Generate file from ``result`` to display segment-level and/or word-level timestamp.
|
| 215 |
+
|
| 216 |
+
Returns
|
| 217 |
+
-------
|
| 218 |
+
str
|
| 219 |
+
String of the content if ``filepath`` is ``None``.
|
| 220 |
+
"""
|
| 221 |
+
segments, segment_level, word_level = _preprocess_args(
|
| 222 |
+
result, segment_level, word_level, min_dur, reverse_text=reverse_text
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
if filetype is None:
|
| 226 |
+
filetype = os.path.splitext(filepath)[-1][1:] or 'srt'
|
| 227 |
+
if filetype.lower() not in SUPPORTED_FORMATS:
|
| 228 |
+
raise NotImplementedError(f'{filetype} not supported')
|
| 229 |
+
if filepath and not filepath.lower().endswith(f'.{filetype}'):
|
| 230 |
+
filepath += f'.{filetype}'
|
| 231 |
+
|
| 232 |
+
if word_level and segment_level:
|
| 233 |
+
if tag is None:
|
| 234 |
+
if default_tag is None:
|
| 235 |
+
tag = ('<font color="#00ff00">', '</font>') if filetype == 'srt' else ('<u>', '</u>')
|
| 236 |
+
else:
|
| 237 |
+
tag = default_tag
|
| 238 |
+
if to_word_level_string_callback is None:
|
| 239 |
+
to_word_level_string_callback = to_word_level_segments
|
| 240 |
+
segments = to_word_level_string_callback(segments, tag)
|
| 241 |
+
elif word_level:
|
| 242 |
+
segments = to_word_level(segments)
|
| 243 |
+
|
| 244 |
+
valid_ts(segments)
|
| 245 |
+
|
| 246 |
+
if segments2blocks is None:
|
| 247 |
+
sub_str = '\n\n'.join(segment2srtblock(s, i, strip=strip) for i, s in enumerate(segments))
|
| 248 |
+
else:
|
| 249 |
+
sub_str = segments2blocks(segments)
|
| 250 |
+
|
| 251 |
+
if filepath:
|
| 252 |
+
_save_as_file(sub_str, filepath)
|
| 253 |
+
else:
|
| 254 |
+
return sub_str
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
def result_to_srt_vtt(result: (dict, list),
|
| 258 |
+
filepath: str = None,
|
| 259 |
+
segment_level=True,
|
| 260 |
+
word_level=True,
|
| 261 |
+
min_dur: float = 0.02,
|
| 262 |
+
tag: Tuple[str, str] = None,
|
| 263 |
+
vtt: bool = None,
|
| 264 |
+
strip=True,
|
| 265 |
+
reverse_text: Union[bool, tuple] = False):
|
| 266 |
+
"""
|
| 267 |
+
Generate SRT/VTT from ``result`` to display segment-level and/or word-level timestamp.
|
| 268 |
+
|
| 269 |
+
Parameters
|
| 270 |
+
----------
|
| 271 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 272 |
+
Result of transcription.
|
| 273 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 274 |
+
Path to save file.
|
| 275 |
+
segment_level : bool, default True
|
| 276 |
+
Whether to use segment-level timestamps in output.
|
| 277 |
+
word_level : bool, default True
|
| 278 |
+
Whether to use word-level timestamps in output.
|
| 279 |
+
min_dur : float, default 0.2
|
| 280 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 281 |
+
tag: tuple of (str, str), default None, meaning ('<font color="#00ff00">', '</font>') if SRT else ('<u>', '</u>')
|
| 282 |
+
Tag used to change the properties a word at its timestamp.
|
| 283 |
+
vtt : bool, default None, meaning determined by extension of ``filepath`` or ``False`` if no valid extension.
|
| 284 |
+
Whether to output VTT.
|
| 285 |
+
strip : bool, default True
|
| 286 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 287 |
+
reverse_text: bool or tuple, default False
|
| 288 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 289 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 290 |
+
|
| 291 |
+
Returns
|
| 292 |
+
-------
|
| 293 |
+
str
|
| 294 |
+
String of the content if ``filepath`` is ``None``.
|
| 295 |
+
|
| 296 |
+
Notes
|
| 297 |
+
-----
|
| 298 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 299 |
+
seems to not suffer from this issue.
|
| 300 |
+
|
| 301 |
+
Examples
|
| 302 |
+
--------
|
| 303 |
+
>>> import stable_whisper
|
| 304 |
+
>>> model = stable_whisper.load_model('base')
|
| 305 |
+
>>> result = model.transcribe('audio.mp3')
|
| 306 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 307 |
+
Saved: audio.srt
|
| 308 |
+
"""
|
| 309 |
+
is_srt = (filepath is None or not filepath.lower().endswith('.vtt')) if vtt is None else not vtt
|
| 310 |
+
if is_srt:
|
| 311 |
+
segments2blocks = None
|
| 312 |
+
to_word_level_string_callback = None
|
| 313 |
+
else:
|
| 314 |
+
def segments2blocks(segments):
|
| 315 |
+
return 'WEBVTT\n\n' + '\n\n'.join(segment2vttblock(s, strip=strip) for i, s in enumerate(segments))
|
| 316 |
+
to_word_level_string_callback = to_vtt_word_level_segments if tag is None else tag
|
| 317 |
+
|
| 318 |
+
return result_to_any(
|
| 319 |
+
result=result,
|
| 320 |
+
filepath=filepath,
|
| 321 |
+
filetype=('vtt', 'srt')[is_srt],
|
| 322 |
+
segments2blocks=segments2blocks,
|
| 323 |
+
segment_level=segment_level,
|
| 324 |
+
word_level=word_level,
|
| 325 |
+
min_dur=min_dur,
|
| 326 |
+
tag=tag,
|
| 327 |
+
strip=strip,
|
| 328 |
+
reverse_text=reverse_text,
|
| 329 |
+
to_word_level_string_callback=to_word_level_string_callback
|
| 330 |
+
)
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
def result_to_tsv(result: (dict, list),
|
| 334 |
+
filepath: str = None,
|
| 335 |
+
segment_level: bool = None,
|
| 336 |
+
word_level: bool = None,
|
| 337 |
+
min_dur: float = 0.02,
|
| 338 |
+
strip=True,
|
| 339 |
+
reverse_text: Union[bool, tuple] = False):
|
| 340 |
+
"""
|
| 341 |
+
Generate TSV from ``result`` to display segment-level and/or word-level timestamp.
|
| 342 |
+
|
| 343 |
+
Parameters
|
| 344 |
+
----------
|
| 345 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 346 |
+
Result of transcription.
|
| 347 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 348 |
+
Path to save file.
|
| 349 |
+
segment_level : bool, default True
|
| 350 |
+
Whether to use segment-level timestamps in output.
|
| 351 |
+
word_level : bool, default True
|
| 352 |
+
Whether to use word-level timestamps in output.
|
| 353 |
+
min_dur : float, default 0.2
|
| 354 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 355 |
+
strip : bool, default True
|
| 356 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 357 |
+
reverse_text: bool or tuple, default False
|
| 358 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 359 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 360 |
+
|
| 361 |
+
Returns
|
| 362 |
+
-------
|
| 363 |
+
str
|
| 364 |
+
String of the content if ``filepath`` is ``None``.
|
| 365 |
+
|
| 366 |
+
Notes
|
| 367 |
+
-----
|
| 368 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 369 |
+
seems to not suffer from this issue.
|
| 370 |
+
|
| 371 |
+
Examples
|
| 372 |
+
--------
|
| 373 |
+
>>> import stable_whisper
|
| 374 |
+
>>> model = stable_whisper.load_model('base')
|
| 375 |
+
>>> result = model.transcribe('audio.mp3')
|
| 376 |
+
>>> result.to_tsv('audio.tsv')
|
| 377 |
+
Saved: audio.tsv
|
| 378 |
+
"""
|
| 379 |
+
if segment_level is None and word_level is None:
|
| 380 |
+
segment_level = True
|
| 381 |
+
assert word_level is not segment_level, '[word_level] and [segment_level] cannot be the same ' \
|
| 382 |
+
'since [tag] is not support for this format'
|
| 383 |
+
|
| 384 |
+
def segments2blocks(segments):
|
| 385 |
+
return '\n\n'.join(segment2tsvblock(s, strip=strip) for i, s in enumerate(segments))
|
| 386 |
+
return result_to_any(
|
| 387 |
+
result=result,
|
| 388 |
+
filepath=filepath,
|
| 389 |
+
filetype='tsv',
|
| 390 |
+
segments2blocks=segments2blocks,
|
| 391 |
+
segment_level=segment_level,
|
| 392 |
+
word_level=word_level,
|
| 393 |
+
min_dur=min_dur,
|
| 394 |
+
strip=strip,
|
| 395 |
+
reverse_text=reverse_text
|
| 396 |
+
)
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
def result_to_ass(result: (dict, list),
|
| 400 |
+
filepath: str = None,
|
| 401 |
+
segment_level=True,
|
| 402 |
+
word_level=True,
|
| 403 |
+
min_dur: float = 0.02,
|
| 404 |
+
tag: Union[Tuple[str, str], int] = None,
|
| 405 |
+
font: str = None,
|
| 406 |
+
font_size: int = 24,
|
| 407 |
+
strip=True,
|
| 408 |
+
highlight_color: str = None,
|
| 409 |
+
karaoke=False,
|
| 410 |
+
reverse_text: Union[bool, tuple] = False,
|
| 411 |
+
**kwargs):
|
| 412 |
+
"""
|
| 413 |
+
Generate Advanced SubStation Alpha (ASS) file from ``result`` to display segment-level and/or word-level timestamp.
|
| 414 |
+
|
| 415 |
+
Parameters
|
| 416 |
+
----------
|
| 417 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 418 |
+
Result of transcription.
|
| 419 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 420 |
+
Path to save file.
|
| 421 |
+
segment_level : bool, default True
|
| 422 |
+
Whether to use segment-level timestamps in output.
|
| 423 |
+
word_level : bool, default True
|
| 424 |
+
Whether to use word-level timestamps in output.
|
| 425 |
+
min_dur : float, default 0.2
|
| 426 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 427 |
+
tag: tuple of (str, str) or int, default None, meaning use default highlighting
|
| 428 |
+
Tag used to change the properties a word at its timestamp. -1 for individual word highlight tag.
|
| 429 |
+
font : str, default `Arial`
|
| 430 |
+
Word font.
|
| 431 |
+
font_size : int, default 48
|
| 432 |
+
Word font size.
|
| 433 |
+
strip : bool, default True
|
| 434 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 435 |
+
highlight_color : str, default '00ff00'
|
| 436 |
+
Hexadecimal of the color use for default highlights as '<bb><gg><rr>'.
|
| 437 |
+
karaoke : bool, default False
|
| 438 |
+
Whether to use progressive filling highlights (for karaoke effect).
|
| 439 |
+
reverse_text: bool or tuple, default False
|
| 440 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 441 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 442 |
+
kwargs:
|
| 443 |
+
Format styles:
|
| 444 |
+
'Name', 'Fontname', 'Fontsize', 'PrimaryColour', 'SecondaryColour', 'OutlineColour', 'BackColour', 'Bold',
|
| 445 |
+
'Italic', 'Underline', 'StrikeOut', 'ScaleX', 'ScaleY', 'Spacing', 'Angle', 'BorderStyle', 'Outline',
|
| 446 |
+
'Shadow', 'Alignment', 'MarginL', 'MarginR', 'MarginV', 'Encoding'
|
| 447 |
+
|
| 448 |
+
Returns
|
| 449 |
+
-------
|
| 450 |
+
str
|
| 451 |
+
String of the content if ``filepath`` is ``None``.
|
| 452 |
+
|
| 453 |
+
Notes
|
| 454 |
+
-----
|
| 455 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 456 |
+
seems to not suffer from this issue.
|
| 457 |
+
|
| 458 |
+
Examples
|
| 459 |
+
--------
|
| 460 |
+
>>> import stable_whisper
|
| 461 |
+
>>> model = stable_whisper.load_model('base')
|
| 462 |
+
>>> result = model.transcribe('audio.mp3')
|
| 463 |
+
>>> result.to_ass('audio.ass')
|
| 464 |
+
Saved: audio.ass
|
| 465 |
+
"""
|
| 466 |
+
if tag == ['-1']: # CLI
|
| 467 |
+
tag = -1
|
| 468 |
+
if highlight_color is None:
|
| 469 |
+
highlight_color = '00ff00'
|
| 470 |
+
|
| 471 |
+
def segments2blocks(segments):
|
| 472 |
+
fmt_style_dict = {'Name': 'Default', 'Fontname': 'Arial', 'Fontsize': '48', 'PrimaryColour': '&Hffffff',
|
| 473 |
+
'SecondaryColour': '&Hffffff', 'OutlineColour': '&H0', 'BackColour': '&H0', 'Bold': '0',
|
| 474 |
+
'Italic': '0', 'Underline': '0', 'StrikeOut': '0', 'ScaleX': '100', 'ScaleY': '100',
|
| 475 |
+
'Spacing': '0', 'Angle': '0', 'BorderStyle': '1', 'Outline': '1', 'Shadow': '0',
|
| 476 |
+
'Alignment': '2', 'MarginL': '10', 'MarginR': '10', 'MarginV': '10', 'Encoding': '0'}
|
| 477 |
+
|
| 478 |
+
for k, v in filter(lambda x: 'colour' in x[0].lower() and not str(x[1]).startswith('&H'), kwargs.items()):
|
| 479 |
+
kwargs[k] = f'&H{kwargs[k]}'
|
| 480 |
+
|
| 481 |
+
fmt_style_dict.update((k, v) for k, v in kwargs.items() if k in fmt_style_dict)
|
| 482 |
+
|
| 483 |
+
if tag is None and 'PrimaryColour' not in kwargs:
|
| 484 |
+
fmt_style_dict['PrimaryColour'] = \
|
| 485 |
+
highlight_color if highlight_color.startswith('&H') else f'&H{highlight_color}'
|
| 486 |
+
|
| 487 |
+
if font:
|
| 488 |
+
fmt_style_dict.update(Fontname=font)
|
| 489 |
+
if font_size:
|
| 490 |
+
fmt_style_dict.update(Fontsize=font_size)
|
| 491 |
+
|
| 492 |
+
fmts = f'Format: {", ".join(map(str, fmt_style_dict.keys()))}'
|
| 493 |
+
|
| 494 |
+
styles = f'Style: {",".join(map(str, fmt_style_dict.values()))}'
|
| 495 |
+
|
| 496 |
+
sub_str = f'[Script Info]\nScriptType: v4.00+\nPlayResX: 384\nPlayResY: 288\nScaledBorderAndShadow: yes\n\n' \
|
| 497 |
+
f'[V4+ Styles]\n{fmts}\n{styles}\n\n' \
|
| 498 |
+
f'[Events]\nFormat: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text\n\n'
|
| 499 |
+
|
| 500 |
+
sub_str += '\n'.join(segment2assblock(s, i, strip=strip) for i, s in enumerate(segments))
|
| 501 |
+
|
| 502 |
+
return sub_str
|
| 503 |
+
|
| 504 |
+
if tag is not None and karaoke:
|
| 505 |
+
warnings.warn(f'[tag] is not support for [karaoke]=True; [tag] will be ignored.')
|
| 506 |
+
|
| 507 |
+
return result_to_any(
|
| 508 |
+
result=result,
|
| 509 |
+
filepath=filepath,
|
| 510 |
+
filetype='ass',
|
| 511 |
+
segments2blocks=segments2blocks,
|
| 512 |
+
segment_level=segment_level,
|
| 513 |
+
word_level=word_level,
|
| 514 |
+
min_dur=min_dur,
|
| 515 |
+
tag=None if tag == -1 else tag,
|
| 516 |
+
default_tag=(r'{\1c' + f'{highlight_color}&' + '}', r'{\r}'),
|
| 517 |
+
strip=strip,
|
| 518 |
+
reverse_text=reverse_text,
|
| 519 |
+
to_word_level_string_callback=(
|
| 520 |
+
(lambda s, t: to_ass_word_level_segments(s, t, karaoke=karaoke))
|
| 521 |
+
if karaoke or (word_level and segment_level and tag is None)
|
| 522 |
+
else None
|
| 523 |
+
)
|
| 524 |
+
)
|
| 525 |
+
|
| 526 |
+
|
| 527 |
+
def result_to_txt(
|
| 528 |
+
result: (dict, list),
|
| 529 |
+
filepath: str = None,
|
| 530 |
+
min_dur: float = 0.02,
|
| 531 |
+
strip=True,
|
| 532 |
+
reverse_text: Union[bool, tuple] = False
|
| 533 |
+
):
|
| 534 |
+
"""
|
| 535 |
+
Generate plain-text without timestamps from ``result``.
|
| 536 |
+
|
| 537 |
+
Parameters
|
| 538 |
+
----------
|
| 539 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 540 |
+
Result of transcription.
|
| 541 |
+
filepath : str, default None, meaning content will be returned as a ``str``
|
| 542 |
+
Path to save file.
|
| 543 |
+
min_dur : float, default 0.2
|
| 544 |
+
Minimum duration allowed for any word/segment before the word/segments are merged with adjacent word/segments.
|
| 545 |
+
strip : bool, default True
|
| 546 |
+
Whether to remove spaces before and after text on each segment for output.
|
| 547 |
+
reverse_text: bool or tuple, default False
|
| 548 |
+
Whether to reverse the order of words for each segment or provide the ``prepend_punctuations`` and
|
| 549 |
+
``append_punctuations`` as tuple pair instead of ``True`` which is for the default punctuations.
|
| 550 |
+
|
| 551 |
+
Returns
|
| 552 |
+
-------
|
| 553 |
+
str
|
| 554 |
+
String of the content if ``filepath`` is ``None``.
|
| 555 |
+
|
| 556 |
+
Notes
|
| 557 |
+
-----
|
| 558 |
+
``reverse_text`` will not fix RTL text not displaying tags properly which is an issue with some video player. VLC
|
| 559 |
+
seems to not suffer from this issue.
|
| 560 |
+
|
| 561 |
+
Examples
|
| 562 |
+
--------
|
| 563 |
+
>>> import stable_whisper
|
| 564 |
+
>>> model = stable_whisper.load_model('base')
|
| 565 |
+
>>> result = model.transcribe('audio.mp3')
|
| 566 |
+
>>> result.to_txt('audio.txt')
|
| 567 |
+
Saved: audio.txt
|
| 568 |
+
"""
|
| 569 |
+
|
| 570 |
+
def segments2blocks(segments: dict, _strip=True) -> str:
|
| 571 |
+
return '\n'.join(f'{segment["text"].strip() if _strip else segment["text"]}' for segment in segments)
|
| 572 |
+
|
| 573 |
+
return result_to_any(
|
| 574 |
+
result=result,
|
| 575 |
+
filepath=filepath,
|
| 576 |
+
filetype='txt',
|
| 577 |
+
segments2blocks=segments2blocks,
|
| 578 |
+
segment_level=True,
|
| 579 |
+
word_level=False,
|
| 580 |
+
min_dur=min_dur,
|
| 581 |
+
strip=strip,
|
| 582 |
+
reverse_text=reverse_text
|
| 583 |
+
)
|
| 584 |
+
|
| 585 |
+
|
| 586 |
+
def save_as_json(result: dict, path: str, ensure_ascii: bool = False, **kwargs):
|
| 587 |
+
"""
|
| 588 |
+
Save ``result`` as JSON file to ``path``.
|
| 589 |
+
|
| 590 |
+
Parameters
|
| 591 |
+
----------
|
| 592 |
+
result : dict or list or stable_whisper.result.WhisperResult
|
| 593 |
+
Result of transcription.
|
| 594 |
+
path : str
|
| 595 |
+
Path to save file.
|
| 596 |
+
ensure_ascii : bool, default False
|
| 597 |
+
Whether to escape non-ASCII characters.
|
| 598 |
+
|
| 599 |
+
Examples
|
| 600 |
+
--------
|
| 601 |
+
>>> import stable_whisper
|
| 602 |
+
>>> model = stable_whisper.load_model('base')
|
| 603 |
+
>>> result = model.transcribe('audio.mp3')
|
| 604 |
+
>>> result.save_as_json('audio.json')
|
| 605 |
+
Saved: audio.json
|
| 606 |
+
"""
|
| 607 |
+
if not isinstance(result, dict) and callable(getattr(result, 'to_dict')):
|
| 608 |
+
result = result.to_dict()
|
| 609 |
+
if not path.lower().endswith('.json'):
|
| 610 |
+
path += '.json'
|
| 611 |
+
result = json.dumps(result, allow_nan=True, ensure_ascii=ensure_ascii, **kwargs)
|
| 612 |
+
_save_as_file(result, path)
|
| 613 |
+
|
| 614 |
+
|
| 615 |
+
def load_result(json_path: str) -> dict:
|
| 616 |
+
"""
|
| 617 |
+
Return a ``dict`` of the contents in ``json_path``.
|
| 618 |
+
"""
|
| 619 |
+
with open(json_path, 'r', encoding='utf-8') as f:
|
| 620 |
+
return json.load(f)
|
stable_whisper/timing.py
ADDED
|
@@ -0,0 +1,275 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import string
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
from typing import TYPE_CHECKING, List, Callable, Optional
|
| 5 |
+
from itertools import chain
|
| 6 |
+
from whisper.audio import TOKENS_PER_SECOND, N_SAMPLES_PER_TOKEN
|
| 7 |
+
from whisper.timing import WordTiming, median_filter, dtw, merge_punctuations
|
| 8 |
+
|
| 9 |
+
if TYPE_CHECKING:
|
| 10 |
+
from whisper.tokenizer import Tokenizer
|
| 11 |
+
from whisper.model import Whisper
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# modified version of whisper.timing.find_alignment
|
| 15 |
+
def find_alignment_stable(
|
| 16 |
+
model: "Whisper",
|
| 17 |
+
tokenizer: "Tokenizer",
|
| 18 |
+
text_tokens: List[int],
|
| 19 |
+
mel: torch.Tensor,
|
| 20 |
+
num_samples: int,
|
| 21 |
+
*,
|
| 22 |
+
medfilt_width: int = 7,
|
| 23 |
+
qk_scale: float = 1.0,
|
| 24 |
+
ts_num: int = 0,
|
| 25 |
+
ts_noise: float = 0.1,
|
| 26 |
+
token_split=None,
|
| 27 |
+
audio_features: torch.Tensor = None
|
| 28 |
+
) -> List[WordTiming]:
|
| 29 |
+
tokens = torch.tensor(
|
| 30 |
+
[
|
| 31 |
+
*tokenizer.sot_sequence,
|
| 32 |
+
tokenizer.no_timestamps,
|
| 33 |
+
*text_tokens,
|
| 34 |
+
tokenizer.eot,
|
| 35 |
+
]
|
| 36 |
+
).to(model.device)
|
| 37 |
+
|
| 38 |
+
# install hooks on the cross attention layers to retrieve the attention weights
|
| 39 |
+
QKs = [None] * model.dims.n_text_layer
|
| 40 |
+
hooks = [
|
| 41 |
+
block.cross_attn.register_forward_hook(
|
| 42 |
+
lambda _, ins, outs, index=i: QKs.__setitem__(index, outs[-1])
|
| 43 |
+
)
|
| 44 |
+
for i, block in enumerate(model.decoder.blocks)
|
| 45 |
+
]
|
| 46 |
+
|
| 47 |
+
with torch.no_grad():
|
| 48 |
+
if audio_features is None:
|
| 49 |
+
audio_features = model.encoder(mel.unsqueeze(0))
|
| 50 |
+
if ts_num:
|
| 51 |
+
if ts_noise is None:
|
| 52 |
+
ts_noise = 0.1
|
| 53 |
+
extra_audio_features = audio_features.repeat_interleave(ts_num, 0)
|
| 54 |
+
torch.manual_seed(0)
|
| 55 |
+
audio_features = torch.cat([audio_features,
|
| 56 |
+
extra_audio_features *
|
| 57 |
+
(1 - (torch.rand_like(extra_audio_features) * ts_noise))],
|
| 58 |
+
dim=0)
|
| 59 |
+
logits = model.decoder(tokens.unsqueeze(0).repeat_interleave(audio_features.shape[0], 0),
|
| 60 |
+
audio_features)
|
| 61 |
+
else:
|
| 62 |
+
logits = model.decoder(tokens.unsqueeze(0), audio_features)
|
| 63 |
+
|
| 64 |
+
logits = logits[0]
|
| 65 |
+
sampled_logits = logits[len(tokenizer.sot_sequence):, : tokenizer.eot]
|
| 66 |
+
token_probs = sampled_logits.softmax(dim=-1)
|
| 67 |
+
text_token_probs = token_probs[np.arange(len(text_tokens)), text_tokens]
|
| 68 |
+
text_token_probs = text_token_probs.tolist()
|
| 69 |
+
|
| 70 |
+
for hook in hooks:
|
| 71 |
+
hook.remove()
|
| 72 |
+
|
| 73 |
+
# heads * tokens * frames
|
| 74 |
+
weights = torch.cat([QKs[_l][:, _h] for _l, _h in model.alignment_heads.indices().T], dim=0)
|
| 75 |
+
weights = weights[:, :, : round(num_samples / N_SAMPLES_PER_TOKEN)]
|
| 76 |
+
weights = (weights * qk_scale).softmax(dim=-1)
|
| 77 |
+
std, mean = torch.std_mean(weights, dim=-2, keepdim=True, unbiased=False)
|
| 78 |
+
weights = (weights - mean) / std
|
| 79 |
+
weights = median_filter(weights, medfilt_width)
|
| 80 |
+
|
| 81 |
+
matrix = weights.mean(axis=0)
|
| 82 |
+
matrix = matrix[len(tokenizer.sot_sequence): -1]
|
| 83 |
+
text_indices, time_indices = dtw(-matrix)
|
| 84 |
+
|
| 85 |
+
if token_split is None:
|
| 86 |
+
words, word_tokens = tokenizer.split_to_word_tokens(text_tokens + [tokenizer.eot])
|
| 87 |
+
else:
|
| 88 |
+
words, word_tokens = token_split
|
| 89 |
+
words.append(tokenizer.decode([tokenizer.eot]))
|
| 90 |
+
word_tokens.append([tokenizer.eot])
|
| 91 |
+
word_boundaries = np.pad(np.cumsum([len(t) for t in word_tokens[:-1]]), (1, 0))
|
| 92 |
+
|
| 93 |
+
jumps = np.pad(np.diff(text_indices), (1, 0), constant_values=1).astype(bool)
|
| 94 |
+
jump_times = time_indices[jumps].clip(min=0) / TOKENS_PER_SECOND
|
| 95 |
+
start_times = jump_times[word_boundaries[:-1]]
|
| 96 |
+
end_times = jump_times[word_boundaries[1:]]
|
| 97 |
+
word_probabilities = [
|
| 98 |
+
np.mean(text_token_probs[i:j])
|
| 99 |
+
for i, j in zip(word_boundaries[:-1], word_boundaries[1:])
|
| 100 |
+
]
|
| 101 |
+
|
| 102 |
+
return [
|
| 103 |
+
WordTiming(word, tokens, start, end, probability)
|
| 104 |
+
for word, tokens, start, end, probability in zip(
|
| 105 |
+
words, word_tokens, start_times, end_times, word_probabilities
|
| 106 |
+
)
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def _split_tokens(tokens: List[int], tokenizer: "Tokenizer"):
|
| 111 |
+
split_by_space = getattr(tokenizer, 'language_code', tokenizer.language) not in {"zh", "ja", "th", "lo", "my"}
|
| 112 |
+
text = tokenizer.decode_with_timestamps(tokens)
|
| 113 |
+
words = []
|
| 114 |
+
word_tokens = []
|
| 115 |
+
curr_tokens = []
|
| 116 |
+
is_append = False
|
| 117 |
+
for token in tokens:
|
| 118 |
+
curr_tokens.append(token)
|
| 119 |
+
curr_text = tokenizer.decode(curr_tokens)
|
| 120 |
+
is_whole = token >= tokenizer.eot
|
| 121 |
+
if not is_whole:
|
| 122 |
+
is_whole = text[:len(curr_text)] == curr_text
|
| 123 |
+
if is_whole and split_by_space:
|
| 124 |
+
is_append = not (curr_text.startswith(" ") or curr_text.strip() in string.punctuation)
|
| 125 |
+
|
| 126 |
+
if is_whole:
|
| 127 |
+
if is_append and len(words) != 0:
|
| 128 |
+
words[-1] += curr_text
|
| 129 |
+
word_tokens[-1].extend(curr_tokens)
|
| 130 |
+
else:
|
| 131 |
+
words.append(curr_text)
|
| 132 |
+
word_tokens.append(curr_tokens)
|
| 133 |
+
text = text[len(curr_text):]
|
| 134 |
+
curr_tokens = []
|
| 135 |
+
|
| 136 |
+
if len(curr_tokens) != 0:
|
| 137 |
+
words.append(curr_text if len(text) == 0 else text)
|
| 138 |
+
word_tokens.append(curr_tokens)
|
| 139 |
+
elif len(text) != 0:
|
| 140 |
+
words[-1] += text
|
| 141 |
+
|
| 142 |
+
return words, word_tokens
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def split_word_tokens(segments: List[dict],
|
| 146 |
+
tokenizer: "Tokenizer",
|
| 147 |
+
*,
|
| 148 |
+
padding: (str, int) = None,
|
| 149 |
+
split_callback: Callable = None):
|
| 150 |
+
if padding is not None:
|
| 151 |
+
if isinstance(padding, str):
|
| 152 |
+
padding = tokenizer.encode(padding)
|
| 153 |
+
else:
|
| 154 |
+
padding = [padding]
|
| 155 |
+
tokens = []
|
| 156 |
+
seg_indices = []
|
| 157 |
+
words = []
|
| 158 |
+
word_tokens = []
|
| 159 |
+
for i, s in enumerate(segments):
|
| 160 |
+
temp_word_tokens = [t for t in s['tokens'] if not isinstance(t, int) or t < tokenizer.eot]
|
| 161 |
+
curr_words, curr_word_tokens = (
|
| 162 |
+
_split_tokens(temp_word_tokens, tokenizer)
|
| 163 |
+
if split_callback is None else
|
| 164 |
+
split_callback(temp_word_tokens, tokenizer)
|
| 165 |
+
)
|
| 166 |
+
assert len(curr_words) == len(curr_word_tokens), \
|
| 167 |
+
f'word count and token group count do not match, {len(curr_words)} and {len(curr_word_tokens)}'
|
| 168 |
+
if (
|
| 169 |
+
padding is not None and
|
| 170 |
+
curr_word_tokens[0][0] != padding and
|
| 171 |
+
(len(tokens) == 0 or tokens[-1] != padding)
|
| 172 |
+
):
|
| 173 |
+
tokens.extend(padding)
|
| 174 |
+
words.append(None)
|
| 175 |
+
word_tokens.append(padding)
|
| 176 |
+
seg_indices.extend([i] * len(curr_words))
|
| 177 |
+
tokens.extend(list(chain.from_iterable(curr_word_tokens)))
|
| 178 |
+
words.extend(curr_words)
|
| 179 |
+
word_tokens.extend(curr_word_tokens)
|
| 180 |
+
|
| 181 |
+
return tokens, (words, word_tokens), seg_indices
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def pop_empty_alignment(alignment: List[WordTiming]):
|
| 185 |
+
return list(reversed([alignment.pop(i) for i in reversed(range(len(alignment))) if alignment[i].word is None]))
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
# modified version of whisper.timing.add_word_timestamps
|
| 189 |
+
def add_word_timestamps_stable(
|
| 190 |
+
*,
|
| 191 |
+
segments: List[dict],
|
| 192 |
+
model: "Whisper",
|
| 193 |
+
tokenizer: "Tokenizer",
|
| 194 |
+
mel: torch.Tensor,
|
| 195 |
+
num_samples: int,
|
| 196 |
+
prepend_punctuations: str = "\"'“¿([{-",
|
| 197 |
+
append_punctuations: str = "\"'.。,,!!??::”)]}、",
|
| 198 |
+
audio_features: torch.Tensor = None,
|
| 199 |
+
ts_num: int = 0,
|
| 200 |
+
ts_noise: float = 0.1,
|
| 201 |
+
min_word_dur: float = 0.1,
|
| 202 |
+
split_callback: Callable = None,
|
| 203 |
+
gap_padding: Optional[str] = ' ...',
|
| 204 |
+
**kwargs,
|
| 205 |
+
):
|
| 206 |
+
if len(segments) == 0:
|
| 207 |
+
return
|
| 208 |
+
|
| 209 |
+
if min_word_dur is None:
|
| 210 |
+
min_word_dur = 0
|
| 211 |
+
|
| 212 |
+
if prepend_punctuations is None:
|
| 213 |
+
prepend_punctuations = "\"'“¿([{-"
|
| 214 |
+
|
| 215 |
+
if append_punctuations is None:
|
| 216 |
+
append_punctuations = "\"'.。,,!!??::”)]}、"
|
| 217 |
+
|
| 218 |
+
def align():
|
| 219 |
+
for seg in segments:
|
| 220 |
+
seg['words'] = []
|
| 221 |
+
|
| 222 |
+
text_tokens, token_split, seg_indices = split_word_tokens(segments, tokenizer,
|
| 223 |
+
padding=gap_padding, split_callback=split_callback)
|
| 224 |
+
|
| 225 |
+
alignment = find_alignment_stable(model, tokenizer, text_tokens, mel, num_samples,
|
| 226 |
+
**kwargs,
|
| 227 |
+
token_split=token_split,
|
| 228 |
+
audio_features=audio_features,
|
| 229 |
+
ts_num=ts_num,
|
| 230 |
+
ts_noise=ts_noise)
|
| 231 |
+
alt_beginning_alignment = pop_empty_alignment(alignment)
|
| 232 |
+
|
| 233 |
+
merge_punctuations(alignment, prepend_punctuations, append_punctuations)
|
| 234 |
+
|
| 235 |
+
time_offset = segments[0]["seek"]
|
| 236 |
+
|
| 237 |
+
assert len(alignment) == len(seg_indices)
|
| 238 |
+
assert (gap_padding is None or len(segments) == len(alt_beginning_alignment))
|
| 239 |
+
for i, timing in zip(seg_indices, alignment):
|
| 240 |
+
if len(timing.tokens) != 0:
|
| 241 |
+
start = timing.start
|
| 242 |
+
end = timing.end
|
| 243 |
+
if (
|
| 244 |
+
len(segments[i]['words']) == 0 and
|
| 245 |
+
((end - start) < min_word_dur) and
|
| 246 |
+
len(alt_beginning_alignment)
|
| 247 |
+
):
|
| 248 |
+
start = alt_beginning_alignment[i].start
|
| 249 |
+
segments[i]['words'].append(
|
| 250 |
+
dict(
|
| 251 |
+
word=timing.word,
|
| 252 |
+
start=round(time_offset + start, 3),
|
| 253 |
+
end=round(time_offset + end, 3),
|
| 254 |
+
probability=timing.probability,
|
| 255 |
+
tokens=timing.tokens
|
| 256 |
+
)
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
align()
|
| 260 |
+
if (
|
| 261 |
+
gap_padding is not None and
|
| 262 |
+
any(
|
| 263 |
+
(word['end'] - word['start']) < min_word_dur
|
| 264 |
+
for seg in segments
|
| 265 |
+
for word in seg['words']
|
| 266 |
+
)
|
| 267 |
+
):
|
| 268 |
+
gap_padding = None
|
| 269 |
+
align()
|
| 270 |
+
|
| 271 |
+
for segment in segments:
|
| 272 |
+
if len(words := segment["words"]) > 0:
|
| 273 |
+
# adjust the segment-level timestamps based on the word-level timestamps
|
| 274 |
+
segment["start"] = words[0]["start"]
|
| 275 |
+
segment["end"] = words[-1]["end"]
|
stable_whisper/utils.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
system_encoding = sys.getdefaultencoding()
|
| 6 |
+
|
| 7 |
+
if system_encoding != "utf-8":
|
| 8 |
+
|
| 9 |
+
def make_safe(string):
|
| 10 |
+
# replaces any character not representable using the system default encoding with an '?',
|
| 11 |
+
# avoiding UnicodeEncodeError (https://github.com/openai/whisper/discussions/729).
|
| 12 |
+
return string.encode(system_encoding, errors="replace").decode(system_encoding)
|
| 13 |
+
|
| 14 |
+
else:
|
| 15 |
+
|
| 16 |
+
def make_safe(string):
|
| 17 |
+
# utf-8 can encode any Unicode code point, so no need to do the round-trip encoding
|
| 18 |
+
return string
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def str_to_valid_type(val: str):
|
| 22 |
+
if len(val) == 0:
|
| 23 |
+
return None
|
| 24 |
+
if '/' in val:
|
| 25 |
+
return [a.split('*') if '*' in a else a for a in val.split('/')]
|
| 26 |
+
try:
|
| 27 |
+
val = float(val) if '.' in val else int(val)
|
| 28 |
+
except ValueError:
|
| 29 |
+
pass
|
| 30 |
+
finally:
|
| 31 |
+
return val
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_func_parameters(func):
|
| 35 |
+
return inspect.signature(func).parameters.keys()
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def isolate_useful_options(options: dict, method, pop: bool = False) -> dict:
|
| 39 |
+
_get = dict.pop if pop else dict.get
|
| 40 |
+
return {k: _get(options, k) for k in get_func_parameters(method) if k in options}
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def safe_print(msg: str, _print=None):
|
| 44 |
+
if msg:
|
| 45 |
+
(_print or print)(make_safe(msg))
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def format_timestamp(
|
| 49 |
+
seconds: float, always_include_hours: bool = False, decimal_marker: str = "."
|
| 50 |
+
):
|
| 51 |
+
assert seconds >= 0, "non-negative timestamp expected"
|
| 52 |
+
milliseconds = round(seconds * 1000.0)
|
| 53 |
+
|
| 54 |
+
hours = milliseconds // 3_600_000
|
| 55 |
+
milliseconds -= hours * 3_600_000
|
| 56 |
+
|
| 57 |
+
minutes = milliseconds // 60_000
|
| 58 |
+
milliseconds -= minutes * 60_000
|
| 59 |
+
|
| 60 |
+
seconds = milliseconds // 1_000
|
| 61 |
+
milliseconds -= seconds * 1_000
|
| 62 |
+
|
| 63 |
+
hours_marker = f"{hours:02d}:" if always_include_hours or hours > 0 else ""
|
| 64 |
+
return (
|
| 65 |
+
f"{hours_marker}{minutes:02d}:{seconds:02d}{decimal_marker}{milliseconds:03d}"
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class UnsortedException(Exception):
|
| 70 |
+
|
| 71 |
+
def __init__(self, message: str = None, data: dict = None):
|
| 72 |
+
if not message:
|
| 73 |
+
message = 'Timestamps are not in ascending order. If data is produced by Stable-ts, please submit an issue.'
|
| 74 |
+
super().__init__(message)
|
| 75 |
+
self.data = data
|
| 76 |
+
|
| 77 |
+
def get_data(self):
|
| 78 |
+
return self.data
|
stable_whisper/video_output.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import subprocess as sp
|
| 3 |
+
import warnings
|
| 4 |
+
from typing import List
|
| 5 |
+
|
| 6 |
+
__all__ = ['encode_video_comparison']
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def encode_video_comparison(
|
| 10 |
+
audiofile: str,
|
| 11 |
+
subtitle_files: List[str],
|
| 12 |
+
output_videopath: str = None,
|
| 13 |
+
*,
|
| 14 |
+
labels: List[str] = None,
|
| 15 |
+
height: int = 90,
|
| 16 |
+
width: int = 720,
|
| 17 |
+
color: str = 'black',
|
| 18 |
+
fontsize: int = 70,
|
| 19 |
+
border_color: str = 'white',
|
| 20 |
+
label_color: str = 'white',
|
| 21 |
+
label_size: int = 14,
|
| 22 |
+
fps: int = 25,
|
| 23 |
+
video_codec: str = None,
|
| 24 |
+
audio_codec: str = None,
|
| 25 |
+
overwrite=False,
|
| 26 |
+
only_cmd: bool = False,
|
| 27 |
+
verbose=True
|
| 28 |
+
) -> (str, None):
|
| 29 |
+
"""
|
| 30 |
+
Encode multiple subtitle files into one video with the subtitles vertically stacked.
|
| 31 |
+
|
| 32 |
+
Parameters
|
| 33 |
+
----------
|
| 34 |
+
audiofile : str
|
| 35 |
+
Path of audio file.
|
| 36 |
+
subtitle_files : list of str
|
| 37 |
+
List of paths for subtitle file.
|
| 38 |
+
output_videopath : str, optional
|
| 39 |
+
Output video path.
|
| 40 |
+
labels : list of str, default, None, meaning use ``subtitle_files`` as labels
|
| 41 |
+
List of labels for ``subtitle_files``.
|
| 42 |
+
height : int, default 90
|
| 43 |
+
Height for each subtitle section.
|
| 44 |
+
width : int, default 720
|
| 45 |
+
Width for each subtitle section.
|
| 46 |
+
color : str, default 'black'
|
| 47 |
+
Background color of the video.
|
| 48 |
+
fontsize: int, default 70
|
| 49 |
+
Font size for subtitles.
|
| 50 |
+
border_color : str, default 'white'
|
| 51 |
+
Border color for separating the sections of subtitle.
|
| 52 |
+
label_color : str, default 'white'
|
| 53 |
+
Color of labels.
|
| 54 |
+
label_size : int, default 14
|
| 55 |
+
Font size of labels.
|
| 56 |
+
fps : int, default 25
|
| 57 |
+
Frame-rate of the video.
|
| 58 |
+
video_codec : str, optional
|
| 59 |
+
Video codec opf the video.
|
| 60 |
+
audio_codec : str, optional
|
| 61 |
+
Audio codec opf the video.
|
| 62 |
+
overwrite : bool, default False
|
| 63 |
+
Whether to overwrite existing video files with the same path as the output video.
|
| 64 |
+
only_cmd : bool, default False
|
| 65 |
+
Whether to skip encoding and only return the full command generate from the specified options.
|
| 66 |
+
verbose : bool, default True
|
| 67 |
+
Whether to display ffmpeg processing info.
|
| 68 |
+
|
| 69 |
+
Returns
|
| 70 |
+
-------
|
| 71 |
+
str or None
|
| 72 |
+
Encoding command as a string if ``only_cmd = True``.
|
| 73 |
+
"""
|
| 74 |
+
vc = '' if video_codec is None else f' -c:v {video_codec}'
|
| 75 |
+
ac = '' if audio_codec is None else f' -c:a {audio_codec}'
|
| 76 |
+
background = f'-f lavfi -i color=size={width}x{height}:rate={fps}:color={color}'
|
| 77 |
+
border = f'-f lavfi -i color=size={width}x3:rate={fps}:color={border_color}'
|
| 78 |
+
audio = f'-i "{audiofile}"'
|
| 79 |
+
cfilters0 = []
|
| 80 |
+
assert labels is None or len(labels) == len(subtitle_files)
|
| 81 |
+
for i, sub in enumerate(subtitle_files):
|
| 82 |
+
label = sub if labels is None else labels[i]
|
| 83 |
+
label = label.replace("'", '"')
|
| 84 |
+
fil = f"[0]drawtext=text='{label}':fontcolor={label_color}:fontsize={label_size}:x=10:y=10[a{i}]," \
|
| 85 |
+
f"[a{i}]subtitles='{sub}':force_style='Fontsize={fontsize}'[b{i}]"
|
| 86 |
+
cfilters0.append(fil)
|
| 87 |
+
cfilters1 = (
|
| 88 |
+
'[1]'.join(
|
| 89 |
+
f'[b{i}]' for i in range(len(cfilters0))
|
| 90 |
+
)
|
| 91 |
+
+
|
| 92 |
+
f'vstack=inputs={len(cfilters0) * 2 - 1}'
|
| 93 |
+
)
|
| 94 |
+
final_fil = ','.join(cfilters0) + f';{cfilters1}'
|
| 95 |
+
ow = '-y' if overwrite else '-n'
|
| 96 |
+
if output_videopath is None:
|
| 97 |
+
name = os.path.split(os.path.splitext(audiofile)[0])[1]
|
| 98 |
+
output_videopath = f'{name}_sub_comparison.mp4'
|
| 99 |
+
cmd = (f'ffmpeg {ow} {background} {border} {audio} '
|
| 100 |
+
f'-filter_complex "{final_fil}"{vc}{ac} -shortest "{output_videopath}"')
|
| 101 |
+
if only_cmd:
|
| 102 |
+
return cmd
|
| 103 |
+
if verbose:
|
| 104 |
+
print(cmd)
|
| 105 |
+
rc = sp.run(cmd, capture_output=not verbose).returncode
|
| 106 |
+
if rc == 0:
|
| 107 |
+
if verbose:
|
| 108 |
+
print(f'Encoded: {output_videopath}')
|
| 109 |
+
else:
|
| 110 |
+
warnings.warn(f'Failed to encode {output_videopath}')
|
| 111 |
+
|
stable_whisper/whisper_compatibility.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
import importlib.metadata
|
| 3 |
+
|
| 4 |
+
import whisper.tokenizer
|
| 5 |
+
|
| 6 |
+
from .utils import get_func_parameters
|
| 7 |
+
|
| 8 |
+
_COMPATIBLE_WHISPER_VERSIONS = (
|
| 9 |
+
'20230314',
|
| 10 |
+
'20230918',
|
| 11 |
+
'20231105',
|
| 12 |
+
'20231106',
|
| 13 |
+
'20231117',
|
| 14 |
+
)
|
| 15 |
+
_required_whisper_ver = _COMPATIBLE_WHISPER_VERSIONS[-1]
|
| 16 |
+
|
| 17 |
+
_TOKENIZER_PARAMS = get_func_parameters(whisper.tokenizer.get_tokenizer)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def warn_compatibility_issues(
|
| 21 |
+
whisper_module,
|
| 22 |
+
ignore: bool = False,
|
| 23 |
+
additional_msg: str = ''
|
| 24 |
+
):
|
| 25 |
+
compatibility_warning = ''
|
| 26 |
+
if not ignore:
|
| 27 |
+
if whisper_module.__version__ not in _COMPATIBLE_WHISPER_VERSIONS:
|
| 28 |
+
compatibility_warning += (f'Whisper {whisper_module.__version__} is installed.'
|
| 29 |
+
f'Versions confirm to be compatible: {", ".join(_COMPATIBLE_WHISPER_VERSIONS)}\n')
|
| 30 |
+
_is_whisper_repo_version = bool(importlib.metadata.distribution('openai-whisper').read_text('direct_url.json'))
|
| 31 |
+
if _is_whisper_repo_version:
|
| 32 |
+
compatibility_warning += ('The detected version appears to be installed from the repository '
|
| 33 |
+
'which can have compatibility issues '
|
| 34 |
+
'due to multiple commits sharing the same version number. '
|
| 35 |
+
f'It is recommended to install version {_required_whisper_ver} from PyPI.\n')
|
| 36 |
+
|
| 37 |
+
if compatibility_warning:
|
| 38 |
+
compatibility_warning = (
|
| 39 |
+
'The installed version of Whisper might be incompatible.\n'
|
| 40 |
+
+ compatibility_warning +
|
| 41 |
+
'To prevent errors and performance issues, reinstall correct version with: '
|
| 42 |
+
f'"pip install --upgrade --no-deps --force-reinstall openai-whisper=={_required_whisper_ver}".'
|
| 43 |
+
)
|
| 44 |
+
if additional_msg:
|
| 45 |
+
compatibility_warning += f' {additional_msg}'
|
| 46 |
+
warnings.warn(compatibility_warning)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def get_tokenizer(model=None, is_faster_model: bool = False, **kwargs):
|
| 50 |
+
"""
|
| 51 |
+
Backward compatible wrapper of :func:`whisper.tokenizer.get_tokenizer` and
|
| 52 |
+
:class:`faster_whisper.tokenizer.Tokenizer`.
|
| 53 |
+
"""
|
| 54 |
+
if is_faster_model:
|
| 55 |
+
import faster_whisper.tokenizer
|
| 56 |
+
tokenizer = faster_whisper.tokenizer.Tokenizer
|
| 57 |
+
params = get_func_parameters(tokenizer)
|
| 58 |
+
if model is not None and 'tokenizer' not in kwargs:
|
| 59 |
+
kwargs['tokenizer'] = model.hf_tokenizer
|
| 60 |
+
else:
|
| 61 |
+
tokenizer = whisper.tokenizer.get_tokenizer
|
| 62 |
+
params = _TOKENIZER_PARAMS
|
| 63 |
+
if model is not None and 'multilingual' not in kwargs:
|
| 64 |
+
kwargs['multilingual'] = \
|
| 65 |
+
(model.is_multilingual if hasattr(model, 'is_multilingual') else model.model.is_multilingual)
|
| 66 |
+
if 'num_languages' in params:
|
| 67 |
+
if hasattr(model, 'num_languages'):
|
| 68 |
+
kwargs['num_languages'] = \
|
| 69 |
+
(model.num_languages if hasattr(model, 'num_languages') else model.model.num_languages)
|
| 70 |
+
elif 'num_languages' in kwargs:
|
| 71 |
+
del kwargs['num_languages']
|
| 72 |
+
return tokenizer(**kwargs)
|
| 73 |
+
|
stable_whisper/whisper_word_level.py
ADDED
|
@@ -0,0 +1,1651 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
from typing import TYPE_CHECKING, List, Optional, Tuple, Union, Callable
|
| 5 |
+
from types import MethodType
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
|
| 8 |
+
import whisper
|
| 9 |
+
from whisper.audio import (
|
| 10 |
+
SAMPLE_RATE, N_FRAMES, HOP_LENGTH, N_SAMPLES, N_SAMPLES_PER_TOKEN, TOKENS_PER_SECOND, FRAMES_PER_SECOND, N_FFT,
|
| 11 |
+
pad_or_trim, log_mel_spectrogram
|
| 12 |
+
)
|
| 13 |
+
from whisper.utils import exact_div
|
| 14 |
+
from whisper.tokenizer import LANGUAGES, TO_LANGUAGE_CODE
|
| 15 |
+
from whisper.decoding import DecodingOptions, DecodingResult
|
| 16 |
+
|
| 17 |
+
from .audio import prep_audio
|
| 18 |
+
from .decode import decode_stable
|
| 19 |
+
from .result import WhisperResult, Segment
|
| 20 |
+
from .timing import add_word_timestamps_stable
|
| 21 |
+
from .stabilization import get_vad_silence_func, wav2mask, mask2timing, timing2mask
|
| 22 |
+
from .non_whisper import transcribe_any
|
| 23 |
+
from .utils import isolate_useful_options, safe_print
|
| 24 |
+
from .whisper_compatibility import warn_compatibility_issues, get_tokenizer
|
| 25 |
+
|
| 26 |
+
if TYPE_CHECKING:
|
| 27 |
+
from whisper.model import Whisper
|
| 28 |
+
|
| 29 |
+
__all__ = ['modify_model', 'load_model', 'load_faster_whisper']
|
| 30 |
+
|
| 31 |
+
warnings.filterwarnings('ignore', module='whisper', message='.*Triton.*', category=UserWarning)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# modified version of whisper.transcribe.transcribe
|
| 35 |
+
def transcribe_stable(
|
| 36 |
+
model: "Whisper",
|
| 37 |
+
audio: Union[str, np.ndarray, torch.Tensor, bytes],
|
| 38 |
+
*,
|
| 39 |
+
verbose: Optional[bool] = False,
|
| 40 |
+
temperature: Union[float, Tuple[float, ...]] = (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
|
| 41 |
+
compression_ratio_threshold: Optional[float] = 2.4,
|
| 42 |
+
logprob_threshold: Optional[float] = -1.0,
|
| 43 |
+
no_speech_threshold: Optional[float] = 0.6,
|
| 44 |
+
condition_on_previous_text: bool = True,
|
| 45 |
+
initial_prompt: Optional[str] = None,
|
| 46 |
+
word_timestamps: bool = True,
|
| 47 |
+
regroup: Union[bool, str] = True,
|
| 48 |
+
ts_num: int = 0,
|
| 49 |
+
ts_noise: float = 0.1,
|
| 50 |
+
suppress_silence: bool = True,
|
| 51 |
+
suppress_word_ts: bool = True,
|
| 52 |
+
use_word_position: bool = True,
|
| 53 |
+
q_levels: int = 20,
|
| 54 |
+
k_size: int = 5,
|
| 55 |
+
time_scale: float = None,
|
| 56 |
+
demucs: Union[bool, torch.nn.Module] = False,
|
| 57 |
+
demucs_output: str = None,
|
| 58 |
+
demucs_options: dict = None,
|
| 59 |
+
vad: bool = False,
|
| 60 |
+
vad_threshold: float = 0.35,
|
| 61 |
+
vad_onnx: bool = False,
|
| 62 |
+
min_word_dur: float = 0.1,
|
| 63 |
+
nonspeech_error: float = 0.3,
|
| 64 |
+
only_voice_freq: bool = False,
|
| 65 |
+
prepend_punctuations: str = "\"'“¿([{-",
|
| 66 |
+
append_punctuations: str = "\"'.。,,!!??::”)]}、",
|
| 67 |
+
mel_first: bool = False,
|
| 68 |
+
split_callback: Callable = None,
|
| 69 |
+
suppress_ts_tokens: bool = False,
|
| 70 |
+
gap_padding: str = ' ...',
|
| 71 |
+
only_ffmpeg: bool = False,
|
| 72 |
+
max_instant_words: float = 0.5,
|
| 73 |
+
avg_prob_threshold: Optional[float] = None,
|
| 74 |
+
progress_callback: Callable = None,
|
| 75 |
+
ignore_compatibility: bool = False,
|
| 76 |
+
**decode_options) \
|
| 77 |
+
-> WhisperResult:
|
| 78 |
+
"""
|
| 79 |
+
Transcribe audio using Whisper.
|
| 80 |
+
|
| 81 |
+
This is a modified version of :func:`whisper.transcribe.transcribe` with slightly different decoding logic while
|
| 82 |
+
allowing additional preprocessing and postprocessing. The preprocessing performed on the audio includes: isolating
|
| 83 |
+
voice / removing noise with Demucs and low/high-pass filter. The postprocessing performed on the transcription
|
| 84 |
+
result includes: adjusting timestamps with VAD and custom regrouping segments based punctuation and speech gaps.
|
| 85 |
+
|
| 86 |
+
Parameters
|
| 87 |
+
----------
|
| 88 |
+
model : whisper.model.Whisper
|
| 89 |
+
An instance of Whisper ASR model.
|
| 90 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 91 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 92 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 93 |
+
verbose : bool or None, default False
|
| 94 |
+
Whether to display the text being decoded to the console.
|
| 95 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 96 |
+
temperature : float or iterable of float, default (0.0, 0.2, 0.4, 0.6, 0.8, 1.0)
|
| 97 |
+
Temperature for sampling. It can be a tuple of temperatures, which will be successfully used
|
| 98 |
+
upon failures according to either ``compression_ratio_threshold`` or ``logprob_threshold``.
|
| 99 |
+
compression_ratio_threshold : float, default 2.4
|
| 100 |
+
If the gzip compression ratio is above this value, treat as failed.
|
| 101 |
+
logprob_threshold : float, default -1
|
| 102 |
+
If the average log probability over sampled tokens is below this value, treat as failed
|
| 103 |
+
no_speech_threshold : float, default 0.6
|
| 104 |
+
If the no_speech probability is higher than this value AND the average log probability
|
| 105 |
+
over sampled tokens is below ``logprob_threshold``, consider the segment as silent
|
| 106 |
+
condition_on_previous_text : bool, default True
|
| 107 |
+
If ``True``, the previous output of the model is provided as a prompt for the next window;
|
| 108 |
+
disabling may make the text inconsistent across windows, but the model becomes less prone to
|
| 109 |
+
getting stuck in a failure loop, such as repetition looping or timestamps going out of sync.
|
| 110 |
+
initial_prompt : str, optional
|
| 111 |
+
Text to provide as a prompt for the first window. This can be used to provide, or
|
| 112 |
+
"prompt-engineer" a context for transcription, e.g. custom vocabularies or proper nouns
|
| 113 |
+
to make it more likely to predict those word correctly.
|
| 114 |
+
word_timestamps : bool, default True
|
| 115 |
+
Extract word-level timestamps using the cross-attention pattern and dynamic time warping,
|
| 116 |
+
and include the timestamps for each word in each segment.
|
| 117 |
+
Disabling this will prevent segments from splitting/merging properly.
|
| 118 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 119 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 120 |
+
Ignored if ``word_timestamps = False``.
|
| 121 |
+
ts_num : int, default 0, meaning disable this option
|
| 122 |
+
Number of extra timestamp inferences to perform then use average of these extra timestamps.
|
| 123 |
+
An experimental option that might hurt performance.
|
| 124 |
+
ts_noise : float, default 0.1
|
| 125 |
+
Percentage of noise to add to audio_features to perform inferences for ``ts_num``.
|
| 126 |
+
suppress_silence : bool, default True
|
| 127 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 128 |
+
suppress_word_ts : bool, default True
|
| 129 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 130 |
+
use_word_position : bool, default True
|
| 131 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 132 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 133 |
+
q_levels : int, default 20
|
| 134 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 135 |
+
Acts as a threshold to marking sound as silent.
|
| 136 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 137 |
+
k_size : int, default 5
|
| 138 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 139 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 140 |
+
time_scale : float, optional
|
| 141 |
+
Factor for scaling audio duration for inference.
|
| 142 |
+
Greater than 1.0 'slows down' the audio, and less than 1.0 'speeds up' the audio. None is same as 1.0.
|
| 143 |
+
A factor of 1.5 will stretch 10s audio to 15s for inference. This increases the effective resolution
|
| 144 |
+
of the model but can increase word error rate.
|
| 145 |
+
demucs : bool or torch.nn.Module, default False
|
| 146 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 147 |
+
a Demucs model to avoid reloading the model for each run.
|
| 148 |
+
Demucs must be installed to use. Official repo. https://github.com/facebookresearch/demucs.
|
| 149 |
+
demucs_output : str, optional
|
| 150 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 151 |
+
Demucs must be installed to use. Official repo. https://github.com/facebookresearch/demucs.
|
| 152 |
+
demucs_options : dict, optional
|
| 153 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 154 |
+
vad : bool, default False
|
| 155 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 156 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 157 |
+
vad_threshold : float, default 0.35
|
| 158 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 159 |
+
vad_onnx : bool, default False
|
| 160 |
+
Whether to use ONNX for Silero VAD.
|
| 161 |
+
min_word_dur : float, default 0.1
|
| 162 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 163 |
+
nonspeech_error : float, default 0.3
|
| 164 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 165 |
+
only_voice_freq : bool, default False
|
| 166 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 167 |
+
prepend_punctuations : str, default '"\'“¿([{-)'
|
| 168 |
+
Punctuations to prepend to next word.
|
| 169 |
+
append_punctuations : str, default '.。,,!!??::”)]}、)'
|
| 170 |
+
Punctuations to append to previous word.
|
| 171 |
+
mel_first : bool, default False
|
| 172 |
+
Process entire audio track into log-Mel spectrogram first instead in chunks.
|
| 173 |
+
Used if odd behavior seen in stable-ts but not in whisper, but use significantly more memory for long audio.
|
| 174 |
+
split_callback : Callable, optional
|
| 175 |
+
Custom callback for grouping tokens up with their corresponding words.
|
| 176 |
+
The callback must take two arguments, list of tokens and tokenizer.
|
| 177 |
+
The callback returns a tuple with a list of words and a corresponding nested list of tokens.
|
| 178 |
+
suppress_ts_tokens : bool, default False
|
| 179 |
+
Whether to suppress timestamp tokens during inference for timestamps are detected at silent.
|
| 180 |
+
Reduces hallucinations in some cases, but also prone to ignore disfluencies and repetitions.
|
| 181 |
+
This option is ignored if ``suppress_silence = False``.
|
| 182 |
+
gap_padding : str, default ' ...'
|
| 183 |
+
Padding prepend to each segments for word timing alignment.
|
| 184 |
+
Used to reduce the probability of model predicting timestamps earlier than the first utterance.
|
| 185 |
+
only_ffmpeg : bool, default False
|
| 186 |
+
Whether to use only FFmpeg (instead of not yt-dlp) for URls
|
| 187 |
+
max_instant_words : float, default 0.5
|
| 188 |
+
If percentage of instantaneous words in a segment exceed this amount, the segment is removed.
|
| 189 |
+
avg_prob_threshold: float or None, default None
|
| 190 |
+
Transcribe the gap after the previous word and if the average word proababiliy of a segment falls below this
|
| 191 |
+
value, discard the segment. If ``None``, skip transcribing the gap to reduce chance of timestamps starting
|
| 192 |
+
before the next utterance.
|
| 193 |
+
progress_callback : Callable, optional
|
| 194 |
+
A function that will be called when transcription progress is updated.
|
| 195 |
+
The callback need two parameters.
|
| 196 |
+
The first parameter is a float for seconds of the audio that has been transcribed.
|
| 197 |
+
The second parameter is a float for total duration of audio in seconds.
|
| 198 |
+
ignore_compatibility : bool, default False
|
| 199 |
+
Whether to ignore warnings for compatibility issues with the detected Whisper version.
|
| 200 |
+
decode_options
|
| 201 |
+
Keyword arguments to construct class:`whisper.decode.DecodingOptions` instances.
|
| 202 |
+
|
| 203 |
+
Returns
|
| 204 |
+
-------
|
| 205 |
+
stable_whisper.result.WhisperResult
|
| 206 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 207 |
+
|
| 208 |
+
See Also
|
| 209 |
+
--------
|
| 210 |
+
stable_whisper.non_whisper.transcribe_any : Return :class:`stable_whisper.result.WhisperResult` containing all the
|
| 211 |
+
data from transcribing audio with unmodified :func:`whisper.transcribe.transcribe` with preprocessing and
|
| 212 |
+
postprocessing.
|
| 213 |
+
stable_whisper.whisper_word_level.load_faster_whisper.faster_transcribe : Return
|
| 214 |
+
:class:`stable_whisper.result.WhisperResult` containing all the data from transcribing audio with
|
| 215 |
+
:meth:`faster_whisper.WhisperModel.transcribe` with preprocessing and postprocessing.
|
| 216 |
+
|
| 217 |
+
Examples
|
| 218 |
+
--------
|
| 219 |
+
>>> import stable_whisper
|
| 220 |
+
>>> model = stable_whisper.load_model('base')
|
| 221 |
+
>>> result = model.transcribe('audio.mp3', vad=True)
|
| 222 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 223 |
+
Saved: audio.srt
|
| 224 |
+
"""
|
| 225 |
+
warn_compatibility_issues(whisper, ignore_compatibility, 'Or use transcribe_minimal().')
|
| 226 |
+
dtype = torch.float16 if decode_options.get("fp16", True) and not getattr(model, 'dq', False) else torch.float32
|
| 227 |
+
if model.device == torch.device("cpu"):
|
| 228 |
+
if torch.cuda.is_available():
|
| 229 |
+
warnings.warn("Performing inference on CPU when CUDA is available")
|
| 230 |
+
if dtype == torch.float16:
|
| 231 |
+
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
|
| 232 |
+
dtype = torch.float32
|
| 233 |
+
|
| 234 |
+
if dtype == torch.float32:
|
| 235 |
+
decode_options["fp16"] = False
|
| 236 |
+
|
| 237 |
+
if 'max_initial_timestamp' not in decode_options:
|
| 238 |
+
decode_options['max_initial_timestamp'] = None
|
| 239 |
+
|
| 240 |
+
device = model.device
|
| 241 |
+
|
| 242 |
+
if time_scale:
|
| 243 |
+
warnings.warn('``time_scale`` is deprecated. It will not affect results.',
|
| 244 |
+
DeprecationWarning, stacklevel=2)
|
| 245 |
+
if decode_options.pop('input_sr', None):
|
| 246 |
+
warnings.warn('``input_sr`` is deprecated. '
|
| 247 |
+
'``audio`` of types numpy.ndarray and torch.Tensor inputs must be already at 16kHz. '
|
| 248 |
+
'To higher sample rates for ``audio`` use str or bytes.',
|
| 249 |
+
DeprecationWarning, stacklevel=2)
|
| 250 |
+
if not demucs_options:
|
| 251 |
+
demucs_options = {}
|
| 252 |
+
if demucs_output:
|
| 253 |
+
if 'save_path' not in demucs_options:
|
| 254 |
+
demucs_options['save_path'] = demucs_output
|
| 255 |
+
warnings.warn('``demucs_output`` is deprecated. Use ``demucs_options`` with ``save_path`` instead. '
|
| 256 |
+
'E.g. demucs_options=dict(save_path="demucs_output.mp3")',
|
| 257 |
+
DeprecationWarning, stacklevel=2)
|
| 258 |
+
if 'device' not in demucs_options:
|
| 259 |
+
demucs_options['device'] = device
|
| 260 |
+
audio = prep_audio(
|
| 261 |
+
audio,
|
| 262 |
+
demucs=demucs,
|
| 263 |
+
demucs_options=demucs_options,
|
| 264 |
+
only_voice_freq=only_voice_freq,
|
| 265 |
+
only_ffmpeg=only_ffmpeg,
|
| 266 |
+
verbose=verbose
|
| 267 |
+
)
|
| 268 |
+
sample_padding = int(N_FFT // 2) + 1
|
| 269 |
+
whole_mel = log_mel_spectrogram(audio, model.dims.n_mels, padding=sample_padding) if mel_first else None
|
| 270 |
+
tokenizer = None
|
| 271 |
+
language = None
|
| 272 |
+
initial_prompt_tokens = []
|
| 273 |
+
task = decode_options.get("task", "transcribe")
|
| 274 |
+
|
| 275 |
+
def detect_language():
|
| 276 |
+
nonlocal tokenizer
|
| 277 |
+
if tokenizer is None:
|
| 278 |
+
if decode_options.get("language", None) is None and model:
|
| 279 |
+
if not model.is_multilingual:
|
| 280 |
+
decode_options["language"] = "en"
|
| 281 |
+
else:
|
| 282 |
+
if verbose:
|
| 283 |
+
print("Detecting language using up to 30 seconds following first non-silent sample. "
|
| 284 |
+
"Use `--language` to specify the language")
|
| 285 |
+
timing_mask = None
|
| 286 |
+
if segment_silence_timing is not None:
|
| 287 |
+
timing_mask = np.logical_and(
|
| 288 |
+
segment_silence_timing[0] <= time_offset,
|
| 289 |
+
segment_silence_timing[1] >= time_offset
|
| 290 |
+
)
|
| 291 |
+
start_sample = (
|
| 292 |
+
None
|
| 293 |
+
if segment_silence_timing is None or not timing_mask.any() else
|
| 294 |
+
round(segment_silence_timing[1][timing_mask.nonzero()[0]][0] * SAMPLE_RATE)
|
| 295 |
+
)
|
| 296 |
+
if start_sample is None:
|
| 297 |
+
nonlocal mel_segment
|
| 298 |
+
curr_mel_segment = mel_segment
|
| 299 |
+
else:
|
| 300 |
+
if whole_mel is None:
|
| 301 |
+
curr_mel_segment = log_mel_spectrogram(
|
| 302 |
+
audio[..., start_sample:start_sample+N_SAMPLES],
|
| 303 |
+
model.dims.n_mels,
|
| 304 |
+
padding=sample_padding
|
| 305 |
+
)
|
| 306 |
+
else:
|
| 307 |
+
start_frame = int(start_sample/HOP_LENGTH)
|
| 308 |
+
curr_mel_segment = whole_mel[..., start_frame:start_frame+N_FRAMES]
|
| 309 |
+
curr_mel_segment = pad_or_trim(curr_mel_segment, N_FRAMES).to(device=device, dtype=dtype)
|
| 310 |
+
_, probs = model.detect_language(curr_mel_segment)
|
| 311 |
+
decode_options["language"] = max(probs, key=probs.get)
|
| 312 |
+
if verbose is not None:
|
| 313 |
+
detected_msg = f"Detected language: {LANGUAGES[decode_options['language']]}"
|
| 314 |
+
if tqdm_pbar.disable:
|
| 315 |
+
print(detected_msg)
|
| 316 |
+
else:
|
| 317 |
+
tqdm_pbar.write(detected_msg)
|
| 318 |
+
|
| 319 |
+
nonlocal language
|
| 320 |
+
language = decode_options["language"]
|
| 321 |
+
tokenizer = get_tokenizer(model, language=language, task=task)
|
| 322 |
+
|
| 323 |
+
if word_timestamps and task == "translate":
|
| 324 |
+
warnings.warn("Word-level timestamps on translations may not be reliable.")
|
| 325 |
+
|
| 326 |
+
if initial_prompt is not None:
|
| 327 |
+
nonlocal initial_prompt_tokens
|
| 328 |
+
initial_prompt_tokens = tokenizer.encode(" " + initial_prompt.strip())
|
| 329 |
+
all_tokens.extend(initial_prompt_tokens)
|
| 330 |
+
|
| 331 |
+
audio_features = None
|
| 332 |
+
|
| 333 |
+
def decode_with_fallback(seg: torch.Tensor,
|
| 334 |
+
ts_token_mask: torch.Tensor = None) \
|
| 335 |
+
-> DecodingResult:
|
| 336 |
+
nonlocal audio_features
|
| 337 |
+
temperatures = [temperature] if isinstance(temperature, (int, float)) else temperature
|
| 338 |
+
decode_result = None
|
| 339 |
+
|
| 340 |
+
for t in temperatures:
|
| 341 |
+
kwargs = {**decode_options}
|
| 342 |
+
if t > 0:
|
| 343 |
+
# disable beam_size and patience when t > 0
|
| 344 |
+
kwargs.pop("beam_size", None)
|
| 345 |
+
kwargs.pop("patience", None)
|
| 346 |
+
else:
|
| 347 |
+
# disable best_of when t == 0
|
| 348 |
+
kwargs.pop("best_of", None)
|
| 349 |
+
|
| 350 |
+
options = DecodingOptions(**kwargs, temperature=t)
|
| 351 |
+
decode_result, audio_features = decode_stable(model,
|
| 352 |
+
seg,
|
| 353 |
+
options,
|
| 354 |
+
ts_token_mask=ts_token_mask if suppress_ts_tokens else None,
|
| 355 |
+
audio_features=audio_features)
|
| 356 |
+
|
| 357 |
+
needs_fallback = False
|
| 358 |
+
if (
|
| 359 |
+
compression_ratio_threshold is not None
|
| 360 |
+
and decode_result.compression_ratio > compression_ratio_threshold
|
| 361 |
+
):
|
| 362 |
+
needs_fallback = True # too repetitive
|
| 363 |
+
if (
|
| 364 |
+
logprob_threshold is not None
|
| 365 |
+
and decode_result.avg_logprob < logprob_threshold
|
| 366 |
+
):
|
| 367 |
+
needs_fallback = True # average log probability is too low
|
| 368 |
+
if (
|
| 369 |
+
no_speech_threshold is not None
|
| 370 |
+
and decode_result.no_speech_prob > no_speech_threshold
|
| 371 |
+
):
|
| 372 |
+
needs_fallback = False # silence
|
| 373 |
+
|
| 374 |
+
if not needs_fallback:
|
| 375 |
+
break
|
| 376 |
+
|
| 377 |
+
return decode_result
|
| 378 |
+
|
| 379 |
+
seek_sample = 0 # samples
|
| 380 |
+
input_stride = exact_div(
|
| 381 |
+
N_FRAMES, model.dims.n_audio_ctx
|
| 382 |
+
) # mel frames per output token: 2
|
| 383 |
+
time_precision = (
|
| 384 |
+
input_stride * HOP_LENGTH / SAMPLE_RATE
|
| 385 |
+
) # time per output token: 0.02 (seconds)
|
| 386 |
+
all_tokens = []
|
| 387 |
+
all_segments = []
|
| 388 |
+
prompt_reset_since = 0
|
| 389 |
+
|
| 390 |
+
def new_segment(
|
| 391 |
+
*, start: float, end: float, tokens: torch.Tensor, result: DecodingResult
|
| 392 |
+
):
|
| 393 |
+
tokens = tokens.tolist()
|
| 394 |
+
text_tokens = [token for token in tokens if token < tokenizer.eot]
|
| 395 |
+
return {
|
| 396 |
+
"seek": round(seek_sample / SAMPLE_RATE, 3), # units in seconds
|
| 397 |
+
"start": start,
|
| 398 |
+
"end": end,
|
| 399 |
+
"text": tokenizer.decode(text_tokens),
|
| 400 |
+
"tokens": tokens,
|
| 401 |
+
"temperature": result.temperature,
|
| 402 |
+
"avg_logprob": result.avg_logprob,
|
| 403 |
+
"compression_ratio": result.compression_ratio,
|
| 404 |
+
"no_speech_prob": result.no_speech_prob,
|
| 405 |
+
}
|
| 406 |
+
|
| 407 |
+
punctuations = prepend_punctuations + append_punctuations
|
| 408 |
+
|
| 409 |
+
total_samples = audio.shape[-1]
|
| 410 |
+
total_duration = round(total_samples / SAMPLE_RATE, 2)
|
| 411 |
+
n_samples_per_frame = exact_div(N_SAMPLES_PER_TOKEN * TOKENS_PER_SECOND, FRAMES_PER_SECOND)
|
| 412 |
+
|
| 413 |
+
silent_timings = [[], []]
|
| 414 |
+
silence_timing = None
|
| 415 |
+
if suppress_silence and vad:
|
| 416 |
+
silence_timing = get_vad_silence_func(onnx=vad_onnx, verbose=verbose)(audio, speech_threshold=vad_threshold)
|
| 417 |
+
|
| 418 |
+
with tqdm(total=total_duration, unit='sec', disable=verbose is not False, desc=task.title()) as tqdm_pbar:
|
| 419 |
+
|
| 420 |
+
def update_pbar():
|
| 421 |
+
nonlocal audio_features
|
| 422 |
+
audio_features = None
|
| 423 |
+
seek_duration = min(total_duration, round(seek_sample / SAMPLE_RATE, 2))
|
| 424 |
+
if not tqdm_pbar.disable:
|
| 425 |
+
tqdm_pbar.update(seek_duration - tqdm_pbar.n)
|
| 426 |
+
if progress_callback is not None:
|
| 427 |
+
progress_callback(seek=seek_duration, total=total_duration)
|
| 428 |
+
|
| 429 |
+
def update_seek():
|
| 430 |
+
nonlocal seek_sample
|
| 431 |
+
seek_sample += segment_samples
|
| 432 |
+
|
| 433 |
+
def fast_forward():
|
| 434 |
+
# fast-forward to the next segment boundary
|
| 435 |
+
update_seek()
|
| 436 |
+
update_pbar()
|
| 437 |
+
|
| 438 |
+
while seek_sample < audio.shape[-1]:
|
| 439 |
+
seek_sample_end = seek_sample + N_SAMPLES
|
| 440 |
+
audio_segment = audio[seek_sample:seek_sample_end]
|
| 441 |
+
time_offset = seek_sample / SAMPLE_RATE
|
| 442 |
+
segment_samples = audio_segment.shape[-1]
|
| 443 |
+
segment_duration = segment_samples / SAMPLE_RATE
|
| 444 |
+
|
| 445 |
+
mel_segment = (
|
| 446 |
+
log_mel_spectrogram(audio_segment, model.dims.n_mels, padding=sample_padding)
|
| 447 |
+
if whole_mel is None else
|
| 448 |
+
whole_mel[..., round(seek_sample / n_samples_per_frame): round(seek_sample_end / n_samples_per_frame)]
|
| 449 |
+
)
|
| 450 |
+
|
| 451 |
+
mel_segment = pad_or_trim(mel_segment, N_FRAMES).to(device=model.device, dtype=dtype)
|
| 452 |
+
|
| 453 |
+
segment_silence_timing = None
|
| 454 |
+
ts_token_mask = None
|
| 455 |
+
if suppress_silence:
|
| 456 |
+
if silence_timing is None:
|
| 457 |
+
ts_token_mask = wav2mask(audio_segment, q_levels=q_levels, k_size=k_size)
|
| 458 |
+
segment_silence_timing = mask2timing(ts_token_mask, time_offset=time_offset)
|
| 459 |
+
else:
|
| 460 |
+
timing_indices = np.logical_and(
|
| 461 |
+
silence_timing[1] > time_offset,
|
| 462 |
+
silence_timing[0] < time_offset + segment_duration
|
| 463 |
+
)
|
| 464 |
+
segment_silence_timing = (silence_timing[0][timing_indices], silence_timing[1][timing_indices])
|
| 465 |
+
|
| 466 |
+
ts_token_mask = timing2mask(*segment_silence_timing, size=1501, time_offset=time_offset)
|
| 467 |
+
|
| 468 |
+
if mn := timing_indices.argmax():
|
| 469 |
+
silence_timing = (silence_timing[0][mn:], silence_timing[1][mn:])
|
| 470 |
+
|
| 471 |
+
if ts_token_mask is not None:
|
| 472 |
+
if ts_token_mask.all(): # segment is silent
|
| 473 |
+
fast_forward()
|
| 474 |
+
continue
|
| 475 |
+
ts_token_mask = pad_or_trim(ts_token_mask, 1501)
|
| 476 |
+
|
| 477 |
+
detect_language()
|
| 478 |
+
decode_options["prompt"] = all_tokens[prompt_reset_since:]
|
| 479 |
+
result: DecodingResult = decode_with_fallback(mel_segment, ts_token_mask=ts_token_mask)
|
| 480 |
+
tokens = torch.tensor(result.tokens)
|
| 481 |
+
|
| 482 |
+
if no_speech_threshold is not None:
|
| 483 |
+
# no voice activity check
|
| 484 |
+
should_skip = result.no_speech_prob > no_speech_threshold
|
| 485 |
+
if logprob_threshold is not None and result.avg_logprob > logprob_threshold:
|
| 486 |
+
# don't skip if the logprob is high enough, despite the no_speech_prob
|
| 487 |
+
should_skip = False
|
| 488 |
+
|
| 489 |
+
if should_skip:
|
| 490 |
+
fast_forward()
|
| 491 |
+
continue
|
| 492 |
+
|
| 493 |
+
current_segments = []
|
| 494 |
+
|
| 495 |
+
timestamp_tokens: torch.Tensor = tokens.ge(tokenizer.timestamp_begin)
|
| 496 |
+
single_timestamp_ending = timestamp_tokens[-2:].tolist() == [False, True]
|
| 497 |
+
|
| 498 |
+
consecutive = torch.where(timestamp_tokens[:-1] & timestamp_tokens[1:])[0]
|
| 499 |
+
consecutive.add_(1)
|
| 500 |
+
if len(consecutive) > 0:
|
| 501 |
+
# if the output contains two consecutive timestamp tokens
|
| 502 |
+
slices = consecutive.tolist()
|
| 503 |
+
if single_timestamp_ending:
|
| 504 |
+
slices.append(len(tokens))
|
| 505 |
+
|
| 506 |
+
last_slice = 0
|
| 507 |
+
for current_slice in slices:
|
| 508 |
+
sliced_tokens = tokens[last_slice:current_slice]
|
| 509 |
+
start_timestamp_pos = (
|
| 510 |
+
sliced_tokens[0].item() - tokenizer.timestamp_begin
|
| 511 |
+
)
|
| 512 |
+
end_timestamp_pos = (
|
| 513 |
+
sliced_tokens[-1].item() - tokenizer.timestamp_begin
|
| 514 |
+
)
|
| 515 |
+
current_segments.append(
|
| 516 |
+
new_segment(
|
| 517 |
+
start=round(time_offset + start_timestamp_pos * time_precision, 3),
|
| 518 |
+
end=round(time_offset + min(end_timestamp_pos * time_precision, segment_duration), 3),
|
| 519 |
+
tokens=sliced_tokens,
|
| 520 |
+
result=result,
|
| 521 |
+
)
|
| 522 |
+
)
|
| 523 |
+
last_slice = current_slice
|
| 524 |
+
|
| 525 |
+
else:
|
| 526 |
+
duration = segment_duration
|
| 527 |
+
timestamps = tokens[timestamp_tokens.nonzero().flatten()]
|
| 528 |
+
if (
|
| 529 |
+
len(timestamps) > 0
|
| 530 |
+
and timestamps[-1].item() != tokenizer.timestamp_begin
|
| 531 |
+
):
|
| 532 |
+
# no consecutive timestamps but it has a timestamp; use the last one.
|
| 533 |
+
end_timestamp_pos = (
|
| 534 |
+
timestamps[-1].item() - tokenizer.timestamp_begin
|
| 535 |
+
)
|
| 536 |
+
duration = min(end_timestamp_pos * time_precision, segment_duration)
|
| 537 |
+
else:
|
| 538 |
+
end_timestamp_pos = 0
|
| 539 |
+
|
| 540 |
+
current_segments.append(
|
| 541 |
+
new_segment(
|
| 542 |
+
start=round(time_offset, 3),
|
| 543 |
+
end=round(time_offset + duration, 3),
|
| 544 |
+
tokens=tokens,
|
| 545 |
+
result=result,
|
| 546 |
+
)
|
| 547 |
+
)
|
| 548 |
+
|
| 549 |
+
# if a segment is instantaneous or does not contain text, remove it
|
| 550 |
+
for i in reversed(range(len(current_segments))):
|
| 551 |
+
seg = current_segments[i]
|
| 552 |
+
if seg["start"] == seg["end"] or seg["text"].strip() in punctuations:
|
| 553 |
+
del current_segments[i]
|
| 554 |
+
|
| 555 |
+
num_samples = (
|
| 556 |
+
min(round(end_timestamp_pos * N_SAMPLES_PER_TOKEN), segment_samples)
|
| 557 |
+
if end_timestamp_pos > 0 else
|
| 558 |
+
segment_samples
|
| 559 |
+
)
|
| 560 |
+
|
| 561 |
+
if word_timestamps:
|
| 562 |
+
add_word_timestamps_stable(
|
| 563 |
+
segments=current_segments,
|
| 564 |
+
model=model,
|
| 565 |
+
tokenizer=tokenizer,
|
| 566 |
+
mel=mel_segment,
|
| 567 |
+
num_samples=num_samples,
|
| 568 |
+
prepend_punctuations=prepend_punctuations,
|
| 569 |
+
append_punctuations=append_punctuations,
|
| 570 |
+
audio_features=audio_features,
|
| 571 |
+
ts_num=ts_num,
|
| 572 |
+
ts_noise=ts_noise,
|
| 573 |
+
split_callback=split_callback,
|
| 574 |
+
gap_padding=gap_padding
|
| 575 |
+
)
|
| 576 |
+
|
| 577 |
+
# if [max_instant_words] of the words in a segment are instantaneous, remove it
|
| 578 |
+
for i in reversed(range(len(current_segments))):
|
| 579 |
+
zero_duration_percent = (
|
| 580 |
+
np.array(
|
| 581 |
+
[w['start'] == w['end'] for w in current_segments[i]['words']]
|
| 582 |
+
)
|
| 583 |
+
.astype(np.float16)
|
| 584 |
+
.mean()
|
| 585 |
+
)
|
| 586 |
+
if zero_duration_percent > max_instant_words:
|
| 587 |
+
del current_segments[i]
|
| 588 |
+
|
| 589 |
+
if avg_prob_threshold and current_segments:
|
| 590 |
+
if (
|
| 591 |
+
single_timestamp_ending and
|
| 592 |
+
(np.mean([w['probability'] for s in current_segments for w in s['words']]) <
|
| 593 |
+
avg_prob_threshold)
|
| 594 |
+
):
|
| 595 |
+
num_samples = segment_samples
|
| 596 |
+
current_segments = []
|
| 597 |
+
else:
|
| 598 |
+
num_samples = round((current_segments[-1]['words'][-1]['end']-time_offset) * SAMPLE_RATE)
|
| 599 |
+
|
| 600 |
+
if len(current_segments) == 0:
|
| 601 |
+
fast_forward()
|
| 602 |
+
continue
|
| 603 |
+
|
| 604 |
+
if segment_silence_timing is not None:
|
| 605 |
+
silent_timings[0].extend(segment_silence_timing[0])
|
| 606 |
+
silent_timings[1].extend(segment_silence_timing[1])
|
| 607 |
+
for seg_i, segment in enumerate(current_segments):
|
| 608 |
+
segment = Segment(**segment).suppress_silence(
|
| 609 |
+
*segment_silence_timing,
|
| 610 |
+
min_word_dur=min_word_dur,
|
| 611 |
+
word_level=suppress_word_ts,
|
| 612 |
+
nonspeech_error=nonspeech_error,
|
| 613 |
+
use_word_position=use_word_position,
|
| 614 |
+
)
|
| 615 |
+
if verbose:
|
| 616 |
+
safe_print(segment.to_display_str())
|
| 617 |
+
current_segments[seg_i] = segment.to_dict()
|
| 618 |
+
|
| 619 |
+
all_segments.extend(
|
| 620 |
+
[
|
| 621 |
+
{"id": i, **segment}
|
| 622 |
+
for i, segment in enumerate(current_segments, start=len(all_segments))
|
| 623 |
+
]
|
| 624 |
+
)
|
| 625 |
+
all_tokens.extend(
|
| 626 |
+
[token for segment in current_segments for token in segment["tokens"]]
|
| 627 |
+
)
|
| 628 |
+
if not single_timestamp_ending or avg_prob_threshold:
|
| 629 |
+
segment_samples = num_samples
|
| 630 |
+
|
| 631 |
+
if not condition_on_previous_text or result.temperature > 0.5:
|
| 632 |
+
# do not feed the prompt tokens if a high temperature was used
|
| 633 |
+
prompt_reset_since = len(all_tokens)
|
| 634 |
+
|
| 635 |
+
fast_forward()
|
| 636 |
+
|
| 637 |
+
# final update
|
| 638 |
+
update_pbar()
|
| 639 |
+
|
| 640 |
+
if model.device != torch.device('cpu'):
|
| 641 |
+
torch.cuda.empty_cache()
|
| 642 |
+
|
| 643 |
+
text = '' if tokenizer is None else tokenizer.decode(all_tokens[len(initial_prompt_tokens):])
|
| 644 |
+
final_result = WhisperResult(dict(text=text,
|
| 645 |
+
segments=all_segments,
|
| 646 |
+
language=language,
|
| 647 |
+
time_scale=time_scale))
|
| 648 |
+
if word_timestamps and regroup:
|
| 649 |
+
final_result.regroup(regroup)
|
| 650 |
+
|
| 651 |
+
if time_scale is not None:
|
| 652 |
+
final_result.rescale_time(1 / time_scale)
|
| 653 |
+
|
| 654 |
+
if len(final_result.text) == 0:
|
| 655 |
+
warnings.warn(f'Failed to {task} audio. Result contains no text. ')
|
| 656 |
+
|
| 657 |
+
final_result.update_nonspeech_sections(*silent_timings)
|
| 658 |
+
|
| 659 |
+
return final_result
|
| 660 |
+
|
| 661 |
+
|
| 662 |
+
def transcribe_minimal(
|
| 663 |
+
model: "Whisper",
|
| 664 |
+
audio: Union[str, np.ndarray, torch.Tensor, bytes],
|
| 665 |
+
*,
|
| 666 |
+
verbose: Optional[bool] = False,
|
| 667 |
+
word_timestamps: bool = True,
|
| 668 |
+
regroup: Union[bool, str] = True,
|
| 669 |
+
suppress_silence: bool = True,
|
| 670 |
+
suppress_word_ts: bool = True,
|
| 671 |
+
use_word_position: bool = True,
|
| 672 |
+
q_levels: int = 20,
|
| 673 |
+
k_size: int = 5,
|
| 674 |
+
demucs: bool = False,
|
| 675 |
+
demucs_output: str = None,
|
| 676 |
+
demucs_options: dict = None,
|
| 677 |
+
vad: bool = False,
|
| 678 |
+
vad_threshold: float = 0.35,
|
| 679 |
+
vad_onnx: bool = False,
|
| 680 |
+
min_word_dur: float = 0.1,
|
| 681 |
+
nonspeech_error: float = 0.3,
|
| 682 |
+
only_voice_freq: bool = False,
|
| 683 |
+
only_ffmpeg: bool = False,
|
| 684 |
+
**options) \
|
| 685 |
+
-> WhisperResult:
|
| 686 |
+
"""
|
| 687 |
+
Transcribe audio using Whisper.
|
| 688 |
+
|
| 689 |
+
This is uses the original whisper transcribe function, :func:`whisper.transcribe.transcribe`, while still allowing
|
| 690 |
+
additional preprocessing and postprocessing. The preprocessing performed on the audio includes: isolating voice /
|
| 691 |
+
removing noise with Demucs and low/high-pass filter. The postprocessing performed on the transcription
|
| 692 |
+
result includes: adjusting timestamps with VAD and custom regrouping segments based punctuation and speech gaps.
|
| 693 |
+
|
| 694 |
+
Parameters
|
| 695 |
+
----------
|
| 696 |
+
model : whisper.model.Whisper
|
| 697 |
+
An instance of Whisper ASR model.
|
| 698 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 699 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 700 |
+
If audio is ``numpy.ndarray`` or ``torch.Tensor``, the audio must be already at sampled to 16kHz.
|
| 701 |
+
verbose : bool or None, default False
|
| 702 |
+
Whether to display the text being decoded to the console.
|
| 703 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 704 |
+
word_timestamps : bool, default True
|
| 705 |
+
Extract word-level timestamps using the cross-attention pattern and dynamic time warping,
|
| 706 |
+
and include the timestamps for each word in each segment.
|
| 707 |
+
Disabling this will prevent segments from splitting/merging properly.
|
| 708 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 709 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 710 |
+
Ignored if ``word_timestamps = False``.
|
| 711 |
+
suppress_silence : bool, default True
|
| 712 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 713 |
+
suppress_word_ts : bool, default True
|
| 714 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 715 |
+
use_word_position : bool, default True
|
| 716 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 717 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 718 |
+
q_levels : int, default 20
|
| 719 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 720 |
+
Acts as a threshold to marking sound as silent.
|
| 721 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 722 |
+
k_size : int, default 5
|
| 723 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 724 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 725 |
+
demucs : bool or torch.nn.Module, default False
|
| 726 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance of
|
| 727 |
+
a Demucs model to avoid reloading the model for each run.
|
| 728 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 729 |
+
demucs_output : str, optional
|
| 730 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 731 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 732 |
+
demucs_options : dict, optional
|
| 733 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 734 |
+
vad : bool, default False
|
| 735 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 736 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 737 |
+
vad_threshold : float, default 0.35
|
| 738 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 739 |
+
vad_onnx : bool, default False
|
| 740 |
+
Whether to use ONNX for Silero VAD.
|
| 741 |
+
min_word_dur : float, default 0.1
|
| 742 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 743 |
+
nonspeech_error : float, default 0.3
|
| 744 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 745 |
+
only_voice_freq : bool, default False
|
| 746 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 747 |
+
only_ffmpeg : bool, default False
|
| 748 |
+
Whether to use only FFmpeg (instead of not yt-dlp) for URls
|
| 749 |
+
options
|
| 750 |
+
Additional options used for :func:`whisper.transcribe.transcribe` and
|
| 751 |
+
:func:`stable_whisper.non_whisper.transcribe_any`.
|
| 752 |
+
Returns
|
| 753 |
+
-------
|
| 754 |
+
stable_whisper.result.WhisperResult
|
| 755 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 756 |
+
|
| 757 |
+
Examples
|
| 758 |
+
--------
|
| 759 |
+
>>> import stable_whisper
|
| 760 |
+
>>> model = stable_whisper.load_model('base')
|
| 761 |
+
>>> result = model.transcribe_minimal('audio.mp3', vad=True)
|
| 762 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 763 |
+
Saved: audio.srt
|
| 764 |
+
"""
|
| 765 |
+
inference_kwargs = dict(
|
| 766 |
+
model=model,
|
| 767 |
+
audio=audio,
|
| 768 |
+
word_timestamps=word_timestamps,
|
| 769 |
+
verbose=verbose
|
| 770 |
+
)
|
| 771 |
+
extra_options = isolate_useful_options(options, transcribe_any, True)
|
| 772 |
+
if demucs or only_voice_freq:
|
| 773 |
+
if 'audio_type' not in extra_options:
|
| 774 |
+
extra_options['audio_type'] = 'torch'
|
| 775 |
+
if 'model_sr' not in extra_options:
|
| 776 |
+
extra_options['model_sr'] = SAMPLE_RATE
|
| 777 |
+
inference_kwargs.update(options)
|
| 778 |
+
return transcribe_any(
|
| 779 |
+
inference_func=whisper.transcribe,
|
| 780 |
+
audio=audio,
|
| 781 |
+
inference_kwargs=inference_kwargs,
|
| 782 |
+
verbose=verbose,
|
| 783 |
+
regroup=regroup,
|
| 784 |
+
suppress_silence=suppress_silence,
|
| 785 |
+
suppress_word_ts=suppress_word_ts,
|
| 786 |
+
q_levels=q_levels,
|
| 787 |
+
k_size=k_size,
|
| 788 |
+
demucs=demucs,
|
| 789 |
+
demucs_output=demucs_output,
|
| 790 |
+
demucs_options=demucs_options,
|
| 791 |
+
vad=vad,
|
| 792 |
+
vad_threshold=vad_threshold,
|
| 793 |
+
vad_onnx=vad_onnx,
|
| 794 |
+
min_word_dur=min_word_dur,
|
| 795 |
+
nonspeech_error=nonspeech_error,
|
| 796 |
+
use_word_position=use_word_position,
|
| 797 |
+
only_voice_freq=only_voice_freq,
|
| 798 |
+
only_ffmpeg=only_ffmpeg,
|
| 799 |
+
force_order=True,
|
| 800 |
+
**extra_options
|
| 801 |
+
)
|
| 802 |
+
|
| 803 |
+
|
| 804 |
+
def load_faster_whisper(model_size_or_path: str, **model_init_options):
|
| 805 |
+
"""
|
| 806 |
+
Load an instance of :class:`faster_whisper.WhisperModel`.
|
| 807 |
+
|
| 808 |
+
Parameters
|
| 809 |
+
----------
|
| 810 |
+
model_size_or_path : {'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1',
|
| 811 |
+
'large-v2', 'large-v3', or 'large'}
|
| 812 |
+
Size of the model.
|
| 813 |
+
|
| 814 |
+
model_init_options
|
| 815 |
+
Additional options to use for initialization of :class:`faster_whisper.WhisperModel`.
|
| 816 |
+
|
| 817 |
+
Returns
|
| 818 |
+
-------
|
| 819 |
+
faster_whisper.WhisperModel
|
| 820 |
+
A modified instance with :func:`stable_whisper.whisper_word_level.load_faster_whisper.faster_transcribe`
|
| 821 |
+
assigned to :meth:`faster_whisper.WhisperModel.transcribe_stable`.
|
| 822 |
+
"""
|
| 823 |
+
from faster_whisper import WhisperModel
|
| 824 |
+
faster_model = WhisperModel(model_size_or_path, **model_init_options)
|
| 825 |
+
|
| 826 |
+
def _inner_transcribe(model, audio, verbose, **faster_transcribe_options):
|
| 827 |
+
if isinstance(audio, bytes):
|
| 828 |
+
import io
|
| 829 |
+
audio = io.BytesIO(audio)
|
| 830 |
+
progress_callback = faster_transcribe_options.pop('progress_callback', None)
|
| 831 |
+
segments, info = model.transcribe(audio, **faster_transcribe_options)
|
| 832 |
+
language = LANGUAGES.get(info.language, info.language)
|
| 833 |
+
if verbose is not None:
|
| 834 |
+
print(f'Detected Language: {language}')
|
| 835 |
+
print(f'Transcribing with faster-whisper ({model_size_or_path})...\r', end='')
|
| 836 |
+
|
| 837 |
+
final_segments = []
|
| 838 |
+
task = faster_transcribe_options.get('task', 'transcribe').title()
|
| 839 |
+
total_duration = round(info.duration, 2)
|
| 840 |
+
|
| 841 |
+
with tqdm(total=total_duration, unit='sec', disable=verbose is not False, desc=task) as tqdm_pbar:
|
| 842 |
+
|
| 843 |
+
def update_pbar(seek):
|
| 844 |
+
tqdm_pbar.update(seek - tqdm_pbar.n)
|
| 845 |
+
if progress_callback is not None:
|
| 846 |
+
progress_callback(seek, total_duration)
|
| 847 |
+
|
| 848 |
+
for segment in segments:
|
| 849 |
+
segment = segment._asdict()
|
| 850 |
+
if (words := segment.get('words')) is not None:
|
| 851 |
+
segment['words'] = [w._asdict() for w in words]
|
| 852 |
+
else:
|
| 853 |
+
del segment['words']
|
| 854 |
+
if verbose:
|
| 855 |
+
safe_print(Segment(**segment).to_display_str())
|
| 856 |
+
final_segments.append(segment)
|
| 857 |
+
update_pbar(segment["end"])
|
| 858 |
+
update_pbar(tqdm_pbar.total)
|
| 859 |
+
|
| 860 |
+
if verbose:
|
| 861 |
+
print(f'Completed transcription with faster-whisper ({model_size_or_path}).')
|
| 862 |
+
|
| 863 |
+
return dict(language=language, segments=final_segments)
|
| 864 |
+
|
| 865 |
+
def faster_transcribe(
|
| 866 |
+
model: WhisperModel,
|
| 867 |
+
audio: Union[str, bytes, np.ndarray],
|
| 868 |
+
*,
|
| 869 |
+
word_timestamps: bool = True,
|
| 870 |
+
verbose: Optional[bool] = False,
|
| 871 |
+
regroup: Union[bool, str] = True,
|
| 872 |
+
suppress_silence: bool = True,
|
| 873 |
+
suppress_word_ts: bool = True,
|
| 874 |
+
use_word_position: bool = True,
|
| 875 |
+
q_levels: int = 20,
|
| 876 |
+
k_size: int = 5,
|
| 877 |
+
demucs: bool = False,
|
| 878 |
+
demucs_output: str = None,
|
| 879 |
+
demucs_options: dict = None,
|
| 880 |
+
vad: bool = False,
|
| 881 |
+
vad_threshold: float = 0.35,
|
| 882 |
+
vad_onnx: bool = False,
|
| 883 |
+
min_word_dur: float = 0.1,
|
| 884 |
+
nonspeech_error: float = 0.3,
|
| 885 |
+
only_voice_freq: bool = False,
|
| 886 |
+
only_ffmpeg: bool = False,
|
| 887 |
+
check_sorted: bool = True,
|
| 888 |
+
progress_callback: Callable = None,
|
| 889 |
+
**options
|
| 890 |
+
) -> WhisperResult:
|
| 891 |
+
"""
|
| 892 |
+
Transcribe audio using faster-whisper (https://github.com/guillaumekln/faster-whisper).
|
| 893 |
+
|
| 894 |
+
This is uses the transcribe method from faster-whisper, :meth:`faster_whisper.WhisperModel.transcribe`, while
|
| 895 |
+
still allowing additional preprocessing and postprocessing. The preprocessing performed on the audio includes:
|
| 896 |
+
isolating voice / removing noise with Demucs and low/high-pass filter. The postprocessing performed on the
|
| 897 |
+
transcription result includes: adjusting timestamps with VAD and custom regrouping segments based punctuation
|
| 898 |
+
and speech gaps.
|
| 899 |
+
|
| 900 |
+
Parameters
|
| 901 |
+
----------
|
| 902 |
+
model : faster_whisper.WhisperModel
|
| 903 |
+
The faster-whisper ASR model instance.
|
| 904 |
+
audio : str or numpy.ndarray or torch.Tensor or bytes
|
| 905 |
+
Path/URL to the audio file, the audio waveform, or bytes of audio file.
|
| 906 |
+
If audio is :class:`numpy.ndarray` or :class:`torch.Tensor`, the audio must be already at sampled to 16kHz.
|
| 907 |
+
verbose : bool or None, default False
|
| 908 |
+
Whether to display the text being decoded to the console.
|
| 909 |
+
Displays all the details if ``True``. Displays progressbar if ``False``. Display nothing if ``None``.
|
| 910 |
+
word_timestamps : bool, default True
|
| 911 |
+
Extract word-level timestamps using the cross-attention pattern and dynamic time warping,
|
| 912 |
+
and include the timestamps for each word in each segment.
|
| 913 |
+
Disabling this will prevent segments from splitting/merging properly.
|
| 914 |
+
regroup : bool or str, default True, meaning the default regroup algorithm
|
| 915 |
+
String for customizing the regrouping algorithm. False disables regrouping.
|
| 916 |
+
Ignored if ``word_timestamps = False``.
|
| 917 |
+
suppress_silence : bool, default True
|
| 918 |
+
Whether to enable timestamps adjustments based on the detected silence.
|
| 919 |
+
suppress_word_ts : bool, default True
|
| 920 |
+
Whether to adjust word timestamps based on the detected silence. Only enabled if ``suppress_silence = True``.
|
| 921 |
+
use_word_position : bool, default True
|
| 922 |
+
Whether to use position of the word in its segment to determine whether to keep end or start timestamps if
|
| 923 |
+
adjustments are required. If it is the first word, keep end. Else if it is the last word, keep the start.
|
| 924 |
+
q_levels : int, default 20
|
| 925 |
+
Quantization levels for generating timestamp suppression mask; ignored if ``vad = true``.
|
| 926 |
+
Acts as a threshold to marking sound as silent.
|
| 927 |
+
Fewer levels will increase the threshold of volume at which to mark a sound as silent.
|
| 928 |
+
k_size : int, default 5
|
| 929 |
+
Kernel size for avg-pooling waveform to generate timestamp suppression mask; ignored if ``vad = true``.
|
| 930 |
+
Recommend 5 or 3; higher sizes will reduce detection of silence.
|
| 931 |
+
demucs : bool or torch.nn.Module, default False
|
| 932 |
+
Whether to preprocess ``audio`` with Demucs to isolate vocals / remove noise. Set ``demucs`` to an instance
|
| 933 |
+
of a Demucs model to avoid reloading the model for each run.
|
| 934 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 935 |
+
demucs_output : str, optional
|
| 936 |
+
Path to save the vocals isolated by Demucs as WAV file. Ignored if ``demucs = False``.
|
| 937 |
+
Demucs must be installed to use. Official repo, https://github.com/facebookresearch/demucs.
|
| 938 |
+
demucs_options : dict, optional
|
| 939 |
+
Options to use for :func:`stable_whisper.audio.demucs_audio`.
|
| 940 |
+
vad : bool, default False
|
| 941 |
+
Whether to use Silero VAD to generate timestamp suppression mask.
|
| 942 |
+
Silero VAD requires PyTorch 1.12.0+. Official repo, https://github.com/snakers4/silero-vad.
|
| 943 |
+
vad_threshold : float, default 0.35
|
| 944 |
+
Threshold for detecting speech with Silero VAD. Low threshold reduces false positives for silence detection.
|
| 945 |
+
vad_onnx : bool, default False
|
| 946 |
+
Whether to use ONNX for Silero VAD.
|
| 947 |
+
min_word_dur : float, default 0.1
|
| 948 |
+
Shortest duration each word is allowed to reach for silence suppression.
|
| 949 |
+
nonspeech_error : float, default 0.3
|
| 950 |
+
Relative error of non-speech sections that appear in between a word for silence suppression.
|
| 951 |
+
only_voice_freq : bool, default False
|
| 952 |
+
Whether to only use sound between 200 - 5000 Hz, where majority of human speech are.
|
| 953 |
+
only_ffmpeg : bool, default False
|
| 954 |
+
Whether to use only FFmpeg (instead of not yt-dlp) for URls
|
| 955 |
+
check_sorted : bool, default True
|
| 956 |
+
Whether to raise an error when timestamps returned by faster-whipser are not in ascending order.
|
| 957 |
+
progress_callback : Callable, optional
|
| 958 |
+
A function that will be called when transcription progress is updated.
|
| 959 |
+
The callback need two parameters.
|
| 960 |
+
The first parameter is a float for seconds of the audio that has been transcribed.
|
| 961 |
+
The second parameter is a float for total duration of audio in seconds.
|
| 962 |
+
options
|
| 963 |
+
Additional options used for :meth:`faster_whisper.WhisperModel.transcribe` and
|
| 964 |
+
:func:`stable_whisper.non_whisper.transcribe_any`.
|
| 965 |
+
|
| 966 |
+
Returns
|
| 967 |
+
-------
|
| 968 |
+
stable_whisper.result.WhisperResult
|
| 969 |
+
All timestamps, words, probabilities, and other data from the transcription of ``audio``.
|
| 970 |
+
|
| 971 |
+
Examples
|
| 972 |
+
--------
|
| 973 |
+
>>> import stable_whisper
|
| 974 |
+
>>> model = stable_whisper.load_faster_whisper('base')
|
| 975 |
+
>>> result = model.transcribe_stable('audio.mp3', vad=True)
|
| 976 |
+
>>> result.to_srt_vtt('audio.srt')
|
| 977 |
+
Saved: audio.srt
|
| 978 |
+
"""
|
| 979 |
+
extra_options = isolate_useful_options(options, transcribe_any, pop=True)
|
| 980 |
+
if demucs or only_voice_freq:
|
| 981 |
+
if 'audio_type' not in extra_options:
|
| 982 |
+
extra_options['audio_type'] = 'numpy'
|
| 983 |
+
if 'model_sr' not in extra_options:
|
| 984 |
+
extra_options['model_sr'] = SAMPLE_RATE
|
| 985 |
+
faster_whisper_options = options
|
| 986 |
+
faster_whisper_options['model'] = model
|
| 987 |
+
faster_whisper_options['audio'] = audio
|
| 988 |
+
faster_whisper_options['word_timestamps'] = word_timestamps
|
| 989 |
+
faster_whisper_options['verbose'] = verbose
|
| 990 |
+
faster_whisper_options['progress_callback'] = progress_callback
|
| 991 |
+
if not demucs_options:
|
| 992 |
+
demucs_options = {}
|
| 993 |
+
if demucs_output:
|
| 994 |
+
if 'save_path' not in demucs_options:
|
| 995 |
+
demucs_options['save_path'] = demucs_output
|
| 996 |
+
warnings.warn('``demucs_output`` is deprecated. Use ``demucs_options`` with ``save_path`` instead. '
|
| 997 |
+
'E.g. demucs_options=dict(save_path="demucs_output.mp3")',
|
| 998 |
+
DeprecationWarning, stacklevel=2)
|
| 999 |
+
|
| 1000 |
+
return transcribe_any(
|
| 1001 |
+
inference_func=_inner_transcribe,
|
| 1002 |
+
audio=audio,
|
| 1003 |
+
inference_kwargs=faster_whisper_options,
|
| 1004 |
+
verbose=verbose,
|
| 1005 |
+
regroup=regroup,
|
| 1006 |
+
suppress_silence=suppress_silence,
|
| 1007 |
+
suppress_word_ts=suppress_word_ts,
|
| 1008 |
+
q_levels=q_levels,
|
| 1009 |
+
k_size=k_size,
|
| 1010 |
+
demucs=demucs,
|
| 1011 |
+
demucs_options=demucs_options,
|
| 1012 |
+
vad=vad,
|
| 1013 |
+
vad_threshold=vad_threshold,
|
| 1014 |
+
vad_onnx=vad_onnx,
|
| 1015 |
+
min_word_dur=min_word_dur,
|
| 1016 |
+
nonspeech_error=nonspeech_error,
|
| 1017 |
+
use_word_position=use_word_position,
|
| 1018 |
+
only_voice_freq=only_voice_freq,
|
| 1019 |
+
only_ffmpeg=only_ffmpeg,
|
| 1020 |
+
force_order=True,
|
| 1021 |
+
check_sorted=check_sorted,
|
| 1022 |
+
**extra_options
|
| 1023 |
+
)
|
| 1024 |
+
|
| 1025 |
+
faster_model.transcribe_stable = MethodType(faster_transcribe, faster_model)
|
| 1026 |
+
from .alignment import align
|
| 1027 |
+
faster_model.align = MethodType(align, faster_model)
|
| 1028 |
+
|
| 1029 |
+
return faster_model
|
| 1030 |
+
|
| 1031 |
+
|
| 1032 |
+
def modify_model(model: "Whisper"):
|
| 1033 |
+
"""
|
| 1034 |
+
Modify an instance if :class:`whisper.model.Whisper`.
|
| 1035 |
+
|
| 1036 |
+
The following are performed:
|
| 1037 |
+
-replace :meth:`whisper.model.Whisper.transcribe` with :func:`stable_whisper.whisper_word_level.transcribe_stable`
|
| 1038 |
+
-assign :meth:`whisper.model.transcribe_minimal` to :func:`stable_whisper.whisper_word_level.transcribe_minimal`
|
| 1039 |
+
-assign :meth:`whisper.model.Whisper.transcribe_original` to :meth:`whisper.model.Whisper.transcribe`
|
| 1040 |
+
-assign :meth:`whisper.model.Whisper.align` to :func:`stable_whisper.alignment.align`
|
| 1041 |
+
-assign :meth:`whisper.model.Whisper.locate` to :func:`stable_whisper.alignment.locate`
|
| 1042 |
+
"""
|
| 1043 |
+
model.transcribe = MethodType(transcribe_stable, model)
|
| 1044 |
+
model.transcribe_minimal = MethodType(transcribe_minimal, model)
|
| 1045 |
+
model.transcribe_original = MethodType(whisper.transcribe, model)
|
| 1046 |
+
from .alignment import align, refine, locate
|
| 1047 |
+
model.align = MethodType(align, model)
|
| 1048 |
+
model.refine = MethodType(refine, model)
|
| 1049 |
+
model.locate = MethodType(locate, model)
|
| 1050 |
+
|
| 1051 |
+
|
| 1052 |
+
# modified version of whisper.load_model
|
| 1053 |
+
def load_model(name: str, device: Optional[Union[str, torch.device]] = None,
|
| 1054 |
+
download_root: str = None, in_memory: bool = False,
|
| 1055 |
+
cpu_preload: bool = True, dq: bool = False) -> "Whisper":
|
| 1056 |
+
"""
|
| 1057 |
+
Load an instance if :class:`whisper.model.Whisper`.
|
| 1058 |
+
|
| 1059 |
+
Parameters
|
| 1060 |
+
----------
|
| 1061 |
+
name : {'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1',
|
| 1062 |
+
'large-v2', 'large-v3', or 'large'}
|
| 1063 |
+
One of the official model names listed by :func:`whisper.available_models`, or
|
| 1064 |
+
path to a model checkpoint containing the model dimensions and the model state_dict.
|
| 1065 |
+
device : str or torch.device, optional
|
| 1066 |
+
PyTorch device to put the model into.
|
| 1067 |
+
download_root : str, optional
|
| 1068 |
+
Path to download the model files; by default, it uses "~/.cache/whisper".
|
| 1069 |
+
in_memory : bool, default False
|
| 1070 |
+
Whether to preload the model weights into host memory.
|
| 1071 |
+
cpu_preload : bool, default True
|
| 1072 |
+
Load model into CPU memory first then move model to specified device
|
| 1073 |
+
to reduce GPU memory usage when loading model
|
| 1074 |
+
dq : bool, default False
|
| 1075 |
+
Whether to apply Dynamic Quantization to model to reduced memory usage and increase inference speed
|
| 1076 |
+
but at the cost of a slight decrease in accuracy. Only for CPU.
|
| 1077 |
+
|
| 1078 |
+
Returns
|
| 1079 |
+
-------
|
| 1080 |
+
model : "Whisper"
|
| 1081 |
+
The Whisper ASR model instance.
|
| 1082 |
+
|
| 1083 |
+
Notes
|
| 1084 |
+
-----
|
| 1085 |
+
The overhead from ``dq = True`` might make inference slower for models smaller than 'large'.
|
| 1086 |
+
"""
|
| 1087 |
+
if device is None or dq:
|
| 1088 |
+
device = "cuda" if torch.cuda.is_available() and not dq else "cpu"
|
| 1089 |
+
if cpu_preload:
|
| 1090 |
+
model = whisper.load_model(name, device='cpu', download_root=download_root, in_memory=in_memory)
|
| 1091 |
+
cuda_index = None
|
| 1092 |
+
if isinstance(device, str) and device.startswith('cuda'):
|
| 1093 |
+
try:
|
| 1094 |
+
cuda_index = [] if device == 'cuda' else [int(device.split(':')[-1])]
|
| 1095 |
+
except ValueError:
|
| 1096 |
+
pass
|
| 1097 |
+
model = model.to(device=device) if cuda_index is None else model.cuda(*cuda_index)
|
| 1098 |
+
else:
|
| 1099 |
+
model = whisper.load_model(name, device=device, download_root=download_root, in_memory=in_memory)
|
| 1100 |
+
modify_model(model)
|
| 1101 |
+
if dq:
|
| 1102 |
+
from .quantization import ptdq_linear
|
| 1103 |
+
ptdq_linear(model)
|
| 1104 |
+
return model
|
| 1105 |
+
|
| 1106 |
+
|
| 1107 |
+
# modified version of whisper.transcribe.cli
|
| 1108 |
+
def cli():
|
| 1109 |
+
import argparse
|
| 1110 |
+
import os
|
| 1111 |
+
from os.path import splitext, split, isfile, join
|
| 1112 |
+
from whisper import available_models
|
| 1113 |
+
from whisper.utils import optional_int, optional_float
|
| 1114 |
+
from .utils import str_to_valid_type, get_func_parameters
|
| 1115 |
+
|
| 1116 |
+
str2val = {"true": True, "false": False, "1": True, "0": False}
|
| 1117 |
+
|
| 1118 |
+
def str2bool(string: str) -> bool:
|
| 1119 |
+
string = string.lower()
|
| 1120 |
+
if string in str2val:
|
| 1121 |
+
return str2val[string]
|
| 1122 |
+
raise ValueError(f"Expected one of {set(str2val.keys())}, got {string}")
|
| 1123 |
+
|
| 1124 |
+
def valid_model_name(name):
|
| 1125 |
+
if name in available_models() or os.path.exists(name):
|
| 1126 |
+
return name
|
| 1127 |
+
raise ValueError(
|
| 1128 |
+
f"model should be one of {available_models()} or path to a model checkpoint"
|
| 1129 |
+
)
|
| 1130 |
+
|
| 1131 |
+
def update_options_with_args(arg_key: str, options: Optional[dict] = None, pop: bool = False):
|
| 1132 |
+
extra_options = args.pop(arg_key) if pop else args.get(arg_key)
|
| 1133 |
+
if not extra_options:
|
| 1134 |
+
return
|
| 1135 |
+
extra_options = [kv.split('=', maxsplit=1) for kv in extra_options]
|
| 1136 |
+
missing_val = [kv[0] for kv in extra_options if len(kv) == 1]
|
| 1137 |
+
if missing_val:
|
| 1138 |
+
raise ValueError(f'Following expected values for the following custom options: {missing_val}')
|
| 1139 |
+
extra_options = dict((k, str_to_valid_type(v)) for k, v in extra_options)
|
| 1140 |
+
if options is None:
|
| 1141 |
+
return extra_options
|
| 1142 |
+
options.update(extra_options)
|
| 1143 |
+
|
| 1144 |
+
OUTPUT_FORMATS_METHODS = {
|
| 1145 |
+
"srt": "to_srt_vtt",
|
| 1146 |
+
"ass": "to_ass",
|
| 1147 |
+
"json": "save_as_json",
|
| 1148 |
+
"vtt": "to_srt_vtt",
|
| 1149 |
+
"tsv": "to_tsv",
|
| 1150 |
+
"txt": "to_txt",
|
| 1151 |
+
}
|
| 1152 |
+
|
| 1153 |
+
OUTPUT_FORMATS = set(OUTPUT_FORMATS_METHODS.keys())
|
| 1154 |
+
|
| 1155 |
+
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 1156 |
+
parser.add_argument("inputs", nargs="+", type=str,
|
| 1157 |
+
help="audio/video filepath/URL(s) to transcribe "
|
| 1158 |
+
"or json file(s) to process into [output_format]")
|
| 1159 |
+
parser.add_argument("--output", "-o", action="extend", nargs="+", type=str,
|
| 1160 |
+
help="output filepaths(s);"
|
| 1161 |
+
"if not specified, auto-named output file(s) will be saved to "
|
| 1162 |
+
"[output_dir] or current dir if not specified.")
|
| 1163 |
+
parser.add_argument("--model", '-m', default="base", type=valid_model_name,
|
| 1164 |
+
help="name of the Whisper model to use")
|
| 1165 |
+
parser.add_argument("--model_dir", type=str, default=None,
|
| 1166 |
+
help="the path to save model files; uses ~/.cache/whisper by default")
|
| 1167 |
+
parser.add_argument("--device", default="cuda" if torch.cuda.is_available() else "cpu",
|
| 1168 |
+
help="device to use for PyTorch inference")
|
| 1169 |
+
parser.add_argument("--cpu_preload", type=str2bool, default=True,
|
| 1170 |
+
help="load model into CPU memory first then move model to specified device; "
|
| 1171 |
+
"this reduces GPU memory usage when loading model.")
|
| 1172 |
+
parser.add_argument("--output_dir", "-d", type=str,
|
| 1173 |
+
help="directory to save the outputs;"
|
| 1174 |
+
"if a path in [output] does not have parent, that output will be save to this directory")
|
| 1175 |
+
parser.add_argument("--output_format", "-f", type=str,
|
| 1176 |
+
help="format of the output file(s); "
|
| 1177 |
+
f"Supported Formats: {OUTPUT_FORMATS}; "
|
| 1178 |
+
"use ',' to separate multiple formats")
|
| 1179 |
+
parser.add_argument("--verbose", '-v', type=int, default=1, choices=(0, 1, 2),
|
| 1180 |
+
help="whether to display the text being decoded to the console; "
|
| 1181 |
+
"if 2, display all the details; "
|
| 1182 |
+
"if 1, display progressbar; "
|
| 1183 |
+
"if 0, display nothing")
|
| 1184 |
+
|
| 1185 |
+
parser.add_argument("--dynamic_quantization", "-dq", action='store_true',
|
| 1186 |
+
help="whether to apply Dynamic Quantization to model "
|
| 1187 |
+
"to reduced memory usage (~half less) and increase inference speed "
|
| 1188 |
+
"at cost of slight decrease in accuracy; Only for CPU; "
|
| 1189 |
+
"NOTE: overhead might make inference slower for models smaller than 'large'")
|
| 1190 |
+
|
| 1191 |
+
parser.add_argument("--task", type=str, default="transcribe",
|
| 1192 |
+
choices=["transcribe", "translate"],
|
| 1193 |
+
help="whether to perform X->X speech recognition ('transcribe') "
|
| 1194 |
+
"or X->English translation ('translate')")
|
| 1195 |
+
parser.add_argument("--language", '-l', type=str, default=None,
|
| 1196 |
+
choices=sorted(LANGUAGES.keys()) + sorted([k.title() for k in TO_LANGUAGE_CODE.keys()]),
|
| 1197 |
+
help="language spoken in the audio, specify None to perform language detection")
|
| 1198 |
+
|
| 1199 |
+
parser.add_argument("--prepend_punctuations", '-pp', type=str, default="\"'“¿([{-",
|
| 1200 |
+
help="Punctuations to prepend to next word")
|
| 1201 |
+
parser.add_argument("--append_punctuations", '-ap', type=str, default="\"'.。,,!!??::”)]}、",
|
| 1202 |
+
help="Punctuations to append to previous word")
|
| 1203 |
+
|
| 1204 |
+
parser.add_argument("--gap_padding", type=str, default=" ...",
|
| 1205 |
+
help="padding prepend to each segments for word timing alignment;"
|
| 1206 |
+
"used to reduce the probability of model predicting timestamps "
|
| 1207 |
+
"earlier than the first utterance")
|
| 1208 |
+
|
| 1209 |
+
parser.add_argument("--word_timestamps", type=str2bool, default=True,
|
| 1210 |
+
help="extract word-level timestamps using the cross-attention pattern and dynamic time warping,"
|
| 1211 |
+
"and include the timestamps for each word in each segment;"
|
| 1212 |
+
"disabling this will prevent segments from splitting/merging properly.")
|
| 1213 |
+
|
| 1214 |
+
parser.add_argument("--regroup", type=str, default="True",
|
| 1215 |
+
help="whether to regroup all words into segments with more natural boundaries;"
|
| 1216 |
+
"specify string for customizing the regrouping algorithm"
|
| 1217 |
+
"ignored if [word_timestamps]=False.")
|
| 1218 |
+
|
| 1219 |
+
parser.add_argument('--ts_num', type=int, default=0,
|
| 1220 |
+
help="number of extra inferences to perform to find the mean timestamps")
|
| 1221 |
+
parser.add_argument('--ts_noise', type=float, default=0.1,
|
| 1222 |
+
help="percentage of noise to add to audio_features to perform inferences for [ts_num]")
|
| 1223 |
+
|
| 1224 |
+
parser.add_argument('--suppress_silence', type=str2bool, default=True,
|
| 1225 |
+
help="whether to suppress timestamp where audio is silent at segment-level"
|
| 1226 |
+
"and word-level if [suppress_word_ts]=True")
|
| 1227 |
+
parser.add_argument('--suppress_word_ts', type=str2bool, default=True,
|
| 1228 |
+
help="whether to suppress timestamps where audio is silent at word-level; "
|
| 1229 |
+
"ignored if [suppress_silence]=False")
|
| 1230 |
+
|
| 1231 |
+
parser.add_argument('--suppress_ts_tokens', type=str2bool, default=False,
|
| 1232 |
+
help="whether to use silence mask to suppress silent timestamp tokens during inference; "
|
| 1233 |
+
"increases word accuracy in some cases, but tends reduce 'verbatimness' of the transcript"
|
| 1234 |
+
"ignored if [suppress_silence]=False")
|
| 1235 |
+
|
| 1236 |
+
parser.add_argument("--q_levels", type=int, default=20,
|
| 1237 |
+
help="quantization levels for generating timestamp suppression mask; "
|
| 1238 |
+
"acts as a threshold to marking sound as silent;"
|
| 1239 |
+
"fewer levels will increase the threshold of volume at which to mark a sound as silent")
|
| 1240 |
+
|
| 1241 |
+
parser.add_argument("--k_size", type=int, default=5,
|
| 1242 |
+
help="Kernel size for average pooling waveform to generate suppression mask; "
|
| 1243 |
+
"recommend 5 or 3; higher sizes will reduce detection of silence")
|
| 1244 |
+
|
| 1245 |
+
parser.add_argument('--time_scale', type=float,
|
| 1246 |
+
help="factor for scaling audio duration for inference;"
|
| 1247 |
+
"greater than 1.0 'slows down' the audio; "
|
| 1248 |
+
"less than 1.0 'speeds up' the audio; "
|
| 1249 |
+
"1.0 is no scaling")
|
| 1250 |
+
|
| 1251 |
+
parser.add_argument('--vad', type=str2bool, default=False,
|
| 1252 |
+
help='whether to use Silero VAD to generate timestamp suppression mask; '
|
| 1253 |
+
'Silero VAD requires PyTorch 1.12.0+;'
|
| 1254 |
+
'Official repo: https://github.com/snakers4/silero-vad')
|
| 1255 |
+
parser.add_argument('--vad_threshold', type=float, default=0.35,
|
| 1256 |
+
help='threshold for detecting speech with Silero VAD. (Default: 0.35); '
|
| 1257 |
+
'low threshold reduces false positives for silence detection')
|
| 1258 |
+
parser.add_argument('--vad_onnx', type=str2bool, default=False,
|
| 1259 |
+
help='whether to use ONNX for Silero VAD')
|
| 1260 |
+
|
| 1261 |
+
parser.add_argument('--min_word_dur', type=float, default=0.1,
|
| 1262 |
+
help="shortest duration each word is allowed to reach for silence suppression")
|
| 1263 |
+
parser.add_argument('--nonspeech_error', type=float, default=0.3,
|
| 1264 |
+
help="relative error of non-speech sections that appear in between a word for "
|
| 1265 |
+
"silence suppression.")
|
| 1266 |
+
|
| 1267 |
+
parser.add_argument('--max_chars', type=int,
|
| 1268 |
+
help="maximum number of character allowed in each segment")
|
| 1269 |
+
parser.add_argument('--max_words', type=int,
|
| 1270 |
+
help="maximum number of words allowed in each segment")
|
| 1271 |
+
|
| 1272 |
+
parser.add_argument('--demucs', type=str2bool, default=False,
|
| 1273 |
+
help='whether to reprocess the audio track with Demucs to isolate vocals/remove noise; '
|
| 1274 |
+
'Demucs official repo: https://github.com/facebookresearch/demucs')
|
| 1275 |
+
parser.add_argument('--demucs_output', action="extend", nargs="+", type=str,
|
| 1276 |
+
help='path(s) to save the vocals isolated by Demucs as WAV file(s); '
|
| 1277 |
+
'ignored if [demucs]=False')
|
| 1278 |
+
parser.add_argument('--only_voice_freq', '-ovf', action='store_true',
|
| 1279 |
+
help='whether to only use sound between 200 - 5000 Hz, where majority of human speech are.')
|
| 1280 |
+
|
| 1281 |
+
parser.add_argument('--strip', type=str2bool, default=True,
|
| 1282 |
+
help="whether to remove spaces before and after text on each segment for output")
|
| 1283 |
+
|
| 1284 |
+
parser.add_argument('--tag', type=str, action="extend", nargs="+",
|
| 1285 |
+
help="a pair tags used to change the properties a word at its predicted time"
|
| 1286 |
+
"SRT Default: '<font color=\"#00ff00\">', '</font>'"
|
| 1287 |
+
"VTT Default: '<u>', '</u>'"
|
| 1288 |
+
"ASS Default: '{\\1c&HFF00&}', '{\\r}'")
|
| 1289 |
+
parser.add_argument('--segment_level', type=str2bool, default=True,
|
| 1290 |
+
help="whether to use segment-level timestamps in output")
|
| 1291 |
+
parser.add_argument('--word_level', type=str2bool, default=True,
|
| 1292 |
+
help="whether to use word-level timestamps in output")
|
| 1293 |
+
|
| 1294 |
+
parser.add_argument('--reverse_text', type=str2bool, default=False,
|
| 1295 |
+
help="whether to reverse the order of words for each segment of text output")
|
| 1296 |
+
|
| 1297 |
+
# ass output
|
| 1298 |
+
parser.add_argument('--font', type=str, default='Arial',
|
| 1299 |
+
help="word font for ASS output(s)")
|
| 1300 |
+
parser.add_argument('--font_size', type=int, default=48,
|
| 1301 |
+
help="word font size for ASS output(s)")
|
| 1302 |
+
parser.add_argument('--karaoke', type=str2bool, default=False,
|
| 1303 |
+
help="whether to use progressive filling highlights for karaoke effect (only for ASS outputs)")
|
| 1304 |
+
|
| 1305 |
+
parser.add_argument("--temperature", type=float, default=0,
|
| 1306 |
+
help="temperature to use for sampling")
|
| 1307 |
+
parser.add_argument("--best_of", type=optional_int,
|
| 1308 |
+
help="number of candidates when sampling with non-zero temperature")
|
| 1309 |
+
parser.add_argument("--beam_size", type=optional_int,
|
| 1310 |
+
help="number of beams in beam search, only applicable when temperature is zero")
|
| 1311 |
+
parser.add_argument("--patience", type=float, default=None,
|
| 1312 |
+
help="optional patience value to use in beam decoding, "
|
| 1313 |
+
"as in https://arxiv.org/abs/2204.05424, "
|
| 1314 |
+
"the default (1.0) is equivalent to conventional beam search")
|
| 1315 |
+
parser.add_argument("--length_penalty", type=float, default=None,
|
| 1316 |
+
help="optional token length penalty coefficient (alpha) "
|
| 1317 |
+
"as in https://arxiv.org/abs/1609.08144, uses simple length normalization by default")
|
| 1318 |
+
|
| 1319 |
+
parser.add_argument("--suppress_tokens", type=str, default="-1",
|
| 1320 |
+
help="comma-separated list of token ids to suppress during sampling; "
|
| 1321 |
+
"'-1' will suppress most special characters except common punctuations")
|
| 1322 |
+
parser.add_argument("--initial_prompt", type=str, default=None,
|
| 1323 |
+
help="optional text to provide as a prompt for the first window.")
|
| 1324 |
+
parser.add_argument("--condition_on_previous_text", type=str2bool, default=True,
|
| 1325 |
+
help="if True, provide the previous output of the model as a prompt for the next window; "
|
| 1326 |
+
"disabling may make the text inconsistent across windows, "
|
| 1327 |
+
"but the model becomes less prone to getting stuck in a failure loop")
|
| 1328 |
+
parser.add_argument("--fp16", type=str2bool, default=True,
|
| 1329 |
+
help="whether to perform inference in fp16; True by default")
|
| 1330 |
+
|
| 1331 |
+
parser.add_argument("--temperature_increment_on_fallback", type=optional_float, default=0.2,
|
| 1332 |
+
help="temperature to increase when falling back when the decoding fails to meet either of "
|
| 1333 |
+
"the thresholds below")
|
| 1334 |
+
parser.add_argument("--compression_ratio_threshold", type=optional_float, default=2.4,
|
| 1335 |
+
help="if the gzip compression ratio is higher than this value, treat the decoding as failed")
|
| 1336 |
+
parser.add_argument("--logprob_threshold", type=optional_float, default=-1.0,
|
| 1337 |
+
help="if the average log probability is lower than this value, treat the decoding as failed")
|
| 1338 |
+
parser.add_argument("--no_speech_threshold", type=optional_float, default=0.6,
|
| 1339 |
+
help="if the probability of the <|nospeech|> token is higher than this value AND the decoding "
|
| 1340 |
+
"has failed due to `logprob_threshold`, consider the segment as silence")
|
| 1341 |
+
parser.add_argument("--threads", type=optional_int, default=0,
|
| 1342 |
+
help="number of threads used by torch for CPU inference; "
|
| 1343 |
+
"supercedes MKL_NUM_THREADS/OMP_NUM_THREADS")
|
| 1344 |
+
|
| 1345 |
+
parser.add_argument('--mel_first', action='store_true',
|
| 1346 |
+
help='process entire audio track into log-Mel spectrogram first instead in chunks')
|
| 1347 |
+
|
| 1348 |
+
parser.add_argument('--only_ffmpeg', action='store_true',
|
| 1349 |
+
help='whether to use only FFmpeg (and not yt-dlp) for URls')
|
| 1350 |
+
|
| 1351 |
+
parser.add_argument('--overwrite', '-y', action='store_true',
|
| 1352 |
+
help='overwrite all output files')
|
| 1353 |
+
|
| 1354 |
+
parser.add_argument('--debug', action='store_true',
|
| 1355 |
+
help='print all input/output pair(s) and all arguments used for transcribing/translating')
|
| 1356 |
+
|
| 1357 |
+
parser.add_argument('--transcribe_method', '-tm', type=str, default='transcribe',
|
| 1358 |
+
choices=('transcribe', 'transcribe_minimal'))
|
| 1359 |
+
|
| 1360 |
+
parser.add_argument('--align', '-a', action="extend", nargs='+', type=str,
|
| 1361 |
+
help='path(s) to TXT file(s) or JSON previous result(s)')
|
| 1362 |
+
|
| 1363 |
+
parser.add_argument('--refine', '-r', action='store_true',
|
| 1364 |
+
help='Refine timestamps to increase precision of timestamps')
|
| 1365 |
+
|
| 1366 |
+
parser.add_argument('--locate', '-lc', action="extend", nargs='+', type=str,
|
| 1367 |
+
help='words to locate in the audio(s); skips transcription and output')
|
| 1368 |
+
|
| 1369 |
+
parser.add_argument('--refine_option', '-ro', action="extend", nargs='+', type=str,
|
| 1370 |
+
help='Extra option(s) to use for refining timestamps; Replace True/False with 1/0; '
|
| 1371 |
+
'E.g. --refine_option "steps=sese" --refine_options "rel_prob_decrease=0.05"')
|
| 1372 |
+
parser.add_argument('--demucs_option', '-do', action="extend", nargs='+', type=str,
|
| 1373 |
+
help='Extra option(s) to use for demucs; Replace True/False with 1/0; '
|
| 1374 |
+
'E.g. --demucs_option "shifts=3" --demucs_options "overlap=0.5"')
|
| 1375 |
+
parser.add_argument('--model_option', '-mo', action="extend", nargs='+', type=str,
|
| 1376 |
+
help='Extra option(s) to use for loading model; Replace True/False with 1/0; '
|
| 1377 |
+
'E.g. --model_option "download_root=./downloads"')
|
| 1378 |
+
parser.add_argument('--transcribe_option', '-to', action="extend", nargs='+', type=str,
|
| 1379 |
+
help='Extra option(s) to use for transcribing/alignment/locating; Replace True/False with 1/0; '
|
| 1380 |
+
'E.g. --transcribe_option "ignore_compatibility=1"')
|
| 1381 |
+
parser.add_argument('--save_option', '-so', action="extend", nargs='+', type=str,
|
| 1382 |
+
help='Extra option(s) to use for text outputs; Replace True/False with 1/0; '
|
| 1383 |
+
'E.g. --save_option "highlight_color=ffffff"')
|
| 1384 |
+
|
| 1385 |
+
parser.add_argument('--faster_whisper', '-fw', action='store_true',
|
| 1386 |
+
help='whether to use faster-whisper (https://github.com/guillaumekln/faster-whisper); '
|
| 1387 |
+
'note: some features may not be available')
|
| 1388 |
+
|
| 1389 |
+
args = parser.parse_args().__dict__
|
| 1390 |
+
debug = args.pop('debug')
|
| 1391 |
+
if not args['language'] and (args['align'] or args['locate']):
|
| 1392 |
+
raise ValueError('langauge is required for --align / --locate')
|
| 1393 |
+
|
| 1394 |
+
is_faster_whisper = args.pop('faster_whisper')
|
| 1395 |
+
model_name: str = args.pop("model")
|
| 1396 |
+
model_dir: str = args.pop("model_dir")
|
| 1397 |
+
inputs: List[Union[str, torch.Tensor]] = args.pop("inputs")
|
| 1398 |
+
outputs: List[str] = args.pop("output")
|
| 1399 |
+
output_dir: str = args.pop("output_dir")
|
| 1400 |
+
output_format = args.pop("output_format")
|
| 1401 |
+
overwrite: bool = args.pop("overwrite")
|
| 1402 |
+
use_demucs = args['demucs'] or False
|
| 1403 |
+
demucs_outputs: List[Optional[str]] = args.pop("demucs_output")
|
| 1404 |
+
args['demucs_options'] = update_options_with_args('demucs_option', pop=True)
|
| 1405 |
+
regroup = args.pop('regroup')
|
| 1406 |
+
max_chars = args.pop('max_chars')
|
| 1407 |
+
max_words = args.pop('max_words')
|
| 1408 |
+
args['verbose'] = False if args['verbose'] == 1 else (True if args['verbose'] == 2 else None)
|
| 1409 |
+
show_curr_task = args['verbose'] is not None
|
| 1410 |
+
strings_to_locate = args.pop('locate')
|
| 1411 |
+
if dq := args.pop('dynamic_quantization', False):
|
| 1412 |
+
args['device'] = 'cpu'
|
| 1413 |
+
if args['reverse_text']:
|
| 1414 |
+
args['reverse_text'] = (args.get('prepend_punctuations'), args.get('append_punctuations'))
|
| 1415 |
+
|
| 1416 |
+
if regroup:
|
| 1417 |
+
try:
|
| 1418 |
+
regroup = str2bool(regroup)
|
| 1419 |
+
except ValueError:
|
| 1420 |
+
pass
|
| 1421 |
+
curr_output_formats: List[str] = output_format.split(',') if output_format else []
|
| 1422 |
+
unsupported_formats = list(set(map(str.lower, curr_output_formats)) - OUTPUT_FORMATS)
|
| 1423 |
+
if outputs:
|
| 1424 |
+
unsupported_formats.extend(list(set(splitext(o)[-1].lower().strip('.') for o in outputs) - OUTPUT_FORMATS))
|
| 1425 |
+
if len(unsupported_formats) != 0:
|
| 1426 |
+
raise NotImplementedError(f'{unsupported_formats} are not supported. Supported formats: {OUTPUT_FORMATS}.')
|
| 1427 |
+
|
| 1428 |
+
has_demucs_output = bool(demucs_outputs)
|
| 1429 |
+
if use_demucs and has_demucs_output and len(demucs_outputs) != len(inputs):
|
| 1430 |
+
raise NotImplementedError(f'[demucs_output] and [inputs] do not match in count. '
|
| 1431 |
+
f'Got {len(demucs_outputs)} and {len(inputs)}')
|
| 1432 |
+
|
| 1433 |
+
if tag := args.get('tag'):
|
| 1434 |
+
assert tag == ['-1'] or len(tag) == 2, f'[tag] must be a pair of str but got {tag}'
|
| 1435 |
+
|
| 1436 |
+
def make_parent(filepath: str):
|
| 1437 |
+
if parent := split(filepath)[0]:
|
| 1438 |
+
os.makedirs(parent, exist_ok=True)
|
| 1439 |
+
|
| 1440 |
+
def is_json(file: str):
|
| 1441 |
+
return file.endswith(".json")
|
| 1442 |
+
|
| 1443 |
+
def call_method_with_options(method, options: dict, include_first: bool = True):
|
| 1444 |
+
def val_to_str(val) -> str:
|
| 1445 |
+
if isinstance(val, (np.ndarray, torch.Tensor)):
|
| 1446 |
+
return f'{val.__class__}(shape:{list(val.shape)})'
|
| 1447 |
+
elif isinstance(val, str):
|
| 1448 |
+
return f'"{val}"'
|
| 1449 |
+
elif isinstance(val, bytes):
|
| 1450 |
+
return f'{type(val)}(len:{len(val)})'
|
| 1451 |
+
elif isinstance(val, torch.nn.Module):
|
| 1452 |
+
return str(type(val))
|
| 1453 |
+
return str(val)
|
| 1454 |
+
|
| 1455 |
+
params = tuple(get_func_parameters(method))
|
| 1456 |
+
if debug:
|
| 1457 |
+
temp_options = {k: options.pop(k) for k in params if k in options}
|
| 1458 |
+
temp_options.update(options)
|
| 1459 |
+
options = temp_options
|
| 1460 |
+
options_str = ',\n'.join(
|
| 1461 |
+
f' {k}={val_to_str(v)}'
|
| 1462 |
+
for k, v in options.items()
|
| 1463 |
+
if include_first or k != params[0]
|
| 1464 |
+
)
|
| 1465 |
+
if options_str:
|
| 1466 |
+
options_str = f'\n{options_str}\n'
|
| 1467 |
+
else:
|
| 1468 |
+
print(options, params)
|
| 1469 |
+
print(f'{method.__qualname__}({options_str})')
|
| 1470 |
+
return method(**options)
|
| 1471 |
+
|
| 1472 |
+
if alignments := args['align']:
|
| 1473 |
+
if unsupported_align_fmts := \
|
| 1474 |
+
[_ext for p in alignments if (_ext := splitext(p)[-1].lower()) not in ('.json', '.txt')]:
|
| 1475 |
+
raise NotImplementedError(
|
| 1476 |
+
f'Unsupported format(s) for alignment: {unsupported_align_fmts}'
|
| 1477 |
+
)
|
| 1478 |
+
if len(inputs) != len(alignments):
|
| 1479 |
+
raise NotImplementedError(
|
| 1480 |
+
f'Got {len(inputs)} audio file(s) but specified {len(alignments)} file(s) to align.'
|
| 1481 |
+
)
|
| 1482 |
+
else:
|
| 1483 |
+
alignments = ['']*len(inputs)
|
| 1484 |
+
|
| 1485 |
+
def finalize_outputs(input_file: str, _output: str = None, _alignment: str = None) -> List[str]:
|
| 1486 |
+
_curr_output_formats = curr_output_formats.copy()
|
| 1487 |
+
basename, ext = splitext(_output or input_file)
|
| 1488 |
+
ext = ext[1:]
|
| 1489 |
+
if _output:
|
| 1490 |
+
if ext.lower() in OUTPUT_FORMATS:
|
| 1491 |
+
_curr_output_formats.append(ext)
|
| 1492 |
+
else:
|
| 1493 |
+
basename = _output
|
| 1494 |
+
if not _curr_output_formats:
|
| 1495 |
+
_curr_output_formats = ["srt" if is_json(input_file) or is_json(_alignment) else "json"]
|
| 1496 |
+
_outputs = [f'{basename}.{ext}' for ext in set(_curr_output_formats)]
|
| 1497 |
+
if output_dir:
|
| 1498 |
+
_outputs = [join(output_dir, o) for o in _outputs]
|
| 1499 |
+
|
| 1500 |
+
return _outputs
|
| 1501 |
+
|
| 1502 |
+
if outputs:
|
| 1503 |
+
if len(outputs) != len(inputs):
|
| 1504 |
+
raise NotImplementedError(f'Got {len(inputs)} audio file(s) but specified {len(outputs)} output file(s).')
|
| 1505 |
+
final_outputs = [finalize_outputs(i, o, a) for i, o, a in zip(inputs, outputs, alignments)]
|
| 1506 |
+
else:
|
| 1507 |
+
if not output_dir:
|
| 1508 |
+
output_dir = '.'
|
| 1509 |
+
final_outputs = [finalize_outputs(i, _alignment=a) for i, a in zip(inputs, alignments)]
|
| 1510 |
+
|
| 1511 |
+
if not overwrite:
|
| 1512 |
+
|
| 1513 |
+
def cancel_overwrite():
|
| 1514 |
+
resp = input(f'{path} already exist, overwrite (y/n)? ').lower()
|
| 1515 |
+
if resp in ('y', 'n'):
|
| 1516 |
+
return resp == 'n'
|
| 1517 |
+
print(f'Expected "y" or "n", but got {resp}.')
|
| 1518 |
+
return True
|
| 1519 |
+
|
| 1520 |
+
for paths in final_outputs:
|
| 1521 |
+
for path in paths:
|
| 1522 |
+
if isfile(path) and cancel_overwrite():
|
| 1523 |
+
return
|
| 1524 |
+
|
| 1525 |
+
if model_name.endswith(".en") and args["language"] not in {"en", "English"}:
|
| 1526 |
+
if args["language"] is not None:
|
| 1527 |
+
warnings.warn(f"{model_name} is an English-only model but receipted "
|
| 1528 |
+
f"'{args['language']}'; using English instead.")
|
| 1529 |
+
args["language"] = "en"
|
| 1530 |
+
|
| 1531 |
+
temperature = args.pop("temperature")
|
| 1532 |
+
increment = args.pop("temperature_increment_on_fallback")
|
| 1533 |
+
if increment is not None:
|
| 1534 |
+
temperature = tuple(np.arange(temperature, 1.0 + 1e-6, increment))
|
| 1535 |
+
else:
|
| 1536 |
+
temperature = [temperature]
|
| 1537 |
+
|
| 1538 |
+
args['temperature'] = temperature
|
| 1539 |
+
|
| 1540 |
+
threads = args.pop("threads")
|
| 1541 |
+
if threads > 0:
|
| 1542 |
+
torch.set_num_threads(threads)
|
| 1543 |
+
|
| 1544 |
+
if debug:
|
| 1545 |
+
print('Input(s) -> Outputs(s)')
|
| 1546 |
+
for i, (input_audio, output_paths, alignment) in enumerate(zip(inputs, final_outputs, alignments)):
|
| 1547 |
+
dm_output = f' {demucs_outputs[i]} ->' if demucs_outputs else ''
|
| 1548 |
+
alignment = f' + "{alignment}"' if alignment else ''
|
| 1549 |
+
print(f'"{input_audio}"{alignment} ->{dm_output} {output_paths}')
|
| 1550 |
+
print('')
|
| 1551 |
+
|
| 1552 |
+
if show_curr_task:
|
| 1553 |
+
model_from_str = '' if model_dir is None else f' from {model_dir}'
|
| 1554 |
+
model_loading_str = f'{"Faster-Whisper" if is_faster_whisper else "Whisper"} {model_name} model {model_from_str}'
|
| 1555 |
+
print(f'Loading {model_loading_str}\r', end='\n' if debug else '')
|
| 1556 |
+
else:
|
| 1557 |
+
model_loading_str = ''
|
| 1558 |
+
|
| 1559 |
+
alignments = args['align']
|
| 1560 |
+
model = None
|
| 1561 |
+
|
| 1562 |
+
def _load_model():
|
| 1563 |
+
nonlocal model
|
| 1564 |
+
if model is None:
|
| 1565 |
+
model_options = dict(
|
| 1566 |
+
name=model_name,
|
| 1567 |
+
model_size_or_path=model_name,
|
| 1568 |
+
device=args.get('device'),
|
| 1569 |
+
download_root=model_dir,
|
| 1570 |
+
dq=dq,
|
| 1571 |
+
)
|
| 1572 |
+
load_model_func = load_faster_whisper if is_faster_whisper else load_model
|
| 1573 |
+
model_options = isolate_useful_options(model_options, load_model_func)
|
| 1574 |
+
update_options_with_args('model_option', model_options)
|
| 1575 |
+
model = call_method_with_options(load_model_func, model_options)
|
| 1576 |
+
if model_loading_str:
|
| 1577 |
+
print(f'Loaded {model_loading_str} ')
|
| 1578 |
+
return model
|
| 1579 |
+
|
| 1580 |
+
for i, (input_audio, output_paths) in enumerate(zip(inputs, final_outputs)):
|
| 1581 |
+
skip_output = False
|
| 1582 |
+
if isinstance(input_audio, str) and is_json(input_audio):
|
| 1583 |
+
result = WhisperResult(input_audio)
|
| 1584 |
+
else:
|
| 1585 |
+
model = _load_model()
|
| 1586 |
+
args['regroup'] = False
|
| 1587 |
+
args['audio'] = input_audio
|
| 1588 |
+
if has_demucs_output:
|
| 1589 |
+
args['demucs_output'] = demucs_outputs[i]
|
| 1590 |
+
transcribe_method = args.get('transcribe_method')
|
| 1591 |
+
text = None
|
| 1592 |
+
if alignments and (text := alignments[i]):
|
| 1593 |
+
if text.endswith('.json'):
|
| 1594 |
+
text = WhisperResult(text)
|
| 1595 |
+
else:
|
| 1596 |
+
with open(text, 'r', encoding='utf-8') as f:
|
| 1597 |
+
text = f.read()
|
| 1598 |
+
args['text'] = text
|
| 1599 |
+
transcribe_method = 'align'
|
| 1600 |
+
if is_faster_whisper and transcribe_method == 'transcribe':
|
| 1601 |
+
transcribe_method = 'transcribe_stable'
|
| 1602 |
+
if strings_to_locate and (text := strings_to_locate[i]):
|
| 1603 |
+
args['text'] = text
|
| 1604 |
+
transcribe_method = 'locate'
|
| 1605 |
+
skip_output = args['verbose'] = True
|
| 1606 |
+
transcribe_method = getattr(model, transcribe_method)
|
| 1607 |
+
transcribe_options = isolate_useful_options(args, transcribe_method)
|
| 1608 |
+
if not text:
|
| 1609 |
+
decoding_options = (
|
| 1610 |
+
isolate_useful_options(args, model.transcribe if is_faster_whisper else DecodingOptions)
|
| 1611 |
+
)
|
| 1612 |
+
if is_faster_whisper:
|
| 1613 |
+
if decoding_options['suppress_tokens']:
|
| 1614 |
+
decoding_options['suppress_tokens'] = (
|
| 1615 |
+
list(map(int, decoding_options['suppress_tokens'].split(',')))
|
| 1616 |
+
)
|
| 1617 |
+
for k in list(decoding_options.keys()):
|
| 1618 |
+
if decoding_options[k] is None:
|
| 1619 |
+
del decoding_options[k]
|
| 1620 |
+
transcribe_options.update(decoding_options)
|
| 1621 |
+
update_options_with_args('transcribe_option', transcribe_options)
|
| 1622 |
+
result: WhisperResult = call_method_with_options(transcribe_method, transcribe_options)
|
| 1623 |
+
|
| 1624 |
+
if skip_output:
|
| 1625 |
+
continue
|
| 1626 |
+
|
| 1627 |
+
if args['refine']:
|
| 1628 |
+
model = _load_model()
|
| 1629 |
+
refine_options = isolate_useful_options(args, model.refine)
|
| 1630 |
+
refine_options['result'] = result
|
| 1631 |
+
update_options_with_args('refine_option', refine_options)
|
| 1632 |
+
call_method_with_options(model.refine, refine_options)
|
| 1633 |
+
|
| 1634 |
+
if args.get('word_timestamps'):
|
| 1635 |
+
if regroup:
|
| 1636 |
+
result.regroup(regroup, verbose=args['verbose'] or debug)
|
| 1637 |
+
if max_chars or max_words:
|
| 1638 |
+
result.split_by_length(max_chars=max_chars, max_words=max_words)
|
| 1639 |
+
|
| 1640 |
+
for path in output_paths:
|
| 1641 |
+
make_parent(path)
|
| 1642 |
+
save_method = getattr(result, OUTPUT_FORMATS_METHODS[splitext(path)[-1][1:]])
|
| 1643 |
+
args['filepath'] = path
|
| 1644 |
+
args['path'] = path
|
| 1645 |
+
save_options = isolate_useful_options(args, save_method)
|
| 1646 |
+
update_options_with_args('save_option', save_options)
|
| 1647 |
+
call_method_with_options(save_method, save_options)
|
| 1648 |
+
|
| 1649 |
+
|
| 1650 |
+
if __name__ == '__main__':
|
| 1651 |
+
cli()
|