LLM Course documentation
Tạo tập dữ liệu của riêng bạn
Tạo tập dữ liệu của riêng bạn

Đôi khi tập dữ liệu mà bạn cần để xây dựng một ứng dụng NLP không tồn tại, vì vậy bạn sẽ cần phải tự tạo. Trong phần này, chúng tôi sẽ hướng dẫn bạn cách tạo một kho tài liệu gồm Các vấn đề về GitHub, thường được sử dụng để theo dõi các lỗi hoặc tính năng trong kho lưu trữ GitHub. Kho tài liệu này có thể được sử dụng cho các mục đích khác nhau, bao gồm:
- Khám phá mất bao lâu để đóng các vấn đề đang mở hoặc yêu cầu kéo về (pull requests)
- Đào tạo multilabel classifier hay trình phân loại đa nhãn có thể gắn thẻ các vấn đề với siêu dữ liệu dựa trên mô tả của vấn đề (ví dụ: “lỗi”, “cải tiến” hoặc “câu hỏi”)
- Tạo công cụ tìm kiếm ngữ nghĩa để tìm những vấn đề nào phù hợp với truy vấn của người dùng
Ở đây chúng ta sẽ tập trung vào việc tạo kho ngữ liệu và trong phần tiếp theo chúng ta sẽ giải quyết ứng dụng tìm kiếm ngữ nghĩa. Để giữ mọi thứ đúng meta, chúng ta sẽ sử dụng các vấn đề GitHub liên quan đến một dự án nguồn mở phổ biến: 🤗 Datasets! Chúng ta hãy xem cách lấy dữ liệu và khám phá thông tin có trong những vấn đề này.
Lấy dữ liệu
Bạn có thể tìm thấy tất cả các vấn đề trong 🤗 Datasets bằng cách điều hướng đến tab Issues. Như thể hiện trong ảnh chụp màn hình bên dưới, tại thời điểm viết bài, có 331 vấn đề đang mở và 668 vấn đề đã đóng.

Nếu bạn nhấp vào một trong những vấn đề này, bạn sẽ thấy nó chứa tiêu đề, mô tả và một bộ nhãn mô tả đặc trưng cho vấn đề. Một ví dụ được hiển thị trong ảnh chụp màn hình bên dưới.

Để tải xuống tất cả các vấn đề của kho lưu trữ, chúng tôi sẽ sử dụng GitHub REST API để thăm dò điểm cuối Issues. Điểm cuối này trả về danh sách các đối tượng JSON, với mỗi đối tượng chứa một số lượng lớn các trường bao gồm tiêu đề và mô tả cũng như siêu dữ liệu về trạng thái của vấn đề, v.v.
Một cách thuận tiện để tải các vấn đề xuống là thông qua thư viện requests, đây là cách tiêu chuẩn để thực hiện các yêu cầu HTTP trong Python. Bạn có thể cài đặt thư viện bằng cách chạy:
!pip install requests
Sau khi thư viện được cài đặt, bạn có thể thực hiện các yêu cầu GET tới điểm cuối Issues bằng cách gọi hàm requests.get(). Ví dụ: bạn có thể chạy lệnh sau để truy xuất vấn đề đầu tiên trên trang đầu tiên:
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)Đối tượng response chứa nhiều thông tin hữu ích về yêu cầu, bao gồm mã trạng thái HTTP:
response.status_code
200trong đó trạng thái 200 có nghĩa là yêu cầu đã thành công (bạn có thể tìm thấy danh sách các mã trạng thái HTTP có thể có tại đây). Tuy nhiên, điều chúng ta thực sự quan tâm là payload hay tải trọng, có thể được truy cập ở nhiều định dạng khác nhau như byte, chuỗi hoặc JSON. Vì chúng ta biết các vấn đề của ta ở định dạng JSON, hãy kiểm tra tải trọng như sau:
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]Ồ, đó là rất nhiều thông tin! Chúng ta có thể thấy các trường hữu ích như title, body, và number mô tả sự cố cũng như thông tin về người dùng GitHub đã mở sự cố.
✏️ Thử nghiệm thôi! Nhấp vào một vài URL trong tải trọng JSON ở trên để biết loại thông tin mà mỗi vấn đề GitHub được liên kết với.
Như đã mô tả trong tài liệu GitHub, các yêu cầu chưa được xác thực được giới hạn ở 60 yêu cầu mỗi giờ. Mặc dù bạn có thể tăng tham số truy vấn per_page để giảm số lượng yêu cầu bạn thực hiện, nhưng bạn vẫn sẽ đạt đến giới hạn tỷ lệ trên bất kỳ kho lưu trữ nào có nhiều hơn một vài nghìn vấn đề. Vì vậy, thay vào đó, bạn nên làm theo hướng dẫn của GitHub về cách tạo personal access token hay token truy cập cá nhân để bạn có thể tăng giới hạn tốc độ lên 5,000 yêu cầu mỗi giờ. Khi bạn có token của riêng mình, bạn có thể bao gồm nó như một phần của tiêu đề yêu cầu:
GITHUB_TOKEN = xxx # Sao chép token GitHub của bạn tại đây
headers = {"Authorization": f"token {GITHUB_TOKEN}"}⚠️ Không dùng chung notebook có dán GITHUB_TOKEN của bạn trong đó. Chúng tôi khuyên bạn nên xóa ô cuối cùng sau khi bạn đã thực thi nó để tránh vô tình làm rò rỉ thông tin này. Tốt hơn nữa, hãy lưu trữ token trong tệp .env và sử dụng thư viện python-dotenv để tải tự động cho bạn dưới dạng biến môi trường.
Bây giờ chúng ta đã có token truy cập của mình, hãy tạo một hàm có thể tải xuống tất cả các vấn đề từ kho lưu trữ GitHub:
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Số vấn đề phải trả về trên mỗi trang
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Truy vấn với trạng thái state=all để nhận được cả vấn đề mở và đóng
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Xả lô cho khoảng thời gian tiếp theo
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)Bây giờ khi ta gọi fetch_issues (), nó sẽ tải xuống tất cả các vấn đề theo lô để tránh vượt quá giới hạn của GitHub về số lượng yêu cầu mỗi giờ; kết quả sẽ được lưu trữ trong tệp repository_name-issues.jsonl, trong đó mỗi dòng là một đối tượng JSON đại diện cho một vấn đề. Hãy sử dụng chức năng này để lấy tất cả các vấn đề từ 🤗 Datasets:
# Tùy thuộc vào kết nối internet của bạn, quá trình này có thể mất vài phút để chạy ...
fetch_issues()Sau khi các vấn đề được tải xuống, chúng tôi có thể lôi chúng cục bộ bằng cách sử dụng các kỹ năng mới khai phá từ phần 2:
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})Tuyệt vời, chúng ta đã tạo tập dữ liệu đầu tiên của mình từ đầu! Nhưng tại sao lại có vài nghìn vấn đề khi tab Sự cố của kho lưu trữ 🤗 Datasets chỉ hiển thị tổng số 1,000 vấn đề 🤔? Như được mô tả trong tài liệu GitHub, đó là vì chúng ta đã tải xuống tất cả kéo các yêu cầu:
REST API v3 của GitHub coi mọi yêu cầu kéo về là một vấn đề, nhưng không phải mọi vấn đề đều là yêu cầu kéo. Vì lý do này, điểm cuối “Issues” có thể trả về cả hai sự cố và kéo các yêu cầu trong phản hồi. Bạn có thể xác định các yêu cầu kéo bằng phím
pull_request. Lưu ý rằngidcủa một yêu cầu kéo được trả về từ các điểm cuối “Issues” sẽ là một id vấn đề.
Vì nội dung của các vấn đề và yêu cầu kéo khá khác nhau, chúng ta hãy thực hiện một số xử lý trước nhỏ để cho phép chúng ta phân biệt giữa chúng.
Làm sạch dữ liệu
Đoạn mã trên từ tài liệu của GitHub cho chúng ta biết rằng cột pull_request có thể được sử dụng để phân biệt giữa các vấn đề và các yêu cầu kéo. Hãy xem xét một mẫu ngẫu nhiên để xem sự khác biệt là gì. Như chúng ta đã làm trong phần 3, chúng ta sẽ xâu chuỗi Dataset.shuffle() và Dataset.select() để tạo một mẫu ngẫu nhiên và sau đó nén cột html_url và pull_request để chúng tôi có thể so sánh các URL khác nhau:
sample = issues_dataset.shuffle(seed=666).select(range(3))
# In ra URL và kéo về các mục yêu cầu
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}Ở đây, chúng ta có thể thấy rằng mỗi yêu cầu kéo được liên kết với các URL khác nhau, trong khi các vấn đề thông thường có mục nhập None. Chúng ta có thể sử dụng sự phân biệt này để tạo một cột is_pull_request mới để kiểm tra xem trường pull_request có phải là None hay không:
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)✏️ Thử nghiệm thôi! Tính thời gian trung bình cần để đóng các vấn đề trong 🤗 Datasets. Bạn có thể thấy hàm Dataset.filter() hữu ích để lọc ra các yêu cầu kéo và các vấn đề đang mở, đồng thời bạn có thể sử dụng hàm Dataset.set_format() để chuyển đổi tập dữ liệu thành DataFrame để bạn có thể dễ dàng thao tác dấu thời gian create_at và closed_at. Đối với điểm thưởng, hãy tính thời gian trung bình cần để đóng các yêu cầu kéo.
Mặc dù chúng ta có thể tiếp tục dọn dẹp tập dữ liệu bằng cách loại bỏ hoặc đổi tên một số cột, nhưng thông thường tốt nhất là giữ tập dữ liệu ở trạng thái “thô” nhất có thể ở giai đoạn này để có thể dễ dàng sử dụng trong nhiều ứng dụng.
Trước khi chúng tôi đẩy tập dữ liệu của mình sang Hugging Face Hub, hãy giải quyết một thứ còn thiếu trong nó: các nhận xét liên quan đến từng vấn đề và yêu cầu kéo. Chúng ta sẽ thêm chúng vào phầi tiếp theo với - bạn đoán được không - chính là API GitHub REST!
Bổ sung tập dữ liệu
Mặc dù chúng tôi có thể tiếp tục dọn dẹp tập dữ liệu bằng cách loại bỏ hoặc đổi tên một số cột, nhưng thông thường tốt nhất là giữ tập dữ liệu ở trạng thái “thô” nhất có thể ở giai đoạn này để có thể dễ dàng sử dụng trong nhiều ứng dụng.
Trước khi chúng tôi đẩy tập dữ liệu của mình sang Trung tâm khuôn mặt ôm, hãy giải quyết một thứ còn thiếu trong nó: các nhận xét liên quan đến từng vấn đề và yêu cầu kéo. Chúng tôi sẽ thêm chúng vào lần tiếp theo với - bạn đoán không - API GitHub REST!
Bổ sung tập dữ liệu
Như được hiển thị trong ảnh chụp màn hình sau, các nhận xét liên quan đến vấn đề hoặc yêu cầu kéo cung cấp nguồn thông tin phong phú, đặc biệt nếu chúng ta quan tâm đến việc xây dựng một công cụ tìm kiếm để trả lời các truy vấn của người dùng về thư viện.

API GitHub REST cung cấp điểm cuối Comments trả về tất cả các nhận xét được liên kết với số vấn đề. Hãy kiểm tra điểm cuối để xem nó trả về những gì:
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]Chúng ta có thể thấy rằng nhận xét được lưu trữ trong trường body, vì vậy hãy viết một hàm đơn giản trả về tất cả các nhận xét liên quan đến một vấn đề bằng cách chọn nội dung body cho mỗi phần tử trong response.json():
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Kiểm tra hàm có hoạt động như mong đợi không
get_comments(2792)["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]Điều này có vẻ ổn, vì vậy hãy sử dụng Dataset.map() để thêm cột comments mới cho từng vấn đề trong tập dữ liệu của mình:
# Tùy thuộc vào kết nối internet của bạn, quá trình này có thể mất vài phút ...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)Bước cuối cùng là lưu tập dữ liệu tăng cường cùng với dữ liệu thô của chúng ta để ta có thể đẩy cả hai vào Hub:
issues_with_comments_dataset.to_json("issues-datasets-with-comments.jsonl")Tải tập dữ liệu lên Hugging Face Hub
Bây giờ chúng ta đã có tập dữ liệu tăng cường của mình, đã đến lúc chuyển nó vào Hub để chúng ta có thể chia sẻ nó với cộng đồng! Để tải tập dữ liệu lên, chúng tôi sẽ sử dụng 🤗 thư viện Hub, cho phép chúng ta tương tác với Hugging Face Hub thông qua API Python. 🤗 Hub được cài đặt sẵn với 🤗 Transformers, vì vậy chúng ta có thể sử dụng trực tiếp. Ví dụ: chúng ta có thể sử dụng hàm list_datasets() để lấy thông tin về tất cả các tập dữ liệu công khai hiện được lưu trữ trên Hub:
from huggingface_hub import list_datasets
all_datasets = list_datasets()
print(f"Number of datasets on Hub: {len(all_datasets)}")
print(all_datasets[0])Number of datasets on Hub: 1487
Dataset Name: acronym_identification, Tags: ['annotations_creators:expert-generated', 'language_creators:found', 'languages:en', 'licenses:mit', 'multilinguality:monolingual', 'size_categories:10K<n<100K', 'source_datasets:original', 'task_categories:structure-prediction', 'task_ids:structure-prediction-other-acronym-identification']Chúng ta có thể thấy rằng hiện có gần 1,500 tập dữ liệu trên Hub và hàm list_datasets() cũng cung cấp một số siêu dữ liệu cơ bản về từng kho lưu trữ tập dữ liệu.
Đối với mục đích của mình, điều đầu tiên chúng ta cần làm là tạo một kho lưu trữ tập dữ liệu mới trên Hub. Để làm điều đó, chúng ta cần một token xác thực, có thể nhận được bằng cách đầu tiên đăng nhập vào Hugging Face Hub bằng hàm notebook_login():
from huggingface_hub import notebook_login
notebook_login()Thao tác này sẽ tạo một tiện ích mà bạn có thể nhập tên người dùng và mật khẩu của mình và token API sẽ được lưu trong ~/.huggingface/token. Nếu bạn đang chạy mã trong một thiết bị đầu cuối, bạn có thể đăng nhập qua CLI để thay thế:
huggingface-cli login
Sau khi thực hiện xong việc này, chúng ta có thể tạo một kho lưu trữ tập dữ liệu mới với hàm create_repo():
from huggingface_hub import create_repo
repo_url = create_repo(name="github-issues", repo_type="dataset")
repo_url'https://huggingface.co/datasets/lewtun/github-issues'Trong ví dụ này, chúng ta đã tạo một kho lưu trữ tập dữ liệu trống có tên là github-issue với tên người dùng lewtun (tên người dùng phải là tên người dùng Hub của bạn khi bạn đang chạy đoạn mã này!)
✏️ Thử nghiệm thôi! Sử dụng tên người dùng và mật khẩu Hugging Face Hub của bạn để lấy token và tạo một kho lưu trữ trống có tên là github-issue. Hãy nhớ không bao giờ lưu thông tin đăng nhập của bạn trong Colab hoặc bất kỳ kho lưu trữ nào khác, vì thông tin này có thể bị kẻ xấu lợi dụng.
Tiếp theo, hãy sao chép kho lưu trữ từ Hub vào máy cục bộ của chúng ta và sao chép tệp tập dữ liệu của chúng ta vào đó. 🤗 Hub cung cấp một lớp Repository tiện dụng bao bọc nhiều lệnh Git phổ biến, do đó, để sao chép kho lưu trữ từ xa, chúng ta chỉ cần cung cấp URL và đường dẫn cục bộ mà ta muốn sao chép tới:
from huggingface_hub import Repository
repo = Repository(local_dir="github-issues", clone_from=repo_url)
!cp issues-datasets-with-comments.jsonl github-issues/Theo mặc định, các phần mở rộng tệp khác nhau (chẳng hạn như .bin, .gz, và .zip) được theo dõi bằng Git LFS để các tệp lớn có thể được tạo phiên bản trong cùng một quy trình làm việc của Git. Bạn có thể tìm thấy danh sách các phần mở rộng tệp được theo dõi bên trong tệp .gitattributes của kho lưu trữ. Để đưa định dạng JSON Lines vào danh sách, chúng ta có thể chạy lệnh sau:
repo.lfs_track("*.jsonl")Sau đó ta có thể dùng Repository.push_to_hub() để đẩy dữ liệu lên Hub:
repo.push_to_hub()
Nếu chúng ta điều hướng đến URL có trong repo_url, bây giờ chúng ta sẽ thấy rằng tệp tập dữ liệu của chúng ta đã được tải lên.
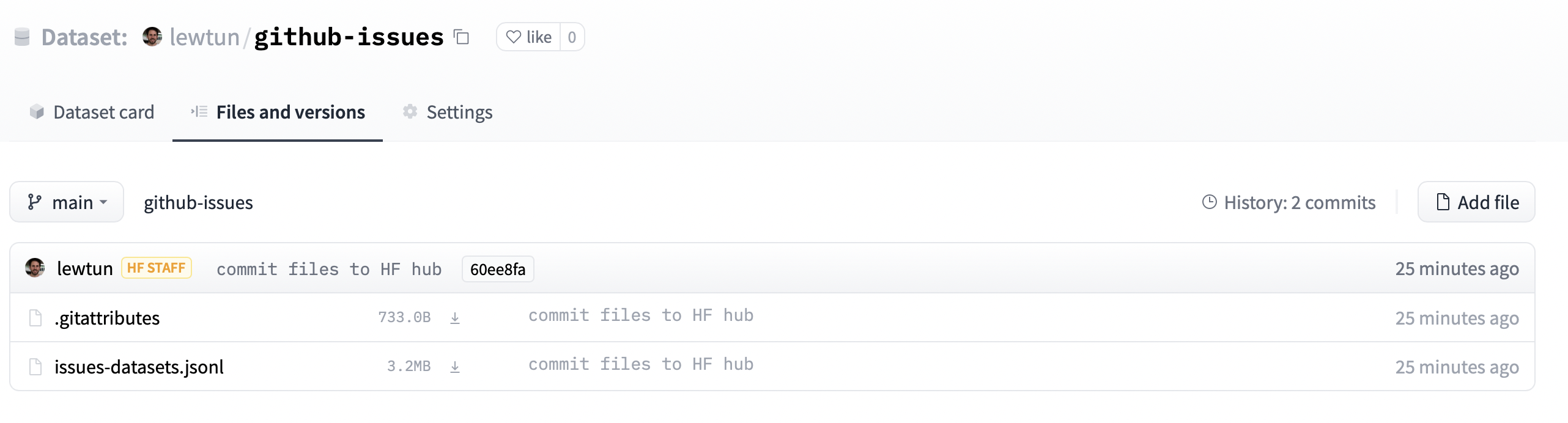
Từ đây, bất kỳ ai cũng có thể tải xuống tập dữ liệu bằng cách chỉ cần cung cấp load_dataset() với ID kho lưu trữ dưới dạng tham số path:
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})Tuyệt vời, chúng ta đã đưa tập dữ liệu của mình vào Hub và nó có sẵn cho những người khác sử dụng! Chỉ còn một việc quan trọng cần làm: thêm dataset card hay thẻ dữ liệu giải thích cách tạo kho tài liệu và cung cấp thông tin hữu ích khác cho cộng đồng.
💡 Bạn cũng có thể tải tập dữ liệu lên Hugging Face Hub trực tiếp từ thiết bị đầu cuối bằng cách sử dụng huggingface-cli và một chút phép thuật từ Git. Tham khảo hướng dẫn 🤗 Datasets để biết chi tiết về cách thực hiện việc này.
Tạo thẻ dữ liệu
Tập dữ liệu được ghi chép đầy đủ có nhiều khả năng hữu ích hơn cho người khác (bao gồm cả tương lai của bạn!), vì chúng cung cấp bối cảnh để cho phép người dùng quyết định xem tập dữ liệu có liên quan đến tác vụ của họ hay không và để đánh giá bất kỳ sai lệch hoặc rủi ro tiềm ẩn nào liên quan đến việc sử dụng tập dữ liệu.
Trên Hugging Face Hub, thông tin này được lưu trữ trong mỗi tệp README.md của kho lưu trữ tập dữ liệu. Có hai bước chính bạn nên thực hiện trước khi tạo tệp này:
- Sử dụng ứng dụng
datasets-taggingđể tạo thẻ siêu dữ liệu ở định dạng YAML. Các thẻ này được sử dụng cho nhiều tính năng tìm kiếm trên Hugging Face Hub và đảm bảo các thành viên của cộng đồng có thể dễ dàng tìm thấy tập dữ liệu của bạn. Vì chúng ta đã tạo tập dữ liệu tùy chỉnh ở đây, bạn sẽ cần sao chép kho lưu trữdatasets-taggingvà chạy ứng dụng cục bộ. Đây là giao diện trông như thế nào:

2.Đọc Hướng dẫn 🤗 Datasets về cách tạo thẻ tập dữ liệu thông tin và sử dụng nó làm mẫu.
Bạn có thể tạo tệp README.md trực tiếp trên Hub và bạn có thể tìm thấy mẫu thẻ dữ liệu trong kho lưu trữ dữ liệu lewtun/github-issues. Ảnh chụp màn hình của thẻ dữ liệu đã điền đầy đủ thông tin được hiển thị bên dưới.

✏️ Thử nghiệm thôi! Sử dụng ứng dụng dataset-tagging và hướng dẫn 🤗 Datasets để hoàn thành tệp README.md cho vấn đề về dữ liệu trên Github của bạn.
Vậy đó! Trong phần này, chúng ta đã thấy rằng việc tạo một tập dữ liệu tốt có thể khá liên quan, nhưng may mắn thay, việc tải nó lên và chia sẻ nó với cộng đồng thì không. Trong phần tiếp theo, chúng ta sẽ sử dụng bộ dữ liệu mới của mình để tạo một công cụ tìm kiếm ngữ nghĩa với 🤗 Datasets có thể so khớp các câu hỏi với các vấn đề và nhận xét có liên quan nhất.
✏️ Thử nghiệm thôi! Thực hiện theo các bước chúng ta đã thực hiện trong phần này để tạo tập dữ liệu về các vấn đề GitHub cho thư viện mã nguồn mở yêu thích của bạn (tất nhiên là chọn thứ khác ngoài 🤗 Datasets!). Để có điểm thưởng, hãy tinh chỉnh bộ phân loại đa nhãn để dự đoán các thẻ có trong trường labels.