
Francois Vieille
commited on
Commit
•
2192266
1
Parent(s):
d1bd60e
init
Browse files- .gitignore +1 -0
- README.md +156 -0
- assets/loss_m_sl_sota_2.PNG +0 -0
- assets/perfs_m_sl_sota_2.PNG +0 -0
- config.json +37 -0
- pytorch_model.bin +3 -0
- sentencepiece.bpe.model +3 -0
- special_tokens_map.json +1 -0
- tokenizer.json +0 -0
- tokenizer_config.json +1 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
test.py
|
README.md
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- fr
|
| 4 |
+
|
| 5 |
+
license: mit
|
| 6 |
+
|
| 7 |
+
pipeline_tag: "token-classification"
|
| 8 |
+
|
| 9 |
+
datasets:
|
| 10 |
+
- squadFR
|
| 11 |
+
- fquad
|
| 12 |
+
- piaf
|
| 13 |
+
|
| 14 |
+
tags:
|
| 15 |
+
- camembert
|
| 16 |
+
- answer extraction
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# Extraction de réponse
|
| 20 |
+
|
| 21 |
+
Ce modèle est _fine tuné_ à partir du modèle [camembert-base](https://huggingface.co/camembert-base) pour la tâche de classification de tokens.
|
| 22 |
+
L'objectif est d'identifier les suites de tokens probables qui pourrait être l'objet d'une question.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Données d'apprentissage
|
| 26 |
+
|
| 27 |
+
La base d'entrainement est la concatenation des bases SquadFR, [fquad](https://huggingface.co/datasets/fquad), [piaf](https://huggingface.co/datasets/piaf).
|
| 28 |
+
Les réponses de chaque contexte ont été labelisées avec le label "ANS".
|
| 29 |
+
|
| 30 |
+
Volumétrie (nombre de contexte):
|
| 31 |
+
* train: 24 652
|
| 32 |
+
* test: 1 370
|
| 33 |
+
* valid: 1 370
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
## Entrainement
|
| 37 |
+
|
| 38 |
+
L'apprentissage s'est effectué sur une carte Tesla V100.
|
| 39 |
+
|
| 40 |
+
* Batch size: 16
|
| 41 |
+
* Weight decay: 0.01
|
| 42 |
+
* Learning rate: 2x10-5 (décroit linéairement)
|
| 43 |
+
* Paramètres par défaut de la classe [TrainingArguments](https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments)
|
| 44 |
+
* Total steps: 1 000
|
| 45 |
+
|
| 46 |
+
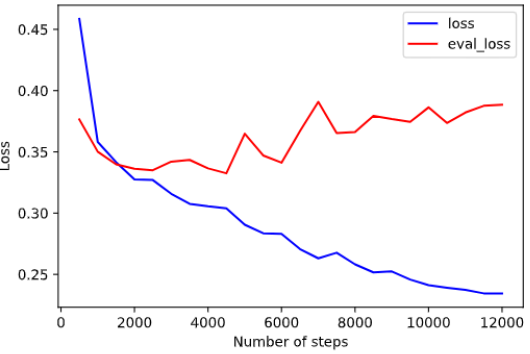
Le modèle semble sur apprendre au delà :
|
| 47 |
+
|
| 48 |
+

|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
## Critiques
|
| 52 |
+
|
| 53 |
+
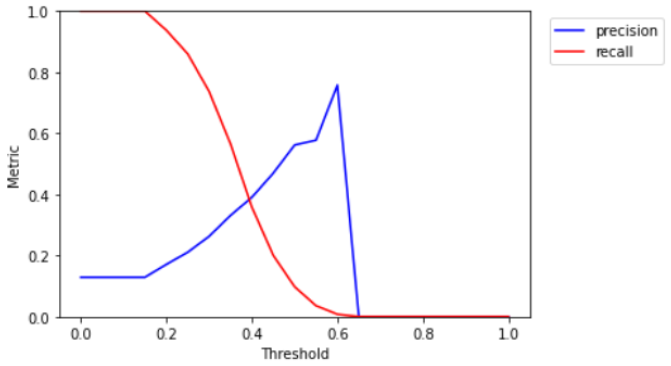
Le modèle n'a pas de bonnes performances et doit être corrigé après prédiction pour être cohérent. La tâche de classification n'est pas évidente car le modèle doit identifier des groupes de token _sachant_ qu'une question peut être posée.
|
| 54 |
+
|
| 55 |
+

|
| 56 |
+
|
| 57 |
+
## Utilisation
|
| 58 |
+
|
| 59 |
+
_Le modèle est un POC, nous garantissons pas ses performances_
|
| 60 |
+
|
| 61 |
+
```python
|
| 62 |
+
from transformers import AutoTokenizer, AutoModelForTokenClassification
|
| 63 |
+
import numpy as np
|
| 64 |
+
|
| 65 |
+
model_name = "lincoln/camembert-squadFR-fquad-piaf-answer-extraction"
|
| 66 |
+
|
| 67 |
+
loaded_tokenizer = AutoTokenizer.from_pretrained(model_path)
|
| 68 |
+
loaded_model = AutoModelForTokenClassification.from_pretrained(model_path)
|
| 69 |
+
text = "La science des données est un domaine interdisciplinaire qui utilise des méthodes, des processus,\
|
| 70 |
+
des algorithmes et des systèmes scientifiques pour extraire des connaissances et des idées de nombreuses données structurelles et non structurées.\
|
| 71 |
+
Elle est souvent associée aux données massives et à l'analyse des données."
|
| 72 |
+
|
| 73 |
+
inputs = loaded_tokenizer(text, return_tensors="pt", return_offsets_mapping=True)
|
| 74 |
+
outputs = loaded_model(inputs.input_ids).logits
|
| 75 |
+
probs = 1 / (1 + np.exp(-outputs.detach().numpy()))
|
| 76 |
+
probs[:, :, 1][0] = np.convolve(probs[:, :, 1][0], np.ones(2), 'same') / 2
|
| 77 |
+
|
| 78 |
+
sentences = loaded_tokenizer.tokenize(text, add_special_tokens=False)
|
| 79 |
+
prob_answer_tokens = probs[:, 1:-1, 1].flatten().tolist()
|
| 80 |
+
offset_start_mapping = inputs.offset_mapping[:, 1:-1, 0].flatten().tolist()
|
| 81 |
+
offset_end_mapping = inputs.offset_mapping[:, 1:-1, 1].flatten().tolist()
|
| 82 |
+
threshold = 0.4
|
| 83 |
+
|
| 84 |
+
entities = []
|
| 85 |
+
for ix, (token, prob_ans, offset_start, offset_end) in enumerate(zip(sentences, prob_answer_tokens, offset_start_mapping, offset_end_mapping)):
|
| 86 |
+
entities.append({
|
| 87 |
+
'entity': 'ANS' if prob_ans > threshold else 'O',
|
| 88 |
+
'score': prob_ans,
|
| 89 |
+
'index': ix,
|
| 90 |
+
'word': token,
|
| 91 |
+
'start': offset_start,
|
| 92 |
+
'end': offset_end
|
| 93 |
+
})
|
| 94 |
+
|
| 95 |
+
for p in entities:
|
| 96 |
+
print(p)
|
| 97 |
+
|
| 98 |
+
# {'entity': 'O', 'score': 0.3118681311607361, 'index': 0, 'word': '▁La', 'start': 0, 'end': 2}
|
| 99 |
+
# {'entity': 'O', 'score': 0.37866950035095215, 'index': 1, 'word': '▁science', 'start': 3, 'end': 10}
|
| 100 |
+
# {'entity': 'ANS', 'score': 0.45018652081489563, 'index': 2, 'word': '▁des', 'start': 11, 'end': 14}
|
| 101 |
+
# {'entity': 'ANS', 'score': 0.4615934491157532, 'index': 3, 'word': '▁données', 'start': 15, 'end': 22}
|
| 102 |
+
# {'entity': 'O', 'score': 0.35033443570137024, 'index': 4, 'word': '▁est', 'start': 23, 'end': 26}
|
| 103 |
+
# {'entity': 'O', 'score': 0.24779987335205078, 'index': 5, 'word': '▁un', 'start': 27, 'end': 29}
|
| 104 |
+
# {'entity': 'O', 'score': 0.27084410190582275, 'index': 6, 'word': '▁domaine', 'start': 30, 'end': 37}
|
| 105 |
+
# {'entity': 'O', 'score': 0.3259460926055908, 'index': 7, 'word': '▁in', 'start': 38, 'end': 40}
|
| 106 |
+
# {'entity': 'O', 'score': 0.371802419424057, 'index': 8, 'word': 'terdisciplinaire', 'start': 40, 'end': 56}
|
| 107 |
+
# {'entity': 'O', 'score': 0.3140853941440582, 'index': 9, 'word': '▁qui', 'start': 57, 'end': 60}
|
| 108 |
+
# {'entity': 'O', 'score': 0.2629334330558777, 'index': 10, 'word': '▁utilise', 'start': 61, 'end': 68}
|
| 109 |
+
# {'entity': 'O', 'score': 0.2968383729457855, 'index': 11, 'word': '▁des', 'start': 69, 'end': 72}
|
| 110 |
+
# {'entity': 'O', 'score': 0.33898216485977173, 'index': 12, 'word': '▁méthodes', 'start': 73, 'end': 81}
|
| 111 |
+
# {'entity': 'O', 'score': 0.3776060938835144, 'index': 13, 'word': ',', 'start': 81, 'end': 82}
|
| 112 |
+
# {'entity': 'O', 'score': 0.3710060119628906, 'index': 14, 'word': '▁des', 'start': 83, 'end': 86}
|
| 113 |
+
# {'entity': 'O', 'score': 0.35908180475234985, 'index': 15, 'word': '▁processus', 'start': 87, 'end': 96}
|
| 114 |
+
# {'entity': 'O', 'score': 0.3890596628189087, 'index': 16, 'word': ',', 'start': 96, 'end': 97}
|
| 115 |
+
# {'entity': 'O', 'score': 0.38341325521469116, 'index': 17, 'word': '▁des', 'start': 101, 'end': 104}
|
| 116 |
+
# {'entity': 'O', 'score': 0.3743852376937866, 'index': 18, 'word': '▁', 'start': 105, 'end': 106}
|
| 117 |
+
# {'entity': 'O', 'score': 0.3943936228752136, 'index': 19, 'word': 'algorithme', 'start': 105, 'end': 115}
|
| 118 |
+
# {'entity': 'O', 'score': 0.39456743001937866, 'index': 20, 'word': 's', 'start': 115, 'end': 116}
|
| 119 |
+
# {'entity': 'O', 'score': 0.3846966624259949, 'index': 21, 'word': '▁et', 'start': 117, 'end': 119}
|
| 120 |
+
# {'entity': 'O', 'score': 0.367380827665329, 'index': 22, 'word': '▁des', 'start': 120, 'end': 123}
|
| 121 |
+
# {'entity': 'O', 'score': 0.3652925491333008, 'index': 23, 'word': '▁systèmes', 'start': 124, 'end': 132}
|
| 122 |
+
# {'entity': 'O', 'score': 0.3975735306739807, 'index': 24, 'word': '▁scientifiques', 'start': 133, 'end': 146}
|
| 123 |
+
# {'entity': 'O', 'score': 0.36417365074157715, 'index': 25, 'word': '▁pour', 'start': 147, 'end': 151}
|
| 124 |
+
# {'entity': 'O', 'score': 0.32438698410987854, 'index': 26, 'word': '▁extraire', 'start': 152, 'end': 160}
|
| 125 |
+
# {'entity': 'O', 'score': 0.3416857123374939, 'index': 27, 'word': '▁des', 'start': 161, 'end': 164}
|
| 126 |
+
# {'entity': 'O', 'score': 0.3674810230731964, 'index': 28, 'word': '▁connaissances', 'start': 165, 'end': 178}
|
| 127 |
+
# {'entity': 'O', 'score': 0.38362061977386475, 'index': 29, 'word': '▁et', 'start': 179, 'end': 181}
|
| 128 |
+
# {'entity': 'O', 'score': 0.364640474319458, 'index': 30, 'word': '▁des', 'start': 182, 'end': 185}
|
| 129 |
+
# {'entity': 'O', 'score': 0.36050117015838623, 'index': 31, 'word': '▁idées', 'start': 186, 'end': 191}
|
| 130 |
+
# {'entity': 'O', 'score': 0.3768993020057678, 'index': 32, 'word': '▁de', 'start': 192, 'end': 194}
|
| 131 |
+
# {'entity': 'O', 'score': 0.39184248447418213, 'index': 33, 'word': '▁nombreuses', 'start': 195, 'end': 205}
|
| 132 |
+
# {'entity': 'ANS', 'score': 0.4091200828552246, 'index': 34, 'word': '▁données', 'start': 206, 'end': 213}
|
| 133 |
+
# {'entity': 'ANS', 'score': 0.41234123706817627, 'index': 35, 'word': '▁structurelle', 'start': 214, 'end': 226}
|
| 134 |
+
# {'entity': 'ANS', 'score': 0.40243157744407654, 'index': 36, 'word': 's', 'start': 226, 'end': 227}
|
| 135 |
+
# {'entity': 'ANS', 'score': 0.4007353186607361, 'index': 37, 'word': '▁et', 'start': 228, 'end': 230}
|
| 136 |
+
# {'entity': 'ANS', 'score': 0.40597623586654663, 'index': 38, 'word': '▁non', 'start': 231, 'end': 234}
|
| 137 |
+
# {'entity': 'ANS', 'score': 0.40272021293640137, 'index': 39, 'word': '▁structurée', 'start': 235, 'end': 245}
|
| 138 |
+
# {'entity': 'O', 'score': 0.392631471157074, 'index': 40, 'word': 's', 'start': 245, 'end': 246}
|
| 139 |
+
# {'entity': 'O', 'score': 0.34266412258148193, 'index': 41, 'word': '.', 'start': 246, 'end': 247}
|
| 140 |
+
# {'entity': 'O', 'score': 0.26178646087646484, 'index': 42, 'word': '▁Elle', 'start': 255, 'end': 259}
|
| 141 |
+
# {'entity': 'O', 'score': 0.2265639454126358, 'index': 43, 'word': '▁est', 'start': 260, 'end': 263}
|
| 142 |
+
# {'entity': 'O', 'score': 0.22844195365905762, 'index': 44, 'word': '▁souvent', 'start': 264, 'end': 271}
|
| 143 |
+
# {'entity': 'O', 'score': 0.2475772500038147, 'index': 45, 'word': '▁associée', 'start': 272, 'end': 280}
|
| 144 |
+
# {'entity': 'O', 'score': 0.3002186715602875, 'index': 46, 'word': '▁aux', 'start': 281, 'end': 284}
|
| 145 |
+
# {'entity': 'O', 'score': 0.3875720798969269, 'index': 47, 'word': '▁données', 'start': 285, 'end': 292}
|
| 146 |
+
# {'entity': 'ANS', 'score': 0.445063054561615, 'index': 48, 'word': '▁massive', 'start': 293, 'end': 300}
|
| 147 |
+
# {'entity': 'ANS', 'score': 0.4419114589691162, 'index': 49, 'word': 's', 'start': 300, 'end': 301}
|
| 148 |
+
# {'entity': 'ANS', 'score': 0.4240635633468628, 'index': 50, 'word': '▁et', 'start': 302, 'end': 304}
|
| 149 |
+
# {'entity': 'O', 'score': 0.3900952935218811, 'index': 51, 'word': '▁à', 'start': 305, 'end': 306}
|
| 150 |
+
# {'entity': 'O', 'score': 0.3784807324409485, 'index': 52, 'word': '▁l', 'start': 307, 'end': 308}
|
| 151 |
+
# {'entity': 'O', 'score': 0.3459452986717224, 'index': 53, 'word': "'", 'start': 308, 'end': 309}
|
| 152 |
+
# {'entity': 'O', 'score': 0.37636008858680725, 'index': 54, 'word': 'analyse', 'start': 309, 'end': 316}
|
| 153 |
+
# {'entity': 'ANS', 'score': 0.4475618302822113, 'index': 55, 'word': '▁des', 'start': 317, 'end': 320}
|
| 154 |
+
# {'entity': 'ANS', 'score': 0.43845775723457336, 'index': 56, 'word': '▁données', 'start': 321, 'end': 328}
|
| 155 |
+
# {'entity': 'O', 'score': 0.3761221170425415, 'index': 57, 'word': '.', 'start': 328, 'end': 329}
|
| 156 |
+
```
|
assets/loss_m_sl_sota_2.PNG
ADDED
|
assets/perfs_m_sl_sota_2.PNG
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/mnt/qaqg_playground/Users/colin.davidson/qa-qg-playground/data/huggingface/args/sl/m-sl-sota-2-test/checkpoint-1000",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CamembertForTokenClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"bos_token_id": 5,
|
| 8 |
+
"classifier_dropout": null,
|
| 9 |
+
"eos_token_id": 6,
|
| 10 |
+
"gradient_checkpointing": false,
|
| 11 |
+
"hidden_act": "gelu",
|
| 12 |
+
"hidden_dropout_prob": 0.1,
|
| 13 |
+
"hidden_size": 768,
|
| 14 |
+
"id2label": {
|
| 15 |
+
"0": "O",
|
| 16 |
+
"1": "ANS"
|
| 17 |
+
},
|
| 18 |
+
"initializer_range": 0.02,
|
| 19 |
+
"intermediate_size": 3072,
|
| 20 |
+
"label2id": {
|
| 21 |
+
"ANS": 1,
|
| 22 |
+
"O": 0
|
| 23 |
+
},
|
| 24 |
+
"layer_norm_eps": 1e-05,
|
| 25 |
+
"max_position_embeddings": 514,
|
| 26 |
+
"model_type": "camembert",
|
| 27 |
+
"num_attention_heads": 12,
|
| 28 |
+
"num_hidden_layers": 12,
|
| 29 |
+
"output_past": true,
|
| 30 |
+
"pad_token_id": 1,
|
| 31 |
+
"position_embedding_type": "absolute",
|
| 32 |
+
"torch_dtype": "float32",
|
| 33 |
+
"transformers_version": "4.11.3",
|
| 34 |
+
"type_vocab_size": 1,
|
| 35 |
+
"use_cache": true,
|
| 36 |
+
"vocab_size": 32005
|
| 37 |
+
}
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21617bf982b06f8965c306991dd6892b1a3fd8c4c5be7f726f57eabdf5c99ab7
|
| 3 |
+
size 440213553
|
sentencepiece.bpe.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:988bc5a00281c6d210a5d34bd143d0363741a432fefe741bf71e61b1869d4314
|
| 3 |
+
size 810912
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "<s>", "eos_token": "</s>", "unk_token": "<unk>", "sep_token": "</s>", "pad_token": "<pad>", "cls_token": "<s>", "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": false}, "additional_special_tokens": ["<s>NOTUSED", "</s>NOTUSED"]}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "<s>", "eos_token": "</s>", "sep_token": "</s>", "cls_token": "<s>", "unk_token": "<unk>", "pad_token": "<pad>", "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "additional_special_tokens": ["<s>NOTUSED", "</s>NOTUSED"], "model_max_length": 512, "special_tokens_map_file": null, "name_or_path": "/mnt/qaqg_playground/Users/colin.davidson/qa-qg-playground/data/huggingface/args/sl/m-sl-sota-2-test/checkpoint-1000", "tokenizer_class": "CamembertTokenizer"}
|