Что делать, если возникла ошибка
В этом разделе мы рассмотрим некоторые распространенные ошибки, которые могут возникнуть при попытке сгенерировать предсказания на основе только что настроенной модели Transformer. Это подготовит вас к разделу 4, где мы рассмотрим, как отладить сам этап обучения.
Для этого раздела мы подготовили репозиторий, и если вы хотите запустить код в этой главе, вам сначала нужно скопировать модель в свой аккаунт на Hugging Face Hub. Для этого сначала авторизуйтесь на Hugging Face Hub. Если вы выполняете этот код в блокноте, вы можете сделать это с помощью следующей служебной функции:
from huggingface_hub import notebook_login
notebook_login()в терминале выполните следующее:
huggingface-cli login
Вас попросят ввести имя пользователя и пароль, токен будет сохранен в ~/.cache/huggingface/. После того как вы вошли в систему, вы можете скопировать репозиторий-шаблон с помощью следующей функции:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Клонируем репозиторий и извлекаем локальный путь
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Создайте пустое репо на хабе
имя_модели = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Клонирование пустого репо
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = имя_модели
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Копирование файлов
copy_tree(template_repo_dir, new_repo_dir)
# Отправить в хаб
repo.push_to_hub()Теперь при вызове copy_repository_template() будет создана копия репозитория-шаблона под вашим аккаунтом.
Отладка пайплайна из 🤗 Transformers
Чтобы начать наше путешествие в удивительный мир отладки моделей трансформеров, рассмотрим следующий сценарий: вы работаете с коллегой над проектом ответа на вопросы, который должен помочь клиентам сайта электронной коммерции найти ответы о потребительских товарах. Ваш коллега отправляет вам сообщение следующего содержания:
Добрый день! Я только что провел эксперимент, используя техники из главы 7 курса Hugging Face, и получил отличные результаты на SQuAD! Думаю, мы можем использовать эту модель в качестве отправной точки для нашего проекта. ID модели на хабе - “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”. Не стесняйтесь протестировать ее :)
и первое, что приходит в голову, это загрузить модель, используя pipeline из 🤗 Transformers:
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""О нет, кажется, что-то пошло не так! Если вы новичок в программировании, подобные ошибки могут показаться вам немного загадочными (что такое OSError?!). Это сообщение является лишь последней частью гораздо большего отчета об ошибке, называемого Python traceback (он же трассировка стека). Например, если вы запустите этот код в Google Colab, вы увидите что-то похожее на содержимое скриншота ниже:
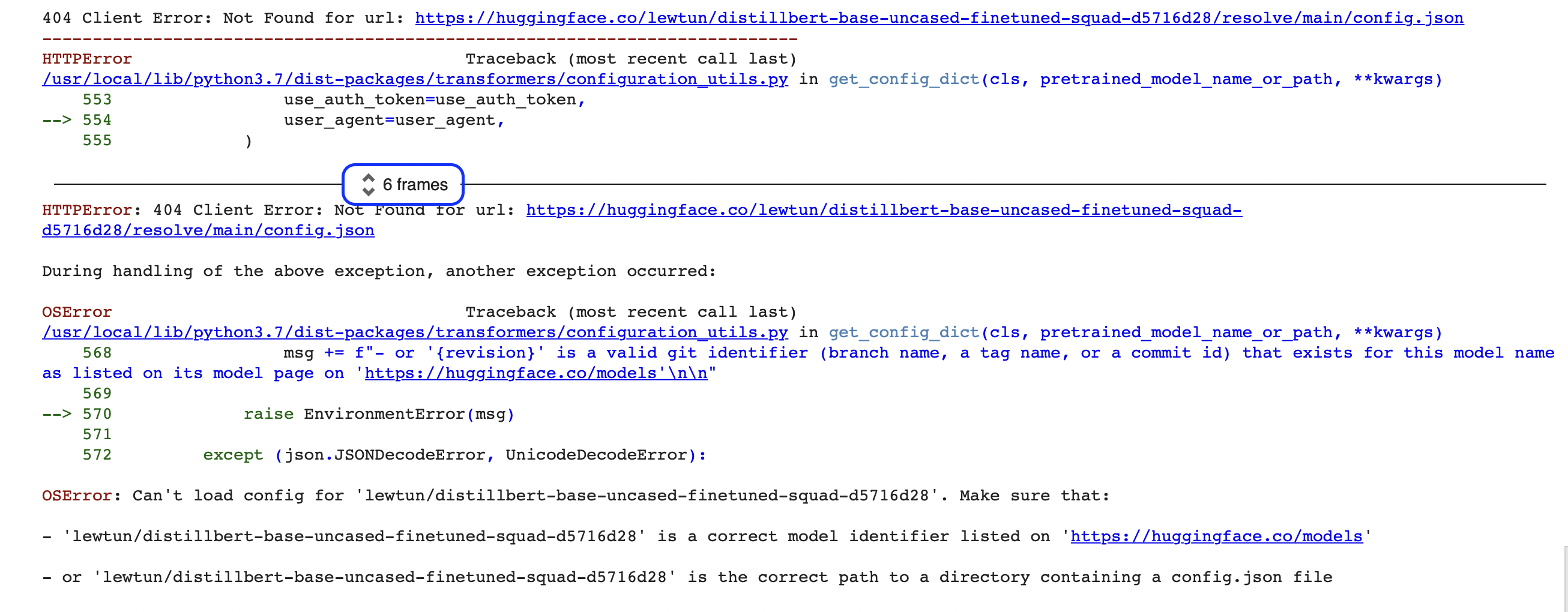
В этих отчетах содержится много информации, поэтому давайте вместе пройдемся по ключевым местам. Первое, что следует отметить, - это то, что трассировки следует читать снизу вверх. Это может показаться странным, если вы привыкли читать английский текст сверху вниз, но это логично: трассировка показывает последовательность вызовов функций, которые делает pipeline при загрузке модели и токенизатора. (Более подробно о том, как работает pipeline под капотом, читайте в Главе 2).
🚨 Видите синюю рамку вокруг “6 frames” в трассировке Google Colab? Это специальная функция Colab, которая помещает отчет в раскрывающийся блок текста. Если вы не можете найти источник ошибки, обязательно раскройте этот блок, нажав на эти две маленькие стрелки.
Последняя строка трассировки указывает на последнее сообщение об ошибке и дает имя исключения, которое было вызвано. В данном случае тип исключения - OSError, что указывает на системную ошибку. Если мы прочитаем сопроводительное сообщение об ошибке, то увидим, что, похоже, возникла проблема с файлом config.json модели, и нам предлагается два варианта ее устранения:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 Если вы столкнулись с сообщением об ошибке, которое трудно понять, просто скопируйте и вставьте его в строку поиска Google или Stack Overflow (да, действительно!). Велика вероятность того, что вы не первый, кто столкнулся с этой ошибкой, и это хороший способ найти решения, которые опубликовали другие члены сообщества. Например, поиск по запросу OSError: Can't load config for на Stack Overflow дает несколько результатов, которые можно использовать в качестве отправной точки для решения проблемы.
В первом предложении нам предлагается проверить, действительно ли идентификатор модели правильный, поэтому первым делом нужно скопировать идентификатор и вставить его в строку поиска Hub:

Хм, действительно, похоже, что модели нашего коллеги нет на хабе… ага, но в названии модели опечатка! В названии DistilBERT есть только одна буква “l”, так что давайте исправим это и поищем вместо нее “lewtun/distilbert-base-uncased-finetuned-squad-d5716d28”:

Хорошо! Теперь давайте попробуем загрузить модель снова с правильным идентификатором модели:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Cнова неудача - добро пожаловать в повседневную жизнь инженера машинного обучения! Поскольку мы исправили ID модели, проблема должна заключаться в самом репозитории. Быстрый способ получить доступ к содержимому репозитория на 🤗 Hub - это функция list_repo_files() библиотеки huggingface_hub:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']Интересно - похоже, что в репозитории нет файла config.json! Неудивительно, что наш pipeline не смог загрузить модель; наш коллега, должно быть, забыл выложить этот файл в Hub после того, как выполнил дообучение. В этом случае проблема кажется довольно простой: мы можем попросить его добавить этот файл, или, поскольку из идентификатора модели видно, что использовалась предварительно обученная модель distilbert-base-uncased, мы можем загрузить конфигурацию для этой модели и отправить ее в наше репо, чтобы посмотреть, решит ли это проблему. Давайте попробуем это сделать. Используя приемы, изученные в Главе 2, мы можем загрузить конфигурацию модели с помощью класса AutoConfig:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 Применяемый здесь подход не является надежным, поскольку наш коллега мог изменить конфигурацию distilbert-base-uncased перед дообучением модели. В реальной жизни мы бы хотели сначала уточнить у него, но для целей этого раздела будем считать, что он использовал конфигурацию по умолчанию.
Затем мы можем отправить это в наш репозиторий моделей вместе с конфигурацией с помощью функции push_to_hub():
config.push_to_hub(model_checkpoint, commit_message="Add config.json")Теперь мы можем проверить, работает ли это, загрузив модель из последнего коммита в ветке main:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}Ура, сработало! Давайте вспомним, что вы только что узнали:
- Сообщения об ошибках в Python называются tracebacks и читаются снизу вверх. Последняя строка сообщения об ошибке обычно содержит информацию, необходимую для поиска источника проблемы.
- Если последняя строка не содержит достаточной информации, пройдите путь вверх по трассировке и посмотрите, сможете ли вы определить, в каком месте исходного кода возникла ошибка.
- Если ни одно из сообщений об ошибках не помогло вам отладить проблему, попробуйте поискать в Интернете решение аналогичной проблемы.
- The
huggingface_hub// 🤗 Hub? предоставляет набор инструментов, с помощью которых вы можете взаимодействовать с репозиториями на Хабе и отлаживать их.
Теперь, когда вы знаете, как отлаживать конвейер, давайте рассмотрим более сложный пример на прямом проходе самой модели.
Отладка прямого прохода модели
Хотя pipeline отлично подходит для большинства приложений, где вам нужно быстро генерировать предсказания, иногда вам понадобится доступ к логам модели (например, если вы хотите применить какую-то пользовательскую постобработку). Чтобы увидеть, что может пойти не так в этом случае, давайте сначала возьмем модель и токенизатор:
tokenizer = reader.tokenizer model = reader.model
Далее нам нужен вопрос, поэтому давайте посмотрим, поддерживаются ли наши любимые фреймворки:
question = "Which frameworks can I use?"Как мы видели в Главе 7, обычные шаги, которые нам нужно предпринять, - это токенизация входных данных, извлечение логитов начальных и конечных токенов, а затем декодирование диапазона ответов:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Выберем наиболее правдоподобную позицию начала ответа с помощью функции argmax
answer_start = torch.argmax(answer_start_scores)
# Выберем наиболее правдоподбную позицию окончания ответа с помощью функции argmax
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""Похоже, что в нашем коде есть ошибка! Но мы не боимся небольшой отладки. Вы можете использовать отладчик Python в блокноте:
или в терминале:
Здесь чтение сообщения об ошибке говорит нам, что у объекта 'list' нет атрибута ‘size’, и мы видим стрелку -->, указывающую на строку, где возникла проблема в model(**inputs). Вы можете отладить это интерактивно, используя отладчик Python, но сейчас мы просто распечатаем фрагмент inputs, чтобы посмотреть, что у нас есть:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]Конечно, это выглядит как обычный list в Python, но давайте перепроверим тип:
type(inputs["input_ids"])listДа, это точно список Python. Так что же пошло не так? Вспомним из Главы 2, что классы AutoModelForXxx в 🤗 Transformers работают с тензорами (либо в PyTorch, либо в TensorFlow), и обычной операцией является извлечение размерности тензора с помощью Tensor.size(), скажем, в PyTorch. Давайте еще раз посмотрим на трассировку, чтобы увидеть, какая строка вызвала исключение:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'Похоже, что наш код пытался вызвать input_ids.size(), но это явно не сработает для Python list. Как мы можем решить эту проблему? Поиск сообщения об ошибке на Stack Overflow дает довольно много релевантных результатов. При нажатии на первый из них появляется вопрос, аналогичный нашему, ответ на который показан на скриншоте ниже:
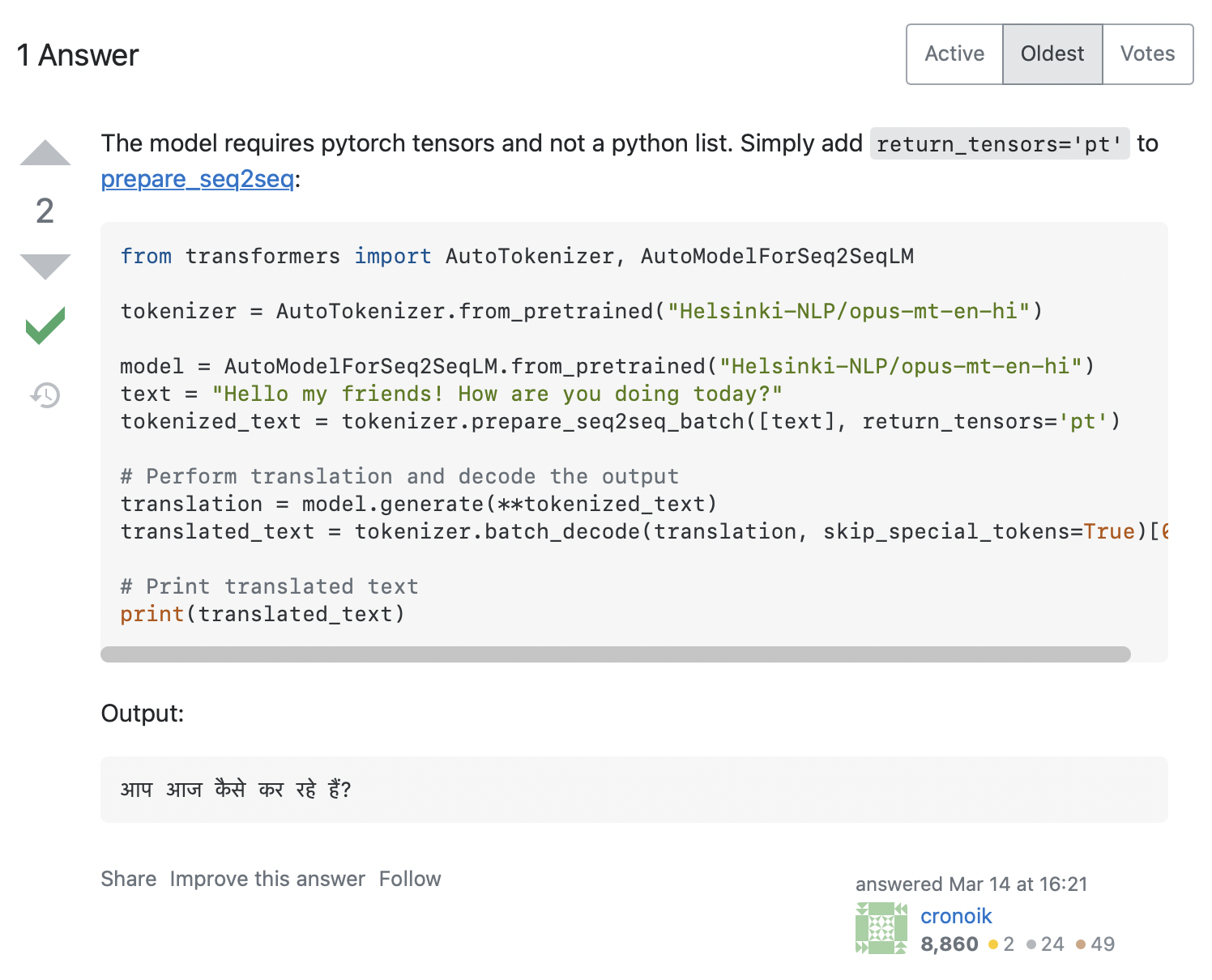
В ответе рекомендуется добавить в токенизатор return_tensors='pt', так что давайте посмотрим, сработает ли это для нас:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Выберем наиболее правдоподобную позицию начала ответа с помощью функции argmax
answer_start = torch.argmax(answer_start_scores)
# Выберем наиболее правдоподбную позицию окончания ответа с помощью функции argmax
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""Отлично, это сработало! Это отличный пример того, насколько полезным может быть Stack Overflow: найдя похожую проблему, мы смогли воспользоваться опытом других членов сообщества. Однако подобный поиск не всегда дает нужный ответ, так что же делать в таких случаях? К счастью, на Hugging Face forums есть гостеприимное сообщество разработчиков, которые могут вам помочь! В следующем разделе мы рассмотрим, как составить хорошие вопросы на форуме, на которые, скорее всего, будет получен ответ.