
Francois Vieille
commited on
Commit
•
87e415f
1
Parent(s):
f707e85
add assets + start to use widget
Browse files
README.md
CHANGED
|
@@ -7,7 +7,22 @@ license: mit
|
|
| 7 |
pipeline_tag: sentence-similarity
|
| 8 |
|
| 9 |
widget:
|
| 10 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
tags:
|
| 13 |
- sentence-transformers
|
|
@@ -19,9 +34,9 @@ tags:
|
|
| 19 |
---
|
| 20 |
|
| 21 |
|
| 22 |
-
## Modèle de représentation d'un message à l'aide de ConvBERT
|
| 23 |
|
| 24 |
-
|
| 25 |
|
| 26 |
L'expérimentation menée au sein de Lincoln avait pour principal objectif de mettre en œuvre des techniques NLP from scratch sur un corpus de messages issus d’un chat Twitch. Ces derniers sont exprimés en français, mais sur une plateforme internet avec le vocabulaire internet que cela implique (fautes, vocabulaire communautaires, abréviations, anglicisme, emotes, ...).
|
| 27 |
|
|
@@ -83,7 +98,7 @@ for i in range(len(sentences1)):
|
|
| 83 |
# Score: 0.5805 | "BibleThump" -vs- "NotLikeThis"
|
| 84 |
|
| 85 |
```
|
| 86 |
-
|
| 87 |
## Entrainement
|
| 88 |
|
| 89 |
* 500 000 messages twitchs échantillonnés (cf description données des modèles de bases)
|
|
@@ -99,9 +114,13 @@ L'ensemble du code d'entrainement sur le github public [lincoln/twitchatds](http
|
|
| 99 |
|
| 100 |
## Application:
|
| 101 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 102 |
### Clustering émission "Backseat":
|
| 103 |
|
| 104 |
-

|
| 107 |
|
|
|
|
| 7 |
pipeline_tag: sentence-similarity
|
| 8 |
|
| 9 |
widget:
|
| 10 |
+
- source_sentence: "elle s'en sort bien"
|
| 11 |
+
sentences:
|
| 12 |
+
- "elle a raison"
|
| 13 |
+
- "elle a tellement raison"
|
| 14 |
+
- "Elle a pas tort"
|
| 15 |
+
- "Elle est vraiment top"
|
| 16 |
+
- "Elle m'a perdu"
|
| 17 |
+
example_title: "Raison or not"
|
| 18 |
+
- source_sentence: "That is a happy person"
|
| 19 |
+
sentences:
|
| 20 |
+
- "That is a happy dog"
|
| 21 |
+
- "That is a very happy person"
|
| 22 |
+
- "Today is a sunny day"
|
| 23 |
+
example_title: "Happy"
|
| 24 |
+
|
| 25 |
+
|
| 26 |
|
| 27 |
tags:
|
| 28 |
- sentence-transformers
|
|
|
|
| 34 |
---
|
| 35 |
|
| 36 |
|
| 37 |
+
## Modèle de représentation d'un message Twitch à l'aide de ConvBERT
|
| 38 |
|
| 39 |
+
Modèle [sentence-transformers](https://www.SBERT.net): cela permet de mapper une séquence de texte en un vecteur numérique de dimension 256 et peut être utilisé pour des tâches de clustering ou de recherche sémantique.
|
| 40 |
|
| 41 |
L'expérimentation menée au sein de Lincoln avait pour principal objectif de mettre en œuvre des techniques NLP from scratch sur un corpus de messages issus d’un chat Twitch. Ces derniers sont exprimés en français, mais sur une plateforme internet avec le vocabulaire internet que cela implique (fautes, vocabulaire communautaires, abréviations, anglicisme, emotes, ...).
|
| 42 |
|
|
|
|
| 98 |
# Score: 0.5805 | "BibleThump" -vs- "NotLikeThis"
|
| 99 |
|
| 100 |
```
|
| 101 |
+
|
| 102 |
## Entrainement
|
| 103 |
|
| 104 |
* 500 000 messages twitchs échantillonnés (cf description données des modèles de bases)
|
|
|
|
| 114 |
|
| 115 |
## Application:
|
| 116 |
|
| 117 |
+
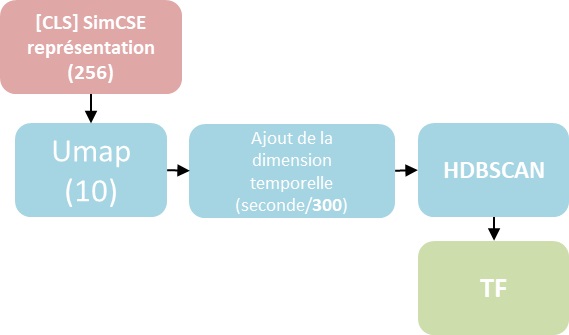
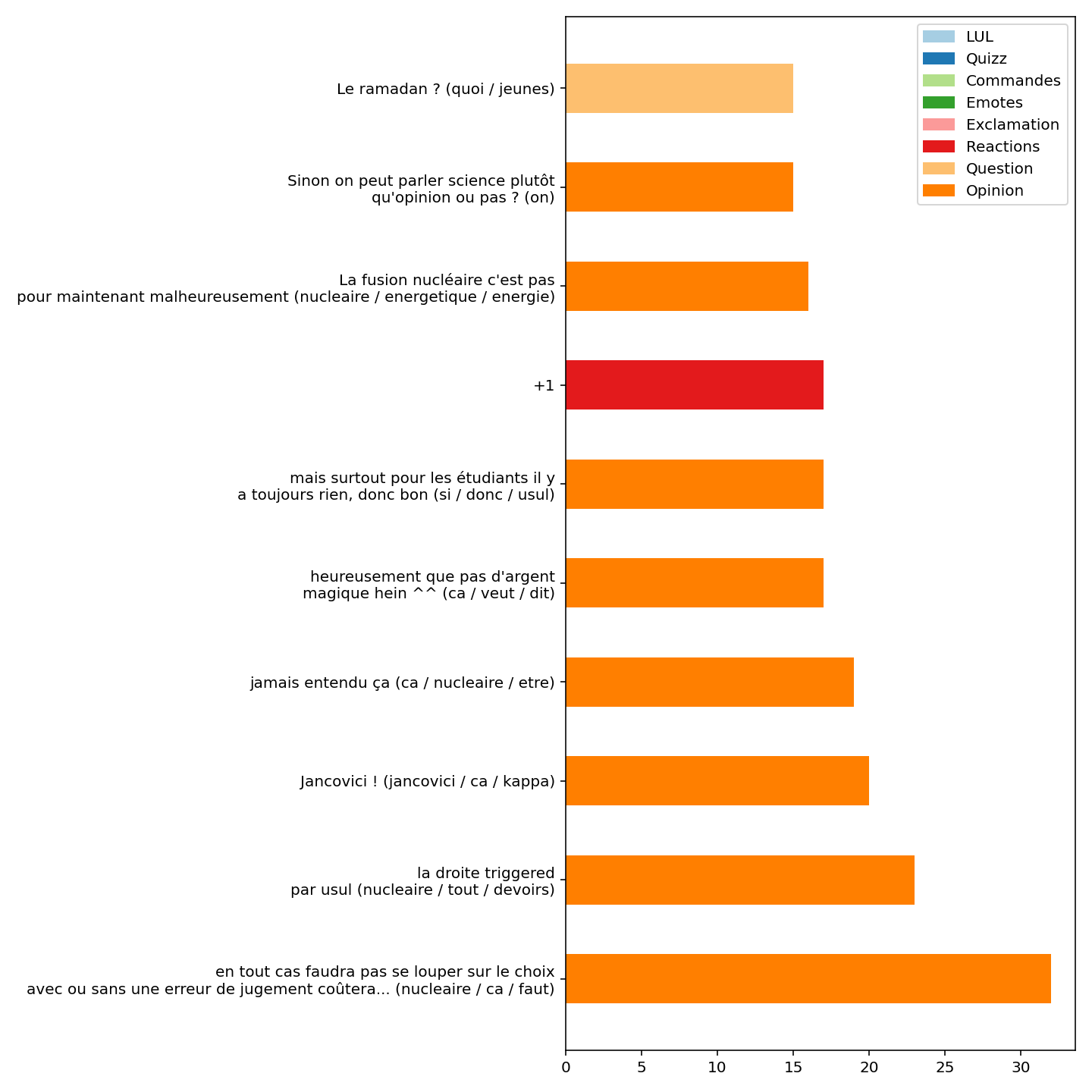
Nous avons utilisé une approche détournée de [BERTopic](https://maartengr.github.io/BERTopic/) pour réaliser un clustering d'un stream en prenant en compte la dimension temporelle: i.e. le nombre de seconde écoulée depuis le début du stream.
|
| 118 |
+
|
| 119 |
+

|
| 120 |
+
|
| 121 |
### Clustering émission "Backseat":
|
| 122 |
|
| 123 |
+

|
| 124 |
|
| 125 |
ou en 🎞️: [youtu.be/EcjvlE9aTls](https://youtu.be/EcjvlE9aTls)
|
| 126 |
|
assets/approche_lincoln_topic_clustering_twitch.jpg
ADDED
|
assets/scale_600_1930_2000.png
ADDED
|