

update the TensorRT part in the README file
Browse files- README.md +10 -2
- configs/metadata.json +2 -1
- docs/README.md +10 -2
README.md
CHANGED
|
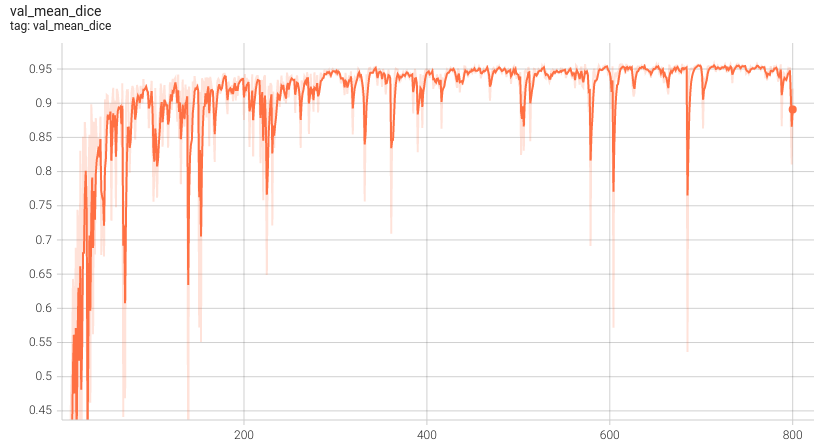
@@ -52,7 +52,7 @@ Dice score is used for evaluating the performance of the model. This model achie
|
|
| 52 |
|
| 53 |
|
| 54 |
#### TensorRT speedup
|
| 55 |
-
The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU.
|
| 56 |
|
| 57 |
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 58 |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
|
@@ -60,13 +60,21 @@ The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The tabl
|
|
| 60 |
| model computation(onnx) | 6.46 | 4.48 | 2.52 | 1.96 | 1.44 | 2.56 | 3.30 | 2.29 |
|
| 61 |
| end2end | 3900.73 | 3823.89 | 3887.37 | 3883.01 | 1.02 | 1.00 | 1.00 | 0.98 |
|
| 62 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
This result is benchmarked under:
|
| 64 |
- TensorRT: 8.5.3+cuda11.8
|
| 65 |
- Torch-TensorRT Version: 1.4.0
|
| 66 |
- CPU Architecture: x86-64
|
| 67 |
- OS: ubuntu 20.04
|
| 68 |
- Python version:3.8.10
|
| 69 |
-
- CUDA version:
|
| 70 |
- GPU models and configuration: A100 80G
|
| 71 |
|
| 72 |
## MONAI Bundle Commands
|
|
|
|
| 52 |

|
| 53 |
|
| 54 |
#### TensorRT speedup
|
| 55 |
+
The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU.
|
| 56 |
|
| 57 |
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 58 |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
|
|
|
| 60 |
| model computation(onnx) | 6.46 | 4.48 | 2.52 | 1.96 | 1.44 | 2.56 | 3.30 | 2.29 |
|
| 61 |
| end2end | 3900.73 | 3823.89 | 3887.37 | 3883.01 | 1.02 | 1.00 | 1.00 | 0.98 |
|
| 62 |
|
| 63 |
+
Where:
|
| 64 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 65 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 66 |
+
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 67 |
+
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 68 |
+
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 69 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 70 |
+
|
| 71 |
This result is benchmarked under:
|
| 72 |
- TensorRT: 8.5.3+cuda11.8
|
| 73 |
- Torch-TensorRT Version: 1.4.0
|
| 74 |
- CPU Architecture: x86-64
|
| 75 |
- OS: ubuntu 20.04
|
| 76 |
- Python version:3.8.10
|
| 77 |
+
- CUDA version: 12.0
|
| 78 |
- GPU models and configuration: A100 80G
|
| 79 |
|
| 80 |
## MONAI Bundle Commands
|
configs/metadata.json
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
-
"version": "0.4.
|
| 4 |
"changelog": {
|
|
|
|
| 5 |
"0.4.6": "fix mgpu finalize issue",
|
| 6 |
"0.4.5": "enable deterministic training",
|
| 7 |
"0.4.4": "add the command of executing inference with TensorRT models",
|
|
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
+
"version": "0.4.7",
|
| 4 |
"changelog": {
|
| 5 |
+
"0.4.7": "update the TensorRT part in the README file",
|
| 6 |
"0.4.6": "fix mgpu finalize issue",
|
| 7 |
"0.4.5": "enable deterministic training",
|
| 8 |
"0.4.4": "add the command of executing inference with TensorRT models",
|
docs/README.md
CHANGED
|
@@ -45,7 +45,7 @@ Dice score is used for evaluating the performance of the model. This model achie
|
|
| 45 |

|
| 46 |
|
| 47 |
#### TensorRT speedup
|
| 48 |
-
The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU.
|
| 49 |
|
| 50 |
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 51 |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
|
@@ -53,13 +53,21 @@ The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The tabl
|
|
| 53 |
| model computation(onnx) | 6.46 | 4.48 | 2.52 | 1.96 | 1.44 | 2.56 | 3.30 | 2.29 |
|
| 54 |
| end2end | 3900.73 | 3823.89 | 3887.37 | 3883.01 | 1.02 | 1.00 | 1.00 | 0.98 |
|
| 55 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
This result is benchmarked under:
|
| 57 |
- TensorRT: 8.5.3+cuda11.8
|
| 58 |
- Torch-TensorRT Version: 1.4.0
|
| 59 |
- CPU Architecture: x86-64
|
| 60 |
- OS: ubuntu 20.04
|
| 61 |
- Python version:3.8.10
|
| 62 |
-
- CUDA version:
|
| 63 |
- GPU models and configuration: A100 80G
|
| 64 |
|
| 65 |
## MONAI Bundle Commands
|
|
|
|
| 45 |

|
| 46 |
|
| 47 |
#### TensorRT speedup
|
| 48 |
+
The `spleen_ct_segmentation` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU.
|
| 49 |
|
| 50 |
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 51 |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
|
|
|
| 53 |
| model computation(onnx) | 6.46 | 4.48 | 2.52 | 1.96 | 1.44 | 2.56 | 3.30 | 2.29 |
|
| 54 |
| end2end | 3900.73 | 3823.89 | 3887.37 | 3883.01 | 1.02 | 1.00 | 1.00 | 0.98 |
|
| 55 |
|
| 56 |
+
Where:
|
| 57 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 58 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 59 |
+
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 60 |
+
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 61 |
+
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 62 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 63 |
+
|
| 64 |
This result is benchmarked under:
|
| 65 |
- TensorRT: 8.5.3+cuda11.8
|
| 66 |
- Torch-TensorRT Version: 1.4.0
|
| 67 |
- CPU Architecture: x86-64
|
| 68 |
- OS: ubuntu 20.04
|
| 69 |
- Python version:3.8.10
|
| 70 |
+
- CUDA version: 12.0
|
| 71 |
- GPU models and configuration: A100 80G
|
| 72 |
|
| 73 |
## MONAI Bundle Commands
|