
Commit
•
149555d
1
Parent(s):
e5dd4ed
Add all files
Browse files- README.md +45 -0
- config.json +71 -0
- environment.yaml +10 -0
- flax_model.msgpack +3 -0
- img/demo_screenshot.png +0 -0
- merges.txt +0 -0
- pipeline.py +110 -0
- requirements.txt +3 -0
- special_tokens_map.json +1 -0
- tokenizer.json +0 -0
- tokenizer_config.json +1 -0
- vocab.json +0 -0
README.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
pipeline_tag: text-to-image
|
| 5 |
+
inference: false
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## DALL·E mini - Generate images from text
|
| 9 |
+
|
| 10 |
+
<img style="text-align:center; display:block;" src="https://raw.githubusercontent.com/borisdayma/dalle-mini/main/img/logo.png" width="200">
|
| 11 |
+
|
| 12 |
+
* [Technical Report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini--Vmlldzo4NjIxODA)
|
| 13 |
+
* [Demo](https://huggingface.co/spaces/flax-community/dalle-mini)
|
| 14 |
+
|
| 15 |
+
### Model Description
|
| 16 |
+
|
| 17 |
+
This is an attempt to replicate OpenAI's [DALL·E](https://openai.com/blog/dall-e/), a model capable of generating arbitrary images from a text prompt that describes the desired result.
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
This model's architecture is a simplification of the original, and leverages previous open source efforts and available pre-trained models. Results have lower quality than OpenAI's, but the model can be trained and used on less demanding hardware. Our training was performed on a single TPU v3-8 for a few days.
|
| 22 |
+
|
| 23 |
+
### Components of the Architecture
|
| 24 |
+
|
| 25 |
+
The system relies on the Flax/JAX infrastructure, which are ideal for TPU training. TPUs are not required, both Flax and JAX run very efficiently on GPU backends.
|
| 26 |
+
|
| 27 |
+
The main components of the architecture include:
|
| 28 |
+
|
| 29 |
+
* An encoder, based on [BART](https://arxiv.org/abs/1910.13461). The encoder transforms a sequence of input text tokens to a sequence of image tokens. The input tokens are extracted from the text prompt by using the model's tokenizer. The image tokens are a fixed-length sequence, and they represent indices in a VQGAN-based pre-trained codebook.
|
| 30 |
+
|
| 31 |
+
* A decoder, which converts the image tokens to image pixels. As mentioned above, the decoder is based on a [VQGAN model](https://compvis.github.io/taming-transformers/).
|
| 32 |
+
|
| 33 |
+
The model definition we use for the encoder can be downloaded from our [Github repo](https://github.com/borisdayma/dalle-mini). The encoder is represented by the class `CustomFlaxBartForConditionalGeneration`.
|
| 34 |
+
|
| 35 |
+
To use the decoder, you need to follow the instructions in our accompanying VQGAN model in the hub, [flax-community/vqgan_f16_16384](https://huggingface.co/flax-community/vqgan_f16_16384).
|
| 36 |
+
|
| 37 |
+
### How to Use
|
| 38 |
+
|
| 39 |
+
The easiest way to get familiar with the code and the models is to follow the inference notebook we provide in our [github repo](https://github.com/borisdayma/dalle-mini/blob/main/dev/inference/inference_pipeline.ipynb). For your convenience, you can open it in Google Colaboratory: [](https://colab.research.google.com/github/borisdayma/dalle-mini/blob/main/dev/inference/inference_pipeline.ipynb)
|
| 40 |
+
|
| 41 |
+
If you just want to test the trained model and see what it comes up with, please visit [our demo](https://huggingface.co/spaces/flax-community/dalle-mini), available in 🤗 Spaces.
|
| 42 |
+
|
| 43 |
+
### Additional Details
|
| 44 |
+
|
| 45 |
+
Our [report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini--Vmlldzo4NjIxODA) contains more details about how the model was trained and shows many examples that demonstrate its capabilities.
|
config.json
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_num_labels": 3,
|
| 3 |
+
"activation_dropout": 0.0,
|
| 4 |
+
"activation_function": "gelu",
|
| 5 |
+
"add_final_layer_norm": false,
|
| 6 |
+
"architectures": [
|
| 7 |
+
"omFlaxBartForConditionalGeneration"
|
| 8 |
+
],
|
| 9 |
+
"attention_dropout": 0.0,
|
| 10 |
+
"bos_token_id": 16384,
|
| 11 |
+
"classif_dropout": 0.0,
|
| 12 |
+
"classifier_dropout": 0.0,
|
| 13 |
+
"d_model": 1024,
|
| 14 |
+
"decoder_attention_heads": 16,
|
| 15 |
+
"decoder_ffn_dim": 4096,
|
| 16 |
+
"decoder_layerdrop": 0.0,
|
| 17 |
+
"decoder_layers": 12,
|
| 18 |
+
"decoder_start_token_id": 16384,
|
| 19 |
+
"dropout": 0.1,
|
| 20 |
+
"early_stopping": true,
|
| 21 |
+
"encoder_attention_heads": 16,
|
| 22 |
+
"encoder_ffn_dim": 4096,
|
| 23 |
+
"encoder_layerdrop": 0.0,
|
| 24 |
+
"encoder_layers": 12,
|
| 25 |
+
"eos_token_id": 16385,
|
| 26 |
+
"force_bos_token_to_be_generated": false,
|
| 27 |
+
"forced_eos_token_id": null,
|
| 28 |
+
"gradient_checkpointing": false,
|
| 29 |
+
"id2label": {
|
| 30 |
+
"0": "LABEL_0",
|
| 31 |
+
"1": "LABEL_1",
|
| 32 |
+
"2": "LABEL_2"
|
| 33 |
+
},
|
| 34 |
+
"init_std": 0.02,
|
| 35 |
+
"is_encoder_decoder": true,
|
| 36 |
+
"label2id": {
|
| 37 |
+
"LABEL_0": 0,
|
| 38 |
+
"LABEL_1": 1,
|
| 39 |
+
"LABEL_2": 2
|
| 40 |
+
},
|
| 41 |
+
"length_penalty": 2.0,
|
| 42 |
+
"max_length": 257,
|
| 43 |
+
"max_position_embeddings": 1024,
|
| 44 |
+
"max_position_embeddings_decoder": 257,
|
| 45 |
+
"min_length": 257,
|
| 46 |
+
"model_type": "bart",
|
| 47 |
+
"no_repeat_ngram_size": 3,
|
| 48 |
+
"normalize_before": false,
|
| 49 |
+
"num_beams": 4,
|
| 50 |
+
"num_hidden_layers": 12,
|
| 51 |
+
"output_past": true,
|
| 52 |
+
"pad_token_id": 1,
|
| 53 |
+
"pos_token_id": 16384,
|
| 54 |
+
"prefix": " ",
|
| 55 |
+
"scale_embedding": false,
|
| 56 |
+
"task_specific_params": {
|
| 57 |
+
"summarization": {
|
| 58 |
+
"early_stopping": true,
|
| 59 |
+
"length_penalty": 2.0,
|
| 60 |
+
"max_length": 142,
|
| 61 |
+
"min_length": 56,
|
| 62 |
+
"no_repeat_ngram_size": 3,
|
| 63 |
+
"num_beams": 4
|
| 64 |
+
}
|
| 65 |
+
},
|
| 66 |
+
"tie_word_embeddings": false,
|
| 67 |
+
"transformers_version": "4.8.2",
|
| 68 |
+
"use_cache": true,
|
| 69 |
+
"vocab_size": 50264,
|
| 70 |
+
"vocab_size_output": 16385
|
| 71 |
+
}
|
environment.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: dalle
|
| 2 |
+
channels:
|
| 3 |
+
- defaults
|
| 4 |
+
dependencies:
|
| 5 |
+
- python=3.9.5
|
| 6 |
+
- pip=21.1.3
|
| 7 |
+
- ipython=7.22.0
|
| 8 |
+
- cudatoolkit
|
| 9 |
+
- pip:
|
| 10 |
+
- -r requirements.txt
|
flax_model.msgpack
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:856b78e6e59f979e319eef43005e913bf2e94ced9e3e93d87d3675373cf0673d
|
| 3 |
+
size 1756329653
|
img/demo_screenshot.png
ADDED
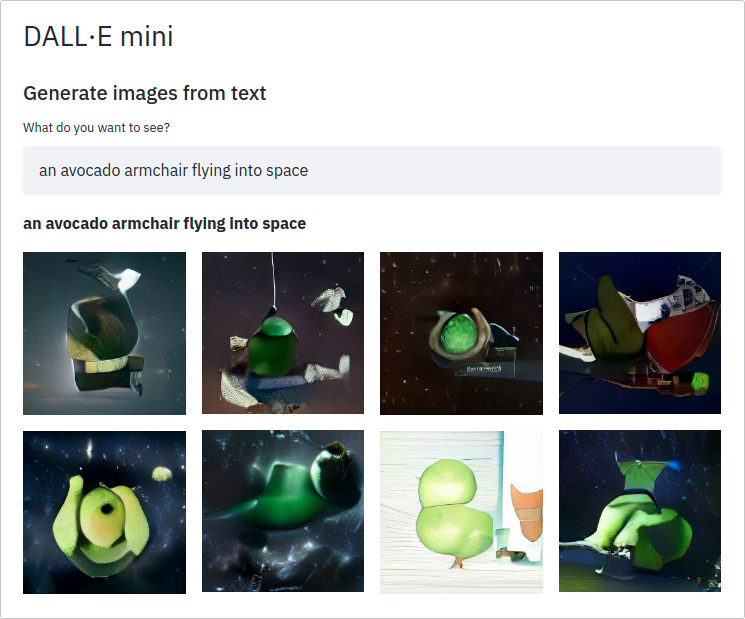
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pipeline.py
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import jax
|
| 3 |
+
import flax.linen as nn
|
| 4 |
+
|
| 5 |
+
from transformers.models.bart.modeling_flax_bart import (
|
| 6 |
+
FlaxBartModule,
|
| 7 |
+
FlaxBartForConditionalGenerationModule,
|
| 8 |
+
FlaxBartForConditionalGeneration,
|
| 9 |
+
FlaxBartEncoder,
|
| 10 |
+
FlaxBartDecoder
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
from transformers import BartConfig
|
| 14 |
+
|
| 15 |
+
from vqgan_jax.modeling_flax_vqgan import VQModel
|
| 16 |
+
import numpy as np
|
| 17 |
+
from PIL import Image
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# Model hyperparameters, for convenience
|
| 21 |
+
OUTPUT_VOCAB_SIZE = 16384 + 1 # encoded image token space + 1 for bos
|
| 22 |
+
OUTPUT_LENGTH = 256 + 1 # number of encoded tokens + 1 for bos
|
| 23 |
+
BOS_TOKEN_ID = 16384
|
| 24 |
+
BASE_MODEL = 'facebook/bart-large-cnn' # we currently have issues with bart-large
|
| 25 |
+
|
| 26 |
+
class CustomFlaxBartModule(FlaxBartModule):
|
| 27 |
+
def setup(self):
|
| 28 |
+
# check config is valid, otherwise set default values
|
| 29 |
+
self.config.vocab_size_output = getattr(self.config, 'vocab_size_output', OUTPUT_VOCAB_SIZE)
|
| 30 |
+
self.config.max_position_embeddings_decoder = getattr(self.config, 'max_position_embeddings_decoder', OUTPUT_LENGTH)
|
| 31 |
+
|
| 32 |
+
# we keep shared to easily load pre-trained weights
|
| 33 |
+
self.shared = nn.Embed(
|
| 34 |
+
self.config.vocab_size,
|
| 35 |
+
self.config.d_model,
|
| 36 |
+
embedding_init=jax.nn.initializers.normal(self.config.init_std, self.dtype),
|
| 37 |
+
dtype=self.dtype,
|
| 38 |
+
)
|
| 39 |
+
# a separate embedding is used for the decoder
|
| 40 |
+
self.decoder_embed = nn.Embed(
|
| 41 |
+
self.config.vocab_size_output,
|
| 42 |
+
self.config.d_model,
|
| 43 |
+
embedding_init=jax.nn.initializers.normal(self.config.init_std, self.dtype),
|
| 44 |
+
dtype=self.dtype,
|
| 45 |
+
)
|
| 46 |
+
self.encoder = FlaxBartEncoder(self.config, dtype=self.dtype, embed_tokens=self.shared)
|
| 47 |
+
|
| 48 |
+
# the decoder has a different config
|
| 49 |
+
decoder_config = BartConfig(self.config.to_dict())
|
| 50 |
+
decoder_config.max_position_embeddings = self.config.max_position_embeddings_decoder
|
| 51 |
+
decoder_config.vocab_size = self.config.vocab_size_output
|
| 52 |
+
self.decoder = FlaxBartDecoder(decoder_config, dtype=self.dtype, embed_tokens=self.decoder_embed)
|
| 53 |
+
|
| 54 |
+
class CustomFlaxBartForConditionalGenerationModule(FlaxBartForConditionalGenerationModule):
|
| 55 |
+
def setup(self):
|
| 56 |
+
# check config is valid, otherwise set default values
|
| 57 |
+
self.config.vocab_size_output = getattr(self.config, 'vocab_size_output', OUTPUT_VOCAB_SIZE)
|
| 58 |
+
|
| 59 |
+
self.model = CustomFlaxBartModule(config=self.config, dtype=self.dtype)
|
| 60 |
+
self.lm_head = nn.Dense(
|
| 61 |
+
self.config.vocab_size_output,
|
| 62 |
+
use_bias=False,
|
| 63 |
+
dtype=self.dtype,
|
| 64 |
+
kernel_init=jax.nn.initializers.normal(self.config.init_std, self.dtype),
|
| 65 |
+
)
|
| 66 |
+
self.final_logits_bias = self.param("final_logits_bias", self.bias_init, (1, self.config.vocab_size_output))
|
| 67 |
+
|
| 68 |
+
class CustomFlaxBartForConditionalGeneration(FlaxBartForConditionalGeneration):
|
| 69 |
+
module_class = CustomFlaxBartForConditionalGenerationModule
|
| 70 |
+
|
| 71 |
+
class PreTrainedPipeline():
|
| 72 |
+
def __init__(self, path=""):
|
| 73 |
+
# IMPLEMENT_THIS
|
| 74 |
+
# Preload all the elements you are going to need at inference.
|
| 75 |
+
# For instance your model, processors, tokenizer that might be needed.
|
| 76 |
+
# This function is only called once, so do all the heavy processing I/O here"""
|
| 77 |
+
self.tokenizer = BartTokenizer.from_pretrained(path)
|
| 78 |
+
self.model = CustomFlaxBartForConditionalGeneration.from_pretrained(path)
|
| 79 |
+
|
| 80 |
+
self.vqgan = VQModel.from_pretrained("flax-community/vqgan_f16_16384", revision="90cc46addd2dd8f5be21586a9a23e1b95aa506a9")
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def __call__(self, inputs: str):
|
| 84 |
+
"""
|
| 85 |
+
Args:
|
| 86 |
+
inputs (:obj:`str`):
|
| 87 |
+
a string containing some text
|
| 88 |
+
Return:
|
| 89 |
+
A :obj:`PIL.Image` with the raw image representation as PIL.
|
| 90 |
+
"""
|
| 91 |
+
tokenized_prompt = self.tokenizer(inputs, return_tensors='jax', padding='max_length', truncation=True, max_length=128)
|
| 92 |
+
key = jax.random.PRNGKey(random.randint(0, 2**32-1))
|
| 93 |
+
encoded_image = self.model.generate(**tokenized_prompt, do_sample=True, num_beams=1, prng_key=key)
|
| 94 |
+
|
| 95 |
+
# remove first token (BOS)
|
| 96 |
+
encoded_image = encoded_image.sequences[..., 1:]
|
| 97 |
+
decoded_image = vqgan.decode_code(encoded_image)
|
| 98 |
+
clipped_image = decoded_image.squeeze().clip(0., 1.)
|
| 99 |
+
|
| 100 |
+
return Image.fromarray(np.asarray(clipped_image * 255, dtype=np.uint8))
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers
|
| 2 |
+
flax
|
| 3 |
+
git+https://github.com/patil-suraj/vqgan-jax.git
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "<s>", "eos_token": "</s>", "unk_token": "<unk>", "sep_token": "</s>", "pad_token": "<pad>", "cls_token": "<s>", "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": false}}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"unk_token": "<unk>", "bos_token": "<s>", "eos_token": "</s>", "add_prefix_space": false, "errors": "replace", "sep_token": "</s>", "cls_token": "<s>", "pad_token": "<pad>", "mask_token": "<mask>", "model_max_length": 1024, "special_tokens_map_file": null, "name_or_path": "./artifacts/model-4oh3u7ca:v54", "tokenizer_class": "BartTokenizer"}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|