

Initial release
Browse files- LICENSE +201 -0
- README.md +176 -0
- configs/inference.json +108 -0
- configs/inference_autoencoder.json +156 -0
- configs/logging.conf +21 -0
- configs/metadata.json +103 -0
- configs/multi_gpu_train_autoencoder.json +42 -0
- configs/multi_gpu_train_diffusion.json +16 -0
- configs/train_autoencoder.json +227 -0
- configs/train_diffusion.json +174 -0
- docs/README.md +169 -0
- docs/data_license.txt +49 -0
- models/model.pt +3 -0
- models/model_autoencoder.pt +3 -0
- scripts/__init__.py +12 -0
- scripts/ldm_sampler.py +60 -0
- scripts/ldm_trainer.py +380 -0
- scripts/losses.py +52 -0
- scripts/utils.py +50 -0
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- monai
|
| 4 |
+
- medical
|
| 5 |
+
library_name: monai
|
| 6 |
+
license: apache-2.0
|
| 7 |
+
---
|
| 8 |
+
# Model Overview
|
| 9 |
+
A pre-trained model for 2D Latent Diffusion Generative Model on axial slices of BraTS MRI.
|
| 10 |
+
|
| 11 |
+
This model is trained on BraTS 2016 and 2017 data from [Medical Decathlon](http://medicaldecathlon.com/), using the Latent diffusion model [1].
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
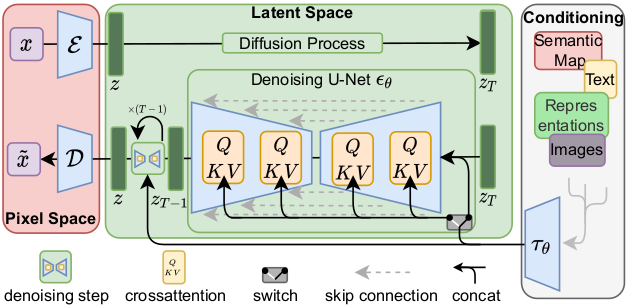
This model is a generator for creating images like the Flair MRIs based on BraTS 2016 and 2017 data. It was trained as a 2d latent diffusion model and accepts Gaussian random noise as inputs to produce an image output. The `train_autoencoder.json` file describes the training process of the variational autoencoder with GAN loss. The `train_diffusion.json` file describes the training process of the 2D latent diffusion model.
|
| 16 |
+
|
| 17 |
+
In this bundle, the autoencoder uses perceptual loss, which is based on ResNet50 with pre-trained weights (the network is frozen and will not be trained in the bundle). In default, the `pretrained` parameter is specified as `False` in `train_autoencoder.json`. To ensure correct training, changing the default settings is necessary. There are two ways to utilize pretrained weights:
|
| 18 |
+
1. if set `pretrained` to `True`, ImageNet pretrained weights from [torchvision](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet50_Weights) will be used. However, the weights are for non-commercial use only.
|
| 19 |
+
2. if set `pretrained` to `True` and specifies the `perceptual_loss_model_weights_path` parameter, users are able to load weights from a local path. This is the way this bundle used to train, and the pre-trained weights are from some internal data.
|
| 20 |
+
|
| 21 |
+
Please note that each user is responsible for checking the data source of the pre-trained models, the applicable licenses, and determining if suitable for the intended use.
|
| 22 |
+
|
| 23 |
+
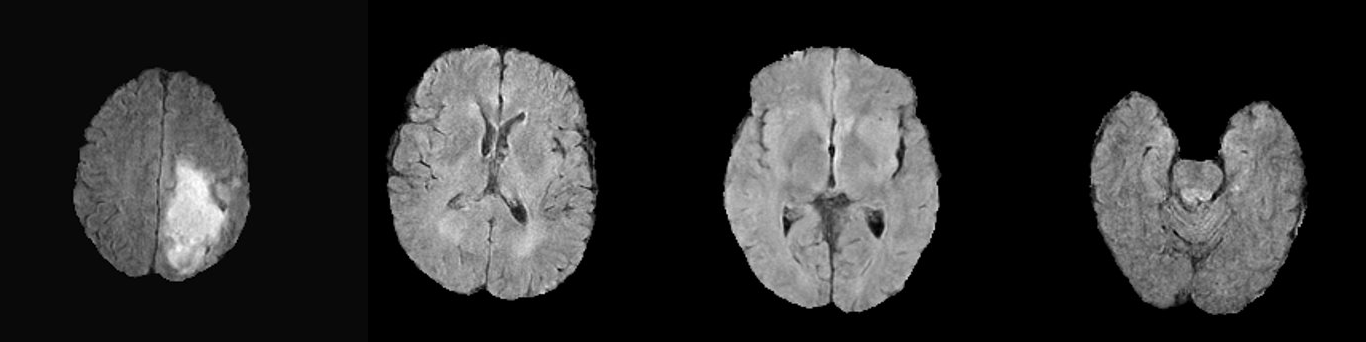
#### Example synthetic image
|
| 24 |
+
An example result from inference is shown below:
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
**This is a demonstration network meant to just show the training process for this sort of network with MONAI. To achieve better performance, users need to use larger dataset like [BraTS 2021](https://www.synapse.org/#!Synapse:syn25829067/wiki/610865).**
|
| 28 |
+
|
| 29 |
+
## MONAI Generative Model Dependencies
|
| 30 |
+
[MONAI generative models](https://github.com/Project-MONAI/GenerativeModels) can be installed by
|
| 31 |
+
```
|
| 32 |
+
pip install lpips==0.1.4
|
| 33 |
+
pip install git+https://github.com/Project-MONAI/GenerativeModels.git@0.2.1
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
## Data
|
| 37 |
+
The training data is BraTS 2016 and 2017 from the Medical Segmentation Decathalon. Users can find more details on the dataset (`Task01_BrainTumour`) at http://medicaldecathlon.com/.
|
| 38 |
+
|
| 39 |
+
- Target: Image Generation
|
| 40 |
+
- Task: Synthesis
|
| 41 |
+
- Modality: MRI
|
| 42 |
+
- Size: 388 3D MRI volumes (1 channel used)
|
| 43 |
+
- Training data size: 38800 2D MRI axial slices (1 channel used)
|
| 44 |
+
|
| 45 |
+
## Training Configuration
|
| 46 |
+
If you have a GPU with less than 32G of memory, you may need to decrease the batch size when training. To do so, modify the `"train_batch_size_img"` and `"train_batch_size_slice"` parameters in the `configs/train_autoencoder.json` and `configs/train_diffusion.json` configuration files.
|
| 47 |
+
- `"train_batch_size_img"` is number of 3D volumes loaded in each batch.
|
| 48 |
+
- `"train_batch_size_slice"` is the number of 2D axial slices extracted from each image. The actual batch size is the product of them.
|
| 49 |
+
|
| 50 |
+
### Training Configuration of Autoencoder
|
| 51 |
+
The autoencoder was trained using the following configuration:
|
| 52 |
+
|
| 53 |
+
- GPU: at least 32GB GPU memory
|
| 54 |
+
- Actual Model Input: 240 x 240
|
| 55 |
+
- AMP: False
|
| 56 |
+
- Optimizer: Adam
|
| 57 |
+
- Learning Rate: 5e-5
|
| 58 |
+
- Loss: L1 loss, perceptual loss, KL divergence loss, adversarial loss, GAN BCE loss
|
| 59 |
+
|
| 60 |
+
#### Input
|
| 61 |
+
1 channel 2D MRI Flair axial patches
|
| 62 |
+
|
| 63 |
+
#### Output
|
| 64 |
+
- 1 channel 2D MRI reconstructed patches
|
| 65 |
+
- 1 channel mean of latent features
|
| 66 |
+
- 1 channel standard deviation of latent features
|
| 67 |
+
|
| 68 |
+
### Training Configuration of Diffusion Model
|
| 69 |
+
The latent diffusion model was trained using the following configuration:
|
| 70 |
+
|
| 71 |
+
- GPU: at least 32GB GPU memory
|
| 72 |
+
- Actual Model Input: 64 x 64
|
| 73 |
+
- AMP: False
|
| 74 |
+
- Optimizer: Adam
|
| 75 |
+
- Learning Rate: 5e-5
|
| 76 |
+
- Loss: MSE loss
|
| 77 |
+
|
| 78 |
+
#### Training Input
|
| 79 |
+
- 1 channel noisy latent features
|
| 80 |
+
- a long int that indicates the time step
|
| 81 |
+
|
| 82 |
+
#### Training Output
|
| 83 |
+
1 channel predicted added noise
|
| 84 |
+
|
| 85 |
+
#### Inference Input
|
| 86 |
+
1 channel noise
|
| 87 |
+
|
| 88 |
+
#### Inference Output
|
| 89 |
+
1 channel denoised latent features
|
| 90 |
+
|
| 91 |
+
### Memory Consumption Warning
|
| 92 |
+
|
| 93 |
+
If you face memory issues with data loading, you can lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
|
| 94 |
+
|
| 95 |
+
## Performance
|
| 96 |
+
|
| 97 |
+
#### Training Loss
|
| 98 |
+
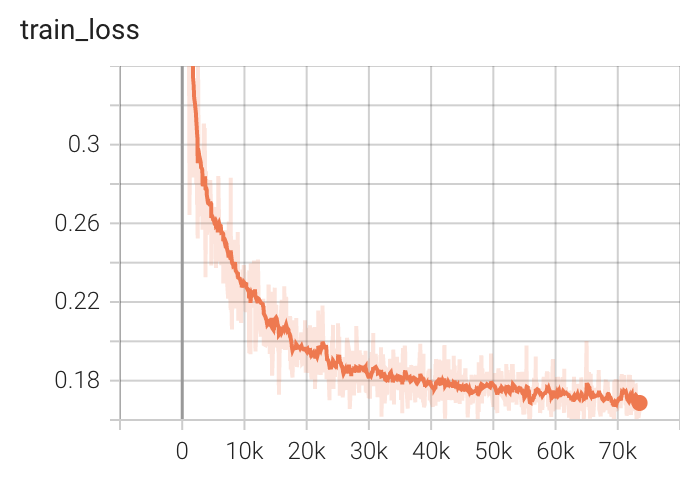
|
| 99 |
+
|
| 100 |
+
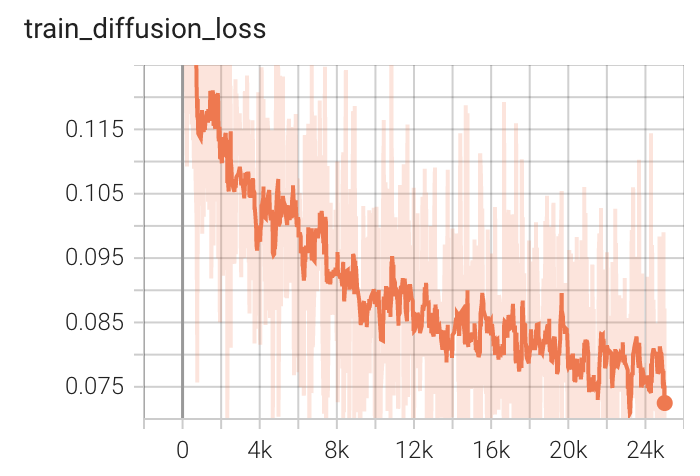
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
## MONAI Bundle Commands
|
| 104 |
+
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 105 |
+
|
| 106 |
+
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
|
| 107 |
+
|
| 108 |
+
### Execute Autoencoder Training
|
| 109 |
+
|
| 110 |
+
#### Execute Autoencoder Training on single GPU
|
| 111 |
+
```
|
| 112 |
+
python -m monai.bundle run --config_file configs/train_autoencoder.json
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
Please note that if the default dataset path is not modified with the actual path (it should be the path that contains Task01_BrainTumour) in the bundle config files, you can also override it by using `--dataset_dir`:
|
| 116 |
+
|
| 117 |
+
```
|
| 118 |
+
python -m monai.bundle run --config_file configs/train_autoencoder.json --dataset_dir <actual dataset path>
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
#### Override the `train` config to execute multi-GPU training for Autoencoder
|
| 122 |
+
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
|
| 123 |
+
|
| 124 |
+
```
|
| 125 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/multi_gpu_train_autoencoder.json']" --lr 4e-4
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
#### Check the Autoencoder Training result
|
| 129 |
+
The following code generates a reconstructed image from a random input image.
|
| 130 |
+
We can visualize it to see if the autoencoder is trained correctly.
|
| 131 |
+
```
|
| 132 |
+
python -m monai.bundle run --config_file configs/inference_autoencoder.json
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
An example of reconstructed image from inference is shown below. If the autoencoder is trained correctly, the reconstructed image should look similar to original image.
|
| 136 |
+
|
| 137 |
+
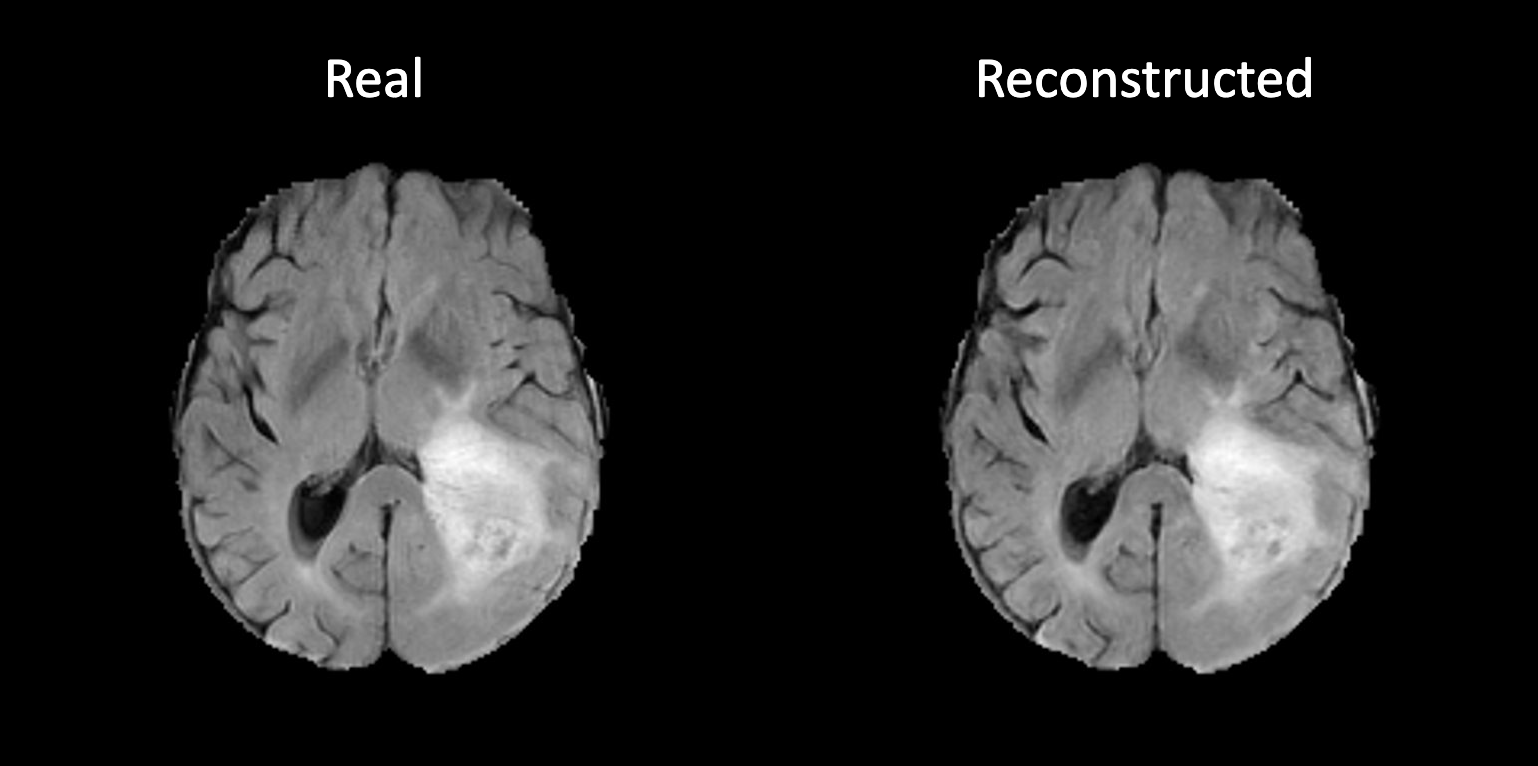
|
| 138 |
+
|
| 139 |
+
### Execute Latent Diffusion Model Training
|
| 140 |
+
|
| 141 |
+
#### Execute Latent Diffusion Model Training on single GPU
|
| 142 |
+
After training the autoencoder, run the following command to train the latent diffusion model. This command will print out the scale factor of the latent feature space. If your autoencoder is well trained, this value should be close to 1.0.
|
| 143 |
+
|
| 144 |
+
```
|
| 145 |
+
python -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json']"
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
#### Override the `train` config to execute multi-GPU training for Latent Diffusion Model
|
| 149 |
+
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
|
| 150 |
+
|
| 151 |
+
```
|
| 152 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json','configs/multi_gpu_train_autoencoder.json','configs/multi_gpu_train_diffusion.json']" --lr 4e-4
|
| 153 |
+
```
|
| 154 |
+
### Execute inference
|
| 155 |
+
The following code generates a synthetic image from a random sampled noise.
|
| 156 |
+
```
|
| 157 |
+
python -m monai.bundle run --config_file configs/inference.json
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
# References
|
| 161 |
+
[1] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
|
| 162 |
+
|
| 163 |
+
# License
|
| 164 |
+
Copyright (c) MONAI Consortium
|
| 165 |
+
|
| 166 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 167 |
+
you may not use this file except in compliance with the License.
|
| 168 |
+
You may obtain a copy of the License at
|
| 169 |
+
|
| 170 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 171 |
+
|
| 172 |
+
Unless required by applicable law or agreed to in writing, software
|
| 173 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 174 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 175 |
+
See the License for the specific language governing permissions and
|
| 176 |
+
limitations under the License.
|
configs/inference.json
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import torch",
|
| 4 |
+
"$from datetime import datetime",
|
| 5 |
+
"$from pathlib import Path",
|
| 6 |
+
"$from PIL import Image",
|
| 7 |
+
"$from scripts.utils import visualize_2d_image"
|
| 8 |
+
],
|
| 9 |
+
"bundle_root": ".",
|
| 10 |
+
"model_dir": "$@bundle_root + '/models'",
|
| 11 |
+
"output_dir": "$@bundle_root + '/output'",
|
| 12 |
+
"create_output_dir": "$Path(@output_dir).mkdir(exist_ok=True)",
|
| 13 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 14 |
+
"output_postfix": "$datetime.now().strftime('sample_%Y%m%d_%H%M%S')",
|
| 15 |
+
"channel": 0,
|
| 16 |
+
"spatial_dims": 2,
|
| 17 |
+
"image_channels": 1,
|
| 18 |
+
"latent_channels": 1,
|
| 19 |
+
"latent_shape": [
|
| 20 |
+
"@latent_channels",
|
| 21 |
+
64,
|
| 22 |
+
64
|
| 23 |
+
],
|
| 24 |
+
"autoencoder_def": {
|
| 25 |
+
"_target_": "generative.networks.nets.AutoencoderKL",
|
| 26 |
+
"spatial_dims": "@spatial_dims",
|
| 27 |
+
"in_channels": "@image_channels",
|
| 28 |
+
"out_channels": "@image_channels",
|
| 29 |
+
"latent_channels": "@latent_channels",
|
| 30 |
+
"num_channels": [
|
| 31 |
+
64,
|
| 32 |
+
128,
|
| 33 |
+
256
|
| 34 |
+
],
|
| 35 |
+
"num_res_blocks": 2,
|
| 36 |
+
"norm_num_groups": 32,
|
| 37 |
+
"norm_eps": 1e-06,
|
| 38 |
+
"attention_levels": [
|
| 39 |
+
false,
|
| 40 |
+
false,
|
| 41 |
+
false
|
| 42 |
+
],
|
| 43 |
+
"with_encoder_nonlocal_attn": true,
|
| 44 |
+
"with_decoder_nonlocal_attn": true
|
| 45 |
+
},
|
| 46 |
+
"network_def": {
|
| 47 |
+
"_target_": "generative.networks.nets.DiffusionModelUNet",
|
| 48 |
+
"spatial_dims": "@spatial_dims",
|
| 49 |
+
"in_channels": "@latent_channels",
|
| 50 |
+
"out_channels": "@latent_channels",
|
| 51 |
+
"num_channels": [
|
| 52 |
+
32,
|
| 53 |
+
64,
|
| 54 |
+
128,
|
| 55 |
+
256
|
| 56 |
+
],
|
| 57 |
+
"attention_levels": [
|
| 58 |
+
false,
|
| 59 |
+
true,
|
| 60 |
+
true,
|
| 61 |
+
true
|
| 62 |
+
],
|
| 63 |
+
"num_head_channels": [
|
| 64 |
+
0,
|
| 65 |
+
32,
|
| 66 |
+
32,
|
| 67 |
+
32
|
| 68 |
+
],
|
| 69 |
+
"num_res_blocks": 2
|
| 70 |
+
},
|
| 71 |
+
"load_autoencoder_path": "$@bundle_root + '/models/model_autoencoder.pt'",
|
| 72 |
+
"load_autoencoder": "$@autoencoder_def.load_state_dict(torch.load(@load_autoencoder_path))",
|
| 73 |
+
"autoencoder": "$@autoencoder_def.to(@device)",
|
| 74 |
+
"load_diffusion_path": "$@model_dir + '/model.pt'",
|
| 75 |
+
"load_diffusion": "$@network_def.load_state_dict(torch.load(@load_diffusion_path))",
|
| 76 |
+
"diffusion": "$@network_def.to(@device)",
|
| 77 |
+
"noise_scheduler": {
|
| 78 |
+
"_target_": "generative.networks.schedulers.DDIMScheduler",
|
| 79 |
+
"_requires_": [
|
| 80 |
+
"@load_diffusion",
|
| 81 |
+
"@load_autoencoder"
|
| 82 |
+
],
|
| 83 |
+
"num_train_timesteps": 1000,
|
| 84 |
+
"beta_start": 0.0015,
|
| 85 |
+
"beta_end": 0.0195,
|
| 86 |
+
"beta_schedule": "scaled_linear",
|
| 87 |
+
"clip_sample": false
|
| 88 |
+
},
|
| 89 |
+
"noise": "$torch.randn([1]+@latent_shape).to(@device)",
|
| 90 |
+
"set_timesteps": "$@noise_scheduler.set_timesteps(num_inference_steps=50)",
|
| 91 |
+
"inferer": {
|
| 92 |
+
"_target_": "scripts.ldm_sampler.LDMSampler",
|
| 93 |
+
"_requires_": "@set_timesteps"
|
| 94 |
+
},
|
| 95 |
+
"sample": "$@inferer.sampling_fn(@noise, @autoencoder, @diffusion, @noise_scheduler)",
|
| 96 |
+
"saver": {
|
| 97 |
+
"_target_": "SaveImage",
|
| 98 |
+
"_requires_": "@create_output_dir",
|
| 99 |
+
"output_dir": "@output_dir",
|
| 100 |
+
"output_postfix": "@output_postfix"
|
| 101 |
+
},
|
| 102 |
+
"generated_image": "$@sample",
|
| 103 |
+
"generated_image_np": "$@generated_image[0,0].cpu().numpy().transpose(1, 0)[::-1, ::-1]",
|
| 104 |
+
"img_pil": "$Image.fromarray(visualize_2d_image(@generated_image_np), 'RGB')",
|
| 105 |
+
"run": [
|
| 106 |
+
"$@img_pil.save(@output_dir+'/synimg_'+@output_postfix+'.png')"
|
| 107 |
+
]
|
| 108 |
+
}
|
configs/inference_autoencoder.json
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import torch",
|
| 4 |
+
"$from datetime import datetime",
|
| 5 |
+
"$from pathlib import Path",
|
| 6 |
+
"$from PIL import Image",
|
| 7 |
+
"$from scripts.utils import visualize_2d_image"
|
| 8 |
+
],
|
| 9 |
+
"bundle_root": ".",
|
| 10 |
+
"model_dir": "$@bundle_root + '/models'",
|
| 11 |
+
"dataset_dir": "@bundle_root",
|
| 12 |
+
"output_dir": "$@bundle_root + '/output'",
|
| 13 |
+
"create_output_dir": "$Path(@output_dir).mkdir(exist_ok=True)",
|
| 14 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 15 |
+
"output_postfix": "$datetime.now().strftime('%Y%m%d_%H%M%S')",
|
| 16 |
+
"channel": 0,
|
| 17 |
+
"spatial_dims": 2,
|
| 18 |
+
"image_channels": 1,
|
| 19 |
+
"latent_channels": 1,
|
| 20 |
+
"infer_patch_size": [
|
| 21 |
+
240,
|
| 22 |
+
240
|
| 23 |
+
],
|
| 24 |
+
"infer_batch_size_img": 1,
|
| 25 |
+
"infer_batch_size_slice": 1,
|
| 26 |
+
"autoencoder_def": {
|
| 27 |
+
"_target_": "generative.networks.nets.AutoencoderKL",
|
| 28 |
+
"spatial_dims": "@spatial_dims",
|
| 29 |
+
"in_channels": "@image_channels",
|
| 30 |
+
"out_channels": "@image_channels",
|
| 31 |
+
"latent_channels": "@latent_channels",
|
| 32 |
+
"num_channels": [
|
| 33 |
+
64,
|
| 34 |
+
128,
|
| 35 |
+
256
|
| 36 |
+
],
|
| 37 |
+
"num_res_blocks": 2,
|
| 38 |
+
"norm_num_groups": 32,
|
| 39 |
+
"norm_eps": 1e-06,
|
| 40 |
+
"attention_levels": [
|
| 41 |
+
false,
|
| 42 |
+
false,
|
| 43 |
+
false
|
| 44 |
+
],
|
| 45 |
+
"with_encoder_nonlocal_attn": true,
|
| 46 |
+
"with_decoder_nonlocal_attn": true
|
| 47 |
+
},
|
| 48 |
+
"load_autoencoder_path": "$@bundle_root + '/models/model_autoencoder.pt'",
|
| 49 |
+
"load_autoencoder": "$@autoencoder_def.load_state_dict(torch.load(@load_autoencoder_path))",
|
| 50 |
+
"autoencoder": "$@autoencoder_def.to(@device)",
|
| 51 |
+
"preprocessing_transforms": [
|
| 52 |
+
{
|
| 53 |
+
"_target_": "LoadImaged",
|
| 54 |
+
"keys": "image"
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"_target_": "EnsureChannelFirstd",
|
| 58 |
+
"keys": "image"
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"_target_": "Lambdad",
|
| 62 |
+
"keys": "image",
|
| 63 |
+
"func": "$lambda x: x[@channel, :, :, :]"
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"_target_": "AddChanneld",
|
| 67 |
+
"keys": "image"
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"_target_": "EnsureTyped",
|
| 71 |
+
"keys": "image"
|
| 72 |
+
},
|
| 73 |
+
{
|
| 74 |
+
"_target_": "Orientationd",
|
| 75 |
+
"keys": "image",
|
| 76 |
+
"axcodes": "RAS"
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
"_target_": "CenterSpatialCropd",
|
| 80 |
+
"keys": "image",
|
| 81 |
+
"roi_size": "$[@infer_patch_size[0], @infer_patch_size[1], 20]"
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"_target_": "ScaleIntensityRangePercentilesd",
|
| 85 |
+
"keys": "image",
|
| 86 |
+
"lower": 0,
|
| 87 |
+
"upper": 100,
|
| 88 |
+
"b_min": 0,
|
| 89 |
+
"b_max": 1
|
| 90 |
+
}
|
| 91 |
+
],
|
| 92 |
+
"crop_transforms": [
|
| 93 |
+
{
|
| 94 |
+
"_target_": "DivisiblePadd",
|
| 95 |
+
"keys": "image",
|
| 96 |
+
"k": [
|
| 97 |
+
4,
|
| 98 |
+
4,
|
| 99 |
+
1
|
| 100 |
+
]
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"_target_": "RandSpatialCropSamplesd",
|
| 104 |
+
"keys": "image",
|
| 105 |
+
"random_size": false,
|
| 106 |
+
"roi_size": "$[@infer_patch_size[0], @infer_patch_size[1], 1]",
|
| 107 |
+
"num_samples": "@infer_batch_size_slice"
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"_target_": "SqueezeDimd",
|
| 111 |
+
"keys": "image",
|
| 112 |
+
"dim": 3
|
| 113 |
+
}
|
| 114 |
+
],
|
| 115 |
+
"final_transforms": [
|
| 116 |
+
{
|
| 117 |
+
"_target_": "ScaleIntensityRangePercentilesd",
|
| 118 |
+
"keys": "image",
|
| 119 |
+
"lower": 0,
|
| 120 |
+
"upper": 100,
|
| 121 |
+
"b_min": 0,
|
| 122 |
+
"b_max": 1
|
| 123 |
+
}
|
| 124 |
+
],
|
| 125 |
+
"preprocessing": {
|
| 126 |
+
"_target_": "Compose",
|
| 127 |
+
"transforms": "$@preprocessing_transforms + @crop_transforms + @final_transforms"
|
| 128 |
+
},
|
| 129 |
+
"dataset": {
|
| 130 |
+
"_target_": "monai.apps.DecathlonDataset",
|
| 131 |
+
"root_dir": "@dataset_dir",
|
| 132 |
+
"task": "Task01_BrainTumour",
|
| 133 |
+
"section": "validation",
|
| 134 |
+
"cache_rate": 0.0,
|
| 135 |
+
"num_workers": 8,
|
| 136 |
+
"download": false,
|
| 137 |
+
"transform": "@preprocessing"
|
| 138 |
+
},
|
| 139 |
+
"dataloader": {
|
| 140 |
+
"_target_": "DataLoader",
|
| 141 |
+
"dataset": "@dataset",
|
| 142 |
+
"batch_size": 1,
|
| 143 |
+
"shuffle": true,
|
| 144 |
+
"num_workers": 0
|
| 145 |
+
},
|
| 146 |
+
"recon_img_pil": "$Image.fromarray(visualize_2d_image(@recon_img), 'RGB')",
|
| 147 |
+
"orig_img_pil": "$Image.fromarray(visualize_2d_image(@input_img[0,0,...]), 'RGB')",
|
| 148 |
+
"input_img": "$monai.utils.first(@dataloader)['image'].to(@device)",
|
| 149 |
+
"recon_img": "$@autoencoder(@input_img)[0][0,0,...]",
|
| 150 |
+
"run": [
|
| 151 |
+
"$@create_output_dir",
|
| 152 |
+
"$@load_autoencoder",
|
| 153 |
+
"$@orig_img_pil.save(@output_dir+'/orig_img_'+@output_postfix+'.png')",
|
| 154 |
+
"$@recon_img_pil.save(@output_dir+'/recon_img_'+@output_postfix+'.png')"
|
| 155 |
+
]
|
| 156 |
+
}
|
configs/logging.conf
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[loggers]
|
| 2 |
+
keys=root
|
| 3 |
+
|
| 4 |
+
[handlers]
|
| 5 |
+
keys=consoleHandler
|
| 6 |
+
|
| 7 |
+
[formatters]
|
| 8 |
+
keys=fullFormatter
|
| 9 |
+
|
| 10 |
+
[logger_root]
|
| 11 |
+
level=INFO
|
| 12 |
+
handlers=consoleHandler
|
| 13 |
+
|
| 14 |
+
[handler_consoleHandler]
|
| 15 |
+
class=StreamHandler
|
| 16 |
+
level=INFO
|
| 17 |
+
formatter=fullFormatter
|
| 18 |
+
args=(sys.stdout,)
|
| 19 |
+
|
| 20 |
+
[formatter_fullFormatter]
|
| 21 |
+
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
configs/metadata.json
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_generator_ldm_20230507.json",
|
| 3 |
+
"version": "1.0.0",
|
| 4 |
+
"changelog": {
|
| 5 |
+
"1.0.0": "Initial release"
|
| 6 |
+
},
|
| 7 |
+
"monai_version": "1.2.0rc5",
|
| 8 |
+
"pytorch_version": "1.13.1",
|
| 9 |
+
"numpy_version": "1.22.2",
|
| 10 |
+
"optional_packages_version": {
|
| 11 |
+
"nibabel": "5.1.0",
|
| 12 |
+
"lpips": "0.1.4"
|
| 13 |
+
},
|
| 14 |
+
"name": "BraTS MRI axial slices latent diffusion generation",
|
| 15 |
+
"task": "BraTS MRI axial slices synthesis",
|
| 16 |
+
"description": "A generative model for creating 2D brain MRI axial slices from Gaussian noise based on BraTS dataset",
|
| 17 |
+
"authors": "MONAI team",
|
| 18 |
+
"copyright": "Copyright (c) MONAI Consortium",
|
| 19 |
+
"data_source": "http://medicaldecathlon.com/",
|
| 20 |
+
"data_type": "nibabel",
|
| 21 |
+
"image_classes": "Flair brain MRI axial slices with 1x1 mm voxel size",
|
| 22 |
+
"eval_metrics": {},
|
| 23 |
+
"intended_use": "This is a research tool/prototype and not to be used clinically",
|
| 24 |
+
"references": [],
|
| 25 |
+
"autoencoder_data_format": {
|
| 26 |
+
"inputs": {
|
| 27 |
+
"image": {
|
| 28 |
+
"type": "image",
|
| 29 |
+
"format": "image",
|
| 30 |
+
"num_channels": 1,
|
| 31 |
+
"spatial_shape": [
|
| 32 |
+
240,
|
| 33 |
+
240
|
| 34 |
+
],
|
| 35 |
+
"dtype": "float32",
|
| 36 |
+
"value_range": [
|
| 37 |
+
0,
|
| 38 |
+
1
|
| 39 |
+
],
|
| 40 |
+
"is_patch_data": true
|
| 41 |
+
}
|
| 42 |
+
},
|
| 43 |
+
"outputs": {
|
| 44 |
+
"pred": {
|
| 45 |
+
"type": "image",
|
| 46 |
+
"format": "image",
|
| 47 |
+
"num_channels": 1,
|
| 48 |
+
"spatial_shape": [
|
| 49 |
+
240,
|
| 50 |
+
240
|
| 51 |
+
],
|
| 52 |
+
"dtype": "float32",
|
| 53 |
+
"value_range": [
|
| 54 |
+
0,
|
| 55 |
+
1
|
| 56 |
+
],
|
| 57 |
+
"is_patch_data": true,
|
| 58 |
+
"channel_def": {
|
| 59 |
+
"0": "image"
|
| 60 |
+
}
|
| 61 |
+
}
|
| 62 |
+
}
|
| 63 |
+
},
|
| 64 |
+
"generator_data_format": {
|
| 65 |
+
"inputs": {
|
| 66 |
+
"latent": {
|
| 67 |
+
"type": "noise",
|
| 68 |
+
"format": "image",
|
| 69 |
+
"num_channels": 1,
|
| 70 |
+
"spatial_shape": [
|
| 71 |
+
64,
|
| 72 |
+
64
|
| 73 |
+
],
|
| 74 |
+
"dtype": "float32",
|
| 75 |
+
"value_range": [
|
| 76 |
+
0,
|
| 77 |
+
1
|
| 78 |
+
],
|
| 79 |
+
"is_patch_data": true
|
| 80 |
+
}
|
| 81 |
+
},
|
| 82 |
+
"outputs": {
|
| 83 |
+
"pred": {
|
| 84 |
+
"type": "feature",
|
| 85 |
+
"format": "image",
|
| 86 |
+
"num_channels": 1,
|
| 87 |
+
"spatial_shape": [
|
| 88 |
+
64,
|
| 89 |
+
64
|
| 90 |
+
],
|
| 91 |
+
"dtype": "float32",
|
| 92 |
+
"value_range": [
|
| 93 |
+
0,
|
| 94 |
+
1
|
| 95 |
+
],
|
| 96 |
+
"is_patch_data": true,
|
| 97 |
+
"channel_def": {
|
| 98 |
+
"0": "image"
|
| 99 |
+
}
|
| 100 |
+
}
|
| 101 |
+
}
|
| 102 |
+
}
|
| 103 |
+
}
|
configs/multi_gpu_train_autoencoder.json
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"device": "$torch.device(f'cuda:{dist.get_rank()}')",
|
| 3 |
+
"gnetwork": {
|
| 4 |
+
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
| 5 |
+
"module": "$@autoencoder_def.to(@device)",
|
| 6 |
+
"device_ids": [
|
| 7 |
+
"@device"
|
| 8 |
+
],
|
| 9 |
+
"find_unused_parameters": true
|
| 10 |
+
},
|
| 11 |
+
"dnetwork": {
|
| 12 |
+
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
| 13 |
+
"module": "$@discriminator_def.to(@device)",
|
| 14 |
+
"device_ids": [
|
| 15 |
+
"@device"
|
| 16 |
+
],
|
| 17 |
+
"find_unused_parameters": true
|
| 18 |
+
},
|
| 19 |
+
"train#sampler": {
|
| 20 |
+
"_target_": "DistributedSampler",
|
| 21 |
+
"dataset": "@train#dataset",
|
| 22 |
+
"even_divisible": true,
|
| 23 |
+
"shuffle": true
|
| 24 |
+
},
|
| 25 |
+
"train#dataloader#sampler": "@train#sampler",
|
| 26 |
+
"train#dataloader#shuffle": false,
|
| 27 |
+
"train#trainer#train_handlers": "$@train#handlers[: -2 if dist.get_rank() > 0 else None]",
|
| 28 |
+
"initialize": [
|
| 29 |
+
"$import torch.distributed as dist",
|
| 30 |
+
"$dist.is_initialized() or dist.init_process_group(backend='nccl')",
|
| 31 |
+
"$torch.cuda.set_device(@device)",
|
| 32 |
+
"$monai.utils.set_determinism(seed=123)",
|
| 33 |
+
"$import logging",
|
| 34 |
+
"$@train#trainer.logger.setLevel(logging.WARNING if dist.get_rank() > 0 else logging.INFO)"
|
| 35 |
+
],
|
| 36 |
+
"run": [
|
| 37 |
+
"$@train#trainer.run()"
|
| 38 |
+
],
|
| 39 |
+
"finalize": [
|
| 40 |
+
"$dist.is_initialized() and dist.destroy_process_group()"
|
| 41 |
+
]
|
| 42 |
+
}
|
configs/multi_gpu_train_diffusion.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"diffusion": {
|
| 3 |
+
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
| 4 |
+
"module": "$@network_def.to(@device)",
|
| 5 |
+
"device_ids": [
|
| 6 |
+
"@device"
|
| 7 |
+
],
|
| 8 |
+
"find_unused_parameters": true
|
| 9 |
+
},
|
| 10 |
+
"run": [
|
| 11 |
+
"@load_autoencoder",
|
| 12 |
+
"$@autoencoder.eval()",
|
| 13 |
+
"$print('scale factor:',@scale_factor)",
|
| 14 |
+
"$@train#trainer.run()"
|
| 15 |
+
]
|
| 16 |
+
}
|
configs/train_autoencoder.json
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import functools",
|
| 4 |
+
"$import glob",
|
| 5 |
+
"$import scripts"
|
| 6 |
+
],
|
| 7 |
+
"bundle_root": ".",
|
| 8 |
+
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 9 |
+
"ckpt_dir": "$@bundle_root + '/models'",
|
| 10 |
+
"tf_dir": "$@bundle_root + '/eval'",
|
| 11 |
+
"dataset_dir": "@bundle_root",
|
| 12 |
+
"pretrained": false,
|
| 13 |
+
"perceptual_loss_model_weights_path": null,
|
| 14 |
+
"train_batch_size_img": 1,
|
| 15 |
+
"train_batch_size_slice": 26,
|
| 16 |
+
"lr": 5e-05,
|
| 17 |
+
"train_patch_size": [
|
| 18 |
+
240,
|
| 19 |
+
240
|
| 20 |
+
],
|
| 21 |
+
"channel": 0,
|
| 22 |
+
"spatial_dims": 2,
|
| 23 |
+
"image_channels": 1,
|
| 24 |
+
"latent_channels": 1,
|
| 25 |
+
"discriminator_def": {
|
| 26 |
+
"_target_": "generative.networks.nets.PatchDiscriminator",
|
| 27 |
+
"spatial_dims": "@spatial_dims",
|
| 28 |
+
"num_layers_d": 3,
|
| 29 |
+
"num_channels": 32,
|
| 30 |
+
"in_channels": 1,
|
| 31 |
+
"out_channels": 1,
|
| 32 |
+
"norm": "INSTANCE"
|
| 33 |
+
},
|
| 34 |
+
"autoencoder_def": {
|
| 35 |
+
"_target_": "generative.networks.nets.AutoencoderKL",
|
| 36 |
+
"spatial_dims": "@spatial_dims",
|
| 37 |
+
"in_channels": "@image_channels",
|
| 38 |
+
"out_channels": "@image_channels",
|
| 39 |
+
"latent_channels": "@latent_channels",
|
| 40 |
+
"num_channels": [
|
| 41 |
+
64,
|
| 42 |
+
128,
|
| 43 |
+
256
|
| 44 |
+
],
|
| 45 |
+
"num_res_blocks": 2,
|
| 46 |
+
"norm_num_groups": 32,
|
| 47 |
+
"norm_eps": 1e-06,
|
| 48 |
+
"attention_levels": [
|
| 49 |
+
false,
|
| 50 |
+
false,
|
| 51 |
+
false
|
| 52 |
+
],
|
| 53 |
+
"with_encoder_nonlocal_attn": true,
|
| 54 |
+
"with_decoder_nonlocal_attn": true
|
| 55 |
+
},
|
| 56 |
+
"perceptual_loss_def": {
|
| 57 |
+
"_target_": "generative.losses.PerceptualLoss",
|
| 58 |
+
"spatial_dims": "@spatial_dims",
|
| 59 |
+
"network_type": "resnet50",
|
| 60 |
+
"pretrained": "@pretrained",
|
| 61 |
+
"pretrained_path": "@perceptual_loss_model_weights_path",
|
| 62 |
+
"pretrained_state_dict_key": "state_dict"
|
| 63 |
+
},
|
| 64 |
+
"dnetwork": "$@discriminator_def.to(@device)",
|
| 65 |
+
"gnetwork": "$@autoencoder_def.to(@device)",
|
| 66 |
+
"loss_perceptual": "$@perceptual_loss_def.to(@device)",
|
| 67 |
+
"doptimizer": {
|
| 68 |
+
"_target_": "torch.optim.Adam",
|
| 69 |
+
"params": "$@dnetwork.parameters()",
|
| 70 |
+
"lr": "@lr"
|
| 71 |
+
},
|
| 72 |
+
"goptimizer": {
|
| 73 |
+
"_target_": "torch.optim.Adam",
|
| 74 |
+
"params": "$@gnetwork.parameters()",
|
| 75 |
+
"lr": "@lr"
|
| 76 |
+
},
|
| 77 |
+
"preprocessing_transforms": [
|
| 78 |
+
{
|
| 79 |
+
"_target_": "LoadImaged",
|
| 80 |
+
"keys": "image"
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"_target_": "EnsureChannelFirstd",
|
| 84 |
+
"keys": "image"
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
"_target_": "Lambdad",
|
| 88 |
+
"keys": "image",
|
| 89 |
+
"func": "$lambda x: x[@channel, :, :, :]"
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"_target_": "AddChanneld",
|
| 93 |
+
"keys": "image"
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"_target_": "EnsureTyped",
|
| 97 |
+
"keys": "image"
|
| 98 |
+
},
|
| 99 |
+
{
|
| 100 |
+
"_target_": "Orientationd",
|
| 101 |
+
"keys": "image",
|
| 102 |
+
"axcodes": "RAS"
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"_target_": "CenterSpatialCropd",
|
| 106 |
+
"keys": "image",
|
| 107 |
+
"roi_size": "$[@train_patch_size[0], @train_patch_size[1], 100]"
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"_target_": "ScaleIntensityRangePercentilesd",
|
| 111 |
+
"keys": "image",
|
| 112 |
+
"lower": 0,
|
| 113 |
+
"upper": 100,
|
| 114 |
+
"b_min": 0,
|
| 115 |
+
"b_max": 1
|
| 116 |
+
}
|
| 117 |
+
],
|
| 118 |
+
"train": {
|
| 119 |
+
"crop_transforms": [
|
| 120 |
+
{
|
| 121 |
+
"_target_": "DivisiblePadd",
|
| 122 |
+
"keys": "image",
|
| 123 |
+
"k": [
|
| 124 |
+
4,
|
| 125 |
+
4,
|
| 126 |
+
1
|
| 127 |
+
]
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"_target_": "RandSpatialCropSamplesd",
|
| 131 |
+
"keys": "image",
|
| 132 |
+
"random_size": false,
|
| 133 |
+
"roi_size": "$[@train_patch_size[0], @train_patch_size[1], 1]",
|
| 134 |
+
"num_samples": "@train_batch_size_slice"
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"_target_": "SqueezeDimd",
|
| 138 |
+
"keys": "image",
|
| 139 |
+
"dim": 3
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"_target_": "RandFlipd",
|
| 143 |
+
"keys": [
|
| 144 |
+
"image"
|
| 145 |
+
],
|
| 146 |
+
"prob": 0.5,
|
| 147 |
+
"spatial_axis": 0
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"_target_": "RandFlipd",
|
| 151 |
+
"keys": [
|
| 152 |
+
"image"
|
| 153 |
+
],
|
| 154 |
+
"prob": 0.5,
|
| 155 |
+
"spatial_axis": 1
|
| 156 |
+
}
|
| 157 |
+
],
|
| 158 |
+
"preprocessing": {
|
| 159 |
+
"_target_": "Compose",
|
| 160 |
+
"transforms": "$@preprocessing_transforms + @train#crop_transforms"
|
| 161 |
+
},
|
| 162 |
+
"dataset": {
|
| 163 |
+
"_target_": "monai.apps.DecathlonDataset",
|
| 164 |
+
"root_dir": "@dataset_dir",
|
| 165 |
+
"task": "Task01_BrainTumour",
|
| 166 |
+
"section": "training",
|
| 167 |
+
"cache_rate": 1.0,
|
| 168 |
+
"num_workers": 8,
|
| 169 |
+
"download": false,
|
| 170 |
+
"transform": "@train#preprocessing"
|
| 171 |
+
},
|
| 172 |
+
"dataloader": {
|
| 173 |
+
"_target_": "DataLoader",
|
| 174 |
+
"dataset": "@train#dataset",
|
| 175 |
+
"batch_size": "@train_batch_size_img",
|
| 176 |
+
"shuffle": true,
|
| 177 |
+
"num_workers": 0
|
| 178 |
+
},
|
| 179 |
+
"handlers": [
|
| 180 |
+
{
|
| 181 |
+
"_target_": "CheckpointSaver",
|
| 182 |
+
"save_dir": "@ckpt_dir",
|
| 183 |
+
"save_dict": {
|
| 184 |
+
"model": "@gnetwork"
|
| 185 |
+
},
|
| 186 |
+
"save_interval": 0,
|
| 187 |
+
"save_final": true,
|
| 188 |
+
"epoch_level": true,
|
| 189 |
+
"final_filename": "model_autoencoder.pt"
|
| 190 |
+
},
|
| 191 |
+
{
|
| 192 |
+
"_target_": "StatsHandler",
|
| 193 |
+
"tag_name": "train_loss",
|
| 194 |
+
"output_transform": "$lambda x: monai.handlers.from_engine(['g_loss'], first=True)(x)[0]"
|
| 195 |
+
},
|
| 196 |
+
{
|
| 197 |
+
"_target_": "TensorBoardStatsHandler",
|
| 198 |
+
"log_dir": "@tf_dir",
|
| 199 |
+
"tag_name": "train_loss",
|
| 200 |
+
"output_transform": "$lambda x: monai.handlers.from_engine(['g_loss'], first=True)(x)[0]"
|
| 201 |
+
}
|
| 202 |
+
],
|
| 203 |
+
"trainer": {
|
| 204 |
+
"_target_": "scripts.ldm_trainer.VaeGanTrainer",
|
| 205 |
+
"device": "@device",
|
| 206 |
+
"max_epochs": 1500,
|
| 207 |
+
"train_data_loader": "@train#dataloader",
|
| 208 |
+
"g_network": "@gnetwork",
|
| 209 |
+
"g_optimizer": "@goptimizer",
|
| 210 |
+
"g_loss_function": "$functools.partial(scripts.losses.generator_loss, disc_net=@dnetwork, loss_perceptual=@loss_perceptual)",
|
| 211 |
+
"d_network": "@dnetwork",
|
| 212 |
+
"d_optimizer": "@doptimizer",
|
| 213 |
+
"d_loss_function": "$functools.partial(scripts.losses.discriminator_loss, disc_net=@dnetwork)",
|
| 214 |
+
"d_train_steps": 1,
|
| 215 |
+
"g_update_latents": true,
|
| 216 |
+
"latent_shape": "@latent_channels",
|
| 217 |
+
"key_train_metric": "$None",
|
| 218 |
+
"train_handlers": "@train#handlers"
|
| 219 |
+
}
|
| 220 |
+
},
|
| 221 |
+
"initialize": [
|
| 222 |
+
"$monai.utils.set_determinism(seed=0)"
|
| 223 |
+
],
|
| 224 |
+
"run": [
|
| 225 |
+
"$@train#trainer.run()"
|
| 226 |
+
]
|
| 227 |
+
}
|
configs/train_diffusion.json
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"ckpt_dir": "$@bundle_root + '/models'",
|
| 3 |
+
"train_batch_size_img": 2,
|
| 4 |
+
"train_batch_size_slice": 50,
|
| 5 |
+
"lr": 5e-05,
|
| 6 |
+
"train_patch_size": [
|
| 7 |
+
256,
|
| 8 |
+
256
|
| 9 |
+
],
|
| 10 |
+
"latent_shape": [
|
| 11 |
+
"@latent_channels",
|
| 12 |
+
64,
|
| 13 |
+
64
|
| 14 |
+
],
|
| 15 |
+
"load_autoencoder_path": "$@bundle_root + '/models/model_autoencoder.pt'",
|
| 16 |
+
"load_autoencoder": "$@autoencoder_def.load_state_dict(torch.load(@load_autoencoder_path))",
|
| 17 |
+
"autoencoder": "$@autoencoder_def.to(@device)",
|
| 18 |
+
"network_def": {
|
| 19 |
+
"_target_": "generative.networks.nets.DiffusionModelUNet",
|
| 20 |
+
"spatial_dims": "@spatial_dims",
|
| 21 |
+
"in_channels": "@latent_channels",
|
| 22 |
+
"out_channels": "@latent_channels",
|
| 23 |
+
"num_channels": [
|
| 24 |
+
32,
|
| 25 |
+
64,
|
| 26 |
+
128,
|
| 27 |
+
256
|
| 28 |
+
],
|
| 29 |
+
"attention_levels": [
|
| 30 |
+
false,
|
| 31 |
+
true,
|
| 32 |
+
true,
|
| 33 |
+
true
|
| 34 |
+
],
|
| 35 |
+
"num_head_channels": [
|
| 36 |
+
0,
|
| 37 |
+
32,
|
| 38 |
+
32,
|
| 39 |
+
32
|
| 40 |
+
],
|
| 41 |
+
"num_res_blocks": 2
|
| 42 |
+
},
|
| 43 |
+
"diffusion": "$@network_def.to(@device)",
|
| 44 |
+
"optimizer": {
|
| 45 |
+
"_target_": "torch.optim.Adam",
|
| 46 |
+
"params": "$@diffusion.parameters()",
|
| 47 |
+
"lr": "@lr"
|
| 48 |
+
},
|
| 49 |
+
"lr_scheduler": {
|
| 50 |
+
"_target_": "torch.optim.lr_scheduler.MultiStepLR",
|
| 51 |
+
"optimizer": "@optimizer",
|
| 52 |
+
"milestones": [
|
| 53 |
+
1000
|
| 54 |
+
],
|
| 55 |
+
"gamma": 0.1
|
| 56 |
+
},
|
| 57 |
+
"scale_factor": "$scripts.utils.compute_scale_factor(@autoencoder,@train#dataloader,@device)",
|
| 58 |
+
"noise_scheduler": {
|
| 59 |
+
"_target_": "generative.networks.schedulers.DDPMScheduler",
|
| 60 |
+
"_requires_": [
|
| 61 |
+
"@load_autoencoder"
|
| 62 |
+
],
|
| 63 |
+
"beta_schedule": "scaled_linear",
|
| 64 |
+
"num_train_timesteps": 1000,
|
| 65 |
+
"beta_start": 0.0015,
|
| 66 |
+
"beta_end": 0.0195
|
| 67 |
+
},
|
| 68 |
+
"inferer": {
|
| 69 |
+
"_target_": "generative.inferers.LatentDiffusionInferer",
|
| 70 |
+
"scheduler": "@noise_scheduler",
|
| 71 |
+
"scale_factor": "@scale_factor"
|
| 72 |
+
},
|
| 73 |
+
"loss": {
|
| 74 |
+
"_target_": "torch.nn.MSELoss"
|
| 75 |
+
},
|
| 76 |
+
"train": {
|
| 77 |
+
"crop_transforms": [
|
| 78 |
+
{
|
| 79 |
+
"_target_": "DivisiblePadd",
|
| 80 |
+
"keys": "image",
|
| 81 |
+
"k": [
|
| 82 |
+
32,
|
| 83 |
+
32,
|
| 84 |
+
1
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"_target_": "RandSpatialCropSamplesd",
|
| 89 |
+
"keys": "image",
|
| 90 |
+
"random_size": false,
|
| 91 |
+
"roi_size": "$[@train_patch_size[0], @train_patch_size[1], 1]",
|
| 92 |
+
"num_samples": "@train_batch_size_slice"
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"_target_": "SqueezeDimd",
|
| 96 |
+
"keys": "image",
|
| 97 |
+
"dim": 3
|
| 98 |
+
}
|
| 99 |
+
],
|
| 100 |
+
"preprocessing": {
|
| 101 |
+
"_target_": "Compose",
|
| 102 |
+
"transforms": "$@preprocessing_transforms + @train#crop_transforms"
|
| 103 |
+
},
|
| 104 |
+
"dataset": {
|
| 105 |
+
"_target_": "monai.apps.DecathlonDataset",
|
| 106 |
+
"root_dir": "@dataset_dir",
|
| 107 |
+
"task": "Task01_BrainTumour",
|
| 108 |
+
"section": "training",
|
| 109 |
+
"cache_rate": 1.0,
|
| 110 |
+
"num_workers": 8,
|
| 111 |
+
"download": "@download_brats",
|
| 112 |
+
"transform": "@train#preprocessing"
|
| 113 |
+
},
|
| 114 |
+
"dataloader": {
|
| 115 |
+
"_target_": "DataLoader",
|
| 116 |
+
"dataset": "@train#dataset",
|
| 117 |
+
"batch_size": "@train_batch_size_img",
|
| 118 |
+
"shuffle": true,
|
| 119 |
+
"num_workers": 0
|
| 120 |
+
},
|
| 121 |
+
"handlers": [
|
| 122 |
+
{
|
| 123 |
+
"_target_": "LrScheduleHandler",
|
| 124 |
+
"lr_scheduler": "@lr_scheduler",
|
| 125 |
+
"print_lr": true
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"_target_": "CheckpointSaver",
|
| 129 |
+
"save_dir": "@ckpt_dir",
|
| 130 |
+
"save_dict": {
|
| 131 |
+
"model": "@diffusion"
|
| 132 |
+
},
|
| 133 |
+
"save_interval": 0,
|
| 134 |
+
"save_final": true,
|
| 135 |
+
"epoch_level": true,
|
| 136 |
+
"final_filename": "model.pt"
|
| 137 |
+
},
|
| 138 |
+
{
|
| 139 |
+
"_target_": "StatsHandler",
|
| 140 |
+
"tag_name": "train_diffusion_loss",
|
| 141 |
+
"output_transform": "$lambda x: monai.handlers.from_engine(['loss'], first=True)(x)"
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"_target_": "TensorBoardStatsHandler",
|
| 145 |
+
"log_dir": "@tf_dir",
|
| 146 |
+
"tag_name": "train_diffusion_loss",
|
| 147 |
+
"output_transform": "$lambda x: monai.handlers.from_engine(['loss'], first=True)(x)"
|
| 148 |
+
}
|
| 149 |
+
],
|
| 150 |
+
"trainer": {
|
| 151 |
+
"_target_": "scripts.ldm_trainer.LDMTrainer",
|
| 152 |
+
"device": "@device",
|
| 153 |
+
"max_epochs": 1000,
|
| 154 |
+
"train_data_loader": "@train#dataloader",
|
| 155 |
+
"network": "@diffusion",
|
| 156 |
+
"autoencoder_model": "@autoencoder",
|
| 157 |
+
"optimizer": "@optimizer",
|
| 158 |
+
"loss_function": "@loss",
|
| 159 |
+
"latent_shape": "@latent_shape",
|
| 160 |
+
"inferer": "@inferer",
|
| 161 |
+
"key_train_metric": "$None",
|
| 162 |
+
"train_handlers": "@train#handlers"
|
| 163 |
+
}
|
| 164 |
+
},
|
| 165 |
+
"initialize": [
|
| 166 |
+
"$monai.utils.set_determinism(seed=0)"
|
| 167 |
+
],
|
| 168 |
+
"run": [
|
| 169 |
+
"@load_autoencoder",
|
| 170 |
+
"$@autoencoder.eval()",
|
| 171 |
+
"$print('scale factor:',@scale_factor)",
|
| 172 |
+
"$@train#trainer.run()"
|
| 173 |
+
]
|
| 174 |
+
}
|
docs/README.md
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Overview
|
| 2 |
+
A pre-trained model for 2D Latent Diffusion Generative Model on axial slices of BraTS MRI.
|
| 3 |
+
|
| 4 |
+
This model is trained on BraTS 2016 and 2017 data from [Medical Decathlon](http://medicaldecathlon.com/), using the Latent diffusion model [1].
|
| 5 |
+
|
| 6 |
+

|
| 7 |
+
|
| 8 |
+
This model is a generator for creating images like the Flair MRIs based on BraTS 2016 and 2017 data. It was trained as a 2d latent diffusion model and accepts Gaussian random noise as inputs to produce an image output. The `train_autoencoder.json` file describes the training process of the variational autoencoder with GAN loss. The `train_diffusion.json` file describes the training process of the 2D latent diffusion model.
|
| 9 |
+
|
| 10 |
+
In this bundle, the autoencoder uses perceptual loss, which is based on ResNet50 with pre-trained weights (the network is frozen and will not be trained in the bundle). In default, the `pretrained` parameter is specified as `False` in `train_autoencoder.json`. To ensure correct training, changing the default settings is necessary. There are two ways to utilize pretrained weights:
|
| 11 |
+
1. if set `pretrained` to `True`, ImageNet pretrained weights from [torchvision](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet50_Weights) will be used. However, the weights are for non-commercial use only.
|
| 12 |
+
2. if set `pretrained` to `True` and specifies the `perceptual_loss_model_weights_path` parameter, users are able to load weights from a local path. This is the way this bundle used to train, and the pre-trained weights are from some internal data.
|
| 13 |
+
|
| 14 |
+
Please note that each user is responsible for checking the data source of the pre-trained models, the applicable licenses, and determining if suitable for the intended use.
|
| 15 |
+
|
| 16 |
+
#### Example synthetic image
|
| 17 |
+
An example result from inference is shown below:
|
| 18 |
+

|
| 19 |
+
|
| 20 |
+
**This is a demonstration network meant to just show the training process for this sort of network with MONAI. To achieve better performance, users need to use larger dataset like [BraTS 2021](https://www.synapse.org/#!Synapse:syn25829067/wiki/610865).**
|
| 21 |
+
|
| 22 |
+
## MONAI Generative Model Dependencies
|
| 23 |
+
[MONAI generative models](https://github.com/Project-MONAI/GenerativeModels) can be installed by
|
| 24 |
+
```
|
| 25 |
+
pip install lpips==0.1.4
|
| 26 |
+
pip install git+https://github.com/Project-MONAI/GenerativeModels.git@0.2.1
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
## Data
|
| 30 |
+
The training data is BraTS 2016 and 2017 from the Medical Segmentation Decathalon. Users can find more details on the dataset (`Task01_BrainTumour`) at http://medicaldecathlon.com/.
|
| 31 |
+
|
| 32 |
+
- Target: Image Generation
|
| 33 |
+
- Task: Synthesis
|
| 34 |
+
- Modality: MRI
|
| 35 |
+
- Size: 388 3D MRI volumes (1 channel used)
|
| 36 |
+
- Training data size: 38800 2D MRI axial slices (1 channel used)
|
| 37 |
+
|
| 38 |
+
## Training Configuration
|
| 39 |
+
If you have a GPU with less than 32G of memory, you may need to decrease the batch size when training. To do so, modify the `"train_batch_size_img"` and `"train_batch_size_slice"` parameters in the `configs/train_autoencoder.json` and `configs/train_diffusion.json` configuration files.
|
| 40 |
+
- `"train_batch_size_img"` is number of 3D volumes loaded in each batch.
|
| 41 |
+
- `"train_batch_size_slice"` is the number of 2D axial slices extracted from each image. The actual batch size is the product of them.
|
| 42 |
+
|
| 43 |
+
### Training Configuration of Autoencoder
|
| 44 |
+
The autoencoder was trained using the following configuration:
|
| 45 |
+
|
| 46 |
+
- GPU: at least 32GB GPU memory
|
| 47 |
+
- Actual Model Input: 240 x 240
|
| 48 |
+
- AMP: False
|
| 49 |
+
- Optimizer: Adam
|
| 50 |
+
- Learning Rate: 5e-5
|
| 51 |
+
- Loss: L1 loss, perceptual loss, KL divergence loss, adversarial loss, GAN BCE loss
|
| 52 |
+
|
| 53 |
+
#### Input
|
| 54 |
+
1 channel 2D MRI Flair axial patches
|
| 55 |
+
|
| 56 |
+
#### Output
|
| 57 |
+
- 1 channel 2D MRI reconstructed patches
|
| 58 |
+
- 1 channel mean of latent features
|
| 59 |
+
- 1 channel standard deviation of latent features
|
| 60 |
+
|
| 61 |
+
### Training Configuration of Diffusion Model
|
| 62 |
+
The latent diffusion model was trained using the following configuration:
|
| 63 |
+
|
| 64 |
+
- GPU: at least 32GB GPU memory
|
| 65 |
+
- Actual Model Input: 64 x 64
|
| 66 |
+
- AMP: False
|
| 67 |
+
- Optimizer: Adam
|
| 68 |
+
- Learning Rate: 5e-5
|
| 69 |
+
- Loss: MSE loss
|
| 70 |
+
|
| 71 |
+
#### Training Input
|
| 72 |
+
- 1 channel noisy latent features
|
| 73 |
+
- a long int that indicates the time step
|
| 74 |
+
|
| 75 |
+
#### Training Output
|
| 76 |
+
1 channel predicted added noise
|
| 77 |
+
|
| 78 |
+
#### Inference Input
|
| 79 |
+
1 channel noise
|
| 80 |
+
|
| 81 |
+
#### Inference Output
|
| 82 |
+
1 channel denoised latent features
|
| 83 |
+
|
| 84 |
+
### Memory Consumption Warning
|
| 85 |
+
|
| 86 |
+
If you face memory issues with data loading, you can lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
|
| 87 |
+
|
| 88 |
+
## Performance
|
| 89 |
+
|
| 90 |
+
#### Training Loss
|
| 91 |
+

|
| 92 |
+
|
| 93 |
+

|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
## MONAI Bundle Commands
|
| 97 |
+
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 98 |
+
|
| 99 |
+
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
|
| 100 |
+
|
| 101 |
+
### Execute Autoencoder Training
|
| 102 |
+
|
| 103 |
+
#### Execute Autoencoder Training on single GPU
|
| 104 |
+
```
|
| 105 |
+
python -m monai.bundle run --config_file configs/train_autoencoder.json
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
Please note that if the default dataset path is not modified with the actual path (it should be the path that contains Task01_BrainTumour) in the bundle config files, you can also override it by using `--dataset_dir`:
|
| 109 |
+
|
| 110 |
+
```
|
| 111 |
+
python -m monai.bundle run --config_file configs/train_autoencoder.json --dataset_dir <actual dataset path>
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
#### Override the `train` config to execute multi-GPU training for Autoencoder
|
| 115 |
+
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
|
| 116 |
+
|
| 117 |
+
```
|
| 118 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/multi_gpu_train_autoencoder.json']" --lr 4e-4
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
#### Check the Autoencoder Training result
|
| 122 |
+
The following code generates a reconstructed image from a random input image.
|
| 123 |
+
We can visualize it to see if the autoencoder is trained correctly.
|
| 124 |
+
```
|
| 125 |
+
python -m monai.bundle run --config_file configs/inference_autoencoder.json
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
An example of reconstructed image from inference is shown below. If the autoencoder is trained correctly, the reconstructed image should look similar to original image.
|
| 129 |
+
|
| 130 |
+

|
| 131 |
+
|
| 132 |
+
### Execute Latent Diffusion Model Training
|
| 133 |
+
|
| 134 |
+
#### Execute Latent Diffusion Model Training on single GPU
|
| 135 |
+
After training the autoencoder, run the following command to train the latent diffusion model. This command will print out the scale factor of the latent feature space. If your autoencoder is well trained, this value should be close to 1.0.
|
| 136 |
+
|
| 137 |
+
```
|
| 138 |
+
python -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json']"
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
#### Override the `train` config to execute multi-GPU training for Latent Diffusion Model
|
| 142 |
+
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
|
| 143 |
+
|
| 144 |
+
```
|
| 145 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json','configs/multi_gpu_train_autoencoder.json','configs/multi_gpu_train_diffusion.json']" --lr 4e-4
|
| 146 |
+
```
|
| 147 |
+
### Execute inference
|
| 148 |
+
The following code generates a synthetic image from a random sampled noise.
|
| 149 |
+
```
|
| 150 |
+
python -m monai.bundle run --config_file configs/inference.json
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
# References
|
| 154 |
+
[1] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
|
| 155 |
+
|
| 156 |
+
# License
|
| 157 |
+
Copyright (c) MONAI Consortium
|
| 158 |
+
|
| 159 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 160 |
+
you may not use this file except in compliance with the License.
|
| 161 |
+
You may obtain a copy of the License at
|
| 162 |
+
|
| 163 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 164 |
+
|
| 165 |
+
Unless required by applicable law or agreed to in writing, software
|
| 166 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 167 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 168 |
+
See the License for the specific language governing permissions and
|
| 169 |
+
limitations under the License.
|
docs/data_license.txt
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Third Party Licenses
|
| 2 |
+
-----------------------------------------------------------------------
|
| 3 |
+
|
| 4 |
+
/*********************************************************************/
|
| 5 |
+
i. Multimodal Brain Tumor Segmentation Challenge 2018
|
| 6 |
+
https://www.med.upenn.edu/sbia/brats2018/data.html
|
| 7 |
+
/*********************************************************************/
|
| 8 |
+
|
| 9 |
+
Data Usage Agreement / Citations
|
| 10 |
+
|
| 11 |
+
You are free to use and/or refer to the BraTS datasets in your own
|
| 12 |
+
research, provided that you always cite the following two manuscripts:
|
| 13 |
+
|
| 14 |
+
[1] Menze BH, Jakab A, Bauer S, Kalpathy-Cramer J, Farahani K, Kirby
|
| 15 |
+
[J, Burren Y, Porz N, Slotboom J, Wiest R, Lanczi L, Gerstner E, Weber
|
| 16 |
+
[MA, Arbel T, Avants BB, Ayache N, Buendia P, Collins DL, Cordier N,
|
| 17 |
+
[Corso JJ, Criminisi A, Das T, Delingette H, Demiralp Γ, Durst CR,
|
| 18 |
+
[Dojat M, Doyle S, Festa J, Forbes F, Geremia E, Glocker B, Golland P,
|
| 19 |
+
[Guo X, Hamamci A, Iftekharuddin KM, Jena R, John NM, Konukoglu E,
|
| 20 |
+
[Lashkari D, Mariz JA, Meier R, Pereira S, Precup D, Price SJ, Raviv
|
| 21 |
+
[TR, Reza SM, Ryan M, Sarikaya D, Schwartz L, Shin HC, Shotton J,
|
| 22 |
+
[Silva CA, Sousa N, Subbanna NK, Szekely G, Taylor TJ, Thomas OM,
|
| 23 |
+
[Tustison NJ, Unal G, Vasseur F, Wintermark M, Ye DH, Zhao L, Zhao B,
|
| 24 |
+
[Zikic D, Prastawa M, Reyes M, Van Leemput K. "The Multimodal Brain
|
| 25 |
+
[Tumor Image Segmentation Benchmark (BRATS)", IEEE Transactions on
|
| 26 |
+
[Medical Imaging 34(10), 1993-2024 (2015) DOI:
|
| 27 |
+
[10.1109/TMI.2014.2377694
|
| 28 |
+
|
| 29 |
+
[2] Bakas S, Akbari H, Sotiras A, Bilello M, Rozycki M, Kirby JS,
|
| 30 |
+
[Freymann JB, Farahani K, Davatzikos C. "Advancing The Cancer Genome
|
| 31 |
+
[Atlas glioma MRI collections with expert segmentation labels and
|
| 32 |
+
[radiomic features", Nature Scientific Data, 4:170117 (2017) DOI:
|
| 33 |
+
[10.1038/sdata.2017.117
|
| 34 |
+
|
| 35 |
+
In addition, if there are no restrictions imposed from the
|
| 36 |
+
journal/conference you submit your paper about citing "Data
|
| 37 |
+
Citations", please be specific and also cite the following:
|
| 38 |
+
|
| 39 |
+
[3] Bakas S, Akbari H, Sotiras A, Bilello M, Rozycki M, Kirby J,
|
| 40 |
+
[Freymann J, Farahani K, Davatzikos C. "Segmentation Labels and
|
| 41 |
+
[Radiomic Features for the Pre-operative Scans of the TCGA-GBM
|
| 42 |
+
[collection", The Cancer Imaging Archive, 2017. DOI:
|
| 43 |
+
[10.7937/K9/TCIA.2017.KLXWJJ1Q
|
| 44 |
+
|
| 45 |
+
[4] Bakas S, Akbari H, Sotiras A, Bilello M, Rozycki M, Kirby J,
|
| 46 |
+
[Freymann J, Farahani K, Davatzikos C. "Segmentation Labels and
|
| 47 |
+
[Radiomic Features for the Pre-operative Scans of the TCGA-LGG
|
| 48 |
+
[collection", The Cancer Imaging Archive, 2017. DOI:
|
| 49 |
+
[10.7937/K9/TCIA.2017.GJQ7R0EF
|
models/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ff03d51a63541e4795869d7edc9176ccea8df91e1afdcd0fedb7600b6b6c54d1
|
| 3 |
+
size 63696253
|
models/model_autoencoder.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b90968ce8a5eb8e71de1c6bf0cbe79e5dc6104fe289a2058ddd62ea18ce78d69
|
| 3 |
+
size 49200645
|
scripts/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
from . import ldm_sampler, ldm_trainer, losses, utils
|
scripts/ldm_sampler.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
from __future__ import annotations
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
from monai.utils import optional_import
|
| 17 |
+
from torch.cuda.amp import autocast
|
| 18 |
+
|
| 19 |
+
tqdm, has_tqdm = optional_import("tqdm", name="tqdm")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class LDMSampler:
|
| 23 |
+
def __init__(self) -> None:
|
| 24 |
+
super().__init__()
|
| 25 |
+
|
| 26 |
+
@torch.no_grad()
|
| 27 |
+
def sampling_fn(
|
| 28 |
+
self,
|
| 29 |
+
input_noise: torch.Tensor,
|
| 30 |
+
autoencoder_model: nn.Module,
|
| 31 |
+
diffusion_model: nn.Module,
|
| 32 |
+
scheduler: nn.Module,
|
| 33 |
+
conditioning: torch.Tensor | None = None,
|
| 34 |
+
) -> torch.Tensor:
|
| 35 |
+
if has_tqdm:
|
| 36 |
+
progress_bar = tqdm(scheduler.timesteps)
|
| 37 |
+
else:
|
| 38 |
+
progress_bar = iter(scheduler.timesteps)
|
| 39 |
+
|
| 40 |
+
image = input_noise
|
| 41 |
+
if conditioning is not None:
|
| 42 |
+
cond_concat = conditioning.squeeze(1).unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
|
| 43 |
+
cond_concat = cond_concat.expand(list(cond_concat.shape[0:2]) + list(input_noise.shape[2:]))
|
| 44 |
+
|
| 45 |
+
for t in progress_bar:
|
| 46 |
+
with torch.no_grad():
|
| 47 |
+
if conditioning is not None:
|
| 48 |
+
input_t = torch.cat((image, cond_concat), dim=1)
|
| 49 |
+
else:
|
| 50 |
+
input_t = image
|
| 51 |
+
model_output = diffusion_model(
|
| 52 |
+
input_t, timesteps=torch.Tensor((t,)).to(input_noise.device).long(), context=conditioning
|
| 53 |
+
)
|
| 54 |
+
image, _ = scheduler.step(model_output, t, image)
|
| 55 |
+
|
| 56 |
+
with torch.no_grad():
|
| 57 |
+
with autocast():
|
| 58 |
+
sample = autoencoder_model.decode_stage_2_outputs(image)
|
| 59 |
+
|
| 60 |
+
return sample
|
scripts/ldm_trainer.py
ADDED
|
@@ -0,0 +1,380 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
from __future__ import annotations
|
| 13 |
+
|
| 14 |
+
from typing import TYPE_CHECKING, Any, Callable, Iterable, Sequence
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
from monai.config import IgniteInfo
|
| 18 |
+
from monai.engines.utils import IterationEvents, default_metric_cmp_fn, default_prepare_batch
|
| 19 |
+
from monai.inferers import Inferer, SimpleInferer
|
| 20 |
+
from monai.transforms import Transform
|
| 21 |
+
from monai.utils import min_version, optional_import
|
| 22 |
+
from monai.utils.enums import CommonKeys, GanKeys
|
| 23 |
+
from torch.optim.optimizer import Optimizer
|
| 24 |
+
from torch.utils.data import DataLoader
|
| 25 |
+
|
| 26 |
+
if TYPE_CHECKING:
|
| 27 |
+
from ignite.engine import Engine, EventEnum
|
| 28 |
+
from ignite.metrics import Metric
|
| 29 |
+
else:
|
| 30 |
+
Engine, _ = optional_import("ignite.engine", IgniteInfo.OPT_IMPORT_VERSION, min_version, "Engine")
|
| 31 |
+
Metric, _ = optional_import("ignite.metrics", IgniteInfo.OPT_IMPORT_VERSION, min_version, "Metric")
|
| 32 |
+
EventEnum, _ = optional_import("ignite.engine", IgniteInfo.OPT_IMPORT_VERSION, min_version, "EventEnum")
|
| 33 |
+
from monai.engines.trainer import SupervisedTrainer, Trainer
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class VaeGanTrainer(Trainer):
|
| 37 |
+
"""
|
| 38 |
+
Generative adversarial network training based on Goodfellow et al. 2014 https://arxiv.org/abs/1406.266,
|
| 39 |
+
inherits from ``Trainer`` and ``Workflow``.
|
| 40 |
+
Training Loop: for each batch of data size `m`
|
| 41 |
+
1. Generate `m` fakes from random latent codes.
|
| 42 |
+
2. Update discriminator with these fakes and current batch reals, repeated d_train_steps times.
|
| 43 |
+
3. If g_update_latents, generate `m` fakes from new random latent codes.
|
| 44 |
+
4. Update generator with these fakes using discriminator feedback.
|
| 45 |
+
Args:
|
| 46 |
+
device: an object representing the device on which to run.
|
| 47 |
+
max_epochs: the total epoch number for engine to run.
|
| 48 |
+
train_data_loader: Core ignite engines uses `DataLoader` for training loop batchdata.
|
| 49 |
+
g_network: generator (G) network architecture.
|
| 50 |
+
g_optimizer: G optimizer function.
|
| 51 |
+
g_loss_function: G loss function for optimizer.
|
| 52 |
+
d_network: discriminator (D) network architecture.
|
| 53 |
+
d_optimizer: D optimizer function.
|
| 54 |
+
d_loss_function: D loss function for optimizer.
|
| 55 |
+
epoch_length: number of iterations for one epoch, default to `len(train_data_loader)`.
|
| 56 |
+
g_inferer: inference method to execute G model forward. Defaults to ``SimpleInferer()``.
|
| 57 |
+
d_inferer: inference method to execute D model forward. Defaults to ``SimpleInferer()``.
|
| 58 |
+
d_train_steps: number of times to update D with real data minibatch. Defaults to ``1``.
|
| 59 |
+
latent_shape: size of G input latent code. Defaults to ``64``.
|
| 60 |
+
non_blocking: if True and this copy is between CPU and GPU, the copy may occur asynchronously
|
| 61 |
+
with respect to the host. For other cases, this argument has no effect.
|
| 62 |
+
d_prepare_batch: callback function to prepare batchdata for D inferer.
|
| 63 |
+
Defaults to return ``GanKeys.REALS`` in batchdata dict. for more details please refer to:
|
| 64 |
+
https://pytorch.org/ignite/generated/ignite.engine.create_supervised_trainer.html.
|
| 65 |
+
g_prepare_batch: callback function to create batch of latent input for G inferer.
|
| 66 |
+
Defaults to return random latents. for more details please refer to:
|
| 67 |
+
https://pytorch.org/ignite/generated/ignite.engine.create_supervised_trainer.html.
|
| 68 |
+
g_update_latents: Calculate G loss with new latent codes. Defaults to ``True``.
|
| 69 |
+
iteration_update: the callable function for every iteration, expect to accept `engine`
|
| 70 |
+
and `engine.state.batch` as inputs, return data will be stored in `engine.state.output`.
|
| 71 |
+
if not provided, use `self._iteration()` instead. for more details please refer to:
|
| 72 |
+
https://pytorch.org/ignite/generated/ignite.engine.engine.Engine.html.
|
| 73 |
+
postprocessing: execute additional transformation for the model output data.
|
| 74 |
+
Typically, several Tensor based transforms composed by `Compose`.
|
| 75 |
+
key_train_metric: compute metric when every iteration completed, and save average value to
|
| 76 |
+
engine.state.metrics when epoch completed. key_train_metric is the main metric to compare and save the
|
| 77 |
+
checkpoint into files.
|
| 78 |
+
additional_metrics: more Ignite metrics that also attach to Ignite Engine.
|
| 79 |
+
metric_cmp_fn: function to compare current key metric with previous best key metric value,
|
| 80 |
+
it must accept 2 args (current_metric, previous_best) and return a bool result: if `True`, will update
|
| 81 |
+
`best_metric` and `best_metric_epoch` with current metric and epoch, default to `greater than`.
|
| 82 |
+
train_handlers: every handler is a set of Ignite Event-Handlers, must have `attach` function, like:
|
| 83 |
+
CheckpointHandler, StatsHandler, etc.
|
| 84 |
+
decollate: whether to decollate the batch-first data to a list of data after model computation,
|
| 85 |
+
recommend `decollate=True` when `postprocessing` uses components from `monai.transforms`.
|
| 86 |
+
default to `True`.
|
| 87 |
+
optim_set_to_none: when calling `optimizer.zero_grad()`, instead of setting to zero, set the grads to None.
|
| 88 |
+
more details: https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html.
|
| 89 |
+
to_kwargs: dict of other args for `prepare_batch` API when converting the input data, except for
|
| 90 |
+
`device`, `non_blocking`.
|
| 91 |
+
amp_kwargs: dict of the args for `torch.cuda.amp.autocast()` API, for more details:
|
| 92 |
+
https://pytorch.org/docs/stable/amp.html#torch.cuda.amp.autocast.
|
| 93 |
+
"""
|
| 94 |
+
|
| 95 |
+
def __init__(
|
| 96 |
+
self,
|
| 97 |
+
device: str | torch.device,
|
| 98 |
+
max_epochs: int,
|
| 99 |
+
train_data_loader: DataLoader,
|
| 100 |
+
g_network: torch.nn.Module,
|
| 101 |
+
g_optimizer: Optimizer,
|
| 102 |
+
g_loss_function: Callable,
|
| 103 |
+
d_network: torch.nn.Module,
|
| 104 |
+
d_optimizer: Optimizer,
|
| 105 |
+
d_loss_function: Callable,
|
| 106 |
+
epoch_length: int | None = None,
|
| 107 |
+
g_inferer: Inferer | None = None,
|
| 108 |
+
d_inferer: Inferer | None = None,
|
| 109 |
+
d_train_steps: int = 1,
|
| 110 |
+
latent_shape: int = 64,
|
| 111 |
+
non_blocking: bool = False,
|
| 112 |
+
d_prepare_batch: Callable = default_prepare_batch,
|
| 113 |
+
g_prepare_batch: Callable = default_prepare_batch,
|
| 114 |
+
g_update_latents: bool = True,
|
| 115 |
+
iteration_update: Callable[[Engine, Any], Any] | None = None,
|
| 116 |
+
postprocessing: Transform | None = None,
|
| 117 |
+
key_train_metric: dict[str, Metric] | None = None,
|
| 118 |
+
additional_metrics: dict[str, Metric] | None = None,
|
| 119 |
+
metric_cmp_fn: Callable = default_metric_cmp_fn,
|
| 120 |
+
train_handlers: Sequence | None = None,
|
| 121 |
+
decollate: bool = True,
|
| 122 |
+
optim_set_to_none: bool = False,
|
| 123 |
+
to_kwargs: dict | None = None,
|
| 124 |
+
amp_kwargs: dict | None = None,
|
| 125 |
+
):
|
| 126 |
+
if not isinstance(train_data_loader, DataLoader):
|
| 127 |
+
raise ValueError("train_data_loader must be PyTorch DataLoader.")
|
| 128 |
+
|
| 129 |
+
# set up Ignite engine and environments
|
| 130 |
+
super().__init__(
|
| 131 |
+
device=device,
|
| 132 |
+
max_epochs=max_epochs,
|
| 133 |
+
data_loader=train_data_loader,
|
| 134 |
+
epoch_length=epoch_length,
|
| 135 |
+
non_blocking=non_blocking,
|
| 136 |
+
prepare_batch=d_prepare_batch,
|
| 137 |
+
iteration_update=iteration_update,
|
| 138 |
+
key_metric=key_train_metric,
|
| 139 |
+
additional_metrics=additional_metrics,
|
| 140 |
+
metric_cmp_fn=metric_cmp_fn,
|
| 141 |
+
handlers=train_handlers,
|
| 142 |
+
postprocessing=postprocessing,
|
| 143 |
+
decollate=decollate,
|
| 144 |
+
to_kwargs=to_kwargs,
|
| 145 |
+
amp_kwargs=amp_kwargs,
|
| 146 |
+
)
|
| 147 |
+
self.g_network = g_network
|
| 148 |
+
self.g_optimizer = g_optimizer
|
| 149 |
+
self.g_loss_function = g_loss_function
|
| 150 |
+
self.g_inferer = SimpleInferer() if g_inferer is None else g_inferer
|
| 151 |
+
self.d_network = d_network
|
| 152 |
+
self.d_optimizer = d_optimizer
|
| 153 |
+
self.d_loss_function = d_loss_function
|
| 154 |
+
self.d_inferer = SimpleInferer() if d_inferer is None else d_inferer
|
| 155 |
+
self.d_train_steps = d_train_steps
|
| 156 |
+
self.latent_shape = latent_shape
|
| 157 |
+
self.g_prepare_batch = g_prepare_batch
|
| 158 |
+
self.g_update_latents = g_update_latents
|
| 159 |
+
self.optim_set_to_none = optim_set_to_none
|
| 160 |
+
|
| 161 |
+
def _iteration(
|
| 162 |
+
self, engine: VaeGanTrainer, batchdata: dict | Sequence
|
| 163 |
+
) -> dict[str, torch.Tensor | int | float | bool]:
|
| 164 |
+
"""
|
| 165 |
+
Callback function for Adversarial Training processing logic of 1 iteration in Ignite Engine.
|
| 166 |
+
Args:
|
| 167 |
+
engine: `VaeGanTrainer` to execute operation for an iteration.
|
| 168 |
+
batchdata: input data for this iteration, usually can be dictionary or tuple of Tensor data.
|
| 169 |
+
Raises:
|
| 170 |
+
ValueError: must provide batch data for current iteration.
|
| 171 |
+
"""
|
| 172 |
+
if batchdata is None:
|
| 173 |
+
raise ValueError("must provide batch data for current iteration.")
|
| 174 |
+
|
| 175 |
+
d_input = engine.prepare_batch(batchdata, engine.state.device, engine.non_blocking, **engine.to_kwargs)[0]
|
| 176 |
+
g_input = d_input
|
| 177 |
+
g_output, z_mu, z_sigma = engine.g_inferer(g_input, engine.g_network)
|
| 178 |
+
|
| 179 |
+
# Train Generator
|
| 180 |
+
engine.g_optimizer.zero_grad(set_to_none=engine.optim_set_to_none)
|
| 181 |
+
g_loss = engine.g_loss_function(g_output, g_input, z_mu, z_sigma)
|
| 182 |
+
g_loss.backward()
|
| 183 |
+
engine.g_optimizer.step()
|
| 184 |
+
|
| 185 |
+
# Train Discriminator
|
| 186 |
+
d_total_loss = torch.zeros(1)
|
| 187 |
+
for _ in range(engine.d_train_steps):
|
| 188 |
+
engine.d_optimizer.zero_grad(set_to_none=engine.optim_set_to_none)
|
| 189 |
+
dloss = engine.d_loss_function(g_output, d_input)
|
| 190 |
+
dloss.backward()
|
| 191 |
+
engine.d_optimizer.step()
|
| 192 |
+
d_total_loss += dloss.item()
|
| 193 |
+
|
| 194 |
+
return {
|
| 195 |
+
GanKeys.REALS: d_input,
|
| 196 |
+
GanKeys.FAKES: g_output,
|
| 197 |
+
GanKeys.LATENTS: g_input,
|
| 198 |
+
GanKeys.GLOSS: g_loss.item(),
|
| 199 |
+
GanKeys.DLOSS: d_total_loss.item(),
|
| 200 |
+
}
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
class LDMTrainer(SupervisedTrainer):
|
| 204 |
+
"""
|
| 205 |
+
Standard supervised training method with image and label, inherits from ``Trainer`` and ``Workflow``.
|
| 206 |
+
Args:
|
| 207 |
+
device: an object representing the device on which to run.
|
| 208 |
+
max_epochs: the total epoch number for trainer to run.
|
| 209 |
+
train_data_loader: Ignite engine use data_loader to run, must be Iterable or torch.DataLoader.
|
| 210 |
+
network: network to train in the trainer, should be regular PyTorch `torch.nn.Module`.
|
| 211 |
+
optimizer: the optimizer associated to the network, should be regular PyTorch optimizer from `torch.optim`
|
| 212 |
+
or its subclass.
|
| 213 |
+
loss_function: the loss function associated to the optimizer, should be regular PyTorch loss,
|
| 214 |
+
which inherit from `torch.nn.modules.loss`.
|
| 215 |
+
epoch_length: number of iterations for one epoch, default to `len(train_data_loader)`.
|
| 216 |
+
non_blocking: if True and this copy is between CPU and GPU, the copy may occur asynchronously
|
| 217 |
+
with respect to the host. For other cases, this argument has no effect.
|
| 218 |
+
prepare_batch: function to parse expected data (usually `image`, `label` and other network args)
|
| 219 |
+
from `engine.state.batch` for every iteration, for more details please refer to:
|
| 220 |
+
https://pytorch.org/ignite/generated/ignite.engine.create_supervised_trainer.html.
|
| 221 |
+
iteration_update: the callable function for every iteration, expect to accept `engine`
|
| 222 |
+
and `engine.state.batch` as inputs, return data will be stored in `engine.state.output`.
|
| 223 |
+
if not provided, use `self._iteration()` instead. for more details please refer to:
|
| 224 |
+
https://pytorch.org/ignite/generated/ignite.engine.engine.Engine.html.
|
| 225 |
+
inferer: inference method that execute model forward on input data, like: SlidingWindow, etc.
|
| 226 |
+
postprocessing: execute additional transformation for the model output data.
|
| 227 |
+
Typically, several Tensor based transforms composed by `Compose`.
|
| 228 |
+
key_train_metric: compute metric when every iteration completed, and save average value to
|
| 229 |
+
engine.state.metrics when epoch completed. key_train_metric is the main metric to compare and save the
|
| 230 |
+
checkpoint into files.
|
| 231 |
+
additional_metrics: more Ignite metrics that also attach to Ignite Engine.
|
| 232 |
+
metric_cmp_fn: function to compare current key metric with previous best key metric value,
|
| 233 |
+
it must accept 2 args (current_metric, previous_best) and return a bool result: if `True`, will update
|
| 234 |
+
`best_metric` and `best_metric_epoch` with current metric and epoch, default to `greater than`.
|
| 235 |
+
train_handlers: every handler is a set of Ignite Event-Handlers, must have `attach` function, like:
|
| 236 |
+
CheckpointHandler, StatsHandler, etc.
|
| 237 |
+
amp: whether to enable auto-mixed-precision training, default is False.
|
| 238 |
+
event_names: additional custom ignite events that will register to the engine.
|
| 239 |
+
new events can be a list of str or `ignite.engine.events.EventEnum`.
|
| 240 |
+
event_to_attr: a dictionary to map an event to a state attribute, then add to `engine.state`.
|
| 241 |
+
for more details, check: https://pytorch.org/ignite/generated/ignite.engine.engine.Engine.html
|
| 242 |
+
#ignite.engine.engine.Engine.register_events.
|
| 243 |
+
decollate: whether to decollate the batch-first data to a list of data after model computation,
|
| 244 |
+
recommend `decollate=True` when `postprocessing` uses components from `monai.transforms`.
|
| 245 |
+
default to `True`.
|
| 246 |
+
optim_set_to_none: when calling `optimizer.zero_grad()`, instead of setting to zero, set the grads to None.
|
| 247 |
+
more details: https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html.
|
| 248 |
+
to_kwargs: dict of other args for `prepare_batch` API when converting the input data, except for
|
| 249 |
+
`device`, `non_blocking`.
|
| 250 |
+
amp_kwargs: dict of the args for `torch.cuda.amp.autocast()` API, for more details:
|
| 251 |
+
https://pytorch.org/docs/stable/amp.html#torch.cuda.amp.autocast.
|
| 252 |
+
"""
|
| 253 |
+
|
| 254 |
+
def __init__(
|
| 255 |
+
self,
|
| 256 |
+
device: str | torch.device,
|
| 257 |
+
max_epochs: int,
|
| 258 |
+
train_data_loader: Iterable | DataLoader,
|
| 259 |
+
network: torch.nn.Module,
|
| 260 |
+
autoencoder_model: torch.nn.Module,
|
| 261 |
+
optimizer: Optimizer,
|
| 262 |
+
loss_function: Callable,
|
| 263 |
+
latent_shape: Sequence,
|
| 264 |
+
inferer: Inferer,
|
| 265 |
+
epoch_length: int | None = None,
|
| 266 |
+
non_blocking: bool = False,
|
| 267 |
+
prepare_batch: Callable = default_prepare_batch,
|
| 268 |
+
iteration_update: Callable[[Engine, Any], Any] | None = None,
|
| 269 |
+
postprocessing: Transform | None = None,
|
| 270 |
+
key_train_metric: dict[str, Metric] | None = None,
|
| 271 |
+
additional_metrics: dict[str, Metric] | None = None,
|
| 272 |
+
metric_cmp_fn: Callable = default_metric_cmp_fn,
|
| 273 |
+
train_handlers: Sequence | None = None,
|
| 274 |
+
amp: bool = False,
|
| 275 |
+
event_names: list[str | EventEnum | type[EventEnum]] | None = None,
|
| 276 |
+
event_to_attr: dict | None = None,
|
| 277 |
+
decollate: bool = True,
|
| 278 |
+
optim_set_to_none: bool = False,
|
| 279 |
+
to_kwargs: dict | None = None,
|
| 280 |
+
amp_kwargs: dict | None = None,
|
| 281 |
+
) -> None:
|
| 282 |
+
super().__init__(
|
| 283 |
+
device=device,
|
| 284 |
+
max_epochs=max_epochs,
|
| 285 |
+
train_data_loader=train_data_loader,
|
| 286 |
+
network=network,
|
| 287 |
+
optimizer=optimizer,
|
| 288 |
+
loss_function=loss_function,
|
| 289 |
+
inferer=inferer,
|
| 290 |
+
optim_set_to_none=optim_set_to_none,
|
| 291 |
+
epoch_length=epoch_length,
|
| 292 |
+
non_blocking=non_blocking,
|
| 293 |
+
prepare_batch=prepare_batch,
|
| 294 |
+
iteration_update=iteration_update,
|
| 295 |
+
postprocessing=postprocessing,
|
| 296 |
+
key_train_metric=key_train_metric,
|
| 297 |
+
additional_metrics=additional_metrics,
|
| 298 |
+
metric_cmp_fn=metric_cmp_fn,
|
| 299 |
+
train_handlers=train_handlers,
|
| 300 |
+
amp=amp,
|
| 301 |
+
event_names=event_names,
|
| 302 |
+
event_to_attr=event_to_attr,
|
| 303 |
+
decollate=decollate,
|
| 304 |
+
to_kwargs=to_kwargs,
|
| 305 |
+
amp_kwargs=amp_kwargs,
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
self.latent_shape = latent_shape
|
| 309 |
+
self.autoencoder_model = autoencoder_model
|
| 310 |
+
|
| 311 |
+
def _iteration(self, engine: LDMTrainer, batchdata: dict[str, torch.Tensor]) -> dict:
|
| 312 |
+
"""
|
| 313 |
+
Callback function for the Supervised Training processing logic of 1 iteration in Ignite Engine.
|
| 314 |
+
Return below items in a dictionary:
|
| 315 |
+
- IMAGE: image Tensor data for model input, already moved to device.
|
| 316 |
+
- LABEL: label Tensor data corresponding to the image, already moved to device.
|
| 317 |
+
- PRED: prediction result of model.
|
| 318 |
+
- LOSS: loss value computed by loss function.
|
| 319 |
+
Args:
|
| 320 |
+
engine: `SupervisedTrainer` to execute operation for an iteration.
|
| 321 |
+
batchdata: input data for this iteration, usually can be dictionary or tuple of Tensor data.
|
| 322 |
+
Raises:
|
| 323 |
+
ValueError: When ``batchdata`` is None.
|
| 324 |
+
"""
|
| 325 |
+
if batchdata is None:
|
| 326 |
+
raise ValueError("Must provide batch data for current iteration.")
|
| 327 |
+
batch = engine.prepare_batch(batchdata, engine.state.device, engine.non_blocking, **engine.to_kwargs)
|
| 328 |
+
if len(batch) == 2:
|
| 329 |
+
images, labels = batch
|
| 330 |
+
args: tuple = ()
|
| 331 |
+
kwargs: dict = {}
|
| 332 |
+
else:
|
| 333 |
+
images, labels, args, kwargs = batch
|
| 334 |
+
# put iteration outputs into engine.state
|
| 335 |
+
engine.state.output = {CommonKeys.IMAGE: images}
|
| 336 |
+
|
| 337 |
+
# generate noise
|
| 338 |
+
noise_shape = [images.shape[0]] + list(self.latent_shape)
|
| 339 |
+
noise = torch.randn(noise_shape, dtype=images.dtype).to(images.device)
|
| 340 |
+
engine.state.output = {"noise": noise}
|
| 341 |
+
|
| 342 |
+
# Create timesteps
|
| 343 |
+
timesteps = torch.randint(
|
| 344 |
+
0, engine.inferer.scheduler.num_train_timesteps, (images.shape[0],), device=images.device
|
| 345 |
+
).long()
|
| 346 |
+
|
| 347 |
+
def _compute_pred_loss():
|
| 348 |
+
# predicted noise
|
| 349 |
+
engine.state.output[CommonKeys.PRED] = engine.inferer(
|
| 350 |
+
inputs=images,
|
| 351 |
+
autoencoder_model=self.autoencoder_model,
|
| 352 |
+
diffusion_model=engine.network,
|
| 353 |
+
noise=noise,
|
| 354 |
+
timesteps=timesteps,
|
| 355 |
+
)
|
| 356 |
+
engine.fire_event(IterationEvents.FORWARD_COMPLETED)
|
| 357 |
+
# compute loss
|
| 358 |
+
engine.state.output[CommonKeys.LOSS] = engine.loss_function(
|
| 359 |
+
engine.state.output[CommonKeys.PRED], noise
|
| 360 |
+
).mean()
|
| 361 |
+
engine.fire_event(IterationEvents.LOSS_COMPLETED)
|
| 362 |
+
|
| 363 |
+
engine.network.train()
|
| 364 |
+
engine.optimizer.zero_grad(set_to_none=engine.optim_set_to_none)
|
| 365 |
+
|
| 366 |
+
if engine.amp and engine.scaler is not None:
|
| 367 |
+
with torch.cuda.amp.autocast(**engine.amp_kwargs):
|
| 368 |
+
_compute_pred_loss()
|
| 369 |
+
engine.scaler.scale(engine.state.output[CommonKeys.LOSS]).backward()
|
| 370 |
+
engine.fire_event(IterationEvents.BACKWARD_COMPLETED)
|
| 371 |
+
engine.scaler.step(engine.optimizer)
|
| 372 |
+
engine.scaler.update()
|
| 373 |
+
else:
|
| 374 |
+
_compute_pred_loss()
|
| 375 |
+
engine.state.output[CommonKeys.LOSS].backward()
|
| 376 |
+
engine.fire_event(IterationEvents.BACKWARD_COMPLETED)
|
| 377 |
+
engine.optimizer.step()
|
| 378 |
+
engine.fire_event(IterationEvents.MODEL_COMPLETED)
|
| 379 |
+
|
| 380 |
+
return engine.state.output
|
scripts/losses.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
from generative.losses import PatchAdversarialLoss
|
| 13 |
+
|
| 14 |
+
intensity_loss = torch.nn.L1Loss()
|
| 15 |
+
adv_loss = PatchAdversarialLoss(criterion="least_squares")
|
| 16 |
+
|
| 17 |
+
adv_weight = 0.5
|
| 18 |
+
perceptual_weight = 1.0
|
| 19 |
+
# kl_weight: important hyper-parameter.
|
| 20 |
+
# If too large, decoder cannot recon good results from latent space.
|
| 21 |
+
# If too small, latent space will not be regularized enough for the diffusion model
|
| 22 |
+
kl_weight = 1e-6
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def compute_kl_loss(z_mu, z_sigma):
|
| 26 |
+
kl_loss = 0.5 * torch.sum(
|
| 27 |
+
z_mu.pow(2) + z_sigma.pow(2) - torch.log(z_sigma.pow(2)) - 1, dim=list(range(1, len(z_sigma.shape)))
|
| 28 |
+
)
|
| 29 |
+
return torch.sum(kl_loss) / kl_loss.shape[0]
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def generator_loss(gen_images, real_images, z_mu, z_sigma, disc_net, loss_perceptual):
|
| 33 |
+
recons_loss = intensity_loss(gen_images, real_images)
|
| 34 |
+
kl_loss = compute_kl_loss(z_mu, z_sigma)
|
| 35 |
+
p_loss = loss_perceptual(gen_images.float(), real_images.float())
|
| 36 |
+
loss_g = recons_loss + kl_weight * kl_loss + perceptual_weight * p_loss
|
| 37 |
+
|
| 38 |
+
logits_fake = disc_net(gen_images)[-1]
|
| 39 |
+
generator_loss = adv_loss(logits_fake, target_is_real=True, for_discriminator=False)
|
| 40 |
+
loss_g = loss_g + adv_weight * generator_loss
|
| 41 |
+
|
| 42 |
+
return loss_g
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def discriminator_loss(gen_images, real_images, disc_net):
|
| 46 |
+
logits_fake = disc_net(gen_images.contiguous().detach())[-1]
|
| 47 |
+
loss_d_fake = adv_loss(logits_fake, target_is_real=False, for_discriminator=True)
|
| 48 |
+
logits_real = disc_net(real_images.contiguous().detach())[-1]
|
| 49 |
+
loss_d_real = adv_loss(logits_real, target_is_real=True, for_discriminator=True)
|
| 50 |
+
discriminator_loss = (loss_d_fake + loss_d_real) * 0.5
|
| 51 |
+
loss_d = adv_weight * discriminator_loss
|
| 52 |
+
return loss_d
|
scripts/utils.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
from monai.utils import first
|
| 14 |
+
from monai.utils.type_conversion import convert_to_numpy
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def compute_scale_factor(autoencoder, train_loader, device):
|
| 18 |
+
with torch.no_grad():
|
| 19 |
+
check_data = first(train_loader)
|
| 20 |
+
z = autoencoder.encode_stage_2_inputs(check_data["image"].to(device))
|
| 21 |
+
scale_factor = 1 / torch.std(z)
|
| 22 |
+
return scale_factor.item()
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def normalize_image_to_uint8(image):
|
| 26 |
+
"""
|
| 27 |
+
Normalize image to uint8
|
| 28 |
+
Args:
|
| 29 |
+
image: numpy array
|
| 30 |
+
"""
|
| 31 |
+
draw_img = image
|
| 32 |
+
if np.amin(draw_img) < 0:
|
| 33 |
+
draw_img[draw_img < 0] = 0
|
| 34 |
+
if np.amax(draw_img) > 0.1:
|
| 35 |
+
draw_img /= np.amax(draw_img)
|
| 36 |
+
draw_img = (255 * draw_img).astype(np.uint8)
|
| 37 |
+
return draw_img
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def visualize_2d_image(image):
|
| 41 |
+
"""
|
| 42 |
+
Prepare a 2D image for visualization.
|
| 43 |
+
Args:
|
| 44 |
+
image: image numpy array, sized (H, W)
|
| 45 |
+
"""
|
| 46 |
+
image = convert_to_numpy(image)
|
| 47 |
+
# draw image
|
| 48 |
+
draw_img = normalize_image_to_uint8(image)
|
| 49 |
+
draw_img = np.stack([draw_img, draw_img, draw_img], axis=-1)
|
| 50 |
+
return draw_img
|