微調掩碼語言模型

對於許多涉及 Transformer 模型的 NLP 程序, 你可以簡單地從 Hugging Face Hub 中獲取一個預訓練的模型, 然後直接在你的數據上對其進行微調, 以完成手頭的任務。只要用於預訓練的語料庫與用於微調的語料庫沒有太大區別, 遷移學習通常會產生很好的結果。
但是, 在某些情況下, 你需要先微調數據上的語言模型, 然後再訓練特定於任務的head。例如, 如果您的數據集包含法律合同或科學文章, 像 BERT 這樣的普通 Transformer 模型通常會將您語料庫中的特定領域詞視為稀有標記, 結果性能可能不盡如人意。通過在域內數據上微調語言模型, 你可以提高許多下游任務的性能, 這意味著您通常只需執行一次此步驟!
這種在域內數據上微調預訓練語言模型的過程通常稱為 領域適應。 它於 2018 年由 ULMFiT推廣, 這是使遷移學習真正適用於 NLP 的首批神經架構之一 (基於 LSTM)。 下圖顯示了使用 ULMFiT 進行域自適應的示例; 在本節中, 我們將做類似的事情, 但使用的是 Transformer 而不是 LSTM!


在本節結束時, 你將在Hub上擁有一個掩碼語言模型(masked language model), 該模型可以自動完成句子, 如下所示:
讓我們開始吧!
🙋 如果您對“掩碼語言建模”和“預訓練模型”這兩個術語感到陌生, 請查看第一章, 我們在其中解釋了所有這些核心概念, 並附有視頻!
選擇用於掩碼語言建模的預訓練模型
首先, 讓我們為掩碼語言建模選擇一個合適的預訓練模型。如以下屏幕截圖所示, 你可以通過在Hugging Face Hub上應用”Fill-Mask”過濾器找到:
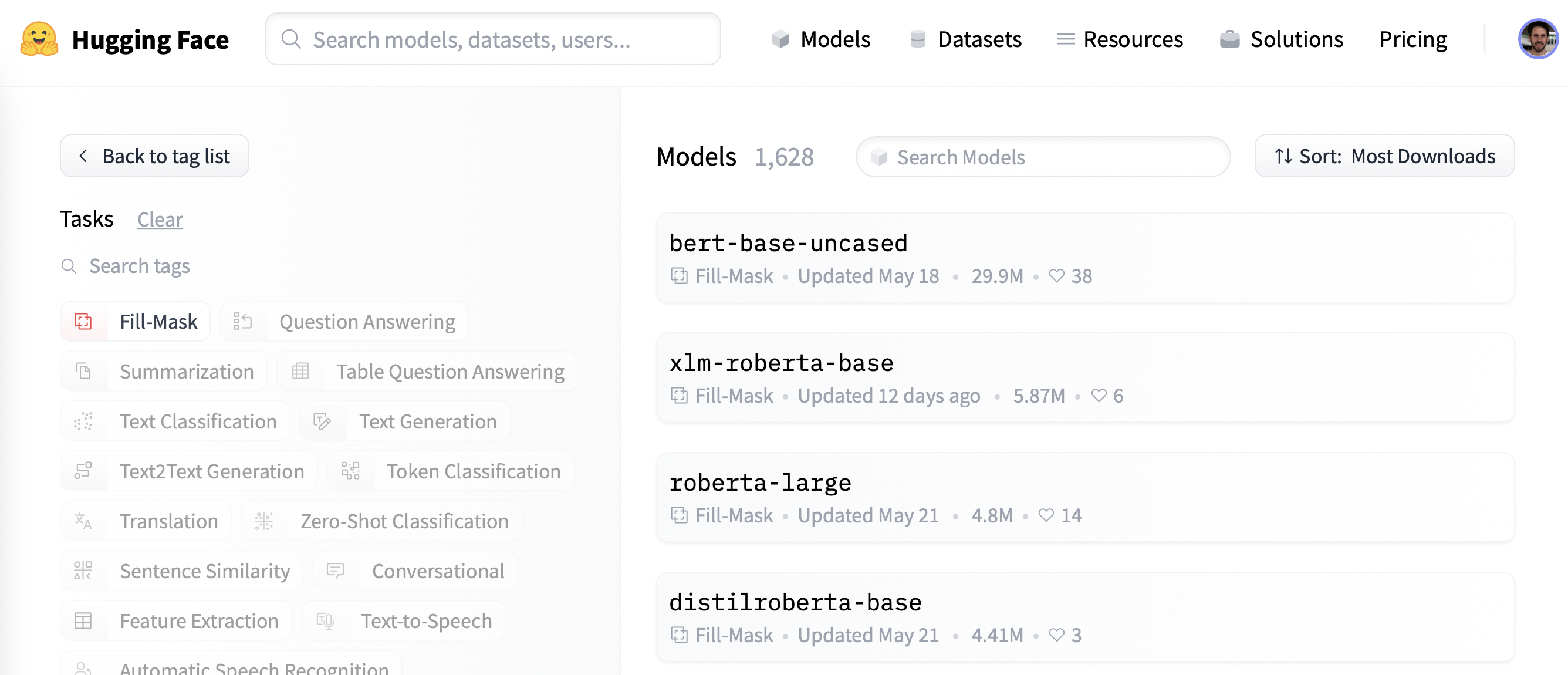
儘管 BERT 和 RoBERTa 系列模型的下載量最大, 但我們將使用名為 DistilBERT的模型。 可以更快地訓練, 而下游性能幾乎沒有損失。這個模型使用一種稱為知識蒸餾的特殊技術進行訓練, 其中使用像 BERT 這樣的大型“教師模型”來指導參數少得多的“學生模型”的訓練。在本節中對知識蒸餾細節的解釋會使我們離題太遠, 但如果你有興趣, 可以閱讀所有相關內容 Natural Language Processing with Transformers (俗稱Transformers教科書)。
讓我們繼續, 使用 AutoModelForMaskedLM 類下載 DistilBERT:
from transformers import AutoModelForMaskedLM
model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)我們可以通過調用 num_parameters() 方法查看模型有多少參數:
distilbert_num_parameters = model.num_parameters() / 1_000_000
print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
print(f"'>>> BERT number of parameters: 110M'")'>>> DistilBERT number of parameters: 67M'
'>>> BERT number of parameters: 110M'DistilBERT 大約有 6700 萬個參數, 大約比 BERT 基本模型小兩倍, 這大致意味著訓練的速度提高了兩倍 — 非常棒! 現在讓我們看看這個模型預測什麼樣的標記最有可能完成一小部分文本:
text = "This is a great [MASK]."作為人類, 我們可以想象 [MASK] 標記有很多可能性, 例如 “day”、 “ride” 或者 “painting”。對於預訓練模型, 預測取決於模型所訓練的語料庫, 因為它會學習獲取數據中存在的統計模式。與 BERT 一樣, DistilBERT 在English Wikipedia 和 BookCorpus 數據集上進行預訓練, 所以我們期望對 [MASK] 的預測能夠反映這些領域。為了預測掩碼, 我們需要 DistilBERT 的標記器來生成模型的輸入, 所以讓我們也從 Hub 下載它:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)使用標記器和模型, 我們現在可以將我們的文本示例傳遞給模型, 提取 logits, 並打印出前 5 個候選:
import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
# Find the location of [MASK] and extract its logits
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
# Pick the [MASK] candidates with the highest logits
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")'>>> This is a great deal.'
'>>> This is a great success.'
'>>> This is a great adventure.'
'>>> This is a great idea.'
'>>> This is a great feat.'我們可以從輸出中看到模型的預測是指日常用語, 鑑於英語維基百科的基礎, 這也許並不奇怪。讓我們看看我們如何將這個領域改變為更小眾的東西 — 高度兩極分化的電影評論!
數據集
為了展示域適配, 我們將使用著名的大型電影評論數據集(Large Movie Review Dataset) (或者簡稱為IMDb), 這是一個電影評論語料庫, 通常用於對情感分析模型進行基準測試。通過在這個語料庫上對 DistilBERT 進行微調, 我們預計語言模型將根據維基百科的事實數據調整其詞彙表, 這些數據已經預先訓練到電影評論中更主觀的元素。我們可以使用🤗 Datasets中的load_dataset()函數從Hugging Face 中獲取數據:
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
imdb_datasetDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})我們可以看到 train 和 test 每個拆分包含 25,000 條評論, 而有一個未標記的拆分稱為 unsupervised 包含 50,000 條評論。讓我們看一些示例, 以瞭解我們正在處理的文本類型。正如我們在本課程的前幾章中所做的那樣, 我們將鏈接 Dataset.shuffle() 和 Dataset.select() 函數創建隨機樣本:
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
for row in sample:
print(f"\n'>>> Review: {row['text']}'")
print(f"'>>> Label: {row['label']}'")
'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.<br /><br />Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
'>>> Label: 0'
'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.<br /><br />The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
'>>> Label: 0'
'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version. <br /><br />My 4 and 6 year old children love this movie and have been asking again and again to watch it. <br /><br />I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.<br /><br />I do not have older children so I do not know what they would think of it. <br /><br />The songs are very cute. My daughter keeps singing them over and over.<br /><br />Hope this helps.'
'>>> Label: 1'是的, 這些肯定是電影評論, 如果你年齡足夠,你甚至可能會理解上次評論中關於擁有 VHS 版本的評論😜! 雖然我們不需要語言建模的標籤, 但我們已經可以看到 0 表示負面評論, 而 1 對應正面。
✏️ 試試看! 創建 無監督 拆分的隨機樣本, 並驗證標籤既不是 0 也不是 1。在此過程中, 你還可以檢查 train 和 test 拆分中的標籤是否確實為 0 或 1 — 這是每個 NLP 從業者在新項目開始時都應該執行的有用的健全性檢查!
現在我們已經快速瀏覽了數據, 讓我們深入研究為掩碼語言建模做準備。正如我們將看到的, 與我們在第三章中看到的序列分類任務相比, 還需要採取一些額外的步驟。讓我們繼續!
預處理數據
對於自迴歸和掩碼語言建模, 一個常見的預處理步驟是連接所有示例, 然後將整個語料庫拆分為相同大小的塊。 這與我們通常的方法完全不同, 我們只是簡單地標記單個示例。為什麼要將所有內容連接在一起? 原因是單個示例如果太長可能會被截斷, 這將導致丟失可能對語言建模任務有用的信息!
因此, 我們將像往常一樣首先標記我們的語料庫, 但是 沒有 在我們的標記器中設置 truncation=True 選項。 我們還將獲取可用的單詞 ID ((如果我們使用快速標記器, 它們是可用的, 如 第六章中所述), 因為我們稍後將需要它們來進行全字屏蔽。我們將把它包裝在一個簡單的函數中, 當我們在做的時候, 我們將刪除 text 和 label 列, 因為我們不再需要它們:
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Use batched=True to activate fast multithreading!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 50000
})
})由於 DistilBERT 是一個類似 BERT 的模型, 我們可以看到編碼文本由我們在其他章節中看到的 input_ids 和 attention_mask 組成, 以及我們添加的 word_ids。
現在我們已經標記了我們的電影評論, 下一步是將它們組合在一起並將結果分成塊。 但是這些塊應該有多大? 這最終將取決於你可用的 GPU 內存量, 但一個好的起點是查看模型的最大上下文大小是多少。這可以通過檢查標記器的 model_max_length 屬性來判斷:
tokenizer.model_max_length
512該值來自於與檢查點相關聯的 tokenizer_config.json 文件; 在這種情況下, 我們可以看到上下文大小是 512 個標記, 就像 BERT 一樣。
✏️ 試試看! 一些 Transformer 模型, 例如 BigBird 和 Longformer, 它們具有比BERT和其他早期Transformer模型更長的上下文長度。為這些檢查點之一實例化標記器, 並驗證 model_max_length 是否與模型卡上引用的內容一致。
因此, 以便在像Google Colab 那樣的 GPU 上運行我們的實驗, 我們將選擇可以放入內存的更小一些的東西:
chunk_size = 128請注意, 在實際場景中使用較小的塊大小可能是有害的, 因此你應該使用與將應用模型的用例相對應的大小。
有趣的來了。為了展示串聯是如何工作的, 讓我們從我們的標記化訓練集中取一些評論並打印出每個評論的標記數量:
# Slicing produces a list of lists for each feature
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
print(f"'>>> Review {idx} length: {len(sample)}'")'>>> Review 0 length: 200'
'>>> Review 1 length: 559'
'>>> Review 2 length: 192'然後我們可以用一個簡單的字典理解來連接所有例子, 如下所示:
concatenated_examples = {
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"])
print(f"'>>> Concatenated reviews length: {total_length}'")'>>> Concatenated reviews length: 951'很棒, 總長度檢查出來了 — 現在, 讓我們將連接的評論拆分為大小為 block_size 的塊。為此, 我們迭代了 concatenated_examples 中的特徵, 並使用列表理解來創建每個特徵的切片。結果是每個特徵的塊字典:
chunks = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]:
print(f"'>>> Chunk length: {len(chunk)}'")'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 55'正如你在這個例子中看到的, 最後一個塊通常會小於最大塊大小。有兩種主要的策略來處理這個問題:
- 如果最後一個塊小於
chunk_size, 請刪除它。 - 填充最後一個塊, 直到其長度等於
chunk_size。
我們將在這裡採用第一種方法, 因此讓我們將上述所有邏輯包裝在一個函數中, 我們可以將其應用於我們的標記化數據集:
def group_texts(examples):
# Concatenate all texts
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# Compute length of concatenated texts
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the last chunk if it's smaller than chunk_size
total_length = (total_length // chunk_size) * chunk_size
# Split by chunks of max_len
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# Create a new labels column
result["labels"] = result["input_ids"].copy()
return result注意, 在 group_texts() 的最後一步中, 我們創建了一個新的 labels 列, 它是 input_ids 列的副本。我們很快就會看到, 這是因為在掩碼語言建模中, 目標是預測輸入批次中隨機掩碼的標記, 並通過創建一個 labels 列, 們為我們的語言模型提供了基礎事實以供學習。
現在, 讓我們使用我們可信賴的 Dataset.map() 函數將 group_texts() 應用到我們的標記化數據集:
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
lm_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 61289
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 59905
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 122963
})
})你可以看到, 對文本進行分組, 然後對文本進行分塊, 產生的示例比我們最初的 25,000 用於 train和 test 拆分的示例多得多。那是因為我們現在有了涉及 連續標記 的示例, 這些示例跨越了原始語料庫中的多個示例。你可以通過在其中一個塊中查找特殊的 [SEP] 和 [CLS] 標記來明確的看到這一點:
tokenizer.decode(lm_datasets["train"][1]["input_ids"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"在此示例中, 你可以看到兩篇重疊的電影評論, 一篇關於高中電影, 另一篇關於無家可歸。 讓我們也看看掩碼語言建模的標籤是什麼樣的:
tokenizer.decode(lm_datasets["train"][1]["labels"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"正如前面的 group_texts() 函數所期望的那樣, 這看起來與解碼後的 input_ids 相同 — 但是我們的模型怎麼可能學到任何東西呢? 我們錯過了一個關鍵步驟: 在輸入中的隨機位置插入 [MASK] 標記! 讓我們看看如何使用特殊的數據整理器在微調期間即時執行此操作。
使用 Trainer API 微調DistilBERT
微調屏蔽語言模型幾乎與微調序列分類模型相同, 就像我們在 第三章所作的那樣。 唯一的區別是我們需要一個特殊的數據整理器, 它可以隨機屏蔽每批文本中的一些標記。幸運的是, 🤗 Transformers 為這項任務準備了專用的 DataCollatorForLanguageModeling 。我們只需要將它轉遞給標記器和一個 mlm_probability 參數, 該參數指定要屏蔽的標記的分數。我們將選擇 15%, 這是 BERT 使用的數量也是文獻中的常見選擇:
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)要了解隨機掩碼的工作原理, 讓我們向數據整理器提供一些示例。由於它需要一個 dict 的列表, 其中每個 dict 表示單個連續文本塊, 我們首先迭代數據集, 然後再將批次提供給整理器。我們刪除了這個數據整理器的 "word_ids" 鍵, 因為它不需要它:
samples = [lm_datasets["train"][i] for i in range(2)]
for sample in samples:
_ = sample.pop("word_ids")
for chunk in data_collator(samples)["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'很棒, 成功了! 我們可以看到, [MASK] 標記已隨機插入我們文本中的不同位置。 這些將是我們的模型在訓練期間必須預測的標記 — 數據整理器的美妙之處在於, 它將隨機化每個批次的 [MASK] 插入!
✏️ 試試看! 多次運行上面的代碼片段, 看看隨機屏蔽發生在你眼前! 還要將 tokenizer.decode() 方法替換為 tokenizer.convert_ids_to_tokens() 以查看有時會屏蔽給定單詞中的單個標記, 而不是其他標記。
隨機掩碼的一個副作用是, 當使用 Trainer 時, 我們的評估指標將不是確定性的, 因為我們對訓練集和測試集使用相同的數據整理器。稍後我們會看到, 當我們使用 🤗 Accelerate 進行微調時, 我們將如何利用自定義評估循環的靈活性來凍結隨機性。
在為掩碼語言建模訓練模型時, 可以使用的一種技術是將整個單詞一起屏蔽, 而不僅僅是單個標記。這種方法稱為 全詞屏蔽。 如果我們想使用全詞屏蔽, 我們需要自己構建一個數據整理器。數據整理器只是一個函數, 它接受一個樣本列表並將它們轉換為一個批次, 所以現在讓我們這樣做吧! 我們將使用之前計算的單詞 ID 在單詞索引和相應標記之間進行映射, 然後隨機決定要屏蔽哪些單詞並將該屏蔽應用於輸入。請注意, 除了與掩碼對應的標籤外, 所有的標籤均為 -100。
import collections
import numpy as np
from transformers import default_data_collator
wwm_probability = 0.2
def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
# Create a map between words and corresponding token indices
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# Randomly mask words
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels)
for word_id in np.where(mask)[0]:
word_id = word_id.item()
for idx in mapping[word_id]:
new_labels[idx] = labels[idx]
input_ids[idx] = tokenizer.mask_token_id
feature["labels"] = new_labels
return default_data_collator(features)Next, we can try it on the same samples as before:
samples = [lm_datasets["train"][i] for i in range(2)]
batch = whole_word_masking_data_collator(samples)
for chunk in batch["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'✏️ 試試看! 多次運行上面的代碼片段, 看看隨機屏蔽發生在你眼前! 還要將 tokenizer.decode() 方法替換為 tokenizer.convert_ids_to_tokens() 以查看來自給定單詞的標記始終被屏蔽在一起。
現在我們有兩個數據整理器, 其餘的微調步驟是標準的。如果您沒有足夠幸運地獲得神話般的 P100 GPU 😭, 在 Google Colab 上進行訓練可能需要一段時間, 因此我們將首先將訓練集的大小縮減為幾千個示例。別擔心, 我們仍然會得到一個相當不錯的語言模型! 在 🤗 Datasets 中快速下采樣數據集的方法是通過我們在 第五章 中看到的 Dataset.train_test_split() 函數:
train_size = 10_000
test_size = int(0.1 * train_size)
downsampled_dataset = lm_datasets["train"].train_test_split(
train_size=train_size, test_size=test_size, seed=42
)
downsampled_datasetDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 10000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 1000
})
})這會自動創建新的 train 和 test 拆分, 訓練集大小設置為 10,000 個示例, 驗證設置為其中的 10% — 如果你有一個強大的 GPU, 可以隨意增加它! 我們需要做的下一件事是登錄 Hugging Face Hub。如果你在筆記本中運行此代碼, 則可以使用以下實用程序函數執行此操作:
from huggingface_hub import notebook_login
notebook_login()這將顯示一個小部件, 你可以在其中輸入你的憑據。或者, 你可以運行:
huggingface-cli login在你最喜歡的終端中登錄。
登陸後, 我們可以指定 Trainer 參數:
from transformers import TrainingArguments
batch_size = 64
# Show the training loss with every epoch
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb",
overwrite_output_dir=True,
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
push_to_hub=True,
fp16=True,
logging_steps=logging_steps,
)在這裡, 我們調整了一些默認選項, 包括 logging_steps , 以確保我們跟蹤每個epoch的訓練損失。我們還使用了 fp16=True 來實現混合精度訓練, 這給我們帶來了另一個速度提升。默認情況下, Trainer 將刪除不屬於模型的 forward() 方法的列。這意味著, 如果你使用整個單詞屏蔽排序器, 你還需要設置 remove_unused_columns=False, 以確保我們不會在訓練期間丟失 word_ids 列。
請注意, 你可以使用 hub_model_id 參數指定要推送到的存儲庫的名稱((特別是你將必須使用該參數向組織推送)。例如, 當我們將模型推送到 huggingface-course organization 時, 我們添加了 hub_model_id="huggingface-course/distilbert-finetuned-imdb" 到 TrainingArguments 中。默認情況下, 使用的存儲庫將在你的命名空間中並以你設置的輸出目錄命名, 因此在我們的示例中, 它將是 "lewtun/distilbert-finetuned-imdb"。
我們現在擁有實例化 Trainer 的所有成分。這裡我們只使用標準的 data_collator, 但你可以嘗試使用整個單詞掩碼整理器並比較結果作為練習:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=downsampled_dataset["train"],
eval_dataset=downsampled_dataset["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)我們現在準備運行 trainer.train() — 但在此之前讓我們簡要地看一下 perplexity, 這是評估語言模型性能的常用指標。
語言模型的perplexity
與文本分類或問答等其他任務不同, 在這些任務中, 我們會得到一個帶標籤的語料庫進行訓練, 而語言建模則沒有任何明確的標籤。那麼我們如何確定什麼是好的語言模型呢? 就像手機中的自動更正功能一樣, 一個好的語言模型是為語法正確的句子分配高概率, 為無意義的句子分配低概率。為了讓你更好地瞭解這是什麼樣子, 您可以在網上找到一整套 “autocorrect fails”, 其中一個人手機中的模型產生了一些相當有趣 (而且通常不合適) 的結果!
假設我們的測試集主要由語法正確的句子組成, 那麼衡量我們的語言模型質量的一種方法是計算它分配給測試集中所有句子中的下一個單詞的概率。高概率表明模型對看不見的例子並不感到 “驚訝” 或 “疑惑”, 並表明它已經學習了語言中的基本語法模式。 perplexity度有多種數學定義, 但我們將使用的定義是交叉熵損失的指數。因此, 我們可以通過 Trainer.evaluate() 函數計算測試集上的交叉熵損失, 然後取結果的指數來計算預訓練模型的perplexity度:
import math
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 21.75較低的perplexity分數意味著更好的語言模型, 我們可以在這裡看到我們的起始模型有一個較大的值。看看我們能不能通過微調來降低它! 為此, 我們首先運行訓練循環:
trainer.train()
然後像以前一樣計算測試集上的perplexity度:
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 11.32很好 — 這大大減少了困惑, 這告訴我們模型已經瞭解了一些關於電影評論領域的知識!
訓練完成後, 我們可以將帶有訓練信息的模型卡推送到 Hub (檢查點在訓練過程中自行保存):
trainer.push_to_hub()
✏️ 輪到你了! 將數據整理器改為全字屏蔽整理器後運行上面的訓練。你有得到更好的結果嗎?
在我們的用例中, 我們不需要對訓練循環做任何特別的事情, 但在某些情況下, 你可能需要實現一些自定義邏輯。對於這些應用, 你可以使用 🤗 Accelerate — 讓我們來看看吧!
使用 🤗 Accelerate 微調 DistilBERT
正如我們在 Trainer 中看到的, 對掩碼語言模型的微調與 第三章 中的文本分類示例非常相似。事實上, 唯一的微妙之處是使用特殊的數據整理器, 我們已經在本節的前面介紹過了!
然而, 我們看到 DataCollatorForLanguageModeling 還對每次評估應用隨機掩碼, 因此每次訓練運行時, 我們都會看到perplexity度分數的一些波動。消除這種隨機性來源的一種方法是應用掩碼 一次 在整個測試集上, 然後使用🤗 Transformers 中的默認數據整理器在評估期間收集批次。為了看看它是如何工作的, 讓我們實現一個簡單的函數, 將掩碼應用於批處理, 類似於我們第一次遇到的 DataCollatorForLanguageModeling:
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
# Create a new "masked" column for each column in the dataset
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}接下來, 我們將此函數應用於我們的測試集並刪除未掩碼的列, 以便我們可以用掩碼的列替換它們。你可以通過用適當的替換上面的 data_collator 來使整個單詞掩碼, 在這種情況下, 你應該刪除此處的第一行:
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
eval_dataset = downsampled_dataset["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset["test"].column_names,
)
eval_dataset = eval_dataset.rename_columns(
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)然後我們可以像往常一樣設置數據加載器, 但我們將使用🤗 Transformers 中的 default_data_collator 作為評估集:
from torch.utils.data import DataLoader
from transformers import default_data_collator
batch_size = 64
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
eval_dataloader = DataLoader(
eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
)從這裡開始, 我們遵循🤗 Accelerate 的標準步驟。第一個任務是加載預訓練模型的新版本:
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)然後我們需要指定優化器; 我們將使用標準的 AdamW:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)有了這些對象, 我們現在可以準備使用 Accelerator 加速器進行訓練的一切:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)現在我們的模型、優化器和數據加載器都配置好了, 我們可以指定學習率調度器如下:
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)在訓練之前要做的最後一件事是: 在 Hugging Face Hub 上創建一個模型庫! 我們可以使用 🤗 Hub 庫來首先生成我們的 repo 的全名:
from huggingface_hub import get_full_repo_name
model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'然後使用來自🤗 Hub 的 Repository 類:
from huggingface_hub import Repository
output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)完成後, 只需寫出完整的訓練和評估循環即可:
from tqdm.auto import tqdm
import torch
import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size)))
losses = torch.cat(losses)
losses = losses[: len(eval_dataset)]
try:
perplexity = math.exp(torch.mean(losses))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)>>> Epoch 0: Perplexity: 11.397545307900472
>>> Epoch 1: Perplexity: 10.904909330983092
>>> Epoch 2: Perplexity: 10.729503505340409很棒, 我們已經能夠評估每個 epoch 的perplexity度, 並確保多次訓練運行是可重複的!
使用我們微調的模型
你可以通過在Hub上使用其他小部件或在本地使用🤗 Transformers 的管道於微調模型進行交互。讓我們使用後者來下載我們的模型, 使用 fill-mask 管道:
from transformers import pipeline
mask_filler = pipeline(
"fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
)然後, 我們可以向管道提供 “This is a great [MASK]” 示例文本, 並查看前 5 個預測是什麼:
preds = mask_filler(text)
for pred in preds:
print(f">>> {pred['sequence']}")'>>> this is a great movie.'
'>>> this is a great film.'
'>>> this is a great story.'
'>>> this is a great movies.'
'>>> this is a great character.'好的 — 我們的模型顯然已經調整了它的權重來預測與電影更密切相關的詞!
這結束了我們訓練語言模型的第一個實驗。在 第六節中你將學習如何從頭開始訓練像 GPT-2 這樣的自迴歸模型; 如果你想了解如何預訓練您自己的 Transformer 模型, 請前往那裡!
✏️ 試試看! 為了量化域適應的好處, 微調 IMDb 標籤上的分類器和預先訓練和微調的Distil BERT檢查點。如果你需要複習文本分類, 請查看 第三章。