

fix figure and weights inconsistent error
Browse files- README.md +5 -5
- configs/metadata.json +3 -2
- configs/train.json +22 -5
- docs/README.md +5 -5
- models/model.pt +2 -2
- models/model.ts +2 -2
README.md
CHANGED
|
@@ -29,8 +29,8 @@ The training was performed with the following:
|
|
| 29 |
- GPU: at least 12GB of GPU memory
|
| 30 |
- Actual Model Input: 96 x 96 x 96
|
| 31 |
- AMP: True
|
| 32 |
-
- Optimizer:
|
| 33 |
-
- Learning Rate:
|
| 34 |
- Loss: DiceCELoss
|
| 35 |
|
| 36 |
### Input
|
|
@@ -43,13 +43,13 @@ Two channels
|
|
| 43 |
- Label 0: everything else
|
| 44 |
|
| 45 |
## Performance
|
| 46 |
-
Dice score is used for evaluating the performance of the model. This model achieves a mean dice score of 0.
|
| 47 |
|
| 48 |
#### Training Loss
|
| 49 |
-
` basically means the same thing as the `model computation`, except that the model is converted through the onnx-torchscript way. We add this line in the table since it has a better performance than the model converted through Torch-TensorRT. The `end2end` means run the bundle end to end with the TensorRT based model converted through Torch-TensorRT. The `torch_fp32` and `torch_amp` is for the pytorch model with or without `amp` mode. The `trt_fp32` and `trt_fp16` is for the TensorRT based model converted in corresponding precision. The `speedup amp`, `speedup fp32` and `speedup fp16` is the speedup ratio of corresponding models versus the pytorch float32 model, while the `amp vs fp16` is between the pytorch amp model and the TensorRT float16 based model.
|
|
|
|
| 29 |
- GPU: at least 12GB of GPU memory
|
| 30 |
- Actual Model Input: 96 x 96 x 96
|
| 31 |
- AMP: True
|
| 32 |
+
- Optimizer: Novograd
|
| 33 |
+
- Learning Rate: 0.002
|
| 34 |
- Loss: DiceCELoss
|
| 35 |
|
| 36 |
### Input
|
|
|
|
| 43 |
- Label 0: everything else
|
| 44 |
|
| 45 |
## Performance
|
| 46 |
+
Dice score is used for evaluating the performance of the model. This model achieves a mean dice score of 0.959.
|
| 47 |
|
| 48 |
#### Training Loss
|
| 49 |
+

|
| 50 |
|
| 51 |
#### Validation Dice
|
| 52 |
+
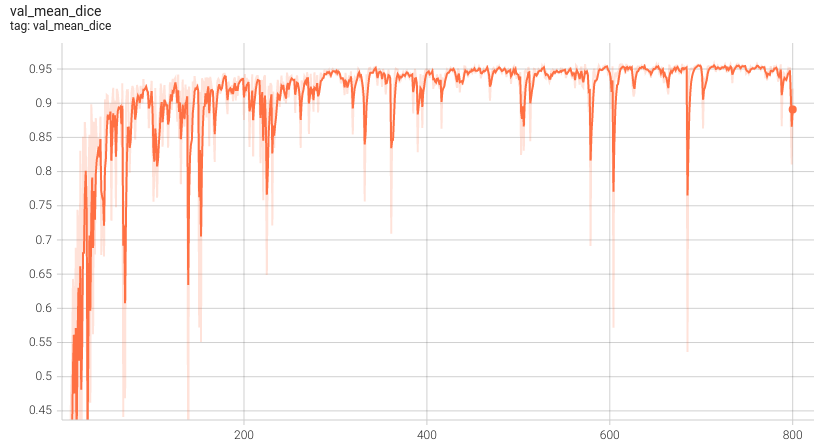
|
| 53 |
|
| 54 |
#### TensorRT speedup
|
| 55 |
The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU. The `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing. The `model computation(onnx)` basically means the same thing as the `model computation`, except that the model is converted through the onnx-torchscript way. We add this line in the table since it has a better performance than the model converted through Torch-TensorRT. The `end2end` means run the bundle end to end with the TensorRT based model converted through Torch-TensorRT. The `torch_fp32` and `torch_amp` is for the pytorch model with or without `amp` mode. The `trt_fp32` and `trt_fp16` is for the TensorRT based model converted in corresponding precision. The `speedup amp`, `speedup fp32` and `speedup fp16` is the speedup ratio of corresponding models versus the pytorch float32 model, while the `amp vs fp16` is between the pytorch amp model and the TensorRT float16 based model.
|
configs/metadata.json
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
-
"version": "0.4.
|
| 4 |
"changelog": {
|
|
|
|
| 5 |
"0.4.2": "use torch 1.13.1",
|
| 6 |
"0.4.1": "update the readme file with TensorRT convert",
|
| 7 |
"0.4.0": "fix multi-gpu train config typo",
|
|
@@ -38,7 +39,7 @@
|
|
| 38 |
"label_classes": "single channel data, 1 is spleen, 0 is everything else",
|
| 39 |
"pred_classes": "2 channels OneHot data, channel 1 is spleen, channel 0 is background",
|
| 40 |
"eval_metrics": {
|
| 41 |
-
"mean_dice": 0.
|
| 42 |
},
|
| 43 |
"intended_use": "This is an example, not to be used for diagnostic purposes",
|
| 44 |
"references": [
|
|
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
+
"version": "0.4.3",
|
| 4 |
"changelog": {
|
| 5 |
+
"0.4.3": "fix figure and weights inconsistent error",
|
| 6 |
"0.4.2": "use torch 1.13.1",
|
| 7 |
"0.4.1": "update the readme file with TensorRT convert",
|
| 8 |
"0.4.0": "fix multi-gpu train config typo",
|
|
|
|
| 39 |
"label_classes": "single channel data, 1 is spleen, 0 is everything else",
|
| 40 |
"pred_classes": "2 channels OneHot data, channel 1 is spleen, channel 0 is background",
|
| 41 |
"eval_metrics": {
|
| 42 |
+
"mean_dice": 0.959
|
| 43 |
},
|
| 44 |
"intended_use": "This is an example, not to be used for diagnostic purposes",
|
| 45 |
"references": [
|
configs/train.json
CHANGED
|
@@ -10,7 +10,8 @@
|
|
| 10 |
"dataset_dir": "/workspace/data/Task09_Spleen",
|
| 11 |
"images": "$list(sorted(glob.glob(@dataset_dir + '/imagesTr/*.nii.gz')))",
|
| 12 |
"labels": "$list(sorted(glob.glob(@dataset_dir + '/labelsTr/*.nii.gz')))",
|
| 13 |
-
"val_interval":
|
|
|
|
| 14 |
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 15 |
"network_def": {
|
| 16 |
"_target_": "UNet",
|
|
@@ -36,15 +37,26 @@
|
|
| 36 |
"network": "$@network_def.to(@device)",
|
| 37 |
"loss": {
|
| 38 |
"_target_": "DiceCELoss",
|
|
|
|
| 39 |
"to_onehot_y": true,
|
| 40 |
"softmax": true,
|
| 41 |
"squared_pred": true,
|
| 42 |
-
"batch": true
|
|
|
|
|
|
|
|
|
|
|
|
|
| 43 |
},
|
| 44 |
"optimizer": {
|
| 45 |
-
"_target_": "
|
| 46 |
"params": "$@network.parameters()",
|
| 47 |
-
"lr": 0.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
},
|
| 49 |
"train": {
|
| 50 |
"deterministic_transforms": [
|
|
@@ -167,6 +179,11 @@
|
|
| 167 |
]
|
| 168 |
},
|
| 169 |
"handlers": [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 170 |
{
|
| 171 |
"_target_": "ValidationHandler",
|
| 172 |
"validator": "@validate#evaluator",
|
|
@@ -193,7 +210,7 @@
|
|
| 193 |
},
|
| 194 |
"trainer": {
|
| 195 |
"_target_": "SupervisedTrainer",
|
| 196 |
-
"max_epochs":
|
| 197 |
"device": "@device",
|
| 198 |
"train_data_loader": "@train#dataloader",
|
| 199 |
"network": "@network",
|
|
|
|
| 10 |
"dataset_dir": "/workspace/data/Task09_Spleen",
|
| 11 |
"images": "$list(sorted(glob.glob(@dataset_dir + '/imagesTr/*.nii.gz')))",
|
| 12 |
"labels": "$list(sorted(glob.glob(@dataset_dir + '/labelsTr/*.nii.gz')))",
|
| 13 |
+
"val_interval": 1,
|
| 14 |
+
"epochs": 800,
|
| 15 |
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 16 |
"network_def": {
|
| 17 |
"_target_": "UNet",
|
|
|
|
| 37 |
"network": "$@network_def.to(@device)",
|
| 38 |
"loss": {
|
| 39 |
"_target_": "DiceCELoss",
|
| 40 |
+
"include_background": true,
|
| 41 |
"to_onehot_y": true,
|
| 42 |
"softmax": true,
|
| 43 |
"squared_pred": true,
|
| 44 |
+
"batch": true,
|
| 45 |
+
"smooth_nr": 1e-05,
|
| 46 |
+
"smooth_dr": 1e-05,
|
| 47 |
+
"lambda_dice": 0.5,
|
| 48 |
+
"lambda_ce": 0.5
|
| 49 |
},
|
| 50 |
"optimizer": {
|
| 51 |
+
"_target_": "Novograd",
|
| 52 |
"params": "$@network.parameters()",
|
| 53 |
+
"lr": 0.002
|
| 54 |
+
},
|
| 55 |
+
"lr_scheduler": {
|
| 56 |
+
"_target_": "torch.optim.lr_scheduler.StepLR",
|
| 57 |
+
"optimizer": "@optimizer",
|
| 58 |
+
"step_size": 5000,
|
| 59 |
+
"gamma": 0.1
|
| 60 |
},
|
| 61 |
"train": {
|
| 62 |
"deterministic_transforms": [
|
|
|
|
| 179 |
]
|
| 180 |
},
|
| 181 |
"handlers": [
|
| 182 |
+
{
|
| 183 |
+
"_target_": "LrScheduleHandler",
|
| 184 |
+
"lr_scheduler": "@lr_scheduler",
|
| 185 |
+
"print_lr": true
|
| 186 |
+
},
|
| 187 |
{
|
| 188 |
"_target_": "ValidationHandler",
|
| 189 |
"validator": "@validate#evaluator",
|
|
|
|
| 210 |
},
|
| 211 |
"trainer": {
|
| 212 |
"_target_": "SupervisedTrainer",
|
| 213 |
+
"max_epochs": "@epochs",
|
| 214 |
"device": "@device",
|
| 215 |
"train_data_loader": "@train#dataloader",
|
| 216 |
"network": "@network",
|
docs/README.md
CHANGED
|
@@ -22,8 +22,8 @@ The training was performed with the following:
|
|
| 22 |
- GPU: at least 12GB of GPU memory
|
| 23 |
- Actual Model Input: 96 x 96 x 96
|
| 24 |
- AMP: True
|
| 25 |
-
- Optimizer:
|
| 26 |
-
- Learning Rate:
|
| 27 |
- Loss: DiceCELoss
|
| 28 |
|
| 29 |
### Input
|
|
@@ -36,13 +36,13 @@ Two channels
|
|
| 36 |
- Label 0: everything else
|
| 37 |
|
| 38 |
## Performance
|
| 39 |
-
Dice score is used for evaluating the performance of the model. This model achieves a mean dice score of 0.
|
| 40 |
|
| 41 |
#### Training Loss
|
| 42 |
-
` basically means the same thing as the `model computation`, except that the model is converted through the onnx-torchscript way. We add this line in the table since it has a better performance than the model converted through Torch-TensorRT. The `end2end` means run the bundle end to end with the TensorRT based model converted through Torch-TensorRT. The `torch_fp32` and `torch_amp` is for the pytorch model with or without `amp` mode. The `trt_fp32` and `trt_fp16` is for the TensorRT based model converted in corresponding precision. The `speedup amp`, `speedup fp32` and `speedup fp16` is the speedup ratio of corresponding models versus the pytorch float32 model, while the `amp vs fp16` is between the pytorch amp model and the TensorRT float16 based model.
|
|
|
|
| 22 |
- GPU: at least 12GB of GPU memory
|
| 23 |
- Actual Model Input: 96 x 96 x 96
|
| 24 |
- AMP: True
|
| 25 |
+
- Optimizer: Novograd
|
| 26 |
+
- Learning Rate: 0.002
|
| 27 |
- Loss: DiceCELoss
|
| 28 |
|
| 29 |
### Input
|
|
|
|
| 36 |
- Label 0: everything else
|
| 37 |
|
| 38 |
## Performance
|
| 39 |
+
Dice score is used for evaluating the performance of the model. This model achieves a mean dice score of 0.959.
|
| 40 |
|
| 41 |
#### Training Loss
|
| 42 |
+

|
| 43 |
|
| 44 |
#### Validation Dice
|
| 45 |
+

|
| 46 |
|
| 47 |
#### TensorRT speedup
|
| 48 |
The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU. The `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing. The `model computation(onnx)` basically means the same thing as the `model computation`, except that the model is converted through the onnx-torchscript way. We add this line in the table since it has a better performance than the model converted through Torch-TensorRT. The `end2end` means run the bundle end to end with the TensorRT based model converted through Torch-TensorRT. The `torch_fp32` and `torch_amp` is for the pytorch model with or without `amp` mode. The `trt_fp32` and `trt_fp16` is for the TensorRT based model converted in corresponding precision. The `speedup amp`, `speedup fp32` and `speedup fp16` is the speedup ratio of corresponding models versus the pytorch float32 model, while the `amp vs fp16` is between the pytorch amp model and the TensorRT float16 based model.
|
models/model.pt
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:57801867b520d353b6b8fa93a511ad4b3050659872255361fcfc5d5b77320692
|
| 3 |
+
size 19297197
|
models/model.ts
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f325fbb60833b0946e234ab14590bde652223503d41f445da879f0396f08a21a
|
| 3 |
+
size 19411907
|