NLP Course documentation
Дообучение модели маскированного языкового моделирования
Дообучение модели маскированного языкового моделирования

Для многих приложений NLP, в которых используются модели-трансформеры, можно просто взять предварительно обученную модель из Hugging Face Hub и дообучить ее непосредственно на ваших данных для решения поставленной задачи. При условии, что корпус, использованный для предварительного обучения, не слишком отличается от корпуса, используемого для дообучения, трансферное обучение обычно дает хорошие результаты.
Однако есть несколько случаев, когда перед обучением специфичной для конкретной задачи головы необходимо дообучить языковые модели на ваших данных. Например, если ваш датасет содержит юридические контракты или научные статьи, ванильная модель трансформер, такая как BERT, обычно рассматривает специфические для области слова в вашем корпусе как редкие токены, и результирующее качество может быть менее чем удовлетворительным. Дообучив языковую модель на данных из домена, вы сможете повысить качество работы во многих последующих задачах, а это значит, что обычно этот шаг нужно выполнить только один раз!
Этот процесс дообучить предварительно обученную языковую модель на данных из домена обычно называют доменной адаптацией (domain adaptation). Он был популяризирован в 2018 году благодаря ULMFiT, которая стала одной из первых нейронных архитектур (основанных на LSTM), заставивших трансферное обучение действительно работать в NLP. Пример доменной адаптации с помощью ULMFiT показан на изображении ниже; в этом разделе мы сделаем нечто подобное, но с трансформером вместо LSTM!


К концу этого раздела у вас будет модель маскированного языкового моделирования на Hub, которая позволяет автоматически дописывать предложения, как показано ниже:
Давайте погрузимся в работу!
🙋 Если термины “маскированное моделирование языка (masked language modeling)” и “предварительно обученная модель (pretrained model)” кажутся вам незнакомыми, загляните в Главу 1, где мы объясняем все эти основные понятия, сопровождая их видеороликами!
Выбор предварительно обученной модели для маскированного моделирования языка
Для начала давайте выберем подходящую предварительно обученную модель для маскированного языкового моделирования. Как показано на следующем скриншоте, вы можете найти список кандидатов, применив фильтр “Fill-Mask” на Hugging Face Hub:
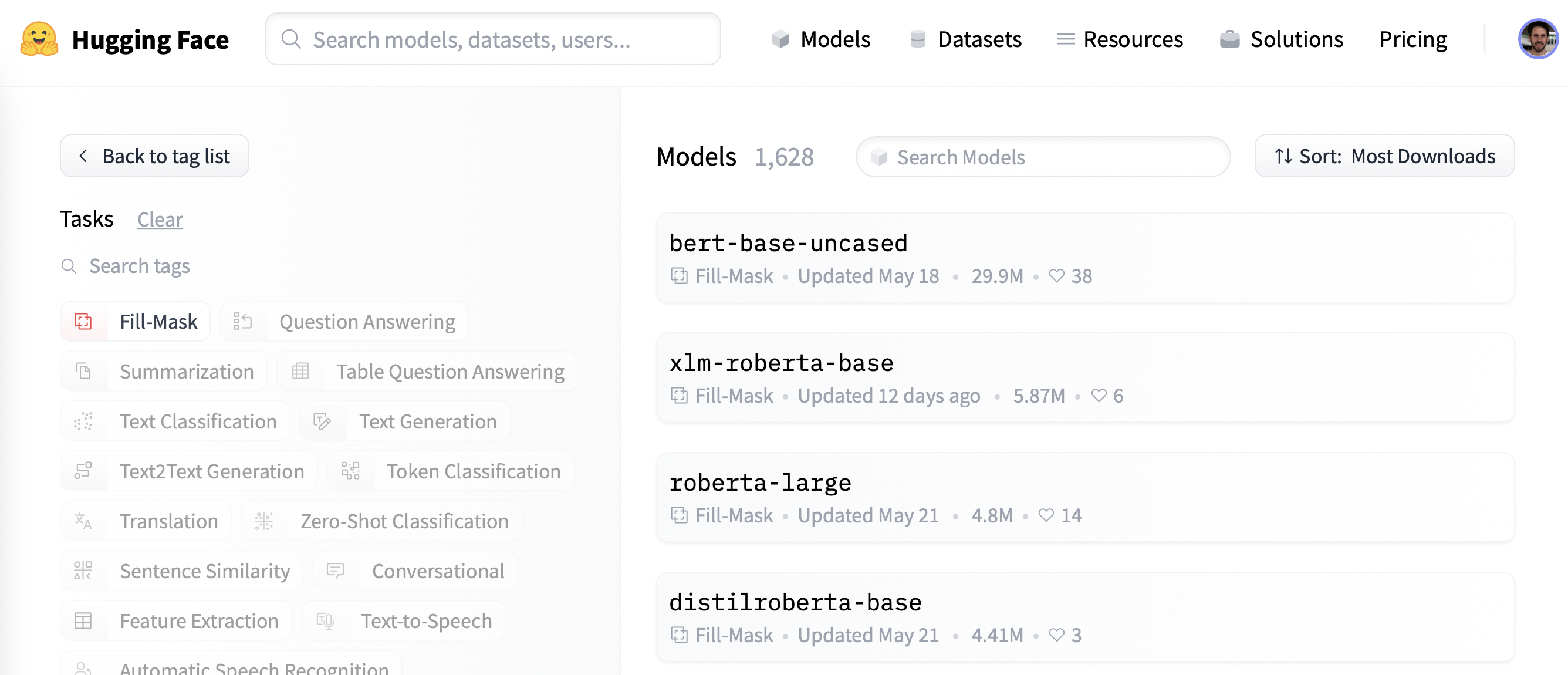
Хотя модели семейства BERT и RoBERTa являются наиболее загружаемыми, мы будем использовать модель под названием DistilBERT которая может быть обучена гораздо быстрее и практически без потерь в качестве. Эта модель была обучена с помощью специальной техники, называемой дистилляцией знаний (knowledge distillation), когда большая “модель-учитель”, такая как BERT, используется для обучения “модели-ученика”, имеющей гораздо меньше параметров. Объяснение деталей дистилляции знаний завело бы нас слишком далеко в этом разделе, но если вам интересно, вы можете прочитать об этом в Natural Language Processing with Transformers (в просторечии известном как учебник по Трансформерам).
Давайте перейдем к загрузке DistilBERT с помощью класса AutoModelForMaskedLM:
from transformers import AutoModelForMaskedLM
model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)Мы можем узнать, сколько параметров имеет эта модель, вызвав метод num_parameters():
distilbert_num_parameters = model.num_parameters() / 1_000_000
print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
print(f"'>>> BERT number of parameters: 110M'")'>>> DistilBERT number of parameters: 67M'
'>>> BERT number of parameters: 110M'Имея около 67 миллионов параметров, DistilBERT примерно в два раза меньше, чем базовая модель BERT, что примерно соответствует двукратному ускорению обучения - неплохо! Теперь посмотрим, какие виды токенов эта модель предсказывает как наиболее вероятные завершения небольшого образца текста:
text = "This is a great [MASK]."Как люди, мы можем представить множество вариантов использования токена [MASK], например “day (день)”, “ride (поездка)” или “painting (картина)“. Для предварительно обученных моделей прогнозы зависят от корпуса, на котором обучалась модель, поскольку она учится улавливать статистические закономерности, присутствующие в данных. Как и BERT, DistilBERT был предварительно обучен на датасетах English Wikipedia и BookCorpus, поэтому мы ожидаем, что прогнозы для [MASK] будут отражать эти домены. Для прогнозирования маски нам нужен токенизатор DistilBERT для создания входных данных для модели, поэтому давайте загрузим и его с хаба:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Теперь, имея токенизатор и модель, мы можем передать наш текстовый пример в модель, извлечь логиты и вывести 5 лучших кандидатов:
import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
# Определеним местоположения [MASK] и извлечем его логиты
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
# Выберем кандидатов [MASK] с наибольшими логитами
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")'>>> This is a great deal.'
'>>> This is a great success.'
'>>> This is a great adventure.'
'>>> This is a great idea.'
'>>> This is a great feat.'Из результатов видно, что предсказания модели относятся к повседневным терминам, что, пожалуй, неудивительно, учитывая основу английской Википедии. Давайте посмотрим, как мы можем изменить эту область на что-то более нишевое - сильно поляризованные обзоры фильмов!
Датасет
Для демонстрации адаптации к домену мы используем знаменитый Large Movie Review Dataset (или сокращенно IMDb) - корпус кинорецензий, который часто используется для тестирования моделей анализа настроения. Дообучив DistilBERT на этом корпусе, мы ожидаем, что языковая модель адаптирует свой словарный запас от фактических данных Википедии, на которых она была предварительно обучена, к более субъективным элементам кинорецензий. Мы можем получить данные из Hugging Face Hub с помощью функции load_dataset() из 🤗 Datasets:
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
imdb_datasetDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})Мы видим, что части train и test состоят из 25 000 отзывов каждая, а часть без меток, называемая unsupervised, содержит 50 000 отзывов. Давайте посмотрим на несколько примеров, чтобы получить представление о том, с каким текстом мы имеем дело. Как мы уже делали в предыдущих главах курса, мы используем функции Dataset.shuffle() и Dataset.select() для создания случайной выборки:
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
for row in sample:
print(f"\n'>>> Review: {row['text']}'")
print(f"'>>> Label: {row['label']}'")
'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.<br /><br />Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
'>>> Label: 0'
'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.<br /><br />The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
'>>> Label: 0'
'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version. <br /><br />My 4 and 6 year old children love this movie and have been asking again and again to watch it. <br /><br />I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.<br /><br />I do not have older children so I do not know what they would think of it. <br /><br />The songs are very cute. My daughter keeps singing them over and over.<br /><br />Hope this helps.'
'>>> Label: 1'Да, это точно рецензии на фильмы, и если вы родились до 1990х, вам будет лучше понятен комментарий в последней рецензии о VHS-версии. 😜! Хотя нам не понадобятся эти метки для языкового моделирования, мы уже видим, что 0 обозначает отрицательный отзыв, а 1 - положительный.
✏️ Попробуйте! Создайте случайную выборку из части unsupervised и проверьте, что метки не являются ни 0, ни 1. В процессе работы вы также можете проверить, что метки в частях train и test действительно равны 0 или 1 - это полезная проверка здравомыслия, которую каждый практикующий NLP должен выполнять в начале нового проекта!
Теперь, когда мы вкратце ознакомились с данными, давайте перейдем к их подготовке к моделированию языка по маске. Как мы увидим, есть несколько дополнительных шагов, которые необходимо сделать по сравнению с задачами классификации последовательностей, которые мы рассматривали в Главе 3. Поехали!
Предварительная обработка данных
Как для авторегрессивного, так и для масочного моделирования языка общим шагом предварительной обработки является объединение всех примеров, а затем разбиение всего корпуса на части одинакового размера. Это сильно отличается от нашего обычного подхода, когда мы просто проводим токенизацию отдельных примеров. Зачем конкатенируем все вместе? Причина в том, что отдельные примеры могут быть обрезаны, если они слишком длинные, и это приведет к потере информации, которая может быть полезна для задачи языкового моделирования!
Итак, для начала мы проведем обычную токенизацию нашего корпуса, но без задания параметра truncation=True в нашем токенизаторе. Мы также возьмем идентификаторы слов, если они доступны (а они будут доступны, если мы используем быстрый токенизатор, как описано в Главе 6), поскольку они понадобятся нам позже для маскирования целых слов. Мы обернем это в простую функцию, а пока удалим столбцы text и label, поскольку они нам больше не нужны:
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Используйте batched=True для активации быстрой многопоточности!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 50000
})
})Поскольку DistilBERT - это BERT-подобная модель, мы видим, что закодированные тексты состоят из input_ids и attention_mask, которые мы уже видели в других главах, а также из word_ids, которые мы добавили.
Теперь, когда мы провели токенизацию рецензий на фильмы, следующий шаг - сгруппировать их вместе и разбить результат на части. Но какого размера должны быть эти части? В конечном итоге это будет зависеть от объема доступной памяти GPU, но хорошей отправной точкой будет узнать, каков максимальный размер контекста модели. Это можно сделать путем проверки атрибута model_max_length токенизатора:
tokenizer.model_max_length
512Это значение берется из файла tokenizer_config.json, связанного с контрольной точкой; в данном случае мы видим, что размер контекста составляет 512 токенов, как и в случае с BERT.
✏️ Попробуйте! Некоторые модели трансформеров, например BigBird и Longformer, имеют гораздо большую длину контекста, чем BERT и другие ранние модели трансформеров. Инстанцируйте токенизатор для одной из этих контрольных точек и проверьте, что model_max_length согласуется с тем, что указано в описании модели.
Поэтому для проведения экспериментов на GPU, подобных тем, что стоят в Google Colab, мы выберем что-нибудь поменьше, что может поместиться в памяти:
chunk_size = 128Обратите внимание, что использование небольшого размера фрагмента может быть вредным в реальных сценариях, поэтому следует использовать размер, соответствующий сценарию использования, к которому вы будете применять вашу модель.
Теперь наступает самое интересное. Чтобы показать, как работает конкатенация, давайте возьмем несколько отзывов из нашего обучающего набора с токенизацией и выведем количество токенов в отзыве:
# С помощью среза получаем список списков для каждого признака
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
print(f"'>>> Review {idx} length: {len(sample)}'")'>>> Review 0 length: 200'
'>>> Review 1 length: 559'
'>>> Review 2 length: 192'Затем мы можем объединить все эти примеры с помощью простого dictionary comprehension, как показано ниже:
concatenated_examples = {
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"])
print(f"'>>> Concatenated reviews length: {total_length}'")'>>> Concatenated reviews length: 951'Отлично, общая длина подтвердилась - теперь давайте разобьем конкатенированные обзоры на части размером chunk_size. Для этого мы перебираем признаки в concatenated_examples и используем list comprehension для создания срезов каждого признака. В результате мы получаем словарь фрагментов для каждого признака:
chunks = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]:
print(f"'>>> Chunk length: {len(chunk)}'")'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 55'Как видно из этого примера, последний фрагмент, как правило, будет меньше максимального размера фрагмента. Существует две основные стратегии решения этой проблемы:
- Отбросить последний фрагмент, если он меньше
chunk_size. - Дополнить последний фрагмент до длины, равной
chunk_size.
Мы воспользуемся первым подходом, поэтому обернем всю описанную выше логику в одну функцию, которую можно применить к нашим токенизированным датасетам:
def group_texts(examples):
# Конкатенируем все тексты
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# Вычисляем длину конкатенированных текстов
total_length = len(concatenated_examples[list(examples.keys())[0]])
# Отбрасываем последний фрагмент, если он меньше chunk_size
total_length = (total_length // chunk_size) * chunk_size
# Разбиваем на фрагменты длиной max_len
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# Создаем новый столбец меток
result["labels"] = result["input_ids"].copy()
return resultОбратите внимание, что на последнем шаге group_texts() мы создаем новый столбец labels, который является копией столбца input_ids. Как мы вскоре увидим, это связано с тем, что при моделировании языка по маске цель состоит в прогнозировании случайно замаскированных токенов во входном батче, и, создавая столбец labels, мы предоставляем базовую истину для нашей языковой модели, на которой она будет учиться.
Теперь давайте применим group_texts() к нашим токенизированным датасетам, используя нашу надежную функцию Dataset.map():
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
lm_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 61289
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 59905
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 122963
})
})Вы можете видеть, что группировка и последующее разбиение текстов на фрагменты позволили получить гораздо больше примеров, чем наши первоначальные 25 000 примеров для частей train и test. Это потому, что теперь у нас есть примеры с непрерывными токенами (contiguous tokens), которые охватывают несколько примеров из исходного корпуса. В этом можно убедиться, поискав специальные токены [SEP] и [CLS] в одном из фрагментов:
tokenizer.decode(lm_datasets["train"][1]["input_ids"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"В этом примере вы можете увидеть два перекрывающихся обзора фильмов: один - о старшей школе, другой - о бездомности. Давайте также посмотрим, как выглядят метки при моделировании языка по маске:
tokenizer.decode(lm_datasets["train"][1]["labels"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"Как и ожидалось от нашей функции group_texts() выше, это выглядит идентично декодированным input_ids - но как тогда наша модель может чему-то научиться? Нам не хватает ключевого шага: вставки токенов [MASK] в случайные позиции во входных данных! Давайте посмотрим, как это можно сделать на лету во время дообучения с помощью специального коллатора данных.
Дообучение DistilBERT с помощью API Trainer
Дообучить модель моделирования языка по маске почти то же самое, что и дообучить модель классификации последовательностей, как мы делали в Главе 3. Единственное отличие заключается в том, что нам нужен специальный коллатор данных, который может случайным образом маскировать некоторые токены в каждом батче текстов. К счастью, 🤗 Transformers поставляется со специальным DataCollatorForLanguageModeling, предназначенным именно для этой задачи. Нам нужно только передать ему токенизатор и аргумент mlm_probability, который указывает, какую долю токенов нужно маскировать. Мы выберем 15 % - это количество используется для BERT и является распространенным выбором в литературе:
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)Чтобы увидеть, как работает случайное маскирование, давайте отправим несколько примеров в коллатор данных. Поскольку он ожидает список dict, где каждый dict представляет собой один фрагмент непрерывного текста, мы сначала выполняем итерацию над датасетом, прежде чем отправить батч коллатору. Мы удаляем ключ "word_ids" для этого коллатора данных, поскольку он его не ожидает:
samples = [lm_datasets["train"][i] for i in range(2)]
for sample in samples:
_ = sample.pop("word_ids")
for chunk in data_collator(samples)["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'Отлично, сработало! Мы видим, что токен [MASK] был случайным образом вставлен в различные места нашего текста. Это будут токены, которые наша модель должна будет предсказать в процессе обучения - и прелесть коллатора данных в том, что он будет случайным образом вставлять [MASK] в каждом батче!
✏️ Попробуйте! Запустите приведенный выше фрагмент кода несколько раз, чтобы увидеть, как случайное маскирование происходит на ваших глазах! Также замените метод tokenizer.decode() на tokenizer.convert_ids_to_tokens(), чтобы увидеть, что иногда маскируется один токен из данного слова, а не все остальные.
Одним из побочных эффектов случайного маскирования является то, что наши метрики оценки не будут детерминированными при использовании Trainer, поскольку мы используем один и тот же коллатор данных для обучающего и тестового наборов. Позже, когда мы рассмотрим дообучение с помощью 🤗 Accelerate, мы увидим, как можно использовать гибкость пользовательского цикла оценки, чтобы заморозить случайность.
При обучении моделей для моделирования языка с маской можно использовать один из методов - маскировать целые слова, а не только отдельные токены. Такой подход называется маскированием целых слов (whole word masking). Если мы хотим использовать маскирование целых слов, нам нужно будет самостоятельно создать коллатор данных. Коллатор данных - это просто функция, которая берет список примеров и преобразует их в батч, так что давайте сделаем это прямо сейчас! Мы будем использовать идентификаторы слов, вычисленные ранее, для создания карты между индексами слов и соответствующими токенами, затем случайным образом определим, какие слова нужно маскировать, и применим эту маску к входным данным. Обратите внимание, что все метки - -100, кроме тех, что соответствуют словам-маскам.
import collections
import numpy as np
from transformers import default_data_collator
wwm_probability = 0.2
def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
# Создаем отображение между словами и соответствующими индексами токенов
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# Случайно маскируем слова
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels)
for word_id in np.where(mask)[0]:
word_id = word_id.item()
for idx in mapping[word_id]:
new_labels[idx] = labels[idx]
input_ids[idx] = tokenizer.mask_token_id
feature["labels"] = new_labels
return default_data_collator(features)Далее мы можем опробовать ее на тех же примерах, что и раньше:
samples = [lm_datasets["train"][i] for i in range(2)]
batch = whole_word_masking_data_collator(samples)
for chunk in batch["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'✏️ Попробуйте! Запустите приведенный выше фрагмент кода несколько раз, чтобы увидеть, как случайное маскирование происходит на ваших глазах! Также замените метод tokenizer.decode() на tokenizer.convert_ids_to_tokens(), чтобы увидеть, что токены из данного слова всегда маскируются вместе.
Теперь, когда у нас есть два колатора данных, остальные шаги по дообучению стандартны. Обучение может занять много времени в Google Colab, если вам не посчастливилось получить мифический GPU P100 😭, поэтому мы сначала уменьшим размер обучающего набора до нескольких тысяч примеров. Не волнуйтесь, мы все равно получим довольно приличную языковую модель! Быстрый способ уменьшить размер датасета в 🤗 Datasets - это функция Dataset.train_test_split(), которую мы рассматривали в Главе 5:
train_size = 10_000
test_size = int(0.1 * train_size)
downsampled_dataset = lm_datasets["train"].train_test_split(
train_size=train_size, test_size=test_size, seed=42
)
downsampled_datasetDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 10000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 1000
})
})Это автоматически создаст новые части train и test, с размером обучающего набора в 10 000 примеров и валидацией в 10 % от этого количества - не стесняйтесь увеличить это значение, если у вас мощный GPU! Следующее, что нам нужно сделать, это авторизоваться на Hugging Face Hub. Если вы выполняете этот код в блокноте, вы можете сделать это с помощью следующей служебной функции:
from huggingface_hub import notebook_login
notebook_login()которая отобразит виджет, где вы можете ввести свои учетные данные. В качестве альтернативы можно выполнить команду:
huggingface-cli loginв вашем любимом терминале и авторизуйтесь там.
После того как мы авторизовались, мы можем указать аргументы для Trainer:
from transformers import TrainingArguments
batch_size = 64
# Показываем потери при обучении для каждой эпохи
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb",
overwrite_output_dir=True,
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
push_to_hub=True,
fp16=True,
logging_steps=logging_steps,
)Здесь мы изменили несколько параметров по умолчанию, включая logging_steps, чтобы обеспечить отслеживание потерь при обучении в каждой эпохе. Мы также использовали fp16=True, чтобы включить обучение со смешанной точностью, что дает нам еще большее улучшение скорости. По умолчанию Trainer удаляет все столбцы, которые не являются частью метода forward() модели. Это означает, что если вы используете коллатор для маскировки слов целиком, вам также нужно установить remove_unused_columns=False, чтобы не потерять колонку word_ids во время обучения.
Обратите внимание, что с помощью аргумента hub_model_id можно указать имя репозитория, в который вы хотите отправить модель (в частности, этот аргумент нужно использовать, чтобы отправить модель в ырепозиторий организации). Например, когда мы отправили модель в репозиторий организации huggingface-course, мы добавили hub_model_id="huggingface-course/distilbert-finetuned-imdb" в TrainingArguments. По умолчанию используемый репозиторий будет находиться в вашем пространстве имен и называться в соответствии с заданной вами выходной директорией, так что в нашем случае это будет "lewtun/distilbert-finetuned-imdb".
Теперь у нас есть все компоненты для создания Trainer. Здесь мы просто используем стандартный data_collator, но вы можете попробовать коллатор для маскирования слов целиком и сравнить результаты в качестве упражнения:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=downsampled_dataset["train"],
eval_dataset=downsampled_dataset["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)Теперь мы готовы запустить trainer.train(), но перед этим давайте вкратце рассмотрим _перплексию (perplexity), которая является общей метрикой для оценки качества языковых моделей.
Перплексия языковых моделей
В отличие от других задач, таких как классификация текстов или ответов на вопросы, где для обучения нам дается помеченный корпус, при языковом моделировании у нас нет никаких явных меток. Как же определить, какая языковая модель является хорошей? Как и в случае с функцией автокоррекции в вашем телефоне, хорошая языковая модель - это та, которая присваивает высокую вероятность грамматически правильным предложениям и низкую вероятность бессмысленным предложениям. Чтобы лучше представить себе, как это выглядит, вы можете найти в Интернете целые подборки “неудач автокоррекции”, где модель в телефоне человека выдает довольно забавные (и часто неуместные) завершения!
Если предположить, что наш тестовый набор состоит в основном из грамматически правильных предложений, то одним из способов измерения качества нашей языковой модели является подсчет вероятностей, которые она присваивает следующему слову во всех предложениях тестового набора. Высокие вероятности указывают на то, что модель не “удивлена” и не “перплексирована” не виденными ранее примерами, и предполагают, что она усвоила основные грамматические закономерности языка. Существуют различные математические определения перплексии, но то, которое мы будем использовать, определяет ее как экспоненту потери перекрестной энтропии. Таким образом, мы можем вычислить перплексию нашей предварительно обученной модели, используя функцию Trainer.evaluate() для вычисления потерь кросс-энтропии на тестовом наборе, а затем взяв экспоненту результата:
import math
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 21.75Более низкий показатель перплексии означает лучшую языковую модель, и мы видим, что наша начальная модель имеет несколько большое значение. Давайте посмотрим, сможем ли мы снизить его, дообучив модель! Для этого сначала запустим цикл обучения:
trainer.train()
и затем вычислить результирующую перплексию на тестовом наборе, как и раньше:
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 11.32Неплохо - это довольно значительное уменьшение перплексии, что говорит о том, что модель узнала что-то новое об области рецензий на фильмы!
После завершения обучения мы можем отправить карточку модели с информацией об обучении в Hub (контрольные точки сохраняются во время самого обучения):
trainer.push_to_hub()
✏️ Попробуйте! Запустите обучение, описанное выше, после замены коллатора данных на коллатор маскирующий все слово. Получили ли вы лучшие результаты?
В нашем случае нам не нужно было делать ничего особенного с циклом обучения, но в некоторых случаях вам может понадобиться реализовать некоторую пользовательскую логику. Для таких случаев вы можете использовать 🤗 Accelerate - давайте посмотрим!
Дообучение DistilBERT с помощью 🤗 Accelerate
Как мы видели на примере Trainer, дообучение модели маскированного языкового моделирования очень похоже на пример классификации текста из Главы 3. Фактически, единственной особенностью является использование специального коллатора данных, о котором мы уже рассказывали ранее в этом разделе!
Однако мы видели, что DataCollatorForLanguageModeling также применяет случайное маскирование при каждой оценке, поэтому мы увидим некоторые колебания в наших оценках перплексии при каждом цикле обучения. Один из способов устранить этот источник случайности - применить маскирование один раз ко всему тестовому набору, а затем использовать стандартный коллатор данных в 🤗 Transformers для сбора батчей во время оценки. Чтобы увидеть, как это работает, давайте реализуем простую функцию, которая применяет маскирование к батчу, подобно нашей первой работе с DataCollatorForLanguageModeling:
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
# Создаем новый "маскированный" столбец для каждого столбца в датасете
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}Далее мы применим эту функцию к нашему тестовому набору и удалим столбцы без маскирования, чтобы заменить их столбцами с маскированием. Вы можете использовать маскирование целых слов, заменив data_collator выше на соответствующий, в этом случае вам следует удалить первую строку здесь:
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
eval_dataset = downsampled_dataset["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset["test"].column_names,
)
eval_dataset = eval_dataset.rename_columns(
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)Затем мы можем настроить загрузчики данных как обычно, но для оценочного набора мы будем использовать default_data_collator из 🤗 Transformers:
from torch.utils.data import DataLoader
from transformers import default_data_collator
batch_size = 64
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
eval_dataloader = DataLoader(
eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
)Здесь мы следуем стандартным шагам 🤗 Accelerate. Первым делом загружаем свежую версию предварительно обученной модели:
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)Затем нужно указать оптимизатор; мы будем использовать стандартный AdamW:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)Теперь, имея эти объекты, мы можем подготовить все для обучения с помощью объекта Accelerator:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)Теперь, когда наша модель, оптимизатор и загрузчики данных настроены, мы можем задать планировщик скорости обучения следующим образом:
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Осталось сделать еще одну последнюю вещь перед обучением: создать репозиторий модели на Hugging Face Hub! Мы можем использовать библиотеку 🤗 Hub, чтобы сначала сгенерировать полное имя нашего репозитория:
from huggingface_hub import get_full_repo_name
model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'затем создадим и клонируем репозиторий, используя класс Repository из 🤗 Hub:
from huggingface_hub import Repository
output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)После этого остается только написать полный цикл обучения и оценки:
from tqdm.auto import tqdm
import torch
import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Обучение
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Оценка
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size)))
losses = torch.cat(losses)
losses = losses[: len(eval_dataset)]
try:
perplexity = math.exp(torch.mean(losses))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
# Сохранение и загрузка
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)>>> Epoch 0: Perplexity: 11.397545307900472
>>> Epoch 1: Perplexity: 10.904909330983092
>>> Epoch 2: Perplexity: 10.729503505340409Круто, мы смогли оценить перплексию для каждой эпохи и обеспечить воспроизводимость нескольких циклов обучения!
Использование нашей дообученной модели
Вы можете взаимодействовать с дообученной моделью либо с помощью ее виджета на Hub, либо локально с помощью pipeline из 🤗 Transformers. Давайте воспользуемся последним вариантом, чтобы загрузить нашу модель с помощью конвейера fill-mask:
from transformers import pipeline
mask_filler = pipeline(
"fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
)Затем мы можем передать конвейеру наш пример текста ” This is a great [MASK]” и посмотреть, каковы 5 лучших прогнозов:
preds = mask_filler(text)
for pred in preds:
print(f">>> {pred['sequence']}")'>>> this is a great movie.'
'>>> this is a great film.'
'>>> this is a great story.'
'>>> this is a great movies.'
'>>> this is a great character.'Отлично - наша модель явно адаптировала свои веса, чтобы прогнозировать слова, которые сильнее ассоциируются с фильмами!
На этом мы завершаем наш первый эксперимент по обучению языковой модели. В разделе 6 вы узнаете, как обучить авторегрессионную модель типа GPT-2 с нуля; загляните туда, если хотите посмотреть, как можно предварительно обучить свою собственную модель трансформера!
✏️ Попробуйте! Чтобы оценить преимущества адаптации к домену, дообучите классификатор на метках IMDb как для предварительно обученных, так и для дообученных контрольных точек DistilBERT. Если вам нужно освежить в памяти классификацию текстов, ознакомьтесь с Главой 3.