
Commit
•
7194c24
1
Parent(s):
334a67e
Upload 4 files
Browse files- README.md +33 -9
- config.json +4 -4
- sentiment_index_and_economy.png +0 -0
- sentiment_inflation.png +0 -0
README.md
CHANGED
|
@@ -13,20 +13,44 @@ widget:
|
|
| 13 |
|
| 14 |
# FinBertPTBR : Financial Bert PT BR
|
| 15 |
|
| 16 |
-
FinBertPTBR is a pre-trained NLP model to analyze sentiment of Brazilian Portuguese financial texts.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
## Usage
|
| 19 |
```python
|
| 20 |
-
from transformers import AutoTokenizer,
|
|
|
|
| 21 |
|
| 22 |
-
|
| 23 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
```
|
| 25 |
|
| 26 |
-
##
|
| 27 |
|
| 28 |
-
- [Vinicius Carmo](https://www.linkedin.com/in/vinicius-cleves/)
|
| 29 |
-
- [Julia Pocciotti](https://www.linkedin.com/in/juliapocciotti/)
|
| 30 |
-
- [Luísa Heise](https://www.linkedin.com/in/lu%C3%ADsa-mendes-heise/)
|
| 31 |
- [Lucas Leme](https://www.linkedin.com/in/lucas-leme-santos/)
|
| 32 |
-
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
# FinBertPTBR : Financial Bert PT BR
|
| 15 |
|
| 16 |
+
FinBertPTBR is a pre-trained NLP model to analyze sentiment of Brazilian Portuguese financial texts.
|
| 17 |
+
|
| 18 |
+
The model was trained in two main stages: language modeling and sentiment modeling. In the first stage, a language model was trained with more than 1.4 million texts of financial news in Portuguese.
|
| 19 |
+
From this first training, it was possible to build a sentiment classifier with few labeled texts (500) that presented a satisfactory convergence.
|
| 20 |
+
|
| 21 |
+
At the end of the work, a comparative analysis with other models and the possible applications of the developed model are presented.
|
| 22 |
+
In the comparative analysis, it was possible to observe that the developed model presented better results than the current models in the state of the art.
|
| 23 |
+
Among the applications, it was demonstrated that the model can be used to build sentiment indices, investment strategies and macroeconomic data analysis, such as inflation.
|
| 24 |
+
|
| 25 |
+
## Applications
|
| 26 |
+
|
| 27 |
+
### Sentiment Index
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+
|
| 31 |
+
### Inflation Analysis
|
| 32 |
+
|
| 33 |
+

|
| 34 |
|
| 35 |
## Usage
|
| 36 |
```python
|
| 37 |
+
from transformers import AutoTokenizer, BertForSequenceClassification
|
| 38 |
+
import numpy as np
|
| 39 |
|
| 40 |
+
pred_mapper = {0: 'negative', 1: 'positive', 2: 'neutral'}
|
| 41 |
+
|
| 42 |
+
tokenizer = AutoTokenizer.from_pretrained("lucas-leme/FinBERT-PT-BR")
|
| 43 |
+
finbertptbr = BertForSequenceClassification.from_pretrained("lucas-leme/FinBERT-PT-BR")
|
| 44 |
+
|
| 45 |
+
tokens = tokenizer(["Hoje a bolsa caiu", "Hoje a bolsa subiu"], return_tensors="pt",
|
| 46 |
+
padding=True, truncation=True, max_length=512)
|
| 47 |
+
finbertptbr_outputs = finbertptbr(**tokens)
|
| 48 |
+
preds = [pred_mapper[np.argmax(pred)] for pred in finbertptbr_outputs.logits.cpu().detach().numpy()]
|
| 49 |
```
|
| 50 |
|
| 51 |
+
## Author
|
| 52 |
|
|
|
|
|
|
|
|
|
|
| 53 |
- [Lucas Leme](https://www.linkedin.com/in/lucas-leme-santos/)
|
| 54 |
+
|
| 55 |
+
## Paper - Stay tuned!
|
| 56 |
+
|
config.json
CHANGED
|
@@ -10,9 +10,9 @@
|
|
| 10 |
"hidden_dropout_prob": 0.1,
|
| 11 |
"hidden_size": 768,
|
| 12 |
"id2label": {
|
| 13 |
-
"0": "
|
| 14 |
-
"1": "
|
| 15 |
-
"2": "
|
| 16 |
},
|
| 17 |
"initializer_range": 0.02,
|
| 18 |
"intermediate_size": 3072,
|
|
@@ -40,4 +40,4 @@
|
|
| 40 |
"type_vocab_size": 2,
|
| 41 |
"use_cache": true,
|
| 42 |
"vocab_size": 29794
|
| 43 |
-
}
|
|
|
|
| 10 |
"hidden_dropout_prob": 0.1,
|
| 11 |
"hidden_size": 768,
|
| 12 |
"id2label": {
|
| 13 |
+
"0": "POSITIVE",
|
| 14 |
+
"1": "NEGATIVE",
|
| 15 |
+
"2": "NEUTRAL"
|
| 16 |
},
|
| 17 |
"initializer_range": 0.02,
|
| 18 |
"intermediate_size": 3072,
|
|
|
|
| 40 |
"type_vocab_size": 2,
|
| 41 |
"use_cache": true,
|
| 42 |
"vocab_size": 29794
|
| 43 |
+
}
|
sentiment_index_and_economy.png
ADDED
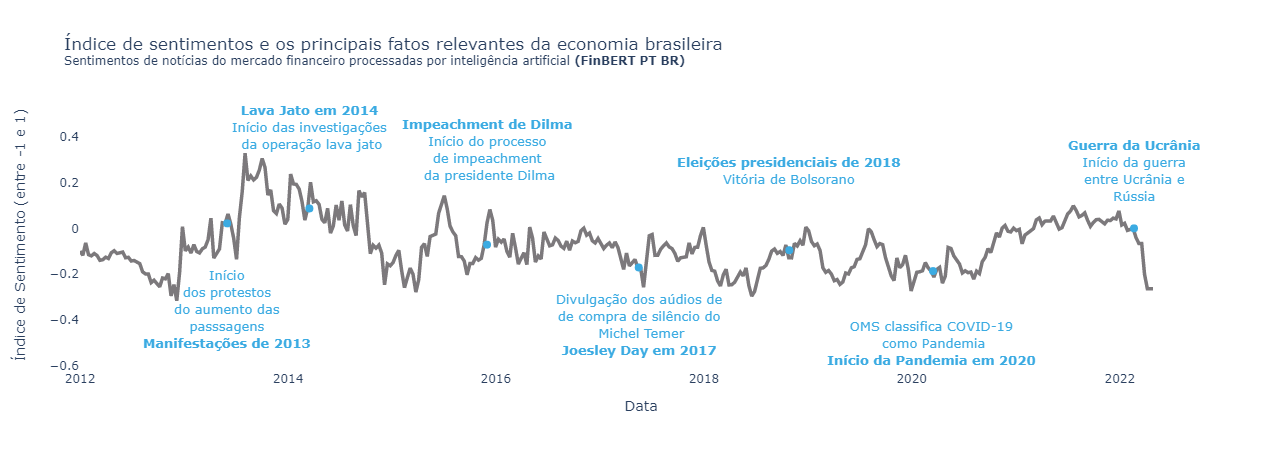
|
sentiment_inflation.png
ADDED
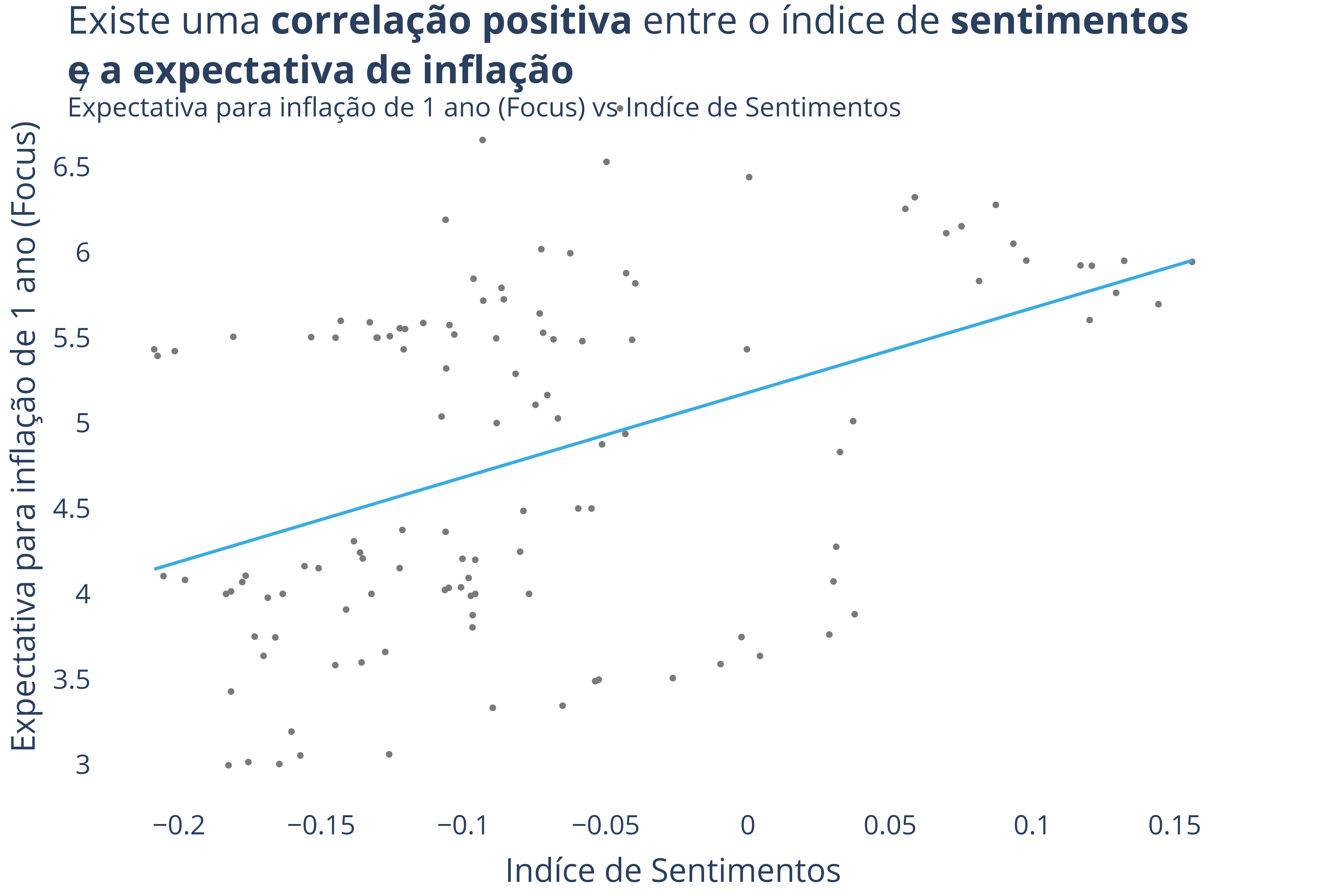
|