出现错误时该怎么办

在本节中,我们将研究当你尝试从新调整的 Transformer 模型生成预测时可能发生的一些常见错误。本节为将 第四节 做准备,在那一节中探索如何调试训练阶段本身。
我们为这一节准备了一个 模板仓库 ,如果你想运行本章中的代码,首先需要将模型复制到自己的 Hugging Face Hub 账号。这需要你在 Jupyter Notebook 中运行以下命令来登录:
from huggingface_hub import notebook_login
notebook_login()或在你最喜欢的终端中执行以下操作:
huggingface-cli login
这里将会提示你输入用户名和密码,登陆后会自动在 ~/.cache/huggingface/ 保存一个令牌 完成登录后,可以使用以下功能克隆模板仓库:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# 克隆仓库并提取本地路径
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# 在 Hub 上创建一个新仓库
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# 克隆空仓库
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# 复制文件
copy_tree(template_repo_dir, new_repo_dir)
# 上传到 Hub 上
repo.push_to_hub()现在当你调用 copy_repository_template() 时,它将在你的帐户下创建模板仓库的副本。
调试 🤗 Transformers 的 pipeline
接下来要开始我们调试 Transformer 模型的奇妙世界之旅,请考虑以下情景:你正在与一位同事合作开发一个问答的项目,这个项目可以帮助电子商务网站的客户找到有关消费品一些问题的回答。假如你的同事给你发了这样一条消息:
嗨!我刚刚使用了 Hugging Face 课程的 第七章 中的技术进行了一个实验,并在 SQuAD 上获得了一些很棒的结果!我觉得我们可以用这个模型作为项目的起点。Hub 上的模型 ID 是
lewtun/distillbert-base-uncased-finetuned-squad-d5716d28。你来测试一下 )
你首先想到的是使用 🤗 Transformers 中的 pipeline :
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""啊哦,好像出了什么问题!如果你是编程新手,这类错误一开始看起来有点神秘 ( OSError 到底是什么?)。其实这里显示的错误只是全部错误报告中最后一部分,称为 Python traceback (又名堆栈跟踪)。例如,如果你在 Google Colab 上运行此代码,你应该会看到类似于以下屏幕截图的内容:
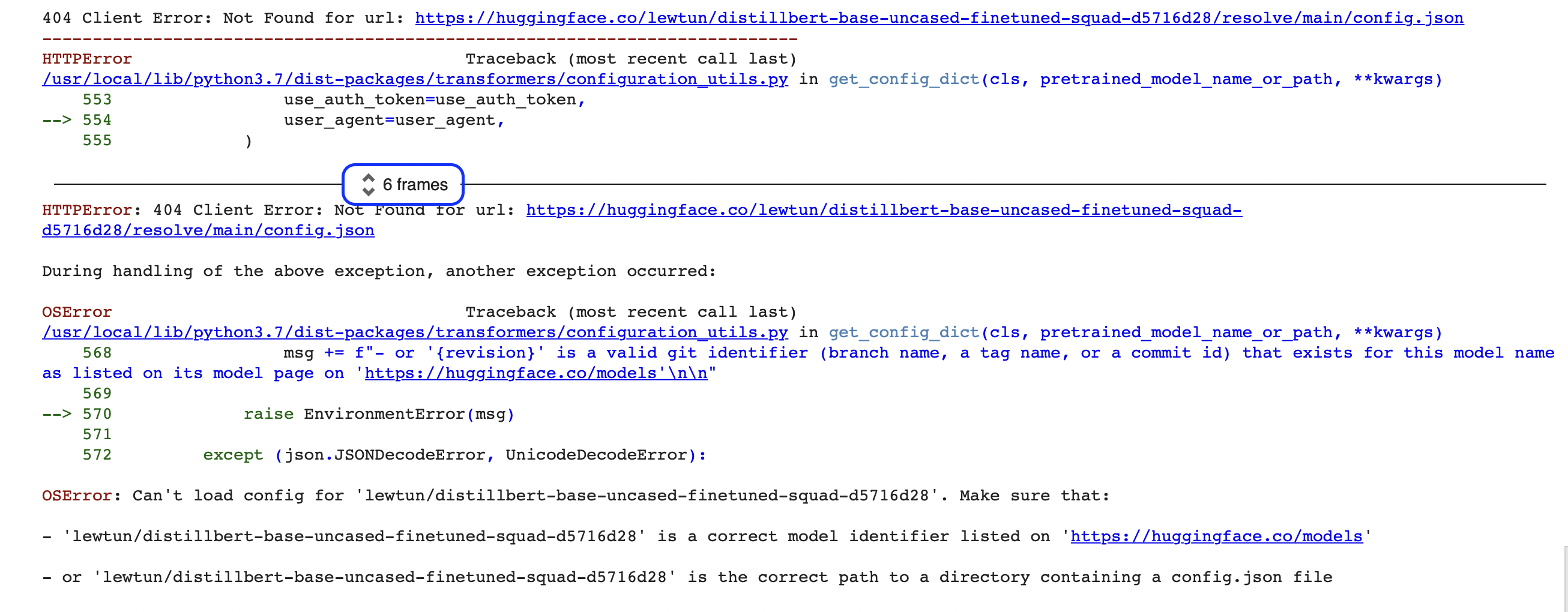
这些报告中包含很多信息,让我们一起来看看关键部分。阅读这样的报告时的阅读顺序比较特殊,应该按照从底部到顶部的顺序阅读,如果你习惯于从上到下阅读文本,这可能听起来很奇怪,但它反映了一个事实:traceback 显示了在下载模型和 tokenizer 时 pipeline 函数调用的顺序。(查看 第二章 了解有关 pipeline 内部原理的更多详细信息。)
🚨 看到 Google Colab 中 traceback 中间 “6 frames” 的椭圆形蓝色框了吗?这是 Colab 的一个特殊功能,它会自动将 traceback 的中间部分压缩为“frames”。如果你无法找到错误的来源,可以通过单击这两个小箭头来展开完整的 traceback。
这意味着 traceback 的最后一行显示的是最后一条错误消息和引发的异常名称。在这里,异常类型是 OSError ,表示这个错误与系统相关。如果我们阅读随之附着的错误消息,我们就可以看到模型的 config.json 文件似乎有问题,这里给出了两个修复的建议:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 如果你遇到难以理解的错误消息,只需将该消息复制并粘贴到 Google 或 Stack Overflow 搜索栏中。你很有可能不是第一个遇到错误的人,因此很有可能在社区中找到其他人发布的解决方案。例如,在 Stack Overflow 上搜索 OSError: Can't load config for 给出了几个 结果 ,可以作为你解决问题的起点。
第一个建议是检查模型 ID 是否真的正确,所以首先要做的就是复制标签并将其粘贴到 Hub 的搜索栏中:

嗯,看起来你同事的模型确实不在 Hub 上。但是仔细看模型名称就会发现,里面有一个错别字!正确的 DistilBERT 的名称中只有一个 “l”,所以让我们修正后寻找 lewtun/distilbert-base-uncased-finetuned-squad-d5716d28:

好的,这次有结果了。现在让我们使用正确的模型 ID 再次尝试下载模型:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""啊,再次失败。不要气馁,欢迎来到机器学习工程师的日常生活!前面我们已经修正了模型 ID,所以问题一定出在仓库本身。这里提供一种快速访问 🤗 Hub 上仓库内容的方法——通过 huggingface_hub 库的 list_repo_files() 函数:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']奇怪的是——仓库中似乎没有配置 config.json 文件!难怪我们的 pipeline 无法加载模型;你的同事一定是在微调后忘记将这个文件上传到 Hub。在这种情况下问题似乎很容易解决:要求他添加文件,或者我们从模型 ID 中可以看出使用的预训练模型是 distilbert-base-uncased ,因此我们可以直接下载此模型的配置文件并将其上传到你们的仓库后查看这样是否可以解决问题。在这里涉及到 第二章 中学习的技巧,使用 AutoConfig 类下载模型的配置文件:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 在这里采用的方法并不是百分之百可靠的,因为你的同事可能在微调模型之前已经调整了 distilbert-base-uncased 配置。在现实情况中,我们应该先与他们核实,但在本节中,我们先假设他们使用的是默认配置。
上一步成功后,可以使用 config 的 push_to_hub() 方法将其上传到模型仓库:
config.push_to_hub(model_checkpoint, commit_message="Add config.json")现在可以通过从最新提交的 main 分支中加载模型来测试是否有效:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}成功了!让我们回顾一下你刚刚学到的东西:
- Python 中的错误消息称为
tracebacks,注意需要从下到上阅读。错误消息的最后一行通常包含定位问题根源所需的信息。 - 如果最后一行没有包含足够的信息,需要进行
tracebacks(向上逐级查看),看看是否可以确定源代码中发生错误的位置。 - 如果没有任何错误消息可以帮助你调试问题,请尝试在线搜索类似问题的解决方案。
huggingface_hub库提供了一套工具,你可以使用这些工具与 Hub 上的仓库进行交互和调试。
现在你知道如何调试 pipeline ,让我们来看一个更棘手的例子,即调试模型本身的前向传播的过程。
调试模型的前向传播
尽管 pipeline 对于大多数需要快速生成预测结果的来说非常应用场景有用,但是有时你需要访问模型的 logits (比如你想要实现一些的自定义后续处理)。为了看看在这种情况下可能会出现什么问题,让我们首先从 pipeline 中获取模型和 tokenizers
tokenizer = reader.tokenizer model = reader.model
接下来我们需要提出一个问题,看看在这个上下文中的模型是否受支持我们最喜欢的框架:
question = "Which frameworks can I use?"正如我们在 第七章 中学习的,我们接下来需要对输入进行 tokenize,提取起始和结束 token 的 logits,然后解码答案所在的文本范围:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# 计算分数的 argmax 获取最有可能的答案开头
answer_start = torch.argmax(answer_start_scores)
# 计算分数的 argmax 获取最有可能的答案结尾
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""看起来我们的代码中有一个错误!不用紧张,你可以在 Notebook 中使用 Python 调试器:
或者跟随我们一起从终端中逐步试验找到错误:
在这里,错误消息告诉我们 'list' object has no attribute 'size' ,我们可以看到一个 --> 箭头指向 model(**inputs) 中引发问题的行。你可以使用 Python 调试器用交互方式来调试它,但在这里我们只需打印出一部分 inputs ,检查一下它的值:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]这当然看起来像一个普通的 Python list ,但让我们仔细检查一下类型:
type(inputs["input_ids"])list是的,的确是一个 Python list 。那么出了什么问题呢?回想一下我们在 第二章 🤗 Transformers 中的 AutoModelForXxx 类中的 tensors (PyTorch 或者 TensorFlow)进行的操作,例如在 PyTorch 中,一个常见的操作是使用 Tensor.size() 方法提取张量的维度。让我们再回到 traceback 中,看看哪一行触发了异常:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'看起来我们的代码试图调用 input_ids.size() ,但 .size() 方法显然不适用于 Python 的 list , list 只是一个容器,不是一个对象。我们如何解决这个问题呢?在 Stack Overflow 上搜索错误消息,可以找到很多相关的 结果 。单击第一个搜索结果,就会找到与我们类似的问题的答案,答案如下面的屏幕截图所示:
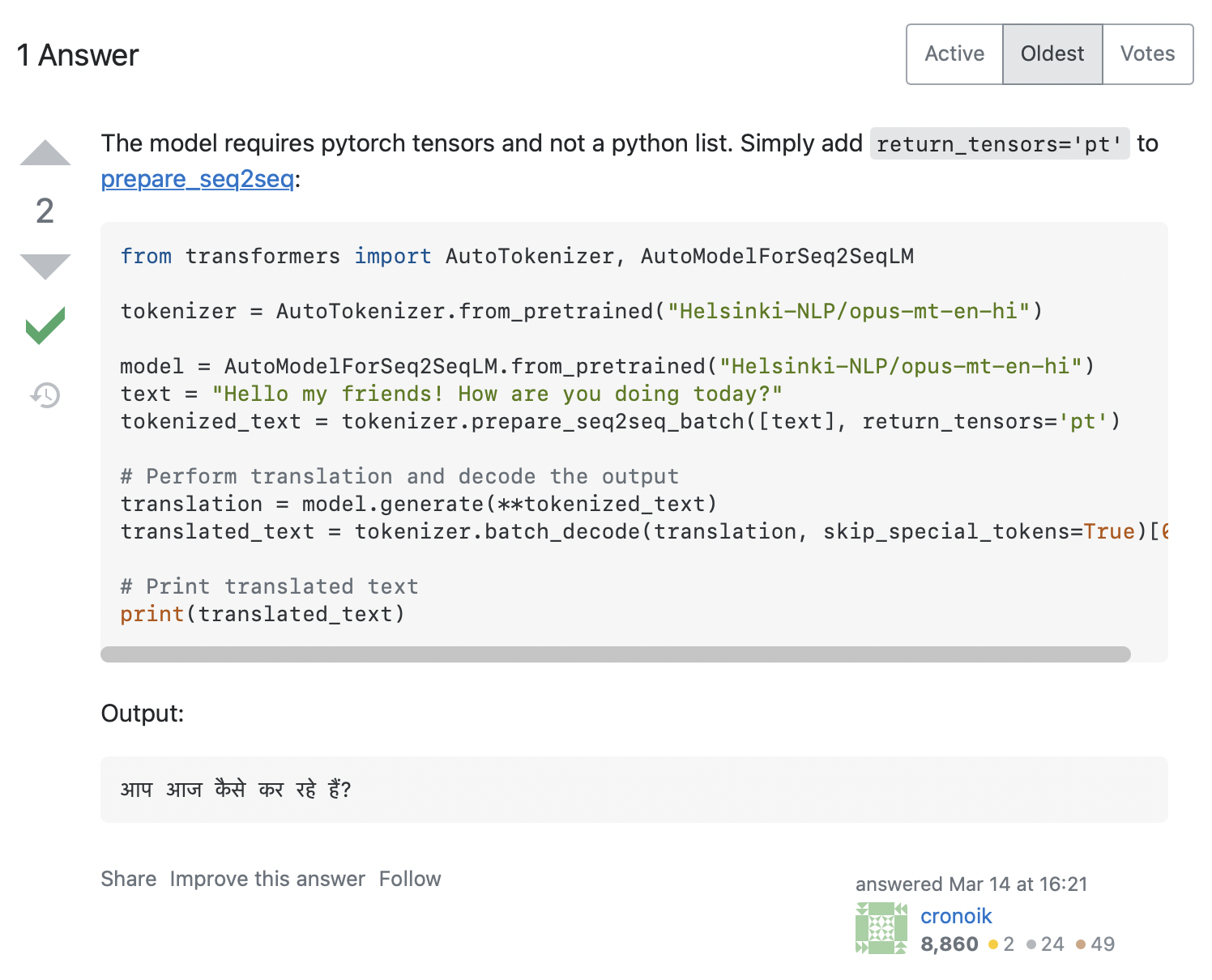
这里建议我们添加 return_tensors='pt' 到 Tokenizer,让我们测试一下是否可以帮助我们解决问题:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# 计算分数的 argmax 获取最有可能的答案开头
answer_start = torch.argmax(answer_start_scores)
# 计算分数的 argmax 获取最有可能的答案结尾
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""成功了!这是一个很好的例子,展示了 Stack Overflow 社区的实用性,搜索类似的问题,我们能够从社区中其他人的经验中受益。然而,像我们这样的搜索不是总能找到相关的答案,那么在这种情况下你该怎么办呢?幸运的是,在 Hugging Face 论坛 上有一个友好的开发者社区可以帮助你!在下一节中,我们将看看在该平台中有效地得到问题的回答。
< > Update on GitHub