
add training png
Browse files- .gitignore +1 -0
- README.md +29 -18
- media/mse.png +0 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
README.md
CHANGED
|
@@ -6,26 +6,29 @@ license: cc-by-4.0
|
|
| 6 |
|
| 7 |
by [Louka Ewington-Pitsos](https://www.linkedin.com/in/louka-ewington-pitsos-2a92b21a0/?originalSubdomain=au) and Ram ____
|
| 8 |
|
| 9 |
-
Heavily inspired by [google/gemma-scope](https://huggingface.co/google/gemma-scope) we are
|
| 10 |
|
| 11 |
-
|
| 12 |
-
|-------|-----|--------------------|-------------------------|
|
| 13 |
-
| 2 | 267.95 | 0.763 | 0.000912 |
|
| 14 |
-
| 5 | 354.46 | 0.665 | 0 |
|
| 15 |
-
| 8 | 357.58 | 0.642 | 0 |
|
| 16 |
-
| 11 | 321.23 | 0.674 | 0 |
|
| 17 |
-
| 14 | 319.64| 0.689 | 0 |
|
| 18 |
-
| 17 | 261.201 | 0.731 | 0 |
|
| 19 |
-
| 20 | 278.06 | 0.706 | 0.0000763 |
|
| 20 |
-
| 22 | 299.96 | 0.684 | 0 |
|
| 21 |
|
| 22 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 23 |
|
| 24 |
### Vital Statistics:
|
| 25 |
|
| 26 |
- Number of tokens trained per autoencoder: 1.2 Billion
|
| 27 |
- Token type: all 257 image tokens (as opposed to just the cls token)
|
| 28 |
-
- Number of images trained per autoencoder:
|
| 29 |
- Training Dataset: [Laion-2b](https://huggingface.co/datasets/laion/laion2B-multi-joined-translated-to-en)
|
| 30 |
- SAE Architecture: topk with k=32
|
| 31 |
- Layer Location: always the residual stream
|
|
@@ -34,15 +37,23 @@ Training logs are available [via wandb](https://wandb.ai/lewington/ViT-L-14-laio
|
|
| 34 |
|
| 35 |
## Usage
|
| 36 |
|
| 37 |
-
## Error
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
| 39 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 40 |
|
| 41 |
-
We calculate
|
| 42 |
|
| 43 |
-
## Subjective Interpretability
|
| 44 |
|
| 45 |
-
To give an intuitive feel for the interpretability of these models we run 500,000 images from laion2b selected at random through the final trained SAE for each layer and record the latent activations for each. We then winnow down to the first 100 features which activate for at least 9 images. We cherry pick 3 of these and display them in a 3x3 grid for each layer. We do this twice, one for the CLS token and once for token 137 (near the middle of the image). Below are the 6 grids for
|
| 46 |
|
| 47 |
|
| 48 |
## Automated Sort EVALs
|
|
|
|
| 6 |
|
| 7 |
by [Louka Ewington-Pitsos](https://www.linkedin.com/in/louka-ewington-pitsos-2a92b21a0/?originalSubdomain=au) and Ram ____
|
| 8 |
|
| 9 |
+
Heavily inspired by [google/gemma-scope](https://huggingface.co/google/gemma-scope) we are releasing a suite of 8 sparse autoencoders for [laion/CLIP-ViT-L-14-laion2B-s32B-b82K](https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K).
|
| 10 |
|
| 11 |
+

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
+
| Layer | MSE | Explained Variance | Dead Feature Proportion |
|
| 14 |
+
|-------|----------|--------------------|-------------------------|
|
| 15 |
+
| 2 | 267.95 | 0.763 | 0.000912 |
|
| 16 |
+
| 5 | 354.46 | 0.665 | 0 |
|
| 17 |
+
| 8 | 357.58 | 0.642 | 0 |
|
| 18 |
+
| 11 | 321.23 | 0.674 | 0 |
|
| 19 |
+
| 14 | 319.64 | 0.689 | 0 |
|
| 20 |
+
| 17 | 261.20 | 0.731 | 0 |
|
| 21 |
+
| 20 | 278.06 | 0.706 | 0.0000763 |
|
| 22 |
+
| 22 | 299.96 | 0.684 | 0 |
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
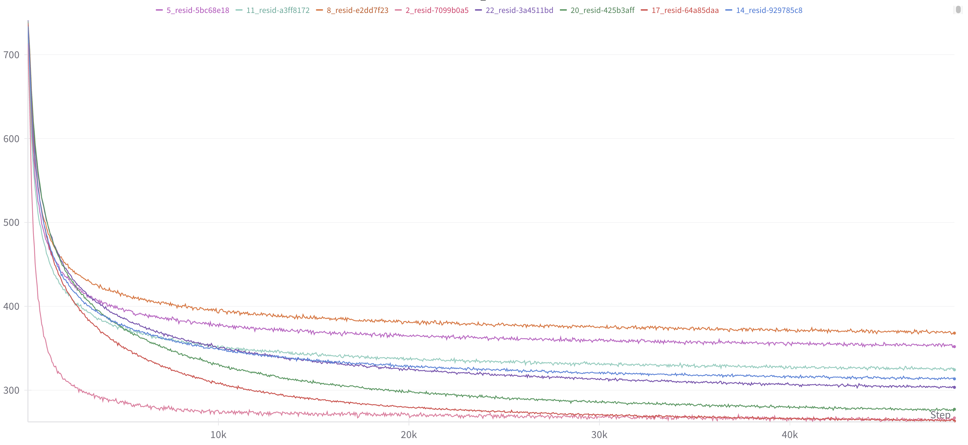
Training logs are available [via wandb](https://wandb.ai/lewington/ViT-L-14-laion2B-s32B-b82K/workspace) and training code is available on [github](https://github.com/Lewington-pitsos/vitsae). The training process is heavily reliant on [AWS ECS](https://aws.amazon.com/ecs/) so may contain some strange artifacts when a spot instance is killed and the training is resumed by another instance. Some of the code is ripped directly from [Hugo Fry](https://github.com/HugoFry/mats_sae_training_for_ViTs).
|
| 26 |
|
| 27 |
### Vital Statistics:
|
| 28 |
|
| 29 |
- Number of tokens trained per autoencoder: 1.2 Billion
|
| 30 |
- Token type: all 257 image tokens (as opposed to just the cls token)
|
| 31 |
+
- Number of unique images trained per autoencoder: 4.5 Million
|
| 32 |
- Training Dataset: [Laion-2b](https://huggingface.co/datasets/laion/laion2B-multi-joined-translated-to-en)
|
| 33 |
- SAE Architecture: topk with k=32
|
| 34 |
- Layer Location: always the residual stream
|
|
|
|
| 37 |
|
| 38 |
## Usage
|
| 39 |
|
| 40 |
+
## Error Formulae
|
| 41 |
+
|
| 42 |
+
We calculate MSE as `(batch - reconstruction).pow(2).sum(dim=-1).mean()` i.e. The MSE between the batch and the un-normalized reconstruction, summed across features. We use batch norm to bring all activations into a similar range.
|
| 43 |
+
|
| 44 |
+
We calculate Explained Variance as
|
| 45 |
|
| 46 |
+
```python
|
| 47 |
+
delta_variance = (batch - reconstruction).pow(2).sum(dim=-1)
|
| 48 |
+
activation_variance = (batch - batch.mean(dim=-1, keepdim=True)).pow(2).sum(dim=-1)
|
| 49 |
+
explained_variance = (1 - delta_variance / activation_variance).mean()
|
| 50 |
+
```
|
| 51 |
|
| 52 |
+
We calculate dead feature proportion as the proportion of features which have not activated in the last 10,000,000 samples.
|
| 53 |
|
| 54 |
+
## Subjective Interpretability
|
| 55 |
|
| 56 |
+
To give an intuitive feel for the interpretability of these models we run 500,000 images from laion2b selected at random through the final trained SAE for each layer and record the latent activations for each. We then winnow down to the first 100 features which activate for at least 9 images. We cherry pick 3 of these and display them in a 3x3 grid for each layer. We do this twice, one for the CLS token and once for token 137 (near the middle of the image). Below are the 6 grids for feature 22. Other grids are available for each layer.
|
| 57 |
|
| 58 |
|
| 59 |
## Automated Sort EVALs
|
media/mse.png
ADDED
|